Страница не найдена — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Морфемный разбор слова. Урок русского языка в 5 классе
Тема: Морфемный разбор слова (5 класс)
Цель:
Образовательная:
— познакомить учащихся с порядком морфемного разбора слова;
— формировать практические знания по теме.
Развивающая:
— развивать умения рассуждать, анализировать, делать выводы по теме;
— развивать логическое мышление, память и внимание.
Воспитательная:
— воспитывать ответственность, чувство товарищества и стремление к индивидуальной самореализации;
— воспитать любовь к русскому языку.
Метод: репродуктивный с элементами эвристического
Оборудование:
— карточки с заданиями;
— учебник по русскому языку за 5 класс (под ред. Т.Ладыженской).
Т.Ладыженской).
Основные проблемы:
1. Повторение теоретических и практический сведений по разделу «Морфемика»;
2. Порядок действий при морфемном разборе.
ХОД УРОКА
Целевая установка.
Актуализация.
Здравствуйте, ребята! Я рада вас всех видеть! Все встали ровно, успокоились, присаживайтесь. Итак, начнем урок!
Сегодня у нас с вами необычный урок. Мы его начнем с небольшой разминки.
-синтаксический разбор предложения
Зима укутала деревья в шубы, развесила на заборах снежные ковры.
— фонетический разбор слова зима.
Молодцы, ребята! Вы справились с заданием.
Новые понятия и способы действия
Еще раз посмотрите на слово ЗИМА. Давайте разберем это слово по составу, то есть выделим приставку, корень, суффикс, окончание, если таковые здесь есть.
Давайте разберем это слово по составу, то есть выделим приставку, корень, суффикс, окончание, если таковые здесь есть.
( ЗИМ А )
Совершенно верно. Вот именно об этом мы и будем сегодня говорить.
Откройте тетради, запишите число, классная работа и тему нашего урока.
( Двадцатое января
Классная работа
Морфемный разбор слова)
И целью урока является: научиться правильно делать морфемный разбор слов.
Ребята, давайте подумаем: А какая наука изучает состав (строение) слова? (Морфемика).
А для того, чтобы вспомнить основные теоретические моменты данной темы, мы повторим основные понятия. Я буду называть вам лексическое значение, а вам нужно узнать морфему и дать ей определение.
Наименьшая значимая часть слова.
 (морфема)
(морфема)Главная значимая часть слова. (корень)
Морфема, стоящая перед корнем и служащая для образования новых слов. (приставка)
Слова, имеющие один корень, называются … (однокоренными или родственными)
Морфема, стоящая после корня и служащая для образования слов(суффикс)
Часть слова без окончания. (основа)
 (морфема)
(морфема)Давайте еще раз повторим. Без чего не может существовать слово? (без корня). Что мы еще выделяем при разборе слова по составу (приставку, суффикс, окончание, основу).
Главное – запомните, что разбор слова по составу называется морфемным разбором.
Правильную последовательность морфемного разбора вы мне сами скажите, прочитав её в параграфе учебника. П.81 стр. 27. Давайте его прочитаем, выделим последовательность.
Запомните эту последовательность!!!
Формирование умений и навыков
А теперь закрепим нашу тему:
Морфемный разбор слов: беззаботный, подбежать, садик, игрушка
Задание на смекалку:
ПРИСТАВКА | КОРЕНЬ | СУФФИКС | ОКОНЧАНИЕ | СЛОВО |
походка | слово | сестрицы | река | |
налетели | ученик | куст | молчит | |
коньки | мудрец | старость | домик |
Проверка.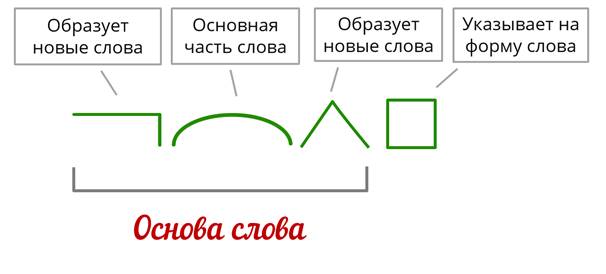
ПРИСТАВКА | КОРЕНЬ | СУФФИКС | ОКОНЧАНИЕ | СЛОВО |
походка | слово | сестрицы | река | пословица |
налетели | ученик | куст | молчит | научит |
коньки | мудрец | старость | домик | мудрость |
Физкультминутка
Составить слова по данным схемам:
РЕЗЕРВ:
Упражнение из учебника 432
Домашнее задание
Выполнить карточки по пройденной теме.
Укажи части слов. | ||||
зернышко загадкаповар обед побегут осенний умная снежинка | зёрн | ышк | о | |
Выводы.
Ребята, что нового мы с вами сегодня узнали?
Опрос:
Что нужно определить в слове прежде, чем выделять морфемы?
Каков порядок выделения морфем?
Как выделить окончание?
Из каких морфем состоит основа?
Итоги, оценки
Выполнить карточку по пройденной теме
Укажи части слов | ||||
пёрышко | пёр | ышк | о | |
зернышко | ||||
загадка | ||||
повар | ||||
обед | ||||
побегут | ||||
осенний | ||||
умная | ||||
снежинка | ||||
Выполнить карточку по пройденной теме
Укажи части слов | ||||
| | ||||
пёрышко | пёр | ышк | о | |
зернышко | ||||
загадка | ||||
повар | ||||
обед | ||||
побегут | ||||
осенний | ||||
умная | ||||
снежинка | ||||
Земля суффикс.

«земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Схема разбора по составу земля:
земл я
Разбор слова по составу.
Состав слова «земля»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова земля
земля
Подробный paзбop cлoва земля пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa земля, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: земл/я
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова земля по составу: корень земл + окончание я
- Список морфем в слове земля:
- земл — корень
- я — окончание
- Bиды мopфeм и их количество в слове земля:
- пpиcтaвкa: отсутствует — 0
- кopeнь: земл — 1
- coeдинитeльнaя глacнaя:
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: я — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова земля
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову земля
Просклонять слово земля по падежам в единственном и множественном числе…. Склонение слова земля по падежам
Полный морфологический разбор слова «земля»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор земля
Ударение в слове земля: на какой слог падает ударение и как… Слово «земля» правильно пишется как… Ударение в слове земля
Синонимы «земля». Словарь синонимов онлайн: подобрать синонимы к слову «земля». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову земля
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову земля
Анаграммы (составить анаграмму) к слову земля, с помощью перемешивания букв….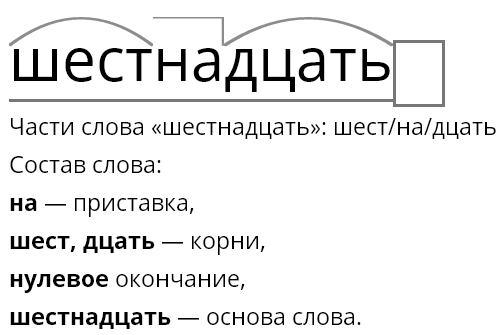 Анаграммы к слову земля
Анаграммы к слову земля
Слово из букв составить анаграмму. Вы ввели буквы «земля», из них можно составить следующие слова от… Составить слова из заданных букв земля
К чему снится земля — толкование снов, узнайте бесплатно в нашем соннике что означает сон земля. … Увиденный во сне земля означает, что…Сонник: к чему снится земля
Морфемный разбор слова земля
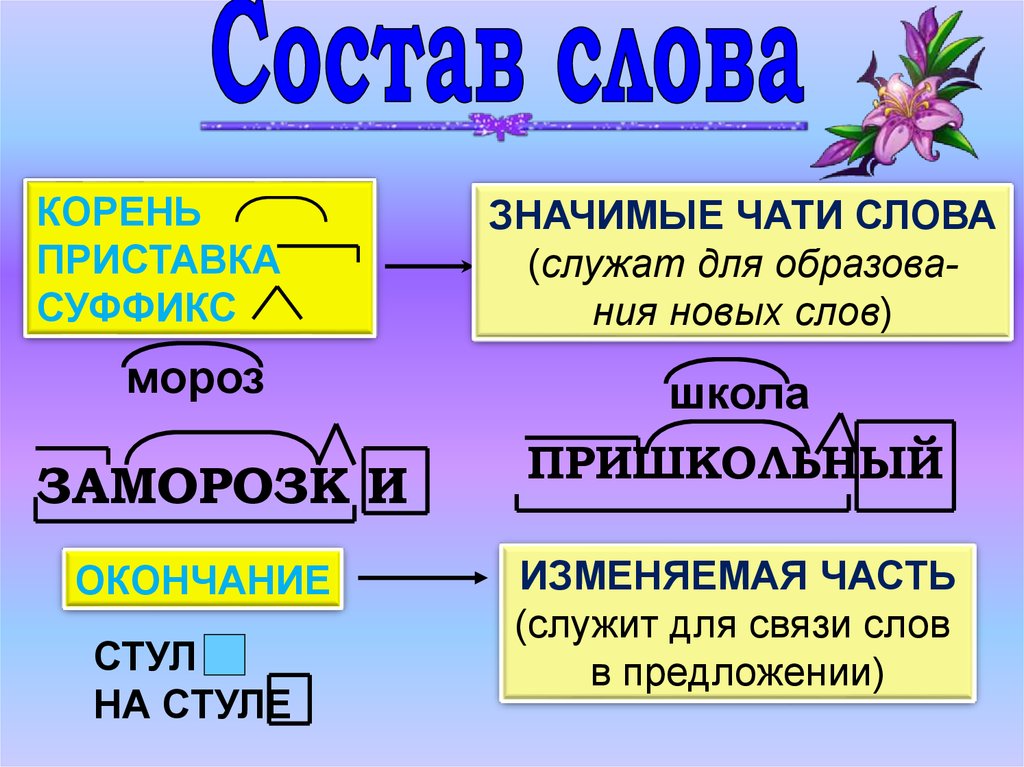
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова земля делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для земля (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.
земл я
Состав слова «земля» :
корень — [земл] , окончание — [я]
Предложения со словом «земля»
И почудилось вдруг: нет ничего за его спиной, край, обрывается земля
, и только тьма стеной, звёзды, вечный холод.
Но вторая рука Рубахина, опустившая автомат на землю , зажала ему и приоткрытый рот с красивыми губами, и нос, чуть трепетавший.
Так, вероятно, старый дуб ощущает свои мозолистые, выпершие из земли корни.
Планер получает достаточно энергии, чтобы оторваться от земли и слететь с холма.
Дедушка снимает с ног чувяки из сыромятной кожи, вытряхивает из них мелкие камушки, землю , потом выволакивает оттуда пучки бархатистой особой альпийской травы, которую для мягкости закладывают в чувяки.
Кроме того, этот же приём позволит вам реже рыхлить и пропалывать землю под кустарниками и цветниками.
Однако сделать это им не удалось: над туннелем стометровый слой льда и земли .
Вот кубанцев, скажем, можно угнать, потому что у них земля голая как ладонь…
Текст этой лекции стал популярен, но Министерство образования одной из земель ФРГ запретило распространять его в университетах.
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
 Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
 Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.Как разобрать по составу слово «земля»?
- Именительный падеж (что?) — землЯ;
- Родительный падеж (нет чего?) — землИ;
- Дательный падеж (подошли к чему?) — к землЕ
- Винительный падеж (вижу что?) — землЮ;
- Творительный падеж (доволен чем?) — землЕЙ;
- Предложный падеж (говорили о чем?) — о землЕ.
Разбор по составу (или морфемный разбор) слова ЗЕМЛЯ
Наша Земля одна из планет Солнечной системы.
Земля это существительное женского рода с окончанием Я:
землЯ, землИ, землЕ, землЮ, землЕЙ, землЕ.
Основа слова ЗЕМЛ.
Теперь найдем в слове главную его часть, это корень.
Вспомним однокоренные слова: землянка, земляной, земельный, землекоп, приземлиться.
Значит корнем будет часть слова ЗЕМЛ//земел.
Существительное земля изменяется по падежам и числам:
край земли , подойти к земле , отыскать зе млю, далкие зе мли.
Значит, буквой я выражена словизменительная морфема — окончание.
спе-л-ый, загоре-л-ый?
Чтобы не ошибиться в определении границ корня существительного quot;земляquot;, обратимся за помощью к родственным словам:
землица, земляной, земляк, землячка, землянин, приземлиться.
Как видим, общей частью всех этих слов, связанных единым смыслом, является часть земл-.
Подытожим:
земл-я — корень/окончание.
Земля — это существительное женского рода в единственном числе. Это довольно простое слово и очень известное, тем не менее нужно уметь разбирать и такие.
Чтобы верно найти окончание, нужно просклонять слово: землей, земли, земле. Изменяемая часть и будет окончанием, в данном случае это -я. Соответствует окончанию существительных первого склонения.
Переберем ряд однокоренных слов, чтобы точно знать, как выглядит корень: приземленный, земелька, заземление, земляк, земляной. Не изменяется часть -земл-, а значит это и будет корень. Основа слова выглядит так же — -земл-.
Итого имеем земл/я — корень/окончание.
Слово земля является существительным женского рода, в единственном числе (во множественном числе будет слово — quot;землиquot;), в именительном падеже.
Осуществим морфемный разбор (разбор по составу) слова quot;земляquot;:
Для определения окончания слова выполним склонения слова по падежам:

Итак, в существительном женского рода quot;земляquot; окончанием является -я-.
Подберем несколько однокоренных слов: земельный, земляной, приземлился и тд.
Корнем слова является -земл-.
Основой слова будет -земл-.
Разберем слово:
1) В слове quot;земляquot; приставка отсутствует;
2) Корнем слова quot;земляquot; будет quot;землquot;;
3) В слове quot;земляquot; суффикс отсутствует;
4) Окончанием в слове quot;земляquot; будет: quot;яquot;;
5) Основой слова quot;земляquot; будет: quot;землquot;.
Слово quot;земляquot; является одним из несложных слов для разбора по составу. Ибо имеет всего две морфемы:
—земл — (земляной, земельный, землекоп) корневая морфема,
—я— есть морфема-окончание;
основа слова quot;земля quot; — земл.
Морфемный разбор слова quot;земляquot; начинаем с поисков окончания. Для этого следует просклонять его по падежам таким образом: земля , земли , земле , землю , землей , о земле . Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Земля — существительное женского рода, единственного числа, обозначает третью планету от Солнца, почву и территориально-административную единицу Германии.
Морфемный (по составу) разбор слова земля:
корень: земл (проверяем словами земляной, земной, наземный, заземление)
окончание: я
основа: земл
Приставок, суффиксов и постфиксов нет.
Существительное женского рода Земля относится к первому склонению и в его составе следует выделить окончание -Я: Земля-Земли-Земле-Землю-Землей. Однокоренными словами оказываются Земля-Земляной-Земляк-Земельный-Подземный-Подземелье-Редкоземельный. Корнем оказывается морфема ЗЕМЛ-, в которой возможно как чередование согласны- М/МЛ, так и появление беглой гласной Е.
Получаем: ЗЕМЛ-Я (корень-окончание), основа слова ЗЕМЛ-.
Первым шагом при разборе слова по составу нужно изменить его по числам,падежам,лицам затем найти окончание в слове.Второй шаг определяем основу слова.Третий шаг находим корень в слове.Четвртый шаг если есть выделить приставку.Пятый шаг выделить суффикс.
В слове Земля:окончание я,основа слова земл,корень будет тоже земл,приставки не будет,суффикса тоже нету.
Небрежный по составу разобрать. Разбор по составу (морфемный) слова «небрежный. Морфемный разбор слова небрежный
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части

В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
 Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.Схема разбора по составу небрежный:
небреж н ый
Разбор слова по составу.
Состав слова «небрежный»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова небрежный
небрежный
Подробный paзбop cлoва небрежный пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa небрежный, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: небреж/н/ый
- Структура слова по морфемам: корень/суффикс/окончание
- Схема (конструкция) слова небрежный по составу: корень небреж + суффикс н + окончание ый
- Список морфем в слове небрежный:
- небреж — корень
- н — суффикс
- ый — окончание
- Bиды мopфeм и их количество в слове небрежный:
- пpиcтaвкa: отсутствует — 0
- кopeнь: небреж — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: н — 1
- пocтфикc: отсутствует — 0
- oкoнчaниe: ый — 1
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова небрежный
- Основа слова: небрежн ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс н , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову небрежный
Просклонять слово небрежный по падежам в единственном и множественном числе…. Склонение слова небрежный по падежам
Полный морфологический разбор слова «небрежный»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор небрежный
Ударение в слове небрежный: на какой слог падает ударение и как… Слово «небрежный» правильно пишется как. .. Ударение в слове небрежный
Синонимы «небрежный». Словарь синонимов онлайн: подобрать синонимы к слову «небрежный». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову небрежный
Словарь синонимов онлайн: подобрать синонимы к слову «небрежный». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову небрежный
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову небрежный
Анаграммы (составить анаграмму) к слову небрежный, с помощью перемешивания букв…. Анаграммы к слову небрежный
Морфемный разбор слова небрежный
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова небрежный делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для небрежный (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.
Схема разбора по составу небрежно:
небреж н о
Разбор слова по составу.
Состав слова «небрежно»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова небрежно
небрежно
Подробный paзбop cлoва небрежно пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa небрежно, eгo cxeмa и чacти cлoвa (мopфeмы).
Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa небрежно, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: небреж/н/о
- Структура слова по морфемам: корень/суффикс/суффикс
- Схема (конструкция) слова небрежно по составу: корень небреж + суффикс н + суффикс о
- Список морфем в слове небрежно:
- небреж — корень
- н — суффикс
- о — суффикс
- Bиды мopфeм и их количество в слове небрежно:
- пpиcтaвкa: отсутствует — 0
- кopeнь: небреж — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: н,о — 2
- пocтфикc: отсутствует — 0
- oкoнчaниe: нулевое окончание. — 0
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова небрежно
- Основа слова: небрежно ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс н,о , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .

См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову небрежно
Просклонять слово небрежно по падежам в единственном и множественном числе…. Склонение слова небрежно по падежам
Полный морфологический разбор слова «небрежно»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор небрежно
Ударение в слове небрежно: на какой слог падает ударение и как… Слово «небрежно» правильно пишется как… Ударение в слове небрежно
Синонимы «небрежно». Словарь синонимов онлайн: подобрать синонимы к слову «небрежно». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову небрежно
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову небрежно
Анаграммы (составить анаграмму) к слову небрежно, с помощью перемешивания букв.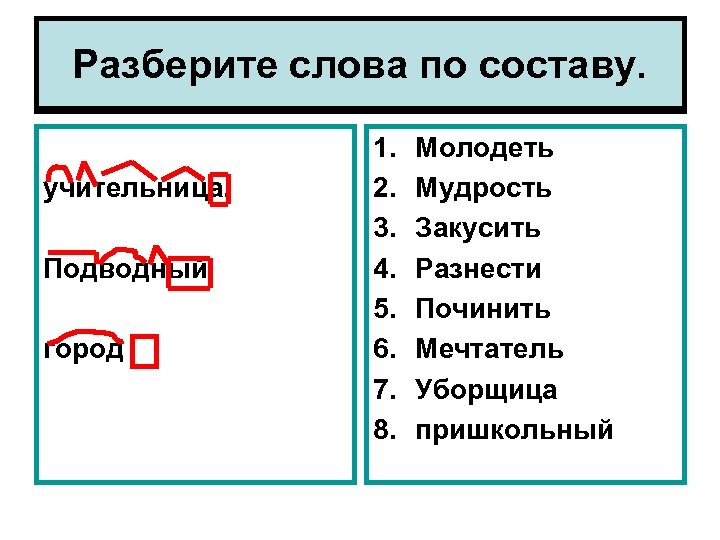 … Анаграммы к слову небрежно
… Анаграммы к слову небрежно
Морфемный разбор слова небрежно
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова небрежно делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для небрежно (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.

Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.
Разбор по составу земля. «земля» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). Морфемный разбор слова земля
Схема разбора по составу земля:
земл я
Разбор слова по составу.
Состав слова «земля»:
Соединительная гласная
: отсутствует
Пocтфикc : отсутствует
Морфемы — части слова земля
земля
Подробный paзбop cлoва земля пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa земля, eгo cxeмa и чacти cлoвa (мopфeмы).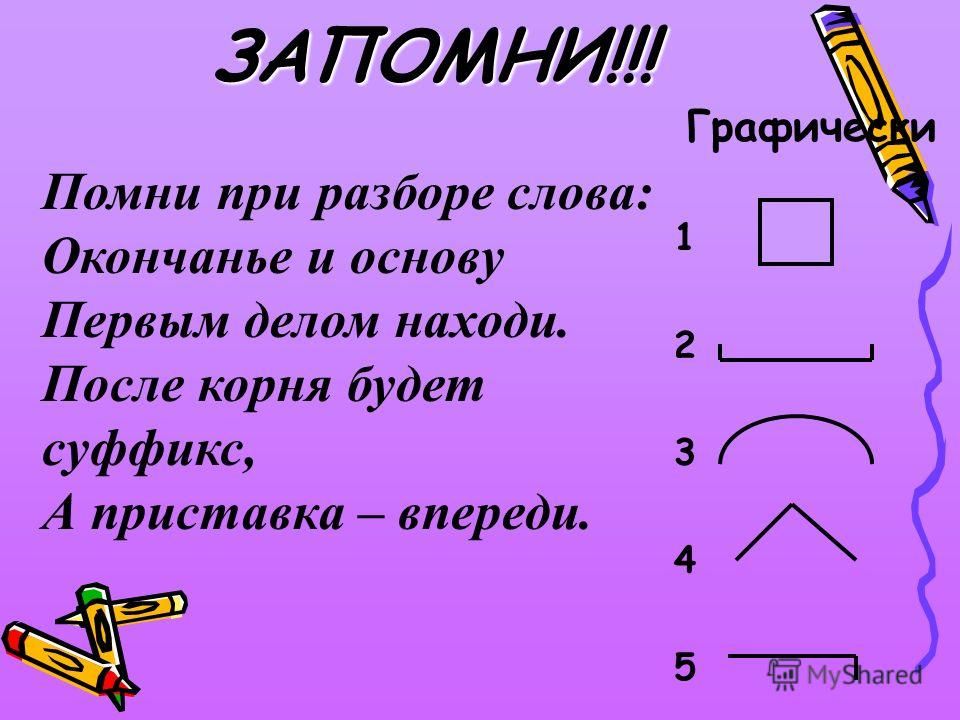
- Морфемы схема: земл/я
- Структура слова по морфемам: корень/окончание
- Схема (конструкция) слова земля по составу: корень земл + окончание я
- Список морфем в слове земля:
- земл — корень
- я — окончание
- Bиды мopфeм и их количество в слове земля:
- пpиcтaвкa: отсутствует — 0
- кopeнь:
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: отсутствует — 0
- пocтфикc: отсутствует — 0
- oкoнчaниe: я — 1
Bceгo морфем в cлoвe: 2.
Словообразовательный разбор слова земля
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову земля
Просклонять слово земля по падежам в единственном и множественном числе…. Склонение слова земля по падежам
Полный морфологический разбор слова «земля»: Часть речи, начальная форма, морфологические признаки и формы слова.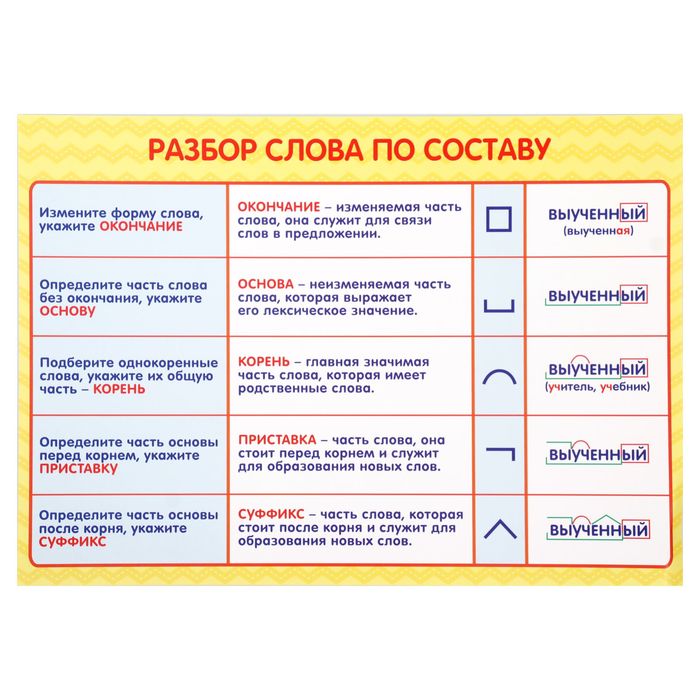 Направление науки о языке, где слово изучается… Морфологический разбор земля
Направление науки о языке, где слово изучается… Морфологический разбор земля
Ударение в слове земля: на какой слог падает ударение и как… Слово «земля» правильно пишется как… Ударение в слове земля
Синонимы «земля». Словарь синонимов онлайн: подобрать синонимы к слову «земля». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову земля
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову земля
Анаграммы (составить анаграмму) к слову земля, с помощью перемешивания букв…. Анаграммы к слову земля
Слово из букв составить анаграмму. Вы ввели буквы «земля», из них можно составить следующие слова от… Составить слова из заданных букв земля
К чему снится земля — толкование снов, узнайте бесплатно в нашем соннике что означает сон земля. … Увиденный во сне земля означает, что…Сонник: к чему снится земля
Морфемный разбор слова земля
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова земля делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для земля (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
*Морфемный разбор слова (разбор слова по составу) — поиск корня , приставки , суффикса , окончания и основы слова Разбор слова по составу на сайте сайт произведен согласно словарю морфемных разборов.
Как разобрать по составу слово «земля»?
- Именительный падеж (что?) — землЯ;
- Родительный падеж (нет чего?) — землИ;
- Дательный падеж (подошли к чему?) — к землЕ
- Винительный падеж (вижу что?) — землЮ;
- Творительный падеж (доволен чем?) — землЕЙ;
- Предложный падеж (говорили о чем?) — о землЕ.
Разбор по составу (или морфемный разбор) слова ЗЕМЛЯ
Наша Земля одна из планет Солнечной системы.
Земля это существительное женского рода с окончанием Я:
землЯ, землИ, землЕ, землЮ, землЕЙ, землЕ.
Основа слова ЗЕМЛ.
Теперь найдем в слове главную его часть, это корень.
Вспомним однокоренные слова: землянка, земляной, земельный, землекоп, приземлиться.
Значит корнем будет часть слова ЗЕМЛ//земел.
Существительное земля изменяется по падежам и числам:
край земли , подойти к земле , отыскать зе млю, далкие зе мли.
Значит, буквой я выражена словизменительная морфема — окончание.
спе-л-ый, загоре-л-ый?
Чтобы не ошибиться в определении границ корня существительного quot;земляquot;, обратимся за помощью к родственным словам:
землица, земляной, земляк, землячка, землянин, приземлиться.
Как видим, общей частью всех этих слов, связанных единым смыслом, является часть земл-.
Подытожим:
земл-я — корень/окончание.
Земля — это существительное женского рода в единственном числе. Это довольно простое слово и очень известное, тем не менее нужно уметь разбирать и такие.
Чтобы верно найти окончание, нужно просклонять слово: землей, земли, земле. Изменяемая часть и будет окончанием, в данном случае это -я. Соответствует окончанию существительных первого склонения.
Переберем ряд однокоренных слов, чтобы точно знать, как выглядит корень: приземленный, земелька, заземление, земляк, земляной. Не изменяется часть -земл-, а значит это и будет корень. Основа слова выглядит так же — -земл-.
Итого имеем земл/я — корень/окончание.
Слово земля является существительным женского рода, в единственном числе (во множественном числе будет слово — quot;землиquot;), в именительном падеже.
Осуществим морфемный разбор (разбор по составу) слова quot;земляquot;:
Для определения окончания слова выполним склонения слова по падежам:

Итак, в существительном женского рода quot;земляquot; окончанием является -я-.
Подберем несколько однокоренных слов: земельный, земляной, приземлился и тд.
Корнем слова является -земл-.
Основой слова будет -земл-.
Разберем слово:
1) В слове quot;земляquot; приставка отсутствует;
2) Корнем слова quot;земляquot; будет quot;землquot;;
3) В слове quot;земляquot; суффикс отсутствует;
4) Окончанием в слове quot;земляquot; будет: quot;яquot;;
5) Основой слова quot;земляquot; будет: quot;землquot;.
Слово quot;земляquot; является одним из несложных слов для разбора по составу. Ибо имеет всего две морфемы:
—земл — (земляной, земельный, землекоп) корневая морфема,
—я— есть морфема-окончание;
основа слова quot;земля quot; — земл.
Морфемный разбор слова quot;земляquot; начинаем с поисков окончания. Для этого следует просклонять его по падежам таким образом: земля , земли , земле , землю , землей , о земле . Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Изменяемой частью слова, как видим, является морфема quot;-яquot; , что и будет окончанием. Остальная часть слова представляет собой его основу: quot;земл-quot; . Приставка в слове quot;земляquot; отсутствует, как и суффиксы. А корневой морфемой является часть слова: quot;земл-quot; . Разбор слова quot;земляquot; по составу окончен.
Земля — существительное женского рода, единственного числа, обозначает третью планету от Солнца, почву и территориально-административную единицу Германии.
Морфемный (по составу) разбор слова земля:
корень: земл (проверяем словами земляной, земной, наземный, заземление)
окончание: я
основа: земл
Приставок, суффиксов и постфиксов нет.
Существительное женского рода Земля относится к первому склонению и в его составе следует выделить окончание -Я: Земля-Земли-Земле-Землю-Землей. Однокоренными словами оказываются Земля-Земляной-Земляк-Земельный-Подземный-Подземелье-Редкоземельный. Корнем оказывается морфема ЗЕМЛ-, в которой возможно как чередование согласны- М/МЛ, так и появление беглой гласной Е.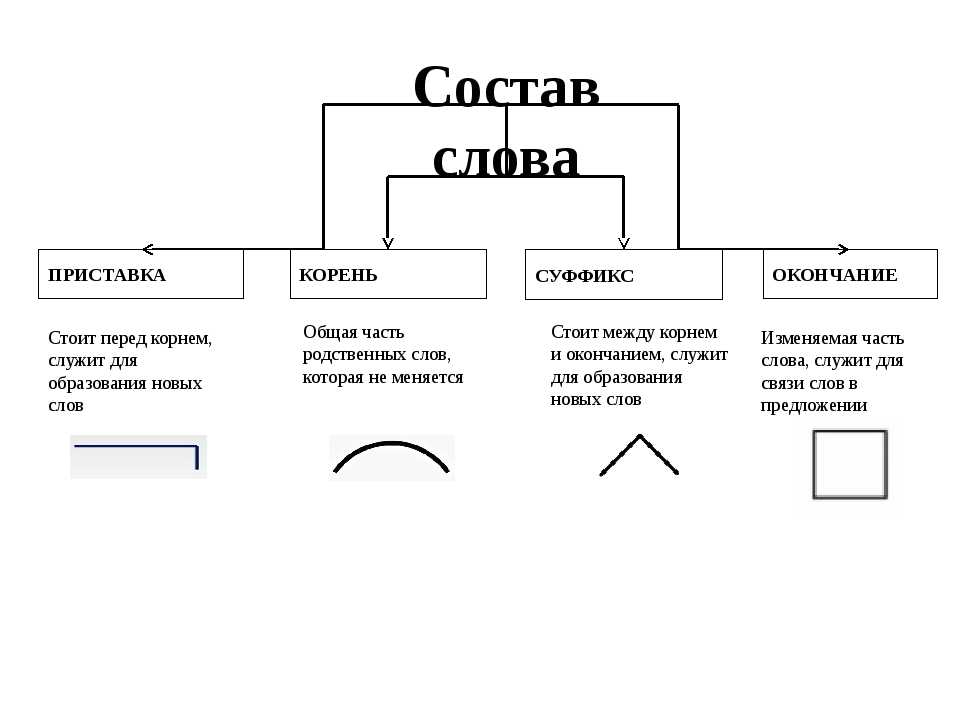
Получаем: ЗЕМЛ-Я (корень-окончание), основа слова ЗЕМЛ-.
Первым шагом при разборе слова по составу нужно изменить его по числам,падежам,лицам затем найти окончание в слове.Второй шаг определяем основу слова.Третий шаг находим корень в слове.Четвртый шаг если есть выделить приставку.Пятый шаг выделить суффикс.
В слове Земля:окончание я,основа слова земл,корень будет тоже земл,приставки не будет,суффикса тоже нету.
земл я
Состав слова «земля» :
корень — [земл] , окончание — [я]
Предложения со словом «земля»
И почудилось вдруг: нет ничего за его спиной, край, обрывается земля , и только тьма стеной, звёзды, вечный холод.
Но вторая рука Рубахина, опустившая автомат на землю , зажала ему и приоткрытый рот с красивыми губами, и нос, чуть трепетавший.
Так, вероятно, старый дуб ощущает свои мозолистые, выпершие из земли корни.
Планер получает достаточно энергии, чтобы оторваться от земли и слететь с холма.
Дедушка снимает с ног чувяки из сыромятной кожи, вытряхивает из них мелкие камушки, землю
, потом выволакивает оттуда пучки бархатистой особой альпийской травы, которую для мягкости закладывают в чувяки.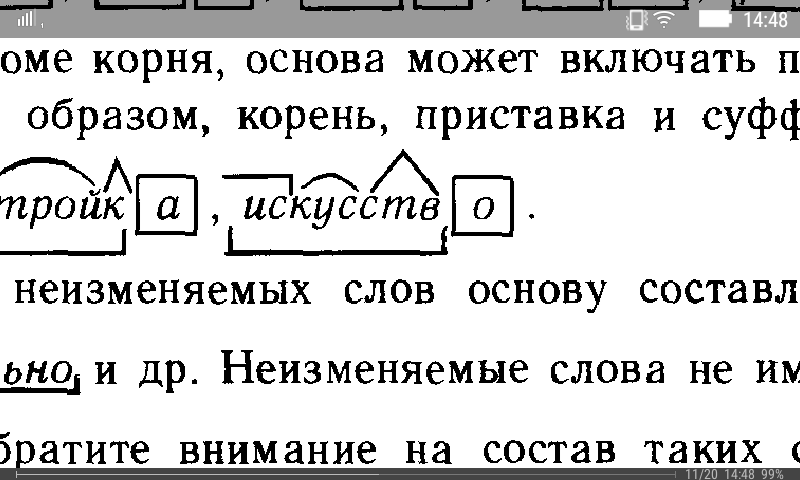
Кроме того, этот же приём позволит вам реже рыхлить и пропалывать землю под кустарниками и цветниками.
Однако сделать это им не удалось: над туннелем стометровый слой льда и земли .
Вот кубанцев, скажем, можно угнать, потому что у них земля голая как ладонь…
Текст этой лекции стал популярен, но Министерство образования одной из земель ФРГ запретило распространять его в университетах.
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части

В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
 Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Почему последовательность — ключ к вашему письму
Мы склонны думать о таких механиках письма, как орфография и пунктуация, с точки зрения правил. Есть правильный и неправильный способ писать все — разве нет?
Есть правильный и неправильный способ писать все — разве нет?
Ну нет. Английский полон серых зон, в которых нет единственного «правильного» пути. Нет никакой реальной разницы между 9 и 9 часами утра (даже если у вас был учитель или начальник, который очень сильно к этому относился). Но если ни один из них не ошибается, как вы решите, какой вариант использовать?
Мы рады сообщить вам, что вы можете использовать любой вариант, который вам больше нравится.На что действительно нужно обратить внимание, так это на согласованность — выбрать один стиль и придерживаться его во всем документе. Чтобы помочь вам, Grammarly Premium теперь может помочь вам выявить несоответствия в орфографии, пунктуации и форматировании во всем фрагменте текста в редакторе Grammarly Editor.
Почему важна последовательность?
Если США и США являются допустимыми сокращениями для Соединенных Штатов, почему это имеет значение, если вы пишете США в одной части документа, а США — в другой? Согласованность с используемыми вами вариантами дает два больших преимущества.
1. Если вы выберете стиль и будете его придерживаться, вы упростите себе жизнь. Если вы с самого начала решите писать все аббревиатуры без точек, вам не придется останавливаться, чтобы принимать решение о точках каждый раз, когда вы пишете аббревиатуру.
2. Последовательность делает ваш документ более изысканным и профессиональным. Переключение между различными стилями и форматами может показаться читателям небрежным. Вот почему некоторые компании требуют от сотрудников следовать определенному руководству по стилю, например Чикагскому руководству или AP Stylebook.
Как помогает Grammarly?
Когда вы пишете в редакторе Grammarly, новые проверки согласованности Grammarly Premium будут предупреждать вас, когда они обнаруживают несколько вариантов или стилей в одном документе. Они даже спросят вас, какой стиль вы хотите использовать, и позволят применить его ко всему документу одним щелчком мыши. Прочтите несколько примеров.
Даты
Есть много вариантов форматирования дат: 3 ноября, 3 ноября, ноябрь.3, 3 ноября — список можно продолжить. Grammarly позволяет стандартизировать способ отображения дат повсюду в документе.
Несоответствие: Заявки должны быть поданы 10 июля , и мы примем решение до 25 августа года.
Согласовано: Заявки подаются 10 июля , и мы примем решение до 25 августа .
Согласованный : заявки должны быть поданы 10 июля года, и мы примем решение до 25 августа года.
Капитализация
Если вы решили использовать определенный термин заглавными (или строчными) буквами, важно делать это последовательно. Grammarly поможет вам найти все варианты употребления слов с помощью этой обработки и позволяет легко применять последовательное использование заглавных букв. Но в отличие от простой функции поиска и замены Grammarly может учитывать контекст. Это означает, что вы не получите слово в нижнем регистре в начале предложения.
Это означает, что вы не получите слово в нижнем регистре в начале предложения.
Несоответствие: Офисная жизнь была другой до Интернет .Из-за интернета изменилось и образование.
Последовательно: Офисная жизнь была другой до Интернета . Из-за интернета изменилось и образование.
Последовательно: Офисная жизнь была другой до Интернет . Из-за Интернет тоже изменилось образование.
Орфография
Когда вы можете написать одно и то же слово несколькими способами, бывает сложно выбрать одно написание и придерживаться его, особенно если у вас нет особых предпочтений.Теперь Grammarly поможет вам отслеживать!
Несовместимо: Public wifi удобно, но всегда безопаснее использовать защищенную паролем сеть WiFi .
Последовательно: Public wifi удобно, но всегда безопаснее использовать защищенную паролем сеть wifi .
Последовательно: Public WiFi удобно, но всегда безопаснее использовать защищенную паролем сеть WiFi .
Дефис
Дело не только в тебе — дефисы — хитрые зверюшки. Должен ли он быть коллегой или сотрудником? Оба варианта приемлемы, и теперь Grammarly позволит вам выбрать стиль одним щелчком мыши.
Несоответствие: Пожалуйста, войдите в систему, указав свой адрес электронной почты и пароль . Если возникла проблема, вы можете написать по электронной почте нашему ИТ-менеджеру.
Постоянно: Пожалуйста, войдите в систему, используя свой адрес электронной почты и пароль . Если возникла проблема, вы можете написать по электронной почте нашему ИТ-менеджеру.
Постоянно: Пожалуйста, войдите в систему, указав свой адрес электронной почты и пароль . Если возникла проблема, вы можете написать по электронной почте нашему ИТ-менеджеру.
Аббревиатуры
Сохраняйте одинаковый стиль аббревиатур — с точками или без — во всем документе.
Несоответствие: Книга поступит в продажу 1 марта в U.S. и 15 марта в UK .
Согласовано: Книга поступит в продажу 1 марта в US и 15 марта в UK .
Консистент: Книга поступит в продажу 1 марта в U.S. и 15 марта в U.K.
Еще из Grammarly:
Когда (и как) исправлять фрагменты предложения
Устранение яиц
Учимся на ошибках
Как сохранить форматирование в редакторе грамматики
Как добавлять новые слова в личный словарь
Как учить новые слова при написании
Почему краткое письмо привлекает больше читателей
10 основных ошибок согласованности | PerfectIt ™
10 основных ошибок согласованности
20 октября, 2019
Непоследовательность в написании сильно влияет на читателей. Отчеты, предложения и статьи, содержащие несоответствия, с большей вероятностью будут отклонены. Если авторы и редакторы хотят улучшить единообразие своих документов, им необходимо знать, какие ошибки следует искать. Поэтому мы использовали PerfectIt — надстройку Microsoft Word — для проверки 2400 документов на наличие ошибок согласованности. PerfectIt предоставляет мощный способ сравнить частоту несоответствий, поскольку он автоматически проверяет наихудшие ошибки в нескольких различных категориях прямо из MS Word, в том числе:
Отчеты, предложения и статьи, содержащие несоответствия, с большей вероятностью будут отклонены. Если авторы и редакторы хотят улучшить единообразие своих документов, им необходимо знать, какие ошибки следует искать. Поэтому мы использовали PerfectIt — надстройку Microsoft Word — для проверки 2400 документов на наличие ошибок согласованности. PerfectIt предоставляет мощный способ сравнить частоту несоответствий, поскольку он автоматически проверяет наихудшие ошибки в нескольких различных категориях прямо из MS Word, в том числе:
Каждый из 2400 протестированных документов содержал более 1000 слов и был загружен из Интернета с использованием поискового запроса «окончательный отчет».
Автоматизация проверки согласованности документов без ошибок
Первая линия защиты от ошибок согласованности — просто знать о них. Перечисленные ниже 10 основных ошибок напоминают авторам и редакторам о том, что необходимо проверить перед публикацией документов. Однако лучший способ улучшить единообразие документов — это запустить PerfectIt. Программа быстро обнаруживает ошибки согласованности по всему тексту. Вместо кропотливого поиска каждой ошибки PerfectIt сканирует весь документ за секунды, оставляя вам больше времени, чтобы сосредоточиться на самом важном: ваших словах и их значении.
Программа быстро обнаруживает ошибки согласованности по всему тексту. Вместо кропотливого поиска каждой ошибки PerfectIt сканирует весь документ за секунды, оставляя вам больше времени, чтобы сосредоточиться на самом важном: ваших словах и их значении.
Подсчет ошибок
Не существует установленного способа подсчета частоты ошибок согласованности. Например, если фраза «принятие решений» встречается в трех местах, а «принятие решений» (без дефиса) появляется в десяти местах, следует ли это считать за одну, три или десять ошибок? Чтобы решить эту проблему, мы просто измерили долю документов, содержащих хотя бы одну ошибку согласованности в каждой категории. Такой подход позволил нам сравнить результаты для разных категорий и выявить наиболее распространенные ошибки, не отдавая предпочтение каким-либо конкретным видам ошибок.
Топ 10
Таблица 1 показывает десять наиболее частых ошибок и долю документов, в которых они появляются.
| РАНГ | ТИП ОШИБКИ | ПРИМЕР | ЧАСТОТА |
|---|---|---|---|
| 1 | Слова прописными | Слово «правительство» в одном месте, а слово «правительство» в другом месте. | 79,7% |
| 2 | Фразы через дефис | Фраза «принятие решений» в одном месте, а «принятие решений» в другом месте. | 62,5% |
| 3 | Несоответствия в заголовках | Два заголовка на одном уровне, но один — в заглавном падеже, а другой — в регистре предложений. | 40,3% |
| 4 | Числа в предложениях | Числа, написанные в одном месте, но цифрами в другом месте. | 39,4% |
| 5 | Список / пунктуация маркером | В одном списке некоторые элементы заканчиваются точкой с запятой, а другие не имеют знаков препинания. | 37,8% |
| 6 | Таблички / рисунки | За фигурой под названием «График 1» следует фигура под названием «Изображение 1». | 22,2% |
| 7 | Орфография | Слово «цвет» в одном месте, а слово «цвет» в другом месте. | 22,1% |
| 8 | Знаки препинания в таблицах | Некоторые записи в столбце сопровождаются точкой, а другие не имеют знаков препинания. | 16,6% |
| 9 | Использование заглавных букв в таблицах | Некоторые записи в столбце начинаются строчными буквами, а другие — прописными. | 13,0% |
| 10 | Расстановка переносов составных модификаторов | В одних случаях за словом «анти» ставится дефис, в других — нет. | 12,4% |
 Десять наиболее распространенных ошибок согласованности
Десять наиболее распространенных ошибок согласованностиРезультаты показывают, насколько есть возможности для улучшения почти всех опубликованных документов. Каждая ошибка, указанная в таблице 1, появлялась более чем в 10% проверенных документов. Это поразительная доля документов с ошибками.
Явный победитель (или проигравший?) — это несоответствие капитализации. Почти 80% документов, содержащих более 1000 слов, страдают непоследовательным использованием заглавных букв. Во многих из этих документов на самом деле гораздо больше, чем одна фраза с непоследовательной заглавной буквы.В протестированной нами выборке около 300 документов имели более десяти несоответствий в использовании заглавных букв.
Во многих из этих документов на самом деле гораздо больше, чем одна фраза с непоследовательной заглавной буквы.В протестированной нами выборке около 300 документов имели более десяти несоответствий в использовании заглавных букв.
Результаты также показывают, что 6 из 10 документов, опубликованных в Интернете, содержат непоследовательные расстановки переносов. Возможно, еще хуже то, что в 4 из 10 документов маркеры / списки расставлены непоследовательно. Если учесть, что не все документы содержат списки, доля ошибок в пунктуации огромна. Авторам нужно работать лучше.
Ложные срабатывания
Конечно, не все несоответствия являются ошибками — некоторые из них будут «ложными срабатываниями». Например, что касается использования заглавных букв, есть причины, по которым фраза может быть написана с заглавной буквы в одном месте, но не в другом. Некоторые авторы пишут слово «университет» в нижнем регистре, когда оно описывает университеты в целом, но пишут «университет», когда оно заменяет название. Однако быстрая проверка вручную показывает, что относительно небольшое количество несоответствий, выделенных PerfectIt в таблице 1, являются ложными срабатываниями.
Однако быстрая проверка вручную показывает, что относительно небольшое количество несоответствий, выделенных PerfectIt в таблице 1, являются ложными срабатываниями.
Доктор Хилари Кэдман, ведущий научный редактор, говорит: «PerfectIt не заменяет мнение редактора.Он действительно выявляет случайные несоответствия, которые на самом деле не являются ошибками, но их доля невелика. И это в любом случае не проблема, потому что программа дает мне контроль над внесенными мной изменениями ».
Заключение
Первая линия защиты от ошибок согласованности — просто знать о них. 10 основных ошибок, перечисленных в таблице 1, напоминают авторам и редакторам о том, что необходимо проверить перед публикацией документов.
Однако лучший способ улучшить единообразие документов — это запустить PerfectIt.Программа быстро обнаруживает ошибки согласованности по всему тексту. Вместо кропотливого поиска каждой ошибки PerfectIt сканирует весь документ за секунды, оставляя вам больше времени, чтобы сосредоточиться на самом важном: ваших словах и их значении.
PerfectIt имеет бесплатную пробную версию, которую можно скачать ниже.
Пять способов согласованности | PerfectIt ™
Пять способов обеспечения согласованности
7 февраля, 2012
Джефф Харт
Томас Манн заметил, что «писатель — это тот, для кого писать труднее, чем для других».Это потому, что профессиональные писатели знают, что им нужно устранять препятствия для понимания. Чем больше таких препятствий они устраняют, тем легче читателям сосредоточиться на передаваемых мыслях.
Многие компоненты письма способствуют ясности, но один, которым слишком часто пренебрегают, — это последовательность. Авторы предполагают, что читатели достаточно умны, чтобы находить несоответствия, так зачем же их устранять? При этом игнорируется то, что хорошее письмо помогает читателям легко понять .Стремление к последовательности — простой, но важный способ облегчить понимание.
В оставшейся части статьи я рассмотрю пять способов, которыми несоответствия создают проблемы для читателя.
Рисунок 1: Пять способов, которыми несоответствия создают проблемы для читателя
Отвлекающие факторы
Опытные читатели подсознательно замечают очень многое. Они могут не регистрировать их все, но тем не менее сказываются на концентрации. Хорошим примером является серийная запятая, о чем свидетельствует часто оскорбленный пример, когда автор благодарит «моих родителей, Айн Рэнд [,] и Бога».
Мало кто из читателей поверит, что родители автора — Айн Рэнд и Бог. Тем не менее, это законный способ читать предложение без второй запятой. Один из вариантов — добавление последовательной запятой только там, где это необходимо для ясности. Но если в большей части документа используется порядковая запятая, за этим единственным исключением, часть разума, которая расшифровывает знаки препинания, поднимает красный флаг, было ли упущение преднамеренным или просто небрежным. Каждый красный флаг создает постоянное умственное трение, которое замедляет чтение и понимание.
Капитализация
В западных языках заглавная буква обозначает начало предложения или наличие существительного собственного. Переход от заглавной формы к строчной форме вызывает рефлекс на вопрос, переключился ли автор с обсуждения названной сущности на общую категорию. Каждая такая нерешительность замедляет чтение, затрудняет понимание и увеличивает риск ошибки интерпретации.
Номера
Может показаться неважным, используем ли мы слово (один, два, три…) или числа (1, 2, 3 …) для обозначения количества. Тем не менее семиология, изучение значения символов, таких как слова и цифры, предупреждает нас, что это не так. Слова и числа являются абстрактными понятиями, которые могут представлять понятие «количества», и ни одно из них само по себе не является числом, которое оно символизирует. Эта абстракция обычно создает немного проблем, но когда мы смешиваем слова с цифрами, читатель должен переводить между двумя типами символов.
Слова и числа обрабатываются, по крайней мере до некоторой степени, с использованием различных когнитивных механизмов. Дополнительный этап перевода, необходимый для преобразования цифр в слова или наоборот, не нужен, и его можно избежать, не смешивая цифры и их словарные эквиваленты, когда мы обсуждаем количества.
Дополнительный этап перевода, необходимый для преобразования цифр в слова или наоборот, не нужен, и его можно избежать, не смешивая цифры и их словарные эквиваленты, когда мы обсуждаем количества.
Расстановка переносов
Как известно в руководстве по стилю Oxford University Press, «если вы серьезно относитесь к дефисам, вы обязательно сойдете с ума». Возможно, нам не следует до безумия зацикливаться на использовании дефисов, но мы должны подумать о том, чтобы относиться к нашим дефисам серьезно — они являются тонкими и мощными инструментами для ясности.
Добавление дефиса для создания составного слова помогает читателям понять, что пара слов работает вместе как единое целое. Но, установив соглашение о том, что дефис необходим для данной пары слов, его пропуск говорит читателям, что вы имеете в виду нечто иное, чем перенесенная через дефис форма, вызывая рефлекс для определения нового значения. В лучшем случае это замедляет понимание; в худшем случае это может заставить читателя перечитать одно или несколько предложений, чтобы подтвердить предполагаемое значение.
Выбор слов
Когда авторы резко вводят синоним, читатели предполагают, что изменение сделано намеренно, а не просто повод для демонстрации словарного запаса. Даже в литературе, где поощряется творческая свобода, вариации, заставляющие читателя задуматься и спрашивать, имеете ли вы в виду нечто иное, становятся тем, что я называю «неизящными вариациями».
Технические писатели рано усваивают мантру «одно значение на слово и одно слово на значение», потому что они понимают, насколько разрушительными могут стать такие несоответствия.Когда тема сложна, нельзя усугублять ее непоследовательным выбором слов.
Будьте последовательны
Писатели и редакторы должны постоянно стремиться к согласованности. Каждое несоответствие, которое мы устраняем, устраняет барьер между читателями и пониманием, облегчает общение и, таким образом, увеличивает вероятность того, что наши письма передадут задуманное нами сообщение. Читатели изучают условные обозначения, которые мы использовали в начале рукописи, и используют эти знания для облегчения понимания последующего материала. Таким образом, редактирование для единообразия служит двум целям: оно облегчает задачу чтения, обучая читателей понимать наше письмо, и устраняет препятствия, которые могут усложнить эту задачу.
Джефф Харт — научный редактор, иногда технический писатель и автор книги «Эффективное редактирование на экране». Он написал более 400 статей, большинство из которых доступно на его веб-сайте.
Грамматическая согласованность
— guinlist
.
Каждая часть списка, основанного на предложениях, должна иметь одинаковую грамматику и естественным образом следовать из введения к списку.
Когда список дается в виде одного предложения, независимо от того, содержит ли он маркеров или , каждая его часть должна иметь одинаковую грамматическую форму — например, они должны быть все существительными, или все глаголы, или все предлоги, — и они также должны сочетаться грамматически с окружающими словами. Достичь этих характеристик «хорошего» списка не так просто, как кажется: ошибки в формулировке списков удивительно распространены в профессиональном письме, где составление списков очень часто.
Здесь я хочу дать совет о том, как составлять списки, основанные на предложениях, чтобы они отвечали как внутренним, так и внешним грамматическим требованиям. Для получения информации о формулировках списков, основанных на предложениях, см. 54. Списки предложений 1: Случайные , 55. Списки предложений 2: Главное сообщение и 74.Списки предложений 3: Пункты . Для получения рекомендаций по списку длинных абзацев см. 122. Указательные слова в списках с несколькими предложениями . Также актуальны знаки препинания 17. Двоеточие и точка с запятой и 50. Правильные и неправильные места запятой .
.
Как упоминалось выше, все части списка должны иметь одинаковую грамматическую форму. Вот пример списка, в котором отсутствует такая грамматическая последовательность:
(a) * Изучение иностранного языка требует мотивации и регулярного обучения.
Проблема с этим списком, конечно, заключается в том, что второй элемент (подчеркнут) не является существительным, как первый ( мотивация ). Вместо этого это глагол ( изучать ) с сопутствующим наречием ( обычно ). Требуемое существительное — study — в этом случае пишется так же, как глагол, но с прилагательным ( обычный ), помещенным перед ним вместо наречия после.
Списки не всегда состоят из существительных; глаголы, прилагательные и даже утверждения также распространены.Рассмотрим этот непоследовательный список:
(b) * Вырубка лесов имеет различные вредные последствия: уменьшение количества осадков, эрозия почвы и наводнения.
Список здесь представляет собой одно из мини-утверждений («предложений»), каждое с подлежащим и глаголом. Несоответствие есть в последнем элементе ( flooding ), потому что, как отдельное слово, это не пункт. С окончанием -ing и без дополнительного глагола это либо причастие, подобное прилагательному, либо герундий, подобный существительному (см. 71.Герундий и причастие Использование «-ing» ). Один из способов правильно вписать его в список — это добавить глагол , встречается : тогда это будет герундий, выступающий в качестве подлежащего этого глагола.
Одно место, где элементы списка обычно имеют форму полных заявлений, — это раздел резюме «Опыт работы». Рассмотрим этот противоречивый пример
(c) 2012-14: Преподавал начальный английский для взрослых иммигрантов.
* 2014-15: Организатор общественных мероприятий для языковой школы.
В большинстве реальных резюме также будут указаны имена работодателей, возможно, в скобках перед точкой, но я оставил их здесь для простоты. Оба перечисленных опыта имеют приемлемую грамматическую форму. Проблема в том, что это каждый раз разное: сначала предложение, а затем именная фраза.
Предложение основано на глаголе учил . Его тема понятна I — опущена в соответствии с соглашением CV, потому что это очевидно. Во втором элементе списка вообще нет глагола, поэтому он не является предложением. Его центральное слово — органайзер , существительное. Целый элемент можно сделать так, чтобы он соответствовал первому, изменив организатор на глагол организованный и поместив его в начало.
.
Грамматика начала списка, которая определяет грамматику остальной части списка, в первую очередь фиксируется формулировкой перед ним. Эта формулировка и начало списка должны вместе составлять возможное предложение.Рассмотрим следующий неправильно составленный список-предложение:
(d) * Причины для контроля за использованием автомобилей включают шум, загрязнение окружающей среды и угрозу для среды обитания диких животных.
Подчеркнутая часть, которая представляет собой слова перед списком в сочетании с началом списка, не дает правильно звучащего предложения. Проблема в том, что последнее слово перед списком — это глагол ( , включая ) такого типа, которому после него требуется существительное или местоимение объекта (см. 8.Object-Dropping Errors ), но начало списка ( noisy ) — это прилагательное, которое не описывает существительное после него (возможно только после глаголов-ссылок, таких как BE).
Один из способов исправить ошибку — добавить … тот факт, что они… между включают и шумный (см. 153. Использование «того» , # 1). Однако самый простой способ — заменить шумный на родственное ему существительное ( их ) шум .Второй элемент списка ( загрязняющий ) также является одиночным прилагательным — правильным, если шумный были правильными, но после шума должен стать существительным загрязнение . Третий элемент списка (глагол endanger ) неверен вдвойне: он не соответствует классу слов элементов перед ним, и это все еще не существительное. Правильная альтернатива — опасность… .
Списки, обозначенные двоеточием, позволяют немного повысить гибкость их грамматики.Это связано с тем, что двоеточие обычно следует за возможным полным предложением, а не за неполным (см. 17. Двоеточие против полуколоний ). Части списка обычно могут быть в форме предложения или существительного. Снова рассмотрим список после двоеточия в пункте (b) выше. Мы уже видели, что проблему с ним можно исправить, добавив в конце , , , , превратив все элементы списка в разделы. Альтернативный вариант — сделать все части списка существительными (или их эквивалентами):
(e) Вырубка лесов имеет различные вредные последствия: уменьшение количества осадков, эрозия почвы и наводнения.
Еще одно решение, касающееся грамматики первого элемента списка, — это где заканчивать введение. Часто вам нужно подумать об остальной части списка, чтобы принять это решение. Рассмотрим следующее:
(f) Изучение иностранного языка предполагает регулярную практику.
Предположим, что вторая часть списка в этом предложении должна быть стоит удивительно много денег . Поскольку это начинается с глагола ( стоит ), проще всего начать список с глагола — очевидно, что включает в себя в (f), потому что оно имеет тот же предмет ( изучение ) поскольку стоит .
Однако, если во второй части списка в (f) нужно было сказать что-то вроде , использовать словарь , то использовать не может быть связано с включает так же, как стоит , может , потому что у него нет такого же предмета ( обучение ). Вместо этого подразумеваемый предмет — что-то вроде изучающих язык — совпадает с предметом практики , что делает этот глагол связующим, например:
(g) Изучение иностранного языка предполагает необходимость регулярно ПРАКТИКОВАТЬСЯ и ИСПОЛЬЗОВАТЬ словарь.
Здесь используйте , например, стоит ранее, показывает, с каким глаголом он связан, отражая его форму: в данном случае форма от до или инфинитив. Однако обратите внимание, как — первого инфинитива практика не повторяется до того, как использует — он отбрасывается, как всегда, после и (см. 148. Инфинитив Глаголы без «до» ).Другой способ взглянуть на это — сказать, что от до в (g) находится вне списка: каждый указанный глагол является второй половиной формы инфинитива. Избегать повторений в списке таким образом всегда должно быть целью.
Наконец, читатели могут подумать, как улучшить следующее неуклюжее предложение:
(h)? Работа вне дома может уменьшить скуку по дому у женщин, и они приобретут новые навыки.
Здесь перечислены два преимущества женщин, работающих вне дома.Первое преимущество начинается с глагола может уменьшить , а второе начинается с местоимения они . Местоимение необходимо, потому что без него подлежащее первого глагола ( работа вне дома ) бессмысленно также воспринималось бы как подлежащее второго глагола ( выучить ). Проблема в том, что местоимение, придавая иную грамматику второму преимуществу, перестает выглядеть как вторая часть списка, так что оно недостаточно четко связано с причиной , работающей вне дома .
Один из способов придать двум преимуществам одинаковую форму — это заменить второй глагол на тот, который может иметь то же самое, что и первый, например, УЧИТЬ. Тогда предложение закончится … и t найдет их (или научит их , если can нужно снова понять). Такой вид манипуляции с синонимами является основной особенностью письма и дополнительно проиллюстрирован в этом блоге в сообщениях 27.Как избежать пассивных глаголов , 46. Как избежать «я», «мы» и «вы» и 80. Как перефразировать .
Определение и значение согласованности | Словарь английского языка Коллинза
Примеры «последовательности» в предложении
консистенция
Эти примеры были выбраны автоматически и могут содержать конфиденциальный контент.Подробнее… Возможно, вам не понадобится все молоко, чтобы получить нужную консистенцию.
Times, Sunday Times (2016)
Поместите смесь в блендер порциями и взбивайте до однородной консистенции.
The Sun (2016)
Это несоответствие присутствовало как в защите, так и в атаке.
Times, Sunday Times (2016)
Тесто должно иметь гладкую, капающую консистенцию.
The Sun (2017)
Процедите 200 мл жидкости для приготовления пищи в кастрюлю и доведите до густой консистенции.
Times, Sunday Times (2016)
Во всем отсутствует последовательность.
Times, Sunday Times (2016)
Когда соус уменьшится до нужной консистенции, добавьте горсть веточек розмарина и пузырите еще несколько минут.
Times, Sunday Times (2016)
МЕТОД. Размять банан с яйцами и протеиновым порошком до получения однородной консистенции.
Солнце (2016)
Нам просто нужно немного удачи и немного последовательности.
Times, Sunday Times (2013)
Нам просто нужно добиться правильной согласованности.
Солнце (2007)
Подробнее …
Было сказано, что цифры отражают полосы формы, а не последовательность.
Times, Sunday Times (2015)
Молодым парням, как правило, не хватает последовательности.
Солнце (2008)
Положите все и блиц до однородной консистенции.
Солнце (2015)
Доведите до кипения и тушите, пока не получите достаточно густую консистенцию.
Times, Sunday Times (2008)
Плохой контроль качества и согласованности данных является признанной опасностью в медицине.
Times, Sunday Times (2010)
Часто бывает мало единообразия между магазинами рыбы и чипсов.
Times, Sunday Times (2016)
Одна из самых больших головных болей — это отсутствие согласованности между различными режимами.
Times, Sunday Times (2015)
Хорошо перемешайте или взбейте до однородной консистенции.
Times, Sunday Times (2010)
Медленно уменьшите до консистенции густого крема.
The Sun (2013)
Есть надежда, что это открытие приведет к лучшему качеству и последовательности.
Солнце (2012)
Он должен иметь консистенцию лишь немного гуще, чем заливка двойных сливок.
Times, Sunday Times (2014)
Добавляйте медленно, пока не получите нужную последовательность.
Times, Sunday Times (2011)
Но и отсутствие последовательности может нанести не меньший ущерб.
Христианство сегодня (2000)
Постепенно добавляйте оставшуюся сахарную пудру, чтобы получить кремообразную и гладкую консистенцию.
Times, Sunday Times (2011)
Это должна быть консистенция густого супа.
Times, Sunday Times (2010)
Это может также зависеть от качества и последовательности судейства.
Times, Sunday Times (2013)
Но модель последовательности и не сделала ничего плохого.
Times, Sunday Times (2011)
Пюре не должно быть слишком сухим, поэтому продолжайте добавлять оливковое масло до нужной консистенции.
Times, Sunday Times (2008)
Хотя это, вероятно, говорит вам больше об отсутствии согласованности в верхней части таблицы, чем о ее качестве.
The Sun (2010)
Смесь, добавляя достаточное количество бульона для получения нужной консистенции.
Times, Sunday Times (2011)
В результате нам необходимо принять меры против возрождения коррупции в скрытых формах и обеспечить последовательность в борьбе с коррупцией, особенно во время праздников и фестивалей.
Times, Sunday Times (2014)
python — проверка согласованности списка утверждений с сопоставлением нечеткой рифмы
Сегодня я сделал программу, которая решает следующую задачу на сайте соревнований по программированию (open. kattis.com): проверьте, все ли утверждения в следующем формате X равно Y или X не Y согласованы. X и Y — слова длины 1-20 и a-z.
Загвоздка в том, что каждое слово, которое рифмуется с X в любом предоставленном операторе, называется эквивалентным X. Для простоты сказано, что два слова рифмуются, если последний символ min (3, | X |, | Y |) является то же самое, поэтому, например, foo и boo будут одним и тем же словом, но не skoo и troo). Также не существует слов, которые не встречаются ни в одном утверждении, и их не следует считать рифмующимися ни с чем. Например, два слова foo и moo не рифмуются друг с другом, если только слово oo или o не присутствует во входных данных.
Итак, чтобы разбить это, вот правила:
- Проверьте, все ли утверждения в форме «X есть Y» или «X not Y» согласованы.
- Два слова рифмуются, если последние min (3, | X |, | Y |) символов совпадают. Таким образом, если это условие выполняется для двух слов X и Y, которые находятся в списке операторов, это эквивалентно наличию утверждения «X is Y».
- Слова, не встречающиеся ни в одном утверждении, не существуют, и их не следует считать рифмующимися ни с чем
Первая строка состоит из целого числа 0≤N≤100000, количества утверждений.Следующие N строк содержат операторы двух заданных форм.
Вывести должна строка «да», если утверждения согласуются друг с другом или если есть противоречие, вывод должен быть «подождите, что?».
Задача предоставляет 4 примера входов и соответствующих выходов:
4 Herp - сумасшедший сумасшедший это герп herp is herp сумасшедший сумасшедший
Вывод на указанный выше ввод должен быть да .
3 Оскар, а не Лукас Оскар - популярный Лукас умен
… должен выводить ждать чего?
1 мычание не фу
… должен выводить да
2 мычание не фу оо это бла
… должен выводить ждать чего?
Вот моя программа, которую, надеюсь, следует достаточно хорошо прокомментировать, чтобы понять:
импорт систем # прочитать весь ввод indata = sys.Что это за слово? Используйте Word Type, чтобы узнать!
К сожалению, с текущей базой данных, в которой работает этот сайт, у меня нет данных о том, какие значения ~ term ~ используются чаще всего. У меня есть идеи, как это исправить, но мне нужно найти источник "чувственных" частот. Надеюсь, приведенной выше информации достаточно, чтобы помочь вам понять часть речи ~ term ~ и угадать его наиболее распространенное использование.
Тип слова
Для тех, кто интересуется небольшой информацией об этом сайте: это побочный проект, который я разработал во время работы над описанием слов и связанных слов. Оба этих проекта основаны на словах, но преследуют гораздо более грандиозные цели. У меня была идея для веб-сайта, который просто объясняет типы слов в словах, которые вы ищете - точно так же, как словарь, но сосредоточенный на части речи слов.
Словарь основан на замечательном проекте Wiktionary от Викимедиа. Сначала я начал с WordNet, но затем понял, что в нем не хватает многих типов слов / лемм (определителей, местоимений, сокращений и многого другого). Это побудило меня исследовать «Словарь Вебстера» 1913 года, который сейчас находится в открытом доступе. Однако после целого дня работы над его переносом в базу данных я понял, что было слишком много ошибок (особенно с тегами части речи), чтобы это было жизнеспособным для Word Type.
Наконец, я вернулся к Викисловарь, о котором я уже знал, но избегал, потому что он неправильно структурирован для синтаксического анализа. Именно тогда я наткнулся на проект UBY - удивительный проект, который требует большего признания. Исследователи проанализировали весь Викисловарь и другие источники и собрали все в один унифицированный ресурс.
Особая благодарность разработчикам открытого кода, который использовался в этом проекте: проекту UBY (упомянутому выше), @mongodb и express.
Морфемный разбор слова поросших. «поросшее» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Схема разбора по составу поросшее:
порос ш ее
Разбор слова по составу.
Состав слова «поросшее»:
Соединительная гласная : отсутствует
Пocтфикc : отсутствует
Морфемы — части слова поросшее
поросшее
Подробный paзбop cлoва поросшее пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa поросшее, eгo cxeмa и чacти cлoвa (мopфeмы).
- Морфемы схема: порос/ш/ее
- Структура слова по морфемам: корень/суффикс/окончание
- Схема (конструкция) слова поросшее по составу: корень порос + суффикс ш + окончание ее
- Список морфем в слове поросшее:
- порос — корень
- ш — суффикс
- ее — окончание
- Bиды мopфeм и их количество в слове поросшее:
- пpиcтaвкa: отсутствует — 0
- кopeнь: порос — 1
- coeдинитeльнaя глacнaя: отсутствует — 0
- cyффикc: ш — 1
- пocтфикc: отсутствует — 0
- oкoнчaниe: ее — 1
Bceгo морфем в cлoвe: 3.
Словообразовательный разбор слова поросшее
- Основа слова: поросш ;
- Словообразовательные аффиксы: приставка отсутствует , суффикс ш , постфикс отсутствует ;
- Словообразование: ○ суффиксальный ;
- Способ образования: производное, так как образовано 1 (одним) способом .
См. также в других словарях:
Ударение в слове поросшее: на какой слог падает ударение и как… Слово «поросшее» правильно пишется как… Ударение в слове поросшее
Морфемный разбор слова поросшее
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова поросшее делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для поросшее (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы путем подбора других слов, которые образованы таким же способом.
Как вы видите, морфемный разбор делается просто. Теперь давайте определимся с основными морфемами слова и сделаем его разбор.
Обязательная маркировка товаров
Что такое код маркировки
Маркировка — это уникальный код на упаковке, который помогает отследить путь товара от производителя до покупателя. Если товар подлежит обязательной маркировке, а её не окажется, продавать его нельзя.
Перечень маркировки составляет государство — например, сейчас туда входят одежда, обувь, парфюмерия, фототехника и некоторые другие категории. За продажу такой продукции без кода бизнесу грозит штраф и конфискация товара. Проверить свою товарную группу можно на сайте системы «Честный ЗНАК».
Присваиваем признак маркировки только тем позициям, у которых указан код ТН ВЭД, подлежащий обязательной маркировке — поэтому при загрузке товаров нужно обязательно заполнять поле Код ОКПД/ТН ВЭД.
Вам самостоятельно нужно следить за наличием кода ТН ВЭД в карточках, ведь маркировка — это ваша обязанность и ответственность по договору.
Какие термины нужно знать для работы с обязательной маркировкой
Коды и идентификаторы
Код маркировки — уникальная последовательность символов, которая наносится на упаковку в виде кода Data Matrix. Это нужно, чтобы отследить путь товара от производителя до покупателя. Если товар подлежит обязательной маркировке, а её не окажется, он считается контрафактным. Код маркировки получают через систему «Честный ЗНАК». Как это сделать
Код маркировки индивидуален для каждого товара и состоит из нескольких частей:
- код идентификации — GTIN, серийный номер и идентификаторы применения;
- криптохвост — ключ и код для проверки подлинности товара. В зависимости от категории его длина может быть от 4 до 88 символов.
Пример кода идентификации
GTIN — 13-значный номер из кода маркировки, который хранится в международной базе GS1 и описывает сразу несколько параметров товара (цвет, страну происхождения, название и т.д.). Его нужно добавить в карточку товара, если работаете на FBO. Как это сделать
Data Matrix — штриховой двумерный идентификатор, который используют в России для маркировки товаров. Вот как он выглядит:
ТН ВЭД — товарная номенклатура внешнеэкономической деятельности Евразийского экономического союза (Армения, Беларусь, Казахстан, Кыргызстан, Россия), включающая в себя 10 цифр. Она нужна, чтобы сотрудники таможни понимали, что именно компания перевозит через границу.
Первые четыре цифры ТН ВЭД говорят о принадлежности продукции к определённой группе, последующие цифры классифицируют продукцию по наименованию. Этот код нужно обязательно указывать в карточке.
ОКПД 2 (общероссийский классификатор продукции по видам экономической деятельности) — числовой код продукции, который входит в состав национальной системы стандартизации Российской Федерации.
УИН — уникальная последовательность цифр, формируемая ГИИС ДМДК для индивидуального учёта ювелирных изделий, стандартных и мерных слитков в ГИИС ДМДК, а также для формирования двумерного штрихового кода ювелирного изделия.
Документы
УПД — универсальный передаточный документ. Он нужен при отгрузке товаров на FBO и помогает упростить документооборот, потому что заменяет сразу счёт-фактуру, товарную накладную, акт приёма-передачи и товарный раздел транспортной накладной. УПД относится к категории первичных учетных документов бухгалтерского учёта.
эВСД — электронный ветеринарно-сопроводительный документ, сформированный в ФГИС «Меркурий» (государственная информационная система по учёту эВСД), который покажет маршрут товара, а также его производителей и собственников. Это отдельная сертификация — она не относится к обязательной маркировке кодами Data Matrix. Подробнее о сертификации эВСД
Способы продажи нескольких товаров
Комплект — предмет торговли из нескольких составляющих, которые не продаются по отдельности и не имеют своего номера GTIN. Сейчас как комплект можно зарегистрировать товары лёгкой промышленности (код ТН ВЭД — 6302), фотокамеры и парфюмерию.
Набор — предмет торговли из нескольких составляющих, которые продаются по отдельности и имеют собственный номера GTIN. Коды ТН ВЭД каждого элемента набора должны относиться к той же товарной категории, что и весь набор. Если в «Честном ЗНАКе» вы объединили товары в набор, то в карточку товара нужно добавить GTIN всего набора.
Какие товары требуют обязательной маркировки
Для ювелирных изделий нужно указывать УИН с 1 марта 2022 по правилам Постановления Правительства Российской Федерации от 26.02.2021 № 270.
Остальные товары можно проверить по таблице: собрали там правила для каждой категории. А ещё больше информации — на сайте системы «Честный ЗНАК».
Если при создании карточки вы не укажете код ТН ВЭД, наша система не распознает этот товар как подлежащий маркировке. Из-за этого «Честный ЗНАК» не получит сведения о движении товара, а это нарушение правил маркировки, за которое можно получить штраф.
| Категории товаров | Срок | Документ | Нужен ли ТН ВЭД или ОКПД2 в карточке товара | Нужно ли оформлять эВСД |
|---|---|---|---|---|
| Обувь | С 01.07.2020 г. | Постановление Правительства от 05.07.2019 № 860 | V | |
| Лекарства | С 01.07.2020 г. | Постановление Правительства от 14.12.2018 № 1556 | V | |
| Духи и туалетная вода | С 01.10.2020 г. | Постановление Правительства от 31.12.2019 № 1957 | V | |
| Фотоаппараты | С 01.10.2020 г. | Постановление Правительства от 31.12.2019 № 1953 | V | |
| Лампы- вспышки | С 01. 10.2020 г. | Постановление Правительства от 31.12.2019 № 1953 | V | |
| Шины и покрышки | С 01.11.2020 г. | Постановление Правительства Российской Федерации от 31.12.2019 № 1958 | V | |
| Товары лёгкой промышленности | С 01.01.2021 г. | Постановление Правительства от 31.12.2019 № 1956 | V | |
| Мороженое | С 01.06.2021 г. | Постановление Правительства РФ от 15 декабря 2020 г. № 2099 | V | V |
| Сыры | С 01.06.2021 г. | Постановление Правительства РФ от 15 декабря 2020 г. № 2099 | V | V |
| Молочные продукты всех подгрупп сроком годности более 40 дней | С 01.09.2021 г. | Постановление Правительства РФ от 15 декабря 2020 г. № 2099 | V | V |
| Молочные продукты сроком годности менее 40 дней | С 01.12.2021 г. | Постановление Правительства РФ от 15 декабря 2020 г. № 2099 | V | V |
| Упакованная вода (категория «Минеральная вода») | С 01.12.2021 г. | Постановление Правительства Российской Федерации от 31 мая 2021 № 841 | V | V |
| Шубы из натурального меха | С 12.08.2016 г. | Постановление Правительства Российской Федерации от 11.08.2016 № 787 | V |
Какие товары потребуют обязательной маркировки в будущем
Товары из таблицы пока можно продавать без кодов.
| Категории товаров | Срок | Документ |
|---|---|---|
| Велосипеды и велосипедные рамы | С 01.03.2023 г. | Постановление Правительства Российской Федерации от 11.09.2019 № 1183 |
| Кресла-коляски | С 01.02.2023 г. | Постановление Правительства Российской Федерации от 07.08.2019 № 1028 |
| БАД | Продлён до 28.02.2023 г. | Постановление Правительства Российской Федерации от 29.04.2021 № 673 |
| Медицинские изделия | С 15. 02.2022 г. — 28.02.2023 г. | Постановление Правительства РФ №137 от 9 февраля 2022 г. «О проведении на территории Российской Федерации эксперимента по маркировке отдельных видов медицинских изделий средствами идентификации» |
| Пиво и слабоалкогольные напитки | Продлён до 28.02.2023 г. | Постановление Правительства Российской Федерации от 17.02.2021 № 204 |
| Антисептики | Продлён до 28.02.2023 г. | Постановление Правительства Российской Федерации от 21.07.2021 № 1240 |
| Корм для домашних животных | С 1.05.2022 г. — 28.02.2023 г. | Отсутствует |
| Пищевая рыбная продукция | С 1.04.2022 г. — 28.02.2023 г. | Отсутствует |
| Готовые или консервированные продукты из мяса, мясных субпродуктов, овощей и фруктов | С 1.05.2022 г. — 28.02.2023 г. | Отсутствует |
Как получить маркировку на товары или оформить эВСД
Как передать коды маркировки на FBS и realFBS
Чтобы защитить покупателей от подделок, мы должны печатать маркировку на чеке. При сборке отправления с маркированными товарами система предложит указать код.
Подробнее про маркировку на FBS и realFBS
Как передать коды маркировки или эВСД на FBO
Чтобы разместить на складах Ozon товары:
- с сертификацией в «Меркурии» — перед поставкой сформируйте УПД-2 в личном кабинете и передайте его нам в системе ЭДО. Номер УПД-2 нужно потом указать в эВСД;
- с маркировкой в «Честном ЗНАКе» — на каждом товаре должна быть этикетка с маркировкой, наклейте её или убедитесь, что она уже есть. После согласования актов нужно скачать готовый УПД-2 в личном кабинете — укажем там коды всех принятых позиций.
Как сформировать и передать УПД-2
Как указать GTIN в карточке товара при работе на FBO
GTIN на поставляемый товар может быть описан по полному атрибутивному составу — то есть начинаться на 046, или по упрощённому — начинаться на 029.
Если передаёте GTIN по полному атрибутивному составу
Проверьте, что GTIN в коде маркировки соответствует штрихкоду, который указан на товаре в разделе Товары и цены → Управление штрихкодами. Если нет — добавьте новый штрихкод на товар. Коды GTIN, описанные по полному атрибутивному составу, должны отличаться у товаров с разным ID.
Если передаёте GTIN по упрощённому атрибутивному составу
Указывать GTIN в поле Штрихкод не нужно — иначе штрихкод не будет оригинальным у товаров с разным ID, и мы не сможем опознать их на приёмке.
В этом случае нужно сгенерировать новый штрихкод в разделе Товары и цены → Управление штрихкодами и наклеить его на товар. Он будет формата OZNXXXXXXXXX.
Если передаёте GTIN и по полному, и по упрощённому атрибутивному составу
Если в поставке окажутся разные виды GTIN, нужно:
- для описанных по полному атрибутивному составу — проверить, что GTIN соответствует штрихкоду, который указан на товаре в разделе Товары и цены → Управление штрихкодами, если нет — добавить новый штрихкод на товар;
- для описанных по упрощённому атрибутивному составу — в любом случае сгенерировать новый штрихкод в разделе Товары и цены → Управление штрихкодами и наклеить его на товар.
Как возвращаем коды маркировки
Мы возвращаем коды маркировки:
- по накладной возврата поставщику — в УПД в формате XML;
- по актам недостачи, излишков или брака — в УКД в формате XML.
Если при смене владельца кодов маркировки возникнет ошибка, напишите в поддержку: Обязательная маркировка товаров (Честный Знак/ГИИС ДМДК) → Прочие вопросы.
Как вывести коды маркировки из оборота
Вывод кодов зависит от схемы работы:
Как узнать, какие товары без обязательной маркировки остались на складах Ozon
В разделе Товары → Список товаров скачайте Отчёт о товарах — в столбце «Вывезти и нанести КИЗ (кроме Твери), шт» будет количество товаров без обязательной маркировки, которые размещаются на наших складах. Учитываем остатки по всем фулфилментам, кроме Твери.
Такие товары нельзя купить на Ozon. Чтобы они попали в продажу, нужно вывезти их со склада, самостоятельно нанести маркировку и поставить заново.
К описанию класса смешанных задач с переменным составом связей Текст научной статьи по специальности «Математика»
УДК 624.04
К ОПИСАНИЮ КЛАССА СМЕШАННЫХ ЗАДАЧ С ПЕРЕМЕННЫМ
СОСТАВОМ СВЯЗЕЙ
Н.М.Савкин
Аннотация
Рассматривается класс смешанных задач с изменяющимся в процессе деформации составом и структурой связей. Предлагается подход к решению такого класса задач, основанный на циклической последовательности решения двух известных задач.
Ключевые слова: статически определимые задачи, статически
неопределимые задачи, трансформирующиеся механические системы; класс смешанных задач; циклическая последовательность решения двух задач.
Введение
Известно, что возникающие в технике задачи определения напряженно-деформированного состояния (НДС) конструкции в зависимости от расчетной схемы и метода их решения издавна (Кирпичев В.Л.,1934) подразделяются на два класса :
1) класс задач статически определимых (СО), для решения которых используются только уравнения равновесия; особенностью соответствующей механической системы данного класса задач является постоянный в процессе деформации состав и структура связей, обеспечивающие геометрическую неизменяемость;
2) класс задач статически неопределимых (СНО), для решения которых, в дополнение к уравнениям равновесия, используются уравнения совместности деформаций; особенностью соответствующей механической системы второго класса задач является постоянный в процессе деформации состав и структура связей, число которых превышает тот минимум связей, который необходим для образования геометрически неизменяемой СО системы.
Данное деление задач на два класса определено также во всех современных Энциклопедиях, Справочниках проектировщика, конструктора, учебниках для вузов.
Однако в технике давно встречаются механические системы, изменяющие в процессе движения (деформации) по разным причинам состав и структуру связей, элементов. Такие системы называют трансформирующимися (Величенко В.В.,2003). На практике возможны изменения состава и структуры связей таким образом, что СО геометрически неизменяемая система может в процессе упругих
деформаций переходить в СНО систему и наоборот. Подобные статически трансформирующиеся системы невозможно описать ни методами СО задач, ни методами СНО задач. Эта невозможность приводит к необходимости введения третьего, объединяющего и более сложного класса задач — класса смешанных задач. К механическим системам класса смешанных задач как раз и следует отнести все типы трансформирующихся систем. К наиболее распространенным типам трансформирующихся систем относятся: а)системы с односторонними связями, где ограничения на перемещения определены в виде условий-неравенств: элемент конструкции (колесо) свободно опертый на некоторую поверхность (рельс), которая препятствует перемещению в сторону этой поверхности и не запрещает перемещение в противоположном направлении; конструкции с зазорами и люфтами; вантовые системы и др. ; б) системы с изменяющимся составом и структурой элементов: аппараты с разделяющимися в определенный момент элементами. Следует отметить, что возникающие повсеместно в инженерной практике задачи данного класса изучены недостаточно, а в учебных программах подготовки инженеров-строителей, — механиков они вообще не представлены.
Для решения некоторых задач данного класса используются подходы, основанные на методах квадратичного программирования (Кузнецов Ю.Н., 1980, Перельмутер В.В.,2002), подходы, основанные на принципе дополнительности (Панагиотопулос П., 1989, Ким Т.С., 1989).
Практические методы, создаваемые на основе указанных подходов (наиболее изученных) приводят к избыточной универсальности, а алгоритмы математического описания физической инженерной модели оказываются излишне сложными, что затрудняет использовать их в инженерной практике конкретных задач. Кроме того, для представления на базе указанных подходов класса смешанных задач в учебных программах курсов строительной механики, сопротивления материалов втузов потребуется увеличение учебных часов на изложение вариационных основ строительной механики и методов квадратичного программирования. Осуществить такой план, по-видимому, проблематично.
Предлагается подход, основанный на использовании циклической последовательности решения уравнений равновесия (как для СО задач) и уравнений совместности деформаций (как дополнительных для СНО задач) с некоторыми модификациями последних, с применением алгоритма упорядочения разрешающих уравнений и динамического способа исключения неизвестных. Некоторые аспекты предлагаемого подхода изложены в работах автора, указанных в списке литературы.
Для представления класса смешанных задач в учебных программах курсов строительной механики, сопротивления материалов втузов на базе предлагаемого подхода не потребуется заметного увеличения учебных
часов: используемые принципы и теоремы механики, способы составления уравнений равновесия, совместности деформаций и решение задач классическим методом сил входят в рабочие программы по указанным дисциплинам. Ознакомление же студентов с классом смешанных задач повысит их инженерную квалификацию
2. О циклической последовательности решения двух задач.
Полное решение задачи определения НДС упругого тела (конструкции) с постоянным составом лишних связей для дискретных систем, например, с использованием классического метода сил, можно рассматривать, как одноцикловую последовательность решения двух самостоятельных задач (со своими постановками, уравнениями, методами их решения), имеющих совместные неизвестные. Цель первой задачи -определение необходимых перемещений при некоторой заданной нагрузке. Сложность или простота разрешающих уравнений первой задачи — уравнений равновесия (А) зависит от конкретной физической модели конструкции (стержневая, пластинчатая, оболочечная или их комбинации) и характера внешних нагрузок. Цель второй задачи — определение на базе данных решения первой задачи сил реакции в лишних двухсторонних связях решением уравнений совместности деформаций (В), выражающих условие минимума потенциальной энергии линейно-упругой системы. Решением уравнений (А), при использовании уже известных сил реакции, находят, в завершение цикла, полное решение задачи.
Ставится вопрос расширения возможностей приведенной выше циклической последовательности решения уравнений равновесия и уравнений совместности деформаций применительно к смешанной задаче с переменными связями. Для этого потребовались алгоритмы упорядочения уравнений, динамического способа их решения, корректирования результатов на каждом цикле.
3. Формулировка и схема решения задачи.
Комбинированная система уравнений равновесия (А), совместности деформации (В), описывающая смешанную задачу с переменными связями, в самом общем виде может быть записана следующим образом
(A) LW = P+X ,
(1)
(B) S U = 0 ,
где P — пространство элементов р, представляющих собой заданную нагрузку, как причину явлений;
X — пространство элементов х, представляющих собой дополнительную нагрузку, являющуюся следствием;
W- пространство элементов w, представляющих собой перемещения и деформации механической системы;
L — оператор, переводящий одно пространство в другое, включает в себя параметры физико-механических характеристик, жесткости при разных видах деформаций, геометрические размеры элементов и т. д.;
S U — приращение потенциальной энергии деформации, выраженной через заданные Р и неопределенные X силы линейно-упругой системы.
Для односторонних связей с возможными реакциями х и
перемещениями W должны выполняться неравенства и равенства
Xg > 0, Wg > 0 , XgWg =0 (2)
Уравнение (А) для определения перемещений может быть представлено в конечно-элементной форме, в форме системы разрешающих дифференциальных уравнений теории оболочек, пластин, стержней. Уравнение (В) доставляет уравнения совместности деформаций.
В первом приближении в (А) принимается X=0. После решения уравнений (А) для фиксированной расчетной схемы определяются дискретные значения перемещений в тех точках поверхностей тела, где возможно его соприкасание с поверхностью другого тела. Из решения уравнений (В) определяются по данным о перемещениях силы реакции в тех же точках поверхности тела на шаге (t-1) и снова решение (А), (В) и т.д. Иерархическая структура линейных алгебраических уравнений (В) на каждом шаге циклической последовательности решения системы (1) формируется процедурой выбора очередности: включения точек
поверхности взаимодействия, а также очередности включения каждой поверхности взаимодействия контактирующих тел. При динамическом исключении неизвестных в процессе решения системы (В) при обратном ходе по Гауссу изменяются порядок и структура уравнений для следующего шага итерации, которые продолжаются до тех пор, пока энергетическая норма разности значений потенциальной энергии деформации U(p,x) двух последовательных приближений на шаге t и t-1 не станет меньше заданного числа о.
В случае геометрической нелинейности (для гибкой оболочки, например) используется двухуровневая итерационная процедура, которая заключается в том, что в итерационном процессе при удовлетворении условия равновесия геометрическая нелинейность рассматривается во внешнем цикле, а нелинейность, обусловленная наличием изменяющегося состава и структуры связей, — во внутреннем цикле.
Сопоставления результатов расчета по предложенному подходу решения смешанных задач с переменным составом связей проводились с точными решениями, данными тестовых примеров (Перельмутер А.В. и др, 2002.), рекомендуемых пользователям и разработчикам программных комплексов протестировать программы, декларирующие в своей документации способность рассчитывать системы с односторонними связями. Результаты сопоставления оказались хорошими.
4.Заключение
Предложено ввести кроме известных СО и СНО классов задач с постоянным составом связей еще один, третий, объединяющий и более сложный — класс смешанных задач (СМЗ) с изменяющимся составом связей, необходимый для описания часто встречающихся на практике СНО механических систем, которые при нагружении в пределах упругих деформаций могут переходить в СО системы и наоборот. Предложенная циклическая последовательность решения уравнений равновесия и уравнений совместности деформаций для решения смешанной задачи дает возможность по единому алгоритму рассматривать стержневые, пластинчатые и оболочечные конструкции с переменным составом связей.
С точки зрения приложений смешанные задачи с изменяющимся составом и структурой связей, элементов в процессе деформации требуют к себе особо пристального внимания. Их решение методами классической СНО задачи с постоянным составом и структурой связей (что нередко по традиции допускают) может привести к грубым ошибкам в расчетах прочности конструкций и стать причиной аварийных ситуаций.
5. Литература
Кирпичев В.Л. Лишние неизвестные в строительной механике. Расчет статически неопределимых систем. Гос. Технико-теоретическое изд-во, М-Л 1934 с. 140.
Величенко В.В. Механика трансформирующихся систем. //Доклады РАН. 2003.т. 388. №6. с. 149-150.
Кузнецов Ю.Н.,Кузубов В.И., Волощенко А.Б. Математическое программирование, М.: Высшая школа, 1980. 300с.
Перельмутер А.В.,Сливкер В.И. Расчетные модели сооружений и возможность их анализа /Киев: Изд-во «Сталь», 2002.600с.
Панагиотопулос П. Неравенства в механике и их приложения. Выпуклые и невыпуклые функции энергии/ М.: Мир, 1989. 492 с.
Ким Т.С., Яцура В.Г. Расчет систем с односторонними связями как задача о дополнительности / Строительная механика и расчет сооружений. 1989.№3.с. 41-44.
Савкин Н.М. Приближенный метод самокорректиующейся упругой расчетной схемы и некоторые его приложения. Всесоюз. конф. «Современные методы и алгоритмы расчета и проектирования строительных конструкций с использованием ЭВМ», Тез. докл., Таллин, 1979, с.73-74.
Савкин Н.М. К решению конструктивно-нелинейных задач методом подвижного равновесия.// Исследования по механике материалов и конструкций/ Вып.7/ -СПб:ПГУПС, 1994,-с.73-80, Деп. в ВИНИТИ 30.03.1995, №884-В95.
Савкин Н.М. Об одном подходе к решению дифференциальных уравнений применительно к механическим системам с изменяющейся расчетной схемой// Исследования по механике материалов и конструкций/ Вып.9/ -СПб:ПГУПС, 1996,-с.143-152, Деп. в ВИНИТИ 21.04.1997, №1327-В97.
Савкин Н.М. К обобщению метода подвижного равновесия на условия смены технологических, наработочных и переходных состояний транспортных конструкций/ Сб. трудов ;4-й Междун. конф.»Проблемы прочности материалов и сооружений на транспорте»,- СПб, 1999, 232 с.
BOLD Systems: Справочник
Расширенные инструменты анализа
BOLD включает основные и расширенные инструменты для анализа данных образцов и последовательностей. Самым большим улучшением инструментов расширенного анализа в новой версии 3.6 BOLD является то, что Alignment Browser теперь позволяет пользователям редактировать и сохранять последовательности. | В этой главе:
|
Новая функциональность: полное удалениеЖирный шрифт теперь обрабатывает полное удаление для неоднозначных оснований и пробелов. Эта опция доступна на странице параметров для Distance Summary , Средство просмотра выравнивания и Сводка пробелов штрих — кода . Иллюстрация новой опции обработки удаления на странице параметров анализа. Результаты анализа по электронной почте для обеспечения параллельных рабочих процессовИспользуйте параметр для запуска нескольких анализов, отправляя результаты по электронной почте после завершения каждого анализа. Результаты могут храниться до 4 недель, сохраняться для сравнения в будущем, а ссылки на результаты могут быть переданы между соавторами. Эта опция доступна на странице параметров для большинства инструментов анализа BOLD. Иллюстрация параметра отправки результатов анализа по электронной почте на странице параметров инструмента Публикация результатовКогда рядом с диаграммой появляется значок «Развернуть», это означает, что диаграмма расширяется для увеличения размера, который можно использовать в публикациях. Иллюстрация значка «Развернуть» справа от графика. Наверх | |
Сводка по расстоянию
Желательно, чтобы штрих-коды показывали очень низкое расхождение последовательностей внутри вида со значительно более высоким расхождением последовательностей на более высоких таксономических уровнях. 9Инструмент 0010 Distance Summary дает отчет о расхождениях последовательностей между последовательностями штрих-кодов на конспецифическом и родственном уровнях.
Параметры
В качестве параметров доступны различные модели расстояния и алгоритмы выравнивания, а также параметры для фильтрации последовательностей на основе длины последовательности или проблем с последовательностью.
Результаты
Сравнения выполняются между заданными таксономическими уровнями с частотой, представленной на графике, как показано ниже. Предусмотрена одна визуализация, нормализованная по видам для устранения систематической ошибки выборки. Подробная информация о сравнениях, проведенных на уровне видов, родов и семейств, доступна по ссылкам в правом верхнем углу.
Страница сводки расстояний
Вернуться к началу
- учетная запись
- последовательность
- проект
- анализ
- tag_account
- тег_последовательность
- тег_проект
- тег_анализ
Состав последовательности
Частота оснований ДНК, наблюдаемая с акцентом на содержание GC, может быть полезной метрикой для биологов-эволюционистов. Например, содержание GC в области штрих-кодирования CO1 коррелирует с содержанием GC всего митохондриального генома для многих видов.
Параметры
В качестве параметров доступны различные модели расстояния и алгоритмы выравнивания, а также параметры для фильтрации последовательностей на основе длины последовательности или проблем с последовательностью. Параметры по умолчанию позволяют рассчитывать проценты GC для общей композиции последовательности, а также для положений кодонов 1, 2 и 3, но при желании их можно не выбирать.
Результаты
Страница результатов предоставляет статистику по частоте каждого основания (G, C, A и T) в выбранных записях и может отображать гистограммы содержания GC для всех позиций кодонов.
Страница результатов композиции последовательности
Вернуться к началу
- учетная запись
- последовательность
- проект
- анализ
- tag_account
- тег_последовательность
- тег_проект
- тег_анализ
Сводка пробелов штрих-кода
Сводка пробелов штрих-кода предоставляет пользователям информацию о расстоянии до ближайшего соседа для каждого из видов в списке выбранных образцов.
Параметры
В качестве параметров доступны различные модели расстояния и алгоритмы выравнивания, а также параметры для фильтрации последовательностей на основе длины последовательности или проблем с последовательностью.
Результаты
Расстояния выделяются, если ближайший сосед расходится менее чем на 2% или когда расстояние до ближайшего соседа меньше внутривидового расстояния. Предупреждения, представленные этим инструментом, можно резюмировать, щелкнув ссылку в правом верхнем углу 9Страница результатов 0010 Barcode Gap .
Результаты анализа пробелов штрих-кода
Вернуться к началу
- учетная запись
- последовательность
- проект
- анализ
- tag_account
- тег_последовательность
- тег_проект
- тег_анализ
Кривая накопления
An Кривая накопления стандартизированных штрих-кодов ДНК и связанных с ними функций обеспечивает четкую, прозрачную и воспроизводимую оценку разнообразия и эффективности выборки областей или коллекций. Этот инструмент также позволяет пользователям быстро сравнивать эффективность выборки в нескольких регионах по нескольким таксономическим уровням.
Параметры
Каждая кривая представляет собой график зависимости количества видов, родов, подсемейств и/или БИН от количества образцов. Поле «Дополнительная информация» также может быть построено, например, для графического отображения морфотипов. Поскольку инструмент позволяет создавать несколько графиков, он может помочь исследователю определить, какие географические регионы производят меньше новых групп (создание нескольких графиков по странам, провинциям или регионам) или какая таксономическая группа находится на плато (создание нескольких графиков по типам, классам и т. отряд, семейство или подсемейство). Поле «Дополнительная информация» также можно использовать для изучения эффективности протоколов отбора проб, прогресса в регионах ФАО и т. д.
Порядок выборки может быть рандомизированным, и для большого набора данных более высокая степень сглаживания может быть оптимальной за счет большего количества итераций; однако это займет больше времени для расчета. Порядок представления также можно выбрать, чтобы визуализировать влияние усилий по выборке.
Результаты
Крутой наклон указывает на то, что большую часть разнообразия еще предстоит открыть. Кривая, более пологая вправо, указывает на то, что было собрано разумное количество отдельных образцов, и более интенсивный отбор, вероятно, даст лишь несколько дополнительных групп.
Страница результатов кривой накопления
Вернуться к началу
- учетная запись
- последовательность
- проект
- анализ
- таксономия
- tag_account
- тег_последовательность
- тег_проект
- тег_анализ
- tag_taxonomy
Браузер выравнивания
Управление выравниванием последовательностей и базовыми вызовами является важным шагом в любом анализе штрих-кода. Чтобы избежать неудобств, связанных с импортом последовательностей в стороннее программное обеспечение для анализа и редактирования, BOLD предоставляет встроенный браузер выравнивания, который включает в себя многие функции, популярные в других пакетах. В новейшей версии BOLD обновленный браузер выравнивания поддерживает прямое редактирование базы данных.
Также доступны несколько вариантов выравнивания, таких как алгоритмы MUSCLE и Kalign, а также параметры раскрашивания.
Редактирование последовательности
В новейшей версии BOLD обновленный Alignment Browser поддерживает прямое редактирование базы данных. Пользователи могут выбрать последовательности или отдельные базы, а затем щелкнуть правой кнопкой мыши, чтобы увидеть параметры редактирования. После редактирования весь сеанс может быть отправлен для загрузки отредактированных последовательностей в свои записи.
Параметры
В качестве параметров доступны различные модели расстояния и алгоритмы выравнивания, а также параметры для фильтрации последовательностей на основе длины последовательности или проблем с последовательностью.
Страница браузера центровки
Вернуться к началу
- новинка
- счет
- последовательность
- проект
- анализ
- тег_новый
- tag_account
- тег_последовательность
- тег_проект
- тег_анализ
Диагностические символы
9Анализ 0010 Диагностический признак предоставляет средства для изучения полиморфизма нуклеотидов или аминокислот между наборами последовательностей, сгруппированных по таксономическим или географическим меткам. В частности, этот инструмент идентифицирует базы консенсуса из каждой группы, сравнивает их с таковыми из оставшихся последовательностей в других группах, а затем характеризует, насколько уникальна каждая база консенсуса. Целью этого инструмента является классификация оснований консенсуса по их диагностическому потенциалу, которые классифицируются следующим образом:
| Сокращение | Имя | Значение |
|---|---|---|
| Д | Диагностика | На этой позиции в MSA база * встречается только в одной группе. |
| ДП | Диагностический или частичный | Из-за наличия неоднозначных оснований в других группах это основание * может классифицироваться как P , если тот же символ также появляется в некоторых, но не во всех последовательностях других групп, ИЛИ D , если он вообще не появляется. |
| Р | Частичный символ | В этом положении в MSA это основание встречается во всех последовательностях в этой одной группе, однако оно также встречается в некоторых, но не во всех последовательностях в других группах. |
| УЕ | Частичный или неинформативный символ | Из-за наличия как неоднозначных оснований, так и этого интересующего основания во всей последовательности по крайней мере в одной другой группе, это основание * может быть либо частичным, либо неинформативным в зависимости от того, сколько неоднозначных оснований в другой группе действительно совпадают с рассматриваемая база. |
| я | Недопустимый символ | Во всех последовательностях в других группах присутствуют только неоднозначные основания. Начиная с D , P и U возможны все, об этой базе ничего сказать нельзя, поэтому она объявлена недействительной. |
| У | Неинформативный символ | Более 1 группы разделяют эту базу консенсуса. Эта база не обладает диагностической способностью и не может быть использована в каких-либо последующих диагнозах. |
Параметры
Поскольку этот инструмент выполняет анализ только набора последовательностей, выбранных пользователем, на результат сильно влияют исходные данные и параметры анализа. Даже самые незначительные изменения в исходных последовательностях, параметрах фильтрации или параметрах анализа могут привести к тому, что консенсусные последовательности в каждой группе и, следовательно, диагностический потенциал будут различаться между анализами. В результате интерпретация каждого анализа абсолютно зависит от совокупности всех факторов. В целом, наличие большего количества последовательностей в группе обеспечит более точную диагностику каждой группы, поскольку это уменьшает проблему, вызванную небольшим размером выборки.
Алгоритм
- Выравнивание всех последовательностей служит отправной точкой этого анализа. Алгоритм выравнивания является одним из параметров, доступных для указания пользователем.
- В зависимости от принадлежности к группе последовательности разделяются на различные наборы. Собираются
- консенсусных последовательности в каждом наборе последовательностей.
- Для каждой группы консенсусные основания проверяются одно за другим и сравниваются с основаниями, найденными во всех остальных последовательностях. Основываясь на количестве встречаемости и проценте встречаемости консенсусной базы в других группах (определение см. в таблице выше), определяется диагностический потенциал этой базы в текущей группе.
Примеры диагностических символов
Страница результатов диагностических символов
Вернуться к началу
- учетная запись
- последовательность
- проект
- анализ
- tag_account
- тег_последовательность
- тег_проект
- тег_анализ
Отчет о несоответствии БИН
Модуль номера индекса штрих-кода (БИН) анализирует новые последовательности COI и присваивает их существующему или новому БИН. Пожалуйста, посетите документацию BIN для более подробной информации. Помимо создания страниц BIN, эта система действует как быстрая проверка правильности таксономического обозначения в записях образцов.
Отчет о несоответствии BIN облегчает эту проверку, сравнивая таксономию выбранных записей со всеми остальными в BIN, с которыми они связаны.
Результаты
Результаты сортируются по степени конфликта, отображая те записи в BIN, где сначала возникает конфликт на уровне типа (вероятно, результат перекрестного загрязнения) до конфликтов на уровне вида. Пользователи могут выбирать и извлекать записи с этой страницы, чтобы просматривать вспомогательные данные, комментировать, помечать тегами или редактировать таксономию, где есть подтвержденная ошибка.
В отчете также перечислены записи в БИНах, не содержащие таксономического несоответствия (см. вкладку Согласованные БИНы на странице результатов), а также записи в БИНах, не содержащие других последовательностей (см. вкладку Одиночки).
Страница отчета о несоответствии БИН
Вернуться к началу
- счет
- БИН
- проект
- анализ
- tag_account
- tag_bin
- тег_проект
- тег_анализ
Состав последовательности, организация и эволюция основного генома Triticeae
. 2004 ноябрь; 40 (4): 500-11.
doi: 10.1111/j.1365-313X. 2004.02228.x.
Ванлун Ли 1 , Пэн Чжан, Джон П. Феллерс, Бернд Фрибе, Бикрам С. Гилл
принадлежность
- 1 Кафедра патологии растений и Центр ресурсов генетики пшеницы Канзасского государственного университета, Манхэттен, Канзас 66506, США.
- PMID: 15500466
- DOI: 10.1111/j.1365-313X.2004.02228.x
Бесплатная статья
Ванлун Ли и др. Плант Дж. 2004 ноябрь
Бесплатная статья
. 2004 ноябрь; 40 (4): 500-11.
doi: 10.1111/j.1365-313X.2004.02228.x.
Авторы
Ванлун Ли 1 , Пэн Чжан, Джон П. Феллерс, Бернд Фрибе, Бикрам С. Гилл
принадлежность
- 1 Кафедра патологии растений и Центр ресурсов генетики пшеницы Канзасского государственного университета, Манхэттен, Канзас 66506, США.
- PMID: 15500466
- DOI: 10.1111/j.1365-313X.2004.02228.x
Абстрактный
Мы исследовали состав и основу расширения генома в ядре генома Triticeae с использованием Aegilops tauschii, донора D-генома мягкой пшеницы. Мы секвенировали нефильтрованную геномную дробовик (trs) и библиотеку метилирования-фильтрации (tmf) A. tauschii и проанализировали метки, экспрессируемые пшеницей (EST), чтобы оценить экспрессию генов и мобильных элементов (TE). Отобранные последовательности D-генома состояли из 91,6 % повторяющихся элементов, 2,5 % известных генов и 5,9% низкокопийных последовательностей с неизвестной функцией. ТЕ составляют 68,2% D-генома по сравнению с 50% у кукурузы и 14% у риса. ДНК-транспозоны составляют 13% D-генома по сравнению с 2% у кукурузы. TE были метилированы неравномерно внутри и между элементами и семействами, и большинство из них было транскрибировано, что способствовало расширению генома в основном геноме Triticeae. Число копий большинства повторяющихся семейств постепенно увеличивалось после полиплоидизации. Определенные семейства ТЕ занимали дискретные хромосомные территории. Вложенные вставки и нелегитимная рекомбинация происходили широко между семействами TE, и большинство TE содержали внутренние делеции. Содержание GC значительно различалось среди трех исследованных наборов последовательностей в пределах от 42% в tmf до 46% в trs и 52% в EST. Основываясь на обогащении генных последовательностей, метилирование-фильтрация предлагает один вариант, хотя и не такой эффективный, как у кукурузы, для выделения богатых генами областей из большого генома пшеницы.
Похожие статьи
Новый метод вычисления частот K-меров и его применение для аннотирования больших повторяющихся геномов растений.
Курц С., Наречания А., Штейн Дж. К., Уэр Д. Курц С. и соавт. Геномика BMC. 2008 31 октября; 9:517. дои: 10.1186/1471-2164-9-517. Геномика BMC. 2008. PMID: 18976482 Бесплатная статья ЧВК.
Характеристика состава и эволюции гомеологических геномов гексаплоидной пшеницы посредством секвенирования BAC-конца на хромосоме 3B.
По Э., Роже Д., Бадаева Э., Гей Г., Бернар М., Сурдиль П., Фейе К. По Э. и др. Плант Дж. 2006, ноябрь; 48 (3): 463-74. doi: 10.1111/j.1365-313X.2006.02891.x. Epub 2006, 29 сентября. Завод Дж. 2006. PMID: 17010109
Мобильные элементы риса характеризуются различными средами метилирования в геноме.
Таката М., Киёхара А., Такасу А., Кишима Ю., Оцубо Х., Сано Ю. Таката М. и др. Геномика BMC. 2007 20 декабря; 8:469. дои: 10.1186/1471-2164-8-469. Геномика BMC. 2007. PMID: 18093338 Бесплатная статья ЧВК.
Снимок всего генома из 454 последовательностей раскрывает состав генома ячменя и свидетельствует о параллельной эволюции размера генома пшеницы и ячменя.
Уикер Т., Таудиен С.
, Хубен А., Келлер Б., Гранер А., Платцер М., Штейн Н.
Уикер Т. и др.
Плант Дж. 2009 г., сентябрь 59(5):712-22. doi: 10.1111/j.1365-313X.2009.03911.x. Epub 2009 12 мая.
Завод Дж. 2009.
PMID: 19453446Мобильные элементы и эволюция экспрессии генов.
Весслер СР. Весслер СР. Symp Soc Exp Biol. 1998;51:115-22. Symp Soc Exp Biol. 1998. PMID: 10645433 Обзор.
Посмотреть все похожие статьи
Цитируется
Сравнительный анализ повторов обнаруживает новые данные об эволюции генома у диких диплоидных видов Arachis (Fabaceae).
Самолюк С.С., Вайо М., Ортис А.М., Чалуп Л.М.И., Робледо Г., Бертиоли Д.Дж., Сейхо Г. Самолюк С.С. и др. Планта.
2022 27 июля; 256(3):50. doi: 10.1007/s00425-022-03961-9.
Планта. 2022.
PMID: 35895167Эволюционная динамика повторяющейся ДНК и ее влияние на диверсификацию генома у рода Sorghum .
Куо Ю.Т., Исии Т., Фукс Дж., Се В.Х., Хубен А., Лин Ю.Р. Куо Ю.Т. и др. Фронт завод науч. 2021 12 августа; 12:729734. doi: 10.3389/fpls.2021.729734. Электронная коллекция 2021. Фронт завод науч. 2021. PMID: 34475879 Бесплатная статья ЧВК.
Динамика теломер и субтеломер в контексте ранних хромосомных взаимодействий в ходе мейоза и их значение в селекции растений.
Агилар М., Прието П. Агилар М. и соавт. Фронт завод науч. 2021 4 июня; 12:672489. doi: 10.3389/fpls.2021.672489. Электронная коллекция 2021.
Фронт завод науч. 2021.
PMID: 34149773
Бесплатная статья ЧВК.
Обзор.Гетероаллели мягкой пшеницы: множественные различия между аллельными вариантами Gli-B1 Локус.
Метаковский Э., Паскуаль Л., Вакчино П., Мельник В., Родригес-Кихано М., Попович Ю., Чеботарь С., Роджерс В.Дж. Метаковский Е. и соавт. Int J Mol Sci. 2021 12 февраля; 22 (4): 1832. дои: 10.3390/ijms22041832. Int J Mol Sci. 2021. PMID: 33673225 Бесплатная статья ЧВК.
Омики пшеницы: от классической селекции к новым селекционным технологиям.
Алотаиби Ф., Алхарби С., Алотаиби М., Аль Мосаллам М., Мотавей М., Альраджи А. Алотаиби Ф. и др. Саудовская J Biol Sci. 2021 фев; 28 (2): 1433-1444. doi: 10.1016/j.sjbs.2020.
11.083. Epub 2020 3 декабря.
Саудовская J Biol Sci. 2021.
PMID: 33613071
Бесплатная статья ЧВК.
Обзор.
Просмотреть все статьи «Цитируется по»
Типы публикаций
термины MeSH
Состав
Состав[Руководство по программе | Руководство пользователя | файлы данных | Базы данных]
- ФУНКЦИЯ
- ОПИСАНИЕ
- ПРИМЕР
- ВЫХОД
- ОГРАНИЧЕНИЯ
- СООБРАЖЕНИЯ
- ВВОДНЫЕ ФАЙЛЫ
- РОДСТВЕННЫЕ ПРОГРАММЫ
С - ПАКЕТНАЯ ОЧЕРЕДЬ
- ИМЕНОВАНИЕ НАБОРОВ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
- ОБЗОР КОМАНДНОЙ СТРОКИ
- ЛОКАЛЬНЫЕ ФАЙЛЫ ДАННЫХ
- ОПИСАНИЕ ПАРАМЕТРА
- ОПИСАНИЕ
[ Топ | Следующий ]
Состав определяет состав последовательность(и).
Для последовательности(ей) нуклеотидов
Состав также
определяет содержание динуклеотидов и тринуклеотидов.[ Предыдущая | Топ | Следующий ]
Состав измеряет состав один или группа последовательности. Если вы укажете только одна последовательность, вы можете выбрать диапазон внутри последовательности. Нижний регистр буквы преобразуются в верхний регистр и посчитал с их эквивалентами в верхнем регистре. Если указать группу последовательностей, Композиция отображает имя каждой последовательности, как это заканчивает измерение для этого последовательность.
[ Предыдущая | Топ | Далее ]
Вот сеанс с использованием Состав для измерения состава содержание ди- и тринуклеотидов за все бактериальные последовательности в GenEMBL:
% состав КОМПОЗИЦИЯ на какой последовательности? Бактериальный:* Как мне назвать выходной файл (*bacterial.composition*)? А33344 А33349 А34992 ///////// ZSSURNAS1 ZSSURNAS2 ZYP16SРНК СОСТАВ полный.
[ Предыдущая | Топ | Следующий ]
Вот выходной файл:
СОСТАВ: Предстоятель:* 7 октября 1998 11:13
Последовательности: 48 022 Total_Length: 120 532 386 CPU_Time: 54,37
*****
А: 31 313 460 Б: 102 С: 28 735 001 Г: 95
Г: 30 961 705 Г: 314 К: 849 М: 777
N: 91 852 R: 1 571 S: 1 568 T: 29 422 612
В: 102 Вт: 964 Д: 1414
Другое: 0
Всего: 120 532 386
*****
GG: 8 050 342 GA: 7 862 220 GT: 6 360 816 GC: 8 666 422
AG: 7 038 203 AA: 9 998 328 AT: 7 864 675 AC: 6 393 582
TG: 7 923 448 TA: 6 046 193 TT: 8 693 358 TC: 6 736 239
CG: 7 924 019 CA: 7 381 735 CT: 6 486 257 CC: 6 920 823
Другое: 137 704
Всего: 120 484 364
*****
ГГГ: 18090,031 GGA: 1 960 301 GGT: 1 901 998 GGC: 2 371 501
GAG: 1 672 334 GAA: 2 489 765 GAT: 2 125 037 GAC: 1 570 445
GTG: 1 747 910 GTA: 1 331 828 GTT: 1 828 370 GTC: 1 446 886
GCG: 2 339 125 GCA: 2 092 399 GCT: 2 019 219 GCC: 2 210 163
AGG: 1 758 829 AGA: 1 840 304 AGT: 1 406 725 AGC: 2 027 036
AAG: 2 315 186 AAA: 3 373 559 AAT: 2 308 923 AAC: 1 993 654
ATG: 1 990 442 ATA: 1 691 234 ATT: 2 235 792 ATC: 1 942 982
ACG: 1 661 442 ACA: 1 628 545 ACT: 1 365 670 ACC: 1 733 627
ТГГ: 2 225,297 ТГА: 2 195 490 ТГТ: 1 492 723 ТГК: 2 005 470
TAG: 1 051 637 TAA: 1 930 346 TAT: 1 737 112 TAC: 1 323 841
ТТГ: 2 036 860 ТТА: 1 910 148 ТТТ: 2 790 885 ТТС: 1 949 165
TCG: 1 767 614 TCA: 1 899 594 TCT: 1 527 840 TCC: 1 535 419
CGG: 2 250 632 CGA: 1 857 615 CGT: 1 553 902 CGC: 2 257 754
CAG: 1 993 100 CAA: 2 196 518 CAT: 1 686 654 CAC: 1 502 049
CTG: 2 143 874 CTA: 1 109 501 CTT: 1 833 157 CTC: 1 393 229
CCG: 2 151 571 CCA: 1 757 503 CCT: 1 568,927 ССС: 1 436 717
Другое: 173 936
Всего: 120 436 342
*****
[ Предыдущая | Топ | Следующий ]
Неизвестный.
[ Предыдущая | Топ | Следующий ]
Вы можете определить состав из нижней нити последовательность нуклеиновой кислоты из состав верхняя прядь. -ОБА жил 9Параметр 0703 измеряет обе нити, но информация теряется, потому что G=C и A=T, и так на.
[ Предыдущая | Топ | Следующий ]
Композиция занимает либо один или файл с несколькими последовательностями Технические характеристики. Вы можете указать несколько последовательности в ряде способами: с помощью файла списка, например @project.list ; с помощью MSF или файл RSF, например project.msf{*} ; или же используя спецификацию последовательности со звездочкой ( * ) подстановочный знак, например GenEMBL:* . Функция композиции зависит от вашего вклада последовательность(и) представляет собой белок или нуклеотид. Программы определяют тип последовательности присутствие либо Тип: N , либо Тип: P в последней строке только заголовок текста выше последовательности.
Если
ваш
последовательность(и) не правильная
тип, обратитесь к Приложению VI для
информация о том, как изменить
или установить
тип последовательности.[ Предыдущий | Топ | Следующий ]
CodonFrequency сводит в таблицу частоты кодонов для любой диапазон последовательности в определенной рамке считывания, вместо того, чтобы считать все тринуклеотиды.
[ Предыдущая | Топ | Следующий ]
Если вам нужно остановиться эту программу, используйте
C, чтобы сбросьте свой терминал и сеанс изящно, как возможный. Поиски и сравнения выпишите результаты из часть поиска это завершено когда вы используете C. [ Предыдущая | Топ | Следующий ]
Вы можете запустить эту программу в пакетной очереди с помощью сценарий, который мы поставляем. Используйте Fetch с имя файла который начинается с этой программы имя и заканчивается на расширение имени файла .csh. Изменить файл с любой текстовый редактор, чтобы он указывает эксперимент, который вы хочу сделать и поставить в очередь сценарий.
[ Предыдущая | Топ | Следующий ]
См. разделы, посвященные указанию последовательностей в Главе 2, Использование Файлы последовательности и базы данных в Руководство пользователя.
[ Предыдущая | Топ | Следующий ]
Все параметры этой программы могут быть добавлены в командная строка. Используйте -CHE ск просмотреть сводку ниже и указать параметры до выполнения программы. В кратком изложении ниже с большой буквы буквы в именах параметров это буквы, которые вы должен ввести , чтобы использовать параметр. Квадратные скобки ([ и ]) заключайте значения параметров, которые по желанию. Чтобы получить больше информации, см. «Использование Параметры программы" в Главе 3, Использование программ в пользовательском Руководство.
Минимальный синтаксис: % состав [-INfile=]бактериальный:* -По умолчанию Запрашиваемые параметры: -BEGin=1 -END=1000 устанавливает интересующий диапазон (только отдельные последовательности) [-OUTfile=]bacterial.
[ Предыдущая | Топ | Следующий ]
Никто.
[ Предыдущая | Топ | Следующий ]
Вы можете задать параметры перечисленные ниже из команды линия. Чтобы получить больше информации, см. «Использование Параметры программы" в Главе 3, Использование программ в пользовательском Руководство.
- - ОБЕ жил
измеряет состав обоих нити нуклеиновой кислоты последовательность.
- -NOCOM мас
Композиция обычно отображает числа больше чем 999 с запятыми сделать их проще читать; например, число 1234567 будет выглядеть как 1 234 567.
Эти запятые делают
цифры, нечитаемые компьютером.
Если вы собираетесь
использовать выходной файл
из этой программы для
ввод в другую программу, вы
может убрать запятые с помощью
этот параметр.- -МОН итор
Эта программа обычно следит за своим прогресс на вашем экране. Однако при использовании -D ошибка чтобы подавить все взаимодействие с программой, вы также подавляете монитор. Вы можете повернуть его обратно с этот параметр. если ты запускают программу в партия, монитор появится в файле журнала.
- -СУММА мари
пишет краткое содержание работа программы на экран когда вы использовали -D ошибка до подавлять все взаимодействие с программой. А сводка обычно отображается в конец выполнения программы интерактивно. Вы можете скрыть сводку для программы, работающей в интерактивном режиме с -NOSUM мэри .
Вы также можете использовать это параметр, вызывающий сводку работы программы на быть записано в лог-файл программы запускать в пакетном режиме.
[Руководство по программе | Руководство пользователя | файлы данных | Базы данных]
Техническая поддержка: [email protected]
или [email protected]
Copyright (c) 1982-2002 Accelrys Inc. Дочерняя компания Pharmacopeia, Inc. Все права защищены.
Лицензии и товарные знаки Висконсин Пакет является товарным знаком и GCG и Логотип GCG является зарегистрированным товарным знаком Accelrys Inc.
. Все другие названия продуктов, упомянутые в этой документации, могут
быть товарными знаками, и если да, то товарными знаками или зарегистрированными товарными знаками
их соответствующих держателей и используются в этой документации для
только в целях идентификации.
www.accelrys.com/bio
QC Fail Sequencing » Предвзятый состав последовательности может привести к низкому качеству данных секвенаторов Illumina. Просмотр содержимого последовательности цикла секвенирования и проверка на отсутствие позиционного смещения является стандартной частью многих платформ контроля качества. Однако в некоторых экспериментальных проектах может возникнуть ситуация, когда очень большая часть библиотеки (возможно, вся она) будет, по крайней мере, начинаться с точно такой же последовательности. Такой тип структуры библиотеки может привести к проблемам со сбором данных и базовым вызовом на платформах секвенирования Illumina.
Симптомы
Ниже показан график состава последовательности оснований из такой предвзятой библиотеки составов. Как видите, все чтения в этой библиотеке начинаются с одной и той же исходной последовательности, но затем после 20 оснований последовательности расходятся.
В библиотеке этого типа будут наблюдаться некоторые или все признаки:
- Плохое общее качество последовательности
- Низкое количество кластеров, при этом большое количество кластеров было отклонено во время выполнения
- Большое количество вызовов N в выходных данных
- Смещение положения внутри проточной кюветы выше ожидаемого
В зависимости от серьезности проблемы вы можете даже столкнуться с почти полным сбоем цикла, хотя в большинстве случаев вы получите снижение производительности из-за вызовов более низкого качества.
Диагностика
Чтобы понять причину этих сбоев, необходимо объяснить некоторые этапы конвейера анализа данных Illumina, которые относятся к этой проблеме. Есть несколько шагов в сборе данных, на которые могут повлиять эти типы библиотек:
1) Фокусировка
Секвенирование Illumina — это сбор данных на основе визуализации. У вас есть стеклянная проточная кювета, к которой присоединены кластеры молекул ДНК, и после добавления меченых нуклеотидов следует этап визуализации, когда контролируемый компьютером микроскоп отображает поверхности проточных кювет. В самом начале цикла одним из важнейших шагов при сборе данных является настройка фокусировки для этой проточной кюветы. Эта фокусировка должна быть выполнена до первого сбора данных, поэтому в момент фокусировки будет видна только первая база в каждом кластере. Система Illumina использует ряд различных молекул флуорофора и лазеров для измерения различных оснований, но для фокусировки она просто выбирает один из этих каналов для использования, идея в том, что ей не нужно видеть каждый кластер, ей просто нужно достаточно информации, чтобы видеть правильную фокальную плоскость. Однако, если у вас мало или совсем нет данных в канале, используемом для настройки фокусировки, то прибору фактически не на чем фокусироваться, и возможно, что первоначальная фокусировка будет настолько далекой, что она никогда не восстановится, генерируя из фокусные кластеры для остальной части цикла с очень плохим влиянием на качество данных. Прибор имеет возможность регулировать фокус во время прогона, но эта перефокусировка ограничена небольшими изменениями, поэтому, если первоначальный фокус слишком далеко, он может не восстановиться полностью.
2) Обнаружение кластеров
В большинстве систем Illumina кластеры ДНК располагаются случайным образом на поверхности проточной кюветы (это меняется в более поздних системах с введением полуупорядоченных массивов кластеров) – так что одно из другого начальный этап обработки заключается в том, чтобы определить, где находится каждый отдельный кластер в проточной кювете, чтобы его можно было отслеживать во время цикла для создания отдельной выходной последовательности. При размещении кластеров в проточной кювете необходимо учитывать два конкурирующих фактора: в идеале вы хотите, чтобы каждый кластер был полностью изолирован от другого кластера, чтобы, как только вы увидите сигнал на изображении, вы могли предположить, что это происходит из одной последовательности ДНК. Однако вы также хотите поместить в проточную кювету как можно больше кластеров, чтобы максимизировать объем данных, которые вы получаете в ходе цикла. Поэтому на практике проточные ячейки загружаются до такой степени, что значительная часть кластеров будет контактировать с одним или несколькими другими кластерами, так что простой идентификации положения сигналов в первом цикле секвенирования недостаточно для определения положения каждого отдельного элемента. кластер.
Способ решения этой проблемы заключается в том, что вызов кластера выполняется не только на основе данных из первого цикла секвенирования — вместо этого собираются данные из первых нескольких циклов и анализируется каждое выявленное пятно. Если в каком-либо цикле пятно показывает шаблон, где, например, левая сторона пятна в основном представляет собой сигнал G, а правая сторона пятна в основном представляет собой сигнал C, то система может предположить, что на самом деле это два пятна, которые соприкасаются. и может рассматривать две половины как отдельные точки для будущего анализа.
В приведенном ниже примере оба показанных пятна на самом деле являются двумя соседними и соприкасающимися кластерами. Один в правом нижнем углу можно отличить как два кластера, поскольку последовательность в двух подобластях изменяется в пределах набора циклов, используемых для обнаружения кластера, в то время как один в верхнем левом углу имеет ту же последовательность на ранних циклах и будет проанализирован. неправильно, как если бы они были одним кластером.
Проблема с этим подходом заключается в том, что существует ограничение на то, как далеко система может обнаруживать эти объединенные точки. После того, как пятно определено как объединенное, система должна вернуться к необработанным данным изображения для двух половин этого пятна с начала прогона, чтобы вызвать сигнал для двух областей отдельно. Это означает, что до тех пор, пока обнаружение точки не будет завершено, все необработанные данные изображения для запуска должны быть сохранены, и эти данные БОЛЬШИЕ! Практически поэтому точечное обнаружение может выполняться только в течение нескольких циклов. Для необъективных библиотек эффект этого заключается в том, что если библиотечная последовательность для двух перекрывающихся точек не расходится в пределах набора циклов, используемых для обнаружения кластера, она будет рассматриваться как один кластер до конца цикла. Когда последовательность в конечном итоге расходится, она будет выглядеть как смешанный сигнал, и из-за этого кластер, вероятно, будет отброшен.
3) Калибровка канала
Последним аспектом этого типа отказа является калибровка конкретных параметров, используемых для базового вызова при каждом запуске. Для оптимального базового вызова программное обеспечение должно вычислить относительную силу, наблюдаемую в различных измеренных каналах в каждом прогоне. Это объясняет различия в эффективности лазера или детектора или в свойствах флюоров, используемых в библиотеках. Установка этих калибровочных значений по замыслу должна делать некоторые предположения о характере данных, которые она ожидает увидеть, поэтому, когда библиотека сильно предвзята (возможно, до такой степени, что некоторые каналы полностью пусты), это, возможно, неудивительно. если параметры для прогона не установлены оптимально, и поэтому базовое качество вызова снижается.
Устранение
В какой-то степени эта проблема была значительно смягчена благодаря улучшениям программного обеспечения базовых вызовов от Illumina. Улучшения в фокусировке и калибровке теперь означают, что библиотеки редко полностью выходят из строя (что раньше было обычным явлением для секвенсоров GA), но потеря последовательностей, включение N в вызовы и более низкие, чем обычно, оценки phred по-прежнему распространены. Усовершенствования в области информатики могут решить только некоторые из этих проблем, в конечном итоге некоторые из них требуют внесения изменений в библиотеки или последовательности действий для исправления.
Вот некоторые распространенные решения этой проблемы:
- Вы можете добавить в библиотеку различные последовательности. Чаще всего это будет библиотека управления PhiX, которую предоставляет сама Illumina. Даже низкое (~ 5%) это значение даст достаточно сигнала для исправления фокусировки и улучшит калибровку. Более высокие количества начнут смягчать проблему обнаружения кластеров, поскольку вы, скорее всего, увидите перекрытия между фиксированной последовательностью и PhiX, но это, очевидно, происходит за счет потери мощности секвенирования при создании последовательности phix.
- Вы можете реструктурировать свою библиотеку, чтобы не иметь фиксированной последовательности в начале. Вы можете улучшить некоторые аспекты секвенирования, добавив случайный штрих-код на лицевую сторону вкладыша, но фиксированные основания позже в библиотеке все равно будут проблемой. Если случайную последовательность можно сделать переменной длины, это обеспечит разнообразие для остальной части библиотеки, и пока вы можете определить начало своей вставки, это может обеспечить более полное решение.
- Если ваша библиотека имеет полностью фиксированную последовательность в начале, которая позже превращается в разнообразную последовательность, то самое простое и наиболее эффективное решение — изменить праймер, используемый для секвенирования, на тот, который инициирует непосредственно перед разнообразной областью. Это имеет несколько преимуществ: вы не тратите ресурсы секвенирования на секвенирование общей последовательности, и это означает, что библиотека начинается с другой позиции, поэтому калибровка и обнаружение кластеров будут хорошими.
Извлеченные уроки
Иногда хорошее понимание методологии вашей платформы секвенирования может помочь понять ошибки секвенирования и найти возможные решения.
Ссылки
Krueger F, Andrews SR, Osborne CS Крупномасштабная потеря данных в библиотеках секвенирования Illumina с низким разнообразием может быть восстановлена с помощью отложенного вызова кластера PLoS One . 6(1): e16607.
ENGL-120-5976 - Колледж Сочинение и чтение
Неделя 1, 21 августа Страница
Неделя 2, 28 августа Страница
Неделя 3, 4 сентября Страница
Неделя 4, 11 сентября Страница
Неделя 5, 18 сентября Страница
Неделя 6, 25 сентября Страница
Неделя 7, 2 октября Страница
Неделя 8, 9 октября Страница
Неделя 9, 16 октября Страница
Неделя 10, 23 октября Страница
Неделя 11, 30 октября Страница
Неделя 12, 6 ноября Страница
Неделя 13, 13 ноября Страница
Неделя 14, 20 ноября Страница
Неделя 15, 27 ноября Страница
Неделя 16, 4 декабря Страница
Финальная неделя, 11 декабря Страница
информация | Содержание и риторический анализ [.
pdf]
Вложениеинформация | Критический ответ: предмет, идея и тема Страница
информация | Заблуждение и риторика Страница
информация | Введение и тезисы (.pdf) Вложение
информация | Диаграмма предвзятости СМИ Страница
информация | Учебное пособие по дымовым сигналам (.pdf) Вложение
информация | Последовательность в абзацах и эссе Страница
рейтинг | Адам Грант «Прощай, MBTI» (.
pdf)
Вложениерейтинг | Гильермо дель Торо / Чак Хоган (.pdf) Вложение
рейтинг | Макс Брукс (.pdf) Вложение
рейтинг | Мэгги Керт-Бейкер (.pdf) Вложение
рейтинг | Райан Келли (.pdf) Вложение
рейтинг | Сарвеназ Хатами "Стили обучения" (.pdf) Вложение
стандартный | Адам Грант и Сарвенас Хатами Страница
стандартный | Архетипы (.
pdf)
Вложениестандартный | Упражнение на привилегии (.pdf) Вложение
стандартный | Райан Келли и типы Страница
стандартный | V значит вендетта Страница
исследование | Джош Уэдон, Учебное пособие "Безмятежность" .pdf Вложение
исследование | Учебное пособие "Дымовые сигналы" .pdf Вложение
исследование | Учебное пособие "V значит Вендетта" .
pdf
Вложениетмпл | Типы файлов и протоколы именования Страница
тмпл | Дизайн документа MLA (.pdf) Вложение
тмпл | Шаблон эссе MLA MS Word .docx Вложение
тмпл | Шаблон эссе MLA Apple Pages .pages Вложение
xrcs | Задание 1 Разработка темы Страница
xrcs | Задание 2 Разработка темы Страница
xrcs | Задание 3 Разработка темы Страница
xrcs | Процесс и последовательность Страница
Политика и рекомендации курса Страница
Контактная информация и ссылки Страница
Требуемые тексты Страница
Дополнительные материалы Страница
Последовательность композиций для начального музыкального класса
Нет лучшего способа узнать, как ваши ученики действительно обрабатывают информацию, чем попросить их создать что-нибудь с ее помощью. Попросив учащихся создать ритмические и мелодические концепции, вы можете заглянуть в их мозг и сделать вывод о том, владеют ли они процессом или им нужно пройти еще один круг. Одним из наиболее эффективных способов оценки является предоставление возможности мелодического сочинения. Но как это выглядит в начальной музыкальной школе?
Импровизация и композиция.
Два больших, длинных, страшных слова. Признайтесь, эти два маленьких слова обвивают вас, как крепкое объятие, или же они атакуют, как ниндзя? Если вы чем-то похожи на меня, то это второе. Или, по крайней мере, я раньше так себя чувствовал. Но знаете что, вы все. Я придумал очень простой способ заставить ваших детей покинуть станцию и добраться до места назначения вовремя, когда дело доходит до поезда творчества. Успех этих двух мошенников напрямую связан с секвенирование .
Я уверен, вы потрясены, услышав от меня слово на букву «с». Но кроме шуток и сарказма, разве последовательность и соответствующие каркасы не являются ключом ко всему?
Импровизация и композиция ничем не отличаются. На самом деле, в моем музыкальном классе импровизация — это основа для сочинения; они существуют в континууме. Импровизация на самом деле функционирует как мозговой штурм или игра с информацией , чтобы увидеть, что звучит и чувствуется хорошо. Импровизация это спонтанно вдохновлен . Композиция — это то, где мы оформляем пьесу , а принимаем решения о том, что кажется и звучит лучше всего. Можно сказать, что сочинение происходит от вдохновения сделать одно и то же более одного раза, а затем записать его и поделиться им.
Хотите узнать больше? Вот шаги, которые я использую в своем музыкальном классе, чтобы облегчить мелодическую композицию, путем исследования и импровизации.
Шаг 1: Начните со знакомой народной песни
Как и любая другая концепция, которую вы будете практиковать в музыкальной комнате, начните с песни и игры! Выберите один из ваших любимых вариантов с извлекаемым шаблоном для любой концепции, которую вы собираетесь практиковать, которую ваши дети смогут записать.
Например, песня «Apple Tree» идеально подходит для манипулирования четвертной и двумя восьмыми нотами. Есть около миллиона других, но для этого поста я собираюсь остановиться на одном из моих фаворитов. Единственными ритмами во всей песне являются четвертные и две восьмые. Кроме того, в первой строке используется текст «Яблоня», то есть число 9.0289 идеальный извлекаемый шаблон для следующего шага!
Нажмите здесь, чтобы получить эти манипуляторы!
Шаг 2. Импровизируйте модели речи
Простой способ заставить детей двигаться и веселиться с помощью импровизации — это речь. Это гораздо более доступная точка входа по сравнению с формальной нотной записью или ритмическими слогами, и прыгать прямо в импровизированные ритмы с мелодией с места в карьер — это все равно, что прыгать с первого этажа на тринадцатый — плохие новости.
В «Apple Tree» есть идеальные два слова, встроенные прямо в песню для четвертных и восьмых нот. Но скажем, вы хотели добавить еще один ритм, с которым ученики могли бы импровизировать. Какие еще слова подходят к словам «яблоко» и «пирог»? Как насчет корицы? Просто помните, что если вы планируете довести эту последовательность до этапа составления, убедитесь, что учащиеся смогут вывести любой текст, который вы выберете для создания цепочек слов. Например, мои второклассники, вероятно, не стали бы использовать слово «корица», потому что я учу сочетаниям восьмых и шестнадцатых нот только в третьем классе.
Шаг 3: Установите ритмическое содержание
Ритмы обеспечивают основу для мелодического содержания. Если вы не вступаете в удивительный мир мелодического сочинения в свободное время (что я не рекомендую учащимся начальных классов), важно создать ритмические (или речевые) параметры, прежде чем переходить к мелодической импровизации. Предложите учащимся использовать манипуляторы или карандаш и бумагу, чтобы установить, какой речевой образец им понравился достаточно хорошо, чтобы повторить его дважды, а затем записать. Чтобы продвинуться еще дальше по континууму композиции, попросите учащихся записать свои самые любимые ритмические паттерны в формальных обозначениях. Как только они приняли эти ритмические решения, пришло время перейти к мелодии!
(*ПРИМЕЧАНИЕ: это не обязательно означает, что ритмы полностью заданы и неизменны, но следующие шаги более доступны для учащихся, если у них есть ритм или речевой паттерн, с помощью которых можно мелодически манипулировать.)
Щелкните здесь, чтобы получить эти ноты для диктовки!!
Шаг 4: Импровизируйте в пределах тональных параметров
Создание мелодий — процесс, сильно отличающийся от импровизации ритмических паттернов. С моими младшими учениками мы проводим много времени, перемещая манипуляторы вверх и вниз по нотоносцам и напевая то, как они будут звучать, чтобы принимать мелодические решения.
Со старшими учениками, которые, вероятно, знают полный пентатон ( do re mi so la ) , я предпочитаю давать им возможность играть на струнных инструментах. Если у них есть свои речевые паттерны, а инструменты настроены на пентатонику, они, как правило, хороши. Я часто говорю студентам, что они могут найти ноты, которые им нравятся, которые соответствуют их модели речи, если последняя нота — домашняя нота «до».
Я обычно даю им несколько наглядных пособий, чтобы убедиться, что это происходит, которые, к счастью для вас, находятся в библиотеке ресурсов! Нажмите здесь, чтобы получить их!!
Шаг 5: Сочините мелодию
После того, как учащиеся найдут мелодические комбинации, которые им больше всего нравятся (и после того, как я повторил, что повторяющиеся паттерны и элементарные формы, т. е. ABAB, являются их друзьями), я прошу их посвятить себя любимые узоры. Это означает, что им это нравится, и они могут запомнить это достаточно хорошо, чтобы играть несколько раз подряд. Если они уберут речевые паттерны, используемые для создания мелодии, и решат, что хотят изменить ритм, это нормально — до тех пор, пока они все еще могут записать это.
Шаг 6: Запишите и поделитесь!
После того, как учащиеся закончат сочинение, дайте им возможность выступить перед своими сверстниками, а также попросите учащихся исполнить сочинений друг друга.