Правильный фонетический разбор слова «каюта» с транскрипцией
Школьная программа по русскому языку предполагает изучение различных видов разборов, в том числе и фонетический. Именно с этого раздела лингвистики, изучающего звуки и звуковое строение слов, и начинается углубленное изучение родной речи. Звуки являются основными кирпичиками в правильном овладении языка. Фонетический разбор слова «каюта» поможет сформировать необходимые в лингвистической работе навыки.
Порядок фонетического разбора
Многие люди, и не только иностранцы, считают русский язык очень сложным. И только малая часть неспециалистов считает, что исследование речи очень увлекательная штука. Изучение же фонетики — это база для правильного произношения. Поэтому освоение ее начинают в 1 классе, буквально с начала сентября, когда еще не все дети даже читать умеют. При этом учителя стараются, чтобы фонетический анализ слов к концу начальной школы происходил на автомате. Это необходимо исходя из следующих соображений:
- Глубже понимается природа орфографии, а это значительный плюс для грамотности.

- Разбор поясняет и объединяет правила проверки сложных букв, в т. ч. и непроизносимых в корнях, приставках, суффиксах и окончаниях.
- Для четкого понимания, что есть слова, которые пишут не так, как говорят.
- Для развития «орфографической зоркости».
- Для понимания и принятия сложных правил русского языка и легкого применения их на практике.

План проведения
Фонетический разбор делают по строго определенному плану. В некоторых школьных программах присутствуют незначительные отличия. Но по общим правилам анализ выполняют в следующем порядке:
- Слово.
- Транскрипция.
- Обозначить ударение.
- Разделить на слоги. Записать их количество.
- Все буквы выписать в столбик, записать количество.
- Рядом с каждой отдельной буквой прописать в квадратных скобках звуки, отображающие имеющиеся буквы.
- Описать звук: гласный или согласный, твердый или мягкий, глухой или звонкий, парный, ударный.
- Записать количество звуков.

Редко, но иногда в правилах рекомендуется пояснить нюансы орфографии, т. е. правила правописания.
Для фанатов русского языка и тех, кто изучает его особенности профессионально в институте, существует ряд дополнительных пунктов при расширенном фонетическом разборе. В этом случае учитываются тонкости современного произношения и изменения прошедшие за последние столетия.
Пример правильного анализа
Для примера подойдет слово «каюта». Согласно правилам сначала записывают транскрипцию и обозначают ударение. Чтобы проделать звуко-буквенный анализ, необходимо определить, сколько звуков в слове «каюта», определить полый состав:
- [ кай´ ута ].
- Ударение на 2 слоге.
- Слово имеет 3 слога: ка-ю-та. Возможны 2 разновидности переноса: каю-та, ка-юта.
- Определить сколько букв и звуков «каюта», правильный ответ:
| Звук | Характеристика | Буква |
| [ к ] | Согласный, тверд. (шумный), парн., глух. (шумный), парн., глух. | к |
| [ а ] | Безударный гласный | а |
| [ й´ ] [ у ] | Согласн.,, мягкий, непарн. звонкий (сонорный) гласный, ударный | ю |
| [ т ] | Согласн., твердый (шумн.), парн. глухой | т |
| [ а ] | Безударн. гласный | а |
Слово имеет 3 гласных и 2 согласных буквы, но 3 гласных и 3 согласных звука. Проверочных слов нет, т. к. «каюта» — словарное. Фонетический разбор слова «каюта» достаточно прост, но имеет нюансы из-за некоторых букв в существительном.
Значение слова
В русский язык слово пришло вначале XVII в. Основное значение — небольшая жилая комната на пароходе, яхте или любом другом судне, отдельное помещение для команды или пассажиров. Может использоваться для обозначения подсобного помещения на корабле. Примеры использования: «Катя зашла в кают-компанию», «Пассажир занял каюту 1-го класса», «У капитана была отдельная от команды каюта».
[PDF] Идентификация границ слова на основе ограничений последовательности фонем при автоматическом непрерывном распознавании речи
- inproceedings{Harrington1988WordBI,
title={Идентификация границы слова на основе ограничений последовательности фонем при автоматическом непрерывном распознавании речи},
автор={Джонатан Харрингтон, Гордон Уотсон и Мэгги Купер},
booktitle={Международная конференция по компьютерной лингвистике},
год = {1988}
}
В этом документе исследуется, в какой степени ограничения последовательности фонем могут использоваться для определения границ слов при распознавании непрерывной речи. Входной набор фонематических транскрипций (без указания границ слов) 145 высказываний, произведённых одним диктором RP. Ограничения выводятся путем сопоставления полного набора из 3 последовательностей фонем, которые могут встречаться за границами слов, с записями в больших словарях, содержащих как цитаты, так и сокращенные формы произношения.
Просмотр в ACL
dl.acm.orgОбнаружение границ слов в широких строках классов и фонем
- Дж. Харрингтон, Г. Уотсон, Мэгги Купер
Лингвистика
- 1 989
Сравнение двух моделей для Word Обнаружение границ в последовательности фонем с использованием рекуррентных нечетких нейронных сетей
Сравниваются две концептуальные модели обнаружения границ слов, называемые моделями предварительного и обратного порядка, и в обеих моделях тестируется производительность RFNN при постобнаружении границ слов.
Использование рекуррентных нечетких нейронных сетей для прогнозирования границ слов в последовательности фонем в персидском языке
- М. Фейзи-Дерахши, М. Кангавари
Информатика
HCI
90 017 2007

Рекуррентная нечеткая нейронная сеть предлагается вместе с его соответствующей структурой и представлен алгоритм обучения, и эта RFNN используется для прогнозирования границ слов, и результаты показывают приемлемую производительность.
Начальная загрузка границ слов: основанный на корпусе снизу вверх подход к сегментации речи
Речь непрерывна, и выделение осмысленных фрагментов для лексического доступа — нетривиальная задача. В этой статье мы используем модели нейронных сетей и более традиционную статистику для изучения использования…
Лексикализованная фонотактическая сегментация слов
- Маргарет М. Флек
Лингвистика
ACL
- 2008
Лексическое ударение и лексическая различимость: Ударные слоги более информативны, но почему?
- Джерри Альтман, Д. Картер
Лингвистика
- 1989
 Картер
КартерЛексический доступ в подключенном распознавании речи
- T ed Briscoe
Лингвистика
ACL
- 1989
В этом документе рассматриваются два вопроса. относительно лексического доступа при распознавании связанной речи: 1) характер предлексического представления, используемого для инициации лексического поиска 2) точки, в которых…
Коннекционистский и статистический подходы к овладению языком: перспектива распределения.
- М. Редингтон, Н. Чейтер
Лингвистика
- 1998
Предполагается, что одной из важных задач коннекционистских исследований в овладении языком является анализ того, какая лингвистическая информация присутствует во входных данных ребенка и как это исследование относится к другим эмпирическим и теоретическим подходам к изучению овладения языком.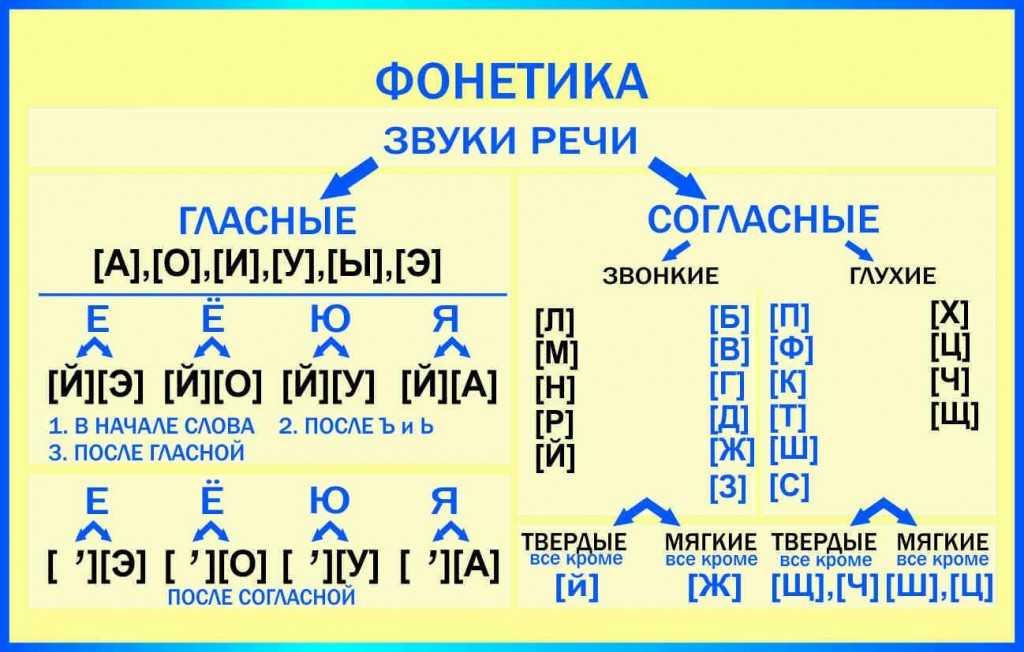
LSA
За последние два года Исполнительный комитет Лингвистического общества Америки (LSA) участвовал в дискуссиях и действиях, которые продвигают LSA в новом направлении для разработки…
Фонотактическая реконструкция зашифрованных разговоров VoIP : Hookt on Fon-iks
Основываясь на выводах сообществ компьютерной лингвистики и распознавания речи, новые методы применяются для разоблачения частей зашифрованных разговоров VoIP путем сегментации наблюдаемого потока пакетов на подпоследовательности, представляющие отдельные фонемы, и классификации этих подпоследовательностей по фонеме, в которой они находятся. кодировать.
Свойства последовательностей согласных внутри слов и за пределами слов
- Л. Ламель, В. Зуэ
Лингвистика
ICASSP
- 1984 900 07
- Дж. Харрингтон, Ян Джонсон, Мэгги Купер
Лингвистика
ECST
- 1987
- Дж. Харрингтон, Энн Джонстон
Лингвистика
- 1987
- Г. Клементс, С. Дж. Кейзер
Лингвистика
- 1983
The Lancaeter-Oslo
- 1978
- Первая версия. Выпущен в ничего не подозревающий мир.
- Первая версия исправлена A. Частично удалена ненужная зависимость mmsyn2.
- Первая версия изменена A. Удалена ненужная зависимость mmsyn2 (и все функции, связанные с векторами). Некоторые улучшения файла Cabal.
- Вторая версия. Добавлен сравнительный режим к возможностям rewritePoemG3 и Phonetic.Languages.Lines модуль. Некоторые улучшения документации.
- Вторая версия исправлена A. В файл README.md добавлены примеры (на английском языке).
- Вторая версия исправлена B. Удалены ненужные скрытые зависимости пакетов и функций, связанных с вектором (которые были
анонсировано в версии 0.1.2.0). Полностью переключен на массивы GHC.Arr, где это необходимо.
- Третья версия. Пакет имеет режим множественных вариаций для исполняемого файла lineVariantsG3, что позволяет использовать модификации в тексте, т.е. г. синонимы, парафразы и т. д. Добавлено больше вариантов свойств на основе нового набора данных для Пакет r-glpk-phonetic-languages-ukrainian-durations. Добавлен новый модуль Phonetic.Languages.Parsing для новой функциональности. Удалена ненужная зависимость print-info.
- Четвертая версия. Добавлена новая строка функций оценки ритмичности («z»-строка). Поведение предыдущих функций также
изменены, поэтому он может понадобиться (в случае, когда результаты имеют какое-то принципиальное значение, например, в научных исследованиях,
а не сам текст) для пересчета результатов с помощью этих функций. Добавлена возможность получить украинский
информационные сообщения при работе исполняемого файла lineVariantsG3 (используя параметр командной строки «+U» не внутри
группы опций). Некоторые улучшения документации.
- Четвертая версия исправлена A. Исправлены некоторые проблемы с файлом README.md. Обновлены границы зависимостей для пакета mmsyn2-array.
- Четвертая версия исправлена B. Обновлена документация на украинском языке, исправлены некоторые текстовые проблемы. См. README.md.
- Четвертая версия, исправленная C. В пакет добавлена краткая инструкция на английском языке.
- Пятая версия. Добавлены две новые строки (строки «w» и «x») в качестве новых стратегий оценки свойств. Обновлены зависимости границы соответственно.
- Пятая версия исправлена A. Изменен файл README.md на просто README, чтобы исправить отображение команды примеры строк в нем.
- Шестая версия. Изменено обозначение модификаторов аргументов командной строки на маленькие буквы,
удален двойной знак ++ (заменен на одинарный +), чтобы упростить использование аргументов командной строки.
Также изменен способ подписи записи в файл для исполняемого файла lineVariantsG3. Добавлены новые строки
свойства для (гипотетической) обработки полиритмии. Среди них строки «c», «s», «t», «u», «v».
Внесены соответствующие изменения в документацию. Изменены границы зависимостей. Добавлена возможность
«вырастить строки» для исполняемых файлов rewritePoemG3 и propertiesTextG3.
- Шестая версия исправлена B. Изменены границы зависимостей, чтобы проблемы решались с помощью функций «0», а не «0». Некоторые улучшения кода (уменьшение дублирования).
- Седьмая версия. Изменены границы зависимостей, так что теперь серии свойств «c», «s», «t», «u» и «v» может быть отрицательным по знаку. Это не меняет логики работы программ и функций. Некоторая документация улучшения.
- Восьмая версия. Изменены границы зависимостей и добавлены новые взвешенные свойства, а также исправлены некоторые проблемы с предыдущие, чтобы они использовали более полную информацию. Добавлен обработчик случая пустой строки для исполняемый файл lineVariantsG3 и связанные с ним функции. Некоторые улучшения документации.
- Восьмая версия исправлена A. Исправлена проблема с неправильным порядком и, следовательно, отображением для разных вариантов и соответствующие свойства в модуле Phonetic.Languages.Simplified.Array.Ukrainian.FuncRep2RelatedG2.
- Девятая версия. Добавлены новые свойства, которые пытаются увеличить важность окончания строки и уменьшить
важность начала строки. Добавлена новая зависимость строкового интерпретатора. Добавлена возможность
для запуска lineVariantsG3 и соответствующих библиотечных функций в рекурсивном интерактивном режиме. Это не
совместимы с ограничениями, поэтому их следует использовать не одновременно с ними (поскольку они меняют свое значение).
Некоторые улучшения документации.
- Десятая версия. Добавлены новые линейно-взвешенные свойства. Исправлены некоторые проблемы с неправильным отображением. Некоторая документация улучшения.
- Переработана десятая версия. Исправлены проблемы с пользовательскими шаблонами полиритмии. Изменено инструкции по документации в редакторе. Соответственно обновлены границы зависимостей.
- Одиннадцатая версия. Добавлен новый режим обработки нескольких источников (+t_ … -t). Добавлена возможность
считать в рекурсивном режиме не только с начала конкатенации слов, но и с конца, используя
широко используемый шаблон программирования отрицательного целочисленного индексирования. Обновил зависимости, чтобы теперь
он может использовать несколько улучшений зависимостей. Некоторые улучшения документации.
- Одиннадцатая версия исправлена A. Исправлена проблема с файлом документации (README).
- Одиннадцатая версия пересмотрена B. Исправлена ошибка, из-за которой не создавалась зависимость phonetic-languages-plus. Обновлено границы зависимости.
- Одиннадцатая версия исправлена C. Исправлена ошибка, из-за которой зависимость массива фонетических языков-украинского языка не построен. Обновлены границы зависимостей. Обновлен файл README с гиперссылками на обновленную документацию. связанных с использованием пакета.
- Одиннадцатая версия исправлена D. Обновлен файл README с гиперссылками на обновленную документацию
связанных с использованием пакета.
- Двенадцатая версия. В программу rewritePoemG3 добавлен режим множественных свойств и расширен сравнительный режим. для него до 7 различных входных исходных файлов. Некоторые улучшения документации.
- Двенадцатая версия исправлена A. Исправлены ошибки в документации по процессам установки и обновления.
- Тринадцатая версия. Добавлена возможность предоставлять пользовательские (чтение из файла с Haskell-подобным синтаксиса) функции для определения длительности слога. Добавлена также возможность использовать только попарные перестановки вместо полного универсального их набора. Обновлены границы зависимостей и документация соответственно. Исправлена проблема с неправильно документированным процессом (пере)установки пакета(ов).
- Тринадцатая версия переработала А. Более глубоко реализован режим попарных перестановок. Некоторые улучшения документации.
Обновлены границы зависимостей.
- Четырнадцатая версия. Исправлен не очень достаточный релиз-кандидат, который использовал функцию хеширования. Если у вас нет обновлены до функции хеширования в течение 30.10.2021-31.10.2021, вам также не нужно обновляться.
- Четырнадцатая версия исправлена A. В некоторой степени исправлены проблемы с дублированием входных аргументов командной строки.
- Пятнадцатая версия. Переключено на представление GHC.Int.Int8. Некоторые улучшения документации.
- Пересмотренная пятнадцатая версия A. Некоторые улучшения документации.
- Пятнадцатая версия исправлена B. Некоторые улучшения документации.
- Пятнадцатая версия переработана C. Некоторые улучшения документации.
- Пятнадцатая версия исправлена D. Некоторые улучшения документации. Если вы обновились хотя бы до 0.15.0.0 версии нет необходимости переустанавливать пакет, просто проверьте документацию по новому обновлению (см. ссылки README). Инструкции призваны следовать строгому научному подходу к источникам, поэтому популярная информация переместилась в прямые гиперссылки, а не библиографию.
- Шестнадцатая версия. Добавлены cli-аргументы в качестве новой зависимости. Изменен способ, которым программы анализируют свои аргументы. Добавлена возможность использовать также минимальный набор перестановок (всего одно слово). Обновил зависимости. Некоторый код улучшения. Обновлена документация новым материалом и исправлены устаревшие примеры вывода.
- Шестнадцатая версия исправлена A.
Шаг к лучшему пониманию акустико-фонетических свойств последовательностей согласных свойства распределения этих последовательностей внутри и за пределами слова изучаются с использованием базы данных нескольких текстовых файлов из разных дискурсов.
Применение ограничений последовательности фонем для определения границ слов при автоматическом непрерывном распознавании речи
CVC и некоторые последовательности CCVC, которые не встречаются в мономорфных словах в словарь на 20 000 слов. Предварительный анализ показывает, что многие последовательности в…
Влияние классов эквивалентности на разбор фонем в слова при распознавании непрерывной речи
CV Фонология: порождающая теория слога
В этой работе представлен новый подход к представлению слогов, CV-уровень; который определяет функциональные позиции внутри слога и представляет собой первое полномасштабное фонологическое обоснование CV-уровня.
Журнал лингвистики
Название этой книги выдает, возможно, некоторую скромность автора, поскольку предлагается значительный объем информации о (морфо)-синтаксической эволюции испанского, португальского и итальянского языков…
Фонетический лексикон. tieyden: Oxford
CV Фонология. Генеративная теория слога
Фонграмма: интерпретатор фонологических правил
Правила редукции структуры слова в автоматическом непрерывном распознавании речи
The Lancaeter-Oslo
Список изменений для фонетических-языков-упрощенных-примеров-массива-0.16.2.0 | Hackage
0.1.0.0 — 02.
 01.2021
01.20210.1.1.0 — 02.01.2021
0.1.2.0 — 02.01.2021
0.2.0.0 — 04.01.2021
0.2.1.0 — 06.01.2021
0.2.2.0 — 20.01.2021

0.3.0.0 — 28.01.2021
0.4.0.0 — 01.02.2021
 Некоторые улучшения документации.
Некоторые улучшения документации.0.4.0.1 — 17.04.2021
0.4.1.0 — 19.04.2021
0.4.2.0 — 31.05.2021
0.5.0.0 — 20.07.2021
0.5.0.1 — 21.07.2021
0.6.0.0 — 28.07.2021
 Изменено обозначение модификаторов аргументов командной строки на маленькие буквы,
удален двойной знак ++ (заменен на одинарный +), чтобы упростить использование аргументов командной строки.
Также изменен способ подписи записи в файл для исполняемого файла lineVariantsG3. Добавлены новые строки
свойства для (гипотетической) обработки полиритмии. Среди них строки «c», «s», «t», «u», «v».
Внесены соответствующие изменения в документацию. Изменены границы зависимостей. Добавлена возможность
«вырастить строки» для исполняемых файлов rewritePoemG3 и propertiesTextG3.
Изменено обозначение модификаторов аргументов командной строки на маленькие буквы,
удален двойной знак ++ (заменен на одинарный +), чтобы упростить использование аргументов командной строки.
Также изменен способ подписи записи в файл для исполняемого файла lineVariantsG3. Добавлены новые строки
свойства для (гипотетической) обработки полиритмии. Среди них строки «c», «s», «t», «u», «v».
Внесены соответствующие изменения в документацию. Изменены границы зависимостей. Добавлена возможность
«вырастить строки» для исполняемых файлов rewritePoemG3 и propertiesTextG3.0.6.1.0 — 30 июля 2021 г.
Шестая версия пересмотрена A. Исправлены проблемы с фиксированной точкой 1.0 (вызванные проблемой в пакете зависимостей фонетические языки-ритмичность).
0.6.2.0 — 31.07.2021
0.
 7.0.0 — 09.08.2021
7.0.0 — 09.08.20210.8.0.0 — 14.08.2021
0.8.1.0 — 2021-08-15
0.9.0.0 — 16.08.2021
 Добавлена новая зависимость строкового интерпретатора. Добавлена возможность
для запуска lineVariantsG3 и соответствующих библиотечных функций в рекурсивном интерактивном режиме. Это не
совместимы с ограничениями, поэтому их следует использовать не одновременно с ними (поскольку они меняют свое значение).
Некоторые улучшения документации.
Добавлена новая зависимость строкового интерпретатора. Добавлена возможность
для запуска lineVariantsG3 и соответствующих библиотечных функций в рекурсивном интерактивном режиме. Это не
совместимы с ограничениями, поэтому их следует использовать не одновременно с ними (поскольку они меняют свое значение).
Некоторые улучшения документации.0.10.0.0 — 17.08.2021
0.10.1.0 — 24.08.2021
0.11.0.0 — 04.09.2021
 Обновил зависимости, чтобы теперь
он может использовать несколько улучшений зависимостей. Некоторые улучшения документации.
Обновил зависимости, чтобы теперь
он может использовать несколько улучшений зависимостей. Некоторые улучшения документации.0.11.0.1 — 06.09.2021
0.11.1.0 — 08.09.2021
0.11.2.0 — 09.09.2021
0.11.3.0 — 09.09.2021

0.12.0.0 — 14.09.2021
0.12.1.0 — 2021-09-15
0.13.0.0 — 14.10.2021
0.13.1.0 — 23.10.2021
 Более глубоко реализован режим попарных перестановок. Некоторые улучшения документации.
Обновлены границы зависимостей.
Более глубоко реализован режим попарных перестановок. Некоторые улучшения документации.
Обновлены границы зависимостей.0.14.0.0 — 31.10.2021
0.14.1.0 — 2021-11-01
0.15.0.0 — 05.11.2021
0.15.1.0 — 08.11.2021
0.15.2.0 — 2021-12-10
0.
 15.2.1 — 11.12.2021
15.2.1 — 11.12.2021