Морфологический разбор слова «выходка»
Часть речи: Существительное
ВЫХОДКА — неодушевленное
Начальная форма слова: «ВЫХОДКА»
| Слово | Морфологические признаки |
|---|---|
| ВЫХОДКА |
|
Все формы слова ВЫХОДКА
ВЫХОДКА, ВЫХОДКИ, ВЫХОДКЕ, ВЫХОДКУ, ВЫХОДКОЙ, ВЫХОДКОЮ, ВЫХОДОК, ВЫХОДКАМ, ВЫХОДКАМИ, ВЫХОДКАХ
Разбор слова по составу выходка
| Основа слова | выходк |
|---|---|
| Приставка | вы |
| Корень | ход |
| Суффикс | к |
| Окончание | а |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ВЫХОДКА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «выходка»
1
Эта выходка лишила его службы и большого майората, который перешел к его двоюродному брату.
Рекенштейны, Вера Ивановна Крыжановская-Рочестер, 1894г.2
Выходка Веренфельса тоже перешла границы;
Рекенштейны, Вера Ивановна Крыжановская-Рочестер, 1894г.3
Выходка эта, несмотря на ее горький тон, обрадовала меня.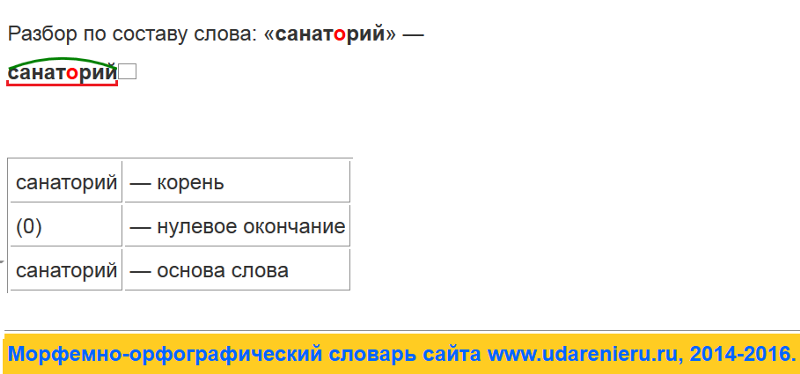
4
Забыта была даже выходка Добрыни Малковича, тем более что все видели, как жрец оказал ему внимание.
Красное Солнышко, Александр Красницкий, 1897г.5
Найти еще примеры предложений со словом ВЫХОДКА
Синтаксический разбор предложения Сначала я старался не зачерпнуть воды или грязи в туфли, но оступился раз, оступился другой — и стало всё равно
Моя комната находится на солнечной стороне, поэтому там всегда светло. Когда я прихожу со школы и попадаю в свою комнату, мне сразу становится спокойно. Зелёный цвет обоев создаёт рабочую атмосферу и желание учиться. Здесь я всегда делаю уроки, это мой кабинет. Моя комната самая маленькая, и это создаёт особое чувство уюта. Я даже люблю убираться дома, это доставляет мне невообразимое удовольствие. Сколько воспоминаний связано с моей детской! Моя комната — уже часть меня, и поэтому я не променяю свой тихий уголок на любую другую комнату. Иногда, когда мне грустно, я люблю закрывать плотные шторы, и тогда в моей комнате становится совсем темно, как ночью. Очень удобно, когда смотришь какой-нибудь фильм, словно находишься в кинотеатре. Когда я вырасту, я надеюсь, что мой дом так же станет частью меня, как и моя комната сейчас.
Когда я прихожу со школы и попадаю в свою комнату, мне сразу становится спокойно. Зелёный цвет обоев создаёт рабочую атмосферу и желание учиться. Здесь я всегда делаю уроки, это мой кабинет. Моя комната самая маленькая, и это создаёт особое чувство уюта. Я даже люблю убираться дома, это доставляет мне невообразимое удовольствие. Сколько воспоминаний связано с моей детской! Моя комната — уже часть меня, и поэтому я не променяю свой тихий уголок на любую другую комнату. Иногда, когда мне грустно, я люблю закрывать плотные шторы, и тогда в моей комнате становится совсем темно, как ночью. Очень удобно, когда смотришь какой-нибудь фильм, словно находишься в кинотеатре. Когда я вырасту, я надеюсь, что мой дом так же станет частью меня, как и моя комната сейчас.
1) считать ( 1 спр. ) — считаешь; считаете; считает.
) — считаешь; считаете; считает.
2) подвозить ( 2 спр.) — подвозишь; подвозим; подвозите; подвозят.
3) чистить ( 2 спр.) — чистишь; чистит; чистим; чистите; чистят.
4) желтеть ( 1 спр.) — желтеешь; желтеет; желтеем; желтеете; желтеют.
5) закрыть ( 1 спр.) — закроешь; закроет; закроем; закроете; закроют.
7) встретиться ( 2 спр.) — встретишься; встретится; встретимся; встретитесь; встретятся.
Какие слова даны в твоем тексте??
3. Золотистая, позолота, золотко…Корень ЗОЛОТ1. коток-кОт, кОтик
серенький-серЕет (небо)
лобок-лОб
хитер-хИтрый
большие-бОльше
2. Васька — подлежащее (существительное), одна черта; ласков, хитер — сказуемое (обстоятельство), волнистая линия
Разбери по составу слова шумный, выходка.
 заморозок. запиши по три слова со следующими орфограмами. с безударными гласными. с разделительным ъ. с разделительным ь. выпиши из диктанта три четырёхсложными словами. мне с ответом
заморозок. запиши по три слова со следующими орфограмами. с безударными гласными. с разделительным ъ. с разделительным ь. выпиши из диктанта три четырёхсложными словами. мне с ответомимя существительное – это знаменательная часть речи, которая обозначает предмет и отвечает на вопросы: кто? что?
начальная форма – им. п., ед. ч.
общее грамматическое значение – предметность.
морфологические признаки – род, склонение, число, падеж, одушевленность и неодушевленность.
разряды существительных.
нарицательные — называют однородные предметы, которые имеют что – то общее, какое – то сходство: дерево, город, здание.
собственные — являются индивидуальными названиями одного предмета, выделяемого из ряда однородных: лев николаевич толстой.
конкретные – называют конкретные предметы и явления из реальной действительности : девочка, ненависть, забота .
собирательные – совокупность одинаковых или подобных друг – другу отдельных предметов как одно целое: студенчество . одушевленные и неодушевленные существительные
одушевленные и неодушевленные существительные
одушевленные существительные обозначают живые существа, а неодушевленные – предмет в собственном смысле слова, в отличии от живых существ.
род имени существительного .
существительные имеют три рода: мужской, женский и средний. существительные по не изменяются.. существуют существительные общего рода, которыми можно назвать и мальчика и девочку: неряха, чистюля . число имен существительных
число существительных указывает на количество предметов (один – не один).
только форму единственного числа имеют:
вещественные существительные: сахар, мука ;
отвлеченные : радость, счастье, грсть ;
собирательные: молодежь, родня;
собственные: москва, новосибирск.
только форму множественного числа имеют:
вещественные существительные: чернила, очистки;
отвлеченные : провода, поминки;
обозначающие парные предметы: ножницы, сани.
в предложении может выполнять функции:
подлежащего: мама пошла в магазин.
дополнения: я взял книгу
определения: я надел пальто в клетку ..
приложения: река обь красивая.обстоятельства: я пришел несмотря на погоду.
сказуемым: моя мама– пилот
Является ли «to» предлогом в «трюке, чтобы заставить этот стул складываться», но как инфинитив «to» в «некоторых уловках, чтобы ускорить ваш …»?
Я редактировал вопрос заголовка (который казался слишком общим и ранее частично рассматривался в ELU). В этих конкретных примерах есть несколько конкретных применений.
«Это уловка для того, чтобы« вроде (вероятно, менее неформально) »- это средство», может сопровождаться настоящим причастным предложением:
Этот императив происходит от причинного «закона»… это ложь перспективность — средство к получению денег
[Электронное руководство по этике и морали] … и в Google есть много запросов по запросу «это средство получить / достичь / заработать .. .»
.»
Другие существительные используются в подобных конструкциях: «Это ключ к пониманию проблемы». В Google более 7 миллионов просмотров по запросу «ключ к пониманию».
…….
[W] Что это уловка для получения лучшего курса валюты?
[Beth Allcock_Daily Express]… и 140 000 просмотров в Google по запросу «это уловка для получения».
«Уловка» тоже идиоматична; например
Магия — это уловка для понимания разума.
[Даремский университет] (и 8 миллионов просмотров в Google по запросу «это уловка»).
Хотя современный анализ сводится к тому, что «получение» в «получении наилучшего курса валюты» (например) является глаголом ( действительно ли имеет дополнение или что-то, что теперь классифицируется как прямой объект), «to» считается здесь предлогом.
……………………..
Обратите внимание, что в той же статье Express есть:
Новости Brexit: валютный эксперт раскрывает трюк, чтобы избежать ослабления фунта .
..

Есть разумное количество совпадений Google для «уловки, чтобы избежать» и «уловки для ускорения», более 1 1/2 миллиона для «уловки, чтобы получить», переходя для (теперь есть нечеткое квантификатор!) 2 миллиона за «хитрость» (но я ожидаю здесь много ложных срабатываний).Я бы классифицировал «трюк с + инфинитивом» (и близкие варианты, такие как «некоторые уловки») как идиоматический, учитывая разумный глагол.
«Кому» здесь означает «с целью / предполагаемой целью использования» [+ ing-form], которую я бы не классифицировал как маркер инфинитива. Приведенный пример может быть проанализирован как остаток после удаления «На странице 21, некоторые уловки для вас, чтобы ускорить вашу косметическую процедуру», что гораздо больше похоже на использование до бесконечности –. Сравните «… инструмент для извлечения скоб».
#forthlang: трюк с макросами
 Как обычно, я буду использовать свою версию Forth, которую вы можете найти здесь.
Как обычно, я буду использовать свою версию Forth, которую вы можете найти здесь.У меня есть пакет учетных записей, который я написал на Perl. Я часто думаю, что интересно попытаться понять, как я могу подойти к проблеме, если бы написал ее на Forth. Perl обрабатывает файл, содержащий список команд.Команды: «#» для комментариев, «ntran» для обычных транзакций и «etran» для операций с капиталом.
Для большинства языков вам потребуется написать какой-то синтаксический анализатор, чтобы разбивать команды на типы и аргументы и отправлять их по команде. С Forth вы можете использовать сам анализатор Forth, чтобы выполнить синтаксический анализ за вас. Вам даже не нужно отправлять по команде; команды могут быть определены как сами слова Forth, которые парсер просто выполняет.
Сделано хорошо, поэтому Forth может ощущаться как DSL.Хотя иногда может показаться, что сантехника немного запутана, когда вы достигнете верхнего уровня, сам код может выглядеть очень «четким».
«ntran» состоит из нескольких полей: штамп даты, дебетовый счет, кредитный счет, сумма и описание. Типичный пример:
нтран 2020-04-18 банк наличными 10.00 "внесены наличные"
Предположим, мы хотим иметь переменные для каждого из этих полей. Стандартный способ использования Forth — использовать слово VARIABLE, например:
переменная dstamp \ определяет переменную для штампа даты переменная dr \ для дебетового счета
и так далее.
Но это немного утомительно. Предположим, мы хотим определить сразу несколько переменных. С этой целью было бы удобно, если бы у нас было такое слово, как VARS :, которое сканировало оставшуюся часть ввода до новой строки и определяло новые переменные для каждого токена в этой строке. Другими словами, мы хотели сделать что-то вроде:
vars: dstamp dr cr amount desc
Вот как это можно реализовать:
: VARS: начать дублирование слова синтаксического анализа, в то время как $ create 0, повторить удаление;
Вы можете увидеть здесь цикл начала… пока… повтора. Это цикл, который анализирует следующее слово ввода в строку (через parse-word), а затем делает что-то похожее на переменное слово (через $ create 0,). «Капля» в конце очищает висящее синтаксическое слово.
Это цикл, который анализирует следующее слово ввода в строку (через parse-word), а затем делает что-то похожее на переменное слово (через $ create 0,). «Капля» в конце очищает висящее синтаксическое слово.
Затем мы можем определить слово «ntran», которое считывает слово из данных и присваивает значения переменным. Мы хотим повторить трюк, который мы использовали для vars :, чтобы написать что-то вроде:
: ntran store: dstamp dr cr amount desc
процесс-нтран; , где PROCESS-NTRAN выполняет некоторую дополнительную обработку, которая нас здесь не касается.Нас интересует слово STORE :, которое будет иметь ту же конструкцию внешнего цикла над строкой, что и VARS :, но с другим внутренним телом.
Паттерн развивается, давайте попробуем абстрагироваться от этого паттерна. Мы хотим написать что-то вроде:
: VARS: строка ($ create 0,) строка; : STORE: строка (поменять местами!) Строка;
, где LINE (фактически фраза «начать синтаксический анализ слова dup while», а) LINE — это фраза «повторять отбрасывание». Нам нужно превратить эти «фразы» в «макросы».Вот как это сделать:
Нам нужно превратить эти «фразы» в «макросы».Вот как это сделать:
: СТРОКА (отложить начало отложить синтаксическое слово отложить дублирование отложить пока; немедленно :) LINE отложить повтор отложить сбросить; немедленно
В этом случае «макрофикация» фраз относительно проста. Вы определяете «макросы», делая их немедленными, и вставляете POSTPONE перед каждым словом. К сожалению, это не всегда так просто, но в данном случае мы избежали некоторых сложностей, которые могут возникнуть.
Есть и другие возможные стратегии, которые можно использовать для достижения того же эффекта, но я не буду их здесь рассматривать.
Я надеюсь, что вы нашли это интересным и пробудили у вас интерес к тому, как сделать Forth похожим на язык очень высокого уровня с лаконичной и гибкой семантикой, даже если вы не понимали его большей части.
Обновление : я только что понял, что мой код для STORE: не будет работать как есть, так как он должен быть НЕМЕДЛЕННО. Правильная реализация:
Правильная реализация:
: МАГАЗИН: линия ( отложить синтаксический анализатор отложить pt найти ячейку + отложить буквально отложить! )линия ; немедленно
Мы видим реализацию:
вары: a b c : foo store: a b а @.б @. cr ; foo 10 20 \ выходы 10 20 foo 30 40 \ выходы 30 40
Finis.
Нравится:
Нравится Загрузка …
СвязанныеForth за 7 простых шагов • JeeLabs
Forth — простой язык с простыми правилами и простой моделью выполнения. Он также является автономным и интерактивный — вы можете ввести это в командной строке:
В ответ вы получите следующее (подробности могут отличаться, все ниже для Mecrisp Forth):
1 2+.добавлен Forth Весь код разбирается на последовательность «слов», которая может быть любой между
пробел. Приведенный выше код состоит из 4 слов: 1 , 2 , + и . — эти
слова работают со стеком данных. Числа «проталкиваются» в стек, т.е.
сначала 
1 , затем 2 . Слово + предопределено, оно заменяет два стека
записи по одной, их сумма. Слово . выводит наивысшее значение из
stack и печатает как число с пробелом.
Поскольку слов больше не осталось, Mecrisp печатает ok. , за которым следует
перевод строки и ждет, пока будет проанализирована новая строка текста, чтобы можно было обработать больше
слова.
Вот и все. Суть форта. Еще несколько таких шагов, и у вас будет полная история.
Чтобы определить это как новое слово demo , введите это (давайте опустим очевидное
закрытие с этого момента):
Слово : начинает определение, а слово ; заканчивает это.добавлен Forth
Новые слова должны быть определены в терминах существующих. Вот еще одно определение:
: JC's-Triple-demo demo demo demo; Имена слов могут быть любыми, кроме пробелов (включая UTF-8 и даже 1 или 2 — но это может привести к большой путанице).
Это шаг 2, теперь вы знаете, как расширить язык.
Определение слов — важный механизм. Вы уже видели данные стек, но есть также стек для слов и их скомпилированного кода, который называется «словарь» в форте.В конец добавляются новые слова, а слова искали в обратном порядке, так что последний будет использоваться, когда слова переопределено.
Слово : является особенным: оно будет анализировать следующее слово во входных данных.
stream и добавьте его как новое определение в словарь. Он также устанавливает
«Состояние» флага для режима компиляции. И затем он возвращается в основной цикл в Forth, чтобы
обработать все остальные слова.
А вот и большая уловка, часть 1: основной цикл анализирует больше слов, но так как флаг состояния установлен, добавит вызовов к этим словам в словарь вместо их выполнения.
В какой-то момент Форт должен будет завершить определение и вернуться в рабочий режим.
Большой трюк, часть 2: слово можно пометить как «немедленно». Когда это
в случае, переопределяет логику состояния в основном цикле и выполняется правильно
прочь, даже в режиме компиляции. Итак, сразу же есть
Когда это
в случае, переопределяет логику состояния в основном цикле и выполняется правильно
прочь, даже в режиме компиляции. Итак, сразу же есть ; слов на форте,
выполняет две вещи: добавляет оператор return в конец словаря и
сбросить флаг состояния в ноль.
Мгновенные слова активируют магическое поведение в форте, потому что они переключают вернуться в режим работы во время компиляции .Они могут делать все, что угодно, (или больше точный: они — это фактически компилятор).
Это шаг 3. Так Forth объединяет «режим выполнения» и «режим компиляции».
Forth имеет условные выражения и циклы. Вот переписанная версия вышеупомянутого:
: loop-demo 3 0 do demo loop; К настоящему времени это должно быть доступно для чтения: 3 и 0 просто добавляются в стек, делать выталкивает их как пределы цикла (в напуганном обратном порядке), затем идет тело цикла,
за которым следует цикл , который предположительно умеет считать и повторять, и
закрывающая точка с запятой, чтобы завершить определение loop-demo .
Неудивительно, что do и loop являются непосредственными словами. Они
добавить код в словарь для реализации цикла do и использовать стек данных
(в режиме компиляции) для отслеживания смещений ветвей. Еще есть слово i чтобы поместить текущее значение цикла в стек. Как видите, общие слова в
Форт обычно имеет очень короткие названия.
Этот пример повторяется до тех пор, пока не будет нажата клавиша (клавиша ? устанавливает флаг на
стек, который используется с по ):
: скучно-демо начать демо-ключ? до того как ; Поскольку , если , делают , начинают и т. Д., Генерируют код, они могут использоваться только внутри определения слов.Вы не можете использовать их в интерактивном режиме, то есть в рабочем режиме, но вы может ввести определение и вызвать его в одной строке.
Непосредственные слова также используются для реализации , если , , иначе , , затем , и несколько
другие слова, основанные на прыжках. Напуганный порядок
Напуганный порядок иначе и , затем занимает немного
привыкаю, но мелочи банальные:
: even-demo 123 2 mod 0 = if. "EVEN!" тогда ;
: even-odd-demo 123 2 mod 0 = если "ЧЕТНЫЙ!" еще ." СТРАННЫЙ!" тогда ; Здесь использовано несколько новых слов. Слово mod используется для вычисления
по модулю два, = сравнивает два значения, а . "..." печатает строку. Примечание
пробел после вводной цитаты: в Forth, все, что — это слово, поэтому
слово print-string называется . " и должно быть заключено в пробелы. Также обратите внимание, что
закрывающая кавычка не требует не , потому что ." слов
особые трюки с парсингом.
Такие нестандартные детали синтаксиса проистекают из того факта, что Форт использует стеки и трактует все как слова — цена простых униформ данных + парсинг модель.
Поздравляю, это был шаг 4, с небольшим заглядыванием внутрь компилятора!
Слова могут вызывать другие слова, а циклы do могут быть вложенными (это может помочь
делать петли как особый способ многократно «вызывать» свое тело).
Это вложение — то же самое, что есть во всех других языках, с использованием «возврата» куча.В Forth стек возврата — это отдельная от стека данных. Это что дает языку его конкатенативный свойства (термин, придуманный спустя десятилетия после изобретения Форта).
Когда определенное слово выполняется, оно помещает указатель текущей инструкции на стек возврата и начинает выполнение собственного кода. Когда он возвращается, он появляется указатель инструкции возвращается из стека возврата и возобновляет работу с того места, где он оставался выключенный. Циклы Do также используют стек возврата для хранения некоторого состояния.
Стек возврата полностью открыт в Forth, что позволяет использовать некоторые удивительные трюки, например, одна линия реализация сопрограмм, а также простая совместная многозадачный выполнение.
При повседневном использовании имеют значение только стеки данных и возврата.
Словарь (т.е. стек кода) и стек для распределения переменных RAM из can
безопасно игнорировать большую часть времени.
А как насчет других данных? Вот определение константы и переменной:
123456789 постоянная MY-CONST
987654321 переменная my-var Константы — это всего лишь константы, их можно использовать везде, где требуется значение, и нажимать их значение в стеке данных при выполнении.добавлен Forth
Для выделения больших областей памяти в ОЗУ используется буфер : слово:
Это выделяет 200-байтовую выровненную по словам область в ОЗУ. Остается доступным
пока my-buffer находится в словаре. Выполнение my-buffer подтолкнет
адрес его буфера в стеке (данных).
Вы прошли шаг 5, теперь вы знаете все о стеках и памяти.
Как вы понимаете, в форте очень много слов, каждое со своим
собственное поведение и эффект стека.Встроенные комментарии между словами под названием ( и ) обычно используются для документирования слова, за которым следует комментарий \ о том, что
оно делает. Если
Если ! были определены в Forth (это не так, это примитив), он мог
задокументированы следующим образом:
:! (u | n a-addr -) \ Сохраняет одно число в памяти
...; Где u | n означает: целое число без знака или со знаком, а a-addr означает выровненный
адрес. Все до - — это то, что ожидается в качестве входных данных стека,
все, что находится после, является результатом стека (в этом примере ничего).Это просто
комментарии и соглашения, Форт все это пропустит.
Аналогично, + можно было бы определить как:
: + (u1 | n1 u2 | n2 - u3 | n3) ...; \ Дополнение Многие слова влияют только на стек данных, но некоторые — на стек возврата. Вот так:
:> r (x -) (R: - x) ...; Это говорит о том, что значение в стеке данных перед вызовом > r закончится
на возвратите стек после этого: поэтому > r перемещает элемент из стека данных в
возвратный стек (лучше снять его снова с r> или rdrop перед
текущее слово возвращается, иначе код, вероятно, выйдет из строя!).
Эти комментарии к эффектам стека являются важной частью документации каждого word, поскольку в Forth обычно нет локальных переменных.
Вот глоссарий предопределенные слова в Mecrisp Forth. Их несколько сотен, но нет заботы: вы можете исследовать и постепенно расширять свой словарный запас — только часть из них необходимы, чтобы начать программировать на форте.
Да, шаг 6 — вы готовы пополнить свой словарный запас Forth!
Последний шаг, который остается, — это попробовать что-то и найти примеры и многое другое. документация в сети.См. Серию «Dive into Forth», часть один, два, и три за недавний исследования здесь, в JeeLabs. В ШИМ модуль (задокументированный здесь) показывает один пример того, как реализовать аппаратную функцию в Forth.
Старый, но полезный материал см. В разделе «Мышление».
Четвертый и стартовый
Четвертые книги Лео Броди, Джулиана
Благородный
вступление,
документы на сайте four.org,
и ссылки, упомянутые на
Форум.
И последнее, что нужно отметить, это то, что Форт живет чрезвычайно «близко к металлу».Любой предложение высокоуровневого кодирования — чисто дым и зеркала. Достаточно быть разумно полезным, а также позволять компилировать и расширять его с помощью больше определений, чтобы делать то, что вам нужно.
И вот оно: Четверть через тысячу шестьсот, эм… слов. Надеюсь, это Введение может помочь вам понять интригующе мощную и лаконичную язык программирования.
Кто или Кого? Каждый раз добивайтесь правильного результата с помощью этих трех приемов
Следует ли использовать , кто, , или , который сбивает с толку множество людей.Основное правило достаточно простое, но даже самые опытные редакторы и писатели могут наткнуться на предложения вроде следующего:
Подумайте о том, кого вы хотите покрыть и кто имеет право на покрытие.
Отчасти проблема в том, что предложение звучит совершенно естественно. И вообще, в повседневном разговоре это нормально. Но в более формальном контексте и, чтобы быть грамматически правильным, первый , который , должен быть , который .
Ниже мы расскажем о трех приемах, как определить, правильно ли , кто , или , кто .
Уловка № 1
Часто повторяемый совет для запоминания того, следует ли использовать who или who : если вы можете заменить слово на he или she или другое местоимение подлежащего, используйте who . Если вы можете заменить его на , его или , ее (или другое местоимение-объект), используйте вместо . Один из способов запомнить этот трюк состоит в том, что и , и , и , которые заканчиваются на буквой m .Так, например:
[Кого / кого] вы любите? Вы любите его ? Вы бы не сказали: «Ты его любишь?» Итак, , а правильный (извините, Бо Диддли).
[Кто / Кто] пишет песни. Он пишет песни. Вы бы не сказали: «Он пишет песни». Так что , кто прав.
Это устройство также работает, когда мы разбираем первый пример в начале этого поста:
Подумайте о [кого / кого] вы хотите прикрыть.Подумайте, хотите ли вы накрыть ему . Так что , который правильно .
Подумайте, [кто / кто] имеет право на страховое покрытие. Подумайте, имеет ли право he страховое покрытие. Так что , кто прав.
Уловка №2
Если первый трюк вам не подходит, попробуйте этот:
- Найдите все глаголы в предложении.
- Найдите подлежащее, соответствующее каждому глаголу.
- Если кто / кто является субъектом (выполняющим действие), используйте who .
- Если кто / кем является объектом (тот, кто получает действие), используйте who .
Давайте посмотрим на наш первый пример: Think о том, кто вы хотите охватить и , кто имеет право на покрытие.
- Глаголы в оранжевом : думают , хотят и это .
- Испытуемые в зеленом : вы (подразумевается), вы и кто .
- Поскольку второй who является субъектом последнего предложения, правильно who .
- Поскольку первый , который не является субъектом, он должен быть объектом (т.е. он получает покрытие), поэтому , которому требуется : подумайте о , которого вы хотите охватить.
Уловка № 3
Этот трюк на самом деле является вариацией на No.2. Если письменные объяснения предметных и объектных местоимений — или грамматики в целом — вызывают у вас головокружение, может помочь более наглядный подход.
Вот наше первоначальное предложение: Подумайте, кого вы хотите освещать и кто имеет право на покрытие.
Давайте разберемся с тем, о чем он действительно спрашивает:
| Две вещи, о которых следует подумать | |
| Кого вы хотите прикрыть | Кто имеет право на страховое покрытие |
Поскольку оба элемента являются объектами мыслей человека, имеется тенденция к желанию использовать , которое на основе субъекта = кто и объект = кого рассуждения выше.
Но вам нужно взглянуть на каждый объект в целом , чтобы определить, как who / who работает в этом предложении, ПЕРЕД анализом того, как каждое предложение функционирует в предложении.
Вот визуальный способ сделать это. В каждом предложении подчеркните тему и выделите глагол. Если who / who подчеркнут, используйте who. Все оставшиеся экземпляры who / who являются объектом, поэтому используйте для них who / . Возвращаясь к нашему примеру:
| Две вещи, о которых следует подумать | |
| Кого вы хотите прикрыть | Кто имеет право на страховое покрытие |
***
Дайте нам знать в комментариях ниже, полезны ли эти уловки, или не стесняйтесь делиться своими собственными!
алгоритм — Как распознать слова в тексте с лексемами, отличными от слов?
Хотя я в целом согласен с ответом Шуша, его подход позволяет легко добиться высокой полноты, но также и низкой точности, т.е.е. вы получите почти все настоящие слова, но также много не слов. Если ваше определение слова слишком ограничительно, это наоборот, но это тоже не то, что вам нужно, так как тогда вы пропустите такие случаи, как «zebra123». Итак, вот несколько идей о том, как повысить точность:
Возможно, стоит подумать, если бы вы могли определить, какие части электронного письма относятся к основному тексту, а какие — к нижним колонтитулам, таким как подписи pgp. Я уверен, что можно найти простые эвристики, подходящие для большинства случаев, например.грамм. вырезать все, что находится ниже строки, состоящей только из символов ‘-‘-.
В зависимости от ваших критериев производительности вы можете проверить, является ли слово реальным словом или содержит реальное слово, сопоставив его с простым списком слов. В сети легко найти исчерпывающие списки английских слов, и вы также можете составить их самостоятельно, извлекая слова из большого и чистого текстового корпуса.
Используя лексический анализатор, вы можете отфильтровать каждый токен, помеченный как неизвестный.
Некоторые простые статистические данные могут сказать вам, насколько вероятно, что что-то является словом. Часто встречающиеся токены — это, скорее всего, слова. Жетоны, которые появляются только один раз или количество которых ниже определенного порога, скорее всего, не являются словами. Распространенные орфографические ошибки должны появляться более одного раза, а необычные можно игнорировать.
В некоторых случаях эти предложения явно не работают для таких случаев, как «zebra123». Опять же, простое обрезание или разделение внутрисловных чисел может помочь.
Мой общий подход заключался бы в том, чтобы сначала идентифицировать токены, которые определенно являются словами (используя предложения выше), затем идентифицировать токены, которые определенно не являются словами (используя регулярное выражение), а затем смотреть (своими глазами) на несколько сотен или тысяч оставшиеся жетоны, чтобы найти общие характеристики, чтобы обрабатывать их отдельно.
Компактное представление деревьев синтаксического анализа
Компактное представление деревьев синтаксического анализаДалее: Анализ Word-графов с вероятностями Up: Эффективное внедрение Предыдущая: Выборочная запоминание и ослабление цели
Часто проводится различие между , распознаванием и парсинг .Распознавание проверяет, может ли данное предложение быть генерируется грамматикой. Обычно распознаватели можно адаптировать к сможет восстановить возможные деревья синтаксического анализа этого предложения (если любой).
В контексте грамматики с определенными предложениями это различие часто размывается, потому что можно создать дерево разбора как часть сложных нетерминальных символов. Таким образом дерево синтаксического анализа предложения может быть построено как побочный эффект фаза распознавания. Если нас интересуют логические формы аналогичный прием можно использовать вместо деревьев синтаксического анализа.Результат из этого, однако, заключается в том, что уже во время распознавания неоднозначности будут приводят к (возможно, экспоненциальному) увеличению времени обработки.
По этой причине мы будем предполагать, что деревья синтаксического анализа — это , а не , построенные
грамматики, но, скорее, это ответственность парсера. Этот
позволяет использовать эффективные методы упаковки . Результат
синтаксическим анализатором будет лес синтаксического анализа : компактное представление
все возможные деревья синтаксического анализа, а не перечисление всего синтаксического анализа
деревья.
Структура «синтаксического леса» в синтаксическом анализаторе угла головы такова: довольно необычно, и поэтому нам потребуется время, чтобы это объяснить. Поскольку синтаксический анализатор в углу головы использует выборочную мемоизацию, традиционные подходы к построению синтаксического леса [2] не применимы. Парсер в углу головы поддерживает таблицу частные деревья деривации, каждое из которых представляет собой успешный путь от лексическая голова (или пробел) до целевой категории. Таблица, состоящая из такие частичные деревья синтаксического анализа называются таблицей истории; его предметы история-предметы.
В частности, каждый элемент истории представляет собой тройку, состоящую из ссылка на элемент результата, имя правила и список троек. Правило имя — это всегда название правила без дочерей (т. е. лексическое вступление или пробел): (лексическая) голова. Каждая тройка в списке тройки представляет собой локальное дерево. Он состоит из названия правила и двух списки ссылок на элементы результата (представляющие список дочерних слева от головы наоборот, а список дочерей справа от глава). Пример прояснит это.Предположим, у нас есть элемент истории:
Таблица истории — это лексикальная грамматика подстановки деревьев, в которой все узлы (кроме узлов подстановки) связаны с правилом идентификатор (исходной грамматики). Эта грамматика выводит в точности все деревья вывода входных данных. 5 В качестве примера рассмотрим грамматика, которая используется в [24] и [2], приведенные здесь в (4) и (4).
Предложение «Я вижу дома мужчину» имеет два происхождения, согласно эта грамматика. Грамматика подстановки лексического дерева в рисунок 5, созданный парсером head-corner, выводит именно эти два вывода. Обратите внимание, что ссылки на элементы используются так же, как и
компьютерные имена нетерминалов в подходе
[2]. Потому что мы используем куски деревьев синтаксического анализа
возможна меньшая упаковка, чем в их подходе.Соответственно,
теоретические требования к пространству наихудшего случая тоже хуже. На практике,
однако это не кажется проблемой: в нашем
экспериментов размер таблицы истории всегда намного меньше, чем
размер других таблиц (это ожидается, потому что последние
таблицы должны записывать сложную информацию о категориях).
Давайте теперь посмотрим, как можно адаптировать парсер из предыдущего раздела.
чтобы иметь возможность утверждать элементы истории. Сначала мы добавляем (output-)
аргумент предиката синтаксического анализа.Шестой аргумент —
ссылка на фактически использованный элемент результата. Предикаты к
анализировать список дочерей пополняется списком таких
Рекомендации. Это позволяет построить термин для каждого местного
дерево в предикате head_corner, состоящее из имени правила
который был применен, и список ссылок использованных элементов результатов
для левой и правой дочерей этого правила. Такое местное дерево
представление — это элемент списка, который поддерживается для каждого
лексическая голова вверх к своей цели.Таким образом, такой список представлен в
снизу вверх все правила и элементы результатов, которые использовались для показа
что эта лексическая фраза действительно была в центре внимания. Если
цель синтаксического анализа была решена, тогда этот список, содержащий историю
информация утверждается в таблице нового типа: таблица ‘HISTORY_ITEM’ / 3. 6
Мы уже утверждали выше, что деревья синтаксического анализа не должны быть явно определено в грамматике. Логические формы часто неявно представляют деривационная история категории.Следовательно обычное использование логических форм как части категорий будет означать, что вы вряд ли когда-нибудь найдете два разных анализа для одного категории, потому что два разных анализа также будут иметь два разные логические формы. Таким образом, упаковка невозможна, и распознаватель будет вести себя так, как если бы он перечислял все деревья синтаксического анализа. Решение этой проблемы — отложить оценку семантической ограничения. На первом этапе все ограничения, относящиеся к логические формы игнорируются. Только если дерево синтаксического анализа восстановлено из parse-forest добавляем ограничения логической формы.Это похоже на подход разработан в CLE [1].
Такой подход может привести к ситуации, когда вторая фаза фактически отфильтровывает некоторые возможные в противном случае деривации, если построение логических форм не композиционное в соответствующий смысл. В таких случаях можно сказать, что первая фаза ненадежен в том смысле, что допускает грамматические дериваты. Первый этап в сочетании со второй фазой конечно еще звук. Более того, если бы такая ситуация возникала очень часто, то первая фаза как правило, бесполезны, и вся работа должна выполняться во время фаза восстановления.Современная архитектура головного парсера воплощает предположение, что такие случаи редки, и что построение логических форм является композиционным.
Составляется различие между семантической и синтаксической информацией. в правила грамматики на основе объявления пользователя. Мы просто Предположим, что на первом этапе синтаксический анализатор обращается только к синтаксическому информации, тогда как на втором этапе как синтаксический, так и семантический информация учтена.
Если предположить, что грамматика строит логические формы, то это не так. Понятно, что мы вообще заинтересованы в деревьях синтаксического разбора. Упрощенный может быть определена версия предиката восстановления, в которой мы только восстановить семантическую информацию корневой категории, но в которой мы не строите деревья синтаксического анализа. Упрощенный вариант можно рассматривать как версия времени выполнения, тогда как деревья синтаксического анализа по-прежнему будут очень полезны для развития грамматики.
Далее: Анализ Word-графов с вероятностями Up: Эффективное внедрение Предыдущая: Выборочная запоминание и ослабление цели Норд Г.Дж. М. ван
1998-09-24
#awesome trick — Извлечение слова по позиции с помощью FILTERXML () »Chandoo.org
Это СУМАСШЕСТВИЕ !!!. Я наткнулся на странное использование FILTERXML (), когда читал сегодня сообщение на форуме. Так что мне не терпелось проверить это. Рад поделиться результатами.
Допустим, у вас есть текст (предложение / фраза / ключевое слово и т. Д.) В ячейке, и вы хотите извлечь n-е слово. К сожалению, в Excel нет формулы SPLIT (). В итоге мы пишем до неприличия длинные формулы массива или используем множество вспомогательных столбцов.
Вот супер-хитрый трюк. Вместо этого используйте FILTERXML ().
См. Этот пример
Как извлекать слова из предложения с помощью FILTERXML
Допустим, у вас есть длинное предложение (или ключевое слово) в ячейке C3.
Шаг 1. Преобразуйте это в действительный XML
Звучит сложно, но это так. Все, что вам нужно сделать, это префикс, вставить и суффикс некоторых тегов. Как это:
= " " & SUBSTITUTE (C3, "", " ") & " "
Это превратит C3 в допустимый блок XML с каждым словом как узел .
Шаг 2. Используйте FILTERXML для извлечения слов
Теперь, когда у нас есть действующий XML, вы можете сказать = FILTERXML (C5, «/ DATA / A [3]»)
, чтобы извлечь третье слово из нашего предложения, преобразованного в XML.
Шаг 3: Шагов больше нет. Наслаждайтесь FILTERXML.
Бонусный трюк: Используйте [last ()], чтобы получить последнее слово. Например, = FILTERXML (C5, «/ DATA / A [last ()]») даст вам последнее слово из предложения.
Посмотрите это — как извлекать слова с помощью FILTERXML () в Excel
Я был так взволнован, узнав об этом, что записал видео прямо в халате.Оценка A (за крутизну), проверьте это ниже или на моей странице на YouTube .
Скачать пример рабочей тетради
Щелкните здесь, чтобы загрузить файл с примером этого совета. Поиграйте с FILTERXML, чтобы узнать больше.
Подробнее о XML и XPATH
Если вы хотите узнать, как работают XML и Xpath, посетите эти страницы.
Что делать, если вы не можете использовать FILTERXML?
FILTERXML работает в Excel 2013 или более поздних версиях. Но если вы используете старую версию Excel или Excel для Mac, то вы не можете полагаться на этот метод. Ознакомьтесь с двумя примерами ниже, чтобы узнать о других способах разделения и извлечения слов из предложений.