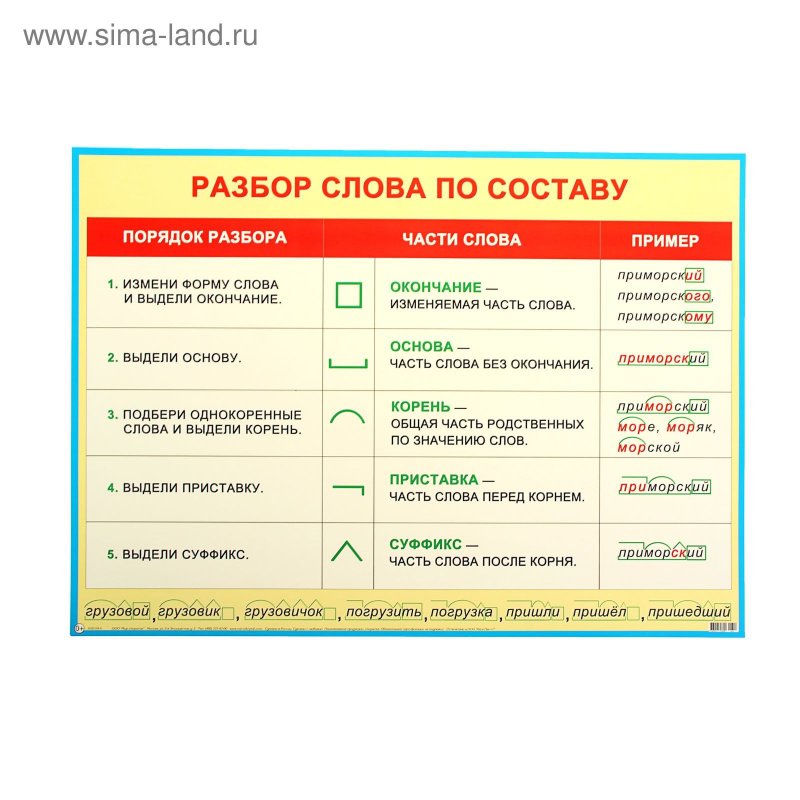
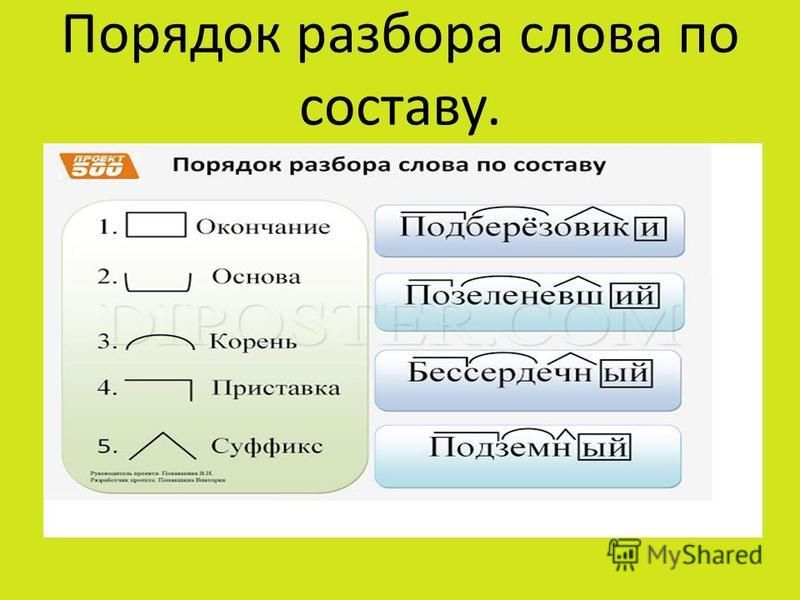
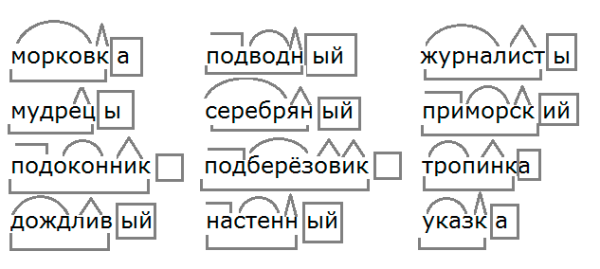
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
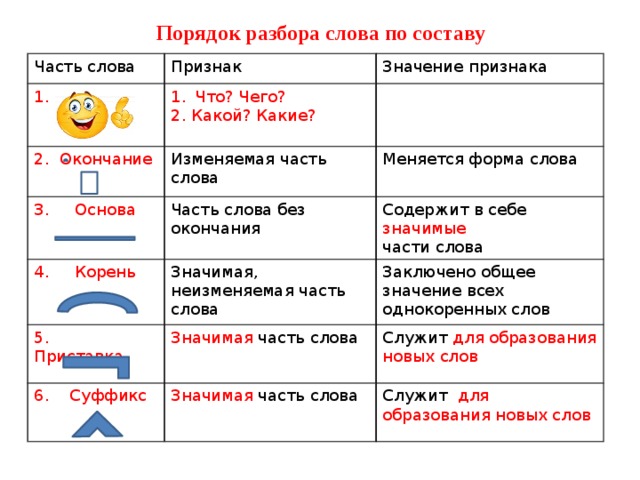
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
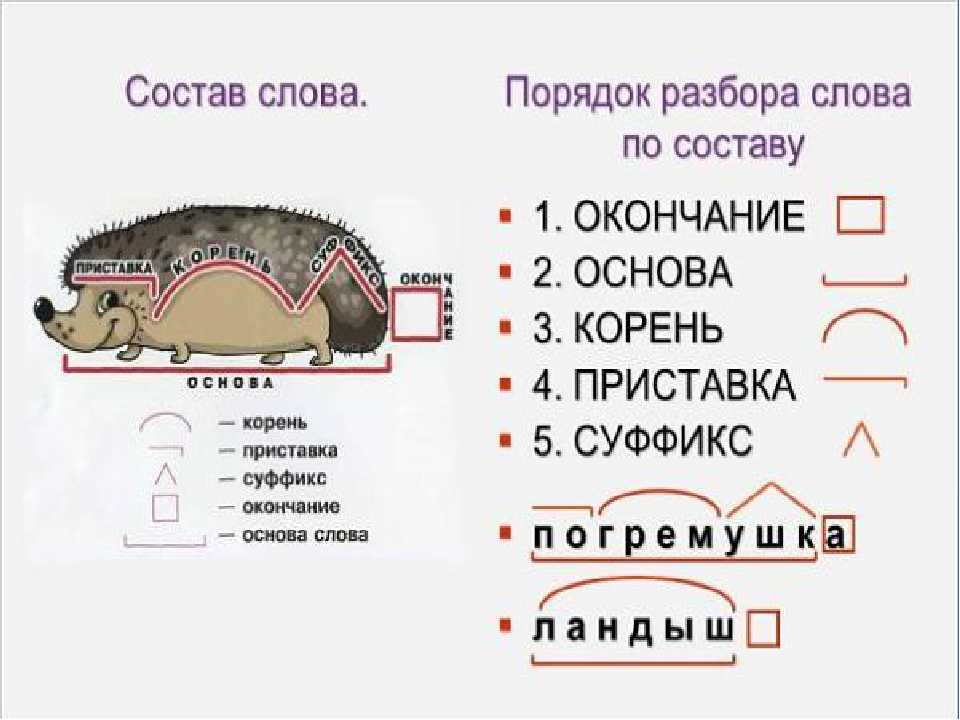
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: мимчаня сейчас и о н с а т сейчас л о т л с р ь сейчас о ч м и е п н сейчас м а с т е р сейчас реносиза сейчас смосарева сейчас ловушка сейчас теслоо 1 секунда назад е-к-л-а-в-и-н-о-и 1 секунда назад корветз 1 секунда назад п о т ь к у с с 1 секунда назад забор 1 секунда назад скакунл 1 секунда назад ряйкааму 2 секунды назад
Страница не найдена
wordmap
Данная страница не найдена или была удалена.
Только что искали:
ильяш 6 секунд назад
лац 8 секунд назад
формула 9 секунд назад
лио 10 секунд назад
кастрация 11 секунд назад
илляш 12 секунд назад
издираемый 14 секунд назад
цепляю 17 секунд назад
карлсон 18 секунд назад
распродажа 18 секунд назад
голяш 18 секунд назад
декстрин 18 секунд назад
лах 23 секунды назад
люф 24 секунды назад
элляш 26 секунд назад
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | безударность | 6 слов | 45 секунд назад | 46. |
| Игрок 2 | зануздывание | 6 слов | 6 минут назад | 46.61.5.240 |
| Игрок 3 | подкрашивание | 110 слов | 1 час назад | 95.29.164.27 |
| Игрок 4 | турбоагрегат | 0 слов | 5 часов назад | 95.153.179.57 |
| Игрок 5 | формула к | 1 слово | 9 часов назад | 46.29.192.203 |
| Игрок 6 | ромс | 0 слов | 1 день назад | 128.204.71.38 |
| Игрок 7 | лиза | 0 слов | 1 день назад | 128.204.71.38 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | тынок | 40:35 | 5 минут назад | 89. 113.139.0 113.139.0 |
| Игрок 2 | нырок | 50:47 | 9 минут назад | 95.153.162.217 |
| Игрок 3 | чирус | 52:53 | 11 минут назад | 89.113.139.0 |
| Игрок 4 | стужа | 48:50 | 16 минут назад | 178.35.33.81 |
| Игрок 5 | мильт | 52:48 | 17 минут назад | 89.113.139.0 |
| Игрок 6 | 50:47 | 24 минуты назад | 89.113.139.0 | |
| Игрок 7 | грунт | 15:12 | 27 минут назад | 178.72.78.150 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Киса | На двоих | 10 вопросов | 4 минуты назад | 89. 23.105.215 23.105.215 |
| Пидорас | На двоих | 15 вопросов | 47 минут назад | 109.62.184.180 |
| Алина | На одного | 20 вопросов | 4 часа назад | 176.59.195.231 |
| Алина | На одного | 20 вопросов | 6 часов назад | 176.59.195.231 |
| Алинус | На одного | 10 вопросов | 7 часов назад | 92.255.135.254 |
| Алинус | На одного | 10 вопросов | 7 часов назад | 92.255.135.254 |
| Дед Афанасий | На одного | 10 вопросов | 7 часов назад | 176.59.199.26 |
| Играть в Чепуху! | ||||
— Когнитивный поиск Azure
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
Навык Извлечение документа извлекает содержимое из файла в конвейере обогащения. Это позволяет вам воспользоваться шагом извлечения документа, который обычно происходит перед выполнением набора навыков с файлами, которые могут быть созданы другими навыками.
Примечание
Этот навык не привязан к Cognitive Services и не требует ключа Cognitive Services. Этот навык извлекает текст и изображения. Извлечение текста бесплатно. Извлечение изображений измеряется когнитивным поиском Azure. В бесплатной службе поиска стоимость 20 транзакций на индексатора в день поглощается, поэтому вы можете бесплатно выполнять краткие руководства, учебные пособия и небольшие проекты. Для базовых, стандартных и более поздних версий извлечение изображений оплачивается.
@odata.type
Microsoft.Skills.Util.DocumentExtractionSkill
Поддерживаемые форматы документов
DocumentExtractionSkill может извлекать текст из документов следующих форматов:
- CSV (см.
 Индексирование больших двоичных объектов CSV)
Индексирование больших двоичных объектов CSV) - ЭМЛ
- EPUB
- ГЗ
- HTML
- JSON (см. Индексирование больших двоичных объектов JSON)
- KML (XML для географических представлений)
- Форматы Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (электронные сообщения Outlook), XML (2003 и 2006 WORD XML)
- Открытые форматы документов: ODT, ODS, ODP
- ПДФ
- Файлы с обычным текстом (см. также Индексирование простого текста)
- РТФ
- XML
- Почтовый индекс
 Индексирование больших двоичных объектов CSV)
Индексирование больших двоичных объектов CSV)Параметры навыков
Параметры вводятся с учетом регистра.
| Допустимые значения | Описание | |
|---|---|---|
Режим разбора | по умолчанию текст json | Установите значение по умолчанию для извлечения документов из файлов, которые не являются чистым текстом или json. Для исходных файлов, содержащих разметку (таких как файлы PDF, HTML, RTF и Microsoft Office), используйте значение по умолчанию для извлечения только текста без языка разметки или тегов. Если Для исходных файлов, содержащих разметку (таких как файлы PDF, HTML, RTF и Microsoft Office), используйте значение по умолчанию для извлечения только текста без языка разметки или тегов. Если parsingMode явно не определен, для него будет установлено значение по умолчанию . Установите текст , если исходные файлы имеют формат TXT. Этот режим синтаксического анализа повышает производительность при работе с текстовыми файлами. Если файлы содержат разметку, этот режим сохранит теги в окончательном выводе. Установите на json для извлечения структурированного содержимого из файлов json. |
данные для извлечения | содержимое и метаданные все метаданные | Установите значение contentAndMetadata , чтобы извлечь все метаданные и текстовое содержимое из каждого файла. Если dataToExtract не определен явно, для него будет установлено значение contentAndMetadata . Установите Установите allMetadata , чтобы извлечь только свойства метаданных для типа контента (например, метаданные, уникальные только для файлов .png). |
конфигурация | См. ниже. | Словарь необязательных параметров, регулирующих способ извлечения документа. В таблице ниже приведены описания поддерживаемых свойств конфигурации. |
| Параметр конфигурации | Допустимые значения | Описание |
|---|---|---|
imageAction | нет generateNormalizedImages generateNormalizedImagePerPage | Установите на нет , чтобы игнорировать встроенные изображения или файлы изображений в наборе данных, или если исходные данные не включают файлы изображений. Это значение по умолчанию. Для оптического распознавания символов и анализа изображений установите значение generateNormalizedImages , чтобы иметь возможность создавать массив нормализованных изображений при взломе документа. Это действие требует, чтобы для Это действие требует, чтобы для parsingMode было установлено значение по умолчанию , а для dataToExtract было установлено значение 9.0080 содержимое и метаданные . Нормализованное изображение относится к дополнительной обработке, приводящей к однородному выходному изображению, размеру и повороту для обеспечения согласованной визуализации, когда вы включаете изображения в результаты визуального поиска (например, фотографии одинакового размера в графическом элементе управления, как показано в демонстрации JFK). Эта информация генерируется для каждого изображения при использовании этой опции. Если вы установите значение generateNormalizedImagePerPage , файлы PDF будут обрабатываться по-другому, поскольку вместо извлечения встроенных изображений каждая страница будет отображаться как изображение и нормализована соответствующим образом. Типы файлов, отличных от PDF, будут обрабатываться так же, как если бы 9Был установлен 0080 generateNormalizedImages .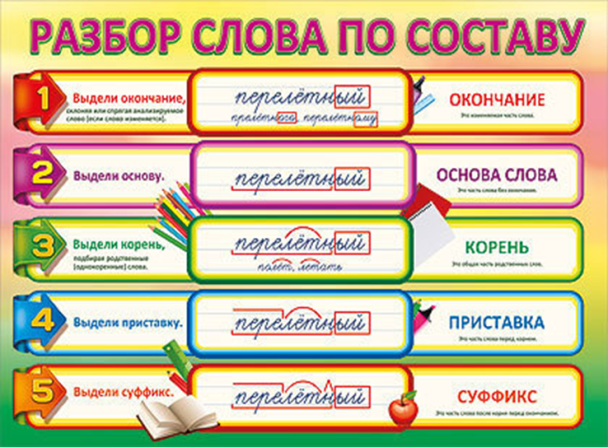 |
нормализованныйImageMaxWidth | Любое целое число от 50 до 10000 | Максимальная ширина (в пикселях) для генерируемых нормализованных изображений. По умолчанию 2000. |
нормализованныйImageMaxHeight | Любое целое число от 50 до 10000 | Максимальная высота (в пикселях) для генерируемых нормализованных изображений. По умолчанию 2000. |
Примечание
Значение по умолчанию 2000 пикселей для максимальной ширины и высоты нормализованного изображения основано на максимальных размерах, поддерживаемых навыком OCR и навыком анализа изображения. Навык OCR поддерживает максимальную ширину и высоту 4200 для языков, отличных от английского, и 10000 для английского. Если вы увеличите максимальные пределы, обработка больших изображений может завершиться ошибкой в зависимости от определения вашего набора навыков и языка документов.
Входные данные навыков
| Имя входа | Описание |
|---|---|
файл_данные | Файл, из которого следует извлечь содержимое. |
Ввод «file_data» должен быть объектом, определенным как:
{
"$тип": "файл",
"data": "Строка файла в кодировке BASE64"
}
В качестве альтернативы его можно определить как:
{
"$тип": "файл",
"url": "URL для скачивания файла",
"sasToken": "НЕОБЯЗАТЕЛЬНО: токен SAS для проверки подлинности, если предоставленный URL-адрес относится к файлу в хранилище BLOB-объектов"
}
Объект ссылки на файл можно сгенерировать одним из трех способов:
Установка для параметра
allowSkillsetToReadFileDataв определении индексатора значения «true». Это создаст путь/document/file_data, который представляет собой объект, представляющий исходные данные файла, загруженные из вашего источника данных BLOB-объектов. Этот параметр применяется только к файлам в хранилище BLOB-объектов.Установка для параметра
imageActionв определении вашего индексатора значения, отличного отнет. Это создает массив изображений, который соответствует требуемому соглашению для ввода в этот навык, если передается индивидуально (то есть /document/normalized_images/*).Если пользовательский навык возвращает объект json, определенный ТОЧНО, как указано выше. Параметр
$typeдолжен быть установлен точно нафайл, а параметрdataдолжен быть закодированным по основанию 64 байтовым массивом данных содержимого файла, или параметрurlдолжен быть правильно отформатированным URL-адресом с доступом для загрузки файл в этом месте.
 Это создает массив изображений, который соответствует требуемому соглашению для ввода в этот навык, если передается индивидуально (то есть
Это создает массив изображений, который соответствует требуемому соглашению для ввода в этот навык, если передается индивидуально (то есть Выходные данные навыка
| Название выходного сигнала | Описание |
|---|---|
содержание | Текстовое содержимое документа. |
normalized_images | Если для imageAction задано значение, отличное от none , новое поле normalized_images будет содержать массив изображений. Дополнительные сведения о формате вывода см. в разделе Извлечение текста и информации из изображений. Дополнительные сведения о формате вывода см. в разделе Извлечение текста и информации из изображений. |
Образец определения
{
"@odata.type": "#Microsoft.Skills.Util.DocumentExtractionSkill",
"parsingMode": "по умолчанию",
"dataToExtract": "контент и метаданные",
"конфигурация": {
"imageAction": "генерировать нормализованные изображения",
"нормализованныйImageMaxWidth": 2000,
"нормализованныйImageMaxHeight": 2000
},
"контекст": "/документ",
"входы": [
{
"имя": "файл_данные",
"источник": "/document/file_data"
}
],
"выход": [
{
"имя": "содержание",
"targetName": "извлеченное_содержимое"
},
{
"имя": "normalized_images",
"targetName": "extracted_normalized_images"
}
]
}
Пример ввода
{
"ценности": [
{
"recordId": "1",
"данные":
{
"файл_данные": {
"$тип": "файл",
"данные": "aGVsbG8="
}
}
}
]
}
Пример вывода
{
"ценности": [
{
"recordId": "1",
"данные": {
"контент": "привет",
"нормализованные_изображения": []
}
}
]
}
См.
 также
также- Встроенные навыки
- Как определить набор навыков
- Как обрабатывать и извлекать информацию из изображений в сценариях когнитивного поиска
Обратная связь
Просмотреть все отзывы о странице
запросов журнала | Документация Grafana Loki
Документация Grafana LokiLogQL: язык запросов журнала Запросы журнала
Открытый исходный код
Все запросы LogQL содержат селектор потока журнала .
При необходимости за селектором потока журналов может следовать конвейер журналов . Конвейер журналов — это набор выражений этапов, связанных вместе и применяемых к выбранным потокам журналов. Каждое выражение может отфильтровывать, анализировать или изменять строки журнала и соответствующие им метки.
В следующем примере показан полный запрос журнала в действии:
{container="query-frontend",namespace="loki-dev"} |= "metrics. go" | логфмт | продолжительность > 10 с и пропускная способность < 500
 go" | логфмт | продолжительность > 10 с и пропускная способность < 500
go" | логфмт | продолжительность > 10 с и пропускная способность < 500
Запрос состоит из:
- селектора потока журналов
{container="query-frontend",namespace="loki-dev"}, который нацелен на контейнерquery-frontendвloki-devпространство имен. - конвейер журналов
|= "metrics.go" | логфмт | продолжительность> 10 с и пропускная способность < 500, который отфильтрует журнал, содержащий словоmetrics.go, затем проанализирует каждую строку журнала, чтобы извлечь больше меток и отфильтровать их.
Чтобы избежать экранирования специальных символов, вы можете использовать
`(обратная кавычка) вместо"при заключении строк в кавычки. Например,`\w+`совпадает с"\\w+". Это особенно полезно при написании регулярного выражения, содержащего несколько обратных косых черт, требующих экранирования.
Селектор потока журналов
Селектор потоков определяет, какие потоки журналов включать в результаты запроса. Поток журнала — это уникальный источник содержимого журнала, например файл.
Затем более детальный селектор потоков журналов уменьшает количество искомых потоков до управляемого объема.
Это означает, что метки, переданные селектору потока журналов, повлияют на относительную производительность выполнения запроса.
Поток журнала — это уникальный источник содержимого журнала, например файл.
Затем более детальный селектор потоков журналов уменьшает количество искомых потоков до управляемого объема.
Это означает, что метки, переданные селектору потока журналов, повлияют на относительную производительность выполнения запроса.
Селектор потока журнала задается одной или несколькими парами ключ-значение, разделенными запятыми. Каждый ключ — это метка журнала, а каждое значение — значение этой метки.
Фигурные скобки ( { и } ) ограничивают селектор потока.
Рассмотрим этот селектор потока:
{app="mysql",name="mysql-backup"}
Все потоки журналов, которые имеют метку app , значение которой равно mysql и метка с именем , значение которой равно mysql-backup будет включен в
результаты запроса.
Поток может содержать другие пары меток и значений,
но только указанные пары в селекторе потока используются для определения
какие потоки будут включены в результаты запроса.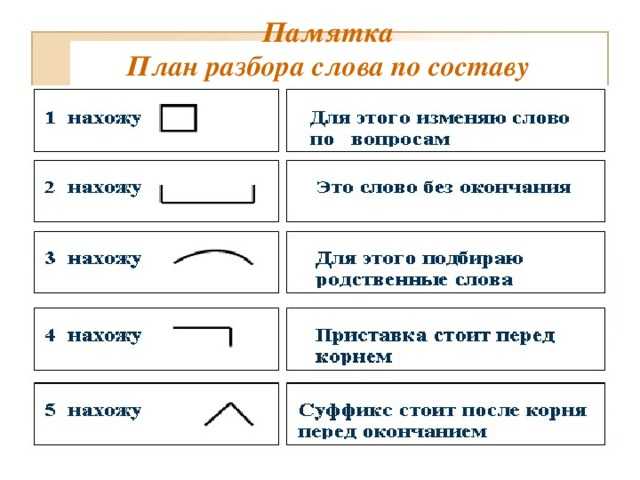
Те же правила, что и для селекторов меток Prometheus, применяются и к селекторам потока журналов Grafana Loki.
Оператор = после имени метки является оператором сопоставления меток .
Поддерживаются следующие операторы сопоставления меток:
-
=: точно равно -
!=: не равно -
=~: регулярное выражение соответствует -
!~ 900 81: регулярное выражение не соответствует
Примеры потоков журнала регулярных выражений:
-
{name =~ "mysql.+"} -
{name !~ "mysql.+"} -
{name !~ `mysql-\d+`}
Примечание: 900 18 В отличие от линии регулярные выражения фильтра, =~ и !~ операторы регулярных выражений полностью закреплены.
Это означает, что выражение регулярного выражения должно соответствовать всей строке , включая символы новой строки . Регулярное выражение
Регулярное выражение . Символ не соответствует новой строке по умолчанию. Если вы хотите, чтобы символ точки регулярного выражения соответствовал символу новой строки, вы можете использовать однострочный флаг, например: (?s)search_term.+ соответствует search_term\n .
В качестве альтернативы вы можете использовать \s (соответствие пробелам, включая новую строку) в сочетании с \S (соответствует не пробельным символам), чтобы соответствовать всем символам, включая символы новой строки.
Обратитесь к синтаксису Google RE2 для получения дополнительной информации.
Новые строки потока журнала регулярных выражений:
-
{name =~ ".*mysql.*"}: не соответствует значениям меток журнала с символом новой строки -
{name =~ "(?s).*mysql. *}: сопоставлять значения меток журнала с символом новой строки -
{name =~ "[\S\s]*mysql[\S\s]*}: сопоставлять значения меток журнала с символом новой строки
Конвейер журналов
Конвейер журналов можно добавить к селектору потоков журналов для дальнейшей обработки и фильтрации потоков журналов. Он состоит из набора выражений. Каждое выражение выполняется в последовательности слева направо для каждой строки журнала. Если выражение отфильтровывает строку журнала, конвейер прекратит обработку текущей строки журнала и начнет обработку следующей строки журнала.
Он состоит из набора выражений. Каждое выражение выполняется в последовательности слева направо для каждой строки журнала. Если выражение отфильтровывает строку журнала, конвейер прекратит обработку текущей строки журнала и начнет обработку следующей строки журнала.
Некоторые выражения могут изменять содержимое журнала и соответствующие метки, которые затем будут доступны для дальнейшей фильтрации и обработки в последующих выражениях. Примером мутации является выражение
| line_format "{{.status_code}}"
Выражения конвейера журналов относятся к одной из трех категорий:
- Выражения фильтрации: выражения линейного фильтра и выражения фильтра меток
- выражения синтаксического анализа
- выражения форматирования: выражения формата строки и выражения формата метки
выражение линейного фильтра
выражение линейного фильтра выполняет распределенную grep по агрегированным журналам из соответствующих потоков журналов. Он ищет содержимое строки журнала,
отбрасывая те строки, которые не соответствуют регистрозависимому выражению.
Он ищет содержимое строки журнала,
отбрасывая те строки, которые не соответствуют регистрозависимому выражению.
Каждое выражение линейного фильтра имеет оператор фильтра за которым следует текст или регулярное выражение. Поддерживаются следующие операторы фильтра:
-
|=: Строка журнала содержит строку -
!=: Строка журнала не содержит строку -
|~: Строка журнала содержит совпадение с регулярным выражением -
!~: Строка журнала не содержит совпадения с регулярным выражением
Примечание: 0080 |~ и !~ операторы регулярных выражений не полностью закреплены.
Это означает, что . символ регулярного выражения соответствует всем символам, включая новые строки .
Примеры выражения фильтра строки:
Сохранить строки журнала, содержащие подстроку «ошибка»:
|= «ошибка»
Полный запрос с использованием этого примера:
{job="mysql"} |= "ошибка"Отбросить строки журнала, содержащие подстроку «kafka.
server:type=ReplicaManager»:!= "kafka.server:type=ReplicaManager"
Полный запрос с использованием этого примера:
{instance=~"kafka-[23]",name="kafka"} != "kafka.server:type=ReplicaManager"Сохраняйте строки журнала, содержащие подстроку, начинающуюся с
tsdb-opsи заканчивающуюсяio:2003. Полный запрос с регулярным выражением:{name="kafka"} |~ "tsdb-ops.*io:2003"Сохранить строки журнала, содержащие подстроку, начинающуюся с
ошибка =, за которым следует 1 или более символов слова. Полный запрос с регулярным выражением:{name="cassandra"} |~ `error=\w+`
 server:type=ReplicaManager»:
server:type=ReplicaManager»: Операторы фильтра могут быть объединены в цепочку.
Фильтры применяются последовательно.
Результаты запроса будут удовлетворять каждому фильтру.
Этот полный пример запроса даст результаты, содержащие строку error ,
и не включайте строку timeout .
{job="mysql"} |= "ошибка" != "тайм-аут"
При использовании |~ и !~ может использоваться регулярное выражение синтаксиса Go (как в Golang) RE2.
По умолчанию соответствие чувствительно к регистру.
Переключитесь на поиск без учета регистра, добавив префикс к регулярному выражению.
с (?i) .
Хотя выражения линейного фильтра можно размещать в любом месте конвейера журналов, почти всегда лучше иметь их в начале. Размещение их в начале повышает производительность запроса, так как он выполняет дальнейшую обработку только тогда, когда строка совпадает. Например, а результаты будут те же запрос указан с
{job="mysql"} |= "ошибка" | json | line_format "{{.ошибка}}"
всегда будет работать быстрее, чем
{job="mysql"} | json | line_format "{{.message}}" |= "ошибка"
Выражения линейного фильтра — это самый быстрый способ фильтрации журналов после
были применены селекторы потока журналов.
Выражения линейного фильтра поддерживают сопоставление IP-адресов. Дополнительные сведения см. в разделе Сопоставление IP-адресов.
Удаление цветовых кодов
Выражения линейного фильтра поддерживают удаление последовательностей ANSI (цветовых кодов) из строка:
{задание = "пример"} | обесцвечивать
Выражение фильтра меток
Выражение фильтра меток позволяет фильтровать строки журнала, используя их исходные и извлеченные метки. Он может содержать несколько предикатов.
Предикат содержит идентификатор метки , операцию и значение для сравнения метки.
Например, с cluster="namespace" кластер является идентификатором метки, операция = и значение "namespace". Идентификатор метки всегда находится слева от операции.
Мы поддерживаем несколько типов значений , которые автоматически выводятся из входных данных запроса.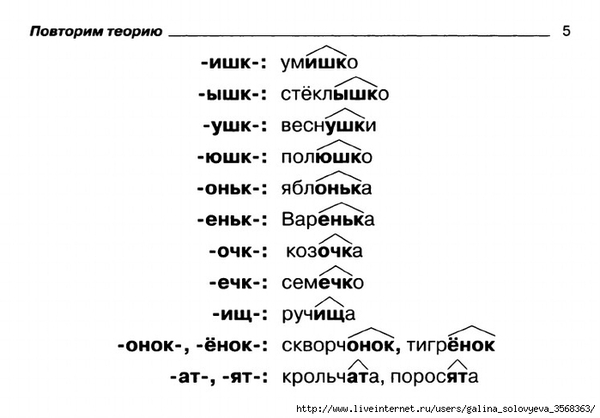
- Строка заключена в двойные кавычки или в обратную сторону, например
"200"или `us-central1`. - Продолжительность — это последовательность десятичных чисел, каждое из которых может содержать дробную часть и суффикс единицы измерения, например «300 мс», «1,5 ч» или «2 ч 55 мин». Допустимые единицы времени: «нс», «нас» (или «мкс»), «мс», «с», «м», «ч».
- Число — число с плавающей запятой (64 бита), например
250,89,923. - Байты — это последовательность десятичных чисел, каждое из которых может содержать дробную часть и суффикс единицы измерения, например «42 МБ», «1,5 КБ» или «20 байт». Допустимые единицы измерения байтов: «b», «kib», «kb», «mib», «mb», «gib», «gb», «tib», «tb», «pib», «pb», «eib». ", "эб".
Строковый тип работает точно так же, как средства сопоставления меток Prometheus используют в селекторе потока журналов. Это означает, что вы можете использовать те же операции (
Это означает, что вы можете использовать те же операции ( = , != , =~ , !~ ).
Только строковый тип может отфильтровать строку журнала с меткой
__error__.
Использование Duration, Number и Bytes преобразует значение метки перед сравнением и поддерживает следующие компараторы:
-
==или=для равенства. -
!=для неравенства. -
>и>=для больше и больше или равно. -
<и<=для меньше и меньше или равно.
Например, logfmt | продолжительность > 1 м и bytes_consumed > 20 МБ
Если преобразование значения метки не удается, строка журнала не фильтруется и добавляется метка __error__ . Чтобы отфильтровать эти ошибки, см. раздел ошибок конвейера.
Вы можете связать несколько предикатов, используя и и или , которые соответственно выражают и и или двоичные операции.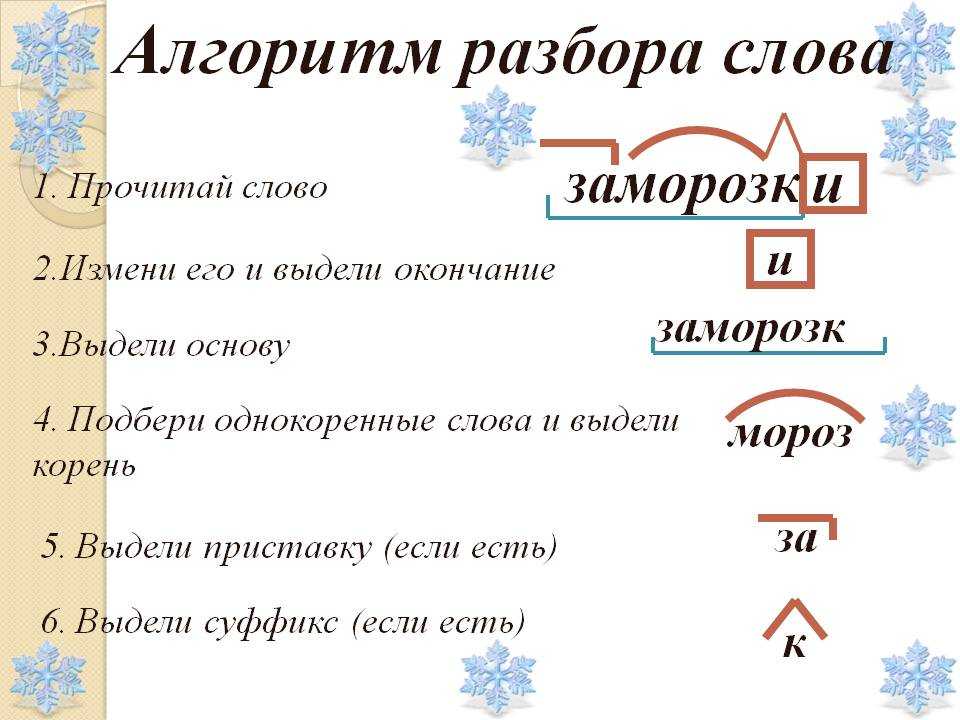
и могут быть эквивалентно выражены запятой, пробелом или другой вертикальной чертой. Фильтры меток можно размещать в любом месте конвейера журналов.
Это означает, что все следующие выражения эквивалентны:
| длительность >= 20 мс или размер == 20 КБ и метод!~"2.." | продолжительность >= 20 мс или размер == 20 КБ | метод!~"2.." | длительность >= 20 мс или размер == 20 КБ, метод!~"2.." | длительность >= 20 мс или размер == 20 КБ метод!~"2.."
Приоритет оценки нескольких предикатов слева направо. Вы можете заключать предикаты в круглые скобки, чтобы задать другой приоритет.
Эти примеры эквивалентны:
| продолжительность >= 20 мс или метод = "GET" и размер <= 20 КБ | ((продолжительность >= 20 мс или метод = "GET") и размер <= 20 КБ)
Чтобы сначала оценить логические и , используйте круглые скобки, как в этом примере:
| продолжительность >= 20 мс или (метод = "GET" и размер <= 20 КБ)
Выражения фильтра меток — это единственное выражение, разрешенное после выражения развертывания.
 Это в основном позволяет фильтровать ошибки при извлечении метрики.
Это в основном позволяет фильтровать ошибки при извлечении метрики.Выражения фильтра меток поддерживают сопоставление IP-адресов. Дополнительные сведения см. в разделе Сопоставление IP-адресов.
Выражение синтаксического анализатора
Выражение синтаксического анализатора может анализировать и извлекать метки из содержимого журнала. Затем эти извлеченные метки можно использовать для фильтрации с помощью выражений фильтра меток или для агрегирования метрик.
Извлеченные ключи-метки автоматически очищаются всеми синтаксическими анализаторами в соответствии с соглашением об именах метрик Prometheus. (Они могут содержать только буквы и цифры ASCII, а также знаки подчеркивания и двоеточия. Они не могут начинаться с цифры.)
Например, трубопровод | json создаст следующее сопоставление:
{ "a.b": {c: "d"}, e: "f" }
->
{a_b_c="d", e="f"}
В случае ошибок, например, если строка не в ожидаемом формате, строка лога не будет фильтроваться, а получит новый __error__ добавлена метка.
Если имя извлеченного ключа метки уже существует в исходном потоке журнала, к извлеченному ключу метки будет добавлено ключевое слово _extracted , чтобы провести различие между двумя метками. Вы можете принудительно переопределить исходную метку, используя выражение средства форматирования метки. Однако, если извлеченный ключ появляется дважды, будет сохранено только последнее значение метки.
Loki поддерживает парсеры JSON, logfmt, pattern, regexp и unpack.
Если есть возможность, проще использовать предопределенные парсеры json и logfmt . Если вы не можете, парсеры pattern и regexp можно использовать для строк журнала с необычной структурой. Парсер шаблона писать проще и быстрее; он также превосходит синтаксический анализатор регулярных выражений .
Один конвейер журналов может использовать несколько синтаксических анализаторов. Это полезно для анализа сложных журналов. Примеры есть в Несколько парсеров.
Примеры есть в Несколько парсеров.
JSON
Парсер json работает в двух режимах:
без параметров :
Добавление
| jsonв ваш конвейер извлечет все свойства json в виде меток, если строка журнала является допустимым документом json. Вложенные свойства объединяются в ключи меток с помощью разделителя_.Примечание: Массивы пропускаются .
Например, парсеры json извлекут из следующего документа:
{ "протокол": "HTTP/2.0", "серверы": ["129.0.1.1", "10.2.1.3"], "запрос": { "время": "6.032", "метод": "ПОЛУЧИТЬ", "хост": "foo.grafana.net", "размер": "55", "заголовки": { "Принимать": "*/*", «Агент пользователя»: «curl/7.68.0» } }, "ответ": { "статус": 401, "размер": "228", "latency_seconds": "6.031" } }Следующий список меток:
"протокол" => "HTTP/2.
0"
"запрос_время" => "6.032"
"метод_запроса" => "ПОЛУЧИТЬ"
"request_host" => "foo.grafana.net"
"размер_запроса" => "55"
"response_status" => "401"
"размер_ответа" => "228"
"response_latency_seconds" => "6,031"
с параметрами :
Использование
| json label="expression", other="expression"в вашем конвейере будет извлекать только указанные поля json в метки. Вы можете указать одно или несколько выражений таким образом, то же самое какlabel_format; все выражения должны быть заключены в кавычки.В настоящее время мы поддерживаем только доступ к полю (
my.field,my["field"]) и доступ к массиву (list[0]) и любую комбинацию из них на любом уровне вложенности (my.list[0]["поле"]).Например,
| json first_server="servers[0]", ua="request.headers[\"User-Agent\"]будет извлечен из следующего документа:{ "протокол": "HTTP/2. 0",
"серверы": ["129.0.1.1","10.2.1.3"],
"запрос": {
"время": "6.032",
"метод": "ПОЛУЧИТЬ",
"хост": "foo.grafana.net",
"размер": "55",
"заголовки": {
"Принимать": "*/*",
«Агент пользователя»: «curl/7.68.0»
}
},
"ответ": {
"статус": 401,
"размер": "228",
"latency_seconds": "6.031"
}
}
Следующий список меток:
"first_server" => "129.0.1.1" "ua" => "curl/7.68.0"
Если массив или объект возвращаются выражением, ему будет присвоена метка в формате json.
Например,
| json server_list="servers", headers="request.headers"будет извлечено:"server_list" => `["129.0.1.1","10.2.1.3"]` "headers" => `{"Accept": "*/*", "User-Agent": "curl/7.68.0"}`Если извлекаемая метка совпадает с исходным полем JSON, выражение можно записать как
| jsonНапример, чтобы извлечь поля
серверовв качестве метки, выражение можно записать следующим образом:| json серверыизвлекут:"серверы" => `["129.
0.1.1","10.2.1.3"]`
Обратите внимание, что
| json-серверытакие же, как| json server="servers"
 0"
"запрос_время" => "6.032"
"метод_запроса" => "ПОЛУЧИТЬ"
"request_host" => "foo.grafana.net"
"размер_запроса" => "55"
"response_status" => "401"
"размер_ответа" => "228"
"response_latency_seconds" => "6,031"
0"
"запрос_время" => "6.032"
"метод_запроса" => "ПОЛУЧИТЬ"
"request_host" => "foo.grafana.net"
"размер_запроса" => "55"
"response_status" => "401"
"размер_ответа" => "228"
"response_latency_seconds" => "6,031"
 0",
"серверы": ["129.0.1.1","10.2.1.3"],
"запрос": {
"время": "6.032",
"метод": "ПОЛУЧИТЬ",
"хост": "foo.grafana.net",
"размер": "55",
"заголовки": {
"Принимать": "*/*",
«Агент пользователя»: «curl/7.68.0»
}
},
"ответ": {
"статус": 401,
"размер": "228",
"latency_seconds": "6.031"
}
}
0",
"серверы": ["129.0.1.1","10.2.1.3"],
"запрос": {
"время": "6.032",
"метод": "ПОЛУЧИТЬ",
"хост": "foo.grafana.net",
"размер": "55",
"заголовки": {
"Принимать": "*/*",
«Агент пользователя»: «curl/7.68.0»
}
},
"ответ": {
"статус": 401,
"размер": "228",
"latency_seconds": "6.031"
}
}
 0.1.1","10.2.1.3"]`
0.1.1","10.2.1.3"]`
logfmt
Парсер logfmt может работать в двух режимах:
без параметры:
Парсер logfmt можно добавить с помощью
| logfmtи извлечет все ключи и значения из строки журнала в формате logfmt.Например, следующая строка журнала:
at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service=8ms status=200
приведет к извлечению следующих меток:
"at" => "info" "метод" => "ПОЛУЧИТЬ" "путь" => "/" "хост" => "grafana.net" "вперед" => "124.133.124.161" "сервис" => "8мс" "статус" => "200"
с параметрами :
Аналогично JSON, с использованием
| logfmt label="expression", other="expression"в конвейере приведет к извлечению только полей, указанных метками.Например,
| logfmt, fwd_ip="fwd"извлечет меткиhostиfwdиз следующей строки журнала:at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service =8мс статус=200
И переименовать
fwdвfwd_ip:"host" => "grafana.net" "fwd_ip" => "124.133.124.161"

Шаблон
Анализатор шаблонов позволяет явно извлекать поля из строк журнала, определяя выражение шаблона ( | шаблон "<выражение-шаблона>" ). Выражение соответствует структуре строки журнала.
Рассмотрим эту строку журнала NGINX.
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76 .247.102, 34.120.177.193" "TLSv1.2" "США" ""
Эту строку журнала можно проанализировать с помощью выражения
для извлечения этих полей:
"ip" => "0.
 191.12.2"
"метод" => "ПОЛУЧИТЬ"
"uri" => "/api/plugins/versioncheck"
"статус" => "200"
"размер" => "2"
"агент" => "Перейти-http-клиент/2.0"
191.12.2"
"метод" => "ПОЛУЧИТЬ"
"uri" => "/api/plugins/versioncheck"
"статус" => "200"
"размер" => "2"
"агент" => "Перейти-http-клиент/2.0"
Выражение шаблона состоит из захватов и литералов.
Захват — это имя поля, разделенное символами < и > . <пример> определяет имя поля пример .
Безымянный захват отображается как <_> . Безымянный захват пропускает соответствующий контент.
Захваты сопоставляются с начала строки или предыдущего набора литералов до конца строки или следующего набора литералов. Если захват не соответствует, парсер шаблона остановится.
Литералы могут быть любой последовательностью символов UTF-8, включая символы пробела.
По умолчанию выражение шаблона привязывается к началу строки журнала. Если выражение начинается с литералов, то строка журнала также должна начинаться с того же набора литералов. Используйте <_> в начале выражения, если вы не хотите привязывать выражение в начале.
Рассмотрим строку журнала
level=debug ts=2021-06-10T09:24:13.472094048Z caller=logging.go:66 traceID=0568b66ad2d9294c msg="POST /loki/api/v1/push (204) 16.65 2862 мс "
Чтобы сопоставить msg=" , используйте выражение:
<_> msg="( ) "
Выражение шаблона недопустимо, если
- Оно не содержит именованного захвата.
- Содержит два последовательных захвата, не разделенных пробелами.
Регулярное выражение
В отличие от logfmt и json, которые неявно извлекают все значения и не принимают никаких параметров, синтаксический анализатор regexp принимает один параметр | regexp ", которое является регулярным выражением, использующим синтаксис Golang RE2.
Регулярное выражение должно содержать хотя бы одно именованное подсовпадение (например, (?P ), каждое подсовпадение будет извлекать разные метки.
Например парсер | регулярное выражение "(?P<метод>\\w+) (?P<путь>[\\w|/]+) \\((?P<статус>\\d+?)\\) (?P<длительность> . будет извлекаться из следующей строки: *)"
*)"
POST /api/prom/api/v1/query_range (200) 1,5 с
эти метки:
"метод" => "POST" "путь" => "/api/prom/api/v1/query_range" "статус" => "200" "длительность" => "1,5 с"
unpack
Парсер unpack анализирует строку журнала JSON, распаковывая все встроенные метки из этапа pack Promtail. Специальное свойство _entry также будет использоваться для замены исходной строки журнала .
Например, используя | распаковать со строкой журнала:
{
"контейнер": "myapp",
"стручок": "стручок-3223f",
"_entry": "исходное сообщение журнала"
}
извлекает контейнер и этикетки pod ; он устанавливает исходное сообщение журнала в качестве новой строки журнала.
Вы можете комбинировать синтаксические анализаторы unpack и json (или любые другие синтаксические анализаторы), если исходная встроенная строка журнала имеет определенный формат.
Выражение формата строки
Выражение формата строки может перезаписывать содержимое строки журнала с использованием формата текста/шаблона.
Он принимает один строковый параметр | line_format "{{.label_name}}" , который является форматом шаблона. Все метки внедряются в шаблон как переменные и доступны для использования с нотацией {{.label_name}} .
Например, следующее выражение:
{container="frontend"} | логфмт | line_format "{{.query}} {{.duration}}"
Извлечет и перезапишет строку журнала, чтобы она содержала только запрос и продолжительность запроса.
Вы можете использовать строку в двойных кавычках для шаблона или обратных кавычек `{{.label_name}}` , чтобы избежать необходимости экранировать специальные символы.
line_format также поддерживает математические функции . Пример:
Если у нас есть следующие метки ip=1.1.1.1 , статус=200 и продолжительность=3000 (мс), мы можем разделить продолжительность на 1000 чтобы получить значение в секундах.
{контейнер = "интерфейс"} | логфмт | line_format "{{.ip}} {{.status}} {{div .duration 1000}}"
Приведенный выше запрос даст нам строка как 1.1.1.1 200 3
См. функции шаблона, чтобы узнать о доступных функциях в формате шаблона.
Выражение формата этикеток
| Выражение label_format может переименовывать, изменять или добавлять метки. Он принимает в качестве параметра список операций равенства, разделенных запятыми, что позволяет выполнять несколько операций одновременно.
Если обе стороны являются идентификаторами меток, например dst=src , операция переименует src 9этикетка 0081 в dst .
В качестве альтернативы правая сторона может быть строкой шаблона (двойные кавычки или обратная кавычка), например dst="{{.status}} {{.query}}" , и в этом случае значение метки dst заменяется по результату оценки текста/шаблона. Это тот же шаблонизатор, что и в | line_format , что означает, что метки доступны как переменные, и вы можете использовать тот же список функций.
В обоих случаях, если метка назначения не существует, создается новая.
Форма переименования dst=src сбросит метку src после переназначения ее на метку dst . Однако форма шаблона сохранит указанные метки, так что dst="{{.src}}" приводит к тому, что dst и src имеют одинаковое значение.
Одно имя метки может появляться только один раз в выражении. Это означает
| label_format foo=bar,foo="new"не допускается, но вы можете использовать два выражения для желаемого эффекта:| label_format foo=бар | label_format foo="new"
Выражение меток перетаскивания
Синтаксис : |отбрасываемое имя, другое_имя, какое-то_имя="некое_значение"
Оператор = после имя метки — это оператор сопоставления меток .
Поддерживаются следующие операторы сопоставления меток:
-
=: точно равно -
!=: не равно -
=~: регулярное выражение соответствует -
!~: регулярное выражение не соответствует
| drop удалит заданные метки в конвейере. Например, для запроса
Например, для запроса {job="varlogs"}|json|drop level, method="GET" со строкой журнала ниже
{"level": "info", "method": "GET", "путь": "/", "хост": "grafana.net", "статус": "200"}
результатом будет
{host="grafana.net", path="status="200"} {"level": "info", "method": "GET", "path": "/" , "хост": "grafana.net", "статус": "200"}
Аналогично, это выражение можно использовать для удаления меток __error__ . Например, для запроса {job="varlogs"}|json|drop __error__ со строкой журнала ниже
INFO GET / loki.net 200
результатом будет
{} INFO GET / loki.net 200
Пример с регулярным выражением и несколькими именами
Для запроса {job="varlogs"}|json|drop level, path, app=~"some-api.*" , со строками журнала ниже
{"app ": "some-api-service", "level": "info", "method": "GET", "path": "/", "host": "grafana.net", "status": "200 }
{"приложение: "другая служба", "уровень": "информация", "метод": "GET", "путь": "/", "хост": "grafana.