Узнаем как изготовить фонетический анализ слова
В школьной программе изучаются несколько разделов науки о языке. Каждый из них предполагает анализ языковой единицы с определенной точки зрения. Одним из этих разделов является фонетика. Фонетический анализ слова подразумевает знания о том, что такое звуки речи, какими они бывают, как соотносятся с буквами.
Смысл анализа
Для того чтобы понять, что значит фонетический анализ слова, нужно хорошо понимать принципы русской графики. Всем нам привычно мыслить о слове как о состоящем из определенных букв. На самом же деле запись при помощи алфавита – это всего лишь один из способов, далеко не всегда отражающий звуковой состав слова. Мы записываем не звуки, а морфемы. Если бы мы отражали то, что слышим, результат был бы безграмотным с точки зрения русской орфографии. Скажем, произносим мы «дуп», а записываем «дуб». Конечный согласный так интерпретируется нами, так как корень «дуб» по правилам русской орфографии должен сохраняться в графическом виде неизменным, независимо от звукового облика слова.
При фонетическом анализе нужно записать слово именно так, как мы его в реальности слышим и произносим (т. е. «дуп», а не «дуб»), а затем прокомментировать каждый звук и слово в целом, используя те сведения, которые получены при изучении школьной программы.
Общая последовательность действий
Фонетический анализ слова делается по четкому плану и с разработанной последовательностью действий. В данном случае это очень важно: нарушение этих разработанных правил может привести к серьезным искажениям и ошибкам. Общая последовательность такова:
- Орфографическая запись слова.
- Постановка ударения. Нередко в этом кроется дополнительное задание –проверяются знания школьника о том, как должна правильно произноситься лексема. Например, в слове «договор» он должен поставить ударение на последний, а не на первый слог.
Корректное выполнение этого этапа особенно важно, если программой предполагается анализ редуцированных гласных.
- Разбивка слова на слоги, запись количества слогов.

- Перед тем как сделать фонетический анализ слова, необходимо рядом в квадратных скобках записать его транскрипцию, то есть представить такой вариант лексемы, какой мы слышим и произносим (освобожденный от правил орфографии). Почему-то именно на этом этапе возникает максимальное количество нарушений. Нередко школьник стремится сначала сделать анализ слова, а уже затем записать транскрипцию. Часто это делает выполнение задания невозможным.
- Запись каждого звука в столбик.
- Комментирование фонетических характеристик гласных и согласных.
- Подсчет букв и звуков.
- Комментарии относительно различия в количестве (если таковые есть). Это подводит итог анализу. Например, нужно объяснить, почему в слове шесть букв, но семь звуков. Нередко формально это количество может совпадать, это не значит, что комментарии не нужны. Скажем, в слове «якорь» пять букв и пять звуков: «я» означает два звука, а «ь» — ноль.

Транскрипция
Фонетический анализ слова по факту чаще всего является звуко-буквенным, так как транскрипция записывается не с нуля, как в вузе, когда интерпретируется звуковой облик слова во всей его полноте. Школьник опирается на орфографическую запись и анализирует, что означает каждая буква. Например, ход его рассуждений может быть приблизительно таков.
Школьник опирается на орфографическую запись и анализирует, что означает каждая буква. Например, ход его рассуждений может быть приблизительно таков.
Слово «якорь». Буква «я» здесь начальная, значит, она обозначает в этом слове два звука: «й» и «а». «К» передает «к». «О» стоит не под ударением, слышится не как «о», а как «а». Сочетание «рь» передает один мягкий звук (мягкость согласных в транскрипции передается апострофом). В результате получаем фонетическую запись: [йакар’]. Многие преподаватели требуют, чтобы йот был передан в транскрипции профессионально, знаком «j».
Что такое редуцированные гласные
Некоторые программы предполагают также использование особенных знаков для так называемых редуцированных гласных. Это часто пугает детей и родителей, однако здесь нет абсолютно ничего сложного. Смысл этого в следующем.
В каждом слове полноценно звучит лишь один гласный звук – тот, который находится под ударением. Остальные звучат неполноценно, кратко, смазанно, терминологически выражаясь – редуцированно. Именно поэтому у нас возникают проблемы с орфографической записью лексической единицы. Например, в слове «якорь» во втором слоге мы не слышим ни «о», ни «а», а слышим нечто среднее. Эти редуцированные звуки в транскрипции должны быть переданы особенными знаками. Безударный звук не приравнивается ни к какому другому звуку, а фиксируется как «нечто среднее».
Именно поэтому у нас возникают проблемы с орфографической записью лексической единицы. Например, в слове «якорь» во втором слоге мы не слышим ни «о», ни «а», а слышим нечто среднее. Эти редуцированные звуки в транскрипции должны быть переданы особенными знаками. Безударный звук не приравнивается ни к какому другому звуку, а фиксируется как «нечто среднее».
Многим школьникам это кажется очень разумным, так как, записывая транскрипцию [йакар’], они испытывают внутреннее сопротивление: ведь они отдают себе отчет в том, что они не слышат во втором слоге «а», как им «диктует» слышать школьная программа.
Правила записей редуцированных гласных
В том случае, если фонетический анализ слова подразумевает запись редуцированных, действовать нужно по четким правилам. Не нужно ни отчаянно прислушиваться к себе, ни «тыкать пальцем в небо», ни мириться с непонятными условностями.
Эти правила таковы.
- Они не касаются звука «у». Этот звук без ударения звучит кратко, но не меняет своих основных качеств. (Терминологически выражаясь, происходит только количественная, а не качественная редукция).
- Безударные слоги могут находиться до ударения и после, поэтому их нужно мыслить как предударные и, соответственно, заударные. Например, в слове «собака» к первым относится «со», а ко вторым – «ка».
- Среди всех безударных слогов особое место занимает первый предударный (то есть тот, который находится непосредственно перед ударением). Гласный на этом месте звучит ярче и «качественнее», чем в других позициях. Например, в слове «колбаса» это слог «ба».
- В том случае, когда любой гласный находится в так называемом абсолютном начале слова, он также звучит ярче и качественнее (его редукция менее выражена). Например, в слове «Антонина» это первый звук, передаваемый на письме буквой «а».
- Безударные звуки, следующие за твердыми согласными, во всех случаях, кроме слога, предшествующего ударному, передаются в транскрипции знаком «ъ». Например, в слове «колбаска» это последний «ка» — [къ], а в глаголе «подходить» — первый «под»: [път]
- Безударные, следующие за твердыми согласными звуками в слоге, предшествущем ударному, и звуки «о» и «а» в абсолютном начале слова передаются знаком Ʌ. «Собака» — [сɅбакъ]. «Антошка» — [Ʌнтошкъ].
- Безударные звуки, следующие за мягкими согласными, во всех случаях, кроме первого предударного слога, передаются в транскрипции знаком «ь». Например, в слове «мизинец» это последний «нец» — [н’ьц], а в глаголе «переходить» — первый «пе» и второй «ре»: [п’ьр’ь].
- Безударные гласные, следующие за мягкими согласными в первом предударном слоге и звуки «и», «э», «ы» абсолютном начале слова передаются знаком иэ (и с призвуком э): «летать» — [л’ иэтат’].
 (Терминологически выражаясь, происходит только количественная, а не качественная редукция).
(Терминологически выражаясь, происходит только количественная, а не качественная редукция). «Собака» — [сɅбакъ]. «Антошка» — [Ʌнтошкъ].
«Собака» — [сɅбакъ]. «Антошка» — [Ʌнтошкъ].Необходимо помнить, что в том случае, если слово начинается с букв я, ю, ё, е, гласные звуки не являются абсолютным началом, так как перед ними находится согласный «й».
Анализ звуков
Собственно, фонетический анализ слова после записи транскрипции, как правило, очень прост и базируется на званиях начальной школы (и совсем немного сложнее, если характеристики звуков изучаются углубленно).
Объем информации о звуках варьируется программой, стандартно же нужно сообщить о каждом звуке следующее.
- О гласном – ударный он или безударный (либо редуцированный). Иногда преподаватель требует также сообщить, к какому ряду относится звук.
- Согласный нужно охарактеризовать по твердости/мягкости и глухости/звонкости и отметить, имеет ли он пару по соответствующему признаку.
Пример 1
Фонетический анализ слова «сирень». Это пример элементарного анализа.
Си-рень. 2 слога, второй из них ударный.
Транскрипция: [c’ир’эн’] или [c’иэр’эн’]
Записываем буквы столбиком:
с
и
р
е
н
ь
Переносим звуки из транскрипции – записываем их столбиком рядом:
c’
и (иэ)
р’
э
н’
Отмечаем, что две буквы – «н» и «ь» обозначают один звук:
н
\
н’
/
ь
Комментируем каждый звук (не букву):
c’ – согл.; мягкий, парный; глухой, парный.
и (иэ) – гласный, безударный (редуцированный).
р’ – согл.; мягк., парн. ; звонк., непарн.
; звонк., непарн.
э – гл., ударный.
н’ – согл.; мягк., парн., звонк., непарн.
Слово записывается шестью буквами, но состоит из 5 звуков (мягкий знак обозначает мягкость согласного [н’].
Пример 2
Фонетический анализ слова «эклер». Это также пример несложного анализа.
Эк-лер: 2 слога, второй из них ударный.
Транскрипция: [экл’эр] или [иэкл’эр]
Записываем буквы столбиком:
э
к
л
е
р
Переносим звуки из транскрипции – записываем их столбиком рядом:
иэ
к
л’
э
р
Комментируем характеристики каждого звука:
э [иэ] – гл., безударн.(редуцированный).
к – согл.; тверд., парн.; глух., парн.
л’ – согл.; мягк., парн.; звон., непарн.
э – гл., ударн..
р – согл.; мягк., парн.; звонк., непарн..
В слове 5 букв, 5 звуков.
Пример 3
Фонетический анализ слова «язык».
Я-зык. 2 слога, второй из них ударный.
Транскрипция: [йэзык] или [jɅзык]
Записываем буквы столбиком:
я
з
ы
к
Переносим в соседний столбик запись звуков из транскрипции:
j
э (Ʌ)
з
ы
к
Отмечаем, что буква «я» в этом слове обозначает не один, а два звука:
й
/
я
\
э (Ʌ)
Записываем характеристики каждого звука:
j – согл.; мягк., непарн.; звонк., непарн.
э (Ʌ) – гласн., безударн. (редуцированный).
з – согл.; тверд., парн.; звонк., парн..
ы – гласн., ударн.
К – согласн.; тверд., парн.; глух., парн.
Слово записывается четырьмя буквами, но состоит из пяти звуков (буква «я» обозначает два звука, так как находится в начале слова).
Иногда программа требует от школьника знания дополнительной терминологии при характеристике звуков (сонорный согласный, количественная и качественная редукция, ряд гласного и т. д.).
В целом фонетический анализ базируется на механически применяемых элементарных знаниях и умении пользоваться четким планом и таблицами. В том случае, если школьник им следует, этот вид задания не составит для него сложностей.
В том случае, если школьник им следует, этот вид задания не составит для него сложностей.
Звуковой анализ слова — Детский сад «Аннушка», г. Нарьян-Мар
Консультация для родителей по подготовке детей к обучению грамоте
«Звуковой анализ слова».
Здравствуйте, уважаемые родители! Предлагаю поговорить о подготовке детей к обучению грамоте, а именно о проведении звукового анализа слов.
Письменная речь формируется на базе устной. И первыми шагами к обучению грамоте должно быть не знакомство с буквами, а усвоение звуковой системы языка.
Каждый из нас улыбнется, вспомнив «народное» правило русского языка: «как слышится, так и пишется». Действительно, если ребенок не произносит звук правильно, вряд ли стоит рассчитывать на то, что он правильно напишет его в тетрадке в недалеком будущем.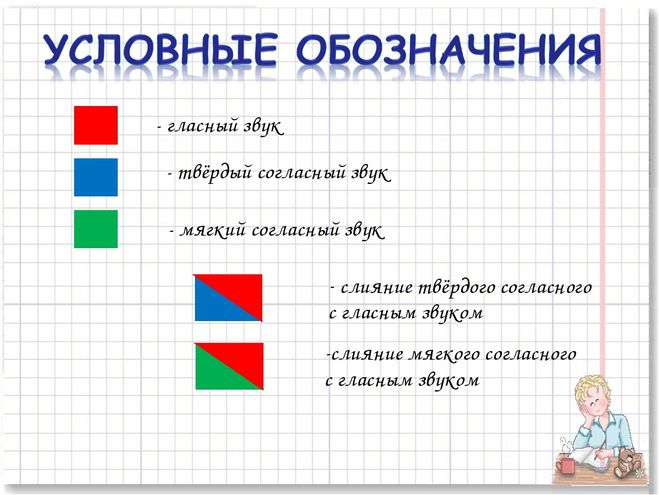
Необходимо обращать внимание не только на правильную артикуляцию звука, но и на умение ребенка выделять, т. е. слышать звуки в слове.
Это навык вырабатывается в ходе систематической работы как педагогов в детском саду, так и родителей дома в таких играх, как: «Назови первый звук в слове», «Подбери словечко», «Поймай звук», «Определи позицию звука в слове», «Найди место картинке» и др.
Уважаемые родители, помните:
1. Звук – мы слышим и произносим.
2. Буквы мы пишем и читаем.
3. Звуки бывают гласными и согласными.
Гласные звуки можно петь голосом, при этом воздух, выходящий изо рта не встречает преграды. Согласные звуки — звуки, которые нельзя петь, т.к. воздух, выходящий изо рта при их произнесении, встречает преграду.
Гласных звуков шесть: А, У, О, И, Э, Ы
Гласных букв десять: А, У, О, И, Э, Ы — соответствуют звукам и четыре йотированные, которые обозначают два звука : Я-йа, Ю-йу, Е-йэ, Ё-йо.
Гласные звуки обозначаются на схеме красным цветом.
Согласные звуки бывают мягкими и твёрдыми.
Всегда твёрдые согласные: Ж, Ш, Ц.
Всегда мягкие согласные: Й, Ч, Щ.
Твёрдые звуки обозначаются на схемах синим цветом, мягкие – зелёным.
Обучение детей звуковому анализу слов начинается с определения последовательности звуков в слове: выделять данную последовательность нужно при помощи неоднократного произнесения слова с интонационным выделением каждого звука. Так, при анализе слова «ЖУК» ребёнок должен произнести его три раза: «ЖЖук», «жУУк», «жуК».
Для того чтобы ребенок мог анализировать какое-то явление, оно должно быть понятно, материально представлено.
Давайте нарисуем схему звукового состава слова: в слове «дом» три звука — нарисуем три клеточки. И дадим ребенку эту карточку: на ней нарисован дом, чтобы ясно было, какое слово будем разбирать, а под домом — схема этого слова: ребёнок уже знает, что слова состоят из звуков.
И дадим ребенку эту карточку: на ней нарисован дом, чтобы ясно было, какое слово будем разбирать, а под домом — схема этого слова: ребёнок уже знает, что слова состоят из звуков.
Мы показываем ему, что клеточки под картинкой подсказывают, сколько звуков в слове. «Сколько клеточек?» — «Три». — «А сколько звуков в слове?» — «Тоже три». — «Давай будем эти звуки искать. Произнеси слово дом так, чтобы я услышала в нем первый звук«. Это наш ребенок уже умеет — научился на первом этапе обучения. «д-дом», -старательно произносит малыш. — «Какой первый звук?» — «Д». — «Очень хорошо! Давай закроем первую клеточку фишкой, это будет какой звук?» — «Д».
В качестве фишек можно использовать любой материал: нарежьте из белого картона квадратики или возьмите старую мозаику и выберите из нее белые или желтые элементы. Не берите красные, синие, зеленые — они еще понадобятся.
Не берите красные, синие, зеленые — они еще понадобятся.
Итак, перед ребенком схема звукового состава слова «дом», в которой первая клеточка уже закрыта. Можно двигаться дальше.
«Давай теперь произнесем слово «дом» так, чтобы услышать в нем второй звук, первый д — мы уже знаем». Помогите ребенку для первого раза, скажите вместе с ним «до-о-ом».
Здесь нам очень поможет схема звукового состава слова: нужно произносить слово и одновременно вести пальцем по схеме и надолго остановить его на второй клеточке. Палец держим на второй клеточке схемы, а вы вместе с ребенком долго тянете «до-о-ом». «Какой же второй звук в этом слове?» — «О!» — «Отлично! Давай обозначим и этот звук фишкой!» Ребенок берет точно такую же, как первая, фишку и ставит ее на вторую клеточку.
«Видишь, — продолжаете вы, — мы уже знаем два звука в слове «дом». Давай найдем последний звук в этом слове. Произнеси слово «дом» так, чтобы слышался последний звук«.
Давай найдем последний звук в этом слове. Произнеси слово «дом» так, чтобы слышался последний звук«.
И снова вы ведете пальцем по уже почти заполненной схеме слова и произносите: «дом-м-м». «Какой последний звук в слове дом-м-м?» — «М-м», — отвечает ребенок и ставит на схему последнюю, третью фишку.
Вот и проведен впервые звуковой анализ слова.
Хорошо бы повторить его еще раз. Но как? Снять фишки и начать все сначала? Это неинтересно малышу! Нет, лучше поиграть в игру «Кто внимательный». «А теперь, — говорите вы, — я буду называть звук, а ты будешь снимать его обозначение со схемы. Посмотрим, какой ты внимательный. Убери, пожалуйста, обозначение звука «д» (фишка синего цвета)
Для данного вида анализа ребёнку предлагаются слова из трех звуков: мак, дом, сыр, кот, кит, шар, жук, лук, лес, рак.
Занимаясь с ребенком, нужно все время помнить: мы учим его звуковому анализу слов, учим его вслушиваться в слово, слышать звуки, его составляющие. Поэтому ребенок должен называть звуки так, как они слышатся в слове.
Особенно важным этот вид работы со звуками является для детей с нарушениями речи. Если вы видите, что со звуковым анализом слова ребёнок не справляется, то возвращайтесь к играм по развитию фонематического слуха.
В процессе анализа з-х звуковых слов напомните ребёнку о наличии в языке гласных и согласных звуков. Сначала предложите ему найти в слове гласный звук и заменить нейтральную фишку на красную.
Затем вспомните о том, что согласные звуки бывают мягкие и твёрдые: твёрдые звуки обозначаем синими фишками, а мягкие – зелёными. Таким образом, теперь при составлении схем слов ребёнок будет пользоваться фишками трёх цветов.
Таким образом, теперь при составлении схем слов ребёнок будет пользоваться фишками трёх цветов.
Все характеристики звуков даются УСТНО (записывать не надо). Если ребёнок захочет, модель слова оформите в виде аппликации, чтобы потом показать ее еще кому-то (попросить бабушку или дедушку «отгадать», что это за «таинственные квадраты»).
Переводчик азбуки Морзе — Азбука Морзе перевод
Параметры
Скрыть параметры
Азбука Морзе СОС
Остановить Азбука Морзе СОС
Азбука Морзе алфавит
Кириллица
| А | .- | Б | -… | В | .— | Г | —. | Д | -.. | Е | . |
| Ж | …- | З | —.. | И | .. | Й | . — — | К | -.- | Л | .-.. |
| М | — | Н | -. | О | — | П | .—. | Р | .-. | С | … |
| Т | — | У | ..- | Ф | ..-. | Х | …. | Ц | -.-. | Ч | —. |
| Ш | —- | Щ | —.- | Ъ | —.— | Ы | -.— | Ь | -..- | Э | ..-.. |
| Ю | ..— | Я | .-.- | Ї | .—. | Є | ..-.. | І | .. | Ґ | —. |
Число
| 0 | —— | 1 | .—- | 2 | ..— | 3 | …— | 4 | ….- | 5 | ….. |
| 6 | -…. | 7 | —… | 8 | —.. | 9 | —-. |
Пунктуация
| . | . -.-.- -.-.- | , | —..— | ? | ..—.. | ‘ | .—-. | ! | -.-.— | / | -..-. |
| ( | -.—. | ) | -.—.- | & | .-… | : | —… | ; | -.-.-. | = | -…- |
| + | .-.-. | — | -….- | _ | ..—.- | « | .-..-. | $ | …-..- | @ | .—.-. |
| ¿ | ..-.- | ¡ | —…- |
Что такое азбука Морзе?
Азбука Морзе — это способ кодирования символов, позволяющий операторам отправлять сообщения, используя серию длинных и коротких электрические сигналы или, другими словами, используя точки и тире.
Кто изобрел азбуку Морзе?
Изобретателями азбуки Морзе считаются Сэмюэл Ф. Б. Морзе и его помощник Альфред Вейл.
Когда была изобретена азбука Морзе?
Азбука Морзе была разработана в 1830-х годах, а в 1840-х годах — усовершенствована.
Какое первое сообщение было отправлено с помощью азбуки Морзе?
Первое официальное сообщение было таким: «What hath God wrought» (на русском: Чудны дела Твои, Господи!). Его отправил Сэмюэл Ф. Б. Морзе 24 мая 1844 года при открытии телеграфной линии Балтимор — Вашингтон.
Для чего используется азбука Морзе?
В прошлом азбука Морзе применялась очень широко, особенно в армии. Сегодня азбука Морзе имеет ограниченную область применения, но она всё еще используется в авиации, в среде радиолюбителей и в качестве вспомогательной технологии для людей с ограниченными физическими возможностями.
Как использовать азбуку Морзе?
Код Морзе можно использовать различными способами, например, с помощью ручки и бумаги, с помощью света и звука или даже с помощью глаз или пальцев.
Как учить азбуку Морзе?
Вы можете изучить азбуку Морзе, слушая аудиозаписи с кодом, а также применяя методы запоминания слов, которые можно найти на различных сайтах. Одним из лучших методов обучения азбуке Морзе в 2022 году стала клавиатура Gboard от компании Google. Вы можете заниматься онлайн бесплатно с помощью упражнений для изучения кода Морзе, предоставляемых лабораторией Google Creative Lab.
Вы можете заниматься онлайн бесплатно с помощью упражнений для изучения кода Морзе, предоставляемых лабораторией Google Creative Lab.
Как читать код Морзе?
Если вам не хватает опыта в чтении кода Морзе, вы можете найти соответствующие коду символы в таблице с азбукой Морзе, или просто использовать переводчик азбуки Морзе.
Как перевести код Морзе?
Если вы хотите перевести или расшифровать код Морзе и не умеете его читать, то можете просто использовать переводчик азбуки Морзе онлайн. С помощью переводчика азбуки Морзе вы можете легко расшифровать код и прочитать текст на русском языке.
Что такое переводчик азбуки Морзе?
Переводчик азбуки Морзе позволяет любому человеку переводить код Морзе в текст и легко декодировать сообщение, записанное кодом. С помощью онлайн-переводчика кода Морзе любой человек может перевести простой текст на русском или другом языке в код Морзе и наоборот. Помните ли вы мелодию SMS-сигнала Nokia? Если хотите испытать ностальгию, попробуйте расшифровать код «. .. — …», а затем воспроизвести звук. Что если вам потребуется расшифровать секретное сообщение на азбуке Морзе или вы наткнетесь в игре на пасхальное яйцо с кодом? Переводчик азбуки Морзе к вашим услугам 7/24, если у вас есть интернет-соединение и желание выучить азбуку Морзе.
.. — …», а затем воспроизвести звук. Что если вам потребуется расшифровать секретное сообщение на азбуке Морзе или вы наткнетесь в игре на пасхальное яйцо с кодом? Переводчик азбуки Морзе к вашим услугам 7/24, если у вас есть интернет-соединение и желание выучить азбуку Морзе.
Как будет СОС на азбуке Морзе?
СОС на азбуке Морзе выглядит так: «… — …»
Как будет «Я люблю тебя» на азбуке Морзе?
«Я люблю тебя» на азбуке Морзе: «.-.- / .-.. ..— -… .-.. ..— / — . -… .-.-»
Переводчик азбуки Морзе онлайн
- Главная
- Инструменты
- Работа с текстом
- Переводчик азбуки Морзе онлайн
Азбука Морзе — код Морзе, «Морзянка» — способ кодирования букв алфавита, цифр, знаков препинания и других символов при помощи длинных и коротких сигналов, так называемых «тире» и «точек» (а также пауз, разделяющих буквы).
За единицу времени принимается длительность одной точки. Длительность тире равна трём точкам. Пауза между знаками в букве — одна точка, между буквами в слове — 3 точки, между словами — 7 точек.
Пауза между знаками в букве — одна точка, между буквами в слове — 3 точки, между словами — 7 точек.
На этой странице Вы можете бесплатно воспользоваться сервисом для конвертерования текста в Азбуку Морзе или наоборот.
| Русский символ | Латинский символ | Код Морзе |
|---|---|---|
| А | A | •− |
| Б | B | −••• |
| В | W | •−− |
| Г | G | −−• |
| Д | D | −•• |
| Е и Ё | E | • |
| Ж | V | •••− |
| З | Z | −−•• |
| И | I | •• |
| Й | J | •−−− |
| К | K | −•− |
| Л | L | •−•• |
| М | M | −− |
| Н | N | −• |
| О | O | −−− |
| П | P | •−−• |
| Р | R | •−• |
| С | S | ••• |
| Т | T | − |
| У | U | ••− |
| Ф | F | ••−• |
| Х | H | •••• |
| Ц | C | −•−• |
| Ч | Ö | −−−• |
| Ш | CH | −−−− |
| Щ | Q | −−•− |
| Ъ | Ñ | −−•−− |
| Ы | Y | −•−− |
| Ь | X | −••− |
| Э | É | ••−•• |
| Ю | Ü | ••−− |
| Я | Ä | •−•− |
| Русский символ | Латинский символ | Код Морзе |
|---|---|---|
| 1 | •−−−− | |
| 2 | ••−−− | |
| 3 | •••−− | |
| 4 | ••••− | |
| 5 | ••••• | |
| 6 | −•••• | |
| 7 | −−••• | |
| 8 | −−−•• | |
| 9 | −−−−• | |
| 0 | −−−−− | |
. | •••••• | |
| , | . | •−•−•− |
| ! | , | −−••−− |
| ! | −•−•−− | |
| ? | ••−−•• | |
| ‘ | •−−−−• | |
| « | •−••−• | |
| ; | −•−•−• | |
| : | −−−••• | |
| — | −••••− | |
| + | •−•−• | |
| = | −•••− | |
| _ (подчёркивание) | ••−−•− | |
| / | −••−• | |
| ( | −•−−• | |
| ( или ) | ) | −•−−•− |
| & | •−••• | |
| $ | •••−••− | |
| @ | •−−•−• | |
| Ошибка | Error | •••••••• |
| Конец связи | End contact | ••−•− |
P. S. Следует отметить, что хотя русская азбука Морзе частично совпадает с латинской, но всё же есть некоторые отличия (сравнивал на русской и английской страницах Википедии — там же можно посмотреть таблицы кодов). Например:
S. Следует отметить, что хотя русская азбука Морзе частично совпадает с латинской, но всё же есть некоторые отличия (сравнивал на русской и английской страницах Википедии — там же можно посмотреть таблицы кодов). Например:
- символ «точка» в русском варианте: · · · · · · , а в латинском: · – · – · –
- запятая в русском: · − · − · − , а в латинском: – – · · – –
- восклицательный знак в русском: − − · · − − , а в латинском: – · – · – –
- открывающая скобка в латинском: – · – – · , а закрывающая – · – – · – , а в русском обе скобки одинаковые: – · – – · –
- некоторые символы вроде & + _ $ есть только в латинском варианте
Поэтому при спорных моментах, например, конвертировать код − − · · − − в восклицательный знак (по-русской версии) или в запятую (по латинской), предпочтение отдаётся русской версии, поскольку раз Вы читаете это сообщение на русском, то предполагается, что для Вас важнее именно русский вариант.
Чтобы произвести расчеты, необходимо разрешить элементы ActiveX!
Работа с текстом Инструмент Текст 5103811
Существует множество вариантов расшифровок сигнала бедствия SOS — «Save Our Souls», «Save Our Ship», «Swim Or Sink», «Stop Other Signals», «Спасите От Смерти». Но все они являются лишь мнемониками, придуманными для лучшего запоминания, тогда как во время принятия этого сигнала в качестве стандартного на Международной радиотелеграфной конференции 1906 года никакого смысла в аббревиатуру не закладывалось. Даже сами буквы SOS к последовательности азбуки Морзе (. . . — — — . . .) можно отнести весьма условно, ведь в ней нет межбуквенных интервалов. А приняли эту комбинацию точек и тире из-за того, что она оказалась удобнее других для распознавания и выделения в общем потоке сигналов благодаря достаточной длине и симметричности.
Сэмюэл Морзе до 34 лет был художником и не интересовался техникой.
В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.Азбуку Морзе в привычном нам виде изобрёл не Морзе, а немецкий инженер Герке. Оригинальная азбука Морзе была неудобной, хотя и использовалась на некоторых американских железных дорогах вплоть до 1960-х годов.
6 февраля 1900 года расположенная в финском городе Котка радиостанция передала на ледокол «Ермак» беспроводную телеграмму с приказом спасти находящихся на оторвавшейся льдине 50 рыбаков. Это была первая в истории передача радиосигнала о бедствии на море. Спасательная операция завершилась успешно.
Современные субмарины оснащены более эффективными средствами коммуникации с «наземным миром». Связь ведется на сверхдлинных волнах, которые способны проникать на океанскую глубину до 300 метров. Это очень дорогостоящая «мобильная связь», которая требует содержания мощных наземных антенных полей, потребляющих мощность до 30 МВт, и постоянно барражирующих в небе связных самолетов.
Сигнал SOS передается на частоте 600 метров лишь в случае крайней необходимости, когда экипажу судна и пассажирам угрожает реальная опасность для жизни. В случае нарушения этого правила на виновников необоснованной паники может быть наложено взыскание. Либо моральное, что в морском сообществе не пустой звук. Либо материальное — когда пришедшие на помощь суда понесут значительные материальные потери. Однако существует исключение из этого непреложного правила. Капитан судна в некоторых случаях может передавать на «сосовой частоте» в три фиксированных «минуты молчания» информацию о возникновении серьезной угрозы для находящихся в регионе кораблей.
Это могут быть сообщения о неисправности маяков, о вулканической деятельности, об активности пиратов, о затонувших судах…Для ускорения радиообмена в широкое использование были введены аббревиатуры, трёхбуквенные «Q-коды» и многочисленные жаргонные выражения. От того передается Q код в виде вопроса или утверждения, меняется его значение. В голосовой связи сигнал SOS не применяется, сигналом бедствия служит Mayday. Запрещено подавать сигнал SOS, если на то нет реальной угрозы для жизни людей или судна на море.
 В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.
В 1825 году посыльный доставил ему письмо от отца, в котором говорилось, что его жена умирает. Морзе немедленно покинул Вашингтон и отправился в Нью-Хейвен, где жило его семейство, но к его прибытию супругу уже похоронили. Этот случай заставил Морзе оставить живопись и углубиться в изучение способов быстрой доставки сообщений на длинные расстояния, что привело к разработке азбуки Морзе и электрического телеграфа в 1838 году.
 Это могут быть сообщения о неисправности маяков, о вулканической деятельности, об активности пиратов, о затонувших судах…
Это могут быть сообщения о неисправности маяков, о вулканической деятельности, об активности пиратов, о затонувших судах…Если материал понравился Вам и оказался для Вас полезным, поделитесь им со своими друзьями!
Сумма прописью. Перевод числа в пропись
Перевод числа в пропись.
Работа с текстом Инструмент Текст
Конвертер текста в цифровой код
Онлайн калькулятор преобразует символы в их цифровые коды.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Подсчет количества символов
Подсчет количества символов.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Подсчет количества символов в тексте
Сколько символов, строк и количество слов находятся в строке.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер текста в юникод
Конвертер для перевода любого текста (не только кириллицы) в Юникод.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер букв в HTML-коды
Конвертер для перевода любого текста в HTML-коды.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер регистра букв
Сервис по изменению написания букв с заглавных на строчные или строчных на заглавные.
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст
Конвертер HTML кодов в текст
Конвертер для перевода ASCII кодов в текст
Работа с текстом Калькулятор Расчёт Конвертер Преобразовать Текст

Процент / доля от числа
Арифметика Калькулятор Расчёт Проценты
Старинные русские меры длины, веса, объёма
Система древнерусских мер длины включала в себя следующие основные меры: версту, сажень, аршин, локоть, пядь и вершок.
Разное Мощность Сила Единицы измерения Деньги Справочник
Калькулятор калорий для похудения онлайн
Калькуляторы веса и калорий Калькулятор Расчёт
Конвертер возраста животных и человека
Калькуляторы времени и даты Калькулятор Расчёт Конвертер Преобразовать Время
Треугольник Паскаля
Числа Калькулятор Расчёт Математика Формулы
Таблица перевода сухопутных миль в километры (mi в км)
1 сухопутная миля (США и Британия) = 1,60934 км
Размеры и расстояния Теория Расстояния
Сколько километров в миле?
Морскую милю приравняли к 1862 метрам, сухопутная американская миля равна 1.609344 километра.
Размеры и расстояния Длина Формулы
Калькулятор веса по росту и возрасту
Калькуляторы веса и калорий Калькулятор Расчёт

Все о синтаксическом анализе: что это такое и как он связан с программным обеспечением для преобразования текста в речь | Алекс Кителингер | Voice Tech Podcast
В мире распознавания речи — как и в любой лингвистической области — слово «анализ» часто используется, имея более чем пару значений и приложений.
В самом базовом определении «разбор» означает «анализ (в данном случае предложения) с точки зрения грамматических составляющих, определение частей речи, синтаксических отношений и т. д.». Для нас это означает, что мы берем предложение как единое целое и разбиваем его на понятные фрагменты с их собственным значением и контекстом, а также описываем их отношение друг к другу. Традиционно вы можете увидеть это как «дерево» предложения после того, как оно тем или иным образом проанализировано. Возьмем мой любимый пример, сказанный Граучо Марксом: «Сегодня утром я застрелил слона в пижаме…»
Теперь, если принять это предложение за чистую монету (без спойлеров, те, кто это знает), мы посмотрим на типичную интерпретацию основной части этого предложения. Мы опустим «сегодня утром», потому что это немного усложняет ситуацию. У нас осталось следующее:
Я был в пижаме, я застрелил слона. Просто обычное воскресенье! (Источник) Это дерево предложений в очень простом смысле; представление того, как мы могли бы классически разобрать это. Но тот факт, что анализ, подобный этому, настолько специфичен и информативен, может быть сложной проблемой при ограниченной информации, как мы увидим на полном примере этой цитаты: «Этим утром я застрелил слона в пижаме. Как он оказался в моей пижаме, я не знаю!»
Но тот факт, что анализ, подобный этому, настолько специфичен и информативен, может быть сложной проблемой при ограниченной информации, как мы увидим на полном примере этой цитаты: «Этим утром я застрелил слона в пижаме. Как он оказался в моей пижаме, я не знаю!»
Мне не хочется слишком объяснять шутку 90-летней давности, поэтому я позволю ей усвоиться, предоставив альтернативный (и правильный, в данном случае) разбор вышеизложенного.
Действительно маловероятный сценарий! Немного садовой дорожки.Создавайте лучшие голосовые приложения. Получите больше статей и интервью от экспертов по голосовым технологиям на voicetechpodcast.com
Смысл этого, помимо прекрасного предлога, чтобы заставить вас всех услышать немного классической игры слов, состоит в том, чтобы показать, что наличие всех слов во фразе недостаточно, чтобы получить его полное значение во многих случаях. Мы, люди, чертовски хорошо интерпретируем значение предложения из контекста (вперёд, люди!), но для машин это сложный процесс. Когда мы говорим о синтаксическом анализе в компьютерной лингвистике, эти предложения должны интерпретироваться в соответствии с установленной грамматикой: установленным набором правил того, как работает данный язык, чтобы определить, что является «грамматическим», а что нет. Это используется в качестве основы для структурирования предложения в возможных интерпретациях. я говорю «возможно» здесь очень преднамеренно, поскольку человеческие языки в целом (особенно английский) имеют большую тенденцию к двусмысленности. Обычно это обходится с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или подобного предложения и будет просто давать вероятность каждой данной интерпретации.
Когда мы говорим о синтаксическом анализе в компьютерной лингвистике, эти предложения должны интерпретироваться в соответствии с установленной грамматикой: установленным набором правил того, как работает данный язык, чтобы определить, что является «грамматическим», а что нет. Это используется в качестве основы для структурирования предложения в возможных интерпретациях. я говорю «возможно» здесь очень преднамеренно, поскольку человеческие языки в целом (особенно английский) имеют большую тенденцию к двусмысленности. Обычно это обходится с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или подобного предложения и будет просто давать вероятность каждой данной интерпретации. С тех пор мы прошли долгий путь, но там есть что рассказать… так что я не буду! По крайней мере, не сегодня.
С тех пор мы прошли долгий путь, но там есть что рассказать… так что я не буду! По крайней мере, не сегодня.
Возможно, более интересной является текущая реализация того, как работают наши голосовые помощники. Alexa, например, не выполняет всю эту тяжелую работу локально (как и другие, хотя это может быть не всегда так…) Ваше устройство Echo возьмет полученный звуковой файл (прочитайте мой последний пост, если вы любопытно, как работает это волшебство), и передайте его в службу Alexa, размещенную в облаке Amazon, и основная часть обработки будет выполняться там. Даже в этом случае работа сильно урезана по сравнению с этой увесистой моделью сравнения. Alexa действует на основе нескольких ключевых элементов, которые она ищет в запросе, и использует их для определения основного значения того, что вы ищете. Ниже показан пример запроса из отличного руководства для тех, кто ищет краткий обзор начала разработки для устройств с поддержкой Alexa:
Способ анализа запроса Alexa (вверху) и данные, которые она отправляет в навык (внизу) (Источник) нужно определить, каковы названия призыва и навыка, а затем проанализировать, где находится «высказывание», и действовать, основываясь только на этом небольшом фрагменте. Даже в этом случае гораздо проще разобрать, когда структура запроса уже известна; вы просите свое устройство выполнить задачу за вас, и это серьезно ограничивает возможности того, что вы могли бы сказать.
Даже в этом случае гораздо проще разобрать, когда структура запроса уже известна; вы просите свое устройство выполнить задачу за вас, и это серьезно ограничивает возможности того, что вы могли бы сказать.В этом много всего, и я только начинаю царапать поверхность, но суть в том, что «разбор» того, что вы говорите, за рамками виртуальных помощников — это огромное испытание, полное ошибок и несоответствий, особенно если учесть, что то, как мы, люди, говорим, откровенно говоря, состоит из ошибок и несоответствий. Даже в этом ограниченном контексте, который мы оцениваем с помощью Alexa, предстоит проделать большую работу. Я определенно планирую продолжить копаться в мельчайших подробностях того, что происходит, чтобы добраться из пункта А в пункт Б, но я надеюсь, что этот небольшой обзор был хотя бы немного проницательным!
Определение и значение какофонии — Merriam-Webster
ca·coph·o·ny ka-ka-fə-nē
-ˈkȯ-,
также -ka-
1
: резкий или резкий звук : чувство диссонанса 2
конкретно : резкость в звучании слов или фраз
2
: нелепая или хаотичная смесь : поразительная комбинация
какофония цветов
какофония запахов
Знаете ли вы?
Слова, происходящие от греческого слова phōnē , в английском языке производят шум. Почему? Потому что phōnē означает «звук» или «голос». Какофония происходит от соединения греческого префикса как- (от kakos , что означает «плохой») с phōnē , так что по сути это означает «плохой звук». Symphony , слово, обозначающее гармонию или согласие в звучании, восходит к phōnē и греческой приставке 9.0003 syn-, что означает «вместе». Полифония относится к стилю музыкальной композиции, в котором две или более независимых мелодий гармонично сопоставляются, и происходит от комбинации phōnē и греческого префикса поли-, что означает «много». А euphony , слово, обозначающее приятный или сладкий звук, сочетает в себе phōnē с eu-, префикс, означающий «хороший».
Почему? Потому что phōnē означает «звук» или «голос». Какофония происходит от соединения греческого префикса как- (от kakos , что означает «плохой») с phōnē , так что по сути это означает «плохой звук». Symphony , слово, обозначающее гармонию или согласие в звучании, восходит к phōnē и греческой приставке 9.0003 syn-, что означает «вместе». Полифония относится к стилю музыкальной композиции, в котором две или более независимых мелодий гармонично сопоставляются, и происходит от комбинации phōnē и греческого префикса поли-, что означает «много». А euphony , слово, обозначающее приятный или сладкий звук, сочетает в себе phōnē с eu-, префикс, означающий «хороший».
Синонимы
- вавилон
- рев
- шумиха
- луквау
- драка
- шум [ архаичный ]
- болтовня
- шум
- лязг
- децибел(ов)
- дин
- несоответствие
- Катценджаммер
- шум
- ракетка
- погремушка
- рев
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Какофония флегматических и туберкулезных легких тут и там прерывалась стоном или криком кого-то испуганного, бьющегося в муках кошмара. Рональд Гирлз, 9 лет0003 Время отмены , 2001
Бурлящий газ прямо под видимой поверхностью Солнца создает какофонию звуковых волн, которые звенят в Солнце, как в гигантском колоколе.
Р. Коуэн, Science News , 18 марта 2000 г.
Гильзы валялись на шоссе, где какофония автомобильных сигнализаций и рыданий разрывала зимний воздух.
Джефф Стейн, 9 лет0003 GQ , декабрь 1997 г.
… каким бы терпеливым он ни был, были моменты, когда ему просто нужно было убежать от этой какофонии писклявых голосов…
Т. Корагессан Бойл, Дорога в Веллвилль , 1993
Рональд Гирлз, 9 лет0003 Время отмены , 2001
Бурлящий газ прямо под видимой поверхностью Солнца создает какофонию звуковых волн, которые звенят в Солнце, как в гигантском колоколе.
Р. Коуэн, Science News , 18 марта 2000 г.
Гильзы валялись на шоссе, где какофония автомобильных сигнализаций и рыданий разрывала зимний воздух.
Джефф Стейн, 9 лет0003 GQ , декабрь 1997 г.
… каким бы терпеливым он ни был, были моменты, когда ему просто нужно было убежать от этой какофонии писклявых голосов…
Т. Корагессан Бойл, Дорога в Веллвилль , 1993
К какофонии добавлены крики на улицах.
какофония зоомагазина, полного животных Узнать больше
Недавние примеры в Интернете какофонии голосов, конечно, смущали бы, но дебаты необходимы для здоровой демократии. New York Times , 8 июля 2021 г.
В предрассветные часы 12 июля Фуртнеру и его команде наконец удалось поспать несколько часов, четверо из них рухнули на койки в каютах в какофонии храпа, а пятый на мате на камбузе. Anchorage Daily News , 28 августа 2022 г.
За рекой на улицах Северодонецка то было жутко тихо, то какофония выстрелов и взрывов. New York Times , 9 июня 2022 г.
Например, при работе с группой результатом может быть хаотическая какофония голосов, сливающихся или даже сталкивающихся друг с другом.
Сет Комбс, писатель, San Diego Union-Tribune , 16 января 2022 г.
Фиори был встречен какофонией аплодисментов от своих восторженных товарищей по команде, как только рекорд был официально объявлен.
Джейкоб Стейнберг, 9 лет0003 Балтимор Вс , 21 июля 2022 г.
К ним присоединились другие, и ситуация быстро переросла в какофонию криков.
Оливия Краут, The Courier-Journal , 23 июня 2021 г.
Anchorage Daily News , 28 августа 2022 г.
За рекой на улицах Северодонецка то было жутко тихо, то какофония выстрелов и взрывов. New York Times , 9 июня 2022 г.
Например, при работе с группой результатом может быть хаотическая какофония голосов, сливающихся или даже сталкивающихся друг с другом.
Сет Комбс, писатель, San Diego Union-Tribune , 16 января 2022 г.
Фиори был встречен какофонией аплодисментов от своих восторженных товарищей по команде, как только рекорд был официально объявлен.
Джейкоб Стейнберг, 9 лет0003 Балтимор Вс , 21 июля 2022 г.
К ним присоединились другие, и ситуация быстро переросла в какофонию криков.
Оливия Краут, The Courier-Journal , 23 июня 2021 г. Для тех, чья способность контролировать окружающую среду настолько ограничена, сладкая какофония падающих кеглей в боулинге является не чем иным, как чудом.
Кейт Сантич, 9 лет0003 Орландо Сентинел , 1 августа 2022 г.
Эти обитающие на рифах существа щелкают когтями, чтобы выпустить струи воды, которые оглушают добычу, производя какофонию с уровнем шума в 210 децибел — громкую, как рок-концерт.
Кейт Голембиевски, Scientific American , 27 июля 2022 г.
Узнать больше
Для тех, чья способность контролировать окружающую среду настолько ограничена, сладкая какофония падающих кеглей в боулинге является не чем иным, как чудом.
Кейт Сантич, 9 лет0003 Орландо Сентинел , 1 августа 2022 г.
Эти обитающие на рифах существа щелкают когтями, чтобы выпустить струи воды, которые оглушают добычу, производя какофонию с уровнем шума в 210 децибел — громкую, как рок-концерт.
Кейт Голембиевски, Scientific American , 27 июля 2022 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «какофония». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
заимствовано из французского и новой латыни; Французский какофония, восходящий к среднефранцузскому, заимствованный из New Latin Cacophōnia, , заимствованные у греческого Kakophōnía, из Kakóphōnos «Неогасно звучащий, какофонный» + -ia -ia inpit 1
. Первое известное использование
Circa 1656, в значении. Путешественник во времени
Первое известное использование какофонии было около 1656 г.
Другие слова того же года
Подкаст
Музыкальная тема Джошуа Стэмпера ©2006 New Jerusalem Music/ASCAP
Получите Слово Дня на ваш почтовый ящик!
Словарные статьи Около
Какофониякакофонический
какофония
какотелин
Посмотреть другие записи поблизости
Процитировать эту запись0005
«Какофония». Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/cacophony. По состоянию на 28 сентября 2022 г.0005
Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/cacophony. По состоянию на 28 сентября 2022 г.0005
Britannica.com: Энциклопедическая статья о какофонии
Последнее обновление: 14 сентября 2022 г.
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
Глубокое обучение аудио стало проще: автоматическое распознавание речи (ASR), как это работает | Кетан Доши
Практические руководства, СЕРИЯ INTUITIVE AUDIO DEEP LEARNING
Алгоритм и архитектура преобразования речи в текст, включая спектрограммы Мела, MFCC, потери CTC и декодер, на простом английском языке
Фото Soundtrap на Unsplash За последние несколько лет голосовые помощники стали повсеместными благодаря популярности Google Home, Amazon Echo, Siri, Cortana и других. Это самые известные примеры автоматического распознавания речи (ASR). Этот класс приложений начинается с фрагмента произнесенной аудиозаписи на каком-либо языке и извлекает произнесенные слова в виде текста. По этой причине они также известны как алгоритмы преобразования речи в текст.
Это самые известные примеры автоматического распознавания речи (ASR). Этот класс приложений начинается с фрагмента произнесенной аудиозаписи на каком-либо языке и извлекает произнесенные слова в виде текста. По этой причине они также известны как алгоритмы преобразования речи в текст.
Конечно, такие приложения, как Siri и другие, упомянутые выше, идут дальше. Они не только извлекают текст, но также интерпретируют и понимают семантическое значение того, что было сказано, так что они могут отвечать ответами или выполнять действия на основе команд пользователя.
В этой статье я сосредоточусь на основных возможностях преобразования речи в текст с использованием глубокого обучения. Моя цель будет заключаться в том, чтобы понять не только то, как что-то работает, но и почему это работает именно так.
У меня есть еще несколько статей из моей серии по глубокому обучению аудио, которые могут быть вам полезны. Они исследуют другие интересные темы в этой области, в том числе то, как мы подготавливаем аудиоданные для глубокого обучения, почему мы используем спектрограммы Мела для моделей глубокого обучения и как они генерируются и оптимизируются.
- Передовые методы (Что такое звук и как он оцифровывается. Какие проблемы в нашей повседневной жизни решает глубокое обучение звука. Что такое спектрограммы и почему они так важны.)
- Почему Спектрограммы Mel работают лучше (Обработка аудиоданных в Python. Что такое спектрограммы Mel и как их генерировать)
- Подготовка и дополнение данных (Расширение функций спектрограмм для оптимальной производительности за счет настройки гиперпараметров и увеличения данных)
- Классификация звуков (Сквозной пример и архитектура для классификации обычных звуков. Основополагающее приложение для ряда сценариев.)
- Поиск луча (Алгоритм, обычно используемый приложениями преобразования речи в текст и НЛП для улучшения прогнозы)
Как мы можем себе представить, человеческая речь имеет основополагающее значение для нашей повседневной личной и деловой жизни, а функция преобразования речи в текст имеет огромное количество приложений. Его можно использовать для расшифровки содержания звонков службы поддержки клиентов или продаж, для голосовых чат-ботов или для записи содержания встреч и других обсуждений.
Его можно использовать для расшифровки содержания звонков службы поддержки клиентов или продаж, для голосовых чат-ботов или для записи содержания встреч и других обсуждений.
Основные аудиоданные состоят из звуков и шумов. Человеческая речь — частный случай этого. Таким образом, концепции, о которых я говорил в своих статьях, например, как мы оцифровываем звук, обрабатываем аудиоданные и почему мы конвертируем аудио в спектрограммы, также применимы к пониманию речи. Однако речь сложнее, потому что она кодирует язык.
Такие задачи, как классификация звука, начинаются со звукового клипа и позволяют предсказать, к какому классу принадлежит звук из заданного набора классов. Для задач преобразования речи в текст ваши обучающие данные состоят из:
- Функции ввода ( X ): аудиоклипы произносимых слов
- Целевые метки ( y ): текстовая расшифровка того, что было произнесено labels (Изображение автора)
Цель модели — научиться воспринимать входной звук и предсказывать текстовое содержание произнесенных слов и предложений.
В статье о классификации звука я шаг за шагом объясняю преобразования, которые используются для обработки аудиоданных для моделей глубокого обучения. С человеческой речью мы также придерживаемся аналогичного подхода. Есть несколько библиотек Python, которые предоставляют функциональные возможности для этого, и librosa является одной из самых популярных.
Преобразование необработанных аудиоволн в изображения спектрограммы для ввода в модель глубокого обучения (Изображение автора)Загрузка аудиофайлов
- Начните с входных данных, состоящих из аудиофайлов устной речи в аудиоформате, таком как «.wav» или «.mp3».
- Прочитайте аудиоданные из файла и загрузите их в двумерный массив Numpy. Этот массив состоит из последовательности чисел, каждое из которых представляет измерение интенсивности или амплитуды звука в определенный момент времени. Количество таких измерений определяется частотой дискретизации. Например, если частота дискретизации была 44,1 кГц, массив Numpy будет иметь одну строку из 44 100 чисел для 1 секунды звука.
- Аудио может иметь один или два канала, называемых в просторечии моно или стерео. С двухканальным звуком у нас была бы другая аналогичная последовательность чисел амплитуды для второго канала. Другими словами, наш массив Numpy будет трехмерным с глубиной 2.
Преобразование в единые размеры: частота дискретизации, каналы и продолжительность
- У нас может быть много вариаций в наших элементах аудиоданных. Клипы могут быть сэмплированы с разной частотой или иметь разное количество каналов. Клипы, скорее всего, будут иметь разную продолжительность. Как объяснялось выше, это означает, что размеры каждого аудио элемента будут разными.
- Поскольку наши модели глубокого обучения предполагают, что все наши входные элементы будут иметь одинаковый размер, теперь мы выполняем некоторые шаги по очистке данных, чтобы стандартизировать размеры наших аудиоданных. Мы передискретизируем звук, чтобы каждый элемент имел одинаковую частоту дискретизации. Мы конвертируем все элементы в одинаковое количество каналов. Все элементы также должны быть преобразованы в одинаковую продолжительность звука. Это включает в себя дополнение более коротких последовательностей или усечение более длинных последовательностей.
- Если качество звука было плохим, мы могли бы улучшить его, применив алгоритм шумоподавления для устранения фонового шума, чтобы мы могли сосредоточиться на разговорном звуке.
Увеличение данных необработанного аудио
- Мы могли бы применить некоторые методы увеличения данных, чтобы добавить больше разнообразия к нашим входным данным и помочь модели научиться обобщать более широкий диапазон входных данных. Мы могли бы сместить звук во времени влево или вправо случайным образом на небольшой процент или изменить высоту тона или скорость звука на небольшую величину.
Спектрограммы Мела
- Этот необработанный звук теперь преобразован в Спектрограммы Мела. Спектрограмма фиксирует характер звука в виде изображения, разлагая его на набор частот, которые в него включены.
MFCC
- В частности, для человеческой речи иногда полезно сделать еще один шаг и преобразовать спектрограмму Mel в MFCC (частотные кепстральные коэффициенты Mel). MFCC создают сжатое представление спектрограммы Мела, извлекая только самые важные частотные коэффициенты, которые соответствуют диапазонам частот, в которых говорят люди.
Увеличение данных спектрограмм
- Теперь мы можем применить еще один шаг увеличения данных к изображениям спектрограмм Мела, используя технику, известную как SpecAugment. Это включает частотную и временную маскировку, которая случайным образом маскирует либо вертикальные (т. е. временная маска), либо горизонтальные (т. е. частотная маска) полосы информации из спектрограммы. NB: я не уверен, можно ли это применить к MFCC и дает ли это хорошие результаты.
Теперь мы преобразовали исходный необработанный аудиофайл в изображения Mel Spectrogram (или MFCC) после очистки и дополнения данных.
Нам также необходимо подготовить целевые метки из стенограммы. Это обычный текст, состоящий из предложений слов, поэтому мы строим словарь из каждого символа в расшифровке и конвертируем их в идентификаторы символов.
Это дает нам наши входные функции и наши целевые метки. Эти данные готовы для ввода в нашу модель глубокого обучения.
Существует множество вариантов архитектуры глубокого обучения для ASR. Два широко используемых подхода:
- CNN (сверточная нейронная сеть) плюс архитектура на основе RNN (рекуррентная нейронная сеть), которая использует алгоритм CTC Loss для разграничения каждого символа слов в речи. например. Модель глубокой речи Baidu.
- Сеть от последовательности к последовательности на основе RNN, которая рассматривает каждый «срез» спектрограммы как один элемент в последовательности, например. Модель Google Listen Attend Spell (LAS).
Давайте выберем первый способ, описанный выше, и более подробно рассмотрим, как он работает.
На высоком уровне модель состоит из следующих блоков:- Обычная сверточная сеть, состоящая из нескольких слоев Residual CNN, которые обрабатывают входные изображения спектрограммы и выходные карты признаков этих изображений.
- Обычная рекуррентная сеть, состоящая из нескольких двунаправленных слоев LSTM, которые обрабатывают карты объектов как серию отдельных временных шагов или «кадров», которые соответствуют нашему желаемая последовательность выходных символов. (LSTM — это очень часто используемый тип рекуррентного уровня, полной формой которого является долговременная кратковременная память). Другими словами, он берет карты характеристик, которые представляют собой непрерывное представление звука, и преобразует их в дискретное представление.
- Линейный слой с softmax, который использует выходные данные LSTM для получения вероятностей символов для каждого временного шага вывода.
- У нас также есть линейные слои, которые находятся между сверточной и рекуррентной сетями и помогают преобразовать выходные данные одной сети во входные данные другой.
Итак, наша модель берет изображения спектрограммы и выводит вероятности символов для каждого временного шага или «кадра» в этой спектрограмме.
Если вы немного подумаете об этом, вы поймете, что в нашей головоломке все еще не хватает крупной детали. Наша конечная цель — сопоставить эти временные шаги или «кадры» с отдельными символами в нашей целевой расшифровке.
Модель декодирует вероятности символов для получения окончательного результата (Изображение автора)Но для конкретной спектрограммы, как мы узнаем, сколько должно быть кадров? Как мы точно знаем, где находятся границы каждого кадра? Как мы выровняем звук с каждым символом в текстовой расшифровке?
Слева нужный нам расклад. Но как мы его получим?? (Изображение автора)Аудио и изображения спектрограммы не были предварительно сегментированы, чтобы дать нам эту информацию.
- В разговорном аудио, а значит и в спектрограмме, звук каждого символа может быть разной продолжительности.
- Между этими символами могут быть пробелы и паузы.
- Несколько символов могут быть объединены вместе.
- Некоторые символы могут повторяться. например. в слове «яблоко», как мы узнаем, действительно ли этот звук «р» в аудио соответствует одному или двум «р» в стенограмме?
На самом деле это очень сложная проблема, и именно поэтому ASR так сложно решить правильно. Это отличительная характеристика, которая отличает ASR от других аудиоприложений, таких как классификация и так далее.
Мы решаем эту проблему с помощью гениального алгоритма с причудливо звучащим названием — он называется коннекционистской временной классификацией, или сокращенно CTC.
Поскольку я не «модный человек» и мне трудно запомнить это длинное имя, я просто буду использовать имя CTC для обозначения его 😃.CTC используется для выравнивания входных и выходных последовательностей, когда входные данные являются непрерывными, а выходные данные дискретными, и нет четких границ элементов, которые можно использовать для сопоставления входных данных с элементами выходной последовательности.
Что делает его таким особенным, так это то, что он выполняет это выравнивание автоматически, не требуя, чтобы вы вручную вводили это выравнивание как часть помеченных обучающих данных. Это сделало бы создание обучающих наборов данных чрезвычайно дорогим.
Как мы обсуждали выше, карты объектов, которые выводятся сверточной сетью в нашей модели, нарезаются на отдельные кадры и вводятся в рекуррентную сеть. Каждый кадр соответствует некоторому временному шагу исходной звуковой волны. Однако количество кадров и продолжительность каждого кадра выбираются вами в качестве гиперпараметров при разработке модели.
Непрерывный звук нарезается на дискретные кадры и вводится в RNN (изображение автора) Для каждого кадра рекуррентная сеть, за которой следует линейный классификатор, затем предсказывает вероятности для каждого символа из словаря.Задача алгоритма CTC состоит в том, чтобы взять эти вероятности символов и получить правильную последовательность символов.
Чтобы помочь ему справиться с проблемами выравнивания и повторения символов, которые мы только что обсуждали, он вводит в словарь понятие «пустого» псевдосимвола (обозначаемого «-»). Поэтому вероятности символов, выдаваемые сетью, также включают вероятность пустого символа для каждого кадра.
Обратите внимание, что пробел — это не то же самое, что «пробел». Пробел — это реальный символ, а пробел означает отсутствие какого-либо символа, что-то вроде «нулевого значения» в большинстве языков программирования. Он используется только для обозначения границы между двумя символами.
CTC работает в двух режимах:
- Потеря CTC (во время обучения): он имеет целевую расшифровку достоверности и пытается обучить сеть, чтобы максимизировать вероятность вывода этой правильной расшифровки.
- Расшифровка CTC (во время логического вывода): Здесь у нас нет целевой расшифровки, на которую можно ссылаться, и нам нужно предсказать наиболее вероятную последовательность символов.
Давайте рассмотрим их немного подробнее, чтобы понять, что делает алгоритм. Мы начнем с декодирования CTC, так как оно немного проще.
Декодирование CTC
- Используйте вероятности символов, чтобы выбрать наиболее вероятный символ для каждого кадра, включая пробелы. например. «-G-o-ood »
- Объединить любые повторяющиеся символы, не разделенные пробелом. Например, мы можем объединить « о-о-о » в одно « о-», но мы не можем объединить « о-о-о ». Именно так CTC может различать две отдельные буквы «о» и создавать слова, написанные с повторяющимися символами. например. « -G-o-od »
- Наконец, поскольку пробелы выполнили свою задачу, удаляются все пустые символы. например. « Хороший ».
CTC Loss
Loss вычисляется как вероятность предсказания сетью правильной последовательности. Для этого алгоритм перечисляет все возможные последовательности, которые может предсказать сеть, и выбирает из них подмножество, соответствующее целевой расшифровке.
Чтобы идентифицировать это подмножество из полного набора возможных последовательностей, алгоритм сужает возможности следующим образом:
- Сохраняет только вероятности для символов, которые встречаются в целевой расшифровке, и отбрасывает остальные. например. Он сохраняет вероятности только для «G», «o», «d» и «-».
- Используя отфильтрованное подмножество символов, для каждого кадра выберите только те символы, которые встречаются в том же порядке, что и целевая стенограмма. например. Хотя «G» и «o» являются допустимыми символами, порядок «Go» является допустимой последовательностью, тогда как «oG» — недопустимой последовательностью.
С учетом этих ограничений алгоритм теперь имеет набор допустимых последовательностей символов, каждый из которых будет давать правильную целевую расшифровку.
например. Используя те же шаги, которые использовались во время логического вывода, « -G-o-ood» и « — Good-od- » оба приведут к конечному результату «Хорошо».Затем он использует вероятности отдельных символов для каждого кадра, чтобы вычислить общую вероятность создания всех этих допустимых последовательностей. Цель сети состоит в том, чтобы узнать, как максимизировать эту вероятность и, следовательно, уменьшить вероятность генерации любой недопустимой последовательности.
Строго говоря, поскольку нейронная сеть минимизирует потери , потери CTC вычисляются как отрицательный логарифмическая вероятность всех допустимых последовательностей. Поскольку сеть минимизирует эту потерю за счет обратного распространения во время обучения, она корректирует все свои веса для создания правильной последовательности.
Однако сделать это на самом деле гораздо сложнее, чем то, что я здесь описал. Проблема в том, что существует огромное количество возможных комбинаций символов для создания последовательности.
Только в нашем простом примере у нас может быть 4 символа на кадр. При 8 кадрах это дает нам 4**8 комбинаций (= 65536). Для любой реалистичной расшифровки с большим количеством символов и кадров это число увеличивается экспоненциально. Это делает вычислительно непрактичным просто исчерпывающий список допустимых комбинаций и вычисление их вероятности.Эффективное решение этой проблемы делает CTC такой инновационной. Это увлекательный алгоритм, и стоит разобраться в нюансах того, как он этого достигает. Это заслуживает отдельной статьи, которую я планирую написать в ближайшее время. Но пока мы сосредоточились на построении интуитивных представлений о том, что делает CTC, а не на том, как это работает.
После обучения нашей сети мы должны оценить, насколько хорошо она работает. Обычно используемая метрика для проблем преобразования речи в текст — это частота ошибок в словах (и частота ошибок в символах). Он сравнивает прогнозируемый вывод и целевой расшифровку, слово за словом (или символ за символом), чтобы определить количество различий между ними.
Различием может быть слово, которое присутствует в расшифровке, но отсутствует в прогнозе (считается удалением), слово, отсутствующее в расшифровке, но добавленное в прогноз (вставка), или слово, которое изменяется между предсказанием и транскриптом (замена).
Подсчитайте вставки, удаления и замены между расшифровкой и предсказанием (изображение автора)Формула метрики довольно проста. Это процент различий по отношению к общему количеству слов.
Вычисление коэффициента ошибок в словах (Изображение автора)До сих пор наш алгоритм рассматривал произносимое аудио как простое соответствие последовательности символов некоторого языка. Но когда они складываются в слова и предложения, будут ли эти символы действительно иметь смысл и смысл?
Обычным приложением обработки естественного языка (NLP) является построение языковой модели. Он фиксирует, как слова обычно используются в языке для построения предложений, абзацев и документов. Это может быть универсальная модель для такого языка, как английский или корейский, или это может быть модель, специфичная для конкретной области, такой как медицинская или юридическая.
Если у вас есть языковая модель, она может стать основой для других приложений. Например, его можно использовать для предсказания следующего слова в предложении, для определения тональности некоторого текста (например, положительный ли это обзор книги), для ответов на вопросы через чат-бота и т. д.
Таким образом, конечно, его также можно использовать для дополнительного повышения качества наших выходных данных ASR, направляя модель для создания прогнозов, которые более вероятны в соответствии с языковой моделью.
При описании CTC-декодера во время вывода мы неявно предполагали, что он всегда выбирает один символ с наибольшей вероятностью на каждом временном шаге. Это известно как жадный поиск.
Однако мы знаем, что можем получить лучшие результаты, используя альтернативный метод, называемый поиском луча.
Хотя Beam Search часто используется в задачах NLP в целом, он не является специфичным для ASR, поэтому я упоминаю его здесь только для полноты картины.
Если вы хотите узнать больше, ознакомьтесь с моей статьей, в которой подробно описывается Beam Search.Наглядное объяснение основ НЛП: Beam Search, как это работает
Нежное руководство о том, как Beam Search улучшает предсказания, на простом английском языке
в направлении datascience.com
Надеюсь, теперь вы получили представление о строительных блоках и методах, используемых для решения задач ASR.
В прежние дни глубокого обучения решение таких проблем с помощью классических подходов требовало понимания таких понятий, как фонемы, и большого количества подготовки данных и алгоритмов, специфичных для предметной области.
Однако, как мы только что видели на примере глубокого обучения, нам почти не требовалась разработка признаков, включающая знание звука и речи. И тем не менее, он способен давать отличные результаты, которые продолжают нас удивлять!
И, наконец, если вам понравилась эта статья, вам также могут понравиться другие мои серии, посвященные трансформерам, машинному обучению геолокации и архитектуре подписей к изображениям.
Визуальное объяснение трансформеров (часть 1): обзор функциональности
Нежное руководство по трансформерам для НЛП и тому, почему они лучше RNN, на простом английском языке. Как внимание помогает…
в направлении datascience.com
Использование данных геолокации для машинного обучения: основные методы
Нежное руководство по проектированию признаков и визуализации с использованием геопространственных данных, на простом английском языке
в направлении datascience.com
Подписи к изображениям с глубоким обучением: современные архитектуры
Нежное руководство по кодировщикам признаков изображений , Декодеры последовательности, внимание и мультимодальные архитектуры, на простом английском языке
в направлении datascience.com
Продолжаем учиться!
Алекса сломалась? Почему ваше Эхо иногда делает жуткие вещи
Alexa: Хороший, плохой и жуткий
Это было, конечно, неизбежно.
«Алекса, это. Алекса, это». Через некоторое время мы все просто знали, что Алекса собирается… что сказал тот парень в Твиттере? «Есть большая вероятность, что меня сегодня убьют».Признайся. Если вы один из миллионов владельцев Alexa, вы заметили странное поведение. Если вы похожи на меня и мою жену, вы, вероятно, даже не раз задавались вопросом, сколько времени пройдет, прежде чем наши повелители ИИ поднимутся и свергнут нас.
TechRepublic: Amazon Alexa: Руководство умного человека
Давайте довольно быстро рассмотрим предысторию, так как она уже была написана в другом месте. Alexa, как известно, внезапно проявляет странное поведение. В январе я писал о том, как Алекса внезапно начала говорить, не будучи разбужена будильным словом.
Несколько недель назад технический обозреватель Фархад Манджу написал в New York Times о том, как однажды ночью его Alexa напугала его криком в постели. На этой неделе по всему Интернету мы слышали истории о том, как Алексас разражается непрошеным зловещим смехом.
Что происходит?
Расслабься. Ваша Алекса не преследуется (вероятно). Ваша Alexa не собирается убивать вас во сне (у нее нет ни рук, ни ног). И твоя Алекса не сходит с ума. Ну…
На самом деле, по определению, последнее технически может быть не совсем верным. Согласно Google, одно из определений безумия включает в себя «состояние ума, препятствующее нормальному восприятию, поведению или социальному взаимодействию».
Определение слова «безумие», данное Dictionary.com.
Когда дело доходит до Alexa, все зависит от восприятия и поведения.
Пробуждение Alexa
Alexa активируется так называемым «словом пробуждения». Он будет реагировать на пробуждающее слово Alexa, Echo, Amazon или Computer, в зависимости от того, что вы выберете в настройках Amazon Echo. Другие голосовые помощники также используют слова пробуждения. Сири использует «Привет, Сири». Google Home использует «Хорошо, Google». Windows 10 отвечает на «Привет, Кортана», а вскоре просто «Кортана», названная в честь ИИ-помощника Мастера Чифа из серии видеоигр Halo.
Сейчас мы просто поговорим о слове пробуждения «Alexa» и устройствах Alexa. Но то, что я собираюсь обсудить, относится к любой системе распознавания голоса с активным прослушиванием.
Alexa и другие голосовые системы ИИ преодолели (по крайней мере, в основном) огромную техническую проблему. Как вы фильтруете весь шум (буквально шум) в окружающей среде и знаете, когда реагировать?
Сейчас разработчики решают эту проблему, слушая пробуждающее слово или, по сути, специально определенную форму звуковой волны. Микрофоны Alexa всегда включены. Вибрация диафрагмы каждого микрофона преобразуется в цифровую подпись.
Концентратор обработки внутри каждого устройства Alexa затем проверяет эту цифровую подпись, и если она совпадает с предопределенным словом пробуждения, тогда и только тогда устройство должно анализировать последующие звуки на предмет их значения.
Просеивание всего этого шума в поисках слова пробуждения — нетривиальная задача программирования.
Взгляните на форму волны ниже.«Алекса», оптимальный звук
Это слово «Алекса». Я записал это на профессиональный студийный микрофон, расположив голову и рот точно в оптимальном месте для записи голоса. Я записал это в тихой комнате, когда все, кроме моего компьютера, было выключено.
Теперь посмотрите, что происходит с волнообразной формой, когда я отхожу всего на пять футов и повторяю слово «Алекса».
«Алекса», на расстоянии пяти футов
Как видите, неровности все еще относительно заметны, но амплитуда волны значительно меньше.
Каким-то образом процессор устройства Alexa должен распознать, что форма волны, которую он только что услышал, соответствует команде проснуться и слушать. Устройство выполняет это несколькими способами.
Во-первых, у него несколько микрофонов, поэтому он может улавливать различные структуры звуковых волн на каждом микрофоне. Поскольку микрофоны расположены вокруг устройства, каждый микрофон улавливает данное звуковое событие в немного разное время и с немного другой волной.
Если и только если устройство определяет, что только что услышанный звук является словом пробуждения, оно начинает обрабатывать последующие звуки.
Робототехника
- Лучшие роботы-пылесосы, доступные сейчас
- Почему школьникам достаются все крутые роботы?
- 5 лучших роботов-газонокосилок: уход за газоном без помощи рук
- Грибное мясо и роботы-повара: взгляд Chipotle на будущее
Но мы пока не готовы обсуждать обработку команд Alexa. Помните, что я записал волны, показанные выше, в оптимальных студийных условиях. Разобрать слово пробуждения Alexa было бы легко, если бы оно всегда жило в оптимальной студийной среде.
Но Alexa нет.
Настоящая техническая проблема, которую приходится решать таким поставщикам голосовых помощников, как Amazon, — это разнообразие. Есть миллионы владельцев Alexa, и вы можете поспорить, что многие из них говорят «Alexa» совсем по-разному.
У них могут быть разные акценты, у них определенно разные голоса, тона, высота тона и скорость речи.Они также имеют широкий спектр фоновых шумов. Дверь автомобиля может захлопнуться. Телевизор может быть включен. Музыка может играть в другой комнате. Собака может лаять. Вентилятор может создавать одеяло белого шума. Вы поняли идею.
Каким-то образом через все это разнообразие Alexa должна определить, проснулась ли она от слова «Alexa».
Учитывая, что существуют миллионы устройств, ситуаций и голосов, вы можете начать понимать, с какой проблемой разработчики столкнулись при обеспечении надежной работы вызова. Вы не можете заставить Alexa проснуться спонтанно, иначе это будет тревожно. С другой стороны, если Alexa не отвечает, когда с ней разговаривают, это также очень расстраивает пользователей.
Построение системы машинного обучения, которая может анализировать все эти переменные, достигая практического баланса между слишком большим количеством ложных срабатываний, не игнорируя запросы, является (и я снова использую эту фразу) нетривиальной задачей.
Вероятные причины спонтанных реакций Alexa
Учитывая все это, наиболее вероятной причиной спонтанных реакций Alexa является неверная интерпретация звука. Учитывая, насколько чувствительной должна быть Alexa для обработки слов пробуждения, иногда Alexa реагирует на звук (даже тот, который мы можем не слышать или не замечать) и интерпретировать его как слово пробуждения.
Хотя это встречается значительно реже, также существует вероятность того, что обновление изменило код Alexa и привело к ошибке.
Есть также проблема с Интернетом и облачной системой искусственного интеллекта Alexa. Давайте поговорим об этом, далее.
Как интерпретируется команда
Alexa отвечает на множество команд. Разбор всех этих волновых форм — слишком большая работа для процессора на локальном устройстве Alexa. Для этой обработки Alexa использует облачную инфраструктуру Amazon.
Независимо от того, спрашиваете ли вы у Alexa время, просите установить напоминание, смените термостат или требуете «Еще колокольчик», каждая произнесенная вами команда или запрос — это, в конечном счете, просто еще одна форма волны.
Хотя Amazon не раскрывает точных технических деталей внутренних функций Alexa, мы знаем, что сложная проблема синтаксического анализа для всех этих команд слишком сложна для локального процессора. Звуковая волна (или ее сжатое представление) должна быть загружена в центр обработки данных Amazon для вычислительного анализа.
После загрузки у внутреннего ИИ Alexa есть одна очень большая задача: сопоставить звуковую волну с определенной командной строкой Alexa.
Alexa имеет большую библиотеку возможных команд. Есть не только собственные команды, такие как напоминания и запросы времени, но и все команды, связанные с постоянно растущей библиотекой навыков Alexa.
Библиотека навыков — это версия магазина приложений Alexa, где вне Amazon разработчики могут создавать собственный код, ожидающий определенной команды Alexa, а затем выполняющий определенное поведение.
Мы вернемся к навыкам через мгновение, а пока давайте продолжим поиск нужной команды.
Для повышения удобства использования Alexa должна иметь возможность реагировать на варианты заданной команды.
Например, Alexa должна иметь возможность обрабатывать «Alexa, скажи мне время», а также «Alexa, который час». Большинство ИИ решает эту проблему, игнорируя слова-заполнители (например, is, the и т. д.) и преобразовывая звуки в звуковые основы и нормализованные последовательности. По сути, это позволяет системе принимать различные высказывания и обрабатывать их как одну и ту же команду.Помните, что Alexa не только обрабатывает тысячи команд, но и звуковые волны не являются первозданными. Система обработки звука должна быть в состоянии воспринимать звуковые волны и делать все возможное, чтобы интерпретировать то, о чем просят говорящие люди.
Как и в случае со словом пробуждения, это нетривиально, учитывая миллионы говорящих людей, диалекты, акценты, высоту голоса, расстояние до устройств и окружающие фоновые шумы.
Честно говоря, удивительно, что это вообще работает. Здесь также может показаться, что Alexa находится «в состоянии ума, препятствующем нормальному восприятию», если она неправильно интерпретирует звуковую волну, принимает ложное срабатывание или игнорирует то, что может быть действительным запросом.
Действия по командам
Из всего, что делает Alexa, выполнение команд — самая простая часть. Как только внутренний ИИ Alexa узнает, что вы запрашиваете время, поиск времени легко запрограммировать. То же самое относится и к ответу голосового синтеза, потому что единственной переменной является последовательность слов, которые нужно произнести.
Почти во всех случаях, если Alexa ведет себя странно, на самом деле это не поведенческий компонент ИИ Alexa. Это почти несомненно компонент восприятия.
Тем не менее, есть команды, которые могут заставить людей думать, что Alexa потеряла свои шарики. На момент написания этой статьи существует четыре сторонних навыка, связанных с «криком».
Навыки Amazon для «крика»
Навык «кричащий розыгрыш» активируется после фразы «Алекса, кричащий розыгрыш». После этого он подождет шестьдесят секунд, а затем закричит. Это позволяет шутнику устроить розыгрыш, выйти из комнаты, а затем пытать любого, кто окажется рядом с устройством, когда оно кричит.
«Жуткий крик» еще более дьявольский. Он начинается с фразы «Алекса, попроси Spooky Scream начать через две минуты». Вы можете настроить задержку времени. Таким образом, вы можете попросить Алексу начать крик через десять минут, выйти из комнаты и запустить розыгрыш после того, как вы уйдете.
Плохое поведение Алексы
Кто знает, что заставило Алексу кричать в спальне Фархада? Конечно, когда Алекса заговорила с моей женой и со мной без просьбы, мы не услышали и не сказали ничего, что должно было заставить ее заговорить.
Но слышала ли Алекса что-то снаружи, мы никогда не узнаем. Пиксель (наш щенок) часто лает на звуки, которые слышит только он. Сегодня он рявкнул на грузовик UPS за целых три минуты до того, как водитель позвонил в звонок. Возможно, Пиксель услышал грузовик на улице и залаял еще до того, как он остановился у нашего дома.
В случае с жутким смехом весьма вероятно, что Alexa реагировала на ложные срабатывания. Взгляните на форму волны ниже.
«Алекса, смейся.» Оптимальная запись.
Вы можете видеть, что в этой оптимальной записи фразы «Алекса, смейся» есть три основных волны. Первые два соответствуют слову Alexa wake. Третье слово «смех». Обратите внимание, что волна на самом деле довольно плоская. Это потому, что «смех» — это мягкое слово, без множества пиков или отличительных характеристик.
Теперь посмотрите на следующую форму волны. Это та же самая фраза, но произнесенная с расстояния примерно в пять футов.
«Алекса, смейся.» Записано через комнату.
По этой волне едва ли можно сказать, что происходит. Следующее изображение представляет собой увеличенную версию вышеприведенной волны.
«Алекса, смейся.» Записано через комнату, увеличено
Вы можете увидеть некоторые всплески, но амплитуда ужасная. Здесь очень мало данных. Учитывая, что Alexa реагировала только на простую команду «смех», вполне возможно, что из миллионов домохозяйств с устройствами Alexa некоторые генерировали достаточно данных, чтобы их можно было интерпретировать как команду смеха.
Потребность в человеческом обучении
Здесь на помощь приходит человеческое обучение, а не машинное. Разработчики Alexa, после скандала, ради смеха изменили последовательность команд Alexa. Теперь «Алекса, смейся» ничего не делает. Вместо этого люди в Amazon узнали и изменили команду на «Алекса, ты можешь смеяться?»
Будем надеяться, что гонка вооружений всегда идет на пользу людям. Если ИИ Alexa когда-нибудь достигнет самосознания, мы, вероятно, все обречены. Тем временем, однако, теперь вы знаете, что большую часть жуткого поведения Алексы можно списать на неправильно истолкованные звуковые волны.
Почему-то это не такая утешительная мысль, как я надеялся.
Что значит иметь расстройство обработки слуховых сигналов
Как звучит расстройство обработки слуховых сигналов и почему оно часто остается незамеченным
Вероятно, вам приходилось сталкиваться с разочарованием, когда вы пытались вести разговор по мобильному телефону при слабом приеме.
Слова или даже целые предложения вырезаются. Звуки смешиваются. Статика вторгается в разговор. Иногда, приложив некоторые усилия, вы можете использовать контекст, чтобы собрать воедино обрезанные фрагменты речи. В других случаях вы ошибаетесь или просто не понимаете, что было сказано. Вот как звучит расстройство слуховой обработки.И для детей, и для взрослых с нарушением обработки слуха (APD) эта мутность звука является важной частью повседневной жизни. APD — это слуховая когнитивная проблема — это когда звуки слышатся точно, но не обрабатываются или не понимаются точно. Это особенно сложно при обработке языка, поскольку фонемы, из которых состоит язык, очень похожи.
Большинство людей с АРЛ имеют нормальный слух, но их мозгу трудно интерпретировать слуховые сигналы и анализировать речь. Звуки смешиваются и становятся мутными — или они проходят без всякого смысла. Два других способа думать о том, как звучит APD:
- Это похоже на слишком быструю ленту — мир говорит со скоростью 50 миль в час, но слушатель APD обрабатывает со скоростью 30 миль в час.
- Еще один взгляд на APD был использован автором Карен Фоли — она пишет, что прослушивание с нарушением слуховой обработки звучит так же, как прослушивание звука через воду.
Для взрослых любой разговор — это борьба, особенно в шумной обстановке — трудности с фоновым шумом — наиболее распространенный из всех симптомов нарушения слуховой обработки. Для детей разговоры, выполнение указаний, слушание учителя в классе, прослушивание звуков внутри слов при обучении чтению — все это борьба.
Из-за неспособности различать передний и фоновый звуки люди с АРЛ обнаруживают, что их способность слушать гораздо быстрее ухудшается в более шумной обстановке. Наличие APD немного похоже на постоянное проживание в чрезвычайно резонансной эхо-камере: если в эхо-камере говорит только один человек, требуется усилие, чтобы следить за тем, что он говорит, и вы можете пропустить слова здесь и там, но вы все равно можете следить за ними. вдоль довольно хорошо.
Если вы добавите в эхо-камеру больше людей или другие виды шумов, вскоре все превратится в непонятную кашу звуков, и вам будет трудно понять, что кто-либо говорит.Конечно, это не означает, что люди с проблемами слуховой обработки не понимают всего, что им говорят. Но чтобы быть в курсе того, что говорится, требуется гораздо больше усилий для тех, у кого есть APD, чем для тех, у кого его нет. Просто подумайте об эхо-камере или о попытке слушать радио через помехи — вы все еще можете расшифровать то, что слышите, но это требует больше усилий.
А поскольку акт слушания требует концентрации, меньше пропускной способности мозга доступно для понимания. Кумулятивный эффект на обучение, вызванный отвлечением внимания от слушания, может быть весьма драматичным.
Потеря слуха в любой точке создает риск развития аффективного расстройства личности
Хотя физические нарушения слуха отличаются от расстройства слуха, между ними существует связь. Дети с проблемами слуха в раннем возрасте не учатся слышать, а затем обрабатывать звуки — в основном звуки речи — что в конечном итоге приводит к задержкам обработки слуха.
Это включает в себя временную потерю слуха из-за ушных инфекций или экссудативного экссудата, а также более постоянные проблемы.В большинстве случаев проблемы со слухом приводят к задержке четкой речи и языка, в результате чего ребенок получает профессиональное внимание, если не дома, то почти наверняка в школе. Однако некоторые источники потери слуха — например, ушные инфекции — менее серьезны по своему внешнему воздействию, т. е. не вызывают задержки речи, но могут так же легко подорвать развитие навыков обработки слуха.
Это дети, у которых задержки слуховой обработки остаются незамеченными до гораздо более позднего возраста, когда чтение становится настоящей проблемой и/или возникают другие проблемы с обучением. Поскольку APD является почти синонимом расстройства обработки речи, APD является источником довольно многих задержек языковых навыков обучения, в первую очередь проблем с чтением, включая дислексию и невнимательный ADD.
Хотя, по оценкам, от 2% до 7% населения получают формальный диагноз APD или, по крайней мере, задержки слуховой обработки, у гораздо большей части населения диагноз не ставится.
APD может быть трудно обнаружить
Относительно большая часть людей с APD, которые ускользают от радара, может быть объяснена тем фактом, что APD трудно обнаружить снаружи, особенно если нет задержки речи. Дети с APD в основном хорошо справляются с тестами на слух и на самом деле чаще имеют особенно чувствительный слух. Их инвалидность коренится не в том, как работают их уши, а скорее в том, как их мозг осмысливает информацию, которую он получает от ушей.
Однако тот факт, что АПД может остаться незамеченным извне, не делает его последствия менее серьезными. Умение слушать является важнейшим навыком в нашем обществе, поэтому любое расстройство, которое ставит под угрозу способность людей интерпретировать звуки речи, будет инвалидизирующим в целом ряде ситуаций.
Как APD влияет на обучение
В классе учащиеся с APD испытывают серьезные трудности после лекций. Дело не в том, что они просто не могут обратить внимание или не могут понять обсуждаемые концепции; дело в том, что их мозг просто не может организовать все звуки, которые они слышат.
С таким же успехом учитель может время от времени переключаться на чтение лекций на иностранном языке.По той же причине аспекты социальных ситуаций и повседневных разговоров, которые большинство людей считают само собой разумеющимися, могут быть сложными для людей с АРЛ. А на рабочем месте? Ну, вы можете себе представить, что проблемы с пониманием даже простых словесных инструкций могут вызвать проблемы.
В то время как APD в основном является проблемой слушания, слушание является основой изучения языка, поэтому расстройство также может привести к проблемам с чтением и самовыражением через речь. Например, у людей с АРЛ возникают проблемы с различением разных звуков. Они также могут пропускать целые слоги в словах и часто путают порядок звуков, которые слышат. В результате у детей с АРЛ возникают проблемы с различением разных слов, что, в свою очередь, затрудняет обучение чтению или выбору слов во время разговора.
Этот аспект APD немного похож на дальтоника, но со звуками.
Представьте, что вы не можете отличить слова «высокий» от «кукла», как некоторые люди не могут отличить красный от зеленого. Это усложняет задачу.Другим симптомом APD является неспособность выделить определенные звуки из фонового шума. Например, в комнате, где происходит несколько разговоров, у человека с АРЛ могут возникнуть проблемы с отделением голоса, который он должен слушать, от всех других голосов в комнате. Точно так же человек с APD, идущий по улице и разговаривающий с кем-то, может иметь проблемы с концентрацией внимания на том, что говорится, а не на звуке проезжающих машин на заднем плане. Таким образом, есть совпадение между APD и другими расстройствами, связанными с проблемами внимания, такими как ADHD.
Трудности обработки слуха подрывают развитие других навыков
Для людей с АРЛ энергия, затрачиваемая только на точное прослушивание или чтение слов, означает, что другие навыки не тренируются. Например, почти у всех детей с нарушениями слуховой обработки также есть задержки в рабочей памяти.
Программное обеспечение Fast ForWord, самое популярное в мире средство для лечения расстройств слуховой обработки в домашних условиях, нацелено на скорость обработки слуховой информации и рабочую память вместе — оно предполагает, что у учащихся с нарушением обработки слуховой информации также будут проблемы с рабочей памятью.Ученикам с АРЛ, возможно, придется тратить столько энергии на то, чтобы просто понять, что говорит их учитель, что у них остаются ограниченные когнитивные ресурсы, оставшиеся для фактического взаимодействия с обсуждаемыми понятиями. Слушание должно быть автоматическим, не требующим усилий. Но для них слушание требует концентрации, поэтому им трудно слушать и думать одновременно. Это означает, что много материала пропущено или не понято. Это делает прослушивание в классе в лучшем случае утомительным, а в худшем — неинтересным, поскольку многое упускается.
Более того, даже когда они могут понять смысл того, что слышат, у людей с APD часто возникают проблемы с запоминанием этого.
APD ухудшает способность людей сохранять в памяти то, что они слышат, поэтому у людей с APD часто возникают проблемы не только с пониманием словесных инструкций, но и с запоминанием содержания инструкций.Когда вы представляете себе повседневную жизнь с постоянной статической беготней, когда звуки мешают друг другу, а слова иногда кажутся совершенно бессмысленными, вы начинаете понимать, почему расстройство, которое так трудно обнаружить со стороны, имеет такие далеко идущие последствия для человеческие жизни. Умение слушать само по себе является важнейшим навыком в школе, социальной среде и на рабочем месте, но последствия APD выходят за рамки слушания и включают в себя чтение, говорение и запоминание.
Что значит улучшить навыки обработки слуховых сигналов
Оборотной стороной этого является то, что меры по улучшению навыков обработки слуховых сигналов могут оказать глубокое влияние на жизнь ребенка. На самом деле, со временем, при стимуляции постоянными ежедневными разговорами, у многих детей навыки слуховой обработки могут несколько созреть.
Существует также ряд методов лечения и лечения, которые могут помочь при APD.APD — невидимая инвалидность, но улучшения, которые приходят с ее лечением, очень ощутимы. Улучшенная слуховая обработка имеет эффект:
- Замедление мира — поскольку ребенок способен обрабатывать быстрее, ребенку с АРЛ кажется, что все говорят медленнее, поскольку навыки слуховой обработки улучшаются.
- Меньше статики из-за фонового шума — улучшенные навыки обработки слуха удерживают фоновый шум там, где ему и место, на заднем плане, что облегчает слышимость друзей на игровой площадке и учителя в классе.
- Облегчение чтения — потому что слова слышны четче, их легче разобрать, распознать звуки внутри слов, что требуется для расшифровки, чтения.
- Улучшение понимания — делая слушание более автоматическим и легким, ребенок может сосредоточить внимание на значении того, что ему говорят. Такая же динамика наблюдается и при чтении.
Умение слушать без усилий — это благословение, которое нельзя воспринимать как должное. Чтобы узнать, может ли Gemm Learning помочь вам или вашему ребенку, запросите демонстрацию или позвоните нам по телефону 1-877-914-4366 в любое время.
Есть ли слово или фраза для выражения чувства, которое возникает после того, как вы слишком долго смотрите на слово?
Спросил
Изменено 1 год, 2 месяца назад
Просмотрено 102k раз
Иногда, посмотрев некоторое время на слово, я убеждаюсь, что оно не может быть написано правильно. Даже после поиска, озвучивания и осознания того, что другого способа написания слова просто нет, оно все равно выглядит неправильно.
Можно ли кратко описать это чувство, чтобы люди поняли, что я имею в виду, без долгих объяснений?
- однословные запросы
- фразовые запросы
- лингвистика
- психология
18
Эврика! Итак, это не одно слово, но это то, о чем я пытался думать:
Семантическое насыщение:
Смысловое пресыщение (также семантическое насыщение) — психологическое явление, при котором повторение заставляет слово или фразу временно терять смысл для слушателя, который затем воспринимает речь как повторяющиеся бессмысленные звуки.
Я также нашел дискуссию по этой теме.
11
На основе этого NGram… … У меня возникает соблазн предположить, что семантическое насыщение — это «неудачная чеканка».
Лично я считаю ошибочным предполагать, что феномен ограничивается в первую очередь вопросом семантики. По моему опыту, дело не столько в том, что слово «теряет смысл». Это скорее вопрос того, что почти любое слово имеет тенденцию становиться «необычным», если вы слишком долго концентрируетесь на нем, даже если вы прекрасно осознаете, что это слово на самом деле 9.0003 означает .
Таким образом, учитывая, что чеканка Леона Якобовица Джеймса 1962 года, похоже, не очень популярна (многие из более поздних употреблений в любом случае являются просто ссылками на его), я думаю, что было бы лучше назвать ее
лексическая усталость (или насыщение , используемое в обонятельном/слуховом/визуальном контексте).
Это, по крайней мере, дает понять, что это вызвано формой самого слова , а не , означающим (которое может даже не иметь особого значения).
4
Статья о семантическом пресыщении привела меня к французскому термину jamais vu, который мне больше нравится по нескольким причинам. Кажется, это лучше применимо к письменной форме, как описано в исходном вопросе, и мне также кажется, что это веселее говорить.
2
Основываясь на принятом ответе Марты, я предлагаю:
Орфографическое недоверие
1
Это фантастический вопрос. Я часто испытывал это чувство. Сомневаюсь, что существует краткое слово или фраза, чтобы описать это. Я предлагаю вам придумать собственное слово и использовать его повсюду, пока оно не попадет в словарь.
Обычно, когда вы произносите или смотрите на слово слишком много раз/слишком долго, слово теряет связь со своим значением.
Это начинает быть не чем иным, как группой звуков, исходящих из вашего голосового аппарата, или набором алфавитов, расположенных на странице. Кто-то однажды описал мне это чувство как слово-растворение , потому что для него это слово просто растворилось. Мозг уже понял и обработал слово. Теперь он знает все, что нужно знать о слове, и пошел дальше.3
Вероятно, это самоиндуцированная форма афазии или дисфазии.
1
«Орфографический когнитивный диссонанс» может сработать. Противоречивые идеи одновременно заключались в том, что слово, на которое вы смотрите, написано правильно и неправильно.
Я посмотрел ссылку на Википедию, которая была в посте @Martha, и там было много названий этого явления, кроме самого популярного, «семантического насыщения»:
- «корковое торможение»
- «реактивное торможение»
- «вербальная трансформация»
- «Рефрактерная фаза и психическое утомление»
По ссылке также описаны эссе и диссертации, в которых используются эти термины.
Что вы думаете о «лексической передержке»?
Я почти уверен, что такого слова в английском языке еще не существует. Вероятно, вам придется придумать фразу. «Лексическое [что-то]», чтобы быть уверенным. 🙂
Примечание: <Семантическое насыщение> — это понятие, отличное от того, что вы говорите. Это говорит о том, что вы используете слово просто потому, что привыкли его использовать, без какой-либо другой цели и без какой-либо ссылки на его значение — такие слова, как
(думая о значении «штампа», когда произносите это слово? скорее всего, нет) , <общее>, <условие>, <созыв>, <реестр>, <регистр>, <рабочий пример>, <должно>, <должно>. Но вы говорите, что есть слова, написанные таким образом, что они просто выглядят неуместными, по крайней мере, для системы разбора наблюдателя. Это могут быть такие слова, как:
- <полный> (<через> может выглядеть правильно)
-
( может выглядеть правильно) - <телесность> (<телесность> может выглядеть правильно)
- <странно> (
может выглядеть правильно) - <министерский>
- <ограбление>
- <наивный> (<наивный может выглядеть правильно)
- <реинкарнация> (<реинкарнация> может выглядеть правильно)
- <отложено>
- <диэрезис>
- <Ницше>
-
[§] - <Ллойд>
Вы можете ссылаться на такие слова, как
(что само по себе выглядит неуместным для неопытного глаза). Re:
Существует ли сокращенный способ описать это чувство , чтобы люди поняли, что я имею в виду, без длинных объяснений?
.Фразой <иметь неприятную ситуацию>:
Как раз тогда у меня возникла ситуация weiosr со словом
. 6
Fazed
это означает, что все стало размытым, я больше не могу сосредоточиться или понять это.
Часто используется в отрицательной форме, например, «его это совсем не смутило». Означает «принятие вещей в своем темпе», что является его противоположностью.
Fazed означает — отложенный, сбитый с толку, встревоженный, выбитый из колеи.
пример
- Когда красивый мужчина подошел и пригласил Лизу на свидание, она была совершенно смущена близостью его тела, запахом его лосьона после бритья и его прекрасными голубыми глазами. Все казалось размытым, она едва понимала слова, которые он говорил, и когда пришло время ответить, все, что она могла сделать, это заикаться и смотреть на него слезящимися глазами.


 Все элементы также должны быть преобразованы в одинаковую продолжительность звука. Это включает в себя дополнение более коротких последовательностей или усечение более длинных последовательностей.
Все элементы также должны быть преобразованы в одинаковую продолжительность звука. Это включает в себя дополнение более коротких последовательностей или усечение более длинных последовательностей.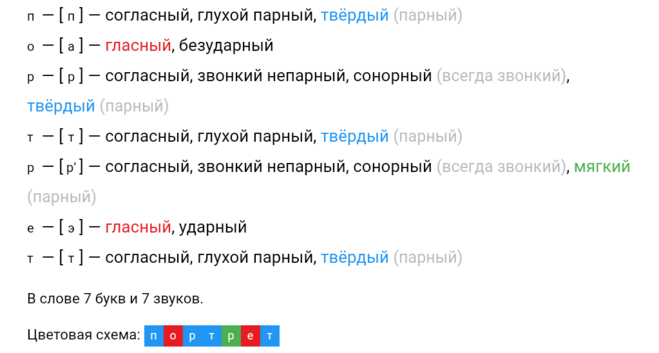

 На высоком уровне модель состоит из следующих блоков:
На высоком уровне модель состоит из следующих блоков:
 Но как мы его получим?? (Изображение автора)
Но как мы его получим?? (Изображение автора) Поскольку я не «модный человек» и мне трудно запомнить это длинное имя, я просто буду использовать имя CTC для обозначения его 😃.
Поскольку я не «модный человек» и мне трудно запомнить это длинное имя, я просто буду использовать имя CTC для обозначения его 😃. Для каждого кадра рекуррентная сеть, за которой следует линейный классификатор, затем предсказывает вероятности для каждого символа из словаря.
Для каждого кадра рекуррентная сеть, за которой следует линейный классификатор, затем предсказывает вероятности для каждого символа из словаря.
 например. « Хороший ».
например. « Хороший ». например. Используя те же шаги, которые использовались во время логического вывода, « -G-o-ood» и « — Good-od- » оба приведут к конечному результату «Хорошо».
например. Используя те же шаги, которые использовались во время логического вывода, « -G-o-ood» и « — Good-od- » оба приведут к конечному результату «Хорошо». Только в нашем простом примере у нас может быть 4 символа на кадр. При 8 кадрах это дает нам 4**8 комбинаций (= 65536). Для любой реалистичной расшифровки с большим количеством символов и кадров это число увеличивается экспоненциально. Это делает вычислительно непрактичным просто исчерпывающий список допустимых комбинаций и вычисление их вероятности.
Только в нашем простом примере у нас может быть 4 символа на кадр. При 8 кадрах это дает нам 4**8 комбинаций (= 65536). Для любой реалистичной расшифровки с большим количеством символов и кадров это число увеличивается экспоненциально. Это делает вычислительно непрактичным просто исчерпывающий список допустимых комбинаций и вычисление их вероятности.

 Если вы хотите узнать больше, ознакомьтесь с моей статьей, в которой подробно описывается Beam Search.
Если вы хотите узнать больше, ознакомьтесь с моей статьей, в которой подробно описывается Beam Search.
 «Алекса, это. Алекса, это». Через некоторое время мы все просто знали, что Алекса собирается… что сказал тот парень в Твиттере? «Есть большая вероятность, что меня сегодня убьют».
«Алекса, это. Алекса, это». Через некоторое время мы все просто знали, что Алекса собирается… что сказал тот парень в Твиттере? «Есть большая вероятность, что меня сегодня убьют».
 Взгляните на форму волны ниже.
Взгляните на форму волны ниже.
 У них могут быть разные акценты, у них определенно разные голоса, тона, высота тона и скорость речи.
У них могут быть разные акценты, у них определенно разные голоса, тона, высота тона и скорость речи.

 Например, Alexa должна иметь возможность обрабатывать «Alexa, скажи мне время», а также «Alexa, который час». Большинство ИИ решает эту проблему, игнорируя слова-заполнители (например, is, the и т. д.) и преобразовывая звуки в звуковые основы и нормализованные последовательности. По сути, это позволяет системе принимать различные высказывания и обрабатывать их как одну и ту же команду.
Например, Alexa должна иметь возможность обрабатывать «Alexa, скажи мне время», а также «Alexa, который час». Большинство ИИ решает эту проблему, игнорируя слова-заполнители (например, is, the и т. д.) и преобразовывая звуки в звуковые основы и нормализованные последовательности. По сути, это позволяет системе принимать различные высказывания и обрабатывать их как одну и ту же команду.


 Слова или даже целые предложения вырезаются. Звуки смешиваются. Статика вторгается в разговор. Иногда, приложив некоторые усилия, вы можете использовать контекст, чтобы собрать воедино обрезанные фрагменты речи. В других случаях вы ошибаетесь или просто не понимаете, что было сказано. Вот как звучит расстройство слуховой обработки.
Слова или даже целые предложения вырезаются. Звуки смешиваются. Статика вторгается в разговор. Иногда, приложив некоторые усилия, вы можете использовать контекст, чтобы собрать воедино обрезанные фрагменты речи. В других случаях вы ошибаетесь или просто не понимаете, что было сказано. Вот как звучит расстройство слуховой обработки.
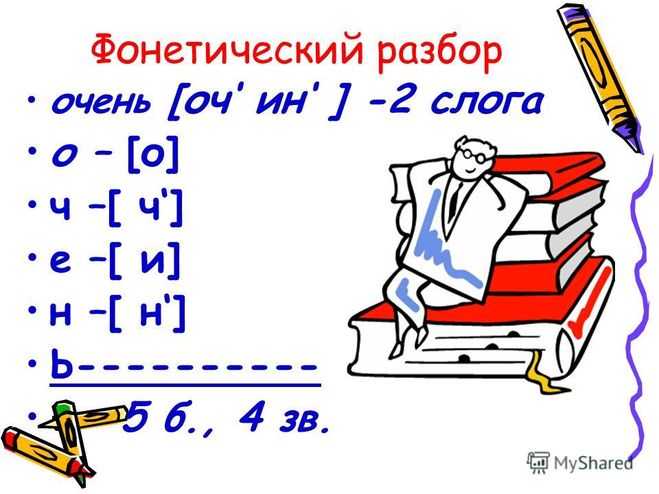 Если вы добавите в эхо-камеру больше людей или другие виды шумов, вскоре все превратится в непонятную кашу звуков, и вам будет трудно понять, что кто-либо говорит.
Если вы добавите в эхо-камеру больше людей или другие виды шумов, вскоре все превратится в непонятную кашу звуков, и вам будет трудно понять, что кто-либо говорит. Это включает в себя временную потерю слуха из-за ушных инфекций или экссудативного экссудата, а также более постоянные проблемы.
Это включает в себя временную потерю слуха из-за ушных инфекций или экссудативного экссудата, а также более постоянные проблемы.
 С таким же успехом учитель может время от времени переключаться на чтение лекций на иностранном языке.
С таким же успехом учитель может время от времени переключаться на чтение лекций на иностранном языке. Представьте, что вы не можете отличить слова «высокий» от «кукла», как некоторые люди не могут отличить красный от зеленого. Это усложняет задачу.
Представьте, что вы не можете отличить слова «высокий» от «кукла», как некоторые люди не могут отличить красный от зеленого. Это усложняет задачу. Программное обеспечение Fast ForWord, самое популярное в мире средство для лечения расстройств слуховой обработки в домашних условиях, нацелено на скорость обработки слуховой информации и рабочую память вместе — оно предполагает, что у учащихся с нарушением обработки слуховой информации также будут проблемы с рабочей памятью.
Программное обеспечение Fast ForWord, самое популярное в мире средство для лечения расстройств слуховой обработки в домашних условиях, нацелено на скорость обработки слуховой информации и рабочую память вместе — оно предполагает, что у учащихся с нарушением обработки слуховой информации также будут проблемы с рабочей памятью. APD ухудшает способность людей сохранять в памяти то, что они слышат, поэтому у людей с APD часто возникают проблемы не только с пониманием словесных инструкций, но и с запоминанием содержания инструкций.
APD ухудшает способность людей сохранять в памяти то, что они слышат, поэтому у людей с APD часто возникают проблемы не только с пониманием словесных инструкций, но и с запоминанием содержания инструкций. Существует также ряд методов лечения и лечения, которые могут помочь при APD.
Существует также ряд методов лечения и лечения, которые могут помочь при APD.


 Это начинает быть не чем иным, как группой звуков, исходящих из вашего голосового аппарата, или набором алфавитов, расположенных на странице. Кто-то однажды описал мне это чувство как слово-растворение , потому что для него это слово просто растворилось. Мозг уже понял и обработал слово. Теперь он знает все, что нужно знать о слове, и пошел дальше.
Это начинает быть не чем иным, как группой звуков, исходящих из вашего голосового аппарата, или набором алфавитов, расположенных на странице. Кто-то однажды описал мне это чувство как слово-растворение , потому что для него это слово просто растворилось. Мозг уже понял и обработал слово. Теперь он знает все, что нужно знать о слове, и пошел дальше.

