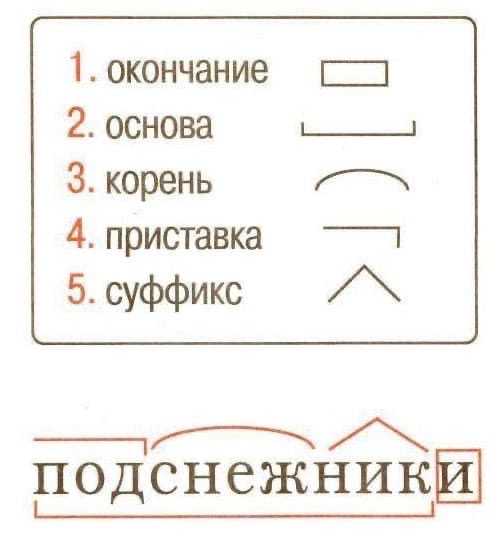
Разбор контекстно-зависимых грамматик
Разбор контекстно-зависимых грамматикДалее: Теория автоматов в XSB Up: Грамматика Предыдущий: Линейный разбор LL(k)
Другой более мощной формой грамматик является класс контекста. чувствительные грамматики. Они содержат правила, содержащие строки как на левосторонний и правосторонний, в отличие от контекстно-свободного правила, которые требуют один символ слева. А ограничение на контекстно-зависимые правила заключается в том, что длина строки в левой части не меньше единицы и меньше или равно длина строки в правой части. (Без этого ограничение, можно получить полную вычислимость по Тьюрингу и признание проблема неразрешима.) В качестве простого примера рассмотрим следующее контекстно-зависимая грамматика:
1. S --> aSBC
2. С --> аВС
3. КБ --> ВС
4. аВ --> аб
5. бБ --> бб
6. до н.э. --> до н.э.
7. СС --> СС
Эта грамматика генерирует все строки, состоящие из непустой последовательности
из a, за которыми следует такое же количество b, за которым следует такое же число
из с.
С
правило SBC 1
правило 2
правило 3
aabBCC правило 4
aabbCC правило 5
правило 6
правило 7
Несмотря на то, что в этом простом примере правила срабатывают по порядку, это не
трудно понять, что правило 3 должно срабатывать достаточное количество раз, чтобы двигаться
все C справа над B, и тогда сработают правила 4-7
достаточное количество раз, чтобы превратить все нетерминалы в терминалы. Теперь вопрос в том, как представить это в XSB. Мы можем думать о
Правила XSB DCG работают на графе, который начинается как линейная цепочка.
представляющий входную строку. Затем каждое контекстно-свободное правило DCG сообщает
как мы можем добавить ребра к этому линейному графу. Например, правило DCG а --> б, в. говорит нам, что если есть дуга от узла X к узлу
Y, отмеченный буквой b, а также дуга из узла Y в узел Z, отмеченная буквой c,
то мы должны добавить дугу от узла X к узлу Z, помеченную a.
a(S0,S):-b(S0,S1),c(S1,S). , читать
справа налево, говорит явно и прямо, что если есть дуга
из S0 в S1, обозначенную b, и дугу из S1 в S, обозначенную c, то существует
— дуга из S0 в S, помеченная символом a. Мы можем думать о правилах DCG как
правила, которые добавляют помеченные дуги к графикам. Это именно так, как
разбор диаграмм понятен. Теперь мы можем расширить этот способ понимания логических грамматик на
контекстно-зависимые правила. Контекстно-зависимое правило, скажем, два
символов в левой части, можно также рассматривать как графогенерирующий
правило, но в этом случае он должен ввести новый узел, а также новый
дуги. Так, например, такое правило, как AB --> CD следующим образом:
а(S0,p1(S0)) :- c(S0,S1), d(S1,S). b(p1(S0),S) :- c(S0,S1), d(S1,S).
b(p1(S0),S) :- c(S0,S1), d(S1,S).
которые явно добавляют дуги и узлы. Мы должны ввести новый
имя нового узла. Мы решили идентифицировать новые узлы с помощью
символ функтора, однозначно определяющий правило и левый
внутренней позиции и связывая ее с именем начального узла в
базовая дуга. Таким образом, в этом случае p1 однозначно идентифицирует (только)
внутреннее положение в левой части этого правила. Другие правила,
и позиции, будут иметь разные функторы для их идентификации
уникально. Теперь мы можем представить контекстно-зависимую грамматику выше, используя
следующие правила XSB: b(p1(S0),S) :- c(S0,S1), d(S1,S).
b(p1(S0),S) :- c(S0,S1), d(S1,S).
:- auto_table. s(S0,S):-слово(S0,a,S1),s(S1,S2),b(S2,S3),c(S3,S). s(S0,S):-слово(S0,a,S1),b(S1,S2),c(S2,S). c(S0,p0(S0)) :- b(S0,S1),c(S1,_S). b(p0(S0),S) :- b(S0,S1),c(S1,S). слово(S0,a,p1(S0)) :- слово(S0,a,S1),слово(S1,b,_S). b(p1(S0),S):-слово(S0,a,S1),слово(S1,b,S). слово(S0,b,p2(S0)) :- слово(S0,b,S1),слово(S1,b,_S). b(p2(S0),S):-слово(S0,b,S1),слово(S1,b,S). слово(S0,b,p3(S0)) :- слово(S0,b,S1),слово(S1,c,_S).
 c(p3(S0),S):-слово(S0,b,S1),слово(S1,c,S).
слово(S0,c,p4(S0)) :- слово(S0,c,S1),слово(S1,c,_S).
c(p4(S0),S):-слово(S0,c,S1),слово(S1,c,S).
% определить слово/3, используя базовое слово (необходимо разделение)
слово(X,Y,Z):- base_word(X,Y,Z).
% разобрать строку... сначала утвердить слова, затем вызвать символ предложения
разобрать (строка): -
отменить_все_таблицы,
retractall (базовое_слово (_, _, _)),
assertWordList(String,0,Len),
с(0,длина).
% утверждает список слов.
утвердитьСписокСлов([],N,N).
assertWordList([Sym|Syms],N,M) :-
N1 это N+1,
утверждать (базовое_слово (N, Sym, N1)),
утвердитьWordList(Syms,N1,M).
c(p3(S0),S):-слово(S0,b,S1),слово(S1,c,S).
слово(S0,c,p4(S0)) :- слово(S0,c,S1),слово(S1,c,_S).
c(p4(S0),S):-слово(S0,c,S1),слово(S1,c,S).
% определить слово/3, используя базовое слово (необходимо разделение)
слово(X,Y,Z):- base_word(X,Y,Z).
% разобрать строку... сначала утвердить слова, затем вызвать символ предложения
разобрать (строка): -
отменить_все_таблицы,
retractall (базовое_слово (_, _, _)),
assertWordList(String,0,Len),
с(0,длина).
% утверждает список слов.
утвердитьСписокСлов([],N,N).
assertWordList([Sym|Syms],N,M) :-
N1 это N+1,
утверждать (базовое_слово (N, Sym, N1)),
утвердитьWordList(Syms,N1,M).
Мы можем запустить эту грамматику для анализа входных строк следующим образом:
Уоррен% xsb XSB версии 1.7.2 (10.07.97) [Вс, оптимальный режим] | ?- [csgram]. [csgram загружен] да | ?- разобрать([a,a,b,b,c,c]). ++Внимание: удаление неполных таблиц... да | ?- разобрать([а,а,а,б,б,в,в,в]). нет | ?- разобрать([а,а,а,а,б,б,б,б,в,в,в,в]).
 ++Внимание: удаление неполных таблиц...
да
| ?-
++Внимание: удаление неполных таблиц...
да
| ?-
Итак, теперь мы обобщили DCG, включив в него обработку контекстно-зависимые грамматики и языки. Встроенная нотация DCG не поддерживает контекстно-зависимые языки, но мы можем написать необходимые правила прямо как правила XSB, как мы сделали выше. Это Интересно отметить, что правила XSB, которые мы генерируем для одного все контекстно-зависимые правила имеют одно и то же тело, и что логическое подразумеваемое
р <- р & с.
q<-r&s.
логически эквивалентны единственной импликации:
p&q <- r&s.
Поэтому было бы очень естественно расширить нотацию Пролога для поддержки
``многоглавые'' правила, которые будут скомпилированы в набор
«одноглавые», т. е. обычные правила Пролога. Если бы мы сделали это, мы
можно написать контекстно-зависимое правило:
АВ --> CD
как единственное (многоголовое) правило XSB:
а(S0,p1(S0)), b(p1(S0),S) :- c(S0,S1), d(S1,S).
что очень похоже на исходное контекстно-зависимое правило.
Далее: Теория автоматов в XSB Up: Грамматика Предыдущий: Линейный разбор LL(k) Дэвид С. Уоррен
1999-07-31
Синтаксический анализ медицинских отчетов с использованием эволюционной оптимизации
- Список журналов
- AMIA Annu Symp Proc
- v.2005; 2005 г.
- PMC1560622
Являясь библиотекой, NLM предоставляет доступ к научной литературе. Включение в базу данных NLM не означает одобрения или согласия с
содержание NLM или Национальных институтов здравоохранения.
AMIA Annu Symp Proc. 2005 г.; 2005: 920.
, PhD, a , PhD, b и, MD b
Информация об авторе Информация об авторских правах и лицензии Отказ от ответственности
Мы сообщаем о синтаксическом парсере для медицинских отчетов который использует генетический алгоритм для эффективного определения конфигурации синтаксического анализа с наивысшим рангом на основе схемы оценки, разработанной в рамках нашей предыдущей работы [1]. Подход тестировался на наборе из 250 предложений из домена радиологии. Время выполнения и сравнение с исчерпывающими методами дано.
Цель нашего синтаксического анализатора состоит в том, чтобы ввести предложение, помеченное частью речи, и
вывести дерево синтаксического анализа с указанием зависимостей слово-слово () [2]. Статистический подход к этой проблеме состоит из двух компонентов.
Открыть в отдельном окне
Пример предложения и решение для синтаксического анализа.
Наш теоретико-полевой подход к синтаксическому анализу фокусируется на оценке условных вероятность. Он использует подход «слово-агент» [3], в котором каждое слово ищет конфигурацию вложения, которая минимизирует функцию энергии, используя особенности, описанные в [1]. Исходное состояние системы таково, что все слова находятся в свободном состоянии . Этим мы подразумеваем, что каждое слово неприкреплено. Полная начальная энергия системы, то это сумма энергий, связанных с каждым словом в предложении в свободное состояние .
Поиск глобальной минимальной конфигурации начинается с первой оценки
возможные места назначения ссылки для каждого слова на основе семантической выборки
ограничения. Хотя большинство парсеров синтаксиса используют грамматические правила, мы
использовать статистический/комбинаторный подход, в котором связи между
языковые элементы рассматриваются как гены. Гены разрешены.
развиваться в соответствии с правилами отбора. Хромосома с наивысшим
пригодность представляет собой решение для разбора синтаксиса. Эволюционный
схема предлагает потенциальное преимущество переносимости в широком спектре
медицинских документов, так как он имеет возможность адаптироваться к местным синтаксическим
особенности.
Хотя большинство парсеров синтаксиса используют грамматические правила, мы
использовать статистический/комбинаторный подход, в котором связи между
языковые элементы рассматриваются как гены. Гены разрешены.
развиваться в соответствии с правилами отбора. Хромосома с наивысшим
пригодность представляет собой решение для разбора синтаксиса. Эволюционный
схема предлагает потенциальное преимущество переносимости в широком спектре
медицинских документов, так как он имеет возможность адаптироваться к местным синтаксическим
особенности.
Эволюционный метод реализован с использованием генетического алгоритма.
основные параметры алгоритма включали: (1) размер популяции (количество
хромосом в популяции), (2) вероятность мутации (бит-инверсия
генов осуществляется для того, чтобы сохранить популяцию разнообразной и
предотвращения захвата в локальные минимумы), (3) уровень элитарности (рассматриваемые хромосомы
быть наиболее подходящими, разрешено размножаться) и (4) скорость вымирания (хромосомы
признаны непригодными для воспроизведения, прекращаются).
Эффективность метода эволюционной оптимизации была проверена на 250 предложениях. представляющий широкий спектр синтаксиса, встречающегося в радиологии отчеты. В большинстве случаев генетический алгоритм сходился к решению менее чем за 500 поколений. Оценивалась точность разбора синтаксиса путем сравнения результатов с результатами исчерпывающего метода, который рассматривает все возможные комбинации ссылок. Результаты также были вручную проверено. В 84% случаев эволюционный метод дал правильные результаты в течение одного запуска. Когда было разрешено несколько запусков, точность достигла 100%. Для примера предложения () существует 20 514 возможных комбинаций ссылок. Исчерпывающий поиск взял 1,944 секунды, чтобы найти решение при той же конфигурации синтаксического анализа был получен за 117 секунд предложенным методом.
Предварительное исследование показывает, что подход эволюционной оптимизации
эффективен, и по сравнению с исчерпывающими методами вычислительно
эффективный.