Части слова. Русский язык, 3 класс: уроки, тесты, задания.
- Предметы
- Русский язык
- 3 класс
-
Корень слова. Однокоренные слова. Чередование согласных звуков в корнях однокоренных слов
-
Непроизносимые согласные в корне слова
-
Сложные слова.
 Соединительные гласные в сложных словах
Соединительные гласные в сложных словах
-
Окончание. Формы слова. Различие однокоренных форм слова
-
Нулевое окончание. Слова без окончаний. Алгоритм выделения окончания
-
Приставка. Образование слов с помощью приставки
-
Суффикс как значимая часть слова.
Алгоритм выделения в слове суффикса
-
Основа слова. Разбор слова по составу. Анализ модели состава слова и подбор слов по этим моделям
 Соединительные гласные в сложных словах
Соединительные гласные в сложных словах
 Алгоритм выделения в слове суффикса
Алгоритм выделения в слове суффикса
Отправить отзыв
§ 14. Варианты значимых частей слова
В разных частях
слова может происходить замена одних
звуков другими, выпадение какого-либо
звука. В результате этого образуются
варианты одной и той же значимой части
слова. Так, в словах берегу —
бережный — беречь один и тот же
корень — берег-, в котором имеется
чередование звуков г//ж//ч.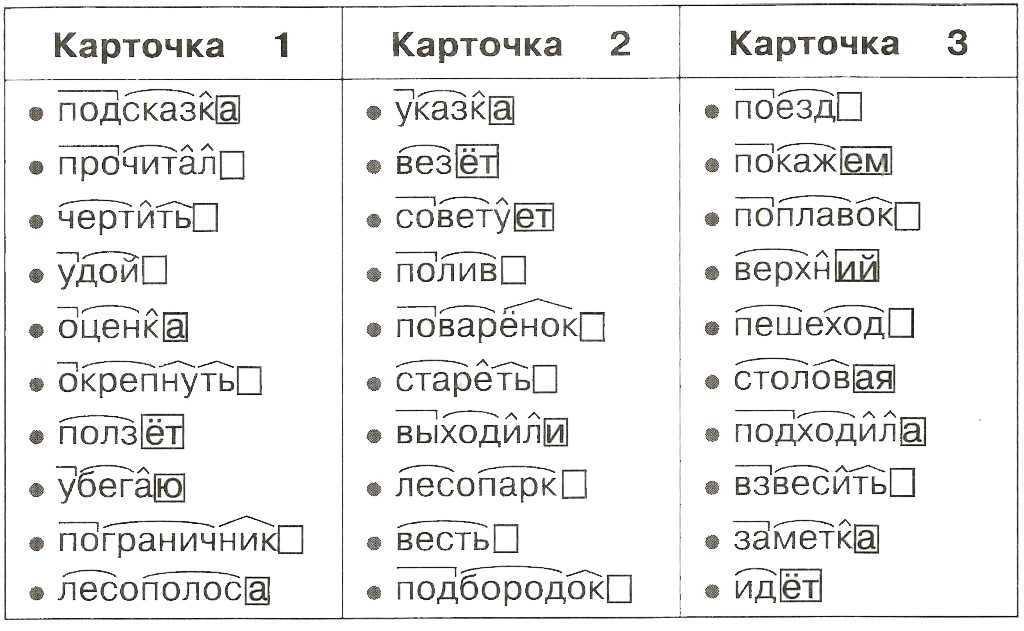 Варианты
могут быть в однокоренных словах и в
разных формах одного и того же слова:
Варианты
могут быть в однокоренных словах и в
разных формах одного и того же слова:
Характерными для русского языка являются чередования гласных о//а (опоздать — опаздывать, загореть — загар), е//и (седло — сидеть, замереть — замирать), е//нуль звука (день — дня), о//нуль звука (сон — сна) и согласных к//ч (пеку — печет), к//ч//ц (кликать — клич — восклицать), г//ж (бегу — бежит), г//ж//з (друг — дружить — друзья), х//ш (ухо — ушной),

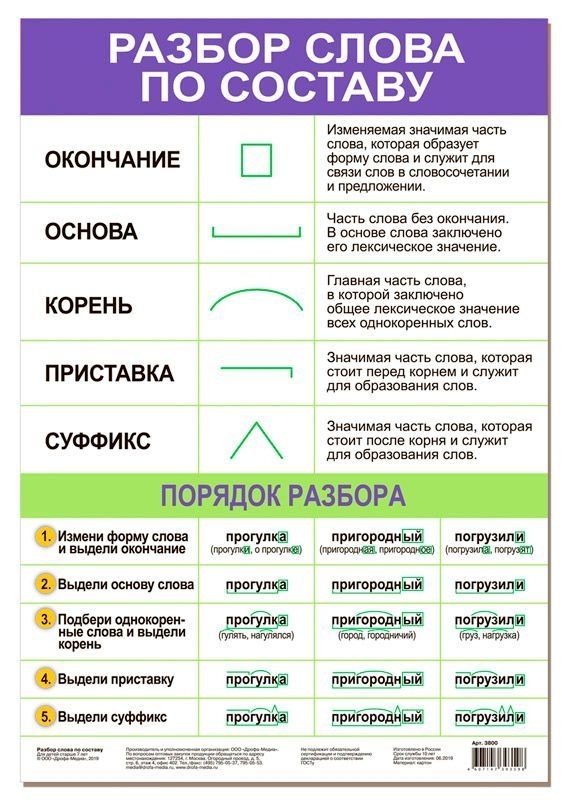
Разбор слова по составу
Разбор слова по составу — это выделение морфем, из которых оно состоит. План разбора 1. Определить, к какой части речи относится слово. 2. Выделить его основу и окончание, если это изменяемая часть речи. 3. Выделить корень, подобрав родственные слова. 4. Выделить приставку (если есть), суффикс (если есть). Доказать, что данные приставки и суффиксы имеются в других словах и выражают то же значение. 5. Представить морфемный состав слова графически.
Словообразование
Словообразование — раздел науки о языке, который изучает способы образования слов. Словообразованием называется также сам процесс создания новых слов на основе имеющихся в языке.
§ 16. Способы образования новых слов
Для образования
слов в русском языке существует несколько
основных способов.
1. Приставочный: распахать пахать, отвезти везти,
небольшой большой,
бесчестный честный,
подкомиссия комиссия.
 Нулевая суффиксация в этом
случае рассматривается как разновидность
суффиксального способа
словообразования.
5. Сложение: а) целых слов: времяпрепровождение, меч-рыба;
б) основ,
корней или частей разных слов: лесопарк,
бледно-голубой, водохранилище,
землемер (в подобных
случаях всегда используются соединительные
гласные).
В
результате сложения могут образовываться
сложносокращенные слова-аббревиатуры: СНГ, МГУ, ФСБ, универмаг,
Сбербанк. 6. Слияние слов из словосочетания или (редко)
из предложения: быстрорастворимый (быстро растворимый), тотчас (тот
час).
7. Переход
слова из одной части речи в другую:
Нулевая суффиксация в этом
случае рассматривается как разновидность
суффиксального способа
словообразования.
5. Сложение: а) целых слов: времяпрепровождение, меч-рыба;
б) основ,
корней или частей разных слов: лесопарк,
бледно-голубой, водохранилище,
землемер (в подобных
случаях всегда используются соединительные
гласные).
В
результате сложения могут образовываться
сложносокращенные слова-аббревиатуры: СНГ, МГУ, ФСБ, универмаг,
Сбербанк. 6. Слияние слов из словосочетания или (редко)
из предложения: быстрорастворимый (быстро растворимый), тотчас (тот
час).
7. Переход
слова из одной части речи в другую:  При усечении образуются слова,
полностью тождественные по значению
производящим словесным единицам. Данный
способ используется, как правило, для
образования имен существительных
разговорного или просторечного
характера.
Примечание. При образовании новых слов может
наблюдаться сочетание нескольких
способов словообразования. Например: тихоокеанский Тихий
океан + -ск- (способ сложения и
суффиксальный способ).
При усечении образуются слова,
полностью тождественные по значению
производящим словесным единицам. Данный
способ используется, как правило, для
образования имен существительных
разговорного или просторечного
характера.
Примечание. При образовании новых слов может
наблюдаться сочетание нескольких
способов словообразования. Например: тихоокеанский Тихий
океан + -ск- (способ сложения и
суффиксальный способ).Анализ адресов | Как разбить адрес на компоненты
Разбор адреса — это процесс разделения почтового адреса на отдельные или сгруппированные компоненты.
Поскольку слово «анализ» означает разделение чего-либо на компоненты, некоторые называют анализ адресов процессом разделения почтового адреса или «извлечения» адреса из строки текста.
Успешный синтаксический анализатор адресов требует аналогичных процессов и навыков, независимо от вашего определения. Независимо от того, делите ли вы реальные адреса на части или извлекаете элементы адреса из блоков текста, вам все равно потребуется определить, где начинается адрес, какие компоненты существуют и где адрес заканчивается.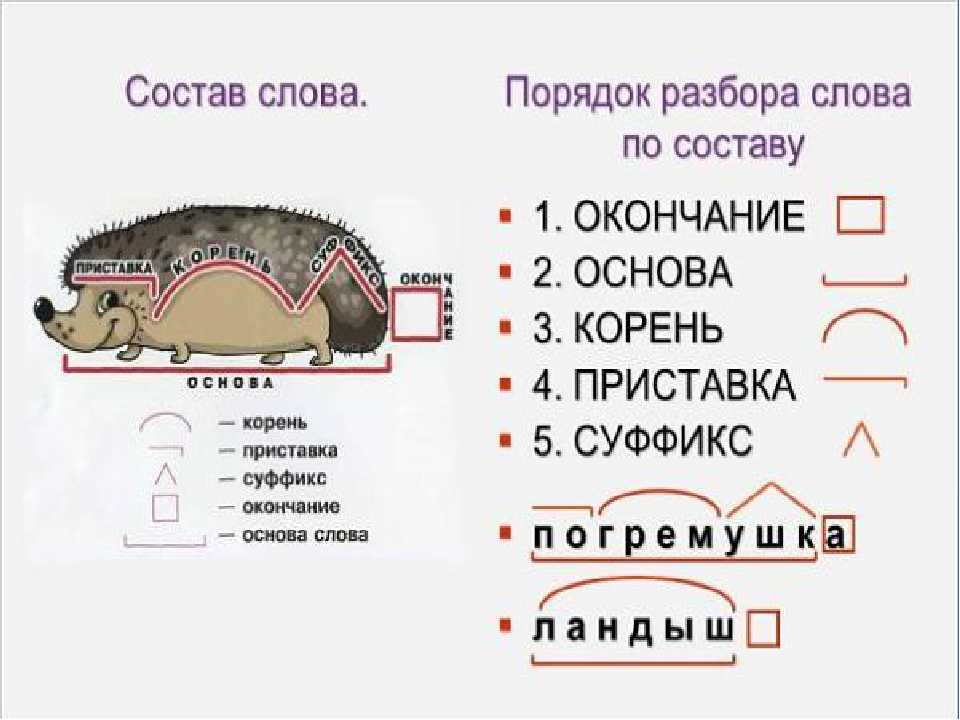
Мы обнаружили, что существует множество способов проверки и проверки адресов.
Мы считаем наши инструменты синтаксического анализа полезными, поэтому мы добавили сюда несколько ссылок.
| Анализ отдельных адресов | Массовый разбор адресов | Парсинг адресов через API |
|---|---|---|
Попробуйте сейчас | Попробуйте сейчас | Попробуйте сейчас |
В этой статье мы рассмотрим:
- Видео: что такое анализ адресов?
- Использование для проанализированных адресов
- Типичные подходы к разбору адресов
- Как анализ адресов используется в геокодировании?
Что такое анализ адресов?
 youtube.com/embed/nQZVUJ6AeBo» title=»What Is Address Parsing and How Do You Do It | Tutorial» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
youtube.com/embed/nQZVUJ6AeBo» title=»What Is Address Parsing and How Do You Do It | Tutorial» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»> Когда большинство людей используют фразу «разбор адреса», они имеют в виду процесс получения адреса или строки текста и разбиения этого адреса на компоненты или отдельные элементы адреса. Это похоже на слово «parse», которое предназначено для разбиения слов или предложений на части, синтаксис и т. д. Давайте проанализируем этот адрес:
1 E King St Apt 1 York PA 17401-1448
Хотя существует множество способов разделения адресной информации, вот наиболее распространенный способ анализа структуры адреса:
- Основной номер: 1 Улица
- Направление: E
- Название улицы: Король
- Суффикс улицы: St
- Street Почтовый адрес: N/A
- Вторичное обозначение: Ste
- Дополнительный номер: 1
- Дополнительное вторичное обозначение: нет данных
- Город: Йорк
- Штат: Пенсильвания
- Почтовый индекс: 17401
- +4 Код: 1448
Как видите, этот адрес был проанализирован (разбит) на соответствующие наборы данных.
Почему парсинг — это всего лишь один шаг в процессе
Парсинг — это не единственный шаг в процессе проверки адресов, но это полезный результат! Получение разобранных адресных данных начинается с:
- Информация введенного адреса
- Затем выполняется синтаксический анализ, и адрес разбивается на компоненты и индивидуально идентифицируется
- Исправлены орфография, регистр и аббревиатура для проанализированных компонентов адреса
- Мы возвращаем ваш стандартный адрес вместе с прекрасно проанализированными адресными данными
Нормализация
Нормализация данных — это преобразование данных в принятый авторитетный формат. Принятый формат обычно определяется признанным руководящим органом, комитетом или органом власти. Точно так же Нормализация адреса — это преобразование адресных данных в принятый формат, определяемый местным почтовым управлением. USPS определяет формат адреса для адресов в Соединенных Штатах.
USPS определяет формат адреса для адресов в Соединенных Штатах.
Когда адресная информация поступает в систему, существует несколько переменных, которые могут различаться. С миллионами адресов в США и миллиардами адресов по всему миру возможны бесконечные комбинации. Давайте использовать адрес, который мы уже разобрали. Адреса могут иметь незначительные отклонения и по-прежнему функционировать для доставки почты:
- 1 E King St, квартира 1 York PA 17401
- 1 E King St Apt 1 York PA 17401
- 1 E King Street Apt 1 York PA 17401
Действительный адрес можно ввести несколькими способами. Информация о точке доставки может содержать различные аббревиатуры, опечатки, регистр или, в случае адресов-псевдонимов, может выглядеть совершенно по-другому. Эти неоднозначности адресов показывают важность нормализации. Все эти входные данные технически правильны, но нормализация и стандартизация берут эти повторяющиеся адреса и возвращают единственный официальный адрес:
- 1 E King St Apt 1 York PA 17401
Использование проанализированных адресов
Несмотря на то, что проанализированные адресные данные могут быть частью процесса проверки адреса и геокодирования, предоставленная информация имеет множество применений. Разбор адресов позволяет:
Разбор адресов позволяет:
- Лучшее сопоставление адресов между наборами данных
- Создание постоянных уникальных идентификаторов
- Более точный анализ данных о местоположении
- Сколько адресов клиентов в городе содержат вторичную адресную информацию, такую как подразделения, квартиры или апартаменты? Более точная информация гарантирует, что информация может быть использована.
- Берет неструктурированные данные и преобразует их в полезную информацию.
- Улучшенное управление адресами, а также лучшее хранение адресов.
- Позволяет нормализовать или стандартизировать
- Может использоваться для дедупликации избыточных адресов в системе
- Он может использоваться компаниями для хранения адресов в их компонентной форме, что означает, что вместо хранения адреса они сохраняют проанализированную адресную информацию.
Типичные подходы к синтаксическому анализу адресов
Когда разработчик думает об анализе и стандартизации реальных адресов, он неизбежно думает, что ответом являются регулярные выражения (Regex). Это может привести к эффекту Даннинга-Крюгера, который просто означает, что вы переоцениваете свои способности что-то делать, особенно по сравнению с способными коллегами. Эффект Даннинга-Крюгера распространен, но адреса не являются регулярными. Таким образом, независимо от того, насколько сложным является ваше регулярное выражение, оно упустит тысячи пограничных случаев, найденных в адресных данных.
Это может привести к эффекту Даннинга-Крюгера, который просто означает, что вы переоцениваете свои способности что-то делать, особенно по сравнению с способными коллегами. Эффект Даннинга-Крюгера распространен, но адреса не являются регулярными. Таким образом, независимо от того, насколько сложным является ваше регулярное выражение, оно упустит тысячи пограничных случаев, найденных в адресных данных.
Адреса улиц также различаются по форматированию в разных областях, так что даже если вы отработаете большинство пограничных случаев для синтаксического анализа с помощью регулярных выражений, и он работает достаточно хорошо в одной области, он все равно может захлебнуться адресами в следующем городе.
Существует 2 подхода к парсингу адресов.
- Запросите адрес у пользователя или клиента в виде компонентов с разными полями для каждого значения. Таким образом, вам не нужно выполнять синтаксический анализ, так как пользователь сделал это за вас. Это не лучший пользовательский интерфейс, который создает более согласованные адресные данные.
- Запросите строку адреса в произвольном стиле или строки адреса в произвольной форме, что означает, что адрес вводится целиком в одной строке.
Запрос адресной строки в виде текста произвольной формы создает больше возможных различий с одним и тем же адресом, поскольку нет ничего, что контролировало бы единообразную запись. Один пользователь может ввести номер квартиры первым, а другой — после улицы. Разбор адреса может выполняться на разных уровнях в зависимости от того, какие детали вам нужны.
Как правило, при разборе адресной строки возвращаемая информация будет сгруппирована по следующим 10 типичным категориям:
- Первичный
- Предварительное направление
- Название улицы
- Индекс улицы
- Почтовое направление
- Вторичное обозначение
- Дополнительный номер
- Город
- Состояние
- Почтовый индекс
Разобрать адрес на Firstline (первые 7 компонентов) и Lastline (последние 3 компонента).
Использование синтаксического анализа регулярных выражений для адреса на разных уровнях невозможно, так как существует слишком много компонентов, которые можно ошибочно принять за другие компоненты. Вот реальный пример адреса:
102 W E ST ELKTON, VA 22827
Вопрос звучит так:
- Что такое W? Это может быть предварительное направление или название улицы.
- Что такое Е? Это может быть название улицы или почтовое направление на улицу W.
- Что такое СТ? Это может быть суффикс улицы или часть названия города.
Еще одна вещь, которую следует учитывать, это адреса, которые не соответствуют стандартному формату, например:
PO BOX 123 LOGAN, UT 84321 HC 13 BOX 438 SNELLVILLE, GA 30078 64 UNIT 4350 DPO, AE 09977
Кроме того, что делать, если заказчик не соблюдает стандартный принятый порядок компонентов, ошибается в написании направления (север, восток, юг, запад) или помещает второстепенное значение перед основным и т. д. .? Просто существует слишком много способов испортить адрес и слишком много неоднозначных случаев, чтобы регулярное выражение работало или было эффективным.
д. .? Просто существует слишком много способов испортить адрес и слишком много неоднозначных случаев, чтобы регулярное выражение работало или было эффективным.
Использование регулярных выражений для разбора адресов Firstline возможно в большинстве случаев, но недостаточно точно, чтобы быть надежным. Например:
1106 SW EAST LOUISE CIR PORT SAINT LUCIE, FL 34953
- Является ли PORT второстепенным обозначением или частью названия города?
- Является ли SAINT второстепенным номером или частью названия города?
В идеальном мире названия городов и штатов должны состоять только из одного слова, тогда, возможно, сработает регулярное выражение. Но в нынешнем виде это не идеальный мир, и у регулярного выражения слишком много способов принять неправильное решение или сообщить об ошибке при получении расплывчатой или неверной информации. Даже если бы регулярное выражение знало все названия городов для всех штатов, как только клиент напишет что-то неправильное, регулярное выражение потерпит неудачу.
Просто для развлечения мы включили ссылку, чтобы сравнить, насколько сложным может быть регулярное выражение. Это регулярное выражение, которое проверяет адрес электронной почты. Держитесь за это, это может спасти чью-то жизнь. Адреса электронной почты должны соответствовать определенному формату, поэтому это регулярное выражение простое, и его трудно испортить. Просто представьте регулярное выражение или серию операторов регулярного выражения для анализа чего-то столь же сложного и подверженного ошибкам, как адрес. Нет, спасибо!
[a-z0-9]+@[a-z]+\.[a-z]{2,3} Как анализ адресов используется в геокодировании?
Прежде чем приступать к геокодированию, необходимо сначала очистить и стандартизировать адресные данные. Чистые данные важны и могут значительно сократить время и энергию, затрачиваемые на проверку информации.
Как упоминалось выше, синтаксический анализ может играть много важных ролей, и в данном конкретном случае ключевую роль играет нормализация или стандартизация, а также дедупликация избыточных адресов. По сути, нам нужно знать, что мы работаем с действительными адресами, чтобы знать, что у нас есть правильные адреса.
По сути, нам нужно знать, что мы работаем с действительными адресами, чтобы знать, что у нас есть правильные адреса.
После анализа адреса можно приступить к стандартизации. После нормализации и стандартизации могут выполняться геокодирование и проверка адреса.
Заключение
Хотя синтаксический анализ адреса — это небольшой шаг в рамках проверки адреса и геолокации, он необходим.
Помогает избавиться от избыточных адресов в наборах данных, может также помочь в создании уникальных идентификаторов, может использоваться для создания полезных фильтров анализа данных, улучшения управления адресами, обеспечения стандартизации адресов и может помочь в очистке данных, а также в де- дублирование.
разбор — В: как разобрать слово, которое может содержать словосочетание пробелов?
Задавать вопрос
спросил
Изменено 1 год, 5 месяцев назад
Просмотрено 152 раза
: Эти журналы почти прибиты, но возникают проблемы с разделом журнала, который обеспечивает действие fail2ban. Обычно это одно слово, но иногда это два слова с пробелом между ними. Я не уверен, как решить эту проблему, и очень признателен за любую помощь. Я провел немало исследований, но не нашел окончательного ответа, даже пробуя различные решения.
Обычно это одно слово, но иногда это два слова с пробелом между ними. Я не уверен, как решить эту проблему, и очень признателен за любую помощь. Я провел немало исследований, но не нашел окончательного ответа, даже пробуя различные решения.
В приведенных ниже примерах вы увидите Restore Ban , Ban и Found . Это то, что я пытаюсь изолировать.
Примеры журналов:
2021-10-20 19:50:39,638 fail2ban.actions [31705]: УВЕДОМЛЕНИЕ [sshd] Восстановление запрета 68.183.15.177 2021-10-20 16:08:16,315 fail2ban.actions [6428]: УВЕДОМЛЕНИЕ [sshd] Бан 141.98.10.121 2021-10-20 17:21:23,807 fail2ban.filter [6428]: INFO [sshd] Found 159.75.130.111 - 2021-10-20 17:21:23
Текущая группа:
fail2banRule01 %{date("гггг-ММ-дд ЧЧ:мм:сс,ССС"):Datetime}\s+fail2ban.%{слово}\s+\[%{число:PID }\]\:\s+%{слово:Уровень}\s+\[%{слово:Тюрьма}\]\s+%{слово:ActionType}\s+%{ipv4:ClientIP}(\s+-\s+%{дата ("гггг-ММ-дд ЧЧ:мм:сс"):ActionDate})?
ПРИМЕЧАНИЕ.