Морфемный разбор слова «шестиклассники» по составу
Выполним разбор по составу слова «шестиклассники», указав два корня, суффиксы и окончание.
Чтобы разобрать по составу слово «шестиклассники», вначале определим, какой частью речи оно является. Это необходимо выяснить, поскольку каждая часть речи или словоформа имеет свой, присущий ей набор морфем.
Морфемный разбор слова «шестиклассники»
Слово «шестиклассники» называет учащихся шестого класса и отвечает на вопрос кто?
По этим грамматическим признакам определим, что это одушевленное имя существительное.
Окончание
Морфемный разбор анализируемого слова начнем с выделения окончания. Окончание имеют только изменяемые самостоятельные части речи.
Это существительное изменяется по падежам:
- голоса (кого?) шестиклассников
- подойдём (к кому?) к шестиклассникам
- дружу (с кем?) с шестиклассниками
Очевидно, что в его составе в форме именительного падежа словоизменительной морфемой является окончание -и, которое не включается в основу:
шестиклассники
Суффикс слова «шестиклассники»
Чтобы выяснить, какой суффикс имеется в составе этого слова, определим способ образования. Рассматриваемое сложное существительное образовано сложением основ простого числительного «шесть» и слова «класс» с присоединением суффикса -ник-, который образует множество слов — названий лиц по роду деятельности:
- наставник
- подводник
- чертежник
- художник
Корни слова
В составе рассматриваемого существительного укажем две главные значимые части шест- и класс-, которые прослеживаются в составе однокоренных слов:
- шестой
- шестнадцать
- шестнадцатый
- классный
- одноклассник
Эти корни соединяются с помощью интерфикса -и-, который участвует в образовании подобных сложных слов с именем числительным в первой части:
- пятиборье
- семиклассник
- восьмитомник
Закончим разбор по составу (морфемный разбор) слова «шестиклассники» итоговой схемой:
шестиклассники — корень/интерфикс/корень/суффикс/окончание.
Kaip susidaryti žodį „uždaryti“? | Naudinga informacija visiems
Aš suprantu žodį quot; closequot ;. Pirmas dalykas, kurį noriu pažymėti, yra šaknis — quot; close to quot ;, tada priešdėlio žodyje nėra, vis tiek reikia pažymėti galūnę quot; кquot ;, pabaigos quot; ийquot; ir kamienas žodyje quot; closequot; — quot; arti ;.
Uždaryti yra būdvardis, reiškiantis artumo laipsnį. Vienakakliai žodžiai — arti, arti, arti, arčiau, judėti arčiau, artėti, apytiksliai. Šaknis yra artima, k yra vienintelis sufiksas ir būdvardžio galūnė.
Būdvardis „Uždaryti“ reiškia ką nors netoliese, pavyzdžiui, artimą draugą. Patikrinkime jo pabaigą, kurios atsisakysime šio žodžio: Uždaryti-Uždaryti-Uždaryti. Matome, kad pabaiga bus -II. Mes ieškome tų pačių šaknų: Close-Close-Closest-Approach. Gauname šaknį BLIZ-, kurioje galimas priebalsių З / Ж kaitaliojimas. lieka priesaga -K-, kuri būdvardžiuose reiškia objekto savybę, kaip žodžiuose RedKiy, TopKiy.
Mes turime: UŽDARYTI-II (šaknies galūnės pabaiga)
Pagrindas: UŽDARYTI.
Kuris? — Uždaryti.
Šis būdvardis yra vyriškas, vienaskaita (daugiskaita bus žodis — quot; closequot;), vardininko ir priegaidės atvejais.
Vykdys analizė pagal kompoziciją (morfeminė analizė arba morfeminė analizė) būdvardžio quot; closequot ;:
Mes pasirenkame keletą panašių savo žodžio šaknų: artimas, požiūris, netoliese, artumas ir kt. Žodžio šaknis bus-uždaryti- (šaknyje yra priebalsių kaitaliojimas z / z).
Keičiant žodį pagal lytį (uždaryti, uždaryti) arba atsisakius jo tais atvejais (uždaryti, uždaryti, uždaryti ir pan.), Pasirenkame žodžio -y- pabaigą.
Pabrėžkime dar vieną žodžio morfemą: tai galūnė -к-.
Žodžio pagrindas bus-uždaryti-.
Būdvardis;Uždarytiquot; (kuris iš jų?) Išardomas taip:
—netoli— žodžio šaknis quot; closequot ;;
—к— žodžio quot; closequot; galūnė ;;
—yi— žodžio quot; closequot; pabaiga ;;
pagrindu uždaryti žodžiai yra: Uždaryti, tai yra, pabaiga nėra įtraukta į žodžio kamieną.
Nustatant būdvardžio quot; closequot; morfeminę kompoziciją, iškart kyla klausimas: kas yra -к-, ar tai šaknies dalis, ar galūnė? Norėdami teisingai nustatyti šaknies ribas, mes pasirinksime susijusius žodžius: artimas, apytikslis, artumas. Dabar iš karto paaiškėjo, kad šaknis žodyje quot; closequot; ir giminingais žodžiais bus dalis šalia. -K- yra priesaga, -th yra pabaiga.
Žodžio pagrindas yra artimas.
Vienakakliai žodžiai quot; closequot; yra „artumo“ dalis; „kaimyno“ dalis.
Žodžio šaknis bus quot; closequot;,
quot; кquot; — tai bus priesaga,
lieka quot; iyquot; Ar pabaiga.
Šio būdvardžio pagrindas bus „artimas ;.
Rusų kalboje morfeminė žodžio quot; closequot; atrodys taip:
1) quot; uždaryti; — duoto žodžio šaknis,
2) kvotė; — duoto žodžio galūnė,
3) „iyquot“; — duoto žodžio pabaiga.
Žodžio pagrindas yra: quot; closequot;
Rekomenduojamas žodžių įvyniojimas: uždaryti.
Nustatykite žodžio pabaigą Uždaryti, jie bus yi Pagrindas šiuo atveju bus Uždaryti.
Šaknį galite apibrėžti atlikdami kitą veiksmą netoli… Žodžių priešdėliai Uždaryti ne, bet yra vienos raidės galūnė к.
Būdvardis quot; closequot; reiškia kintamąsias kalbos dalis. Panagrinėkime kompoziciją.
Linksnis -ii (žodžių formos — artimas, artimas).
Žodžio pagrindas yra artimas.
Žodžio šaknis yra artima (palyginimui — artima, artima).
K-sufiksas.
Слова «прямы» морфологический и фонетический разбор
1. простосердечный
2. искренний
3. откровенный
4. честный
5. прямолинейный
6. честной
7. безусловный
8. явный
9. недипломатичный
10. неискривленный
11. непосредственный
12. несомненный
13. столбовой
14. чистосердечный
15. беспересадочный
16. беспосадочный
17. прям
прям
18. истинный
19. форменный
20. нелицемерный
21. неприкрытый
22. нескрываемый
23. очевидный
24. ровный
25. прямодушный
26. настоящий
27. точный
28. чистый
29. истый
30. сущий
31. открытый
32. субстантивный
33. ближайший
34. правдивый
35. полный
36. резкий
37. срезанный
38. строевой
39. ортогенный
40. онлайновый
41. прямехонький
42. прямешенький
43. чистейший
44. отъявленный
45. на все сто
46. в полном смысле слова
47. чистой воды
48. чистейшей воды
49. с головы до ног
50. самый что ни на есть
51. решительный
52. бесспорный
53. заведомый
54. самоочевидный
55. само собой разумеющийся
56. не вызывающий сомнений
57. не подлежащий сомнению
58. ярко выраженный
59. стройный
60. лобовой
61. рубаха-парень
62. называет все вещи своими именами
63. называет все своими именами
64. весь наружу
65. режет правду матку
66. душа нараспашку
67. что на уме, то и на языке
68. орто
69. беззатейный
70. беззатейливый
71. безлестный
72. нековарный
73. безоколичный
74. безокольный
75. безуклонный
76. беспритворливый
77. беспритворный
78. беспритворчивый
79. беспристрастный
80. нескрытный
81. неумытный
82. беспосредственный
83. беспосредный
84. беспромежный
85. недвуличный
86. прямиковый
87. нелицеприимный
88. бесхитростный
Предложение(повторение) — Мегаобучалка
База данных КИМов и творческих заданий (контрольные, диктанты, тесты)
ДИКТАНТЫ
Диктант служит средством проверки орфографических и пунктуационных умений и навыков.
Грамматический разбор есть средство проверки степени понимания учащимися изучаемых грамматических явлений, умения производить простейший языковой анализ слов и предложений.
Оценки:
«5» – за работу, в которой нет ошибок.
«4» – за работу, в которой допущено 1–2 ошибки.
«3» – за работу, в которой допущено 3–5 ошибок.
«2» – за работу, в которой допущено более 5 ошибок.
Ошибкой в диктанте следует считать:
- нарушение правил орфографии при написании слов;
- замену слов;
- отсутствие знаков препинания в пределах программы данного класса;
- неправильное написание словарных слов.
За ошибку в диктанте не считаются:
- ошибки на те разделы орфографии и пунктуации, которые не изучались;
- единичный пропуск точки в конце предложения, если первое слово следующего предложения записано с заглавной буквы;
- единичный случай замены одного слова другим без искажения смысла.
За одну ошибку в диктанте считаются:
- два исправления;
- две пунктуационные ошибки;
- повторение ошибок в одном и том же слове.
Негрубыми ошибками считаются следующие:
- повторение одной и той же буквы в слове;
- недописанное слово;
- перенос слова, одна часть которого написана на одной строке, а вторая опущена;
- дважды записанное одно и то же слово в предложении.
Грамматические задания
«5» ставится за безошибочное выполнение всех заданий.
«4» ставится, если ученик правильно выполнил не менее 3/4 заданий.
«3» ставится, если ученик правильно выполнил не менее 1/2 заданий.
«2» ставится, если ученик не справился с большинством грамматических заданий.
ДИКТАНТ № 1 по теме «Предложение»
Цель: проверка остаточных знаний по программе второго класса и навыков каллиграфического написания букв.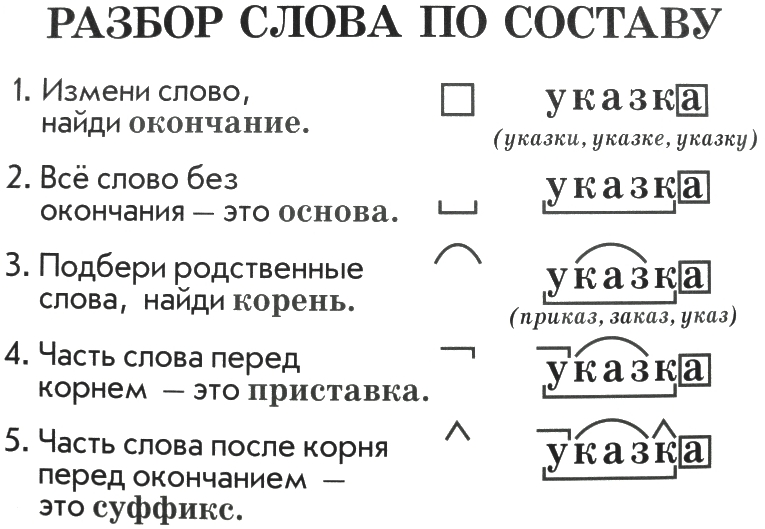
Осенью
Мы часто ходим в ближайший лесок. Красив русский лес осенью. Яркие краски радуют глаз. Падают сухие листья. Земля покрылась пёстрым ковром. Шуршит под ногами пожухлая трава. В лесу смолкли птичьи песни. Вода в лесных ручьях чистая. Хорошо дышать свежим воздухом.
Слова для справок: ходим, воздухом.
Грамматическое задание:
- Записать цифрой, сколько слов в первом предложении.
- Слова русский, листьяразделить для переноса.
ДИКТАНТ № 2 по теме «Слово в языке и речи»
Цель: проверить умение применять на практике повторенные орфограммы.
Прощание с осенью
В октябре стоит сырая погода. Весь месяц льют дожди. Дует осенний ветер. Шумят в саду деревья.
Ночью перестал дождь. Выпал первый снег. Кругом светло. Всё вокруг стало нарядным. Две вороны сели на берёзу. Посыпался пушистый снежок. Дорога подмёрзла. Хрустят листья и трава на тропе у дома. (49 слов)
Слова для справок: стало, подмёрзла.
Грамматическое задание:
- В первом предложении подчеркнуть подлежащее и сказуемое.
- Выписать из текста слово, в котором букв больше, чем звуков.
ДИКТАНТ № 3 по теме «Состав слова»
Ближе к жилью.
В лютый зимний холод всякая птица спешит к жилью человека. Там легче добыть пищу. Голод убивает обычный страх. Люди перестают пугать осторожную лесную живность. Тетерев и куропатка залетают в хранилища с зерном. Русаки ночью постоянно скачут в сад и огород. Ласки устраивают охоту на мышей в подвалах. Беляки прибегают щипать душистое сено из стогов.
Однажды через открытую дверь в сторожку влетела синичка. Она стала клевать крошки на столе.
Слова для справок: постоянно.
- Разберите по составу слова зимний, душистое, сторожка.
- Подбери однокоренные слова к слову
- Выпишите из текста два глагола с приставками. Приставки выделите.
ДИКТАНТ № 4 по теме «Правописание корней слова»
Снеговик
Стоит чудесный зимний день. Падает лёгкий снег. Деревья одеты в белые шубки. Спит пруд под ледяной коркой. Яркое солнце на небе.
Выбежала группа ребят. Они стали лепить снеговика. Глазки сделали ему из светлых льдинок, рот и нос из морковки, а брови из угольков. Радостно и весело всем!
1. В первом предложении подчеркните грамматическую основу, определите части речи.
2. Разберите по составу слова белые, морковки.
3. Найдите в тексте и запишите по одному слову с проверяемым безударным гласным в корне, парным по глухости-звонкости согласным, непроизносимым согласным. Рядом запишите проверочные слова.
ДИКТАНТ № 5 по теме «Правописание частей слова»
Оляпка
Декабрь. Мороз. Кругом лежит снег. На деревьях пушистые снежинки. С берёз и осин листья давно опали. Только на дубах желтеют листья. Тишина.
Вдруг донеслась весёлая песенка. Я оглянулся. На берегу реки сидела птичка. Я шагнул к ней. Птичка кинулась в воду и пропала. Я решил, что она утонула. Но кто это бежит по дну речки? Это оляпка или водяной воробей.
Слова для справок: оляпка , водяной.
1. Разберите по членам предложения третье предложение.
2. Разберите по составу слова осинки, переход.
3. Найдите в тексте и подчеркните два слова с безударными гласными в корне, которые можно проверить.
ДИКТАНТ № 6 по теме «Имя существительное»
Летом
Мой товарищ Витя гостил летом у брата. Село Юрьево стоит на берегу реки. Заиграет утром луч солнца, а друзья уже у реки. А вот и первая рыбка – ёрш. Ловили мальчики и крупную рыбу. Попадался сом, окунь, лещ.
Село Юрьево стоит на берегу реки. Заиграет утром луч солнца, а друзья уже у реки. А вот и первая рыбка – ёрш. Ловили мальчики и крупную рыбу. Попадался сом, окунь, лещ.
Ребята часто ходили в лес за грибами. Однажды они зашли в лесную глушь. Тишина. Только в овраге журчал ключ. Много грибов набрали мальчики в лесной чаще.
- Запишите по два существительных женского, мужского и среднего рода.
- Запишите пять имён существительных с шипящим звуком на конце.
- Разберите слова по составу: рыбка, тишина, лесною. ДИКТАНТ № 7 по теме « Правописание окончаний имён существительных»
Летучая мышь
Мы открыли гараж и увидели летучую мышь. Это интересное животное. Днём летучая мышь спит. Широкие крылья закрывают зверька, как плащ. Гаснет последний солнечный луч. Наступает ночь. Летучие мыши ищут добычу.
Учёные пытались объяснить замечательную способность зверька находить дорогу в темноте. Залепляли глазки, нос. Мышь облетала опасные места. Когда мышь пищит, тончайший звук доходит до преграды и идёт назад. Чуткие ушки зверька ловят сигнал.
1. Определить падеж имён существительных в последнем предложении.
2. Разобрать слово гараж как часть речи.
3. Разобрать по составу слова интересно, глазки, находит. ДИКТАНТ № 8 по теме «Имя прилагательное»
Весна
Над полями и лесами светит яркое солнце. Потемнели в полях дороги. Посинел на реке лёд. В долинах зажурчали звонкие ручьи. Надулись на деревьях смолистые почки. На ивах появились мягкие пуховки.
Выбежал на опушку робкий заяц. Вышла на поляну старая лосиха с лосёнком. Вывела медведица на первую прогулку своих медвежат.
- Подчеркните в четвёртом предложении главные члены, выпишите словосочетания.

- Замените прилагательные антонимами и запишите полученные словосочетания: трусливый мальчик, узкий ручей.
- Определите род, число, падеж в словосочетаниях сосновую шишку, крепким клювом.

ДИКТАНТ № 9 по теме «Глагол»
Весеннее утро
Это случилось в апреле. Рано утром проснулось солнце и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Снегом покрыли поля и холмы. На деревьях сосульки развесили.
Засветило солнце и съело утренний лёд. По долине побежал весёлый, говорливый ручеёк. Вдруг под корнями берёзки он заметил глубокую норку. В норке сладко спал ёжик. Ёж осенью нашёл это укромное местечко. Он ещё не хотел вставать. Но холодный ручей забрался в сухую постельку и разбудил ежа
1. Разобрать седьмое предложение по членам.
2. Разобрать по составу слова засветило, берёзки, утренний.
3. Определить время, лицо, число глаголов побежал, взглянешь, принесу.
ДИКТАНТ № 10 по теме «Итоговый контрольный диктант»
Весной.
Весеннее солнце пригрело землю. Зазвенела весенняя капель. У домов галдят крикливые воробьи. С пригорков побежали говорливые ручейки. На полях зазеленели хлеба. Ветки ивы покрылись золотыми шарами. В лесу зацвели голубенькие подснежники. Синички весело перелетали с ветки на ветку. Они искали в складках коры деревьев червячков. Тетерева слетелись на поляны. Птицы чертили по земле крыльями и затевали шумные игры. Скоро прилетят на родину журавли. (64 слова)
Задание. 1 вариант: Выполнить разбор 3 предложения. Разобрать по составу слово крикливые. Определить время глагола в 1 предложении.
2 вариант: Выполнить разбор 4 предложения. Разобрать по составу слово
 Определить время глагола в последнем предложении.
Определить время глагола в последнем предложении.Тест 1
Предложение(повторение)
Вариант 1
Морфологический разбор имени прилагательного «ближайший» онлайн. План разбора.
Для слова «ближайший» найдено 2 варианта морфологического разбора
- Часть речи. Общее значение
Часть речи слова «ближайший» — имя прилагательное - Морфологические признаки.
- ближний (именительный падеж единственного числа мужского рода)
- Постоянные признаки:
- относительное
- единственное число
- именительный падеж
- мужской род
- превосходная степень.
Аналогичные тенденции характерны для компоненты ожиданий изменения материального положения домохозяйства в ближайший год.
Выполняет роль определения.
- Часть речи. Общее значение
Часть речи слова «ближайший» — имя прилагательное - Морфологические признаки.
- близкий (именительный падеж единственного числа мужского рода)
- Постоянные признаки: Непостоянные признаки:
- единственное число
- именительный падеж
- мужской род
- превосходная степень.
К сожалению, ближайший магазин «Электротовары» уже закрылся, а бежать в другой уже не было времени.
Выполняет роль определения.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора прилагального
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (именительный падеж, единственное число)
- Постоянные признаки:
- Разряд по значению:
- Качественное (может быть в большей или меньшей степени).
- Относительное (не может быть в большей или меньшей степени)
- Притяжательное (обозначает принадлежность кому-либо)
- Качественное (может быть в большей или меньшей степени).
- У качественных
- Степень сравнения
- Краткая и полная форма
- У всех прилагательных:
- Падеж
- Число
- Род(в единственном числе)
- Разряд по значению:
- Синтаксическая роль (подчеркнуть как член предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
14 голосов, оценка 4.643 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор имени прилагательного «ближайший» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
Какая часть речи выделена жирным шрифтом «ближайший»?
Части речи — дело теории. У разных людей разные теории, и в результате они по-разному классифицируют слова.
Обычно цель теории — как можно проще описать наблюдаемое нами поведение. Вместо того, чтобы описывать каждое слово по отдельности, мы начинаем с объединения слов в кучу, если можем описать их одинаково. Но всегда есть несколько исключений, которые не вписываются в наши категории, и мы должны описывать их отдельно.Либо мы описываем исключение само по себе, либо выбираем ближайшую категорию и составляем список ее отличий от обычных членов этой категории.
В этом случае, вероятно, самый простой ответ — сказать, что это предлог . Он проходит все обычные тесты для предлога. Но рядом с имеет несколько особенностей, которые делают очень немногие предлоги: он склоняется! Он имеет сравнительную и превосходную формы: ближе к и ближе к . Довольно необычно! И его можно изменить с помощью наречий (например, очень близко к окну или намного ближе к окну ).Это тоже необычно! Вот что Quirk et al. (1985, с.663) должны сказать:
Простой предлог рядом с и сложные предлоги рядом с и рядом с (все локативы; cf 9.20) удовлетворяют всем трем критериям предлогов. В то же время они имеют определенное сходство с прилагательными и наречиями. Рядом с (to) и рядом с — единственные предлоги, которые имеют как сравнение, так и усиление [.] (выделено автором)
Но это, конечно, не , а только возможных ответов. Вы можете аргументировать свою классификацию другими способами. Дело в том, что он отличается от других предлогов. Но и в другие категории он тоже не вписывается. так что нам делать?
Главное не в том, какая это часть речи. Скорее, самое главное, чтобы вы понимали , как используется . В этом случае вы можете использовать такую категорию, как «предлог», в качестве отправной точки, а затем описать, чем она отличается от центральных элементов этой категории.Поэтому, когда я называю рядом с «предлогом со сравнительной и превосходной формами, который может быть изменен наречиями», я изо всех сил стараюсь сделать описание как можно более простым. Это все.
Я предлагаю вам придумать любое описание, которое имеет для вас наибольший смысл, и использовать его.
Анализировать синонимы, анализировать антонимы | Тезаурус Мерриам-Вебстера
понимать что-то, внимательно рассматривая его части- У меня проблемы с разбором ваших слов — не могли бы вы перефразировать то, что вы сказали?
- Нам нужно время, чтобы проанализировать огромный объем данных, представленных в отчете.

- аудит,
- чек (выезд),
- кон,
- осмотреть,
- осмотреть,
- выходить,
- Наблюдать,
- обзор,
- скан,
- внимательно изучить,
- обследование,
- вид
АЛГОРИТМ БЛИЖАЙШЕГО СЛОВА — ОБРАЗОВАТЕЛЬНЫЕ СИСТЕМЫ KURZWEIL I
АЛГОРИТМ БЛИЖАЙШЕГО СЛОВА Предпосылки изобретения Это изобретение в целом относится к средствам обучения и, в частности, к читающим машинам, которые используются как часть лечебной программы чтения, чтобы помочь людям с ограниченными возможностями обучения.
Как известно в данной области техники, читающие машины использовались для улучшения образовательных достижений людей с ограниченными способностями к обучению. Как правило, известные читающие машины основаны на компьютерах. То есть читающие машины часто включают в себя персональный компьютер со специализированным программным обеспечением, которое обеспечивает функцию читающей машины. Кроме того, считывающие машины включают в себя другие компоненты типа ПК, такие как монитор, аудиосистему, диск или запоминающее устройство большой емкости и клавиатуру.
Как правило, специализированное программное обеспечение обрабатывает исходный входной документ и генерирует синтетическую речь, чтобы пользователь мог услышать, как компьютер читает через документ слово, строку, предложение и т. Д.вовремя. Часто эти считывающие машины включают в себя сканер, чтобы предоставить читателю один способ ввода исходных документов.
Сканер сканирует документ и передает на персональный компьютер представление документа в виде файла изображения. Персональный компьютер с помощью программного обеспечения для оптического распознавания символов создает файл OCR, включающий сгенерированную текстовую информацию. Файл OCR используется программным обеспечением системы отображения для отображения текстового представления отсканированного документа на мониторе.Текст файла
OCR также используется программным обеспечением синтеза речи для синтеза речи.
Таким образом, одна проблема с известными системами заключается в том, что визуальный дисплей, который предоставляется пользователю, является символьным или основанным на OCR представлением отсканированного документа. Хотя это может быть удовлетворительным для некоторых типов документов, таких как те, которые имеют простой текст без столбцов или заголовков, в других типах документов, которые имеют контекст, например столбцы, заголовки и т. Д., Или документы с графическим содержимым, контекстом и графическим содержимым. теряются при отображении OCR-представления документа.
В обычных читающих машинах и компьютерных системах в целом часто необходимо определить ближайшее слово, связанное с позицией мыши. То есть пользователь будет указывать на место на дисплее компьютерной системы с помощью указывающего устройства, такого как мышь. Компьютер определяет, на что на самом деле указывает пользователь, исследуя, какое слово ближе всего к позиции, указанной мышью. Ближайшая позиция определяется путем анализа структуры данных, содержащей каждое из слов, отображаемых на мониторе, для нахождения позиции слова, наиболее близкой к позиции, указанной мышью.Одна проблема возникает при использовании этого подхода в тех ситуациях, когда часто выполняются операции перетаскивания мыши. Вышеописанный алгоритм может не обеспечивать точное соответствие тексту, на который фактически указывает мышь.
Эта проблема усугубляется, если на мониторе отображается графическое представление документа. Часто выбирается неправильный текст, потому что пользователь не точно помещает мышь или другое указывающее устройство непосредственно на желаемый элемент изображения.Кроме того, могут возникать незначительные несовпадения между изображением, отображаемым на мониторе, и текстовым файлом, связанным с изображением.
Краткое изложение изобретения В соответствии с настоящим изобретением компьютерная программа, находящаяся на машиночитаемом носителе, включает в себя инструкции для побуждения компьютера отображать из файла изображения представление изображения сканированного документа на мониторе компьютера. Программное обеспечение находит ближайшее слово к положению указателя на мониторе в преобразованном представлении изображения в текстовом файле, определяя, соответствуют ли координаты, связанные с положением указателя на изображении, координатам, определяющим границу вокруг выбранной одной из множества областей изображение, отображаемое на мониторе, и для выбранной одной из областей, охватывающих координаты, положение указателя, определение ближайшей линии к координатам и для ближайшей линии выбор одного из выбранных слов в строке в соответствии с тем, выбранная позиция находится выше или ниже области, определенной около линии. При такой компоновке, исследуя позиции области, строки и слова, обеспечивается более точное соответствие тексту, на который фактически указывает указательное устройство,
При такой компоновке, исследуя позиции области, строки и слова, обеспечивается более точное соответствие тексту, на который фактически указывает указательное устройство,
. Это верно, даже если на мониторе отображается графическое представление документа. Таким образом, уменьшается частота выбора неправильного текста, вызванного, например, несовпадением или неточным размещением пользователем.
Краткое описание чертежей Вышеупомянутые признаки и другие аспекты изобретения будут подробно описаны далее с помощью сопроводительных чертежей, на которых: фиг.1 — блок-схема системы чтения; ИНЖИР. 2 — блок-схема, показывающая этапы, используемые при отображении представления сканированного изображения документа для использования в системе чтения по фиг. 1; ИНЖИР. 3 — блок-схема, показывающая этапы, используемые для связывания выбранного пользователем текста на отображаемом представлении изображения с текстом, сгенерированным OCR, чтобы обеспечить синтез голоса и выделение представления изображения; Фиг. 4A-4C — блок-схемы, которые показывают этапы, используемые при вычислении ближайшего слова для использования в процессе, описанном в связи с фиг.3; ИНЖИР. 4D — графическая иллюстрация части графического представления текста, отображаемого на мониторе, полезного для понимания процесса, показанного на фиг. 4A-4C; ИНЖИР. 5 — блок-схема, показывающая этапы, используемые для выделения выбранного слова для использования в процессе, описанном в связи с фиг. 3; ИНЖИР. 6 — схематическое представление структуры данных, используемой в процессе, показанном на фиг. 3;
РИС. 7-9 — схематические изображения подробных частей структуры данных фиг. 6; и фиг.10A-10C — блок-схемы альтернативного варианта осуществления для определения ближайшего слова; и фиг. 11 — графическая иллюстрация части графического представления текста, отображаемого на мониторе, полезного для понимания процесса, показанного на фиг. 10A-10C.
Описание предпочтительных вариантов осуществления Обратимся теперь к фиг. 1 показано, что считывающий аппарат 10 включает в себя компьютерную систему 12. Компьютерная система 12, как правило, представляет собой персональный компьютер или, альтернативно, может быть компьютером другого типа и обычно включает в себя центральный процессор (не показан), который является частью процессора 14. .Предпочтительной реализацией процессора 14 является система на базе Pentiums от Intel Corporation, Санта-Клара, Калифорния, хотя в качестве альтернативы можно использовать другие процессоры. Помимо ЦП, процессор включает в себя основную память, кэш-память и схемы интерфейса шины (не показаны). Компьютерная система 12 включает в себя элемент 16 массовой памяти, здесь обычно жесткий диск, связанный с системами персональных компьютеров.
1 показано, что считывающий аппарат 10 включает в себя компьютерную систему 12. Компьютерная система 12, как правило, представляет собой персональный компьютер или, альтернативно, может быть компьютером другого типа и обычно включает в себя центральный процессор (не показан), который является частью процессора 14. .Предпочтительной реализацией процессора 14 является система на базе Pentiums от Intel Corporation, Санта-Клара, Калифорния, хотя в качестве альтернативы можно использовать другие процессоры. Помимо ЦП, процессор включает в себя основную память, кэш-память и схемы интерфейса шины (не показаны). Компьютерная система 12 включает в себя элемент 16 массовой памяти, здесь обычно жесткий диск, связанный с системами персональных компьютеров.
Система считывания 10 дополнительно включает в себя стандартную клавиатуру 18 ПК, стандартный монитор 20, а также динамики 22, звуковую карту (не показана), указательное устройство, такое как мышь 19 и сканер 24, все они подключены к различным портам. компьютерной системы 10 через соответствующие интерфейсы и программные драйверы (не показаны).Компьютерная система
12 здесь работает под операционной системой WindowsNTs Microsoft Corporation, хотя в качестве альтернативы могут использоваться другие системы.
На элементе 16 массовой памяти находится программное обеспечение 30 отображения и преобразования изображений (фиг. 2), которое управляет отображением сканированного изображения, полученного со сканера 24.
Кроме того, программное обеспечение 30 позволяет пользователю управлять различными функциями читатель, обратившись к изображению документа, отображаемому на мониторе.
Теперь обратимся к фиг. 2, этапы, используемые в программном обеспечении 30 отображения и преобразования изображений, включают сканирование входного документа для получения файла изображения (этап 32). Как правило, входной документ сканируется обычным способом и создает файл 31 изображения, который подается в модуль 34 оптического распознавания символов (OCR). Модуль 34 OCR использует обычные методы оптического распознавания символов для данных, предоставленных из отсканированного изображения 32. для создания структуры выходных данных 35.В качестве альтернативы представления, подобные изображениям, могут использоваться в качестве источника, такого как сохраненная версия документа с битовой отображением.
Модуль 34 OCR использует обычные методы оптического распознавания символов для данных, предоставленных из отсканированного изображения 32. для создания структуры выходных данных 35.В качестве альтернативы представления, подобные изображениям, могут использоваться в качестве источника, такого как сохраненная версия документа с битовой отображением.
Предпочтительное расположение структуры выходных данных описано со ссылкой на фиг. 6-9. Однако здесь достаточно сказать, что массив структур данных OCR, обычно обозначаемый как 35, созданный на этапе 34, включает в себя информацию, соответствующую текстовой информации или преобразованному тексту OCR, а также информацию о положении и размере, связанную с конкретным текстовым элементом.Информация о положении и размере связывает текстовый элемент с его положением на изображении
, представляющем документ, как отображено на мониторе 20.
Обращаясь к фиг. 7, поэтому можно видеть, что элемент 140 структуры данных включает в себя для конкретного слова текстовое представление OCR слова, хранящегося в поле 142. Структура 140 данных также имеет позиционную информацию, включая информацию о координатах оси X, хранящуюся в поле 143, Информация о координатах оси Y хранится в поле 144, информация о высоте хранится в поле 145, а информация о ширине хранится в поле 146.Эта позиционная информация определяет границы воображаемого прямоугольника, охватывающего область, связанную с соответствующим словом. То есть, если указательное устройство, такое как мышь, имеет координаты в пределах области этого прямоугольника, то можно сказать, что мышь указывает на слово в определенном прямоугольнике.
Файл 31 изображения также подается в систему 38 отображения, которая обычным образом обрабатывает файл изображения, чтобы разрешить его отображение на мониторе на этапе 39.
Как показано, текстовый файл 35 обеспечивает ввод вместе с другие команды, управляемые операционной системой (не показаны) для модуля 40, который используется для связывания действий, инициированных пользователем, с изображением, представляющим отсканированный документ. Кроме того, как файл 31 изображения, так и текстовый файл 35 хранятся в системе чтения для использования во время сеанса и могут постоянно храниться для последующего использования. Файлы хранятся с использованием обычных методов, общих для WindowsNT или других типов операционных систем.
Кроме того, как файл 31 изображения, так и текстовый файл 35 хранятся в системе чтения для использования во время сеанса и могут постоянно храниться для последующего использования. Файлы хранятся с использованием обычных методов, общих для WindowsNT или других типов операционных систем.
Теперь обратимся к фиг. 3, пользователь управляет работой системы 10 считывания со ссылкой на изображение, отображаемое на мониторе 20, с помощью шагов, обычно показываемых программным модулем 40.
Пользователь может инициировать считывание отсканированного документа в начале документа, выбор режима чтения.В качестве альтернативы, пользователь может начать чтение документа из любой точки документа, наглядно указав на представление изображения элемента из отсканированного документа, отображаемого на мониторе на этапе 42. Элемент документа является фактическим представлением изображения отсканированного документа. а не обычное представление текстового файла. Элемент может быть отдельным словом текста, строкой, предложением, абзацем, областью и т. Д. Пользователь активирует функцию, позволяющую считывающему устройству генерировать синтезированную речь, связанную с выбранным представлением изображения элемента документа.В целях пояснения предполагается, что элементом документа является слово. Помимо указания на слово, указатель, такой как мышь, может указывать в тексте изображения другими способами, которые имитируют поведение указателя, обычно используемое в компьютерных текстовых дисплеях и программах обработки текстов. Например, просто указывая на слово, программа выбирает позицию в тексте перед словом; тогда как при наведении указателя на слово и двойном щелчке кнопки мыши слово будет выделено и указание на слово, а щелчок альтернативной кнопкой мыши выбирает несколько слов, начиная с
ранее определенной точки и заканчивая указанным словом.
Пользователь может использовать мышь или другой тип указывающего устройства, чтобы выбрать определенное слово. После выбора программное обеспечение выбирает координаты, связанные с местоположением, на которое указывает мышь 19 (фиг. 1) на этапе 44.
1) на этапе 44.
Используя эти координаты, определяется слово или другой элемент документа, ближайший к координатам мыши.
Информация в структуре 100 данных используется для генерации выделения слова, когда оно появляется на элементе отображения, а также синтезированной речи, как будет описано ниже.
Этап поиска 46, как будет дополнительно описано со ссылкой на фиг. 4A-4C будет искать ближайшее слово. В качестве альтернативы, этап 46’а поиска будет описан со ссылками на фиг. Также можно использовать 10A-10C.
Операция поиска, выполняемая на этапе поиска 46 ‘, основана на различных атрибутах отсканированного изображения.
После определения ближайшего слова или ближайшего элемента документа на шаге 46 или 46 ‘выделение применяется к области, связанной с элементом или словом на шаге 48.Текст, соответствующий ближайшему элементу документа, также извлекается на этапе 50, и текстовое представление подается в синтезатор 52 речи для выработки электрических сигналов, соответствующих речи. Электрические сигналы подаются в аудиосистему 54 для воспроизведения речи, соответствующей ближайшему элементу документа, в то время как монитор 20 отображает элемент, и к элементу применяется выделение.
Теперь обратимся к фиг. 4A-4C показан процесс 46, используемый для определения ближайшего слова в отсканированном изображении.
На этапе 60 инициализируется указатель, и максимальное значение загружается в поле 51b смещения структуры 51 (фиг. 4D). Поле 51b смещения используется для хранения наименьшего смещения между границей слова и координатами указывающего устройства. Указатель, инициализированный на этапе 60, является указателем или индексом в структуре 35 данных, сгенерированной OCR (фиг. 6). Программное обеспечение 46 извлекает каждую запись слова в структуре данных 35, чтобы определить для этого слова в соответствии с информацией относительного положения изображения, связанной со словом, сгенерированным текстом OCR, является ли это конкретное слово самым близким словом к координатам, связанным с указанием пользователя. устройство.
устройство.
На этапе 62 выбираются координаты, связанные с первым из слов. На этапе 64 координаты, связанные с первым из выбранных слов, используются, чтобы определить, указывает ли указывающее устройство на местоположение в поле 655, которое определено вокруг слова. Таким образом, как показано вместе с фиг. 4D мышь указывает на точку 61 с координатами Xi, Yj. Для любого элемента документа на отсканированном изображении предполагается, что здесь существует воображаемый прямоугольник 655 вокруг слова «ИЗОБРАЖЕНИЕ» на фиг.4D. Таким образом, если координаты указывающего устройства попадают в прямоугольник 655, то указывающее устройство будет считаться указывающим на элемент документа «ИЗОБРАЖЕНИЕ», связанный с блоком 655.
В структуре данных 35 каждое из слов будет связано с ним Текст OCR, преобразованный из файла 31 изображения, а также данные о положении и размере, которые определяют положение и размер слова, как оно появляется в исходном документе. Соответственно, эта информация также определяет местонахождение слова в том виде, в котором оно отображается в отображаемом графическом представлении документа.Таким образом, при определении слова, ближайшего к позиции, на которую указывает мышь, необходимо определить границы поля, которое занимает конкретное слово.
На шаге 64 программное обеспечение определяет, попадает ли точка 61 в рамку, принимая во внимание следующее: Для положения координат мыши (X, Y) положение, на которое указывает мышь, можно считать находящимся в пределах области слово-изображение, имеющее точки, определенные координатами (ai, bj) и (Ck, dl), где ck = ai + w и dl = bj-h, если X z ai и Y: bj и X Если это условие удовлетворяется, то можно считать, что точка 61 находится внутри прямоугольника, и, следовательно, на этапе 66 управление переходит непосредственно к этапу 50 (фиг. 4B). Таким образом, исходя из информации, упомянутой выше, точка (c, d) может быть определена путем добавления ширины прямоугольника к координате x (ai), связанной с изображением, и вычитания высоты прямоугольника из координаты y ( bj) связанный с изображением. Если, однако, точка 61 не находится внутри прямоугольника, как показано, то программное обеспечение 46 определяет слово, которое является ближайшим к точке 61 на этапе 68, с помощью одного из нескольких алгоритмов.Первый алгоритм, который можно использовать, заключается в вычислении расстояния от согласованного угла прямоугольника, связанного со словом, до положения указателя 61 мыши. В общем, расстояние (S) до согласованного угла будет вычисляться как » Метод Пифагора следующим образом: S ((X-ai) 2 + (Y-bj) 2) -2 В качестве альтернативы это уравнение можно использовать в каждом углу каждого прямоугольника, и дальнейшая обработка может быть использована для определения, какой из четырех значения, предоставленные из каждого угла, на самом деле являются наименьшим значением для каждого поля. В любом случае вычисленное значение (S) сравнивается с предыдущим значением, сохраненным в поле смещения 51b. Первоначально поле 51b имеет максимальное значение, сохраненное в нем, а меньшее из двух значений сохраняется в поле 51b на этапе 72. Соответственно, первое вычисленное значение и индекс, связанный со словом, сохраняются в структуре 51, как показано на фиг. . 4С. На этапе 74 определяется, является ли это концом структуры данных. Если это конец структуры данных, тогда управление переходит к шагу 50 и, следовательно, к шагу 52.Если это не конец структуры данных, то указатель увеличивается на шаге 76, а следующее слово в структуре данных, определяемое новым значением указателя, выбирается на шаге 62. Второй раз через процесс 46 в целом будет таким же, как и в первый раз, за исключением того, что на этапе 72 будет определено, больше ли ранее сохраненное значение (Sp) в полях 51a, 51b, чем текущее вычисленное значение (Sc) для текущего слова. Если текущее значение (Sc) меньше предыдущего значения Sp, то текущее значение заменяет предыдущее значение в поле 51b, а индекс, связанный с текущим значением, заменяет предыдущий индекс, сохраненный в поле 51a. Таким образом, структура 51 отслеживает наименьшее вычисленное расстояние (S) и индекс (то есть слово), связанный с вычисленным расстоянием. Процесс продолжается до тех пор, пока не будут исследованы позиционные данные для всех слов в структуре данных, связанной с конкретным изображением. Значения, которые остаются в структуре данных 51 в конце процесса, таким образом, соответствуют ближайшему слову к месту, на которое указывают координаты 61 мыши. Теперь вернемся к фиг.3, после определения ближайших координат для ближайшего элемента данных процесс 40 применяет выделение в соответствии с выбранным элементом. В предшествующих методах выделения можно просто выделить строку или абзац в текстовом представлении, отображаемом на мониторе. Выделением будет текущее слово, которое читается пользователю вслух. Хотя это приемлемо, предпочтительный подход, описанный здесь, применяет двойное выделение и все же предпочтительно применяет двойное выделение к изображению отсканированного документа. Выбранный абзац или предложение выделяется первым прозрачным цветом, тогда как каждое отдельное слово, произносимое через синтезатор речи на этапе 52, выделяется вторым, другим прозрачным цветом. Соответственно, выделение применяется на этапе 48 способом, который будет описан ниже. Теперь обратимся к фиг. 5 показан процесс 48 выделения, включающий в себя этап 80, на котором событие ожидает программное обеспечение 48. Событие обычно является операцией, управляемой прерыванием операционной системы, которая указывает любую одну из ряда операций, например, пользователь устройство 10 для чтения, инициирующее синтез слова, предложения или абзаца.Процесс 48 выделения остается в этом состоянии до тех пор, пока не произойдет событие. Когда происходит событие, все предыдущее выделение выключается на этапе 82. Предыдущее выделение выключается путем отправки сообщения (не показано) в систему 38 отображения, заставляющего систему отображения удалять выделение. На этапе 84 процесс выделения проверяет, была ли заполнена единица текста. Если блок текста был завершен, то выделение блока также отключается на шаге 90. Программа проверяет условие выхода на шаге 91 после того, как координаты были получены. Условием выхода, показанным на этапе 91, может быть любое из нескольких случаев, например достижение последнего слова в массиве структур 35 данных OCR или пользовательская команда прекратить поступать с клавиатуры 18 или другого устройства ввода. Если условие выхода возникло на этапе 91, процедура 48 переходит к этапу 92. Если условие выхода не возникло, следующий блок определяется на этапе 93.Следующая единица текста определяется с помощью стандартных методов анализа массива текстовых структур OCR 35. Таким образом, следующая единица определяется путем поиска точек, например, для разграничения конца предложения, а также отступов и пустых строк для поиска абзацев. . Кроме того, изменения координаты Y можно использовать для подсказки предложений и строк. Также можно использовать другие функции структуры документа. Следующий блок затем выделяется на этапе 94, давая команду программному обеспечению 38 системы отображения (фиг.2) применить прозрачный цвет к выбранному следующему блоку. Это первый уровень выделения, предусмотренный для единицы представления изображения отсканированного документа. Управление переходит обратно к этапу 86. На этапе 86, который происходит непосредственно с этапа 84 или с этапа 92, выбираются координаты следующего слова, которое должно быть синтезировано и выделено. Программное обеспечение проверяет условие выхода на этапе 88 после того, как координаты были выбраны. Условием выхода, показанным на этапе 88, может быть любое из нескольких событий, например достижение последнего слова в массиве структур 35 данных OCR или пользовательская команда на останов, подаваемая с клавиатуры 18 или другого устройства ввода.Если условие выхода возникло на этапе 88, процедура 48 переходит к этапу 89. Указатель на следующее слово в структуре данных 35 затем увеличивается на шаг 98 для получения следующего слова. Второе выделение обеспечивается путем отправки сообщения на системное программное обеспечение 38 дисплея, содержащего информацию о местоположении, извлеченную из структуры данных.Этот процесс продолжается до тех пор, пока на этапе 88 не произойдет условие выхода. Следует отметить, что одиночное и двойное выделение выше было описано как применение двух различных прозрачных цветов к выбранным представлениям изображения отображаемого документа. В качестве альтернативы, однако, могут использоваться другие признаки выделения, такие как полужирный текст, изменение стиля или размера шрифта, курсив, выделение выделенного текста в рамку и подчеркивание. Кроме того, можно использовать комбинации этих других знаков с цветами или без них. Обратимся теперь к фиг. 6-9 показан предпочтительный формат для структуры 35 данных, обеспечиваемый этапом 34 OCR. Структура 35 данных организована иерархически. Вверху структуры данных находится страница, структура данных 110. Страница включает в себя указатели 110a-110e на каждую из множества областей 120. Область представляет собой область прямоугольной формы, которая состоит из одной или нескольких прямоугольных строк текста. . Если в области несколько строк текста, строки не перекрываются в вертикальном направлении .То есть, начиная с верхней строки, нижняя часть каждой строки находится над верхней частью следующей строки. Здесь регионы могут включать заголовки, заголовки, столбцы и так далее. Заголовки могут или не могут перекрывать более одного столбца и так далее. Области также включают в себя множество указателей 120a-120e на каждую из соответствующих строк 130, показанных в структуре 130 данных. Как показано вместе с ФИГ.7-9, подробная структура пунктов 140, 130 и 120 включает в себя множество полей. Так, например, фиг. 7 для слова включает в себя текстовое поле 142, которое содержит текст, сгенерированный OCR, и имеет поля 143 и 144, которые предоставляют информацию о прямоугольных координатах x и y, соответственно, а также поля 145 и 146, которые предоставляют здесь информацию о высоте и ширине. Аналогичные данные представлены для линий, показанных на фиг. 8, а также области, показанные на фиг. 9. Теперь будет описан предпочтительный способ 46 ‘определения ближайшего слова, связанного с положением мыши или другого указывающего устройства.Этот подход особенно выгоден для тех ситуаций, когда часто выполняются операции перетаскивания мыши. Изображение может не обеспечивать точное соответствие тексту, как определено системой распознавания OCR. Также иногда выбирается неправильный текст, потому что пользователь не точно помещает мышь или другое указывающее устройство непосредственно на желаемый элемент изображения. Кроме того, когда указатель расположен в пустом пространстве между строками или в белом пространстве слева или справа от строк, выбор слова, ближайшего к указателю, не всегда дает результат, которого обычно ожидал бы пользователь компьютера, на основе поведения выбора мыши на стандартных компьютерных текстовых дисплеях.Кроме того, могут возникать незначительные несовпадения между изображением, отображаемым на дисплее, и текстовым файлом OCR. Таким образом, например, рассмотрим точку 61c на рисунке 11. В методе 46, описанном ранее, ближайшее слово, которое является «OF» в предыдущей строке, будет выбрано в качестве выбранного слова. Но на стандартных компьютерных дисплеях точка выбора будет после слова «ПОСЛЕДНИЙ». Подход, показанный вместе с фиг. 10A-10C будет иметь тенденцию уменьшать некоторые из этих ошибок. Теперь обратимся к фиг. 10A, указатели снова инициализируются для первой из областей, как показано на этапе 180, и координаты граничного прямоугольника области выбираются на этапе 182 из структуры данных 120. Позиция (X, Y) указателя вычисляется чтобы определить, попадает ли он в рамку, определяющую регион. Чтобы дополнительно проиллюстрировать этот процесс, также сделана ссылка на фиг. 11, на котором показан образец области, содержащей множество строк текста изображения и блоков, проиллюстрированных вокруг области, строк и слова.Также показаны три позиции 61, 61а, 61b для образцов указательного устройства (не показаны). Вычисление для области выполняется аналогично вычислению прямоугольника для слова , описанного в связи с фиг. 5A-5C, за исключением того, что позиционная информация, содержащаяся в структуре 120 данных области, используется для определения рамки или другой границы, связанной с областью. Координаты (r6, s6) и (t6, u6) обозначают воображаемый прямоугольник вокруг проиллюстрированной области на фиг.11. Если на этапе 186 определяется, что координаты указателя попадают в рамку (как 61 и 61a-61d, фиг. 11), то процесс разветвляется, чтобы определить ближайшую строку на этапе 201 (фиг. 10B). В противном случае обработка продолжается до этапа 187, чтобы определить, достиг ли процесс последней области в структуре 120 данных области. Если она не достигла последней структуры, указатель увеличивается на этапе 194, указывая на следующую область в данных. структура 120. Если процесс 46 ‘достиг последней структуры, следовательно, координаты устройства указателя не указывают ни на какое слово, как 61, (фиг.11). Поэтому используется предварительно определенное слово, и процесс завершается. Если на этапе 186 было определено, что координаты попадают в рамку области, то на этапе 201 аналогичный процесс используется для определения ближайшей строки, за исключением того, что используются данные строки, связанные со структурой 130 данных (фиг. позиционирующего устройства попадают выше прямоугольника, связанного с линией как точка 61а, то программное обеспечение выберет первое слово строки здесь слово «ТЕКСТ». Если координаты попадают выше нижней границы линейного прямоугольника, как точка 61b, тогда программное обеспечение переходит к этапу 220. Как показано вместе с фиг. 10B, программное обеспечение инициализирует указатель на верхнюю строку в области (на этапе 201) и выбирает координаты строки на этапе 202. Выбранные координаты соответствуют верхней и нижней координатам воображаемого прямоугольника, расположенного вокруг строки. .На этапе 204 программное обеспечение вычисляет, находится ли Y-координата указывающего устройства над линией. Это достигается путем сравнения значения координаты Y указывающего устройства с координатой Y (m4) самой верхней точки, определяющей прямоугольник вокруг линии, как показано для точки 61b. Если на этапе 206 определяется, что координата Y находится выше прямоугольника, определенного для строки, программное обеспечение выбирает первое слово на этапе 208 строки и готово. В противном случае программное обеспечение определяет, находится ли координата Y над нижней частью рамки, определяющей линию, используя тот же подход, что и для верхней части линии, за исключением использования, например, координаты (04).Если определено, что координата Y равна или выше нижней части прямоугольника, определяющего линию, как точка 61b, тогда программное обеспечение переходит к этапу 220 (фиг. 10C). Координата X указателя уже известна как находящаяся в регионе и здесь не проверяется. Это позволяет обнаруживать короткие строки. короче ширины области. Например, короткие строки могут появляться в начале и конце абзацев или в тексте, который не выровнен по ширине, чтобы сформировать прямое правое поле.В противном случае он переходит к этапу 212, где определяется, является ли текущая строка последней строкой в структуре данных 230. Если это не последняя строка в структуре данных 230, указатель увеличивается на этапе 216, чтобы указать на следующую более низкую строку. линия в регионе. Если это последняя строка в структуре данных и координата Y не была выше верхней части строки и не выше нижней части строки, программное обеспечение выбирает на этапе 214 слово после слова в последней строке, как для точки 61c, и готово. Теперь обратимся к фиг. 10C, указатели снова инициализируются первым из слов в строке, как показано на этапе 220, и координаты слова выбираются на этапе 222 из структуры данных 140. Позиция X указателя вычисляется, чтобы определить, является ли или нет, он попадает в правую часть текущего слова или слева от нее на этапе 224, как для пункта 61a. Это вычисление выполняется путем сравнения значения X координаты указателя со значением X правой стороны блока, определенного для слова, здесь координаты aS точки (a5, b5).Если значение координаты X для блока меньше или равно значению координаты X указывающего устройства, то указывающее устройство считается указывающим на левую сторону правой стороны слова. На этапе 226 определяется, указывает ли указатель на левую часть правой стороны слова. Если это так, то на этапе 227 для пункта 61d выбирается конкретное слово «ТЕКСТ», и процесс завершается. В противном случае на этапе 228 процесс определяет, достигло ли оно последнего слова в структуре 140 данных.Если он не достиг последнего слова в структуре 140 данных, указатель увеличивается на шаге 234, чтобы указать на следующее слово справа. Если оно достигло последнего слова в структуре 140 данных, программное обеспечение на этапе 230 выберет слово после последнего слова в строке (не показано), и процесс будет завершен. Выбранное слово пересылается на этапы 48 на фиг. 3. Таким образом, двойное выделение, как описано со ссылкой на фиг. 5, и синтез речи, как описано выше, выполняется для слова, выбранного этим процессом. После описания предпочтительных вариантов осуществления изобретения следует отметить, что могут использоваться другие варианты осуществления, включающие их концепции. Соответственно, считается, что изобретение не должно ограничиваться раскрытыми вариантами осуществления, а должно быть ограничено только духом и объемом прилагаемой формулы изобретения. Это третья статья из этой серии статей о Python для обработки естественного языка.В предыдущей статье мы увидели, как библиотеки Python NLTK и spaCy могут использоваться для выполнения простых задач NLP, таких как токенизация, стемминг и лемматизация. Мы также увидели, как выполнять части речевого тегирования, распознавания именованных сущностей и синтаксического анализа существительных. Однако все эти операции выполняются над отдельными словами. В этой статье мы сделаем шаг вперед и исследуем словарный запас и сопоставление фраз с помощью библиотеки spaCy. Мы определим шаблоны, а затем посмотрим, какие фразы соответствуют определенному нами шаблону.Это похоже на определение регулярных выражений, включающих части речи. Библиотека spaCy поставляется с инструментом Для сопоставления на основе правил необходимо выполнить следующие шаги: Первым шагом является создание объекта сопоставления: Следующим шагом является определение шаблонов, которые будут использоваться для фильтрации похожих фраз.Предположим, мы хотим найти фразы «быстрая коричневая лиса», «быстрая коричневая лисица», «быстрая коричневая лисица» или «быстрая коричневая лисица». Для этого нам нужно создать следующие четыре шаблона: В приведенном выше сценарии Атрибут токена После того, как шаблоны определены, нам нужно добавить их к объекту Здесь QBF — это имя нашего сопоставителя. Вы можете дать ему любое имя. Наш сопоставитель готов. Следующий шаг — применить сопоставление к текстовому документу и посмотреть, сможем ли мы найти совпадение. Давайте сначала создадим простой документ: Для применения сопоставителя к документу. Документ необходимо передать как параметр объекту сопоставления. Результатом будут все идентификаторы фраз, сопоставленных в документе, а также их начальная и конечная позиции в документе. Результат выполнения сценария выше выглядит так: Из вывода видно, что найдены четыре фразы.Первое длинное число в каждом выводе — это идентификатор совпавшей фразы, второе и третье числа — это начальная и конечная позиции фразы. Чтобы на самом деле лучше просмотреть результат, мы можем перебирать каждую совпавшую фразу и отображать ее строковое значение. Выполните следующий скрипт: Выход: На выходе вы можете увидеть все совпавшие фразы вместе с их словарными идентификаторами, а также начальной и конечной позицией. Официальная документация из библиотеки sPacy содержит подробную информацию обо всех токенах и подстановочных знаках, которые могут использоваться для сопоставления фраз. Например, атрибут «*» определен для поиска одного или нескольких экземпляров токена. Давайте напишем простой шаблон, который может идентифицировать фразу «быстро — коричневый — лисица» или быстро — коричневый — лис. Сначала удалим предыдущее сопоставление Далее нам нужно определить наш новый паттерн: Шаблон Как видите, в нашем документе есть две фразы quick — brown — fox и quick-brown — fox, которые должны соответствовать нашему шаблону. Применим нашу матрицу к документу и посмотрим результат: Результат выполнения сценария выше выглядит так: Из вывода видно, что наш сопоставитель успешно сопоставил две фразы. В последнем разделе мы увидели, как мы можем определить правила, которые можно использовать для идентификации фраз из документа.Помимо определения правил, мы можем напрямую указать фразы, которые мы ищем. В этом разделе мы будем выполнять сопоставление фраз в статье Википедии об искусственном интеллекте. Прежде чем мы увидим шаги по выполнению сопоставления фраз, давайте сначала проанализируем статью в Википедии, которую мы будем использовать для выполнения сопоставления фраз. Выполните следующий скрипт: Скрипт подробно описан в моей статье «Реализация Word2Vec с библиотекой Gensim в Python». Действия по выполнению сопоставления фраз очень похожи на сопоставление на основе правил. В качестве первого шага вам необходимо создать объект Обратите внимание, что в предыдущем разделе мы создали объект На втором этапе вам необходимо создать список фраз для сопоставления, а затем преобразовать этот список в документы spaCy NLP, как показано в следующем скрипте: Наконец, вам нужно добавить список фраз в средство сопоставления фраз. Здесь имя нашего сопоставителя — AI. Как и сопоставление на основе правил, нам снова нужно применить наш сопоставитель фраз к документу. Однако наша проанализированная статья не в формате документа spaCy. Поэтому мы преобразуем нашу статью в формат документа sPacy, а затем применим к статье наш сопоставитель фраз. В выводе у нас будут все идентификаторы всех совпавших фраз вместе с их начальным и конечным индексами в документе, как показано ниже: Чтобы увидеть строковое значение совпадающих фраз, выполните следующий скрипт: В выводе вы увидите значение строки совпадающих фраз, как показано ниже: Из выходных данных вы можете увидеть все три фразы, которые мы пытались найти, а также их начальный и конечный индексы и идентификаторы строк. Прежде чем мы закончим эту статью, я просто хотел коснуться концепции стоп-слов. Стоп-слова — это английские слова, такие как «the», «a», «an» и т. Д., Которые сами по себе не имеют никакого значения. Стоп-слова часто не очень полезны для задач НЛП, таких как классификация текста или языковое моделирование. Поэтому часто лучше удалить эти стоп-слова перед дальнейшей обработкой документа. Библиотека spaCy содержит 305 стоп-слов. Кроме того, в зависимости от наших требований, мы также можем добавлять или удалять стоп-слова из библиотеки spaCy. Чтобы увидеть стоп-слова spaCy по умолчанию, мы можем использовать атрибут В выводе вы увидите все стоп-слова SPacy: Вы также можете проверить, является ли слово стоп-словом или нет. Так как «wonder» не является стоп-словом spaCy, в выходных данных вы увидите Чтобы добавить или удалить стоп-слова в spaCy, вы можете использовать методы Затем нам нужно установить для тега Сопоставление фраз и словаря — одна из наиболее важных задач обработки естественного языка. В этой статье мы продолжили обсуждение того, как использовать Python для выполнения сопоставления на основе правил и фраз. Кроме того, мы видели стоп-слова spaCy. В следующей статье мы подробно рассмотрим части тегов речи и распознавания именованных сущностей. НЬЮ-ЙОРК (AP) — Обещания кампании могли быть изменены, а некоторые добровольно установленные сроки перенесли.Но среди вещей, которые сохранились нетронутыми в первые месяцы работы новой администрации, является безошибочно особый стиль речи президента Дональда Трампа. Торговая марка Трампа полна бессвязных, заполненных в сторону всплесков простых, но окончательных слов, наполненных самодовольной бравадой и утверждениями о том, что проверяющие факты работают сверхурочно. внутренний фильтр. Это стало источником любопытства как для лингвистов, так и для непрофессионалов, что вновь вызвало недавнее интервью Associated Press с Трампом, которое дало новую возможность для анализа разновидности президентского ораторского искусства, ранее не записанного. «Это раздвигает границы лингвистического анализа», — сказала историк Кристен Кобес Дю Мез. Взгляд на некоторые особенности выступления Трампа: ___ НОВЫЙ ПРЕЗИДЕНТСКИЙ СЦЕНАРИЙ Трамп привлек внимание масс отчасти потому, что его голос звучал иначе, чем ожидалось от политиков. Кэтлин Холл Джеймисон, профессор Школы коммуникации Анненберга при Пенсильванском университете, сказала, что импровизированную речь Трампа лучше всего описать как поток сознания, большое изменение от того, к чему мы привыкли, от тех, кто ищет — и занимает — высшее офис в земле. «Раньше публичное выступление президента было вымышленной речью, это считалось речью. Президенты готовились к выступлениям, президенты готовились к пресс-конференциям, у президентов были готовые ответы на вопросы », — сказала она. С Трампом шаблон тщательно отобранных слов, протестированных фокус-группой, был нарушен. ___ ПОВТОРЕНИЕ, ОТСТУПЛЕНИЯ И НЕ СЕКВИТУРЫ Интервью AP — лишь последний пример излюбленной тактики выступления Трампа.Выбор слов обычно прост: для Трампа все ужасно или невероятно, лучше или хуже. Часты отступления. И повторы повсюду: когда Трамп хочет донести свою точку зрения, он делает это снова и снова. Тогда есть знакомые non sequiturs. Например, в одном предвыборном выступлении Трамп начинает говорить о ядерной сделке с Ираном только для того, чтобы уйти далеко и подробно рассказать о своем дяде, который был ученым. В начале интервью AP он неожиданно упомянул канцлера Германии Ангелу Меркель, заявив, что его химия с ней была прекрасной.Затем он продолжает говорить, что ему дали заслугу за его «отличную химию со всеми лидерами», и даже когда интервьюер пытается сместить обсуждение, он возвращается к тому, что он хочет сделать, снова говоря об установлении «удивительных отношений». »,« Прекрасные отношения »и« отличная химия ». «Есть много повторений, выстраивание моделей доверия со слушателем, повторение« вы знаете », — сказал Пол Брин, старший преподаватель Вестминстерского университета в Англии. Трамп также предложил свой метод выбора слов: простые термины, которые он часто выбирает, могут быть более эффективными, чем витиеватое красноречие, к которому слушатели могут привыкнуть от президентов. «Я ходил в школу Лиги плюща. Я очень образован. Я знаю слова; У меня самые лучшие слова », — сказал он во время кампании. ___ ОЧЕНЬ, СУПЕР-ДУПЕР, ВЕЛИКОЛЕПНО На протяжении всего интервью Трампа с AP его замечания полны «словесных интенсификаторов», как выражается Дю Мез, заведующего кафедрой истории в Колледже Кальвина.Это означает такие вещи, как «очень, очень» и «много, много» или, что очень редко, «супер-пупер». «Я не знаю, чтобы какой-либо президент когда-либо использовал слово« супер-пупер »в своей риторике раньше», — сказал Дю Мез. Тем не менее, хотя она сказала, что президента иногда высмеивают за его элементарный выбор слов: «Что касается устной риторики, вам нужен более простой класс. Это более эффективный способ общения «. Эрик Эктон, лингвист из Университета Восточного Мичигана, отметил склонность Трампа к превосходным степеням, включая «самые большие», «самые жесткие» и «самые сильные».И, конечно же, слово Трамп, вышитое на шапках предвыборной кампании, повторяется десятки раз в ходе часовой беседы. «Кажется, ему действительно нравится слово« великий », — сказал Эктон. ___ ТЕЛЕПРОМПТЕР VS. КРУГЛЫЙ ПАРЕНЬ Как и все, манера речи Трампа может варьироваться в зависимости от обстановки. Джон Боуг, лингвист Вашингтонского университета, говорит, что коммюнике Трампа в целом можно разделить на три группы: спонтанные выступления; тщательно подготовленные адреса по сценарию; и твиты. Сценарий речей максимально приближен к президентской норме, а его обращение на совместном заседании Конгресса в феврале чаще всего указывается как пример того, как Трамп отражает прошлое лидеров. Самые напыщенные разговоры звучат в спонтанных высказываниях Трампа или в наспех написанных твитах. Но все это имеет очень специфический оттенок. «Существует стиль речи, который ассоциируется с жесткими нью-йоркцами, стереотипом о мужчинах в Нью-Йорке, и мы обычно связываем его с мужчинами из рабочего класса», — сказал Боуг.«Они не только откровенны, но и крутые парни». ___ SALESMAN’S SPIEL? В Бараке Обаме вы часто слышали, как адвокат на работе говорит осторожно и с некоторой видимостью самоконтроля, сказал Джеймисон. У Трампа проблески бизнесмена проявляются в его категоричных заявлениях и неоднократных утверждениях о том, что он успешен и вызывает восхищение. «Он говорит вам, что бренд Трампа — хороший бренд, что всем нравится бренд Трампа», — сказал Джеймисон. Дэвид Бивер, лингвист из Техасского университета в Остине, сказал, что Трамп копирует тактику рекламодателей, предпочитая эмоциональное убеждение рациональности. Это означает графические образы, перемешанные с яркими словами, и язык, более типичный для уличных людей, чем для государственных деятелей. «Когда вы в последний раз слышали, как президент дважды в одном предложении произносит« подонок »?» — спросил Бивер. ___ Седенски можно связаться по адресу [email protected] или https://twitter.com/sedensky За последние несколько лет область искусственного интеллекта продвинулась так быстро, и о нем было написано так много, что, скорее всего, вы слышали о некоторых впечатляющих результатах в обработке естественного языка. Например, читая Википедию, программа может научиться проводить аналогии: Я написал простую программу, чтобы убедиться в этом сам. Мне было любопытно: На какие сложные вопросы он может ответить? Этот блог представляет собой очень легкое введение в тему. Что узнал fastText, прочитав Википедию? Давайте откроем файл размером 2 ГБ и посмотрим: Отлично, с этим форматом должно быть легко работать.Каждая строка содержит одно слово, представленное в виде вектора в 300-мерном пространстве. Если бы это было в 2D, мы могли бы представить это следующим образом: Единственная разница в том, что каждое слово имеет не 2 координаты, а 300. Слова во входном файле удобно отсортированы по частоте. Для моих экспериментов будет достаточно работы с 100 тысячами самых распространенных английских слов, поэтому я скопировал первые 100 тысяч строк в отдельный файл. Чтобы упростить работу с моим первым проектом, я решил использовать простой Python 3 без дополнительных зависимостей.Я также использую Mypy, средство проверки статического типа для Python. Сначала мы определим класс для представления каждого слова: Затем загрузим данные в память: Мы разобрали файл в Теперь у нас есть векторы в памяти, и мы можем ответить на всевозможные вопросы о них.Первый вопрос, который у меня возник, был: Какое слово в векторном пространстве ближе всего к заданному слову? Как вычислить расстояние между двумя векторами слов a, b? Вы можете сказать «евклидово расстояние», но косинусное сходство работает намного лучше для нашего случая использования. Из средней школы (или Википедии): В Python: Теперь мы можем найти слова, похожие на заданный вектор: Нам просто нужны простые служебные функции для печати связанных слов: Пора попробовать: Впечатляет! Похоже, что слова с высоким косинусным сходством связаны друг с другом либо синтаксически («корни,« укорененный »»), либо семантически («корни» и «трава», «руки» и «ноги»). Давайте попробуем что-нибудь посложнее. Имея два слова, такие как «Париж» и «Франция», между которыми существует семантическая связь (Париж — столица Франции), и третье слово «Рим», можем ли мы вывести «Италия»? Оказывается, для этого можно просто складывать и вычитать векторы! Это потому, что векторы этих слов имеют определенное отношение в пространстве: Как ни удивительно: Следовательно: Мы будем искать слова, близкие к Давайте реализуем это: Зададим несколько вопросов: Это работает! 🎉 Прочитав Википедию, fastText кое-что узнал о заглавных буквах, роде, неправильных глаголах и прилагательных (!) Давайте попробуем еще несколько: А также: Модель не все понимает правильно Как бы вы завершили следующие аналогии? Суши готовят из риса и других ингредиентов, пиццу — из теста / салями / сыра и т. Д. Стейк готовят из мяса. Рубашка — это разновидность одежды, телефон — разновидность электроники, чаша — разновидность посуды. Мы читаем книгу и смотрим телевизор. Давайте посмотрим на ответы: Также: Как мы видим, fastText не делает ‘ Я правильно понимаю каждую аналогию. Может быть, если мы посмотрим на список предложений, а не на первое, найдутся лучшие ответы? В двух случаях второй предложение было действительно хорошим.Однако похоже, что связь между «рубашкой» и «одеждой» остается загадкой. Когда я впервые увидел эти результаты на своем ноутбуке, я был совершенно потрясен. Эта программа состоит из нескольких строк Python и заставляет вас чувствовать себя умным, и на самом деле понимает , о чем вы спрашиваете. После того, как я задал несколько сложных вопросов, я понял, что программа может ответить «очень неправильно», чего никогда бы не сделал ни один человек. Это может заставить вас подумать, что модель все-таки не такая уж умная. Однако учтите следующее: векторы были обучены на английском тексте, но, в отличие от человека, алгоритм обучения имел нулевое предыдущее знание английского языка . За несколько часов чтения Википедии он довольно хорошо изучил английскую грамматику, а также многие семантические отношения между концепциями реального мира. Он может делать то же самое с немецким, тайским, китайским или любым другим языком при достаточном количестве текста. Сколько времени нужно ребенку, чтобы развить логическое мышление, прежде чем он сможет ответить на вопросы, подобные тем, которые приведены в этом посте? Как насчет того, чтобы взрослый выучил иностранный язык? Как насчет того, чтобы сделать это на двух или трех языках? Для человека требуются годы, а для Word2vec или fastText — несколько часов. Весь код из этого поста доступен на GitHub. Вам понадобится только Python 3 и предварительно обученные векторы, чтобы запустить код и самостоятельно искать интересные взаимосвязи между словами. Если вам это понравилось, подпишитесь на меня в Twitter. Я хотел сделать пост как можно короче, охватывая самые важные основы и интересные результаты.Не стесняйтесь продолжить чтение для получения более подробной информации. Когда я впервые реализовал алгоритм, я получал неверные результаты, например: Это потому, что вектор ответов, вычисленный как На самом деле, почти все ответы, которые я получал, просто повторяли одно из входных слов. Я добавил хитрость, чтобы пропустить эти повторяющиеся слова в списке предлагаемых ответов, и начал получать интересные ответы, как показано выше. Этот хак называется в коде ОБНОВЛЕНИЕ: Томас Миколов, автор fastText, ответил на Facebook, сказав, что то, что я сделал, на самом деле является хорошо известным трюком, и это правильно. Я написал всего несколько строк кода и получил потрясающие результаты.Это потому, что вся магия заключается в векторах, обученных с помощью fastText на гигабайтах английского текста из Википедии и других источников. Существуют и другие библиотеки, похожие на fastText, например Word2vec и GloVe. Как работают эти библиотеки? Это довольно большая тема для другого поста, но идея состоит в том, что слова, встречающиеся в схожих контекстах, должны иметь схожие векторы. Идеи, такие как n-граммы и представление слов в виде векторов, существовали долгое время, но только в 2013 году были опубликованы документ Word2vec и его реализация, показавшие «значительное повышение точности при гораздо меньших вычислительных затратах». Томаш Миколов работал как над Word2Vec, так и над fastText. Я только узнаю об этом сейчас, но лучше поздно, чем никогда 🙂 Я согласен с Майклом Болином в том, что «статическая типизация — важная функция при выборе языка для большого программного проекта» (сообщение в блоге).Типы помогают мне сделать код более читабельным и менее ошибочным. Даже для этого небольшого проекта обнаружение ошибок в Atom еще до запуска кода было чрезвычайно полезным и сэкономило мне много времени. Что замечательно, среда выполнения Python 3 принимает аннотации типов. Любой желающий может запустить мой код без дополнительной настройки. Нет необходимости преобразовывать код перед его запуском, как, например, при использовании Flow с JavaScript. Код вообще не оптимизирован и почти не обрабатывает ошибки.По крайней мере, мы могли бы нормализовать все векторы, чтобы ускорить вычисление косинусного сходства (один вызов Вот что делает функция Первоначально выполняется попыток полного анализа каждого предложения.Если синтаксический анализ не возвращается до истечения выделенного времени , синтаксический анализатор переходит в режим ожидания. С этого момента синтаксическому анализатору разрешено пропускать порции ввода для достижения терминала стартера для следующего компонента, который будет проанализирован, и закрывать текущий opea один (или единицы) любым частичным Представление . Результатом является приблизительный частичный синтаксический анализ , который показывает общую структуру предложения , из которого могут отсутствовать некоторые составляющие .Фрагменты, пропущенные на первом проходе, не выбрасываются, вместо этого они анализируются простым фразовым постпроцессором , который ищет словосочетания существительных и

 Например, единицей может быть слово, строка, предложение или абзац, например, по выбору пользователя.
Например, единицей может быть слово, строка, предложение или абзац, например, по выбору пользователя. В противном случае на этапе 96 к изображению применяется вторая подсветка, здесь предпочтительно с другим прозрачным цветом и применяется только к слову, которое должно быть синтезироваться синтезатором речи 52.
В противном случае на этапе 96 к изображению применяется вторая подсветка, здесь предпочтительно с другим прозрачным цветом и применяется только к слову, которое должно быть синтезироваться синтезатором речи 52. Строки соответственно имеют указатели 130a-130e на каждое из слов, содержащихся в строке.
Строки соответственно имеют указатели 130a-130e на каждое из слов, содержащихся в строке.
 8). для позиционной информации и информации индекса, такой как координаты (14, m4) и (n4, o4). Опять же, для каждой строки в конкретной области информация о местоположении используется, чтобы определить, находятся ли координаты указывающего устройства в пределах поля, определенного для линии с помощью информации о местоположении, связанной с линией.Если координаты
8). для позиционной информации и информации индекса, такой как координаты (14, m4) и (n4, o4). Опять же, для каждой строки в конкретной области информация о местоположении используется, чтобы определить, находятся ли координаты указывающего устройства в пределах поля, определенного для линии с помощью информации о местоположении, связанной с линией.Если координаты Линии часто на
Линии часто на
Словарь и сопоставление фраз с помощью SpaCy
Сопоставление на основе правил
Matcher , который можно использовать для определения пользовательских правил для сопоставления фраз. Процесс использования инструмента Matcher довольно прост. Первое, что вам нужно сделать, это определить шаблоны, которые вы хотите сопоставить. Затем вам нужно добавить шаблоны в инструмент Matcher и, наконец, вы должны применить инструмент Matcher к документу, с которым вы хотите сопоставить свои правила.Лучше всего это пояснить на примере. Создание объекта сопоставления
импорт просторный
nlp = spacy.  load ('en_core_web_sm')
из spacy.matcher import Matcher
m_tool = Матчер (nlp.vocab)
load ('en_core_web_sm')
из spacy.matcher import Matcher
m_tool = Матчер (nlp.vocab)
Определение шаблонов
p1 = [{'НИЖНИЙ': 'quickbrownfox'}]
p2 = [{'LOWER': 'quick'}, {'IS_PUNCT': True}, {'LOWER': 'brown'}, {'IS_PUNCT': True}, {'LOWER': 'fox'}]
p3 = [{'НИЖНИЙ': 'быстрый'}, {'НИЖНИЙ': 'коричневый'}, {'НИЖНИЙ': 'лиса'}]
p4 = [{'НИЖНИЙ': 'быстрый'}, {'НИЖНИЙ': 'brownfox'}]
LOWER определяет, что фраза должна быть преобразована в нижний регистр перед сопоставлением. Matcher , который мы создали ранее.
m_tool.add ('QBF', Нет, p1, p2, p3, p4)
Применение сопоставителя к документу
фраза = nlp (u 'Быстрая коричневая лисица перепрыгивает через ленивую собаку.Быстрая бурая лисица хорошо кушает. \
быстрая лисица мертва. собака скучает по быстрому лису ')
 Выполните следующий скрипт:
Выполните следующий скрипт:
keyword_matches = m_tool (предложение)
печать (фраза_матчи)
[(12825528024649263697, 1, 6), (12825528024649263697, 13, 16), (12825528024649263697, 21, 22), (12825528024649263697, 29, 31)]
для match_id, start, end во фразе_matches:
string_id = nlp.vocab.strings [match_id]
промежуток = предложение [начало: конец]
print (match_id, string_id, start, end, span.текст)
12825528024649263697 QBF 1 6 бурый бурый лис
12825528024649263697 QBF 13 16 быстрая коричневая лисица
12825528024649263697 QBF 21 22 quickbrownfox
12825528024649263697 QBF 29 31 быстрый коричневый фокс
Дополнительные параметры сопоставления на основе правил
QBF .
m_tool.remove ('QBF')
p1 = [{'LOWER': 'quick'}, {'IS_PUNCT': True, 'OP': '*'}, {'LOWER': 'коричневый'}, {'IS_PUNCT': True, 'OP': '*'}, {'НИЖНИЙ': 'лиса'}]
m_tool.  добавить ('QBF'; Нет; p1)
добавить ('QBF'; Нет; p1)
p1 будет соответствовать всем фразам, в которых есть одна или несколько знаков препинания во фразе quick brown fox . Давайте теперь определим наш документ для фильтрации:
фраза = nlp (u'Быстрая - коричневая - лисица перепрыгивает через быструю коричневую - лису ')
keyword_matches = m_tool (предложение)
для match_id, начало, конец фразе_matches:
string_id = nlp.Dictionary.strings [match_id]
промежуток = предложение [начало: конец]
print (match_id, string_id, start, end, span.text)
12825528024649263697 QBF 1 6 quick - коричневый - лисий
12825528024649263697 QBF 10 15 быстро-коричневый --- лисий
Фразовое соответствие
Это более эффективный способ сопоставления фраз.
импорт BS4 как BS
импортировать urllib.a-zA-Z] ',' ', Processing_article)
Processing_article = re.sub (r '\ s +', '', обработанная_статья)
 Вы можете пойти и прочитать статью, если хотите понять, как работает синтаксический анализ в Python.
Вы можете пойти и прочитать статью, если хотите понять, как работает синтаксический анализ в Python. Processing_article содержит документ, который мы будем использовать для сопоставления фраз. Создать объект сопоставления фраз
PhraseMatcher . Это делает следующий сценарий:
импорт просторный
nlp = spacy.load ('en_core_web_sm')
из spacy.matcher импортировать PhraseMatcher
фраза_matcher = PhraseMatcher (nlp.vocab)
Matcher . В данном случае мы создаем объект PhraseMathcer . Создать список фраз
фраз = ['машинное обучение', 'роботы', 'интеллектуальные агенты']
шаблоны = [nlp (текст) для текста во фразах]
фраза_matcher.add ('AI', Нет, * шаблоны)
Применение сопоставителя к документу
предложение = nlp (processing_article)
matched_phrases = сопоставление_ фраз (предложение)
[(5530044837203964789, 37, 39),
(5530044837203964789, 402, 404),
(5530044837203964789, 693, 694),
(5530044837203964789, 1284, 1286),
(5530044837203964789, 3059, 3061),
(5530044837203964789, 3218, 3220),
(5530044837203964789, 3753, 3754),
(5530044837203964789, 5212, 5213),
(5530044837203964789, 5287, 5288),
(5530044837203964789, 6769, 6771),
(5530044837203964789, 6781, 6783),
(5530044837203964789, 7496, 7498),
(5530044837203964789, 7635, 7637),
(5530044837203964789, 8002, 8004),
(5530044837203964789, 9461, 9462),
(5530044837203964789, 9955, 9957),
(5530044837203964789, 10784, 10785),
(5530044837203964789, 11250, 11251),
(5530044837203964789, 12290, 12291),
(5530044837203964789, 12411, 12412),
(5530044837203964789, 12455, 12456)]
для match_id, start, end в matched_phrases:
string_id = nlp.  Dictionary.strings [match_id]
промежуток = предложение [начало: конец]
print (match_id, string_id, start, end, span.text)
Dictionary.strings [match_id]
промежуток = предложение [начало: конец]
print (match_id, string_id, start, end, span.text)
5530044837203964789 AI 37 39 интеллектуальных агентов
5530044837203964789 AI 402 404 машинное обучение
5530044837203964789 AI 693 694 роботов
5530044837203964789 AI 1284 1286 машинное обучение
5530044837203964789 AI 3059 3061 интеллектуальные агенты
5530044837203964789 AI 3218 3220 машинное обучение
5530044837203964789 AI 3753 3754 роботов
5530044837203964789 AI 5212 5213 роботов
5530044837203964789 AI 5287 5288 роботов
5530044837203964789 AI 6769 6771 машинное обучение
5530044837203964789 AI 6781 6783 машинное обучение
5530044837203964789 AI 7496 7498 машинное обучение
5530044837203964789 AI 7635 7637 машинное обучение
5530044837203964789 AI 8002 8004 машинное обучение
5530044837203964789 AI 9461 9462 роботов
5530044837203964789 AI 9955 9957 машинное обучение
5530044837203964789 AI 10784 10785 роботов
5530044837203964789 AI 11250 11251 роботов
5530044837203964789 AI 12290 12291 роботов
5530044837203964789 AI 12411 12412 роботов
5530044837203964789 AI 12455 12456 роботов
стоп-слова
stop_words модели spaCy, как показано ниже:
импорт просторный
sp = spacy.  load ('en_core_web_sm')
печать (sp.Defaults.stop_words)
load ('en_core_web_sm')
печать (sp.Defaults.stop_words)
{'меньше', 'кроме', 'верх', 'я', 'три', 'пятнадцать', 'а', 'есть', 'те', 'все', 'потом', 'все' , 'без', 'должен', 'имеет', 'любой', 'так или иначе', 'сохранить', 'через', 'дно', 'получить', 'действительно', 'это', 'еще', ' десять »,« что угодно »,« делаю »,« хотя »,« восемь »,« различный »,« я »,« поперек »,« где угодно »,« сам »,« всегда »,« таким образом »,« есть » , 'после', 'следует', 'возможно', 'в', 'вниз', 'владеть', 'скорее', 'в отношении', 'который', 'где угодно', 'откуда', 'будет', ' была ',' как ',' сама ',' сейчас ',' могла бы ',' пожалуйста ',' позади ',' каждый ',' кажется ',' одна ',' от ',' через ',' ее ' , 'стать', 'ее', 'там', 'перед', 'чей', 'до', 'против', 'после', 'вверх', 'куда', 'два', 'пять', ' одиннадцать ',' почему ',' ниже ',' вне ',' тогда как ',' серьезный ',' шесть ',' дать ',' также ',' стал ',' его ',' в любом случае ',' ни один ' , 'снова', 'на', 'else', 'иметь', 'несколько', 'тем самым', 'кто угодно', 'еще', 'часть', 'просто', 'потом', 'в основном', ' видеть ',' настоящим ',' не ',' могу ',' однажды ',' поэтому ',' вместе ',' кого ',' в другом месте ',' заранее ',' сами ',' с ',' казаться ',' многие ',' на ',' бывшие ',' есть ',' кто ',' становясь ',' бывшим ',' между ',' не может ',' он ' , 'то', 'первый', 'больше', 'хотя', 'когда', 'под', 'где', 'мой', 'после чего', 'кто угодно', 'по направлению', 'по', ' четыре ',' с ',' среди ',' переместить ',' каждый ',' сорок ',' каким-то образом ',' как ',' кроме ',' использовано ',' если ',' имя ',' когда ' , 'когда-либо', 'однако', 'иначе', 'сто', 'кроме того', 'твой', 'иногда', 'тот', 'пустой', 'другой', 'где', 'она', ' достаточно ',' довольно ',' повсюду ',' что угодно ',' она ',' и ',' делает ',' выше ',' внутри ',' показать ',' внутри ',' это ',' назад ' , 'made', 'никто', 'off', 're', 'между тем', 'than', 'none', 'двадцать', 'call', 'you', 'next', 'there', ' в нем ',' иди ',' или ',' казался ',' такой ',' недавно ',' уже ',' мой ',' сам ',' an ',' количество ',' после ',' а именно ' , 'такой же', 'их', 'из', 'твой', 'мог', 'быть', 'сделано', 'целое', 'кажущееся', 'кто-то', 'эти', 'по направлению', ' среди ',' становится ',' за ',' через ',' за ',' рядом ',' оба ',' последний ',' наш ',' ну ',' сделать ',' нигде ',' примерно ',' были ',' другие ',' причитающиеся ',' сами ',' если ',' после этого ',' даже ',' тоже ',' большинство ' , 'все', 'наш', 'что-то', 'сделал', 'используя', 'полный', 'пока', 'будет', 'только', 'ни', 'часто', 'сторона', ' быть ',' меньше ',' больше ',' немного ',' по ',' было ',' очень ',' на ',' в ',' девять ',' никто ',' несколько ',' я ' , 'один', 'третий', 'здесь', 'но', 'далее', 'здесь', 'ли', 'потому что', 'либо', 'далее', 'действительно', 'так', ' где-то ',' мы ',' тем не менее ',' последний ',' имел ',' они ',' оттуда ',' почти ',' ca ',' везде ',' сам ',' нет ',' мы ' , 'may', 'при', 'take', 'around', 'never', 'them', 'to', 'until', 'do', 'what', 'say', 'двенадцать', ' ничего »,« в течение »,« шестьдесят »,« когда-нибудь »,« нас »,« пятьдесят »,« много »,« для »,« другое »,« следовательно »,« он »,« положил »}
 Для этого вы можете использовать атрибут
Для этого вы можете использовать атрибут is_stop , как показано ниже:
sp.vocab ['чудо']. Is_stop
False . sp.Defaults.stop_words.add () и sp.Defaults.stop_words.remove () соответственно.
sp.Defaults.stop_words.add ('чудо')
is_stop для wonder значение True, как показано ниже:
sp.словарь ['чудо']. is_stop = Верно
Заключение
лингвистов ищут слова в синтаксическом анализе ораторского искусства Трампа

 «Я думаю, что есть реальный метод в том, что другие могут представить как его безумие».
«Я думаю, что есть реальный метод в том, что другие могут представить как его безумие».
Играем с векторами слов.В последние несколько лет область искусственного интеллекта… | Мартин Коничек | The Startup
мужчина для короля, как женщина для ___? (королева). Я не обучал модели машинного обучения. Вместо этого я загрузил предварительно обученные векторы английских слов, созданные с помощью библиотеки fastText.
Я не обучал модели машинного обучения. Вместо этого я загрузил предварительно обученные векторы английских слов, созданные с помощью библиотеки fastText. Первый взгляд на данные
хорошо -0,1242 -0,0674 -0,1430 -0,0005 -0,0345 ...
день 0,0320 0,0381 -0,0299 -0,0745 -0,0624 ...
три 0,0304 0,0070 -0,0708 0,0689 -0,0005 .. .
знаю -0,0370 -0,0138 0,0392 -0,0395 -0,1591 ...
... Использование Python 3
слов = load_words ('data / words.vec') Список [Word] . Эта часть довольно проста, поэтому мы оставим детали в конце поста и сразу перейдем к интересным. Косинусное подобие
 Идея в том, что абсолютная длина вектора не имеет значения, что интересно, так это угол между двумя векторами .
Идея в том, что абсолютная длина вектора не имеет значения, что интересно, так это угол между двумя векторами . >>> print_related (слова, 'испания')
британия, англия, франция, европа, германия, испанский, италия >>> print_related (слова, 'названный')
названный, дублированный, названный, упомянутый, названный, названный, описано >>> print_related (слова, 'хотя')
хотя, однако, но, тогда как, а, поскольку, Тем не менее >>> print_related (слова, 'оружие')
ноги, рука, оружие, пальто, пальто, вооружение, руки >>> print_related (слова, 'корни')
корень, происхождение, стебли, начало, корни, трава, традиции Завершите предложение: Париж для Франции, как Рим для ___
вектор («Франция») - вектор («Париж») = answer_vector - вектор («Рим»)
вектор («Франция») - вектор («Париж») + вектор ( "Рим") = answer_vector
answer_vector . answer_vector не будет точно соответствовать «Италии», но должен быть близок.
>>> print_analogy ('Париж', 'Франция', 'Рим', слова)
Париж-Франция похожа на Рим-Италия >>> print_analogy ( 'мужчина', 'король', 'женщина', слова)
мужчина-король подобен женщине-королеве >>> print_analogy ('гулять', 'гулял', 'идти', слова)
гулять-гулять - это как пошло-пошло >>> print_analogy ('quick', 'quickest', 'far', words)
quick-quickest как далеко дальше Английский-Jaguar похож на немецкий-BMW // Дорогие автомобили
Английский-Vauxhall похож на немецкий-Opel // Более дешевые автомобили Немецкий BMW похож на американский Lexus // Дорогие автомобили
Немецкий Opel похожий на американский Chrysler // Более дешевые автомобили >>> print_analogy ('dog', 'mammal', 'eagle ', слова)
собака-млекопитающее похожа на орла-птицу
1.суши-рис похож на пиццу -___
2. суши-рис похож на стейк -___
3. рубашка-одежда как телефон -___
4. рубашка-одежда как миска -___
5. чтение книг похоже на телевизор -___ суши-рис похож на пиццу-пшеницу // имеет смысл
суши-рис похож на стейк-курицу
рубашка-одежда похожа на еду из миски
рубашка-одежда похожа на телефон-мобильный
книга -чтение похоже на TV-TV >>> print_analogy ('do', 'done', 'go', words)
do-done похоже на go-separated 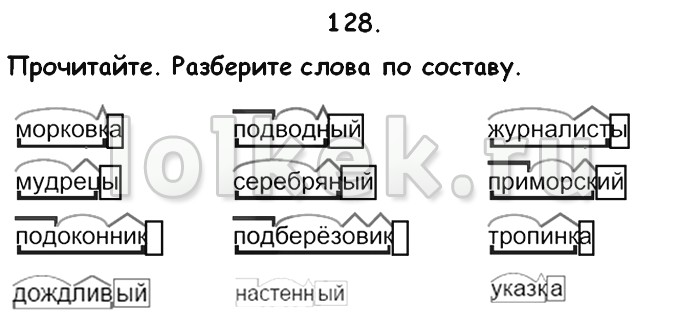 Результаты впечатляют, но когда они ошибаются, они кажутся далекими.
Результаты впечатляют, но когда они ошибаются, они кажутся далекими. суши-рис похож на стейк-
[курица (0,58), говядина ( 0,56), картофель (0,56), кукуруза (0,55)] чтение книг похоже на телевизор-
[телевизор (0,68), просмотр (0,64), слушание (0,57), просмотр (0,57)] рубашка-одежда похожа на миску- [еда, хлопья, рис, каша] рубашка-одежда похожа на телефон- [мобильный, сотовый] Заключение
 Люди учатся совсем не так, как эти алгоритмы. Люди могут лучше изучать концепции и на основе гораздо меньшего количества данных, но на это у нас уходит гораздо больше времени.
Люди учатся совсем не так, как эти алгоритмы. Люди могут лучше изучать концепции и на основе гораздо меньшего количества данных, но на это у нас уходит гораздо больше времени. Небольшой прием
мужчина-король похож на женщину-короля
answer = vector (king ) -вектор (мужчина) + вектор (женщина) был очень близок к слову «король». Другими словами, вычитание вектора для «мужчины» и добавление вектора для «женщины» очень мало повлияло на исходный вектор для «короля», вероятно, потому, что эти «мужчина» и «женщина» связаны между собой. is_redundant . Как были получены векторы?
 Например, если слово «пицца» часто встречается рядом с такими словами, как «ел», «ресторан» и «итальянский», вектор для пиццы будет иметь большое косинусное сходство с векторами этих слов.Слова, которые редко встречаются в тексте вместе, будут иметь низкий косинус сходства, потенциально вплоть до -1.
Например, если слово «пицца» часто встречается рядом с такими словами, как «ел», «ресторан» и «итальянский», вектор для пиццы будет иметь большое косинусное сходство с векторами этих слов.Слова, которые редко встречаются в тексте вместе, будут иметь низкий косинус сходства, потенциально вплоть до -1. История
Зачем использовать типы в Python?
Оптимизация
sorted_by_similarity для ответа на один вопрос занимает около 7 секунд на моем MacBook Pro для 100 тысяч слов). Вероятно, нам следует использовать numpy. Процесс Python использует почти 1 ГБ памяти. Мы могли бы использовать существующую реализацию, которая может просто загружать файл и отвечать на вопросы. Все это выходит за рамки этой публикации. Я хотел посмотреть, смогу ли я написать очень простой код с нуля, чтобы ответить на некоторые интересные вопросы.
Загрузка и очистка данных
load_words : load_words_raw просто считывает файл построчно и анализирует каждую строку в Word . Мы загрузили 100 тысяч слов с 300 измерениями каждое, а процесс Python использует почти 1 ГБ памяти (!) — это плохо, но пока мы с этим смиримся. remove_stop_words отбрасывает слова, которые начинаются или заканчиваются не буквенно-цифровыми символами, такими как «интер-», «спасибо».»И« —redrose64 ». У нас осталось 98 648 слов. remove_duplicates игнорирует знаки препинания, поэтому «Великобритания», «Великобритания» и «UK» — это одно и то же слово, сохраненное только один раз. У нас осталось 97 190 слов. Есть еще несколько дубликатов, например «годы» и «годы». Мы могли бы проигнорировать регистр, но тогда мы потеряем различие между «нами» и «США» (Соединенные Штаты). Быстрый и надежный синтаксический анализатор естественного языка
, а затем присоединяет восстановленный материал
к основной структуре синтаксического анализа. .
.
Механизм тайм-аута реализован с использованием прямой передачи параметров
и в настоящее время
ограничен только частью нетерминальных элементов, используемых грамматикой
.Предположим, что X — такой нетерминал, и
, что он появляется в правой части производственной S
—> XY Z. Набор «стартеров» вычисляется для Y,
, который состоит из теги слов, которые могут встречаться как крайняя левая составляющая
Y. Этот набор передается как параметр
, в то время как синтаксический анализатор пытается распознать X в
входных данных. Если X распознается успешно в течение заданного времени
, то синтаксический анализатор переходит к синтаксическому анализу Y, а
больше ничего не происходит.С другой стороны, если синтаксический анализатор
не может определить, есть ли X на входе или
нет, то есть он не преуспевает и не терпит неудачу в синтаксическом анализе X
до истечения времени ожидания, незавершенная составляющая X равна
закрывается с частичным закрытием, и синтаксический анализатор перезапускается
на ближайшем элементе из установленных для Y, что
можно найти в оставшейся части ввода. Если Y
перезаписывается в пустую строку, стартеры для Z справа от Y
добавляются к стартовым элементам для Y, и оба набора
передаются в качестве параметра в X.В качестве примера рассмотрите следующие предложения в анализаторе TIP: ~ 1
предложение (P)
: —
assertion ([], P).
утверждение
(SR, P): —
пункт (SR, Pl), sordin (SR, PI, P).
пункт (SR, P)
: —
sa ([pdt, dr, cd, pp, ppS, J j, Jjr,
j Js, nn, nns, np, nps], PAl),
субъект ([vbd, vbz, vbp], Tail, P 1),
глагольная фраза (SR, Tail, PI, PA1, P),
subtail (хвост).
это (SR, P)
: —
то, утверждение
(SR, P).
В приведенном выше предложении (конечное) предложение
n Пункты немного упрощены, а некоторые аргументы
удалены для объяснения причин.
переписывает в (необязательное) дополнение предложения (SA), тему
, глагольную фразу и правое дополнение подлежащего
(СУБТЕЙЛ, также необязательно). За исключением подгруппы
tail, каждый предикат имеет параметр, который определяет список
«стартовых» тегов для перезапуска синтаксического анализатора, если оценка
этого предиката превысит выделенную часть времени
.Таким образом, в случае, если sa прерывается до завершения его оценки, синтаксический анализатор перепрыгнет через некоторые элементы неанализируемой части ввода в поисках
слова, которое могло бы начинать предметную фразу (либо pre-
определитель, определитель, счетное слово, местоимение, прилагательное
, существительное или имя собственное). Аналогичным образом, когда истекло время
subject, синтаксический анализатор перезапустится с
глагольной фразой либо в vbz, либо в vbd, либо в vbp (конечные формы глагола
).Обратите внимание, что если истекло время ожидания глагольной фразы, то фрагмент
будет проигнорирован, и глагольная фраза и предложение будут закрыты
, а синтаксический анализатор перезапустится с элемента набора
SR, переданного в предложение из утверждения. Также обратите внимание на
, что в продукте верхнего уровня для предложения набор star-
ter для утверждения инициализируется как пустой: если на этом уровне происходит сбой
, продолжение невозможно.
Когда время ожидания нетерминала истекло и синтаксический анализатор
перескакивает через фрагмент ввода ненулевой длины,
предполагает, что пропущенная часть была неким суб-
, составляющим закрытый нетерминал.Соответственно, заполнитель
остается в структуре синтаксического анализа под узлом
, где доминирует этот нетерминал, который будет позже заполнен некоторым номинальным материалом, восстановленным из
фрагмента,
. Примеры, приведенные в Приложении
, показывают приблизительные структуры синтаксического анализа, генерируемые TIP.