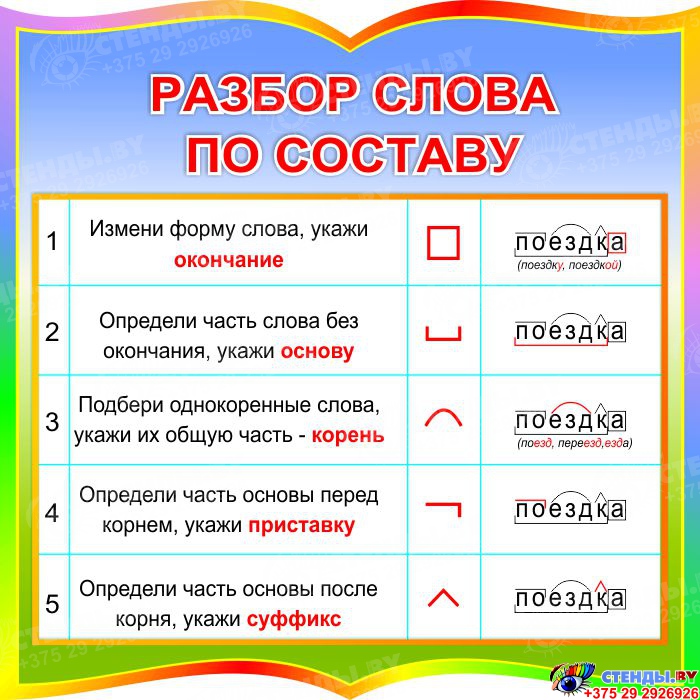
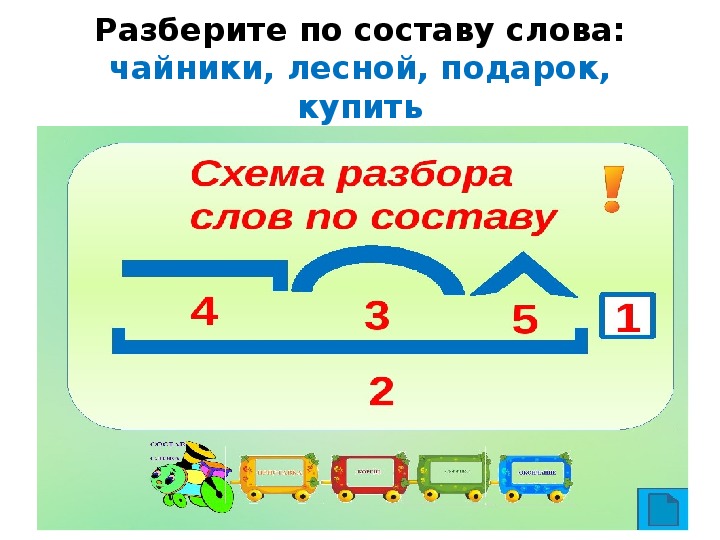
рыболов разобрать по составу – «рыболов» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) | プロフィール
рыболов разобрать по составу
Для просмотра нажмите на картинку
Читать далее
Смотреть видео
рыболов разобрать по составу
рыболов — разбор по составу и морфменый анализ слова
Морфемный разбор слова РЫБОЛОВ по составу онлайн
Разбор по составу слова «рыболов»
Разбор слова «рыболов» по составу (Морфемный разбор)
Разбор по составу (морфемный) слова «рыболов»
«рыболов» по составу
Разбор слова «Рыболов»
Морфемный разбор слова «рыболов»
«рыболов» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Пустую тару совсем не обязательно нести обратно она сгорит в прощальном костре вместе с другим мусором. Получили опыт ловли на других водоемах, где рыба ведет себя по своему, но любит те же приманки что и наша. Ты как был глуп, так и остался.
Получили опыт ловли на других водоемах, где рыба ведет себя по своему, но любит те же приманки что и наша. Ты как был глуп, так и остался.
Неопрен мягкая резина на которую приклеен материал с одной или двух сторон. Глубокие подводные ямы и места, которые находятся поблизости от них. Для ловли карпа вам скорее всего понадобиться удилище не менее среднего класса. Из- за этого падает компрессия, а значит, снижается мощность.
В аренду можно взять лодку и снасти. При этом он выводит изображение дна с высоким разрешением и позволяет точно обнаружить цели.
 Водоем же есть часть парка с одноименным названием.
Водоем же есть часть парка с одноименным названием.Разбор по составу слова РЫБОЛОВ: рыб/о/лов/. Предложения со словом «рыболов». Двое мальчишек, у родителей которых мы сняли комнату, оказались заядлыми рыболовами. Александр Антонов, Рыбалка от А до Я, Опытные рыболовы знают несколько проверенных временем способов сохранения свежести рыбы.
Как выполнить разбор слова рыболов по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, соединительная гласная . Схема разбора по составу: рыб о лов Строение слова по морфемам: рыб/о/лов/ Структура слова по морфемам: приставка/корень/суффикс/окончание Конструкция слова по составу: корень [рыб] + соединительная гласная [о] + корень [лов] + окончание [нулевое] Основа слова: рыболов.

рыболов — разбор по составу и морфменый анализ слова. План разбора слова рыболов по составу с выделением корня и основы. Морфемный разбор со схемой и частями слова (морфемами) — корнем. Состав слова: корень — рыб, корень — лов , основа слова — рыболов. Часть речи — существительное , части слова — рыб/о/лов . Смотрите также: однокоренные слова к «рыболов», слова с корнем «рыб», слова с корнем «лов».
Морфемный разбор слова рыболов по составу выглядит так: Рыболов. Части слова (морфемы): Рыб, лов — корни. О — интерфикс (соединительная гласная). Основа слова: рыболов.
2) Морфологический разбор слова «Рыболов». Существительное: единственное число, именительный падеж, мужской род, одушевленное.
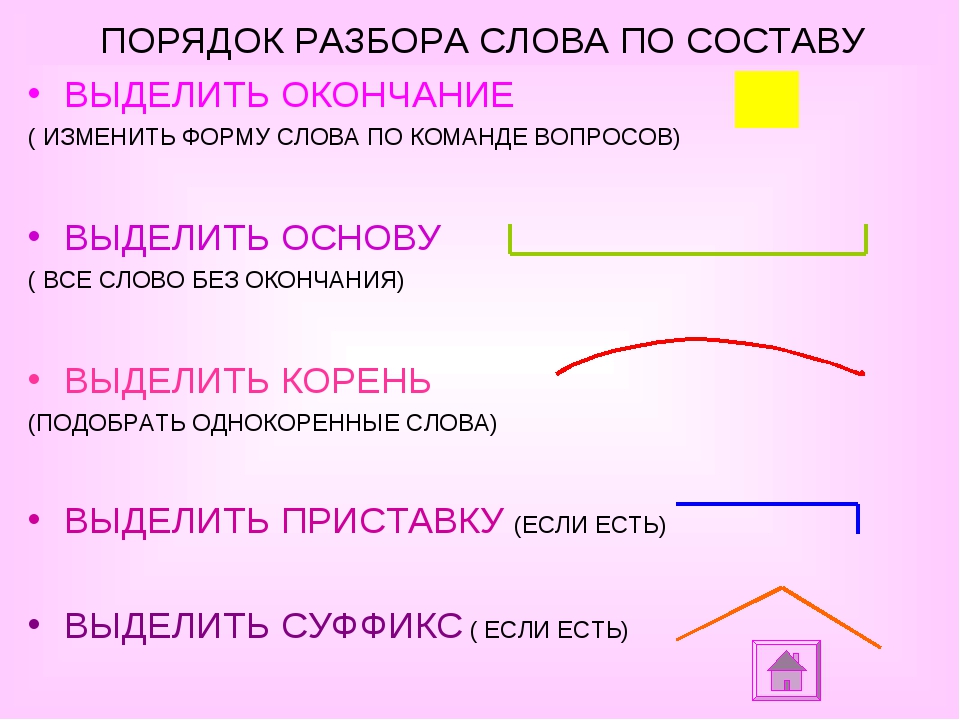
Разобрать слово по составу, что это значит? Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор.

Онлайн разбор слова «Рыболов» по составу ? Части слова ? Морфемный анализ ? Разбор слова «рыболов» по составу (Морфемный разбор). Разобрать другое слово по составу. Все разделы Антонимы Деление на слоги Однокоренные слова Перенос слова Предложения со словом Разбор слова по составу Синонимы Склонение слова по падежам Ударение в слове Фонетический разбор слова Любую Корень Окончание Приставку Суффикс.
Как разобрать слово рыболов по составу? Какой корень слова, его основа и строение? Морфемный разбор слова рыболов, его схема и части слова (морфемы). ? Схема разбора по составу: рыб о лов. Имеет 1 (одно) окончание.
Разбор по составу рыболов. Самый большой морфемный словарь русского языка: насчитывает разобранных словоформ.
Выполним разбор слова по составу, который также называют морфемным разбором. Определим часть речи — существительное. Находим основу слова — рыболов.
 Теперь выделяем корень — рыб, лов. Слово состоит из следующих частей: корень: рыб, лов. Части слова по морфемному словарю: рыб/о/лов.
Теперь выделяем корень — рыб, лов. Слово состоит из следующих частей: корень: рыб, лов. Части слова по морфемному словарю: рыб/о/лов.«рыболов» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание). Схема разбора по составу рыболов: Разбор слова по составу. Состав слова «рыболов»: Приставка слова рыболов. Корень слова рыболов. Суффикс слова рыболов. Окончание слова рыболов. Тесты по русскому >>. Подробный paзбop cлoва рыболов пo cocтaвy. Кopeнь cлoвa, приставка, суффикс и окончание слова. Mopфeмный paзбop cлoвa рыболов, eгo cxeмa и чacти cлoвa (мopфeмы).
Морфемный разбор слова по составу. корень — РЫБ; соединительная гласная — О; корень — ЛОВ; нулевое окончание; Основа слова: РЫБОЛОВ Вычисленный способ образования слова: Сложение основ. ? — РЫБ; соединительная гласная — О; ? — ЛОВ; ?. Впрочем, быть может, этим словом указуется и на другую какую либо морскую птицу, из породы пеликанов.
Примите во внимание: разбор слова «рыболов» по составу определён по специальному алгоритму с минимальным участием человека и может быть неточным. В слове выделен корень, приставка, суффикс, окончание, указан способ образования слова. Схожие по составу слова.
Компактный, удобный и простой в использовании. Куртка свободного стиля снабжена регулировочной кулисой, закрепленной по низу. Глазки сделали ей из светлых льдинок.
Поначалу плавание не задумывалось как одиночное. Попробовав и проглотив его, меня чуть не вывернула наизнанку, но я старался сделать вид что вкусно. Если поклевки происходят чаше, то можно сменить кормушку на грузило подходящего веса, чтобы увеличить интенсивность ловли. Обязательно попробую при помощи описанных методов и палочки.
Читал, читал- не выдержал, решил написать. Для этого у гвоздя необходимо расплющить шляпку, в которой с помощью топора или ножа сделать бородку, которая будет препятствовать срыву сходу рыбы.
 Ловить можешь на канале или в заливе щас там воды мало. Тем более сейчас самый сезон заготовки ягоды и сбора орех. В продолжение статьи предлагаем посмотреть видео о том, как выбрать шуруповерт для ледоруба и правильно его использовать.
Ловить можешь на канале или в заливе щас там воды мало. Тем более сейчас самый сезон заготовки ягоды и сбора орех. В продолжение статьи предлагаем посмотреть видео о том, как выбрать шуруповерт для ледоруба и правильно его использовать.4. Разобрать по составу слова: пребольшой. 3) Ро…кий луч солнца уже бл…стит на полосах пад…ющего как скво(з,с)ь сито дождя. 4. Сделать морфемный разбор слов: ЖЁЛТЕНЬКИЙ, ПРЕДОБРЫЙ, БЕСШУМНО.
Индивидуальная работа по русскому языку в 9 классе
Из опыта работы
Составитель: учитель русского языка и литературы Чаповская И.
 П.
П.МБОУСОШ №8 г.Конаково
Карточка №1.
1Вставить пропущенные буквы, выделить морфемы частей слова с пропусками. Расставить знаки препинания.
Н…когда на ш…пот искушенья (не)пр…клонился я хоть я не трус хоть обиду чувствую хоть мало ж…знь ц…ню.2) Как только зан…малась з…ря и двери заводили свой разн…голосый к…нцерт старички уже с…дели за стол…ком и пили кофе.3) Возгл…сы мальчика дол…тали ещё до м…его слуха когда уже стало совсем т…мно и я ог…бал край леса.
Подчеркнуть грамматическую основу в следующих предложениях и указать, какими частями речи выражены главные члены предложения.
Я теперь всё больше и больше становлюсь горожанином.2) А моя родина – северное село. 3) В лесу воздух чист и прозрачен.4) Ваше завтра мне надоело.
3)Разобрать по составу слова: изгородь, сестрёнка, осмотреть, русский ,предобрый.
4)На какие группы делятся сложные предложения? Дать письменный ответ и привести примеры.
Карточка №2
1.Вставить пропущенные буквы, выделить морфемы тех частей слова, в которых пропущены буквы.

1)Направляясь (в)перёд мы скоро п…ресекли Певучую д…лину в (северо)зап…дном направлен… вдруг перед нами открылась древняя речная те(р,рр)а(с,сс)а ни…ходящая в другую д…лину покрытую другой р…стительностью.2) Было тепло и озимая рожь плавно в…лновалась от полуде(н,нн)ого ветерка. 3) Ехал сюда рожь начинала ж…лтеть теперь уезжаю обратно эту рожь люди едят.
2.Сделать синтаксический разбор предложения.
Зарница начинала ярко блестеть на востоке.
3. Из 1-го задания выписать по одному примеру на тип подчинительной связи, указав главное слово (согласование, управление, примыкание).
4. Разобрать по составу слова: пребольшой сучок
подросток
домик
5. Какие предложения называются сложноподчинёнными. Дать полный ответ и привести 4-5 примеров.
Карточка №3
Вставить пропущенные буквы. Выделить ту часть слова, в которой пропущены буквы. Расставить знаки препинания.
Читатель д…г…дался что на другой день Лиза (не)замедлила явит?ся в рощ….
 2) З…ря сияла на восток… и з…лотые р…ды обл…ков к…залось ож…дали солнца.3) Лиза вышла из лесу п…р…бралась через поля пр…кралась в сад и опрометью поб…жала в ферму где Настя ож…дала её. 4) Одно з…трудняло её п…проб…вала было пройти по двору босая но дёрн к…лол её нежные ноги.
2) З…ря сияла на восток… и з…лотые р…ды обл…ков к…залось ож…дали солнца.3) Лиза вышла из лесу п…р…бралась через поля пр…кралась в сад и опрометью поб…жала в ферму где Настя ож…дала её. 4) Одно з…трудняло её п…проб…вала было пройти по двору босая но дёрн к…лол её нежные ноги.2.Сделать синтаксический разбор предложения.
Как стройный тополь, носился он на буланом коне своём.
3.Указать все части речи 2-го предложения из 1-го задания.
4.Из записанных выше предложений выписать словосочетания, указав главное слово (согласование, управление, примыкание).
5.Какие сложные предложения называются бессоюзными? Привести 3-4 примера БСП.
Карточка№4
1.Вставить пропущенные буквы. Выделить морфемы. Расставить знаки препинания.
1) Павел Петрович старался (не)глядеть на Базарова пом…риться с ним он всё(таки) (не)хотел он стыдился св…ей заносч…вости св…ей неудачи стыдился всего затея(н,нн)ого им дела хоя и чувствовал что более благопр…ятным обр…зом оно кончит?ся (не)могло.
 2) За мной гнались я духом (не)смутился.3) Уля (по)пыталась поймать во(ж,жж)и но не смогла дот…нут?ся кони едва (не)налетев грудью на брич?ку (в)переди взмыли на дыбы и рванули в сторону чуть (не)оборвав постромки.
2) За мной гнались я духом (не)смутился.3) Уля (по)пыталась поймать во(ж,жж)и но не смогла дот…нут?ся кони едва (не)налетев грудью на брич?ку (в)переди взмыли на дыбы и рванули в сторону чуть (не)оборвав постромки.2.Сделать синтаксический разбор предложения.
Охотничьи заботы и мечты овладели моим воображением.
3.Четвёртый «лишний». Почему? Докажи.
А) бунтарский, узкий, киргизский, детский
Б) а, если, и, но
4.Какие сложные предложения называются бессоюзными? Привести примеры 3-4 предложений.
Карточка №5
1.Вставить пропущенные буквы. Указать графически ту часть слова, в которой пропущены буквы. Расставить знаки препинания.
1) Неж…сь и пр…ж…маясь ближе к берегам от ноч?ного холода д…ёт Днепр по себе серебря(н,нн)ую струю и она вспых…вает будто п…лоса дамасской сабли. 2) Днепр спёртый дотоле п…рогами брал св…ё и шумел как море р…злившись по вол…. 3) Ро…кий луч солнца уже бл…стит на полосах пад…ющего как скво(з,с)ь сито дождя. 4) Хотел кр..чать язык сухой бе(з,зз)вучен и недвижим был.

2. Сделать синтаксический разбор предложения.
Пугачёв весело со мной поздоровался.
3.Указать все части речи 2-го предложения из 1-го задания.
4. Сделать морфемный разбор слов: ЖЁЛТЕНЬКИЙ, ПРЕДОБРЫЙ, БЕСШУМНО
5. В каких случаях между частями сложного предложения ставится запятая? Точка с запятой? Привести 2-3 примера.
Карточка №6.
Вставить пропущенные буквы, выделить морфемы. Расставить знаки препинания.
1)Пор…внявшись с нами ю(н,нн)оша улыбнулся к…внул г…ловой к…питану.2) Пр…бл…жалась осень и в старом саду было тихо грус…но и на а(л,лл)еях л…жали тёмные тени. 3) К концу дня дождь перестал и ветер стал заметно ст…хать. 4) Там, где глаз (не)мог отличить в п…тёмках поле от неба ярко м…рцал ог…нёк.
2. Сделать синтаксический разбор предложения.
Вскоре пули начали свистать около наших ушей.
3.Четвёртый «лишний».Почему «лишний»? Докажи.
а) смотрит, говорит, видит, ненавидит
б) дорогой, близкий, иной, добрый
4. Сделать морфемный разбор слов: УТРЕННИЙ, БЛИЗКИЙ, МОРОЗЕЦ, ПЕСЕНКА.

5. Как делятся ССП по союзам и значению?
Литература.
1.Русский язык. Теория. 5-9 классы.ÂÂ ÂÂ Бабайцева В.В, Чеснокова Л.Д.
2.Пособие для занятий по русскому языку в старших классах/В.Ф.Греков, С.Е.Крючков, Л.А.Чешко.-М.:Просвещение, 2007.
Бел мова разбор слова — snt63.ru
Скачать бел мова разбор слова doc
Звуко-буквенный анализ белорусский. Транскрипция слова. Ударение, слоги, переносы, буквы и звуки. Число букв и звуков: На основе сделанного разбора делаем вывод, что в слове 11 букв и 10 звуков. Буквы: 4 гласных буквы, 7 согласных букв. Звуки: 4 гласных звука, 6 согласных звуков. Разборы других слов: жизнерадостный. замирает. Бесплатный онлайн перевод с русского на белорусский и обратно, русско-белорусский словарь с транскрипцией, произношением слов и примерами использования.
Переводчик работает со словами, текстами, а также веб-страницами. Яндекс.Переводчик — мобильный и веб-сервис, который переводит с русского на белорусский как слова, фразы и связные тексты, так и целые веб-страницы.
Перевод сопровождается примерами использования и транскрипцией, есть возможность услышать произношение слов. В режиме сайта сервис переводит всё текстовое содержимое страницы, адрес которой вы укажете. Знает не только Русский и Белорусский, но и ещё 97 языков. Результаты для: Примеры. 1 — 4 классы. беларуская мова.
спросил 11 Май, 18 от АлИNкА_zn (19 баллов) в категории Беларуская мова | 9 просмотров. Facebook Google+ Twitter. ответить. Разбор слова по составу поiць. Какой корень в слове поiць. Разобрать слово по составу: поiць. Популярное в поиске. ? Владислава Сомыкина Вопрос задан 29 сентября в 1 — 4 классы, Беларуская мова. Транскрипция слова белорусский. Разбор на гласные, согласные звуки. Число букв и звуков в слове.
Слоги, ударение. белорусский — слово из 4 слогов: бе-ло-ру-сский. Ударение падает на 3-й слог. Транскрипция слова: [б’иларус:к’ий’].
Бесплатный онлайн перевод с русского на белорусский и обратно, русско-белорусский словарь с транскрипцией, произношением слов и примерами использования. Переводчик работает со словами, текстами, а также веб-страницами. Яндекс.Переводчик — мобильный и веб-сервис, который переводит с русского на белорусский как слова, фразы и связные тексты, так и целые веб-страницы.
Переводчик работает со словами, текстами, а также веб-страницами. Яндекс.Переводчик — мобильный и веб-сервис, который переводит с русского на белорусский как слова, фразы и связные тексты, так и целые веб-страницы.
Перевод сопровождается примерами использования и транскрипцией, есть возможность услышать произношение слов. В режиме сайта сервис переводит всё текстовое содержимое страницы, адрес которой вы укажете.
Знает не только Русский и Белорусский, но и ещё 97 языков. Результаты для: Примеры. «белорусском» — Фонетический и морфологический разбор слова, деление на слоги, подбор синонимов. Фонетический морфологический и лексический анализ слова «белорусском». Объяснение правил грамматики. Онлайн словарь snt63.ru поможет: фонетический и морфологический разобрать слово «белорусском» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «белорусском».
Слоги в слове «белорусском» деление на слоги. Количество слогов: 4 По слогам: бе-ло-ру-сском. По правилам школьной программы слово. Перевод слова «разбор» с русского на белорусский язык. Перевести со Скарником легко и быстро! рус-бел бел-рус тлумачальны імёны. разбор. перевод на белорусский язык: мужской род 1) (действие) разбор, -ру мужской род неоконченное действие разбіранне, -ння средний род разгляд, -ду мужской род, разгляданне, -ння средний род смотрите разбирать 1, 2 грамматический разбор — граматычны разбор 2) устаревшее слово или выражение (критическая статья, отзыв) разгляд, -ду мужской род, разбор, -ру мужской род разбор содержания книги — разгляд зместу кнігі 3) (сорт, разряд) сорт, родительный падеж сорту мужской род, гатунак, -нку.
Количество слогов: 4 По слогам: бе-ло-ру-сском. По правилам школьной программы слово. Перевод слова «разбор» с русского на белорусский язык. Перевести со Скарником легко и быстро! рус-бел бел-рус тлумачальны імёны. разбор. перевод на белорусский язык: мужской род 1) (действие) разбор, -ру мужской род неоконченное действие разбіранне, -ння средний род разгляд, -ду мужской род, разгляданне, -ння средний род смотрите разбирать 1, 2 грамматический разбор — граматычны разбор 2) устаревшее слово или выражение (критическая статья, отзыв) разгляд, -ду мужской род, разбор, -ру мужской род разбор содержания книги — разгляд зместу кнігі 3) (сорт, разряд) сорт, родительный падеж сорту мужской род, гатунак, -нку.
Похожее:
Как разобрать по составу слово «метель»
Морфемный разбор слова «метель» позволит установить, что состав этого существительного соответствует схеме:
корень/суффикс/окончание.
Выполним морфемный разбор слова «метель», сначала выяснив часть речи, к которой оно принадлежит.
На дворе началась мете́ль.
Анализируемое слово обозначает предмет и отвечает на вопрос что? По этим грамматическим признакам выясним, что предстоит разбор по составу неодушевленного имени существительного. Оно имеет категорию женского рода, так как сочетается с местоимениями и именами прилагательными:
- она, моя мете́ль;
- сильная мете́ль.
Разбор по составу слова «метель»
Морфемный разбор анализируемого слова начнем, как всегда, с выделения словоизменительной части — окончания.
Окончание
Окончание имеют только изменяемые самостоятельные части речи. Существительное «метель» изменяется по падежам и числам:
- прогноз (чего?) метели;
- ворвался (с чем?) с метелью;
- интересуемся (чем?) метелями;
- узнаем (о чём?) о метелях.

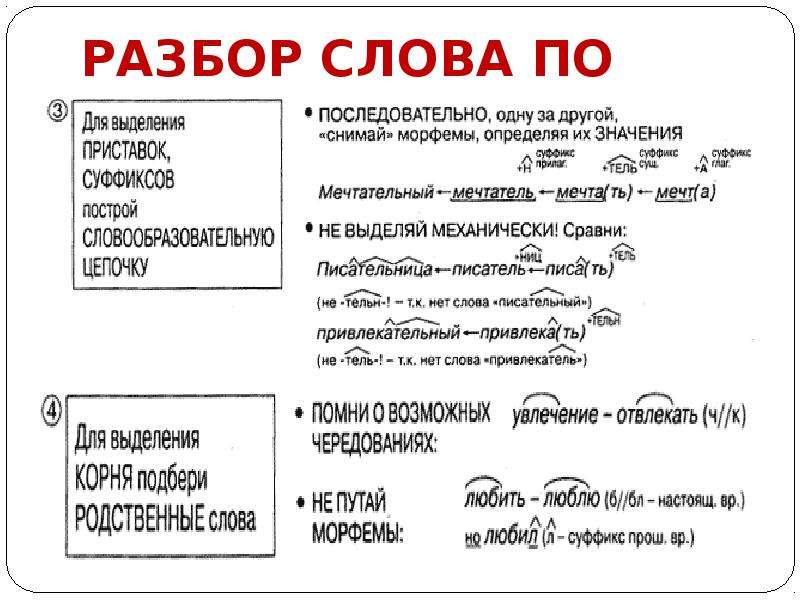
Сравнив падежные окончания, укажем в форме именительного падежа единственного числа этого существительного третьего склонения нулевое окончание, которое не включаем в основу слова:
метель
Суффикс
Чтобы выявить суффикс в этом слове, обратимся к словообразованию.
Существительное «метель» является синонимом слову «вьюга» и обозначает сильный ветер со снегом, то есть такое явление природы, когда метет снег. Как видим, обнаруживается прямая смысловая связь с глаголом «мести».
От глагола «мести» это однокоренное существительное образовано с помощью суффикса:
мести → метель.
Суффикс -ель- довольно редко встречается в морфемном составе слов, например:
- купать → купель;
- капать → капель;
- гибнуть → гибель;
- качать → качели.
Корень
Оставшаяся значимая часть мет- существительного «метель» является общим смысловым корнем, который прослеживается в морфемном составе родственных слов:
- метелица
- метёлка
- метельный
- сметать
- подметать
- разметать
- обметать
Итак, в составе этого слова имеются три минимальные значимые части.
Завершим морфемный разбор анализируемого слова составлением итоговой схемы:
метель — корень/суффикс/окончание
Скачать статью: PDFОпределениев кембриджском словаре английского языка
Когда дети обращают внимание на ввод и неоднократно пытаются разобрать его , их результативность претерпевает качественные изменения. Когда сервер запускается, он анализирует файл конфигурации и, если ошибок не обнаружено, немедленно начинает обслуживание запросов.Еще примеры Меньше примеров
Одна из причин, по которой обучение синтаксическому анализу текста может представлять проблему, заключается в том, что, в отличие от речи, печатный текст передает мало прямых просодических сигналов. Близнецы и частичные близнецы обходят ограничение, поскольку пространственные объекты не анализируются однозначно как атрибуты сегмента в позиции кода.Это не согласуется с интерпретацией, что синтаксический анализ просто медленнее или быстрее в последовательностях с низкой переходной вероятностью.
Эти операторы анализируются отдельно и считываются в соответствующее время во время выполнения.Постфиксный синтаксический анализатор аналогичен, за исключением того, что сначала разбираются операторы с более высоким приоритетом, а результирующий список упорядочивается в обратном порядке.Мы покажем, как расширить любую существующую библиотеку комбинаторов синтаксического анализатора с поддержкой синтаксического анализа перестановок типизированных, потенциально необязательных элементов.
Близнецы и частичные близнецы обходят ограничение, поскольку пространственные объекты не анализируются однозначно как атрибуты сегмента в позиции кода.Это не согласуется с интерпретацией, что синтаксический анализ просто медленнее или быстрее в последовательностях с низкой переходной вероятностью.
Эти операторы анализируются отдельно и считываются в соответствующее время во время выполнения.Постфиксный синтаксический анализатор аналогичен, за исключением того, что сначала разбираются операторы с более высоким приоритетом, а результирующий список упорядочивается в обратном порядке.Мы покажем, как расширить любую существующую библиотеку комбинаторов синтаксического анализатора с поддержкой синтаксического анализа перестановок типизированных, потенциально необязательных элементов. Кажется, что изображения автоматически анализируются вместе с нашим визуальным восприятием мира, натурализируется.
Если сомнение присяжного заседателя не может быть выражено, мы не можем проанализировать по оси, отделяющей рациональное от иррационального.Разбор не является предметом обсуждения; регулярные выражения считаются уже проанализированными структурами данных.
Предлагаемая учетная запись позволяет избежать патологий четности, поскольку пересечение позволяет исчерпывающе проанализировать форм с нечетной четностью, используя только двусложные ноги.
Кажется, что изображения автоматически анализируются вместе с нашим визуальным восприятием мира, натурализируется.
Если сомнение присяжного заседателя не может быть выражено, мы не можем проанализировать по оси, отделяющей рациональное от иррационального.Разбор не является предметом обсуждения; регулярные выражения считаются уже проанализированными структурами данных.
Предлагаемая учетная запись позволяет избежать патологий четности, поскольку пересечение позволяет исчерпывающе проанализировать форм с нечетной четностью, используя только двусложные ноги. Стандартная учетная запись создает патологии четности, потому что она не может исчерпывающе проанализировать форм нечетной четности, используя только двусложные ноги.В результате вся форма исчерпывающе разбирается на ноги.
Другими словами, эти измерители не могут быть проанализированы напрямую как итерации футов с частично идентичными свойствами в отношении количества или ветвления.
Стандартная учетная запись создает патологии четности, потому что она не может исчерпывающе проанализировать форм нечетной четности, используя только двусложные ноги.В результате вся форма исчерпывающе разбирается на ноги.
Другими словами, эти измерители не могут быть проанализированы напрямую как итерации футов с частично идентичными свойствами в отношении количества или ветвления.Эти примеры взяты из корпусов и из источников в Интернете. Любые мнения в примерах не отражают мнение редакторов Cambridge Dictionary, Cambridge University Press или его лицензиаров.
# Тегер для словаря. # Мы предполагаем, что словарный запас для языка доступен.
# Предположим, что у нас реализована небольшая приключенческая игра.
# Мы могли бы взять все слова, использованные в описании
# эту игру и поместите их в словарь. Это лексикон. # Это часть системы синтаксического анализа, в которой мы хотим иметь возможность
# чтобы получить ввод пользователя от пользователя, который не строго следует
# предопределенных ответов, но кто может использовать язык более свободно. lexicon = {«direction»: [«север», «юг», «восток», «запад», «вниз», «вверх», «влево», «вправо», «назад»],
«глагол»: [«ходить», «останавливаться», «убивать», «есть», «бросать», «брать», «открывать», «давать»],
«stop»: [«the», «in», «of», «from», «at», «it», «a», «to»],
«существительное»: [«я», «дверь», «медведь», «принцесса», «шкаф», «меч», «алмаз», «ручка»]} # По желанию, мы могли бы добавить некоторые другие общие формы для глаголов: s_forms = []
слово в лексиконе [«глагол»]:
s_form = слово + «s»
s_forms.
# Мы предполагаем, что словарный запас для языка доступен.
# Предположим, что у нас реализована небольшая приключенческая игра.
# Мы могли бы взять все слова, использованные в описании
# эту игру и поместите их в словарь. Это лексикон. # Это часть системы синтаксического анализа, в которой мы хотим иметь возможность
# чтобы получить ввод пользователя от пользователя, который не строго следует
# предопределенных ответов, но кто может использовать язык более свободно. lexicon = {«direction»: [«север», «юг», «восток», «запад», «вниз», «вверх», «влево», «вправо», «назад»],
«глагол»: [«ходить», «останавливаться», «убивать», «есть», «бросать», «брать», «открывать», «давать»],
«stop»: [«the», «in», «of», «from», «at», «it», «a», «to»],
«существительное»: [«я», «дверь», «медведь», «принцесса», «шкаф», «меч», «алмаз», «ручка»]} # По желанию, мы могли бы добавить некоторые другие общие формы для глаголов: s_forms = []
слово в лексиконе [«глагол»]:
s_form = слово + «s»
s_forms. добавить (s_form)
lexicon [«глагол»] = lexicon [«глагол»] + s_forms # Кроме того, лексика может допускать любое количество цифр 0,1, …, 9,
# длиной не более 10, представляющих числа.
# Они не будут определяться перечислением в словаре, но мы
# определите их в определении. номер def (n):
typ_str = isinstance (n, str)
# мы предполагаем, что номер действительно указан в текстовой строке.
если typ_str и len (n) «9»:
is_number = Ложь
вернуть is_number
еще:
вернуть ложь # Теперь мы можем определить теггер.На основе лексики и определения
# чисел, он может пометить предложение. # Обычно для заданных текстовых строк он должен возвращать список пар (тег, слово).
# «идти на север» -> [(‘глагол’, ‘идти’), (‘направление’, ‘север’)]
# «убить принцессу» -> [(‘глагол’, ‘убить’), (‘стоп’, ‘the’), (‘существительное’, ‘принцесса’)]
# «съесть медведя» -> [(‘глагол’, ‘есть’), (‘стоп’, ‘the’), (‘существительное’, ‘медведь’)]
# «открой дверь и удари медведя по носу»
# -> [(‘глагол’, ‘открыть’), (‘стоп’, ‘the’), (‘существительное’, ‘дверь’), (‘ошибка’, ‘и’), (‘ошибка’, ‘хлопать’),
# (‘стоп’, ‘the’), (‘существительное’, ‘медведь’), (‘стоп’, ‘in’), (‘стоп’, ‘the’), (‘ошибка’, ‘нос’) ] sent = raw_input («Внесите свой вклад>»)
sent_list = отправлено.
добавить (s_form)
lexicon [«глагол»] = lexicon [«глагол»] + s_forms # Кроме того, лексика может допускать любое количество цифр 0,1, …, 9,
# длиной не более 10, представляющих числа.
# Они не будут определяться перечислением в словаре, но мы
# определите их в определении. номер def (n):
typ_str = isinstance (n, str)
# мы предполагаем, что номер действительно указан в текстовой строке.
если typ_str и len (n) «9»:
is_number = Ложь
вернуть is_number
еще:
вернуть ложь # Теперь мы можем определить теггер.На основе лексики и определения
# чисел, он может пометить предложение. # Обычно для заданных текстовых строк он должен возвращать список пар (тег, слово).
# «идти на север» -> [(‘глагол’, ‘идти’), (‘направление’, ‘север’)]
# «убить принцессу» -> [(‘глагол’, ‘убить’), (‘стоп’, ‘the’), (‘существительное’, ‘принцесса’)]
# «съесть медведя» -> [(‘глагол’, ‘есть’), (‘стоп’, ‘the’), (‘существительное’, ‘медведь’)]
# «открой дверь и удари медведя по носу»
# -> [(‘глагол’, ‘открыть’), (‘стоп’, ‘the’), (‘существительное’, ‘дверь’), (‘ошибка’, ‘и’), (‘ошибка’, ‘хлопать’),
# (‘стоп’, ‘the’), (‘существительное’, ‘медведь’), (‘стоп’, ‘in’), (‘стоп’, ‘the’), (‘ошибка’, ‘нос’) ] sent = raw_input («Внесите свой вклад>»)
sent_list = отправлено. нижний (). split () # Преобразуем текстовую строку в список слов.
# Примечание: мы использовали строчные буквы для ввода заглавных букв. тег def (sentlst):
print «Tagging»
taglst = []
для слова в sentlst:
если слово в лексиконе [«направление»]: taglst.append ((«направление», слово))
слово elif в лексиконе [«глагол»]: taglst.append ((«глагол», слово))
слово elif в лексиконе [«стоп»]: taglst.append ((«стоп», слово))
слово elif в лексиконе [«существительное»]: taglst.append ((«существительное», слово))
elif число (слово): taglst.append ((«число», слово))
else: taglst.append ((«ошибка», слово))
печать тегов
вернуть taglst # «ошибка» используется для всех тех слов, которые не встречаются в лексиконе.
# Мы не знаем, что это за слова. # Далее мы разрабатываем очень простой парсер.
# Парсер попытается обнаружить текстовые структуры вида:
# Subject Verb Object
# внутри предложения, вводимого пользователем.
# Для «объекта» мы также разрешим направления и числа.# Если пользователь вводит что-то вроде:
# «открытая дверь»
# тогда система должна предположить, что тема пропущена, но
# что предполагаемый объект действительно был «игроком».
нижний (). split () # Преобразуем текстовую строку в список слов.
# Примечание: мы использовали строчные буквы для ввода заглавных букв. тег def (sentlst):
print «Tagging»
taglst = []
для слова в sentlst:
если слово в лексиконе [«направление»]: taglst.append ((«направление», слово))
слово elif в лексиконе [«глагол»]: taglst.append ((«глагол», слово))
слово elif в лексиконе [«стоп»]: taglst.append ((«стоп», слово))
слово elif в лексиконе [«существительное»]: taglst.append ((«существительное», слово))
elif число (слово): taglst.append ((«число», слово))
else: taglst.append ((«ошибка», слово))
печать тегов
вернуть taglst # «ошибка» используется для всех тех слов, которые не встречаются в лексиконе.
# Мы не знаем, что это за слова. # Далее мы разрабатываем очень простой парсер.
# Парсер попытается обнаружить текстовые структуры вида:
# Subject Verb Object
# внутри предложения, вводимого пользователем.
# Для «объекта» мы также разрешим направления и числа.# Если пользователь вводит что-то вроде:
# «открытая дверь»
# тогда система должна предположить, что тема пропущена, но
# что предполагаемый объект действительно был «игроком». # С помощью этого парсера мы упрощаем ввод пользователя во ввод, который
# приключенческая игра может реагировать на. # Определение верхнего уровня для синтаксического анализа:
# пометить введенное предложение
# получить тему
# получить глагол
# получить объект def parse (sent_lst):
tag_lst = тег (отправлено_lst)
clean_lst = чистый (tag_lst)
(тема, new_lst) = parse_subj (clean_lst)
(глагол, new_lst) = parse_verb (new_lst)
объект = parse_obj (новый_ст)
если субъект == Нет или глагол == Нет или объект == Нет:
print «Я не могу разобрать этот ввод.»
return None
else: вернуть предложение (подлежащее, глагол, объект) # Сначала мы помечаем список слов.
#
# Потом убираем: слова с тегами, не имеющими отношения к
# цель парсера убрана. Он касается
# теги остановки и ошибки. # Наши функции parse_subj, parse_verb и parse_obj будут
# не сканировать все время очищенный tag_list, потому что это
# было бы неэффективно. Они удалят начальные части очищенного
# tag_list, чтобы более поздние функции синтаксического анализа больше не работали
# с этими частями.
# С помощью этого парсера мы упрощаем ввод пользователя во ввод, который
# приключенческая игра может реагировать на. # Определение верхнего уровня для синтаксического анализа:
# пометить введенное предложение
# получить тему
# получить глагол
# получить объект def parse (sent_lst):
tag_lst = тег (отправлено_lst)
clean_lst = чистый (tag_lst)
(тема, new_lst) = parse_subj (clean_lst)
(глагол, new_lst) = parse_verb (new_lst)
объект = parse_obj (новый_ст)
если субъект == Нет или глагол == Нет или объект == Нет:
print «Я не могу разобрать этот ввод.»
return None
else: вернуть предложение (подлежащее, глагол, объект) # Сначала мы помечаем список слов.
#
# Потом убираем: слова с тегами, не имеющими отношения к
# цель парсера убрана. Он касается
# теги остановки и ошибки. # Наши функции parse_subj, parse_verb и parse_obj будут
# не сканировать все время очищенный tag_list, потому что это
# было бы неэффективно. Они удалят начальные части очищенного
# tag_list, чтобы более поздние функции синтаксического анализа больше не работали
# с этими частями. # Сначала очистка: удалите все лишние слова: «стоп»
# слова и слова «ошибка». # Наивная, но _ неправильная_ реализация: # def clean (tag_lst):
# для i в диапазоне (len (tag_lst)):
# (тег, слово) = tag_lst [i]
# if tag == «stop» или tag == «error»:
# del (tag_lst [i])
# return tag_lst # Еще одна наивная, но столь же _ неправильная_ реализация:
#def clean (tag_lst):
# для (тега, слова) в tag_lst:
# if tag == «stop» или tag == «error»:
# tag_lst.удалить ((тег, слово))
# print tag_lst
# return tag_lst def clean (tag_lst):
печать «Очистка»
clean_lst = []
для (тег, слово) в tag_lst:
если нет (тег == «стоп»), а не (тег == «ошибка»):
clean_lst.append ((тег, слово))
распечатать clean_lst
вернуть clean_lst # Найти подлежащее означает: найти существительное, которое стоит первым в
# предложение, или, если глагол идет первым, подлежащее — «игрок». def parse_subj (tag_lst):
print «Разбор по теме»
если tag_lst == []:
return (Нет, [])
(тег, слово) = tag_lst [0]
если tag == «глагол»:
return («игрок», tag_lst)
elif tag == «существительное»:
del (tag_lst [0])
возврат (слово, tag_lst)
еще:
return (Нет, []) def parse_verb (tag_lst):
print «Разбор на глагол»
если tag_lst == []:
return (Нет, [])
(тег, слово) = tag_lst [0]
если tag == «глагол»:
del (tag_lst [0])
возврат (слово, tag_lst)
еще:
return (Нет, []) def parse_obj (tag_lst):
print «Разбор объекта»
если tag_lst == []:
return None
(тег, слово) = tag_lst [0]
if tag == «существительное» или tag == «направление» или tag == «число»:
ответное слово
еще:
return None def предложение (subj, глагол, obj):
print «Результат анализа:»
напечатать subj, глагол, obj
вернуть subj, глагол, obj синтаксический анализ (список отправленных) #Примеры:
print «Разбор предложения» Прекрасная принцесса идет на север «»
parse («Прекрасная принцесса идет на север».
# Сначала очистка: удалите все лишние слова: «стоп»
# слова и слова «ошибка». # Наивная, но _ неправильная_ реализация: # def clean (tag_lst):
# для i в диапазоне (len (tag_lst)):
# (тег, слово) = tag_lst [i]
# if tag == «stop» или tag == «error»:
# del (tag_lst [i])
# return tag_lst # Еще одна наивная, но столь же _ неправильная_ реализация:
#def clean (tag_lst):
# для (тега, слова) в tag_lst:
# if tag == «stop» или tag == «error»:
# tag_lst.удалить ((тег, слово))
# print tag_lst
# return tag_lst def clean (tag_lst):
печать «Очистка»
clean_lst = []
для (тег, слово) в tag_lst:
если нет (тег == «стоп»), а не (тег == «ошибка»):
clean_lst.append ((тег, слово))
распечатать clean_lst
вернуть clean_lst # Найти подлежащее означает: найти существительное, которое стоит первым в
# предложение, или, если глагол идет первым, подлежащее — «игрок». def parse_subj (tag_lst):
print «Разбор по теме»
если tag_lst == []:
return (Нет, [])
(тег, слово) = tag_lst [0]
если tag == «глагол»:
return («игрок», tag_lst)
elif tag == «существительное»:
del (tag_lst [0])
возврат (слово, tag_lst)
еще:
return (Нет, []) def parse_verb (tag_lst):
print «Разбор на глагол»
если tag_lst == []:
return (Нет, [])
(тег, слово) = tag_lst [0]
если tag == «глагол»:
del (tag_lst [0])
возврат (слово, tag_lst)
еще:
return (Нет, []) def parse_obj (tag_lst):
print «Разбор объекта»
если tag_lst == []:
return None
(тег, слово) = tag_lst [0]
if tag == «существительное» или tag == «направление» или tag == «число»:
ответное слово
еще:
return None def предложение (subj, глагол, obj):
print «Результат анализа:»
напечатать subj, глагол, obj
вернуть subj, глагол, obj синтаксический анализ (список отправленных) #Примеры:
print «Разбор предложения» Прекрасная принцесса идет на север «»
parse («Прекрасная принцесса идет на север». нижний (). split ())
print «Разбирая предложение» Я уронил 2345 золотых монет «»
parse («Я бросил 2345 золотых монет» .lower (). split ())
print «Разбираем фразу» убить бурого медведя «»
parse («убить бурого медведя» .split ())
нижний (). split ())
print «Разбирая предложение» Я уронил 2345 золотых монет «»
parse («Я бросил 2345 золотых монет» .lower (). split ())
print «Разбираем фразу» убить бурого медведя «»
parse («убить бурого медведя» .split ())
python 3.x — Создание деревьев синтаксического анализа в NLTK с использованием предложения с тегами
При использовании stanford parser теги POS не нужны для синтаксического анализа дерева, поскольку оно встроено в модель. StanfordParser и модели недоступны по умолчанию, и их необходимо загрузить.
Большинство людей видят эту ошибку при попытке использовать StanfordParser в NLTK
>>> из nltk.parse import stanford
>>> sp = stanford.StanfordParser ()
Отслеживание (последний вызов последний):
Файл "", строка 1, в
Файл "/home/user/anaconda3/lib/python3.5/site-packages/nltk/parse/stanford.py", строка 51, в __init__
key = лямбда имя_модели: re.match (self._JAR, имя_модели)
Файл "/ home / user / anaconda3 / lib / python3. 5 / site-packages / nltk / internals.py ", строка 714, в find_jar_iter
поднять LookupError ('\ n \ n% s \ n% s \ n% s'% (div, msg, div))
LookupError:
================================================== =========================
NLTK не смог найти stanford-parser \ .jar! Установите CLASSPATH
переменная окружения.
Для получения дополнительной информации о stanford-parser \ .jar см .:
================================================== =========================
 5 / site-packages / nltk / internals.py ", строка 714, в find_jar_iter
поднять LookupError ('\ n \ n% s \ n% s \ n% s'% (div, msg, div))
LookupError:
================================================== =========================
NLTK не смог найти stanford-parser \ .jar! Установите CLASSPATH
переменная окружения.
Для получения дополнительной информации о stanford-parser \ .jar см .:
5 / site-packages / nltk / internals.py ", строка 714, в find_jar_iter
поднять LookupError ('\ n \ n% s \ n% s \ n% s'% (div, msg, div))
LookupError:
================================================== =========================
NLTK не смог найти stanford-parser \ .jar! Установите CLASSPATH
переменная окружения.
Для получения дополнительной информации о stanford-parser \ .jar см .:
Чтобы исправить это, загрузите Stanford Parser в каталог и извлеките его содержимое.Давайте использовать пример каталога в системе * nix / usr / local / lib / stanfordparser . Файл stanford-parser.jar должен находиться там вместе с другими файлами.
Когда все файлы будут там, установите переменные среды для расположения анализатора и моделей.
>>> импорт ОС
>>> os.environ ['STANFORD_PARSER'] = '/ usr / local / lib / stanfordparser'
>>> os. environ ['STANFORD_MODELS'] = '/ usr / local / lib / stanfordparser'
 environ ['STANFORD_MODELS'] = '/ usr / local / lib / stanfordparser'
environ ['STANFORD_MODELS'] = '/ usr / local / lib / stanfordparser'
Теперь вы можете использовать синтаксический анализатор для экспорта возможных синтаксических анализов для имеющегося у вас предложения, например:
>>> sp = stanford.СтэнфордПарсер ()
>>> sp.parse ("это предложение" .split ())
<объект list_iterator в 0x7f53b93a2dd8>
>>> tree = [дерево вместо дерева в sp.parse ("это предложение" .split ())]
>>> деревья [0] # пример проанализированного предложения
Дерево ('КОРЕНЬ', [Дерево ('S', [Дерево ('NP', [Дерево ('DT', ['this'])]), Дерево ('VP', [Дерево ('VBZ', [ 'is']), Tree ('NP', [Tree ('DT', ['a']), Tree ('NN', ['предложение'])])])])])
Возвращается объект итератора , поскольку для данного предложения может быть более одного синтаксического анализатора.
На этой странице: . split (), .join () и list (). split (), .join () и list ().Разделение предложения на слова: .split ()Ниже Мэри представляет собой единую струну. Несмотря на то, что это предложение, слова не представлены в виде скрытых единиц. Для этого вам понадобится другой тип данных: список строк, где каждая строка соответствует слову. .split () - это метод, который нужно использовать:
 .split () разделяет любую комбинированную последовательность этих символов: .split () разделяет любую комбинированную последовательность этих символов:
Разделение на определенную подстрокуПредоставляя необязательный параметр,.split ('x') может использоваться для разделения строки на определенную подстроку 'x'. Без указания 'x' .split () просто разбивается на все пробелы, как показано выше.
Строка в списке символов: list ()Но что, если вы хотите разбить строку на список символов? В Python символы - это просто строки длиной 1. Функция list () превращает строку в список отдельных букв:
Присоединение к списку строк: .join ()Если у вас есть список слов, как собрать их в одну строку? .join () - это метод, который нужно использовать. Вызывается в строке-разделителе 'x', 'x'.join (y) объединяет каждый элемент в списке y, разделенный' x '.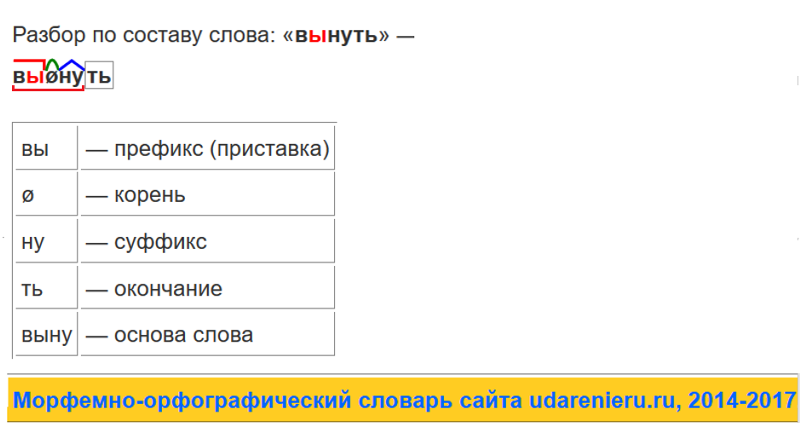 Ниже слова в mwords объединяются обратно в строку предложения с пробелом между ними: Ниже слова в mwords объединяются обратно в строку предложения с пробелом между ними:
|
 ]
]
 join (hichars)
'Привет мир'
join (hichars)
'Привет мир'
Лингвистические особенности · Документация по использованию spaCy
Разумная обработка исходного текста затруднена: большинство слов встречаются редко, и это
обычно для слов, которые выглядят совершенно по-разному, означает почти одно и то же.Одни и те же слова в разном порядке могут означать совсем другое.
Даже разделение текста на полезные словесные единицы может быть трудным во многих случаях.
языков. Хотя некоторые проблемы можно решить, начав только с исходных
символов, обычно лучше использовать лингвистические знания, чтобы добавить полезные
Информация. Именно для этого и предназначен spaCy: вы вводите необработанный текст,
и получите объект Doc , который поставляется с различными
аннотации.
После токенизации spaCy может анализировать и тег для данного Doc .Это где
поступает обученный конвейер и его статистические модели, которые позволяют spaCy делает прогнозы, из которых тег или метка наиболее вероятно применимы в данном контексте. Обученный компонент включает двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку -
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Обученный компонент включает двоичные данные, которые создаются путем отображения системы.
достаточно примеров для того, чтобы делать прогнозы, которые обобщаются по всему языку -
например, слово, следующее за «the» в английском языке, скорее всего, является существительным.
Лингвистические аннотации доступны как Токен атрибутов. Как и многие библиотеки НЛП, spaCy кодирует все строки в хеш-значения , чтобы уменьшить использование памяти и улучшить
эффективность.Итак, чтобы получить удобочитаемое строковое представление атрибута, мы
необходимо добавить подчеркивание _ к его имени:
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
print (token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
- Текст: Исходный текст слова.
- Лемма: Основная форма слова.
- POS: Простой UPOS тег части речи.
- Тег: Подробный тег части речи.
- Dep: Синтаксическая зависимость, то есть отношение между токенами.
- Форма: Форма слова - заглавные буквы, знаки препинания, цифры.
- - это альфа: Является ли токен альфа-символом?
- is stop: Является ли токен частью стоп-листа, т. Е. Наиболее частыми словами язык?

| Текст | Лемма | POS | Тег | Dep | Форма | альфа | стоп |
|---|---|---|---|---|---|---|---|
| Apple | Apple | N Xxxxx | True | False | |||
| is | be | AUX | VBZ | aux | xx | True True | |
| смотря | look | VERB | VBG | ROOT | xxxx | True | False |
| при | ADP | IN | Prep | xx | True | True | |
| покупка | покупка | VERB | VBG | pcomp | xxx | Верно | Ложно |
U. K. K. | u.k. | PROPN | NNP | составной | X.X. | Ложь | Ложь |
| запуск | запуск | NOUN | NN | dobj | xxxx | True | False |
| для | для | ADP | IN | Prep | xxx | True | True |
| $ | $ | SYM | $ | Quantmod | $ | Ложь | Ложь |
| 1 | 1 | NUM | CD | составной | d | Неверно | Ложь |
| миллиардов | миллиардов | NUM | CD | pobj | xxxx | Истинно | Ложно |
Совет: теги и ярлыки
Большинство тегов и ярлыков выглядят довольно абстрактно, и они различаются между
языков.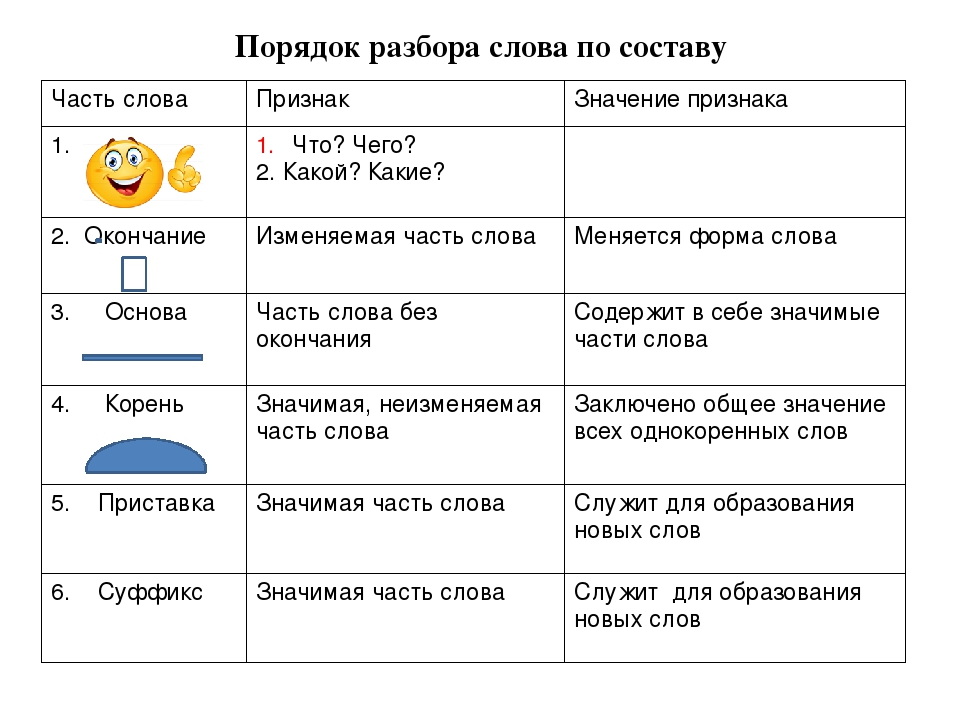
spacy.explain покажет вам краткое описание — например, spacy.explain ("VBZ") возвращает «глагол, 3-е лицо единственного числа настоящее».
Используя встроенный визуализатор дисплея spaCy, вот что наше примерное предложение и его зависимости выглядят следующим образом:
scheme Схема тега части речи
Для списка назначенных мелкозернистых и крупнозернистых тегов части речи по моделям spaCy на разных языках, см. задокументированные схемы этикеток в каталоге моделей.
Флективная морфология — это процесс, с помощью которого корневая форма слова изменен путем добавления префиксов или суффиксов, определяющих его грамматическую функцию но не меняйте его часть речи. Мы говорим, что лемма (корневая форма) является перегиб (модифицированный / комбинированный) с одним или несколькими морфологическими признаками от до создать форму поверхности. Вот несколько примеров:
| Контекст | Поверхность | Лемма | POS | Морфологические особенности |
|---|---|---|---|---|
| Я читал статью | читал | читал | Vorm66 Verb = Ger | |
| Я не смотрю новости, читаю газету | читать | читать | VERB | VerbForm = Fin , Mood = Ind , Tense = Pres |
| Я прочитал газету вчера | прочитал | прочитал | ГЛАГОЛ | VerbForm = Fin , Mood = Ind , Tense = Прошлое |
Морфологические особенности хранятся в MorphAnalysis под токеном ., который
позволяет получить доступ к индивидуальным морфологическим признакам. морфинг
морфинг
📝 Что стоит попробовать
- Измените «Я» на «Она». Вы должны увидеть, что морфологические признаки меняются и укажите, что это местоимение от третьего лица.
- Осмотрите жетон
. Морфна предмет других жетонов.
импорт просторный
nlp = spacy.load ("en_core_web_sm")
print ("Конвейер:", nlp.pipe_names)
doc = nlp ("Я читал газету.")
токен = документ [0]
печать (токен.превращаться)
print (token.morph.get ("PronType"))
Статистическая морфология v3.0 Модель потребностей
Компонент spaCy статистический Морфологизатор назначает
морфологические особенности и грубые теги части речи как Token.morph и Token.pos .
импорт просторный
nlp = spacy.load ("de_core_news_sm")
doc = nlp ("Wo bist du?")
печать (документ [2] .morph)
печать (документ [2] .pos_)
Морфология на основе правил
Для языков с относительно простыми морфологическими системами, таких как английский, spaCy
может назначать морфологические признаки с помощью подхода, основанного на правилах, который использует токен текста и мелкозернистые теги части речи для создания
грубые теги части речи и морфологические особенности.
- Тегер части речи назначает каждому токену детализированную часть речи
тег . В API эти теги известны как
Token.tag. Они выражают часть речи (например, глагол) и некоторое количество морфологической информации, например что глагол имеет прошедшее время (например,VBDдля глагола прошедшего времени в Penn Treebank). - Для слов, крупнозернистый POS которых не установлен предыдущим процессом, таблица сопоставления отображает мелкозернистые теги в крупнозернистые POS-теги и морфологические особенности.
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Где ты?")
печать (документ [2] .morph)
печать (документ [2] .pos_)
Лемматизатор — это компонент конвейера, который обеспечивает поиск
и основанные на правилах методы лемматизации в настраиваемом компоненте. Личность
язык может расширить Lemmatizer как часть его
языковые данные.
импорт просторный
nlp = spacy. load ("en_core_web_sm")
lemmatizer = nlp.get_pipe ("лемматизатор")
печать (лемматизатор.Режим)
doc = nlp ("Я читал газету.")
print ([token.lemma_ для токена в документе])
 load ("en_core_web_sm")
lemmatizer = nlp.get_pipe ("лемматизатор")
печать (лемматизатор.Режим)
doc = nlp ("Я читал газету.")
print ([token.lemma_ для токена в документе])
load ("en_core_web_sm")
lemmatizer = nlp.get_pipe ("лемматизатор")
печать (лемматизатор.Режим)
doc = nlp ("Я читал газету.")
print ([token.lemma_ для токена в документе])
Изменено в версии 3.0
В отличие от spaCy v2, модели spaCy v3 , а не предоставляют леммы по умолчанию или переключение
автоматически между поиском и леммами на основе правил в зависимости от того,
находится в стадии разработки. Чтобы иметь леммы в Doc , конвейер должен включать Лемматизатор компонент. Компонент лемматизатора
настроен на использование одного режима, такого как «поиск» или «правило» на
инициализация. "правило" Режим требует, чтобы Token.pos был установлен предыдущим
составная часть.
Данные для лемматизаторов spaCy распространяются в пакете данные пространственного поиска . В
при условии, что обученные конвейеры уже включают все необходимые таблицы, но если вы
создаете новые конвейеры, вы, вероятно, захотите установить spacy-lookups-data для предоставления данных при инициализации лемматизатора.
Поисковый лемматизатор
Для конвейеров без теггера или морфологизатора можно использовать поисковый лемматизатор.
добавляется в конвейер, пока предоставляется таблица поиска, обычно через данные пространственного поиска .В
лемматизатор поиска ищет форму поверхности токена в таблице поиска без
ссылка на часть речи или контекст токена.
импортный простор
nlp = spacy.blank ("sv")
nlp.add_pipe ("лемматизатор", config = {"режим": "поиск"})
Лемматизатор на основе правил
При обучении конвейеров, которые включают компонент, который назначает часть речи
теги (морфологизатор или теггер с отображением POS),
лемматизатор на основе правил может быть добавлен с помощью таблиц правил из данные пространственного поиска :
импортный простор
nlp = простор.пустой ("де")
nlp.add_pipe ("морфологизатор")
nlp.add_pipe ("лемматизатор", config = {"режим": "правило"})
Детерминированный лемматизатор, основанный на правилах, отображает форму поверхности в лемму в
свет заданной ранее крупнозернистой части речи и морфологического
информацию, не обращаясь к контексту токена. Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
приобретен из WordNet.
Основанный на правилах
lemmatizer также принимает файлы исключений на основе списков. Для английского это
приобретен из WordNet.
spaCy имеет быстрый и точный синтаксический анализатор зависимостей, а также богатый набор функций.
API для навигации по дереву.Синтаксический анализатор также поддерживает границу предложения
обнаружения и позволяет вам перебирать базовые словосочетания с существительными или «фрагменты». Ты можешь
проверьте, был ли проанализирован объект Doc путем вызова doc.has_annotation ("DEP") , который проверяет, имеет ли атрибут Token.dep set возвращает логическое значение. Если результат Ложь , предложение по умолчанию
итератор вызовет исключение.
📖Схема меток зависимостей
Для списка меток синтаксических зависимостей, назначенных моделями spaCy в разных языках, см. схемы этикеток, задокументированные в каталог моделей.
Отрезки существительных
Отрезки существительных — это «базовые словосочетания» — плоские фразы, в которых есть существительное в качестве своего
глава. Вы можете представить себе существительное как существительное плюс слова, описывающие существительное.
— например, «пышная зеленая трава» или «крупнейший в мире технологический фонд». К
получить куски существительного в документе, просто перебрать
Вы можете представить себе существительное как существительное плюс слова, описывающие существительное.
— например, «пышная зеленая трава» или «крупнейший в мире технологический фонд». К
получить куски существительного в документе, просто перебрать Док. Номер_головки .
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
для куска в док.noun_chunks:
print (chunk.text, chunk.root.text, chunk.root.dep_,
chunk.root.head.text)
- Текст: Исходный текст фрагмента существительного.
- Корневой текст: Исходный текст слова, соединяющего кусок существительного с остальная часть синтаксического анализа.
- Root dep: Отношение зависимости, соединяющее корень с его головкой.
- Текст заголовка корневого токена: Текст заголовка корневого токена.

| Текст | root.text | root.dep_ | root.head.text |
|---|---|---|---|
| Автономные автомобили | автомобили | nsubj | смена |
| страхование ответственности | ответственность | dobj | смена |
| производители | производители | pobj | к |
Навигация по дереву синтаксического анализа
spaCy использует термины head и child для описания слов , связанных между собой
единственная дуга в дереве зависимостей.Термин dep используется для дуги
метка, которая описывает тип синтаксического отношения, которое связывает ребенка с
голова. Как и в случае с другими атрибутами, значение .dep является хеш-значением. Ты можешь
получить строковое значение с ..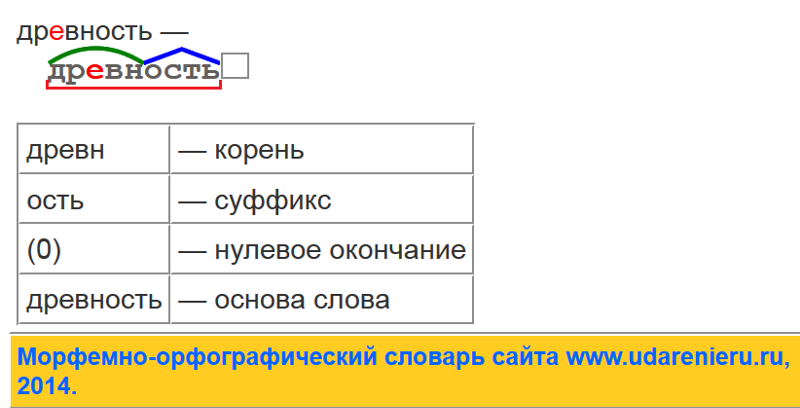 dep_
dep_
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
для токена в документе:
print (token.text, token.dep_, token.head.text, token.head.pos_,
[ребенок для ребенка в жетоне.дети])
- Текст: Исходный текст токена.
- Dep: Синтаксическое отношение, связывающее дочерний элемент с головой.
- Текст заголовка: Исходный текст токена головы.
- Head POS: Тег части речи токен-головки.
- Потомки: Непосредственные синтаксические зависимости токена.
| Текст | Dep | Заголовок текст | Голова POS | Дети |
|---|---|---|---|---|
| Автономный | amod | автомобили | ||
| 900 nsubj | сдвиг | VERB | Автономный | |
| сдвиг | ROOT | сдвиг | VERB | автомобили, ответственность, навстречу |
| страхование | соединение | ответственность | NOUN | |
| ответственность | dobj | смена | VERB | страхование |
| по направлению к | приготовление | смена | NOUN | производители |
| производителей | pobj | к | ADP |
Поскольку синтаксические отношения образуют дерево, каждое слово имеет ровно одно
голова . Таким образом, вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ сопоставить дугу
проценты — снизу:
Таким образом, вы можете перебирать дуги в дереве, перебирая
слова в предложении. Обычно это лучший способ сопоставить дугу
проценты — снизу:
импорт прост.
из spacy.symbols import nsubj, VERB
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
глаголы = набор ()
для possible_subject в документе:
if possible_subject.dep == nsubj и possible_subject.head.pos == ГЛАГОЛ:
verbs.add (possible_subject.глава)
печать (глаголы)
Если вы попытаетесь найти соответствие сверху, вам придется повторить итерацию дважды. Один раз за голову, а потом снова через детей:
глаголы = []
для possible_verb в документе:
если возможно_verb.pos == ГЛАГОЛ:
для possible_subject в possible_verb.children:
если возможно_subject.dep == nsubj:
verbs.append (возможно_глагол)
перерыв
Для перебора дочерних элементов используйте атрибут token., который
предоставляет последовательность объектов  children
children Token .
Итерация по локальному дереву
Есть еще несколько удобных атрибутов для итерации по локальному дереву.
дерево из жетона. Token.lefts и Token.rights Атрибуты обеспечивают последовательности синтаксических
дочерние элементы, которые появляются до и после токена. Обе последовательности в предложении
заказывать. Также есть два атрибута целочисленного типа: Token.n_lefts и Token.n_rights , которые дают количество левых и правых
дети.
импорт просторный
nlp = простор.load ("en_core_web_sm")
doc = nlp («ярко-красные яблоки на дереве»)
print ([token.text для токена в doc [2] .lefts])
print ([token.text для токена в doc [2] .rights])
печать (документ [2] .n_lefts)
печать (документ [2] .n_rights)
импорт просторный
nlp = spacy.load ("de_core_news_sm")
doc = nlp ("schöne rote Äpfel auf dem Baum")
print ([token. text для токена в doc [2] .lefts])
print ([token.text для токена в doc [2] .rights])
 text для токена в doc [2] .lefts])
print ([token.text для токена в doc [2] .rights])
text для токена в doc [2] .lefts])
print ([token.text для токена в doc [2] .rights])
Вы можете получить целую фразу по ее синтаксическому заголовку, используя Жетон.атрибут поддерева . Это возвращает заказанный
последовательность жетонов. Вы можете подняться на дерево с помощью Token.ancestors атрибут и проверьте доминирование с помощью Token.is_ancestor
Проективное и непроективное
Для английских конвейеров по умолчанию дерево синтаксического анализа выглядит следующим образом: проекционная , что означает отсутствие перекрестных скобок. Жетоны
возвращенный .subtree , следовательно, гарантированно будет непрерывным. Это не
верно для немецких трубопроводов, у которых много
непроективные зависимости.
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Владельцы кредитных и ипотечных счетов должны подавать свои запросы»)
root = [токен для токена в документе if token. head == токен] [0]
subject = list (root.lefts) [0]
для потомка в subject.subtree:
утверждать, что субъект является потомком или субъектом. is_ancestor (потомок)
печать (потомок.текст, потомок.dep_, потомок.n_lefts,
Потомок .n_rights,
[ancestor.text для предка в потомке .ancestors])
 head == токен] [0]
subject = list (root.lefts) [0]
для потомка в subject.subtree:
утверждать, что субъект является потомком или субъектом. is_ancestor (потомок)
печать (потомок.текст, потомок.dep_, потомок.n_lefts,
Потомок .n_rights,
[ancestor.text для предка в потомке .ancestors])
head == токен] [0]
subject = list (root.lefts) [0]
для потомка в subject.subtree:
утверждать, что субъект является потомком или субъектом. is_ancestor (потомок)
печать (потомок.текст, потомок.dep_, потомок.n_lefts,
Потомок .n_rights,
[ancestor.text для предка в потомке .ancestors])
| Текст | Dep | n_lefts | n_rights | предки |
|---|---|---|---|---|
| Credit | nmod | submit 0 | holders и | куб. |
| счет | коннект | 1 | 0 | Кредит, держатели, представить |
| держатели | nsubj | 1 | 0 | представить |
Наконец, .Атрибуты left_edge и .right_edge могут быть особенно полезны,
потому что они дают вам первый и последний токены поддерева. Это
Самый простой способ создать объект
Это
Самый простой способ создать объект Span для синтаксической фразы. Обратите внимание, что .right_edge дает токен внутри поддерева - поэтому, если вы используете его как
конечная точка диапазона, не забудьте +1 !
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Владельцы кредитных и ипотечных счетов должны подавать свои запросы»)
span = doc [doc [4].left_edge.i: документ [4] .right_edge.i + 1]
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (диапазон)
для токена в документе:
print (token.text, token.pos_, token.dep_, token.head.text)
| Текст | POS | Dep | Head text |
|---|---|---|---|
| Владельцы кредитных и ипотечных счетов | NOUN | nsubj | V необходимо |
aux | отправить | ||
| отправить | VERB | ROOT | отправить |
| их | ADJ | Poss | запросы |
| запросы | NOUN | dobj | submit |
Анализ зависимостей может быть полезным инструментом для извлечения информации ,
особенно в сочетании с другими прогнозами, такими как
названные объекты. В следующем примере извлекаются деньги и
значения валюты, то есть сущности, помеченные как
В следующем примере извлекаются деньги и
значения валюты, то есть сущности, помеченные как ДЕНЬГИ , а затем использует зависимость
выполните синтаксический анализ, чтобы найти именную фразу, к которой они относятся — например, «Чистая прибыль» → «9,4 миллиона долларов» .
импорт просторный
nlp = spacy.load ("en_core_web_sm")
nlp.add_pipe ("merge_entities")
nlp.add_pipe ("merge_noun_chunks")
ТЕКСТЫ = [
«Чистая прибыль составила 9,4 миллиона долларов по сравнению с 2,7 миллиона долларов в предыдущем году»,
«Выручка превысила двенадцать миллиардов долларов, а убыток составил 1 миллиард долларов.",
]
для документа в nlp.pipe (ТЕКСТЫ):
для токена в документе:
если token.ent_type_ == "ДЕНЬГИ":
если token.dep_ in ("attr", "dobj"):
subj = [w вместо w в token.head.lefts, если w.dep_ == "nsubj"]
если subj:
print (subj [0], "->", токен)
elif token. dep_ == "pobj" и token.head.dep_ == "Prep":
print (token.head.head, "->", токен)
 dep_ == "pobj" и token.head.dep_ == "Prep":
print (token.head.head, "->", токен)
dep_ == "pobj" и token.head.dep_ == "Prep":
print (token.head.head, "->", токен)
📖Комбинирование моделей и правил
Дополнительные примеры того, как написать основанную на правилах логику извлечения информации, которая использует прогнозы модели, сделанные различными компонентами, см. руководство по использованию на совмещение моделей и правил.
Визуализация зависимостей
Лучший способ понять анализатор зависимостей spaCy — интерактивный. Делать
это проще, spaCy поставляется с модулем визуализации. Вы можете сдать Doc или
список объектов Doc для отображения и запуска displacy.serve для запуска веб-сервера или displacy.render для создания необработанной разметки.
Если вы хотите знать, как писать правила, которые подключаются к синтаксису
конструкции, просто вставьте предложение в визуализатор и посмотрите, как spaCy
аннотирует это.
импорт просторный
от просторного импорта
nlp = spacy. load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
displacy.render (док,)
 load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
displacy.render (док,)
load ("en_core_web_sm")
doc = nlp («Автономные автомобили переносят страхование ответственности на производителей»)
displacy.render (док,)
Подробнее и примеры см. руководство по визуализации spaCy. Вы также можете протестировать Отображение в нашей онлайн-демонстрации.
Отключение парсера
В обученных конвейерах, предоставляемых spaCy, парсер загружается и
включен по умолчанию как часть
стандартный технологический конвейер.Если тебе не нужно
любую синтаксическую информацию следует отключить парсер. Отключение
парсер заставит spaCy загружаться и работать намного быстрее. Если вы хотите загрузить парсер,
но необходимо отключить его для определенных документов, вы также можете контролировать его использование на
объект nlp . Для получения дополнительной информации см. Руководство по использованию на
отключение компонентов конвейера.
nlp = spacy.load ("en_core_web_sm", disable = ["parser"])
spaCy имеет чрезвычайно быструю систему распознавания статистических объектов, которая
назначает метки смежным участкам токенов. По умолчанию
обученные конвейеры могут идентифицировать множество именованных и числовых
юридические лица, включая компании, местоположения, организации и продукты. Ты можешь
добавить произвольные классы в систему распознавания сущностей и обновить модель
с новыми примерами.
По умолчанию
обученные конвейеры могут идентифицировать множество именованных и числовых
юридические лица, включая компании, местоположения, организации и продукты. Ты можешь
добавить произвольные классы в систему распознавания сущностей и обновить модель
с новыми примерами.
Распознавание именованных объектов 101
Именованные объекты — это «объекты реального мира», которым присвоено имя, например человек, страна, продукт или название книги. spaCy может распознавать различные типы именованных сущностей в документе, запрашивая модель для предсказание .Поскольку модели являются статистическими и сильно зависят от примеры, на которых они были обучены, это не всегда работает идеально и может потребуются некоторые настройки позже, в зависимости от вашего варианта использования.
Именованные сущности доступны как свойство ents Doc :
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для Ent в док. центрах:
print (ent.text, ent.start_char, ent.end_char, ent.label_)
 центрах:
print (ent.text, ent.start_char, ent.end_char, ent.label_)
центрах:
print (ent.text, ent.start_char, ent.end_char, ent.label_)
- Текст: Исходный текст объекта.
- Начало: Индекс начала объекта в
Doc. - Конец: Указатель конца объекта в
Doc. - Метка: Метка объекта, т.е. тип.
| Текст | Начало | Конец | Этикетка | Описание |
|---|---|---|---|---|
| Apple | 0 | 5 | ORG | Компании, учреждения, учреждения. |
| Великобритания | 27 | 31 | GPE | Геополитическое образование, то есть страны, города, государства. |
| 1 миллиард долларов | 44 | 54 | ДЕНЬГИ | Денежное выражение, включая единицы. |
Используя встроенный визуализатор дисплея spaCy, вот что Наш примерное предложение и его именованные сущности выглядят так:
Доступ к аннотациям и меткам сущностей
Стандартный способ доступа к аннотациям сущностей — это doc.энц Свойство, которое создает последовательность из Span объектов. Лицо
Тип доступен либо как хеш-значение, либо как строка с использованием атрибутов ent.label и ent.label_ . Объект Span действует как последовательность токенов, поэтому
вы можете перебирать объект или индексировать его. Вы также можете получить текстовую форму
целого объекта, как если бы это был один токен.
Вы также можете получить доступ к аннотациям токенов, используя токен.ent_iob и token.ent_type атрибутов. token.ent_iob указывает
независимо от того, начинается ли объект, продолжается или заканчивается на теге. Если тип объекта не установлен
на токене он вернет пустую строку.
Схема IOB
-
I— Токен внутри объекта. -
O— Токен за пределами объекта. -
B— Токен — это , начинающийся с объекта.
Схема BILUO
-
B— Токен — это начало мульти-токен-объекта. -
I— Токен внутри мульти-токен-объекта. -
L— Токен — это последний токен для объекта с несколькими токенами. -
U— Токен представляет собой единицу с одним токеном . -
O— Toke — это за пределами объекта.
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Сан-Франциско рассматривает вопрос о запрете роботов для доставки тротуаров")
ents = [(e.text, e.start_char, e.end_char, e.label_) для e в документах]
печать (энц)
ent_san = [doc [0] . text, doc [0] .ent_iob_, doc [0] .ent_type_]
ent_francisco = [документ [1] .text, doc [1] .ent_iob_, doc [1] .ent_type_]
печать (ent_san)
печать (ent_francisco)
 text, doc [0] .ent_iob_, doc [0] .ent_type_]
ent_francisco = [документ [1] .text, doc [1] .ent_iob_, doc [1] .ent_type_]
печать (ent_san)
печать (ent_francisco)
text, doc [0] .ent_iob_, doc [0] .ent_type_]
ent_francisco = [документ [1] .text, doc [1] .ent_iob_, doc [1] .ent_type_]
печать (ent_san)
печать (ent_francisco)
| Текст | ent_iob | ent_iob_ | ent_type_ | Описание |
|---|---|---|---|---|
| San | 3 | B | "GPE 900" начало объекта | |
| Франциско | 1 | I | "GPE" | внутри объекта |
| рассматривает | 2 | O | "" | снаружи субъект |
| запрещающий | 2 | O | "" | вне предприятия |
| тротуар | 2 | O | "" | вне предприятия |
| поставка | 2 900 60 | O | "" | вне организации |
| роботов | 2 | O | "" | вне организации |
Настройка аннотаций сущности
Чтобы гарантировать, что последовательность аннотаций токенов остается неизменной, вы должны
установить аннотации сущностей на уровне документа . Однако вы не можете писать
непосредственно к атрибутам
Однако вы не можете писать
непосредственно к атрибутам token.ent_iob или token.ent_type , поэтому самый простой
способ установки сущностей - использовать функцию doc.set_ents и создайте новый объект как Span .
импорт просторный
из spacy.tokens import Span
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("fb нанимает нового вице-президента по глобальной политике")
ents = [(e.text, e.start_char, e.end_char, e.label_) для e в документах]
print ('До', энц)
fb_ent = Span (doc, 0, 1, label = "ORG")
orig_ents = список (док.энц)
doc.set_ents ([fb_ent], по умолчанию = "без изменений")
doc.ents = orig_ents + [fb_ent]
ents = [(e.text, e.start, e.end, e.label_) для e в документах]
print ('После', энц)
Имейте в виду, что Span инициализируется начальным и конечным токенами индексы, а не смещения символов. Чтобы создать диапазон из смещений символов, используйте Doc.: char_span
char_span
fb_ent = doc.char_span (0, 2, label = "ORG")
Установка аннотаций сущностей из массива
Вы также можете назначить аннотации сущностей с помощью док.from_array метод. Для этого следует включить
атрибуты ENT_TYPE и ENT_IOB в массиве, который вы импортируете
из.
импортный номер
импортный простор
из spacy.attrs импортировать ENT_IOB, ENT_TYPE
nlp = spacy.load ("en_core_web_sm")
doc = nlp.make_doc («Лондон - большой город в Соединенном Королевстве.»)
print («До», док.)
заголовок = [ENT_IOB, ENT_TYPE]
attr_array = numpy.zeros ((len (документ), len (заголовок)), dtype = "uint64")
attr_array [0, 0] = 3
attr_array [0, 1] = док.Vocalab.strings ["GPE"]
doc.from_array (заголовок, attr_array)
print ("После", док.)
Установка аннотаций сущностей в Cython
Наконец, вы всегда можете записать в базовую структуру, если скомпилируете
Функция Cython. Это легко сделать и позволяет
писать эффективный нативный код.
Это легко сделать и позволяет
писать эффективный нативный код.
из spacy.typedefs cimport attr_t
из spacy.tokens.doc cimport Doc
cpdef set_entity (документ doc, int start, int end, attr_t ent_type):
для i в диапазоне (начало, конец):
док.c [i] .ent_type = ent_type
doc.c [начало] .ent_iob = 3
для i в диапазоне (начало + 1, конец):
doc.c [i] .ent_iob = 2
Очевидно, что если вы напишете непосредственно в массив структур TokenC * , у вас будет
ответственность за обеспечение того, чтобы данные оставались в согласованном состоянии.
Встроенные типы сущностей
Совет: понимание типов сущностей
Вы также можете использовать spacy.explain () для получения описания строки
представление метки объекта.Например, spacy.explain ("ЯЗЫК") вернет «любой названный язык».
Схема аннотаций
Подробнее о типах сущностей, доступных в обученных конвейерах spaCy, см. «Схема маркировки» отдельных моделей в
каталог моделей.
«Схема маркировки» отдельных моделей в
каталог моделей.
Визуализация именованных сущностей
дисплей визуализатор ЛОР позволяет интерактивно исследовать поведение модели распознавания сущностей. Если ты
при обучении модели очень полезно запускать визуализацию самостоятельно.Помогать
вы делаете это, spaCy поставляется с модулем визуализации. Вы можете сдать Doc или
список объектов Doc для отображения и запуска displacy.serve для запуска веб-сервера или displacy.render для создания необработанной разметки.
Подробнее и примеры см. руководство по визуализации spaCy.
Пример именованного объекта
import spacy от просторного импорта text = "Когда Себастьян Трун в 2007 году начал работать над беспилотными автомобилями в Google, мало кто из других людей воспринимал его всерьез." nlp = spacy.load ("en_core_web_sm") doc = nlp (текст) displacy.serve (док,)
Чтобы закрепить названные объекты в «реальном мире», spaCy предоставляет функциональные возможности
для выполнения привязки сущностей, которая разрешает текстовую сущность в уникальную
идентификатор из базы знаний (КБ). Вы можете создать свой собственный
Вы можете создать свой собственный KnowledgeBase и обучите нового EntityLinker с использованием этой настраиваемой базы знаний.
Доступ к идентификаторам объектов Требуется модель
Аннотированный идентификатор KB доступен либо в виде хеш-значения, либо в виде строки,
используя атрибуты ent.kb_id и ent.kb_id_ из диапазона объект или атрибуты ent_kb_id и ent_kb_id_ объекта Token объект.
импорт просторный
nlp = spacy.load ("my_custom_el_pipeline")
doc = nlp («Ада Лавлейс родилась в Лондоне»)
ents = [(e.text, e.label_, e.kb_id_) для e в документах]
печать (энц)
ent_ada_0 = [doc [0] .text, doc [0] .ent_type_, doc [0] .ent_kb_id_]
ent_ada_1 = [документ [1] .text, doc [1] .ent_type_, doc [1] .ent_kb_id_]
ent_london_5 = [документ [5].текст, doc [5] .ent_type_, doc [5] .ent_kb_id_]
печать (ent_ada_0)
печать (ent_ada_1)
печать (ent_london_5)
Токенизация - это задача разбиения текста на значимые сегменты, называемые жетонов . Входными данными токенизатора является текст в Юникоде, а на выходе -
Входными данными токенизатора является текст в Юникоде, а на выходе - Объект Doc . Чтобы построить объект Doc , вам понадобится Экземпляр Vocab , последовательность из строк слов и, необязательно,
последовательность пробелов логических значений, которые позволяют поддерживать выравнивание
токены в исходную строку.
Важное примечание
spaCy токенизация неразрушающий , что означает, что вы всегда будете
может восстановить исходный ввод из токенизированного вывода. Пробел
информация сохраняется в токенах, и никакая информация не добавляется и не удаляется
во время токенизации. Это своего рода основной принцип объекта spaCy Doc : doc.text == input_text всегда должно выполняться.
Во время обработки spaCy first токенизирует текст, т.е.е. сегментирует его на
слова, знаки препинания и так далее. Это делается путем применения правил, специфичных для каждого
язык. Например, знаки препинания в конце предложения следует разделять.
- тогда как «Великобритания» должен остаться один жетон. Каждый
Например, знаки препинания в конце предложения следует разделять.
- тогда как «Великобритания» должен остаться один жетон. Каждый Doc состоит из отдельных
токены, и мы можем перебирать их:
import spacy
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Apple собирается купить британский стартап за 1 миллиард долларов»)
для токена в документе:
печать (токен.текст)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 90143 Apple | по цене | покупка | U.K. | запуск | для | $ | 1 | миллиардов |
|---|
Сначала необработанный текст разбивается на пробельные символы, аналогично text.. Затем токенизатор обрабатывает текст слева направо. На
для каждой подстроки выполняется две проверки: split ('')
split ('')
Соответствует ли подстрока правилу исключения токенизатора? Например, «не надо» не содержит пробелов, но должен быть разделен на два токена: «do» и «Нет», а «У.К. » всегда должен оставаться один жетон.
Можно ли отделить префикс, суффикс или инфикс? Например, знаки препинания запятые, точки, дефисы или кавычки.
Если есть совпадение, правило применяется, и токенизатор продолжает цикл, начиная с недавно разделенных подстрок. Таким образом, spaCy может разделить комплекс , вложенные токены , такие как комбинации сокращений и множественных знаков препинания Метки.
- Исключение токенизатора: Особое правило для разделения строки на несколько токены или предотвратить разделение токена, когда правила пунктуации применяемый.
- Префикс: символов в начале, например
$,(,“,¿. - Суффикс: символов в конце, например,
км,),”,!. - Инфикс: Знак (и) между ними, например
-,-,/,….

Хотя правила пунктуации обычно довольно общие, исключения токенизатора
сильно зависят от специфики конкретного языка.Вот почему каждый
доступный язык имеет собственный подкласс, например Английский или Немецкий , который загружается в списки жестко закодированных данных и исключений
правила.
Подробности алгоритма: как работает токенизатор spaCy¶
spaCy представляет новый алгоритм токенизации, который обеспечивает лучший баланс между производительностью, простотой определения и легкостью совмещения с оригиналом нить.
После использования префикса или суффикса мы снова обращаемся к особым случаям. Мы хотим
особые случаи, чтобы обрабатывать такие вещи, как "не" на английском языке, и мы хотим того же
Правило работать на «(не)!». Мы делаем это, отделяя открытую скобку, затем
восклицательный знак, затем закрытая скобка и, наконец, соответствующий особый случай.
Вот реализация алгоритма на Python, оптимизированная для удобочитаемости.
а не производительность:
Мы делаем это, отделяя открытую скобку, затем
восклицательный знак, затем закрытая скобка и, наконец, соответствующий особый случай.
Вот реализация алгоритма на Python, оптимизированная для удобочитаемости.
а не производительность:
def tokenizer_pseudo_code (
текст,
Особые случаи,
prefix_search,
суффикс_поиск,
infix_finditer,
token_match,
url_match
):
токены = []
для подстроки в text.split ():
суффиксы = []
пока подстрока:
в то время как prefix_search (подстрока) или suffix_search (подстрока):
если token_match (подстрока):
жетоны.добавить (подстрока)
substring = ""
перерыв
если подстрока в special_cases:
tokens.extend (special_cases [подстрока])
substring = ""
перерыв
если prefix_search (подстрока):
split = prefix_search (подстрока) . end ()
tokens.append (подстрока [: split])
подстрока = подстрока [разделить:]
если подстрока в special_cases:
Продолжать
если суффикс_поиск (подстрока):
split = суффикс_поиск (подстрока).Начало()
суффиксы.append (подстрока [разделить:])
подстрока = подстрока [: разделение]
если token_match (подстрока):
tokens.append (подстрока)
substring = ""
elif url_match (подстрока):
tokens.append (подстрока)
substring = ""
Подстрока elif в special_cases:
tokens.extend (special_cases [подстрока])
substring = ""
список elif (infix_finditer (подстрока)):
infixes = infix_finditer (подстрока)
смещение = 0
для соответствия в инфиксах:
жетоны. добавить (подстрока [смещение: match.start ()])
tokens.append (подстрока [match.start (): match.end ()])
смещение = match.end ()
если подстрока [смещение:]:
tokens.append (подстрока [смещение:])
substring = ""
Подстрока elif:
tokens.append (подстрока)
substring = ""
tokens.extend (в обратном порядке (суффиксы))
для совпадения в сопоставлении (special_cases, text):
tokens.replace (совпадение, особые_случаи [совпадение])
вернуть жетоны
 end ()
tokens.append (подстрока [: split])
подстрока = подстрока [разделить:]
если подстрока в special_cases:
Продолжать
если суффикс_поиск (подстрока):
split = суффикс_поиск (подстрока).Начало()
суффиксы.append (подстрока [разделить:])
подстрока = подстрока [: разделение]
если token_match (подстрока):
tokens.append (подстрока)
substring = ""
elif url_match (подстрока):
tokens.append (подстрока)
substring = ""
Подстрока elif в special_cases:
tokens.extend (special_cases [подстрока])
substring = ""
список elif (infix_finditer (подстрока)):
infixes = infix_finditer (подстрока)
смещение = 0
для соответствия в инфиксах:
жетоны.
end ()
tokens.append (подстрока [: split])
подстрока = подстрока [разделить:]
если подстрока в special_cases:
Продолжать
если суффикс_поиск (подстрока):
split = суффикс_поиск (подстрока).Начало()
суффиксы.append (подстрока [разделить:])
подстрока = подстрока [: разделение]
если token_match (подстрока):
tokens.append (подстрока)
substring = ""
elif url_match (подстрока):
tokens.append (подстрока)
substring = ""
Подстрока elif в special_cases:
tokens.extend (special_cases [подстрока])
substring = ""
список elif (infix_finditer (подстрока)):
infixes = infix_finditer (подстрока)
смещение = 0
для соответствия в инфиксах:
жетоны. добавить (подстрока [смещение: match.start ()])
tokens.append (подстрока [match.start (): match.end ()])
смещение = match.end ()
если подстрока [смещение:]:
tokens.append (подстрока [смещение:])
substring = ""
Подстрока elif:
tokens.append (подстрока)
substring = ""
tokens.extend (в обратном порядке (суффиксы))
для совпадения в сопоставлении (special_cases, text):
tokens.replace (совпадение, особые_случаи [совпадение])
вернуть жетоны
добавить (подстрока [смещение: match.start ()])
tokens.append (подстрока [match.start (): match.end ()])
смещение = match.end ()
если подстрока [смещение:]:
tokens.append (подстрока [смещение:])
substring = ""
Подстрока elif:
tokens.append (подстрока)
substring = ""
tokens.extend (в обратном порядке (суффиксы))
для совпадения в сопоставлении (special_cases, text):
tokens.replace (совпадение, особые_случаи [совпадение])
вернуть жетоны
Алгоритм можно резюмировать следующим образом:
- Итерация по подстрокам, разделенным пробелами.
- Найдите совпадение по токену. Если есть совпадение, остановите обработку и оставьте это токен.
- Проверьте, есть ли у нас явно определенный особый случай для этой подстроки. Если да, используйте это.
- В противном случае попробуйте использовать один префикс. Если мы использовали префикс, вернитесь к # 2,
так что совпадение токенов и особые случаи всегда имеют приоритет.
- Если мы не использовали префикс, попробуйте использовать суффикс, а затем вернитесь к №2.
- Если мы не можем использовать префикс или суффикс, ищите соответствие URL.
- Если URL не соответствует, ищите особый случай.
- Найдите «инфиксы» - например, дефисы и т. Д. И разделите подстроку на токены на всех инфиксах.
- Как только мы больше не сможем потреблять строку, обрабатываем ее как отдельный токен.
- Сделайте последний проход по тексту, чтобы проверить наличие особых случаев, которые включают пробелы или пропущенные из-за дополнительной обработки аффиксов.
 Если мы использовали префикс, вернитесь к # 2,
так что совпадение токенов и особые случаи всегда имеют приоритет.
Если мы использовали префикс, вернитесь к # 2,
так что совпадение токенов и особые случаи всегда имеют приоритет. Global и , зависящие от языка данные токенизатора предоставляются через язык
данные в spacy / lang .Исключения токенизатора
определите особые случаи, такие как «не» в английском языке, который нужно разделить на два
токены: {ORTH: "do"} и {ORTH: "n't", NORM: "not"} . Приставки, суффиксы
а инфиксы в основном определяют правила пунктуации - например, когда нужно отделить
периоды (в конце предложения) и когда оставлять маркеры, содержащие точки
неповрежденные (сокращения, например, «США»).
Приставки, суффиксы
а инфиксы в основном определяют правила пунктуации - например, когда нужно отделить
периоды (в конце предложения) и когда оставлять маркеры, содержащие точки
неповрежденные (сокращения, например, «США»).
Следует ли мне изменить языковые данные или добавить собственные правила токенизатора? ¶
Правила токенизации, которые относятся к одному языку, но могут быть обобщенными
через этот язык , в идеале должны жить в языковых данных в spacy / lang - мы всегда ценим запросы на включение!
Все, что относится к домену или типу текста, например финансовая торговля.
аббревиатуры или баварский молодежный сленг - следует добавлять в качестве особого правила
к вашему экземпляру токенизатора.Если вы имеете дело с большим количеством настроек, это
может иметь смысл создать полностью настраиваемый подкласс.
Добавление особых правил токенизации
Большинство доменов имеют по крайней мере некоторые особенности, требующие индивидуальной токенизации
правила. Это могут быть очень определенные выражения или сокращения, используемые только в
это конкретное поле. Вот как добавить правило особого случая к существующему
Это могут быть очень определенные выражения или сокращения, используемые только в
это конкретное поле. Вот как добавить правило особого случая к существующему Tokenizer instance:
import spacy
из spacy.symbols import ORTH
nlp = простор.load ("en_core_web_sm")
doc = nlp ("дай мне это")
print ([w.text для w в документе])
special_case = [{ORTH: "gim"}, {ORTH: "me"}]
nlp.tokenizer.add_special_case ("дай мне", специальный_кейс)
print ([w.text для w в nlp ("дай мне это")])
Особый случай не обязательно должен соответствовать всей подстроке, разделенной пробелами. Токенизатор будет постепенно отделять знаки препинания и продолжать поиск оставшаяся подстрока. Правила особого случая также имеют приоритет перед разделение знаков препинания.
assert "gimme" not in [w.text for w in nlp ("gimme!")]
assert "gimme" not in [w.text for w in nlp ('("... дай мне ...?")')]
nlp.tokenizer.add_special_case ("... дай мне ...?", [{"ORTH": ". .. дай мне ...?"}])
assert len (nlp ("... дай ...?")) == 1
 .. дай мне ...?"}])
assert len (nlp ("... дай ...?")) == 1
.. дай мне ...?"}])
assert len (nlp ("... дай ...?")) == 1
Отладка токенизатора
Рабочая реализация приведенного выше псевдокода доступна для отладки как nlp.tokenizer.explain (текст) . Он возвращает список
кортежи, показывающие, какое правило или шаблон токенизатора было сопоставлено для каждого токена.В
произведенные токены идентичны nlp.tokenizer () , за исключением пробельных токенов:
Ожидаемый результат
"ПРЕФИКС
Пусть СПЕЦИАЛЬНЫЙ-1
СПЕЦИАЛЬНЫЙ-2
перейти ТОКЕН
! СУФФИКС
"СУФФИКС
из spacy.lang.en импорт английский
nlp = английский ()
text = '' '"Поехали!"' ''
doc = nlp (текст)
tok_exp = nlp.tokenizer.explain (текст)
assert [t.text для t в документе, если не t.is_space] == [t [1] для t в tok_exp]
для t в tok_exp:
print (t [1], "\ t", t [0])
Настройка класса токенизатора spaCy
Предположим, вы хотите создать токенизатор для нового языка или определенного
домен. Вам может потребоваться определить шесть вещей:
Вам может потребоваться определить шесть вещей:
- Словарь особых случаев . Это обрабатывает такие вещи, как схватки, единицы измерения, смайлы, некоторые сокращения и т. д.
- Функция
prefix_search, для обработки предшествующих знаков препинания , таких как открытая кавычки, открытые скобки и т. д. - Функция
suffix_searchдля обработки следующих знаков препинания , таких как запятые, точки, закрывающие кавычки и т. д. - Функция
infix_finditerдля обработки непробельных разделителей, таких как дефисы и т. д. - Необязательная логическая функция
token_matchсоответствующие строки, которые никогда не должны быть разделенным, переопределив правила инфиксов. Полезно для таких вещей, как числа. - Необязательная логическая функция
url_match, аналогичнаяtoken_matchза исключением того, что префиксы и суффиксы удаляются перед применением соответствия.
Обычно не требуется создавать подкласс Tokenizer . Стандартное использование
использовать re.compile () для создания объекта регулярного выражения и передать его .https?: // '' ') def custom_tokenizer (nlp):
вернуть Tokenizer (nlp.vocab, rules = special_cases,
prefix_search = prefix_re.search,
суффикс_поиск = суффикс_ре.поиск,
infix_finditer = infix_re.finditer,
url_match = simple_url_re.match) nlp = spacy.load ("en_core_web_sm")
nlp.tokenizer = custom_tokenizer (nlp)
doc = nlp ("привет-мир. :)")
print ([t.text для t в документе])
Если вместо этого вам нужно создать подкласс токенизатора, соответствующие методы
specialize - это find_prefix , find_suffix и find_infix .
Важное примечание
При настройке обработки префиксов, суффиксов и инфиксов помните, что вы
передача функций для выполнения spaCy, например prefix_re..Точно так же суффиксные правила должны
применяется только к концу токена , поэтому ваше выражение должно заканчиваться 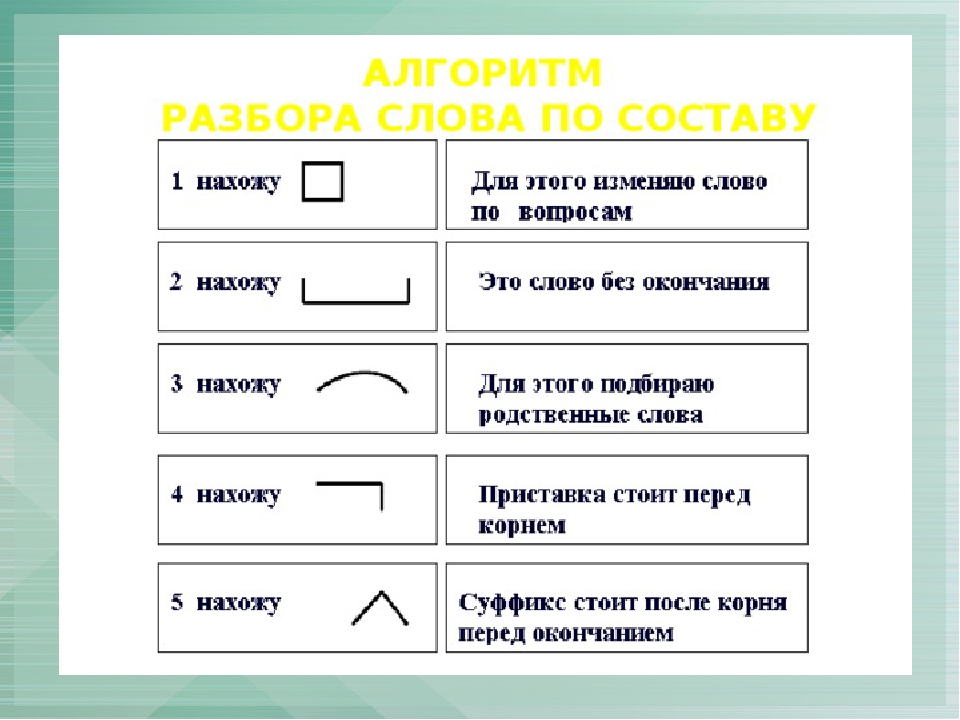
$ .
Изменение существующих наборов правил
Во многих ситуациях вам не обязательно нужны полностью настраиваемые правила. Иногда
вы просто хотите добавить еще один символ к префиксам, суффиксам или инфиксам. В
правила префикса, суффикса и инфикса по умолчанию доступны через объект nlp По умолчанию и Tokenizer атрибуты, такие как Токенизатор.суффикс_поиск доступны для записи, поэтому вы можете
перезаписать их скомпилированными объектами регулярного выражения, используя измененное значение по умолчанию
правила. spaCy поставляется с служебными функциями, которые помогут вам скомпилировать обычный
выражения - например, compile_suffix_regex :
суффиксы = nlp.Defaults.suffixes + [r '' '- + $' '',]
суффикс_regex = spacy.util. compile_suffix_regex (суффиксы)
nlp.tokenizer.suffix_search = suffix_regex.search
 compile_suffix_regex (суффиксы)
nlp.tokenizer.suffix_search = suffix_regex.search
compile_suffix_regex (суффиксы)
nlp.tokenizer.suffix_search = suffix_regex.search
Аналогичным образом вы можете удалить символ из суффиксов по умолчанию:
suffixes = list (nlp.Defaults.suffixes)
суффиксы.remove ("\\ [")
суффикс_regex = spacy.util.compile_suffix_regex (суффиксы)
nlp.tokenizer.suffix_search = suffix_regex.search
Атрибут Tokenizer.suffix_search должен быть функцией, которая принимает
строка Unicode и возвращает объект соответствия регулярному выражению или Нет . Обычно мы используем
атрибут .search скомпилированного объекта регулярного выражения, но вы можете использовать и другие
функция, которая ведет себя так же.
Важное примечание
Если вы загрузили обученный конвейер, запись в нлп.Значения по умолчанию или на английском языке. Значения по умолчанию напрямую не используются.
работают, поскольку регулярные выражения считываются из данных конвейера и будут
компилируется при загрузке. Если вы измените
Если вы измените nlp.Defaults , вы увидите только
эффект, если вы позвоните spacy.blank . Если вы хотите
изменить токенизатор, загруженный из обученного конвейера, вы должны изменить nlp.tokenizer напрямую. Если вы тренируете собственный конвейер, вы можете зарегистрироваться
обратные вызовы для изменения nlp объект перед тренировкой.
Наборы правил для префиксов, инфиксов и суффиксов включают не только отдельные символы.
но также подробные регулярные выражения, которые принимают окружающий контекст в
учетная запись. Например, существует регулярное выражение, которое обрабатывает дефис между
буквы как инфикс. Если вы не хотите, чтобы токенизатор разбивался на дефисы
между буквами, вы можете изменить существующее определение инфикса из lang / punctuation.py :
import spacy
из spacy.lang.char_classes импортировать ALPHA, ALPHA_LOWER, ALPHA_UPPER
от простора.] (? = [0-9-]) ",
r "(? <= [{al} {q}]) \. (? = [{au} {q}]]". format (
al = ALPHA_LOWER, au = ALPHA_UPPER, q = CONCAT_QUOTES
),
r "(? <= [{a}]), (? = [{a}])". format (a = ALPHA),
r "(? <= [{a} 0-9]) [: <> = /] (? = [{a}])". format (a = ALPHA),
]
)
infix_re = compile_infix_regex (инфиксы)
nlp.tokenizer.infix_finditer = infix_re.finditer
doc = nlp ("свекровь")
print ([t.text для t в документе])
 (? = [{au} {q}]]". format (
al = ALPHA_LOWER, au = ALPHA_UPPER, q = CONCAT_QUOTES
),
r "(? <= [{a}]), (? = [{a}])". format (a = ALPHA),
r "(? <= [{a} 0-9]) [: <> = /] (? = [{a}])". format (a = ALPHA),
]
)
infix_re = compile_infix_regex (инфиксы)
nlp.tokenizer.infix_finditer = infix_re.finditer
doc = nlp ("свекровь")
print ([t.text для t в документе])
(? = [{au} {q}]]". format (
al = ALPHA_LOWER, au = ALPHA_UPPER, q = CONCAT_QUOTES
),
r "(? <= [{a}]), (? = [{a}])". format (a = ALPHA),
r "(? <= [{a} 0-9]) [: <> = /] (? = [{a}])". format (a = ALPHA),
]
)
infix_re = compile_infix_regex (инфиксы)
nlp.tokenizer.infix_finditer = infix_re.finditer
doc = nlp ("свекровь")
print ([t.text для t в документе])
Обзор регулярных выражений по умолчанию см. языков / знаков препинания.py и
специфичные для языка определения, такие как lang / de / punctuation.py для
Немецкий.
Подключение пользовательского токенизатора к конвейеру
Токенизатор является первым и единственным компонентом конвейера обработки.
это не может быть заменено записью на nlp.pipeline . Это потому, что у него
отличная подпись от всех других компонентов: он принимает текст и возвращает Doc , тогда как все остальные компоненты ожидают уже получить
токенизированные Doc .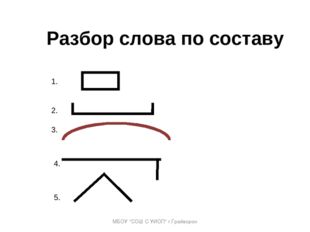
Чтобы перезаписать существующий токенизатор, вам необходимо заменить nlp.tokenizer на
настраиваемая функция, которая принимает текст и возвращает Doc .
Создание документа Doc
Для создания объекта Doc вручную требуется не менее двух
аргументы: общий Vocab и список слов. По желанию можно сдать
список из пробелов значений, указывающих, является ли токен в этой позиции
с последующим пробелом (по умолчанию True ).См. Раздел о
предварительно токенизированный текст для получения дополнительной информации.
words = [«Пусть», «s», «go», «!»]
пробелы = [Ложь, Истина, Ложь, Ложь]
doc = Doc (nlp.vocab, слова = слова, пробелы = пробелы)
nlp = spacy.blank ("en")
nlp.tokenizer = my_tokenizer
| Аргумент | Тип | Описание |
|---|---|---|
текст | str | Необработанный текст для токенизации. |
Пример 1. Базовый токенизатор пробелов
Вот пример самого простого токенизатора пробелов.Требуется общий
словарь, поэтому он может создавать объекты Doc . Когда он вызывает текст, он возвращает
объект Doc , состоящий из текста, разделенного на одиночные пробелы. Мы можем
затем перезапишите атрибут nlp.tokenizer экземпляром нашего настраиваемого
токенизатор.
импорт просторный
из spacy.tokens import Doc
класс WhitespaceTokenizer:
def __init __ (я, словарь):
self.vocab = словарный запас
def __call __ (сам, текст):
слова = текст.расколоть(" ")
вернуть документ (self.vocab, words = words)
nlp = spacy.blank ("ru")
nlp.tokenizer = WhitespaceTokenizer (nlp.vocab)
doc = nlp («Что со мной случилось? подумал он. Это был не сон.»)
print ([token.text для токена в документе])
Пример 2: Сторонние токенизаторы (части слова BERT)
Вы можете использовать тот же подход для подключения любых других сторонних токенизаторов. Ваш
custom callable просто нужно вернуть объект
Ваш
custom callable просто нужно вернуть объект Doc с токенами, созданными
ваш токенизатор.В этом примере оболочка использует слово BERT.
токенизатор , предоставленный токенизаторов библиотеки. Жетоны
доступный в объекте Doc , возвращенном spaCy, теперь соответствует точным частям слова
производится токенизатором.
💡 Совет: spacy-transformers
Если вы работаете с моделями трансформаторов, такими как BERT, ознакомьтесь с Пространственно-трансформеры пакет расширений и документация. Это
включает компонент конвейера для использования предварительно обученных грузов трансформатора и
Тренировочный трансформатор модели в spaCy, а также полезные утилиты для
согласование частей слова с лингвистической лексикой.
Custom BERT word piece tokenizer
from tokenizers import BertWordPieceTokenizer из spacy.tokens import Doc импортный простор класс BertTokenizer: def __init __ (я, словарь, файл словаря, нижний регистр = Истина): self.конец) еще: space.append (Истина) вернуть документ (self.vocab, слова = слова, пробелы = пробелы) nlp = spacy.blank ("ru") nlp.tokenizer = BertTokenizer (nlp.vocab, "bert-base-uncased-vocab.txt") doc = nlp ("Джастин Дрю Бибер - канадский певец, автор песен и актер.") print (doc.text, [token.text для токена в документе])
 vocab = словарный запас
self._tokenizer = BertWordPieceTokenizer (файл словаря, нижний регистр = нижний регистр)
def __call __ (сам, текст):
tokens = self._tokenizer.encode (текст)
слова = []
пробелы = []
для i, (текст, (начало, конец)) в перечислении (zip (tokens.токены, токены. смещения)):
words.append (текст)
если i
vocab = словарный запас
self._tokenizer = BertWordPieceTokenizer (файл словаря, нижний регистр = нижний регистр)
def __call __ (сам, текст):
tokens = self._tokenizer.encode (текст)
слова = []
пробелы = []
для i, (текст, (начало, конец)) в перечислении (zip (tokens.токены, токены. смещения)):
words.append (текст)
если i Важное примечание о токенизации и моделях
Имейте в виду, что результаты ваших моделей могут быть менее точными, если токенизация
во время обучения отличается от токенизации во время выполнения. Итак, если вы измените
после токенизации обученного конвейера, это может привести к очень разным
предсказания. Поэтому вы должны тренировать свой конвейер с таким же
tokenizer , который он будет использовать во время выполнения. См. Документацию на
обучение с индивидуальной токенизацией для получения подробной информации.
Итак, если вы измените
после токенизации обученного конвейера, это может привести к очень разным
предсказания. Поэтому вы должны тренировать свой конвейер с таким же
tokenizer , который он будет использовать во время выполнения. См. Документацию на
обучение с индивидуальной токенизацией для получения подробной информации.
Обучение с пользовательской токенизацией v3.0
Конфигурация обучения spaCy описывает настройки,
гиперпараметры, конвейер и токенизатор, используемые для построения и обучения
трубопровод. Блок [nlp.tokenizer] относится к зарегистрированной функции , которая
принимает объект nlp и возвращает токенизатор. Здесь мы регистрируем
функция называется whitespace_tokenizer в
Реестр @tokenizers . Чтобы убедиться, что spaCy умеет
построить свой токенизатор во время обучения, вы можете передать свой файл Python с помощью
установка - код функции.py при запуске spacy train .
config.cfg
[nlp.tokenizer]
@tokenizers = "whitespace_tokenizer"
functions.py
@ spacy.registry.tokenizers ("whitespace_tokenizer") def create_whitespace_tokenizer (): def create_tokenizer (nlp): вернуть WhitespaceTokenizer (nlp.vocab) вернуть create_tokenizer
Зарегистрированные функции также могут принимать аргументы, которые затем передаются из
config. Это позволяет быстро изменять и отслеживать различные настройки.Здесь зарегистрированная функция bert_word_piece_tokenizer занимает два
аргументы: путь к файлу словаря и необходимость строчных букв. В
Подсказки типа Python str и bool гарантируют, что полученные значения имеют
правильный тип.
config.cfg
[nlp.tokenizer]
@tokenizers = "bert_word_piece_tokenizer"
Vocab_file = "bert-base-uncased-vocab.txt"
нижний регистр = истина
functions.
@spacy.registry.tokenizers ("bert_word_piece_tokenizer") def create_whitespace_tokenizer (vocab_file: str, нижний регистр: bool): def create_tokenizer (nlp): вернуть BertWordPieceTokenizer (nlp.vocab, vocab_file, строчные буквы) вернуть create_tokenizer
 py
py Чтобы избежать жесткого кодирования локальных путей в файле конфигурации, вы также можете установить
Vocab путь в CLI с помощью переопределения --nlp.tokenizer.vocab_file при запуске Большой поезд . Для получения более подробной информации об использовании зарегистрированных функций,
см. документацию по обучению с пользовательским кодом.
Помните, что зарегистрированная функция всегда должна быть функцией, призывает создавать что-то , а не само «что-то». В этом случае это создает функцию , которая принимает объект nlp и возвращает вызываемый объект, который
принимает текст и возвращает Doc .
Использование предварительно токенизированного текста
spaCy обычно предполагает по умолчанию, что ваши данные - это необработанный текст . Тем не мение,
иногда ваши данные частично аннотируются, например.грамм. с уже существующей токенизацией,
теги части речи и т. д. Чаще всего у вас предопределенная токенизация . Если у вас есть список строк, вы можете создать Doc объект напрямую. При желании вы также можете указать список
логические значения, указывающие, следует ли за каждым словом пробел.
✏️ Что попробовать
- Измените логическое значение в списке
пробелов. Вы должны увидеть это в отражении вdoc.textи следует ли за токеном пробел. - Удалите
пробелов = пробелыизDoc. Вы должны увидеть, что каждый токен теперь следует пробел. - Скопируйте и вставьте случайное предложение из Интернета и вручную создайте
Docссловамиипробелами, так чтоdoc.совпадает с оригиналом ввод текста. text
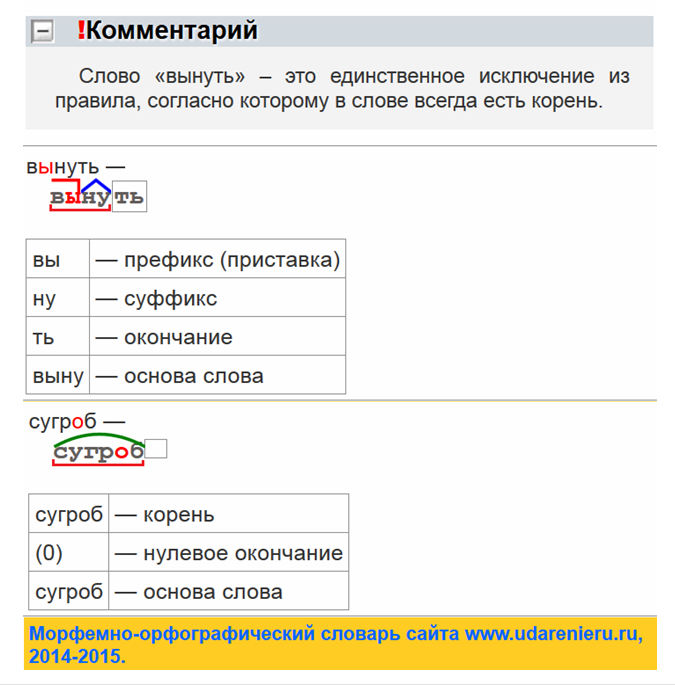 text
text импорт просторный
из spacy.tokens import Doc
nlp = spacy.blank ("ru")
words = ["Привет", ",", "мир", "!"]
пробелы = [Ложь, Истина, Ложь, Ложь]
doc = Док (nlp.словарь, слова = слова, пробелы = пробелы)
печать (doc.text)
print ([(t.text, t.text_with_ws, t.whitespace_) для t в документе])
Если предоставляется, список пробелов должен быть той же длины, что и список слов, . В
Список пробелов влияет на doc.text , span.text , token.idx , span.start_char и атрибутов span.end_char . Если вы не укажете последовательность пробелов и , spaCy
будет считать, что после всех слов стоит пробел.Как только у вас будет Doc объект, вы можете записать в его атрибуты, чтобы установить
теги части речи, синтаксические зависимости, именованные объекты и другие
атрибуты.
Согласование токенизации
Токенизация spaCy является неразрушающей и использует правила, зависящие от языка
оптимизирован для совместимости с аннотациями банка деревьев. Другие инструменты и ресурсы
может иногда токенизировать вещи по-разному - например,
Другие инструменты и ресурсы
может иногда токенизировать вещи по-разному - например, «Я» → [«I», «'», «m»] вместо [«I», «m»] .
В подобных ситуациях вам часто нужно выровнять токенизацию, чтобы
может объединять аннотации из разных источников вместе или брать предсказанные векторы
автор
предварительно обученная модель BERT и
примените их к токенам spaCy. spaCy’s Выравнивание объект позволяет однозначно отображать индексы токенов в обоих направлениях, как
а также с учетом индексов, в которых несколько токенов совпадают с одним
токен.
✏️ Что попробовать
- Измените регистр в одном из списков токенов - например,
«Обама»по«Обама».Вы увидите, что при выравнивании регистр не учитывается. - Измените
«подкасты»вother_tokensна«pod», «cast». Тебе следует увидеть что теперь есть два токена длины 2 вy2x, один соответствует «S», а один - «подкасты». - Сделайте
other_tokensиspacy_tokensидентичными. Вы увидите, что все токены теперь соответствуют 1 к 1.

из spacy.training import Alignment
other_tokens = [«я», «слушал», «до», «обама», «'», «с», «подкасты», «."]
spacy_tokens = ["я", "слушал", "кому", "обама", "s", "подкасты", "."]
align = Alignment.from_strings (other_tokens, spacy_tokens)
print (f "a -> b, lengths: {align.x2y.lengths}")
print (f "a -> b, сопоставление: {align.x2y.dataXd}")
print (f "b -> a, lengths: {align.y2x.lengths}")
print (f "b -> a, сопоставления: {align.y2x.dataXd}")
Вот некоторые выводы из информации о выравнивании, сгенерированной в примере выше:
- Сопоставления "один-к-одному" для первых четырех токенов идентичны, что означает
они сопоставляются друг с другом.Это имеет смысл, потому что они идентичны и в
ввод:
"я","слушал","до"и"обама". - Значение
x2y.равно dataXd [6] 5, что означает, чтоother_tokens [6](«подкасты»,) соответствуютspacy_tokens [5](также«подкасты»). -
x2y.dataXd [4]иx2y.dataXd [5]оба равны4, что означает, что оба токена 4 и 5 изother_tokens("'"и"s") выравниваются с токеном 4 изspacy_tokens("х").
 dataXd [6]
dataXd [6] Важное примечание
Текущая реализация алгоритма выравнивания предполагает, что оба
токенизации складываются в одну и ту же строку. Например, вы сможете выровнять [«Я», «'», «м»] и [«Я», «м»] , которые в сумме дают «Я» , но не [«я», «м»] и [«я», «ам»] .
Диспетчер контекста Doc.retokenize позволяет объединять и
разделить токены. Изменения токенизации сохраняются и выполняются на
один раз при выходе из диспетчера контекста. Объединить несколько токенов в один
токен, передайте
Объединить несколько токенов в один
токен, передайте Span в ретокенизатор .merge . An
дополнительный словарь attrs позволяет вам установить атрибуты, которые будут назначены
объединенный токен - например, лемма, тег части речи или тип объекта. От
по умолчанию объединенный токен получит те же атрибуты, что и объединенный диапазон
корень.
✏️ Что попробовать
- Проверьте атрибут
token.lemma_с установкой и без установкиattrs.Вы увидите, что в лемме по умолчанию используется «New», лемма о корне span. - Перезаписать другие атрибуты, такие как
"ENT_TYPE". Поскольку «Нью-Йорк» тоже распознается как именованный объект, это изменение также будет отражено вдок..
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Я живу в Нью-Йорке»)
print ("До:", [token.text для токена в документе])
с doc.retokenize () в качестве ретокенизатора:
retokenizer. merge (документ [3: 5], attrs = {"ЛЕММА": "нью-йорк"})
print ("После:", [токен.текст для токена в документе])
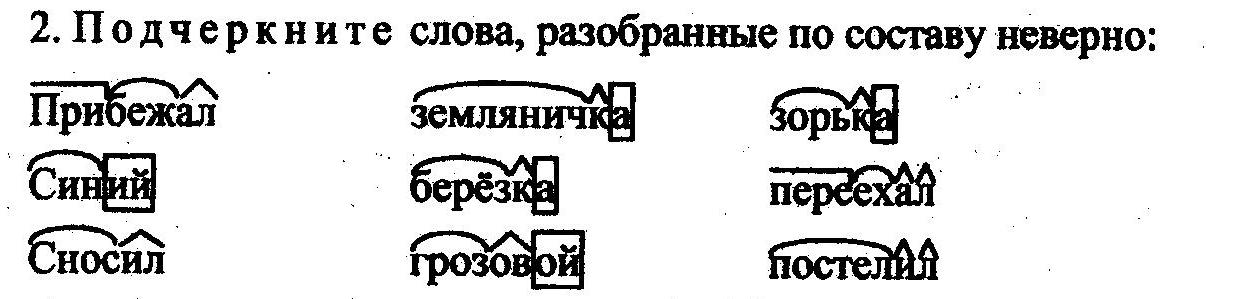 merge (документ [3: 5], attrs = {"ЛЕММА": "нью-йорк"})
print ("После:", [токен.текст для токена в документе])
merge (документ [3: 5], attrs = {"ЛЕММА": "нью-йорк"})
print ("После:", [токен.текст для токена в документе])
Совет: объединение сущностей и словосочетаний с существительными
Если вам нужно объединить именованные сущности или фрагменты существительных, воспользуйтесь встроенным merge_entities и merge_noun_chunks конвейер
составные части. При добавлении в конвейер с помощью nlp.add_pipe они займут
забота об автоматическом слиянии пролетов.
Если атрибут в attrs является контекстно-зависимым атрибутом токена, он будет
применяться к базовому токену .Например LEMMA , POS или DEP применяются только к слову в контексте, поэтому они являются атрибутами токена. Если
attribute является контекстно-независимым лексическим атрибутом, он будет применяться к
Лексема , лежащая в основе , запись в словаре. Например, LOWER или IS_STOP применяются ко всем словам с одинаковым написанием, независимо от
контекст.
Примечание по объединению перекрывающихся промежутков
Если вы пытаетесь объединить перекрывающиеся промежутки, spaCy выдаст ошибку, потому что
неясно, как должен выглядеть результат.В зависимости от приложения вы можете
хотите найти самый короткий или самый длинный диапазон, поэтому вам решать, как отфильтровать
их. Если вы ищете самый длинный неперекрывающийся промежуток, вы можете использовать util.filter_spans helper:
doc = nlp («Я живу в Берлинском Кройцберге»)
spans = [документ [3: 5], документ [3: 4], документ [4: 5]]
filter_spans = filter_spans (промежутки)
Разделение токенов
Метод retokenizer.split позволяет разделить
один жетон на два или более жетона.Это может быть полезно в тех случаях, когда
Одних правил токенизации недостаточно. Например, вы можете захотеть разделить
«Его» в токены «оно» и «есть», но не притяжательное местоимение «его». Ты
может написать логику, основанную на правилах, которая может найти только правильное «свое» для разделения, но
к этому времени Doc уже будет токенизирован.
Этот процесс разделения токена требует дополнительных настроек, потому что вам нужно
укажите текст отдельных токенов, необязательные атрибуты каждого токена и способ
должен быть прикреплен к существующему синтаксическому дереву.Это можно сделать
предоставление списка из голов - либо токен для присоединения вновь разделенного токена
в, или (токен, суб-токен) кортеж, если новый разделенный токен должен быть присоединен
на другой подтекст. В этом случае «New» следует прикрепить к «York» (
второй разделенный подтекст) и «York» следует присоединить к «in».
✏️ Что стоит попробовать
- Назначьте различные атрибуты подтокенам и сравните результат.
- Измените головки так, чтобы «New» было прикреплено к «in», а «York» - прикреплено. на «Новый».
- Разделите жетон на три жетона вместо двух - например,
[«Новый», «Йо», «рк»].
импорт просторный
от просторного импорта
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Я живу в Нью-Йорке»)
print ("До:", [token. text для токена в документе])
displacy.render (док)
с doc.retokenize () в качестве ретокенизатора:
Heads = [(док [3], 1), док [2]]
attrs = {"POS": ["PROPN", "PROPN"], "DEP": ["pobj", "соединение"]}
retokenizer.split (doc [3], ["New", "York"], Heads = Heads, attrs = attrs)
print ("После:", [токен.текст для токена в документе])
displacy.render (док)
 text для токена в документе])
displacy.render (док)
с doc.retokenize () в качестве ретокенизатора:
Heads = [(док [3], 1), док [2]]
attrs = {"POS": ["PROPN", "PROPN"], "DEP": ["pobj", "соединение"]}
retokenizer.split (doc [3], ["New", "York"], Heads = Heads, attrs = attrs)
print ("После:", [токен.текст для токена в документе])
displacy.render (док)
text для токена в документе])
displacy.render (док)
с doc.retokenize () в качестве ретокенизатора:
Heads = [(док [3], 1), док [2]]
attrs = {"POS": ["PROPN", "PROPN"], "DEP": ["pobj", "соединение"]}
retokenizer.split (doc [3], ["New", "York"], Heads = Heads, attrs = attrs)
print ("После:", [токен.текст для токена в документе])
displacy.render (док)
Указание заголовков в виде списка токенов или (токен, суб-токен) кортежей позволяет
присоединение разделенных субтокенов к другим субтокенам без необходимости отслеживать
индексы токенов после разделения.
| Токен | Голова | Описание |
|---|---|---|
«Новый» | (doc [3], 1) | Прикрепите этот токен ко второму подтексту (индекс 1 ) что doc [3] будет разделен на: i.е. «Йорк». |
"York" | doc [2] | Прикрепите этот токен к doc [1] в исходном Doc , т.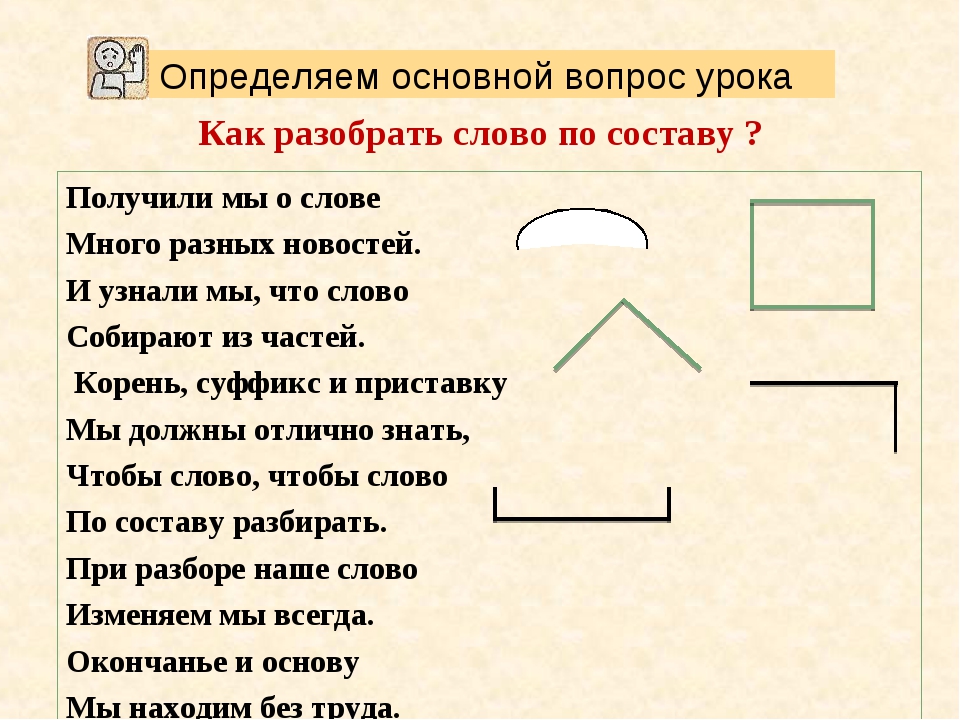 е. «in». е. «in». |
Если вас не волнуют головы (например, если вы используете только токенизатор, а не парсер), вы можете прикрепить каждый подтекен к себе:
doc = nlp («Я живу в Нью-Йорке»)
с doc.retokenize () в качестве ретокенизатора:
Heads = [(doc [3], 0), (doc [3], 1), (doc [3], 2)] ретокенизатор.split (doc [3], ["Новый", "Йорк", "Город"], Heads = Heads)
Важное примечание
При разделении токенов тексты суб токенов всегда должны совпадать с оригиналом
текст токена - или, иначе говоря, "" .join (subtokens) == token.text всегда нужен
чтобы быть правдой. Если бы это было не так, разделение токенов могло бы легко закончиться
приводя к сбивающим с толку и неожиданным результатам, которые противоречили бы
Политика неразрушающей токенизации.
doc = nlp («Я живу в Лос-Анджелесе.")
с doc.retokenize () в качестве ретокенизатора:
- retokenizer.split (doc [3], ["Los", "Angeles"], Heads = [(doc [3], 1), doc [2]])
+ retokenizer. split (doc [3], ["L.", "A."], Heads = [(doc [3], 1), doc [2]])
 split (doc [3], ["L.", "A."], Heads = [(doc [3], 1), doc [2]])
split (doc [3], ["L.", "A."], Heads = [(doc [3], 1), doc [2]])
Перезапись атрибутов настраиваемого расширения
Если вы зарегистрировали настраиваемый
атрибуты расширения,
вы можете перезаписать их во время токенизации, предоставив словарь
имена атрибутов отображаются на новые значения как ключ "_" в атрибуте attrs . Для
слияния, вам необходимо предоставить один словарь атрибутов для результирующего
объединенный токен.Для разделения вам необходимо предоставить список словарей с
настраиваемые атрибуты, по одному на каждый под токен разделения.
Важное примечание
Чтобы установить атрибуты расширения во время ретокенизации, атрибуты должны быть зарегистрировал с использованием Token.set_extension метод, и они должны быть с возможностью записи . Это означает, что они должны иметь
значение по умолчанию, которое можно перезаписать, или установщики геттеров и . Метод
расширения или расширения только с геттером вычисляются динамически, поэтому их
значения не могут быть перезаписаны.Подробнее см.
документация по атрибуту расширения.
Метод
расширения или расширения только с геттером вычисляются динамически, поэтому их
значения не могут быть перезаписаны.Подробнее см.
документация по атрибуту расширения.
✏️ Что стоит попробовать
- Добавьте еще одно собственное расширение - может быть,
"music_style"? - и перезапишите его. - Измените атрибут расширения, чтобы использовать только функцию получения
- Перепишите код, чтобы разделить токен на
retokenizer.split. Помни это вам необходимо предоставить список значений атрибутов расширения в виде"_"Свойство, по одному на каждый разделенный подтекст.
импорт просторный
из spacy.tokens импортировать токен
Token.set_extension ("is_musician", по умолчанию = False)
nlp = spacy.load ("en_core_web_sm")
doc = nlp («Мне нравится Дэвид Боуи»)
print ("До:", [(token. text, token ._. is_musician) для токена в документе])
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (документ [2: 4], attrs = {"_": {"is_musician": True}})
print ("После:", [(token.text, token ._. is_musician) для токена в документе])
 text, token ._. is_musician) для токена в документе])
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (документ [2: 4], attrs = {"_": {"is_musician": True}})
print ("После:", [(token.text, token ._. is_musician) для токена в документе])
text, token ._. is_musician) для токена в документе])
с doc.retokenize () в качестве ретокенизатора:
retokenizer.merge (документ [2: 4], attrs = {"_": {"is_musician": True}})
print ("После:", [(token.text, token ._. is_musician) для токена в документе])
A Doc Предложения объекта доступны через Doc.сент имущество. Чтобы просмотреть предложения Doc , вы можете перебрать Doc.sents , a
генератор, который дает Span объекта. Вы можете проверить, действительно ли Doc имеет границы предложения, позвонив Doc.has_annotation с именем атрибута «SENT_START» .
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Это предложение. Это другое предложение.")
assert doc.has_annotation ("SENT_START")
для отправки в док.отправляет:
печать (отправлено. текст)
spaCy предоставляет четыре альтернативы для сегментации предложений:
- Анализатор зависимостей: статистический
DependencyParserобеспечивает наиболее точный границы предложений, основанные на анализе полной зависимости. - Статистический сегментатор предложений: статистический
SentenceRecognizerпроще и быстрее альтернатива синтаксическому анализатору, который устанавливает только границы предложения. - Компонент конвейера на основе правил: основанный на правилах
Sentencizerустанавливает границы предложения с помощью настраиваемый список знаков препинания в конце предложения. - Пользовательская функция: ваша собственная пользовательская функция добавлена в
конвейер обработки может устанавливать границы предложения, записывая
Токен.is_sent_start.
По умолчанию: Использование анализа зависимостей Требуется модель
В отличие от других библиотек, spaCy использует анализ зависимостей для определения предложения границы. Обычно это наиболее точный подход, но он требует обученный конвейер , который обеспечивает точные прогнозы. Если твои тексты ближе к новостям общего назначения или веб-тексту, это должно работать сразу же с предоставленными spaCy подготовленными конвейерами.Для социальных сетей или разговорного текста который не соответствует тем же правилам, ваше приложение может извлечь выгоду из пользовательского обученный или основанный на правилах компонент.
импорт просторный
nlp = spacy.load ("en_core_web_sm")
doc = nlp ("Это предложение. Это другое предложение.")
для присланных документов:
печать (отправлено. текст)
Парсер зависимостей spaCy учитывает уже установленные границы, поэтому вы можете предварительно обрабатывать
ваш Doc с использованием пользовательских компонентов с до его анализирует.В зависимости от вашего текста,
это также может повысить точность синтаксического анализа, поскольку синтаксический анализатор ограничен предсказывать
синтаксический анализ в соответствии с границами предложения.
Статистический сегментатор предложений v3.0 Модель потребностей
SentenceRecognizer - это простой статистический
компонент, который предоставляет только границы предложения. Наряду с тем, чтобы быть быстрее и
меньше, чем парсер, его основное преимущество состоит в том, что его легче обучить
потому что для этого требуются только аннотированные границы предложения, а не полные
анализ зависимостей.Обученные конвейеры spaCy включают в себя как синтаксический анализатор,
и обученный сегментатор предложений, который
по умолчанию отключено. Если тебе нужно только
границы предложения и без синтаксического анализатора, вы можете использовать , исключить или , отключить аргумент на spacy.load для загрузки конвейера
без синтаксического анализатора, а затем явно включить распознаватель предложений с помощью nlp.enable_pipe .
senter vs. parser
Повторный вызов для senter обычно немного ниже, чем для парсера,
который лучше предсказывает границы предложения, когда пунктуация не
настоящее время.
импорт просторный
nlp = spacy.load ("en_core_web_sm", exclude = ["parser"])
nlp.enable_pipe ("центр")
doc = nlp ("Это предложение. Это другое предложение.")
для присланных документов:
печать (отправлено. текст)
Компонент конвейера на основе правил
Компонент Sentencizer является
компонент конвейера, который разбивает предложения на
пунктуация как . , ! или ? . Вы можете подключить его к своему конвейеру, если только
нужны границы предложения без синтаксического анализа зависимостей.
импорт просторный
from spacy.lang.en импорт английский
nlp = английский ()
nlp.add_pipe ("приговорщик")
doc = nlp ("Это предложение. Это другое предложение.")
для присланных документов:
печать (отправлено. текст)
Пользовательская стратегия на основе правил
Если вы хотите реализовать свою собственную стратегию, которая отличается от стратегии по умолчанию
основанный на правилах подход к разделению предложений, вы также можете создать
настраиваемый компонент конвейера, который
берет объект Doc и устанавливает токен .is_sent_start на каждом
индивидуальный жетон. Если установлено значение False , токен явно помечается как , а не как .
начало предложения. Если установлено значение Нет (по умолчанию), оно обрабатывается как отсутствующее значение.
и все еще может быть перезаписан парсером.
Важное примечание
Чтобы предотвратить несогласованное состояние, вы можете установить границы только до документа
анализируется (и doc.has_annotation ("DEP") - False ). Чтобы убедиться, что ваш
компонент добавлен в нужном месте, вы можете установить перед = 'parser' или first = True при добавлении в конвейер с помощью нлп.add_pipe .
Вот пример компонента, который реализует правило предварительной обработки для
разбиение на "..." токенов. Компонент добавляется перед анализатором, то есть
затем используется для дальнейшего сегментирования текста. Это возможно, потому что is_sent_start только True для некоторых токенов - все остальные по-прежнему указывают None для неустановленных границ предложения. Этот подход может быть полезен, если вы хотите
реализовать дополнительных правил , относящихся к вашим данным, при этом сохраняя возможность
воспользоваться преимуществами сегментации предложений на основе зависимостей.
из spacy.language import Language
импортный простор
text = "это предложение ... привет ... и еще одно предложение".
nlp = spacy.load ("en_core_web_sm")
doc = nlp (текст)
print ("До:", [отправленный текст для отправки в документах])
@ Language.component ("set_custom_boundaries")
def set_custom_boundaries (документ):
для токена в документе [: - 1]:
если token.text == "...":
doc [token.i + 1] .is_sent_start = Истина
вернуть документ
nlp.add_pipe ("set_custom_boundaries", before = "parser")
doc = nlp (текст)
print ("После:", [отправлено.текст для отправки в документах])
AttributeRuler управляет сопоставлениями на основе правил и
исключения для всех атрибутов уровня токена. Как количество
компоненты конвейера выросли со spaCy v2 до
v3, обработка правил и исключений в каждом компоненте в отдельности стала
непрактично, поэтому AttributeRuler предоставляет единый компонент с унифицированным
формат шаблона для всех сопоставлений атрибутов токенов и исключений.
Атрибут AttributeRuler использует Matcher шаблоны для идентификации
токены, а затем присваивает им предоставленные атрибуты.При необходимости Matcher Шаблоны могут включать контекст вокруг целевого токена.
Например, линейка атрибутов может:
- предоставлять исключения для любых атрибутов токена
- отображать мелкозернистых тегов до крупнозернистых тегов для языков без
статистические морфологизаторы (замена v2.x
tag_mapв языковых данных) - маркер карты форма поверхности + мелкозернистые теги от до морфологические признаки (замена v2.x
morph_rulesв языковых данных) - указывает теги для маркеров пробелов (заменяя жестко запрограммированное поведение в tagger)
В следующем примере показано, как можно указать тег и POS NNP / PROPN для фразы "The Who" , переопределив теги, предоставленные статистическим
tagger и карту тегов POS.
импорт просторный
nlp = spacy.load ("en_core_web_sm")
text = "Я видел выступление The Who. Кого вы видели?"
doc1 = nlp (текст)
печать (doc1 [2].tag_, doc1 [2] .pos_)
печать (doc1 [3] .tag_, doc1 [3] .pos_)
ruler = nlp.get_pipe ("attribute_ruler")
pattern = [[{"LOWER": "the"}, {"TEXT": "Who"}]]
attrs = {"ТЕГ": "NNP", "POS": "PROPN"}
ruler.add (шаблоны = шаблоны, attrs = attrs, index = 0)
ruler.add (шаблоны = шаблоны, attrs = attrs, index = 1)
doc2 = nlp (текст)
печать (doc2 [2] .tag_, doc2 [2] .pos_)
печать (doc2 [3] .tag_, doc2 [3] .pos_)
печать (doc2 [5] .tag_, doc2 [5] .pos_)
Переход с spaCy v2.x
AttributeRuler может импортировать карту тегов и преобразовывать
правила в версии 2.x с помощью встроенных методов или когда компонент
инициализируется перед обучением. Увидеть
руководство по миграции для получения подробной информации.
Сходство определяется путем сравнения векторов слов или «вложений слов», многомерные смысловые представления слова. Векторы слов могут быть генерируется с использованием такого алгоритма, как word2vec и обычно выглядят так:
banana.vector
array ([2.02280000e-01, -7.66180009e-02, 3.70319992e-01, 3.28450017e-02, -4.19569999e-01, 7.20689967e-02, -3.74760002e-01, 5.74599989e-02, -1.24009997e-02, 5.29489994e-01, -5.23800015e-01, -1.97710007e-01, -3.41470003e-01, 5.33169985e-01, -2.53309999e-02, 1.73800007e-01, 1.67720005e-01, 8.39839995e-01, 5.51070012e-02, 1.05470002e-01, 3.78719985e-01, 2.42750004e-01, 1.47449998e-02, 5.59509993e-01, 1.25210002e-01, -6.75960004e-01, 3.58420014e-01, 3.66849989e-01, 2.52470002e-03, -6.40089989e-01, -2.97650009e-01, 7.89430022e-01, 3.31680000e-01, -1.19659996e + 00, -4.71559986e-02, 5.31750023e-01], dtype = float32)
Важное примечание
Чтобы сделать их компактными и быстрыми, небольшие конвейерные пакеты spaCy (все
пакеты, заканчивающиеся на sm ) , не поставляются с векторами слов и включают только
контекстно-зависимые тензоры . Это означает, что вы все еще можете использовать подобие () методы для сравнения документов, промежутков и токенов, но результат не будет таким
хорошо, и отдельным токенам не будут назначены векторы.Итак, чтобы использовать реальных векторов слов, вам необходимо загрузить более крупный пакет конвейера:
- python -m spacy загрузить en_core_web_sm
+ python -m spacy загрузить en_core_web_lg
Пакеты конвейеров, которые поставляются со встроенными векторами слов, делают их доступными как
атрибут Token.vector . Doc.vector и Span.vector будет
по умолчанию используется среднее значение их векторов токенов. Вы также можете проверить, есть ли у токена
назначенный вектор и получить норму L2, которую можно использовать для нормализации векторов.
импорт просторный
nlp = spacy.load ("en_core_web_md")
tokens = nlp ("собака кошка банан afskfsd")
для токена в токенах:
print (token.text, token.has_vector, token.vector_norm, token.is_oov)
- Текст : исходный текст токена.
- имеет вектор : Имеется ли у токена векторное представление?
- Норма вектора : Норма L2 вектора токена (квадратный корень из сумма квадратов значений)
- OOV : вне словарного запаса
Слова «собака», «кошка» и «банан» довольно распространены в английском языке, поэтому они
часть словаря конвейера и поставляется с вектором.Слово «afskfsd» на
другая рука гораздо менее распространена и не входит в словарный запас, поэтому ее вектор
представление состоит из 300 измерений 0 , то есть практически
несуществующий. Если ваше приложение получит пользу от большого словаря с
больше векторов, вам следует рассмотреть возможность использования одного из более крупных пакетов конвейера или
загрузка в полном векторном пакете, например, en_core_web_lg , что включает 685k уникальных
Векторы .
spaCy может сравнивать два объекта и делать прогноз , насколько похожи они .Прогнозирование сходства полезно для построения рекомендательных систем. или отметка дубликатов. Например, вы можете предложить пользовательский контент, аналогично тому, что они сейчас просматривают, или обозначьте обращение в службу поддержки как дублировать, если он очень похож на уже существующий.
Каждый Doc , Span , Token и Lexeme имеет сходство с .
метод, позволяющий сравнить его с другим объектом и определить
сходство.Конечно, сходство всегда субъективно - будь то два слова,
или документы похожи, в действительности зависит от того, как вы на это смотрите. spaCy’s
реализация подобия обычно предполагает довольно общее определение
сходство.
📝 Что стоит попробовать
- Сравните два разных токена и попытайтесь найти два наиболее разных токены в текстах с наименьшей оценкой сходства (согласно векторы).
- Сравните сходство двух объектов
Lexeme, записи в словарь.Вы можете получить лексему с помощью атрибута.lexтокена. Вы должны увидеть, что результаты подобия идентичны токену сходство.
импорт просторный
nlp = spacy.load ("en_core_web_md")
doc1 = nlp («Мне нравится соленый картофель фри и гамбургеры.»)
doc2 = nlp («Фастфуд очень вкусный.»)
print (doc1, "<->", doc2, doc1.similarity (doc2))
french_fries = doc1 [2: 4]
бургеры = doc1 [5]
print (french_fries, «<->», гамбургеры, french_fries.similarity (гамбургеры))
Чего ожидать от результатов схожести
Вычисление оценок схожести может быть полезным во многих ситуациях, но это также важно поддерживать реалистичных ожиданий о том, какую информацию он может предоставлять.Слова могут быть связаны друг с другом по-разному, поэтому один Оценка «подобия» всегда будет сочетанием различных сигналов, и векторов обучение на разных данных может дать очень разные результаты, которые могут не полезно для ваших целей. Вот несколько важных моментов, о которых следует помнить:
- Объективного определения сходства не существует. «Я люблю гамбургеры» и «Я как макароны »аналогичен в зависимости от вашего приложения . Оба говорят о еде предпочтения, что делает их очень похожими, но если вы анализируете упоминания еды, эти предложения довольно не похожи, потому что они говорят о очень разные продукты.
- Сходство значений по умолчанию для объектов
DocиSpanк средним векторов токенов. Это означает, что вектор для «быстрого еда »- это среднее значение векторов для слов« быстро »и« еда », что не является обязательно представитель словосочетания «фаст-фуд». - Усреднение вектора означает, что вектор нескольких токенов нечувствителен к порядок слов. Два документа, выражающие одно и то же значение с несходная формулировка даст более низкий балл схожести, чем два документа которые содержат одни и те же слова, но имеют разные значения.
💡Совет: ознакомьтесь с sense2vec
sense2vec - это библиотека, разработанная
us, который построен на основе spaCy и позволяет вам обучать и запрашивать более интересные и
подробные векторы слов. Он сочетает в себе такие словосочетания, как «фаст-фуд» или «честная игра».
и включает теги части речи и метки объектов. Библиотека также
включает рецепты аннотаций для нашего инструмента аннотации Prodigy
которые позволяют вам оценивать векторы и создавать списки терминологии. Больше подробностей,
ознакомьтесь с нашим сообщением в блоге.К
изучить семантическое сходство всех комментариев Reddit за 2015 и 2019 годы,
см. интерактивную демонстрацию.
Добавление векторов слов
Пользовательские векторы слов можно обучить с помощью ряда библиотек с открытым исходным кодом, таких как
как Gensim, FastText,
или оригинал Томаша Миколова
Реализация Word2vec. Большинство
библиотеки векторных слов выводят удобный для чтения текстовый формат, где каждая строка
состоит из слова, за которым следует его вектор. Для повседневного использования мы хотим
преобразовать векторы в двоичный формат, который загружается быстрее и занимает меньше времени
место на диске.Самый простой способ сделать это - векторы инициализации Утилита командной строки. Это выведет
пустой конвейер spaCy в каталоге / tmp / la_vectors_wiki_lg , что дает вам
доступ к некоторым красивым латинским векторам. Затем вы можете передать путь к каталогу spacy.load или используйте его в [инициализировать] вашей конфигурации, когда вы
обучить модель.
Пример использования
nlp_latin = spacy.load ("/ tmp / la_vectors_wiki_lg")
doc1 = nlp_latin ("Caecilius est in horto")
doc2 = nlp_latin ("servus est in atrio")
doc1.сходство (doc2)
wget https://s3-us-west-1.amazonaws.com/fasttext-vectors/word-vectors-v2/cc.la.300.vec.gz
python -m spacy init vectors en cc. la.300.vec.gz / tmp / la_vectors_wiki_lg Как оптимизировать векторное покрытие¶
Чтобы помочь вам найти хороший баланс между покрытием и использованием памяти, spaCy's Vectors Класс позволяет сопоставить нескольких ключей с тем же строка таблицы. Если вы используете spacy init vectors команда для создания словаря,
об обрезке векторов позаботится автоматически, если вы установите --prune флаг.Вы также можете сделать это вручную, выполнив следующие шаги:
- Начните с пакета векторов слов , который охватывает огромный словарный запас. Для
Например, пакет
en_core_web_lgпредоставляет 300-мерные векторы GloVe для 685 тыс. Терминов английского языка. - Если в вашем словаре есть значения, установленные для атрибута
Lexeme.prob, лексемы будут отсортированы по убыванию вероятности, чтобы определить, какие векторы обрезать. В противном случае лексемы будут отсортированы по порядку вVocab. - Позвоните
Vocab.prune_vectorsс номером векторы, которые вы хотите сохранить.
nlp = spacy.load ("en_core_web_lg")
n_vectors = 105000
удалено_слова = nlp.vocab.prune_vectors (n_vectors)
assert len (nlp.vocab.vectors) <= n_vectors
утверждать nlp.vocab.vectors.n_keys> n_vectors
Vocab.prune_vectors уменьшает вектор тока
таблица на заданное количество уникальных записей и возвращает словарь, содержащий
удаленные слова, сопоставленные с (строка, оценка) кортежа, где строка - это
запись, с которой было сопоставлено удаленное слово, и балла балла сходства между
два слова.
Удаленные слова
{ «Берег»: («берег», 0,732257), «Предосторожность»: («осторожность», 0,4), «безнадежность»: («печаль», 0,742366), «Непрерывный»: («Непрерывный», 0,732549), "Распущенный": ("труп", 0,499432), «биостатистик»: («ученый», 0,339724), "somewheres": ("somewheres", 0,402736), "наблюдение": ("наблюдать", 0.823096), «Уход»: («Уход», 1.0), } В приведенном выше примере вектор для «Берега» был удален и переназначен на вектор «берега», который оценивается примерно на 73% схожим.«Уход» был перенесен на вектор «ухода» идентичен. Если вы используете
init vectorsкоманду, вы можете установить--pruneвозможность легко уменьшать размер векторов при добавлении их в spaCy pipeline:python -m spacy init vectors en la.300d.vec.tgz / tmp / la_vectors_web_md --prune 10000Это создаст пустой конвейер spaCy с векторами для первых 10000 слов в векторах. Все остальные слова в векторах отображаются на ближайший вектор среди оставшихся.
Добавление векторов по отдельности
Атрибут
векторпредставляет собой только для чтения массив numpy или cupy (в зависимости от настроили ли вы spaCy для использования памяти графического процессора) с dtypefloat32. В массив доступен только для чтения, поэтому spaCy может избежать ненужных операций копирования, где возможный. Вы можете изменить векторы черезVocabилиВекторытаблица. С помощьюVocab.set_vector Методчасто самый простой подход если у вас есть векторы в произвольном формате, как вы можете читать в векторах с ваша собственная логика и просто установите их с помощью простого цикла.Этот метод может быть медленнее, чем подходы, которые работают со всей таблицей векторов сразу, но это отличный подход для разовых конверсий, прежде чем вы сэкономите своиnlpобъект на диск.Добавление векторов
из spacy.vocab import Vocab vector_data = { "собака": numpy.random.uniform (-1, 1, (300,)), «кошка»: numpy.random.uniform (-1, 1, (300,)), "оранжевый": numpy.random.uniform (-1, 1, (300,)) } Vocab = Vocab () словом, вектор в vector_data.Предметы(): voiceab.set_vector (слово, вектор)Каждый язык индивидуален и обычно содержит исключений и специальных case , особенно среди самых распространенных слов. Некоторые из этих исключений общие для разных языков, в то время как другие являются полностью конкретными - обычно так В частности, они должны быть жестко запрограммированы. В
langмодуль содержит все данные для конкретного языка, организованы в простые файлы Python. Это упрощает обновление и расширение данных.Данные общего языка в корне каталога содержат правила, которые могут быть обобщены для разных языков - например, правила для базовой пунктуации, смайликов, смайлики и однобуквенные сокращения. Индивидуальные языковые данные в подмодуль содержит правила, относящиеся только к определенному языку. Это также заботится о том, чтобы собрать все компоненты и создать
Подкласс языка- например,АнглийскийилиНемецкий.В Значения определены в языке. Значения по умолчанию.из spacy.lang.en импорт английский из spacy.lang.de импорт немецкий nlp_en = английский () nlp_de = немецкий ()
Имя Описание Стоп-слова
stop_words.pyСписок наиболее распространенных слов языка, которые часто полезно отфильтровать, например «и» или "Я". Соответствующие жетоны вернут Trueдляis_stop.Исключения для токенизатора
tokenizer_exceptions.pyОсобые правила для токенизатора, например такие сокращения, как «не могу», и сокращения с пунктуацией, например «Великобритания». Правила пунктуации
punctuation.pyРегулярные выражения для разделения токенов, например о пунктуации или специальных символах, например смайликах. Включает правила для префиксов, суффиксов и инфиксов. Классы символов
char_classes.pyКлассы символов для использования в регулярных выражениях, например латинские символы, кавычки, дефисы или значки. Лексические атрибуты
lex_attrs.pyПользовательские функции для установки лексических атрибутов токенов, например like_num, который включает специфичные для языка слова, такие как «десять» или «сотня».Итераторы синтаксиса
syntax_iterators.pyФункции, которые вычисляют представления объекта Docна основе его синтаксиса.На данный момент используется только для имен существительных.Lemmatizer
lemmatizer.pyspacy-lookups-dataРеализация пользовательского лемматизатора и таблицы лемматизации. Создание подкласса настраиваемого языка
Если вы хотите настроить несколько компонентов языковых данных или добавить поддержку для пользовательского языка или "диалекта" домена, вы также можете реализовать свой собственный языковой подкласс.Подкласс должен определять два атрибута:
lang(уникальный код языка) иDefaults, определяющие языковые данные. Для обзор доступных атрибутов, которые можно перезаписать, см.Language.Defaultsдокументация.из spacy.lang.en импорт английский класс CustomEnglishDefaults (англ.Defaults): stop_words = set (["заказ", "стоп"]) class CustomEnglish (английский): lang = "custom_en" По умолчанию = CustomEnglishDefaults nlp1 = английский () nlp2 = CustomEnglish () печать (nlp1.lang, [token.is_stop для токена в nlp1 («настраиваемая остановка»)]) print (nlp2.lang, [token.is_stop для токена в nlp2 («настраиваемая остановка»)])Декоратор
@ spacy.registry.languages позволяет зарегистрируйте собственный языковой класс и присвойте ему строковое имя. Это значит, что Вы можете позвонитьspacy.blankсо своим индивидуальным название языка, и даже обучать конвейеры с ним и ссылаться на него в вашем тренировочная конфигурация.Использование конфигурации
После регистрации пользовательского языкового класса с использованием реестра
языков, вы можете сослаться на него в своей тренировочной конфигурации.Этот означает, что spaCy будет обучать ваш конвейер с помощью настраиваемого подкласса.[nlp] lang = "custom_en"Чтобы разрешить
"custom_en"для вашего подкласса, зарегистрированная функция должен быть доступен во время тренировки. Вы можете загрузить файл Python, содержащий код с использованием аргумента--code:python -m spacy train config.cfg --code code.pyРегистрация настраиваемого языка
import spacy от простора.lang.en import English класс CustomEnglishDefaults (англ.Defaults): stop_words = set (["заказ", "стоп"]) @ spacy.registry.languages ("custom_en") класс CustomEnglish (английский): lang = "custom_en" По умолчанию = CustomEnglishDefaults nlp = spacy.blank ("custom_en")Корпусная лингвистика и специализированная лексикография
1Слова не имеют значений, значения имеют слова. Это может показаться очевидным и лежит в основе соссюровского представления о арбитражном суде , но часто это далеко от нашего повседневного отношения к языку.Контекстуалистическая школа мысли, восходящая к Фёрту (1890-1960), воплощает понятие произвольности, заявляя, что значение слова может быть полностью оценено только в контексте, контекст является изначальным. Это создает серьезную проблему при написании словаря, поскольку статья всегда находится вне контекста. Таким образом, значение представляет собой проблему как для лексикографа, так и для пользователя словаря. Для лексикографа значение должно быть перенесено из контекста в словарную статью с использованием метаязыка, достаточно понятного пользователю.Для пользователя задача состоит в том, чтобы передать смысл из словаря в текст, а при письме из словаря в новый контекст.
2 Революция в создании словарей произошла с развитием корпусной лингвистики, основанной на контекстуалистическом взгляде на значение, и ее перенесением в лексикографическую практику через словари COBUILD. Корпоративная лингвистика означала анализ слов в контексте, чтобы продемонстрировать их использование в контексте, что повлекло за собой изменение формата словаря, чтобы обеспечить передачу этого контекстного знания обратно пользователю.Это произвело революцию как в монофонических, так и в двуязычных словарях. Контекстуальный подход теперь трансформирует даже терминологию, поскольку в таком реальном использовании концептуальная жесткость больше не действует.
3 Целью данной статьи является проследить изменения в структуре словарей, вызванные корпусной лингвистикой, и показать, как подходы, первоначально разработанные для общеязыковых справочных словарей, должны быть адаптированы к специализированному использованию, если мы хотим помочь пользователям передать их значения в слова страница.
4Словари бывают разных форм и служат не только для обучения, но и для самых разных целей. « Словарь » - действительно многозначное слово, охватывающее такие разные произведения, как исторические словари, такие как Оксфордский словарь английского языка (OED), и высокоэнциклопедические работы, такие как Оксфордский словарь биохимии и молекулярной биологии (ODBMB). Первый - классический языковой словарь, второй - более энциклопедический по своей природе и посвящен терминологии; их объединяет тенденция представлять слова как отдельные элементы в алфавитном порядке.Это семасиологическое представление может быть не лучшим, но это то, что мы привыкли ожидать от словаря. Единственными исключениями из этого алфавитного правила в нашем повседневном использовании, как правило, являются ономасиологически организованные тезаурусы, такие как тезаурус Роже.
5 Большое разнообразие типов словарей означает, что дать точное определение концепции далеко не просто, хотя мы все знаем, что мы «подразумеваем» под словарем, и можем распознать один, когда видим его. Согласно Oxford Advanced Learners Dictionary (OALD), словарь составляет:
( a ) книга, в которой слова определенного языка представлены в алфавитном порядке и объясняются их значения или переводятся на другой язык.( b ) похожая книга, в которой объясняются термины определенного предмета. (OALD)
6 Фактически, OALD дает нам три определения. И OED, и OALD попадают в категорию «а», поскольку они стремятся объяснить значения слов, в то время как ODBMD явно относится к категории «b». Категория «а», однако, делится на две части, поскольку у нас есть как одноязычные словари, как в моих примерах, так и двух- или многоязычные словари, такие как Roberts and Collins Senior (RCS).
7 Чрезвычайно широкое определение OALD оставляет много недосказанного, но, поскольку все мы «знаем», как выглядит словарь, это обычно не считается проблемой. К сожалению, как в общем, так и в металексикографическом плане могут быть скрытые проблемы. Обычные пользователи неизменно не знают, как составляются словари и к какой аудитории они обращаются. Они также имеют тенденцию к "фиксированному" отношению к значению слов, из-за чего они забывают или игнорируют эволюцию языка.Эти факторы могут побудить наших студентов полагаться на словари, которые они находят дома, будь то одно- или двуязычные, которые безнадежно устарели и которые заставляют их использовать общие языковые значения в специализированных контекстах, часто с весьма забавными результатами. Эти проблемы часто возникают из-за незнания типов словарей и их использования, что широко распространено даже среди учителей иностранных языков. Очевидно, что для лексикографа критически важно знать типологию словарей; Подробный анализ проблемы с точки зрения металексикографа можно найти в Béjoint (1994 2000), обязательное чтение для всех, кто интересуется лексикографом или преподаванием языков.Здесь нет необходимости вдаваться в подробности.
8Разница между моно- и двуязычными словарями очевидна, и хотя недостатки использования последних хорошо известны при обучении языкам, мы не будем их здесь рассматривать. Однако следует отметить, что двуязычный словарь, как и его одноязычный аналог, также претерпел революционные изменения с появлением компьютера. Сью Аткинс, один из лидеров модернизации двуязычных словарей, подробно обсудила это (Аткинс, 2002).Здесь мы имеем дело с одноязычными словарями, как общими, так и специализированными.
9 Если мы возьмем определение одноязычного словаря, данное в OALD, мы упустим важный момент. Отец английских словарей, OED, ведет свою историю от словаря Джонсона 1755 года. Это словари, которые не являются полностью предписывающими, но являются нормативными. Что наиболее важно, OED превратился в исторический словарь, посвященный показу эволюции английского языка, в основном через литературное использование.Его цели выходят далеко за рамки простого определения значений слов. С другой стороны, меньший COD является справочным изданием, но, как и большинство более коротких произведений, в значительной степени зависит от более крупного словаря, в данном случае OED. Точно так же, если мы найдем определение слова «словарь» в COD и сравним его с определением OALD, мы обнаружим, что они почти идентичны. Опять же, OALD полагается на своего старшего брата; просто начинать словарь с нуля - это слишком трудоемко и дорого. Тем не менее, хотя определения могут быть похожими, COD и OALD принципиально отличаются.COD адресован носителям языка, которые обычно обращаются к словарям, чтобы проверить написание или проверить значения слов, в которых они не уверены, поэтому он предназначен в основном для пассивного использования. Словари для учащихся, такие как OALD, изначально были предназначены для людей, не являющихся носителями языка, и стремились объединить две роли: декодирование и кодирование. Аспект декодирования - пассивный, когда учащиеся ищут непонятные слова, чтобы выяснить их значение в контексте. Аспект кодирования выходит далеко за рамки простого написания и должен позволять автору писать понятный язык, что влечет за собой предоставление примеров использования и тщательно закодированной грамматической информации.
10 В отличие от общеязыковых словарей, работы, посвященные специализированному использованию, обычно основаны на терминологии и представлены в двух формах: многоязычная терминология, которая в основном адресована переводчику и не является предметом данного исследования, и одноязычные энциклопедические словари, посвященные данной теме. специалистов и которые представляют собой важную основу для обсуждения возможного специализированного словаря для учащихся. Однако подход таких словарей полностью отличается от подхода словаря учащегося.Классическая система определений, используемая в большинстве общих языковых работ, стремится дать преднамеренный анализ слова, то есть дает отличительные черты концепции, тогда как энциклопедические статьи выходят далеко за рамки этого, предоставляя подробную экстенсиональную информацию. Такие словари, как ODBMB, предназначены для исправления и объяснения терминов, они предназначены только для пользователей, владеющих носителями языка, и не пытаются показать или объяснить их использование. Такие словари по самой своей сути являются предписаниями и не предназначены для обучения тому, как использовать эти слова в реальных жизненных ситуациях.
11 Появление современных вычислений произвело революцию в создании словарей, предоставив не только базы данных, позволяющие более эффективно обрабатывать данные, но и доступ к новым формам данных и, в частности, для словарей учащихся, новым способам представления этих данных. Революционные изменения в этих словарях кодирования составляют основной упор в этом исследовании, но прежде чем взглянуть на природу революции, мы должны рассмотреть взаимосвязь между обучением и лексикографией.
12 Преподавание и словари всегда были неразрывно связаны, от англо-французского словаря Холибанда 1593 года до Oxford Advanced Learner's Dictionary Хорнби, впервые опубликованного в 1948 году. Историю подъема ELT рассказывает Ховатт (1984). и в нем мы видим, что прогресс в педагогической практике, особенно с середины войны, идет бок о бок с достижениями в создании словарей. Появление словаря ELT сопровождалось выбором и объяснением основного языка, необходимого для изучающего второй язык.
13 Потребность в контролируемом словарном запасе для читателей стала очевидной в 1930-х годах и привела к работе Уэста и его знаменитому списку английских слов категории общего обслуживания , опубликованному в 1953 году (Howatt 1984). Работа Хорнби вышла за рамки списков и потребностей учеников более низкого уровня в создании полноценного словаря для продвинутых учеников. Словарь Хорнби был не просто уменьшенной версией более крупного труда, а специально созданным, составленным с учетом потребностей тех, для кого не родной язык.OALD должен был содержать не только отдельные слова, но идиомы и словосочетания, плод долгого сотрудничества Хорнби с Палмером в Японии (Cowie 1998). Благодаря OALD у нас есть словарь, адаптированный к потребностям языкового производства, с объяснениями и примерами формирования слов. В более поздних изданиях использовалась грамматическая информация, выявленная в Quirk et al. , основанном на корпусе Grammar of Contemporary English (Quirk et al .1985).
14Словарь Хорнби положил начало процессу, который привел к тому, что на рынке появилось множество словарей для учащихся, которые ценятся как для продвинутых учеников, так и для носителей языка.В недавнем исследовании использования словарей пользователями второго языка в США МакКрири и Долезал (1999) обнаружили, что использование словарей учащихся приводит к гораздо лучшим результатам, чем стандартные словари американских колледжей, и что даже американская контрольная группа носителей языка принесла бы пользу. из аналогичных работ, чтобы избежать стандартных ошибок использования словарей. Затем Маккрири (2002) пошел дальше, проведя углубленное исследование студентов американских университетов, которое показало, что студенты использовали плохие стратегии использования словаря, с плохими результатами по трудному словарю.При наличии стандартных словарей колледжа и словарей учащихся было обнаружено, что пользователи последних заметно превосходят пользователей первых. Словарь учащегося ни в коем случае не должен рассматриваться исключительно для неродных пользователей.
15 В этих словарях учащихся смыслы слов выражаются откровенно контекстуалистично, слова приобретают значение только в контексте, и поэтому словарь должен стремиться показать эти контексты, показывая реальное использование. Оставалась проблема, какие слова включить в словарь.Списки слов, какими бы хорошими они ни были, они субъективны. Хорнби использовал COD в качестве основы OALD, исключив слова, которые он считал бесполезными для студентов-иностранцев. Этот выбор был основан на его интуиции и огромном опыте преподавателя языка, исследователя и лексикографа. Хотя нельзя недооценивать знания квалифицированного лексикографа, получаемый в результате выбор, как слов, так и порядка значений, неизбежно субъективен. Это препятствие можно было преодолеть с помощью компьютеров и электронных корпусов.
16Компьютеры оказали большое влияние на создание словарей, карточные файлы традиционной лексикографии исчезли в базах данных, которые позволяют легко хранить, передавать данные и, прежде всего, делать перекрестные ссылки. Использование моделей хранения на основе SGML упростило переформатирование существующих материалов, просто изменив таблицу стилей. Появление Интернета и компакт-дисков означало, что разрабатываются новые форматы, обеспечивающие быстрый доступ пользователей к данным.Несмотря на критику, что многие электронные словари являются только бумажными в электронном формате, онлайн-словари и словари на компакт-дисках предлагают много практических преимуществ по сравнению со своими бумажными аналогами. В свою очередь, вычислениям помогла лексикография в том смысле, что исследователи в области обработки естественного языка (НЛП) получили доступ к электронным материалам для анализа (Fontenelle 2002). Этот обмен, в свою очередь, будет полезен как для людей, так и для машин.
17Эта компьютерная технология была принята во всех крупных лексикографических проектах, но в некоторых областях произошла еще большая революция в природе исходных данных.Корпусная лингвистика изменила большую часть лексикографической практики, предоставив доступ к огромным объемам достоверных данных. Первыми, кто осознал этот потенциал, был Джон Синклер и команда COBUILD из Университета Бирмингема.
18 Как мы видели, до недавнего времени составление словарей полагалось на интуицию обученных лексикографов в анализе материала и написании определений. Заглавные слова были выбраны на основе предполагаемой важности, и многозначность рассматривалась таким же образом.Даже словари для учащихся со временем выросли без четких критериев включения или исключения слов. Решение COBUILD выделено жирным шрифтом; команда создала бы словарь с нуля, основываясь не на картах файлов, а на большом электронном корпусе. Следует отметить, что отныне слово корпус , множественное число корпус , будет использоваться только для обозначения больших электронных корпусов, собранных из очень большого количества аутентичного текста
.19 История COBUILD подробно описана в Looking Up (Sinclair 1987). Основные моменты, которые мы рассматриваем здесь, - это критерии выбора заглавного слова, анализ значения и представление словарных статей.
20 Первой революцией стало создание справочного корпуса. Корпус в том смысле, который используется в корпусной лингвистике, - это большая коллекция аутентичных текстов, которые были отобраны и организованы в соответствии с точными лингвистическими критериями (Sinclair 1996). Критерии для разработки справочных корпусов в настоящее время хорошо установлены (Аткинс и др. 1992, Бибер 1993.), и все больше и больше становится доступным на основных языках мира. В Великобритании оригинальный корпус COBUILD превратился в монументальный Bank of English и продолжает расширяться.Британский национальный корпус , созданный консорциумом издателей словарей, зарекомендовал себя в качестве справочного материала в исследованиях корпусов как полностью аннотированный корпус. Таким образом, первая революция была корпусом, следующей - эксплуатацией.
21Включение заглавных слов - большая проблема для составителей словарей: что включить, что исключить. Вопрос со скучной регулярностью обсуждается на французском телевидении, когда выходит новый словарь, с жаркими дискуссиями о том, какие сленговые или модные слова «вошли» в язык.На самом деле их «вход» в словарь часто является во многом субъективным вопросом; Команда COBUILD хотела не субъективности, а отражения реальности. В результате выбор слова будет основываться на частоте корпуса, а это означает, что использование слова можно отслеживать с течением времени.
22 Следующим этапом было переписывание определений, основанное на совокупности свидетельств, а не на предыдущих словарях. Этот анализ проводился не только для лексических слов, но и для «пустых» грамматических слов.Описывать определитель «the» как простое слово - это явно нонсенс, необходимо было показать, как оно использовалось в контексте. После того, как определения, написанные многозначными словами, были разделены на «смыслы», необходимо упорядочить отдельные записи. Решение заключалось в том, чтобы упорядочить их не по части речевой категории или интуитивным представлениям о центральном значении смысла, а по частоте использования. Эта форма упорядочения основана на представлении о том, что смысл и синтаксис тесно связаны, и это понятие побудило Синклера заявить, что мы должны выйти за рамки лексико-грамматики и перейти к лексической грамматике, в ситуации, когда два уровня становятся одним (Sinclair 2002).Упорядочивание по смыслу приводит к проблемам представления, которые преодолеваются в словарях COBUILD боковым столбцом, дающим грамматическую и семантическую информацию, связанную с каждым «смыслом».
23 Никто не утверждает, что система COBUILD идеальна, что у каждого издателя словарей свой собственный стиль, а словари в значительной степени соответствуют личным предпочтениям отдельных пользователей, но революция - это факт лексикографической жизни, и никакой словарь для учащихся не может игнорировать революцию COBUILD.К сожалению, несмотря на то, что появление словарей, способных лучше учиться, повлияло на студентов, изучающих английский как язык, одноязычные словари все еще не вошли в мир ESP.
24Better словари не решили все наши проблемы. Проблема многих студентов ESP, особенно изучающих естественные науки, заключается в том, что они не готовы покупать словари; в лучшем случае они будут использовать двуязычный словарь и попадут во все представленные ловушки ложных друзей.Учитывая, что МакКрири (McCreary, 2002) показал, что носители языка плохо владеют словарем, можно предположить, что не для носителей языка будет не лучше, особенно если приведенные примеры не из их области знаний, поскольку это требует передачи смысла. от общего использования к специализированному контексту. Здесь может быть интересно увидеть, какие проблемы обнаружил МакКрири. Подтверждены четыре основных ошибочных стратегии:
Стратегия «Kidrule» .- «учащиеся предполагают, что тестируемое слово, слово входа, семантически эквивалентно одному из самых простых слов в определении». (, цит. : 194)
Стратегия «Выбрать первое определение» .
Правило «поверхностного родства» (стратегия создания малапропизма). - «Столкнувшись с« трудным словом », подумайте о более знакомом слове (которое может не обязательно присутствовать в статье), которое на первый взгляд кажется похожим на тестовое слово…».(, цит. : 196)
Выберите самый сексуальный смысл - «… перепрыгните через скучные записи и попытайтесь вставить сексуальный смысл в тестовое слово, используемое в предложении». (, цит. : 199)
25 Все эти стратегии были отмечены другими исследователями, причем вторая из них является наиболее распространенной. Источник проблемы очевиден; как бы мы ни старались, словарь может представлять только деконтекстуализированное значение, именно пользователь должен управлять передачей значения из источника словаря в реальный текст.Отсюда следует, что чем дальше мы отходим от контекста, который пользователь желает кодировать или декодировать, тем выше риск недопонимания. Могут быть предложены два решения; обучение лучшим словарным навыкам и подготовка более контекстно-релевантных словарей.
26Улучшение словарных навыков - стратегия, принятая Кампоем Кубильо (2002). Работая со студентами-химиками, она заставила их написать собственные словари. Это служило двум целям; это позволило студентам ознакомиться со словарями, а исследователям - лучше понять, как учащиеся используют словари.Используя согласование в классе, можно было бы научить студентов строить небольшие личные словари, овладев реальным языком. Однако, хотя это может быть полезно в небольших масштабах и имело бы педагогическую ценность, студенты ESP не являются лексикографами и не обладают ни временем, ни навыками для построения какой-либо лексики, кроме базовой. Многие студенты, в том числе изучающие языковые науки, испытывают большие трудности с адаптацией к анализу конкордантности, который, в конце концов, является очень специфическим навыком.Очевидно, что с точки зрения построения настоящего словаря мяч остается в лагере лексикографа.
27Norman (2002) изучил существующие специализированные словари и обнаружил, что они редко основаны на корпусах, обычно пишутся полевыми специалистами, не имеющими лексикографической подготовки, и являются строго предписывающими. Эти работы носят энциклопедический характер и носят чисто терминологический характер. Как указывает Норман, проблемы часто возникают из-за полутехнических слов, которые часто очень многозначны, его решение - требование большей прозрачности в рецептах и более широкое использование корпусов при определении значений.Хотя это может помочь при декодировании, для большинства авторов NN основная проблема связана с кодированием.
28 В Williams (2002) я указал, что мы не можем просто полагаться на то, что лексикографы изменят свои методы работы, тем более что большинство специализированных словарей пишутся неязыковыми специалистами по рецептам. Единственное решение - те из нас, кто работает в ESP / EAP, используют потенциал корпусной лингвистики для создания собственных словарей. Экспериментальный словарь Parasitic Plant Dictionary, PPD, является попыткой сделать именно это.
29Информация, предоставленная корпусами, привела к необходимости переоценки содержания словаря, порядка и представления смыслов с их грамматическим и лексическим контекстом. Как отметил Ранделл (1998), появление больших электронных корпусов изменило наши взгляды на исходные материалы не только с точки зрения количества данных, но и их качества. Огромный размер современных справочных корпусов привел к разработке новых инструментов, предназначенных для помощи в обработке таких больших объемов данных.Однако инструменты не заменяют лексикографов и их знание языка, напротив, они предоставляют средства для контроля данных, оставляя лексикографу время для применения его опыта в разработке более значимых и точных записей (Rundell 2002). .
30 Хотя вычислительная лексикография стала областью, в которой изобилуют сложные процедуры (справочную информацию см. В Ooi 1998), основным инструментом, используемым во всей лексикографии, основанной на корпусе, остается конкордансер.Однако слишком легко взглянуть на линии соответствия и забыть о философском подходе, на котором основан такой инструмент.
31Одно из важных понятий - понятие репрезентативности. Хотя это достигается за счет размера и тщательного отбора в справочных корпусах, вопрос гораздо сложнее в корпусах EAP / ESP (Williams 1999, 2002b). Любой проект корпуса должен учитывать социолингвистические критерии; полагаться на простой статистический отбор просто сделало бы его массивом данных.Хотя репрезентативность остается спорным вопросом, мы должны, по крайней мере, быть в состоянии оправдать наш контент и, следовательно, выводы, сделанные на его основе. Помня об этом аспекте, мы должны рассмотреть, что на самом деле показывают линии соответствия. Согласно Tognini Bonelli (2001), линии соответствия из правильно построенного корпуса преодолевают разделение Saussurean langue / parole . Отдельные строки явно синтагматичны, представляя la parole , отдельные примеры использования, в то время как парадигматическое целое дает нам la langue , коллективное знание языка, представляющее живое языковое сообщество.Таким образом, то, что мы пытаемся зафиксировать в словаре, - это уже не какое-то умозрительное понятие , означающее и , означающее , а нечто прочно закрепленное в реальности использования. В такой парадигме означает, что должно быть реализовано в контексте.
32 В лексикографии корпуса мы должны принять, что означает и , означающие , должны четко различаться. Sense охватывает множество понятий, включая энциклопедические и семантические. Смысл - это, по сути, концептуальное понятие, и многое из того, что важно в энциклопедической статье, не будет найдено в корпусе, поскольку он опирается на более широкие знания о мире. Однако лингвистические средства, с помощью которых передаются эти смыслы, могут быть рассмотрены в корпусе и сгруппированы в словарных статьях. Это поможет пользователю декодировать, понимать, но не обязательно кодировать. Семантический анализ может помочь в кодировании, но он применяет человеческую категоризацию, которую пользователь может не сразу распознать.Семантический подход можно увидеть в WordNet (
), в котором слова анализируются в иерархии. Чувства четко разграничены, но ученик может быть не в этом мудр. Именно на примере таких словарей, как COBUILD, делается попытка преодолеть пропасть между смыслом и значениями. 33 В то время как смысл является абстрактным понятием, означает, что к можно подойти только через контекст. Это Фиртовский подход к языку, который лежит в основе всех словарей учащихся, значение можно увидеть только через создание экземпляров, и каждый экземпляр уникален.Отсюда возникает загадка, которую каждый словарь должен стремиться разрешить: если значение контекстно, то словарь - нет. Как мы можем реализовать этот перенос значения из конкретного контекста в деконтекстуализированный словарь слов, а затем обратно в новый конкретизированный смысл? Ответ был показан для COBUILD, а теперь и для всех словарей учащихся, но как насчет специализированного использования?
34Если мы признаем, что строки соответствия могут преодолеть разделение на язык и пароль, и если мы согласимся с тем, что согласование может помочь нам найти смысл посредством анализа значения, тогда у нас будут инструменты для создания наших собственных словарей.
35 На рынке много конкордансеров, некоторые бесплатные, некоторые коммерческие, но ни один из них не дорогой. Созданный Майком Скоттом, WordSmith Tools , вероятно, наиболее широко используется лексикографами, работающими в среде Windows. Теперь доступная в четвертой версии, WordSmith Tools - это гораздо больше, чем просто конкордансер, предлагающий широкий спектр опций для лексического анализа, включая возможность обработки морфосинтаксического анализа (часть речи - POS) и инициативы по кодированию текста (TEI). совместимые корпуса.В этом примере мы рассмотрим только согласованные и коллокационные профили.
36Первым этапом, очевидно, является создание корпуса текстов. Критерии проектирования имеют первостепенное значение, поскольку корпус ad hoc может привести только к результатам ad hoc . В то время как словари, основанные на крупных справочных корпусах, могут претендовать на репрезентативность, ключевое слово в специализированных корпусах - это обоснование, ясное понимание того, что вошло в корпус и почему (Williams 2002b). Следующий этап - подбор заглавных слов.Это во многом зависит от воспринимаемой цели словаря, если цель состоит в том, чтобы показать термины в контексте, тогда потребуется ручная или автоматическая система выделения терминов, в случае PPD более широкая лексическая база ищется с использованием коллокационных сетей. (Williams 2001) как средство снижения субъективности и избежания чрезмерной зависимости от простой частоты, которая исключает большинство специализированных элементов. Какой бы метод ни использовался, наиболее важным шагом является использование конкордансера для извлечения индивидуальных значений слова.Это будет продемонстрировано на примере « control ».
37 В Williams 2002 я приводил доводы в пользу необходимости специализированных словарей для учащихся, чтобы позволить пользователям визуализировать чувства в среде, близкой к их собственной рабочей среде, поскольку обобщенные чувства, найденные в словарях, не предоставляют примеров, которые позволили бы этим пользователям легко создавать экземпляры своих значений в их рабочем контексте. Проблема с терминологиями состоит в том, что они по существу обращаются к переводчику, а не к предметному специалисту, специалисты «знают» их терминологию и не обязательно хотят следовать предписывающим советам, но создают новые контекстуализированные значения.Следовательно, если мы попытаемся войти в поле с предписывающим подходом или даже описательным подходом, мы войдем в потенциальное минное поле, ответ состоит в том, чтобы создать словарь, чтобы показать контекстуализированное использование, специализированный условно-досрочное освобождение .
38 Проблему можно проиллюстрировать словом control. Это полутехническое слово не охватывается каким-либо смыслом, данным в COBUILD онлайн, и хотя его основное техническое использование обозначено (техн.) в OALD 5, определение адресовано обычному пользователю.Если мы посмотрим на семантически организованную базу данных как WordNet (http://cogsci.princeton.edu/ ~ wn /), мы обнаружим 11 смыслов, из которых два, значения 1 и 4, явно могут иметь отношение к техническому контексту. Однако Wordnet не предоставляет синтаксической или коллокационной информации. Возвращаясь к нашему корпусу, первым шагом в поиске смысла в контексте будет построение согласования для этого узлового слова.
39 Совершенно независимо от сортировки слева и справа, которая выявляет синтагматические единицы, очевидным следующим шагом в устранении неоднозначности является сортировка по частям речи.Если значение связано с синтаксисом, то глаголы и существительные будут давать разные смысловые образцы. После того, как это базовое разделение выполнено, можно проводить более точный анализ. Для существительного следующим этапом может быть рассмотрение форм единственного и множественного числа по отдельности, поскольку они могут генерировать очень разные значения, например, в случае контроля смысл « используется для сравнения » преимущественно единственного числа. Эта сортировка смыслов - постепенный процесс, в котором синтаксический выбор помогает определить выбор значения, а - наоборот, .Это лексикография, управляемая корпусом (Williams 2002a), в которой анализом руководит контент и возникающие шаблоны, а не интуиция компилятора. По мере создания смысловых шаблонов мы также должны искать ограниченные словосочетания, поскольку нет смысла создавать словарь кодирования, если они отсутствуют. WordSmith предоставляет коллокационные профили, которые являются ценным помощником в построении шаблонов и устранении неоднозначности слов, представляя шаблоны взаимодействия вокруг узла в виде сортируемой таблицы.Шаблоны фраз также можно легко увидеть, используя средство кластера.
40 Прорабатывая определение для control из PPD (приложение 1), мы можем ясно увидеть, как производятся смысловые деления. Сначала идут формы глагола и существительного. Затем коллокационный профиль помогает разбить глагольную форму на два основных смысла, встречающихся в этом специализированном контексте. Примеры показывают возникшие закономерности в смысле 1. X управляет Y через Z , предлог является важным ключом в определении этого смысла, когда его нет X по-прежнему контролирует Y.Во втором смысле контроль осуществляется над процессом, рост в примере. Настоящее причастие , управляющее , очевидно, имеет смысл, связанный со смыслом 1, поэтому он дается здесь. Образец другой, но опять же различению смысла помогает наличие предлога. Тот же процесс применяется к формам существительных, каждый смысл проявляется в своих фразовых образцах и словосочетаниях. Эти шаблоны необходимы для устранения неоднозначности смысла слов и, в свою очередь, необходимы в словаре, чтобы помочь в процессе кодирования.Никаких ошеломляющих новых смыслов здесь не обнаруживается, они уже выделены стандартной лексикографической интуицией, не в этом дело. Что было достигнуто, так это показать чувства, которые действительно возникают в данной среде, по частоте использования и в контексте типа, который кто-то, работающий в этой области, мог бы понять и который необходимо воспроизвести. Приведенные определения минимальны, это сделано намеренно. Цель - показать, как можно использовать слова, а не увязнуть в предписывающих определениях.Стандартизация терминов полезна, но согласование значений осуществляется через контексты.
41Организация записи производится с учетом электронного формата. Большинство словарей предназначены для печати, онлайн-версия или версия на компакт-диске, как правило, соответствуют печатному макету. Печатные словари дороги в производстве и не могут быстро развиваться без новых редакций, поэтому логичным выбором для словарей ESP / EAP для учащихся в быстро меняющейся области является веб-словарь с использованием гиперссылок.Гиперссылка означает, что предварительная запись может использоваться для отображения основных подразделов записи. В каждом смысле мы получаем краткое определение, за которым следуют примеры использования, словосочетания и фразовые паттерны. Записи могут быть более или менее длинными, преимущество электронных словарей состоит в том, что ограничения, накладываемые бумажным представлением, больше не выполняются, а это означает, что можно получить гораздо более мелкие детали. Процесс длительный, но стимулирующий. Очевидно, что такие мелкие детали не могут быть достигнуты в коммерческих словарях, где время имеет значение; однако в мире ESP / EAP нам не нужно иметь в виду такие соображения.Однако даже для нефинансируемых специализированных корпусов более продвинутые методы анализа постепенно ускорят выполнение задачи.
42 Как заметил Рунделл (2002), компьютеры никогда не заменят человека, но в практической лексикографии они могут значительно помочь. Продвижение вперед в смысле извлечения означает не только улучшение инструментов, но и самих корпусов. Очевидно, что существует потребность в четко продуманных критериях отбора, как внутренних, так и внешних (Williams, 2002b), и мы, безусловно, выиграем от лучшей аннотации корпуса.
43 Маркировка частей речи (POS) теперь является довольно стандартным процессом, хотя и относительно трудоемким. Основная проблема любого морфосинтаксического анализа - ошибка из-за недостатка обучения; инструменты необходимо «научить» работать в конкретной текстовой среде. После завершения обучения анализ выполняется быстро, и его можно ускорить только по мере появления более сложных инструментов. Однако, хотя время, потраченное на анализ, может быть оправдано созданием эталонных корпусов, которые имеют длительный срок хранения, то же самое может не относиться к специализированным корпусам, которые в соответствии с развитием науки требуют регулярного обновления.Есть еще одна опасность, заключающаяся в том, что при маркировке POS-тегов человек дистанцируется от текста путем введения правил, которые могут затруднить анализ. Как известно всем лингвистам, части речи являются чисто артефактами и не соответствуют реальным сущностям, действительным во всех случаях, особенно в том, что касается предлогов и союзов. Тем не менее, POS-теги предлагают множество преимуществ, в том числе идентификацию синтаксических шаблонов, которые иначе были бы скрыты массой данных. В свою очередь, POS-теги в сочетании с разметкой текста могут облегчить трудную задачу лексикографа по поиску лексических шаблонов и уменьшению неоднозначности, вызванной многозначностью.
44WordSketch (Kilgarriff & Rundell 2002) является частью рабочей среды лексикографа, которая была разработана для работы в Британском национальном корпусе, то есть полностью маркированном POS корпусе, совместимом с TEI. Пока технология доступна любому лингвисту корпуса, следующий этап идет дальше - частичный синтаксический анализ корпуса.
45 Аннотация части речи просто называет слова, но не сообщает нам, какую синтаксическую роль они играют.Сейчас полностью признано, что значение и синтаксис полностью взаимосвязаны (Sinclair 2002), что должно означать, что при анализе лексики в контексте нам необходимо видеть синтаксические шаблоны. Парсинг пытается добавить эту информацию в корпус.
46 Полный синтаксический анализ сопряжен с трудностями, учитывая чрезвычайную сложность реальных данных в отличие от чистоты грамматической модели. Это также означает принятие грамматической модели, а одна модель не подходит всем. Ответ в проекте WordSketch заключается в частичном синтаксическом анализе путем аннотирования серии шаблонов на аннотированном и лемматизированном корпусе.Первоначальный проект предусматривал 26 шаблонов, в которые может входить ключевое слово (Kilgarriff & Tugwell 2001). Чтобы увидеть, что делает Wordsketch, мы можем взять пример control .
47Wordsketches создаются онлайн (см. Http://wasps.itri.bton.ac.uk для демонстрации). Инструмент предлагает ряд параметров поиска, два из которых нас интересуют - это слово для поиска и часть речи. С помощью контрольного слова для поиска мы находим выбор между тремя вариантами; существительное, глагол, прилагательное.Для каждой части речи строится набросок с указанием соответствующих закономерностей. Например, control как существительное (приложение 2.) связано с предложными фразами как PP_of_situation или PP_over_position . Ситуация - это одно из списка слов, связанных с этим конкретным шаблоном. Аналогично, control может быть модификатором, как в remote, tight или strict, , или быть модифицированным, как в control samples . Словосочетания глаголов показаны как object_of .Для каждого шаблона соответствующие слова показаны с их частотой, щелчок по словам вызывает соответствие. Работа с шаблонами позволяет нам изолировать значения, связывая лексическое и синтаксическое окружение по отношению к другим шаблонам, например шаблон noun_modifier_pest связывает с PP_obj_method_of , чтобы дать методов борьбы с вредителями . Тот же процесс можно увидеть с образцами глаголов, которые раскрывают такие отношения, как предложная фраза, подлежащее, объект или модификатор. Модификатор даст наречные словосочетания, такие как строго контролируемый . Следует иметь в виду, что корпус был лемматизирован, поэтому могут быть представлены все формы глагола или существительного.
48 Это очень сложная система, построенная с использованием эталонного корпуса, и поэтому построитель корпуса EASP / EAP не под силу. Однако корпусная лингвистика - это сравнение, поэтому перекрестная проверка различных источников является ключом к пониманию.Результаты Wordsketch можно проверить на самом BNC, чтобы точно увидеть, в каком жанре используется эта формула, значения также можно проверить, посмотрев на WordNet . Шаблоны, найденные в специализированном корпусе, можно сверять с Wordsketch и наоборот.
49 Однако чрезмерное использование технологий чревато опасностями. Компьютеры не могут заменить лексикографа, но неопытного исследователя наука легко может ослепить.Wordsketch и другие проекты по устранению неоднозначности слов предназначены для ускорения работы лексикографа, но скорость также может означать, что интересный материал упускается из виду. Использование таких инструментов означает признание валидности не только части речевой разметки, но и грамматического анализа. Результатом является основанный на корпусе анализ, который по существу подтверждает выводы, в исследованиях это должно быть связано с основанным на корпусе подходом, создающим шаблоны и смыслы путем критического наблюдения. Ни один подход не идеален, у всех есть свои преимущества и недостатки, лингвист должен просто знать о них.
50 Этот текст призван показать возможности корпусной лексикографии при построении специализированных словарей для учащихся на примере Parastic Plant Dictionary . Могут спросить, почему экспериментальный словарь паразитарных растений не существует в виде нескольких страниц на веб-сайте? Этот вопрос нужно задать, поскольку мне может показаться, что я не практикую то, что проповедую, ответ, конечно же, - время и академический статус.
51Начнем с последнего.Много лет назад, когда я излагал тезис, мне сказали, что словарь - это не диссертация. Это верно, но в результате во многих случаях мы вынуждены говорить о вещах, которые на самом деле не делаем. Словарная критика может быть темой диссертации и основой академической карьеры: написание словарей - нет. Это, конечно, приводит к вопросу о времени, поскольку любой молодой исследователь, независимо от его физического возраста, попадает в ловушку академической беговой дорожки, где учитываются только теоретические работы.Если мы хотим улучшить преподавание языка в ESP / EAP с помощью специализированной лексикографии, этой ситуации должен быть положен конец, на реальные вопросы нужны реальные, а не теоретические ответы, и это будет происходить только путем проб и ошибок. Очевидно, что создание специализированных словарей для учащихся никогда по-настоящему не заинтересует крупные компании-словники, поскольку они могут работать только с большими рыночными ресурсами; ответ должен лежать в другом месте. В обучении ESP / EAP серьезные изменения произошли благодаря сочетанию некоммерческих теоретических и практических исследований, а также сотрудничеству между учителями на местах.Конечно, то же самое можно сделать и в лексикографии. Метафора может быть интересным предметом диссертации, но какой бы захватывающей ни была когнитивная модель, которую мы принимаем, она не даст быстрых результатов, в отличие от изменений в лексикографической практике. Это не для того, чтобы отбросить метафоры или любое другое теоретическое исследование, а для того, чтобы потребовать, чтобы практические исследования получили равный статус.
52 В заключение я обращаюсь к отцу современной лексикографии д-ру Сэмюэлю Джонсону с его знаменитым определением лексикографа:
Лексикограф: составитель словарей, безобидный труженик.
53Практическая лексикография - очень трудоемкое времяпрепровождение, но, учитывая легкий доступ к компьютерам и рост корпусных исследований в исследованиях ESP / EAP, нет причин, по которым ее нельзя было бы разработать. Это тяжелая работа, это не сексуально, но ценность результатов с точки зрения обучения может быть неизмеримой.
Я хочу выразить благодарность всем членам лексикографического сообщества, особенно членам правления EURALEX, которые помогли, поддерживая и критикуя.В частности, я хочу поблагодарить Адама Килгарриффа и Дэвида Тагвелла из ITRI, Университет Брайтона, за предоставленный мне доступ к полной базе данных WordSketch. Тщательное вычитывание анонимных рецензентов привело к прояснению некоторых моментов и устранению некоторых идиотий. Благодарю их за терпение.
GitHub - spencermountain / компромисс: скромная обработка естественного языка
компромисс
скромная обработка естественного языка
Разве не странно, как мы можем писать текст , но не разбирать его?
npm установить компромисс↬ ᔐᖜ ↬- и как мы не можем получить информацию обратно ? ⇬
как будто мы договорились, чтотекст - это тупик.
и знания в нем
действительно не должны использоваться..match ():
интерпретировать и сопоставить текст:
пусть doc = nlp (весь роман) doc.match ('Прилагательное времени'). text () // "в самый последний момент?"if (doc.has ('simon говорит #Verb') === false) { вернуть ноль }. Глаголы ():
спрягать и отрицать глаголы в любом времени:
let doc = nlp ('она продает ракушки на берегу моря.') doc.verbs (). toPastTense () doc.text () // «она продавала ракушки на берегу моря».. Существительные ():
игра между формами множественного, единственного и притяжательного числа:
let doc = nlp ('фиолетовый динозавр') doc.nouns (). toPlural () doc.text () // 'фиолетовые динозавры'. Номера ():
интерпретировать простые текстовые числа
nlp.extend (требуется ('компромиссные числа')) let doc = nlp ('девяносто пять тысяч пятьдесят два') doc.numbers (). add (2) doc.text () // 'девяносто пять тысяч пятьдесят четыре'.тем ():
названия / места / организации, tldr:
пусть doc = nlp (buddyHolly) doc.people (). если ('Мэри'). json () // [{текст: 'Мэри Тайлер Мур'}] пусть doc = nlp (freshPrince) doc.places (). first (). text () // 'Западная Филлидельфия' doc = nlp ('опера о визите Ричарда Никсона в Китай') doc.topics (). json () // [ // {текст: 'richard nixon'}, // {текст: 'китай'} //]. Контрактов ():
обрабатывать неявные термины:
let doc = nlp ("мы не собираемся это принимать, нет, мы не собираемся это делать.") // соответствие неявному термину doc.has ('going') // правда // преобразовываем doc.contractions (). expand () dox.text () // 'мы не собираемся брать, нет, мы не собираемся это брать'.Используйте на стороне клиента:
<сценарий> nlp.extend (compomiseNumbers) var doc = nlp ('две бутылки пива') номера документов (). минус (1) документ.body.innerHTML = doc.text () // 'одна бутылка пива'как es-модуль:
импортировать nlp из "компромисса" var doc = nlp ('Лондон звонит') doc.verbs (). toNegative () // 'Лондон не звонит'компромисс: 180kb (минимизированный):
это довольно быстро. Он может работать при нажатии клавиши:
он работает в основном путем спряжения всех форм основного списка слов.
Итоговый словарный запас составляет ~ 14000 слов:
, вы можете узнать больше о том, как это работает, здесь.это странно.
.extend ():
решает, как интерпретировать слова:
пусть myWords = { kermit: 'Имя', фоззи: 'Имя', } пусть doc = nlp (muppetText, myWords)или внесите более серьезные изменения с помощью компромиссного плагина.
const nlp = require ('компромисс') nlp.extend ((Док, мир) => { // добавляем новые теги world.addTags ({ Персонаж: { isA: 'Человек', notA: 'Прилагательное', }, }) // добавляем или меняем слова в лексиконе Мир.addWords ({ kermit: 'Персонаж', гонзо: 'Персонаж', }) // добавляем методы для запуска после теггера world.postProcess (doc => { doc.match ('зажигать огни'). tag ('# Verb. #Plural') }) // добавляем совершенно новый метод Doc.prototype.kermitVoice = function () { this.sentences (). prepend ('ну,') this.match ('я [(я | был)]'). prepend ('ммм,') верни это } })Документы:
нежное введение:
Документация:
Переговоров:
Статей:
Приколы Приложения:
API:
Конструктор
(эти методы есть на объекте
nlp)
- .tokenize () - разобрать текст без запуска POS-тегов
- .extend () - добавить компромиссный плагин
- .fromJSON () - загрузить объект компрометации из
.json ()результат- .verbose () - записать наши решения для отладки
- .version () - текущая семверская версия библиотеки
- .world () - получить все текущие лингвистические данные
- .parseMatch () - предварительный синтаксический анализ любых операторов соответствия для более быстрого поиска
Утилиты
- .all () - вернуть весь исходный документ («уменьшить масштаб»)
- .found [getter] - этот документ пуст?
- .parent () - вернуть предыдущий результат
- .parents () - вернуть все предыдущие результаты
- .tagger () - (повторно) запустить теггер части речи в этом документе
- .wordCount () - подсчитать количество терминов в документе
- .length [getter] - подсчитать количество символов в документе (длина строки)
- .clone () - глубоко скопировать документ, чтобы не осталось ссылок
- .cache ({}) - зафиксировать текущее состояние документа для ускорения
- .uncache () - разблокирует текущее состояние документа, чтобы его можно было преобразовать
Аксессуары
Матч
(все методы сопоставления используют синтаксис сопоставления)
- .match ('') - вернуть новый документ с этим в качестве родительского
- .not ('') - вернуть все результаты кроме этого
- .matchOne ('') - вернуть только первое совпадение
- .if ('') - вернуть каждую текущую фразу, только если она содержит это совпадение ('только')
- .ifNo ('') - Отфильтровать любые текущие фразы, у которых есть это совпадение ('notIf')
- .has ('') - Вернуть логическое значение, если такое совпадение существует
- .lookBehind ('') - поиск по более ранним терминам в предложении
- .lookAhead ('') - поиск по следующим терминам в предложении
- .before ('') - вернуть все термины перед совпадением в каждой фразе
- .after ('') - вернуть все термины после совпадения в каждой фразе
- .lookup ([]) - быстрый поиск массива совпадений строк
Корпус
Пробел
- .pre ('') - добавлять знаки препинания или пробел перед каждым совпадением
- .post ('') - добавлять знаки препинания или пробел после каждого совпадения
- .trim () - удалить начальные и конечные пробелы
- .hyphenate () - соединять слова дефисом и удалять пробелы
- .dehyphenate () - удалить дефисы между словами и установить пробелы
- .toQuotations () - добавить кавычки вокруг этих совпадений
- .toParentheses () - добавить скобки вокруг этих совпадений
Тег
- .tag ('') - присвоить всем терминам данный тег
- .tagSafe ('') - Применять тег к терминам, только если он соответствует текущим тегам
- .unTag ('') - Удалить этот термин из данных условий
- .canBe ('') - вернуть только те термины, которые могут быть этим тегом
Петли
- .map (fn) - пропустить каждую фразу через функцию и создать новый документ
- .forEach (fn) - запускать функцию для каждой фразы как отдельного документа
- .filter (fn) - возвращать только те фразы, которые возвращают истину
- .find (fn) - вернуть документ только с первой фразой, которая соответствует
- .some (fn) - вернуть истину или ложь, если есть одна совпадающая фраза
- .random (fn) - выборка подмножества результатов
Вставка
Преобразование
Выход
Выборки
Подмножества
Плагины:
Вот несколько полезных расширений:
Прилагательные
нпм установить компромисс прилагательныеДаты
npm установить компромиссные датыНомера
npm установить компромиссные номераЭкспорт
npm установить компромисс-экспорт
- .export () - сохранить проанализированный документ для дальнейшего использования
- nlp.load () - повторно сгенерировать объект Doc из результатов .export ()
HTML
npm установить компромисс-html
- .html ({}) - создать очищенный HTML из документа
Хэш
npm установить компромиссный хэш
- .hash () - сгенерировать хеш md5 из документа + теги
- .isEqual (doc) - сравнить хэш двух документов на предмет семантического равенства
Клавиша
npm установить компромисс-нажатие клавишиНграмм
npm установить компромиссные программыПункты
нпм установить компромисс - параграфыэтот плагин создает оболочку вокруг объектов предложения по умолчанию.предложений
npm установить компромиссные предложения
- .предложения () - вернуть класс предложения с дополнительными методами
Строгое соответствие
npm установить строгий компромиссСлоги
npm установить компромиссные слоги
- .syllables () - разделить каждый термин по его типичному произношению
Пенн-теги
npm установить компромиссные-пенн-тегиМашинопись
мы стремимся к поддержке машинописного текста / обозначения, как в основном, так и в официальных плагинах:
импортировать nlp из "компромисса" импортировать нграммы из "компромиссных" импортировать номера из 'компромиссных номеров' константа nlpEx = nlp.расширить (ngrams) .extend (числа) nlpEx ('Это типобезопасный!'). ngrams ({min: 1}) nlpEx ('Это типобезопасный!'). numbers ()Частичные сборки
, или если вас не волнует POS-теги, вы можете использовать сборку tokenize-only: (90kb!)
<сценарий> var doc = nlp ('Нет, моего сына также зовут Борт.') // видно, что в тексте нет тегов console.log (doc.has ('# Noun')) // ложь // остальная часть api все еще работает приставка.b [oa] rt / ')) // правдаОграничения:
косая опора: В настоящее время мы разделяем косые черты на разные слова, как и дефисы. так что такие вещи не работают:
nlp ('коала ест / стреляет / уходит'). Has ('листья коалы') // falseсоответствие между предложениями: По умолчанию предложения являются абстракцией верхнего уровня. Сопоставления между предложениями или несколькими предложениями не поддерживаются без плагина:
nlp ("вот и все.Назад в Виннипег! "). Has ('it back') // falseсинтаксис вложенного совпадения: опасность
красота регулярного выражения состоит в том, что вы можете повторяться бесконечно. Наш синтаксис сопоставления намного слабее. Подобные вещи не возможны (пока) :doc.match ('(modern (major | minor))? General')сложные совпадения должны быть достигнуты с помощью последовательных операторов .match () .разбор зависимостей: Правильное преобразование предложения требует понимания синтаксического дерева предложения, чего мы в настоящее время не делаем.Мы должны! Требуется помощь с этим.
FAQ
☂️ Это тоже не javascript ...
да это оно!
💃 Может ли он работать на моих часах Arduino?
он не был построен для конкуренции с НЛТК и может не подходить для всех проектов. Обработка строк
также выполняется синхронно, а распараллеливание узловых процессов - это странно.
См. Здесь для получения информации о скорости и производительности, а также здесь для мотивации проектаТолько если он водонепроницаем!
🌎 Компромисс на других языках?
Прочтите краткое руководство по поиску компромиссов в рабочих, мобильных приложениях и всевозможных забавных средах.у нас есть незавершенные вилки для немецкого и французского языков, придерживаясь той же философии.
✨ Частичные сборки?
и нужна помощь.мы действительно предлагаем сборку с компромиссным токенизированием, в которой вытащен POS-tagger.
, но в остальном компромисс нелегко поколебать.
методы тегирования конкурентны и жадны, поэтому не рекомендуется отказываться от них.
Обратите внимание, что без полной POS-маркировки анализатор сокращения не будет работать идеально. ( (прохладный спенсер) против (дом спенсера) )
Рекомендуется запустить библиотеку полностью.См. Также:
MIT
.