Русско-немецкий словарь
wordmap
Немецкий язык — один из популярнейших в мире. Уступает он только, пожалуй, английскому, русскому и китайскому. К сожалению, для многих русскоговорящих пользователей интернета немецкий — весьма сложный язык. Достаточно немного изменить порядок слов в предложении, и все, носитель языка вас не поймет. В таких случаях на помощь приходят русско-немецкие словари и онлайн-переводчики. Один из таких есть и на нашем сайте.
Почему для перевода лучше использовать WordMap
Онлайн-словарей и переводчиков много, но мы рекомендуем пользоваться именно нашим, и вот почему:
- Встроена огромная база слов, как современных, так и тех, которые используют в отдаленных городах Германии.
- Перевод осуществляется максимально точно.
- Наш переводчик не будет выдавать неправильно составленных предложений с нечитабельными участками — «умный» алгоритм переводит слова и фразы так, чтобы их понимали носители языка.
- Пользоваться сервисом предельно просто — достаточно вбить нужную фразу в строку перевода и подождать одну секунду, пока система сделает перевод.

- Есть ряд дополнительных функций, необходимых всем, кто работает с текстом: поиск синонимов и антонимов, переводы на другие языки, поиск слов по буквам, подбор рифм и так далее.

Кому подойдет переводчик WordMap
WordMap — универсальный сервис, он подойдет всем:
- Студентам и школьникам, которым нужно получить быстрый перевод немецких слов или предложений.
- Преподавателям, которые столкнулись с неизвестным словом, например сленговым.
- Копирайтерам и редакторам, которые работают с немецкими СМИ и сайтами.
- Людям, не знающим языка, которые столкнулись с текстом на немецком (инструкции к технике, текстовые ошибки и уведомления в смартфоне, сообщение/письмо от родственника, исторические документы и так далее).
- Всем, кто начинает и/или уже учит немецкий язык.
- Людям, которые вступили в переписку с жителем Германии, но при этом не могут подобрать нужные слова для диалога или же не до конца понимают, что пишет собеседник.
Переводить с нашей помощью — просто. Убедитесь в этом самостоятельно!
Только что искали:
псевдогамиями 1 секунда назад
бездетная 1 секунда назад
эффектировавших 1 секунда назад
пикачун 3 секунды назад
шайка негодяев 3 секунды назад
приятности 3 секунды назад
халтурин 3 секунды назад
касается ереси 4 секунды назад
тапхирено 4 секунды назад
праушм 4 секунды назад
древо-жизни 4 секунды назад
датско-исландский 5 секунд назад
пильщицкими 5 секунд назад
ивчева 6 секунд назад
заделать течь 7 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | кот | 0 слов | 2 часа назад | 5. 187.71.151 187.71.151 |
| Игрок 2 | подиум | 7 слов | 4 часа назад | 91.193.130.8 |
| Игрок 3 | таинственность | 88 слов | 5 часов назад | 95.29.166.199 |
| Игрок 4 | радиотехника | 150 слов | 6 часов назад | 95.29.166.199 |
| Игрок 5 | сороконожка | 60 слов | 7 часов назад | 95.29.166.199 |
| Игрок 6 | апельсин | 45 слов | 7 часов назад | 95.29.166.199 |
| Игрок 7 | бот | 0 слов | 13 часов назад | 188.162.52.18 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | чрево | 39:40 | 11 минут назад | 176. 98.51.142 98.51.142 |
| Игрок 2 | пурга | 45:51 | 40 минут назад | 176.98.51.142 |
| Игрок 3 | нитон | 22:27 | 4 часа назад | 135.125.225.246 |
| Игрок 4 | башка | 49:53 | 4 часа назад | 135.125.225.246 |
| Игрок 5 | тенка | 48:50 | 4 часа назад | 79.165.240.116 |
| Игрок 6 | намет | 55:54 | 4 часа назад | 109.87.179.226 |
| Игрок 7 | лошак | 38:43 | 4 часа назад | 91.193.130.8 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Я | На одного | 10 вопросов | 14 минут назад | 176. 98.51.142 98.51.142 |
| Міша | На одного | 20 вопросов | 2 часа назад | 213.174.21.52 |
| Ніхто | На одного | 10 вопросов | 10 часов назад | 93.183.194.3 |
| Герміона | На одного | 10 вопросов | 10 часов назад | 93.183.194.3 |
| Джіні | На одного | 10 вопросов | 10 часов назад | 93.183.194.3 |
| 1 | На одного | 5 вопросов | 1 день назад | 92.124.65.110 |
| Марина | На одного | 10 вопросов | 1 день назад | 5.228.158.31 |
| Играть в Чепуху! | ||||
Тест по русскому языку 3 класс по теме «Состав слова» | Тест по русскому языку (3 класс) на тему:
Тест по русскому языку
3 класс
Тема «Состав слова»
Сомова Раиса Владимировна
Учитель начальных классов
ГБОУ СОШ «Центр образования» пос. Варламово
Варламово
446012 Самарская область, г. Сызрань, ул. Днепропетровская, д. 62
1. Какие слова называются однокоренными?
1)все слова, корень которых пишется одинаково
2)слова, имеющие одинаковый состав
3)слова, имеющие одинаковое значение
4)слова, имеющие одинаковый корень с одним и тем же значением
2. Впишите на месте пропуска название выделенной части слова.
1)снежИНКа __________________
2)подСТАВка __________________
3)РАСсвело ____________________
4)играЕТ _______________________
3. В каком ряду все слова имеют приставку ДО- ?
1)(до)катил, (до)летел, (до)писал
2)(до)ктор,(до)быча, (до)ждь
3)(до)стены, (до)брата, (до)мовой
4)(до)сох, (до)шел, (до)мовой
4. Какие глаголы не являются однокоренными?
1)зацвести — отцвести
2)прикрепить — присоединить
3)приехал — уехал
4) прилетел — подлетел
5. Какое слово не имеет приставки?
Какое слово не имеет приставки?
1)напильник;
2)наклейка;
3)нарост;
4)надежда.
6. Какое слово не является однокоренным в данной группе слов?
1)слеза;
2)слезливый;
3)прослезился;
4)слезает;
7. Какие слова соответствуют схеме: приставка, корень, суффикс, окончание?
1)беленький;
2)походные;
3)рассказы;
4)прихватка.
8. В какой строке даны разные формы одного и того же слова.
1)лист, листок, листочек
2)дар, дарить, подарок
3)скрипач, скрипачи, скрипачей
4)лес, лесной, лесник
9.Какое слово является однокоренным к слову роспись и соответствует схеме: приставка, корень, суффикс, окончание?
1)рос
2)писатель
3)вопросы
4)записка
10.Какие слова неверно разобраны по составу.
1)игрушк-а
2)вы-печ-к-а
3)под-вод-н-ый
4)с-теп-н-ой.
11.Найди лишнее
1)детский
2)пересадка
3)морячка
4)дружба
Ключ к тесту «Состав слова»
№ вопроса | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Вариант ответа | 4) | 1)суффикс 2)корень 3)приставка 4)окончание | 1) | 2) | 4) | 4) | 2), 4) | 3) | 4) | 1), 4) | 2) |
Баллы | 1 | 4 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 2 | 1 |
Итого | 17 баллов |
«5» | «4» | «3» | «2» |
94 -100 % | 76 — 93% | 75 -53% | меньше 53 % |
17-16 баллов | 15-13 баллов | 12 — 9 баллов | Меньше 9 баллов |
грамматик на Прологе
грамматик на ПрологеДалее: Пролог как база данных Up: Введение в Пролог Предыдущий: Планирование машины
Далее мы обратимся к более сложным примерам программирования на Прологе. Пролог
изначально был придуман как язык программирования для написания
приложения на естественном языке, и, таким образом, Пролог является очень элегантным
язык для выражения грамматик. Пролог даже имеет встроенный синтаксис
специально создан для написания грамматик. Часто говорят, что с
Prolog one получает встроенный парсер бесплатно. В этом разделе мы будем
посмотрите, почему это утверждение сделано (и иногда оспаривается).
Пролог
изначально был придуман как язык программирования для написания
приложения на естественном языке, и, таким образом, Пролог является очень элегантным
язык для выражения грамматик. Пролог даже имеет встроенный синтаксис
специально создан для написания грамматик. Часто говорят, что с
Prolog one получает встроенный парсер бесплатно. В этом разделе мы будем
посмотрите, почему это утверждение сделано (и иногда оспаривается).
Рассмотрим следующую простую контекстно-свободную грамматику для небольшого фрагмент англ.
В этой грамматике мы можем вывести такие простые предложения, как:
мужчина любит женщину
каждая женщина ходит
женщине нравится парк
Мы можем написать простую программу на Прологе для распознавания этого языка,
написание анализатора рекурсивного спуска. Сначала мы должны решить, как
обрабатывать входную строку. Мы будем использовать список в Прологе. Для каждого
nonterminal мы создадим процедуру Prolog для распознавания строк
сгенерированный этим нетерминалом. Каждая процедура будет состоять из двух
аргументы. Первым будет входной параметр, состоящий из
список, представляющий входную строку. Второй будет выводом
аргумент и будет установлен процедурой в оставшуюся часть
входная строка после того, как начальный сегмент, совпавший с нетерминалом,
был удален. Пример поможет понять, как это работает.
процедура для 9Например, 0036 np
Мы будем использовать список в Прологе. Для каждого
nonterminal мы создадим процедуру Prolog для распознавания строк
сгенерированный этим нетерминалом. Каждая процедура будет состоять из двух
аргументы. Первым будет входной параметр, состоящий из
список, представляющий входную строку. Второй будет выводом
аргумент и будет установлен процедурой в оставшуюся часть
входная строка после того, как начальный сегмент, совпавший с нетерминалом,
был удален. Пример поможет понять, как это работает.
процедура для 9Например, 0036 np
[a,woman,loves,a,man] и вернется во второй раз
аргумент список [loves,a,man] . Сегмент, удаленный
процедура, [женщина] , является NP. Программа на Прологе:
s(S0,S):-np(S0,S1), vp(S1,S).
np(S0,S) :- det(S0,S1), n(S1,S).
vp(S0,S):- tv(S0,S1), np(S1,S).
vp(S0,S) :- v(S0,S).
det(S0,S) :- S0=[the|S].
det(S0,S) :- S0=[a|S].
det(S0,S) :- S0=[каждый|S].
n(S0,S) :- S0=[man|S].
n(S0,S) :- S0=[женщина|S].
n(S0,S) :- S0=[парк|S].
tv(S0,S) :- S0=[любит|S].
tv(S0,S):- S0=[лайки|S].
v(S0,S) :- S0=[прогулки|S].
Первый пункт определяет процедуру  n(S0,S) :- S0=[man|S].
n(S0,S) :- S0=[женщина|S].
n(S0,S) :- S0=[парк|S].
tv(S0,S) :- S0=[любит|S].
tv(S0,S):- S0=[лайки|S].
v(S0,S) :- S0=[прогулки|S].
n(S0,S) :- S0=[man|S].
n(S0,S) :- S0=[женщина|S].
n(S0,S) :- S0=[парк|S].
tv(S0,S) :- S0=[любит|S].
tv(S0,S):- S0=[лайки|S].
v(S0,S) :- S0=[прогулки|S].
s для распознавания
фразы. Список ввода S0 передается в процедуру s ,
и он должен установить S как оставшуюся часть списка S после того, как предложение было удалено из начала. Для этого он
использует две подпроцедуры: сначала вызывает np для удаления NP, и
затем он вызывает vp , чтобы удалить из этого VP. Поскольку грамматика
говорит, что S — это NP, за которым следует VP, это будет правильно
вещь. Остальные правила абсолютно аналогичны. Поместив эту программу в файл с именем gramma.P , мы можем загрузить
и выполните его на наших примерах предложений следующим образом:
% xsb XSB версии 1.4.1 (11.09.21) [последовательный, одно слово, оптимальный режим] | ?- [грамматика].
 [Компиляция ./грамматики]
[грамматика скомпилирована, затраченное процессорное время: 1,14 секунды]
[грамматика загружена]
да
| ?- s([а,мужчина,любит,женщину],[]).
да
| ?- s([каждая,женщина,гуляет],[]).
да
| ?- s([женщина,любит,парк],[]).
да
| ?- s([a,женщина,любит,прак],[]).
нет
| ?-
[Компиляция ./грамматики]
[грамматика скомпилирована, затраченное процессорное время: 1,14 секунды]
[грамматика загружена]
да
| ?- s([а,мужчина,любит,женщину],[]).
да
| ?- s([каждая,женщина,гуляет],[]).
да
| ?- s([женщина,любит,парк],[]).
да
| ?- s([a,женщина,любит,прак],[]).
нет
| ?-
s процедура с входной строкой в качестве первого аргумента, и мы дали
пустой список в качестве второго аргумента, потому что мы хотим, чтобы он соответствовал
вся входная строка, после просмотра s ничего не осталось. Приведенная выше грамматика называется Definite Clause Grammar (DCG) и
Пролог поддерживает специальный синтаксис правил для записи DCG. Синтаксис
проще, намного ближе к синтаксису, используемому при написании контекстно-свободных
грамматические правила. При использовании синтаксиса DCG у программиста нет
для записи всех строковых переменных, пропущенных через нетерминал
вызовы процедур; это сделает компилятор. Здесь следующее то же самое
Пролог-программа аналогична приведенной выше, но написана как DCG:
При использовании синтаксиса DCG у программиста нет
для записи всех строковых переменных, пропущенных через нетерминал
вызовы процедур; это сделает компилятор. Здесь следующее то же самое
Пролог-программа аналогична приведенной выше, но написана как DCG:
с --> нп, вп.
нп --> дет, н.
вп --> тв, нп.
вп --> в.
дет --> [the].
дет --> [а].
det --> [каждый].
п --> [человек].
п --> [женщина].
п --> [парк].
тв --> [любит].
тв --> [лайки].
v --> [ходит].
Обратите внимание, что в этих «определениях процедур» используется символ --> .
вместо :- для отделения заголовка процедуры от процедуры
тело. Компилятор Пролога преобразует такие правила (почти) точно в
программу выше, добавив дополнительные аргументы к предикатным символам
и обработка списков как терминалов. «Почти» потому, что
действительно переводит, например, один список слов [любит] выше к вызову процедуры 'C'(S0,loves,S) и включает
определение этого нового предиката как:
'С'([Слово|Строка],Слово,Строка).
Это дает точно такой же эффект, как и программа на Прологе для
грамматика приведена выше.
Рассмотрим другой пример грамматики, на этот раз для простой арифметики.
выражения над целыми числами с операторами + и * :
выражение --> термин, доптермин.
добавить термин --> [].
addterm --> [+], выр.
термин --> фактор, мультифактор.
мультифактор --> [].
мультифактор --> [*], терм.
фактор --> [I], {целое число (I)}.
фактор --> ['('], выр, [')'].
Есть несколько вещей, которые следует отметить в отношении этого DCG. Обратите внимание, что список
записи, представляющие терминалы, не обязательно должны появляться в одиночку на
правые части правил DCG, но могут сопровождать нетерминалы. Также
обратите внимание на первое правило для factor ; у него есть переменная ( I )
в списке, который заставит его сопоставляться и, таким образом, будет установлен в
следующий входной символ. Следующий вызов процедуры заключен в
брекеты. Это означает, что он не соответствует ни одному входному символу, и поэтому его
перевод на Пролог НЕ приводит к тому, что строковые переменные
добавлен. Остается только вызов процедуры Prolog с одним
аргумент:
Это означает, что он не соответствует ни одному входному символу, и поэтому его
перевод на Пролог НЕ приводит к тому, что строковые переменные
добавлен. Остается только вызов процедуры Prolog с одним
аргумент: целое число(I) . Процедура integer является Прологом.
встроенный, который проверяет, является ли его аргумент целым числом. Обратите внимание также
что мы должны заключать круглые скобки в окончательном правиле. В противном случае,
Читатель Пролога не сможет правильно разобрать их как атомы.Рассмотрим несколько примеров выполнения этой грамматики:
% xsb
XSB версии 1.4.1 (11.09.21)
[последовательный, одно слово, оптимальный режим]
| ?- [грамматика].
[Компиляция ./грамматики]
[грамматика скомпилирована, затраченное процессорное время: 1,309 секунды]
[грамматика загружена]
да
| ?- выражение([4,*,5,+,1],[]).
да
| ?- expr([1,+,3,*,'(',2,+,4,')'],[]).
да
| ?- выражение([4,5,*],[]).
нет
| ?-
Эта грамматика не самая очевидная для написания этой
язык выражения. Он специально сконструирован, чтобы его не оставили
рекурсивный. Выше мы упоминали, что пишем рекурсивный
синтаксический анализатор спуска для грамматики, и это то, что можно получить для DCG
из стратегии выполнения Пролога. Прологовое выполнение базового
детерминированные машины и использование стека для их планирования
естественно дает парсер рекурсивного спуска. И хорошо известно, что
анализатор рекурсивного спуска не может обрабатывать леворекурсивные грамматики; Это
войдет в бесконечный цикл на них. Поэтому в Прологе мы должны избегать
леворекурсивные грамматики.
Он специально сконструирован, чтобы его не оставили
рекурсивный. Выше мы упоминали, что пишем рекурсивный
синтаксический анализатор спуска для грамматики, и это то, что можно получить для DCG
из стратегии выполнения Пролога. Прологовое выполнение базового
детерминированные машины и использование стека для их планирования
естественно дает парсер рекурсивного спуска. И хорошо известно, что
анализатор рекурсивного спуска не может обрабатывать леворекурсивные грамматики; Это
войдет в бесконечный цикл на них. Поэтому в Прологе мы должны избегать
леворекурсивные грамматики.
Также синтаксический анализатор рекурсивного спуска может быть весьма неэффективным на некоторых
грамматики, потому что он может повторно анализировать одну и ту же подстроку много раз. В
на самом деле, есть грамматики, для которых парсеры рекурсивного спуска требуют времени
экспоненциально зависит от длины входной строки. При использовании DCG в
Prolog, программист должен знать об этих ограничениях и программировать
вокруг них. Именно поэтому некоторые люди реагируют на
заявляют, что «Вы получаете синтаксический анализатор бесплатно с Прологом» с «Возможно, но
это не синтаксический анализатор, который я хочу использовать».
Именно поэтому некоторые люди реагируют на
заявляют, что «Вы получаете синтаксический анализатор бесплатно с Прологом» с «Возможно, но
это не синтаксический анализатор, который я хочу использовать».
(Еще один пример добавления аргументов и использования word/3 вместо струны?).
Далее: Пролог как база данных Up: Введение в Пролог Предыдущий: Планирование машины Дэвид С. Уоррен
1999-07-31
Лингвистические идеи для понимания естественного языка: анализ синтаксиса и составных частей
Анализ синтаксиса и составных частей
Человеческий язык невероятно сложен и постоянно меняется. Тем не менее, свободно говоря на одном или нескольких языках, люди могут понимать его почти неявно.
Лингвистика — это наука о человеческом языке, целью которой является описание его структуры, значения и того, как люди используют его в различных контекстах. При подходе к задаче понимания естественного языка (NLU), такой как классификация намерений, анализ настроений или ответы на вопросы, популярные архитектуры глубокого обучения, такие как LSTM и Transformers, могут проделать впечатляющую работу. Однако у этих подходов все еще есть проблемы с языковыми явлениями, которые мы, люди, понимаем без задней мысли.
Однако у этих подходов все еще есть проблемы с языковыми явлениями, которые мы, люди, понимаем без задней мысли.
Применение лингвистической теории может помочь нам приблизиться к пониманию языка на человеческом уровне, чтобы дополнить существующие алгоритмы и архитектуры для задач NLU. В этом сообщении блога мы возьмем один пример в качестве примера того, как может выглядеть это приложение лингвистической теории.
Давайте рассмотрим классификацию намерений, которую часто используют чат-боты и виртуальные помощники, чтобы понять, о чем спрашивает пользователь, чтобы дать правильный ответ. Модели классификации намерений обычно строятся для обеспечения единой классификации намерений для каждого высказывания. Итак, мы ожидаем, что модель классифицирует вопрос «Который час?» как вопрос о текущем времени, чтобы предоставить пользователю текущее время. Но люди не всегда разбивают свои предложения на отдельные намерения. Разговаривая с виртуальным помощником, вы можете спросить: «Который час и когда закрывается ресторан?» Или, разговаривая с Софией, помощником по виртуальным льготам Businessolver, на своем портале льгот для сотрудников, вы можете сказать: «Я хочу проверить свою франшизу, просмотреть свое заявление и изменить информацию о моем сыне». Модель, обученная извлекать одно намерение из одного предложения, никогда не сможет предоставить все детали, которые ищет пользователь, если она не сможет идентифицировать все вопросы, которые пользователь задает, в одном высказывании.
Модель, обученная извлекать одно намерение из одного предложения, никогда не сможет предоставить все детали, которые ищет пользователь, если она не сможет идентифицировать все вопросы, которые пользователь задает, в одном высказывании.
Что нам нужно, так это модель, которая может обеспечить классификацию одного или нескольких намерений, если пользователь задает более одного вопроса. Один из способов сделать это — обучить совершенно новый тип модели, которая может выводить несколько намерений. Это может быть дорогостоящей стратегией, если у нас еще нет помеченного набора данных высказываний с несколькими намерениями. Вместо этого предположим, что мы хотим продолжать использовать модель с одним намерением, которая у нас уже есть. Мы можем применить лингвистическую теорию, используя синтаксический разбор для расширения существующей модели.
Чтобы понять синтаксический анализ, нам сначала нужно иметь общее представление о том, что означает синтаксис в лингвистике. Давайте ненадолго отойдем от нашего примера классификации намерений.
Что такое синтаксический анализ?
Предложения структурированы, то есть предложения — это не просто набор слов, которые мы можем расположить в любом порядке, чтобы создать одно и то же значение. Рассмотрим следующие два предложения:
A. Собака укусила человека.
B. Мужчина укусил собаку.
Эти два предложения содержат одни и те же слова и одинаковый порядок тегов частей речи. Единственная разница заключается в порядке появления этих слов. В этом случае перестановка слов «собака» и «человек» меняет подлежащее и дополнение глагола «укусить», тем самым меняя значение слов «кто был укушен», а кто «укусил». кусаться.
Синтаксическая структура также играет роль в определении приемлемости предложений в языке. Например, если вы носитель английского языка, вы, вероятно, согласитесь с этим примером c. ниже не является грамматическим предложением:
C. Собака бит человек.
И снова это предложение содержит все те же слова, что и предложения в a.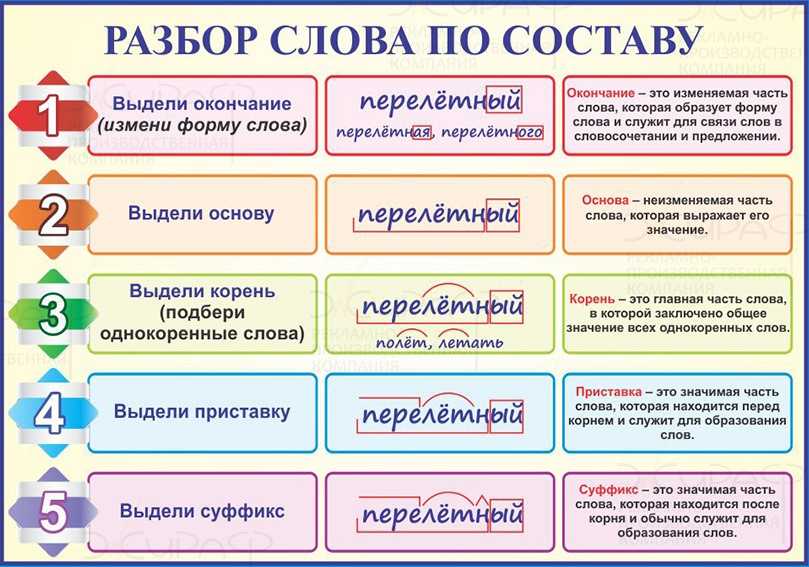 и б. но порядок этих слов нарушает наши правила ментальной грамматики английского языка. Документируя эти мыслительные правила, лингвисты могут создавать грамматики, которые затем можно использовать для комментирования структуры предложения.
и б. но порядок этих слов нарушает наши правила ментальной грамматики английского языка. Документируя эти мыслительные правила, лингвисты могут создавать грамматики, которые затем можно использовать для комментирования структуры предложения.
В этом контексте грамматика означает нечто несколько отличное от того, чему нас учат в начальной школе. Грамматика в лингвистике не используется, чтобы сказать говорящим, как использовать язык (например, «Не разделяйте инфинитивы!»). Вместо этого грамматики используются для опишите , как носители естественно используют язык. Например, наблюдая за носителями английского языка, мы можем узнать, что существительные, такие как «собака», «мужчина», «друг ее сестры» или «это», могут встречаться в одном и том же месте в предложении. Возьмите приведенные ниже предложения в качестве примера:
- Собака съела лакомство.
- Мужчина съел угощение.
- Подруга ее сестры съела угощение.
- Он съел угощение.

Хотя все четыре из этих предложений имеют разные значения, мы можем видеть, что все четыре именные группы, которые мы описали выше, могут выполнять одну и ту же часть синтаксической структуры предложения — в этом случае все они являются подлежащим глагола «съел». . Примечательно, что независимо от длины этих именных словосочетаний они функционируют как единое целое в структуре предложения. Это свойство словосочетания функционировать как отдельная единица в предложении называется округ .
Составляющие не ограничиваются именными словосочетаниями. Предложения могут содержать глагольные фразы (например, «укусить мужчину»), предложные фразы (например, «рядом с кроватью»), наречные фразы (например, «сонно») и т. д. Мы можем создавать грамматики, записывая правила, описывающие, как слова можно комбинировать. составлять члены и предложения. Взгляните на дерево синтаксического анализа предложения «Собака укусила человека» ниже, а затем мы обсудим грамматику, которая использовалась для создания этого дерева.
Может быть не сразу понятно, что означают все метки и строки в этом дереве синтаксического анализа — мы доберемся до них через мгновение. Во-первых, давайте подумаем о составляющих этого дерева. Составляющая в дереве синтаксического анализа определяется как все слова, имеющие общий узел-предок. Ранее мы обсуждали, что «собака» является составной частью именной группы. Обратите внимание, что слова «the» и «собака» имеют общий предковый узел «NP» (существительное словосочетание). Точно так же мы можем видеть, что все слова в составе глагольной фразы «укусить человека» имеют общий предковый узел VP (глагольная фраза). Мы также можем использовать это дерево, чтобы увидеть, что не является составной частью . Например, последовательность слов «собака укусила» является составной частью , а не , потому что, хотя они имеют общий узел-предок S (предложение), этот узел S также является предком слова «человек». Другими словами, «собака укусила» не является составной частью, поскольку не включает все слова в общем предковом узле.
Теперь, когда мы начинаем понимать, как идентифицировать составляющие, глядя на дерево, давайте посмотрим на грамматику, которая использовалась для создания этого дерева синтаксического анализа. Приведенная ниже грамматика представляет собой очень маленький игрушечный пример грамматики, которую можно использовать для описания структуры ограниченного числа предложений на английском языке.
S (Предложение) → NP VP NP (существительное) → Det Nom Nom (номинальное) → N Nom | Н VP (Глагол) → V NP N (существительное) → кошка | собака | мужчина | женщина | человек V (Глагол) → бит | укусы | лижет | лизнул Det (Определитель) → the
В этой нотации символ слева от стрелки (называемый неконечным символом ) может быть образован элементом(ами) справа от стрелки. Например, предложение (S) может быть образовано комбинацией именной фразы (NP), предшествующей глагольной фразе (VP). Символ вертикальной черты (|) означает «или», поэтому номинальное имя (Nom) может состоять либо из существительного (N), за которым следует номинальное, либо из одного существительного. Обратите внимание, что некоторые правила содержат только список слов справа от стрелки. Слова называются терминальных символов, потому что они встречаются только на листьях (узлах, не имеющих дочерних элементов) дерева синтаксического анализа. В большинстве случаев символ слева от правила с одним символом слова справа совпадает с тегом части речи для этого слова.
Обратите внимание, что некоторые правила содержат только список слов справа от стрелки. Слова называются терминальных символов, потому что они встречаются только на листьях (узлах, не имеющих дочерних элементов) дерева синтаксического анализа. В большинстве случаев символ слева от правила с одним символом слова справа совпадает с тегом части речи для этого слова.
Используя эту грамматику, давайте построим дерево синтаксического анализа, которое мы видели выше. Существует несколько способов построить дерево синтаксического анализа, но для простоты мы построим его снизу вверх. Во-первых, мы смотрим на слова в нашем предложении «Собака больше человека» и смотрим, какие правила мы можем применить. Похоже, что все слова имеют соответствующее правило, которое дает метку этому отдельному слову. Давайте нарисуем эти метки:
Вы могли заметить, что мы добавили две метки к существительным в предложении – сначала метку существительного, затем именную метку. Хотя это важное различие в лингвистике, для нашего случая использования мы можем предположить, что существительные и именные по сути являются одной и той же категорией.
Хотя это важное различие в лингвистике, для нашего случая использования мы можем предположить, что существительные и именные по сути являются одной и той же категорией.
Теперь, когда у нас есть метки над каждым словом, что приводит к последовательности меток — Det, Nom, V Det, Nom — мы можем снова взглянуть на нашу грамматику, чтобы увидеть, какие правила могут применяться к последовательности меток. Поскольку у нас есть последовательность «Det Nom», мы можем применить правило NP → Det Nom. На самом деле, мы можем применить это правило дважды, так как в нашем предложении есть две последовательности «Det Nom»:
С помощью этого правила мы образовали две новые именные группы, и наша последовательность меток узлов теперь выглядит так: NP, V, NP. Порядок символов в правой части правила имеет значение при применении грамматики. Таким образом, хотя в нашей грамматике нет правила, образующего составную часть последовательности «NP V», — это правило, образующее составную часть последовательности «V NP»: VP → V NP. Поэтому мы можем добавить новый узел VP и соединить его с дочерними узлами V и NP:
Поэтому мы можем добавить новый узел VP и соединить его с дочерними узлами V и NP:
Наконец, у нас есть только два узла в нашей последовательности меток: NP, VP. Это именно та последовательность меток, которая нам нужна для выполнения правила грамматики, формирующего предложение: S → NP VP. Добавляя этот узел, мы приходим к нашему окончательному дереву синтаксического анализа:
Мы знаем, что мы закончили синтаксический анализ предложения, потому что теперь у нас есть только один узел в верхней части дерева, и нет нижних узлов, которые были бы отсоединены от него. дерево – все они имеют родительский узел. Кроме того, единственный узел, который у нас остался, — это узел S, поэтому мы знаем, что создали структуру предложения, которая соответствует строке слов, с которой мы начали.
Важно отметить, что это очень упрощенный пример дерева синтаксического анализа избирательного округа. По этой теме можно еще многому научиться, включая различные фреймворки для синтаксического анализа (такие как x-bar, минимализм, HPSG, для вашего удовольствия) и различные синтаксические теории, которые сообщают правила в грамматике и результирующую древовидную структуру. Существуют также совершенно другие способы анализа предложения, такие как анализ зависимостей, который фокусируется на грамматических отношениях между отдельными словами (например, субъект, объект, модификатор и т. д.), а не на отношениях и структурах целых составляющих. Каждый из этих способов аннотирования структуры предложения может быть использован в различных приложениях НЛП. В этом сообщении блога давайте вернемся к нашему примеру классификации намерений и посмотрим, как даже это простое понимание синтаксического анализа групп может расширить систему NLU.
Существуют также совершенно другие способы анализа предложения, такие как анализ зависимостей, который фокусируется на грамматических отношениях между отдельными словами (например, субъект, объект, модификатор и т. д.), а не на отношениях и структурах целых составляющих. Каждый из этих способов аннотирования структуры предложения может быть использован в различных приложениях НЛП. В этом сообщении блога давайте вернемся к нашему примеру классификации намерений и посмотрим, как даже это простое понимание синтаксического анализа групп может расширить систему NLU.
Применение синтаксиса к системам NLU:
Вспомните разговор с Софией, нашим виртуальным помощником по льготам, который мы обсуждали выше. Мы хотели, чтобы модель NLU понимала вопрос «Я хочу проверить свою франшизу, просмотреть свое заявление и отредактировать информацию о моем сыне». Пользователь спрашивает о трех разных задачах; «проверить мою франшизу», «просмотреть мою заявку» и «изменить информацию о моем сыне». В этом примере мы видим, что эти три задачи являются частью списка, где каждый из элементов списка представляет что-то, что пользователь хочет сделать. Мы знаем это, потому что списку предшествует фраза «Я хочу». Итак, как мы можем использовать синтаксический анализ избирательных округов, чтобы помочь нам решить эту проблему? Давайте посмотрим на дерево синтаксического анализа для этого предложения:
В этом примере мы видим, что эти три задачи являются частью списка, где каждый из элементов списка представляет что-то, что пользователь хочет сделать. Мы знаем это, потому что списку предшествует фраза «Я хочу». Итак, как мы можем использовать синтаксический анализ избирательных округов, чтобы помочь нам решить эту проблему? Давайте посмотрим на дерево синтаксического анализа для этого предложения:
Это дерево выглядит немного иначе, чем примеры, которые мы видели раньше, но основная идея та же. (Он был создан синтаксическим анализатором Stanford CoreNLP, о котором вы можете узнать больше здесь. Метки также немного отличаются, поскольку его грамматика основана на Penn Treebank, который использует свой собственный набор тегов.)
Верхняя часть структуры этого предложения выглядит почти идентично нашему предыдущему примеру — есть предложение (S), которое состоит из именной группы (NP), за которой следует глагольная группа (VP). Просто глагольная фраза в этом предложении немного сложнее, чем та, которую мы видели раньше. Частью этой сложности является наличие координированной глагольной фразы, то есть глагольной фразы, состоящей из двух или более других глагольных фраз (в данном случае трех других глагольных фраз). Мы можем визуально идентифицировать эту координированную глагольную фразу (обведена зеленым в дереве выше) по наличию более чем одного дочернего компонента и наличию координирующего союза CC (в данном случае «и»). Координируемые элементы — это ВП, обозначенные красными квадратами. Они являются потомками самой верхней ВП внутри зеленого круга, за исключением пунктуации и сочинительного союза. Если мы посмотрим на каждую из этих скоординированных глагольных фраз, мы увидим, что это именно то, что мы надеялись идентифицировать — три разных запроса, которые делает пользователь — «проверить мою франшизу», «просмотреть мою претензию» и «изменить информацию о моем сыне». ».
Частью этой сложности является наличие координированной глагольной фразы, то есть глагольной фразы, состоящей из двух или более других глагольных фраз (в данном случае трех других глагольных фраз). Мы можем визуально идентифицировать эту координированную глагольную фразу (обведена зеленым в дереве выше) по наличию более чем одного дочернего компонента и наличию координирующего союза CC (в данном случае «и»). Координируемые элементы — это ВП, обозначенные красными квадратами. Они являются потомками самой верхней ВП внутри зеленого круга, за исключением пунктуации и сочинительного союза. Если мы посмотрим на каждую из этих скоординированных глагольных фраз, мы увидим, что это именно то, что мы надеялись идентифицировать — три разных запроса, которые делает пользователь — «проверить мою франшизу», «просмотреть мою претензию» и «изменить информацию о моем сыне». ».
Если наша система NLU имеет доступ к дереву синтаксического анализа для этого предложения, мы могли бы использовать наши знания о структуре координатной фразы, чтобы извлечь три запроса, которые делает пользователь.
Как София будет использовать синтаксис?
В случае Софии, виртуального помощника Businesssolver, мы работаем над тем, как внедрить этот синтаксический анализ в наше распознавание намерений, чтобы София могла понимать, когда пользователи задают несколько вопросов одновременно. В идеале мы хотели бы, чтобы София могла сказать: «Я понимаю, что вы хотите поговорить о вашей франшизе, ваших требованиях и вашем иждивении. С чего бы вы хотели начать?» Затем пользователь может выбрать, какую тему обсудить в первую очередь, и София предложит пользователю вернуться к другим темам позже в разговоре.
Для этого нашему экстрактору списков на основе синтаксиса потребуется дополнительная работа. Хотя синтаксический анализ группы может надежно помочь нам извлечь элементы списка, у нас нет никакой гарантии, что эти элементы действительно соответствуют отдельным темам, как это определено нашими намерениями.
Например, в предложении «Я проверил свою франшизу и просмотрел свое заявление, но я не вижу, где изменить информацию о моем сыне», мы, вероятно, извлекли бы элементы списка «проверил мою франшизу» и «просмотрел мое заявление». ” Но пользователь действительно спрашивает об информации своего сына. Есть несколько способов смягчить эту проблему, один из которых заключается в поиске подсказок, указывающих на то, что в списке говорится о нескольких темах, например, в списке, которому предшествуют слова «Я хочу». Другой возможностью может быть рассмотрение соединения, которое присоединяется к элементу списка. Мы могли бы найти образец, который показывает, что мы должны относиться к спискам, соединенным с помощью «но», иначе, чем к спискам, соединенным с помощью «и». можно быть уверенным, что они будут надежно давать правильный результат.
” Но пользователь действительно спрашивает об информации своего сына. Есть несколько способов смягчить эту проблему, один из которых заключается в поиске подсказок, указывающих на то, что в списке говорится о нескольких темах, например, в списке, которому предшествуют слова «Я хочу». Другой возможностью может быть рассмотрение соединения, которое присоединяется к элементу списка. Мы могли бы найти образец, который показывает, что мы должны относиться к спискам, соединенным с помощью «но», иначе, чем к спискам, соединенным с помощью «и». можно быть уверенным, что они будут надежно давать правильный результат.
Надеюсь, этот пример даст вам представление о том, как синтаксический анализ групп может быть полезен в задачах NLU. Подводя итог: поскольку синтаксис предложения так тесно связан с его значением, мы можем творчески использовать эту структуру, чтобы помочь приложениям искусственного интеллекта понимать язык ближе к тому, как это делают люди. Это может быть особенно полезно при дополнении нейронных подходов, которые часто представляют собой «черный ящик».