Конспект урока русского языка п теме «Разбор слов по составу» 2 класс УМК «Планета Знаний»
разбор слов по составу.
Закрепление по теме
Цели деятельности учителя: учить выполнять разбор слова по составу; совершенствовать умение работать с памятками по устному и графическому разбору слов, отвечать на вопросы по теме.
Планируемые результаты: личностные: осуществляют самоконтроль при выполнении письменных заданий; метапредметные: регулятивные – научатся следовать рекомендациям памяток при анализе и списывании текстов; получат возможность научиться намечать действия при работе в паре; познавательные – научатся выполнять разбор слова по составу, осуществлять поиск необходимой информации для выполнения учебных заданий, используя справочные материалы учебника; коммуникативные – научатся договариваться и приходить к общему решению, работая в паре; получат возможность научиться задавать вопросы, уточняя непонятное в тексте;
Ход урока
Организационный момент..
− Сегодня будем учиться выполнять анализ (разбор) слова по составу.
Актуализация знаний.
Слово делится на части,
Ах, какое это счастье!
Может каждый грамотней
Сделать слово из частей.
Мы познакомились со всеми частями слова. Итак, внимание!
Какие части слова вы знаете?
-Давайте вспомним, что же такое корень? Что вы о нём знаете?
— А если к слову «корень» подставить «ОК» , стало «корешок».
— Что же такое –ок-?
— Что же такое суффикс?
— Что вы знаете о приставке?
• Игра с приставками.
− Я буду называть вам только приставки, а вы попробуете догадаться, что с ними нужно делать, к какому слову «подключить», ой, нет! – приставить. Представьте себе, что вы сидите перед телевизором. Я вам говорю: «В-!» Что вы сделаете? (Включим телевизор.)
− А если я скажу пере-? (Переключим на другую программу.)
− Теперь представьте, что мы с вами сидим на стульях на некотором расстоянии друг от друга.
− Что вы сделаете, если я скажу подо-? (Пододвинемся к Вам вместе со стульями.)
− А если я скажу ото-? (Тогда отодвинемся.)
− Что заметили, играя в эту игру? (Каждая приставка имеет своё значение.) Именно благодаря этому мы прекрасно понимаем друг друга.
− Составьте слова из рассыпанных частей слов.
По-, нес-, вы-, пере-, шёл.
От-, по-, за-, ехал.
На-, под-, над-, писал.
− Запишите полученные слова. Выделите приставки.
− Что происходит со словом после того, как меняется приставка? (Образуется новое слово с другим значением.)
— Какая часть слова называется изменяемой?
Добавьте окончания к словам, выделите окончания.
Мороз, запах, холод, поход, добр, молод, нёс, вёз.
III. Работа по учебнику.
− Выполните графический анализ слова по составу в упражнении 1. (детёныши (начинает летать).)
− Прочитайте, как можно устно рассказать о составе слова «подводный».
− Прочитайте слова в упражнении 2. В какой строке даны однокоренные слова, а в какой – формы одного и того же слова? (Школа, (у) школы, (к) школе, (в) школу, школой – это формы одного и того же слова.
Школа, пришкольный (участок), школьная (пора) − однокоренные слова.)
− Выпишите слова по схемам.
− Какое слово задумано в упражнении 3? (Подкормка.)
− Запишите слово-отгадку, разделяя его для переноса. Обозначьте значимые части слова.
При переносе старайтесь не отрывать букву от корня.
− Загадайте своё слово таким же образом, как в упражнении 3.
− Приставка – как в слове «подберёзовик».
Суффикс – как в слове «цветник».
Окончание – как в слове «конь».
Слово-отгадка:
− Какие слова в упражнении 5 вызывают улыбку?
− Разберите письменно по составу выделенные слова.
IV. Рефлексия деятельности.
− Что нового узнали на уроке? Назовите части слова.
− Без какой значимой части слово не существует? (Без корня.)
− Какие части слова помогают образовывать однокоренные слова? (Суффикс, приставка.)
Домашнее задание: упражнение 6 (рабочая тетрадь)
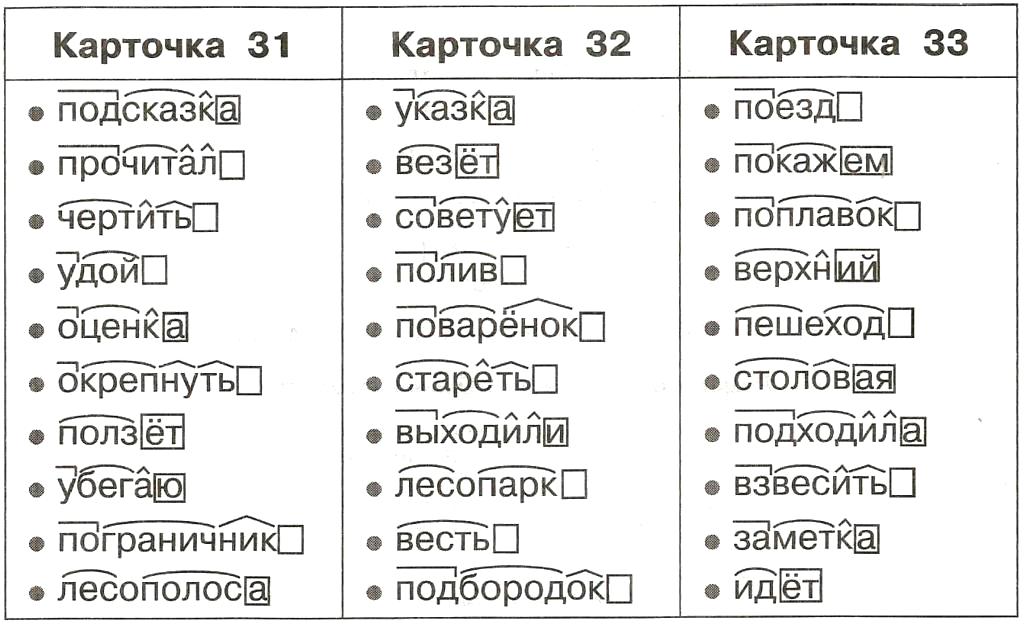
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «пень», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ПЕНЬ, пня, м.
1. Нижняя часть ствола срубленного, спиленного или сломленного дерева вместе с оставшимися в земле корнями и комлем. Корчевать пни. Пни на вырубке. Как п. стоит кто-н. (неподвижно, бессмысленно; разг. неодобр.). Молчит, как п. кто-н. (ничего не говорит; разг. неодобр.).
Корчевать пни. Пни на вырубке. Как п. стоит кто-н. (неподвижно, бессмысленно; разг. неодобр.). Молчит, как п. кто-н. (ничего не говорит; разг. неодобр.).
2. перен. Тупой бесчувственный человек (разг. пренебр.). Разве этот п. может что-н. понять?
• Через пень колоду (разг. неодобр.) кое-как, небрежно, плохо.
В лесу живёт, пню молится кто (разг. ирон.) о тёмном, невежественном человеке.
| уменьш.
| прил. пенёчный, ая, ое (к 1 знач.) и пнёвый, ая, ое (к 1 знач.).
Фонетический (звуко-буквенный) разбор
Пе́нь
Пень — слово из 1 слога: Пень. Ударение ставится однозначно на единственную гласную в слове.
Транскрипция слова: [п’эн’]
п — [п’] — согласный, глухой парный, мягкий (парный)
е — [э] — гласный, ударный
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
ь — не обозначает звука
В слове 4 буквы и 3 звука.
Цветовая схема: пень
Разбор слова «пень» по составу
пень
Части слова «пень»: пень
Состав слова:
пень — корень,
нулевое окончание,
пень — основа слова.
разбор слова по составу и словообразовательный разбор выход, опилки, вырасти, наконечник,
Найти все обособления в тексте и обозначить их
Акимов, опытный охотник, пробирался по кустарнику. Берег снова вздымался вверх, и начиналось редколесь
… е: ель, сосна, береза.
Увидев внизу землянку, Акимов направился к ней. Окруженная слева и справа желтыми зарослями осоки, она приютилась у берега, возле самой воды.
Он раскрыл дверь, и на него пахнуло копченой рыбой, нежным ароматом скошенного сена.
синквейн на слова венера
спишите расставляя недостающие знаки препинания вставляя пропущенные буквы укажите условия обособления приложений-
1. Составьте из группы предложений текст. Определите смысловые отношении между ними и расставьте их в нужной последовательности. Как вы будете искать … первое предложение?
1.С какими частями речи(с существительными и с прилагательными) можно соотнести перечисленные местоимения? никакой ,ничто, что-нибудь ,мой, тот, его(с … обака), она. 2.Устно определи разряды местоимений и в каждой строке найди лишнее слово. а) никто(не явился), некого(обвинять), нечего ( делать), некто(в шапочке). б)твой (учебник), себя (не узнал), свой (человек), мой (бегемот). в) кое-кто (напакостил), нечто (ужасное), ничто (не помешает), кто-нибудь (поможет). г) такой (вот случай), каждый (пятиклассник), любой (крокодил), (приготовил) сам.
помогите пожалуйста соедини слова в пары Составь и запиши с ними предложения Добавь второстепенные члены небо туча дождь капельки забарабанили начал … ся надвинулась потемнело подчеркни грамматическую основу предложения
выпишите раскрывая скобки вставляя пропущенные буквы в которых выделенные слова являются предлогами 1. я находилась у дедушки (в) продолжени..всего ле
… та 2. читатели заинтересованы (в) продолжени…рассказа 3. обнаружились важные детали (в) следстви…об аварии 4.(Не)смотря на трудности, поход завершился удачно
я даю 25 баллов
обнаружились важные детали (в) следстви…об аварии 4.(Не)смотря на трудности, поход завершился удачно
я даю 25 баллов
текста. Какие слова, по-вашему, если основную смысловую нагрузку?354. Прочитайте. Какова основная мысль текста? Озаглавьте его. Определите стильУ кажд … ого времени года своя музыка.Снег померк. Весёлой струйкой с…ребряные шарики торопливо скаты-вают…ся с крыш. Мелодично поёт, звонко Тикает к…пель. Тихо пер…звани-ваются б…ющиеся сосульки и вдребезги разбивают…ся, точно оброненныйхрусталь. А в кустах слышит…ся частый звон серебр…ного колокольчика. Этозаливают…СЯ Овсянки.Солнечный луч всюду з…водит тихую музыку весны, а птицы и водапо…певают ей.По Д. Зуеву• Спишите текст, вставьте пропущенные буквы.Найдите в тексте 1) простое нераспространённое предложение, 2) сложноесоюзное предложение. Укажите в них основы.
Умение играть на инструменте помогает вам ценить музыку? ЭССЕ
Выпишите словосочетания и найдите главное слово. Весною мы пошли в лес. Взошло солнце. Подул лёгкий ветерок. Все деревья в лесу запели. У каждого дере … ва была своя песня. Нежно пела берёза. Свою мужественную песню пел дуб. Задумчиво напевала верба. Кудрявая рябина пела тревожно. Её песня навевала мысли о бурной грозе в тёмную ночь.
Репетитор по русскому
Сочинение ЕГЭ 2016 по русскому языку — это задание повышенной сложности, поэтому необходимо очень внимательно отнестись к его выполнению, а значит, и к подготовке.
В данной статье я попытаюсь подробно разобрать план сочинения и особенности его написания. Независимо от содержания текста, лучше всего пользоваться следующим планом, составленным на основе критериев оценивания:
1) Формулировка проблемы
2) Комментарий к проблеме
3) Позиция автора по выбранной проблеме
4) Собственное мнение (согласие или несогласие)
5) Доказательство своего мнения (включая не менее 2-х аргументов)
Для гармоничности изложения и композиционной целостности желательно включить в свою работу вступление и заключение (но это не обязательно).
К1. Формулировка проблемы
Проблема текста — это предмет обсуждения, вопрос, над которым рассуждает автор.
Как правило, исходный текст включает не менее 2-3 тем, каждая из которых может стать основой вашей работы. Выбор должен определяться ответом на два вопроса:
1) Какая проблема находится в центре внимания автора?
2) К какой проблеме вам легче подобрать аргументы?
Как определить проблему?
При выявлении проблемы текста можно использовать следующий способ:
- Сформулируйте основную мысль автора в виде законченного предложения.
- Подумайте, на какой вопрос отвечает это предложение.
Разберем на примере:
Прочитав текст несколько раз я выделяю две проблемы:
1) проблема духовного существования человека в современном мире
2) проблема снижения интереса к чтению в XXI веке
Я выбираю вторую. На основе собственного впечатления от прочитанного текста я составил вступление, а проблему сформулировал в виде вопроса:
Вспоминаю, как в детстве просил родителей прочитать сказку. Они читали. Я вырос, давно уже читаю сам, как «бумажные» книги, так и электронные. Но все чаще вижу нарастающее равнодушие к чтению и литературе в целом.
Неужели книга перестала играть в жизни общества и человека привычную для нее роль? Над этой проблемой размышляет И. Косолапов.
В качестве вступления можно было привести статистику:
Согласно официальной статистике Всероссийского центра изучения общественного мнения, треть россиян не хранит дома книг, другая треть, имея книги, их не читает.
К2. Комментарий к проблеме
Комментарий — это пояснение, толкование выбранной проблемы. Комментарий помогает более детально охарактеризовать проблему, а также, показать как автор подходит к её раскрытию. При написании сочинения комментарий служит связующим звеном между проблемой и позицией автора. Главное требование к комментарию — опора на текст.
При написании сочинения комментарий служит связующим звеном между проблемой и позицией автора. Главное требование к комментарию — опора на текст.
Следующие вопросы могут послужить основой для комментария к проблеме:
Как автор относится к предмету описания?
Какие аргументы приводит автор?
На каких примерах автор раскрывает проблему? Какими событиями иллюстрирует её?
Как относится автор к предмету описания (герою)?
Насколько проблема волнует автора?
В чем сущность данной проблемы?
Какова актуальность проблемы? Насколько она значима?
Использует ли автор противопоставление? Если да, то что противопоставляет?
Комментируем нашу проблему:
Рассуждая о судьбе книги в XXI веке, автор противопоставляет книгу и достижения технического прогресса. При этом автор сталкивает мнения разных поколений: Л.Леонова, который назвал книгу «бескорыстным верным другом», и молодого программиста, определившего книгу как «кипу пыльной бумаги». И. Косолапов рассуждает о преимуществах и недостатках техники перед книгой, и находит вторую более предпочтительной и полезной.
К3. Авторская позиция
Авторская позиция — это ответ на вопрос обозначенный в проблеме.
Авторская позиция является итогом размышления, выводом к которому автор приходит (в рамках выбранной проблемы). Авторская позиция может выражаться прямо (в отдельных предложениях, обращениях к читателю) либо косвенно (в поступках героев, художественных деталях).
Автор убеждает нас в том, что книга нисколько не потеряла своей ценности, а технические достижения не смогут и не должны заменить её. Книга несет очень важную образовательную функцию, она учит и воспитывает человека. Техника и компьютеры призваны облегчать нашу повседневность, делать её более комфортной, но они не должны занимать собой всю нашу жизнь.
К4. Аргументация экзаменуемым собственного мнения по проблеме
В первую очередь нам необходимо выразить своё мнение, соглашаясь или не соглашаясь с мнением автора.
Моё мнение:
Я полностью разделяю мнение И.Косолапова о том, что книга в наше время незаслуженно забыта, хотя значение её по-прежнему велико. Я думаю, что в наш информационный век постоянное использование компьютеров и разнообразных гаджетов приведет к деградации общества, вырождению человеческой мысли.
Структура аргумента
Для получения максимального количества баллов нам необходимо привести не менее 2-х аргументов (один из которых опирается на художественную, научную, публицистическую литературу). Приведенный пример должен выступать как яркий микротекст и доказывать нашу позицию.
Моя аргументация:
1. К подобным неутешительным выводам приходили и фантасты ХХ века (логический переход). Один из которых, Рей Брэдбери, в своей антиутопии «451 градус по Фаренгейту» описывает потребительское общество, опирающееся на массовую культуру. В этом социуме люди окружили себя материальными ценностями, телевидением и развлечениями. Книги, в свою очередь, строго запрещены и подлежат сожжению, дабы ни одна критическая мысль не попала в человеческое сознание (аргумент). Когда я вижу, как люди тратят свое время на телевидение и социальные сети, я понимаю, о чем предупреждал нас Р.Брэдбери. Важная задача стоит перед нами, с помощью книг сохранить связь с интеллектуальным наследием человечества (микровывод).
2. Насколько высока может быть роль книг в духовном становлении личности мы можем узнать в произведениях М.Горького: «Детство», «В людях», «Мои университеты». Герой повестей Алеша Пешков считает, что именно книги помогли ему преодолеть тяжелые жизненные испытания.
Как видите, я привожу два примера из художественной литературы. В качестве аргумента также можно использовать: ссылки на кинофильм, спектакль, исторические события, официальную статистику, высказывания известных людей и примеры из личного опыта.
Аргументируя свою позицию, я использую «аргумент к угрозе»(доказывая негативные последствия игнорирования тезиса привожу антиутопию Р.Брэдбери) и «аргумент к обещанию» (на примере Пешкова показываю как важны книги).
Заключение
Заключение должно подводить итог нашим размышлениям по проблеме.
В своем заключении я сначала использую обращение, а потом обобщаю проблему, указываю на её глобальную важность.
Хочется обратиться к современникам: друзья, погружаться в художественные миры гораздо интереснее и полезнее, чем блуждать в интернет-паутине! Помните, что культура развивается в первую очередь за счет сохранения мудрости предыдущих поколений, хранящейся в книгах.
Надеюсь материал был Вам полезен.
5 класс. Русский язык. Способы словообразования — Состав слова.
Комментарии преподавателя1. Морфемика – это раздел языкознания, в котором изучается система морфем языка и морфемная структура слов.
Морфема – это минимальная значимая часть слова.
Морфемы: корень, суффикс, приставка, окончание.
Рис. 1. Морфемы.
2.Корень – это обязательная часть слова.
Только из корня состоят служебные слова (но, для, если), междометия (ах, алло), многие наречия (очень, весьма), неизменяемые существительные (алоэ, кенгуру) и прилагательные (беж, макси).
Корни, которые могут употребляться только в сочетании с приставками или суффиксами, называются связанными (об-у-ть, раз-у-ть; о-де-ть, раз-де-ть).
3.Приставка — словообразовательная морфема, стоящая перед корнем или другой приставкой (пере-делать, пре-хорошенький, при-морье, кое-где, пере—о-деть).
Рис.2. Приставка.
4.Суффикс — словообразовательная морфема, стоящая после корня (стол-ик, красн-е-ть).
Рис. 3. Суффикс.
В лингвистике наряду с суффиксом выделяют также постфикс — словообразовательную морфему, стоящую после окончания или формообразующего суффикса (умы-ть-ся, к-ого-либо).
5.Окончание — формообразующая морфема, выражающая грамматические значения рода, лица, числа и падежа (хотя бы одно из них!) и служащая для связи слов в словосочетании и предложении,
Окончание есть только у изменяемых слов. Нет окончаний у служебных слов, наречий, неизменяемых существительных и прилагательных, деепричастий, инфинитива.
У некоторых сложных существительных и числительных несколько окончаний.
Сравните: тр-и-ст-а, тр-ех-сот-□, диван□-кровать□, диван-а-кроват-и.
Нулевая морфема – это значимое отсутствие морфемы.
Стола – Р.п.
Стол□ – И.п. или В.п.
Нулевой суффикс мы выделяем, например, в форме прошедшего времени нёс (сравните: нес-л-а) или форме повелительного наклонения читай.
План морфемного разбора слова:
1. Выделяем окончание и основу слова.
2. Выделяем корень слова, подбирая однокоренные слова.
3. Выделяем приставки и суффиксы.
Образец морфемного разбора:
Двухэтажный (окончания –ух, -ый, основа … (такая основа называется прерывистой), корни дв-, этаж-, суффикс –н-).
Переулок (окончание нулевое, основа переулок, корень –ул-, приставка пере-, суффикс –ок).
Словообразование – это процесс образования производных слов и раздел языкознания, изучающий этот процесс.
Способы словообразования:
Приставочный: делать – переделать
Суффиксальный: синий – синенький
Приставочно-суффиксальный: стакан – подстаканник
Усечение: заместитель – зам
Сложение: лес+степь – лесостепь
Сращение: вечнозеленый
Аббревиация: Московский государственный университет – МГУ, сберегательный банк – сбербанк
Субстантивация (переход прилагательного или причастия в существительное): столовая
Смешанные способы словообразования: орден+носить = орденоносец (сложение и суффиксация)
План словообразовательного разбора слова:
1. Поставить слово в начальную форму.
2. Определить слово, от которого оно образовано. Например, обновление – обновить (а не новый).
3. Объяснить значение исследуемого слова через значение слова, от которого оно образовано (например, слушатель – тот, кто слушает).
4. Выделить основу, от которой образовано исследуемое слово.
5. Указать средство словообразования.
6. Указать способ словообразования.
Образец словообразовательного разбора:
1. Под-окон-ник – окно
Основа окн-
Средства словообразования: приставка под- и суффикс –ник. Способ словообразования: приставочно-суффиксальный
2. Мир(о)твор-ец – мир+творить
Основы, от которых образовано слово, — мир- и твор-
Средства словообразования: сложение основ и суффикс –ец.
Способ словообразования: сложение и суффиксация
10. Домашнее задание
Домашнее задание
Упражнения №
Задание №1. Даны слова: петь, учить, одеть, знал, столик, верхом, рано, волчонок, новее, ворча. Для каких слов из перечисленных годится следующий морфемный разбор:?
Задание №2. Даны слова: обучить, приходила, узнали, подоконник, треугольник, встряска, настольный, излишне, снова. Для каких слов из перечисленных годится следующий морфемный разбор:
ИСТОЧНИКИ
http://www.youtube.com/watch?v=AeX6EALboR8
http://doc4web.ru/russkiy-yazik/konspekt-uroka-dlya-klassa-sostav-slova-i-slovoobrazovanie.html
http://nsportal.ru/shkola/russkiy-yazyk/library/2014/10/28/konspekt-uroka-sostav-slova-5-klass
http://nsportal.ru/shkola/russkiy-yazyk/library/2012/12/01/konspekt-uroka-russkogo-yazyka-v-5-klasse-po-temezakreplenie
| 1 | «В начале было Слово…» | история | история | 2 |
| литература | литература | 3 | ||
| 2 | «Наследники Левши» | физика | физика | 3 |
| 3 | XIII Южно-Российская межрегиональная олимпиада школьников «Архитектура и искусство» по комплексу предметов (рисунок, живопись, композиция, черчение) | искусство, черчение | рисунок, живопись, композиция, черчение | 2 |
| 4 | Всероссийская олимпиада по финансовой грамотности, финансовому рынку и защите прав потребителей финансовых услуг | финансовая грамотность | экономика | 3 |
| 5 | Всероссийская олимпиада учащихся музыкальных колледжей | хоровое дирижирование | дирижирование (дирижирование академическим хором) | 2 |
| инструменты народного оркестра | искусство концертного исполнительства (концертные народные инструменты) | 2 | ||
| струнные инструменты | искусство концертного исполнительства (концертные струнные инструменты) | 3 | ||
| теория и история музыки | музыковедение, музыкознание и музыкально-прикладное искусство (музыкальная журналистика и редакторская деятельность в средствах массовой информации) | 2 | ||
| музыкальная педагогика и исполнительство | музыкознание и музыкально-прикладное искусство (музыкальная педагогика) | 3 | ||
| 6 | Всероссийская олимпиада школьников «Высшая проба» | биология | биология | 2 |
| востоковедение | востоковедение и африканистика | 2 | ||
| дизайн | дизайн | 1 | ||
| журналистика | журналистика | 1 | ||
| иностранный язык | иностранный язык | 1 | ||
| восточные языки | иностранный язык | 2 | ||
| электроника и вычислительная техника | инфокоммуникационные технологии и системы связи, информатика и вычислительная техника | 2 | ||
| информатика | информатика | 1 | ||
| история | история | 1 | ||
| история мировых цивилизаций | история | 2 | ||
| культурология | культурология | 1 | ||
| математика | математика | 1 | ||
| основы бизнеса | менеджмент, государственное и муниципальное управление | 3 | ||
| обществознание | обществознание | 1 | ||
| политология | политология, обществознание | 1 | ||
| право | право | 1 | ||
| психология | психология | 2 | ||
| русский язык | русский язык | 1 | ||
| социология | социология, обществознание | 1 | ||
| физика | физика | 3 | ||
| филология | филология, литература | 1 | ||
| философия | философия, обществознание | 1 | ||
| химия | химия | 2 | ||
| экономика | экономика | 1 | ||
| финансовая грамотность | экономика | 2 | ||
| 7 | Всероссийская олимпиада школьников «Миссия выполнима. Твое призвание-финансист!» Твое призвание-финансист!» | история | история | 3 |
| математика | математика | 3 | ||
| обществознание | обществознание | 3 | ||
| экономика | экономика | 3 | ||
| 8 | Всероссийская олимпиада школьников «Нанотехнологии — прорыв в будущее!» | нанотехнологии | химия, физика, математика, биология | 1 |
| 9 | Всероссийская Сеченовская олимпиада школьников | биология | биология | 3 |
| 10 | Всероссийская Толстовская олимпиада школьников | история | история | 2 |
| обществознание | обществознание | 3 | ||
| литература | педобразование профиль «русский язык и литература», филология профиль «отечественная филология» | 3 | ||
| 11 | Всероссийская экономическая олимпиада школьников имени Н.Д. Кондратьева | экономика | экономика | 1 |
| 12 | Всероссийский конкурс научных работ школьников «Юниор» | инженерные науки | естественные науки, инженерные науки, приборостроение, ядерная энергетика и технологии, физико-технические науки и технологии, технологии материалов, нанотехнологии и наноматериалы, мехатроника и робототехника | 3 |
| естественные науки | естественные науки, промышленная экология и биотехнологии, экология и природопользование | 2 | ||
| 13 | Всесибирская открытая олимпиада школьников | астрономия | астрономия | 3 |
| биология | биология | 2 | ||
| информатика | информатика | 1 | ||
| математика | математика | 2 | ||
| физика | физика | 2 | ||
| химия | химия | 1 | ||
| 14 | Вузовско-академическая олимпиада по программированию на Урале | программирование | информатика | 3 |
| 15 | Герценовская олимпиада школьников | география | география | 2 |
| иностранные языки | иностранные языки | 2 | ||
| 16 | Городская открытая олимпиада школьников по физике | физика | физика | 2 |
| 17 | Государственный аудит | обществознание | обществознание | 2 |
| 18 | Инженерная олимпиада школьников | физика | физика | 2 |
| 19 | Интернет-олимпиада школьников по физике | физика | физика | 2 |
| 20 | Кутафинская олимпиада школьников по праву | право | право | 2 |
| 21 | Межвузовская олимпиада школьников «Первый успех» | педагогические науки и образование | педагогическое образование, психолого-педагогическое образование, педагогическое образование (с двумя профилями подготовки), специальное (дефектологическое) образование | 2 |
| 22 | Междисциплинарная олимпиада школьников имени В. И. Вернадского И. Вернадского | гуманитарные и социальные науки | история, обществознание | 1 |
| 23 | Международная олимпиада школьников «Искусство графики» | рисунок | графика, дизайн | 2 |
| графический дизайн | дизайн | 2 | ||
| 24 | Межрегиональная олимпиада по праву «ФЕМИДА» | право | обществознание | 2 |
| 25 | Межрегиональная олимпиада школьников «САММАТ» | математика | 01.03.00 математика и механика, 02.03.00 компьютерные и информационные науки, 09.03.00 информатика и вычислительная техника, 10.03.00 информационная безопасность | 3 |
| 26 | Межрегиональная олимпиада школьников «Архитектура и искусство» по комплексу предметов (рисунок, композиция) | искусство | рисунок, композиция | 2 |
| 27 | Межрегиональная олимпиада школьников «Будущие исследователи — будущее науки» | биология | биология | 2 |
| история | история | 2 | ||
| математика | математика | 3 | ||
| русский язык | русский язык | 2 | ||
| физика | физика | 3 | ||
| химия | химия | 2 | ||
| 28 | Межрегиональная олимпиада школьников «Евразийская лингвистическая олимпиада» | иностранный язык | иностранный язык | 2 |
| 29 | Межрегиональная олимпиада школьников им. В.Е.Татлина | рисунок | искусство | 2 |
| композиция | искусство | 2 | ||
| графика | искусство | 2 | ||
| 30 | Межрегиональная олимпиада школьников им. И.Я. Верченко И.Я. Верченко | компьютерная безопасность | информационная безопасность | 3 |
| математика | математика, криптография | 2 | ||
| 31 | Межрегиональная олимпиада школьников на базе ведомственных образовательных организаций | иностранный язык | иностранный язык | 3 |
| математика | математика | 2 | ||
| обществознание | обществознание | 3 | ||
| физика | физика | 3 | ||
| 32 | Межрегиональная отраслевая олимпиада школьников «Паруса надежды» | математика | математика | 3 |
| техника и технологии | техника и технологии строительства, информационная безопасность, электро- и теплоэнергетика, машиностроение, техносферная безопасность и природообустройство, техника и технологии наземного транспорта, управление в технических системах, экономика и управление, сервис и туризм | 3 | ||
| 33 | Межрегиональные предметные олимпиады федерального государственного автономного образовательного учреждения высшего образования «Казанский (Приволжский) федеральный университет» | иностранный язык | иностранный язык | 2 |
| физика | физика | 3 | ||
| химия | химия | 2 | ||
| 34 | Межрегиональный экономический фестиваль школьников «Сибириада. Шаг в мечту» | экономика | экономика, обществознание | 2 |
| 35 | Многопредметная олимпиада «Юные таланты» | география | география | 1 |
| геология | геология | 3 | ||
| химия | химия | 1 | ||
| 36 | Многопрофильная инженерная олимпиада «Звезда» | естественные науки | компьютерные и информационные науки, биологические науки, архитектура, техника и технологии строительства, информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, электро- и теплоэнергетика, ядерная энергетика и технологии, машиностроение, оружие и системы вооружения, химические технологии, промышленная экология и биотехнологии, техносферная безопасность и природообустройство, прикладная геология, горное дело, нефтегазовое дело и геодезия, технологии материалов, техника и технологии наземного транспорта, авиационная и ракетно-космическая техника, аэронавигация и эксплуатация авиационной и ракетно-космической техники, техника и технологии кораблестроения и водного транспорта, управление в технических системах, нанотехнологии и наноматериалы, технологии легкой промышленности, сельское, лесное и рыбное хозяйство, экономика и управление | 3 |
| техника и технологии | технологии материалов, машиностроение, электроэнергетика, авиационная и ракетно-космическая техника, техника и технологии наземного транспорта, техника и технологии кораблестроения и водного транспорта | 2 | ||
| 37 | Многопрофильная олимпиада школьников Уральского федерального университета «Изумруд» | история | история | 3 |
| математика | математика | 3 | ||
| обществознание | обществознание | 3 | ||
| политология | обществознание | 3 | ||
| социология | обществознание | 3 | ||
| русский язык | русский язык | 3 | ||
| физика | физика | 3 | ||
| 38 | Московская олимпиада школьников | астрономия | астрономия | 1 |
| генетика | биология, математика | 3 | ||
| география | география | 1 | ||
| информатика | информатика | 1 | ||
| история искусств | искусство | 1 | ||
| изобразительное искусство | искусство | 2 | ||
| история | история | 2 | ||
| математика | математика | 1 | ||
| робототехника | математика, информатика | 3 | ||
| обществознание | обществознание | 2 | ||
| право | право | 2 | ||
| лингвистика | русский язык, иностранный язык | 1 | ||
| филология | русский язык, литература, филология | 2 | ||
| физика | физика | 1 | ||
| предпрофессиональная | физика, информатика, химия | 3 | ||
| химия | химия | 1 | ||
| экономика | экономика | 2 | ||
| финансовая грамотность | экономика | 3 | ||
| 39 | Общероссийская олимпиада школьников «Основы православной культуры» | основы православной культуры | теология, история | 2 |
| 40 | Объединённая межвузовская математическая олимпиада школьников | математика | математика | 2 |
| 41 | Объединённая международная математическая олимпиада «Формула Единства» / «Третье тысячелетие» | математика | математика | 2 |
| физика | физика | 3 | ||
| 42 | Океан знаний | история | история | 3 |
| обществознание | обществознание | 3 | ||
| русский язык | русский язык | 3 | ||
| 43 | Олимпиада Кружкового движения Национальной технологической инициативы | программная инженерия финансовых технологий | информатика и вычислительная техника, информационная безопасность, компьютерные и информационные науки | 3 |
| умный город | информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, электро — и теплоэнергетика, электроника и автоматика физических установок, техносферная безопасность и природообустройство, технологии материалов, управление в технических системах, компьютерные и информационные науки | 3 | ||
| большие данные и машинное обучение | информатика и вычислительная техника, компьютерные и информационные науки | 2 | ||
| аэрокосмические системы | информатика и вычислительная техника, электроника, радиотехника и системы связи, прикладная математика и информатика, мехатроника и робототехника, управление в технических системах | 3 | ||
| интеллектуальные робототехнические системы | информатика и вычислительная техника, электроника, радиотехника и системы связи, управление в технических системах, компьютерные и информационные науки | 1 | ||
| беспилотные авиационные системы | информатика и вычислительная техника, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, авиационная и ракетно-космическая техника, аэронавигация и эксплуатация авиационной и ракетно-космической техники, управление в технических системах | 2 | ||
| технологии беспроводной связи | компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи, управление в технических системах | 2 | ||
| интеллектуальные энергетические системы | компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи, электро — и теплоэнергетика, управление в технических системах | 3 | ||
| искусственный интеллект | математика и механика, компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность | 3 | ||
| информационная безопасность | математика и механика, компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи | 3 | ||
| автоматизация бизнес-процессов | математика и механика, компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи, автоматизация технологических процессов и производств, управление в технических системах, экономика и управление | 2 | ||
| композитные технологии | машиностроение, нанотехнологии и наноматериалы, материаловедение и технологии материалов, ракетные комплексы и космонавтика, наноинженерия | 3 | ||
| инженерные биологические системы: агробиотехнологии | науки о земле, биологические науки, фотоника, приборостроение, оптические и биотехнические системы и технологии, электро- и теплоэнергетика, машиностроение, химические технологии, промышленная экология и биотехнологии, техносферная безопасность и природообустройство, сельское, лесное и рыбное хозяйство | 3 | ||
| анализ космических снимков и геопространственных данных | науки о земле, информатика и вычислительная техника, природообустройство и водопользование, прикладная геология, горное дело, нефтегазовое дело и геодезия, водные пути, порты и гидротехнические сооружения, управление водным транспортом и гидрографическое обеспечение судоходства, сельское, лесное и рыбное хозяйство, экономика, государственное и муниципальное управление, бизнес-информатика, зарубежное регионоведение, регионоведение россии, востоковедение и африканистика, туризм | 3 | ||
| водные робототехнические системы | приборостроение, информатика и вычислительная техника, электроника, радиотехника и системы связи, мехатроника и робототехника, управление в технических системах, кораблестроение, океанотехника и системотехника объектов морской инфраструктуры | 2 | ||
| нейротехнологии и когнитивные науки | прикладная математика и информатика, математическое обеспечение и администрирование информационных систем, прикладная информатика, фотоника, приборостроение, оптические и биотехнические системы и технологии, управление в технических системах, психология | 2 | ||
| передовые производственные технологии | прикладная математика и информатика, механика и математическое моделирование, прикладная математика и информатика, математика и компьютерные науки, информатика и вычислительная техника, информационные системы и технологии, программная инженерия, автоматизация технологических процессов и производств, конструкторско-технологическое обеспечение машиностроительных производств, мехатроника и робототехника | 2 | ||
| спутниковые системы | физика и астрономия, информатика и вычислительная техника, электроника, радиотехника и системы связи, физико-технические науки и технологии, авиационная и ракетно-космическая техника, аэронавигация и эксплуатация авиационной и ракетно-космической техники, управление в технических системах | 3 | ||
| наносистемы и наноинженерия | физика и астрономия, химия, биологические науки, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, химические технологии, технологии материалов, нанотехнологии и наноматериалы | 2 | ||
| автономные транспортные системы | фундаментальная информатика и информационные технологии, информатика и вычислительная техника, машиностроение, системы управления движением и навигация, аэронавигация и эксплуатация авиационной и ракетно-космической техники, управление в технических системах | 3 | ||
| летающая робототехника | фундаментальная информатика и информационные технологии, информатика и вычислительная техника, электроника, радиотехника и системы связи, системы управления движением и навигация, аэронавигация и эксплуатация авиационной и ракетно-космической техники, управление в технических системах | 3 | ||
| геномное редактирование | экология и природопользование, биологические науки, химические технологии, промышленная экология и биотехнологии, техносферная безопасность и природообустройство, наноинженерия, агроинженерия, ветеринария и зоотехния | 3 | ||
| 44 | Олимпиада Курчатов | математика | математика | 2 |
| физика | физика | 2 | ||
| 45 | Олимпиада МГИМО МИД России для школьников | гуманитарные и социальные науки | история, обществознание | 2 |
| 46 | Олимпиада по комплексу предметов «Культура и искусство» | технический рисунок и декоративная композиция | декоративно-прикладное искусство и народные промыслы, технология художественной обработки материалов, искусство костюма и текстиля, конструирование изделий легкой промышленности, технологии и проектирование текстильных изделий, технология изделий легкой промышленности, информационные системы и технологии, технология полиграфического и упаковочного производства, прикладная информатика, профессиональное обучение | 1 |
| академический рисунок, живопись, композиция, история искусства и культуры | дизайн, графика, монументально-декоративное искусство, декоративно-прикладное искусство и народные промыслы, технология художественной обработки материалов, искусство костюма и текстиля, конструирование изделий легкой промышленности, технологии и проектирование текстильных изделий, технология изделий легкой промышленности, информационные системы и технологии, технология полиграфического и упаковочного производства, прикладная информатика, профессиональное обучение (по отраслям) | 1 | ||
| 47 | Олимпиада РГГУ для школьников | иностранный язык | иностранный язык | 2 |
| история | история | 2 | ||
| литература | литература | 2 | ||
| русский язык | русский язык | 2 | ||
| 48 | Олимпиада Университета Иннополис «Innopolis Open» | информатика | информатика | 2 |
| математика | математика | 3 | ||
| 49 | Олимпиада школьников «Гранит науки» | информатика | компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность, машиностроение, управление в технических системах, экономика и управление | 3 |
| естественные науки | науки о земле, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, электро- и теплоэнергетика, машиностроение, техносферная безопасность и природоустройство, прикладная геология, горное дело, нефтегазовое дело и геодезия, техника и технологии наземного транспорта | 3 | ||
| химия | химия, науки о земле, биологические науки, химические технологии, промышленная экология и биотехнологии, технологии материалов | 2 | ||
| 50 | Олимпиада школьников «Ломоносов» | биология | биология | 1 |
| география | география | 1 | ||
| геология | геология | 1 | ||
| журналистика | журналистика | 1 | ||
| иностранный язык | иностранный язык | 1 | ||
| информатика | информатика | 1 | ||
| политология | история | 2 | ||
| международные отношения и глобалистика | история | 1 | ||
| история | история | 1 | ||
| история российской государственности | история | 1 | ||
| литература | литература | 1 | ||
| математика | математика | 1 | ||
| философия | обществознание | 1 | ||
| обществознание | обществознание | 1 | ||
| экология | почвоведение, экология и природопользование | 2 | ||
| психология | психология | 1 | ||
| русский язык | русский язык | 1 | ||
| физика | физика | 2 | ||
| инженерные науки | фундаментальная и прикладная химия, прикладные математика и физика | 3 | ||
| космонавтика | фундаментальная математика и механика | 2 | ||
| механика и математическое моделирование | фундаментальные математика и механика | 3 | ||
| робототехника | фундаментальные математика и механика, мехатроника и робототехника, фундаментальная информатика и информационные технологии | 3 | ||
| химия | химия | 1 | ||
| право | юриспруденция | 1 | ||
| 51 | Олимпиада школьников «Надежда энергетики» | информатика | информатика | 3 |
| физика | физика | 3 | ||
| комплекс предметов (физика, информатика, математика) | физика, информатика, математика | 3 | ||
| 52 | Олимпиада школьников «Покори Воробьёвы горы!» | биология | биология | 1 |
| география | география | 2 | ||
| журналистика | журналистика | 1 | ||
| иностранный язык | иностранный язык | 1 | ||
| история | история | 2 | ||
| литература | литература | 1 | ||
| математика | математика | 1 | ||
| обществознание | обществознание | 1 | ||
| физика | физика | 1 | ||
| 53 | Олимпиада школьников «Робофест» | физика | физика | 2 |
| 54 | Олимпиада школьников «Физтех» | биология | биология | 3 |
| математика | математика | 2 | ||
| физика | физика | 1 | ||
| 55 | Олимпиада школьников «Шаг в будущее» | программирование | информатика и вычислительная техника | 2 |
| математика | математика | 3 | ||
| инженерное дело | математика и механика, компьютерные и информационные науки, информатика и вычислительная техника, информационная безопасность, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, электро- и теплоэнергетика, ядерная энергетика и технологии, машиностроение, физико-технические науки и технологии, оружие и системы вооружения, техносферная безопасность и природоустройство, технологии материалов, техника и технологии наземного транспорта, авиационная и ракетно-космическая техника, управление в технических системах, нанотехнологии и наноматериалы | 2 | ||
| компьютерное моделирование и графика | математика и механика, компьютерные и информационные науки, информатика и вычислительная техника, электроника, радиотехника и системы связи, фотоника, приборостроение, оптические и биотехнические системы и технологии, электро- и теплоэнергетика, ядерная энергетика и технологии, машиностроение, физико-технические науки и технологии, оружие и системы вооружения, техносферная безопасность и природоустройство, технологии материалов, техника и технологии наземного транспорта, авиационная и ракетно-космическая техника, управление в технических системах, нанотехнологии и наноматериалы | 3 | ||
| физика | физика | 2 | ||
| 56 | Олимпиада школьников по информатике и программированию | информатика | информатика | 1 |
| 57 | Олимпиада школьников по программированию «ТехноКубок» | информатика | информатика и икт | 1 |
| 58 | Олимпиада Российской академии народного хозяйства и государственной службы при Президенте Российской Федерации | иностранный язык | английский язык | 2 |
| журналистика | журналистика | 2 | ||
| история | история | 2 | ||
| иностранный язык | китайский язык | 2 | ||
| обществознание | обществознание | 2 | ||
| политология | политология | 2 | ||
| экономика | экономика, математика | 3 | ||
| 59 | Олимпиада школьников Санкт-Петербургского государственного университета | биология | биология | 1 |
| география | география | 1 | ||
| журналистика | журналистика | 1 | ||
| китайский язык | иностранный язык | 2 | ||
| иностранный язык | иностранный язык | 1 | ||
| филология | иностранный язык, литература, русский язык | 1 | ||
| информатика | информатика | 1 | ||
| история | история | 1 | ||
| медицина | лечебное дело, стоматология, психология, клиническая психология, психология служебной деятельности | 1 | ||
| математика | математика | 1 | ||
| обществознание | обществознание | 1 | ||
| социология | обществознание, история | 1 | ||
| право | право | 1 | ||
| инженерные системы | прикладная математика и информатика, механика и математическое моделирование, прикладные математика и физика, радиофизика, системный анализ и управление, химия, физика и механика материалов | 3 | ||
| физика | физика | 2 | ||
| химия | химия | 1 | ||
| экономика | экономика | 2 | ||
| 60 | Олимпиада школьников федерального государственного бюджетного образовательного учреждения высшего образования «Всероссийский государственный университет юстиции (РПА Минюста России)» «В мир права» | история | история | 3 |
| право | обществознание, право | 3 | ||
| 61 | Олимпиада Юношеской математической школы | математика | математика | 2 |
| 62 | Открытая межвузовская олимпиада школьников Сибирского Федерального округа «Будущее Сибири» | физика | физика | 3 |
| химия | химия | 2 | ||
| 63 | Открытая олимпиада Северо-Кавказского федерального университета среди учащихся образовательных организаций «45 параллель» | география | география | 2 |
| 64 | Открытая олимпиада школьников | информатика | информатика | 1 |
| математика | математика | 3 | ||
| 65 | Открытая олимпиада школьников по программированию | информатика | информатика | 1 |
| 66 | Открытая олимпиада школьников по программированию «Когнитивные технологии» | информатика и икт | информатика | 2 |
| 67 | Открытая региональная межвузовская олимпиада вузов Томской области (ОРМО) | география | география | 3 |
| история | история | 2 | ||
| литература | литература | 2 | ||
| математика | математика | 3 | ||
| русский язык | русский язык | 3 | ||
| физика | физика | 3 | ||
| 68 | Открытая химическая олимпиада | химия | химия | 2 |
| 69 | Отраслевая олимпиада школьников «Газпром» | информационные и коммуникационные технологии | информатика | 3 |
| физика | физика | 3 | ||
| химия | химия | 3 | ||
| 70 | Отраслевая физико-математическая олимпиада школьников «Росатом» | математика | математика | 2 |
| физика | физика | 1 | ||
| 71 | Плехановская олимпиада школьников | иностранный язык | английский язык, немецкий язык | 3 |
| экономика | обществознание | 3 | ||
| финансовая грамотность | обществознание | 3 | ||
| русский язык | русский язык | 2 | ||
| 72 | Региональный конкурс школьников Челябинского университетского образовательного округа | иностранный язык | иностранный язык | 3 |
| 73 | Санкт-Петербургская олимпиада школьников | астрономия | астрономия | 1 |
| математика | математика | 1 | ||
| химия | химия | 1 | ||
| 74 | Северо-Восточная олимпиада школьников | филология | русский язык, литература | 3 |
| 75 | Сибирская межрегиональная олимпиада школьников «Архитектурно-дизайнерское творчество» | архитектура, изобразительные и прикладные виды искусств | архитектура, дизайн, дизайн архитектурной среды, градостроительство | 2 |
| 76 | Строгановская олимпиада на базе МГХПА им. С.Г. Строганова С.Г. Строганова | рисунок, живопись, скульптура, дизайн | искусство, дизайн | 1 |
| 77 | Телевизионная гуманитарная олимпиада школьников «Умницы и умники» | гуманитарные и социальные науки | журналистика, зарубежное регионоведение, международные отношения, политология, реклама и связи с общественностью | 1 |
| 78 | Турнир городов | математика | математика | 1 |
| 79 | Турнир имени М.В. Ломоносова | астрономия и науки о земле | астрономия | 3 |
| биология | биология | 2 | ||
| история | история | 2 | ||
| литература | литература | 2 | ||
| математика | математика | 2 | ||
| лингвистика | русский язык, иностранный язык, математика | 2 | ||
| физика | физика | 2 | ||
| химия | химия | 3 | ||
| 80 | Университетская олимпиада школьников «Бельчонок» | информатика | информатика | 3 |
| математика | математика | 3 | ||
| химия | химия | 3 | ||
| 81 | Учитель школы будущего | иностранный язык | востоковедение и африканистика, педагогическое образование (профиль «иностранный язык»), лингвистика, филология | 3 |
| 82 | Филологическая олимпиада для школьников 5-11 классов «Юный словесник» | филология | русский язык, литература | 2 |
| 83 | Межрегиональная открытая олимпиада по музыкально-теоретическим дисциплинам для учащихся детских музыкальных школ и детских школ искусств | теория и история музыки | сольфеджио, музыкальная литература | 3 |
(PDF) Анализ комбинаторной категориальной грамматики через планирование в программировании набора ответов
Этот расширенный инструмент вычислительной семантики, мы стремимся создать выходной формат для AS PCC GTK, совместимый с Boxer
.
Поскольку наша структура является общей структурой синтаксического анализа, мы можем легко сравнивать различные наборы правил CCG
с точки зрения их эффективности и нормализации. Мы также подозреваем, что улучшение масштабируемости
ccg.asp возможно с использованием альтернативного набора комбинаторных правил вместо того, которое в настоящее время реализовано в ccg
.жерех Повышение типа — основной источник недетерминизма в синтаксическом анализе CCG и одна из причин
ложных деревьев синтаксического анализа и длительного времени синтаксического анализа. В будущем мы хотели бы оценить подход, в котором
частично исключает повышение типа, вставляя его во все комбинаторы без повышения типа. Похожая стратегия
была предложена для комбинаторов композиции Виттенбургом [30] .16 Комбинирование правил CCG таким образом создает на
дополнительных комбинаторов, однако эти правила содержат меньше недетерминированных предположений о повышении категорий.
Уменьшенный недетерминизм должен повысить эффективность решения без потери каких-либо выводов CCG.
Благодарности. Мы хотели бы поблагодарить Джона Биверса и Владимира Лифшица за ценные подробные комментарии
к докладу семинара, в котором представлены предварительные результаты этой работы [21]. Мы особенно благодарны
Брайану Силверторну за то, что он поделился с нами экспериментальными результатами, представленными на Рисунке 3. Мы
в долгу перед Джейсоном Болдриджем, Марчелло Бальдуччини, Йоханом Босом, Эсрой Эрдем, Майклом Финком, Майклом Гельфондом,
Джухен Ли, и Мирославу Трущинскому за полезные обсуждения и комментарии, относящиеся к теме этой работы
.Юлия Лиерлер получила стипендию CRA / NSF 2010 Computing Innovation Fellowship. Peter Sch ¨
uller
был поддержан проектом ICT08-020 Венского фонда науки и технологий (WWTF).
Ссылки
1. Биверс, Дж .: Документация: реализация CCG для LKB. Tech. представитель Стэнфордского университета, Центр изучения языка и информации
Tech. представитель Стэнфордского университета, Центр изучения языка и информации
(2003)
2. Биверс, Дж., Саг, И.: Многоточие в координатах и очевидная неконструктивная координация.В: Международная конференция по грамматике
Head-Driven Phrase Structure Grammar (HPSG’04). стр. 48–69 (2004)
3. Биверс, Дж .: Комбинаторно-категориальная грамматика по типу наследования. В: Международная конференция по компьютерной лингвистике
(COLING’04) (2004)
4. Бос Дж .: Семантический анализ широкого охвата с боксером. В: Бос, Дж., Делмонте, Р. (ред.) Семантика в обработке текста.
ШАГ 2008 Материалы конференции. С. 277–286. Исследования в области вычислительной семантики, публикации колледжа
(2008)
5.Чиматти, А., Писторе, М., Траверсо, П .: Автоматизированное планирование. В: ван Хармелен, Ф., Лифшиц, В., Портер, Б. (ред.)
Справочник по представлению знаний. Elsevier (2008)
6. Кларк, С., Карран, Дж. Р.: Лог-линейные модели для анализа CCG с широким охватом. В: Конференция SIGDAT по эмпирическим методам
в обработке естественного языка (EMNLP-03) (2003)
7. Кларк, С., Карран, Дж. Р.: Анализ WSJ с использованием CCG и лог-линейных моделей. В: Материалы 42-го ежегодного собрания
Ассоциации компьютерной лингвистики (ACL’04).С. 104–111. Барселона, Испания (2004)
8. Кларк С., Курран Дж. Р.: Эффективный статистический анализ с широким охватом с помощью CCG и лог-линейных моделей. Вычислительная
Лингвистика 33 (4), 493–552 (2007)
9. Джорджевич Б., Курран Дж.Р .: Эффективный комбинаторный категориальный грамматический синтаксический анализ. В: Proceedings of the 2006 Aus-
tralasian Language Technology Workshop (ALTW). С. 3–10 (2006)
10. Даути, Д .: Повышение типа, функциональная композиция и неконституционные соединения.В: Oehrle, R.T., Bach, E.,
Wheeler, D. (eds.) Категориальные грамматики и структуры естественного языка, т. 32. С. 153–197. Дордрехт, Рейдель
32. С. 153–197. Дордрехт, Рейдель
(1988)
11. Дрешер, К., Уолш, Т .: Моделирование грамматических ограничений с помощью программирования набора ответов. В: Gallagher, J.P., Gelfond,
M. (eds.) Технические сообщения 27-й Международной конференции по логическому программированию, ICLP 2011.
vol. 11, стр. 28–39 (2011)
12. Эйснер, Дж .: Эффективный синтаксический анализ нормальной формы для комбинаторно-категориальной грамматики.В: Материалы 34-го ежегодного собрания
Ассоциации компьютерной лингвистики (ACL’96). С. 79–86 (1996)
13. Эйтер, Т., Фабер, В., Леоне, Н., Пфайфер, Г., Поллерес, А .: Подход логического программирования к планированию состояния знаний —
ning : Семантика и сложность. ACM Trans. Comput. Logic 5, 206–263 (апрель 2004 г.)
14. Гебсер, М., K¨
, ониг, А., Шауб, Т., Тиле, С., Вебер, П .: Библиотека BioASP: решения ASP для системная биология.
В: 22-я Международная конференция IEEE по инструментам с искусственным интеллектом (ICTAI’10).т. 1, pp. 383–389
(2010)
16 Виттенбург ввел новый набор комбинаторных правил, объединив комбинаторы функциональной композиции с
другими комбинаторами. Путем исключения исходных комбинаторов функциональной композиции некоторые ложные деревья синтаксического анализа больше не могут быть получены.
Обучение грамматике в контексте
На этой странице
Деконтекстуализированное обучение грамматике, направленное на идентификацию и маркировку классов слов и синтаксических структур, не способствует улучшению письма.
Скорее, учебная программа по письму, которая привлекает внимание к грамматике письма встроенным и целенаправленным образом в соответствующие моменты обучения, является более позитивным путем вперед. (Myhill, Lines and Watson, 2012, стр.30).
Взгляд на грамматику как на ресурс смысла долгое время находился в центре внимания в Австралии и реализовывался, в частности, через жанровую педагогику (см. , Например, Christie, 2002; Christie & Derewianka, 2008; Rose & Martin, 2012; Rothery, 1989, с. 1994).
, Например, Christie, 2002; Christie & Derewianka, 2008; Rose & Martin, 2012; Rothery, 1989, с. 1994).
Недостаточно рассказать об общей структуре текста.Учащимся начальной школы необходимо научить, каким образом язык открывает «репертуар безграничных возможностей» по мере того, как они составляют все более сложные тексты (Myhill, Lines and Watson, 2012, p. 30).
Это требует развития металингвистической осведомленности, то есть «грамматически обоснованных знаний о языке» (Macken-Horarik, Love & Unsworth 2011, p. 11), которые поддерживают принятие языковых решений (Myhill, Jones, & Watson, 2016).
Учащиеся EAL / D и студенты, изучающие грамматикуEAL / D, не являются «чистыми листами» и имеют, явно или неявно, определенную форму понимания грамматики на английском или своем родном языке.По мере того, как они изучают английский и продолжают совершенствовать свои родные языки, студенты EAL / D обычно хорошо понимают, как работает язык (метаязыковая осведомленность).
Грамматические особенности будут отличаться в зависимости от языка учащихся. Например, в английском множественном числе существительные обычно обозначаются буквами «s» или «es», как в «girls» и «daisies». В индонезийском языке множественное число может происходить путем удвоения существительного (buku-buku saya — мои книги), в то время как формы множественного числа не существуют в мандаринском диалекте. Таким образом, учащиеся EAL / D могут быть незнакомы с конкретной формой или могут придавать значение другим способом.
С другой стороны, изучающие EAL / D также могут четко осознавать, что существуют грамматические различия между английским и их родным языком. Они могут быть очень восприимчивы к явным инструкциям по грамматике в значимом контексте.
Все учащиеся EAL / D имеют разный опыт владения английским языком. Некоторые ученики приезжают из стран, где английский может быть официальным языком или языком обучения с 3-го класса. Некоторые родители могут вводить английский намного раньше в жизни своих детей через частные школы английского языка, репетиторство или короткие поездки в англоязычные страны. Другие учащиеся EAL / D могли прервать учебу в результате войны и политических волнений в их родных странах, но они переехали и жили в различных лагерях, где говорили на английском и других языках.
Другие учащиеся EAL / D могли прервать учебу в результате войны и политических волнений в их родных странах, но они переехали и жили в различных лагерях, где говорили на английском и других языках.
Как и при любом обучении, важно оценить предыдущие знания учащихся и определить их потребности. Учителя могут обращаться к таким текстам, как Learner English (Swan & Smith, 2001), чтобы узнать о ключевых грамматических особенностях языков, на которых говорят учащиеся в их классе.
Важность языковых знаний признана в языковой составляющей Викторианской учебной программы, английский язык, где «учащиеся развивают свои знания английского языка и того, как он работает» (VCAA).
Три подстила:
- Язык для взаимодействия
- Структура и организация текста
- Выражение и развитие идей обеспечивают дальнейшее развитие этих знаний.
Язык для социальных взаимодействий
Как язык, используемый для различных формальных и неформальных социальных взаимодействий, зависит от цели и аудитории
Оценочный язык
Как язык используется для выражения мнений и вынесения оценочных суждений о людях, местах и предметах и тексты
Цель, аудитория и структуры различных типов текстов
Как тексты служат разным целям и как структуры типов текстов различаются в зависимости от цели текста
Связность текста
Как тексты работают как единое целое благодаря языковым особенностям, которые связывать части текста вместе, такие как абзацы, связки, существительные и связанные с ними местоимения
Пунктуация
Как пунктуация выполняет различные функции в тексте.
Концепции печати и экрана. Различные условные обозначения, которые применяются к тому, как текст отображается на странице или экране
Грамматика на уровне предложений и предложений
Что такое предложение и как простые, составные и сложные предложения строятся с помощью одного предложения (простого) или путем объединения предложений с использованием различных типов союзов (составных и сложных)
Грамматика уровня слов
Различные классы слов, используемых в английском языке (существительные, глаголы и т. Д.) и функции, которые они выполняют в предложениях и когда они объединены в определенные узнаваемые группы, такие как группы фраз и существительных
Д.) и функции, которые они выполняют в предложениях и когда они объединены в определенные узнаваемые группы, такие как группы фраз и существительных
Визуальный язык
Как изображения работают в текстах для передачи значений, особенно в сочетании с другими элементами, такими как печать и звук
Принципы, лежащие в основе преподавания языка
Хамфри, Дрога и Физ (2012) представляют фундаментальные принципы мышления о языке как системе ресурсов для создания смысла, принципы, которые также определяют языковую составляющую викторианской учебной программы:
- Язык — это организован в соответствии со своими функциями.
- Язык — это богатый, многоуровневый ресурс с неограниченным потенциалом создания смысла. Текст — это язык, используемый для достижения определенной социальной цели.
- Грамматика — это система шаблонов и структур, набор ресурсов, используемых для организации слов в предложения, которые образуют значения в текстах.
- Есть много разновидностей языка. Разнообразие языков, которые мы используем в любое время, определяется контекстом, в котором они используются. (Хамфри, Дрога и Физ, 2012, стр.1)
Кроме того, учащиеся также должны знать о развитии понимания того, что такое «правильное» употребление в английском языке (например, согласование подлежащего и глагола — я иду, он идет), или о знании различных классов слов, таких как существительные, глаголы, прилагательные. Студенты также должны понимать, как язык работает на уровне текста, предложения и слова.
Macken-Horarik, Love, Sandiford и Unsworth (2017) описывают три шага для того, чтобы направить разговор о языке на разных уровнях в письменных (и устных) текстах:
- определить форму или класс слова / слов в тексте (например, «Мы составили план», если «план» — это существительное, или «Мы планируем уйти», если «план» — это глагол).
- описать, как слово или единица работает или функционирует (например, группы существительных рассказывают нам о персонажах в рассказе, кто они, как они выглядят)
- объясняют, как варианты выбора работают в тексте и почему (например, «Сильный Глаголы действия используются для одного персонажа, но менее сильные — для другого, чтобы показать, что один персонаж был более сильным лидером и на него можно было положиться.
 ’). (Маккен-Хорарик, Лав, Сандифорд и Ансуорт, 2017, стр.15).
’). (Маккен-Хорарик, Лав, Сандифорд и Ансуорт, 2017, стр.15).
 ’). (Маккен-Хорарик, Лав, Сандифорд и Ансуорт, 2017, стр.15).
’). (Маккен-Хорарик, Лав, Сандифорд и Ансуорт, 2017, стр.15).Образцы или тексты наставников
Образцы или тексты наставников должны использоваться для иллюстрации выбора языка, который учащиеся могут использовать в своих собственных текстах. Это позволяет установить четкие связи между текстами, которые читают учащиеся, текстами, которые они составляют, и тем, как они говорят о текстах, которые они читают и сочиняют.
По мере того, как учителя работают с образцами или наставническими текстами, можно выработать общий язык для разговоров о языке или метаязыке.Установление метаязыка не только поддерживает развивающиеся знания учащихся о языке, но также позволяет учителям и учащимся проводить целенаправленное обсуждение текстов, которые они читают и пишут, используя общий понятный язык.
Выбор образцов текстов или текстов наставника должен отражать аутентичные примеры текстов, которые иллюстрируют фокус обучения. Это может включать выбор отрывка или отрывков из текста для учебных целей.
При использовании модельных или наставнических текстов учителю или ученику необязательно указывать все варианты языка или даже все варианты выбора конкретного языка, например глаголы.
Скорее, выделение избранных примеров, которые иллюстрируют направленность преподавания, — это эффективный способ привлечь внимание студентов к языку и тому, как он используется в тексте.
В повествовании это может означать просмотр того, где используются глаголы действия или действия или где используются глаголы восприятия, и что они говорят нам о персонаже и о том, что он / она думает в разных точках повествования.
Развитие лингвистического контроля
По мере того, как дети учатся в начальной школе, лингвистические изменения в их контроле над письменной речью становятся очевидными.Ключевые сдвиги в развитии, которые происходят в лингвистическом контроле письма с первых лет начальной школы до подросткового возраста, подробно описаны в работах Кристи и Деревянка (2008) и Маккен-Хорарик, Лав, Сандифорд и Ансуорт (2017).
Это исследование подчеркивает, как грамматику можно рассматривать как инструмент для понимания того, как работает текст, и как эти знания могут помочь развивающимся писателям.
Для учителей, понимание лингвистического развития в письменной форме дает им возможность «обеспечивать более эффективную обратную связь, а также помогает им избегать более поверхностных оценок, ориентированных на« правильность »(Macken-Horarik & Sandiford, 2016, p.81).
Исследования траекторий развития письма в таких областях, как структура предложений, показывают, что развитие письма может быть более тесно связано с письменной компетенцией, чем с возрастом (Myhill, 2008, стр. 284). Однако основные этапы развития обычно достигаются в пределах ориентировочного возраста.
Краткое изложение основных изменений, которые могут произойти в начальных классах школы (в соответствии с разделами языка викторианской учебной программы), можно найти здесь.
Изменения в контроле письменной речи (docx — 31.5kb) — Christie & Derewianka
Сводку основных языковых ресурсов для повествования, пересчета, аргументации, процедуры, информационного отчета, объяснения (в соответствии с подразделами викторианской учебной программы) можно получить по следующим ссылкам:
Батт, Д., Фэи, Р., Физ, S & Spinks, S. (2012). Использование функциональной грамматики: Руководство исследователя (3-е издание). Южная Ярра: Macmillan Education Australia.
Кристи, Ф. (2002). Анализ дискурса в классе.Лондон: Continuum.
Кристи Ф. и Деревянка Б. (2008). Школьный дискурс: обучение письму через годы обучения. Лондон и Нью-Йорк: Континуум.
Деревянка Б. и Джонс П. (2016). Обучение языку в контексте (2-е изд.). Южный Мельбурн, Вик: Издательство Оксфордского университета.
Хамфри, С., Дрога, Л., Физ, С. (2012). Грамматика и значение. Новый город. PETAA.
Macken-Horarik, M., Love, K., Sandiford, C. & Unsworth, L. (2017). Функциональная грамматика: переосмысление знаний о языке и имидже для школьного английского.Оксон, Великобритания: Рутледж.
Маккен-Хорарик М., Лав К. и Ансуорт Л. (2011). Грамматика «достаточно хороша» для школьного английского в 21 веке: четыре задачи в реализации потенциала. Австралийский журнал языка и грамотности, 34 (1), 9-21.
Маккен-Хорарик, М. и Сандифорд, К. (2016). Диагностика развития: грамматика для отслеживания успеваемости учащихся в сочинении повествования. Международный журнал языковых исследований, 10 (3), 61-94.
Майхилл, Д., Джонс, С.И Уотсон, А. (2016). Написание разговоров: стимулирование металингвистической дискуссии о письме. Исследования в области образования, 31 (1), 23-44.
Myhill, D., Lines, H. & Watson, A. (2012). Осмысление смысла с помощью грамматики: репертуар возможностей. Английский в Австралии, 47 (3), 29-38.
Роуз Д. и Мартин Дж. Р. (2012). Учимся писать, читать, чтобы учиться: Жанр, знания и педагогика в Сиднейской школе: Лондон: Равноденствие.
Ротери, Дж. (1989). Изучение языка.В Р. Хасан и Дж. Р. Мартин (ред.), Развитие языка: язык обучения, культура обучения (стр.199 — 256). Норвуд, Нью-Джерси: Ablex.
Ротери, Дж. (1994). Изучение грамотности в школьном английском (напишите правильные ресурсы для грамотности и обучения). Сидней: Программа для школ столичного востока для малоимущих.
LATA039.dvi
% PDF-1.4 % 1 0 объект > эндобдж 5 0 obj /Заголовок /Предмет / Автор /Режиссер / CreationDate (D: 20210321194822-00’00 ‘) / ModDate (D: 20110620174235 + 02’00 ‘) >> эндобдж 2 0 obj > эндобдж 3 0 obj > эндобдж 4 0 obj > поток
Что такое встраивание слов для текста?
Последнее обновление 7 августа 2019 г.
Вложения слов — это тип представления слов, который позволяет словам со схожим значением иметь аналогичное представление.
Они представляют собой распределенное представление текста, что, возможно, является одним из ключевых достижений в области впечатляющей производительности методов глубокого обучения при решении сложных задач обработки естественного языка.
В этом посте вы познакомитесь с подходом встраивания слов для представления текстовых данных.
Заполнив этот пост, вы будете знать:
- Что такое метод встраивания слов для представления текста и чем он отличается от других методов извлечения признаков.
- Что существует 3 основных алгоритма для обучения встраиванию слова из текстовых данных.
- Что вы можете либо обучить новое вложение, либо использовать предварительно обученное вложение для своей задачи обработки естественного языка.
Начните свой проект с моей новой книги «Глубокое обучение для обработки естественного языка», включающей пошаговых руководств и файлов исходного кода Python для всех примеров.
Приступим.
Что такое встраивание слов в текст?
Фотография Хизер, некоторые права защищены.
Обзор
Этот пост разделен на 3 части; их:
- Что такое вложения слов?
- Алгоритмы встраивания слов
- Использование вложений слов
Нужна помощь с глубоким обучением текстовых данных?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с кодом).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ ускоренный курс прямо сейчас
Что такое вложения слов?
Вложение слов — это заученное представление текста, в котором слова, имеющие одинаковое значение, имеют аналогичное представление.
Именно такой подход к представлению слов и документов можно считать одним из ключевых достижений глубокого обучения в решении сложных проблем обработки естественного языка.
Одно из преимуществ использования плотных и низкоразмерных векторов — вычислительные: большинство инструментов нейронных сетей плохо работают с разреженными векторами очень высокой размерности.… Основным преимуществом плотных представлений является возможность обобщения: если мы считаем, что некоторые функции могут давать аналогичные подсказки, стоит предоставить представление, которое способно уловить эти сходства.
— стр. 92, Методы нейронных сетей в обработке естественного языка, 2017.
Вложения слов на самом деле представляют собой класс методов, при которых отдельные слова представляются как векторы с действительными значениями в заранее определенном векторном пространстве. Каждое слово сопоставляется с одним вектором, и значения вектора изучаются способом, напоминающим нейронную сеть, и, следовательно, этот метод часто относят к области глубокого обучения.
Ключом к подходу является идея использования плотного распределенного представления для каждого слова.
Каждое слово представлено вектором с действительными значениями, часто с десятками или сотнями измерений. Это контрастирует с тысячами или миллионами измерений, необходимых для разреженных представлений слов, таких как одноразовое кодирование.
связать с каждым словом в словаре вектор признаков распределенного слова… Вектор признаков представляет различные аспекты слова: каждое слово связано с точкой в векторном пространстве.Количество функций… намного меньше, чем размер словаря
— Нейро-вероятностная языковая модель, 2003.
Распределенное представление изучается на основе использования слов. Это позволяет словам, которые используются одинаково, приводить к похожим представлениям, естественным образом передавая их значение. Этому можно противопоставить четкое, но хрупкое представление в модели мешка слов, где, если явно не управлять, разные слова имеют разные представления, независимо от того, как они используются.
За этим подходом стоит более глубокая лингвистическая теория, а именно «гипотеза распределения » Зеллига Харриса, которую можно резюмировать следующим образом: слова, имеющие схожий контекст, будут иметь схожие значения. Для более подробной информации см. Статью Харриса 1956 года «Распределительная структура».
Это понятие, позволяющее употреблению слова определять его значение, можно резюмировать с помощью часто повторяемой шутки Джона Ферта:
Вы должны знать слово по компании, в которой оно находится!
— стр. 11, «Краткий обзор лингвистической теории 1930-1955 гг.», В «Исследованиях по лингвистическому анализу 1930-1955, 1962».
Алгоритмы встраивания слов
Методы встраивания слов изучают вещественное векторное представление для предопределенного словаря фиксированного размера из корпуса текста.
Процесс обучения либо объединяется с моделью нейронной сети для выполнения некоторой задачи, такой как классификация документов, либо является неконтролируемым процессом с использованием статистики документов.
В этом разделе рассматриваются три метода, которые можно использовать для изучения встраивания слова из текстовых данных.
1. Встраиваемый слой
Уровень внедрения, из-за отсутствия лучшего названия, представляет собой встраивание слов, которое изучается совместно с моделью нейронной сети для конкретной задачи обработки естественного языка, такой как языковое моделирование или классификация документов.
Требуется, чтобы текст документа был очищен и подготовлен таким образом, чтобы каждое слово было закодировано по очереди. Размер векторного пространства указывается как часть модели, например 50, 100 или 300 измерений. Векторы инициализируются небольшими случайными числами. Слой внедрения используется во внешнем интерфейсе нейронной сети и подбирается контролируемым образом с использованием алгоритма обратного распространения.
… когда входные данные нейронной сети содержат символические категориальные признаки (например, признаки, которые принимают один из k различных символов, например слова из закрытого словаря), обычно связывают каждое возможное значение признака (т.е.е., каждое слово в словаре) с d-мерным вектором для некоторого d. Эти векторы затем считаются параметрами модели и обучаются вместе с другими параметрами.
— стр. 49, Методы нейронных сетей в обработке естественного языка, 2017.
Слова с горячим кодированием отображаются в векторы слов. Если используется многослойная модель персептрона, то векторы слов объединяются перед подачей в качестве входных данных в модель. Если используется рекуррентная нейронная сеть, то каждое слово может использоваться как один вход в последовательности.
Этот подход к изучению слоя встраивания требует большого количества обучающих данных и может быть медленным, но при этом будет изучаться встраивание, ориентированное как на конкретные текстовые данные, так и на задачу НЛП.
2. Word2Vec
Word2Vec — это статистический метод для эффективного обучения автономному встраиванию слов из корпуса текста.
Разработан Томасом Миколовым и др. в Google в 2013 году в ответ на повышение эффективности обучения встраиванию на основе нейронных сетей, и с тех пор он стал де-факто стандартом для разработки предварительно обученного встраивания слов.
Кроме того, работа включала анализ выученных векторов и изучение векторной математики для представлений слов. Например, вычитание « мужественности » из « король » и добавление « женского достоинства » дает слово « королева », улавливая аналогию « король для королевы, поскольку мужчина есть женщине “.
Мы обнаружили, что эти представления на удивление хороши для улавливания синтаксических и семантических закономерностей в языке, и что каждое отношение характеризуется смещением вектора, зависящим от отношения.Это позволяет использовать векторные рассуждения на основе смещений между словами. Например, отношения мужчина / женщина изучаются автоматически, и с помощью индуцированных векторных представлений «Король — Мужчина + Женщина» дает вектор, очень близкий к «Королеве».
— Лингвистические закономерности в представлениях слов в непрерывном пространстве, 2013.
Были представлены две разные модели обучения, которые можно использовать как часть подхода word2vec для изучения встраивания слов; их:
- Непрерывный мешок слов, или модель CBOW.
- Непрерывная модель скип-грамма.
Модель CBOW изучает встраивание, предсказывая текущее слово на основе его контекста. Модель непрерывной скип-граммы учится, предсказывая окружающие слова по текущему слову.
Модель непрерывной скип-граммы обучается, предсказывая окружающие слова по текущему слову.
Обучающие модели Word2Vec
Взято из «Эффективной оценки представлений слов в векторном пространстве», 2013 г.
Обе модели ориентированы на изучение слов с учетом их местного контекста использования, где контекст определяется окном соседних слов.Это окно является настраиваемым параметром модели.
Размер скользящего окна сильно влияет на сходство результирующих векторов. Большие окна имеют тенденцию производить больше тематических сходств […], в то время как меньшие окна имеют тенденцию производить больше функциональных и синтаксических сходств.
— стр. 128, Методы нейронных сетей в обработке естественного языка, 2017.
Ключевым преимуществом этого подхода является то, что высококачественные вложения слов могут быть эффективно изучены (низкая пространственная и временная сложность), что позволяет изучать более крупные вложения (больше измерений) из гораздо больших массивов текста (миллиарды слов).
3. перчатка
Алгоритм глобальных векторов для представления слов, или GloVe, является расширением метода word2vec для эффективного изучения векторов слов, разработанного Пеннингтоном и др. в Стэнфорде.
Классическая модель представления слов в векторном пространстве была разработана с использованием методов матричной факторизации, таких как скрытый семантический анализ (LSA), которые хорошо справляются с использованием глобальной текстовой статистики, но не так хороши, как изученные методы, такие как word2vec, для захвата значения и демонстрации его на такие задачи, как вычисление аналогий (например,грамм. пример Короля и Королевы выше).
GloVe — это подход, объединяющий глобальную статистику методов матричной факторизации, таких как LSA, с локальным контекстным обучением в word2vec.
Вместо того, чтобы использовать окно для определения локального контекста, GloVe создает явный контекст слова или матрицу совпадения слов, используя статистику по всему текстовому корпусу. Результатом является обучающая модель, которая в целом может улучшить встраивание слов.
GloVe — это новая глобальная лог-билинейная модель регрессии для неконтролируемого изучения представлений слов, которая превосходит другие модели в задачах аналогии слов, сходства слов и распознавания именованных сущностей.
— GloVe: глобальные векторы для представления слов, 2014.
Использование вложений слов
У вас есть несколько вариантов, когда приходит время использовать встраивание слов в вашем проекте обработки естественного языка.
В этом разделе описаны эти варианты.
1. Выучите вложение
Вы можете выучить встраивание слов для вашей задачи.
Это потребует большого количества текстовых данных, чтобы гарантировать, что полезные вложения будут изучены, например, миллионы или миллиарды слов.
У вас есть два основных варианта при обучении внедрению слов:
- Learn it Standalone , где модель обучается изучать встраивание, которое сохраняется и используется как часть другой модели для вашей задачи позже. Это хороший подход, если вы хотите использовать одно и то же встраивание в нескольких моделях.
- Совместное обучение , где встраивание изучается как часть большой модели для конкретной задачи. Это хороший подход, если вы собираетесь использовать встраивание только для одной задачи.
2. Повторное использование вложения
Исследователи часто делают предварительно обученные встраивания слов доступными бесплатно, часто по разрешительной лицензии, чтобы вы могли использовать их в своих собственных академических или коммерческих проектах.
Например, для бесплатной загрузки доступны вложения слов word2vec и GloVe.
Их можно использовать в своем проекте вместо обучения собственным вложениям с нуля.
У вас есть два основных варианта использования предварительно обученных встраиваний:
- Статический , где вложение остается статичным и используется как компонент вашей модели.Это подходящий подход, если встраивание хорошо подходит для вашей проблемы и дает хорошие результаты.
- Обновлено , где предварительно обученное вложение используется для заполнения модели, но встраивание обновляется совместно во время обучения модели. Это может быть хорошим вариантом, если вы хотите получить максимальную отдачу от модели и реализовать свою задачу.
Какой вариант следует использовать?
Изучите различные варианты и, если возможно, проверьте, какой из них дает наилучшие результаты при решении вашей проблемы.
Возможно, начните с быстрых методов, таких как использование предварительно обученного встраивания, и используйте новое встраивание только в том случае, если оно приведет к повышению производительности вашей проблемы.
Учебники по внедрению Word
В этом разделе перечислены некоторые пошаговые руководства, которым вы можете следовать, чтобы использовать встраивание слов и внедрить встраивание слов в свой проект.
Дополнительная литература
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
Статьи
Статьи
Проектов
Книги
Сводка
В этом посте вы открыли для себя вложения Word как метод представления текста в приложениях глубокого обучения.
В частности, вы выучили:
- Что такое метод встраивания слов для представления текста и чем он отличается от других методов выделения признаков.
- Что существует 3 основных алгоритма для обучения встраиванию слова из текстовых данных.
- Что вы можете обучить новое встраивание или использовать предварительно обученное встраивание в своей задаче обработки естественного языка.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разрабатывайте модели глубокого обучения для текстовых данных уже сегодня!
Создавайте собственные текстовые модели за считанные минуты
… всего несколькими строками кода Python
Узнайте, как это сделать, в моей новой электронной книге:
Deep Learning for Natural Language Processing
Он предоставляет руководств для самообучения по таким темам, как:
Пакет слов, встраивание слов, языковые модели, создание титров, перевод текста и многое другое …
Наконец-то привнесите глубокое обучение в свои проекты по обработке естественного языка
Пропустить академики.Только результаты.
Посмотрите, что внутриСиамская сеть долговременной краткосрочной памяти на основе зависимостей для изучения представлений предложений
Abstract
Текстовые представления играют важную роль в области обработки естественного языка (НЛП). Эффективность задач НЛП, таких как понимание текста и извлечение информации, можно значительно повысить с помощью правильного текстового представления. Поскольку нейронные сети постепенно применяются для изучения представления слов и фраз, были разработаны довольно эффективные модели изучения представлений короткого текста, такие как непрерывный мешок слов (CBOW) и модели пропуска грамм, и они широко используются в разнообразные задачи НЛП.Из-за сложной структуры, порождаемой более длинными текстовыми представлениями, такими как предложения, алгоритмы, подходящие для изучения коротких текстовых представлений, не применимы для изучения длинных текстовых представлений. Одним из методов изучения длинных текстовых представлений является сеть Long Short-Term Memory (LSTM), которая подходит для обработки последовательностей. Однако стандартный LSTM неадекватно обращается к первичной структуре предложения (субъект, предикат и объект), что является важным фактором для создания соответствующих представлений предложений.Чтобы решить эту проблему, в этом документе предлагается модель LSTM на основе зависимостей (D-LSTM). D-LSTM делит представление предложения на две части: базовый компонент и вспомогательный компонент. D-LSTM использует предварительно обученный анализатор зависимостей для получения информации о первичном предложении и создания вспомогательных компонентов, а также использует стандартную модель LSTM для генерации основных компонентов предложения. Для генерации представления предложения вводится весовой коэффициент, который может регулировать соотношение основных и вспомогательных компонентов в предложении.По сравнению с представлением, изученным стандартным LSTM, представление предложения, изученное D-LSTM, содержит большее количество полезной информации. Результаты экспериментов показывают, что D-LSTM превосходит стандартный LSTM для предложений, содержащих данные о композиционном знании (SICK).
Образец цитирования: Zhu W, Yao T, Ni J, Wei B, Lu Z (2018) Сиамская сеть долговременной краткосрочной памяти на основе зависимостей для обучения репрезентациям предложений. PLoS ONE 13 (3): e0193919.https://doi.org/10.1371/journal.pone.0193919
Редактор: Xuchu Weng, Ханчжоуский педагогический университет, Китай
Поступила: 30 августа 2017 г .; Одобрена: 21 февраля 2018 г .; Опубликован: 7 марта 2018 г.
Авторские права: © 2018 Zhu et al. Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Все соответствующие файлы доступны по адресу: https://github.com/jx00109/dependency-based-siamese-lstm.
Финансирование: Работа над этой статьей поддержана Национальным фондом естественных наук Китая (№ 61572434 и № 61303097) для WZ. Спонсор не имел никакого отношения к дизайну исследования, сбору и анализу данных, принятию решения о публикации или подготовке рукописи.
Конкурирующие интересы: Авторы заявили, что конкурирующих интересов не существует.
Введение
Изучение текстовых представлений — жизненно важная часть обработки естественного языка (НЛП) и важна для последующих задач НЛП. В последнее время изучение представлений фраз и предложений привлекло внимание многих исследователей, добившихся определенных успехов [1].
Исследования коротких текстовых представлений достигли ряда достижений, и модель непрерывного мешка слов Миклова (CBOW) и модель скип-грамм (модель непрерывной скип-граммы) являются одними из самых известных моделей.Представления слов, полученные из этих моделей, обеспечивают относительно хорошую производительность во многих задачах НЛП, включая аналогии слов [2, 3]. В последнее время интересы сместились в сторону расширения этих идей за пределы уровня отдельных слов на более крупные объемы текста, такие как предложения. Исследователи надеются напрямую изучить представление предложений через сумму или среднее значение, основанное на представлении слов, и они достигли удовлетворительных результатов для некоторых простых задач НЛП [4]. Из-за переменной длины и сложной структуры предложений эти простые алгоритмы не могут обрабатывать сложные задачи (такие как оценка сходства между двумя предложениями).Чтобы решить эту проблему, Кирос, Тай и Ле предложили методы изучения представлений предложений фиксированной длины [5–7].
Среди всех моделей для изучения представлений предложений, модели рекуррентной нейронной сети (RNN), особенно модель Long Short-Term Memory (LSTM) [8], являются одними из наиболее подходящих моделей для обработки предложений, и они достигли значительного успеха в тексте. категоризация [9] и машинный перевод [10]. Таким образом, этот документ также представил сети LSTM в сиамской модели LSTM на основе зависимостей (D-LSTM) для повышения производительности.
В этой статье предложение состоит из двух частей: основного компонента и вспомогательного компонента. Мы улучшили традиционный метод, который использует стандартный LSTM для изучения представлений предложений, и предложили D-LSTM, который основан на зависимости предложений для изучения представлений предложений. D-LSTM может читать предложения разной длины для создания представлений фиксированной длины. Базовый компонент, содержащий фундаментальную информацию о предложении, получается с помощью стандартной языковой модели LSTM.Вспомогательный компонент содержит основную информацию о предложении (в основном от подлежащего, предиката и объекта предложения) и генерируется после выполнения синтаксического анализа зависимости предложения. При генерации представления предложения основной компонент занимает доминирующее положение, а вспомогательный компонент играет вспомогательную роль. В этой статье был введен весовой коэффициент (α), который может регулировать соотношение основного и вспомогательного компонентов в представлении предложения, чтобы узнать окончательное представление предложения.В задаче на подобие предложений представление предложения, изученное D-LSTM, дало подходящие результаты.
Ключевым вкладом этого исследования является разделение представления предложения на две части, то есть базовый компонент и вспомогательный компонент. Вдохновленный этой идеей, в данной статье предлагается модель D-LSTM, которая может собирать более обширную информацию о предложении, чем стандартная модель LSTM, и изучать эффективное представление предложения. Эффекты различных пропорций основного компонента и вспомогательного компонента в представлении предложения были тщательно исследованы с помощью серии экспериментов.Добавление вспомогательного компонента в базовое представление может улучшить производительность представления предложения.
Связанные работы
После того, как Бенжио предложил нейронную вероятностную языковую модель [11], популярность нейронных сетей для изучения текстовых представлений возросла. В последнее время были достигнуты многочисленные достижения в изучении представлений на уровне слов с помощью нейронных сетей, таких как известная модель CBOW [3]. Из-за естественных преимуществ RNN и LSTM в обработке последовательностей исследователи начали применять RNN и LSTM для лучшего изучения представлений предложений.Например, Кирос предложил модель пропуска мыслей, которая может расширить подход word2vec с пропуском грамматики с уровня слова до уровня предложения [5]. RNN адаптируют стандартные нейронные сети с прямой связью для данных последовательности ( x 1 ,… x T ), и при каждом t ∈ {1,…, T } обновляет вектор скрытого состояния ч т выполняются через (1)
Хотя RNN демонстрируют удовлетворительную производительность при обработке последовательностей, они также представляют собой значительный недостаток, связанный с долговременной зависимостью, который обсуждался многими исследователями [12].Сети LSTM специально разработаны, чтобы избежать проблемы долгосрочной зависимости. Подобно RNN, LSTM последовательно обновляет представление скрытого состояния; однако эти шаги также полагаются на ячейку памяти, которая содержит четыре компонента (которые являются векторами действительных значений): состояние памяти c t и выходной вентиль o t , которые определяют, как состояние памяти влияет на другие устройства, а также элементы ввода и забвения i t и f t соответственно, которые управляют тем, что хранится в памяти и удаляется из памяти на основе каждого нового ввода и Текущее состояние.Следующие обновления выполнялись для каждого t ∈ {1,…, T } в LSTM, параметризованном матрицами весов W i , W f , W c , W o , U i , U f , U c 906 906 903 и U34 векторы смещения 90 b i , b f , b c , b o : (2) (3) (4) (5) (6) (7)
Доступно множество вариантов LSTM.Один популярный вариант, предложенный Герсом и Шмидхубером, добавляет «соединения в виде глазков» [13]. Другой вариант — закрытый рекуррентный блок (ГРУ) [14]. Хотя доступно множество вариантов LSTM, Грефф провел сравнение популярных вариантов и выявил их сходство, и результаты показали, что функция «забыть» вентиль и выходная активация может быть наиболее важными компонентами в LSTM [15].
Недавно аналогичный подход к методам нейронной сети позволил значительно улучшить производительность.Tai, Socher и Manning (2015) предложили Tree-LSTM, которые обобщают чувствительную к порядку цепную структуру стандартных LSTM на древовидные топологии сети [6]. Каждое предложение преобразуется в дерево синтаксического анализа (с использованием отдельно обученного синтаксического анализатора), и Tree-LSTM составляет свое скрытое состояние в данном узле дерева из соответствующего слова и скрытых состояний всех дочерних узлов. По сравнению со стандартной моделью LSTM, Tree-LSTM представляют собой ворота забывания для каждого дочернего узла, что позволяет Tree-LSTM выборочно получать информацию о дочернем узле и создавать лучшее представление предложения.
С развитием нейронных сетей новая архитектура сиамской сети также используется для изучения представлений предложений [16, 17]. Кентер, Борисов и Рийке предложили модель сиамского непрерывного мешка слов (сиамский CBOW), основанную на сиамской сети [18]. Их работа показала, что вложения слов, обученные с помощью доступных в настоящее время методов, не оптимизированы для задачи представления предложений, тогда как сиамский CBOW решает эту проблему путем прямого обучения, а затем усреднения встраивания слов.Базовая нейронная сеть изучает вложения слов, предсказывая окружающие предложения из представления предложения.
Джонас и Адитья объединили сиамскую сеть с LSTM и предложили свою манхэттенскую модель LSTM (MaLSTM) для моделирования семантического сходства между предложениями [19]. Модель MaLSTM показана на рис. 1.
Рис. 1. Модель MaLSTM.
MaLSTM использует LSTM для чтения слов-векторов, которые представляют каждое входное предложение, и использует его окончательное скрытое состояние как векторное представление для каждого предложения.Сходства между этими представлениями используются в качестве предикторов семантического сходства.
https://doi.org/10.1371/journal.pone.0193919.g001
В MaLSTM используются два LSTM: LSTM a и LSTM b ( a = LSTM b в их эксперименте). Каждый LSTM обрабатывает предложение во входной паре предложений.LSTM изучает отображение из пространства последовательностей переменной длины d в -мерных векторах в ( d в = 300, d rep = 50). Каждое предложение (представленное как последовательность векторов слов) x 1 ,.…, x T передается в LSTM, который обновляет свое скрытое состояние в каждом индексе последовательности с помощью уравнений (2) — (7). Окончательное представление предложения кодируется, что является последним скрытым состоянием модели.Для данной пары предложений предопределенная функция подобия применяется к LSTM-представлениям (в их исследовании). Сходства в пространстве представления впоследствии используются, чтобы сделать вывод о семантическом сходстве, лежащем в основе предложений. Эмпирически результаты довольно стабильны для различных типов простых функций подобия; однако функция g, использующая манхэттенское расстояние, немного превосходит другие разумные альтернативы, такие как косинусное подобие [20]. Кроме того, методы предварительного обучения и расширения синонимов для аналогичных наборов данных были применены для расширения ограниченных данных обучения.
Материалы и методы
Сиамская модель LSTM на основе зависимостей
Модель LSTM имеет естественное преимущество в обработке последовательностей, таких как предложения. По сравнению со словами, предложения имеют более сложную структуру, и между словами в одном предложении наблюдаются различные отношения. Чтобы изучить более мощные представления предложений, следует учитывать разницу между предложениями и словами. Как упоминалось ранее, полное представление предложения состоит из двух частей: базового компонента v basic , который содержит базовую информацию о предложении, и вспомогательного компонента v supp , который содержит информацию об основном предложении. (в первую очередь от подлежащего, сказуемого и объекта предложения).Основываясь на этой идее, в данной статье предлагается D-LSTM, показанный на рис. 2.
Рис. 2. Модель LSTM на основе зависимостей.
D-LSTM использует LSTM для чтения векторов слов и использует свое окончательное скрытое состояние в качестве базового компонента v basic для каждого предложения. D-LSTM выполняет синтаксический анализ зависимостей во входном предложении и генерирует вспомогательный компонент v supp для каждого предложения. Вводя весовой коэффициент α , D-LSTM генерирует представление предложения v согласно v basic и v supp , а затем прогнозирует сходство между ними. представления.
https://doi.org/10.1371/journal.pone.0193919.g002
Сетевая структура, аналогичная описанной в Mueller et al. [19] используется для разработки модели D-LSTM. D-LSTM считывает предложения a и b, используя два LSTM, и генерирует векторы фиксированной длины и в качестве основных компонентов a и b соответственно (описано в другом разделе). При создании базового компонента D-LSTM также выполняет анализ зависимостей a и b, чтобы получить отношения между словами в предложении.D-LSTM генерирует вспомогательные компоненты и суммирует скрытые состояния, которые соответствуют входным словам, имеющим определенную взаимосвязь в предложении (описанном в другом разделе).
В этом исследовании основной компонент предложения занимает доминирующее положение, а вспомогательный компонент играет вспомогательную роль. Таким образом, D-LSTM вводит весовой коэффициент α, который может регулировать соотношение основного компонента к поддерживающему компоненту в представлении предложения для генерации полного представления предложения.Окончательное представление предложения можно рассчитать по следующей формуле: (8)
Когда α = 0, D-LSTM = MaLSTM.
Выходной уровень D-LSTM может быть изменен в соответствии с конкретной проблемой. В этом исследовании изучается схожесть предложений, и сходство между v ( a ) и v ( b ) может быть вычислено с помощью функции сходства.
Базовый и вспомогательный компоненты предложения описаны в следующих подразделах.
Базовый компонент
Базовый компонент содержит основную информацию о предложении. Распространенным методом получения базового компонента является модель набора слов, которая не учитывает порядок слов в предложении и напрямую получает представление предложения путем суммирования (или применения другого математического вычисления) представления слов, которое соответствует слово. Однако полученные таким образом представления предложений не учитывают важную информацию, такую как порядок каждого слова в предложении.Чтобы решить эту проблему, в данном исследовании была выбрана модель LSTM для изучения базового компонента предложения. Во-первых, D-LSTM преобразует каждое слово во входном предложении в вложение слов (в эксперименте использовались предварительно обученные векторы word2vec). Во-вторых, D-LSTM обновляет свое состояние памяти c t и скрытое состояние h t при каждом t ∈ {1,2,…, T } в соответствии с формулами (2) — (7). Наконец, модель генерирует набор C = { c 1 , c 2 ,…, c T }, который содержит все состояния памяти, и устанавливает H = { h 1 , h 2 ,…, h T }, который содержит все скрытые состояния, где T представляет собой общее количество слов в предложении.
Поскольку LSTM последовательно принимает входные данные и генерирует состояния памяти и скрытые состояния в текущий момент на основе выходных данных в предыдущий момент, состояния памяти и скрытые состояния, которые генерируются в конкретный момент, содержат всю ранее введенную информацию. Таким образом, в этой статье в качестве основного компонента предложения выбирается v basic = h T , что аналогично предложению Mueller et al.[19]. Например, как показано на рис. 2, и.
Опорный элемент
В дополнение к базовому компоненту вспомогательный компонент содержит вспомогательную информацию в представлении предложения в этой статье. Чтобы изучить вспомогательный компонент предложения, Stanford Parser [21], который представляет собой синтаксический анализатор естественного языка, который определяет грамматическую структуру предложений, такую как группы слов, которые идут вместе (например, как «фразы»), и слова которые представляют подлежащее или объект глагола, используются для выполнения синтаксического анализа зависимостей в предложениях.Всего наблюдается 37 универсальных синтаксических отношений, таких как номинальный субъект (nsubj), объект (obj) и косвенный объект (iobj). С лингвистической точки зрения предложение состоит из различных компонентов, таких как подлежащее, сказуемое, объект, атрибутивное прилагательное, наречивая фраза и дополнения. Из всех компонентов подлежащее, сказуемое и объект играют самые важные роли в предложении; таким образом, D-LSTM помечает слова в анализе, которые имеют отношение * subj (включая номинальный и клаузальный субъект), которое может идентифицировать подлежащее предложения, и * obj (включая прямой объект и косвенный объект), которое может идентифицировать предикат и объект предложения и генерирует горячий вектор v d .D-LSTM генерирует вспомогательный компонент по следующей формуле: (9) где — значение i-мерного измерения v d и h i ∈ H — скрытое состояние, которое соответствует i-му слову. Результаты, полученные с помощью Stanford Parser, перечислены в таблице 1.
Согласно результатам анализа, приведенным в таблице 1, и. Опорные компоненты можно рассчитать по формуле (9):
Эксперимент
Данные.
В эксперименте используются два набора данных: предложение, включающее набор данных композиционных знаний (SICK) и набор данных до обучения.
Набор данных SICK — это помеченный набор данных, содержащий 9927 (5000 для обучения / 4927 для тестирования) пар предложений [1]. Каждая пара предложений аннотирована меткой родства ∈ [1,5], которая соответствует средней степени родства, оцененной десятью разными людьми, и каждая из пар предложений SICK также была помечена как один из трех классов: следствие, противоречие или нейтральный , которые должны быть предсказаны для тестовых примеров.
Набор данных до обучения состоит из отдельных данных пары предложений, предоставленных для предыдущей задачи SemEval 2013 Semantic Textual Similarity. Набор данных до обучения содержит примерно 11000 пар предложений, которые также имеют метку ∈ [1,5] [22].
Оценка семантического родства
Оценочные метрики.
В задаче семантического родства есть три показателя оценки: коэффициент корреляции Пирсона, корреляция Спирмена и среднеквадратичная ошибка (MSE).Коэффициент корреляции Пирсона является официальной основой рейтинга, и мы в основном оцениваем модель на основе коэффициента корреляции Пирсона.
Коэффициент корреляции Пирсона (PCC), который также называют коэффициентом Пирсона r, является общей метрикой для задач семантического текстового сходства, а коэффициент корреляции продукта-момента Пирсона (PPMCC) или двумерная корреляция является мерой. линейной корреляции между двумя переменными X и Y. PPMCC имеет значение от +1 до -1, где 1 представляет полную положительную линейную корреляцию, 0 означает отсутствие линейной корреляции, а -1 представляет полную отрицательную линейную корреляцию [23 ].Цель задания — получить максимально возможную ОКК для тестовой выборки.
Коэффициент ранговой корреляции Спирмена между двумя переменными равен корреляции Пирсона между ранговыми значениями этих двух переменных [24]; тогда как корреляция Пирсона оценивает линейные отношения, корреляция Спирмена оценивает монотонные отношения (линейные или нет). Если нет повторяющихся значений данных, идеальная корреляция Спирмена +1 или -1 возникает, когда каждая из переменных является идеальной монотонной функцией другой.Интуитивно корреляция Спирмена между двумя переменными будет высокой, когда наблюдения имеют одинаковый (или идентичный, для корреляции 1) ранг (т. Е. Метку относительного положения наблюдений внутри переменной: 1-й, 2-й, 3-й и т. Д.) Между две переменные, и низкий, когда наблюдения имеют разный (или полностью противоположный, при корреляции -1) ранг между двумя переменными.
MSE оценщика (процедуры оценки ненаблюдаемой величины) измеряет среднее квадратов ошибок, то есть разницу между оценщиком и тем, что оценивается.MSE — это функция риска, соответствующая ожидаемому значению квадратичной потери ошибок или квадратичной потери [25].
Детали обучения.
D-LSTM имеет две версии: D-LSTM с предварительно обученными данными и D-LSTM без предварительно обученных данных.
Параметры D-LSTM инициализируются распределением Гаусса (μ = 0,0, σ = 0,02) и отдельным большим значением 2,5 для смещения затвора забывания, чтобы облегчить моделирование зависимости на больших расстояниях. В версии до обучения набор данных до обучения используется для предварительного обучения модели, а предварительно обученная модель будет продолжать обучаться в качестве начальной модели фазы обучения.
На этапе обучения используются 300-мерные вложения word2vec, и они не обновляются в процессе обучения. D-LSTM использует 50-мерные скрытые представления h t и ячейки памяти c t . Оптимизация параметров выполняется с использованием метода Ададелты Цайлера [26] и ограничения градиента (изменение масштаба градиентов, в которых норма превышает пороговое значение), чтобы избежать проблемы взрывных градиентов [27].
Результаты.
Мы реализуем MaLSTM (без калибровки регрессии и увеличения синонимов) и D-LSTM (предварительно обученные и без предварительно обученных версий) с Tensorflow. Код скоро станет общедоступным.
Значения r Пирсона, корреляции Спирмена и MSE для всех моделей, использующих данные испытаний SICK, перечислены в таблице 2. Названия моделей, выделенные жирным шрифтом, представляют модели с предварительным обучением, а числа в скобках представляют альфа-значения для модели.Первые четыре модели — самые популярные на SemEval 2014 [28].
Из результатов, показанных в таблице 2, D-LSTM (0,5) имеет лучший коэффициент корреляции Пирсона и коэффициент корреляции Спирмена на тестовом наборе, чем лучшие материалы SemEval 2014 и MaLSTM, независимо от того, прошли ли они предварительное обучение или нет. В то же время мы заметили, что D-LSTM (0,5) имеет немного худшую MSE, чем первая отправка SemEval 2014 года (примерно на 0,019 выше). Однако мы считаем, что MSE является нестабильной метрикой, и мы провели дополнительный эксперимент, чтобы показать, что MSE менее стабильна, чем корреляция Пирсона.Имея в общей сложности 4927 выборок в тестовом наборе, мы удалили 50 худших прогнозов модели (примерно 1%) и пересчитали коэффициент корреляции Пирсона и MSE. При этом мы обнаружили, что MSE изменилась на 7%, в то время как коэффициент корреляции Пирсона изменился только на 1%, что показывает, что по сравнению с MSE коэффициент корреляции Пирсона является относительно стабильным и надежным показателем оценки. Это также причина, по которой в большинстве задач на подобие в качестве основного показателя оценки используется коэффициент корреляции Пирсона, а не MSE.
Классификация происхождения
Оценочные метрики.
Каждая пара предложений SICK также относится к одному из трех классов: следствие, противоречие или нейтральный. Модели оцениваются с точки зрения точности классификации. Цель задачи — получить наивысшую точность тестового набора.
Детали обучения.
Мы используем наиболее эффективную модель в эксперименте на подобие, чтобы получить представление предложения, после чего мы вычисляем простые характеристики (также успешно использованные в [6]): поэлементные (абсолютные) различия,.Используя только эти возможности, мы обучаем SVM с радиальным базисом, используя тот же метод, что и [19], для классификации меток следования.
Результаты.
Точность тестового набора для всех моделей показана в таблице 3. Первые четыре модели являются лучшими представленными на SemEval 2014 [28], последняя модель представляет собой простую модель SVM с функциями, изученными D-LSTM, а остальные — недавно предложенные методы [29–31].
Обсуждение
Влияние поддерживающего компонента
против Supp на моделиЧтобы изучить изменения в производительности модели после добавления поддерживающего компонента, в этом разделе сравнивается D-LSTM (α = 0.5) с помощью MaLSTM. В этом эксперименте были исследованы обе версии каждой модели (предварительно обученная и необученная), и результаты показаны на рис. 3.
Рис. 3. Изменение коэффициента Пирсона на тренировочных шагах.
Горизонтальная ось представляет количество эпох обучения, а вертикальная ось представляет r Пирсона. Сплошная линия указывает на модель с предварительным обучением, а пунктирная линия указывает на модель без предварительного обучения (толстая линия указывает на D-LSTM, а тонкая линия указывает на MaLSTM).
https://doi.org/10.1371/journal.pone.0193919.g003
Кривая показывает, что производительность моделей MaLSTM и D-LSTM может быть улучшена путем предварительного обучения, и показывает, что D-LSTM имеет более высокий уровень подготовки. эффективность (коэффициент Пирсона у D-LSTM выше, чем у MaLSTM с теми же эпохами обучения). По окончании обучения D-LSTM имеет более высокий коэффициент Пирсона, чем MaLSTM. Хотя стандартный LSTM действительно уделяет достаточное внимание основной структуре предложения, наш D-LSTM включает эту структурную информацию при генерации представления предложения; таким образом, можно получить лучшее представление.
Влияние весового коэффициента α на обучение модели
Чтобы описать влияние различных весовых факторов на обучение модели, мы выбрали весовые коэффициенты α = 0,0 (такие же, как в MaLSTM), α = 0,2, α = 0,5 для дальнейшего анализа, и результаты показаны на рисунке 4 ( некоторые весовые коэффициенты не показаны, так как кривые частично перекрываются).
Рис. 4. Коэффициент Пирсона различных весовых коэффициентов на разных этапах тренировки.
Горизонтальная ось представляет количество эпох обучения, а вертикальная ось представляет значение r Пирсона.Пунктирная линия указывает на MaLSTM, жирная сплошная линия указывает на D-LSTM с α = 0,2, а тонкая сплошная линия указывает на D-LSTM с α = 0,5.
https://doi.org/10.1371/journal.pone.0193919.g004
Когда весовой коэффициент увеличивается в определенном диапазоне, наклон кривой увеличивается, что указывает на то, что параметры модели были лучше оптимизированы. Этот результат демонстрирует, что структурная информация предложения (которая в первую очередь относится к подлежащему, предикату и объекту) оказывает важное влияние на задачу сходства предложений.С увеличением доли структурной информации в представлении предложения модель может захватывать более мощные представления предложений для точной оценки сходства между предложениями.
Влияние весового коэффициента α на производительность модели
В этом разделе выбирается α ∈ {0.0,0.1,0.2,…, 1.0} для изучения влияния весового коэффициента на производительность модели. Значения r Пирсона для D-LSTM с каждым α показаны на рис. 5.
Рис 5.Коэффициент Пирсона D-LSTM с каждым весовым коэффициентом.
Горизонтальная ось представляет весовой коэффициент, а вертикальная ось представляет коэффициент Пирсона r. Пунктирная линия указывает на модель без предварительного обучения, а сплошная линия указывает на модель с предварительным обучением.
https://doi.org/10.1371/journal.pone.0193919.g005
Как показано на рис.5, значения r Пирсона для D-LSTM в тестовом наборе выше, чем значения r Пирсона для MaLSTM (α = 0.0), независимо от того, была ли модель предварительно обучена. Основываясь на тренде сплошной линии, значения r Пирсона для D-LSTM увеличиваются, а затем уменьшаются. Когда α ∈ [0,5,0,6], значение r Пирсона достигло максимума для тестового набора. И наоборот, пунктирная линия не подчиняется закону, подобному сплошной. Разница между сплошной и пунктирной линиями заключается в том, что в наборе данных SICK без данных предварительного обучения находится только 9927 пар предложений, и этого количества недостаточно для обучения подходящей модели LSTM.Дополнительные данные перед обучением расширяют возможности D-LSTM по захвату мощного представления.
Примеры прогнозов MaLSTM и D-LSTM
Для изучения конкретных предсказаний D-LSTM и MaLSTM после добавления вспомогательного компонента в этом разделе выбираются конкретные пары предложений из набора тестов, как показано в Таблице 4.
Для первой пары MaLSTM фокусируется только на основной информации предложения и уделяет минимальное внимание основным компонентам предложения.Таким образом, прилагательное «коричневый и белый» перед подлежащим «собака» мешает прогнозам MaLSTM, тогда как D-LSTM избегает этой проблемы, уделяя должное внимание подлежащему, сказуемому и объекту предложения. В третьей паре эти два предложения длиннее, чем первая пара, что указывает на большее количество шума, такого как «маленький», в предложении. Однако D-LSTM показывает удовлетворительные характеристики.
Для второй пары значения двух предложений противоположны, но структура двух предложений аналогична, и хотя эта информация соответствующим образом фиксируется D-LSTM, MaLSTM не распознает это открытие.В результате D-LSTM дает более точные прогнозы, чем MaLSTM. Четвертая пара предложений также имеет противоположные значения, хотя основное отличие состоит в том, что в последнем есть слово «не», которое может сильно повлиять на значение предложения (особенно при анализе настроений). Это различие действительно влияет на прогнозы MaLSTM. Однако D-LSTM может ослабить влияние «не» на представление предложения с помощью анализа зависимостей, что позволяет D-LSTM сосредоточить больше внимания на человеке / резке / пластине в предложении, чем на других компонентах.Таким образом, предсказание D-LSTM похоже на истинную метку.
Выводы
В этой статье предлагается новая модель D-LSTM для изучения мощных представлений предложений, которые разделены на две части: базовый компонент и вспомогательный компонент. D-LSTM изучает базовый и вспомогательный компоненты предложения различными методами. Для изучения базового компонента D-LSTM использует стандартную сеть LSTM. Чтобы преодолеть нехватку помеченных данных, обучающие данные были расширены дополнительными парами предложений.Чтобы изучить вспомогательный компонент, D-LSTM использует предварительно обученный синтаксический анализатор для анализа входного предложения, а затем маркирует субъект, предикат и объект в предложении для создания представления зависимости и, наконец, изучает вспомогательный компонент. Весовой коэффициент α вводится для корректировки важности основного и вспомогательного компонентов и изучения представления предложения.
Это исследование экспериментально продемонстрировало, что увеличение доли поддерживающего компонента в представлении предложения увеличивает мощность представления.Влияние весового коэффициента α на тренировочный процесс и результаты было тщательно исследовано. Результаты показывают, что увеличение значения весового коэффициента улучшает эффективность обучения в определенном диапазоне, а также производительность модели. Чтобы объяснить, почему производительность D-LSTM превосходит стандартную LSTM, в этой статье были выбраны пары предложений в тестовом наборе и сопоставлены их прогнозы. В предложениях с большим количеством прилагательных или поворотных слов, таких как «не», D-LSTM может ослабить шум и изучить более мощные представления предложений, что полезно для выявления сходства между предложениями.
Благодарности
Работа над этой статьей поддержана Национальным фондом естественных наук Китая (№ 61572434 и № 61303097).
Список литературы
- 1. Марелли М., Бентивогли Л., Барони М., Бернарди Р., Менини С., Зампарелли Р. и др. SemEval @ COLING. 2014: 1–8.
- 2. Миколов Т., Чен К., Коррадо Г., Дин Дж. Эффективная оценка представлений слов в векторном пространстве. arXiv: 1301.3781v3 [Препринт]. 2013 [цитируется 27 декабря 2017 года]: [12 стр.]. Доступно по ссылке: https://arxiv.org/abs/1301.3781
- 3. Миколов Т., Суцкевер И., Чен К., Коррадо Г., Дин Дж. Распределенные представления слов и фраз и их композиционность. Достижения в области нейронных систем обработки информации. 2013: 3111–3119.
- 4. Айер М., Манджуната В., Бойд-Грабер Дж. Глубокая неупорядоченная композиция соперничает с синтаксическими методами классификации текста. ACL (1). 2015: 1681–1691.
- 5. Кирос Р., Чжу Ю., Салахутдинов Р. Р., Земель Р., Уртасун Р. Торральба А.Пропускные векторы. Достижения в области нейронных систем обработки информации. 2015: 3294–3302.
- 6. Тай К. С., Сочер Р., Мэннинг С. Д. Улучшенные семантические представления из древовидных сетей с долговременной краткосрочной памятью. arXiv: 1503.00075v3 [Препринт], 2015 [цитируется 27 декабря 2017 года]: [11 стр.]. Доступно по ссылке: https://arxiv.org/abs/1503.00075
- 7. Ле Кью, Миколов Т. Распределенные представления приговоров и документов. Материалы 31-й Международной конференции по машинному обучению (ICML-14).2014: 1188–1196.
- 8. Хохрайтер С., Шмидхубер Дж. Долговременная кратковременная память. Нейронные вычисления, 1997, 9 (8): 1735–1780. pmid: 9377276
- 9. Грейвс А. Разметка контролируемых последовательностей с помощью рекуррентных нейронных сетей. Springer Science & Business Media. 2012.
- 10. Суцкевер И., Виньялс О., Ле К. В. Последовательность для последовательного обучения с помощью нейронных сетей. Достижения в области нейронных систем обработки информации. 2014: 3104–3112.
- 11.Bengio Y, Ducharme R, Vincent P, Jauvirr C. Нейронная вероятностная языковая модель. Журнал исследований машинного обучения. 2003, 3 (фев): 1137–1155.
- 12. Bengio Y, Simard P, Frasconi P. Изучение долгосрочных зависимостей с помощью градиентного спуска сложно. IEEE-транзакции в нейронных сетях. 1994, 5 (2): 157–166. pmid: 18267787
- 13. Герс Ф. А., Шмидхубер Дж. Повторяющиеся сети, которые время и счет. Нейронные сети, 2000. IJCNN 2000, Труды международной совместной конференции IEEE-INNS-ENNS по.IEEE, 2000, 3: 189–194. DOI: 10.1109 / IJCNN.2000.861302
- 14. Чо К., Ван Мерриенбоер Б., Гульчере С., Бахданау Д., Бугарес Ф., Хольгер Швенк и др. Изучение представлений фраз с использованием кодировщика-декодера RNN для статистического машинного перевода. arXiv: 1406.1078v3 [Препринт]. 2014 [цитируется 27 декабря 2017 года]: [15 стр.]. Доступно по ссылке: https://arxiv.org/abs/1406.1078
- 15. Грефф К., Шривастава Р. К., Коутник Дж. LSTM: поисковая космическая одиссея. Транзакции IEEE в нейронных сетях и обучающих системах, 2016 г.pmid: 27411231
- 16. Чопра С., Хадселл Р., Лекун Ю. Дискриминационное изучение метрики сходства с применением проверки лицом к лицу. Компьютерное зрение и распознавание образов, 2005. CVPR 2005. Конференция компьютерного общества IEEE, посвященная. IEEE, 2005: 539–546 т. 1. DOI: 10.1109 / CVPR.2005.202
- 17. Норузи М., Флит Д. Дж., Салахутдинов Р. Дистанционное метрическое обучение Хэмминга. Международная конференция по системам обработки нейронной информации (NIPS 2012). 2012: 1061–1069.
- 18. Кентер Т., Борисов А., де Рийке М. Сиамский язык: Оптимизация встраивания слов для представлений предложений. arXiv: 1606.04640v1 [Препринт]. 2016 [цитируется 27 декабря 2017 года]: [11 стр.]. Доступно по ссылке: https://arxiv.org/abs/1606.04640
- 19. Мюллер Дж., Тьягараджан А. Сиамские рекуррентные архитектуры для изучения сходства предложений. Тридцатая конференция AAAI по искусственному интеллекту. AAAI Press, 2016: 2786–2792.
- 20. Йих В., Тутанова К., Платт Дж. С., Мик К.Изучение дискриминационных проекций для измерения текстового сходства. Труды пятнадцатой конференции по компьютерному изучению естественного языка. Ассоциация компьютерной лингвистики, 2011: 247–256.
- 21. Данки Чен и Кристофер Д. Мэннинг. Быстрый и точный парсер зависимостей с использованием нейронных сетей. Труды ЕМНЛП 2014.
- 22. Agirre E, Cer D, Diab M, Gonzalez-agirre A, Guo W. sem 2013 общая задача: семантическое текстовое сходство, включая пилотную проверку типизированного подобия.В * SEM 2013: Вторая совместная конференция по лексической и вычислительной семантике. Ассоциация компьютерной лингвистики. 2013.
- 23. Коэффициент корреляции Пирсона [Интернет]. Википедия. Фонд Викимедиа; 2017 [цитируется 28 декабря 2017 г.]. Доступно по ссылке: https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
- 24. Коэффициент ранговой корреляции Спирмена [Интернет]. Википедия. Фонд Викимедиа; 2017 [цитируется 28 декабря 2017 г.]. Доступно по адресу: https: // en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
- 25. Среднеквадратичная ошибка [Интернет]. Википедия. Фонд Викимедиа; 2017 [цитируется 28 декабря 2017 г.]. Доступно по ссылке: https://en.wikipedia.org/wiki/Mean_squared_error
- 26. Цайлер М. Д. АДАДЕЛТА: Метод адаптивной скорости обучения. arXiv: 1212.5701v1 [Препринт]. 2012 [цитируется 27 декабря 2017 года]: [6 стр.]. Доступно по ссылке: https://arxiv.org/abs/1212.5701
- 27. Паскану Р., Миколов Т., Бенжио Ю.О сложности обучения рекуррентных нейронных сетей. Компьютерные науки, 2013, 52 (3): 337–345.
- 28.
СемЭваль-2014 Задача 1 [Интернет]. Результаты
- 29. Льен Э., Куйлеков М. Семантический анализ текстового следования. Материалы 14-й Международной конференции по технологиям парсинга. 2015: 40–49.
- 30. Абзианидзе Л.Tableau Prover для естественной логики и языка. ЕМНЛП. 2015: 2492–2502.
- 31. Bowman S R, Angeli G, Potts C. Большой аннотированный корпус для изучения логического вывода на естественном языке.