Морфологический разбор слова «понятия»
Часть речи: Существительное
ПОНЯТИЯ — неодушевленное
Начальная форма слова: «ПОНЯТИЕ»
| Слово | Морфологические признаки |
|---|---|
| ПОНЯТИЯ |
|
| ПОНЯТИЯ |
|
| ПОНЯТИЯ |
|
Все формы слова ПОНЯТИЯ
ПОНЯТИЕ, ПОНЯТЬЕ, ПОНЯТИЯ, ПОНЯТЬЯ, ПОНЯТИЮ, ПОНЯТЬЮ, ПОНЯТИЕМ, ПОНЯТЬЕМ, ПОНЯТИИ, ПОНЯТЬИ, ПОНЯТИЙ, ПОНЯТИЯМ, ПОНЯТЬЯМ, ПОНЯТИЯМИ, ПОНЯТЬЯМИ, ПОНЯТИЯХ, ПОНЯТЬЯХ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПОНЯТИЯ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «понятия»
Примеры предложений со словом «понятия»
1
Свою страну, Родину – это понятно, но понятие Родины для каждого из нас складывается из многих понятий, в том числе из понятия семьи.
Шапка Мономаха, Алексей Лухминский, 2016г.
2
Его понятия о женитьбе поэтому не были похожи на понятия большинства его знакомых, для которых женитьба была одним из многих общежитейских дел;
Анна Каренина, Лев Толстой, 1878г.
3
Бедная девушка понятия не имеет, что некто, о чьем существовании она понятия не имеет, только что удлинил срок ее жизни с двух месяцев до четырех.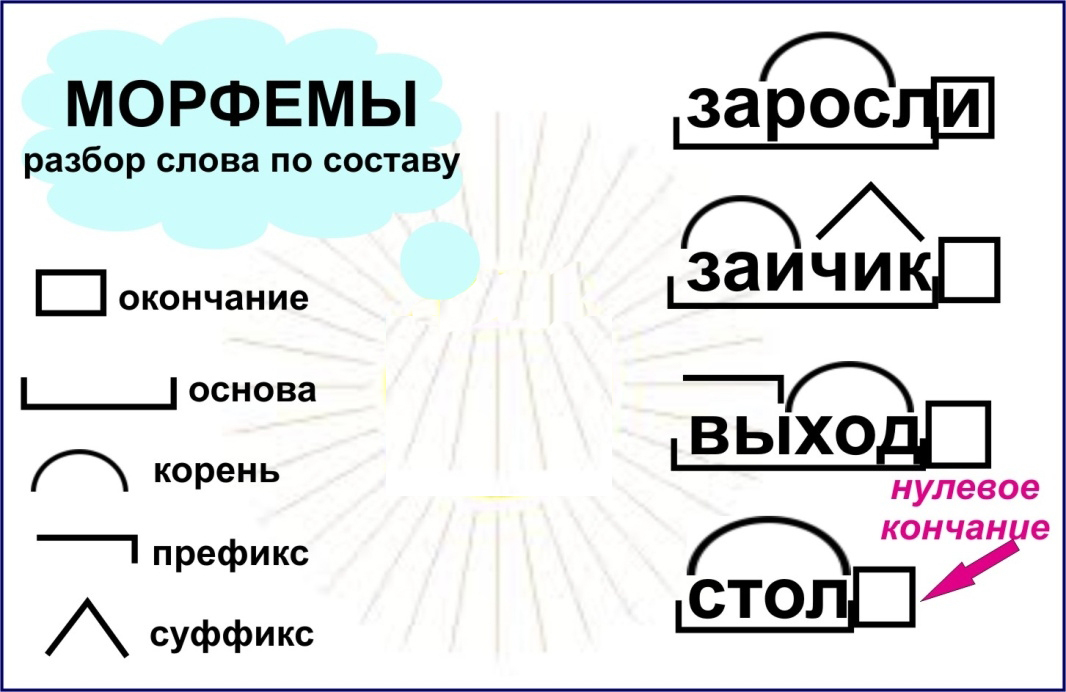
Царица иудейская, Нина Косман, 2017г.
4
Я понятия не имел, куда приткнуть свой фаллос (по-моему, я даже не имел понятия, что он так называется;
Легкий мужской роман, Анатолий Андреев, 2001г.
5
Отсутствие понятия «болезнь» влечет за собой и отсутствие понятия «здоровье» – одно определяется через противопоставление другому.
Любовь и смысл жизни (сборник), Михаил Веллер, 2012г.
Морфемика и словообразование – понятие, разбор и примеры кратко (6 класс, русский язык)
4.1
Средняя оценка: 4. 1
1
Всего получено оценок: 138.
Обновлено 3 Декабря, 2022
4.1
Средняя оценка: 4.1
Всего получено оценок: 138.
Обновлено 3 Декабря, 2022
Изучением морфемной структуры слова занимаются два раздела языкознания: словообразование и морфемика. Разница между ними состоит в том, что морфемика рассматривает части, из которых состоит слово и его формы, а словообразование — способ, которым слово в языке образовалось. Обе науки не просто расширяют наши знания о языке, они способствуют повышению практической грамотности. Ведь, по исследованиям учёных, на 80 % грамотность человека зависит от понимания, из каких морфем состоит слово, как оно образовалось.
Что представляют собой морфемика и словообразование
Эти разделы лингвистики тесно связаны между собой, как связаны науки о звучании слова: фонетика и орфоэпия. Чем отличаются понятия морфемики и словообразования? Кратко эту разницу можно сформулировать так: морфемика рассматривает состав слова, а словообразование изучает, как он (состав слова) сложился.
Главной единицей в обеих науках является морфема. Это минимальная значимая часть слова. Морфема — самая маленькая единица языка, которая имеет значение.
Звуки, конечно, ещё меньше, чем морфема, но они не имеют значения.
Морфемы могут быть:
- словообразующими (корень, суффикс, приставка);
- формообразующими (некоторые суффиксы, возникающие или исчезающие при изменении слова, окончание).
В основу слова входят только словообразующие морфемы.
Словообразующие морфемы меняют основу, создают новое слово с новым значением:
Формообразующие морфемы изменяют форму слова. Примеры такого изменения можно увидеть, склоняя слово или меняя его о лицо, число и род: степь, степи, степями, в степях, спишь, спим, спите, спят, красные, красными, красный, красная. Как видите, основа остаётся без изменения, меняется только формообразующая морфема — окончание. В русском языке формообразующими могут быть не только окончания, но и суффиксы. Примером формообразующих суффиксов является суффикс -Л-, образующий форму глагола прошедшего времени, или суффикс -ЕН-, который возникает в разносклоняемых существительных при склонении: время — времени, гуляет — гулял. Формообразующие суффиксы в основу не входят.
Как видите, основа остаётся без изменения, меняется только формообразующая морфема — окончание. В русском языке формообразующими могут быть не только окончания, но и суффиксы. Примером формообразующих суффиксов является суффикс -Л-, образующий форму глагола прошедшего времени, или суффикс -ЕН-, который возникает в разносклоняемых существительных при склонении: время — времени, гуляет — гулял. Формообразующие суффиксы в основу не входят.
Морфемный и словообразовательный разбор
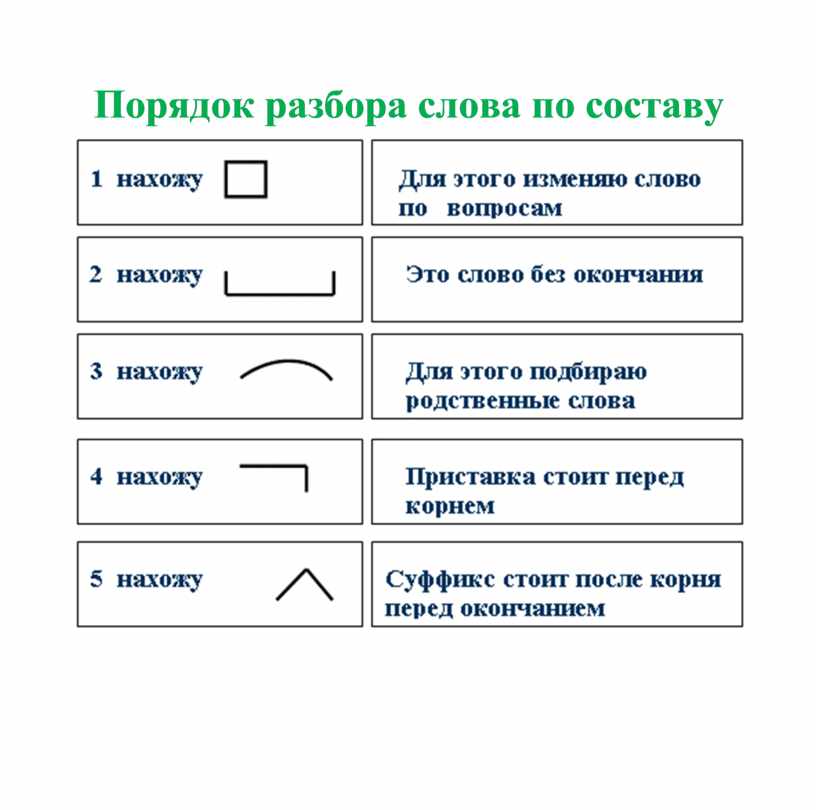
Морфемный разбор, с которым школьники знакомятся ещё в начальной школе, направлен на выяснение морфемного состава слова. Его порядок:
- Выделение основы и окончания (в том числе нулевого).
- Выделение корня.
- Выделение остальных морфем (приставки и суффикса), если они есть.
Целью словообразовательного разбора, навыками которого овладевают ученики 6 класса, является выяснение способа образования слова. Для этого:
- Выделяем основу и окончание слова в начальной форме.

- Находим слово, от которого анализируемое слово образовалось.
- Выделяем морфему, которая изменила основу слова.
- Определяем способ, которым слово образовано.

Словообразовательный разбор не ставит целью выяснение всей словообразовательной цепочки вплоть до самого первого исходного слова. Нужно найти слово, от которого исследуемое произошло. Они не должны отличаться друг от друга больше, чем на две морфемы.
Что мы узнали?
Морфемика и словообразование — близкие друг другу разделы языкознания. Обе науки изучают слово с точки зрения его морфемного состава. Разница в том, что словообразование исследует, каким способом, при помощи каких морфем возникло в языке это слово. Морфемика же исследует морфемный состав слова. Она отвечает на вопрос, из каких значимых частей состоит его основа, какие формообразующие морфемы участвуют в образовании его формы.
Тест по теме
Доска почёта
Чтобы попасть сюда — пройдите тест.
Пока никого нет. Будьте первым!
Оценка статьи
4.1
Средняя оценка: 4.1
Всего получено оценок: 138.
А какая ваша оценка?
Что такое анализ данных? | Блог Nanonets
Ищете решение для анализа данных?
Попробуйте Nanonets для анализа данных из PDF-файлов, вложений электронной почты, счетов, счетов, квитанций и многого другого.
Попробуйте Nanonets бесплатно
Внедрение больших данных в бизнес-модели полностью изменило наше восприятие бизнеса и технологий. Тем не менее, это привело к необходимости в тяжелых инструментах для извлечения, анализа и обработки такого огромного объема данных. Кроме того, как и естественные языки, компьютерные языки и языки программирования требуют точного перевода для обеспечения эффективного общения.
Именно здесь синтаксический анализ данных вступает в игру и решает проблему понимания сложных данных. Синтаксический анализ данных преобразует неструктурированные или нечитаемые данные в хорошо структурированные и легко читаемые данные.
Синтаксический анализ данных преобразует неструктурированные или нечитаемые данные в хорошо структурированные и легко читаемые данные.
Самое приятное в анализе данных то, что независимо от того, работаете ли вы в команде разработчиков компании или имеете дело с клиентами, играющими роль в маркетинге, вам необходимо понимать данные для поддержания своей производительности, развития новых предприятий или общения с клиентами. . Короче говоря, для долгосрочного успеха в бизнесе важно знать данные.
В этой статье мы объясним структуру анализаторов данных, как они могут помочь вашей организации и как анализ данных упрощает понимание данных. Кроме того, мы подскажем, стоит ли вам разработать свой парсер или купить его для нужд вашей компании.
Начнем.
Что такое анализ данных?
Анализ данных Определение Проще говоря, анализ данных — это преобразование данных из одного формата в другой. Например, если текст находится в формате HTML, синтаксический анализ данных может помочь вам преобразовать файл в более читаемый формат, такой как обычный текст.
Это популярный процесс преобразования данных, обычно используемый в компиляторах, где нам нужно преобразовать компьютерный код в более простой машинный код. Точно так же, когда веб-разработчики пишут код, работающий на оборудовании, им приходится использовать синтаксические анализаторы данных. Точный процесс также используется в механизмах SQL, где механизмы SQL сначала анализируют запрос SQL, а затем выполняют его и показывают результаты.
Анализ данных также полезен в случае парсинга веб-страниц, поскольку данные, извлеченные с веб-страницы после парсинга, обычно трудно понять. Таким образом, парсер данных делает их более читабельными и подготавливает к более качественному анализу исследователями.
Мощные анализаторы данных могут преобразовывать любые данные в другой формат. Например, они могут преобразовать необработанный HTML-код в объект JSON или преобразовать страницу JavaScript в удобочитаемый файл CSV.
Однако важным аспектом разбора данных является то, что не каждый фрагмент информации преобразуется во время процедуры разбора данных. Это связано с тем, что программы имеют свои собственные правила синтаксического анализа.
Это связано с тем, что программы имеют свои собственные правила синтаксического анализа.
Как работает анализатор данных?
С точки зрения вычислительной техники синтаксический анализ данных — это процесс анализа строки символов, специальных символов или структур данных с использованием обработки естественного языка (NLP), а затем структурирование данной информации из наборов данных и организация ее в соответствии с определенным пользователем. определенные правила. Или, другими словами, это метод извлечения информации из файлов и их фильтрация.
Тем не менее, как и лингвистическое определение синтаксического анализа, весь процесс синтаксического анализа данных вращается вокруг тщательного изучения предложений и отображения некоторых семантических отношений между ними.
Структура анализатора данных
Анализатор данных состоит из двух компонентов: лексического анализа и синтаксического анализа. Некоторые парсеры также имеют компонент семантического анализа. Он берет уже проанализированные и структурированные данные и применяет к ним значение. Например, семантический компонент будет дополнительно фильтровать данные на положительные или отрицательные, полные или неполные и т. д. и повышать качество окончательных данных.
Он берет уже проанализированные и структурированные данные и применяет к ним значение. Например, семантический компонент будет дополнительно фильтровать данные на положительные или отрицательные, полные или неполные и т. д. и повышать качество окончательных данных.
Как это работает?
Вот как работает анализатор данных —
● Прежде всего, анализатор различает информацию строки HTML и распознает, какие данные действительно ценны и необходимы для дальнейших операций.
● Теперь, следуя заранее написанным правилам и кодам синтаксических анализаторов, он выбирает необходимую информацию и преобразует ее в JSON, CSV или другой формат.
Важно отметить, что анализатор данных не привязан к какому-либо конкретному формату данных. Скорее это инструмент, который конвертирует данные из одного формата в другой, и весь процесс изменения формата зависит от сборки парсера.
Использование анализа данных
Анализаторы данных используются для многих технологий и языков, таких как:
● Java и другие языки программирования
● HTML и XML
● Интерактивный язык данных и язык определения объектов
● SQL и другие языки баз данных
● Языки моделирования
● Языки сценариев
● HTTP и другие интернет-протоколы
Хочу анализировать данные из документов PDF или автоматизировать анализ данных с помощью рабочих процессов? Попробуйте бесплатно парсер данных Nanonets. Начните бесплатный пробный период. Кредитная карта не требуется.
Начните бесплатный пробный период. Кредитная карта не требуется.
Попробуйте Nanonets бесплатно
Какие существуют типы анализа данных?
Анализ данных обычно использует два типа подходов для семантического анализа текста, т. е. анализ данных на основе грамматики и анализ данных на основе данных. Давайте подробно обсудим оба подхода —
Анализ данных на основе грамматики
В этом методе анализатор данных использует набор формальных правил грамматики и выполняет задачу анализа. Простыми словами, предложения из неструктурированных данных сначала фрагментируются, а затем трансформируются в более структурированный и понятный формат.
Однако у этого подхода есть одна проблема: ему не хватает надежности. Таким образом, чтобы преодолеть эту проблему, грамматические ограничения часто ослабляются, так что предложения, выходящие за рамки обычной грамматики, могут быть исключены для анализа синтаксического анализа данных.
Популярным подмножеством анализа данных на основе грамматики является анализ текста, который анализирует заданную строку. Этот тип процесса синтаксического анализа очень успешен в решении проблемы устранения неоднозначности, с которой сталкиваются обычные методы синтаксического анализа.
Этот тип процесса синтаксического анализа очень успешен в решении проблемы устранения неоднозначности, с которой сталкиваются обычные методы синтаксического анализа.
Анализ данных на основе данных
Анализ данных на основе данных основан на вероятностной модели преобразования. В отличие от дедуктивного подхода к анализу текста, используемого моделями синтаксического анализа на основе грамматики, он применяет методы, основанные на правилах, семантические уравнения и обработку естественного языка (NLP) для структурирования результирующих предложений и их анализа.
Этот подход к синтаксическому анализу использует интеллектуальные статистические синтаксические анализаторы и современные банки деревьев для получения широкого охвата языков. Вот почему разговорные языки и предложения, которые требуют точности, но относятся к предметной области и не имеют маркировки, обычно управляются синтаксическим анализом данных на основе данных.
Автоматизируйте процессы обработки документов с помощью анализатора данных и документов Nanonets. Извлекайте данные из счетов-фактур, удостоверений личности или любого документа на автопилоте!
Извлекайте данные из счетов-фактур, удостоверений личности или любого документа на автопилоте!
Разобрать данные сейчас
Преимущества программного обеспечения для анализа данных
Оптимизация работы
Наиболее существенное преимущество анализа данных заключается в том, что он помогает вам ориентироваться в огромном количестве данных, упрощая их и делая более читабельными. Следовательно, это позволяет организации быть более продуктивной и эффективной.
Экономия времени
Анализаторы данных помогают компаниям, предоставляя им правильный алгоритм или правильный инструмент для извлечения данных из их текущей формы. Затем он преобразует данные в другую форму и автоматизирует процесс, который в противном случае пришлось бы выполнять вручную. В результате это помогает компании работать быстрее, чем когда-либо. Кроме того, организации могут использовать свои человеческие ресурсы в другом месте для решения более важных задач.
Улучшенный пользовательский интерфейс
Когда компании имеют в своем распоряжении массу данных, им приходится бороться с их использованием, извлечением, управлением, анализом и т. д.
Синтаксический анализ данных делает данные более доступными и увеличивает возможности поиска. Он создает файлы, которые в противном случае было бы трудно читать или компилировать на компьютерах компании, более доступные, чем раньше. Кроме того, когда эти файлы данных станут легко читаемыми, конечный продукт, предлагаемый бизнес-профессионалам, может стать более читабельным, чем раньше.
Модернизация ваших данных
Данные, накопленные предприятиями, могут быть устаревшими и могут быть недоступны в текущем формате. Другими словами, может быть сложно использовать такие сохраненные данные. Однако эти данные могут быть чрезвычайно ценны для понимания развития компании или для любого другого использования.
Синтаксический анализ данных может быстро изменить формат этих данных и сделать их доступными для расшифровки и использования в соответствии с современными требованиями. И кто знает, какие данные станут палочкой-выручалочкой для вашей компании в будущем!
И кто знает, какие данные станут палочкой-выручалочкой для вашей компании в будущем!
Хотите использовать роботизированную автоматизацию процессов? Ознакомьтесь с программным обеспечением для обработки документов на основе рабочего процесса Nanonets. Нет кода. Платформа без проблем.
Попробуйте Nanonets бесплатно
Варианты использования анализа данных
С точки зрения использования, анализаторы данных используются в различных отраслях для различных целей. Вот некоторые из их применений в различных сферах деятельности:
Оптимизация бизнес-процессов
Анализаторы данных помогают компаниям структурировать неструктурированные наборы данных и преобразовывать их в полезную информацию. Вот почему предприятия используют парсеры данных для оптимизации рабочих процессов извлечения данных.
Точно так же парсеры данных используются для инвестиционного анализа, маркетинга, управления социальными сетями и других бизнес-приложений. Аналитики данных, программисты, маркетологи и инвесторы могут наблюдать значительное повышение своей производительности с помощью парсеров данных.
Аналитики данных, программисты, маркетологи и инвесторы могут наблюдать значительное повышение своей производительности с помощью парсеров данных.
Финансы и бухгалтерский учет
Банки и NBFC используют анализ данных для очистки миллиардов данных о клиентах и извлечения соответствующей информации из приложений. Он также используется для анализа кредитных отчетов, инвестиционных портфелей, проверки доходов и получения точной информации о клиентах.
Финансовые фирмы также используют синтаксические анализаторы данных для определения процентных ставок и сроков погашения кредита.
Судоходство и логистика
Предприятия, которые продают онлайн-продукты или услуги, используют анализ данных для извлечения информации о счетах и доставке. Синтаксический анализ также используется для управления отгрузочными этикетками и проверки правильности формата данных.
Недвижимость
Агентства по недвижимости используют технологии анализа данных для извлечения данных из электронных писем владельцев недвижимости и застройщиков или платформ CRM, а затем обрабатывают информацию для передачи агентам по недвижимости. Эти детали, такие как контактные данные, адреса собственности, данные о денежных потоках и источники потенциальных клиентов, очень прибыльны для компаний, занимающихся недвижимостью, и помогают им совершать покупки, аренду и продажи.
Эти детали, такие как контактные данные, адреса собственности, данные о денежных потоках и источники потенциальных клиентов, очень прибыльны для компаний, занимающихся недвижимостью, и помогают им совершать покупки, аренду и продажи.
Инвестиционный анализ
Разумные инвестиции требуют получения большого количества соответствующих данных, таких как исследование акционерного капитала, оценка стартапов, прогнозы доходов и конкурентный анализ. Сбор и анализ всех таких данных занимает много времени.
Использование инструментов веб-скрапинга вместе с парсером данных может упростить эти задачи, оптимизировать рабочий процесс и позволить вам направить ресурсы в другое место, предоставляя при этом более глубокий анализ.
Кроме того, инструменты анализа данных могут предоставить инвесторам и аналитикам данных более полную информацию для принятия правильных бизнес-решений.
Вот почему крупные инвесторы, хедж-фонды и другие профессионалы в области инвестиций используют инструменты веб-скрапинга и анализа данных для оценки стартапов, прогнозирования доходов и даже для отслеживания социальных настроений и получения точных сведений о рынке.
Работаете ли вы со счетами и квитанциями или беспокоитесь о проверке личности, воспользуйтесь парсером данных Nanonets для извлечения текста из PDF-документов бесплатно . Используется более чем 500 предприятиями для анализа более 30 миллионов документов.
Начать синтаксический анализ документов сейчас
Стоит ли создавать собственный анализатор данных?
Самый важный вопрос заключается в том, должна ли ваша организация создавать собственный анализатор данных или нет. Давайте выясним, сравнив плюсы и минусы создания вашего программного обеспечения для анализа данных.
Плюсы создания собственного синтаксического анализатора
- Настройка в соответствии с вашими потребностями — Наиболее значительным преимуществом создания программного обеспечения для синтаксического анализа текста является то, что оно специально настраивается для вашей организации. Таким образом, это помогает внутренним командам выполнять специфические требования вашей компании к синтаксическому анализу.
- Дешевле — Обычно создание парсера обходится дешевле.
- Дает вам больше контроля — Когда вы разрабатываете собственный анализатор данных, вы лучше контролируете любые решения, которые должны принимать для обновления и обслуживания вашего анализатора данных.
 Таким образом, это помогает внутренним командам выполнять специфические требования вашей компании к синтаксическому анализу.
Таким образом, это помогает внутренним командам выполнять специфические требования вашей компании к синтаксическому анализу.Минусы создания собственного синтаксического анализатора данных
- Обучение персонала — Основная проблема с технологией синтаксического анализа данных заключается в том, что вы должны обучить весь свой персонал ее использованию.
- Дорого — Во-вторых, затраты на создание пользовательского программного обеспечения синтаксического анализатора относительно высоки, поскольку для этого требуется много времени и ресурсов. Если вам нужно создать парсер, вам нужно будет нанять и обучить целую внутреннюю команду.
- Требует много планирования и усилий- Такие виды интеллектуальных решений требуют тщательного планирования и собственных выделенных серверов для мгновенного анализа. Таким образом, вам может понадобиться купить или построить мощный сервер, достаточно быстрый для анализа информации.
- Миграция — Если вам необходимо мигрировать ваши системы, ваши синтаксические анализаторы могут быть несовместимы с новыми системами и потребуют обновления.
- Техническое обслуживание — Парсер нуждается в регулярном обслуживании, а это означает, что вам придется тратить больше денег и времени.

Таким образом, вам может понадобиться анализатор данных для удовлетворения ваших требований или повышения эффективности вашей организации. В этом случае вам следует выбрать парсер данных, совместимый с вашими устаревшими системами и предназначенный для различных вариантов использования.
Автоматизируйте ручные процессы с помощью парсера документов Nanonets. Экономьте время, усилия и деньги, повышая эффективность! Начните бесплатный пробный период. Кредитная карта не требуется.
Экономьте время, усилия и деньги, повышая эффективность! Начните бесплатный пробный период. Кредитная карта не требуется.
Попробуйте Nanonets бесплатно
Покупка анализатора данных: альтернатива созданию собственного анализатора данных
Теперь, если вы не хотите создавать свой собственный анализатор, другим вариантом является покупка инструмента, который анализирует данные за вас. Многие компании продают инструменты синтаксического анализа, которые можно настроить в соответствии со своими требованиями и внедрить в свои операции. Вам не нужно беспокоиться о том, чтобы тратить время и силы на создание парсера, чтобы пользоваться его преимуществами.
Вот плюсы покупки парсера данных
● Никаких затрат на человеческие ресурсы — Когда вы покупаете парсер, вам не нужно тратить ни копейки на человеческие ресурсы. Все будет сделано, включая обслуживание парсера и серверов.
● Более быстрое решение проблем — Если на пути вашего анализатора возникнут какие-либо проблемы, вам не нужно беспокоиться, поскольку компания, у которой вы покупаете инструменты, будет иметь обширные знания о его обслуживании и быть ознакомленной с их технологиями.
● Меньше шансов на отказ или сбой — Парсеры, предназначенные для продажи, уже протестированы и усовершенствованы в соответствии с требованиями рынка. Таким образом, будет меньше шансов на сбой или проблемы в целом.
Однако покупка парсера имеет несколько недостатков. Начнем с того, что это будет немного дороже. Во-вторых, у вас не будет слишком много контроля над ним по сравнению с парсером, созданным вашей собственной командой. Поэтому вы должны взвесить все «за» и «против», а затем выбрать правильный подход для ваших требований к парсингу.
Правильный синтаксический анализатор для вас также зависит от ваших требований к синтаксическому анализу и объема работы по синтаксическому анализу, выполняемой вашей организацией. Например, если вам нужен простой синтаксический анализатор, опытный разработчик может сделать его за неделю. Однако, если он сложный, весь процесс разработки может занять месяцы.
Nanonets для анализа данных
Nanonets — это платформа автоматизации документооборота. Nanonets можно использовать для анализа данных из любого документа: PDF, Word, отсканированного или цифрового документа. Наш инструмент для анализа данных может извлекать данные с помощью 9Точность 5% при использовании нашего встроенного программного обеспечения OCR.
Nanonets можно использовать для анализа данных из любого документа: PDF, Word, отсканированного или цифрового документа. Наш инструмент для анализа данных может извлекать данные с помощью 9Точность 5% при использовании нашего встроенного программного обеспечения OCR.
Вот некоторые особенности, которые делают Nanonets отличным выбором для анализа данных:
- Программное обеспечение OCR с точностью 95% или более
- Автоматизируйте поиск документов из электронной почты, дисков и т. д.
- Простая интеграция с более чем 5000 приложений
- Современный пользовательский интерфейс
- Круглосуточная поддержка
- Никаких скрытых платежей
- Рабочие процессы на основе правил
- Навсегда бесплатный план
Попробуйте Nanonets бесплатно
Заключение
Подводя итог, можно сказать, что синтаксический анализ данных является чрезвычайно полезной технологией для таких организаций, как управляющие фирмы, страховые компании и т. д., которая может сделать информацию более доступной и удобной, чем раньше. Эта интеллектуальная технология автоматизирует ручную работу по извлечению данных и делает бизнес-операции более гибкими и масштабируемыми. Преобразованные данные можно использовать для обмена информацией с клиентами, партнерами и командами.
д., которая может сделать информацию более доступной и удобной, чем раньше. Эта интеллектуальная технология автоматизирует ручную работу по извлечению данных и делает бизнес-операции более гибкими и масштабируемыми. Преобразованные данные можно использовать для обмена информацией с клиентами, партнерами и командами.
Поэтому, если вы еще не подумали о включении хорошего синтаксического анализатора, вам следует сделать это сегодня.
Часто задаваемые вопросы
Какие инструменты необходимы для анализа данных?
Это ведущие инструменты извлечения данных, используемые для беспрепятственного извлечения данных.
● Нанонеты: интеллектуальная платформа автоматизации документов
● Scraper API
● Import.io
● Altair Monarch
Что такое проанализированный файл?
Когда строка команд, обычно компьютерная программа, фрагментируется на легко обрабатываемые компоненты, а затем анализируется на предмет правильного синтаксиса и становится легко читаемой, она называется проанализированным файлом документа.
Зачем нужен синтаксический анализ?
Нажатие данных превращает сложные или даже непонятные файлы в простые, читаемые. Например, чтение данных в необработанном HTML может вызвать у вас затруднения. Анализатор данных преобразует их в более читаемый формат, например, в обычный текст.
Как выполняется разбор данных?
Подобно обычному синтаксическому анализу, когда мы берем предложение, разбиваем его на разные части речи, а затем определяем грамматические отношения между словами для интерпретации предложения, синтаксический анализ данных анализирует символы и структуры данных.
Он использует обработку естественного языка (NLP) и структурирует информацию из наборов данных, организуя ее и определяя ее значение.
Почему вы анализируете данные?
Анализ данных — это когда вы берете некоторые неструктурированные данные и преобразуете их в другие форматы файлов, такие как JSON и CSV, и добавляете дополнительную структуру к данной информации. Таким образом, мы превращаем нечитаемые данные в более полные и простые для понимания.
Таким образом, мы превращаем нечитаемые данные в более полные и простые для понимания.
Nanonets онлайн OCR и OCR API имеют много интересных вариантов использования t шляпа может оптимизировать эффективность вашего бизнеса, сократить расходы и ускорить рост. Узнайте, как варианты использования Nanonets могут применяться к вашему продукту.
Обновление: сообщение, первоначально опубликованное в июле 2022 года, обновлено в августе 2022 года. анализировать синтаксическую структуру предложений.
Вероятностный анализ — это тип синтаксического анализа, который использует вероятность и статистику для анализа и создания наиболее вероятной синтаксической структуры для данного предложения.
Scope
- В этой статье мы узнаем о синтаксическом анализе и различных аспектах синтаксического анализа.
- Мы также узнаем о морфологическом разборе и вероятностной контекстно-свободной грамматике (PCFG).
- Мы разберемся с вероятностной моделью и проблемами с вероятностной контекстно-свободной грамматикой.
- Затем мы узнаем о вероятностной лексикализованной CFG, человеческом разборе, иерархии Хомского, лексикализации и о том, как вычислять вероятности лексикализованных правил.

Предварительные условия
Прежде чем мы перейдем к дополнительным темам этой статьи, давайте кратко рассмотрим некоторые основы, необходимые для этой статьи.
Введение в грамматику
Грамматика — это система правил, регулирующих структуру предложений в языке; это включает в себя правила формирования слов, фраз, пунктов и предложений и определяет правильный порядок и расположение этих элементов.
- Грамматика является важным аспектом языка, поскольку помогает нам эффективно общаться и понимать друг друга, когда мы говорим или пишем. Это также помогает убедиться, что предложения ясны, правильны и связны.
- Грамматика может быть сложной, но понимание основ может помочь нам улучшить общение между людьми и сделать нас более уверенными и эффективными пользователями языка.
Грамматика позволяет системам НЛП точно обрабатывать и понимать входные данные на естественном языке, необходимые для таких задач, как машинный перевод, резюмирование текста и извлечение информации.
Элементы семантического анализа
Семантический анализ касается того, как слова и предложения понимаются говорящими и слушающими в языке и как значение предложения выводится из значений его слов и их расположения в предложении.
- Различные элементы семантического анализа включают изучение значений слов, структуры предложений и отношений между словами и их контекстом.
- Семантический анализ также включает в себя изучение того, как слова и предложения могут иметь разное значение в разных контекстах и как говорящие и слушатели используют контекст и фоновые знания, чтобы понять значение предложения.
Семантический анализ — важный аспект грамматики, который помогает нам понять значение языка и эффективно общаться.
Введение в лексикализованный синтаксический анализ
Лексикализованный синтаксический анализ — это тип синтаксического анализа, который включает информацию из лексикона языка, который представляет собой полный набор слов и их значений для повышения точности синтаксического анализа.
- Синтаксический анализатор в лексикализованном синтаксическом анализе использует слова в предложении, а также их значения в лексиконе для управления процессом синтаксического анализа, что позволяет синтаксическому анализатору устранять неоднозначность между несколькими возможными деревьями синтаксического анализа для предложения и выбирать наиболее вероятный синтаксический анализ на основе значения слов в предложении.
- Лексикализованный синтаксический анализ основан на построении древовидной структуры из набора токенов, которые при правильном анализе предложения могут возвращать подфразы для определения синтаксической структуры предложения.
Введение в вероятностный анализ
Вероятностный анализ, в отличие от лексикализованного анализа, представляет собой тип анализа, который использует вероятности и статистические модели для определения наиболее вероятного анализа предложения.
- Синтаксический анализатор использует набор правил и вероятностей вероятностного анализа для определения наиболее вероятной синтаксической структуры предложения.
- Структура такого типа позволяет синтаксическому анализатору учитывать контекст предложения и вероятность различных синтаксических структур и выбирать наиболее вероятный синтаксический анализ с учетом контекста.
Как лексический, так и вероятностный синтаксический анализ могут повысить точность и эффективность систем обработки естественного языка и обычно используются во многих приложениях НЛП.
Введение
Теперь, когда вы вкратце рассказали о предварительных требованиях к этой статье — грамматике, элементах семантического анализа, лексикализованном анализе и вероятностном анализе, мы можем перейти к более сложным темам статьи, а также рассмотреть синтаксический анализ и анализ. подробно о его видах.
Что такое синтаксический анализ?
Синтаксический анализ — это процесс анализа строки текста, такой как предложение или абзац, для определения грамматической структуры и взаимосвязи между словами, содержащимися в тексте.
- Процесс синтаксического анализа включает определение частей речи, таких как существительные, глаголы и прилагательные, и определение того, как они связаны друг с другом с помощью синтаксических правил.
- Синтаксический анализ можно использовать для извлечения смысла из текста и помощи компьютерам в понимании и обработке ввода на естественном языке.
- Синтаксический анализ также можно назвать процедурной интерпретацией грамматики, когда он просматривает пространство различных деревьев и находит оптимальное дерево для данного предложения.
Deep Vs. Поверхностный синтаксический анализ: Глубокий и поверхностный синтаксический анализ — это два подхода, используемых в обработке естественного языка (НЛП) для анализа и понимания структуры предложений в тексте.
- Поверхностный синтаксический анализ: Также известен как легкий синтаксический анализ или фрагментация, когда предложение делится на более короткие фрагменты или фразы, такие как именные и глагольные фразы. Этот подход обеспечивает ограниченный анализ структуры предложения без учета зависимостей между словами.
- Глубокий синтаксический анализ: Он также известен как полный синтаксический анализ или синтаксический анализ и включает анализ предложения для определения зависимостей между словами и ролей, которые они играют в предложении. Такой подход обеспечивает более подробный и точный анализ структуры предложения, в том числе грамматических отношений между словами.
 Этот подход обеспечивает ограниченный анализ структуры предложения без учета зависимостей между словами.
Этот подход обеспечивает ограниченный анализ структуры предложения без учета зависимостей между словами.Давайте кратко рассмотрим некоторые из синтаксических анализаторов, обычно используемых практиками и в отрасли, чтобы увидеть, как они работают, и лучше понять дальнейшие концепции в статье.
Парсер Shift-reduce: Синтаксический анализатор Shift-reduce — это восходящий анализатор, работающий на основе анализа структуры предложений в тексте.
- Он начинается с отдельных слов в предложении и объединяет их в более сложные структуры, такие как фразы и предложения, пока не будет получено полное дерево синтаксического анализа, представляющее синтаксическую структуру предложения.
- Синтаксический анализатор выполняет этот процесс, многократно применяя к входному предложению две операции, известные как сдвиг и сокращение.
- Операция сдвига: В этой операции синтаксический анализатор перемещает одно слово из входных данных в дерево синтаксического анализа.
- Операция сокращения: В этой операции синтаксический анализатор объединяет два или более слова в дереве синтаксического анализа в большую синтаксическую единицу.
- Чередуя операции сдвига и сокращения, синтаксический анализатор сдвига-свертки строит дерево синтаксического анализа для предложения шаг за шагом.
- Он начинается с отдельных слов в предложении и объединяет их в более сложные структуры, такие как фразы и предложения, пока не будет получено полное дерево синтаксического анализа, представляющее синтаксическую структуру предложения.
Парсер рекурсивного спуска: Парсер рекурсивного спуска — это нисходящий анализатор, который начинает с общей структуры предложения и разбивает его на все более мелкие части, пока не идентифицирует отдельные слова в предложении.
- Синтаксический анализатор выполняет этот процесс, разделяя входное предложение на набор рекурсивных правил или производных, которые определяют возможные последовательности слов, которые могут появиться в предложении.
- Каждое произведение соответствует нетерминальному символу в грамматике языка, представляющему часть структуры предложения, например именную группу или глагольную группу.
- Для синтаксического анализа предложения синтаксический анализатор начинает с сопоставления входных данных с начальным символом грамматики, а затем рекурсивно применяет соответствующие продукционные правила для идентификации составляющих предложения и построения дерева синтаксического анализа, представляющего его структуру.
- Синтаксический анализатор выполняет этот процесс, разделяя входное предложение на набор рекурсивных правил или производных, которые определяют возможные последовательности слов, которые могут появиться в предложении.
Анализатор диаграмм: Анализаторы диаграмм вместо этого используют графическую модель для анализа синтаксической структуры предложения. Анализаторы диаграмм представляют предложения в виде диаграммы или таблицы, где каждое слово занимает ячейку в диаграмме.
- Синтаксический анализатор использует набор правил для анализа диаграммы и выявления зависимостей между словами, в конечном итоге создавая дерево синтаксического анализа или другое представление синтаксической структуры предложения.
- Парсеры диаграмм часто используются в других системах обработки естественного языка для анализа грамматической структуры предложений и извлечения из них полезной информации. Они особенно полезны для обработки сложных предложений и устранения двусмысленности в структуре предложения.
- Синтаксический анализатор использует набор правил для анализа диаграммы и выявления зависимостей между словами, в конечном итоге создавая дерево синтаксического анализа или другое представление синтаксической структуры предложения.
Анализатор регулярных выражений: Анализ регулярных выражений или анализ регулярных выражений — это метод анализа текстовых данных с использованием регулярных выражений.
- Регулярные выражения — это мощный инструмент для сопоставления шаблонов в текстовых данных, и их можно использовать для широкого круга задач, таких как проверка ввода, поиск подстрок и извлечение данных из текста.
- Шаблон регулярного выражения при синтаксическом анализе регулярного выражения используется для поиска в теле текста, и все совпадения с шаблоном идентифицируются и возвращаются. Анализаторы
- регулярных выражений — это очень эффективный способ обработки текстовых данных, поскольку он позволяет выполнять сопоставление сложных шаблонов с использованием компактного и выразительного синтаксиса. Поэтому синтаксический анализ регулярных выражений также широко используется во многих языках программирования и инструментах обработки текста.
Анализатор зависимостей: Анализ зависимостей в НЛП — это метод, используемый для анализа грамматической структуры предложения путем выявления зависимостей между различными словами в предложении и определения их отношений на основе ролей, которые они играют в предложении.
- Анализ зависимостей полезен для многих задач обработки естественных языков, таких как извлечение информации, суммирование текста, маркировка семантических ролей (SRL) и других приложений за пределами NLP, таких как синтаксическое разбиение на фрагменты и анализ групп.
- Предложение разбивается на несколько компонентов с лежащей в его основе идеей о том, что существует прямая связь (называемая зависимостями) между каждой языковой единицей предложения.
- Каждое слово в предложении представлено как узел в древовидной структуре, а зависимости между словами представлены как ребра между узлами.
- Такая иерархическая структура предложения обеспечивает четкое представление и предоставляет полезную информацию о значении и намерении предложения.
- Каждое слово в предложении представлено как узел в древовидной структуре, а зависимости между словами представлены как ребра между узлами.


 Поэтому синтаксический анализ регулярных выражений также широко используется во многих языках программирования и инструментах обработки текста.
Поэтому синтаксический анализ регулярных выражений также широко используется во многих языках программирования и инструментах обработки текста.
Морфологический анализ
Морфологический анализ при обработке естественного языка — это анализ слова для определения составляющих его морфем, которые являются наименьшими единицами значения в языке. Обычно это делается для лучшего понимания смысла и грамматики предложения.
- Морфологический анализ — сложная задача, особенно в языках со сложной морфологией, таких как английский.
- Пример: unbreakable можно морфологически разделить на три морфемы: un-, break и -able.
- Первая морфема «не-» указывает на отрицание, вторая морфема «разрыв» является корнем слова, а третья морфема «-способен» указывает на способность что-то делать.
- Вместе эти три морфемы придают слову общее значение «неразрывный».
Основные проблемы, связанные с морфологическим анализом
- Неоднозначность: Многие слова в английском языке имеют несколько возможных морфологических анализов, что затрудняет определение точной структуры слова.
- Пример: Слово «неожиданно» может быть проанализировано как «неожиданно» или «неожиданно».
- Неизвестные слова: Морфологические синтаксические анализаторы должны иметь возможность обрабатывать неизвестные слова, которые могут отсутствовать в их обучающих данных. Это может быть очень сложной задачей, поскольку синтаксический анализатор должен иметь возможность обобщать известные слова до неизвестных, чтобы обеспечить точный анализ.
- Разреженность данных: a Для обучения морфологических синтаксических анализаторов требуется большое количество аннотированных данных, но аннотирование текстовых данных для морфологического синтаксического анализа является трудоемкой и трудоемкой задачей, и может быть трудно получить достаточно данных для обучения морфологического синтаксического анализа. качественный парсер.
- Сложность выполнения: Морфологический синтаксический анализ включает в себя анализ структуры слов на детальном уровне, что может сделать задачу сложной и трудной для реализации, что затрудняет разработку точных и эффективных морфологических синтаксических анализаторов.


Вероятностная контекстно-свободная грамматика (PCFG)
Вероятностно-контекстно-свободная грамматика (PCFG) — это тип грамматики, который используется при обработке естественного языка и представляет собой вероятностную версию стандартной контекстно-свободной грамматики (CFG), которая представляет собой набор правил, используемых для генерации строк слов на конкретном языке, где параметры модели — это вероятности, присвоенные грамматическим правилам.
- Вероятности всех продукций, переписывающих данный нетерминал, должны в сумме равняться 1, определяя распределение для каждого нетерминала.
- Генерация строк является вероятностной, когда производственные вероятности используются для недетерминированного выбора продукции для перезаписи данного нетерминала.
- Каждое правило связано с вероятностью, которая указывает вероятность того, что правило будет использовано для создания данного предложения. Это позволяет PCFG моделировать неопределенность, присущую естественному языку, и делать более точные прогнозы относительно структуры предложений.
- Допущение независимости — одно из ключевых свойств PCFG, где вероятность последовательности узлов зависит только от непосредственного материнского узла, а не от какого-либо узла над ним или за пределами текущего компонента.
- В зависимости от контекста могут использоваться различные правила, позволяющие PCFG моделировать неопределенность и изменчивость, присущие естественному языку.

PCFG — хороший способ решить проблемы неоднозначности в области синтаксической структуры.
Вероятностная модель
Подобно контекстно-свободной грамматике, вероятностная контекстно-свободная грамматика G может быть определена пятеркой: G=(M,T,R,S,P)G = (M, T, R, S , P)G=(M,T,R,S,P), где:
- M — набор нетерминальных символов
- T — набор терминальных символов
- R — набор продукционных правил
- S — начальный символ
- P — множество вероятностей по продукционным правилам
Проблемы с PCFG
- PCFG страдают от различных проблем, среди которых две наиболее существенные слабости — отсутствие чувствительности к лексической информации и отсутствие чувствительности к структурным предпочтениям.
- Из-за этих двух проблем PCFG не всегда могут охватить весь спектр синтаксических вариаций и двусмысленностей, существующих в естественных языках, что приводит к ошибкам и неправильным анализам, особенно при работе с предложениями, которые структурно сложны или содержат несколько возможных интерпретаций. Лексикализованные PCFG
- разработаны для решения этих проблем и работают лучше по сравнению с PCFG.
- Сложность: Еще одна серьезная проблема с PCFG заключается в том, что они могут быть очень сложными, что затрудняет их понимание и работу с ними. Сложность затрудняет разработку PCFG, которая точно представляет структуру данного языка, а также затрудняет реализацию и использование PCFG в практическом приложении.
- Доступность данных: PCFG также имеют проблему, потому что им часто требуется большой объем обучающих данных для получения точных результатов. Это может быть проблемой при работе с языками с ограниченным количеством аннотированного текста или при попытке разобрать предложения, содержащие новые или необычные конструкции.


Вероятностная лексикализированная CFG
Вероятностная лексикализированная контекстно-свободная грамматика (PLCFG) также представляет собой тип грамматики, используемый при обработке естественного языка для создания и анализа предложений на заданном языке.
Это комбинация лексикализованной контекстно-свободной грамматики, в которой лексические элементы этого слова используются в качестве основных единиц для построения предложений, и вероятностных моделей, которые присваивают вероятности различным правилам и структурам грамматики.
Вероятностная лексикализированная контекстно-свободная грамматика устраняет несколько отдельных недостатков, которые проистекают из предположений о независимости PCFG, из которых наиболее часто отмечается отсутствие лексикализации.
- Вероятность того, что VP расширится до глагола, за которым следуют две именные группы, не зависит от выбора глагола, участвующего в PCFG. Это недостаток, поскольку такая возможность гораздо более вероятна с дипереходными глаголами, такими как рука или сказать, чем с другими глаголами.
- Вероятность того, что VP расширится до глагола, за которым следуют две именные группы, не зависит от выбора глагола, участвующего в PCFG.
 Это недостаток, поскольку такая возможность гораздо более вероятна с дипереходными глаголами, такими как рука или сказать, чем с другими глаголами.
Это недостаток, поскольку такая возможность гораздо более вероятна с дипереходными глаголами, такими как рука или сказать, чем с другими глаголами.Сочетание лексикализации с вероятностными моделями позволяет вероятностной лексикализованной модели CFG учитывать вероятность различных предложений и структур, что делает ее полезной для таких задач, как моделирование языка и машинный перевод.
Человеческий анализ
Человеческий анализ — это процесс, обычно выполняемый людьми, которые используют свои знания грамматики и синтаксиса, чтобы понять значение и цель данного предложения; это осуществляется путем анализа и интерпретации структуры предложений естественного языка.
- Человеческий анализ может быть трудным и трудоемким, особенно при работе с длинными или сложными предложениями, но это важный навык для всех, кто хочет работать с данными естественного языка, например, лингвистов, исследователей языка и естественных наук. специалисты по обработке речи.
- Существуют разные подходы к человеческому синтаксическому анализу, и конкретный используемый метод может различаться в зависимости от целей человека или группы, проводящих анализ.
- Некоторые распространенные методы разбора человеком включают ручной анализ, когда человек читает и интерпретирует предложение, вычислительные методы, когда для анализа предложения используется компьютерная программа, а также сочетание ручного и вычислительного подходов.
 специалисты по обработке речи.
специалисты по обработке речи.Иерархия Хомского
Иерархия Хомского — это классификация формальных языков, названная в честь лингвиста Ноама Хомского. Это способ организации и классификации различных типов языков на основе их структуры и правил, регулирующих их создание.
Иерархия Хомского состоит из четырех уровней:
- Языки типа 0 , также известные как неограниченные грамматики , являются наиболее общим и мощным типом языка. Они могут генерировать бесконечное количество предложений и могут быть описаны машиной Тьюринга.
- Языки типа 1 , также известные как контекстно-зависимые грамматики , являются строгим подмножеством языков типа 0 и генерируются линейным ограниченным автоматом и могут быть описаны контекстно-зависимой грамматикой.
- Языки типа 2 , также известные как контекстно-свободные грамматики , являются строгим подмножеством языков типа 1 и генерируются автоматом выталкивания вниз и могут быть описаны контекстно-свободной грамматикой.
- Тип 3 языка , также известный как обычных языка , является строгим подмножеством языков типа 2. Они генерируются конечным автоматом и могут быть описаны регулярным выражением.
 Они могут генерировать бесконечное количество предложений и могут быть описаны машиной Тьюринга.
Они могут генерировать бесконечное количество предложений и могут быть описаны машиной Тьюринга. Иерархия Хомского важна в теоретической информатике и лингвистике, поскольку она обеспечивает основу для изучения формальных свойств языков и алгоритмов, которые можно использовать для их обработки.
Что такое лексикализация?
Лексикализация — это процесс, при котором слово выражает понятие путем превращения фразы или предложения в одно слово или последовательность слов.
- Лексикализация осуществляется путем объединения наиболее важных слов во фразе или предложении для сохранения значения исходной фразы или предложения.
- Пример: быть честным может быть лексикализировано как откровенно или откровенно.
- Исследования различных вариантов использования лексикализации и их результаты показывают, что для различных задач и приложений НЛП необходимо включать лексикализацию.
- Существует строгая корреляция между компонентами значения, включенными в корень слова, и его синтаксическими свойствами, кросс-лингвистические различия в объединении компонентов значения в корнях слов, данные по лексикализации могут быть полезны для устранения неоднозначности смысла слова (WSD) и всего, что связано с этим. Приложения.

Лексизация — это общая черта многих языков, которая делает общение более эффективным и лаконичным.
Пример
- Если мы посмотрим на пару примеров предложений — Я ел пиццу с оливками, Я ел пиццу с друзьями. Использование PCFG в этом контексте имеет некоторые ограничения, связанные с отсутствием контекста.
- Оба примера предложений имеют разное дерево синтаксического анализа. В первом предложении with оливки — это предлог именной группы «пицца», а во втором — «с друзьями» — предлог глагольной группы «съел».
- PCFG не может назначить правильную структуру для каждого предложения, потому что выше лексического уровня или листьев предложения выглядят одинаково и имеют одинаковую последовательность POS.
- Лексизация модели PCFG добавляет слова к правилам грамматики. Таким образом, для нашего примера у нас будет: VP/ate->VP/atePP/friends; NP/pizza->NP/pizzaPP/olivesVP/ate -> VP/ate PP/friends; NP/пицца -> NP/пицца PP/оливкиVP/ели->VP/atePP/друзья; NP/пицца->NP/пиццаPP/оливки.
- Использование этих добавленных слов является более экономичным, поскольку они короче, чем соответствующие лежащие в их основе предложения или парафразы, и их легче использовать в качестве элементов предложений.
- Пример: Основываясь на лексикализации, никто не говорит, что кто-то пишет книгу для кого-то другого, а тот часто притворяется, что это его работа; вместо этого говорят «писатель-призрак».
- Лексизация также добавляет правила с более низкой вероятностью, где PCFG может дополнительно назначить правильную структуру, используя вероятности правил.

Вычисление вероятностей лексикализованных правил
Вероятности лексикализованных правил — это вероятности, связанные с конкретным набором правил для данного языка; их можно рассчитать, используя корпус текста.
- Первым шагом является определение набора правил, для которых вы хотите рассчитать вероятности, включая правила грамматики, синтаксиса и семантики.
- Как только мы определили правила, мы можем использовать статистический метод, такой как оценка максимального правдоподобия, для расчета вероятностей. Этот процесс включает в себя подсчет количества повторений каждого правила в корпусе и деление полученного результата на общее количество правил в корпусе.
- Пример: Если конкретное правило встречается 100 раз в совокупности из 1000 правил, вероятность этого правила будет равна 0,1.

Качество вероятностей будет зависеть от размера и качества корпуса, используемого для расчета. Более крупный и разнообразный корпус, как правило, обеспечивает более точные вероятности.
Заключение
- Синтаксический анализ — это процесс анализа строки текста, например предложения или абзаца, для определения грамматической структуры и взаимосвязи между словами, содержащимися в тексте.
- Лексикон языка — это полный набор слов и их значений для повышения точности синтаксического анализа.
