делаем синтаксический разбор предложения :: SYL.ru
От клетки до ёлочки. Выбираем трендовые варианты для верхней теплой одежды
Монохромный макияж — хит осеннего сезона: советы по созданию трендового мейапа
Подходит к коротким и длинным: 10 идей стрижек с прямой челкой
Каким будет трендовый макияж 2022: в моде снова 60-е
С рюшами и атласные: восемь моделей элегантных и стильных женских рубашек
Немного льда не повредит: как пожарить сочный лук
Чтоб урожай был знатным. Готовим подкормку для смородины из крахмала
Челка-шторка и прямые волосы — идеальное сочетание: несколько идей с фото
Смесь меда и молока: пять секретов красивой кожи женщин Ближнего Востока
Автор Ирина Шикло
Значение синтаксического разбора
Слова и словосочетания — это составляющие каждого предложения на письме и в устной речи. Для его построения следует четко понимать, какая должна быть между ними связь, чтобы построить грамматически правильное высказывание. Именно поэтому одной из важных и сложных тем в школьной программе русского языка является синтаксический разбор предложения. При таком разборе проводится полный анализ всех компонентов высказывания и устанавливается имеющаяся между ними связь. Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Для его построения следует четко понимать, какая должна быть между ними связь, чтобы построить грамматически правильное высказывание. Именно поэтому одной из важных и сложных тем в школьной программе русского языка является синтаксический разбор предложения. При таком разборе проводится полный анализ всех компонентов высказывания и устанавливается имеющаяся между ними связь. Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Правила разбора словосочетаний
Анализ определенного словосочетания, взятого из контекста, является относительно простым в разделе синтаксиса русского языка. Для того чтобы его произвести, определяют, какое из слов выступает главным, а какое — зависимым, и определяют, к какой части речи каждое из них относится. Далее необходимо определить синтаксическую связь между этими словами. Всего их выделяют три:
Всего их выделяют три:
- Согласование – это своего рода подчинительная связь, при которой род, число и падеж для всех элементов словосочетания определяет главное слово. Например: отдаляющийся поезд, летящая комета, светящее солнце.
- Управление также является одним из видов подчинительной связи, оно может быть сильным (когда падежная связь слов необходима) и слабым (когда падеж зависимого слова не предопределен). Например: поливать цветы – поливать из лейки; освобождение города – освобождение армией.
- Примыкание – это также подчинительный вид связи, однако он относится лишь к неизменяемым и не склоняемым по падежам словам. Зависимость такие слова выражают лишь смыслом. Например: езда верхом, непривычно грустный, очень страшно.
Пример синтаксического разбора словосочетаний
Синтаксический разбор словосочетания должен выглядеть примерно так: «красиво говорит»; главное слово – «говорит», зависимое – «красиво». Эту связь определяют посредством вопроса: говорит (как?) красиво. Слово «говорит» использовано в настоящем времени в единственном числе и третьем лице. Слово «красиво» – это наречие, а потому в данном словосочетании выражается синтаксическая связь – примыкание.
Слово «говорит» использовано в настоящем времени в единственном числе и третьем лице. Слово «красиво» – это наречие, а потому в данном словосочетании выражается синтаксическая связь – примыкание.
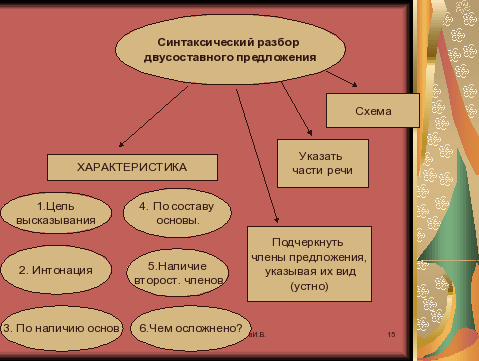
Схема синтаксического разбора простого предложения
Синтаксический разбор предложения немного похож на анализ словосочетания. Состоит он из нескольких этапов, которые позволят изучить структуру и отношение всех составляющих его компонентов:
- В первую очередь определяют цель высказывания отдельно взятого предложения, все они делятся на три вида: повествовательные, вопросительные и восклицательные, или побудительные. Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного – восклицательный.
- Далее следует выделить грамматическую основу предложения – подлежащее и сказуемое.
- Следующий этап – описание строения предложения.
 Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.
Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова. - Далее синтаксический разбор предложения предусматривает разбор всех слов по их принадлежности к частям речи, роду, числу и падежу.
- Завершающий этап – объяснение поставленных в предложении знаков препинания.
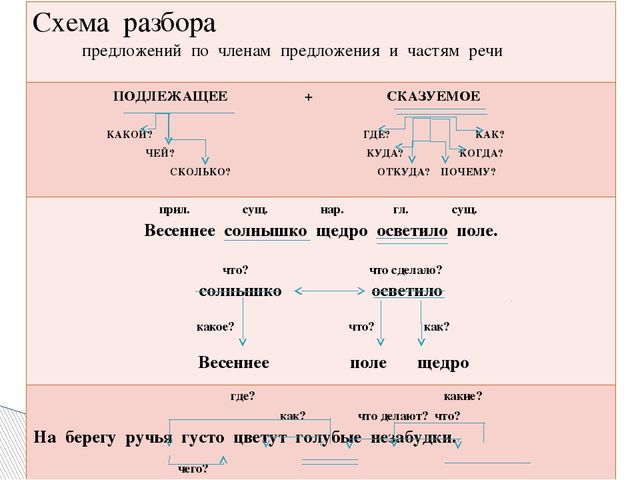 Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.
Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.Пример синтаксического разбора простого предложения
Теория теорией, но без практики нельзя закрепить ни одной темы. Именно поэтому в школьной программе много времени уделяется синтаксическим разборам словосочетаний и предложений. И для тренировки можно брать самые простые предложения. Например: «Девушка лежала на пляже и слушала прибой».
Например: «Девушка лежала на пляже и слушала прибой».
- Предложение повествовательное и невосклицательное.
- Главные члены предложения: девушка – подлежащее, лежала, слушала – сказуемые.
- Данное предложение двусоставное, полное и распространенное. В качестве осложнений выступают однородные сказуемые.
- Разбор всех слов предложения:
- «девушка» — выступает в роли подлежащего и является существительным женского рода в единственном числе и именительном падеже;
- «лежала» — в предложении является сказуемым, относится к глаголам, имеет женский род, единственное число и прошедшее время;
- «на» — это предлог, служит для связи слов;
- «пляже» — отвечает на вопрос «где?» и является обстоятельством, в предложении выражено существительным мужского рода в предложном падеже и единственном числе;
- «и» — союз, служит для соединения слов;
- «слушала» — второе сказуемое, глагол женского рода в прошедшем времени и единственном числе;
- «прибой» — в предложении является дополнением, относится к имени существительному, имеет мужской род, единственное число и употреблено в винительном падеже.

Обозначение частей предложения на письме
При синтаксическом разборе словосочетаний и предложений используются условные подчеркивания, которые обозначают принадлежность слов к тому или иному члену предложения. Так, например, подлежащее подчеркивают одной линией, сказуемое — двумя, определение обозначают волнистой линией, дополнение – пунктиром, обстоятельство – пунктиром с точкой. Для того чтобы правильно определить, какой именно член предложения перед нами, следует поставить к нему вопрос от одной из частей грамматической основы. К примеру, на вопросы имени прилагательного отвечает определение, дополнение определяется вопросами косвенных падежей, обстоятельство указывает на место, время и причину и отвечает на вопросы: «где?» «откуда?» и «почему?»
Синтаксический разбор сложного предложения
Порядок разбора сложного предложения немного отличается от вышеприведенных примеров, а потому не должен вызвать особых трудностей. Однако все должно быть по порядку, и поэтому учитель усложняет задачу лишь после того, как дети научились разбирать простые предложения. Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
- Сначала определяют цель высказывания и эмоциональную окраску.
- Далее выделяют грамматические основы в предложении.
- Следующий шаг – определение связи, которая может осуществляться при помощи союза или без него.
- Далее следует указать, посредством какой связи соединены две грамматических основы в предложении. Это могут быть интонация, а также сочинительные или подчинительные союзы. И тут же сделать вывод, каким является предложение: сложносочиненным, сложноподчиненным или бессоюзным.
- Следующий этап разбора – это синтаксический анализ предложения по его частям. Производят его по схеме для простого предложения.
- В заключение анализа следует построить схему предложения, на которой будет видна связь всех его частей.
Связь частей сложного предложения
Как правило, для связи частей в сложных предложениях употребляются союзы и союзные слова, перед которыми обязательно ставится запятая. Такие предложения называются союзными. Делятся они на два вида:
Такие предложения называются союзными. Делятся они на два вида:
- Сложносочиненные предложения, соединенные посредством союзов а, и, или, то, но. Как правило, обе части в таком высказывании равноправны. Например: «Солнце светило, а облака плыли».
- Сложноподчиненные предложения, в которых используются такие союзы и союзные слова: чтобы, как, если, где, куда, так как, хотя и другие. В таких предложениях всегда одна часть зависит от другой. Например: «Солнечные лучи заполнят комнату, как только пройдет туча».
Похожие статьи
- Виды сложных предложений: таблица, примеры. Основные виды сложных предложений
- Аллитерация: примеры в литературе
- Морфологический разбор разных частей речи
- Синтаксический разбор и значение фразеологизма «авгиевы конюшни»
- Работа с возражениями. Примеры, техника, упражнения
- Что такое причастный оборот? Правила его образования, применения и выделения на письме
 Примеры, техника, упражнения
Примеры, техника, упражненияТакже читайте
Синтаксический разбор простого предложений — Правила и примеры — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
делаем синтаксический разбор предложения :: SYL.ru
Значение синтаксического разбора
Слова и словосочетания — это составляющие каждого предложения на письме и в устной речи. Для его построения следует четко понимать, какая должна быть между ними связь, чтобы построить грамматически правильное высказывание. Именно поэтому одной из важных и сложных тем в школьной программе русского языка является синтаксический разбор предложения. При таком разборе проводится полный анализ всех компонентов высказывания и устанавливается имеющаяся между ними связь. Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Помимо этого, определение структуры предложения позволяет правильно расставить в нем знаки препинания, что достаточно важно для каждого грамотного человека. Как правило, данная тема начинается с разбора простых словосочетаний, а после детей учат проводить синтаксический разбор предложения.
Правила разбора словосочетаний
Анализ определенного словосочетания, взятого из контекста, является относительно простым в разделе синтаксиса русского языка. Для того чтобы его произвести, определяют, какое из слов выступает главным, а какое — зависимым, и определяют, к какой части речи каждое из них относится. Далее необходимо определить синтаксическую связь между этими словами. Всего их выделяют три:
- Согласование – это своего рода подчинительная связь, при которой род, число и падеж для всех элементов словосочетания определяет главное слово. Например: отдаляющийся поезд, летящая комета, светящее солнце.
- Управление также является одним из видов подчинительной связи, оно может быть сильным (когда падежная связь слов необходима) и слабым (когда падеж зависимого слова не предопределен). Например: поливать цветы – поливать из лейки; освобождение города – освобождение армией.
- Примыкание – это также подчинительный вид связи, однако он относится лишь к неизменяемым и не склоняемым по падежам словам. Зависимость такие слова выражают лишь смыслом. Например: езда верхом, непривычно грустный, очень страшно.
 Например: поливать цветы – поливать из лейки; освобождение города – освобождение армией.
Например: поливать цветы – поливать из лейки; освобождение города – освобождение армией.Пример синтаксического разбора словосочетаний
Синтаксический разбор словосочетания должен выглядеть примерно так: «красиво говорит»; главное слово – «говорит», зависимое – «красиво». Эту связь определяют посредством вопроса: говорит (как?) красиво. Слово «говорит» использовано в настоящем времени в единственном числе и третьем лице. Слово «красиво» – это наречие, а потому в данном словосочетании выражается синтаксическая связь – примыкание.
Схема синтаксического разбора простого предложения
Синтаксический разбор предложения немного похож на анализ словосочетания. Состоит он из нескольких этапов, которые позволят изучить структуру и отношение всех составляющих его компонентов:
- В первую очередь определяют цель высказывания отдельно взятого предложения, все они делятся на три вида: повествовательные, вопросительные и восклицательные, или побудительные. Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного – восклицательный.
- Далее следует выделить грамматическую основу предложения – подлежащее и сказуемое.
- Следующий этап – описание строения предложения. Оно может быть односоставное с одним из главных членов или двусоставное с полной грамматической основой. В первом случае дополнительно нужно указать, каким именно предложение является по характеру грамматической основы: глагольным или назывным. А далее определить, есть ли в структуре высказывания второстепенные члены, и указать, распространенное оно или нет. На этом этапе также следует указать, осложненное ли предложение. Осложнениями считают однородные члены, обращения, обороты и вводные слова.
- Далее синтаксический разбор предложения предусматривает разбор всех слов по их принадлежности к частям речи, роду, числу и падежу.
- Завершающий этап – объяснение поставленных в предложении знаков препинания.
 Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного – восклицательный.
Для каждого из них характерен свой знак. Так, в конце повествовательного предложения, рассказывающего о каком-либо событии, стоит точка; после вопроса, естественно, — вопросительный знак, а в конце побудительного – восклицательный.
Пример синтаксического разбора простого предложения
Теория теорией, но без практики нельзя закрепить ни одной темы. Именно поэтому в школьной программе много времени уделяется синтаксическим разборам словосочетаний и предложений. И для тренировки можно брать самые простые предложения. Например: «Девушка лежала на пляже и слушала прибой».
- Предложение повествовательное и невосклицательное.
- Главные члены предложения: девушка – подлежащее, лежала, слушала – сказуемые.
- Данное предложение двусоставное, полное и распространенное. В качестве осложнений выступают однородные сказуемые.
- Разбор всех слов предложения:
- «девушка» — выступает в роли подлежащего и является существительным женского рода в единственном числе и именительном падеже;
- «лежала» — в предложении является сказуемым, относится к глаголам, имеет женский род, единственное число и прошедшее время;
- «на» — это предлог, служит для связи слов;
- «пляже» — отвечает на вопрос «где?» и является обстоятельством, в предложении выражено существительным мужского рода в предложном падеже и единственном числе;
- «и» — союз, служит для соединения слов;
- «слушала» — второе сказуемое, глагол женского рода в прошедшем времени и единственном числе;
- «прибой» — в предложении является дополнением, относится к имени существительному, имеет мужской род, единственное число и употреблено в винительном падеже.

Обозначение частей предложения на письме
При синтаксическом разборе словосочетаний и предложений используются условные подчеркивания, которые обозначают принадлежность слов к тому или иному члену предложения. Так, например, подлежащее подчеркивают одной линией, сказуемое — двумя, определение обозначают волнистой линией, дополнение – пунктиром, обстоятельство – пунктиром с точкой. Для того чтобы правильно определить, какой именно член предложения перед нами, следует поставить к нему вопрос от одной из частей грамматической основы. К примеру, на вопросы имени прилагательного отвечает определение, дополнение определяется вопросами косвенных падежей, обстоятельство указывает на место, время и причину и отвечает на вопросы: «где?» «откуда?» и «почему?»
Синтаксический разбор сложного предложения
Порядок разбора сложного предложения немного отличается от вышеприведенных примеров, а потому не должен вызвать особых трудностей. Однако все должно быть по порядку, и поэтому учитель усложняет задачу лишь после того, как дети научились разбирать простые предложения. Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
Для проведения анализа предлагается сложное высказывание, которое имеет несколько грамматических основ. И здесь следует придерживаться такой схемы:
- Сначала определяют цель высказывания и эмоциональную окраску.
- Далее выделяют грамматические основы в предложении.
- Следующий шаг – определение связи, которая может осуществляться при помощи союза или без него.
- Далее следует указать, посредством какой связи соединены две грамматических основы в предложении. Это могут быть интонация, а также сочинительные или подчинительные союзы. И тут же сделать вывод, каким является предложение: сложносочиненным, сложноподчиненным или бессоюзным.
- Следующий этап разбора – это синтаксический анализ предложения по его частям. Производят его по схеме для простого предложения.
- В заключение анализа следует построить схему предложения, на которой будет видна связь всех его частей.
Связь частей сложного предложения
Как правило, для связи частей в сложных предложениях употребляются союзы и союзные слова, перед которыми обязательно ставится запятая.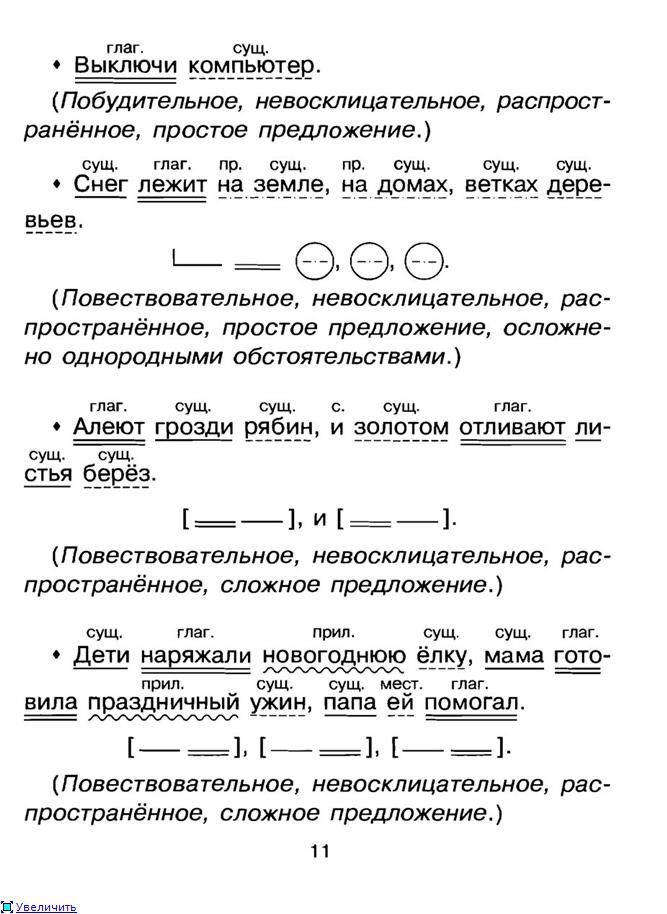 Такие предложения называются союзными. Делятся они на два вида:
Такие предложения называются союзными. Делятся они на два вида:
- Сложносочиненные предложения, соединенные посредством союзов а, и, или, то, но. Как правило, обе части в таком высказывании равноправны. Например: «Солнце светило, а облака плыли».
- Сложноподчиненные предложения, в которых используются такие союзы и союзные слова: чтобы, как, если, где, куда, так как, хотя и другие. В таких предложениях всегда одна часть зависит от другой. Например: «Солнечные лучи заполнят комнату, как только пройдет туча».
Порядок синтаксического разбора сложносочинённого предложения
План разбора:
Вид предложения по цели высказывания (повествовательное, вопросительное или побудительное).
- Вид предложения по эмоциональной окраске (восклицательное или невосклицательное).
Сложное.
Союзное.
Сложносочинённое.
Количество частей в составе сложного, их границы (выделить грамматические основы в простых предложениях).
Средства связи между частями (указать союзы и определить значение сложного предложения).
Схема предложения.

Образец разбора:
Была зима, но все последние дни стояла
. (И.Бунин).
(Повествовательное, невосклицательное, сложное, союзное, сложносочинённое, состоит из двух частей, между первой и второй частями выражено противопоставление, части соединены противительным союзом
Схема предложения:
[ ]1, но [ ]2.
Порядок синтаксического разбора сложноподчинённого предложения
План разбора:
Союзное.
Сложноподчинённое.
Количество частей (выделить грамматические основы в простых предложениях).
Главная и придаточная части.
Что распространяет придаточная часть.
Чем присоединяется придаточная часть.
Расположение придаточной части.
Тип придаточной части.
Схема сложноподчинённого предложения.

Когда она играла внизу на рояле1, я вставал и слушал2. (А.П. Чехов)
(Повествовательное,
невосклицательное, сложное, союзное,
сложноподчинённое, состоит из двух
частей. 2-я часть главная, 1-я – придаточная,
придаточная часть распространяет
главную часть и присоединяется к ней
союзом когда,
придаточная часть располагается перед
главной, тип придаточной части –
придаточное времени).
Схема предложения:
Когда?
(союз когда…)1, [ … ]2.
придаточное
времени
Сущ.. глаг. союз мест. Глаг. пр. прил. сущ.
Путники увидели,
что они
[ ____ ], (что…).
Порядок синтаксического разбора бессоюзного сложного предложения
План разбора:
Вид предложения по цели высказывания (повествовательное, вопросительное или побудительное).
Вид предложения по эмоциональной окраске (восклицательное или невосклицательное).
Сложное.
Бессоюзное.
Количество частей (выделить грамматические основы в простых предложениях).
Схема предложения.

Образец разбора:
Песенка кончилась1 – раздались обычные рукоплескания 2. (И.С. Тургенев)
(Повествовательное, невосклицательное, сложное, бессоюзное, состоит из двух частей, первая часть указывает на время действия того, о чём говорится во второй части, между частями ставится тире.)
Схема предложения:
[]1 — []2 .
17
Синтаксический разбор
Синтаксический разбор предложения, будь оно простое или сложное — задача обычно не из легких при анализе текста. Синтаксический разбор – это грамматическая характеристика синтаксических единиц, а именно словосочетаний, простых и сложных предложений.
Синтаксический разбор словосочетания
Во-первых, выделите из текста словосочетание, во-вторых, в выделенном словосочетании определите главное и зависимое от него слово, выясните способ синтаксической связи и не забудьте указать, через какие части речи выражены главное и зависимое слова. В-третьих, укажите грамматический смысл словосочетания.
В-третьих, укажите грамматический смысл словосочетания.
Разбор по членам предложения
Разбор синтаксической конструкции по членам требует обширных знаний русского языка и внимательности. Для того чтобы выполнить разбор без ошибок, желательно следовать приведённому ниже плану:
1. Сначала определите вид предложения. Установите, простое оно или сложное.
2. Посмотрите на строение предложения: односоставное оно или двусоставное. Зачастую путают односоставные конструкции с неполными двусоставными конструкциями. В односоставных предложениях обычно отсутствует подлежащее, в неполном двусоставном может отсутствовать любой главный член. Кроме того, в тексте подлежащее можно выделить из придаточного предложения, или какого-либо другого, связанного по смыслу с односоставным.
3. Затем укажите распространенность или нераспространенность.
4. Отметьте, осложненное ли это предложение: вводными словами, однородными членами, обращениями и др.
5. Выполните разбор по членам предложения, объясните, какими частями речи выражены слова.
6. Определите, каким образом расставлены знаки препинания. При условии присутствия в предложении однородных членов, нужно обязательно определить их часть речи и к какому слову они относятся, а также каким образом они связаны в предложении.
7. Если в предложении присутствуют обособленные члены, то необходимо выяснить, через какой член предложения выражен обособленный оборот, а затем разобрать его структуру.
8. Обязательно укажите, есть ли в предложении прямая речь.
Разбор сложного предложения
Для начала определите, какого типа сложное предложение: сложносочиненное, сложноподчиненное или бессоюзное.
Синтаксический разбор сложносочиненного предложения
Определите вид предложения. У простых предложений, содержащихся в сложном, выделите грамматические основы. Укажите, при помощи каких союзов простые предложения связаны в сложное. Объясните, каким образом расставлены знаки препинания. Выполните разбор простых предложений.
Синтаксический разбор сложноподчиненного предложения
Определите вид предложения, выделите простые составляющие. Выясните, какое из предложений главное, а какое – придаточное. Покажите, каким образом расставлены знаки препинания в предложении. Выполните разбор простых предложений.
Выясните, какое из предложений главное, а какое – придаточное. Покажите, каким образом расставлены знаки препинания в предложении. Выполните разбор простых предложений.
Синтаксический разбор бессоюзного предложения
Сначала необходимо определить вид предложения. Затем выделить подлежащее и сказуемое в каждом из предложений. Выяснить численность простых предложений в сложном и отношения между ними. Объяснить, каким образом расставлены знаки препинания в предложении.
Синтаксический разбор сложного предложения с разными видами связи
Выясните вид предложения. Определите грамматические основы простых составляющих. Объясните, как организованы предложения в сложном, каким образом расставлены знаки препинания. Выполните разбор по членам.
Наш великий русский язык не только богат и красив, но и сложен, поэтому изучать его нужно долго и упорно! Приведённый выше материал поможет понять структуру анализируемого текста и научит писать стилистически грамотно.
Разбор предложений с помощью ДРУГОГО инструмента естественного языка: LinkGrammar
- Тип:
- Разговор
- Уровень аудитории:
- Новичок
- Категория:
- Наука
11 марта 14:10 – 14:55
Описание
Многие из вас, вероятно, знакомы с NLTK, замечательным набором инструментов естественного языка для Python. Возможно, вы не знакомы с Linkgrammar — системой разбора предложений, созданной в университете Карнеги-Мелон. Linkgrammar довольно надежен и работает «из коробки» так, как NLTK не работает для синтаксического анализа предложений.
Возможно, вы не знакомы с Linkgrammar — системой разбора предложений, созданной в университете Карнеги-Мелон. Linkgrammar довольно надежен и работает «из коробки» так, как NLTK не работает для синтаксического анализа предложений.
Аннотация
NLTK — фантастическая библиотека с широкими возможностями. Но часто я обнаруживаю, что мне нужно что-то, что просто делает то, что я хочу, без необходимости выяснять все детали. Примером этого является разбор предложений. Быстрый поиск в Google по синтаксическому анализу предложений с помощью NLTK возвращает ряд статей, описывающих, как написать собственную грамматику и определить синтаксический анализатор на основе этой грамматики и синтаксического анализа предложений.Это отлично подходит для игрушечных задач и обучения, но если вам действительно нужно анализировать предложения «из дикой природы», написание собственной грамматики — огромная задача.
Введите ссылку. Linkgrammar был разработан в университете Карнеги-Мелон и теперь поддерживается разработчиками Abiword в качестве основы для их возможностей проверки грамматики. Он отлично работает из коробки и терпим к неточностям, обнаруженным в аутентичном тексте.
Он отлично работает из коробки и терпим к неточностям, обнаруженным в аутентичном тексте.
Вот набросок структуры выступления:
- Введение в доклад с обзором структуры
- Обсудить NLTK и признать все, что он предлагает
- Показать примеры кода, найденного в Интернете, для создания простого синтаксического анализатора с помощью NLTK
- Показать предложение синтаксического анализа фрагмента кода с помощью pylinkgrammar
- Существующие привязки представляли собой простую обертку SWIG библиотеки C.Я расширил эти привязки, чтобы предложить более Pythonic интерфейс.
- Показать примеры: Сначала простые предложения
- Связи между словами имеют разные типы, и существует набор правил, определяющих, какие слова и какого типа слова могут иметь определенные связи между собой
- Покажите пример: несколько более сложные версии исходного предложения для обозначения различий в типах ссылок
- Показать примеры использования различных параметров синтаксического анализа
- Показать примеры создания составляющих деревьев
- Обсудить историю/предысторию системы грамматики ссылок: разработана в CMU, в настоящее время поддерживается AbiWord и используется в проекте RelEx и др.
- Что такое грамматика ссылок и чем она отличается от других подходов?
- Большинство систем синтаксического анализа создают составные деревья фраз; показать примеры
- Опишите правила, которые Linkgrammar использует для создания ссылок между словами
- Показать примеры определения грамматики
- Постобработка этих связей позволяет создать стандартное составное дерево фраз.
- Показать больше примеров составляющих деревьев фраз
- Что нужно сделать?
- Чем вы можете помочь?
Разбор предложения (особенно хорошего предложения, такого как цитата, пословица…)
1. Синтаксический анализ Алгоритм Грамматика — это просто декларативное утверждение того, что образует правильное предложение.
2. Ускорение процесса разбора может быть достигнуто за счет исключения разборов с низкой вероятностью.5.8.
3. Теперь я буду обсуждать процесс разбора диаграммы со ссылкой на эти требования.
4. Затем психолингвисты создают теории человеческого синтаксического анализа , а компьютерные лингвисты создают теории автоматизированного синтаксического анализа.
5. Основная проблема с разбором сверху вниз заключается в потере времени на расширение правил, которые не могут быть удовлетворены входными данными.
6. Сериализация — это операция, обратная разбору XML .
7. Анализ глобального запроса создает дерево запросов.
8. Разбор Метод: Единицей выборки является каждый уникальный символ.
9. Маркировка семантической роли — это неглубокий семантический метод анализа .
10. Он показывает, как вручную закодировать аргумент командной строки , анализируя .
11. Как и DOM, синтаксические анализаторы SAX управляют полным процессом синтаксического анализа .
12. Это приведет к тому, что SAX остановит процесс анализа .
13. Лексический анализатор с использованием таблицы LR синтаксического анализа унифицирует метод построения лексического анализатора и синтаксического анализатора, упрощает проектирование и построение компилятора.
Лексический анализатор с использованием таблицы LR синтаксического анализа унифицирует метод построения лексического анализатора и синтаксического анализатора, упрощает проектирование и построение компилятора.
14. Анализируя этот выходной файл, вы можете определить изменения между исходным каталогом и целевым ссылочным каталогом.
14. Sentencedict.com — это словарь предложений, в котором вы можете найти красивые предложения для большого количества слов.
15.Обсуждается форматирование и анализ базовых типов данных , а также использование регулярных выражений для обработки текста.
16. Expat — это ориентированная на события библиотека XML синтаксического анализа с открытым исходным кодом, созданная Джеймсом Кларком.
17. Это включает в себя подробный процесс разбора имени записи и преобразования его в совместимый формат.
18. Разбор фреймворков — обширная тема, требующая изучения для получения полной картины; эти две статьи являются хорошим началом как для читателей, так и для меня.
19. Направленный путь синтаксический анализ разработан на основе прогнозного анализа и теории диаграммы переходов состояний.
20. В этой главе более подробно исследуется влияние таких классов эквивалентности на разбор фонем в слова. 6.1.1.
21. Оценка вероятности также может повысить эффективность алгоритма разбора за счет исключения альтернатив с низкой вероятностью.
22. Еще одним важным мотивом является мотивация психолингвистов, которые разрабатывают компьютерные анализирующие системы в качестве испытательных стендов для гипотез о человеческой лингвистической обработке.
23. Для определения происхождения предложения необходимо использовать алгоритм разбора .
24. Обратите внимание, что поскольку вы имеете дело как с механизмом запроса/ответа, так и с анализом XML , блок try/catch обрамляет всю эту функцию.
25. Это временное отношение между временем события и временем выступления или другим эталонным временем, которое может быть получено с помощью временной фразы , анализирующей китайского текста.
26. Таким образом, в районе Йингмаили Таримского бассейна изучается метод анализа сейсмических атрибутов для распознавания магматических пород с использованием трехмерных сейсмических данных.
27. Большая часть кода примера FUSE fusexmp.c представляет собой параметр , анализирующий , обработку ошибок и шаблон.
28. Мы обсудим использование этих методов и моделей в различных приложениях, включая синтаксический синтаксический анализ , извлечение информации, статистический машинный перевод и обобщение.
29. В этой статье на конкретных примерах автор представляет два подхода к анализу : анализ снизу вверх и анализ сверху вниз.
30. Идентификация «максимальной фразы существительного (MNP)» может обеспечить надежную поддержку системы автоматического синтаксического анализа и системы машинного перевода.
Применение семантической вероятностной контекстно-свободной грамматики к обработке медицинского языка. Предварительное исследование разбора предложений о лекарствах
https://doi. org/10.1016/j.jbi.2011.08.009Get rights and content Было показано, что основанные на подъязыках грамматики являются эффективным методом обработки медицинского языка.Однако, учитывая сложность медицинской области, синтаксические анализаторы, использующие такие грамматики, неизбежно сталкиваются с неоднозначными предложениями, которые могут быть интерпретированы различными группами продукционных правил и, следовательно, приводят к двум или более деревьям синтаксического анализа. Одно возможное решение, которое ранее широко не исследовалось, состоит в том, чтобы дополнить продукцию в грамматиках медицинских подъязыков вероятностями для устранения неоднозначности. В этом исследовании мы связали вероятности с продукционными правилами в семантической грамматике для результатов лечения и оценили ее эффективность в уменьшении неоднозначности синтаксического анализа.Используя существующий набор данных из задачи i2b2 NLP (обработка естественного языка) 2009 года для извлечения лекарств, мы разработали семантическую CFG (контекстно-свободную грамматику) для разбора предложений о лекарствах и вручную создали банк дерева из 4564 предложений о лекарствах из кратких выписок.
org/10.1016/j.jbi.2011.08.009Get rights and content Было показано, что основанные на подъязыках грамматики являются эффективным методом обработки медицинского языка.Однако, учитывая сложность медицинской области, синтаксические анализаторы, использующие такие грамматики, неизбежно сталкиваются с неоднозначными предложениями, которые могут быть интерпретированы различными группами продукционных правил и, следовательно, приводят к двум или более деревьям синтаксического анализа. Одно возможное решение, которое ранее широко не исследовалось, состоит в том, чтобы дополнить продукцию в грамматиках медицинских подъязыков вероятностями для устранения неоднозначности. В этом исследовании мы связали вероятности с продукционными правилами в семантической грамматике для результатов лечения и оценили ее эффективность в уменьшении неоднозначности синтаксического анализа.Используя существующий набор данных из задачи i2b2 NLP (обработка естественного языка) 2009 года для извлечения лекарств, мы разработали семантическую CFG (контекстно-свободную грамматику) для разбора предложений о лекарствах и вручную создали банк дерева из 4564 предложений о лекарствах из кратких выписок. Используя Treebank, мы получили основанную на семантике PCFG (вероятностную контекстно-свободную грамматику) для разбора предложений о лекарствах. Наша оценка с использованием 10-кратной перекрестной проверки показала, что синтаксический анализатор PCFG значительно улучшил производительность синтаксического анализа по сравнению с синтаксическим анализатором CFG.
Используя Treebank, мы получили основанную на семантике PCFG (вероятностную контекстно-свободную грамматику) для разбора предложений о лекарствах. Наша оценка с использованием 10-кратной перекрестной проверки показала, что синтаксический анализатор PCFG значительно улучшил производительность синтаксического анализа по сравнению с синтаксическим анализатором CFG.
Основные моменты
► Первая попытка применить PCFG для семантического разбора клинического текста. ► Аннотированный банк деревьев из 4564 предложений о лекарствах, основанный на грамматике подъязыка. ► PCFG эффективно уменьшил двусмысленность при разборе предложений о лекарствах.
Ключевые слова
Обработка естественного языка
Синтаксический анализ
Вероятностная контекстно-свободная грамматика
Грамматики подъязыков
Рекомендуемые статьиСсылки на статьи (0)
Copyright © 2011 Elsevier Inc.Все права защищены.
Рекомендуемые статьи
Ссылки на статьи
.
Синтаксический разбор — что это
Ученик, освоивший программу средней школы, должен уметь анализировать строение предложения на родном языке. Грамотный синтаксический разбор – это очень полезный навык, являющийся залогом знания пунктуации и способности быстро осваивать грамматический строй иностранного языка, а также составлять на нем предложения. Именно поэтому к нему следует относиться не как к некоему формальному требованию, а как к одному из ключевых умений.
По программе курса «Русский язык» синтаксический разбор предполагает прежде всего характеристику предложения по таким параметрам, как цель высказывания, эмоциональная составляющая и количество основ. И если с первыми двумя проблем, как правило, не возникает, то уже на этапе характеристики основ у ребенка могут возникнуть сложности. Далее требуется выделить и охарактеризовать второстепенные члены предложения, и здесь очень часто ученики допускают множество ошибок, влекущих за собой и пунктуационные ошибки, и плохие оценки за разбор. Образец синтаксического разбора в этих случаях помогает мало, необходимо обучение четкой последовательности действий и пониманию сути задания.
Образец синтаксического разбора в этих случаях помогает мало, необходимо обучение четкой последовательности действий и пониманию сути задания.
Самые распространенные ошибки
Одной из самых распространенных ошибок является стремление выполнить синтаксический разбор предложения, анализируя слова по очереди – от первого к последнему. Как правило, если школьник так приступает к анализу предложения, то именно по этому пути он идет и при переводе иностранного текста на русский язык, что заведомо неверно. Это свидетельствует о том, что обучающийся не видит структуры предложения, не понимает его строения и связей между членами предложения, роли каждого из них в высказывании. Отсюда и ошибки при их идентификации и характеристиках.
Вторая ошибка – это пропуск одной из основ предложения. Можно найти подлежащее и сказуемое и остановиться в поиске основ, все остальные слова в предложении привязывая к найденной.
Третья распространенная ошибка заключается в неумении увидеть нестандартную грамматическую основу. Например, в предложении «Я так и не понял вчера, кто вы на самом деле», можно не найти подлежащее и сказуемое в придаточном предложении или вообще пропустить эту основу.
Например, в предложении «Я так и не понял вчера, кто вы на самом деле», можно не найти подлежащее и сказуемое в придаточном предложении или вообще пропустить эту основу.
Наконец, еще одним затруднением, приводящим к сбою, часто становятся односоставные предложения, особенно в составе сложных. «Все мы заметили, как быстро сейчас вечереет». Если при анализе предложения «Вечереет» школьники нередко оказываются готовы увидеть сказуемое, то это же предложение, распространенное второстепенными членами и выступающее в роли придаточного, либо ставит в тупик, либо просто не замечается.
Стандартно в такого типа предложениях ошибочно находят подлежащее «сейчас» либо даже «быстро». Та же ошибка встречается, например, в предложении типа «Нам рассказали, как это место выглядело пять лет назад и как быстро здесь построили дом». Отсутствие запятой между основами из-за соподчинения придаточных провоцирует на ошибку и пропуск третьей – односоставной – основы.
Наконец, пятая большая группа ошибок заключается в нераспознавании осложненных предложений и приписывание, скажем, обособленным определениям и обстоятельствам, а также вводным словам роли грамматических основ либо в построении неверного пути распространения предложения.
Причины ошибок
Причина первой ошибки – невладение алгоритмом разбора, незнание того, как делать синтаксический разбор. Причина второй – отсутствие достаточного опыта, причина третьей, четвертой и пятой – недостаточная информированность и слабая база рассмотренных и проанализированных конструкций.
В этой статье мы остановимся на первой ошибке и сосредоточимся на сути синтаксического разбора, умении анализировать строение, механизм предложения.
Обучение и самообучение структурному подходу
Итак, синтаксический разбор – это прежде всего действия по четкому алгоритму и умение ясно видеть структуру предложения.
Начинать лучше не с анализа предложений, тем более сложных и запутанных – в этом случае обучающийся всегда будет действовать несколько вслепую и не будет уверен в правильности разбора. Одним из надежных и быстрых способов обучения умению анализировать структуру, чувствовать ее и уверенно составлять схему предложения является составление предложений с постепенным добавлением второстепенных членов и четким проговариванием того, что именно изменяется на каждом этапе, а также с вычерчиванием стрелок, показывающих зависимость слов, и поисков путей распространения предложения.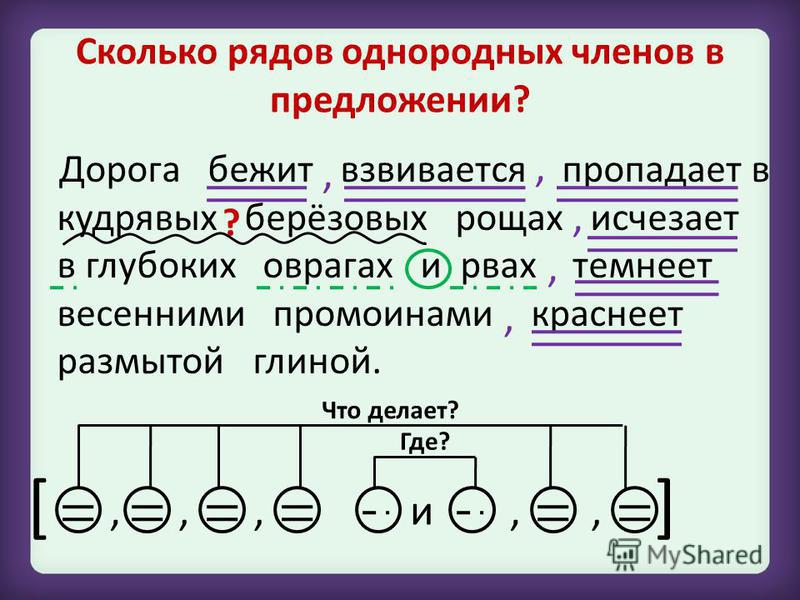 Это задание подходит и при обучении ребенка, и при самообучении.
Это задание подходит и при обучении ребенка, и при самообучении.
При таком постепенном «одевании» основы и ее распространении будет очевидно, как устроено предложение. Эта практика, к слову, обычно хорошо сказывается на умении не только переводить с иностранного языка, но и говорить на нем.
Простое предложение. Распространение подлежащего
«Щенок прибежал». Это грамматическая основа.
Распространяем подлежащее. Чей щенок? «Мой щенок прибежал». Какой щенок? «Мой рыжий щенок прибежал». Еще какой щенок? «Мой рыжий веселый щенок прибежал». Еще какой? «Мой рыжий веселый и лукавый щенок прибежал». Что еще можно сказать про то, какой он? «Мой рыжий веселый и лукавый щенок в кудряшках прибежал».
Сейчас мы распространили подлежащее пятью определениями.
Распространение сказуемого
Распространяем сказуемое. Прибежал откуда? С улицы. Куда? Домой. «Мой рыжий веселый и лукавый щенок в кудряшках прибежал домой с улицы».
Распространение второстепенных членов группы подлежащего
Распространяем второстепенные члены предложения группы подлежащего. Насколько веселый? Невероятно. В каких кудряшках? В крупных.
Насколько веселый? Невероятно. В каких кудряшках? В крупных.
Разумеется, это простой пример. Чем неоднороднее и разнообразнее будут связи членов предложения, тем больший опыт приобретет обучающийся и тем выше будет процент вероятности, что далее он с легкостью «распутает» самые сложные на первый взгляд предложения, так как синтаксический разбор – это прежде всего умение «выпрямить», схематизировать любое высказывание, в независимости от порядка слов.
Распространение второстепенных членов группы сказуемого
Распространяем второстепенные члены предложения группы сказуемого. Как шлепая? Смешно. Как топая? Громко.
«Мой рыжий невероятно веселый и лукавый щенок в крупных кудряшках, смешно шлепая и громко топая, прибежал с улицы».
При самостоятельном составлении предложений по такому алгоритму очевидны связи слов, структура предложения, а следовательно, и его пунктуация.
Как можно увидеть, это задание чрезвычайно простое. Обычно оно выполняется обучающимися любых возрастов с большой охотой, и сложностей в построении схемы предложения не возникает, так как связи между словами очевидны, а между тем это основа обучения тому, как сделать синтаксический разбор грамотно и осознанно.
Инверсии и трансформации
После того как окончательное предложение разобрано, в нем идентифицированы все члены и установлены все связи, очень полезно трансформировать его, переставив местами слова, и снова сделать его анализ. «Смешно шлепая и громко топая, прибежал с улицы домой мой рыжий щенок в крупных кудряшках, невероятно веселый и лукавый». Анализ таких инверсий, а также упражение в трансформировании формируют привычку видеть в самых запутанных предложения их структуру и понимать, как устроены высказывания.
Переход к сложным предложениям
Выше был рассмотрен путь обучения умению видеть структуру простого предложения. Однако синтаксический разбор – это анализ не только простых, но и сложных предложений. При этом важно понимать связи предложений друг с другом, отличать равноправные предложения и их сочинительную связь от иерархических отношений и подчинительной связи. Особенно часто возникают сложности в установлении характера и специфики подчинительной связи.
Разобраться в основах анализа сложного предложения поможет то же самое упражнение. Самый верный путь к пониманию особенностей структуры и работы механизма – это самостоятельное изготовление этого механизма. Это касается и предложений.
Продолжим наш пример, для простоты и краткости пока взяв за скобки второстепенные члены.
Щенок прибежал. Зачем? Поиграть. «Щенок прибежал поиграть». В предложении появилось обстоятельство цели. Попробуем его распространить. Поиграть с кем? С детьми. Подчеркнем цель словом «чтобы». «Щенок прибежал, чтобы поиграть с детьми». В высказывании все еще нет второго субъекта и предиката. «С детьми» — это дополнение. Сделаем так, чтобы дополнение, то есть, по смыслу, второй субъект, стало вторым подлежащим – вошло в основу нового придаточного предложения: «Щенок прибежал, чтобы дети с ним поиграли».
Такие транформации ценны тем, что показывают, какую роль играет придаточное предложение, как может разворачиваться и сворачиваться предикативность. Такая игра научит расставлять акценты, и любое предложение станет прозрачным по своей структуре, анализ которой, как уже говорилось, и составляет суть синтаксического разбора.
Такая игра научит расставлять акценты, и любое предложение станет прозрачным по своей структуре, анализ которой, как уже говорилось, и составляет суть синтаксического разбора.
Школьная программа дисциплины «Русский язык» синтаксический разбор предложения в основном подает как некую теоретическую надстройку, однако это прежде всего развитие речевых навыков и умения осознанно подходить к построению предложения. Такой операционный подход, повторимся, очень хорошо сказывается и на изучении иностранных языков, и на пунктуационной грамотности, и на умении писать тексты на родном языке.
Глава 20 Правила синтаксического анализа
Глава 20 Правила синтаксического анализаВ этой главе вы узнаете о: ShowHide
О правилах синтаксического анализа
Правила синтаксического анализа — это маркеры, определяемые пользователем. Помимо стандартного формата определения отчета, модуль отчетов EventTracker предоставляет простой, но мощный журнал Flex Reports, средство создания отчетов.
Это помогает анализировать и включать части засоренного системного журнала, такие как сообщения и описания событий Windows, в виде столбцов в отчеты.
помогает вам определять новые токены, связывать их с шаблонами динамических отчетов и создавать гибкие отчеты. EventTracker отображает проанализированные данные под теми токенами, которые вы определили.
При настройке отчетов Flex вы также можете выбрать интересующие вас столбцы отчета, применить фильтры, отсортировать столбцы отчета и изменить порядок столбцов, которые должны отображаться в отчетах.
Короче говоря Правила синтаксического анализа помогают манипулировать данными и создавать понятные отчеты.
Необходимость добавления правил синтаксического анализа в отчет Flex
Проверка компонентов данных журнала занимает много времени. Данные содержат фрагменты информации.
Поскольку ценная информация содержится в описании журнала, должен быть способ разбить и проанализировать данные и превратить их в ценную бизнес-информацию.
Кроме того, не существует стандартизированного формата сообщений, поскольку разные поставщики систем NIX придерживаются разных соглашений.
Например, значения, разделенные запятыми, текст фиксированной ширины и текст произвольной формы используются администратором для расшифровки сообщений системного журнала.
Использование токенов в EventTracker
Часто возникают вопросы:
· ‘Недостаточно ли создавать отчеты Flex с помощью шаблонов, поставляемых с EventTracker?’
· Достаточно ли гибок EventTracker для добавления токенов?
· Если да, не предоставляет ли EventTracker какие-либо предопределенные токены для упрощения моей работы?
· Можно ли определить собственные токены?
Если вас волнуют эти вопросы, расслабьтесь!
EventTracker поставляется вместе с точно определенным набором токенов для вашего удобства.
Часто задаваемые вопросы: если я привяжу новое значение токена к правилу синтаксического анализа, будут ли эти значения токена постоянно сохраняться в базе данных?
На ваше усмотрение. При определении нового Token-Value у вас есть возможность постоянно сохранять Token-Values в базе данных или привязывать Token-Value только для одного экземпляра генерации отчета.
Предыдущие знания
Желательно хорошо знать и понимать форматы сообщений системного журнала для различных версий систем NIX. Хотя основные принципы настаивают на простоте, создатели системного журнала пишут сообщения в соответствии со своей прихотью и капризом. Так что приспособьтесь к среде, в которой вы работаете, чтобы понять синтаксис и семантику сообщений системного журнала.
Компоненты правил синтаксического анализа
Компоненты Правила синтаксического анализа — это основные элементы, необходимые для формирования ваших запросов для извлечения необходимых данных из сообщений журнала.
Жетон
Токен— это «ключ», который механизм создания отчетов рассматривает как точку отсчета и рассматривает строку, которая прошла успешно для синтаксического анализа. Предоставление токена необязательно и может содержать:
· Символы (a, b, c…)
· Числа (1, 2, 3…)
· Специальные символы (#, $, %), пробел…
· или комбинация всех трех (a1#)
Возникновение правила синтаксического анализа
Если в описании есть несколько вхождений токена, механизм отчетов рассматривает только первое вхождение в качестве контрольной точки. Итак, будьте конкретны, когда формулируете свой запрос.
Отображаемое имя
Отображаемое имя — это временно предполагаемое имя (псевдоним) для запрошенной строки.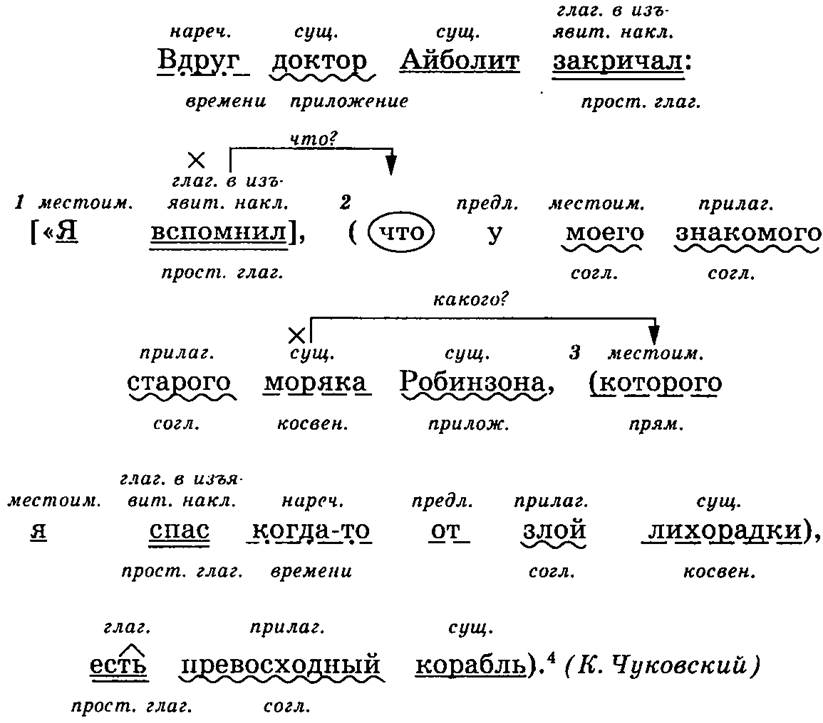 Это имя будет отображаться как «токен» в отчете. Обязательно указывать отображаемое имя, оно должно быть уникальным во всем отчете. Вы можете выбрать любое имя и может содержать:
Это имя будет отображаться как «токен» в отчете. Обязательно указывать отображаемое имя, оно должно быть уникальным во всем отчете. Вы можете выбрать любое имя и может содержать:
· символов
· номера
· или комбинация этих двух
· специальные символы не принимаются
Сепаратор
Разделитель — это символ или слово, разделяющее ключ и значение в описании. Необязательно предоставлять разделитель и может содержать:
· символов
· номера
· специальные символы
· или комбинация всех трех
Терминатор
Терминатор — это символ или слово, определяющее конец пары ключ-значение в описании. Запрошенная строка извлекается до первого появления терминатора. Необязательно предоставлять терминатор и может содержать:
· Символов
· Числа
· Специальные символы
· или комбинация всех трех
Таким образом, правило синтаксического анализа обеспечивает гибкость настройки:
· Выбор данных
· Сортировка последовательностей
Просмотр правил разбора
1 Чтобы просмотреть правила синтаксического анализа, выберите раскрывающийся список Admin , а затем выберите Правила синтаксического анализа .
Отображаются группы Token-Value по умолчанию. EventTracker предоставляет предопределенные правила синтаксического анализа.
2 Для поиска по значениям токенов щелкните раскрывающийся список Token-Value и выберите нужный вариант.
3 Введите критерии поиска в поле поиска, а затем щелкните значок Search .
Пример. Чтобы найти значение токена «политика аудита», введите слово «политика аудита» в поле поиска, а затем щелкните значок поиска. Отображается соответствующая информация.
4 Чтобы очистить критерии поиска, выберите значок Очистить все .
Добавить группы значений токена
Группы значения токена по умолчанию доступны на панели значения токена.
1 Чтобы добавить новую группу, щелкните значок.
2 Введите соответствующее имя группы, описание и нажмите OK .
Создана новая группа значений токена.
Добавить правило
1 Чтобы добавить новое правило, нажмите кнопку Добавить правило .
2 Введите соответствующие данные и нажмите Добавить .
· Пример. Следующие пары «ключ-значение» можно добавить следующим образом.
· Отображаемое имя: Сводка журналов
· Токен: время регистрации
· Разделитель ‘:’
· Терминатор: \n
· Новое правило отображается на панели Token-Value.
2 ПРИМЕЧАНИЕ |
Может быть более одного Token-Value с одним и тем же отображаемым именем, но один из токенов, разделитель или терминатор должен быть другим/уникальным. Пример: Отображаемое имя такое же, как на приведенном ниже снимке экрана, но разделитель другой.
|

3 Чтобы изменить значение токена, нажмите кнопку Изменить , внесите необходимые изменения и нажмите Сохранить .
2 ПРИМЕЧАНИЕ |
Вы можете редактировать только одно Token-Value за раз. |
4 Чтобы удалить значение маркера, нажмите кнопку Удалить .
5 Чтобы значение маркера в другую группу, нажмите Переместить в группу.
2 ПРИМЕЧАНИЕ |
Вы можете перейти в другую группу, если помимо выбранной существуют другие группы Token-Value. |

Мастер значения токена
1 Чтобы просмотреть Мастер значения токена , выберите Admin , выберите Правила синтаксического анализа .
По умолчанию отображаются группы Token-Value .
2 Нажмите кнопку Мастер значения токена .
Мастер значения токена отображает окно Sample Logs.
3 Нажмите любой из значков Извлечь пары значений токена .
Create Token-Value Отображается вкладка с дополнительными данными.
4 Выберите список значений токенов и нажмите кнопку Добавить >> .
Пример: выберите Имя клиента в списке значений токенов и нажмите Добавить .
Отображение сведений о значении токена.
Вы можете изменить отображаемые значения по умолчанию.
5 Нажмите Подтвердить, , а затем нажмите Сохранить.
Использовать шаблон по умолчанию
1 Выберите Admin , а затем выберите Parsing Rules .
Отображаются группы Token-Value по умолчанию. EventTracker предоставляет предопределенные правила синтаксического анализа.
2 Выберите вкладку Template .
Группа Шаблоны отображается на левой панели, а Шаблоны отображаются на правой панели.
3 Чтобы выполнить поиск по имени группы, введите имя в поле Search и щелкните значок поиска.
4 Для экспорта или импорта конфигурации используйте значок экспорта или значок импорта .
Создать новый шаблон
1. В мастере значения токена выберите вкладку «Создать значение токена »,
. 2. Добавьте описание и нажмите Создать шаблон.
На следующей странице отображается:
3. Введите необходимые изменения в опции Token Value и Token .
4. Введите имя шаблона .
5. Чтобы отфильтровать значения, щелкните значок .
EventTracker: отображается окно «Определенный шаблон».
6. Введите соответствующие данные и нажмите Добавить .
Пример: введите имя токена (т. е. новый токен), выходное значение (т. е. параметр).
Вы можете выбрать регулярное выражение или разделитель. Регулярное выражение используется для поиска определенного шаблона.
· Выберите разделитель «-». Это может быть пробел, знак равенства «=» и т. д.
· Выберите порядковые значения (например, числовые), чтобы еще больше разделить правила.
7. Нажмите Добавить в столбец шаблона .
Нажмите Добавить в столбец шаблона .
8. Нажмите кнопку Сохранить .
Теперь в окне «Определить правила синтаксического анализа» созданный новый шаблон отображается в Шаблон вкладка.
Создание отчетов Flex
1 Войдите в EventTracker Enterprise, щелкните значок Reports и выберите Dashboard или Configuration .
2 Нажмите кнопку New в Dashboard/Configuration .
3 Выберите любой из отчетов Compliance / Security / Operations / Flex / Alphabetical вкладка .
4 Разверните узел дерева отчетов и выберите любой отчет. Выберите Тип отчета как По запросу . Щелкните Далее.
Например: на вкладке Flex Reports выберите Logs , а затем выберите Summary .
Тип отчета выбран как По запросу.
EventTracker отображает мастер отчетов.
5 Нажмите Следующий >>.
6 Выберите необходимые параметры (например, Сайты , Группа, Системы, Показать все сайты, Все системы ).
7 Выберите Realtime или File Transfer , а затем нажмите Next>>.
8 Выберите требуемый параметр Interval и Limit to time Range.
9 Выберите нужный Тип экспорта (т. е. файл PDF, документ Word, файл HTML, быстрый просмотр (не сохраняется на жестком диске )).
10 Выберите требуемый вариант формата .
—————————————————————- —————————————————
Пример:
а. Если вы выберете опцию правила синтаксического анализа . Щелкните Далее>>.
Сводка журналов отображается для выбора правила синтаксического анализа.
б. Щелкните гиперссылку Select Parsing Rule .
Отображается окно правила синтаксического анализа поиска.
с. Выберите необходимые параметры и нажмите кнопку ОК.
Отображается сводка журналов (т. е. шаг 5).
д. Выберите любой параметр Сводка ; выберите соответствующий параметр в раскрывающемся списке Сортировать по .
эл. Выберите маркера карты с одинаковым «тегом» в один столбец , если требуется.
(ИЛИ)
ф. Если вы выбрали Token Template , нажмите Next>>.
г. Выберите шаблон. (т.е. введите имя шаблона, которое вы ранее настроили в Правилах синтаксического анализа – Мастер значения токена)
ч. Выберите/введите необходимые параметры и нажмите Далее>>.
————————————————— ————————————
11 Нажмите кнопку Next>> .
12 Введите соответствующие данные Уточнить и Фильтровать .
13 Нажмите кнопку Next>> .
14 Введите соответствующие данные Заголовок , Верхний колонтитул , Нижний колонтитул и Описание .
15 Нажмите кнопку Next>> .
Просмотрите сведения о стоимости и настройте отображение окна параметров публикации.
2 ПРИМЕЧАНИЕ |
Параметры публикации отключены, так как выбран параметр «По запросу» (обработка в приоритетном режиме). |
16 Нажмите кнопку Next>> .
Отображается последний шаг Завершение мастера настройки отчета .
17 Выберите Создать отчет.
Анализ данных журнала | Документация New Relic
Синтаксический анализ — это процесс разделения неструктурированных данных журнала на атрибуты (пары ключ/значение). Вы можете использовать эти атрибуты для фасетирования или фильтрации журналов полезными способами. Это, в свою очередь, помогает вам создавать более качественные графики и оповещения.
Вы можете использовать эти атрибуты для фасетирования или фильтрации журналов полезными способами. Это, в свою очередь, помогает вам создавать более качественные графики и оповещения.
New Relic анализирует данные журнала в соответствии с правилами. В этом документе описывается, как работает анализ журналов, как использовать встроенные правила и как создавать собственные правила.
Вы также можете создавать, запрашивать и управлять правилами анализа журналов с помощью NerdGraph, нашего API GraphQL, по адресу api.newrelic.com/graphiql. Для получения дополнительной информации см. наш учебник NerdGraph по разбору.
Пример синтаксического анализа
Хорошим примером является стандартный журнал доступа NGINX, содержащий неструктурированный текст. Это полезно для поиска, но не более того. Вот пример типичной строки:
127.180.71.3 - - [10/May/1997:08:05:32 +0000] "GET /downloads/product_1 HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~ exp12ubuntu10.
 21)"
21)" В неанализируемом формате вам потребуется выполнить полнотекстовый поиск, чтобы ответить на большинство вопросов. После синтаксического анализа журнал организован в атрибуты, такие как код ответа и URL-адрес запроса :
"remote_addr": "93.180.71.3",
"время": "1586514731",
"метод": "ПОЛУЧИТЬ",
"путь": "/downloads/product_1",
"версия": "HTTP/1.1",
"ответ": "304",
"bytesSent": 0,
"user_agent": "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21)"
Синтаксический анализ упрощает создание пользовательских запросов, учитывающих эти значения. Это поможет вам понять распределение кодов ответов по URL-адресам запросов и быстро найти проблемные страницы.
Как работает синтаксический анализ журналов
Вот обзор того, как New Relic реализует синтаксический анализ журналов:
По умолчанию используется поле сообщения WHERE , определяющего, какие журналы будет пытаться анализировать правило. logtype . Однако вы не ограничены использованием logtype ; один или несколько атрибутов могут использоваться в качестве критериев соответствия в предложении NRQL WHERE . | |
|---|---|
Когда |
|
Как |
|
 Однако можно выбрать любое поле/атрибут, даже не существующее в ваших данных.
Однако можно выбрать любое поле/атрибут, даже не существующее в ваших данных. Будьте внимательны при определении критериев соответствия для правила синтаксического анализа. Если критерий основан на атрибуте, который не существует до тех пор, пока не будет выполнен синтаксический анализ или обогащение, эти данные не будут присутствовать в журналах при сопоставлении. В результате парсинга не будет.
Будьте внимательны при определении критериев соответствия для правила синтаксического анализа. Если критерий основан на атрибуте, который не существует до тех пор, пока не будет выполнен синтаксический анализ или обогащение, эти данные не будут присутствовать в журналах при сопоставлении. В результате парсинга не будет.Атрибуты синтаксического анализа с использованием Grok
Шаблоны синтаксического анализа задаются с использованием Grok, отраслевого стандарта для анализа сообщений журнала. Любой входящий журнал с полем logtype будет проверен на соответствие нашим встроенным шаблонам, и, если возможно, к журналу будет применен соответствующий шаблон Grok.
Grok — это расширенный набор регулярных выражений, который добавляет встроенные именованные шаблоны для использования вместо буквальных сложных регулярных выражений. Например, вместо того, чтобы помнить, что целое число может быть сопоставлено с регулярным выражением
Например, вместо того, чтобы помнить, что целое число может быть сопоставлено с регулярным выражением (?:[+-]?(?:[0-9]+)) , вы можете просто написать %{INT} использовать шаблон Grok INT , который представляет то же самое регулярное выражение.
Вы всегда можете использовать сочетание регулярных выражений и имен шаблонов Grok в вашей соответствующей строке. Для получения дополнительной информации см. наш список синтаксиса Grok и поддерживаемых типов.
Имена переменных должны быть заданы явно и должны быть строчными, например %{URI:uri} . Такие выражения, как %{URI} или %{URI:URI} , не будут работать.
Посмотрите наше видео на YouTube (около 6 минут), чтобы узнать, как использовать отладчик Grok при создании шаблонов правил синтаксического анализа Grok:
Запись журнала может выглядеть примерно так:
"message": "54.
 3 .120.2 2048 0"
3 .120.2 2048 0" Эта информация является точной, но не совсем понятно, что она означает. Шаблоны Grok помогают извлекать и понимать нужные данные телеметрии. Например, такая запись в журнале гораздо проще в использовании:
"host_ip": "43.3.120.2",
"bytes_received": 2048,
"bytes_sent": 0
Для этого создайте шаблон Grok, который извлекает эти три поля; например:
"%{IP:host_ip} %{INT:bytes_received} %{INT:bytes_sent}"
После обработки ваша запись журнала будет включать поля host_ip , bytes_received и bytes_sent . Теперь вы можете использовать эти поля в New Relic для фильтрации, фасетирования и выполнения статистических операций с данными журнала. Дополнительные сведения о том, как анализировать журналы с помощью шаблонов Grok в New Relic, см. в нашем блоге.
Если у вас есть правильные разрешения, вы можете создать правила синтаксического анализа в нашем пользовательском интерфейсе, чтобы создавать, тестировать и включать синтаксический анализ Grok. Например, чтобы получить определенный тип сообщения об ошибке для одной из ваших микрослужб, называемой Inventory Services, вы должны создать правило синтаксического анализа Grok, которое ищет определенное сообщение об ошибке и продукт. Для этого:
Например, чтобы получить определенный тип сообщения об ошибке для одной из ваших микрослужб, называемой Inventory Services, вы должны создать правило синтаксического анализа Grok, которое ищет определенное сообщение об ошибке и продукт. Для этого:
Дайте правилу имя; например,
Ошибка анализа служб инвентаризации.Определите NRQL
ГДЕ 9пункт 0756, который действует как предварительный фильтр для входящих журналов; например,entity.name='Inventory Service'. Этот предварительный фильтр сужает количество журналов, которые должны быть обработаны вашим правилом, удаляя ненужную обработку.Добавить правило разбора Grok; например:
Ошибка инвентаризации: %{DATA:error_message} для продукта %{INT:product_id}
Где:
-
Ошибка инвентаризации: Имя вашего правила синтаксического анализа -
error_message: сообщение об ошибке, которое вы хотите выбрать -
product_id: идентификатор продукта для службы инвентаризации
Проверьте шаблон Grok, чтобы увидеть, совпадают ли какие-либо входящие журналы.
Включите и сохраните правило синтаксического анализа.
Вскоре вы увидите, что ваши журналы Inventory Service пополнились двумя новыми полями:
error_messageиproduct_id. Отсюда вы можете запрашивать эти поля, создавать диаграммы и информационные панели, устанавливать оповещения и т. д.Подробную информацию см. в нашей документации по добавлению пользовательских правил синтаксического анализа в пользовательском интерфейсе.

Паттерны GROK Нажмите grok-patterns , чтобы просмотреть наиболее часто используемые шаблоны. Имя шаблона — это просто удобное для пользователя имя, представляющее регулярное выражение. Они в точности равны соответствующему регулярному выражению.
OPTIONAL_EXTRACTED_ATTRIBUTE_NAME , если указано, это имя атрибута, который будет добавлен в ваше сообщение журнала со значением, соответствующим имени шаблона. Это эквивалентно использованию именованной группы захвата с использованием регулярных выражений. Если это не предусмотрено, то правило синтаксического анализа будет просто соответствовать области вашей строки, но не будет извлекать атрибут с его значением.
Если это не предусмотрено, то правило синтаксического анализа будет просто соответствовать области вашей строки, но не будет извлекать атрибут с его значением.
OPTIONAL_TYPE указывает тип значения атрибута для извлечения. Если он опущен, значения извлекаются как строки. Например, чтобы извлечь значение 123 из "Размер файла: 123" как число в атрибуте размер_файла , используйте значение : %{INT:file_size:int} .
Supported types are:
Type specified in Grok | Type stored in the New Relic database |
|---|---|
| |
| |
| |
| |
| |
| |
| ISO 8601 time as a |
| JSON structured data, take a look to Parsing JSON mixed with plain text for more information |
Конвейер журналов New Relic анализирует ваши сообщения журнала JSON по умолчанию, но иногда у вас есть сообщения журнала JSON, смешанные с обычным текстом. В этой ситуации вы также хотите иметь возможность анализировать их, а затем фильтровать с помощью атрибутов JSON.
В этой ситуации вы также хотите иметь возможность анализировать их, а затем фильтровать с помощью атрибутов JSON.
В этом случае вы можете использовать тип json grok, который будет анализировать JSON, захваченный шаблоном grok. Этот формат состоит из трех основных частей: синтаксиса grok, префикса, который вы хотели бы присвоить анализируемым атрибутам json, и типа grok json . Используя тип json grok, вы можете извлекать и анализировать JSON из неправильно отформатированных журналов; например, если ваши журналы имеют префикс строки даты/времени:
2015-05-13T23:39:43.945958Z {"событие": "TestRequest", "статус": 200, "ответ": {"заголовки": {"X-Custom": "foo"}}, "запрос": {"заголовки": { "X-Custom": "bar"}}}
Чтобы извлечь и проанализировать данные JSON из этого формата журнала, создайте следующее выражение Grok:
%{TIMESTAMP_ISO8601:containerTimestamp} %{GREEDYDATA:my_attribute_prefix: json}
Итоговый журнал:
введите с помощьюcontainerTimestamp: "2015-05-13T23:39:43.
my_attribute_prefix.event: "TestRequest"
my_attribute_prefix.status: 200
my_attribute_prefix.response.headers.X-Custom: «foo»
my_attribute_prefix.request.headers.X-Custom: «bar»
 945958Z"
945958Z" :json(_CONFIG_) :-
json({"dropOriginal": true}): удалить фрагмент JSON, который использовался при синтаксическом анализе. Если установлено значениеtrue(значение по умолчанию), правило синтаксического анализа удалит исходный фрагмент JSON. Обратите внимание, что атрибуты JSON останутся в поле сообщения. -
json({"dropOriginal": false}): это покажет извлеченную полезную нагрузку JSON. Если установлено значениеfalse, полная полезная нагрузка только в формате JSON будет отображаться под атрибутом, названным вmy_attribute_prefixвыше. Обратите внимание, что атрибуты JSON останутся здесь в поле сообщения, а также предоставят пользователю 3 разных представления данных JSON. Если вас беспокоит хранение всех трех версий, рекомендуется использовать значение по умолчанию true. -
json({"depth": 62}): Уровни глубины, которые вы хотите проанализировать значение JSON (по умолчанию 62).
 Если вас беспокоит хранение всех трех версий, рекомендуется использовать значение по умолчанию
Если вас беспокоит хранение всех трех версий, рекомендуется использовать значение по умолчанию Организация по типу журнала
Конвейер приема журналов New Relic может анализировать данные, сопоставляя событие журнала с правилом, описывающим, как следует анализировать журнал. Существует два способа анализа событий журнала:
- Использование встроенного правила.
- Определение пользовательского правила.
Правила представляют собой комбинацию логики сопоставления и логики синтаксического анализа. Сопоставление выполняется путем определения соответствия запроса атрибуту журналов. Правила обратной силы не имеют. Журналы, собранные до создания правила, не анализируются этим правилом.
Самый простой способ упорядочить журналы и способы их анализа — включить поле logtype в событие журнала.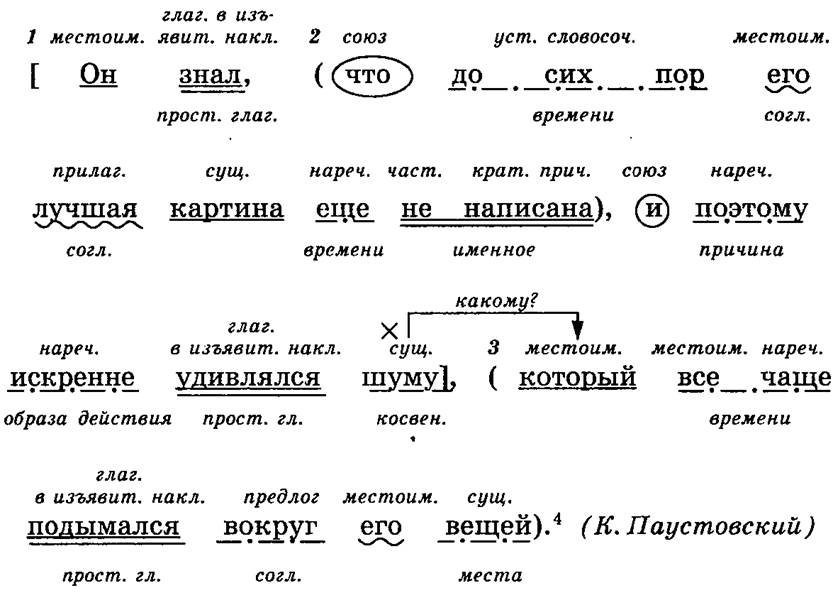 Это сообщает New Relic, какое встроенное правило следует применять к журналам.
Это сообщает New Relic, какое встроенное правило следует применять к журналам.
Важно
Когда правило синтаксического анализа становится активным, данные, анализируемые этим правилом, постоянно изменяются. Это не может быть отменено.
Ограничения
Синтаксический анализ требует больших вычислительных ресурсов, что создает риск. Анализ выполняется для пользовательских правил, определенных в учетной записи, и для сопоставления шаблонов с журналом. Большое количество шаблонов или плохо определенные пользовательские правила потребляют огромное количество памяти и ресурсов ЦП, а также требуют очень много времени для выполнения.
Чтобы предотвратить проблемы, мы применяем два ограничения на синтаксический анализ: на сообщение, на правило и на учетную запись.
Лимит | Описание |
|---|---|
PER-MESSAGE-RULE | 9079|
На учетную запись | Ограничение на учетную запись существует для предотвращения использования учетными записями ресурсов, превышающих их справедливую долю. Ограничение учитывает общее время, затраченное на обработку 90 836 всех 90 837 сообщений журнала для учетной записи в минуту. Предел не является фиксированным значением; он масштабируется вверх или вниз пропорционально объему данных, ежедневно хранимых учетной записью, и размеру среды, которая впоследствии выделяется для поддержки этого клиента. |
 более 100 мс. Если этот предел достигнут, система прекратит попытки проанализировать сообщение журнала с помощью этого правила.
более 100 мс. Если этот предел достигнут, система прекратит попытки проанализировать сообщение журнала с помощью этого правила.Подсказка
Чтобы легко проверить, достигнуты ли ограничения скорости, перейдите в свою систему. Ограничивает страницу в пользовательском интерфейсе New Relic.
Ограничивает страницу в пользовательском интерфейсе New Relic.
Встроенные правила синтаксического анализа
Для распространенных форматов журналов уже созданы хорошо зарекомендовавшие себя правила синтаксического анализа. Чтобы воспользоваться преимуществами встроенных правил синтаксического анализа, добавьте атрибут logtype при пересылке журналов. Установите значение, указанное в следующей таблице, и правила для этого типа журнала будут применяться автоматически.
Список встроенных правил
Следующие значения атрибутов типа журнала сопоставляются с предопределенным правилом синтаксического анализа. Например, чтобы запросить Application Load Balancer:
- В пользовательском интерфейсе New Relic используйте формат
logtype:"alb". - Из NerdGraph используйте формат
logtype = 'alb'.
Чтобы узнать, какие поля анализируются для каждого правила, см.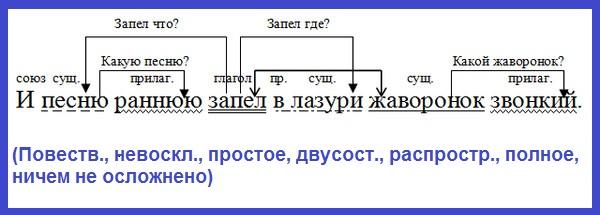 нашу документацию о встроенных правилах анализа.
нашу документацию о встроенных правилах анализа.
| Log source | Example matching query |
|---|---|---|
| Apache access logs | |
| Apache error logs | |
| Application load balancer logs | |
| Cassandra logs | |
| CloudFront (standard web logs) | |
| CloudFront (real-time web logs) | |
| Elastic Load Balancer logs | |
| HAProxy logs | |
| KTranslate container health logs | |
| ||
| Linux messages | |
| Microsoft IIS server logs - W3C format | |
| Журналы MongoDB | |
| Monit logs | |
| MySQL error logs | |
| NGINX access logs | |
| NGINX error logs | |
| Postgresql logs | |
| Журналы Rabbitmq 7 00756 | |
| Redis logs | |
| Route 53 logs | |
| SYSLOGS с RFC5424 FORMAT | 9999999999999999999999999999999999999999999999999999999999 999999999999999999999999999999999999999999999999999999999999999н.
 0756
0756Добавьте атрибут
тип журнала При объединении журналов важно предоставить метаданные, которые облегчают организацию, поиск и анализ этих журналов. Один простой способ сделать это — добавить атрибут тип журнала к сообщениям журнала при их отправке. Встроенные правила синтаксического анализа применяются по умолчанию к определенным значениям logtype .
Подсказка
Поля logType , logtype и LOGTYPE поддерживаются для встроенных правил. Для простоты поиска мы рекомендуем использовать единый синтаксис в вашей организации.
Вот несколько примеров того, как добавить тип журнала в журналы, отправляемые некоторыми из наших поддерживаемых способов доставки.
Добавить тип журнала в качестве атрибута . Вы должны установить тип журнала для каждого именованного источника.
- имя: простой файл
файл: /путь/к/файлу
атрибуты:
тип журнала: fileRaw
- имя: nginx-example
файл: /var/log/nginx.
атрибуты:
тип журнала: nginx
 log
log Добавить блок фильтра в файл .5conf6 70795,
использует record_transformer для добавления нового поля. В этом примере мы используем тип журнала из nginx для запуска встроенного правила синтаксического анализа NGINX. Ознакомьтесь с другими примерами Fluentd.
<контейнеры фильтров>
@type record_transformer
enable_ruby true
#Добавить тип журнала для активации встроенного правила разбора журналов доступа nginx "time"]
#Добавить поля имени хоста и тега ко всем записям фильтрующий блок на
.conf, который используетrecord_modifierдля добавления нового поля. В этом примере мы используем тип журналаизnginxдля запуска встроенного правила синтаксического анализа NGINX. Ознакомьтесь с другими примерами Fluent Bit.[FILTER]
Name record_modifier
Match *
Record type logtype nginx
Record hostname ${HOSTNAME}
Record service_name Sample-App-Name
4add_fieldизменить фильтр, чтобы добавить новое поле.изnginxдля запуска встроенного правила синтаксического анализа NGINX. Ознакомьтесь с другими примерами Logstash.filter {
mutate {
add_field => {
"logtype" => "nginx"
"service_name" => "myservicename"
"hostname" => "%{003}" 9003
Вы можете добавить атрибуты в запрос JSON, отправляемый в New Relic. В этом примере мы добавляем
logtypeатрибут со значениемnginxдля запуска встроенного правила синтаксического анализа NGINX. Узнайте больше об использовании Logs API.POST /журнал/v1 HTTP/1.1 Хост: log-api.newrelic.com Тип содержимого: приложение/json X-лицензионный ключ: YOUR_LICENSE_KEY Принимать: */* Длина контента: 133 { "отметка времени": TIMESTAMP_IN_UNIX_EPOCH , "message": "Пользователь ' xyz ' вошел в систему", "logtype": "журналы доступа", "сервис": "логин-сервис", "имя хоста": " login.Создание и просмотр пользовательских правил синтаксического анализа
Многие журналы имеют уникальный формат или структуру. Для их анализа необходимо построить и применить пользовательскую логику.
В левой навигационной панели пользовательского интерфейса журналов выберите Анализ , затем создайте собственное правило анализа с допустимым предложением NRQL
WHEREи шаблоном Grok.Для создания собственных настраиваемых правил синтаксического анализа и управления ими:
- Перейдите на страницу one.newrelic.com > Журналы .
- В меню Управление данными в левой навигационной панели пользовательского интерфейса журналов щелкните Анализ , затем щелкните Создать правило анализа .
- Введите имя нового правила синтаксического анализа.
- Выберите существующее поле для анализа (по умолчанию =
сообщение) или введите новое имя поля.- Введите действительное предложение NRQL
WHERE, соответствующее журналам, которые вы хотите проанализировать.- Выберите соответствующий журнал, если он существует, или щелкните вкладку Вставить журнал , чтобы вставить образец журнала.
- Введите правило синтаксического анализа и убедитесь, что оно работает, просмотрев результаты в разделе Вывод . Чтобы узнать о Grok и пользовательских правилах синтаксического анализа, прочитайте запись в нашем блоге о том, как анализировать журналы с помощью шаблонов Grok.
- Включите и сохраните пользовательское правило синтаксического анализа.
Чтобы просмотреть существующие правила синтаксического анализа:
- Перейдите на страницу one.newrelic.com > Журналы .
- Из Управление данными в левой навигационной панели пользовательского интерфейса журналов щелкните Анализ .
Устранение неполадок
Если синтаксический анализ не работает должным образом, это может быть связано с:
 В этом примере мы используем тип журнала
В этом примере мы используем тип журнала  example.com г.»
}
example.com г.»
} 
- Логика: Логика сопоставления правил синтаксического анализа не соответствует нужным журналам.
- Время: Если ваше правило сопоставления синтаксического анализа нацелено на значение, которого еще не существует, оно завершится ошибкой. Это может произойти, если значение добавляется позже в конвейере как часть процесса обогащения.
- Ограничения: Каждую минуту выделяется фиксированное количество времени для обработки журналов с помощью синтаксического анализа, шаблонов, фильтров удаления и т. д. Если было потрачено максимальное количество времени, синтаксический анализ будет пропущен для дополнительных записей событий журнала.

Чтобы устранить эти проблемы, создайте или настройте собственные правила синтаксического анализа.
Пользовательский инструмент синтаксического анализа | Документация InsightIDR
Пользовательский инструмент синтаксического анализа позволяет создавать настраиваемые правила синтаксического анализа для извлечения данных журнала, которые наиболее соответствуют потребностям вашей организации. С помощью Custom Parsing Tool вы можете:
С помощью Custom Parsing Tool вы можете:
- Анализировать журналы в формате, неизвестном InsightIDR, что позволяет извлекать и отслеживать данные, которые не извлекаются InsightIDR автоматически.
- Дальнейший анализ записей журнала для включения дополнительных полей, которые не анализируются по умолчанию.
Например, если вы используете инструмент электронной медицинской карты (EHR), вам может потребоваться проанализировать идентификаторы пациентов, успешные и неудачные попытки входа в систему и типы событий EHR. С помощью этих данных вы можете создавать рабочие информационные панели, которые отслеживают данные, которые исключительно важны для нужд вашего бизнеса.
Создать собственные правила синтаксического анализа очень просто. Custom Parser предоставляет интерфейс, который вы можете использовать, чтобы показать InsightIDR именно то, что вы хотите извлечь из журналов. На основе вашего ввода он автоматически генерирует шаблоны, необходимые для извлечения данных.
Что нужно знать о пользовательских правилах синтаксического анализа
При создании собственного синтаксического анализатора следует помнить о некоторых вещах: данные отображаются в поиске по журналу.
 Если ваши данные не отображаются в поиске по журналам, это может указывать на проблему с вашим правилом синтаксического анализа. Дополнительные сведения см. в разделе «Устранение неполадок».
Если ваши данные не отображаются в поиске по журналам, это может указывать на проблему с вашим правилом синтаксического анализа. Дополнительные сведения см. в разделе «Устранение неполадок».Как работают пользовательские синтаксические анализаторы
Пользовательские синтаксические анализаторы применяются к необработанным событиям, которые представляют собой строки текста, собранные источником событий. Ваше пользовательское правило синтаксического анализа будет анализировать необработанные события при загрузке в Insight Cloud. Чтобы построить правило, вы определяете значения, извлеченные из строки журнала, и значения, с которыми вы хотите их сопоставить. С помощью специального инструмента синтаксического анализа вы также можете нормализовать структуру своих журналов, упрощая поиск полей, которые вы хотите извлечь.
С помощью специального инструмента синтаксического анализа вы также можете нормализовать структуру своих журналов, упрощая поиск полей, которые вы хотите извлечь.
Шаги для создания пользовательского правила синтаксического анализа:
- Задача 1. Назовите правило
- Задача 2. Выберите журнал
- Задача 3. Создайте фильтр
- Задача 4. Извлеките поля из журнала
- Задача 5. Массовое применение правил Создайте пользовательское 900 Правило синтаксического анализа
- Запустите Custom Parsing Tool. В левом меню перейдите к поиску по журналу и выберите Пользовательский анализ данных > Создать пользовательское правило анализа .
- Когда вы перейдете в Custom Parsing Tool, выполните задачи 1–5, чтобы создать собственные правила.
- Введите уникальное имя.
- Щелкните Далее: выберите Журналы .
- В разделе Шаг 1: Журнал выберите журнал, из которого вы хотите извлечь поля.
- Под Шаг 2: Примеры строк журнала выберите диапазон времени. Если вы не видите какие-либо образцы данных, вам может потребоваться увеличить выбранный временной диапазон.
- Щелкните Далее: Создать фильтр .
- Введите значения, которые вы хотите включить в фильтр.
- Нажмите «Применить». Этот фильтр будет применяться к любым данным до того, как они будут проанализированы этим правилом
- Щелкните Далее: Извлечь поля .
- Выделите данные, которые вы хотите извлечь из журнала выборки. Инструмент Custom Parsing автоматически выделяет совпадающие данные в других строках журнала. При извлечении данных мы рекомендуем не включать скобки или кавычки, так как это может затруднить поиск полей в дальнейшем.
- Если вас устраивают выбранные данные, нажмите Подтвердить .
- Назовите свое поле и нажмите Добавить поле .
- Повторяйте шаги 1–3, пока не извлечете все поля, которые хотите включить в правило. Вы также можете переключиться в редактор регулярных выражений, чтобы дополнительно определить правило синтаксического анализа с помощью регулярного выражения.
- Щелкните Далее: Массовое применение правил .
- Редактор регулярных выражений поддерживает только регулярные выражения RE2. В настоящее время безымянные группы захвата не поддерживаются.
- Поля, извлекаемые в управляемом режиме, будут отображаться как автоматически сгенерированные регулярные выражения в редакторе регулярных выражений и могут отличаться по формату от написанных человеком регулярных выражений.
- Имена групп не могут содержать цифры, специальные символы или пробелы.
- Любые изменения, сделанные в редакторе регулярных выражений, будут безвозвратно утеряны, если вы вернетесь в управляемый режим.
- На этапе извлечения поля нажмите Открыть в редакторе регулярных выражений .
- Чтобы определить поля, которые вы хотите извлечь, введите регулярные выражения в текстовом редакторе.
- Когда будете готовы, нажмите Применить . Ваши недавно извлеченные поля будут отображаться в разделе сводки слева от редактора в разделе «Извлечь поля». В предварительном просмотре образца журнала вы также увидите выделение части строки журнала, извлекаемой вашим запросом.
- Щелкните Далее: массовое применение правил .
- Перейдите к поиску по журналам, выберите «Синтаксический анализ пользовательских данных» в правом верхнем углу и нажмите «Управление правилами синтаксического анализа» .
- На странице «Управление правилами синтаксического анализа» найдите правило, которое нужно обновить, и щелкните значок «Редактировать ».
- В меню слева перейдите к поиску по журналу и выберите Анализ пользовательских данных > Управление правилами синтаксического анализа . В таблице Управление правилами синтаксического анализа отображаются все правила синтаксического анализа.
- Найдите правило синтаксического анализа, которое вы хотите удалить, и щелкните значок Удалить .
Чтобы создать правило, определите значения, извлеченные из строки журнала, и значения, с которыми вы хотите их сопоставить.
Для начала:

Задача 1. Назовите свое правило
Следует использовать уникальное и описательное имя, чтобы впоследствии можно было легко найти правило. Например, если вы хотите создать правила синтаксического анализа для журналов брандмауэра, вы можете ввести «Журнал брандмауэра 1».
Чтобы добавить имя:
Задача 2. Выберите журнал
Эта задача состоит из двух шагов: выбора журнала и установки диапазона времени. Диапазон времени позволяет просмотреть определенный диапазон журналов, в которых есть поля, которые вы хотите проанализировать. Строки журнала отображаются от самых старых до самых новых, поэтому важно выбрать временной диапазон, который будет генерировать наиболее релевантную выборку данных. В Задаче 4 вы извлечете поля из этих строк журнала.
Чтобы выбрать журнал:

Задача 3: Создание фильтра
Далее давайте определимся, нужно ли вам создавать фильтр. Для этого просмотрите структуру строк вашего журнала: если ваши потоки журналов имеют несколько форматов для событий журнала, выполните этот шаг, чтобы убедиться, что ваше пользовательское правило синтаксического анализа применяется только к соответствующим журналам. Однако, если ваши строки журнала имеют одинаковый формат, вы можете пропустить этот шаг и перейти к Задаче 4: Извлечение полей.
Фильтры, добавленные в пользовательское правило синтаксического анализа, применяются к входящим журналам до их анализа. Скажем, например, у вас есть источник событий, который отправляет события DNS, VPN и брандмауэра в одной строке журнала. Вы можете создать фильтр, фокусирующийся на событиях брандмауэра, что позволит лучше отслеживать вредоносные действия, происходящие на этом уровне.
Вы можете создать фильтр, фокусирующийся на событиях брандмауэра, что позволит лучше отслеживать вредоносные действия, происходящие на этом уровне.
Чтобы создать фильтр:
В этом задании выберите, какие данные вы хотите извлечь из журнала, используя управляемый режим, или извлеките поля вручную с помощью редактора регулярных выражений. Управляемый режим — это режим по умолчанию для новых правил синтаксического анализа.
Управляемый режим
Чтобы извлечь поля:
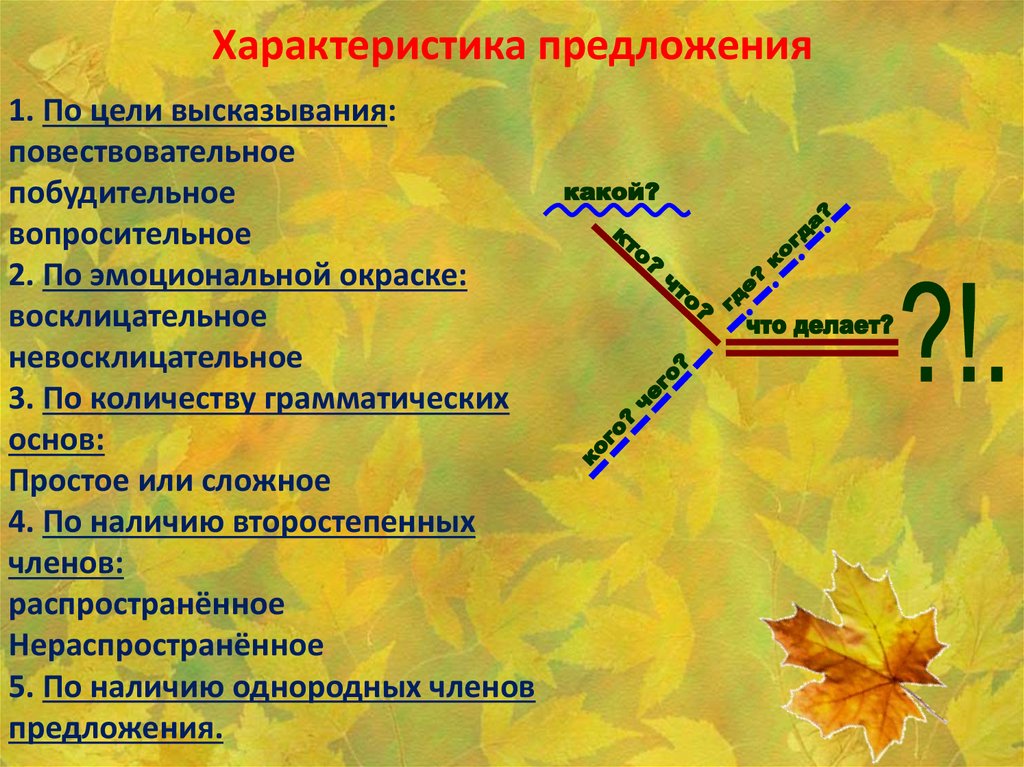
Редактор регулярных выражений
Используйте Редактор регулярных выражений для ручного извлечения полей с регулярными выражениями. Вы можете использовать редактор, чтобы завершить весь процесс извлечения поля, или вы можете начать в управляемом режиме и использовать редактор регулярных выражений для точной настройки извлеченных полей.
Прежде чем начать, обратите внимание на следующее:
 В настоящее время безымянные группы захвата не поддерживаются.
В настоящее время безымянные группы захвата не поддерживаются.Чтобы извлечь поля:

Правила, измененные с помощью редактора регулярных выражений, нельзя отменить.
Если вы измените или создадите правило синтаксического анализа с помощью редактора регулярных выражений, а затем сохраните его, вы не сможете вернуться в управляемый режим. Если вы хотите отредактировать правило синтаксического анализа, которое было изменено или создано с помощью редактора регулярных выражений, вы должны использовать для этого редактор регулярных выражений.
Задача 5. Массовое применение правил
Вы можете применить новые пользовательские правила синтаксического анализа к другим журналам. Для этого выберите свои журналы из списка предлагаемых журналов.
Вы должны выбрать журналы, идентичные формату созданного вами правила синтаксического анализа. Например, если ваши образцы журналов являются журналами брандмауэра, вы можете выбрать соответствующие журналы брандмауэра из этого списка.
Управление пользовательскими правилами синтаксического анализа
Изменить правило синтаксического анализа
Вы можете отредактировать правило, чтобы учесть изменения в формате журнала, добавить дополнительные поля или уточнить существующий выбор полей. Обратите внимание, что изменения не применяются задним числом к существующим журналам. Применение изменений к новым журналам может занять до 10 минут.
Чтобы изменить правило синтаксического анализа:
Просмотреть все правила синтаксического анализа
В меню слева перейдите к поиску по журналу и выберите Анализ пользовательских данных > Управление правилами синтаксического анализа . В таблице Управление правилами синтаксического анализа отображаются все правила синтаксического анализа.
В таблице Управление правилами синтаксического анализа отображаются все правила синтаксического анализа.
В меню слева перейдите к поиску по журналу и выберите Анализ пользовательских данных > Управление правилами анализа . В таблице Управление правилами синтаксического анализа отображаются все правила синтаксического анализа.
В столбце Извлеченные поля показаны извлеченные поля для каждого правила синтаксического анализа.
Просмотр журналов для правила синтаксического анализа
В меню слева перейдите к поиску в журнале и выберите Анализ пользовательских данных > Управление правилами синтаксического анализа . Правила парсинга Manage 9В таблице 0837 отображаются все правила разбора.
В столбце Журналы показаны журналы, к которым применяется правило синтаксического анализа.
Удаление правила синтаксического анализа
Удаление правила синтаксического анализа может повлиять на информационные панели, запросы и настраиваемые оповещения, использующие его данные. Пожалуйста, просмотрите ваши запросы. После удаления правила синтаксического анализа вы не сможете отменить изменения.
Пожалуйста, просмотрите ваши запросы. После удаления правила синтаксического анализа вы не сможете отменить изменения.
Обратите внимание, что после удаления правила синтаксического анализа новые входящие данные не будут анализироваться. Ранее проанализированные данные останутся в проанализированном состоянии.
Чтобы удалить правило синтаксического анализа:
Устранение неполадок с пользовательскими правилами синтаксического анализа
Ниже приведены некоторые распространенные ситуации и способы их решения.
Мой синтаксический анализатор перестал анализировать мои журналы
Если Custom Parsing Tool больше не анализирует ваши журналы, наиболее вероятной причиной является то, что входящие журналы больше не соответствуют созданным вами правилам анализа, обычно потому, что изменение, внесенное в отправляющее устройство, изменило формат журналы.