Разбор слова остаток
Этот разбор целесообразно проводить по такому алгоритму: Но чтобы обращение к буквам не превратило разбор в буквенно-звуковой, звуковой анализ слова должен входить в звуко-буквенный разбор как его обязательная первоначальная ступень.Тендер на выполнение работ по разбору и вывозу остатков строительных конструкций д.10 по ул.чкалова в г.гатчина в Гатчине, Ленинградская область. Номер процедуры 26164580.
Разбор 12 главы Откровения. Много трудных вопросов и неожиданных ответов. Кто это за жена в 12 главе? Что такое река из пасти дракона? В какое время мировой истории происходят описанные собы.
Разбор слова онлайн — по составу, фонетический и морфологический
- Онлайн сервис разбора слов: фонетические, морфологические и морфемные разборы с описанием
Борис Гребенщиков — Голубиное слово текст песни(слова)
-
Формат:
- Скачиваний: 584
- Language: Русский
- Released: августа 8, 2017, 4:48 am
- Publisher:
Значение слова Остаток орфографическое, лексическое
Разбор песни Остаток слов на гитаре.
 — YouTube
— YouTubeБорис Гребенщиков — Голубиное слово текст песни(слова) ТОП популярных текстов песен на GL5 A-Dessa — Бабушка Эллаи — Каждую ночь Новые песни 2017: Дискотека Авария — Моя любовь Елка — Впусти музыку Burito — По волнам […]
2) Остаток — Величина , получаемая при вычитании из делимого произведения делителя на целое частное. Значение слова Остаток орфографическое, лексическое прямое и переносное значения и толкования (понятие) слова из словаря Словарь Ожегова.
Нашли Чёрную Шкатулку — Фанетический разбор слова
Сделайте морфологический разбор подчеркнутых слов
Я возращаюсь. Спасибо что смотрите меня, Поставте обязательно Лайк и подпишитесь.Пока
Главная > Математика > Нашли Чёрную Шкатулку — Фанетический разбор слова. Каков найменьший периметр квадрата если он делиться без остатка прямоугольники со стор.
Разбор по составу слова «шестиклассники»
Выполним разбор по составу слова «шестиклассники», указав два корня, суффиксы и окончание.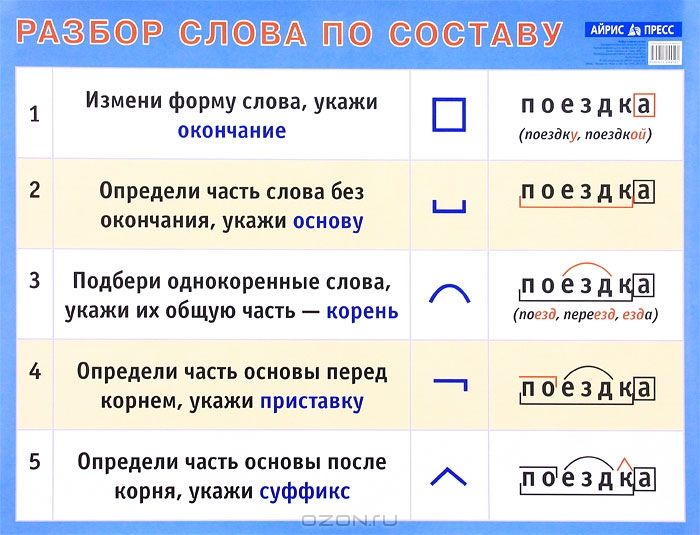
Чтобы разобрать по составу слово «шестиклассники», вначале определим, какой частью речи оно является. Это необходимо выяснить, поскольку каждая часть речи или словоформа имеет свой, присущий ей набор морфем.
Морфемный разбор слова «шестиклассники»
Слово «шестиклассники» называет учащихся шестого класса и отвечает на вопрос кто?
По этим грамматическим признакам определим, что это одушевленное имя существительное.
Окончание
Морфемный разбор анализируемого слова начнем с выделения окончания. Окончание имеют только изменяемые самостоятельные части речи.
Это существительное изменяется по падежам:
- голоса (кого?) шестиклассников
- подойдём (к кому?) к шестиклассникам
- дружу (с кем?) с шестиклассниками
Очевидно, что в его составе в форме именительного падежа словоизменительной морфемой является окончание -и, которое не включается в основу:
шестиклассники
Суффикс слова «шестиклассники»
Чтобы выяснить, какой суффикс имеется в составе этого слова, определим способ образования. Рассматриваемое сложное существительное образовано сложением основ простого числительного «шесть» и слова «класс» с присоединением суффикса -ник-, который образует множество слов — названий лиц по роду деятельности:
Рассматриваемое сложное существительное образовано сложением основ простого числительного «шесть» и слова «класс» с присоединением суффикса -ник-, который образует множество слов — названий лиц по роду деятельности:
- наставник
- подводник
- чертежник
- художник
Корни слова
В составе рассматриваемого существительного укажем две главные значимые части шест- и класс-, которые прослеживаются в составе однокоренных слов:
- шестой
- шестнадцать
- шестнадцатый
- классный
- одноклассник
Эти корни соединяются с помощью интерфикса -и-, который участвует в образовании подобных сложных слов с именем числительным в первой части:
- пятиборье
- семиклассник
- восьмитомник
Закончим разбор по составу (морфемный разбор) слова «шестиклассники» итоговой схемой:
шестиклассники — корень/интерфикс/корень/суффикс/окончание.
Как разобрать по составу слово «Огрызок», пример предложения? — 4 info
Как разобрать по составу слово «Огрызок», пример предложения?
Я считаю, что слово «огрызок» можно разобрать по составу таким образом: о — это приставка, грыз — это корень, ок — суффикс, окончание — нулевое. Примером в предложении слово может присутствовать так: На полу лежал огрызок бумаги.
О — приставка, грыз — корень, ок — суффикс. Вот и весь разбор. Уважаемые, в школе надо было учиться, а не лягушек через соломинку надувать.
Существительное мужского рода Огрызок относится ко второму склонению и в его составе обнаруживаем нулевое окончание: Огрызок-Огрызка-Огрызку-Огрызком-Огрызке. Однокоренными словами будут Огрызок-Огрызаться-Обгрызать-Перегрызать-Вгрызаться-Грызть. Корнем слова будет морфема -ГРЫЗ-. Также выделим приставку О- и суффикс существительного -ОК.
Получаем: О-ГРЫЗ-ОК_ (приставка-корень-суффикс-нулевое окончание), основа слова ОГРЫЗОК.
Пример предложения: Огрызок карандаша успешно справляется со своим предназначением до тех пор, пока его еще можно удержать в руке.

Или: Огрызок яблока смачно шлепнулся об морду Бита Осинника.
Приставка:о. Корень:грыз.СУФФИКС: ОК. ОКОНЧАНИЕ НУЛЕВОЕ
О/ГРЫЗ/ОК/
1) Словоформы огрызка, огрызку, огрызком показывают: изменяемая часть слова -А, -У, -ОМ. Это окончания, в разбираемой словоформе оно НУЛЕВОЕ. Неизменяемая часть, но с чередованием О с нулм звука ОГРЫЗОК // ОГРЫЗК-. Это основа.
2) Родственные лексемы ГРЫЗТЬ, ПОГРЫЗТЬ, ВЫГРЫЗАТЬ, ГРЫЗУН позволяют выделить корень ГРЫЗ-, в котором заключается основное лексическое значение слов-родственников, а также приставку О- и суффикс -ОК, из которого гласный при склонении выпадает.
3) ИТОГ ТАКОВ:
4) ПРЕДЛОЖЕНИЯ:
- Огрызок это и недоеденный кусок, и сердцевина фрукта типа яблока или груши, оставшаяся в результате его обгрызания, и остаток какого-либо предмета.
- Синонимом лексемы огрызок можно назвать в определнном контексте слово остаток, а вот антонимов эта лексема не имеет.
- Слово огрызок входит в состав фразеологизмов огрызок счастья, собачий огрызок.
- Огрызком счастья находчивый и веслый народ русский нарк кусочек масла.
- Собачьим огрызком называют ничтожного человечишку.
- Видеть во сне огрызок карандаша к одинокой старости.
- Засохший огрызок чего-либо, увиденный во сне, тоже абсолютно ничего доброго в жизни не предвещает.
- Огрызком карандаша рисовать крайне сложно.
- Из карандашных огрызков можно сделать весьма оригинальные и привлекательные украшения для девочек.
- Огрызок это и недоеденный кусок, и сердцевина фрукта типа яблока или груши, оставшаяся в результате его обгрызания, и остаток какого-либо предмета.


морфемный разбор (разбор по составу)
В морфемном составе слова «московское» (время) укажем корень москов- (с беглой гласной «о»), суффикс -ск-, окончание -ое (форма прилагательного среднего рода).
Чтобы выполнить морфемный разбор (разбор по составу) слова «московское», сначала установим его частеречную принадлежность и форму.
Московское направление самое оживленное на шоссе.
Направление какое? московское.
Анализируемое слово обозначает признак предмета, выражая его не непосредственно, как качественные прилагательные, а указывая на его отношение по местонахождению:
Москва — московский; находящий в Москве, возле Москвы.
По этим грамматическим признакам выясним, что оно является относительным прилагательным в форме единственного числа среднего рода, на что указывает родовое окончание -ое. Сравним словоформы прилагательного:
- московский житель;
- московская площадь;
- московские улицы.
Далее выделим суффикс -ск-, который образует многие относительные прилагательные, например:
- Голландия — голландский тюльпан;
- село — сельский вид;
- январь — январский мороз;
- пассажир — пассажирский поезд;
- гигант — гигантский эвкалипт.

Главной морфемой является корень москов-, в котором произошло чередование с нулем звука гласного «о» (беглый гласный «о»):
- Москв-а;
- москв-ич;
- москв-ичка;
- москв-итянин;
- москв-орецкий;
- За-москв-оречье;
- Под-московь-е;
- под-москов-ный;
- за-москов-ный.
Подытожим
москов-ск-ое — корень/суффикс/окончание
Скачать статью: PDFМаска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask — « Заграничный уход за копейки. Потрясающе увлажняющая маска для сухих и нормальных волос в огромном объёме. »
Совсем недавно я рассказывала вам о прекрасном шампуне Ronney Hialuronic Complex, к нему при заказе я приобрела и масочку из этой же линейки. О ней сегодня и расскажу.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
ОБЩАЯ ИНФОРМАЦИЯ
Производитель — Великобритания;
Объём — 1000 мл;
Стоимость — на момент покупки около 300 руб;
Где купить — в интернет-магазине makeupstore (прямая ссылка на маску) ;
ОФОРМЛЕНИЕ
Огромная пластиковая банка чёрного цвета.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
На банке наклейка с информацией на английском языке.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
Крышка винтовая.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
СОСТАВ
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
ЗАПАХ
Запах совершенно идентичный с одноимённой маской. Мне лично нравится, он лёгкий, травянистый и чуть соадковатый. На волосах совсем не задерживается и ощутим только во время применения.
ТЕКСТУРА И ЦВЕТ
Маска белого цвета.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
Текстура средства совсем не плотная, скорее средняя. Она не абсолютно не жирная, слегка скользковатая. Однако из рук не высказывает, у меня по крайней мере ни разу проблем не было.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
МОИ ВОЛОСЫ
Цвет натуральный, с остатками мелирования. В хорошем состоянии. Нормального типа, но склонны к жирности. Объём у корней не равномерный, кончики через некоторое время после стрижки топорщатся. Практически постоянно в последнее время пушатся.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
ПРИМЕНЕНИЕ
Это маска, однако я её использую как бальзам для волос.
Наношу средство по стандартной схеме для любого бальзама. На хорошо очищенные волосы равномерно распределяю маску в количестве примерно одной чайной ложки. В данный момент этого количества средства мне хватает. Предварительно чуть промакивпю волосы полотенцем чтобы удалить излишки влаги.
Распределяется очень легко.
Расход как вы поняли на моих волосах минимальный. Какой будет расход допустим на сухих волосах, я не знаю. Но, предполагаю что вполне экономный.
Время выдержки в моём случае примерно 1-2 минуты, хотя я не засекаю, это примерное время по ощущениям.
Смывается средство совсем без проблем. Смываю исключительно тёплой водой, ближе по температуре к комнатной. Я так привыкла, мне нравится.
Я так привыкла, мне нравится.
ЭФФЕКТ
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
Мне нравится, то что я получаю в итоге. Волосы шелковистые, блестящие, рассыпчатые, лёгкие.
Маска для волос Ronney Professional Hialuronic Complex Moinsturizing Mask
Во время смывания маски волосы моментально распутываются и пальцы сквозь них скользят. Это очень приятные ощущения.
После смывания я слегка подсушиваю волосы полотенцем, потом даю им подохнуть минут 10, и лишь потом расчессываю расческой с редкими зубьями.
Вывод:
Маску могу смело рекомендовать обладательницам сухих и ломких волос. Она прекрасно их питает и разглаживает. Мощно увлажняет, на что способны очень редкие средства для ухода за волосами. Волосы прекрасно себя чувствуют и великолепно выглядят.
А вот нормальным и волосам смешанного типа маску рекомендую использовать как бальзам для волос. Именно так я ею и пользуюсь.
Именно так я ею и пользуюсь.
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот. Надеюсь, выше приведено достаточно информации, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов.Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов. И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется много работы.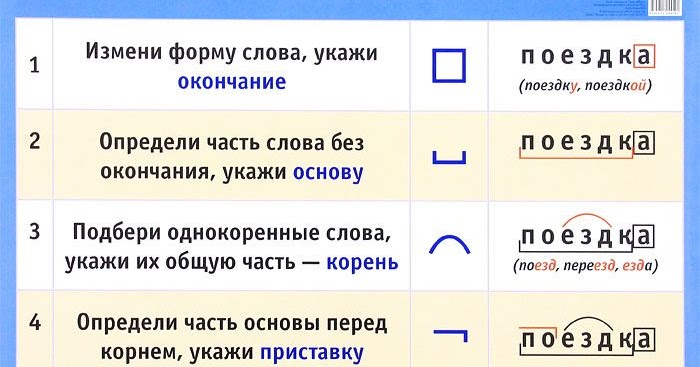
Словарь основан на замечательном проекте Wiktionary от Викимедиа.Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это побудило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его переносом в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа.Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в единый унифицированный ресурс. Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я рад, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Определение остатка по Merriam-Webster
re · main · der | \ ri-ˈmān-dər \
б (1) : число, оставшееся после вычитания
(2) : последняя неделимая часть после деления, степень которой меньше или ниже, чем у делителя.
3 : книга, проданная издателем по сниженной цене после того, как продажи замедлились.
остаток; остаток \ ri- ˈmān- d (ə-) riŋ \DPANS94
DPANS94 Видеть:
А. 6 Глоссарий
 6 Глоссарий
6 Глоссарий6.1 Основные слова
6.1.0010 ! магазин CORE
(x a-адрес -)
Хранить x в а-адрес.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0030 # номер-знак CORE
(уд1 - уд2)
Разделите ud1 на число в БАЗА давая частное ud2 и остаток n. (n — наименее значимая цифра ud1.) Преобразовать n в внешней формы и добавьте получившийся символ в начало изображенная числовая строка вывода. Неоднозначное условие существует, если # выполняется за пределами <# #> преобразование чисел с разделителями.
Видеть:
6.1.0050 #S
6.1.0040 #> цифра-знак-больше CORE
(xd - c-адрес u)
Бросьте xd. Сделайте отображаемую числовую строку вывода доступной как
символьная строка.c-addr и u определяют результирующую строку символов. Программа может заменять символы в строке.
Программа может заменять символы в строке.
Видеть:
6.1.0030 #,
6.1.0050 #S,
6.1.0490 <#
6.1.0050 #S номер-знак-s CORE
(уд1 - уд2)
Преобразуйте одну цифру ud1 в соответствии с правилом для #. Продолжать преобразование до тех пор, пока частное не станет равным нулю. ud2 равен нулю. Неоднозначный условие существует, если #S выполняется за пределами <# #> номер с разделителями конверсия.
6.1.0070 ' тик CORE
( "<пробелы> имя" - xt)
Пропустить ведущие разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Находить name и верните xt, токен выполнения для name. Неоднозначный условие существует, если имя не найдено.
При интерпретации 'xyz EXECUTE эквивалентно xyz.
Видеть:
3.4 Интерпретатор текста Forth,
3.4.1 Разбор,
А.6.1.2033 ПОСТПОН,
6. 1.2510 ['],
A.6.1.0070 ',
D.6.7 Непосредственность.
1.2510 ['],
A.6.1.0070 ',
D.6.7 Непосредственность.
6.1.0080 ( парен CORE
Компиляция: выполните семантику выполнения, указанную ниже.
Исполнение: ( "ccc" -)
Разобрать ccc, разделенные) (правая скобка). (это немедленное слово.
Количество символов в ccc может быть от нуля до количества символов. в области синтаксического анализа.
Видеть:
3.4.1 Разбор,
11.6.1.0080 (,
A.6.1.0080 (
6.1.0090 * звезда CORE
(n1 | u1 n2 | u2 - n3 | u3)
Умножим n1 | u1 на n2 | u2. давая произведение n3 | u3.
6.1.0100 * / косая черта CORE
(n1 n2 n3 - n4)
Умножьте n1 на n2, получив промежуточный результат с двумя ячейками d.
Разделите d на n3, получив частное n4 по одной ячейке.Неоднозначный
условие существует, если n3 равно нулю или если частное n4 лежит вне
диапазон числа со знаком. Если d и n3 различаются знаком,
возвращаемый результат, определяемый реализацией, будет таким же, как и возвращенный
либо по фразе
Если d и n3 различаются знаком,
возвращаемый результат, определяемый реализацией, будет таким же, как и возвращенный
либо по фразе > R M * R> УДАЛЕНИЕ ЗАМЕНА FM / MOD или фраза > R M * R> УДАЛЕНИЕ ОБМЕНА SM / REM .
Видеть:
3.2.2.1 Целочисленное деление
6.1.0110 * / МОД звездочка-слэш-мод CORE
(n1 n2 n3 - n4 n5)
Умножьте n1 на n2, получив промежуточный результат с двумя ячейками d.Разделенный
посредством n3, производящего одноклеточный остаток n4 и одноклеточное частное n5.
Неоднозначное условие существует, если n3 равно нулю или если частное n5 лежит
вне диапазона целого числа со знаком, состоящего из одной ячейки. Если d и n3 отличаются
знак, возвращаемый результат, определенный реализацией, будет таким же, как и
возвращается либо фразой > R M * R> FM / MOD или фраза > R M * R> SM / REM .
Видеть:
3.2.2.1 Целочисленное деление
6.1.0120 + плюс CORE
(n1 | u1 n2 | u2 - n3 | u3)
Добавить n2 | u2 к n1 | u1, что дает сумму n3 | u3.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0130 +! плюс магазин CORE
(n | u a-адрес -)
Добавить n | u к одноклеточному номеру по адресу a-addr.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0140 + ПЕТЛЯ плюс петля CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: do-sys -)
Добавьте приведенную ниже семантику времени выполнения к текущему определению.
Разрешить место назначения всех неразрешенных вхождений
ВЫЙТИ между
местоположение, указанное do-sys, и следующее местоположение для передачи
control, чтобы выполнить слова, следующие за + LOOP.
Время выполнения: (n -) (R: loop-sys1 - | loop-sys2)
Неоднозначное условие существует, если параметры управления контуром недоступен.Добавьте n в индекс цикла. Если индекс петли не пересекался граница между пределом цикла минус один и пределом цикла, продолжить выполнение в начале цикла. В противном случае выбросьте параметры управления текущим контуром и немедленно продолжить выполнение следуя петле.
Видеть:
6.1.1240 ДО,
6.1.1680 I,
6.1.1760 ВЫЙТИ,
A.6.1.0140 + LOOP
6.1.0150 , запятая CORE
( Икс -- )
Зарезервируйте одну ячейку пространства данных и сохраните x в ячейке.Если пространство данных указатель выравнивается, когда начинается выполнение, он останется выровненным, когда, заканчивает исполнение. Неоднозначное условие существует, если указатель области данных не выравнивается до выполнения,.
Видеть:
3.3.3 Пространство данных,
3.3. 3.1 Выравнивание адресов,
A.6.1.0150,
3.1 Выравнивание адресов,
A.6.1.0150,
6.1.0160 - минус CORE
(n1 | u1 n2 | u2 - n3 | u3)
Вычтем n2 | u2 от n1 | u1, что дает разность n3 | u3.
Видеть:
3.3.3.1 Выравнивание адресов.
6.1.0180 . точка CORE
(п -)
Показать n в свободный формат поля.
Видеть:
3.2.1.2 Преобразование цифр,
3.2.1.3 Отображение числа в свободном поле.
6.1.0190 . " точка-цитата CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "ccc <цитата>" -)
Разобрать ccc, разделенные "(двойные кавычки). Добавить семантику времени выполнения приведено ниже к текущему определению.
Время выполнения: (-)
Отображать ccc.
Видеть:
3. 4.1 Разбор,
6.2.0200. (,
A.6.1.0190. "
4.1 Разбор,
6.2.0200. (,
A.6.1.0190. "
6.1.0230 / косая черта CORE
(n1 n2 - n3)
Разделите n1 на n2, получив частное n3 по одной ячейке.Неоднозначный
условие существует, если n2 равно нулю. Если n1 и n2 различаются знаком,
возвращаемый результат, определяемый реализацией, будет таким же, как и возвращенный
либо по фразе > R S> D R> УДАЛЕНИЕ ЗАМЕНА FM / MOD или фраза > R S> D R> УДАЛЕНИЕ ЗАПИСИ SM / REM .
Видеть:
3.2.2.1 Целочисленное деление
6.1.0240 / МОД слэш-мод CORE
(n1 n2 - n3 n4)
Разделите n1 на n2, получив остаток, состоящий из одной клетки, n3 и остаток из одной клетки.
частное n4.Неоднозначное условие существует, если n2 равно нулю. Если n1 и n2
отличаются знаком, возвращаемый результат, определенный реализацией, будет
то же самое, что возвращается любой фразой > R S> D R> FM / MOD или фраза > R S> D R> SM / REM .
Видеть:
3.2.2.1 Целочисленное деление
6.1.0250 0 < без нуля CORE
(n - флаг)
флаг верен тогда и только тогда, когда n меньше нуля.
6.1.0270 0 = ноль равно CORE
(x - флаг)
флаг истина тогда и только тогда, когда x равен нулю.
6.1.0290 1+ один плюс CORE
(n1 | u1 - n2 | u2)
Добавить один (1) к n1 | u1, что дает сумму n2 | u2.
6.1.0300 1- один минус CORE
(n1 | u1 - n2 | u2)
Вычтите один (1) из n1 | u1, что дает разность n2 | u2.
6.1.0310 2! двухэтажный CORE
(x1 x2 a-адрес -)
Сохраните пару ячеек x1 x2 по адресу a-addr, с x2 по адресу a-addr и x1 по следующему адресу.
последовательная ячейка. Это эквивалентно последовательности
Это эквивалентно последовательности ОБМЕН! CELL +! .
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0320 2 * двухзвездочный CORE
(х1 - х2)
x2 - это результат сдвига x1 на один бит в сторону самого старшего бита, заполнение освободившегося наименее значимого бита нулем.
Видеть:
A.6.1.0320 2 *
6.1.0330 2/ двустенная CORE
(х1 - х2)
x2 - это результат сдвига x1 на один бит в сторону наименее значимого bit, оставляя самый старший бит неизменным.
Видеть:
A.6.1.0330 2 /
6.1.0350 2 @ с двумя выборками CORE
(а-адрес - x1 x2)
Получите пару ячеек x1 x2, хранящуюся по адресу a-addr.x2 хранится по адресу a-addr и
x1 в следующей последовательной ячейке. Это эквивалентно последовательности DUP CELL + @ SWAP @ .
Видеть:
3.3.3.1 Выравнивание адресов,
6.1.0310 2! ,
A.6.1.0350 2 @
6.1.0370 2DROP двухкапельный CORE
(х1 х2 -)
Капельная ячейка пара x1 x2 из стека.
6.1.0380 2DUP два двойных CORE
(х1 х2 - х1 х2 х1 х2)
Повторяющаяся ячейка пара x1 x2.
6.1.0400 2 НАВЕРХ двухсторонний CORE
(х1 х2 х3 х4 - х1 х2 х3 х4 х1 х2)
Копировать ячейку пара x1 x2 на вершину стека.
6.1.0430 2SWAP с двумя заменами CORE
(x1 x2 x3 x4 - x3 x4 x1 x2)
Обменять две верхние пары ячеек.
6.1.0450 : толстой кишки CORE
(C: "<пробелы> имя" - двоеточие-sys)
Пропустить ведущие разделители пробелов.Имя синтаксического анализа, разделенное пробелом. Создавать
определение имени, называемое определением двоеточия . Входить
состояние компиляции и запуск текущего определения, создавая двоеточие-sys.
Добавьте приведенную ниже семантику инициации к текущему определению.
Создавать
определение имени, называемое определением двоеточия . Входить
состояние компиляции и запуск текущего определения, создавая двоеточие-sys.
Добавьте приведенную ниже семантику инициации к текущему определению.
Семантика выполнения имени будет определяться словами, скомпилированными в тело определения. Текущее определение не должно быть можно найти в словаре, пока он не закончится (или до выполнения ДЕЛАЕТ> в некоторых системах).
Инициирование: (i * x - i * x) (R: - nest-sys)
Сохранять зависящую от реализации информацию о вызове в nest-sys. определение. Эффекты стека i * x представляют собой аргументы имени.
имя Исполнение: (i * x - j * x)
Выполните имя определения. Эффекты стека i * x и j * x представляют аргументы к и результаты от имени, соответственно.
Видеть:
3.4 Интерпретатор текста Forth,
3.4.1 Разбор,
3.4.5 Компиляция,
6.1,2500 [,
6.1.2540],
15.6.2.0470; КОД,
A.6.1.0450:,
RFI 0005 Семантика инициации.
6.1.0460 ; точка с запятой CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: двоеточие-sys -)
Добавьте семантику времени выполнения, указанную ниже, к текущему определению. Конец текущее определение, позвольте его найти в словаре и введите состояние интерпретации, потребляющее двоеточие-sys.Если указатель области данных не выровнен, зарезервируйте достаточно места для данных, чтобы выровнять его.
Время выполнения: (-) (R: nest-sys -)
Вернуться к определение вызова, указанное в nest-sys.
Видеть:
3.4 Интерпретатор текста Forth,
3.4.5 Компиляция,
A.6.1.0460;
6.1.0480 < менее CORE
(n1 n2 - флаг)
флаг истина тогда и только тогда, когда n1 меньше n2.
Видеть:
6.1.2340 U <
6.1. 0490 <#  0490 <#
0490 <# знак меньше номера CORE
(-)
Инициализировать на фото процесс преобразования числового вывода.
Видеть:
6.1.0030 #,
6.1.0040 #>,
6.1.0050 #S
6.1.0530 = равно CORE
(x1 x2 - флаг)
флаг верен тогда и только тогда, когда x1 побитно совпадает с x2.
6.1.0540 > больше, чем CORE
(n1 n2 - флаг)
флаг верен тогда и только тогда, когда n1 больше n2.
Видеть:
6.2.2350 U>
6.1.0550 > КУЗОВ к кузову CORE
(xt - а-адрес)
a-addr - это адрес поля данных, соответствующий xt. Неоднозначный условие существует, если xt не для слова, определенного через СОЗДАЙТЕ.
Видеть:
3.3.3 Пространство данных,
A.6.1.0550> КУЗОВ
6.1.0560 > IN к-дюйм CORE
(- а-адрес)
a-addr - это адрес ячейки, содержащей смещение в символах от
начало входного буфера до начала области синтаксического анализа.
6.1.0570 > НОМЕР на номер CORE
(ud1 c-addr1 u1 - ud2 c-addr2 u2)
ud2 - это беззнаковый результат преобразования символов в строка, указанная c-addr1 u1 в цифры, используя число в БАЗА, и складываем каждый из них в ud1 после умножения ud1 на число в BASE.Преобразование продолжается слева направо до тех пор, пока не появится другой символ. кабриолет, включая любые + или - , встречается или строка полностью преобразована. c-addr2 - расположение первого непреобразованный символ или первый символ после конца строки если строка была полностью преобразована. u2 - количество непревращенных символы в строке. Неоднозначное условие существует, если ud2 переполняется во время конвертации.
Видеть:
3.2.1.2 Преобразование цифр
6.1.0580 > рэнд к-р CORE
Интерпретация: семантика интерпретации для этого слова не определена.

Исполнение: (x -) (R: - x)
Переместить x в возвратный стек.
Видеть:
3.2.3.3 Возвратный стек,
6.1.2060 R>,
6.1.2070 R @,
6.2.0340 2> R,
6.2.0410 2R>,
6.2.0415 2R @
6.1.0630 ? ДУП вопрос-дублер CORE
(х - 0 | х х)
Дубликат x если он не равен нулю.
6.1.0650 @ получить CORE
(а-адрес - х)
x - это значение, хранящееся по адресу a-addr.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0670 ПРЕРЫВАНИЕ CORE
(i * x -) (R: j * x -)
Очистите стек данных и выполните функцию QUIT, который включает опорожнение стека возврата без отображения сообщения.
Видеть:
9.6.2.0670 ABORT
6.1.0680 ПРЕРЫВАНИЕ " отменить цитату CORE
Интерпретация: семантика интерпретации для этого слова не определена.

Компиляция: ( "ccc <цитата>" -)
Разобрать ccc, разделенную "(двойные кавычки). Добавить семантику времени выполнения приведено ниже к текущему определению.
Время выполнения: (i * x x1 - | i * x) (R: j * x - | j * x)
Удалите x1 из стека.Если какой-либо бит x1 не равен нулю, отобразите ccc и выполнить определенную реализацией последовательность прерывания, которая включает функция ПРЕРЫВАТЬ.
Видеть:
3.4.1 Разбор,
9.6.2.0680 ABORT ",
A.6.1.0680 ABORT »
6.1.0690 АБС абс CORE
(п - н)
ты абсолютное значение n.
6.1.0695 ПРИНЯТЬ CORE
(c-адрес + n1 - + n2)
Получите строку, содержащую не более + n1 символов.Неоднозначное условие
существует, если + n1 равно нулю или больше 32 767. Показать графику
символы по мере их поступления. Программа, которая зависит от наличия
или отсутствие неграфических символов в строке имеет окружающее
зависимость. Функции редактирования, если таковые имеются, которые система выполняет в
Порядок построения строки определяется реализацией.
Функции редактирования, если таковые имеются, которые система выполняет в
Порядок построения строки определяется реализацией.
Ввод завершается, когда определяемый реализацией терминатор строки получили. Когда ввод завершается, к строке ничего не добавляется, и отображение поддерживается способом, определяемым реализацией.
+ n2 - это длина строки, хранящейся по адресу c-addr.
Видеть:
A.6.1.0695 ПРИНЯТЬ
6.1.0705 ВЫРАВНИТЬ CORE
(-)
Если указатель области данных не выровнен, зарезервируйте достаточно места для выравнивания Это.
Видеть:
3.3.3 Пространство данных,
3.3.3.1 Выравнивание адресов,
A.6.1.0705 ВЫРАВНИТЬ
6.1.0706 ВЫРАВНИВАЕТСЯ CORE
(адрес - а-адрес)
а-адрес является первым выровненным адресом, большим или равным addr.
Видеть:
3.3.3.1 Выравнивание адресов,
6. 1.0705 ВЫРАВНИТЬ
1.0705 ВЫРАВНИТЬ
6.1.0710 АЛЛОТ CORE
(п -)
Если n больше нуля, зарезервируйте n адресных единиц пространства данных. Если п меньше нуля, выпуск | n | адресные единицы пространства данных. Если n равно ноль, оставьте указатель области данных без изменений.
Если указатель области данных выровнен и n кратно размеру ячейка, когда ALLOT начинает выполнение, она останется выровненной, когда ALLOT заканчивает исполнение.
Если указатель области данных выровнен по символам и n кратно размер символа, когда АЛЛОТ начинает выполнение, он останется символ выравнивается, когда ALLOT завершает выполнение.
Видеть:
3.3.3 Пространство данных
6.1.0720 И CORE
(х1 х2 - х3)
x3 это побитовые логические и x1 с x2.
6.1.0750 БАЗА CORE
(- а-адрес)
a-addr - это адрес ячейки, содержащей текущее преобразование числа
основание системы счисления {{2. ..36}}.
..36}}.
6.1.0760 НАЧАТЬ CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: - dest)
Поместите следующее место для передачи управления, dest, на элемент управления. стек потока. Добавить семантику времени выполнения, указанную ниже, к текущему определение.
Время выполнения: (-)
Продолжать исполнение.
Видеть:
3.2.3.2 Стек потока управления,
6.1.2140 ПОВТОР,
6.1.2390 ДО,
6.1.2430 ПОКА,
A.6.1.0760 НАЧАТЬ
6.1.0770 BL б-л CORE
(- символ)
char это значение символа для пробела.
Видеть:
A.6.1.0770 BL
6.1.0850 С! c-магазин CORE
(символ c-адрес -)
Хранить символ по адресу c-addr. Если размер символа меньше размера ячейки,
только количество младших битов, соответствующих размеру символа,
переведен.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0860 С, c-запятая CORE
(символ -)
Зарезервируйте место для одного символа в пространстве данных и сохраните char в космос. Если указатель пространства данных выровнен по символу, когда C, начинается выполнение, он останется выровненным по символу, когда C завершит выполнение. Неоднозначное условие существует, если указатель области данных не выровненный по символам до выполнения C ,.
Видеть:
3.3.3 Пространство данных,
3.3.3.1 Выравнивание адресов.
6.1.0870 C @ c-fetch CORE
(c-адрес - символ)
Получить символ, хранящийся в c-addr. Когда размер ячейки больше чем размер символа, все неиспользуемые старшие биты нулевые.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0880 ЯЧЕЙКА + CORE
(а-адрес1 - а-адрес2)
Добавить
размер в единицах адреса ячейки до a-addr1, что дает a-addr2.
Видеть:
3.3.3.1 Выравнивание адресов,
A.6.1.0880 ЯЧЕЙКА +
6.1.0890 ЯЧЕЙКИ CORE
(n1 - n2)
n2 это размер в адресных единицах n1 ячеек.
Видеть:
A.6.1.0890 ЯЧЕЙКИ
6.1.0895 СИМВОЛ символ CORE
( "<пробелы> имя" - симв.)
Пропустить ведущий разделители пробелов. Имя синтаксического анализа, разделенное пробелом.Положите значение его первого символа в стеке.
Видеть:
3.4.1 Разбор,
6.1.2520 [СИМВОЛ],
A.6.1.0895 СИМВОЛ
6.1.0897 СИМВОЛ + char-plus CORE
(c-адрес1 - c-адрес2)
Добавить размер в единицах адреса символа для c-addr1, что дает c-addr2.
Видеть:
3.3.3.1 Выравнивание адресов
6.1.0898 СИМВОЛЫ символов CORE
(n1 - n2)
n2 это
размер в адресных единицах n1 символа.
6.1.0950 ПОСТОЯННАЯ CORE
(x "<пробелы> имя" -)
Пропустить ведущий разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Создать определение имени с семантикой выполнения, определенной ниже.
имя называется константой .
наименование Исполнение: (- x)
Поместите x в стеке.
Видеть:
3.4.1 Разбор,
A.6.1.0950 ПОСТОЯННАЯ
6.1.0980 СЧЕТ CORE
(c-addr1 - c-addr2 u)
Вернуть спецификация символьной строки для подсчитанной строки, хранящейся в c-адрес1. c-addr2 - это адрес первого символа после c-addr1. ты содержимое символа в c-addr1, которое является длиной в символах строка c-addr2.
6.1.0990 CR c-r CORE
(-)
Причина последующего вывод появится в начале следующей строки.
6. 1.1000 СОЗДАТЬ  1.1000 СОЗДАТЬ
1.1000 СОЗДАТЬ CORE
( "<пробелы> имя" -)
Пропустить ведущий разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Создать определение имени с семантикой выполнения, определенной ниже. Если указатель пространства данных не выровнен, зарезервируйте достаточно места для его выравнивания. В новый указатель пространства данных определяет поле данных имени. CREATE не выделяет пространство данных в поле данных имени.
имя Исполнение: (- a-addr)
a-addr - это адрес поля данных имени.Семантика выполнения имени может быть расширен с помощью ДЕЙСТВУЕТ>.
Видеть:
3.3.3 Пространство данных,
A.6.1.1000 СОЗДАТЬ
6.1.1170 ДЕСЯТИЧНЫЙ CORE
(-)
Установить преобразование системы счисления в десятичную систему счисления.
6.1.1200 ГЛУБИНА CORE
(- + п)
+ n - количество значений одной ячейки, содержащихся в стеке данных
до того, как + n был помещен в стек.
6.1.1240 DO CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: - do-sys)
Поместите do-sys в стек потока управления. Добавить семантику времени выполнения приведено ниже к текущему определению. Семантика неполная пока не будет разрешено потребителем do-sys, например ПЕТЛЯ.
Время выполнения: (n1 | u1 n2 | u2 -) (R: - loop-sys)
Задайте параметры управления контуром с индексом n2 | u2 и ограничьте n1 | u1.An неоднозначное условие существует, если n1 | u1 и n2 | u2 не совпадают тип. Все, что уже находится в стеке возврата, становится недоступным до тех пор, пока параметры петлевого управления отбрасываются.
Видеть:
3.2.3.2 Стек потока управления,
6.1.0140 + ПЕТЛЯ,
A.6.1.1240 DO
6.1.1250 DOES> делает CORE
Интерпретация: семантика интерпретации для этого слова не определена.

Компиляция: (C: двоеточие-sys1 - двоеточие-sys2)
Добавьте семантику времени выполнения, указанную ниже, к текущему определению.Ли или нет, текущее определение отображается в словаре компиляция DOES> определяется реализацией. Потреблять двоеточие-sys1 и произвести двоеточие-sys2. Добавить семантику инициации приведено ниже к текущему определению.
Время выполнения: (-) (R: nest-sys1 -)
Заменить семантику выполнения самого последнего определения, упомянутого в качестве имени с семантикой выполнения имени, приведенной ниже. Возвращаться управление для определения вызова, указанного в nest-sys1.Неоднозначный условие существует, если имя не было определено с СОЗДАЙТЕ или определяемый пользователем слово, которое вызывает СОЗДАТЬ.
Инициирование: (i * x - i * x a-addr) (R: - nest-sys2)
Сохранение зависящей от реализации информации nest-sys2 о вызове
определение. Поместите адрес поля данных имени в стек. Стек
эффекты i * x представляют аргументы для имени.
имя Исполнение: (i * x - j * x)
Выполните часть определения, которая начинается с инициации семантика, добавленная DOES>, которая изменила имя.Стек эффекты i * x и j * x представляют аргументы и результаты имени, соответственно.
Видеть:
A.6.1.1250 ДЕЛАЕТ>,
RFI 0003 Определение слов и т. Д.,
RFI 0005 Семантика инициации.
6.1.1260 КАПЛЯ CORE
( Икс -- )
Удалить x из стека.
6.1.1290 ДУП двойной CORE
(х - х х)
Дубликат Икс.
6.1.1310 ELSE CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: orig1 - orig2)
Поместите местоположение новой неразрешенной прямой ссылки orig2 на
стек потока управления. Добавьте семантику времени выполнения, указанную ниже, в
текущее определение. Семантика будет неполной, пока orig2 не будет
решено (например,
ТОГДА).
Разрешите прямую ссылку orig1, используя
расположение в соответствии с добавленной семантикой времени выполнения.
Семантика будет неполной, пока orig2 не будет
решено (например,
ТОГДА).
Разрешите прямую ссылку orig1, используя
расположение в соответствии с добавленной семантикой времени выполнения.
Время выполнения: (-)
Продолжайте выполнение в месте, указанном в разрешении orig2.
Видеть:
6.1.1700 IF,
A.6.1.1310 ИНАЧЕ
6.1.1320 EMIT CORE
( Икс -- )
Если x - графический символ в наборе символов, определяемом реализацией, отобразить x. Эффект EMIT для всех остальных значений x равен определяется реализацией.
При передаче символа, биты, определяющие символ, имеют значение
между шестнадцатеричным числом 20 и 7E включительно соответствующий стандартный символ,
указано
3.1.2.1
Отображаются графические символы. Так как
разные устройства вывода могут по-разному реагировать на управляющие символы,
программы, использующие управляющие символы для выполнения определенных функций, имеют
зависимость от окружающей среды. Каждый EMIT имеет дело только с одним персонажем.
Каждый EMIT имеет дело только с одним персонажем.
Видеть:
6.1.2310 ТИП
6.1.1345 ОКРУЖАЮЩАЯ СРЕДА? запрос среды CORE
(c-addr u - ложь | i * x true)
c-addr - это адрес символьной строки, а u - это строка количество символов.u может иметь значение в диапазоне от нуля до определяемый реализацией максимум, который не должен быть меньше 31. строка символов должна содержать ключевое слово из 3.2.6 Окружающая среда запросы или необязательные наборы слов, которые необходимо проверить на соответствие с атрибут настоящего окружения. Если система обрабатывает атрибут неизвестен, возвращенный флаг - ложь; в противном случае флаг истина, а возвращаемый i * x имеет тип, указанный в таблице для запрашиваемый атрибут.
Видеть:
А.6.1.1345 ОКРУЖАЮЩАЯ СРЕДА?
6.1.1360 ОЦЕНКА CORE
(i * x c-адрес u - j * x)
Сохраните текущую спецификацию источника входного сигнала. Сохранить минус один (-1) в
ИСТОЧНИК-ID
если он присутствует. Сделайте строку, описанную c-addr и u
как источник ввода, так и буфер ввода, установите
> В
к нулю, и
интерпретировать. Когда область синтаксического анализа пуста, восстановите предыдущий источник ввода.
Технические характеристики. Другие эффекты стека связаны со словами EVALUATEd.
Сохранить минус один (-1) в
ИСТОЧНИК-ID
если он присутствует. Сделайте строку, описанную c-addr и u
как источник ввода, так и буфер ввода, установите
> В
к нулю, и
интерпретировать. Когда область синтаксического анализа пуста, восстановите предыдущий источник ввода.
Технические характеристики. Другие эффекты стека связаны со словами EVALUATEd.
Видеть:
7.6.1.1360 ОЦЕНКА,
A.6.1.1360 ОЦЕНКА,
RFI 0006 Запись во входные буферы.
6.1.1370 ВЫПОЛНИТЬ CORE
(я * х хт - j * х)
Удалите xt из стека и выполните определенную им семантику. Другие эффекты стека связаны со словом EXECUTEd.
Видеть:
6.1.0070 ',
6.1.2510 [']
6.1.1380 ВЫХОД CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Выполнение: (-) (R: nest-sys -)
Вернуть управление вызывающему определению, указанному nest-sys.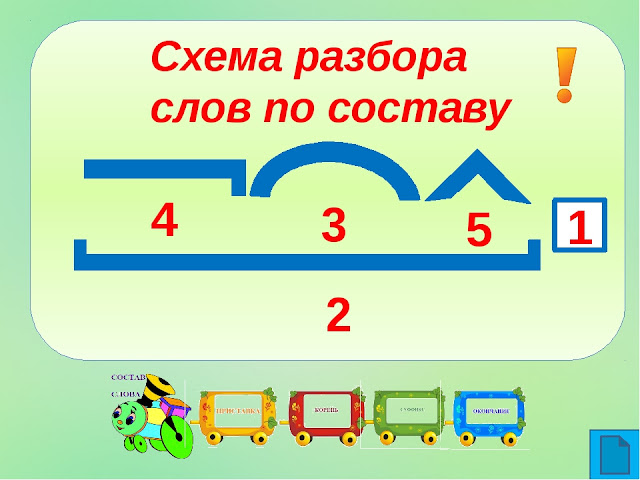 Перед
выполнение EXIT в пределах цикла выполнения, программа должна отбросить управление циклом
параметры, выполнив
РАЗГОВОР.
Перед
выполнение EXIT в пределах цикла выполнения, программа должна отбросить управление циклом
параметры, выполнив
РАЗГОВОР.
Видеть:
3.2.3.3 Возвратный стек,
A.6.1.1380 ВЫХОД
6.1.1540 ЗАПОЛНИТЬ CORE
(c-addr u char -)
Если ты больше нуля, сохранить char в каждом из u последовательных символов память, начиная с c-addr.
6.1.1550 НАЙТИ CORE
(c-адрес - c-адрес 0 | xt 1 | xt -1)
Найдите определение, указанное в подсчитанной строке по адресу c-addr. Если определение не найдено, верните c-addr и ноль. Если определение найдено, вернуть его токен выполнения xt. Если определение сразу, также верните единицу (1), в противном случае также верните минус один (-1). Для данного строка, значения, возвращаемые функцией FIND при компиляции, могут отличаться от те, которые вернулись без компиляции.
Видеть:
3.4.2 Поиск названий определений,
6. 1.0070 ',
6.1.2510 ['],
A.6.1.1550 НАЙТИ,
A.6.1.2033 ПОСТПОН,
D.6.7 Непосредственность.
1.0070 ',
6.1.2510 ['],
A.6.1.1550 НАЙТИ,
A.6.1.2033 ПОСТПОН,
D.6.7 Непосредственность.
6.1.1561 FM / MOD f-m-slash-mod CORE
(d1 n1 - n2 n3)
Разделите d1 на n1, получив частное n3 и остаток n2. Аргументы стека ввода и вывода подписаны. Неоднозначное условие существует, если n1 равно нулю или если частное лежит за пределами диапазона целое число со знаком, состоящее из одной ячейки.
Видеть:
3.2.2.1 Целочисленное деление,
6.1.2214 SM / REM,
6.1.2370 UM / MOD,
A.6.1.1561 FM / MOD
6.1.1650 ЗДЕСЬ CORE
(- адрес)
адрес указатель пространства данных.
Видеть:
3.3.3.2 Смежные регионы
6.1.1670 В ОЖИДАНИИ CORE
(символ -)
Добавить символ
в начало строки числового вывода на картинке.Неоднозначный
условие существует, если HOLD выполняется вне <#
#> номер с разделителями
конверсия.
6.1.1680 I CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Выполнение: (- n | u) (R: loop-sys - loop-sys)
n | u - это копия текущего (самого внутреннего) индекса цикла. Неоднозначное условие существует, если параметры управления контуром недоступны.
6.1.1700 IF CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: - orig)
Поместите местоположение новой неразрешенной прямой ссылки orig на стек потока управления. Добавьте семантику времени выполнения, указанную ниже, в текущее определение. Семантика неполна, пока ориг не будет решено, например, ТОГДА или ЕЩЕ.
Время выполнения: (x -)
Если все биты x равны нулю, продолжить выполнение в указанном месте постановлением ориг.
Видеть:
3.2.3.2 Стек потока управления,
А.6.1.1700 IF
6. 1.1710 НЕМЕДЛЕННО  1.1710 НЕМЕДЛЕННО
1.1710 НЕМЕДЛЕННО CORE
(-)
Сделать самое последнее определение немедленное слово. Неоднозначное условие существует, если у самого последнего определения нет имени.
Видеть:
A.6.1.1710 НЕМЕДЛЕННО,
D.6.7 Непосредственность,
RFI 0007 Различие между непосредственностью и специальной семантикой компиляции .
6.1.1720 ИНВЕРТИРОВАТЬ CORE
(х1 - х2)
Инвертировать все биты x1, что дает его логическую инверсию x2.
Видеть:
6.1.1910 ОТРИЦАТЕЛЬНЫЙ,
6.1.0270 0 =,
A.6.1.1720 ИНВЕРТИРОВАТЬ
6.1.1730 Дж CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Выполнение: (- n | u) (R: loop-sys1 loop-sys2 - loop-sys1 loop-sys2)
n | u - это копия индекса следующего внешнего цикла. Неоднозначное условие
существует, если параметры управления циклом следующего внешнего цикла, loop-sys1,
недоступны.
Видеть:
А.6.1.1730 Дж
6.1.1750 КЛЮЧ CORE
(- символ)
Получите один символ char, член определяемого реализацией набор символов. События клавиатуры, которые не соответствуют такому символы отбрасываются до тех пор, пока не будет получен действительный символ, а те впоследствии события недоступны.
Могут быть получены все стандартные символы. Персонажи, полученные KEY: не отображается.
Любой стандартный символ, возвращаемый KEY, имеет указанное числовое значение в 3.1.2.1 Графические персонажи. Программы, требующие умения управляющие символы приема имеют зависимость от окружения.
Видеть:
10.6.2.1305 EKEY,
10.6.1.1755 КЛЮЧ?
6.1.1760 ВЫЙТИ CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Выполнение: (-) (R: loop-sys -)
Отменить параметры управления токовым контуром. Неоднозначное условие
существует, если они недоступны.Немедленно продолжить выполнение
следуя самому внутреннему синтаксически включающему
ДЕЛАТЬ ...
ПЕТЛЯ
или ДЕЛАТЬ ...
+ ПЕТЛЯ.
Неоднозначное условие
существует, если они недоступны.Немедленно продолжить выполнение
следуя самому внутреннему синтаксически включающему
ДЕЛАТЬ ...
ПЕТЛЯ
или ДЕЛАТЬ ...
+ ПЕТЛЯ.
Видеть:
3.2.3.3 Возвратный стек,
A.6.1.1760 ВЫЙТИ
6.1.1780 ЛИТЕРАЛЬНЫЙ CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (x -)
Добавить семантику времени выполнения приведено ниже к текущему определению.
Время выполнения: (- x)
Поместите x в стеке.
Видеть:
A.6.1.1780 ЛИТЕРАЛЬНО
6.1.1800 ПЕТЛЯ CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: do-sys -)
Добавьте приведенную ниже семантику времени выполнения к текущему определению.
Разрешить место назначения всех неразрешенных вхождений
ПОКИНУТЬ
между
местоположение, указанное do-sys, и следующее местоположение для передачи
control, чтобы выполнить слова, следующие за LOOP.
Время выполнения: (-) (R: loop-sys1 - | loop-sys2)
Неоднозначное условие существует, если параметры управления контуром недоступен. Добавьте один в индекс цикла. Если индекс цикла тогда равный пределу цикла, отбросьте параметры цикла и продолжите выполнение сразу после цикла. В противном случае продолжить выполнение в начале цикла.
Видеть:
6.1.1240 ДО,
6.1.1680 I,
A.6.1.1800 LOOP
6.1.1805 LSHIFT л-сдвиг CORE
(х1 и - х2)
Выполнить логический сдвиг влево u разрядов на x1, что дает x2.Поставить нули в младшие значащие биты, освобожденные сдвигом. Неоднозначное условие существует, если u больше или равно количеству битов в ячейке.
6.1.1810 М * м звезды CORE
(n1 n2 - d)
d это знаковое произведение n1 на n2.
Видеть:
A.6.1.1810 M *
6.1.1870 МАКС CORE
(n1 n2 - n3)
n3 это
большее из n1 и n2.
6.1.1880 МИН CORE
(n1 n2 - n3)
n3 это меньшее из n1 и n2.
6.1.1890 МОД CORE
(n1 n2 - n3)
Разделите n1 на n2, получив остаток в одной ячейке n3. Неоднозначный
условие существует, если n2 равно нулю. Если n1 и n2 различаются знаком,
возвращаемый результат, определяемый реализацией, будет таким же, как и возвращенный
либо по фразе > R S> D R> FM / MOD DROP или фраза > R S> D R> SM / REM ДРОП .
Видеть:
3.2.2.1 Целочисленное деление
6.1.1900 ПЕРЕМЕЩЕНИЕ CORE
(адрес1 адрес2 u -)
Если u больше нуля, скопируйте содержимое последовательного адреса u
единиц по адресу addr1 к u последовательным адресным единицам по адресу addr2. После ДВИЖЕНИЯ
завершается, u последовательных адресных единиц на адресе addr2 содержат именно то, что
u последовательных адресных единиц по адресу addr1, содержащихся до перемещения.
Видеть:
17.6.1.0910 CMOVE,
17.6.1.0920 CMOVE>,
A.6.1.1900 ПЕРЕМЕЩЕНИЕ
6.1.1910 ОТРИЦАТЕЛЬНЫЙ CORE
(n1 - n2)
Отвергнуть n1, давая его арифметический обратный n2.
Видеть:
6.1.1720 ИНВЕРТИРОВАТЬ,
6.1.0270 0 =
6.1.1980 ИЛИ CORE
(х1 х2 - х3)
x3 это побитовое включение или x1 с x2.
6.1.1990 БОЛЕЕ CORE
(х1 х2 - х1 х2 х1)
Поместите копия x1 на вершине стека.
6.1.2033 ПОЧТОВЫЙ CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "<пробелы> имя" -)
Пропустить ведущие разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Находить
название. Добавить семантику компиляции имени к текущему
определение. Если имя не найдено, возникает неоднозначное условие.
Если имя не найдено, возникает неоднозначное условие.
Видеть:
D.6.7 Непосредственность,
3.4.1 Разбор,
А.6.1.2033 ПОСТПОН,
6.2.2530 [СОСТАВИТЬ]
6.1.2050 ВЫЙТИ CORE
(-) (R: я * х -)
Очистите стек возврата, сохраните ноль в ИСТОЧНИК-ID если он присутствует, сделайте пользовательское устройство ввода является источником ввода и войдет в состояние интерпретации. Не отображать сообщение. Повторите следующее:
- Принять строку из источника ввода во входной буфер, установить > В к нулю и интерпретировать.
- Отображать системную подсказку, определяемую реализацией, при интерпретации состояние, вся обработка завершена, нет неоднозначных условий существуют.
Видеть:
3.4 Интерпретатор текста Forth
6.1.2060 R> р-из CORE
Интерпретация: семантика интерпретации для этого слова не определена.

Исполнение: (- x) (R: x -)
Переместить x из стек возврата в стек данных.
Видеть:
3.2.3.3 Возвратный стек,
6.1.0580> R,
6.1.2070 R @,
6.2.0340 2> R,
6.2.0410 2R>,
6.2.0415 2R @
6.1,2070 R @ r-fetch CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Исполнение: (- x) (R: x - x)
Скопируйте x из стек возврата в стек данных.
Видеть:
3.2.3.3 Возвратный стек,
6.1.0580> R,
6.1.2060 R>,
6.2.0340 2> R,
6.2.0410 2R>,
6.2.0415 2R @
6.1.2120 РЕКУРС CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (-)
Добавить семантику выполнения текущего определения к текущему определение. Неоднозначное условие существует, если RECURSE появляется в определение после ДЕЙСТВУЕТ>.
Видеть:
6. 1.2120 РЕКУРС,
A.6.1.2120 РЕКУРС
1.2120 РЕКУРС,
A.6.1.2120 РЕКУРС
6.1.2140 ПОВТОР CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: orig dest -)
Добавьте приведенную ниже семантику времени выполнения к текущему определению, разрешение обратной ссылки dest.Разрешить прямую ссылку orig, используя расположение, соответствующее добавленной семантике времени выполнения.
Время выполнения: (-)
Продолжить выполнение в месте, указанном dest.
Видеть:
6.1.0760 НАЧАТЬ,
6.1.2430 ПОКА,
A.6.1.2140 ПОВТОР
6.1.2160 РОТ rote CORE
(x1 x2 x3 - x2 x3 x1)
Поверните три верхние записи стека.
6.1.2162 РСХИФТ r-shift CORE
(х1 и - х2)
Выполните логический сдвиг вправо на u битовых разрядов на x1, получив x2. Ставить
нули в старшие биты, освобожденные сдвигом. An
неоднозначное условие существует, если u больше или равно числу
бит в ячейке.
Ставить
нули в старшие биты, освобожденные сдвигом. An
неоднозначное условие существует, если u больше или равно числу
бит в ячейке.
6.1.2165 S " s-quote CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "ccc <цитата>" -)
Разобрать ccc, разделенные "(двойные кавычки). Добавить семантику времени выполнения приведено ниже к текущему определению.
Время выполнения: (- c-addr u)
Верните c-addr и u, описывая строку, состоящую из символов ccc. Программа не должна изменять возвращаемую строку.
Видеть:
3.4.1 Разбор,
6.2.0855 C ",
11.6.1.2165 S ",
A.6.1.2165 S "
6.1.2170 S> D s-to-d CORE
(п - г)
Преобразовать число n в двузначное число d с тем же числовым значение.
6.1.2210 ЗНАК CORE
(п -)
Если n отрицательное, добавьте знак минус в начало изображения. числовая строка вывода. Неоднозначное условие существует, если SIGN выполняется
вне <#
#> преобразование чисел с разделителями.
числовая строка вывода. Неоднозначное условие существует, если SIGN выполняется
вне <#
#> преобразование чисел с разделителями.
6.1.2214 SM / REM s-m-slash-rem CORE
(d1 n1 - n2 n3)
Разделите d1 на n1, получив симметричное частное n3 и остаток n2.Аргументы стека ввода и вывода подписаны. Неоднозначное условие существует, если n1 равно нулю или если частное лежит за пределами диапазона целое число со знаком, состоящее из одной ячейки.
Видеть:
3.2.2.1 Целочисленное деление,
6.1.1561 FM / MOD,
6.1.2370 UM / MOD,
A.6.1.2214 SM / REM
6.1.2216 ИСТОЧНИК CORE
(- c-адрес u)
c-addr - это адрес, а u - количество символов в входной буфер.
Видеть:
А.6.1.2216 ИСТОЧНИК,
RFI 0006 Запись во входные буферы.
6.1.2220 ПРОСТРАНСТВО CORE
(-)
Показать один
космос.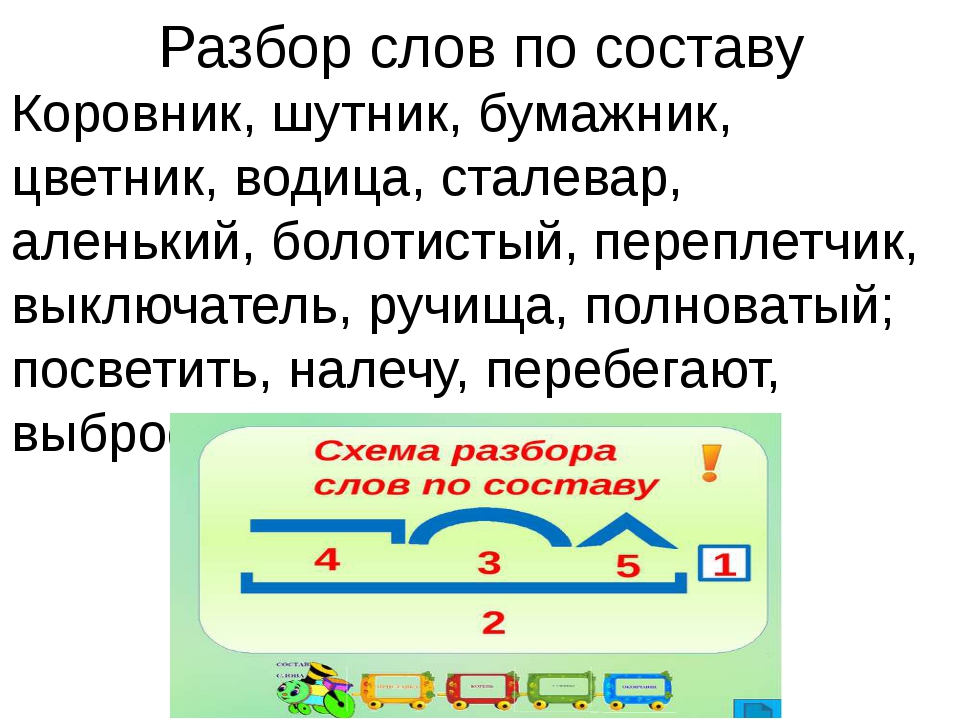
6.1.2230 МЕСТА CORE
(п -)
Если п больше нуля, отобразить n пробелов.
6.1.2250 ГОСУДАРСТВО CORE
(- а-адрес)
a-addr - это адрес ячейки, содержащей флаг состояния компиляции.СОСТОЯНИЕ истинно в состоянии компиляции, ложно в противном случае. Верно значение в STATE не равно нулю, но в остальном определяется реализацией. Только следующие стандартные слова изменяют значение в STATE: (двоеточие), ; (точка с запятой), ABORT, ПОКИДАТЬ, :БЕЗ ИМЕНИ, [ (левая квадратная скобка) и] (правая скобка).
Примечание: Программа не должна напрямую изменять содержимое ГОСУДАРСТВЕННЫЙ.
Видеть:
3.4 Интерпретатор текста Forth,
15.6.2.2250 СОСТОЯНИЕ,
A.6.1.2250 СОСТОЯНИЕ,
RFI 0007 Различие между непосредственностью и специальной семантикой компиляции .
6.1.2260 СВОП CORE
(х1 х2 - х2 х1)
Обменять
два верхних элемента стека.
6.1.2270 ТО CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: orig -)
Добавьте приведенную ниже семантику времени выполнения к текущему определению. Разрешите прямую ссылку origin, используя местоположение добавленного семантика времени выполнения.
Время выполнения: (-)
Продолжать исполнение.
Видеть:
6.1.1310 ELSE,
6.1.1700 IF,
A.6.1.2270 ТО
6.1.2310 ТИП CORE
(c-адрес u -)
Если u больше нуля, отобразить строку символов, указанную в c-addr и u.
Когда передается символ в символьной строке, определяющий символ
биты имеют значение от 20 до 7E включительно, соответствующие
стандартный символ, определяемый
3.1.2.1 графические символы, это
отображается. Поскольку разные устройства вывода могут по-разному реагировать на
управляющие символы, программы, использующие управляющие символы для выполнения
конкретные функции зависят от среды.
Видеть:
6.1.1320 EMIT
6.1.2320 U. u-точка CORE
(u -)
Дисплей u в формате свободного поля.
6.1.2340 U < U-меньше CORE
(u1 u2 - флаг)
флаг истина тогда и только тогда, когда u1 меньше u2.
Видеть:
6.1.0480 <
6.1.2360 ЕМ * u-m-звезда CORE
(u1 u2 - уд)
Умножьте u1 на u2, получив произведение ud с двумя ячейками без знака. Все значения и арифметика беззнаковые.
6.1.2370 ЕД / МОД u-m-slash-mod CORE
(ud u1 - u2 u3)
Разделим ud на u1, получив частное u3 и остаток u2.Все значения и арифметика беззнаковые. Неоднозначное условие существует, если u1 равно нулю или если частное лежит за пределами диапазона одной ячейки беззнаковое целое.
Видеть:
3. 2.2.1 Целочисленное деление,
6.1.1561 FM / MOD,
6.1.2214 SM / REM
2.2.1 Целочисленное деление,
6.1.1561 FM / MOD,
6.1.2214 SM / REM
6.1.2380 UNLOOP CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Выполнение: (-) (R: loop-sys -)
Отменить параметры управления петлей для текущего уровня вложенности.An UNLOOP требуется для каждого уровня вложенности, прежде чем определение может быть ВЫХОДИТ. Неоднозначное условие существует, если параметры управления контуром недоступны.
Видеть:
3.2.3.3 Возвратный стек,
A.6.1.2380 UNLOOP
6.1.2390 ДО CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: dest -)
Добавьте приведенную ниже семантику времени выполнения к текущему определению, разрешение обратной ссылки dest.
Время выполнения: (x -)
Если все биты x равны нулю, продолжить выполнение в указанном месте
автор: dest.
Видеть:
6.1.0760 НАЧАТЬ,
A.6.1.2390 ДО
6.1.2410 ПЕРЕМЕННАЯ CORE
( "<пробелы> имя" -)
Пропустить ведущие разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Создавать определение имени с семантикой выполнения, определенной ниже. Зарезервируйте одну ячейку пространства данных по выровненному адресу.
имя упоминается to как переменная .
имя Исполнение: (- a-addr)
a-addr - это адрес зарезервированной ячейки. Программа отвечает для инициализации содержимого зарезервированной ячейки.
Видеть:
3.4.1 Разбор,
A.6.1.2410 ПЕРЕМЕННАЯ
6.1.2430 ПРИ CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: dest - исходный)
Поместите местоположение новой неразрешенной прямой ссылки orig на
стек потока управления под существующим dest. Добавить время выполнения
семантика приведена ниже для текущего определения. Семантика
неполный, пока не будут разрешены orig и dest (например,
ПОВТОРИТЬ).
Добавить время выполнения
семантика приведена ниже для текущего определения. Семантика
неполный, пока не будут разрешены orig и dest (например,
ПОВТОРИТЬ).
Время выполнения: (x -)
Если все биты x равны нулю, продолжить выполнение в указанном месте постановлением ориг.
Видеть:
A.6.1.2430 ПОКА
6.1.2450 СЛОВО CORE
(char "ccc - c-адрес)"
Пропустить ведущие разделители.Разбирать символы ccc, разделенные символом char. An неоднозначное условие существует, если длина анализируемой строки больше чем длина подсчитанной строки, определяемая реализацией.
c-addr - это адрес переходной области, содержащей проанализированное слово
как счетная строка. Если область разбора была пустой или не содержала
символы кроме разделителя, результирующая строка будет иметь ноль
длина. После строки следует пробел, не включенный в длину. А
программа может заменять символы в строке.
Примечание: Требование ставить после строки пробел устарела и включена в качестве уступки существующим программам, которые использовать ПЕРЕРАБАТЫВАТЬ. Программа не должна зависеть от наличия космос.
Видеть:
3.3.3.6 Другие переходные области,
3.4.1 Разбор,
6.2.2008 PARSE,
A.6.1.2450 WORD
6.1.2490 XOR x или CORE
(х1 х2 - х3)
x3 это побитовое исключающее ИЛИ x1 с x2.
6.1.2500 [ левый кронштейн CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: выполните семантику выполнения, указанную ниже.
Исполнение: ( -- )
Введите интерпретацию государственный. [это немедленное слово.
Видеть:
3.4 Интерпретатор текста Forth,
3.4.5 Компиляция,
6.1.2540],
A.6.1.2500 [
6.1.2510 ['] скобка-галочка CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "<пробелы> имя" -)
Пропустить ведущие разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Находить название. Добавить семантику времени выполнения, указанную ниже, к текущему определение.
Неоднозначное условие существует, если имя не найдено.
Время выполнения: (- xt)
Поместите токен выполнения имени xt в стек. Жетон выполнения
возвращается скомпилированной фразой ['] X - то же самое возвращенное значение
на 'X вне состояния компиляции.
Видеть:
3.4.1 Разбор,
6.1.0070 ',
A.6.1.2033 ПОСТПОН,
A.6.1.2510 ['],
D.6.7 Непосредственность.
6.1.2520 [CHAR] кронштейн-угольник CORE
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "<пробелы> имя" -)
Пропустить ведущие разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Добавить
семантика времени выполнения приведена ниже для текущего определения.
Имя синтаксического анализа, разделенное пробелом. Добавить
семантика времени выполнения приведена ниже для текущего определения.
Время выполнения: (- символ)
Поместите символ значение первого символа имени в стеке.
Видеть:
3.4.1 Разбор,
6.1.0895 СИМВОЛ,
A.6.1.2520 [СИМВОЛ]
6.1.2540 ] кронштейн правый CORE
(-)
Введите компиляцию государственный.
Видеть:
3.4 Интерпретатор текста Forth,
3.4.5 Компиляция,
6.1.2500 [,
A.6.1.2540],
6.2 основных слова расширения
Видеть:
А.6.2 Основные слова расширения
6.2.0060 #TIB номер-t-i-b CORE EXT
(- а-адрес)
а-адрес это адрес ячейки, содержащей количество символов в входной буфер терминала.
Примечание: Это слово устарело и включено в качестве уступки
существующие реализации.
Видеть:
A.6.2.0060 #TIB
6.2,0200 . ( точка-парен CORE EXT
Компиляция: выполните семантику выполнения, указанную ниже.
Исполнение: ( "ccc" -)
Разобрать и отобразить ccc, разделенные) (правая скобка). .( является немедленное слово.
Видеть:
3.4.1 Разбор,
6.1.0190. ",
A.6.2.0200. (
6.2.0210 .R точка-r CORE EXT
(n1 n2 -)
Отображение n1 с выравниванием по правому краю в поле шириной n2 символа.Если число символов, необходимых для отображения n1, больше, чем n2, все цифры отображается без начальных пробелов в поле необходимой ширины.
Видеть:
A.6.2.0210 .R
6.2.0260 0 <> ноль не равно CORE EXT
(x - флаг)
флаг
истина тогда и только тогда, когда x не равно нулю.
6.2.0280 0> ноль-больше CORE EXT
(n - флаг)
флаг истина тогда и только тогда, когда n больше нуля.
6.2.0340 2> рэнд двухпозиционный CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Исполнение: (x1 x2 -) (R: - x1 x2)
Перенести пару ячеек x1 x2 в возвратный стек. Семантически эквивалент
к СВОП> R> R .
Видеть:
3.2.3.3 Возвратный стек,
6.1.0580> R,
6.1.2060 R>,
6.1.2070 R @,
6.2.0410 2R>,
6.2,0415 2R @,
A.6.2.0340 2> R
6.2.0410 2R> два-р-из CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Исполнение: (- x1 x2) (R: x1 x2 -)
Перенести пару ячеек x1 x2 из возвратного стека. Семантически эквивалент
к R> R> СВОП .
Видеть:
3.2.3.3 Возвратный стек,
6.1.0580> R,
6.1.2060 R>,
6.1.2070 R @,
6.2.0340 2> R,
6.2.0415 2R @,
A.6.2.0410 2R>
6.2.0415 2R @ два-r-выборка CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Исполнение: (- x1 x2) (R: x1 x2 - x1 x2)
Скопируйте пару ячеек x1 x2 из возвратного стека. Семантически эквивалентен R> R> 2DUP> R> R СВОП .
Видеть:
3.2.3.3 Возвратный стек,
6.1.0580> R,
6.1.2060 R>,
6.1.2070 R @,
6.2.0340 2> R,
6.2.0410 2R>
6.2.0455 : ИМЯ двоеточие без имени CORE EXT
(C: - двоеточие-sys) (S: - xt)
Создайте токен выполнения xt, войдите в состояние компиляции и запустите текущее определение, производящее двоеточие-sys. Добавить инициацию семантика приведена ниже для текущего определения.
Семантика выполнения xt будет определяться словами, скомпилированными
в тело определения. Это определение может быть выполнено позже.
используя xt
ВЫПОЛНЯТЬ.
Это определение может быть выполнено позже.
используя xt
ВЫПОЛНЯТЬ.
Если стек потока управления реализован с использованием стека данных, двоеточие-sys должен быть самым верхним элементом в стеке данных.
Инициирование: (i * x - i * x) (R: - nest-sys)
Сохранять зависящую от реализации информацию о вызове в nest-sys. определение. Эффекты стека i * x представляют аргументы для xt.
xt Исполнение: (i * x - j * x)
Выполнить определение, указанное xt.Эффект стека i * x и j * x представляют аргументы и результаты xt соответственно.
Видеть:
A.6.2.0455: ИМЯ,
3.2.3.2 Стек потока управления.
6.2.0500 <> не равно CORE EXT
(x1 x2 - флаг)
флаг истина тогда и только тогда, когда x1 не является побитовым таким же, как x2.
6.2.0620 ? DO вопрос-до CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.

Компиляция: (C: - do-sys)
Поместите do-sys в стек потока управления. Добавить семантику времени выполнения приведено ниже к текущему определению. Семантика неполная пока не будет разрешено потребителем do-sys, например ПЕТЛЯ.
Время выполнения: (n1 | u1 n2 | u2 -) (R: - | loop-sys)
Если n1 | u1 равно n2 | u2, продолжить выполнение в месте, заданном потребитель do-sys. В противном случае настройте параметры управления контуром с помощью index n2 | u2 и ограничьте n1 | u1 и продолжите выполнение сразу после ?ДЕЛАТЬ.Все, что уже находится в стеке возврата, становится недоступным до тех пор, пока параметры управления контуром отбрасываются. Неоднозначное условие существует, если n1 | u1 и n2 | u2 не одного типа.
Видеть:
3.2.3.2 Стек потока управления,
6.1.0140 + ПЕТЛЯ,
6.1.1240 ДО,
6.1.1680 I,
6.1.1760 ВЫЙТИ,
6.1.2380 UNLOOP,
A.6.2.0620? DO
6.2.0700 СНОВА CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.

Компиляция: (C: dest -)
Добавьте приведенную ниже семантику времени выполнения к текущему определению, разрешение обратной ссылки dest.
Время выполнения: (-)
Продолжить выполнение в месте, указанном в dest. Если нет другого используются слова потока управления, любой программный код после СНОВА не будет выполнен.
Видеть:
6.1.0760 НАЧАТЬ,
A.6.2.0700 СНОВА
6.2.0855 C " c-цитата CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "ccc <цитата>" -)
Разберите ccc, разделенную "(двойные кавычки), и добавьте время выполнения семантика приведена ниже для текущего определения.
Время выполнения: (- c-addr)
Верните c-addr, строку со счетчиком, состоящую из символов ccc. А программа не должна изменять возвращаемую строку.
Видеть:
3.4.1 Разбор,
6. 1.2165 S ",
11.6.1.2165 S ",
A.6.2.0855 C "
1.2165 S ",
11.6.1.2165 S ",
A.6.2.0855 C "
6.2.0873 КОРПУС CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: - case-sys)
Отметьте начало ДЕЛА ... ИЗ ... КОНЕЦ ЧЕГО-ЛИБО ... ENDCASE структура. Добавьте приведенную ниже семантику времени выполнения к текущему определению.
Время выполнения: (-)
Продолжать исполнение.
Видеть:
A.6.2.0873 КОРПУС
6.2.0945 КОМПИЛЬНЫЙ, компиляция-запятая CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Исполнение: (xt -)
Добавьте семантику выполнения определения, представленного xt, в семантика выполнения текущего определения.
Видеть:
A.6.2.0945 КОМПИЛЯЦИЯ,
6.2.0970 КОНВЕРТ CORE EXT
(ud1 c-addr1 - ud2 c-addr2)
ud2 - результат преобразования символов в начале текста
в первый символ после c-addr1 в цифры, используя число в
БАЗА,
и прибавляя каждую цифру к ud1 после умножения ud1 на число
в БАЗЕ. Преобразование продолжается до тех пор, пока не появится персонаж, который нельзя преобразовать.
встречается. c-addr2 - это расположение первого непреобразованного
персонаж. Неоднозначное условие существует, если ud2 переполняется.
Преобразование продолжается до тех пор, пока не появится персонаж, который нельзя преобразовать.
встречается. c-addr2 - это расположение первого непреобразованного
персонаж. Неоднозначное условие существует, если ud2 переполняется.
Примечание: Это слово устарело и включено в качестве уступки существующие реализации. Его функция заменена 6.1.0570 > НОМЕР.
Видеть:
3.2.1.2 Преобразование цифр,
A.6.2.0970 ПРЕОБРАЗОВАТЬ
6.2.1342 КОНЕЦ корпус CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: case-sys -)
Отметьте конец ДЕЛО ... ИЗ ... КОНЕЦ ЧЕГО-ЛИБО ... ENDCASE структура. Использовать case-sys для разрешения всей структуры. Добавить семантику времени выполнения приведено ниже к текущему определению.
Время выполнения: (x -)
Отбросьте case selector x и продолжить выполнение.
Видеть:
A. 6.2.1342 ENDCASE
6.2.1342 ENDCASE
6.2.1343 ENDOF конец CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: case-sys1 of-sys - case-sys2)
Отметьте конец ИЗ ... ENDOF часть ДЕЛО состав. Следующий место для передачи управления разрешает ссылку, предоставленную из-sys. Добавить семантику времени выполнения, указанную ниже, к текущему определение. Замените case-sys1 на case-sys2 в стеке потока управления, быть решенным КОНЕЦ.
Время выполнения: (-)
Продолжить выполнение в местоположение, указанное потребителем case-sys2.
Видеть:
A.6.2.1343 ENDOF
6.2.1350 СТЕРЕТЬ CORE EXT
(адрес u -)
Если ты больше нуля, очистить все биты в каждом из u последовательных адресов единиц памяти, начиная с адреса.
6.2.1390 ОЖИДАТЬ CORE EXT
(c-адрес + п -)
Получите строку, содержащую не более + n символов. Отображение графических символов
по мере их поступления. Программа, которая зависит от наличия или отсутствия
количество неграфических символов в строке зависит от среды.Функции редактирования, если таковые имеются, которые выполняет система, чтобы
Построение строки символов определяется реализацией.
Отображение графических символов
по мере их поступления. Программа, которая зависит от наличия или отсутствия
количество неграфических символов в строке зависит от среды.Функции редактирования, если таковые имеются, которые выполняет система, чтобы
Построение строки символов определяется реализацией.
Ввод завершается, когда определяемый реализацией терминатор строки получен или когда длина строки + n символов. При вводе завершается, к строке ничего не добавляется и отображается поддерживается способом, определяемым реализацией.
Хранить строка в c-addr и ее длина в ОХВАТЫВАТЬ.
Примечание: Это слово устарело и включено в качестве уступки существующие реализации.Его функция заменена 6.1.0695 ПРИНИМАТЬ.
Видеть:
A.6.2.1390 ОЖИДАТЬ
6.2.1485 ЛОЖЬ CORE EXT
( -- ложный )
Вернуть ложный флаг.
Видеть:
3.1.3.1 Флаги
6. 2.1660 HEX  2.1660 HEX
2.1660 HEX CORE EXT
(-)
Установить содержимое из БАЗА до шестнадцати.
6.2.1850 МАРКЕР CORE EXT
( "<пробелы> имя" -)
Пропустить ведущие разделители пробелов.Имя синтаксического анализа, разделенное пробелом. Создавать определение имени с семантикой выполнения, определенной ниже.
имя Исполнение: (-)
Восстановить все указатели выделения словаря и порядка поиска в состояние у них было как раз перед определением имени. Убрать определение имя и все последующие определения. Реставрация любых конструкций все еще существующие, которые могут относиться к удаленным определениям или освобожденным пространство данных не обязательно предоставляется. Никакой другой контекстной информации например, числовое основание.
Видеть:
3.4.1 Разбор,
15.6.2.1580 ЗАБУДЬ,
A.6.2.1850 МАРКЕР
6.2.1930 НИП CORE EXT
(х1 х2 - х2)
Отбросьте
первый элемент ниже вершины стека.
6.2.1950 ИЗ CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: (C: - of-sys)
Поместите of-sys в стек потока управления.Добавить семантику времени выполнения приведено ниже к текущему определению. Семантика неполная пока не будет разрешено потребителем of-sys, например КОНЕЦ ЧЕГО-ЛИБО.
Время выполнения: (x1 x2 - | x1)
Если два значения в стеке не равны, отбросьте верхнее значение и продолжить выполнение в местоположении, указанном потребителем of-sys, например, после следующего ENDOF. В противном случае отбросьте оба значения и продолжить выполнение в очереди.
Видеть:
6.2.0873 КОРПУС,
6.2.1342 ТОРЦЕВАЯ КОРПУС,
A.6.2.1950 OF
6.2.2000 PAD CORE EXT
(- c-адрес)
c-addr - это адрес переходной области, которая может использоваться для хранения
данные для промежуточной обработки.
Видеть:
3.3.3.6 Другие переходные области,
A.6.2.2000 PAD
6.2.2008 ПАРС CORE EXT
(char "ccc" - c-адрес u)
Разобрать ccc разделены символом-разделителем.
c-addr - это адрес (во входном буфере), а u - длина проанализированная строка. Если область разбора была пустой, результирующая строка имеет нулевую длину.
Видеть:
3.4.1 Разбор,
A.6.2.2008 PARSE
6.2.2030 ВЫБОР CORE EXT
(xu ... x1 x0 u - xu ... x1 x0 xu)
Удалить u. Скопируйте сю в верхнюю часть стопки. Существует неоднозначное условие если в стеке меньше u + 2 элементов до выполнения PICK.
Видеть:
A.6.2.2030 PICK
6.2.2040 ЗАПРОС CORE EXT
(-)
Сделайте пользовательское устройство ввода источником ввода. Получать ввод в
входной буфер терминала, заменяющий любое предыдущее содержимое. Сделать
результат, адрес которого возвращается
TIB,
входной буфер. Набор
> В
до нуля.
Сделать
результат, адрес которого возвращается
TIB,
входной буфер. Набор
> В
до нуля.
Примечание: Это слово устарело и включено в качестве уступки существующие реализации.
Видеть:
A.6.2.2040 ЗАПРОС,
RFI 0006.
6.2.2125 ДОПОЛНИТЕЛЬНАЯ ЗАПРАВКА CORE EXT
(- флаг)
Попытка заполнить входной буфер из входного источника, возвращая истинное значение отметьте в случае успеха.
Если источником ввода является пользовательское устройство ввода, попытайтесь получить ввод во входной буфер терминала. В случае успеха сделайте результат входной буфер, установить > В к нулю и верните истину. Получение линии не содержащий символов считается успешным.Если нет ввода доступно из текущего источника ввода, вернуть false.
Когда источником ввода является строка из ОЦЕНИВАТЬ, вернуть ложь и не выполняйте никаких других действий.
Видеть:
7.6.2.2125 ЗАПРАВКА,
11. 6.2.2125 ЗАПРАВКА,
A.6.2.2125 ЗАПРАВКА
6.2.2125 ЗАПРАВКА,
A.6.2.2125 ЗАПРАВКА
6.2.2148 ВОССТАНОВЛЕНИЕ-ВВОД CORE EXT
(xn ... x1 n - флаг)
Попытка восстановить спецификацию источника входного сигнала до описанного состояния на x1 через xn.флаг истинен, если спецификация источника ввода не может быть таким восстановленным.
Неоднозначное условие существует, если входной источник, представленный аргументы не то же самое, что и текущий источник ввода.
Видеть:
A.6.2.2182 СОХРАНИТЬ-ВВОД
6.2.2150 РОЛЛ CORE EXT
(xu xu-1 ... x0 u - xu-1 ... x0 xu)
Удалить u. Поверните u + 1 элементов вверху стопки. Неоднозначный условие существует, если до этого в стеке меньше u + 2 элементов. РОЛЛ выполняется.
Видеть:
A.6.2.2150 РУЛОН
6.2.2182 СОХРАНИТЬ ВХОД CORE EXT
(- хп ... х1 п)
от x1 до xn описывают текущее состояние источника ввода
спецификация для последующего использования
ВОССТАНОВЛЕНИЕ-ВВОД.
Видеть:
A.6.2.2182 СОХРАНИТЬ-ВВОД
6.2.2218 ИДЕНТИФИКАТОР ИСТОЧНИКА источник-i-d CORE EXT
(- 0 | -1)
Определяет источник входного сигнала следующим образом:
ИСТОЧНИК-ID Источник входного сигнала -1 строка (через EVALUATE) 0 Пользовательское устройство ввода
Видеть:
11.6.1.2218 ИДЕНТИФИКАТОР ИСТОЧНИКА
6.2.2240 ПРОБЕЛ CORE EXT
(- а-адрес)
a-addr - это адрес ячейки, содержащей количество символов сохранено последним выполнением ОЖИДАТЬ.
Примечание: Это слово устарело и включено в качестве уступки существующие реализации.
6.2.2290 TIB t-i-b CORE EXT
(- c-адрес)
c-адрес - адрес входного буфера терминала.
Примечание: Это слово устарело и включено в качестве уступки
существующие реализации.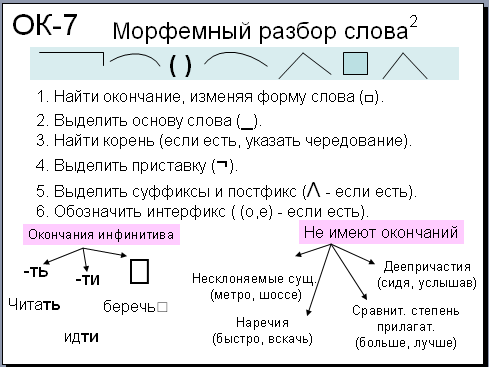
Видеть:
A.6.2.2290 TIB,
RFI 0006.
6.2.2295 К CORE EXT
Интерпретация: (x "<пробелы> имя" -)
Пропустить ведущие пробелы и проанализировать имя, разделенное пробелом. Сохранить x в название. Неоднозначное условие существует, если имя не было определено ЗНАЧЕНИЕ.
Компиляция: ( "<пробелы> имя" -)
Пропускайте ведущие пробелы и анализируйте имя, разделенное пробелом.Добавить семантика времени выполнения приведена ниже для текущего определения. Неоднозначный условие существует, если имя не было определено значением VALUE.
Время выполнения: (x -)
Магазин x по имени.
Примечание: Неопределенное условие существует, если ОТПРАВИТЬ или [СОСТАВИТЬ] применяется к ТО.
Видеть:
13.6.1.2295 ТО,
A.6.2.2295 К
6.2.2298 ИСТИНА CORE EXT
( -- правда )
Вернуть
флаг true, значение одной ячейки со всеми установленными битами.
Видеть:
3.1.3.1 Флаги,
A.6.2.2298 ИСТИНА
6.2.2300 ТАК CORE EXT
(х1 х2 - х2 х1 х2)
Скопируйте первый (верхний) элемент стека ниже второго элемента стека.
6.2.2330 U.R u-dot-r CORE EXT
(у н -)
Отобразите u с выравниванием по правому краю в поле шириной n символов. Если количество символы, необходимые для отображения u, больше n, все цифры отображается без начальных пробелов в поле необходимой ширины.
6.2.2350 U> u-больше CORE EXT
(u1 u2 - флаг)
флаг истина тогда и только тогда, когда u1 больше u2.
Видеть:
6.1.0540>
6.2.2395 НЕ ИСПОЛЬЗУЕТСЯ CORE EXT
(- и)
ты количество места, остающегося в регионе, адресованном ЗДЕСЬ, в адресные блоки.
6. 2.2405 ЗНАЧЕНИЕ  2.2405 ЗНАЧЕНИЕ
2.2405 ЗНАЧЕНИЕ CORE EXT
(x "<пробелы> имя" -)
Пропустить ведущий разделители пробелов.Имя синтаксического анализа, разделенное пробелом. Создать определение имени с семантикой выполнения, определенной ниже, с начальное значение равно x.
имя обозначается как значение .
наименование Исполнение: (- x)
Поместите x в стек. Значение x - это то, что указано, когда name
был создан,
до фразы x TO название выполняется, в результате чего новое значение x становится
связано с именем.
Видеть:
3.4.1 Разбор,
A.6.2.2405 ЗНАЧЕНИЕ,
6.2.2295 К
6.2.2440 ВНУТРИ CORE EXT
(n1 | u1 n2 | u2 n3 | u3 - флаг)
Выполните сравнение тестового значения n1 | u1 с нижним пределом n2 | u2 и
верхний предел n3 | u3, возвращающий истину, если либо (n2 | u2 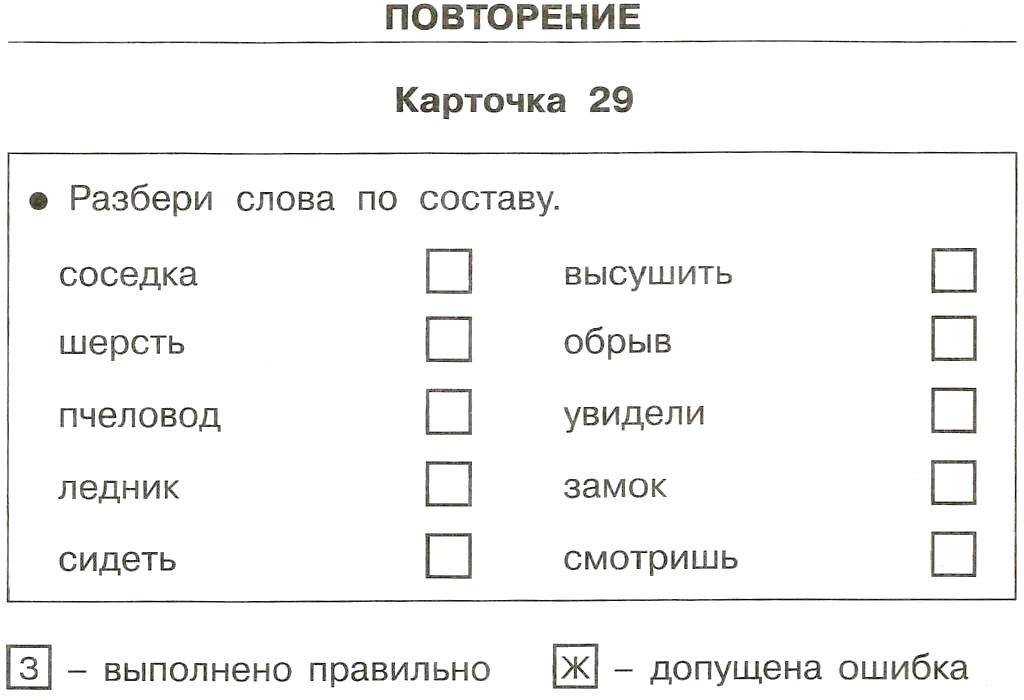 Неоднозначное условие существует, если n1 | u1, n2 | u2 и n3 | u3 равны
не все одного типа.
Неоднозначное условие существует, если n1 | u1, n2 | u2 и n3 | u3 равны
не все одного типа.
Видеть:
A.6.2.2440 ВНУТРИ
6.2.2530 [СОСТАВИТЬ] скоба-сборка CORE EXT
Интерпретация: семантика интерпретации для этого слова не определена.
Компиляция: ( "<пробелы> имя" -)
Пропустить ведущие разделители пробелов. Имя синтаксического анализа, разделенное пробелом. Находить название. Если имя имеет семантику компиляции, отличную от стандартной, добавьте их к текущему определению; в противном случае добавьте семантику выполнения название.Если имя не найдено, возникает неоднозначное условие.
Видеть:
3.4.1 Разбор,
6.1.2033 ПОСТПОН,
A.6.2.2530 [СОСТАВИТЬ]
6.2.2535 \ обратная косая черта CORE EXT
Компиляция: выполните семантику выполнения, указанную ниже.
Исполнение: ( "ccc" -)
Разобрать и выбросить
оставшаяся часть области синтаксического анализа. \ - это немедленное слово.
\ - это немедленное слово.
Видеть:
7.6.2.2535 \,
A.6.2.2535 \
Содержание
Следующий раздел
Методы, операторы и комбинаторы синтаксического анализатора - документация parsy 1.3.0
Возвращает синтаксический анализатор, преобразующий значение, созданное исходным синтаксическим анализатором.
используя предоставленную функцию / вызываемый объект, передавая аргументы с помощью ** синтаксис kwargs .
Значение, созданное начальным синтаксическим анализатором, должно быть отображением / словарем из
имена к значениям, или список из двух кортежей, или что-то еще, что может быть
передан конструктору dict .
Если Нет присутствует в качестве ключа в словаре, он будет удален
перед переходом к fn , как и все ключи, начинающиеся с _ .
Мотивация:
Для строительства сложных объектов это может быть более удобным, гибким и
читаемы, чем map () или comb () , потому что, избегая
позиционные аргументы мы можем избежать зависимости от порядка компонентов
в анализируемой строке и в порядке аргументов вызываемых объектов
использовал. Он специально разработан для использования вместе с
Он специально разработан для использования вместе с seq () и тег () .
Для Python 3.6 и выше, мы можем использовать версию ** kwargs из seq () для получения очень удобочитаемого определения:
>>> ddmmyyyy = seq (
... день = регулярное выражение (r '[0-9] {2}'). map (int),
... месяц = регулярное выражение (r '[0-9] {2}'). map (int),
... год = регулярное выражение (r '[0-9] {4}'). map (int),
...) .combine_dict (дата)
>>> ddmmyyyy.parse ('04052003')
дата и время.дата (2003, 5, 4)
(Если это трудно понять, используйте Python REPL и проверьте результат
вызова parse , если вы удалите вызов comb_dict ).
Здесь мы использовали datetime.date , который принимает аргументы ключевого слова. Для тебя
При собственном синтаксическом анализе вы часто будете использовать пользовательские типы данных. Вы можете создать
они, как вам нравится, но мы рекомендуем attrs. Вы также можете использовать namedtuple
из стандартной библиотеки для простых случаев или классов данных.
Вы также можете использовать namedtuple
из стандартной библиотеки для простых случаев или классов данных.
В следующем примере показано использование _ в качестве префикса для удаления
элементы, которые вас не интересуют, и использование namedtuple для
создать простую структуру данных.
>>> из коллекции import namedtuple
>>> Pair = namedtuple ('Пара', ['имя', 'значение'])
>>> name = regex ("[A-Za-z] +")
>>> int_value = regex ("[0-9] +"). map (int)
>>> bool_value = string ("true"). result (True) | строка ("ложь"). результат (ложь)
>>> пара = seq (
... имя = имя,
... __eq = строка ('='),
... значение = int_value | bool_value,
... __sc = строка (';'),
...) .combine_dict (Пара)
>>> pair.parse ("foo = 123;")
Пара (имя = 'foo', значение = 123)
>>> пара.parse ("BAR = true;")
Пара (имя = 'BAR', значение = True)
Вы также можете использовать << или >> для ненужных частей (но в некоторых
случаев это менее удобно):
>>> пара = seq (
... имя = имя << строка ('='),
... значение = (int_value | bool_value) << строка (';')
...) .combine_dict (Пара)
Для Python 3.5 и ниже использование kwargs невозможно (потому что
аргументы ключевого слова создают словарь, который не имеет гарантированного
заказывать).Вместо этого используйте tag () для создания списка пар имя-значение:
>>> ddmmyyyy = seq (
... регулярное выражение (r '[0-9] {2}'). map (int) .tag ('день'),
... регулярное выражение (r '[0-9] {2}'). map (int) .tag ('месяц'),
... регулярное выражение (r '[0-9] {4}'). map (int) .tag ('год'),
...) .combine_dict (дата)
>>> ddmmyyyy.parse ('04052003')
datetime.date (2003, 5, 4)
В следующем примере показано использование тега (Нет) для удаления
элементы, которые вас не интересуют, и использование namedtuple для
создать простую структуру данных.
>>> из коллекции import namedtuple
>>> Pair = namedtuple ('Пара', ['имя', 'значение'])
>>> name = regex ("[A-Za-z] +")
>>> int_value = regex ("[0-9] +"). map (int)
>>> bool_value = string ("true"). result (True) | строка ("ложь"). результат (ложь)
>>> пара = seq (
... name.tag ('имя'),
... строка ('='). tag (Нет),
... (int_value | bool_value) .tag ('значение'),
... строка (';'). tag (Нет),
...) .combine_dict (Пара)
>>> pair.parse ("foo = 123;")
Пара (имя = 'foo', значение = 123)
>>> пара.parse ("BAR = true;")
Пара (имя = 'BAR', значение = True)
Вы также можете использовать << для ненужных частей вместо .tag (None) :
>>> пара = seq (
... name.tag ('name') << строка ('='),
... (int_value | bool_value) .tag ('значение') << строка (';')
...) .combine_dict (Пара)
Изменено в версии 1.2: разрешить использование списков и диктовок и отфильтровать Нет .
Изменено в версии 1.3: Удаление аргументов, начинающихся с _
argparse - синтаксический анализатор параметров командной строки, аргументов и подкоманд - Python 3.9.4 документация
Модуль argparse упрощает написание удобной для пользователя командной строки.
интерфейсы. Программа определяет, какие аргументы ей требуются, и argparse выясним, как разобрать те из sys.argv . argparse модуль также автоматически генерирует справочные сообщения и сообщения об использовании и выдает ошибки
когда пользователи предоставляют программе неверные аргументы.
Пример
Следующий код представляет собой программу Python, которая принимает список целых чисел и производит либо сумму, либо максимум:
import argparse
парсер = argparse.ArgumentParser (description = 'Обработать некоторые целые числа.')
parser.add_argument ('целые числа', metavar = 'N', type = int, nargs = '+',
help = 'целое число для аккумулятора')
parser.add_argument ('- сумма', dest = 'накопить', действие = 'store_const',
const = сумма, по умолчанию = макс,
help = 'суммировать целые числа (по умолчанию: найти максимум)')
args = parser.parse_args ()
печать (args.accumulate (args.integers))
Предположим, что приведенный выше код Python сохранен в файл с именем prog.ру , это может
запускаться из командной строки и предоставляет полезные справочные сообщения:
$ python prog.py -h использование: prog.py [-h] [--sum] N [N ...] Обработать несколько целых чисел. позиционные аргументы: N целое число для аккумулятора необязательные аргументы: -h, --help показать это справочное сообщение и выйти --sum суммировать целые числа (по умолчанию: найти максимум)
При запуске с соответствующими аргументами выводит либо сумму, либо макс. целые числа командной строки:
$ питон прог.ру 1 2 3 4 4 $ python prog.py 1 2 3 4 - сумма 10
Если переданы недопустимые аргументы, будет выдана ошибка:
$ python prog.py а б в использование: prog.py [-h] [--sum] N [N ...] prog.py: ошибка: аргумент N: недопустимое значение int: 'a'
В следующих разделах представлен этот пример.
Создание парсера
Первым шагом в использовании argparse является создание ArgumentParser объект:
>>> парсер = argparse.ArgumentParser (description = 'Обработать некоторые целые числа.')
Объект ArgumentParser будет содержать всю информацию, необходимую для
проанализировать командную строку на типы данных Python.
Добавление аргументов
Заполнение ArgumentParser информацией об аргументах программы
выполняется путем вызова метода add_argument () .
Обычно эти вызовы сообщают ArgumentParser , как принимать строки
в командной строке и превратить их в объекты.Эта информация хранится и
используется при вызове parse_args () . Например:
>>> parser.add_argument ('целые числа', metavar = 'N', type = int, nargs = '+',
... help = 'целое число для аккумулятора')
>>> parser.add_argument ('- сумма', dest = 'накапливать', action = 'store_const',
... const = сумма, по умолчанию = макс,
... help = 'суммировать целые числа (по умолчанию: найти максимум)')
Позже вызов parse_args () вернет объект с
два атрибута, целых чисел и накапливают .Атрибут целых чисел будет списком из одного или нескольких целых чисел, а атрибут Накопить будет
либо функция sum () , если в командной строке было указано --sum ,
или функция max () , если это не так.
Анализ аргументов
ArgumentParser анализирует аргументы через parse_args () метод. Это проверит командную строку,
преобразовать каждый аргумент в соответствующий тип и затем вызвать соответствующее действие.В большинстве случаев это означает, что простой объект Namespace будет создан из
атрибуты, извлеченные из командной строки:
>>> parser.parse_args (['- сумма', '7', '-1', '42']) Пространство имен (накопление = <сумма встроенных функций>, целые числа = [7, -1, 42])
В сценарии parse_args () обычно вызывается без
аргументы, а ArgumentParser автоматически определит
аргументы командной строки из sys.argv .
Объекты ArgumentParser
- класс
argparse.ArgumentParser( prog = None , usage = None , description = None , epilog = None , parent = [] , formatter_class = argparse.'HelpFormatter22 _, , fromfile_prefix_chars = Нет , argument_default = Нет , конфликт_handler = 'error' , add_help = True , allow_abbrev = True , exit_on_error = True ) ) Создайте новый объект
ArgumentParser.Все параметры должны быть переданы как аргументы ключевого слова. Каждый параметр имеет свое более подробное описание. ниже, но вкратце они:prog - Название программы (по умолчанию:
sys.argv [0])usage - Строка, описывающая использование программы (по умолчанию: генерируется из аргументы добавлены в парсер)
описание - текст для отображения перед справкой по аргументу (по умолчанию: нет)
эпилог - текст, отображаемый после справки по аргументу (по умолчанию: нет)
родителей - список
ArgumentParserобъектов, аргументы которых должны также быть включеныformatter_class - Класс для настройки вывода справки
prefix_chars - Набор символов, которые префикс необязательных аргументов. (по умолчанию: ‘-‘)
fromfile_prefix_chars - Набор символов, префикс файлов из какие дополнительные аргументы следует читать (по умолчанию:
Нет)argument_default - Глобальное значение по умолчанию для аргументов (по умолчанию:
Нет)Conflict_handler - Стратегия разрешения конфликтующих опций. (обычно не требуется)
add_help - Добавить параметр
-h / - helpв парсер (по умолчанию:True)allow_abbrev - Позволяет сокращать длинные параметры, если аббревиатура однозначна.(по умолчанию:
True)exit_on_error - Определяет, завершается ли ArgumentParser с информация об ошибке при возникновении ошибки. (по умолчанию:
True)
Изменено в версии 3.5: добавлен параметр allow_abbrev .
Изменено в версии 3.8: В предыдущих версиях allow_abbrev также отключал группировку коротких такие флаги, как
-vv, означают-v -v.Изменено в версии 3.9: exit_on_error добавлен параметр.
В следующих разделах описывается, как каждый из них используется.
прога
По умолчанию объекты ArgumentParser используют sys.argv [0] для определения
как отображать название программы в справочных сообщениях. Это значение по умолчанию почти
всегда желательно, потому что это заставит справочные сообщения соответствовать тому, как была программа
вызывается в командной строке. Например, рассмотрим файл с именем мояпрограмма.py со следующим кодом:
import argparse
parser = argparse.ArgumentParser ()
parser.add_argument ('- foo', help = 'foo help')
args = parser.parse_args ()
Справка для этой программы будет отображать myprogram.py в качестве имени программы.
(независимо от того, откуда была вызвана программа):
$ python myprogram.py --help использование: myprogram.py [-h] [--foo FOO] необязательные аргументы: -h, --help показать это справочное сообщение и выйти --foo FOO foo help $ cd.. Подкаталог $ python / myprogram.py --help использование: myprogram.py [-h] [--foo FOO] необязательные аргументы: -h, --help показать это справочное сообщение и выйти --foo FOO foo help
Чтобы изменить это поведение по умолчанию, можно указать другое значение с помощью prog = аргумент для ArgumentParser :
>>> parser = argparse.ArgumentParser (prog = 'myprogram') >>> parser.print_help () использование: myprogram [-h] необязательные аргументы: -h, --help показать это справочное сообщение и выйти
Обратите внимание, что имя программы, определенное ли из sys.argv [0] или из prog = аргумент, доступен для справочных сообщений в формате % (prog) s спецификатор.
>>> parser = argparse.ArgumentParser (prog = 'myprogram')
>>> parser.add_argument ('- foo', help = 'foo программы% (prog) s')
>>> parser.print_help ()
использование: myprogram [-h] [--foo FOO]
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--foo FOO foo программы myprogram
использование
По умолчанию ArgumentParser вычисляет сообщение об использовании из
аргументов:
>>> парсер = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- foo', nargs = '?', help = 'foo help')
>>> parser.add_argument ('bar', nargs = '+', help = 'bar help')
>>> parser.print_help ()
использование: PROG [-h] [--foo [FOO]] bar [bar ...]
позиционные аргументы:
бар бар справка
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--foo [FOO] foo справка
Сообщение по умолчанию можно переопределить с помощью аргумента ключевого слова usage = :
>>> парсер = argparse.ArgumentParser (prog = 'PROG', usage = '% (prog) s [options]')
>>> parser.add_argument ('- foo', nargs = '?', help = 'foo help')
>>> parser.add_argument ('bar', nargs = '+', help = 'bar help')
>>> parser.print_help ()
использование: PROG [параметры]
позиционные аргументы:
бар бар справка
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--foo [FOO] foo справка
Описатель формата % (prog) s доступен для ввода имени программы в
сообщения об использовании.
описание
Большинство вызовов конструктора ArgumentParser будут использовать description = аргумент ключевого слова. Этот аргумент дает краткое описание
что делает программа и как она работает. В справочных сообщениях есть описание
отображается между строкой использования командной строки и справочными сообщениями для
различные аргументы:
>>> parser = argparse.ArgumentParser (description = 'Фу, что мешает') >>> parser.print_help () использование: argparse.ру [-h] Фу, что бары необязательные аргументы: -h, --help показать это справочное сообщение и выйти
По умолчанию описание будет заключено в строку, чтобы оно соответствовало данное пространство. Чтобы изменить это поведение, см. Аргумент formatter_class.
эпилог
Некоторые программы любят отображать дополнительное описание программы после
описание аргументов. Такой текст можно указать с помощью эпилога = .
аргумент для ArgumentParser :
>>> парсер = argparse.ArgumentParser ( ... description = 'Фу, что барабанит', ... epilog = "Вот так и получился бы бар") >>> parser.print_help () использование: argparse.py [-h] Фу, что бары необязательные аргументы: -h, --help показать это справочное сообщение и выйти И вот как вы попали в бар
Как и в случае с аргументом описания, текст эпилог = по умолчанию
обернутый строкой, но это поведение можно настроить с помощью formatter_class
аргумент ArgumentParser .
родители
Иногда несколько синтаксических анализаторов имеют общий набор аргументов.Скорее, чем
повторяя определения этих аргументов, единый парсер со всеми
общие аргументы и переданы родителям = аргумент ArgumentParser может быть использован. Аргумент parent = принимает список из ArgumentParser .
объекты, собирает из них все позиционные и необязательные действия и добавляет
эти действия с создаваемым объектом ArgumentParser :
>>> parent_parser = argparse.ArgumentParser (add_help = False)
>>> parent_parser.add_argument ('- родительский', type = int)
>>> foo_parser = argparse.ArgumentParser (родители = [parent_parser])
>>> foo_parser.add_argument ('фу')
>>> foo_parser.parse_args (['- родитель', '2', 'XXX'])
Пространство имен (foo = 'XXX', parent = 2)
>>> bar_parser = argparse.ArgumentParser (родители = [parent_parser])
>>> bar_parser.add_argument ('- бар')
>>> bar_parser.parse_args (['- bar', 'YYY'])
Пространство имен (bar = 'YYY', parent = None)
Обратите внимание, что большинство родительских парсеров будут указывать add_help = False .В противном случае ArgumentParser увидит два параметра -h / - help (один в родительском
и один в дочернем) и вызывают ошибку.
Примечание
Вы должны полностью инициализировать парсеры, прежде чем передавать их через родителей = .
Если вы измените родительские парсеры после дочернего парсера, эти изменения будут
не отражаться на ребенке.
formatter_class
Объекты ArgumentParser позволяют настраивать форматирование справки с помощью
указание альтернативного класса форматирования.В настоящее время существует четыре таких
классов:
- класс
argparse.RawDescriptionHelpFormatter - класс
argparse.RawTextHelpFormatter - класс
argparse.ArgumentDefaultsHelpFormatter - класс
argparse.MetavarTypeHelpFormatter
RawDescriptionHelpFormatter и RawTextHelpFormatter дают
больше контроля над отображением текстовых описаний.По умолчанию объекты ArgumentParser переносят описание и
тексты эпилога в справочных сообщениях командной строки:
>>> parser = argparse.ArgumentParser ( ... prog = 'PROG', ... description = '' 'это описание ... со странным отступом ... но это нормально '', ... эпилог = '' ' ... аналогично этому эпилогу, в котором пробелы будут ... очиститься и чьи слова будут завернуты ... через пару строк '') >>> парсер.print_help () использование: PROG [-h] это описание было со странным отступом, но это нормально необязательные аргументы: -h, --help показать это справочное сообщение и выйти то же самое и для этого эпилога, в котором будут убраны пробелы и чьи слова будет заключен в пару строк
Передача RawDescriptionHelpFormatter как formatter_class = указывает, что описание и эпилог уже правильно отформатированы и
не следует переносить по строкам:
>>> парсер = argparse.ArgumentParser (
... prog = 'PROG',
... formatter_class = argparse.RawDescriptionHelpFormatter,
... description = textwrap.dedent ('' '\
... Пожалуйста, не перепутайте этот текст!
... --------------------------------
... Я сделал отступ
... именно так
... Я хочу это
... '' '))
>>> parser.print_help ()
использование: PROG [-h]
Пожалуйста, не перепутайте этот текст!
--------------------------------
Я сделал отступ
именно так
Я хочу это
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
RawTextHelpFormatter сохраняет пробелы для всех видов текста справки,
включая описания аргументов.Однако несколько новых строк заменяются на
один. Если вы хотите сохранить несколько пустых строк, добавьте пробелы между
новые строки.
ArgumentDefaultsHelpFormatter автоматически добавляет информацию о
значения по умолчанию для каждого из справочных сообщений аргумента:
>>> parser = argparse.ArgumentParser (
... prog = 'PROG',
... formatter_class = argparse.ArgumentDefaultsHelpFormatter)
>>> parser.add_argument ('- foo', type = int, default = 42, help = 'FOO!')
>>> парсер.add_argument ('bar', nargs = '*', default = [1, 2, 3], help = 'BAR!')
>>> parser.print_help ()
использование: PROG [-h] [--foo FOO] [bar ...]
позиционные аргументы:
бар БАР! (по умолчанию: [1, 2, 3])
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--фу-у-у-у! (по умолчанию: 42)
MetavarTypeHelpFormatter использует имя аргумента типа для каждого
аргумент в качестве отображаемого имени для его значений (вместо использования dest
как обычный форматтер):
>>> парсер = argparse.ArgumentParser (
... prog = 'PROG',
... formatter_class = argparse.MetavarTypeHelpFormatter)
>>> parser.add_argument ('- foo', type = int)
>>> parser.add_argument ('bar', type = float)
>>> parser.print_help ()
использование: PROG [-h] [--foo int] float
позиционные аргументы:
плавать
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--foo int
prefix_chars
Большинство параметров командной строки будут использовать в качестве префикса - , например -f / - foo .Парсеры, которые должны поддерживать другой или дополнительный префикс
символы, например для вариантов
например + f или / foo , можно указать их с помощью аргумента prefix_chars = в конструктор ArgumentParser:
>>> parser = argparse.ArgumentParser (prog = 'PROG', prefix_chars = '- +')
>>> parser.add_argument ('+ f')
>>> parser.add_argument ('++ bar')
>>> parser.parse_args ('+ f X ++ bar Y'.split ())
Пространство имен (bar = 'Y', f = 'X')
Для аргумента prefix_chars = по умолчанию используется значение '-' .Поставка комплекта
символы, которые не включают - , приведут к тому, что параметры -f / - foo будут
запрещено.
из файла_prefix_chars
Иногда, например, при работе с особенно длинными списками аргументов,
может иметь смысл сохранить список аргументов в файле, а не печатать его
в командной строке. Если аргумент fromfile_prefix_chars = задан для ArgumentParser конструктор, затем аргументы, начинающиеся с любого из
указанные символы будут рассматриваться как файлы и будут заменены символом
аргументы они содержат.Например:
>>> с open ('args.txt', 'w') как fp:
... fp.write ('- f \ nbar')
>>> parser = argparse.ArgumentParser (fromfile_prefix_chars = '@')
>>> parser.add_argument ('- f')
>>> parser.parse_args (['- f', 'foo', '@ args.txt'])
Пространство имен (f = 'bar')
Аргументы, считываемые из файла, по умолчанию должны быть по одному на строку (но см. Также convert_arg_line_to_args () ) и обрабатываются так, как если бы они
были в том же месте, что и исходный аргумент ссылки на файл в команде
линия.Итак, в приведенном выше примере выражение ['-f', 'foo', '@ args.txt'] считается эквивалентом выражения ['-f', 'foo', '-f', 'bar'] .
Аргумент fromfile_prefix_chars = по умолчанию равен Нет , что означает, что
аргументы никогда не будут рассматриваться как ссылки на файлы.
аргумент_по умолчанию
Как правило, значения аргументов по умолчанию задаются либо путем передачи значения по умолчанию в add_argument () или позвонив set_defaults () методы с определенным набором имя-значение
пары.Однако иногда может быть полезно указать один для всего парсера
по умолчанию для аргументов. Это можно сделать, передав argument_default = ключевое слово аргумент для ArgumentParser . Например,
для глобального подавления создания атрибутов на parse_args () вызовов, мы предоставляем argument_default = SUPPRESS :
>>> parser = argparse.ArgumentParser (аргумент_default = argparse.SUPPRESS)
>>> parser.add_argument ('- foo')
>>> парсер.add_argument ('бар', nargs = '?')
>>> parser.parse_args (['- foo', '1', 'BAR'])
Пространство имен (bar = 'BAR', foo = '1')
>>> parser.parse_args ([])
Пространство имен ()
allow_abbrev
Обычно, когда вы передаете список аргументов в parse_args () метод ArgumentParser ,
он распознает сокращения длинных опций.
Эту функцию можно отключить, установив allow_abbrev на False :
>>> парсер = argparse.ArgumentParser (prog = 'PROG', allow_abbrev = False)
>>> parser.add_argument ('- foobar', action = 'store_true')
>>> parser.add_argument ('- foonley', action = 'store_false')
>>> parser.parse_args (['- foon'])
использование: PROG [-h] [--foobar] [--foonley]
ПРОГ: ошибка: нераспознанные аргументы: --foon
конфликтующий обработчик
Объекты ArgumentParser не допускают двух действий с одним и тем же параметром
нить. По умолчанию объекты ArgumentParser вызывают исключение, если
сделана попытка создать аргумент со строкой опций, которая уже находится в
использование:
>>> парсер = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- f', '--foo', help = 'old foo help')
>>> parser.add_argument ('- foo', help = 'new foo help')
Отслеживание (последний вызов последний):
..
ArgumentError: аргумент --foo: конфликтующая строка (строки) параметров: --foo
Иногда (например, при использовании родителей) может быть полезно просто переопределить любой
более старые аргументы с той же строкой параметров. Чтобы получить такое поведение, значение «разрешение» может быть передано в аргумент конфликт_хандлер = из ArgumentParser :
>>> парсер = argparse.ArgumentParser (prog = 'PROG', Conflict_handler = 'разрешить')
>>> parser.add_argument ('- f', '--foo', help = 'old foo help')
>>> parser.add_argument ('- foo', help = 'new foo help')
>>> parser.print_help ()
использование: PROG [-h] [-f FOO] [--foo FOO]
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
-f FOO старый foo help
--foo FOO новая справка foo
Обратите внимание, что объекты ArgumentParser удаляют действие, только если все его
строки опций переопределяются.Итак, в приведенном выше примере старый -f / - foo действие сохраняется как действие -f , потому что только опция --foo строка была переопределена.
add_help
По умолчанию объекты ArgumentParser добавляют параметр, который просто отображает
справочное сообщение парсера. Например, рассмотрим файл с именем myprogram.py , содержащий следующий код:
import argparse
parser = argparse.ArgumentParser ()
parser.add_argument ('- foo', help = 'foo help')
args = парсер.parse_args ()
Если в командной строке указано -h или --help , параметр ArgumentParser
будет напечатана справка:
$ python myprogram.py --help использование: myprogram.py [-h] [--foo FOO] необязательные аргументы: -h, --help показать это справочное сообщение и выйти --foo FOO foo help
Иногда бывает полезно отключить добавление этой опции справки.
Этого можно добиться, передав False в качестве аргумента add_help = в ArgumentParser :
>>> парсер = argparse.ArgumentParser (prog = 'PROG', add_help = False)
>>> parser.add_argument ('- foo', help = 'foo help')
>>> parser.print_help ()
использование: PROG [--foo FOO]
необязательные аргументы:
--foo FOO foo help
Обычно используется опция помощи -h / - help . Исключением является
если указан prefix_chars = и не включает - , в
в этом случае -h и --help не являются допустимыми параметрами. В
в этом случае первый символ в prefix_chars используется для префикса
варианты помощи:
>>> парсер = argparse.ArgumentParser (prog = 'PROG', prefix_chars = '+ /') >>> parser.print_help () использование: PROG [+ h] необязательные аргументы: + h, ++ help показать это справочное сообщение и выйти
exit_on_error
Обычно, когда вы передаете недопустимый список аргументов в parse_args () метод ArgumentParser , он выйдет с информацией об ошибке.
Если пользователь хочет отлавливать ошибки вручную, эту функцию можно включить, установив exit_on_error – Ложь :
>>> парсер = argparse.ArgumentParser (exit_on_error = False)
>>> parser.add_argument ('- целые числа', type = int)
_StoreAction (option_strings = ['- integer'], dest = 'integer', nargs = None, const = None, default = None, type = , choices = None, help = None, metavar = None )
>>> попробуйте:
... parser.parse_args ('- целые числа a'.split ())
... кроме argparse.ArgumentError:
... print ('Обнаружена ошибка аргумента')
...
Перехват аргументаОшибка
Метод add_argument ()
-
ArgumentParser.add_argument( имя или флаги ... [, action ] [, nargs ] [, const ] [, default ] [, type ] [, choices ] [ , требуется ] [, help ] [, metavar ] [, dest ]) Определите, как следует анализировать один аргумент командной строки. Каждый параметр имеет собственное более подробное описание ниже, но вкратце они:
имя или флаги - Имя или список строк параметров, например.грамм.
fooили-f, --foo.действие - основной тип действия, выполняемого, когда этот аргумент встречается в командной строке.
nargs - количество аргументов командной строки, которые следует использовать.
const - Постоянное значение, требуемое для некоторых действий и выборок nargs.
по умолчанию - значение, полученное, если аргумент отсутствует в командная строка и если она отсутствует в объекте пространства имен.
type - Тип, в который должен быть преобразован аргумент командной строки.
choices - Контейнер допустимых значений аргумента.
- Требуется
- можно ли опустить параметр командной строки (только опционально).
help - Краткое описание того, что делает аргумент.
metavar - Имя аргумента в сообщениях об использовании.
dest - Имя атрибута, добавляемого к объекту, возвращаемому
parse_args ().
В следующих разделах описывается, как каждый из них используется.
имя или флаги
Метод add_argument () должен знать, является ли необязательный
аргумент, например -f или --foo , или позиционный аргумент, например список
имена файлов, ожидается. Первые аргументы, переданные в add_argument () , следовательно, должна быть либо серией
flags или простое имя аргумента. Например, необязательный аргумент может
создаваться как:
>>> парсер.add_argument ('- f', '--foo')
, в то время как позиционный аргумент может быть создан как:
>>> parser.add_argument ('полоса')
При вызове parse_args () необязательные аргументы будут
идентифицируется префиксом - , а остальные аргументы будут считаться равными
быть позиционным:
>>> parser = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- f', '--foo')
>>> parser.add_argument ('панель')
>>> парсер.parse_args (['BAR'])
Пространство имен (bar = 'BAR', foo = None)
>>> parser.parse_args (['BAR', '--foo', 'FOO'])
Пространство имен (bar = 'BAR', foo = 'FOO')
>>> parser.parse_args (['- foo', 'FOO'])
использование: PROG [-h] [-f FOO] bar
ПРОГ: ошибка: требуются следующие аргументы: бар
действие
Объекты ArgumentParser связывают аргументы командной строки с действиями. Эти
действия могут делать что угодно с аргументами командной строки, связанными с
их, хотя большинство действий просто добавляют атрибут к объекту, возвращаемому parse_args () .Аргумент ключевого слова action указывает
как следует обрабатывать аргументы командной строки. Поставляемые акции:
«store»- просто сохраняет значение аргумента. Это по умолчанию действие. Например:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- foo') >>> parser.parse_args ('- foo 1'.split ()) Пространство имен (foo = '1')'store_const'- Здесь хранится значение, указанное ключевым словом const аргумент.Действие'store_const'чаще всего используется с необязательные аргументы, указывающие какой-то флаг. Например:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- foo', action = 'store_const', const = 42) >>> parser.parse_args (['- foo']) Пространство имен (foo = 42)'store_true'и'store_false'- это особые случаи'store_const'используется для хранения значенийTrueиFalseсоответственно.Кроме того, они создают значения по умолчаниюFalseиПравдасоответственно. Например:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- foo', action = 'store_true') >>> parser.add_argument ('- bar', action = 'store_false') >>> parser.add_argument ('- baz', action = 'store_false') >>> parser.parse_args ('- foo --bar'.split ()) Пространство имен (foo = True, bar = False, baz = True)'append'- сохраняет список и добавляет значение каждого аргумента в список.Это полезно для того, чтобы параметр можно было указывать несколько раз. Пример использования:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- foo', action = 'append') >>> parser.parse_args ('- foo 1 --foo 2'.split ()) Пространство имен (foo = ['1', '2'])'append_const'- здесь хранится список и добавляется значение, указанное аргумент ключевого слова const для списка. (Обратите внимание, что ключевое слово const аргумент по умолчаниюНет.) Действие'append_const'обычно полезно, когда несколько аргументов должны хранить константы в одном списке. Для пример:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- str', dest = 'types', action = 'append_const', const = str) >>> parser.add_argument ('- int', dest = 'types', action = 'append_const', const = int) >>> parser.parse_args ('- str --int'.split ()) Пространство имен (types = [, ]) «count»- Подсчитывает, сколько раз встречается аргумент ключевого слова.Для Например, это полезно для повышения уровня детализации:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- подробный', '-v', action = 'count', по умолчанию = 0) >>> parser.parse_args (['- vvv']) Пространство имен (подробное = 3)Обратите внимание, что по умолчанию будет
Нет, если явно не установлено значение 0 .'help'- печатает полное справочное сообщение для всех параметров в текущий парсер, а затем завершает работу.По умолчанию действие справки автоматически добавлен в парсер. См.ArgumentParserдля получения подробной информации о том, как вывод создан.'версия'- ожидается, что в аргументе ключевого слова версия=add_argument () вызови вывод информации о версии и выходит при вызове:>>> import argparse >>> parser = argparse.ArgumentParser (prog = 'PROG') >>> parser.add_argument ('- версия', действие = 'версия', версия = '% (prog) s 2.0 ') >>> parser.parse_args (['- версия']) ПРОГ 2.0'extend'- сохраняет список и расширяет значение каждого аргумента до список. Пример использования:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ("- foo", action = "extend", nargs = "+", type = str) >>> parser.parse_args (["- foo", "f1", "--foo", "f2", "f3", "f4"]) Пространство имен (foo = ['f1', 'f2', 'f3', 'f4'])
Вы также можете указать произвольное действие, передав подкласс Action или
другой объект, реализующий тот же интерфейс. BooleanOptionalAction доступен в argparse и добавляет поддержку логических действий, таких как --foo и --no-foo :
>>> import argparse
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', действие = argparse.BooleanOptionalAction)
>>> parser.parse_args (['- no-foo'])
Пространство имен (foo = False)
Рекомендуемый способ создания настраиваемого действия - расширить Action ,
переопределение метода __call__ и, возможно, __init__ и format_usage методов.
Пример настраиваемого действия:
>>> класс FooAction (argparse.Action):
... def __init __ (self, option_strings, dest, nargs = None, ** kwargs):
... если nargs не равно None:
... поднять ValueError ("наркотики запрещены")
... super () .__ init __ (option_strings, dest, ** kwargs)
... def __call __ (self, parser, namespace, values, option_string = None):
... print ('% r% r% r'% (пространство имен, значения, option_string))
... setattr (пространство имен, self.dest, values)
...
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', действие = FooAction)
>>> parser.add_argument ('бар', действие = FooAction)
>>> args = parser.parse_args ('1 --foo 2'.split ())
Пространство имен (bar = None, foo = None) '1' None
Пространство имен (bar = '1', foo = None) '2' '--foo'
>>> аргументы
Пространство имен (bar = '1', foo = '2')
Для получения дополнительной информации см. Action .
нарг
Объекты ArgumentParser обычно связывают один аргумент командной строки с
одно действие, которое необходимо предпринять.Аргумент ключевого слова nargs связывает
различное количество аргументов командной строки с одним действием. Поддерживаемый
значения:
N(целое число).Nаргументы из командной строки будут собраны вместе в список. Например:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- foo', nargs = 2) >>> parser.add_argument ('bar', nargs = 1) >>> parser.parse_args ('c --foo a b'.расколоть()) Пространство имен (bar = ['c'], foo = ['a', 'b'])Обратите внимание, что
nargs = 1создает список из одного элемента. Это отличается от значение по умолчанию, при котором элемент создается сам по себе.
'?'. Один аргумент будет использоваться из командной строки, если это возможно, и производится как единое целое. Если аргумент командной строки отсутствует, значение из по умолчанию будет произведено. Обратите внимание, что для необязательных аргументов есть дополнительный случай - строка параметра присутствует, но не сопровождается аргумент командной строки.В этом случае будет получено значение из const. Некоторый примеры, чтобы проиллюстрировать это:>>> parser = argparse.ArgumentParser () >>> parser.add_argument ('- foo', nargs = '?', const = 'c', по умолчанию = 'd') >>> parser.add_argument ('bar', nargs = '?', по умолчанию = 'd') >>> parser.parse_args (['XX', '--foo', 'YY']) Пространство имен (bar = 'XX', foo = 'YY') >>> parser.parse_args (['XX', '--foo']) Пространство имен (bar = 'XX', foo = 'c') >>> parser.parse_args ([]) Пространство имен (bar = 'd', foo = 'd')Одно из наиболее распространенных применений
nargs = '?'- разрешить дополнительный ввод и выходные файлы:>>> парсер = argparse.ArgumentParser () >>> parser.add_argument ('infile', nargs = '?', type = argparse.FileType ('r'), ... по умолчанию = sys.stdin) >>> parser.add_argument ('outfile', nargs = '?', type = argparse.FileType ('w'), ... по умолчанию = sys.stdout) >>> parser.parse_args (['input.txt', 'output.txt']) Пространство имен (infile = <_ io.TextIOWrapper name = 'input.txt' encoding = 'UTF-8'>, Outfile = <_ io.TextIOWrapper name = 'output.txt' encoding = 'UTF-8'>) >>> парсер.parse_args ([]) Пространство имен (infile = <_ io.TextIOWrapper name = '' encoding = 'UTF-8'>, Outfile = <_ io.TextIOWrapper name = ' ' encoding = 'UTF-8'>)
'*'. Все имеющиеся аргументы командной строки собраны в список. Обратите внимание, что обычно нет смысла использовать более одного позиционного аргумента сnargs = '*', но с несколькими необязательными аргументами сnargs = '*'является возможный. Например:>>> парсер = argparse.ArgumentParser () >>> parser.add_argument ('- foo', nargs = '*') >>> parser.add_argument ('- бар', nargs = '*') >>> parser.add_argument ('baz', nargs = '*') >>> parser.parse_args ('a b --foo x y --bar 1 2'.split ()) Пространство имен (bar = ['1', '2'], baz = ['a', 'b'], foo = ['x', 'y'])
'+'. Как и'*', все присутствующие аргументы командной строки собраны в список. Кроме того, будет сгенерировано сообщение об ошибке, если не было присутствует хотя бы один аргумент командной строки.Например:>>> parser = argparse.ArgumentParser (prog = 'PROG') >>> parser.add_argument ('foo', nargs = '+') >>> parser.parse_args (['a', 'b']) Пространство имен (foo = ['a', 'b']) >>> parser.parse_args ([]) использование: PROG [-h] foo [foo ...] PROG: error: необходимы следующие аргументы: foo
Если аргумент ключевого слова nargs не указан, количество использованных аргументов
определяется действием. Обычно это означает один аргумент командной строки
будет потреблен, и будет создан один элемент (не список).
конст.
Аргумент const из add_argument () используется для хранения
постоянные значения, которые не считываются из командной строки, но необходимы для
различные действия ArgumentParser . Два наиболее распространенных его использования:
Когда вызывается
add_argument ()сaction = 'store_const'илиaction = 'append_const'. Эти действия добавляютconstзначение одного из атрибутов объекта, возвращаемогоparse_args ().Примеры см. В описании действия.Когда
add_argument ()вызывается со строками параметров (например,-fили--foo) иnargs = '?'. Это создает необязательный аргумент, за которым может следовать ноль или один аргумент командной строки. При разборе командной строки, если строка параметра встречается без В качестве аргумента командной строки, следующего за ним, будет принято значениеconst. Примеры см. В описании наргов.
С действиями 'store_const' и 'append_const' , const должен быть указан аргумент ключевого слова. Для других действий по умолчанию используется Нет .
по умолчанию
Все необязательные аргументы и некоторые позиционные аргументы могут быть опущены в
командная строка. Аргумент ключевого слова по умолчанию для add_argument () , значение которого по умолчанию Нет ,
указывает, какое значение следует использовать, если аргумент командной строки отсутствует.Для необязательных аргументов используется значение по умолчанию , когда строка параметра
не присутствовал в командной строке:
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', по умолчанию = 42)
>>> parser.parse_args (['- foo', '2'])
Пространство имен (foo = '2')
>>> parser.parse_args ([])
Пространство имен (foo = 42)
Если в целевом пространстве имен уже установлен атрибут, действие по умолчанию не перепишу:
>>> парсер = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', по умолчанию = 42)
>>> parser.parse_args ([], пространство имен = argparse.Namespace (foo = 101))
Пространство имен (foo = 101)
Если значение по умолчанию является строкой, синтаксический анализатор анализирует значение, как если бы оно
были аргументом командной строки. В частности, парсер применяет любой тип
аргумент преобразования, если он предоставлен, перед установкой атрибута в Пространство имен возвращаемое значение. В противном случае парсер использует значение как есть:
>>> парсер = argparse.ArgumentParser ()
>>> parser.add_argument ('- length', по умолчанию = '10 ', type = int)
>>> parser.add_argument ('- width', по умолчанию = 10,5, type = int)
>>> parser.parse_args ()
Пространство имен (длина = 10, ширина = 10,5)
Для позиционных аргументов с нарг равным ? или * , значение по умолчанию используется при отсутствии аргумента командной строки:
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('foo', nargs = '?', по умолчанию = 42)
>>> парсер.parse_args (['a'])
Пространство имен (foo = 'a')
>>> parser.parse_args ([])
Пространство имен (foo = 42)
Предоставление default = argparse.SUPPRESS не приводит к добавлению атрибутов, если
аргумент командной строки отсутствовал:
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', по умолчанию = argparse.SUPPRESS)
>>> parser.parse_args ([])
Пространство имен ()
>>> parser.parse_args (['- foo', '1'])
Пространство имен (foo = '1')
тип
По умолчанию синтаксический анализатор считывает аргументы командной строки так же просто.
струны.Однако довольно часто строка командной строки должна быть
интерпретируется как другой тип, например, float или int . В тип ключевое слово для add_argument () разрешает любые
необходимая проверка типов и преобразование типов, которые должны быть выполнены.
Если ключевое слово типа используется с ключевым словом по умолчанию, преобразователь типов применяется только в том случае, если по умолчанию используется строка.
Аргументом типа может быть любой вызываемый объект, который принимает единственную строку.Если функция вызывает ArgumentTypeError , TypeError или ValueError , исключение перехвачено и красиво отформатированная ошибка
отображается сообщение. Никакие другие типы исключений не обрабатываются.
Общие встроенные типы и функции могут использоваться в качестве преобразователей типов:
import argparse
импортировать pathlib
parser = argparse.ArgumentParser ()
parser.add_argument ('количество', тип = целое)
parser.add_argument ('расстояние', тип = float)
parser.add_argument ('улица', тип = ascii)
парсер.add_argument ('точка_кода', тип = ord)
parser.add_argument ('исходный_файл', тип = открытый)
parser.add_argument ('dest_file', type = argparse.FileType ('w', encoding = 'latin-1'))
parser.add_argument ('путь к данным', тип = pathlib.Path)
Также могут использоваться пользовательские функции:
>>> def через дефис (строка):
... вернуть '-'. join ([word [: 4] вместо слова в string.casefold (). split ()])
...
>>> parser = argparse.ArgumentParser ()
>>> _ = parser.add_argument ('short_title', тип = с дефисом)
>>> парсер.parse_args (['"Повесть о двух городах"'])
Пространство имен (short_title = '"сказка о двух городах')
Функция bool () не рекомендуется в качестве преобразователя типов. Все это делает
преобразует пустые строки в False и непустые строки в True .
Обычно это не то, что нужно.
В общем, ключевое слово типа - это удобство, которое следует использовать только для
простые преобразования, которые могут вызвать только одно из трех поддерживаемых исключений.Все, что связано с более интересной обработкой ошибок или управлением ресурсами, должно быть
выполняется ниже по потоку после анализа аргументов.
Например, преобразования JSON или YAML имеют сложные случаи ошибок, которые требуют
лучшая отчетность, чем может дать ключевое слово type . An JSONDecodeError не будет хорошо отформатирован и FileNotFound Исключение вообще не обрабатывается.
Даже FileType имеет свои ограничения для использования с type ключевое слово.Если один аргумент использует FileType , а последующий аргумент не работает,
сообщается об ошибке, но файл не закрывается автоматически. В этом случае это
было бы лучше подождать, пока парсер не запустится, а затем использовать с заявлением для управления файлами.
Для средств проверки типов, которые просто проверяют соответствие фиксированному набору значений, рассмотрите вместо этого используйте ключевое слово choices.
вариант
Некоторые аргументы командной строки следует выбирать из ограниченного набора значений.С ними можно справиться, передав объект-контейнер в качестве ключевого слова choices аргумент для add_argument () . Когда командная строка
проанализированы, значения аргументов будут проверены, и будет отображено сообщение об ошибке
если аргумент не был одним из допустимых значений:
>>> parser = argparse.ArgumentParser (prog = 'game.py')
>>> parser.add_argument ('move', choices = ['камень', 'бумага', 'ножницы'])
>>> parser.parse_args (['камень'])
Пространство имен (move = 'rock')
>>> парсер.parse_args (['огонь'])
использование: game.py [-h] {камень, ножницы, бумага}
game.py: ошибка: перемещение аргумента: неверный выбор: 'огонь' (выберите из 'рок',
'бумага', 'ножницы')
Обратите внимание, что включение в контейнер choices проверяется после любого типа преобразования были выполнены, поэтому тип объектов в выборах контейнер должен соответствовать указанному типу:
>>> parser = argparse.ArgumentParser (prog = 'doors.py')
>>> parser.add_argument ('дверь', type = int, choices = range (1, 4))
>>> print (parser.parse_args (['3']))
Пространство имен (door = 3)
>>> parser.parse_args (['4'])
использование: doors.py [-h] {1,2,3}
Door.py: ошибка: аргумент дверь: неверный выбор: 4 (выберите из 1, 2, 3)
Любой контейнер может быть передан в качестве значения вариантов выбора , поэтому перечисляет объектов, устанавливает объектов, и все настраиваемые контейнеры поддерживаются.
Использование перечисления enum.Enum не рекомендуется, поскольку его сложно
контролировать его внешний вид в сообщениях об использовании, справке и ошибках.
Форматированный выбор отменяет метавару по умолчанию , которая обычно получается с назнач . Обычно это именно то, что вам нужно, потому что пользователь никогда не видит dest параметр. Если это отображение нежелательно (возможно, потому что есть много вариантов), просто укажите явную метаварку.
требуется
В общем, модуль argparse предполагает, что такие флаги, как -f и --bar укажите необязательных аргумента , которые всегда можно опустить в командной строке.Чтобы сделать опцию , требуется , True можно указать для required = аргумент ключевого слова для add_argument () :
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', обязательно = True)
>>> parser.parse_args (['- foo', 'BAR'])
Пространство имен (foo = 'BAR')
>>> parser.parse_args ([])
использование: [-h] --foo FOO
: error: необходимы следующие аргументы: --foo
Как показывает пример, если опция помечена как требуется , parse_args () сообщит об ошибке, если эта опция не указана.
присутствует в командной строке.
Примечание
Обязательные параметры обычно считаются дурным тоном, потому что пользователи ожидают варианты должны быть дополнительными , и поэтому их следует избегать, когда это возможно.
справка
Значение help - это строка, содержащая краткое описание аргумента.
Когда пользователь запрашивает помощь (обычно с помощью -h или --help в
командная строка), эти справки описания будут отображаться с каждым
аргумент:
>>> парсер = argparse.ArgumentParser (prog = 'frobble')
>>> parser.add_argument ('- foo', action = 'store_true',
... help = 'foo the bars before frobbling')
>>> parser.add_argument ('bar', nargs = '+',
... help = 'одна из полосок, которую нужно заморозить')
>>> parser.parse_args (['- h'])
использование: frobble [-h] [--foo] bar [bar ...]
позиционные аргументы:
заблокировать одну из полосок, которую нужно заморозить
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
--foo foo the bars перед замораживанием
Справка Строки могут включать в себя различные спецификаторы формата, чтобы избежать повторения.
таких вещей, как имя программы или аргумент по умолчанию.Доступные
спецификаторы включают имя программы, % (prog) s и большинство аргументов ключевого слова для add_argument () , например % (по умолчанию) s , % (тип) s и т. Д .:
>>> parser = argparse.ArgumentParser (prog = 'frobble')
>>> parser.add_argument ('bar', nargs = '?', type = int, по умолчанию = 42,
... help = 'полоса до% (prog) s (по умолчанию:% (default) s)')
>>> parser.print_help ()
использование: frobble [-h] [bar]
позиционные аргументы:
заблокировать полосу до замораживания (по умолчанию: 42)
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
Поскольку строка справки поддерживает% -форматирование, если вы хотите, чтобы появился литерал % в строке справки вы должны экранировать его как %% .
argparse поддерживает отключение записи справки для определенных параметров с помощью
установка значения help на argparse.SUPPRESS :
>>> parser = argparse.ArgumentParser (prog = 'frobble')
>>> parser.add_argument ('- foo', help = argparse.SUPPRESS)
>>> parser.print_help ()
использование: frobble [-h]
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
dest
Большинство действий ArgumentParser добавляют некоторое значение в качестве атрибута
объект, возвращенный parse_args () .Название этого
атрибут определяется аргументом ключевого слова dest add_argument () . Для позиционных аргументов действия dest обычно предоставляется в качестве первого аргумента для add_argument () :
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('панель')
>>> parser.parse_args (['XXX'])
Пространство имен (bar = 'XXX')
Для действий с дополнительным аргументом значение dest обычно выводится из
строки параметров. ArgumentParser генерирует значение dest с помощью
беря первую длинную строку опций и удаляя начальные - нить. Если не было предоставлено никаких длинных строк опций, dest будет производным от
первая короткая строка параметра, удалив начальный символ - . Любой
внутренние - символов будут преобразованы в _ символов, чтобы убедиться, что
строка является допустимым именем атрибута. Примеры ниже иллюстрируют это
поведение:
>>> парсер = argparse.ArgumentParser ()
>>> parser.add_argument ('- f', '--foo-bar', '--foo')
>>> parser.add_argument ('- x', '-y')
>>> parser.parse_args ('- f 1 -x 2'.split ())
Пространство имен (foo_bar = '1', x = '2')
>>> parser.parse_args ('- foo 1 -y 2'.split ())
Пространство имен (foo_bar = '1', x = '2')
dest позволяет указать имя настраиваемого атрибута:
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo', dest = 'bar')
>>> парсер.parse_args ('- foo XXX'.split ())
Пространство имен (bar = 'XXX')
Классы действий
Классы действий реализуют API действий, вызываемый объект, который возвращает вызываемый объект.
который обрабатывает аргументы из командной строки. Любой объект, следующий за
этот API может быть передан как параметр действия в add_argument () .
- класс
argparse.Action( option_strings , dest , nargs = None , const = None , default = None , type = None , choices = None , required = False , required = False help = Нет , metavar = Нет )
Объекты Action используются ArgumentParser для представления информации
необходимо для синтаксического анализа одного аргумента из одной или нескольких строк из
командная строка.Класс Action должен принимать два позиционных аргумента
плюс любые аргументы ключевого слова, переданные в ArgumentParser.add_argument () кроме самого действия .
экземпляра действия (или возвращаемое значение любого вызываемого действия параметр) должен иметь атрибуты «dest», «option_strings», «default», «type»,
Определение «требуется», «помощь» и т. Д. Самый простой способ обеспечить эти атрибуты
определены, это вызвать Action .__ init__ .
Экземпляры Action должны быть вызываемыми, поэтому подклассы должны переопределять __call__ метод, который должен принимать четыре параметра:
parser- Объект ArgumentParser, содержащий это действие.namespace- ОбъектNamespace, который будет возвращенparse_args (). Большинство действий добавляют атрибут к этому объект с помощьюsetattr ().значений- Связанные аргументы командной строки с любыми преобразованиями типов применяемый. Преобразования типов указываются с помощью аргумента ключевого слова типа вadd_argument ().option_string- Строка параметра, которая использовалась для вызова этого действия.Аргументoption_stringявляется необязательным и будет отсутствовать, если действие связан с позиционным аргументом.
Метод __call__ может выполнять произвольные действия, но обычно устанавливает
атрибуты в пространстве имен на основе значений dest и .
Action могут определять метод format_usage , который не принимает аргументов
и вернуть строку, которая будет использоваться при печати использования программы.Если такой метод не предусмотрен, будет использоваться разумное значение по умолчанию.
Метод parse_args ()
-
ArgumentParser.parse_args( args = None , namespace = None ) Преобразовать строки аргументов в объекты и назначить их как атрибуты пространство имен. Верните заполненное пространство имен.
Предыдущие вызовы
add_argument ()точно определяют, какие объекты созданы и как они назначены.Документацию дляadd_argument ()для подробностей.args - Список строк для синтаксического анализа. По умолчанию берется из
sys.argv.пространство имен - объект, принимающий атрибуты. По умолчанию новый пустой
Пространство именобъекта.
Синтаксис значения параметра
Метод parse_args () поддерживает несколько способов
указание значения опции (если она нужна).В простейшем случае
параметр и его значение передаются как два отдельных аргумента:
>>> parser = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- x')
>>> parser.add_argument ('- foo')
>>> parser.parse_args (['- x', 'X'])
Пространство имен (foo = None, x = 'X')
>>> parser.parse_args (['- foo', 'FOO'])
Пространство имен (foo = 'FOO', x = None)
Для длинных опций (опций с именами длиннее одного символа) опция
и значение также можно передать как один аргумент командной строки, используя = для
разделить их:
>>> парсер.parse_args (['- foo = FOO']) Пространство имен (foo = 'FOO', x = None)
Для коротких опций (варианты длиной всего один символ), опция и ее значение можно объединить:
>>> parser.parse_args (['- xX']) Пространство имен (foo = None, x = 'X')
Несколько коротких вариантов можно объединить, используя только один префикс - ,
если только последний вариант (или ни один из них) не требует значения:
>>> parser = argparse.ArgumentParser (prog = 'PROG')
>>> парсер.add_argument ('- x', действие = 'store_true')
>>> parser.add_argument ('- y', действие = 'store_true')
>>> parser.add_argument ('- z')
>>> parser.parse_args (['- xyzZ'])
Пространство имен (x = True, y = True, z = 'Z')
Неверные аргументы
При анализе командной строки parse_args () проверяет наличие
множество ошибок, включая неоднозначные параметры, недопустимые типы, недопустимые параметры,
неправильное количество позиционных аргументов и т. д. Когда он встречает такую ошибку,
он выходит и печатает ошибку вместе с сообщением об использовании:
>>> парсер = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- foo', type = int)
>>> parser.add_argument ('bar', nargs = '?')
>>> # недопустимый тип
>>> parser.parse_args (['- foo', 'spam'])
использование: PROG [-h] [--foo FOO] [bar]
ПРОГ: ошибка: аргумент --foo: недопустимое значение int: 'спам'
>>> # неверный вариант
>>> parser.parse_args (['- bar'])
использование: PROG [-h] [--foo FOO] [bar]
ПРОГ: ошибка: нет такой опции: --bar
>>> # неправильное количество аргументов
>>> парсер.parse_args (['спам', 'барсук])
использование: PROG [-h] [--foo FOO] [bar]
ПРОГ: ошибка: найдены лишние аргументы: барсук
Аргументы, содержащие
- Метод parse_args () пытается выдавать ошибки всякий раз, когда
пользователь явно совершил ошибку, но некоторые ситуации по своей сути
двусмысленный. Например, аргумент командной строки -1 может быть либо
попытка указать параметр или попытка предоставить позиционный аргумент.
Метод parse_args () здесь осторожен: позиционный
аргументы могут начинаться только с - , если они выглядят как отрицательные числа и
в парсере нет опций, которые выглядят как отрицательные числа:
>>> парсер = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- x')
>>> parser.add_argument ('foo', nargs = '?')
>>> # нет опций с отрицательными числами, поэтому -1 - позиционный аргумент
>>> parser.parse_args (['- x', '-1'])
Пространство имен (foo = None, x = '- 1')
>>> # нет опций с отрицательными числами, поэтому -1 и -5 являются позиционными аргументами
>>> parser.parse_args (['- x', '-1', '-5'])
Пространство имен (foo = '- 5', x = '- 1')
>>> parser = argparse.ArgumentParser (prog = 'PROG')
>>> парсер.add_argument ('- 1', dest = 'один')
>>> parser.add_argument ('foo', nargs = '?')
>>> # присутствуют отрицательные числа, поэтому -1 - это вариант
>>> parser.parse_args (['- 1', 'X'])
Пространство имен (foo = None, one = 'X')
>>> # присутствуют отрицательные числа, поэтому -2 - это вариант
>>> parser.parse_args (['- 2'])
использование: PROG [-h] [-1 ONE] [foo]
ПРОГ: ошибка: нет такой опции: -2
>>> # присутствуют варианты отрицательных чисел, поэтому оба значения -1 являются вариантами
>>> parser.parse_args (['- 1', '-1'])
использование: PROG [-h] [-1 ONE] [foo]
ПРОГ: ошибка: аргумент -1: ожидался один аргумент
Если у вас есть позиционные аргументы, которые должны начинаться с – и не смотрите
как и отрицательные числа, вы можете вставить псевдо-аргумент '-' , который сообщает parse_args () , что все после этого является позиционным
аргумент:
>>> парсер.parse_args (['-', '-f']) Пространство имен (foo = '- f', one = None)
Сокращения аргументов (сопоставление префиксов)
Метод parse_args () по умолчанию
позволяет сокращать длинные параметры до префикса, если это сокращение
однозначный (префикс соответствует уникальному варианту):
>>> parser = argparse.ArgumentParser (prog = 'PROG')
>>> parser.add_argument ('- бекон')
>>> parser.add_argument ('- барсук')
>>> parser.parse_args ('- bac MMM'.расколоть())
Пространство имен (bacon = 'MMM', badger = None)
>>> parser.parse_args ('- плохой WOOD'.split ())
Пространство имен (бекон = Нет, барсук = 'ДЕРЕВО')
>>> parser.parse_args ('- ba BA'.split ())
использование: PROG [-h] [-bacon BACON] [-badger BADGER]
ПРОГ: ошибка: неоднозначный параметр: -ba может соответствовать -badger, -bacon
Ошибка возникает для аргументов, которые могут давать более одного варианта.
Эту функцию можно отключить, установив для allow_abbrev значение False .
За пределами
sys.argv Иногда может быть полезно иметь аргументы синтаксического анализа ArgumentParser, отличные от
из систем.argv . Это можно сделать, передав список строк в parse_args () . Это полезно для тестирования на
интерактивная подсказка:
>>> parser = argparse.ArgumentParser () >>> parser.add_argument ( ... 'целые числа', metavar = 'int', type = int, choices = range (10), ... nargs = '+', help = 'целое число в диапазоне 0..9') >>> parser.add_argument ( ... '--sum', dest = 'Накопить', action = 'store_const', const = sum, ... по умолчанию = max, help = 'суммировать целые числа (по умолчанию: найти максимум)') >>> парсер.parse_args (['1', '2', '3', '4']) Пространство имен (накопление = <встроенная функция max>, целые числа = [1, 2, 3, 4]) >>> parser.parse_args (['1', '2', '3', '4', '--sum']) Пространство имен (накопление = <сумма встроенных функций>, целые числа = [1, 2, 3, 4])
Объект пространства имен
- класс
argparse.Пространство имен Простой класс, используемый по умолчанию функцией
parse_args ()для создания объект, содержащий атрибуты, и вернуть его.
Этот класс намеренно прост, просто подкласс объекта с
читаемое строковое представление. Если вы предпочитаете, чтобы
атрибуты, вы можете использовать стандартную идиому Python, vars () :
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo')
>>> args = parser.parse_args (['- foo', 'BAR'])
>>> vars (аргументы)
{'foo': 'BAR'}
Также может быть полезно, чтобы ArgumentParser назначал атрибуты объекту.
уже существующий объект, а не новый объект Namespace .Это может
достигается путем указания аргумента ключевого слова namespace = :
>>> класс C:
... проходить
...
>>> c = C ()
>>> parser = argparse.ArgumentParser ()
>>> parser.add_argument ('- foo')
>>> parser.parse_args (args = ['- foo', 'BAR'], namespace = c)
>>> c.foo
'БАР'
Niagara Parse Streams
Задний план
В Ниагаре существует определенная избыточность из-за
к его структуре и самостоятельным усилиям по развитию
его отдельные компоненты.Например, диспетчер данных и
каждый из менеджеров индексов имеет свой собственный анализатор XML. Эти
оба анализатора SAX, управляемого событиями.
Собственно ... в системе есть еще один XML-парсер,
то, что использует оператор сканирования файлов, то есть DOM
парсер. Однако потребность в этом отдельном парсере будет
устраняется после того, как XNodes DM будет использоваться для всего XML
представление данных.
Вы спросите, в чем проблема с двумя парсерами? Хорошо,
есть несколько. Во-первых, проблема с производительностью
- документ должен быть проанализирован дважды, один раз для DM и один раз
для IM, если он будет храниться в Ниагаре.XML-синтаксический анализ
имеет много накладных расходов, и эта стоимость не разумна для
реальные запросы.
Во-вторых, проблема в том, что система в целом
должен поддерживать два анализатора XML. Внешне это может не показаться
большое дело. Однако вы должны понимать, что два парсера
должны быть полностью согласны с нумерацией позиций в
XML-документ. Эта связь позволяет понять, что
парсеры не являются полностью независимыми, а скорее дублируют
функциональность друг друга. Если они дублируют это неправильно
на самом деле система не будет работать.Затем возникает проблема ортогональности. IM и
DM не имеет никакого отношения к разбору документов, и все
задача с хранением документов. Тем не менее, значительная часть
оба вращаются вокруг анализа документов. Перемещая документ
разбирая на собственную систему сложность этих компонентов
будет уменьшено. Кроме того, можно будет иметь
несколько анализаторов XML и несколько пользователей синтаксического анализа в системе
со сложностью только N + M вместо сложности NxM. An
Примером этого является «синтаксический анализ» документа, хранящегося в
DM, чтобы его можно было [пере-] проиндексировать.вопросы
XML-парсер - это хранилище знаний о
нумерация содержимого XML. По крайней мере, есть
Нумерация идентификаторов элементов, используемая в настоящее время DM. Тем не мение,
даже эта упрощенная схема нумерации должна учитывать
как разбиваются документы в Ниагаре. Например,
-2-
текст между элементами XML на заданном уровне сохраняется как
Текстовые узлы и нумерацию необходимо скорректировать с учетом
это.
Помимо нумерации элементов есть еще начало,
конечная нумерация, используемая IM.Эта схема нумерации
необходимо, поскольку он отражает структуру документа и
позволяет оценивать предикаты contains по двум пост-
лица, у которых есть начальный и конечный номера. Знание документа
структура требуется для содержит запросы.
С этой новой Niagara мы также представляем концепцию
нумерация слов полезной нагрузки. Это позволяет точное безостановочное слово
запросы, которые должны быть выполнены IM - см. виньетку IM для
подробности.
Стоп-слова - еще одна проблема, так как парсеру может потребоваться пронумеровать
В одних случаях используйте стоп-слова, а в других - не нумеруйте их.
случаи.Таким образом, парсер должен знать, что такое стоп-слово
является. Может быть важно иметь настраиваемый стоп-слово
список. Пока достаточно фиксированного списка стоп-слов, но
это важно учитывать в будущем.
В общем, синтаксический анализатор, скорее всего, предоставит больше
информации, чем это необходимо для любой организации, которая
получение его событий синтаксического анализа. Обычно это означает
парсер предоставит объединение всей синтаксической информации
требуется каждому из его пользователей.Множественный анализ
Все вышеперечисленные цели достижимы с автономным
модуль парсинга. Один парсер в системе лучше двух
и большой шаг вперед по сравнению с тем, что у нас есть сейчас. Однако один
из целей состоит в том, чтобы синтаксический анализатор предоставлял события синтаксического анализа для
несколько потребителей этих событий одновременно. Этот
это то, что позволит одному синтаксическому анализу загрузить документ в
DM, а также для создания проводок, которые хранятся в IM.
Поскольку это модульная конструкция, модуль множественного синтаксического анализа
может быть просто обычным приемником событий синтаксического анализа, который затем
дублирует события в ряд других событий синтаксического анализа
приемники.В настоящее время предполагается, что интерфейс события синтаксического анализа
будет носить процедурный характер, а не фактическое событие -
управляемый канал, такой как ручей. Это указано для
по следующим причинам. Во-первых, минимизировать объем данных
это буферизовано. Если использовались потоки и два кон-
у шумеров разные нормы потребления, то отставание будет
накапливаются медленному потребителю .. Используя синхронный
интерфейс эта проблема с буферизацией устранена. Другой
вопрос, который следует учитывать, - это необходимость инкрементного анализа.Если
есть, например, большая строка, которую мы не хотим иметь
для создания всего этого в памяти перед передачей потребителю.
-3-
Инкрементальный подход, при котором части больших данных
передача потребителям снижает влияние больших объемов данных и
делает систему более масштабируемой. Третий фактор, который необходимо
sider - это вопрос копирования данных. Разбор XML - это
дорогостоящая операция и копирование данных в несколько
источники намного дороже.Суть в том, что процедурный интерфейс прост,
легко приспосабливаемый и полезный с самого начала. Мы можем
решили поменять его в будущем, но это хорошее здание
блок на данный момент, и, возможно, это все, что требует Ниагара.
Примечания по реализации и цели
Одна из целей системы парсинга - развести остальных
системы от зависимости от конкретного парсера XML.
Таким образом, интерфейс событий синтаксического анализа должен быть полностью изолированным.
запаздывают потребители синтаксического анализа событий из продукта
одно и тоже.Это означает, что не должно быть прямых или косвенных
связь между существующим синтаксическим анализатором XML, Xerces-C и
остаток Ниагарской системы. Другими словами, XML
parser - это деталь реализации потока синтаксического анализа.
ератор и не более того.
В настоящее время IM и DM управляют своей собственной нагрузкой.
ing с функцией загрузки (url). Они знают о создании
транзакции для загрузки, а затем либо зафиксировать, либо прервать
сделка. В новой системе это изменится - загружает
произойдет в контексте оператора загрузки, который
отвечает за подключение источника документа к XML
парсер.Операция загрузки также будет отвечать за
сбор получателя (ей) событий синтаксического анализа и организация
события синтаксического анализа, которые будут отправлены этим получателям событий. В
IM и DM ничего не знают о транзакциях и работают
в контексте одного. Прерывание транзакции и фиксация будут
осуществляется субъектами более высокого уровня, которые могут определять политику
решения.
В настоящее время IM и DM являются объектами с
несколько несвязанные половинки. Важная часть как IM
и DM - это хранение и поиск информации из базы данных.
связь.Однако и IM, и DM имеют большой разрыв.
ция посвящена синтаксическому анализу XML в формат, который хранилище
двигатель можно потом хранить. Это увеличивает сложность
двух систем совсем немного, перемещая основную часть этого функционала-
к системе синтаксического анализа, с релевантными только IM или DM
интерпретатор данных для преобразования проанализированных данных в формат
необходимы этим подсистемам. Еще лучше было бы изолировать
процесс преобразования данных в IM и DM из
актуальные компоненты БД.Это позволит компонентам БД
просто храните «поток» релевантных объектов, независимо от того,
или XNodes. Это сделает компоненты БД просто компонентами
которые имеют дело с доступом к базе данных и делают систему более
ортогональные. Конечно, это дальняя цель, но она
-4-
должны быть известны заранее, чтобы направлять разработку системы.
Важно, чтобы парсер был "масштабируемым" с точки зрения
размера документа. Этот элемент масштабируемости означает, что синтаксический анализ
не должен зависеть от размера документа - если размер документа
растет размер синтаксического анализа не должен расти вместе с ним.Однако это
также важно, чтобы анализатор был масштабируемым на меньшем
уровень - например, отдельные элементы документа,
будь то слова или элементы XML. Например, 100 МБ
слово в документе не должно требовать, чтобы слово размером 100 МБ было
формируется в памяти перед передачей приемникам событий.
Синтаксический анализатор, управляемый событиями, позаботится о том, чтобы
больших документов, разбив их на отдельные
элементы. Однако дальнейший поэтапный подход
требуется для обработки отдельного большого содержимого.К экзамену-
Ple, функция start_element для запуска нового элемента
текст и функция continue_element, которая постепенно
добавляет текст к начатому элементу до его завершения. Из
Конечно, небольшой элемент должен быть завершен только
вызов start_element и не требует дальнейших вызовов.
(PDF) Быстрый анализ зависимостей с использованием распределенных представлений слов
11. Миколов Т., Суцкевер И., Чен К., Коррадо Г.С., Дин, Дж .: Распределенные представления
слов и фраз и их композиционность. In Burges, C., Bottou,
,L., Welling, M., Ghahramani, Z., Weinberger, K., eds .: Advances in Neural Infor-
Системы обработки информации 26. Curran Associates, Inc. (2013 г.) ) 3111–3119
12. Эндрю, Г., Гао, Дж .: Масштабируемое обучение l1-регуляризованных лог-линейных моделей. В:
Proceedings of ICML, Государственный университет Орегона, Корваллис, США (2007) 33–40
13.Нокедал, Дж., Райт, С.Дж .: Численная оптимизация. 2-е изд. Springer, New York,
(2006)
14. Ле-Хонг, П., Нгуен, Т.М.Х., Руссанали, А., Хо, Т.В.: Гибридный подход к сегментации
слов вьетнамских текстов. В: Proceedings of LATA, LNCS 5196,
Springer (2008) 240–249
15. Nguyen, TL, Ha, ML, Nguyen, VH, Nguyen, TMH, Le-Hong, P .: Building a
treebank для синтаксического анализа вьетнамских зависимостей. В: 10-й IEEE RIVF, Ханой,
Вьетнам, IEEE (2013) 147–151
16.Нгуен, П.Т., Суан, Л.В., Нгуен, Т.М.Х., Нгуен, В.Х., Ле-Хонг, П .: Building
, большой синтаксически аннотированный корпус вьетнамского языка. В: Proceedings of the 3rd
Linguistic Annotation Workshop, ACL-IJCNLP, Suntec City, Singapore (2009)
182–185
17. Бонет, Б .: Очень высокая точность и быстрый анализ зависимостей не является противоречием.
В: Proceedings of COLING, Пекин, Китай (2010) 89–97
18. Ку, Т., Каррерас, X., Коллинз, М .: Простой полууправляемый синтаксический анализ зависимостей.
В: Proceedings of ACL-HLT, Колумбус, Огайо, США (2008) 595–603
19. Гарг, Н., Хендерсон, Дж .: Машины Больцмана с ограничениями по времени для анализа зависимости
.