Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
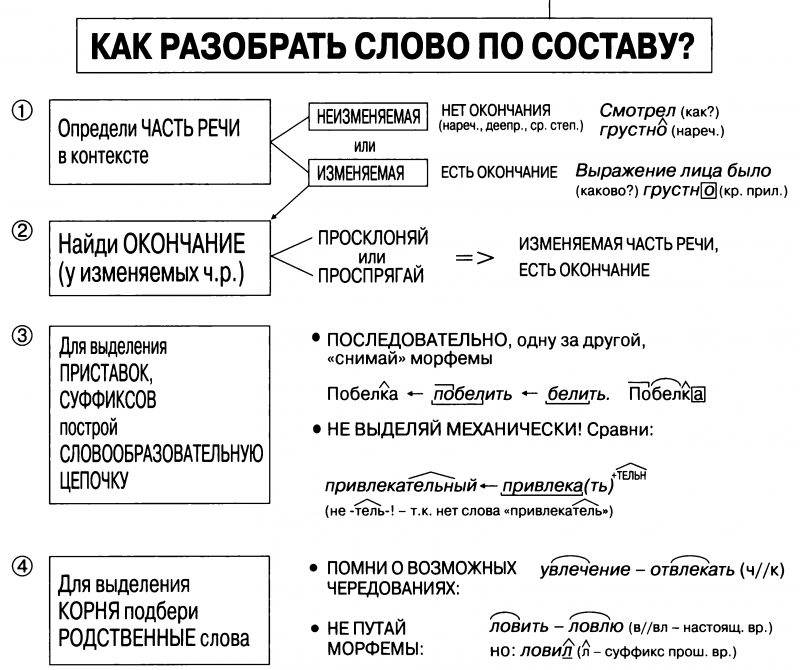
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.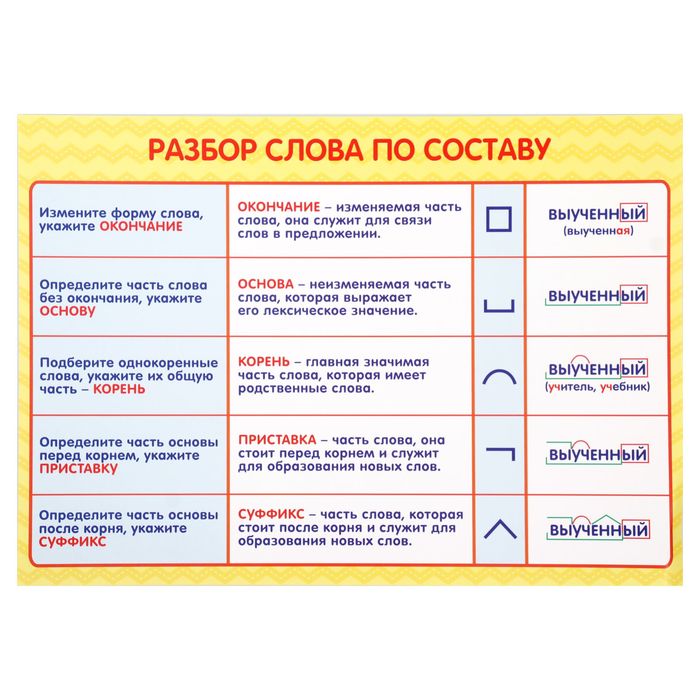
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: класс судна 1 секунда назад рьниаос 1 секунда назад таматамаканахолли 1 секунда назад теплица 1 секунда назад желудок 1 секунда назад я р г к д а 1 секунда назад соен лн 1 секунда назад стройка 1 секунда назад канутси 1 секунда назад словарь 1 секунда назад н а п е р с т о к 1 секунда назад спицани 1 секунда назад типолик 1 секунда назад лопсы 1 секунда назад карбоко 1 секунда назад
python — Разбить число на составляющие
На вход функцией input подается 6-значеное число. Нужно разбить его на на отдельные числа. Например: 123456 -> 1 2 3 4 5 6. Делается это для того, чтобы проверить эквивалентность суммы первой и второй тройки чисел (Задача о счастливом билете). В программировании я начинающий и желательно всё сделать операциями div, mod, if-else
В программировании я начинающий и желательно всё сделать операциями div, mod, if-else
a = int(input())
b = a//1000
one = b//100
two = b%11
three = b%10
c = a%1000
four = c//100
five = c%11
six = c%10
if (one+two+three)==(four+five+six):
print ('Счастливый')
else:
print ('Обычный')
- python
- python-2.x
- числа
0
Можно, конечно, честно посчитать остатки от деления и т.д., но проще всего разбить на символы строку, а потом перевести эти символы обратно в числа. Делается это во второй строке следующей программы:
a = 123456 b = map(int, str(a)) print b if len(b)==6: print "Happy" if b[0] + b[1] + b[2] == b[3] + b[4] + b[5] else "Unhappy"
Если очень хочется честным образом делить на 10, то можно вторую строку этой программы заменить на такой фрагмент:
b = [] while a > 0: b.append(a % 10) a = a // 10 b = b[::-1] # так можно развернуть, если бы нам был важен порядок print b
Теперь по тексту Вашей программы: почему-то берётся остаток от деления на 11 (в строках two = b%11 и five = c%11, хотя правильно было бы поделить на 10, а потом взять остаток от деления на 10 (two = (b // 10) % 10).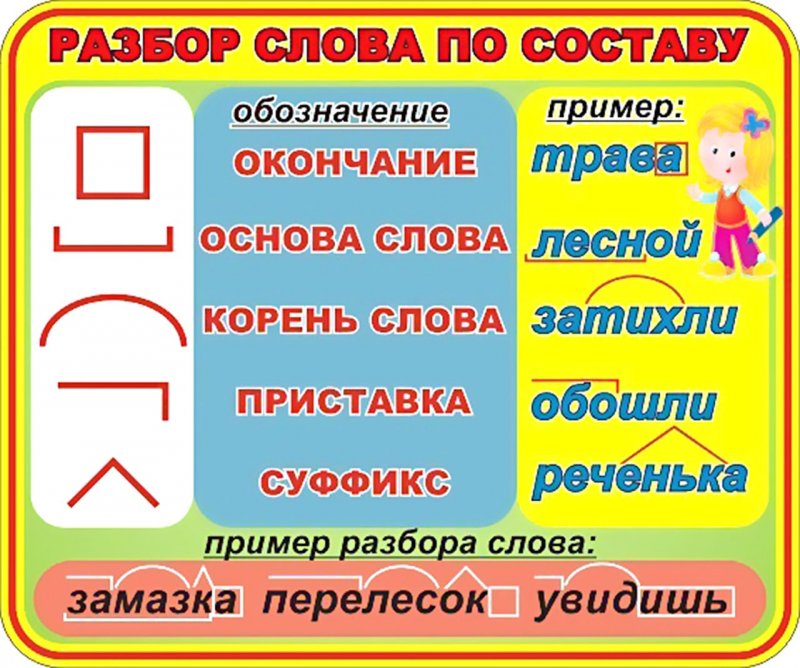
Дополнение:
Если нам важно поддержать случаи входных значений a менее, чем шестизначных, то можно поменять всего одну строчку:
while len(b) < 6: # теперь в b заведомо будет 6 элементов
Также рекомендую изучить код из соседнего ответа (от jfs), так как в нём есть ряд интересных моментов.
2
Чтобы найти сумму цифр числа, заданного в виде строки:
def sum_digits(s):
return sum(map(int, s))
это идиоматичный способ для данной задачи в Питоне.
sum_digits() функцию можно использовать, чтобы определить является ли заданное число «счастливым»:
#!/usr/bin/env python3
s = input()
middle = len(s) // 2 # середина
if middle == 0 or sum_digits(s[:middle]) == sum_digits(s[-middle:]):
print('Счастливый')
else:
print('Обычный')
Число считается «счастливым», если сумма цифр левой половины равна сумме цифр правой половины числа. Пустая строка (нет цифр) — в качестве вырожденного случая — также рассматривается «счастливой».
Пустая строка (нет цифр) — в качестве вырожденного случая — также рассматривается «счастливой».
Если хочется, можно использовать деление, чтобы разбить неотрицательное целое число на отдельные цифры:
def digits_recursive(n, digits=[]):
return digits_recursive(n // 10, [n % 10] + digits) if n else digits or [0]
Пример:
>>> digits_recursive(123) [1, 2, 3]
Или то же самое, используя явный цикл:
def digits_iterative(nonneg):
digits = []
while nonneg:
digits += [nonneg % 10]
nonneg //= 10
return digits[::-1] or [0]
Пример:
>>> digits_iterative(123) [1, 2, 3] >>> sum(_) 6
Видел это задание во вводном курсе Python до изучения массивов и функций типа map() так что в том случае корректней было вот такое решение.
a = int(input())
b = a//1000
one = b // 100
two = b // 10 % 10
three = b % 10
c = a % 1000
four = c // 100
five = c // 10 % 10
six = c % 10
if (one+two+three)==(four+five+six):
print ('Счастливый')
else:
print ('Обычный')
num = list('123321')
summ_1 = int(num[0]) + int(num[1]) + int(num[2]) #cумма первых трех
summ_2 = int(num[3]) + int(num[4]) + int(num[5]) #cумма последних трех трех
1
Тут еще прикол в том, что в задаче написано, что вводится строка. И задача решается совсем просто.
И задача решается совсем просто.
a = input()
b = int(a[0])+int(a[1])+int(a[2])
c = int(a[3])+int(a[4])+int(a[5])
if c == b:
print('Счастливый')
else:
print('Обычный')
n = input() # ввод b = list(n) # делаем с этого числа список из цифр (они будут сохранятся как текст) c = [ int(el) for el in b] # делаем из текста числа для каждого элемента списка (можете в интернете посмотреть генераторы списков)
1
a = int(input())
summa = 0
forcha = 0
for i in range(3):
d = a // (10 ** ((len(str(a)))-1))
a %= (10 ** ((len(str(a)))-1))
summa += d
for j in range(3):
g = a // (10 ** ((len(str(a))) - 1))
a %= (10 ** ((len(str(a))) - 1))
forcha += g
if summa == forcha:
print("Счастливый")
else:
print("Не счастливый")
1
Если про счастливый билет, то можно так:
is_happy = lambda x: x % 1e3 % 9 == x // 1e3 % 9
Тогда можно писать что-то вроде:
is_happy(888978) # True is_happy(265827) # False
Тут не прямое суммирование, а так называемое «корневое число», когда цифры суммируются рекурсивно, пока не останется только одна.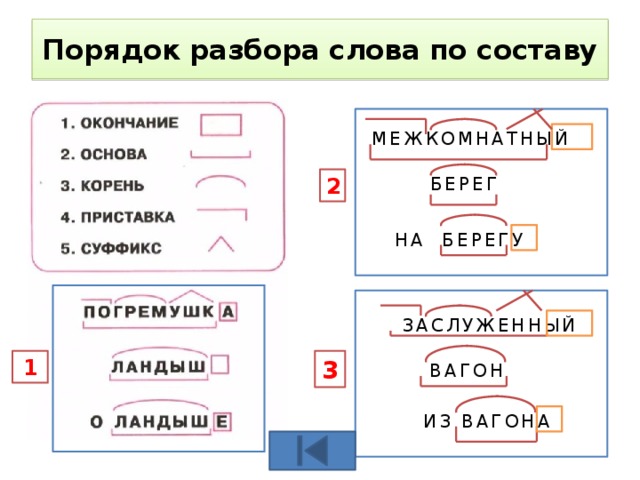
Если пары не по 3 числа, а по 4, тогда вместо 1e3 пишем 1e4, если по 2 — соответственно 1e2, ну и так далее.
Если надо прямо по-русски написать, то ну вот так вот сделайте:
{True: 'Счастливый', False: 'Несчастливый'}[is_happy(235631)]
# Или так, будет выполняться быстрее, но первый вариант читабельнее
is_happy(235631) and 'Счастливый' or 'Несчастливый'
numbers = list(input())
if int(numbers[0]) +int(numbers[1]) + int(numbers[2]) == int(numbers[3]) +int(numbers[4]) + int(numbers[5]):
print('Счастливый')
else:
print('Несчастливый')
1
Анализ химического состава
Анализ химического состава проводится для широкого круга целей, от идентификации и характеристики материала до мониторинга контроля качества. Анализ дает ценную информацию об элементах пробы. Анализ химического состава или элементный анализ может быть качественным (определение присутствия элементов) и количественным (определение количества каждого из них).
Анализ химического состава
- Проверка соответствия стандарту или спецификации (ASME, MIL, ASTM и т. д.)
- Оценка сырья
- Обнаружение примесей
- Определите сплавы
проводится с использованием оптического эмиссионного спектрометра, который обеспечивает компьютеризированную обработку и представление результатов.
Приложения
- Чугун и сталь и их сплавы
- Алюминий и его сплавы
- Медь и ее сплавы
- Никель и его сплавы
- Кобальт и его сплавы
- Магний и его сплавы
- Свинец и его сплавы
- Олово и его сплавы
- Титан и его сплавы
- Цинк и его сплавы
Подробнее
Химический анализ является важным испытанием для проверки того, что поставляемый материал соответствует требованиям к конструкции или продукту; или определить обрабатываемость, долговечность и свариваемость материала.
 Химический анализ является одним из важных методов поддержки исследования анализа отказов. В настоящее время технологии в сталелитейной промышленности более конкурентоспособны и инновационны. Производители выпускают новые разновидности конкретных современных сталей для удовлетворения технологических потребностей. Эти технологии могут добавлять, увеличивать или уменьшать некоторые критические элементы в производстве современной стали, чтобы сделать ее легче, прочнее и устойчивее к теплу, химическим веществам или окружающей среде. Качество материала должно быть разработано и контролироваться для обеспечения соответствия состава требованиям.
Химический анализ является одним из важных методов поддержки исследования анализа отказов. В настоящее время технологии в сталелитейной промышленности более конкурентоспособны и инновационны. Производители выпускают новые разновидности конкретных современных сталей для удовлетворения технологических потребностей. Эти технологии могут добавлять, увеличивать или уменьшать некоторые критические элементы в производстве современной стали, чтобы сделать ее легче, прочнее и устойчивее к теплу, химическим веществам или окружающей среде. Качество материала должно быть разработано и контролироваться для обеспечения соответствия состава требованиям.Nusatek предоставляет два (2) типа возможностей для проверки или идентификации химического состава. У нас есть новейшие технологии для анализа химического состава с использованием передовых методов оптической эмиссионной спектрометрии (ОЭС) и рентгеновской флуоресценции (РФ) на основе устройств с зарядовой связью (ПЗС). Каждый метод имеет свои возможности и преимущества.
Мы также предоставляем различные блоки сертифицированных эталонных материалов (CRM), чтобы гарантировать, что все приведенные результаты химического анализа являются достоверными и удовлетворительными.Клиенты всегда требуют передовых технологий и точных результатов. Вы всегда можете проконсультироваться с нами, чтобы выбрать лучший метод, основанный на ваших потребностях. Наши технические специалисты имеют большой опыт в области свойств металлов и компетентны в выборе наилучшего метода химического анализа.
Спектрометрия оптического излучения
Спектрометрия атомного излучения (AES) — это метод химического анализа, который использует интенсивность света, или наклонен, п. на определенной длине волны, чтобы определить количество элемента в образце. Длина волны атомной спектральной линии идентифицирует элемент, а интенсивность излучаемого света пропорциональна количеству атомов элемента.
Искровая или дуговая атомно-эмиссионная спектроскопия используется для анализа металлических элементов в твердых образцах. Электрическая дуга или искра проходят через образец, нагревая его до высокой температуры, чтобы возбудить атомы внутри него. Возбужденные атомы аналита излучают свет с характерными длинами волн, который можно рассеять с помощью монохроматора и обнаружить. В прошлом, когда условия искры или дуги обычно плохо контролировались, анализ элементов в образце был качественным. Однако современные искровые источники с управляемыми разрядами можно считать количественными.
Принцип оптико-эмиссионной спектрометрии
Оптико-эмиссионная спектрометрия включает применение электрической энергии в виде искры, генерируемой между электродом и металлическим образцом, посредством чего испаренные атомы переводятся в высокоэнергетическое состояние в так называемом «разрядная плазма».
Эти возбужденные атомы и ионы в плазме разряда создают уникальный спектр излучения, специфичный для каждого элемента, как показано справа.
Таким образом, один элемент генерирует множество характерных эмиссионных спектральных линий.Таким образом, можно сказать, что свет, генерируемый разрядом, представляет собой совокупность спектральных линий, генерируемых элементами в образце. Этот свет разделяется дифракционной решеткой для извлечения спектра излучения целевых элементов. Интенсивность каждого спектра излучения зависит от концентрации элемента в образце. Детекторы (фотоумножители) измеряют наличие или отсутствие или наличие спектра, выделенного для каждого элемента, и интенсивность спектра для выполнения качественного и количественного анализа элементов.
Оптическая система
Данная спектрометрическая система оснащена креплением Пашена-Рунге. Операционная технология использует приложение Solder Checker для определения длины волны, возникающей в процессе искрового разряда. Новый прибор на основе устройства с зарядовой связью (ПЗС) с высоким разрешением и технологией Clear Spectrum обнаруживает генерируемый импульс и анализирует данные, что позволяет получать более быстрые и надежные результаты.
Рисунок 1: Система ПЗС в оборудовании OES- Пробоподготовка : Без покрытия поверхности, очистить от жира или загрязнений, требуется финишная шлифовка поверхности
- Размер образца : плоская поверхность на твердом образце (12–100 мм, ширина)
- Химические элементы detec t : Все элементы относятся к каталожным номерам блоков CRM
Рисунок 3: Коллекция блоков CRM
 Химический анализ является одним из важных методов поддержки исследования анализа отказов. В настоящее время технологии в сталелитейной промышленности более конкурентоспособны и инновационны. Производители выпускают новые разновидности конкретных современных сталей для удовлетворения технологических потребностей. Эти технологии могут добавлять, увеличивать или уменьшать некоторые критические элементы в производстве современной стали, чтобы сделать ее легче, прочнее и устойчивее к теплу, химическим веществам или окружающей среде. Качество материала должно быть разработано и контролироваться для обеспечения соответствия состава требованиям.
Химический анализ является одним из важных методов поддержки исследования анализа отказов. В настоящее время технологии в сталелитейной промышленности более конкурентоспособны и инновационны. Производители выпускают новые разновидности конкретных современных сталей для удовлетворения технологических потребностей. Эти технологии могут добавлять, увеличивать или уменьшать некоторые критические элементы в производстве современной стали, чтобы сделать ее легче, прочнее и устойчивее к теплу, химическим веществам или окружающей среде. Качество материала должно быть разработано и контролироваться для обеспечения соответствия состава требованиям. Мы также предоставляем различные блоки сертифицированных эталонных материалов (CRM), чтобы гарантировать, что все приведенные результаты химического анализа являются достоверными и удовлетворительными.
Мы также предоставляем различные блоки сертифицированных эталонных материалов (CRM), чтобы гарантировать, что все приведенные результаты химического анализа являются достоверными и удовлетворительными.
 Таким образом, один элемент генерирует множество характерных эмиссионных спектральных линий.
Таким образом, один элемент генерирует множество характерных эмиссионных спектральных линий.
Анализ состава программного обеспечения (SCA) — Palo Alto Networks
Заблаговременно устраняйте уязвимости открытого исходного кода и проблемы с соблюдением условий лицензии с помощью интеграции разработчиков и контекстно-зависимой приоритизации.
Запросить бесплатную пробную версию
ПОЧЕМУ ЭТО ВАЖНОНАШ ПОДХОДМОДУЛИРЕСУРСЫ
По мере того, как уязвимости становятся все более распространенными и неуловимыми, организациям требуется более быстрый, простой и удобный способ устранения рисков с открытым исходным кодом.
 Размытая грань между облачной инфраструктурой и уровнями приложений дает возможность защитить исходный код, встроенный в инструменты DevOps. Применяя комплексный подход к обеспечению безопасности и соответствия требованиям с открытым исходным кодом, организации могут свести к минимуму количество ложных срабатываний, расставить приоритеты в результатах и быстрее обеспечивать безопасность кода.
Размытая грань между облачной инфраструктурой и уровнями приложений дает возможность защитить исходный код, встроенный в инструменты DevOps. Применяя комплексный подход к обеспечению безопасности и соответствия требованиям с открытым исходным кодом, организации могут свести к минимуму количество ложных срабатываний, расставить приоритеты в результатах и быстрее обеспечивать безопасность кода.Прочитайте об исследовании Unit 42 уязвимостей в открытом коде.
Скачать отчет
1
Облачные приложения зависят от открытого исходного кода
Программное обеспечение с открытым исходным кодом является важным компонентом облачных приложений, что дает разработчикам преимущество при создании новых функций, не изобретая велосипед. Однако при всех своих преимуществах стороннее программное обеспечение с открытым исходным кодом создает риски безопасности и соответствия требованиям, которые необходимо устранять в рамках любой облачной программы безопасности.
2
Разрастание зависимостей порождает риск
Программное обеспечение с открытым исходным кодом содержит много уровней зависимостей пакетов, что затрудняет определение того, где и как части OSS используются в стеке приложений. Более того, уязвимости часто скрыты в транзитивных пакетах. Отслеживание этих уязвимостей и лицензий требует непрерывного комплексного подхода.
Более того, уязвимости часто скрыты в транзитивных пакетах. Отслеживание этих уязвимостей и лицензий требует непрерывного комплексного подхода.
3
Разрозненные инструменты безопасности вызывают пробелы в покрытии
Без полного контекста инфраструктуры приложения трудно определить, действительно ли обнаруженная уязвимость обнаружена в приложении или представляет низкий риск. Благодаря объединению данных о безопасности приложений и инфраструктуры уязвимости обнаруживаются в контексте всей кодовой базы, что позволяет лучше расставлять приоритеты и быстрее исправлять.
Prisma Cloud позволяет разработчикам легко устранять риски с открытым исходным кодом, не замедляя работу.
Благодаря интеграции с инструментами DevOps, а также с кодом, сборкой, развертыванием и средой выполнения, Prisma Cloud активно сканирует пакеты с открытым исходным кодом на наличие уязвимостей и проблем с соблюдением условий лицензии. Модель данных Prisma Cloud, которая связывает инфраструктуру на уровне кода и слабые места приложений, полная экстраполяция зависимостей и детальные исправления версий, отличает его от других решений SCA.
- Единое представление подключенной инфраструктуры и рисков приложений
- Интегрировано в инструменты и рабочие процессы разработчика
- Полная безопасность жизненного цикла пакетов и образов контейнеров
- Создано на надежных источниках
- Удобная для разработчиков интеграция
- Безграничное сканирование дерева зависимостей
- Исправление изменения версии
- Анализ лицензий и аудиторская отчетность
- Пользовательские правила применения
ОБЛАЧНОЕ РЕШЕНИЕ PRISMA
Контекстно-зависимый подход к анализу состава программного обеспечения, ориентированный на разработчиков
Высокоточный и контекстно-зависимый
Построенный на основе самых авторитетных баз данных уязвимостей и подключенный к самой надежной в отрасли базе данных политик инфраструктуры, Prisma Cloud Software Composition Analysis (SCA) выявляет уязвимости в контексте, который необходим разработчикам для понимания риска и быстро внедрять исправления. Prisma Cloud обеспечивает широту и глубину охвата открытого исходного кода, необходимые для устранения следующей серьезной уязвимости:
Prisma Cloud обеспечивает широту и глубину охвата открытого исходного кода, необходимые для устранения следующей серьезной уязвимости:
Сканирование на разных языках и в менеджерах пакетов с непревзойденной точностью
Выявление уязвимостей в пакетах с открытым исходным кодом с поддержкой всех самых популярных языков и более чем 30 исходных источников данных для минимизации ложных срабатываний.
Используйте ведущие в отрасли источники для полной уверенности в безопасности с открытым исходным кодом
Prisma Cloud сканирует зависимости с открытым исходным кодом, где бы они ни находились, и сравнивает их с общедоступными базами данных, такими как NVD и Prisma Cloud Intelligence Stream, для выявления уязвимостей и получения важной информации об исправлениях.
Соединение рисков инфраструктуры и приложений
Сосредоточьтесь на уязвимостях, которые действительно обнаружены в вашей кодовой базе, чтобы бороться с ложными срабатываниями и быстрее определять приоритеты исправлений.
Выявление уязвимостей на любой глубине зависимости
Prisma Cloud использует данные диспетчера пакетов для экстраполяции деревьев зависимостей на самый дальний уровень для выявления скрытых от глаз рисков с открытым исходным кодом.
Визуализация и каталогизация цепочки поставок программного обеспечения
Диаграмма цепочки поставок предоставляет сводную инвентаризацию ваших конвейеров и кода. Визуализация всех этих связей, а также возможность генерировать спецификацию программного обеспечения (SBOM) упрощает отслеживание рисков приложений и понимание вашей поверхности атаки.

Полностью интегрирован с гибкими исправлениями
Только разработчики имеют полный контекст того, как и где используются библиотеки с открытым исходным кодом, поэтому предоставление им обратной связи — лучший способ исправить уязвимости. Используя встроенные средства разработки Prisma Cloud и расширяемость наших инструментов командной строки, SCA полностью интегрирован в рабочие процессы разработчиков, поэтому уязвимости обнаруживаются в нужном месте в нужное время:
Используя встроенные средства разработки Prisma Cloud и расширяемость наших инструментов командной строки, SCA полностью интегрирован в рабочие процессы разработчиков, поэтому уязвимости обнаруживаются в нужном месте в нужное время:
Интеграция средств защиты с открытым исходным кодом в инструменты и рабочие процессы разработчиков
Дайте разработчикам уверенность в интеграции новых пакетов в свои кодовые базы с обратной связью об уязвимостях в режиме реального времени через IDE и запросы на включение/слияние VCS.
Создание и применение настраиваемых политик на протяжении всего жизненного цикла
Интегрируйте управление уязвимостями для сканирования репозиториев, реестров, конвейеров CI/CD и сред выполнения и определения того, какое программное обеспечение заблокировано или разрешено.
Исправление проблем без внесения критических изменений
Получите рекомендуемое наименьшее обновление для устранения уязвимостей в прямых и транзитивных зависимостях без риска нарушения критических функций.
Устраняйте сразу несколько проблем с помощью гибкого выбора отдельных версий для каждого пакета.Создание спецификации программного обеспечения
Prisma Cloud найдет зависимости в репозиториях и создаст спецификацию программного обеспечения (SBOM) и спецификацию материалов инфраструктуры (IBOM), а также экспортирует их в стандартные форматы.
 Устраняйте сразу несколько проблем с помощью гибкого выбора отдельных версий для каждого пакета.
Устраняйте сразу несколько проблем с помощью гибкого выбора отдельных версий для каждого пакета.Часть CNAPP
Единственный способ обеспечить полный охват при защите облачных приложений — это поиск уязвимостей на каждом уровне и этапе жизненного цикла разработки. SCA — это всего лишь один из компонентов облачной платформы защиты приложений Prisma Cloud, который выявляет риски от кода до облака.
Выявление рисков в коде, когда разработчики создают и тестируют программное обеспечение
Проверяйте пакеты и образы с открытым исходным кодом на наличие уязвимостей и проблем соответствия в репозиториях, таких как GitHub, и реестрах, таких как Docker, Quay, Artifactory и других.
Блокировка развертываний для проверенных образов
Используйте сканирование образов Prisma Cloud и анализ изолированной программной среды контейнера для выявления и блокировки вредоносных образов и допускайте использование только безопасных образов.
Предотвратить активность в любой среде выполнения
Управляйте всеми политиками времени выполнения с централизованной консоли, чтобы гарантировать, что безопасность всегда присутствует как часть каждого развертывания. Сопоставление инцидентов с инфраструктурой MITRE ATT&CK, а также подробная криминалистическая экспертиза и обширные метаданные помогают командам SOC отслеживать угрозы для эфемерных облачных рабочих нагрузок.
Контекстно-зависимая безопасность среды выполнения
Обнаружение и предотвращение неправильных конфигураций и уязвимостей, которые приводят к утечке данных и нарушению нормативных требований во время выполнения, с помощью полной инвентаризации облачных ресурсов, оценки конфигурации, автоматизированных исправлений и многого другого.


Соответствие лицензии OSS
Не ждите ручной проверки соответствия, чтобы выяснить, что библиотека с открытым исходным кодом не соответствует вашим требованиям к использованию лицензии. Prisma Cloud каталогизирует лицензии с открытым исходным кодом для зависимостей и может предупреждать или блокировать развертывания на основе настраиваемых политик лицензирования:
Избегайте дорогостоящих нарушений лицензии на открытый исходный код
Своевременная обратная связь и блокировка сборок на основе нарушений лицензии на пакеты с открытым исходным кодом с поддержкой всех популярных языков и менеджеров пакетов.
Использовать политики по умолчанию, основанные на стандартном отраслевом использовании
Стандартные политики поставляются с определенными уровнями серьезности для распространенных типов лицензий и сопоставлением шаблонов для языка нестандартных типов лицензий, чтобы упростить определение допустимого использования.
