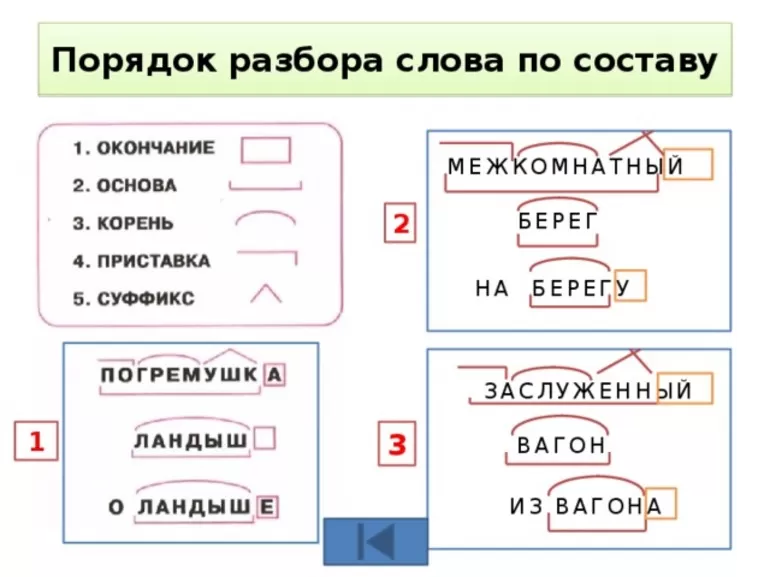
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «покрыть», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ПОКРЫТЬ, рою, роешь; ытый; сов.
1. см. крыть.
2. кого-что. Положить, наложить сверху на кого-что-н. П. кого-н. одеялом. П. голову платком (повязать платок). П. забор краской (покрасить).
3. кого-что. Заполнить, усеять чем-н. по поверхности. Облака покрыли небо. П. переплёт тиснёными узорами. Тело покрыто сыпью.
4. что. О звуках: заглушить, превзойдя в силе. Оркестр покрыл шум толпы. П. речь аплодисментами. П. слова рассказчика смехом.
5. что. Возместить чем-н. П. задолженность. П. издержки, расходы.
6. кого-что. Помочь укрыть, скрыть, не выдав чей-н. проступок, преступление. П. своих сообщников. П. чьюн. вину. П. грех.
7. что. Передвигаясь, преодолеть какое-н. расстояние. Самолёт покрыл большие пространства.
8. кого (что). О животных: оплодотворить (спец.).
• Покрыть позором или презрением кого-что (книжн.) навлечь на кого-что-н. позор, презрение.
Покрыть славой кого-что (высок.) прославить кого-что-н.
Покрыть тайной что (книжн.) скрыть, сделать совершенно неизвестным для других.
| несов. покрывать, аю, аешь.
| сущ. покрытие, я, ср. (ко 2, 3, 5, 6, 7 и 8 знач.).
Фонетический (звуко-буквенный) разбор
покры́ть
покрыть — слово из 2 слогов: по-крыть. Ударение падает на 2-й слог.
Транскрипция слова: [пакрыт’]
п — [п] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
к — [к] — согласный, глухой парный, твёрдый (парный)
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
ы — [ы] — гласный, ударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 7 букв и 6 звуков.
Цветовая схема: покрыть
Ударение в слове проверено администраторами сайта и не может быть изменено.
Разбор слова «покрыть» по составу
покрыть (программа института)
покрыть (школьная программа)
Части слова «покрыть»: по/кры/ть
Часть речи: глагол
Состав слова:
по — приставка,
кры — корень,
нет окончания,
покры — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow. js and linear regression.
js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфологический разбор деепричастия «покрывая» онлайн. План разбора.
Для слова «покрывая» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «покрывая» — деепричастие - Морфологические признаки.
- покрывать (неопределённая форма глагола)
- неизменяемая форма, несовершенный вид, настоящее время
Слабый камень этот беспрестанно щелушится и осыпается, покрывая мелким мусором проложенную под обрывом узенькую проездную дорожку.
Выполняет роль обстоятельства.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора деепричастия
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (неопределенная форма глагола)
- Неизменяемость
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).

- Возвратность (-сь)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
8 голосов, оценка 4.625 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор деепричастия «покрывая» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
Все о синтаксическом анализе: что это такое и как оно связано с программным обеспечением для преобразования текста в речь | Алекс Кителингер | Voice Tech Podcast
Суть этого, помимо прекрасного предлога, заставляющего всех вас услышать немного классической игры слов, заключается в том, чтобы показать, что наличия всех слов во фразе недостаточно, чтобы обрести ее полное значение во многих словах. случаи. Мы, люди, чертовски хорошо умеем интерпретировать значение предложения из контекста (идите, люди!), Но для машин это сложный процесс. Когда мы говорим о синтаксическом анализе в компьютерной лингвистике, эти предложения должны интерпретироваться с помощью установленной грамматики: установленного набора правил того, как работает данный язык, чтобы определить, что является «грамматическим», а что нет.Это используется в качестве основы для разбивки предложения на возможные интерпретации. Я говорю «возможно» здесь очень сознательно, поскольку человеческие языки в целом (конечно, английский) имеют большую тенденцию к двусмысленности. Обычно это достигается с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или аналогичного предложения и просто давать вероятность каждой данной интерпретации.С тех пор мы прошли долгий путь, но есть, что рассказать… так что я не буду! По крайней мере, не сегодня.
Обычно это достигается с помощью одного из нескольких методов машинного обучения; большая часть этого основана на частоте определенных типов высказываний. В одном из первоначально предложенных методов синтаксического анализа (с использованием вероятностных контекстно-свободных грамматик ) неоднозначное предложение будет сравниваться с другими экземплярами того же или аналогичного предложения и просто давать вероятность каждой данной интерпретации.С тех пор мы прошли долгий путь, но есть, что рассказать… так что я не буду! По крайней мере, не сегодня.
Более интересным, пожалуй, является текущая реализация того, как работают наши голосовые помощники. Alexa, например, не выполняет всю эту тяжелую работу локально (как и другие, хотя это может быть не всегда …) Ваше устройство Echo будет принимать звуковой файл, который он получил (прочтите мой последний пост, если вы любопытно, как работает эта магия), и передать его в службу Alexa, размещенную в облаке Amazon, и основная часть обработки выполняется там.Даже в этом случае работа очень урезана по сравнению с этой весомой сравнительной моделью. Alexa действует на основе нескольких ключевых элементов, которые она ищет в запросе, и использует их для определения основного значения того, что вы ищете. Ниже приведен пример запроса из отличного руководства для тех, кто хочет получить краткий обзор начала разработки для устройств с поддержкой Alexa:
Способ анализа запроса Alexa (вверху) и данные, которые он отправляет навыку (внизу) (Источник) Эти и большинство примеров такого же типа запросов от голосовых помощников заметно упрощены, так как все, что действительно нужно сделать, это определить названия вызова и навыков, а затем проанализировать, где «высказывание» ”Есть и будет основываться только на этом небольшом фрагменте.Даже в этом случае гораздо проще разобрать, когда структура запроса уже известна; вы просите устройство выполнить за вас задачу, и это сильно ограничивает возможности того, что вы могли бы сказать.
В этом много всего, и я только начинаю царапать поверхность, но суть в том, что «разбор» того, что вы говорите за пределами виртуальных помощников, — это огромное испытание, связанное с ошибками и несоответствиями, особенно если учесть, что то, как мы, люди, говорим, откровенно говоря, содержит ошибки и несоответствия.Даже в этом ограниченном контексте, который мы оцениваем с помощью Alexa, предстоит проделать большую работу. Я определенно планирую продолжить копаться в мельчайших деталях того, что происходит от A до B, но я надеюсь, что этот небольшой взгляд был, по крайней мере, немного проницательным!
Часто задаваемые вопросы о проверке грамматики в Word
Что означает наличие в Word средства проверки грамматики «естественного языка»?
Средство проверки грамматики в Word выполняет всесторонний и точный анализ (также известный как «синтаксический анализ») отправленного текста, вместо того, чтобы просто использовать серию эвристик (или сопоставление с образцом) для выявления ошибок.Инструмент проверки грамматики анализирует текст на синтаксическом уровне и на более глубоком, логическом уровне, чтобы понять взаимосвязь между действиями и людьми или вещами, которые выполняют эти действия. Например, средство проверки грамматики Word анализирует следующее сложное предложение
Легенда гласит, что это Королевство было создано тремя древними магами, чьи магические силы правили миром и сделали их бессмертными и всемогущими. и переписывает его с пассивного голоса на активный для ясности.Инструмент проверки грамматики также выделяет относительное предложение между запятыми:
Легенда гласит, что это Королевство создали три древних мага, чьи магические силы правили миром и сделали их бессмертными и всемогущими. Примечание. Эта функция не включена по умолчанию. Чтобы включить эту функцию, выполните следующие действия:
Начальное слово.
В меню Инструменты щелкните
Параметры .На вкладке Орфография и грамматика в области Грамматика измените поле Стиль письма на
Нажмите ОК , чтобы закрыть диалоговое окно
Параметры .

Кто разработал средство проверки грамматики Word?
Средство проверки грамматики полностью разработано и принадлежит Microsoft.
В чем основные различия между инструментом проверки грамматики Word и другими решениями сторонних поставщиков для проверки грамматики?
Одно из ключевых различий между средством проверки грамматики Word и другими решениями проверки грамматики заключается в том, что средство проверки грамматики в Word использует передовые методы синтаксического анализа для понимания структуры предложения. Сторонние решения для проверки грамматики могут в основном полагаться на «сопоставление с образцом».«Сопоставление с образцом» означает, что программа использует метод сопоставления проверенного текста с образцами текста, которые хранятся во внутренней базе данных.
Как называются файлы средства проверки грамматики и где они установлены?
Программа Word Setup по умолчанию устанавливает средство проверки грамматики. Средство проверки грамматики английского языка (США) состоит из двух файлов:
Msgr3en.dll установлена в следующую папку:
Диск : \ Program Files \ Common Files \ Microsoft Shared \ Proof \ 1033
Msgr3en.
lex установлен в следующую папку:Диск : \ Program Files \ Common Files \ Microsoft Shared \ Proof \
 lex установлен в следующую папку:
lex установлен в следующую папку:Сколько памяти требуется моему компьютеру, чтобы Word мог проверять грамматику в моем документе при вводе текста?
Word автоматически включает средство проверки грамматики, если на вашем компьютере достаточно свободной памяти.Метод проверки грамматики, который включается при установке и первом запуске Word, зависит от объема доступной памяти на вашем компьютере.
Использование средства проверки грамматики вручную (8 МБ или более):
Для запуска средства проверки грамматики при нажатии кнопки «Орфография и грамматика» в меню «Инструменты» на вашем компьютере должно быть более 8 мегабайт (МБ) физической памяти. Если у вас меньше 8 МБ, функция проверки грамматики при вводе отключена по умолчанию при первом запуске Word.
Автоматически использовать средство проверки грамматики (12 МБ или более):
Для запуска проверки грамматики при постоянном вводе параметра (для отображения грамматических ошибок с волнистым подчеркиванием) на вашем компьютере должно быть не менее 12 МБ физической ОЗУ . Если на вашем компьютере меньше 12 МБ ОЗУ, при первом запуске Word устанавливается флажок «Скрыть грамматические ошибки».
Чтобы включить Проверять грамматику при вводе , наведите указатель на «Параметры» в меню «Инструменты», щелкните вкладку «Орфография и грамматика», а затем щелкните, чтобы установить флажок «Проверка грамматики при вводе ».
Примечание. Для всех западноевропейских языков, кроме английского, опция
Проверять грамматику при вводе по умолчанию отключена. (Средство проверки грамматики английского языка входит в состав всех версий Word.)
Где находятся записи реестра для средства проверки грамматики?
Важно! Этот раздел, метод или задача содержат шаги, которые говорят вам, как изменить реестр. Однако при неправильном изменении реестра могут возникнуть серьезные проблемы.Поэтому убедитесь, что вы внимательно выполните следующие действия. Для дополнительной защиты сделайте резервную копию реестра перед его изменением. Затем вы можете восстановить реестр в случае возникновения проблемы. Для получения дополнительных сведений о резервном копировании и восстановлении реестра щелкните следующий номер статьи базы знаний Microsoft:
Однако при неправильном изменении реестра могут возникнуть серьезные проблемы.Поэтому убедитесь, что вы внимательно выполните следующие действия. Для дополнительной защиты сделайте резервную копию реестра перед его изменением. Затем вы можете восстановить реестр в случае возникновения проблемы. Для получения дополнительных сведений о резервном копировании и восстановлении реестра щелкните следующий номер статьи базы знаний Microsoft:
322756 Как создать резервную копию и восстановить реестр в Windows
Параметры грамматики для каждого пользователя:
Примечание Word создает этот параметр, если параметр не существует в реестре Windows:
HKEY_CURRENT_USER \ Software \ Microsoft \ Shared Tools \ Proofing Tools \ Grammar \ MSGrammar В этом подразделе Word регистрирует номер версии грамматики (3.0 в случае английского), идентификаторы языков (1033 в случае американского английского) и настройки грамматики, которые вы выбираете на вкладке Орфография и грамматика в диалоговом окне Параметры (меню Инструменты). В Word вы можете выбрать два стиля письма на вкладке «Орфография и грамматика»: «Грамматика и стиль» или «Только грамматика». Эти параметры определены в записях «Имя» в подразделе «Набор параметров 0» и в подразделе «Набор параметров 1». Для каждого из этих параметров вы также можете установить правила, которые Word использует для проверки грамматики. Чтобы установить эти правила, нажмите «Настройки» на вкладке «Орфография и грамматика».Эти настройки также хранятся в виде двоичных инструкций в записях данных в подразделе Option Set 0 и Option Set 1 подразделе.
Примечание. Если вы обновили более раннюю версию Word, записи имен будут определены как случайные, стандартные, формальные, технические или специальные, а не только как «Грамматика и стиль» или «Грамматика». В этом случае в реестре будут подключи от Option Set 0 до Option Set 4, которые соответствуют каждому из этих стилей записи.
Настройки грамматической машины:
Примечание. Этот параметр должен существовать для проверки грамматики на определенном языке.
HKEY_LOCAL_MACHINE \ Software \ Microsoft \ Shared Tools \ Proofing Tools \ Grammar Под этим ключом находятся идентификаторы языков (1033, 2057, 3081), атрибуты стиля Normal и значения Dictionary и Engine, которые содержат, соответственно, полные пути к Файлы .lex и .dll.
Примечание. Не все файлы проверки грамматики языка автоматически регистрируются после копирования файлов грамматики в определенное место. Поэтому всегда рекомендуется использовать программу установки для установки файлов проверки грамматики (и других средств проверки).
Почему средство проверки грамматики помечает слова, которые не следует отмечать, и почему предлагает неправильные предложения?
Как правило, средство проверки грамматики неправильно отмечает слова или предлагает неверные предложения, когда синтаксический анализатор (то есть компонент проверки грамматики, который анализирует лингвистическую структуру предложения) не может определить правильную структуру анализируемого предложения.
Несмотря на то, что инструмент проверки грамматики является современным в своей категории, он (как и любая другая имеющаяся в продаже программа проверки грамматики) не идеален.Поэтому, когда вы используете средство проверки грамматики, вы можете столкнуться с некоторым количеством «ложных» или «подозрительных» отметок и последующих неправильных предложений; однако средство проверки грамматики в Word 2002 и более поздних версиях значительно улучшено по сравнению с более ранними версиями Microsoft Word.
Почему средство проверки грамматики не может обнаружить ошибки во фразе «Мы посетили два магазина, чтобы …»?
Средство проверки грамматики предназначено для выявления ошибок, которые обычные пользователи совершают каждый день. Вы всегда можете составлять предложения, которые могут сбить с толку инструмент проверки грамматики.
Вы всегда можете составлять предложения, которые могут сбить с толку инструмент проверки грамматики.
Когда средство проверки грамматики работает в фоновом режиме (волнистые подчеркивания), почему он помечает ошибки в другом порядке, чем когда я нажимаю «Орфография и грамматика» в меню «Инструменты»?
При выборе пункта «Орфография и грамматика» в меню «Инструменты» средство проверки грамматики запускается на переднем плане и управляет документом. То есть, вы не можете работать со своим документом, пока инструмент проверки грамматики проверяет ваш документ.
Однако, когда средство проверки грамматики работает в фоновом режиме (волнистые подчеркивания), оно пытается добиться логического потока слева направо и не так критично для структуры предложения, как при запуске проверки грамматики. инструмент вручную (на переднем плане). Поэтому, когда средство проверки грамматики работает в фоновом режиме, ошибка, помеченная первой, всегда является той, которая возвращает предложение, независимо от ее положения в предложении.
Почему «Игнорировать все» не работает так, как я ожидал?
Например, если я нажму «Игнорировать все» для этого предложения, которое помечено как фрагмент
После обеда.в том же сеансе проверки инструмент проверки грамматики останавливается на других предложениях, которые также помечены как фрагменты, например:
Над моим трупом. Инструмент проверки грамматики классифицирует (внутренне) эти два предложения как разные типы фрагментов. В этих примерах средство проверки грамматики игнорирует один из этих типов, но не другой. Отсюда очевидная несогласованность в том, как работает «Игнорировать все».
Почему ошибки помечаются не в порядке слева направо?
В большинстве случаев средство проверки грамматики пытается помечать ошибки слева направо. В некоторых случаях это невозможно, потому что средство проверки грамматики хочет, чтобы вы сначала исправили наиболее логичную ошибку (эта ошибка может быть не первой). В этом случае ошибки пунктуации или пробелов помечаются перед конкретными или ограниченными грамматическими ошибками.
В некоторых случаях это невозможно, потому что средство проверки грамматики хочет, чтобы вы сначала исправили наиболее логичную ошибку (эта ошибка может быть не первой). В этом случае ошибки пунктуации или пробелов помечаются перед конкретными или ограниченными грамматическими ошибками.
Почему одни пассивные предложения помечаются и предлагается переписать, а другие пропускаются?
Примечание. Эта проблема возникает с другими правилами в дополнение к правилу пассивного построения.
Например, следующее пассивное предложение не помечается:
Срок действия настоящего Соглашения начинается с Даты вступления в силу и продолжается до тех пор, пока Volcano Coffee не расторгнет его в письменной форме в любое время, с указанием причины или без нее. Для определенных типов предложений, когда нет четкого синтаксического предмета, средство проверки грамматики не пытается пометить предложение.
Когда я щелкаю правой кнопкой мыши по грамматической ошибке (ошибка, отмеченная волнистым подчеркиванием), почему в контекстном меню не отображаются те же параметры, которые доступны в диалоговом окне «Орфография и грамматика»?
Например, если элемент помечен, а средство проверки грамматики не предлагает предложения, единственные доступные варианты — игнорировать предложение (и, возможно, пропустить другие ошибки в этом предложении) или щелкнуть команду грамматики, чтобы вызвать проверку орфографии. и диалоговое окно «Грамматика».
Для фонового режима (волнистые подчеркивания) инструмент проверки грамматики использует упрощенный интерфейс. Если вы хотите просмотреть все возможные ошибки в предложении, вы должны нажать Грамматика в контекстном меню.
Почему некоторые пары слов, которые часто путают, работают только в одном направлении?
Например, в средстве проверки грамматики слова «блоха» и «бегство» помечены как слова, которые часто путают, но с парой «ваш» и «вы» только слово «ваш» помечается как часто путают слово.
Средство проверки грамматики однонаправленно обрабатывает некоторые часто путающие пары слов, чтобы упростить задачу для синтаксического анализатора. Инструмент проверки грамматики был разработан таким образом, чтобы уменьшить количество элементов, которые помечаются инструментом проверки грамматики, но не являются истинными грамматическими ошибками.
Если предложение помечено как слишком длинное, почему это единственный совет для предложения?
Длинные предложения часто трудно читать, как для людей, так и для средства проверки грамматики.Инструмент проверки грамматики недостаточно сложен, чтобы обнаруживать грамматические ошибки в длинных предложениях. Если вы сомневаетесь в грамматической точности длинного предложения, вам следует разбить его на более мелкие предложения.
Почему средство проверки правописания игнорирует текст, заключенный в кавычки?
Средство проверки грамматики предполагает, что текст в прямой цитате не подлежит критике.
Почему средство проверки грамматики игнорирует текст во вложенных документах, таких как верхние и нижние колонтитулы и аннотации?
Инструмент проверки грамматики не анализирует текст в верхних, нижних колонтитулах или примечаниях.Верхние и нижние колонтитулы обычно не содержат полных предложений. Точно так же аннотации могут быть написаны фрагментами предложений и не подходят для проверки грамматики.
Почему я не могу изменить параметры грамматики и стиля письма по умолчанию, например длину предложения?
Эти значения по умолчанию встроены в грамматику и стиль письма. Грамматика и стиль письма по умолчанию, которые встроены, включают:
В следующей таблице перечислены конкретные значения по умолчанию для встроенной грамматики и стиля письма.
Параметр стиля Встроенная настройка
—————————————— —————-
Длина длинного предложения 60 слов
Последовательные существительные более 3
Последовательные предложные фразы более 3
Слова в раздельных инфинитивах более 1
Что означает грамматическая статистика?
Когда Microsoft Word завершит проверку орфографии и грамматики, он может отобразить информацию об уровне чтения документа, включая оценки читабельности (см. Вопрос 20).Каждый показатель удобочитаемости основан на среднем количестве слогов в слове и слов в предложении.
Вопрос 20).Каждый показатель удобочитаемости основан на среднем количестве слогов в слове и слов в предложении.
Текст оценивается по 100-балльной шкале; чем выше оценка, тем легче понять документ. Для большинства стандартных документов стремитесь набрать примерно от 60 до 70 баллов.
На каких формулах основана эта статистика?
Оценка Flesch Reading Ease
Формула оценки Flesch Reading Ease:
206.835 — (1,015 x ASL) — (84,6 x ASW)
где:
ASL = средняя длина предложения (количество слов, деленное на количество предложений)
ASW = среднее количество слогов в слове (количество слогов деленное на количество слов)
Оценка уровня успеваемости по Флешу-Кинкейду
Оценка по шкале Флеша-Кинкейда оценивает текст на уровне начальной школы США. Например, оценка 8,0 означает, что восьмиклассник может понять документ. Для большинства стандартных документов стремитесь набрать примерно 7 баллов.От 0 до 8,0.
Формула оценки уровня оценки Флеша-Кинкейда:
(0,39 x ASL) + (11,8 x ASW) — 15,59
где:
ASL = средняя длина предложения (количество слов, деленное на количество предложений)
ASW = среднее количество слогов в слове (число слогов, разделенных на количество слов)
Кто использует эти стандарты чтения?
Различные государственные учреждения требуют, чтобы определенные документы или формы соответствовали определенным стандартам удобочитаемости.Например, в некоторых штатах требуется, чтобы у страховых бланков была определенная оценка удобочитаемости.
Сколько слов и фраз в грамматическом словаре?
Грамматический словарь включает примерно 99 000 слов и словосочетаний в их неизменяемой форме. (То есть в это число не входят такие слова, как «go», «children» и т. Д., Которые являются изменяемыми формами «go» и «child». )
)
На чем основан грамматический словарь?
Он основан на Словаре современного английского языка Лонгмана и Словаре английского языка американского наследия, третье издание.
Чем отличается инструмент проверки грамматики английского языка, если я использую его для текста на английском языке в Великобритании и на английском языке в США?
Разница между проверкой текста на английском и американском языках заключается, прежде всего, в различиях в орфографии между двумя языками. Например, «цвет» в отличие от «цвет». Эти отклонения не влияют на грамматику.
Большинство грамматических правил применимо ко всему английскому тексту (США и U.К.). Однако некоторые грамматические правила различаются в зависимости от выбранного языка:
Множественные предварительные модификаторы, которые очень часто используются в британском английском, помечаются не для британского английского, а для американского английского.
Соглашение между подлежащим и глаголом с собирательными существительными, где глагол используется во множественном числе, не помечается в британском английском, а помечается в U.С. Английский. См. Следующий пример:
Команда планирует в ближайшее время мобилизоваться.
Почему некоторые объяснения не связаны с отмеченной ошибкой?
Например, в предложении
Пойдем домой. объяснение в инструменте проверки грамматики не упоминает конкретно сбивающую с толку пару let / let.
Грамматические пояснения предназначены для охвата наиболее общих случаев в рамках каждого правила, чтобы не перегружать экранный текст.
(PDF) Влияние падежа и порядка слов на синтаксический анализ предложений на финском языке: анализ фиксации взгляда
Фрейзер, Л. , и Флорес д’Аркайс, Г. (1989). Разбор, управляемый заполнителем: исследование заполнения пробелов на голландском языке.
, и Флорес д’Аркайс, Г. (1989). Разбор, управляемый заполнителем: исследование заполнения пробелов на голландском языке.
Журнал памяти и языка, 28, 331_344.
Хакулинен А. и Карлссон Ф. (1980). Финский синтаксис в тексте: методология и некоторые результаты количественного исследования
. Северный журнал лингвистики, 3, 93_129.
Хакулинен А., Карлссон Ф. и Вилкуна М. (1980). Suomen tekstilauseiden piirteita
¨: Kvantitatiivinen
tutkimus [Особенности финских текстовых предложений: количественное исследование]. Хельсинки: Департамент общего
лингвистики, Хельсинкский университет.
Хокинс, Дж. А. (1983). Универсалии порядка слов. Нью-Йорк: Academic Press.
Hemforth, B., Konieczny, L., & Strube, G. (1993). Стратегии инкрементной синтаксической обработки и синтаксического анализа.
Труды XV ежегодной конференции Общества когнитивных наук (стр. 539_544). Хиллсдейл, Нью-Джерси:
Lawrence Erlbaum Associates, Inc.
Holmes, V.M., & O’Regan, J.K. (1981). Паттерны фиксации глаз при чтении предложений относительного предложения
. Журнал вербального обучения и вербального поведения, 20, 417_430.
Hyo
na
¨, J. (1995). Привлекают ли внимание читателей неправильные сочетания букв? Доказательства с местонахождения №
прописью.Журнал экспериментальной психологии: человеческое восприятие и производительность, 21, 68_81.
Hyo
na
¨, J. & Lindeman, J. (1994). Синтаксический контекст влияет на распознавание слов: исследование развития.
Скандинавский журнал психологии, 35, 27_37.
Jarvella, R.J. (1979). Непосредственная обработка памяти и дискурса. В G.H. Бауэр (ред.), Психология
обучения и мотивации (Том 13). Нью-Йорк: Academic Press.
Каан, Э.(1997). Обработка неоднозначностей subject_object на голландском языке. Кандидатская диссертация, Гронинген (Нидерланды — страны
,).
Кайл, М. (1989). Достоверность реплики, стоимость реплики и типы обработки при понимании предложений на французском и
(1989). Достоверность реплики, стоимость реплики и типы обработки при понимании предложений на французском и
испанском языках. В Б. МакУинни и Э. Бейтс (ред.), Межъязыковое исследование обработки предложений (стр. 77_
117). Нью-Йорк: Издательство Кембриджского университета.
Кинг Дж. И Джаст М.А. (1991). Индивидуальные отличия в синтаксической обработке: Роль рабочей памяти
.Журнал памяти и языка, 30, 580_602.
Конечны, Л. (1996). Обработка человеческих предложений: подход к синтаксическому анализу, ориентированный на семантику. Фрайбург: Uni-
versity of Freiburg, IIG-Berichte 3.
Lorch, R.F., Jr., & Myers, J.L. (1990). Регрессионный анализ данных повторных измерений в когнитивных исследованиях
. Журнал экспериментальной психологии: обучение, память и познание, 16, 149_157.
Макдональд, М.С., Перлмуттер, штат Нью-Джерси, и Зайденберг, М.С. (1994). Лексическая природа синтаксической неоднозначности
Разрешение. Психологическое обозрение, 101, 676_703.
MacWhinney, B., & Ple
íh, C. (1988). Обработка ограничительных относительных предложений на венгерском языке. Cogni-
ция, 29, 95_141.
MacWhinney, B., Ple
íh, C., & Bates, E. (1985). Развитие толкования предложений на венгерском —
ian. Когнитивная психология, 17, 178_209.
Меклингер, А., Шриферс, Х., Steinhauer, K., & Friederici, A. (1995). Обработка относительных предложений
, различающихся по синтаксическим и семантическим параметрам: анализ связанных с событием потенциалов. Память и
Познание, 23, 477_494.
Митчелл, округ Колумбия, Куетос, Ф., Корли, M.M.B., & Brysbaert, M. (1995). Основанные на воздействии модели анализа человека
: доказательства использования грубых (нелексических) статистических записей. Journal of Psycholin-
Guistic Research, 24, 469_488.
Muller, P., Cavegn, D., d’Ydewalle, G., & Gro
ner, R. (1993). Сравнение нового трекера лимба, техники отражения роговицы
Сравнение нового трекера лимба, техники отражения роговицы
, отслеживания взгляда Пуркинье и электроокулографии. В G. d’Ydewalle & J. Van
Rensbergen (Eds.), Perception and co gnition: Advances in ey e motion research (стр. 393_401).
Амстердам: Северная Голландия.
Ниеми Дж., Лайне М. и Туоминен Дж. (1995). Когнитивная морфология на финском языке: основы новой модели
.Язык и когнитивные процессы, 9, 423_446.
Payne, D.L. (Ред.) (1992). Прагматика гибкости порядка слов. Амстердам: Джон Бенджаминс.
Prichett, B.L. (1991). Положение головы и неоднозначность парсинга. Журнал психолингвистических исследований, 20,
251_270.
Saukkone n, P., Haipus, M., Niemikorpi, A., & Sulkala, H. (1979). Suomen kielen taajuussa nasto
[Частотный словарь финского языка]. Порвоо: WSOY.
CA SE M AR KI NG AND W OR D OR DE R 857
java — Поиск неявного разрыва страницы в текстовом документе с помощью синтаксического анализа xml
Мне нужно извлечь содержимое первой страницы текстового документа.Если я посмотрю на openxml для документа wordML, я смогу увидеть такие вещи, как: или казалось бы происходит, когда пользователь вводит жесткий разрыв страницы.
Я не понимаю, в каких случаях происходит . Это происходит в некоторых случаях подразумеваемого разрыва страницы, но не во всех.
Например: я набрал какой-то текст, а затем несколько раз нажал клавишу ввода, и курсор переместился на следующую страницу, и если я все еще нажимаю клавишу ввода несколько раз на новой странице, это то, что я получаю
** ДОКУМЕНТ.XML **
-
- <ш: г>
Всем веселья ТЕКСТ.
- <ш: г>
Всем веселья ТЕКСТ.
Как вы могли видеть, даже несмотря на то, что курсор переходит на следующую страницу, когда я набираю Enter, нет никакой подсказки относительно этого действия в файле document.xml в папке извлеченных документов Word. Может ли кто-нибудь помочь мне найти неявный разрыв страницы в текстовом документе, чтобы я мог извлечь содержимое первой страницы документа? Если нет способа обнаружить конкретное содержимое страницы в openxml, как работают инструменты преобразования pdf, когда каждая страница документа Word преобразуется как страница в pdf?
Пожалуйста, не предлагайте использовать API, такие как POI, которые не позволяют извлекать определенное содержимое страницы.Изменить: причина обнаружения неявного разрыва страницы заключается в том, что моя задача включает извлечение изображения обложки в текстовом документе. Эвристика, за которой я следую: «если первая страница документа содержит только изображение, то это изображение обложки, иначе есть нет изображения обложки «. Поэтому мне нужно получить только содержимое первой страницы и проверить, есть ли на ней только изображение. Как я могу это сделать?
Найти тип текущего прочитанного объекта Word во время синтаксического анализа с помощью модуля python-openxml python-docx
Я хочу извлечь текст и таблицы из файла в формате docx.Для этого я использую библиотеку Python 3 python-docx; работает неплохо, текст и таблицы извлекаются правильно.
Однако мой вариант использования требует, чтобы я анализировал текст и таблицы в том же порядке , в котором они появляются в документе, т.е. во время обработки страницы мне нужно знать тип текущего читаемого объекта (объекты понимаются в Word-смысл, то есть абзац, таблица и т.д.), чтобы сохранить этот порядок документа.
Возможно, мои объяснения сбивают с толку, поэтому я позволю вам взглянуть на код, который я написал, непосредственно вдохновленный этой частью документации:
def readLines (self):
# Загрузить парсер документов DOCX. docxDocument = docx.Document (self._fileHandle)
# Добавить каждую строку абзаца в строку.
pagesLines = []
для абзаца в docxDocument.paragraphs:
для строки в paragraph.text.split ('\ n'):
pagesLines.append (кортеж ([строка, 0]))
# Добавить каждую строку из таблиц.
для таблицы в docxDocument.tables:
для строки в таблице. строк:
для ячейки в row.cells:
для абзаца в ячейке. абзацы:
для строки в paragraph.text.split ('\ n'):
pagesLines.append (кортеж ([строка, 0]))
# Вернуть список строк.
вернуть страницы
 docxDocument = docx.Document (self._fileHandle)
# Добавить каждую строку абзаца в строку.
pagesLines = []
для абзаца в docxDocument.paragraphs:
для строки в paragraph.text.split ('\ n'):
pagesLines.append (кортеж ([строка, 0]))
# Добавить каждую строку из таблиц.
для таблицы в docxDocument.tables:
для строки в таблице. строк:
для ячейки в row.cells:
для абзаца в ячейке. абзацы:
для строки в paragraph.text.split ('\ n'):
pagesLines.append (кортеж ([строка, 0]))
# Вернуть список строк.
вернуть страницы
docxDocument = docx.Document (self._fileHandle)
# Добавить каждую строку абзаца в строку.
pagesLines = []
для абзаца в docxDocument.paragraphs:
для строки в paragraph.text.split ('\ n'):
pagesLines.append (кортеж ([строка, 0]))
# Добавить каждую строку из таблиц.
для таблицы в docxDocument.tables:
для строки в таблице. строк:
для ячейки в row.cells:
для абзаца в ячейке. абзацы:
для строки в paragraph.text.split ('\ n'):
pagesLines.append (кортеж ([строка, 0]))
# Вернуть список строк.
вернуть страницы
(Пожалуйста, не учитывайте добавленный кортеж к списку pagesLines , поскольку они используются только для хранения метаданных, используемых моим синтаксическим анализатором, но документ docx не может предоставить: кортеж добавляется только для обеспечения совместимости с парсер и удаляется в вызывающей функции).
Как видите, проблема в том, что я должен прочитать сначала весь текст, содержащийся в абзацах, объектах , затем весь текст, содержащийся в таблицах объектов.
Наконец, мой вопрос: существует ли метод для синтаксического анализа docx на уровне объекта Word, определяющий во время синтаксического анализа тип объекта (абзац, таблица и т. Д.), Чтобы иметь возможность вызвать правильный метод извлечения текста?
Другими словами, можно ли написать что-то, что циклически повторяется в документе и позволяет узнать тип текущего объекта, чтобы иметь возможность правильно анализировать эту часть документа?
Помощь будет принята с благодарностью!
Спасибо!
Лингвистические особенности· Документация по использованию spaCy
Разумная обработка необработанного текста затруднена: большинство слов встречаются редко, и это
общее для слов, которые выглядят совершенно по-разному, чтобы означать почти одно и то же. Одни и те же слова в разном порядке могут означать совсем другое.
Даже разделение текста на полезные словесные единицы может быть трудным во многих случаях.
языков. Хотя некоторые проблемы можно решить, начав только с сырых
символов, обычно лучше использовать лингвистические знания, чтобы добавить полезные
Информация. Именно для этого и предназначен spaCy: вы вводите необработанный текст,
и получите объект
Одни и те же слова в разном порядке могут означать совсем другое.
Даже разделение текста на полезные словесные единицы может быть трудным во многих случаях.
языков. Хотя некоторые проблемы можно решить, начав только с сырых
символов, обычно лучше использовать лингвистические знания, чтобы добавить полезные
Информация. Именно для этого и предназначен spaCy: вы вводите необработанный текст,
и получите объект Doc , который поставляется с различными
аннотации.
После токенизации spaCy может анализировать и тегов для данного Doc .Это где
поступает обученный конвейер и его статистические модели, которые позволяют spaCy делают прогнозы из которых тег или метка наиболее вероятно применимы в этом контексте.
Обученный компонент включает двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку —
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Лингвистические аннотации доступны как Токен атрибутов. Как и многие библиотеки НЛП, spaCy кодирует все строки в хеш-значения , чтобы уменьшить использование памяти и улучшить
эффективность.Итак, чтобы получить удобочитаемое строковое представление атрибута, мы
необходимо добавить подчеркивание _ к его имени:
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
print (token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
- Текст: Исходный текст слова.
- Лемма: Основная форма слова.
- POS: Простой UPOS тег части речи.
- Тег: Подробный тег части речи.
- Dep: Синтаксическая зависимость, то есть связь между токенами.
- Форма: Форма слова — заглавные буквы, знаки препинания, цифры.
- is alpha: Является ли токен альфа-символом?
- is stop: Является ли токен частью стоп-листа, т. Е. Наиболее частыми словами язык?

| Текст | Лемма | POS | Тег | Dep | Форма | альфа | стоп | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Apple Apple | nsubj | Xxxxx | Истинно | Ложно | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| is | be | AUX | 9012 | 906 906 907 904 | True | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| вид | внешний вид | VERB | VBG | ROOT | x6xxx 906 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| покупка | 47 VERB | 906 | Верно | Ложно | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| U.K. | u.k. | PROPN | NNP | соединение | X.X. | Ложь | Ложь | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| запуск | запуск | NOUN | NN | dobj | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| для | для | ADP | IN | преп | $ | Quantmod | $ | Ложный | Ложный | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 1 | 904 906 d | Ложь | Ложь | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| миллиардов | миллиардов | NUM | CD | pobj | xxxx | | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||