Диагностическая работа по русскому языку за 4 класс. | Методическая разработка по русскому языку (4 класс) на тему:
О.В. Грудачёва
учитель начальных классов МБОУ «Излучинская ОСШ УИОП № 1»
СПЕЦИФИКАЦИЯ
диагностической работы по русскому языку
для учащихся, оканчивающих 4 класс начальной школы
1. Цель диагностической работы – выяснить уровень овладения учащимися основными знаниями и умениями по русскому языку к концу 4 класса, а также сформированность некоторых общеучебных умений – правильное восприятие учебной задачи, контроль и корректировка собственных действий по ходу выполнения задания.
2. Содержание диагностической работы соответствует обязательному минимуму содержания начального общего образования и требованиям программ к знаниям, умениям и навыкам учащихся 4-го класса четырёхлетней начальной школы.
Особенностью данной диагностической работы является проведение её на этапе завершения обучения в начальной школе, поэтому на определение содержания проверочных работ не влияет тот факт, что участвующие в государственном эксперименте школы вели обучение по УМК «Начальная школа XXI века» (руководитель проекта Н. Ф.Виноградова) либо по другой программе.
Ф.Виноградова) либо по другой программе.
3. Отбор и распределение заданий. На основе анализа обязательного минимума содержания и программных требований к знаниям, умениям и навыкам учащихся 4-го класса четырёхлетней начальной школы для контроля были выделены следующие блоки содержания курса русского языка: фонетика, состав слова, морфология, орфография, синтаксис и пунктуация. Распределение заданий диагностической работы по этим блокам содержания курса русского языка четвертого класса представлено в таблице 1.
Таблица 1. Блоки содержания | Число (%) заданий |
Фонетика | 2 (9%) |
Состав слова | 3 (14%) |
Морфология | 5 ( 23%) |
Орфография | 8 (36 %) |
Синтаксис и пунктуация | 4 (18 %) |
Итого: | 22 (100%) |
Знания, умения и навыки учащихся, которые проверяются в каждом из заданий, приведены в плане диагностической работы (таблица 2).
4. Структура диагностической работы. Диагностическая работа содержит 22 задания, отличающихся по содержанию, сложности и типу.
По своей сложности 22 задания работы могут быть разделены на две группы.
Первая группа – базовые задания (БЗ), которые составляют 70% от всех заданий работы (14 заданий). Они проверяют, как усвоены учащимися требования программы. С помощью этих заданий проверяется умение учащихся применять знания в знакомых ситуациях. Такие задания отрабатываются на уроках русского языка, а соответствующие знания и умения должны быть хорошо усвоены большинством учащихся.
Вторая группа — задания повышенной сложности (ПС). Они составляют 30 % от всех заданий (8 заданий). Эти задания не превышают требований программы, но имеют большую сложность по сравнению с базовыми. Они даются в непривычной для четвероклассника формулировке, или их выполнение требует последовательного поэтапного самоконтроля ученика. Повышенная сложность заданий связана с тем, что наряду с усвоением знаний проверяется также сформированность общеучебных умений и познавательной деятельности учащихся.
В диагностической работе используются три типа заданий:
— задания с выбором ответа (ВО) (18 заданий из 22), к каждому из которых предлагается 4 варианта ответа, из которых только один правильный;
— задания с кратким ответом (КО) (2 задания из 22), требующие разбора слова по составу и записи краткого ответа в несколько слов после предварительного выбора ответа;
— задания с развернутым ответом (РО) (2 задания из 22), в которых необходимо распределить слова на группы или объяснить свой ответ.
Порядок следования заданий и их основные характеристики представлены в таблице 2.
План диагностической работы
Номер задания | Блок содержания |
ОБЪЕКТ КОНТРОЛЯ | Уровень сложности задания | Тип задания | Примерное время выполнения |
1 | 1 | умение устанавливать связи между графической формой слова и его звуковым составом | (БЗ) | ВО | 1 мин. |
2 | 1 | умение различать звуки и буквы | (БЗ) | ВО | 1 мин. |
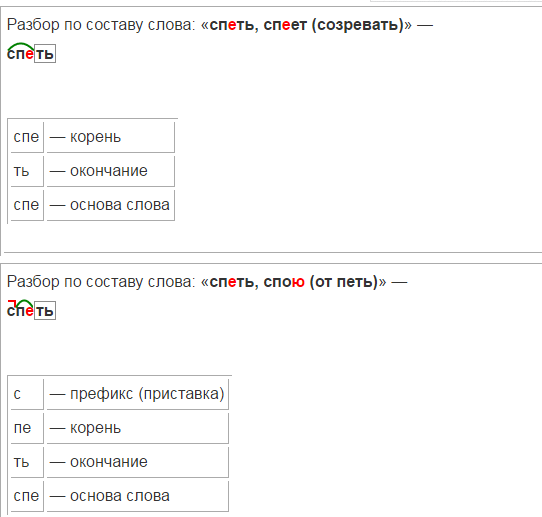
3 | 2 | умение различать значимые части слова | (БЗ) | ВО | 2 мин. |
4 | 2 | понимание морфемного состава слова | (ПС) | РО | 4 мин. |
5 | 2 | умение проводить морфемный анализ в нестандартной ситуации (на примере искусственного языка) | (ПС) | КО | 3 мин. |
6 | 4 | умение определять и записывать безударные падежные окончания имён существительных | (БЗ) | ВО | 1 мин. |
7 | 4 | умение определять принадлежность слова к определенному склонению и падежу, определять выбор падежного окончания | (БЗ) | ВО | 3 мин. |
8 | 3 | умение определять принадлежность слова к определенному склонению, обосновывать написание падежных окончаний | (ПС) | КО | 2 мин. |
9 | 4 | понимание способа проверки безударных окончаний имён существительных | (ПС) | РО | 4 мин. |
10 | 4 | понимание способа рассуждения при выборе падежного окончания имени существительного | (ПС) | ВО | 2 мин. |
11 | 3 | знание грамматических признаков имени прилагательного | (БЗ) | ВО | 1 мин. |
12 | 4 | умение определять и записывать безударные падежные окончания имён прилагательных | (БЗ) | ВО | 1 мин. |
13 | 4 | умение определять падеж имени прилагательного | (БЗ) | ВО | 1 мин. |
14 | 4 | умение найти ошибку в словах с изученными орфограммами | (БЗ) | ВО | 1 мин. |
15 | 3 | умение определить правильный способ действия при определении безударного личного окончания глагола | (БЗ) | ВО | 1 мин. |
16 | 3 | умение определить время глагола | (ПС) | ВО | 2 мин. |
17 | 4 | умение применять правило о правописании частицы не с глаголами | (БЗ) | ВО | 1 мин. |
18 | 4 | умение применять правило о правописании неопределённой формы и 3-го лица глаголов (-ться, -тся) | (БЗ) | ВО | 1 мин. |
19 | 5 | знание о структуре предложения | (БЗ) | ВО | 1 мин. |
20 | Умение различать предложения с однородными сказуемыми (подлежащими) | (ПС) | ВО | 2 мин. | |
21 | 5 | знание о членах предложения | (БЗ) | ВО | 2 мин. |
22 | 5 | знание об однородных членах предложения и постановке знаков препинания между ними | (ПС) | ВО | 2 мин. |






5. Время и способ выполнения заданий. На выполнение диагностической работы отводится один/два урока. Каждый ученик получает текст одного из вариантов диагностической работы, в котором отмечает или записывает свои ответы на задания.
На выполнение диагностической работы отводится один/два урока. Каждый ученик получает текст одного из вариантов диагностической работы, в котором отмечает или записывает свои ответы на задания.
6. Варианты работы. Диагностической работа составлена из 1 варианта.
7. Оценка выполнения заданий и работы в целом.
За каждое верно выполненное задание базового и повышенного уровней ученик получает один балл. Если задание выполнено неверно или не выполнялось – то выставляется 0 баллов. Максимальное количество баллов за выполнение всех заданий работы – 25 баллов.
Если в результате выполнения всей проверочной работы ученик набрал менее 8 баллов – это низкий уровень выполнения работы; от 8 до 16 баллов – средний уровень выполнения работы; 17 баллов и более – высокий уровень выполнения работы.
ДИАГНОСТИЧЕСКАЯ РАБОТА ПО РУССКОМУ ЯЗЫКУ 4 КЛАСС
ВАРИАНТ 1
Ф.И. ученика _______________________________________________
Обведи ○ или отметь √ букву выбранного тобой ответа.
1. Сколько звуков и букв в слове «сердце»?
А. 6 звуков, 6 букв
Б. 5 звуков, 6 букв
В. 6 звуков, 5 букв
Г. 7 звуков, 6 букв
2. Найди слово, написание которого не соответствует его произношению.
А. зубки
Б. тонкий
В. пальма
Г. верба
3. Отметь слово, в котором нет приставки.
А. подосиновик
Б. подошва
В. подбежать
Г. поднебесный
4. Запиши слова в четыре столбика в зависимости от того, в какой части
слова находится орфограмма.
маленький, (в) доме, морской, порезал, цветной, сыночек, (на) полке, покрасил
приставка | корень | суффикс | окончание |
5. В сказке Л. Кэрролла «Алиса в Зазеркалье» есть слово БАХРЯЧКА
В сказке Л. Кэрролла «Алиса в Зазеркалье» есть слово БАХРЯЧКА
Известно, что слово бахрячка изменяется так: бахрячке, бахрячку, бахрячкой
У этого слова есть родственные слова: бахрячик, хрячить, бахрячный,
В словах бахрячка, хрумка, шорьки одинаковый суффикс.
В словах бахрячка, баляка, бавярка, балуйка одинаковая приставка.
Разбери по составу слово БАХРЯЧКА
6. В словосочетании найди существительное, в котором нужно дописать окончание «-е».
А. сидел на ветк___
Б. написал в тетрад___
В. говорили о честност___
Г. поехал к дедушк___
7. Какое окончание и почему имеет слово деревня в словосочетании
«жить в деревн____»?
А. окончание -е, потому что это существительное 1 скл., П.п.
Б. окончание -е, потому что это существительное 2 скл., П.п.
В. окончание -и , потому что это существительное 3 скл., П.п.
Г. окончание -е, потому что это существительное 2 скл., Д.п.
8. Какие окончания имеют в предложном падеже (П.п.) слова метель и камень?
Какие окончания имеют в предложном падеже (П.п.) слова метель и камень?
А. Слова имеют одинаковые окончания, так как______________________________
Б. Слова имеют разные окончания, так как__________________________________
9. Выбери правильное утверждение.
А. Безударные окончания существительных третьего склонения можно проверить окончаниями слова мышь.
Б. Безударные окончания существительных второго склонения можно проверить окончаниями слова зеркало.
В. Безударные окончания существительных первого склонения можно проверить окончаниями слова вишня.
Г. Безударные окончания существительных третьего склонения можно проверить окончаниями слова степь.
Объясни свой выбор.
Я выбрал это утверждение, потому что____________________________________
10. Найди правильный способ рассуждения при написании безударного окончания им. существ.
А. о песне, потому что о воде;
Б. о дочери, потому что о любви;
В. о дятле, потому что о трубе;
о дятле, потому что о трубе;
Г. по дороге, потому что по верёвке;
11. Выбери правильное высказывание.
А. Имена существительные не имеют три склонения.
Б. Имена существительные изменяются по падежам.
В. Имена существительными не согласуются с именами прилагательные в роде, числе и падеже.
Г. Имена существительные изменяются по родам.
12. В словосочетании найди прилагательное, в котором нужно дописать окончание «-ем».
А. вышел ранн___ утром
Б. написал о говорящ___ попугае
В. сказка о син___ море
Г. рассказал о любящ___ сыне
13. В каком словосочетании верно определён падеж имени прилагательного?
А. о великой (П.п.) стране
Б. сочной (Д.п.) травой
В. по узкой (П.п.) тропе
Г. с добрыми (Т.п.) друзьями
14. Найди словосочетание, в котором допущена ошибка.
А. на дальний дороге
Б. по узкой тропинке
по узкой тропинке
В. в синем небе
Г. по зелёной тропинке
15. К какой части речи относится слово читаешь?
А. глагол
Б. имя прилагательное
В. местоимение
Г. имя существительное
16. У какого глагола правильно определено время?
А. прочитаю (прошедшее время)
Б. читаю (настоящее время)
В. написала (прошедшее время)
Г. писала (будущее время)
17. Какой глагол написан с частицей НЕ правильно?
А. ненавижу
Б. несделал
В. невыучил
Г. не посчитал
18. Какой из глаголов относится к 1-ому лицу?
А. ждёт
Б. нести
В. пляшем
Г. сверкать
19. Найди верное утверждение.
А. Наличие главных членов – основной признак распространённого предложения.
Б. Подлежащее и определение составляют грамматическую основу предложения.
В. Подлежащее – второстепенный член предложения.
Г. Предложение может не иметь второстепенных членов.
20. Найди предложение с однородными дополнениями.
А. На уроке физкультуры ученики бегают, прыгают.
Б. Ира и Марина пошли в лес за грибами.
В. Мама собрала в саду яблоки и груши.
Г. Осенью с деревьев осыпаются красные, жёлтые, оранжевые листья.
21. Какое предложение соответствует изображенной ниже схеме?
_______ .
А. Воет за окном сильная вьюга.
Б. С визгом затормозила грузовая машина.
В. На ветке сидит маленький воробей.
Г. Шумные ручейки мчаться к реке.
22. Найди предложение, в котором правильно поставлены запятые.
А. Яблоки были красные но кислые.
Б. Бабушка поставила на стол сушки а Валя сахарницу.
В. Мы вырастили в огороде морковь, свёклу и редиску.
Г. Мама заварила чай, а папа достал банку с вареньем
Морфологический разбор слова читаешь — ответ на Uchi.
 ru
ruОтвет или решение2
К
Читаешь
1. Глагол; обозначает действие; отвечает на вопрос что делаешь?
2. Н. ф. – читать. Морфологические признаки:
А) Постоянные морфологические признаки:
1) несовершенный вид;
2) невозвратный;
3) переходный;
4) I спряжение.
Б) Непостоянные морфологические признаки. Употреблён в форме:
1) изъявительного наклонения;
2) настоящего времени;
3) единственного числа;
4) 2-го лица.
3. В предложении является сказуемым.
Н
В предложенном задании нас просят сделать морфологический разбор глагола «читаешь». Для выполнения данного задания сначала подробно рассмотрим схему морфологического разбора для глаголов.
Порядок морфологического разбора глагола
- Сначала определяем часть речи и задаём вопрос.
- Ставим вопрос начальной формы и пишем инфинитив предложенного глагола.
- Определяем постоянные признаки, к которым относятся: совершенный (что сделать?) или несовершенный (что делать?) вид, переходность (переходный или непереходный), возвратность (с возвратным суффиксом «ся» возвратный, без него невозвратный), спряжение (первое спряжение, если в начальной форме глагол оканчивается на «-еть», «-ать», «-оть», «-ыть» и другие, кроме исключений: гнать, держать, смотреть, видеть, дышать, слышать, ненавидеть, зависеть, терпеть, вертеть, обидеть; второе спряжение, если оканчивается на «-ить», кроме исключений: брить, стелить, зиждиться).

- Определяем непостоянные признаки глагола, к которым относятся: время (настоящее, прошедшее или будущее в зависимости от вопроса), число (единственное или множественное), род (мужской, женский или средний — только для прошедшего времени) лицо (первое, второе или третье — только для настоящего и будущего времени).
- Роль в предложение, то есть каким членом предложения является.
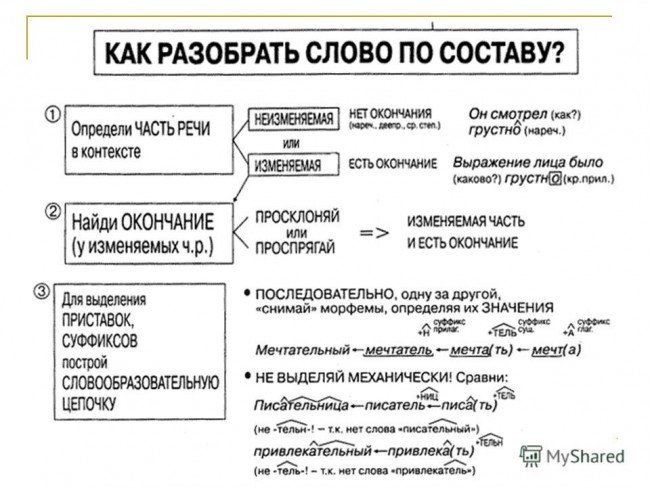
Теперь, когда мы знаем весь порядок морфологического разбора глагола, можем провести разбор слова «читаешь» по схеме.
Морфологический разбор слова «читаешь»
- Читаешь — что делаешь? — глагол.
- Что делать? — читать.
- Постоянные признаки: (что делать?) несовершенный вид, переходный, невозвратный, первое спряжение (оканчивается на «-ать»).
- Непостоянные признаки: (что делаешь?) настоящее время, единственное число, род не определить для настоящего времени, второе лицо (ты читаешь).
- Роль в предложении определим, придумав предложение со словом «читаешь»:
«Последнее время ты слишком много читаешь». «Ты» — подлежащее, «читаешь» — сказуемое.
«Ты» — подлежащее, «читаешь» — сказуемое.
Таким образом, с помощью плана морфологического разбора глагола, мы осуществили разбор слова «читаешь».
Знаешь ответ?
Как написать хороший ответ?Как написать хороший ответ?
Будьте внимательны!
- Копировать с других сайтов запрещено. Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂
- Публикуются только развернутые объяснения. Ответ не может быть меньше 50 символов!
0 /10000
Разбор— Perl: Как читать текстовый файл слово за словом, начиная с определенного шаблона?
спросил
Изменено 7 лет, 3 месяца назад
Просмотрено 440 раз
Я пытаюсь написать скрипт, который читает текстовый файл с разделителями-пробелами и распознает определенный шаблон ШАБЛОН .
PATTERN сценарий должен прочитать RANDOM_NUMBER слов, начиная с PATTERN . Например, предположим, что ШАБЛОН — это a , а RANDOM_NUMBER — это 7 . Затем для этого текстового файла:1 2 3 4 5 6 а б в г д е g h i j k j
Я хотел бы получить:
a b c d e f грамм
в качестве вывода.
Пока что я научился распознавать эти закономерности, но не знаю, что с этим делать дальше. Как лучше всего читать слова?
Кстати, я просмотрел чтение текстового файла в Perl пословно, а не построчно, и это слишком расплывчато для моих целей. Кроме того, ответы не дают много объяснений с точки зрения того, что делает код.
- perl
- разбор
1
Итак, фокус здесь в том, чтобы установить $/ — разделитель записей. Если мы установим его на ' ' , мы сможем перебирать по одному «слову» за раз.
Затем мы можем использовать оператор диапазона, чтобы «обнаружить», находимся ли мы между нашими шаблонами.
местный $/ = ' ';
в то время как ( <ДАННЫЕ> ) {
если ( m/a/ .. 10 ) { print; }
}
Теперь это печатает из a в «поле 10», что не особенно полезно, потому что «счетчик» начинается в начале файла. (By
Таким образом, вместо этого мы, вероятно, хотим «запуститься», когда наблюдаемое условие истинно, и продолжить ряд других итераций:
#!/usr/bin/perl
использовать строгий;
использовать предупреждения;
местный $/ = ' ';
пока (<ДАННЫЕ>) {
если (м/а/) {
Распечатать;
for ( 2 .. 7 ) { print scalar ; } #2, потому что у нас уже есть "1"
последний; #при условии, что мы хотим сделать это только один раз.
}
}
__ДАННЫЕ__
1 2 3 4 5 6
а б в г д е
g h i j k j
Что печатает:
a b c d e f грамм
6
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Разбор— Поиск текста в PDF с использованием Python?
Проблема
Я пытаюсь определить тип документа (например, ходатайство, переписка, повестка в суд и т. д.), просматривая его текст, предпочтительно используя Python. Все PDF-файлы доступны для поиска, но я не нашел решения для его анализа с помощью python и применения скрипта для его поиска (если не считать сначала преобразования его в текстовый файл, но это может быть ресурсоемким для n документов).
д.), просматривая его текст, предпочтительно используя Python. Все PDF-файлы доступны для поиска, но я не нашел решения для его анализа с помощью python и применения скрипта для его поиска (если не считать сначала преобразования его в текстовый файл, но это может быть ресурсоемким для n документов).
Что я уже сделал
Я изучил документацию по pypdf, pdfminer, Adobe pdf и любые вопросы, которые смог найти (хотя ни один из них, похоже, не помог решить эту проблему напрямую). PDFminer, похоже, обладает наибольшим потенциалом, но после прочтения документации я даже не знаю, с чего начать.
Существует ли простой и эффективный метод чтения PDF-текста по страницам, строкам или всему документу? Или любые другие обходные пути?
- питон
- разбор
- текст
2
Это называется анализом PDF, и это очень сложно, потому что:
- Формат PDF предназначен для печати, а не для анализа. Внутри PDF-документа
текст не находится в определенном порядке (если порядок не важен для печати), большую часть времени
исходная структура текста теряется (буквы могут не группироваться
так как слова и слова не могут быть сгруппированы в предложения, и порядок их размещения в
бумага часто бывает случайной).
- Существует множество программ для создания PDF-файлов, многие из которых неисправны.
 Внутри PDF-документа
текст не находится в определенном порядке (если порядок не важен для печати), большую часть времени
исходная структура текста теряется (буквы могут не группироваться
так как слова и слова не могут быть сгруппированы в предложения, и порядок их размещения в
бумага часто бывает случайной).
Внутри PDF-документа
текст не находится в определенном порядке (если порядок не важен для печати), большую часть времени
исходная структура текста теряется (буквы могут не группироваться
так как слова и слова не могут быть сгруппированы в предложения, и порядок их размещения в
бумага часто бывает случайной).Такие инструменты, как PDFminer, используют эвристику для повторной группировки букв и слов в зависимости от их положения на странице. Я согласен, интерфейс довольно низкоуровневый, но он имеет больше смысла, когда вы знаете какую проблему они пытаются решить (в конце концов, важно выбрать, насколько близко от соседей должна быть буква/слово/строка, чтобы считаться частью абзаца).
Дорогой альтернативой (с точки зрения времени/мощности компьютера) является создание изображений для каждой страницы и передача их в OCR. Возможно, стоит попробовать, если у вас очень хорошее OCR.
Итак, мой ответ — нет, не существует простого и эффективного метода извлечения текста из PDF-файлов — если ваши документы имеют известную структуру, вы можете точно настроить правила и получить хорошие результаты, но это всегда азартная игра.
Я бы очень хотел оказаться неправым.
[обновление]
Ответ не изменился, но недавно я участвовал в двух проектах: один из них использует компьютерное зрение для извлечения данных из отсканированных больничных бланков. Другой извлекает данные из судебных протоколов. Что я узнал:
В 2018 году компьютерное зрение станет доступным для простых смертных. Если у вас есть хороший образец уже классифицированных документов, вы можете использовать OpenCV или SciKit-Image для извлечения признаков и обучения классификатора машинного обучения для определения типа документа. является.
Если PDF-файл, который вы анализируете, доступен для поиска, вы можете очень далеко извлечь весь текст, используя программное обеспечение, такое как pdftotext, и байесовский фильтр (алгоритм того же типа, который используется для классификации СПАМ).

Таким образом, не существует надежного и эффективного метода извлечения текста из PDF-файлов, но он может вам и не понадобиться для решения поставленной задачи (классификация типов документов).
4
Я совсем новичок, но у меня работает этот скрипт:
# импортировать пакеты
импортировать PyPDF2
импортировать повторно
#открываем pdf файл
объект = PyPDF2.PdfFileReader("test.pdf")
# получить количество страниц
Число страниц = объект.getNumPages()
# определить ключевые термины
Строка = "Социальные"
# извлечь текст и выполнить поиск
для i в диапазоне (0, NumPages):
PageObj = объект.getPage(i)
print("это страница " + str(i))
Текст = PageObj.extractText()
# печать(текст)
ResSearch = re.search(строка, текст)
печать (ResSearch)
4
Я написал обширные системы для компании, в которой я работаю, для преобразования PDF-файлов в данные для обработки (счета-фактуры, расчеты, отсканированные билеты и т.
pdftotext , часть набора инструментов xpdf. Этот инструмент быстро преобразует PDF-файлы с возможностью поиска в текстовый файл, который вы можете читать и анализировать с помощью Python. Подсказка: используйте -макет аргумент. И, кстати, не все PDF-файлы доступны для поиска, а только те, которые содержат текст. Некоторые PDF-файлы содержат только изображения без текста.4
Недавно я начал использовать ScraperWiki, чтобы делать то, что вы описали.
Вот пример использования ScraperWiki для извлечения данных PDF.
Функция scraperwiki.pdftoxml() возвращает структуру XML.
Затем вы можете использовать BeautifulSoup, чтобы преобразовать его в навигационное дерево.
Вот мой код для —
импорта scraperwiki, urllib2
из bs4 импортировать BeautifulSoup
защита send_Request (url):
#Получить содержимое, независимо от того, является ли файл HTML, XML или PDF
pageContent = urllib2. urlopen(url)
страница возвратаСодержание
def process_PDF (расположение файла):
#Используйте это, чтобы получить PDF, конвертировать в XML
pdfToProcess = send_Request (расположение файла)
pdfToObject = скребокwiki.pdftoxml(pdfToProcess.read())
вернуть pdfToObject
def parse_HTML_tree (contentToParse):
# возвращает навигационное дерево, которое вы можете перебирать
суп = BeautifulSoup (contentToParse)
вернуть суп
pdf = process_PDF('http://greenteapress.com/thinkstats/thinkstats.pdf')
pdfToSoup = parse_HTML_tree (pdf)
супToArray = pdfToSoup.findAll('текст')
для строки в soapToArray:
линия печати
 urlopen(url)
страница возвратаСодержание
def process_PDF (расположение файла):
#Используйте это, чтобы получить PDF, конвертировать в XML
pdfToProcess = send_Request (расположение файла)
pdfToObject = скребокwiki.pdftoxml(pdfToProcess.read())
вернуть pdfToObject
def parse_HTML_tree (contentToParse):
# возвращает навигационное дерево, которое вы можете перебирать
суп = BeautifulSoup (contentToParse)
вернуть суп
pdf = process_PDF('http://greenteapress.com/thinkstats/thinkstats.pdf')
pdfToSoup = parse_HTML_tree (pdf)
супToArray = pdfToSoup.findAll('текст')
для строки в soapToArray:
линия печати
urlopen(url)
страница возвратаСодержание
def process_PDF (расположение файла):
#Используйте это, чтобы получить PDF, конвертировать в XML
pdfToProcess = send_Request (расположение файла)
pdfToObject = скребокwiki.pdftoxml(pdfToProcess.read())
вернуть pdfToObject
def parse_HTML_tree (contentToParse):
# возвращает навигационное дерево, которое вы можете перебирать
суп = BeautifulSoup (contentToParse)
вернуть суп
pdf = process_PDF('http://greenteapress.com/thinkstats/thinkstats.pdf')
pdfToSoup = parse_HTML_tree (pdf)
супToArray = pdfToSoup.findAll('текст')
для строки в soapToArray:
линия печати
Этот код напечатает большую уродливую кучу из тегов .
Каждая страница отделена , если вас это утешит.
Если вам нужен контент внутри тегов , который может включать заголовки, заключенные, например, в , используйте line.contents
Если вам нужна только каждая строка текста, не включая теги , используйте line. getText()
getText()
Это грязно и болезненно, но это будет работать для PDF-документов с возможностью поиска. До сих пор я нашел это точным, но болезненным.
2
Вот решение, которое мне показалось удобным для этой проблемы. В переменной text вы получаете текст из PDF для поиска в нем. Но я также сохранил идею выделения текста ключевыми словами, как я нашел на этом сайте: https://medium.com/@rqaiserr/how-to-convert-pdfs-into-searchable-key-words-with-python. -85aab86c544f откуда я взял это решение, хотя сделать nltk было не очень просто, оно может пригодиться для дальнейших целей:
импорт PyPDF2
импортировать текст
из nltk.tokenize импортировать word_tokenize
из nltk.corpus импортировать стоп-слова
def searchInPDF (имя файла, ключ):
вхождения = 0
pdfFileObj = открыть (имя файла, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
num_pages = pdfReader.numPages
количество = 0
текст = ""
в то время как количество < num_pages:
pageObj = pdfReader. getPage (количество)
количество +=1
текст += pageObj.extractText()
если текст != "":
текст = текст
еще:
text = text.process(имя файла, метод='tesseract', язык='eng')
токены = word_tokenize (текст)
знак препинания = ['(',')',';',':','[',']',',']
stop_words = стоп-слова.слова('английский')
ключевые слова = [слово в токенах, если не слово в стоп-словах и не слово в знаках препинания]
для k в ключевых словах:
если ключ == k: вхождения+=1
возвращать вхождения
pdf_filename = '/home/florin/Downloads/python.pdf'
search_for = 'строка'
печать searchInPDF (pdf_filename,search_for)
 getPage (количество)
количество +=1
текст += pageObj.extractText()
если текст != "":
текст = текст
еще:
text = text.process(имя файла, метод='tesseract', язык='eng')
токены = word_tokenize (текст)
знак препинания = ['(',')',';',':','[',']',',']
stop_words = стоп-слова.слова('английский')
ключевые слова = [слово в токенах, если не слово в стоп-словах и не слово в знаках препинания]
для k в ключевых словах:
если ключ == k: вхождения+=1
возвращать вхождения
pdf_filename = '/home/florin/Downloads/python.pdf'
search_for = 'строка'
печать searchInPDF (pdf_filename,search_for)
getPage (количество)
количество +=1
текст += pageObj.extractText()
если текст != "":
текст = текст
еще:
text = text.process(имя файла, метод='tesseract', язык='eng')
токены = word_tokenize (текст)
знак препинания = ['(',')',';',':','[',']',',']
stop_words = стоп-слова.слова('английский')
ключевые слова = [слово в токенах, если не слово в стоп-словах и не слово в знаках препинания]
для k в ключевых словах:
если ключ == k: вхождения+=1
возвращать вхождения
pdf_filename = '/home/florin/Downloads/python.pdf'
search_for = 'строка'
печать searchInPDF (pdf_filename,search_for)
Я согласен с @Paulo Сбор данных в формате PDF — это огромная проблема. Но вы можете добиться успеха с pdftotext , который является частью пакета Xpdf, бесплатно доступного здесь:
http://www.foolabs.com/xpdf/download.html
Этого должно быть достаточно для ваших целей, если вы просто поиск отдельных ключевых слов.
pdftotext — это утилита командной строки, но очень простая в использовании. Это даст вам текстовые файлы, с которыми вам будет легче работать.
Если вы используете bash, есть хороший инструмент под названием pdfgrep, Поскольку это находится в репозитории apt, вы можете установить его с помощью:
sudo apt install pdfgrep
Он хорошо удовлетворил мои потребности.
Поиск ключевых слов в PDF-файлах — непростая задача. Я пытался использовать библиотеку pdfminer с очень ограниченным успехом. Это в основном потому, что PDF-файлы являются воплощением столпотворения, когда дело доходит до структуры. Все в PDF может стоять отдельно или быть частью горизонтального или вертикального раздела, назад или вперед. У Pdfminer были проблемы с переводом одной страницы, не распознаванием шрифта, поэтому я попробовал другое направление — оптическое распознавание символов документа. Это сработало почти идеально.
Wand преобразует все отдельные страницы PDF-файла в большие двоичные объекты изображений, а затем вы запускаете распознавание символов для этих двоичных объектов. В качестве объекта BytesIO у меня есть содержимое файла PDF из веб-запроса. BytesIO — это потоковый объект, который имитирует загрузку файла, как если бы объект отрывался от диска, что wand требует в качестве параметра файла. Это позволяет вам просто брать данные в память вместо того, чтобы сначала сохранять файл на диск, а затем загружать его.
В качестве объекта BytesIO у меня есть содержимое файла PDF из веб-запроса. BytesIO — это потоковый объект, который имитирует загрузку файла, как если бы объект отрывался от диска, что wand требует в качестве параметра файла. Это позволяет вам просто брать данные в память вместо того, чтобы сначала сохранять файл на диск, а затем загружать его.
Вот очень простой блок кода, который поможет вам начать работу. Я могу представить себе различные функции, которые будут перебирать разные URL-адреса/файлы, разные поиски по ключевым словам для каждого файла и различные действия, которые необходимо предпринять, возможно, даже для каждого ключевого слова и файла.
# http://docs.wand-py.org/en/0.5.9/ # http://www.imagemagick.org/script/formats.php # brew install freetype imagemagick # варить установить PIL # варить установить tesseract # pip3 установить палочку # pip3 установить pyocr импортировать pyocr.builders запросы на импорт из io импортировать BytesIO из PIL импортировать изображение как PI из wand.
 image импорт изображения
если __name__ == '__main__':
pdf_url = 'https://www.vbgov.com/government/departments/city-clerk/city-council/Documents/CurrentBriefAgenda.pdf'
запрос = запросы.получить(pdf_url)
content_type = req.headers['Content-Type']
модифицированный_дата = req.headers['Последнее изменение']
content_buffer = BytesIO (req.content)
search_text = 'туристическая инвестиционная программа'
если content_type == 'приложение/pdf':
инструмент = pyocr.get_available_tools()[0]
lang = 'eng', если tool.get_available_languages().index('eng') >= 0 иначе нет
image_pdf = изображение (файл = content_buffer, формат = 'pdf', разрешение = 600)
image_jpeg = image_pdf.convert('jpeg')
для img в image_jpeg.sequence:
img_page = изображение (изображение = изображение)
txt = инструмент.image_to_string(
PI.open(BytesIO(img_page.make_blob('jpeg'))),
язык = язык,
строитель=pyocr.
image импорт изображения
если __name__ == '__main__':
pdf_url = 'https://www.vbgov.com/government/departments/city-clerk/city-council/Documents/CurrentBriefAgenda.pdf'
запрос = запросы.получить(pdf_url)
content_type = req.headers['Content-Type']
модифицированный_дата = req.headers['Последнее изменение']
content_buffer = BytesIO (req.content)
search_text = 'туристическая инвестиционная программа'
если content_type == 'приложение/pdf':
инструмент = pyocr.get_available_tools()[0]
lang = 'eng', если tool.get_available_languages().index('eng') >= 0 иначе нет
image_pdf = изображение (файл = content_buffer, формат = 'pdf', разрешение = 600)
image_jpeg = image_pdf.convert('jpeg')
для img в image_jpeg.sequence:
img_page = изображение (изображение = изображение)
txt = инструмент.image_to_string(
PI.open(BytesIO(img_page.make_blob('jpeg'))),
язык = язык,
строитель=pyocr. builders.TextBuilder()
)
если search_text в txt.lower():
print('Предупреждение! {} {} {}'.format(search_text, txt.lower().find(search_text),
дата_изменения))
Закрыть()
builders.TextBuilder()
)
если search_text в txt.lower():
print('Предупреждение! {} {} {}'.format(search_text, txt.lower().find(search_text),
дата_изменения))
Закрыть()
Этот ответ следует за ответом @Emma Yu:
Если вы хотите распечатать все совпадения строкового шаблона на каждой странице.
(Обратите внимание, что код Эммы печатает совпадение на странице):
import PyPDF2
импортировать повторно
pattern = input("Введите шаблон строки для поиска: ")
fileName = input("Введите путь и имя файла: ")
объект = PyPDF2.PdfFileReader (имя файла)
число страниц = объект.getNumPages ()
для i в диапазоне (0, numPages):
pageObj = объект.getPage(i)
текст = pageObj.extractText()
для совпадения в re.finditer(шаблон, текст):
print(f'Номер страницы: {i} | Соответствие: {match}')
Версия, использующая PyMuPDF. Я считаю, что он более надежен, чем PyPDF2.