What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
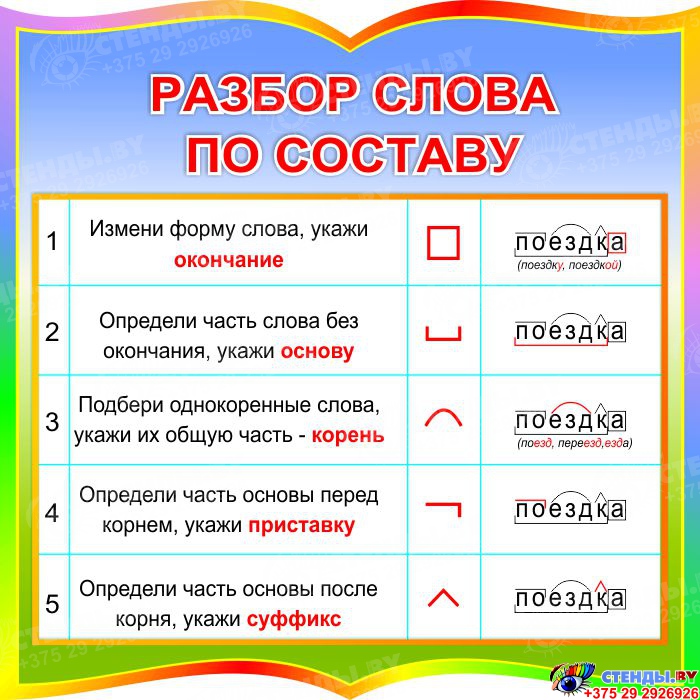
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «phenomenon» in English?
How to pronounce «often» in English?
How to pronounce «pyruvate» in English?
How to pronounce «entrepreneur» in English?
How to pronounce «non-repudiation» in English?
How to pronounce «ontology» in English?
How to pronounce «Streptococcus pneumoniae» in English?
How to pronounce «cytokinesis» in English?
How to pronounce «ubiquitin» in English?
How to pronounce «proteasome» in English?
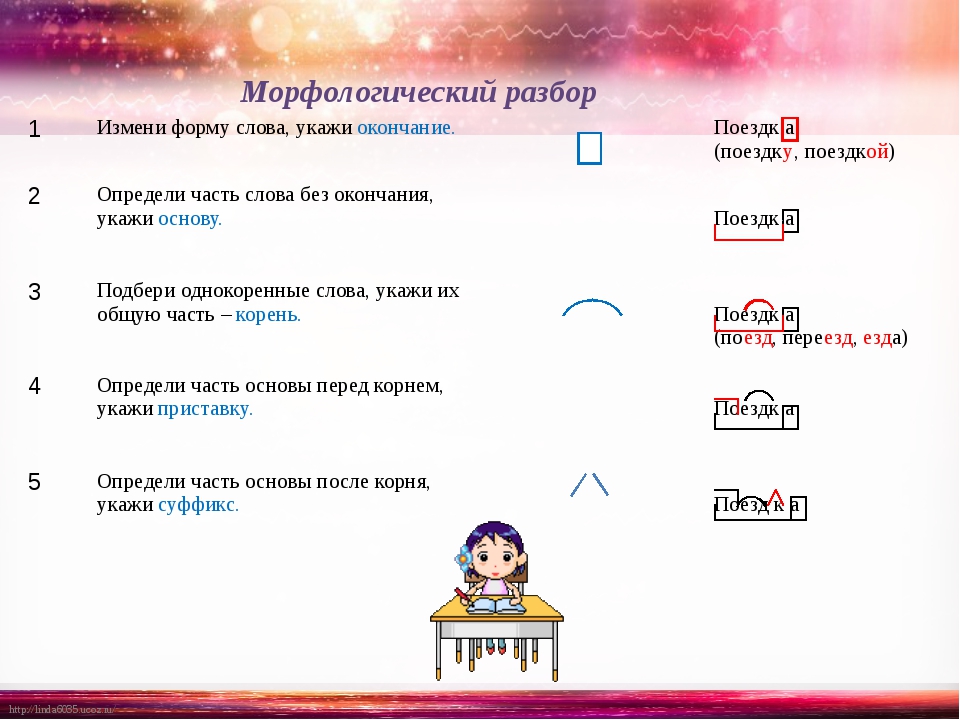
Морфологический разбор слова «поразительно»
Слово можно разобрать в 2 вариантах, в
зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Наречие
2 вариант разбора
Часть речи: Краткое прилагательное
ПОРАЗИТЕЛЬНО — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПОРАЗИТЕЛЬНЫЙ»
| Слово | Морфологические признаки |
|---|---|
| ПОРАЗИТЕЛЬНО |
|
Все формы слова ПОРАЗИТЕЛЬНО
ПОРАЗИТЕЛЬНЫЙ, ПОРАЗИТЕЛЬНОГО, ПОРАЗИТЕЛЬНОМУ, ПОРАЗИТЕЛЬНЫМ, ПОРАЗИТЕЛЬНОМ, ПОРАЗИТЕЛЬНАЯ, ПОРАЗИТЕЛЬНОЙ, ПОРАЗИТЕЛЬНУЮ, ПОРАЗИТЕЛЬНОЮ, ПОРАЗИТЕЛЬНОЕ, ПОРАЗИТЕЛЬНЫЕ, ПОРАЗИТЕЛЬНЫХ, ПОРАЗИТЕЛЬНЫМИ, ПОРАЗИТЕЛЕН, ПОРАЗИТЕЛЬНА, ПОРАЗИТЕЛЬНО, ПОРАЗИТЕЛЬНЫ, ПОРАЗИТЕЛЬНЕЕ, ПОРАЗИТЕЛЬНЕЙ, ПОПОРАЗИТЕЛЬНЕЕ, ПОПОРАЗИТЕЛЬНЕЙ, ПОРАЗИТЕЛЬНЕЙШИЙ, ПОРАЗИТЕЛЬНЕЙШЕГО, ПОРАЗИТЕЛЬНЕЙШЕМУ, ПОРАЗИТЕЛЬНЕЙШИМ, ПОРАЗИТЕЛЬНЕЙШЕМ, ПОРАЗИТЕЛЬНЕЙШАЯ, ПОРАЗИТЕЛЬНЕЙШЕЙ, ПОРАЗИТЕЛЬНЕЙШУЮ, ПОРАЗИТЕЛЬНЕЙШЕЮ, ПОРАЗИТЕЛЬНЕЙШЕЕ, ПОРАЗИТЕЛЬНЕЙШИЕ, ПОРАЗИТЕЛЬНЕЙШИХ, ПОРАЗИТЕЛЬНЕЙШИМИ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПОРАЗИТЕЛЬНО» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «поразительно»
1
«Но как это поразительно, – сказал он себе, неторопливо выходя из библиотеки, – право же, поразительно, что он ей понравился.
Мидлмарч, Джордж Элиот, 1872г.2
«Благородный», «истинно немецкий», «поразительно, поразительно милый», «страшно милый» – много ли из этого почерпнешь?
Групповой портрет с дамой, Генрих Бёлль, 1971г.
3
Нет, ну поразительно просто, поразительно!..
Андерманир штук, Евгений Клюев, 2010г.Поразительно ли глупая, поразительно ли правдивая;
Оставь компас себе, Петр Альшевский5
Таким поразительно мужественным, таким поразительно красивым!
Любви все возрасты покорны, Антонина ЕвстратоваНайти еще примеры предложений со словом ПОРАЗИТЕЛЬНО
Какие есть однокоренные слова к слову шарф?
На этот вопрос нельзя ответить однозначно — ударение будет зависеть от значения корня «язык»
, что проясняется только в контексте.
- Если имеется в виду «язык» как орган речи, то ударение ставится на А: языковАя (речевая) практика, языковАя группа.
- Если слово «язык» спользуется в значении «языкОвая мышца» (мясной продукт), то ударение ставится на О: языкОвая колбаса. Это словосочетание можно рассматривать как термин, потому что в других словосочетания слово «языкОвая» больше нигде не встречается.
Рутина — это навык, умение, приобретенное упражнением без пособия теоретических основ, следование шаблону, превратившемуся в механическую привычку, монотонная, неинтересная работа, застой в делах и в образе жизни, безответное следование обычаю, консерватизм, боязнь всего нового. Вот такие значения имеет это слово в русском языке, куда оно пришло из французского языка. Французское слово «routine» означает навык, рутину, косность. Само это слово образовано от «route», которое переводится как «дорога, путь».
Прост. Пренебр. Петь очень плохо, неприятным голосом; плохо играть на музыкальном инструменте. Видал? кричит на ухо брату Дядюшкин председатель, указывая на оркестр… А чего они так тянут в разные стороны, козла дерут?
Граммар наци — это человек, нетерпимо относящийся к любому проявлению действительной или кажущейся ему безграмотности в чужих словах или текстах. Он способен прицепиться к любой мелочи, даже к совсем небольшой ошибке, и всячески возмущаться по её поводу, обзывать и третировать ошибшегося. Подробнее об этом типаже людей,их поведении и впечатлении, которое оно производит на окружающих, рассказывает эта статья.
В 2015 году минимальный балл по русскому языку снова вернулся к отметке 36 баллов. Это значит, что выпускнику нужно набрать 17 первичных баллов, чтобы при переводе в 100-балльную систему было 36. Но за разные задания дают разное количество баллов: за какие-то вопросы по 1 баллу, за другие по 2, третьи — 4 и 5, поэтому надо постараться правильно выполнить 17 заданий, чтобы уж точно набрать проходной минимум.
Но за разные задания дают разное количество баллов: за какие-то вопросы по 1 баллу, за другие по 2, третьи — 4 и 5, поэтому надо постараться правильно выполнить 17 заданий, чтобы уж точно набрать проходной минимум.
Контрольные работы по русскому языку 8 класс
Диктант – это вид орфографического упражнения, сущность которого для учащихся состоит в записи воспринимаемого на слух предложения, слова, текста.
8 класс 1 четверть
С давних времен дружит человек с зеленым миром. Этот мир дает человеку различные строительные материалы, вылечивает многие болезни, украшает жизнь. Некоторые деревья и цветы древние народы обожествляли, создавая легенды об их удивительных свойствах. Символом мужества и мастерства в Древней Греции считался лавр, поэтому лавровым венком или его ветвью украшали победителей битв и турниров, ученых, поэтов, художников.
На протяжении многих тысяч лет известна маслина, лающая ценное и важное оливковое масло. Оливковая ветвь – это символ мира. Кедр, символизирующий долголетие и мощь, устойчив и сохраняется в земле очень долго. Его прочная древесина используется для постройки судов и зданий.
Оливковая ветвь – это символ мира. Кедр, символизирующий долголетие и мощь, устойчив и сохраняется в земле очень долго. Его прочная древесина используется для постройки судов и зданий.
✒️ Грамматическое задание:
- Выпишите из текста 3 словосочетания с разными видами связи, выполните их разбор
1 вариант из 1 абзаца;
2 вариант из 2 абзаца. ;- Выполните морфемный разбор слов:
1 вариант вылечивает, создавая, лавровый;
2 вариант дающая, сохраняется, долго.
8 класс 2 четверть
Русская баня упоминается в самых древних исторических источниках. Легендарная княгиня Ольга своих врагов, погубивших ее мужа, сожгла в бане. В другой легенде рассказывается об иностранцах, побывавших на Руси. Их удивляло, что русские хлестали себя в жарком поту распаренным березовым веником, когда уходили в баню мыться.
Этот забавивший иностранцев удивительный обычай сыграл свою роль в судьбе народа. В средние века, когда эпидемии одна за другой косили страны Центральной и Западной Европы, обычай еженедельно мыться спасал народ от болезней, закалял людей, давал жизнестойкость.
Поразительно и то, что бани не >исчезли, когда подавляющее большинство населения переселилось в современные квартиры с ваннами. Бани потеряли свою гигиеническую функцию. В выходные дни люди ходят в баню ради закалки, ради удовольствия.
✒️ Грамматическое задание:
- Озаглавьте текст
- Объясните орфограммы в подчеркнутых словах
- Выполните морфемный разбор слов: потеряли, погубивших, выходные (дни)
- Объясните постановку знаков препинания во 2 предложении 1 абзаца .
8 класс 3 четверть
На этой лесной поляне Европа встречается с Азией. Две елки. Одна – в Европе, другая – в Азии. Холодно на поляне. Люди замерзли, греются, бегая из Европы в Азию и обратно.
Два великих материка встречаются на Уральском хребте, глядят друг на друга через реку Урал. Есть что-то значительное в минуте, когда в первый раз пересекаешь границу материков. Сзади – тысячи километров, впереди – подернутые морозом гребни синих лесов, новые тысячи километров твоей земли.
Есть что-то значительное в минуте, когда в первый раз пересекаешь границу материков. Сзади – тысячи километров, впереди – подернутые морозом гребни синих лесов, новые тысячи километров твоей земли.
Первым границу по Уральским горам провел русский географ петровских времен Василий Татищев. Он заметил, что реки с Урала текут в двух направлениях. Одни текут в Печору и Каму, другие – в Обь. Замечено было, что растительность за горами тоже заметно меняется. Татищев первым дал им название: Уральские горы. Так определили границу между Европой и Азией.
✒️ Грамматическое задание:
- Произведите синтаксический разбор 5 предложения из 1 абзаца
- Выпишите два односоставных предложения, укажите их вид
- Выполните морфемный разбор любого наречия, глагола, деепричастия.
Итоговый диктант за 8 класс
В то утро я впервые услышал поразившую меня игру на пастушьем рожке. Я смотрел в открытое окно, лежа в постели.
Улица была залита розовым светом встававшего за домами солнца. Открылись ворота двора, и пастух-хозяин, в новой синей рубахе, в сапогах и высокой шляпе, похожей на цилиндр, вышел на середину пустынной улицы, поставил у ног свою шляпу, перекрестился и приложил обеими руками длинный рожок к губам. Рожок заиграл так громко, что даже в ушах звенело. Но это только сначала. Потом он стал забирать выше, жальче. И вдруг заиграл что-то радостное, и мне стало весело. Замычали вдали коровы, стали понемногу подходить ближе. А пастух все играл, забыв про все. Играл, запрокинув голову, играл в небо. Когда пастух переводил дыхание, раздавались восхищенные голоса, славившие его игру.
Открылись ворота двора, и пастух-хозяин, в новой синей рубахе, в сапогах и высокой шляпе, похожей на цилиндр, вышел на середину пустынной улицы, поставил у ног свою шляпу, перекрестился и приложил обеими руками длинный рожок к губам. Рожок заиграл так громко, что даже в ушах звенело. Но это только сначала. Потом он стал забирать выше, жальче. И вдруг заиграл что-то радостное, и мне стало весело. Замычали вдали коровы, стали понемногу подходить ближе. А пастух все играл, забыв про все. Играл, запрокинув голову, играл в небо. Когда пастух переводил дыхание, раздавались восхищенные голоса, славившие его игру.
✒️ Грамматическое задание:
- Озаглавьте текст;
- Обозначьте в тексте одно обстоятельство, выраженное деепричастным оборотом, и одно определение, выраженное причастным оборотом. Составьте схемы.
Контрольная работа №1 на тему: «Повторение»
Подарки лесного царя
Убавился день, и низкие тучи грозят дождём и снегом. Облетели с веток последние листья. В лесу поселились тишь и пустота, но кое-где оставил лесной царь подарки. Вот у опушки видны кусты шиповника, а в них спрятались плоды. Вот на верхушке орешника прячутся золотче орешки. А вот укрылась под листиком волнушка. На болотистых кочках созрела, но ещё горчит красная клюква.
Облетели с веток последние листья. В лесу поселились тишь и пустота, но кое-где оставил лесной царь подарки. Вот у опушки видны кусты шиповника, а в них спрятались плоды. Вот на верхушке орешника прячутся золотче орешки. А вот укрылась под листиком волнушка. На болотистых кочках созрела, но ещё горчит красная клюква.
Всё это подарки лесного царя. Они тем, кто любит и знает природу.
✒️ Грамматическое задание:
- Разобрать по членам предложения и частям речи первое предложение.
- Найти подлежащее и сказуемое в предложении «Вот у опушки видны кусты шиповника …»
- Найти и обозначить однородные члены в последнем предложении, составить схему этого предложения.
Контрольная работа №2 на тему: «Повторение»
Поздняя осень
В начале ноября солнце редким гостем появляется на небе. Всё чаще проплывают над головой низкие дождевые облака. Дуют холодные ветры. Вот резкий порыв ветра пригнул к земле гибкие стебли травы и сорвал с деревьев увядшие листья. Покружилась лёгкая листва в воздухе и легла на землю мягким ковром.
Покружилась лёгкая листва в воздухе и легла на землю мягким ковром.
С утра моросит дождь. После него на дорожках сада остаются лужи и липкая, как смола, грязь За ночь лужицы покрываются прозрачной, как стекло, корочкой льда. Скоро-скоро первый снежок покроет землю гладкой белой пеленой.
Задание:
- Первое предложение разобрать по членам предложения с указанием частей речи.
- Найти и подчеркнуть в них однородные члены предложения, обозначить главное слово.
Контрольная работа №3 по теме: «Состав слова»
Враги и друзья пшеничного поля
Крестьянин вспахал землю. Попало в землю зерно. От влаги оно набухло, проросло и пробилось к свету зелёным листком. Всё поле покрылось нежными побегами. Но тут напали на пшеницу враги – сорняки. Люди начали с ними борьбу. Ведь пшенице надо перезимовать под снегом.
Пришла зима с морозами и метелями. Мороз был врагом пшеницы, а снег — другом. Съёжились от мороза зелёные листочки. Сгубил бы он пшеницу, но выпал снег и накрыл поле тёплым одеялом.
Сгубил бы он пшеницу, но выпал снег и накрыл поле тёплым одеялом.
Задание:
- Разобрать по составу слова: «Проросло, перезимовали, хлебовозка, листочки».
- Обозначить приставки в словах в первом абзаце.
- Составить схему последнего предложения, подчеркнуть в нём подлежащее и сказуемое.
Контрольная работа за полугодие
Мишки научили
Это случилось в моё первое путешествие по тайге. Прошли бурелом и поставили шалаш под скалой. Внесли вещи и рухнули от усталости на зелёную подстилку.
Разбудил нас грохот и треск. Мы выскочили из шалаша и отбежали под сосны. Только тогда поняли причину камнепада.
У края скалы возились два медвежонка. Они сгребали лапами и сбрасывали их. Булыжники крушили наше жилище. Вдруг появилась медведица и увела своих верхолазов.
Хороший урок мы получили. Нельзя строить в тайге шалаш под скалами
Задание:
- Разобрать по составу слова «бурелом, камнепад, верхолазов, отбежали, сгребали, скалой».
- Разобрать по членам предложения с указанием частей речи предложение «Мы выскочили из шалаша и отбежали под сосны».
Контрольная работа №5 по теме «Имя существительное».
О Михаиле Пришвине.
Детство и юность Пришвина прошли в средней полосе России. Его семья жила в усадьбе около деревни. Здесь от деревни к деревне тянутся леса, поля, огороды, сады с чудесными растениями. Берега рек заросли плачущей ивой.
Ещё мальчиком научился он всматриваться и вслушиваться в природу. Его чуткое ухо слышало шорох листьев и шепот ветра, а зоркий глаз видел каждую травинку.
С ружьём и записной книжкой побывал Пришвин на Урале, в Сибири, Карелии. Он открыл в природе много тайн и подарил их своим читателям.
А вы, ребята, читали его книги?
Задание:
- Написать пять несклоняемых существительных.
- Морфологический разбор существительного «заросли ивой».
- Разобрать по членам предложения с указанием частей речи предложение «Берега рек заросли плачущей ивой».
- Определить склонение существительных в предложении «С ружьём и записной книжкой побывал Пришвин на Урале, в Сибири, Карелии».
Контрольная работа №6 по теме: «Имя прилагательное»
Медведь
Каждую ночь медведь приходил к охотничьей избушке и съедал улов рыбы. Мы поставили капкан с зубьями. Сверху навалили рыбьи головы. А медведи снизу капкан ковырнул, он захлопнулся. Зверь спокойно рыбу съел и убежал.
Зарядили мы ружьё и пошли в тайгу. Вдруг в кустах медвежья голова показалась. Не успели мы ружья вскинуть. Домой мы шли без добычи. У обрыва опять из кустов медведь на нас смотрит. Мы замерли от такого медвежьего нахальства.
Пусть живёт, раз он такой хитрый.
Задание:
- Морфологический разбор прилагательного «от медвежьего нахальства».
- Определить род прилагательных: Заячий след, лисья нора, тюленье стадо, рысьи глаза, медвежья берлога.
- Из второго абзаца выписать предложение с однородными членами и нарисовать его схему.
- В первом предложении определить падеж прилагательного.
- В первом абзаце найти сложное предложение, найти подлежащее и сказуемое, определить, какими частями речи выражены.

Контрольная работа №7 по теме «Личные местоимения»
Просьба
На косогоре жила берёзка. Рядом с ней стояла старая ель. Там белка шелушила орешки и роняла семена. Семечки летели и ложились у ног берёзки.
Испугалась красавица. Станут семена ёлками – метёлками и закроют от неё солнце. Обратилась она к ветру за помощью. Для него унести семена подальше пара пустяков.
Растут ёлочки, а берёзка стоит одна далеко от них. Однажды налетел ураган. Испугалась красавица, стала просить ёлочек прикрыть её. Но ёлочки уже не могли летать. Корни их не пускали.
Задание:
- Найти сложное предложение и составить схему этого предложения.
- Местоимения «от неё» «для него» разобрать как часть речи.
- В первом абзаце найти и обозначить в предложениях однородные члены.
- Разобрать по членам предложения с указанием частей речи предложение «Обратилась она к ветру за помощью».

Контрольная работа №8 по теме «Глагол. Правописание слов с шипящей на конце.»
Ночь в лесу
Между туч выглянуло солнце. Его последний луч был добрым и грустным. Тихая ночь опускалась на поляну. По листочкам низкого кустарника пробежала едва заметная дрожь. Это ветерок торопился прилечь в мягкой траве. Под корягой чуть журчал студёный ключ. В эту пору цвёл ландыш. Его нежный запах легко узнаёшь. Природа отдыхала. Вдруг на поляну вышел ёж. На колючках он нёс какой-то съедобный груз.
Куда ты спешишь, малыш? И чего пыхтишь? Тебе помочь?
Задание:
- Третье предложение разобрать по членам предложения с указанием частей речи.
- Определить время глаголов.
Цель диктантов:
Повторить и систематизировать изученный на уроках материал, выполнить работу над ошибками.
Поурочные разработки по русскому языку: 7 класс
Горашова Н.Г. Поурочные разработки по русскому языку: 7 класс: к учебнику М. Т. Баранова и др. «Русский язык: 7 класс» / Н. Г. Горашова.— 3-е изд., перераб. — М.: Издательство «Экзамен», 2009. —413, [3] с. (Серия «Учебно-методический комплект»).Содержание
Тематическое планирование …………………………………………………………………..5
I четверть
Урок 1. Русский язык как развивающееся явление …………………………………………..8
Урок 2. Синтаксис. Синтаксический разбор ………………………………………………..10
Урок 3. Пунктуация. Пунктуационный разбор ……………………………………………. 12
Урок 4. Лексика и фразеология ………………………………………………………………13
Урок 5. Лексика и фразеология ………………………………………………………………15
Урок 6. Фонетика и орфография. Фонетический разбор слова ……………………………18
Урок 7. Фонетика и орфография …………………………………………………………….20
Урок 8. Словообразование и орфография …………………………………………………..21
Урок 9. Морфемный и словообразовательный разбор. ……………………………………23
Урок 10. Морфология и орфография.
Морфологический разбор слова ………………………………………………….25
Урок 11. Морфология и орфография ………………………………………………………..26
Урок 12. Морфология и орфография ………………………………………………………..28
Урок 13. Контрольный диктант ………………………………………………………………30
Урок 14. Р/р. Текст ……………………………………………………………………………31
Урок 15. Стили литературного языка ………………………………………………………32
Урок 16. Подготовка к домашнему сочинению по картине
И. И. Бродского «Летний сад осенью» …………………………………………..34
Урок 17. Причастие как часть речи …………………………………………………………35
Урок 18. Морфологические признаки у причастий.
Признаки глагола у причастия ……………………………………………………37
Урок 19. Морфологические признаки причастий. Признаки
прилагательного у причастия …………………………………………………….38
Урок 20. Р/р. Публицистический стиль ……………………………………………………..41
Урок 21. Склонение причастий и правописание гласных
в падежных окончаниях причастий ………………………………………………42
Урок 22. Причастный оборот. Знаки препинания
при причастном обороте ………………………………………………………….44
Урок 23. Причастный оборот. Знаки препинания
при причастном обороте ………………………………………………………….45
Урок 24. Р/р. Описание внешности человека ………………………………………………47
Урок 25. Сочинение-описание по картине В. И. Хабарова
«Портрет Милы» …………………………………………………………………..49
Урок 26. Сочинение-описание по картине В. И. Хабарова
«Портрет Милы ……………………………………………………………………50
Урок 27. Действительные и страдательные причастия …………………………………… 51
Урок 28. Действительные причастия настоящего времени ………………………………. 53
Урок 29. Действительные причастия прошедшего времени ………………………………54
Урок 30. Страдательные причастия настоящего времени …………………………………56
Урок 31. Страдательные причастия прошедшего времени ……………………………… 59
Урок 32. Краткие страдательные причастия ………………………………………………. 61
Урок 33. Гласные перед Н в полных и кратких
страдательных причастиях ………………………………………………………..63
Урок 34. Одна и две буквы Н в суффиксах
страдательных причастий прошедшего времени.
Одна буква Н в отглагольных прилагательных ……………………………… 64
Урок 35. Одна и две буквы Н в суффиксах
страдательных причастий прошедшего времени
и отглагольных прилагательных ……………………………………………….. 66
Урок 36. Формирование орфографических умений и навыков
(урок-игра) ……………………………………………………………………….. 68
*Урок 36. Отличие причастий от отглагольных прилагательных ………………………. 69
Урок 37. Контрольный диктант ………………………………………………………………72
Урок 38. Работа над ошибками, допущенными в диктанте ……………………………… 73
Урок 39. Морфологический разбор причастия ……………………………………………. 74
Урок 40. Слитное и раздельное написание
НЕ с причастиями ……………………………………………………………….. 76
Урок 41. Выборочное изложение по упр. 130 ……………………………………………. 77
Урок 42. Буквы Е и Ё после шипящих в суффиксах
страдательных причастий прошедшего времени ……………………………… 78
Урок 43. Повторение темы «Причастие» …………………………………………………. 80
Урок 44. Повторение темы «Причастие …………………………………………………… 81
Урок 45. Повторение темы «Причастие …………………………………………………… 83
*Урок 43. Повторение, причастия …………………………………………………………. 85
*Урок44. Переход причастий в прилагательные
и существительные ……………………………………………………………… .86
*Урок 45. Повторение причастия. Самостоятельная работа
по теме «Причастие» …………………………………………………………… 88
Урок 46. Контрольный диктант по теме «Причастие» …………………………………… 89
Урок 47. Работа над ошибками допущенными
в контрольном диктанте ………………………………………………………… 91
II четверть
Урок 48. Деепричастие как часть речи ……………………………………………………. 92
Урок 49. Морфологические признаки у деепричастия.
Признаки глагола и наречия у деепричастия …………………………………… 94
Урок 50. Деепричастный оборот Запятые
при деепричастном обороте ……………………………………………………… 96
Урок 51. Раздельное написание НЕ с деепричастиями ………………………………….. 98
Урок 52. Деепричастия несовершенного вида ……………………………………………. 99
Урок 53. Деепричастия совершенного вида ……………………………………………….101
Урок 54. Сочинение по картине С. Григорьева «Вратарь» ………………………………102
Урок 55. Сочинение по картине С. Григорьева «Вратарь ………………………………..103
Урок 56. Морфологический разбор деепричастия ………………………………………..103
Урок 57. Повторение деепричастия ………………………………………………………..105
*Урок 57. Повторение деепричастия ………………………………………………………106
Урок 58. Контрольный диктант по теме «Деепричастие» ……………………………… 107
Урок 59. Работа над ошибками, допущенными в диктанте.
Тестирование ……………………………………………………………………..109
Урок 60. Наречие как часть речи …………………………………………………………..111
Урок 61. Смысловые группы наречий ……………………………………………………..112
Урок 62. Смысловые группы наречий ……………………………………………………..114
Урок 63. Способы образования наречий …………………………………………………..115
Урок 64. Р/р. Сочинение по картине И. Попова «Первый снег» …………………………118
Урок 65. Сочинение по картине И. Попова «Первый снег ……………………………….119
Урок 66. Степени сравнения наречий ………………………………………………………119
Урок 67. Степени сравнения наречий ………………………………………………………121
Урок 68. Морфологический разбор наречия ………………………………………………122
Урок 69. Контрольный диктант по теме «Наречие» ………………………………………124
Урок 70. Работа над ошибками, допущенными
в контрольном диктанте …………………………………………………………125
Урок 71. Слитное и раздельное написание НЕ с наречиями
на -О и -Е …………………………………………………………………………126
Урок 72. Слитное и раздельное написание НЕ с наречиями
на -О и -Е …………………………………………………………………………128
Урок 73. Буквы Е и И в приставках НЕ- и НИ-
отрицательных наречий ………………………………………………………….129
Урок 74. Буквы Е и И в приставках НЕ- и НИ-
отрицательных наречий ………………………………………………………….131
Урок 75. Изложение …………………………………………………………………………132
*Урок 75. Р/р. Сочинение-рассуждение по видимому тексту ……………………………133
Урок 76. Одна и две буквы Н в наречиях на -О и -Е ………………………………………135
Урок 77. Р/р. Описание действий …………………………………………………………..137
Урок 78. Буквы О и Е после шипящих на конце наречий ………………………………..138
Урок 79. Буквы О и А на конце наречий …………………………………………………..140
Урок 80. Буквы О и А на конце наречий …………………………………………………..141
Урок 81. Р/р. Сочинение по картине Е.Н. Широкова «Друзья» ………………………….142
Урок 82. Р/р. Сочинение по картине Е.Н. Широкова «Друзья» ………………………….144
III четверть
Урок 83. Дефис между частями слова в наречиях …………………………………………144
Урок 84. Дефис между частями слова в наречиях …………………………………………146
Урок 85. Слитное и раздельное написание приставок в наречиях,
образованных от существительных прилагательных,
местоимений и количественных числительных …………………………………147
Урок 86. Слитное и раздельное написание приставок в наречиях,
образованных от существительных, прилагательных,
числительных и местоимений …………………………………………………..149
Урок 87. Мягкий знак после шипящих на конце наречий ………………………………..150
Урок 88. Повторение темы «Наречие» …………………………………………………….151
Урок 89. Повторение темы «Наречие ………………………………………………………152
Урок 90. Повторение темы «Наречие ………………………………………………………153
Урок 91. Повторение темы «Наречие» …………………………………………………….155
Урок 92. Контрольная работа по теме «Наречие» ………………………………………..156
Урок 93. Работа над ошибками, допущенными
в контрольной работе ……………………………………………………………158
Урок 94. Категория состояния ……………………………………………………………..159
Урок 95. Слова категории состояния ………………………………………………………161
Урок 96. Морфологический разбор категории состояния ………………………………..162
Урок 97. Р/р. Изложение (описание действия) ……………………………………………163
Урок 98. Повторение темы «Категория состояния» ………………………………………165
Урок 99. Сочинение на Лингвистическую тему …………………………………………. 166
Урок 100.Служебные части речи …………………………………………………………..167
Урок 101. Предлог как часть речи …………………………………………………………168
Урок 102. Употребление предлогов ………………………………………………………..170
Урок 103. Непроизводные и производные предлоги ……………………………………..172
Урок 104. Простые и составные предлоги …………………………………………………173
Урок 105. Морфологический разбор предлога ……………………………………………175
Урок 106. Р/р. Сочинение по картине А. В. Сайкиной
«Детская спортивная школа» ……………………………………………………177
Урок 107. Р/р. Сочинение по картине А. В. Сайкиной
«Детская спортивная школа ……………………………………………………..178
Урок 108.Слитное и раздельное написание производных
предлогов …………………………………………………………………………179
Урок 109. Слитное и раздельное написание производных
предлогов …………………………………………………………………………180
Урок 110. Повторение темы «Предлог» ……………………………………………………181
Урок 111. Повторение темы «Предлог» ……………………………………………………183
Урок 112. Контрольный диктант по теме «Предлог» …………………………………….184
Урок 113. Работа над ошибками, допущенными
в контрольном диктанте ……………………………………………………….185
Урок 114. Союз как часть речи …………………………………………………………….186
Урок 115. Простые и составные союзы ……………………………………………………187
Урок 116. Сочинительные и подчинительные союзы …………………………………….188
Урок 117. Запятая в сложном предложении ………………………………………………190
Урок 118. Запятая в сложном предложении ………………………………………………192
Урок 119. Сочинительные союзы ………………………………………………………….194
Урок 120. Сочинительные союзы ………………………………………………………….195
Урок 121. Подчинительные союзы …………………………………………………………197
Урок 122. Подчинительные союзы …………………………………………………………199
Урок 123. Морфологический разбор союза ……………………………………………….201
Урок 124. Р/р. Сочинение «Книга — наш друг и советчик» …………………………….202
Урок 125. Р/р. Сочинение «Книга — наш друг и советчик»
(по тексту упр. 343) …………………………………………………………….203
Урок 126. Слитное написание союзов тоже, также, чтобы, зато …………………………203
Урок 127. Слитное написание союзов также, тоже, чтобы, зато …………………………205
Урок 128.Повторение темы «Союз» ……………………………………………………….207
Урок 129. Повторение темы «Союз ………………………………………………………..208
Урок 130. Контрольный диктант по теме «Союз» ………………………………………..210
Урок 131. Работа над ошибками, допущенными в диктанте …………………………….211
Урок 132. Частица как часть речи ………………………………………………………….211
IV четверть
Урок 133. Разряды частиц. Формообразующие частицы …………………………………213
Урок 134. Смысловые частицы …………………………………………………………….214
Урок 135. Смысловые частицы …………………………………………………………….215
Урок 136. Закрепление орфографических умений и навыков ……………………………217
Урок 137. Р/р. Сочинение «Как мне стать чемпионом» ………………………………….218
Урок 138. Раздельное и дефисное написание частиц …………………………………….219
Урок 139. Раздельное и дефисное написание частиц …………………………………….220
Урок 140. Р/р. Сочинение по картине К. Ф. Юона
«Конец зимы. Полдень» ………………………………………………………..221
Урок 141. Р/р. Сочинение по картине К. Ф. Юона
«Конец зимы. Полдень» …………………………………………………………222
Урок 142. Морфологический разбор частиц ………………………………………………223
Урок 143. Отрицательные частицы НЕ и НИ ……………………………………………..224
Урок 144. Отрицательные частицы НЕ и НИ ……………………………………………..225
Урок 145. Различение приставки НЕ- и частицы НЕ ……………………………………..226
Урок 146. Различение приставки НЕ- и частицы НЕ ……………………………………..227
Урок 147. Р/р. Сочинение по данному рассказу …………………………………………..228
Урок 148. Частица ни, приставка НИ, союз НИ—НИ …………………………………….229
Урок 149. Повторение темы «Частица» ……………………………………………………230
Урок 150. Повторение темы «Частица» ……………………………………………………232
Урок 151. Повторение правописания служебных частей речи …………………………..236
Урок 152. Контрольный диктант по теме «Частица» …………………………………….238
Урок 153. Работа над ошибками, допущенными
в контрольном диктанте …………………………………………………………239
*Урок 153. Повторение темы «Служебные части речи» …………………………………240
Урок 154. Междометие как часть речи ……………………………………………………242
Урок 155. Дефис в междометиях и знаки препинания
при междометиях …………………………………………………………………243
Урок 156. Урок-игра по теме «Междометие ………………………………………………244
Урок 157. Контрольное изложение …………………………………………………………245
Урок 158. Контрольное изложение …………………………………………………………247
Урок 159. Повторение. Разделы науки о языке ……………………………………………247
Урок 160. Повторение. Текст. Стили речи …………………………………………………249
Урок 161. Р/р. Рецензия на текст из книги Д. Тенмплтона
«Всемирные законы жизни» ……………………………………………………250
Урок 162. Р/р. Рецензия на текст из книги Д. Тенмплтона
«Всемирные законы жизни» ………………………………………………….. 252
Урок 163. Повторение. Фонетика и графика ………………………………………………252
Урок 164. Лексика и фразеология ………………………………………………………….254
Урок 165. Повторение. Словообразование ………………………………………………..256
Урок 166. Повторение. Мофология ………………………………………………………..258
Урок 167. Повторение. Орфография ……………………………………………………….259
Урок 168. Контрольный итоговый диктант ……………………………………………….260
Урок 169. Повторение. Синтаксис, пунктуация …………………………………………..261
Урок 170. Итоговое тестирование за курс русского языка
седьмого класса …………………………………………………………………262
Тематическое планирование
7 класс. 5 часов в неделю (170 часов)
№
Содержание
Кол-во часовпо теме
1 ЧЕТВЕРТЬ (47 уроков)
1
Русский язык как развивающееся явление
1
Повторение изученного в 5—6 классах (12 + 3)
2
Синтаксис. Синтаксический разбор
1
3
Пунктуация. Пунктуационный разбор
1
4, 5
Лексика и фразеология
2
6, 7
Фонетика и орфография. Фонетический разбор слова
2
8, 9
Словообразование и орфография. Морфемный и словообразовательный разбор
2
10, 11, 12
Морфология и орфография. Морфологический разбор слова
3
13
Контрольный диктант
1
14
Р/р. Текст
1
15
Р/р. Стили речи
1
16
Р/р. Подготовка к домашнему сочинению по картине И.И. Бродского «Летний сад осенью»
1
Причастие (26+5)
17
Причастие как часть речи
1
18
Морфологические признаки у причастия. Признаки глагола у причастия
1
19
Признаки прилагательного у причастия
1
20
Р/р. Публицистический стиль
1
21
Склонение причастий и правописание гласных в падежных окончаниях причастий
1
22, 23
Причастный оборот. Выделение причастного оборота запятыми
2
24
Р/р. Описание внешности человека
1
25, 26
Р/р. Описание внешности человекаСочинение по картине В. И. Хабарова «Портрет Милы»
2
27, 28, 29, 30, 31
Действительные и страдательные причастия
5
32
Краткие причастия
1
33
Гласные перед н в полных и кратких страдательных причастиях
1
34, 35
Одна и две буквы н в суффиксах страдательных причастий прошедшего времени и в отглагольных прилагательных
2
36
Формирование орфографических умений и навыков.Урок-игра.
*Отличие причастий от глагольных прилагательных.
1
37
Контрольный диктант
1
38
Работа над ошибками, допущенными в контрольном диктанте
1
39
Морфологический разбор причастия
1
40
Слитное и раздельное написание не с причастиями.
1
41
Р/р. Выборочное изложение по упр. 130
1
42
Буквы е и ё после шипящих в суффиксах страдательных причастий прошедшего времени
1
43, 44, 45,
Повторение темы «Причастие»* Переход прич. в прилаг. и сущ.
* Самостоят. работа по теме «Причастие»
1, * 1,1, * 1,
1, * 1
46
Контрольный диктант по теме «Причастие»
1
47
Работа над ошибками, допущенными в контрольном диктанте
1
2 ЧЕТВЕРТЬ (35 уроков)
Деепричастие (10+2)
48
Деепричастие как часть речи
1
49
Морфологические признаки у деепричастия. Признаки глагола и наречия у деепричастия
1
50
Деепричастный оборот. 3пятые при деепричастном обороте
1
51
Раздельное написание не с деепричастиями
1
52
Деепричастия несовершенного вида
1
53
Деепричастия совершенного вида
1
54, 55
Р/р. Сочинение по картине С. Григорьева «Вратарь»
2
56
Морфологический разбор деепричастия
1
57
Повторение темы «Деепричастие»
1
58
Контрольный диктант по теме «Деепричастие»
1
59
Работа над ошибками, допущенными в контрольном диктанте
1
Наречие (28 + 6)
60
Наречие как часть речи
1
61, 62
Смысловые группы наречий
2
63
Способы образования наречий
1
64, 65
Р/р. Контрольное сочинение по картине И. Попова «Первый снег»
2
66, 67
Степени сравнения наречий
2
68
Морфологический разбор наречия
1
69
Контрольный диктант
1
70
Работа над ошибками, допущенными в контрольном диктанте
1
71, 72
Слитное и раздельное написание не с наречиями на -о и -е
2
73, 74
Буквы е и и в приставках не— и ни— отрицательных наречий
2
75
Р/р. Изложение* Р/р Сочинение-рассуждение по видимому тексту
1
76
Одна и две буквы н в наречиях на –о и -е
1
77
Р/р. Описание действий
1
78
Буквы о и е после шипящих на конце наречий
1
79, 80
Буквы о и а на конце наречий
2
81, 82
Р/р. Сочинение по картине Е. Н. Широкова «Друзья»
2
3 ЧЕТВЕРТЬ (50 уроков)
83, 84
Дефис между частями слова в наречиях
2
85, 86
Слитное и раздельное написание приставок в наречиях, образованных от существительных и количественных числительных
2
87
Мягкий знак после шипящих на конце наречий
1
88, 89, 90, 91
Повторение темы «Наречие»
4
92
Контрольная работа по теме «Наречие»
1
93
Работа над ошибками, допущенными в контрольной работе
1
Слово категории состояния (4 +2)
94, 95
Категория состояния как часть речи
2
96
Морфологический разбор категории состояния
1
97
Р/р. Изложение
1
98
Повторение темы «Категория состояния»
1
99
Р/р. Сочинение на лингвистическую тему
1
100
Служебные части речи
1
Предлог (11 +2)
101
Предлог как часть речи
1
102
Употребление предлогов
1
103
Непроизводные и производные предлоги
1
104
Простые и составные предлоги
1
105
Морфологический разбор предлога
1
106, 107
Р/р. Сочинение по картине А.В. Сайкиной «Детская спортивная школа»
2
108, 109
Слитное и раздельное написание производных предлогов
2
110, 111
Повторение темы «Предлог»
2
112
Контрольный диктант по теме «Предлог»
1
113
Работа над ошибками, допущенными в контрольном диктанте
1
Союз (16+2)
114
Союз как часть речи
1
115
Простые и составные союзы
1
116
Союзы сочинительные и подчинительные
1
117, 118
Запятая в сложном предложении
2
119, 120
Сочинительные союзы
2
121, 122
Подчинительные союзы
2
123
Морфологический разбор союза
1
124, 125
Р/р. Сочинение-рассуждение
2
126, 127
Слитное написание союзов также, тоже, чтобы
2
128, 129
Повторениетемы«Союз»
2
130
Контрольный диктант по теме «Союз»
1
131
Работа над ошибками, допущенными в контрольном диктанте
1
Частица (18 + 4)
132
Частица как часть речи
1
4 ЧЕТВЕРТЬ (38 уроков)
133
Разряды частиц. Формообразующие частицы
1
134, 135, 136
Смысловые частицы
3
137
Р/р. Сочинение «Как мне стать чемпионом»
1
138, 139
Раздельное и дефисное написание частиц
2
140, 141
Р/р. Сочинение по картине К.Ф. Юона «Конец зимы. Полдень»
2
142
Морфологический разбор частиц
1
143, 144
Отрицательные частицы не и ни
2
145, 146
Различение частицы и приставки не-
2
147
Сочинение-рассказ по данному сюжету
1
148
Частица ни, приставка ни-, союз ни-ни
1
149, 150
Повторение темы «Частица»
2
151
Повторение правописания служебных частей речи
1
152
Контрольный диктант по теме «Частица»
1
153
Работа над ошибками, допущенными в контрольном диктанте* Повторение по теме «Служебные части речи»
1
Междометие (3 + 1)
154
Междометие как часть речи
1
155
Дефис в междометиях и знаки препинания при междометиях
1
156
Урок-игра по теме «Междометие»
1
157, 158
Р/р. Изложение
2
Повторение (11 +2)
159
Разделы науки о языке
1
160
Текст. Стили речи
1
161, 162
Р/р. Сочинение по теме «Дело мастера боится»
2
163
Фонетика и графика
1
164
Лексика и фразеология
1
165
Словообразование
1
166
Повторение. Морфология
1
167
Повторение. Орфография
1
168
Контрольный итоговый диктант
1
169
Повторение. Синтаксис и пунктуация
1
170
Итоговое тестирование
1
I четверть
Урок 1
Поделитесь с Вашими друзьями:
Кто писал за Шекспира? • Arzamas
Убийства, вскрытия гробниц, подделки и подлоги, призванные доказать, что произведения Шекспира писал не Шекспир
Автор Дмитрий Иванов
О жизни и творчестве Уильяма Шекспира сохранились десятки исторических документов. Он был хорошо известен своим современникам как поэт и драматург, чьи сочинения неоднократно издавались и цитировались в стихах и прозе. Обстоятельства его рождения, образование, образ жизни Подавляющее число драматургов были выходцами из ремесленных семей (Шекспир — сын перчаточника, Марло — сын сапожника, Бен Джонсон — сын каменщика и т. д.). Из детей ремесленников в Англии еще в XV веке пополнялись актерские труппы (возможно, это связано со средневековой традицией постановки мистерий, в которых принимали участие ремесленные гильдии). В целом театральная профессия предполагала неаристократическое происхождение. В то же время уровень образования у Шекспира был достаточным для этого занятия. Он прошел обычную грамматическую школу (тип английиской школы, где преподавали античные языки и литературу), но она давала всё для профессии драматурга. — все соответствовало тому времени, когда профессия драматурга еще считалась низкой, но театры уже приносили своим владельцам немалый доход. Наконец, Шекспир был и актером, и автором пьес, и пайщиком театральной труппы, он почти двадцать лет провел репетируя и выступая на сцене. Несмотря на все это, до сих пор ведутся споры, был ли Уильям Шекспир автором пьес, сонетов и поэм, опубликованных под его именем. Сомнения впервые возникли в середине XIX века. С тех пор на свет появилось множество гипотез, приписывающих авторство шекспировских произведений кому-то еще.
Именами Бэкона, Оксфорда, Ратленда, Дерби и Марло список потенциальных кандидатов в Шекспиры, конечно, не ограничивается. Всего их насчитывается несколько десятков, в том числе такие экзотические, как королева Елизавета, ее преемник король Яков I Стюарт, автор «Робинзона Крузо» Даниэль Дефо или английский поэт-романтик Джордж Гордон Байрон. Но, в сущности, неважно, кого именно те или иные «исследователи» считают подлинным Шекспиром. Важнее понять, почему именно Шекспиру раз за разом отказывают в праве называться автором своих произведений.
Дело не в том, что о жизни Шекспира якобы ничего достоверно не известно. Напротив, после 200 лет разысканий о Шекспире собрано поразительно много свидетельств, и сомневаться в авторстве его сочинений не приходится: для этого нет решительно никаких исторических оснований.
Для сомнений, однако, есть основания эмоционального свойства. Мы — наследники романтического перелома, произошедшего в европейской культуре в начале XIX века, когда возникли новые представления о творчестве и фигуре поэта, неизвестные прежним столетиям (не случайно первые сомнения в Шекспире зародились именно в 1840-е годы). В самом общем виде это новое представление можно свести к двум взаимосвязанным чертам. Первая: поэт гениален во всем, в том числе в обычной жизни, и существование поэта неотделимо от его творчества; он резко отличается от обычного обывателя, его жизнь подобна яркой комете, которая летит быстро и так же быстро сгорает; его с первого взгляда невозможно спутать с человеком непоэтического склада. И вторая: что бы этот поэт ни писал, он всегда будет говорить о себе, об уникальности своего существования; любое его произведение будет исповедью, в любой строчке отразится вся его жизнь, корпус его текстов — его поэтическая биография.
Шекспир не укладывается в подобное представление. В этом он схож со своими современниками, но лишь ему выпало стать, перефразируя Эразма, драматургом на все времена. Мы не требуем, чтобы по законам романтического искусства жили Расин, Мольер, Кальдерон или Лопе де Вега: мы чувствуем, что между нами и ними стоит барьер. Творчество Шекспира способно этот барьер преодолевать. Следовательно, с Шекспира и спрос особый: в глазах многих он должен соответствовать нормам (а точнее, мифам) нашего времени.
Впрочем, от этого заблуждения имеется надежное лекарство — научное историческое знание, критический подход к расхожим представлениям века. Шекспир не хуже и не лучше своего времени, а оно не хуже и не лучше других исторических эпох — их не надо приукрашивать или переделывать, их надо постараться понять.
Arzamas предлагает шесть самых долгоживущих версий того, кто мог писать за Шекспира.
Версия № 1
Фрэнсис Бэкон (1561–1626) — философ, писатель, государственный деятель
1 / 2
Фрэнсис Бэкон. Гравюра Уильяма Маршалла. Англия, 1640 годNational Portrait Gallery, London
2 / 2
Делия Бэкон. 1853 годWikimedia Commons
Дочь разорившегося поселенца из американского штата Коннектикут Делия Бэкон (1811–1859) была не первой, кто пытался приписать сочинения Шекспира перу Фрэнсиса Бэкона, но широкую публику познакомила с этой версией именно она. Ее вера в собственное открытие была так заразительна, что знаменитые писатели, к которым она обращалась за помощью, — американцы Ральф Уолдо Эмерсон, Натаниел Готорн и британец Томас Карлайл — не могли ей отказать. Благодаря их поддержке Делия Бэкон приехала в Англию и в 1857 году опубликовала 675-страничную «Подлинную философию пьес Шекспира». В этой книге говорилось, что Уильям Шекспир был всего лишь неграмотным актером и жадным дельцом, а пьесы и стихи под его именем сочиняла группа «высокородных мыслителей и поэтов» во главе с Бэконом — якобы таким образом автор «Нового органона» рассчитывал обойти цензурные ограничения, не дававшие ему открыто излагать свою новаторскую философию (о том, что в елизаветинской Англии пьесы также подвергались цензуре, Делия, видимо, ничего не знала).
Впрочем, автор «Подлинной философии» никаких подтверждений в пользу своей гипотезы не представила: доказательства, считала Делия, лежат либо в могиле Фрэнсиса Бэкона, либо в могиле Шекспира. С тех пор многие антишекспирианцы уверены, что настоящий автор распорядился похоронить рукописи «шекспировских» пьес вместе с собой, и если их найти, то вопрос будет решен раз и навсегда В свое время это привело к настоящей осаде исторических захоронений по всей Англии. Делия первой обращалась за разрешением вскрыть могилу Бэкона в Сент-Олбани, правда, безуспешно..
Идеи Делии нашли множество последователей. В качестве доказательств они предъявляли мелкие литературные параллели между сочинениями Бэкона и Шекспира, вполне объяснимые единством письменной культуры того времени, — а также то, что автор шекспировских пьес имел вкус к философии и был осведомлен о жизни ряда европейских королевских домов Например, это наваррский двор, изображенный в комедии «Бесплодные усилия любви»..
Разворот из книги Фрэнсиса Бэкона «О достоинстве и преумножении наук» с примером двухлитерного шифра. Лондон, 1623 год Folger Shakespeare LibraryСущественным развитием первоначальной гипотезы можно считать попытки разгадать «шифр Бэкона». Дело в том, что Фрэнсис Бэкон работал над усовершенствованием методов стеганографии — тайнописи, которая на взгляд непосвященного человека выглядит как полноценное сообщение со своим собственным смыслом В частности, он предложил метод шифрования букв английского алфавита, напоминающий современный двоичный код.. Бэконианцы уверены, что их герой писал пьесы под маской Шекспира вовсе не ради успеха у публики — «Ромео и Джульетта», «Гамлет» и «Король Лир», «Двенадцатая ночь» и «Буря» служили прикрытием для некоего тайного знания.
Версия № 2
Эдуард де Вер (1550–1604), 17-й граф Оксфордский, — придворный, поэт, драматург, покровитель искусств и наук
Эдуард де Вер. Копия утраченного портрета 1575 года. Неизвестный художник. Англия, XVII век National Portrait Gallery, LondonПростой учитель английского языка, называвший себя потомком графов Дерби, Томас Лоуни (1870–1944) не верил, что «Венецианского купца» Эту пьесу Лоуни из года в год читал с учениками в классе. мог написать человек неблагородного происхождении, никогда не бывавший в Италии. Усомнившись в авторстве комедии о Шейлоке, Лоуни взял в руки антологию елизаветинской поэзии и обнаружил, что поэма Шекспира «Венера и Адонис» (1593) написана той же строфой и тем же размером, что и стихотворение Эдуарда де Вера «Женская изменчивость» (1587). Де Вер, 17-й граф Оксфордский, мог похвастать древностью рода и хорошим знакомством с Италией, был известен современникам не только как поэт, но и как автор комедий (не сохранившихся).
В 1920 году Лоуни выпустил книгу «Опознанный Шекспир», которая нашла немало поклонников, хотя дата смерти графа — 1604 год — отрезает от шекспировского канона целый ряд поздних пьес, в том числе «Короля Лира», «Макбета», «Антония и Клеопатру», «Зимнюю сказку» и «Бурю». Впрочем, Лоуни нашел выход: якобы Оксфорд, умирая, оставил целый ворох незаконченных рукописей, впоследствии завершенных кем-то грубо
и наспех Правда, автору «Опознанного Шекспира» пришлось исключить из канона «Бурю», слишком явно привязанную к историческим событиям второй половины 1600-х годов.. Последователи Лоуни, чтобы избежать некоторых противоречий в датировке пьес, постарались их передатировать.
Лоуни не скрывал дилетантского характера своих исследований и даже гордился им: «Вероятно, проблема все еще не решена именно потому, — писал он в предисловии к „Опознанному Шекспиру“, — что до сих пор ею занимались ученые». Позже оксфордианцы То есть последователи версии Лоуни. Название получили по титулу Эдуарда де Вера, графа Оксфордского. решили призвать на помощь юристов: в 1987 и 1988 годах в присутствии судей Верховного суда США и лондонского Миддл Темпла соответственно последователи гипотезы Лоуни вступили в открытый диспут с шекспироведами (в Лондоне им, в частности, противостоял самый почтенный из ныне живущих специалистов по Шекспиру профессор Стэнли Уэллс). К несчастью для организаторов, судьи оба раза присудили победу ученым. Зато оксфордианцам удалось потеснить бэконинацев — на сегодняшний день оксфордианская версия антишекспиризма является наиболее популярной.
Среди самых известных последователей Лоуни был психиатр Зигмунд Фрейд, который в молодые годы склонялся к бэконианству, а в 1923 году, после знакомства с «Опознанным Шекспиром», перешел в оксфордианство. Так, в 1930-х годах Фрейд стал развивать параллели между судьбой короля Лира и биографией графа Оксфордского: у обоих было по три дочери, и если английский граф о своих совсем не заботился, то легендарный британский король, по контрасту, отдал своим дочерям все, что имел. Бежав от нацистов в Лондон в 1938 году, Фрейд написал Лоуни теплое письмо и назвал его автором «замечательной книги», а незадолго до смерти на основании того, что Оксфорд в детстве потерял горячо любимого отца и якобы возненавидел мать за ее следующий брак, приписал Гамлету Эдипов комплекс.
Версия № 3
Роджер Мэннерс (1576–1612), 5-й граф Ратленд, — придворный, покровитель искусств
Роджер Мэннерс, 5-й граф Ратленд. Портрет работы Иеремии ван дер Эйдена. Около 1675 года Belvoir Castle / Bridgeman Images / FotodomБельгийский политик-социалист, преподаватель французской литературы и писатель-символист Селестен Дамблон (1859–1924) заинтересовался шекспировским вопросом, узнав о документе, обнаруженном в одном из семейных архивов в 1908 году. Из него следовало, что в 1613 году дворецкий Фрэнсиса Мэннерса, 6-го графа Ратленда, заплатил крупную сумму «господину Шекспиру» и его коллеге-актеру Ричарду Бербеджу, которые придумали и нарисовали на графском щите остроумную эмблему, чтобы Мэннерс достойно предстал на рыцарском турнире. Это открытие насторожило Дамблона: он обратил внимание, что старший брат Фрэнсиса, Роджер Мэннерс, 5-й граф Ратленд, умер в 1612 году — практически тогда же, когда Шекспир перестал писать для сцены. Кроме того, Роджер Мэннерс находился в дружеских отношениях с графом Саутгемптоном (аристократом, которому Шекспир посвятил две свои поэмы и которого считают главным адресатом шекспировских сонетов), а также с графом Эссексом, чье падение в 1601 году косвенно затронуло и актеров театра «Глобус» В феврале 1601 года Эссекс попытался поднять восстание против королевы. Накануне сторонники графа уговорили актеров поставить старую хронику Шекспира «Ричард II», в которой речь шла о свержении монарха. Восстание провалилось, Эссекс был казнен (его обвинителем выступил Фрэнсис Бэкон). Саутгемптон надолго попал в тюрьму. Актеров «Глобуса» вызывали для объяснений, но никаких последствий для них это не имело.. Мэннерс путешествовал по странам, служившим местом действия для многих шекспировских пьес (Франция, Италия, Дания), и даже учился в Падуе вместе с двумя датчанами, Розенкранцем и Гильденстерном (широко распространенные датские фамилии того времени). В 1913 году Дамблон обобщил эти и другие рассуждения в написанной по-французски книге «Лорд Ратленд — это Шекспир».
Обложка книги «Игра об Уильяме Шекспире, или Тайна Великого Феникса» Издательство «Международные отношения»У версии Дамблона есть последователи и в России: так, Илья Гилилов Илья Гилилов (1924–2007) — литературовед, писатель, ученый секретарь Шекспировской комиссии Российской академии наук на протяжении почти трех десятков лет., автор книги «Игра об Уильяме Шекспире, или Тайна Великого Феникса» (1997), утверждал, что за Шекспира сочиняла группа авторов во главе с юной женой графа Ратленда Елизаветой — дочерью прославленного придворного, писателя и поэта Филипа Сидни. Гилилов при этом основывался на совершенно произвольной передатировке Честеровского сборника, включающего стихотворение Шекспира «Феникс и Голубь» (1601, по мнению Гилилова, — 1613). Он утверждал, что Ратленд, Елизавета и другие сочиняли пьесы и сонеты в сугубо конспирологических целях — чтобы увековечить свой тесный круг, в котором справлялись какие-то лишь им ведомые ритуалы. Ученый мир, за исключением нескольких резких отповедей, книгу Гилилова проигнорировал.
Версия № 4
Уильям Стэнли (1561–1642), 6-й граф Дерби, — драматург, государственный деятель
1 / 2
Уильям Стэнли, 6-й граф Дерби. Портрет работы Уильяма Дерби. Англия, XIX векThe Right Hon. Earl of Derby / Bridgeman Images / Fotodom
2 / 2
Абель Лефранк. Около 1910-х годовLibrary of Congress
Историк французской литературы, специалист по Франсуа Рабле Абель Лефранк (1863–1952) впервые задумался о шансах Уильяма Стэнли стать кандидатом в «настоящие Шекспиры» после выхода книги уважаемого английского исследователя Джеймса Гринстрита под названием «Прежде неизвестный благородный автор елизаветинских комедий» (1891). Гринстриту удалось обнаружить письмо от 1599 года за подписью Джорджа Феннера, тайного агента католической церкви, в котором говорилось, что граф Дерби не может быть полезен католикам, так как «занят сочинением пьес для простых актеров».
В 1918 году Лефранк опубликовал книгу «Под маской Уильяма Шекспира», в которой признает Дерби куда более подходящим кандидатом в Шекспиры, чем предыдущие претенденты, хотя бы потому, что графа звали Уильям и его инициалы совпадают с шекспировскими. К тому же в частных письмах он подписывался так же, как лирический герой 135-го сонета — Will, а не Wm и не Willm, как это делал сам стратфордский Шекспир на сохранившихся документах. Далее, Дерби был опытным путешественником, в частности, тесно знакомым с наваррским двором.
Неудивительно, полагал Лефранк, что в «Генрихе V» есть несколько обширных вставок на французском языке, которым Дерби хорошо владел. К тому же, полагал специалист по Рабле, знаменитый образ Фальстафа был создан под влиянием «Гаргантюа и Пантагрюэля», в шекспировское время еще не переведенного на английский язык.
При всей остроумности этих рассуждений у дербианской версии было мало шансов встать вровень с оксфордианской: книга Лефранка была написана по-французски, и к тому времени, когда она вышла, Томас Лоуни (кстати, называвший себя потомком графа Дерби), уже выдвинул свои доводы в пользу Эдуарда де Вера.
Версия № 5
Кристофер Марло (1564–1593) — драматург, поэт
Предполагаемый портрет Кристофера Марло. Неизвестный художник. 1585 год Corpus Christi College, CambridgeСын сапожника, родившийся в один год с Шекспиром и сумевший закончить Кембридж лишь благодаря щедрости архиепископа Кентерберийского, Кристофер Марло оказался чуть ли не единственным кандидатом в Шекспиры неблагородного происхождения. Впрочем, Келвин Хоффман (1906–1986), американский рекламный агент, поэт и драматург, выпустивший в 1955 году книгу «Убийство человека, который был „Шекспиром“», приписал Марло любовную связь с благородным Томасом Уолсингемом, покровителем поэтов и младшим братом могущественного сэра Фрэнсиса Уолсингема, государственного секретаря и начальника тайной службы при королеве Елизавете. По версии Хоффмана, именно Томас Уолсингем, узнав, что Марло грозит арест по обвинению в атеизме и богохульстве, решил спасти возлюбленного, имитировав его убийство. Соответственно, в трактирной ссоре в Дептфорде в 1593 году был убит не Марло, а какой-то бродяга, чей труп выдали за обезображенное тело драматурга (он был убит ударом кинжала в глаз). Сам Марло под чужим именем спешно отплыл во Францию, скрывался в Италии, но вскоре вернулся в Англию, поселившись уединенно неподалеку от Скедбери — имения Томаса Уолсингема в графстве Кент. Там он и сочинял «шекспировские» произведения, передавая рукописи своему покровителю. Тот посылал их сперва переписчику, а потом, для постановки на сцене, лондонскому актеру Уильяму Шекспиру — человеку, начисто лишенному воображения, но верному и молчаливому.
Обложка первого издания книги «Убийство человека, который был „Шекспиром“».1955 год Grosset & Dunlap
Хоффман начал свои изыскания с подсчета фразеологических параллелизмов в сочинениях Марло и Шекспира, а позже познакомился с трудами американского профессора Томаса Менденхолла, составившего «словарные профили» разных писателей (с помощью целой команды женщин, трудолюбиво пересчитавших миллионы слов и букв в словах). На основании этих разысканий Хоффман заявил о полном сходстве стилей Марло и Шекспира. Однако большая часть всех этих «параллелизмов» на поверку таковыми не являлись, другая часть относилась к общеупотребительным словам и конструкциям, а определенный слой явных параллелей свидетельствовал о хорошо известном факте: молодой Шекспир вдохновлялся трагедиями Марло, многому научившись у автора «Тамерлана Великого», «Мальтийского еврея» и «Доктора Фауста» Сегодня можно только гадать, во что вылилось бы творческое соперничество двух елизаветинских гениев, если бы не смерть Марло в 1593 году — кстати, в подробностях зафиксированная королевским коронером, чьи выводы засвидетельствовало жюри из 16 человек..
В 1956 году Хоффман добился разрешения вскрыть склеп Уолсингемов, где он надеялся найти подлинные рукописи Марло — Шекспира, но обнаружил только песок. Однако поскольку трогать собственно гробницы, лежавшие под полом, Хоффману запретили, он заявил, что его гипотеза, не будучи подтверждена, все же и не полностью опровергнута.
Версия № 6
Группа авторов
Уильям Шекспир. Гравюра Джона Честера Баттра. Около 1850 года Folger Shakespeare LibraryПопытки обнаружить за сочинениями Шекспира целую группу авторов предпринимались неоднократно, хотя по поводу какого-то определенного ее состава сторонники этой версии договориться не могут. Вот несколько примеров.
В 1923 году служащий британской администрации в Индии Х. Т. С. Форрест опубликовал книгу под названием «Пять авторов „шекспировских сонетов“», в которой рассказал о поэтическом турнире, устроенном графом Саутгемптоном. За объявленную графом награду в искусстве сочинения сонетов, по мнению Форреста, соревновались сразу пять крупных поэтов елизаветинской эпохи: Сэмюэль Дэниэл, Барнаби Барнс, Уильям Уорнер, Джон Донн и Уильям Шекспир. Соответственно, все пятеро и являются авторами сонетов, которые, полагал Форрест, с тех пор ошибочно приписывали одному Шекспиру. Характерно, что один из этой компании, автор эпической поэмы «Альбионова Англия» Уорнер, совсем не писал сонетов, а другой, Джон Донн, прибегал к форме сонета только для сочинения религиозных стихов.
В 1931 году Гилберт Слейтер, экономист и историк, выпустил книгу «Семь Шекспиров», в которой соединил имена практически всех претендентов, наиболее популярных среди антишекспирианцев. По его версии, в сочинении произведений Шекспира участвовали: Фрэнсис Бэкон, графы Оксфорд, Ратленд и Дерби, Кристофер Марло Слейтер считал, что Марло «возродился» к жизни в 1594 году под именем Шекспира., а также сэр Уолтер Рэли и Мэри, графиня Пемброук (литератор и сестра сэра Филипа Сидни). Женщины нечасто предлагались и предлагаются на роль Шекспира, но для графини Пемброук Слейтер сделал исключение: по его мнению, явным присутствием женской интуиции отмечены «Юлий Цезарь» и «Антоний и Клеопатра», а также — в особенности — «Как вам это понравится», которую Мэри не просто написала, но еще и вывела саму себя в образе Розалинды.
Оригинальную теорию в 1952 году предложил британский подполковник Монтегю Дуглас, автор книги «Лорд Оксфорд и шекспировская группа». По его версии, королева Елизавета доверила графу Оксфорду руководить отделом пропаганды, который должен был выпускать патриотические памфлеты и пьесы. Граф достойно выполнил поручение, собрав под именем Шекспира целый синдикат авторов, в числе которых были вельможи — Фрэнсис Бэкон, граф Дерби — и известные драматурги: Марло, Джон Лили и Роберт Грин. Любопытно при этом, что перу Грина принадлежит один из главных документов, подтверждающих авторство Шекспира, — в памфлете «Крупица ума, сторицей оплаченная раскаянием» (1592), написанном незадолго до смерти, Грин злобно напал на некоего актера — «ворону-выскочку», украшенную «нашим опереньем», который дерзнул составить конкуренцию драматургам предыдущего поколения. Намеренно переиначенная автором памфлета фамилия Shakescene («потрясающий сцену» вместо Shakespeare, «потрясающий копьем») и чуть измененная цитата из третьей части «Генриха VI» не оставляют сомнений в том, в кого Грин мечет сатирические молнии. Впрочем, версия подполковника Дугласа хромает не только в этом пункте: если исторические хроники Шекспира еще можно (с очень большой натяжкой) считать подходящими для патриотического воспитания подданных, то зачем было отделу пропаганды возиться с «Ромео и Джульеттой», не говоря уже о «Гамлете» и «Отелло», решительно непонятно.
Помогите пожалуйста разобрать по составу слова:ЗАМАЗКА,ЗАПИСКА,ЗАЙЧИХА И ЗАБАВА?
Смеется-смеясь суффикс сь.
Споткнется никак не поставить в сь, здесь суффикс ся.
Пройтись суффикс сь.
Пройтись суффикс сь.
Повернуться-повернусь суффикс сь.
Сложное слово споткнется начальная форма: споткнуться.
По-приставка , друж -корень , и, ть, ся суффикс . Подружишься -основание , окончание нулевое
Вчера яблоневое дерево в нашем саду дало новый расточек.
Герань- комнатное растение.
Главным образом термин «отрасль» применяется к экономике.
Заросли джунглей порой бывают непроходимы.
«Счастья в жизни нет, есть только зарницы его» (знаменитая цитата)
Вскоре он перестал касаться земли.
Вновь повторилось жгучее прикосновение холодного ветра.
Это предложение,пожалуй, меня заинтересовало.
Не нужно предпологать.
Утренняя Заря выводит на небесный свод его белых коней, а Вечерняя Заря на закате принимает их.
1. Я так быстро научился плавать благодаря своим способностям.
2. Я укрепил свое здоровье благодаря закаливанию.
3. Я всегда готов к ответу у доски благодаря тому, что учу все уроки.
4. Я знаю так много фактов из истории русского языка благодаря чтению дополнительной литературы.
Лодка, подплывающая к берегу, была полна людей.
Цветок, растущий на клумбе, вдруг завял.
Пруд, заросший камышами, был живописен.
Мальчик. решивший задачу, получил хорошую отметку.
Стол, сломанный вечером, уже отремонтировали.
— как говорящий «разбирает» свои комментарии?
Трудно отклонить это как совпадение, учитывая, что Коэн — юрист и тщательно проанализировал его комментариев в этой ситуации. Он регулярно предлагал то, что казалось отрицанием, но не отрицал полностью деталей того, о чем писал журнал.
Адвокат Трампа только что замешал Трампа в выплате Сторми Дэниэлса?
Что здесь означает parse ?
Я видел подобное использование в журналистике, где:
- Это больше относится к выражению (или даже к продукту выражения), а не к анализу.
- Иногда имеет значение уклончиво , запутать или притвориться .
Для меня традиционное определение здесь не совсем подходит:
Коэн — юрист, и тщательно изучил / проанализировал (подробно) его комментариев в этой ситуации.
Но я тоже не могу придумать синонима авторского значения.
Другое применение
Самые ранние , которые он проанализировал свои слова , которые я нашел, относятся к 1998 году:
Буш тщательно проанализировал свои слова , в отличие от рожденного свыше христианина.
Таких стало много с 2000 года (спасибо @GetzelR). Я слышу, что они почти идентичны . Он тщательно подбирал слова .
Но есть несколько похожих на мой оригинальный отрывок.
Re. Описание политического изгнания (2004):
Аристид очень ясно дал понять, что то, что произошло на Гаити, было современным похищением […] Он был зол и решителен, очень прямолинеен и никогда не разобрал своих слов ».
Re.Позиция Теда Круза по иммиграции (2015):
Как ловкий адвокат, Круз разбирал свои слова по вопросу об амнистии
[…] Как можно догадаться, достоверность заявления Круза во многом зависит от того, что он подразумевает под «легализацией».
Re. Запрет президента Трампа на поездки — это не запрет на поездки (2017 г.):
Спайсер появился перед СМИ после первого распоряжения и изо всех сил попытался проанализировать слов .[…] «Это не запрет. Это нужно для того, чтобы убедиться, что люди, которые приходят, проверены должным образом … запрет будет означать, что люди не могут войти ».
Re. Вступительные показания Джеймса Коми (2017):
Лексическая категорияЯ думаю, что в этой формулировке найдется что-то для всех. Там достаточно, чтобы республиканцы напали на бывшего директора Коми и защищали президента, и там достаточно для демократов, чтобы защитить бывшего директора Коми и напасть на президента.[…] Там много парсинга слов.
— обзор
5.2.1 Обзор ресурсов, разработанных для обработки сербского языка
Для обработки сербского языка было разработано множество ресурсов, которые могут быть использованы для целей нашего исследования, но многие из них быть измененным или улучшенным. Большая часть этих ресурсов была разработана в системе Unitex [22], а часть из них была адаптирована для системы GATE [23].
Система Unitex — это система с открытым исходным кодом, разработанная Себастьеном Помье в Институте Гаспара-Монж, Университет Парижа в Марн-ла-Валле, в 2001 году. Это система обработки корпуса, основанная на автоматизированной технологии, которая находится в постоянном развитии. Система используется во всем мире для задач НЛП, поскольку она обеспечивает поддержку ряда различных языков и многоязычных задач обработки.
Одной из основных частей системы являются электронные словари типа DELA (Dictionnaires Electroniques du Laboratoire d’Automatique Documentaire et Linguistique или электронные словари LADL), которые представлены на рис.2. Система состоит из словарей DELAS (простые формы DELA) и DELAF (DELA флективных форм). Словари DELAS — это словари простых слов, не изменяемых форм, в то время как словари DELAF содержат все изменяемые формы простых слов. С другой стороны, система содержит словари составных DELAC (DELA составных форм) и словари складываемых составных форм DELACF (DELA составных склонных форм).
Рис. 2. Система электронных словарей DELA.
Морфологические словари в формате DELA были предложены в Лаборатории автоматической документации и лингвистики под руководством Мориса Гросса. Формат словарей DELA подходит для решения задач сегментации текста и морфологической, синтаксической и семантической обработки текста. Подробнее о формате DELA можно найти в [24].
Морфологические электронные словари в формате DELA представляют собой простые текстовые файлы. Каждая строка в этих файлах содержит запись слова и измененную форму слова.Другими словами, каждая строка содержит лемму слова и некоторую грамматическую, семантическую и флективную информацию.
Пример записи из словаря DELAF на английском языке: « таблицы, таблица.N + Conc: p ». Флективная форма таблицы является обязательной, таблица является леммой записи, а N + Conc представляет собой последовательность грамматической и семантической информации (N обозначает существительное, а Conc обозначает, что это существительное — конкретный объект), p — флективный код, который указывает на то, что существительное является множественным числом.
Словари этого типа для сербского языка разрабатываются группой НЛП на математическом факультете Белградского университета. Согласно [21], нынешний объем сербского морфологического словаря DELAS (простых слов) содержит 130 000 лемм. Большинство лемм из словаря DELAS относятся к общей лексике, а остальные относятся к разным видам простых имен собственных. Словарь DELAF содержит около 4 300 000 словоформ с заданными грамматическими категориями.Размер словарей DELAC и DELACF составляет примерно 10 500 и 54 000 лемм соответственно.
Аналогичный пример записи из сербского словаря простых словоформ с соответствующим грамматическим и семантическим кодом: padao, padati. V + Imperf + It + Iref: Gms, где словоформа padao является единственным (S) мужским родом (M) активного причастия прошедшего времени (G) глагола (V) padati «падать», который несовершенное (Imperf), непереходное (It) и рефлексивное (Iref).
Другой тип ресурсов, разработанный для сербского языка, — это различные типы конечных преобразователей. Конечные преобразователи используются для выполнения морфологического анализа, а также для распознавания и аннотирования фраз в текстах прогнозов погоды с соответствующими тегами XML, такими как ENAMEX, TIMEX и NUMEX, как мы объясняли ранее.
Пример графа конечного преобразователя для распознавания временных выражений и их аннотации с помощью тегов TIMEX представлен на рис. 3. Этот граф конечного преобразователя может распознавать последовательность « 14.01.2012 . » из текста нашего примера прогноза погоды и аннотируйте его тегом TIMEX, чтобы его можно было извлечь в форме «DATE_TIME: 14.01.2012.»
Рис. 3. Граф преобразователя с конечным числом состояний для извлечения и аннотирования временных выражений.
Другая система, которая больше подходит для решения проблемы IE (и CM), — это бесплатное программное обеспечение с открытым исходным кодом GATE (общая архитектура для текстовой инженерии). Система GATE или некоторые из ее компонентов уже используются для ряда различных задач НЛП на нескольких языках.Система GATE — это архитектура и среда разработки для приложений НЛП. GATE разрабатывается NLP Group Университета Шеффилда с 1995 года.
Архитектура GATE состоит из трех частей: языковые ресурсы, ресурсы обработки и визуальные ресурсы. Эти компоненты независимы, поэтому с системой могут работать разные типы пользователей. Программисты могут работать над разработкой алгоритмов для НЛП или настраивать внешний вид визуальных ресурсов для своих нужд, в то время как лингвисты могут использовать алгоритмы и языковые ресурсы без каких-либо дополнительных знаний о программировании.
Визуальные ресурсы, графический пользовательский интерфейс, останется в исходной форме для целей данного исследования. Это позволит визуализировать и редактировать языковые ресурсы и ресурсы обработки. Языковые ресурсы для этого исследования включают корпуса текстов прогнозов погоды на нескольких языках и концептуальную модель прогноза погоды, которая будет построена. Необходимые изменения Ресурсов обработки, особенно модификации для применения к обработке сербских текстов, представлены ниже.
Задача IE в GATE встроена в систему ANNIE (почти новое извлечение информации). Подробную информацию об ANNIE можно найти в [25]. Система ANNIE включает в себя следующие ресурсы обработки: Tokeniser, Sentence Splitter, POS (часть речи) tagger, Gazetteer, Semantic Tagger и Orthomatcher. Каждый из перечисленных ресурсов создает аннотации, необходимые для следующего ресурса обработки в списке:
- •
Tokeniser разбивает текст на токены (слова, числа, символы, белые шаблоны и знаки препинания).Токенизатор можно использовать для обработки текстов на разных языках с небольшими изменениями или без них.
- •
Sentence Splitter сегментирует текст на предложения, используя каскады конечных преобразователей. Он также не зависит от приложения и языка.
- •
POS Tagger назначает тег части речи (тег лексической категории, например, существительное, глагол) в форме аннотации к каждому слову. Английская версия POS Tagger, входящая в систему GATE, основана на тэггере Brill.Это не зависящий от приложения, но зависящий от языка ресурс, который должен быть полностью изменен для сербского языка.
- •
Другой ресурс, зависящий от языка, но зависящий от приложения, — это Gazetteer, который содержит списки городов, стран, личных имен, организаций и т. Д. Gazetteer использует эти списки для аннотирования появления элементов списка в текстах. .
- •
Semantic Tagger основан на языке JAPE (Java Annotations Pattern Engine) [26].JAPE выполняет конечную обработку аннотаций на основе регулярных выражений, и его важной характеристикой является то, что он может использовать концептуальные модели (онтологии).
Semantic Tagger включает набор грамматик JAPE, где каждая грамматика состоит из набора фаз, а каждая фаза представляет собой набор правил. Кроме того, правила содержат левую и правую стороны. Левая сторона (LHS) правила описывает шаблон аннотации, который обычно распознается на основе операторов регулярного выражения Клини.Правая сторона (RHS) правила описывает действие, которое должно быть предпринято после того, как LHS распознает шаблон, например, создание новой аннотации. Это ресурс, зависящий от приложения и языка.
- •
Orthomatcher идентифицирует отношения между именованными объектами, обнаруженными Semantic Tagger. Он создает новые аннотации на основе отношений между именованными объектами. Это независимый от приложения и языка ресурс.
Основная цель — разработать ресурсы, зависящие от языка или приложения (Gazetteer, POS Tagger и Semantic Tagger) для сербского языка.Путь, который мы выбрали для решения этой проблемы, — использовать ранее описанные ресурсы, разработанные для системы Unitex, и адаптировать их для использования в системе GATE. Изменение списков географического справочника — это простой процесс перевода с одного языка на другой. Построение грамматик JAPE с поддержкой онтологий для области прогноза погоды требует первоначальной разработки соответствующего подъязыка и концептуальной модели, которые будут обсуждаться в следующем подразделе в качестве предмета текущих исследований авторов.Проблема создания подходящего POS Tagger очень сложна и не будет здесь подробно описываться.
Вкратце, мы сделали оболочку для Unitex, поэтому ее можно использовать непосредственно в системе GATE для создания электронных словарей для заданных текстов прогноза погоды и механизма для создания соответствующей аннотации POS Tagger для каждого слова. Это решение проблемы, хотя и имеет несколько недостатков, может стать хорошей основой для создания семантических тегов, основанных на концептуальных моделях и системах IE в целом.
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов.Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. А так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется слишком много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа.Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это побудило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его преобразованием в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа.Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я рад, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Алгоритм— Как разобрать список слов по упрощенной грамматике?
Вот рабочий пример Haskell. Оказывается, нужно изучить несколько приемов, прежде чем вы сможете заставить его работать! Нулевая вещь, которую нужно сделать, — это шаблон: отключить ужасное ограничение мономорфизма, импортировать некоторые библиотеки и определить некоторые функции, которых нет в библиотеках (но должны быть):
{- # LANGUAGE NoMonomorphismRestriction # -}
Контроль импорта.Аппликативный ((<*))
импорт Control.Monad
импортировать Text.ParserCombinators.Parsec
убедитесь, что p x = guard (p x) >> return x
singleToken t = tokenPrim id (\ pos _ _ -> incSourceColumn pos 1) (убедитесь (== t))
anyOf xs = выбор (карта singleToken xs)
Теперь, когда нулевая вещь сделана … сначала мы определяем тип данных для наших абстрактных синтаксических деревьев. Здесь мы можем просто проследить за формой грамматики. Однако, чтобы было удобнее, я учел некоторые грамматические правила; в частности, два правила
NP => N | Det N | Det Adj N
VB => V | V НП
, когда дело доходит до написания синтаксического анализатора, более удобно записать:
NP => N | Det (Adj | пусто) N
VB => V (NP | пусто)
В любой хорошей книге по синтаксическому анализу есть глава о том, почему такой вид факторинга является хорошей идеей.Итак, тип АСТ:
данные Предложение
= Сложное NounPhrase VerbPhrase
| Простой VerbPhrase
data NounPhrase
= Сокращенное Существительное
| Длинная статья (Может быть, прилагательное) Существительное
данные VerbPhrase
= VerbPhrase Глагол (может быть, существительное)
type Noun = String
тип Verb = String
type Article = String
type Прилагательное = Строка
Тогда мы можем сделать наш парсер. Этот еще больше следует (разложенной) грамматике! Единственная проблема здесь в том, что мы всегда хотим, чтобы наш синтаксический анализатор обрабатывал все предложение, поэтому мы должны явно попросить его сделать это, потребовав «eof» — или конец «файла».
s = (liftM2 Комплексный np vp <|> liftM Simple vp) <* eof
np = liftM Short n <|> liftM3 Long det (optionMaybe adj) n
vp = liftM2 VerbPhrase v (optionMaybe np)
n = anyOf [«я», «ты», «автобус», «торт», «медведь»]
v = anyOf ["обнимать", "любить", "разрушать", "я"]
det = anyOf ["a", "the"]
adj = anyOf ["розовый", "стильный"]
Последняя часть — токенизатор. Для этого простого приложения мы просто разметим на основе пробелов, поэтому встроенная функция слов работает нормально.Давай попробуем! Загрузите весь файл в ghci:
* Main> parse s "stdin" (слова "я люблю розовый торт")
Справа (Комплекс (Короткое «i») (VerbPhrase «любовь» (Просто (Длинное «the» (Просто «розовый») «торт»))))
* Главная> разобрать s "stdin" (слова "я люблю розовый торт")
Левый "stdin" (строка 1, столбец 3):
неожиданный "розовый"
ожидая окончания ввода
Здесь справа указывает на успешный синтаксический анализ, а слева указывает на ошибку. Номер «столбца», указанный в ошибке, на самом деле является номером слова, в котором произошла ошибка, из-за того, как мы вычисляем исходные позиции в singleToken .
(PDF) LSTM Easy-first Dependency Parsing with Pre-обученные вложения слов и встраивания слов на уровне символов на вьетнамском языке
Таблица III
ВЬЕТНАМСКИЕ РЕЗУЛЬТАТЫ ПАРСИРОВАНИЯ ЗАВИСИМОСТИ НА РАЗНЫХ ПАРСЕРАХ
Model Gold POS Tag Auto POS Tag
LAS% UAS% LAS%BistT 79,33 72,53 76,56 68,22
BistG 79,39 73,17 76,28 68,40
Easy-first (Word + POS) 79,29 71,44 77,51 68,27
+ Char 80,58 72,95 78,01 68,01 68.82
+ Skip-gram 79,69 72,23 76,91 67,77
+ Char 80,91 72,98 78,26 69,04
+ Подслово 79,50 71,94 77,16 67,96
+ Char 80,56 72,37 78,13 68,56
Использование дополнительных символов на уровне
для встраивания слов
Формированиеповышает точность синтаксического анализатора easy-first (0,79%
UAS и 1,51% LAS). Замена встраивания слов
встраиванием слов на уровне символов показывает небольшое увеличение производительности парсера
(0.39% UAS и 0,09% LAS).
Эти результаты показывают, что использование встраивания слов на уровне символов
может повысить точность синтаксического анализа.
Использование предварительно обученного слова em-
как пропуска граммы, так и подслова увеличивает точность синтаксического анализатора. Несмотря на то, что
разница в охвате словаря между skip-граммом и
подсловом велика (40%), точность парсера, использующего skip-
грамм, только выше, чем подслово на 0,16%. Мы обнаружили, что в наших тестовых данных
разница в покрытии токена (процент токена
в тестовых данных, который появляется в предварительно обученных встраиваниях слов)
между двумя наборами данных составляет всего 5% (75.39% для скип-грамма и
70,95% для подслова).
Среди всех функций, которые мы применили к парсеру Tree LSTM easy-first
, наилучший результат синтаксического анализа дает комбинация встраивания слов + встраивания POS-тегов
+ встраивание слов на уровне символов + встраивание предварительно обученных слов
(80,91% UAS и
72,98% LAS). Наша модель превзошла парсер BistG
и показала самые современные характеристики на VnDT.
V. ЗАКЛЮЧЕНИЕ
Мы продемонстрировали эффективность встраивания слов
перед обучением и встраивания слов на уровне символов в качестве функций для
Vietnamese easy-first dependency parsing.
В будущей работе мы хотели бы обучить встраиванию слов
уровня символа в более крупные корпуса и использовать его в качестве предварительно обученных функций
, например, предварительно обученных встраиваний слов.
VI. ПОДТВЕРЖДЕНИЕ
Это исследование финансируется Университетом информационных технологий —
nology — Вьетнамским национальным университетом Хошимина в рамках гранта
номер D1-2017-13.
ССЫЛКИ
[1] Nivre, Joakim, et al. ”CoNLL 2007 разделяет задачу на зависимости pars-
ing.”Труды Совместной конференции 2007 г. по эмпирическим методам
в обработке естественного языка и вычислительному естественному языку
Learning (EMNLP-CoNLL). 2007.
[2] Seddah, Djam ´
e, Sandra K¨
ubler и Reut Tsarfaty. «Представляем общую задачу
spmrl 2014 по синтаксическому анализу морфологически насыщенных языков».
Труды первого совместного семинара по статистическому синтаксическому анализу мор-
фологически богатых языков и синтаксическому анализу неканонических
языков.2014.
[3] Бухгольц, Сабина и Эрвин Марси. «Совместная задача CoNLL-X по синтаксическому анализу многоязычных
зависимостей». Труды Десятой конференции по компьютерному изучению естественного языка
. Ассоциация компьютерной лингвистики
, 2006.
[4] Макдональд, Райан и Жоаким Нивр. «Описание ошибок моделей анализа зависимостей, управляемых данными
». Труды Совместной конференции
2007 г. по эмпирическим методам обработки естественного языка и
вычислительного обучения естественному языку (EMNLP-CoNLL).2007.
[5] Чиу, Джейсон П.К. и Эрик Николс. «Распознавание именованных лиц с помощью
двунаправленных LSTM-CNN». Препринт arXiv arXiv: 1511.08308 (2015).
[6] Богданау, Дмитрий, Кёнхён Чо и Йошуа Бенджио. «Машинный перевод Neural
путем совместного обучения согласованию и переводу». arXiv
препринт arXiv: 1409.0473 (2014).
[7] Нивр, Йоаким, Йохан Холл и Йенс Нильссон. ”Maltparser: управляемый данными генератор синтаксического анализа
для анализа зависимостей.”Труды LREC. Vol. 6.
2006.
[8] Суцкевер, Илья, Ориол Виньялс, Куок В. Ле. «Последовательность для последовательности
обучения с помощью нейронных сетей». Достижения в области нейронной обработки информации —
информационных систем. 2014.
[9] Дайер, К., Баллестерос, М., Линг, В., Мэтьюз, А., и Смит, Н. А.
(2015). Анализ зависимостей на основе переходов со стеком длинной краткосрочной памяти
. Препринт arXiv arXiv: 1505.08075.
[10] Баллестерос, М., Дайер, К., Голдберг, Ю., и Смит, Н. А. (2017). Greedy
Анализ зависимостей на основе переходов со стеком lstms. Вычислительная
Лингвистика, 43 (2), 311-347.
[11] Кипервассер, Элияху и Йоав Голдберг. «Простой первый анализ зависимостей
с иерархическим деревом LSTM». Препринт arXiv arXiv: 1603.00375
(2016).
[12] Кипервассер, Элиягу и Йоав Голдберг. ”Простой и точный анализ зависимости
плотности с использованием двунаправленных представлений функций LSTM.”ArXiv
препринт arXiv: 1603.04351 (2016).
[13] Баллестерос, Мигель, Крис Дайер и Ноа А. Смит. «Улучшен синтаксический анализ
на основе переходов путем моделирования символов вместо слов с помощью
lstms». Препринт arXiv arXiv: 1508.00657 (2015).
[14] Thi, Luong Nguyen, et al. «Создание банка деревьев для вьетнамской зависимости —
анализ плотности». Вычислительные и коммуникационные технологии, исследования,
Инновации и видение будущего (RIVF), 2013 Национальная конференция IEEE RIVF Inter-
по.IEEE, 2013.
[15] Нгуен, Д.К., Нгуен, Д.К., Фам, С.Б., Нгуен, П.Т., и Ле
, Нгуен, М. (2014, июнь). От преобразования банка деревьев к автоматическому синтаксическому анализу зависимостей
для вьетнамского языка. В Международной конференции
Приложения естественного языка к базам данных / информационным системам
(стр. 196-207). Спрингер, Чам.
[16] Нгуен, Киет В. и Нган Луу-Туи Нгуен. ”Вьетнамский переход —
анализ зависимостей с функциями супертэга.”Знание и
Системная инженерия (KSE), Восьмая международная конференция 2016 г.
IEEE, 2016. 175-180). IEEE.
[17] Ву-Ман, К., Луонг, А. Т., и Ле-Хонг, П. (2015, декабрь). Im-
доказательство разбора зависимостей на вьетнамском языке с использованием распределенных представлений слов
. В материалах шестого международного симпозиума
Информационные и коммуникационные технологии (стр. 54-60). ACM.
[18] Нгуен, Д. К., Драс, М., и Джонсон, М.(2016). Эмпирическое исследование
для анализа вьетнамской зависимости. Труды австралийского семинара
Ассоциации языковых технологий, 2016 г., стр. 143–149. Получено
с http://www.aclweb.org/anthology/U16-1017
[19] Голдберг, Йоав и Майкл Эльхадад. «Эффективный алгоритм для первого ненаправленного синтаксического анализа зависимостей easy-
». Human Language Technolo- gies —
gies: Ежегодная конференция североамериканского отделения в 2010 г.
Ассоциации компьютерной лингвистики.Ассоциация компьютерной лингвистики
, 2010.
[20] Ма, Джи и др. «Простая маркировка pos и анализ зависимостей с поиском по лучу
». Труды 51-го ежегодного собрания Ассоциации компьютерной лингвистики
(Том 2: Краткие статьи). Vol. 2. 2013.
[21] Баллестерос, М., Дайер, К., и Смит, Н.А. (2015). Улучшенный парсинг на основе перехода
путем моделирования символов вместо слов с помощью lstms. arXiv
препринт arXiv: 1508.00657.
[22] Goldberg, Y., & Nivre, J. (2012). Динамический оракул для разбора зависимостей arc-eager
. Труды COLING 2012, 959-976.
[23] Mikolov, Tomas, et al. «Распределенные представления слов и словосочетаний
и их композиционность». Достижения в области нейронной обработки информации
систем. 2013.
[24] Bojanowski, Piotr, et al. «Обогащение векторов слов подсловной информацией.» Препринт arXiv arXiv: 1607.04606 (2016).
ожидание, байесовская оценка и анализ «достаточно хорошо»
Trends Cogn Sci. Авторская рукопись; доступно в PMC 2019 25 октября.
Опубликован в окончательной отредактированной форме как:
PMCID: PMC6814003
NIHMSID: NIHMS1054897
Департамент психологии, Калифорнийский университет, Дэвис, 1 Шилдс-авеню, Дэвис, Калифорния 95616, США
Окончательная отредактированная версия этой статьи издателем доступна в Trends Cogn Sci. См. Другие статьи в PMC, в которых цитируется опубликованная статья.Abstract
Процессы синтаксического анализа устанавливают зависимости между словами в предложении. Эти зависимости влияют на то, как понимающие приписывают значение составным частям предложения. Классические подходы к синтаксическому анализу полностью описывают его как восходящий анализ сигналов. Более поздние подходы отводят понимающему более активную роль, позволяя индивидуальному опыту, знаниям и убеждениям понимающего влиять на его или ее интерпретацию. В этом обзоре описываются разработки в трех связанных аспектах исследования обработки предложений: упреждающая обработка, байесовские / шумно-канальные подходы к обработке предложений и гипотеза «достаточно хорошего» синтаксического анализа.
Ключевые слова: синтаксис , синтаксический анализ, теорема Байеса, зашумленные каналы, достаточно хороший синтаксический анализ
Синтаксический синтаксический анализ: тогда и сейчас
Синтаксический синтаксический анализ представляет собой набор мыслительных процессов, которые устраняют разрыв между уровнем слова и дискурсом. уровень семантических процессов. Эти процессы интерфейса служат для построения или восстановления зависимостей между словами в строке [1–5] (см. [6,7] о роли синтаксиса и грамматики в производстве). Структурные зависимости, концептуальная информация, предоставляемая словами содержания, и принципы, определяющие, как тематические назначения ролей выводятся из грамматических функций, определяют стандартную буквальную интерпретацию, назначаемую предложению.Возьмем, к примеру, содержательные слова «смущение», «медсестра» и «доктор». Этих слов недостаточно, чтобы понять, кто что сделал с кем (или как, когда и где). Синтаксические подсказки и процессы синтаксического анализа предоставляют информацию, необходимую для определения того, кто что и кому сделал. Хотя значение, присвоенное данному высказыванию, зависит от множества факторов, ни одна теория понимания языка не может быть полной без учета синтаксиса (или грамматики) и синтаксического анализа.
Психолингвисты давно обсуждают, в какой степени синтаксис и синтаксический анализ представляют собой автономную модульную подсистему в рамках более широкого набора процессов языкового производства и понимания [8–11]. Преобладающее мнение состоит в том, что, хотя есть аспекты синтаксического анализа, которые не могут быть включены в другие уровни обработки (например, лексические или дискурсивные процессы), существуют сильные взаимодействия между синтаксическими процессами и другими аспектами лингвистической интерпретации (например,, предшествующий лингвистический контекст, параллельная просодия) и между синтаксическими процессами и аспектами познания за пределами строго лингвистических систем [3,12–15]. Примеры аспектов интерпретации, которые требуют синтаксических вычислений, включают упаковку фраз (включение или исключение слов из фраз), решения о присоединении модификатора (в случаях, когда модифицирующее выражение может принадлежать только одному из набора предыдущих слов) и определение тета домены и назначение тематических ролей (см. Глоссарий), среди прочего [16–19].
Все согласны с тем, что синтаксис играет важную роль в выводе значений, но произошел сдвиг от строго восходящих, последовательных, инкапсулированных представлений о языковой интерпретации к более интерактивным учетным записям. Три группы взаимосвязанных событий меняют взгляд психолингвистов на интерпретацию языка в целом и природу процессов синтаксического анализа в частности. К ним относятся относительно недавний упор на процессы прогнозирования или упреждения, применение байесовской оценки вероятности к пониманию языка и изменение взглядов на понимание языка через призму удовлетворительной или достаточно хорошей обработки [20–25].
Роль предвкушения
Устный перевод происходит быстро и постепенно [26,27]. Понимающие могут определить семантические и синтаксические характеристики слова и его отношение к предшествующему контексту в течение нескольких сотен миллисекунд после встречи с ним. Любая учетная запись, которая предполагает, что обработка происходит строго снизу вверх (анализ сигналов, за которым следует распознавание слов и лексический доступ, за которым следует синтаксический анализ, за которым следует интеграция новой информации с предыдущим синтаксическим и семантическим контекстом), сильно ограничена скоростью на котором понимающие могут получить доступ к подробной информации о вновь встреченных словах.Один из способов объяснить невероятно быстрый и постепенный характер интерпретации — это предположить, что понимающие предвосхищают предстоящий ввод, а не пассивно ждут, пока сигнал развернется, а затем реагируют на него. Результаты различных экспериментальных парадигм показывают, что понимающие различают более вероятные и менее вероятные продолжения. При чтении более предсказуемые слова пропускаются чаще, чем менее предсказуемые [28–30]. Эксперименты с визуальным миром также показывают, что понимающие активно предвидят или предсказывают неизбежное появление еще не встреченной информации [20].В этих экспериментах с визуальным миром участники просматривают массив, содержащий изображения различных объектов (например, торта, девушки, трехколесного велосипеда и мыши). При просмотре массива участники слушают предложения. Если предложение начинается с фразы «Маленькая девочка будет ездить …», участники будут делать движения глаз в сторону изображения трехколесного велосипеда даже до смещения глагола «ездить». Однако это не просто рефлекс, основанный на ассоциации между поездкой и трехколесным велосипедом. Если визуальный ряд включает в себя маленькую девочку, мужчину, трехколесный велосипед и мотоцикл, участники делают упреждающие движения глаз в сторону трехколесного велосипеда, когда слушают «Маленькая девочка будет ездить»… ’. Однако они совершают упреждающие движения к мотоциклу в том же визуальном ряду, если подлежащее существительное — «человек» (например, «Мужчина будет ездить …»). Связанные с событием потенциальные эксперименты показывают, что контексты, поддерживающие предсказание, производят меньшие ответы N400, чем менее поддерживающие контексты, даже когда внутрилексическая ассоциация поддерживается постоянной [31].
Подобные результаты показывают, что, по крайней мере, в средах обработки, где небольшое количество референтов делается визуально заметными, участники способны определить, как предложение будет продолжаться.Эти прогнозы могут относиться к тому, какое понятие, вероятно, будет упомянуто далее, но они могут быть даже более конкретными. Например, исследование ДеЛонга и его коллег [32], связанное с потенциальным событием, предоставило доказательства того, что понимающие ожидали фонологической формы предстоящей пары слов (определитель и существительное). Кроме того, кажется, что участники действуют в соответствии с этими предсказаниями до того, как они получат окончательные восходящие доказательства, подтверждающие или опровергающие предсказание (т. Е. Когда контекст делает одно продолжение более вероятным, чем другие, глаза фиксируют изображение, представляющее вероятное продолжение, до того, как понимающий услышит слово, которое относится к этому объекту).
Хотя исследователи согласны с тем, что ожидание и предсказание происходят во время интерпретации предложений, точные средства, с помощью которых понимающие получают предсказания, в настоящее время не совсем понятны. Следовательно, нам нужны учетные записи, которые могут рассказать нам, как делаются прогнозы, что, в свою очередь, скажет нам, почему одни прогнозы делаются, а другие нет. Гипотезы о том, как делаются прогнозы, включают использование производственной системы для имитации говорящего [33,76], использование внутрилексической активации распространения [34] или использование схематического знания событий [35].Простая гипотеза ассоциации слова и слова становится менее правдоподобной из-за экспериментов, показывающих, что синтаксические факторы влияют на реакцию на слово, когда лексическая ассоциация с предыдущим контекстом остается постоянной [36]. Кроме того, слова, которые не соответствуют синтаксически управляемой тематической роли, не пользуются преимуществом обработки просто потому, что они связаны с другими словами содержания в предложении [37]. Например, слово топор прочно ассоциируется с существительным лесорубом. Несмотря на эту сильную ассоциацию, топор обрабатывается не быстрее, чем обычно, во фрейме предложения «Лесоруб рубил топор».Интересно, что нейрофизиологический ответ на слово, которое связано с другими словами содержания в предложении, изменяется в зависимости от контекста предшествующего дискурса [31,38–41]. Когда контекст дискурса активирует схему событий, которая включает в себя конкретное понятие, слово, относящееся к этому понятию, вызовет меньшую реакцию N400, даже если это слово не подходит для непосредственного синтаксического контекста. Следовательно, представления знаний о событиях, а не простое лексическое совпадение, по-видимому, предоставляют понимающим основу для получения прогнозов.
Байесовская оценка и зашумленные каналы
Понимающие могут предвидеть неизбежное появление определенных лексических элементов, относящихся к активированным представлениям событий. Исследования синтаксических процессов показывают, что понимающие также могут предвидеть структурные свойства предложений до того, как восходящие сигналы предоставят окончательные доказательства за или против данной структурной гипотезы. Идея о том, что на синтаксический синтаксический анализ может влиять вероятность или вероятность определенных синтаксических структур, на самом деле существует уже давно [2,3,42].Trueswell и его коллеги были одними из первых, кто предоставил доказательства того, что условная вероятность структурного анализа в данном контексте влияет на нагрузку обработки, налагаемую на понимающего [10,43]. Точное время и природа вероятностных влияний трактуются по-разному в разных интерпретациях синтаксического анализа [19,44–46].
Более поздние эксперименты показывают, что на распознавание слов влияет соответствие между профилем распределения категории слова и предшествующим синтаксическим контекстом [47].Слово, которое неоднозначно относится к существительному или глаголу (например, карта, вращение), может чаще использоваться как существительное или как глагол, или может одинаково часто встречаться в каждой категории. Слова с предвзятым отношением к существительным требовали больше времени, чтобы распознать их в минимальном контексте, который благоприятствовал значению глагола («to card»), в то время как противоположное было верно для неоднозначных слов с предвзятым отношением к глаголам («вращение»). Несколько исследований показывают, что лексическая статистика, присущая отдельным словам в предложении (например, частота, с которой глагол встречается с прямым объектом по сравнению с дополнением предложения), влияет на время, необходимое для синтаксического анализа предложения.Есть также свидетельства того, что синтаксический контекст, в котором появляется слово, влияет на лексическую обработку (распознавание слова / лексическое решение). Подразумевается, что лексические и синтаксические уровни обработки накладывают ограничения друг на друга, а не то, что один уровень имеет полный приоритет над другим.
Предыдущие исследования показывают, что понимающие предвидят, как выражения будут продолжаться (в терминах понятий, которые могут быть упомянуты, форм, которые будут использоваться для обозначения этих понятий, и синтаксических структур, которые могут быть выражены).Создание таких прогнозов влечет за собой привилегированные концепции, которые имеют отношение к описанной ситуации, а также может повлечь за собой ожидание неизбежного появления определенных слов. Точно так же понимающие могут развивать гипотезы, которые дают некоторым синтаксическим структурам преимущество перед другими в упреждающей манере. Информация, которая в некотором роде более предсказуема или более актуальна, будь то лексическая, концептуальная или структурная, должна активироваться сильнее, чем другие виды информации. В этом случае понимающий должен иметь какие-то средства для определения того, что более вероятно, а что менее вероятно.Недавние подходы к обработке предложений включают три утверждения, относящиеся к предсказанию. Во-первых, у понимающих нет достоверного внутреннего представления входных данных [48,49]. Во-вторых, понимающие используют всю доступную информацию для вычисления вероятности различных интерпретаций с учетом сигналов, имеющихся во входных данных [21,24,50–54]. В-третьих, неудачные предсказания — важный фактор в онлайн-реакции на ввод и в способе получения знаний о языке [50]. Неожиданные отчеты предполагают, что информационная ценность данного слова в предложении является функцией его вероятности в контексте.Слова с относительно меньшей вероятностью несут больше информации, чем слова с большей вероятностью. При прочих равных, менее вероятные (более удивительные) слова приводят к большим изменениям в базе знаний, которая используется для получения прогнозов (см. [55,56] для соответствующего подхода).
Во многих случаях интерпретация, полученная из «низкокачественного» представления входных данных, будет соответствовать предполагаемому значению говорящего, но в других случаях предварительное знание понимающих приведет к систематическим искажениям в интерпретации.Эти искажения могут возникать из-за того, что интерпретация зависит не только от сигнала. Интерпретация также зависит от того, насколько понимающий знает, что вероятно, а что нет, до прихода сигнала. Байесовский механизм должен учитывать информацию о базовой скорости при получении оценок вероятности. Понимающие объединяют базовую информацию (насколько вероятна данная интерпретация при отсутствии каких-либо доказательств) с информацией, доступной в стимуле, чтобы ранжировать интерпретации от более вероятных к менее вероятным.Если сигнал зашумлен или передается по зашумленному каналу, интерпретация будет систематически смещена в сторону более высокочастотной интерпретации.
Формулировка Гибсона с коллегами этого типа объяснения вводит идею о том, что степень воспринимаемого шума и предположения о видах искажений, которые могут возникнуть из-за шума, влияют на интерпретации, которые понимающие приписывают предложениям [24]. Учитывая, что канал передачи зашумлен, понимающий может предположить, что в сигнале отсутствует компонент.Шум не обязательно должен быть чисто экологическим. «Внутренний шум» может быть вызван невниманием, отвлечением, усталостью или скукой. Эти внутренние факторы влияют на скорость восприятия информации, а также на характер и качество долговременной памяти для языкового ввода [57–59].
Компреендеры с меньшей вероятностью предполагают, что что-то было ложно добавлено к сигналу. Это приводит к предсказаниям о том, как понимающие будут реагировать на определенные типы предложений, которые (если сигнал воспринимается точно) являются аномальными.Например, если человек услышал или прочитал «Мать дала свечу девушке», это будет менее неприятно, чем слушание или чтение «Мать дала девушку свечке» (хотя лицензированная интерпретация одинакова в обоих случаях). В первом случае предложение можно «исправить», если предположить, что шум уничтожил часть сигнала между «свечой» и «этим». Шум — менее правдоподобное объяснение аномалии во втором предложении. Гибсон и его коллеги показали, что показатель отклонения, основанный на количестве и типах правок, необходимых для того, чтобы сделать семантически аномальное предложение правдоподобным, дает точные оценки степени, в которой участники оценили бы аномальное предложение как правдоподобное.Эти различия в приемлемости не предсказываются счетом, согласно которому понимающие всегда воспринимают предложение точно.
Подобные предположения могут учитывать другие эффекты синтаксической сложности [60] и эффекты помех, основанные на подобии [60,61]. Интерференция, основанная на памяти, основана на идее, что ментальные представления могут мешать друг другу и что более схожие ментальные представления интерферируют друг с другом в большей степени, чем менее схожие представления. Это напоминает систематическое неправильное восприятие, которое, как предполагается, лежит в основе ошибок интерпретации в сообщениях с зашумленным каналом.«Доктор» и «юрист» может быть трудно различить на семантическом уровне точно так же, как «в» и «как» трудно различить на фонологическом уровне. Сторонники шумного канала утверждают, что последняя проблема объясняет явления обработки в определенном типе сложного предложения «садовая дорожка» [62]. Структуры, которые предъявляют более высокие требования к памяти, могут быть более восприимчивыми к помехам (внутренним или внешним). Точно так же шум может иметь большее влияние, когда два представления более похожи с точки зрения их фонологии (например,g., кошелек медсестры) или значение (например, врач – адвокат), чем когда они более отчетливы (медсестра – сумочка, доктор – хомяк) [63].
Проблемы для моделей с зашумленным каналом
Хотя байесовская оценка и гипотезы зашумленного канала учитывают различные эмпирические явления, остается неясным, можно ли вычислить, полученные для конкретных типов предложений, с вычислительной точки зрения для естественного языка в более широком смысле. Это происходит из-за комбинаторного взрыва, который происходит для любой системы, которая должна вычислять интерпретации, как для сигнала, так и для ближайших соседей в разных измерениях (фонологических, лексических, синтаксических) и разных размерах зерна [64].Байесовские подходы к синтаксическому анализу предполагают, что понимающий должен вычислять и оценивать не только синтаксические структуры и интерпретации, которые могут быть присвоены точно воспринимаемой строке, но также и всех ближайших соседей, которые будут получены при редактировании строки. Учитывая количество возможных лексических, структурных и семантических замен, количество вычисленных интерпретаций будет астрономическим. Однако могут быть способы ограничить пространство поиска, чтобы пространство последовательно включало предполагаемую интерпретацию, не требуя вычисления и оценки огромного количества альтернативных интерпретаций [65].
Леви [49] отметил, что байесовские модели каналов с шумом сталкиваются с проблемой предсказания и объяснения широкого спектра экспериментальных результатов по широкому спектру задач и типов предложений. Байесовские модели каналов с шумом могут сопротивляться расширению по нескольким причинам. В настоящее время большая часть эмпирических данных в пользу моделей с шумным каналом исходит из приговоров, своего рода «автономной» задачи. Автономные задачи — это задачи, которые измеряют последствия понимания, а не сам процесс понимания.Учетная запись с полным покрытием должна иметь возможность обрабатывать результаты как офлайн, так и онлайн. Во-вторых, непонятно, почему система, которой безразлична точная природа сигнала, будет надежно и очень быстро обнаруживать грамматические ошибки. Однако, как отмечают Филлипс и Льюис, понимающие «обнаруживают практически любую лингвистическую аномалию в течение нескольких сотен миллисекунд после появления аномалии во входных данных» ([66], с. 19). В-третьих, некоторые онлайн-доказательства гипотезы о зашумленном канале получены из очень ограниченных сред обработки.Например, в статье Леви и его коллег о сокращенной обработке относительных предложений основное внимание уделяется возможности того, что понимающие могут ошибочно воспринять слово «at» как слово «as» [62]. Понимающие часто неверно истолковывают такие предложения, как «Тренер улыбнулся игроку, который бросил фрисби», как означающие, что игрок бросил фрисби (грамматика допускает, что кто-то подбросил игроку фрисби). Модель с шумным каналом приписывает это неверное толкование неправильному восприятию предложения (люди слышат это как «Тренер улыбнулся , так как игрок бросил фрисби»).В эксперименте 2009 года все экспериментальные предложения имели сокращенные относительные придаточные предложения в позиции объекта, и всем им предшествовало слово «at». Тем не менее, трудности с обработкой и неправильная интерпретация могут остаться, даже если слово «at» будет заменено различными другими словами (улыбнулся рядом …, улыбнулся перед …, с тоской улыбнулся в сторону …), которые не так путают с ‘ as ‘, хотя соответствующий эксперимент не проводился. Наконец, как отмечают Пилкканнен и МакЭлри, любой вид недостаточной спецификации, включая модели зашумленного канала, может быть не в состоянии объяснить, как конструируются новые значения в первую очередь ([67], с.540). Системы интерпретации, основной функцией которых является распознавание образов, без некоторых важных дополнений не обладают способностью присваивать значения незнакомым образцам. Также, вероятно, нецелесообразно предполагать синтаксическую недостаточную спецификацию в производстве, поскольку говорящие должны в конечном итоге выбрать один набор морфосинтаксических и фонологических форм для любого данного предложения [6,7]. Понимание и производство не обязательно должны действовать в точности одинаково, но есть существенные доказательства того, что совместное представление и аналогичные, если не идентичные процессы построения синтаксической структуры во время производства и понимания [68].
Удовлетворение
Байесовские подходы / подходы с шумовым каналом к синтаксическому анализу предполагают, что интерпретация может быть основана не на произведенном сигнале, а на приближении сигнала понимающим. Это приближение зависит как от реплик, извлеченных из сигнала, так и от предшествующих представлений о событиях, от того, что говорящие могут сказать об этих событиях, и от того, как они могут структурировать свои выражения. Эти предположения в значительной степени, если не полностью, совместимы с целым рядом исследований, основанных на гипотезе достаточно хорошего синтаксического анализа [22,23,69].Феррейра и его коллеги обнаружили, что понимающие часто получали значения, несовместимые с грамматически лицензированными интерпретациями временно синтаксически неоднозначных предложений, а также предложений, которые были однозначными. Например, участники интерпретировали выражение «Пока Мэри одевала ребенка, играла на полу» как означающее, что Мэри одевала ребенка. Это значение не подтверждается сигналом (лицензионное значение состоит в том, что Мэри одевалась сама). Понимающие также систематически неверно истолковывают семантически аномальные предложения (предложения, для которых лицензионное значение неправдоподобно), особенно когда синтаксическая структура менее частая или неканоническая.Понимающие будут склонны интерпретировать предложение пассивного голоса «Мышь съела сыр» как означающее, что мышь съела сыр. Эта тенденция сильнее, чем для предложений с активным голосом, таких как «Сыр съел мышь» (). Есть также некоторые свидетельства того, что понимающие не разрешают синтаксические двусмысленности, связанные с присоединением модификаторов, если это специально не предлагается сделать с помощью вопросов на понимание [70], хотя этот эффект различается в кросс-лингвистическом плане и может зависеть от емкости рабочей памяти понимающих [71,72] .Поскольку интерпретации понимающих в этих исследованиях систематически склонялись к правдоподобным значениям, эти результаты предлагают четкую демонстрацию эффектов предшествующих знаний и убеждений. То есть они указывают на то, что аномальные интерпретации не принимаются, даже если синтаксис предложения дает четкие указания на то, что аномальное значение было задумано. Таким образом, результаты напрямую совместимы с байесовским / шумным канальным подходом к интерпретации предложений.
Архитектура обработки, в которой лексическая информация по умолчанию переопределяет синтаксически полученные значения, отображается слева.Согласно этим предположениям, синтаксис вычисляется, а затем игнорируется в пользу лексически полученных значений. Правая сторона показывает, как мог бы получиться аналогичный результат интерпретации, если бы полностью отказаться от синтаксических вычислений.
Эти результаты сами по себе не различают две гипотезы, касающиеся синтаксического и семантического анализа. Во-первых, понимающие вычисляли синтаксическую форму, продиктованную доступными подсказками, выводили семантические интерпретации из синтаксической формы, а затем отклоняли эти значения, поскольку они противоречили предыдущим убеждениям (т.е. мыши едят сыр, а не наоборот). Во-вторых, семантические интерпретации были получены из лексического содержания предложений без использования синтаксически управляемого тематического назначения ролей. Эта последняя гипотеза синтаксической недостаточной спецификации была бы совместима с предложением зашумленного канала (то есть понимающие получают приблизительный набор структур для данной строки). Однако недавняя работа, связанная с реакцией понимающих на возвратные местоимения, ставит под сомнение гипотезу синтаксической недостаточной спецификации [73].Читая предложения, похожие на «После того, как банкир позвонил, отец / мать Стива забеспокоились и дали себе пять дней на ответ», читатели продемонстрировали влияние гендерного несоответствия на рефлексивное местоимение «сам». Это означает, что читатели проводили больше времени, когда местоимение (он сам) не совпадало с полом предыдущего существительного (мать).
Этот эффект несовпадения должен возникать только в том случае, если понимающие построили детальную синтаксическую структуру предложения (на основе предыдущих исследований влияния структуры предложения на со-ссылку) [14,61].Эти результаты предполагают, что понимающие не недооценивают синтаксическую форму, но что правдоподобные семантические интерпретации, полученные в начале предложения, не всегда смещаются на основе более поздних событий обработки [74–76]. Следовательно, хотя понимающие могут отдавать предпочтение разумным интерпретациям менее разумным (основанным на общих знаниях мира или контекстуально предоставленной информации), это не означает, что синтаксические структуры не вычисляются или не способствуют интерпретации предложений. Если это верно, возможно, потребуется изменить допущение о недостаточном синтаксисе зашумленного канала.Если бы предположение о множественных активациях синтаксической структуры, взвешенных по частоте и сходству с сигналом, было отброшено, потребовалось бы другое объяснение эффектов расстояния редактирования. Возможно, такие эффекты могут быть результатом процессов восстановления, которые предполагаются в описаниях синтаксического повторного анализа или самоконтроля и самокоррекции во время производства речи. Согласно такому подходу, понимающие будут строить и оценивать одну синтаксическую структуру за раз. Когда эта структура приводила к ошибочной интерпретации, понимающие предпринимали изменения синтаксической структуры или правки на основе слов (например,g., «сыр» заменяется на «главный»), чтобы согласовать интерпретации на уровне слова, синтаксисе и на уровне предложения.
Открытые вопросы
Гипотеза байесовского / шумного канала отвечает на несколько вопросов о том, как строятся прогнозы. Например, это указывает, что условная вероятность различных синтаксических интерпретаций вычисляется путем комбинирования информации базовой скорости с оценкой вероятности, управляемой сигналом. Другие вопросы о том, как составляются прогнозы, остаются без ответа.Делаются ли прогнозы поэтапно или прогнозирование работает как неявный лексический отбор, когда в конечном итоге выбирается один кандидат? Зависит ли предсказание от подражания говорящему или писателю? Если так, то можно было бы ожидать, что принуждение понимающих к скрытой артикуляции нарушит процесс предсказания. Другой набор вопросов касается того, в какой степени для предсказания требуются свободные ресурсы внимания и рабочей памяти. Если прогноз зависит от бесплатных ресурсов, можно ожидать увидеть индивидуальные различия.Понимающие с лучшим исполнительным контролем или большей емкостью оперативной памяти должны делать больше предсказаний и предсказывать с большим успехом, чем постигающие с меньшими ресурсами. Индивидуальные различия также могут быть обнаружены в том, как понимающие приобретают знания, которые определяют оценки априорной вероятности. Учитывая, что байесовский учет обращается к базовой оценке информации как к фактору, влияющему на предсказание, разные понимающие с разной степенью восприятия языкового ввода должны делать разные прогнозы или, по крайней мере, делать одни и те же прогнозы с разной степенью достоверности.Учитывая, что знания о событиях используются в прогнозах [39], понимающие с разной степенью опыта в данной области контента должны получать разные прогнозы, основанные на их различных концептуальных представлениях о предметной области. Здесь снова ресурсы могут быть важным фактором. Если сбор априорных значений является бесплатным и автоматическим, простое знакомство с шаблонами в языке должно привести к предварительным оценкам вероятности, которые близко соответствуют шаблонам для всего языка. Если, однако, корректировка априорных значений зависит от несоответствия между прогнозируемыми и наблюдаемыми входными данными, если создание прогноза требует эмуляции говорящего, и если все это требует некоторой степени внимания, простое воздействие не приведет к получению базовой информации или изменений. в существующих оценках априорной вероятности.Если это так, то связанные с задачей факторы, влияющие на глубину обработки, могут играть важную роль в сборе и модификации информации базовой скорости [70,77]. Все эти вопросы потребуют тщательного изучения, прежде чем можно будет с уверенностью предъявить претензии.
Заключительные замечания
Классические описания синтаксического анализа представляют его как в значительной степени реактивный процесс. Согласно этим классическим представлениям, слова идентифицируются, вычисляются синтаксические зависимости и структурированные последовательности подвергаются семантическому анализу.Этот восходящий, инкапсулированный взгляд на обработку не предлагает элегантных или ясных объяснений экспериментальным результатам, таким как открытие Альтманна и Камиде о том, что внимание переключается на концепции, которые еще не имеют аналогов в сигнале [20]. Альтернативные подходы включают представление о том, что понимающие используют предшествующие знания, чтобы предсказать, как строка, вероятно, будет разворачиваться, с точки зрения как ее лексического и семантического содержания, так и ее синтаксической структуры. Гипотеза зашумленного канала развивает этот подход, фокусируясь на тех предположениях, которые есть у понимающих относительно искажения сигнала.Байесовские подходы, как и предшествующие лексические подходы к синтаксическому анализу, основанные на ограничениях, предполагают, что синтаксический анализ строки влечет за собой одновременное вычисление и оценку набора структурных и семантических альтернатив. Гипотеза достаточно хорошего синтаксического анализа похожа на байесовские / шумно-канальные отчеты в том смысле, что она предполагает, что предшествующие убеждения понимающих сильно влияют на интерпретацию, полученную для данного предложения. Это предположение подтверждается выводами о том, что понимающие предпочитают правдоподобные незаконные интерпретации неправдоподобным, грамматически обоснованным толкованиям.
Благодарности
Этот проект был поддержан наградами Национального научного фонда (1024003, 0541953) и Национальных институтов здравоохранения (1R01HD073948, MH099327). Автор благодарит доктора Киля Кристиансона и двух анонимных рецензентов за содержательные комментарии к предыдущему проекту.
Глоссарий
| Потенциалы, связанные с событиями (ERP) | , когда нейроны срабатывают, они генерируют электрический ток, который можно обнаружить на коже черепа.Нейронная активность вызывает систематические колебания электрического тока. Эта деятельность возникает в ответ на различные раздражители. Подача стимула приводит к ERP — паттерну электрической активности на коже черепа, которая возникает из-за стимула. |
| Размер зерна | вероятностные счета, включая байесовские / шумные счета, предполагают, что люди отслеживают закономерности в языке. Эти закономерности могут встречаться на разных уровнях специфичности. Например, наиболее распространенная структура в английском языке — это существительное – глагол – существительное (NVN) (субъект – глагол – объект).Это очень большой размер зерна. Однако такой глагол, как чихание, почти никогда не принимает прямого объекта. Чаще всего выражается как существительное – глагол (НВ). Таким образом, при мелком размере зерна чихание наиболее вероятно появится в структуре NV. При большем размере зерна наиболее вероятной структурой является NVN. |
| Лексическая совместимость | некоторые слова чаще встречаются вместе, чем другие; полицейская машина скорее полицейская кошка. |
| Лексический элемент / лексическая обработка | лексический элемент — это примерно одно слово.Лексическая обработка относится к умственным операциям, которые извлекают или активируют сохраненные знания о словах по мере необходимости во время понимания и производства. |
| N400 ответ | N400 является характеристикой мозговых волн. Амплитуда (размер) N400 зависит от того, как часто слово появляется в языке, насколько хорошо значение слова соответствует его контексту, а также от других факторов, которые затрудняют идентификацию и интеграцию слова. |
| Сокращенные относительные предложения | относительные предложения — это выражения, которые изменяют предшествующие существительные.Они часто сигнализируются релятивизатором, таким словом, как «это». Выражение «Кот, который нравится моей сестре», «который нравится моей сестре» является относительным предложением, изменяющим cat. Если бы слово «that» было удалено, относительное предложение было бы сокращенным относительным предложением. |
| Схема | структура знаний в долговременной памяти, которая отражает знания человека об определенном виде событий. Например, схема ресторана кодирует типичных участников, объекты и события, которые происходят, когда человек идет в ресторан. |
| Дополнение предложения | иногда глаголы появляются с целым предложением в качестве аргумента (в отличие, например, от просто существительной фразы). В предложении «Джон знает, что ответ находится в книге», «ответ находится в книге» — это дополнение предложения, которое определяется глаголом «знает». (Что знает Джон? Ответ находится в книге.) |
| Синтаксический анализ | включает в себя набор мысленных операций, которые обнаруживают и используют подсказки в предложениях, чтобы определить, как слова соотносятся друг с другом. |
| Синтаксическая структура | ментальное представление, которое фиксирует зависимости между словами в предложениях. |
| Тематические роли | абстрактные семантические классы, которые фиксируют общие роли, которые множество различных сущностей и объектов играют в разных предложениях. Например, в предложениях «Джон пил молоко» и «Джон тычет медведей» Джон является инициатором описанного действия. Джон — тематический агент. В двух предложениях молоко и медведи находятся на приемной стороне действия, поэтому они тематические пациенты. |
| Тета-домены | согласно Фрейзеру и Клифтону [16] некоторые слова в предложениях назначают тематические роли другим словам в предложении. Тета-домен — это та часть предложения, для которой данное слово назначает тематические роли. |
Ссылки
1. Фрейзер Л. (1979) О понимании предложений: стратегии синтаксического анализа, Клуб лингвистов Университета Индианы [Google Scholar] 2. Ford M и другие. (1982) Теория синтаксического замыкания, основанная на компетенциях, в ментальном представлении грамматических отношений (Bresnan JW, ed.), стр. 727–796, MIT Press [Google Scholar] 3. Макдональд MC и другие. (1994) Лексическая природа разрешения синтаксической неоднозначности. Psychol. Rev 101, 676–703 [PubMed] [Google Scholar] 4. Пикеринг MJ и ван Гомпель RPG (2006) Синтаксический анализ в Справочнике по психолингвистике (2-е изд.) (Traxler MJ и Gernsbacher MA, ред.), Стр. 455–503, Elsevier [Google Scholar] 5. Traxler MJ (2012) Введение в психолингвистику: понимание науки о языке, Wiley – Blackwell [Google Scholar] 6. Феррейра В. и Гриффин З. (2006) Свойства продукции разговорной речи В Справочнике по психолингвистике (2-е изд.) (Тракслер М.Дж. и Гернсбахер М.А., ред.), Стр.21–60, Elsevier [Google Scholar] 7. Levelt WJM (1989) Speaking: From Intention to Articulation, MIT Press [Google Scholar] 8. Altmann GTM и Steedman MJ (1988) Взаимодействие с контекстом во время обработки человеческих предложений. Познание 30, 191–238 [PubMed] [Google Scholar] 10. Trueswell JC и другие. (1993) Глагольные ограничения в обработке предложений: разделение эффектов лексического предпочтения от садовых дорожек. J. Exp. Psychol. Учить. Mem. Cogn 19, 528–553 [PubMed] [Google Scholar] 11. Клифтон С и другие. (2003) Использование тематической ролевой информации при синтаксическом анализе: пересмотр синтаксической автономии обработки.J. Mem. Lang 49, 317–334 [Google Scholar] 12. Федоренко Е и другие. (2009) Структурная интеграция в языке и музыке: свидетельство общей системы. Mem. Cogn 37, 1–9 [PubMed] [Google Scholar] 13. Шафер AJ и другие. (2005) Просодические влияния на производство и понимание синтаксической двусмысленности в игровой задаче беседы В подходах к изучению использования языков в мире: психолингвистические, лингвистические и вычислительные перспективы на стыке традиций продукта и действия (Tanenhaus M и Trueswell J, ред.), стр.209–225, MIT Press [Google Scholar] 14. Шиперс С и другие. (2011) Структурное праймирование в когнитивных областях: от простой арифметики до присоединения относительного предложения. Psychol. Наука 22, 1319–1326 [PubMed] [Google Scholar] 15. Таненхаус МК и другие. (1995) Интеграция визуальной и лингвистической информации при понимании устной речи. Наука 268, 1632–1634 [PubMed] [Google Scholar] 16. Фрейзер Л. и Клифтон С. мл. (1996) Construal, MIT Press [Google Scholar] 17. Фрейзер Л. и Фодор Дж. Д. (1978) Колбасная машина: новая двухступенчатая модель синтаксического анализа.Познание 6, 291–325 [Google Scholar] 18. Джекендофф Р. (2002) Основы языка, Издательство Оксфордского университета [Google Scholar] 19. Traxler MJ и другие. (1998) Дополнительная привязанность не является формой разрешения лексической двусмысленности. J. Mem. Lang 39, 558–592 [Google Scholar] 20. Altmann GTM и Kamide Y (1999) Инкрементальная интерпретация глаголов: ограничение области последующей ссылки. Познание 73, 247–264 [PubMed] [Google Scholar] 21. Коричневый M и другие. (2012) Синтаксис кодирует информационную структуру: свидетельства понимания прочитанного в режиме онлайн.J. Mem. Lang 66, 194–209 [Google Scholar] 22. Феррейра Ф и другие. (2002) Достаточно хорошие представления в понимании языка. Curr. Реж. Psychol. Наука 11, 11–15 [Google Scholar] 23. Феррейра Ф. и Патсон Н.Д. (2007) «Достаточно хороший» подход к пониманию языка. Lang. Лингвист. Компас 1, 71–83 [Google Scholar] 24. Гибсон Э и другие. (2013) Рациональная интеграция зашумленных свидетельств и предшествующих семантических ожиданий в интерпретации предложений. Proc. Natl. Акад. Sci. США 110, 8051–8056 [Бесплатная статья PMC] [PubMed] [Google Scholar] 25.Маховальд К. и другие. (2012) Информация / теория информации: говорящие выбирают более короткие слова в прогнозирующем контексте. Познание 126, 313–318 [PubMed] [Google Scholar] 26. Марслен-Уилсон WD (1973) Лингвистическая структура и речевое затенение с очень короткими задержками. Природа 244, 522–523 [PubMed] [Google Scholar] 27. Марслен-Уилсон В.Д. и Тайлер Л.К. (1975) Структура обработки восприятия предложения. Природа 257, 784–786 [PubMed] [Google Scholar] 28. Райнер К. (1998) Движение глаз при чтении и обработке информации: 20 лет исследований.Psychol. Бык 124, 372–422 [PubMed] [Google Scholar] 29. Райнер К. и Поллацек А. (1989) Психология чтения, Эрльбаум [Google Scholar] 30. Чой В. и Гордон ПК (2014) Пропуск слов во время чтения предложения: влияние лексичности на парафовеальную обработку. Atten. Восприятие. Психофизики 76, 201–213 [Бесплатная статья PMC] [PubMed] [Google Scholar] 31. Lau EF и другие. (2013) Отделение эффектов предсказания N400 от ассоциации в контексте отдельных слов. J. Cogn. Неврологи 25, 484–502 [Бесплатная статья PMC] [PubMed] [Google Scholar] 32.Делонг К и другие. (2005) Вероятностная предварительная активация слова во время понимания речи на основе электрической активности мозга. Nat. Неврологи 8, 1117–1121 [PubMed] [Google Scholar] 33. Пикеринг MJ и Гаррод S (2013) Интегрированная теория языкового производства и понимания. Behav. Brain Sci 36, 329–347 [PubMed] [Google Scholar] 34. Schwanenflugel PJ и LaCount KL (1988) Семантическая взаимосвязь и объем упрощения для следующих слов в предложениях. J. Exp. Psychol. Учить. Mem. Cogn 14, 344–354 [Google Scholar] 35.Шэнк Р. и Абельсон Р.П. (1977) Сценарии, планы, цели и понимание: исследование структур человеческого знания, Эрлбаум [Google Scholar] 36. Моррис Р.К. (1994) Влияние контекста предложения на уровне лексики и сообщения на время фиксации при чтении. J. Exp. Psychol. Учить. Mem. Cogn 20, 92–103 [PubMed] [Google Scholar] 37. Traxler MJ и другие. (2000) Эффекты обработки в понимании предложений: эффекты ассоциации и интеграции. J. Психолингвист. Res 29, 581–595 [PubMed] [Google Scholar] 38. Кемблин СС и другие.(2007) Взаимодействие конгруэнтности дискурса и лексической ассоциации во время обработки предложения: данные ERP и отслеживание взгляда. J. Mem. Lang 56, 103–128 [Бесплатная статья PMC] [PubMed] [Google Scholar] 40. Hess DJ и другие. (1995) Влияние глобального и локального контекста на лексическую обработку во время понимания языка. J. Exp. Psychol. Gen 124, 62–82 [Google Scholar] 41. Traxler MJ и Foss DJ (2000) Влияние ограничения предложения на прайминг в понимании естественного языка. J. Exp. Psychol. Учить.Mem. Cogn 26, 1266–1282 [PubMed] [Google Scholar] 42. Элман Дж. (1991) Распределенные представления, простые рекуррентные сети и грамматическая структура. Мах. Учить 17, 195–225 [Google Scholar] 43. Trueswell JC и другие. (1994) Семантические влияния на синтаксический анализ: использование тематической ролевой информации в разрешении синтаксической неоднозначности. J. Mem. Lang 33, 285–318 [Google Scholar] 44. Пикеринг MJ и другие. (2000) Разрешение неоднозначности в обработке приговоров: доказательства против основанных на частоте счетов. J. Mem. Lang 43, 447–475 [Google Scholar] 45.Пикеринг MJ и Traxler MJ (2003) Доказательства против использования частоты подкатегории при обработке неограниченных зависимостей. Lang. Cogn. Процесс 18, 469–473 [Google Scholar] 46. Ван Гомпель РПГ и другие. (2001) Повторный анализ в обработке приговоров: доказательства против существующих основанных на ограничениях и двухэтапных моделей. J. Mem. Lang 45, 225–258 [Google Scholar] 47. Федоренко Е и другие. (2012) Взаимодействие источников синтаксической и лексической информации в языковой обработке: случай неоднозначности существительного и глагола.J. Cogn. Наука 13, 249–285 [Google Scholar] 48. Леви Р. (2008) Синтаксическое понимание, основанное на ожиданиях. Познание 106, 1126–1177 [PubMed] [Google Scholar] 49. Леви Р. (2008) Модель с зашумленным каналом рационального понимания человеческих предложений при неопределенных входных данных. В материалах конференции 2008 г. по эмпирическим методам обработки естественного языка, стр. 234–243. Ассоциация компьютерной лингвистики [Google Scholar] 50. Hale JT (2001) Вероятностный ранний синтаксический анализатор как психолингвистическая модель. В материалах второго заседания Североамериканского отделения Ассоциации компьютерной лингвистики, стр.159–166. Ассоциация компьютерной лингвистики [Google Scholar] 51. Hale JT (2011) Что бы сделал рациональный синтаксический анализатор. Cogn. Наука 35, 399–443 [Google Scholar] 52. Jaeger FT и Snider NE (2013) Выравнивание как следствие адаптации ожидания: на синтаксическое прайминг влияет ошибка предсказания простого числа с учетом как предыдущего, так и недавнего опыта. Познание 127, 57–83 [Бесплатная статья PMC] [PubMed] [Google Scholar] 56. Чанг Ф и другие. (2012) Языковая адаптация и обучение: откровение о неявном обучении.Lang. Лингвист. Компас 6, 259–278 [Google Scholar] 57. Райхле ЭД и другие. (2010) Движения глаз при бездумном чтении. Psychol. Наука 21, 1300–1310 [PubMed] [Google Scholar] 59. Школьник JW и другие. (2011) Мета-осознание, разъединение восприятия и блуждающий разум. Trends Cogn. Наука 15, 319–326 [PubMed] [Google Scholar] 60. Гибсон Э (1998) Лингвистическая сложность: локальность синтаксических зависимостей. Познание 68, 1–76 [PubMed] [Google Scholar] 61. Гордон ПК и другие. (2001) Помехи памяти во время языковой обработки.J. Exp. Psychol. Учить. Mem. Cogn 23, 381–405 [Google Scholar] 62. Леви Р и другие. (2009) Движение глаз свидетельствует о том, что читатели сохраняют неопределенность в отношении прошлых языковых вводных данных и действуют в соответствии с ней. Proc. Natl. Акад. Sci. США 106, 21086–21090 [Бесплатная статья PMC] [PubMed] [Google Scholar] 63. Acheson DJ и MacDonald MC (2011) Рифмы, которые читатель прочитал, перепутали значение: фонологические эффекты во время понимания предложения в режиме онлайн. J. Mem. Lang 65, 193–207 [Бесплатная статья PMC] [PubMed] [Google Scholar] 64.Митчелл Д.К. (1987) Лексическое руководство по синтаксическому анализу человека: локус и характеристики обработки In Attention and Performance XII (Coltheart M, ed.), Стр. 601–618, Erlbaum [Google Scholar] 65. Дубей А и другие. (2013) Вероятностное моделирование дискурсивной обработки предложений. Вершина. Cogn. Наука 5, 425–451 [PubMed] [Google Scholar] 66. Филлипс С. и Льюис С. (2013) Порядок производных в синтаксисе: свидетельства и архитектурные последствия. Stud. Лингвист 6, 11–47 [Google Scholar] 67. Pylkkannen L и McElree BD (2006) Интерфейс синтаксиса и семантики: он-лайн составление значения предложения.537–577, Elsevier [Google Scholar] 68. Тули К. М. и Бок Дж. К. (2014) О соотношении структурной персистентности в языковом производстве и понимании. Познание 132, 101–136 [Бесплатная статья PMC] [PubMed] [Google Scholar] 69. Кристиансон К.А. и другие. (2001) Тематические роли, распределенные вдоль садовой дорожки, сохраняются. Cogn. Психол 42, 368–407 [PubMed] [Google Scholar] 70. Свитс Б и другие. (2008) Недостаточная спецификация синтаксических двусмысленностей: свидетельства самостоятельного чтения. Mem. Cogn 36, 201–216 [PubMed] [Google Scholar] 71.Свитс Б и другие. (2007) Роль рабочей памяти в разрешении синтаксической неоднозначности: психометрический подход. J. Exp. Psychol. Gen 136, 64–81 [PubMed] [Google Scholar] 72. Traxler MJ (2010) Иерархический анализ линейного моделирования рабочей памяти и неявной просодии в разрешении двусмысленности дополнительной привязанности. J. Психолингвист. Res 38, 491–509 [PubMed] [Google Scholar] 73. Слэттери TJ и другие. (2013) Сохраняющиеся неправильные интерпретации предложений садовой дорожки возникают из-за конкурирующих синтаксических представлений.J. Mem. Lang 69, 104–120 [Google Scholar] 74. Кристиансон К. и другие. (2010) Влияние правдоподобия на структурное грунтование. J. Exp. Psychol. Учить. Mem. Cogn 36, 538–544 [PubMed] [Google Scholar] 75. Пикеринг MJ и Traxler MJ (2001) Стратегии обработки неограниченных зависимостей: лексическая информация и назначение глагола – аргумента. J. Exp. Psychol. Учить. Mem. Cogn 27, 1401–1410 [PubMed] [Google Scholar] 76. Пикеринг MJ и Traxler MJ (1998) Правдоподобие и восстановление после садовых дорожек: исследование отслеживания взгляда.J. Exp. Psychol. Учить. Mem. Cogn 24, 940–961 [Google Scholar] 77. Кристиансон К. и Люк С. (2011) Контекст усиливает первоначальные неверные истолкования текста. Sci. Stud. Читать 15, 136–166 [Google Scholar]Dog может дать подсказку о том, как приобретается язык
Доктор Пилли не знает, насколько большой словарный запас мог бы освоить Chaser. Когда она набрала 1000 заданий, он устал учить слова и переключился на более интересные темы, такие как грамматика.
Один из вопросов, поднятых исследованием Рико, касался того, что происходило в голове у собаки, когда ее просили что-то принести.Думал ли он о своих игрушках как о предметах с пометками «принеси-мяч», «принеси-фрисби», «принеси-куклы», или он понимал слово «принеси» отдельно от предмета, как люди?
Доктор Пилли ответил на этот вопрос, обучив Чейзера трем различным действиям: лапать, обнюхивать и брать предмет. Затем ей подарили три ее игрушки, и они правильно лаяли, носили или приносили каждую в зависимости от данной ей команды. «Этот эксперимент убедительно демонстрирует, что Чейзер понимал, что глагол имеет значение», — сказал д-р.- сказал Пилли.
Все 1022 слова в словаре Chaser являются именами собственными. Доктор Пилли также обнаружил, что Чейзера можно обучить распознавать категории, другими словами нарицательные существительные. Она правильно выполняет команду «Принеси фрисби» или «Принеси мяч». Она также может учиться путем исключения, как это делают дети. Если ее попросят принести новую игрушку со словом, которое она не знает, она выберет ее из знакомых.
Почти каждое взаимодействие между людьми и животными преследует призрак Умного Ганса, немецкой лошади, которая в начале 1900-х годов вытаскивала ответы на арифметические задачи своим копытом.Психолог Оскар Пфунгст обнаружил, что Ганс получит правильный ответ, только если спрашивающий также знает ответ. Затем он показал, что лошадь может улавливать мельчайшие движения головы и тела вопрошающего. Поскольку зрители напрягались, когда Ганс подходил к нужному количеству ударов, и расслаблялись, когда он достигал этого, лошадь точно знала, когда остановиться.
Люди проецируют свои ожидания на животных, особенно на собак, и могут легко убедить себя, что животное совершает какой-то человеческий подвиг, хотя на самом деле оно просто читает сигналы, бессознательно подаваемые хозяином.Хотя исследователи хорошо осведомлены об этой ловушке, интерпретировать поведение животных особенно сложно. В текущем выпуске ведущего журнала Animal Behavior два предыдущих эксперимента с собаками были признаны неудачными.
В одном из отчетов исследователи говорят, что им не удалось подтвердить эксперимент, показывающий, что собаки заразительно зевают, когда зевают люди. Другой отчет опровергает ранее сделанный вывод о том, что собаки могут различать рациональные и иррациональные действия.