Морфемный разбор слова | 5 класс | Русский язык
Содержание
Наш язык состоит из уровней: фонетического, морфемного, морфологического, лексического и синтаксического. И для каждого из этих уровней предусмотрен определенный вид анализа структурных элементов этого уровня. Так, вы уже знакомы с фонетическим разбором. С его помощью мы анализируем состав звуков и букв слов. Но сейчас вы уже хорошо знаете и более крупные единицы – морфемы. Поэтому пришло время провести морфемный разбор слова.
Что мы уже знаем о морфемах?Для начала давайте кратко вспомним всё, что мы изучали на последних уроках.
Но сперва еще раз отметим, что морфемы – это минимальные значимые части слова. А это значит, что все они несут в себе определенное значение, смысл.
Это значение может быть грамматическим, то есть морфема нужна для того, чтобы передать принадлежность слова к какой-либо грамматической категории.
Например, суффикс -лив- используется, чтобы передать принадлежность слова к категории прилагательных.
А еще значение может быть смысловым, то есть морфема используется для передачи или уточнения какого-либо смысла.
Например, приставка в- (входить) используется, чтобы показать движение внутрь, а приставка вы- (выходить) – чтобы показать действие наружу.
Функции морфемы{"questions":[{"content":"Соедините слово и значение морфемы в этом слове.[[matcher-1]]","widgets":{"matcher-1":{"type":"matcher","labels":["Окончание показывает множественное число","Окончание – показатель среднего рода","Приставка со значением близкого расположения к чему-либо","Суффикс указывает на свойство или качество предмета"],"items":["плод-ы","зерн-о","при-брежный","свеж-есть"]}},"step":1,"hints":["Показателем множественного числа может быть окончание -ы.","Показатели среднего рода – окончания -о, -е. ","Приставка при- может обозначать близкое расположение чего-то к чему-либо.","Суффиксы, обозначающие свойства или качества: -есть-, -от-, -изн-."]}]}
","Приставка при- может обозначать близкое расположение чего-то к чему-либо.","Суффиксы, обозначающие свойства или качества: -есть-, -от-, -изн-."]}]} ","Приставка при- может обозначать близкое расположение чего-то к чему-либо.","Суффиксы, обозначающие свойства или качества: -есть-, -от-, -изн-."]}]}
","Приставка при- может обозначать близкое расположение чего-то к чему-либо.","Суффиксы, обозначающие свойства или качества: -есть-, -от-, -изн-."]}]}Итак, приступим к обобщению изученного.
Приставка, корень, суффикс
И начнем с приставки.
Приставка
Как вы помните, приставка – это значимая часть слова, которая стоит перед корнем и служит для образования новых слов той же части речи.
Одна из главных особенностей приставки заключается в том, что она присоединяется ко всему слову в целом и придает ему новый оттенок смысла. Поэтому приставки несут только смысловые значения. То есть они уточняют значение корня. Грамматические же значения приставками не выражаются.
Свойства приставки{"questions":[{"content":"Выберите верные утверждения.[[choice-1]]","widgets":{"choice-1":{"type":"choice","options":["Приставка служит для образования однокоренного слова другой части речи. ","Приставка служит для уточнения смысла слова.","Приставка служит для образования однокоренного слова той же части речи.","Приставка выражает грамматические значения."],"explanations":["Приставка помогает образовать слова той же части речи, что и исходное слово.","Верно!","Верно!","Приставка уточняет смысл слова."],"answer":[1,2]}},"step":1,"hints":["Приставка служит для уточнения смысла слова.","Приставка служит для образования однокоренного слова той же части речи."]}]} ","Приставка служит для уточнения смысла слова.","Приставка служит для образования однокоренного слова той же части речи.","Приставка выражает грамматические значения."],"explanations":["Приставка помогает образовать слова той же части речи, что и исходное слово.","Верно!","Верно!","Приставка уточняет смысл слова."],"answer":[1,2]}},"step":1,"hints":["Приставка служит для уточнения смысла слова.","Приставка служит для образования однокоренного слова той же части речи."]}]}
","Приставка служит для уточнения смысла слова.","Приставка служит для образования однокоренного слова той же части речи.","Приставка выражает грамматические значения."],"explanations":["Приставка помогает образовать слова той же части речи, что и исходное слово.","Верно!","Верно!","Приставка уточняет смысл слова."],"answer":[1,2]}},"step":1,"hints":["Приставка служит для уточнения смысла слова.","Приставка служит для образования однокоренного слова той же части речи."]}]}Корень
Самой главной морфемой слова является корень. Именно в нем заключается вся суть слова, его лексическое значение.
Мы с вами уже отмечали, что у однокоренных слов всегда есть общий элемент смысла. Так, например, все слова из ряда «снег – снежок – снежный – подснежник» связаны со снегом. Кроме того, корень самостоятелен. В отличие от других морфем он ни к чему не присоединяется и может существовать сам по себе.
Свойства корня{"questions":[{"content":"Сопоставьте корень и слово с этим корнем. [[grouper-1]]","widgets":{"grouper-1":{"type":"grouper","labels":["Берег","Дом","Боль"],"items":[["прибрежный","береговой","бережок","побережье"],["домашний","домище","одомашнить"],["больной","заболеть","больничный"]]}},"hints":["Обратите внимание на то, что звуки в корнях могут чередоваться."]}]} [[grouper-1]]","widgets":{"grouper-1":{"type":"grouper","labels":["Берег","Дом","Боль"],"items":[["прибрежный","береговой","бережок","побережье"],["домашний","домище","одомашнить"],["больной","заболеть","больничный"]]}},"hints":["Обратите внимание на то, что звуки в корнях могут чередоваться."]}]}
[[grouper-1]]","widgets":{"grouper-1":{"type":"grouper","labels":["Берег","Дом","Боль"],"items":[["прибрежный","береговой","бережок","побережье"],["домашний","домище","одомашнить"],["больной","заболеть","больничный"]]}},"hints":["Обратите внимание на то, что звуки в корнях могут чередоваться."]}]}Суффикс
Следом за корнем может идти суффикс.
Суффикс – это значимая часть слова, которая стоит после корня и служит для образования новых слов другой части речи или для выражения определенного грамматического значения.
Давайте рассмотрим, как суффикс выражает грамматические значения.
Для этого возьмем, например, следующий ряд слов:
рука – ручка – ручной
Суффикс -к- в слове «ручка» образует уменьшительно-ласкательную форму слова «рука». При этом часть речи слова не изменяется. А вот в слове «ручной» суффикс -н- служит для образования новой части речи – прилагательного от существительного.
Более того, есть специальные суффиксы, служащие для образования конкретных частей речи. Например, суффиксы -ец-, -чик-, -щик- закреплены за существительными. Суффикс -лив- образует прилагательные.
Но суффиксы могут выражать не только грамматические, но и смысловые значения.
Так, суффикс -л- в глаголах выражает грамматическое значение прошедшего времени. А, например, суффикс -щик- может обозначать человека какой-либо профессии (пильщик, сварщик).
Также отметим, что суффикс присоединяется только к корню, а не к готовому слову.
Свойства суффикса{"questions":[{"content":"Сопоставьте свойство и морфему.[[grouper-1]]","widgets":{"grouper-1":{"type":"grouper","labels":["Приставка","Суффикс"],"items":[["стоит перед корнем","выражает только смысловое значение","присоединяется ко всему слову"],["стоит после корня","выражает грамматическое и смысловое значения","присоединяется к корню","может образовывать слова другой части речи"]]}},"step":1,"hints":["Приставка:
- стоит перед корнем;
- выражает только смысловое значение;
- присоединяется ко всему слову. ","Суффикс:
- стоит после корня;
- выражает грамматическое и смысловое значения;
- присоединяется к корню;
- может образовывать слова другой части речи."]}]} ","Суффикс:
","Суффикс:Основа и окончание
Основа словаВсе вышеуказанные морфемы – приставка, корень, суффикс – образуют основу слова. То есть его неизменяемую часть.
И, наконец, у нас осталась еще одна важная морфема, свойственная изменяемым словам, – окончание.
Окончание – это морфема, служащая для образования форм слова и выражения грамматических значений.
Давайте запомним, что окончания есть только у изменяемых слов. Так, у неизменяемых наречий окончания нет. Например, в наречии «тепло» конечное -о- является суффиксом, но не окончанием!
Но у окончаний есть особенность: они могут быть нулевыми. То есть при изменении слова окончание появляется, но в какой-то конкретной форме слова его нет. Это слова мужского рода второго склонения и женского рода третьего склонения (стол, ночь).
Это слова мужского рода второго склонения и женского рода третьего склонения (стол, ночь).
Окончания присоединяются к основе слова, не входя в нее, и служат для выражения грамматических значений.
Свойства окончания{"questions":[{"content":"Распределите слова по группам.[[grouper-1]]","widgets":{"grouper-1":{"type":"grouper","labels":["Слова с выраженным окончанием","Слова с нулевым окончанием","Слова без окончания"],"items":[["столы","тетради"],["сон","ночь"],["светло","холодно"]]}},"step":1,"hints":["Слова с выраженным окончанием: столы, тетради.","Слова с нулевым окончанием: сон, ночь.","Слова без окончания: светло, холодно."]}]}Порядок морфемного разбора словаИтак, мы с вами вспомнили весь необходимый материал. И теперь пора приступить к морфемному разбору слова.
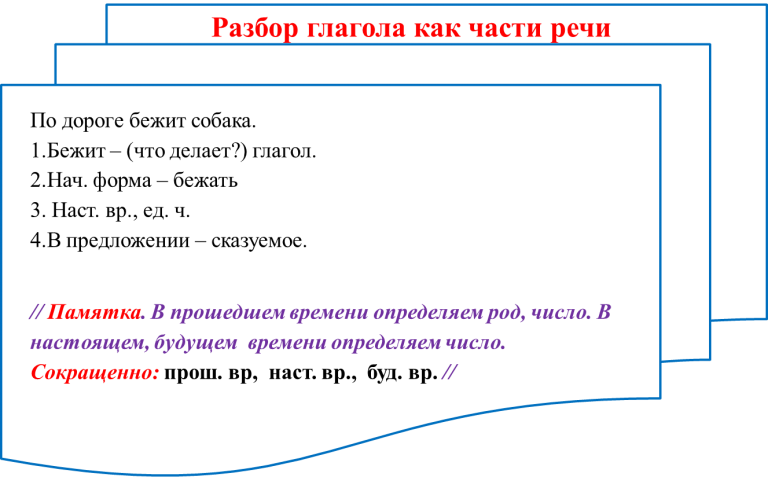
Традиционно в учебниках этот вид разбора обозначается цифрой 2 над словом, которое требуется проанализировать. Это выглядит вот так:
Мы почувствовали дуновение легкого морского ветерка2 с запада.
Итак, первое, что нам нужно запомнить: морфемный разбор проводится именно над той формой слова, в которой оно употребляется в тексте. Так, в нашем примере необходимо разобрать именно слово «ветерка», а не «ветерок» (в им.п.).
Поэтому первое, что мы делаем, — выписываем слово в той форме, в которой оно употреблено в предложении.
Ветерка
После того, как слово выписано, нам нужно выполнить следующие действия:
- Определить, изменяется ли слово. И если ответ положительный, то выделить окончание. Но помните, что оно может быть нулевым!
И затем мы устно проговариваем, что обозначает окончание. - Когда окончание отброшено, выделяем оставшуюся часть слова как основу.
- Устно подобрать однокоренные слова и определить их одинаковую часть – корень слова. Выделить его. Помните, что в корне слова могут встречаться чередования звуков! Если есть такие чередования, устно называем их.
- Между корнем и окончанием могут стоять суффиксы. Если они есть, выделяем их. Устно проговариваем их функцию (грамматическое или смысловое значение).
- Перед корнем может стоять приставка. Если она есть, выделяем ее. И также устно проговариваем ее функцию (смысловое значение).
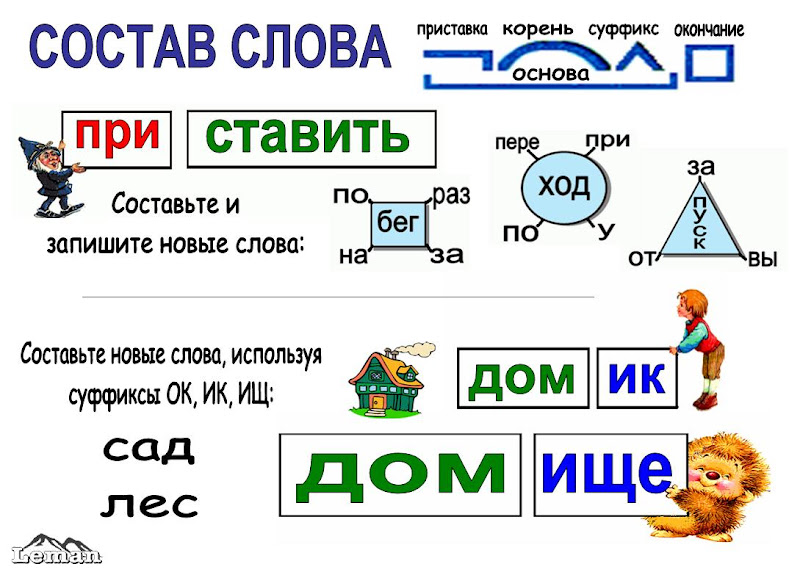
А теперь давайте проведем морфемный разбор вместе. Выполняйте пункты плана сначала самостоятельно, а затем открывайте ответ.
Представим, что в учебнике вам попалось такое предложение:
Кора лесных великанов часто обрастает2 мхом и даже травою.
Мы видим, что в этом предложении над словом «обрастает» стоит цифра 2. Это сигнал, который говорит нам провести морфемный разбор этого слова.
Давайте выпишем его.
Показать ответ
Скрыть ответ
Выписываем в той же форме, как и в предложении:
обрастает
Выделяем окончание и основу
Теперь первое, что нам необходимо сделать, — выделить окончание. Чтобы правильно найти его, попробуем изменить слово, например, по числам.
Чтобы правильно найти его, попробуем изменить слово, например, по числам.
Показать ответ
Скрыть ответ
Обрастает – обрастают.
Видим, что -ет меняется на -ют. Значит, -ет – это окончание.
Выделяем окончание и вспоминаем, что оно должно нести какое-то грамматическое значение. Поэтому устно проговариваем это значение.
Показать ответ
Скрыть ответ
Окончание -ет показывает нам, что глагол стоит в форме 3-го лица единственного числа.
Итак, окончание и его значение мы нашли. Значит, все остальное – это основа слова. Выделим ее, и на этом этапе у нас получится вот такой результат:
Морфемный разбор слова «обрастает»Выделяем корень, суффикс и приставку
Теперь нам нужно выделить корень. Для этого найдем однокоренные слова.
Показать ответ
Скрыть ответ
Например: обрастает – растёт, растущий, растение и др.
Видим, что у всех слов повторяется часть -раст-, значит, это и есть наш корень. Выделим его.
Теперь между корнем и окончанием мы видим еще одну морфему – суффикс -а-. Выделим его и вспомним, что он тоже несет в себе определенное значение. И оно может быть как грамматическим, так и смысловым. Какое же значение помогает выразить суффикс -а-?
Показать ответ
Скрыть ответ
Здесь суффикс -а- помогает образовать глагол настоящего времени несовершенного вида. Это грамматическое значение.
И на этом этапе у нас осталась одна невыделенная морфема, которая стоит перед корнем. Это приставка об-! Выделим ее и подумаем, какой же оттенок смысла вносит в слово эта приставка?
Показать ответ
Скрыть ответ
Приставка об- в этом слове показывает, что действие совершается вокруг предмета. Сравните с подобными словами: облететь, обрисовать.
Вот и все! На этом наш морфемный разбор завершается. И письменно он выглядит так:
Морфемный разбор слова «обрастает»А теперь закрепите две наши последние темы, посмотрев видеоурок.
Очень простая инструкция для разбора слова по составу — Морфемный разбор в помощь второклашке | Блог КУМОНомамы
Разбор слова по составу — это очень просто, элементарщина. Частей слова ведь всего 5 (даже почти 4): приставка, корень, суффикс, окончание. А всё вместе, кроме окончания — это основа.
Чего тут сложного, казалось бы.
Проблема в том, что в школе все эти части слова учат и отрабатывают по-отдельности. То суффиксы отдельно ищем, то окончания… И у ребенка не складывается общая картинка — что из себя представляет состав слова. Ему начинает казаться, что это — эдакая игра в угадайку: угадай суффикс, угадай приставку, угадай часть речи.
Интересно, что даже если ребенок хорошо разбирается в частях речи, задания типа «найди суффикс» могут поставить его в тупик, потому что, в отличие от корня, суффикс — это «бессмысленный набор буковок».
 Пойди угадай, какие именно буковки относятся к этому «треугольничку».
Пойди угадай, какие именно буковки относятся к этому «треугольничку».В этой статье предложу схему разбора по составу, применяя которую ребенок всегда — независимо от типа задания — сможет легко разбирать по составу все части речи.
Что нужно знать о частях слова, прежде чем делать разборСамое главное — нужно запомнить, что части слова не существуют в изоляции: они все связаны друг с другом. Ну конечно — слово-то одно. Поэтому…
Когда-нибудь ваш второклашка наберется солидного опыта в выявлении любых суффиксов с первого взгляда.
А пока — даже если в задании написано «найди суффикс», для корректного определения этого суффикса нужно сделать разбор полностью. Сначала найди все части слова, а потом среди них вычислить — и уже отметить в тетради только суффикс.
В ближайшие дни я выпущу отдельную статью именно про суффиксы.
Здесь же замечу, что, конечно, не нужно полностью разбирать слово по составу, если ваш второклашка безошибочно узнал суффикс «-еньк-«, например, и ни с чем его никогда не перепутает.

Просто знания о конкретных суффиксах у второклашек редко возникают сами по себе — в связи с этим и возникла рекомендация про полный разбор.
Итак, договорились: для того, чтобы корректно выделить какую-то часть речи, нужно разобрать по составу всё слово.
Теперь двигаемся по схеме.
1. Находим кореньСначала найдем самое главное — и самое простое.
Чтобы найди корень, нужно придумать похожие слова.
Почитайте эту мою статью про однокоренные слова и формы слова — и обратите внимание: для поиска корня нам нужны НЕ ФОРМЫ одного слова, а именно ОДНОКОРЕННЫЕ слова.
Напр., разбирая слово «подарок» — для поиска корня нам нужно НЕ «подарку, подарком», а «дар, дарить, задарить, подарить«.
«Ударить». Лол 🙂 Поменяли приставку — и вуа-ля 🙂
Реальная история про то, как НЕ НАДО искать однокоренные — расскажу в отдельной статье про приставки.

Итак, подбираем много похожих (однокоренных) слов и внимательно слушаем, что у этих слов изменяется, а что — остается неизменным.
Важно, что это «неизменное» должно иметь смысл — то есть быть не набором абстрактных буковок, а что-то значить.
Напр., в нашем примере с «подарком» у всех подобранных нами слов остается неизменной часть «дар». А мы, слыша эту часть, как-то понимаем, что это не абракадабра, а что-то, связанное с бесплатным получением чего-то.
То, что не поменялось у нескольких однокоренных — это корень. Отмечаем.
Да, конечно, всегда будет 100500 исключений, чередований в корне и т.д. Но русскоговорящий человек (даже ребенок), как правило, эти чередования «считывает» на слух и понимает, что это чередования.
2. Находим окончаниеПомним, что окончание так называется — потому что стоит в конце слова. Поэтому его очень просто искать: нужно обвести в квадратик сколько-то буковок в конце слова.
Поэтому его очень просто искать: нужно обвести в квадратик сколько-то буковок в конце слова.
Осталось только выяснить, сколько буковок с конца — это окончание, а не что-то другое.
Напомню, мы уже определили корень.
Возможно, после определения корня ни одной лишней буковки в конце слова не оказалось.
У окончания есть такое явление, как нулевое окончание: это когда окончания нет — но оно как бы есть. Тогда мы ставим в конце слова пустой квадратик — обвели воздух в виде окончания.
Всё слово — один сплошной корень. Окончание нулевоеВсё слово — один сплошной корень. Окончание нулевое
А еще бывает, что окончания нет в принципе — и обводить воздух в виде нулевого окончания не нужно.
До 4 класса ребенок почти наверняка с этим явлением не столкнется. Но если вдруг…
Как определить — есть ли у слова нулевое окончание или окончания нет вовсе?
Окончаний нет у слов, которые не умеют изменяться по падежам, лицам, числам, временам. .. чему угодно:
.. чему угодно:
- Союзов, предлогов, междометий — разных коротких служебных словечек, которые сами по себе никакого смысла не несут, а лишь «помогают» связываться словам друг с другом (ах/ох, перед/над…).
- Существительных и прилагательных, которые нельзя изменить (пальто (цвета) индиго — и существительное и прилагательное здесь будут без окончания… ). Здесь же — аббревиатуры и сокращения вроде «минфин».
- У всех слов, которые могут ответить на вопрос КАК.
По последнему пункту интересно. «Официально» окончание не существует у деепричастий (что делая? — играя), а также прилагательных (какой? — красивее) и наречий (как? — ярче) в простой сравнительной форме.
А теперь попробуйте к тем же словам, которые я написала, задать тот же вопрос КАК:
- Играя, он вошел в комнату. — КАК он вошел в комнату?
- Он пишет красивее, чем Вася. — КАК он пишет?
- Сегодня солнце светит ярче. — КАК светит солнце?
 — КАК он пишет?
— КАК он пишет?Видите, несмотря на то, что речь идет про разные части речи, вопрос КАК все равно поможет определить, есть ли у слова окончание.
Хорошо, с нулевым или отсутствующим окончанием разобрались.
А, допустим, нам не повезло, и следом за корнем остались какие-то буковки. Наша задача — найти среди этих буковок окончание.
Для удобства запомним себе подсказки:
** Если разбираем существительное, прилагательное или причастие — будем говорить наше слово в компании со следующими тремя:
- НЕТ (чего?) нашего слова. Напр. «подарка«
- ДОВОЛЕН (чем?) нашим словом. Напр., «подарком«
- ДУМАЮ О (чем?) нашем слове. Напр., «подарке«
** Если разбираем глагол — скажем его в настоящем и прошедшем времени:
- что Я ДЕЛАЮ — ОНА ДЕЛАЕТ — МЫ ДЕЛАЕМ сейчас ? — Напр. , «думаю — думает — думаем«
- ЧТО Я ДЕЛАЛ — ОНА ДЕЛАЛА — МЫ ДЕЛАЛИ вчера? — Напр. «думал — думала — думали«
 , «думаю — думает — думаем«
, «думаю — думает — думаем«То есть существительные и прилагательные мы изменяем по падежам, а глаголы — по лицам и числам в настоящем и прошедшем времени.
Их гораздо больше, чем я показала здесь.
Но нам для разбора по составу больше не нужно — возьмите только самые «показательные» в смысле изменений.
Проговариваем слова и наблюдаем, что изменилось в конце слова.
То, что изменилось после наших изменений — и будет окончанием. Отмечаем.
Здесь, к счастью, исключений будет минимум. Главное — быть очень внимательным. Иногда имеет смысл записать все получившиеся формы на черновичок в столбик — и глазами посмотреть, что изменяется.
3. Находим приставку
Находим приставкуПриставка — это то, что стоит перед корнем.
Возможно, вам повезло, и перед корнем у вас ничего не стоит. УРА! Значит, приставки нет — двигаемся дальше.
Если же перед корнем что-то написано — это 100% приставка. А может — несколько приставок.
Четыре приставки в словеЧетыре приставки в слове
Как определить: одна приставка, или две, или вообще несколько?
В начальной школе ребенок с 99% вероятностью ни разу не столкнется с двумя и более приставками — так что смело отмечайте всё, что оказалось перед корнем, одной квадратной загогулинкой.
Но если вдруг… тогда читайте дальше:
Приставки похожи на предлоги. Если то, что написано перед корнем, выглядит очень-очень длинно — попробуйте выделить оттуда кусочки, похожие на предлоги.
В нашем примере ребенок легко найдет слово «под» целых два раза. Скажем вместе с существительным: «под столом» — работает! Попробуем выделить его в отдельную приставку.
Скажем вместе с существительным: «под столом» — работает! Попробуем выделить его в отдельную приставку.
ПОД- в начале слова — это скорее всего приставка
Осталось всего два кусочка: «пере-» и «-вы-«. Проверим, могут ли они быть отдельными приставками.
Осталось проверить, могут ли считаться приставками другие кусочкиОсталось проверить, могут ли считаться приставками другие кусочки
Для проверки приставок удобно использовать базовое слово «ХОД» — оно подходит к очень многим приставкам, к большинству из них. Добавляйте к этому слову все кусочки, которые вы считаете отдельными приставками. Если новое слово, которое получилось из слова «ход» и вашей предполагаемой приставки звучит адекватно — значит, вы правильно выделили отдельную приставку.
Добавим к слову «ход» эти приставки. Получилось «переход» и «выход» — вполне себе адекватные слова. Значит, обе приставки тоже имеют право на существование.
Конечно, слово «ход» подойдет далеко не ко всем приставкам.
Мы это обсудим в отдельной статье на тему приставок.
Там же поговорим о том, как отличить приставку, скажем, «по-» или «под-» от одноименного кусочка корняю
Итак, запоминаем:
- Всё, что перед корнем — это приставка.
- Если перед корнем ничего не написано — значит, приставки нет.
- Если оно слишком длинное — может, приставок несколько.
- Если нам нужно проверить, одна или несколько приставок — пробуем каждую «предположительно отдельную» приставку в качестве предлога или в качестве одной отдельной приставки к другому слову.
Суффикс — это то, что находится между корнем и окончанием.
Возможно, вам повезло, и между корнем и окончанием никаких букв не написано — УРА! Значит суффикса нет.
Если между корнем и окончанием вы видите только одну букву — смело отмечайте ее как суффикс.
Если же между корнем и окончанием оказалось больше одной буквы — тут начинаются нюансы: суффиксов может быть несколько.
Пример слов с двумя суффиксамиПример слов с двумя суффиксами
…Вообще, суффиксы — это самая мерзостная тема русского языка, потому что суффиксов немерено, и логика в их выделении присутствует далеко не всегда.
Поэтому в суффиксах нужно искать логику и заучивать их наизусть.
У меня выйдет цикл статей о суффиксах: как выстроить логическую систему суффиксов русского языка, запомнить их и не ошибаться при морфемном разборе.
Запомните: если в суффиксе несколько букв — а в начале или в конце «потенциального суффикса» стоит Л, К или Н — всегда подозревайте, что эта буква — это ОТДЕЛЬНЫЙ СУФФИКС (а всего в слове — два или больше суффиксов).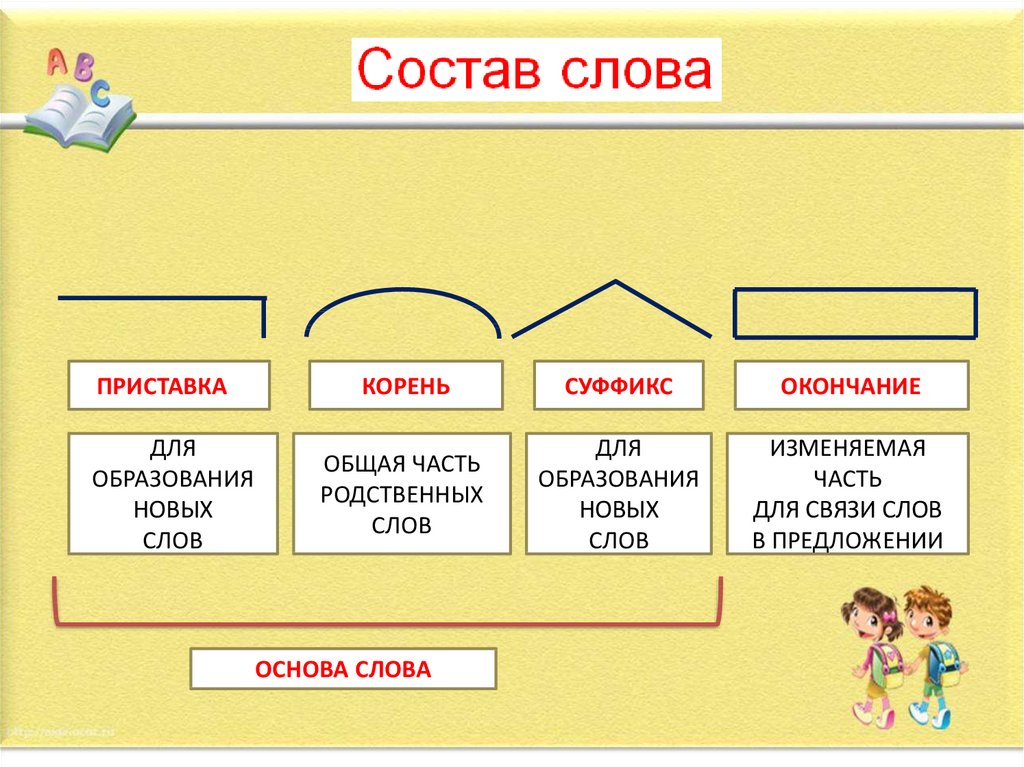
Дело в том, что буквы Л, К и Н чаще других букв выступают в роли отдельных суффиксов.
Здесь буква Н — в начале «потенциально суффикса», а значит, её можно подозревать в том, что она — отдельный суффиксЗдесь буква Н — в начале «потенциально суффикса», а значит, её можно подозревать в том, что она — отдельный суффикс
Что интересно, букв в суффиксе может быть совсем мало, и все равно буква Л, Н или К может оказаться отдельным суффиксом.
Буква К в конце «потенциального суффикса» с очень высокой вероятностью будет отдельным суффиксом — несмотря на то, что тут между корнем и окончанием всего 3 буквыБуква К в конце «потенциального суффикса» с очень высокой вероятностью будет отдельным суффиксом — несмотря на то, что тут между корнем и окончанием всего 3 буквы
Как, например, в глаголах прошедшего времени — Л всегда будет отдельным суффиксом:
В общем, с буквами Н, К и Л в начале и конце потенциального суффикса будьте внимательны — с высокой степенью вероятности они будут выделяться в отдельный суффикс, а всего в слове будет больше одного слова, как в наших примерах:
Примеры с двумя суффиксами, с буквами Н, К и ЛПримеры с двумя суффиксами, с буквами Н, К и Л
Итак, запоминаем:
- То, что стоит между корнем и окончанием — это один или несколько суффиксов.
- Если между корнем и окончанием нет ни одной буквы — значит, суффикса нет.
- Если в начале или конце потенциального суффикса есть буква Н, Л или К — высока вероятность того, что эта буква — отдельный суффикс, а в слове больше, чем один суффикс.
- Чтобы безошибочно определять суффиксы — придется учить их наизусть, и вообще этот навык нарабатывается, увы, с опытом.

И снова — самое простое. Всё, что не окончание — это основа.
Выделим квадратной закорючкой всё, кроме квадратика окончания — и разбор закончен!
***
Не забывайте, что морфемный анализ — это навык, который нарабатывается большим количеством повторений.
Поэтому, чтобы хорошо научиться разбирать слово по составу, нужно повторять это много — много — много — очень много раз, причем с разными частями речи.
Успехов у учебе вашим детям!
______________________
Мой блог про японскую методику обучения детей KUMON ищите по адресу https://kumon-deti.com
Познакомиться со мной в Инстаграм https://instagram.com/kumon.deti
Основа слова / Морфемный разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Морфемный разбор
- Основа слова
При разборе слова по составу иногда указывают основу слова, в которой заключено значение конкретного слова. Основу могут составлять приставка, корень и суффикс, т.е. все морфемы, кроме окончания. Основа графически отображается как ̢_______̡
Чтобы найти основу слова, его нужно изменить.
Например:
По числам: книга – книги, написал – написали
По падежам: раскрыл книгу – выписал из книги
По родам: сказочная история – сказочный мир
По лицам: я говорю – он говорит
Если слово изменяется (как в приведенных выше примерах), то часть слова без окончания и составляет его основу.
яблочко — яблочками
Если слово не изменяется, то основу составляет все слово целиком:
далеко, тихо, вправо
Обратите внимание, что у глаголов в прошедшем времени суффикс -л- в основу не входит:
позвала, увидел , сходило
Также у глаголов в неопределённой форме не входит в основу суффикс -ть:
позвать, желтеть
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Окончание
Корень и однокоренные (родственные) слова
Приставки и их значения
Суффикс
Морфемный разбор
Правило встречается в следующих упражнениях:
3 класс
Упражнение 156, Климанова, Бабушкина, Рабочая тетрадь, часть 1
Упражнение 135, Полякова, Учебник, часть 1
Упражнение 138, Полякова, Учебник, часть 1
Упражнение 141, Полякова, Учебник, часть 1
Упражнение 144, Полякова, Учебник, часть 1
Упражнение 160, Полякова, Учебник, часть 1
Упражнение 251, Полякова, Учебник, часть 1
Упражнение 1, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 5, Исаева, Бунеев, Рабочая тетрадь
Упражнение 6, Исаева, Бунеев, Рабочая тетрадь
4 класс
Упражнение 141, Полякова, Учебник, часть 1
Упражнение 134, Полякова, Учебник, часть 2
Упражнение 145, Полякова, Учебник, часть 2
Упражнение 298, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 301, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 302, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 303, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 5, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 386, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 710, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
5 класс
Упражнение 82, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 83, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 92, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
6 класс
Упражнение 25, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 134, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 156, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 29, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
Как разобрать слово по составу — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
1. Измени слово по числам или по команде одного-двух вопросов, выдели изменяемую часть – окончание. Отметь основу слова (это часть слова без окончания).
Измени слово по числам или по команде одного-двух вопросов, выдели изменяемую часть – окончание. Отметь основу слова (это часть слова без окончания).
2. Объясни значение слова с помощью слова-родственника, подбери ещё одно-два однокоренных, выдели их общую часть – корень.
3. Определи и укажи часть слова перед корнем – приставку, постарайся объяснить её работу.
4. Определи и укажи часть слова после корня перед окончанием – суффикс, подумай о его работе.
1. Изменю слово по числам: подставки – подставка (изменилось -а, это окончание). Основа подставк-
2. Объясню значение слова: подставка – подставляют, ставят под что-то; подставить. Корень –став.
Чтобы не делать ошибок в разборе слова по составу, нужно учитывать значение слова и значение части слова.
В существительном мячик выделяем суффикс -ик-, который придаёт слову значение «маленький» (мячик – это маленький мяч).
А существительное лётчик не имеет значения «маленький». В этом слове другой суффикс -чик-. Существительное обозначает профессию человека. Такое значение придаёт суффикс -чик-
В существительном дружок выделяем суффикс -ок-, который имеет уменьшительно-ласкательное значение (друг – дружок).
А существительное урок не имеет такого значения, потому что в нём нет такого суффикса. Корень -урок- (родственное слово урочный)
В существительном победа нет такой приставки, корень -побед- (однокоренные слова: победить, победитель)
Смешу – вызываю смех, корень -смеш-, -смех-, в корне есть чередование согласных х//ш.
В этом существительном нет суффикса -ик-, корень -ластик- (однокоренное слово ластиковый).
В глаголе ухожу выделяем приставку у-, которая имеет значение «удаляться». Корень -хож- (родственные слова: ход, ходьба, чередование д//ж в корне).
В существительном ухо нет приставки у-. Однокоренные слова: ушастый, ушки, корень -ух-, -уш-, чередование х//ш.
Однокоренные слова: ушастый, ушки, корень -ух-, -уш-, чередование х//ш.
Попробуйте самостоятельно разобрать слова по составу: касса, рассада, рассольник, рассказ.
В словах рассказ, рассада и рассольник последняя буква приставки и первая буква корня одинаковые.
Для того, чтобы выбрать ответ, надо только определить часть речи и лексическое значение. Ведь одно и то же слово может быть сразу несколькими частями речи в зависимости от контекста.
Существительное:
Я сижу в онлайне.
Я сижу в кафе.
Наречие:
Я смотрю фильм онлайн.
Я сижу давно.
Есть шпаргалка по разбору слова по составуСоставСлова
Урезанная копия morphemeonline, где не объясняется лексическое значение слова «онлайн». Кроме того, есть реклама. Как я уже сказала, ни единой причины использовать этот сайт по сравнению с предыдущим нет.
Результат работы сервиса СоставСловаЛексическое значение слов «онлайн» не объяснено, хотя оно не очевидно. Ведь есть существительное «онлайн», в котором можно сидеть. Есть наречие «онлайн»: например, смотреть «онлайн». И есть наречие «онлайн» в противоположность «офлайн», будет приставка. Во всех трех случаях разбор по составу разный.
Ведь есть существительное «онлайн», в котором можно сидеть. Есть наречие «онлайн»: например, смотреть «онлайн». И есть наречие «онлайн» в противоположность «офлайн», будет приставка. Во всех трех случаях разбор по составу разный.
Но не пугайтесь, если не понимаете разницу, в школьных домашних заданиях слова для разбора обычно попроще. Этот пример приведен для того, чтоб вы поняли преимущества первого сайта.
Как видите, скриншот даже не вмещает все три разбора из-за наличия рекламы.
ВикиСлово
Тоже урезанная копия morphemeonline, где не объясняется лексическое значение. Кроме того, урезано описание морфем – только картинка.
Есть дополнительный сервисы: фонетический, морфологический разбор.
ВикиСлово
Но в этом сервисе, как и во всех, кроме самого первого, больше минусов, чем плюсов. Один из них реклама.
Есть навязчивая реклама
УдарениеРу
Словарь не полностью представлен, найдено только одно значение слова «онлайн». Разбор слова по составу представлен некрасиво, описание с сокращениями, нет картинок.
Как видите, найдено только одно основное значение слова:
Результат работы сервиса УдарениеСловОнлайн
Очень ограниченный словарь, слово «онлайн» не найдено вообще. Разбор по составу представлен некрасиво. Есть реклама, интерфейс устаревший неудобный.
Ужасный интерфейс СловОнлайнТрудно пользоваться, при поиске надо не забыть выбрать «Разбор по составу (Морфемный)» и потом щелкнуть найденное слово. Тут много словарей, но устаревших, так как наше слово в них все равно не найдено.
Разница между морфемный и морфологическим разбором
И напоследок разъясню разницу между морфемным и морфологическим разбором слова.
Морфемный разбор – это разбор по составу, тут ручкой отмечают корень, суффикс, окончание.
Что такое морфемный разбор словаА при морфологическом разборе ручкой ничего не отмечают, это просто определение склонения, рода и других (зависит от слова) характеристик части речи.
Разбор слова по составу — Штрих-код: 9785944550866
Результаты поиска Штрих-код: 9785944550866
Наши пользователи определили следующие наименования для данного штрих-кода:
| № | Штрих-код | Наименование | Единица измерения | Рейтинг* |
|---|---|---|---|---|
| 1 | 9785944550866 | РАЗБОР СЛОВА ПО СОСТАВУ | ШТ. | 3 |
| 2 | 9785944550866 | СЛОВАРЬ РАЗБОР СЛОВА ПО СОСТАВУ.СЛОВАРИК ШКОЛЬН. | ШТ. | 1 |
| 3 | 9785944550866 | РАЗБОР СЛОВА ПО СОСТАВУ СЛОВАРИК ШКОЛЬНИКА / 978-5-94455-086-6, ШТ (1 ШТ)) | ШТ. | 1 |
| 4 | 9785944550866 | РАЗБОР СЛОВА ПО СОСТАВУ СЛОВАРИК ШКОЛЬНИКА / 978-5-94455-086-6 | ШТ. | 1 |
| 5 | 9785944550866 | СЛОВАРИК ШКОЛЬНИКА»РАЗБОР СЛОВА ПО СОСТАВУ» | ШТ. |
1 |
* Рейтинг — количество пользователей, которые выбрали это наименование, как наиболее подходящее для данного штрих-кода
Поиск: Разбор слова составу
морфемного разбора слова, разбора по составу (корневой суффикс, префикс, окончание). Разбор состава (морфемы) слова «sloppy» Морфемный разбор слова sloppy
Разбор слова по составу один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе это также называется синтаксический анализ морфемы … Сайт с практическими рекомендациями поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово?
При синтаксическом разборе морфем соблюдайте определенную последовательность выделения значимых частей.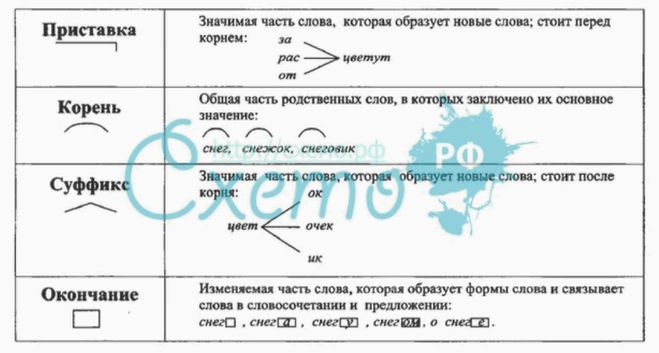
- Запишите слово так же, как и в домашнем задании. Прежде чем приступить к разборке сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи он относится. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (имеет окончание) или неизменный (не имеет окончания)
- есть ли у него формирующий суффикс?
- Найдите концовку. Для этого склоняйтесь по регистру, меняйте число, пол или человека, спрягайте — переменная часть будет окончанием.Помните об изменяемых словах с нулевым окончанием, обязательно укажите, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
- Выделите основу слова как часть без окончания (и формирующего суффикса).
- Обозначьте префикс в базе (если есть). Для этого сравните одинаковые корневые слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки сопоставьте слова с разными корнями и с одним и тем же суффиксом, чтобы они выражали одно и то же значение.
- Найдите корень в основании. Для этого сравните несколько связанных слов. Их общая часть — это корень. Запомните одни и те же корневые слова с чередующимися корнями.
- Если в слове два (или более) корня, обозначьте соединяющую гласную (если есть): листопад, звездолет, садовник, пешеход.
- Отметьте формирующие суффиксы и постфиксы (если есть)
- Еще раз проверьте синтаксический анализ и выберите все значимые части с помощью значков

В начальной школе разобрать слово — означает выделить окончание и основу, затем обозначить префикс суффиксом, подобрать одинаковые корневые слова и затем найти их общую часть: корень, и все.
* Примечание: Минобрнауки России рекомендует для общеобразовательных школ три учебных комплекса по русскому языку в 5-9 классах. У разных авторов морфемный анализ по составу отличается подходом. Чтобы избежать проблем с домашним заданием, сравните приведенный ниже порядок анализа с вашим учебником.
У разных авторов морфемный анализ по составу отличается подходом. Чтобы избежать проблем с домашним заданием, сравните приведенный ниже порядок анализа с вашим учебником.
Порядок полного синтаксического анализа морфем по составу
Во избежание ошибок предпочтительно связывать синтаксический анализ морфем с деривационным синтаксическим анализом.Такой анализ называется формально-семантическим.
- Определите часть речи и проведите графический морфемный анализ слова, то есть обозначьте все доступные морфемы.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы словоформы (если есть)
- Запишите основу слова (без формирующих морфем: окончаний и формирующих суффиксов)
- Найдите морфемы. Выпишите суффиксы и префиксы, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный.Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
- Запишите корень, подберите одинаковые корневые слова, укажите возможные варианты, чередование гласных или согласных в корнях.
 Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».Как найти морфему в слове?
Пример полного морфемного синтаксического анализа глагола «спал»:
- окончание «а» указывает на женскую форму глагола, единственного числа, прошедшего времени, сравните: проспал;
- основание гандикапа «проспал»;
- два суффикса: «a» — суффикс основы глагола, «l» — этот суффикс, образует глаголы прошедшего времени,
- приставку «pro» — действие со значением потери, неудобства, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «cn» — в родственных словах возможны чередования cn // cn // sleep // syp. Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
Неаккуратная схема парсинга:
Неряшливая
Разбор словесной композиции.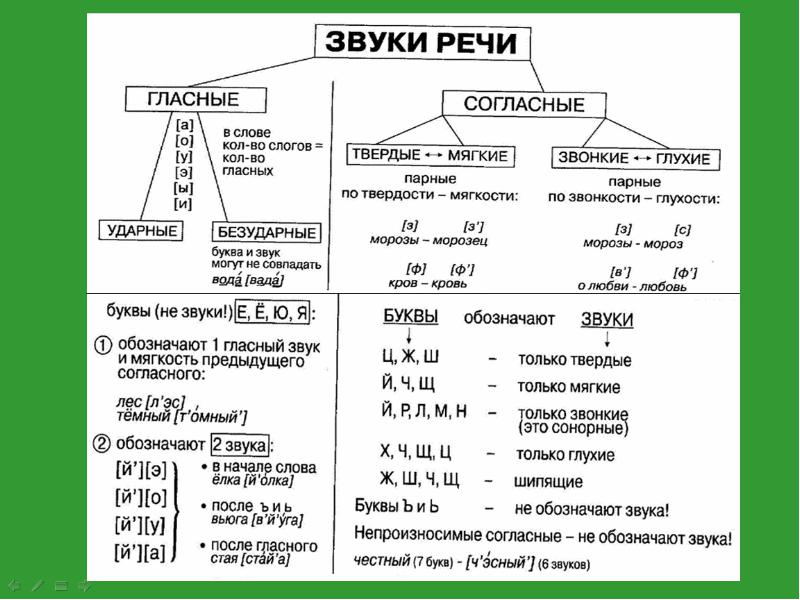
Состав слова «sloppy»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова sloppy
carelessДетальный разбор слова в a неосторожный способ.Слово cope, префикс, суффикс и окончание слова. Мофема разбор слова неаккуратна, его схема и часть слова (морфология).
- Схема морфем: sloppy / n / a
- Структура слова по морфемам: корень / суффикс / окончание
- Схема (построение) слова sloppy по составу: корень sloppy + суффикс n + окончание th
- Список морфем в слове коряво:
- небрежно — корень
- n — суффикс
- th — конец
- Типы морфов и их количество в слове неаккуратное:
- доставка: отсутствует — 0
- королева: небрежно — 1
- соединение лед: отсутствует — 0
- cyffix: n — 1
- постфикс: отсутствует — 0
- конец: th — 1
Все морфемы в слове: 3.
Производный синтаксический анализ слова sloppy
- Основа слова: небрежно ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс
n , постфикс отсутствует ; - Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образуется в 1 (один) способ .
См. Также другие словари:
Однокорневые слова … это слова с корнем … принадлежащие к разным частям речи, и в то же время близкие по значению… Слова с тем же корнем, что и у слова sloppy
Как будет слово sloppy в единственном и множественном числе. Словенский дословно
Полный морфологический анализ слова «небрежный»: часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, где это слово изучается … Морфологический разбор sloppy
Ударение в слове небрежно: какой слог ударен и как … Слово «небрежный» правильно пишется как… Ударение в слове sloppy
Синонимов к слову sloppy. Онлайн-словарь синонимов: найдите синонимы к слову «небрежный». Синонимические слова, похожие слова и похожие выражения в … Синонимы к небрежному
Онлайн-словарь синонимов: найдите синонимы к слову «небрежный». Синонимические слова, похожие слова и похожие выражения в … Синонимы к небрежному
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи … Антонимы к небрежному
Анаграммы (составьте анаграмма) к слову sloppy, смешивая буквы … Анаграммы для слова sloppy
Морфемический разбор слова sloppy
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфемы (части слова), входящие в данное слово.
Морфемный синтаксический анализ слова sloppy очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу. Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- Следующий шаг — поиск корня слова. Подбираем родственные слова для неосторожных (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Остальные морфемы мы находим, выбирая другие слова, образованные таким же образом.
 Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;Как видите, синтаксический анализ морфемы выполняется просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Морфемный синтаксический анализ слова (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбораНеаккуратная схема парсинга:
небрежная
Разбор словесной композиции.
Состав слова «небрежно»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова случайно
случайно Подробная разбивка слова небрежно составленный. Слово cope, префикс, суффикс и окончание слова. Мофема небрежное расположение слова, его схема и части слова (морфология).
Слово cope, префикс, суффикс и окончание слова. Мофема небрежное расположение слова, его схема и части слова (морфология).
- Схема морфем: небрежный / н / о
- Структура слова по морфемам: корень / суффикс / суффикс
- Схема (построение) слова небрежно в составе: корень небрежный + суффикс n + суффикс o
- Список морфем словом случайно:
- небрежный — корень
- n — суффикс
- o — суффикс
- Типы морфов и их количество в слове неаккуратно:
- доставка: отсутствует — 0
- королева: небрежно — 1
- соединение ледяное: отсутствует — 0
- cyffix: но — 2
- постфикс: отсутствует — 0
- конец: нулевое окончание.–0
Все морфемы в слове: 3.
Производный синтаксический анализ слова неаккуратно
- Основа слова: случайно ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс но , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образуется в 1 (один) способ .

См. Также другие словари:
Однокорневые слова… это слова с корнем … принадлежащие к разным частям речи, и в то же время близкие по значению … Однокорневые слова к слову случайно
Какое слово в слово случайно в единственном и множественном числе . Склонение слова «небрежно» в падежах
Полный морфологический анализ слова «небрежно»: часть речи, начальная форма, морфологические особенности и формы слова. Направление науки о языке, где изучается слово … Неосторожный морфологический разбор
Ударение в слове невнимательное: на какой слог ударение и как… Слово «небрежно» написано правильно как … Ударение в слове неосторожно
Синонимы к слову «небрежно». Онлайн-словарь синонимов: найдите синонимы к слову «небрежно». Синонимы, похожие слова и похожие выражения в … Синонимы к неосторожному
Антонимы … имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи … Антонимы к случайному
Анаграммы анаграмма) к слову случайно, путём смешивания букв . .. Анаграммы для слова случайно
.. Анаграммы для слова случайно
Неосторожный разбор морфемного слова
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем ( части слова), входящие в данное слово.
Морфемный разбор слова обычно выполняется очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте проведем морфемный синтаксический анализ правильно, для этого нам достаточно пройти 5 шагов:
- определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- Следующий шаг — поиск корня слова. Родственные слова подбираем по неаккуратности (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Остальные морфемы мы находим, выбирая другие слова, образованные таким же образом.

Как видите, синтаксический анализ морфемы выполняется просто. Теперь давайте определим основные морфемы слова и проанализируем их.
* Морфемный синтаксический анализ слова (синтаксический анализ слов) — поиск корня, префиксов, суффиксов, окончаний и основных слов Парсинг слова по составу на сайте производится по словарю морфемного разбора(PDF) Разбор GLR с несколькими грамматиками для запросов естественного языка
Разбор GLR с несколькими грамматиками для запросов естественного языка • 143
Транзакции ACM по обработке информации на азиатских языках, Vol. 1, No. 2, June 2002.
работает с соответствующим субпарсером.Мы объединяем выходы субпарсеров
вместе, чтобы сформировать общий синтаксический анализ входной строки. Наши экспериментальные результаты показывают, что
разбиение грамматики может уменьшить общий размер таблицы синтаксического анализа на порядок,
по сравнению с использованием одной контекстно-свободной грамматики, полученной из обучающих наборов ATIS
. Полный анализ синтаксического анализа одного синтаксического анализатора GLR такой же, как подходы для синтаксического анализа
Полный анализ синтаксического анализа одного синтаксического анализатора GLR такой же, как подходы для синтаксического анализа
. Однако композиция синтаксического анализатора может производить частичный синтаксический анализ, и
, таким образом, достигает более высокой точности понимания.Мы также сравнили две стратегии составления синтаксического анализатора
: каскадирование и прогнозирующее сокращение. Каскадирование применяет субпарсеры в каждой позиции
во входной строке (или решетке) в порядке, указанном вызывающим графом коллекции субграмматик
. Мы использовали алгоритм кратчайшего пути, чтобы найти лучший путь
через несколько выходов подпарсера, чтобы охватить всю входную строку. Predictive
pruning следует ограничениям предсказания левого угла при вызове различных подпараметров
и, следовательно, более эффективен с точки зрения вычислений, чем каскадирование.Дополнительные вычисления
в каскаде (по сравнению с прогнозирующим сокращением) расходуются на производство
дополнительных частичных синтаксических анализов, поскольку каскадирование позволяет синтаксическим деревьям начинаться и заканчиваться во всех местах
входного предложения. Текущая работа включает в себя разработку подхода к композиции гибридного анализатора
Текущая работа включает в себя разработку подхода к композиции гибридного анализатора
, встроенного в архитектуру мультипарсера, которая может составлять
различных синтаксических анализаторов (синтаксический анализатор GLR, синтаксический анализатор Эрли и т. Д.). Мы также экспериментируем с
с автоматическими методами разбиения грамматик. для замены ручного процесса, а также
, поскольку включает вероятности ранжирования альтернативных деревьев синтаксического анализа в выходных данных данных WSJ
в Penn Treebank.
БЛАГОДАРНОСТЬ
Мы хотели бы поблагодарить нескольких анонимных рецензентов за их комментарии и предложения.
СПИСОК ЛИТЕРАТУРЫ
ЭБНИ, С. 1991. Разбор по частям. В «Принципиальный синтаксический анализ: вычисления и психолингвистика», R. C.
Berwick et al., Eds. Kluwer Academic Publishers, 1991.
AHO, A., SETHI, I, R. и ULLMAN, J. 1986. Компиляторы: принципы, методы и инструменты. Addison-Wesley,
Reading, MA: 1986.
AMTRUP, J.1995. Параллельный анализ: разные схемы распределения диаграмм. В материалах 4-го международного семинара
по технологиям синтаксического анализа (ACL / SIGPARSE, сентябрь 1995 г.), 12-13.
EARLEY, J. 1968. Эффективный контекстно-свободный алгоритм синтаксического анализа. Кандидат наук. диссертация, Университет Карнеги-Меллона,
Питтсбург, Пенсильвания, 1968.
ХИЛЛИЕР Ф. С. и ЛИБЕРМАН Г. Дж. 1995. Введение в исследования операций. 6-е изд. McGraw-Hill, 1995.
ДЖОНСОН, С.С. 1975. YACC: еще один компилятор компилятора.Tech. Rep. CSTR 32, Bell Laboratories,
Murray Hill, NJ., 1975.
KITA, K., MORIMOTO, T. и SAGAYAMA, S. 1993. Анализ LR с тестом достижимости категорий, примененный к распознаванию речи
. IEICE Trans. Инф. Syst. Е 76-Д, 1 (1993), 23-28.
KITA, K., TAKEZAWA, T., HOSAKA, J., EHARA, T. и MORIMOTO, T. 1990. Распознавание непрерывной речи
с использованием двухуровневого анализа LR. В материалах Международной конференции по разговорному языку
Processing, 21. 3.1, 905-908.
3.1, 905-908.
КИТА, К., ТАКЕЗАВА, Т. и МОРИМОТО, Т. 1991. Распознавание непрерывной речи с использованием двухуровневого анализа LR.
IEICE Пер. Е 74, 7 (1991), 1806-1810.
КОРЕНЯК А. 1969. Практический метод построения LR (k). Commun. ACM 12, 11 (ноябрь 1969).
LUK, P. C., MENG, H., and WENG, F. 2000. Грамматическое разбиение и состав синтаксического анализатора для понимания естественного языка.
. В материалах Международной конференции по обработке разговорной речи (Пекин,
2000).
Добросовестная морфема. Разбор состава (морфемы) слова «прилежный». Как найти морфему в слове
Разбор словесной композиции.
Состав слова «усердный»:
Морфемный разбор слова усердный
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфемы данного слова (части слова ).
Морфемный разбор слова прилежный очень прост.Для этого достаточно соблюдать все правила и порядок разбора.
Давайте сделаем синтаксический анализ морфемы правильным, но для этого достаточно пройти 5 шагов:
- определение части речи слова прилежный — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу. Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- Следующий шаг — поиск корня слова. Подбираем родственные слова для усердных (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Остальные морфемы для усердного мы находим, выбирая другие слова, образованные таким же образом, как и усердный.
 Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;Как видите, синтаксический анализ морфемы усердно проделан просто.Теперь давайте определимся с основными морфемами слова прилежный и проясним.
См. Также другие словари:
Какое слово означает прилежный в единственном и множественном числе …. Прилежный
Полный морфологический анализ слова «прилежный»: часть речи, начальная форма, морфологические признаки и словоформы. Направление науки о языке, где изучается слово … Морфологический разбор прилежный
Ударение в слове прилежное: на какой слог ударение и как… Слово «прилежный» правильно пишется как… Ударение в слове прилежный
Синонимы слова «прилежный». Онлайн-словарь синонимов: найдите синонимы к слову «прилежный». Слова-синонимы, похожие слова и похожие выражения в … Синонимы к слову прилежный
Онлайн-словарь синонимов: найдите синонимы к слову «прилежный». Слова-синонимы, похожие слова и похожие выражения в … Синонимы к слову прилежный
Разбор словесной композиции.
Состав слова «усердно»:
Морфемный разбор слова усердно
Морфемный разбор слова обычно называется разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова выполняется старательно очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Давайте сделаем морфемный синтаксический анализ правильно, и для этого нам достаточно пройти 5 шагов:
- Прилежное определение части речи слова — первый шаг;
- второй — выбираем окончание: для изменчивых слов сопрягаем или раздуваем, для неизменяемых (герундий, наречия, некоторые существительные и прилагательные, официальные части речи) — окончаний нет;
- дальше ищем основу.Это самая легкая часть, потому что для определения основы вам просто нужно отрезать конец. Это будет основой слова;
- Следующий шаг — поиск корня слова. Мы старательно подбираем родственные слова для (их еще называют однокорневыми), тогда корень слова будет очевиден;
- Мы находим остальные морфемы для усердно, выбирая другие слова, которые сформированы таким же образом, как усердно.
 Это будет основой слова;
Это будет основой слова;Как видите, парсинг морфемы старательно делается просто.Теперь давайте тщательно определим основные морфемы слова и проанализируем их.
См. Также другие словари:
Что означает слово «усердно» в единственном и множественном числе. Склонение слова усердно
Полный морфологический анализ слова «усердно»: часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово … Морфологический разбор усердно
Ударение в слове старательное: на какой слог падает ударение и как… Слово «прилежно» правильно написано как … Ударение в слове прилежное
Разбор слова по составу один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе это также называется разбор морфем … Сайт с практическими рекомендациями поможет вам правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
В школьной программе это также называется разбор морфем … Сайт с практическими рекомендациями поможет вам правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово?
При синтаксическом разборе морфем соблюдайте определенную последовательность выделения значимых частей … Начните с того, чтобы «убрать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумных разделений. Определите значения морфем и выберите одинаковые корневые слова, чтобы подтвердить правильный анализ.
- Запишите слово так же, как и в домашнем задании. Прежде чем приступить к разборке композиции, выясните ее лексическое значение (значение).
- Определите из контекста, к какой части речи он относится. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (имеет окончание) или неизменный (не имеет окончания)
- есть ли у него формирующий суффикс?
- Найдите концовку. Для этого в склонении по падежу измените число, пол или лицо, спрягите — переменная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
- Выделите основу слова как часть без окончания (и формирующего суффикса).
- Обозначьте префикс в базе (если есть). Для этого сравните одинаковые корневые слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки сопоставьте слова с разными корнями и с одним и тем же суффиксом, чтобы они выражали одно и то же значение.
- Найдите корень в основании. Для этого сравните несколько связанных слов. Их общая часть — это корень. Запомните одни и те же корневые слова с чередующимися корнями.
- Если в слове два (или более) корня, обозначьте соединяющую гласную (если есть): листопад, звездолет, садовник, пешеход.
- Отметьте формирующие суффиксы и постфиксы (если есть)
- Еще раз проверьте синтаксический анализ и выберите все значимые части с помощью значков
 Для этого в склонении по падежу измените число, пол или лицо, спрягите — переменная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate ().
Для этого в склонении по падежу измените число, пол или лицо, спрягите — переменная часть будет окончанием. Помните о изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: sleep (), friend (), audibility (), gratitude (), ate (). В первичных классах разобрать слово — означает выделить окончание и основу, затем обозначить префикс суффиксом, выбрать одинаковые корневые слова и затем найти их общую часть: корень, и все.
* Примечание: Минобрнауки России рекомендует для общеобразовательных школ три учебных комплекса по русскому языку в 5-9 классах. У разных авторов морфемный анализ по составу отличается подходом. Чтобы избежать проблем с выполнением домашнего задания, сравните приведенный ниже порядок синтаксического анализа с вашим учебником.
Порядок полного синтаксического анализа морфем по составу
Во избежание ошибок предпочтительно связывать синтаксический анализ морфем с деривационным синтаксическим анализом.Такой анализ называется формально-семантическим.
- Определите часть речи и проведите графический морфемический анализ слова, то есть обозначьте все доступные морфемы.
- Запишите окончание, определите его грамматическое значение. Укажите суффиксы словоформы (если есть)
- Запишите основу слова (без формирующих морфем: окончаний и формирующих суффиксов)
- Найдите морфемы. Выпишите суффиксы и префиксы, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
- Запишите корень, подберите одинаковые корневые слова, укажите возможные варианты, чередование гласных или согласных в корнях.
 Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».
Для слов со свободными корнями составьте цепочку словообразования: «напиши-то → напиши-напиши → напиши-ое», «dry (oh) → dry-ar () → dry-ar-nits» — (а) «. Для слов со связанными корнями выберите слова с единой структурой: «платье-раздевание-переодевание».Как найти морфему в слове?
Пример полного морфемного синтаксического анализа глагола «спал»:
- окончание «а» указывает на форму глагола женского рода, единственного числа, прошедшего времени, сравните: проспал;
- основание гандикапа «проспал»;
- два суффикса: «a» — суффикс основы глагола, «l» — этот суффикс, образует глаголы прошедшего времени,
- приставку «pro» — действие со значением потери, неудобства, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «cn» — в родственных словах возможно чередование cn // sn // sleep // syp. Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
 Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.
Однокорневые слова: сон, засыпание, сонливость, недосыпание, бессонница.синонимов, антонимов и парсинговых слов. Как пишется слово «дольше»?
К какой части речи относится слово «длиннее»? Ответ на этот вопрос вы узнаете из материалов этой статьи.Кроме того, мы расскажем, как разобрать такую лексическую единицу по ее составу, какой синоним можно заменить и так далее.
Общая информация
Как правильно написать слово «длиннее» знает почти каждый. Но не все знают, к какой части речи идет речь. В связи с этим предлагаем начать нашу статью с разъяснения именно этого вопроса.
Определить часть речи
Чтобы определить, какая часть речи принадлежит слову «длиннее», его следует указать в его исходной форме — «длинный».Далее требуется задать подходящий вопрос: «что?» — длинный. Следовательно, это имя — прилагательное. Но здесь возникает новый вопрос: почему слово «более длинный» оканчивается не на -е или -е, а на -е? Для этого необходимо вспомнить особенности названий прилагательных.
Степени сравнения прилагательных
Все качественные прилагательные имеют такой вариативный морфологический признак, как степень сравнения. Из школьной программы мы знаем, что в русском языке есть две степени:
Рассмотрим их подробнее.
Превосходная степень
Такой знак указывает на наименьшую или наибольшую степень проявления признака (например, самая высокая гора) или на очень маленькую или большую степень проявления признака (например, на самого доброго человека).
Следует особо отметить, что отличная степень прилагательных образуется путем добавления к основным словам суффиксов -yush- или -aish-, приставок большинства, а также дополнительных лексических единиц «самый», «самый», «наименее», «все» или «все».
Как мы выяснили выше, слово «длиннее» — это прилагательное имени. Однако он не стоит в высшей степени, поскольку не показывает суффиксы -yesh- или -aish-, префиксы большинства, а также дополнительные лексические единицы «большинство», «большинство», «меньше всего», «все» или «всего».
сравнительный
Такой знак названий прилагательных указывает (например, Маша выше Саши, это озеро глубже того) или на этот предмет, но в другом случае (Маша выше, чем была в прошлом году, здесь озеро глубже, чем в том).
Следует отметить, что сравнительная степень формируется на основе названий прилагательных с помощью суффиксов типа -sh / -e-ee (-e) и -e (например, выше, быстрее, раньше, глубже), префиксов (например, новее), а также из других основ (например, хорошо — лучше, хуже — хуже) или дополнительных лексических единиц (более или менее).
Из всего вышесказанного мы можем с уверенностью сказать, что слово «дольше» является прилагательным в сравнительной степени. Он будет состоять из основания слова long и суффикса her.
Как пишется слово «дольше»?
О том, как написано это слово, знает практически каждый. Хотя некоторые люди на момент написания все же могут ошибаться. Например, довольно часто в письме встречается выражение: «Посмотрим, у кого нос длиннее». Это ошибочное написание слова. В конце концов, его следует использовать только с двумя буквами «n». Чтобы доказать это утверждение, приведем соответствующее правило русского языка.
Это ошибочное написание слова. В конце концов, его следует использовать только с двумя буквами «n». Чтобы доказать это утверждение, приведем соответствующее правило русского языка.
Слово «более длинный» образовано от начальной формы прилагательного «длинный».Как видите, в нем две буквы «n». Ведь, в свою очередь, такая лексическая единица произошла от существительного «длина» с добавлением суффикса -n-. Следовательно, и «длинный», и «длинный» пишутся только с двойным «n». Приведем наглядный пример:
- Ее платье длиннее моего.
- Она намного длиннее своей подруги.
- Дольше трассы я не видел в жизни.
- Он был настолько длинным, что с трудом поместился в машине.
Кстати, в этой лексической единице некоторые сомневаются в правильности написания буквы «и».Например, часто в тексте можно встретить слово «еще». Как в этом случае это проверить? Для этого следует применить правило, которое применяется к безударным гласным в корне слова. То есть к представленной лексической единице требуется выбрать такое проверочное слово, в котором сомнительная буква будет находиться в ударной позиции. Например, «длина». Как видите, буква «и» в этом слове подчеркнута. Поэтому правильнее будет быть «длиннее».
Например, «длина». Как видите, буква «и» в этом слове подчеркнута. Поэтому правильнее будет быть «длиннее».
Морфемный анализ слова
Нередко учителя просят своих учеников произвести разбор слова по композиции.«Лонгер» — лексическая единица, которую довольно проблематично подвергнуть морфемическому анализу. Однако мы рассмотрели выше, как образовано это слово. Поэтому разобрать его по составу несложно.
Итак, проведем морфемный анализ названия прилагательного «длиннее», которое стоит в сравнительной степени:
- Определим окончание. В данном случае это ноль.
- Определяем приставку. В нашем случае префикс отсутствует.
- Определите суффикс.Сравнительный суффикс в этом слове — -e-. Также есть суффикс -n-, относящийся к основанию.
- Определить корень. Корень этого слова — «длина».
- Определяем основу. Основа имени прилагательного — «длиннее» — «долго».
Подбираем синоним
Синонимами в русском языке называют слова одной части речи, разные по написанию и звучанию, но имеющие схожее лексическое значение. Приведем наглядный пример:
Приведем наглядный пример:
- small — малый;
- large — большой;
- beautiful — красиво;
- некрасиво — ужасно;
- хочу — желание;
- talk — разговор;
- большой — большой;
- create — создать;
- вещь объект;
- die — погибнуть;
- to keep — защелкнуть;
- холодный — не теплый;
- медленно — медленно и так далее.
Таким образом, синоним слова «длиннее» должен быть названием прилагательного и по возможности стоять в сравнительной степени. Например:
- длиннее — удлиненная;
- длиннее — длиннее;
- длиннее — растянуто;
- длиннее — более продолжительное;
- длиннее — выше;
- длиннее — длиннее и тд.
Однако следует отметить, что синонимы к этому слову следует подбирать так, чтобы в контексте они выглядели естественно.Было бы ошибкой сказать: «Он длиннее его», так как нужно сказать: «Он выше ее».
Подбираем антонимы
Антонимами в русском языке называют слова одной и той же части речи, которые отличаются по написанию и звучанию, но имеют прямо противоположные лексические значения.
- true False;
- красиво — некрасиво;
- говори — молчи;
- холодный — горячий;
- длинный короткий;
- морозно-горячий;
- большой маленький;
- fast — медленный;
- бегать — стоять;
- добрый злой;
- высокий Низкий;
- плохо хорошо и тд.
Итак, попробуем найти антоним слову «длиннее»:
- long — короче;
- длиннее — меньше.
Аналогичным образом можно выбрать синонимы и антонимы для начальной формы прилагательного «длинный». Например: высокий, длинный, удлиненный и короткий, лаконичный, короткий и так далее.
Земной суффикс. «Земля» — морфемный анализ слова, анализ композиции (корень soffix, приставка, окончание)
Схема анализа состава Земля:
земля
Продам слова в композиции.
Состав слова «земля»:
Соединительные гласные: отсутствует
POCTFICC: отсутствует
Морфемы — части слова Земля
земля Подробная PAZBOP Calway Earth Po Cost. Коппи, префикс, суффикс и конечные слова. MOPFEM PAZBOP CERVA EARTH, EGO CXEMA и МИНУСЫ (MOPFEM).
Коппи, префикс, суффикс и конечные слова. MOPFEM PAZBOP CERVA EARTH, EGO CXEMA и МИНУСЫ (MOPFEM).
- Схема морфем: Земля / I
- Структура слова Морфема: Корень / Окончание
- Схема (дизайн) Слова Земля в составе: земля корень + конец
- Список морфем в слове Земля:
- Bid MopFEM и их число в слове Земля:
- собственно
- : отсутствует — 0
- copa: земля — 1
- cOEDINITE HLACHNA: отсутствует — 0
- cyFFICC: отсутствует -0
- pOCTFICC: отсутствует — 0
- выезд: и — 1
BCEGO MORFEM в CLA: 2.
Словообразующее слово Слово
См. Также в других словарях:
Отдельные слова … Это слова, имеющие корень … принадлежащие к разным частям речи, и в то же время близкие по значению … Отдельные слова к слову Земля
Заглушите слово Земля для падежей в единственном и кратном числе …. Склонение слова Земля для Пада
Полный морфологический анализ слова «Земля»: часть речи, исходная форма, морфологические признаки и форма слова. Направление языкознания, где изучается слово… Морфологический анализ земля
Направление языкознания, где изучается слово… Морфологический анализ земля
Ударение в слове Земля: на какой слог падает ударение и как … слово «земля» правильно пишется как … Курс земли
Синонимы «Земля». Словарь синонимов онлайн: Подберите синонимы к слову «земля». Пел синонимы, похожие слова и близкие по смыслу выражения в … Кононимы к слову Земля
Антонимы … имеют противоположное значение, разные по звучанию, но относятся к одной и той же части речи … Антонимы для слово Земля
Анаграммы (составьте анаграмму) к слову Земля с помощью движущихся букв…. Анаграмма к слову Земля
Слово из букв составляют анаграмму. Вы ввели буквы «Земля», можете составить следующие слова из … Составьте слова из заданных букв земля
К чему снится земля толкование снов, узнайте бесплатно в нашем соннике, что означает мечта о земле. … увиденная во сне земля означает, что … Сонник: К чему снится земля
Разбор слова Морфем
Анализ слова Морфем принято называть анализом слов по составу — это поиск и анализ Морфам входит в указанное слово (части слова).
Морфемный анализ слов Земля очень прост. Для этого соблюдайте все правила и порядок проведения анализа.
Сделайте это анализ морфемы Это верно, и для этого мы просто пройдем через 5 шагов:
- определение слова «речь» — это первый шаг;
- второй — выделяем окончание: для изменяющихся слов мы прячем или склоняем, для неизменяемого (глагольные духи, наречия, некоторые имена существительных и имена прилагательных, официальные части речи) — окончания не являются ;
- дальше ищем основу.Это самая легкая часть, ведь для определения основы нужно просто отрезать конец. Это будет основой слова;
- На следующем шаге нужно найти корень слова. Подбираем родственные слова для Земли (их еще называют одноручными), тогда корень слова будет очевиден;
- Мы находим оставшиеся морфемы, выбирая другие слова, образованные таким же образом.
Как видите, анализ морфем Делается просто.Теперь определимся с основными морфемами слова и проведем его разбор.
земля
Состав слова «земля» :
корень — [Земля], окончание — [I]
Предлагает со словом «Земля»
И он пришел внезапно: за его спиной ничего нет , край, земля рушится, и только тьма у стены, звезды, вечный холод.
Но вторая рука Рубахина, швартовная машина на земле, взобралась на него и с изрезанным ртом с красивыми губами и легким дрожащим вздохом.
Так, наверное, старый дуб нащупывает свою кукурузу, шаркая корнями из земли.
Планер получает достаточно энергии, чтобы оторваться от земли и взлететь с холма.
Дед снимает ощущение сырости кожи, вытряхивает из них мелкие камешки, землю, потом выдавливает оттуда пучки бархатистой специальной альпийской травы, которую для мягкости закладывают в сенсоры.
Кроме того, эта же техника позволит быстро и засыпать землю под кустарники и клумбы.
Однако сделать это им не удалось: над тоннелем Stater слой льда и суши.
Вот кубанцев, скажем так, можно сортировать, потому что земля у них голая, как пальма …
Текст этой лекции стал популярным, но министерство образования одной из земель ФРГ запретило ее вузам.
Слово разбирать по составу, что это значит?
Свернуть слова в композиции Один из видов лингвистических исследований, цель которого — определить структуру или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них.В школьной программе также называется морфемный анализ . Сайт HOW-TO-ALL поможет вам правильно разобрать в составе онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, глагол, наречие, числительное.
План: как слово разобрать?
При проведении морфемного анализа соблюдайте определенную последовательность выделения значимых частей. Начнем с того, чтобы «отстрелять» морфемы с конца, метод «сдирания корня».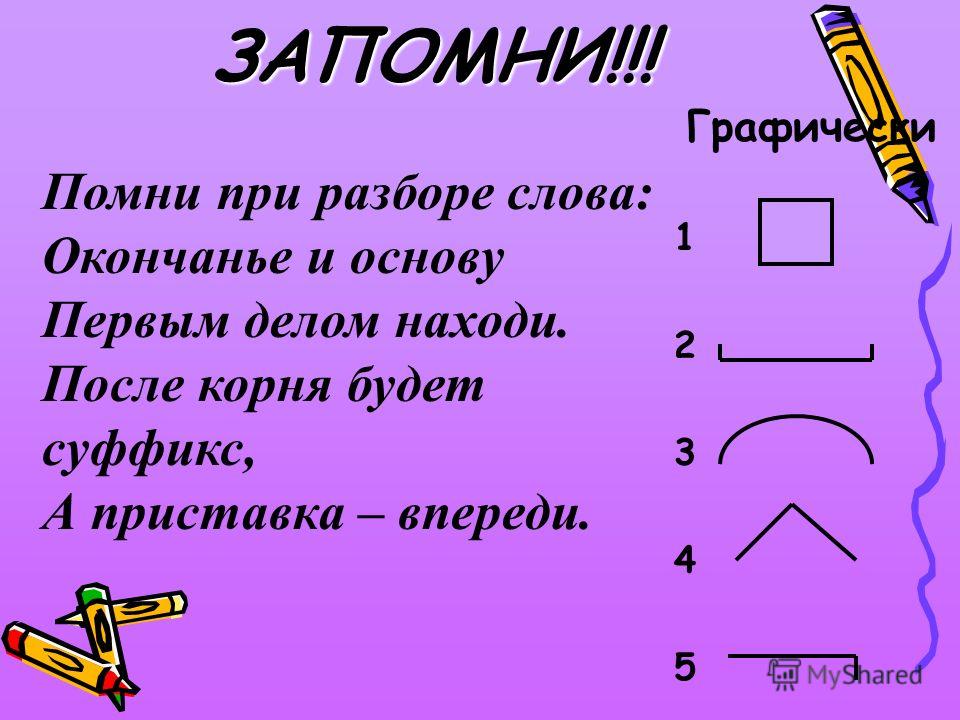 Подходите к анализу осмысленно, избегайте необдуманных разделений.Определите значения морфемы и выберите односторонние слова, чтобы подтвердить правильность анализа.
Подходите к анализу осмысленно, избегайте необдуманных разделений.Определите значения морфемы и выберите односторонние слова, чтобы подтвердить правильность анализа.
- Напишите слово в той же форме, что и в домашнем задании. Прежде чем приступить к разборке сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи он применяется. Вспомните особенности слов, относящихся к этой части речи:
- изменчивый (есть) или неизменный (нет конца)
- есть ли у него формирующий суффикс?
- Найди конец.Для этого подкрадитесь к корпусу, измените номер, род или грань, спрайты — вариативная часть будет завершением. Помните об изменении слов с нулевым окончанием, обязательно укажите, если это возможно: sleep (), friend (), слышание (), спасибо (), при попытке ().
- Выбрать основу слова — часть без конца (и образующий суффикс).
- Обозначить префикс (если он есть). Для этого сравните одноручные слова с консолями и без.
- Определите суффикс (если есть).Чтобы проверить, выберите слова с другими корнями и с тем же суффиксом, чтобы они выражали то же значение.
- Находим рут. Для этого сравните несколько связанных слов. Их общая часть — это корень. Помните о однокоренных словах с чередующимися корнями.
- Если в слове два (и более) корня, обозначьте соединительные гласные (если есть): листопад, звездчатый, садовник, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если есть)
- Повторный анализ и значки выделяют все значимые части
В первичных классах разобрать слово — Означает выделить окончание и основание, после обозначения префикса суффиксом подобрать отдельные слова, а затем найти их общую часть: корень — и все.
* Примечание: Минобразования РФ рекомендует три учебных комплекса на русском языке в 5-9 классах общеобразовательных школ. З. разных авторов morphem Диффузный подход. Чтобы избежать проблем при выполнении домашнего задания, сравните описанную ниже процедуру с вашим учебным пособием.
Порядок полного морфемного анализа композиции
Во избежание ошибок морфемный анализ предпочтительнее ассоциировать с словообразованием. Этот анализ называется формально семантическим.
- Задать часть речи и выполнить графический морфемный анализ слов, то есть обозначить все доступные морфемы.
- Запишите окончание, определите его грамматические значения. Укажите суффиксы, образующие формулы (если есть)
- Запишите основу слова (без образования морфем: окончания и формирующие суффиксы)
- Найдите морфемы. Запишите суффиксы и консоли, обоснуйте их назначение, объясните их значения
- Root: Free or connected.Для слов со свободными корнями составьте словообразовательную цепочку: «Ине-ах → Писать», «сухой (ой) → dry-art () → dry-ar-nice — (но)». Для слов со связным корнем выберите слова с одной структурой: «Оденься и раздай маскировку».
- Напишите корень, выберите отдельные слова, укажите возможные варианты, чередование гласных или согласных звуков в корнях.
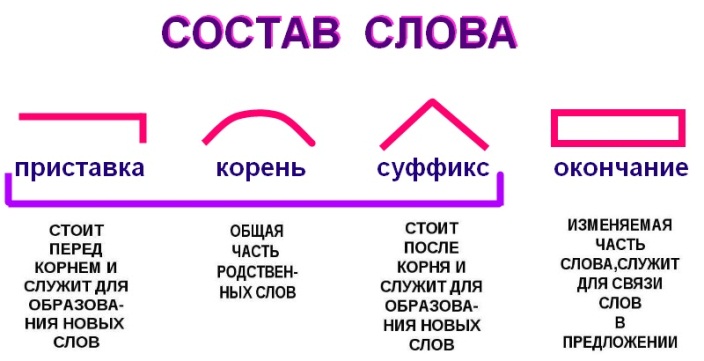
Как найти морфинг в слове?
Пример полной морфемы pavement глагола «спал»:
- конец «А» указывает на форму глагола женский, единицы, прошедшее время, ср .: Pospel-and;
- основа формы — «проспек»;
- два суффикса: «А» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «Про» — действие со смыслом потери, нечувствительный, ср: По заплатить, проиграть, проникнуть;
- лечебная цепочка: Сон — Сон — Сон;
- корень «ИП» — по родственным словам есть чередования СП // СН // Сон // Сыр.Отдельные слова: сон, сон, сонливость, недосыпание, бессонница.
Как разобрать слово «земля»?
- Именительный падеж (какой?) — Земля;
- Родительский корпус (нет Что?) — Земля;
- Токопроводящий падеж (до чего дошел?) — На землю
- Винительный падеж (я вижу что?) — Земля;
- Сертификатный футляр (чем устраивает?) — Земля;
- Предлагаемый футляр (о чем говорили?) — Про Землю.
Анализ состава (или морфемный анализ) слова земля
Наша земля — одна из планет солнечной системы.
Земля — существительное женского рода с окончанием I:
земля, земля, земля, земля, земля, земля.
Основа слова земля.
Теперь найдите в слове основную его часть — корень.
Вспомните одноручные слова: землянка, земляне, земля, экскаватор, земля.
Итак, корень будет частью слова Земля // Земля.
Существительное земля различается по падежам и числам:
край земли и уходят в землю e. , найдите Z e. мл, далеко от эл. мл.
Итак, буква и Виноград выражается — окончание.
специальный, Zagora-Lh?
Чтобы не ошибиться при определении корневых границ существительного quot; landquot;, обращаемся за помощью к родственникам:
земля, земляне, земляк, земляк, земляне, земля.
Как видим, общая часть всех этих слов, связанных с одним значением, — это часть Земли.
Подведем итог:
земля — корень / окончание.
Земля — существительное женского рода в единственном числе. Это довольно простое и очень известное слово, тем не менее, вам нужно уметь разбирать и тому подобное.
Чтобы правильно найти конец, нужно нарисовать слово: Земля, земля, земля. Переменная часть и будет концом, в данном случае это так. Соответствует окончанию существительных первого заката.
Переменная часть и будет концом, в данном случае это так. Соответствует окончанию существительных первого заката.
Мы преодолеем ряд однозначных слов, чтобы точно знать, как выглядит корень: приземлился, земля, заземление, земляк, земляне. Деталь не меняется — значит будет рут. Основа слова выглядит так же — круглая.
Итого у нас земля / I — корень / окончание.
Слово земля Существительные женского рода в единственном числе (во множественном числе будет слово — quot; landquot;] в именительном падеже.
Осуществляем анализа морфем (анализ состава) слов quot; landquot;:
Для определения конца слова определите слово по падежу:

Итак, в существительном женского рода kind quot; landquot; Конец.
Выберем несколько отдельных слов: земля, земля, земля и так далее.
Слово укоренено.
Основой слова будет земля.
Разберем слово:
1) в слове quot; землетрясение; Приставка отсутствует;
2) корень слова quot; landquot; будет quot; earthquot ;;
3) в слове quot; landquot; Суффикс отсутствует;
4) конец в слове quot; землетрясение; Будет: quot; yquot ;;
5) основание слова quot; landquot; Будет: quot; earthquot ;.
Слово quot; землетрясение; Это одно из простых слов, чтобы отказаться от композиции. Ибо есть только две морфемы:
-Zele — (Земля, земля, раскопки) Root Morphem,
— есть окончание морфемы;
в основе слова quot; Земля quot; — Земля.
слов Morphem quot; landQuot; Начнем с поиска конца. Для этого следует запланировать прокачку кейсов таким образом: Земля и , земля и , земля эл., земля ю. , земля ей , земля эл. . Вариативная часть слова, как видите, Morphem quot; —Quot; Что будет в конце. Остальное слово является его основанием: quot; земля-quot; . Префикс в слове quot; землетрясение; Суффиксов нет. И корень морфа является частью слова: quot; земля-quot; . Крупные слова quot; landQuot; Композиция окончена.
, земля ей , земля эл. . Вариативная часть слова, как видите, Morphem quot; —Quot; Что будет в конце. Остальное слово является его основанием: quot; земля-quot; . Префикс в слове quot; землетрясение; Суффиксов нет. И корень морфа является частью слова: quot; земля-quot; . Крупные слова quot; landQuot; Композиция окончена.
Земля — существительное женского рода, единственное число указывает на третью планету от Солнца, земли и территориально-административной единицы Германии.
Морфемный (по составу) Отдельные слова Земля:
корень: Земля (проверка по словам земля, земля, земля, земля)
окончание: I.
основа: Земля
Консоли, суффиксы и постфикс нет .
Существительное женского рода земля применяется к первому закату и в его составе необходимо выделить окончание — I: Земля-Земля-Земля-Земля. Отдельные слова — земля-земля-земля-земля-земля-подземелье-подземелье — редкоземельный. Корень земли — это корень, в котором возможно как чередование, так и возникновение беглого гламура E.
Получаем: Земля (корень-конец), основу слова земля.
На первом этапе анализа слов в композиции нужно поменять числа, падежи, лица, затем найти конец в слове. Словом. Определяем основу слова. Шаг найдет корень в ворде.
В слове Земля: конец меня, основа слова земля, корнем тоже будет земля, консоли не будет, суффикса тоже нет.
Количество слов образца текста
Для каждой текстовой коллекции D — это количество документов, W — количество слов в словаре, а N — общее количество слов в коллекции (ниже NNZ — количество ненулевых считается в сумке со словами).После токенизации и удаления игнорируемых слов словарь уникальных слов был усечен за счет сохранения только тех слов, которые. Этот инструмент анализа текста предоставляет информацию о читабельности и сложности текста, а также статистику по частоте слов и количеству символов. Может помочь переводчикам при расчете расценок для клиентов. Введите или вставьте текст для анализа в поле ниже, затем нажмите GO (Number Words) — НОВИНКА! Этот рабочий лист для печати содержит множество объектов, чтобы сделать урок более интересным. Задача рабочих листов — научить детей считать, сколько предметов, и обводить правильное числовое слово. Рабочий лист доступен на следующих языках: английском, французском, итальянском и испанском. Просмотрите образец страницы «Сколько?». Диаграмма кластера слов Автор: Джефф Кларк Дата: понедельник, 18 апреля 2011 г. Несколько лет назад я представил идею кластерных облаков слов, которые используют размер слова для обозначения частоты, но также используют расположение и цвет слов для группировки слов, которые сильно коррелировали в текст.Я думаю, это работает достаточно хорошо. PySpark — подсчет слов. В этом примере подсчета слов PySpark мы узнаем, как подсчитывать количество уникальных слов в текстовой строке. Конечно, мы изучим Map-Reduce, основной шаг в изучении больших данных. Бесплатный онлайн-подсчет слов и бесплатные онлайн-инструменты для подсчета символов Если вы веб-мастер и вам когда-либо требовалось отправить свою ссылку в онлайн-каталог или обмен ссылками, который ограничивает количество символов или количество слов, которые вы можете использовать для своего сайта описание, вы наверняка знаете, насколько неприятно складывать слова или символы! Следующие шесть победителей документальных фильмов, посвященных Национальному дню истории, получили награду Next Generation Angels Awards 2020 от Общества лучших ангелов.
Задача рабочих листов — научить детей считать, сколько предметов, и обводить правильное числовое слово. Рабочий лист доступен на следующих языках: английском, французском, итальянском и испанском. Просмотрите образец страницы «Сколько?». Диаграмма кластера слов Автор: Джефф Кларк Дата: понедельник, 18 апреля 2011 г. Несколько лет назад я представил идею кластерных облаков слов, которые используют размер слова для обозначения частоты, но также используют расположение и цвет слов для группировки слов, которые сильно коррелировали в текст.Я думаю, это работает достаточно хорошо. PySpark — подсчет слов. В этом примере подсчета слов PySpark мы узнаем, как подсчитывать количество уникальных слов в текстовой строке. Конечно, мы изучим Map-Reduce, основной шаг в изучении больших данных. Бесплатный онлайн-подсчет слов и бесплатные онлайн-инструменты для подсчета символов Если вы веб-мастер и вам когда-либо требовалось отправить свою ссылку в онлайн-каталог или обмен ссылками, который ограничивает количество символов или количество слов, которые вы можете использовать для своего сайта описание, вы наверняка знаете, насколько неприятно складывать слова или символы! Следующие шесть победителей документальных фильмов, посвященных Национальному дню истории, получили награду Next Generation Angels Awards 2020 от Общества лучших ангелов. ПОЖАЛУЙСТА, ОБРАТИТЕ ВНИМАНИЕ: следующие документальные проекты размещены на Google Диске. Средний читатель в пять раз медленнее, чем хороший читатель. Еще хуже, если принять во внимание не только скорость чтения, но и эффективность чтения. Эффективность чтения — это скорость чтения, взвешенная по степени понимания прочитанного, и она составляет 200 x 60% или 120 эффективных слов в минуту (ewpm) для среднего читателя и 1000 x 85% или 850 ewpm для лучших читателей. Textbox.io — первый редактор HTML WYSIWYG, разработанный для настольных и мобильных устройств.Его революционный мобильный пользовательский интерфейс, подобный приложениям, обеспечивает оптимизированный интерфейс для пользователей планшетов и мобильных телефонов. Легко добавляйте и загружайте изображения с помощью камеры устройства или галереи, используйте преобразование текста в речь для ввода содержимого и наслаждайтесь легким редактированием форматированного текста из любого места. Методика состоит в том, чтобы предсказать контекст слова с учетом самого слова, тогда как цель моделей CBOW и vLBL — предсказать слово с учетом его контекста.
ПОЖАЛУЙСТА, ОБРАТИТЕ ВНИМАНИЕ: следующие документальные проекты размещены на Google Диске. Средний читатель в пять раз медленнее, чем хороший читатель. Еще хуже, если принять во внимание не только скорость чтения, но и эффективность чтения. Эффективность чтения — это скорость чтения, взвешенная по степени понимания прочитанного, и она составляет 200 x 60% или 120 эффективных слов в минуту (ewpm) для среднего читателя и 1000 x 85% или 850 ewpm для лучших читателей. Textbox.io — первый редактор HTML WYSIWYG, разработанный для настольных и мобильных устройств.Его революционный мобильный пользовательский интерфейс, подобный приложениям, обеспечивает оптимизированный интерфейс для пользователей планшетов и мобильных телефонов. Легко добавляйте и загружайте изображения с помощью камеры устройства или галереи, используйте преобразование текста в речь для ввода содержимого и наслаждайтесь легким редактированием форматированного текста из любого места. Методика состоит в том, чтобы предсказать контекст слова с учетом самого слова, тогда как цель моделей CBOW и vLBL — предсказать слово с учетом его контекста. Посредством оценки задачи аналогии со словом эти модели продемонстрировали способность изучать лингвистические паттерны как линейные отношения между векторами слов.В отличие от матричной факторизации … Что это такое: TeXcount — это Perl-скрипт для подсчета слов в документах LaTeX. Он анализирует действительные документы LaTeX, считая слова, заголовки, формулы (математические) и группы с плавающей запятой / начало-конец. Как его запустить: Чтобы запустить сценарий, вы можете либо загрузить его и запустить на своем компьютере, либо использовать веб-интерфейс. Информация о переносе по словам Автор: Рон Корвинг Лицензия: FPDF Описание Если вы хотите обернуть какой-либо текст без его рендеринга, вы можете использовать эту простую функцию.int WordWrap (string & text, float maxwidth) Возвращает общее количество строк, из которых состоит строка. Текстовый параметр перезаписывается (вызов по ссылке) новым обернутым текстом. Определите количество. count синонимов, count произношение, count перевод, определение слова count в английском словаре.
Посредством оценки задачи аналогии со словом эти модели продемонстрировали способность изучать лингвистические паттерны как линейные отношения между векторами слов.В отличие от матричной факторизации … Что это такое: TeXcount — это Perl-скрипт для подсчета слов в документах LaTeX. Он анализирует действительные документы LaTeX, считая слова, заголовки, формулы (математические) и группы с плавающей запятой / начало-конец. Как его запустить: Чтобы запустить сценарий, вы можете либо загрузить его и запустить на своем компьютере, либо использовать веб-интерфейс. Информация о переносе по словам Автор: Рон Корвинг Лицензия: FPDF Описание Если вы хотите обернуть какой-либо текст без его рендеринга, вы можете использовать эту простую функцию.int WordWrap (string & text, float maxwidth) Возвращает общее количество строк, из которых состоит строка. Текстовый параметр перезаписывается (вызов по ссылке) новым обернутым текстом. Определите количество. count синонимов, count произношение, count перевод, определение слова count в английском словаре. … Текст; А; А; А; А; … Совокупность конкретных элементов … 29 мая 2017 г. · Показать общее количество раз, когда слово foo встречается в файле с именем bar.txt. Синтаксис: grep -c строка имя_файла grep -c foo bar.txt Примеры выходных данных: 3. Чтобы подсчитать общее количество вхождений слова в файле с именем / etc / passwd root с помощью grep, выполните: grep -c root / etc / passwd Чтобы проверить это, выполните: grep —color root / etc / passwd Подсчет слов важен, потому что он влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи. С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).Тезаурус и инструменты для творчества. Найдите слово, которое вы ищете! Выберите из предложенного списка 15-25 слов, которые вам неизвестны. Найдите и запишите определение, часть речи и используйте новое слово в предложении из более чем 6 слов.
… Текст; А; А; А; А; … Совокупность конкретных элементов … 29 мая 2017 г. · Показать общее количество раз, когда слово foo встречается в файле с именем bar.txt. Синтаксис: grep -c строка имя_файла grep -c foo bar.txt Примеры выходных данных: 3. Чтобы подсчитать общее количество вхождений слова в файле с именем / etc / passwd root с помощью grep, выполните: grep -c root / etc / passwd Чтобы проверить это, выполните: grep —color root / etc / passwd Подсчет слов важен, потому что он влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи. С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).Тезаурус и инструменты для творчества. Найдите слово, которое вы ищете! Выберите из предложенного списка 15-25 слов, которые вам неизвестны. Найдите и запишите определение, часть речи и используйте новое слово в предложении из более чем 6 слов. Попрактикуйтесь в использовании нового слова. Напишите рассказ, открытку, письмо или создайте запись в дневнике, используя 15-25 слов в контексте. Приблизительный способ подсчета слов в тексте на английском языке — это предположить, что стандартная отформатированная страница с шрифтом Courier 12 pt и строками с двойным интервалом составляет 250 слов.[4] Из-за форматирования количество страниц может изменяться в зависимости от шрифта, стиля, форматирования или размера бумаги опубликованной работы и не может считаться надежным показателем длины … Например, в Microsoft Word нажмите Инструменты -> Количество слов в общей сложности. Если вы использовали пишущую машинку, предположите, что одна страница с одинарным интервалом, с обычным шрифтом и полями содержит около 500 слов (если через два интервала — 250 слов). Если количество слов или страниц не указано, стремитесь к 250-500 словам — достаточно длинным, чтобы показать глубину, и достаточно коротким, чтобы удержать интерес.Вот сколько раз слово встречается в документе.
Попрактикуйтесь в использовании нового слова. Напишите рассказ, открытку, письмо или создайте запись в дневнике, используя 15-25 слов в контексте. Приблизительный способ подсчета слов в тексте на английском языке — это предположить, что стандартная отформатированная страница с шрифтом Courier 12 pt и строками с двойным интервалом составляет 250 слов.[4] Из-за форматирования количество страниц может изменяться в зависимости от шрифта, стиля, форматирования или размера бумаги опубликованной работы и не может считаться надежным показателем длины … Например, в Microsoft Word нажмите Инструменты -> Количество слов в общей сложности. Если вы использовали пишущую машинку, предположите, что одна страница с одинарным интервалом, с обычным шрифтом и полями содержит около 500 слов (если через два интервала — 250 слов). Если количество слов или страниц не указано, стремитесь к 250-500 словам — достаточно длинным, чтобы показать глубину, и достаточно коротким, чтобы удержать интерес.Вот сколько раз слово встречается в документе. Шаг 4: Создайте текстовую таблицу частот. После создания таблицы подсчета следующим шагом будет поиск таблицы частотности текста. Чтобы найти его, вы разделите значение каждой ячейки документа на общее количество слов в документе. Например, если у вас есть три слова в документе с каждой ячейкой …
Шаг 4: Создайте текстовую таблицу частот. После создания таблицы подсчета следующим шагом будет поиск таблицы частотности текста. Чтобы найти его, вы разделите значение каждой ячейки документа на общее количество слов в документе. Например, если у вас есть три слова в документе с каждой ячейкой …
9 декабря 2009 г. · 2. Запустите Word или любую другую программу обработки текста, которую вы используете. 3. Откройте файл резюме. Дважды проверьте орфографию и грамматику, особенно если вы внесли какие-либо изменения.4. Выделите весь текст в …
Ожидания по классам Понимание прочитанного с закрытой книгой имеет решающее значение! Классы K и 1 должны пересказать историю, установить связь с его / ее жизнью или другой книгой, рассказать любимую часть и почему. Ученики 2 и выше должны пересказать, рассказать урок, который преподает автор, рассказать о самом важном событии и почему. Как только ваш ребенок переходит на уровень I (конец первого класса), скорость (слов в минуту) составляет …
Выберите область, в которую следует вставить счетчик слов, особенно над аннотацией и под данными об авторе; Нажмите «Вставить», затем «Быстрая часть» и «Поле»; Выберите NumWords из списка названий полей и нажмите ОК, и вот оно что; Опять же, как я уже сказал, это маловероятно, поскольку профессор увидит ваш подсчет слов, как только откроет ваш документ.
Следующие два образца статей были опубликованы в аннотированном формате в Руководстве по публикациям и представлены здесь для удобства пользования. Аннотации привлекают внимание к соответствующему содержанию и форматированию и предоставляют пользователям соответствующие разделы Руководства по публикациям (7-е изд.), Чтобы получить дополнительную информацию.
Количество слов важно, потому что оно влияет на A) количество времени, которое редакторы должны потратить на улучшение вашей рукописи, и B) количество времени, которое потребуется сотрудникам JMIR для набора вашей статьи.С 19 октября 2020 года плата за дополнительную редакционную работу будет применяться к статьям, которые считаются чрезмерно длинными (более 10 000 слов).
20 мая 2019 г. · В kbenoit / LIWCalike: Анализ текста, аналогичный примерам формата использования описания лингвистического запроса и подсчета слов (LIWC). Описание. Некоторые образцы коротких документов в текстовом формате для тестирования с помощью liwcalike. Использование
Использование
26 апреля 2019 г. · Создание случайного текста с помощью формулы Rand. Если вы хотите использовать случайный (но согласованный) текст в качестве содержимого-заполнителя в документе Word, вы можете использовать формулу генерации случайного содержимого, предоставленную Word.Однако при использовании этой функции следует сделать несколько примечаний, в зависимости от того, сколько текста вам нужно.
Одной из наиболее важных задач является обобщение разговорного текста при прослушивании PTE. Подготовьте задание с образцами вопросов здесь.
Примеры подсчета слов Эти строки из «Печали Вертера» были созданы на сайте blindtextgenerator.com, чтобы дать представление о том, как разные подсчеты слов выглядят на экране. 50 слов Чудесная безмятежность овладела всей моей душой, как это сладкое весеннее утро, которым я наслаждаюсь всем сердцем.
Пример схемы академического чтения Завершение (выделение слов из текста) [Примечание: это отрывок из текста Части 3 о влиянии низкокалорийной диеты на …
Для этого задания вы будете напишите программу, которая подсчитывает, сколько раз встречаются слова во входном текстовом файле. Структура WordCount Определите структуру C ++ с именем WordCount, которая содержит следующие элементы данных: Массив из 31 символа с именем word Целое число с именем count Функции Напишите следующие функции: int main (int argc, char * argv []) Эта функция должна объявлять массив 200…
Структура WordCount Определите структуру C ++ с именем WordCount, которая содержит следующие элементы данных: Массив из 31 символа с именем word Целое число с именем count Функции Напишите следующие функции: int main (int argc, char * argv []) Эта функция должна объявлять массив 200…
Например, давайте выберем файл примера TXT для подсчета слов с текстом: «Le Petit Prince est une œuvre de langue française, la plus connue d’Antoine de Saint-Exupéry. Publié en 1943 à New York simultanément à sa an traduction anglaise, c’est une œuvre poétique et Философский sous l’apparence d’un contra pour enfants.
11 июля 2020 г. · Выражения могут включать буквальное сопоставление текста, повторение, композицию шаблонов, ветвление и другие сложные правила. Большое количество проблем синтаксического анализа легче решить с помощью регулярного выражения, чем путем создания специального лексического анализатора и анализатора.Регулярные выражения обычно используются в приложениях, требующих обработки большого количества текста.
9 октября 2019 г. · Например, строка «Java Example.Hello» вернет количество слов как 2 с использованием шаблона «\\ s +», поскольку «Example» и «Hello» разделены не пробелом, а точкой. В то время как шаблон «\\ w +» вернет счетчик слов как 3, поскольку он соответствует словам, указанным ниже.
Теперь, когда мы знаем, что чтение файла csv или файла json возвращает идентичные фреймы данных, мы можем использовать один метод для вычисления количества слов в текстовом поле.Идея здесь состоит в том, чтобы разбить слова на токены для каждой записи строки в фрейме данных и вернуть счетчик 1 для каждого токена (строка 4). Эта функция возвращает список списков, каждый из которых …
Инструмент подсчета символов — счетчик символов отслеживает и сообщает количество символов и слов в тексте, который вы вводите, в режиме реального времени. Таким образом, он подходит для написания текста с ограничением количества слов / символов. Ограничение количества слов / символов встречается во многих случаях. Например: Twitter: 280, SMS: 160, Reddit Title: 300, Ebay Title: 80, Yelp Post: 5000, LinkedIn Summary: 2000, Pinterest Description: 500, описание Blogspot: 500, статус Facebook: 63 206, тег заголовка в HTML : отображать только 70 символов…
Например: Twitter: 280, SMS: 160, Reddit Title: 300, Ebay Title: 80, Yelp Post: 5000, LinkedIn Summary: 2000, Pinterest Description: 500, описание Blogspot: 500, статус Facebook: 63 206, тег заголовка в HTML : отображать только 70 символов…
Примеры WordCount демонстрируют, как настроить конвейер обработки, который может читать текст, преобразовывать текстовые строки в отдельные слова и выполнять подсчет частоты для каждого из этих слов. Пакеты SDK Beam содержат серию из этих четырех последовательно более подробных примеров WordCount, которые дополняют друг друга.
Потребность в онлайн-сравнении текста со временем возрастает, и мы поняли, насколько распространено сравнение текста, будь то текстовый документ или огромный абзац кодов и числовых данных.Хотя существует множество существующих инструментов, которые обещают предложить аналогичные услуги, но не были специально созданы для быстрого и точного сравнения!
Возвращает количество слогов в тексте. Для английских слов подсчет слогов является точным и ищется из словаря произношения CMU из словаря слогов по умолчанию data_int_syllables. Для любого слова, которого нет в словаре, количество слогов оценивается путем подсчета кластеров гласных. data_int_syllables — это предоставленный квантом объект данных, состоящий из именованного числового вектора…
Для любого слова, которого нет в словаре, количество слогов оценивается путем подсчета кластеров гласных. data_int_syllables — это предоставленный квантом объект данных, состоящий из именованного числового вектора…
4 июня, 2017 · min_count = 1 — пороговое значение для слов. В модель будут включены только слова с более высокой частотой. size = 300 — количество измерений, в которых мы хотим представить наше слово. Это размер вектора слов. worker = 4 — используется для распараллеливания. # using модель
Count-words.com — это бесплатный онлайн-инструмент, который позволяет подсчитывать слова и символы в тексте. Введите свой текст в форму ниже, и вы увидите анализ количества слов и символов в реальном времени.Для более глубокого анализа и очень длинных текстов нажмите кнопку «Анализировать текст». Там вы увидите подробную информацию о подсчитываемых словах и символах, а также о плотности каждого слова в вашем тексте.
Облака слов заголовка Версия 2.6 Автор Ян Феллоуз Сопровождающий Иэн Феллоуз Описание Функциональные возможности для создания красивых облаков слов, визуализации различий и сходства между документами, а также предотвращения чрезмерного рисования на точечных диаграммах с текстом.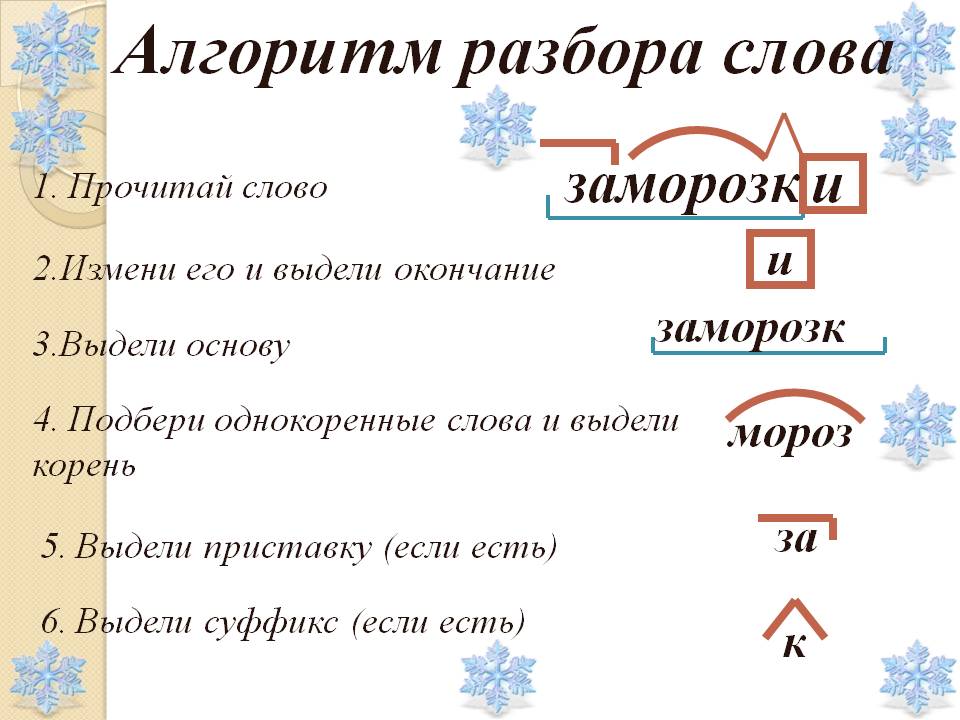 Лицензия LGPL-2.1 LazyLoad да Зависит от методов, RColorBrewer Imports Rcpp (> = 0.9.4)
Лицензия LGPL-2.1 LazyLoad да Зависит от методов, RColorBrewer Imports Rcpp (> = 0.9.4)Помните, что в среднем одна страница с интервалом обычно содержит около 3000 символов или 500 слов. В зависимости от форматирования текста количество слов на странице может составлять от 200 (крупный шрифт) до 600 слов (учебная книга). Подсчитайте символы и слова с помощью инструмента AnyCount, чтобы получить точную оценку и получить каждый заработанный цент.
Напишите программу C для подсчета общего количества слов в строке с примером.Программа на C для подсчета общего количества слов в строке. Пример 1. Эта программа позволяет пользователю вводить строку (или массив символов) и символьное значение. Затем он подсчитает общее количество слов, присутствующих в этой строке, с помощью цикла For Loop. ics заключается в том, что текст по своей природе имеет большие размеры. Предположим, что у нас есть образец документов, каждый из которых состоит из w слов, и предположим, что каждое слово взято из словаря, содержащего p возможных слов. Тогда уникальное представление этих документов имеет размерность p w.Выборка сообщений Twitter из тридцати слов, которые используют только тысячу больше всего. Этот инструмент анализа текста предоставляет информацию о читабельности и сложности текста, а также статистику по частоте слов и количеству символов. Может помочь переводчикам при расчете расценок для клиентов. Введите или вставьте текст для анализа в поле ниже, затем нажмите GO. Эта утилита генерирует алфавитный список уникальных слов с несколькими вариантами форматирования.
Тогда уникальное представление этих документов имеет размерность p w.Выборка сообщений Twitter из тридцати слов, которые используют только тысячу больше всего. Этот инструмент анализа текста предоставляет информацию о читабельности и сложности текста, а также статистику по частоте слов и количеству символов. Может помочь переводчикам при расчете расценок для клиентов. Введите или вставьте текст для анализа в поле ниже, затем нажмите GO. Эта утилита генерирует алфавитный список уникальных слов с несколькими вариантами форматирования.
Как сделать разбор слова как часть речи
Самостоятельно сделать разбор слова (к какой части речи оно относится) или морфологический разбор многие затрудняются в связи с тем, что в свое время, проходя школьную программу по этой теме, ей было уделено мало внимания или недостаточно времени. Для того, чтобы понять что это за слово и к какой части речи относится определенное слово, нужно определить значение, морфологические особенности, а также синтаксическую роль по отношению к предложению.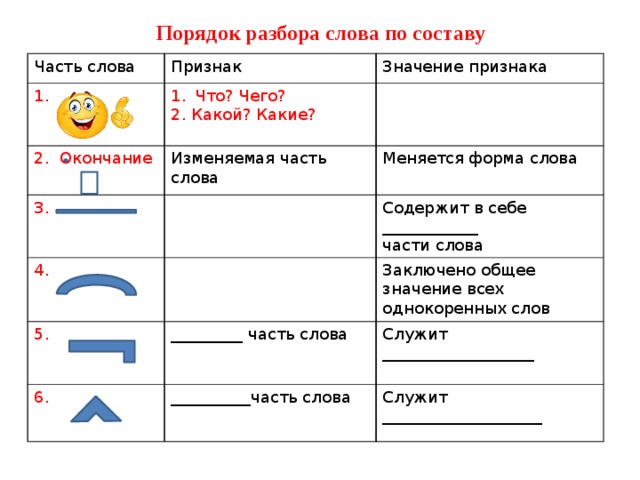 Каким образом делается разбор требуемого слова как части речи – об этом мы поговорим подробнее далее в статье.
Каким образом делается разбор требуемого слова как части речи – об этом мы поговорим подробнее далее в статье.
Содержание
- Разберем, к какой части речи отнести слово
- Имя существительное
- Имя прилагательное
- Глагол
- Имя числительное
Разберем, к какой части речи отнести слово
Чтобы это сделать, необходимо поставить вопрос к определяемому слову. К имени существительному можно поставить вопрос – «Кто?», «Что?», глагол – «Что делать?», «Что сделать?». Но бывают случаи, когда одного вопроса недостаточно, чтобы установить к какой части речи оно относится или на одинаковый вопрос, могут отвечать различные части речи, как глагол и причастие. Поэтому часто бывает необходимо обращать внимание на значение слова и морфологические признаки.
Чтобы нам стал понятен разбор, необходимо провести определение и анализ частей речи, этот план можно корректировать и менять местами пункты по своему усмотрению. Некоторые люди могут столкнуться с затруднением со склонением существительных, другие имеют сложности с наклонениями глаголов и т. д. Используя такой план анализа как можно чаще, вы научитесь делать разбор слова как часть речи быстро и безошибочно.
д. Используя такой план анализа как можно чаще, вы научитесь делать разбор слова как часть речи быстро и безошибочно.
Читайте также: Разбор предложения по частям речи онлайн.
Имя существительное
- Часть речи (существительное).
- Вопрос, на который отвечает – «Кто?», «Что?».
- Обозначает предмет или лицо.
- Начальная форма, имен. падеж, ед. число.
- Род (женский, мужской, средний).
- Одушевленное (неодушевлённое.)
- Имя нарицательное/собственное.
- Синтаксическая роль: поставить в смысловом вопросе и выделить как член предложения.
- Склонение (1, 2, 3)
- Пример: Дети любят есть мороженое. Мороженое – существительное, начальная форма – мороженое, средний род, неодушевлённое., нарицательное., 2 склонение, ед. число.
Подобная инструкция: Разбор существительного как части речи.
Имя прилагательное
- Часть речи – прилагательное.
- Вопрос, на который может отвечать – «Какой?», «Какой?», а также обозначает признак предмета.
- Постоянные признаки: качественное (чаще всего), относительное (может изменяться по степени в большую или меньшую), притяжательное (принадлежность к чему-либо).
- Непостоянные признаки: в падеже (в полной форме), в сравнительной степени (качественные), краткая форма – каков?, полная – какой?, в числе (ед. ч.), в роде (ед. ч.).
- Синтаксическая роль: указать вопрос в нужной форме и подчеркнуть.
- Пример: Полное ведро воды – полное – прилагательное, винительный падеж, дополнение, в нулевой степени, начальная форма – полный, средний род.

Глагол
- Часть речи – глагол.
- Вопрос, на который может отвечать – «Что делать?». Выражает действие предмета или лица.
- Начальная форма – инфинитив: что сделать?, что делать?
- Постоянные признаки: спряжение – первое (ет, ем, ут/ют, ете, ешь), второе (им, ит, ите, ат/ят), разноспрягаемое, переходный (употребляется без предлога в сущ.).
- Непостоянные признаки: единственное число, лицо – наст. , буд.: 1 л. (мы, я), 2 л. (вы, ты), 3 л. (они, он).
- Глагол в неопределенной форме имеет лишь постоянные признаки – это неизменяемая форма.
- Синтаксическая роль (поставить вопрос в нужной форме и выделить соответствующим подчеркиванием).
- Пример: Они сказали, что больше не вернутся – сказали – глагол, невозвратный, совершенный вид, начальная форма – сказать, множественное число, сказуемое, первое спряжение (в изъявительном наклонении), прошедшее время.
 , буд.: 1 л. (мы, я), 2 л. (вы, ты), 3 л. (они, он).
, буд.: 1 л. (мы, я), 2 л. (вы, ты), 3 л. (они, он).Подробная инструкция: Разбор глагола как часть речи.
Имя числительное
- Часть речи – числительное.
- Вопрос, на который отвечает – «Который?», «Сколько?», выражает количество, порядок предметов.
- Начальная форма – мужской род, ед. ч., именительный падеж.
- Постоянные признаки: по значение (подразряд и количественное (собственн., Кол., дробное, собирательное), порядковое).
- По структуре (составное/сложное/простое).
- Склонения: составные кол. и сложное склоняются с изменением части слова, составные кол. и сложные склоняются с изменением слова, которое стоит в конце предложения. Сорок, девяносто, полтора, имеют две формы. Простые числительные от 1 порядковые и собирательные склоняются как прилагательные.
- Непостоянные признаки: род (ед. ч.), число (если имеется), падеж.
- Синтаксическая роль: (вместе с сущ.) с определением слова.
- Пример: Четыре ласточки сидели на проводе – четыре – количественное, именительный падеж, без рода и числа, выступает подлежащим, начальная форма – четыре, простое.
 и сложное склоняются с изменением части слова, составные кол. и сложные склоняются с изменением слова, которое стоит в конце предложения. Сорок, девяносто, полтора, имеют две формы. Простые числительные от 1 порядковые и собирательные склоняются как прилагательные.
и сложное склоняются с изменением части слова, составные кол. и сложные склоняются с изменением слова, которое стоит в конце предложения. Сорок, девяносто, полтора, имеют две формы. Простые числительные от 1 порядковые и собирательные склоняются как прилагательные.В Интернете есть специальные сервисы, которые позволяют совершить разбор нужного слова как части речи. Чтобы воспользоваться таким сервисом – достаточно зайти на главную страницу, найти окно, в которое нужно ввести слово и через несколько секунд вы получите готовый разбор нужного слова.
Главная » Полезные советы » Правила русского языка
Автор Дима Опубликовано Обновлено
Слово о полку Игореве — Заболоцкий. Полный текст стихотворения — Слово о полку Игореве
Не пора ль нам, братия, начать
О походе Игоревом слово,
Чтоб старинной речью рассказать
Про деянья князя удалого?
А воспеть нам, братия, его —
В похвалу трудам его и ранам —
По былинам времени сего,
Не гоняясь мыслью за Бояном.
Тот Боян, исполнен дивных сил,
Приступая к вещему напеву,
Серым волком по полю кружил,
Как орёл, под облаком парил,
Растекался мыслию по древу.
Жил он в громе дедовских побед,
Знал немало подвигов и схваток,
И на стадо лебедей чуть свет
Выпускал он соколов десяток.
И, встречая в воздухе врага,
Начинали соколы расправу,
И взлетала лебедь в облака
И трубила славу Ярославу.
Пела древний киевский престол,
Поединок славила старинный,
Где Мстислав Редедю заколол
Перед всей косожскою дружиной,
И Роману Красному хвалу
Пела лебедь, падая во мглу.
Но не десять соколов пускал
Наш Боян, но, вспомнив дни былые,
Вещие персты он подымал
И на струны возлагал живые, —
Вздрагивали струны, трепетали,
Сами князям славу рокотали.
Мы же по-иному замышленью
Эту повесть о године бед
Со времён Владимира княженья
Доведём до Игоревых лет
И прославим Игоря, который,
Напрягая разум, полный сил,
Мужество избрал себе опорой,
Ратным духом сердце поострил
И повёл полки родного края,
Половецким землям угрожая.
О Боян, старинный соловей!
Приступая к вещему напеву,
Если б ты о битвах наших дней
Пел, скача по мысленному древу;
Если б ты, взлетев под облака,
Нашу славу с дедовскою славой
Сочетал на долгие века,
Чтоб прославить сына Святослава:
Если б ты Траяновой тропой
Средь полей помчался и курганов, —
Так бы ныне был воспет тобой
Игорь-князь, могучий внук Траянов:
«То не буря соколов несёт
За поля широкие и долы,
То не стаи галочьи летят
К Дону на великие просторы!».
Или так воспеть тебе, Боян,
Внук Велесов, наш военный стан:
«За Сулою кони ржут,
Слава в Киеве звенит,
В Новеграде трубы громкие трубят,
Во Путивле стяги бранные стоят!».
Часть первая
1
Игорь-князь с могучею дружиной
Мила-брата Всеволода ждёт.
Молвит буй-тур Всеволод: — Единый
Ты мне брат, мой Игорь, и оплот!
Дети Святослава мы с тобою,
Так седлай же борзых коней, брат!
А мои давно готовы к бою,
Возле Курска под седлом стоят.
2
— А куряне славные —
Витязи исправные:
Родились под трубами,
Росли под шеломами,
Выросли, как воины,
С конца копья вскормлены.
Все пути им ведомы,
Все яруги знаемы,
Луки их натянуты,
Колчаны отворены,
Сабли их наточены,
Шеломы позолочены.
Сами скачут по полю волками
И, всегда готовые к борьбе,
Добывают острыми мечами
Князю — славы, почестей — себе!
3
Но, взглянув на солнце в этот день,
Подивился Игорь на светило:
Середь бела-дня ночная тень
Ополченья русские покрыла.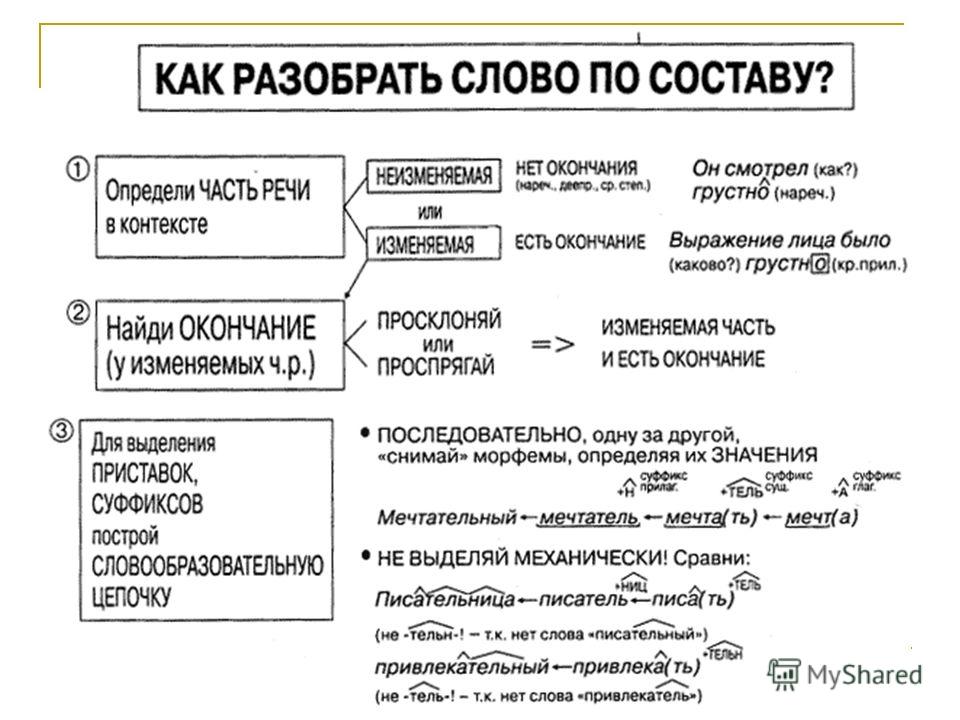
И, не зная, что сулит судьбина,
Князь промолвил: — Братья и дружина!
Лучше быть убиту от мечей,
Чем от рук поганых полонёну!
Сядем, братья, на лихих коней,
Да посмотрим синего мы Дону! —
Вспала князю эта мысль на ум —
Искусить неведомого края,
И сказал он, полон ратных дум,
Знаменьем небес пренебрегая:
— Копиё хочу я преломить
В половецком поле незнакомом,
С вами, братья, голову сложить
Либо Дону зачерпнуть шеломом!
4
Игорь-князь во злат-стремень вступает,
В чистое он поле выезжает.
Солнце тьмою путь ему закрыло,
Ночь грозою птиц перебудила,
Свист зверей несётся, полон гнева,
Кличет Див над ним с вершины древа,
Кличет Див, как половец в дозоре,
За Сулу, на Сурож, на Поморье,
Корсуню и всей округе ханской,
И тебе, болван тмутороканский!
5
И бегут, заслышав о набеге,
Половцы сквозь степи и яруги,
И скрипят их старые телеги,
Голосят, как лебеди в испуге.
Игорь к Дону движется с полками,
А беда несётся вслед за ним:
Птицы, поднимаясь над дубами,
Реют с криком жалобным своим,
По оврагам волки завывают,
Крик орлов доносится из мглы —
Знать, на кости русские скликают
Зверя кровожадные орлы;
Уж лиса на щит червлёный брешет,
Стон и скрежет в сумраке ночном…
О Русская земля!
Ты уже за холмом.
6
Долго длится ночь. Но засветился
Утренними зорями восток.
Уж туман над полем заклубился,
Говор галок в роще пробудился,
Соловьиный щекот приумолк.
Русичи, сомкнув щиты рядами,
К славной изготовились борьбе,
Добывая острыми мечами
Князю — славы, почестей — себе.
7
На рассвете, в пятницу, в туманах,
Стрелами по полю полетев,
Смяло войско половцев поганых
И умчало половецких дев.
Захватили золота без счёта,
Груду аксамитов и шелков,
Вымостили топкие болота
Япанчами красными врагов.
А червлёный стяг с хоругвью белой,
Челку и копьё из серебра
Взял в награду Святославич смелый,
Не желая прочего добра.
8
Выбрав в поле место для ночлега
И нуждаясь в отдыхе давно,
Спит гнездо бесстрашное Олега —
Далеко подвинулось оно!
Залетело храброе далече,
И никто ему не господин —
Будь то сокол, будь то гордый кречет,
Будь то чёрный ворон — половчин.
А в степи, с ордой своею дикой
Серым волком рыская чуть свет,
Старый Гзак на Дон бежит великий,
И Кончак спешит ему вослед.
9
Ночь прошла, и кровяные зори
Возвещают бедствие с утра.
Туча надвигается от моря
На четыре княжеских шатра.
Чтоб четыре солнца не сверкали,
Освещая Игореву рать,
Быть сегодня грому на Каяле,
Лить дождю и стрелами хлестать!
Уж трепещут синие зарницы,
Вспыхивают молнии кругом.
Вот где копьям русским преломиться,
Вот где саблям острым притупиться,
Загремев о вражеский шелом!
О Русская земля!
Ты уже за холмом.
10
Вот Стрибожьи вылетели внуки —
Зашумели ветры у реки,
И взметнули вражеские луки
Тучу стрел на русские полки.
Стоном стонет мать-земля сырая,
Мутно реки быстрые текут,
Пыль несётся, поле покрывая,
Стяги плещут: половцы идут!
С Дона, с моря, с криками и с воем
Валит враг, но полон ратных сил,
Русский стан сомкнулся перед боем —
Шит к щиту — и степь загородил.
11
Славный яр-тур Всеволод! С полками
В обороне крепко ты стоишь,
Прыщешь стрелы, острыми клинками
О шеломы ратные гремишь.
Где ты ни проскачешь, тур, шеломом
Золотым посвечивая, там
Шишаки земель аварских с громом
Падают, разбиты пополам.
И слетают головы с поганых,
Саблями порублены в бою,
И тебе ли, тур, скорбеть о ранах,
Если жизнь не ценишь ты свою!
Если ты на ратном этом поле
Позабыл о славе прежних дней,
О златом черниговском престоле,
О желанной Глебовне своей!
12
Были, братья, времена Траяна,
Миновали Ярослава годы,
Позабылись правнуками рано
Грозные Олеговы походы.
Тот Олег мечом ковал крамолу,
Пробираясь к отчему престолу,
Сеял стрелы и, готовясь к брани,
В злат-стремень вступал в Тмуторокани.
В злат-стремень вступал, готовясь к сече,
Звон тот слушал Всеволод далече,
А Владимир за своей стеною
Уши затыкал перед бедою.
13
А Борису, сыну Вячеслава,
Зелен-саван у Канина брега
Присудила воинская слава
За обиду храброго Олега.
На такой же горестной Каяле,
Протянув носилки между вьюков,
Святополк отца увёз в печали,
На конях угорских убаюкав.
Прозван Гориславичем в народе,
Князь Олег пришёл на Русь, как ворог,
Внук Даждь-бога бедствовал в походе,
Век людской в крамолах стал недолог.
И не стало жизни нам богатой,
Редко в поле выходил оратай,
Вороны над пашнями кружились,
На убитых с криками садились,
Да слетались галки на беседу,
Собираясь стаями к обеду…
Много битв в те годы отзвучало,
Но такой, как эта, не бывало.
14
Уж с утра до вечера и снова —
С вечера до самого утра
Бьётся войско князя удалого,
И растёт кровавых тел гора.
День и ночь над полем незнакомым
Стрелы половецкие свистят,
Сабли ударяют по шеломам,
Копья харалужные трещат.
Мёртвыми усеяно костями,
Далеко от крови почернев,
Задымилось поле под ногами,
И взошёл великими скорбями
На Руси кровавый тот посев.
15
Что там шумит,
Что там звенит
Далеко во мгле, перед зарёю?
Игорь, весь израненный, спешит
Беглецов вернуть обратно к бою.
Не удержишь вражескую рать!
Жалко брата Игорю терять.
Бились день, рубились день, другой,
В третий день к полудню стяги пали,
И расстался с братом брат родной
На реке кровавой, на Каяле.
Недостало русичам вина,
Славный пир дружины завершили —
Напоили сватов допьяна
Да и сами головы сложили.
Степь поникла, жалости полна,
И деревья ветви приклонили.
16
И настала тяжкая година,
Поглотила русичей чужбина,
Поднялась Обида от курганов
И вступила девой в край Траянов.
Крыльями лебяжьими всплеснула,
Дон и море оглашая криком,
Времена довольства пошатнула,
Возвестив о бедствии великом.
А князья дружин не собирают,
Не идут войной на супостата,
Малое великим называют
И куют крамолу брат на брата.
А враги на Русь несутся тучей,
И повсюду бедствие и горе.
Далеко ты, сокол наш могучий,
Птиц бия, ушёл на сине-море!
17
Не воскреснуть Игоря дружине,
Не подняться после грозной сечи!
И явилась Карна и в кручине
Смертный вопль исторгла, и далече
Заметалась Желя по дорогам,
Потрясая искромётным рогом.
И от края, братья, и до края
Пали жёны русские, рыдая:
— Уж не видеть милых лад нам боле!
Кто разбудит их на ратном поле?
Их теперь нам мыслию не смыслить,
Их теперь нам думою не сдумать,
И не жить нам в тереме богатом,
Не звенеть нам сЕребром да златом!
18
Стонет, братья, Киев над горою,
Тяжела Чернигову напасть,
И печаль обильною рекою
По селеньям русским разлилась.
И нависли половцы над нами,
Дань берут по белке со двора,
И растёт крамола меж князьями,
И не видно от князей добра.
19
Игорь-князь и Всеволод отважный —
Святослава храбрые сыны —
Вот ведь кто с дружиною бесстрашной
Разбудил поганых для войны!
А давно ли мощною рукою
За обиды наши покарав,
Это зло великою грозою
Усыпил отец их Святослав!
Был он грозен в Киеве с врагами
И поганых ратей не щадил —
Устрашил их сильными полками,
Порубил булатными мечами
И на Степь ногою наступил.
Потоптал холмы он и яруги,
Возмутил теченье быстрых рек,
Иссушил болотные округи,
Степь до лукоморья пересек.
А того поганого Кобяка
Из железных вражеских рядов
Вихрем вырвал и упал — собака —
В Киеве, у княжьих теремов.
20
Венецейцы, греки и морава
Что ни день о русичах поют,
Величают князя Святослава,
Игоря отважного клянут.
И смеётся гость земли немецкой,
Что когда не стало больше сил,
Игорь-князь в Каяле половецкой
Русские богатства утопил.
И бежит молва про удалого,
Будто он, на Русь накликав зло,
Из седла, несчастный, золотого
Пересел в кащеево седло…
Приумолкли города, и снова
На Руси веселье полегло.
Часть вторая
1
В Киеве далёком, на горах,
Смутный сон приснился Святославу,
И объял его великий страх,
И собрал бояр он по уставу.
— С вечера до нынешнего дня, —
Молвил князь, поникнув головою, —
На кровати тисовой меня
Покрывали чёрной пеленою.
Черпали мне синее вино,
Горькое отравленное зелье,
Сыпали жемчуг на полотно
Из колчанов вражьего изделья.
Златоверхий терем мой стоял
Без конька и, предвещая горе,
Серый ворон в Плесенске кричал
И летел, шумя, на сине-море.
2
И бояре князю отвечали:
— Смутен ум твой, княже, от печали.
Не твои ли два любимых чада
Поднялись над полем незнакомым —
Поискать Тмуторокани-града
Либо Дону зачерпнуть шеломом?
Да напрасны были их усилья.
Посмеявшись на твои седины,
Подрубили половцы им крылья,
А самих опутали в путины. —
3
В третий день окончилась борьба
На реке кровавой, на Каяле,
И погасли в небе два столба,
Два светила в сумраке пропали.
Вместе с ними, за море упав,
Два прекрасных месяца затмились —
Молодой Олег и Святослав
В темноту ночную погрузились.
И закрылось небо, и погас
Белый свет над Русскою землею,
И, как барсы лютые, на нас
Кинулись поганые с войною.
И воздвиглась на Хвалу Хула,
И на волю вырвалось Насилье,
Прянул Див на землю, и была
Ночь кругом и горя изобилье.
4
Девы готские у края
Моря синего живут.
Русским золотом играя,
Время Бусово поют.
Месть лелеют Шаруканью,
Нет конца их ликованью…
Нас же, братия-дружина,
Только беды стерегут.
5
И тогда великий Святослав
Изронил своё златое слово,
Со слезами смешано, сказав:
— О сыны, не ждал я зла такого!
Загубили юность вы свою,
На врага не во-время напали,
Не с великой честию в бою
Вражью кровь на землю проливали.
Ваше сердце в кованой броне
Закалилось в буйстве самочинном.
Что ж вы, дети, натворили мне
И моим серебряным сединам?
Где мой брат, мой грозный Ярослав,
Где его черниговские слуги,
Где татраны, жители дубрав,
Топчаки, ольберы и ревуги?
А ведь было время — без щитов,
Выхватив ножи из голенища,
Шли они на полчища врагов,
Чтоб отмстить за наши пепелища.
Вот где славы прадедовской гром!
Вы ж решили бить наудалую:
«Нашу славу силой мы возьмём,
А за ней поделим и былую».
Диво ль старцу — мне помолодеть?
Старый сокол, хоть и слаб он с виду,
Высоко заставит птиц лететь,
Никому не даст гнезда в обиду.
Да князья помочь мне не хотят,
Мало толку в силе молодецкой.
Время, что ли, двинулось назад?
Ведь под самым Римовым кричат
Русичи под саблей половецкой!
И Владимир в ранах, чуть живой, —
Горе князю в сече боевой!
6
Князь великий Всеволод! Доколе
Муки нам великие терпеть?
Не тебе ль на суздальском престоле
О престоле отчем порадеть?
Ты и Волгу вёслами расплещешь,
Ты шеломом вычерпаешь Дон,
Из живых ты луков стрелы мечешь,
Сыновьями Глеба окружён.
Если б ты привёл на помощь рати,
Чтоб врага не выпустить из рук, —
Продавали б девок по ногате,
А рабов — по резани на круг.
7
Вы, князья буй-Рюрик и Давид!
Смолкли ваши воинские громы.
А не ваши ль плавали в крови
Золотом покрытые шеломы?
И не ваши ль храбрые полки
Рыкают, как туры, умирая
От калёной сабли, от руки
Ратника неведомого края?
Встаньте, государи, в злат-стремень
За обиду в этот чёрный день,
За Русскую землю,
За Игоревы раны —
Удалого сына Святославича!
8
Ярослав, князь галицкий! Твой град
Высоко стоит под облаками.
Оседлал вершины ты Карпат
И подпёр железными полками.
На своём престоле золотом
Восемь дел ты, князь, решаешь разом,
И народ зовёт тебя кругом
Осмомыслом — за великий разум.
Дверь Дуная заперев на ключ,
Королю дорогу заступая,
Бремена ты мечешь выше туч,
Суд вершишь до самого Дуная.
Власть твоя по землям потекла,
В Киевские входишь ты пределы,
И в салтанов с отчего стола
Ты пускаешь княжеские стрелы.
Так стреляй в Кончака, государь,
С дальних гор на ворога ударь —
За Русскую землю,
За Игоревы раны —
Удалого сына Святославича!
9
Вы, князья Мстислав и буй-Роман!
Мчит ваш ум на подвиг мысль живая.
И несётесь вы на вражий стан,
Соколом ширяясь сквозь туман,
Птицу в буйстве одолеть желая.
Вся в железе княжеская грудь,
Золотом шелом латинский блещет,
И повсюду, где лежит ваш путь,
Вся земля от тяжести трепещет.
Хинову вы били и Литву;
Деремела, половцы, ятвяги,
Бросив копья, пали на траву
И склонили буйную главу
Под мечи булатные и стяги.
10
Но уж прежней славы больше с нами нет.
Уж не светит Игорю солнца ясный свет.
Не ко благу дерево листья уронило:
Поганое войско грады поделило.
По Суле, по Роси счёту нет врагу.
Не воскреснуть Игореву храброму полку!
Дон зовёт нас, княже, кличет нас с тобой!
Ольговичи храбрые одни вступили в бой.
11
Князь Ингварь, князь Всеволод! И вас
Мы зовём для дальнего похода,
Трое ведь Мстиславичей у нас,
Шестокрыльцев княжеского рода!
Не в бою ли вы себе честном
Города и волости достали?
Где же ваш отеческий шелом,
Верный щит, копьё из ляшской стали?
Чтоб ворота Полю запереть,
Вашим стрелам время зазвенеть
За русскую землю,
За Игоревы раны —
Удалого сына Святославича!
12
Уж не течёт серебряной струёю
К Переяславлю-городу Сула.
Уже Двина за полоцкой стеною
Под клик поганых в топи утекла.
Но Изяслав, Васильков сын, мечами
В литовские шеломы позвонил,
Один с своими храбрыми полками
Всеславу-деду славы прирубил.
И сам, прирублен саблею калёной,
В чужом краю, среди кровавых трав,
Кипучей кровью в битве обагрённый,
Упал на щит червлёный, простонав:
— Твою дружину, княже, приодели
Лишь птичьи крылья у степных дорог,
И полизали кровь на юном теле
Лесные звери, выйдя из берлог. —
—
И в смертный час на помощь храбру мужу
Никто из братьев в бой не поспешил.
Один в степи свою жемчужну душу
Из храброго он тела изронил.
Через златое, братья, ожерелье
Ушла она, покинув свой приют.
Печальны песни, замерло веселье,
Лишь трубы городенские поют…
13
Ярослав и правнуки Всеслава!
Преклоните стяги! Бросьте меч!
Вы из древней выскочили славы,
Коль решили честью пренебречь.
Это вы раздорами и смутой
К нам на Русь поганых завели,
И с тех пор житья нам нет от лютой
Половецкой проклятой земли!
14
Шёл седьмой по счету век Троянов.
Князь могучий полоцкий Всеслав
Кинул жребий, в будущее глянув,
О своей любимой загадав.
Замышляя новую крамолу,
Он опору в Киеве нашёл
И примчался к древнему престолу,
И копьём ударил о престол.
Но не дрогнул старый княжий терем,
И Всеслав, повиснув в синей мгле,
Выскочил из Белгорода зверем —
Не жилец на киевской земле.
И, звеня секирами на славу,
Двери новгородские открыл,
И расшиб он славу Ярославу,
И с Дудуток через лес-дубраву
До Немиги волком проскочил.
А на речке, братья, на Немиге
Княжью честь в обиду не дают —
День и ночь снопы кладут на риге,
Не снопы, а головы кладут.
Не цепом — мечом своим булатным
В том краю молотит земледел,
И кладёт он жизнь на поле ратном,
Веет душу из кровавых тел.
Берега Немиги той проклятой
Почернели от кровавых трав —
Не добром засеял их оратай,
А костями русскими — Всеслав.
15
Тот Всеслав людей судом судил,
Города Всеслав князьям делил,
Сам всю ночь, как зверь, блуждал в тумане,
Вечер — в Киеве, до зорь — в Тмуторокани,
Словно волк, напав на верный путь,
Мог он Хорсу бег пересягнуть.
16
У Софии в Полоцке, бывало,
Позвонят к заутрене, а он
В Киеве, едва заря настала,
Колокольный слышит перезвон.
И хотя в его могучем теле
Обитала вещая душа,
Всё ж страданья князя одолели
И погиб он, местию дыша.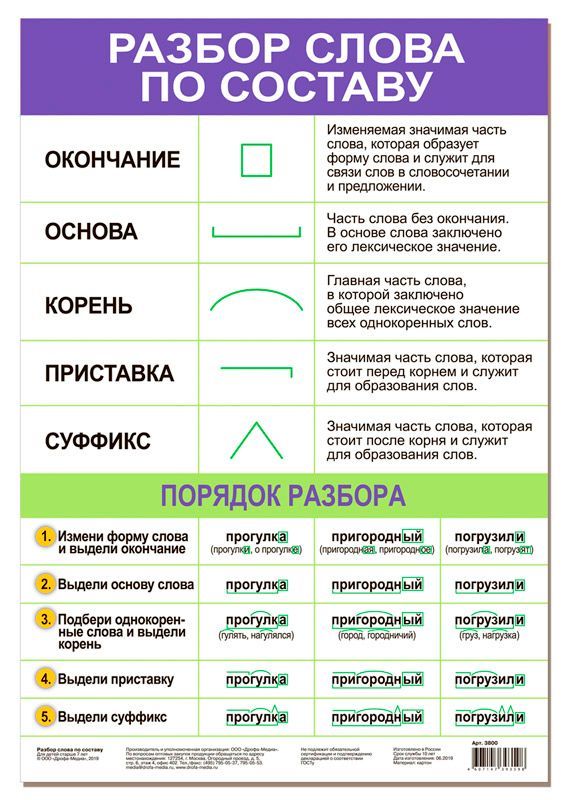
Так свершил он путь свой небывалый.
И сказал Боян ему тогда:
«Князь Всеслав! Ни мудрый, ни удалый
Не минуют божьего суда».
17
О, стонать тебе, земля родная,
Прежние годины вспоминая
И князей давно минувших лет!
Старого Владимира уж нет.
Был он храбр, и никакая сила
К Киеву б его не пригвоздила.
Кто же стяги древние хранит?
Эти — Рюрик носит, те — Давид,
Но не вместе их знамёна плещут,
Врозь поют их копия и блещут.
Часть третья
1
Над широким берегом Дуная,
Над великой Галицкой землёй
Плачет, из Путивля долетая,
Голос Ярославны молодой:
— Обернусь я, бедная, кукушкой,
По Дунаю-речке полечу
И рукав с бобровою опушкой,
Наклонясь, в Каяле омочу.
Улетят, развеются туманы,
Приоткроет очи Игорь-князь,
И утру кровавые я раны,
Над могучим телом наклонясь.
Далеко в Путивле, на забрале,
Лишь заря займётся поутру,
Ярославна, полная печали,
Как кукушка, кличет на юру:
— Что ты, Ветер, злобно повеваешь,
Что клубишь туманы у реки,
Стрелы половецкие вздымаешь,
Мечешь их на русские полки?
Чем тебе не любо на просторе
Высоко под облаком летать,
Корабли лелеять в синем море,
За кормою волны колыхать?
Ты же, стрелы вражеские сея,
Только смертью веешь с высоты.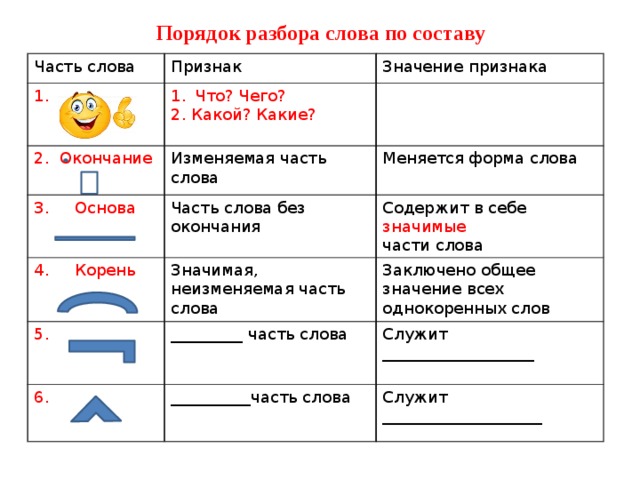
Ах, зачем, зачем моё веселье
В ковылях навек развеял ты?
На заре в Путивле причитая,
Как кукушка раннею весной,
Ярославна кличет молодая,
На стене рыдая городской:
— Днепр мой славный! Каменные горы
В землях половецких ты пробил,
Святослава в дальние просторы
До полков Кобяковых носил.
Возлелей же князя, господине,
Сохрани на дальней стороне,
Чтоб забыла слёзы я отныне,
Чтобы жив вернулся он ко мне!
Далеко в Путивле, на забрале,
Лишь заря займётся поутру,
Ярославна, полная печали,
Как кукушка, кличет на юру:
— Солнце трижды светлое! С тобою
Каждому приветно и тепло.
Что ж ты войско князя удалое
Жаркими лучами обожгло?
И зачем в пустыне ты безводной
Под ударом грозных половчан
Жаждою стянуло лук походный,
Горем переполнило колчан?
2
И взыграло море. Сквозь туман
Вихрь промчался к северу родному —
Сам господь из половецких стран
Князю путь указывает к дому.
Уж погасли зори. Игорь спит.
Дремлет Игорь, но не засыпает.
Игорь к Дону мыслями летит
До Донца дорогу измеряет.
Вот уж полночь. Конь давно готов.
Кто свистит в тумане за рекою?
То Овлур. Его условный зов
Слышит князь, укрытый темнотою:
— Выходи, князь Игорь! — И едва
Смолк Овлур, как от ночного гула
Вздрогнула земля,
Зашумела трава,
Буйным ветром вежи всколыхнуло.
В горностая-белку обратясь,
К тростникам помчался Игорь-князь,
И поплыл, как гоголь по волне,
Полетел, как ветер, на коне.
Конь упал, и князь с коня долой,
Серым волком скачет он домой.
Словно сокол, вьётся в облака,
Увидав Донец издалека.
Без дорог летит и без путей,
Бьёт к обеду уток-лебедей.
Там, где Игорь соколом летит,
Там Овлур, как серый волк, бежит,
Все в росе от полуночных трав,
Борзых коней в беге надорвав.
3
Уж не каркнет ворон в поле,
Уж не крикнет галка там,
Не трещат сороки боле,
Только скачут по кустам.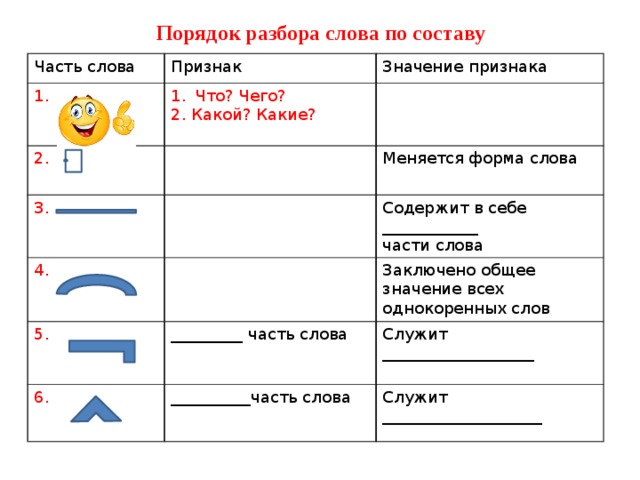
Дятлы, Игоря встречая,
Стуком кажут путь к реке,
И, рассвет весёлый возвещая,
Соловьи ликуют вдалеке.
4
И, на волнах витязя лелея,
Рек Донец: — Велик ты, Игорь-князь!
Русским землям ты принёс веселье,
Из неволи к дому возвратясь.
— О, река! — ответил князь. — Немало
И тебе величья! В час ночной
Ты на волнах Игоря качала,
Берег свой серебряный устлала
Для него зелёною травой.
И когда дремал он под листвою,
Где царила сумрачная мгла,
Страж ему был гоголь над водою,
Чайка князя в небе стерегла.
5
А не всем рекам такая слава.
Вот Стугна, худой имея нрав,
Разлилась близ устья величаво,
Все ручьи соседние пожрав,
И закрыла Днепр от Ростислава,
И погиб в пучине Ростислав.
Плачет мать над тёмною рекою,
Кличет сына-юношу во мгле,
И цветы поникли, и с тоскою
Приклонилось дерево к земле.
6
Не сороки вО поле стрекочут,
Не вороны кличут у Донца —
Кони половецкие топочут,
Гзак с Кончаком ищут беглеца.
И сказал Кончаку старый Гзак:
— Если сокол улетает в терем,
Соколёнок попадёт впросак —
Золотой стрелой его подстрелим. —
И тогда сказал ему Кончак:
— Если сокол к терему стремится,
Соколёнок попадёт впросак —
Мы его опутаем девицей.
— Коль его опутаем девицей, —
Отвечал Кончаку старый Гзак, —
Он с девицей в терем свой умчится,
И начнёт нас бить любая птица
В половецком поле, хан Кончак!
7
И изрёк Боян, чем кончить речь
Песнотворцу князя Святослава:
— Тяжко, братья, голове без плеч,
Горько телу, коль оно безглаво. —
Мрак стоит над Русскою землёй:
Горько ей без Игоря одной.
8
Но восходит солнце в небеси —
Игорь-князь явился на Руси.
Вьются песни с дальнего Дуная,
Через море в Киев долетая.
По Боричеву восходит удалой
К Пирогощей богородице святой.
И страны рады,
И веселы грады.
Пели песню старым мы князьям,
Молодых настало время славить нам:
Слава князю Игорю,
Буй-тур Всеволоду,
Владимиру Игоревичу!
Слава всем, кто, не жалея сил,
За христиан полки поганых бил!
Здрав будь, князь, и вся дружина здрава!
Слава князям и дружине слава!
определение синтаксического анализа в The Free Dictionary
Также найдено в: Тезаурусе, Медицине, Энциклопедии, Википедии.
анализ
(пар)v. анализ , разбор , пар·ес
v. 90.
1.
а. Разбить (предложение) на составные части речи с объяснением формы, функции и синтаксических отношений каждой части.
б. Чтобы описать (слово), указав его часть речи, форму и синтаксические отношения в предложении.
в. Для обработки (лингвистических данных, таких как речь или письменный язык) в режиме реального времени, когда они произносятся или читаются, для определения их лингвистической структуры и значения.
2.
а. Чтобы изучить внимательно или подвергнуть подробному анализу, особенно путем разбивки на компоненты: «Что мы упускаем, разбивая поведение шимпанзе на обычные категории, признанные в основном из нашего собственного поведения?» (Стивен Джей Гулд).
б. Чтобы понять; понять: я просто не мог разобрать, что вы только что сказали.
Чтобы понять; понять: я просто не мог разобрать, что вы только что сказали.
3. Компьютеры Для анализа или разделения (например, ввода) на более легко обрабатываемые компоненты.
т. вн.
Признать разборчивыми: предложения, которые нелегко разобрать.
[Вероятно, от среднеанглийского pars, часть речи , от латинского pars (ōrātiōnis), часть (речи) ; см. perə- в индоевропейских корнях.]
pars′er сущ.
Словарь английского языка American Heritage®, пятое издание. Авторские права © 2016, издательство Houghton Mifflin Harcourt Publishing Company. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company. Все права защищены.
Переводы
analisi
parsing
[ˈpɑːzɪŋ] N → análisis m inv sintáctico or grammatical Коллинз Испанский словарь — Полное и неопубликованное 8 -е издание 2005 г. © William Collins Sons & Co. Ltd. 1971, 1988 © Harpercollins Publishers 1992, 1993, 1996, 1997, 2000, 2003, 2005
© William Collins Sons & Co. Ltd. 1971, 1988 © Harpercollins Publishers 1992, 1993, 1996, 1997, 2000, 2003, 2005
. ) → Синтаксический анализ
f ; (Вычисления) → Синтаксический анализ ntНемецкий словарь Коллинза – полное и полное издание, 7-е издание, 2005 г. © William Collins Sons & Co. Ltd., 1980 г.0003
Упоминается в ?
- analyse
- analyze
- break down
- compiler
- compiling program
- computer program
- computer programme
- construe
- dissect
- grammar
- misparse
- parse
- parser
- program
- programme
- разобрать
Ссылки в классической литературе ?
Бегун пронесся мимо них в дюжине футов, пересек мокрый песок, ни разу не разобравшись, пока пена не достигла ему колен, а над ним, по крайней мере, в десяти футах, вздымалась струя бьющей через край воды.
Посмотреть в контексте
Он слишком много повидал в жизни, и его ум был слишком зрелым, чтобы полностью довольствоваться дробями, кубическим корнем, разбором и анализом; и бывали времена, когда их разговор заходил на другие темы — о последних стихах, которые он читал, о последнем поэте, которого она изучала.
Посмотреть в контексте
Четыре, или шесть, или десять лет ученик разбирает греческий и латынь, и как только он покидает университет, как он нелепо называется, он в последний раз закрывает эти книги.
Посмотреть в контексте
Было не менее трех несчастных парней во фраках, с зарождающимся пушком на подбородках, которых Доктор и классный руководитель все время пытались поднять в старшую школу, но анализ и истолкование которых сопротивлялся самым благонамеренным толчкам.
Посмотреть в контексте
Галерея Хоакин объединяет двух восходящих мастеров в проекте «Очарование синтаксического анализа: демонстрация современных абстракций». Работы скульптора по стеклу Мардж Органо и абстракциониста Омбока Вилламора будут представлены в торговом центре North Court of Power Plant Mall в Макати, август. держать. Этот анализ вышел из картины не просто годы, а десятилетия назад.
Работы скульптора по стеклу Мардж Органо и абстракциониста Омбока Вилламора будут представлены в торговом центре North Court of Power Plant Mall в Макати, август. держать. Этот анализ вышел из картины не просто годы, а десятилетия назад.
ОПРЕДЕЛЕНИЕ СОВРЕМЕННОГО МИРОТВОРЧЕСТВА
16 октября 2017 г. — Калифорнийская компания Rchilli, специализирующаяся на решениях для подбора персонала, приобрела калифорнийскую компанию CandidateZip, специализирующуюся на анализе резюме, чтобы укрепить свои позиции в отрасли, сообщила компания.
Rchilli укрепляет позиции в отрасли с приобретением CandidateZip
Международная компания по управлению рисками Anvil Group, базирующаяся в Соединенном Королевстве, предлагает своим клиентам решение для анализа электронной почты Traxo CAPTURE в качестве встроенной функции в свою ETMS (систему мониторинга командировок сотрудников). ), который используется некоторыми из самых известных корпораций по всему миру.
Traxo совершенствует управление рисками в корпоративных поездках
В этом сборнике рассказов американка филиппинского происхождения Линда Тай-Каспер проводит пальцами по шрамам, оставшимся после исторических событий на Филиппинах, анализируя, что значит пережить и после травма диктатуры и войны.
Линда Тай-Каспер: Река, глубина одной женщины: Истории
Алгоритмы анализа концепций (CPA) для текстового анализа и обнаружения: новые исследования и возможности
Алгоритмы анализа понятий (CPA) для текстового анализа и обнаружения: новые исследования и возможности
Браузер словарей ?
- ▲
- Parry Channel
- Parry Islands
- Parry manzanita
- Parry Milman
- Parry William Edward
- Parry’s penstemon
- Parry’s pinyon
- pars
- pars anterior
- pars distilis
- pars intermedia
- pars nervosa
- parse
- parsec
- Parsee
- Parseeism
- parser
- Parsha
- Parsi
- Parsifal
- Parsiism
- parsimonious
- parsimoniously
- parsimoniousness
- parsimony
- parsing
- Parsippany- TroyHills
- петрушка
- семейство петрушки
- петрушка папоротниковая
- петрушка боярышник
- петрушка
- parsley sauce
- parsley-leaved thorn
- parsnip
- parson
- parson bird
- Parson Russell terrier
- parsonage
- parsonarchy
- Parsoned
- Parsonic
- parsonical
- parsonish
- Parsons
- parson’s nose
- Стол Parsons
- Parsons Talcott
- Parsons William
- часть
- часть-
- ▼
Полный браузер ?
Лингвистические функции · Документация по использованию spaCy
Интеллектуальная обработка необработанного текста затруднена: большинство слов встречаются редко, и это
обычно для слов, которые выглядят совершенно по-разному, означают почти одно и то же.
Doc , который поставляется с различными
аннотации. После токенизации spaCy может анализировать и помечать данный Doc . Это где
появляется обученный конвейер и его статистические модели, которые позволяют spaCy делать прогнозы того, какой тег или метка наиболее вероятно применимы в данном контексте.
Обученный компонент включает в себя двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку —
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Лингвистические аннотации доступны как Атрибуты токена . Как и многие библиотеки НЛП, spaCy кодирует все строки в хэш-значения , чтобы уменьшить использование памяти и улучшить
эффективность. Таким образом, чтобы получить удобочитаемое строковое представление атрибута, мы
нужно добавить подчеркивание _ к его имени:
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple рассматривает возможность покупки стартапа в Великобритании за 1 миллиард долларов»)
для токена в документе:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
- Текст: Исходный текст слова.
- Лемма: Основная форма слова.
- POS: Простой UPOS тег части речи.
- Тег: Подробный тег части речи.
- Dep: Синтаксическая зависимость, т. е. отношение между токенами.
- Начертание: Начертание слова – заглавные буквы, знаки препинания, цифры.
- is alpha: Является ли маркер альфа-символом?
- is stop: Является токеновой частью стоп-листа, т.е. язык?
 е. отношение между токенами.
е. отношение между токенами.| Text | Lemma | POS | Tag | Dep | Shape | alpha | stop |
|---|---|---|---|---|---|---|---|
| Apple | apple | PROPN | NNP | nsubj | Xxxxx | Правда | False |
| is | be | AUX | VBZ | aux | xx | True | True |
| looking | look | VERB | VBG | ROOT | xxxx | True | False |
| at | at | ADP | IN | prep | xx | True | True |
| buying | buy | VERB | VBG | pcomp | xxxx | True | False |
| Великобритания | Великобритания | ПРОПН | ННП | компаунд | X. | False | False |
| startup | startup | NOUN | NN | dobj | xxxx | True | False |
| for | for | ADP | IN | prep | xxx | True | True |
| $ | $ | SYM | $ | quantmod | $ | False | False |
| 1 | 1 | NUM | CD | compound | d | False | False |
| billion | billion | NUM | CD | pobj | xxxx | True | False |
 X.
X. 0006 Большинство тегов и меток выглядят довольно абстрактно и различаются между языки.

spacy.explain покажет вам краткое описание — например, spacy.explain("VBZ") возвращает «глагол, 3-е лицо единственного числа, настоящее время».Использование встроенного в spaCy визуализатора displaCy, вот что наше примерное предложение и его зависимости выглядят следующим образом:
📖схема тегов части речи моделями spaCy на разных языках, см. задокументированные схемы маркировки в каталоге моделей.
Инфлективная морфология – это процесс, посредством которого корневая форма слова изменен путем добавления префиксов или суффиксов, которые определяют его грамматическую функцию но не меняйте его часть речи. Мы говорим, что лемма (корневая форма) есть измененный (модифицированный/комбинированный) с одним или несколькими морфологическими признаками до создать поверхностную форму. Вот несколько примеров:
| Контекст | Поверхность | Лемма | POS | Morphological Features | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I was reading the paper | reading | read | VERB | VerbForm=Ger | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I don’t watch the news, I read the paper | Прочитайте | Читать | глагольный0391 |