Как разобрать слово существует по составу
В каком слове правописание суффикса определяется правилом «В бесприставочном причастии совершенного вида пишется «НН»? Укажите правильный вариант отве … та: 1)неизменным 2)брошенная 3)смягчённый 4)постоянный
Помогите пожалуйстаНапишите письмо Лёле. Выразите своё отношение к поступку девочки. Вам помогут следующие вопросы:1.Какие чувства вызывает у вас Куса … ка?2.Как вы оцениваете поступок Лёли?3.Что бы вы сделали на её месте?4.Что бы вы хотели сказать или посоветовать ЛёлеНе меньше 100 слов
стебель тонкий, а ствол____________.
в 5-м предложений найди слово, Состав которого соот-ветствует схеме: корень суфикс , окончанте Выпиши это слово, обозначь его части.предложение: скоро … мой друг рассказал мне,что один охотник продает хорошую взрослую собаку
Составьте и запишите диалог на тему история семьи Краткий диалог 4 класс
Подберите к данным глаголам синонимы и антонимы из слов для выбора. Образец: Веселиться — радоваться, грустить.Веселиться, торопиться, отнимать, обожа … ть, загрязнить, гасить, закрыть, закончить, отталкивать.Слова для выбора: спешить,спешить, радоваться, отби-рать, медлить, дарить, ненавидеть, испачкать,отпихивать, любить, начать, отчистить, грустить,тушить, затворить, зажигать, открыть, завершить,притягивать.
здравствуйте памагите пожалуйста если не знаете не пешите
Прочитай текст. Определи время глаголов время глаголовВесь мир знаетV) ГалилеоГалилея как выдающегося итальянского астронома. Этотучёный усовершенство … вал (телескоп и с его помощью доказал (м), что мы живём (м) на планете Земля, котораявращается () вокруг Солнца.ВПроверить
замени данные в скобках имена существительные однокоренными именами прилагательными запиши получившиеся словосочетания выдели окончания имен прилагате … льных укажи их род. (тростник) сахар — (гигант) завод — (честь) слово — (доблесть) труд — (известность) артистка — (капуста) лист — (местность) жительница — Помогите пожалуйста!
Упражнение 326 помогитее ответ
Как разобрать слово по составу? Пример морфемного разбора
Разобрать слово по составу следует, указав следующие морфемы: приставку, корень, суффикс, окончание, соединительную морфему, постфикс.
Окончание в составе слова
Выполнение разбора слова по составу, обычно необходимо начинать с выделения окончания, которое не входит в его основу. Для этого определим, изменяемое ли слово перед нами, есть ли у него окончание. С этой точки зрения важно, к какой части речи относится анализируемая лексема.
Помним, что у неизменяемых частей речи и форм слов нет окончания:
1. у несклоняемых существительных
- драже, метро, такси, рагу, каноэ, боа.
2. У несклоняемых прилагательных
- платье миди;
- юбка гофре;
- язык ханты;
- вес нетто;
- брюки хаки.
3. У наречий на конце вычленим только суффиксы:
- быстро
- неспроста
- врукопашную
- по-польски
4. В морфемном составе деепричастий имеются формообразующие суффиксы:
- гулять — гуляя
- сбежать — сбежав
- открыть — открывши
- нести — нёсши
5. В форме простой сравнительной степени прилагательных и наречий вычленим суффиксы:
- ходить тише;
- стало радостнее;
- говорите громче.
Основа слова
Выделив окончание в изменяемом слове, которое склоняется, спрягается или изменяется по родам и числам, остальную часть лексемы обозначим как основу слова.
- создание
- красивый
- двадцатый
- отправим
Помним, что в основу слова не входят формообразующие суффиксы причастий, деепричастий, формы прошедшего времени глагола, постфикс формы повелительного наклонения глагола -те, суффиксы простой сравнительной степени прилагательных и наречий.
Примеры
- лелеющий ребенка
- вылинявшая рубашка
- видимый издали
- задуманный проект
- растертый в порошок
- гуляя по набережной
- открыв книгу
- вычертила график
- нарежьте кусочками
- шагать веселее
- стал слаще
Приставка в составе слова
Затем выделим приставку в слове, если она есть. Чтобы убедиться, есть ли эта морфема в слове, можно убрать ее и посмотреть, существует ли в лексике русского языка такое самостоятельное слово, или, второй вариант проверки, — менять предполагаемую приставку на другую:
Чтобы убедиться, есть ли эта морфема в слове, можно убрать ее и посмотреть, существует ли в лексике русского языка такое самостоятельное слово, или, второй вариант проверки, — менять предполагаемую приставку на другую:
сорвать — рвать; оторвать, надорвать, перервать, урвать.
Результативным способом определения приставки в составе слова является подбор лексем с такой же приставкой:
содрать, собрать, совместить, согласиться.
В морфемном составе лексемы может быть несколько приставок, тогда целесообразно составить словообразовательную цепочку и добраться до первого производящего слова:
небезынтересный — безынтересный — интересный.
Суффикс в составе слов
Теперь займемся суффиксом слова. Посмотрим, существует ли слово без такого суффикса:
- седина — седой,;
- вкладчик — вклад;
- бодрость — бодр, бодрый.
Подберем слова с таким же суффиксом и убедимся, что такой суффикс существует:
бодрость — нежность, весёлость, радость.
И теперь после последовательного вычленения всех морфем осталась главная часть слова — корень. Чтобы точно определить границы корня и убедиться, правильно ли мы его выделили, займемся подбором родственных слов. Как известно, общая часть родственных слов, в которой заключено основное лексическое значение слова, и есть корень.
Бодрость — бодрый, бодро (шагать), бодренький, бодриться.
Пример разбора слова по составу
Рассмотрим в качестве примера морфемный разбор слова «безрадостный».
Это изменяемое прилагательное, значит, вычленим окончание -ый, сравнив его формы:
- безрадостная неделя;
- безрадостное настроение;
- безрадостные новости.


Определим основу слова — безрадостн-:
безрадостный
Далее укажем приставку без-, как и в составе слов:
- бездомный
- безработный
Чтобы вычленить суффиксы в слове «безрадостный», восстановим словообразовательную цепочку:
безрадостный ← радостный ← радость ← рад (нет полной формы прилагательного).
Как видим, в составе прилагательного можем выделить суффиксы -ость-, -н-.
Оставшаяся часть слова -рад- является корнем, который прослеживается в родственных словах:
- радость
- радостный
- радовать (ся)
Закончим разбор по составу итоговой записью:
безрадостный — приставка/корень/суффикс/суффикс/окончание
Видеоурок «Разбор глагола по составу»
Скачать статью: PDFРазбор по составу слова существует please
Однажды какой-то человек кинул возле Байкала мусор .Я сказал ему не надо платить не надо кидать возле Байкала мусор пускай он живёт. Потом мы с подругой плавали возле Байкала и увидели что на берегу его ужасно много мусора. мы все убрали решили Живи Байкал пока мы рядом.
ЧАСТИЦА «ПУСКАЙ»
Я думаю, что даже через 50лет русский язык не изменится. Алфавит останется тем же, что и сейчас. Ну а слова, конечно же, будут новые.
Алфавит останется тем же, что и сейчас. Ну а слова, конечно же, будут новые.
Сделать по-другому
Разделить поровну
Поступить по уму
Простить по-дружески
Светить по-летнему
Вести хозяйство по-крестьянски
Дружить по-искренному
Говорить по-немецки
Занятие, по-видимому, не состоится
Поступить по-товарищески
Одеваться по-французски
Репортаж с открытия выставки «Современное необычное искусство»
Сегодня мы поведем наш репортаж с выставки, открывшейся в Музее изобразительного искусства. Тема выставки — «Современное искусство». Прямо у входа нас встречает необычная скульптура, изготовленная из пластиковых бутылок. Чуть дальше стоит велосипед, где вместо колес привинчены большие кубы, а вместо руля — шар. Еще одним необычным экспонатом выставки является скульптура человека во весь рост, изготовленная полностью из…вышедших из строя компьютеров!
На выставке много людей. были замечены несколько известных художников и скульпторов.
Эта выставка — новое слово в искусстве. Приходите, не пожалеете!
словообразование — Слова без корня
В русском языке имеется громадное количество слов, в которых нет корня.
Источник: А может так быть, чтобы в слове не было корня? В каком слове нет корня? | bolshoyvopros.ru.
В русском языке, как ни странно, существуют слова без корня. Это глаголы снять, поднять, принять, занять, вынуть, взять, изъять и т. д. Они образованы таким способом: приставка, суффикс -н (встречается не во всех), глагольный суффикс и окончание. Ко всем этим глаголам можно подобрать пару несовершенного вида, которая будет содержать в себе морфему «-им-«: поднимать, принимать и т. д. Как ни странно, это корень этих слов. Все они образованы от слова «иметь». То есть, хотя эти слова между собой имеют мало общего, они образованы от одного и того же слова. Также от этих слов образуются существительные или прилагательные, имеющие в своём составе морфему «-ём-» или «-йм-«: приём, займ, выемный. Это тот же корень, но здесь происходит чередование.
Источник: Слова без корня в русском языке | pikabu.ru.
В русском языке слов, у которых не было бы корня, нет. Существует лишь одно исключение – это глагол «вынуть», где «вы-» — это приставка, «ну» — это суффикс, а «ть» — это суффикс, характерный для формы инфинитива.
Но и здесь не все так однозначно. Некоторые языковеды относят этот глагол к тем немногим словам, у которых исходного корня в этимологическом плане просто не существует. Правда, это совсем не показатель того, что в его составе корня нет. Основа, которую именуют непроизводной, присуща всем словам без исключения, и она является тем самым компонентом, который мотивирует значение слова. Если говорить об описываемом глаголе, то его корень не совпадает с корнем, выделяемым в слове на момент возникновения этой лексической единицы в языке.
Характеризуемое слово образовывается от «яти» путем присоединения приставки «вы-». Это слово является аналогом современного «брать». Таким способом образуется немало и других слов, например: «внять» (с приставкой «вън-»), «взять» (с приставкой «въз-»), «изъять» (с приставкой «изъ-»), «объять» (с приставкой «объ») и т.д.
Исходная форма глагола «выяти» и «выимати», как и родственные слова «сняти» — «снимати», «вняти» — «внимати» со временем приобрела букву «н», которую можно назвать «вставочной». Следствием этого и стало появление таких форм, как «вынять» и «вынимать».
Позже форма «вынять» (совершенный вид) под влиянием звучания глаголов «кинуть», «сдвинуть», «стукнуть», «сгинуть» и др. получила известную всем форму «вынуть». Здесь речь идет не только о таком явлении, как переразложение, но и о процессе аппликации морфем.
В настоящее время в глаголе «вынуть» (совершенный вид) непроизводной формой основы считается «-н-». Подобный однозвуковой вид является еще и суффиксом, форма выражения которого характеризуется однократностью действия (для сравнения: «вынь», «вынет», «вынут», «вынем»).
В современном русском разбор слова «вынуть» на морфемы будет выглядеть следующим образом: «вы-н-у-ть», где «вы-» — это приставка, «-н-» — это непроизводная форма, которая в других родственных словах чередуется с «-ем-» («выемка»), «-ним-» — («вынимать»), «-н-» — это и суффикс, указывающий на однократность действия, «-у-» — это суффикс, являющийся классовым показателем (аналогично суффиксам «-а-» — «звать», «-е-» — «тереть», «-о-» — «колоть»), «-ть» — элемент инфинитива.
Подытожив все вышесказанное, можно сказать, что с одной стороны, у слова «вынуть» есть корень, если принимать эту морфему за непроизводную форму, которая представляет собой стержень лексического значения слова. Но вместе с тем у этого глагола корня, под которым подразумевают «главный» исходный материал лексической единицы, нет.
Источник: РУССКИЙ ЯЗЫК — ЭТО МЫ | ok.ru.
Разбор по составу слово пулемет
Разбор слова по составу подразумевает деление его на отдельные морфемы: корень, окончание, приставка, суффикс. Существует схема анализа, облегчающая работу.
План морфемного состава слова
- Задать вопрос для определения части речи.
- Окончанием называют изменяемую часть слова. Меняем слово: спрягаем или склоняем, таким образом найдем эту часть.
- Основа — оставшаяся после отделения окончания часть слова. Там будем искать корень, приставку и суффикс.
- Корнем называют общую часть родственных слов. Чтобы корректно выделить, ищем максимально возможное количество однокоренных слов.
- Приставку ищем перед корнем, в начале слова.
- Суффикс находится после корня, перед окончанием.
Не во всех словах присутствуют все морфемы.
Отсутствующее окончание, как в нашем слове «пулемет» называют нулевым. В неизменяемых словах, как наречие, деепричастие, нет окончаний.
Много слов без приставки и без суффикса, как в нашем случае в слове «пулемет». В то же время можно найти и с несколькими приставками, суффиксами и даже корнями. В слове «пуленепробиваемый» два суффикса, две приставки и два корня.
Суффикс «ся» (или «сь») , стоящий после окончания называют постфикс. Основная функция у суффикса — образование новых слов. Суффикс «л» используют для образования прошедшего времени глагола и он не входит в основу. В слове «запылился» постфикс «ся» стоит в конце слова, после окончания. Суффикс «л» образовал прошедшее время, не входит в состав основы.
Суффикс «л» образовал прошедшее время, не входит в состав основы.
Морфемный разбор слова «пулемет»
- Вопрос, на который отвечает слово «что?» — существительное.
- «Пулеметом», «пулемету», «пулеметы», «пулеметами» — так определили окончание слова, оно нулевое.
- Основа — все слово «пулемет».
- Однокоренные слова: «бомбометание», «пулеметчица», «пуля», «пулять», «разметаться», «гранатометчик», «противопульный», «бомбомет», «гранатомет», «взметнуться», «пулевой», «пулеметный», «пулька», «минометчик», «миномет»», «минометный», «пуленепробиваемый», «пулелитейный». В нашем слове будет два корня «пул» и «мет».
- Приставки в слове нет.
- Суффикса нет.
haskell — Разбор элемента, который может существовать или не существовать с библиотекой HXT
У меня проблема с HXT. Я хочу разобрать файл совы, и у меня проблема со стрелкой, потому что он не хочет разбирать дерево! Я видел, что проблема в том: Во-первых, код:
import System.Environment --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] <- getArgs
parser <- runX (readDocument [withValidate no] src >>> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = getAttrValue "rdf: ресурс"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className <- parseClass - , при этом я должен иметь возможность анализировать файл совы на каждом узле, где он существует, в этом примере:
Но когда я хочу разобрать такое дерево, оно просто не вычисляет и не выбрасывает его!
<сова: эквиваленткласс>
<сова: Класс>
0
Почему? Потому что узла подкласса не существует! Но я хочу, чтобы класс был доступен там, и поместил его в мои данные, даже если подкласс не существует! Итак, как это возможно?
Моя последняя версия:
Система импорта. Окружающая среда --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] <- getArgs
parser <- runX (readDocument [withValidate no] src >>> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = (getAttrValue "rdf: resource") `orElse` arr (const" ")
--Test (é Preciso Reesta Definição) uma falha se o nome tiver o "#"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className <- parseClass -  Окружающая среда --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] <- getArgs
parser <- runX (readDocument [withValidate no] src >>> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = (getAttrValue "rdf: resource") `orElse` arr (const" ")
--Test (é Preciso Reesta Definição) uma falha se o nome tiver o "#"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className <- parseClass -
Окружающая среда --para uso do getArgs
импортировать Data.List.Split (splitOn)
data Class = Class {
имя :: Строка,
subClassOf :: String
} извлечение (Показать, уравнение)
main = делать
[src] <- getArgs
parser <- runX (readDocument [withValidate no] src >>> getClass)
парсер печати
parseClass = ifA (hasAttr "rdf: about") (getAttrValue "rdf: about") (getAttrValue "rdf: ID")
parseSubClass = (getAttrValue "rdf: resource") `orElse` arr (const" ")
--Test (é Preciso Reesta Definição) uma falha se o nome tiver o "#"
split l = if (length (splitOn "#" l)> 1) then (splitOn "#" l !! 1) else l
atTag tag = deep (isElem >>> hasName tag)
getClass = atTag "сова: класс" >>>
proc l -> делать
className <- parseClass - Dynamic Parsing - Sumo Logic
Dynamic Parsing позволяет автоматически извлекать поля из сообщений журнала JSON при выполнении поиска.Это позволяет просматривать поля из журналов JSON без необходимости вручную указывать логику синтаксического анализа.
Dynamic Parsing извлекает поля JSON при выполнении запроса во время поиска (время выполнения). Динамический синтаксический анализ для JSON можно рассматривать как правило извлечения поля времени выполнения (FER). По умолчанию вашей учетной записи предоставляется один FER времени выполнения, который охватывает все ваши данные.
Если этот FER определен, любой поиск данных JSON будет автоматически анализировать их поля JSON, которые вы затем можете использовать в своем поисковом запросе, как и любое другое поле.
У вас есть выбор из двух режимов на странице поиска, которые позволяют управлять динамическим анализом. Динамический синтаксический анализ активируется, когда поиск выполняется в режиме автоматического анализа , более подробную информацию о режимах можно найти в разделе «Использование динамического синтаксического анализа».
Преимущества использования динамического анализа
- В отличие от FER времени загрузки, где поля являются постоянными, даже когда FER редактируются или удаляются, FER времени выполнения и соответствующие им проанализированные поля могут быть обновлены или удалены в любой момент времени.
- Dynamic Parsing полезен, когда ваша схема журнала часто изменяется, например, если поля часто добавляются или удаляются, что особенно актуально для журналов настраиваемых приложений. Sumo автоматически обнаруживает изменение в вашей схеме и может соответствующим образом корректировать вывод.
Настроить динамический анализ
По умолчанию в вашей учетной записи настроен FER времени выполнения, который применяется ко всем вашим данным. Стандартное время выполнения FER с именем JSON Auto Parsing - All Sources нельзя редактировать или удалять.С этим настроенным FER вам не нужно ничего настраивать для использования динамического анализа. Однако применение одного FER ко всем вашим данным может быть не оптимальным для ваших нужд, поскольку оно будет применяться для каждого поискового запроса (включая те, которые могут не запрашивать какие-либо журналы JSON). Более подробную информацию можно найти в лучших практиках разработки правил.
Для оптимизации производительности поиска вы можете вручную настроить динамический анализ, указав свои собственные FER во время выполнения.
У FER времени выполненияесть область действия, точно такая же, как у FER времени загрузки, которая определяет, какие поиски применимы к динамическому синтаксическому анализу , автоматическому режиму анализа .Для работы динамического синтаксического анализа ваш запрос должен иметь область, определенную в FER времени выполнения, в противном случае Auto Parse Mode не будет применяться.
Перейти к Управление данными > Журналы > Правила извлечения полей .
Нажмите кнопку + Добавить в правом верхнем углу таблицы, чтобы создать FER.
Появляется следующая форма:
Введите следующие параметры:
Название правила .Введите имя, которое упрощает идентификацию правила.
Применяется по номеру . Выберите Время работы .
Объем . Выберите Specific Data и определите объем ваших данных JSON. Вы можете определить свой источник данных JSON как имя раздела (индекс), sourceCategory, имя хоста, имя сборщика или любые другие метаданные, которые описывают ваши данные JSON.Думайте о Scope как о первой части специального поиска перед первой вертикальной чертой (|). Вы будете использовать область действия, чтобы выполнить поиск по правилу. Вы не можете использовать в своей области такие ключевые слова, как «информация» или «ошибка».
Всегда настраивайте автоматическое извлечение JSON (извлечение поля времени выполнения) для определенного имени раздела (рекомендуется) или определенного источника. В противном случае логика автоматического анализа может работать в источниках данных, где она не применима, и приведет к дополнительным накладным расходам, которые могут ухудшить производительность ваших запросов. Лучшие методы для настройки Scope
Ниже приведены рекомендуемые подходы к настройке динамического синтаксического анализа JSON:- Если вы не используете разделы, мы рекомендуем использовать поля метаданных, такие как _sourceCategory, _sourceHost или _collector, для определения области.
- Мы рекомендуем создать отдельный раздел для набора данных JSON и использовать этот раздел в качестве области для извлечения поля времени выполнения. Например, предположим, что у вас есть журналы AWS Cloudtrail, и они хранятся в разделе
_index = cloudtrailв Sumo.Вы можете создать FER времени выполнения с областью действия_index = cloudtrail. Создание отдельного раздела и использование его в качестве области для извлечения поля времени выполнения гарантирует, что логика автоматического анализа применяется только к необходимым разделам.
Просмотрите данные формы и, когда будете удовлетворены, нажмите Сохранить .

 Например, предположим, что у вас есть журналы AWS Cloudtrail, и они хранятся в разделе
Например, предположим, что у вас есть журналы AWS Cloudtrail, и они хранятся в разделе Теперь, когда у вас есть хотя бы один созданный FER среды выполнения, вы можете начать запрашивать данные JSON, и поля внутри этих полезных данных JSON будут автоматически извлечены.
Использовать динамический анализ
Хотя FER времени выполнения настроен на автоматический запуск, вы можете выборочно применить их к своим поисковым запросам на странице поискового запроса журнала. Чтобы использовать динамический анализ, выберите Auto Parse Mode из раскрывающегося списка под полем Time Range, выделенным красным на снимке экрана ниже.
Доступны два режима:
- Режим автоматического анализа
- Будет анализировать все поля, обнаруженные в вашем источнике данных JSON, независимо от того, используете ли вы их в своем запросе или нет.
- Поддерживается в классических панелях мониторинга и поиске по расписанию. Этот режим применим только при поиске источников данных JSON, которые были правильно настроены в среде выполнения FER.
- Ручной режим
- Поля не будут анализироваться автоматически, если они не определены в FER времени загрузки. Пользователи должны вручную указать дальнейшую логику синтаксического анализа.
- Этот режим предназначен для опытных пользователей, которые заинтересованы в максимальной производительности и знают, как разбирать нужные поля.

Ссылка на проанализированные поля JSON
Обозреватель полей и таблица сообщений с результатами поиска имеют несколько полезных функций.
Обозреватель полей:
- Поле ввода для поиска позволяет искать поля по имени.
- структур JSON вложены с опциями разворачивания и сворачивания.
- Кнопка копирования доступна справа от каждого поля, что позволяет легко скопировать имя поля.
Таблица результатов поиска:
- Вы можете копировать имена полей из структур JSON. После выбора (щелкните и выделите) ключ JSON в результатах щелкните правой кнопкой мыши и выберите Копировать имя поля . См. Изменение поиска на вкладке сообщений для получения подробной информации о других предоставляемых параметрах.
При копировании имени поля с использованием этой опции автоматически форматируются имена полей, содержащие специальные символы. Например, имя поля, показанное на снимке экрана, - это общего временного ряда , оно будет автоматически отформатировано до % «общего временного ряда» для правильной работы в поисковом запросе.
- Кнопка копирования доступна справа от имени каждого столбца (поля), что позволяет легко скопировать имя поля.
Основные правила
FER времени выполнения применяются только к журналам, которые соответствуют области запроса. При выполнении поискового запроса сначала определяется, соответствует ли какой-либо из FER времени выполнения области действия запроса. Применяются те FER времени выполнения с совпадающей областью действия. FER во время выполнения применяются для каждой строки журнала, только если журнал содержит элемент JSON.
Например, FER времени выполнения с областью действия:
_sourcecategory = A- Запрос
_sourcecategory = Bне применяется, поскольку область действия не перекрывается областью FER времени выполнения. - Запрос
_sourcecategory = A или _sourcecategory = Bприменяется только к строкам журнала, которые попадают в_sourcecategory = A, в то время как остальные строки журнала не анализируются с помощью этого FER времени выполнения.
- Запрос
Если поле не существует в схеме сообщения журнала, для поля отображаются нулевые результаты (вместо ошибки).
FER времени приема имеют приоритет при назначении полей. FER времени выполнения не отменяет присвоение поля из FER времени приема.
Конфликты между полями загрузки и времени выполнения оцениваются каждой строкой журнала следующими способами:
Если поле «Время загрузки» имеет допустимое значение или пусто, а поле «Время выполнения» не существует, применяется значение из поля «Время загрузки».
Если поле «Время загрузки» не существует или пусто, а поле «Время выполнения» имеет допустимое значение или пусто, применяется значение из поля «Время выполнения».
Если оба поля Ingest и Run Time имеют допустимые значения, применяется значение из поля Ingest Time.
- Пробелы в именах полей автоматически переформатируются в символы подчеркивания.

Ограничения
Ограничения на количество полей
- Динамический анализ извлекает до 100 полей в сообщении. Это 100 полей включает все встроенные и проанализированные поля.
- Итоговые поля, отображаемые в браузере полей, состоят из всех полей, извлеченных по строкам журнала.
- Обозреватель полей отображает количество полей, а также распределение значений каждого поля. Эти вычисления выполняются для первых 200 полей, которые анализируются во время выполнения FER.
pydrake.multibody.parsing - документация pydrake
Разбор SDF и URDF для MultibodyPlant и SceneGraph.
- класс
pydrake.multibody.parsing.AddFrame -
__init__ Самостоятельная инициализация. См. Справку (type (self)) для точной подписи.
-
наименование Имя добавляемого фрейма. Если указана область действия, модель будет переопределена. пример; в противном случае будет использоваться экземпляр `X_PF.base_frame`s.
-
X_PF Поза добавляемой рамы,
F, w.r.t. родительская рамаP(как определяетсяX_PF.base_frame).
-
-
pydrake.multibody.parsing.GetScopedFrameByName( plant: pydrake.multibody.plant.MultibodyPlant_ [float], full_name: str ) → pydrake.multibody.tree.Frame_ [float] Эквивалент
GetScopedFrameByName Может быть, но выдает, если кадр не найден.
-
pydrake. Многотело.парсинг.GetScopedFrameName( plant: pydrake.multibody.plant.MultibodyPlant_ [float], кадр: pydrake.multibody.tree.Frame_ [float] ) → str Создает и возвращает имя кадра с заданной областью для запрошенного кадра.
-
pydrake.multibody.parsing.LoadModelDirectives( имя файла: str ) → pydrake.multibody.parsing.ModelDirectives
- класс
pydrake.multibody.parsing.МодельДиректива Структура верхнего уровня для схемы файла yaml директив модели.
-
__init__ Самостоятельная инициализация. См. Справку (type (self)) для точной подписи.
-
- класс
pydrake.multibody.parsing.ModelInstanceInfo Удобная структура для хранения всей информации для добавления модели экземпляр из файла.
-
__init__ Самостоятельная инициализация. См. Справку (type (self)) для точной подписи.
-
имя_детской_кадры Это имя кадра с незаданной областью, принадлежащее
model_instance.
-
модель_экземпляр
-
название_модели Название модели (возможно, область действия).
-
путь_модели Путь к файлу.
-
имя_ родительского_фрейма ПРЕДУПРЕЖДЕНИЕ - Это родительский кадр с незаданной областью , который считается уникальным.
-
X_PC
-

- класс
pydrake.multibody.parsing.PackageMap Сопоставляет имена пакетов ROS с их полным путем в локальной файловой системе. Это используется парсерами SDF и URDF при синтаксическом анализе файлов, которые ссылаются на Пакеты ROS для ресурсов, таких как файлы сетки.
-
__init__( self: pydrake.multibody.parsing.PackageMap ) → Нет Конструктор, инициализирующий пустую карту.
-
Добавить( self: pydrake.multibody.parsing.PackageMap , имя_пакета: str , путь_пакета: str ) → Нет Добавляет пакет
имя_пакетаи его путь,путь_пакета. Броски еслиpackage_nameуже присутствует в этой PackageMap, или еслипуть_пакетане существует.
-
AddPackageXml( self: pydrake.multibody.parsing.PackageMap , filename: str ) → Нет Добавляет запись в эту PackageMap для данного
package.xmlимя файла. Выдается, еслиfilenameне существует или его встроенное имя уже существует на этой карте.
-
Содержит( self: pydrake.multibody.parsing.PackageMap , имя_пакета: str ) → bool Возвращает true тогда и только тогда, когда эта PackageMap содержит
package_name.
-
GetPath( self: pydrake.multibody.parsing.PackageMap , имя_пакета: str ) → str Получает путь, связанный с пакетом
имя_пакета. Отменяет, если в этой PackageMap нет пакета с именемpackage_name.
-
PopulateFromEnvironment( self: pydrake.multibody.parsing.PackageMap , environment_variable: str ) → Нет Получает один или несколько путей из переменной среды
переменная среды.Ползет вниз по каталогу дерево (-а), начиная с пути (-ов) для поиска файловpackage.xml. Для каждого из этих файлов этот метод добавляет новую запись в этот PackageMap, где ключ - это имя пакета, как указано вpackage.xml, а значение - это путь к файлуpackage.xml. Можно указать несколько путей, разделив их с помощью символа «:» условное обозначение. Например, переменная среды может содержать [путь 1]: [путь 2]: [путь 3] для поиска трех разных путей.
-
PopulateFromFolder( self: pydrake.multibody.parsing.PackageMap , путь: str ) → Нет Обходит дерево каталогов, начиная с пути
package.xml. Для каждого из этих каталоги, этот метод добавляет новую запись в эту PackageMap, где ключ - это имя пакета, как указано вpackage.xmlи путь к каталогу - это значение.
-
PopulateUpstreamToDrake( self: pydrake.multibody.parsing.PackageMap , model_file: str ) → Нет Сканирует вверх по дереву каталогов от
model_fileдоdrakeпоискpackage.файлов. Добавляет пакеты, описанные эти файлы xml package.xml. Еслиmodel_fileотсутствует вdrake, этот метод возвращается, ничего не делая.- Параметр
файл_модели: - Файл модели, каталог которого является началом поиска
упаковка.xmlфайлов. Этот файл должен быть файлом SDF или URDF.
- Параметр
-
размер( self: pydrake.multibody.parsing.PackageMap ) → int Возвращает количество записей в этой PackageMap.
-

 xml
xml - класс
pydrake.multibody.parsing.Парсер Разбирает входные файлы SDF и URDF в MultibodyPlant и (необязательно) SceneGraph.
-
__init__( self: pydrake.multibody.parsing.Parser, plant: pydrake.multibody.plant.MultibodyPlant_ [float], scene_graph: pydrake.geometry.SceneGraph_ [float] = Нет ) → Нет Создает парсер, который добавляет модели к данному объекту и (необязательно) сцена_граф.
- Параметр
завод: - Указатель на изменяемый объект MultibodyPlant, для которого выполняется синтаксический анализ.
модель (ы) будут добавлены;
plant-> is_finalized ()должно остатьсяНеверно, пока заводэтим. - Параметр
граф_сцены: - Указатель на изменяемый объект SceneGraph, используемый для геометрии. регистрация (для моделирования визуальной или контактной геометрии). Может быть nullptr.
- Параметр
-
AddAllModelsFromFile( self: pydrake.multibody.parsing.Parser , имя_файла: str ) → Список [pydrake.multibody.tree.ModelInstanceIndex] Анализирует файл SDF или URDF с именем
Файлыимя_файлаи добавляет все его модели дозавод.SDF могут содержать несколько элементов
Файлыplantдля каждого тегаURDF содержат один элемент
будет добавлен в завод.- Параметр
имя_файла: - Имя анализируемого файла SDF или URDF. Тип файла будет выводиться из расширения.
Возвращает: Набор индексов экземпляра модели для вновь добавленных моделей. Вызывает: RuntimeError в случае ошибок. - Параметр
-
AddModelFromFile( self: pydrake.multibody.parsing.Parser , имя_файла: str , имя_модели: str = '' ) → pydrake.multibody.tree.ModelInstanceIndex Анализирует файл SDF или URDF с именем
имя_файлаи добавляет одну модель кзавод.Было бы ошибкой вызывать это, используя файл SDF с дополнительными чем один элемент- Параметр
имя_файла: - Имя анализируемого файла SDF или URDF. Тип файла будет выводиться из расширения.
- Параметр
имя_модели: - Имя, данное вновь созданному экземпляру этой модели. Если
пусто, атрибут name из
Возвращает: Индекс экземпляра для вновь добавленной модели. Вызывает: RuntimeError в случае ошибок. - Параметр
-
AddModelFromString( self: pydrake.multibody.parsing.Parser , file_contents: str , file_type: str , имя_модели: str = '' ) → pydrake.multibodyIndex.Model Анализирует данные SDF или URDF XML, переданные в
file_contentsи добавляет одну модель кplant. Вызывать это с помощью SDF - ошибка.
с более чем одним элементом - Параметр
file_contents: - Анализируемые XML-данные.
- Параметр
тип_файла: - Формат данных; должно быть либо «sdf», либо «urdf».
- Параметр
имя_модели: - Имя, данное вновь созданному экземпляру этой модели. Если
пусто, атрибут name из
Возвращает: Индекс экземпляра для вновь добавленной модели. Вызывает: RuntimeError в случае ошибок. - Параметр
-
package_map( self: pydrake.multibody.parsing.Parser ) → pydrake.multibody.parsing.PackageMap Получает изменяемую ссылку на PackageMap, используемый этим синтаксическим анализатором.
-
 Новая модель
экземпляры будут добавлены в
Новая модель
экземпляры будут добавлены в  Вызывать это с помощью SDF - ошибка.
с более чем одним элементом
Вызывать это с помощью SDF - ошибка.
с более чем одним элементом -
pydrake.multibody.parsing.ProcessModelDirectives( директивы: pydrake.multibody.parsing.ModelDirectives, plant: pydrake.multibody.plant.MultibodyPlant_ [float], parser: pydrake.multibody.parsing.Parser .Inbody List [pydrake.multibody.parsing.Parser ) → ] Обрабатывает директивы модели для данного MultibodyPlant.
Примечание
аргумент ModelWeldErrorFunction, описанный выше, скорее всего, исчезнут, когда будет разработан более чистый механизм.Примечание:
pydrake в настоящее время не поддерживает функцию ModelWeldErrorFunction .
Анализ данных с помощью Jackson с использованием kotlin
Введение в модуль Jackson Kotlin и обнуляемый тип Kotlin для отсутствующих значений в данных
Jackson - одна из известных библиотек для анализа данных XML или JSON, хотя для Kotlin требуются некоторые ключевые факторы чтобы избежать неожиданных проблем.
По умолчанию Java предоставляет конструктор по умолчанию (если нет параметризованного конструктора), который используется Jackson для синтаксического анализа ответа на классы POJO или bean-компонентов.
Kotlin предоставляет функцию классов данных , которые не предоставляют конструктор по умолчанию (вместо этого он использует конструктор параметризации), поэтому синтаксический анализ ответа в Kotlin приведет к исключению InvalidDefinitionException как:
, где Person class это простой data class с двумя свойствами
data class Person (var name: String, var occation: String)
и журнал исключений.
Исключение в потоке "main" com.Fastxml.jackson.databind.exc.InvalidDefinitionException: невозможно создать экземпляр `Person` (не существует создателей, таких как конструктор по умолчанию): невозможно десериализовать из значения объекта (нет создателя на основе делегатов или свойств)
в [Источник: (String ) "{
" имя ":" Павнет ",
" занятие ":" Инженер-программист "
}"
Классы данных имеют ограничение на наличие хотя бы одного параметра первичного конструктора, поэтому конструктор по умолчанию / без аргументов не используется. доступно по умолчанию в классах данных.
Джексон не может найти конструктор по умолчанию, поэтому он не может создать объект класса Person и выбросить исключение InvalidDefinitionException .
Эта проблема может быть исправлена с помощью аннотации @JsonProperty , которая проинструктирует Jackson использовать сеттеры и геттеры для синтаксического анализа как:
Исключение также можно исправить, создав нормальный класс вместо data class как:
Внутри компилятор сгенерирует общедоступных установщиков / получателей для доступа к свойствам класса и будет иметь конструктор по умолчанию .
Образец сценария анализа электронной почты Resilient
V32.2 платформы Resilient содержит готовый сценарий Python под названием «Образец сценария: обработка входящей электронной почты (v32.2)». При обновлении до V32.2 любые существующие организации и впоследствии созданные организации будут иметь новый сценарий.
Скрипт предназначен для синтаксического анализа электронной почты на объектах сообщения электронной почты. Он выполняет следующие функции:
Новым инцидентам нужен владелец - либо лицо, указанное по адресу электронной почты, либо по имени группы.В предоставленном сценарии это значение оставлено пустым. Вам необходимо отредактировать скрипт, чтобы добавить устойчивого пользователя в качестве владельца. Например, чтобы изменить владельца на [email protected], найдите строку 8 сценария:
Белый список - это список надежных элементов данных, которые не должны становиться подозрительными артефактами; например, IP-адрес вашего собственного почтового сервера. В скрипте используются две категории белых списков: IP-адрес и URL-домен. Эти белые списки настраиваются путем изменения данных в скрипте.
Первоначально эти белые списки состоят из закомментированных записей, которые служат примерами данных, которые вы, возможно, захотите исключить из рассмотрения. Белые списки не действуют, если вы не раскомментируете записи и не составите грамматически правильный список или не добавите собственные записи.
Белые списки IP-адресов разделены на отдельные списки IPv4 и IPv6. Эти списки применяются к IP-адресам, полученным путем сопоставления с образцом в теле сообщения электронной почты. Если IP-адрес появляется в белом списке, он не добавляется как артефакт к инциденту.
Существует две категории записей в белом списке IP: CIDR (бесклассовая междоменная маршрутизация) и IPRange. Например, в IP V4 IBM владеет сетью 9 класса A. Вы также можете добавить в белый список диапазон IP-адресов, например 12.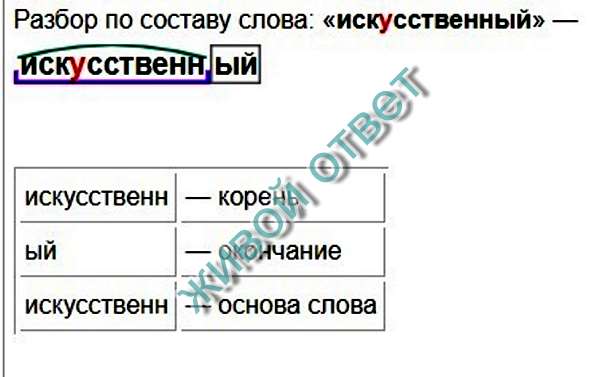 0.0.1 - 12.5.5.5 . Чтобы добавить эти критерии в белый список, вы должны добавить следующее в ipV4WhiteList:
0.0.1 - 12.5.5.5 . Чтобы добавить эти критерии в белый список, вы должны добавить следующее в ipV4WhiteList:
"9.0.0.0/8",
"12.0.0.1-12.5.5.5"
Вы также можете добавить в белый список явный IP-адрес, например 13,13.13,13 . Это будет определено следующим образом:
"13.13.13.13"
Белые списки IP v6 работают аналогично. Например, чтобы добавить V6 CIDR aaaa :: / 16 в белый список, вы должны добавить «aaaa :: / 16» в ipV6WhiteList. Например:
# Белый список для IP-адресов V4
ipV4WhiteList = WhiteList ([
...
])# Белый список для IP-адресов V6
ipV6WhiteList = WhiteList ([
...
])
должен стать:
# Белый список для IP-адресов V4
ipV4WhiteList = WhiteList ([
"9.0.0.0 / 8 ",
" 12.0.0.1-12.5.5.5 ",
" 13.13.13.13 "
])# Белый список для IP-адресов V6
ipV6WhiteList = WhiteList ([
" aaaa :: / 16 "
] )
Белые списки доменов URL
Белый список доменов применяется к URL, найденным в теле письма. Если домен из белого списка обнаружен в потенциальном артефакте URL, он не добавляется к инциденту. Домены могут быть добавлены явно, например mail.businessname.com, или с использованием подстановочного знака, например *.otherbusinessname.com. Например:
# Белый список доменов
domainWhiteList = WhiteList ([
# "*. Ibm.com"
])
станет:
# Белый список доменов
domainWhiteList = WhiteList ([
"mail.businessname.com" ,
"* .otherbusinessname.com"
])
Расширение и настройка
Есть два подхода к расширению и настройке этой функции:
- Запуск нескольких сценариев для одного и того же электронного письма.
- Измените предоставленный сценарий.
По разным причинам добавление большего количества скриптов, как правило, лучше, чем усложнение одного скрипта. Можно ожидать, что платформа Resilient будет принимать несколько категорий сообщений электронной почты из различных интеграций. Некоторая обработка сообщений электронной почты может быть общей, а некоторая обработка может зависеть от категории или интеграции. Сохранение общей обработки в одном сценарии и специализированной обработки в других позволит сделать реализацию более чистой и удобной в обслуживании.
Можно ожидать, что платформа Resilient будет принимать несколько категорий сообщений электронной почты из различных интеграций. Некоторая обработка сообщений электронной почты может быть общей, а некоторая обработка может зависеть от категории или интеграции. Сохранение общей обработки в одном сценарии и специализированной обработки в других позволит сделать реализацию более чистой и удобной в обслуживании.
Каждое выполнение сценария выполняется в пределах определенных вычислительных квот - 5 секунд времени выполнения или 50 000 выполняемых строк Python. Обработка регулярных выражений выполняется модулем _re_ Python, выполнение которого считается частью квоты. Можно создать сложное регулярное выражение, выполнение которого требует интерпретации большого количества строк Python в конкретном сообщении электронной почты. Выполнение многих таких сложных регулярных выражений может превысить ограничение в 50 000 строк.
Примеры
Расширение решения для работы с отчетами о фишингеСценарий: электронные письма, поступающие в определенный почтовый ящик, отражают людей, пересылающих сообщения, подозреваемые в фишинге. Сценарии, работающие с этими сообщениями электронной почты, должны, помимо обычной обработки в образце сценария, записывать адрес электронной почты репортера как возможный объект фишинг-атаки и записывать отправителя переадресованного фишингового сообщения электронной почты как подозрительного.
Решение: добавьте следующий сценарий на платформу Resilient:
import redef addArtifact (regex, artifactType, description):
"" "Этот метод добавляет новые артефакты к инциденту, полученному из совпадений регулярного выражения
параметр в теле письма.
Параметр "regex" - регулярное выражение для сопоставления с содержимым тела письма.
Параметр "artifactType" - тип артефакта (ов).
Параметр "description" - описание артефакта (s).
"" "
dataList = set (re.
if dataList isnotNoneandlen (dataList)> 0:
map (lambda theArtifact: Incident.addArtifact (artifactType , theArtifact, description), dataList)###
# Основная линия начинается здесь
#### Добавьте «Фишинг» в качестве типа инцидента для связанного инцидента
инцидент.incident_type_ids.append («Фишинг»)# Добавить в инцидент информацию об отправителе электронной почты в качестве получателя попытки фишинга
ReportingUserInfo = emailmessage.from.address
, если emailmessage.from.name не None:
reportingUserInfo = u "{0} <{1}>". format (emailmessage.from.name, emailmessage.from.address)
инцидент.addArtifact ("Электронная почта Recipient ", reportingUserInfo," Получатель подозрительного письма ")# Извлечь информацию об отправителе электронной почты, исходя из предположения, что пересылается рыболовное письмо
, если не emailmessage.body.content is None:
addArtifact (r" From: (. *. * ) \ n "," Отправитель электронной почты "," Подозрительный отправитель электронной почты ")
addArtifact (r" Reply-To: (.*) \ n ",« Отправитель электронной почты »,« Подозрительный отправитель электронной почты (Reply-To) »)
 findall (regex, emailmessage.body.content)) # Использование набора для обеспечения уникальности
findall (regex, emailmessage.body.content)) # Использование набора для обеспечения уникальности Важно, чтобы указанный выше сценарий для фишинга запускался после общего сценария, поскольку общий сценарий вызывает инцидент переменная должна быть установлена, и специфичный для фишинга скрипт ожидает, что это уже было сделано. Два самых простых альтернативных способа сделать это:
- Специфичный для фишинга скрипт должен запускаться как второй скрипт правила для нескольких скриптов, которое сначала запускает стандартный сценарий.
- Сценарий для фишинга должен запускаться в отдельном правиле, которое запускается впоследствии.
В любом случае специфичный для фишинга сценарий должен запускаться только при условии, что в созданном сообщении электронной почты указано, что это отчет о фишинге.
Сценарий: одной темы сообщения электронной почты может быть недостаточно для сбора связанных электронных писем в один инцидент.
Может оказаться, что тема сообщения электронной почты недостаточно конкретна или надежна для использования в качестве способа сбора связанных электронных писем.В частности, может иметь место атака, когда несколько векторов атаки используются в одной кампании, что может привести к получению множества различных типов сообщений электронной почты для этой одной кампании.
Одним из решений проблемы является создание нового поля в инциденте, содержащего идентификатор кампании. Этот идентификатор может быть получен из содержимого сообщений электронной почты или выбран из жестко запрограммированного списка, когда кампания распознается сценарием синтаксического анализа.
Решение:
- Создайте новое настраиваемое поле инцидента для идентификатора кампании типа Текст.
- Скопируйте образец сценария синтаксического анализа в новый сценарий.
- Измените новый сценарий, чтобы создать значение для идентификатора кампании, либо выбрав текст из содержимого сообщений электронной почты, либо выбрав из жестко заданного списка идентификаторов кампании, если выполняются определенные критерии.
- Чтобы связать сообщение электронной почты с существующим инцидентом, найдите инциденты, поле идентификатора кампании которых совпадает со значением идентификатора кампании для сообщения электронной почты.Это заменит поиск по теме сообщения электронной почты.
- Если подходящий инцидент не найден, создайте новый инцидент и установите для его поля идентификатора кампании значение идентификатора кампании.
- Измените правила так, чтобы новый сценарий выполнялся вместо примера сценария.
Apache Lucene - синтаксис парсера запросов
Обзор
Хотя Lucene предоставляет возможность создавать свои собственные запросы через свой API, он также предоставляет богатый запрос языка через Query Parser, лексер, который интерпретирует строку в запрос Lucene с помощью JavaCC.
Как правило, синтаксис парсера запросов может отличаться от отпустить к выпуску. На этой странице описан синтаксис по состоянию на текущий выпуск. Если вы используете другой версии Lucene, пожалуйста, обратитесь к копии docs / queryparsersyntax.html, который был распространен с версией, которую вы используете.
Прежде чем использовать предоставленный анализатор запросов, обратите внимание на следующее:
- Если вы программно генерируете строку запроса, а затем анализируя его с помощью парсера запросов, вам следует серьезно подумать о создании ваши запросы напрямую через API запросов.Другими словами, запрос парсер предназначен для текста, вводимого человеком, а не для программного текст.
- Нетокенизированные поля лучше всего добавлять непосредственно в запросы, а не через парсер запросов. Если значения поля генерируются программно приложением, то также следует запросить предложения для этого поля. Анализатор, который использует парсер запросов, предназначен для преобразования введенных человеком текст к условиям.Создаваемые программой значения, такие как даты, ключевые слова и т. Д., должны последовательно генерироваться программой.
- В форме запроса поля, которые представляют собой общий текст, должны использовать запрос парсер. Все остальные, такие как диапазоны дат, ключевые слова и т. Д., Лучше добавлять. напрямую через API запросов. Поле с ограниченным набором значений, которые можно указать в раскрывающемся меню, не следует добавлять в строка запроса, которая впоследствии анализируется, а скорее добавляется как Предложение TermQuery.
Термины
Запрос разбит на термины и операторы. Есть два типа терминов: отдельные термины и фразы.
Отдельный термин - это отдельное слово, например «тест» или «привет».
Фраза - это группа слов, заключенная в двойные кавычки, например "hello dolly".
Несколько терминов можно комбинировать с логическими операторами, чтобы сформировать более сложный запрос (см. Ниже).
Примечание. Анализатор, используемый для создания индекса, будет использоваться для терминов и фраз в строке запроса.Поэтому важно выбрать анализатор, который не будет мешать терминам, используемым в строке запроса.
Поля
Lucene поддерживает полевые данные. При выполнении поиска вы можете указать поле или использовать поле по умолчанию. Имена полей и поле по умолчанию зависят от реализации.
Вы можете выполнить поиск в любом поле, введя имя поля, двоеточие ":" и затем искомый термин.
В качестве примера предположим, что индекс Lucene содержит два поля, заголовок и текст, а текст является полем по умолчанию.Если вы хотите найти документ под названием «Правильный путь», который содержит текст «не ходи этим путем», вы можете ввести:
заголовок: "Верный путь" И текст: иди
или
title: "Делай правильно" И правильно
Поскольку текст является полем по умолчанию, индикатор поля не требуется.
Примечание. Поле действительно только для термина, которому оно предшествует, поэтому запрос
title: Сделай правильно
Найдет только «Do» в поле заголовка.Он найдет «это» и «справа» в поле по умолчанию (в данном случае в текстовом поле).
Модификаторы терминов
Lucene поддерживает изменение условий запроса, чтобы обеспечить широкий диапазон параметров поиска.
Поиск по шаблону
Lucene поддерживает поиск с использованием подстановочных знаков, состоящих из одного и нескольких символов, в рамках одного термина (не внутри фразовых запросов).
Чтобы выполнить поиск с использованием подстановочных знаков, состоящих из одного символа, используйте "?" условное обозначение.
Чтобы выполнить поиск с использованием подстановочных знаков, состоящих из нескольких символов, используйте символ «*».
Поиск с использованием односимвольных подстановочных знаков ищет термины, соответствующие термину с замененным единственным символом. Например, для поиска по запросу «текст» или «тест» можно использовать поиск:
те? Т
При поиске с использованием подстановочных знаков, состоящих из нескольких символов, выполняется поиск 0 или более символов. Например, для поиска теста, тестов или тестировщика можно использовать поиск:
тест *
Вы также можете использовать поиск по шаблону в середине термина.
тэ * т
Примечание: нельзя использовать * или? символ в качестве первого символа поиска.
Нечеткие поиски
Lucene поддерживает нечеткий поиск на основе алгоритма расстояния Левенштейна или алгоритма редактирования расстояния. Чтобы выполнить нечеткий поиск, используйте символ тильды «~» в конце одного слова Term. Например, чтобы найти термин, похожий по написанию на «бродить», используйте нечеткий поиск:
роуминг ~
В этом поиске будут найдены такие термины, как пена и блуждание.
Начиная с Lucene 1.9 дополнительный (необязательный) параметр может указывать необходимое сходство. Значение находится в диапазоне от 0 до 1, при значении, близком к 1, будут сопоставляться только термины с более высоким сходством.Например:
роуминг ~ 0,8
Если параметр не задан, по умолчанию используется 0,5.
Поиск по близости
Lucene поддерживает поиск слов на определенном расстоянии. Чтобы выполнить поиск по близости, используйте символ тильды "~" в конце фразы. Например, для поиска «apache» и «jakarta» в пределах 10 слов друг от друга в документе используйте поиск:
"jakarta apache" ~ 10
Поиск по диапазону
Range Queries позволяют сопоставлять документы, значения полей которых находятся между нижней и верхней границей, указанной в запросе диапазона.Запросы диапазона могут включать или исключать верхнюю и нижнюю границы. Сортировка производится лексикографически.
mod_date: [20020101 TO 20030101]
Это позволит найти документы, поля mod_date которых имеют значения от 20020101 до 20030101 включительно. Обратите внимание, что запросы диапазона не зарезервированы для полей даты. Вы также можете использовать запросы диапазона с полями без даты:
название: {Aida TO Carmen} Здесь находятся все документы, названия которых находятся между Аидой и Кармен, кроме Аиды и Кармен.4 "Apache Lucene"
По умолчанию коэффициент усиления равен 1. Хотя коэффициент усиления должен быть положительным, он может быть меньше 1 (например, 0,2)
Логические операторы
Логические операторы позволяют комбинировать термины с помощью логических операторов. Lucene поддерживает логические операторы AND, «+», OR, NOT и «-» (Примечание: логические операторы должны быть ЗАГЛАВНЫМИ).
Оператор OR является оператором соединения по умолчанию. Это означает, что если между двумя терминами нет логического оператора, используется оператор OR.Оператор OR связывает два термина и находит соответствующий документ, если какой-либо из терминов существует в документе. Это эквивалентно объединению с использованием множеств. Символ || можно использовать вместо слова ИЛИ.
Для поиска документов, содержащих "jakarta apache" или просто "jakarta", используйте запрос:
"jakarta apache" jakarta
или
"Джакарта Апаче" ИЛИ Джакарта
И
Оператор AND сопоставляет документы, в которых оба термина существуют в любом месте текста одного документа.Это эквивалентно пересечению с использованием множеств. Вместо слова AND можно использовать символ &&.
Для поиска документов, содержащих "jakarta apache" и "Apache Lucene", используйте запрос:
"jakarta apache" И "Apache Lucene"
+
Оператор «+» или «обязательный» требует, чтобы термин после символа «+» существовал где-то в поле одного документа. "~ *?: \
Чтобы экранировать эти символы, используйте \ перед символом.Например, для поиска (1 + 1): 2 используйте запрос:
\ (1 \ +1 \) \: 2
Survey123 - Ошибка шаблона отчета
Я разрабатываю шаблон отчета Survey123 и получаю следующее сообщение об ошибке [Ошибка: не удалось проанализировать "$ {RMMAL27_Y_type}". Поле "$ {RMMAL27_Y_type}" не существует или не может быть найдено в текущей области синтаксического анализа. "].
Поле существует в моих данных, и я копирую его прямо из предоставленных примеров того, как работать с полем для отчета шаблон.
- В моем настроенном шаблоне отчета вопрос отформатирован следующим образом:
- Имеются ли в юрисдикции заранее определенные и задокументированные промежуточные области и точки распространения (POD) для получения и распределения ресурсов?
$ {RMMAL27 | selected: "y"} Да
$ {# RMMAL27_Y}
$ {RMMAL27_Y_type}
Тип Имя местоположения: $ {RMMAL27_Y_name}
Тип Местоположение Адрес: $ {RMMAL27_Y_address_}, $ {RMMAL27_Y_MAL_27_Y_city}
$ {/ RMMAL27_Y}
$ {RMMAL27 | выбрано: "n"} №
$ {RMMAL27_N | selected: "no"} Помощь не требуется.
$ {RMMAL27_N | selected: "assist"} Юрисдикции требуется техническая помощь для разработки этого плана / протокола и определения промежуточной зоны и местоположений POD.
Примечания к промежуточному местоположению: $ {RMMAL27_N_notes_stage}
Примечания к расположению POD: $ {RMMAL27_N_notes_pod}
- В загружаемом шаблоне из Survey123 поля показаны как:
Расположение промежуточных и POD (по крайней мере, по одному)
$ {# RMMAL27_Y}
Пожалуйста, выберите тип местоположения
$ {RMMAL27_Y_type}
Расположение промежуточной стадии и POD - Местоположение
$ {RMMAL_27_locality}
Тип местоположения
Тип Расположение Улица Адрес
$ {RMMAL27_Y_address}
Тип Расположение Город
$ {RMMAL27_Y_city}
Тип Местоположение Почтовый индекс
$ 9000_zip2000 $ 9000_zip2000 $ выберите {9MAL272] карта
$ {RMMAL27_Y_geopoint}
-------------------------------------- ------------------------- ------------------------------
$ {/ RMMAL27_Y}
- Я также получаю сообщение об ошибке "Произошла ошибка при рендеринге механизмом отчетов.