Разбери по составу слова: низкие, отметили, перелетали.
Морфемы составляют слова. Разбираем слово на составные по схеме при этом не всегда обнаружим корень, приставку, суффикс и окончание.
Есть слова только с корнем (суп) или несколькими корнями (двухсоткилометровый), 2-3 приставками (беспомощность, предрасположенность), тремя суффиксами (бесхитростный, убыточный).
Анализ состава слова
- Вопрос к слову определяет часть речи.
- Окончанием зовется изменяемая часть слова. Склоняя/спрягая слово, меняем его.
- Основа — остаток после отделения окончания. Корень, приставку и суффикс следует искать там.
- Корнем именуются общая часть родственных слов.
- В начале слова, перед корнем, найдем приставку.
- Суффикс стоит после корня, перед окончанием.
Неизменяемые слова (жабо), наречия, деепричастия не имеют окончаний. В изменяемом слове не просматривается окончание нулевое (прилетел).
Суффикс порой находится не перед окончанием, постфикс «ся» (отметился).
Примеры разбора слов по составу
Слово «низкие»
- «Какие?» — прилагательное.
- Ищем окончание, изменяемую часть слова: «низкий», «низкая», «низкое» — «ие».
- Основа — «низк».
- Родственные слова: «низко», «низковатый»,
«низкокачественный», «низковато». Общая «низк» будет корнем. - Приставки нет.
- Суффикса нет.
«Перелетали»
- Глагол, потому что вопрос «что делали?».
- Изменяемая часть: «перелетал», перелетала», «перелетало» указывает на окончание «и».
- Основа в слове — «перелета».
- Родственные слова: «летать», «перелететь», «перелет», «взлет», полет», «влетать», «прилетать», «полет». Общая часть слов «лет» именуется корнем.
- Приставка — пре.
- Суффиксы: а, л.
«Отметили»
- «Что сделали?» — глагол.
- Ищем изменяемую часть: «отметило, «отметила», «отметил» — разыскали окончание «и».

- Основа — «отмети».
- Родственные слова: «отметиться», «метить», «заметить», «отметка», «отмечаться», «метка», «наметить», «разметить». Общая часть «мет» зовется корнем.
- Приставка — от.
- Суффиксы: и, л.

В словах»отметили», «пролетели» суффикс «л» употреблялся для формирования прошедшего времени глагола, составляющей основы он не является.
Помогите срочнооооо Разбор слова НИЗКИЕ по составу Разбор по членам предложение НИЗКИЕ
Подчеркните, дополнение, обстоятельство и др На далёком горизонте показались отблески зари. На тополей и березе затрепетали листья. В ночном воздухе ч … увствовалась влажность
Отдам поселение баллы 589Перепишите. Сделайте полный морфологический разбор выде- ленных глагольных форм. Определите их роль в тексте. Найдите в текст … е глаголы, образованные префиксальным способом.
Надите синоним к слову дорога Путь, шоссе, трасса, поле,
I. Спишите текст
Путешествие по Арлю
Арль – маленький французский город. Но когда-то он был велик и знаменит. Завоевавшие Арль римляне превратили мале
… нькое поселение на берегу Роны в крупный экономический центр. Ткачи, золотых дел мастера, оружейники вели бойкую торговлю. Был воздвигнут Форум, построена громадная арена, античный театр, акведук длиной в семьдесят пять километров. Город, процветал.
Нашествие варваров положило конец процветанию. Город стал кормиться за счет туристов, руин и былого величия. Вот краткая история города, прожившего ни больше, ни меньше, как двадцать пять веков.
Бродить по улицам Арля – одно наслаждение. Идешь не торопясь по узенькой, мощенной камнем улочке – и вдруг перед тобой что-то большое, с арками, колоннами. Оказывается, это римская арена, та самая, где гибли когда-то гладиаторы. В средние века арена была крепостью, защищавшей целый город с домами, улицами, даже церковью. Сейчас от города ничего не осталось, но реставраторы с великим тактом и вкусом восстановили стены крепости, искусственно создав патину времени. Новые, такие же обветренные, иссеченные дождями части здания ничем не отличаются от старых.
Но когда-то он был велик и знаменит. Завоевавшие Арль римляне превратили мале
… нькое поселение на берегу Роны в крупный экономический центр. Ткачи, золотых дел мастера, оружейники вели бойкую торговлю. Был воздвигнут Форум, построена громадная арена, античный театр, акведук длиной в семьдесят пять километров. Город, процветал.
Нашествие варваров положило конец процветанию. Город стал кормиться за счет туристов, руин и былого величия. Вот краткая история города, прожившего ни больше, ни меньше, как двадцать пять веков.
Бродить по улицам Арля – одно наслаждение. Идешь не торопясь по узенькой, мощенной камнем улочке – и вдруг перед тобой что-то большое, с арками, колоннами. Оказывается, это римская арена, та самая, где гибли когда-то гладиаторы. В средние века арена была крепостью, защищавшей целый город с домами, улицами, даже церковью. Сейчас от города ничего не осталось, но реставраторы с великим тактом и вкусом восстановили стены крепости, искусственно создав патину времени. Новые, такие же обветренные, иссеченные дождями части здания ничем не отличаются от старых.
Летчик бросает машину вниз потому что только на предельной скорости можно проскачить через грозу. Выделить члены предложения
Помогите, пожалуйста! Подчеркните орфограмму Давно сняли пахучую антоновка. Налетел осений ветер. Тряхнул вершины деревьев. В саду над землёй взлетели … и закружились осенние листья
Отдаю последние баллы помогите пожалуйста
Перепишите. Сделайте полный морфологический разбор выде-
ленных глагольных форм. Определите их роль в
… тексте. Найдите
в тексте глаголы, образованные префиксальным способом. Муравейник… Как хочет…ся ковырнуть его палкой! Но
лучше не делай этого, а присяд…, п…следи за таинстве…ой
Жизнью. И, смотриш…, найдет…ся кто-нибудь, об…яснит, что
лес Зд…ровьем своим обязан этим маленьким муравьям. Одно
дело — слышать ра…сказ на школьном уроке, другое — уви-
деть ручей, который не высох бы, если бы не срубили лес у
руч…я. А сами руч…и… Большая река наполняет…ся только
этими ручейками. Засорились, заглохли — мелеет река.
З
Муравейник… Как хочет…ся ковырнуть его палкой! Но
лучше не делай этого, а присяд…, п…следи за таинстве…ой
Жизнью. И, смотриш…, найдет…ся кто-нибудь, об…яснит, что
лес Зд…ровьем своим обязан этим маленьким муравьям. Одно
дело — слышать ра…сказ на школьном уроке, другое — уви-
деть ручей, который не высох бы, если бы не срубили лес у
руч…я. А сами руч…и… Большая река наполняет…ся только
этими ручейками. Засорились, заглохли — мелеет река.
З
Древнерусское слово X, впоследствии претерпевшему русском языке некоторое фонетическое изменение , относится к глаголу Y так же, как клинъ к Z, и по п … роисхождению означает «(приготовленный) из молотого» (то есть из муки). Какие слова мы заменили на X, Y и Z
Выпишите из текста 3 качественных прилагательных и образуйте краткую форму, сравнительную и превосходную степени сравнения
===========================
… ================================================
Текст:
Приближался весенний месяц май. Для него гремел мартовский лед в грозном ледоходе, чтобы освободилась река и напоила землю, дала жизнь хрупкой зелени. Апрельское солнышко старается растопить остатки рыхлого снега и освободить место пахучему ландышу.
В эти дни леса еще не совсем одеты, но на лиственных деревьях уже набухли клейкие почки. На темно-зеленых елях появились нежные и легкие кисточки.
У птиц в это время очень много забот. Надо выбрать тихое место для гнезда, прочно его свить, мягко выстелить мягчайшим пухом.
Это не мешает трудолюбивым птичкам разливать вокруг свои задорные песни. Даже в туманных сумерках, не утихает весенний концерт.
Для него гремел мартовский лед в грозном ледоходе, чтобы освободилась река и напоила землю, дала жизнь хрупкой зелени. Апрельское солнышко старается растопить остатки рыхлого снега и освободить место пахучему ландышу.
В эти дни леса еще не совсем одеты, но на лиственных деревьях уже набухли клейкие почки. На темно-зеленых елях появились нежные и легкие кисточки.
У птиц в это время очень много забот. Надо выбрать тихое место для гнезда, прочно его свить, мягко выстелить мягчайшим пухом.
Это не мешает трудолюбивым птичкам разливать вокруг свои задорные песни. Даже в туманных сумерках, не утихает весенний концерт.
Найдите глаголы в условном наклонении. Ответ обведите. А отправил, могу, разрешает; Б сказал бы, знал бы, решил бы; В приходи, намажь, отрежь.
Морфологический разбор причастий онлайн
Морфологический разбор причастий онлайнПричастие — изменяемая часть речи, при морфологическом разборе причастия учитывают постоянные и непостоянные морфологические признаки. В предложениях причастия чаще всего являются определением.
В предложениях причастия чаще всего являются определением.
Перечислим характеристики причастий для составления морфологического разбора.
- Общее значение: означает признак предмета по действию.
- Вопрос: какой? (ставится в нужной форме).
- Начальная форма: именительный падеж, единственное число, мужской род.
- Морфологические признаки:
Постоянные признаки: действительное или страдательное, время, вид.
Непостоянные признаки: полная или краткая форма (у страдательных), падеж (в полной форме), число, род. - Синтаксическая роль:
Определение;
Краткие страдательные — именная часть составного сказуемого.
План разбора
- Часть речи, от какого глагола образовано, общее значение.
- Морфологические признаки:
- Начальная форма — именительный падеж, единственное число, мужской род.
- Постоянные признаки: действительное или страдательное, время, вид.
- Непостоянные признаки: полная или краткая форма (у страдательных), падеж (в полной форме), число, род.
- Синтаксическая роль.

Пример разбора
Даны предложения: «Первая комната была оклеена по брёвнам старыми газетами. По небу, гонимые ветром, бежали низкие, серые, рваные облака.» (К. Симонов).
Задание: сделать морфологический разбор слов оклеена, гонимые.
- Оклеена — причастие, обозначает признак предмета по действию (комната, которую оклеили), образовано от глагола оклеить.
- Морфологические признаки:
- Начальная форма — оклеенный.
- Постоянные признаки: страдательное, прошедшее время, совершенный вид.
- Непостоянные признаки: краткая форма, единственное число, женский род.
- В предложении является именной частью составного сказуемого (какова?): оклеена.
- Гонимые — причастие, обозначает признак предмета по действию (облака, которые гонит ветер), образовано от глагола гнать.
- Морфологические признаки:
- Начальная форма — гонимый.
- Постоянные признаки: страдательное, настоящее время, несовершенный вид.
- Непостоянные признаки: полная форма, именительный падеж, множественное число.
- Начальная форма — гонимый.
- В предложении является определением (какие?): гонимые.

Наш сайт делает морфологический разбор причастий. Введите слово в текстовое поле и нажмите кнопку.
Слова с буквой ё пишите через букву ё (не через е!). Пчелы и пчёлы или слезы и слёзы — разные слова, имеющие разные морфологические разборы.
morphologyonline.ru — морфологический разбор слов
Урок 9. какие бывают главные и второстепенные члены предложения — Русский язык — 4 класс
Русский язык, 4 класс
Урок № 9.
Тема: Какие бывают главные и второстепенные члены предложения.
ОРГАНИЗАЦИОННЫЙ МОМЕНТ:
Цель нашего урока – научиться разбирать предложение по составу.
Задачи:
- Узнать, какие бывают члены предложения, какая у них функция и как они выделяются при разборе.
- Научиться находить основу предложения.
- Порассуждать, какие бывают предложения.

Результаты:
- Узнаем, что такое основа предложения, главные и второстепенные члены.
- Научимся находить и выделять члены предложения, определять, какой частью речи они выражены.
- Потренируемся выделять предложения в тексте.
Тезаурус
Главные члены предложения – это грамматическая основа предложения.
Подлежащее – это главный член предложения, который обозначает, о ком или о чём говорится в предложении, и отвечает на вопросы: кто? или что?
Сказуемое – это главный член предложения, который связан с подлежащим и отвечает на вопросы: что делает предмет? каков предмет? что такое предмет? кто такой?
Второстепенными называют все члены предложения, кроме подлежащего и сказуемого.
Определение – это второстепенный член предложения, который обозначает признак предмета и отвечает на вопросы какой? чей?
Дополнение – это второстепенный член предложения, который отвечает на вопросы косвенных падежей.
Обстоятельство – это второстепенный член предложения, который обозначает место (где? куда? откуда?), время (когда? с каких пор? до каких пор?), причину (почему? отчего?), образ действия (как? каким образом?) и пр.
Список литературы
Основная литература
- Канакина В. П., Горецкий В. Г. Русский язык. 4 класс: учеб. для общеобразоват. организаций. В 2 ч. Ч. 1 — М.: Просвещение, 2018. – 160 с.
- Канакина В. П., Горецкий В. Г. Русский язык. 4 класс: учеб. для общеобразоват. организаций. В 2 ч. Ч. 2 — М.: Просвещение, 2018. – 160 с.
Дополнительная литература
- Канакина В. П. Русский язык. Рабочая тетрадь. 4 класс. В 2 ч. Ч. 1. — М.: Просвещение, 2018.
- Канакина В. П. Русский язык. Рабочая тетрадь. 4 класс. В 2 ч. Ч. 2. — М.: Просвещение, 2018.
- Канакина В. П. и др. Русский язык. 4 класс. Электронное приложение. — М.: Просвещение, 2011.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Сегодня на уроке мы поговорим о строительстве. Но не домов, а предложений. В качестве строительных материалов мы будем использовать члены предложения.
Но не домов, а предложений. В качестве строительных материалов мы будем использовать члены предложения.
- Какие члены предложения вы помните?
Подлежащее, сказуемое, определение, дополнение, обстоятельство.
Чтобы построить дом, сначала нужно залить фундамент – главную часть, на которой будет держаться вся постройка. В предложении роль такого фундамента выполняет грамматическая основа: подлежащее и сказуемое. Подлежащее обозначает человека или предмет, о котором говорится в предложении. Сказуемое обозначает действие в предложении.
Дома бывают разные: высокие и малоэтажные, большие и маленькие. Это зависит от стен. В предложении стены – это второстепенные члены предложения: определение характеризует предмет или человека, обстоятельство рассказывает о времени, месте, причине и способе действия, дополнение сообщает дополнительную информацию.
Чтобы дом был готов нужна ещё крыша. В предложении крыша – это знаки препинания: точка, восклицательный знак, вопросительный знак. Многоточие.
Многоточие.
- Вспомните, от чего зависит выбор знака?
Конечно, от интонации.
Подлежащее и сказуемое называются основой предложения, а определение, дополнение и обстоятельство – второстепенными членами предложения.
Давайте подставим в схему реальные слова:
Умные ребята быстро строят предложения.
Посмотрите, как они связаны между собой. Подлежащее обычно выражено именем существительным обязательно в именительном падеже. Сказуемое зависит от подлежащего и обычно выражено глаголом, определение может зависеть от любого существительного и обычно выражено прилагательным или притяжательным местоимением, обстоятельство зависит от сказуемого и обычно выражено наречием или существительным с предлогом, дополнение часто зависит от сказуемого или других членов предложения и обычно выражено существительным в косвенном падеже.
ДОПОЛНИТЕЛЬНО
Предложения, которые состоят только из подлежащего и сказуемого называются нераспространенными: Наступила зима.
Предложения, которые состоят из главных и второстепенных членов называются распространёнными: Сегодня наступила настоящая снежная зима.
Познакомьтесь со схемой разбора предложения на странице 149 учебника:
Пользуясь этой схемой, сделайте разбор предложения в тетради:
Скоро в саду распустятся красивые белые лилии.
ПРАКТИЧЕСКАЯ ЧАСТЬ
Задание 1.
Соедините члены предложения и части речи, которыми они чаще всего выражены.
- Подлежащее 1. Глагол
- Сказуемое 2. Наречие
- Определение 3. Прилагательное
- Обстоятельство 4. Существительное
Задание 2. Разгадайте кроссворд:
- Главный член предложения, обозначающий действие.
- Второстепенный член предложения, обозначающий признак действия.
- Второстепенный член предложения, обозначающий предмет, поясняет сказуемое
- Главный член предложения, обозначающий предмет.
- Второстепенный член предложения, обозначающий признак предмета.

1 |
|
|
|
|
|
|
|
|
|
| 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Задание 3. Отделите части речи от членов предложения:
Отделите части речи от членов предложения:
Существительные, определение, дополнение, глагол, прилагательное, сказуемое, наречие, подлежащее, местоимение, предлог, союз, обстоятельство
Части речи | Члены предложения |
Задание 4. Выделите цветом вопросы косвенных падежей
Как? Когда? Кого? Кому? О чем? Кто? Зачем? Что делать? О ком? Кем? Что? Где?
Задание 5. Выделите в тексте грамматические основы предложений:
Летели и летели осеннее листья. Ветер подхватил их и погнал к речке. По зеркальной воде поплыли золотые монетки. На краю деревни заиграл рожок. Это пастух собирал стадо. Я выхожу из дома, беру весла и иду к речке. Восток светлеет, розовеет. Река словно похорошела, выпрямилась. Под первыми лучами солнца засверкали, заискрились капельки воды. Стояла чудесная пора осени.
Задание 6. Составьте из слов и знаков препинания предложения, чтобы получился текст.
Слова: осени, дни, холодные, наступили;
в, плавали. жёлтые, лужах, листья;
жёлтые, лужах, листья;
небу, низкие, ползли, по, тучи;
Знаки: . . .
Задание 7. Соотнесите предложения и схемы.
- Ребята по лесной тропинке вышли на поляну.
- Анна и Инна угостили ребят печеньем.
- Радостные вернулись ребята с прогулки!
- [_______ _________].
- [_______ и _______ _________].
- [________ ___________]!
Задание 8. Соедините название второстепенного члена предложения и его обозначение в схеме:
Определение
Дополнение
Обстоятельство
Сказуемое
________
________
________
Задание 9. Спишите предложение в тетрадь и выпишите грамматическую основу предложения.
В воздухе кружатся белые снежинки.
Задание 10. Подчеркните второстепенные члены предложения:
Покраснели осинки, пожелтели берёзки. Гроздья ягод созрели на рябинах. Кругом растёт пушистый ельник. Зеленеют молодые елочки. Из земли бьёт чистый родник.
Задание 11. Вставьте пропущенные буквы.
Вставьте пропущенные буквы.
Ясное в..сеннее утро. Развернулись на ни..ких кустиках м..л..дые л..сточки. Из з..мли выглядывают у..кие стрелки свежей тра..ки. Покачиваются на бере..ке лё..кие серё..ки.
Задание 12. Зачеркните лишнее слово в каждом ряду. Объясните свой выбор.
- Определение, подлежащее, дополнение, обстоятельство.
- Существительное, прилагательное, сказуемое, наречие.
- Подлежащее, сказуемое, определение, союз
Задание 13.
Определите член предложения, который повторяется в предложении:
- В саду растут яблоки, груши и персики. ____________________________
- Я был в Москве, в Таганроге и во Владивостоке. ____________________________
- Девочка бежала и смеялась. ____________________________
Задание 14* Составьте рассказ по картинке и выделите в нём второстепенные члены предложения.
КОНТРОЛЬНЫЙ МОДУЛЬ
Вариант 1
1. Главные члены предложения — это …
- Словосочетание
- Подлежащее и сказуемое
- Подлежащее и глагол
2. Какой член предложения отвечает на вопросы КАКОЙ? КАКАЯ? КАКОЕ? КАКИЕ?
Какой член предложения отвечает на вопросы КАКОЙ? КАКАЯ? КАКОЕ? КАКИЕ?
- Подлежащее
- Определение
- Сказуемое
3. Каким членом предложения является выделенное слово:
Мама мыла пол в комнате брата.
- Сказуемое
- Подлежащее
- Дополнение
Вариант 2.
1. Главные члены предложения это…
- Подлежащее и сказуемое
- Существительное и глагол
- Словосочетание
2. Какой член предложения отвечает на вопросы: Как? Когда? Где? Куда?
- Подлежащее
- Обстоятельство
- Сказуемое
3. Я слушала музыку, и не слышала, как мама вошла
- Подлежащее
- Обстоятельство
- Сказуемое
ОТВЕТЫ:
Задание 1.
1-4, 2-1, 3-3, 4-2
Задание 2.
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 | с | к | а | з | у | е | м | о | е |
| 4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| б |
|
| п |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| с |
| 5 | о | п | р | е | д | е | л | е | н | и | е |
|
|
|
|
|
|
|
| т |
|
| д |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 | д | о | п | о | л | н | е | н | и | е |
|
|
|
|
|
|
|
|
|
|
|
|
| я |
|
| е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| т |
|
| ж |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| е |
|
| а |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| л |
|
| щ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ь |
|
| е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| с |
|
| е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| т |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| в |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| о |
|
|
|
|
|
|
|
|
|
|
|
|
|
Задание 3.
Части речи: существительное, глагол, прилагательное, наречие, предлог, союз, местоимение
Члены предложения: определение, дополнение, сказуемое, подлежащее, обстоятельство
Задание 4.
Кого? Кому? О чём? О ком? Кем?
Задание 5.
Летели и летели осеннее листья. Ветер подхватил их и погнал к речке. По зеркальной воде поплыли золотые монетки. На краю деревни заигралрожок. Это пастух собирал стадо. Я выхожу из дома, беру весла и иду к речке. Восток светлеет, розовеет. Река словно похорошела, выпрямилась. Под первыми лучами солнца засверкали, заискрились капельки воды. Стояла чудесная пора осени.
Задание 6.
Наступили холодные дни осени. В лужах плавали жёлтые листья. По небу ползли низкие тучи.
Задание 7.
1-1, 2-2, 3-3
Задание 8.
________ дополнение
________ определение
________обстоятельство
Сказуемое — лишнее
Задание 9.
Снежинки кружатся.
Задание 10.
Покраснели осинки, пожелтели берёзки. Гроздья ягод созрели на рябинах/ на рябинах. Кругом растёт пушистый ельник. Зеленеют молодые ёлочки. Из земли бьёт чистый родник.
Задание 11.
Ясное весеннее утро. Развернулись на низких кустиках молодые листочки. Из земли выглядывают узкие стрелки.
Задание 12.
- обстоятельство. (Подлежащее – это главный член предложение, а остальные – второстепенные)
- Существительное, прилагательное,
сказуемое, наречие. (Сказуемое – это член предложения, а остальные – части речи) - Подлежащее, сказуемое, определение,
союз (Союз –это часть речи, а остальные – члены предложения)
Задание 13.
- Подлежащее
- Обстоятельство
- Сказуемое
Контрольный модуль
В-1
1. 2
2. 2
3. 3
В-2
1. 1
2. 2
3.3
Разобрать по составу слова просторной придорожная зимние
Стали туманными не ясными.
Не любят спокойную погоду.
Не глубокий овраг.
Белело не подвижное небо.
Не большой деревеньки?.
Использовала правила: Не с глаголами пишется раздельно , не с прилагательными если слово существует без частицы не то пишется раздельно , а если нет то слитно. Тоже самое правила можно привести к глаголам
Например «ненавидеть» слова «навидеть» нет поэтому пишем слитно.
получи 5!!!!!!!! ; — )
Что могло бы хлопать так?
Может, листьями лопух?
Может, крыльями петух?
Таня встретила бычка.
Это рыжий Борька.
Борька вместо молочка
Съел полыни горькой.
Закричила Таня:-Кинь!
Выплюнь горькую полынь!
Не послушался бычок,
Лёг тихонько на бочок.
Такой
Такого
Такому
Такого
Таким
о Таком

2. Ненастно (Не употребляется без НЕ).
3. Не редко, а часто (Есть противопоставление).
4. Не легко, а трудно (Есть противопоставление).
(PDF) Неглубокий синтаксический анализ только на основе слов: тематическое исследование
другая категория, как в случае VP / S-NOM в примере
.
2.1 Представление задачи и метод оценки
Чтобы сформулировать задачу как машинно-обучаемую классификационную задачу
, мы используем представление, которое кодирует
совместную задачу разбиения на части и тегирования функций предложения
в каждом предложении. экземпляры классификации слов. Как
показано в таблице 2.1, экземпляр (который соответствует
строкам в таблице) состоит из значений
единиц для всех функций (столбцов) и кода фрагмента функции
для слова фокуса. Функции de-
записывают ключевое слово и его локальный контекст. Для фрагментов кода
Для фрагментов кода
мы принимаем кодирование «Внутреннее»,
«Внешнее» и «Между» (IOB), исходное
из (Ramshaw and Marcus, 1995). Для функциональной части кода
значением является либо функция
для заголовка фрагмента, либо фиктивное значение
NOFUNC для всех не-заголовков.Для создания задачи на базе POS
все слова заменяются стандартными тегами POS gold-
, связанными с ними в Penn
Treebank. Для комбинированной задачи одновременно используются оба типа функций.
Когда учащемуся представлены новые экземпляры
из удерживаемого материала, его задача, таким образом, состоит в том, чтобы назначить комбинированные коды функциональных блоков
либо словам, либо
POS в контексте. Из последовательности предсказанных
кодов фрагментов функций можно восстановить полное разбиение на фрагменты и назначение функций
.Как бы то ни было, прогнозы
могут быть несовместимыми, блокируя прямую реконструкцию
полного синтаксического анализа младшего
. Мы использовали следующие четыре правила
Мы использовали следующие четыре правила
для решения таких проблем: (1) Когда за кодом фрагмента O
следует код фрагмента B, или когда за кодом фрагмента
I следует код фрагмента B с
a другой тип блока, B преобразуется в I.
(2) Когда более чем одно слово в блоке получает
код функции, код функции крайнего правого слова
принимается как код функции блока.(3) Если все
слов фрагмента получают теги NOFUNC, предыдущий код функции
назначается самому правому слову
фрагмента. Это предварительное, оцененное на обучающем наборе,
представляет собой наиболее частый функциональный код для этого типа блока
.
Чтобы измерить успешность нашего ученика, мы сравниваем
с точностью, отзывчивостью и их средним гармоническим значением,
с F-оценкой
1
с
= 1 (Van Rijsbergen, 1979).В
оценке комбинированного разделения функций фрагмент
считается правильным только тогда, когда его границы, его тип
и его функция определены правильно.
2.2 Подготовка данных
Наш общий набор данных состоит из всех 74 024 предложений
в Wall Street Journal, Brown и ATIS Cor-
подразделах Penn Treebank III. Мы выполнили
, доминировали порядок предложений в этом наборе данных,
, а затем разделили его на десять разделов 90% / 10%
с непересекающимися 10% частями, чтобы запустить 10-
-кратные эксперименты с перекрестной проверкой (Вайс и Ку-
,Ликовски, 1991).Чтобы предоставить обучающие наборы разного размера для экспериментов с кривой обучения, каждый обучающий набор
(из 66 627 предложений) был также обрезан до
следующих размеров: 100 предложений, 500, 1000, 2000,
5000 , 10,000, 20,000 и 50,000. Все данные были преобразованы в экземпляры, как показано в таблице 2.1. Для общего набора данных
это дает 1 637 268 экземпляров, по одному для
каждого слова или знака препинания. 62 472 типа слов
встречаются в общем наборе данных, а 874 различных функциональных кода —
кодов фрагментов.
2.3 Классификатор: обучение на основе памяти
Возможно, выбор алгоритма не имеет решающего значения в экспериментах с кривой обучения
. Во-первых, мы стремимся измерить
, чтобы определить относительные различия, возникающие в результате выбора
типов входных данных. Во-вторых, есть признаки того, что
, увеличивающий обучающий набор языковой обработки
задач, дает гораздо больший прирост производительности, чем
, варьирующийся между алгоритмами при фиксированных размерах обучающего набора;
кроме того, эти различия также имеют тенденцию к уменьшению
с большими наборами данных (Banko and Brill, 2001).
Обучение на основе памяти (Stanfll and Waltz,
1986; Aha et al., 1991; Daelemans et al., 1999b) — это
контролируемый алгоритм индуктивного обучения для изучения
задач классификации. Обучение на основе памяти обрабатывает
набор помеченных (предварительно классифицированных) обучающих экземпляров
как точки в многомерном пространстве признаков, а
сохраняет их как таковые в базе экземпляров в памяти
(а не выполняя некоторую абстракцию над
их). Классификация в обучении на основе памяти
Классификация в обучении на основе памяти
выполняется алгоритмом
-NN (Cover and Hart,
1967), который ищет «ближайших соседей»
в соответствии с функцией расстояния между двумя in-
1
F
прецизионный отзыв
прецизионный отзыв
Полный анализ
Полный анализследующий: Сопутствующие работы Up: анализ Предыдущая: Разбор словосочетания существительное
Полный анализ
Подход к синтаксическому анализу словосочетаний с существительными, изложенный в предыдущем
раздел можно использовать для генерации деревьев синтаксического анализа, содержащих фразы
произвольные фразы.В этом случае для выполнения полного
парсинг.
Идея не нова.
[Ejerhed and Church (1983)] представляют шведскую грамматику, которая включает именные фразы
правила чанка.
[Abney (1991)] описывает синтаксический анализатор фрагментов, который состоит из двух частей:
один, который находит базовые фрагменты, и другой, который прикрепляет фрагменты
друг к другу, чтобы получить деревья синтаксического анализа. [Daelemans (1995)] предложил находить зависимости на большом расстоянии с помощью
каскад ленивых учеников, среди которых были составные идентификаторы.[Ратнапархи (1998)] построил парсер на основе чанкера с
дополнительный восходящий процесс, который определяет, в какой позиции
начинать новые фразы или присоединяться к избирателям с более ранними.
Благодаря такому подходу он получил самые современные результаты синтаксического анализа.
[Брантс (1999)] применил к задаче каскад фрагментов марковской модели.
разбора немецких предложений.
Мы расширили наши методы синтаксического анализа именных фраз до синтаксического анализа.
произвольные фразы [Tjong Kim Sang (2001b)].
Мы также представим здесь основные результаты этого исследования.
[Daelemans (1995)] предложил находить зависимости на большом расстоянии с помощью
каскад ленивых учеников, среди которых были составные идентификаторы.[Ратнапархи (1998)] построил парсер на основе чанкера с
дополнительный восходящий процесс, который определяет, в какой позиции
начинать новые фразы или присоединяться к избирателям с более ранними.
Благодаря такому подходу он получил самые современные результаты синтаксического анализа.
[Брантс (1999)] применил к задаче каскад фрагментов марковской модели.
разбора немецких предложений.
Мы расширили наши методы синтаксического анализа именных фраз до синтаксического анализа.
произвольные фразы [Tjong Kim Sang (2001b)].
Мы также представим здесь основные результаты этого исследования.
Стандартные наборы данных для тестирования статистических парсеров различны.
чем те, которые мы использовали в нашей более ранней работе над фрагментами и мелкими
парсинг.
Наборы данных были взяты из Wall Street Journal (WSJ).
часть Penn Treebank [Marcus et al. (1993)], но они содержат
разные сегменты.
Данные обучения состоят из разделов 02-21 (39 832 предложения), в то время как
раздел 23 используется в качестве тестовых данных (2416 предложений).
Наборы данных состоят из слов и тегов частей речи, которые имеют
был сгенерирован тегером части речи, описанным
[Ратнапархи (1996)].В данных типы фраз ADVP и PRT свернуты в один
категории и при оценке расстановки знаков препинания в
дерево синтаксического анализа было проигнорировано.
Эти адаптации были сделаны разными авторами для того, чтобы
можно сравнить результаты своих систем с первыми
исследование, в котором использовались эти наборы данных [Magerman (1995)] и все последующие
Работа.
(1993)], но они содержат
разные сегменты.
Данные обучения состоят из разделов 02-21 (39 832 предложения), в то время как
раздел 23 используется в качестве тестовых данных (2416 предложений).
Наборы данных состоят из слов и тегов частей речи, которые имеют
был сгенерирован тегером части речи, описанным
[Ратнапархи (1996)].В данных типы фраз ADVP и PRT свернуты в один
категории и при оценке расстановки знаков препинания в
дерево синтаксического анализа было проигнорировано.
Эти адаптации были сделаны разными авторами для того, чтобы
можно сравнить результаты своих систем с первыми
исследование, в котором использовались эти наборы данных [Magerman (1995)] и все последующие
Работа.
В нашей работе над произвольным синтаксическим анализом мы были заинтересованы в поиске
ответ на четыре вопроса.
Чтобы получить эти ответы, мы провели тесты с меньшими
наборы данных, которые были взяты из стандартных данных обучения для этого
Задача: разделы 15-18 WSJ в качестве обучающих данных и раздел 20 как тестовые данные. Первой темой, которая нас интересовала, было влияние контекста.
размер и размер исследуемого ближайшего соседства (параметр k
обучаемого на основе памяти) от производительности парсера.
Мы взяли парсер именных фраз, разработанный в предыдущем разделе,
сняли ограничение на создание только словосочетаний с существительными и применили его
к этому набору данных при использовании разных размеров контекста и значений для
параметр k для классификаторов, которые идентифицировали фразы выше базового
уровни.
Различные типы фрагментов были получены с использованием
Двухфазный подход к разбиению на части (см. Раздел 3.3).
Лучшая конфигурация, которую мы нашли, была контекстом двух левых и двух
правильные слова и теги POS с k равно 1.
Размер ближайшего соседства меньше, чем использовалось в нашей предыдущей работе.
(3) и лучший размер контекста меньше, чем в нашей существительной фразе
дробление работы (4).
Однако лучший размер контекста, который мы нашли для этой задачи, — это как раз
то же, что и в [Ратнапархи (1998)].
Первой темой, которая нас интересовала, было влияние контекста.
размер и размер исследуемого ближайшего соседства (параметр k
обучаемого на основе памяти) от производительности парсера.
Мы взяли парсер именных фраз, разработанный в предыдущем разделе,
сняли ограничение на создание только словосочетаний с существительными и применили его
к этому набору данных при использовании разных размеров контекста и значений для
параметр k для классификаторов, которые идентифицировали фразы выше базового
уровни.
Различные типы фрагментов были получены с использованием
Двухфазный подход к разбиению на части (см. Раздел 3.3).
Лучшая конфигурация, которую мы нашли, была контекстом двух левых и двух
правильные слова и теги POS с k равно 1.
Размер ближайшего соседства меньше, чем использовалось в нашей предыдущей работе.
(3) и лучший размер контекста меньше, чем в нашей существительной фразе
дробление работы (4).
Однако лучший размер контекста, который мы нашли для этой задачи, — это как раз
то же, что и в [Ратнапархи (1998)].
Вторая тема, которая нас интересовала, — это тип обучающих данных.
который следует использовать для поиска фраз выше базового уровня.В ходе анализа существительных фраз мы обнаружили, что лучшая производительность
можно получить, используя только данные текущего уровня фразы.
Это вызовет проблемы для нашего парсера, поскольку глубина дерева может
достигнет 31 в нашем корпусе, но обучения будет мало
материал, доступный для этих фраз высокого уровня, если мы будем использовать то же
конфигурация обучения, как в нашей работе по синтаксическому анализу существительной фразы.
Мы протестировали две разные конфигурации обучения, чтобы убедиться, что мы
может использовать больше обучающих данных для этой задачи без потери производительности.С первым из них, используя текущий, предыдущий и следующий уровень фразы,
производительность была также (F = 77,13), так как при использовании только
текущий уровень (77,17).
Однако, когда мы обучили каскад чункеров при использовании скобок
из всех уровней фраз производительность упала до 67,49. Мы решили продолжать использовать текущий уровень фразы только в
данные обучения, несмотря на проблемы с определением более высокого уровня
фразы.
Мы решили продолжать использовать текущий уровень фразы только в
данные обучения, несмотря на проблемы с определением более высокого уровня
фразы.
В результатах, представленных в этой статье, точность
ставки всегда были выше, чем показатели отзыва.Отчасти это вызвано методом, который мы используем для балансировки открытых
скобки и закрывающие скобки.
Он удаляет все скобки, которые не могут быть сопоставлены с другими скобками, которые
примерно то же самое, что и условия принятия, которые, вероятно, будут
исправить и выбросить все остальные.
Мы хотели проверить, сможем ли мы добиться более сбалансированной точности и
процент отзыва, потому что мы надеялись, что это приведет к лучшему
Оценка F.
Поэтому мы протестировали два альтернативных метода комбинирования
кронштейны.
Первые игнорировали тип открытых скобок и позволяли закрывать
скобы комбинируются с открытыми скобами любого типа.Второй метод позволял открывать скобки, чтобы они совпадали с закрытыми скобками.
любого типа. К сожалению, ни первый (F = 72,33), ни второй
метод (76.06) смог получить ту же скорость F, что и наш
стандартный способ совмещения скобок.
Поэтому мы решили остановиться на последнем.
К сожалению, ни первый (F = 72,33), ни второй
метод (76.06) смог получить ту же скорость F, что и наш
стандартный способ совмещения скобок.
Поэтому мы решили остановиться на последнем.
Последний вопрос, который мы хотели изучить, — это производительность.
продвижение парсера на разных уровнях процесса.
Отзыв парсера должен увеличиваться с каждым дополнительным шагом в
каскад фрагментов, но мы также хотели бы знать, как точность и
F прогрессировал.Мы измерили это для нашего небольшого набора данных настройки параметров и
обнаружил, что отзыв действительно увеличился до уровня 30 из максимум 32
и после этого оставалась неизменной.
Точность упала до того же уровня, оставшись на том же уровне
впоследствии, в то время как F достиг максимального значения на уровне 19 и
упал впоследствии.
Причина более позднего падения значения F заключается в том, что в то время как
отзыв все еще растет, он не может компенсировать потерю
точность на более поздних уровнях.
Поскольку мы хотим оптимизировать коэффициент F, мы решили
ограничить количество каскадных блоков в нашем синтаксическом анализаторе до 19 уровней. Мы добавили дополнительный этап постобработки, который после 19 уровней
обработки добавляет скобки (S) вокруг предложений, которые не
уже были определены как пункты.
Мы добавили дополнительный этап постобработки, который после 19 уровней
обработки добавляет скобки (S) вокруг предложений, которые не
уже были определены как пункты.
Мы применили лучшую конфигурацию парсера, найденную к стандартному
парсинг данных.
Наш парсер использовал произвольный чункер с описанной конфигурацией
в Разделе 3.3 (Большинство голосов пяти систем, использующих
различные представления данных), но обучены с соответствующими данными для
эта задача.
Фразы более высокого уровня были идентифицированы каскадом из 19 фрагментов, каждый
из которых имел пару независимых классификаторов с открытыми и закрытыми скобками
который использовал контекст из двух левых и двух правых слов и тегов POS
только при обучении со скобками текущего уровня.На каждом уровне открытые и закрытые скобки были объединены в блоки по
удаление всех скобок, которые не могут быть сопоставлены с скобкой
того же типа.
Парсер содержал процесс постобработки, в который добавлен пункт
скобки вокруг предложений, которые не были определены как предложения после
19 этапов обработки. Этот синтаксический анализатор фрагментов получил скорость F 80,49 на WSJ.
раздел 23 (точность 82,34% и отзыв 78,72%).
Этот синтаксический анализатор фрагментов получил скорость F 80,49 на WSJ.
раздел 23 (точность 82,34% и отзыв 78,72%).
Производительность нашего парсера фрагментов скромна по сравнению с
современные статистические парсеры, которые получают около 90
F rate [Коллинз (1999), Чарняк (2000)].Однако у нас есть несколько предложений по улучшению его
представление.
Во-первых, мы могли бы попытаться предоставить синтаксическому анализатору доступ к дополнительной информации,
например о нижних уровнях фраз.
В настоящее время парсер знает только заголовочные слова и типы фраз
дочери фраз, которые строятся, а это может не быть
достаточно.
Во-вторых, мы могли бы попытаться найти лучший метод прогнозирования скобок
позиции.
По причинам, описанным в предыдущем разделе, мы не могли использовать
большинство голосов систем, использующих разные представления.Это могло помочь улучшить производительность.
Наконец, мы хотели бы изменить жадный подход нашего парсера.
В настоящее время он выбирает лучшую сегментацию кусков на каждом уровне и
основывается на этом, но в идеале он мог бы запомнить некоторые
ближайших к лучшим конфигурациям и выполнить обратное отслеживание из
предыдущий выбор, когда это необходимо. Такой подход, вероятно, значительно повысит производительность.
(как показано [Ратнапархи (1998)], таблица 6.5).
Практическая проблема, которую здесь необходимо решить, заключается в том, что в ближайшем
альтернативные классы обучения на основе памяти соседей не получают
меры доверия.Скорее, наборы расстояний, зависящих от предметов, используются для определения
удобство использования классов.
Сравнение частичных деревьев требует сравнения наборов расстояний и
не совсем понятно, как это должно быть сделано.
Такой подход, вероятно, значительно повысит производительность.
(как показано [Ратнапархи (1998)], таблица 6.5).
Практическая проблема, которую здесь необходимо решить, заключается в том, что в ближайшем
альтернативные классы обучения на основе памяти соседей не получают
меры доверия.Скорее, наборы расстояний, зависящих от предметов, используются для определения
удобство использования классов.
Сравнение частичных деревьев требует сравнения наборов расстояний и
не совсем понятно, как это должно быть сделано.
Эти дополнительные меры, вероятно, улучшат производительность
парсер чанков.
Однако сомнительно, стоит ли продолжать это
подход.
Текущая версия парсера уже требует много памяти и
время обработки: более секунды на слов только для фрагментов
по сравнению с всего лишь 0.14 секунд на предложений для статистического
парсер, работавший лучше [Ратнапархи (1998)].
Дополнительные расширения, вероятно, еще больше замедлят работу парсера, поэтому мы
не уверены, стоит ли расширение этого подхода.
следующий: Сопутствующие работы Up: анализ Предыдущая: Разбор словосочетания существительное Эрик Тьонг Ким Санг 2002-03-13
Информатика | Бесплатный полнотекстовый | О словосочетаниях и их взаимодействии с синтаксическим анализом и переводом
1. Введение
Многословные выражения — «своеобразные интерпретации, которые пересекают границы слов» [1] — широко признаны ключевой проблемой для обработки естественного языка (НЛП). Действительно, они рассматриваются как «боль в шее» для НЛП [1] или «крепкий орешек» [2]. Выражения из нескольких слов (далее — MWE) охватывают широкий спектр явлений 1, таких как именованные сущности, функциональные слова из нескольких слов, именные соединения, конструкции глагол-частица, глагольные выражения, идиомы, пословицы и т. Д., Которые все имеют Общим является тот факт, что они должны рассматриваться как единое целое, а не пословно и, следовательно, требуют особого, целостного подхода в системах НЛП. Особенно важный подкласс MWE представлен так называемыми « институционализированные »фразы или словосочетания (напр.г., проливной дождь, заядлый курильщик, серьезная травма, удовлетворить потребность, выразить благодарность, глубоко влюблен). Словосочетания — это выражения, которые относительно регулярны с синтаксической и семантической точки зрения, но статистически уникальны. Составляющие слова, в принципе, связаны с помощью обычных грамматических процессов, таких как сочетание существительного с модификатором, дающее номинальную фразу, значение которой может быть выведено из значения частей.
Действительно, они рассматриваются как «боль в шее» для НЛП [1] или «крепкий орешек» [2]. Выражения из нескольких слов (далее — MWE) охватывают широкий спектр явлений 1, таких как именованные сущности, функциональные слова из нескольких слов, именные соединения, конструкции глагол-частица, глагольные выражения, идиомы, пословицы и т. Д., Которые все имеют Общим является тот факт, что они должны рассматриваться как единое целое, а не пословно и, следовательно, требуют особого, целостного подхода в системах НЛП. Особенно важный подкласс MWE представлен так называемыми « институционализированные »фразы или словосочетания (напр.г., проливной дождь, заядлый курильщик, серьезная травма, удовлетворить потребность, выразить благодарность, глубоко влюблен). Словосочетания — это выражения, которые относительно регулярны с синтаксической и семантической точки зрения, но статистически уникальны. Составляющие слова, в принципе, связаны с помощью обычных грамматических процессов, таких как сочетание существительного с модификатором, дающее номинальную фразу, значение которой может быть выведено из значения частей. Тем не менее, что необычно, своеобразно или нерегулярно в таких выражениях, так это то, что они предпочтительнее альтернативных лексикализаций: сравните, например, светофор, который представляет собой словосочетание, институциональную фразу, с такими сочетаниями, как * директор движения или * регулятор перекрестков, которые почти не встречаются в языке (пример из [1]).Такие комбинации сильно зависят от языка и в значительной степени указывают на степень беглости языкового высказывания или вывода, производимого системой НЛП. Даже если они поддаются разложению на части, вычислительные системы все равно должны их обрабатывать целостным образом, чтобы избежать неестественных или неудобных формулировок. По мнению нескольких исследователей (например, [4,5,6]), словосочетания являются наиболее многочисленными. среди всех типов MWE. Фактически, «ни один фрагмент естественного устного или письменного английского языка не свободен от словосочетаний» [7].Важность словосочетаний «стоит в их вездесущности» [5].
Тем не менее, что необычно, своеобразно или нерегулярно в таких выражениях, так это то, что они предпочтительнее альтернативных лексикализаций: сравните, например, светофор, который представляет собой словосочетание, институциональную фразу, с такими сочетаниями, как * директор движения или * регулятор перекрестков, которые почти не встречаются в языке (пример из [1]).Такие комбинации сильно зависят от языка и в значительной степени указывают на степень беглости языкового высказывания или вывода, производимого системой НЛП. Даже если они поддаются разложению на части, вычислительные системы все равно должны их обрабатывать целостным образом, чтобы избежать неестественных или неудобных формулировок. По мнению нескольких исследователей (например, [4,5,6]), словосочетания являются наиболее многочисленными. среди всех типов MWE. Фактически, «ни один фрагмент естественного устного или письменного английского языка не свободен от словосочетаний» [7].Важность словосочетаний «стоит в их вездесущности» [5]. Также важно отметить, что, в отличие от большинства других типов многословных выражений, словосочетания могут встречаться в широком диапазоне синтаксических шаблонов. Ниже приводится список синтаксических конфигураций, обычно связанных с словосочетаниями в английском языке: прилагательное-существительное (заядлый курильщик), существительное- (сказуемое) -адъективное (усилия [быть] посвященными), существительное-существительное (суицидальная атака), существительное-предлог- существительное (раунд переговоров), существительное-предлог (исследование), прилагательное-предлог (без ума от), подлежащее-глагол (возникает проблема), глагол-объект (удовлетворить требование), глагол-предлог-аргумент (довести до кипения), глагол-предлог (зависит от), наречие-глагол (полностью поддерживаю), наречие-прилагательное (очень важно), прилагательное-согласование-прилагательное (приятный и теплый).Кроме того, лексикографические данные показывают, что этот список можно значительно расширить [8]. Подводя итог, можно сказать, что словосочетания — это идиосинкратические синтагматические комбинации, которые не ограничиваются данным классом слов или данным набором синтаксических паттернов [9].
Также важно отметить, что, в отличие от большинства других типов многословных выражений, словосочетания могут встречаться в широком диапазоне синтаксических шаблонов. Ниже приводится список синтаксических конфигураций, обычно связанных с словосочетаниями в английском языке: прилагательное-существительное (заядлый курильщик), существительное- (сказуемое) -адъективное (усилия [быть] посвященными), существительное-существительное (суицидальная атака), существительное-предлог- существительное (раунд переговоров), существительное-предлог (исследование), прилагательное-предлог (без ума от), подлежащее-глагол (возникает проблема), глагол-объект (удовлетворить требование), глагол-предлог-аргумент (довести до кипения), глагол-предлог (зависит от), наречие-глагол (полностью поддерживаю), наречие-прилагательное (очень важно), прилагательное-согласование-прилагательное (приятный и теплый).Кроме того, лексикографические данные показывают, что этот список можно значительно расширить [8]. Подводя итог, можно сказать, что словосочетания — это идиосинкратические синтагматические комбинации, которые не ограничиваются данным классом слов или данным набором синтаксических паттернов [9].
Исследователи уже давно пытались охарактеризовать феномен словосочетания, обращаясь к нему с разных сторон. Однако до сих пор нет согласованного определения, а понятие словосочетания обычно сопровождается расплывчатостью и путаницей.Словосочетания остаются менее изученными и менее понятными, чем другие типы MWE, в частности, идиомы (пнуть ведро), конструкции со светлым глаголом (прогуляться) или конструкции глагол-частица (искать).
В этой статье мы делаем акцент на особом аспекте, который отличает словосочетания от других выражений и который делает их особенно трудными для обработки вычислительными системами: высокая морфосинтаксическая гибкость словосочетаний. Составляющие слова в словосочетании, в принципе, могут подвергаться полному спектру морфологических и синтаксических преобразований, которые возможны для регулярных сочетаний в языке (см. Примеры 1 и 2).Напротив, другие выражения, такие как именованные сущности (Нью-Йорк), соединения (инвалидное кресло) или идиомы (быть на седьмом небе, «быть чрезвычайно довольным»), относительно фиксированы или заморожены, и эта характеристика действует как полезное различение. функция и позволяющая более локальную (и, следовательно, более экономичную в вычислительном отношении) автоматическую обработку.
функция и позволяющая более локальную (и, следовательно, более экономичную в вычислительном отношении) автоматическую обработку.Что касается гибкого характера словосочетаний, стоит отметить, что в областях НЛП и перевода стандарт категорий данных ISO 12620 описывает словосочетания как «[] повторяющееся словосочетание, характеризующееся связностью, в которой компоненты словосочетания должны сосуществуют в высказывании или серии высказываний, даже если они не обязательно должны находиться в непосредственной близости друг от друга »(курсив наш).Это определение подчеркивает важную особенность словосочетаний, а именно несмежность составных слов, которая является следствием синтаксической гибкости этих выражений.
Действительно, эта несмежность, возможно, является одной из самых больших проблем, с которыми сталкиваются системы НЛП при обработке словосочетаний. Поскольку словосочетания демонстрируют (почти) полную синтаксическую изменчивость, их обработка требует работы с широким спектром синтаксических преобразований, в которых могут возникать словосочетания. Их высокая вариативность требует сложных лингвистических подходов, способных точно определять словосочетания во многих синтаксических контекстах и учитывать зависимости между ними, чтобы в конечном итоге обеспечить их надлежащую обработку в таких приложениях, как синтаксический анализ или перевод.
Их высокая вариативность требует сложных лингвистических подходов, способных точно определять словосочетания во многих синтаксических контекстах и учитывать зависимости между ними, чтобы в конечном итоге обеспечить их надлежащую обработку в таких приложениях, как синтаксический анализ или перевод.
Еще один аспект, на котором наша работа особенно сосредоточена, — это интеграция коллокаций в реальные конвейеры NLP, то есть их использование в клиентских приложениях на естественном языке. Разработка точных методов идентификации коллокаций была главной заботой в области НЛП уже пару десятилетий; однако использованию коллокаций в других приложениях НЛП уделялось значительно меньше внимания. В этой статье мы обращаемся к проблеме соединения приложения извлечения (или идентификации) коллокации с двумя основными приложениями НЛП, а именно синтаксическим синтаксическим анализом и машинным переводом.Мы исследуем, является ли синергетический подход, при котором информация распределяется между задачей идентификации коллокации и двумя другими задачами, более эффективен, чем стандартный подход, в котором задачи выполняются независимо друг от друга.
 Статья построена следующим образом. В разделе 2 мы сосредоточимся на использовании синтаксического анализа для извлечения словосочетаний. Мы исследуем соответствующую работу и обрисовываем нашу собственную методологию извлечения, которая опирается на полный синтаксический анализ для получения словосочетаний из текстовых корпусов на нескольких языках. В Разделе 3 мы рассматриваем работу, в которой связанные с переводом технологии, такие как выравнивание предложений и слов, используются для определения словосочетаний. Кроме того, мы описываем наш собственный метод определения эквивалентов перевода для словосочетаний с использованием архивов переводов.Раздел 4 и Раздел 5 посвящены использованию знаний о коллокациях для синтаксического анализа и перевода. В разделе 4 мы обсуждаем степень, в которой словосочетания в настоящее время учитываются в системах синтаксического анализа; Затем мы представляем подход, в котором идентификация словосочетания и синтаксический анализ выполняются одновременно, а не по отдельности, как в предыдущей работе.
Статья построена следующим образом. В разделе 2 мы сосредоточимся на использовании синтаксического анализа для извлечения словосочетаний. Мы исследуем соответствующую работу и обрисовываем нашу собственную методологию извлечения, которая опирается на полный синтаксический анализ для получения словосочетаний из текстовых корпусов на нескольких языках. В Разделе 3 мы рассматриваем работу, в которой связанные с переводом технологии, такие как выравнивание предложений и слов, используются для определения словосочетаний. Кроме того, мы описываем наш собственный метод определения эквивалентов перевода для словосочетаний с использованием архивов переводов.Раздел 4 и Раздел 5 посвящены использованию знаний о коллокациях для синтаксического анализа и перевода. В разделе 4 мы обсуждаем степень, в которой словосочетания в настоящее время учитываются в системах синтаксического анализа; Затем мы представляем подход, в котором идентификация словосочетания и синтаксический анализ выполняются одновременно, а не по отдельности, как в предыдущей работе. В разделе 5 рассматривается вопрос интеграции словосочетаний и других типов многословных выражений в системы машинного перевода.В нем также представлено исследование, направленное на оценку влияния словосочетаний на результаты внутренней системы перевода, основанной на правилах. Наконец, в Разделе 6 статья завершается анализом текущей обработки словосочетаний и, при необходимости, указанием более адекватных альтернатив обработки.
В разделе 5 рассматривается вопрос интеграции словосочетаний и других типов многословных выражений в системы машинного перевода.В нем также представлено исследование, направленное на оценку влияния словосочетаний на результаты внутренней системы перевода, основанной на правилах. Наконец, в Разделе 6 статья завершается анализом текущей обработки словосочетаний и, при необходимости, указанием более адекватных альтернатив обработки.2. Использование синтаксического анализа для идентификации словосочетания
Развитие извлечения словосочетаний как области исследований привело к все более широкому внедрению лингвистического анализа в качестве важного шага предварительной обработки.Этот шаг позволяет более точно идентифицировать кандидатов, которые затем оцениваются с использованием статистических методов и, в частности, так называемых показателей ассоциации (например, взаимная информация, t-оценка, z-оценка, χ2, логарифмическое отношение правдоподобия; см. описания и сравнительные оценки ассоциативных показателей в [11,12,13,14]. Методы предварительной обработки постепенно эволюционировали от более мелких форм анализа к более глубоким, по мере того, как становились доступными все более совершенные технологии, от токенизации, стемминга и лемматизации до разбиения на мелкие фрагменты. синтаксический анализ, анализ зависимостей или полный синтаксический анализ.Необходимость лингвистического анализа входного текста оправдана необходимостью учитывать высокую морфосинтаксическую вариативность, характеризующую словосочетания. Стаббс [15] проанализировал, например, появление пары «медведь-подобие» в корпусе и обнаружил следующее распределение флективных форм для словесного компонента to bear: медведи 18%, медведь 11%, нос 11%, подшипник 4 %. Вместе эти формы составляют большую долю (44%) от общего числа словосочетаний подобия существительного (1085).Пример 1 суммирует эту информацию в обозначениях Стаббса.
Методы предварительной обработки постепенно эволюционировали от более мелких форм анализа к более глубоким, по мере того, как становились доступными все более совершенные технологии, от токенизации, стемминга и лемматизации до разбиения на мелкие фрагменты. синтаксический анализ, анализ зависимостей или полный синтаксический анализ.Необходимость лингвистического анализа входного текста оправдана необходимостью учитывать высокую морфосинтаксическую вариативность, характеризующую словосочетания. Стаббс [15] проанализировал, например, появление пары «медведь-подобие» в корпусе и обнаружил следующее распределение флективных форм для словесного компонента to bear: медведи 18%, медведь 11%, нос 11%, подшипник 4 %. Вместе эти формы составляют большую долю (44%) от общего числа словосочетаний подобия существительного (1085).Пример 1 суммирует эту информацию в обозначениях Стаббса. Пример 1. Морфологические вариации в словосочетаниях: нотация Стаббса для группирования изменяемых форм словосочетаний.
сходство 1085 <медведи 18%, медведи 11%, ствол 11%, подшипники 4%> 44%
Этот пример иллюстрирует важность выполнения лексического анализа входящего текста, чтобы лучше определять возможные сочетания слов. Фактически, большая часть работы по извлечению словосочетаний [16,17,18,19] основана на лексическом анализе в сочетании с фильтрацией на основе части речи (POS) комбинаций, рассматриваемых в окне из пяти слов, называемом коллокационный диапазон.В дополнение к лексическому анализу, синтаксический анализ входного текста часто считался необходимым, особенно для языков, которые демонстрируют более свободный порядок слов, таких как немецкий или корейский. Для таких языков методы извлечения, разработанные для английского языка (например, Xtract [20]), неэффективны, так как они не могут восстановить систематические зависимости на большом расстоянии и учесть позиционную неоднозначность аргументов. Как сообщает, например, Брейдт [21], даже отличить субъекты от объектов на немецком языке сложно без синтаксического анализа. Поэтому автор предложил сократить коллокационный диапазон до трех слов, чтобы исключить существительные, не связанные с глаголами. Эта стратегия привела к повышению точности, но это улучшение произошло за счет отзыва. Аналогичным образом Kim et al. [22] сообщили, что такая методика, как Xtract [20], которая очень популярна в английском языке и основана на выборе вариантов словосочетания среди пар слов, которые встречаются на стабильном расстоянии в тексте, совершенно не подходит для корейского языка из-за высокой синтаксическая гибкость.Учитывая заметную гибкость словосочетаний, некоторые исследователи указали, что извлечение словосочетаний в идеале должно полагаться на синтаксический анализ исходных корпусов [12,13,20,23,24]. Однако, несмотря на их теоретические аргументы, синтаксический анализ использовался лишь в небольшом количестве практических работ. В таких (исключительных) случаях кандидаты на коллокацию идентифицируются как пары слов в синтаксической взаимосвязи, а не как пары слов в коллокационной области, как в преобладающих бессинтаксических подходах.
Поэтому автор предложил сократить коллокационный диапазон до трех слов, чтобы исключить существительные, не связанные с глаголами. Эта стратегия привела к повышению точности, но это улучшение произошло за счет отзыва. Аналогичным образом Kim et al. [22] сообщили, что такая методика, как Xtract [20], которая очень популярна в английском языке и основана на выборе вариантов словосочетания среди пар слов, которые встречаются на стабильном расстоянии в тексте, совершенно не подходит для корейского языка из-за высокой синтаксическая гибкость.Учитывая заметную гибкость словосочетаний, некоторые исследователи указали, что извлечение словосочетаний в идеале должно полагаться на синтаксический анализ исходных корпусов [12,13,20,23,24]. Однако, несмотря на их теоретические аргументы, синтаксический анализ использовался лишь в небольшом количестве практических работ. В таких (исключительных) случаях кандидаты на коллокацию идентифицируются как пары слов в синтаксической взаимосвязи, а не как пары слов в коллокационной области, как в преобладающих бессинтаксических подходах. Есть сообщения, например, о работе с коллокациями с использованием полного синтаксического анализа для немецкого [25], китайского [26] и голландского [27]. Аналогичная работа была проделана для английского языка [28], языка, на котором также проводились эксперименты по извлечению словосочетаний с использованием аннотированных вручную синтаксических банков дерева [29,30]. Кроме того, анализ зависимостей использовался для ряда языков, включая английский [31,32], французский [33] и чешский [34]. Кроме того, относительно больший объем работы был посвящен извлечению словосочетаний на основе поверхностного синтаксического анализа, например.g., для английского [35], немецкого [36], французского [11,37,38] и, в частности, в многоязычной системе Sketch Engine [39]. Важным фактором, отличающим эти системы извлечения на основе синтаксиса, является производительность задействованный парсер. В некоторых случаях авторы сообщают о довольно высокой частоте ошибок синтаксического анализа, а также о проблемах с надежностью, что приводит к исключению более длинных предложений, состоящих из 20 слов и более [27,31,32].
Есть сообщения, например, о работе с коллокациями с использованием полного синтаксического анализа для немецкого [25], китайского [26] и голландского [27]. Аналогичная работа была проделана для английского языка [28], языка, на котором также проводились эксперименты по извлечению словосочетаний с использованием аннотированных вручную синтаксических банков дерева [29,30]. Кроме того, анализ зависимостей использовался для ряда языков, включая английский [31,32], французский [33] и чешский [34]. Кроме того, относительно больший объем работы был посвящен извлечению словосочетаний на основе поверхностного синтаксического анализа, например.g., для английского [35], немецкого [36], французского [11,37,38] и, в частности, в многоязычной системе Sketch Engine [39]. Важным фактором, отличающим эти системы извлечения на основе синтаксиса, является производительность задействованный парсер. В некоторых случаях авторы сообщают о довольно высокой частоте ошибок синтаксического анализа, а также о проблемах с надежностью, что приводит к исключению более длинных предложений, состоящих из 20 слов и более [27,31,32]. В других случаях грамматический охват синтаксического анализатора сообщается как ограниченный, так как система извлечения неспособна справиться с некоторыми типами синтаксических преобразований, такими как релятивизация [28].Помимо базовой технологии предварительной обработки и конкретных мер ассоциации, используемых для ранжирования кандидатов, системы извлечения также сильно различаются по диапазону синтаксических конфигураций, которые они принимают во внимание. Некоторые системы идентифицируют кандидатов одного типа или нескольких конкретных синтаксических типов, например, глагол-предлог [29], предлог-существительное-предлог, предложная фраза-глагол [27], глагол-объект, существительное-прилагательное, глагол-наречие [ 26] или словосочетаний [11,37,38]. Тем не менее, другие системы нацелены на более широкий охват, например.г., [25,39].
В других случаях грамматический охват синтаксического анализатора сообщается как ограниченный, так как система извлечения неспособна справиться с некоторыми типами синтаксических преобразований, такими как релятивизация [28].Помимо базовой технологии предварительной обработки и конкретных мер ассоциации, используемых для ранжирования кандидатов, системы извлечения также сильно различаются по диапазону синтаксических конфигураций, которые они принимают во внимание. Некоторые системы идентифицируют кандидатов одного типа или нескольких конкретных синтаксических типов, например, глагол-предлог [29], предлог-существительное-предлог, предложная фраза-глагол [27], глагол-объект, существительное-прилагательное, глагол-наречие [ 26] или словосочетаний [11,37,38]. Тем не менее, другие системы нацелены на более широкий охват, например.г., [25,39]. Хотя обычно считается необходимым для получения высококачественных результатов, извлечение на основе синтаксиса не всегда рассматривается как жизнеспособное решение в сообществе НЛП. Иногда от него отказываются из-за недоступности синтаксических анализаторов; в других случаях причина отсутствия предварительной обработки исходных корпусов с помощью синтаксического синтаксического анализатора берется на основе различных аргументов, таких как неэффективность по времени, недостаточная точность или недостаточная надежность. Чтобы усилить скептицизм, не было проведено никакой сравнительной оценки, чтобы убедительно доказать превосходство извлечения на основе синтаксиса над более простой альтернативой без синтаксиса.
Иногда от него отказываются из-за недоступности синтаксических анализаторов; в других случаях причина отсутствия предварительной обработки исходных корпусов с помощью синтаксического синтаксического анализатора берется на основе различных аргументов, таких как неэффективность по времени, недостаточная точность или недостаточная надежность. Чтобы усилить скептицизм, не было проведено никакой сравнительной оценки, чтобы убедительно доказать превосходство извлечения на основе синтаксиса над более простой альтернативой без синтаксиса.
 Система извлечения, первоначально разработанная для английского и французского языков, позже была расширена на новые языки, поддерживаемые парсером Fips, то есть испанский, итальянский, немецкий, греческий и румынский. Fips — надежный символьный парсер, основанный на концепциях генеративной грамматики. Он выполняет «глубокий» синтаксический анализ входного предложения, используя совместную индексацию для отслеживания экстрапозиционных составляющих, т. Е. Составляющих, которые «переместились» из исходного (канонического) положения в поверхностное из-за синтаксических преобразований, например, показанные в Примере 2:
Система извлечения, первоначально разработанная для английского и французского языков, позже была расширена на новые языки, поддерживаемые парсером Fips, то есть испанский, итальянский, немецкий, греческий и румынский. Fips — надежный символьный парсер, основанный на концепциях генеративной грамматики. Он выполняет «глубокий» синтаксический анализ входного предложения, используя совместную индексацию для отслеживания экстрапозиционных составляющих, т. Е. Составляющих, которые «переместились» из исходного (канонического) положения в поверхностное из-за синтаксических преобразований, например, показанные в Примере 2:Пример 2. Синтаксические вариации в словосочетаниях: примеры преобразований.
- 2.
пассивирование
- 3.
опрос
 В примере 1, например, лицо глагола встречается в придаточном предложении, в то время как его вызов объекта находится в главном предложении.Как видно из Примера 3, показывающего (упрощенный) вывод синтаксического анализа, синтаксический анализатор правильно идентифицирует «глубокий» объект лица, создавая цепочку совместной индексации (помеченную i), которая содержит пустую составляющую в позиции объекта глагола face. , ei, относительное местоимение, которое и именная фраза во главе с вызовами. Благодаря этому механизму пара глагол-объект face-challenge может быть успешно идентифицирована как потенциальное словосочетание. Было проведено два масштабных оценочных эксперимента, чтобы оценить влияние синтаксического анализа на качество результатов извлечения словосочетания.Результаты, полученные с использованием метода извлечения на основе синтаксиса, сравнивались с результатами, полученными при использовании базового варианта без синтаксиса. Базовый план состоит из применения так называемого метода скользящего окна к лемматизированным и отфильтрованным данным POS, что означает, что все возможные комбинации в окне из пяти слов, которые соответствуют выбранным шаблонам POS, рассматриваются как кандидаты.
В примере 1, например, лицо глагола встречается в придаточном предложении, в то время как его вызов объекта находится в главном предложении.Как видно из Примера 3, показывающего (упрощенный) вывод синтаксического анализа, синтаксический анализатор правильно идентифицирует «глубокий» объект лица, создавая цепочку совместной индексации (помеченную i), которая содержит пустую составляющую в позиции объекта глагола face. , ei, относительное местоимение, которое и именная фраза во главе с вызовами. Благодаря этому механизму пара глагол-объект face-challenge может быть успешно идентифицирована как потенциальное словосочетание. Было проведено два масштабных оценочных эксперимента, чтобы оценить влияние синтаксического анализа на качество результатов извлечения словосочетания.Результаты, полученные с использованием метода извлечения на основе синтаксиса, сравнивались с результатами, полученными при использовании базового варианта без синтаксиса. Базовый план состоит из применения так называемого метода скользящего окна к лемматизированным и отфильтрованным данным POS, что означает, что все возможные комбинации в окне из пяти слов, которые соответствуют выбранным шаблонам POS, рассматриваются как кандидаты. В обоих случаях применялся показатель логарифмического отношения правдоподобия [41]. Первый эксперимент был проведен в одноязычной среде на французских данных из корпуса Хансарда заседаний канадского парламента, общее количество которых составило около 1.2 миллиона слов. Топ-500 типов пар были вручную оценены тремя судьями, и результаты показали статистически значимое улучшение точности по сравнению с исходным уровнем без синтаксиса (99% против 78,3% с точки зрения грамматичности2; 65,9% против 57% в с точки зрения лексикографического интереса результатов.3)
В обоих случаях применялся показатель логарифмического отношения правдоподобия [41]. Первый эксперимент был проведен в одноязычной среде на французских данных из корпуса Хансарда заседаний канадского парламента, общее количество которых составило около 1.2 миллиона слов. Топ-500 типов пар были вручную оценены тремя судьями, и результаты показали статистически значимое улучшение точности по сравнению с исходным уровнем без синтаксиса (99% против 78,3% с точки зрения грамматичности2; 65,9% против 57% в с точки зрения лексикографического интереса результатов.3)Пример 3. Пример вывода синтаксического анализа (A = прилагательное, Adv = наречие, C = дополняющий, D = определитель, N = существительное, P = фраза, T = время, V = глагол).
Второй эксперимент был проведен кросс-лингвистически, на французском, английском, итальянском и испанском параллельных данных из корпуса Европарламента о заседаниях Европейского парламента, всего около трех.В среднем 7 миллионов слов на каждый язык. Для выбора данных оценки использовалась стратегия стратифицированной выборки с последовательностями из 50 типов пар, взятых с разных уровней в выходном списке (верхний — 0%, 1%, 3%, 5% и 10%). Команды из двух судей вручную оценили в общей сложности 2000 типов пар. Результаты снова показали статистически значимые улучшения по сравнению с исходным уровнем (средняя грамматическая точность 88,8% против 33,2%; средняя лексикографическая точность 43,2% против 17,2%; и средняя точность коллокации 32,9% против 12,8%).
Для выбора данных оценки использовалась стратегия стратифицированной выборки с последовательностями из 50 типов пар, взятых с разных уровней в выходном списке (верхний — 0%, 1%, 3%, 5% и 10%). Команды из двух судей вручную оценили в общей сложности 2000 типов пар. Результаты снова показали статистически значимые улучшения по сравнению с исходным уровнем (средняя грамматическая точность 88,8% против 33,2%; средняя лексикографическая точность 43,2% против 17,2%; и средняя точность коллокации 32,9% против 12,8%). Важно отметить, что самые лучшие результаты базовой линии относительно свободны от шума, поскольку мера ассоциации успешно устраняет множество ошибочных пар из верхних позиций. Однако точность быстро ухудшается для предметов на более низких позициях: по мере того, как частота пар уменьшается, одна мера неэффективна для устранения шума. Напротив, подход, основанный на синтаксисе, гарантирует лучшее глобальное качество результатов, а это означает, что даже кандидаты с более низкими оценками не имеют шума.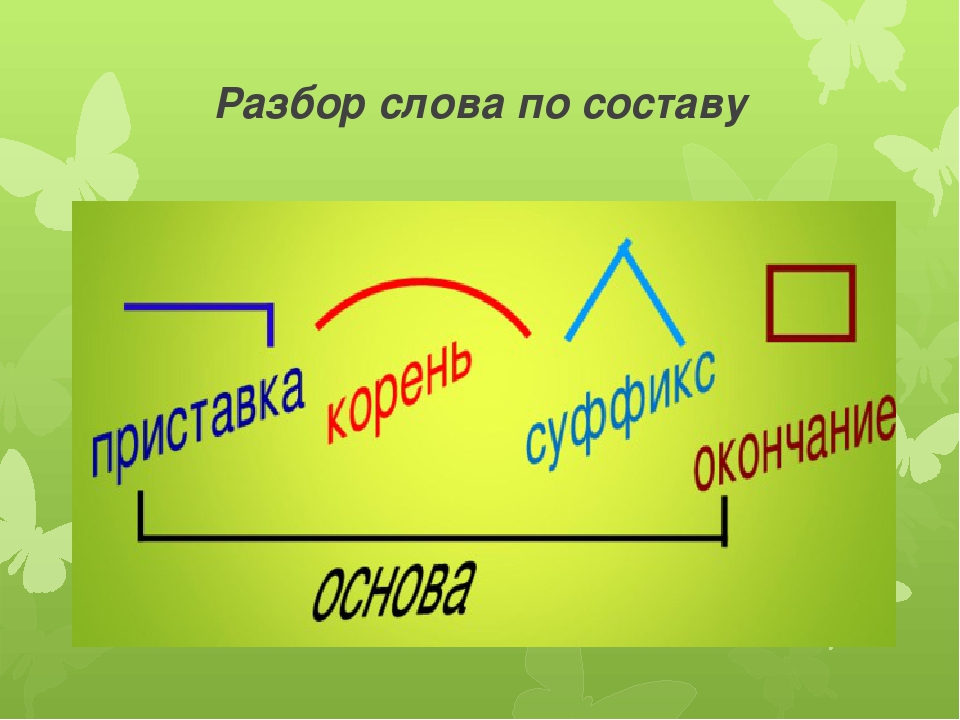 Это особенно важно, поскольку лексические данные имеют асимметричное распределение Ципфа, и большинство возможных комбинаций получают низкие оценки из-за их низкой частоты совпадения; тем не менее, они потенциально интересны с лексикографической точки зрения. Проведение лексикографической работы над списком без шума — одно из основных преимуществ синтаксических подходов к извлечению словосочетаний.
Это особенно важно, поскольку лексические данные имеют асимметричное распределение Ципфа, и большинство возможных комбинаций получают низкие оценки из-за их низкой частоты совпадения; тем не менее, они потенциально интересны с лексикографической точки зрения. Проведение лексикографической работы над списком без шума — одно из основных преимуществ синтаксических подходов к извлечению словосочетаний.
4. Использование словосочетаний для синтаксического анализа
Как указано Sag et al. [1], MWE являются ключевой проблемой для обработки естественного языка, потому что они не могут быть обработаны композиционными методами, так как это может привести к избыточной генерации (например,g., создание фразы типа * регулятор перекрестка вместо светофора). Более того, они не могут быть проанализированы с помощью обычных грамматических процессов, поскольку они идиосинкразические (например, в выражении в строке отсутствует определитель: * в строке). Для учета MWE, присутствующих в языке, в практической работе НЛП обычно используется решение, состоящее из перечисления MWE в лексиконе и токенизации входного текста с использованием подхода слов с пробелами для распознавания MWE. У этого подхода есть два основных недостатка.Во-первых, это отсутствие гибкости, поскольку многие выражения позволяют лексическому материалу располагаться между составными словами, и подход слов с пробелами неадекватен для обработки таких ситуаций. Вторая — проблема лексического распространения, поскольку выражения обычно имеют вариативность, и перечисление всех возможных форм в лексиконе было бы непрактичным.
[1], MWE являются ключевой проблемой для обработки естественного языка, потому что они не могут быть обработаны композиционными методами, так как это может привести к избыточной генерации (например,g., создание фразы типа * регулятор перекрестка вместо светофора). Более того, они не могут быть проанализированы с помощью обычных грамматических процессов, поскольку они идиосинкразические (например, в выражении в строке отсутствует определитель: * в строке). Для учета MWE, присутствующих в языке, в практической работе НЛП обычно используется решение, состоящее из перечисления MWE в лексиконе и токенизации входного текста с использованием подхода слов с пробелами для распознавания MWE. У этого подхода есть два основных недостатка.Во-первых, это отсутствие гибкости, поскольку многие выражения позволяют лексическому материалу располагаться между составными словами, и подход слов с пробелами неадекватен для обработки таких ситуаций. Вторая — проблема лексического распространения, поскольку выражения обычно имеют вариативность, и перечисление всех возможных форм в лексиконе было бы непрактичным. Таким образом, подход слов с пробелами не может обобщать и плохо справляется с вариациями [1]. Эти проблемы становятся еще более острыми в случае словосочетаний.Как указано в разделе 1, словосочетания являются наиболее гибкими среди всех видов MWE, что делает подход слов с пробелами совершенно неадекватным для их представления и обработки. Нет никаких систематических ограничений на количество форм компонента словосочетания (например, глагол), порядок компонентов словосочетания или количество слов, которые могут находиться между ними (см. Пример 2). Коллокации расположены на пересечении лексики и грамматики; следовательно, они не могут быть объяснены исключительно лексическим компонентом системы синтаксического анализа.Вместо этого они также должны быть интегрированы в грамматический компонент, поскольку синтаксический анализатор должен учитывать все их возможные синтаксические реализации. В качестве альтернативы подходу предварительной обработки слов с пробелами коллокации могут распознаваться синтаксическим анализатором после анализа входное предложение было выполнено в соответствии с подходом, подобным тому, который описан в разделе 2.
Таким образом, подход слов с пробелами не может обобщать и плохо справляется с вариациями [1]. Эти проблемы становятся еще более острыми в случае словосочетаний.Как указано в разделе 1, словосочетания являются наиболее гибкими среди всех видов MWE, что делает подход слов с пробелами совершенно неадекватным для их представления и обработки. Нет никаких систематических ограничений на количество форм компонента словосочетания (например, глагол), порядок компонентов словосочетания или количество слов, которые могут находиться между ними (см. Пример 2). Коллокации расположены на пересечении лексики и грамматики; следовательно, они не могут быть объяснены исключительно лексическим компонентом системы синтаксического анализа.Вместо этого они также должны быть интегрированы в грамматический компонент, поскольку синтаксический анализатор должен учитывать все их возможные синтаксические реализации. В качестве альтернативы подходу предварительной обработки слов с пробелами коллокации могут распознаваться синтаксическим анализатором после анализа входное предложение было выполнено в соответствии с подходом, подобным тому, который описан в разделе 2. Опять же, этот подход не полностью уместен с точки зрения синтаксического анализа, и причина кроется в важном наблюдении, что предварительные знания о коллокациях очень важны для парсинг.Совместные предпочтения, наряду с другими типами информации, такими как ограничения выбора и рамки подкатегории, являются основным средством структурного разрешения неоднозначности. Фактически, коллокационные отношения между словами в предложении оказались полезными для выбора наиболее правдоподобного среди всех деревьев синтаксического анализа, сгенерированных для предложения [56,57,58,59]. Как мы покажем позже в этом разделе, более подходящим подходом является включение словосочетаний в грамматический компонент синтаксического анализатора, так что идентификация словосочетаний и построение дерева синтаксического анализа становятся взаимодействующими процессами, которые происходят одновременно и информируют каждого Другие.Далее мы рассмотрим, в какой степени MWE / коллокационные знания были включены в системы синтаксического анализа для повышения их производительности.
Опять же, этот подход не полностью уместен с точки зрения синтаксического анализа, и причина кроется в важном наблюдении, что предварительные знания о коллокациях очень важны для парсинг.Совместные предпочтения, наряду с другими типами информации, такими как ограничения выбора и рамки подкатегории, являются основным средством структурного разрешения неоднозначности. Фактически, коллокационные отношения между словами в предложении оказались полезными для выбора наиболее правдоподобного среди всех деревьев синтаксического анализа, сгенерированных для предложения [56,57,58,59]. Как мы покажем позже в этом разделе, более подходящим подходом является включение словосочетаний в грамматический компонент синтаксического анализатора, так что идентификация словосочетаний и построение дерева синтаксического анализа становятся взаимодействующими процессами, которые происходят одновременно и информируют каждого Другие.Далее мы рассмотрим, в какой степени MWE / коллокационные знания были включены в системы синтаксического анализа для повышения их производительности. Ряд исследований предоставили эмпирические доказательства того, что действительно распознавание MWE / коллокаций приводит к лучшим результатам синтаксического анализа. Например, Брун [60] сравнил покрытие французского синтаксического анализатора с распознаванием терминологии и без него на этапе предварительной обработки. Она обнаружила, что интеграция 210 номинальных терминов в компоненты предварительной обработки синтаксического анализатора привела к значительному сокращению количества альтернативных синтаксических анализов (в среднем по 4.21 до 2,79). Автор сообщает, что исключенные синтаксические разборы были семантически нежелательными и что не было исключено ни одного действительного анализа. Аналогичным образом Zhang et al. [61] расширили лексикон на 373 дополнительных лексических элемента MWE и получили значительное увеличение грамматического охвата синтаксического анализатора английского языка (на 14,4%, с 4,3% до 18,7%). В случаях, упомянутых выше, слова с пробелами подход был использован для представления MWE.
Ряд исследований предоставили эмпирические доказательства того, что действительно распознавание MWE / коллокаций приводит к лучшим результатам синтаксического анализа. Например, Брун [60] сравнил покрытие французского синтаксического анализатора с распознаванием терминологии и без него на этапе предварительной обработки. Она обнаружила, что интеграция 210 номинальных терминов в компоненты предварительной обработки синтаксического анализатора привела к значительному сокращению количества альтернативных синтаксических анализов (в среднем по 4.21 до 2,79). Автор сообщает, что исключенные синтаксические разборы были семантически нежелательными и что не было исключено ни одного действительного анализа. Аналогичным образом Zhang et al. [61] расширили лексикон на 373 дополнительных лексических элемента MWE и получили значительное увеличение грамматического охвата синтаксического анализатора английского языка (на 14,4%, с 4,3% до 18,7%). В случаях, упомянутых выше, слова с пробелами подход был использован для представления MWE.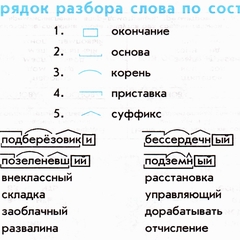 Напротив, Alegria et al. [62] и Villavicencio et al. [63] использовали композиционный подход к кодированию MWE, способный улавливать более морфосинтаксически гибкие MWE.Алегрия и др. [62] показали, что при использовании процессора MWE на этапе предварительной обработки своего парсера (в разработке) для Basque достигается значительное улучшение точности тегов POS. Villavicencio et al. [63] обнаружили, что простое добавление 21 нового MWE в лексикон привело к значительному увеличению охвата грамматики (с 7,1% до 22,7%) без изменения грамматической точности. Кроме того, область интенсивных исследований в области синтаксического анализа — это в частности, касается использования лексических предпочтений, частот совпадения, словосочетаний и контекстуально похожих слов для устранения неоднозначности присоединения предложных фраз (PP).Таким образом, для этой цели было разработано большое количество неконтролируемых методов [56,64,65], контролируемых методов [57,58] и комбинированных методов [66].
Напротив, Alegria et al. [62] и Villavicencio et al. [63] использовали композиционный подход к кодированию MWE, способный улавливать более морфосинтаксически гибкие MWE.Алегрия и др. [62] показали, что при использовании процессора MWE на этапе предварительной обработки своего парсера (в разработке) для Basque достигается значительное улучшение точности тегов POS. Villavicencio et al. [63] обнаружили, что простое добавление 21 нового MWE в лексикон привело к значительному увеличению охвата грамматики (с 7,1% до 22,7%) без изменения грамматической точности. Кроме того, область интенсивных исследований в области синтаксического анализа — это в частности, касается использования лексических предпочтений, частот совпадения, словосочетаний и контекстуально похожих слов для устранения неоднозначности присоединения предложных фраз (PP).Таким образом, для этой цели было разработано большое количество неконтролируемых методов [56,64,65], контролируемых методов [57,58] и комбинированных методов [66]. Однако, как указано в [56], узким местом этого направления работы является то, что синтаксическим анализаторам не хватает именно той информации, основанной на корпусе, которая требуется для разрешения неоднозначности. Выполнение синтаксического анализа и идентификации словосочетаний, таким образом, является круговой проблемой, для которой в предыдущей литературе не было решения. В оставшейся части этого раздела мы описываем новый подход к обработке словосочетаний, реализованный в связи с разработкой парсера Fips, состоящий из одновременного выполнения из двух задач, анализ предложения и определение словосочетания [67].Короче говоря, идея состоит в том, что когда синтаксический анализатор обрабатывает лексический элемент, который отмечен в лексиконе как часть словосочетания, при попытке присоединить его к другому элементу, он сначала проверяет словарный запас словосочетания на наличие синтаксически совместимой записи и, если он найден , он дает высокий приоритет конструкции, в которой прикреплены два компонента.
Однако, как указано в [56], узким местом этого направления работы является то, что синтаксическим анализаторам не хватает именно той информации, основанной на корпусе, которая требуется для разрешения неоднозначности. Выполнение синтаксического анализа и идентификации словосочетаний, таким образом, является круговой проблемой, для которой в предыдущей литературе не было решения. В оставшейся части этого раздела мы описываем новый подход к обработке словосочетаний, реализованный в связи с разработкой парсера Fips, состоящий из одновременного выполнения из двух задач, анализ предложения и определение словосочетания [67].Короче говоря, идея состоит в том, что когда синтаксический анализатор обрабатывает лексический элемент, который отмечен в лексиконе как часть словосочетания, при попытке присоединить его к другому элементу, он сначала проверяет словарный запас словосочетания на наличие синтаксически совместимой записи и, если он найден , он дает высокий приоритет конструкции, в которой прикреплены два компонента. Таким образом, механизм идентификации коллокации включен в составную процедуру присоединения анализатора.
Таким образом, механизм идентификации коллокации включен в составную процедуру присоединения анализатора. Хорошо известно, что, учитывая высокую частоту лексических двусмысленностей и высокий уровень недетерминированности грамматик естественного языка, грамматические синтаксические анализаторы сталкиваются с рядом альтернатив, число которых растет экспоненциально с увеличением длины входного предложения.Алгоритмы синтаксического анализа используют различные эвристики, чтобы ограничить количество альтернатив и, таким образом, гарантировать, что производительность синтаксического анализа удовлетворительна для обработки больших корпусов. Коллокации вносят решающий вклад в процесс устранения неоднозначности, помогая синтаксическому анализатору пройти через лабиринт альтернатив. Таким образом, идентификация коллокации — это не бремя — дополнительная задача, которую необходимо решить, — а процесс, который помогает синтаксическому анализатору. Словосочетания, как правило, состоят из очень неоднозначных слов, и их определение помогает выбрать между альтернативами. Например, в случае побития рекорда оба компонента неоднозначны, если взяты по отдельности, и именно их комбинация помогает синтаксическому анализатору выбрать подходящие категории и показания.
Например, в случае побития рекорда оба компонента неоднозначны, если взяты по отдельности, и именно их комбинация помогает синтаксическому анализатору выбрать подходящие категории и показания.
Пример 4. Альтернативный анализ для фразы «Управление человеческими ресурсами».
Чтобы измерить влияние сочетания идентификации коллокации и задач синтаксического анализа, мы провели эксперименты, в которых мы сравнили новую версию синтаксического анализатора с предыдущей версией, которая не использует коллокации для решений о присоединении.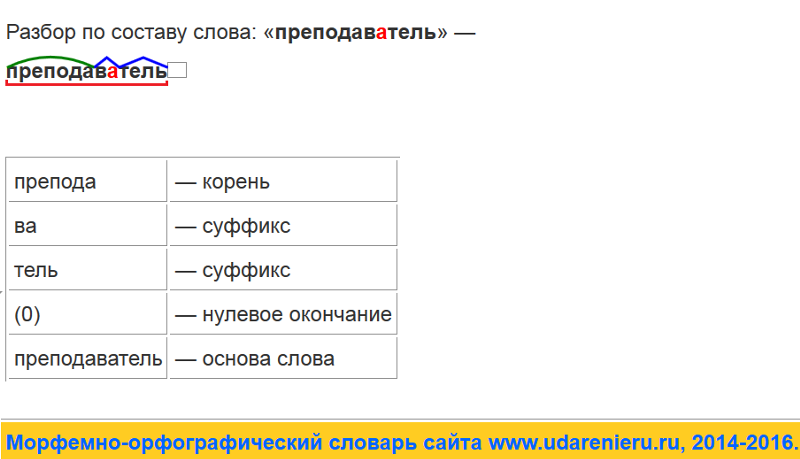 Мы оценили влияние процедуры, объединяющей синтаксический анализ и идентификацию коллокации, на выполнение обеих задач, синтаксический анализ и идентификацию коллокации. На корпусе новостных статей из журнала The Economist [68], который насчитывает чуть более 0,5 миллиона слов, мы получили заметное увеличение охвата синтаксического анализатора, выраженного в количестве полностью проанализированных предложений (83,3% против 81,7%), а также повышение точности идентификации словосочетаний (93,7% против 81,6%).
Мы оценили влияние процедуры, объединяющей синтаксический анализ и идентификацию коллокации, на выполнение обеих задач, синтаксический анализ и идентификацию коллокации. На корпусе новостных статей из журнала The Economist [68], который насчитывает чуть более 0,5 миллиона слов, мы получили заметное увеличение охвата синтаксического анализатора, выраженного в количестве полностью проанализированных предложений (83,3% против 81,7%), а также повышение точности идентификации словосочетаний (93,7% против 81,6%).Результаты соответствуют предыдущим отчетам о влиянии включения MWE в системы синтаксического анализа; разница заключается в том, что в нашем подходе полностью учтена синтаксическая гибкость MWE.Вместе эти результаты показывают значительную роль, которую эти выражения играют в производительности систем языкового анализа.
5. Использование словосочетаний в машинном переводе
Помимо того, что они полезны для приложений НЛП, связанных с анализом языка, информация о словосочетаниях, полученная из корпусов, имеет решающее значение для приложений, связанных с производством текста, таких как создание естественного языка и машинный перевод. Совместное использование считается ключевым фактором для получения более приемлемого результата в этих приложениях [28,69].Несмотря на их относительно прозрачное значение, словосочетания создают значительные проблемы с точки зрения языкового производства, поскольку они являются «идиомами кодирования» [70]. Лексический выбор ограничен стилизованной формой, которая зависит от языка. Поэтому регулярный выбор и, в случае машинного перевода, дословный перевод неуместны, так как они могут привести к неестественным, если не к неудобным, формулировкам, известным как антиколлокации [30] (например, * обвинять задержку, дословный перевод французского обвинителя ретард, «задержка опыта»).Чтобы проиллюстрировать важность словосочетаний для машинного перевода, рассмотрим французские комбинации grande Внимание, grande diversité и grande vitesse, в которых прилагательное grande «большой» изменяет существительные «внимание», разнообразие и скорость. Дословный перевод приведет к неадекватным формулировкам на английском языке: * большое внимание, * большое разнообразие, * большая скорость. Правильный перевод, большое внимание, широкий диапазон и высокая скорость показывают необходимость использования словосочетаний в целевом языке: одно и то же прилагательное, grande, переводится тремя разными способами, в зависимости от изменяемого существительного.
Как обсуждалось в разделе 3, значительный объем работы был посвящен извлечению эквивалентов перевода из корпусов, например [26,45,47,48], и представлению коллокационных знаний в вычислительной лексике для машинного перевода и генерация естественного языка [69,71]. Однако имеется очень мало отчетов о фактическом использовании коллокационных знаний в таких системах. Один из таких отчетов относится к системе машинного перевода Logos, которая использует словосочетания, извлеченные с помощью метода Орлиака и Диллинджера [28].Утверждается, что контекстно-зависимый выбор целевых лексических элементов, обеспечиваемый словосочетаниями, «обеспечивает значительное улучшение читабельности и воспринимаемого качества произведенного перевода» [28]. Другой отчет Лю и др. [72] касается интеграции словосочетаний в систему статистического машинного перевода (SMT). Авторы показывают, что их метод значительно улучшает производительность как выравнивания слов, так и качества перевода. В последующем эксперименте Liu et al. [73] используют словосочетания исходного языка для переупорядочивания для SMT, что снова приводит к значительным улучшениям.В более общем плане, что касается MWE, есть дополнительные доказательства, поступающие из отчетов, показывающих, что включение двуязычных MWE в системы SMT приводит к повышению качества результатов перевода. Например, Bai et al. [49] добавили 1171 китайско-английский MWE в свои системы SMT и получили значительное улучшение в баллах BLEU. Точно так же Цветков и Винтнер [74] сообщили, что добавив 2955 пар переводов MWE в систему SMT с иврита на английский, они получили статистически значимое улучшение показателей BLEU и Meteor.Кроме того, Bouamor et al. [75] использовали различные стратегии для интеграции в свою англо-французскую систему SMT двуязычных фраз, извлеченных из обучающего корпуса из 100 000 предложений, обнаружив увеличение показателей BLEU и Meteor. Стоит отметить, что системы SMT на основе фраз уже включают MWE / коллокационную систему. знания как результат обучения их языку и моделям перевода на больших (параллельных) корпусах. Эти системы успешно справляются с локальными сопоставлениями, но, возможно, они плохо подходят для обработки сопоставлений, компоненты которых не находятся в непосредственной близости друг от друга.Как отмечает Бабич и др. [76] выразился,В том же ключе Бод [77] указывает, что несмежные фразы представляют собой реальную проблему для систем SMT, и предоставляет эмпирические доказательства того, что такие фразы значительно способствуют повышению точности перевода. В самом деле, мы также обнаружили, что SMT-системы очень чувствительны к синтаксической среде исходных словосочетаний, а также к лексической среде [78].Как видно из примера 5, одно и то же исходное словосочетание правильно переводится с английского на французский, когда встречается в данном контексте и неправильно переводится в другом контексте:«Вывод SMT часто на удивление хорош в отношении коротких словосочетаний, но часто (…) правильный выбор упускается в случаях, когда ограничения выбора влияют на удаленные слова».
Пример 5. Совместные переводы с английского на французский.
люди, которые полагаются на нас в оказании полной поддержки, когда это необходимо les gens qui comptent sur nous pour apporter un soutien complete quand il est néecessaire
и, безусловно, правильно оказывать массовую поддержку этим областям […] и это уверенность в праве собственности на массивные домены.
Требуется дальнейшее исследование, чтобы проверить, сопровождается ли положительный результат улучшенного перевода словосочетания аналогичным улучшением общего качества предложения.Однако, учитывая массовое присутствие словосочетаний в языке и их роль в беглости языка, мы предполагаем, что улучшение перевода словосочетаний является одним из основных компонентов повышения общего качества переводов.
Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник «чувственных» частот.Надеюсь, выше приведено достаточно информации, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов. Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете — точно так же, как словарь, но сосредоточенный на части речи слов.И так как у меня уже была большая часть инфраструктуры с двух других сайтов, я подумал, что для ее запуска и работы не потребуется много работы.
Словарь основан на замечательном проекте Wiktionary от Викимедиа. Сначала я начал с WordNet, но затем понял, что в нем отсутствуют многие типы слов / лемм (определители, местоимения, сокращения и многое другое). Это заставило меня исследовать словарь Вебстера издания 1913 года, который сейчас находится в открытом доступе.Однако после целого дня работы над его переносом в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа. Именно тогда я наткнулся на проект UBY — удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс.Я просто извлек записи из Викисловаря и закинул их в этот интерфейс! Так что работы потребовалось немного больше, чем ожидалось, но я счастлив, что продолжил работать после пары первых промахов.
Особая благодарность разработчикам открытого исходного кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.js.
В настоящее время это основано на версии викисловаря, которой несколько лет. Я планирую в ближайшее время обновить его до более новой версии, и это обновление должно внести множество новых смысловых значений для многих слов (или, точнее, леммы).
Инвесторы и экономисты готовятся к новой опасной игре: анализ слов Трампа
НЬЮ-ЙОРК (Рейтер) — Подойдите, Джанет Йеллен. У главы Федеральной резервной системы есть претендент на звание оратора, наиболее пристально изучаемый Уолл-стрит, — это Дональд Трамп.
Кандидат в президенты США от республиканцев Дональд Трамп проводит митинг кампании в Делавэре, штат Огайо, США, 20 октября 2016 года. REUTERS / Джонатан Эрнст / Фото из архива
Финансовое сообщество внимательно следит за всеми новыми избранными президентами США, чтобы выяснить, что они политика означает для рынков.Но стиль речи Трампа, часто использующий энтимемы или неполные предложения, которые оставляют место для интерпретации, наряду с расплывчатыми или противоречивыми обещаниями кампании, делает его еще более сложным для расшифровки.
«Его заявления безумны. Он говорит необычные вещи, такие как строительство стены и получение оплаты за нее из Мексики, которые, как вы знаете, просто не произойдут », — сказал Аллан Мельцер, историк из ФРС и профессор политической экономии в Университете Карнеги-Меллона в Питтсбурге.
«Но его действия, в отличие от заявлений, были очень умеренными», — сказал он.
Доказательство того, что Трамп заставляет политиков и инвесторов ловить каждое его слово, был представлен вскоре после примирительной речи республиканца в среду утром. Облигации упали, а акции выросли, поскольку инвесторы сделали предварительные ставки на то, что несколько расплывчатая платформа экономических стимулов Трампа приведет к корпоративным прибылям и более высокой инфляции.
Ставки высоки. Имея Палату представителей и Сенат, контролируемые республиканцами, Трамп имеет возможность использовать свое время у власти, чтобы радикально изменить американскую экономику.
Он пообещал резко сократить налоги, расходы на инфраструктуру и дерегулирование экономики и хочет отменить Obamacare. Эти меры, по его словам, ускорят рост и помогут повысить заработную плату тех, кто проиграл в глобализованном мире, где рабочие места «среднего класса» были ограничены.
При дефиците бюджета США всего 3,2 процента от валового внутреннего продукта по сравнению с 9,8 процентами в 2009 году и почти рекордно низкими процентными ставками у Трампа есть возможности для масштабного фискального стимулирования, по крайней мере, в краткосрочной перспективе.
Его сдержанная благодарственная речь намекнула, что инфраструктура является приоритетом. Трамп сказал, что он «восстановит наши шоссе, мосты, туннели, аэропорты, школы, больницы (и) нашу инфраструктуру, которая, кстати, станет непревзойденной».
Во время предвыборной кампании речи Трампа были полны превосходных степеней и незавершенных мыслей, которые только усложняли дело для трейдеров и наблюдателей за экономической политикой. Эти энтимемы — риторический прием, лежащий в основе убедительного стиля речи, который помог катапультировать миллиардера в Белый дом.
Попытка разобрать его слова — это одно. По словам Брайана Шапиро, генерального директора SPAG Funds, небольшого глобального макрохедж-фонда, управляющего из Нью-Йорка, фактически заставить деньги работать быстро, опираясь на них, сопряжено с гораздо большим риском, чем обычно.
«Я не отреагирую на это, но мир будет», — сказал он. «Я думаю, что у людей случится сердечный приступ, если они будут реагировать на каждое слово».
«TRUMP LITE»
Консультационная фирма по экономическим вопросам Fathom Consulting назвала результаты выборов «Trump Lite»: мир, в котором, будучи избранным президентом, он не желал бы или не мог проводить некоторые из своих более радикальных мер, таких как строительство стены в граница с Мексикой, массовые депортации иммигрантов и широкомасштабные протекционистские меры.
«Рынки ждут, чтобы увидеть, будет ли у нас кампания Трампа, который говорил риторикой, или президента Трампа, который будет более прагматичным в своем подходе», — сказал Комал Шри-Кумар, президент Sri-Kumar Global. Стратегии.
Экономисты и управляющие фондами, а также директивные органы ФРС хотят посмотреть, какие вопросы будут уделять Трампу приоритетом. Пока есть признаки того, что он будет добиваться снижения налогов, дополнительных военных расходов и пересмотра Закона о доступном медицинском обслуживании президента Барака Обамы, получившего название Obamacare.
Президент ФРС Чикаго Чарльз Эванс, выступая перед журналистами во время голосования американцев во вторник, сказал, что попытается выяснить, будет ли фискальная политика нового президента «более симулятивной, примерно такой же или хуже», добавив уровень волатильность рынка может дать ключ к разгадке.
У Трампа нет определенной экономической команды. Неясно, последует ли он примеру Питера Наварро, профессора Калифорнийского университета в Ирвине, исследования которого предполагают более жесткую торговую позицию в отношении Китая; или мог ли он придерживаться союзников с Уолл-стрит, таких как бывший выпускник Goldman Sachs Стивен Мнучин, которого Трамп назвал потенциальным министром финансов.
«Бюджетный план Трампа в его нынешнем виде довольно расплывчат и не складывается», — сказал Пол Эшворт, главный экономист Capital Economics в Торонто. «Мы ожидаем, что какой-то бюджетный план будет следовать республиканской повестке дня, но он, вероятно, будет намного меньше по масштабу, чем тот, который изначально планировал Трамп».
Хотя ожидается, что эти вопросы политики сохранятся даже после того, как Трамп сменит Обаму в январе, «характер назначений в кабинете Трампа и тон их слушаний по утверждению либо ослабят, либо увеличат премию за неопределенность на рынках», — написал Стивен Риккиуто U.С. главный экономист Mizuho.
Помимо Наварро и Мнучина, все взоры будут прикованы к тому, смогут ли в конечном итоге вернуться в качестве советников многие консервативные экономисты, такие как декан бизнес-школы Колумбийского университета Гленн Хаббард, который покинул Трампа во время кампании, вызвавшей разногласия.
Тем не менее, телеведущий, ставший избранным президентом, в прошлом изо всех сил пытался сохранить размеренный тон, показанный в его победной речи. Например, во время своей кампании Трамп, похоже, предположил, что Соединенные Штаты могут пересмотреть свои долги, чтобы заключить более выгодную сделку, и на этот комментарий он быстро ответил.
Его прошлые критические замечания в адрес Йеллен как человека, которому должно быть «стыдно» за свои политические действия, и комментарии о том, что она удерживает процентные ставки на низком уровне по политическим причинам, могут взбудоражить рынки, если они повторятся во время его ожидания вступления в должность в январе.
«Некоторое время ему удавалось держать это под контролем, — сказал Мельцер. «Сможет ли он сделать это как президент, во многом определит, добьется ли он успеха».
Дополнительный отчет Яшасвини Сваминатан и Лоуренс Делевинь; редактирование Дэвида Чанса и Эдварда Тобина
% PDF-1.5 % 259 0 объект > эндобдж xref 259 89 0000000015 00000 н. 0000002181 00000 п. 0000002310 00000 н. 0000002362 00000 н. 0000003024 00000 н. 0000003480 00000 н. 0000003773 00000 н. 0000003855 00000 н. 0000003963 00000 н. 0000004124 00000 п. 0000004327 00000 н. 0000004532 00000 н. 0000004694 00000 н. 0000004856 00000 н. 0000005018 00000 н. 0000005180 00000 н. 0000005368 00000 н. 0000011160 00000 п. 0000011258 00000 п. 0000012016 00000 п. 0000012421 00000 п. 0000012594 00000 п. 0000012713 00000 п. 0000012774 00000 п. 0000013057 00000 п. 0000021225 00000 п. 0000022141 00000 п. 0000022164 00000 п. 0000022187 00000 п. 0000022243 00000 п. 0000022431 00000 п. 0000022621 00000 п. 0000022810 00000 п. 0000023007 00000 п. 0000023194 00000 п. 0000023383 00000 п. 0000023544 00000 п. 0000024177 00000 п. 0000024388 00000 п. 0000025328 00000 п. 0000025727 00000 н. 0000026039 00000 п. 0000026599 00000 н. 0000027544 00000 п. 0000028485 00000 п. 0000028771 00000 п. 0000029709 00000 п. 0000030109 00000 п. 0000030485 00000 п. 0000030780 00000 п. 0000031153 00000 п. 0000031531 00000 п. 0000031971 00000 п. 0000032918 00000 п. 0000033320 00000 п. 0000033816 00000 п. 0000034181 00000 п. 0000035121 00000 п. 0000035520 00000 п. 0000035960 00000 п. 0000036891 00000 п. 0000037624 00000 п. 0000038001 00000 п. 0000127986 00000 п. 0000228266 00000 н. 0000276351 00000 н. 0000314651 00000 н. 0000377134 00000 н. 0000395865 00000 н. 0000406830 00000 н. 0000406908 00000 н. 0000407003 00000 н. 0000407097 00000 н. 0000407211 00000 н. 0000407367 00000 н. 0000407464 00000 н. 0000407614 00000 н. 0000407723 00000 н. 0000407877 00000 н.
Как создать инструмент для синтаксического анализа резюме | автор: Low Wei Hong
Вот сложная часть.Есть несколько способов справиться с этим, но я поделюсь с вами лучшими способами, которые я обнаружил, и базовым методом.
Базовый метод
Давайте сначала поговорим о базовом методе. Базовый метод, который я использую, — сначала очистить ключевые слова для каждого раздела (здесь я имею в виду опыт , образование , личные данные и другие ), а затем использовать регулярное выражение для их сопоставления.
Например, я хочу извлечь название университета.Поэтому я сначала нахожу веб-сайт, содержащий большинство университетов, и просматриваю их. Затем я использую регулярное выражение, чтобы проверить, можно ли найти это название университета в конкретном резюме. В случае обнаружения эта информация будет извлечена из резюме.
Таким образом, я могу создать базовый метод, который я буду использовать для сравнения производительности моего другого метода синтаксического анализа.
Лучший метод
С другой стороны, вот лучший метод, который я обнаружил.
Во-первых, я разделю простой текст на несколько основных разделов.Например, опыт , образование , личные данные и другие . Что я делаю, так это набор ключевых слов для заголовка каждого основного раздела, например, Опыт работы , Образование , Резюме , Другие навыки и т. Д.
Конечно, вы можете попытаться создать модель машинного обучения, которая могла бы сделать разделение, но я выбрал самый простой способ.
После этого будет отдельный скрипт для обработки каждого основного раздела отдельно.Каждый сценарий будет определять свои собственные правила, которые используют очищенные данные для извлечения информации для каждого поля. Правила в каждом скрипте на самом деле довольно грязные и сложные. Поскольку я хотел бы, чтобы эта статья была как можно более простой, я не буду раскрывать ее сейчас. Если вам интересно узнать подробности, прокомментируйте ниже!
Один из методов машинного обучения, который я использую, заключается в том, чтобы различать название компании и название должности . Причина, по которой я использую здесь модель машинного обучения, заключается в том, что я обнаружил несколько очевидных закономерностей, позволяющих отличить название компании от названия должности, например, когда вы видите ключевые слова « Private Limited» или «Pte Ltd», вы уверены, что это название компании.
Где взять данные для обучения?
Я поскреб данные из greenbook, чтобы узнать названия компании, и загрузил названия должностей из этого репозитория Github.
После получения данных я просто обучил очень простую наивную байесовскую модель, которая может повысить точность классификации должностей как минимум на 10%.
Короче говоря, моя стратегия синтаксического анализа парсера резюме — это разделяй и властвуй .