разбор слова по составу .поставил
противника разбор слова по составу
Укажите правильную словообразовательную цепочку:
Нужно написать сочинение 15-20 предложений на тему моё любимое животное. Про кота.пожалуйста.. зарание спасибо ))
Прочитай текст. Выпиши глаголы,задай к ним вопросы и определи вид,спр Этих птиц любят. Ещё бы — ведь существует такое поверье, что аисты приносят сча … стье! Именно эта птица устраивает своё большое широкое гнездо, сложенное из прутьев и веток, прям на крыше деревенского дома. когда белый аист прилетел к человеческому жилищу, никто точно не помнит. Но люди очень дорожат дружбой с аистом, ждут, когда аисты поселятся на крыше дома, заботливо оберегают их покой. Если аисты устроят гнездо на крыше вашего дома, то каждую весну они снова и снова станут прилетать сюда.
литературный диктант сам расказ:блестят коньки, блестит каток пушистый снег искрится, надень коньки свои, дружок, попробуй прокатиться. пускай тебя ши … пнёт мороз смотри не испугайся. пусть заморозит он до слез ему не поддавайся! не отступать, скользи вперёд, лети быстрее птицы. мороз сердитый отстаёт от тех, кто не боится
494. Ты уже был(а) в роли режиссёра, когда создавал(а)фильм о профессии твоего родственника. А сейчас тебесоздать фильм о жизни звезды. Выбери какую-н … ибудь звездуна небе, расскажи о трёх самых интересных событиях из еежизни. 20-30 слов.
Безопасность на воде. Виды предложений по интонацииПрочитай выразительно стихотворение. Определи в нём восклицательные предложения.Когда вокруг грохоч … ет громИ молния сверкает,Не лезь в открытый водоём!Ведь всякое бывает.И если ты в грозу попал,Не плавай, не купайся.Лишь только дождик застучал,На берег выбирайся!Верных ответов: 2Лишь только дождик застучал,На берег выбирайся!И если ты в грозу попал,Не плавай, не купайся.Когда вокруг грохочет громИ молния сверкает,Не лезь в открытый водоём!Ведь всякое бывает.НазадПроверить
литературный диктант 89 лист 495 ое упражнение
Каким членом предложения является выделенное слово Венеру часто называют близнецом земли и потому что она похожа на нашу планету и размером и массойПО … МОГИТЕ ПЖ СРОЧНО!!!
21. Выпишите ключевые слова из по-следних трёх абзацев.Всу-2. Найдите4-М абзацеществительные по теме «Природныеявления» и запишите их в начальнойформе
… .3. Найдите5-м абзаце прила-гательные, обозначающие цвет, и вы-пишите их вместе с существительнымив начальной форме.4. Найдите в 4-6 абзацах сравнения.Что с чем сравнивается?5. Объясните лексическое значениеглаголов внимаешь, перепадали, раз-ветрило. Как они образованы?«тает6. Что означает выражениелуна»? В какое время дня это проис-ходит?
Выпишите ключевые слова из по-следних трёх абзацев.Всу-2. Найдите4-М абзацеществительные по теме «Природныеявления» и запишите их в начальнойформе
… .3. Найдите5-м абзаце прила-гательные, обозначающие цвет, и вы-пишите их вместе с существительнымив начальной форме.4. Найдите в 4-6 абзацах сравнения.Что с чем сравнивается?5. Объясните лексическое значениеглаголов внимаешь, перепадали, раз-ветрило. Как они образованы?«тает6. Что означает выражениелуна»? В какое время дня это проис-ходит?
Дидактический материал по русскому языку 5 класс
Контрольный диктант по теме
«Повторение изученного в начальных классах»
Вариант 1
Мы идем по узкой дорожке берегом большого озера. Над ближним лесом встает солнце. Под яркими лучами солнца сверкает голубое озеро. За ним широкой полосой легло болото. Тут шагать опасно.
Мы входим в зеленую чащу. Ровными рядами стоят высокие сосны. Редкий луч солнца льется через густую зелень. Под деревьями прохладно. Тишь и глушь в лесу.
В этой местности живут пушистые белки. Вот зверек прыгнул с ветки на ветку, уронил сосновую шишку.
Мы постояли у опушки и пошли к деревне. Крутой подъем ведет в гору. Там конец нашего пути. (88 слов)
Грамматическое задание.
Озаглавьте текст.
Обозначить части речи в предложении Над ближним лесом встает солнце. (1 вариант),
Мы входим в зеленую чащу. ( 2 вариант).
Разберите слова по составу:
Входим, пушистые, ветки. (1 вариант)
Сверкает , редкий, дорожке (2 вариант)
Выпишите несколько слов с орфограммой в корне слова
Контрольный диктант (№1)
по теме: «Повторение изученного в начальных классах»
Вариант 2
В саду с ветки на ветку перелетает шустрая птичка. Спина у неё серая, грудка жёлтая, на голове чёрная шапочка. Это синица. В сад она прилетела за жучками. Большой вред наносят они садам. Одни грызут листья на фруктовых деревьях, другие портят плоды. Возьмёшь яблоко, разломишь, а внутри червяк. Вот этих вредителей ловит синица. Увидит зорким глазом добычу, схватит её клювом и съест. А клюв у синицы тонкий, в любую щёлку пролезет.
Одни грызут листья на фруктовых деревьях, другие портят плоды. Возьмёшь яблоко, разломишь, а внутри червяк. Вот этих вредителей ловит синица. Увидит зорким глазом добычу, схватит её клювом и съест. А клюв у синицы тонкий, в любую щёлку пролезет.
Много разных жуков съедает она за день. Даже не верится, что у маленькой птички может быть такой аппетит.
Люди называют синицу сторожем наших садов.
Грамматическое задание.
Озаглавьте текст.
Обозначить части речи в первом предложении (1 вариант),
В сад она прилетела за жучками ( 2 вариант).
Разберите слова по составу:
Наносят, фруктовых, грудка. (1 вариант)
Разломишь, маленькой, шапочка (2 вариант)
Выпишите несколько слов с орфограммой в корне слова
3 вариант
На опушке молодого леса есть пруд. Из него бьёт подземный ключ. Это в болотах и вязких трясинах рождается Волга. Отсюда она направляется в далекий путь. Наши поэты и художники прославляли красоту родной реки в удивительных сказках, песнях, картинах.
Низкий берег покрыт кустарниками и зеленым ковром лугов. На лугу пестреют цветочки. Их сладкий запах разливается в мягком воздухе. Полной грудью вдыхаешь аромат лугов. Откос на набережной реки очень красив. Местные жители любят проводить тут выходные дни. Они любуются окрестностями, занимаются рыбной ловлей, купаются. (82 слова)
Задания.
Придумать название текста.
Подчеркнуть орфограммы (гласные и согласные ) корня, требующие проверки.
Выбрать из текста слово с безударным гласным в корне и написать к нему проверочное слово, поставив ударение.
Разобрать по составу слово подземный (1 вар.), выходные (2 вар.).
4 вариант
Лес уже сбросил листву. Дни наступили пасмурные, но тихие, без ветра. Настоящие дни поздней осени.
В такой тусклый день идешь по лесной тропинке, кругом тишь. Не слышишь пения птиц, шороха листьев. Только иногда упадет на землю тяжелый созревший желудь. На голых листьях повисли капли росы от ночного тумана.
Не слышишь пения птиц, шороха листьев. Только иногда упадет на землю тяжелый созревший желудь. На голых листьях повисли капли росы от ночного тумана.
Легко дышит осенней свежестью грудь, хочется идти все дальше и дальше по желтой от листвы тропинке.
Вдруг среди листвы видишь пестрый комочек. Это птица обо что-то сильно ударилась во время полета.
«Надо взять ее домой, а то в лесу птицу мигом разыщет и съест лисица», — решаю я.
(По И.Соколову-Микитову.)
Задания.
Выделенное предложение запишите поморфемно.
Выпишите три слова с орфограммами, обозначьте орфограммы
Контрольный диктант по теме
«Синтаксис и пунктуация»
Вариант 1
Погода стала меняться. Из-за далекого горизонта неслись и приближались низкие облака. Солнце выглянуло из-за туч, мелькнуло в голубом просвете и исчезло. Потемнело. Налетел резкий ветер. Он зашумел тростником, бросил в воду сухие листья и погнал их по реке. «Дождь пойдёт», — проговорила Нина.
Ветер налетает с новой силой, морщит гладь реки, а потом стихает. Зашуршал камыш, и на воде появились кружки от первых капель. Река покрылась пузырьками, когда сплошной полосой хлестнул проливной дождь. Валерка громко закричал: «Бежим, ребята!»
Но вот ветер утих, появилось солнце. Редкие капли дождя падали на землю. Они повисали в траве, и в каждой капле отражалось солнце. (100 слов)
(По В. Астафьеву)
Грамматическое задание:
Графически объяснить написание безударных гласных в корнях глаголов
1 вар. — в 1-ом абзаце
2-ой вар. — во 2-ом абзаце
Графически объяснить пунктуацию в предложениях
1 вар. — «Дождь пойдёт», — проговорила Нина.
Зашуршал камыш, и на воде появились кружки от первых капель.
2-ой вар. —
Ветер налетает с новой силой, морщит гладь реки, а потом стихает.
Валерка громко закричал: «Бежим, ребята!»
Контрольный диктант по теме
«Синтаксис и пунктуация»
Вариант 2
О пословицах
Пословица — это краткое мудрое изречение народа. Пословицы легко и быстро запоминаются, потому что они похожи на короткие стихотворения и песни.
Пословицы легко и быстро запоминаются, потому что они похожи на короткие стихотворения и песни.
В пословицах заключается народный ум, народная правда, мудрое суждение о жизни, о людях.
Сохранилось много старых пословиц, в которых говорится о тяжёлой жизни народа. Много пословиц о труде, потому что создавал пословицы трудовой народ.
В них ценится и мастерство, и его умная выдумка. Есть пословицы, где высмеиваются лентяи, болтуны. Мы знаем, что пословицы имеют прямой и переносный смысл. Пословица учит, а поговорка даёт яркую оценку событиям или человеку.
Грамматическое задание:
Графически объяснить постановку знаков препинания в предложениях
1 вар. — в 1-ом абзаце
2-ой вар. — во 3-ем абзаце
Произвести синтаксический разбор предложения
1 вар. — Пословица — это краткое мудрое изречение народа.
2-ой вар. — В пословицах заключается народный ум, народная правда, мудрое суждение о жизни, о людях.
Разобрать по составу слова:
1 вар — поговорка
2 вар. — выдумка
Контрольный диктант по теме
«Синтаксис »
ХОЧЕШЬ СТАТЬ ПОВЕЛИТЕЛЕМ ПТИЦ?
Если я захочу, птицы сами прилетят ко мне.
Нет, я не волшебник. Я не шепчу заклинаний, и у меня нет волшебной палочки, но зато есть волшебная полочка.
На вид она совсем проста: фанерка с деревянными бортиками.
Чтобы прилетели птицы, нужно на полочку насыпать крупы и хлебных крошек и выставить её за окно.
Полочка сразу станет волшебной, и на неё прилетят голуби и воробьи. К вам наведаются и синицы, если укрепить на полочке кусочек сала. Положите на полочку горсть рябины, и сразу её будут клевать снегири. Сделайте доброе для пернатых!
(89 слов)
Выбрать из текста сложное предложение, подчеркнуть грамматические основы.
Выписать 3 слова с безударным гласным в корне слова, обозначить орфограмму.
Контрольный диктант по теме
«Синтаксис »
ЧТО ЗА ЗВЕРЬ?
Выпал первый снег. И все кругом стало белым. Деревья, земля, крыши — все белое.
И все кругом стало белым. Деревья, земля, крыши — все белое.
Девочке Кате захотелось по снежку погулять. Вышла она на крыльцо. Вдруг видит в снегу на ступеньках следы.
— Что за зверек тут ходит? — подумала девочка.
Бросила Катя на крыльцо котлетку и убежала. День прошел, ночь прошла. Проснулась Катя утром — и скорей на крыльцо. Котлетка цела! А следов стало еще больше. Бросила Катя косточку из супа. Утром смотрит — зверек косточки не трогал. Может быть, это зайчик? Тогда Катя почистила красную морковку и оставила ее на крыльце. Утром глядит, а морковки нет. Зверек приходил и всю морковку съел. Что это за зверек?
(По Е.Чарушину)
Грамматические задания
I вариант1) Найдите и выпишите одно предложение с однородными сказуемыми, подчеркните грамматическую основу.
2) Найдите и выпишите односоставное предложение.
3) Выпишите словосочетание со связью согласование.
II вариант
1) Найдите и выпишите одно сложное предложение, подчеркните грамматические основы.
2) Найдите и выпишите безличное предложение.
3) Выпишите словосочетание со связью управление.
Контрольный диктант по теме
«Синтаксис и пунктуация»
Заячьи лапы.
Поздно ночью рассказал мне дед Ларион историю о необыкновенном зайце.
В августе ходил дед охотиться, попался ему заяц с рваным левым ухом. Дед выстрелил в него из старого ружья, но промахнулся.
Дед пошел дальше, но затревожился. Он понял, что начался лесной пожар. Ветер перешел в ураган. Огонь стремительно мчался по земле. Дед побежал по кочкам. И в это время выскочил заяц с рваным ухом Он бежал медленно, волочил задние лапы, потому что они обгорели.
Дед знал, что звери лучше чуют опасность и всегда спасаются. Он побежал за зайцем. Дед плакал от страха и кричал: «Погоди, милый, не беги так шибко!».
Заяц вывел деда из огня. Когда они выбежали из леса, оба упали от усталости. Дед подобрал зайца, отнес домой и вылечил.
(По К. Паустовскому)
Паустовскому)
Грамматические задания.
Выписать все словосочетания из первого предложения второго абзаца. Одно из них разобрать.
Начертить схему предложения с прямой речью.
Выполнить пунктуационный разбор второго предложения.
Выполнить синтаксический разбор последнего предложения.
Контрольный диктант по теме «Морфемика. Орфография. Культура речи».
Вариант 1
Летняя гроза
Темнеет, хмурится небо. Набегают мрачные грозовые тучи. Затихает старый бор, готовится к бою. Сильный порыв ветра вырывается из-за вершин деревьев, кружится пылью по дороге и мчится вперед.
Ударили по листьям первые крупные капли дождя, и вскоре на землю обрушилась стена воды. Сверкнула молния, прокатился по небу гром.
Быстро проходит летняя гроза. Но вот светлеет туманная даль. Небо начинает голубеть. Над полем, над лесом, над водной гладью плывет легкий пар. Уже и солнце горячее выглянуло, а дождь еще не прошел. Это капают с деревьев и блестят на солнце дождинки. (85 слов.)
(ПО Б. Т и м о ф е е в у.)
По мере написания диктанта объяснить безударную гласную в корнях глаголов первого абзаца.
Разобрать по составу слова:
1 вариант Набегают, крупные, дождинки
2 вариант Затихает, туманная, порыв
Контрольный диктант
по теме: «Морфемика. Орфография. Культура речи.».
Охраняйте леса!
У нас часто леса гибнут от безжалостного обращения с ними. Люди бессознательно бросают спичку, и от ее огня погибают большие участки леса. Много леса вырубают. Срубить дерево легко, а чтобы вырастить его, надо десятки лет.
За посадками молодых деревьев следит лесовод. Он устанавливает места, которые пострадали от пожара, намечает, где надо расчистить лес от бурелома, отводит участки для работы лесорубов, участвует в борьбе с вредителями леса. Гусеницы иногда съедают подрастающие побеги, объедают листья. Зайцы, мыши обгрызают корни молодых деревьев. Но есть у леса и друзья — птицы. Они прекрасные помощники лесоводов.
Гусеницы иногда съедают подрастающие побеги, объедают листья. Зайцы, мыши обгрызают корни молодых деревьев. Но есть у леса и друзья — птицы. Они прекрасные помощники лесоводов.
Берегите, ребята, лес! Это наше богатство. (98 слов)
Г р а м м а т и ч е с к ое з а д а н и е:
По мере написания диктанта объяснить безударную гласную в корнях глаголов первого абзаца.
Разобрать по составу слова:
1 вариант лесовод, бросают, десятки
2 вариант лесорубы, отводит, посадками
Контрольный диктант
по теме: «Морфемика. Орфография. Культура речи.».
Земли с травянистой растительностью называются лугом. Самые ценные луга располагаются в поймах рек. Ежегодно весной во время половодья поймы заливаются водой. Вода спадает, и луговые растения во влажной земле растут быстро. Под ярким солнцем луга зеленеют и покрываются густым ковром душистых трав.
Много интересного можно увидеть на лугу! Вот сидит на травинке небольшой жук, прыгнул и скрылся в траве кузнечик. В танце пролетели бабочки. Гудит домовитый шмель.
В лугах расположились перепела, куропатки, гнездится редкая птица дрофа. В некоторых местах обитают журавли. Здесь можно встретить зайца, потому что он очень любит бобовые растения. В густой луговой траве живут кроты, мыши, лягушки.
Луга используют как сенокосы и пастбища. На них косят траву, заготавливают сено. Коровы, лошади, овцы с аппетитом поедают луговые растения.
(120 слов)
Задания к тексту:
1) 1-й вариант: выпишите слова с чередованием гласных в корне -раст-, — рос-. Графически объясните выбор гласной.
2-й вариант: выпишите слова с чередованием гласных в корне -лаг-, -лож-. Графически объясните выбор гласной.
2) 1-й вариант: выпишите однокоренные слова с корнем -вод-, разберите их по составу.
2-й вариант: выпишите однокоренные слова с корнем -луг-, разберите их по составу.
Контрольный диктант
по теме: «Морфемика. Орфография. Культура речи.».
Орфография. Культура речи.».
Случится в лесу страшный пожар. На большом участке выгорит вся растительность. Первым деревом, которое вырастет на пепелище, будет береза. Она любит свет и простор, не боится лютых морозов и весенних заморозков, встречается на вечной мерзлоте.
Растет береза быстро, недаром лесоводы называют ее гонким деревом. Уже через несколько лет после пожара поднимется на горелом месте молодая поросль. Пройдет еще несколько лет, и многие светолюбивые березки зачахнут в тени своих рослых собратьев. Тогда появятся под пологом березового леса молоденькие ели, пихты, лиственницы и сосны. А через 60 — 80 лет березу полностью вытеснят. Зашумит здесь хвойный бор.
А на опушке или поляне береза проживет долго и станет настоящей великаншей. Возраст таких отдельных деревьев достигает 150 лет.
(113 слов)
Задания к тексту:
1) Найдите слова с корнем -раст-, -рос-. Графически объясните выбор гласной в корне.
2) 1-й вариант: найдите сложное предложение и подчеркните его грамматические основы.
2-й вариант: найдите предложение с однородными членами и подчеркните их.
Контрольный диктант с грамматическим заданием по теме «Имя существительное»
Кайры
Над шумным, пенным морем поднимается скала. У неё нет обычной вершины. Солёная морось, хлёсткие долгие дожди, тающие по весне тяжёлые снега и ураганы с Тихого океана точили, размывали, выдували её. На месте острой вершины образовалось каменистое плато.
На плато множество чёрно — белых птиц. Это кайры.
Яйцо кайры тяжёлое. Скорлупа у него толстая, крепкая. Белок — голубой, словно сгусток морского воздуха. Кайры заботливы, хлопотливы.
Они великолепные ныряльщики, и под водой крылья для них служат как широкие крепкие плавники.
Птицы у самого дна гоняются за рыбёшками, а яйца их остаются лежать на плоской вершине скалы. Они разные: голубые и голубовато — зелёные, белые и коричневые. И все в тёмных кляксах. Солнце лучами греет яйца сбоку, сверху. Дотронешься до скорлупы — тёплая. («Всё о птицах»; 115 слов)
Солнце лучами греет яйца сбоку, сверху. Дотронешься до скорлупы — тёплая. («Всё о птицах»; 115 слов)
Грамматическое задание:
1.Синтаксический разбор простого предложения
1 вариант: Над шумным, пенным морем поднимается скала. 2 вариант: На месте острой вершины образовалось каменистое плато.
2. Разбор словосочетания: 1 вариант: поднимается над морем; 2 вариант: каменистое плато.
3.Морфологический разбор существительного:
1 вариант: (над) морем; 2 вариант: плато.
4. Морфемный разбор
1 вариант: хлёсткие, рыбёшками; 2 вариант: каменистое, сгусток.
Контрольный диктант с грамматическим заданием по теме «Имя прилагательное»
Павлиний глаз.
Бывают в августе душные вечера. Ждёшь восхода луны, но и луна не приносит прохлады. В такие вечера прилетает ко мне в избушку большой ночной павлиний глаз. Он мечется у свечки, задевает лицо сухими крыльями. Бабочка порхает по кабинету, садится на письменный стол.
Пожалуй, он не видит меня и не понимает, откуда я взялся, зачем зажигаю свечу.
Он летает над свечой, как хозяин, а я боюсь, что он опалит крылья. Но поймать его никак не могу. Я задуваю свечу, и уходит в окно большой ночной павлиний глаз искать другие окна и свечи. (Коваль Ю.И. «Поздним вечером ранней весной» ( Рассказы, повести.) 115 слов)
Грамматическое задание:
1.Синтаксический разбор простого предложения
1 вариант: Он мечется у свечки, задевает лицо сухими крыльями.2 вариант: Бабочка порхает по кабинету, садится на письменный стол.
2. Разбор словосочетания: 1 вариант: сухими крыльями; 2 вариант: садится на стол.
3.Морфологический разбор прилагательного:
1 вариант: сухими; 2 вариант: письменный.
4. Морфемный разбор
1 вариант: задуваю, избушку; 2 вариант: ночной, садится.
5. Фонетический разбор:
1 вариант: свечу; 2 вариант: крылья.
Контрольный диктант с грамматическим заданием по теме «Глагол»
Грибной дождь
Мелкий грибной дождь сонно сыплется из низких туч, и лужи от этого дождя всегда тёплые.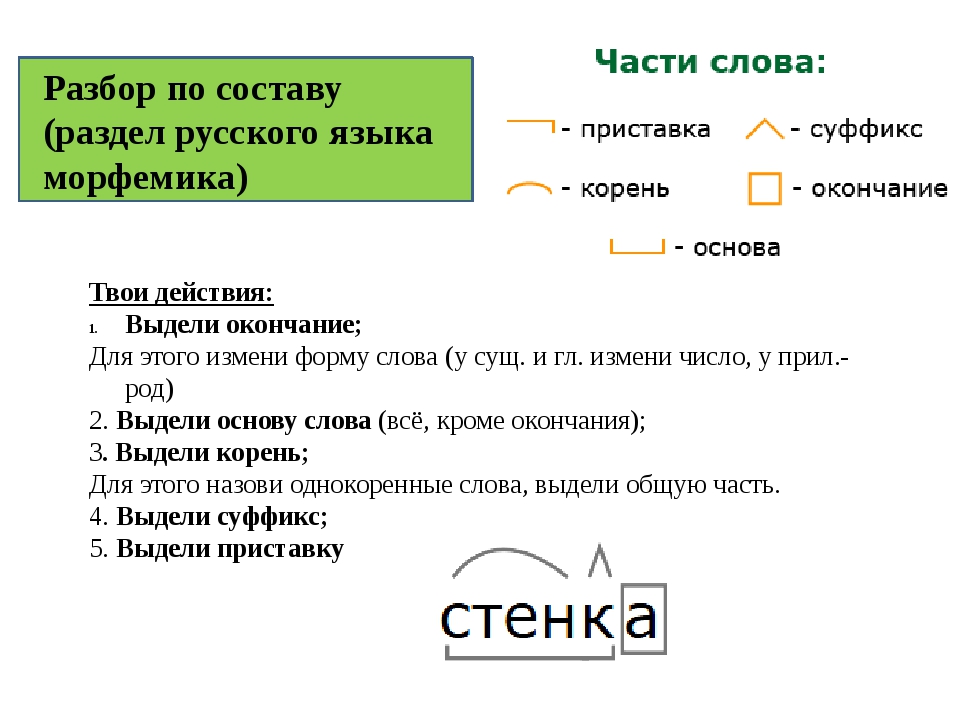 Он не звенит, а шепчет что-то своё и чуть заметно возится в кустах, будто трогает мягкой лапкой то один лист, то другой. После него начинают буйно лезть грибы: липкие маслята, жёлтые лисички, румяные рыжики, опенки и бесчисленные поганки.
Он не звенит, а шепчет что-то своё и чуть заметно возится в кустах, будто трогает мягкой лапкой то один лист, то другой. После него начинают буйно лезть грибы: липкие маслята, жёлтые лисички, румяные рыжики, опенки и бесчисленные поганки.
Во время грибных дождей в воздухе попахивает дымком, а в реке хорошо ловится хитрая и осторожная рыба.
О слепом дожде, идущем при солнце, в народе говорят: «Царевна плачет». Сверкающие на солнце капли этого дождя похожи на крупные слёзы.
Можно подолгу следить за игрой света во время дождя, за разнообразием звуков — от мерного стука по тесовой крыше и до жидкого звона в водосточной трубе. До сплошного, напряжённого гула, когда дождь льёт, как говорится, стеной.
Всё это только ничтожная часть того, что можно сказать о дожде.(К.Г.Паустовский «Золотая роза»; 115 слов)
Грамматическое задание:
1.Синтаксический разбор сложного предложения
1 вариант: Мелкий грибной дождь сонно сыплется из низких туч, и лужи от этого дождя всегда тёплые. 2 вариант: Во время грибных дождей в воздухе попахивает дымком, а в реке хорошо ловится хитрая и осторожная рыба.
2. Разбор словосочетания: 1 вариант: сыплется из туч; 2 вариант: попахивает дымком.
3.Морфологический разбор глагола:
1 вариант: сыплется; 2 вариант: попахивает.
4. Морфемный разбор
1 вариант: возится, трогает; 2 вариант: следить, ловится.
Контрольный диктант с грамматическим заданием по теме «Повторение изученного за курс 5 класса»
В самолёте во время грозы
Самолёт набирает высоту. Моторы его натужно гудят, обшивка трещит от встречного ветра. Он часто проваливается в воздушные ямы, но упрямо лезет наверх, чтобы подняться над тучей и там переждать грозу.
Все пассажиры молчат. Многие задёргивают шёлковые шторы, чтобы не видеть страшной чёрной тучи. Только мальчик смотрит в окно. Ему нравится эта дикая, волшебная красота, эта страшная чернота, над которой они летят.
Вдруг самолёт клюнул носом и стремительно несётся к земле. Лётчик бросает машину вниз, потому что только на предельной скорости можно проскочить через грозу.
Это продолжается минут пять. Рядом появляется земля, и самолёт катится по твёрдой бетонной дорожке. (В.Железников «Мальчик с красками»» 120 слов)
Грамматическое задание:
1.Синтаксический разбор сложного предложения
1 вариант: Моторы его натужно гудят, обшивка трещит от встречного ветра. 2 вариант: Рядом появляется земля, и самолёт катится по твёрдой бетонной дорожке.
2. Разбор словосочетания: 1 вариант: от встречного ветра; 2 вариант: по бетонной дорожке.
3.Морфологический разбор:
1 вариант: гудят; 2 вариант: (по) дорожке.
4. Морфемный разбор
1 вариант: шёлковые, видеть, лётчик; 2 вариант: волшебная, несётся, самолёт.
5. Фонетический разбор:1 вариант: пять; 2 вариант: часто
Контрольная работа по теме « Фонетика, графика, орфоэпия»
Вариант1
1.Фонетика — это наука .. .а) о языке; б) о словарном составе языка; в) о звуках речи.
2.Укажи звонкие согласные звуки- а) [в,ф, г,к], б) [р,б, г,в], в) [р,ф, г,к].
3.Укажи только твердые согласные звуки — а) [ф,ж,к], б) [б, ш,в], в) [ж,ш, ц].
4.Запиши название букв алфавита с 11по 18.
5.Запиши слова и расставь в них ударение : свекла, договор, каталог, щавель, квартал, банты, звонит, алфавит, крапива, туфля.
6.В каком слове на месте Ч произносится ) [Ш]? а) чтобы, б)почему, в)четко
7. В каком слове звуков больше, чем букв? а)район; б)сияние; в)декабрь;
8. В каком слове все согласные звуки твёрдые? а)тушь; б) горсть; в) четки;
9. В каком слове произносится звук [ч’]? а) счет; б) грузчик; в) чемпионат.
10.Затранскрибируй слова, одного сделай фонетический разбор : юбилей, вьюжный, скользкий, яшма.
Контрольная работа по теме « Фонетика, графика, орфоэпия»
Вариант1
1. Орфоэпия-это наука… а)о языке; б)правилах произношения; в)правилах написания слов.
Орфоэпия-это наука… а)о языке; б)правилах произношения; в)правилах написания слов.
2.Укажи глухие согласные звуки- а) [ш,ф, с,к], б) [р,с, г,в], в) [р,ф, г,к].
3.Укажи только мягкие согласные звуки — а) [ф’,ж’, й’], б) [б’,л’,в’], в) [й’,ч’,щ’].
4.Запиши название букв алфавита с 19 по 26.
5.Запиши слова и расставь в них ударение : досуг, кухонный, красивее, свекла, договор, шофер, столяр, позвонит, алфавит, процент.
6.В каком слове на мечте Ч произносится ) [Ш]? а)пчела, б) что, в) черт.
7. В каком слове звуков больше, чем букв? а)птица; б)дождь; в) елочка;
8. В каком слове все согласные звуки твёрдые? а)мышь; б)печь; в)рой;
9. В каком слове нет звука [т]? а)расчистить; б)подписчик; в) брусчатка.
10. Затранскрибируй слова, одного сделай фонетический разбор : южный, тюбик, дождь, семья.
Контрольная работа по теме «Лексика».
1 вариант.
1) Выберите правильный вариант ответа окончания фразы «Лексика — это…»
А) раздел науки о языке, в котором изучаются части речи;
Б) раздел науки о языке, в котором изучается словарный состав языка;
В) раздел науки о языке, в котором изучается строение слова.
2) Выберите вариант правильного объяснения лексического значения выделенного слова в предложении «На площади стоял обелиск из полированного черного мрамора».
А) Клиновидный инструмент, по которому ударяют, рубя металл, обрабатывая камень;
Б) Основание памятника, колонны статуи, а также подставка, на которую устанавливается что-либо;
В) памятник, сооруженный в виде постепенно сужающегося кверху граненого столба.
3) Определи, в каком ряду все словосочетания даны в переносном значении
А) ветер воет, горит костер, сушить весла;
Б) золотые украшения, гора урожая, холодный взгляд;
В) море новостей, плакал лес, горячее сердце.
4) Определите, чем являются выделенные слова в словосочетаниях по отношению друг к другу: язык пламени — изучать язык.
А) синонимы;
Б) омонимы;
В) антонимы.
5) Подберите синонимы к слову, выделенному в предложении: «Великий русский писатель Михаил Афанасьевич Булгаков был, как и многие другие писатели, врачом».
……………………………………………………………………………………….
6) Подчеркните слова в предложении, которые являются антонимами.
Землю — родную землю, Родину — освобождают, территорию — захватывают. Хозяин — на земле, на территории — завоеватель, покоритель. Так что же нам эта земля — земля-кормилица, Родина? Или территория?
7) На месте пропуска запиши слова-синонимы к заимствованным словам:
Офис — ………………………
трасса — ……………………….
иллюстрация — ……………..
8) Объясните значение фразеологизмов словами-синонимами, придумай предложения с ними.
На краю света………………
Чуть свет…………
9) Произведи лексический разбор выделенного слова в предложении «Гаснет вечер, даль синеет, солнышко садится».
Контрольная работа по теме «Лексика».
2 вариант.
1) Выберите правильный вариант ответа окончания фразы «Лексика — это…»
А) раздел науки о языке, в котором изучаются части речи;
Б) раздел науки о языке, в котором изучается словарный состав языка;
В) раздел науки о языке, в котором изучается строение слова.
2) Выберите вариант правильного объяснения лексического значения выделенного слова в предложении «К патриотизму нельзя только призывать, его нужно заботливо воспитывать».
А) любовь к родине, преданность своему отечеству, своему народу;
Б) мнение, суждение, резко расходящееся с обычным, общепринятым;
В) Искренность, правдивость, чистосердечность .
3) Определи, в каком ряду все словосочетания даны в переносном значении
А) волк воет, золотые руки, красить краской;
Б) мягкий взгляд, седые сопки, черствый человек;
В) море цветов, красное платье, твердая земля.
4) Определите, чем являются выделенные слова в словосочетаниях по отношению друг к другу: заключить мир — сказочный мир.
А) антонимы;
Б) синонимы;
В) омонимы.
5) Подберите синонимы к слову, выделенному в предложении: «Вокруг зеленела бархатная трава».
…………………………………………………………………………………………….
6) Подчеркните слова в предложении, которые являются антонимами.
Было время, когда человек был не великаном, а карликом, не хозяином природы, а ее рабом. Но теперь все изменилось, и природа очень часто страдает от деяний человека.
7) На месте пропуска запиши слова-синонимы к заимствованным словам:
фейерверк — ………………………
яхта — …………….………………….
автограф — ………………………..
8) Объясните значение фразеологизмов словами-синонимами, придумай предложения с ними.
Не разлить водой………………………………………………………………………….
Сквозь землю провалиться………………………………………………………………
9) Произведи лексический разбор выделенного слова в предложении «…А в ответ колоски шелестят: «Золотые нас руки растят».
Здоровье и космос — Татьяна Лямзина — Будем здоровы (экс-Мединфо) — Эхо Москвы, 12.04.2021
И сегодня, в День Космонавтики мы поговорим про здоровье и космос. Уже давно установлено, что длительное пребывание в космическом пространстве оказывается опасным для человеческого организма. Ведь на него влияют микрогравитация, радиация и изоляция. Но в чем конкретно состоит риск для здоровья человека, решили разобраться в BBC. Обычно члены экипажа МКС проводят на ее борту по шесть месяцев, но иногда бывают исключения из этого правила. Например, американец Скотт Келли поставил в 2016 году рекорд, проведя в компании с российским космонавтом Михаилом Корниенко 340 суток в космосе. У Скотта есть брат-близнец Марк, который оставался на Земле. Поэтому воздействие долгосрочного воздействия космоса на его организм можно было изучать методом сравнения с идентичным организмом его брата.
После возвращения на Землю Скотт прошел интенсивный курс обследования, который и выявил целый ряд проблем. Прежде всего космонавт жаловался на боль в мускулах, утрату гибкости, уменьшение костной массы и атрофию мускулов. Также наблюдались некоторая отечность и рост внутричерепного давления. У него также были проблемы с кожей — сыпь и раздражения, а по возвращении на Землю в первые дни, когда он снова стал дышать земным воздухом, испытывал тошноту и головокружения.
Также наблюдались некоторая отечность и рост внутричерепного давления. У него также были проблемы с кожей — сыпь и раздражения, а по возвращении на Землю в первые дни, когда он снова стал дышать земным воздухом, испытывал тошноту и головокружения.
Исследователи считают, что результаты экспериментов с участием Скотта Келли окажутся весьма полезными при оценке возможных рисков дальних космических полетов, например, к Марсу и другим планетам Солнечной системы. Ведь полет к Марсу и обратно потребует не менее 30 месяцев пребывания в космосе, что намного превышает все рекорды нахождения человека на борту МКС и других космических аппаратов.
Так какие же проблемы со здоровьем возможны у космонавтов? Быстрое изменение силы тяжести может приводить к сокращению плотности костной ткани на 1% в месяц. Это может приводить к остеопорозу, переломам костей и других долгосрочным проблемам. Микрогравитация может приводить также к возникновению отёков, вызванных приливом крови в верхней части тела, повышению артериального и внутричерепного давления, что отрицательно воздействует на зрение и состояние многих внутренних органов. Роль правильного питания и физических упражнений становится очень важной, требуются также специальные меры, например, прием лекарств и ношение специальной одежды.
Жизнь в условиях изоляции и в стесненном пространстве может приводить и к психологическим трудностям. Отсутствие естественного суточного ритма может вызывать депрессию и проблемы со сном. На борту МКС используется светодиодное освещение, которое имитирует естественную смену света и тьмы на Земле.
В условиях замкнутого пространства меняется также микрофлора человеческого организма. Иммунная система ослабевает, и поэтому приходится тщательно контролировать присутствие микробов и вирусов у обитателей станции.
Воздействие радиационного облучения на борту МКС намного сильнее, чем на поверхности Земли. Поэтому возрастает риск возникновения раковых заболеваний и заболеваний нервной системы.
В преддверии Дня космонавтики в Музее военной формы состоялось открытие нового выставочного проекта «60 космических лет». Посетители смогут увидеть личные вещи Юрия Гагарина – фонарик, лётную куртку, бритвенный прибор, побывавшие в космосе полётный костюм и очки Андрияна Николаева, повседневную форму Алексея Леонова и Владимира Комарова (лётчика-космонавта «№ 7»). Экспозиция будет дополнена подлинными фотоснимками, в том числе, сделанными за несколько минут до старта, при посадке Юрия Гагарина в космический аппарат «Восток-1».
В Государственном музее Востока открылась выставка художника-космиста Бориса Смирнова-Русецкого «Идущий к звёздам». Открытие художественной выставки к юбилейному Дню космонавтики неслучайно. «Идущий к звёздам» — это и космонавт «номер 1», открывший космическую эру, и художник, устремлённый к духовным высотам. Это каждый человек, дерзающий перешагнуть грань неведомого на пути познания тайн Вселенной.
Выставочный проект «Космос наш!», исследующий космическую тему в работах художников XXI века, пройдет в галерее ARTSTORY до 30 мая 2021 года. Выставка проводится в год важнейшего юбилея – 60-летия первого полета человека в космос. В мультидисциплинарном проекте экспонируются работы 40 художников из Москвы и разных городов России.
Люди, столкнувшиеся с новой короновирусной инфекцией, часто жалуются на постковидный синдром, который еще долгое время преследует их после болезни. Пациенты отмечают у себя когнитивные расстройства, слабость, нарушение памяти, головные боли, одышку, повышенную утомляемость, испытывают проблемы со сном. Сегодня врачи все чаще сходятся во мнении, что практически всем переболевшим COVID-19 нужна реабилитация, которая поможет им вернуться к прежней жизни.
Пациенты отмечают у себя когнитивные расстройства, слабость, нарушение памяти, головные боли, одышку, повышенную утомляемость, испытывают проблемы со сном. Сегодня врачи все чаще сходятся во мнении, что практически всем переболевшим COVID-19 нужна реабилитация, которая поможет им вернуться к прежней жизни.
Осложнения после COVID-19 в зависимости от тяжести и течения заболевания могут затрагивать буквально все жизненно важные органы: легкие, сердце, кровеносную систему, печень, почки, кишечник, нервную систему и т.д. В большей степени страдают легкие и сердце. Из-за нарушения процесса газообмена формируется фиброз легких, который снижает насыщаемость организма кислородом. Отклонения в работе сердца проявляются в виде миокардита (воспаление сердечной мышцы) и нарушениях проводимости сердечной мышцы из-за тромбообразования. Чтобы восстановиться организму необходим дополнительный кислород. Как правило, в полной мере его может обеспечить кислородная барокамера, в которой под давлением 1,5 атмосферы подается чистый кислород. При повышенном давлении кислород намного эффективнее растворяется во всех жидких средах, при этом улучшается кровообращение в тканях, активизируются обменные процессы, стимулируется выработка антиоксидантов, отвечающих за функционирование клеток, органов и систем. Во время процедуры запускаются восстановительные процессы во всех тканях – нервных, мышечных, костных и хрящевых, происходит омоложение кожи, восстановление и заживление тканей. Процедура оказывает общеукрепляющее действие на весь организм человека. Такая реабилитация используется для космонавтов, вернувшихся из космических полетов.
По словам Евгении Мурашкиной, врача-физиотерапевта АО «Медицина», члена международного общества физической и реабилитационной медицины, такой способ реабилитации сегодня является одним из лучших для быстрого восстановления после ковида особенно для тех, кто перенес вирус в средней и тяжелых формах. В 2020 году гипербарическая оксигенация включена в международные рекомендации по лечению и реабилитации после COVID-19 и является ключевым инструментом в процессе кислородной поддержки организма.
Будем здоровы!
Почему минздрав Крыма игнорирует результаты прокурорских проверок
Фото: из открытых источников Сети Интернет
Министерство здравоохранения Крыма игнорирует результаты прокурорских проверок и предоставляет ложные сведения в ответах на обращения граждан в связи с ситуацией, сложившейся вокруг Ленинской центральной районной больницы.
Недавно заместитель главы республиканского минздрава Антон Лясковский, сославшись на информацию администрации медучреждения, поставил под сомнение выводы прокуратуры о ненадлежащих условиях хранения медикаментов в гаражном боксе Ленинской ЦРБ, где среди ящиков с мусором и облезлых стен с осыпающейся штукатуркой находилось более 1500 бутылок с солевыми растворами.
Так, чиновник назвал необорудованное для хранения лекарственных средств помещение с туалетом, «складом временного хранения инфузионных растворов и средств индивидуальной защиты». По его словам, администрация больницы перепрофилировала гаражное помещение во временный склад по причине нехватки свободного места в основном аптечном складе.
В минздраве полагают, что в неоснащённом приборами для регистрации параметров воздуха ангаре, ежедневно ведётся журнал учёта температурного режима и влажности воздуха, а сами лекарства хранятся с соблюдением установленного температурного режима.
«По факту прокурорской проверки склада временного хранения медикаментов ГБУЗ РК «Ленинская ЦРБ» представлений, предписаний, постановлений о возбуждении дел административного производства в адрес медучреждения не поступало», — спешно отрапортовал Антон Лясковский.
Между тем 29 марта в адрес главврача Эдуарда Гаптракипова поступило очередное представление прокуратуры Ленинского района об устранении нарушений требований законодательства в сфере здравоохранения, законодательства об охране здоровья граждан, соблюдения требований санитарно-эпидемиологического законодательства, законодательства об антитеррористической защищённости.
В представлении надзорного ведомства сообщается о нарушении правил хранения лекарственных средств, которые регламентированы приказом министерства здравоохранения и социального развития Российской Федерации № 706н от 23 августа 2010 года и являются обязательными к исполнению администрацией ГБУЗ РК «Ленинская ЦРБ».
Выводы прокуратуры были однозначными: медикаменты хранились в гараже без соблюдения элементарных санитарных норм. Кроме того, как указывается в акте прокурорского реагирования, в помещениях не поддерживается необходимая температура и влажность воздуха, отсутствует кондиционер и другое оборудование, позволяющее обеспечить хранение лекарственных средств в соответствии с нормативными требованиями.
Также, отмечают в надзорном ведомстве, помещения для хранения лекарственных средств не обеспечены стеллажами, шкафами, поддонами и подворотниками, а учёт температурного режима ведётся ненадлежащим образом, поскольку в помещении отсутствуют приборы для регистрации параметров воздуха.
«Выявленные нарушения не отвечают требованиям действующего законодательства, являются недопустимыми и нарушают требования конституционного права граждан на охрану здоровья, в том числе несовершеннолетних», — говорится в представлении прокуратуры.
Тем не менее в минздраве Крыма так не считают, как впрочем, не замечают вполне обоснованные претензии местных жителей к результатам работы главврача ЦРБ Гаптракипова.
Между тем ситуацию усугубляет, в том числе и отсутствие реакции на подтверждённые прокуратурой нарушения законодательства об антитеррористической защищённости в деятельности должностных лиц медучреждения.
Как сообщается в материалах проверки, на объектах здравоохранения, входящих в структуру Ленинской ЦРБ и состоящих из 11 врачебных амбулаторий и 36 фельдшерско-акушерских пунктов, до сих пор не выполнено антитеррористическое обследование и категорирование зданий.
В прокуратуре также подчеркнули, что паспорта безопасности объектов не разработаны и не утверждены в установленном порядке.
«Причинами и условиями вышеуказанных нарушений стало ненадлежащее выполнение служебных обязанностей должностными лицами ГБУЗ РК «Ленинская ЦРБ», а также отсутствие должного контроля над подчинёнными со стороны главврача», — резюмировали сотрудники надзорного ведомства.
Ранее в отношении должностных лиц ГБУЗ РК «Ленинская ЦРБ» проводились многочисленные проверки, в ходе которых выявлялись нарушения Трудового Кодекса РФ в части выплаты заработной платы ниже минимально допустимого уровня оплаты труда.
Кроме того подтверждалась информация о нарушениях законодательства о санитарно-эпидемиологическом благополучии населения, а также о недостаточном обеспечении стационарных отделений необходимыми медикаментами и оборудованием.
Морфологический разбор глагола «поставил» онлайн. План разбора.
Для слова «поставил» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «поставил» — глагол - Морфологические признаки.
- поставить (инфинитив)
- Постоянные признаки:
- 2-е спряжение
- переходный
- совершенный вид
- изъявительное наклонение
- единственное число
- прошедшее время
- мужской род.
Активировал зонд, поставил ему задачу.
Выполняет роль сказуемого.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).

- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
11 голосов, оценка 4.455 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «поставил» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
границ | ULTRA: универсальная грамматика как универсальный синтаксический анализатор
Введение
Одним из самых значительных достижений лингвистической теории в последнее время является появление высококачественных наборов данных по всему диапазону межъязыковых вариаций. В прошлом генеративные исследования обычно полагались на детальное изучение одного или нескольких языков для выявления синтаксических механизмов. Хотя этот подход, безусловно, плодотворен, накопление информации о большом количестве языков открывает новые возможности для улучшения понимания.
В порождающей грамматике значительное внимание уделяется рекурсии как (или даже ) фундаментальному свойству языка (обсуждение см. В Berwick and Chomsky, 2016). Это формализуется в основной операции под названием Merge, объединяющей два синтаксических объекта (в конечном итоге построенных из лексических элементов) в набор, содержащий оба. Рекурсия следует из способности Merge применять к собственному выводу. Слияние также фиксирует тот важный факт, что предложения имеют внутреннюю структуру (составные части в квадратных скобках), причем каждый уровень соответствует приложению слияния.
В Berwick and Chomsky, 2016). Это формализуется в основной операции под названием Merge, объединяющей два синтаксических объекта (в конечном итоге построенных из лексических элементов) в набор, содержащий оба. Рекурсия следует из способности Merge применять к собственному выводу. Слияние также фиксирует тот важный факт, что предложения имеют внутреннюю структуру (составные части в квадратных скобках), причем каждый уровень соответствует приложению слияния.
Вопреки этой концепции, я утверждаю, что концептуальной ошибкой является рассмотрение предложений как групп (будь то наборы или что-то еще) лексических единиц. Ошибка заключается в представлении о лексических единицах как о связанных единицах, существующих на одном уровне. Это также приводит к мысли о предложениях как о одноуровневых представлениях. Слова, попросту говоря, не вещей ; они представляют собой пару процессов, протянутых во времени. В контексте понимания релевантными процессами являются распознавание слова и интеграция его значения в интерпретацию.Я развиваю новый взгляд на структуру предложений с точки зрения этих двух типов процессов. Важно отметить, что нетривиальные отношения определяют их относительную последовательность: одно слово может встречаться раньше, чем другое в поверхностном порядке, но его значение может быть интегрировано позже. Рассмотрение предложений как единых, вневременных представлений, построенных на непроницаемых лексических атомах, оставляет нас неспособными уловить фундаментально вовлеченные временные явления, в которых два аспекта каждого слова не связаны вместе, а процессы для разных слов переплетаются.
В этой статье предлагается новая модель грамматических механизмов, получившая название ULTRA (Универсальный реактивный автомат с линейным преобразованием). В локальных синтаксических доменах, образующих расширенную проекцию лексического корня (такого как глагол или существительное), ULTRA использует алгоритм стековой сортировки Кнута (1968) для прямого сопоставления поверхностных порядков слов с лежащей в основе базовой структурой. Сопоставление успешно только для 213 приказов избегания. Это интригующий результат, поскольку избегание 213, возможно, ограничивает вариацию нейтрального порядка слов в разных языках в различных синтаксических областях.Хотя локальные звуковые и смысловые представления в этой модели являются последовательностями, иерархическая структура, тем не менее, возникает в динамическом действии отображения. Обнаруженные здесь структуры в квадратных скобках, хотя и эпифеноменальные, очень похожи на структуры, построенные Merge, с некоторыми существенными различиями (возможно, в пользу нынешней теории).
Сопоставление успешно только для 213 приказов избегания. Это интригующий результат, поскольку избегание 213, возможно, ограничивает вариацию нейтрального порядка слов в разных языках в различных синтаксических областях.Хотя локальные звуковые и смысловые представления в этой модели являются последовательностями, иерархическая структура, тем не менее, возникает в динамическом действии отображения. Обнаруженные здесь структуры в квадратных скобках, хотя и эпифеноменальные, очень похожи на структуры, построенные Merge, с некоторыми существенными различиями (возможно, в пользу нынешней теории).
Сортировка по стеку оказалась эффективной процедурой для связывания порядка слов и иерархической интерпретации, включая линеаризацию, смещение, композицию и помеченные скобки.Теория предлагает реализацию как процесс исполнения в реальном времени. Преследование этого понимания значительно изменяет границы между производительностью и компетенцией. Примечательно, что ULTRA не требует никаких параметров, зависящих от языка; инвариантный алгоритм служит грамматическим устройством для всех языков. Проще говоря, я предполагаю, что Universal Grammar — это универсальный синтаксический анализатор.
Тем не менее, стековая сортировка — это слишком ограниченный механизм для описания всех явлений человеческого синтаксиса. Остается незавершенным три вида эффектов: неограниченная рекурсия, ненейтральный порядок и существование явно различных языков.Более того, понимание стековой сортировки как системы обработки сталкивается с двумя очевидными проблемами: это однонаправленный синтаксический анализатор, который не является тривиально обратимым для производства; и это противоречит убедительным доказательствам пословной постепенности в понимании.
Хотя построение полной модели синтаксиса и обработки выходит далеко за рамки данной статьи, проблемы, возникающие при построении модели синтаксического анализа как грамматики на сортировке стека, требуют рассмотрения. Я обращаюсь к различию между реактивными и предсказательными процессами, рассматривая стековую сортировку как универсальную реактивную процедуру. Отдельный прогностический модуль играет решающую роль в производстве и в появлении четких, относительно жестких порядков слов. Прогнозирование также помогает согласовать ULTRA с инкрементной интерпретацией. Я обращаюсь к свойствам памяти для решения дальнейших проблем, предполагая, что первичная память (отличная от памяти недавнего времени, лежащей в основе стековой сортировки) является источником другого кластера синтаксических свойств, включая перемещение на большие расстояния, пересекающиеся зависимости и специальный синтаксис «левая периферия.Наконец, я предполагаю, что эпизодическая память — независимо иерархическая по структуре у людей — играет ключевую роль в лингвистической рекурсии.
Отдельный прогностический модуль играет решающую роль в производстве и в появлении четких, относительно жестких порядков слов. Прогнозирование также помогает согласовать ULTRA с инкрементной интерпретацией. Я обращаюсь к свойствам памяти для решения дальнейших проблем, предполагая, что первичная память (отличная от памяти недавнего времени, лежащей в основе стековой сортировки) является источником другого кластера синтаксических свойств, включая перемещение на большие расстояния, пересекающиеся зависимости и специальный синтаксис «левая периферия.Наконец, я предполагаю, что эпизодическая память — независимо иерархическая по структуре у людей — играет ключевую роль в лингвистической рекурсии.
Структура статьи следующая. В разделе Linear Base утверждается, что «базовая» структура внутри каждого локального синтаксического домена представляет собой последовательность. Раздел * 213 в «Нейтральном порядке слов» исследует обобщение, согласно которому «213-избегание» ограничивает возможности нейтрального по отношению к информации порядка слов в разных языках. Раздел «Сортировка стека как грамматический механизм» предлагает процедуру сортировки стека для выявления «избегания 213» в порядке слов.Раздел Stack-Sorting: Linearization, Displacement, Composition и Labeled Brackets показывает, как дальнейшие синтаксические эффекты следуют из сортировки по стеку. Раздел Сравнение с существующими учетными записями Universal 20 сравнивает ULTRA с существующими учетными записями избегания 213 в порядке слов, уделяя особое внимание Universal 20. Раздел Universal Grammar as Universal Parser преследует реализацию стековой сортировки в реальном времени. В разделе «Возможные расширения более полной теории синтаксиса» рассматриваются проблемы, связанные с принятием стековой сортировки в качестве ядра универсальной грамматики, и приводится набросок некоторых возможных расширений.Раздел Заключение завершается.
Линейная база
Синтаксическая комбинация может принимать разные формы. Появляется новая точка зрения, согласно которой сочетание в значительной степени поддерживает отношения между головой и дополнением (Starke, 2004; Jayaseelan, 2008). В этом контексте термин «голова» имеет как минимум два разных значения. Во-первых, в любой комбинации двух синтаксических объектов один является «более важным» по отношению к составному значению. Назовем это понятие головы корнем , отметив, что в расширенных проекциях существительных и глаголов лексическое существительное или корень глагола является семантически доминантным.Другой смысл головы касается того, какой элемент определяет комбинаторное поведение композиции; назовем это понятие головы меткой .
Появляется новая точка зрения, согласно которой сочетание в значительной степени поддерживает отношения между головой и дополнением (Starke, 2004; Jayaseelan, 2008). В этом контексте термин «голова» имеет как минимум два разных значения. Во-первых, в любой комбинации двух синтаксических объектов один является «более важным» по отношению к составному значению. Назовем это понятие головы корнем , отметив, что в расширенных проекциях существительных и глаголов лексическое существительное или корень глагола является семантически доминантным.Другой смысл головы касается того, какой элемент определяет комбинаторное поведение композиции; назовем это понятие головы меткой .
В старых теориях структуры фраз два смысла головы (корень и метка) сходились в одном элементе; существительное, например, в сочетании со всеми его модификаторами в существительной фразе. Таким образом, головокружение соотносится с иерархическим доминированием; корень проецировал свой ярлык над своими иждивенцами. Для иллюстрации комбинация прилагательного и существительного, например красных книг , будет представлена следующим образом.
Этот традиционный вывод о взаимосвязи зависимости и иерархии опровергнут современной синтаксической картографией (Rizzi, 1997; Cinque, 1999 и последующие работы). Картографические подходы предполагают, что синтаксическая комбинация следует строгой, кросс-лингвистической однородной иерархии внутри каждой расширенной проекции. Эта иерархия включает в себя последовательность функциональных глав, лицензионную комбинацию с различными модификаторами в строгом порядке. Фраза красных книг представлена следующим образом.
Здесь прилагательное — это спецификатор специализированного функционального заголовка (F), который маркирует композицию, определяя ее комбинаторное поведение. В картографических изображениях головы равномерно на ниже их иждивенцев, которые появляются выше по позвоночнику.
Вопросы возникают по поводу этих представлений, которые постулируют обилие невысказанного материала. Любопытное наблюдение заключается в том, что функциональные заголовки и их спецификаторы явно не встречаются вместе, как это формализовано в обобщенном двойном фильтре компаундирования Купмана (2000).
Любопытное наблюдение заключается в том, что функциональные заголовки и их спецификаторы явно не встречаются вместе, как это формализовано в обобщенном двойном фильтре компаундирования Купмана (2000).
Starke (2004) развивает наблюдение Купмана дальше, утверждая, что заголовки и спецификаторы не встречаются одновременно, потому что они представляют собой токенов одного типа , конкурирующих за одну позицию. Старке преобразовывает картографический корешок в абстрактную функциональную последовательность ( fseq ), позиции которой могут быть обозначены как лексическим, так и фразовым материалом. Следуя концепции Старке, комбинация прилагательного и существительного будет представлена, как показано ниже.
Мы снова изменили традиционные выводы об иерархии глав и иждивенцев.Тем не менее, понятие корня (выделение существительного) по-прежнему имеет решающее значение, поскольку модификаторы расположены в иерархическом порядке, продиктованном и fseq.
Синтаксическая комбинация этого типа является последовательной в пределах каждой расширенной проекции. Эти «базовые» последовательности кодируют композицию «снизу вверх», поэтому естественно упорядочить последовательность таким же образом (снизу вверх). База (т.е. fseq, картографический корешок) широко считается единообразной для разных языков и выражает «тематическое», информационно-нейтральное значение (в отличие от дискурсивно-информационной структуры).
Грамматика, согласно любой теории, определяет формальное отображение, связывающее звук и значение (точнее, внешнюю и внутреннюю формы, с учетом неслышащих модальностей). Эта спецификация может принимать разные формы. Последовательное представление основы позволяет очень просто сформулировать звуково-смысловое отображение. Эта переформулировка дает принципиальное описание класса универсалий порядка слов. Более того, в то время как интерфейсные объекты (порядок слов и базовые деревья), участвующие в отображении, являются последовательностями, заключенная в скобки иерархическая структура возникает как динамический эффект.
Существуют различные способы концептуализации взаимосвязи между базовым и поверхностным порядком слов. Обычное мнение состоит в том, что база упорядочивает входные данные до производных, давая поверхностный порядок слов в качестве выходных данных. Эта направленность подразумевается в терминах, используемых для описания отношения иерархия-порядок: линеаризация , экстернализация и т. Д. Эта статья преследует другую точку зрения, где поверхностные порядки слов являются входными данными для алгоритма, который пытается собрать основу как выход. Примечательно, что единственные исходные данные, которые сходятся на единой основе в рамках этого процесса, — это 213-избегание; порядок слов, содержащих 213, приводит к отклонению от нормы.
* 213 В нейтральном порядке слов
213-избегание, возможно, улавливает возможности нейтрального по отношению к информации порядка слов в различных синтаксических областях на разных языках. Под 213-избеганием я подразумеваю запрет на порядок поверхности… b… a… c …, для элементов a ≫ b ≫ c , где ≫ указывает c-команду в стандартных представлениях дерева базы ( эквивалентно доминирование в деревьях Старке). Другими словами, нейтральные порядки слов, кажется, избегают последовательности элементов от среднего до высокого-низкого (под) из одного fseq.Элементы, образующие этот запрещенный контур, не обязательно должны быть смежными, в порядке поверхности или в основании fseq.
Широко распространено мнение, что 213-избегание ограничивает варианты упорядочивания кластеров глаголов, хорошо известных в западногерманском языке (см. Обзор в Wurmbrand, 2006). Обширный обзор голландских диалектов, проведенный Barbiers et al. (2008), обнаружил очень мало примеров этого порядка; Немецкие диалекты, кажется, тоже избегают этого порядка. Между тем Zwart (2007) анализирует порядок 213 в кластерах голландских глаголов как включающий экстрапозицию последнего элемента.
Наиболее изученной областью, поддерживающей избегание 213 в порядке слов, является Universal 20 Гринберга, описывающая порядок именных фраз.
«Когда какие-либо или все элементы (указательное, числовое и описательное прилагательное) предшествуют существительному, они всегда находятся в указанном порядке. Если они следуют, то порядок либо тот же, либо полная противоположность »(Greenberg, 1963, стр. 87).
Последующие работы улучшили эту картину. Cinque (2005) сообщает, что только 14 из 24 логически возможных порядков этих элементов засвидетельствованы как информационно-нейтральные порядки (Таблица 1).
Таблица 1 . Возможный порядок именных фраз. Cinque (2005, стр. 319–320) отчет о количестве языков, представленных в каждом порядке, дается числом: 0 = не подтверждено; 1 = очень мало языков; 2 = несколько языков; 3 = много языков; 4 = очень много языков.
Чинкве описывает эти факты с ограничением движения с единой базы. В частности, он предлагает, чтобы все движения перемещали существительное или что-то, что его содержит, влево (раздел «Сравнение с существующими счетами Universal 20» подробно описывает теорию Чинкве и связанные с ней описания).Что запрещено, так это движение остатка.
Порядок именных фраз подчиняется простому обобщению: подтвержденные порядки — это все и только 213 перестановки, избегающие перестановок. Все непроверенные заказы имеют 213 подпоследовательностей. Например, неподтвержденный * Num Dem Adj N содержит подпоследовательности Num Dem Adj … и Num Dem… N , представляющие контуры среднего-высокого-низкого значения относительно fseq.
Сортировка стека как грамматический механизм
Существует особенно простая процедура, которая отображает порядок слов, избегающих 213, в единую основу, называемая сортировкой стека.Я описываю адаптацию алгоритма сортировки стека Кнута (1968), который использует память «последний пришел — первым вышел» (стек) для сортировки элементов по их относительному порядку в базе. Это частичный алгоритм сортировки: он достигает желаемого результата только для некоторых входных порядков.
(4) S АЛГОРИТМ ТАК-СОРТИРОВКИ D ОПРЕДЕЛЕНИЯ
Пока ввод не пуст, I: следующий элемент ввода.
If I ≫ S, Pop. S: элемент наверху стека.
Else Push. x ≫ y: x c-команды y в
база (например, Dem ≫ N).
Пока Stack не пуст, Push: перемещает I из входа
в стек.
Поп. Pop: перемещает S из стека
для вывода.
(4) отображает все и только 213-избегающие порядки слов в 321-подобную иерархию, соответствующую основанию. Заказы, содержащие 213, сопоставляются с отклоняющимся выходом, отличным от базового. По предположению, именно поэтому такие порядки типологически недоступны: они автоматически отображаются в неинтерпретируемом порядке композиции. Это объясняет шаблон Universal 20 (Таблицы 2, 3).
Таблица 2 . Результат стековой сортировки логически возможных порядков из 4 элементов, в формате вход → выход.
Таблица 3 . Вычисления сортировки стека для 4-х порядков.
Давайте проиллюстрируем, как (4) разбирает некоторые порядки именных фраз: Dem-Adj-N, N-Dem-Adj, * Adj-Dem-Num.
(5) Dem-Adj-N: PUSH (Dem), PUSH (Adj), PUSH (N),
POP (N), POP (Adj), POP (Dem).
(6) N-Dem-Adj: PUSH (N), POP (N), PUSH (Dem), PUSH (Adj),
POP (Настр.), POP (Дем.).
Для аттестованных заказов номинальные категории POP в порядке
(7) * Adj-Dem-N: PUSH (Настр.), POP (Настр.), PUSH (Дем.),
PUSH (N), POP (N), POP (Дем).
Для неподтвержденного порядка 213, элементы POP в девиантном порядке *
Это хорошо: (4) сопоставляет подтвержденные заказы их универсальному значению, одновременно исключая не подтвержденные заказы. Но помимо такого сопоставления, адекватная грамматика должна объяснять другие аспекты знания языка, включая брекетинг поверхностной структуры.Если грамматика рассматривает поверхностные порядки и базовые структуры как последовательности (локально), откуда может взяться такая заключенная в скобки структура?
Сортировка стопкой: линеаризация, смещение, композиция и маркированные скобки
В этом разделе я показываю, что сортировка стека эффективно охватывает линеаризацию, смещение и композицию, а также назначение скобок с однозначной пометкой и без поиска. Более того, все это выполняется без параметров, зависящих от языка.
В стандартном представлении («Y-модель») линеаризация и композиция — это отдельные операции интерфейса, интерпретирующие структуры, построенные в автономном синтаксическом модуле с помощью Merge.В ULTRA линеаризация идет в другом направлении, поэтапно загружая в память поверхностный порядок слов и собирая их заново в порядке композиционной интерпретации.
Смещение — естественное свойство грамматики сортировки стека
Смещение — естественная особенность сортировки стопкой; с одной точки зрения, это основное свойство системы. В стандартных отчетах составляющие, составляющие вместе при интерпретации, должны появляться смежными в поверхностном порядке. Такое расположение вызвано грамматиками фразовой структуры.Смещение, при котором элементы, составляющие вместе, разделяются промежуточными элементами в порядке поверхности, всегда казалось удивительным свойством, нуждающимся в объяснении.
В ULTRA все работает иначе. Ключевое предположение представления на основе слияния отвергается: нет уровня представления, охватывающего порядок слов и fseq в унифицированном объекте более высокого порядка. Вместо этого порядок слов и базовая иерархия — это несвязанные последовательности, связанные динамически. Несмежные элементы ввода вполне могут оказаться смежными на выходе.Смещение, а не исключение, является правилом; каждый элемент в поверхностном порядке «преобразуется», проходя через память перед извлечением для интерпретации.
Скобки и метки без примитивного округа
Алгоритм (4) неявно назначает помеченную в скобках структуру каждому порядку поверхности, почти точно совпадая со структурами, присвоенными такими учетными записями, как Cinque (2005). Явно нажатие (сохранение от порядка слов до стека) соответствует левой скобке, а выталкивание (извлечение из стека для интерпретации) — правой скобке.Эти операции применяются к одному элементу за раз; естественно думать, что этот элемент обозначает соответствующую скобку. См. Таблицу 4, в которой представлены вычисления сортировки стека для всех перестановок поверхностей трехэлементной базы.
Таблица 4 . Вычисления с сортировкой стека для порядков из 3 элементов.
При рассмотрении этих скобок, последовательность нажатий и извлечений (сохранение и извлечение) для каждого порядка неявно определяет дерево, как показано на рисунке 1. Это так называемые деревья Дика, набор всех упорядоченных корневых деревьев с фиксированным числом. узлов (здесь 4).Сравните их с деревьями с бинарным ветвлением, указанными в отчете Cinque (2005), с неостаточным движением влево, влияющим на основание с ветвлением вправо (рис. 2). Скобки почти идентичны, как и их ярлыки, но есть некоторые вольности с техническими деталями аккаунта Cinque.
Рисунок 1 . Скобки и соответствующие деревья push-pop для принятых (сортированных по стеку) порядков из трех элементов. Это просто деревья Дика с 4 узлами.
Рисунок 2 .Деревья с бинарным ветвлением для производных аттестованных порядков трех элементов, избегающих перемещения остатков, с соответствующими скобками. Лексический корень (например, N в существительной фразе) показан черным треугольником, а структуры с концом и следом движения представлены двойной ветвью ||. Деревья представлены таким образом, чтобы выделить соответствие с деревьями Дика для этих порядков, полученных в результате сортировки стека.
Если отложить в сторону 321 дерево (а) на данный момент, деревья Дика представляют собой систематические сжатия без потерь деревьев Чинкве, при этом каждое поддерево, которое является ветвящейся вправо гребенкой в дереве Чинкве, заменено линейным деревом (см. 2008) в дереве Дика.Для этого соответствия, которое сводится к сокращению всех терминалов в двоичном дереве, лексический корень (например, существительное в DP) не должен сокращаться. Элементы из поверхностного порядка связаны с каждым узлом дерева Дика, кроме самого высокого, с линейным порядком чтения слева направо среди сестринских узлов и сверху вниз по унарным ветвящимся путям. Например, для порядка 132 поверхности 1 связан с единственным бинарным ветвящимся узлом в его дереве Дика, 3 и 2 — с его левой и правой дочерними элементами (рис. 3).
Рисунок 3 .Два представления в квадратных скобках 132 порядка поверхности и соответствующие деревья. Слева — структура, найденная при чтении операций сортировки стека в скобках; Элементы поверхности идентифицируются каждым узлом (кроме самого верхнего, пунктирного). Линейный порядок считывается сверху вниз по унарным ветвящимся путям и слева направо среди сестринских узлов. В соответствующем двоичном ветвящемся дереве, представляющем его происхождение перемещением (справа) , ярко выраженные элементы идентифицируются только с конечными узлами.
Между тем, порядок 321, которому присвоено троичное дерево путем сортировки стека, имеет два производных, исключающих перемещение остатков. В одном из возможных выводов 3 инвертируют, причем 2 сразу после объединения 2, затем 32 комплекса перемещаются за 1 после объединения 1. В другом возможном выводе сначала объединяется полная базовая структура, затем 23 перемещаются влево, а затем влево перемещается всего 3.
Ключевой эмпирический вопрос заключается в том, демонстрируют ли 321 порядок две отдельные заключенные в скобки структуры, как это позволяют трактовки бинарного ветвления, или только единственная, «плоская» структура, предсказанная здесь.Проблема становится еще более острой для 4 элементов, как в Universal 20, где существует до 5 различных производных слияния для порядка 4321. К счастью, это ( N Adj Num Dem ) является наиболее распространенным порядком именных фраз; будущие исследования должны пролить свет на эту проблему.
Сводка раздела
Stack-sorting захватывает удивительное количество синтаксического механизма, обычно разделенного между различными модулями. В обычном представлении автономный генераторный движок строит составляющие структуры, интерпретируемые на интерфейсах дальнейшими процессами линеаризации и композиции.В ULTRA линеаризация и композиция отражают единую процедуру. Составная структура не является примитивной, но записывает этапы хранения и извлечения, с помощью которых сортировка стека собирает интерпретацию. Это создает структуру поверхности в квадратных скобках, обозначенную соответствующим образом, в значительной степени идентичную структуре в скобках в учетных записях, постулирующих движение (внутреннее слияние) от единой основы (сформированной с помощью внешнего слияния). Однако там, где стандартные теории допускают множественные выводы для некоторых порядков поверхностей (и неоднозначную бинарную ветвящуюся структуру), в настоящем описании назначается уникальная внебинарная скобка.Примечательно, что специфические языковые особенности не играют никакой роли в движении. Смещение обрабатывается автоматически путем сортировки стека и фактически является его основной функцией.
Сравнение с существующими счетами Universal 20
В этом разделе сравнивается учетная запись сортировки стека Universal 20 с существующими учетными записями на основе слияния (Cinque, 2005; Steddy and Samek-Lodovici, 2011; Abels and Neeleman, 2012). Я утверждаю, что учетная запись сортировки стека проще, при этом избегая проблем, которые возникают в каждой из этих существующих альтернатив.
Счет Чинкве (2005)
Cinque предлагает кросс-лингвистически однородную базовую иерархию, отражающую фиксированный порядок внешнего слияния. Он предполагает, что движение (внутреннее слияние) происходит равномерно влево, в то время как основание ветвится вправо, в соответствии с LCA Кейна (1994). Он оговаривает, что остаточное движение в именной фразе запрещено: каждое движение влияет на существительное или на составляющую, содержащую его. Его базовая структура для именной группы — (8).
Открытые модификаторы — это спецификаторы выделенных функциональных глав (например,г., X 0 ), ниже договорные фразы, предусматривающие посадочные площадки для передвижения. Эта структура и его предположения о движении выводят все и только подтвержденные приказы. Англоязычный порядок Dem-Num-Adj-N поверхности без движения; все другие порядки включают некоторую последовательность движений NP или что-то, что ее содержит.
Счет Абельса и Нилмана (2012)
Abels и Neeleman (2012) модифицируют анализ Cinque, отбрасывая элементы, введенные для соответствия LCA (включая согласованные фразы и специальные функциональные главы).Они утверждают, что LCA не играет объяснительной роли; все, что требуется, — это движение влево, а остаточное движение запрещено. Они допускают свободную линеаризацию сестринских узлов, используя значительно более простую базовую структуру (9). Они опускают метки для нетерминальных узлов как не относящиеся к их анализу (Abels and Neeleman, 2012: 34).
По их теории, восемь подтвержденных приказов могут быть получены без движения, изменяя линейный порядок сестер. Остальные подтвержденные заказы требуют движения влево без остатка.В принципе, их система допускает расширенный набор выводов Чинкве (2005); некоторые порядки могут быть получены путем выбора линеаризации или перемещения. Однако, ограничивая внимание строго необходимыми операциями и предполагая, что свободная линеаризация проще, чем перемещение, их вывод обычно проще, чем у Cinque.
Рассказ Стедди и Самека-Лодовичей (2011)
Стедди и Самек-Лодовичи (2011) предлагают еще один вариант анализа Чинкве (2005).Они предлагают теоретико-оптимальное объяснение, сохраняя базовую структуру Чинкве (8). Линейный порядок определяется набором ограничений Align-Left (10), по одному для каждого открытого элемента.
(10) а. N-L — Выровнять (NP, L, AgrWP, L)
Совместите левый край NP с левым краем AgrWP.
г. A-L — Выровнять (AP, L, AgrWP, L)
Совместите левый край AP с левым краем AgrWP.
г. NUM-L — Выровнять (NumP, L, AgrWP, L)
Выровняйте левый край NumP с левым краем AgrWP.
г. DEM-L — Выровнять (DemP, L, AgrWP, L)
Совместите левый край DemP с левым краем AgrWP.
(Из Стедди и Самек-Лодовичи, 2011: 450).
Эти ограничения выравнивания вызывают нарушение для каждого явного элемента или трассы, отделяющей соответствующий элемент от левого края домена, и ранжируются по-разному для разных языков. Подтвержденные заказы являются оптимальными кандидатами при некотором ранжировании ограничений. Непроверенные заказы исключаются, потому что они «гармонически ограничены»: какой-либо другой кандидат подвергается меньшему количеству нарушений более высокого ранга при любом ранжировании ограничений.Таким образом, они могут отказаться от ограничений передвижения, принятых Чинкве (2005) и Абельсом и Нилманом (2012). Вместо этого левосторонний, не остаточный характер движения выпадает из принципов выравнивания.
Проблемы с существующими учетными записями
Хотя эти учетные записи различаются в деталях, у них есть некоторые проблемные особенности. Во-первых, все они отражают шаблон порядка слов на трех уровнях объяснения: (i) единообразная базовая структура, (ii) синтаксическое движение и (iii) принципы линеаризации.Во всех трех учетных записях (i) описывает порядок внешнего слияния. Подробности пунктов (ii) и (iii) различаются в зависимости от счета. Для Cinque (2005) и Steddy and Samek-Lodovici (2011) все заказы, кроме Dem-Num-Adj-N , связаны с движением; Abels и Neeleman (2012) требуют перемещения только для шести подтвержденных заказов. Что касается линеаризации, Cinque (2005) использует LCA Кейна (1994); Абельс и Нилман (2012) имеют движение равномерно влево, но сестры, генерируемые базой, свободно линеаризуются на основе специфики языка; У Стедди и Самек-Лодовичи (2011) есть ранжирование ограничений для конкретного языка.
Все эти учетные записи требуют разной грамматики для разных порядков. В системе Cinque (2005) необходимо изучить особенности, управляющие определенными движениями. То же самое верно для Abels и Neeleman (2012) с дополнительным изучением порядка для сестринских узлов. Стедди и Самек-Лодовичи (2011) требуют изучения ранжирования ограничений, которое дает начало каждому порядку. Таким образом, все эти рассказы сталкиваются с проблемами, связанными с языками, допускающими свободу порядка в ДП; по сути, они должны допускать недоопределенные или конкурирующие грамматики, чтобы фиксировать различные порядки.
Наконец, все эти описания имеют некоторую степень структурной или грамматической двусмысленности для некоторых порядков. Для Cinque (2005) одна из разновидностей двусмысленности возникает при выборе того, следует ли переместить функциональную категорию или фразу «Соглашение», в которую она встроена; у этого выбора нет явного рефлекса. Хотя его теория резко ограничивает количество и место посадки возможных перемещений, эти ограничения несколько искусственны; Немногое существенное изменилось бы, если бы мы постулировали дополнительные тихие функциональные уровни для выполнения дальнейших движений или разрешили использование нескольких спецификаторов.В пределе это позволяет использовать весь спектр неоднозначных производных, обсуждаемых в разделе Stack-Sorting: Linearization, Displacement, Composition, and Labeled Brackets. Подход Абельса и Нилмана (2012) допускает эту двусмысленность среди различных производных движений, а также получение множества порядков посредством перемещения или переупорядочения сестринских узлов. Наконец, Стедди и Самек-Лодовичи (2011) сталкиваются с другой проблемой неоднозначности: некоторые порядки согласуются с множественным ранжированием ограничений (таким образом, множественными грамматиками).
Сравнение со счетом сортировки стека
Учетная запись с сортировкой по стеку лучше справляется с этими проблемами. Вместо постулирования отдельных уровней принципов основы, движения и линеаризации соответствующий механизм реализуется в рамках одного алгоритмического процесса. Алгоритм сортировки универсален, он избегает специфичных для языка функций для управления движением, упорядочивания дочерних узлов или ограничений выравнивания рангов. Такая теория идеально подходит для объяснения феномена свободного порядка слов.Более того, каждый заказ вызывает уникальную последовательность операций хранения и извлечения, отслеживая уникальный брекетинг. В доменах, характеризующихся нейтральным порядком слов и одним fseq, нет ложной структурной или грамматической двусмысленности для любого порядка слов.
Универсальная грамматика как универсальный синтаксический анализатор
В этом разделе развивается точка зрения, согласно которой сортировка стека может сформировать основу для инвариантного механизма производительности, реализуя универсальную грамматику как универсальный синтаксический анализатор. Это изменяет традиционные выводы о компетентности и успеваемости, обеспечивая при этом новое представление о том, что такое грамматика.
Переосмысление компетенции и производительности
В генеративных счетах существует фундаментальное разделение между компетенцией и производительностью (Chomsky, 1965). Компетенция включает в себя знание языка, рассматриваемое как абстрактное вычисление, определяющее структурную декомпозицию бесконечного числа предложений. Отдельные системы производительности получают доступ к знаниям системы компетенций во время обработки в реальном времени. В терминах трехуровневого описания систем обработки информации Марра (1982), компетентность соответствует высшему вычислительному уровню, определяя , что делает система , и , почему, .Производительность довольно свободно соответствует нижнему, алгоритмическому уровню, описывающему , как вычисление выполняется, шаг за шагом.
Конечно, иерархия Марра применима к обработке информации на языке в рамках данной теории, как и любой другой. Однако разделение труда между этими компонентами здесь существенно перерисовывается, и гораздо больше бремени объяснения ложится на производительность. Существенное отличие состоит в том, что в ULTRA заключенная в скобки структура не входит в компетенцию.Вместо этого такая структура возникает во взаимодействии компетенции с алгоритмом сортировки стека во время синтаксического анализа в реальном времени. Знания, приписываемые грамматике компетенций, проще, включая врожденный fseq в качестве основного компонента. В некотором смысле это согласуется с взглядами недавней работы Хомского, в которой компетенция фундаментально ориентирована на вычисление интерпретаций с экстернализацией «вспомогательными».
Универсальный синтаксический анализатор
Новое утверждение ULTRA состоит в том, что существует единый синтаксический анализатор для всех языков.Это отходит от почти универсального предположения, что синтаксические анализаторы интерпретируют грамматики конкретного языка. Но даже в рамках этого традиционного взгляда была признана привлекательность универсальных механизмов.
«Ключевым моментом, однако, является то, что поиск должен быть поиском универсалий, даже — и, возможно, особенно — в области обработки. Ибо может показаться, что самая сильная теория синтаксического анализа — это та, которая утверждает, что интерпретатор грамматики сам по себе является универсальным механизмом, т.е. что существует один сильно ограниченный интерпретатор грамматики, который является подходящей машиной для синтаксического анализа всех естественных языков »(Marcus, 1980, p.11).
Идея «синтаксический анализатор — это грамматика» имеет долгую историю; см. Phillips (1996, 2003), Kempson et al. (2001), а также статьи в Fodor and Fernandez (2015) о недавней перспективе. Фодор называет это представлением (PGO) только грамматики производительности .
«Теория общественного мнения вступает в игру с одним мощным преимуществом: должны быть психологические механизмы для разговора и понимания, и соображения простоты, таким образом, возлагают бремя доказательства на любого, кто заявляет, что существует нечто большее» (Fodor, 1978, стр.470).
Однако, допуская, что это влечет за собой более простую теорию, Фодор отвергает эту идею, не находя мотивации для движения за пределами автономной грамматики ( там же ., 472). Это предполагает, что движение принципиально сложно для синтаксического анализа механизмов (которые должны предпочесть фразово-структурные механизмы трансформационным). Однако в ULTRA смещение не является сложностью по сравнению с более простыми механизмами; смещение — это основной механизм.
Смещение не является уникальной особенностью человеческого языка
Часто говорят, что смещение присуще только человеческому языку, и искусственные коды избегают этого свойства.Но смещение появляется в языках программирования точно в том же смысле, что и в ULTRA. Простой пример иллюстрирует: порядок, в котором пользователи нажимают клавиши на калькуляторе, не является порядком, в котором выполняются соответствующие вычисления. На практике калькуляторы компилируют входные данные в обратную польскую нотацию для машинного использования с помощью алгоритма маневрового двора Дейкстры (SYA).
Пример не праздный; алгоритм сортировки стека (4) по существу идентичен SYA. Лексические заголовки (существительные и глаголы) «перенаправляются» непосредственно на интерпретацию, как числовые константы в калькуляторе.Между тем спутники, образующие их расширенные проекции, сортируются в соответствии с их относительным рангом, как и арифметические операторы. По этой аналогии картографический порядок соответствует порядку приоритета арифметических операторов.
На самом деле, хотя это свойство мало используется, SYA является протоколом сортировки; многие заказы на ввод приводят к одному и тому же внутреннему расчету. Как пользователи калькуляторов, мы используем одну схему ввода (инфиксную нотацию), но подойдут и другие. Стандартизированный порядок ввода для калькуляторов имеет тот же статус, что и отдельные языки по отношению к ULTRA: пользователи могут придерживаться узких привычек упорядочивания, но алгоритм автоматически обрабатывает многие другие заказы.
Грамматичность и грамматичность
Одна из центральных задач, приписываемых грамматике, — отличать грамматические предложения языка от неграмматических строк. В ULTRA знание грамматики сильно отличается от знания грамматики и . Первый вид знания в основном касается компьютерных интерпретаций. Но инвариантный процесс, интерпретирующий поверхностный порядок одного языка, может одинаково интерпретировать порядки других языков. С этой точки зрения существует только один I-язык и единственная грамматика производительности, которая его обеспечивает.Хотя этот вывод является привлекательным, остается важный вопрос: откуда берутся отдельные языки с явно различающейся грамматикой?
Возможные расширения более полной теории синтаксиса
В этом разделе рассматриваются два типа проблем, возникающих при интерпретации стековой сортировки как устройства производительности. Первый касается согласования теории с тем, что известно о языковой обработке в реальном времени; второй касается расширения модели до свойств синтаксиса, которые остаются необъясненными.Даже подробное обсуждение этих проблем, не говоря уже об оправдании каких-либо решений, выходит за рамки данной статьи. Цель состоит в том, чтобы просто набросать проблемы и указать направления для дальнейшей работы.
Реакция против предсказания: инкрементность и жесткий порядок слов
Что касается обработки, то одна проблема состоит в том, что этому подходу, кажется, противоречат убедительные доказательства пословной инкрементальности в понимании (особенно в парадигме визуального мира; см. Tanenhaus and Trueswell, 2006).ULTRA является «пешеходом» в том смысле, против которого предостерегает Стейблер (1991). В каждом домене интерпретация «снизу вверх» не может начаться, пока не будет обнаружен лексический корень fseq.
Одна из возможностей согласования ULTRA с инкрементальностью основана на различии между реактивными процессами, такими как процедура сортировки стека и прогнозная обработка (см. Braver et al., 2007; Huettig and Mani, 2016). Идея состоит в том, что сортировка стека является реактивным механизмом языкового восприятия; это контрастирует — и обязательно дополняется — возможностями прогнозирования, связанными с нисходящей обработкой и производством.Только последняя система содержит выученные языковые грамматические знания. Это предложение перекликается с другими подходами с двухэтапным процессом синтаксического анализа, такими как Sausage Machine Фрейзера и Фодора (1978). ULTRA похож на их предварительный упаковщик фраз (PPP), быстрый низкоуровневый конструктор структур, отличающийся от крупномасштабного решения проблем их диспетчера структуры предложений (SSS). Маркус выражает аналогичную точку зрения, описывая синтаксический анализатор как «быстрый,« глупый »черный ящик» (Marcus, 1980: 204), производящий частичный анализ, дополненный интеллектуальным решением проблем для построения крупномасштабной структуры.
Я предполагаю, что доказательства постепенного увеличения количества слов за слово могут быть согласованы с существующей теорией посредством взаимодействия между реакцией и предсказанием, используя понятие «гиперактивность» (Momma et al., 2015). Идея состоит в том, что понимание может пропустить вперед, создавая видимость инкрементности, если лексический корень (существительное или глагол) предоставляется заранее путем предсказания. Что-то вроде этого кажется правдой.
«Появляется все больше свидетельств того, что постигающие часто выстраивают структурные позиции в своих анализах до того, как столкнутся со словами во входных данных, которые фонологически реализуют эти позиции […] Возьмем только один пример, в таком языке, который является окончательным, например, в японском, может потребоваться система построения структуры для создания позиции для заголовка фразы до того, как она завершит аргументы и дополнения, предшествующие заголовку »(Phillips and Lewis, 2013, p.19).
Дополнительная система прогнозирования может помочь решить еще две проблемы для ULTRA: объяснить, как возможно производство, и почему существуют разные языки с различным, относительно жестким порядком слов. Алгоритм сортировки стека — это однонаправленный синтаксический анализатор; не существует тривиального способа «повернуть поток вспять» для производства. Столкнувшись с этой неопределенностью, было бы естественно полагаться на предсказание, чтобы обеспечить порядок слов в производстве. Чтобы упростить производство, полезно, чтобы порядок слов был предсказуемым; в свою очередь, с помощью этой системы можно изучить тенденции порядка слов в языковой среде.Это предполагает наличие петли обратной связи и вероятного пути возникновения и расхождения относительно жестких порядков слов.
Первенство vs. новизна и двойственность семантики
Ряд важных синтаксических свойств остается невыясненным. Чтобы распространить предложение на отдаленно адекватную теорию, эти свойства должны быть как-то рассмотрены. К ним относятся, во-первых, группа синтаксических свойств, относящихся к синтаксису A-bar, и так называемая двойственность семантики. Я предполагаю, что этот особый вид синтаксиса связан с важным различием в краткосрочной памяти между первичностью и новизной, опираясь на модель начала-конца (SEM) Хенсона (1998).В модели Хенсона первенство и новизна — разные эффекты, отражающие кодирование с адресацией по содержанию двух аспектов последовательной позиции.
Время давности естественно связано с памятью стека (последним вошел, первым ушел). С другой стороны, первенство естественным образом описывается очередью (первым пришел — первым ушел). Помимо оптимального порядка доступа, существует еще одно важное различие между эффектами первенства и новизны. Проще говоря, первый элемент в последовательности остается первым элементом независимо от того, сколько элементов следует за ним; сигнатура первичности данного элемента относительно стабильна во временном масштабе, соответствующем синтаксическому анализу.Новизна отличается: каждый элемент в последовательности — это новый правый край, подавляющий доступность памяти на основе недавнего времени всего, что ему предшествует. Таким образом, мы ожидаем своего рода давления «используй или потеряй» в недавней памяти, но не в первичной памяти.
Предварительно я хотел бы предположить, что в основе двойственности семантики и разделения между A-штрихом и A-синтаксисом лежат различные коды памяти первичности и недавности. Своевременность, связанная со стеком, является основой для информационной нейтральной локальной перестановки, обычно характеризующейся вложенными зависимостями.Предположение, что первенство играет решающую роль в ненейтральном синтаксисе, напоминающем A-bar, предполагает объяснение группы удивительных свойств. Наиболее очевидна ассоциация дискурсивно-информационных эффектов с «левой периферией»: левый край доменов — это то место, где мы ожидаем, что первичная память будет играть значительную роль. Вовлечение первичной памяти также предполагает анализ эффектов превосходства в множественных конструкциях белых движений. В теориях, основанных на слияниях, такие конструкции (демонстрирующие перекрестные зависимости) проблематичны и требуют условных приспособлений, таких как Richards (1997), «подбирая» деривации.Думая об эффектах, связанных с первичной памятью, можно предположить более простое объяснение: упорядочение нескольких WH-фраз — это вопрос доступа «первым пришел — первым ушел» (память очереди). Последнее свойство этой альтернативной синтаксической системы, которое можно рационализировать, — это перемещение на большие расстояния. Возможно, доступность перемещения на дальние расстояния для отношений A-bar является результатом стабильности первичной памяти, что делает элементы, встречающиеся на левой периферии, доступными для последующего вызова без особого труда, в отличие от недавней памяти (которая может поддерживать только короткие, локальные отзывать).Хотя это наводит на размышления, обращение к обширной литературе по синтаксису A-bar следует оставить на будущее.
А как насчет рекурсии?
Последняя проблема, вырисовывающаяся на заднем плане, — это рекурсия. ULTRA работает в синтаксических доменах, характеризуемых одним fseq. Это требует некоторого комментария, поскольку рекурсия является фундаментальным свойством синтаксиса. Для рекурсии также могут иметь решающее значение свойства памяти и вмешательство дополнительной системы прогнозирования. Интересно, что эпизодическая память человека, по-видимому, имеет независимую иерархическую структуру, возможно, в отличие от родственных животных (Tulving, 1999; Corballis, 2009).В модели SEM эпизодические маркеры создаются для групп внутри сгруппированных последовательностей (Henson, 1998). Лингвистическая рекурсия требует некоторого дополнительного механизма для обработки токена группы, соответствующего одной последовательности, как токена элемента в другой последовательности.
Как обсуждалось в разделе «Сравнение с существующими учетными записями Universal 20», в ULTRA структурная неоднозначность не возникает без двусмысленности смысла в пределах отдельных доменов. Однако структурная неоднозначность неизбежно возникает, когда присутствуют несколько доменов, с точки зрения того, какой домен внедряется в другой или где прикрепить элемент, который мог бы занимать позиции в двух разных доменах.Вот где «быстрый, глупый черный ящик» беспомощен и должен обращаться к другим ресурсам. Одним из очевидных источников помощи в объединении нескольких доменов является отдельная система прогнозирования с доступом к нисходящим сведениям о правдоподобных значениях в контексте. Постоянная проблема разрешения неоднозначности встраивания также дает мотивацию к жесткому порядку слов, что резко снижает возможности прикрепления.
Важным моментом является то, что скобки определены относительно конкретного fseq.Рекурсивное встраивание одного домена в другой (например, номинал в качестве аргумента глагола) включает проекцию скобки, соответствующей всей вложенной фразе, в пределах области встраивания. Рассмотрим следующий пример.
(11) Собака гналась за мячом.
Здесь есть три области сортировки: две номинальные проекции, встроенные в третью, вербальную проекцию (не считая возможности, что предложения содержат две области, фазы vP и CP). Их УЛЬТРА-брекетинг показан ниже.
(12) NP1 = [ [ собака ] ]
NP2 = [ a [ шаровой шар ] a ]
VP = [ NP1 [ чеканка ] [ NP2 NP2 ] NP1 ]
Этот пример иллюстрирует неоднозначность, которая сопровождает внедрение. Проблема в том, как связать именные фразы с позициями в глаголе fseq (то есть с тета-ролями). Поскольку тета-роли явно не выражены (регистр — ненадежный ориентир), реактивный синтаксический анализатор должен использовать внешние средства (например, специфичные для языка привычки упорядочивания или предсказания правдоподобных интерпретаций).
Последний пункт о рекурсии возвращается к вопросу о том, как работают калькуляторы, с помощью алгоритма маневровой верфи Дейкстры. Такие вычисления рекурсивны. Но рекурсия не обрабатывается алгоритмом синтаксического анализа; скорее, он возникает на уровне интерпретации, когда частичные результаты арифметических операций используются в дальнейших вычислениях. Аналогичный вывод (рекурсия является семантической, а не синтаксической) возможен в рамках настоящей структуры, учитывая сходство между ULTRA и SYA. Примечательно, что обе процедуры компилируют ввод в обратную польскую нотацию, так называемый язык конкатенативного программирования, однозначно выражающий рекурсивные иерархические операции в последовательном формате.
Нужен ли вообще алгоритм?
Я показал, как особенно простой алгоритм улавливает ряд синтаксических явлений. Но вопрос в том, почему — это алгоритм ? В принципе возможны другие процедуры сортировки, которые могут привести к другим профилям предотвращения перестановок. Как мы можем оправдать выбор стековой сортировки в качестве правильной процедуры для синтаксического сопоставления?
Есть три важных ингредиента. Первый — это ориентация системы на анализатор, сопоставляющий звук со смыслом.Это не является логически необходимым; это просто один из разумных вариантов. Второй фактор — это линейность звука и смысла. Это просто для звуковых последовательностей, но гораздо меньше для интерпретаций, где это просто смелая гипотеза. Третий ингредиент — это выбор стековой памяти. Это может быть правдоподобно связано с эффектом модальности: внятный речевой ввод порождает необычно сильные эффекты новизны (Surprenant et al., 1993). Кажется небольшим скачком предположить, что формальный стек, используемый в алгоритме, может просто (и грубо) отражать преобладание эффектов новизны в памяти для лингвистического материала.
До сих пор сортировка стека была реализована с использованием явного алгоритма. Это может быть ненужным. Вместо того, чтобы думать о сортировке стека как о наборе явных инструкций, мы могли бы переосмыслить ее как антиконфликтное предубеждение между доступностью элементов в памяти с точки зрения эффектов давности и извлечением для жесткой последовательности интерпретации. Если это на правильном пути, возможно, что не пришлось развиваться новому когнитивному механизму, чтобы объяснить эти эффекты. Остается понять, откуда берется само упорядочение интерпретаций (fseq) — вопрос, на котором я не буду здесь рассуждать.
Заключение
Подводя итог, простой алгоритм (4) отображает 213-избегающие порядки слов в восходящую композиционную последовательность, отображая 213-содержащие порядки в девиантные последовательности. Хотя входные и выходные данные сопоставления представляют собой последовательности, присутствует иерархическая структура: алгоритмические шаги реализуют левую и правую скобки, почти точно там, где их помещают стандартные учетные записи. Учетная запись отличается от стандартных учетных записей тем, что для всех заказов назначена однозначная брекетинг.
Эта модель улучшает существующие учетные записи ограничений порядка слов, которые требуют дополнительных условий (например,g., ограничения на движение вместе с принципами линеаризации), помимо построения основной синтаксической структуры. В ULTRA эти эффекты выпадают из единственного процесса в реальном времени. В свою очередь, синтаксическое смещение, долгое время считавшееся любопытным усложнением, становится фундаментальным грамматическим механизмом. Не требуется изучение специфических свойств языка; одна грамматика интерпретирует множество порядков.
Должно быть ясно, что описанная здесь система является лишь частью синтаксического познания. Эта система строит одну расширенную проекцию за раз; необходимы дополнительные механизмы для встраивания одного домена в другой.Однако это может быть достоинством: возникает соблазн определить области работы этой архитектуры с помощью фаз, которые, таким образом, являются особенными по принципиальным причинам.
Более того, сортировка стека обрабатывает только нейтральную информацию структуры. Это игнорирует другой важный компонент синтаксиса, так называемую структуру дискурсивной информации, связанный с потенциально дальними зависимостями A-bar. Этот недостаток также может быть достоинством, предлагающим принципиальную основу двойственности семантики.Я предположил, что первичная память играет центральную роль в этих эффектах, потенциально объясняя несколько любопытных свойств (левизну, большое расстояние и пересечение).
Поднимая взгляд, можно сделать больший вывод, что большая часть механизма синтаксического познания может сводиться к эффектам, не специфичным для языка. Излишне говорить, что это всего лишь программный набросок; будущие исследования определят, можно ли и каким образом объединить стековую сортировку ULTRA в более полную модель языка.
Авторские взносы
Автор подтверждает, что является единственным соавтором данной работы, и одобрил ее к публикации.
Заявление о конфликте интересов
Автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могут быть истолкованы как потенциальный конфликт интересов.
Благодарности
Части этой работы были впервые разработаны на семинаре для выпускников Университета Аризоны (2015 г.) и представлены на Симпозиуме POL в Токио (2016 г.), LCUGA 3 (2016 г.) и Ежегодном собрании LSA (2017 г.).Я благодарен публике на этих площадках и многочисленным коллегам за полезные обсуждения. Я хотел бы поблагодарить следующих: Клауса Абельса, Дэвида Аджера, Боба Бервика, Тома Бевер, Эндрю Карни, Ноама Хомски, Гульельмо Чинкве, Дженнифер Калбертсон, Сэндиуэй Фонг, Томаса Графа, Джона Хейла, Хайди Харли, Норберта Хорнштейна, Майкл Джарретт, Ричард Кейн, Хильда Купман, Диего Кривочен, Марко Кульман, Массимо Пиаттелли-Пальмарини, Колин Филлипс, Пол Пьетроски, Маркус Саерс, Йосуке Сато, Дэн Сиддики, Доминик Спортиш, Хуан Урьягерека, Элли ван Гелдерен, Эндрю Уэгэрека, Элли ван Гелдерен и Уилсон.Я особенно благодарен аспирантам, которые участвовали в моей исследовательской группе Stack-Sorting Research (2015-2016). Конечно, все ошибки и недоразумения в этой статье — мои собственные.
Сноски
Список литературы
Абельс, К., Нилман, А. (2012). Линейные асимметрии и LCA. Синтаксис 15, 25–74. DOI: 10.1111 / j.1467-9612.2011.00163.x
CrossRef Полный текст | Google Scholar
Барбирс, С., ван дер Аувера, Дж., Беннис, Х., Бёф, Э., де Фогелар, Г., и ван дер Хам, М. (2008). Синтаксический атлас голландских диалектов, Vol. II , Амстердам: Издательство Амстердамского университета.
Google Scholar
Бервик Р., Хомский Н. (2016). Почему только мы: язык и эволюция . Кембридж, Массачусетс: MIT Press.
Google Scholar
Бравер Т.С., Грей Дж. Р. и Берджесс Г. К. (2007). «Объяснение множества разновидностей вариаций рабочей памяти: двойные механизмы когнитивного контроля», в Variation in Working Memory , eds A.Конвей, К. Джарролд, М. Кейн, А. Мияке и Дж. Тоуз (Нью-Йорк, Нью-Йорк: издательство Оксфордского университета), 76–106.
Google Scholar
Чези К. и Моро А. (2015). «Тонкая зависимость между компетенцией и производительностью», в 50 лет спустя: размышления об аспектах Хомского , ред. Á. Дж. Галлего и Д. Отт (Кембридж, Массачусетс: Рабочие документы Массачусетского технологического института по лингвистике), 33–46.
Google Scholar
Хомский, Н. (1965). Аспекты теории синтаксиса .Кембридж, Массачусетс: MIT Press.
Google Scholar
Хомский, Н. (1995). Программа минимализма . Кембридж, Массачусетс: MIT Press.
Google Scholar
Чинкве, Г. (1999). Наречия и функциональные головы: кросс-лингвистическая перспектива . Оксфорд: Издательство Оксфордского университета.
Google Scholar
Чинкве, Г. (2005). Получение универсальных 20 Гринберга и их исключения. Лингвистический справочник 36, 315–332. DOI: 10.1162/002438
CrossRef Полный текст | Google Scholar
Делл, Г. С., Чанг, Ф. (2014). P-цепь: связь производства предложений и их нарушений с пониманием и усвоением. Фил. Пер. R. Soc. В 369: 20120394. DOI: 10.1098 / rstb.2012.0394
PubMed Аннотация | CrossRef Полный текст | Google Scholar
Фодор, Дж. Д. (1978). Стратегии синтаксического анализа и ограничения на преобразования. Лингвистический справочник 9, 427–473.
Google Scholar
Фодор, Дж. Д., Фернандес, Э. (2015). Спецвыпуск по грамматикам и синтаксическим анализаторам: к единой теории знания и использования языков. J. Психолингвист. Res. 44, 1–5. DOI: 10.1007 / s10936-014-9333-3
CrossRef Полный текст
Фрейзер, Л., и Фодор, Дж. Д. (1978). Колбасная машина: новая модель двухэтапного разбора. Познание 6, 291–325. DOI: 10.1016 / 0010-0277 (78)
-1
CrossRef Полный текст | Google Scholar
Гринберг, Дж.(1963). «Некоторые универсалии грамматики с особым упором на порядок значимых элементов», в Universals of Language , изд. Дж. Гринберг (Кембридж, Массачусетс: MIT Press), 73–113.
Google Scholar
Хюттиг, Ф., и Мани, Н. (2016). Необходимо ли предсказание для понимания языка? Возможно нет. Lang. Cogn. Neurosci. 31, 19–31. DOI: 10.1080 / 23273798.2015.1072223
CrossRef Полный текст | Google Scholar
Джаясилан, К.А.(2008). Простая структура фразы и синтаксис без спецификатора. Биолингвистика 2, 87–106.
Google Scholar
Джоши А. К. (1990). Обработка скрещенных и вложенных зависимостей: автоматическая точка зрения на психолингвистические результаты. Lang. Cogn. Процесс 5, 1–27. DOI: 10.1080 / 0169096
02095
CrossRef Полный текст | Google Scholar
Кейн Р. (1994). Антисимметрия синтаксиса . Кембридж, Массачусетс: MIT Press.
Google Scholar
Кемпсон, Р., Мейер-Виол, В., и Габбей, Д. (2001). Динамический синтаксис . Оксфорд: Блэквелл.
Google Scholar
Кнут, Д. (1968). Искусство программирования, Vol. 1. Основные алгоритмы . (Ридинг, Массачусетс: Эддисон-Уэсли).
Купман, Х. (2000). Синтаксис спецификаторов и заголовков . Лондон: Рутледж.
Маркус, М. П. (1980). Теория синтаксического распознавания естественных языков . Кембридж, Массачусетс: MIT Press.
Google Scholar
Марр, Д.(1982). Видение: компьютерное исследование представления и обработки визуальной информации человеком . Нью-Йорк, штат Нью-Йорк: В. Х. Фриман.
Momma, S., Slevc, L.R., и Phillips, C. (2015). «Время планирования глаголов в активных и пассивных предложениях», в плакате , представленном на 28-й ежегодной конференции CUNY по обработке человеческих приговоров (Лос-Анджелес, Калифорния).
Google Scholar
Филлипс К. и Льюис С. (2013). Порядок образования производных в синтаксисе: свидетельства и архитектурные последствия. Шпилька. Линг. 6, 11–47.
Google Scholar
Ричардс, Н. (1997). Что куда движется и когда на каком языке? Докторская диссертация, Массачусетский технологический институт.
Ричардс, Н. (2010). Прорезывающие деревья . Кембридж, Массачусетс: MIT Press.
Google Scholar
Рицци, Л. (1997). «Тонкая структура левой периферии», в Elements of Grammar: Handbook in Generative Syntax , ed L. Haegeman (Dordrecht: Kluwer), 281–337.
Google Scholar
Шмид Т. и Фогель Р. (2004). Диалектные вариации в немецких трехглагольных кластерах: поверхностно-ориентированное описание ОТ. J. Compar. Германский линг. 7, 235–274. DOI: 10.1023 / B: JCOM.0000016639.53619.94
CrossRef Полный текст
Шихан М., Биберауэр Т., Робертс И., Песецки Д. и Холмберг А. (2017). Последнее-за-окончательное условие: синтаксический универсал, Vol. 76 , Кембридж, Массачусетс: MIT Press.
Стейблер, Э.П. младший (1991). «Избегайте парадокса пешехода», в Principle-Based Parsing: Computing and Psycholinguistics , eds R. Berwick, S. Abney, and C. Tenny (Dordrecht: Kluwer), 199–237.
Google Scholar
Starke, M. (2004). «Об отсутствии спецификаторов и природе голов», в The Cartography of Syntactic Structures, Vol. 3: Структуры и за пределами , под ред. А. Беллетти. (Нью-Йорк, Нью-Йорк: издательство Оксфордского университета), 252–268.
Стедди, С., и Самек-Лодович, В. (2011). О некграмматичности движения остатка в выводе универсального Гринберга 20. Linguistic Inquiry 42, 445–469. DOI: 10.1162 / LING_a_00053
CrossRef Полный текст | Google Scholar
Стидман, М. (2000). Синтаксический процесс . Кембридж, Массачусетс: MIT Press.
Google Scholar
Таненхаус, М. К., Трюзуэлл, Дж. К. (2006). «Движение глаз и понимание устной речи», в Справочнике по психолингвистике , ред. М.Тракслер и М. А. Гернсбахер (Нью-Йорк, Нью-Йорк: Elsevier Academic Press), 863–900.
Google Scholar
Тулвинг, Э. (1999). «Об уникальности эпизодической памяти», в Cognitive Neuroscience of Memory , ред. Л. Нильссон и Х. Дж. Маркович (Ашленд, Огайо: Хогрефе и Хубер), 11–42.
Google Scholar
Вурмбранд, С. (2006). «Группы глаголов, повышение и реструктуризация глаголов», в The Blackwell Companion to Syntax , Vol. V, редакторы М. Эверарт и Х.ван Римсдейк (Оксфорд: Блэквелл), 227–341.
Google Scholar
Zwart, C.J. (2007). Некоторые заметки о происхождении и распространении IPP-эффекта. Groninger Arbeiten zur Germanistischen Linguistik 45, 77–99.
Google Scholar
Разбор истории о плагиате Б. Симоне
Обновление: Незадолго до публикации этого поста (но после его написания) Б. Симона ответила в Instagram, повторив, что плагиат совершила команда, с которой она работала, но призналась, что «уронила мяч».Она также говорит, что берет на себя полную ответственность как генеральный директор своего бренда.
Б. Симона, возможно, наиболее известная по роли в Wild ‘N Out , певица, актриса и комик, которая стремилась добавить еще одно название в свой постоянно растущий список: Автор.
Однако все прошло не так гладко, как она, вероятно, надеялась. В марте она опубликовала свою книгу « Девочка: прояви ту жизнь, которую ты хочешь» , руководство, которое, как она надеялась, поможет другим найти свой собственный путь к успеху.
Продвигая книгу, она охарактеризовала ее как «личную» и сказала: «Я вложила все свое сердце в эту книгу и знаю, что она поможет многим людям во всем мире!»
Однако 13 июня начали циркулировать обвинения в том, что части книги были изъяты у других, менее известных авторов. Первым залпом выступил Элл Дюкло из Boss Girl Bloggers, который в своем твите подчеркнул, что список из книги Б. Симоне идентичен тому, что она опубликовала ранее.
Хотелось бы, чтобы @TheBSimone ПРЕКРАСНО брала труд мелких создателей контента и продавала его как свой собственный !!!
Отвратительно.Это не предпринимательство. Это плагиат. pic.twitter.com/CCSQ88A85e
— Ell // BossGirlBloggers (@BGbloggers) 13 июня 2020 г.
Вскоре другие также отметили дополнительные совпадения, всегда уделяя внимание спискам, руководствам и другим элементам книги.
Это вызвало бурю споров вокруг Б. Симона, который уже столкнулся с негативной реакцией на более ранние заявления о продолжающихся гражданских беспорядках в Соединенных Штатах и о том, следует ли предпринимателям встречаться с не предпринимателями.
Менеджер Б. Симоне, Мэри Сидс, вмешалась и сказала, что проблема не в письме Б. Симоне, а в дизайнерской фирме, которую они наняли для завершения работы. Далее они заявили, что участвуют в судебном процессе с фирмой и «пытаются с этим разобраться».
https://twitter.com/lady_luck45/status/1271884625237
- 8
Другие также защищали Б. Симон, в первую очередь рэпер Мик Миллс, сказав в одном твите: «Би Симона отменила, потому что она нашла книгу и выбралась из дно, какие крупные компании вы отменяете за то, что подрывают нашу культуру? »
Однако позже он добавил, что никогда не разбирался в том, в чем ее обвиняли, а вместо этого пытался сделать более широкую точку зрения.
Я даже не проверял, что она на самом деле делала. Я просто устал видеть, как черные отменяют черных… они поставили нас на последнее место, и без того остынь от этого дерьма https://t.co/YEjZVrqxoO
— Meek Mill (@MeekMill ) 14 июня 2020 г.
В конце концов, сама книга больше не продается на сайте Б. Симоне. Поскольку он доступен на Amazon и других розничных магазинах, они не являются официальными релизами.
Хотя это не похоже на конец сказки, есть еще много чего распаковать и изучить.
Анализ плагиата
Плагиат сам по себе очень очевиден. Приведенные примеры указывают на то, что в книге есть построчное и дословное копирование / вставка. Один даже включал элементы дизайна из оригинала. Если эти страницы не были скопированы из предоставленных источников, то они явно имеют общий источник. Короче говоря, это никак не могло быть словами Б. Симона.
Однако это не то, что отрицает Б. Симона или, по крайней мере, ее менеджер. Похоже, они признают, что в книге есть плагиат, и вместо этого возлагают вину на дизайнерскую компанию, с которой они работали над изданием книги.
Такое объяснение действительно возможно. Хотя мы, как сторонние наблюдатели, не имеем возможности точно знать, какие части книги кем были написаны, это не является диковинкой для списков, вставок и других элементов, написанных третьей стороной.
Я столкнулся с этим в своей консультационной практике. Меня вызвали для расследования предполагаемого плагиата в учебнике, и я обнаружил, что он был изолирован от подписей и вопросов, элементов, написанных не названными авторами. Они работали со сторонней фирмой над дизайном и редактированием книги, и эти элементы были от этой компании.
Тем не менее, если будет показано, что контент является плагиатом, то есть из основного текста работы, это будет совсем другое дело. Но на данный момент все обвинения сосредоточены вокруг списков и действий, о которых Б. Симона вполне могла не писать.
Однако это не полностью оправдывает Б. Симоне в данном случае. Каждый раз, когда вы публикуете книгу со своим именем и заявляете, что работа принадлежит вам, вы несете ответственность за ее честность. Даже если эта работа написана писателем-призраком, вы все равно несете за нее ответственность, поскольку на кону стоит ваша репутация и ваш бренд.
Мы уже видели это раньше. Еще в 2013 году Джейн Гудолл обвинили в плагиате в своей книге Seeds of Hope , но Гудолл возложила вину на своего соавтора. В более недавнем случае, в скандале с плагиатом Кристины Серруя фигурировал автор романа-плагиата, который, в свою очередь, возложил вину на своего писателя-призрака. Было много предупреждений о том, что что-то подобное может произойти, но это предупреждение не было учтено.
Совершенно очевидно, что Б. Симона и никто из ее сотрудников тщательно изучили эту книгу.Беглая проверка на плагиат, вероятно, позволила бы обнаружить эти проблемы и решить вопрос до того, как он был бы опубликован. Хотя это услуга, которую я предоставляю на своем консультационном сайте, это то, что почти любой издатель должен уметь делать самостоятельно.
Даже если Б. Симона не была тем, кто вставил плагиатные разделы, отсутствие должной осмотрительности не освещает ее или эту работу в лучшем свете. Для человека, чье послание — упорный труд и его приверженность, эта история сильно подрывает ее послание.
Bottom Line
Для ясности, в этой истории есть элементы, на которых я не останавливаюсь, но считаю, что они чрезвычайно важны. Например, чернокожая Б. Симона обвиняется в плагиате как от белых, так и от черных авторов. Частью этой истории стала негативная реакция на негативную реакцию и вопрос о том, должны ли чернокожие женщины «отменять» других чернокожих женщин.
Это было подчеркнуто в твитах Мика Милла, в котором говорилось, что не существует аналогичного стимула для отмены компаний, грабящих черную культуру.Это, безусловно, важный момент и заслуживает обсуждения, но я не тот, у кого он есть. Я не являюсь экспертом в этой области и не имею личного опыта в этих вопросах. В этом пространстве есть гораздо более важные голоса, и я не хочу их отнимать.
Однако, с точки зрения чистого плагиата, совершенно очевидно, что книга Б. Симоне содержала значительные фрагменты плагиата. Хотя обвинение в ошибках сторонней дизайнерской фирмы может показаться оправданием, очень легко это может оказаться правдой.
Учитывая, что перекрывающийся контент на момент написания этой статьи ограничен списками и викторинами, весьма вероятно, что они были написаны не самой Б. Симон, а, напротив, были написаны издателем, редактором или дизайнером. Это очень распространенный способ сборки таких книг.
Тем не менее, это вызывает вопросы о тщательности, которая была вложена в книгу, и о том, выполнили ли Б. Симона или ее команда необходимые проверки, чтобы убедиться, что посторонний контент не был плагиатом. Это важный шаг, но многие издатели отказываются от него.
Если бы я был членом команды Б. Симоне, я бы начал забегать вперед. Поделитесь поданным иском и подробно объясните, как это произошло. Прозрачность — единственный реальный путь вперед. В противном случае эти обвинения будут продолжать преследовать ее и, учитывая ее упорный труд и настойчивость, будут подрывать ее на каждом шагу.
Люди склонны прощать прошлые ошибки, когда дело касается плагиата, но только тогда, когда это прощение было заслужено.
Разбор файлов FASTA — Python для биологов 0.Документация 2.0
Формат файла FASTA
файлов FASTA используются для хранения данных последовательности. Его можно использовать как для нуклеотидных и белковые последовательности. В случае ДНК нуклеотиды представлены с использованием их однобуквенные сокращения: A, T, C и G. В случае белков амино кислоты представлены с использованием их однобуквенных сокращений, например А для аланина и W для триптофана.
Запись FASTA начинается с однострочного идентификатора. Эта строка идентификатора всегда
начинается с символа «больше» > .
Ниже приведен пример записи ДНК FASTA, взятой из www.cbs.dtu.dk/services/NetGene2/fasta.php.
> HSBGPG Человеческий ген костного белка gla (BGP) GGCAGATTCCCCCTAGACCCGCCCGCACCATGGTCAGGCATGCCCCTCCTCATCGCTGGGCACAGCCCAGAGGGT ATAAACAGTGCTGGAGGCTGGCGGGGCAGGCCAGCTGAGTCCTGAGCAGCAGCCCAGCGCAGCCACCGAGACACC ATGAGAGCCCTCACACTCCTCGCCCTATTGGCCCTGGCCGCACTTTGCATCGCTGGCCAGGCAGGTGAGTGCCCC CACCTCCCCTCAGGCCGCATTGCAGTGGGGGCTGAGAGGAGGAAGCACCATGGCCCACCTCTTCTCACCCCTTTG GCTGGCAGTCCCTTTGCAGTCTAACCACCTTGTTGCAGGCTCAATCCATTTGCCCCAGCTCTGCCCTTGCAGAGG GAGAGGAGGGAAGAGCAAGCTGCCCGAGACGCAGGGGAAGGAGGATGAGGGCCCTGGGGATGAGCTGGGGTGAAC CAGGCTCCCTTTCCTTTGCAGGTGCGAAGCCCAGCGGTGCAGAGTCCAGCAAAGGTGCAGGTATGAGGATGGACC TGATGGGTTCCTGGACCCTCCCCTCTCACCCTGGTCCCTCAGTCTCATTCCCCCACTCCTGCCACCTCCTGTCTG GCCATCAGGAAGGCCAGCCTGCTCCCCACCTGATCCTCCCAAACCCAGAGCCACCTGATGCCTGCCCCTCTGCTC CACAGCCTTTGTGTCCAAGCAGGAGGGCAGCGAGGTAGTGAAGAGACCCAGGCGCTACCTGTATCAATGGCTGGG GTGAGAGAAAAGGCAGAGCTGGGCCAAGGCCCTGCCTCTCCGGGATGGTCTGTGGGGGAGCTGCAGCAGGGAGTG GCCTCTCTGGGTTGTGGTGGGGGTACAGGCAGCCTGCCCTGGTGGGCACCCTGGAGCCCCATGTGTAGGGAGAGG AGGGATGGGCATTTTGCACGGGGGCTGATGCCACCACGTCGGGTGTCTCAGAGCCCCAGTCCCCTACCCGGATCC CCTGGAGCCCAGGAGGGAGGTGTGTGAGCTCAATCCGGACTGTGACGAGTTGGCTGACCACATCGGCTTTCAGGA GGCCTATCGGCGCTTCTACGGCCCGGTCTAGGGTGTCGCTCTGCTGGCCTGGCCGGCAACCCCAGTTCTGCTCCT CTCCAGGCACCCTTCTTTCCTCTTCCCCTTGCCCTTGCCCTGACCTCCCAGCCCTATGGATGTGGGGTCCCCATC ATCCCAGCTGCTCCCAAATAAACTCCAGAAG
Ниже приведен пример записи белка FASTA, взятой из en.wikipedia.org/wiki/FASTA_format.
> gi | 5524211 | gb | AAD44166.1 | цитохром b [Elephas maximus maximus] LCLYTHIGRNIYYGSYLYSETWNTGIMLLLITMATAFMGYVLPWGQMSFWGATVITNLFSAIPYIGTNLV EWIWGGFSVDKATLNRFFAFHFILPFTMVALAGVHLTFLHETGSNNPLGLTSDSDKIPFHPYYTIKDFLG LLILILLLLLLALLSPDMLGDPDNHMPADPLNTPLHIKPEWYFLFAYAILRSVPNKLGGVLALFLSIVIL GLMPFLHTSKHRSMMLRPLSQALFWTLTMDLLTLTWIGSQPVEYPYTIIGQMASILYFSIILAFLPIAGX IENY
Обратите внимание, что файл FASTA может содержать более одной записи. Ниже приводится пример (также из Википедии).
> ПОСЛЕДОВАТЕЛЬНОСТЬ_1 MTEITAAMVKELRESTGAGMMDCKNALSETNGDFDKAVQLLREKGLGKAAKKADRLAAEG LVSVKVSDDFTIAAMRPSYLSYEDLDMTFVENEYKALVAELEKENEERRRLKDPNKPEHK IPQFASRKQLSDAILKEAEEKIKEELKAQGKPEKIWDNIIPGKMNSFIADNSQLDSKLTL MGQFYVMDDKKTVEQVIAEKEKEFGGKIKIVEFICFEVGEGLEKKTEDFAAEVAAQL > ПОСЛЕДОВАТЕЛЬНОСТЬ_2 SATVSEINSETDFVAKNDQFIALTKDTTAHIQSNSLQSVEELHSSTINGVKFEEYLKSQI ATIGENLVVRRFATLKAGANGVVNGYIHTNGRVGVVIAAACDSAEVASKSRDLLRQICMH
Работа с «большими данными»
Термин «большие данные» немного расплывчатый.Но это конечно возможно для создания файлов последовательности, которые слишком велики для хранения в RAM (оперативная память).
В этих случаях необходимо иметь возможность читать часть файла и «уступать» записи по мере обработки файла. Другими словами содержимое всего файла никогда не сохраняется в ОЗУ.
В конкретном случае обработки файлов FASTA необходимо иметь возможность «уступить» FASTA записывает, как каждый работает с файлом. Это означает, что один не может создать функцию, которая создает большой список записей FASTA и возвращает тот список.Скорее нужно создать функцию, которая «дает» записи FASTA. во время обработки файла FASTA.
Этого можно добиться с помощью ключевого слова yield .
Чтобы проиллюстрировать это, представьте, что у вас есть текстовый файл, в котором количество символов в каждой строке было ключевым показателем. Ниже приведена функция, которая принимает имя файла в качестве входного параметра и возвращает список целых чисел представляющий количество символов в каждой строке.
def chars_per_line (имя_файла):
"" "Возвращает список целых чисел, представляющих количество символов в строке."" "
data_collection = []
с open (имя_файла, "r") как fh:
для строки в fh:
num_chars = len (строка)
data_collection.append (строка)
вернуть data_collection
Вышеупомянутая функция столкнулась бы с проблемами, если бы файл был действительно большим.
Это потому, что список data_collection хранится в RAM.
Если в файле было больше строк, чем памяти компьютера, вызов
функция приведет к ошибке MemoryError .
Ниже приведена функция, которая решает эту проблему, «уступая» длины линий по мере их обработки, в обход необходимость хранить всю структуру данных в оперативной памяти.
def chars_per_line_iterator (имя_файла):
"" "Выведите целые числа, представляющие количество символов в строке." ""
с open (имя_файла, "r") как fh:
для строки в fh:
num_chars = len (строка)
yield num_chars
Как это можно использовать на практике? Практическое применение могло бы быть записывать результаты в файл. Этого можно добиться, используя код ниже.
с open ("chars_per_line.txt", "w") как fh:
для num_chars в chars_per_line_iterator ("my_big_file.текст"):
fh.write (str (число_знаков))
fh.write ("\ n")
Как оформить резюме Раздел образования: советы и примеры
Многие соискатели вкладывают свою энергию в составление резюме, создавая основную часть своего резюме: разделы, посвященные опыту и навыкам. В результате об образовании отстают. Но с системами отслеживания кандидатов, анализирующими резюме и анализирующими требования к должностным инструкциям, следует уделять больше внимания (и лучшему форматированию). Мы здесь, чтобы прямо указать, как отформатировать учебный раздел резюме.
Что включать в раздел «Образование» в резюме
Перво-наперво. Что должно быть включено в ваш образовательный раздел резюме? Вот основные сведения:
- Название учебного заведения
- Степень
- Расположение школы
- Годы обучения
Оттуда вы можете добавить академические награды, стипендии и другие достижения, если применимо. Вы можете также включать курсовую работу, но только в том случае, если она абсолютно соответствует должности, на которую вы претендуете.Если вы все же включаете курсовую работу, используйте названия каждого курса в качестве описания вместо номеров курсов.
Если курсовая работа кажется вам не подходящей, подумайте о включении соответствующих проектов или групп, в которых вы действительно преуспели. Например, дипломная работа, инициатива по изменению школьной политики или впечатляющая группа на территории кампуса, которую вы возглавляли . Все, что иллюстрирует ваши увлечения и имеет отношение к работе, заслуживает внимания.
Добавление дополнительных деталей, например курсовых работ и проектов, лучше всего подходит для соискателей, которые недавно закончили обучение или имеют минимальный опыт работы.Подробнее о форматировании проектов и курсовых работ мы поговорим позже.
Сопроводительное письмо также является отличным местом для расширения вашей курсовой работы.
Как назвать заголовок раздела «Образование»? Jobscan проанализировал коллекцию резюме и обнаружил, что 35% используют нетрадиционные названия для названия своего учебного заголовка. Это может вызвать ошибки синтаксического анализа в ATS, что приведет к ненужной дисквалификации. Простой заголовок «Образование» — лучший вариант. Он не занимает много места, и ATS точно знает, как его разбирать.
Jobscan анализирует ваше резюме на соответствие описанию должности, чтобы убедиться, что раздел вашего образования соответствует требованиям среди других проверок названий должностей, профессиональных навыков, измеримых результатов и других передовых методов ATS и найма.
Jobscan анализирует ваше резюме, как ATS, и сообщает, узнаваемо ли ваше образование.Где указать средний балл в резюме
Вы должны указать свой средний балл в разделе образования рядом с вашей специальностью. Если вы получили отличия в своем университете (с отличием или с отличием), эти награды должны быть указаны под вашей специальностью курсивом, а рядом с ними стоит ваш средний балл.
Вот как это должно выглядеть:
DePaul University | Чикаго, Иллинойс | Декабрь 2009 г. — март 2013 г.
Бакалавр искусств по английской композиции (средний балл: 3,75)
Имейте в виду, что вам следует указывать свой средний балл в своем резюме только в том случае, если он выше 3,5 и если вы недавно закончили школу. Если вы недавно закончили обучение и ваш средний балл ниже 3,5, используйте пространство, чтобы вместо этого рассказать о впечатляющем дипломном проекте для выпускников (или о чем-то в этом роде).
Как включить несовершеннолетнего в свое резюме
Если ваш несовершеннолетний имеет непосредственное отношение к работе, на которую вы претендуете, возможно, стоит включить его в свое резюме.Указание вашего несовершеннолетнего может помочь выделить соответствующие навыки, которые помогут вам опередить конкурентов.
Вы должны указать несовершеннолетний в своем резюме рядом со специальностью. Например:
DePaul University, Чикаго, Иллинойс, декабрь 2009 г. — март 2013 г.
Бакалавр гуманитарных наук, основное английское сочинение, второстепенная журналистика
Если вы включаете свой средний балл, он может идти в самом конце, помимо minor, например:
DePaul University, Чикаго, Иллинойс, декабрь 2009 г. — март 2013 г.
Бакалавр искусств, основное английское сочинение, второстепенная журналистика (средний балл: 3.75)
Формат раздела «Образование» для резюме
Многие ATS анализируют информацию из резюме кандидата в цифровой профиль кандидата. Если ваше образование неправильно отформатировано, велика вероятность, что информация будет неправильно проанализирована или вообще не учтена.
Обычно степень указывается перед школой, но если вы учились во впечатляющем университете Лиги плюща, ведущее место с названием школы не повредит.
Помните, что раздел твердого образования будет включать название школы, полученную степень (или основную / второстепенную), местонахождение школы и дату окончания.Например:
Бакалавр искусств: театр, шекспировский, 2016
Колумбийский колледж, Чикаго, Иллинойс,
или
Магистр делового администрирования, 2014 год
Университет Вирджинии, Шарлоттсвилль, 9
Степень бакалавра, начальное образование и преподавание, 2013
Университет Индианы Блумингтон, Блумингтон, IN
Общества: Дельта Дельта Дельта, Среда обитания человечества , Группа поддержки студентов
Если вы все еще получаете степень, вы можете указать «ожидаемую дату окончания», но четко укажите, что вы еще не закончили учебу.Как и в приведенных выше примерах, вам не нужно указывать дату начала (хотя вы можете, если хотите). Например:
Бакалавр наук: Гражданское строительство
Вашингтонский университет, Сент-Луис, Миссури.
Ожидаемая дата окончания 2019
Если вы учились в колледже, но не окончили его, все равно допустимо включить ваше высшее образование, если оно соответствует требованиям работы — просто укажите количество полученных кредитов. Например:
University of Miami, Coral Gables, FL
English Composition, 65 кредитных часов
Куда идет отдел образования?
В какой из разделов вашего резюме вы решите поместить свое образование, зависит от того, на каком этапе вашей карьеры вы находитесь.Например, если вы недавно закончили обучение и практически не имеете опыта, раздел «Образование» — ваш лучший актив, и его следует разместить в верхней части резюме (над «Опыт работы»).
С другой стороны, если у вас есть некоторый профессиональный опыт, вы должны сделать это в центре внимания, решив разместить свой раздел образования ниже «Опыт работы».
Если вы недавно вернулись в школу, вы можете поставить свой раздел образования на самый верх. Например, ветеранам, которые пошли в школу после ухода из армии, рекомендуется ставить свое образование выше своего опыта при переходе от военного к гражданскому.
Однако, если вы вернулись в школу, готовясь к смене карьеры, но все еще хотите работать в своей нынешней области, продолжайте подчеркивать свой прошлый опыт.
Организация нескольких степеней в резюме
При организации различных школ, которые вы посещали, перечисляйте их в обратном хронологическом порядке. Другими словами, наивысшая полученная степень должна быть наверху. Например, ваша степень магистра должна быть указана над степенью бакалавра.
Вы учились в колледже? В таком случае вам не нужно указывать степень своего среднего образования.Информация о вашей средней школе должна быть указана только в том случае, если вы все еще учитесь в средней школе или колледже. Если вы закончили колледж, более высокая степень может занять место в вашем резюме вместо средней школы.
Как включить учебу за границу в свое резюме
Добавление семестра или года обучения за границу в свое резюме может показать работодателям, что вы начинающий. Эта информация не должна занимать много места, и ее также следует включить в раздел образования.
Правильное место для обучения за границей в вашем резюме — чуть ниже университета, который вы закончили.Вы можете отформатировать его так же, как вы форматируете другие учреждения, которые посещали. Например:
DePaul University, Чикаго, Иллинойс, декабрь 2009 г. — март 2013 г.
Бакалавр искусств, основная английская композиция, небольшая журналистика
Università degli Studi di Firenze, Флоренция, Италия (обучение за рубежом) сентябрь 2010 г. — Декабрь 2010 г.
- Закончил курс журналистики и международных отношений.
- Свободно владеет итальянским языком
Все, что вы включаете в свое резюме, должно иметь отношение к работе, на которую вы претендуете.Было бы хорошо упомянуть курсовую работу и другие виды деятельности, относящиеся к этой работе, при включении вашего опыта обучения за границей.
Примеры разделов резюме
Бакалавр прикладных наук (BASc.), Международный бизнес, 2013
Государственный университет Иллинойса, Блумингтон, Иллинойс
Джорджтаунский университет, Школа бизнеса Макдонау, 2010-2014 гг. Бакалавр искусств, бухгалтерский учет / финансы
Университет Майами, Корал-Гейблс, Флорида
Бакалавр гуманитарных наук (B.A.) Социальная психология, 2013
Доктор фармацевтических наук (PharmD), Magna Cum Laude, 2015
Университет Батлера, Индианаполис, IN
Бакалавр инженерных, гражданских и экологических наук, 2009
Vanderbilt Университет, Нашвилл, TN
Университет Каттолики, Милан, Италия
Степень бакалавра, маркетинг и финансы, 2011
Университет Пердью, Западный Лафайет, IN
Степень бакалавра, 2012 год, гостиничный менеджмент
Деятельность: Межвузовская ассоциация квиддича
Университет Фордхэма, Бронкс, Нью-Йорк
Бакалавр, бизнес-администрирование, финансы, 2007-2011 гг.
Версия этой статьи была первоначально опубликована 24 ноября 2014 года Тристой Винни. Он был переписан 26 июля 2018 г.
Фильтры текстового процессора
Фильтры текстового процессораДо полного списка фильтров
PostScript
- p2h для Unix (linux, sunos) на стадии альфа: требуется ghostscript. Контакты: [email protected] (Майкл Ритцерт)
- ps2html. Требуется интерпретатор PostScript, например GhostScript.Контакты: [email protected], [email protected] (Джерри Уилан).
- PS2HTML Контакты: [email protected] (Алессандро Агостини), [email protected] (Стефано Черрети)
- и посмотрите webify
- Filtrix от Blueberry Software для Windows и UNIX выполняет двунаправленное преобразование между FrameMaker, HTML, Word, Interleaf, WordPerfect и другими форматами. Поддерживает стили, таблицы, графику.
- WordPort с продвинутого компьютера Innovations Inc для DOS и Windows обеспечивает преобразование между многими словами форматы процессора, а также преобразование в HTML.
- WebConvert для Windows 95 / NT из Lightspeed Software преобразует популярные файлы текстовых процессоров в / из HTML по одному файлу за время или в пакетном режиме.
- KEYpak от ANE Resources Inc. предлагает преобразование в HTML и между различными источниками форматы. Работает в Windows, UNIX, OpenVMS, OS390.
- Линейка OEM-продуктов Outside In от Inso — это технология фильтрации, учитывающая форматы файлов многих текстовых процессоров, электронных таблиц, баз данных, растровых изображений, рисунков и форматы презентаций.Он предлагает экспорт в HTML на основе шаблонов для платформ Win32 и Unix.
- StarOffice от Star Division это офисный пакет для Windows, Unix и т. д. может экспортировать (конвертировать) в HTML все форматы, которые он может импортировать, включая MS-Word и RTF. Он может работать через сеть, используя ftp или HTTP GET и PUT. Доступны неанглоязычные версии.
- Cyberleaf от Interleaf (для Unix и совсем скоро для Windows NT). Преобразует Interleaf, FrameMaker, Microsoft Word RTF, WordPerfect и ASCII. форматы.Он также преобразует графику в формат GIF или PostScript.
- HTML Transit from InfoAccess (для Windows). Предлагает прямой перевод Форматы Microsoft Word, WordPerfect, WordPro (AmiPro), FrameMaker и Interleaf. а также текст ASCII и RTF. Поддерживает основные графические форматы.
- Веб-издатель от SkiSoft (для Windows 3.1 и более поздних версий) преобразует форматы RTF и MIF.
- KeyView для Windows позволяет конвертировать широкий диапазон форматов. Контакты: [email protected] (Марлен Роббинс)
См. Также продукты, поддерживающие несколько форматов текстовых процессоров
- rtftohtml
создает HTML из документов, содержащих графику, таблицы, текст и
уравнения.Работает в UNIX, Macintosh, DOS / Windows и т. Д.
На основе инструментов RTF П. Дюбуа из Висконсина.
Контакты: [email protected] (Крис Гектор)
- rtfdtohtml может конвертировать файлы RTF и RTFD, созданные на NeXTSTEP или Системы OPENSTEP. На основе (и требует) rtftohtml. Должен работать практически в любой UNIX-подобной системе. Контакты: [email protected] (Эльмар Людвиг)
- rtf2html (более ограничено) Контакт: [email protected] (Чак Шоттон)
- MARTHA — это небольшой бесплатный конвертер для DOS.(Документация также на французском языке — en français). Контакты: [email protected] (Ив Санье)
- Скрудж из BetaSoft (Веб-сайт также на немецком языке — auch auf Deutsch) — условно-бесплатный конвертер RTF в HTML. составная часть. Включен пример приложения Scrooge Converter. Контакты: [email protected] (Майкл Джастин)
- WEB * LITE от Virtual Media Technology — это конвертер RTF в HTML для Windows со многими расширенными функциями.
- LatinByrd для NEXTSTEP / OPENSTEP преобразует RTF, RTFD или простые документы ASCII или деревья документов.Преобразует отдельные изображения TIFF и EPS в формат GIF и JPEG. Доступно на английском, французском и немецком языках. Контакты: [email protected] (Стефан Шнайдер)
- TagPerfect — это RTF в SGML (например, HTML, HTML0, HTML1, HTML2, HTML3 …) конвертер. Преобразуем и проанализируем существующие документы RTF. Контактное лицо: 100043,3201 @ compuserve.com (Эрик ван Хервейнен)
- E-Publish от Stat Tech позволяет создание HTML-документов из исходных файлов Winword или RTF.
- Конвертер RTFact RTF в HTML из Iconovex поставляется вместе с их системой AnchorPage или приобретается отдельно.
- См. Также Радуга ниже
- word2x преобразует двоичный файл Word для Windows .doc (не RTF) файлы в HTML (а также LaTeX). Контакты: [email protected] (Дункан Симпсон)
- TextToHTML для Mac от Logic n.v. обрабатывает как RTF, так и обычный текст. (Вашему браузеру нужны фреймы для доступа к своему сайту). Контакт: [email protected] (Крис Коппитерс)
- mswtohtml — это простое приложение, написанное на AppleScript для Macintosh, которое конвертирует файлы Microsoft Word 6.0 в HTML.Контакты: [email protected] (Дэн Берриос)
- См. Также информацию о надстройках для HoTMetal.
- HTML-HyperEditor может читать файлы RTF. Контакты: [email protected] (Ларс-Улоф Альбертсон).
- KatalogMaster (также на немецком языке — auch auf Deutsch) для Windows имеет средства для импорт документов в формате RTF.
Кроме того, следующее позволяет использовать MS Word в качестве редактора или конвертера HTML.
- Ed’s HTML Converter 97 — это конвертер для Microsoft Word 97, который обрабатывает концевые сноски и таблицы.Контакты: [email protected] (Эдди Бирмингем)
- WordToWeb от Solutionsoft это надстройка для Word 95 или 97 в Windows 95 или NT. Может создавать полностью отформатированные связанные публикации в формате HTML.
- ANT_HTML — это Шаблон Word, конвертирующий документы в HTML и обратно в среде WYSIWYG, а Crackerjack — это Редактор HTML шаблонов Word. Они работают в Word для Windows, Word для Mac, NT и WIN 95 в международных версиях Word 6.0 и выше. Контакт: jswift @ telacommunications.com (Джилл Свифт)
- WebAuthor Надстройка HTML для Word для Windows 6.0 от Quarterdeck
- Интернет-помощник для Word 6.0 для Windows от Microsoft.
- EasyHTML от Eon Solutions для всех версий Word для Windows позволяет пользователям создавать HTML-страницы из документов Word. EasyHelp / Web — это двойная инструмент разработки, который создает как HTML-страницы, так и файлы WinHelp.
- Шаблон RTFTOHTM WinWord и инструменты преобразования. Контакты: [email protected]
- CU_HTML.DOT — это шаблон документа Word для Windows 2.0 и 6.0, который позволяет пользователям создавать HTML-документы внутри Word в режиме WYSIWYG и сгенерируйте соответствующий HTML-файл. Контакты: [email protected]
- GT_HTML.DOT альфа-версия Технологического исследовательского института Джорджии (GTRI) набора макросов Microsoft Word в облегчить создание HTML-документов. Макросы содержатся в шаблон документа, который предоставляет псевдо WYSIWYG среда разработки. Теперь работает и на Mac. Обращаться: gt_html @ gatch.edu (Джеффри Гровер, Джон Дэвис III, Боб Джонстон)
- HTML Author — это шаблон Word для Windows с макросами. Это поддерживает неанглийские версии Word. Это также начинает есть некоторые функции HTML3. В текущей версии поддерживаются простые таблицы. Контакты: [email protected]
- HTML Convertor — программа Word для Windows 6 который преобразует любой текстовый файл, который он может прочитать, в полный и точный HTML-файл. Контакты: [email protected] (Бен Томпсон)
- 2 Html от Group Cortex — это условно-бесплатный макрос для Word 6.0 для Macintosh. Преобразует заголовки, списки, таблицы и т. Д. Преобразует каталог. Контакты: [email protected]
- Другой набор условно-бесплатных шаблонов документов Word 6.0 / Word 97 и макросов можно найти здесь. Контакт: [email protected] (Алан Дж. Лазер)
- TagWizard превращает Word 6.0 в интерактивный редактор SGML и HTML. Контактное лицо: 100043,3201 @ compuserve.com (Эрик ван Хервейнен)
- tbl2html преобразует таблицу в формате Word в HTML. Контакты: [email protected].мил (Джон Диркман).
- Другой tbl2html — это преобразователь таблиц WinWord 6.0 в HTML. Контакты: [email protected] (Юрий Михайлович Лесюк)
См. Также продукты, поддерживающие несколько форматов текстовых процессоров
- Набор макросов WordPerfect для преобразования из WordPerfect 5.1 для DOS. Контакты: [email protected] (Дэвид Адамс)
- WPTOHTML Макросы WordPerfect: wpt51d10.zip для WordPerfect 5.1 и wpt60d10.zip для WordPerfect 6.0 для DOS. Контакты: [email protected] (Хантер Монро)
- WP2X конвертирует WP 5.1 ко многим вещам, включая HTML 1.0. Работает только под Unix. Контакты: [email protected] (Майкл Ричардсон)
- слов макрос (макрос word perfect 5.1, в настоящее время в значительной степени замененный WPTOHTML) Контакт: [email protected] (Стив МакКоли)
- Wp2Html преобразует WordPerfect документы в HTML (включая таблицы, уравнения, рисунки и т. д.) Пробная версия для DOS также работает на многих разновидностях UNIX. Контакты: [email protected] (Эндрю Скривен)
- WPAHTML для Windows конвертирует Wordperfect 5.0, 5.1 и 5.2 в HTML 2.0 и выше. Также на испанском языке (en español). Контакты: [email protected] (Хуан Карлос Родригес).
- Интернет-издатель от Corel является доступно дополнение к WordPerfect 6.1 через ftp (также Internet Publisher Pro). Смотрите также Corel и Интернет
- См. Также информацию о надстройках для HoTMetal.
См. Также продукты, поддерживающие несколько форматов текстовых процессоров
- Webmaker, изначально разработан в CERN и теперь доступен от Harlequin это решение веб-публикации для создания полнофункциональные веб-страницы из документов FrameMaker.Контакты: [email protected] (Кейт М. Корбетт), [email protected] (Бертран Руссо и др.)
- Frame2html. См. Примечание к выпуску для версии 0.8.9 Контакты: [email protected] (Джон Стефенсон фон Течнер)
- fmtoweb — создатель фреймов для HTML Perl-скрипт для UNIX. Обрабатывает графику и уравнения (через ImageMagick и Ghostscript) а также таблицы. Преобразует перекрестные ссылки, оглавления и индексировать файлы по гипертекстовым ссылкам. Контакты: [email protected] (Питер Дж. Мартин)
- WebWorks Publisher из Корпорация Quadralay.
- MifMucker это приложение для управления документами и книгами Frame. Это содержит фильтр для преобразования документов FrameMaker в HTML. Контакты: [email protected] (Кен Харвард)
- Выпуск 5 Framemaker включает интегрированный Конвертер HTML.
- www_and_frame. Видеть Поддержка информации о текущей ситуации и источнике. Контакт: [email protected] (Дэн Коннолли)
- Мифтран (файл miftran.tgz). (Конвертер MIF в HTML, написанный на C. См. README). Контакты: jimmc @ eskimo.com (Джим Макбит)
- mif.pl это библиотека Perl для анализа формата обмена фреймов (MIF), предназначенная для использования фильтрами. Контакт: [email protected] (Эрл Худ)
- edc2html это программа на Perl, которая генерирует HTML-документ для позволяют перемещаться по структуре каталога элементов FrameBuilder. Контакт: [email protected] (Эрл Худ)
troff и т. Д.
- ms2html (ms в html) Контактное лицо: [email protected] (Оскар Нирстраз)
- me2html для макросов troff me основан на этом.Контакты: [email protected] (Джон М. Тройер)
- troff2html. Perl-скрипт для макросов me. Контакты: [email protected] (Джон М. Тройер)
- Другой troff2html использует nroff для выполнения большей части своей работы и поэтому совместим со многими препроцессорами troff такие как tbl и отсылка. Контакты: [email protected] (Джим Бриггс).
- Еще один troff2html на основе улучшенной версии mm2html. Лучше всего работает с макросами «mm», а также поддерживает «ms», но людям нужно было это проверить.Контакт: http://www.pathname.com/~quinlan/ (Дэниел Куинлан)
- И еще troff2html Perl-скрипт принимает дополнительные правила трансляции для пакетов макросов, таких как как -ms -mv и -man. Большинство правил преобразования — это таблицы ASCII, поэтому их можно изменить по своему усмотрению. Контакт: [email protected] (Мик Фармер)
- анрофф это основанный на схемах, программируемый, расширяемый транслятор troff с бэкэндами для HTML 2.0 и макросами -man и -ms. Контакты: [email protected] (Оливер Лауманн)
- мм2html предварительная альфа-версия Perl-скрипта nroff mm в HTML, в значительной степени основанного на ms2html и fm2html.Контакты: [email protected]
TeX, LaTeX и т. Д.
- TeX4ht это система разработки на основе TeX с широкими возможностями настройки для гипертекст. Он поставляется со встроенными настройками по умолчанию для обычного TeX и LaTeX. Контакты: [email protected] (Эйтан Гурари)
- T T H это переводчик TeX в HTML. Переводит простой TeX и LaTeX в почти эквивалент в HTML3.2. Занимается математикой, определениями, таблицы и многое другое, не прибегая к встроенной графике.Контакты: [email protected] (Ян Хатчинсон).
- латекс2html Конвертер LaTeX в HTML (скрипты Perl). Обрабатывает больше сложное форматирование LaTeX, например математика, и имеет набор пиктограммы, которые используются для навигации, а также для обозначения сносок и ссылок. (См. Также статью От LaTeX к HTML и обратно в ЦЕРН.
- Примечание: преобразователь l2h для [email protected] (Джон Кимбалл) больше не доступен.
- LaTeX2hyp — это программа на языке C, конвертирует LaTeX в HTML, текст, справку TurboVision, RTF или WinHelp RTF.
- math3html — это Математика и таблицы LaTeX в переводчик HTML3.
- вулканизировать — это простой скрипт на Perl, который обрабатывает большую часть нематематических документов LaTeX. Контакты: [email protected] (Марк-Джейсон Доминус)
- Hyperlatex позволяет использовать подмножество LaTeX для создавать документы в формате HTML. Контакты: [email protected] (Отфрид Шварцкопф)
- tex2rtf преобразует LaTeX в HTML, а также в RTF, Windows Help RTF и wxHelp. (Источник доступен здесь).Контакты: [email protected]
- Парсер LaTeX l2x может использоваться для создания HTML. Контакты: [email protected] (Хеннинг Шульцринне)
- JAM — это метаязык с конвертерами для HTML, LaTeX и RTF.
- БЕТА-формат — это интеграция LaTeX и HTML в новый синтаксис, близкий к HTML, с конвертером DOS, который переводится в LaTeX или HTML. Контакты: [email protected] (Хорст Вассенберг)
- YODL — это язык описания документов с пакет конвертации в LaTeX или HTML, а также в другие форматы.
- axtex — это фильтр для извлечения «объектов» LaTeX, встроенных в HTML. и создать .tex и, наконец, файл изображения для каждого из них, и создать HTML-файл с соответствующими встроенными строками. Контакты: [email protected] (Филип Трифт)
- HyperTeX состоит из постоянно растущего набора стандартов и программного обеспечения, которое позволяет Документы на основе TeX для более полной интеграции в WWW (через форматы DVI или PDF). См. FAQ, или информацию на LANL. Контакты: [email protected] (Артур Смит)
BibTeX и т. Д.
- bibtex2html принимает файл BibTeX в качестве аргумента и создает библиографию HTML вместе с документом HTML, содержащим список все записи в формате BibTeX. Доступны бинарные файлы для популярных систем Unix. Контакты: [email protected]
- bib2html — это оболочка скрипт плюс два файла стилей BibTeX. Контакты: [email protected] (Дэвид Котц)
- Другой bib2html — это Perl скрипт с файлом стиля.Он берет библиографию BibTeX и форматирует ее в HTML. Он также может создавать ссылки на произвольные URL-адреса и версии документов в формате PostScript, PDF или DVI. Он поставляется со сценарием CGI, позволяющим выполнять поиск по библиографии. Контакт: [email protected] (Дэвид Халл)
- bibhtml — это сценарий Perl 5. Ссылки на BibTeX могут быть включены в качестве якорей в HTML-документы, и bibhtml может использоваться создать на их основе библиографию в формате HTML. Контакты: [email protected] (Ханс Пайджманс)
- Другой нагрудник состоит из сценария Perl и файла стиля BibTeX, которые позволяют скомпилировать библиография для коллекции файлов HTML.Контакты: [email protected] (Норман Грей).
- Есть сценарий Tcl для текстового редактора Mac Alpha для преобразования .bbl в HTML.
- Сетевая библиография AT&T использует сценарии для индексации файлов BibTeX и конвертировать их в HTML на лету при извлечении. Контакты: [email protected] (Хеннинг Шульцринне)
- Библиография по автономным агентам в HCI и CSCW в Бирмингеме Великобритания также имеет инструменты для поиска BibTeX и добавления html-разметки в файлы BibTeX.Контакт: [email protected] (Энди Вуд)
- Также есть информация по Управление библиографиями BibTeX, используемыми для сервера библиографий по информатике в Карлсруэ. Контакты: [email protected] (Альф-Кристиан Ахилл)
Texinfo
texi2html Контакты: [email protected]
DECwrite, документ VAX
- decw2html (сценарий Perl для обработки вывода SGML) Контакт: [email protected]
- Вот сценарий awk для преобразования SDML в HTML.Контакты: [email protected] (Стив Лайонел)
- DOCU2HTML — это сценарий DCL для грубого преобразования файлов VAX Document SDML в HTML. Контакт: [email protected] (Джулиан Банн)
Interleaf
QuarkXPress
Сайт beyondexpress.com предлагает советы графическим дизайнерам, использующим QuarkXPress, по созданию веб-страниц с помощью BeyondPress и других инструментов. Контакты: [email protected] (Кип Шоу)
- qt2www Perl-скрипт для конвертировать текстовые файлы с тегами Quark в HTML.Это универсальная утилита преобразования; он читает в файле карты, который перечисляет теги Quark, используемые в исходном файле, и как они должны быть переведен в HTML. Версии для Unix, DOS и Macintosh. Контакты: [email protected] (Джереми Хилтон)
- HTML Xport — это скромное, но работающее расширение Xtension для экспорта в HTML для QuarkXpress. Доступно через ftp://mars.aliens.com/pub/Macintosh/HTML_Xport.sit (Или попробуйте архивы info-mac). Контакты: [email protected], [email protected] (Эрик Кнудструп)
- e-Gate от Rosebud Technologies берет файлы QuarkXpress и генерирует HTML или структурированные файлы ASCII, а также форматы JPEG или GIF для графики.Он также будет структурировать статьи, чтобы их можно было хранить и управлять ими в базах данных.
- BeyondPress (ранее Gateway) от Astrobyte — это XTension, который переводит документы QuarkXPress в HTML. Контакты: [email protected].
- Соберите HTML от Logic n.v. это XTension, который позволяет конвертировать текст из Quark страницы в формат HTML. (Вашему браузеру нужны фреймы для доступа к своему сайту). Стили могут быть преобразованы в префиксы HTML и суффиксы. Collect не подходит для преобразования полных страниц Quark; Это лучше подходит для «вырезания» статей с больших страниц (например.грамм. газета) для Интернет-публикация.
- HexWeb XT от HexMac — это XTension, который генерирует файлы HTML из страниц QuarkXPress. Для Macintosh, а вскоре и для Windows 95. (Вашему браузеру нужны фреймы для доступа к своему сайту).
- Вот примечание о некоторых других продуктах.
- Также доступны несколько комплектов экспортных фильтров.
PageMaker
- Дэйв Скрипт AppleScript, который работает с PageMaker 5.0 для извлечения статей и преобразовать их в HTML.Контакты: [email protected] (Джефф Бултер)
- WebSucker для Mac помогает конвертировать длинные документы Pagemaker 5.0 или 6.0 в HTML. Он хорош для преобразования документов с большим количеством историй, поскольку создает настраиваемый оглавление, чтобы связать все истории вместе. Доступен в виде стека гиперкарт или автономного толстого двоичного файла. Новый релиз версии 2.8 не требует AppleScript. (см. также info-mac архивы). Контакты: [email protected] (Митчелл С. Коэн).
- PM2html — дополнение PageMaker для Windows доступны от EDCO как в бесплатной, так и в производственной версиях.
- pm2html — еще одно дополнение PageMaker.
- Adobe PageMaker 6.0 имеет подключаемый модуль HTML Author который позволяет пользователям PageMaker экспортировать публикации PageMaker в формат HTML.
ClarisWorks, MacWrite и т. Д.
AmiPro
См. Также продукты, поддерживающие несколько форматов текстовых процессоров
- AmiWeb это пакет, который позволяет вам составлять HTML-документы с помощью AmiPro для Windows.
- еще одна утилита для AmiPro
Писец
Есть технический отчет Создание HTML-документов с помощью Scribe для пользователей системы производства документов Scribe.Контакты: [email protected] (Гленн Трюитт)
- Интернет-помощник для Powerpoint для Windows 95 от Microsoft. Превращает слайды в HTML-страницы; гиперссылки автоматически настраиваются для перехода с одной перейти к другому.
- HexWeb Slidemaster от HexMac — это инструмент, который позволяет публиковать слайд-шоу «Убеждение» в Интернете. (Вашему браузеру нужны фреймы для доступа к своему сайту).
- wwwfoil обрабатывает файл структуры текста, созданный Adobe Persuasion, и преобразует его в HTML.Он также будет выполнять несколько других полезных задач, необходимых для подготовки онлайн-презентаций для образование. Контакты: [email protected] (Джеффри Фокс)
- Вот несколько примечаний по преобразованию PowerPoint в HTML
- и посмотреть webify
EndNote
EndNote2html — это «стиль» для Библиографический инструмент EndNote. Это заставляет EndNote для Microsoft Word связывать ссылки в тексте с соответствующими строчку в списке литературы. Контакты: [email protected] (Алк Дрансфельд)
Linuxdoc-SGML
Linuxdoc-SGML — это пакет для форматирования текста, основанный на SGML. это создаст HTML, а также другие размеченные документы.
Rainbow — это аннотированный SGML DTD с конвертерами для текстовые документы (в формате RTF) и документы, созданные Пакеты Ventura Publisher и Quark Express DTP. Требуется дополнительное программное обеспечение для преобразования SGML в HTML.
__________________________________________________________________
РС, ЦЕРН 19 марта 1999 г.микроформатов2 — Microformats Wiki
Добро пожаловать на домашнюю страницу микроформатов2.
Сводка
Microformats2 — это последняя версия микроформатов, самый простой способ разметки структурированной информации в HTML.Microformats2 упрощает использование и реализацию для как для авторов (издателей), так и для разработчиков (исполнителей парсеров).
Микроформаты2 заменяют и заменяют классические микроформаты (иногда называемые микроформатами1), а также включают уроки, извлеченные из микроданных и rdfa.
простых микроформата2 примера
Вот несколько примеров простых микроформатов2 вместе с каноническим JSON.
пример человека
Фрэнсис Берриман
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Фрэнсис Берриман"]
}
}]
}
гиперссылка
- Простая ссылка на человека с гиперссылкой
Бен Уорд
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Бен Уорд"],
"url": ["http://benward.me"]
}
}]
}
изображение человека с гиперссылкой
- Простое изображение человека с гиперссылкой

Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Rohit Khare"],
"url": ["http: // rohit.khare.org/ "],
"фото": ["https://s3.amazonaws.com/twitter_production/profile_images/53307499/180px-Rohit-sq_bigger.jpg"]
}
}]
}
Дополнительные сведения о простых случаях в микроформатах2 подразумеваемые свойства.
подробный пример человека
<а href = "http://blog.lizardwrangler.com/" > Митчелл Бейкер ( @MitchellBaker ) Mozilla Foundation
Митчелл отвечает за определение направления и масштабов Mozilla Foundation и ее деятельности.
Стратегия Лидерство
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"фото": ["https://webfwd.org/content/about-experts/300.mitchellbaker/mentor_mbaker.jpg "],
"name": ["Митчелл Бейкер"],
"url": [
"http://blog.lizardwrangler.com/",
"https://twitter.com/MitchellBaker"
],
"org": ["Mozilla Foundation"],
«примечание»: [«Митчелл отвечает за определение направления и объема Mozilla Foundation и ее деятельности».],
"категория": [
"Стратегия",
«Лидерство»
]
}
}]
}
детали из примеров
Детали, продемонстрированные на примерах:
- JSON
«тип»использует полное имя корневого класса микроформата (например,грамм.«h-card») для последовательной идентификации. - : все свойства являются необязательными и синтаксически множественными с проанализированными значениями, предоставленными в порядке документа; определенные микроформаты (и приложения к ним) могут применять особую / сингулярную семантику к первому значению свойства.
микроформаты2 дизайн
microformats2 имеет следующие ключевые конструктивные особенности:
- Префиксы для имен классов
- Все имена классов микроформатов используют префиксы.Префиксы синтаксиса независимы от словарей , которые разрабатываются отдельно.
-
h- *для имен корневых классов (например,h-card) -
p- *для свойств обычного текста (например,p-name) -
u- *для свойств URL (например,u-photo) -
dt- *для свойств даты / времени (например,dt-bday) -
e- *для встроенных свойств разметки (например,грамм.e-note)
Дополнительные сведения см. В условных обозначениях префиксов microformats2.
- Плоские наборы дополнительных свойств
- Все микроформаты состоят из корня и набора свойств. Иерархические данные представлены вложенными микроформатами, обычно как сами значения свойств. Все свойства являются необязательными и потенциально многозначными (приложения, которым требуется особая семантика, могут использовать первый экземпляр).
- Одноклассная разметка для общего использования
- Для обычных простых шаблонов разметки требуется только одно имя корневого класса микроформата, которое парсеры используют для поиска нескольких общих свойств:
имя,URL,фото.Это демонстрируют приведенные выше примеры простых микроформатов2.
Анализ каждого префикса (включая создание канонического JSON) подробно описан в следующих разделах:
Примечание: Большинство свойств указываются и используются с одним конкретным префиксом (а иногда с двумя или тремя), что очевидно из контекста. Однако любой префикс синтаксического анализа можно использовать с любым свойством, особенно если вы найдете для этого вескую причину!
словари v2
Статус: черновик .Просмотрите и оставьте отзыв в #microformats на freenode.
См. Ниже краткое содержание словаря.
h-adr
Микроформат h-adr предназначен для разметки структурированных местоположений, таких как адреса, физические и / или почтовые. Это обновление для adr.
имя корневого класса: h-adr
profile / itemtype: http://microformats.org/profile/h-adr
объектов недвижимости:
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующее имя корневого класса и имена свойств.Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств. Если обнаружен «h-adr», не ищите «adr» в том же элементе.
compat root class name: adr
properties: (анализируется как p- простой текст, если не указано иное)
-
почтовый ящик -
расширенный адрес -
ул. -
населенный пункт -
регион -
почтовый индекс -
название страны
h-card
Микроформат h-card предназначен для разметки людей и организаций.Это обновление hCard 1.0.
имя корневого класса: h-card
profile / itemtype: http://microformats.org/profile/h-card
объектов недвижимости:
-
имя р -
p-honorific-prefix -
p-имя-имя -
p-дополнительное-имя -
р-фамилия -
p-sort-string -
p-почетный суффикс -
р-ник -
электронная почта -
u-логотип -
u-фото -
u-url -
u-uid -
р-категория -
п-адр -
п-почтовый ящик -
p-расширенный-адрес -
р-улица-адрес -
р-местность -
р-область -
p-индекс -
p-название страны -
p-label -
p-geoилиu-geoс RFC 5870 geo: URL, новое в vcard4 (vCard 4 RFC 6350) -
p-широта -
p-долгота -
p-altitude— новое в vcard4 (vCard 4 RFC 6350 из RFC 5870) -
п-тел -
p-note -
dt-bday -
U-образный ключ -
п-орг -
p-job-title— ранее «title» в hCard, без неоднозначности. -
p-роль -
u-imppсогласно RFC 4770, новое в vcard4 (vCard 4 RFC 6350) -
p-sexновый в vcard4 (vCard 4 RFC 6350) -
p-гендерная идентичностьновое в vcard4 (vCard 4 RFC 6350) -
dt -iversaryНовое в vcard4 (vCard 4 RFC 6350) - …
Зарезервированные свойства: (свойства не используются (если вообще) на практике)
-
p-название-организации -
p-организационная единица -
п-тз -
dt-rev - …
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующее имя корневого класса и имена свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств. Если «h-card» найдена, не ищите «vcard» на том же элементе.
compat root class name: vcard
properties: (анализируется как p- простой текст, если не указано иное)
-
fn— синтаксический анализ какp-name -
почетный префикс -
имя -
доп. Имя -
фамилия -
почетный суффикс -
ник -
электронная почта— синтаксический анализ как u- -
логотип— синтаксический анализ как u- -
фото— разбирать как u- -
url— синтаксический анализ как u- -
uid— синтаксический анализ как u- -
категория -
adr— синтаксический анализ какp-adr h-adrвключая корневой класс сопоставленияadr -
расширенный адрес -
ул. -
населенный пункт -
регион -
почтовый индекс -
название страны -
этикетка -
geo— проанализировать какp-geo h-geo, включая корневой класс соответствияgeo -
широта -
долгота -
тел. -
примечание -
bday— синтаксический анализ как dt- -
ключ— синтаксический анализ как u- -
org -
название организации -
организационная единица -
название— синтаксический анализ как p-job-title -
роль - …
Зарезервировано: (свойства обратной совместимости, которые парсеры МОГУТ реализовать , если они это сделают, они ДОЛЖНЫ реализовать следующим образом:
-
tz -
rev— синтаксический анализ как dt- - …
Примечание: использование значения ‘value’ в ‘tel’ должно автоматически обрабатываться при поддержке шаблона класса значений. А пока подсвойство ‘type’ для ‘tel’ отбрасывается / игнорируется. Если есть очевидная документально подтвержденная потребность в дополнительных типах телефонов (например,грамм. факс), мы можем ввести новые свойства квартиры по мере необходимости (например, p-tel-fax).
h-вход
Микроформат h-entry предназначен для разметки синдицируемого контента, такого как сообщения в блогах, заметки, статьи, комментарии, фотографии и т.п. Это обновление hAtom 0.1.
имя корневого класса: h-entry
profile / itemtype: http://microformats.org/profile/h-entry
объектов недвижимости:
-
p-name(было p-entry-title, см. Проблемы) -
p-summary(было p-entry-summary, см. Проблемы) -
электронный контент(был электронный контент, см. Проблемы) -
dt-опубликовано -
dt-обновлено -
п-автор -
р-категория -
u-url -
u-uid -
п-гео -
p-широта -
p-longitude
Это обновление для hAtom 0.1.
Мозговой штурм:
Следующие свойства являются предлагаемыми дополнениями к h-entry сверх того, что предоставляет hAtom (или Atom), на основе различных существующих соглашений о разметке предварительного просмотра ссылок:
-
u-фото -
u-audio— учтите специальные правила обработки для -
u-video— учтите специальные правила обработки для -
u-in-reply-to— для ссылок на другие сообщения, на которые это сообщение является ответом (комментарий относительно и т. Д.)
Обратная совместимость:
(*) реализации hAtom, которые выполняют настраиваемое отображение или преобразование (например, в Atom XML) СЛЕДУЕТ предпочесть p-name вместо p-entry-title и использовать значение p-entry-title ( s) в качестве запасного варианта, если нет p-name .
Для обратной совместимости hAtom анализаторам microformats2 СЛЕДУЕТ обнаруживать следующие имена корневых классов и свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств.Если «h-запись» найдена, не ищите «hentry» в том же элементе.
compat root class name: hentry
properties: (анализируется как p- простой текст, если не указано иное)
-
entry-title— синтаксический анализ какp-name -
запись-сводка -
entry-content— синтаксический анализ: e- -
опубликовано— анализируется как dt- -
обновлено— синтаксический анализ как dt- -
автор— включая compat rootvcardпри отсутствииh-card -
категория -
geo— разобрать какp-geo h-geoвключая корень compatgeo -
широта -
долгота - …
FAQ:
- Что такое
p-nameзаметки?- Несколько вариантов, от самых простых до самых подробных.
- то же, что и свойство p-content / e-content.
- то же, что и элемент заголовка
- первое предложение свойства p-content / e-content . Для целей распространения и предварительного просмотра ссылок может быть лучше предоставить только первое предложение заметки как
p-name. Точно так же, если только часть контента синдицируется на другие сайты, эта часть может быть помечена какp-summary.
- Несколько вариантов, от самых простых до самых подробных.
- …
Решенные проблемы:
- 2012-245 Решено. См. Обсуждение / консенсус IRC в 2012–243 для:
- Используйте
p-summaryвместоp-entry-summary.Историческая семантика «вступления-резюме» ничем существенным (или заметным) не отличается от «резюме». Свертывание этих двух слов еще больше упростит общие словари микроформатов2. В микроформатах2 записи-резюме больше нет. - Используйте
e-contentвместоe-entry-content. То же самое и преимущество. В микроформатах2 entry-content больше нет. - drop
p-entry-title. Ненужные и подпадают под «p-name».Рассмотрел бы переход к обратной совместимости только в том случае, если будут представлены примеры — ожидается, что в ближайшее время будут обновлены известные способы публикации.
- Используйте
h-событие
Микроформат h-event предназначен для разметки событий. Это обновление hCalendar 1.0.
имя корневого класса: h-event
profile / itemtype: http://microformats.org/profile/h-event
объектов недвижимости:
-
имя р -
п-сводка(*) -
dt-start -
dt-конец -
dt-duration -
п-описание -
u-url -
р-категория -
p-location -
п-гео -
p-широта -
p-долгота - …
Это обновление hCalendar 1.0.
(*) реализации, специфичные для hCalendar, которые выполняют настраиваемое отображение или преобразование (например, в iCalendar .ics) СЛЕДУЕТ предпочитать p-name вместо p-summary и использовать значение (я) p-summary как резервный вариант, если нет p-name .
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующее имя корневого класса и имена свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств.Если обнаружено «h-событие», не ищите «vevent» на том же элементе.
compat root class name: vevent
properties: (анализируется как p- простой текст, если не указано иное)
-
сводка— синтаксический анализ какp-name -
dtstart— синтаксический анализ какdt-start -
dtend— синтаксический анализ какdt-end -
duration— синтаксический анализ какdt-duration -
описание -
url— синтаксический анализ как u- -
категория -
расположение— включая compat rootvcardпри отсутствииh-cardи compat rootadrпри отсутствииh-adr -
geo— разобрать какp-geo h-geoвключая корень compatgeo -
широта -
долгота - …
h-geo
Микроформат h-geo предназначен для разметки геофизических координат WGS84. Это обновление для Geo.
имя корневого класса: h-geo
profile / itemtype: http://microformats.org/profile/h-geo
объектов недвижимости:
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующее имя корневого класса и имена свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств.Если найдено «h-geo», не ищите «geo» на том же элементе.
compat имя корневого класса: geo properties: (анализируется как обычный текст p- , если не указано иное)
h-элемент
Микроформат h-item предназначен для разметки элемента h-обзора или h-продукта. Это обновление части hReview 0.4 (в процессе).
имя корневого класса: h-item
profile / itemtype: http: // microformats.org / profile / h-item
объектов недвижимости:
Примечание: на практике из-за правил подразумеваемых свойств microformats2 ожидается, что для большинства случаев использования «h-item» вообще не потребуются какие-либо явные свойства (поскольку парсеры microformats2 будут выводить свойства name, photo и url из структура элемента с «h-item» и содержащееся в нем содержимое / элементы, если таковые имеются).
h-продукт
Микроформат h-product предназначен для разметки продуктов. Это обновление hProduct.
имя корневого класса: h-product
profile / itemtype: http://microformats.org/profile/h-product
объектов недвижимости:
-
p-name— наименование товара -
u-фото— фото товара -
p-brand— производитель, также может быть вложеннаяh-card -
p-категория— категории или теги произвольной формы, примененные к элементу рецензентом -
электронное описание -
u-url— URL продукта -
u-идентификатор— включает тип (e.грамм. mpn, upc, isbn, issn, sn, vin, sku и т. д.) и значение. -
p-review— обзор продукта, также может быть вложенныйh-review -
p-price— розничная цена продукта
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующие имена корневых классов и свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств.Если обнаружен «h-продукт», не ищите «h-продукт» на том же элементе.
compat root class name: hproduct
properties: (анализируется как p- простой текст, если не указано иное)
-
fn— синтаксический анализ какp-name -
фото— разбирать как u- -
марка -
категория -
описание -
идентификатор— синтаксический анализ как u- -
url— синтаксический анализ как u- -
обзор— включая compat root classhreviewпри отсутствииh-review -
цена
Примечание. HProduct имеет по крайней мере одно экспериментальное свойство, которое было принято в реальном мире благодаря поддержке поиска hProduct в Google Search и поисковой системе Microsoft Bing.Сейчас это: цена
ч-рецепт
Микроформат h-recipe предназначен для разметки рецептов блюд. Это обновление hRecipe 0.22.
имя корневого класса: h-recipe
profile / itemtype: http://microformats.org/profile/h-recipe
объектов недвижимости:
-
p-name— название рецепта -
р-ингредиент— описывает один или несколько ингредиентов, используемых в рецепте. -
p-yield— Указывает количество, произведенное по рецепту, например, сколько людей он удовлетворяет -
электронная инструкция— метод рецепта. -
dt-duration— время, необходимое для приготовления блюда, описанного в рецепте. -
u-photo— сопроводительное изображение
Экспериментальные свойства с широким распространением
-
p-summary— предоставляет краткое резюме или введение -
p-author— человек, который написал рецепт с помощью h-карты -
dt-published— дата публикации рецепта -
p-Nutrition— информация о питании, такая как калории, жир, пищевые волокна и т. Д. - …
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующее имя корневого класса и имена свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств. Если найден «h-рецепт», не ищите «hrecipe» на том же элементе.
compat root class name: hrecipe
properties: (разбирается как p- простой текст, если не указано иное)
-
fn— синтаксический анализ какp-name -
ингредиент -
доход -
инструкции— синтаксический анализ как e- -
продолжительность— синтаксический анализ как dt- -
фото— разбирать как u- -
сводка -
автор— включая compat rootvcardпри отсутствииh-card -
питание
Примечание: hRecipe 0.22 имеет ряд экспериментальных свойств, которые нашли применение в реальном мире благодаря поддержке поиска рецептов в поиске Google в hRecipe. Это: резюме, автор, опубликовано и питание.
h-резюме
Микроформат h-resume предназначен для разметки резюме. Это обновление hResume.
имя корневого класса: h-resume
profile / itemtype: http://microformats.org/profile/h-resume
объектов недвижимости:
-
p-summary— обзор квалификаций и целей -
p-contact— текущая контактная информация на h-карте -
p-образование— образованиеh-календарьсобытие, годы, вложенныеh-cardшколы, местонахождение. -
p-опыт— работа или другой профессиональный опытh-календарьсобытие, годы, вложенныеh-cardорганизации, местонахождение, должность. -
p-skill— навык или способность, необязательно включая уровень и / или продолжительность опыта -
p-affiliation— affiliation with ah-cardorganization
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующие имя корневого класса и имена свойств.Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств. Если найдено «h-резюме», не ищите «hresume» в том же элементе.
compat root class name: hresume
properties: (анализируется как p- простой текст, если не указано иное)
-
сводка -
контакт— включая compat rootvcardпри отсутствииh-card -
образование— включая compat rootveventпри отсутствииh-event -
опыт— включая compat rootveventпри отсутствииh-event -
умение -
принадлежность— включая корень соответствияvcardпри отсутствииh-card
Примечание: навык имеет предлагаемое расширение компетенции с явным резюме, рейтингом и / или компонентами продолжительности.Основываясь на существующем внедрении в реальном мире, мы должны рассмотреть словарь h-компетенций со свойствами p-summary, p-rating и dt-duration.
h-обзор
Микроформат h-review предназначен для разметки обзоров. Это обновление для hReview 0.4 (в процессе). См. Также h-элемент.
имя корневого класса: h-review
profile / itemtype: http://microformats.org/profile/h-review
объектов недвижимости:
-
p-name— название обзора -
p-item— вещь проверена i.е. компания или человек (h-card), событие (h-событие), место (h-adr или h-geo), продукт (h-product), веб-сайт, URL-адрес или другой элемент (h-item). -
p-reviewer— автор обзора -
dt-review— дата и время написания обзора -
p-rating— значение от 1 до 5, обозначающее оценку предмета (5 лучших). -
p-best— определить лучшее значение рейтинга.может быть численно ниже худшего. -
p-худший— определить худшее значение рейтинга. может быть численно выше наилучшего. -
электронное описание— полный текст письменной оценки и мнения рецензента -
p-категория— категории или теги произвольной формы, примененные к элементу рецензентом -
u-url— URL обзора
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующие имена корневых классов и свойств.Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств. Если обнаружен «h-обзор», не ищите «h-обзор» в том же элементе.
compat root class name: hreview
properties: (анализируется как p- простой текст, если не указано иное)
-
сводкасинтаксический анализ какp-name -
fn— проанализировать как p-name проверяемого элемента (p-item h-item p-name) -
фото— проанализировать как u-фото рассматриваемого товара (p-item h-item u-photo) -
url— проанализировать как u-url проверяемого элемента (p-item h-item u-url) -
обозреватель— включая совместимую корневую vcard при отсутствии h-карты -
dtreviewed— синтаксический анализ как dt- -
рейтинг -
лучшее -
худший -
описание— синтаксический анализ как e- -
rel = "tag"— синтаксический анализ как p-категория -
rel = "self bookmark"— разбирается как u-url .обратите внимание, что значение атрибутаrelобрабатывается как набор, разделенный пробелами, поэтому любое присутствие «self» и «bookmark» в таком наборе в значении rel допускается.
Примечание. Формат hReview 0.4 (в процессе) имеет три свойства, которые используют атрибут rel : тег , постоянная ссылка (через значения self и закладки ) и лицензия . Анализаторам Microformats2 СЛЕДУЕТ отображать эти URL-адреса в коллекцию rel с ограниченным объемом страницы.
h-review-aggregate
Микроформат h-review-aggregate предназначен для разметки совокупных обзоров одного элемента. Это обновление hReview-aggregate 0.2. См. Также h-элемент.
имя корневого класса: h-review-aggregate
profile / itemtype: http://microformats.org/profile/h-review-aggregate
объектов недвижимости:
-
p-name— название обзора -
p-item— вещь проверена i.е. компания или человек (h-card), событие (h-событие), место (h-adr или h-geo), продукт (h-product), веб-сайт, URL-адрес или другой элемент (h-item). -
p-rating— значение от 1 до 5, указывающее среднюю оценку элемента (5 лучших). -
p-best— определить лучшее значение рейтинга. может быть численно ниже худшего. -
p-худший— определить худшее значение рейтинга. может быть численно выше наилучшего. -
p-count— количество собранных отзывов. -
p-голосов— количество рецензентов, которые оценили продукт, что повысило его среднюю оценку. -
p-категория— категории или теги произвольной формы, примененные к элементу рецензентом -
u-url— URL обзора
Для обратной совместимости анализаторам microformats2 СЛЕДУЕТ обнаруживать следующие имена корневых классов и свойств. Анализатор микроформатов2 может использовать существующие классические микроформаты Анализаторы микроформатов для извлечения этих свойств.Если обнаружен «h-review-aggregate», не ищите «hreview-aggregate» в том же элементе.
compat root class name: hreview-aggregate
properties: (анализируется как p- простой текст, если не указано иное)
-
сводкасинтаксический анализ какp-name -
fn— проанализировать как p-name проверяемого элемента (p-item h-item p-name) -
фото— проанализировать как u-фото рассматриваемого товара (p-item h-item u-photo) -
url— проанализировать как u-url проверяемого элемента (p-item h-item u-url) -
рейтинг -
лучшее -
худший -
счет -
голосов -
rel = "tag"— синтаксический анализ как p-категория -
rel = "self bookmark"— разбирается как u-url .обратите внимание, что значение атрибутаrelобрабатывается как набор, разделенный пробелами, поэтому любое присутствие «self» и «bookmark» в таком наборе в значении rel допускается.
v2 словарные заметки
Примечания:
- Все словари v2 определены как плоские списки свойств объекта / элемента и, таким образом, могут использоваться в синтаксисе микроформатов-2, как показано, или в элементах микроданных, или RDFa. Префиксы синтаксического анализа свойств микроформатов-2 «p-», «u-», «dt-», «e-» опускаются при использовании определенных свойств в itemprop микроданных и свойстве RDFa, поскольку эти синтаксисы имеют свои собственные правила синтаксического анализа для конкретных элементов. URL-адреса профиля
- предоставляются для использования с атрибутом HTML4
profile, атрибутомitemtypeмикроданных и атрибутами RDFavocabиtypeof(хотя последний требует отсечения конечного сегмента профиля для атрибута typeof, остальное оставив в словаре). Свойства - microformats2 также могут быть явно привязаны как URI с использованием вместо этого профиля rel, предложения атрибута профиля HTML5 или атрибута словаря HTML5.Если для вас важны термины, связанные с URI, пожалуйста, проявите интерес к профилю rel, атрибуту профиля HTML5 или внесите свой вклад в черновик html5-vocab.
v2 список дел
Сделать:
- напишите простое руководство по созданию / началу работы с разметкой микроформатов-2 для нового контента
- примеров в каждой спецификации h- *, перечисленных выше, о том, как встраивать в них другие микроформаты
- актуальных профильных документов на http://microformats.org/profile/h-* упомянутых выше URL.
- При необходимости предоставьте любой необходимый язык, специфичный для микроданных (например, чтобы он был сравнительно понятен образцу словаря микроданных vCard4 / hCard1. Также при необходимости предоставьте любой необходимый язык, специфичный для RDFa. Желательно, чтобы оба языка были независимыми от общего словаря.
- написать руководство по переносу, сопоставление свойств v1 -> v2
- вариант использования: простой поиск / замена в шаблонах (например, если веб-автор не помнит существующие словари микроформатов и где они их использовали).
- советует использовать * оба * в существующих шаблонах (например, в случае, если некоторый CSS зависит от существующих микроформатов)
- анализирует / документирует, насколько хорошо модель и словари микроформатов2 удовлетворяют сценариям использования, используемым для разработки / создания микроданных.
объединение микроформатов
Поскольку микроформаты2 используют простые плоские наборы свойств для каждого микроформата, несколько микроформатов объединяются для обозначения дополнительной структуры.
h-место проведения мероприятия h-карта
События обычно содержат информацию о месте проведения с дополнительной структурой, например адресную информацию.Например:
IndieWebCamp 2012 г. с до в Геолоки , 920 SW 3rd Ave. Suite 400 , Портленд , ИЛИ
Вложенная h-карта, используемая для структурирования p-местоположения h-события, представлена как структурированное значение для «location» в JSON, которое имеет дополнительный ключ «value», представляющий версию обычного текста, полученную из p-расположение.
Разобранный JSON:
{
"Предметы": [{
"тип": ["h-событие"],
"характеристики": {
"name": ["IndieWebCamp 2012"],
"url": ["http://indiewebcamp.com/2012"],
"start": ["2012-06-30"],
"конец": ["2012-07-01"],
"место расположения": [{
"значение": "Геолоки",
"type": ["h-card"],
"характеристики": {
"name": ["Geoloqi"],
"org": ["Geoloqi"],
"url": ["http://geoloqi.com/"],
"street-address": ["920 SW 3rd Ave. Suite 400"],
"locality": ["Портленд"],
"регион": ["Орегон"]
}
}]
}
}]
}
вопросов:
- Должна ли вложенная карта hCard присутствовать также как элемент верхнего уровня в JSON? — Тантек, 02:02, 19 июня 2012 г. (UTC)
- Мой текущий (2012-243) наклон нет.- Тантек 18:53, 30 августа 2012 г. (UTC)
- Если да, то как избежать расширения JSON, геометрически пропорционального глубине вложения микроформатов? (Или мы не беспокоимся об этом?)
- Должны быть канонический иерархический JSON и канонический уплощенный JSON? — Тантек, 02:02, 19 июня 2012 г. (UTC)
- Мой текущий (2012–243) наклон — нет, мы придерживаемся одного канонического JSON для uf2, который является иерархическим. — Тантек 18:53, 30 августа 2012 г. (UTC)
- Если да, то должен ли сглаженный JSON содержать ссылки из свойств на вложенные микроформаты, которые были перенесены на верхний уровень за сглаживание? — Тантек, 02:02, 19 июня 2012 г. (UTC)
- Если да, то какому соглашению следует / следует JSON для таких синтетических локальных ссылочных идентификаторов? — Тантек, 02:02, 19 июня 2012 г. (UTC)
Примечания:
- Значение «location» отражает видимый текст его элемента, включая пробелы и знаки препинания, а также аббревиатуру состояния «OR».Значения свойства ‘h-card’ — это только то, что размечено и, таким образом, включают значения структуры без дополнительных знаков препинания, а состояние принимает развернутую форму из атрибута
titleего элемента
h-card org h-card
Люди часто публикуют общую информацию о своей компании, а не конкретную для них, и в этом случае они могут пожелать инкапсулировать ее в отдельно вложенный микроформат. Например. вот простой пример h-карты со свойством org:
Митчелл Бейкер (Mozilla Foundation)
с источником:
<а href = "http: // blog.lizardwrangler.com/ " > Митчелл Бейкер ( Mozilla Foundation )
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Митчелл Бейкер"],
"url": ["http://blog.lizardwrangler.com/"],
"org": ["Mozilla Foundation"]
}
}]
}
Иногда такие организации имеют гиперссылку на веб-сайт организации:
Митчелл Бейкер (Mozilla Foundation)
Вы можете отметить это вложенной h-картой:
<а href = "http: // blog.lizardwrangler.com/ " > Митчелл Бейкер ( Mozilla Foundation )
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Митчелл Бейкер"],
"url": ["http://blog.lizardwrangler.com/"],
"org": [{
"value": "Mozilla Foundation",
"type": ["h-card"],
"характеристики": {
"name": ["Mozilla Foundation"],
"url": ["http: // mozilla.org / "]
}
}]
}
}]
}
Примечание: вложенная h-карта подразумевает свойства ‘name’ и ‘url’, как и любая другая h-карта только для имени корневого класса на .
ТОЛЬКО ДЛЯ ПОСТАВЩИКОВ:
Вложенная «h-карта» также может быть помечена как «h-org», что добавляет ее к массиву типов вложенного микроформата, и все это как часть свойства, указанного в «p-org».
<а href = "http: // blog.lizardwrangler.com/ " > Митчелл Бейкер ( Mozilla Foundation )
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Митчелл Бейкер"],
"url": ["http://blog.lizardwrangler.com/"],
"org": [{
"value": "Mozilla Foundation",
"тип": ["h-card", "h-org"],
"характеристики": {
"name": ["Mozilla Foundation"],
"url": ["http: // mozilla.org / "]
}
}]
}
}]
}
ТОЛЬКО ДЛЯ ПОСТАВЩИКОВ:
Без имени класса свойств, такого как 'p-org', содержащего все вложенные объекты вместе, нам нужно ввести другой массив для вложенных дочерних элементов (аналогично существующему понятию дочерних элементов DOM) микроформата, который не привязан к конкретному имущество:
<а href = "http://blog.lizardwrangler.com/" > Митчелл Бейкер ( Mozilla Foundation )
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Митчелл Бейкер"],
"url": ["http://blog.lizardwrangler.com/"]
},
"дети": [{
"тип": ["h-card", "h-org"],
"характеристики": {
"name": ["Mozilla Foundation"],
"url": ["http://mozilla.org/"]
}
}]
}]
}
Поскольку для элемента с классами «h-card» и «h-org» нет имени класса свойств, микроформат, представляющий этот элемент, собирается в дочерний массив.
Такой вложенный микроформат подразумевает некоторую взаимосвязь (включение, связь), но не так полезен, как если бы вложенный микроформат был определенным свойством своего родителя.
По этой причине авторам не рекомендуется публиковать вложенные микроформаты без имени класса свойств, а вместо этого при вложении микроформатов авторы всегда должны указывать имя класса свойств (например, 'p-org') для того же элемента, что и корневой. имя (я) класса вложенного микроформата (например, «h-card» и / или «h-org»).
ТОЛЬКО ДЛЯ ПОСТАВЩИКОВ:
Или вложенный объект можно было пометить только с помощью h-card. Источник:
<а href = "http://blog.lizardwrangler.com/" > Митчелл Бейкер ( Mozilla Foundation )
Разобрано JSON:
{
"Предметы": [{
"type": ["h-card"],
"характеристики": {
"name": ["Митчелл Бейкер"],
"url": ["http: // blog.lizardwrangler.com/ "]
},
"дети": [{
"type": ["h-card"],
"характеристики": {
"name": ["Mozilla Foundation"],
"url": ["http://mozilla.org/"]
}
}]
}]
}
ЗАДАНИЕ: Добавьте пример h-карты h-события и JSON для реальных примеров публикации, таких как Swing Time: Classes in Southern England.
авторская
минимальная разметка
Наилучший способ использования микроформатов-2 - это как можно меньше дополнительной разметки.Это сохраняет ваш код более чистым, улучшает его ремонтопригодность и, следовательно, качество и долговечность ваших микроформатов.
Одно большое преимущество микроформатов-2 перед предыдущими микроформатами (и другими) - это возможность добавлять одно имя класса к существующему элементу для создания структурированного элемента.
Для начала ознакомьтесь с простыми примерами вверху, например
Простые hCards работают, просто добавляя class = "h-card" :
Фрэнсис Берриман Бен Уорд


- Совет: внутри открытого тега поместите
классатрибут сначала , затем любые атрибуты содержимого человеческого текста (например,alt), затем атрибуты URL (например,hrefsrc) и, наконец, другие атрибуты ( е.грамм.стиль). Размещение атрибута класса в первую очередь тесно связывает его с самим именем / тегом элемента, делает его более очевидным и, следовательно, с большей вероятностью будет обновляться.
обратная совместимость
Если вы полагаетесь на текущие микроформаты Реализации микроформатов, пока они обновляются для поддержки микроформатов2, вы можете включать как существующие классические микроформаты, так и разметку микроформатов2.
Вкратце: используйте оба набора имен классов одновременно.
При этом используйте их в одном элементе, указав сначала имя класса микроформатов-2, а сразу после него имя существующего класса микроформатов.
Вот микроформаты-2 hCard сверху с текущей разметкой hCard 1.0, которые могут потребовать добавления элемента-оболочки (например, ), чтобы отделить элемент имени корневого класса от явных элементов имени класса свойств:
Фрэнсис Берриман Бен Уорд
Советы:
- сначала используйте имя класса микроформатов-2, например
-
class = "h-card vcard" -
class = "u-url url"
-
- и объедините их в пары при использовании элемента для нескольких свойств, например.грамм.:
-
class = "p-name fn u-url url" -
class = "p-name fn u-photo photo"
-
- помещает классы микроформатов после классов для CSS (поскольку авторы страниц, вероятно, будут больше взаимодействовать со своими собственными классами для дизайна, чем с классами микроформатов), например как используется на отдельных микроформатах Страницы событий микроформатов:
-
class = "event-page h-event vevent"
-
Префиксы (h-, p- и т. Д.) Имен классов микроформатов2 обеспечивают более легкое распознавание, и если за ними следует одноименное имя существующего класса , их легче распознать как связанные и, таким образом, сохранить вместе, если разметка сохраняется с течением времени.
Вопросы и ответы по теме: При использовании и h-card, и vcard, что должно быть первым и почему?
добавочных номеров
microformats2 расширяется с помощью двух отдельных, но синтаксически схожих префиксов расширений для экспериментов, предназначенных для повторения и развития, и для расширений конкретных поставщиков, не предназначенных для стандартизации.
экспериментальные расширения
Были времена, когда определенные сайты хотели расширить микроформаты за пределы набора свойств в словаре микроформатов и в настоящее время не имеют экспериментального способа сделать это - попытаться проверить, подходит ли функция (или даже весь формат) интересно в реальном мире, прежде чем потрудиться продолжить исследование и пройти через процесс микроформатов.Таким образом:
Для экспериментальных расширений с целью создания прототипов, чтобы узнать больше, выполнить итерацию в направлении возможной стандартизации, используйте префикс -x- перед именами корневых классов и классов свойств.
В частности:
- '* -x-' + '-' + значимое имя для имен корневого каталога и класса свойств
- где "*" указывает односимвольный префикс, как определено выше
- , где «x» обозначает буквальный «x» для экспериментального расширения
Примеры:
- «p-x-prepare-time» - возможное имя экспериментального свойства, которое будет добавлено в h-recipe после рассмотрения / документирования реального использования / освоения.
Дополнительные примеры см. В разделе microformats2-experimental-properties.
добавочные номера поставщиков
Для расширений, зависящих от поставщика, в микроформатах2 используется механизм, аналогичный расширению поставщика CSS, с использованием синтаксиса, аналогичного экспериментальным расширениям, за исключением префикса поставщика вместо литерала «x».
- '* -x-' + '-' + значимое имя для имен корневого каталога и класса свойств
- где "*" указывает односимвольный префикс, как определено выше
- , где «x» указывает префикс поставщика (более одного символа, e.грамм. например, аббревиатуры расширения поставщика CSS или некоторые стандартные символы, избегая первых слов / фраз / сокращений свойств микроформатов, таких как dt-, числа, разрешенные после первого символа)
Примеры:
- «h-bigco-one-ring» - гипотетическое имя корневого класса микроформата «одно кольцо», зависящее от поставщика bigco.
- «p-goog-Preptime» - для представления расширения свойства Google «Preptime» до hRecipe 0.22 (кроме того: «duration» может быть другим типом свойства, который следует рассматривать отдельно от «datetime», поскольку на него могут распространяться другие правила синтаксического анализа.)
Дополнительные примеры см. В разделе vendor-prefixes.
фон расширений
Этот механизм расширяемости представляет собой композицию следующих (по крайней мере частично) успешных синтаксисов расширения:
В частности:
Проприетарные расширения форматов обычно были недолговечными экспериментальными неудачами, за одним большим недавним исключением.
Собственные или экспериментальные реализации свойств CSS3 оказались очень успешными.
Было много применений свойств радиуса границы и анимации / переходов, которые используют свойства CSS с префиксами, зависящими от поставщика, например:
- -moz-border-radius
- -webkit-border-radius
и т. Д.
Обратите внимание, что это просто строковые префиксы , не привязанные к какому-либо URL-адресу, и, следовательно, не пространства имен в любом практическом смысле этого слова. Это довольно важное различие, поскольку отказ от привязки к URL-адресу упростил их поддержку и использование.
Такое использование свойств CSS, зависящих от поставщика, позволило более широким сообществам веб-дизайнеров / разработчиков / разработчиков экспериментировать и повторять новые функции CSS, пока эти функции разрабатывались и стандартизировались.
Преимущества были двоякими:
- дизайнеров смогли быстрее создавать более привлекательные сайты (по крайней мере, в некоторых браузерах) Функции
- были протестированы на рынке / в реальных условиях, прежде чем быть полностью стандартизованы, что привело к улучшению функций. и расширения заголовка HTTP, согласно RFC 2045, раздел 6.3, RFC 3798, раздел 3.3 и Википедия: поля заголовка HTTP - нестандартные заголовки (вместо этого можно использовать ссылку RFC) соответственно, например:
Некоторые стандартные типы начинались как экспериментальные "x-" типы, таким образом сначала демонстрируя этот эксперимент, а затем стандартизировать подход, который работал по крайней мере в некоторых случаях:
- image / x-png (стандартизировано как image / png, оба в соответствии с RFC2083)
Дополнительные сведения см. В разделе microformats2-origins # VENDOR_EXTENSIONS.
валидаторов
микроформата2 валидатора:
новое! Проверьте свою микроформатированную веб-страницу с помощью:
Barnaby Walters имеет размещенную версию анализатора микроформатов php-mf2 с открытым исходным кодом, в которой вы можете ввести свою разметку в текстовое поле и посмотреть, как она анализируется:
Более подробный список валидаторов см. На странице валидаторов микроформатов.
Примеры в дикой природе
Пожалуйста, добавьте новые примеры микроформатов-2 в начало этого списка. Когда он становится слишком большим, мы можем переместить его на отдельную страницу, например, microformats-2-examples-in-wild.
- ...
- Дэвид Джон Мид отмечает свой профиль, сообщения в блоге и комментарии с помощью h-card, h-entry и h-cite на davidjohnmead.com
- Брайан Суда помечает свои сообщения в блоге с помощью h-entry и h-card по желанию. Is
- Эштон Макаллан отмечает свои сообщения в блоге, репосты, комментарии и лайки с помощью h-entry, h-card и h-cite на acegiak.нетто
- Эмма Куо отмечает свои записи в блоге и заметки h-entry и h-card на notenoughneon.com
- Скотт Дженсон отмечает свои записи в блоге h-entry и h-card на jenson.org
- Эмили Макаллен отмечает свои сообщения в блоге h-entry и h-card на blackwoolholiday.com
- Райан Барретт отмечает свои записи в блоге, заметки, ответы и лайки h-entry и h-card на snarfed.org
- Барри Фрост отмечает свои записи h-entry, h-card и h-cite на barryfrost.com
- Эмбер Кейс отмечает свой профиль, сообщения в блогах, ответы и заметки с помощью h-entry и h-card на caseorganic.com
- Йоханнес Эрнст помечает свои сообщения в блоге h-записью на Upon2020.com
- Мишель де Йонг отмечает свой профиль и отмечает h-entry и h-card на michielbdejong.com
- Майк Тейлор отмечает свой профиль и сообщения в блоге с помощью h-card и h-entry на bear.im
- Эрин Джо Ричи отмечает свой профиль, сообщения и комментарии, используя h-card, h-entry и h-cite с idno на erinjo.это
- Джина Паради отмечает свой профиль, сообщения в блоге, заметки и комментарии, используя h-card, h-entry и h-cite на jeena.net
- Энди Сильвестр помечает свой профиль, сообщения в блоге и комментарии, используя h-card и h-entry на andysylvester.com (примечание: с 13 марта 2014 года для комментариев используется h-entry вместо правильного h-cite --bw 14 : 44, 13 марта 2014 г. (UTC))
- Хакан Демир отмечает свои сообщения в блоге о купонах и ваучерах h-entry и h-card на gutscheinflagge.de
- Хлоя Вейл помечает свои сообщения в блоге h-записью на chloeweil.com
- Christophe Ducamp отмечает свои сообщения в блоге и профиль h-entry и h-card на christopheducamp.com
- Гленн Джонс помечает свои сообщения в блоге, заметки, ответы, профиль и комментарии с помощью h-entry, h-card и h-cite на glennjones.net
- Маркус Пови отмечает свои сообщения в блоге и профиль с h-entry и h-card на marcus-povey.co.uk
- Eugen Busoiu отмечает свой веб-профиль с помощью h-card на eugenbusoiu.com]
- Маттиас Пфефферле помечает свои сообщения в блоге, комментарии и профиль с помощью h-card, h-cite и h-entry в блоге notizblog.org
- Кайл Махан отмечает свой профиль и записи с помощью h-card и h-entry на kylewm.com
- Эмиль Бьёрклунд помечает свои сообщения в блоге h-записью и h-карточкой (пример)
- App.net развернул поддержку h-card и h-entry на всех страницах профиля и страницах с постоянными ссылками по состоянию на 06.08.2013 (пример)
- Бретт Комнс помечает свои сообщения h-записью и h-картой (пример)
- Бен Вердмюллер помечает свои сообщения h-card и h-entry, u-in-reply-to и u-like (пример)
- Сандип Шетти отмечает свои сообщения h-card и h-entry, а также черновиком u-in-reply-to и экспериментальными u-подобными свойствами (пример)
- Лоран Эшенауэр помечает свои сообщения знаком h (пример)
- Том Моррис помечает свои сообщения с помощью h-записи (пример)
- Sinolandquality размечает часть своего контента с помощью h-feed и h-entry для sinolandquality.com
- W3Conf 2013 использует h-событие для главного события и h-карту для всех докладчиков и известных участников. В h-карточках особенно хорошо используются подразумеваемые свойства имени, URL и фотографии.
- SemPress - это тема WordPress, которая поддерживает h-card, h-feed / h-entry и h-as- *
- The Pastry Box Project использует h-card и h-entry разметку на своей домашней странице и страницах с отдельными мыслями
- Том Моррис использует h-card и XFN - сеть друзей XHTML для разметки своего блога.
- Аарон Пареки использует h-card для разметки как авторства, так и ссылок на людей в постоянных ссылках своих заметок, например 2012/230 / ответ / 1.
- Тантек Челик использует h-карту, h-событие и h-запись на своей домашней странице, а также h-запись во всех постоянных ссылках на сообщения, например Сообщение 2012–243, с rel-prev / rel-next (если применимо) для обозначения предыдущих / следующих сообщений и с rel-author на его домашнюю страницу с канонической картой hCard для обозначения авторства.
- Барнаби Уолтерс использует h-card на своей домашней странице, h-card, h-entry и разметку XFN на своей странице заметок.
- 25.01.2013 Барнаби Уолтерс: Experimental Markup - описывает, как он использует микроформаты 2 словаря:
h-adr,h-card,h-entry,h-event,h-geo,h-reviewи экспериментальные словари:h-feed(встроенный для истории обновлений), объекты потоков активностиh-as-article,h-as-collection,h-as-note,h-as-update, а также экспериментальные свойства:u-alternateиu-as-downstream-duplicate(ссылки на копии POSSE) иu-in-reply-to(ссылки на контент, на который публикуются ответы).
- 25.01.2013 Барнаби Уолтерс: Experimental Markup - описывает, как он использует микроформаты 2 словаря:
- microformats.org на 7-летней презентации с h-event и h-card разметкой для людей и организаций.
- Rise of the Indie Web hCards (с форума Personal Democracy Forum 2012 # pdf12 # pdf2012) содержит микроформаты2 h-Calendar и h-card разметку
- WebMaker от Mozilla имеет микроформат2 h-календарь и h-карту для поиска событий (например, поиск возле Портленда, штат Орегон) и страниц событий (например, IndieWebCamp 2012). [2]
- WebFWD от Mozilla содержит микроформаты2 разметки h-card на страницах экспертов и команд
- IndieWebCamp имеет микроформаты2 разметки h-событий с вложенными h-карточками для организаторов и места проведения. На странице
- Mozilla Events есть микроформаты2 разметки h-событий с участниками, отмеченными h-карточкой.
- В блоге Esri PDX есть h-запись во всех сообщениях (по состоянию на 19.10.2013) и h-product разметка на страницах проекта
в автономном режиме
- равномерно размечает общие страницы с постоянными ссылками с h-записью, а также минимальными h-картами и экспериментальными p-подобными свойствами
Реализации
новое! Проверьте свою микроформатированную веб-страницу с помощью:
Ввод Live Textarea
Используйте любой из них, чтобы ввести разметку HTML + microformats2 и увидеть результат анализа!
Инструменты для ведения блогов
Преобразователи
- granary - это библиотека и REST API, которая преобразует между изолированными API, ActivityStreams, микроформатами2 и Atom (все направления).Поддерживаемые разрозненные версии включают Facebook, Twitter, Instagram, Google+ и Flickr. Пользователи включают, среди прочего, Bridgy, Woodwind, facebook-atom и twitter-atom.
- XRay (исходный код) - возвращает нормализованное представление данных микроформатов по URL-адресу
Парсеры
Парсеры, библиотеки с открытым исходным кодом, в алфавитном порядке по языкам программирования:
Парсеры в производстве
Следующие парсеры очень высокого качества, находятся в активной разработке и используются на действующих сайтах в Интернете в производственной среде.
Ява
- any23 Apache Any23 (Anything to Triples)] библиотека, веб-сервис и инструмент командной строки, который извлекает структурированные данные в формате RDF из различных веб-документов: http://any23.apache.org
Javascript
- анализатор микроформатов как для браузера, так и для node.js
Ранее:
- микроформат-узел Node.js анализатор микроформатов2
- microformat-shiv - кроссбраузерный анализатор микроформатов javascript2, который также может использоваться в расширениях браузера.
PHP
- php-mf2 - синтаксический анализатор микроформатов PHP
Питон
- mf2py Python microformats2 синтаксический анализатор
Рубин
- indieweb / microformats-ruby Ruby анализатор микроформатов
Haskell
- myfreeweb / microformats2-parser Haskell microformats2 parser
Анализаторы разработки
Следующие синтаксические анализаторы находятся в разработке и имеют ключевые функции микроформатов2, но являются неполными, не полностью протестированы или имеют другие ограничения.Взносы приветствуются!
Эрланг
- hazybluedot / mf2erl Парсер Erlang microformats2
Эликсир
- ckruse / microformats-elixir Elixir microformats2 parser
Перейти
- willnorris / микроформаты Golang microformats2 parser
Ява
- Apache Any23 библиотека, веб-служба и инструмент командной строки, который извлекает структурированные данные в формате RDF из различных веб-документов.Поддерживает микроформаты 1 и 2.
- mf2j Анализатор микроформатов Java на ранней стадии
Perl
- Web :: Microformats2 Perl microformats2 синтаксический анализатор
Эксперименты
Эксперименты и другие доказательства концепции поддержки синтаксического анализа микроформат2.
Вылет
Презентации
Презентации о микроформатах2:
Отзывы
Истоки
Эта страница изначально использовалась для мозгового штурма и разработки микроформатов2 в исследовательской манере, с формулировками проблем, вопросами, уроками, извлеченными из прошлого, и другими форматами.
Теперь, когда спецификация синтаксического анализа микроформатов2 является спецификацией микроформатов, первоначальный мозговой штурм был перенесен на отдельную страницу для всех, кто хочет больше узнать о том, как мы пришли к дизайну микроформатов2 и как он развивался в первые годы.
См. Также
Ссылка на файл Dockerfile| Документация Docker
Приблизительное время чтения: 81 минута
Docker может автоматически создавать образы, читая инструкции из
Файл Docker.Dockerfile- это текстовый документ, содержащий все команды пользователь может вызвать командную строку для сборки изображения. Использованиеdocker buildпользователи могут создать автоматизированную сборку, которая запускает несколько командных строк инструкции по порядку.На этой странице описаны команды, которые можно использовать в
Dockerfile. Когда вы прочитав эту страницу, обратитесь кDockerfileBest Практики для ориентированного на чаевые гида.Использование
Команда docker build создает образ из файл Dockerfile
PATHилиURL.PATH- это каталог на вашем локальном файловая система. URL-адресКонтекст обрабатывается рекурсивно. Итак,
PATHвключает все подкаталоги и URL-адрес$ сборка докеров.Отправка контекста сборки демону Docker 6.51 МБ ...Сборка выполняется демоном Docker, а не интерфейсом командной строки. Первым делом сборка процесс отправляет демону весь контекст (рекурсивно). В большинстве случаях лучше всего начать с пустого каталога в качестве контекста и сохранить Dockerfile в этом каталоге. Добавьте только файлы, необходимые для создания Dockerfile.
Предупреждение
Не используйте корневой каталог
/в качествеPATH, так как это вызывает сборку передать все содержимое вашего жесткого диска демону Docker.Чтобы использовать файл в контексте сборки,
Dockerfileссылается на указанный файл в инструкции, например, инструкцияCOPY. Чтобы увеличить сборку производительности, исключите файлы и каталоги, добавив файл.dockerignoreв каталог контекста. Для получения информации о том, как создать.dockerignoreфайл см. документацию на этой странице.Традиционно
DockerfileназываетсяDockerfileи находится в корневом каталоге. контекста.Вы используете флаг-fсdocker build, чтобы указать на Dockerfile. в любом месте вашей файловой системы.$ docker build -f / путь / к / a / Dockerfile.Вы можете указать репозиторий и тег для сохранения нового изображения, если сборка выполнена успешно:
$ docker build -t shykes / myapp.Чтобы пометить изображение в нескольких репозиториях после сборки, добавить несколько параметров
-tпри запуске командыbuild:$ docker build -t shykes / myapp: 1.0.2 -t shykes / myapp: последняя версия.Перед тем, как демон Docker выполнит инструкции из
Dockerfile, он выполняет предварительная проверкаDockerfileи возвращает ошибку, если синтаксис неверен:$ docker build -t test / myapp. Отправка контекста сборки демону Docker 2.048 kB Ответ об ошибке от демона: Неизвестная инструкция: RUNCMDДемон Docker запускает инструкции из
Dockerfileодну за другой, фиксация результата каждой инструкции к новому изображению, если необходимо, прежде чем, наконец, вывести идентификатор вашего новое изображение.Демон Docker автоматически очистит контекст, который вы послал.Обратите внимание, что каждая инструкция выполняется независимо и вызывает новый образ. будет создан - поэтому
RUN cd / tmpне повлияет на следующий инструкции.По возможности Docker будет повторно использовать промежуточные образы (кеш), чтобы значительно ускорить процесс сборки
docker. На это указывает сообщениеUsing cacheв выводе консоли. (Для получения дополнительной информации см. Руководство по передовой практикеDockerfile:$ docker build -t svendowideit / ambassador.Отправка контекста сборки демону Docker 15,36 КБ Шаг 1/4: ИЗ альпийского: 3,2 ---> 31f630c65071 Шаг 2/4: ОБСЛУЖИВАНИЕ [email protected] ---> Использование кеша ---> 2a1cf5f Шаг 3/4: ЗАПУСТИТЕ apk update && apk add socat && rm -r / var / cache / ---> Использование кеша ---> 21ed6e7fbb73 Шаг 4/4: CMD env | grep _TCP = | (sed 's /.*_ ПОРТ _ \ ([0-9] * \) _ TCP = tcp: \ / \ / \ (. * \): \ (. * \) / socat -t 100000000 TCP4-LISTEN: \ 1 , fork, reuseaddr TCP4: \ 2: \ 3 \ & / '&& echo wait) | ш ---> Использование кеша ---> 7ea8aef582cc Успешно построенный 7ea8aef582ccКэш сборки используется только для образов, имеющих локальную родительскую цепочку.Это означает что эти изображения были созданы предыдущими сборками или всей цепочкой изображений был загружен
docker load. Если вы хотите использовать кеш сборки определенного image вы можете указать его с помощью параметра--cache-from. Изображения, указанные с помощью--cache-fromне обязательно иметь родительскую цепочку и может быть извлечен из другой реестры.Когда вы закончите сборку, вы готовы изучить Pushing a репозиторий в свой реестр .
BuildKit
Начиная с версии 18.09, Docker поддерживает новый бэкэнд для выполнения ваших сборки, предоставляемые moby / buildkit проект. Бэкэнд BuildKit предоставляет множество преимуществ по сравнению со старым выполнение. Например, BuildKit может:
- Обнаружение и пропуск неиспользуемых этапов сборки
- Распараллелить независимые этапы сборки
- Постепенно переносите только измененные файлы в контексте сборки между сборками
- Обнаружение и пропуск передачи неиспользуемых файлов в контексте сборки
- Используйте внешние реализации Dockerfile со многими новыми функциями
- Избегайте побочных эффектов с остальной частью API (промежуточные изображения и контейнеры)
- Назначьте приоритет кешу сборки для автоматического удаления
Чтобы использовать бэкэнд BuildKit, вам необходимо установить переменную среды
DOCKER_BUILDKIT = 1в интерфейсе командной строки перед вызовом сборки докераЧтобы узнать об экспериментальном синтаксисе Dockerfile, доступном для BuildKit-based сборки ссылаются на документацию в репозитории BuildKit.
Формат
Вот формат файла Dockerfile
# Комментарий ИНСТРУКЦИЯ аргументыВ инструкции не учитывается регистр. Однако по соглашению они быть ЗАГЛАВНЫМ, чтобы легче отличать их от аргументов.
Docker запускает инструкции в файле
Dockerfileпо порядку.Dockerfileдолжен Начните с инструкцииFROM. Это может быть после парсера директивы, комментарии и глобальная область видимости ARG. ИнструкцияFROMуказывает родительский элемент . Картинка , откуда вы строительство.ИЗможет предшествовать только одна или несколько инструкцийARG, которые объявить аргументы, которые используются виз строквDockerfile.Docker обрабатывает строки, которые начинаются с с
#как комментарий, если только строка не допустимая директива парсера.Маркер#везде else в строке рассматривается как аргумент. Это позволяет использовать такие операторы, как:# Комментарий RUN echo "мы запускаем несколько интересных вещей"Строки комментариев удаляются перед выполнением инструкций Dockerfile, что означает, что комментарий в следующем примере не обрабатывается оболочкой выполнение команды
echo, и оба приведенных ниже примера эквивалентны:RUN echo hello \ # комментарий МирСимволы продолжения строки в комментариях не поддерживаются.
Примечание о пробеле
Для обратной совместимости начальные пробелы перед комментариями (
#) и инструкции (такие какRUN) игнорируются, но не рекомендуется. Ведущие пробелы не сохраняется в этих случаях, поэтому следующие примеры эквивалент:# это строка комментария RUN echo привет Беги эхо мир# это строка комментария RUN echo привет Беги эхо мирОбратите внимание, однако, что пробел в команде аргументов , таких как команды следующие за
RUN, сохраняются, поэтому следующий пример печатает `hello world` с ведущими пробелами, как указано:RUN echo "\ Привет\ Мир"Директивы парсера
Директивы парсера необязательны и влияют на способ, которым последующие строки в
Dockerfile обрабатываются.Директивы парсера не добавляют слоев в сборку, и не будет отображаться как этап сборки. Директивы парсера записываются как специальный тип комментария в виде# директива = значение. Единая директива можно использовать только один раз.После обработки комментария, пустой строки или инструкции конструктора Docker больше не ищет директивы парсера. Вместо этого он обрабатывает все отформатированное в качестве директивы парсера в качестве комментария и не пытается проверить, может ли он быть директивой парсера.Следовательно, все директивы парсера должны быть в самом начале верхняя часть
Dockerfile.Директивы синтаксического анализатора не чувствительны к регистру. Однако по соглашению они быть строчными. Соглашение также должно включать пустую строку после любого директивы парсера. Символы продолжения строки не поддерживаются в парсере директивы.
Из-за этих правил все следующие примеры недействительны:
Недействителен из-за продолжения строки:
Недействителен из-за двукратного появления:
# директива = значение1 # директива = значение2 ОТ ImageNameСчитается комментарием из-за появления после инструкции строителя:
ИЗ ImageName # директива = значениеСчитается комментарием из-за того, что он появляется после комментария, который не является синтаксическим анализатором. директива:
# О моем dockerfile # директива = значение ОТ ImageNameДиректива unknown рассматривается как комментарий из-за того, что она не распознана.В кроме того, известная директива рассматривается как комментарий, так как она появляется после комментарий, который не является директивой парсера.
# unknowndirective = значение # knowndirective = значениеВ директиве синтаксического анализатора разрешены пробелы, не прерывающие строку. Следовательно следующие строки обрабатываются одинаково:
# директива = значение # директива = значение # директива = значение # директива = значение # dIrEcTiVe = значениеПоддерживаются следующие директивы парсера:
синтаксис
# syntax = [ссылка на удаленное изображение]Например:
# синтаксис = docker / dockerfile # синтаксис = docker / dockerfile: 1.0 # синтаксис = docker.io / docker / dockerfile: 1 # syntax = docker / dockerfile: 1.0.0-экспериментальный # синтаксис = example.com / user / repo: tag @ sha256: abcdef ...Эта функция доступна, только если используется серверная часть BuildKit.
Синтаксическая директива определяет расположение построителя Dockerfile, который используется для создание текущего Dockerfile. Бэкэнд BuildKit позволяет легко использовать внешние реализации построителей, которые распространяются как образы Docker и выполнить внутри среды песочницы контейнера.
РеализацияCustom Dockerfile позволяет:
- Автоматически получать исправления без обновления демона
- Убедитесь, что все пользователи используют одну и ту же реализацию для создания вашего файла Docker.
- Используйте последние функции без обновления демона
- Попробуйте новые экспериментальные или сторонние функции
Официальные релизы
Docker распространяет официальные версии образов, которые можно использовать для сборки Dockerfiles в репозитории
docker / dockerfileна Docker Hub.Есть два каналы, на которых выпускаются новые изображения: стабильные и экспериментальные.Стабильный канал следует за семантическим управлением версиями. Например:
-
docker / dockerfile: 1.0.0- разрешить только неизменяемую версию1.0.0 -
docker / dockerfile: 1.0- разрешить версии1.0. * -
docker / dockerfile: 1- разрешить версии1. *. * -
docker / dockerfile: latest- последний выпуск на стабильном канале
Экспериментальный канал использует инкрементное управление версиями с основным и второстепенным компонент из стабильного канала на момент релиза.Например:
-
docker / dockerfile: 1.0.1-экспериментальный- разрешить только неизменяемую версию1.0.1-экспериментальный -
docker / dockerfile: 1.0-experimental- последние экспериментальные выпуски после1.0 -
docker / dockerfile: экспериментальный- последний выпуск на экспериментальном канале
Вам следует выбрать канал, который лучше всего соответствует вашим потребностям. Если ты только хочешь исправления ошибок, вы должны использовать
docker / dockerfile: 1.0. Если вы хотите извлечь выгоду из экспериментальные функции, вам следует использовать экспериментальный канал. Если вы используете экспериментальный канал, более новые выпуски могут быть несовместимы с предыдущими версиями, поэтому рекомендуется использовать неизменяемый вариант полной версии.Основные сборки и ночные выпуски функций см. В описании в исходный репозиторий.
побег
или
Директива escape
Файл Docker.Если не указан, escape-символ по умолчанию -\.Управляющий символ используется как для экранирования символов в строке, так и для избежать новой строки. Это позволяет команде
Dockerfileохватывают несколько строк. Обратите внимание, что независимо от того, экранирует липарсердиректива включена вDockerfile, экранирование не выполняется в командаRUN, кроме конца строки.Установка escape-символа на
`особенно полезна наWindows, где\- разделитель пути к каталогу.`согласован с Windows PowerShell.Рассмотрим следующий пример, который неочевидным образом дает сбой на
Окна. Второй\в конце второй строки будет интерпретироваться как escape для новой строки вместо цели escape из первых\. Точно так же\в конце третьей строки будет, если предположить, что это действительно обрабатывается как инструкция, потому что она рассматривается как продолжение строки.Результат этого файла докеров заключается в том, что вторая и третья строки считаются одним инструкция:С microsoft / nanoserver КОПИРОВАТЬ testfile.txt c: \\ RUN dir c: \Результатов в:
PS C: \ John> docker build -t cmd. Отправка контекста сборки демону Docker 3,072 КБ Шаг 1/2: С microsoft / nanoserver ---> 22738ff49c6d Шаг 2/2: КОПИРОВАТЬ testfile.txt c: \ RUN dir c: GetFileAttributesEx c: RUN: система не может найти указанный файл. PS C: \ Джон>Одним из решений вышеизложенного может быть использование
/в качестве цели как дляCOPYинструкция иdir.Однако этот синтаксис в лучшем случае сбивает с толку, поскольку он не естественно для путей наWindows, и в худшем случае подвержен ошибкам, так как не все команды наWindowsподдерживает/в качестве разделителя пути.При добавлении директивы парсера
escapeследующийDockerfileпреуспеет как ожидается с использованием естественной семантики платформы для путей к файлам вWindows:# escape = ` С microsoft / nanoserver КОПИРОВАТЬ тестовый файл.txt c: \ RUN dir c: \Результатов в:
PS C: \ John> docker build -t завершается успешно --no-cache = true. Отправка контекста сборки демону Docker 3,072 КБ Шаг 1/3: С microsoft / nanoserver ---> 22738ff49c6d Шаг 2/3: КОПИРОВАТЬ testfile.txt c: \ --->de338de
Снятие промежуточного контейнера 4db9acbb1682
Шаг 3/3: ЗАПУСК dir c: \
---> Запуск в a2c157f842f5
Том на диске C не имеет метки.
Серийный номер тома 7E6D-E0F7.
Каталог c: \
05.10.2016 17:04 1,894 Лицензия.текст
05.10.2016 14:22 -
$ {variable: -word}указывает, что если установлена переменная, то результат будет это значение.Еслипеременнаяне установлена, результатом будетслово. -
$ {переменная: + слово}указывает, что если установлена переменнаясловобудет результат, иначе результат будет пустой строкой.
Замена окружающей среды
Переменные среды (объявленные с помощью оператора ENV ) также могут быть
используются в определенных инструкциях как переменные, которые должны интерпретироваться Файл Docker .Экраны также обрабатываются для включения синтаксиса, похожего на переменную.
в заявление буквально.
Переменные среды обозначены в Dockerfile либо с $ имя_переменной или $ {имя_переменной} . К ним относятся одинаково, и
синтаксис скобок обычно используется для решения проблем с именами переменных без
пробел, например $ {foo} _bar .
Синтаксис $ {variable_name} также поддерживает некоторые из стандартных bash модификаторы, указанные ниже:
Во всех случаях слово может быть любой строкой, включая дополнительную среду
переменные.
Экранирование возможно путем добавления \ перед переменной: \ $ foo или \ $ {foo} ,
например, будет преобразовано в литералы $ foo и $ {foo} соответственно.
Пример (проанализированное представление отображается после # ):
ОТ busybox
ENV FOO = / бар
WORKDIR $ {FOO} # WORKDIR / бар
ДОБАВЛЯТЬ . $ FOO # ДОБАВИТЬ. /бар
КОПИРОВАТЬ \ $ FOO / quux # КОПИРОВАТЬ $ FOO / quux
Переменные среды поддерживаются следующим списком инструкций в
файл Dockerfile :
-
ДОБАВИТЬ -
КОПИЯ -
ENV -
EXPOSE -
ИЗ -
ТАБЛИЧКА -
СИГНАЛ ОСТАНОВА -
ПОЛЬЗОВАТЕЛЬ -
ОБЪЕМ -
WORKDIR -
ONBUILD(в сочетании с одной из поддерживаемых инструкций выше)
При замене переменной среды будет использоваться одно и то же значение для каждой переменной на протяжении всей инструкции.Другими словами, в этом примере:
ENV abc = привет
ENV abc = пока def = $ abc
ENV ghi = $ abc
приведет к тому, что def будет иметь значение hello , а не bye . Тем не мение, ghi будет иметь значение bye , потому что он не является частью той же инструкции
который установил abc на bye .
.dockerignore файл
Прежде чем интерфейс командной строки докера отправит контекст демону докера, он выглядит
для файла с именем .dockerignore в корневом каталоге контекста.
Если этот файл существует, интерфейс командной строки изменяет контекст, чтобы исключить файлы и
каталоги, соответствующие шаблонам в нем. Это помогает избежать
без необходимости отправлять большие или конфиденциальные файлы и каталоги на
daemon и потенциально добавляя их к изображениям, используя ADD или COPY .
Интерфейс командной строки интерпретирует файл .dockerignore как разделенный новой строкой
список шаблонов, похожих на файловые глобусы оболочек Unix.Для
целей сопоставления, корень контекста считается как
рабочий и корневой каталог. Например, выкройки / foo / bar и foo / bar оба исключают файл или каталог с именем bar в подкаталоге foo каталога PATH или в корне git
репозиторий, расположенный по адресу URL . Ни то, ни другое не исключает ничего.
Если строка в файле .dockerignore начинается с # в столбце 1, то эта строка
считается комментарием и игнорируется перед интерпретацией CLI.
Вот пример файла .dockerignore :
# comment
* / темп *
* / * / темп *
темп?
Этот файл вызывает следующее поведение сборки:
| Правило | Поведение |
|---|---|
# комментарий | Игнорируется. |
* / темп * | Исключить файлы и каталоги, имена которых начинаются с temp , из любого непосредственного подкаталога корня.Например, простой файл /somedir/ Contemporary.txt исключается, как и каталог / somedir / temp . |
* / * / темп * | Исключить файлы и каталоги, начинающиеся с temp , из любого подкаталога, находящегося на два уровня ниже корня. Например, /somedir/subdir/ Contemporary.txt исключен. |
темп? | Исключить файлы и каталоги в корневом каталоге, имена которых являются односимвольным расширением temp .Например, / tempa и / tempb исключены. |
Сопоставление выполняется с помощью Go
путь к файлу. правила соответствия. А
шаг предварительной обработки удаляет начальные и конечные пробелы и
устраняет . и .. элементы с использованием Go
filepath.Clean. Линии
пустые после предварительной обработки игнорируются.
Beyond Go. Соответствие правилам, Docker также поддерживает специальный
строка с подстановочным знаком ** , которая соответствует любому количеству каталогов (включая
нуль).Например, ** / *. Go исключит все файлы, заканчивающиеся на .go .
которые находятся во всех каталогах, включая корень контекста сборки.
Строки начинающиеся с ! (восклицательный знак) можно использовать для исключения
к исключениям. Ниже приведен пример файла .dockerignore , который
использует этот механизм:
* .md
! README.md
Все файлы уценки , кроме README.md , исключены из контекста.
Размещение ! правила исключения влияют на поведение: последний
строка .dockerignore , которая соответствует конкретному файлу, определяет
независимо от того, включен он или исключен. Рассмотрим следующий пример:
* .md
! README * .md
README-secret.md
В контекст не включаются файлы уценки, кроме файлов README, кроме README-secret.md .
Теперь рассмотрим этот пример:
*.мкр
README-secret.md
! README * .md
Включены все файлы README. Средняя линия не действует, потому что ! README * .md соответствует README-secret.md и идет последним.
Вы даже можете использовать файл .dockerignore , чтобы исключить файл Dockerfile и файлов .dockerignore . Эти файлы по-прежнему отправляются демону
потому что они нужны ему для работы. Но инструкции ADD и COPY не копируйте их на изображение.
Наконец, вы можете указать, какие файлы включать в
контекст, а не исключаемый. Для этого укажите * как
первый шаблон, за которым следует один или несколько ! шаблонов исключений.
Примечание
По историческим причинам паттерн
.игнорируется.
ИЗ
ОТ [--platform = ] [AS ]
или
ОТ [--platform = ] [: ] [AS ]
или
ОТ [--platform = ] [@ ] [AS ]
Инструкция FROM инициализирует новый этап сборки и устанавливает Базовое изображение для последующих инструкций.Таким образом,
допустимый Dockerfile должен начинаться с инструкции FROM . Изображение может быть
любое действительное изображение - особенно легко начать с , вытащив изображение из Публичные репозитории .
-
ARG- единственная инструкция, которая может предшествоватьFROMвDockerfile. См. Понять, как взаимодействуют ARG и FROM. -
ИЗможет появляться несколько раз в одном Dockerfileотдо создавать несколько образов или использовать один этап сборки как зависимость для другого.Просто запишите последний идентификатор изображения, выводимый коммитом перед каждым новымИЗинструкция. Каждая инструкцияFROMочищает любое состояние, созданное предыдущим инструкции. - При желании можно дать имя новому этапу сборки, добавив
имя ASкИЗинструкция. Имя может использоваться в последующихОТиCOPY --from =инструкции для ссылки на образ, созданный на этом этапе. - Тег
дайджест Значениянеобязательны.Если вы опустите любой из них, builder по умолчанию предполагаетпоследний тег. Строитель возвращает ошибку, если он не может найти значение тега.
Необязательный флаг --platform можно использовать для указания платформы образа.
в случае, если ОТ ссылается на многоплатформенный образ. Например, linux / amd64 , linux / arm64 или windows / amd64 . По умолчанию целевая платформа сборки
запрос используется. В значении этого флага можно использовать глобальные аргументы сборки,
например автоматические платформенные ARG
позволяет принудительно перейти на платформу собственной сборки ( --platform = $ BUILDPLATFORM ),
и использовать его для кросс-компиляции на целевой платформе внутри сцены.
Понять, как взаимодействуют ARG и FROM
FROM инструкции поддерживают переменные, которые объявлены любыми ARG инструкции, которые происходят до первых ОТ .
ARG CODE_VERSION = последний
ИЗ базы: $ {CODE_VERSION}
CMD / код / запуск приложения
ИЗ дополнительных услуг: $ {CODE_VERSION}
CMD / код / дополнительные функции
ARG , объявленный перед FROM , находится вне стадии сборки, поэтому он
не может использоваться ни в одной инструкции после ИЗ .Чтобы использовать значение по умолчанию ARG , объявленный перед первым FROM , использует инструкцию ARG без
значение внутри стадии сборки:
ARG VERSION = последняя
ОТ busybox: $ VERSION
ВЕРСИЯ ARG
ВЫПОЛНИТЬ echo $ VERSION> image_version
ЗАПУСК
RUN имеет 2 формы:
-
RUN <команда>(форма оболочки , команда запускается в оболочке, которая по умолчанию/ bin / sh -cв Linux илиcmd / S / Cв Windows) -
RUN ["исполняемый файл", "param1", "param2"]( exec form)
Команда RUN выполнит любые команды на новом уровне поверх
текущее изображение и зафиксируйте результаты.Полученное зафиксированное изображение будет
используется для следующего шага в Dockerfile .
Наслоение RUN инструкций и генерация коммитов соответствует ядру
концепции Docker, где коммиты дешевы, а контейнеры могут быть созданы из
любой момент в истории изображения, как в системе управления версиями.
Форма exec позволяет избежать изменения строки оболочки, а RUN команды, использующие базовый образ, не содержащий указанного исполняемого файла оболочки.
Оболочка по умолчанию для оболочки Форма может быть изменена с помощью оболочки ОБОЛОЧКА команда.
В оболочке в форме вы можете использовать \ (обратная косая черта) для продолжения одиночного
Инструкцию RUN на следующую строку. Например, рассмотрим эти две строки:
RUN / bin / bash -c 'source $ HOME / .bashrc; \
эхо $ HOME '
Вместе они эквивалентны одной строке:
RUN / bin / bash -c 'source $ HOME /.bashrc; эхо $ HOME '
Чтобы использовать другую оболочку, отличную от ‘/ bin / sh’, используйте форму exec , передаваемую в желаемый снаряд. Например:
RUN ["/ bin / bash", "-c", "echo hello"]
Примечание
Форма exec анализируется как массив JSON, что означает, что вы должны заключать слова в двойные кавычки («), а не в одинарные кавычки (»).
В отличие от формы оболочки , форма exec не вызывает командную оболочку.Это означает, что нормальной обработки оболочки не происходит. Например, RUN ["echo", "$ HOME"] не будет выполнять подстановку переменных в $ HOME .
Если вам нужна обработка оболочки, используйте форму оболочки или выполните
непосредственно оболочку, например: RUN ["sh", "-c", "echo $ HOME"] .
При использовании формы exec и непосредственном выполнении оболочки, как в случае с
форма оболочки, это оболочка, которая выполняет переменную среды
расширение, а не докер.
Примечание
В форме JSON необходимо избегать обратных косых черт.Это особенно актуально в Windows, где обратная косая черта является разделителем пути. В противном случае следующая строка будет рассматриваться как форма оболочки из-за отсутствия является действительным JSON и неожиданным образом терпит неудачу:
RUN ["c: \ windows \ system32 \ tasklist.exe"]Правильный синтаксис для этого примера:
RUN ["c: \\ windows \\ system32 \\ tasklist.exe"]
Кэш для RUN инструкций не становится недействительным автоматически во время
следующая сборка.Кеш для такой инструкции, как RUN apt-get dist-upgrade -y будет повторно использован во время следующей сборки. В
кэш для RUN инструкций можно сделать недействительным с помощью --no-cache флаг, например docker build --no-cache .
См. Файл Dockerfile Лучшие практики
руководство для получения дополнительной информации.
Кэш для команд RUN можно сделать недействительным с помощью инструкций ADD и COPY .
Известные проблемы (RUN)
Проблема 783 связана с файлом. проблемы с разрешениями, которые могут возникнуть при использовании файловой системы AUFS. Ты может заметить это при попытке, например,
rmфайла.Для систем с последней версией aufs (т. Е. Опция крепления
dirperm1может быть установленным), докер попытается исправить проблему автоматически, установив слои с опциейdirperm1. Более подробно по вариантуdirperm1можно найдено по адресуaufs, справочная страницаЕсли ваша система не поддерживает
dirperm1, проблема описывает обходной путь.
CMD
Инструкция CMD имеет три формы:
-
CMD ["исполняемый файл", "param1", "param2"](форма exec , это предпочтительная форма) -
CMD ["param1", "param2"](как параметров по умолчанию для ENTRYPOINT ) -
CMD command param1 param2( форма оболочки )
В Dockerfile может быть только одна инструкция CMD .Если вы укажете более одного CMD тогда только последний CMD вступит в силу.
Основная цель CMD - предоставить значения по умолчанию для выполняющейся
контейнер. Эти значения по умолчанию могут включать исполняемый файл или опускать
исполняемый файл, и в этом случае вы должны указать ENTRYPOINT инструкция тоже.
Если CMD используется для предоставления аргументов по умолчанию для инструкции ENTRYPOINT ,
обе инструкции CMD и ENTRYPOINT должны быть указаны с JSON
формат массива.
Примечание
Форма exec анализируется как массив JSON, что означает, что вы должны использовать двойные кавычки («) вокруг слов, а не одинарные кавычки (‘).
В отличие от формы оболочки , форма exec не вызывает командную оболочку.
Это означает, что нормальной обработки оболочки не происходит. Например, CMD ["echo", "$ HOME"] не будет выполнять подстановку переменных в $ HOME .
Если вам нужна обработка оболочки, используйте форму оболочки или выполните
оболочку напрямую, например: CMD ["sh", "-c", "echo $ HOME"] .При использовании формы exec и непосредственном выполнении оболочки, как в случае с
форма оболочки, это оболочка, которая выполняет переменную среды
расширение, а не докер.
При использовании в форматах оболочки или exec инструкция CMD устанавливает команду
для выполнения при запуске образа.
Если вы используете форму оболочки из CMD , то <команда> будет выполняться в / bin / sh -c :
ОТ ubuntu
CMD echo "Это тест."| туалет -
Если вы хотите, чтобы запускал свой без оболочки , вы должны
выразите команду как массив JSON и укажите полный путь к исполняемому файлу. Эта форма массива является предпочтительным форматом CMD . Любые дополнительные параметры
должны быть индивидуально выражены в виде строк в массиве:
ОТ ubuntu
CMD ["/ usr / bin / wc", "- справка"]
Если вы хотите, чтобы ваш контейнер запускал каждый раз один и тот же исполняемый файл, тогда
вам следует рассмотреть возможность использования ENTRYPOINT в сочетании с CMD .Видеть ВХОД .
Если пользователь указывает аргументы для docker run , то они переопределят
по умолчанию указано в CMD .
Примечание
Не путайте
RUNсCMD.RUNфактически запускает команду и фиксирует результат;CMDничего не выполняет во время сборки, но указывает предполагаемая команда для изображения.
ТАБЛИЧКА
LABEL <ключ> = <значение> <ключ> = <значение> <ключ> = <значение>...
Инструкция LABEL добавляет метаданные к изображению. A LABEL - это
пара ключ-значение. Чтобы включить пробелы в значение LABEL , используйте кавычки и
обратная косая черта, как при синтаксическом анализе командной строки. Несколько примеров использования:
LABEL "com.example.vendor" = "ACME Incorporated"
LABEL com.example.label-with-value = "foo"
LABEL version = "1.0"
LABEL description = "Этот текст иллюстрирует \
эти значения-метки могут занимать несколько строк ".
Изображение может иметь более одной метки.Вы можете указать несколько меток на одна линия. До Docker 1.10 это уменьшало размер окончательного образа, но это уже не так. Вы по-прежнему можете указать несколько ярлыков в одной инструкции одним из следующих двух способов:
LABEL multi.label1 = "value1" multi.label2 = "value2" other = "value3"
LABEL multi.label1 = "значение1" \
multi.label2 = "значение2" \
другое = "значение3"
Метки, включенные в базовые или родительские изображения (изображения в строке ИЗ ), являются
унаследовано вашим изображением.Если метка уже существует, но с другим значением,
последнее примененное значение имеет приоритет над любым ранее установленным значением.
Для просмотра меток изображения используйте команду docker image inspect . Ты можешь использовать
параметр --format для отображения только меток;
образ докера проверить --format = '' myimage
{
"com.example.vendor": "ACME Incorporated",
"com.example.label-with-value": "foo",
"версия": "1.0",
"description": "Этот текст показывает, что значения меток могут занимать несколько строк.",
"multi.label1": "значение1",
"multi.label2": "значение2",
"другое": "значение3"
}
MAINTAINER (устарело)
Инструкция MAINTAINER устанавливает поле Author сгенерированных изображений.
Инструкция LABEL - гораздо более гибкая версия этого, и вы должны использовать
вместо этого, поскольку он позволяет устанавливать любые требуемые метаданные, и их можно просмотреть
легко, например с докером осмотрите . Чтобы установить метку, соответствующую MAINTAINER поле, которое вы можете использовать:
LABEL keeper = "SvenDowideit @ home.org.au "
Затем это будет видно из docker inspect с другими метками.
EXPOSE
EXPOSE <порт> [<порт> / <протокол> ...]
Инструкция EXPOSE сообщает Docker, что контейнер прослушивает
указанные сетевые порты во время выполнения. Вы можете указать, прослушивает ли порт
TCP или UDP, по умолчанию - TCP, если протокол не указан.
Инструкция EXPOSE фактически не публикует порт.Он функционирует как
тип документации между человеком, который создает изображение, и человеком, который
запускает контейнер, о том, какие порты предполагается опубликовать. На самом деле
опубликуйте порт при запуске контейнера, используйте флаг -p в докере , запустите для публикации и сопоставления одного или нескольких портов или флаг -P для публикации всех открытых
порты и сопоставьте их с портами высокого порядка.
По умолчанию EXPOSE предполагает TCP. Вы также можете указать UDP:
Чтобы открыть как TCP, так и UDP, включите две строки:
EXPOSE 80 / tcp
EXPOSE 80 / udp
В этом случае, если вы используете -P с docker run , порт будет открыт один раз
для TCP и один раз для UDP.Помните, что -P использует эфемерный хост высокого порядка
порт на хосте, поэтому порт не будет одинаковым для TCP и UDP.
Независимо от настроек EXPOSE , вы можете переопределить их во время выполнения, используя
флаг -p . Например
docker run -p 80: 80 / tcp -p 80: 80 / udp ...
Чтобы настроить перенаправление портов в хост-системе, см. Использование флага -P.
Команда docker network поддерживает создание сетей для связи между
контейнеров без необходимости раскрывать или публиковать определенные порты, потому что
подключенные к сети контейнеры могут связываться друг с другом через любые
порт.Для получения подробной информации см.
обзор этой функции.
ENV
Инструкция ENV устанавливает для переменной среды <ключ> значение <значение> . Это значение будет в окружении для всех последующих инструкций.
на этапе сборки и может быть заменен встроенным в
многие тоже. Значение будет интерпретировано для других переменных среды, поэтому
символы кавычек будут удалены, если они не экранированы. Подобно синтаксическому анализу командной строки,
кавычки и обратные косые черты могут использоваться для включения пробелов в значения.
Пример:
ENV MY_NAME = "Джон Доу"
ENV MY_DOG = Рекс \ Собака \
ENV MY_CAT = пушистый
Инструкция ENV позволяет установить несколько переменных <ключ> = <значение> ... за один раз, и приведенный ниже пример даст те же чистые результаты в финальном
изображение:
ENV MY_NAME = "Джон Доу" MY_DOG = Рекс \ Собака \
MY_CAT = пушистый
Переменные среды, установленные с помощью ENV , будут сохраняться при запуске контейнера.
из полученного изображения.Вы можете просмотреть значения, используя docker inspect и
измените их, используя docker run --env .
Сохранение переменной среды может вызвать непредвиденные побочные эффекты. Например,
установка ENV DEBIAN_FRONTEND = noninteractive изменяет поведение apt-get ,
и может запутать пользователей вашего изображения.
Если переменная среды нужна только во время сборки, а не в финале изображение, рассмотрите возможность установки значения для одной команды:
RUN DEBIAN_FRONTEND = неинтерактивный apt-get update && apt-get install -y...
Или используя ARG , который не сохраняется в окончательном образе:
ARG DEBIAN_FRONTEND = не интерактивный
ЗАПУСТИТЬ apt-get update && apt-get install -y ...
Альтернативный синтаксис
Инструкция
ENVтакже допускает альтернативный синтаксисENV <ключ> <значение>, исключая=. Например:Этот синтаксис не позволяет устанавливать несколько переменных среды в одиночная инструкция
ENVи может сбивать с толку.Например, следующие устанавливает единственную переменную среды (ONE) со значением"TWO = THREE = world":Альтернативный синтаксис поддерживается для обратной совместимости, но не рекомендуется. по причинам, указанным выше, и может быть удален в будущем выпуске.
ДОБАВИТЬ
ADD имеет две формы:
ДОБАВИТЬ [--chown = : ] ...
ДОБАВИТЬ [--chown = <пользователь>: <группа>] ["",... "<самый лучший>"]
Последняя форма требуется для путей, содержащих пробелы.
Примечание
Функция
--chownподдерживается только в файлах Dockerfiles, используемых для сборки контейнеров Linux, и не будет работать с контейнерами Windows. Поскольку концепции владения пользователями и группами не переводить между Linux и Windows, использование/ etc / passwdи/ etc / groupдля преобразование имен пользователей и групп в идентификаторы ограничивает эту функцию только жизнеспособной для контейнеров на базе ОС Linux.
Инструкция ADD копирует новые файлы, каталоги или URL-адреса удаленных файлов из и добавляет их в файловую систему образа по пути .
Можно указать несколько ресурсов , но если они являются файлами или
каталоги, их пути интерпретируются относительно источника
контекст сборки.
Каждый может содержать подстановочные знаки, и сопоставление будет выполняться с использованием Go
Путь файла.Правила матча. Например:
Чтобы добавить все файлы, начинающиеся с «hom»:
В примере ниже ? заменяется любым одиночным символом, например, «home.txt».
- это абсолютный путь или путь относительно WORKDIR , в который
источник будет скопирован в целевой контейнер.
В приведенном ниже примере используется относительный путь и добавляется «test.txt» к :
ADD test.txt relativeDir /
Принимая во внимание, что в этом примере используется абсолютный путь и добавляется «test.txt» к / absoluteDir /
ДОБАВИТЬ test.txt / absoluteDir /
При добавлении файлов или каталогов, содержащих специальные символы (например, [ и ] ), вам нужно избегать этих путей, следуя правилам Голанга, чтобы предотвратить
их не рассматривать как совпадающий образец. Например, чтобы добавить файл
с именем arr [0] .txt , используйте следующее;
Все новые файлы и каталоги создаются с UID и GID, равными 0, если только
необязательный флаг --chown указывает имя пользователя, имя группы или UID / GID
комбинация, чтобы запросить конкретное право собственности на добавленный контент.В
формат флага --chown позволяет использовать строки имени пользователя и группы.
или прямые целочисленные UID и GID в любой комбинации. Предоставление имени пользователя без
groupname или UID без GID будут использовать тот же числовой UID, что и GID. Если
указывается имя пользователя или имя группы, корневая файловая система контейнера
Файлы / etc / passwd и / etc / group будут использоваться для выполнения перевода.
от имени до целого UID или GID соответственно. Следующие примеры показывают
допустимые определения для флага --chown :
ДОБАВИТЬ --chown = 55: файлы mygroup * / somedir /
ДОБАВИТЬ --chown = bin файлы * / somedir /
ДОБАВИТЬ --chown = 1 файл * / somedir /
ДОБАВИТЬ --chown = 10: 11 файлов * / somedir /
Если корневая файловая система контейнера не содержит / etc / passwd или / etc / group файлы и имена пользователей или групп используются в --chown флаг, сборка завершится ошибкой при операции ADD .Использование числовых идентификаторов требует
без поиска и не будет зависеть от содержимого корневой файловой системы контейнера.
В случае, если - это URL-адрес удаленного файла, место назначения будет
имеют разрешения 600. Если удаленный файл, который извлекается, имеет HTTP Last-Modified header, будет использоваться временная метка из этого заголовка
для установки mtime в конечном файле. Однако, как и любой другой файл
обработано во время ADD , mtime не будут включены в определение
от того, был ли изменен файл и должен ли обновляться кеш.
Примечание
Если вы собираете, передавая
Dockerfileчерез STDIN (docker build -), контекста сборки нет, поэтому Dockerfileможет содержать только инструкциюADDна основе URL. Вы также можете пройти сжатый архив через STDIN: (сборка докеров -), Dockerfileв корне архива и остальная часть архив будет использоваться в качестве контекста сборки.
Если ваши файлы URL защищены с помощью аутентификации, вам необходимо использовать RUN wget , ЗАПУСТИТЕ curl или воспользуйтесь другим инструментом из контейнера в качестве инструкции ADD не поддерживает аутентификацию.
Примечание
Первая обнаруженная инструкция
ADDсделает кеш недействительным для всех следуя инструкциям из файла Dockerfile, если содержимоеимеет измененный.Это включает аннулирование кеша дляRUNинструкций. См.DockerfileBest Practices. руководство - Использование кеша сборки для дополнительной информации.
ADD подчиняется следующим правилам:
Путь
ADD ../something / something, потому что первый шагdocker build- отправить контекстный каталог (и подкаталоги) в демон докера.Если
Если
<путь> / <имя файла>. Например,ADD http: // example.com / foobar /будет создайте файл/ foobar. URL-адрес должен иметь нетривиальный путь, чтобы в этом случае можно найти соответствующее имя файла (http://example.comне будет работать).Если
Примечание
Сам каталог не копируется, только его содержимое.
Если
tar -x, результатом является объединение:- Все, что было на пути назначения и
- Содержимое исходного дерева, конфликты разрешены в пользу из «2.”По каждому файлу.
Примечание
Определен ли файл как распознанный формат сжатия или нет выполняется исключительно на основе содержимого файла, а не имени файла. Например, если пустой файл заканчивается на
.tar.gz, это не будет будет распознан как сжатый файл, и не будет генерировать какие-либо сообщение об ошибке декомпрессии, скорее файл будет просто скопирован в назначения.Если
/, он будет считаться каталогом и будет записано содержимое/ base ( ) Если указано несколько ресурсов
/.Если
Если
КОПИЯ
КОПИЯ имеет две формы:
КОПИРОВАТЬ [--chown = : ] ... <самый>
КОПИРОВАТЬ [--chown = : ] ["", ... ""]
Эта последняя форма требуется для путей, содержащих пробелы
Примечание
Функция
--chownподдерживается только в файлах Dockerfiles, используемых для сборки контейнеров Linux, и не будет работать с контейнерами Windows. Поскольку концепции владения пользователями и группами не переводить между Linux и Windows, использование/ etc / passwdи/ etc / groupдля преобразование имен пользователей и групп в идентификаторы ограничивает возможность использования этой функции только для Контейнеры на базе ОС Linux.
Инструкция COPY копирует новые файлы или каталоги из и добавляет их в файловую систему контейнера по пути .
Можно указать несколько ресурсов , но пути к файлам и
каталоги будут интерпретироваться относительно источника контекста
сборки.
Каждый может содержать подстановочные знаки, и сопоставление будет выполняться с использованием Go
Путь файла.Правила матча. Например:
Чтобы добавить все файлы, начинающиеся с «hom»:
В примере ниже ? заменяется любым одиночным символом, например, «home.txt».
- это абсолютный путь или путь относительно WORKDIR , в который
источник будет скопирован в целевой контейнер.
В приведенном ниже примере используется относительный путь и добавляется «test.txt» к :
КОПИРОВАНИЕ тест.txt relativeDir /
Принимая во внимание, что в этом примере используется абсолютный путь и добавляется «test.txt» к / absoluteDir /
КОПИРОВАТЬ test.txt / absoluteDir /
При копировании файлов или каталогов, содержащих специальные символы (например, [ и ] ), вам нужно избегать этих путей, следуя правилам Голанга, чтобы предотвратить
их не рассматривать как совпадающий образец. Например, чтобы скопировать файл
с именем arr [0] .txt , используйте следующее;
КОПИЯ обр. [[] 0].txt / mydir /
Все новые файлы и каталоги создаются с UID и GID, равными 0, если только
необязательный флаг --chown указывает имя пользователя, имя группы или UID / GID
комбинация, чтобы запросить конкретное право собственности на скопированный контент. В
формат флага --chown позволяет использовать строки имени пользователя и группы.
или прямые целочисленные UID и GID в любой комбинации. Предоставление имени пользователя без
groupname или UID без GID будут использовать тот же числовой UID, что и GID.Если
указывается имя пользователя или имя группы, корневая файловая система контейнера
Файлы / etc / passwd и / etc / group будут использоваться для выполнения перевода.
от имени до целого UID или GID соответственно. Следующие примеры показывают
допустимые определения для флага --chown :
КОПИЯ --chown = 55: файлы mygroup * / somedir /
КОПИРОВАТЬ --chown = bin файлы * / somedir /
КОПИРОВАТЬ --chown = 1 файл * / somedir /
КОПИРОВАТЬ --chown = 10: 11 файлов * / somedir /
Если корневая файловая система контейнера не содержит / etc / passwd или / etc / group файлы и имена пользователей или групп используются в --chown флаг, сборка завершится ошибкой при операции КОПИРОВАТЬ .Использование числовых идентификаторов требует
нет поиска и не зависит от содержимого корневой файловой системы контейнера.
Примечание
При сборке с использованием STDIN (сборка докеров
-) нет контекст сборки, поэтому COPYиспользовать нельзя.
Необязательно COPY принимает флаг --from = , который можно использовать для установки
исходное местоположение на предыдущем этапе сборки (созданное с помощью FROM .. AS )
который будет использоваться вместо контекста сборки, отправленного пользователем.В случае сборки
этап с указанным именем не может быть найден изображение с таким же именем
попытался использовать вместо этого.
COPY подчиняется следующим правилам:
Путь
../something / something, потому что первый шагdocker build- отправить контекстный каталог (и подкаталоги) в демон докера.Если
Примечание
Сам каталог не копируется, только его содержимое.
Если
/, он будет считаться каталогом и будет записано содержимое/ base ( ) Если указано несколько ресурсов
/.Если
Если
Примечание
Первая обнаруженная инструкция
COPYсделает кеш недействительным для всех следуя инструкциям из файла Dockerfile, если содержимоеимеет измененный. Это включает аннулирование кеша дляRUNинструкций. См.DockerfileBest Practices. руководство - Использование кеша сборки для дополнительной информации.
ВХОД
ENTRYPOINT имеет две формы:
Форма exec , которая является предпочтительной формой:
ENTRYPOINT ["исполняемый файл", "параметр1", "параметр2"]
Оболочка форма:
ENTRYPOINT команда param1 param2
ENTRYPOINT позволяет настроить контейнер, который будет работать как исполняемый файл.
Например, следующий запускает nginx с содержимым по умолчанию, прослушивая на порту 80:
$ docker run -i -t --rm -p 80:80 nginx
Аргументы командной строки для docker run будут добавлены в конце концов
элементы в exec образуют ENTRYPOINT , и переопределят все указанные элементы
используя CMD .
Это позволяет передавать аргументы в точку входа, то есть docker run передаст аргумент -d точке входа.Вы можете переопределить инструкцию ENTRYPOINT , используя команду docker run --entrypoint флаг.
Оболочка форма предотвращает использование любых аргументов командной строки CMD или , запускаемых из командной строки .
используется, но имеет тот недостаток, что ваш ENTRYPOINT будет запускаться как
подкоманда / bin / sh -c , которая не передает сигналы.
Это означает, что исполняемый файл не будет PID 1 контейнера - и
будет не получать сигналы Unix - поэтому ваш исполняемый файл не получит SIGTERM из docker stop .
Будет действовать только последняя инструкция ENTRYPOINT в файле Dockerfile .
Exec form Пример ENTRYPOINT
Вы можете использовать форму exec из ENTRYPOINT для установки довольно стабильных команд по умолчанию.
и аргументы, а затем используйте любую форму CMD для установки дополнительных значений по умолчанию, которые
с большей вероятностью будут изменены.
ОТ ubuntu
ENTRYPOINT ["верх", "-b"]
CMD ["-c"]
Когда вы запустите контейнер, вы увидите, что top - единственный процесс:
$ docker run -it --rm --name test top -H
наверх - 08:25:00 до 7:27, пользователей 0, средняя загрузка: 0.00, 0,01, 0,05
Темы: всего 1, 1 запущен, 0 спит, 0 остановлен, 0 зомби
% ЦП: 0,1 мкс, 0,1 сист, 0,0 ни, 99,7 ид, 0,0 ват, 0,0 выс, 0,0 си, 0,0 ст
KiB Mem: всего 2056668, использовано 1616832, свободно 439836, буферов 99352
KiB Swap: всего 1441840, 0 используется, 1441840 бесплатно. 1324440 кэшированных Mem
PID ПОЛЬЗОВАТЕЛЬ PR NI VIRT RES SHR S% CPU% MEM TIME + COMMAND
1 корень 20 0 19744 2336 2080 R 0,0 0,1 0: 00,04 верх
Для дальнейшего изучения результата вы можете использовать docker exec :
$ docker exec -it test ps aux
USER PID% CPU% MEM VSZ RSS TTY STAT ВРЕМЯ НАЧАЛА КОМАНДА
корень 1 2.6 0,1 19752 2352? Сс + 08:24 0:00 наверх -b -H
корень 7 0,0 0,1 15572 2164? R + 08:25 0:00 пс доп.
И вы можете изящно запросить завершение работы top с помощью docker stop test .
Следующий файл Dockerfile показывает использование ENTRYPOINT для запуска Apache в
передний план (т.е. как PID 1 ):
ОТ debian: стабильный
ЗАПУСТИТЬ apt-get update && apt-get install -y --force-yes apache2
ВЫБРАТЬ 80 443
ТОМ ["/ var / www", "/ var / log / apache2", "/ etc / apache2"]
ENTRYPOINT ["/ usr / sbin / apache2ctl", "-D", "FOREGROUND"]
Если вам нужно написать стартовый сценарий для одного исполняемого файла, вы можете убедиться, что
последний исполняемый файл получает сигналы Unix, используя exec и gosu команды:
#! / Usr / bin / env bash
set -e
если ["$ 1" = 'postgres']; тогда
chown -R postgres "$ PGDATA"
если [-z "$ (ls -A" $ PGDATA ")"]; тогда
gosu postgres initdb
фи
exec gosu postgres "$ @"
фи
exec "$ @"
Наконец, если вам нужно выполнить дополнительную очистку (или связаться с другими контейнерами)
при завершении работы или координируете более одного исполняемого файла, вам может потребоваться
что сценарий ENTRYPOINT получает сигналы Unix, передает их, а затем
работает еще:
#! / Bin / sh
# Примечание: я написал это с помощью sh, поэтому он работает и в контейнере busybox
# ИСПОЛЬЗУЙТЕ ловушку, если вам нужно также выполнить ручную очистку после остановки службы,
# или вам нужно запустить несколько сервисов в одном контейнере
trap "эхо TRAPed signal" HUP INT QUIT TERM
# запустить службу в фоновом режиме здесь
/ usr / sbin / apachectl начало
echo "[нажмите клавишу ввода для выхода] или запустите 'docker stop '"
читать
# остановить обслуживание и очистить здесь
эхо "остановка Apache"
/ usr / sbin / apachectl стоп
echo "вышел из $ 0"
Если вы запустите этот образ с docker run -it --rm -p 80:80 --name test apache ,
затем вы можете исследовать процессы контейнера с помощью docker exec или docker top ,
а затем попросите скрипт остановить Apache:
$ docker exec -it test ps aux
USER PID% CPU% MEM VSZ RSS TTY STAT ВРЕМЯ НАЧАЛА КОМАНДА
корень 1 0.1 0,0 4448 692? Сс + 00:42 0:00 / bin / sh /run.sh 123 cmd cmd2
корень 19 0,0 0,2 71304 4440? Сс 00:42 0:00 / usr / sbin / apache2 -k start
www-data 20 0,2 0,2 360468 6004? Сл 00:42 0:00 / usr / sbin / apache2 -k start
www-data 21 0,2 0,2 360468 6000? Сл 00:42 0:00 / usr / sbin / apache2 -k start
корень 81 0,0 0,1 15572 2140? R + 00:44 0:00 пс доп.
$ docker top test
КОМАНДА ПОЛЬЗОВАТЕЛЯ PID
10035 root {run.ш} / bin / sh /run.sh 123 cmd cmd2
10054 корень / usr / sbin / apache2 -k start
10055 33 / usr / sbin / apache2 -k начало
10056 33 / usr / sbin / apache2 -k начало
$ / usr / bin / time тест остановки докера
контрольная работа
реальный 0 м 0,27 с
пользователь 0 м 0,03 с
sys 0m 0,03 с
Примечание
Вы можете отменить настройку
ENTRYPOINT, используя--entrypoint, но это может только установить двоичный файл на exec (sh -cне будет использоваться).
Примечание
Форма exec анализируется как массив JSON, что означает, что вы должны заключать слова в двойные кавычки («), а не в одинарные кавычки (»).
В отличие от формы оболочки , форма exec не вызывает командную оболочку.
Это означает, что нормальной обработки оболочки не происходит. Например, ENTRYPOINT ["echo", "$ HOME"] не будет выполнять подстановку переменных в $ HOME .Если вам нужна обработка оболочки, используйте форму оболочки или выполните
оболочку напрямую, например: ENTRYPOINT ["sh", "-c", "echo $ HOME"] .
При использовании формы exec и непосредственном выполнении оболочки, как в случае с
форма оболочки, это оболочка, которая выполняет переменную среды
расширение, а не докер.
Форма оболочки Пример ENTRYPOINT
Вы можете указать простую строку для ENTRYPOINT , и она будет выполняться в / bin / sh -c .Эта форма будет использовать обработку оболочки для замены переменных среды оболочки,
и будет игнорировать любые аргументы командной строки CMD или docker run .
Чтобы гарантировать, что docker stop будет сигнализировать о любом длительно работающем исполняемом файле ENTRYPOINT правильно, вам нужно не забыть запустить его с exec :
ОТ ubuntu
ENTRYPOINT exec top -b
Когда вы запустите этот образ, вы увидите единственный процесс PID 1 :
$ docker run -it --rm --name test top
Mem: 1704520K используется, 352148K бесплатно, 0K shrd, 0K buff, 140368121167873K кэшировано
ЦП: 5% usr 0% sys 0% nic 94% idle 0% io 0% irq 0% sirq
Средняя нагрузка: 0.08 0,03 0,05 2/98 6
PID PPID СТАТИСТИКА ПОЛЬЗОВАТЕЛЯ VSZ% VSZ% КОМАНДА ЦП
1 0 корень R 3164 0% 0% top -b
Который аккуратно выходит на остановку докера :
$ / usr / bin / time docker stop test
контрольная работа
реальный 0 м 0,20 с
пользователь 0 м 0,02 с
sys 0m 0,04 с
Если вы забыли добавить exec в начало вашего ENTRYPOINT :
ОТ ubuntu
ENTRYPOINT top -b
CMD --ignored-param1
Затем вы можете запустить его (присвоив ему имя для следующего шага):
$ docker run -it --name test top --ignored-param2
Mem: 1704184K используется, 352484K бесплатно, 0K SHRD, 0K бафф, 140621524238337K кэшировано
ЦП: 9% usr 2% sys 0% nic 88% idle 0% io 0% irq 0% sirq
Средняя нагрузка: 0.01 0,02 0,05 2/101 7
PID PPID СТАТИСТИКА ПОЛЬЗОВАТЕЛЯ VSZ% VSZ% КОМАНДА ЦП
1 0 корень S 3168 0% 0% / bin / sh -c top -b cmd cmd2
7 1 корень R 3164 0% 0% top -b
Из вывода top видно, что указанный ENTRYPOINT не является PID 1 .
Если вы затем запустите docker stop test , контейнер не выйдет правильно - остановить команду будет принудительно отправить SIGKILL после тайм-аута:
$ docker exec -it test ps aux
КОМАНДА ПОЛЬЗОВАТЕЛЯ PID
1 корень / bin / sh -c top -b cmd cmd2
7 корень верхний -b
8 корневых ps aux
$ / usr / bin / time тест остановки докера
контрольная работа
реальный 0м 10.19 с
пользователь 0 м 0,04 с
sys 0m 0,03 с
Понять, как взаимодействуют CMD и ENTRYPOINT
Инструкции CMD и ENTRYPOINT определяют, какая команда выполняется при запуске контейнера.
Есть несколько правил, описывающих их сотрудничество.
Dockerfile должен указывать хотя бы одну из команд
CMDилиENTRYPOINT.ENTRYPOINTдолжен быть определен при использовании контейнера в качестве исполняемого файла.CMDследует использовать как способ определения аргументов по умолчанию для командыENTRYPOINTили для выполнения специальной команды в контейнере.CMDбудет переопределен при запуске контейнера с альтернативными аргументами.
В таблице ниже показано, какая команда выполняется для различных комбинаций ENTRYPOINT / CMD :
| Нет ВХОДА | ENTRYPOINT exec_entry p1_entry | ENTRYPOINT [«exec_entry», «p1_entry»] | |
|---|---|---|---|
| Нет CMD | ошибка , недопустима | / bin / sh -c exec_entry p1_entry | exec_entry p1_entry |
| CMD [«exec_cmd», «p1_cmd»] | exec_cmd p1_cmd | / bin / sh -c exec_entry p1_entry | exec_entry p1_entry exec_cmd p1_cmd |
| CMD [«p1_cmd», «p2_cmd»] | p1_cmd p2_cmd | / bin / sh -c exec_entry p1_entry | exec_entry p1_entry p1_cmd p2_cmd |
| CMD exec_cmd p1_cmd | / bin / sh -c exec_cmd p1_cmd | / bin / sh -c exec_entry p1_entry | exec_entry p1_entry / bin / sh -c exec_cmd p1_cmd |
Примечание
Если
CMDопределен из базового образа, установкаENTRYPOINTбудет сброситьCMDна пустое значение.В этом случаеCMDдолжен быть определен в текущее изображение имеет значение.
ТОМ
Инструкция VOLUME создает точку монтирования с указанным именем
и помечает его как хранящие внешние тома с собственного хоста или другого
контейнеры. Значение может быть массивом JSON, VOLUME ["/ var / log /"] или обычным
строка с несколькими аргументами, например VOLUME / var / log или VOLUME / var / log
/ var / db . Для получения дополнительной информации / примеров и инструкций по монтажу через
Клиент Docker, см. Общий доступ к каталогам через тома документация.
Команда docker run инициализирует вновь созданный том любыми данными.
который существует в указанном месте в базовом образе. Например,
рассмотрите следующий фрагмент Dockerfile:
ОТ ubuntu
ЗАПУСК mkdir / myvol
RUN echo "hello world"> / myvol / приветствие
ОБЪЕМ / мивол
Результатом этого файла Dockerfile является образ, который вызывает запуск докера на
создайте новую точку монтирования по адресу / myvol и скопируйте файл приветствия во вновь созданный том.
Примечания об указании томов
Помните о томах в Dockerfile .
Тома в контейнерах на базе Windows : при использовании контейнеров на базе Windows место назначения тома внутри контейнера должно быть одним из:
- несуществующий или пустой каталог
- диск, отличный от
C:
Изменение громкости из Dockerfile : Если какие-либо шаги сборки изменят данные в томе после того, как они были объявлены, эти изменения будут отменены.
Форматирование JSON : список анализируется как массив JSON. Вы должны заключать слова в двойные кавычки (
"), а не в одинарные кавычки (').Каталог хоста объявлен во время выполнения контейнера : Каталог хоста (точка монтирования) по своей природе зависит от хоста. Это для сохранения имиджа переносимость, поскольку не может быть гарантирована доступность заданного каталога хоста на всех хостах.По этой причине вы не можете смонтировать каталог хоста из в Dockerfile. Инструкция
VOLUMEне поддерживает указаниеhost-dirпараметр. Вы должны указать точку монтирования при создании или запуске контейнера.
ПОЛЬЗОВАТЕЛЬ
или
Инструкция USER устанавливает имя пользователя (или UID) и, возможно, пользователя
группа (или GID) для использования при запуске образа и для любых RUN , CMD и ENTRYPOINT инструкции, которые следуют за ним в Dockerfile .
Обратите внимание, что при указании группы для пользователя у пользователя будет только указанное членство в группе. Любое другое настроенное членство в группах будет проигнорировано.
Предупреждение
Если у пользователя нет основной группы, тогда изображение (или следующее инструкции) будет запущен с корневой группой
.В Windows сначала необходимо создать пользователя, если это не встроенная учетная запись. Это можно сделать с помощью команды
net user, вызываемой как часть файла Dockerfile.
ОТ microsoft / windowsservercore
# Создать пользователя Windows в контейнере
RUN net user / добавить патрика
# Установите его для последующих команд
ПОЛЬЗОВАТЕЛЬ патрик
WORKDIR
Инструкция WORKDIR устанавливает рабочий каталог для любого RUN , CMD , ENTRYPOINT , COPY и ADD инструкции, которые следуют за ним в Dockerfile .
Если WORKDIR не существует, он будет создан, даже если он не используется ни в одном
последующая инструкция Dockerfile .
Инструкцию WORKDIR можно использовать несколько раз в файле Dockerfile . Если
указан относительный путь, он будет относительно пути предыдущего WORKDIR инструкция. Например:
WORKDIR / a
РАБОЧИЙ ДИРЕК b
РАБОЧИЙ ДИРЕК c
RUN pwd
Результат последней команды pwd в этом файле Dockerfile будет / a / b / c .
Инструкция WORKDIR может разрешить переменные среды, ранее установленные с помощью ENV .Вы можете использовать только переменные среды, явно заданные в Dockerfile .
Например:
ENV DIRPATH = / путь
WORKDIR $ DIRPATH / $ DIRNAME
RUN pwd
Результат последней команды pwd в этом файле Dockerfile будет следующим: / путь / $ DIRNAME
ARG
ARG <имя> [= <значение по умолчанию>]
Инструкция ARG определяет переменную, которую пользователи могут передавать во время сборки в
построитель с помощью команды docker build с использованием --build-arg флаг.Если пользователь указывает аргумент сборки, который не был
определенный в Dockerfile, сборка выводит предупреждение.
[Предупреждение] Один или несколько аргументов сборки [foo] не использовались.
Dockerfile может включать одну или несколько инструкций ARG . Например,
это действительный файл Dockerfile:
ОТ busybox
ARG user1
ARG buildno
# ...
Предупреждение:
Не рекомендуется использовать переменные времени сборки для передачи секретов, например ключи github, учетные данные пользователя и т. д.Значения переменных времени сборки видны любой пользователь образа с помощью команды
docker history.См. «Сборку образов с помощью BuildKit». раздел, чтобы узнать о безопасных способах использования секретов при создании изображений.
Значения по умолчанию
Инструкция ARG может дополнительно включать значение по умолчанию:
ОТ busybox
ARG user1 = someuser
ARG buildno = 1
# ...
Если инструкция ARG имеет значение по умолчанию и если значение не передано
во время сборки построитель использует значение по умолчанию.
Область применения
Определение переменной ARG вступает в силу со строки, на которой оно
определен в Dockerfile не из использования аргумента в командной строке или
в другом месте. Например, рассмотрим этот Dockerfile:
ОТ busybox
ПОЛЬЗОВАТЕЛЬ $ {пользователь: -some_user}
Пользователь ARG
USER $ пользователь
# ...
Пользователь создает этот файл, позвонив:
$ docker build --build-arg user = what_user.
ПОЛЬЗОВАТЕЛЬ в строке 2 оценивается как some_user , поскольку пользовательская переменная определена в
следующая строка 3. ПОЛЬЗОВАТЕЛЬ в строке 4 оценивается как what_user как пользователь определено, и значение what_user было передано в командной строке. До его определения ARG инструкция, любое использование переменной приводит к пустой строке.
Инструкция ARG выходит за рамки в конце сборки
этап, на котором это было определено. Чтобы использовать аргумент на нескольких этапах, каждый этап должен
включить инструкцию ARG .
ОТ busybox
НАСТРОЙКИ ARG
ЗАПУСТИТЬ ./ run / setup $ НАСТРОЙКИ
ОТ busybox
НАСТРОЙКИ ARG
RUN ./run/другие $ НАСТРОЙКИ
Использование переменных ARG
Вы можете использовать команду ARG или ENV , чтобы указать переменные, которые
доступный для инструкции RUN . Переменные среды, определенные с помощью
Команда ENV всегда заменяет инструкцию ARG с тем же именем. Рассмотреть возможность
этот Dockerfile с инструкциями ENV и ARG .
ОТ ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER = v1.0.0
RUN echo $ CONT_IMG_VER
Затем предположим, что этот образ создан с помощью этой команды:
$ docker build --build-arg CONT_IMG_VER = v2.0.1.
В этом случае инструкция RUN использует v1.0.0 вместо настройки ARG передано пользователем: v2.0.1 Это поведение похоже на оболочку
сценарий, в котором переменная с локальной областью видимости переопределяет переменные, переданные как
аргументы или унаследованные от окружения, с точки его определения.
Используя приведенный выше пример, но с другой спецификацией ENV , вы можете создать больше
полезные взаимодействия между ARG и ENV инструкции:
ОТ ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER = $ {CONT_IMG_VER: -v1.0.0}
RUN echo $ CONT_IMG_VER
В отличие от инструкции ARG , значения ENV всегда сохраняются во встроенном
изображение. Рассмотрим сборку докеров без флага --build-arg :
Используя этот пример файла Dockerfile, CONT_IMG_VER все еще сохраняется в образе, но
его значение будет v1.0,0 , поскольку это значение по умолчанию установлено в строке 3 инструкцией ENV .
Метод расширения переменных в этом примере позволяет передавать аргументы
из командной строки и сохраните их в окончательном образе, используя ENV инструкция. Расширение переменных поддерживается только для ограниченного набора
Инструкции Dockerfile.
Предопределенные группы ARG
Docker имеет набор предопределенных переменных ARG , которые можно использовать без
соответствующая инструкция ARG в Dockerfile.
-
HTTP_PROXY -
http_proxy -
HTTPS_PROXY -
https_proxy -
FTP_PROXY -
ftp_proxy -
NO_PROXY -
no_proxy
Чтобы использовать их, просто передайте их в командной строке с помощью флага:
--build-arg <имя переменной> = <значение>
По умолчанию эти предопределенные переменные исключаются из вывода история докеров .Их исключение снижает риск случайной утечки.
конфиденциальная информация аутентификации в переменной HTTP_PROXY .
Например, рассмотрите возможность создания следующего Dockerfile, используя --build-arg HTTP_PROXY = http: // user: [email protected]
ОТ ubuntu
RUN echo "Hello World"
В этом случае значение переменной HTTP_PROXY недоступно в история докеров и не кешируется.Если бы вы изменили местоположение, и ваш
прокси-сервер изменен на http: // user: [email protected] , последующий
build не приводит к пропуску кеша.
Если вам нужно переопределить это поведение, вы можете сделать это, добавив ARG заявление в Dockerfile следующим образом:
ОТ ubuntu
ARG HTTP_PROXY
RUN echo "Hello World"
При создании этого Dockerfile HTTP_PROXY сохраняется в история докеров , и изменение его значения делает недействительным кеш сборки.
Автоматические платформенные ARG в глобальном масштабе
Эта функция доступна только при использовании серверной части BuildKit.
Docker предопределяет набор из переменных ARG с информацией о платформе
узел, выполняющий сборку (платформа сборки) и на платформе
результирующее изображение (целевая платформа). Целевая платформа может быть указана с помощью
флаг --platform в сборке docker .
Следующие переменные ARG устанавливаются автоматически:
-
TARGETPLATFORM- платформа результата сборки.Например,linux / amd64,linux / arm / v7,windows / amd64. -
TARGETOS- компонент ОС TARGETPLATFORM -
TARGETARCH- компонент архитектуры TARGETPLATFORM -
TARGETVARIANT- вариантный компонент TARGETPLATFORM -
BUILDPLATFORM- платформа узла, выполняющего сборку. -
BUILDOS- компонент ОС BUILDPLATFORM -
BUILDARCH- компонент архитектуры BUILDPLATFORM -
BUILDVARIANT- вариантный компонент BUILDPLATFORM
Эти аргументы определены в глобальной области, поэтому не определяются автоматически.
доступны внутри этапов сборки или для ваших команд RUN .Разоблачить одну из
эти аргументы внутри стадии сборки переопределяют его без значения.
Например:
ОТ альпийский
ЦЕЛЕВАЯ ПЛАТФОРМА ARG
RUN echo "Я создаю для $ TARGETPLATFORM"
Влияние на кэширование сборки
ARG Переменные не сохраняются в построенном образе, как переменные ENV .
Однако переменные ARG действительно влияют на кеш сборки аналогичным образом. Если
Dockerfile определяет переменную ARG , значение которой отличается от предыдущего
build, то при первом использовании происходит «промах в кэше», а не при его определении.В
в частности, все инструкции RUN , следующие за инструкцией ARG , используют ARG переменная неявно (как переменная среды), что может вызвать промах в кеше.
Все предопределенные переменные ARG освобождаются от кэширования, если нет
соответствует заявлению ARG в файле Dockerfile .
Например, рассмотрим эти два файла Dockerfile:
ОТ ubuntu
ARG CONT_IMG_VER
RUN echo $ CONT_IMG_VER
ОТ ubuntu
ARG CONT_IMG_VER
RUN echo привет
Если вы укажете --build-arg CONT_IMG_VER = в командной строке, в обоих
случаях спецификация в строке 2 не вызывает промахов в кэше; строка 3 делает
вызвать промах кеша. ARG CONT_IMG_VER вызывает идентификацию строки RUN
аналогично запуску CONT_IMG_VER = , поэтому, если изменения, мы получаем промах кеша.
Рассмотрим другой пример в той же командной строке:
ОТ ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER = $ CONT_IMG_VER
RUN echo $ CONT_IMG_VER
В этом примере промах кэша происходит в строке 3. Промах случается из-за того, что
значение переменной в ENV ссылается на переменную ARG и что
переменная изменяется через командную строку.В этом примере ENV команда заставляет изображение включать значение.
Если инструкция ENV переопределяет инструкцию ARG с тем же именем, например
этот Dockerfile:
ОТ ubuntu
ARG CONT_IMG_VER
ENV CONT_IMG_VER = привет
RUN echo $ CONT_IMG_VER
Строка 3 не вызывает промаха кеша, потому что значение CONT_IMG_VER является
константа ( привет ). В результате переменные среды и значения, используемые в RUN (строка 4) не меняется между сборками.
СТРОИТЕЛЬСТВО
Команда ONBUILD добавляет к изображению команду триггера для
выполняться позже, когда изображение используется в качестве основы для
другая сборка. Триггер будет выполнен в контексте
последующая сборка, как если бы она была вставлена сразу после
Инструкция FROM в нижележащем Dockerfile .
Любая инструкция сборки может быть зарегистрирована как триггер.
Это полезно, если вы создаете изображение, которое будет использоваться в качестве основы. для создания других образов, например среды сборки приложения или демон, который можно настроить в соответствии с настройками пользователя.
Например, если ваше изображение является многоразовым конструктором приложений Python, оно
потребует, чтобы исходный код приложения был добавлен в конкретный
каталог, и может потребоваться, чтобы сценарий сборки вызывал после что. Вы не можете просто позвонить по номеру ADD и RUN сейчас, потому что вы еще не
иметь доступ к исходному коду приложения, и он будет другим для
каждая сборка приложения. Вы можете просто предоставить разработчикам приложений
с шаблоном Dockerfile для копирования и вставки в свое приложение, но
это неэффективно, подвержено ошибкам и сложно обновлять, потому что
смешивается с кодом конкретного приложения.
Решение состоит в том, чтобы использовать ONBUILD для регистрации предварительных инструкций в
запустить позже, на следующем этапе сборки.
Вот как это работает:
- Когда он встречает инструкцию
ONBUILD, построитель добавляет запускать метаданные создаваемого изображения. Инструкция иначе не влияет на текущую сборку. - В конце сборки список всех триггеров сохраняется в
манифест изображения, под ключом
OnBuild.Их можно проверить с помощью Докерпроверяет команду. - Позже образ может быть использован в качестве основы для новой сборки, используя
ИЗинструкция. В рамках обработки инструкцииFROM, нисходящий компоновщик ищет триггерыONBUILDи выполняет их в том же порядке, в котором они были зарегистрированы. Если какой-либо из триггеров сбой, инструкцияFROMпрерывается, что, в свою очередь, вызывает построить на провал. Если все триггеры выполнены успешно, инструкцияFROMзавершается, и сборка продолжается как обычно. - Триггеры удаляются из окончательного изображения после выполнения. В Другими словами, они не наследуются «внуками».
Например, вы можете добавить что-то вроде этого:
ДОБАВИТЬ ДОБАВИТЬ. / приложение / src
ONBUILD RUN / usr / local / bin / python-build --dir / app / src
Предупреждение
Цепочка инструкций
ONBUILDс использованиемONBUILD ONBUILDне допускается.
Предупреждение
Команда
ONBUILDне может запускать инструкцииFROMилиMAINTAINER.
СИГНАЛ ОСТАНОВА
Команда STOPSIGNAL устанавливает сигнал системного вызова, который будет отправлен в контейнер для выхода.
Этот сигнал может быть действительным числом без знака, которое соответствует позиции в таблице системных вызовов ядра, например 9,
или имя сигнала в формате SIGNAME, например SIGKILL.
ЗДОРОВЬЕ
Инструкция HEALTHCHECK имеет две формы:
-
HEALTHCHECK [OPTIONS] Команда CMD(проверьте состояние контейнера, запустив команду внутри контейнера) -
HEALTHCHECK NONE(отключить все проверки работоспособности, унаследованные от базового образа)
Инструкция HEALTHCHECK сообщает Docker, как тестировать контейнер, чтобы проверить, что
он все еще работает.Это может обнаружить такие случаи, как застревание веб-сервера в
бесконечный цикл и неспособность обрабатывать новые соединения, даже если сервер
процесс все еще продолжается.
Когда для контейнера задана проверка работоспособности, он имеет статус работоспособности в
в дополнение к его нормальному статусу. Этот статус изначально равен , начиная с . Всякий раз, когда
проверка работоспособности проходит, он становится здоровым (в каком бы состоянии он ни находился ранее).
После определенного количества последовательных отказов он становится неработоспособным .
Опции, которые могут появиться перед CMD :
-
--interval = DURATION(по умолчанию:30s) -
--timeout = ПРОДОЛЖИТЕЛЬНОСТЬ(по умолчанию:30 с) -
--start-period = DURATION(по умолчанию:0s) -
--retries = N(по умолчанию:3)
Проверка работоспособности сначала запустится с интервалом секунды после того, как контейнер будет начался, а затем снова интервал секунды после завершения каждой предыдущей проверки.
Если один запуск проверки занимает больше времени, чем тайм-аут секунды, то проверка считается потерпевшим неудачу.
Требуется повторная попытка последовательных сбоя проверки работоспособности контейнера
считать нездоровой .
период запуска обеспечивает время инициализации для контейнеров, которым требуется время для начальной загрузки. Отказ датчика в течение этого периода не будет засчитан в максимальное количество повторных попыток. Однако, если проверка работоспособности прошла успешно в течение начального периода, контейнер считается началось, и все последовательные сбои будут засчитываться в максимальное количество повторных попыток.
В Dockerfile может быть только одна инструкция HEALTHCHECK . Если вы перечислите
более одного, тогда только последний HEALTHCHECK вступит в силу.
Команда после ключевого слова CMD может быть командой оболочки (например, HEALTHCHECK
CMD / bin / check-running ) или массив exec (как и другие команды Dockerfile;
см. например ENTRYPOINT для подробностей).
Состояние выхода команды указывает на состояние работоспособности контейнера.Возможные значения:
- 0: успех - контейнер исправен и готов к использованию
- 1: неисправно - контейнер работает некорректно
- 2: зарезервировано - не использовать этот код выхода
Например, каждые пять минут проверять, может ли веб-сервер обслужить главную страницу сайта за три секунды:
HEALTHCHECK --interval = 5m --timeout = 3s \
CMD curl -f http: // localhost / || выход 1
Для облегчения отладки неисправных зондов любой выходной текст (в кодировке UTF-8), записываемый командой
на stdout или stderr будет храниться в состоянии работоспособности и может быть запрошен с помощью докер осмотреть .Такой вывод должен быть коротким (только первые 4096 байт).
хранятся в настоящее время).
При изменении состояния работоспособности контейнера возникает событие health_status .
с новым статусом.
ОБОЛОЧКА
SHELL ["исполняемый файл", "параметры"]
Команда SHELL разрешает оболочку по умолчанию, используемую для оболочки в форме .
команды, которые нужно переопределить. Оболочка по умолчанию в Linux - ["/ bin / sh", "-c"] и далее
Windows - ["cmd", "/ S", "/ C"] .Инструкция SHELL должна быть записана в формате JSON.
форма в Dockerfile.
Инструкция SHELL особенно полезна в Windows, где есть
две часто используемые и совершенно разные собственные оболочки: cmd и powershell , как
Также доступны альтернативные снаряды, включая SH .
Инструкция SHELL может появляться несколько раз. Каждая инструкция SHELL отменяет
все предыдущие инструкции SHELL и влияют на все последующие инструкции.Например:
ОТ microsoft / windowsservercore
# Выполняется как cmd / S / C echo по умолчанию
RUN эхо по умолчанию
# Выполняется как cmd / S / C powershell -команда Write-Host по умолчанию
RUN powershell - команда Write-Host по умолчанию
# Выполняется как powershell -command Write-Host hello
ОБОЛОЧКА ["powershell", "-команда"]
RUN Write-Host привет
# Выполняется как cmd / S / C echo hello
SHELL ["cmd", "/ S", "/ C"]
RUN echo привет
На следующие инструкции может повлиять инструкция SHELL , когда
Оболочка , форма из них используется в Dockerfile: RUN , CMD и ENTRYPOINT .
Следующий пример представляет собой распространенный шаблон, который можно найти в Windows.
оптимизировано с помощью инструкции SHELL :
RUN powershell -команда Execute-MyCmdlet -param1 "c: \ foo.txt"
Докер запускает команду:
cmd / S / C powershell -команда Execute-MyCmdlet -param1 "c: \ foo.txt"
Это неэффективно по двум причинам. Во-первых, есть ненужная команда cmd.exe
вызываемый процессор (он же оболочка).Во-вторых, каждая инструкция RUN в оболочке форма требует дополнительной powershell -команды перед командой.
Чтобы сделать это более эффективным, можно использовать один из двух механизмов. Один должен используйте JSON-форму команды RUN, например:
RUN ["powershell", "-command", "Execute-MyCmdlet", "-param1 \" c: \\ foo.txt \ ""]
Хотя форма JSON однозначна и не использует ненужный cmd.exe,
это требует большей многословности за счет двойных кавычек и экранирования.Альтернативный
механизм должен использовать команду SHELL и форму оболочки ,
сделать синтаксис более естественным для пользователей Windows, особенно в сочетании с
директива парсера escape :
# escape = `
С microsoft / nanoserver
SHELL ["powershell", "- команда"]
RUN New-Item -ItemType Directory C: \ Example
ДОБАВИТЬ Execute-MyCmdlet.ps1 c: \ example \
ЗАПУСТИТЬ c: \ example \ Execute-MyCmdlet -sample 'hello world'
Результат:
PS E: \ docker \ build \ shell> docker build -t shell.Отправка контекста сборки демону Docker 4.096 КБ
Шаг 1/5: С microsoft / nanoserver
---> 22738ff49c6d
Шаг 2/5: SHELL powershell -команда
---> Запуск в 6fcdb6855ae2
---> 6331462d4300
Снятие промежуточного контейнера 6fcdb6855ae2
Шаг 3/5: ЗАПУСК New-Item -ItemType Directory C: \ Example
---> Запуск в d0eef8386e97
Каталог: C: \
Режим LastWriteTime Длина Имя
---- ------------- ------ ----
г ----- 28.10.2016 11:26 Пример
---> 3f2fbf1395d9
Снятие промежуточного контейнера d0eef8386e97
Шаг 4/5: ДОБАВИТЬ Execute-MyCmdlet.ps1 c: \ example \
---> a955b2621c31
Снятие промежуточного контейнера b825593d39fc
Шаг 5/5: ЗАПУСТИТЬ c: \ example \ Execute-MyCmdlet 'hello world'
---> Запуск в be6d8e63fe75
Привет мир
---> 8e559e9bf424
Снятие промежуточного контейнера be6d8e63fe75
Успешно построено 8e559e9bf424
PS E: \ докер \ сборка \ оболочка>
Команда SHELL также может использоваться для изменения способа, которым
оболочка действует. Например, используя команду SHELL cmd / S / C / V: ON | OFF в Windows, с задержкой
семантика раскрытия переменных среды может быть изменена.
Команда SHELL также может использоваться в Linux, если требуется альтернативная оболочка.
требуются такие как zsh , csh , tcsh и другие.
Особенности внешней реализации
Эта функция доступна только при использовании серверной части BuildKit.
СборкаDocker поддерживает экспериментальные функции, такие как монтирование кеша, секреты сборки и ssh-пересылка, которая включается с помощью внешней реализации строитель с синтаксической директивой.Чтобы узнать об этих функциях, обратитесь к документации в репозитории BuildKit.
Примеры файлов Docker
Ниже вы можете увидеть несколько примеров синтаксиса Dockerfile.
# Nginx
#
# ВЕРСИЯ 0.0.1
ОТ ubuntu
LABEL Description = "Это изображение используется для запуска исполняемого файла foobar" Vendor = "ACME Products" Version = "1.0"
ЗАПУСТИТЬ apt-get update && apt-get install -y inotify-tools nginx apache2 openssh-server
# Firefox через VNC
#
№ ВЕРСИЯ 0.3 ОТ ubuntu # Установите vnc, xvfb для создания фальшивого дисплея и firefox
ЗАПУСТИТЬ apt-get update && apt-get install -y x11vnc xvfb firefox
ЗАПУСТИТЬ mkdir ~ / .vnc
# Установить пароль
ЗАПУСТИТЬ x11vnc -storepasswd 1234 ~ / .