Как разобрать по составу слова «прилавок» и «лавочка»?
Какой морфемный разбор слов «прилавок» и «лавочка»?
2
Дублон
Ответы (7):
Share
1
Слово «прилавок» — содержит следующие морфемы (или по другому их можно назвать части слова):
приставка — при, корень — лавок
Основа слова — прилавок.
Приставочный или префиксальный способ образования слова.
Значение слова «Прилавок»
Слово «лавочка» — содержит следующие морфемы (или по другому их можно назвать части слова):
корень — лавоч, суффикс — к, окончание — а.
Основа слова — лавочк.
Суффиксальный способ образования слова.
Значение слова «Лавочка»
Share
2
Морфемный разбор существительного женского рода «лавочка»:
- окончание «-а», слово изменяется по падежам и числам, поэтому окончание легко выделяется,
- основа «лавочк-«, часть слова без окончания,
- суффикс «-к-«, от «лавка,
- корень «лавоч-«, чередование нуль звука//о (лавк-//лавОч-) и чередование к//ч (лавК-//лавоЧ-).

Морфемный разбор существительного «прилавок»:
- окончание нулевое, проявляется в других формах (например, Р.п. прилавкА),
- основа «прилавок-«, часть слова без окончания,
- приставка «при-«, есть слово без этой приставки,
- корень «-лавок-«, есть чередование нуль звука//о (прилавОк//прилавка).
Share
1
Слово Прилавок отвечает на вопрос Что? и оказывается существительным мужского рода, которое обладает нулевым окончанием: Прилавок-Прилавка-Пр
Однокоренными словами оказываются: Прилавок-Лавочка-Лав
Следовательно корнем слова будет морфема -лавок.
Далее выделим в составе слова приставку при-.
Получаем: при-лавок_ (приставка-корень-ну
Слово Лавочка отвечает на вопрос Что? и оказывается существительным женского рода, которое обладает окончанием: -а: Лавочка-Лавочки-Лаво
Выделим здесь тот же корень лавоч-.
Далее выделим в составе слова суффикс существительного -к-.
Получаем: лавоч-к-а (корень-суффикс-окон
1
Слово «прилавок» это имя существительное отвечает на вопрос «Что?», неодушевлённое, мужского рода единственного числа, винительный падеж.
Разбор по составу слова «прилавок» имеет вид:
при — приставка;
лавок — это корень;
окончание нулевое.
Основа слова является — прилавок .
Способ образования слова: префиксальный (приставочный).
Слово «лавочка» это имя существительное отвечает на вопрос «Что?», неодушевлённое, женского рода единственного числа, именительный падеж.
Разбор по составу слова «лавочка» имеет вид:
лавоч — это корень;
к — суффикс;
а]окончание.
Основа слова является — лавочк .
Способ образования слова: суффиксальный.
Share
1
В данном вопросе нам требуется сделать морфемный разбор слов прилавок и лавочка.
Вот как это сделаем с каждым словом по очереди
Разбор по составу слова прилавок. Основа данного слова прилавок. Слово прилавок является существительным. Оно состоит из приставки при и корня лавок. В итоге получается схема приставка — корень, а именно при — лавок.
Способ образования слова приставочный.
Разбор по составу слова лавочка. Основа данного слова лавочк. Слово лавочка является существительным. Оно состоит из корня лавоч, суффикса К и окончания а. Видим схему корень — суффикс — окончание, а именно лавоч — к — а.
Share
В любом случае слова «прилавок» и лавочка» являются однокоренными словами и происходят от слова «лавка», где корень «лавк», а -о- беглое гласное.В первом слове лавок — корень, -при- приставки.
Лавочка — лавоч -корень,к- суффикс. а — окончание.
Share
Слово прилавок разбирается по составу таким образом:
при — это приставка
лавок — это корень
окончание нулевое, основа прилавок
Слово лавочка:
корень — лавоч
суффикс — к
окончание а
Основа слова это лавочк.
«Айнтрахт» – команда-трансформер с левым защитником в ключевой роли (Костич – топ). В контратаках в ЛЕ им не было равных
Содержание:
- 1 Победа над «Барсой» – главный спектакль «Айнтрахта». Это не совпадение – с такими соперниками им удобнее
- 2 «Франкфурт» не любит владеть мячом, но обожает открытые матчи. Схема помогает устраивать им перестрелки
- 3 Филип Костич – левый латераль и мозг команды
- 4 В позиционных атаках тоже помогает схема-трансформер. Постепенно команда становится вариативнее
- 5 ***
 Постепенно команда становится вариативнее
Постепенно команда становится вариативнееРазбор Вадима Лукомского.
«Айнтрахт» обыграл «Рейнджерс» по пенальти в финале Лиги Европы (1:1 до серии). Финал получился драматичным и местами приятным для просмотра, но обошелся без тактического триллера. В этот раз интереснее разобрать не конкретную игру, а путь команды Оливера Гласнера к триумфу.
Начнем с очевидного вопроса: как 11-е место в Бундеслиге сочетается со вполне заслуженной победой в еврокубке?
Победа над «Барсой» – главный спектакль «Айнтрахта». Это не совпадение – с такими соперниками им удобнее
На самом деле ситуация даже радикальнее, чем кажется на первый взгляд. По ожидаемым очкам «Айнтрахт» даже не 11-й, а 14-й в Бундеслиге. То есть не получится сказать, что сильная команда из-за невезения провалила сезон в чемпионате, но круто собиралась на топовые матчи в Европе.
В Бундеслиге «Франкфурт» – действительно непримечательная и посредственная команда. Именно в рамках рисунка игры, который им предлагается в большинстве встреч Бундеслиги. Да, парадокс «Айнтрахта» строится именно на контрасте между удобным и неудобным рисунком игры. Конечно, такое понятие применимо почти к любой команде, но ни у кого оно не достигает таких крайностей.
Да, парадокс «Айнтрахта» строится именно на контрасте между удобным и неудобным рисунком игры. Конечно, такое понятие применимо почти к любой команде, но ни у кого оно не достигает таких крайностей.
В Лиге Европы «Айнтрахт» выбился в финал с самой трудной сеткой плей-офф с 2008-го. С этого сезона аналитическая компания 21st Club ведет свой клубный рейтинг. По средней трудности соперника «Франкфурту» нет равных:
Модель тут помогает поместить сетку плей-офф в контекст и сравнить с прошлыми сезонами, но мощь соперников можно ощутить и через простое перечисление – «Бетис» (5-е место в Ла Лиге), «Барселона» (2-е место в Ла Лиге) и «Вест Хэм» (7-е место в АПЛ). Все противники из двух сильнейших чемпионатов Европы – все проводят достойный сезон.
«Айнтрахт» уничтожил их на контратаках. Лишь с «Вест Хэмом» рисунок был иным – там немцы так и не показали свою мощь, продрались за счет деталей – в первом матче повезло с плохой реализаций «Вест Хэма»; а во втором – с ранним удалением.
С «Бетисом» и «Барселоной» команда Гласнера кайфовала, получив комфортные условия. В обоих случаях залогом успеха стали выездные матчи с 65%+ владения у соперника. В обоих случаях они создавали огромную долю моментов в быстрых атаках. В обоих случаях «Франкфурт» мог побеждать крупнее.
Завязанный на этой особенности контраст чуть менее прослеживается и во внутреннем чемпионате. В Бундеслиге «Айнтрахт» на 6-м месте в таблице гостевых матчей, но 16-й – по домашним. Проще говоря, чем смелее играет соперник, тем удобнее «Франкфурту». По количеству быстрых атак, которые завершаются ударом или касанием внутри чужой штрафной, команда Гласнера на 3-м месте в «Бундеслиге».
«В определенных условиях мы можем обыграть любого. В этом сезоне мы побеждали в Мюнхене и Барселоне. Наша система хорошо работает против трудных соперников», – рассказывал вингер Йенс Петтер Хауге.
А вот более подробный анализ от спортивного директора клуба Маркуса Креше: «Как правило, в Бундеслиге – особенно в домашних матчах – мы встречаемся с оппонентами, который обороняются глубоко, вынуждая нас искать решения на чужой трети поля. Пространства перекрыты, играть становится непросто, а в роли контратакующей команды выступает сам соперник.
Пространства перекрыты, играть становится непросто, а в роли контратакующей команды выступает сам соперник.
Все иначе, когда у нас есть открытое пространство. Если соперник играет в более атакующей манере, мы можем играть через переходные эпизоды – нам проще в таком футболе, чем при взламывании соперника на его трети».
«Франкфурт» не любит владеть мячом, но обожает открытые матчи. Схема помогает устраивать им перестрелки
Интересная особенность контратакующих побед «Франкфурта» в том, что команда играет вторым номером, но не ставит автобус. Наоборот, устраивает перестрелки, в которых оказывается острее. То есть сценарии с владением у соперника нужен им, чтобы получить пространство для контратак, а не чтобы вымучивать результат, стоя у своих ворот.
Если соперник забирает мяч (следовательно, пространство для отрывов есть), команда Гласнера не выжидает у своих ворот, а, наоборот, делает все, чтобы в матче было максимальное количество переходов мяча и ошибок. Соперник тоже получает шансы ловить «Франкфурт» на моментах дезорганизованности, но ставка делается на то, что «Франкфурт» лучше накажет в таких условиях.
Олицетворением этого замысла служит схема «Айнтрахта». Команда встречает позиционные атаки соперника в 5-4-1, но не садится слишком глубоко:
Скриншоты сделаны в InStatScout
В этой схеме «Айнтрахт» не выжидает, а проявляет агрессию каждый раз, когда мяч на флангах.
В такие моменты очень резко выдвигается крайний защитник, а оставшиеся перестраиваются на четверку:
Вот аналогичная трансформация, но на другом фланге по ходу этой же атаки. В этот раз завершится отбором и классической для «Франкфурта» контратакой:
Дополнительный бонус такого подхода: часто игроком, который начинает контратаку, становится латераль – Костич или Кнауфф. Во-первых, оба здорово тащят мяч на пространстве. Во-вторых, это означает, что тройки атакующих игроков (как минимум) создает им варианты. В случае, если бы мяч отбирал/перехватывал игрок без дриблинга терялся бы ритм. В случае, если бы отбирал кто-то из атакующих игроков, на одного футболиста меньше поддерживало бы атаку.
Схожая трансформация происходит и при высоком прессинге – тогда схема переходит в 4-2-4, где одним из игроков в последней линии становится крайний защитник (в этом примере Кнауфф):
Такой подход рождает моменты в обе стороны – если пройти первую линию давления, получится опасная атака соперника. Очень многое в игре «Франкфурта» завязано на четкости маневров при трансформации схемы и на выборе момента для начала активной фазы давления. В данном случае все закончилось высоким отбором и опаснейшим моментом в штрафной «Бетиса»:
Филип Костич – левый латераль и мозг команды
В составе «Айнтрахта» есть звезда, о которой стоит поговорить отдельно – Филип Костич. Он бросается в глаза еще до стартового свистка матчей – при взгляде на составы. Левый защитник под 10-м номером.
Кажется, эта нестандартная деталь на интуитивном уровне побуждает за ним следить – и серб не разочаровывает:
Вот список параметров, в которых Костич лидирует – переводы, разрезающие пасы, навесы, предударные действия, пасы в штрафную, точные навесы. Все так или иначе завязаны на игре в пас, но обратите внимание, насколько разные по типажу передачи ему подвластны. Здесь и работа плеймейкера, и прямая угроза разных типов. Особенно впечатляет лидерство по пасам в штрафную:
Все так или иначе завязаны на игре в пас, но обратите внимание, насколько разные по типажу передачи ему подвластны. Здесь и работа плеймейкера, и прямая угроза разных типов. Особенно впечатляет лидерство по пасам в штрафную:
Космический отрыв от второго места подчеркивает, насколько сильно игра команды заточена на Филипа. Также очевиден его любимый прием – в каждый из последних 4 сезонов Бундеслиги (включая нынешний) Костич входил в топ-2 по количеству точных подач с игры. Уровень его подач – топовый.
Еще одно качество, которое не так просто измерить цифрами, подмечал Гласнер: «Филип обладает выдающимся даром замечать и находить пасом свободного игрока в центре. Он делает это, даже если находится под серьезнейшим давлением. И не только замечает, но и достаточно одарен технически, чтобы исполнить нужный пас».
С точки зрения статистики передачи, которые возвращают мяч с фланга в центр на свободного партнера, не фиксируются отдельно, но с точки зрения развития атак они категорически важны.
Для «Айнтрахта» Костич – ключевой элемент любимого сценария (связывает контратаки и нестандартными решениями находит партнеров) и единственное светлое пятно при неудобном сценарии (дают ему мяч, он вешает – какие-то моменты возникают).
Еще одно важное качество – поставленный удар. 7 сезонов подряд Костич не опускается ниже планки в 4 гола (мощно для его позиции). В этом сезоне, кроме этих голов, было 8 ударов, которые создавали ситуацию под добивание.
В общем, для «Айнтрахта» – огромная удача, что такой топ до сих пор в команде (уже четвертый сезон). Ближе всего к уходу он был этим летом. В конце лета Костич очень хотел в «Лацио» – даже бойкотировал тренировки и отказывался играть в одном матче.
«Лацио» хотел завершить сделку, «Айнтрахт» на фоне желания игрока был готов к переговорам, но история сенсационно заглохла с формулировкой «не получили официального предложения». Сначала «Лацио» обвинил немецкий клуб во лжи, но позже выяснилось, что «Лацио» просто отправил официальное предложение не на ту почту – вместо окончания «eintrachtfrankfurt.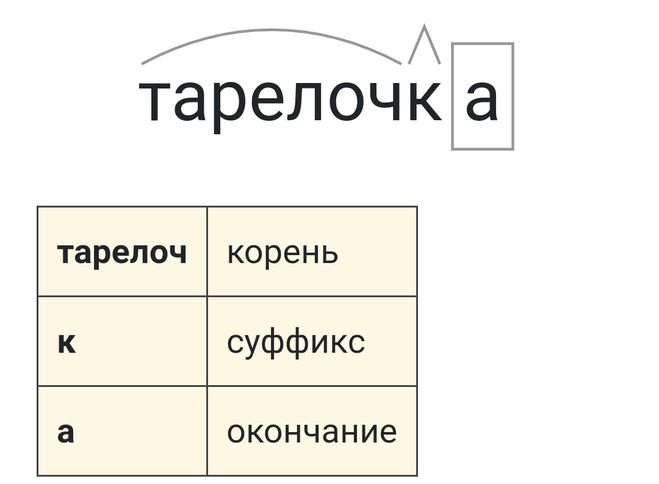 de» использовали «eintrachtfranfurt.de».
de» использовали «eintrachtfranfurt.de».
Из-за опечатки Костич остался в «Айнтрахте». Из-за Костича «Айнтрахт» выиграл Лигу Европы.
В позиционных атаках тоже помогает схема-трансформер. Постепенно команда становится вариативнее
Важно отметить, что описанные механизмы – и топовый Костич – были построены при прошлом тренере Ади Хюттере. Нельзя недооценивать его вклад в успех. Гласнер вернулся к его схеме и футболу после неудачных экспериментов на старте кампании. Его заслуга – в мотивации и микроменеджменте в конкретных матчах.
Но один важный апгрейд «Франкфурт» получил буквально зимой. В команду ворвался арендованный у «Дортмунда» Ансгар Кнауфф. Теперь оба фланга несут более прямую угрозу. Кнауфф не так вариативен, как Костич, но у него очень мощные проходы с мячом. Это дает возможность трансформировать схему на любом из флангов.
Трансформация происходит через крайних центральных защитников, которые подключаются по флангу и по эпизоду становятся крайними защитниками:
Так выглядит тепловая карта левого ЦЗ Эвана Ндика – по действиям с мячом он больше похож на левого защитника:
Справа – на фланге Кнауффа – играет Альмами Туре. Трансформация в правого защитника его более явная:
Трансформация в правого защитника его более явная:
Этот прием не стоит переоценивать. Позиционная атака в команде точно не выдающаяся, но в ключевой отрезок вчерашнего матча в середине второго тайма «Айнтрахт» владел мячом за 60%, атаковал именно таким образом и все-таки организовал моменты.
***
Подытожим. «Айнтрахт» – это:
• категорическая зависимость от игры вторым номером – возможно, самая явная в Европе;
• но не автобус – им неинтересно выжидать ошибку, им интересно вскрывать пространство;
• возможно, самая зависимая от своего левого защитника команда мира – частично из-за мощи Костича, который давно перерос клуб;
• команда-трансформер – переходы с пятерки на четверку и обратно отлажены почти идеально со времен Хюттера. Это не просто интересная для изучения тактическая фишка, а правда важнейший инструмент команды во всех стадиях.
Разобрать по составу слова: гладиатор, раритетная, раколовка? Разобрать
образование
Разобрать по составу слова: гладиатор, раритетная, раколовка?
Слово «гладиатор» — это имя существительное, отвечает на вопрос «Кто?», одушевлённое, мужского рода единственного числа, именительный падеж. Разбор по составу слова «гладиатор» имеет вид:
гладиатор — это корень;
нулевое окончание.
Основа слова является — гладиатор .
Разбор по составу слова «раритетная» имеет вид:
раритет — это корень ;
н — суффикс ;
ая — окончание .
Основа слова является — раритетн .
Способ образования слова — суффиксальный.
Разбор по составу слова «раколовка» имеет вид:
рак — это корень ;
ол — суффикс ;
ов — суффикс;
к — суффикс;
а — окончание .
Основа слова является — раколовк .
Способ образования слова — суффиксальный.
Разбор по составу слова «гладиатор» имеет вид:
гладиатор — это корень;
нулевое окончание.
Основа слова является — гладиатор .
Разбор по составу слова «раритетная» имеет вид:
раритет — это корень ;
н — суффикс ;
ая — окончание .
Основа слова является — раритетн .
Способ образования слова — суффиксальный.
Разбор по составу слова «раколовка» имеет вид:
рак — это корень ;
ол — суффикс ;
ов — суффикс;
к — суффикс;
а — окончание .
Основа слова является — раколовк .
Способ образования слова — суффиксальный.
Существительное мужского рода Гладиатор имеет нулевое окончание: Гладиатор-Гладиатора-Гладиатору-Гладиатором. Однокоренные слова Гладиатор-Гладиаторский. Корень слова Гладиатор.
Получаем: ГЛАДИАТОР_ (корень-нулевое окончание), основа слова ГЛАДИАТОР.
Прилагательное Раритетная имеет окончание женского рода -АЯ: Раритетная-Раритетный-Раритетное. Однокоренными словами будут Раритетный-Раритет. Корнем слова оказывается РАРИТЕТ-. Также выделим в слове суффикс прилагательного -Н-. Получаем: РАРИТЕТ-Н-АЯ (корень-суффикс-окончание), основа слова РАРИТЕТН-.
Странное существительное Раколовка имеет окончание -А: Раколовка-Раколовку-Раколовке-Раколовкой. Слово это сложное и выделим в нем два корня. Первый корень будет РАК- и однокоренные слова Рак-Раковый-Ракоед. Второй корень -ЛОВ- и однокоренные слова Ловля-Ловить-Ловец. Между корнями выделим соединительную гласную -О-, а после второго корня суффикс -К-.
Получаем: РАК-О-ЛОВ-К-А (корень-соединительная гласная-корень-суффикс-окончание), основа слова РАКОЛОВК-.
Получаем: РАРИТЕТ-Н-АЯ (корень-суффикс-окончание), основа слова РАРИТЕТН-.
Странное существительное Раколовка имеет окончание -А: Раколовка-Раколовку-Раколовке-Раколовкой. Слово это сложное и выделим в нем два корня. Первый корень будет РАК- и однокоренные слова Рак-Раковый-Ракоед. Второй корень -ЛОВ- и однокоренные слова Ловля-Ловить-Ловец. Между корнями выделим соединительную гласную -О-, а после второго корня суффикс -К-.
Получаем: РАК-О-ЛОВ-К-А (корень-соединительная гласная-корень-суффикс-окончание), основа слова РАКОЛОВК-.
Морфемный анализ Слово «гладиатор» имеет: корень «-гладиатор-«, однокоренное слово — гладиаторский (бой) нулевое окончание основа слова — все слово «гладиатор-» Слово «раритетная» имеет: корень «-раритет-» суффикс «-н-» окончание «-ая» (раритетную, раритетной) основа слова «раритетн-» Слово «раколовка» имеет: два корня: «-рак-» (раковый, раки) и «-лов-» (ловить, ловля, улов) «-о-» — соединительная гласная «-к-» — суффикс «-а» окончание (раколовку, раколовке) основа слова «раколовк-«
Если человек закончил только бакалавриат, то поступать в магистратуру точно стоит. Я, несмотря на то, что имею диплом специалиста, отучилась еще и в магистратуре и получила ученую степень магистра. Магистратура помогла мне поднять свой профессиональный уровень. На зарплате мое обучение никак не отразилось, но училась я для себя, еще и бесплатно. Если бы еще можно было бесплатно в магистратуре поучиться, то еще бы поучилась, только уже по другому направлению. А то практических знаний уже много, а теория уже забывается, да и новые направления в развитии науки дают в магистратуре.
Еще плюсом магистратуры служит то, что можно и в аспирантуру поступить. Можно даже работу продолжать по своей магистерской диссертации.
Я, несмотря на то, что имею диплом специалиста, отучилась еще и в магистратуре и получила ученую степень магистра. Магистратура помогла мне поднять свой профессиональный уровень. На зарплате мое обучение никак не отразилось, но училась я для себя, еще и бесплатно. Если бы еще можно было бесплатно в магистратуре поучиться, то еще бы поучилась, только уже по другому направлению. А то практических знаний уже много, а теория уже забывается, да и новые направления в развитии науки дают в магистратуре.
Еще плюсом магистратуры служит то, что можно и в аспирантуру поступить. Можно даже работу продолжать по своей магистерской диссертации.Больше ответов
Популярные вопросы из категории: образование
образование
Как бы Вы поступили, если, вернувшись из 1 класса, ребёнок продекламировал?…
образование
В чем смысл выражения «небо с овчинку покажется»?…
образование
Почему «лучшее — враг хорошего»?…
образование
Журналистика это что?. 2t…
2t…
Математика, 21.03.2019 00:10
Две стрелки насажены на одну ось и в некоторый момент времени совмещены. одна из стрелок описывает круг за 12 часов, а другая за 16 часов. за какое время стрелки совместяться опять…
Геометрия, 21.03.2019 00:10
Найти площадь паролелограмма если его стороны ровны 9 и 16 см2 а угол между ними 30%…
Русский язык, 21.03.2019 00:10
Уверенность каждого за свой завтрашний день. какая тут ошибка, граматическая или лексическая и почему…
Геометрия, 21.03.2019 00:10
Сторона треугольника равна 12см а высота проведённая к ней в три раза меньше стороны, найдите площадь треугольника….
Физика, 21.03.2019 00:10
Медный шар имеет объем 240 см2 и массу 1,78 кг. определить объем полости внутри этого шара….
Обществознание, 21.03.2019 00:10
Укажи какие ресурсы необходимы для удовлетворения следующих потребностей: в пище, в чистоте и уюте, в тепле, в общении, в безопасности жилища…
Алгебра, 21. 2 + 3x / x+4…
2 + 3x / x+4…
Грамматически укореняем себя с помощью деревьев синтаксического анализа | Вайдехи Джоши | basecs
Грамматически укореняем себя с помощью деревьев синтаксического анализа!Размышление обо всех абстракциях, окружающих нас в мире технологий, иногда может быть ошеломляющим. Это особенно верно, когда вы пытаетесь осмыслить новую парадигму или раскрыть слои одной или нескольких концепций, которые вы пытаетесь понять.
В контексте изучения компьютерных наук существует слишком много абстракций, чтобы знать, видеть или распознавать их все, не говоря уже о способности понять их все!
Абстракции — это мощные вещи, когда вы можете заглянуть за их пределы и понять, как что-то абстрагируется и почему, может сделать вас лучшим программистом. Однако, по той же причине, каждая абстракция была создана с какой-то целью: чтобы никто из нас не беспокоился о них изо дня в день! Мы не должны постоянно думать об абстракциях, и по большей части очень немногие из нас на самом деле так думают. Но вот в чем дело — некоторые абстракции более равны, чем другие. Те, которые, вероятно, волнуют большинство инженеров, связаны с тем, как они взаимодействуют со своим компьютером, и с тем, как их компьютер на самом деле понимает их. Даже если никому из нас никогда не придется писать алгоритм пузырьковой сортировки, если мы напишем код, то нам придется взаимодействовать с нашими машинами.
Но вот в чем дело — некоторые абстракции более равны, чем другие. Те, которые, вероятно, волнуют большинство инженеров, связаны с тем, как они взаимодействуют со своим компьютером, и с тем, как их компьютер на самом деле понимает их. Даже если никому из нас никогда не придется писать алгоритм пузырьковой сортировки, если мы напишем код, то нам придется взаимодействовать с нашими машинами.
Наконец-то пришло время нам разобраться в этих тайнах и понять абстракции, лежащие в основе наших рабочих процессов как программистов.
Древовидная структура данных снова и снова всплывает в наших компьютерных приключениях. Мы видели, как они использовались для хранения данных всех типов, мы видели самобалансирующиеся, в то время как другие были оптимизированы для хранения и хранения данных. Мы даже рассмотрели, как манипулировать деревьями, поворачивая и перекрашивая их, чтобы убедиться, что они соответствуют набору правил.
Но, несмотря на все эти различные формы флоры структур данных, существует одна конкретная итерация древовидной структуры данных, которую нам еще предстоит открыть. Даже если бы мы ничего не знали о компьютерных науках, о том, как сбалансировать дерево или о том, как работает древовидная структура данных, все программисты ежедневно взаимодействуют с одним типом древовидной структуры в силу того простого факта, что каждый разработчик, пишущий код, должны убедиться, что их код понятен их машинам.
Даже если бы мы ничего не знали о компьютерных науках, о том, как сбалансировать дерево или о том, как работает древовидная структура данных, все программисты ежедневно взаимодействуют с одним типом древовидной структуры в силу того простого факта, что каждый разработчик, пишущий код, должны убедиться, что их код понятен их машинам.
Эта структура данных называется деревом синтаксического анализа, и это (одна из) лежащих в основе абстракций, позволяющих сделать код, который мы пишем как программисты, «читаемым» для наших компьютеров.
Дерево синтаксического анализа: определение. По своей сути дерево синтаксического анализа представляет собой иллюстрированную графическую версию грамматической структуры предложения. Деревья синтаксического анализа на самом деле уходят корнями в область лингвистики, но они также используются в педагогике, изучающей преподавание. Деревья синтаксического анализа часто используются для обучения студентов тому, как идентифицировать части предложения, и являются распространенным способом введения грамматических понятий. Вполне вероятно, что каждый из нас взаимодействовал с ними с точки зрения построения диаграмм предложений, которым некоторые из нас могли научиться в начальной школе.
Вполне вероятно, что каждый из нас взаимодействовал с ними с точки зрения построения диаграмм предложений, которым некоторые из нас могли научиться в начальной школе.
Дерево синтаксического анализа — это на самом деле просто «диаграммная» форма предложения; это предложение может быть написано на любом языке, а это значит, что оно может соответствовать любому набору грамматических правил.
Составление диаграмм предложений включает в себя разбиение одного предложения на мельчайшие и наиболее отчетливые части. Если мы подумаем о деревьях синтаксического анализа с точки зрения построения диаграмм предложений, мы быстро начнем понимать, что в зависимости от грамматики и языка предложения дерево синтаксического анализа действительно может быть построено множеством различных способов!
Но что такое компьютерная версия «предложения»? И как мы собираемся изобразить это на диаграмме?
Что ж, полезно начать с примера того, с чем мы уже знакомы, так что давайте освежим нашу память, нарисовав диаграмму обычного английского предложения.
На иллюстрации, показанной здесь, у нас есть простое предложение: "Вайдехи съел пирог" . Поскольку мы знаем, что дерево синтаксического анализа — это всего лишь схематичное предложение, мы можем построить дерево синтаксического анализа из этого примерного предложения. Помните, что на самом деле все, что мы пытаемся сделать, — это определить различные части этого предложения и разбить его на самые маленькие, наиболее отчетливые части.
Мы можем начать с разделения предложения на две части: существительное , «вайдехи» и глагольная фраза , «съел пирог» . Так как существительное не может быть далее разбито, мы оставим слово "Вайдехи" как есть. Другой способ думать об этом — тот факт, что, поскольку мы не можем дальше разбивать существительное, от этого слова не будет дочерних узлов.
А как насчет глагольной фразы, "съел пирог" ? Ну, эта фраза еще не разбита на простейшую форму, не так ли? Мы можем разобрать его еще дальше. Во-первых, слово
Во-первых, слово «съел» — это глагол, а «пирог» — это скорее существительное — на самом деле, если быть точным, это именное словосочетание . Если мы разделим «съел пирог» , мы можем разделить его на глагол и именную группу. Поскольку глагол не может быть изображен с какими-либо дополнительными деталями, слово «съел» станет конечным узлом в нашем дереве синтаксического анализа.
Итак, теперь осталось только словосочетание "пирог" . Мы можем разделить эту фразу на две отдельные части: существительное «пирог» и его определитель , известный как любое модифицирующее слово существительного. В данном случае определителем является слово "the" .
Как только мы разделим нашу группу существительных, мы закончим разделять наше предложение! Другими словами, мы закончили построение диаграммы нашего дерева синтаксического анализа. Когда мы посмотрим на наше дерево синтаксического анализа, мы заметим, что наше предложение по-прежнему читается так же, и мы на самом деле вообще не изменили его. Мы просто взяли предложение, которое нам дали, и, используя правила английской грамматики, разделили его на мельчайшие, наиболее отчетливые части.
Когда мы посмотрим на наше дерево синтаксического анализа, мы заметим, что наше предложение по-прежнему читается так же, и мы на самом деле вообще не изменили его. Мы просто взяли предложение, которое нам дали, и, используя правила английской грамматики, разделили его на мельчайшие, наиболее отчетливые части.
Что на самом деле означает парсить что-то?В английском языке наименьшая «часть» каждого предложения — это слово; слова могут быть объединены в фразы, такие как именные или глагольные фразы, которые, в свою очередь, могут быть объединены с другими фразами для создания выражения предложения.
Однако это всего лишь один пример того, как одно конкретное предложение на одном конкретном языке с собственным набором грамматических правил может быть представлено в виде дерева синтаксического анализа. Это же предложение выглядело бы совсем по-другому на другом языке, особенно если бы оно должно было следовать собственному набору грамматических правил.
В конечном счете, грамматика и синтаксис языка — включая способ построения предложений этого языка — становятся правилами, определяющими, как определяется этот язык, как мы пишем на нем и как те из нас, кто говорить на языке в конечном итоге будет понимать и интерпретировать его.
Интересно, что мы знали, как нарисовать простое предложение «Вайдехи съел пирог». , потому что мы уже были знакомы с грамматикой английского языка. Представьте, если бы в нашем предложении вообще отсутствовало существительное или глагол? Что случилось бы? Что ж, мы, вероятно, прочтем предложение в первый раз и быстро поймем, что это вообще не предложение! Скорее, мы бы прочитали его и почти сразу увидели, что имеем дело с фрагмент предложения или неполный фрагмент предложения.
Однако единственная причина, по которой мы смогли бы распознать фрагмент предложения, заключается в том, что мы знали правила английского языка, а именно, что (почти) каждое предложение нуждается в существительном и глаголе, чтобы считаться действительным. Грамматика языка — это то, как мы можем проверить, допустимо ли предложение в языке; этот процесс «проверки» на достоверность называется разбором предложения.
Грамматика языка — это то, как мы можем проверить, допустимо ли предложение в языке; этот процесс «проверки» на достоверность называется разбором предложения.
Процесс разбора предложения, чтобы понять его, когда мы читаем его в первый раз, включает в себя те же мыслительные шаги, что и построение предложения в виде диаграммы, а построение диаграммы предложения включает в себя те же шаги, что и построение дерева разбора. Когда мы читаем предложение в первый раз, мы делаем работу по его мысленной деконструкции и анализу.
Как оказалось, компьютеры делают то же самое с кодом, который мы пишем!
Итак, теперь мы знаем, как составить схему и разобрать предложение на английском языке. Но как это применимо к коду? А что такое «предложение» в нашем коде?
Итак, мы можем думать о дереве синтаксического анализа как о иллюстрированной «картинке» того, как выглядит наш код. Если мы представим наш код, нашу программу или хотя бы простейший сценарий в виде предложения, мы, вероятно, довольно быстро поймем, что весь код, который мы пишем, можно просто упростить до наборов выражений.
Это становится более понятным на примере, поэтому давайте рассмотрим очень простую программу-калькулятор. Используя одно выражение, мы можем использовать грамматические «правила» математики для создания дерева синтаксического анализа из этого выражения. Нам нужно найти самые простые, наиболее четкие единицы нашего выражения, а это значит, что нам нужно разбить наше выражение на более мелкие сегменты, как показано ниже.
Нахождение грамматики в математических выражениях.Мы заметим, что отдельное математическое выражение имеет свои собственные грамматические правила; даже простое выражение (например, два числа, умноженные вместе, а затем добавленные к другому числу) можно было бы разделить на еще более простые выражения внутри самих себя.
Представление математических выражений в виде дерева разбора. Но давайте для начала проведем простой расчет. Как мы могли бы создать дерево синтаксического анализа, используя математическую грамматику для такого выражения, как 2 х 8 ?
Если мы подумаем о том, как на самом деле выглядит это выражение, мы увидим, что здесь есть три отдельные части: выражение слева, выражение справа и операция, которая умножает их две вместе.
Изображение, показанное здесь, изображает выражение 2 x 8 в виде дерева синтаксического анализа. Мы увидим, что оператор x — это часть выражения, которую нельзя упростить дальше, поэтому у него нет дочерних узлов.
Выражение слева и справа может быть упрощено до его конкретных терминов, а именно 2 и 8 . Как и в примере с английским предложением, который мы рассматривали ранее, одно математическое выражение может содержать внутренних выражений внутри него, а также отдельных терминов , например фраза 2 x 8 , или множителей , например число . 2 как индивидуальное выражение.
Но что произойдет после того, как мы создадим это дерево разбора? Мы заметим, что иерархия дочерних узлов здесь немного менее очевидна, чем в нашем предыдущем примере с предложением. оба 2 и 8 находятся на одном уровне, так как мы можем это интерпретировать?

Ну, мы уже знаем, что есть разные способы обхода дерева в глубину. В зависимости от того, как мы перемещаемся по этому дереву, это единственное математическое выражение 2 x 8 может быть интерпретировано и прочитано по-разному. Например, если бы мы прошли через это дерево, используя обходов в порядке , мы прочитали бы левое дерево, корневой уровень, а затем правое дерево, в результате чего 2 -> х -> 8 .
Но если бы мы решили пройтись по этому дереву, используя обход предварительного порядка , мы бы сначала прочитали значение на корневом уровне, затем в левом поддереве, а затем в правом поддереве, что дало бы нам x -> 2 - > 8 . И если бы мы использовали обход в обратном порядке , мы бы прочитали левое поддерево, правое поддерево, а затем, наконец, прочитали бы корневой уровень, что привело бы к 2 -> 8 -> x .
Деревья синтаксического анализа показывают нам, что представляют собой наши выражения выглядят как , раскрывая конкретный синтаксис наших выражений, что часто означает, что одно дерево синтаксического анализа может выражать «предложение» различными способами. По этой причине деревья синтаксического анализа также часто называют конкретными синтаксическими деревьями или CST для краткости. Когда эти деревья интерпретируются или «читаются» нашими машинами, должны существовать строгие правила в отношении того, как эти деревья анализируются, чтобы в итоге мы получили правильное выражение со всеми терминами в правильном порядке и в правильном порядке. место!
По этой причине деревья синтаксического анализа также часто называют конкретными синтаксическими деревьями или CST для краткости. Когда эти деревья интерпретируются или «читаются» нашими машинами, должны существовать строгие правила в отношении того, как эти деревья анализируются, чтобы в итоге мы получили правильное выражение со всеми терминами в правильном порядке и в правильном порядке. место!
Но большинство выражений, с которыми мы имеем дело, более сложны, чем просто 2 x 8 . Даже для программы-калькулятора нам, вероятно, придется выполнять более сложные вычисления. Например, что произойдет, если мы захотим найти такое выражение, как 5 + 1 x 12 ? Как будет выглядеть наше дерево синтаксического анализа?
Как оказалось, проблема с деревьями синтаксического анализа заключается в том, что иногда вы можете получить более одного дерева.
Неоднозначная грамматика в действии (разборе)! Более конкретно, может быть более одного результата для одного анализируемого выражения. Если мы предположим, что деревья синтаксического анализа сначала считываются с самого нижнего уровня, мы можем начать видеть, как иерархия конечных узлов может привести к тому, что одно и то же выражение будет интерпретировано двумя совершенно разными способами, в результате чего будут получены два совершенно разных значения.
Если мы предположим, что деревья синтаксического анализа сначала считываются с самого нижнего уровня, мы можем начать видеть, как иерархия конечных узлов может привести к тому, что одно и то же выражение будет интерпретировано двумя совершенно разными способами, в результате чего будут получены два совершенно разных значения.
Например, на иллюстрации выше есть два возможных дерева синтаксического анализа для выражения 5 + 1 x 12 . Как мы видим в левом дереве разбора, иерархия узлов такова, что сначала будет оцениваться выражение 1 x 12 , а затем продолжится сложение: 5 + (1 x 12) . С другой стороны, правильное дерево синтаксического анализа сильно отличается; иерархия узлов заставляет сначала выполнить сложение ( 5 + 1 ), а затем перемещается вверх по дереву, чтобы продолжить умножение: (5 + 1) х 12 .
Неоднозначная грамматика в языке — это именно то, что вызывает такую ситуацию: когда неясно, как должно быть построено синтаксическое дерево, оно может быть построено (по крайней мере) более чем одним способом.
Борьба с неоднозначной грамматикой в качестве компилятораНо вот загвоздка: неоднозначная грамматика создает проблемы для компилятора!
Основываясь на правилах математики, которые большинство из нас учили в школе, мы по своей сути знаем, что умножение всегда должно выполняться перед сложением. Другими словами, только левое дерево синтаксического анализа в приведенном выше примере действительно правильно на основе грамматики математики. Помните: грамматика определяет синтаксис и правила любого языка, будь то английское предложение или математическое выражение.
Но откуда компилятору знать эти правила? Ну просто не может быть! Компилятор не будет знать, как читать код, который мы пишем, если мы не зададим ему грамматические правила, которым нужно следовать. Если компилятор увидит, что мы написали математическое выражение, например, которое может привести к двум разным деревьям синтаксического анализа, он не будет знать, какое из двух деревьев синтаксического анализа выбрать, и, таким образом, он не будет знать, как даже читать или интерпретировать наш код.
Именно по этой причине в большинстве языков программирования обычно избегают неоднозначной грамматики. На самом деле, большинство синтаксических анализаторов и языков программирования намеренно решают проблемы неоднозначности с самого начала. Язык программирования обычно имеет грамматику, обеспечивающую приоритет , что заставит некоторые операции или символы иметь более высокий вес/значение, чем другие. Примером этого является гарантия того, что всякий раз при построении дерева синтаксического анализа умножение имеет более высокий приоритет, чем сложение, так что когда-либо может быть построено только одно дерево синтаксического анализа.
Еще один способ борьбы с двусмысленностью — применение способа интерпретации грамматики. Например, в математике, если у нас есть такое выражение, как 1 + 2 + 3 + 4 , мы изначально знаем, что должны начинать сложение слева и продвигаться вправо. Если бы мы хотели, чтобы наш компилятор понял, как это сделать с нашим собственным кодом, нам нужно было бы применить оставил ассоциативность , что сузило бы наш компилятор так, что при разборе нашего кода он создал бы дерево разбора, которое помещает коэффициент 4 ниже в иерархии дерева разбора, чем фактор 1 .
Эти два примера часто называют правилами устранения неоднозначности в дизайне компилятора, поскольку они создают определенные синтаксические правила, гарантирующие, что мы никогда не столкнемся с неоднозначной грамматикой, которая может сильно запутать наш компилятор.
Если двусмысленность является корнем всех зол дерева синтаксического анализа, то ясность является предпочтительным режимом работы. Конечно, мы можем добавить правила устранения неоднозначности, чтобы избежать двусмысленных ситуаций, которые заставят наш бедный маленький компьютер зайти в тупик при чтении нашего кода, но на самом деле мы делаем гораздо больше. Или, скорее, именно языки программирования, которые мы используем, делают настоящую тяжелую работу!
Поясню. Мы можем думать об этом так: одним из способов добавить ясности математическому выражению являются круглые скобки. Фактически, это то, что большинство из нас, вероятно, сделало бы для выражения, с которым мы имели дело ранее: 5 + 1 х 12 . Вероятно, мы прочитали бы это выражение и, вспомнив порядок действий, который мы изучили в школе, переписали бы его в уме так:
Вероятно, мы прочитали бы это выражение и, вспомнив порядок действий, который мы изучили в школе, переписали бы его в уме так: 5 + (1 x 12) . Скобка () помогла нам прояснить само выражение и два выражения, которые по своей сути находятся внутри него. Эти два символа узнаваемы для нас, и если бы мы поместили их в наше дерево синтаксического анализа, у них не было бы дочерних узлов, потому что они не могут быть разбиты дальше.
Это то, что мы называем терминалами , которые также широко известны как токены . Они имеют решающее значение для всех языков программирования, потому что помогают нам понять, как части выражения соотносятся друг с другом, и синтаксические отношения между отдельными элементами. Некоторые общие токены в программировании включают знаки операций ( + , -, x , /), круглые скобки ( () ) и зарезервированные условные слова (9). 0035, если ,
0035, если , , затем , , иначе , и ). Некоторые токены используются для уточнения выражений, поскольку они могут указывать, как разные элементы связаны друг с другом.
Итак, каковы все остальные элементы в нашем дереве синтаксического анализа? У нас явно больше, чем просто , если и + знаков в нашем коде! Ну, нам также обычно приходится иметь дело с наборами нетерминалов , которые являются выражениями, терминами и факторами, которые потенциально могут быть разбиты дальше. Это фразы/идеи, которые содержат в себе другие выражения, такие как выражение (8 + 1) / 3 .
Как терминалы, так и нетерминалы имеют определенное отношение к месту их появления в дереве синтаксического анализа. Как следует из их названия, символ терминала всегда будет заканчиваться листьями дерева синтаксического анализа; это означает, что не только операторы, круглые скобки и зарезервированные условные операторы являются «терминалами», но и все значения факторов, которые представляют строку, число или понятие, которое находится в каждом конечном узле. Все, что разбито на мельчайшие части, фактически всегда будет «терминалом».
Все, что разбито на мельчайшие части, фактически всегда будет «терминалом».
С другой стороны, внутренние узлы дерева синтаксического анализа — неконечные узлы, которые являются родительскими узлами — это нетерминальных символов, и именно они представляют применение правил грамматики языка программирования.
Дерево синтаксического анализа становится намного легче понять, визуализировать и идентифицировать, как только мы поймем, что это не что иное, как представление нашей программы и всех символов, понятий и выражений в ней.
Понимание роли синтаксического анализатораНо какова ценность дерева синтаксического анализа? Мы не думаем об этом как программисты, но ведь это должно существовать по какой-то причине, верно?
Ну, как оказалось, дерево синтаксического анализа больше всего заботит синтаксический анализатор , который является частью компилятора, который обрабатывает процесс синтаксического анализа всех кода, который мы пишем.
Процесс синтаксического анализа на самом деле просто берет некоторые входные данные и строит из них дерево синтаксического анализа. Этими входными данными могут быть самые разные вещи, такие как строка, предложение, выражение или даже целая программа.
Независимо от того, какие входные данные мы передаем, наш синтаксический анализатор будет разбирать эти входные данные на грамматические фразы и строить из них дерево разбора. На самом деле синтаксический анализатор играет две основные роли в контексте нашего компьютера и процесса компиляции:
- При задании допустимой последовательности токенов он должен быть в состоянии сгенерировать соответствующее дерево разбора, следуя синтаксису языка.
- При задании недопустимой последовательности токенов он должен обнаруживать синтаксическую ошибку и сообщать программисту, написавшему код, о проблеме в его коде.
И это действительно так! Это может показаться очень простым, но если мы начнем рассматривать, насколько массивными и сложными могут быть некоторые программы, мы быстро начнем понимать, насколько четко должны быть вещи, чтобы синтаксический анализатор действительно выполнял эти две, казалось бы, простые роли.
Например, даже простому синтаксическому анализатору нужно много сделать, чтобы обработать синтаксис такого выражения, как 1 + 2 + 3 x 4 .
- Во-первых, из этого выражения нужно построить дерево разбора. Входная строка, которую получает синтаксический анализатор, может не отображать никакой связи между операциями, но синтаксическому анализатору необходимо создать дерево синтаксического анализа, которое это делает.
- Однако для этого необходимо знать синтаксис языка и правила грамматики, которым необходимо следовать.
- После того, как он действительно сможет создать одно дерево синтаксического анализа (без двусмысленности), он должен иметь возможность извлекать токены и нетерминальные символы и располагать их так, чтобы иерархия дерева синтаксического анализа была правильной.
- Наконец, синтаксический анализатор должен гарантировать, что при оценке этого дерева оно будет оцениваться слева направо с операторами одинакового приоритета.
- Но подождите! Он также должен убедиться, что при обходе этого дерева с использованием метода неупорядоченного обхода снизу никогда не возникает ни одной синтаксической ошибки!
- Конечно, если ломает , синтаксический анализатор должен посмотреть на ввод, выяснить, где он сломается, а затем сообщить об этом программисту.

Если вам кажется, что это очень много работы, то это потому, что так оно и есть. Но не беспокойтесь слишком сильно о том, чтобы сделать все это, потому что это работа синтаксического анализатора, и большая часть ее абстрагируется. К счастью, анализатору помогают другие части компилятора. Подробнее об этом на следующей неделе!
К счастью для нас, разработка компилятора — это то, чему хорошо учат почти в каждой учебной программе по информатике, и существует достаточное количество надежных ресурсов, которые помогут нам понять различные части компилятора, включая синтаксический анализатор и синтаксический анализ. дерево. Однако, как и в случае с большинством контента CS, многие из них могут быть трудными для восприятия, особенно если вы не знакомы с концепциями или используемым жаргоном. Ниже приведены еще несколько ресурсов, удобных для начинающих, которые по-прежнему хорошо объясняют деревья синтаксического анализа, если вы захотите узнать еще больше.
Ниже приведены еще несколько ресурсов, удобных для начинающих, которые по-прежнему хорошо объясняют деревья синтаксического анализа, если вы захотите узнать еще больше.
- Дерево синтаксического анализа, интерактивный Python
- Грамматика, синтаксический анализ, обход дерева, профессора Дэвид Грайс и Дуг Джеймс
- Давайте создадим простой интерпретатор, часть 7, Руслан Спивак
- Руководство по синтаксическому анализу: алгоритмы и терминология, Габриэле Томассетти2 9032 Томассетти2
- Лекция 2: Абстрактный и конкретный синтаксис, Аарне Ранта
- Компиляторы и интерпретаторы, профессор Чжун Шао
- Основы компиляции — Парсер, Джеймс Алан Фаррелл
Модель синтаксического анализа и рациональная теория памяти
1. Введение
В рациональной теории познания утверждается, что когнитивные функции во многом формируются нашей адаптацией к окружающей среде. С этой точки зрения предполагается, что различные аспекты нашего поведения можно объяснить как результат оптимизации структуры окружающей среды. Рациональная теория познания оказалась плодотворной в объяснении закономерностей в категоризации, обучении, общении и рассуждении, среди прочего (Anderson, 1990, 1991; Oaksford and Chater, 19).94, 2007; Тененбаум и др., 2011; Франке и Ягер, 2016 г.; Пиантадоси и др., 2016).
Рациональная теория познания оказалась плодотворной в объяснении закономерностей в категоризации, обучении, общении и рассуждении, среди прочего (Anderson, 1990, 1991; Oaksford and Chater, 19).94, 2007; Тененбаум и др., 2011; Франке и Ягер, 2016 г.; Пиантадоси и др., 2016).
Одним из особенно успешных случаев рациональной теории было ее применение к изучению человеческой памяти, как обобщается в Anderson (1991). Предполагая, что человеческая память должна стремиться предоставить информацию, необходимую в конкретной ситуации, и что извлечение элементов из памяти требует больших затрат и времени, можно было бы ожидать, что извлечение элемента связано с вероятностью того, что он необходим. То есть элементы, которые, скорее всего, будут необходимы в конкретной ситуации, будут иметь приоритет при поиске. Поскольку поиск упорядочен по вероятности потребности, ожидается, что для вызова менее необходимых элементов потребуется больше времени. Кроме того, если поиск прекращается, когда стоимость поиска превышает некоторый порог, мы ожидаем, что чем меньше потребность в предмете, тем больше вероятность того, что его отзыв не удастся. Эти предсказания в значительной степени подтвердились, см. Anderson (1991).
Эти предсказания в значительной степени подтвердились, см. Anderson (1991).
Рациональная теория памяти сыграла важную роль в развитии когнитивной архитектуры Adaptive Control of Thought-Rational, ACT-R (Anderson and Lebiere, 1998; Anderson et al., 2004), которая, в свою очередь, сыграла важную роль. в психолингвистических моделях анализа (Lewis and Vasishth, 2005; Lewis et al., 2006; Reitter et al., 2011; Engelmann et al., 2013; Vogelzang et al., 2017; Brasoveanu and Dotlačil, 2020). Льюис и Васишт (2005) и последующие работы показали, в частности, что рациональная теория памяти, реализованная в ACT-R, проницательна при анализе паттерна припоминания при формировании зависимостей при разборе, например, зависимости подлежащее-глагол, как в (1 -а) и антецедентно-рефлексивной зависимости, как в (1-б) (см. также Lewis et al., 2006; Van Dyke, 2007; Wagers et al., 2009).; Диллон и др., 2013 г.; Куш и др., 2015; Лаго и др., 2015; Ягер и др., 2017; Ягер и др., 2020 г.; Нисенбойм и др., 2018; Виллата и др. , 2018 г.; Энгельманн и др., 2019; Васишт и др., 2019; Smith and Vasishth, 2020 и др.).
, 2018 г.; Энгельманн и др., 2019; Васишт и др., 2019; Smith and Vasishth, 2020 и др.).
Это подводит нас к теме исследования данной статьи, а именно к изучению того, могут ли другие аспекты, в которых синтаксический анализ должен полагаться на память, также рассматриваться как соответствующие исследовательской программе рациональной теории познания. В частности, во время понимания и производства носители языка должны постоянно полагаться на свои прошлые знания правил синтаксического анализа. Например, в (1) читатели не смогут правильно понять предложения, если не вспомнят, что в английском языке подлежащее обычно предшествует глаголу, за глаголом следует дополнение, в английском языке есть предлоги (а не послелоги) и т. д. С точки зрения рациональной теории памяти ожидается, что поиск правил синтаксического анализа, таких как эти, должен следовать общим соображениям, изложенным выше, т. е. правила синтаксического анализа должны извлекаться в порядке вероятности их необходимости, и порядок должен монотонно коррелировать с задержками и точность. Мы покажем, что синтаксический анализ действительно можно построить на основе рациональной теории памяти. Полученная модель может, кроме того, правильно предсказывать качественные данные в психолингвистике (феномен садовой дорожки), а ее предсказания соответствуют поведенческим показателям в психолингвистическом корпусе (Natural Stories Corpus, Futrell et al., 2018).
Мы покажем, что синтаксический анализ действительно можно построить на основе рациональной теории памяти. Полученная модель может, кроме того, правильно предсказывать качественные данные в психолингвистике (феномен садовой дорожки), а ее предсказания соответствуют поведенческим показателям в психолингвистическом корпусе (Natural Stories Corpus, Futrell et al., 2018).
Структура статьи следующая: в следующем разделе мы кратко представляем рациональную теорию памяти как часть когнитивной архитектуры ACT-R. Далее мы представляем синтаксические анализаторы на основе переходов, разработанные в компьютерной лингвистике, и показываем, как можно комбинировать синтаксический анализ на основе переходов и когнитивные архитектуры. Затем когнитивно информированный синтаксический анализатор оценивается на примерах садовых дорожек и данных из Natural Stories Corpus. Наконец, наше исследование кратко сравнивается с родственными работами по вычислительной психолингвистике.
2. Моделирование извлечения памяти в рациональной теории
Адаптивное управление мыслью-Рациональное предполагает, в соответствии со своим названием, что различные когнитивные функции следует моделировать как случай рациональной теории познания. Здесь мы сосредоточимся на том, как память и извлечение памяти формализованы в ACT-R.
Здесь мы сосредоточимся на том, как память и извлечение памяти формализованы в ACT-R.
ACT-R предполагает два типа памяти: процедурную память и декларативную память. Мы сосредоточимся здесь на последней, декларативной памяти, которая используется для хранения фактических знаний. 1
Целью системы декларативной памяти должно быть воспроизведение части информации i , необходимой для достижения текущей цели. Как это принято в ACT-R, мы формализуем фрагменты информации в виде фрагментов. Это матрицы значений атрибутов или, в терминологии ACT-R, матрицы значений слотов. Пример фрагмента, представляющего упрощенную часть информации, полученной в зависимости в (1-a), показан в (2). В этом обозначении имена слотов отображаются слева, а их значения — справа. Кусок представляет собой знание того, что подлежащее во множественном числе в форме студента было встречено и сохранено в памяти.
Предполагая, что извлечение фрагмента является дорогостоящим и требует времени, извлечение из памяти должно быть ограничено. Оптимальная система поиска будет отдавать приоритет тем частям, которые, скорее всего, необходимы для текущей цели. В общем, следует считать, что отзыв части информации, чанк i , скорректированный на значение текущей цели G , не должен превышать стоимость извлечения C .
Оптимальная система поиска будет отдавать приоритет тем частям, которые, скорее всего, необходимы для текущей цели. В общем, следует считать, что отзыв части информации, чанк i , скорректированный на значение текущей цели G , не должен превышать стоимость извлечения C .
Задача рациональной теории памяти состоит в том, чтобы найти разумную оценку P ( i ). В ACT-R предполагается, что P ( i ), вероятность того, что i необходимы, обусловлена двумя источниками информации: (i) историей H i , что то есть прошлое использование i и (ii) текущий контекст Q . Таким образом, нам нужно оценить P ( и | H i , Q ), что легко сделать с помощью правила Байеса. Однако вместо прямого выражения условной вероятности в ACT-R стандартно используется оценка логарифмических шансов. Оценка выражается в (4) ( i c является дополнением к i , т. е. ; Q , текущий контекст, состоит из индексов j , которые мы называем репликами).
е. ; Q , текущий контекст, состоит из индексов j , которые мы называем репликами).
Вывод в (4) делает общее предположение, что хотя вероятность того, что i необходимы, зависит от H i и Q , вероятности сигналов 94 j текущий контекст Q взаимно независимы и не зависят от истории H i , обусловленных i (см. Anderson, 1991). Лог-шансы в (4) имеют особый статус в ACT-R. Они называются активацией i , записывается как A i . Активация состоит из двух частей: компонента истории [первое дополнение в (4)] и компонента контекста [второе дополнение в (4)]. В ACT-R компонент истории называется активацией базового уровня, сокращенно B i , а компонент контекста называется активацией распространения, сокращенно S i . Мы можем переписать формулу следующим образом 2 :
Давайте посмотрим, как ACT-R оценивает компоненты истории и контекста. Прежде чем сделать это, мы хотим подчеркнуть две вещи. Во-первых, теория, которую мы собираемся обсудить, в целом и широко принята исследовательским сообществом ACT-R. Во-вторых, важно понимать, что оценки как компонента истории, так и компонента контекста — это не просто произвольные уравнения, которые соответствуют данным памяти. Они должны отражать оценки, которые ум делает из структуры окружающей среды, чтобы прийти к наилучшей оценке P ( i ), используемое в (3), как и следовало бы ожидать от рациональной теории познания. Однако мы не будем приводить доказательства того, что следующие оценки являются обобщением структуры окружающей среды, так как это было сделано в другом месте (см. Anderson, 1991).
Прежде чем сделать это, мы хотим подчеркнуть две вещи. Во-первых, теория, которую мы собираемся обсудить, в целом и широко принята исследовательским сообществом ACT-R. Во-вторых, важно понимать, что оценки как компонента истории, так и компонента контекста — это не просто произвольные уравнения, которые соответствуют данным памяти. Они должны отражать оценки, которые ум делает из структуры окружающей среды, чтобы прийти к наилучшей оценке P ( i ), используемое в (3), как и следовало бы ожидать от рациональной теории познания. Однако мы не будем приводить доказательства того, что следующие оценки являются обобщением структуры окружающей среды, так как это было сделано в другом месте (см. Anderson, 1991).
Активация базового уровня B i фрагмента дана в (6) и отражает тот факт, что вероятность того, что фрагмент будет использован в следующий раз, уменьшается как степенная функция времени, прошедшего с момента последней операции. использования, но на него также влияет количество раз, когда фрагмент был использован. Активация базового уровня выражается как логарифм суммы tk-d, где t k — время, прошедшее между моментом предъявления k и временем извлечения. d — отрицательная экспонента (затухание), свободный параметр ACT-R, для которого часто устанавливается значение по умолчанию 0,5. «Презентация» в ACT-R означает две вещи. Либо это относится к моменту, когда блок был создан в первый раз (т. е. кто-то узнал конкретный факт), либо к моменту, когда блок был успешно вызван из декларативной памяти для использования в каком-либо контексте, после чего он сохраняется в снова декларативная память.
Активация базового уровня выражается как логарифм суммы tk-d, где t k — время, прошедшее между моментом предъявления k и временем извлечения. d — отрицательная экспонента (затухание), свободный параметр ACT-R, для которого часто устанавливается значение по умолчанию 0,5. «Презентация» в ACT-R означает две вещи. Либо это относится к моменту, когда блок был создан в первый раз (т. е. кто-то узнал конкретный факт), либо к моменту, когда блок был успешно вызван из декларативной памяти для использования в каком-либо контексте, после чего он сохраняется в снова декларативная память.
Второй элемент в расчете активации приведен в (7). Чтобы расчеты были управляемыми, вводятся некоторые упрощающие допущения (см. Anderson, 1991; Anderson and Lebiere, 1998). Во-первых, предполагается, что реплики и в текущем контексте независимы друг от друга (и от истории H i ), обусловлены i . Во-вторых, знаменатель, который должен быть P ( j | i c ), упрощается до P ( j ), поскольку обусловливает j нерелевантной частью информации i c и не может существенно влиять на вероятности. Полученный логарифм отношений вероятностей logP(j|i)P(j) называется ассоциативной силой и обычно обозначается аббревиатурой S ji . Уравнение также включает вес W , который является свободным параметром, взвешивающим компонент контекста активации.
Полученный логарифм отношений вероятностей logP(j|i)P(j) называется ассоциативной силой и обычно обозначается аббревиатурой S ji . Уравнение также включает вес W , который является свободным параметром, взвешивающим компонент контекста активации.
Наконец, уравнение в (8) показывает, как ACT-R оценивает ассоциативную силу S ji . Это уравнение используется только в том случае, если сигнал j предсказывает фрагмент i . Если это не так, S ji устанавливается равным 0. Несколько упрощая, ACT-R предполагает, что сигнал предсказывает фрагмент, если сигнал появляется как значение в фрагменте.
S — это логарифм размера декларативной памяти, но обычно он выбирается вручную как достаточно большое значение, чтобы S ji всегда было положительным (см. Bothell, 2017). ). fan j — это количество чанков в памяти, значением которых является cue j . Обсуждение того, почему (8) аппроксимирует logP(j|i)P(j), см. в Brasoveanu and Dotlačil (2020). Также полезно заметить, что формула S ji также выражает следующую интуицию: ассоциативная сила (и, следовательно, активация) будет большой, когда j появляется только в нескольких фрагментах, так как в этом случае j является высокопредсказательным для каждого из этих кусочки; ассоциативная сила будет уменьшаться, если в декларативной памяти будет больше фрагментов, содержащих 90 393 j 90 394 в качестве своего значения (эмпирические данные см. Anderson, 1974; Anderson and Lebiere, 1998; Anderson and Reder, 1999).
Обсуждение того, почему (8) аппроксимирует logP(j|i)P(j), см. в Brasoveanu and Dotlačil (2020). Также полезно заметить, что формула S ji также выражает следующую интуицию: ассоциативная сила (и, следовательно, активация) будет большой, когда j появляется только в нескольких фрагментах, так как в этом случае j является высокопредсказательным для каждого из этих кусочки; ассоциативная сила будет уменьшаться, если в декларативной памяти будет больше фрагментов, содержащих 90 393 j 90 394 в качестве своего значения (эмпирические данные см. Anderson, 1974; Anderson and Lebiere, 1998; Anderson and Reder, 1999).
Наконец, формула в (9) показывает, как A i связано со временем извлечения блока из декларативной памяти, T i . Отношение между A i и T i модулируется двумя свободными параметрами, F , коэффициентом задержки, и f , показателем задержки.
Когда оба параметра установлены на 1 (их значение по умолчанию), время выборки чанка i — это просто экспонента его отрицательной активации, которая представляет собой обратную вероятность того, что фрагмент i необходим в текущем контексте [см. (4)]:
Из (10) следует, что чем больше a чанк необходим для достижения текущей цели, тем быстрее он будет извлечен.
Проиллюстрируем, как складываются все уравнения, на примере из введения, зависимости подлежащее-глагол.
Предположим, что мы понимаем или произносим глагол в (11-a) и хотим извлечь фрагмент студентов , чтобы решить зависимость субъект-глагол. Для целей этой иллюстрации мы предполагаем, что фрагмент представлен в памяти, как показано в (11-b), повторяющемся из (2). Зависимость должна быть разрешена для целей интерпретации, поскольку слушатели должны знать, кто агент знает . Это также необходимо для производственных целей, поскольку говорящим нужно знать, какую флективную форму должен иметь глагол.
Активация предмета студента , его логарифмическая вероятность того, что блок необходим, состоит из активации базового уровня и активации распространения. Предположим, что с момента сохранения фрагмента в памяти прошло 1 с, и фрагмент не использовался повторно. Тогда активация базового уровня, рассчитанная с использованием уравнения (6), равна:
Активация распространения, рассчитанная с использованием уравнений (7) и (8), приведена в (13). Обратите внимание, что сигналы [подлежащее], [множественное число] являются сигналами в текущем контексте, т. Е. Мы предполагаем для этого примера, что эти два сигнала присутствуют в когнитивном контексте при разрешении зависимости субъект-глагол.
Предположим, что свободный параметр S установлен равным 1, а также вес W . Поскольку обе реплики появляются в блоке студентов , мы должны вычислить оба слагаемых как:
Единственная часть, которую необходимо решить, — это значение веера для двух реплик. Предположим, что в памяти нет другого подлежащего и еще одного элемента множественного числа. Затем вычисления выполняются следующим образом:
Предположим, что в памяти нет другого подлежащего и еще одного элемента множественного числа. Затем вычисления выполняются следующим образом:
Наконец, мы можем рассчитать время поиска следующим образом:
Основываясь на обсуждении этого примера, можно отметить, что модель декларативной памяти ACT-R делает несколько прогнозов относительно времени извлечения. Некоторые из них приведены в пунктах ниже:
• Чем больше времени прошло с момента последнего использования блока, тем ниже активация блока на базовом уровне. Следовательно, фрагменты, которые использовались давно, будут извлекаться медленнее, чем недавно использовавшиеся фрагменты.
• Чем реже использовался чанк, тем ниже базовый уровень активации чанка. Следовательно, фрагменты, которые редко используются, будут извлекаться медленнее, чем часто используемые фрагменты.
• Чем больше фрагмент соответствует сигналам текущего контекста, тем выше усиление от активации распространения. Следовательно, фрагменты с более высокими совпадениями с репликами должны извлекаться быстрее.
Следовательно, фрагменты с более высокими совпадениями с репликами должны извлекаться быстрее.
• Увеличение веера сигнала увеличивает время извлечения элемента. Например, представьте, что в декларативной памяти хранится больше фрагментов со значением во множественном числе . Тогда ассоциативная сила любого фрагмента с во множественном числе будет ниже, и, следовательно, для извлечения таких фрагментов потребуется больше времени.
В той мере, в какой эти качественные предсказания подтверждаются, у нас есть подтверждающие доказательства рациональной теории памяти, реализованной в ACT-R. В той мере, в какой количественные прогнозы модели могут быть хорошо приспособлены к поисковым данным, у нас также есть доказательства того, что оценки истории и контекстного компонента (4) в ACT-R находятся на правильном пути.
Были собраны различные доказательства, показывающие, что качественные, а также количественные прогнозы модели поиска в ACT-R оправданы. Андерсон (1991) и Андерсон и Лебьер (1998) представляют подтверждающие данные из общих когнитивных задач (независимо от языка). В психолингвистике Льюис и соавт. (2006), Jäger et al. (2017 г.); Ягер и др. (2020), среди прочего, обобщают доказательства того, что по крайней мере некоторые случаи поиска зависимостей можно смоделировать как случай поиска ACT-R.
В психолингвистике Льюис и соавт. (2006), Jäger et al. (2017 г.); Ягер и др. (2020), среди прочего, обобщают доказательства того, что по крайней мере некоторые случаи поиска зависимостей можно смоделировать как случай поиска ACT-R.
Целью этой статьи является применение модели поиска и памяти ACT-R к новой области. Мы исследуем, как рациональная теория памяти может моделировать синтаксический анализ знаний и как модель синтаксического анализа может быть встроена в ACT-R. Мы покажем, что если рассматривать шаги синтаксического анализа как фрагменты декларативной памяти, извлечение которых управляется теми же правилами, что и другие элементы памяти, модель памяти ACT-R становится непосредственно применимой к синтаксическому анализу. Активация, связанная с извлеченными этапами синтаксического анализа, может затем использоваться для моделирования влияния контекста на процессинг, например, исследования, которые в основном являются областью психолингвистических теорий синтаксического анализа, таких как теория неожиданностей (Hale, 2001). В той мере, в какой результирующая модель синтаксического анализа делает правильные количественные и качественные прогнозы, мы строим доказательства того, что к трудностям обработки, наблюдаемым во время синтаксического анализа, можно подойти с точки зрения рациональной теории памяти. Гипотеза, изучаемая в этой статье, дополнительно исследуется в Dotlačil (принято) 3 , в котором также изучается, как отдельные компоненты системы поиска ACT-R влияют на поиск шагов синтаксического анализа и как поиск знаний синтаксического анализа взаимодействует с поиском зависимостей в обработке.
В той мере, в какой результирующая модель синтаксического анализа делает правильные количественные и качественные прогнозы, мы строим доказательства того, что к трудностям обработки, наблюдаемым во время синтаксического анализа, можно подойти с точки зрения рациональной теории памяти. Гипотеза, изучаемая в этой статье, дополнительно исследуется в Dotlačil (принято) 3 , в котором также изучается, как отдельные компоненты системы поиска ACT-R влияют на поиск шагов синтаксического анализа и как поиск знаний синтаксического анализа взаимодействует с поиском зависимостей в обработке.
В разделе 3 мы вводим синтаксический анализ на основе переходов и показываем, как такие синтаксические анализаторы могут быть созданы на примере декларативной памяти в ACT-R. В разделе 4 мы показываем, как модель может быть связана с данными о времени реакции, и оцениваем ее качественные и количественные прогнозы.
3. Синтаксический анализ на основе переходов
Мы вводим синтаксические анализаторы на основе переходов и показываем, что они могут быть в значительной степени встроены в ACT-R и объединены со структурами памяти, обсуждаемыми в разделе 2. Такая комбинация напрямую обеспечивает поведенческие анализы. предсказания, которые будут проверены в следующих разделах.
Такая комбинация напрямую обеспечивает поведенческие анализы. предсказания, которые будут проверены в следующих разделах.
Синтаксические анализаторы на основе переходов — это системы синтаксического анализа, которые предсказывают переходы из одного состояния в другое в соответствии с решениями, принятыми классификатором. Поскольку классификатор играет решающую роль в парсерах этого типа, эти парсеры также называются парсерами на основе классификаторов.
Синтаксические анализаторы на основе переходов чаще всего реализуются для грамматик зависимостей и, возможно, они наиболее успешны и широко распространены при построении графов зависимостей (Nivre et al., 2007). Однако они также применялись для синтаксического анализа фраз (Kalt, 2004; Sagae, Lavie, 2005; Liu, Zhang, 2017; Китаев, Клейн, 2018, и др.). В этой статье также разрабатывается синтаксический анализатор, основанный на переходе структуры фразы. Мы представляем вариант алгоритма синтаксического анализа на основе перехода, основанный на сдвиге, который, возможно, является наиболее распространенным типом синтаксического анализатора на основе перехода для структур фраз, и показываем, как его можно понять с точки зрения систем памяти, обсуждавшихся в предыдущем разделе.
3.1. Алгоритм синтаксического анализа фразовой структуры на основе переходов
Алгоритм синтаксического анализа работает с двумя базами данных, стеком построенных деревьев S и стеком предстоящих слов с их POS (тегами части речи) W. Когда начинается синтаксический анализ, S пусто, а W переносит следующие слова по мере их появления в предложении, так что первое слово появляется в начале стека, за ним следует второе слово и т. д.
Разбор продолжается путем выбора действий на основе содержимого S и W Каждый шаг разбора P является функцией от S,W до действий A, то есть P:S×W↝A. В рассматриваемом нами варианте парсера есть три действия, которые может выбрать парсер:
• сдвиг
• уменьшение
• постулат пробел
Первое действие, сдвиг , извлекает верхний элемент из стека W и помещает его как тривиальное дерево в стек S. Элементом в W является пара 〈 слово, POS〉, дерево, перемещенное в стек, представляет собой просто тег POS с терминалом, являющимся фактическим словом.
Второе действие, reduce
, извлекает верхний элемент (если редукция унарная) или два верхних элемента (если редукция бинарная) из стека построенных деревьев S и создает новое дерево. Если редукция является унарной, новое дерево имеет только одну дочернюю структуру под корнем, дерево, которое только что было извлечено из стека. Если редукция бинарная, то у вновь созданного дерева есть две дочери, два дерева, которые только что были извлечены из стека. В любом случае вновь построенное дерево помещается на вершину стека S. Предполагается, что все деревья не более чем двоичные, поэтому никаких дальнейших сокращений, кроме двоичных, не требуется. Наконец, третье действие, постулирует пробел , постулирует пробел и разрешает его в его антецедент. Не каждый синтаксический анализатор в компьютерной лингвистике предполагает это действие, т. е. реализованные синтаксические анализаторы могут работать только путем сдвига и сокращения (но см. Crabbé, 2015; Coavoux and Crabbé, 2017a,b в качестве примеров синтаксических анализаторов на основе переходов, которые учитывают разрешение пробелов).
Есть несколько ограничений на три действия. Во-первых, сдвиг не может быть применен, когда W пусто. Когда S пуст, никакое сокращение не может быть применено, а когда оно имеет только одно дерево, двоичное сокращение не может быть применено. Наконец, между двумя сменами может быть применено не более двух действий по пропуску постулатов. Это последнее ограничение гарантирует, что система не впадет в бесконечный регресс постулирования разрыва.
Проиллюстрируем шаги парсера shift-reduce на простом примере: парсинг мальчик танцует . Структура фразы показана на рис. 1, а шаги синтаксического анализа:
Рисунок 1 . Фраза мальчик танцует .
В этом иллюстративном примере мы предполагаем, что синтаксический анализатор знает, какова правильная структура фразы, и проводит синтаксический анализ в направлении этой структуры. Конечно, ключевой вопрос заключается в том, что происходит, когда структура фразы неизвестна и синтаксический анализатор должен предсказать, какое действие следует предпринять. Это обсуждается в следующем разделе.
Конечно, ключевой вопрос заключается в том, что происходит, когда структура фразы неизвестна и синтаксический анализатор должен предсказать, какое действие следует предпринять. Это обсуждается в следующем разделе.
3.2. Шаги синтаксического анализа как извлечения памяти
На этапе синтаксического анализа необходимо решить, какое действие (среди сдвиг, уменьшение и пробел постулата ) должно быть выполнено, и, если выбрано сокращение , как должно быть выполнено сокращение: следует оно должно быть унарным или бинарным, и какой должна быть корневая метка вновь построенного дерева?
Мы исследуем гипотезу о том, что этап синтаксического анализа можно рассматривать как случай извлечения из памяти. Прошлые шаги синтаксического анализа формируют декларативную память синтаксического анализатора. Синтаксический анализатор извлекает из памяти шаг (или шаги) синтаксического анализа, который имеет наибольшую вероятность того, что он потребуется для текущей цели. Текущая цель, в свою очередь, состоит в разборе предложения. С этой точки зрения синтаксический анализ — это всего лишь конкретная реализация рациональной теории памяти, которая может быть встроена в ACT-R. Активация шага синтаксического анализа, т. е. логарифмическая вероятность того, что шаг необходим, вычисляется из компонента истории и компонента контекста. Первый выводится из времени, прошедшего с момента использования и повторного использования шага, последний рассчитывается на основе сигналов в текущем контексте и распространения активации от этих сигналов на фрагменты в декларативной памяти.
Текущая цель, в свою очередь, состоит в разборе предложения. С этой точки зрения синтаксический анализ — это всего лишь конкретная реализация рациональной теории памяти, которая может быть встроена в ACT-R. Активация шага синтаксического анализа, т. е. логарифмическая вероятность того, что шаг необходим, вычисляется из компонента истории и компонента контекста. Первый выводится из времени, прошедшего с момента использования и повторного использования шага, последний рассчитывается на основе сигналов в текущем контексте и распространения активации от этих сигналов на фрагменты в декларативной памяти.
Хотя контекст можно рассматривать как полные деревья в S и всю информацию в W, мы значительно ограничим объем информации в двух базах данных. Будем предполагать, что S и W несут только некоторые признаки деревьев и предстоящих слов, перечисленных в (17). Таким образом, сам синтаксический анализатор никогда не имеет полного снимка структуры фразы, которую он выводит. Он несет только минимальную локальную информацию. Структуру фразы всегда можно реконструировать с помощью шагов синтаксического анализа, предпринятых агентом ACT-R (и, возможно, людьми), но не существует единого снимка, в котором вся информация доступна агенту. Эта позиция распространена при анализе ACT-R, см., например, Lewis and Vasishth (2005).
Структуру фразы всегда можно реконструировать с помощью шагов синтаксического анализа, предпринятых агентом ACT-R (и, возможно, людьми), но не существует единого снимка, в котором вся информация доступна агенту. Эта позиция распространена при анализе ACT-R, см., например, Lewis and Vasishth (2005).
Признаки должны быть знакомы, возможно, за исключением лексического заголовка. Голова — это терминал, который проецирует свою фразу (глагол — это голова глагольной фразы, существительное — голова именной фразы и т. д.; см. Collins, 1997 о проекции головы в вычислительных синтаксических анализаторах, которым следует эта работа).
Все функции в (17) распространяют активацию на фрагменты, хранящиеся в декларативной памяти, которые, в свою очередь, представляют все шаги синтаксического анализа, выполненные в прошлом. Вызов правильного шага синтаксического анализа — это случай извлечения из памяти, который следует правилам, описанным в разделе 2. Следовательно, предполагается, что для разных шагов синтаксического анализа может потребоваться разное количество времени в зависимости от времени, необходимого для их извлечения. Шаги синтаксического анализа с более высокими активациями будут вызваны быстрее, чем шаги синтаксического анализа с более низкими активациями. Активации, в свою очередь, основаны на активации базового уровня и активации распространения, т. е. оценках ACT-R истории и компонента контекста при расчете необходимых шансов журнала для фрагмента.
Шаги синтаксического анализа с более высокими активациями будут вызваны быстрее, чем шаги синтаксического анализа с более низкими активациями. Активации, в свою очередь, основаны на активации базового уровня и активации распространения, т. е. оценках ACT-R истории и компонента контекста при расчете необходимых шансов журнала для фрагмента.
4. Моделирование данных чтения
Мы представляем реализацию модели синтаксического анализа предложений, основанную на рациональном подходе к памяти, и обсуждаем два тематических исследования, проверяющих реализацию. 4 Раздел 4.1 знакомит с моделью. В разделе 4.2 исследуется, может ли синтаксический анализатор предсказать трудности обработки для выбранных явлений садовой дорожки. В разделе 4.3 исследуется, можно ли использовать синтаксический анализатор для моделирования данных о времени самостоятельного чтения из Natural Stories Corpus (Futrell et al., 2018).
4.1. Модель синтаксического анализа
Мы предполагаем, что декларативная память состоит из фрагментов, которые представляют правильные прошлые шаги синтаксического анализа. Эти фрагменты собираются из данных Penn Treebank (PTB) (Marcus et al., 1993). Стандартно мы разбиваем секцию данных PTB следующим образом: все секции до секции 21 включительно используются для обучения синтаксического анализатора, т. е. для сбора правильных шагов синтаксического анализа; раздел 22 используется для разработки; раздел 23 используется для проверки точности синтаксического анализатора. Перед обучением мы предварительно обрабатываем и готовим структуру фразы путем (i) преобразования фраз в бинарные структуры способом, описанным в Roark (2001) (о причинах этого см. Roark, 2001; Sagae and Lavie, 2005), (ii) аннотирование фраз с информацией о заголовке, (iii) удаление нерелевантной информации (индексы корреферентности фраз), (iv) лемматизация токенов, чтобы лексические заглавия сохранялись как леммы, а не как изменяемые токены.
Эти фрагменты собираются из данных Penn Treebank (PTB) (Marcus et al., 1993). Стандартно мы разбиваем секцию данных PTB следующим образом: все секции до секции 21 включительно используются для обучения синтаксического анализатора, т. е. для сбора правильных шагов синтаксического анализа; раздел 22 используется для разработки; раздел 23 используется для проверки точности синтаксического анализатора. Перед обучением мы предварительно обрабатываем и готовим структуру фразы путем (i) преобразования фраз в бинарные структуры способом, описанным в Roark (2001) (о причинах этого см. Roark, 2001; Sagae and Lavie, 2005), (ii) аннотирование фраз с информацией о заголовке, (iii) удаление нерелевантной информации (индексы корреферентности фраз), (iv) лемматизация токенов, чтобы лексические заглавия сохранялись как леммы, а не как изменяемые токены.
Синтаксический анализ новых предложений состоит из вызова из декларативной памяти необходимых фрагментов, т. е. шагов анализа, собранных из PTB. Отзыв управляется активацией фрагментов. Для расчета активации каждого чанка применяются формулы из раздела 2. Мы предполагаем, что синтаксический анализатор вызовет три фрагмента с наибольшим количеством активаций и выберет действие, которое является наиболее распространенным среди этих трех фрагментов. 5 Синтаксический анализатор повторяет эту процедуру, пока не встретит смена . В этот момент синтаксический анализатор завершил интеграцию слова n и может переключить свое внимание на слово n + 1. Активации, собранные во время синтаксического анализа, усредняются. Их можно использовать для прямого прогнозирования трудностей обработки, как в разделе 4.2, или для расчета времени реакции, как в разделе 4.3.
Отзыв управляется активацией фрагментов. Для расчета активации каждого чанка применяются формулы из раздела 2. Мы предполагаем, что синтаксический анализатор вызовет три фрагмента с наибольшим количеством активаций и выберет действие, которое является наиболее распространенным среди этих трех фрагментов. 5 Синтаксический анализатор повторяет эту процедуру, пока не встретит смена . В этот момент синтаксический анализатор завершил интеграцию слова n и может переключить свое внимание на слово n + 1. Активации, собранные во время синтаксического анализа, усредняются. Их можно использовать для прямого прогнозирования трудностей обработки, как в разделе 4.2, или для расчета времени реакции, как в разделе 4.3.
Активация чанка представляет собой сумму активации базового уровня и активации распространения. Для активации на базовом уровне нам необходимо оценить, как часто шаг синтаксического анализа использовался в прошлом и сколько времени прошло. Оценка исходит из частоты шагов синтаксического анализа, собранных из PTB. Частоты могут быть преобразованы в активацию базового уровня в соответствии с процедурой, описанной Reitter et al. (2011), см. также Дотлачил (2018) и Брасовяну и Дотлачил (2020). Процедура кратко изложена в Приложении А.
Оценка исходит из частоты шагов синтаксического анализа, собранных из PTB. Частоты могут быть преобразованы в активацию базового уровня в соответствии с процедурой, описанной Reitter et al. (2011), см. также Дотлачил (2018) и Брасовяну и Дотлачил (2020). Процедура кратко изложена в Приложении А.
Активация распространения вычисляется на основе соответствия между значениями в фрагментах и признаками в текущем когнитивном контексте в момент, когда вспоминается шаг синтаксического анализа. Особенности суммированы в (17).
4.2. Случай 1: Предложения садовой дорожки
Мы начинаем исследование предсказаний синтаксического анализатора с рассмотрения избранных явлений садовой дорожки, взятых из предыдущей литературы (Bever, 1970; Frazier, 1978; Marcus, 1978; Gibson, 1991; Pritchett, 1992).
Мы моделируем предсказания для пар в (18)–(21). В каждой паре предложение (а) является классическим примером садовой дорожки. Предложение (б) имеет ту же или почти идентичную интерпретацию, что и садовая дорожка. Однако, поскольку устранение неоднозначности происходит в начале предложения (b), эффекта садовой дорожки не наблюдается.
Однако, поскольку устранение неоднозначности происходит в начале предложения (b), эффекта садовой дорожки не наблюдается.
Мы хотим посмотреть, как синтаксический анализатор анализирует (18)–(21) и какие значения активации предсказываются для слов в предложениях. Мы ожидаем, что активация извлеченных шагов синтаксического анализа должна быть ниже для случаев садовой дорожки [примеры (а)] по сравнению со случаями (б). Это должно происходить на целевых словах, словах, при обработке которых трудности должны находиться в предложениях садовой дорожки. Целевые слова упало на для (18), упало на на (19), стало на (20) и бит на (21). Мы ожидаем, что активация предложений типа «садовая дорожка» уменьшится в точке неоднозначности, потому что базовая активация шагов разбора должна быть низкой (предложения «садовой дорожки» не должны быть очень частыми в естественных данных) и потому что активация распространения должна быть низкой ( предложения садовой дорожки перемещают нас в синтаксический контекст, который не может найти хорошего совпадения на прошлых этапах синтаксического анализа, поэтому не многие сигналы будут распространять активацию).
Активации на слово графически представлены на рисунке 2. Для этого расчета мы приняли значения свободных параметров по умолчанию и установили максимальную ассоциативную силу, S , из уравнения (8) равной 20. Как мы видим, примеры (а) показывают более низкую активацию, чем примеры (б) в целевом слове. Кроме того, за одним исключением, классической парой в (18), разница не только идет в предсказанном направлении, но и велика в критическом слове (2 точки активации и более). Заметьте также, что контраст в активациях обычно распространяется на следующие слова. Поскольку более низкая активация приводит к более высокому времени поиска, мы видим, что модель способна предсказать увеличение времени чтения в предложениях садовой дорожки. Кроме того, фрагменты с более низкой активацией имеют более высокую вероятность неудачного извлечения (Андерсон, 19 лет).91; Андерсон и Лебьер, 1998). Следовательно, уменьшение активации может объяснить трудности с обработкой в целом, в частности, неспособность обеспечить правильный разбор предложений с садовыми дорожками (Pritchett, 1992). 6
6
Рисунок 2 . Активаций на слово для пар предложений (18)–(21). Желтые полосы представляют активацию в предложениях, которые рано устраняют неоднозначность. Синие полосы — это активации предложений садовой дорожки. Многоточием отмечены активации слов, которые вызывают эффект садовой дорожки.
Структуры словосочетаний, построенные синтаксическим анализатором, верны для всех примеров (b), за исключением (21-b), в котором синтаксический анализатор ошибочно прикрепляет именное словосочетание a bandage внутри относительного предложения. Для предложений (а) синтаксический анализатор борется с точкой устранения неоднозначности, и шаги синтаксического анализа, которые он извлекает, не являются адекватными структурами фраз. Он предоставляет структуры фраз, которые являются неправильными, но в которых локально построенные фразы комбинируются правдоподобным образом. Неправильные синтаксические анализы для (а) предложений были выбраны синтаксическим анализатором, потому что они имели самые высокие значения активации в контексте. Это означает, что если мы ограничим наше внимание правильных синтаксических разборов, контраст между предложениями садовой дорожки и их аналогами (b) будет еще больше в критических словах.
Это означает, что если мы ограничим наше внимание правильных синтаксических разборов, контраст между предложениями садовой дорожки и их аналогами (b) будет еще больше в критических словах.
Одна пара, в которой контраст между примерами (а) и (б) идет в правильном направлении, но настолько мал, что контраст активации почти не имеет значения, представляет собой случай (18). Тот факт, что предложение садовой дорожки почти не отличается от базового, может быть вызван тем, что мы не моделируем дискурсивные и семантические явления, а Крейн и Стидман (19).85) убедительно показал, что эта садовая дорожка чувствительна к своему контексту. Поскольку модель не принимает во внимание контекст, она упускает из виду эффекты дискурса, влияющие на активацию.
В заключение мы видим, что контрасты в активации извлеченных шагов синтаксического анализа могут быть связаны с трудностями обработки и предсказывают когнитивные трудности, наблюдаемые в предложениях садовой дорожки.
4.
 3. Моделирование данных чтения корпуса
3. Моделирование данных чтения корпуса4.3.1. Введение
Мы изучаем прогнозы модели синтаксического анализа для корпуса естественных историй (NSC, Futrell et al., 2018). NSC представляет собой корпус, содержащий 10 английских повествовательных текстов с 10 245 лексическими токенами. Тексты были отредактированы таким образом, чтобы в них содержались различные синтаксические конструкции, в том числе очень редкие. Корпус был прочитан 181 носителем английского языка с использованием парадигмы движущегося окна для самостоятельного чтения, и данные для самостоятельного чтения были опубликованы вместе с текстами. Кроме того, все предложения были аннотированы Стэнфордским парсером (Klein and Manning, 2003) в соответствии с условными обозначениями PTB, проверены и исправлены вручную. Тот факт, что NSC имеет множество синтаксических конструкций и включает управляемые вручную PTB-совместимые синтаксические анализы, делает корпус особенно удобным для вычислительного моделирования синтаксического анализа.
4.3.2. Модель чтения
Синтаксический анализатор, указанный в разделах 2 и 3 и реализованный в разделе 4.1, будет использоваться для моделирования самостоятельного чтения предложений в корпусе. Однако, чтобы убедиться, что парсер не сбивается, на каждом слове мы собираем правильный парсер, предоставленный NSC. Этот правильный синтаксический анализ используется в качестве контекста для извлечения: на основе этого синтаксического анализа синтаксический анализатор пытается получить шаг синтаксического анализа из декларативной памяти. Декларативная память состоит из шагов синтаксического анализа, собранных из PTB, подробности см. в разделе 4.1. Затем записывается средняя активация извлеченных фрагментов. После того, как синтаксический анализ слова завершен, правильный синтаксический анализ снова рассматривается для следующего слова. Это означает, что синтаксический анализатор будет иметь правильную синтаксическую структуру для каждого слова и будет использовать правильный контекст для поиска.
Важно отметить, что при самостоятельном чтении читатели делают гораздо больше, чем просто извлекают и применяют шаги синтаксического анализа. Кажется бесспорным, что модель, имитирующая самостоятельное чтение, должна, по крайней мере, визуально обращать внимание на слово n , извлекать лексическую информацию об этом слове, анализировать, нажимать клавишу (чтобы открыть следующее слово) и перемещать визуальное внимание на следующее. слово, слово n + 1. Мы добавим эти части и объединим их с моделью синтаксического анализа, чтобы построить более реалистичную модель чтения. Добавленные детали не создаются ad hoc , они основаны на (упрощенных) моделях визуального внимания и самостоятельного чтения (Anderson and Lebiere, 1998; Brasoveanu and Dotlačil, 2020).
Последовательное поведение, такое как чтение, моделируется в ACT-R как случай процедурного знания, которое упорядочивает процессы, такие как упомянутые выше, и вызывает различные подмодули (зрение, декларативная память, двигательный модуль) для выполнения конкретных задач. . Процессы связаны между собой и контролируются процессуальной системой. На рисунке 3 мы представляем процессы в виде прямоугольников, которые процедурная система запускает в порядке, указанном стрелками. Предполагается, что эти процессы повторяются для каждого слова. Запуск каждого из этих процессов занимает одинаковое количество времени в процедурной системе, указанной в (22).
. Процессы связаны между собой и контролируются процессуальной системой. На рисунке 3 мы представляем процессы в виде прямоугольников, которые процедурная система запускает в порядке, указанном стрелками. Предполагается, что эти процессы повторяются для каждого слова. Запуск каждого из этих процессов занимает одинаковое количество времени в процедурной системе, указанной в (22).
Рисунок 3 . Последовательная модель чтения по одному слову. Каждая коробка представляет один процесс. Стрелки показывают порядок запуска процессов. Есть две стрелки из извлечения шагов синтаксического анализа , потому что извлечение зависит от wh запускается только тогда, когда синтаксический анализатор постулирует пробел.
Кроме того, подмодули, участвующие в процессе, требуют дополнительного времени обработки в зависимости от их собственных свойств.
Процесс посещает слово визуально обращает внимание на слово. Чтобы упростить модель, мы предположим, что визуальное внимание занимает фиксированное количество времени в соответствии с базовыми моделями ACT-R (Bothell, 2017). Предполагается, что обслуживание занимает 50 мс, значение по умолчанию для запуска процесса в ACT-R. Поскольку визуальное внимание моделируется как фиксированное количество времени, любое соответствие модели данным должно управляться только процессами поиска: поиском лексической информации или поиском синтаксической информации, которые являются единственными двумя процессами поиска, рассматриваемыми в этой статье. бумага.
Предполагается, что обслуживание занимает 50 мс, значение по умолчанию для запуска процесса в ACT-R. Поскольку визуальное внимание моделируется как фиксированное количество времени, любое соответствие модели данным должно управляться только процессами поиска: поиском лексической информации или поиском синтаксической информации, которые являются единственными двумя процессами поиска, рассматриваемыми в этой статье. бумага.
Процессы нажатия клавиш и перемещения зрительного внимания взаимодействуют с моторным модулем и зрительным модулем соответственно. Нажать клавишу смоделировано с учетом базовой модели двигательных действий в ACT-R, которая основана на когнитивной архитектуре EPIC (Bothell, 2017). Предполагается, что читатели держат пальцы на клавише, которую нужно нажать. В этом случае простая модель двигательных действий в ACT-R, используемая здесь, постулирует, что для нажатия клавиши требуется 150 мс. Важно отметить, что в это время процедурная система может выполнять любые другие действия в последовательной модели. Это означает, что перемещение визуального внимания может происходить одновременно с нажатием клавиш.
Это означает, что перемещение визуального внимания может происходить одновременно с нажатием клавиш.
Процессы извлекают lex. информация, получение шагов синтаксического анализа и получение wh-зависимых — это процессы, зависящие от декларативной памяти. Все процессы занимают не менее r времени каждый. Кроме того, они также потребуют дополнительного времени: количества времени, необходимого для извлечения фрагмента из декларативной памяти. Все соответствующие уравнения для расчета времени поиска приведены в разделе 2. Повторим, что время поиска является функцией активации извлеченного фрагмента и модулируется двумя свободными параметрами (23-a). Активация рассчитывается как сумма активации базового уровня и активации распространения (23-b).
Активация базового уровня и активация распространения были подробно рассмотрены в разделе 2. Напомним, что у этих активаций было несколько свободных параметров: затухание d , вес W , максимальная ассоциативная сила S . Мы установили для первых двух параметров значения по умолчанию 0,5 и 1 соответственно (см. Anderson and Lebiere, 1998; Bothell, 2017). Максимальная ассоциативная сила установлена на уровне 20, чтобы гарантировать, что ассоциативная сила всегда будет положительной (см. Bothell, 2017). Кроме того, r , время запуска процесса процедурной системой, см. (22), установлено равным 33 мс, поскольку в Dotlačil (принято) 3 было установлено, что это среднее значение для модели ACT-R, которая имитирует чтение в эксперименте по самостоятельному чтению. Наконец, компонент времени, необходимый для расчета активации базового уровня, рассчитывается таким же образом для извлечения лексической информации (слов) и извлечения шагов синтаксического анализа. Он выводится из частоты слов и шагов синтаксического анализа на основе процедуры, кратко изложенной в Приложении A.
Мы установили для первых двух параметров значения по умолчанию 0,5 и 1 соответственно (см. Anderson and Lebiere, 1998; Bothell, 2017). Максимальная ассоциативная сила установлена на уровне 20, чтобы гарантировать, что ассоциативная сила всегда будет положительной (см. Bothell, 2017). Кроме того, r , время запуска процесса процедурной системой, см. (22), установлено равным 33 мс, поскольку в Dotlačil (принято) 3 было установлено, что это среднее значение для модели ACT-R, которая имитирует чтение в эксперименте по самостоятельному чтению. Наконец, компонент времени, необходимый для расчета активации базового уровня, рассчитывается таким же образом для извлечения лексической информации (слов) и извлечения шагов синтаксического анализа. Он выводится из частоты слов и шагов синтаксического анализа на основе процедуры, кратко изложенной в Приложении A.
Это оставляет нам два параметра, необходимых для оценки времени извлечения из активаций: F и f . Они будут оцениваться с помощью процедуры байесовского моделирования.
Они будут оцениваться с помощью процедуры байесовского моделирования.
4.3.3. Байесовское моделирование
Есть два параметра, которые нам нужно смоделировать, чтобы подогнать модель чтения к данным корпуса: F и f . Мы оценим их с помощью байесовских методов (см. Дотлачил, 2018 г., Брасовяну и Дотлачил, 2018 г., Брасовяну и Дотлачил, 2019 г.)., Брасовяну и Дотлачил, 2020 г .; Rabe et al., 2021 — другие примеры сочетания байесовского моделирования с когнитивными моделями ACT-R; см. Weaver, 2008; Dotlačil, 2018 за аргументы, почему это необходимо).
Предположим, что структура модели показана на рисунке 4. На этом графике верхний слой представляет априорные вероятности, а нижняя часть — вероятность. ACT-R (F;f) — это когнитивная модель чтения ACT-R, описанная в предыдущем разделе. При запуске и поставке с F и f значений, он выводит задержки на слово. Затем задержки модели оцениваются по данным, предполагая, что вероятность является нормальным распределением (измеряется в миллисекундах) со стандартным отклонением 20 мс (нижняя часть графика). Фактические данные, которые мы пытаемся смоделировать, представляют собой среднее время чтения (mRT) на слово в корпусе для самостоятельного чтения. Мы выбираем первые две (из 10) истории для оценки параметров. В каждой истории есть заметный эффект ускорения по мере того, как читатели продвигаются дальше первых нескольких предложений. Поскольку наша модель этого не представляет, мы решили удалить первые 10 предложений из каждой истории. Кроме того, мы моделируем mRT только начиная со второго слова и заканчивая предпоследним словом в каждом предложении, поскольку первое и последнее слова имеют тенденцию быть выбросами из-за эффектов начала и завершения. Кроме того, начальные слова также являются выбросами в нашей модели (см. также сноску 6 к тексту).
Фактические данные, которые мы пытаемся смоделировать, представляют собой среднее время чтения (mRT) на слово в корпусе для самостоятельного чтения. Мы выбираем первые две (из 10) истории для оценки параметров. В каждой истории есть заметный эффект ускорения по мере того, как читатели продвигаются дальше первых нескольких предложений. Поскольку наша модель этого не представляет, мы решили удалить первые 10 предложений из каждой истории. Кроме того, мы моделируем mRT только начиная со второго слова и заканчивая предпоследним словом в каждом предложении, поскольку первое и последнее слова имеют тенденцию быть выбросами из-за эффектов начала и завершения. Кроме того, начальные слова также являются выбросами в нашей модели (см. также сноску 6 к тексту).
Рисунок 4 . Байесовская модель для оценки параметров корпуса естественных историй.
Предполагается следующая априорная структура параметров:
• F ~ Гамма (α = 2, β = 10)
• f ~ Гамма (α = 2, β = 4)
Учитывая эти априорные значения, значения в диапазоне 0–1 наиболее вероятны, но очень низкие значения наказываются. Априоры для параметров имеют средние значения 0,2 и 0,5 соответственно. Эти априорные предположения учитывают предыдущие выводы о том, что когда F и f оцениваются по языковым исследованиям, включая данные по чтению, они ниже 1, но обычно не слишком малы, а F , как правило, меньше, чем f (Brasoveanu and Dotlačil, 2018, 2020).
Априоры для параметров имеют средние значения 0,2 и 0,5 соответственно. Эти априорные предположения учитывают предыдущие выводы о том, что когда F и f оцениваются по языковым исследованиям, включая данные по чтению, они ниже 1, но обычно не слишком малы, а F , как правило, меньше, чем f (Brasoveanu and Dotlačil, 2018, 2020).
Оценка параметров проводилась с использованием PYMC3 и MCMC-выборки с 1200 вытягиваниями, 2 цепями и 400 выжиганием. Цепочки выборки совпали, о чем свидетельствует значение Rhat (Rhat для F составил 1,036; Rhat для f было 1,028).
4.3.4. Результаты
Средние значения, медианы и значения стандартного отклонения для коэффициента задержки ( F ) и показателя задержки ( f ) апостериорных распределений можно увидеть в таблице 1.
Таблица 1 . Расчетные значения параметров.
Средние и медианные значения для F соответствуют оценке в предыдущих моделях чтения Bayesian + ACT-R (Brasoveanu and Dotlačil, 2018, 2020). Однако оценка f больше, чем в предыдущих исследованиях чтения. Возможно, это связано с тем, что предыдущие исследования чтения не принимали во внимание поиск шагов синтаксического анализа, сосредоточившись только на лексическом поиске, и что предыдущие исследования в основном рассматривали экспериментальные данные, в то время как это исследование моделирует корпусные данные.
Однако оценка f больше, чем в предыдущих исследованиях чтения. Возможно, это связано с тем, что предыдущие исследования чтения не принимали во внимание поиск шагов синтаксического анализа, сосредоточившись только на лексическом поиске, и что предыдущие исследования в основном рассматривали экспериментальные данные, в то время как это исследование моделирует корпусные данные.
Для дальнейшего изучения модели мы проверяем выборки из ее апостериорного распределения предсказанных RT (т. е. RT, которые модель чтения предсказывает с использованием апостериорного распределения подобранных параметров). Мы ожидаем, что они должны коррелировать с наблюдаемыми средними ВУ. Это связано с тем, что модель имитирует два этапа обработки, а именно лексический поиск и синтаксический анализ. На лексический поиск влияет активация слов, которая зависит от частоты и приводит к тому, что для извлечения менее часто встречающихся слов требуется больше времени, чем для более часто встречающихся (см. Приложение А для оценки активации базового уровня на основе частоты). На синтаксический поиск влияет активация шагов синтаксического анализа, которая представляет собой сумму активации базового уровня и активации распространения. Активация базового уровня связана с частотой точно так же, как активация слова, и требует больше времени для извлечения менее частых шагов синтаксического анализа (см. Приложение A). Кроме того, если читатель находится в редком синтаксическом контексте (т. е. в необычной синтаксической конструкции), он с меньшей вероятностью найдет шаги синтаксического анализа в прошлом, которые обеспечили бы хорошее совпадение. Это приводит к снижению активации распространения, что опять же влияет на время считывания. Наконец, синтаксический анализатор моделирует wh-зависимость и извлекает wh-слова, увеличивая время чтения, когда wh-слова находятся далеко от пробела, из-за снижения их активации.
Приложение А для оценки активации базового уровня на основе частоты). На синтаксический поиск влияет активация шагов синтаксического анализа, которая представляет собой сумму активации базового уровня и активации распространения. Активация базового уровня связана с частотой точно так же, как активация слова, и требует больше времени для извлечения менее частых шагов синтаксического анализа (см. Приложение A). Кроме того, если читатель находится в редком синтаксическом контексте (т. е. в необычной синтаксической конструкции), он с меньшей вероятностью найдет шаги синтаксического анализа в прошлом, которые обеспечили бы хорошее совпадение. Это приводит к снижению активации распространения, что опять же влияет на время считывания. Наконец, синтаксический анализатор моделирует wh-зависимость и извлекает wh-слова, увеличивая время чтения, когда wh-слова находятся далеко от пробела, из-за снижения их активации.
Теперь проверим предсказания модели. Во-первых, мы запускаем простую линейную модель с прогнозируемыми RT на слово (т. е. RT, которые модель чтения предсказывает с использованием апостериорного распределения подобранных параметров) в качестве независимой переменной и наблюдаемыми средними RT в качестве зависимой переменной. Мы видим в сводке линейной модели, приведенной в таблице 2, что оценка максимального правдоподобия (MLE) предсказанного RT очень близка к 1, т. е. в наилучшем линейном соответствии между предсказанным и наблюдаемым RT увеличение на 1 мс в предсказанные RT соответствуют увеличению наблюдаемых RT на 1 мс. В таблице 3 показано соответствие линейной модели пересечения + прогнозируемого RT. Как мы видим, предсказанные RT являются очень значимым предиктором наблюдаемых средних RT.
е. RT, которые модель чтения предсказывает с использованием апостериорного распределения подобранных параметров) в качестве независимой переменной и наблюдаемыми средними RT в качестве зависимой переменной. Мы видим в сводке линейной модели, приведенной в таблице 2, что оценка максимального правдоподобия (MLE) предсказанного RT очень близка к 1, т. е. в наилучшем линейном соответствии между предсказанным и наблюдаемым RT увеличение на 1 мс в предсказанные RT соответствуют увеличению наблюдаемых RT на 1 мс. В таблице 3 показано соответствие линейной модели пересечения + прогнозируемого RT. Как мы видим, предсказанные RT являются очень значимым предиктором наблюдаемых средних RT.
Таблица 2 . Линейная модель с Predictive RT в качестве единственной независимой переменной.
Таблица 3 . Линейная модель с Intercept и Predictive RT.
Вывод из Таблицы 3 показывает, что наша модель чтения может учитывать некоторые аспекты данных самостоятельного чтения. Однако мы хотим увидеть, что эта возможность моделирования выходит за рамки того, что могут учитывать поверхностные характеристики текста, т. е. положение, длина слова или частота строк, которые, как известно, влияют на время чтения. По этой причине мы рассматриваем более сложную модель, обобщенную в таблице 4. Мы рассматриваем следующие вмешивающиеся факторы: (i) история (история 1 или история 2, первая из которых является эталонным уровнем), (ii) Z ОДИН (позиция слова в его рассказе, z-преобразованная), (iii) P ПОЛОЖЕНИЕ (позиция слова в его предложении, z-преобразованная), (iv) взаимодействие S ТОРИ × Z ОДИН , (v) взаимодействие Z ONE × P OSITION , (vi) L OG (F REQ ) (логарифмическая частота), (vii) N CHAR (длина слово по количеству символов, z-преобразованное), (viii) взаимодействие N CHAR × L OG (F REQ ), (ix) L OG (B IGRAM ) (логарифмическая вероятность), (x) L OG (T RIGRAM ) (логарифмическая вероятность триграммы). Частоты и вероятности биграмм и триграмм представлены в NSC. Большинство ошибок, которые мы вводим, учитываются при оценке вычислительных психолингвистических моделей на основе корпусных данных (Demberg and Keller, 2008; Boston et al., 2011; Hale, 2014 и др.). Мы видим, что даже после добавления вмешивающихся факторов предсказанные RT остаются важным предиктором, и эффект идет в ожидаемом (положительном) направлении (9).0393 t = 3,66, p = 0,0003). Таким образом, наша модель синтаксического анализа фиксирует аспекты чтения данных, которые не учитываются поверхностными факторами, например частотами строк, положением, количеством символов и их взаимодействием. 7
Таблица 4 . Полная линейная модель для РТ в НБК.
Для дальнейшего изучения прогнозов нашей байесовской модели + ACT-R и фактических данных мы разделили наборы прогнозируемых и наблюдаемых данных на децили на основе триграмм, частот слов и фактических наблюдаемых средних значений RT. Графические сводки по децилям представлены на рисунке 5. Для вероятностей триграмм и частот униграмм мы видим, что данные, предсказанные моделью, следуют тренду фактических данных, а среднее предсказанное RT, как правило, близко к наблюдаемому среднему RT в каждом дециле. (с небольшим расхождением в 6-м и 7-м децилях Частоты, для которых модель предполагает, что средние ВУ быстрее на 10 и 9РС). В случае последнего графика, на котором данные разделены по децилям наблюдаемого среднего RT, модель копирует линейный тренд данных, т. е. предсказанное увеличение среднего RT на дециль. Эта тенденция также подтверждается очень значимой корреляцией Пирсона между прогнозируемым средним RT и наблюдаемым средним RT, разделенным по децилям ( r = 0,88, p < 0,001). Однако по сравнению с фактическими данными модель имеет гораздо меньше экстремальных значений на обоих концах децильного спектра и, как следствие. Хотя он фиксирует линейную тенденцию в данных, он завышает RT в нижних децилях и занижает RT в высоких децилях.
Рисунок 5 . Сводные данные о среднем и стандартном отклонении модели и данных, разделенные на триграммы, частоту и наблюдаемые децили среднего RT. Метка оси x показывает верхнюю точку отсечки на дециль (указывается в логарифмическом масштабе в случае частоты). В случае Частоты присутствуют только 9 децилей. Это связано с тем, что одно слово ( ) охватывает два верхних дециля.
Наконец, мы сравниваем предсказания нашей модели с другой моделью чтения ACT-R, представленной в Boston et al. (2011). Модель Бостона и др. (2011) моделирует поиск зависимостей, используя допущения рациональной памяти ACT-R. В отличие от нашей работы, Boston et al. (2011) не моделируют построение структуры, то есть знание шагов синтаксического анализа, с использованием памяти ACT-R. 8 По этой причине мы ожидаем, что временные прогнозы нашей модели останутся значимыми предикторами, когда прогнозы Boston et al. (2011) включены в линейную модель данных чтения НБК. Чтобы проверить это, мы построили временные прогнозы модели чтения ACT-R Boston et al. (2011) для подкорпуса NSC, который мы использовали для тестирования (первые два рассказа). 9 Мы протестировали модель поиска ACT-R Boston et al. (2011) с различными уровнями ширины луча k ( k = 1, 3, 9, 20, 50, 100), где k указывает количество синтаксических разборов, построенных параллельно. Оказалось, что прогнозы модели с низкими числами 90 393 k 90 394 ( 90 393 k 90 394 ≤ 20) не оказали существенного влияния на наши данные чтения NSC. Для 90 393 k 90 394 = 50 и 90 393 k 90 394 = 100 модель показала очень широкий диапазон прогнозируемых времен считывания (от 50 до 5000 мс). Когда мы удалили предсказания за пределами 2000 мс, предсказания модели были значимыми (β = 0,005, т = 3,1). Важно отметить, что предсказания нашей модели P REDICTED RT также были значимыми (β = 0,2, t = 4,1). Это подтверждает положение о том, что наша модель фиксирует свойства чтения, отсутствующие в модели ACT-R, которая имитирует только поиск зависимостей с использованием теории памяти ACT-R.
4.4. Сводка результатов
Мы представили эмпирические доказательства модели синтаксического анализа, построенной на предположениях рациональной теории памяти, предложенной Андерсоном (19).91) и встроенный в ACT-R. Было собрано два вида доказательств. Во-первых, трудности с обработкой явлений садовой дорожки соответствуют падению активации извлеченных шагов синтаксического анализа. Во-вторых, модель синтаксического анализа в сочетании с некоторыми базовыми предположениями о чтении использовалась для моделирования данных самостоятельного чтения из Корпуса естественных историй. После подгонки двух параметров полученная модель показала очень значимую корреляцию с наблюдаемым временем чтения. Модель смогла зафиксировать аспекты данных чтения, которые не были захвачены другими низкоуровневыми факторами, такими как частота строк, положение или длина слова. Мы оставляем открытым вопрос о том, какие конкретные аспекты рациональной памяти могут играть доминирующую роль в подборе модели, в частности, какие из активаций базового уровня и активации распространения были решающими в нашем открытии.
5. Сравнение с родственными работами
5.1. Анализаторы в вычислительной психолингвистике
Можно разделить вычислительные психолингвистические подходы к анализу на два типа: теории, основанные на опыте, и теории, основанные на памяти. В теориях, основанных на опыте, изучается, как прошлый опыт работы с синтаксическими структурами влияет на синтаксический анализ, чаще всего из-за ожиданий, которые читатели формируют во время обработки предложений. Популярной структурой подходов, основанных на опыте, является теория неожиданностей (Hale, 2001; Boston et al., 2008, 2011; Levy, 2008, 2011; Smith and Levy, 2013 и др.). В теориях, основанных на памяти, изучается, как узкое место памяти влияет на хранение и поиск во время обработки. Теория локальности зависимостей является примером основанного на памяти объяснения трудностей обработки (Gibson, 19).98), а также теории, изучающие эффект интеграции и отзыва информации при разборе стеков (Van Schijndel and Schuler, 2013; Shain et al. , 2016; Rasmussen and Schuler, 2018). Другой теорией, основанной на памяти, является активационный подход к разрешению зависимостей, часто реализуемый в ACT-R (см. Lewis and Vasishth, 2005; Lewis et al., 2006).
Два типа подходов имеют разные преимущества. В то время как теории, основанные на опыте, могут объяснить трудности обработки, связанные с частотой строительства и локальными неоднозначностями (феномен садовой дорожки), подходы, основанные на памяти, используются для фиксации эффектов локальности. Однако интеграция двух учетных записей в одну структуру, возможно, все еще остается открытым вопросом. В большинстве отчетов два направления исследований просто объединяются как две разные и отдельные части модели (Demberg and Keller, 2008; Boston et al., 2011; Levy et al., 2013; Van Schijndel and Schuler, 2013).
В отличие от только что упомянутых подходов текущий счет строит единый анализ трудностей обработки, обусловленных опытом и памятью. Предполагается, что обе трудности вызваны ограничениями памяти при воспроизведении, как это предсказывают системы рациональной памяти. Единственная разница заключается в том, что извлекается: трудности обработки, связанные с памятью, возникают, когда система памяти пытается вспомнить недавно созданную фразу/элемент, чтобы удовлетворить зависимость, и сталкивается с проблемами; трудности, обусловленные опытом, возникают, когда та же самая система памяти пытается вспомнить шаг синтаксического анализа и сталкивается с проблемами. Трудности первого типа хорошо изучены в вычислительной психолингвистике в целом и в области моделирования с использованием когнитивных архитектур, таких как ACT-R, в частности (см. Lewis and Vasishth, 2005; Lewis et al., 2006; Dubey et al. ., 2008; Reitter et al., 2011; Engelmann et al., 2013; Engelmann, 2016; Vogelzang et al., 2017; Brasoveanu and Dotlačil, 2020). Важно отметить, что второй тип трудностей исследовался гораздо меньше с этой точки зрения. Эту статью можно рассматривать как попытку углубить наше понимание этой темы. В этом отношении эта статья продвигает текущие анализы чтения ACT-R, в частности, Lewis and Vasishth (2005), которые не обобщают синтаксический анализ, а вместо этого полагаются только на закодированные вручную правила для избранных синтаксических конструкций. В Futrell and Levy (2017) была разработана единая структура для обоих типов трудностей обработки, которая обеспечивает анализ на вычислительном уровне (в отличие от анализа на алгоритмическом уровне, разработанном здесь) и подходит к проблеме с противоположной стороны. направление. Футрелл и Леви (2017) проводят единый анализ трудностей обработки, расширяя теорию неожиданностей дополнительным компонентом (шумовой контекст), чтобы фиксировать трудности, связанные с памятью.
В работах по когнитивной архитектуре можно обнаружить тесное сходство между этой оценкой и моделями Reitter et al. (2011) и Хейл (2014).
В отличие от Reitter et al. (2011), текущий счет не моделирует производство, а фокусируется на понимании и не изучает заполнение синтаксических правил. Кроме того, Reitter et al. (2011) разработали модель для получения качественных эффектов при прайминге, а в этой статье показано, что с помощью применения моделей ACT-R в байесовской структуре можно моделировать количественные закономерности данных. Фактически, представленный подход позволяет разработать модель, в которой профиль чтения трудностей обработки, обусловленных опытом, количественно ограничивает профиль чтения проблем обработки памяти, поскольку оба явления моделируются одинаковым образом и модулируются одним и тем же образом. свободные параметры. Это также предполагается в этой статье (например, синтаксический анализатор для Natural Stories Corpus предполагает ту же модель для поиска wh-зависимости, лексического поиска и поиска шагов синтаксического анализа). Однако подробное исследование взаимодействия разных случаев поиска в одной и той же модели выходит за рамки данной статьи. См. Дотлачил (принято) 3 для дальнейшей работы в этом направлении.
Наконец, Хейл (2014), главы 7 и 8, выводит трудности обработки, обусловленные опытом, как случай (неудачного, менее вероятного) компиляции/сплоченности продукции. Эта позиция не противоречит текущей учетной записи, а, наоборот, дополняет ее. В то время как в этой работе изучается роль декларативной памяти при разборе, Хейл (2014) фокусируется на роли процедурной памяти при разборе. Последняя позиция, вероятно, исследовалась гораздо более подробно в психолингвистике и в ACT-R, чем предыдущая позиция, начиная с основополагающих работ Льюиса (19).93) и Льюис и Васишт (2005). В этом отношении нынешнее предложение можно рассматривать как нарушение этой традиции. Однако оба типа памяти имеют решающее значение для ACT-R, а также для других когнитивных архитектур (см. Anderson, 2007), и их взаимодействие необходимо для учета сложных моделей обучения (Lebiere, 1999; Taatgen and Anderson, 2002). Вполне вероятно, что весьма нетривиальная задача, такая как построение синтаксической структуры, выиграет от исследований, которые не ограничивают ее исследование системой процедурной памяти.
5.2. Синтаксический анализ на основе переходов в вычислительной (психо)лингвистике
Анализаторы на основе переходов были популярным выбором парсеров в компьютерной лингвистике, особенно для грамматик зависимостей (см. Nivre et al., 2007; Zhang and Clark, 2008; Kübler et al., 2009). Одним из преимуществ синтаксических анализаторов на основе переходов по сравнению с синтаксическим анализом на основе графов и синтаксическим анализом на основе грамматики является то, что они являются быстрыми, инкрементальными и позволяют отображать расширенные функции (Nivre, 2004; McDonald and Nivre, 2011). Синтаксические анализаторы на основе переходов также применялись для разбора структуры фразы (Kalt, 2004; Sagae and Lavie, 2005). Недавние синтаксические анализаторы на основе нейронных переходов для построения структуры фраз имеют значение F1 около 9.5% на участке 23 ПТБ (Лю, Чжан, 2017; Китаев, Кляйн, 2018). Парсеры на основе переходов также использовались в вычислительной психолингвистике для моделирования данных ЭЭГ (рекуррентные грамматики нейронных сетей; Dyer et al., 2016; Hale et al., 2018) и данных чтения (Boston et al., 2008; Rasmussen and Schuler, 2018). 10
Хотя высокая точность современного синтаксического анализа на основе переходов обнадеживает, так как предполагает, что эта линия синтаксического анализа может в конечном итоге использоваться для создания очень точного синтаксического анализатора, мы должны отметить, что наш синтаксический анализатор это далеко не такая точность. При тестировании на участке 23 Penn Treebank синтаксический анализатор показывает точность меток как 70,2, отзыв меток как 72,4, F1 как 71,3. Когда мы ограничиваем внимание предложениями из 40 слов или менее, как это обычно бывает, точность меток составляет 73,7, а запоминаемость меток — 75,9., а F1 — 74,8. 11
Существует несколько причин низкой производительности. Во-первых, было обнаружено, что один из недостатков синтаксических анализаторов на основе переходов по сравнению с другим классом синтаксических анализаторов, управляемых данными, синтаксическими анализаторами на основе графов, заключается в том, что они ухудшаются с увеличением длины предложения и увеличением зависимости, т. е. ошибка размножение (McDonald and Nivre, 2011). Традиционные синтаксические анализаторы на основе переходов, включая синтаксический анализатор в этой статье, исследуют только один путь. Им приходится жадно выбирать, по какому пути они пойдут, и придерживаться его до конца предложения. Таким образом, ранние ошибки распространят ошибку на все предложение. Усовершенствованные синтаксические анализаторы на основе переходов смягчают этот тип ошибок с помощью поиска луча или методов восстановления после ошибок. Хотя адаптация этих методов может быть исследована для психолингвистики, нас в первую очередь интересует не максимальная точность синтаксического анализатора сложных предложений Penn Treebank, а синтаксический анализ, подобный человеческому. Известно, что человек-процессор также демонстрирует распространение ошибок при синтаксическом анализе, о чем свидетельствует тот факт, что читатели изо всех сил пытаются восстановиться из предложений садовой дорожки, чем дольше может удерживаться неправильная интерпретация (например, Frazier and Rayner, 19).82). Таким образом, априори не ясно, следует ли избегать распространения ошибок.
Другая причина, по которой мы видим низкую точность, заключается в том, что синтаксический анализатор предполагает очень прямую связь между экземплярами памяти и шагом синтаксического анализа. Шаг синтаксического анализа просто сохраняется в декларативной памяти. 12 Это отличается от сложных методов обучения, обычно применяемых в современных нейроанализаторах. Соответственно, современные вычислительные парсеры предполагают гораздо более богатую систему признаков. Они обогащены моделями векторного пространства, представляющими лексическую информацию, а синтаксическая информация обычно инкапсулируется в 200 или более признаков, в то время как наш парсер имеет 19Особенности.
В любом случае, стоит отметить, что хотя точность синтаксического анализатора не очень высока, она достаточна для исследования, представленного в этой статье. Выбранные примеры в разделе 4.2 корректно построены синтаксическим анализатором, если они не ведут к садовой дорожке, а синтаксический анализатор в разделе 4.3 исправлялся в конце каждого шага (слова) в соответствии с золотым стандартом, представленным в корпусе, гарантируя, что построенный разбор правильный.
Решение использовать простую модель признаков обусловлено тем фактом, что мы хотим сначала установить, что эта модель синтаксического анализа может быть полезна для прогнозирования времени чтения. Для этого желательно, чтобы модель была как можно более понятной и простой, в противном случае было бы неясно, связаны ли результаты, представленные в разделе 4, с моделью синтаксического анализа или с какой-то путаницей, которая нас не интересует (например, значение подобия присутствует в векторных пространствах слов). По той же причине в настоящее время мы использовали восходящий алгоритм синтаксического анализа, хотя есть веские аргументы в пользу того, что восходящий алгоритм синтаксического анализа неадекватен с когнитивной точки зрения. Существуют хорошо известные для психолингвистики проблемы восходящего синтаксического анализа: он накапливает элементы в стеке в правоветвящихся структурах, страдает от несвязности и имеет проблемы при привязке к пошаговой интерпретации (см. Resnik, 19).92; Крокер, 1999). Мы предположили восходящий алгоритм синтаксического анализа, поскольку он, возможно, является наиболее распространенным алгоритмом синтаксического анализа для синтаксических анализаторов структуры фраз на основе переходов и, таким образом, служит очень хорошей отправной точкой. Мы оставляем это на будущее, чтобы посмотреть, смогут ли другие алгоритмы синтаксического анализа, особенно синтаксические анализаторы левого угла, улучшить текущие результаты моделирования.
6. Заключение
В этой статье представлен и протестирован психолингвистический синтаксический анализатор, который был разработан с использованием идей рациональной теории памяти. Было показано, что рациональная теория памяти может быть объединена с синтаксическим анализом на основе переходов для создания анализатора, управляемого данными, который может быть встроен в когнитивную архитектуру ACT-R. Синтаксический анализатор был протестирован на предложениях садовой дорожки, и было показано, что синтаксический анализатор в значительной степени предсказывает трудности обработки в правильных точках устранения неоднозначности. Парсер также был оценен на онлайн-поведенческих данных из корпуса для самостоятельного чтения, и было показано, что парсер может быть приспособлен к данным и моделировать количественные закономерности во времени чтения.
Заявление о доступности данных
Необработанные данные, подтверждающие выводы этой статьи, доступны по адресу https://github.com/jakdot/parsing-model-and-a-rational-theory-of-memory.
Вклад авторов
JD внес свой вклад в разработку теории, кодирования и моделирования. PH способствовал кодированию и моделированию.
Финансирование
Исследование, представленное в этой статье, было поддержано грантом NWO VC.GW.17.122.
Конфликт интересов 9Активации также очень низки в начале каждого предложения, независимо от того, имеем ли мы дело с предложением садовой дорожки или нет. Это артефакт выбранной модели. Большинство сигналов для распространения активации исходят из уже построенных древовидных структур. Конечно, в начале предложения ничего или почти ничего не построено, поэтому реплик в начале мало и, следовательно, активация распространения низка. Этого свойства модели можно избежать, например, если считать не только совпадения в построенных деревьях, но и совпадения по положению в предложении как подсказки, которые могут усилить активации.
9Точность метки рассчитывается как количество правильно построенных составляющих, деленное на количество всех составляющих, предложенных синтаксическим анализатором. Отзыв метки рассчитывается как количество правильно построенных составляющих, деленное на количество всех составляющих, присутствующих в золотом стандарте. F1 — среднее гармоническое двух показателей точности. Для расчета для точности используются только нетерминальные составляющие (т. е. тривиальные составляющие, такие как 〈 a, DT 〉, игнорируются, чтобы показатели точности не завышались искусственно). 9Синтаксический анализатор можно отнести к синтаксическому анализу на основе памяти, см. Daelemans et al. (2004). Однако, в отличие от прошлых случаев синтаксического анализа на основе памяти, которые были вдохновлены структурами памяти для обеспечения наилучшей точности синтаксического анализа, управляемого данными, текущий подход основан на структурах памяти для соединения синтаксического анализа с поведенческими измерениями в режиме онлайн. Такая связь не рассматривается в подходе Daelemans et al. (2004).Ссылки
Андерсон, Дж. Р. (1974). Извлечение пропозициональной информации из долговременной памяти. Познан. Психол . 6, 451–474. doi: 10.1016/0010-0285(74)-8
CrossRef Full Text | Google Scholar
Андерсон, Дж. Р. (1990). Адаптивный характер мышления . Хиллсдейл, Нью-Джерси: Lawrence Erlbaum Associates.
Google Scholar
Андерсон, Дж. Р. (1991). Является ли человеческое познание адаптивным? Поведение. Науки о мозге . 14, 471–517. doi: 10.1017/S0140525X00070801
CrossRef Полный текст | Google Scholar
Андерсон, Дж. Р. (2007). Как человеческий разум может появиться в физической вселенной ? Нью-Йорк, штат Нью-Йорк: Издательство Оксфордского университета.
Google Scholar
Андерсон, Дж. Р., Ботелл, Д., и Бирн, М. Д. (2004). Комплексная теория разума. Психология. Версия . 111, 1036–1060. doi: 10.1037/0033-295X. 111.4.1036
CrossRef Full Text | Google Scholar
Андерсон Дж. Р. и Лебьер К. (1998). Атомные компоненты мышления . Хиллсдейл, Нью-Джерси: Lawrence Erlbaum Associates.
Google Scholar
Андерсон Дж. Р. и Редер Л. М. (1999). Эффект веера: новые результаты и новые теории. Дж. Экспл. Психол. Генерал . 128, 186–197. doi: 10.1037/0096-3445.128.2.186
Полный текст CrossRef | Google Scholar
Бевер, Т. Г. (1970). «Когнитивная основа для лингвистических структур», в Познание и развитие языка , изд. Дж. Хейс (Нью-Йорк, штат Нью-Йорк: Wiley), 279–362.
Google Scholar
Бостон, М. Ф., Хейл, Дж., Клигль, Р., Патил, У., и Васишт, С. (2008). Затраты на синтаксический анализ как предикторы трудности чтения: оценка с использованием потсдамского корпуса предложений. J. Eye Mov. Рез . 2, 1–12. doi: 10.16910/jemr.2.1.1
Полный текст CrossRef | Google Scholar
Бостон, М. Ф., Хейл, Дж. Т., Васишт, С. , и Клигл, Р. (2011). Параллельная обработка и трудности с пониманием предложений. Ланг. Познан. Процесс . 26, 301–349. doi: 10.1080/016.2010.4
CrossRef Full Text | Google Scholar
Ботелл, Д. (2017). Справочное руководство ACT-R 7 . Доступно в Интернете по адресу: http://act-r.psy.cmu.edu/actr7.x/reference-manual.pdf
Google Scholar
Брасовяну А. и Дотлачил Дж. (2018). «Расширяемая структура для моделей механистической обработки: от репрезентативных лингвистических теорий до количественного сравнения моделей», в материалах Международной конференции по когнитивному моделированию 2018 г. .
Google Scholar
Брасовяну А. и Дотлачил Дж. (2019). «Количественное сравнение генеративных теорий», в Proceedings of the Berkeley Linguistic Society 2018 44 (Беркли, Калифорния).
Google Scholar
Брасовяну А. и Дотлачил Дж. (2020). Компьютерное когнитивное моделирование и лингвистическая теория . Серия «Язык, познание и разум» (LCAM). Спрингер (открытый доступ). doi: 10.1007/978-3-030-31846-8
Полный текст CrossRef | Google Scholar
Коаву М. и Краббе Б. (2017a). «Пошаговый анализ структуры прерывистой фразы с переходом через пробел», в материалах 15-й конференции Европейского отделения Ассоциации компьютерной лингвистики: том 1, длинные статьи (Валенсия: Ассоциация компьютерной лингвистики), 1259–1270. doi: 10.18653/v1/E17-1118
Полный текст CrossRef | Google Scholar
Коаву М. и Краббе Б. (2017b). «Многоязычный лексикализованный синтаксический анализ с вспомогательными задачами на уровне слов», в материалах 15-й конференции Европейского отделения Ассоциации компьютерной лингвистики (Валенсия), 331–336. doi: 10.18653/v1/E17-2053
CrossRef Полный текст | Академия Google
Коллинз, М. (1997). «Три генеративные лексикализованные модели для статистического анализа», в материалах Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics (Мадрид), 16–23. doi: 10.3115/976909.979620
Полный текст CrossRef | Google Scholar
Краббе, Б. (2015). «Многоязычный дискриминативный анализ лексикализованной структуры фраз», в Трудах конференции 2015 г. по эмпирическим методам обработки естественного языка (Лиссабон), 1847–1856. дои: 10.18653/v1/D15-1212
Полнотекстовая перекрестная ссылка | Google Scholar
Крейн С. и Стидман М. (1985). «О том, чтобы не идти по садовой дорожке: использование контекста процессором психологического синтаксиса», в Анализ естественного языка: психологические, вычислительные и теоретические перспективы , редакторы Д. Доути, Л. Карттунен и А. Цвикки (Кембридж : Издательство Кембриджского университета), 320–358. doi: 10.1017/CBO9780511597855.011
CrossRef Полный текст | Google Scholar
Крокер, М. В. (1999). «Механизмы обработки предложений», в Language Processing , редакторы С. Гаррод и М. Пикеринг (Лондон: Psychology Press Hove), 191–232.
Google Scholar
Дэлеманс В. , Заврел Дж., Ван Дер Слоот К. и Ван ден Бош А. (2004). TiMBL: Тилбургское обучающее устройство на основе памяти . Тилбург: Тилбургский университет.
Google Scholar
Демберг В. и Келлер Ф. (2008). Данные корпусов отслеживания взгляда как свидетельство теории сложности синтаксической обработки. Познание 109, 193–210. doi: 10.1016/j.cognition.2008.07.008
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Диллон Б., Мишлер А., Слоггет С. и Филлипс К. (2013). Контрастные профили вторжения для согласия и анафоры: экспериментальные и модельные данные. Дж. Мем. Ланг . 69, 85–103. doi: 10.1016/j.jml.2013.04.003
Полный текст CrossRef | Google Scholar
Дотлачил, Дж. (2018). Создание считывателя ACT-R для корпусных данных отслеживания взгляда. Верх. Познан. Наука . 10, 144–160. doi: 10.1111/tops.12315
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Дубей, А. , Келлер, Ф., и Стерт, П. (2008). Вероятностная корпусная модель синтаксического параллелизма. Познание 109, 326–344. doi: 10.1016/j.cognition.2008.09.006
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Дайер, К., Кункоро, А., Бальестерос, М., и Смит, Н. А. (2016). «Рекуррентные грамматики нейронных сетей», в Материалы конференции 2016 г. Североамериканского отделения Ассоциации вычислительной лингвистики (Сан-Диего, Калифорния), 199–209. doi: 10.18653/v1/N16-1024
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Энгельманн Ф. (2016). На пути к интегрированной модели обработки предложений при чтении (докторская диссертация), Потсдамский университет, Потсдам, Германия.
Google Scholar
Энгельманн Ф., Ягер Л. А. и Васишт С. (2019 г.). Влияние известности и ассоциации реплик на процессы поиска: вычислительный счет. Познан. Наука . 43:e12800. doi: 10.1111/cogs.12800
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Энгельманн Ф. , Васишт С., Энгберт Р. и Клигль Р. (2013). Платформа для моделирования взаимодействия синтаксической обработки и управления движением глаз. Верх. Познан. Наука . 5, 452–474. doi: 10.1111/tops.12026
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Франке М. и Ягер Г. (2016). Вероятностная прагматика, или Почему правило Байеса, вероятно, важно для прагматики. З. Шпрахвисс . 35, 3–44. doi: 10.1515/zfs-2016-0002
Полный текст CrossRef | Google Scholar
Фрейзер, Л. (1978). О понимании предложений: стратегии синтаксического анализа (докторская диссертация), Коннектикутский университет, Сторрс, Коннектикут, США.
Google Scholar
Фрейзер Л. и Рейнер К. (1982). Совершение и исправление ошибок при понимании предложений: движения глаз при анализе структурно неоднозначных предложений. Познан. Психол . 14, 178–210. doi: 10.1016/0010-0285(82)-1
CrossRef Полный текст | Google Scholar
Futrell, R. , Gibson, E., Tily, H.J., Blank, I., Vishnevetsky, A., Piantadosi, S.T., et al. (2018). «Сборник естественных историй», в Proceedings of LREC 2018, Одиннадцатая международная конференция по языковым ресурсам и оценке (Миядзаки), 76–82.
Google Scholar
Футрелл Р. и Леви Р. (2017). «Удивление от шумового контекста как модель стоимости обработки предложений человеком», в Материалы 15-й конференции Европейского отделения Ассоциации компьютерной лингвистики: том 1, длинные документы (Валенсия), 688–698. doi: 10.18653/v1/E17-1065
Полный текст CrossRef | Google Scholar
Гибсон, Э. (1991). Вычислительная теория лингвистической обработки человека: ограничения памяти и нарушение обработки (докторская диссертация), Университет Карнеги-Меллона, Питтсбург, Пенсильвания, США.
Google Scholar
Гибсон Э. (1998). Лингвистическая сложность: локальность синтаксических зависимостей. Познание 68, 1–76. doi: 10.1016/S0010-0277(98)00034-1
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Хейл, Дж. (2001). «Вероятностный синтаксический анализатор Эрли как психолингвистическая модель», в материалах Proceedings of the 2nd Meeting of the North American Association for Computational Linguistics (Stroudsburg, PA), 159–166. doi: 10.3115/1073336.1073357
Полный текст CrossRef | Академия Google
Хейл, Дж., Дайер, К., Кункоро, А., и Бреннан, Дж. Р. (2018). «Поиск синтаксиса в энцефалографии человека с помощью поиска луча», в материалах 56-го ежегодного собрания Ассоциации вычислительной лингвистики (том 1: длинные статьи) (Мельбурн, Виктория). doi: 10.18653/v1/P18-1254
CrossRef Полный текст | Google Scholar
Хейл, Дж. Т. (2014). Автоматные теории человеческого понимания предложений . Стэнфорд, Калифорния: публикации CSLI.
Google Scholar
Харт Б. и Рисли Т. Р. (1995). Значимые различия в повседневном опыте маленьких американских детей . Балтимор, Мэриленд: Издательство Пола Х. Брукса.
Google Scholar
Ягер Л. А., Энгельманн Ф. и Васишт С. (2017). Основанное на сходстве вмешательство в понимание предложений: обзор литературы и байесовский метаанализ. Дж. Мем. Ланг . 94, 316–339. doi: 10.1016/j.jml.2017.01.004
Полный текст CrossRef | Академия Google
Ягер, Л. А., Мерцен, Д., Ван Дайк, Дж. А., и Васишт, С. (2020). Пересмотр моделей интерференции в согласовании субъекта и глагола и возвратных рефлексах: исследование с большой выборкой. Дж. Мем. Ланг . 111:104063. doi: 10.1016/j.jml.2019.104063
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Кальт, Т. (2004). «Индукция жадных контроллеров для детерминированных синтаксических анализаторов банка деревьев», в Трудах конференции 2004 г. по эмпирическим методам обработки естественного языка (Барселона).
Google Scholar
Китаев Н. и Кляйн Д. (2018). «Анализ избирательных округов с помощью кодировщика с самостоятельным вниманием», в материалах 56-го собрания Ассоциации вычислительной лингвистики (Мельбурн, Виктория). doi: 10.18653/v1/P18-1249
CrossRef Полный текст | Google Scholar
Кляйн Д. и Мэннинг К.Д. (2003). «Синтаксический анализ A*: быстрый точный анализ Витерби», в материалах Proceedings of the Human Language Technology Conference and The North American Association for Computational Linguistics (HLT-NAACL) , 119–126. doi: 10.3115/1073445.1073461
Полный текст CrossRef | Google Scholar
Кюблер С., Макдональд Р. и Нивре Дж. (2009). Анализ зависимостей . Обобщающие лекции по технологиям человеческого языка. Издательство Морган и Клейпул.
Google Scholar
Куш Д., Лидз Дж. и Филлипс К. (2015). Чувствительный к отношениям поиск: свидетельство связанных переменных местоимений. Дж. Мем. Ланг . 82, 18–40. doi: 10.1016/j.jml.2015.02.003
Полнотекстовая перекрестная ссылка | Google Scholar
Лаго С., Шалом Д. Э., Сигман М., Лау Э. Ф. и Филлипс К. (2015). Привлечение соглашения в испанском понимании. Дж. Мем. Ланг . 82, 133–149. doi: 10.1016/j.jml.2015.02.002
CrossRef Полный текст | Google Scholar
Лебьер, К. (1999). Динамика познания: модель когнитивной арифметики ACT-R. Kognitionswissenschaft 8, 5–19. doi: 10.1007/s001970050071
Полный текст CrossRef | Академия Google
Леви, Р. (2008). Синтаксическое понимание, основанное на ожиданиях. Познание 106, 1126–1177. doi: 10.1016/j.cognition.2007.05.006
CrossRef Полный текст | Google Scholar
Леви, Р. (2011). «Интеграция моделей неожиданного и неопределенного ввода в понимание онлайн-предложений: формальные методы и эмпирические результаты», в Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (Портленд, Орегон), 1055–1065.
Google Scholar
Леви Р., Федоренко Э. и Гибсон Э. (2013). Синтаксическая сложность русских относительных предложений. Дж. Мем. Ланг . 69, 461–495. doi: 10. 1016/j.jml.2012.10.005
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Льюис, Р. (1993). Теория понимания предложений человеком, основанная на архитектуре (докторская диссертация), Университет Карнеги-Меллона, Питтсбург, Пенсильвания, США.
Академия Google
Льюис, Р., и Васишт, С. (2005). Модель обработки предложений, основанная на активации, как квалифицированное извлечение памяти. Познан. Наука . 29, 1–45. doi: 10.1207/s15516709cog0000_25
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Льюис Р.Л., Васишт С. и Ван Дайк Дж.А. (2006). Вычислительные принципы рабочей памяти при понимании предложений. Познание тенденций. Наука . 10, 447–454. doi: 10.1016/j.tics.2006.08.007
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Лю, Дж., и Чжан, Ю. (2017). Разбор составляющих на основе переходов по порядку. Пер. доц. вычисл. Лингвист . 5, 413–424. doi: 10.1162/tacl_a_00070
Полный текст CrossRef | Google Scholar
Маркус, член парламента (1978). Теория синтаксического распознавания естественного языка (докторская диссертация), Массачусетский технологический институт, Кембридж, Массачусетс, США.
Google Scholar
Маркус, М. П., Марцинкевич, М. А., и Санторини, Б. (1993). Создание большого аннотированного корпуса английского языка: банк деревьев PENN. Вычисл. Лингвист . 19, 313–330. doi: 10.21236/ADA273556
Полный текст CrossRef | Google Scholar
Макдональд Р. и Нивр Дж. (2011). Анализ и интеграция парсеров зависимостей. Вычисл. Лингвист . 37, 197–230. doi: 10.1162/coli_a_00039
Полный текст CrossRef | Google Scholar
Ниценбойм, Б., Васишт, С., Энгельманн, Ф., и Суков, К. (2018). Исследовательский и подтверждающий анализ при обработке предложений: пример интерференции чисел в немецком языке. Познан. Наука . 42, 1075–1100. doi: 10. 1111/cogs.12589
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Нивр, Дж. (2004). «Инкрементальность в детерминированном синтаксическом анализе зависимостей», в материалах семинара по добавочному синтаксическому анализу: объединение инженерии и познания (Страудсбург, Пенсильвания), 50–57. doi: 10.3115/1613148.1613156
CrossRef Full Text | Google Scholar
Nivre, J., Hall, J., Nilsson, J., Chanev, A., Eryigit, G., Kübler, S., et al. (2007). Maltparser: независимая от языка система анализа зависимостей на основе данных. Нац. Ланг. Eng . 13, 95–135. doi: 10.1017/S13513244505
Полный текст CrossRef | Google Scholar
Оксфорд М. и Чейтер Н. (1994). Рациональный анализ задачи выбора как оптимального выбора данных. Психология. Версия . 101:608. doi: 10.1037/0033-295X.101.4.608
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Оксфорд, М., и Чейтер, Н. (2007). Байесовская рациональность: вероятностный подход к человеческому мышлению . Издательство Оксфордского университета.
Реферат PubMed | Google Scholar
Пиантадоси, С. Т., Тененбаум, Дж. Б., и Гудман, Н. Д. (2016). Логические примитивы мышления: эмпирические основы композиционных когнитивных моделей. Психология. Версия . 123, 392-424. doi: 10.1037/a0039980
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Притчетт Б.Л. (1992). Грамматическая грамотность и разборчивость . Чикаго, Иллинойс: Издательство Чикагского университета.
Google Scholar
Рабе, М. М., Паапе, Д., Васишт, С., и Энгберт, Р. (2021). Динамическое когнитивное моделирование синтаксической обработки и управления движением глаз при чтении. PsyArXiv . doi: 10.31234/osf.io/w89zt
Полный текст CrossRef | Google Scholar
Расмуссен, Н. Э., и Шулер, В. (2018). Анализ левого угла с распределенной ассоциативной памятью производит эффект неожиданности и локальности. Познан. Наука . 42, 1009–1042. doi: 10.1111/cogs.12511
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Рейтер Д., Келлер Ф. и Мур Дж. Д. (2011). Вычислительная когнитивная модель синтаксического прайминга. Познан. Наука . 35, 587–637. doi: 10.1111/j.1551-6709.2010.01165.x
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Резник, П. (1992). «Разбор левого угла и психологическое правдоподобие», в материалах Proceedings of the Fourteen International Conference on Computational Linguistics (Нант). doi: 10.3115/9.9
Полный текст CrossRef | Google Scholar
Рорк, Б. (2001). Вероятностный нисходящий анализ и языковое моделирование. Вычисл. Лингвист . 27, 249–276. doi: 10.1162/08
01750300526Полный текст CrossRef | Google Scholar
Сагае, К., и Лави, А. (2005). «Синтаксический анализатор на основе классификатора с линейной сложностью во время выполнения», в Proceedings of the Ninth International Workshop on Parsing Technology (Ванкувер, Британская Колумбия), 125–132. дои: 10.3115/1654494.1654507
Полнотекстовая перекрестная ссылка | Google Scholar
Шейн К., Ван Шейндел М., Футрелл Р., Гибсон Э. и Шулер В. (2016). «Доступ к памяти во время пошаговой обработки предложений приводит к задержке чтения», в Proceedings of the Workshop on Computational Linguistics for Linguistic Complexity (CL4LC) (Osaka), 49–58.
Google Scholar
Смит Г. и Васишт С. (2020). Принципиальный подход к выбору признаков в моделях обработки предложений. Познан. Наука . 44:e12918. doi: 10.1111/cogs.12918
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Смит, Нью-Джерси, и Леви, Р. (2013). Влияние предсказуемости слов на время чтения логарифмическое. Познание 128, 302–319. doi: 10.1016/j.cognition.2013.02.013
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Таатген, Н. А., и Андерсон, Дж. Р. (2002). Почему дети учатся говорить «сломан»? Модель изучения прошедшего времени без обратной связи. Познание 86, 123–155. doi: 10.1016/S0010-0277(02)00176-2
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Тененбаум Дж. Б., Кемп К., Гриффитс Т. Л. и Гудман Н. Д. (2011). Как вырастить ум: статистика, структура и абстракция. Наука 331, 1279–1285. doi: 10.1126/science.1192788
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ван Дайк, Дж. А. (2007). Эффекты помех от грамматически недоступных компонентов во время обработки предложения. Дж. Эксп. Психол. Учиться. Мем. Код . 33:407. doi: 10.1037/0278-7393.33.2.407
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ван Шейндел, М., и Шулер, В. (2013). «Анализ затрат на обработку частоты и памяти», в материалах конференции 2013 года Североамериканского отделения Ассоциации вычислительной лингвистики: технологии человеческого языка (Атланта, Джорджия), 95–105.
Google Scholar
Васишт С. , Нисенбойм Б., Энгельманн Ф. и Бурхерт Ф. (2019 г.). Вычислительные модели процессов поиска при обработке предложений. Познание тенденций. Наука . 23, 968–982. doi: 10.1016/j.tics.2019.09.003
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Виллата С., Табор В. и Франк Дж. (2018). Вмешательство в кодирование и поиск в понимании предложений: свидетельство согласия. Перед. Психол . 9:2. doi: 10.3389/fpsyg.2018.00002
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Vogelzang, M., Mills, A.C., Reitter, D., Van Rij, J., Hendriks, P., and Van Rijn, H. (2017). На пути к когнитивно ограниченным моделям обработки языка: обзор. Перед. Коммуна . 2:11. doi: 10.3389/fcomm.2017.00011
Полный текст CrossRef | Google Scholar
Уэйджерс, М. В., Лау, Э. Ф., и Филлипс, К. (2009). Привлечение соглашения в понимании: представления и процессы. Дж. Мем. Ланг . 61, 206–237. doi: 10.1016/j. jml.2009.04.002
Полнотекстовая перекрестная ссылка | Google Scholar
Уивер, Р. (2008). Параметры, прогнозы и вычислительное моделирование доказательств: статистическое представление, основанное на данных ACT-R. Познан. Наука . 32, 1349–1375. doi: 10.1080/03640210802463724
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Чжан Ю. и Кларк С. (2008). «Рассказ о двух синтаксических анализаторах: исследование и объединение синтаксического анализа зависимостей на основе графов и переходов», в Трудах конференции 2008 г. по эмпирическим методам обработки естественного языка (Гонолулу, Гавайи), 562–571. doi: 10.3115/1613715.1613784
Полный текст CrossRef | Google Scholar
Приложение A. Вычисление активации базового уровня по частотам слов/правил
Мы хотим рассчитать B i по частоте. d является свободным параметром и может быть проигнорирован в этом обсуждении.
Рассмотрим 15-летнего говорящего. Как мы можем оценить, как часто слово/шаг синтаксического анализа x использовался в языковых взаимодействиях, в которых участвовал говорящий?
Во-первых, заметим, что мы знаем относительную частоту x . Мы собираем это из Британского национального корпуса (для слов) и из корпуса Penn Treebank (для шагов синтаксического анализа).
Мы знаем продолжительность жизни говорящего (15 лет), поэтому, если мы знаем общее количество слов, которым подвергался средний 15-летний говорящий, мы можем легко подсчитать, сколько раз в среднем было использовано x на основе на частоте х. Хорошее приблизительное количество слов, с которыми сталкивается говорящий в год, можно найти у Харта и Рисли (19).95). Основываясь на записях 42 семей, Харт и Рисли подсчитали, что дети понимают от 10 до 35 миллионов слов в год, в значительной степени в зависимости от социального класса семьи, и это количество увеличивается линейно с возрастом. Согласно исследованию, 15-летний подросток прочитал от 50 до 175 миллионов слов. Для простоты модель будет работать со средним значением 112,5 миллионов слов, как общее количество слов, с которыми столкнулся 15-летний говорящий. Это консервативная оценка, поскольку она не учитывает производство и лингвистическую экспозицию, связанную со средствами массовой информации. Кроме того, мы предполагаем, что каждое слово сопровождается одним шагом синтаксического анализа, поэтому шагов синтаксического анализа столько же, сколько слов (опять же, это упрощение, которое не должно навредить моделированию).
Теперь мы знаем, как перейти от частоты к количеству использований x . Снова упрощая, мы предполагаем, что использование, t k выше, равномерно распределяется в течение срока службы.
Описанная здесь процедура была успешно использована для перевода частоты в активацию и, в конечном счете, времени реакции при построении предложений (Reitter et al., 2011), времени чтения с отслеживанием глаз (Dotlačil, 2018) и времени реакции в задачах лексического решения (Brasoveanu and Dotlačil). , 2020).
Грамматика структуры фраз
Грамматика структуры фразДалее: Компиляция программ ALE Вверх: Без названия Предыдущий: Определенные пункты
Компонент обработки структуры фразы ALE свободно основан на
на сочетании функциональных возможностей системы PATR-II и
система DCG, встроенная в Prolog. Грубо говоря, АЛЭ
предоставляет систему, подобную системе DCG, с двумя основными
различия. Первое отличие связано с тем, что ALE
использует логические описания значений атрибутов структур типизированных объектов
для представления категорий и их частей, в то время как DCG используют
члены первого порядка (или, возможно, их циклические варианты). Секунда
Основное отличие состоит в том, что ALE использует восходящую активную диаграмму.
синтаксический анализатор, а не кодировать грамматики непосредственно в виде предложений Пролога и
оценивая их сверху вниз и в глубину. В духе DCG, ALE позволяет прикреплять процедуры с определенными пунктами и
оценивается в произвольных точках структуры фразы
правило, с той разницей, что эти правила задаются определенным
предложения в системе логического программирования ALE, а не напрямую
в Прологе.
Грамматика фразовой структуры состоит из двух основных компонентов: один для для описания лексических статей и один для описания правил грамматики. Мы рассмотрим эти компоненты по очереди, после обсуждения парсинга алгоритм.
Нет необходимости полностью понимать используемый алгоритм синтаксического анализа. ALE, чтобы использовать его возможности для разработки грамматик. Но для те пользователи, которые заинтересованы в эффективности и написании грамматик с процессуальные приложения, это важная информация.
В системе ALE используется восходящий анализатор активных диаграмм, который были адаптированы к реализации грамматик значений атрибутов в Пролог. Самый важный факт, о котором следует помнить, это то, что правила оцениваются слева направо. Большая часть реализации соображения следуют из этого принципа оценки правила и его конкретная реализация на Прологе.
Диаграмма заполняется с использованием комбинации поиска в глубину и в ширину.
контроль. В частности, ребра заполняются справа налево,
хотя правила оцениваются слева направо. Более того,
синтаксический анализатор работает в ширину в том смысле, что он постепенно
перемещается по строке справа налево, по одному слову за раз,
запись всех неактивных ребер, которые могут быть созданы, начиная с
текущая левая позиция в строке. Например, в
string Ребенок вчера бегал, порядок обработки такой
следует. Сначала просматриваются лексические статьи для вчерашнего дня,
и занесены в график как неактивные ребра. За каждое неактивное ребро
который добавляется на диаграмму, правила также срабатывают в соответствии с
восходящее правило разбора диаграммы. Но никакие активные ребра не записываются.
Активные ребра — это чисто динамические структуры, существующие только локально для
использовать схемы копирования и возврата Пролога. Преимущество
разбор справа налево заключается в том, что когда активное ребро предлагается
восходящее правило, каждое неактивное ребро может потребоваться завершить
уже найдено. Настоящая причина разбора справа налево
стратегия состоит в том, чтобы позволить активным ребрам быть представленными динамически,
при этом оценивая правила слева направо. В то время как
Общая стратегия направлена снизу вверх и направлена в ширину, поскольку она шагает
постепенно через строку, заполняя все возможные неактивные
края, остальная обработка выполняется сначала в глубину, чтобы
сохраняйте как можно больше структур данных динамическими, чтобы избежать копирования
кроме того, что делается механизмом возврата Пролога. В
в частности, лексические элементы, восходящее правило и активные ребра
все оцениваются в глубину, что совершенно правильно, потому что они
все начинаются с одной и той же левой точки (перед текущим словом в
справа налево проходят через строку) и, таким образом, не взаимодействуют с
друг друга.
Правила могут включать цели с определенным пунктом до, между или после
характеристики категорий. Эти цели оцениваются, когда они
найденный. Например, если цель встречается между двумя категориями на
правая часть правила, гол оценивается после первого
категория найдена, но до второй. Цели
оценивается механизмом разрешения определенных предложений ALE, который
работает по принципу «сначала в глубину». Таким образом, следует позаботиться о том, чтобы
убедитесь, что необходимые переменные в цели созданы до цели
называется. Решение всех целей должно заканчиваться конечным
(возможно пустое) количество решений с учетом
переменные, которые создаются при их вызове.
Анализатор прекратит работу после обнаружения всех неактивных ребер. выводится из лексических статей и правил грамматики. Как вещи стенд, ALE не отслеживает дерево синтаксического анализа. Конечно, если грамматика такова, что может быть бесконечное число производных произведено, ALE не завершится. Такое бесконечное количество деривации могут проникать либо через рекурсивные унарные правила, либо через оценку целей.
Текущая версия ALE не имеет механизма обнаружения
дублирующие края. Таким образом, нет механизма предотвращения
распространение ложных неоднозначностей через синтаксический анализ. Категория С охватывающую данную подпоследовательность, называется ложной , если есть
другая категория, охватывающая ту же подпоследовательность, так что C является
подпадает под . Необходимо записывать только самую общую категорию
для обеспечения добротности. Кроме того, может быть дело в том, что
избыточность в том смысле, что есть два производных одного и того же
категория. ALE также не может обнаружить эту ситуацию. Этот
использовалась стратегия, а не стандартная, которая проверяет
включение при добавлении ребра, потому что было сочтено, что большинство
грамматики не имеют ложной двусмысленности. Наиболее унифицированный
грамматики включают некоторое понятие тематической или функциональной структуры
представляющий смысл предложения. В этих случаях большинство
структурные неоднозначности приводят к семантическим неоднозначностям. Таким образом, это было бы
на самом деле замедлить алгоритм, чтобы постоянно проверять условие
что никогда не происходит. Будущие версии ALE должны позволять пользователю
установить флаг, определяющий наличие ложной двусмысленности и
избыточность захватывается во время синтаксического анализа.
Лексические записи в ALE указаны как перезаписываемые. правила, заданные следующим синтаксисом BNF:
Например, в лексиконе категориальной грамматики в приложении предоставляется следующая лексическая запись вместе с соответствующими макросами:::= ---> .
Джон --->
@pn(j).
pn(имя) макрос
synsem: @ np (имя),
@ квантификатор_бесплатно.
np(инд) макрос
син: нп,
сем: инд.
макрос quantifier_free
qstore:[].
г.
Если читать декларативно, это правило говорит о том, что слово john имеет
лексическая категория наиболее общего удовлетворения описания
@pn(j), что равно: кот
СИНСЕМ базовый
SYN нп
СЭМ j
Электронный_список QSTORE
Обратите внимание, что эта лексическая запись эквивалентна той, что дана без
макросы от: Джон --->
synsem:(syn:np,
сем: к),
qstore:электронный_список.
Макросы полезны как метод организации лексической информации для
держите его согласованным во всех лексических статьях. Лексическая статья для
слово бежит это:запусков ---> @ iv((run,runner:Ind),Ind).В этой записи используются вложенные макросы, а также совместное использование структуры. расширяется до категории:
кот
SYNSEM назад
Синтез ARG
SYN нп
SEM [0] sem_obj
RES SYN s
SEM запустить
БЕГУН [0]
Электронный_список QSTORE
Это также иллюстрирует, как параметры макроса на самом деле обрабатываются как
переменные.Для каждого слова может быть предоставлено несколько лексических статей. Дизъюнкции также может использоваться в лексических статьях. Таким образом, первые три лексических записи, вместе взятые, идентичны четвертому:
банк --->
синоним: существительное,
sem: берег_ реки.
банк --->
синоним: существительное,
sem:money_bank.
банк --->
син: глагол,
sem:roll_plane.
банк --->
(син. : существительное,
сэм:( берег реки
; money_bank
)
; син: глагол,
sem: roll_plane
).
г.
Обратите внимание, что эта последняя запись использует стандартные соглашения о макете Пролога.
помещать каждое конъюнктивное и дизъюнктивное на отдельной строке с запятыми в
конец строк, а дизъюнкции отмечены вертикально выровненными
скобки в начале строк.Компилятор находит все самые общие удовлетворяющие лексические элементы. во время компиляции, сообщая о тех лексических элементах, которые неудовлетворительные описания. В приведенном выше случае с банком второй комбинированный метод немного быстрее во время компиляции, но их производительность во время выполнения идентична. Причина этого в том, что оба записи имеют один и тот же набор наиболее общих удовлетворяющих факторов.
ALE поддерживает построение больших словарей, так как опирается на
Механизм хэширования Пролога для фактического поиска лексической записи для
слово во время разбора снизу вверх. Также можно использовать ограничения на типы
применять условия к лексическим представлениям, что позволяет
факторизация информации.
ALE позволяет пользователю указывать определенные категории как встречающиеся. без соответствующей поверхностной струны. К ним обычно относят несколько вводит в заблуждение, поскольку пустых категорий , или иногда как пустых производств . В ALE они поддерживаются специальным объявление формы :
пусто <описание>.Где
Например, обычная трактовка голых множественных чисел состоит в том, чтобы выдвинуть гипотезу о пустой определитель. Например, рассмотрим контраст между предложения дети перевернули мои мусорные баки и ребенок перевернул мои мусорные баки . В предыдущем предложении, имеющем множественное число предмет, нет соответствующего определителя. В нашей категории грамматики, мы могли бы предположить пустой определитель со следующим лексическая запись (представлена здесь с развернутыми макросами):
пусто @ где(некоторые).Конечно, следует отметить, что эта запись не соответствует система типов категориальной грамматики в приложении, так как она предполагает функция числа на существительных и именных словосочетаниях.
Пустые категории дороги для вычисления при анализе снизу вверх
схема такая, как используется в ALE. Причина этого в том, что
эти категории должны быть вставлены в каждую позицию в диаграмме
во время синтаксического анализа (с одинаковыми начальной и конечной точками). Если пустой
категории вызывают локальную структурную неоднозначность, синтаксический анализ будет замедлен
соответственно, когда эти структуры рассчитываются, а затем
распространяется. Рассмотрим пустой определитель, приведенный выше. Так и будет
создать неактивное ребро в каждом узле диаграммы, а затем сопоставить
перенаправить схему правила приложения и искать каждое ребро справа от него
ищет номинальное дополнение. Потому что относительно немного
существительные в предложении, не так много именных словосочетаний будет создано этим
правило, и поэтому не так много структурных неоднозначностей будет распространяться. Но в
такое предложение как детям нравятся игрушки , будет край
охватывающий детей, таких как игрушки , соответствующие пустому определителю
анализ детей . Соответствующая именная группа создана
охватывающий игрушек не будет распространяться дальше, так как нет возможности
чтобы объединить именное словосочетание с определителем . Но сейчас
рассмотрите пустые категории косой черты формы в GPSG.
Эти категории в сочетании с правилами передачи косой черты
примерно удвоенное время синтаксического анализа, даже для предложений, которые можно проанализировать
без таких категорий. Причина в том, что эти пустые
категории сильно недоопределены и, таким образом, имеют много вариантов для
комбинации. Таким образом, пустые категории следует использовать с осторожностью.
предпочтительно в средах, где их эффекты не будут распространяться.
Еще одно предостережение касается пустых категорий: они может встречаться в конструкциях с другими пустыми категориями. Например, если мы укажем категории и как пустые категории, и есть правило, позволяющее построить C из a и a , то C также будет пустой категорией. Эти комбинации пустых категорий вычисляются во время выполнения и могут быть бремя обработки, если они применяются слишком продуктивно. Имейте в виду, что ALE вычисляет все неактивные ребра, которые могут быть получены из заданная входная строка, поэтому нет возможности устранить дополнительную работу производится пустыми категориями, взаимодействующими с другими категориями, в том числе пустые.
Существует существенное ограничение на использование пустых категорий в
АЛЭ. Несмотря на то, что пустые категории копируются в диаграмму, если
правило включает более одного экземпляра пустой категории, охватывающей
ту же часть диаграммы, работа не гарантируется. За
Например, если категории a и b объявлены
пусто, и есть такое грамматическое правило, как c —> a, b, то
не гарантируется, что c будет построено. С другой
стороны, если правило c —> a, d, b, и если d не пусто,
тогда правило будет работать нормально; это только использование двух
смежные пустые категории в правиле, вызывающем проблемы. Этот
проблема может быть решена во время компиляции, но потребует
значительная переработка как лексического процессора, так и синтаксического анализатора.
Лексические правила обеспечивают механизм для выражения избыточности в
лексика, например виды флективной морфологии, используемые для слова
классы, словообразовательная морфология с суффиксами и префиксами,
а также нулевые производные, обнаруженные при детранзитивизации,
номинализация некоторых разновидностей и так далее. Формат ALE
обеспечивает изложение лексических правил, сходных с теми, которые встречаются в обоих
PATR-II и HPSG.
Для их эффективной реализации лексические правила, а также их влияние на лексические статьи компилируются почти так же, как грамматики. Чтобы усилить свою силу, лексические правила, как и правила грамматики, разрешить произвольное процедурное присоединение с определенным ALE ограничения.
Система лексических правил ALE продуктивна тем, что позволяет
лексические правила, применяемые последовательно к их собственному выходу или выходу
других лексических правил. Таким образом, можно получить номинал runner от глагола run , а затем получить множественное число
номинальные бегунов из бегунов и так далее. В то же время,
лексическая система привязана к фиксированной границе глубины, которая может быть
указанный пользователем. Эта граница ограничивает количество правил, которые могут
применяться к любой данной категории. Граница применения правил
определяется командой, такой как следующая, которая должна появиться
строка изначально где-то во входном файле :
:-lex_rule_depth(2).Конечно, можно использовать границы, отличные от 2. Граница указывает сколько применений лексических правил может быть сделано, и может быть 0. Если во входном файле имеется более одной такой спецификации, последний будет тот, который используется.
Формат лексических правил следующий :
г.::= lex_rule морфы <морфы>. ::= <описание> **> <описание> | <описание> **> <описание> если <цель> <морфы> ::= <морф> | <морф>, <морф> ::= ( ) становится ( ) | ( ) становится ( ) когда <пролог_цель> ::= | <атомный_строковый_шаблон>, <строковый_шаблон> <атомная_строка_шаблон> ::= <атом> | <вар> | <список( )> ::= | <вар>
Пример лексического правила почти со всеми наворотами
(процессуальное прикрепление пока откладываем) это: множественное_n lex_rule
(п,
число: петь)
**> (п,
число: плюс)
морфы
гусь становится гусями,
[k,e,y] становится [k,e,y,s],
(X, человек) становится (X, мужчины),
(X, F) становится (X, F, es), когда фрикативный (F),
(X,ey) становится (X,[i,e,s]),
X становится (X,s).
фрикативный ([s]).
фрикативный ([c, h]).
фрикативный ([s, h]).
фрикативный ([x]).
Мы будем использовать это лексическое правило, чтобы объяснить поведение лексического
система правил. Во-первых, обратите внимание, что имя лексического правила в данном случае
multiple_n, в общем случае должен быть атомом Пролога. Обратите внимание, что
круглые скобки верхнего уровня вокруг описаний и
узоры нужны. Если цель Пролога, в этом случае
фрикативный (F) был сложной целью, то его нужно было бы
также в скобках. Следующее, что следует отметить о лексическом правиле
состоит в том, что есть два описания — первое описывает ввод
категории к правилу, а второй описывает выходную категорию. Это произвольные описания, и они могут содержать дизъюнкции,
макросы и т. д. Мы вернемся к предложениям для фрикативных/1
вскоре. Обратите внимание, что закономерности в морфологическом компоненте
построенный из переменных, последовательностей и списков. Таким образом, простая переписка
можно указать либо с помощью атомов, как с гусем выше, либо с помощью
список, как в [k,e,y], или с последовательностью, как в (X,man), или
с обоими, как в (X,[i,e,s]). Синтаксис морфологического
операции таковы, что в последовательностях атомы могут использоваться как сокращение
для списков персонажей. Но списки должны состоять из переменных или
только отдельные символы. Таким образом, мы не могли бы использовать (X,[F]) в
фрикативный падеж, поскольку F сама по себе является сложным списком, таким как
[с, ч] или [х]. Но в целом переменные в пределах
отдельные символы могут отображаться в списках. Основная операция лексического правила довольно проста. Во-первых, каждый
лексическая запись, включающая слово и категорию, которая создается
во время компиляции проверяется, удовлетворяет ли его категория
входное описание лексического правила. Если это так, то новая категория
генерируется для удовлетворения выходного описания лексического правила, если
возможный. Обратите внимание, что может быть несколько решений, и все
решения рассматриваются и генерируются. Таким образом, несколько решений для
входные или выходные описания приводят к множеству лексических статей.
После того, как входные и выходные категории были вычислены, слово входная лексическая статья подается через морфологический анализатор на создать соответствующее выходное слово. В отличие от категориального компонента лексических правил будет построено только одно выходное слово, основанное на первый совпавший шаблон ввода/вывода.
Входное слово сопоставляется с шаблонами в левой части
морфологических произведений. Когда обнаруживается, что вход
совпадения слов, любое условие, налагаемое предложением when на
производство оценивается. Этот порядок наложен так, что Пролог
У цели будут созданы экземпляры всех переменных для входной строки.
В этот момент вызывается Пролог для оценки предложения when. В самом ограниченном случае, как показано в приведенном выше лексическом правиле,
Пролог используется только для предоставления сокращений для классов. Таким образом
определение фрикатива/1 состоит только из единичных предложений. За
тем, кто не знаком с Прологом, эта стратегия может быть использована в целом для
простые морфологические сокращения. Оценка этих целей требует
F во входном шаблоне, чтобы соответствовать одной из заданных строк.
Сокращение использования атомов только для списков их символов
работает в пределах морфологических последовательностей. В частности,
Цели пролога не наследуют автоматически способность лексического
система использовать атомы в качестве аббревиатуры для списков, поэтому они должны быть
приведены в списках. Заменив фрикативный звук (ш) на
фрикативный ([s, h]) не дал бы предполагаемой интерпретации.
Переменные последовательностей в морфологических произведениях всегда будут
инстанцированы в списки, даже если они представляют собой одиночные символы. За
Например, рассмотрим приведенное выше лексическое правило с каждым выписанным атомом
как явный список:
[g,o,o,s,e] становится [g,e,e,s,e],
[k,e,y] становится [k,e,y,s],
(X,[m,a,n]) становится (X,[m,e,n]),
(X,F) становится (X,F,[e,s]), когда фрикативный (F),
(X,[e,y]) становится (X,[i,e,s]),
X становится (X,[s]).
В этом примере s в окончательной продукции задается как
список, хотя это всего лишь один символ. Морфологические продукты рассматриваются по одному, пока не
совпадает. Этот порядок допускает форму дополнения, посредством чего
специальные формы, например, для неправильного множественного числа слова гусь
и ключ, который должен быть указан явно. Это также позволяет
субрегулярности, такие как правило для фрикативов выше, чтобы переопределить
более общие правила. Таким образом, входное слово пляж становится
пляжи, потому что пляж соответствует (X,F) с X =
[b,e,a] и F = [c,h], цель фрикативный ([c,h]) преуспевает
и слово пляжи соответствует шаблону вывода
(X, F, [e, s]), созданный после сопоставления ввода с
([b,e,a],[c,h],[e,s]). Точно так же слова, оканчивающиеся на [e, y], имеют
эта последовательность заменена на [i,e,s] во множественном числе, поэтому
неправильная форма требуется для ключей, которые в противном случае соответствовали бы
этот узор. Наконец, последнее правило соответствует любому входу, потому что оно
просто переменная, и вывод, который она производит, просто суффиксирует
[с] на вход.
Для лексических правил без морфологического эффекта продукция:
X становится Xдостаточно. Для того, чтобы лексические операции могли быть изложены полностью в пределах Пролог, можно использовать правило, подобное следующему:
X становится Y, когда morph_plural(X,Y)В этом случае при вызове morph_plural(X,Y) X будет инстанцируется в список символов на входе, и как результат вызова, Y должен быть реализован в основном списке вывод символов.
Наконец, обратимся к случаю лексических правил с процедурными вложения, как в следующем (упрощенном) примере из HPSG:
извлечение lex_rule
местный:(кошка:(голова:H,
подкатегория: Xs),
продолжение: С),
нелокальный:(to_bind:Bs,
унаследовано: есть)
**> местный:(кошка:(голова:H,
подкатегория:Xs2),
продолжение: С),
нелокальный:(to_bind:Bs,
унаследовано: [G|Is])
если
выбрать(G,Xs,Xs2)
морфы
Х становится Х.
выберите (X, (hd: X), Xs), если это правда.
выберите(X,[Y|Xs],[Y|Ys]), если
выберите (X, Xs, Ys).
Этот пример иллюстрирует важный момент, помимо использования
условия на категории в лексических правилах. Дело в том, что даже
хотя только LOCAL CAT SUBCAT и NONLOCAL IHERITED
пути затронуты, информация, которая остается неизменной, также должна быть
упомянул. Например, если бы спецификация cont:C была
опущены либо во входном описании нашей выходной категории, либо в
выходная категория правила будет иметь полностью неограниченный
ценность содержания. Это отличается от стандартного характера обычного
представление лексических правил, которое предполагает всю информацию, которая
не был явно указан, разделяется между входом и
выход. В качестве другого примера мы также должны указать, что HEAD
и функции TO_BIND должны быть скопированы из входа в
выход; иначе не было бы их спецификации в
вывод правила. Этот факт следует из описания
применение лексических правил: они сопоставляют данную категорию с
введите описание и создайте наиболее общее соответствие категории (категорий)
выходное описание.Возвращаясь к использованию условий в приведенном выше правиле, select/3 предикат определен так, что он выбирает свой первый аргумент в виде списка член своего второго аргумента, возвращая третий аргумент как второй аргумент с удаленным выбранным элементом. По сути, вышеуказанное лексическое правило создает новую лексическую запись, похожую на оригинальная запись, за исключением того факта, что один из элементов на список подкатегорий ввода удаляется из списка подкатегорий и добавляется в унаследованное значение на выходе. Больше ничего не меняется.
Процедурно определенное предложение вызывается после лексического правила.
сопоставило описание ввода с категорией ввода. Нравиться
морфологической системы данное управляющее решение было принято для обеспечения
что соответствующие переменные создаются в момент выполнения условия
разрешено. Условием здесь может быть произвольная цель, но если она
сложный, все должно быть в скобках. Порезы
не следует употреблять в условиях на лексические правила (см. комментарии к
сокращений в правилах грамматики ниже, которые также применяются к сокращениям в лексических
правила).
В настоящее время ALE не проверяет наличие избыточности или записей. которые включают друг друга либо в базовом лексиконе, либо после закрытия по лексическим правилам. ALE не применяет лексические правила к пустым категории.
Грамматические правила в ALE представляют собой разновидность структуры фразы, с аннотации как для целей, которые необходимо решить, так и для описания значений атрибутов категорий. Синтаксис БНФ для правила следующие :
<правило> ::= <правило_имя> правило <описание> ===> <правило_тело>.
<тело_правила> ::= <пункт_правила>
| <пункт_правила>, <тело_правила>
::= cat>
| кошки> <описание>
| цель> <цель>
г. Дальше
ограничение на правила, не выраженное в синтаксисе BNF
выше, заключается в том, что должен быть хотя бы один пункт правила поиска категории
в каждом своде правил.Таким образом, пустые производства не допускаются и будут помечены как ошибки во время компиляции.
Простой пример такого правила без каких-либо целей выглядит следующим образом:
правило s_np_vp
(син.: с,
sem:(VPSem,
агент: NPSem))
===>
кошка>
(син.: нп,
агр: агр,
сем: NPSem),
кошка>
(син: вп,
агр: агр,
сем:VPSem).
Есть несколько вещей, на которые следует обратить внимание в отношении этого правила. Во-первых, это
скобки вокруг категории и описания матери
необходимый. Глядя на то, что означает правило, оно допускает комбинацию
категории np с категорией типа vp, если они имеют
совместимые (унифицируемые) значения для агр. Затем он занимает
семантика результата должна быть семантикой глагольной фразы, с
дополнительная информация о том, что семантика именной группы заполняет
роль агента.Несмотря на то, что синтаксический анализ происходит справа налево, правила оцениваются слева направо, так что описания дочери категории оцениваются в том порядке, в котором они указаны. Это важно при рассмотрении целей, которые могут чередоваться с поиском в диаграмме согласованных дочерних категорий.
В отличие от правил PATR-II, но похожих на правила DCG, «объединения» определяются переменным совпадением, а не уравнениями пути, в то время как значения пути указываются с использованием двоеточия, а не чем с помощью уравнения пути второго типа. Правило выше похоже на правило PATR-II, которое будет выглядеть примерно следующим образом:
x0 ---> x1, x2, если
(x0 syn) == s,
(x1 син) == np,
(х2 син) == вп,
(x0 сем) == (x2 сем),
(агент x0 sem) == (x1 sem),
(x1 посев) == (x2 посев)
В отличие от лексических статей, правила не распространяются на структуры признаков.
во время компиляции. Скорее, они скомпилированы в
операции копирования структуры, включающие поиск в таблице функций и
символы типа, операции унификации для переменных, последовательность для
конъюнкцию и создание точки выбора для дизъюнкции. В этом случае
символов функций и типов выполняется двойное хеширование для типа
добавляемой структуры, а также функции или
добавляемый тип. Дополнительные операции возникают из-за приведения типов
которые требуют добавления функций или типов. Таким образом, нет ничего подобного
дизъюнктивное преобразование правил в нормальную форму во время компиляции, так как
для лексических статей. В частности, при наличии местного
дизъюнкции в правиле, оно будет оцениваться локально во время выполнения. За
Например, рассмотрим следующее правило, которое является локальной частью
Схема HPSG 1:
схема 1 правило
(кот:(голова:голова,
подкатегория: []),
продолжение:продолжение)
===>
кошка>
(тема,
кошка: голова:( субст
; спецификация: HeadLoc,
))
кошка>
(ХедЛок,
кошка:(голова:голова,
подкатегория:[Subj]),
продолжение: продолжение).
Обратите внимание, что существует дизъюнкция в значении cat:head для
первая дочерняя категория (субъект в данном случае). Это дизъюнкция
представляет собой тот факт, что основная стоимость является либо существенной
категория (один из типов subst) или имеет значение спецификатора, которое
делится со всей второй дочерью. Но выбор между
дизъюнкции в первой дочери этого правила производятся локально, когда
дочерняя категория полностью известна и, таким образом, не создает ненужных
экземпляры правил. Оператор Cats> используется для распознавания списка
дочери, длина которых не может быть определена до времени выполнения.
Дочери, признанные частью спецификации котов>, не являются
признали так быстро, в результате. Обратите внимание также на интерпретацию
коты> требует, чтобы его аргумент относился к типу
список, который должен быть определен вместе с ne_list,
e_list и т. д., а также функции HD и TL, которые мы
определено выше. Эта проверка не производится с помощью унификации, поэтому
Аргумент недоопределенного списка также не будет работать. Если аргумент
коты> не включены в список, то правило, в котором
аргумент никогда не будет соответствовать какому-либо входу, и возникнет ошибка времени выполнения. сообщение будет передано. Этот оператор полезен для так называемых «плоских»
правила, такие как Схема 2 HPSG, часть которой дается (в
упрощенная форма) ниже:
правило схема2
(кот:(голова:голова,
подкат:[Subj]))
===>
кошка>
(кот:(голова:голова,
подкатегория:[Тема|Композиции])),
коты> Комп.
Поскольку различные лексические единицы имеют списки SUBCAT различных
длины, напр. ноль для имен собственных, один для непереходных глаголов, два
для переходных глаголов, кошки> требуется, чтобы соответствовать
фактический список дополнений во время выполнения.Обычно требуется, чтобы цель производила результат для аргумент кошек>. Если это сделано, цель должна быть помещена перед кошками>. Наше использование кошек> проблематично в том, что мы требуем аргумента котов> для оценки списка фиксированных длина. Таким образом, следующая окончательная версия схемы HPSG 2 не сработает:
правило схема2
(кот:(голова:голова,
подкатегория:[SubjSyn]))
===>
коты> Компы,
кошка>
(кот:(голова:голова,
подкатегория:[Subj|Comps])).
Один из способов обойти это — указать некоторую конечную верхнюю границу для
размер списка Comps с помощью ограничения.... цель> three_or_less(Comps), ... three_or_less([]) если правда. three_or_less([_]), если это правда. three_or_less([_,_]), если это правда. three_or_less([_,_,_]), если это правда.Проблема с этой стратегией с точки зрения эффективности заключается в том, что произвольные последовательности трех категорий будут проверяться в каждой точке в грамматике; в английском случае поиском руководит типы, созданные в Comps, а также длина этого списка. Из с теоретической точки зрения, невозможно получить действительно неограниченное аргументы длины таким образом.
Общая трактовка ALE дизъюнкции в описаниях, которая
расширение логики значения атрибута Каспера и Раунда (1986) для
правила структуры фразы, является значительным улучшением по сравнению с такой системой, как
PATR-II, который не допускал бы дизъюнкции в правиле, таким образом
заставляя пользователя выписывать полные варианты правил, которые только
различаются локально. Дизъюнкции в правилах действительно создают локальные точки выбора,
хотя, даже если первая цель в дизъюнкции та, которая
разрешимый.
Это связано с тем, что в общем случае обе части дизъюнкции могут быть согласуются с заданной категорией и приводят к двум решениям. Или один disjunct может быть отброшен как несовместимый только тогда, когда его переменные далее конкретизируется в другом месте правила.
Наконец, следует сохранить иметь в виду, что описание материнской категории оценивается для большинства общие удовлетворители только после категорий и целей в теле правило было решено.
Более сложное правило, взятое из категориальной грамматики в приложение, и предполагающее нетривиальную цель, заключается в следующем:
правило обратного_приложения
(син.: Z,
qstore:Qs)
===>
кошка>
(синем: Y,
qstore:Qs1),
кошка>
(синоним: (назад,
аргумент: Y,
разрешение: Z),
qstore:Qs2),
цель>
добавить (Qs1, Qs2, Qs).
г.
Обратите внимание, что цель в этом правиле расположена после двух категорий
описания. Следовательно, он будет оцениваться после категорий
соответствие описаниям уже найдено, что обеспечивает
В этом случае создаются экземпляры переменных Qs1 и Qs2.
Затем цель append(Qs1,Qs2,Qs) оценивается ALE.
механизм разрешения определенных оговорок. Все возможные решения проблемы
цель находятся с результирующими экземплярами, переносимыми в
правило. Эти решения находятся с помощью встроенного поиска в глубину.
в распознаватель определенных ограничений ALE. В целом цели могут
чередоваться со спецификациями категории, предоставляя пользователю
контроль за моментом выстрела по воротам. Также обратите внимание, что цели могут быть
произвольный цели без сокращений ALE с определенным пунктом, и, таким образом, может
включают дизъюнкции, союзы и отрицания. Возможны порезы,
однако в коде любого литерального предложения, указанного в
процессуальное присоединение. Сами насадки должны быть без надрезов, чтобы
избегайте того, чтобы сокращение имело приоритет над всем правилом после
компиляции, тем самым предотвращая применение правила к другим ребрам в
диаграмме или для применения более поздних правил. Вместо этого, если желательны сокращения в
правил, они должны быть заключены во вспомогательный предикат, который
ограничивать объем разреза. Например, в контексте
правило структуры фразы, а не цель формы: голов>
(а, !, б)
необходимо закодировать это следующим образом: голов>
с
где предикат c определяется следующим образом: с, если
(а, !, б).
Это предотвращает откат через прорезь в воротах, но не
заблокировать дальнейшее применение правила. Подобная стратегия должна
использоваться для сокращений в лексических правилах.В качестве стратегии программирования правила должны быть сформулированы подобно Прологу. пункты, чтобы они вышли из строя как можно раньше. Таким образом, особенности которые различают, применимо ли правило, должны встречаться первыми в описания категорий. Единственная работа, связанная с проверкой того, правило применимо до той точки, где оно терпит неудачу.
Как и в случае с PATR-II, ALE является RE-полным. (эквивалентно Тьюринг-эквивалентному), что означает, что любой вычислимый
язык можно закодировать. Таким образом, можно представить неразрешимое
грамматики, даже не прибегая к процессуальной привязке
возможно с произвольными целями определенного предложения. С его смесью
стратегии оценки в глубину и в ширину, ALE не
строго полным в отношении предполагаемой семантики, если
с помощью грамматики может быть сгенерировано бесконечное количество ребер. Этот
ситуация похожа на ту, что в Прологе, где декларативно
безупречная программа может зависнуть в работе.
Далее: Компиляция программ ALE Вверх: Без названия Предыдущий: Определенные пункты
Боб Карпентер
Ср, 26 июля, 14:25:05 по восточному поясному времени 1995
Познакомьтесь с передовым алгоритмом анализа контента MotionPoint для перевода веб-сайтов
Каждый поставщик услуг по переводу веб-сайтов использует алгоритмы анализа контента для подготовки онлайн-контента к переводу. Некоторые лучше, чем другие. Технология MotionPoint лидирует в отрасли.
Что такое алгоритм синтаксического анализа?
Для тех, кто не знаком с анализом контента, поставщики переводов веб-сайтов используют поисковые роботы веб-сайтов, запрограммированные для обнаружения текста и других медиафайлов, чтобы определить объем переводимого контента веб-сайта.
Их алгоритмы синтаксического анализа затем отделяют переводимый текст от кода и определяют, как разделить этот контент на легко переводимые текстовые блоки, называемые сегментами . Сегментами могут быть фразы, предложения или целые абзацы. Затем эти сегменты переводятся либо программным обеспечением, либо лингвистами.
Алгоритм MotionPoint отличается от конкурентов не тем, что он делает, , а тем, как он это делает — и тем, как он генерирует высококачественные сегменты для перевода.
Интеллектуальный синтаксический анализ экономит деньги наших клиентов
Гибкость нашего алгоритма и наша способность детально настраивать объем проектов перевода веб-сайтов экономят деньги наших клиентов.
Мы можем настроить объем вашего проекта следующим образом:
- Лучшее соответствие потребностям вашего бизнеса
- Оптимизация требуемого уровня перевода
- Получите максимальную отдачу от ограниченного бюджета на перевод
Например, MotionPoint может блокировать определенные сегменты, чтобы предотвратить перевод страниц или разделов веб-сайта, которые не являются критически важными. Разделы с менее важным содержанием также могут быть помечены для недорогого машинного перевода.
Кроме того, MotionPoint всегда оптимизирует синтаксический анализ для увеличения числа повторений сегментов, что дополнительно снижает затраты на перевод. Типичным примером являются описания продуктов, которые следуют шаблону. Этот контент часто отображается в виде предложений или заголовков с предсказуемой структурой на нескольких страницах, таких как тип продукта, размер продукта или цвет продукта.
Компания MotionPoint всегда оптимизирует синтаксический анализ для увеличения повторения сегментов , , что дополнительно снижает затраты на перевод.
Другие поставщики рассматривают каждую вариацию этих фраз как уникальные сегменты, требующие перевода. Это увеличивает стоимость перевода до небес. MotionPoint по-разному относится к этому контенту.
Наш синтаксический анализ можно настроить для распознавания этих шаблонов и поручить нашим лингвистам заранее перевести эту шаблонную структуру и все ее содержимое (например, все варианты цветов продукта, хранящиеся в вашей базе данных продуктов). Затем мы приказываем нашей технологии обнаружения контента постоянно игнорировать эти «шаблонные» фразы, поскольку они уже переведены.
Повторяющиеся структуры также часто встречаются в метаописаниях. В этих случаях эти структуры являются дословными повторениями, с той лишь разницей, что используются двойные кавычки по сравнению с одинарными кавычками, а также наличие HTML в мета-описании. Интеллектуальная технология MotionPoint знает, что это точно такой же контент, и стандартизирует алгоритм для оптимизации захвата практически идентичного текста для перевода.
Это гарантирует, что эти сегменты больше никогда не будут идентифицированы для перевода, что снижает затраты на перевод. Переведенные мета-описания обеспечивают дополнительное SEO-преимущество.
Способность MotionPoint оптимизировать свой алгоритм для динамического контента является еще одним ключевым отличием.
Оптимизация алгоритма для динамического контента — еще одно отличие технологии MotionPoint. Большинство веб-сайтов используют динамически загружаемый персонализированный контент, например, приветственные сообщения, приветствующие пользователей по имени, или контент, основанный на местоположении пользователя. Такой персонализированный опыт удобен для клиентов, но создает проблемы для поставщиков переводов. Переводимые строки этого динамически генерируемого контента скрываются в коде приложений или базах данных, что сбивает с толку большинство поставщиков.
Чтобы компенсировать этот недостаток опыта, поставщики взимают плату со своих клиентов за перевод динамически загружаемого перевода фразы каждый раз, когда создается этот сегмент. Это увеличивает расходы.
Компания MotionPoint взимает плату только один раз за перевод контента, независимо от того, сколько раз он использовался онлайн или за его пределами. Вы можете продолжать предоставлять персонализированные онлайн-услуги своим клиентам по всему миру, не беспокоясь о стремительном росте затрат на перевод.
Вывод
Все поставщики переводов веб-сайтов используют тот или иной алгоритм анализа содержимого, но не все созданы одинаковыми. Готовое решение MotionPoint создано с целью снижения эксплуатационных расходов и сложности локализации веб-сайта.
В то время как другие поставщики пытаются максимизировать затраты на перевод, наше решение и наша технология анализа контента призваны обеспечить эффективность и экономию средств, чтобы вы могли добиться успеха на мировых рынках и расширить свое присутствие еще больше.
Последнее обновление: 05 декабря 2017 г.
Учебник № 15: Синтаксический анализ I контекстно-свободных грамматик и алгоритм CYK
Введение
В настоящее время доминирующей парадигмой обработки естественного языка является создание огромных языковых моделей на основе архитектуры преобразователя. Такие модели, как GPT3, содержат миллиарды параметров, которые в совокупности описывают совместную статистику фрагментов текста и оказались чрезвычайно успешными в широком диапазоне задач.
Однако эти модели явно не используют преимущества структуры языка; Носители языка понимают, что предложение синтаксически верно, даже если оно бессмысленно. Подумайте о том, как бесцветные зеленые идеи сон яростно похож на правильный английский язык, тогда как яростно спящие идеи зеленый бесцветный не 1 . Формально эта структура описывается грамматикой , которая представляет собой набор правил, способных генерировать бесконечное количество предложений, каждое из которых звучит правильно, даже если ничего не значит.
В этом блоге мы рассмотрим более раннюю работу по моделированию грамматической структуры. Мы представляем алгоритм CYK, который находит лежащую в основе синтаксическую структуру предложений и формирует основу многих алгоритмов лингвистического анализа. Алгоритмы элегантны и интересны сами по себе. Однако мы также считаем, что эта тема остается актуальной и в эпоху больших трансформаторов. Мы предполагаем, что будущее НЛП будет заключаться в объединении гибких преобразователей с лингвистически информированными алгоритмами для достижения систематического и композиционного обобщения при обработке языка.
Наше обсуждение будет сосредоточено на контекстно-свободных грамматиках или CFG . Они обеспечивают математически точную структуру, в которой предложения строятся путем рекурсивного объединения более мелких фраз, обычно называемых составляющими . 2 Предложения в CFG анализируются с помощью древовидной структуры, в которой предложение рекурсивно генерируется фраза за фразой (рис. 1).
Рисунок 1. Пример разбора предложения «Собака в саду». Предложение разбирается на составляющие части речи (POS) категории, представленные в древовидной структуре. Категории POS и типы словосочетаний: предложение (S), именное словосочетание (NP), определитель (DT), глагольное словосочетание (VP), глагол настоящего времени (VBZ), предложное словосочетание (PP), предлог (P) и существительное. (НН).
Проблема восстановления базовой структуры предложения известна как разбор . К сожалению, естественный язык неоднозначен, и поэтому не может быть единственно возможного значения; рассмотрим предложение Я видел его в бинокль. Здесь неясно, держит ли бинокль подлежащее или дополнение предложения (рис. 2). Чтобы справиться с этой неоднозначностью, нам потребуются взвешенные и вероятностные расширения контекстно-свободной грамматики (называемые соответственно WCFG и PCFG). Это позволяет нам вычислить число, которое показывает, насколько «хорошей» является каждая возможная интерпретация предложения.
Рисунок 2. Разбор предложения «Я видел его в бинокль» на составляющие части речи (POS) категории (например, существительное) и типы фраз (например, глагольная фраза), представленные в древовидной структуре. Категории POS и типы словосочетаний: предложение (S), именное словосочетание (NP), глагольное словосочетание (VP), глагол прошедшего времени (VBD), предложное словосочетание (PP), предлог (P), определитель (DT) и существительное. (НН). а) В этом разборе бинокль есть у «я». б) Второй возможный разбор того же предложения, в котором биноклем владеет «он».
В части I этой серии двух блогов мы вводим понятие контекстно-свободной грамматики и рассматриваем, как анализировать предложения с использованием этой грамматики. Затем мы описываем алгоритм распознавания CYK , который определяет, можно ли проанализировать предложение в соответствии с заданной грамматикой. Во второй части мы вводим вышеупомянутые взвешенные контекстно-свободные грамматики и показываем, как можно адаптировать алгоритм CYK для вычисления различных величин, включая наиболее вероятную структуру предложения. В части III мы вводим вероятностные контекстно-свободные грамматики и представляем алгоритм внутри-снаружи , который эффективно вычисляет ожидаемое количество правил в грамматике для всех возможных анализов предложения. Эти ожидаемые значения используются на этапе E процедуры максимизации ожидания для изучения весов правила.
Деревья синтаксического анализа
Прежде чем заняться этими проблемами, мы сначала обсудим свойства дерева синтаксического анализа (рис. 3). Корень дерева помечен как «предложение» или «начало». Листья или клеммы дерева содержат слова предложения. Родители этих листьев называются претерминалом и содержат категории частей речи (POS) слов (например, глагол, существительное, прилагательное, предлог). Слова считаются принадлежащими к той же категории, если предложение остается синтаксически допустимым при их замене. Например: {грустный, счастливый, взволнованный, скучающий} человек в кафе. Это известно как тест замены . Над претерминалом категории слов собраны вместе в фраз .
Рисунок 3. Дерево разбора более сложного предложения. Категории POS здесь: предложение (S), именная группа (NP), определитель (DT), существительное (NN), глагольная группа (VP), глагол третьего лица единственного числа (VBZ) и герундий (VBG).
Есть еще три важных момента, на которые стоит обратить внимание. Во-первых, глагольная фраза, выделенная пурпурным цветом, имеет троих дочерних элементов. Однако теоретического предела этому числу нет. Мы могли бы легко добавить предложные фразы в саду и под деревом и так далее. Сложность предложения на практике ограничена человеческой памятью, а не самой грамматикой.
Во-вторых, грамматическая структура допускает рекурсию. В этом примере глагольная фраза встроена во вторую глагольную фразу, которая сама встроена в третью глагольную фразу. Наконец, отметим, что дерево синтаксического анализа устраняет неоднозначность смысла предложения. С грамматической точки зрения, возможно, это была кость, которая наслаждалась каждым моментом. Однако ясно, что это не так, поскольку глагольная фраза, соответствующая наслаждению, присоединена к глагольной фразе, соответствующей еде, а не кости (см. также рисунок 2).
Контекстно-свободные грамматики
В этом разделе мы представляем более формальную трактовку контекстно-свободных грамматик. *$, где $*$ обозначает звезду Клини. Неформально это означает, что каждое правило грамматики представляет собой упорядоченную пару, где первый элемент – нетерминал из $\mathcal{V}$, а второй – любая возможная строка, содержащая терминалы из $\Sigma$ и нетерминал из $\ математический{V}$. Например, B$\rightarrow$ab, C$\rightarrow$Baa и A$\rightarrow$AbCa — все правила производства.
A контекстно-свободная грамматика – это набор $G=\{\mathcal{V}, \Sigma, \mathcal{R}, S\}$, состоящий из нетерминалов $\mathcal{V}$, терминалов $\Sigma$, продукционные правила $\mathcal{R}$ и начальный символ $S$. Ассоциированный контекстно-свободный язык состоит из всех возможных строк терминалов, которые могут быть получены из грамматики.
Неофициально термин контекстно-свободный означает, что каждое производственное правило начинается с одного нетерминального символа. Контекстно-свободные грамматики являются частью 9{3})$ время, где $n$ — количество наблюдаемых терминалов. Разбор более выразительных грамматик в иерархии Хомского имеет экспоненциальную сложность. На самом деле контекстно-свободные грамматики не считаются достаточно выразительными для моделирования реальных языков. Было изобретено много других типов грамматики, которые являются более выразительными и поддающимися разбору за полиномиальное время, но они выходят за рамки этого поста.
| Язык | Распознаватель | Сложность синтаксического анализа 93)$ $O(n)$ |
Таблица 1. Иерархия языков Хомского. По мере того как тип грамматики становится проще, требуемая модель вычислений (распознаватель) становится менее общей, а сложность синтаксического анализа уменьшается.
Пример Рассмотрим контекстно-свободную грамматику, сгенерировавшую пример на рис. 4. Здесь множество нетерминалов $\mathcal{V}=\{\mbox{VP, PP, NP, DT, NN , VBZ, IN,}\ldots\}$ содержит начальный символ, фразы и претерминалы. Набор терминалов $\Sigma=\{$The,dog, is, in, the, garden, $\ldots \}$ содержит слова. Продукционные правила в грамматике, связанной с этим примером, включают:
Конечно, полная модель английской грамматики содержит намного больше нетерминалов, терминалов и правил, чем мы наблюдали в этом единственном примере. Суть в том, что древовидная структура на рисунке 4 может быть создана повторным применением конечного набора правил.
Рисунок 4. Пример предложения для демонстрации правил контекстно-свободной грамматики
Нормальная форма ХомскогоПозже мы опишем алгоритм распознавания CYK. Это берет предложение и контекстно-свободную грамматику и определяет, существует ли допустимое дерево синтаксического анализа, которое может объяснить предложение с точки зрения правил производства CFG. Однако алгоритм CYK предполагает, что контекстно-свободная грамматика находится в Нормальная форма Хомского (CNF) . Грамматика находится в CNF, если она содержит только следующие типы правил:
\begin{align} \tag{binary non-terminal}
\text{A} &\rightarrow \text{B} \; \text{C} \\
\tag{унарный терминал}
\text{A} &\rightarrow \text{a} \\
\tag{удалить предложение}
\text{S} &\rightarrow \epsilon
\ end{align}
, где A, B и C — нетерминалы, a — токен, S — начальный символ, а $\epsilon$ представляет пустую строку.
Правило двоичного нетерминала означает, что нетерминал может создать ровно два других нетерминала. Примером может служить правило $S \rightarrow \text{NP} \; \text{VP}$ на рисунке 4. Правило унарного терминала означает, что нетерминал может создать один терминал. Правило $\text{NN} \rightarrow$ $\text{dog}$ на рисунке 4 является примером. Правило удаления предложения позволяет грамматике создавать пустые строки, но на практике мы избегаем $\epsilon$-произведений.
Обратите внимание, что дерево синтаксического анализа на рисунке 3 имеет номер , а не в нормальной форме Хомского, поскольку оно содержит правило $\text{VP} \rightarrow \text{VBG} \; \текст{НП} \; \text{ВП}$. В случае обработки естественного языка есть две основные задачи по преобразованию грамматики в CNF:
- Мы имеем дело с правилами, которые создают более двух нетерминалов, создавая новые промежуточные нетерминалы (рис. 5а).
- Мы удаляем унарные правила, такие как A →→ B, создавая новый узел A_B (рис. 5b).
Рисунок 5. Преобразование в нормальную форму Хомского. а) Преобразование небинарных правил путем введения новых нетерминальных B_C. б) Устранение унарных правил путем создания новых нетерминальных A_B.
Обе эти операции вводят в грамматику новые нетерминалы. Действительно, в первом случае мы можем ввести разное количество новых нетерминалов в зависимости от того, какие дочерние элементы мы выбираем для объединения. Можно показать, что в худшем случае преобразование CFG в эквивалентную грамматику в нормальной форме Хомского приводит к квадратичному увеличению количества правил. Заметим также, что хотя преобразование КНФ является наиболее популярным, оно не является единственным и даже не самым эффективным вариантом.
Разбор
Имея грамматику в нормальной форме Хомского, мы можем обратить внимание на разбор предложения. Алгоритм синтаксического анализа вернет допустимое дерево синтаксического анализа, подобное показанному на рис. 6, если предложение имеет допустимый анализ, или укажет, что такого действительного дерева синтаксического анализа не существует.
Рисунок 6. Пример дерева разбора предложения Джефф обучает студентов геометрии. В этом предложении $n=4$ терминалов. Он имеет $n-1=3$ внутренних узлов, представляющих нетерминалы, и $n=4$ предтерминальных узлов.
Отсюда следует, что один из способов характеристики алгоритма синтаксического анализа состоит в том, что он выполняет поиск по множеству всех возможных деревьев синтаксического анализа. Наивный подход может состоять в том, чтобы тщательно перебирать эти деревья, пока мы не найдем то, которое подчиняется всем правилам грамматики и дает предложение. В следующем разделе мы рассмотрим размер этого пространства поиска, обнаружим, что оно очень велико, и придем к выводу, что этот метод грубой силы неразрешим.
Количество деревьев разбора 909{n-1}C_{n-i}C_{i}. \tag{1}\end{equation} Рис. 7. Интуиция для числа $C_{n}$ бинарных деревьев с $n$ внутренних узлов. а) Существует только одно дерево с одним внутренним узлом, поэтому $C_{1}=1$. б) Чтобы сгенерировать все возможные деревья с $n=2$ внутренних узлов, мы добавляем новый корень (красное поддерево). 5 = 176160768 возможных деревьев синтаксического анализа.
Рисунок 8. Минимальный набор грамматических правил в нормальной форме Хомского для разбора примерного предложения Я видел его в бинокль. а) Правила, касающиеся претерминалов и терминалов. Обратите внимание, что слово пила неоднозначно и может быть глаголом (означающим наблюдаемое) или существительным (означающим инструмент для резки дерева). б) Правила, связывающие нетерминалы друг с другом.
Даже этот минимальный пример имел очень большое количество возможных объяснений. Теперь учтите, что (i) средняя длина предложения, написанного Чарльзом Диккенсом, составляла 20 слов с соответствующими $C_{20}=6 564 120 420$ возможными бинарными деревьями и (ii) что в реалистическом языке гораздо больше частей речи и типов предложений. модель английского языка. Понятно, что существует огромное количество возможных синтаксических анализов, и нецелесообразно использовать полный перебор для нахождения допустимых.
Алгоритм CYK Алгоритм CYK (названный в честь изобретателей Джона Кока, Дэниела Янгера и Тадао Касами) был первым алгоритмом синтаксического анализа с полиномиальным временем, который можно было применять к неоднозначным CFG (т. для той же строки). В своей простейшей форме алгоритм CYK решает задачу распознавания ; он определяет, может ли строка $\mathbf{w}$ быть получена из грамматики $G$. Другими словами, алгоритм берет предложение и контекстно-свободную грамматику и возвращает TRUE, если существует допустимое дерево синтаксического анализа, или FALSE в противном случае.
Этот алгоритм обходит необходимость пробовать все возможные деревья, используя тот факт, что полное предложение создается путем объединения подпунктов или, что то же самое, дерево разбора создается путем объединения поддеревьев. Дерево допустимо только в том случае, если его поддеревья также действительны. Алгоритм работает снизу вверх по дереву, сохраняя возможные допустимые поддеревья по мере продвижения и строя более крупные поддеревья из этих компонентов без необходимости их повторного вычисления. Таким образом, CYK представляет собой динамическое программирование 9.0008 алгоритм.
Алгоритм CYK состоит всего из нескольких строк псевдокода:
0 # Инициализировать структуру данных 1 диаграмма[1.
Алгоритм прост, но его трудно понять только из кода. В следующем разделе мы представим рабочий пример, который значительно облегчит понимание. Прежде чем мы это сделаем, давайте сделаем несколько наблюдений высокого уровня. Алгоритм состоит из четырех разделов:
- Диаграмма: В строке 1 мы инициализируем структуру данных, которая обычно называется диаграммой в контексте синтаксического анализа. Это можно представить как таблицу $n×n$, где $n$ — длина предложения. В каждой позиции у нас есть двоичный вектор длины $V$, где $V=|mathcal{V}|$ — количество нетерминалов (т. е. общее количество типов предложений и частей речи).
- Части речи: В строках 4–6 мы просматриваем каждое слово в предложении и определяем, совместима ли каждая часть речи (существительное, глагол и т. д.).
- Основной цикл: В строках 8–13 мы выполняем три цикла и назначаем графику нетерминалы. Это группирует слова в возможные допустимые подфразы.
- Возвращаемое значение: В строке 15 мы возвращаем TRUE, если начальный символ $S$ имеет значение TRUE в позиции $(n,1)$.
Сложность алгоритма легко различить. Строки 93 \cdot |R|)$.
Чтобы облегчить понимание алгоритма CYK, воспользуемся рабочим примером разбора предложения Я видел его в бинокль. Мы уже видели на рисунке 2, что это предложение имеет два возможных значения. Предположим, что минимальная грамматика с рисунка 8 достаточна для разбора предложения. В следующих четырех подразделах мы по очереди рассмотрим четыре части алгоритма.
На рис. 9 показана диаграмма для нашего примера предложения, которое само по себе показано в дополнительной строке под диаграммой. Каждый элемент диаграммы соответствует подстроке предложения. Первый индекс диаграммы $l$ представляет длину этой подстроки, а второй индекс $p$ — начальную позицию. Итак, элемент диаграммы в позиции (4,2) представляет собой подстроку длины четыре и начинается со слова два, которое встречается с ним с помощью . Мы не используем верхнюю треугольную часть диаграммы.
Алгоритм CYK проходит через каждый из элементов диаграммы, начиная со строк длины 1 и обрабатывая каждую позицию, а затем переходя к строкам длины 2 и так далее, пока мы, наконец, не рассмотрим все предложение. Это объясняет циклы в строках 9 и 10. Третий цикл рассматривает возможные двоичные разбиения строк и индексируется $s$. Для позиции (4,2) строку можно разделить на увидели $|$ его с ($s=1$, синие квадраты), увидели его $|$ с ($s=2$, зеленые квадраты), или видел его с $|$ ($s=3$, красные прямоугольники). 9{th}$ строки диаграммы, существует $l-1$ способов разделить подстроку на две части. Например, строка в сером прямоугольнике в позиции (4,2) может быть разделена 4-1 = 3 способами, которые соответствуют синим, зеленым и красным заштрихованным прямоугольникам, и эти разбиения индексируются переменной $s$.
Теперь, когда мы поняли значение диаграммы и то, как она индексируется, давайте шаг за шагом рассмотрим алгоритм. Сначала мы имеем дело со строками длины $l=1$ (т. е. с отдельными словами). Мы проходим по каждому унарному правилу $A \rightarrow w_p$ в грамматике и устанавливаем эти элементы в TRUE на диаграмме (рис. 10). Здесь есть только одна двусмысленность: слово увидел , которое может быть глаголом в прошедшем времени или существительным. Этот процесс соответствует строкам 5-6 алгоритма.
Рисунок 10. Применение унарных правил в алгоритме CYK. Мы рассматриваем подстроки длины 1 (т. е. отдельные слова) и отмечаем, какие части речи могут составлять это слово. В этой ограниченной грамматике есть только одна двусмысленность — слово «пила», которое может быть прошедшим временем слова «видеть» или «деревообрабатывающий инструмент». Обратите внимание, что это та же диаграмма, что и на рис. 9, но строки расположены в шахматном порядке, чтобы было легче рисовать последующие шаги алгоритма.
Главный контурВ основном цикле мы рассматриваем подстроки возрастающей длины, начиная с пар слов и заканчивая полной длиной предложения. Для каждой подстроки мы определяем, существует ли правило вида $\text{A}\rightarrow \text{B}\;\text{C}$, которое может ее вывести.
Начнем со строк длины $l=2$. Очевидно, что их можно разделить только одним способом. Для каждой позиции мы отмечаем на диаграмме все нетерминалы A, которые можно разложить для получения частей речи B и C в ячейках, соответствующих отдельным словам (рисунок 11).
Рисунок 11. Основной цикл для строк длины $l=2$. Рассматриваем каждую пару слов по очереди (т.е. работаем по строке $l=2$). Есть только один способ разделить пару слов, поэтому для каждой позиции мы просто рассматриваем, может ли каждое правило грамматики объяснить части речи в ячейках в строке $l=1$, которые соответствуют отдельным словам. Итак, позиция (2,1) оставлена пустой, так как нет правила вида $\text{A}\rightarrow \text{NP}\;\text{NN}$ или $\text{A}\rightarrow \ текст{NP}\;\text{VBD}$. Позиция (2,2) содержит $\text{VP}$, так как мы можем использовать правило $\text{VP}\rightarrow \text{VBD}\:\text{NP}$ и так далее.
В следующем внешнем цикле мы рассматриваем подстроки длины $l=3$ (рисунок 12). Для каждой позиции мы ищем правило, которое может вывести три слова. Однако теперь мы также должны рассмотреть два возможных способа разделения подстроки длины 3. Например, для позиции $(3,2)$ мы пытаемся вывести подстроку, с которой он видел. Это можно разделить, как если бы он видел его $|$ с соответствующими позициями (2,2)$|$(1,4), которые содержат VP и P соответственно. Однако правила вида $\text{A}\rightarrow\text{VP}\;\text{P}$ не существует. Точно так же нет правила, по которому можно было бы вывести расщепленную пилу $|$, поскольку не было правила, по которому можно было бы вывести его. Следовательно, мы оставляем позицию $(3,2)$ пустой. Однако в позиции $(3,4)$ может быть применено правило $\text{PP}\rightarrow \text{P}\;\text{NP}$, как указано в подписи к рисунку 12.
Рисунок 12. Основной цикл для строк $l=3$. Рассматриваем каждую тройку слов по очереди (т.е. работаем по строке $l=3$). Мы можем разделить каждую тройку двумя возможными способами, и для каждого ящика мы рассмотрим, существует ли правило, объясняющее каждое разделение. Например, для позиции (3,4), соответствующей подстроке с биноклем, мы можем объяснить с помощью нетерминала P из строки $l=1$ и бинокля с нетерминалом NP из строки $l =2$, используя правило $\text{PP}\rightarrow\text{P}\;\text{NP}$. Следовательно, мы добавляем PP в позицию (3,4).
Мы продолжаем этот процесс, работая вверх по диаграмме для все более и более длинных подстрок (рисунок 13). Для каждой длины подстроки мы рассматриваем каждую позицию и каждое возможное разделение и добавляем нетерминалы в диаграмму, где мы находим применимое правило. Отметим, что позиция $(5,2)$ на рис. 13б, соответствующая подстроке «видел его в бинокль», особенно интересна. Здесь возможны два правила $\text{VP}\rightarrow\text{VP}\;\text{PP}$ и $\text{VP}\rightarrow\text{VBD}\;\text{NP}$, которые оба приходят к выводу, что подстрока может быть получена нетерминальным VP. Это соответствует исходной двусмысленности в предложении.
Рис. 13. Продолжение основного цикла CYK для строк а) длины $l=4$ б) длины $l=5$ и в) длины $l=6$. Обратите внимание на двусмысленность на панели (b), где есть два возможных маршрута для назначения нетерминального VP позиции (5,2), соответствующей подстрокам видел $|$ его в бинокль и видел его $|$ в бинокль. Это отражает двусмысленность предложения; бинокль может быть либо у меня, либо у него.
Когда мы доходим до самой верхней строки диаграммы ($l=6$), мы рассматриваем все предложение целиком. На этом этапе мы выясняем, можно ли использовать начальный символ $S$ для получения всей строки. Если такое правило есть, то предложение правильно с точки зрения грамматики, а если нет, то нет. Это соответствует последней строке псевдокода алгоритма CYK. В этом примере мы используем правило $S\rightarrow \text{NP}\;\text{VP}$, объясняем все жало с помощью именной группы I и глагольной группы увидели его в бинокль и делаем вывод, что предложение верно в этом контексте свободная грамматика.
Базовый алгоритм CYK просто возвращает двоичную переменную, указывающую, можно ли разобрать предложение по грамматике $G$. Часто нас интересует получение дерева (деревьев) синтаксического анализа. На рис. 14 наложены пути, ведущие к начальному символу в левом верхнем углу рис. 11–13. Эти пути образуют общий лес разбора ; два дерева имеют общие черные пути, но красные пути есть только в первом дереве, а синие пути — только во втором дереве. Эти два дерева соответствуют двум возможным значениям предложения (рис. 15).
Рис. 14. Наложение путей, ведущих к начальному символу в позиции (6,1) с рис. 11-13. Они описывают два перекрывающихся дерева, образующих общий лес синтаксического анализа: общие части показаны черным, пути только в первом дереве — красным, а пути только во втором дереве — только синим. Это деревья синтаксического анализа для двух возможных значений этого предложения.
Эти два рисунка показывают, что восстановить дерево синтаксического анализа после запуска алгоритма CYK несложно, если мы кэшируем входные данные для каждой позиции на диаграмме. Мы просто начинаем с начального символа в позиции (6,1) и спускаемся вниз по дереву. В любой точке, где есть два входа в ячейку, возникает неоднозначность, и мы должны перечислить все комбинации этих неоднозначностей, чтобы найти все допустимые синтаксические анализы. Этот метод аналогичен другим задачам динамического программирования (например, каноническая реализация алгоритма самой длинной общей подпоследовательности вычисляет только размер подпоследовательности, но обратные указатели позволяют извлекать саму подпоследовательность).
Рисунок 15. Два дерева на рисунке 14 точно соответствуют двум возможным деревьям синтаксического анализа, которые объясняют это предложение в соответствии с предоставленной грамматикой. а) В этом анализе у меня есть бинокль. б) Второй возможный анализ того же предложения, в котором бинокль есть у него.
Более сложный примерПредыдущий пример был относительно однозначным. Чтобы немного позабавиться, мы также покажем результаты для известного сложного для понимания предложения Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo. Удивительно, но это допустимое английское предложение. Чтобы понять это, вам нужно знать, что (i) buffalo — это существительное во множественном числе, описывающее животных, также известных как бизоны, (ii) Buffalo — это город, и (iii) buffalo — это глагол, означающий «запугивать». Смысл предложения таков:
Бизоны из города Баффало, запуганные другими зубрами из города Буффало, сами запугивают еще одного бизона из города Буффало.
Чтобы еще больше усложнить задачу, предположим, что текст написан строчными буквами, поэтому каждый экземпляр buffalo может соответствовать любому из трех значений. Не могли бы вы придумать грамматику, которая присваивает этому предложению интуитивный анализ? На рисунке 16 мы приводим минимальную, но достаточную грамматику, которая позволяет алгоритму CYK найти единственное и разумное дерево синтаксического анализа для этого странного предложения.
Рисунок 16. Запуск алгоритма CYK для предложения buffalo buffalo buffalo buffalo buffalo buffalo buffalo buffalo. Алгоритм CYK возвращает TRUE, так как он может поместить начальный символ $S$ в верхний левый угол графика. Красные линии показывают обратное отслеживание дерева синтаксического анализа до составных частей речи.
Краткое описание алгоритма CYK В этой части блога мы описали алгоритм CYK для задачи распознавания; алгоритм определяет, может ли строка быть сгенерирована данной грамматикой. Это классический пример алгоритма динамического программирования, который исследует экспоненциальное пространство поиска за полиномиальное время, сохраняя промежуточные результаты. Другой способ думать об алгоритме CYK из менее процедурный и более декларативный перспектива заключается в том, что он выполняет логическую дедукцию. Аксиомы — это правила грамматики, а факты — это слова. Для заданной длины подстроки мы выводим новые факты, применяя правила грамматики $G$ и факты (или аксиомы), которые мы ранее вывели о более коротких подстроках. Мы продолжаем применять правила, чтобы получить новые факты о том, какая подстрока может быть получена с помощью $G$, с целью доказать, что $S$ порождает предложение.
Обратите внимание, что мы использовали нетрадиционную индексацию диаграммы в нашем описании. Для более типичной презентации обратитесь к этим слайдам.
В части II мы рассмотрим присвоение вероятностей продукционным правилам, поэтому, когда синтаксический анализ неоднозначен, мы можем присвоить вероятности различным значениям. Мы также рассмотрим алгоритм внутри-снаружи, который помогает узнать эти вероятности.
1 Этот известный пример использовался в Syntactic Structures Ноама Хомского в 1957 году, чтобы мотивировать независимость синтаксиса и семантики.
2 Идея о том, что предложения рекурсивно строятся из более мелких связных частей, восходит как минимум к санскритской сутре из примерно 4000 стихов, известной как Аштадхьяи, написанной Панини, вероятно, примерно в 6-4 веках до нашей эры.
Работайте с нами!
Впечатлена работой команды? Borealis AI ищет сотрудников на различные должности в разных командах. Посетите нашу страницу вакансий прямо сейчас и откройте для себя возможности присоединиться к аналогичным важным проектам!
Карьера в Borealis AIПЕРЕФРАЗИРУЙТЕ СЛОВО И РАЗБИРАЙТЕ ПРЕДОСТЕРЕЖЕНИЕ
Слово «разбор» покрыло много тем с тех пор, как в августе прошлого года я заметил, что этот грамматический термин проникает в повседневное употребление.
В то время технически подкованные читатели объяснили, что парсингом теперь занимаются компьютеры, а не только преподаватели английского языка, объясняющие грамматику, и они предположили, что кибериспользование стало источником все большего знакомства с ним среди обычных людей. Но синтаксический анализ нашел более быстрый способ распространять себя: с тех пор, как оно вошло в лексикон президентских скандалов, оно за одну ночь превратилось из загадочного в чрезмерно используемое. Люди, которые никогда не слышали это слово две недели назад, уже говорят, что им надоело синтаксический анализ.
Все началось с того, что пресс-секретарь Клинтона Майк Маккарри ответил — или нет — на вопросы о первом отрицании президентом истории Моники Левински. На просьбу уточнить, МакКарри только повторял: «Я не буду разбирать это утверждение». И прежде, чем вы успели сказать «косвенный объект», Сэм, Коки, Тед и их гости начали анализировать, как профессионалы.
Люди также читают…
Если вас огорчил блиц-анализ, подумайте о возможной серебряной подкладке. По мере того, как слово возрождалось, оно использовалось не только в собственном смысле — для тщательного анализа, как бы описания структуры предложения, — но и как замена части. По мере того, как насыщение СМИ распространяет информацию об истинном значении синтаксического анализа, возможно, этот выскочка синтаксического анализа завянет и умрет.
Очередное злоупотребление синтаксическим разбором пытается пустить корни на благодатной почве скандала. «Я не понимаю, почему президент так разбирает свои слова, — говорит гость CNN. — Есть подозрения, что Клинтон разбирает свои слова», — сообщает канадская газета. А один обозреватель ссылается на то, что президент «притворяется, и анализирует, и ласкает формулировки».
Все эти примеры приписывают синтаксический анализ не тому человеку. Говорит президент, слушатели разбирают его высказывания. Он может взвешивать свои слова, или перемалывать их, или даже ласкаться, но он не анализирует. Если вы не можете заменить анализ в предложении, вы, вероятно, не говорите о синтаксическом анализе.
Получайте местные новости на свой почтовый ящик!
* Я понимаю и соглашаюсь с тем, что регистрация или использование этого сайта означает согласие с его пользовательским соглашением и политикой конфиденциальности.
Связанные с этой новостью
Самые популярные
Болезни роста: Гринсборо расширяется, но не все этому рады
За первые шесть месяцев этого года город присоединил 1094 акра земли, превзойдя рекордные 736 акров, присоединенные за весь 2021 год.
В течение многих лет церковный «вторник хот-догов» был местом, где Гринсборо угощает мясом и приветствует
Хот-дог Вторник богат гостеприимством в Объединенной методистской церкви Хиншоу.
Леонард Питтс-младший: Мы верим Гершелю Уокеру
Майя Энджелоу, познакомьтесь с Гершелем Уокером, кандидатом от республиканцев в Сенат США.
1 человек погиб в пятницу вечером в результате аварии на Вендовер-авеню в Хай-Пойнте, сообщает полиция Дорога. Полиция заявила, что по этому делу не будет предъявлено никаких обвинений, что стало седьмым ДТП со смертельным исходом в городе в этом году.
Южные баптисты разорвали связи с ЛГБТ-дружественной церковью в Гринсборо
Во вторник комитет одобрил заявление о том, что баптистская церковь Колледж-Парк в Гринсборо не находится в «дружеском сотрудничестве» из-за ее «открытого подтверждения, одобрения и одобрения гомосексуального поведения». что противоречит теологическим консервативным позициям деноминации. Фактически, Колледж-Парк проголосовал в 1999 году за выход из деноминации, и на его веб-сайте отмечается, что он не является членом Южной баптистской конвенции, а скорее является членом более прогрессивных баптистских организаций.
Выбор читателей: узнайте, кто победил в этом году в округе Рокингем
Вы проголосовали, теперь узнайте, кто получил высшие награды за все: от лучшего поставщика провизии до места для пикника № 1 в округе Рокингем.
ОБНОВЛЕНИЕ: Полицейское удостоверение личности жертвы нападения со смертельным исходом в среду в Гринсборо
Офицеры ответили в 12:56. в блок 2700 Бьюкенен-роуд для сообщения о нападении при отягчающих обстоятельствах, говорится в сообщении полиции. Они обнаружили одного раненого, и Скорая помощь доставила пострадавшего в местную больницу.
Анонимные доноры хотят пожертвовать 1 миллион долларов на газон на Пейдже; школьный совет говорит OK
Анонимная группа доноров предложила выделить 1 миллион долларов на установку поля с искусственным покрытием на стадионе Мэрион Кирби в средней школе Пейдж, и Совет по образованию округа Гилфорд единогласно проголосовал за принятие денег.
Южные баптисты разорвали связи с церковью Гринсборо из-за позиции, дружественной к ЛГБТК .