Справочный раздел Приемы самоконтроля при орфографической проверке
Чтение орфографическое
Самодиктант
Изучение правил на допущенные ошибки.
Заучивание правописания словарных слов.
Разбор слова по частям: корень, суффикс, приставка. Подбор одноморфемных слов.
Проверка гласного звука в корне (поставить под ударение).
Что такое «орфографическое» чтение?
Это чтение слова так, как оно написано. Обычно мы пишем ВОДА, а читаем [вада], пишем СЧАСТЬЕ, а читаем [щастье], пишем ДРУГ, а читаем [друк]. При орфографическом чтении будем читать [вода], [счастье], [друг].
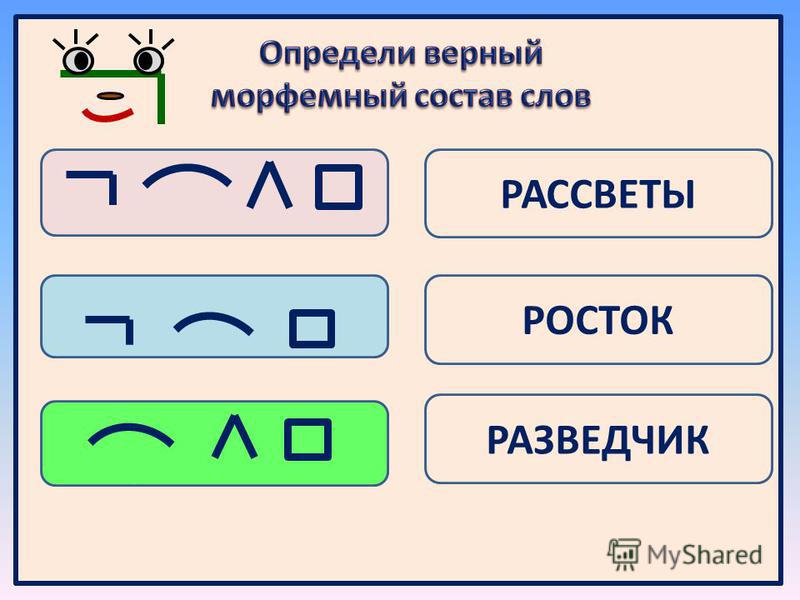
Как разобрать слово по составу?
Разобрать
слово по составу – это выделить его
части: корень, приставку, суффикс,
окончание. Многие части русских слов
пишутся одинаково: С-казать и С-делать
(слышится: [Ск]азать, но [Зд]елать). Как
только вы установили, из каких частей
состоит слово, почти наверняка вы сможете
его правильно записать.
Как
только вы установили, из каких частей
состоит слово, почти наверняка вы сможете
его правильно записать.
Разбор слова по составу начинается с выделения окончания и основы. Прежде чем выделить окончание установите, изменяется ли слово по родам, числам, падежам, лицам. К неизменяемым словам в русском языке относятся: наречие (тихо), некоторые существительные и прилагательные иноязычного происхождения (шоссе, бордо), неопределенная форма глагола (бежать), деепричастие (читая), сравнительная степень прилагательного (более), предлоги, частицы, союзы (в, потому что, ли, же). Неизменяемые слова не имеют окончания.
Чтобы выделить окончание изменяемого
слова, нужно подобрать другую форму
этого же слова и сравнить ее с данной: лесной, лесная, лесными; сделаю,
сделаешь, сделают. Изменяемая часть
этих форм: -ОЙ, -АЯ,-ЫМИ-; -Ю, -ЕШЬ, -ЮТ- это
окончание.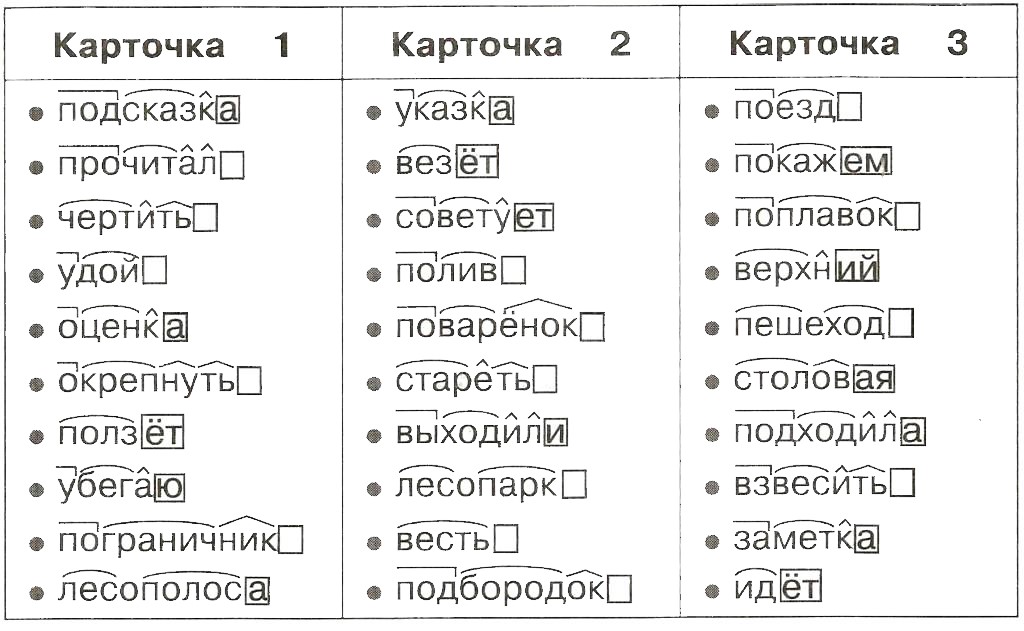
Чтобы выделить корень слова, нужно подобрать к нему однокоренные, или родственные слова: лесной-лес-лесник; делать-дело. Корнем слова называется общая часть родственных слов: -ЛЕС-,-ДЕЛ-.
Часть слова, которая стоит до корня – это приставка. В слове лесной нет приставки. В слове сделать приставка С-. В слове может быть несколько приставок, например: ПО-НА-делать.
Часть слова, которая стоит после корня называется суффиксом: -Н- в слове лесной; -А- в слове сделать.
Чтобы проверить, правильно ли вы выделили
части слова, можно подобрать одноморфемное слово: слово с одинаковой  д.
д.
Что такое самодиктант?
Это диктант, который вы можете написать без посторонней помощи. Для самодиктанта можно выбрать любой текст: из учебника, художественной литературы или специального сборника диктантов. Сначала вы внимательно рассматриваете текст одного предложения, состав каждого слова, затем по памяти записываете это предложение, вспоминая, как были написаны слова и где стояли знаки препинания.
Определение части речи слов в русском тексте (POS-tagging) на Python 3 / Хабр
Пусть, дано предложение “Съешьте еще этих мягких французских булок, да выпейте чаю.”, в котором нам нужно определить часть речи для каждого слова:
[('съешьте', 'глаг.'), ('еще', 'нареч.'), ('этих', 'местоим. прил.'), ('мягких', 'прил.'), ('французских', 'прил.'), ('булок', 'сущ.'), ('да', 'союз'), ('выпейте', 'глаг.'), ('чаю', 'сущ.')]
Зачем это нужно? Например, для автоматического определения тегов для блог-поста (для отбора существительных). Морфологическая разметка является одним из первых этапов компьютерного анализа текста.
Морфологическая разметка является одним из первых этапов компьютерного анализа текста.
Существующие решения
Конечно, все уже придумано до нас. Существует mystem от Яндекса, TreeTagger с поддержкой русского языка, на питоне есть nltk, а также pymorphy от kmike. Все эти утилиты отлично работают, правда, у pymorphy нет поддержки питона 3, а у nltk поддержка третей версии питона только в бете (и там вечно что-то отваливается). Но реальная цель для создания модуля — академическая, понять как работает морфологический анализатор.
Алгоритм
Для начала разберемся, как обычный человек определяет к какой части речи относится слово.
- Обычно мы знаем к какой части речи относится знакомое нам слово. Например, мы знаем, что “съешьте” — это глагол.
- Если нам встречается слово, которое мы не знаем, то мы можем угадать часть речи, сравнивая с уже знакомыми словами. Например, мы можем догадаться, что слово “конгруэнтность” — это существительное, т.
 е. имеет окончание “-ость”, присущее обычно существительным.
е. имеет окончание “-ость”, присущее обычно существительным. - Мы также можем догадаться какая это часть речи, проследив за цепочкой слов в предложении: “съешьте французских x
- Длина слова также может дать полезную информацию. Если слово состоит всего лишь из одной или двух букв, то скорее всего это предлог, местоимение или союз.
 е. имеет окончание “-ость”, присущее обычно существительным.
е. имеет окончание “-ость”, присущее обычно существительным.Конечно, для компьютера эта задача будет несколько сложнее, т.к. у него нет той базы знаний, которой обладает человек. Но мы постараемся смоделировать обучение компьютера, используя доступные нам данные.
Данные
Для обучения нашего скрипта я использовал национальный корпус русского языка. Часть корпуса, СинТагРус, представляет собой коллекцию текстов с размеченной информацией для каждого слова, такой как, часть речи, число, падеж, время глагола и т.д. Так выглядит часть корпуса в XML формате:
Так выглядит часть корпуса в XML формате:
<se> <w><ana lex="между" gr="PR"></ana>М`ежду</w> <w><ana lex="то" gr="S-PRO,n,sg=ins"></ana>тем</w> <w><ana lex="конкурент" gr="S,m,anim=pl,nom"></ana>конкур`енты</w> <w><ana lex="наступать" gr="V,ipf,intr,act=pl,praes,3p,indic"></ana>наступ`ают</w> <w><ana lex="на" gr="PR"></ana>на</w> <w><ana lex="пятка" gr="S,f,inan=pl,acc"></ana>п`ятки</w> . </se> <se> <w><ana lex="вот" gr="PART"></ana>Вот</w> <w><ana lex="так" gr="ADV-PRO"></ana>так</w>, <w><ana lex="за" gr="PR"></ana>з`а</w> <w><ana lex="пять" gr="NUM=acc"></ana>пять</w> <w><ana lex="минута" gr="S,f,inan=pl,gen"></ana>мин`ут</w> <w><ana lex="до" gr="PR"></ana>до</w> <w><ana lex="съемка" gr="S,f,inan=pl,gen"></ana>съёмок</w> , <w><ana lex="родиться" gr="V,pf,intr,med=m,sg,praet,indic"></ana>род`илс`я</w> <w><ana lex="новый" gr="A=m,sg,nom,plen"></ana>н`овый</w> <w><ana lex="персонаж" gr="S,m,anim=sg,nom"></ana>персон`аж</w> .</se>

Предложения заключены в теги <se>, внутри которых расположены слова в теге <w>. Информация о каждом слове содержится в теге <ana>, аттрибут lex соответствует лексеме, gr — грамматические категории. Первая категория — это часть речи:
'S': 'сущ.',
'A': 'прил.',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.'
SVM
В качестве алгоритма обучения я выбрал метод опорных векторов (SVM). Если вы не знакомы с SVM или алгоритмами машинного обучения в общем, то представьте, что SVM это некий черный ящик, который принимает на вход характеристики данных, а на выходе классификацию по заранее заданным категориям. В качестве характеристик мы зададим, например, окончание слова, а в качестве категорий — части речи.
В качестве характеристик мы зададим, например, окончание слова, а в качестве категорий — части речи.
Чтобы черный ящик автоматически распознавал часть речи, для начала его нужно обучить, т.е. дать много характеристик примеров на вход, и соответствующие им части речи на выход. SVM построит модель, которая при достаточных данных будет в большинстве случаев корректно определять часть речи.
Даже в академических целях реализовать SVM лень, поэтому воспользуемся готовой библиотекой LIBLINEAR на С++, которая имеет обертку для питона. Для обучения модели используем функцию
''' съешьте - глагол выпейте - глагол чаю - сущ.
 '''
x = [{1001: 1, 2001: 1, 3001: 1}, # 1001 - съешьте, 2001 - ьте, 3001 - те
{1002: 1, 2002: 1, 3001: 1}, # 1002 - выпейте, 2002 - йте, 3001 - те
{1003: 1, 2003: 1, 3002: 1}] # 1003 - чаю, 2003 - чаю, 3002 - аю
y = [1, 1, 2] # 1 - глагол, 2 - сущ.
import liblinearutil as svm
problem = svm.problem(y, x) # создаем задачу
param = svm.parameter('-c 1 -s 4') # параметры обучения
model = svm.train(prob, param) # обучаем модель
# используем модель для распознания слова 'съешьте'
label, acc, vals = svm.predict([0], {1001: 1, 2001: 1, 3001: 1}, model, '') # [0] - обозначает, что часть речи нам неизвестна
'''
x = [{1001: 1, 2001: 1, 3001: 1}, # 1001 - съешьте, 2001 - ьте, 3001 - те
{1002: 1, 2002: 1, 3001: 1}, # 1002 - выпейте, 2002 - йте, 3001 - те
{1003: 1, 2003: 1, 3002: 1}] # 1003 - чаю, 2003 - чаю, 3002 - аю
y = [1, 1, 2] # 1 - глагол, 2 - сущ.
import liblinearutil as svm
problem = svm.problem(y, x) # создаем задачу
param = svm.parameter('-c 1 -s 4') # параметры обучения
model = svm.train(prob, param) # обучаем модель
# используем модель для распознания слова 'съешьте'
label, acc, vals = svm.predict([0], {1001: 1, 2001: 1, 3001: 1}, model, '') # [0] - обозначает, что часть речи нам неизвестна
В итоге наш алгоритм такой:
- Читаем файл корпуса и для каждого слова определяем его характеристики: само слово, окончание (2 и 3 последних буквы), приставка (2 и 3 первые буквы), а также части речи предыдущих слов
- Каждой части речи и характеристике присваиваем порядковый номер и создаем задачу для обучения SVM
- Обучаем модель SVM
- Используем обученную модель для определения части речи слов в предложении: для этого каждое слово нужно опять представить в виде характеристик и подать на вход SVM модели, которая подберет наиболее подходящий класс, т.

Реализация
С исходными кодами можете ознакомиться здесь: github.com/irokez/Pyrus/tree/master/src
Корпус
Для начала нужно получить размеченный корпус. Национальный корпус русского языка распространяется очень загадочным образом. На самом сайте корпуса можно только производить поиск по текстам, но при этом скачать целиком корпус нельзя:
“Оффлайновая версия корпуса недоступна, однако для свободного пользования предоставляется случайная выборка предложений (с нарушенным порядком) из корпуса со снятой омонимией объёмом 180 тыс. словоупотреблений (90 тыс. – пресса, по 30 тыс. из художественных текстов, законодательства и научных текстов)”.
При этом в википедии написано
“The corpus will be made available off-line and distributed for non-commercial purposes, but currently due to some technical and/or copyright problems it is accessible only on-line.
 ”
”Хотя для наших целей пойдет и небольшая выборка из корпуса, доступная тут: www.ruscorpora.ru/download/shuffled_rnc.zip
Файлы в полученном архиве нужно пропустить через утилиту convert-rnc.py, которая переводит текст в UTF-8 и исправляет XML разметку. После этого, возможно, еще нужно пофиксить XML вручную (xmllint вам в помощь). Файл rnc.py содержит простой класс Reader для чтения нормализованных XML файлов нац. корпуса.
import xml.parsers.expat class Reader: def __init__(self): self._parser = xml.parsers.expat.ParserCreate() self._parser.StartElementHandler = self.start_element self._parser.EndElementHandler = self.end_element self._parser.CharacterDataHandler = self.char_data def start_element(self, name, attr): if name == 'ana': self._info = attr def end_element(self, name): if name == 'se': self._sentences.append(self._sentence) self._sentence = [] elif name == 'w': self._sentence.
 append((self._cdata, self._info))
elif name == 'ana':
self._cdata = ''
def char_data(self, content):
self._cdata += content
def read(self, filename):
f = open(filename)
content = f.read()
f.close()
self._sentences = []
self._sentence = []
self._cdata = ''
self._info = ''
self._parser.Parse(content)
return self._sentences
append((self._cdata, self._info))
elif name == 'ana':
self._cdata = ''
def char_data(self, content):
self._cdata += content
def read(self, filename):
f = open(filename)
content = f.read()
f.close()
self._sentences = []
self._sentence = []
self._cdata = ''
self._info = ''
self._parser.Parse(content)
return self._sentences
Метод Reader.read(self, filename) читает файл и выдает список предложений:
[[('Вод`итель', {'lex': 'водитель', 'gr': 'S,m,anim=sg,nom'}), ('дес`ятки', {'lex': 'десятка', 'gr': 'S,f,inan=sg,gen'}), ('кот`орую', {'lex': 'который', 'gr': 'A-PRO=f,sg,acc'}), ('прест`упники', {'lex': 'преступник', 'gr': 'S,m,anim=pl,nom'}), ('пойм`али', {'lex': 'поймать', 'gr': 'V,pf,tran=pl,act,praet,indic'}), ('у', {'lex': 'у', 'gr': 'PR'}), ('ВВЦ', {'lex': 'ВВЦ', 'gr': 'S,m,inan,0=sg,gen'}), ('оказ`ал', {'lex': 'оказать', 'gr': 'V,pf,tran=m,sg,act,praet,indic'}), ('им', {'lex': 'они', 'gr': 'S-PRO,pl,3p=dat'}), ('`яростное', {'lex': 'яростный', 'gr': 'A=n,sg,acc,inan,plen'}), ('сопротивл`ение', {'lex': 'сопротивление', 'gr': 'S,n,inan=sg,acc'}), ('за', {'lex': 'за', 'gr': 'PR'}), ('что', {'lex': 'что', 'gr': 'S-PRO,n,sg=acc'}), ('поплат`ился', {'lex': 'поплатиться', 'gr': 'V,pf,intr,med=m,sg,praet,indic'}), ('ж`изнью', {'lex': 'жизнь', 'gr': 'S,f,inan=sg,ins'})]]
Обучение и разметка текста
Библиотеку SVM можно скачать тут: http://www. csie.ntu.edu.tw/~cjlin/liblinear/. Чтобы обертка под питон заработала под 3-й версией я написал небольшой патч.
csie.ntu.edu.tw/~cjlin/liblinear/. Чтобы обертка под питон заработала под 3-й версией я написал небольшой патч.
Файл pos.py содержит два основных класса: Tagger и TaggerFeatures. Tagger — это, собственно, класс, который осуществляет разметку текста, т.е. определяет для каждого слова его часть речи. Метод Tagger.train(self, sentences, labels) принимает в качестве аргументов список предложений (в том же формате, что и выдает rnc.Reader.read), а также список частей речи для каждого слова, после чего обучает SVM модель, используя библиотеку LIBLINEAR. Обученная модель впоследствии сохраняется (через метод Tagger.save), чтобы не обучать модель каждый раз. Метод Tagger.label(self, sentence) производит разметку предложения.
Класс TaggerFeatures предназначен для генерации характеристик для обучения и разметки. TaggerFeatures.from_body() возвращает характеристику по форме слова, т.е. возвращает ID слова в корпусе. TaggerFeatures.from_suffix() и TaggerFeatures. \w-]|$)’.format(‘|’.join(pos.tagset)))
tagger = pos.Tagger()
sentence_labels = []
sentence_words = []
for sentence in sentences:
labels = []
words = []
for word in sentence:
gr = word[1][‘gr’]
m = re_pos.match(gr)
if not m:
print(gr, file = sys.stderr)
pos = m.group(1)
if pos == ‘ANUM’:
pos = ‘A-NUM’
label = tagger.get_label_id(pos)
if not label:
print(gr, file = sys.stderr)
labels.append(label)
body = word[0].replace(‘`’, »)
words.append(body)
sentence_labels.append(labels)
sentence_words.append(words)
tagger.train(sentence_words, sentence_labels, True)
tagger.train(sentence_words, sentence_labels)
tagger.save(‘tmp/svm.model’, ‘tmp/ids.pickle’)
\w-]|$)’.format(‘|’.join(pos.tagset)))
tagger = pos.Tagger()
sentence_labels = []
sentence_words = []
for sentence in sentences:
labels = []
words = []
for word in sentence:
gr = word[1][‘gr’]
m = re_pos.match(gr)
if not m:
print(gr, file = sys.stderr)
pos = m.group(1)
if pos == ‘ANUM’:
pos = ‘A-NUM’
label = tagger.get_label_id(pos)
if not label:
print(gr, file = sys.stderr)
labels.append(label)
body = word[0].replace(‘`’, »)
words.append(body)
sentence_labels.append(labels)
sentence_words.append(words)
tagger.train(sentence_words, sentence_labels, True)
tagger.train(sentence_words, sentence_labels)
tagger.save(‘tmp/svm.model’, ‘tmp/ids.pickle’)
После того, как модель обучена и сохранена, мы, наконец, получили скрипт для разметки текста. Пример использования показан в test.py:
import sys
import pos
sentence = sys.argv[1].split(' ')
tagger = pos.Tagger()
tagger.load('tmp/svm.model', 'tmp/ids.pickle')
rus = {
'S': 'сущ.',
'A': 'прил. ',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.',
'INIT': 'инит',
'NONLEX': 'нонлекс'
}
tagged = []
for word, label in tagger.label(sentence):
tagged.append((word, rus[tagger.get_label(label)]))
print(tagged)
 ',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.',
'INIT': 'инит',
'NONLEX': 'нонлекс'
}
tagged = []
for word, label in tagger.label(sentence):
tagged.append((word, rus[tagger.get_label(label)]))
print(tagged)
',
'NUM': 'числ.',
'A-NUM': 'числ.-прил.',
'V': 'глаг.',
'ADV': 'нареч.',
'PRAEDIC': 'предикатив',
'PARENTH': 'вводное',
'S-PRO': 'местоим. сущ.',
'A-PRO': 'местоим. прил.',
'ADV-PRO': 'местоим. нареч.',
'PRAEDIC-PRO': 'местоим. предик.',
'PR': 'предлог',
'CONJ': 'союз',
'PART': 'частица',
'INTJ': 'межд.',
'INIT': 'инит',
'NONLEX': 'нонлекс'
}
tagged = []
for word, label in tagger.label(sentence):
tagged.append((word, rus[tagger.get_label(label)]))
print(tagged)
Работает так:$ src/test.py "Съешьте еще этих мягких французских булок, да выпейте же чаю"
[('Съешьте', 'глаг.'), ('еще', 'нареч.'), ('этих', 'местоим. прил.'), ('мягких', 'прил.'), ('французских', 'прил.'), ('булок,', 'сущ.'), ('да', 'союз'), ('выпейте', 'глаг.'), ('же', 'частица'), ('чаю', 'сущ.')]
Тестирование
Для оценки точности классификации работы алгоритма, метод обучения Tagger.train() имеет необязательного параметр cross_validation, который, если установлен как True, выполнит перекрестную проверку, т. е. данные обучения разбиваются на K частей, после чего каждая часть по очереди используется для оценки работы метода, в то время как остальная часть используется для обучения. Мне удалось добиться средней точности в 92%, что вполне неплохо, учитывая, что была использована лишь доступная часть нац. корпуса. Обычно точность разметки части речи колеблется в пределах 96-98%.
е. данные обучения разбиваются на K частей, после чего каждая часть по очереди используется для оценки работы метода, в то время как остальная часть используется для обучения. Мне удалось добиться средней точности в 92%, что вполне неплохо, учитывая, что была использована лишь доступная часть нац. корпуса. Обычно точность разметки части речи колеблется в пределах 96-98%.
Заключение и планы на будущее
В общем, было интересно поработать с нац. корпусом. Видно, что работа над ним проделана большая, и в нем содержится большое количество информации, которую хотелось бы использовать в полной мере. Я послал запрос на получение полной версии, но ответа пока, к сожалению, нет.
Полученный скрипт разметки можно легко расширить, чтобы он также определял другие морфологические категории, например, число, род, падеж и др. Чем я и займусь в дальнейшем. В перспективе хотелось бы, конечно, написать синтаксический парсер русского языка, чтобы получить структуру предложения, но для этого нужна полная версия корпуса.
Буду рад ответить на вопросы и предложения.
Исходный код доступен здесь: github.com/irokez/Pyrus
Демо: http://vps11096.ovh.net:8080
Comprise против Compose | YourDictionary
Если вы устали пытаться понять разницу между составом и составлением, то вы попали в нужное место. Первым шагом к пониманию различий является понимание определений включения и составления.
Разница между Comprise и Compose
Рассмотрим определения слов включать и составлять, двух слов, которые обычно путают друг с другом. Это даст вам основу того, что каждое слово означает само по себе, чтобы вы могли правильно их использовать.
- Comprise — глагол, означающий «содержать». Слово используется в начале предложения.
Пример: Дом состоит из десяти комнат и трех ванных комнат. - Составление — это глагол, означающий «сочетать», «приводить в порядок» или «придумывать». Слово используется ближе к концу предложения.
Пример: Десять комнат и три ванные комнаты составляют дом.

Разбираемся в использовании Comprise
Теперь, когда вы знаете определение слова «comprise» , Следующим шагом будет убедиться, что вы понимаете, как правильно его использовать. Овладение этим навыком требует понимания правильного употребления слов и развития способности распознавать неправильное употребление.
Надлежащее использование Comprise
Comprise в своей простейшей форме означает «содержать». Например, можно правильно сказать: «На ферме десять коров, три лошади, пять овец и четыре свиньи». Это все равно, что сказать: «На ферме десять коров, три лошади, пять овец и четыре свиньи».
Неправильное использование Comprise
Было бы неправильно, если бы вы сказали: «Десять коров, три лошади, пять овец и четыре свиньи составляют ферму». Если вы используете слово «содержать», целое должно стоять на первом месте. Целое, которым в данном случае является ферма, должно стоять в предложении раньше, чем его части, такие как коровы, лошади, овцы и свиньи.
Пример приложения Comprise по сравнению с Compose
Просмотрите следующие утверждения, указывающие на правильное и неправильное использование слова comprise. Убедитесь, что вы понимаете обоснование.
Класс состоит из 16 мальчиков и 12 девочек. (правильно)
В правильном ответе вы можете заменить слово «содержит» на «содержит», и предложение останется правильным. Это не относится к неправильному ответу. Поскольку слово «содержать» означает «содержать», вариант, в котором можно было бы заменить определение слова, является правильным.
Всего в классе 16 мальчиков и 12 девочек . (неверно)
Класс — это целое, а ученики — его части. Таким образом, чтобы использовать состав, целое (класс) должно появиться в предложении раньше, чем ученики, которые являются частями.
Разбираемся в использовании Compose
Теперь, когда вы поняли, как правильно использовать состав, следующим шагом будет изучение того, когда использовать слово состав. Слово «сочинять» означает «составлять или комбинировать». Хотя это слово похоже на слово «содержать», оно имеет другое значение.
Слово «сочинять» означает «составлять или комбинировать». Хотя это слово похоже на слово «содержать», оно имеет другое значение.
Правильное использование слова Compose
Неправильный вариант, указанный в разделе использования слова compose, иллюстрирует ситуации, когда правильно использовать слово compose.
Всего в классе 16 мальчиков и 12 девочек . (правильно)
Составить — правильное слово, потому что определение «составлять» можно правильно заменить на сочинение. Другим индикатором, который уместно использовать в данном контексте, является тот факт, что часть (16 мальчиков и 12 девочек) предшествует целому (классу).
Неправильное использование Compose
Неправильно использовать compose и compose взаимозаменяемо. Хотя эти слова не связаны друг с другом, они не имеют одинакового значения. Если вы используете композицию в предложении, которое действительно должно содержать слово включать, то в предложении есть ошибка.
Класс состоит из 16 мальчиков и 12 девочек. (неверно)
Как упоминалось ранее, слово включает в себя и будет правильным термином в предложении, построенном подобно этому. Слово «содержит» может быть правильно заменено на «содержит» в этой группе слов, в то время как ни одно из определений «составлять» не подходит. Чтобы состав был правильным выбором, весь (класс) должен следовать за частью (16 мальчиков и 12 девочек).
Пример Application Compose и Comprise
Просмотрите следующие утверждения, указывающие на правильное и неправильное использование слова comprise.
Смесь яиц, муки, масла, молока и сахара составляет торт. (правильно)
Фраза «составить», которая является определением сочинения, может быть заменена словом сочинить в предложении. Части (яйца, мука, масло и т. д.) стоят перед целым (торт) в предложении.
Смесь яиц, муки, масла и молока составляют торт.
 (неверно)
(неверно)Суммируя разницу
По сути, слова включать и составлять используются в противоположных ситуациях. Их значения схожи, но в некотором смысле они противоположны с точки зрения того, как они используются.
- Compose (содержать) используется, когда часть предшествует целому.
- Comprise (сочетать или составлять) используется, когда целое предшествует части.
Практические упражнения
Выберите правильное слово для каждого примера ниже. Не заглядывайте в ответы до тех пор, пока не попробуете все пункты самостоятельно.
Выберите правильное слово для каждого из следующих утверждений.
- Оркестр (составляет/сочиняет) духовые, деревянные духовые, ударные и струнные инструменты.
- Множественный выбор, заполнение пробелов и вопросы верно/неверно (составить/составить) выпускного экзамена.
- Мой идеальный сад (включает / состоит из) листовой зелени, помидоров, огурцов и бамии.
- Походы в парки, музеи и пещеры (включает / составляет) мой идеальный отпуск.
- Мое идеальное свидание (включает в себя) изысканную еду и прогулку по пляжу под лунным светом.
Практические упражнения Ответы
Правильные ответы следующие:
- состоит из
- Compose
- Сочиняет
- . Содержит
. Интересная скручивание 9005
Другое. Другое значение. относится к фразам «состоит из» и «состоит из».
- Многие справочники по грамматике предполагают, что фраза «состоит из» всегда неверна. Когда вы думаете об этом, это имеет смысл. Не имеет смысла говорить «состоит из», но имеет смысл сказать «состоит из».
- Однако фраза «состоит из» часто используется и становится все более популярной среди специалистов по грамматике. Например, некоторые специалисты считают правильным сказать: «На ферме десять коров, три лошади, пять овец и четыре свиньи». и «В классе 16 мальчиков и 12 девочек».

Это хороший пример того, как язык постоянно развивается. Однако, если вы хотите быть уверены, что никто не задастся вопросом, возможно, вы неправильно используете слово, лучше избегать использования «состоит из», по крайней мере, до тех пор, пока оно не станет общепринятым.
Узнайте больше об использовании Word
Правильное использование слов имеет решающее значение при письме. Если ваше письмо ограничено школьными заданиями, у вас есть работа, требующая письма, или вы занимаетесь писательским творчеством в качестве хобби или профессии, чем больше вы узнаете о том, как выбирать правильные слова, тем лучше будет ваше письмо. Потратьте некоторое время на то, чтобы научиться выбирать между другими словами, которые часто путают, например, «дальше» и «дальше». Если вы обнаружите, что правописание является более сложным, чем выбор слова, просмотрите некоторые из наиболее часто употребляемых в английском языке слов с ошибками.
Онг о различиях между устной и письменной культурой
Уолтер Онг характеризует основные различия между языками устной и письменной культур в следующих терминах:
[Возможно] несколько обобщить психодинамику первичных устных культур, то есть устных культур, не затронутых письмом. … Полностью грамотные люди с большим трудом могут себе представить, что такое первичная устная культура, то есть культура, не знающая ни письма, ни даже возможности письма. Попробуйте представить себе культуру, в которой никто никогда ничего не искал. В первичной устной культуре выражение «искать что-то» — пустая фраза: оно не имело бы никакого мыслимого значения. Без письма слова как таковые не имеют визуального присутствия, даже если объекты, которые они представляют, визуальны. Это звуки. Вы можете «перезвонить» им — «напомнить» им. Но «искать» их негде. У них нет ни фокуса, ни следа (визуальная метафора, показывающая зависимость от письма), ни даже траектории. Это явления, события.
… Полностью грамотные люди с большим трудом могут себе представить, что такое первичная устная культура, то есть культура, не знающая ни письма, ни даже возможности письма. Попробуйте представить себе культуру, в которой никто никогда ничего не искал. В первичной устной культуре выражение «искать что-то» — пустая фраза: оно не имело бы никакого мыслимого значения. Без письма слова как таковые не имеют визуального присутствия, даже если объекты, которые они представляют, визуальны. Это звуки. Вы можете «перезвонить» им — «напомнить» им. Но «искать» их негде. У них нет ни фокуса, ни следа (визуальная метафора, показывающая зависимость от письма), ни даже траектории. Это явления, события.
В первичной устной культуре мысли и выражения, как правило, бывают следующих видов.
(i) Дополнительный, а не подчиненный
Знакомым примером аддитивного устного стиля является повествование о сотворении в Бытии 1:1-5, которое действительно является текстом, но сохраняет узнаваемые устные образцы. Версия Дуэ (1610 г.), созданная в культуре со все еще массивными оральными остатками, во многих отношениях близка к аддитивному еврейскому оригиналу … :
Версия Дуэ (1610 г.), созданная в культуре со все еще массивными оральными остатками, во многих отношениях близка к аддитивному еврейскому оригиналу … :
В начале Бог сотворил небо и землю. И земля была пуста и пуста, и тьма была над бездною; и дух Божий носился над водами. И сказал Бог: будь светом. И был сделан свет. И увидел Бог свет, что это хорошо; и он отделил свет от тьмы. И назвал он свет днем, а тьму ночью; и был вечер и утро одного дня.
Девять вводных «и». Приспособленный к чувствам, формируемым в большей степени письмом и печатью, Новая американская Библия (1970) переводит:
В начале, когда Бог сотворил небо и землю, земля была бесформенной пустыней, и тьма покрывала бездну, а сильный ветер носился над водами. Тогда Бог сказал: «Да будет свет», и стал свет. Бог видел, как хорош был свет. Затем Бог отделил свет от тьмы. Бог назвал свет «днем», а тьму — «ночью». Так наступил вечер, а за ним утро — первый день.
Два вводных «и», каждое из которых находится в сложносочиненном предложении. Дуэ переводит еврейское we или wa («и») просто как «и». Новый американец переводит это «и», «когда», «тогда», «таким образом» или «пока», чтобы обеспечить поток повествования с аналитическим, аргументированным подчинением, которое характеризует письмо (Chafe 1982) и которое кажется более естественным в письме. тексты ХХ века. … Письменный дискурс развивает более сложную и фиксированную грамматику, чем устный дискурс, потому что для обеспечения смысла он в большей степени зависит просто от языковой структуры, поскольку ему не хватает нормальных полных экзистенциальных контекстов, которые окружают устный дискурс и помогают определить значение в устном дискурсе несколько независимо от грамматики. …
Дуэ переводит еврейское we или wa («и») просто как «и». Новый американец переводит это «и», «когда», «тогда», «таким образом» или «пока», чтобы обеспечить поток повествования с аналитическим, аргументированным подчинением, которое характеризует письмо (Chafe 1982) и которое кажется более естественным в письме. тексты ХХ века. … Письменный дискурс развивает более сложную и фиксированную грамматику, чем устный дискурс, потому что для обеспечения смысла он в большей степени зависит просто от языковой структуры, поскольку ему не хватает нормальных полных экзистенциальных контекстов, которые окружают устный дискурс и помогают определить значение в устном дискурсе несколько независимо от грамматики. …
(ii) Агрегативный, а не аналитический
Эта характеристика тесно связана с зависимостью от формул для реализации памяти. Элементы устной мысли и выражения, как правило, представляют собой не столько простые целые числа, сколько кластеры целых чисел, такие как параллельные термины или фразы или предложения, противоположные термины или фразы или предложения, эпитеты. Устный народ предпочитает, особенно в официальной речи, не солдата, а храброго солдата; не принцесса, а прекрасная принцесса; не дуб, а крепкий дуб. Таким образом, устное выражение несет груз эпитетов и другого формулярного багажа, который высокая грамотность отвергает как громоздкий и утомительно избыточный из-за его совокупного веса (Ong 19).77, стр. 188-212). …
Устный народ предпочитает, особенно в официальной речи, не солдата, а храброго солдата; не принцесса, а прекрасная принцесса; не дуб, а крепкий дуб. Таким образом, устное выражение несет груз эпитетов и другого формулярного багажа, который высокая грамотность отвергает как громоздкий и утомительно избыточный из-за его совокупного веса (Ong 19).77, стр. 188-212). …
(iii) Избыточное или «обильное»
Мысль требует некоторой непрерывности. Письмо устанавливает в тексте «линию» непрерывности вне сознания. Если отвлечение сбивает с толку или стирает из ума контекст, из которого возникает материал, который я сейчас читаю, контекст можно восстановить, выборочно просматривая текст. Зацикливание может быть совершенно случайным, чисто ad hoc . Разум концентрирует свою энергию на движении вперед, потому что то, во что он зацикливается, лежит вне его, всегда доступное по частям на исписанной странице. В устной речи ситуация иная. Вне ума нет ничего, к чему можно было бы вернуться, ибо устное высказывание исчезло, как только оно было произнесено. Следовательно, ум должен продвигаться вперед медленнее, удерживая в фокусе внимания многое из того, с чем он уже имел дело. Избыточность, повторение только что сказанного уверенно удерживает и говорящего, и слушающего в нужном направлении.
Следовательно, ум должен продвигаться вперед медленнее, удерживая в фокусе внимания многое из того, с чем он уже имел дело. Избыточность, повторение только что сказанного уверенно удерживает и говорящего, и слушающего в нужном направлении.
Поскольку избыточность характеризует устное мышление и речь, в глубоком смысле она более естественна для мышления и речи, чем редкая линейность. Разреженно-линейное или аналитическое мышление и речь — это искусственное творение, структурированное технологией письма. Устранение избыточности в значительных масштабах требует технологии, позволяющей избежать времени, а именно письма, которое налагает некоторую нагрузку на психику, не позволяя выражению впадать в более естественные паттерны. Психика может справиться с этим напряжением отчасти потому, что почерк — физически очень медленный процесс — обычно около одной десятой скорости устной речи (Чейф 19).82). При письме ум вынужден работать в замедленном режиме, что дает ему возможность вмешиваться в более нормальные, избыточные процессы и реорганизовывать их. …
…
(iv) Консервативный или традиционалистский
Поскольку в первичной устной культуре концептуализированное знание, которое не повторяется вслух, вскоре исчезает, устные общества должны прилагать огромные усилия, повторяя снова и снова то, что с трудом выучивалось на протяжении веков. Эта потребность устанавливает в высшей степени традиционалистский или консервативный склад ума, который не без оснований препятствует интеллектуальным экспериментам. Знания трудно достать и они драгоценны, и общество высоко ценит тех мудрых стариков и старух, которые специализируются на их сохранении, которые знают и могут рассказать истории о былых днях. Хранение знаний вне ума, письменность и, тем более, печать принижают фигуры мудрого старца и мудрой старухи, повторяющих прошлое, в пользу более молодых открывателей чего-то нового.
Письмо, конечно, по-своему консервативно. Вскоре после того, как он впервые появился, он заморозил правовые кодексы в раннем Шумере. Но, беря на себя консервативные функции, текст освобождает ум от консервативных задач, то есть от работы памяти, и таким образом позволяет уму обратиться к новым размышлениям (Хейвлок, 1963, с. 254–305). Действительно, остаточная оральность данной хирографической культуры может быть в определенной степени рассчитана по мнемонической нагрузке, которую она оставляет на разум, то есть по объему запоминания, требуемому образовательными процедурами данной культуры (Гуди 19).68а, стр. 13-14). …
254–305). Действительно, остаточная оральность данной хирографической культуры может быть в определенной степени рассчитана по мнемонической нагрузке, которую она оставляет на разум, то есть по объему запоминания, требуемому образовательными процедурами данной культуры (Гуди 19).68а, стр. 13-14). …
(v) Близко к человеческому жизненному миру
В отсутствие сложных аналитических категорий, которые зависят от письма для структурирования знаний на расстоянии от жизненного опыта, устные культуры должны концептуализировать и вербализовать все свои знания с более или менее тесной связью с человеческим жизненным миром, уподобляя чуждый, объективный мир смерти. непосредственное, знакомое взаимодействие людей. Хирографическая (письменная) культура и, тем более, типографская (печатная) культура могут дистанцировать и в некотором роде денатурировать даже человеческое перечисление таких вещей, как имена лидеров и политические подразделения, в абстрактный, нейтральный список, полностью лишенный контекста человеческих действий. В устной культуре нет более нейтрального носителя, чем список. …
В устной культуре нет более нейтрального носителя, чем список. …
(vi) Агонистичное тонирование
Многие, если не все, устные или остаточно устные культуры кажутся грамотным чрезвычайно агонистичными в их вербальном исполнении и даже в их образе жизни. Письмо поощряет абстракции, которые отделяют знания от той области, где люди борются друг с другом. Он отделяет знающего от известного. Сохраняя знание в жизненном мире человека, устная речь помещает знание в контекст борьбы. Притчи и загадки используются не только для хранения знаний, но и для вовлечения других в словесный и интеллектуальный бой: произнесение одной пословицы или загадки побуждает слушателей дополнить ее более подходящей или противоречивой (Авраам 19).68; 1972). …
(vii) Сочувствие и участие, а не объективное дистанцирование
Для устной культуры обучение или знание означает достижение тесной, эмпатической, коллективной идентификации с известным (Havelock 1963, стр. 145–146), «смирение с этим». Письмо отделяет знающего от известного и, таким образом, создает условия для «объективности» в смысле личного отчуждения или дистанцирования. …
Письмо отделяет знающего от известного и, таким образом, создает условия для «объективности» в смысле личного отчуждения или дистанцирования. …
(viii) Гомеостатический
В отличие от письменных обществ устные общества можно охарактеризовать как гомеостатические (Гуди и Уатт 19).68, стр. 31-4). Иными словами, устные общества в значительной степени живут в настоящем, которое поддерживает себя в равновесии или гомеостазе, отбрасывая воспоминания, которые больше не имеют отношения к настоящему. … Печатные культуры изобрели словари, в которых различные значения слова в том виде, в каком оно встречается в текстах, подлежащих датированию, могут быть записаны в виде формальных определений. Таким образом, известно, что слова имеют слои значений, многие из которых совершенно не имеют отношения к обычным значениям в настоящем. Словари рекламируют семантические несоответствия.
В устных культурах, конечно, нет словарей и мало семантических разногласий. Значение каждого слова контролируется тем, что Гуди и Уотт (1968, с. 29) называют «прямой семантической ратификацией», то есть реальными жизненными ситуациями, в которых это слово используется здесь и сейчас. Устный ум не интересуется определениями (Luria 1976, стр. 48-99). Слова приобретают свои значения только из своей всегда настойчивой действительной среды обитания, которая не является, как в словаре, просто другими словами, но включает в себя также жесты, голосовые интонации, выражение лица и всю человеческую, экзистенциальную обстановку, в которой реально произносимое слово всегда происходит. Значения слов постоянно исходят из настоящего… .
29) называют «прямой семантической ратификацией», то есть реальными жизненными ситуациями, в которых это слово используется здесь и сейчас. Устный ум не интересуется определениями (Luria 1976, стр. 48-99). Слова приобретают свои значения только из своей всегда настойчивой действительной среды обитания, которая не является, как в словаре, просто другими словами, но включает в себя также жесты, голосовые интонации, выражение лица и всю человеческую, экзистенциальную обстановку, в которой реально произносимое слово всегда происходит. Значения слов постоянно исходят из настоящего… .
(ix) Ситуативный, а не абстрактный
Все концептуальное мышление в определенной степени абстрактно. Таким образом, «конкретный» термин, такой как «дерево», не относится просто к единичному «конкретному» дереву, но является абстракцией, выведенной из индивидуальной, чувственной действительности, прочь от нее; оно относится к понятию, которое не является ни этим деревом, ни тем деревом, но может применяться к любому дереву.