Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: нимфажр сейчас жнбагор 1 секунда назад руина 1 секунда назад сапотьсо 1 секунда назад таркарс 1 секунда назад ч а т т о с а 1 секунда назад иаклапт 1 секунда назад аливрз 1 секунда назад некрофобия 2 секунды назад и к а т н з и щ 2 секунды назад кордебалетные 2 секунды назад попарывать 2 секунды назад цвтикра 2 секунды назад п т е о р з 2 секунды назад сиюонкз 3 секунды назад
Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Использование некоторых словоформ тоже имеет несколько вариаций.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- определить его корректное написание;
- понять, как правильно в нем ставить ударение.
Площадка предлагает ознакомиться с историей возникновения слова. Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.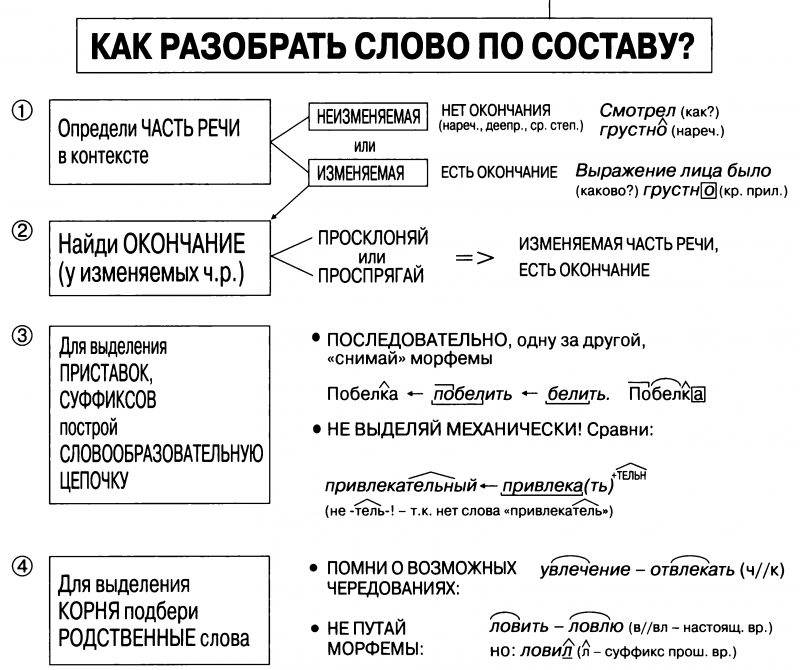
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций. Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
в состояние деятельности 1 секунда назад
инуоткзя 1 секунда назад
отдавливавшему 1 секунда назад
асорова 1 секунда назад
сжитом 2 секунды назад
водим 2 секунды назад
ломитав 2 секунды назад
ачкапр 2 секунды назад
надежность 2 секунды назад
на еженедельной основе 3 секунды назад
адыля 5 секунд назад
реалистка 5 секунд назад
чития 7 секунд назад
гфенома 7 секунд назад
взошедши 7 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | катапульта | 0 слов | 1 час назад | 213. 24.125.32 24.125.32 |
| Алина | превысокомногорассмотрительствующий | 30 слов | 2 часа назад | 217.66.152.207 |
| Игрок 3 | арбуз | 13 слов | 2 часа назад | 93.80.180.10 |
| Игрок 4 | социопат | 42 слова | 2 часа назад | 93.80.180.10 |
| Анчоус | социопат | 40 слов | 3 часа назад | 95.86.212.225 |
| Игрок 6 | кот | 1 слово | 10 часов назад | 94.233.248.234 |
| Игрок 7 | лихорадочная | 21 слово | 11 часов назад | 188.170.72.59 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | товарищ | 22:30 | 14 минут назад | 46. 138.3.86 138.3.86 |
| Игрок 2 | хирот | 48:51 | 30 минут назад | 176.98.51.142 |
| Игрок 3 | сопун | 53:54 | 38 минут назад | 176.98.51.142 |
| Игрок 4 | пончо | 51:60 | 2 часа назад | 81.177.127.98 |
| Игрок 5 | яство | 42:43 | 2 часа назад | 95.153.176.65 |
| Игрок 6 | отток | 26:26 | 3 часа назад | 178.35.31.97 |
| Игрок 7 | облов | 50:53 | 3 часа назад | 81.177.127.98 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Владдевственница | На двоих | 15 вопросов | 3 часа назад | 95. 86.212.225 86.212.225 |
| Аня Великая | На двоих | 20 вопросов | 3 часа назад | 95.86.212.225 |
| Абобус | 10 вопросов | 4 часа назад | 176.99.82.36 | |
| Катя | На одного | 15 вопросов | 4 часа назад | 89.250.8.156 |
| Аня | На одного | 10 вопросов | 7 часов назад | 94.28.144.113 |
| Алексей | На двоих | 20 вопросов | 10 часов назад | 85.140.5.189 |
| Ррен | На одного | 5 вопросов | 13 часов назад | 80.83.234.27 |
| Играть в Чепуху! | ||||
Лекция 9: Разбор
Источник: лекция9. мд
1/36
мд
1/36В этой главе мы разработаем нисходящий синтаксический анализатор LL, который может обнаруживать контекстно-зависимые грамматики.
Источник: лекция9.мд 2/36Синтаксический анализатор — это программный компонент, который берет входные данные (часто текст) и строит структуру данных — часто какое-то дерево синтаксического анализа, абстрактное синтаксическое дерево или другую иерархическую структуру — предоставляя структурное представление входных данных, проверяя правильность синтаксиса в процесс.
Википедия
Источник: лекция9.мд 3/36введите Парсер[+A] = Location => XorErrors[String, (A, Int)]
Разработан на основе тех же концепций функционального дизайна, которые дали нам:
ТипRand[A] = RNG => (A, RNG)Источник: лекция9.мд 4/36
класс корпуса Местоположение(
ввод: строка, смещение: целое число) {
. ..
}
..
}
 ..
}
..
}
A Парсер[+A] будет сканировать свой ввод с заданного смещения.
Location("foobar", 3) — парсер будет смотреть на «bar».
Это контрастирует с альтернативным подходом, который делает смещение ненужным: сокращение входной строки. Тогда отзыв Parser менее информативен.
Альтернатива — обрезание потребленных символов строки и прохождение по хвосту. Первая часть строки теряется, если в строке возникает ошибка.
Источник: лекция9.мд 5/36Слева: парсер отклоняет ввод
Справа: Парсер принимает ввод
XorErrors[Строка, (A, Целое)] // эквивалентно Xor[NonEmptyList[String], (A, Int)]Источник: лекция9.мд 6/36
Внутри Слева :
NonEmptyList[String] накапливает ошибки.
Эти String должны объяснить, почему Parser[+A] отклонил ввод.
Внутри Справа :
(A, Int) содержит токен типа A и количество символов, использованных для создания этого токена.
Мы будем разрабатывать различные типы токена .
Источник: лекция9.мд 8/36 Здесь токен равен Строка .
строка определения (обнаружение: строка): Parser [String] =
(место: Местоположение) => {
val соответствует: Boolean =
обнаружить.regionMatches(0, loc.input,
лок.смещение, обнаружение.длина())
если (совпадает)
Правильно((обнаружить, обнаружить.длина()))
еще
Слева(НепустойСписок(
s"$обнаружить не в ${loc.input}
по смещению ${loc.offset}"
))
}
Источник: лекция9.мд
9/36 Для наших парсеров требуется Местоположение в качестве входных данных. Это оборачивает ввод в
Это оборачивает ввод в Location .
def run[A](parserA: Parser[A])(ввод: строка): XorErrors[Строка, (A, Целое)] = parserA (Местоположение (ввод, 0))Источник: лекция9.мд 10/36
val detectFoo: Parser[String] = строка("foo")
val документ = "foobar"
вал результатFoo:
XorErrors[Строка, (Строка, Целое число)] =
запустить (обнаружитьFoo) (документ)
// `parserResultToString`
// красиво форматирует вывод `Xor`
println(parserResultToString(resultFoo))
Источник: лекция9.мд
11/36 [информация] Запуск slideCode.lecture9.SimpleParser...
документ
фубар
обнаружить «foo»
Правильно: принять. дерево токенов = foo |
потребляемые символы = 3
Нам нужен парсер «конец поля»; эквивалентно регулярному выражению $ или \z .
scala> "\\z".Источник: лекция9.мд 13/36
 r
res1: scala.util.matching.Regex = \z
scala> "\\z".r.regex
res2: Строка = \z
r
res1: scala.util.matching.Regex = \z
scala> "\\z".r.regex
res2: Строка = \z
// пример ввода: "\\z".r def регулярное выражение (r: регулярное выражение): Parser [String] = строка (r.регулярное выражение)
регулярное выражение создает Parser[String] , который будет принимать заданный Scala Regex
значение: Parser[String] =
регулярное выражение("\\z".r)
Теперь у нас есть парсер «конец поля», эквивалентный «$»
Источник: лекция9.мд 14/36 val detectFoo: Parser[String] = строка("foo")
val eof: Parser[String] = регулярное выражение("\\z".r)
Источник: лекция9.мд
15/36 продукт последовательно ставит два парсера.
по определению продукт[A,B](parserA: Parser[A],
parserB: => Парсер[B]):
Парсер[(А,В)] = {
def f(a: A, b: => B): (A,B) = (a,b)
map2 (парсерA, парсерB) (f)
}
Если оба синтаксических анализатора примут их ввод, они создадут токены А и В .
Parser[A] потребляет столько, сколько ему нужно, затем устанавливает смещение для Parser[B] .
map2 и его зависимости будут показаны позже.
val detectFooEOF = продукт (detectFoo, eof) val resultFooEOF = запустить (обнаружитьFooEOF) (документ) println (parserResultToString (resultFooEOF))Источник: лекция9.мд 17/36
документ
фубар
обнаружить 'foo' с концом поля
Слева: Отклонить.
Ошибки синтаксического анализа: \z не в foobar по смещению 3
Источник: лекция9.мд
18/36 по умолчанию flatMap[A,B](parserA: Parser[A])
(aParserB: A => Parser[B]): Parser[B] = ...
def map[A,B](parserA: Parser[A])
(f: A => B): Parser[B] = ...
def map2[A,B,C](parserA: Parser[A],
parserB: => Парсер[B])
(f: (A,=>B)=>C): Parser[C] = . ..
Источник: лекция9.мд
19/36 ..
..
Напомним, что единица для рандов всегда генерировала одно и то же «случайное» значение.
по определению единица [A] (a: A): ранд [A] = кольцо => (а, кольцо)
Аналогично, блок для Парсер всегда принимает .
по определению преуспевает [A] (a: A): Parser [A] = (loc: Location) => Right((a, 0)) def unit[A](a: A): Parser[A] = success(a)Источник: лекция9.мд 20/36
Напомним, что при использовании комбинаторов Rand ,
ГСЧ было передано неявно . На одну ошибку меньше — неправильное обращение с RNG .
Rand[A] = RNG => (A, RNG)Источник: лекция9.мд 21/36
В Парсер ,
Location(input, offset) передается неявно.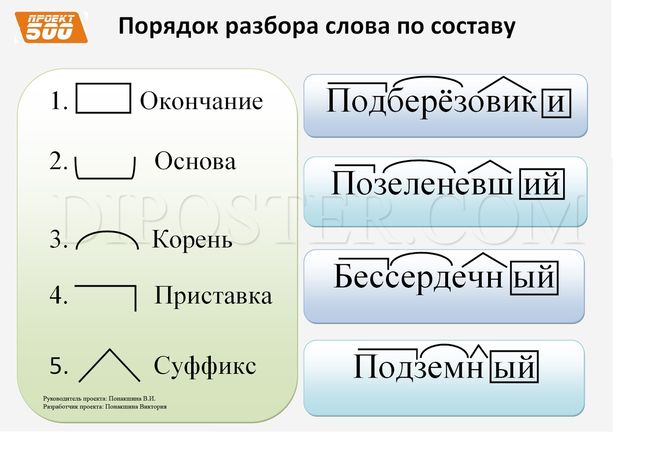
введите Парсер[+A] = Location => XorErrors[String, (A, Int)]
Правая часть Xor используется для увеличения Location — потребления символов входной строки.
по определению advanceParserResult[A]( xor: XorErrors[String,(A,Int)], потребляемый: Int): XorErrors[String, (A, Int)] = ...Источник: лекция9.мд 22/36
Мы упоминали ранее:
» Парсер[А] потребляет столько, сколько нужно, затем устанавливает смещение для Parser[B] .»
по определению продукт[A,B](parserA: Parser[A],
parserB: => Парсер[B]):
Парсер[(А,В)] = {
def f(a: A, b: => B): (A,B) = (a,b)
map2 (парсерA, парсерB) (f)
}
Вы где-нибудь здесь видите Location или offset ? Передается неявно .
def or[A](p1: Parser[A], p2: => Parser[A]): Парсер[А] = .
 ..
..
или — это наша первая подсказка, что мы строим LL Parser для самого левого принятого производного дерева синтаксиса.
Мы отдаем приоритет левому вводу или .
запечатанная черта Алфавит класс case X (вложенный: Алфавит) расширяет Алфавит класс case Y (вложенный: Алфавит) расширяет Алфавит case объект Z расширяет алфавитИсточник: лекция9.мд 25/36
«Пуск» -> Х
Х -> хУ
Y -> уX | YZ
Я -> Я
Принято:
«xyz» в X(Y(Z))
«xyxyxyz» в X(Y(X(Y(X(Y(Z))))))
«xyxyxyxyxyz» в X(Y(X(Y(X(Y(X(Y(X(Y(Z))))))))))
Отклонено:
«xxxyyyz»
«xyyyz»
(хотя 9Токены 0019 X , Y и Z могут содержать эти строки)
 мд
26/36
мд
26/36 документ: xyxyxyxyz
Правильно: принять.
дерево токенов = X(Y(X(Y(X(Y(X(Y(Z))))))))
потребляемые символы = 9
------------
документ: xyyyxyz
Слева: Отклонить.
Ошибки разбора:
x не в xyyyxyz по смещению 2
z не в xyyyxyz по смещению 2
Источник: лекция9.мд
27/36 запечатанная черта Алфавит
класс case AC (вложенный: Алфавит) расширяет Алфавит {
переопределить def toString = "A"+nested.toString+"C"
}
case объект B расширяет алфавит {
переопределить определение toString = "B"
}
Источник: лекция9.мд
28/36«Пуск» -> аБк
Б -> аБк | б
Принято:
«abc» в AC(B)
«aabcc» в AC(AC(B))
Отклонено:
«ааабсс»
«ааббсс»
Источник: лекция9.мд 29/36// Последовательности двух парсеров, // игнорируя результат первого.Источник: лекция9.мд 30/36
 def skipL[B](p: Parser[Any], p2: => Parser[B]):
Парсер[B] =
map2(p, p2)((_,b) => b)
// Последовательность двух парсеров,
// игнорируя результат второго.
def skipR[A](p: Parser[A], p2: => Parser[Any]):
Парсер[А] =
карта2(р, р2)((а,_) => а)
def skipL[B](p: Parser[Any], p2: => Parser[B]):
Парсер[B] =
map2(p, p2)((_,b) => b)
// Последовательность двух парсеров,
// игнорируя результат второго.
def skipR[A](p: Parser[A], p2: => Parser[Any]):
Парсер[А] =
карта2(р, р2)((а,_) => а)
def Surround[A](слева: Parser[Any],
справа: парсер[любой])
(посередине: => Parser[A]): Parser[A] =
skipL(слева, skipR(посередине, справа))
// необходимо для "aBc"
Источник: лекция9.мд
31/36Разбор без EOF в конце
[информация] Запуск slideCode.lecture9.ABC
документ: абв
Правильно: принять. дерево токенов = ABC |
потребляемые символы = 3
---------------------------
документ: abcccc
Правильно: принять. дерево токенов = ABC |
потребляемые символы = 3
Источник: лекция9.мд
32/36Разбор с EOF в конце
документ: abcccc Слева: Отклонить.Источник: лекция9.мд 33/36 Источник: лекция9.мд 34/36
 Ошибки разбора: \z не в abcccc
по смещению 3
---------------------------
документ: aaabccc
Правильно: принять. дерево токенов = AAABCCC |
потребляемые символы = 7
Ошибки разбора: \z не в abcccc
по смещению 3
---------------------------
документ: aaabccc
Правильно: принять. дерево токенов = AAABCCC |
потребляемые символы = 7
Глава в основном посвящена функциональному дизайну
Это сложное первое знакомство с синтаксическим анализом и грамматиками
Фиксация— важная функция, которую мы упустили. Это дает пользователю парсера контроль над поиском с возвратом.- Наша реализация всегда откатывается, когда это возможно.
- Иногда полезно заблокировать поиск с возвратом и отклонить его.
Наша упрощенная реализация жестко связывает Parser как:
введите Парсер[+A] = Location => XorErrors[String, (A, Int)]
Реализация книги значительно сложнее.
В книге тип Parser часто меняется в главе, чтобы продемонстрировать нисходящие рассуждения о возможных реализациях и алгебраическом дизайне. Исследуются различные входы и выходы Parser[+A] .
отказ: Аргументы
В руководстве мы указали тип аргумента опции следующим образом:
импорт com.monovore.decline._
импортировать java.nio.file.Path
val path = Opts.option[Path]("input", "Путь к входному файлу.")
// путь: Opts[Path] = Opts(--input <путь>)
Это делает для нас две разные вещи:
- Указывает функцию разбора — когда пользователь передает строку в качестве аргумента,
откажусьпостараюсь и интерпретировать его как путь и сообщить об ошибке, если это не так. - Указывает «метавар» по умолчанию — текст
<путь>, который вы можете увидеть в выводе выше. Это помогает пользователю понять, какой ввод ваша программа ожидает в этой позиции.

Эта информация предоставляется классом типов com.monovore.decline.Argument . reject предоставляет экземпляры для многих часто используемых типов стандартных библиотек: строк, чисел, путей, URI…
java.time поддержка reject имеет встроенную поддержку библиотеки java.time , представленной в Java 8,
включая экземпляры аргументов для Duration , ZonedDateTime , ZoneId , Instant и другие.
Вам нужно будет получить их с помощью явного импорта:
импортировать java.time._
импортировать com.monovore.decline.time._
val fromDate = Opts.option[LocalDate]("fromDate", help = "Локальная дата, с которой начать просмотр данных")
// fromDate: Opts[LocalDate] = Opts(--fromDate )
val timeout = Opts.option[Duration]("timeout", help = "Timeout Operation")
// время ожидания: Opts[Duration] = Opts(--timeout )
По умолчанию анализируется с использованием стандартных форматов ISO 8601. Если вы хотите использовать собственный формат времени,
Если вы хотите использовать собственный формат времени, reject также предоставляет Argument компоновщиков, которые принимают java.time.format.DateTimeFormatter .
Например, вы можете определить собственный синтаксический анализ для LocalDate , вызвав localDateWithFormatter :
импорт java.time.format.DateTimeFormatter
импортировать com.monovore.decline.time.localDateWithFormatter
val myDateArg: Аргумент[LocalDate] = localDateWithFormatter(
DateTimeFormatter.ofPattern("дд/мм/гг")
)
// myDateArg: Argument[LocalDate] = Argument()
Как правило, для любого типа даты или времени должен быть доступен метод xWithFormatter .
усовершенствованный опора reject поддерживает уточненные типы через модуль reject-refined .
Уточненные типы добавляют дополнительный уровень безопасности, украшая стандартные типы предикатами, которые проходят проверку. автоматически во время компиляции.
Хотя аргументы командной строки не могут быть проверены во время компиляции,
Проверка во время выполнения усовершенствованных типов аргументов все еще может предотвратить
введение недопустимых значений пользователем.
автоматически во время компиляции.
Хотя аргументы командной строки не могут быть проверены во время компиляции,
Проверка во время выполнения усовершенствованных типов аргументов все еще может предотвратить
введение недопустимых значений пользователем.
Чтобы использовать reject-refined , добавьте в свой build.sbt следующее:
libraryDependencies += "com.monovore" %% "отклонение уточнения" % "2.4.1"
В качестве примера давайте определим простой уточненный тип и используем его в качестве аргумента командной строки.
импорт eu.timepit.refined.api.Refined
импортировать eu.timepit.refined.numeric.Positive
импортировать com.monovore.decline.refined._
тип PosInt = Int уточненный положительный
val lines = Command("lines", "Разобрать положительное количество строк.") {
Opts.argument[PosInt]("количество")
}
// строки: Command[PosInt] = com.monovore.decline.Command@112e43cf
Мы видим, что положительные числа обрабатываются корректно, но значения, равные нулю или меньшему, не сработают:
строк.
 parse(Seq("10"))
// res0: Либо[Help, PosInt] = Right(10)
строки.parse(Seq("0"))
// res1: Both[Help, PosInt] = Left(Предикат не выполнен: (0 > 0).
//
// Использование: строк <количество>
//
// Разбираем положительное количество строк.
//
// Опции и флаги:
// --помощь
// Показать этот текст справки.)
parse(Seq("10"))
// res0: Либо[Help, PosInt] = Right(10)
строки.parse(Seq("0"))
// res1: Both[Help, PosInt] = Left(Предикат не выполнен: (0 > 0).
//
// Использование: строк <количество>
//
// Разбираем положительное количество строк.
//
// Опции и флаги:
// --помощь
// Показать этот текст справки.)
перечисление ПоддержкаNB: начиная с версии 2.1 и перехода на Scala 3, 9Поддержка перечисления 0019 прекращена. Если вы все еще используете перечисление
для Scala 2, вы можете придерживаться либо более старой версии, либо переопределить… реализацияArgumentдляEnumEntryобычно проста.
reject также поддерживает enumeratum через модуль reject-enumeratum .
Enumeratum предоставляет мощную Scala-идиоматическую и удобную для Java реализацию перечислений.
Чтобы использовать enumeratum , добавьте в свой build. следующее: sbt
sbt
libraryDependencies += "com.monovore" %% "decline-enumeratum" % "2.4.1"
Например,
мы определим простое перечисление в соответствии с требованиями enumeratum ,
и используйте его как аргумент командной строки:
импорт _root_.enumeratum._
импортировать com.monovore.decline.enumeratum._
запечатанная черта Color расширяет EnumEntry с помощью EnumEntry.Lowercase
цвет объекта расширяет Enum[Color] {
случай объект Красный расширяется Цвет
case объект Зеленый расширяет цвет
случай объект Синий расширяется Цвет
значения val = findValues
}
val color = Command("color", "Вернуть выбранный цвет.") {
Опц.аргумент[Цвет]()
}
Этот синтаксический анализатор должен успешно прочитать красный , зеленый или синий , и потерпеть неудачу на чем-либо еще.
(Примечание: парсеры чувствительны к регистру!)
color.parse(Seq("красный"))
color.parse(Seq("черный"))
color. parse(Seq("Красный"))
 parse(Seq("Красный"))
parse(Seq("Красный"))
перечисление также поддерживает перечисления значений , которые являются перечислениями, основанными на значении, отличном от фактического
имя значения перечисления. Вот тот же тип перечисления, что и раньше, но подкрепленный целым числом:
импорт _root_.enumeratum.values._
импортировать com.monovore.decline.enumeratum._
запечатанный абстрактный класс IntColor (значение значения: Int) расширяет IntEnumEntry
объект IntColor расширяет IntEnum[IntColor] {
объект case Red расширяет IntColor(0)
объект case Зеленый расширяет IntColor(1)
объект case Blue расширяет IntColor(2)
значения val = findValues
}
val intColor = Command("int-color", "Показывает выбранный цвет") {
Опц.аргумент[IntColor]()
}
Анализаторы значений ожидают базовое значение перечисления.
Наш новый Синтаксический анализатор IntEnum потерпит неудачу на чем угодно, кроме 0 , 1 или 2 .
intColor.parse(Seq("0"))
intColor.parse(Seq("красный"))
intColor.parse(Seq("8"))
Определение собственного
В некоторых случаях вам может потребоваться аргумент командной строки, который не совсем соответствует какому-либо предоставленному типу. Допустим, у вас есть следующий тип конфигурации «ключ-значение»:
. Конфигурация класса корпуса(ключ: строка, значение: строка)
Вы можете определить опцию, которая собирает список конфигов, указав настраиваемый метавар и добавление дополнительной логики проверки и синтаксического анализа:
импорт котов.данные.Проверено
Opts.option[String]("config", "Укажите дополнительную конфигурацию", metavar = "ключ:значение")
.mapValidated {строка =>
string.split(":", 2) соответствует {
case Массив (ключ, значение) => Validated.valid (Config (ключ, значение))
case _ => Validated.invalidNel(s"Неверная пара ключ:значение: $string")
}
}
// res2: Opts[Config] = Opts(--config <ключ:значение>)
В большинстве случаев это работает отлично! Однако для более крупных приложений —
где многие различные параметры, подкоманды или программы могут захотеть использовать это
один и тот же базовый тип конфигурации — делать такие вещи каждый раз многословно и
подвержен ошибкам.
Достаточно просто связать вместе метавары и логику синтаксического анализа в экземпляре Аргумент :
неявное значение configArgument: Argument[Config] = new Argument[Config] {
определение чтения (строка: строка) = {
string.split(":", 2) соответствует {
case Массив (ключ, значение) => Validated.valid (Config (ключ, значение))
case _ => Validated.invalidNel(s"Неверная пара ключ:значение: $string")
}
}
def defaultMetavar = "ключ:значение"
}
// configArgument: Argument[Config] = Argument()
…и затем определение новых опций, которые принимают конфиги, становится тривиальным:
Opts.option[Config]("config", "Укажите дополнительную конфигурацию")
// res3: Opts[Config] = Opts(--config <ключ:значение>)
Отсутствующие экземпляры
В некоторых случаях снижение намеренно , а не определило экземпляр Аргумента для определенного типа — поскольку
являются лучшими способами добиться того же эффекта. Некоторые примеры:
Некоторые примеры:
-
Булево значение: поддержкаBooleanаргументов, таких какOpts.option[Boolean]("verbose", ???)приведет к использованию командной строки, напримерmy-command --verbose true… но пользователи других инструментов командной строки POSIX ожидаютmy-command --verbose. Вы можете получить этот более идиоматический стиль с помощьюOpts.flag("verbose", ???).orFalse; рассмотрите возможность использования этого вместо этого! -
java.io.File,java.net.URL: эти типы в основном заменены лучшими альтернативами (java.nio.file.Pathиjava.net.URIсоответственно), и они поддерживают простые преобразования в старые типы для взаимодействия с существующим кодом. -
List[A]: вы можете ожидать, что сможете определитьOpts.option[List[String]](...)для разбора списка разделенных запятыми строки, например--exclude foo,bar.
