Синтаксический разбор слова
Часто пользователи ищут в сети синтаксический анализ какого-либо слова. По этому запросу обычно получают результаты по разбору предложений и словосочетаний. Но почему так происходит? Давайте в этом разберемся далее и приведем примеры такого разбора.
Все дело в том, что разобрать слово синтаксически нельзя. Можно сделать разбор только словосочетания или всего предложения. В школьной программе этой теме выделено довольно много времени для усвоения материала, а также большое количество практических уроков, чтобы ученики сами научились делать такой разбор. Но мы с вами сегодня опишем в общих чертах, как делать синтаксический анализ.
Содержание
- Как делать синтаксический разбор предложения
- Порядок разбора предложения по словам
- Анализ сложносочиненной конструкции
- Синтаксический разбор сложноподчиненных предложений с придаточными
- Анализ сложной конструкции с различными связными элементами
Как делать синтаксический разбор предложения
Если нужно выполнить синтаксический анализ словосочетания, сделайте следующее:
- Определите словосочетание.
 Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова. - Определите синтаксическое общее между словами.
- Выделите грамматическое значение для каждого.
 Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.Порядок разбора предложения по словам
Порядок действий будет следующим:
- Установите, каким выступает предложение по типу высказывания (вопросительное, побудительное, повествовательное).
- Далее нужно указать, из каких частей состоит предложение, его состав. Нужно сказать, что оно простое, односоставное/двусоставное, определить тип – безличное/личное. Предложение является нераспространенным или наоборот. Полное/неполное, если нет, то указать, каких именно частей в нем не достает.
- Если простое предложение осложнено обособленными, однородными членами предложения, отметьте это в синтаксическом разборе.
- Сделайте разбор простого предложения по членам, по ходу отмечая, к каким частям речи их отнести. Для этого соблюдайте порядок: первыми в предложении определите сказуемое и подлежащее, после них найдите второстепенные члены предложения.
- Предоставьте доводы о знаках препинания, если они имеются в предложении.

Для сказуемого нужно определить, каким оно является – составным или глагольным. Определите чем оно выступает. Если простое – укажите для него форму глагола, для составного глагольного – определить его состав, составное именное – чем выступает именная часть, какая связка применяется.
Если предложение имеет однородные члены предложения, укажите, чем выражены эти члены, и какими средствами они соединяются (союзы, интонация и союзы). В предложениях, которые имеют обособления, необходимо определить, чем выступает весь оборот. После этого нужно определить, чем выступает каждое слово в обороте, каким членом предложения является. Укажите, что предложение в своем составе имеет прямую речь. Определите слова говорящего, а также прямую речь.
Анализ сложносочиненной конструкции
Порядок действий:
- Аналогично, как и с простым предложением, назовите и определить тип высказывания.
- Определите грамматический фундамент каждого отдельного простого предложения. Прочитайте их по отдельности.
- Обозначите вид союзов, которыми связываются простые предложения в составе сложного (разделительные, соединительные, противительные). Определите, каким выступает сложное предложение (противопоставление, чередование событий, перечисление).
- Определите роль знаков препинания, объясните их расстановку.
- Затем нужно разобрать каждое предложение по отдельности как простое.

Далее рассмотрим пошаговый синтаксический разбор сложноподчиненного предложения (в составе одно придаточное):
- Отметить, каким сложноподчиненное предложение является (вопросительным, повествовательным).
- Разбить на простые предложения, найти грамматическую основу для каждого.
- Выделить, какое предложение из простых является главным.
- Определить по особенностям строения, чем присоединяется, к чему относится, чем выступает это сложноподчиненное предложение.
- Пояснить расстановку знаков препинания.
- Придаточное и главное разобрать подобно простым.

Синтаксический разбор сложноподчиненных предложений с придаточными
Анализ состоит из следующих этапов:
- Определите цель высказывания сложноподчиненного предложения, отметьте это.
- Установите грамматическую роль каждого простого предложения.
- Определить среди простых придаточное и главное.
- Укажите признаки подчиненного предложения – параллельное, однородное, последовательное (возможно комбинированное).
- Объясните надобность каждого знака препинания.
Анализ сложной конструкции с различными связными элементами
Порядок действий:
- Установите цели высказывания.
- Укажите основу грамматики отдельного простого предложения.
- Указать, что предложение имеет разные виды связи.
- Выделите по смысловому признаку, каким образом соединены простые предложения.
- Объясните каждый знак препинания, его значение.
В статье мы рассмотрели, почему нельзя выполнить синтаксический разбор какого-либо слова, и как правильно выполнять анализ предложений.
Главная » Полезные советы » Правила русского языка
Автор Дима Опубликовано Обновлено
Морфемный разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Морфемный разбор
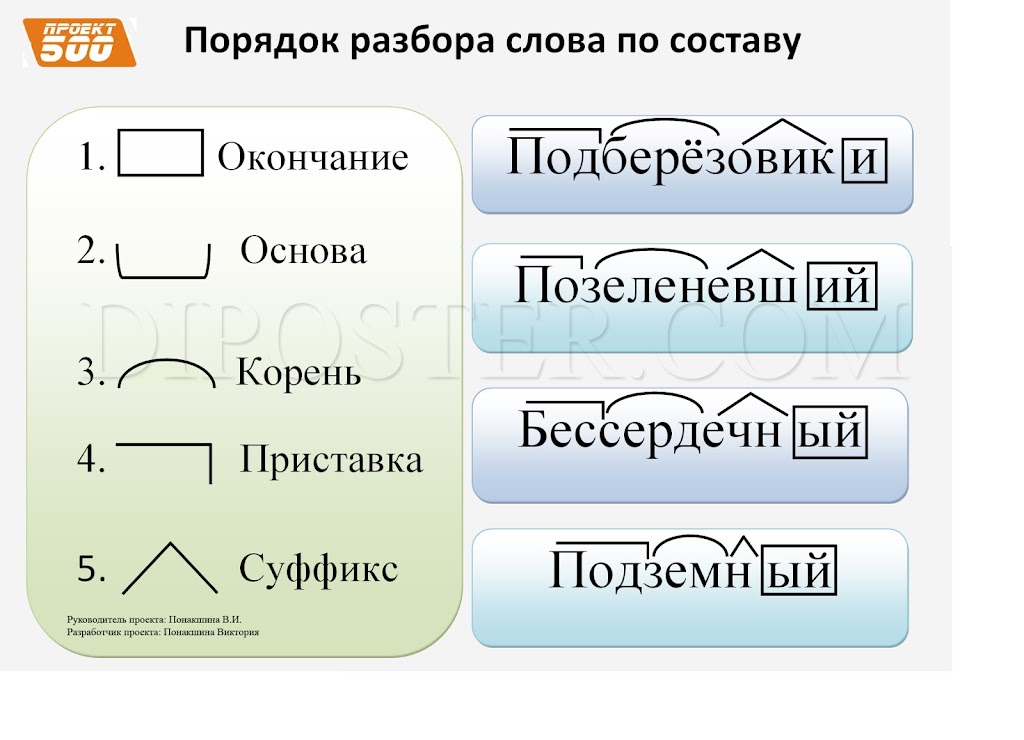
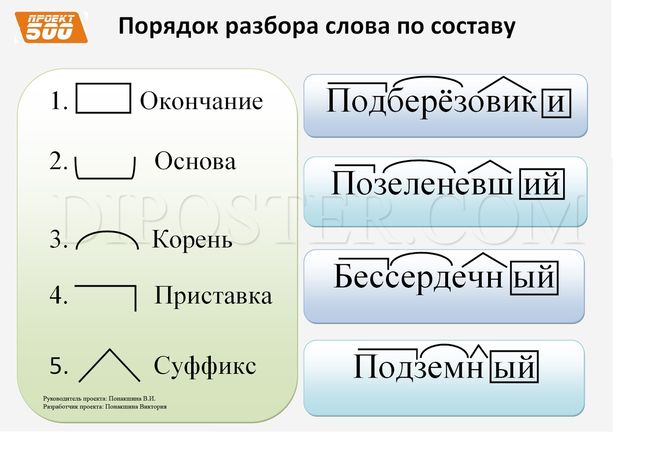
Морфемный разбор – это разбор слова по составу или разбор слова на морфемы. Морфема является значимой частью слова, потому что она выражает какое – то значение. Всего в русском языке выделяют 4 морфемы – это корень, приставка, суффикс и окончание.
Всего в русском языке выделяют 4 морфемы – это корень, приставка, суффикс и окончание.
Пример:
Котики – выделяем три морфемы. Каждая морфема имеет значение:
Корень кот — означает животное
Суффикс -ик – показывает, что речь идет о маленьком коте
Окончание –и указывает на множественное число имени существительного (котиков много, а не один).
Теперь мы знаем, почему морфему называют значимой частью слова.
Слово для морфемного разбора обозначается надстрочной цифрой «2»: сестра2.
Пример рассуждений:
Ольга переделает2 домашнее задание.
Переделает – это глагол. Выделяем окончание – ет, которое указывает на форму третьего лица единственного числа. Переделает – означает сделает заново, значение «заново» этому слову придает приставка пере- (перечитать, переделать). Выделяем приставку. Корень дел находим, сравнивая родственные слова – дело, сделал, поделка. Суффикс – а- в глаголах показывает значение действия.
Выделяем приставку. Корень дел находим, сравнивая родственные слова – дело, сделал, поделка. Суффикс – а- в глаголах показывает значение действия.
Итак, в слове четыре морфемы: переделает
Порядок морфемного разбора (разбора слова по составу):
- Определи, к какой части речи относится слово
- Найди окончание и обведи его рамочкой
- Выдели часть слова без окончания — ̢_______̡. Это основа слова
- Найди корень и выдели дугой
- Найди приставку и обозначь ее значком
- Найди суффикс и отметь его значком
Помни, что некоторых морфем в слове может и не быть.
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Окончание
Основа слова
Корень и однокоренные (родственные) слова
Приставки и их значения
Суффикс
Правило встречается в следующих упражнениях:
2 класс
Упражнение 2, Климанова, Бабушкина, Учебник, часть 2
Упражнение 1, Бунеев, Бунеева, Пронина, Учебник
3 класс
Упражнение 208, Канакина, Горецкий, Учебник, часть 1
Упражнение 159, Канакина, Рабочая тетрадь, часть 1
Упражнение 6, Канакина, Горецкий, Учебник, часть 2
Упражнение 81, Канакина, Горецкий, Учебник, часть 2
Упражнение 193, Канакина, Горецкий, Учебник, часть 2
Упражнение 204, Канакина, Горецкий, Учебник, часть 2
Упражнение 150, Климанова, Бабушкина, Рабочая тетрадь, часть 1
Упражнение 194, Полякова, Учебник, часть 1
Упражнение 158, Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 7, Исаева, Бунеев, Рабочая тетрадь
4 класс
Упражнение 21, Канакина, Горецкий, Учебник, часть 1
Упражнение 28, Канакина, Горецкий, Учебник, часть 1
Упражнение 196, Канакина, Горецкий, Учебник, часть 1
Упражнение 84, Канакина, Рабочая тетрадь, часть 1
Упражнение 37, Канакина, Горецкий, Учебник, часть 2
Упражнение 139, Канакина, Горецкий, Учебник, часть 2
Упражнение 150, Канакина, Горецкий, Учебник, часть 2
Упражнение 170, Канакина, Горецкий, Учебник, часть 2
Упражнение 4, Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 376, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
5 класс
Упражнение 33, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 75, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 89, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 136, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 146, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 365, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 3, Разумовская, Львова, Капинос, Учебник
Упражнение 109, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 115, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 280, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
6 класс
Упражнение 94, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 303, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 589, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 108, Разумовская, Львова, Капинос, Учебник
Упражнение 65, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
Упражнение 335, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
Упражнение 360, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
Упражнение 564, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
Упражнение 572, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
Упражнение Повторение стр. 154-155,
Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
154-155,
Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 2
7 класс
Упражнение Повторение стр. 102 — 105 , Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 292, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 296, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 391, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 456, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 464, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 465, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 153, Разумовская, Львова, Капинос, Учебник
Упражнение 526, Разумовская, Львова, Капинос, Учебник
Упражнение 596, Разумовская, Львова, Капинос, Учебник
8 класс
Упражнение 25, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 128, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 370, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 117, Разумовская, Львова, Капинос, Учебник
Упражнение 337, Разумовская, Львова, Капинос, Учебник
Упражнение 361, Разумовская, Львова, Капинос, Учебник
Упражнение 389, Разумовская, Львова, Капинос, Учебник
Упражнение 408, Разумовская, Львова, Капинос, Учебник
Упражнение 67, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 166, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Синтаксический разбор слова
Правила русского языка
54321
0 (0 votes)
The estimated reading time is 2 minutes
Часто пользователи ищут в сети синтаксический разбор какого-либо слова. По этому запросу обычно получают результаты по разбору предложений и словосочетаний. Но почему так происходит? Давайте в этом разберемся далее и приведем примеры такого разбора.
По этому запросу обычно получают результаты по разбору предложений и словосочетаний. Но почему так происходит? Давайте в этом разберемся далее и приведем примеры такого разбора.
Все дело в том, что разобрать слово синтаксически нельзя. Можно сделать разбор только словосочетания или всего предложения. В школьной программе этой теме выделено довольно много времени для усвоения материала, а также большое количество практических уроков, чтобы ученики сами научились делать такой разбор. Но мы с вами сегодня опишем в общих чертах, как делать синтаксический анализ.
Содержание статьи:
- Как делать синтаксический разбор предложения
- Порядок разбора предложения по словам
- Анализ сложносочиненной конструкции
- Синтаксический разбор сложноподчиненных предложений с придаточными
- Анализ сложной конструкции с различными связными элементами
Как делать синтаксический разбор предложения
Если нужно выполнить синтаксический анализ словосочетания, сделайте следующее:
- Определите словосочетание. Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
- Определите синтаксическое общее между словами.
- Выделите грамматическое значение для каждого.
 Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.Порядок разбора предложения по словам
Порядок действий будет следующим:
- Установите, каким выступает предложение по типу высказывания (вопросительное, побудительное, повествовательное).
- Далее нужно указать, из каких частей состоит предложение, его состав. Нужно сказать, что оно простое, односоставное/двусоставное, определить тип – безличное/личное. Предложение является нераспространенным или наоборот. Полное/неполное, если нет, то указать, каких именно частей в нем не достает.
- Если простое предложение осложнено обособленными, однородными членами предложения, отметьте это в синтаксическом разборе.
- Сделайте разбор простого предложения по членам, по ходу отмечая, к каким частям речи их отнести. Для этого соблюдайте порядок: первыми в предложении определите сказуемое и подлежащее, после них найдите второстепенные члены предложения.
- Предоставьте доводы о знаках препинания, если они имеются в предложении.
Синтаксический разбор. Порядок.

Для сказуемого нужно определить, каким оно является – составным или глагольным. Определите чем оно выступает. Если простое – укажите для него форму глагола, для составного глагольного – определить его состав, составное именное – чем выступает именная часть, какая связка применяется.
Если предложение имеет однородные члены предложения, укажите, чем выражены эти члены, и какими средствами они соединяются (союзы, интонация и союзы). В предложениях, которые имеют обособления, необходимо определить, чем выступает весь оборот. После этого нужно определить, чем выступает каждое слово в обороте, каким членом предложения является. Укажите, что предложение в своем составе имеет прямую речь. Определите слова говорящего, а также прямую речь.
Анализ сложносочиненной конструкции
Порядок действий:
- Аналогично, как и с простым предложением, назовите и определить тип высказывания.
- Определите грамматический фундамент каждого отдельного простого предложения. Прочитайте их по отдельности.
- Обозначите вид союзов, которыми связываются простые предложения в составе сложного (разделительные, соединительные, противительные). Определите, каким выступает сложное предложение (противопоставление, чередование событий, перечисление).
- Определите роль знаков препинания, объясните их расстановку.
- Затем нужно разобрать каждое предложение по отдельности как простое.

Далее рассмотрим пошаговый синтаксический разбор сложноподчиненного предложения (в составе одно придаточное):
- Отметить, каким сложноподчиненное предложение является (вопросительным, повествовательным).
- Разбить на простые предложения, найти грамматическую основу для каждого.
- Выделить, какое предложение из простых является главным.
- Определить по особенностям строения, чем присоединяется, к чему относится, чем выступает это сложноподчиненное предложение.
- Пояснить расстановку знаков препинания.
- Придаточное и главное разобрать подобно простым.
План синтаксического разбора предложения

Синтаксический разбор сложноподчиненных предложений с придаточными
Анализ состоит из следующих этапов:
- Определите цель высказывания сложноподчиненного предложения, отметьте это.
- Установите грамматическую роль каждого простого предложения.
- Определить среди простых придаточное и главное.
- Укажите признаки подчиненного предложения – параллельное, однородное, последовательное (возможно комбинированное).
- Объясните надобность каждого знака препинания.
Анализ сложной конструкции с различными связными элементами
Порядок действий:
- Установите цели высказывания.
- Укажите основу грамматики отдельного простого предложения.
- Указать, что предложение имеет разные виды связи.
- Выделите по смысловому признаку, каким образом соединены простые предложения.
- Объясните каждый знак препинания, его значение.

В статье мы рассмотрели, почему нельзя выполнить синтаксический разбор какого-либо слова, и как правильно выполнять анализ предложений.
Leave a comment
Встроенные правила разбора журнала | Документация New Relic
New Relic может анализировать распространенные форматы журналов в соответствии со встроенными правилами, поэтому вам не нужно создавать собственные правила анализа. Вот правила разбора журнала, их шаблоны Grok и анализируемые поля.
- Чтобы включить встроенный анализ журнала, см. нашу документацию для добавления атрибута
logtype. - Для программного управления правилами синтаксического анализа используйте NerdGraph, наш API в формате GraphQL, по адресу api. newrelic.com/graphiql. Для получения дополнительной информации см. руководство NerdGraph по созданию, запросу и удалению правил синтаксического анализа.
 newrelic.com/graphiql. Для получения дополнительной информации см. руководство NerdGraph по созданию, запросу и удалению правил синтаксического анализа.
newrelic.com/graphiql. Для получения дополнительной информации см. руководство NerdGraph по созданию, запросу и удалению правил синтаксического анализа. Источник: logtype = 'apache'
Grok:
%{IPORHOST:clientip} %{USER:identst} %{%{HTTP}ATE[\%USER:auth}ATE[ ] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{ NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}
Результаты:
-
clientip: IP-адрес клиента. -
глагол: глагол HTTP -
ident: идентификатор пользователя клиента, делающего запрос -
ответ: код состояния HTTP ответа -
запрос: URI и версия запроса6 : HTTP-версия запроса
rawrequest: Необработанный HTTP-запрос, если данные отправленыбайт: Количество отправленных байтовreferrer: HTTP referrerАгент: пользовательский агент клиента
Источник: Logtype = 'Apache_error'
Grok:
\ [%{Data: Apache_error.
 TimestAmp} \ [%{%{%{%{Data: Apache_error.timestam :apache_error.source}:%{DATA:level}\] \[pid %{NUMBER:apache_error.pid}(:tid %{NUMBER:apache_error.tid})?\] (%{DATA:apache_error.sourcecode}\ (%{NUMBER:apache_error.linenum}\): )?(?:\[client %{IPORHOST:apache_error.clientip}:%{POSINT:apache_error.port}\] ){0,1}%{GREEDYDATA:apache_error .сообщение}
TimestAmp} \ [%{%{%{%{Data: Apache_error.timestam :apache_error.source}:%{DATA:level}\] \[pid %{NUMBER:apache_error.pid}(:tid %{NUMBER:apache_error.tid})?\] (%{DATA:apache_error.sourcecode}\ (%{NUMBER:apache_error.linenum}\): )?(?:\[client %{IPORHOST:apache_error.clientip}:%{POSINT:apache_error.port}\] ){0,1}%{GREEDYDATA:apache_error .сообщение} Результаты:
-
APACHE_ERROR.TIMESTAMP: TimeStamp оператора log -
APACHE_ERROR.SOURCE: исходный модуль -
Уровень: Lod -
66.Ache_erach_errach_errach_errach_errach_errach_errach_errach_errach_errach_errach. PID apache (идентификатор процесса) -
apache_error.tid: TID apache (идентификатор потока) -
apache_error.sourcecode: исходный код apache -
apache_error.linenum 9%{NOTSSPACE:type} %{TIMESTAMP_ISO8601:time} %{NOTSSPACE:elb} %{NOTSSPACE:client_ip}:%{NOTSSPACE:client_port} ((%{NOTSPACE:target_ip}:%{NOTSSPACE:target_port})|-) %{NOTSSPACE:request_processing_time} %{NOTSSPACE:target_processing_time} %{NOTSSPACE:response_processing_time} %{NOTSSPACE:elb_status_code} %{NOTSSPACE:target_status_code} %{NOTSPACE:received_bytes} %{NOTSSPACE:sent_bytes} "%{DATA:request}" "%{DATA:user_agent}" %{NOTSSPACE:ssl_cipher} %{NOTSSPACE:ssl_protocol} %{NOTSSPACE:target_group_arn} "%{DATA:trace_id}" "%{NOTSSPACE:domain_name}" "%{NOTSSPACE:chosen_cert_arn}" %{NOTSSPACE:matched_rule_priority} %{TIMESTAMP_ISO8601:request_creation_time} "%{NOTSPACE:actions_executed}" "%{NOTSPACE:redirect_url}" "%{NOTSPACE:error_reason}" (?:"|)%{DATA:target_port_list}(? :"|) (?:"|)%{DATA:target_status_code_list}(?:"|) "%{NOTSPACE:classification}" "%{NOTSSPACE:classification_reason}"Результаты:
Поле
Определение
9000 77 7 9017 9017 9017 9017 9017- 2 7
- .
9017 9017 7 9017 7 9017 9017 9017 9017 9017 9017 7 9017 9017 9017 9000- 2
- 7. Possible values are:
-
http: HTTP -
https: HTTP over SSL/TLS -
h3: HTTP/2 over SSL/TLS -
ws: WebSockets -
wss: WebSockets через SSL/TLS
elbИдентификатор ресурса балансировщика нагрузки. Если вы анализируете записи журнала доступа, обратите внимание, что идентификаторы ресурсов могут содержать косую черту (
/).CLIENT_IPIP -адрес запроса клиента
Client_portPortiing.0003target_ipIP-адрес цели, которая обработала этот запрос.
- Если клиент не отправил полный запрос, балансировщик нагрузки не может отправить запрос целевому объекту, и для этого значения устанавливается значение
-. - Если целью является лямбда-функция, это значение равно
–. - Если запрос заблокирован AWS WAF, это значение равно
–, а значениеelb_status_codeустановлен на403.
target_portIP-порт цели, которая обработала этот запрос.
- Если клиент не отправил полный запрос, балансировщик нагрузки не может отправить запрос целевому объекту, и для этого значения устанавливается значение
-. - Если целью является лямбда-функция, это значение равно
–. - Если запрос заблокирован AWS WAF, это значение равно
–, а значениеelb_status_codeравно403.
target_port_listIP-адрес и порт цели, которая обработала этот запрос.
- Если клиент не отправил полный запрос, балансировщик нагрузки не может отправить запрос целевому объекту, и для этого значения устанавливается значение
-. - Если целью является лямбда-функция, это значение устанавливается на
-. - Если запрос заблокирован AWS WAF, это значение устанавливается равным
–, а значениеelb_status_codeустанавливается равным403.
request_processing_timeОбщее время, прошедшее (в секундах, с точностью до миллисекунды) с момента получения балансировщиком нагрузки запроса до момента его отправки целевому объекту.
- Это значение равно
-1, если балансировщик нагрузки не может отправить запрос целевому объекту. Это может произойти, если цель закрывает соединение до истечения времени простоя или если клиент отправляет искаженный запрос. - Это значение также может быть установлено на
-1, если зарегистрированная цель не отвечает до истечения времени простоя.
target_processing_timeОбщее время, прошедшее (в секундах, с точностью до миллисекунды) с момента, когда балансировщик нагрузки отправил запрос на цель, до того момента, когда цель начала отправлять заголовки ответов.
- Это значение равно
-1, если балансировщик нагрузки не может отправить запрос целевому объекту. Это может произойти, если цель закрывает соединение до истечения времени простоя или если клиент отправляет искаженный запрос. - Это значение также может быть установлено на
-1, если зарегистрированная цель не отвечает до истечения времени простоя.
response_processing_timeОбщее время, прошедшее (в секундах, с точностью до миллисекунды) с момента получения балансировщиком нагрузки заголовка ответа от цели до начала отправки ответа клиенту. Сюда входит как время ожидания в очереди балансировщика нагрузки, так и время установления соединения от балансировщика нагрузки к клиенту.
Это значение равно
-1, если балансировщик нагрузки не может отправить запрос целевому объекту. Это может произойти, если цель закрывает соединение до истечения времени простоя или если клиент отправляет искаженный запрос.ELB_STATUS_CODEКод состояния от ответа от нагрузки BALANCER
. necken_STATUS_CODE. Это значение записывается только в том случае, если соединение с целью было установлено и цель отправила ответ. В противном случае устанавливается значение 9.0006 - . Received_bytesРазмер запроса в байтах, полученного от клиента (запрашивающего). Для HTTP-запросов сюда входят заголовки. Для WebSockets это общее количество байтов, полученных от клиента при подключении.
sent_bytesРазмер ответа в байтах, отправляемого клиенту (запрашивающему).
Для HTTP-запросов сюда входят заголовки. Для WebSockets это общее количество байтов, отправленных клиенту по соединению.Запросhttp-запрос
Пользователь neplifire. Строка состоит из одного или нескольких идентификаторов продукта, продукта/версии. Если строка длиннее 8 КБ, она усекается.ssl_cipherШифр SSL. Это значение равно
–, если прослушиватель не является прослушивателем HTTPS.ssl_protocolПротокол SSL. Это значение равно
–, если прослушиватель не является прослушивателем HTTPS.target_group_arnИмя ресурса Amazon (ARN) целевой группы0007
Содержимое заголовка
X-AMZN-TRACE-ID, прилагаемое в двойные цитатыDomain_nameDomain_Name
.
в двойных кавычках. Это значение равно –, если клиент не поддерживает SNI или домен не соответствует сертификату, а клиенту предоставляется сертификат по умолчанию.selected_cert_arnARN сертификата, предоставленного клиенту, заключенный в двойные кавычки.
- Установите значение
повторное использование сеанса, если сеанс используется повторно. - Установите значение
–, если прослушиватель не является прослушивателем HTTPS.
matched_rule_priorityЗначение приоритета правила, которое соответствует запросу.
- Если правило соответствует, это значение от
1-50000. - Если правило не соответствует и было выполнено действие по умолчанию, это значение устанавливается равным
0. - Если при оценке правил возникает ошибка, устанавливается значение
-1. - Для любой другой ошибки устанавливается значение
-.
request_creation_timeВремя, когда балансировщик нагрузки получил запрос от клиента в формате ISO 8601.
action_executedДействия, предпринятые при обработке запроса, заключены в двойные кавычки. Это значение представляет собой список, разделенный запятыми, который может включать значения, описанные в
action_taken. Если не было предпринято никаких действий, например, для неправильно сформированного запроса, это значение равно-.redirect_urlURL-адрес цели перенаправления для заголовка местоположения ответа HTTP, заключенный в двойные кавычки. Если никаких действий по перенаправлению не предпринималось, это значение равно 9.0006 - .
error_reasonКод причины ошибки, заключенный в двойные кавычки.
- Если запрос не выполнен, это один из кодов ошибок, описанных в разделе Коды причин ошибок.
- Если предпринятые действия не включают действие аутентификации или цель не является лямбда-функцией, этому значению присваивается значение
–.
классификацияКлассификация.
причина_классификацииПричина классификации.
Источник:
logtype = 'cassandra'Grok
%{WORD:cassandra.log.level}%{SPACE}\\%[%{NOTSPACE}\\ cassandra.thread.thread {TIMESTAMP_ISO8601:cassandra.timestamp} %{NOTSPACE:cassandra.source}:%{INT:cassandra.line.number} - %{GREEDYDATA:cassandra.message}
Результаты
-
cassandra.log.level: Уровень журнала сообщения (все, трассировка, отладка, информация, предупреждение, ошибка, выкл.) -
cassandra.: Имя потока, выдающего журнал оператор thread -
cassandra.timestamp: временная метка журнала -
cassandra.source: имя исходного файла%{NOTSSPACE:date}%{SPACE}%{NOTSSPACE:time}%{SPACE}%{NOTSSPACE:x_edge_location}%{SPACE}%{NOTSPACE:sc_bytes}%{SPACE}%{NOTSPACE:c_ip}%{SPACE} %{NOTSSPACE:cs_method}%{SPACE}%{NOTSSPACE:cs_host}%{SPACE}%{NOTSSPACE:cs_uri_stem}%{SPACE}%{NOTSSPACE:sc_status}%{SPACE}%{NOTSSPACE:cs_referer}%{SPACE} %{NOTSSPACE:cs_user_agent}%{SPACE}%{NOTSSPACE:cs_uri_query}%{SPACE}%{NOTSSPACE:cs_Cookie}%{SPACE}%{NOTSSPACE:x_edge_result_type}%{SPACE}%{NOTSSPACE:x_edge_request_id}%{SPACE} %{NOTSSPACE:x_host_header}%{SPACE}%{NOTSSPACE:cs_protocol}%{SPACE}%{NOTSSPACE:cs_bytes}%{SPACE}%{NOTSSPACE:time_taken}%{SPACE}%{NOTSSPACE:x_forwarded_for}%{SPACE} %{NOTSSPACE:ssl_protocol}%{SPACE}%{NOTSSPACE:ssl_cipher}%{SPACE}%{NOTSSPACE:x_edge_response_result_type}%{SPACE}%{NOTSPACE:cs_protocol_version}%{SPACE}%{NOTSPACE:fle_status}%{SPACE} %{NOTSSPACE:fle_encrypted_fields}%{SPACE}%{NOTSPACE:c_port}%{SPACE}%{NOTSSPACE:time_to_first_byte}%{SPACE}%{NOTSSPACE:x_edge_detailed_result_type}%{SPACE}%{NOTSPACE:sc_content_type}%{SPACE} %{NOTSPACE:sc_content_len}%{S ТЕМП}%{NOTSSPACE:sc_range_start}%{SPACE}%{NOTSSPACE:sc_range_end}Results:
Field
Definition
x_edge_locationThe edge location that served the request.
Каждое граничное местоположение идентифицируется трехбуквенным кодом и произвольно назначаемым номером; например, DFW3.Трехбуквенный код обычно соответствует коду аэропорта Международной ассоциации воздушного транспорта для аэропорта вблизи граничного местоположения. (Эти сокращения могут измениться в будущем.)
sc_bytesОбщее количество байтов, предоставленных CloudFront зрителю в ответ на запрос, включая заголовки; например,
1045619. Для соединений WebSocket это общее количество байтов, отправленных с сервера клиенту через соединение.c_ipIP-адрес зрителя, сделавшего запрос, в формате IPv4 или IPv6. Если зритель использовал прокси-сервер HTTP или балансировщик нагрузки для отправки запроса, значение
c_ip— это IP-адрес прокси-сервера или балансировщика нагрузки. См. такжеX-Forwarded-For.CS_METHODМетод HTTP -запроса:
DEDETE,GET,HEAD,70007,, ,7,, , , , , , , , , , , , , , , , , , .cs_hostДоменное имя раздачи CloudFront; например,
d111111abcdef8.cloudfront.net.cs_uri_stemЧасть URI, определяющая путь и объект; например,
/images/cat.jpg. Знаки вопроса в URL-адресах и строках запросов не включаются.sc_statusКод состояния HTTP; например,
200. Код состояния000указывает, что средство просмотра закрыло соединение (например, закрыло вкладку браузера) до того, как CloudFront смог ответить на запрос. Если средство просмотра закрывает соединение после того, как CloudFront начинает отправлять ответ, журнал содержит соответствующий код состояния HTTP.cs_refererИмя домена, отправившего запрос. Общие рефереры включают поисковые системы, другие веб-сайты, которые напрямую ссылаются на ваши объекты, и ваш собственный веб-сайт.
cs_user_agentЗначение заголовка User-Agent в запросе. Заголовок User-Agent идентифицирует источник запроса, например тип устройства и браузера, отправившего запрос, и поисковую систему, если применимо.
cs_uri_queryЧасть строки запроса URI, если таковая имеется. Если URI не содержит строку запроса, значением этого поля является дефис (
-).cs_cookieЗаголовок файла cookie в запросе, включая пары имя-значение и связанные атрибуты.
- Если вы включите ведение журнала файлов cookie, CloudFront регистрирует файлы cookie во всех запросах независимо от того, какие файлы cookie вы выбрали для пересылки в источник.
- Если запрос не включает заголовок файла cookie, значением этого поля является дефис (
-).
x_edge_result_typeКак CloudFront классифицирует ответ после того, как последний байт покинул граничное местоположение. В некоторых случаях тип результата может меняться между временем, когда CloudFront готов отправить ответ, и временем, когда CloudFront заканчивает отправку ответа.
x_edge_request_idЗашифрованная строка, однозначно идентифицирующая запрос. В заголовке ответа это
x-amz-cf-id.x_host_headerЗначение, которое средство просмотра включило в заголовок узла для этого запроса.
Это доменное имя в запросе.- Если вы используете доменное имя CloudFront в своих URL-адресах объектов, это поле содержит это доменное имя.
- Если вы используете альтернативные доменные имена в URL-адресах ваших объектов, например
http://example.com/logo.png, это поле содержит альтернативное доменное имя, напримерexample.com. Чтобы использовать альтернативные доменные имена, вы должны добавить их в свой дистрибутив.
cs_protocolThe protocol that the viewer specified in the request:
http,https,ws, orwss.cs_bytesКоличество байтов данных, включенных средством просмотра в запрос, включая заголовки. Для соединений WebSocket это общее количество байтов, отправленных клиентом на сервер по соединению.
time_takenКоличество секунд (с точностью до тысячных долей секунды; например, 0,002) между моментом, когда пограничный сервер CloudFront получает запрос зрителя, и временем, когда CloudFront записывает последний запрос.
байт ответа на выходную очередь пограничного сервера, измеренный на сервере.С точки зрения зрителя, общее время получения полного объекта будет больше, чем это значение, из-за сетевой задержки и буферизации TCP.
x_forwarded_forЕсли средство просмотра использовало прокси-сервер HTTP или балансировщик нагрузки для отправки запроса, значение
c_ipв поле 5 — это IP-адрес прокси-сервера или балансировщика нагрузки. В этом случае это поле представляет собой IP-адрес зрителя, отправившего запрос.Это поле содержит адреса IPv4 и IPv6, если применимо. Если средство просмотра не использовало прокси-сервер HTTP или балансировщик нагрузки, значение
x_forwarded_forпредставляет собой дефис (-).ssl_protocol. Возможные значения включают:
ssl_cipher.
Возможные значения включают в себя:ECDHE-RSA-AES128-GCM-SHA256ECDHE-RSA-AES128-SHA256ECDHE-RSA-AES128-SHAECDHE-RSA-AES128-SHAECDHE-RSA-AES256-GCM-SHA384ECDHE-RSA-AES256-SHA384ECDHE-RSA-AES256-SHAAES128-GCM- SHA256AES256-GCM-SHA384AES128-SHA256AES256-SHAAES128-SHADES-CBC3-SHARC4-MD5.
6 ECDHE-rsa-aes128-SHA6.0003x_edge_response_result_typeКак CloudFront классифицировал ответ непосредственно перед возвратом ответа зрителю.
Возможные значения:-
Обращение: CloudFront предоставил объект зрителю из пограничного кэша. -
RefreshHit: CloudFront обнаружил объект в пограничном кеше, но срок его действия истек, поэтому CloudFront связался с источником, чтобы убедиться, что в кеше находится последняя версия объекта. -
Промах: запрос не может быть удовлетворен объектом в пограничном кэше, поэтому CloudFront перенаправляет запрос на исходный сервер и возвращает результат средству просмотра. -
LimitExceeded: Запрос отклонен из-за превышения лимита CloudFront. -
CapacityExceeded: CloudFront вернул ошибку503, так как в пограничном расположении не было достаточно емкости во время запроса для обслуживания объекта. -
Ошибка: обычно это означает, что запрос привел к ошибке клиента (sc_statusравно4xx) или ошибке сервера (sc_statusравно5xx). Если значение x_edge_result_typeравноError, а значение этого поля равно вместоОшибка, клиент отключился до окончания загрузки. -
Перенаправление: CloudFront перенаправляет с HTTP на HTTPS. Еслиsc_status— это403, и вы настроили CloudFront для ограничения географического распространения вашего контента, возможно, запрос поступил из ограниченного местоположения.
cs_protocol_versionВерсия HTTP, указанная средством просмотра в запросе. Возможные значения включают:
-
http/0,9 -
HTTP/1,0 -
HTTP/1,1 -
HTTP/2,0
- ....9016 9000 9000 9000 9000 111117 9000 9000 9000 9000
9000 9000 9000 9000 9000 9000 9000- 9000 9000 9000
- .
для дистрибутива это поле содержит код, указывающий, успешно ли обработано тело запроса.Если для дистрибутива не настроено шифрование на уровне поля, значение представляет собой дефис (
-).fle-encrypted-fieldsКоличество полей, зашифрованных CloudFront и отправленных в источник. CloudFront передает обработанный запрос источнику по мере шифрования данных, поэтому
полей с шифрованием файламогут иметь значение, даже если значениесостояния файлаявляется ошибкой.Если для раздачи не настроено шифрование на уровне полей, значение
файловых зашифрованных полей— это дефис (—).c_portНомер порта запроса от вьювера.
time_to_first_byteКоличество секунд между получением запроса и записью первого байта ответа, измеренное на сервере.
x_edge_detailed_result_typeКогда
x-edge-result-typeне равноError, это поле содержит то же значение, что иx-edge-result-type. Когдаx-edge-result-typeравноError, это поле содержит конкретный тип ошибки.sc_content_typeЗначение заголовка HTTP Content-Type ответа.
sc_content_lenЗначение заголовка HTTP Content-Length ответа.
sc_range_startЕсли ответ содержит заголовок HTTP Content-Range, это поле содержит начальное значение диапазона.
sc-range-endЕсли ответ содержит заголовок HTTP Content-Range, это поле содержит значение конца диапазона.
Результаты:
Поле
Определение
x_edge_location5 Ребро, которое обслуживало запрос. Каждое граничное местоположение идентифицируется трехбуквенным кодом и произвольно назначаемым номером; например, DFW3. Трехбуквенный код обычно соответствует коду аэропорта Международной ассоциации воздушного транспорта для аэропорта рядом с граничным местоположением. (Эти сокращения могут измениться в будущем.)sc_bytesОбщее количество байтов, предоставленных CloudFront зрителю в ответ на запрос, включая заголовки; например,
1045619. Для соединений WebSocket это общее количество байтов, отправленных с сервера клиенту через соединение.c_ipIP-адрес зрителя, сделавшего запрос. Если зритель использовал прокси-сервер HTTP или балансировщик нагрузки для отправки запроса, значение
c_ip— это IP-адрес прокси-сервера или балансировщика нагрузки.CS_METHODМетод HTTP -запроса:
DEDETE,GET,HEAD,70007,, ,7,, , , , , , , , , , , , , , , , , , .cs_hostДоменное имя раздачи CloudFront; например,
d111111abcdef8.cloudfront.net.cs_uri_stemЧасть URI, определяющая путь и объект; например,
/images/cat.jpg. Знаки вопроса (?) в URL-адресах и строках запросов не включаются в журнал.sc_statusКод состояния HTTP (например,
200). Код состояния000указывает, что средство просмотра закрыло соединение (например, закрыло вкладку браузера) до того, как CloudFront смог ответить на запрос.Если средство просмотра закрывает соединение после того, как CloudFront начинает отправлять ответ, журнал содержит соответствующий код состояния HTTP.
cs_refererИмя домена, отправившего запрос. Общие рефереры включают поисковые системы, другие веб-сайты, которые напрямую ссылаются на ваши объекты, и ваш собственный веб-сайт.
cs_user_agentЗначение заголовка User-Agent в запросе. Заголовок User-Agent идентифицирует источник запроса, например тип устройства и браузера, отправившего запрос, и поисковую систему, если применимо.
cs_uri_queryЧасть строки запроса URI, если таковая имеется. Если URI не содержит строку запроса, значением этого поля является дефис (
-).cs_cookieЗаголовок файла cookie в запросе, включая пары имя-значение и связанные атрибуты.
- Если вы включите ведение журнала файлов cookie, CloudFront регистрирует файлы cookie во всех запросах, независимо от того, какие файлы cookie вы выбрали для пересылки в источник.
- Если запрос не включает заголовок файла cookie, значением этого поля является дефис (
-).
x_edge_result_typeКак CloudFront классифицирует ответ после того, как последний байт покинул граничное местоположение.
В некоторых случаях тип результата может меняться между временем, когда CloudFront готов отправить ответ, и временем, когда CloudFront заканчивает отправку ответа.x_edge_request_idЗашифрованная строка, однозначно идентифицирующая запрос. В заголовке ответа это
x-amz-cf-id.x_host_headerЗначение, которое средство просмотра включило в заголовок узла для этого запроса. Это доменное имя в запросе.
- Если вы используете доменное имя CloudFront в своих URL-адресах объектов, это поле содержит это доменное имя.
- Если вы используете альтернативные доменные имена в URL-адресах своих объектов, например
[http://example.com/logo.png, это поле содержит альтернативное доменное имя, напримерexample.com. Чтобы использовать альтернативные доменные имена, вы должны добавить их в свой дистрибутив.
cs_protocolThe protocol that the viewer specified in the request:
http,https,ws, orwss.cs_bytesКоличество байтов данных, включенных средством просмотра в запрос, включая заголовки. Для соединений WebSocket это общее количество байтов, отправленных клиентом на сервер по соединению.
time_takenКоличество секунд (с точностью до тысячных долей секунды; например, 0,002) между моментом, когда пограничный сервер CloudFront получает запрос зрителя, и временем, когда CloudFront записывает последний запрос. байт ответа на выходную очередь пограничного сервера, измеренный на сервере.
С точки зрения зрителя, общее время получения полного объекта будет больше, чем это значение, из-за сетевой задержки и буферизации TCP.
x_forwarded_forЕсли средство просмотра использовало прокси-сервер HTTP или балансировщик нагрузки для отправки запроса, значение
c_ipв поле 5 — это IP-адрес прокси-сервера или балансировщика нагрузки. В этом случае это поле представляет собой IP-адрес зрителя, отправившего запрос. Это поле содержит адреса IPv4 и IPv6, если применимо.Если средство просмотра не использовало прокси-сервер HTTP или балансировщик нагрузки, значение
x_forwarded_forпредставляет собой дефис (-).ssl_protocol. Возможные значения включают:
- SSLv3
- TLSv1
- TLSv1.1
- TLSv1.2
Когда
cs_protocolв поле 17 равноhttp, значением этого поля является дефис (-).
ssl_cipherWhen
cs_protocolin field 17 ishttps, this field contains the SSL/TLS cipher that the client and CloudFront negotiated for encrypting the request and response. Возможные значения включают:ECDHE-RSA-AES128-GCM-SHA256ECDHE-RSA-AES128-SHA256ECDHE-RSA-AES128-SHAECDHE-RSA-AES256-GCM- SHA384ECDHE-RSA-AES256-SHA384ECDHE-RSA-AES256-SHAAES128-GCM-SHA256AES256-GCM-SHA384AES128-SHA256AES256-SHAAES128-SHADES-CBC3-SHARC4-MD5When
cs_protocolhttp, значение этого поля — дефис (-).
x_edge_response_result_typeКак CloudFront классифицировал ответ непосредственно перед возвратом ответа зрителю. Возможные значения включают:
-
Обращение: CloudFront предоставил объект зрителю из пограничного кэша. -
RefreshHit: CloudFront обнаружил объект в пограничном кэше, но срок его действия истек, поэтому CloudFront связался с источником, чтобы убедиться, что в кэше есть последняя версия объекта. -
Промах: запрос не может быть удовлетворен объектом в пограничном кэше, поэтому CloudFront перенаправляет запрос на исходный сервер и возвращает результат средству просмотра. -
LimitExceeded: запрос был отклонен из-за превышения лимита CloudFront. -
CapacityExceeded: CloudFront вернул ошибку503, так как в пограничном расположении не было достаточной емкости во время запроса для обслуживания объекта. -
Ошибка: обычно это означает, что запрос привел к ошибке клиента (sc_statusравно4xx) или ошибке сервера (sc_statusравно5xx). Если значениеx_edge_result_type— этоОшибка, и значение этого поля равно , а неОшибка, клиент отключился до завершения загрузки. -
Перенаправление: CloudFront перенаправляет с HTTP на HTTPS. Еслиsc_status— это403, и вы настроили CloudFront для ограничения географического распространения вашего контента, возможно, запрос поступил из ограниченного местоположения.
cs_protocol_versionВерсия HTTP, указанная зрителем в запросе. Possible values include:
-
HTTP/0.9 -
HTTP/1.0 -
HTTP/1.1 -
HTTP/2. 0
fle_statusWhen field- для раздачи настроено шифрование уровня, это поле содержит код, указывающий, успешно ли обработано тело запроса. Если для раздачи не настроено шифрование на уровне полей, значением этого поля является дефис (
-).Когда CloudFront успешно обрабатывает текст запроса, шифрует значения в указанных полях и пересылает запрос в источник, значение этого поля равно
Обработано. В этом случае значениеx_edge_result_typeпо-прежнему может указывать на ошибку на стороне клиента или сервера.Если запрос превышает предел шифрования на уровне поля,
статус файласодержит один из следующих кодов ошибки, а CloudFront возвращает код состояния HTTP400зрителю.fle-encrypted-fieldsКоличество полей, зашифрованных CloudFront и отправленных в источник.
CloudFront передает обработанный запрос источнику по мере шифрования данных, поэтому fle_encrypted_fieldsможет иметь значение, даже если значениеfle_statusявляется ошибкой.Если для дистрибутива не настроено шифрование на уровне полей, значение
fle_encrypted_fields— это дефис (—).c_portНомер порта запроса от вьювера.
time_to_first_byteКоличество секунд между получением запроса и записью первого байта ответа, измеренное на сервере.
x_edge_detailed_result_typeКогда
x_edge_result_typeне равноОшибка, это поле содержит то же значение, что иx_edge_result_type. Когдаx_edge_result_typeравноError, это поле содержит конкретный тип ошибки.sc_content_typeЗначение заголовка HTTP Content-Type ответа.
sc_content_lenЗначение заголовка HTTP Content-Length ответа.
sc_range_startЕсли ответ содержит заголовок HTTP Content-Range, это поле содержит начальное значение диапазона.
sc-range-endЕсли ответ содержит заголовок HTTP Content-Range, это поле содержит значение конца диапазона.
Источник:
logtype = 'haproxy_http'Grok:
%{Hostport: Client} \\ [ %{not Space: aproxy_timest {nt. %\ NOTSPACE:backend_name}/%{NOTSSPACE:server_name} %{NUMBER:time_queue}/%{NUMBER:time_backend_connect}/%{NUMBER:time_duration} %{NUMBER:bytes_read} %{NOTSSPACE:termination_state} %{NUMBER:actconn}/ %{NUMBER:feconn}/%{NUMBER:beconn}/%{NUMBER:srvconn}/%{NUMBER:повторных попыток} %{NUMBER:srv_queue}/%{NUMBER:backend_queue}
%{HOSTPORT:client} \\[%{NOTSSPACE:haproxy_timestamp}\\] %{NOTSSPACE:frontend_name} %{NOTSPACE:backend_name}/%{NOTSSPACE:server_name} %{NUMBER:time_client_req}/%{ NUMBER:time_queue}/%{NUMBER:time_backend_connect}/%{NUMBER:time_server_response}/%{NUMBER:time_duration} %{NUMBER:status_code} %{NUMBER:bytes_read} %{NOTSPACE:captured_request_cookie} %{NOTSPACE:captured_response_cookie} % {NOTSPACE:termination_state_with_cookie_status} %{NUMBER:actconn}/%{NUMBER:feconn}/%{NUMBER:beconn}/%{NUMBER:srvconn}/%{NUMBER:повторных попыток} %{NUMBER:srv_queue}/%{NUMBER: backend_queue}?( \\\"%{GREEDYDATA:full_http_request}\\\")?( %{NOTSPACE:captured_response_headers})?
Результаты:
-
Клиент: Источник IP/порт этого запроса -
HAPROXY_TIMESTAMP: TimeStam backend_name : Имя бэкенда, используемого в этом запросе -
server_name: Имя сервера в группе бэкенда, используемой в этом запросе -
time_client_req: Время ожидания полного запроса от клиента (мс) -
Time_queue: Время ожидания в очереди (MS) -
Time_backend_connect: время для установления подключения к серверу назначения (MS) -
Time_server_response: время назначения на сервер отправки (MS) -
6. : Общее время активности запроса в HAProxy (мс) -
status_code: Код ответа HTTP -
bytes_read: Всего байтов, прочитанных в этом запросе -
capture_request_cookie: захваченный cookie с запроса -
Captude_Response_cookie: захваченное cookie с ответа -
Termination_state: Состояние сеанса при отключении -
соединения -
feconn: внешние соединения -
beconn: внутренние соединения -
SRVConn: Серверные соединения -
RESRIES: RETRIES -
SRV_QUEUE: Размер очереди на сервера -
. : Захваченный заголовок ответа
Backend_Queue: Back-End Queue SizeИсточник:
logtype = 'ktranslate-health'Grok:
%{NOTSPACE:timestamp} ktranslate(/)?(%{GREEDYDATA:container_service})? \[%{NOTSPACE:severity}] %{GREEDYDATA:message}
Результаты:
-
метка времени: время журнала -
container_service : уникальный идентификатор, используемый для различения контейнеров ktranslate. Это устанавливается во время выполнения Docker с необязательным флагом --service_name -
серьезность: серьезность строки журнала -
Сообщение: Поле сообщения содержит сообщение о свободной форме, в котором предоставлена информация о событии
Источник:
logtype = 'linux_cron'Grok:
99000 %{syslagtmest: linux_cron. отметка времени} %{NOTSPACE:linux_cron.hostname} %{DATA:linux_cron.process}(\[%{NUMBER:linux_cron.pid:integer}\])?: (\(%{DATA:linux_cron.user}\)) ?%{GREEDYDATA:linux_cron.message}Результаты:
-
linux_cron.timestamp: время журнала -
Linux_cron.hostname: Linux Server Hostname -
Linux_CRON.Process: Linux Cron -название -
66.pocess: Linux Cron -Name -
6. PID (идентификатор процесса) -
linux_cron.: пользователь linux, выполнивший cron user -
linux_cron.message: сообщение журнала
0007
Grok:
%{SYSLOGTIMESTAMP:linux_messages.timestamp} %{NOTSPACE:linux_messages.hostname} %{DATA:linux_messages.process}(\[%{NUMBER:linux_messages.pid}\[%{NUMBER:linux_messages.pid}\]:integer ?: %{GREEDYDATA:linux_messages.message}
Results:
-
linux_messages.timestamp: The time of the log -
linux_messages.hostname: The linux server hostname -
linux_messages.process: имя процесса Linux -
linux_messages.pid: PID Linux (идентификатор процесса) -
Linux_message.message: журнал
Источник:
. {TIMESTAMP_ISO8601:log_timestamp} %{NOTSPACE:server_ip} %{WORD:метод} %{NOTSPACE:uri} %{NOTSPACE:uri_query} %{NOTSPACE:server_port} %{NOTSPACE:имя пользователя} %{NOTSPACE:client_ip} %{NOTSPACE :user_agent} %{NOTSSPACE:referer} %{NOTSSPACE:status} %{NOTSSPACE:substatus} %{NOTSSPACE:win32_status} %{NOTSPACE:time_taken}Результаты:
IIS допускает несколько вариантов конфигурации.
Если вы настроили какие-либо параметры, отличные от значений по умолчанию, наш шаблон Grok не будет анализировать ваши журналы. В этом случае мы рекомендуем использовать пользовательский синтаксический анализ.Источник:
logtype = 'mongodb'GROK:
%{TimeStamp_iso8601: mongodb.timestamp} %{Word: mongodb.severity} %{wordb.compontmp}. {WORD:mongodb.context}\] %{GREEDYDATA:mongodb.message}
Результаты:
-
mongodb.timestamp: Отметка времени оператора журнала I = информационный, D1-5 = отладочный) -
mongodb.component: категория потока, выдающего оператор журнала -
mongodb.context: имя потока, выдающего оператор журнала -
mongodb.mesage: сообщение RAW MongoDB
Источник:
Logtype = 'Monit'GROK:
\\ : state} %{space}: %{greedyData: сообщение}
Результаты:
-
Состояние: Серьезность логарифмической линии -
Сообщение: сообщение
Source:
66: Сообщение.
logtype = 'mysql-ошибка' Grok:
\\ [%{Word: log_level} \\]
'nginx'
Grok:
%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb } %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS :referrer} %{QS:агент}
Результаты:
-
Clientip: IP -адрес клиента -
Глагол: HTTP -глагол -
Идентификация: идентификация пользователя клиента, выполняющий запрос -
. Код состояния HTTP ответа -
request: URI и запрос -
httpversion: HTTP-версия запроса -
rawrequest: необработанный HTTP-запрос, если данные публикуются 9(?%{YEAR:year}[./-]%{MONTHNUM:month}[./-]%{MONTHDAY:day}[- ]%{TIME:time}) \\[%{LOGLEVEL: серьезность}\\] %{POSINT:pid}#%{NUMBER}: %{GREEDYDATA:errormessage}(?:, client: (? %{IP:clientip}|%{HOSTNAME:hostname}))( ?:, сервер: %{IPORHOSTORUNDERSCORE:сервер})(?:, запрос: %{QS:запрос})?(?:, восходящий поток: \"%{URI:восходящий поток}\")?(?:, хост: %{QS:host})?(?:, referrer: \"%{URI:referrer}\")?$ Результаты:
-
серьезность: серьезность строки журнала -
PID: идентификатор процесса сервера -
Errormessage: Сообщение об ошибке -
Clientip: IP -адрес Calling Client -
Сервер: сервер IP -адрес - . request
-
upstream: URI восходящего потока -
host: имя хоста сервера -
referrer: HTTP referrer
0007
Grok:
%{DATA:postgresql.timestamp} \[%{NUMBER:postgresql.pid}\] %{WORD:level}:\s+%{GREEDYDATA:postgresql.message}
Результаты
-
Postgresql.timestamp: TimeStamp of the Log -
Postgresql.pid: идентификатор процесса сервера -
Уровень: Лога.Источник:
logtype = 'rabbitmq'Grok:
%{TIMESTAMP_ISO8601:rabbitmq.timestamp} \[%{LOGLEVEL:rabbitmq.log.level}\] \<%{DATA:rabbitmq.pid}\> %{GREEDYDATA:rabbitmq. message}
Результаты:
-
rabbitmq.timestamp: Отметка времени журнала нет) -
rabbitmq.pid: идентификатор процесса строки журнала -
Rabbitmq.: Сообщение об ошибке RabbitMQ message
Источник:
logtype = 'Redis'Grok:
%{Posint: Redis.pid { %{не SPACE: не SPACE: не SPACE: не SPACE. role} (?
[\d-]+ [a-zA-Z]+ [\d]+ [\d:]+.[\d]{3}) %{NOTSPACE:redis.log.level } %{GREEDYDATA:redis.message} Результаты:
-
redis.pid: Идентификатор процесса строки журнала -
redis.role: Роль экземпляра (X sentinel, C RDB/AOF записывающий дочерний элемент, S подчиненный, M ведущий) -
redistimestamp: Метка времени журнала сообщение (.debug, - подробное, * уведомление, # предупреждение) -
redis.message: Сообщение об ошибке redis
Источник:
4 :logtype = 'route-53'90
Gro -
-
log_format_version: Версионный формат журнала. -
zone_id: идентификатор размещенной зоны, связанной со всеми DNS-запросами в этом журнале. -
запрос: Домен или субдомен, указанный в запросе. -
query_type: либо тип записи DNS, указанный в запросе, либоЛЮБОЙ. -
response_code: Код ответа DNS, который Route 53 вернул в ответ на запрос DNS. -
протокол: протокол, который использовался для отправки запроса, TCP или UDP. -
edge_location: Пограничное местоположение Route 53, которое ответило на запрос. Каждое местоположение ребра идентифицируется трехбуквенным кодом и произвольным числом; например,DFW3. Трехбуквенный код обычно соответствует коду аэропорта Международной ассоциации воздушного транспорта для аэропорта рядом с граничным местоположением. (Эти сокращения могут измениться в будущем.) -
resolver_ip: IP-адрес преобразователя DNS, отправившего запрос на Route 53. -
edns_client_subnet: Частичный IP-адрес клиента, от которого исходит запрос, если он доступен от преобразователя DNS.
%{NUMBER:log_format_version} %{TIMESTAMP_ISO8601} %{WORD:zone_id} %{IPORHOST:query} %{WORD:query_type} %{WORD:код_ответа} %{WORD:протокол} %{WORD:edge_location} %{IP :resolver_ip} %{GREEDYDATA:edns_client_subnet}
Результаты:
Источник:
тип_журнала = 'syslog-rfc5424'Grok:
<%{NONNEGINT:pri_}>%{NONNEGINT:pri_IST:version} 8(STANNEGINT:logst.0ONTIME) }|-) +(?:%{HOSTNAME:hostname}|-) +(?:\\-|%{NOTSSPACE:app.name}) +(?:\\-|%{NOTSSPACE:procid}) ( ?:\\-|%{NOTSPACE:msgid}) +(?:\[%{DATA:structured.data}\]|-|) +%{GREEDYDATA:message}
Результаты:
-
pri: Приоритет представляет как средство сообщения, так и серьезность. -
версия: версия протокола системного журнала. -
log.timestamp: Исходная метка времени. -
имя хоста: Машина, которая первоначально отправила сообщение Syslog. -
app.name: Устройство или приложение, создавшее сообщение. -
procid: Имя или идентификатор процесса, связанный с системой Syslog. -
msgid: Идентифицирует тип сообщения. -
Structured.data: Строковое значение структурированных данных. -
sd.sd-id.sd-param-name: Содержимоеstructured.dataтакже разбивается на отдельные атрибуты в соответствии с предопределенным соглашением об именах:sd.sd-id.sd-имя-параметра. См. приведенные ниже примеры анализа структурированных данных. -
сообщение: Сообщение в произвольной форме, предоставляющее информацию о событии.
Примеры разбора структурированных данных:
Структурированные данные
[example one="1" two="2"]будут разобраны на два разных атрибута:sd.example.one: "1"
sd.example.two: "2"
Если один и тот же блок структурированных данных содержит повторяющиеся имена параметров, к имени атрибута также добавляется суффикс на основе индекса.
Например, структурированные данные [example number="1" number="2"]будет проанализировано как:sd.example.number.0: "1"
sd.example.number.1: "2"
Для структурированных данных с присвоенными номерами предприятия также анализируется дополнительный атрибут. Например, структурированные данные
[example@123 number="1"]будут проанализированы как:sd.example.enterprise.number: 123
sd.example.number: "1"
Часто задавали вопросы о проверке грамматики в Word
Версию этой статьи для Microsoft Word 2000 см. по адресу
211519.Версию этой статьи для Microsoft Word 98 см. по адресу
181863.Версию этой статьи для Microsoft Word 97 см. по адресу
167655.Резюме
В этой статье приведены ответы на наиболее часто задаваемые вопросы о средстве проверки грамматики в Microsoft Office Word 2007, Microsoft Office Word 2003 и Microsoft Word 2002.
Дополнительная информация
Что означает наличие в Word средства проверки грамматики "естественного языка"?
Средство проверки грамматики в Word выполняет всесторонний и точный анализ (также известный как «разбор») отправленного текста вместо того, чтобы просто использовать серию эвристик (или сопоставление с образцом) для отметки ошибок. Инструмент проверки грамматики анализирует текст на синтаксическом уровне и на более глубоком логическом уровне, чтобы понять взаимосвязь между действиями и людьми или вещами, которые выполняют эти действия. Например, средство проверки грамматики Word анализирует следующее сложное предложение 9.0003
Легенда гласит, что это Королевство было создано тремя древними магами, чьи магические силы управляли миром и сделали их бессмертными и всемогущими.
. и переписывает его из пассивного залога в активный залог для ясности. Средство проверки грамматики также выделяет относительное предложение между запятыми:Легенда гласит, что три древних мага, чьи магические силы управляли миром и сделали их бессмертными и всемогущими, создали это Королевство. Примечание. По умолчанию эта функция не включена. Чтобы включить эту функцию, выполните следующие действия:
Запустить Word.
В меню Инструменты выберите
Параметры .На вкладке Правописание и грамматика в области Грамматика измените поле Стиль письма на Грамматика и стиль .
Щелкните OK , чтобы закрыть диалоговое окно
Параметры .
Кто разработал средство проверки грамматики Word?
Средство проверки грамматики полностью разработано и принадлежит Microsoft.
Каковы основные различия между средством проверки грамматики Word и другими решениями для проверки грамматики от сторонних поставщиков?
Одно из ключевых отличий средства проверки грамматики Word от других решений для проверки грамматики заключается в том, что средство проверки грамматики в Word использует расширенные методы синтаксического анализа для понимания структуры предложения.
Сторонние решения для проверки грамматики могут полагаться в основном на «сопоставление с образцом». «Сопоставление с образцом» означает, что программа использует метод, который сопоставляет проверяемый текст с образцами текста, хранящимися во внутренней базе данных.Каковы имена файлов средства проверки грамматики и где они установлены?
Программа установки Word по умолчанию устанавливает средство проверки грамматики. Средство проверки грамматики английского языка (США) состоит из двух файлов:
.Msgr3en.dll установлен в следующую папку:
Диск :\Program Files\Common Files\Microsoft Shared\Proof\1033
 org/ListItem">
org/ListItem">Msgr3en.lex установлен в следующую папку:
Диск :\Program Files\Common Files\Microsoft Shared\Proof\
-
Сколько памяти требуется моему компьютеру, чтобы Word мог проверять грамматику в моем документе по мере его ввода?
Word автоматически включает средство проверки грамматики, если на компьютере достаточно свободной памяти. Метод проверки грамматики, который включается при настройке и первом запуске Word, зависит от объема доступной памяти на вашем компьютере.
Использование средства проверки грамматики вручную (8 МБ или более):
Чтобы запустить средство проверки грамматики при нажатии кнопки Правописание и грамматика в меню Сервис, ваш компьютер должен иметь более 8 мегабайт (МБ) физической оперативной памяти. Если у вас меньше 8 МБ, функция Проверять грамматику при вводе по умолчанию отключена при первом запуске Word.
Автоматически использовать средство проверки грамматики (12 МБ или более):
Чтобы постоянно запускать параметр Проверять грамматику при вводе (чтобы отображать грамматические ошибки волнистым подчеркиванием), на вашем компьютере должно быть не менее 12 МБ физической памяти. . Если на вашем компьютере менее 12 МБ ОЗУ, при первом запуске Word будет установлен флажок «Скрыть грамматические ошибки».
Чтобы включить Проверять грамматику при вводе , выберите «Параметры» в меню «Сервис», перейдите на вкладку «Правописание и грамматика» и установите флажок «Проверять грамматику при вводе ».
Примечание Для всех западноевропейских языков, кроме английского, параметр
Проверять грамматику при вводе по умолчанию отключен. (Средство проверки английской грамматики включено во все версии Word.)Где находятся записи реестра для средства проверки грамматики?
Важно! Этот раздел, метод или задача содержат шаги, которые сообщают вам, как изменить реестр.
Однако при неправильном изменении реестра могут возникнуть серьезные проблемы. Поэтому убедитесь, что вы выполните следующие действия внимательно. Для дополнительной защиты создайте резервную копию реестра перед его изменением. Затем вы можете восстановить реестр, если возникнет проблема. Для получения дополнительных сведений о резервном копировании и восстановлении реестра щелкните следующий номер статьи базы знаний Майкрософт:322756 Резервное копирование и восстановление реестра в Windows
Параметры грамматики для каждого пользователя:Примечание Word создает этот параметр, если параметр не существует в реестре Windows:
HKEY_CURRENT_USER\Software\Microsoft\Shared Tools\Proofing Tools\Grammar\MSGrammar В этом подразделе Word регистрирует номер версии грамматики (3.0 в случае английского), идентификаторы языка (1033 в случае американского английского) и параметры грамматики, которые вы выбираете на вкладке Правописание и грамматика в диалоговом окне «Параметры» (меню «Инструменты»).
В Word на вкладке «Правописание и грамматика» можно выбрать два стиля письма: «Грамматика и стиль» или «Только грамматика». Эти параметры определяются в записях Name в подразделах Option Set 0 и Option Set 1. Для каждого из этих параметров вы также можете установить правила, которые Word использует для проверки грамматики. Чтобы установить эти правила, нажмите «Настройки» на вкладке «Правописание и грамматика». Эти настройки также хранятся в виде двоичных инструкций в записях данных в подразделах Option Set 0 и Option Set 1.Примечание. Если вы обновили более раннюю версию Word, записи имени будут определены как случайные, стандартные, формальные, технические или пользовательские, а не только как «Грамматика и стиль» или «Грамматика». В этом случае реестр будет иметь подразделы от Option Set 0 до Option Set 4, которые соответствуют каждому из этих стилей написания.
Настройки Grammar Machine:
Примечание. Этот параметр должен существовать для проверки грамматики на определенном языке.
HKEY_LOCAL_MACHINE\Software\Microsoft\Shared Tools\Proofing Tools\Grammar В этом ключе находятся идентификаторы языков (1033, 2057, 3081), атрибуты обычного стиля и значения Dictionary и Engine, которые содержат соответственно полные пути к .lex и .dll файлы.
Примечание Не все файлы проверки грамматики языка автоматически регистрируются после копирования файлов грамматики в определенное место. Поэтому всегда рекомендуется использовать программу установки для установки файлов проверки грамматики (и других средств проверки).
Почему средство проверки грамматики помечает слова, которые не следует помечать, и почему предлагает неверные предложения?
Как правило, средство проверки грамматики неправильно отмечает слова или предлагает неверные предложения, когда синтаксический анализатор (то есть компонент проверки грамматики, который анализирует лингвистическую структуру предложения) не может определить правильную структуру анализируемого предложения.
Несмотря на то, что средство проверки грамматики является самым современным в своей категории, оно (как и любая другая коммерчески доступная программа проверки грамматики) не является совершенным. Поэтому, когда вы используете средство проверки грамматики, вы можете столкнуться с некоторым количеством флажков «ложь» или «подозрение» и последующими неправильными предложениями; однако средство проверки грамматики в Word 2002 и более поздних версиях значительно улучшено по сравнению с более ранними версиями Microsoft Word.
Почему средство проверки грамматики не может обнаружить ошибки во фразе «Мы обошли два магазина, чтобы…»?
Средство проверки грамматики предназначено для обнаружения ошибок, которые обычные пользователи совершают каждый день. Вы всегда можете составить предложения, которые могут запутать инструмент проверки грамматики.
 org/ListItem">
org/ListItem">Когда средство проверки грамматики работает в фоновом режиме (подчеркнуто волнистой линией), почему оно помечает ошибки в другом порядке, чем когда я нажимаю «Правописание и грамматика» в меню «Сервис»?
При выборе пункта Орфография и грамматика в меню Сервис средство проверки грамматики запускается на переднем плане и получает контроль над документом. То есть вы не можете работать с документом, пока инструмент проверки грамматики проверяет ваш документ.
Однако, когда средство проверки грамматики работает в фоновом режиме (подчеркнуто волнистой линией), оно пытается добиться логического потока слева направо и не так критично относится к структуре предложения, как при запуске проверки грамматики инструмент вручную (на переднем плане). Таким образом, когда средство проверки грамматики работает в фоновом режиме, ошибка, отмеченная первой, всегда возвращает предложение, независимо от ее положения в предложении.
 org/ListItem">
org/ListItem">Почему "Игнорировать все" не работает так, как я ожидал?
Например, если я нажму «Игнорировать все» для этого предложения, которое помечено как фрагмент
После подачи обеда. в том же сеансе проверки средство проверки грамматики останавливается на других предложениях, которые также помечены как фрагменты, например:
Над моим трупом. Инструмент проверки грамматики классифицирует (внутренне) эти два предложения как разные типы фрагментов. В этих примерах средство проверки грамматики игнорирует один из этих типов, но не другой. Таким образом, очевидное несоответствие в том, как работает Ignore All.
Почему ошибки не отмечаются в последовательности слева направо?
В большинстве случаев средство проверки грамматики пытается помечать ошибки слева направо. В некоторых случаях это невозможно, потому что средство проверки грамматики требует, чтобы вы сначала исправили наиболее логичную ошибку (эта ошибка может быть не первой ошибкой).
В этом случае ошибки пунктуации или пробелов помечаются перед конкретными или ограниченными грамматическими ошибками.Почему некоторые пассивные предложения помечаются флажком и предлагается переписать, а другие пропускаются?
Примечание. Эта проблема возникает с другими правилами в дополнение к правилу пассивной конструкции.
Например, следующее пассивное предложение не помечено:
Срок действия настоящего Соглашения начинается с Даты вступления в силу и продолжается до тех пор, пока Volcano Coffee не расторгнет его в письменной форме в любое время по причине или без таковой. Для некоторых типов предложений, когда нет четкого синтаксического подлежащего, средство проверки грамматики не пытается пометить предложение.
Почему, когда я щелкаю правой кнопкой мыши грамматическую ошибку (ошибка, отмеченная волнистой линией), в контекстном меню не отображаются те же параметры, которые доступны в диалоговом окне «Правописание и грамматика»?
Например, если элемент отмечен флажком, а средство проверки грамматики не предлагает подсказок, доступны только следующие варианты: проигнорировать предложение (и, возможно, пропустить другие ошибки в этом предложении) или щелкнуть команду Грамматика, чтобы вызвать Проверка орфографии.
диалоговое окно Грамматика.В фоновом режиме (волнистые подчеркивания) средство проверки грамматики использует упрощенный интерфейс. Если вы хотите просмотреть все возможные ошибки в предложении, вы должны нажать Грамматика в контекстном меню.
Почему некоторые пары слов, которые обычно путают, работают только в одном направлении?
Например, в средстве проверки грамматики и "блоха", и "беги" помечаются как часто путаемые слова, но с парой "ваш" и "вы" только слово "ваш" помечается как обычное путаное слово.
Средство проверки грамматики обрабатывает некоторые пары слов, которые часто путают, однонаправленно, чтобы упростить анализатору проблему. Средство проверки грамматики было разработано таким образом, чтобы уменьшить количество элементов, отмеченных средством проверки грамматики, но не являющихся истинными грамматическими ошибками.
Когда предложение помечается как слишком длинное, почему это единственный совет, который дается для предложения?
Длинные предложения часто трудно читать как для людей, так и для средства проверки грамматики. Инструмент проверки грамматики недостаточно совершенен, чтобы обнаруживать грамматические ошибки в длинных предложениях. Если вы сомневаетесь в грамматической правильности длинного предложения, вам следует разбить его на предложения меньшего размера.
Почему средство проверки правописания игнорирует текст, заключенный в кавычки?
Средство проверки грамматики предполагает, что текст в прямой цитате не подлежит критике.
 org/ListItem">
org/ListItem">Почему средство проверки грамматики игнорирует текст во вложенных документах, например заголовки, нижние колонтитулы и аннотации?
Средство проверки грамматики не анализирует текст в верхних и нижних колонтитулах или аннотациях. Верхние и нижние колонтитулы обычно не содержат полных предложений. Точно так же аннотации могут быть написаны во фрагментах предложений и не подходят для проверки грамматики.
Почему я не могу изменить значения параметров грамматики и стиля письма по умолчанию, например длину предложения?
Эти значения по умолчанию встроены в грамматику и стиль письма. Встроенные значения по умолчанию для грамматики и стиля письма включают:
Длина длинного предложения
org/ListItem">
Следующие существительные
Последовательные предложные фразы
Слова в разделенных инфинитивах
В следующей таблице перечислены конкретные значения встроенной грамматики и стиля письма по умолчанию.
Опция стиля Встроенная настройка
-------------------------------------------------------- ----------------Длина длинного предложения 60 слов
Следующие друг за другом существительные более 3
Следующие друг за другом предложные фразы более 3
Слова в разделенных инфинитивах более 1
org/ListItem">
Что означает грамматическая статистика?
Когда Microsoft Word завершит проверку орфографии и грамматики, он может отобразить информацию об уровне чтения документа, включая оценки удобочитаемости (см. вопрос 20). Каждая оценка удобочитаемости основывается на среднем количестве слогов в слове и слов в предложении.
Текст оценивается по 100-балльной шкале; чем выше балл, тем легче понять документ. Для большинства стандартных документов старайтесь получить от 60 до 70 баллов.
На каких формулах основана эта статистика?
Оценка легкости чтения по Флешу
Формула для оценки легкости чтения по Флешу:
206,835 - (1,015 x ASL) - (84,6 x ASW)
где:ASL = средняя длина предложения (количество слов, деленное на количество предложений)
ASW = среднее количество слогов в слове (количество слогов, деленное на количество слов)
Flesch-Kincaid Grade Балл за уровень
Оценка Flesch-Kincaid Grade Level оценивает текст на уровне начальной школы США.
Например, оценка 8,0 означает, что восьмиклассник может понять документ. Для большинства стандартных документов стремитесь к оценке примерно от 7,0 до 8,0.Формула оценки уровня Флеша-Кинкейда:
(0,39 x ASL) + (11,8 x ASW) - 15,59
где:ASL = средняя длина предложения (количество слов, деленное на количество предложений)
ASW = среднее количество слогов в слове (количество слогов, разделенных на количество слов)
Кто использует эти стандарты чтения?
Различные государственные учреждения требуют, чтобы определенные документы или формы соответствовали определенным стандартам удобочитаемости. Например, в некоторых штатах требуется, чтобы страховые формы имели определенный балл удобочитаемости.
org/ListItem">
Сколько слов и фраз в грамматическом словаре?
Грамматический словарь содержит около 99 000 слов и выражений в неизмененной форме. (То есть в это число не входят такие слова, как «пошел», «дети» и т. д., которые являются изменчивыми формами слов «идти» и «ребенок».)
На чем основан грамматический словарь?
Он основан на Словаре современного английского языка Лонгмана и Словаре английского языка американского наследия, третье издание.
Чем средство проверки грамматики английского языка отличается, если я запускаю его на тексте на английском языке в Великобритании и на английском языке в США?
Разница между проверкой текста на английском языке для Великобритании и текста на английском языке для США в первую очередь заключается в различиях в правописании между двумя языками.
Например, «цвет» в отличие от «цвет». Эти различия не влияют на грамматику.Большинство правил грамматики применимы ко всем текстам на английском языке (США и Великобритания). Однако некоторые грамматические правила различаются в зависимости от выбранного языка:
Премодификаторы множественного числа, которые очень часто используются в британском английском, помечаются не для британского английского, а для американского английского.
Согласование подлежащего и глагола с собирательными существительными, где глагол используется во множественном числе, не помечается в британском английском, но помечается в американском английском. См. следующий пример:
Группа планирует мобилизацию в ближайшее время.
Почему некоторые объяснения не связаны с отмеченной ошибкой?
Например, в предложении
Пошли домой. объяснение в средстве проверки грамматики конкретно не упоминает запутанную пару lets/let's.
Объяснения грамматики предназначены для охвата наиболее общих случаев в каждом правиле, чтобы избежать переполнения текста на экране.
Глава 15 — Разбор
Руководство пользователя REBOL/Core
Основное содержание
Отправить нам отзывСодержимое:
1. Обзор
2. Простое разделение
3. Грамматические правила
4. Пропуск ввода
5. Типы соответствия
6. Рекурсивные правила
7. Вычисление
7.1 Возвращаемое значение
7.2 Выражения в правилах
7. 3 Копирование ввода
7.4 Маркировка ввода
7.5 Изменение строки
7.6 Использование объектов
7.7 Отладка
8. Работа с пространствами
9. Блоки и диалекты. Подблоки
10. Сводка операций синтаксического анализа
10.1 Общие формы
10.2 Указание количества
10.3 Пропуск значений
10.4 Получение значений
10.5 Использование слов
10.6 Совпадения значений (только разбор блоков)
10.7 Слова типа данных1. Обзор
Синтаксический анализ разбивает последовательность символов или значений на более мелкие части. Его можно использовать для распознавания символов или значений, которые происходить в определенном порядке. Помимо обеспечения мощного, читаемый и поддерживаемый подход к регулярным выражениям сопоставление с образцом, синтаксический анализ позволяет создавать собственные языки для конкретных целей.
Функция parse имеет общий вид:
правила синтаксического анализа серий
Аргумент серии — это ввод, который анализируется и может быть строкой.
или блок. Если аргумент является строкой, он анализируется по символам. Если
аргумент представляет собой блок, он анализируется по значению.Аргумент rules указывает, как аргумент серии проанализировано. Аргумент rules может быть строкой для простых типов синтаксического анализа. или блок для сложного синтаксического анализа.
Функция parse также допускает два уточнения: /all и /кейс . /all уточнение анализирует все символы внутри строки, включая все разделители, такие как пробел, табуляция, новая строка, запятая и точка с запятой. Уточнение /case анализирует строка на основе регистра. Если /случай не указан, верхний и нижние регистры обрабатываются одинаково.
2. Простое разделение
Простая форма синтаксического анализа для разделения строк:
строка разбора нет
Функция parse разделяет входной аргумент, строку, в блок из нескольких строк, разбивая каждую строку, где бы он встречает разделитель, такой как пробел, табуляция, новая строка, запятая, или точка с запятой.
Аргумент none указывает, что никакой другой
разделители, отличные от этих. Например:парсинг зонда "Поездка займет 21 день" нет [«Поездка» «займет» «21» «дней»]
Аналогично,
анализ зонда "здесь там, везде; ок" нет ["здесь" "там" "везде" "хорошо"]
Обратите внимание, что в приведенном выше примере запятые и точки с запятой были удалены. из полученных строк.
Вы можете указать собственные разделители во втором аргументе parse . Например, следующий код анализирует номер телефона с дефисом (-) разделители:
анализ зонда "707-467-8000" "-" ["707" "467" "8000"]
В следующем примере используется знак равенства (=) и двойная кавычка (") в качестве разделители:
разбор пробы
{="}
["IMG" "SRC" "test.gif" "WIDTH" "123"]
В следующем примере строка анализируется только на основе запятых; любые другие разделители игнорируются. Следовательно, пробелы внутри строк не удаляются:
Обычно при анализе строк любые пробелы (пробел, табуляция, строки) удаляются.
автоматически обрабатываются как разделители. Чтобы избежать этого действия, вы можете использовать
/ любое уточнение. Сравните эти два примера: 9(нулевой)" 3. Правила грамматики
Функция parse принимает правила грамматики, написанные на диалект REBOL. Диалекты — это подъязыки REBOL, которые используют одна и та же лексическая форма для всех типов данных, но допускает различный порядок значения внутри блока. В пределах этого диалекта грамматика и словарный запас REBOL изменен, чтобы сделать его похожим по структуре на хорошо известный BNF (Backus-Naur Form), который обычно используется для указания языковых грамматик, сетевых протоколов, форматы заголовков и т. д.
Чтобы определить правила, используйте блок для указания последовательности входов. За Например, если вы хотите проанализировать строку и вернуть символы "the телефон", можно использовать правило:
разобрать строку ["телефон"]
Чтобы разрешить любое количество пробелов или отсутствие пробелов между словами, напишите правило вот так:
разобрать строку ["the" "phone"]
Альтернативные правила можно указать вертикальной чертой (|).
Например:["телефон" | "радио"]
принимает строки, соответствующие любому из следующих:
телефон радио
Правило может содержать блоки, которые рассматриваются как подправила. Следующее строка:
[["а" | "тот"] ["телефон" | "радио"] ]
принимает строки, соответствующие любому из следующих:
телефон радио телефон радио
Для большей читабельности выпишите подправила отдельным блоком и дайте им имя, чтобы помочь указать их цель:
статья: ["а" | "то"] устройство: ["телефон" | "радио"] строка разбора [устройство статьи]
Помимо сопоставления одного экземпляра строки, вы можете предоставить количество или диапазон, который повторяет совпадение. В следующем примере представлен количество:
[3 "а" 2 "б"]
, который принимает строки, соответствующие:
ааабб
Следующий пример предоставляет диапазон:
[1 3 "а" "б"]
, который принимает строки, соответствующие любому из следующих:
аб ааб аааб
Начальная точка диапазона может быть нулевой, что означает, что это необязательно.
[0 3 "а" "б"]
принимает строки, соответствующие любому из следующих:
б аб ааб аааб
Используйте или , чтобы указать, что один или несколько символов совпадают. Используйте любой , чтобы указать, что совпадают ноль или более символов. Например, вместо используется в следующей строке:
.[некоторые "а" "б"]
принимает строки, содержащие один или несколько символов a и b:
аб ааб аааб ааааб
В следующем примере используется любой:
[любое "а" "б"]
, который принимает строки, содержащие ноль или более символов a или б:
б аб ааб аааб ааааб
Слова некоторые и любые также могут использоваться на блоки. Например:
[некоторые ["а" | "б"]]
принимает строки, содержащие любую комбинацию символов a и б.
Еще один способ указать, что символ является необязательным, — указать альтернативный выбор:
["а" | "б" | никто]
В этом примере допустимы строки, содержащие a или b или никто.
Значение none полезно для указания необязательных шаблонов или для перехвата случаи ошибки, когда ни один шаблон не соответствует.
4. Пропуск ввода
пропустить , до и до слова позволяют пропустить ввод.
Используйте пропуск , чтобы пропустить один символ, или используйте его с повторите , чтобы пропустить несколько символов:
["а" пропустить "б"] ["а" 10 пропустить "б"] ["а" 1 10 пропустить]
Чтобы пропустить, пока не будет найден определенный символ, используйте для:
[от "а" до "б"]
В предыдущем примере синтаксический анализ начинается с a и заканчивается на b, но не включает б.
Чтобы включить конечный символ, используйте через:
["а" через "б"]
В предыдущем примере синтаксический анализ начинается с a, заканчивается на b и включает б.
Следующее правило находит заголовок HTML-страницы и печатает его:
страница: читать http://www.
rebol.com/
разобрать страницу [через скопировать текст в ] печатать текст РЕБОЛ ТехнологииПервый от до находит тег заголовка и сразу проходит мимо Это. Затем входная строка копируется в переменную с именем text до тех пор, пока конечный тег найден (но он не проходит мимо него, иначе текст будет включать тег).
5. Типы соответствия
При синтаксическом анализе строк эти типы данных и слова могут использоваться для сопоставления символов во входной строке:
Тип матча
Описание
"абв"
соответствует всей строке
#"с"
соответствует одному символу
бирка
соответствует строке тега
конец
соответствует концу ввода
(набор битов )
соответствует любому указанному символу в наборе
Чтобы использовать все эти слова (кроме набора битов, что поясняется ниже) в одно правило, используйте:
[ ["отлично" | "невероятный"] #"!" конец]
В этом примере анализируются входные строки:
отлично! невероятно!
Конец указывает, что во входном потоке ничего не следует.
Весь ввод проанализирован. Это необязательно в зависимости от того, parse Возвращаемое значение функции должно быть проверено. См. оценку
раздел ниже для получения дополнительной информации.Тип данных bitset заслуживает более подробного объяснения. Битовые наборы используется для эффективного указания наборов символов. Функция charset позволяет указывать отдельные символы или диапазоны символов. Например, строка:
цифра: кодировка "0123456789"
определяет набор символов, содержащий цифры. Это позволяет использовать такие правила, как:
[3 цифры "-" 3 цифры "-" 4 цифры]
, который может анализировать телефонные номера вида:
707-467-8000
Чтобы принять любое количество цифр, обычно пишут правило:
цифры: [какая-то цифра]
Набор символов также может указывать диапазоны символов. Например, набор цифровых символов мог быть записан как:
цифра: кодировка [#"0" - #"9"]
Кроме того, вы можете комбинировать определенные символы и диапазоны символов:
the-set: кодировка ["+-.
" #"0" - #"9"]
Чтобы расширить это, вот буквенно-цифровой набор символов:
алфавит: кодировка [#"0" - #"9" #"A" - #"Z" #"a" - #"z"]
Наборы символовтакже можно изменить с помощью вставки и удалить функции, или комбинации наборов могут быть созданы с помощью объединение и пересекаются с функциями . Эта линия копирует набор цифровых символов и добавляет к нему точку:
цифра-точка: вставить копию цифры "."
Следующие строки определяют полезные наборы символов для синтаксического анализа:
цифра: кодировка [#"0" - #"9"] альфа: кодировка [#"A" - #"Z" #"a" - #"z"] alphanum: объединение буквенных цифр
6. Рекурсивные правила
Вот пример набора правил, который анализирует математические выражения и дает приоритет (приоритет) используемых математических операторов:
выражение: [термин ["+" | "-"] выражение | срок] термин: [фактор ["*" | "/"] термин | фактор] фактор: [основной фактор "**" | начальный] первичный: [какая-то цифра | "(" выражение ")"] цифра: кодировка "0123456789"Теперь мы можем анализировать многие типы математических выражений.
Следующие примеры
вернуть true, указывая, что выражения были действительными:анализ зонда "1 + 2 * ( 3 - 2 ) / 4" выражение истинный разбор пробы "4/5+3**2-(5*6+1)" выражение истинный
Обратите внимание, что в примерах некоторые правила ссылаются сами на себя. За Например, правило expr включает expr. Это полезно метод определения повторяющихся последовательностей и комбинаций. Правило рекурсивный --относится к самому себе.
При использовании рекурсивных правил необходимо соблюдать осторожность, чтобы предотвратить бесконечную рекурсию. Например:
выражение: [выражение ["+" | "-"] срок]
создает бесконечный цикл, потому что первое, что делает выражение, это использует снова выраж.
7. Оценка
Обычно вы анализируете строку, чтобы получить некоторый результат. Вы хотите сделать больше, чем просто убедитесь, что строка действительна, вы хотите что-то сделать во время ее анализа.
Например, вы можете захотеть выбрать подстроки из разных частей
строку, создавать блоки связанных значений или вычислять значение.7.1 Возвращаемое значение
В примерах из предыдущих глав показано, как анализировать строки, но нет результатов были произведены. Это делается только для проверки того, что строка имеет указанный грамматика; значение, возвращенное из синтаксического анализа , указывает на его успех. Следующие примеры показывают это:
анализ зонда "a b c" ["a" "b" "c"] истинный анализ зонда "a b" ["a" "c"] ЛОЖЬ
Функция разбора возвращает значение true, только если она достигает конец входной строки. Неудачное совпадение останавливает синтаксический анализ серии. Если синтаксический анализ исчерпывает значения для поиска перед достигнув конца ряда, он не пересекает ряд и возвращается ложь :
анализ зонда "a b c d" ["a" "b" "c"] ЛОЖЬ анализ зонда "a b c d" [от "b" до "d"] истинный анализ зонда "a b c d" [до "b" до конца] истинный
7.
2 Выражения в правилахВ правило можно включить выражение REBOL, которое будет оцениваться при синтаксический анализ достигает этой точки в правиле. Скобки используются для укажите такие выражения:
string: "в этом предложении есть телефон" строка синтаксического анализа зонда [ на "а" на "телефон" (выведите "найден телефон") в конец ] нашел телефон истинныйПример выше анализирует строку телефон и печатает сообщение нашел телефон после завершения матча. Если строки a или телефон отсутствует и разбор невозможен, выражение не оценивается.
Выражения могут появляться в любом месте правила, а несколько выражений могут встречаются в разных частях правила. Например, следующий код печатает разные строки в зависимости от того, какие входы были найдены:
разобрать строку [ "а" | "тот" на "телефон" (напечатать "ответить") | на "радио" (печать "слушай") | на "тв" (печать "смотреть") ] отвечать string: "на полке есть радио" разобрать строку [ "а" | "тот" на "телефон" (напечатать "ответить") | на "радио" (печать "слушай") | на "тв" (печать "смотреть") ] СлушатьВот пример, который подсчитывает, сколько раз тег предварительного формата HTML появляется в текстовой строке:
количество: 0 страница: читать http://www.
rebol.com/docs/dictionary.html
разобрать страницу [любая [через (count: count + 1)]] количество печатей 777
7.3 Копирование ввода
Наиболее распространенное действие, выполняемое с помощью разбора , — это сбор деталей. анализируемой строки. Это делается с копией , и это за которым следует имя переменной, в которую вы хотите скопировать строку. следующий пример анализирует заголовок веб-страницы:
разобрать страницу [через
скопировать текст в ] печатать текст REBOL/основной словарьПример работает, пропуская текст, пока не найдет <название> ярлык. Вот где он начинает делать копию ввода stream и установка переменной с именем text для ее хранения. Копия операция продолжается до закрытия <title> тег найден.
Действие копирования также можно использовать с целыми блоками правил. Например, для правило:
[копировать заголовок ["H" ["1" | "2" | "3"]]
строка заголовка содержит весь h2, h3 или строка h4.
Это также работает для больших многоблочных правил.7.4 Маркировка ввода
Действие copy создает копию найденной подстроки, но это не всегда желательно. В некоторых случаях лучше сохранить текущая позиция входного потока в переменной.
ПРИМЕЧАНИЕ. Слово копия , используемое при синтаксическом анализе, отличается от копирование функции, используемой в выражениях REBOL. Parse использует диалект REBOL, а копия имеет другое значение в этом диалект.
В следующем примере переменная начала содержит ссылку на строка ввода страницы сразу после <title>. окончание относится к строке страницы непосредственно перед . Эти переменные можно использовать так же, как они будет использоваться с любой другой серией.
разобрать страницу [ черезначало: до окончание: (изменение/часть начала окончания «Справочного руководства по Word») ]Вы можете видеть, что приведенное выше выражение синтаксического анализа фактически изменило содержимое название:
разобрать страницу [через
скопировать текст в ] печатать текст Справочное руководство WordВот еще один пример, который отмечает положение каждого тега таблицы в HTML.
файл:страница: читать http://www.rebol.com/index.html таблицы: сделать блок! 20 разобрать страницу [ любой [в "<таблицу" пометить: через ">" (добавить индекс таблиц? отметка) ] ]Блок таблиц теперь содержит позицию каждого тега:
для каждой таблицы таблицы [ print ["таблица найдена по индексу:" таблица] ] таблица найдена по индексу: 836 таблица найдена по индексу: 2076 таблица найдена по индексу: 3747 таблица найдена по индексу: 3815 таблица найдена по индексу: 4027 таблица найдена по индексу: 4415 таблица найдена по индексу: 6050 таблица найдена по индексу: 6556 таблица найдена по индексу: 7229 таблица найдена по индексу: 8268ПРИМЕЧАНИЕ. Текущая позиция во входной строке также может быть модифицированный. В следующем разделе объясняется, как это делается.
7.5 Изменение строки
Теперь, когда вы знаете, как получить позицию входного ряда, вы также можно использовать другие функции серии, включая вставку , удалите , а замените .
Чтобы написать сценарий, который
заменяет все вопросительные знаки (?) на восклицательные (!), пишет:str: "Где индейка? Вы видели индейку?" разобрать ул [некоторые [в "?" отметка: (изменить отметку "!") пропустить]] печатать ул. Где индейка! Вы видели индейку!
Пропуск в конце опережает ввод над новым характер, что в данном случае не обязательно, но это хорошая практика.
В качестве другого примера, чтобы вставить текущее время везде слово время появляется в каком-то тексте, напишите:
str: "в это время я хотел бы увидеть изменение времени" разобрать ул [ некоторые [к "времени" отметка: (удалить/разделить метку 4 метки: вставить метку сейчас/время) :отметка ] ] печатать ул. в это 14:42:12, я бы хотел увидеть изменение 14:42:12Обратите внимание на слово :mark, использованное выше. Он устанавливает вход на новый должность. Функция вставки возвращает новую позицию только мимо вставки текущего времени.
Слово :mark используется для установки
вход в эту позицию.7.6 Использование объектов
При анализе большой грамматики из набора правил переменные используются для создания грамматика более читабельна. Однако переменные являются глобальными и могут стать путают с другими переменными, которые имеют такое же имя где-то еще в программа.
Решение этой проблемы состоит в том, чтобы использовать объект, чтобы сделать все слова правил локально для контекста. Например:
парсер тегов: сделать объект! [ тэги: сделай блок! 100 текст: сделать строку! 8000 html-код: [ скопировать тег ["<" через ">"] (добавить тег тега) | скопировать txt в "<" (добавить текст txt) ] теги разбора: func [сайт [url!]] [ очистить теги очистить текст парсить читать сайт [до "<" какого-то html-кода] foreach теги теги [print tag] печатать текст ] ] тег-парсер/парсер-теги http://www.rebol. com
7.7 Отладка
По мере написания правил иногда требуется отладка. В частности, вы может захотеть узнать, как далеко вы продвинулись в анализе правила.
Функцию трассировки можно использовать для наблюдения за операцией синтаксического анализа. прогресс, но это может вывести тысячи строк, которые трудно обзор.
Лучшим способом является вставка отладочных выражений в правила синтаксического анализа. Как например, для отладки правила:
[в "
вставьте функцию печати после ключевых разделов для мониторинга ваш прогресс по правилу:
[в "
В этом примере печатаются 1, 2 и 3, как правило обработанный.
Другой подход состоит в том, чтобы распечатать часть входной строки в качестве синтаксического анализа. бывает:
[ в "
Если это делается часто, можно создать для этого правило:
здесь: [где: (напишите где)] [ на "
Функцию копирования также можно использовать для указания того, что подстроки анализировались по мере обработки правила.
8. Работа с пробелами
Функция разбора обычно игнорирует все промежуточные пробелы между шаблонами, которые он сканирует. Например, правило:
["а" "б" "в"]
возвращает строки, которые соответствуют:
азбука до н.э. аб в а б в а б в
и другие комбинации с аналогичным интервалом.
Чтобы применить определенное соглашение об интервалах, используйте синтаксический анализ с параметром /все доработка. В предыдущем примере это уточнение заставляет анализировать только для первого случая (abc).
разобрать/все "abc" ["a" "b" "c"]
Указание / все уточнения заставляют каждый символ в входной поток, с которым нужно работать, включая разделители по умолчанию, такие как пробел, табуляция, новая строка.
Для обработки пробелов в правилах создайте набор символов, указывающий допустимые символы пробела:
spacer: кодировка уменьшить [табуляция новой строки #" "]
Если вы хотите, чтобы между каждой буквой был один пробел, напишите:
["а" разделитель "б" разделитель "с"]
Чтобы разрешить несколько пробелов, напишите:
пробелы: [некоторый пробел] ["а" пробелы "б" пробелы "с"]
Для более сложных грамматик создайте набор символов, позволяющий сканировать строка до пробела.
без пробела: дополнение пробел в-пространство: [какое-то не-пространство | конец] слова: сделать блок! 20 разобрать/весь текст [ some [скопировать слово в пробел (добавить слово слова) spacer] ]В предыдущем примере создается блок из всех его слов. Функция дополнения инвертирует набор символов. Теперь он содержит все , кроме символов пробела, которые вы определили ранее. Набор символов без пробела содержит все символы, кроме пробела. персонажи. Правило to-space принимает один или несколько символов до символ пробела или конец входного потока. Главное правило предполагает начало со словом, скопируйте это слово до пробела, затем пропустите символ пробела и начать следующее слово.
9. Разбор блоков и диалектов
Блоки анализируются аналогично строкам. Набор правил определяет порядок ожидаемые значения. Однако, в отличие от разбора строк, разбор блоков не касается символов или разделителей.
Разбор блоков происходит на
уровень значений, многократно облегчающий определение правил грамматики и работу с ними.
Быстрее.Синтаксический анализ блоков — самый простой способ создания REBOL диалектов . Диалекты — это подъязыки REBOL, которые используют одну и ту же лексическую форму для всех данных. типы, но допускают другой порядок значений внутри блока. значения нет необходимости соответствовать нормальному порядку, требуемому аргументами функции REBOL. Диалекты способны обеспечить большую выразительную силу для определенных областей языка. использовать. Например, сами правила парсера указаны как диалект.
9.1 Сопоставление слов
При синтаксическом анализе блока для сопоставления со словом укажите слово как буквальный:
'имя 'когда 'пустой
9.2 Сопоставление типов данных
Вы можете сопоставить значение любого типа данных, указав данные введите слово.
См. Совпадения типов данных ниже.Тип данных Слово
Описание
строка!
соответствует любой строке в кавычках
раз!
соответствует в любое время
дата!
соответствует любой дате
кортеж!
соответствует любому кортежу
ПРИМЕЧАНИЕ. Не забудьте знак "!" это часть имени или ошибка будет сгенерировано.
9.3 Недопустимые символы
операций синтаксического анализа разрешенных для блоков являются те, которые с конкретными персонажами.
Например, нельзя указать совпадение с первым
буква слова или строки, а также символы пробела или новой строки.9.4 Примеры диалектов
Несколько кратких примеров помогут проиллюстрировать синтаксический анализ блоков:
блок: [когда 10:30] вывести блок синтаксического анализа ['когда 10:30] print parse block ['когда время!] блок синтаксического анализа ['когда установлено время! (время печати)]
Обратите внимание, что определенное слово можно сопоставить, используя его буквальное слово в правило (как в случае «когда»). Тип данных может быть указан скорее чем значение, как в строках выше, содержащих время! . В Кроме того, переменной может быть присвоено значение с помощью набора . операция.
Как и в случае со строками, при разборе блоков можно указать альтернативные правила:
правило: [некоторые [ 'когда установлено время время! | 'где установить место строки! | 'кто поставил лиц [слово! | блокировать!] ]]Эти правила позволяют вводить информацию в любом порядке:
разобрать [ кто Фред где "Центр города" когда 9:30 ] правило печать [время место лица]В этом примере можно было бы использовать присваивание переменной, но он иллюстрирует, как обеспечить альтернативный порядок ввода.
Вот еще один пример, оценивающий результаты синтаксического анализа:
правило: [ установить количество целых! установить строку str! (количество циклов [print str]) ] parse [3 "отличная работа"] правило parse [3 "шалаш" 1 "поход"] [какое-то правило]Наконец, вот более сложный пример:
правило: [ установить действие ['купить | 'продавать] задать целое число! 'акции' в установить цену деньги! (любое действие = 'продать [ print [цена "дохода" * число] итого: всего + (цена * количество) ][ print ["себестоимость" цена * число] итого: итого - (цена * количество) ] ) ] всего: 0 разобрать правило [продать 100 акций по $123,45] напечатать ["всего:" всего] всего: 0 разобрать [ продать 300 акций по $890,08 купить 100 акций по $120,45 продать 400 акций по $270,89 ] [какое-то правило] напечатать ["всего:" всего]Следует отметить, что это один из способов использования выражений, использующих диалект концепция, впервые описанная в главе 4, может быть оценена .
9.5 Анализ подблоков
При анализе блока, если найден подблок, он рассматривается как один значение блока ! тип данных. Однако для разбора подблок, вы должны рекурсивно вызвать синтаксический анализатор для подблока. в слова обеспечивает эту возможность. Ожидается, что следующий значение во входном блоке является подблоком для анализа. Это как если бы блок! Был предоставлен тип данных . Если следующее значение не блок! Тип данных , совпадение не удается и превращается в . ищет альтернативы или выходит из правила. Если следующим значением является блок, синтаксический анализатор правило, которое следует за словом в , используется для начала синтаксического анализа подблок. Оно обрабатывается так же, как подправило.
правило: [дата! в [строка! время!]] данные: [10 января 2000 г. ["Юкайя" 10:30]] вывести правило разбора данных
Все обычные операции парсера могут быть применены к в .
правило: [ установить дату дату! установить информацию в [string! время!]] ] данные: [10 января 2000 г. ["Юкайя" 10:30]] вывести правило разбора данных распечатать информацию правило: [дата! скопировать элементы 2 в [string! время!]] данные: [10 января 2000 г. ["Юкия" 10:30] ["Рим" 2:45]] вывести правило разбора данных зондовые предметы10. Обзор операций синтаксического анализа
10.1 Общие формы
Оператор
Описание
|
альтернативное правило
[блок]
подправило
(пароль)
оценить выражение REBOL
10.
2 Указание количестваОператор
Описание
нет
ничего не соответствует
опция
ноль или один раз
некоторые
один или несколько раз
любой
ноль или более раз
12
повтор шаблона 12 раз
1 12
повтор шаблона от 1 до 12 раз
0 12
шаблон повтора от 0 до 12 раз
10.
3 Пропуск значенийОператор
Описание
пропустить
пропустить значение (или несколько, если указано повторение)
от до
предварительный ввод значения или типа данных
с по
предварительный ввод через значение или тип данных
10.4 Получение значений
Оператор
Описание
набор
установить следующее значение переменной
копия
скопировать следующую последовательность совпадений в переменную
10.
5 Использование словОператор
Описание
слово
поисковое значение слова
слово:
отметить текущую позицию входного ряда
:слово
установить текущую позицию входного ряда
'слово
буквально соответствует слову (блок синтаксического анализа)
10.6 Совпадения значений (только анализ блока)
Оператор
Описание
"Фред"
соответствует строке "fred"
%данные
соответствует имени файла %data
10:30
соответствует времени 10:30
1.
2.3соответствует кортежу 1.2.3
10.7 Слова типов данных
Слово
Описание
9Тип 0002! соответствует любому типу данных
Обновлено 15 апреля 2005 г. - Авторские права REBOL Technologies - Отформатировано с помощью MakeDoc2Правила синтаксического анализа журнала — Coralogix
Правила помогают обрабатывать, анализировать и реструктурировать данные журнала для подготовки к мониторингу и анализу. Это позволяет извлекать важную информацию, структурировать неструктурированные журналы, отбрасывать ненужные части журналов, маскировать поля из соображений соответствия, исправлять неправильно отформатированные журналы, блокировать прием данных журналов на основе содержимого журналов и многое другое.
Внутри Coralogix правила организованы внутри групп правил . Каждая группа имеет имя и набор правил с логическим отношением И/ИЛИ между ними. Журналы обрабатываются в соответствии с порядком группы правил (сверху вниз), а затем в соответствии с порядком правил в группе правил и в соответствии с логическими операторами между ними (И/ИЛИ).
См. здесь учебник Rules API.
Группы правил
Чтобы создать группу правил в пользовательском интерфейсе Coralogix, перейдите к Поток данных->Правила анализа и нажмите кнопку «НОВАЯ ГРУППА ПРАВИЛ» или выберите один из вариантов быстрого создания правила в полях ниже. The options for rules include:
- Parse
- Extract
- Extract JSON
- Replace
- Block
- Timestamp Extract
- Remove Fields
- [New] Stringify JSON Field
- [New] Parse JSON Field
Форма определения группы правил состоит из нескольких разделов:
Описание
Каждая группа имеет имя и может иметь необязательное описание.
Сопоставитель правил
Раздел Сопоставитель правил определяет запрос. Только журналы, соответствующие запросу Rule Matcher, будут обрабатываться группой. Это важно для того, чтобы через групповые правила проходили только нужные журналы, а также из соображений производительности.
Запрос сопоставления правил определяется путем выбора набора приложений, подсистем и серьезностей. Только журналы, которые соответствуют всем компонентам запроса, будут обрабатываться группой. Все записи в этом разделе необязательны. Отсутствие выбора поля или определение регулярного выражения означает, что группа правил будет работать во всех ваших журналах.
Правила
Вот различные типы правил, которые можно создать в Coralogix:
Анализ
Правило анализа использует именованные группы захвата RegEx. Группы становятся анализируемыми полями журнала, а значение, связанное с каждой группой, становится значением поля. RegEx не обязательно должен соответствовать всему журналу, только именованные группы захвата RegEx (значения в пределах «< >») и значение, которое они захватывают, будут частью реконструированного журнала.
В следующем примере журнал ошибок типа Heroku L/H, отправленный из Heroku в виде неструктурированного журнала, преобразуется в журнал JSON. 9"\s]*)$
Итоговый журнал:
{ «носок»: «клиент», «серьезность»: «предупреждение», «код_ошибки»: «h37», «desc»: «Запрос клиента прерван», «метод»: «ПОСТ», «путь»: «/отправить/», «хост»: «myapp.herokuapp.com», «идентификатор_запроса»: «», «вперед»: «17.17.17.17», «дино»: «веб.1», «подключиться»: «1», «сервис»: «0», «статус»: «499», «байт»: «0», "протокол":"" }В отличие от правила синтаксического анализа, правило извлечения оставит исходный журнал нетронутым и просто добавит в него поля в корне. В следующем примере извлекается информация из сообщения поля и создаются два новых поля, «байты» и «статус», которые можно запрашивать и визуализировать в Coralogix. 9"]+)
Итоговый журнал:
{ "уровень":"ИНФО", "message": "200 байт отправлено, статус в порядке", «Байт»: «200», «Статус»: «ОК» }Если исходный журнал неструктурирован, в него будут добавлены поля на основе именованных групп захвата, а исходный журнал будет сохранен в текстовом поле.
Используя предыдущий пример, он переключит исходный журнал на неструктурированный."уровень": "ИНФОРМАЦИЯ", "сообщение": "200 байт отправлено, статус в порядке",
Итоговый журнал:
{ "байты": "200", "текст": "\"уровень\":\"ИНФО\", \"сообщение\": \"200 байт отправлено, статус в порядке\"" , "Статус": "ОК" }Правила извлечения JSON принимают значение ключа и используют его для перезаписи одного из полей метаданных Coralogix. В этом примере мы извлекаем значение из поля под названием «рабочий» и используем его для заполнения поля метаданных Coralogix под названием «Категория».
Исходное поле всегда является текстовым, а поле JSON Key должно содержать имя поля, из которого вы хотите извлечь значение. Поле назначения — это поле метаданных, которое будет перезаписано этим значением. Это правило часто используется для извлечения и установки серьезности, а также для установки полей метаданных, таких как «Категория», которые влияют на алгоритмы классификации.
Исходный журнал:
{ «идентификатор_транзакции»: 12543, «рабочий»: «А23», «Сообщение»: «успех» }Журнал не изменится в интерфейсе Logs , но поле «категория» метаданных Coralogix будет заполнено «A23» в приведенном выше примере.
Заменить
Обычный вариант использования правила Заменить — исправить неправильно отформатированные журналы JSON. В следующем примере журналы JSON отправляются с префиксом даты, который нарушает формат JSON и превращает их в неструктурированные журналы. Следующее регулярное выражение идентифицирует подстроку для замены в журнале.
Исходный журнал:
2020-08-07 {"status":"OK", "user":John Smith", "ops":"J1"}RegEx:
.*{Итоговый журнал:
{"status": "OK", "user": John Smith, "ops": "J1"}Вложенные поля
В следующем примере показано, как использовать команду Replace правило для перестроения журнала с вложенными полями.
Вложенные поля являются ограничением в правилах извлечения и синтаксического анализа.Исходный журнал: 9$]*)
Каждая из круглых скобок представляет группу захвата, к которой в данном случае можно обратиться с помощью $n n=1..7.
Строка замены:
$1:{\"имя\":\"$2\",\"адрес\":\"$3\",\"город\":\"$4\",\ "state\":\"$5\",\"zip\":\"$6\"},$7Это результирующий журнал:
{ "упс":"G1", "Пользователь":{ "name":"Джон Смит", "address":"2125 Sierra Ventura Dr.", "город": "Саннивейл", "состояние": "CA", «Почтовый индекс»: «» }, "статус":"305" } inner_json
inner_json — это специальное правило замены, которое знает, как взять значение поля в журнале json, которое включает строковый (экранированный) допустимый json, и преобразовать его в объект.
В следующем примере исходный журнал:
{ "сервер":"опа", "IBC":"45ML", "нить": "1201", "message":"{\"first_name\":\"Джон\", \"last_name\":\"Смит\", \"userID\":\"AB12345\", \"длительность\":45} " }Поле message имеет строковое значение, которое является экранированным допустимым json.
Наше специальное правило замены изменит имя поля с исходного имени «message» на «inner_json»:
Регулярное выражение:
«message»\s*:\s*»{\s*\ \»
Идентифицирует сообщение имени поля с началом экранированного json.
Строка замены:
"inner_json":"{\"
Заменяет только имя поля и ничего больше.
Итоговый журнал:
{ "сервер":"опа", "внутренний_json":{ "first_name":"Джон" , "last_name":"Смит" , "идентификатор пользователя":"AB12345" , "длительность":45 } }Блокировать
Правила блокировки позволяют фильтровать входящие журналы. Как и в случае с другими правилами, ядром правила будет регулярное выражение, определяющее журналы, которые необходимо заблокировать (или разрешить). В этом примере все журналы, содержащие подстроку «sql_error_code 28000», будут заблокированы.
RegEx :
sql_error_code=28000
Правила блокировки имеют два дополнительных параметра:
- Блокировать все соответствующие журналы: Будет блокировать любой журнал, который соответствует Rule Matcher и Block Rule
- Блокировать все несоответствующие журналы: Будет блокировать любой журнал, который не соответствует Rule Matcher и Block Rule
Установка флажка « Просмотр заблокированных журналов в Livetail » блокирует журналы, но архивирует их на S3 ( если достижение включено в TCO > Archive), и журналы будут видны в LiveTail.
Это более совершенный вариант, позволяющий присвоить журналам низкий приоритет, как описано здесь. Только 15% объема журналов с низким приоритетом учитывается в квоте.Логика блокировки указывает, будет ли правило блокировать все журналы, которые до соответствуют регулярному выражению или обратному выражению; все журналы, которые не соответствуют регулярному выражению. В приведенном выше примере установка флажка «блокировать все несоответствующие журналы» заблокировала бы все журналы, кроме тех, которые содержат строку
sql_error_code\s*=\s*28000Timestamp Extract
Временная метка Coralogix для каждого журнала запись назначается нашей принимающей конечной точкой при поступлении журналов. Правило Timestamp Extract позволяет заменить временную метку Coralogix для записи в журнале значением пользовательского поля временной метки из вашего журнала. При настройке этого правила убедитесь, что вы выбрали правильное исходное поле, а затем выберите стандарт формата поля, с которым вы лучше всего знакомы.
Наконец, вам нужно будет отредактировать текстовое поле Формат времени, указав формат, соответствующий полю времени вашего журнала. После установки всех трех параметров вы должны использовать тестер Sample log и ожидать совпадения, указывающего на то, что правило смогло преобразовать формат вашего поля времени в формат времени Coralogix, который представляет собой временные метки Unix в наносекундах, разделенные на 100 (17 цифр).Давайте проверим несколько примеров:
с этой записью в журнале:
{ «идентификатор_транзакции»: 12543, «рабочий»: «А23», "Сообщение":"успех", "время": "2021-01-11T15:04:05.000000+0100" }Я выбирал стандарт strftime и устанавливал формат времени в соответствии с моим форматом строки поля времени, который в данном случае также соответствует предложенному формату по умолчанию.
Мы видим, что это привело к совпадению, поэтому мы можем продолжить и сохранить это правило.
дает эту запись в журнале:
{ «идентификатор_транзакции»: 12543, «рабочий»: «А23», "Сообщение":"успех", "время": "2021-01-11T00:12:34+01:00" }Теперь я выбирал стандарт макетов времени Go и устанавливал формат времени в соответствии с моим форматом строки поля времени.
Мы видим, что это привело к совпадению.
дает эту запись в журнале:
{ «идентификатор_транзакции»: 12543, «рабочий»: «А23», "Сообщение":"успех", "время": "03/мар/2021:08:34:12 +0000" }Теперь я выбирал стандарт strftime и устанавливал формат времени в соответствии с моим форматом строки поля времени. Этот вариант использования немного сложнее, поскольку мой формат поля времени мало чем отличается от предложенного по умолчанию, %Y-%m-%dT%H:%M:%S.%f%z, например. 2021-01-11T15:04:05.000000+0100. Одним из них является формат месяца, который в нашем случае имеет тип сокращенного названия месяца, поэтому мне нужно было найти ссылку на strftime и я обнаружил, что %b представляет формат сокращенного названия месяца. Используя %b и добавив другие необходимые изменения, я смог создать соответствующий формат.
Мы видим, что это привело к совпадению.
дает эту запись в журнале:
{ «идентификатор_транзакции»: 12543, «рабочий»: «А23», "Сообщение":"успех", "время": "2021-01-11T15:04:05. 000000+0100"
} Я снова выбрал стандарт strftime, но установил неправильный формат времени, игнорируя %z (часть часового пояса), что привело к несоответствию формату строки моего поля времени. Мы должны изменить формат времени перед сохранением правила, иначе оно не будет работать.
Удалить поля
9Правило 0013 Remove Fields позволяет легко удалять определенные поля из любой записи журнала JSON, содержащей их, на стороне Coralogix, что не всегда возможно во время выполнения. Таким образом, вы создаете более чистую структуру для ваших журналов, чтобы обеспечить лучшую видимость ваших данных. 10 % удаляемого объема данных засчитываются в счет квоты, как и заблокированные данные (согласно правилу блокировки).
Давайте проверим пример, сначала назовем ваше правило и дадим ему осмысленное описание.
откройте диалоговое окно «Исключенные поля», в нем откроется список всех доступных полей, ранее сопоставленных с вашими индексами, и выберите поля для удаления.
Убедитесь, что ваше правило работает, используя раздел Sample log.
Образец журнала
При создании правила вы можете использовать область экрана «образец журнала» для проверки правила. Просто создайте или вставьте журнал в эту область, и он покажет вам результаты обработки журнала правилом. В этом примере правило Parse обрабатывает журнал в области «Образец журнала», а результат отображается в области «Результаты»:
Stringify JSON Fields
Это правило позволяет изменить массив или объект из формата JSON. в текст, чтобы уменьшить количество полей, но при этом сохранить данные в Coralogix, чтобы их можно было найти с помощью поиска по произвольному тексту.
Шаги по настройке:
- Нажмите «Поток данных».
- Нажмите на правила синтаксического анализа.
- Выберите правило поля Stringify Json из списка правил.
- Настройте имя группы, средства сопоставления правил и все, что необходимо для вашего правила.
- Исходное поле: поле, которое вы хотите преобразовать в текст.
- Сохранить или удалить опцию исходного поля.
- Выберите Сохранить, если хотите сохранить исходное поле с его содержимым.
- Выберите Удалить, если вы хотите удалить исходное поле и его содержимое.
- Поле назначения — это новое поле, в которое вы хотите поместить содержимое источника.
В приведенном ниже примере у меня есть поле с именем sessionIssuer, которое является абстрактным, и я собираюсь изменить его на текст и дать ему новое имя, называемое приложением.
Исходное сообщение:
Новое сообщение с выбранным полем удаления источника:
Новое сообщение с полем сохранения источника:
Анализ поля JSON
С помощью правила поля Parse Json можно без труда преобразовывать экранированные или строковые журналы в формат JSON.
Выберите экранированное поле, выберите поле назначения для записи, и все готово.
- Выберите поле «Источник» — это поле, которое вы пытаетесь отменить.
- Выберите «Объединить в и перезаписать», только если вы пытаетесь перезаписать или объединить данные в уже существующее поле. Если вы пытаетесь создать новое поле, эти 2 параметра не имеют значения.
- Опция Сохранить исходное поле сохраняет исходное поле и его содержимое.
- Удалить исходное поле удалит исходное поле и его содержимое.
В приведенном ниже примере мы удаляем экранирование журнала и делаем его в формате JSON.
Исходное сообщение:
Сообщение после правила:
Примечание. Если вы выбрали поле назначения, которое вызовет исключение сопоставления, появится всплывающее сообщение, информирующее вас о том, что вы создадите исключение, если вы применяете это правило.
Логика группы правил
Чтобы добавить правила в группу после создания первого журнала, необходимо выполнить два действия:
- Выберите тип правила в раскрывающемся списке «ДОБАВИТЬ ПРАВИЛО»
- Выберите логическую связь между последним правилом и новым (И/Или)
Пример: Правило-1 И Правило-2 будет означать, что журнал всегда будет обрабатываться по обоим правилам.
Правило-1 ИЛИ Правило-2 означает, что журнал будет обрабатываться либо по Правилу-1, либо по Правилу-2, в зависимости от того, какое из них совпадет первым, или ни по одному, если ни одно из них не соответствует журналу. Другими словами, если Правило-1 совпадает с журналом, то Правило-2 к нему вообще не применяется.Группы правил: порядок выполнения
Журналы обрабатываются различными группами правил в соответствии с порядком групп. При «входе» в группу журнал сначала сопоставляется с запросом «Сопоставление правил». Если он совпадает, он будет продолжен в правилах группы. Внутри группы журнал будет сопоставляться с Правилами в соответствии с их порядком и логикой. Оно будет сопоставляться вниз по списку правил до тех пор, пока не будет сопоставлено правило, за которым следует логический оператор ИЛИ. Операторы ИЛИ и И в группе не следуют математическому порядку операций. Правила применяются мгновенно, поэтому выходные данные одного правила становятся входными данными для следующего.
Примечание: Понятно, что порядок правил и групп важен и может повлиять на результат обработки журнала.
В качестве примера посмотрите на эти два правила, которые анализируют журналы Postgres Heroku: /2
В конце журнала подписчиков есть дополнительная запись, follower_lag_commits. Это означает, что правило «Лидер» захватит оба журнала, потому что оно менее строгое и все остальные поля совпадают. Follower будет соответствовать только журналам Follower (первая тестовая строка не захватывается в примере Follower, потому что в ней нет дополнительной записи). Это означает, что правило последователя будет выполняться первым.
Еще одним фактором является производительность. Лучшей практикой является размещение правил блокировки на первом месте и использование «Сопоставителя правил», когда это возможно. Это предотвратит ненужную обработку логов и ускорит обработку ваших данных.
Порядок выполнения правил внутри группы можно изменить, перетащив правило на новое место относительно других правил.
То же самое касается групп правил. Вы можете изменить их порядок, перетаскивая их вверх и вниз по списку.
Поиск групп правил
Чтобы быстро найти интересующую группу правил, вы можете использовать функцию поиска для поиска правил. Вы можете использовать правила или имена групп в поле поиска произвольного текста.
Редактирование правил и групп
Чтобы отредактировать группу правил или правило внутри группы, щелкните группу, внесите изменения и нажмите «СОХРАНИТЬ ИЗМЕНЕНИЯ».
Что такое парсер? Определение, типы и примеры
По
- Бен Луткевич, Технический писатель
В компьютерных технологиях синтаксический анализатор — это программа, которая обычно является частью компилятора. Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Парсеры разбивают входные данные на такие части, как существительные (объекты), глаголы (методы) и их атрибуты или параметры. Затем они управляются другими программами, такими как другие компоненты компилятора. Синтаксический анализатор также может проверить, были ли предоставлены все необходимые входные данные.
Как работает синтаксический анализ?Синтаксический анализатор — это программа, входящая в состав компилятора, а синтаксический анализ — часть процесса компиляции. Парсинг происходит на этапе анализа компиляции.
При синтаксическом анализе код берется из препроцессора, разбивается на более мелкие части и анализируется, чтобы другое программное обеспечение могло его понять. Синтаксический анализатор делает это, создавая структуру данных из входных данных.
Точнее, человек пишет код на понятном человеку языке, таком как C++ или Java, и сохраняет его в виде набора текстовых файлов. Синтаксический анализатор принимает эти текстовые файлы в качестве входных данных и разбивает их, чтобы их можно было перевести на целевую платформу.
Анализатор состоит из трех компонентов, каждый из которых обрабатывает разные этапы процесса анализа. Три этапа:
Учитывая набор символов x+z=11, лексический анализатор разделит его на серию токенов и классифицирует их, как показано.Этап 1: Лексический анализ
Лексический анализатор — или сканер — берет код из препроцессора и разбивает его на более мелкие части. Он группирует входной код в последовательности символов, называемые лексемами, каждая из которых соответствует токену. Токены — это единицы грамматики языка программирования, понятные компилятору.
Лексические анализаторы также удаляют из ввода пробелы, комментарии и ошибки.
Этап 2: синтаксический анализ
Синтаксический анализатор принимает (x+y)*3 в качестве входных данных и возвращает это дерево синтаксического анализа, которое позволяет синтаксическому анализатору понять уравнение.На этом этапе синтаксического анализа проверяется синтаксическая структура ввода с использованием структуры данных, называемой деревом синтаксического анализа или деревом вывода.
Анализатор синтаксиса использует маркеры для построения дерева синтаксического анализа, которое объединяет предопределенную грамматику языка программирования с маркерами входной строки. Синтаксический анализатор сообщает о синтаксической ошибке, если синтаксис неверен.Этап 3: Семантический анализ
Семантический анализ сверяет дерево синтаксического анализа с таблицей символов и определяет, является ли оно семантически непротиворечивым. Этот процесс также известен как контекстно-зависимый анализ. Он включает проверку типов данных, проверку меток и проверку управления потоком.
Если предоставлен код:
с плавающей запятой а = 30,2; число с плавающей запятой b = a*20
, то анализатор будет рассматривать 20 как 20.0 перед выполнением операции.
В некоторых источниках только этап синтаксического анализа называется синтаксическим анализом, поскольку он генерирует дерево синтаксического анализа. Они не учитывают лексический и семантический анализ.
Синтаксический анализ происходит на первых трех этапах процесса компиляции — лексическом, синтаксисе и семантическом анализе. Какие существуют основные типы парсеров?При создании языка программного обеспечения его создатели должны указать набор правил. Эти правила обеспечивают грамматику, необходимую для построения правильных операторов языка.
Ниже приведен набор грамматических правил для простого вымышленного языка, который содержит всего несколько слов:
<предложение> ::= <субъект> <глагол> <объект>
<тема> ::= <статья> <существительное>
<статья> ::= the | a
<существительное> ::= собака | кошка | человек
<глагол> ::= домашние животные | fed
<объект> ::= <статья> <существительное>В этом языке предложение должно содержать подлежащее, глагол и существительное в указанном порядке, а отдельные слова должны соответствовать частям речи. Подлежащее – это артикль, за которым следует существительное.
Существительное может быть одним из следующих трех слов: собака , кошка или человек . А глаголом может быть только домашних животных или кормящих .Синтаксический анализ проверяет оператор, предоставленный пользователем в качестве входных данных, на соответствие этим правилам, чтобы доказать, что оператор действителен. Разные алгоритмы парсинга проверяют в разном порядке. Существует два основных типа парсеров:
- Нисходящие парсеры. Они начинаются с правила вверху, например <предложение> ::= <субъект> <глагол> <объект>. Имея входную строку «Человек накормил кошку», синтаксический анализатор просматривает первое правило и просматривает все правила, проверяя их правильность. В этом случае первое слово — это
, оно следует правилу подлежащего, и синтаксический анализатор продолжит чтение предложения в поисках . - Парсеры «снизу вверх». Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
Проще говоря, нисходящие синтаксические анализаторы начинают свою работу с начального символа грамматики в верхней части дерева синтаксического анализа. Затем они продвигаются вниз от правила к предложению. Синтаксические анализаторы снизу вверх работают от предложения к правилу.
Помимо этих типов, важно знать два типа деривации. Вывод — это порядок, в котором грамматика согласовывает входную строку. Их:
- Парсеры LL . Они анализируют ввод слева направо, используя самое левое производное, чтобы сопоставить правила грамматики с вводом. Этот процесс выводит строку, которая проверяет ввод, расширяя крайний левый элемент дерева синтаксического анализа.
- LR-парсеры . Эти входные данные анализируются слева направо, используя крайний правый вывод. Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Кроме того, существуют другие типы парсеров, в том числе следующие:
- Парсеры рекурсивного спуска. Парсеры рекурсивного спуска возвращаются после каждого решения, чтобы перепроверить точность. Парсеры рекурсивного спуска используют синтаксический анализ сверху вниз.
- Парсеры Эрли. Они анализируют все контекстно-свободные грамматики, в отличие от парсеров LL и LR. Большинство реальных языков программирования не используют контекстно-свободные грамматики.
- Парсеры Shift-reduce. Смещают и сокращают входную строку. На каждом этапе строки они сокращают слово до правила грамматики. Этот подход уменьшает строку до тех пор, пока она не будет полностью проверена.
Парсеры используются, когда необходимо абстрактно представить входные данные из исходного кода в виде структуры данных, чтобы их можно было проверить на правильность синтаксиса.
Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.К технологиям, использующим синтаксический анализ для проверки входных данных кода, относятся следующие:
Языки программирования. Парсеры используются во всех языках программирования высокого уровня, включая следующие:
- С++
- Расширяемый язык разметки или XML
- Язык гипертекстовой разметки или HTML
- Препроцессор гипертекста или PHP
- Ява
- JavaScript
- Обозначение объекта JavaScript или JSON
- Перл
- Питон
Языки баз данных. Языки баз данных, такие как язык структурированных запросов, также используют синтаксические анализаторы.
Протоколы . Протоколы, такие как протокол передачи гипертекста и удаленные вызовы функций через Интернет, используют синтаксические анализаторы.
Генератор парсеров . Генераторы синтаксического анализа принимают грамматику в качестве входных данных и генерируют исходный код, который выполняет синтаксический анализ в обратном порядке. Они создают синтаксические анализаторы из регулярных выражений, которые представляют собой специальные строки, используемые для управления и сопоставления шаблонов в тексте.
Синтаксический анализ — это фундаментальная концепция разработки программного обеспечения и теории вычислений. Однако большинство ИТ-специалистов могут обойтись без глубокого понимания синтаксического анализа, используя платформы с низким кодом, которые позволяют пользователям создавать программы без написания тысяч строк кода.
Узнайте плюсы и минусы использования платформ с низким кодом на предприятии. Последнее обновление: июль 2022 г.
Продолжить чтение О парсере- Памятка Terraform: известные команды, HCL и многое другое
- Как стать хорошим Java-программистом без образования
- Интерпретируемые и компилируемые языки: в чем разница?
- Исправление 10 самых распространенных ошибок времени компиляции в Java
- 7 советов по выбору правильной библиотеки Java
компилятор
Автор: Роберт Шелдон
компьютерная лингвистика (CL)
Автор: Александр Гиллис
НЛП и ИИ повышают эффективность автоматизированного хранилища данных
Автор: Лиза Морган
обработка естественного языка (NLP)
Автор: Бен Луткевич
ПоискSoftwareQuality
- Сделайте качество приоритетом в своей культуре разработки программного обеспечения
Команде разработчиков программного обеспечения необходимо качество, чтобы обеспечить надежный продукт.
Вот несколько способов обеспечить качество во всех аспектах разработки... - Инструменты и методы модернизации приложений COBOL
Варианты модернизации кода COBOL варьируются от простой, но дорогостоящей перезаписи приложения до автоматизированных инструментов, которые могут конвертировать ...
- Тернистый путь Xandr к успеху в области автоматизации тестирования программного обеспечения ИИ
Инструмент для тестирования программного обеспечения на основе искусственного интеллекта Mabl уменьшил количество ошибок и усложнил тестирование для рекламной компании Xandr, но первоначальный ...
SearchCloudComputing
- Oracle оптимизирует расходы на AWS, поддержку многооблачных баз данных
Oracle разрешает пользователям своих баз данных получать доступ к этим сервисам в конкурирующих облаках, активно преследуя клиентов AWS в ...
- Сравните AWS Glue и Azure Data Factory
AWS Glue и Фабрика данных Azure имеют ключевые отличия, несмотря на то, что являются схожими сервисами.
Узнайте, что лучше всего подходит для вашей организации ... - Как VMware Explore 2022 изменил мое мнение
Многооблачные и облачные стратегии стали основными темами VMware Explore 2022. Ознакомьтесь с ключевыми объявлениями из ...
TheServerSide.com
- 5 советов, как перейти от программиста к менеджеру
Разработчики, которые хотят перейти от программиста к менеджеру, должны иметь другое мышление и различные навыки. Эти пять ...
- Является ли HTML языком программирования?
В отличие от Java, Python или C, HTML не является языком программирования, поскольку в нем отсутствуют переменные, условные операторы или итерации...
- 8 технических профессий, которые не требуют программирования
Ищете работу в сфере ИТ, не связанную с программированием? Эти восемь технических ролей важны в любой организации, где нет программирования.
..
Разработка лексических правил для анализа функциональных слов ASD-STE100 в ARTEMIS с точки зрения ролевой и справочной грамматики | Fumero-Pérez
Европейская ассоциация аэрокосмической и оборонной промышленности. 2017. Международная спецификация по подготовке технической документации на контролируемом языке 7 (январь).
Болл, Дж. 2017. «Использование NLU в контексте для ответов на вопросы: улучшение задач BABI в Facebook». https://arxiv.org/ftp/arxiv/papers/1709/1709.04558.pdf. (По состоянию на 24 апреля 2019 г.).
Кортес-Родригес, Ф. 2016. «На пути к вычислительной реализации RRG». Círculo de Lingüística Aplicada a la Comunicación 65: 75-108.
Кортес-Родригес, Ф. и Р. Майрал-Усон. 2016. «Построение вычислительной грамматики RRG». Ономазеин 34: 86-117.
Кортес-Родригес, Ф. и К. Родригес-Хуарес. 2018. «Разбор фразовых составляющих в ASD-STE с помощью ARTEMIS». Вопросы когнитивной лингвистики 3: 97-109.
Диас-Галан, А.
2018. «Глубокий анализ для авиационной отрасли: настройка ARTEMIS для анализа простых предложений в ASD STE-100». Вопросы когнитивной лингвистики 3: 83-96.Диас-Галан, А. и М. Фумеро-Перес. 2016. «Разработка правил синтаксического анализа в ARTEMIS: случай вспомогательной вставки Do». Понимание смысла и представления знаний: от теоретической и когнитивной лингвистики до обработки естественного языка. ред. К. Периньян-Паскуаль и Э. Местре-Местре. Кембридж: Издательство Кембриджских ученых. 283-302.
Дидрихсен, Э. 2014. «Роль и справочный грамматический синтаксический анализатор для немецкого языка». Языковая обработка и грамматика. Роль функционально ориентированных вычислительных моделей. ред. Б. Нолан и К. Периньян-Паскуаль. Амстердам / Филадельфия: Джон Бенджаминс. 105-142.
Фумеро-Перес, М. 2018. «Адаптация ARTEMIS к анализу контролируемого языка». Вопросы когнитивной лингвистики 3: 71-82.
Фумеро-Перес, М. и А. Диас-Галан. 2017. «Взаимодействие правил синтаксического анализа и конструкций предикатов аргументов: последствия для структуры Grammaticon в FunGramKB».
Revista de Lingüística y Lenguas Aplicadas 12: 33-44.Голдберг, А. 1995. Конструкции: подход строительной грамматики к структуре аргументов. Чикаго: Чикагский университет Press
Гость, Э. 2008. «Анализ ролевой и справочной грамматики». Исследования интерфейса синтаксис-семантика-прагматика. Эд. Р. Ван Валин. Амстердам: Джон Бенджаминс. 435-454.
Майрал Усон, Р. и Ф. Кортес Родригес. 2017. «Автоматическое представление значения текста с помощью системы на основе интерлингва (ARTEMIS). Еще один шаг к вычислительному представлению RRG». Журнал компьютерных лингвистических исследований 1: 61-87.
Майрал Усон, Р. и Ф. Руис де Мендоса. 2009 г.. «Уровни описания и объяснения в смысловом построении». Деконструкция конструкций. ред. К. Батлер и Дж. Мартин Ариста. Амстердам: Джон Бенджаминс. 53-98.
Мартин-Диас, М. 2017. «Отчет об английском языке YES / Нет вопросительных предложений в ARTEMIS». Revista de Lenguas Para Fines Específicos 23 (1): 421-62.
Освальд Р.
и Л. Каллмейер (ожидается). «К формализации ролевой и справочной грамматики». Чтобы появиться в разделе «Применение и расширение ролей» и «Справочная грамматика». ред. Р. Кайлувейт, Э. Штаудингер и Л. Кюнкель. Издательство Фрайбургского университета. http://user.phil.hhu.de/~osswald/publications/osswald_kallmeyer-rrg_formalization.pdf. (По состоянию на 10 октября 2018 г.)Periñán-Pascual, C. 2012. «En defensa del procesamiento del languaje natural fundamentado en la lingüística teórica». Ономазеин 26: 13-48.
Периньян-Паскуаль, К. 2013. «На пути к модели конструктивного значения для понимания естественного языка». Связывание конструкций в функциональной лингвистике: роль конструкций в грамматиках RRG (серия «Исследования языка»). ред. Б. Нолан и Э. Дидрихсен. Амстердам/Филадельфия: Джон Бенджаминс. 205-230.
Периньян-Паскуаль, К. и Ф. Аркас-Тунес. 2010. «Архитектура FungramKB». Материалы 7-й Международной конференции по языковым ресурсам и оценке. ред. Н. Кальцолари, К.
Чукри, Б. Мегаард, Дж. Мариани, Дж. Одейк, С. Пиперидис, М. Рознер и Д. Тапиас. Мальта: Европейская ассоциация языковых ресурсов. 2667-2674.Периньян-Паскуаль, К. и Ф. Аркас-Тунес. 2014. «Реализация конструктора CLS в ARTEMIS». Языковая обработка и грамматика роль функционально ориентированных вычислительных моделей. ред. Б. Нолан и К. Периньян-Паскуаль. Амстердам / Филадельфия: Джон Бенджаминс. 164-196.
Периньян-Паскуаль, К. и Р. Майрал Усон. 2010а. «Грамматика COREL: концептуальный язык представления». Ономазеин 21: 11-45.
Периньян-Паскуаль, К. и Р. Майрал Усон. 2010b «Улучшение UniArab с помощью FunGramKB». Procesamiento del Lenguaje Natural 44: 19-26.
Родригес-Хуарес, К. 2017. «О вычислительной обработке конструкций: место локативных конструкций в базе знаний». Ономазеин 21: 11-45.
Руис де Мендоса, Ф. и Р. Майрал Усон. 2008. «Уровни описания и сдерживающие факторы в смысловой конструкции: введение в лексическую конструктивную модель». Folia Linguística 42 (2): 355-400.
 9017 9017 7 9017 7 9017 9017 9017 9017 9017 9017 7 9017 9017 9017 9000
9017 9017 7 9017 7 9017 9017 9017 9017 9017 9017 7 9017 9017 9017 9000

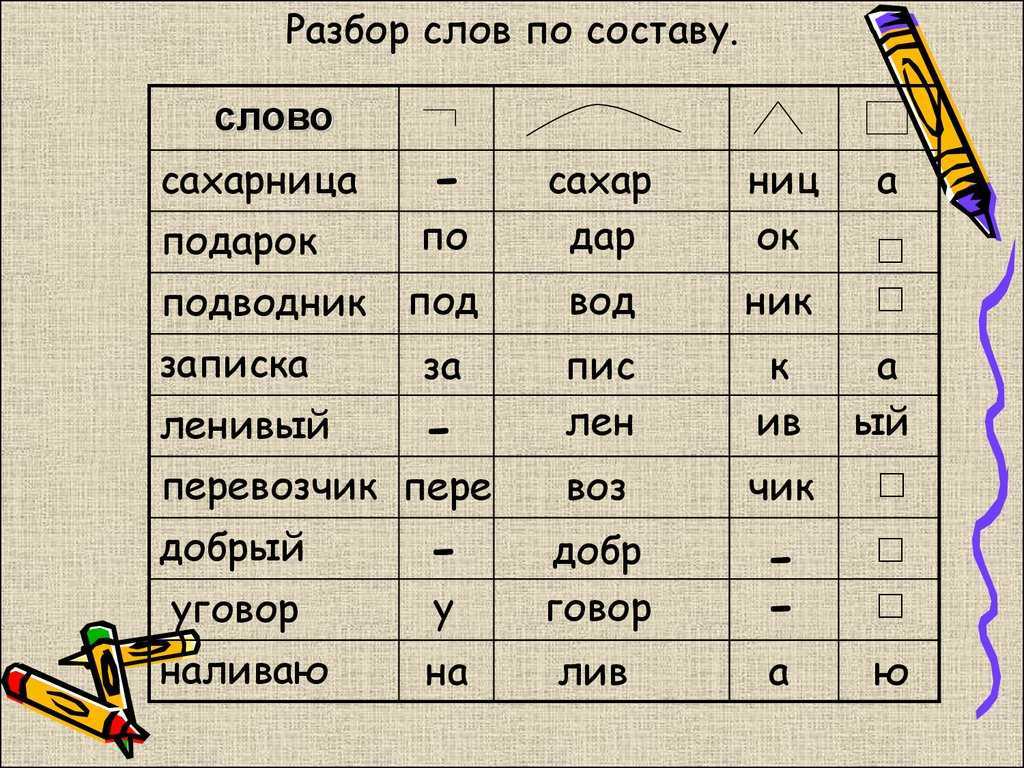

 Для HTTP-запросов сюда входят заголовки. Для WebSockets это общее количество байтов, отправленных клиенту по соединению.
Для HTTP-запросов сюда входят заголовки. Для WebSockets это общее количество байтов, отправленных клиенту по соединению. в двойных кавычках. Это значение равно
в двойных кавычках. Это значение равно 
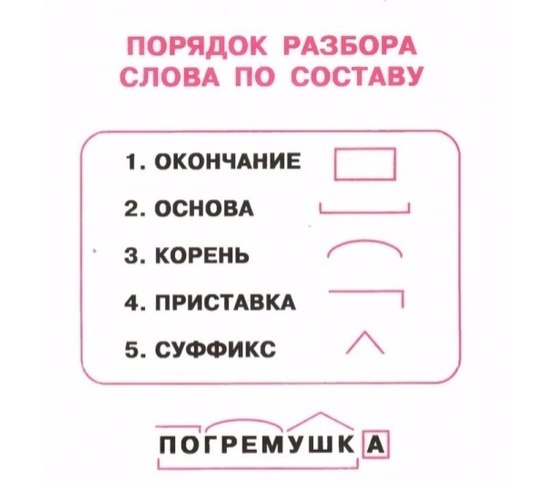
 thread
thread  Каждое граничное местоположение идентифицируется трехбуквенным кодом и произвольно назначаемым номером; например,
Каждое граничное местоположение идентифицируется трехбуквенным кодом и произвольно назначаемым номером; например, 
 Если средство просмотра закрывает соединение после того, как CloudFront начинает отправлять ответ, журнал содержит соответствующий код состояния HTTP.
Если средство просмотра закрывает соединение после того, как CloudFront начинает отправлять ответ, журнал содержит соответствующий код состояния HTTP.
 Это доменное имя в запросе.
Это доменное имя в запросе. байт ответа на выходную очередь пограничного сервера, измеренный на сервере.
байт ответа на выходную очередь пограничного сервера, измеренный на сервере.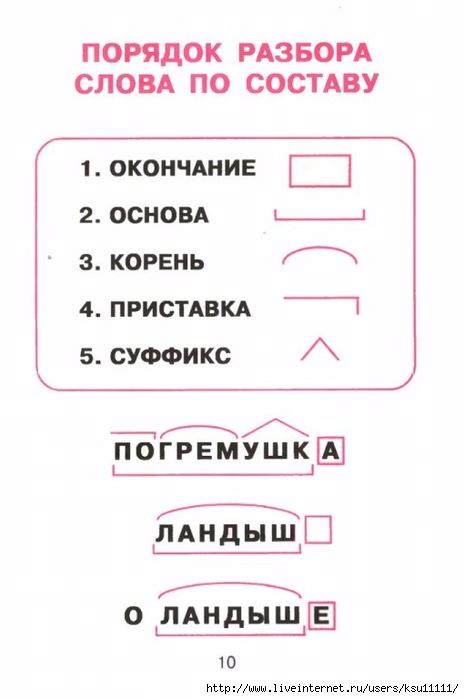 Возможные значения включают в себя:
Возможные значения включают в себя: Возможные значения:
Возможные значения: Если значение
Если значение  для дистрибутива это поле содержит код, указывающий, успешно ли обработано тело запроса.
для дистрибутива это поле содержит код, указывающий, успешно ли обработано тело запроса.
 Каждое граничное местоположение идентифицируется трехбуквенным кодом и произвольно назначаемым номером; например,
Каждое граничное местоположение идентифицируется трехбуквенным кодом и произвольно назначаемым номером; например, 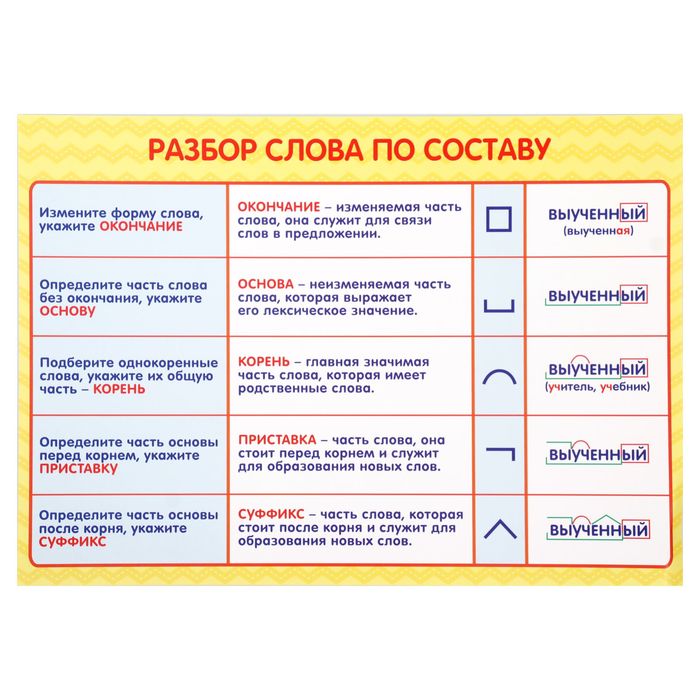

 В некоторых случаях тип результата может меняться между временем, когда CloudFront готов отправить ответ, и временем, когда CloudFront заканчивает отправку ответа.
В некоторых случаях тип результата может меняться между временем, когда CloudFront готов отправить ответ, и временем, когда CloudFront заканчивает отправку ответа.
 В этом случае это поле представляет собой IP-адрес зрителя, отправившего запрос. Это поле содержит адреса IPv4 и IPv6, если применимо.
В этом случае это поле представляет собой IP-адрес зрителя, отправившего запрос. Это поле содержит адреса IPv4 и IPv6, если применимо.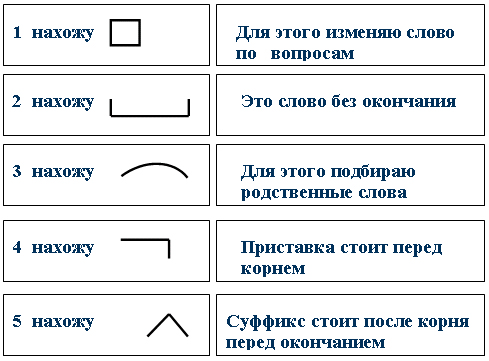
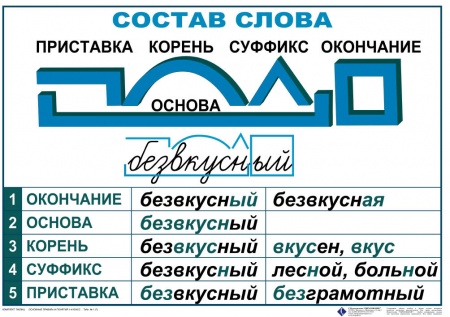
 0
0  CloudFront передает обработанный запрос источнику по мере шифрования данных, поэтому
CloudFront передает обработанный запрос источнику по мере шифрования данных, поэтому 
 : Общее время активности запроса в HAProxy (мс)
: Общее время активности запроса в HAProxy (мс) Это устанавливается во время выполнения Docker с необязательным флагом
Это устанавливается во время выполнения Docker с необязательным флагом  user
user  Если вы настроили какие-либо параметры, отличные от значений по умолчанию, наш шаблон Grok не будет анализировать ваши журналы. В этом случае мы рекомендуем использовать пользовательский синтаксический анализ.
Если вы настроили какие-либо параметры, отличные от значений по умолчанию, наш шаблон Grok не будет анализировать ваши журналы. В этом случае мы рекомендуем использовать пользовательский синтаксический анализ. logtype = 'mysql-ошибка'
logtype = 'mysql-ошибка'  request
request message
message 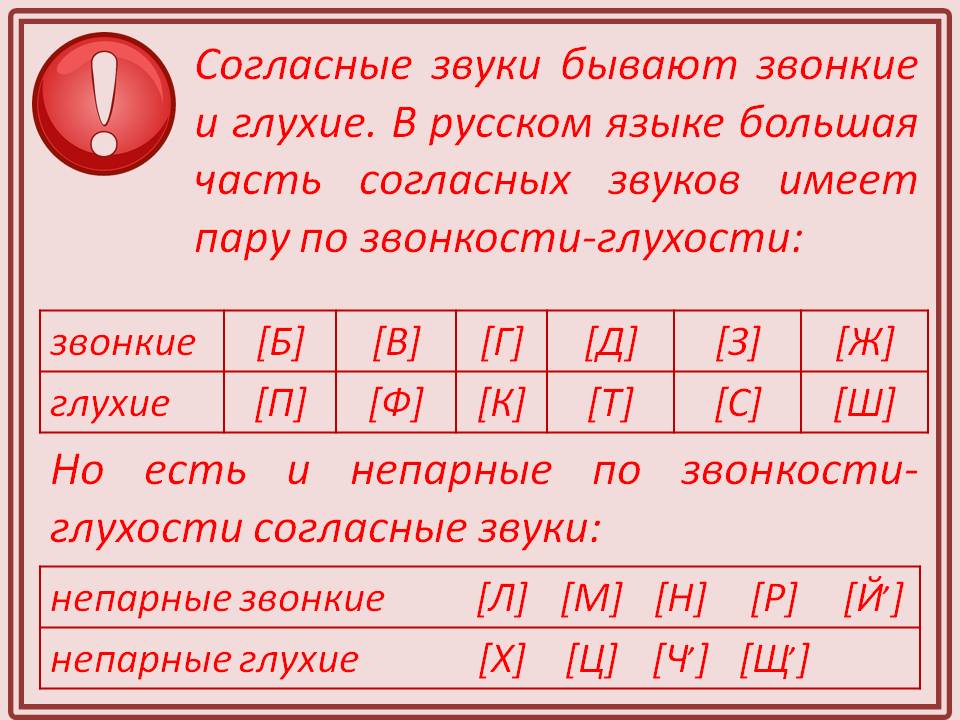


 Например, структурированные данные
Например, структурированные данные 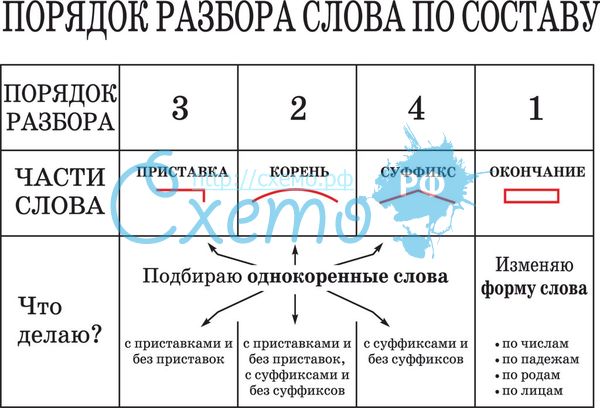
 и переписывает его из пассивного залога в активный залог для ясности. Средство проверки грамматики также выделяет относительное предложение между запятыми:
и переписывает его из пассивного залога в активный залог для ясности. Средство проверки грамматики также выделяет относительное предложение между запятыми:
 Сторонние решения для проверки грамматики могут полагаться в основном на «сопоставление с образцом». «Сопоставление с образцом» означает, что программа использует метод, который сопоставляет проверяемый текст с образцами текста, хранящимися во внутренней базе данных.
Сторонние решения для проверки грамматики могут полагаться в основном на «сопоставление с образцом». «Сопоставление с образцом» означает, что программа использует метод, который сопоставляет проверяемый текст с образцами текста, хранящимися во внутренней базе данных.
 Однако при неправильном изменении реестра могут возникнуть серьезные проблемы. Поэтому убедитесь, что вы выполните следующие действия внимательно. Для дополнительной защиты создайте резервную копию реестра перед его изменением. Затем вы можете восстановить реестр, если возникнет проблема. Для получения дополнительных сведений о резервном копировании и восстановлении реестра щелкните следующий номер статьи базы знаний Майкрософт:
Однако при неправильном изменении реестра могут возникнуть серьезные проблемы. Поэтому убедитесь, что вы выполните следующие действия внимательно. Для дополнительной защиты создайте резервную копию реестра перед его изменением. Затем вы можете восстановить реестр, если возникнет проблема. Для получения дополнительных сведений о резервном копировании и восстановлении реестра щелкните следующий номер статьи базы знаний Майкрософт: В Word на вкладке «Правописание и грамматика» можно выбрать два стиля письма: «Грамматика и стиль» или «Только грамматика». Эти параметры определяются в записях Name в подразделах Option Set 0 и Option Set 1. Для каждого из этих параметров вы также можете установить правила, которые Word использует для проверки грамматики. Чтобы установить эти правила, нажмите «Настройки» на вкладке «Правописание и грамматика». Эти настройки также хранятся в виде двоичных инструкций в записях данных в подразделах Option Set 0 и Option Set 1.
В Word на вкладке «Правописание и грамматика» можно выбрать два стиля письма: «Грамматика и стиль» или «Только грамматика». Эти параметры определяются в записях Name в подразделах Option Set 0 и Option Set 1. Для каждого из этих параметров вы также можете установить правила, которые Word использует для проверки грамматики. Чтобы установить эти правила, нажмите «Настройки» на вкладке «Правописание и грамматика». Эти настройки также хранятся в виде двоичных инструкций в записях данных в подразделах Option Set 0 и Option Set 1.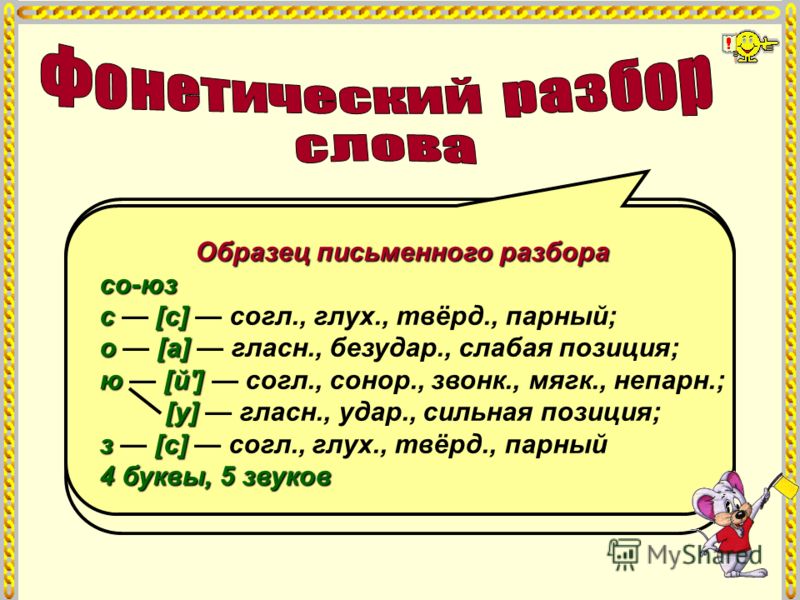

 В этом случае ошибки пунктуации или пробелов помечаются перед конкретными или ограниченными грамматическими ошибками.
В этом случае ошибки пунктуации или пробелов помечаются перед конкретными или ограниченными грамматическими ошибками. диалоговое окно Грамматика.
диалоговое окно Грамматика.
 {="}
["IMG" "SRC" "test.gif" "WIDTH" "123"]
{="}
["IMG" "SRC" "test.gif" "WIDTH" "123"]