Морфологический разбор слова «проиграть»
Часть речи: Инфинитив
ПРОИГРАТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПРОИГРАТЬ»
| Слово | Морфологические признаки |
|---|---|
| ПРОИГРАТЬ |
|
Все формы слова ПРОИГРАТЬ
ПРОИГРАТЬ, ПРОИГРАЛ, ПРОИГРАЛА, ПРОИГРАЛО, ПРОИГРАЛИ, ПРОИГРАЮ, ПРОИГРАЕМ, ПРОИГРАЕШЬ, ПРОИГРАЕТЕ, ПРОИГРАЕТ, ПРОИГРАЮТ, ПРОИГРАВ, ПРОИГРАВШИ, ПРОИГРАЕМТЕ, ПРОИГРАЙ, ПРОИГРАЙТЕ, ПРОИГРАВШИЙ, ПРОИГРАВШЕГО, ПРОИГРАВШЕМУ, ПРОИГРАВШИМ, ПРОИГРАВШЕМ, ПРОИГРАВШАЯ, ПРОИГРАВШЕЙ, ПРОИГРАВШУЮ, ПРОИГРАВШЕЮ, ПРОИГРАВШЕЕ, ПРОИГРАВШИЕ, ПРОИГРАВШИХ, ПРОИГРАВШИМИ, ПРОИГРАННЫЙ, ПРОИГРАННОГО, ПРОИГРАННОМУ, ПРОИГРАННЫМ, ПРОИГРАННОМ, ПРОИГРАН, ПРОИГРАННАЯ, ПРОИГРАННОЙ, ПРОИГРАННУЮ, ПРОИГРАННОЮ, ПРОИГРАНА, ПРОИГРАННОЕ, ПРОИГРАНО, ПРОИГРАННЫЕ, ПРОИГРАННЫХ, ПРОИГРАННЫМИ, ПРОИГРАНЫ
Разбор слова по составу проиграть
проигра
ть| Основа слова | проигра |
|---|---|
| Приставка | про |
| Корень | игр |
| Суффикс | а |
| Глагольное окончание | ть |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПРОИГРАТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «проиграть»
1
«Проиграть битву – не значит проиграть войну».
Форексмен, Александр Малашкин2
Так глупо проиграть, как я проиграл, ни на что не похоже!
Саломея, или Приключения, почерпнутые из моря житейского, Александр Вельтман, 1848г.3
Что касается последнего, то он играл довольно внимательно и рассчитывал, кажется, чтоб не проиграть, – и не проиграл.
Тысяча душ, Алексей Феофилактович Писемский, 1858г.4
Шалунов дурашливо запричитал: «Проиграл, проиграл, проиграл…» Тогда Курасов вынул небольшой плоский кинжальчик, висевший у него на поясе в ножнах.
5
Ты проиграл, потому что хотел проиграть.
Исторический орнамент, Эсфирь КоблерНайти еще примеры предложений со словом ПРОИГРАТЬ
Всё познаётся в сравнении. «Спартак» и «Ростов» — лидеры по приросту очков в РПЛ 08.06.2023 читать блог на SOCCER.RU
Сравниваем показатели от сезона к сезону.
«Оренбург» и «Факел» выступили успешнее, чем «Уфа» и «Рубин». Набрали больше очков. Если Евсеев останется в РПЛ, то «Факел» не повторит ошибку «Уфы». А «Оренбург» набрал на 8 очков больше, чем год назад было у «Ростова» и «Спартака». Только «Торпедо» тянет на дно статистику новичков ушедшего сезона. 11 пунктов это невероятно слабый показатель. Год назад «Арсенал» занял последнее место с 23 очками. А теперь сравним прибыли и убытки клубов, которые провели в РПЛ минимум два сезона подряд.
13-е место. «Сочи» — минус 18 очков
Самое резкое падение. Без Федотова серебряный призер прошлого сезона в РПЛ скатился на десятое место. Потеряли 18 пунктов, то есть столько, как за весь сезон набрали «Химки». «Сочи» явно может играть лучше, но не угадали с тренерами.
12-е место. «Химки» — минус 14 очков
Развал клуба и команды. Крепкий середняк РПЛ, который в этом сезоне тоже легко мог финишировать рядом с «Динамо» и «Локомотивом», если бы не выгнали Юрана, оказался в Первой лиге. Предсказуемый результат, клуб уничтожили изнутри.
11-е место. «Крылья Советов» — минус 9 очков
Самая невезучая команда. Разница между ожидаемыми и реальными очками минус 10. И природа отката другая, чем у «Сочи» и «Химок». Нельзя вечно прощаться с сильнейшими игроками без последствий. Селекция выручает Осинькина, Гарре забивает, но Писарский сразу не заиграл.
10-е место. «Динамо» — минус 8 очков
Всего восемь пунктов разницы, но это откат с третьего места на девятое. Причем учтите, что пять очков Йоканович подарил «Факелу». Дважды уступали «Сочи». Проигрывали тем, с кем должны конкурировать в борьбе за первую тройку. Бувачу нужно хорошо подумать, выбирая тренера. Еще один промах может привести к катастрофе.
9-е место. «Локомотив» — минус 2 очка
Напоминание, что «железнодорожникам» не удался и прошлый сезон, когда потратили еще больше денег. Теперь «Локомотив» устроит распродажу, может избавиться от 15 футболистов. Зато повезло с зимними трансферами. Лантратов, Дзюба и молодые игроки помогли Галактионову. Но через год нужно быть в первой пятерке такого списка.
8-е место. «Краснодар» — минус 2 очка
Тот же показатель, что у «Локомотива», но без драматизма. Конечно, Сафонов весной чудил, словно не было крутой осени, но Ивич явно грамотнее, чем предыдущие наставники «горожан», не считая Ганчаренко. Клуб Галицкого потерял таких игроков, как Кабелла, но есть неплохие новички, вроде Алонсо. Через год надо напоминать, как были в тройке.
Клуб Галицкого потерял таких игроков, как Кабелла, но есть неплохие новички, вроде Алонсо. Через год надо напоминать, как были в тройке.
7-е место. «Пари НН» — плюс 2 очка
Для середняка, который потерял главного тренера, это достойный результат. Конечно, не обошлось без странных решений. В «Пари НН» запаниковали, убрав наставника, но выбор в пользу Юрана сработал. Команда разгромила в гостях «Родину» 3:0, отличные шансы остаться в РПЛ и дальше бороться за выживание. Быть может, даже успешно.
6-е место. «Урал» — плюс 3 очка
Так бывает, если пригласить парочку приличных футболистов и не забыть поставить на опытного тренера. Ганчаренко по пути в финал Кубка России отвлекся от РПЛ, хватало глупых поражений. Но «Урал» — это сильный середняк. Даже через год, если будут деньги и не убегут ключевые иностранцы, продолжат бороться за сохранение места в элите.
5-е место. «Зенит» — плюс 5 очков
Было 65 пунктов год назад, стало 70, невзирая на досрочный титул и наплевательскую игру в последних турах. «Зенит» легко защитил титул. Семак пять раз подряд стал чемпионом как тренер. Будет шестой титул? Зависит от планов Малкома, Вендела и другие ключевых игроков. Российский костяк не потянет, да и форвард не помешает.
4-е место.
ЦСКАПопали в тройку по приросту пунктов, ведь у «Ахмата» тоже плюс восемь очков. Но поставим «армейцев» чуть ниже. Федотов однозначно среди героев сезона, и одновременно его подопечных нужно поругать за игры против «Спартака», «Локомотива», «Сочи», «Динамо» и «Пари НН». В пяти матчах легко могли набрать на 10 пунктов больше. А это 68 очков в общей таблице и чемпионская борьба с «Зенитом».
3-е место. «Ахмат» — плюс 8 очков
Если ЦСКА недоработал, исходя из возможностей и класса тренера, то «Ахмат» — красавцы.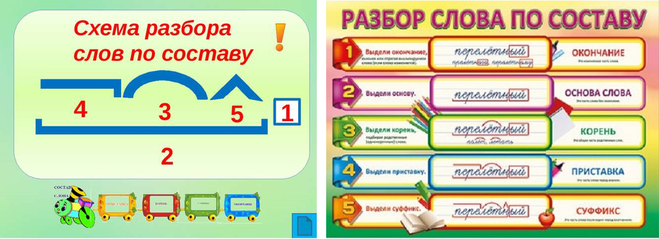 После смены наставника и сложного старта с двумя победами в шести турах удалось перестроиться. Ташуеву пригодились классные легионеры, заиграли крепкие россияне из состава. «Ахмат» не прыгнул выше головы, не оказался в первой тройке, но пятое место после «Ростова» это тоже достижение.
После смены наставника и сложного старта с двумя победами в шести турах удалось перестроиться. Ташуеву пригодились классные легионеры, заиграли крепкие россияне из состава. «Ахмат» не прыгнул выше головы, не оказался в первой тройке, но пятое место после «Ростова» это тоже достижение.
2-е место. «Ростов» — плюс 15 очков
Середняк прошлого сезона был фаворитом в борьбе за вторую строчку весной. Но дальше «Ростов» потерял очки в 8 матчах, скатились на четвертую строчку. Но Карпин может сказать, что иначе быть не могло, учитывая глубину состава и трансферные возможности. Посмотрим, кто покинет «Ростов» и кого подпишут. А пока отмечаем, что Комличенко, Уткин, Глебов, Осипенко и Песьяков добавили 15 пунктов от сезона к сезону.
1-е место. «Спартак» — плюс 16 очков
А вот и чемпион в номинации. Но эта победа объясняется глубиной падения год назад. Даже тогда в таблице ожидаемых очков «Спартак» был на четвертом месте. Потеряли с Виторией и Ваноли 10 пунктов, которые заслужили, исходя из статистики. В свете информации третье место Абаскаля уже не кажется невероятным достижением. Забрали свое. Команда по-прежнему перспективная. Но важно не потерять Промеса после вердиктов в судах, где он обвиняемый,
В свете информации третье место Абаскаля уже не кажется невероятным достижением. Забрали свое. Команда по-прежнему перспективная. Но важно не потерять Промеса после вердиктов в судах, где он обвиняемый,
Разбор позволяет отметить, что «Локомотив» и «Динамо» могут рвануть вверх. «Крылья Советов», если сохранят состав, будут радовать чаще. А вот ЦСКА и «Спартаку» пора переходить к турборежиму, чтобы угнаться за «Зенитом», который и мощный, и достаточно везучий, особенно в атаке.
крутых вещей, которые можно делать с помощью Pydantic | Гидеон Коллер | The Startup
Опубликовано в·
Чтение: 11 мин.·
6 октября 2020 г. Модели Pydantic Pydantic — полезная библиотека для анализа и проверки данных. Он приводит типы ввода к объявленному типу (используя подсказки типов), накапливает все ошибки, используя ValidationError , а также хорошо документирован, что делает его легко обнаруживаемым.
За время использования Pydantic я обнаружил несколько моментов, которые не были очевидны для меня сразу, а также столкнулся с несколькими ловушками. Поскольку мне потребовалось некоторое время, чтобы обнаружить их, я решил, что пришло время поделиться ими с миром.
Прежде чем мы начнем, обратите внимание на несколько вещей:
- Я добавил в код пронумерованные комментарии (# 1, # 2 и т. д.), на которые я сразу же ссылаюсь после фрагмента кода, чтобы объяснить код.
- Каждая функция/ловушка имеет ссылку в следующем разделе, поэтому вы можете сразу перейти к тем, которые вас интересуют.
Итак, без лишних слов, вот что, как я узнал, можно делать с Pydantic:
- Используйте псевдонимы полей, чтобы хорошо работать с внешними форматами
- Копировать и установить, не выполнять проверку типов
- Добавление ограничений к моделям
- Принудительное применение моделей со строгостью типов
- Определение моделей без ключей и значений
- Управление настройками с типами Literal
- Использование Pydantic для выполнения проверки аргументов функций
- Сводка
Используйте псевдонимы полей для удобной работы с внешними форматами
Когда данные проходят через границы нашей системы, такие как внешние API, базы данных, очереди обмена сообщениями и т. д., нам иногда нужно следовать соглашениям об именах других (CamelCase vssnake_case и т. д.) .
д., нам иногда нужно следовать соглашениям об именах других (CamelCase vssnake_case и т. д.) .
В некоторых случаях это может привести к некоторым странным соглашениям Python:
- ̵i̵n̵ ̵P̵y̵t̵h̵o̵n̵
id— это встроенная функция в Python (Jylpah правильно указал, чтоid— это функция, а не зарезервированное ключевое слово в Python, как я изначально писал), но мы должны использовать его, чтобы следовать внешнему соглашению об именах. - В Python мы обычно используем змеиный регистр в качестве соглашения об именах, но опять же, мы вынуждены следовать другому соглашению об именах.
- Поскольку мы хотим, чтобы модель представляла внешние данные, мы вынуждены следовать другим соглашениям.
- Мы также можем получать данные из внешнего источника в формате JSON или в другом формате.
- Мы по-прежнему вынуждены следовать этим внешним условностям.
В других случаях это может привести к неожиданным результатам:
- Чтобы избежать использования
idв качестве имени поля (поскольку это зарезервированное ключевое слово), мы переименовываем наше поле.
- Удивительно (или, по крайней мере, удивительно для меня), Pydantic скрывает поля, начинающиеся со знака подчеркивания (независимо от того, как вы пытаетесь получить к ним доступ).

Pydantic позволяет решить эти проблемы с помощью псевдонимов полей:
- Вот как мы объявляем псевдоним поля в Pydantic. Обратите внимание, что псевдоним должен соответствовать соглашениям об именовании.
- При создании моделей с псевдонимами мы передаем входные данные, соответствующие псевдонимам.
- Мы обращаемся к полю через имя поля (а не псевдоним поля).
- Остерегайтесь создавать эти модели с реальными именами полей (а не с псевдонимами), так как это не сработает. Ознакомьтесь с прикрепленным выпуском Github, чтобы узнать больше об этом.
- При преобразовании наших моделей во внешние форматы нам нужно указать Pydantic использовать псевдоним (вместо внутреннего имени), используя имя аргумента
by_alias.
Копировать и установить не выполнять проверку типа
Помимо передачи значений через конструктор, мы также можем передавать значения через копирование и обновление или с помощью сеттеров (модели Pydantic по умолчанию изменяемы). Однако они имеют удивительное поведение.
Однако они имеют удивительное поведение.
При копировании и обновлении никакая проверка не выполняется. Мы можем видеть это в следующем примере:
- Создайте обычную модель, которая принуждает типы ввода.
- Копировать
Пиццас несовместимым входным значением. - Удивительно, но наша модель копируется «успешно» без возникновения ошибки
ValidationError.
Установка значения — еще один пример, когда Pydantic не выполняет никаких проверок:
- Еще раз: создайте обычную модель, которая принуждает типы ввода.
- Установить несовместимое входное значение
toppings_count. - Удивительно, но
ValidationErrorне возникает, когда мы устанавливаемtoppings_countс неверным значением.
К счастью, Pydantic позволяет довольно легко решить вышеупомянутую проблему установки:
-
Внутренний класс Configопределяет пользовательские конфигурации наших моделей. - Так мы говорим Pydantic, чтобы наши сеттеры выполняли проверки (и приведение типов) к входным данным.
- Pydantic теперь выполняет приведение типов, как мы и ожидали (по крайней мере, как я ожидал).
- Несовместимые типы вызывают
ValidationErrorс.

Я не смог найти простого способа сделать то же самое для копирования и обновления (кроме перезаписи copy )
Добавление ограничений в модели , int , List[str] и т. д. Однако во многих случаях этих типов недостаточно, и мы можем захотеть дополнительно ограничить типы.
Дальнейшее ограничение типов наших моделей, как правило, выгодно, так как оно имеет тенденцию уменьшать объем кода (и условных выражений), обеспечивает быструю обработку ошибок (обычно на границах нашей системы), обеспечивает лучшую обработку ошибок и лучше отражает требования нашей предметной области (существует очень интересная лекция, которая связана с этим называется ограничения освобождают свободы ограничивают). Pydantic предоставляет несколько вариантов добавления ограничений.
Pydantic предоставляет несколько вариантов добавления ограничений.
Пользовательские типы Pydantic
Pydantic поставляется с несколькими полезными пользовательскими типами. Некоторые конкретные типы:
- URL-адреса — ввод должен соответствовать схеме URL-адреса. Также имеет набор функций для извлечения различных частей URL.
- Пути к файлам — ввод должен быть действительным существующим файлом.
- UUID — ввод должен представлять допустимый UUID.
- Типы секретов — скрыть значения при печати или отображении в виде JSON.
- Номера платежных карт — ввод должен соответствовать схеме номера платежной карты. Также предоставляет способ доступа к соответствующим частям номера (марка, корзина и т. д.).
- Обязательно ознакомьтесь с документацией, так как их больше.
Типы ограничений
Можно определить примитивные типы, которые имеют больше ограничений на свои значения. Это особенно полезно для сокращения количества случаев, с которыми должны иметь дело наши системы. Некоторыми примерами являются непустые строки, непустые списки, положительные целые числа, диапазон чисел или строка, соответствующая определенному регулярному выражению.
Некоторыми примерами являются непустые строки, непустые списки, положительные целые числа, диапазон чисел или строка, соответствующая определенному регулярному выражению.
Рассмотрим следующий пример:
-
конструкцияявляется типом ограниченногоstr—strдолжен иметь не менее 1 символа. -
conlistявляется типом ограниченногоList[int]— список должен иметь хотя бы одну оценку. - Проверка имени не требуется, поскольку
Пользователигарантированно имеют хотя бы один символ в имени (конечно, при условии, что непустые строки являются допустимыми именами). - Мы можем немедленно использовать
maxнаUserбаллов, посколькуоцениваеткак гарантированно непустое — я считаю, что это самая интересная часть при использовании ограниченных типов, мы избегаем многих пограничных случаев. - Pydantic проверяет, что имя
- Pydantic проверяет, что
балловне пусты. - Входные данные, не соответствующие ограничениям, приводят к тому, что Pydantic выдает
ValidationError.

Различие между пользовательскими типами и ограниченными типами заключается в том, что пользовательские типы — это новые типы с соответствующим поведением (например, URL-адрес имеет host атрибут), в то время как ограниченные типы — это просто примитивные типы, которые могут принимать только подмножество домена своих входов (например, PositiveInt — это просто int , экземпляр которого может быть создан только из положительных int s).
Пользовательские валидаторы
Когда пользовательских типов и типов ограничений Pydantic недостаточно и нам нужно выполнить более сложную логику проверки, мы можем прибегнуть к пользовательским валидаторам Pydantic. Это в основном пользовательские функции проверки, которые мы добавляем к моделям.
Принуждение моделей к строгости типов
Чтобы объяснить строгие типы, давайте начнем с двух примеров:
- Мы ожидаем, что наши пользователи предоставят ответ
bool. - Может быть некоторая двусмысленность в ответе пользователя. Пользователь написал «да», но мы интерпретировали это как
True(это может быть ожидаемым поведением, но здесь есть место для ошибки). - Приведение типа приводит к потере информации, в результате чего 2 разных сводки получают одинаковую оценку.
Эти проблемы возникают из-за того, что Pydantic приводит значения к соответствующим типам. В большинстве случаев приведение типов удобно, но в некоторых случаях мы можем захотеть определить более строгие типы, которые предотвращают приведение типов.
Вот пример того, как это можно сделать:
- Мы сообщаем Pydantic, что
user_inputявляется строго логическим типом. - Только
TrueиFalseможно использовать в качестве входных данных дляuser_input. - Значения, которые обычно приводятся к
bool, больше не приводятся и приводят к возникновению ошибкиValidationError. -
scoreтеперь может принимать толькоints и никакие другие типы. -
Совместимые типы intбольше не принудительно выполняются, что приводит к возникновению ошибкиValidationError.

Неопределение моделей ключ-значение
Большинство моделей, которые мы используем с Pydantic (и примеры до сих пор), представляют собой просто набор пар ключ-значение. Однако не все входные данные могут быть представлены только входными данными типа «ключ-значение».
Рассмотрим следующий пример:
-
Именане могут представлять список изstr, так как он должен быть инициализирован полемзначений, но входные данные не соответствуют этому ожиданию — это приводит к ошибкеTypeError. - Аналогично,
Имяне может быть создано без использования имени поля значения
В некоторых случаях полезно определять модели, которые являются просто специализированными представлениями примитивных типов. Эти специализированные типы ведут себя точно так же, как их примитивные аналоги, но имеют другое значение для нашей программы.
Давайте посмотрим, как этого добиться:
-
__root__— это наш способ сообщить Pydantic, что наша модель не представляет собой обычную модель «ключ-значение». - Несмотря на то, что
Ageимеет значение 42, оно не равно обычному примитиву 42int. -
parse_obj— это еще один удобный метод анализа входных данных. - Pydantic поддерживает приведение типов для пользовательских моделей
__root__.
Эти заказные 9Модели 0013 __root__ могут быть полезны в качестве входных данных, как мы можем видеть в следующем примере:
-
age_in_daysможет сосредоточиться только на выполнении расчета дней и не требует дополнительной проверки или кода синтаксического анализа. -
__root__Модели выполняют приведение типов так же, как и любые другие модели. - Если мы будем непослушны и достаточно постараемся, мы, очевидно, сможем предоставить
age_in_daysзначение, не являющееся возрастом, но с mypy мы можем, по крайней мере, обнаружить некоторые проблемы с типизацией.
Помимо того, что мы уже обсуждали, __root__ модели имеют следующие интересные следствия: обычный int . При вызове foo легко случайно передать аргументы в неправильном порядке.
Возраст определяется как пользовательский 9Модель 0013 __root__ , когда мы конвертируем Person в JSON, Age ведет себя так же, как обычный int .До сих пор мы обсуждали преимущества, однако есть несколько вещей, которые мы должны учитывать:
- Хотя это круто, этим можно легко злоупотребить и сделать его сложным/сложным в использовании. Часть того, что делает Python таким увлекательным, — это его простота — имейте в виду и старайтесь не злоупотреблять этой функцией.
- Хотя преждевременная оптимизация является корнем всех зол, использование этих моделей в критичных к производительности разделах может стать узким местом (поскольку мы добавляем больше объектов, проверок и т. д.). Помните об этом, стремясь к производительности (это также верно для «обычных» моделей Pydantic, а не только для пользовательских
__root__моделей).
 Часть того, что делает Python таким увлекательным, — это его простота — имейте в виду и старайтесь не злоупотреблять этой функцией.
Часть того, что делает Python таким увлекательным, — это его простота — имейте в виду и старайтесь не злоупотреблять этой функцией. Определение этих пользовательских __root__ моделей может быть полезным при правильном использовании .
Управление настройками с помощью типов Literal
Есть еще одна полезная функция, которая работает с __root__ , но сначала давайте обсудим, как Pydantic помогает нам справляться с чтением и анализом переменных среды.
Много кода, который я видел для чтения и анализа настроек приложений, страдает от двух основных проблем: 1. много кода для чтения, анализа и обработки ошибок (поскольку переменные среды могут отсутствовать, быть написаны с ошибками или содержать несовместимое значение) — обычно они представлены в виде служебного кода. 2. когда есть несколько ошибок, мы обычно запускаем очень раздражающий цикл попыток прочитать конфигурации, сбой при первой ошибке (сбой программы), исправление ошибки, повтор * N (где N — количество ошибок конфигурации)
много кода для чтения, анализа и обработки ошибок (поскольку переменные среды могут отсутствовать, быть написаны с ошибками или содержать несовместимое значение) — обычно они представлены в виде служебного кода. 2. когда есть несколько ошибок, мы обычно запускаем очень раздражающий цикл попыток прочитать конфигурации, сбой при первой ошибке (сбой программы), исправление ошибки, повтор * N (где N — количество ошибок конфигурации)
Очевидно, что это очень раздражает, но, к счастью, с Pydantic эти проблемы очень легко решить с помощью Pydantic BaseSettings . Это более или менее все, что нам нужно сделать:
- Определить модель Pydantic со всеми необходимыми полями и их типами.
2. Наследовать от Pydantic BaseSettings, чтобы сообщить, что мы ожидаем, что эта модель будет прочитана и проанализирована из среды (или файла .env и т. д.)
3. Создайте модель без каких-либо входных значений (значения считываются из окружающая среда).
4. Поскольку есть ошибки, попытка прочитать
Поскольку есть ошибки, попытка прочитать Config приводит к возникновению ValidationError .
5. Поскольку Pydantic накапливает ошибки с ValidationError , мы можем видеть все ошибки сразу.
BaseSettings сама по себе очень полезная функция, но часто нам нужно читать разные модели (разные поля и типы), где каждая модель определяется средой, в которой мы работаем. Как мы можем добиться этого с помощью Pydantic?
Этого можно достичь, комбинируя типы Literal, Union Types и __root__ (которые мы рассматривали ранее). Вот план игры:
- Определить разные модели конфигурации (производство/постановка/локальная и т. д.)
- Каждая модель конфигурации также будет включать поле
env(я обычно называю этиenvилиprofile, но вы можете выбрать любое имя, которое вам нравится) с типом Literal, представляющим имя соответствующей среды. - Определите тип объединения всех возможных моделей конфигурации.
- Используйте
parse_obj_as, чтобы Pydantic прочитал его в соответствии с фактическим значениемENV.

Давайте посмотрим на код:
- У нас есть разные модели для каждой среды, в которой мы работаем — обратите внимание, что каждая модель также имеет соответствующий тип Literal.
-
Контекстможет быть либоLocalContext, либоProdContext— так Pydantic узнает, что он может читать одно или другое и ничего больше. -
parse_obj_as, за которым следует пустой словарь, — это наш способ указать Pydantic читатьContextв качестве настроек. Обратите внимание, что посколькуContextможет быть либоLocalContext, либоProdContext, он должен иметь типBaseSettings. Это означает, что нам не нужно предоставлять какие-либо аргументы дляparse_obj_asпри его вызове. -
локальныйсоответствует литеральному типулокальныйи, следовательно,LocalContextчитается. -
prodсоответствует литеральному типуprodи поэтомуProdContextчитается. - Если произошел сбой при чтении
Context, мы выдаемValidationError.

Редактировать: изначально я опубликовал несколько более сложную версию этого кода, но благодаря Нуно Андре мне удалось ее упростить.
Обратите внимание, что нам, очевидно, все еще нужно программно проверить переменную env , чтобы узнать, какой контекст мы на самом деле читаем (так как он был определен переменной среды), но:
- Нам нужно только прочитать и проанализировать контекст один раз из среды, а не делать это в 2 этапа: 1. прочитать только переменную
envиз среды. 2. прочитать остальные переменные среды в соответствии с переменнойenv. - Иногда мы хотим, чтобы имя среды было доступно нам для ведения журнала, мониторинга и т. д., поэтому наличие
envможет оказаться не излишним и может оказаться полезным.

Использование Pydantic для проверки аргументов функций
Эта функция очень новая (все еще находится в стадии бета-тестирования на момент написания этой статьи), поэтому убедитесь, что вы прочитали документацию, прежде чем использовать эту функцию в рабочей среде или сильно полагаться на нее.
До сих пор мы использовали способность Pydantic проверять и анализировать аргументы, когда использовали модели Pydantic. Но что происходит, когда у нас есть функция, которая не использует модель Pydantic в качестве аргументов, а использует только обычные аргументы? Можем ли мы каким-то образом использовать Pydantic для проверки этих аргументов?
Здесь в игру вступает validate_arguments. По сути, это декоратор Python, который мы можем добавить к любой функции с подсказками типа, а Pydantic проверит аргументы функции (работает и с методами).
Рассмотрим пример:
- Нет модели Pydantic. Несмотря на то, что
повторных попыток— этоPositiveInt, мы не получим никаких проверок. - Возникает ошибка
AttributeError, так какget_payloadпереданы неправильные аргументы. Также обратите внимание на второй тестовый пример, где оба аргумента недействительны. Когда это произойдет, мы получим толькоAttributeErrorдля первого аргумента, а не для обоих.
Мы можем добавить проверки к функции, используя validate_arguments :
- Для того, чтобы приводить типы ввода или сбой для недопустимых входных данных, нам нужно добавить декоратор
validate_arguments. - Поскольку
validate_argumentsфактически выполняет проверку ввода Pydantic, недопустимые входные данные больше не допускаются. - Pydantic вызывает
ValidationErrorпри неправильном вводе.
Не имеет прямого отношения к validate_arguments , но если мы уже используем Pydantic, мы можем сделать функцию get_payload еще лучше, указав типы, которые нам действительно нужны, например:
-
urlперемещеноулк более конкретному типуHttpUrl. - Так как
HttpUrlуже является действительным URL-адресом, нет необходимости выполнять его проверку внутри функции — опять же, наличие более ограниченных типов помогло нам устранить сложность.

Хотя новый, validate_arguments кажется действительно хорошим и полезным дополнением к Pydantic.
Резюме
С Pydantic очень легко начать работу, но также легко упустить некоторые из его более полезных функций. Эти функции важно знать, поскольку они могут помочь нам улучшить общее качество кода и найти лучшие способы обработки ошибок — и все это с относительно небольшими усилиями.
Fro 101 — Fro 2.0.0 документация
Объекты Parser — это рабочие лошадки модуля fro, обеспечивающие все основные функции синтаксического анализа модуля.
Однако в их работе есть несколько тонкостей, о которых пойдет речь в этом разделе.
Разбор путем перебора
Концептуально, когда объект Parser анализирует строку, он сначала пытается «использовать» начальную часть строки,
и из него произвести стоимость.
Если синтаксическому анализатору не удается проанализировать строку, то он не может ее проанализировать. В противном случае парсер успешен
в синтаксическом анализе строки, если (и только если) он потребляет всю строку во время пережевывания. Эта концептуальная модель будет
полезно для понимания того, что происходит, когда объекты Parser объединяются в новые анализаторы.
Например, fro.intp — это синтаксический анализатор, который использует непустые последовательности цифр (и другие вещи).
вы могли бы ожидать увидеть целое число, например начальный знак минус) и выдает соответствующие "2358" он будет потреблять начальную часть "2358" (которая оказывается всей строкой) и из нее производит
значение int 2358 . Поскольку синтаксический анализатор потребляет всю строку во время пережевывания, синтаксический анализ выполнен успешно.:
Поскольку синтаксический анализатор потребляет всю строку во время пережевывания, синтаксический анализ выполнен успешно.:
fro.intp.parse_str("2358") # chomps "2358" дает 2358, успешный синтаксический анализ!
При синтаксическом анализе строки "123abc" будет использована начальная часть "123" , производя значение int 123 . Однако синтаксический анализ будет неудачным, так как оставшиеся "abc" не были использованы.:
fro.intp.parse_str("123abc") # chomps "123" выдает 123, неудачный синтаксический анализ
Наконец, при синтаксическом анализе строки "abc123" он не сможет потреблять какую-либо часть строки, так как нет
начальная часть, содержащая только цифры. Начиная с fro.intp потребляет только непустые последовательности цифр, он не может
потреблять пустую начальную часть (что, как правило, разрешено анализаторам).:
fro.
 intp.parse_str("abc123") # ничего не может поглотить, неудачный анализ
intp.parse_str("abc123") # ничего не может поглотить, неудачный анализ
Объединение синтаксических анализаторов: состав
С помощью этой модели гораздо проще понять, что происходит при объединении синтаксических анализаторов.
В качестве примера рассмотрим состав парсера. Учитывая два парсера p1 и p2 , композиция р1 и p2 — это новый синтаксический анализатор, отдельный от p1 и p2 , но зависящий от них. При пережевывании струны сначала p1 попытка глотнуть. Если p1 успешно перебирает, то p2 перебирает оставшуюся неиспользованную часть строки.
Если либо p1 , либо p2 не могут поглотить, композиция не поглотит успешно. Если оба p1 и p2 умеют жевать и производить ценности v1 и v2 соответственно, то композиция потребляет обе порции
которые потребляют p1 и p2 и создают кортеж (v1, v2) .
В качестве примера рассмотрим следующее:
a_to_z = fro.rgx(r"[a-z]*") # потребляет, а затем создает строки, соответствующие регулярному выражению
композиция_parser = fro.comp([fro.intp, az_parser]) # композиция fro.intp и a_to_z
композиция_parser.parse_str("2357primes")
Когда композиция_парсер пытается поглотить "2357primes" , сначала fro.intp будет потреблять "2357" (выкл. "2357primes" ) и произвести 2357 , затем az_parser потребляет "простых чисел" (из "простых чисел" , т.е.
что остается после fro.intp ‘s chomp) и выдает "простых" . Поэтому композиция_парсер потребляет "2357primes" и создает кортеж (2357, «простые») . Поскольку композиция_парсер грызет весь
строка успешно анализируется.
Другой пример:
twoints_parser = fro.
 comp([fro.intp, fro.intp])
twoints_parser.parse_str("149") # что произойдет??
comp([fro.intp, fro.intp])
twoints_parser.parse_str("149") # что произойдет??
Когда twoints_parser пытается проглотить "149" , первый fro.intp потребляет "149" и производит 149 .
Однако на второй fro.intp 9 ничего не останется0014 для потребления, поэтому он ничего не съест.
Поскольку второй fro.intp не может грызть, композиция не может грызть и, следовательно, не может анализироваться.
Этот пример подчеркивает важное свойство парсеров fro: парсеры недальновидны. Если первый fro.intp в
вышеприведенный пример знал, что за ним следует еще один fro.intp , он, возможно, мог только пережевывать первые две цифры,
оставив "9" для второй fro.intp , и композиция могла создать кортеж (14, 9) . Однако, fro.intp основан на регулярном выражении [0-9]+ , которое соответствует как можно большему количеству цифр, поэтому потребляет
как можно больше цифр во время жевания.
Наконец, вы можете составить более двух синтаксических анализаторов вместе. Рассмотрим следующее:
композиция = fro.comp([fro.intp, fro.rgx(r"@"), fro.intp, fro.rgx(r"@"), fro.intp])
композиция.parse_str("123@45@6") # возвращает кортеж (123, "@", 45, "@", 6)
Когда композиция пытается съесть "123@45@6" , первый fro.intp потребляет "123" и производит 123 .
Затем оставшиеся неиспользованные "@45@6" передаются первому синтаксическому анализатору r"@" для chomp, который потребляет и производит "@" . После этого оставшиеся неиспользованные "45@6" передаются второму fro.intp , так что это продолжается для каждого
дочерних парсеров композиции. Дочерние парсеры выдают значения 123 , "@" , 45 , "@" , и 6 соответственно, поэтому композиция производит кортеж (123, "@", 45, "@", 6) .
Фрагменты
При синтаксическом анализе большого текстового файла желательно не считывать весь файл в память. Вместо этого перебор файла по частям приводит к гораздо лучшему использованию памяти.
Для обеспечения эффективного использования памяти Fro разбивает анализируемый текст на «фрагменты». Когда парсер жует, он грызет по одному фрагменту за раз и переходит к следующему фрагменту только после того, как он полностью потреблял текущую. Парсеры регулярных выражений, которые используются для построения практически любой другой тип синтаксического анализатора может работать только внутри одного фрагмента.
Рассмотрим пример:
композиция = fro.comp([r"abc", r"def"]) # первый аргумент функции parse(..) - это набор чанков для разбора композиция.parse(["abcd", "ef"]) # Этот синтаксический анализ завершится ошибкой. Первый синтаксический анализатор регулярных выражений отрежет «abc» от первого # чанк "abcd", оставив "d" позади. Второй парсер регулярных выражений попытается откусить # оставшуюся часть первого фрагмента, но не удалось.
 Поскольку регулярные выражения не могут
# "перейти" к следующему чанку, если текущий чанк не используется полностью, он
# неважно, что во втором чанке нас ждут "ef".
Поскольку регулярные выражения не могут
# "перейти" к следующему чанку, если текущий чанк не используется полностью, он
# неважно, что во втором чанке нас ждут "ef".
По умолчанию строки текстового файла служат фрагментами файла. Если вы хотите
разделить входной текст на куски другим способом, вы можете передать любую итерируемую коллекцию
строки в метод parse(..) синтаксического анализатора, и синтаксический анализатор будет обрабатывать каждый элемент
как отдельный кусок.
Поскольку синтаксический анализатор может перейти к следующему фрагменту только после того, как полностью израсходует текущий фрагмент, важно, чтобы синтаксический анализатор мог однозначно решить, как разобрать фрагмент, прежде чем перейти к следующий. Чтобы сделать это более конкретным, давайте рассмотрим другой пример:
a_then_b = fro.comp([r"a", r"b"]) a_then_c = fro.comp([r"a", r"c"]) # fro.alt(..) создает анализатор чередования, дополнительную информацию см. в документации ab_or_ac = fro.
 alt([a_then_b, a_then_c])
ab_or_ac.parse(["а", "с"])
# Этот синтаксический анализ завершится ошибкой. Парсер ab_or_ac сначала попытается проанализировать с помощью a_then_b.
# Регулярное выражение r"a" съест весь первый фрагмент ("a"). Когда регулярное выражение r"b" пытается
# пережевать второй кусок ("c"), не получится. На данный момент парсер имеет
# уже продвинулся ко второму фрагменту, поэтому он не может вернуться к первому
# чанк, чтобы попытаться пережевать с помощью a_then_c, так что это немедленно потерпит неудачу.
alt([a_then_b, a_then_c])
ab_or_ac.parse(["а", "с"])
# Этот синтаксический анализ завершится ошибкой. Парсер ab_or_ac сначала попытается проанализировать с помощью a_then_b.
# Регулярное выражение r"a" съест весь первый фрагмент ("a"). Когда регулярное выражение r"b" пытается
# пережевать второй кусок ("c"), не получится. На данный момент парсер имеет
# уже продвинулся ко второму фрагменту, поэтому он не может вернуться к первому
# чанк, чтобы попытаться пережевать с помощью a_then_c, так что это немедленно потерпит неудачу.
В приведенном выше примере синтаксический анализатор не может знать, как интерпретировать "a" в первом блоке без
глядя на второй кусок. То есть синтаксический анализатор не знает, является ли "а" частью чего-то, что a_then_b распознает или часть того, что a_then_c распознает. В этом случае,
он вслепую выбирает a_then_b и терпит неудачу.
Как насчет всех приведенных выше примеров, где мы только что вызвали parser.