Звуко-буквенный разбор слова (памятка)консультация (3 класс) на тему
Русский язык 3 класс 1 часть учебник звуко буквенный разбор слова
По теме: методические разработки, презентации и конспекты
Памятка для учащихся «Звуко-буквенный разбор слова».
Памятка для учащегося начальной школы «Звуко-буквенный разбор слова». Можно создать папку «Краткий справочник», который будет помогать учащимся в обучении.
Звуко-буквенный (фонетический) разбор слова
Памятка звуко-буквенного (фонетического) разбора слова.
Фонетический разбор слова (памятка)
Памятка «Звуко-буквенный разбор слова»
Памятки для детей по звуко-буквенному разбору слов. Образец разбора.
Памятка по обучению грамоте «Звуко-буквенный разбор слова»
Памятка достаточно локанично вмещает в себя информацию о звуках. Она поможет детям быстро дать хаактеристику звуку, соблюдая порядок. Реокмендую для 1 класса.
Памятка по звуко — буквенному разбору слова.

Звуко — буквенный разбор слова осваивается детьми с 1 класса. Для понятного и крепкого усвоения важно использовать наглядный материал и памятку.
Карточка-памятка: «звуко-буквенный разбор слова»
Карточка-памятка может использоваться, как раздаточный материал в помощь детям на уроках русского языка в начальной школе.
Памятка для учащихся «Звуко-буквенный разбор слова».
Памятка для учащегося начальной школы «Звуко-буквенный разбор слова». Можно создать папку «Краткий справочник», который будет помогать учащимся в обучении.
Звуко-буквенный (фонетический) разбор слова
Памятка звуко-буквенного (фонетического) разбора слова.
Фонетический разбор слова (памятка)
Памятка «Звуко-буквенный разбор слова»
Памятки для детей по звуко-буквенному разбору слов. Образец разбора.
Памятка по обучению грамоте «Звуко-буквенный разбор слова»
Памятка достаточно локанично вмещает в себя информацию о звуках. Она поможет детям быстро дать хаактеристику звуку, соблюдая порядок. Реокмендую для 1 класса.
Она поможет детям быстро дать хаактеристику звуку, соблюдая порядок. Реокмендую для 1 класса.
Памятка по звуко — буквенному разбору слова.
Звуко — буквенный разбор слова осваивается детьми с 1 класса. Для понятного и крепкого усвоения важно использовать наглядный материал и памятку.
Карточка-памятка: «звуко-буквенный разбор слова»
Карточка-памятка может использоваться, как раздаточный материал в помощь детям на уроках русского языка в начальной школе.
Карточка-памятка: «звуко-буквенный разбор слова»
По теме методические разработки, презентации и конспекты.
Nsportal. ru
24.05.2017 18:35:25
2017-05-24 18:35:25
Источники:
Https://nsportal. ru/nachalnaya-shkola/materialy-dlya-roditelei/2015/04/20/zvuko-bukvennyy-razbor-slova-pamyatka
Как делать звуко-буквенный разбор слова? » /> » /> .keyword { color: red; }
Русский язык 3 класс 1 часть учебник звуко буквенный разбор слова
Звуко-буквенный разбор слова — это характеристика звукового и буквенного состава слова. Чтобы его выполнить, пишется Транскрипция — точная запись звукового состава слова.
Чтобы его выполнить, пишется Транскрипция — точная запись звукового состава слова.
Звуко-буквенный (фонетический) разбор слова необходим для осознанного овладения русским языком, грамотного написания слов, особенно в тех случаях, когда в словах есть безударные гласные, непроизносимые согласные, буквы, обозначающие два звука, буквы, не обозначающие звуков и пр.
Звуко-буквенный разбор — это анализ звукового состава слова и его буквенного отображения на письме.
Фонетический разбор выполняется в несколько этапов. Звуко-буквенный разбор предполагает деление слова на слоги в соответствии с количеством гласных звуков, постановку ударения, запись звучания слова. Затем проводится фонетический анализ каждого звука. Фонетический разбор завершается подсчетом количества букв и звуков.
Буквы и звуки
Чтобы правильно выполнить звуко-буквенный разбор слова, научимся различать, что на бумаге мы видим Буквы, а когда произносим слово, то слышим Звуки. Буквы — это графические знаки, с помощью которых можно обозначить звуки речи.
Буквы — это графические знаки, с помощью которых можно обозначить звуки речи.
Гласные буквы и звуки
Гласные звуки образуются при свободном прохождении воздуха изо рта. Они состоят только из голоса. В русском языке имеются
Гласные звуки [а], [о], [у], [э], [ы] звучат после твердых согласных звуков, а буквы «и», «е», «ё», «ю», «я» и «ь» обозначают, что предыдущий согласный звук является мягким. Эта фонетическая мягкость обозначается специальным значком — апострофом:
- лён [л’ о н] редис [р’ и д’ и с] соль [с о л’]
Для выполнения звуко-буквенного разбора следует поставить в слове ударение.
Под ударением гласные звуки звучат отчетливо, а без ударения они искажаются:
- буква «о» обозначает звук [а];
- после согласных буквы «е», «я» без ударения соответствует звуку [и]
Каждый гласный звук в одиночку или в сочетании с одним или с несколькими согласными согласными образует фонетический слог:
- бо-ло-то кра-со-та у-ди-ви-тель-ный ли-ни-я
Согласные буквы и звуки
В русской речи звучат 36 согласных звуков. При их произношении выдыхаемый воздух трется об губы, язык и щеки, в результате чего возникает шум.
При их произношении выдыхаемый воздух трется об губы, язык и щеки, в результате чего возникает шум.
Всегда звонкие согласные [л], [м], [н], [р] произносятся с участием голоса и минимальным шумом.
Если согласные звуки произносятся с бо́льшей долей голоса и шума, то образуются звонкие согласные:
Каждому звонкому согласному соответствует парный глухой согласный, который произносится с большей долей шума, чем голоса:
- [б] — [п]; [в] — [ф]; [г] — [ к]; [д] — [т]; [ж] — [ш]; [з] — [с].
Буквы «х», «ц», «ч», «щ» обозначают глухие согласные [х], [ц], [ч’], [щ’], у которых нет парных звонких согласных.
Согласные звуки бывают твердые и мягкие:
[б] — [б’], [в] — [в’], [г] — [г’], [д] — [д’], [з] — [з’], [к] — [к’], [л] — [л’], [м] — [м’], [н] — [н’], [п] — [п’], [р] — [р’], [с] — [с’], [т] — [т’], [ф] — [ф’], [х] — [х’]
Выполняя звуко-буквенный анализ, учитываем, что буквы «й», «ч» и «щ» обозначают всегда мягкие звуки [й’], [ч’], [щ’],
Как научиться делать звуко-буквенный разбор
Для того, чтобы научиться делать звуко-буквенный разбор слова, важно понимать, что часто орфографическая запись слова и его звучание не совпадают. В слове может быть:
В слове может быть:
- одинаковое количество звуков; звуков больше, чем букв; букв больше, чем звуков.
Примеры
- не́бо [н’ э б а] — 4 буквы, 4 звука ярлы́к [й ‘а р л ы к] — 5 букв, 6 звуков купа́ть [к у п а т’] — 6 букв, 5 звуков
При записи звукового состава слова следует учитывать, что буквы «е», «ё», «ю», «я» могут обозначать Два звука в следующих позициях в слове:
1. в начале слова:
- е́ дкий [ й’ э т к’и й’] ё мкий [ й’ о м к’ и й’] ю́ ный [ й’ у н ы й’] я́ сли [ й’ а с’ л’ и]
2. после других гласных звуков:
- по е зди́ть [п а й’ э з’ д’ и т’] по ё м [п а й’ о м] ка ю́ та [к а й’ у т а] ма я́ к [м а й’ а к]
3. после разделительных «ь» и «ъ»:
- жюль е́ н [ж у л’ й’ э’ н] въ е́ хать [в й ‘э х а т’] курь ё з [к у р’ й’ о с] отъ ё м [а т й’ о м] рь я́ ный [р’ й’ а н ы й’] изъ я́ н [и з’ й’ а н] вь ю́ нок [в’ й’ у н о к] предъ ю биле́йный [п р’ и д й’ у б’ и л’ э й’ н ы й’]
Как видим, в таких словах всегда больше звуков, чем букв.
После согласных звуков буквы «е», «ё», «ю», «я» обозначают их мягкость:
- с е л [с’ э л] н ё с [н’ о с] л ю к [л’ у к] п я ть [п’ а т’]
Записывая звучание слова, следует учитывать, что в русском языке происходит фонетический процесс оглушения звонких согласных, находящихся перед глухим согласным и в конце слова, и, наоборот, озвончения глухих согласных перед звонким согласным, кроме «л», «м», «н», «р», «в», «й»:
В словах с буквосочетанием «зж» слышится длинный мягкий звук [ж’]:
- брю зж а́ть [б р’ у ж’ а т’] мо зж ечо́к [м а ж’ и ч’ о к]
В конце глаголов буквосочетания — тся и — ться звучат как [ца]:
- бои́тся [б а и ц а]; стели́ться [с’ т’ и л и ц а].
В словах, в которых есть «ь», который обозначает мягкость предыдущего согласного звука или является морфологическим знаком, указывающим на принадлежность слова к женскому роду, букв насчитываем больше, а звуков меньше:
- знать [з н а т’] — 5 букв, 4 звука; речь [р ‘э ч’] — 4 буквы, 3 звука.

Мягкие согласные звуки могут смягчать предыдущий согласный звук.
Послушаем, как звучат слова:
- све́чка [ с’ в’ э ч’ к а] гво́зди [г во з’ д’ и] жизнь [ж ы з’ н’] зо́нтик [з о н’ т’ и к]
Образец фонетического разбора
Источник изображения: fedsp. com
Пример звуко-буквенного разбора
Чтобы выполнить звуко-буквенный разбор, запишем слово и поставим в нем ударение. Разделим его на фонетические слоги. Учитывая все фонетические изменения в слове, запишем по вертикали буквы и соответствующие им звуки слова в квадратных скобках. Дадим фонетическую характеристику каждому звуку.
Например, выполним фонетический разбор слова «ёлочный»:
Ёлочный [й’ о л а ч’ н ы й’]
Ё-ло-чный — 3 слога. Первый слог ударный.
- буква «ё» — [й’] — согласный, звонкий непарный, мягкий непарный; [о] — гласный ударный; буква «л» — [л] — согласный звонкий непарный, твердый парный; буква «о» — [а] — гласный безударный; буква «ч» — [ч’] — согласный, глухой непарный, мягкий непарный; буква «н»- [н] — согласный звонкий непарный, твердый парный; буква «ы» — [ы] — гласный безударный; буква «й» — [й’] — согласный, звонкий непарный, мягкий непарный.

В слове «ёлочный» 7 букв, 8 звуков.
Если у вас возникнут трудности при проведении звуко-буквенного (фонетического) разбора слова, то всегда можно проверить себя на сайте phoneticonline. ru.
Разделим его на фоне ти че ские сло ги.
Russkiiyazyk. ru
09.05.2020 2:01:18
2020-05-09 02:01:18
Источники:
Https://russkiiyazyk. ru/fonetika/zvuko-bukvennyiy-analiz-slova. html
Фонетический разбор: памятка для начальной школы.
- Главная
- Учебники и учебные пособия…
- Фонетический разбор: памятка для…
▼ ▼ Почитать книгу онлайн можно внизу страницы ▼ ▼
▲ Скачать PDF ▲
для ознакомления
Бесплатно скачать книгу издательства Феникс «Фонетический разбор: памятка для начальной школы. — Издание 5-е Матекина Э.И.» для ознакомления. The book can be ready to download as PDF.
Все отзывы (рецензии) на книгу
Оставьте свой отзыв, он будет первым. Спасибо.
Спасибо.
Фонетический разбор: памятка для начальной школы. — Издание 5-е Матекина Э.И.
Этой книги НЕТ на складе.
Сообщить о поступлении
Новые тиражи или похожие книги
▼ ▼ Книги этого издания на складе уже НЕТ!
ВНИМАНИЕ! Посмотрите, пожалуйста, возможно, новое издание интересующей Вас книги уже есть на складе. В этом случае книга будет в следующем списке книг (сразу после этого текста!). Перейдите на страницу книги и ее можно будет купить. Спасибо. ▼ ▼
| Название книги | Фонетический разбор: памятка для начальной школы. — Издание 5-е |
| ФИО автора | Матекина Э.И. |
| Год публикации | 2018 |
| Издательство | Феникс |
| Раздел каталог | Учебники и учебные пособия по гуманитарным, естественно- научным, общественным дисциплинам |
| Серия книги | Наша началочка |
| ISBN | 978-5-222-30824-0 |
| Артикул | O0096671 |
| Количество страниц | 32 страниц |
| Тип переплета | мяг. * * |
| Полиграфический формат издания | 60*84/16 |
| Вес книги | 38 г |
| Книг в наличии | — |
Книга закончилась, ее нет на складе.
Возможно, через некоторое время появится следующее издание, однако, указать точную дату сейчас сложно.
Аннотация к книге «Фонетический разбор: памятка для начальной школы. — Издание 5-е» (Авт. Матекина Э.И.)
В данной памятке представлен фонетический (звуко-буквенный) разбор слов в разделе программы школьного курса по русскому языку, предусмотренный программой начальной школы. В памятке приведены примеры и методические рекомендации по выполнению заданий, которые помогут учащимся правильно в устной и письменной форме производить эвуко-буквенный разбор слова. Пособие может быть использовано в следующих случаях: для объяснения, закрепления и обобщения пройденного материала, для восполнения пробелов в знаниях: в качестве дополнительного материала: для подготовки домашних заданий. Памятка предназначена для учеников начальных классов, учителей, родителей.
Памятка предназначена для учеников начальных классов, учителей, родителей.
Читать книгу онлайн…
К сожалению, для этого издания чтение онлайн недоступно…
Другие книги раздела «Учебники и учебные пособия по гуманитарным, естественно- научным, общественным дисциплинам»
Философия: конспект лекций
Формулы по физике .
Возможна доставка книги в ПсковСеверодвинскЛипецкМурманскОрскАртемКрасноярскНабережные ЧелныЖелезнодорожныйПермьСаранскИжевскСочиНевинномысскКрасногорскЭлистуУссурийскСаратовКаспийскКостромуКызылИркутскНовокузнецкЧебоксарыНорильскВоронежРязаньЯкутскНефтеюганскКраснодарПензуЙошкар-ОлуКопейскВологдуВладивостокАнгарскНовороссийскМосквуКурганТомскОдинцовоУфуДимитровградДзержинскАбаканВолгодонскНоябрьскАстраханьМиассПодольскКомсомольск-на-АмуреНижний ТагилВолжскийНовомосковскЕссентукиТамбовБлаговещенскНовосибирскСанкт-ПетербургРыбинскБарнаулЖуковскийКисловодскНижневартовскЗлатоустМагнитогорскЛенинск-КузнецкийЧеркесскПятигорскНаходкуОктябрьскийБалашихаНовочебоксарскКалининградСалаватИвановоКазаньНижнекамскРубцовскВладимирЭнгельсКемеровоЧелябинскСарапулНогинскСеверскКалугуСерпуховПетрозаводскУлан-УдэДербентЯрославльОрелПетропавловск-КамчатскийСтерлитамакОбнинскБийскКамышинАрхангельскБратскЧитуСамаруПервоуральскМайкопТверьВолгоградБелгородСмоленскСызраньАчинскНефтекамскВеликий НовгородЕлецКурскДомодедовоКаменск-УральскийЕкатеринбургУльяновскСтарый ОсколМеждуреченскАльметьевскБерезникиСыктывкарПрокопьевскАрзамасКовровСургутТольяттиБрянскЧереповецАрмавирНижний НовгородБалаковоМуромОмскНовый УренгойКировКоролевНовокуйбышевскТюменьЭлектростальХабаровскСергиев ПосадТулуСтавропольЮжно-СахалинскОренбург, а также в любой другой город страны Почтой России или транспортной компанией.
Слова «памятках» морфологический и фонетический разбор
Фонетический морфологический и лексический анализ слова «памятках». Объяснение правил грамматики.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «памятках» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «памятках».
Содержимое:
- 1 Как перенести слово «памятках»
- 2 Морфологический разбор слова «памятках»
- 3 Разбор слова «памятках» по составу
- 4 Сходные по морфемному строению слова «памятках»
- 5 Предложения со словом «памятках»
- 6 Сочетаемость слова «памятках»
- 7 Значение слова «памятках»
- 8 Как правильно пишется слово «памятках»
- 9 Ассоциации к слову «памятках»
Как перенести слово «памятках»
па—мятках
памя—тках
памят—ках
Морфологический разбор слова «памятках»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: множественное;
падеж: предложный;
отвечает на вопрос: (говорю/думаю) О чём?
Начальная форма:
памятка
Разбор слова «памятках» по составу
| памят | корень |
| к | суффикс |
| а | окончание |
памятка
Сходные по морфемному строению слова «памятках»
Сходные по морфемному строению слова
Предложения со словом «памятках»
Кстати, в рюкзак первого вброса мы вложили небольшую памятку по использованию канала.
Сергей Садов, Уйти, чтобы выжить, 2010.
Любая детская шапочка, рукавичка или женский платок, жалко брошенный в этот день на петербургских снегах, оставались памяткой того, что царь должен умереть, что царь умрёт.
Осип Мандельштам, Воспоминания. Шум времени, 2016.
После первых же боёв финским командованием были составлены различные памятки по борьбе с советскими танками, которые активно рассылались в войска.
Максим Коломиец, Зимняя война: «Ломят танки широкие просеки», 2014.
Сочетаемость слова «памятках»
1. специальная памятка
2. небольшую памятку
3. оставить памятку
4. (полная таблица сочетаемости)
Значение слова «памятках»
ПА́МЯТКА , -и, род. мн. -ток, дат. -ткам, ж. 1. Свод кратких наставлений, правил, кратких сведений о чем-л., а также книжка, содержащая подобный свод правил. (Малый академический словарь, МАС)
(Малый академический словарь, МАС)
Как правильно пишется слово «памятках»
Орфография слова «памятках»Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «памятках» в прямом и обратном порядке:
Ассоциации к слову «памятках»
Степанов
Санкт-петербург
Инструкция
Вырезка
Блокнот
Сувенир
Отметина
Гипноз
Патриция
Полка
Распорядок
Шрам
Пользование
Перечень
Видное
Преодоление
Безделушка
Метрополитен
Диета
Привратник
- Снайпер
Архитектура
Дневник
Акула
Грегори
Изложение
Заметка
Школьник
Бумажка
Заповедник
Посещение
Мик
Крокодил
Переводчик
Трактат
Наставление
Плакат
Гимназия
Вирус
Запись
Сборник
Пассажир
Копия
Училище
Техник
Холодильник
Документ
Книжка
Надпись
Банда
Чин
Солдатский
Пехотный
Юбилейный
Археологический
Краткий
Петербургский
Карманный
Архитектурный
Потерпевший
Мусорный
Цифровой
Знаковый
Исторический
Охранный
Былой
Печатный
Кое-какой
Гвардейский
Офицерский
Текущий
Временный
Медицинский
Культурный
Отпечатать
Приколоть
Приклеить
Вручать
Отсылать
Отъезжать
Вручить
Продиктовать
Значиться
Составить
Напечатать
Сочинить
Написать
Просмотреть
Висеть
Являть
Записать
Перебирать
Оставить
Прочесть
Побелеть
Включать
Издать
Боком
Категорически
Видать
Опубликовано: 2021-07-18
Лексическое и фонетическое влияние на фонолексическое кодирование трудных контрастов второго языка: понимание непринятия слов
Введение
Важнейшей частью изучения второго языка (L2) является создание неродного словаря. Это может быть очень сложной задачей, особенно когда L2 изучается в более позднем возрасте и в условиях, не связанных с погружением, как это имеет место для многих изучающих английский язык по всему миру (например, Díaz et al., 2012). Для этого типа учащихся большая часть обучения происходит в формальной обстановке обучения (например, в классе), и на L2 редко говорят за пределами этой среды. Это довольно ограниченное взаимодействие с L2 имеет очевидные негативные последствия для усвоения неродной лексики. Во-первых, относительно бедный ввод приводит к уменьшению воздействия на отдельные слова L2, что часто препятствует их прочной интеграции в долговременную память (Gollan et al., 2008) и почти всегда приводит к меньшему размеру словарного запаса в L2 по сравнению с носителем. язык (L1; Нация, 2006). Во-вторых, для слов, которые становятся частью лексикона L2, нехватка входных данных L2 приводит к тому, что вновь установленные лексические представления становятся фонологически расплывчатыми или «нечеткими» (Cook and Gor, 2015; Cook et al.
Это может быть очень сложной задачей, особенно когда L2 изучается в более позднем возрасте и в условиях, не связанных с погружением, как это имеет место для многих изучающих английский язык по всему миру (например, Díaz et al., 2012). Для этого типа учащихся большая часть обучения происходит в формальной обстановке обучения (например, в классе), и на L2 редко говорят за пределами этой среды. Это довольно ограниченное взаимодействие с L2 имеет очевидные негативные последствия для усвоения неродной лексики. Во-первых, относительно бедный ввод приводит к уменьшению воздействия на отдельные слова L2, что часто препятствует их прочной интеграции в долговременную память (Gollan et al., 2008) и почти всегда приводит к меньшему размеру словарного запаса в L2 по сравнению с носителем. язык (L1; Нация, 2006). Во-вторых, для слов, которые становятся частью лексикона L2, нехватка входных данных L2 приводит к тому, что вновь установленные лексические представления становятся фонологически расплывчатыми или «нечеткими» (Cook and Gor, 2015; Cook et al. , 2016; Lancaster and Gor, 2016). ). Это означает, что кодирование фонетических категорий в лексические представления (т. е. фонолексическое кодирование) не такое надежное, как кодирование исконных лексических единиц, что в значительной степени способствует тому, что распознавание произнесенных слов L2 довольно подвержено ошибкам и характеризуется ложной лексической конкуренцией (например, Вебер и Катлер, 2004; Кук и др., 2016).
, 2016; Lancaster and Gor, 2016). ). Это означает, что кодирование фонетических категорий в лексические представления (т. е. фонолексическое кодирование) не такое надежное, как кодирование исконных лексических единиц, что в значительной степени способствует тому, что распознавание произнесенных слов L2 довольно подвержено ошибкам и характеризуется ложной лексической конкуренцией (например, Вебер и Катлер, 2004; Кук и др., 2016).
Дополнительным препятствием для создания надежных лексических репрезентаций L2 является то, что учащиеся неизбежно сталкиваются с трудностями при попытке освоить фонологию неродного языка. В частности, фонологические контрасты L2, которые не являются частью L1, очень часто являются источником трудностей восприятия. Так обстоит дело, например, с английским различием между /r/ и /l/ для носителей японского языка (Goto, 1971; Bradlow et al., 1999) и контрастом гласных между /ε/ и /æ/ для L1-немецкие изучающие английский язык (Llompart and Reinisch, 2017, 2019)а, 2020; Eger and Reinisch, 2019a,b), что и является объектом настоящего исследования. И / r / — / l /, и / ε / — / æ / являются примерами того, что Бест и Тайлер (2007) назвали ассимиляциями одной категории в своей модели фонологического обучения L2; то есть сценарий, в котором два телефона L2 воспринимаются как воспринимаемые близко к одному и тому же телефону L1. Неоднократно было показано, что трудности восприятия с контрастами L2 в отношениях однокатегорийной ассимиляции приводят к неточностям репрезентации слов, содержащих эти контрасты (например, Broersma, 2012; Llompart and Reinisch, 2019).б). Важно отметить, что эти неточности сохраняются надолго, поскольку они, по-видимому, сохраняются даже после того, как носители L2 уже научились воспринимать фонетические различия между телефонами L2 (Diaz et al., 2012; Darcy et al., 2013; Amengual, 2016). ; Лломпарт, 2021). Например, Llompart (2021) представил доказательства слабого кодирования контраста /ε/-/æ/ в английских словах даже немецкими изучающими английский язык, которые имели большой опыт работы с L2 и могли различать две гласные в слове.
И / r / — / l /, и / ε / — / æ / являются примерами того, что Бест и Тайлер (2007) назвали ассимиляциями одной категории в своей модели фонологического обучения L2; то есть сценарий, в котором два телефона L2 воспринимаются как воспринимаемые близко к одному и тому же телефону L1. Неоднократно было показано, что трудности восприятия с контрастами L2 в отношениях однокатегорийной ассимиляции приводят к неточностям репрезентации слов, содержащих эти контрасты (например, Broersma, 2012; Llompart and Reinisch, 2019).б). Важно отметить, что эти неточности сохраняются надолго, поскольку они, по-видимому, сохраняются даже после того, как носители L2 уже научились воспринимать фонетические различия между телефонами L2 (Diaz et al., 2012; Darcy et al., 2013; Amengual, 2016). ; Лломпарт, 2021). Например, Llompart (2021) представил доказательства слабого кодирования контраста /ε/-/æ/ в английских словах даже немецкими изучающими английский язык, которые имели большой опыт работы с L2 и могли различать две гласные в слове. задание на фонетическое опознание.
задание на фонетическое опознание.
Задание, которое неоднократно использовалось для оценки фонологической устойчивости лексических репрезентаций у учащихся позднего L2, представляет собой лексическое решение, включающее настоящие слова и «неправильно произнесенные» неслова. В такой задаче слова Я2 предъявляются на слух либо в канонической форме, либо с систематическими фонологическими заменами, превращающими их в неслова. Затем участников просят решить, являются ли представленные элементы реальными словами в L2 (Díaz et al., 2012; Darcy et al., 2013; Darcy and Thomas, 2019).; Лломпарт и Райниш, 2019b; Мельник и Пеперкамп, 2019, 2021). Задачи на лексическое решение этого типа помогли пролить свет на несколько вопросов, касающихся фонолексического кодирования сложных L2-контрастов. Во-первых, данные о лексических решениях послужили подтверждением выводов предыдущих исследований слежения за глазами в визуальном мире (Weber and Cutler, 2004; Cutler et al., 2006) о том, что кодирование этих сложных контрастов является асимметричным и модулируется доброкачественностью. соответствие категорий L2 ближайшей категории L1. Как обсуждалось Катлером и соавт. (2006), более подходящая категория L2 по контрасту (т. е. более похожая на категорию L1) считается доминирующей и более надежно кодируется в соответствующие слова L2, чем худшая подходящая альтернатива, кодирование которой обычно менее точно. . Для / ε / — / æ / / ε / приписывается эта доминирующая роль до такой степени, что / æ / был переименован в предыдущих исследованиях как не- / ε / или * / ε /, чтобы подчеркнуть его более слабое фонолексическое кодирование. (Llompart and Reinisch, 2017; см. также Hayes-Harb and Masuda, 2008). Данные о лексических решениях голландцев (Simon et al., 2014) и немцев, изучающих английский язык (Llompart and Reinisch, 2019).б; Llompart, 2021) помог охарактеризовать эту асимметрию, показав, что учащиеся более чувствительны к замене гласных, когда целевая гласная должна быть /ε/ (например, *l[æ]mon), чем в контекстах, в которых она должна быть /æ/ (например, *dr[ε]gon). Во-вторых, недавние исследования с использованием этой парадигмы изучили роль, которую индивидуальные различия в популяции учащихся могут играть в отношении фонолексического кодирования.
соответствие категорий L2 ближайшей категории L1. Как обсуждалось Катлером и соавт. (2006), более подходящая категория L2 по контрасту (т. е. более похожая на категорию L1) считается доминирующей и более надежно кодируется в соответствующие слова L2, чем худшая подходящая альтернатива, кодирование которой обычно менее точно. . Для / ε / — / æ / / ε / приписывается эта доминирующая роль до такой степени, что / æ / был переименован в предыдущих исследованиях как не- / ε / или * / ε /, чтобы подчеркнуть его более слабое фонолексическое кодирование. (Llompart and Reinisch, 2017; см. также Hayes-Harb and Masuda, 2008). Данные о лексических решениях голландцев (Simon et al., 2014) и немцев, изучающих английский язык (Llompart and Reinisch, 2019).б; Llompart, 2021) помог охарактеризовать эту асимметрию, показав, что учащиеся более чувствительны к замене гласных, когда целевая гласная должна быть /ε/ (например, *l[æ]mon), чем в контекстах, в которых она должна быть /æ/ (например, *dr[ε]gon). Во-вторых, недавние исследования с использованием этой парадигмы изучили роль, которую индивидуальные различия в популяции учащихся могут играть в отношении фонолексического кодирования. Здесь результаты показывают, что более надежное кодирование сложных контрастов L2 связано со способностью учащихся к фонетической категоризации для этого конкретного контраста (Silbert et al., 2015; Simonchyk and Darcy, 2017; Darcy and Holliday, 2019).), а также размер их словарного запаса L2 (Daidone, 2020; Llompart, 2021).
Здесь результаты показывают, что более надежное кодирование сложных контрастов L2 связано со способностью учащихся к фонетической категоризации для этого конкретного контраста (Silbert et al., 2015; Simonchyk and Darcy, 2017; Darcy and Holliday, 2019).), а также размер их словарного запаса L2 (Daidone, 2020; Llompart, 2021).
Что, однако, не получило большого внимания в этой конкретной литературе, так это роль, которую специфические свойства предмета, как лексические, так и фонетические, могут играть в способности учащихся воспринимать настоящие слова, содержащие спутанные L2-фоны, и успешно отвергать не-слова, которые отличаются от реальных слов в этих конкретных телефонах. Это так, несмотря на то, что изучение таких свойств может иметь решающее значение для нашего понимания влияния, которое лексические факторы могут оказывать на фонолексическое кодирование телефонов в сложных контрастах L2, вопрос, который еще недостаточно изучен. В качестве первого шага в этом направлении в настоящем исследовании представлена серия дополнительных анализов данных о лексических решениях немецких изучающих английский язык (как сообщается в Llompart and Reinisch, 2019). b и Llompart, 2021), целью которого было оценить влияние лексической частоты слов L2, плотности фонологического соседства и акустики критической гласной на способность учащихся отвергать слова, не содержащие /ε/-/æ/ неправильного произношения (например, *l [æ]мон, *др[ε]гон). Хотя роль, которую эти факторы могут играть в отношении точности восприятия реальных слов, также представляет собой вопрос теоретического интереса, показатели усвоения реальных слов не оценивались в этом исследовании из-за предельных показателей учащихся с реальными / ε / — и / æ /. -слова в Llompart and Reinisch (2019б) и Llompart (2021) 1 .
b и Llompart, 2021), целью которого было оценить влияние лексической частоты слов L2, плотности фонологического соседства и акустики критической гласной на способность учащихся отвергать слова, не содержащие /ε/-/æ/ неправильного произношения (например, *l [æ]мон, *др[ε]гон). Хотя роль, которую эти факторы могут играть в отношении точности восприятия реальных слов, также представляет собой вопрос теоретического интереса, показатели усвоения реальных слов не оценивались в этом исследовании из-за предельных показателей учащихся с реальными / ε / — и / æ /. -слова в Llompart and Reinisch (2019б) и Llompart (2021) 1 .
Для ответов на неправильно произнесенные не-слова в принципе ожидается, что как лексические свойства представленных элементов, так и акустический образ слуховых стимулов, соответствующих этим элементам, должны влиять на лексические решения учащихся. Что касается лексической частоты, можно ожидать, что неслова, построенные на высокочастотных словах, труднее отвергнуть, чем неслова, основанные на менее частотных словах. Задачи на лексическое решение, подобные описанным выше, основаны на хорошо задокументированном эффекте Ганонга (Ganong, 19).80), чтобы сместить реакцию участников в сторону рассмотрения стимулов как «настоящих слов». Ganong (1980) создал стимул, который был неоднозначным между /t/ и /d/, добавил тот же стимул к -спросить и -ash и попросил слушателей классифицировать первоначальный телефон как /t/ или /d/ в каждый контекст. Было обнаружено, что слушатели с большей вероятностью классифицируют его как / t / в контексте ?ask и как / d / в контексте flash, тем самым показывая, что лексические знания определяют восприятие речи, когда сигнал акустически неоднозначен. Следуя из этого, в настоящей экспериментальной парадигме, в которой слушателям предъявляют элементы, подобные *dr[ε]gon, и спрашивают, являются ли они настоящими словами английского языка или нет, ожидается, что они с большей вероятностью ответят «слово», чем « nonword» всякий раз, когда акустической информации недостаточно, чтобы они могли быть уверены в подлинности подмененного или неправильно произнесенного телефона.
Задачи на лексическое решение, подобные описанным выше, основаны на хорошо задокументированном эффекте Ганонга (Ganong, 19).80), чтобы сместить реакцию участников в сторону рассмотрения стимулов как «настоящих слов». Ganong (1980) создал стимул, который был неоднозначным между /t/ и /d/, добавил тот же стимул к -спросить и -ash и попросил слушателей классифицировать первоначальный телефон как /t/ или /d/ в каждый контекст. Было обнаружено, что слушатели с большей вероятностью классифицируют его как / t / в контексте ?ask и как / d / в контексте flash, тем самым показывая, что лексические знания определяют восприятие речи, когда сигнал акустически неоднозначен. Следуя из этого, в настоящей экспериментальной парадигме, в которой слушателям предъявляют элементы, подобные *dr[ε]gon, и спрашивают, являются ли они настоящими словами английского языка или нет, ожидается, что они с большей вероятностью ответят «слово», чем « nonword» всякий раз, когда акустической информации недостаточно, чтобы они могли быть уверены в подлинности подмененного или неправильно произнесенного телефона. Важно отметить, что это влечение к «словным» ответам должно быть сильнее, чем чаще слушатели сталкивались со словами, которые служили базовой формой для не слов в L2 (Coltheart et al., 19).77; Эндрюс, 1996; Переа и др., 2005; но см. Politzer-Ahles et al., 2020).
Важно отметить, что это влечение к «словным» ответам должно быть сильнее, чем чаще слушатели сталкивались со словами, которые служили базовой формой для не слов в L2 (Coltheart et al., 19).77; Эндрюс, 1996; Переа и др., 2005; но см. Politzer-Ahles et al., 2020).
Известно, что плотность фонологического соседства, как и лексическая частота, оказывает большое влияние на лексический доступ и, в частности, на лексические решения. Однако для рассматриваемой здесь задачи неясно, должна ли высокая плотность фонологического соседства способствовать или препятствовать точному отбрасыванию неправильно произносимых неслов. С одной стороны, учитывая, что более высокая плотность фонологического соседства имеет тенденцию препятствовать слуховому распознаванию слов, усиливая лексическую конкуренцию (Luce and Pisoni, 1998; Vitevitch, 2002a,b), можно было бы ожидать, что более высокая плотность будет склонять слушателей к «словным» ответам на не-слова так же, как и высокие лексические частоты. С другой стороны, можно было бы альтернативно предсказать, что более высокая плотность соседей может повысить точность отбрасывания неслов. Более высокая фонологическая плотность соседства почти всегда должна означать более крупные кластеры слов с похожим звучанием, содержащих один и тот же целевой телефон L2. Следовательно, особенно для сложных фонологических контрастов L2, существование нескольких фонологически сходных словоформ с определенной категорией L2 в контрасте (а не с другой) может быть полезным для установления прочных связей между соответствующей фонетической категорией и словоформами L2 ( см. Llompart, 2021). Из-за этого сценарий, в котором точность отклонения неслова увеличивается в зависимости от количества соседних слов с той же целевой категорией, которую имеет данная форма, также правдоподобен.
Более высокая фонологическая плотность соседства почти всегда должна означать более крупные кластеры слов с похожим звучанием, содержащих один и тот же целевой телефон L2. Следовательно, особенно для сложных фонологических контрастов L2, существование нескольких фонологически сходных словоформ с определенной категорией L2 в контрасте (а не с другой) может быть полезным для установления прочных связей между соответствующей фонетической категорией и словоформами L2 ( см. Llompart, 2021). Из-за этого сценарий, в котором точность отклонения неслова увеличивается в зависимости от количества соседних слов с той же целевой категорией, которую имеет данная форма, также правдоподобен.
Что касается акустических свойств соответствующих звуков L2 в не словах, в задачах лексического решения обычно используются стимулы, в которых неправильное произношение было вызвано естественным образом, и это имеет место в Llompart and Reinisch (2019b) и Llompart (2021), исследованиях, которые предоставил набор данных для анализа здесь. По замыслу использование стимулов, вызванных естественным образом, означает, что телефоны-мишени должны демонстрировать некоторые вариации в своей акустике, скорее всего, связанные с окружающими телефонами (например, Strange et al., 2007) и присущими вариациями внутри говорящего. Следовательно, уместный вопрос здесь, и тот, который еще не был решен, заключается в том, насколько учащиеся чувствительны к мелкозернистым акустическим вариациям в задаче, где их в основном просят сосредоточиться на лексике стимулов. В принципе, можно предсказать, что для неслов с систематической заменой гласных, чем более акустически различима замена и, следовательно, чем дальше от канонической гласной находится «неправильно произносимая» гласная, тем легче учащимся обнаружить несоответствие и отклонить. эти не слова. Хотя это вероятная возможность для неправильного произношения с использованием телефонов L2, не приводящего к трудностям восприятия, менее очевидно, что это должно быть в случае не слов, содержащих неродные для восприятия неродные телефоны, такие как / ε / и / æ / для немецких изучающих английский язык.
По замыслу использование стимулов, вызванных естественным образом, означает, что телефоны-мишени должны демонстрировать некоторые вариации в своей акустике, скорее всего, связанные с окружающими телефонами (например, Strange et al., 2007) и присущими вариациями внутри говорящего. Следовательно, уместный вопрос здесь, и тот, который еще не был решен, заключается в том, насколько учащиеся чувствительны к мелкозернистым акустическим вариациям в задаче, где их в основном просят сосредоточиться на лексике стимулов. В принципе, можно предсказать, что для неслов с систематической заменой гласных, чем более акустически различима замена и, следовательно, чем дальше от канонической гласной находится «неправильно произносимая» гласная, тем легче учащимся обнаружить несоответствие и отклонить. эти не слова. Хотя это вероятная возможность для неправильного произношения с использованием телефонов L2, не приводящего к трудностям восприятия, менее очевидно, что это должно быть в случае не слов, содержащих неродные для восприятия неродные телефоны, такие как / ε / и / æ / для немецких изучающих английский язык. Поскольку фонетические категории для этих телефонов, скорее всего, не так четко определены, учащиеся могут не использовать различия в акустике стимулов между элементами в качестве ориентира для своих суждений (Díaz et al., 2012; Llompart and Reinisch, 2019).а).
Поскольку фонетические категории для этих телефонов, скорее всего, не так четко определены, учащиеся могут не использовать различия в акустике стимулов между элементами в качестве ориентира для своих суждений (Díaz et al., 2012; Llompart and Reinisch, 2019).а).
Наконец, стоит отметить, что в Llompart and Reinisch (2019b) и Llompart (2021) было два разных типа неправильно произносимых неслов для интересующего контраста L2 (/ε/-/æ/). Это были элементы, в которых /ε/ был заменен на [æ] (например, *l[æ]mon), и элементы, в которых /æ/ был заменен на [ε] (например, *dr[ε]gon). Важно отметить, что эти два типа различаются в двух важных аспектах. Во-первых, это различие в степени соответствия ближайшей категории L1 канонической гласной (т. е. /ε/ > /æ/) и реализации неправильно произносимых гласных (т. е. обсуждалось выше, обязательно повлияет на восприятие и лексическое кодирование этих телефонов. Второе ключевое отличие заключается в том, что для учащихся, не использующих метод погружения, два типа неправильного произношения не в равной степени соответствуют их опыту в их повседневной среде обучения L2. Немцы, изучающие английский язык в Германии, с большой вероятностью столкнутся со случаями, когда /æ/ произносится с акустическими свойствами, более близкими к /ε/ (например, h[ε]ppy, pl[ε]n, dr[ε]gon ) в речи однокурсников и, возможно, даже учителей английского языка (см. Eger and Reinisch, 2019а; Llompart and Reinisch, 2019a для акустических данных), тогда как обратная картина (например, st[æ]p, l[æ]mon) маловероятна. Таким образом, эти критические различия оправдывают дополнительный вопрос о том, могут ли эффекты лексической частоты, фонологической плотности соседства и акустики гласных различаться между двумя исследуемыми типами неправильно произносимых неслов.
Немцы, изучающие английский язык в Германии, с большой вероятностью столкнутся со случаями, когда /æ/ произносится с акустическими свойствами, более близкими к /ε/ (например, h[ε]ppy, pl[ε]n, dr[ε]gon ) в речи однокурсников и, возможно, даже учителей английского языка (см. Eger and Reinisch, 2019а; Llompart and Reinisch, 2019a для акустических данных), тогда как обратная картина (например, st[æ]p, l[æ]mon) маловероятна. Таким образом, эти критические различия оправдывают дополнительный вопрос о том, могут ли эффекты лексической частоты, фонологической плотности соседства и акустики гласных различаться между двумя исследуемыми типами неправильно произносимых неслов.
Материалы и методы
Участники
Данные 116 участников были включены во все анализы, представленные в разделе «Результаты». Тридцать семь участников были немцами, изучающими английский язык (19самки, средний возраст = 25,32, SD = 4,37), включенные в анализ Llompart and Reinisch (2019b). Эти участники были студентами Мюнхенского университета Людвига-Максимилиана (LMU), которые выросли в немецких одноязычных семьях, провели не более 6 месяцев в англоязычной стране и не были зачислены на курсы, проводимые английским отделением университета. . Остальные 79 участников составили две группы учащихся, протестированных в Лломпарте (2021 г.). Первая группа состояла из 49 человек.Немецкие изучающие английский язык, обучающиеся в Эрланген-Нюрнбергском университете им. Фридриха Александра (FAU; 35 женщин, средний возраст = 24,22, SD = 4,26), которые были набраны в соответствии с теми же критериями, что и предыдущая группа. Вторая группа состояла из 30 английских специалистов и студентов университетов, готовящихся стать английскими профессионалами, также набранными в FAU (17 женщин, средний возраст = 28,5, SD = 12,32). Это были либо преподаватели языка в языковом центре университета ( N = 5) или студенты, обучающиеся по программам бакалавриата и магистратуры, предлагаемым Департаментом английских и американских исследований ( N = 25). В настоящем исследовании и вслед за Llompart (2021) первые две группы будут обычно называться изучающими английский язык немецким языком на «среднем уровне», а последняя группа в дальнейшем будет именоваться «продвинутыми» изучающими английский язык немецкими языками.
. Остальные 79 участников составили две группы учащихся, протестированных в Лломпарте (2021 г.). Первая группа состояла из 49 человек.Немецкие изучающие английский язык, обучающиеся в Эрланген-Нюрнбергском университете им. Фридриха Александра (FAU; 35 женщин, средний возраст = 24,22, SD = 4,26), которые были набраны в соответствии с теми же критериями, что и предыдущая группа. Вторая группа состояла из 30 английских специалистов и студентов университетов, готовящихся стать английскими профессионалами, также набранными в FAU (17 женщин, средний возраст = 28,5, SD = 12,32). Это были либо преподаватели языка в языковом центре университета ( N = 5) или студенты, обучающиеся по программам бакалавриата и магистратуры, предлагаемым Департаментом английских и американских исследований ( N = 25). В настоящем исследовании и вслед за Llompart (2021) первые две группы будут обычно называться изучающими английский язык немецким языком на «среднем уровне», а последняя группа в дальнейшем будет именоваться «продвинутыми» изучающими английский язык немецкими языками. Подробную информацию о самоотчетах о владении и использовании языка для этих участников, полученную с помощью вопросников по языковому фону, можно найти в Llompart and Reinisch (2019).б) и Llompart (2021) 2 .
Подробную информацию о самоотчетах о владении и использовании языка для этих участников, полученную с помощью вопросников по языковому фону, можно найти в Llompart and Reinisch (2019).б) и Llompart (2021) 2 .
Материалы
Все участники выполняли одно и то же задание на лексическое решение. В этом задании реальные слова английского языка, а также неслова, созданные путем систематических фонологических замен реальных слов, были представлены на слух, и участники должны были решить, является ли каждый стимул реальным словом английского языка или нет. Как описано в Llompart and Reinisch (2019b) и Llompart (2021), материалы включали 304 уникальных английских слова, 52 из которых содержали телефоны в сложном контрасте L2 /ε/-/æ/. Остальные 252 слова включали 5 противопоставлений (/i/-/I/, /ɔ:/-/u/, /p/-/t/, /k/-/m/ и /b/-/v/), которые ожидалось, что это не вызовет проблем у носителей немецкого языка. Важно отметить, что половина слов была выбрана так, чтобы они отображались в задании как канонически произведенные, а другая половина была представлена как не слова, в которых были заменены телефоны в соответствующих контрастах. Таким образом, наборы канонически произведенных слов и неправильно произнесенных неслов содержали разные лексические единицы. Для /ε/-/æ/ это означало, что 13 слов с /æ/ появлялись с /æ/, произносимыми как [æ], и 13 различных слов были представлены с /æ/, неправильно произносимыми как [ε] (h[æ]mmer vs. *др[ε]гон). Та же манипуляция проводилась для элементов с / ε / (d [ε] sert против * l [æ] mon), и та же процедура была применена к контрастам наполнителя. В то время как для критических элементов целью всегда была первая ударная гласная, для наполнителей положение критических телефонов в слове могло варьироваться. Все 304 слова были записаны мужчиной, говорящим на южно-британском английском, в их правильной форме, а половина элементов, то есть тех, которые предназначены для использования в качестве неслов, также были записаны с подходящими фонологическими заменами.
Таким образом, наборы канонически произведенных слов и неправильно произнесенных неслов содержали разные лексические единицы. Для /ε/-/æ/ это означало, что 13 слов с /æ/ появлялись с /æ/, произносимыми как [æ], и 13 различных слов были представлены с /æ/, неправильно произносимыми как [ε] (h[æ]mmer vs. *др[ε]гон). Та же манипуляция проводилась для элементов с / ε / (d [ε] sert против * l [æ] mon), и та же процедура была применена к контрастам наполнителя. В то время как для критических элементов целью всегда была первая ударная гласная, для наполнителей положение критических телефонов в слове могло варьироваться. Все 304 слова были записаны мужчиной, говорящим на южно-британском английском, в их правильной форме, а половина элементов, то есть тех, которые предназначены для использования в качестве неслов, также были записаны с подходящими фонологическими заменами.
Процедура
Участники были протестированы либо в звукопоглощающей кабине, либо в тихой комнате в своих университетах. Задача лексического решения была реализована в программном обеспечении Psychopy 2 (в Llompart and Reinisch, 2019b; v. 1.83.01) или Psychopy 3 (в Llompart, 2021; v. 3.0.2; Peirce et al., 2019). Слуховые стимулы предъявлялись через наушники на комфортном уровне прослушивания. Перед началом задания участников проинструктировали, что они будут слушать, как носитель английского языка произносит английские слова и придумывает слова, которые в некоторых случаях могут звучать похоже на английские слова. Их задачей было указать для каждого элемента, считают ли они его настоящим словом в английском языке. В каждом испытании на экране показывались два прямоугольника: зеленый с надписью «слово» с левой стороны и красный с надписью «ни слова» с правой стороны и предъявлен слуховой раздражитель. Участники должны были нажать «1» на цифровой клавиатуре (в Llompart and Reinisch, 2019 г.).б) или крайняя левая кнопка панели ответов (в Лломпарте, 2021 г.), чтобы указать, что слуховой стимул был настоящим словом, и «0» или крайняя правая клавиша панели ответов, если они считали, что стимул не был настоящим словом.
Задача лексического решения была реализована в программном обеспечении Psychopy 2 (в Llompart and Reinisch, 2019b; v. 1.83.01) или Psychopy 3 (в Llompart, 2021; v. 3.0.2; Peirce et al., 2019). Слуховые стимулы предъявлялись через наушники на комфортном уровне прослушивания. Перед началом задания участников проинструктировали, что они будут слушать, как носитель английского языка произносит английские слова и придумывает слова, которые в некоторых случаях могут звучать похоже на английские слова. Их задачей было указать для каждого элемента, считают ли они его настоящим словом в английском языке. В каждом испытании на экране показывались два прямоугольника: зеленый с надписью «слово» с левой стороны и красный с надписью «ни слова» с правой стороны и предъявлен слуховой раздражитель. Участники должны были нажать «1» на цифровой клавиатуре (в Llompart and Reinisch, 2019 г.).б) или крайняя левая кнопка панели ответов (в Лломпарте, 2021 г.), чтобы указать, что слуховой стимул был настоящим словом, и «0» или крайняя правая клавиша панели ответов, если они считали, что стимул не был настоящим словом. . Время ответов участников не ограничивалось. 304 предмета были представлены в рандомизированном порядке. Перед началом задания участникам было представлено 10 практических проб для ознакомления с процедурой. На выполнение задания у участников ушло примерно от 15 до 20 минут.
. Время ответов участников не ограничивалось. 304 предмета были представлены в рандомизированном порядке. Перед началом задания участникам было представлено 10 практических проб для ознакомления с процедурой. На выполнение задания у участников ушло примерно от 15 до 20 минут.
Результаты
 ., 2012). Кроме того, для акустических стимулов, соответствующих этим элементам, значения F1 и F2 (в герцах) критических гласных в середине гласного были извлечены с использованием сценария Praat (Boersma and Weenink, 2009).), чтобы также можно было изучить потенциальное влияние акустики неправильно произносимой гласной. Затем для каждого элемента была рассчитана оценка разницы между F2 и F1 (F2–F1), чтобы можно было использовать только одно значение для каждого элемента в анализе. Известно, что в британском английском у [ε] более низкая F1 и более высокая F2, чем у [æ] (Deterding, 1997; Llompart and Reinisch, 2017). Следовательно, разница F2–F1 всегда должна быть выше для [ε], чем для [æ]. Так было и в случае с настоящими стимулами, поскольку среднее значение F2–F1 /æ/-неслов, в которых первая гласная воспроизводилась подобно [ε], составляло 1187 Гц ( SD = 91), а среднее значение F2–F1 /ε/-неслов (т. е. с /ε/, полученным как [æ]) составляло 568 Гц ( SD = 103). Значение F2–F1 критической гласной в каждом из /ε/- и /æ/-неслов представлено в таблице 1 вместе с лексической частотой и фонологической плотностью соседства слова, от которого произошло неслово.
., 2012). Кроме того, для акустических стимулов, соответствующих этим элементам, значения F1 и F2 (в герцах) критических гласных в середине гласного были извлечены с использованием сценария Praat (Boersma and Weenink, 2009).), чтобы также можно было изучить потенциальное влияние акустики неправильно произносимой гласной. Затем для каждого элемента была рассчитана оценка разницы между F2 и F1 (F2–F1), чтобы можно было использовать только одно значение для каждого элемента в анализе. Известно, что в британском английском у [ε] более низкая F1 и более высокая F2, чем у [æ] (Deterding, 1997; Llompart and Reinisch, 2017). Следовательно, разница F2–F1 всегда должна быть выше для [ε], чем для [æ]. Так было и в случае с настоящими стимулами, поскольку среднее значение F2–F1 /æ/-неслов, в которых первая гласная воспроизводилась подобно [ε], составляло 1187 Гц ( SD = 91), а среднее значение F2–F1 /ε/-неслов (т. е. с /ε/, полученным как [æ]) составляло 568 Гц ( SD = 103). Значение F2–F1 критической гласной в каждом из /ε/- и /æ/-неслов представлено в таблице 1 вместе с лексической частотой и фонологической плотностью соседства слова, от которого произошло неслово.
Таблица 1. Лексическая частота, плотность фонологического соседства и значения F2–F1 критических гласных для каждого из /ε/- и /æ/-неслов, проанализированных в настоящем исследовании.
Перед любым анализом данные лексических решений, соответствующие ответам на /ε/- и /æ/-неслова, были сначала усечены путем исключения всех испытаний, содержащих неслова, основанные на словах, с которыми участники не были знакомы. Это оценивалось с помощью вопросника знакомства со словом, который вводили после задания на лексическое решение. Только 26 испытаний были исключены по этим причинам (0,86% всех /ε/- и /æ/-несловных испытаний). Перед непосредственной оценкой влияния лексической частоты, фонологической плотности соседства и акустики гласных на ответы учащихся данные сначала были представлены в обобщенную регрессионную модель смешанных эффектов с функцией логистической связи (пакет lme4 1.1–23 в версии R 3.6.3; Bates et al., 2015) по данным о точности с гласным [/ε/ (произносится как [æ]; *l[æ]mon) -/æ/ (произносится как [ε]; *dr[ε]gon)] и Группа (средний уровень в Llompart and Reinisch (2019 г.)b), промежуточный в Llompart (2021) и продвинутый в Llompart (2021)) в качестве представляющих интерес переменных. Эта модель была разработана для использования в качестве базовой модели, на которой впоследствии должны были быть проверены эффекты лексической частоты, плотности фонологического соседства и акустики гласных (см. Ниже).
Перед непосредственной оценкой влияния лексической частоты, фонологической плотности соседства и акустики гласных на ответы учащихся данные сначала были представлены в обобщенную регрессионную модель смешанных эффектов с функцией логистической связи (пакет lme4 1.1–23 в версии R 3.6.3; Bates et al., 2015) по данным о точности с гласным [/ε/ (произносится как [æ]; *l[æ]mon) -/æ/ (произносится как [ε]; *dr[ε]gon)] и Группа (средний уровень в Llompart and Reinisch (2019 г.)b), промежуточный в Llompart (2021) и продвинутый в Llompart (2021)) в качестве представляющих интерес переменных. Эта модель была разработана для использования в качестве базовой модели, на которой впоследствии должны были быть проверены эффекты лексической частоты, плотности фонологического соседства и акустики гласных (см. Ниже).
Базовая модель имела ответ (0 = неверный, 1 = правильный) в качестве категориальной зависимой переменной. Гласный кодировался по контрасту таким образом, что / ε / кодировался как -0,5, а / æ / как 0,5. Группа была перекодирована как две линейно независимые противоположности, которые в дальнейшем будут обозначаться как «Мастерство» и «Учеба». «Умение» было закодировано для отражения различий в точности между двумя группами учащихся среднего уровня и группой учащихся продвинутого уровня. Следовательно, испытания для первых двух групп были закодированы как -0,25, а испытания, соответствующие последним, были закодированы как 0,5. «Исследование» было включено для оценки потенциальных различий между двумя промежуточными группами учащихся, которые были набраны в рамках двух разных исследований и в двух разных учреждениях, но с соблюдением одних и тех же требований к набору. Данные учащихся среднего уровня в Llompart and Reinisch (2019 г.)b) были закодированы как -0,5, данные от учащихся среднего уровня в Лломпарте (2021 г.) были закодированы как 0,5, а данные от продвинутых участников того же исследования были закодированы как 0. Квалификация и учеба не могли взаимодействовать, но взаимодействия между каждый из этих предикторов и гласный были включены.
Группа была перекодирована как две линейно независимые противоположности, которые в дальнейшем будут обозначаться как «Мастерство» и «Учеба». «Умение» было закодировано для отражения различий в точности между двумя группами учащихся среднего уровня и группой учащихся продвинутого уровня. Следовательно, испытания для первых двух групп были закодированы как -0,25, а испытания, соответствующие последним, были закодированы как 0,5. «Исследование» было включено для оценки потенциальных различий между двумя промежуточными группами учащихся, которые были набраны в рамках двух разных исследований и в двух разных учреждениях, но с соблюдением одних и тех же требований к набору. Данные учащихся среднего уровня в Llompart and Reinisch (2019 г.)b) были закодированы как -0,5, данные от учащихся среднего уровня в Лломпарте (2021 г.) были закодированы как 0,5, а данные от продвинутых участников того же исследования были закодированы как 0. Квалификация и учеба не могли взаимодействовать, но взаимодействия между каждый из этих предикторов и гласный были включены. Структура случайных эффектов состояла из случайных пересечений для Участников и случайного наклона для Гласных над Участниками. Случайные перехваты для элементов не были включены, потому что элемент коррелирует с лексической частотой, фонологической плотностью соседства и акустикой гласных (т. е. каждый элемент имеет одно значение для каждой переменной) и, таким образом, будет проблематичным для дополнительного анализа, изучающего их влияние.
Структура случайных эффектов состояла из случайных пересечений для Участников и случайного наклона для Гласных над Участниками. Случайные перехваты для элементов не были включены, потому что элемент коррелирует с лексической частотой, фонологической плотностью соседства и акустикой гласных (т. е. каждый элемент имеет одно значение для каждой переменной) и, таким образом, будет проблематичным для дополнительного анализа, изучающего их влияние.
Модель выявила значительное влияние Гласных ( b = -0,98; z = -9,68; p < 0,001) и Умения ( b = 1,58; z = 5,66; p < 0,001). Влияние изучения не было значительным (b = -0,03; z = -0,14; p = 0,89), равно как и взаимодействие между гласным и владением и гласным и изучением (оба p > 0,1). Следовательно, было обнаружено, что слушатели были более точными с /ε/ → [æ] неправильным произношением (/ε/-неслова, например, *l[æ]mon; M = 50,67% правильно, SD = 50,01), чем с заменами /æ/ → [ε] (/æ/-неслова, например, *dr[ε]gon; M = 31,52% правильно, SD = 46,47) по всем направлениям, а учащиеся, отмеченные как продвинутые в Llompart (2021), в целом были более точными ( M = 58,61% правильных ответов, SD = 49,28), чем две группы учащихся среднего уровня (2019: M = 35,5% правильно, SD = 47,88, 2021: M = 34,6% правильно, SD = 47,59), у которых точность отклонения неслова была почти одинаковой.
После этого отдельно для каждого из трех представляющих интерес предикторов (то есть лексической частоты, плотности фонологического соседства и акустики гласных) были проведены прямые пошаговые сравнения моделей (Zhang et al., 2020) между i) базовой моделью, описанной выше (структура со случайными эффектами: Гласная|Участник) и моделью, включающей случайные наклоны для одного из предикторов над Участниками (например, Гласная + Частота|Участник), и ii) между моделью, включающей только случайные наклоны, и моделью, включающей эти случайные наклоны плюс термин взаимодействия с гласной над участниками (например, гласная * частота | участник). Сравнения проводились с помощью тестов логарифмического правдоподобия с использованием функции anova() в R. Эти сравнения оценивали, улучшила ли дополнительная сложность структуры случайных эффектов соответствие моделей. В частности, сравнения между базовой моделью и моделями только со случайными наклонами были выполнены, чтобы установить, модулируют ли лексическая частота, фонологическая плотность соседства и акустика гласных лексические ответы участников по всем направлениям, в то время как сравнения между моделями с условиями взаимодействия и без них определили, были ли эффекты квалифицированы типом элементов, не являющихся словами (/ ε / — не слова против / æ / — не слова).
Эта аналитическая процедура была выбрана потому, что она позволяла исследовать эффекты конкретных предметов независимым образом, при этом принимая во внимание эффекты на уровне популяции, о которых уже сообщалось в предыдущих исследованиях. Анализируя, позволяет ли модель учитывать вариации, вызванные различной чувствительностью участников к лексической частоте, плотности соседства и акустике гласных, улучшается соответствие модели фактическим данным, можно определить, повлияли ли эти свойства отдельных элементов на участников. ответы без необходимости иметь дело с недостатками, которые были бы неизбежны, если бы эти предикторы были просто добавлены в структуру модели с фиксированными эффектами. Во-первых, этот подход позволяет избежать намеренно завышенной оценки эффектов свойств, специфичных для предмета, как это было бы в случае, если бы они были проанализированы как единственные фиксированные эффекты, игнорируя, таким образом, эффекты, которые были выявлены как в отношении целевых гласных, так и в отношении различий между группами учащихся. показано в предыдущих исследованиях. Во-вторых, что очень важно, эта процедура также предотвратила то, что вклады исследованных показателей, специфичных для предмета, были затемнены сильными эффектами вышеупомянутых переменных.
показано в предыдущих исследованиях. Во-вторых, что очень важно, эта процедура также предотвратила то, что вклады исследованных показателей, специфичных для предмета, были затемнены сильными эффектами вышеупомянутых переменных.
Результаты сравнения модели между базовой моделью и тремя отдельными моделями, включая случайные наклоны для лексической частоты, фонологической плотности соседства и акустики гласных соответственно, по участникам показали, что добавление случайного наклона для лексической частоты по сравнению с участниками улучшило соответствие модели [χ 2 (3) = 8,50, p < 0,05], а также добавление наклона для акустики гласных [χ 2 (3) = 36,61, p < 0,001]. В отличие от этого, добавление наклона для плотности окружения не привело к улучшению [χ 2 (3) = 1,44, р = 0,70]. Кроме того, сравнение между моделями только со случайным наклоном и моделями, включающими термин взаимодействия с гласной, показало, что условия взаимодействия между гласной и лексической частотой по участникам [χ 2 (4) = 17,52, p < 0,01] и между гласной и Neighborhood Density [χ 2 (4) = 28,80, p < 0,001] улучшили соответствие соответствующих моделей. Модель, включающая взаимодействие между акустикой гласных и гласными над участниками, имела серьезные проблемы с конвергенцией, которые делали ее неинтерпретируемой. Однако сравнение с использованием упрощенных моделей, в которых незначительные взаимодействия между гласными и владением, а также гласными и изучением были удалены из структуры с фиксированными эффектами, показало, что добавление члена взаимодействия между акустикой гласных и гласными над участниками к структуре случайных эффектов значительно улучшена подгонка упрощенной модели со случайными наклонами только для акустики гласных [χ 2 (4) = 29,50, р < 0,001].
Модель, включающая взаимодействие между акустикой гласных и гласными над участниками, имела серьезные проблемы с конвергенцией, которые делали ее неинтерпретируемой. Однако сравнение с использованием упрощенных моделей, в которых незначительные взаимодействия между гласными и владением, а также гласными и изучением были удалены из структуры с фиксированными эффектами, показало, что добавление члена взаимодействия между акустикой гласных и гласными над участниками к структуре случайных эффектов значительно улучшена подгонка упрощенной модели со случайными наклонами только для акустики гласных [χ 2 (4) = 29,50, р < 0,001].
На основе значительных улучшений соответствия модели, связанных с добавлением условий взаимодействия в структуру случайных эффектов, данные были разделены по гласным, а эффекты добавления случайных наклонов для лексической частоты, плотности окружения и акустики гласных были количественно определены для каждой гласной. отдельно путем сравнения базовой модели только со случайными перехватами (1 | Участник) с моделями со случайными наклонами для лексической частоты, плотности фонологического соседства и акустики гласных, соответственно, по участникам (например, частота | участник). Для /æ/-неслов (например, *dr[ε]gon) наклоны для лексической частоты [χ 2 (3) = 21,88, p < 0,001] и плотности окружения [χ 2 (3) = 26,07, p < 0,001] по сравнению с участниками улучшили соответствие модели, в то время как наклон для акустики гласных не изменился. [χ 2 (3) = 1,00, p = 0,80]. Для /ε/-неслов (например, *l[æ]mon) возникла противоположная картина. Случайный наклон для акустики гласных по сравнению с участниками существенно улучшил соответствие модели [χ 2 (3) = 63,29, p < 0,001], в то время как наклон для лексической частоты [χ 2 (3) = 0,40, p = 0,94] и плотность соседей [χ 2 (3) = 1,75, p = 0,62] этого не сделали. Эти результаты идеально согласуются с паттернами, наблюдаемыми в исходных данных, представленных на рисунке 1, на котором представлены диаграммы рассеивания точности отклонения неслов для /æ/-неслов (верхний ряд) и /ε/-неслов (нижний ряд) в зависимости от лексического состава.
Для /æ/-неслов (например, *dr[ε]gon) наклоны для лексической частоты [χ 2 (3) = 21,88, p < 0,001] и плотности окружения [χ 2 (3) = 26,07, p < 0,001] по сравнению с участниками улучшили соответствие модели, в то время как наклон для акустики гласных не изменился. [χ 2 (3) = 1,00, p = 0,80]. Для /ε/-неслов (например, *l[æ]mon) возникла противоположная картина. Случайный наклон для акустики гласных по сравнению с участниками существенно улучшил соответствие модели [χ 2 (3) = 63,29, p < 0,001], в то время как наклон для лексической частоты [χ 2 (3) = 0,40, p = 0,94] и плотность соседей [χ 2 (3) = 1,75, p = 0,62] этого не сделали. Эти результаты идеально согласуются с паттернами, наблюдаемыми в исходных данных, представленных на рисунке 1, на котором представлены диаграммы рассеивания точности отклонения неслов для /æ/-неслов (верхний ряд) и /ε/-неслов (нижний ряд) в зависимости от лексического состава. частота (слева), плотность окрестности (в центре) и акустика гласных (справа). Линии регрессии и коэффициенты корреляции (т.е. r ) также приведены для лучшего описания отношений между этими переменными.
частота (слева), плотность окрестности (в центре) и акустика гласных (справа). Линии регрессии и коэффициенты корреляции (т.е. r ) также приведены для лучшего описания отношений между этими переменными.
Рисунок 1. Диаграммы рассеяния точности отклонения неслова для /æ/-неслов (верхний ряд) и /ε/-неслов (нижний ряд) в зависимости от лексической частоты (слева), плотности соседства (в центре) и гласных акустика (справа). Линии регрессии и коэффициенты корреляции (т. е. r ) приведены для иллюстрации.
Подводя итог, можно сказать, что сравнение моделей показало, что точность отклонения несловесных элементов для заданий, содержащих неправильное произношение спутанных телефонов L2, была модулирована по всем направлениям как лексической частотой элементов, так и акустикой критических гласных. Однако значительные взаимодействия и последующий анализ показали, что относительный вклад лексической частоты, плотности соседства и акустики гласных различался между /æ/-несловами и /ε/-несловами. В первом случае более низкая лексическая частота и более высокая плотность фонологического соседства способствовали более высокой точности, тогда как значения F2–F1 критических гласных не сильно коррелировали с точностью отклонения неслова (см. Рисунок 1, верхний ряд). Для /ε/-неслов более высокая точность отклонения неслова была связана только с более низкими значениями F2–F1 (т. е. более похожими на [æ]) для критических гласных (см. рис. 1, нижний ряд). Диаграммы рассеивания, аналогичные показанным на рис. 1, но с разделением данных по группам, представлены на рис. 2. Изучение рис. 2 дополнительно показывает, что асимметричные паттерны для двух типов неправильно произносимых неслов в высокой степени согласуются между тремя группами участников, включенных в выборку. .
В первом случае более низкая лексическая частота и более высокая плотность фонологического соседства способствовали более высокой точности, тогда как значения F2–F1 критических гласных не сильно коррелировали с точностью отклонения неслова (см. Рисунок 1, верхний ряд). Для /ε/-неслов более высокая точность отклонения неслова была связана только с более низкими значениями F2–F1 (т. е. более похожими на [æ]) для критических гласных (см. рис. 1, нижний ряд). Диаграммы рассеивания, аналогичные показанным на рис. 1, но с разделением данных по группам, представлены на рис. 2. Изучение рис. 2 дополнительно показывает, что асимметричные паттерны для двух типов неправильно произносимых неслов в высокой степени согласуются между тремя группами участников, включенных в выборку. .
Рисунок 2. Диаграммы рассеяния точности отклонения неслова для /æ/-неслов (верхний ряд) и /ε/-неслов (нижний ряд) в зависимости от лексической частоты (слева), плотности соседства (в центре) и гласных акустика (справа) с данными, разделенными по группам. Продвинутые учащиеся в Llompart (2021 г.) отмечены черным цветом, учащиеся среднего уровня в Llompart (2021 г.) — темно-синим, а учащиеся среднего уровня в Llompart and Reinisch (2019b) — голубым. Линии регрессии (продвинутые учащиеся показаны пунктирной линией, средние учащиеся — сплошными линиями) приведены для иллюстрации.
Продвинутые учащиеся в Llompart (2021 г.) отмечены черным цветом, учащиеся среднего уровня в Llompart (2021 г.) — темно-синим, а учащиеся среднего уровня в Llompart and Reinisch (2019b) — голубым. Линии регрессии (продвинутые учащиеся показаны пунктирной линией, средние учащиеся — сплошными линиями) приведены для иллюстрации.
Дискуссия
В настоящем исследовании изучалось влияние специфических для элементов свойств, связанных как с организацией лексики L2, так и с акустикой сбиваемых категорий L2, на точность отбраковки неслов, отличающихся только от настоящих слов в телефонах сложного языка. Фонологический контраст L2. Была проведена серия дополнительных анализов данных о лексических решениях немецких изучающих английский язык (Llompart and Reinisch, 2019b; Llompart, 2021) для оценки влияния i) лексической частоты L2 (не)представленных слов, ii) их фонологических плотности соседства и iii) спектральное изображение критических телефонов L2, на способность учащихся отвергать не слова, содержащие / ε / — / æ / неправильное произношение. Это факторы, которые не рассматривались в предыдущих исследованиях, но тщательное изучение которых могло бы улучшить наше понимание того, как лексические свойства модулируют фонолексическое кодирование телефонов в сложных L2-контрастах, а также того, в какой степени учащиеся чувствительны к мелким фонетическим деталям относительно телефоны в таких контрастах при выполнении задач лексического поиска. Несмотря на то, что результаты настоящего исследования следует интерпретировать с осторожностью, поскольку они основаны на ограниченном наборе (не)слов L2, предназначенных только для одного контраста L2 и одной группы учащихся, они представляют собой первую ступеньку к лучшей характеристике этих проблем. , которые дополнительно обсуждаются ниже.
Это факторы, которые не рассматривались в предыдущих исследованиях, но тщательное изучение которых могло бы улучшить наше понимание того, как лексические свойства модулируют фонолексическое кодирование телефонов в сложных L2-контрастах, а также того, в какой степени учащиеся чувствительны к мелким фонетическим деталям относительно телефоны в таких контрастах при выполнении задач лексического поиска. Несмотря на то, что результаты настоящего исследования следует интерпретировать с осторожностью, поскольку они основаны на ограниченном наборе (не)слов L2, предназначенных только для одного контраста L2 и одной группы учащихся, они представляют собой первую ступеньку к лучшей характеристике этих проблем. , которые дополнительно обсуждаются ниже.
Перед тем, как фактически измерить влияние лексической частоты, плотности соседства и акустики гласных в настоящем исследовании, однако, был проведен первый анализ для оценки различий в точности в зависимости от гласной или типа элемента (/ε/-неслова против гласных). /æ/-nonwords) и группа учащихся. Этот анализ был проведен для подтверждения предыдущих результатов с помощью большего набора данных и, что наиболее важно, для того, чтобы модель можно было затем использовать в качестве основы для количественной оценки эффектов интересующих лексических и фонетических предикторов на более позднем этапе. Результаты показали, что учащиеся лучше обнаруживали неправильное произношение /ε/ → [æ] (/ε/-неслова; например, *l[æ]mon), чем неправильное произношение /æ/ → [ε] (/æ/-неслова; например, , *dr[ε]gon) и что группа продвинутых учащихся, включенная в анализ, превзошла две группы, помеченные как учащиеся среднего уровня. Это повторяет результаты предыдущих исследований, показывающих асимметрию отклонения слов без слов для слов с трудными фонологическими контрастами L2 (Darcy et al., 2013; Simon et al., 2014; Llompart and Reinisch, 2019).б; Melnik and Peperkamp, 2019, 2021), а также эффекты мастерства и использования при невербальном отклонении для этого типа заданий (Sebastián-Gallés et al.
/æ/-nonwords) и группа учащихся. Этот анализ был проведен для подтверждения предыдущих результатов с помощью большего набора данных и, что наиболее важно, для того, чтобы модель можно было затем использовать в качестве основы для количественной оценки эффектов интересующих лексических и фонетических предикторов на более позднем этапе. Результаты показали, что учащиеся лучше обнаруживали неправильное произношение /ε/ → [æ] (/ε/-неслова; например, *l[æ]mon), чем неправильное произношение /æ/ → [ε] (/æ/-неслова; например, , *dr[ε]gon) и что группа продвинутых учащихся, включенная в анализ, превзошла две группы, помеченные как учащиеся среднего уровня. Это повторяет результаты предыдущих исследований, показывающих асимметрию отклонения слов без слов для слов с трудными фонологическими контрастами L2 (Darcy et al., 2013; Simon et al., 2014; Llompart and Reinisch, 2019).б; Melnik and Peperkamp, 2019, 2021), а также эффекты мастерства и использования при невербальном отклонении для этого типа заданий (Sebastián-Gallés et al. , 2005; Amengual, 2016; Llompart, 2021). В дополнение к этому, еще одним важным открытием было то, что показатели точности для двух групп учащихся среднего уровня, которые были набраны и протестированы в разных университетах, но с помощью одной и той же процедуры набора, оказались чрезвычайно схожими. Это свидетельствует о том, что выборки Llompart and Reinisch (2019b) и Llompart (2021) были сопоставимы, и говорит в пользу высокой надежности этой экспериментальной парадигмы при использовании с поздними учениками L2 и применении систематических требований к набору.
, 2005; Amengual, 2016; Llompart, 2021). В дополнение к этому, еще одним важным открытием было то, что показатели точности для двух групп учащихся среднего уровня, которые были набраны и протестированы в разных университетах, но с помощью одной и той же процедуры набора, оказались чрезвычайно схожими. Это свидетельствует о том, что выборки Llompart and Reinisch (2019b) и Llompart (2021) были сопоставимы, и говорит в пользу высокой надежности этой экспериментальной парадигмы при использовании с поздними учениками L2 и применении систематических требований к набору.
Главный вопрос, однако, заключался в том, влияют ли лексическая частота, плотность фонологического соседства и акустика гласных на точность отклонения неслова в дополнение к ранее упомянутым эффектам. Это оценивалось путем манипулирования наличием или отсутствием случайных наклонов для трех переменных, а также условиями взаимодействия между ними и гласной в структуре случайных эффектов моделей, в то время как структура фиксированных эффектов оставалась постоянной. В этом отношении результаты показали, что как лексические свойства целевых элементов, так и акустика критических гласных способствовали характеристике вариации, наблюдаемой для несловного отклонения, хотя и по-разному для двух типов исследованных элементов. Для /æ/-неслов (т. е. неправильного произношения /æ/ → [ε]) лексические факторы оказывали сильное модулирующее воздействие: во-первых, неслова, чьи аналоги в реальном слове имели более низкую частоту, легче отвергались, чем те, которые имели более высокую частоту. Во-вторых, неслова, основанные на словах с большим количеством лексических соседей, отбрасывались легче, чем слова с меньшим количеством соседей (см. рис. 1, 2, верхний ряд). Напротив, для /ε/-неслов (т. е. неправильного произношения /ε/ → [æ]) точное отбрасывание отдельных элементов было тесно связано с акустикой критического гласного (/ε/ произносится как [æ]), как выше частота отклонения была связана с более экстремально [æ]-подобными спектральными артикуляциями /ε/ (см.
В этом отношении результаты показали, что как лексические свойства целевых элементов, так и акустика критических гласных способствовали характеристике вариации, наблюдаемой для несловного отклонения, хотя и по-разному для двух типов исследованных элементов. Для /æ/-неслов (т. е. неправильного произношения /æ/ → [ε]) лексические факторы оказывали сильное модулирующее воздействие: во-первых, неслова, чьи аналоги в реальном слове имели более низкую частоту, легче отвергались, чем те, которые имели более высокую частоту. Во-вторых, неслова, основанные на словах с большим количеством лексических соседей, отбрасывались легче, чем слова с меньшим количеством соседей (см. рис. 1, 2, верхний ряд). Напротив, для /ε/-неслов (т. е. неправильного произношения /ε/ → [æ]) точное отбрасывание отдельных элементов было тесно связано с акустикой критического гласного (/ε/ произносится как [æ]), как выше частота отклонения была связана с более экстремально [æ]-подобными спектральными артикуляциями /ε/ (см. рис. 1, 2, нижний ряд). Таким образом, результаты показали явную асимметрию между /ε/-несловами и /æ/-несловами для двух лексических факторов, а также для акустики гласных.
рис. 1, 2, нижний ряд). Таким образом, результаты показали явную асимметрию между /ε/-несловами и /æ/-несловами для двух лексических факторов, а также для акустики гласных.
Что касается акустики гласных, то тот факт, что она модулировала отклонение /ε/-неслов (например, *l[æ]mon), но не /æ/-неслов (например, *dr[ε]gon), указывает на то, что Учащиеся L2 действительно были чувствительны к небольшим различиям в акустических свойствах критических гласных при оценке лексики слов и сходных по звучанию неслов, но только тогда, когда неправильное произношение в последних шло в одном конкретном направлении. Возможное объяснение этой асимметрии состоит в том, что более надежное кодирование /ε/ (по сравнению с /æ/) в лексическом представлении слов L2 приводит не только к более высокой точности при отклонении элементов, в которых гласный произносится неправильно, как уже было показано ( Саймон и др., 2014 г. Лломпарт и Райниш, 2019 г.б), но и к повышенной внимательности к тому, насколько велико (или мало) несоответствие между ожидаемой категорией и акустикой ввода. Основываясь на том же аргументе, отсутствие связи между акустикой гласных и отказом от неправильного произношения типа *dr[ε]gon можно объяснить «более нечетким» представлением /æ/ в словах L2, содержащих эту гласную. Это сделает изучающих L2 более терпимыми к неправильному произношению и, следовательно, менее точными в своих суждениях, а также снизит их чувствительность к величине несоответствия между вводом и канонической гласной. Кроме того, обратите внимание, что для интересующего контраста L2 критические различия в периферии между двумя гласными также могли внести свой вклад в этот асимметричный паттерн. Учитывая, что /æ/ является более периферийным, чем /ε/ в английском пространстве гласных, неправильное произношение, связанное с заменой менее периферийной гласной более периферийной, могло быть более заметным, чем противоположный тип, усиливая эффект, что небольшие акустические различия в более периферийная область пространства гласных может иметь влияние на восприятие учащимися и последующие решения (Полька и Бон, 2003, 2011).
Основываясь на том же аргументе, отсутствие связи между акустикой гласных и отказом от неправильного произношения типа *dr[ε]gon можно объяснить «более нечетким» представлением /æ/ в словах L2, содержащих эту гласную. Это сделает изучающих L2 более терпимыми к неправильному произношению и, следовательно, менее точными в своих суждениях, а также снизит их чувствительность к величине несоответствия между вводом и канонической гласной. Кроме того, обратите внимание, что для интересующего контраста L2 критические различия в периферии между двумя гласными также могли внести свой вклад в этот асимметричный паттерн. Учитывая, что /æ/ является более периферийным, чем /ε/ в английском пространстве гласных, неправильное произношение, связанное с заменой менее периферийной гласной более периферийной, могло быть более заметным, чем противоположный тип, усиливая эффект, что небольшие акустические различия в более периферийная область пространства гласных может иметь влияние на восприятие учащимися и последующие решения (Полька и Бон, 2003, 2011).
Вторая наблюдаемая асимметрия связана с лексической частотой и фонологической плотностью соседства, которые, как было установлено, влияют только на точность отклонения для /æ/-неслов. Что касается лексической частоты, возможное объяснение состоит в том, что она играла роль только для неправильного произношения /æ/ → [ε], потому что они очень часто встречаются в английском языке с немецким акцентом, и учащиеся, скорее всего, имели опыт с элементами такого рода (Эгер и Райниш). , 2019b; Llompart and Reinisch, 2019a, 2020). Таким образом, эффект лексической частотности можно объяснить тем фактом, что более частые (не)слова с /æ/, представленные в задании, например спасибо , возможно, неоднократно звучало как *th[ε]nk в речи других людей, говорящих на L1, в то время как менее частые слова, такие как привычка , вероятно, не так часто. Следовательно, это привело бы к тому, что учащиеся с большей вероятностью считали бы *th[ε]nk настоящим английским словом, чем *h[ε]bit. Для /ε/-неслов, наоборот, поскольку неправильное произношение в этих элементах (/ε/ → [æ]) не является типичным маркером речи с акцентом L1, количество воздействия ввода с акцентом L1 не ожидается. чтобы иметь значение, и это могло бы объяснить отсутствие эффекта лексической частоты для этих элементов. Поскольку для правильной оценки того, действительно ли входные характеристики L2 могут быть источником этой асимметрии, потребуется подробная информация о входных данных учащихся L2, это объяснение по-прежнему нуждается в дальнейшем исследовании.
Для /ε/-неслов, наоборот, поскольку неправильное произношение в этих элементах (/ε/ → [æ]) не является типичным маркером речи с акцентом L1, количество воздействия ввода с акцентом L1 не ожидается. чтобы иметь значение, и это могло бы объяснить отсутствие эффекта лексической частоты для этих элементов. Поскольку для правильной оценки того, действительно ли входные характеристики L2 могут быть источником этой асимметрии, потребуется подробная информация о входных данных учащихся L2, это объяснение по-прежнему нуждается в дальнейшем исследовании.
Наконец, эффект фонологической плотности соседства для /æ/-неслов указывает на то, что для наиболее проблематичной категории в сравнении (т. вероятно, учащиеся заметили соответствующие неправильные произношения 3 . Это говорит о том, что высокая плотность фонологического соседства может поддерживать точное фонолексическое кодирование гласного в конкретных лексических представлениях L2, вероятно, за счет усиления связи между сложной неродной фонетической категорией и сгруппированными лексическими единицами.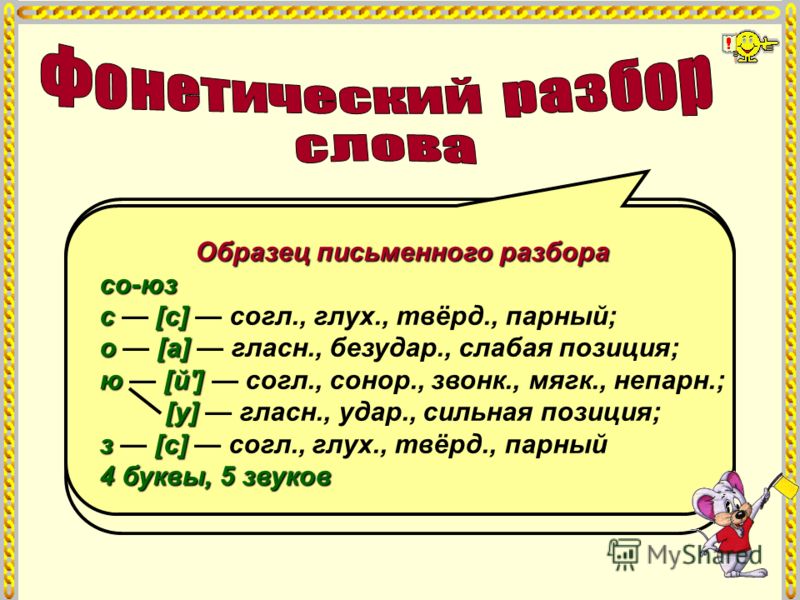 Для слов, содержащих / ε /, плотность фонологического соседства может быть не столь важной из-за доминирующей роли / ε / в фонологическом контрасте и его относительно легкой перцептивной идентификации (Weber and Cutler, 2004; Cutler et al., 2006).
Для слов, содержащих / ε /, плотность фонологического соседства может быть не столь важной из-за доминирующей роли / ε / в фонологическом контрасте и его относительно легкой перцептивной идентификации (Weber and Cutler, 2004; Cutler et al., 2006).
В целом, настоящее исследование дает первое приближение к вопросу о том, как лексика и восприятие речи переплетаются в фонолексическом кодировании сложных контрастов L2 с позиции, ориентированной на предмет. Сложные фонологические контрасты L2 вводят дополнительный уровень «нечеткости» в лексические представления L2, которые, как известно, уже являются нечеткими из-за неотъемлемых характеристик самого обучения L2 (Cook and Gor, 2015; Cook et al., 2016; Ланкастер и Гор). , 2016). Предыдущие исследования показали, что для неродных фонологических контрастов, в которых два телефона L2 различаются тем, насколько хорошо они соответствуют категориям L1, трудности, вызванные такими телефонами, несимметричны (Weber and Cutler, 2004; Cutler et al. , 2006). ; Дарси и др., 2013; Симончик и Дарси, 2017, 2018; Мельник и Пеперкамп, 2019, 2021). Это исследование вносит свой вклад в эту литературу, предполагая, что эти асимметрии могут также распространяться на то, как происходит фонолексическое кодирование. Основываясь на настоящих результатах, кодирование наиболее подходящей или доминирующей категории L2 (т. Е. / ε /), по-видимому, не сильно ограничено лексическими свойствами конкретных лексических единиц L2, такими как лексическая частота и плотность фонологического соседства. Это, в дополнение к эффектам акустики гласных, наблюдаемым для /ε/-неслов, предполагает, что для этой категории кодирование может быть более непосредственно связано с фонетическим восприятием учащимися контраста. Обратите внимание, что эта идея хорошо объясняет результаты Llompart и Reinisch (2019).б), которые обнаружили, что только для ответов на (не)слова с фонологическим /ε/ (а не /æ/) можно обнаружить связь с перцептивной гибкостью учащихся в распределенной учебной задаче.
, 2006). ; Дарси и др., 2013; Симончик и Дарси, 2017, 2018; Мельник и Пеперкамп, 2019, 2021). Это исследование вносит свой вклад в эту литературу, предполагая, что эти асимметрии могут также распространяться на то, как происходит фонолексическое кодирование. Основываясь на настоящих результатах, кодирование наиболее подходящей или доминирующей категории L2 (т. Е. / ε /), по-видимому, не сильно ограничено лексическими свойствами конкретных лексических единиц L2, такими как лексическая частота и плотность фонологического соседства. Это, в дополнение к эффектам акустики гласных, наблюдаемым для /ε/-неслов, предполагает, что для этой категории кодирование может быть более непосредственно связано с фонетическим восприятием учащимися контраста. Обратите внимание, что эта идея хорошо объясняет результаты Llompart и Reinisch (2019).б), которые обнаружили, что только для ответов на (не)слова с фонологическим /ε/ (а не /æ/) можно обнаружить связь с перцептивной гибкостью учащихся в распределенной учебной задаче. Напротив, для менее подходящей, недоминантной категории (т. разместить эти элементы в словарном запасе учащихся и, возможно, связано с их знакомством с родным и неродным входом. Следовательно, можно предположить, что фонолексическое кодирование /æ/ действует в большей степени по частям (Lieven et al., 19).97; Pine and Lieven, 1997) модулируется опытом учащихся с языком L2 и даже с конкретными словами L2 (Llompart, 2019, 2021). Будущие исследования, включающие более крупные образцы элементов и, в идеале, также изучение данных других экспериментальных парадигм, которые используют лексический поиск, теперь будут необходимы, чтобы установить, в какой степени выводы, полученные в результате невербального отклонения в этом исследовании, являются надежными и обобщаемыми.
Напротив, для менее подходящей, недоминантной категории (т. разместить эти элементы в словарном запасе учащихся и, возможно, связано с их знакомством с родным и неродным входом. Следовательно, можно предположить, что фонолексическое кодирование /æ/ действует в большей степени по частям (Lieven et al., 19).97; Pine and Lieven, 1997) модулируется опытом учащихся с языком L2 и даже с конкретными словами L2 (Llompart, 2019, 2021). Будущие исследования, включающие более крупные образцы элементов и, в идеале, также изучение данных других экспериментальных парадигм, которые используют лексический поиск, теперь будут необходимы, чтобы установить, в какой степени выводы, полученные в результате невербального отклонения в этом исследовании, являются надежными и обобщаемыми.
Заявление о доступности данных
В этом исследовании были проанализированы общедоступные наборы данных. Эти данные можно найти здесь: https://osf.io/u7syd/ (Open Science Framework).
Заявление об этике
Этическая экспертиза и одобрение не требовались для исследования с участием людей в соответствии с местным законодательством и институциональными требованиями.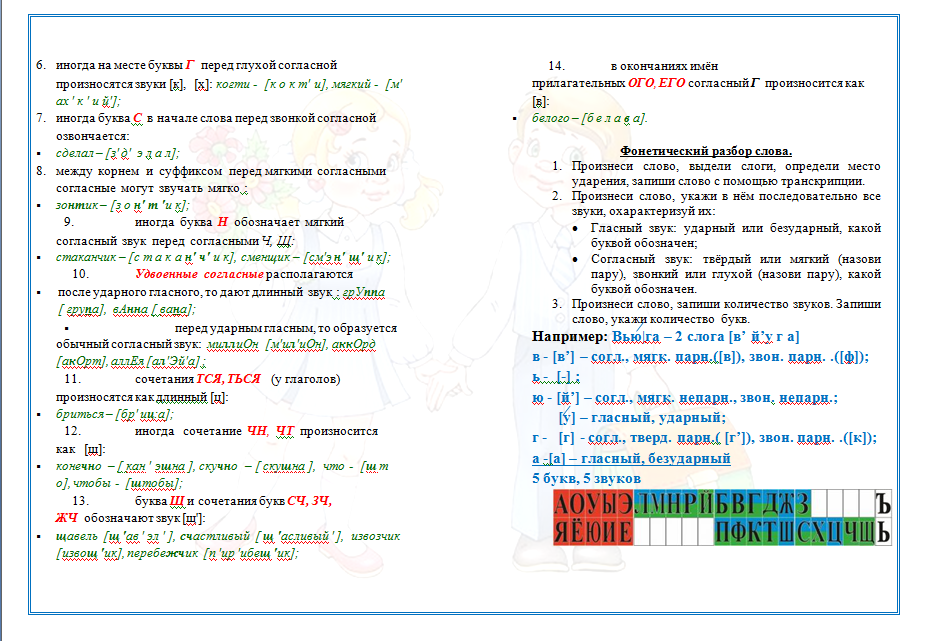 Пациенты/участники предоставили письменное информированное согласие на участие в этом исследовании.
Пациенты/участники предоставили письменное информированное согласие на участие в этом исследовании.
Авторские взносы
ML несет единоличную ответственность за концепцию исследования, анализ и интерпретацию данных, а также составление рукописи.
Финансирование
Эта работа финансировалась за счет звания профессора Александра фон Гумбольдта (ID-1195918), присужденного Еве Домбровской, заведующей кафедрой языка и познания на факультете английских и американских исследований Университета им. Фридриха Александра в Эрлангене-Нюрнберге.
Конфликт интересов
Автор заявляет, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности 9
Чтобы проиллюстрировать эффект потолка для принятия реальных слов, процент правильных ответов на стимулы реальных слов по гласным (/ε/-слова и /æ/-слова) для различных групп, протестированных в Llompart and Reinisch (2019b) и Llompart (2021). ) представлены в виде дополнительной таблицы 1. Кроме того, в дополнительной таблице 2 представлены результаты модели с точно такой же структурой, что и базовая модель, указанная в разделе «Результаты», но основанной на ответах на реальные слова вместо неправильно произносимых слов. В отличие от модели в разделе «Результаты», модель для реальных слов не показывает существенных различий в точности в зависимости от гласной или группы учащихся. 9 Полученные показатели использования языка различались в разных исследованиях и поэтому не могут быть полностью сопоставимы. Напротив, показатели владения английским языком и разговорного английского языка были одинаковыми для двух исследований, хотя и получены с использованием немного разных шкал. Несмотря на это, когда средние значения для всех трех групп участников, указанные в первоначальных исследованиях, преобразуются в общую шкалу от 0 до 10 (0 = очень плохо; 10 = очень хорошо), можно заметить, что учащиеся среднего уровня в Llompart и Райниш (2019 г.
) представлены в виде дополнительной таблицы 1. Кроме того, в дополнительной таблице 2 представлены результаты модели с точно такой же структурой, что и базовая модель, указанная в разделе «Результаты», но основанной на ответах на реальные слова вместо неправильно произносимых слов. В отличие от модели в разделе «Результаты», модель для реальных слов не показывает существенных различий в точности в зависимости от гласной или группы учащихся. 9 Полученные показатели использования языка различались в разных исследованиях и поэтому не могут быть полностью сопоставимы. Напротив, показатели владения английским языком и разговорного английского языка были одинаковыми для двух исследований, хотя и получены с использованием немного разных шкал. Несмотря на это, когда средние значения для всех трех групп участников, указанные в первоначальных исследованиях, преобразуются в общую шкалу от 0 до 10 (0 = очень плохо; 10 = очень хорошо), можно заметить, что учащиеся среднего уровня в Llompart и Райниш (2019 г. В качестве дополнительной проверки фонологической плотности соседства было оценено, отличаются ли плотности на элемент от значений, указанных в таблице 1, когда рассматривались только соседи, содержащие одну и ту же целевую гласную (по сравнению со всеми соседями). Корреляционный анализ показал, что общая плотность соседства и плотность соседства, включающая только соседей с одинаковыми гласными, были почти идеально коррелированы [ r (24) = 0,98, p < 0,001].
В качестве дополнительной проверки фонологической плотности соседства было оценено, отличаются ли плотности на элемент от значений, указанных в таблице 1, когда рассматривались только соседи, содержащие одну и ту же целевую гласную (по сравнению со всеми соседями). Корреляционный анализ показал, что общая плотность соседства и плотность соседства, включающая только соседей с одинаковыми гласными, были почти идеально коррелированы [ r (24) = 0,98, p < 0,001].Ссылки
Аменгуаль, М. (2016). Восприятие специфичных для языка фонетических категорий не гарантирует точного фонологического представления в лексиконе ранних билингвов. Заяв. Психолингвист. 37, 1221–1251. doi: 10.1017/S0142716415000557
CrossRef Полный текст | Google Scholar
Эндрюс, С. (1996). Процессы лексического поиска и выбора: эффекты путаницы с транспонированными буквами. Дж. Мем. Ланг. 35, 775–800. doi: 10.1006/jmla.1996.0040
Полнотекстовая перекрестная ссылка | Google Scholar
Бейтс Д. , Махлер М., Болкер Б. и Уокер С. (2015). Подгонка линейных моделей смешанных эффектов с использованием lme4. Дж. Стат. ПО 67:1406. doi: 10.18637/jss.v067.i01
, Махлер М., Болкер Б. и Уокер С. (2015). Подгонка линейных моделей смешанных эффектов с использованием lme4. Дж. Стат. ПО 67:1406. doi: 10.18637/jss.v067.i01
Полный текст CrossRef | Google Scholar
Best, CT, and Tyler, MD (2007). «Восприятие речи на неродном языке и на втором языке: общие черты и взаимодополняемость», в Языковой опыт в изучении речи на втором языке: в честь Джеймса Эмиля Флеге , ред. О. С. Бон и М. Дж. Манро (Амстердам: Джон Бенджаминс), 13–34. doi: 10.1075/lllt.17.07bes
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Бурсма, П., и Венинк, Д. (2009). Праат: фонетика на компьютере. Компьютерная программа URL: http://www.praat.org
Google Scholar
Брэдлоу А.Р., Акахане-Ямада Р., Писони Д.Б. и Тохкура Ю. (1999). Обучение японских слушателей распознавать английские / r / и / l /: долгосрочное сохранение обучения в восприятии и воспроизведении. Восприятие. Психофиз. 61, 977–985. doi: 10.3758/BF03206911
doi: 10.3758/BF03206911
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Броерсма, М. (2012). Повышенная лексическая активация и снижение конкуренции при прослушивании второго языка. Ланг. Когнит. Процесс. 27, 1205–1224. doi: 10.1080/016
.2012.660170CrossRef Full Text | Google Scholar
Coltheart, M., Davelaar, E., Jonasson, JT, and Besner, D. (1977). «Доступ к внутреннему лексикону», в Внимание и производительность, том VI , изд. С. Дорник (Нью-Джерси: Эрлбаум), 535–556.
Google Scholar
Кук С.В. и Гор К. (2015). Лексический доступ в L2: дефицит репрезентации или ограничение обработки? Мент. Лекс. 10, 247–270. doi: 10.1075/ml.10.2.04coo
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Кук С.В., Панджа Н.Б., Ланкастер А.К. и Гор К. (2016). Нечеткие неродные фонолексические представления приводят к нечетким отображениям формы в значение. Фронт. Психол. 7:1345. doi: 10.3389/fpsyg.2016.01345
7:1345. doi: 10.3389/fpsyg.2016.01345
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Катлер А., Вебер А. и Отаке Т. (2006). Асимметричное отображение фонетических репрезентаций в лексические при аудировании на втором языке. Дж. Тел. 34, 269–284. doi: 10.1016/j.wocn.2005.06.002
CrossRef Полный текст | Google Scholar
Дайдоне, Д. (2020). Как учащиеся запоминают слова на своем втором языке: влияние индивидуальных различий в восприятии, когнитивных способностях и размере словарного запаса. Кандидат наук диссертация, Блумингтон: Университет Индианы.
Google Scholar
Дарси И., Дайдоне Д. и Кодзима К. (2013). Асимметричный лексический доступ и нечеткие лексические представления у изучающих второй язык. Мент. Лекс. 8, 372–420. doi: 10.1075/ml.8.3.06dar
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Дарси, И., и Холлидей, Дж. Дж. (2019). «Обучение старому слову новым трюкам: фонологические обновления в ментальном лексиконе L2», в материалах 10-й конференции по изучению произношения и преподаванию второго языка 9. 0016, редакторы Дж. Левис, К. Нэгл и Э. Тодей (Эймс: Государственный университет Айовы), 10–26.
0016, редакторы Дж. Левис, К. Нэгл и Э. Тодей (Эймс: Государственный университет Айовы), 10–26.
Google Scholar
Дарси, И., и Томас, Т. (2019). Когда синий — двусложное слово: перцептивная эпентезия в ментальном лексиконе изучающих второй язык. Билинг. Ланг. Познан. 22, 1141–1159. doi: 10.1017/S13667281050
Полный текст CrossRef | Google Scholar
Детердинг, Д. (1997). Форманты гласных монофтонгов в стандартном южно-британском английском произношении. Дж. Междунар. тел. доц. 27, 47–55.
Google Scholar
Диас Б., Миттерер Х., Броерсма М. и Себастьян-Галлес Н. (2012). Индивидуальные различия в фонологических процессах L2 поздних билингвов: от акустико-фонетического анализа к лексическому доступу. Учиться. Индивид. Отличаться. 22, 680–689. doi: 10.1016/j.lindif.2012.05.005
CrossRef Полный текст | Google Scholar
Эгер, Н. А., и Райниш, Э. (2019a). Влияние собственного голоса и производственных навыков на распознавание слов на втором языке. Дж. Эксп. Психол. Учиться. Мем. Познан. 45, 552–571. doi: 10.1037/xlm0000599
Дж. Эксп. Психол. Учиться. Мем. Познан. 45, 552–571. doi: 10.1037/xlm0000599
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Эгер, Н. А., и Райниш, Э. (2019b). Роль акустических сигналов и мастерство слушателя в восприятии акцента в неродных звуках. Шпилька. Второй Ланг. Acquis. 41, 179–200. doi: 10.1017/S0272263117000377
CrossRef Полный текст | Google Scholar
Ganong, WF (1980). Фонетическая категоризация в слуховом восприятии слов. Дж. Эксп. Психол. Гум. Восприятие. Выполнять. 6, 110–125. doi: 10.1037/0096-1523.6.1.110
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Голлан, Т. Х., Монтойя, Р. И., Сера, К., и Сандовал, Т. С. (2008). Большее использование почти всегда означает меньший частотный эффект: старение, двуязычие и гипотеза более слабых звеньев. Дж. Мем. Ланг. 58, 787–814. doi: 10.1016/j.jml.2007.07.001
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Гото, Х. (1971). Слуховое восприятие нормальными взрослыми японцами звуков «Л» и «Р». Нейропсихология 9, 317–323. doi: 10.1016/0028-3932(71)-3
(1971). Слуховое восприятие нормальными взрослыми японцами звуков «Л» и «Р». Нейропсихология 9, 317–323. doi: 10.1016/0028-3932(71)-3
CrossRef Full Text | Google Scholar
Хейс-Харб, Р., и Масуда, К. (2008). Развитие способности лексически кодировать новые фонематические контрасты второго языка. Второй язык. Рез. 24, 5–33. doi: 10.1177/0267658307082980
CrossRef Full Text | Google Scholar
Ланкастер А. и Гор К. (2016). Абстракция фонологических репрезентаций у взрослых, не являющихся носителями языка. Проц. Лингвистические соц. Являюсь. 1:24. doi: 10.3765/plsa.v1i0.3725
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ливен, Э. В. М., Пайн, Дж. М., и Болдуин, Г. (1997). Лексическое обучение и раннее грамматическое развитие. Дж. Чайлд Ланг. 24, 187–219. doi: 10.1017/S0305000996002930
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лломпарт, М. (2019). Преодоление разрыва между фонетическими способностями и лексикой в изучении второго языка. Кандидат наук диссертация, Мюнхен: Мюнхенский университет Людвига-Максимилиана.
(2019). Преодоление разрыва между фонетическими способностями и лексикой в изучении второго языка. Кандидат наук диссертация, Мюнхен: Мюнхенский университет Людвига-Максимилиана.
Google Scholar
Лломпарт, М. (2021). Способность к фонетической категоризации и размер словарного запаса способствуют кодированию сложных фонологических контрастов второго языка в лексике. Билинг. Ланг. Познан. 24, 481–496. doi: 10.1017/S1366728
0656
Полный текст CrossRef | Google Scholar
Лломпарт, М., и Райниш, Э. (2017). Артикуляционная информация помогает кодировать лексические контрасты на втором языке. Дж. Эксп. Психол. Гум. Восприятие. Выполнять. 43, 1040–1056. doi: 10.1037/xhp0000383
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лломпарт, М., и Райниш, Э. (2019a). Подражание на втором языке опирается на фонологические категории, но не отражает продуктивного использования сложных звуковых контрастов.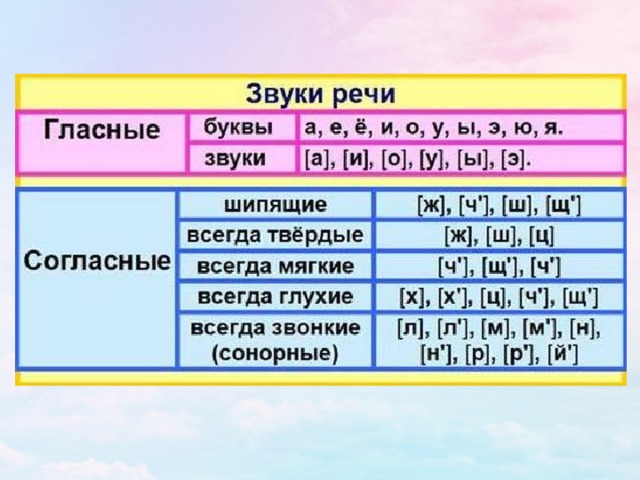 Ланг. Речь 62, 594–622. doi: 10.1177/0023830
Ланг. Речь 62, 594–622. doi: 10.1177/0023830
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лломпарт, М., и Райниш, Э. (2019 г.б). Надежность фонолексических представлений связана с фонетической гибкостью для сложных звуковых контрастов второго языка. Biling.Lang. Познан. 22, 1085–1100. doi: 10.1017/S13667280925
Полный текст CrossRef | Google Scholar
Лломпарт, М., и Райниш, Э. (2020). Фонологическая форма лексических единиц модулирует кодирование сложных звуковых контрастов второго языка. Дж. Экспл. Психол. Учиться. Мем. Познан. 46, 1590–1610. дои: 10.1037/xlm0000832
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Люс П.А. и Пизони Д.Б. (1998). Распознавание произносимых слов: модель активации соседства. Ухо Слушай. 19, 1–36.
Google Scholar
Мариан В., Бартолотти Дж., Чабал С. и Шук А. (2012). CLEARPOND: кросс-лингвистический ресурс с легким доступом для фонологической и орфографической плотности соседства. PLoS One 7:e43230. doi: 10.1371/journal.pone.0043230
PLoS One 7:e43230. doi: 10.1371/journal.pone.0043230
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Мельник, Г. А., и Пеперкамп, С. (2019). Перцептивное удаление и асимметричный лексический доступ у изучающих второй язык. Дж. Акуст. соц. Являюсь. 145, EL13–EL18. doi: 10.1121/1.5085648
CrossRef Полный текст | Google Scholar
Мельник Г. А. и Пеперкамп С. (2021). Фонетическое обучение с высокой вариативностью улучшает лексическую обработку второго языка: данные онлайн-обучения французов, изучающих английский язык. Билинг. Ланг. Познан. 24, 497–506. дои: 10.1017/S1366728
0644
Полнотекстовая перекрестная ссылка | Google Scholar
Nation, I. (2006). Насколько большой словарный запас необходим для чтения и аудирования? Кан. Мод. Ланг. Ред. 63, 59–82. doi: 10.3138/cmlr.63.1.59
CrossRef Full Text | Google Scholar
Пирс Дж., Грей Дж. Р., Симпсон С., Макаскилл М., Хохенбергер Р. , Сого Х. и др. (2019). PsychoPy2: эксперименты с поведением стали проще. Поведение. Рез. Методы 51, 195–203. дои: 10.3758/s13428-018-01193-й
, Сого Х. и др. (2019). PsychoPy2: эксперименты с поведением стали проще. Поведение. Рез. Методы 51, 195–203. дои: 10.3758/s13428-018-01193-й
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Переа, М., Роза, Э., и Гомес, К. (2005). Эффект частотности псевдослов в задаче лексического решения. Восприятие. Психофиз. 67, 301–314. doi: 10.3758/BF03206493
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Пайн, Дж. М., и Ливен, Э. В. М. (1997). Паттерны слотов и рамок и разработка категории определителя. Заяв. Психолингвист. 18, 123–138. дои: 10.1017/S0142716400009930
Полнотекстовая перекрестная ссылка | Google Scholar
Politzer-Ahles, S., Lee, KK, and Shen, L. (2020). Эффекты Ганонга для частоты могут быть неустойчивыми. Дж. Акуст. соц. Являюсь. 147, EL37–EL42. doi: 10.1121/10.0000562
CrossRef Полный текст | Google Scholar
Полька Л. и Бон О.-С. (2003). Асимметрия в восприятии гласных. Речь Комм. 41, 221–231. doi: 10.1016/S0167-6393(02)00105-X
Асимметрия в восприятии гласных. Речь Комм. 41, 221–231. doi: 10.1016/S0167-6393(02)00105-X
Полный текст CrossRef | Академия Google
Полька Л. и Бон О.-С. (2011). Структура Natural Referent Vowel (NRV): новый взгляд на раннее фонетическое развитие. Дж. Тел. 39, 467–478. doi: 10.1016/j.wocn.2010.08.007
CrossRef Полный текст | Google Scholar
Себастьян-Гальес, Н., Эчеверриа, С., и Бош, Л. (2005). Влияние первоначального воздействия на лексическое представление: сравнение ранних и одновременных билингвов. Дж. Мем. Ланг. 52, 240–255. doi: 10.1016/j.jml.2004.11.001
Полнотекстовая перекрестная ссылка | Google Scholar
Силберт Н. Х., Смит Б. К., Джексон С. Р., Кэмпбелл С. Г., Хьюз М. М. и Таре М. (2015). Неродная фонематическая дискриминация, фонологическая кратковременная память и изучение слов. Дж. Тел. 50, 99–119. doi: 10.1016/j.wocn.2015.03.001
CrossRef Full Text | Google Scholar
Саймон Э.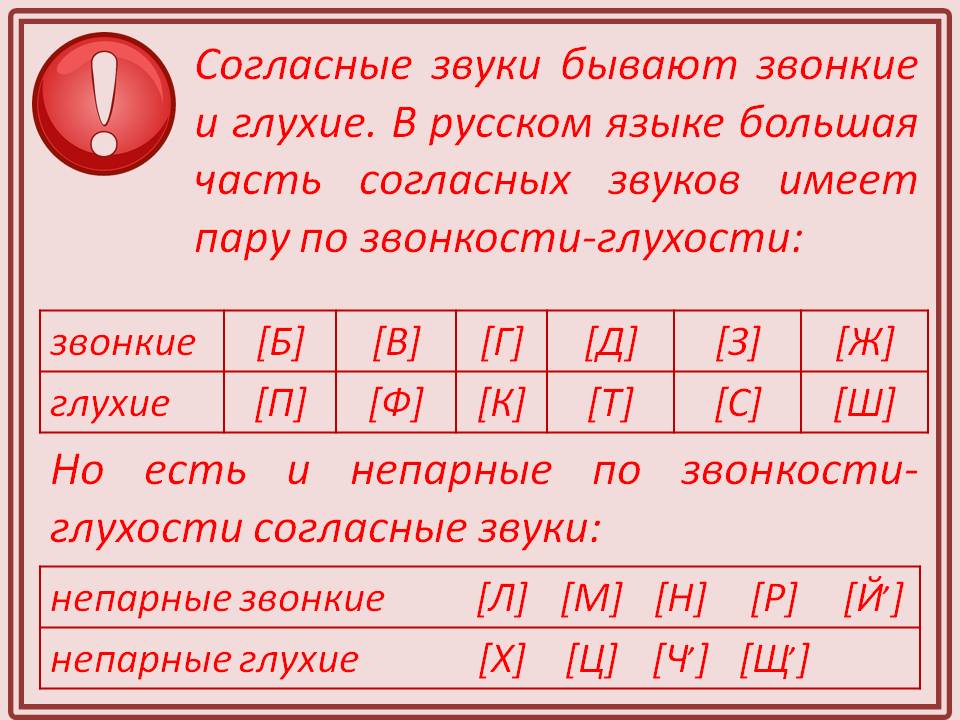 , Сьерпс М. Дж. и Фиккерт П. (2014). Фонологические репрезентации в родной и неродной лексике детей. Билинг. Ланг. Познан. 17, 3–21. doi: 10.1017/S1366728
, Сьерпс М. Дж. и Фиккерт П. (2014). Фонологические репрезентации в родной и неродной лексике детей. Билинг. Ланг. Познан. 17, 3–21. doi: 10.1017/S1366728
Полный текст CrossRef | Google Scholar
Симончик А. и Дарси И. (2017). «Лексическое кодирование и восприятие палатализованных согласных в русском языке L2», в Трудах 8-й конференции по изучению и преподаванию второго языка , под редакцией М. О’Брайена и Дж. Левиса (Эймс: Государственный университет Айовы), 121–132 .
Google Scholar
Симончик А. и Дарси И. (2018). Влияние орфографии на лексическое кодирование палатализованных согласных в русском языке L2. Ланг. Речь 61, 522–546. doi: 10.1177/0023830
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Стрэндж В., Вебер А., Леви Э. С., Шафиро В., Хисаги М. и Ниши К. (2007). Акустическая изменчивость внутри и между гласными немецкого, французского и американского английского: эффекты фонетического контекста. Дж. Акуст. соц. Являюсь. 122, 1111–1129. doi: 10.1121/1.2749716
Дж. Акуст. соц. Являюсь. 122, 1111–1129. doi: 10.1121/1.2749716
CrossRef Полный текст | Google Scholar
ван Хеувен В. Дж. Б., Мандера П., Кеулерс Э. и Брисберт М. (2014). Subtlex-UK: новая и улучшенная база данных частоты слов для британского английского. QJ Exp. Психол. 67, 1176–1190. doi: 10.1080/17470218.2013.850521
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М.С. (2002a). Влияние плотности начала на распознавание устной речи. Дж. Экспл. Психол. Гум. Восприятие. Выполнять. 28, 270–278. doi: 10.1037/0096-1523.28.2.270
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Витевич М.С. (2002b). Натуралистический и экспериментальный анализ эффектов частоты слов и плотности соседства в слуховых оговорках. Ланг. Речь 45, 407–434. doi: 10.1177/0023830
50040501
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Вебер А. и Катлер А.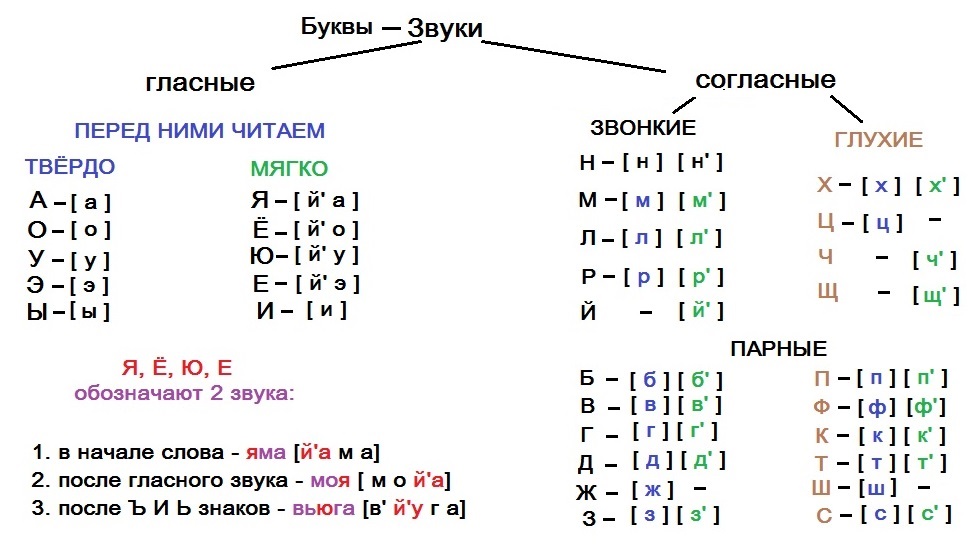 (2004). Лексическая конкуренция в распознавании неродной устной речи. Дж. Мем. Ланг. 50, 1–25. doi: 10.1016/S0749-596X(03)00105-0
(2004). Лексическая конкуренция в распознавании неродной устной речи. Дж. Мем. Ланг. 50, 1–25. doi: 10.1016/S0749-596X(03)00105-0
Полный текст CrossRef | Google Scholar
Чжан, Х., Карлсон, М.Т., и Диас, М.Т. (2020). Изучение влияния фонологических соседей на поиск слов и фонетические вариации в парадигмах именования слов и изображений. Ланг. Познан. Неврологи. 35, 980–991. doi: 10.1080/23273798.2019.1686529
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Телефон(фонетика): объяснение, список и символы
телефон (фонетика): объяснение, список и символы | StudySmarterВыберите язык
Предлагаемые языки:
Европа
английский (DE) английский (Великобритания)
StudySmarter — универсальное учебное приложение.
4.8 • Рейтинг +11k
Более 3 миллионов загрузок
Бесплатно
Сохранять
Распечатать
Редактировать
СОДЕРЖАНИЕ :
ОГЛАВЛЕНИЕ
Что такое телефон в фонетике?
В лингвистике телефон (от греческого fōnḗ ) — это отдельный звук речи. Мы изучаем телефоны в фонетике , разделе лингвистики, который занимается физическим производством и приемом звука. Телефоны не привязаны к конкретным языкам и не всегда важны для понимания значения слова. Телефоны представлены буквами и символами из I международного фонетического алфавита (IPA) .
Мы изучаем телефоны в фонетике , разделе лингвистики, который занимается физическим производством и приемом звука. Телефоны не привязаны к конкретным языкам и не всегда важны для понимания значения слова. Телефоны представлены буквами и символами из I международного фонетического алфавита (IPA) .
Давайте рассмотрим пример:
Посмотрите на слова spin и pat . Оба они содержат букву p ; однако звуки речи немного отличаются. Глядя на фонетическую транскрипцию слов, мы можем сравнить два разных телефона.
[sp ɪ n] и [pʰæt]
Как видите, слово spin содержит 4 телефона (s, p, ɪ, и n) и слово pat имеет 3 (pʰ, æ и t). Обратите внимание, что первым телефоном в слове pat является символ p , сопровождаемый маленьким h — это потому, что p произносится с придыханием (произносится с выдохом). Независимо от того, произносим ли мы слово pat с выдохом, значение слова не изменится, и большинство людей поймут, что вы говорите. Однако телефон [pʰ] показывает нам реальный звук, когда [p] используется в этом слове.
Независимо от того, произносим ли мы слово pat с выдохом, значение слова не изменится, и большинство людей поймут, что вы говорите. Однако телефон [pʰ] показывает нам реальный звук, когда [p] используется в этом слове.
Вам может быть интересно, что означают все эти странные буквы в скобках — это подводит нас к символам, используемым для обозначения телефонов и международного фонетического алфавита.
Символы для телефонов
Международный фонетический алфавит (IPA) представляет собой систему для представления фонетических звуков (телефонов) с помощью символов.
Он был разработан учителем языка Полом Пасси в 1888 году и представляет собой систему фонетических символов, основанную в основном на латинице. Диаграмма была первоначально создана как способ точного представления звуков речи и теперь используется лингвистами и преподавателями иностранных языков по всему миру.
IPA стремится представить все качества речи и звуков, присутствующих в языке, включая гласные, согласные, просодические особенности (высоту, интонацию и тон), промежутки между звуками и слоги.
В настоящее время МФА включает:
Легочные согласные — Звуки, издаваемые давлением воздуха из легких. Все согласных в английском языке являются легочными.
Нелегочные согласные — Звуки, которые не производятся давлением воздуха из легких. В английском языке нет нелегочных согласных.
Монофтонги — Одиночные гласные звуки в слоге.
Дифтонги — Два гласных звука в слоге.
Надсегментарии — Группа символов, представляющая просодические особенности речи.
Тона и словесные акценты — Используется при расшифровке тональных языков, таких как вьетнамский.
Диакритические знаки — Маленькие знаки, указывающие на незначительные различия в произношении.


Диакритические знаки — это небольшие метки, расположенные выше, ниже или рядом с буквообразными символами, чтобы показать небольшие различия в звуках и произношении. В IPA 44 различных диакритических знака. Некоторые распространенные из них включают:
- ◌̥ Безмолвный
- ◌̬ Звонкий
- ʰ С придыханием
- ◌̃ Назализированный
Диаграмма IPA
Таблица IPA включает в себя все звуки IPA и таблицы их звуков. — Wikimedia Commons (рис. 1)
Важно отметить, что IPA не привязан к какому-либо конкретному языку и может использоваться во всем мире, чтобы помочь изучающим язык.
Как расшифровать произношение по телефону?
Когда мы описываем телефоны, мы используем узкую транскрипцию (включая как можно больше аспектов конкретного произношения) и помещаем буквы и символы между двумя квадратными скобками ( [ ] ). Фонетическая транскрипция дает нам много информации о том, как физически производить звуки.
Фонетическая транскрипция слова ножницы : [ˈsɪzəz] .
Диакритический знак [ ‘ ] над s показывает, что это слоговый согласный звук, т. е. звук, который сам по себе образует слог.
Телефоны и фонемы
Мы уже говорили, что телефоны — это отдельные звуки речи, так что же такое фонемы?
Фонема — это наименьшая единица осмысленного звука в конкретном языке. В английском языке существует 44 различных фонемы (20 различных гласных и 24 согласных звука).
Если вы уже видели транскрипцию английского произношения, вы, вероятно, видели фонематическую транскрипцию. Рассмотрим пример:
. Фонематическая транскрипция слова book — /bʊk/ . Как видите, слово book состоит из трех различных фонем (b, ʊ и k).
В то время как телефоны не обязательно важны для понимания значения слов, фонемы важны! Если одну фонему заменить другой, это может полностью изменить значение слова.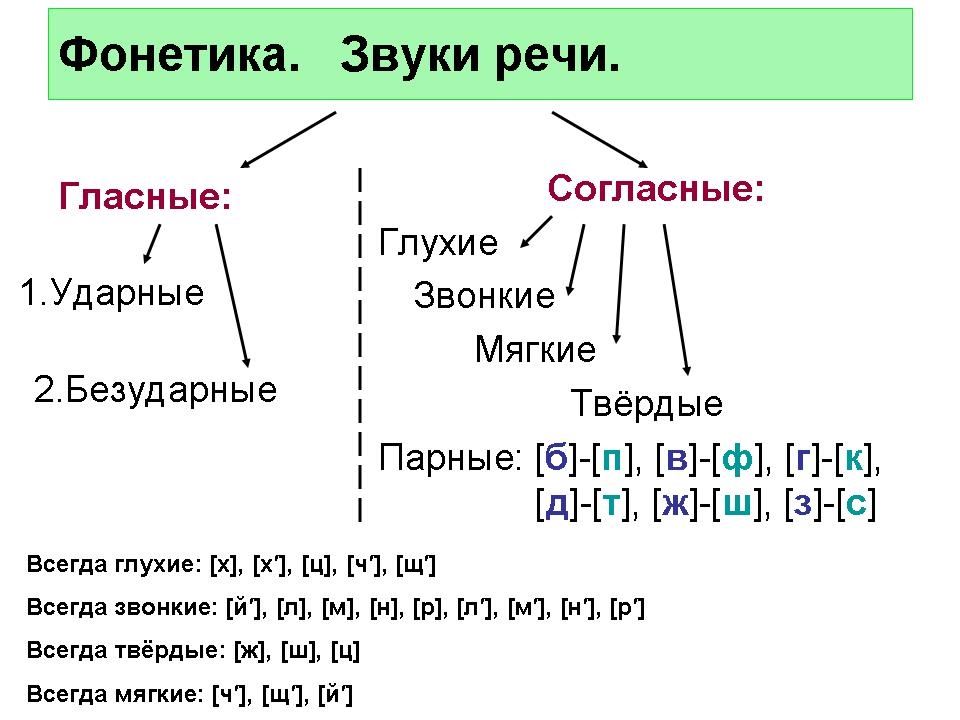 Возьмем, к примеру, слова овца и простыня. Окончания фонемы разные (/p/ и /t/), в результате получается два совершенно разных слова!
Возьмем, к примеру, слова овца и простыня. Окончания фонемы разные (/p/ и /t/), в результате получается два совершенно разных слова!
Вы можете определить, является ли транскрипция фонетической или фонематической, посмотрев на скобки, в которые она заключена. Фонетическая транскрипция заключена в квадратные скобки ( [ ] ), а фонематическая транскрипция заключена в косую черту ( / / ).
Что такое аллофоны?
Аллофон — это термин, используемый для описания группы телефонов , представленных одной фонемой на определенном языке.
Например, на английском языке телефоны [tʰ] (с придыханием), [t] (без придыхания) и [tʃ] (аффрикация) представлены одной фонемой / t / — это делает их все аллофонами для фонемы / t /.
Посмотрите на следующие слова: T rick, Tack, Stack .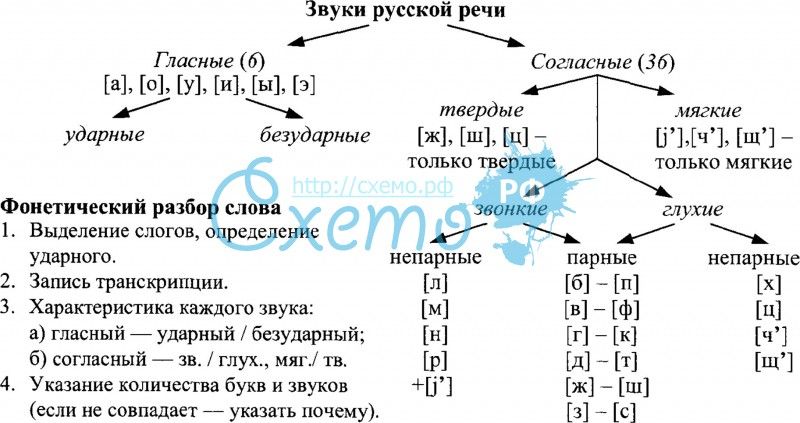 Каждое слово содержит один из предыдущих аллофонов фонемы /t/. Можете ли вы выяснить, какое слово имеет какой аллофон?
Каждое слово содержит один из предыдущих аллофонов фонемы /t/. Можете ли вы выяснить, какое слово имеет какой аллофон?
Ответы:
Trick = [tʃ] (africated — T произносит звук ‘CH’)
Такс = [тʰ] (придыхание — выдох воздуха после Т)
Стек = [т] (без придыхания)
7
Телефон – выдача ключей
- A телефон — это любой отдельный звук речи, который не относится к какому-либо конкретному языку.
- Мы изучаем телефоны в фонетике, области лингвистики, которая занимается физическим производством и приемом звука.
- Телефоны представлены буквами и символами из Международного фонетического алфавита (IPA). При создании фонетической транскрипции мы включаем как можно больше подробностей о произношении и помещаем транскрипцию в две квадратные скобки. Например, фонетическая транскрипция IPA — это [aɪ pʰiː eɪ].
- Изменения в произношении, такие как с придыханием или без придыхания (с выдохом воздуха или без), представлены небольшими знаками, называемыми диакритическими знаками .
- Телефоны отличаются от фонем тем, что они не зависят от языка и не играют существенной роли в значении слов.
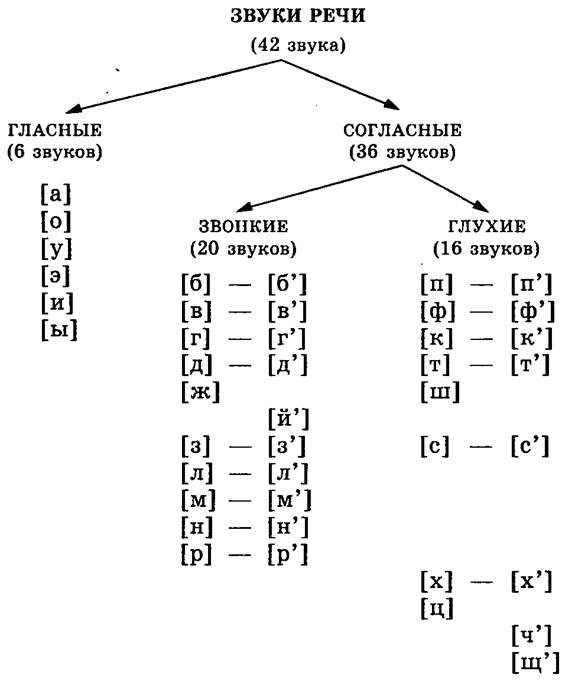
Ссылки
- Рис. 1. Международная фонетическая ассоциация, CC BY-SA 3.0, через Wikimedia Commons
Часто задаваемые вопросы о телефоне
Согласно фонетике, телефон – это отчетливый звук речи.
Примером телефона является звук [pʰ] . Это согласный звук Р с придыханием (выдохом воздуха). Диакритический знак «ʰ» дает нам дополнительную информацию о том, как правильно произносить звук p.
Телефонный отчетливый звук речи. Аллофон — это термин, используемый для описания группы телефонов , представленных одной фонемой на определенном языке. Например, [tʰ] (с придыханием), [t] (без придыхания) и [tʃ] (аффрикация) — все это аллофоны для фонемы /t/.
Телефоны транскрибируются с использованием международного фонетического алфавита. Для расшифровки телефонов делается узкая транскрипция.
Телефоны изучаются в фонетике и представляют собой отдельные звуки речи, не характерные для какого-либо языка. Фонемы — это исследования в области фонологии, которые представляют собой наименьшие значимые звуковые единицы и зависят от языка.
 org/Thing» data-name=»flashcards-dot»> Финальная викторина по телефону
org/Thing» data-name=»flashcards-dot»> Финальная викторина по телефонуВопрос
Верно или неверно: для расшифровки телефонов мы используем квадратные скобки.
Показать ответ
Ответ
Верно. Мы используем квадратные скобки [] для расшифровки phone и косые скобки // для расшифровки фонем.
Показать вопрос
Вопрос
Сколько телефонов в слове собака?
Показать ответ
Ответ
Слово собака имеет три формы: [d], [ɒ] и [g].
Показать вопрос
Вопрос
Сколько телефонов в слове телефон ?
Показать ответ
Ответ
В слове phone четыре телефона: [f], [ə], [ʊ] и [n].
Показать вопрос
Вопрос
Сколько телефонов в слове замок ?
Показать ответ
Ответ
Слово замок имеет четыре формы: [ˈk], [ɑː], [s] и [l].
Показать вопрос
Вопрос
Сколько телефонов в мире выходные ?
Показать ответ
Ответ
В слове «выходные» шесть звуков: [ˈw], [iː], [kˈ], [ɛ], [n] и [d].
Показать вопрос
Вопрос
Сколько телефонов в мире ссылка ?
Показать ответ
Ответ
Слово изгнание имеет пять звуков: [ˈɛ], [k], [s], [aɪ] и [l].
Показать вопрос
Вопрос
Что такое фонема?
Показать ответ
Ответ
Фонема представляет собой наименьшую, наиболее отчетливую звуковую единицу языка.
Показать вопрос
Вопрос
Чем отличаются телефоны от фонем в фонетике?
Показать ответ
Ответ
Отличие в том, что согласно фонетике, телефон — это отдельный звук речи, не влияющий на значение слов. Иными словами, фонема – это звук речи, который может образовать новое слово с другим значением, если заменить одну фонему другой.
Показать вопрос
Вопрос
Верно или неверно: в слове король звук к не произносится с придыханием.
Показать ответ
Ответ
Неверно: звук k произносится с придыханием и транскрибируется как [kʰ].
Показать вопрос
Вопрос
Верно или неверно: гласная [ʌ] не является телефоном.
Показать ответ
Ответ
Неверно: гласную [ʌ] можно отнести к категории телефона.
Показать вопрос
Вопрос
Верно или неверно: согласный звук /d/ — это телефон.
Показать ответ
Ответ
Неверно: это вопрос с подвохом, потому что согласная [d] — это телефон, но не тогда, когда его представляет косая черта.
Показать вопрос
Вопрос
Верно или неверно: согласный [с] — это телефон.
Показать ответ
Ответ
Показать вопрос
Вопрос
Верно или неверно: телефоны — это абстрактные термины.
Показать ответ
Ответ
Неверно: телефоны — это физические звуки, а фонемы — это абстрактные термины.
Показать вопрос
Вопрос
Верно или неверно: телефоны дают больше информации о звучании слова, чем фонемы.
Показать ответ
Ответ
Показать вопрос
Вопрос
Верно или неверно: Телефоны можно использовать только с наддувом.
Показать ответ
Ответ
Неверно: Телефоны бывают без наддува и без наддува.
Показать вопрос
Подробнее о телефоне
Откройте для себя подходящий контент для ваших предметов
Не нужно обманывать, если у вас есть все необходимое для успеха! Упаковано в одно приложение!
Учебный план
Будьте идеально подготовлены вовремя с индивидуальным планом.
Тесты
Проверьте свои знания с помощью игровых тестов.
Карточки
Создавайте и находите карточки в рекордно короткие сроки.
Заметки
Создавайте красивые заметки быстрее, чем когда-либо прежде.
Учебные наборы
Все учебные материалы в одном месте.
Документы
Загружайте неограниченное количество документов и сохраняйте их в Интернете.
Study Analytics
Определите сильные и слабые стороны вашего исследования.
Еженедельные цели
Ставьте индивидуальные учебные цели и зарабатывайте баллы за их достижение.
Умные напоминания
Хватит откладывать на потом наши напоминания об учебе.
Награды
Зарабатывайте очки, открывайте значки и повышайте уровень во время учебы.
Волшебный маркер
Создавайте карточки в заметках полностью автоматически.
Умное форматирование
Создавайте самые красивые учебные материалы, используя наши шаблоны.
Фонетика
Фонетика Фонетика Доктор К. Джордж Бори
Шиппенсбургский университет
Фонетика – это наука о звуки языка. Эти звуки называются фонемами. Есть буквально сотни из них используются на разных языках. Даже один такой язык, как английский, требует от нас различать около 40! ключевое слово здесь различать. Мы на самом деле делаем намного лучше различия между звуками, но английский язык требует только 40. другие различения — это то, что позволяет нам обнаруживать различия в акценты и диалекты, идентифицировать людей и различать крошечные нюансы речи, указывающие на вещи, выходящие за рамки очевидного значения слова.
Речевой тракт
Чтобы изучить звуки языка, нам сначала нужно изучить голосовой тракт. Начало речи
с легкими, которые выталкивают воздух
извлеките и втяните его. Первоначальная цель состояла, конечно, в том, чтобы получить
кислород и устраняют углекислый газ. Но это также необходимо для
речь. Есть фонемы, которые немного больше, чем
дыхание: например, h.
Далее гортань или Голос окно. Он находится на стыке трахеи или дыхательного горла, выходящего из легкие и пищевод выходит из желудка. В гортани у нас есть отверстие называется голосовой щелью, надгортанником, который покрывает голосовую щель когда мы глотаем, и вокал шнуры. Голосовые связки состоят из двух слизистых лоскутов. мембрана, натянутая поперек голосовой щели, как на этой фотографии:
Голосовые связки могут напрягаться и ослабляться и могут вибрировать, когда воздух проталкивается мимо них, создавая звук. Некоторые фонемы используют это звучат, и называются звонкими. Примеры включают гласные (например, a, e, i, o и u) и некоторые согласных (например, м, л и р). Другие фонемы делают не затрагивать голосовые связки, такие как согласные h, t или s, и т. д. называются незвонкими.
Область над голосовой щелью называется глоткой или верхней частью глотки. Это
можно затянуть, чтобы сделать глотку
согласные буквы. В английском их нет, но они звучат
например, когда вы пытаетесь вытащить кусок пищи обратно из горла.
В верхней части глотки находится отверстие для носовых ходов (называемое носоглотки, если вы заинтересованы). Когда мы позволяем воздуху проходить в нос во время говоря, звуки, которые мы издаем, называются носовыми. Примеры включают м, н, и звук пения.
Большая часть действий во время речи, конечно же, происходит во рту. особенно при взаимодействии языка с крышей рот. Небо рта имеет несколько специфических областей: в самой задней части, как раз перед носовым проходом, находится тот маленький мешочек, который называется язычок. Его основной функция как бы увлажняет воздух и издает определенные звуки называется, очевидно, увулярным. Самый известный из них — звук «р», произносимый в задней части рта. некоторые говорящие по-французски и по-немецки. Увулярный, глоточный и гортанный звуки часто называют желобами.
Далее идет мягкое небо, называемое небной занавеской. Если вы повернете свой язык
назад до упора и надавите, вы почувствуете, насколько он мягкий
является. Когда вы говорите k или g, вы используете velum, поэтому они
называются велярными согласными.
Далее вперед твердое небо. Довольно много согласных образуются с помощью твердого неба, например, с, ш, n, и l, и называются небными. Сразу за зубами находится зубной гребень или альвеола. Вот где много из нас делают наши т и д — альвеолярными согласные буквы.
На самом внешнем краю рта у нас есть зубы и губы. Стоматологические согласные производятся путем прикосновения языком к зубам. На английском мы делаем второй звучит так. Обратите внимание, что один из них озвучен (й в худ.) и один глухой (й в худ.).
Губами мы тоже можем издавать несколько звуков. Простейший,
возможно, двугубные
звуки, издаваемые сжатием губ, а затем выпуском звука,
например, p и b, или удерживая их вместе и выпуская воздух
через нос, образуя двугубную носовую m. Мы также можем использовать
верхние зубы с нижней губой для губно-зубных звуков. Это
как мы делаем f, например.
Кстати, у нас также есть два названия используемых частей языка различными частями рта: передний край называется корона, а спина называется спинкой. Звучит так, как будто t, th и s созданы короной, а k, g и ng изготавливаются со спинкой.
Согласные
Согласные – это звуки, которые включают полную или частичную блокировку воздушный поток. В английском языке согласные буквы p, b, t, d, ch, j, k, g, ж, в, т, дч, с, з, ш, ж, м, н, нг, л, р, ш и у. Они есть классифицируются по-разному, в зависимости от речевого тракта детали, которые мы только что обсудили.
1. Остановки, также известные как взрывные устройства. Воздух заблокирован на мгновение, затем отпущен. В английском языке это p, b, t, d, k, и г.
а. Двугубные взрывные: p
(глухой) и б (озвученный)
б. Альвеолярные взрывные: t (глухой) и d (звонкий)
в. Веларовые взрывчатые вещества: k (глухой) и g (звонкий)
Во многих языках за взрывными словами может следовать придыхание, т. звучит как х. В китайском языке, например, есть различие между р, произносимым четко, и р с придыханием. Мы используем оба в Английский (pit vs poo), но это не различие, которое отделяет один смысл от другого.
2. Фрикативные звуки включают немного сопротивлялся потоку воздуха. В английском языке к ним относятся f, v, th, dh, s, z, sh, zh и h.
а. Лабиодентальные фрикативы:
f (глухой) и v (звонкий)
б. Зубные фрикативы: th (как в тонком — глухой) и dh
(как в — озвучено)
в. Альвеолярные фрикативные: s (глухой) и z (звонкий)
д. Небные фрикативные: sh (глухой) и zh (как s в
зрение — озвучено)
е. Гортанный фрикативный звук: h (глухой)
3. Аффрикаты — это звуки которые включают взрывной звук, за которым сразу же следует фрикативный звук расположение. В английском языке есть ch (глухой) и j (звонкий). Многие считают их смесями: т-ш и д-ж.
4. Носовые звуки
осуществляется при прохождении воздуха через нос. По-английски это м,
н и нг.
а. Двугубные носовые: m
б. Альвеолярный нос: №
в. Велар носовой: нг
5. Жидкости — это звуки с очень небольшим сопротивлением воздуха. В английском у нас есть l и r, которые оба альвеолярные, но различаются по форме языка. Для л дотрагиваемся кончиком до гребня зубов и выпускаем воздух вокруг обеих сторон. Для r мы почти перекрываем воздух на обоих стороны и пропустите его вверху. Обратите внимание, что существует множество вариации l и r в других языках и даже в самом английском языке!
6. Полугласные звуки
это, как следует из названия, почти гласные. По-английски мы
есть w и y, которые, как вы можете видеть, очень похожи на гласные, такие как oo и
э-э, но с почти сомкнутыми губами для w (двугубный) и языком
почти касаясь неба для y (палатальный). Они также
называются планками, так как они
обычно «скользят» в позиции гласных или из них (например, ву, да, ау,
и оу).
Во многих языках, например в русском, существует целый набор палатализованных согласных, что означает за ними следует буква y перед гласной. Это также называется на скольжении.
Гласные
В английском языке около 14 гласных. Именно они найдены в эти слова: beet, bit, bait, bet, bat, car, pot (на британском англ.), купил, лодку, книгу, ботинок, птичку, но, а то давным-давно. Есть также три дифтонга или двойные гласные: укус, корова и мальчик. Дифтонги предполагают скольжение. Вы можете услышать букву y в укусить и мальчик, и ж в корова. Собственно, звуки в приманку и лодка также является дифтонгом (со скольжением по y и w соответственно), но первые части дифтонгов отличаются от соседних звуков сделал ставку и купил.
Гласные классифицируются по трем параметрам:
1. Высота языка во рту — низкая, средняя или высокая
высокие — свекла, бит, сапог и книга
середина наживка, пари, но, лодка, купил, птица и назад
низкие летучая мышь, автомобиль и британский горшок
2.
Насколько далеко вперед или назад поднимается язык во рту — спереди, по центру или сзади спереди — это свекла, удила, наживка, ставка и летучая мышь
центр но, птица, и в назад
сзади ботинок, книга, лодка, купленный и британский горшок
3. Насколько округлены или не округлены губы
гласные переднего ряда неокругленные
средние и задние гласные округлены
Идея округления может показаться ненужной, пока вы не поймете, что многие Языки имеют закругленные гласные переднего ряда, такие как немецкий ü и ö и французские u и eu — и многие из них имеют неокругленные гласные заднего ряда — например, японский u. Если вы изучали французский язык в средней школе, вы может вспомнить, как учитель говорил вам говорить чай с округлыми губами для французского ту. Это не лучший способ научить звуку, но он показывает вам, где это вписывается в схему.
Есть еще одно измерение, которое не имеет ничего общего с английским языком,
но это важно во многих языках, и это длина гласных. Гласные могут быть
короткий или длинный, и это просто вопрос того, как долго вы будете продолжать
звук. Самое близкое, что мы получаем в английском языке, это то, что гласная в beet
длиннее (а также выше), чем гласная в бите. То же самое
за сапог и книгу, и за пойманный и британский котел.
В некоторых языках, например, во французском, гласные имеют еще одно качество. и это назальность. Некоторые гласные произносятся с потоком воздуха через нос, а также рот. Первоначально это были просто гласные, за которыми следовали носовые согласные буквы. Но со временем французы смешали гласные и носовые в одну единицу.
IPA
За многие годы лингвисты разработали сложную таблицу фонем.
для расшифровки звуков всех языков мира. Это
называется международным фонетическим
Алфавит, и большая его часть представлена в таблицах ниже. если ты
получить вопросительные знаки или маленькие квадратики, это означает, что ваш компьютер не
оснащены юникодом, в котором
случае вам придется искать в другом месте
за
графики такие.
Согласные
| | | двугубный | губо- стоматологический | стоматологический | альвеолярный | ретрофлекс | палато- альвеолярный | небный | велар | язычок | голосовая щель |
| взрывчатые вещества | ув. | р | | | т | ʈ | | с | к | q | ʔ |
| v. | б | | | д | ɖ | | ɟ | г | ɢ | | |
| фрикативные | ув. | Φ | ф | θ | с | ʂ | | и | х | х | ч |
| v. | β | v | ð | г | ʐ | ʒ | ʝ | γ | ʁ | ɦ | |
| носовые | | м | ɱ | | п | ɳ | | ɲ | ŋ | ɴ | |
| полугласные | ув. | ʍ | | | | | | | | | |
| v. | с | ʋ | | № | ɻ | | й | | | | |
| прокат/ трель | | в | | | р | | | | | ʀ | |
| с резьбой/ откидной | | | | | ɾ | ɽ | | | | | |
| боковые части | | | | | л | ɭ | | λ | л | | |
| боковой -фрикативы | ув. | | | | № | | | | | | |
| т. | | | | и | | | | | | |
Гласные
| | передний | центральный | задняя часть |
| высокий | я
у | ɨ
ʉ | ɯ
ты |
| | ɪ
ʏ | | ʊ |
| средний | е
ø | ɜ ə ɵ | ɤ
о |
| | ɛ
– | ɐ | ɔ |
| низкий | æ | | α
ɒ |
Длина гласного отмечается двоеточием после гласного, например.
я:Носовые гласные обозначаются тильдой над гласной, например ã
Есть еще десятки фонем помимо тех, что указаны в предыдущих таблицах, но один набор особенно интересен: клики. Щелчки — это звуки сделанный создав вакуум языком, а затем резко щелкнув язык прочь. Мы используем их сами, хотя и не как часть слова: Когда мы «ц-ц-ц», когда мы кудахтаем, и когда мы делаем щелчок в уголках рта, когда говорим лошади получить двигаться дальше. Щелчки используются в бушменских языках и в языки банту, имевшие с ними длительный контакт. Самый лучший известен язык банту кхоса из-за знаменитого южного Африканская певица Мириам Макеба.
Ударение и тон
Во многих языках мира, включая английский, слова
дифференцированы с помощью стресса.
Один слог обычно имеет более высокий тон
(«вверх» по музыкальной шкале), а иногда и немного больше силы. Это
как мы различаем аффект
(в качестве
во влиянии) и аффект (как
в эмоциях), для
пример. В более длинных словах может быть даже второй
полуударный слог, как в математике: мат имеет первичную
стресс, математика имеет второстепенное значение
стресс. В IPA первичным ударением является
обозначается предшествующей слогу высокой вертикальной чертой,
вторичный с низкой вертикальной линией.
Обратите внимание, что даже если нам не нужно использовать ударение для различения слова, мы используем его в любом случае. Иногда мы можем сказать, где человек от того, как они используют стресс: страховка обычно подчеркивается сюр; южане подчеркивают его на внутренней стороне. Но многие языки не использовать стресс вообще. На наш слух они звучат довольно монотонно.
В некоторых других языках используются динамические стресс или тонус. Шведский пример. Это означает, что происходит фактическое изменение ударение внутри слогов. В шведском языке два тона:
Сингл тон начинается с высокого и идет вниз. Если одно тоновое слово имеет второе слог, этот слог безударный. Однотоновые слова не звучит очень необычно для англоговорящих.
Двойник
тон встречается только
в двухсложных словах. Первая подача начинается в среднем диапазоне
высоты тона, а второй тон начинается с высокого и идет вниз. Если там
третий слог, безударный. Двойной тон придает
слово напевное качество для носителей английского языка.
Эти тона различают многие слова в шведском языке. В сингле тон, анден, томтен, укушенный и слагет означают утку, здание, бит, и битва соответственно. В двойном тоне они означают дух, эльф, покусан и побит соответственно! Английский также использует динамическое ударение или тона, но только целые фразы, такие как повышение тона в конце вопросов.
Но во многих языках Африки и Азии используются гораздо более сложные тона, и на самом деле называются тональными языки. Китайский — самый известный пример. Несмотря на то что слова часто состоят из более чем одного слога, каждый слог имеет особый смысл. И китайский использует очень ограниченное количество фонемы. Это тоны, которые мешают каждому слогу сотни значений. Их пять:
Тон 1 — высокий
и уровень (как в хей!)
Тон 2 — средний, затем повышающийся (как в
ты?)
Тон 3 — средний, нисходящий, затем восходящий (как в
Мама!? говорит нытье
подросток)
Тон 4 — высокий, затем падающий (как в речи Тома
разочарованной мамой)
Например, простой слог yi может означать множество различных значений.
вещи. Тон 1 означает ткань, тон 2 означает
подозреваю, с тоном 3 это означает стул, а с тоном 4 это означает
значение. Слог ву означает дом, ничего, пять и туман,
соответственно. А ма означает мать, пеньку, коня и ругать.
В официальной транскрипции четыре тона обозначаются ¯,
´, ˇ и `.В тайском языке пять тонов: высокий, средний, низкий, восходящий и падение. В африканском языке катамба их шесть, к ним добавляются падающие, затем повышающийся тон. В кантонском диалекте девять тонов: высокий долгий, высокий короткая, средняя длинная, средняя короткая, низкая длинная, низкая короткая, высокая падающая, среднее падение и низкий подъем.
Мы не знаем, как возникают тональные языки. Многие считают, что он
делать с фонемами или даже целыми слогами, которые были потеряны, но
так или иначе повлияло на произношение. Но это затрудняет
объяснить, что кантонский диалект, в котором сохранилось много старых согласных окончаний,
девяти тонов, в то время как его родственник мандаринского диалекта китайского языка, утративший эти
концовок, всего четыре. Конечно, лингвист из Китая мог бы спросить
как нетональные языки потеряли свои тона!
Один интересный момент заключается в том, что тональность часто пересекается с родственными линии. В Азии, например, тональность встречается в китайском, тайском, и вьетнамский — неродственные языки. С другой ручной, тибетский и бирманский родственны китайскому, но не тональны; ни кхмер, родственник вьетнамца. Самый африканский языки тональные, а суахили нет. Хауса, говорят на Нигерия тональна, а родственницы вроде арабки нет. это возможно, та или иная языковая семья влияла на окружающих он или был родным для области до того, как в нее вторглись носители другой язык.
© Copyright 2005, C. George Boeree
Примеры развития фонологической осведомленности
На этой странице приведены примеры упражнений для развития основных навыков фонологической осведомленности. Важно помнить, что деятельность по фонологическому осознанию не обязательно должна происходить с письменными буквами. Первоначально работа над фонологическим восприятием происходит без письменного слова (например, с использованием реальных предметов, изображений и фишек).
По мере развития фонологических знаний учащимся важно участвовать в фонологических мероприятиях, которые связывают звуки (фонемы) с образами букв (графемами).
Аллингтон и др. (1998) отмечают важность целенаправленного использования ряда ресурсов, таких как детские стишки, загадки, песни, стихи и книги для чтения вслух, которые манипулируют звуками, чтобы привлечь внимание младших школьников к звукам разговорной речи.
Например, использование знакомой стишки, такой как «Пять обезьянок», обеспечивает игривый и осмысленный контекст для маленьких учащихся:
Пять маленьких обезьянок прыгают на кровати
Одна упала и ударилась головой
Мама позвала доктора, и доктор сказал ,
«Больше никаких обезьян, прыгающих по кровати!»
Занятия и уроки по фонологическому развитию должны широко включать:
- Выделение понятий фонологического восприятия в песнях, рифмах, стихах, рассказах и письменных текстах по:
В приведенных ниже примерах показаны некоторые способы включения фонологической осведомленности в повседневную деятельность в классе.
Примеры упражнений:
Знание слоговУчащиеся садятся в круг. Каждый ученик хлопает в ладоши по слогам своего имени, например. Лю-си (хлопать в ладоши)
Это также можно делать с помощью клавы, других форм перкуссии тела
Групповое время рифмуется с движением, топает ногами в такт или по слогу, например. ступни, ступни, ступни, ступни, марширование вверх и вниз по улице
Таинственный мешок – заполните знакомыми предметами, учащиеся вытягивают предмет, называют его, хлопают в ладоши по слогам – напр. ‘лев’ — li-on, ‘ball’ — мяч, ‘octopus’ — осьминог
Разложите на ковре t-диаграмму (можно использовать веревку или клейкую ленту), дети выбирают предмет из место, чтобы принести на ковер и классифицировать в зависимости от количества слогов, например. т-схема может состоять из 1 слога и 2+ слогов, дети размещают свои объекты соответственно (шляпа в 1 слоге, карандаш в 2+ слогах)
Урок базового уровня: Развитие восприятия слогов
Текст: «Я гуляла», Сью Уильямс и Джули Вивас
О тексте: Маленькая девочка идет на прогулку и встречает по пути несколько разноцветных сельскохозяйственных животных.
Текст содержит
- Повторяющиеся структуры предложений
- Вопросы и ответы
- Сопроводительный текст, соответствующий иллюстрациям
- Ритм и рифма
Ссылки на учебный план
Викторианская учебная программа (английский), Чтение и просмотр: Языковое выражение и развитие идей:
Основание: Признание того, что тексты состоят из слов и групп слов, которые имеют значение (Описание содержания VCELA144)
Викторианская учебная программа (английский), Чтение и Просмотр: Грамотность-Интерпретация, анализ, оценка:
Foundation: чтение текстов со знакомой структурой и элементами, отработка фразировки и беглости речи, а также отслеживание значения с использованием понятий о печати и возникающих звуковых, семантических, контекстуальных и грамматических знаниях (описание содержания VCELY152)
Викторианская учебная программа (английский), разговорная речь и аудирование: язык-фоника и знание слов:
Foundation: определение рифмованных слов, аллитерационных моделей, слогов и некоторых звуков (фонем) в произносимых словах (описание содержания VCELA168)
Теория/практика связи
Компонентом фонологии является знание слогов. Понимание слогов, то есть понимание того, что слова можно разбить на части, помогает учащимся расшифровывать слова при чтении и произносить слова по буквам при письме. Прежде чем сосредоточиться на слогах в печатном тексте, важно, чтобы учащиеся развили слуховое восприятие слогов. Детская литература, в которой есть рифмы и повторения, обеспечивает привлекательный контекст для учащихся, чтобы они могли развивать свои навыки слогового построения.
Дополнительные ресурсы
Предметы и изображения для последующей работы.
Намерения к обучению
Мы учимся определять слоги в словах.
Критерии успеха
Я могу хлопать в такт тексту.
Я умею хлопать по слогам в словах с одним, двумя или тремя слогами.
Я умею классифицировать слова на группы по количеству слогов.
Роль читателя
Декодер текста – применение знаний по слогам для декодирования текста
Размер группы
Малая группа
Ход урока
- Чтение я пошел Прогулка к учащимся, поощрение хорового чтения текста.
- Повторите чтение, побуждая учащихся читать и хлопать в такт тексту.
- Напишите текст на полосках с длинными предложениями и используйте указатель, чтобы выделить слоги. Учащиеся хлопают в такт и определяют слова, в которых есть два хлопка (два слога) – ходьба, взгляд, желтый
- Прочитайте еще раз и используйте разную перкуссию тела для односложных и двухсложных слов.
- Прочитайте еще раз, и учащиеся используют ударные инструменты, чтобы выделить слоги.
- Ученики сосредотачиваются на цвете животных и находят цвета, которые имеют два хлопка.
- Последующее задание: Учащиеся классифицируют предметы или изображения по количеству слогов.
Оценка
Попросите учащихся хлопнуть в ладоши части текста.
Дифференциация
Для начинающих читателей слоги могут быть определены с помощью хлопков и обсуждены как «хлопки в словах». Как только учащиеся освоятся с этой концепцией, можно будет использовать термин слоги.
- Карточные игры с рифмами
- Сортировка предметов по рифмам Волосатый Маклари, Комната на метле, Груффало
- У меня есть, у кого есть? У учеников есть карточка/предмет, им нужно найти другого ученика в классе, у которого есть карточка/предмет, рифмующийся с их карточкой, например. ученику с лягушкой нужно найти ученика с собакой
- книга с песней — Один слон вышел поиграть
- с использованием песен с действиями, чтобы выделить рифму:
Мои руки холодеют,
Я думаю, что они синеют Мне нужно что-то, чтобы согреть их, но что я могу сделать?Я могу тереть их, тереть, вертеть ими,
Я могу трясти их, трясти и стучать ими по земле.Я могу тереть их, тереть, вертеть ими,
Я могу трясти их, трясти и стучать ими по земле.
Для получения дополнительной информации см.: Практический пример: Идентификация и создание рифмующихся слов
Аллитерация- чтение стихов — у Кенна Несбитта есть несколько примеров, а также как писать стихи с использованием аллитерации
- анализ стихотворения, чтобы найти все аллитерации (это можно выделить)
- чтение книги — напр. Лиса в носках (доктор Сьюз), Волосатый Маклари
- сочинение собственных стихотворений-аллитераций всем классом/малыми группами
- использование скороговорок
- с использованием (и/или созданием) словесных колес, записывая произносимые слова. Это можно делать индивидуально на небольших досках или плакатах в группах
- сортируя слова по времени — это можно делать на интерактивной доске, учащиеся могут объединять слова в одинаковые группы, например все слова, оканчивающиеся на -at, сгруппированы вместе
- игра «кусочки» — учащиеся выбирают начало и рифму, если получается настоящее слово, они сохраняют его, если это не слово, оно возвращается в стопку. например ‘tr’ и ‘ack’ = дорожка — реальное слово, ‘cl’ и ‘at’ = clat — не слово
- игры на совпадение с картой начала и соответствующей картой изморози (например, ресурсы sparklebox)
- бросьте слово — начало (один кубик), изморозь (второй кубик), прочитайте слово, затем запишите под слово/не слово
- семейства слов
Для получения дополнительной информации см. :
Практический пример: смешивание и сегментация начала и мороза
- сортировка объектов или изображений по начальным или конечным звукам
- бинго
- маркировка начальных звуков объектов в ответе на рисование
- изучение слов — выделение начальных и конечных звуков
Базовый урок — начальные звуки
Текст: «Я гуляла», Сью Уильямс и Джули Вивас
О тексте Маленькая девочка идет на прогулку и встречает несколько красочных сельскохозяйственные животные по пути.
Текст содержит
- повторяющиеся структуры предложений
- вопросы и ответы
- вспомогательный текст, соответствующий иллюстрациям
- ритм и рифма
Ссылки на учебную программу
Викторианская учебная программа (английский), чтение и просмотр: язык
- базовый уровень: понимание того, что тексты состоят из слов и групп слов, которые имеют значение (описание содержания VCELA144)
- распознать все прописные и строчные буквы и наиболее распространенный звук, который представляет каждая буква (описание содержания VCELA146)
Victorian Curriculum (английский), Reading and Viewing: Literacy
- Чтение текстов со знакомой структурой и чертами, отработка фразировки и беглости речи, а также отслеживание значения с использованием понятий о печатном языке и возникающих звуковых, семантических, контекстуальных и грамматических знаниях (описание содержания VCELY152)
Викторианская учебная программа (английский), письмо: фонетика и Знание слов
- Понимать, что произносимые звуки и слова могут быть записаны, и уметь писать некоторые часто встречающиеся слова и другие знакомые слова, включая их названия (Описание содержания VCELA157)
Викторианская учебная программа (английский язык), Разговорная речь и аудирование: язык
- Определение рифмованных слов, моделей аллитерации, слогов и некоторых звуков (фонем) в произносимых словах (описание содержания VCELA168)
- Викторианская учебная программа (английский язык), Разговорная речь и аудирование : Литература Изменение знакомых текстов (Описание содержания VCELT173)
Связи между теорией и практикой
Повторное чтение текста дает учащимся возможность проверить беглость, фразировку и выражение. Многократное чтение текста с первыми читателями позволяет учащимся сосредоточиться на конкретном аспекте грамотности в знакомом контексте. Повторные чтения могут происходить индивидуально, с партнером или в группе.
Дополнительные ресурсы
Карточки с цветными прилагательными и названиями животных, написанными на них – зеленая утка, коричневая лошадь, красная корова и т. д.
Цель обучения:
Мы учимся использовать первый звук, чтобы помочь нам читать слова .
Критерии успеха:
Я могу определить первый звук слова.
Я могу произнести первый звук в слове.
Я могу найти слова в тексте, глядя на первый звук.
Я могу перечитать текст, чтобы улучшить беглость речи.
Роль Читателя
Декодер текста – использование фонологических знаний и фонетических знаний для декодирования текстов.
Размер группы
Малая группа
Последовательность урока
- Прочитайте текст «Я гуляла» Сью Уильямс и Джули Вивас.
- Учащимся выдается набор карточек с написанными на них названиями животных из сказки – черная кошка, рыжая корова, желтая собака и т.д. Перечитайте текст, останавливаясь на названиях животных. Учащиеся находят название и цвет животного по своему набору карточек.
- Предложите учащимся обосновать свои доводы в пользу выбора карточки. Помогите учащимся сосредоточиться на начальных звуках.
- Оценка Раздайте учащимся несколько предложений из текста, которые были вырезаны и переставлены. Учащиеся используют свои знания текста и начальные звуки слов, чтобы расположить слова в правильном порядке.
- Измените текст, чтобы создать большую книгу для группы. Учащиеся иллюстрируют и используют для хорового чтения. Учащиеся используют свои развивающиеся знания о начальных звуках, чтобы определить слова, обозначающие животное и его описание.
Дифференциация
Дополнительную поддержку учащимся, которые еще не уверены в фонетике, можно оказать с помощью иллюстрированных карточек с алфавитом. Учитель может поощрять учащихся использовать свои фонематические знания, задавая вопросы для сравнения и обращаясь к карточкам с алфавитом. Например: Корова начинается с того же звука, что и машина или луна, корова/машина или корова/луна.
- интерактивная доска — перетаскивайте буквы, чтобы сформировать слова CVC (можно расширить), дети смешивают звуки вместе, чтобы составить настоящее слово
- игра в угадай слово
- сегментация — Сколько звуков вы слышите? Это может быть записано/графически на бумаге и буфере обмена
- Использование магнитных букв для разделения слов по звукам, перемещение их по доске, смешивание и сегментирование
- удаление букв или манипулирование ими — это также можно сделать на доске
Практические примеры
- Аллитерация уровня 1 (в разделе практических примеров набора инструментов)
- Базовый уровень — Слушание и рифмование слов
Что такое Международный фонетический алфавит (МФА)?
Самое замечательное в обучении с Duolingo заключается в том, что наши уроки разрабатываются экспертами в области преподавания — от лингвистов до исследователей и бывших преподавателей иностранных языков в колледжах. У нас есть много людей, которые работают над улучшением Duolingo, потому что им всего 9 лет.0606 люблю язык! Поскольку они так много знают о языке, они знают много об инструментах и ресурсах, которые обычный человек может не использовать ежедневно, но которые любой изучающий язык найдет увлекательным.
Введите: Международный фонетический алфавит (также известный как IPA), который является лишь одним из примеров этих очень крутых языковых инструментов! Он используется лингвистами и учителями языков для обучения произношению и представления звуков разных языков, но большинство изучающих язык не знают, как его использовать! К счастью для вас, мы здесь, чтобы удовлетворить ваше любопытство и помочь вам использовать IPA на любом языке, который вы изучаете. (И если вы оказались здесь по ошибке, ища рекомендации о хмельном пиве… извините. Но оставайтесь здесь! Мы обещаем, что это весело.)
Так что же такое Международный фонетический алфавит?
IPA был впервые введен в конце 1800-х годов группой преподавателей французского и английского языков и лингвистов во главе с Полом Пасси. Он был основан на предыдущих попытках разработать лучшую систему письменного представления устной речи. Эти лингвисты стремились решить три основные проблемы, возникающие при работе с языками: буквы не всегда соответствуют одним и тем же звукам, даже в пределах одного языка; системы письма в разных языках сильно различаются; и они ограничены в том, что могут рассказать вам о звуках языка.
Проблема первая: трудно понять, какой звук соответствует какой букве
Многие системы письма затрудняют точное определение звуков слова. Из-за перипетий истории многие системы письма используют одну и ту же букву для обозначения разных звуков и/или разные комбинации букв для обозначения одного и того же звука. Английский язык является ярким примером и печально известен своим привередливым правописанием и запутанными правилами произношения. Но в IPA каждому звуку соответствуют отдельные символы. Обратите также внимание на использование косой черты, чтобы отличить символы IPA от обычных букв:
Буквы одинаковые, звуки разные
| Буква | Символ МФА | Пример слова |
|---|---|---|
| и | /у/ | д и де |
| и | / ʊ / | р у т |
| и | / ʌ / | р у тт |
Одинаковые звуки, разные буквы
| Письмо | Символ МФА | Пример слова |
|---|---|---|
| Шт. | /я/ | b шт. d |
| ее | /я/ | тр ее |
| эй | /я/ | к эй |
| и | /я/ | ч и с |
Это разъяснение является одним из самых больших преимуществ IPA. Например, вам не нужно полагаться на хитрый английский алфавит и путаться в том, какой звук «u» вы имеете в виду: с IPA каждый может использовать одну систему для написания одних и тех же звуков. И, конечно же, при сравнении языков с разными системами письма полезно иметь единую систему, на которую можно ссылаться!
Проблема вторая: не все буквы одинаковы в разных языках
Даже если вы хорошо понимаете систему письма (скажем, латинский алфавит английского языка), ваше понимание звуков и произношения не обязательно будет одинаковым для разных языков. Например, во французском языке буква «j» чаще всего обозначает звук /ʒ/, как в joie (тот же звук в rouge ), но в испанском «j» чаще всего обозначает звук /x. / или /h/, как в ajo (английское произношение будет a- или ). Так что, если вы пытаетесь сравнивать языки и говорить об их звучании, использование одного и того же алфавита может на самом деле вас запутать!
Проблема третья: сложно уместить все детали в одном алфавите
Почти всегда есть исключения, даже в языке, использующем алфавит, где одна буква соответствует только одному звуку. Это связано с тем, что некоторые детали произношения обычно не фиксируются стандартными системами письма. Например, возьмем испанское слово dedo («палец»), что в МФА транскрибируется как [ˈd̪e.ðo]. Эти две буквы «д» могут выглядеть одинаково, когда слово написано «обычными» буквами, но в устах говорящего по-испански они на самом деле разные! Это потому, что когда звук «d» встречается между двумя гласными, но не в ударном слоге, он становится [ð] (что на самом деле является тем же звуком «th», что и в начале английского « th em»).
Однако IPA не является идеальной системой. Это не очень полезно для отображения более тонких аспектов звуков; для этого лингвисты используют более специализированные системы, такие как /spectrograms/(https://australianlinguistics.com/acoustic-analysis-2/spectrograms/). К тому же это не действительно универсальный. Поскольку он был создан западными лингвистами, он основан на латинском алфавите, который используется во многих западноевропейских языках, и поэтому ориентирован на простоту использования людьми, которые уже читают и пишут на языках, использующих этот алфавит.
Как читать диаграмму IPA?
Итак, как мы видели, в каждом языке по-разному используются одни и те же буквы, даже если они кажутся идентичными. Одно из лучших применений IPA в качестве изучающего язык (или актера, или певца!) заключается в том, что он позволяет вам быстро увидеть, как произносятся вещи. Это поддерживает изучение произношения и позволяет быстрее осваивать новое произношение. Вам не нужно изучать весь IPA, чтобы сделать это! Но изучение символов и звуков вашего родного языка, а также того, который вы изучаете, может действительно помочь с точки зрения сравнения, как мы обсуждали ранее, как произносится «d» в испанском и английском языках.
Фактически, IPA представляет 107 различных согласных и гласных, но ни один язык не использует их все! В английском языке используется примерно 44 из этих звуков, в то время как в испанском их сравнительно меньше, всего около 24.
Таблица IPA разбита на несколько подтаблиц. Вверху находятся легочных согласных, означающих согласные, образованные воздухом, вытекающим из ваших легких (включая все согласные, используемые в английском языке). Эта таблица продуманно организована таким образом, чтобы было ясно, как следует произносить каждый звук: крайний левый столбец помечен цифрой 9.0606 способом , в котором согласный произносится (например, если он произносится с жужжащей вибрацией в части рта, это фрикативный звук, такой как /s/ или /z/), а самый верхний ряд помечен место (например, bilabial означает, что звук произносится обеими губами).
Кроме того, звуки перечислены парами: звук справа звонкий , что означает, что голосовые связки вибрируют при его произнесении, а слева (если есть!) не вибрировать, чтобы сделать это. (Ага, это означает, что /s/ и /z/ произносятся одинаково, в одном и том же месте, и единственная разница заключается в их звучании! Произнесите каждое из них, положив руки на шею, чтобы почувствовать голос. складки включаются и выключаются, чтобы почувствовать разницу.)
Затем у вас есть поддиаграмма для гласных IPA. Эта часть диаграммы также разбита таким образом, чтобы показать, где звук издается во рту. В верхней части «высокие» или «близкие» гласные произносятся языком выше во рту (например, /i/ в слове «bead», которое мы видели ранее), в то время как «низкие» или «открытые» гласные (например, /æ/ как в «летучая мышь») произносятся с опущенным языком и шире открытым ртом. Точно так же «передние» гласные произносятся, когда язык ближе к передней части рта, и, как вы уже догадались, «задние» гласные, когда он расположен ближе к задней части рта!
В МФА есть много, много других интересных и важных особенностей, помимо простых согласных и гласных. К ним относятся непульмонические согласные, такие как щелкающие согласные, которые составляют важные части таких языков, как зулу и коса, или отрывочных (согласные, произносимые только с использованием воздуха во рту, быстрым взрывом), встречающиеся в таких языках, как кечуа и аймара. . Три другие важные категории:
- Маркеры тона: они показывают тона, которые различают слова во многих языках, таких как китайский, вьетнамский, панджаби и чероки
- Диакритические знаки: это меньшие знаки, которые предоставляют дополнительную информацию о том, как произносится буква, например, маленькая таблица под первым / d / в испанском языке [ˈd̪e.ðo]
- Надсегментарные знаки: они используются для демонстрации важных аспектов произношения, таких как ударение, где слоги начинаются и заканчиваются, а также длина гласного
Как использовать Международный фонетический алфавит?
Немного информации об IPA помогает понять, как использовать ее для собственного обучения! Помимо полезности для лингвистов, некоторые знания об IPA могут помочь в изучении языка! Это особенно удобно для людей, которые хотят разблокировать свои навыки произношения. Итак, как лучше всего это сделать?
Начните со сравнения символов/звуков вашего родного языка и символов/звуков вашего нового языка. Полезно искать что-то вроде «Таблица IPA для испанского языка» или «IPA на испанском и английском языках», чтобы получить сравнительные ресурсы, такие как этот или этот.
Затем посмотрите, чем отличаются звуки вашего языка от звуков вашего нового языка — какие звуки общие для ваших языков, а какие совершенно новые? Которые немного отличаются, но сделаны похожим образом?
Прочитав о сходствах и различиях, практикуйтесь, практикуйтесь, практикуйтесь! Вашему рту нужна помощь в изучении его новых положений, точно так же, как мышце, когда вы начинаете заниматься новым видом спорта. Эта интерактивная диаграмма IPA — отличный способ услышать отдельные звуки и их различия; этот веб-сайт транскрипции позволяет вам увидеть, как данное слово пишется в IPA на нескольких разных языках; и этот веб-сайт/приложение для английского, испанского и немецкого языков использует IPA вместе с иллюстрациями рта, чтобы четко показать, как происходит произношение.
Приключения IPA не за горами!
Если вы интересуетесь лингвистикой или даже экспериментируете с изобретением собственного сконструированного языка (conlang), то IPA вам просто неоценим. Если вы хотите глубже понять, как звуки работают в разных языках и внутри них, IPA будет вашим лучшим другом! А с таким лучшим другом, как IPA, возможности /ˈɛnd.ləs/.*
*Это «бесконечно» для вас, новички в IPA!
Выберите любое слово на этой странице, чтобы проверить его определение и произношение. в словаре. Нажмите коричневые слова для всплывающего объяснения. | © Томаш П. Синальски, Antimoon.com Эта таблица содержит все звуки (фонемы), используемые в английском языке. Для каждого звука он дает:
Чтобы распечатать диаграмму, используйте версию PDF для печати.
В этой таблице перечислены все звуки, которые можно услышать в британском и американском английском?№ На этой странице представлены символы, используемые в фонетических транскрипциях в современных словарях. для изучающих английский язык. В нем не перечислены все возможные звуки американского или британского английского языка. Например, на этой странице нет списка
обычный т (слышно в этом произношении буква ) и
щиток t (слышен в этом) с отдельными символами.
Он объединяет их под одним символом: Так что на этой странице на самом деле перечислены фонем (групп звуков), а не отдельные звуки . Каждый символ на диаграмме может соответствовать многим
разные (но похожие) звуки в зависимости от слова и акцента говорящего. Возьмите фонему Набор фонетических символовВы не найдете фонетических символов на клавиатуре вашего компьютера. Как их вводить в документе Word, сообщении электронной почты или Сбор СРС?
|