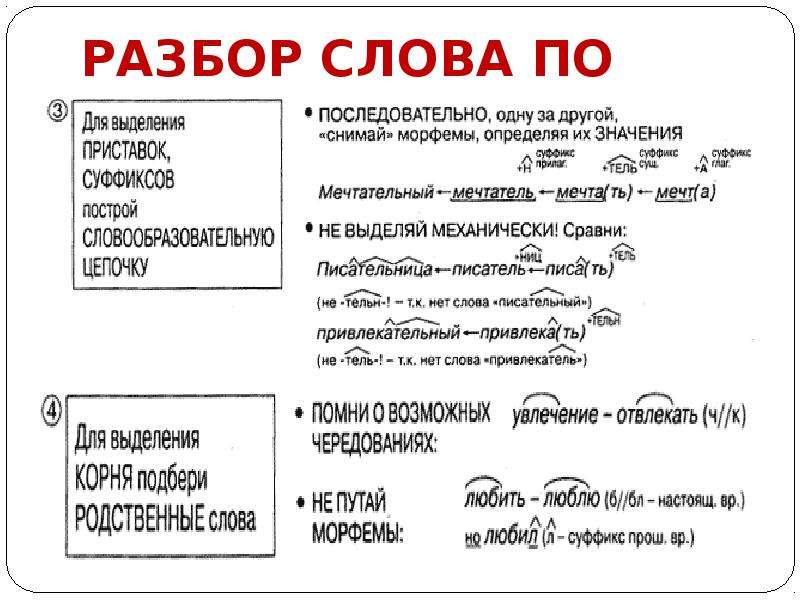
пояснительную записку; учебно-тематический план; содержание тем учебного курса; перечень учебно-методического обеспечения
Рабочая программа по русскому языку представляет собой целостный документ, включающий пять разделов: пояснительную записку; учебно-тематический план; содержание тем учебного курса; перечень учебно-методического обеспечения
1 2 3 4 5 6 7 8 9 … 82
1 2 3 4 5 6 7 8 9 … 82 База данных защищена авторским правом ©psihdocs.ru 2023 | Главная страница Автореферат Анализ Анкета Бағдарламасы Бизнес-план Биография Бюллетень Викторина Выпускная работа Глава Диплом |
 «___»___________2013г. «___»___________2013г
«___»___________2013г. «___»___________2013г
assemdisassem
Что такое машинный язык? Что такое язык ассемблера? Очевидно, инженеры-компьютерщики должны это знать. Почему средние программисты знаете о них?
Машинный язык
Вот машинный язык для фрагмента кода
(для процессора IA-32), который берет (из стека)
один 32-битный целочисленный аргумент — назовем его n — и возвращает
через eax значение 3n+1, если n четное, и 4n-3, если n нечетное.
1000101101001100001001000000010010001011110000011001100100110011 1100001001001011110000101000001111100000000000010011001111000010 0010101111000010100011010100010001001001000000010111010000000111 10001101000001001000110111111110111111111111111000011
Двоичный файл слишком сложно читать. Давайте использовать шестнадцатеричный:
8b 4c 24 04 8b c1 99 33 c2 2b c2 83 e0 01 33 c2 2b c2 8d 44 49 01 74 07 8d 04 8d fd ff ff ff c3
Как узнать, что он делает? Можешь глянуть на Интел
Руководство разработчика программного обеспечения, том 2, в Приложении A, «Карта кодов операций», или
любой из нескольких онлайн-источников, которые объясняют машинный язык.
Работая над этим, он показывает, что 8B — это первый байт.
инструкции MOV, которая перемещается из регистра или ячейки памяти
в реестр; чтобы узнать, какие операнды, мы смотрим в
следующие байты. Второй байт, 4C, указывает, что регистр
мы движемся в это ecx, и что источник движения
определяется из следующих двух байтов. Байты 24 и 04 означают
мы добавляем содержимое esp и 4, чтобы найти исходный адрес.
Байты 24 и 04 означают
мы добавляем содержимое esp и 4, чтобы найти исходный адрес.
Язык ассемблера
Немногие могут сказать, без чего «обходится» 8B 4C 24 04 много усилий, но большинство из них с небольшим знакомством с архитектура процессора будет понимать
мов екх, [esp+4]
Это удобное для человека перекодирование машинного языка называется языком ассемблера.
Когда вы переходите с машинного языка на язык ассемблера, процесс называется «разборка». Вот машина язык из нашего вышеприведенного примера вместе с дизассемблированным кодом:
0: 8b 4c 24 04 mov ecx, [исп+4] 4: 8б с1 ход еакс, есх 6: 99 кдд 7: 33 c2 xor eax, edx 9: 2b c2 sub eax, edx б: 83 e0 01 и eax, 1 e: 33 c2 xor eax, edx 10: 2b c2 sub eax, edx 12: 8d 44 49 01 lea eax, [ecx+ecx*2+1] 16: 74 07 йе 01fh 18: 8d 04 8d fd ff ff ff lea eax, [ecx*4-3] 1f: c3 возб
Обратите внимание, что не существует установленных правил относительно того, какой язык ассемблера
должен выглядеть; на самом деле версия, которую мы видели выше, использует Синтаксис NASM . Вот та же программа, использующая синтаксис GAS :
Вот та же программа, использующая синтаксис GAS :
. 0: 8b 4c 24 04 movl 0x4(%esp,1),%ecx 4: 8b c1 movl %ecx,%eax 6: 99 клтд 7: 33 c2 xorl %edx,%eax 9: 2b c2 subl %edx,%eax b: 83 e0 01 и $0x1,%eax e: 33 c2 xorl %edx,%eax 10: 2b c2 subl %edx,%eax 12:8д 44 4901 реальное 0x1(%ecx,%ecx,2),%eax 16: 74 07 йе 0x1f 18: 8d 04 8d fd ff ff ff leal 0xffffffffd(,%ecx,4),%eax 1f: c3 ret
NASM и GAS — это программы, называемые ассемблерами . Они
перевести язык ассемблера на машинный язык. После всего,
если мы хотим, чтобы наша программа работала, мы должны получить машину
код (т.е. байты типа 8B 4C 24 04… в память. Мы
нельзя ожидать, что люди сделают это напрямую, поэтому пишем на ассемблере
язык и пусть ассемблер сделает все остальное. Этот процесс
называется сборкой, и если вы хотите сделать это вручную, см. Приложение B
Тома 2 Руководства по разработке программного обеспечения Intel.
Вы можете дизассемблировать вручную, посмотрев на карту кода операции как
мы указали выше, хотя программы дизассемблера существуют.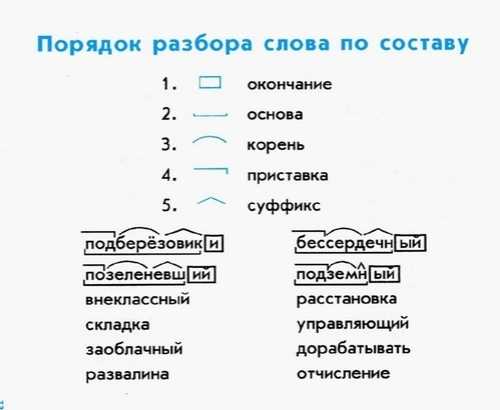
Программам на ассемблере нужно больше, чем просто инструкции процессора
(например, добавить , mov и так далее…). Им нужны директивы
сообщить ассемблеру, например, какие символы и метки импортировать
и экспортировать, чтобы код мог использовать код, написанный в других файлах. Другой
директивы необходимы, чтобы сообщить ассемблеру, что некоторые байты
должны рассматриваться как данные, а не как код, и в конечном итоге
хранится в сегментах только для чтения во время работы.
Зачем изучать этот материал?
Даже если вы никогда не программируете на ассемблере, и даже несмотря на то, что современные компиляторы часто производят лучший код, чем программисты на ассемблере, вы должны изучать машины и язык ассемблера, потому что (см. Брайант и О’Халларон, стр. 154):- Чтение вывода компилятора на языке ассемблера дает вам
понимание возможностей компилятора.

- Чтение вывода компилятора на языке ассемблера дает вам возможность определить, где и почему программа неэффективный.
- Иногда полезно знать, где компилятор выделил ваши данные и как он сопоставил ваши потоки с системой потоки.
- Многие атаки на компьютерные системы используют знание представление программ на машинном уровне.
Разборка — функция IDE | Встроенный микроконтроллер C
В этой статье давайте разберемся с функцией дизассемблирования IDE.
Что именно дизассемблировать код?
Если вы проверите значение словаря, дизассемблирование означает перевод из машинного кода в язык программирования более высокого уровня.
Рисунок 1. Словарное значение дизассемблирования
В нашем случае дизассемблирование означает, что у нас есть инструмент под названием Дамп объекта. Мы берем этот инструмент и запускаем его в исполняемом файле, который мы создали, то есть в файле .elf. И мы можем вернуть инструкции по сборке, сгенерированные для программы, которую мы написали. Это будет полезно, если вы хотите выполнить отладку на уровне инструкций.
Мы берем этот инструмент и запускаем его в исполняемом файле, который мы создали, то есть в файле .elf. И мы можем вернуть инструкции по сборке, сгенерированные для программы, которую мы написали. Это будет полезно, если вы хотите выполнить отладку на уровне инструкций.
В среде IDE также есть окно дизассемблирования, из которого вы можете наблюдать за сгенерированными инструкциями. IDE также делает то же самое, поэтому она также запускает инструмент objdump внутри файла elf.
Давайте зайдем в IDE и посмотрим, как получить функцию дизассемблирования. Теперь, когда вы находитесь в режиме отладки, вам нужно перейти в «Окно», «Показать представление» и нажать «Разборка».
Как показано на рисунке 3.
Рисунок 3. Инструкции в окне разборки
Это инструкции, сгенерированные для нашего кода. Все это инструкции ARM, или строго говоря, это инструкции Thumb-2 архитектуры набора инструкций ARM.
Рисунок 4. Архитектура процессора и набор инструкций
Обратите внимание, что здесь используется процессор ARM Cortex M4, а архитектура процессора — ARMv7E-M. Это название архитектуры процессора. В этой архитектуре используется ISA (архитектура набора инструкций), разработанная ARM, а название архитектуры набора инструкций — Thumb-2, набор 16- и 32-битных инструкций.
Это название архитектуры процессора. В этой архитектуре используется ISA (архитектура набора инструкций), разработанная ARM, а название архитектуры набора инструкций — Thumb-2, набор 16- и 32-битных инструкций.
Это инструкции ARM, которые генерируются для нашей основной функции. Мы проверяем код здесь (строка 19). Это случай чтения, изменения и записи, как показано на рисунке 5.
Рисунок 5. Инструкции ARM
Здесь вы видите эквивалентный ассемблерный код. Символы синего цвета — это мнемоника сборки, символы коричневого цвета — это коды операций, а символы зеленого цвета — это место, где размещается код операции для этой мнемоники инструкции.
Если вы заметили это, значит, у него есть набор инструкций по загрузке и сохранению. Сначала данные считываются из ячеек памяти в регистры процессора с помощью инструкций загрузки.
Сначала данные считываются из ячеек памяти в регистры процессора с помощью инструкций загрузки.
Вариант чтения, изменения и записи нашего кода (строка 19) имеет место, как показано на рисунке 5. Случай чтения — это чтение из ячейки памяти в регистры процессора. После этого Изменить случай операции Добавить. Итак, добавляются два регистра, и результат помещается в регистр r3. И после этого это запись обратно в ячейку памяти. Теперь содержимое r3 записывается обратно в ячейку памяти.
Если вы не видите этот код операции, щелкните здесь правой кнопкой мыши и выберите Показать коды операций.
Рисунок 6. Показать коды операций
И здесь вы можете видеть, что, несмотря на то, что мы написали только этот код операции, дизассемблирование показывает много кода, потому что вы вызвали здесь printf, который включает коды из стандартной библиотеки. Так, потому что наш проект также использует стандартную библиотеку.
Так, потому что наш проект также использует стандартную библиотеку.
Вы также можете проверить этот дизассемблированный инструмент с помощью инструмента objdump в вашем файле .elf. Например, введите команду arm-none-eabi-objdump.exe .
Рисунок 7. Инструмент Objdump
И вы можете использовать аргумент -d . То есть дизассемблировать — отображать ассемблерное содержимое исполняемых секций.
Рисунок 8. Инструмент Objdump
Я запускаю эту команду -d 003Add.elf . Посмотрите на рисунок 9; он дизассемблирует все разделы кода и дает вам сгенерированный ассемблерный код.
Много кода. Несмотря на то, что ваша программа выглядит очень простой, так как вы использовали printf, все эти коды из стандартной библиотеки включены.
Несмотря на то, что ваша программа выглядит очень простой, так как вы использовали printf, все эти коды из стандартной библиотеки включены.
Наш основной код находится прямо здесь. Наш основной код начинается с этого места 8000290 в памяти программы, и вталкивает {r7, lr} в качестве первой инструкции нашей основной функции, и вы можете видеть, что большинство инструкций имеют 16 бит.
И поскольку он использует наборы инструкций Thumb-2, некоторые инструкции также 32-битные. Например, инструкция f000 f927 является 32-битной инструкцией. Итак, если вы хотите узнать больше о Thumb-2, перейдите на веб-сайт ARM и изучите архитектуру набора инструкций Thumb-2, и обсуждение полностью выходит за рамки этой статьи.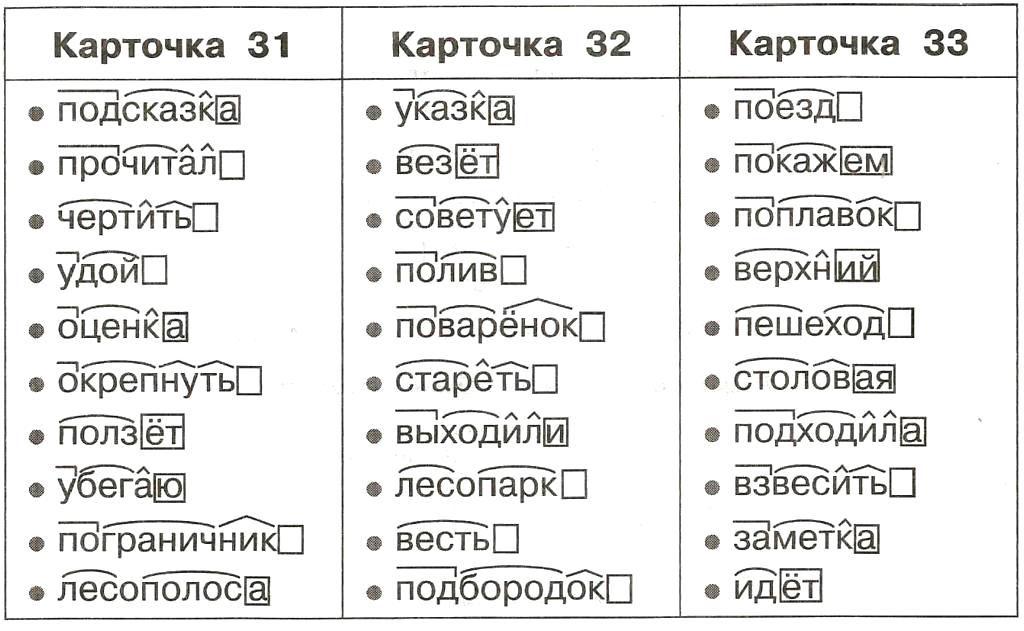
Речь идет о дизассемблировании, так что используйте его всякий раз, когда хотите выполнить отладку на уровне инструкций.
Я хочу отладить, что именно происходит в этой строке кода → result = g_data1 + g_data2;
Итак, я бы просто поставил две точки останова. Просто дважды щелкните по этой синей полосе и поставьте точку останова. Вы можете видеть, что в правой части окна дизассемблирования также вставлены две точки останова.
Рисунок 10. Отладка кода
Если я запущу код, вы увидите, что все эти инструкции выполняются, и я получил результат. Итак, результат такой, как показано на рис. 10.
10.
Но если вы хотите выполнить отладку этой строки на уровне инструкций, вам придется вставить точки останова в окно дизассемблирования. Позвольте мне все сбросить.
Я хочу посмотреть, что именно происходит в этих двух инструкциях, 0x0000064b и 0x00001a68. Я бы поставил здесь точку останова (рис. 11), а затем запустил код. А теперь позвольте мне проверить регистр r2, потому что это был затронутый регистр.
Проверим регистратора r2. Теперь давайте перейдем к регистрам, r2. И здесь вы можете видеть это, поэтому значение из памяти данных считывается и помещается во внутренний регистр r2. То есть -4000.
Рисунок 11. Отладка на уровне инструкций
Теперь изменим формат на шестнадцатеричный. Из r3 (адреса) значение считывается и помещается в r2.
Из r3 (адреса) значение считывается и помещается в r2.
И что после этого произойдет, если r3 будет загружен с другим адресом? Посмотрим, что это за адрес. Удалите точку останова в первой строке и поместите точку останова здесь, в следующей строке, и запустите. И содержимое r3 теперь изменяется на это значение 0x20000004, чтобы получить следующее значение.
Рисунок 13. Отладка на уровне инструкций
После этого поставлю точку останова в следующей строке и запустим. И здесь мы видим, что теперь r3 содержит 0xc8, что не что иное, как 200. Итак, теперь r2 имеет -4000, а r3 имеет 200. После этого выполняется add.
Рисунок 14. Отладка на уровне инструкций Вы видите, что добавление выполняется, и результат помещается в регистр r3. Результат следует записать обратно в память данных в переменную результат .