Ответы на олимпиадные задания для 11 класса
46,0% 33,2% разбора слов Состав слова Умение различать формы слова и родственные слова Б 1 балл 100,0% 71,0% 59,7%
по отдельным м (4 класс, конец 2011/2012 учебного года) (курсивом отмечены, проверяющие знания из раздела, который не является обязательным для овладения всеми учащимися) БЛОК 1 1_1 В.1, 1 В.8, 6 1.1.1
Подробнее46,0% 33,2% разбора слов Состав слова Умение различать формы слова и родственные слова Б 1 балл 83,3% 42,3% 59,7%
БЛОК 1 знание/умение Результаты выполнения (в %) 1_1 В.1, 1 В.8, 6 1.1.1 Фонетика и графика Умение различать звуки и буквы Б 59,1% 62,1% 1_2 В.
ИСТОРИЯ РУССКОГО ЯЗЫКА
Ю.Г. Захарова ИСТОРИЯ РУССКОГО ЯЗЫКА УЧЕБНОЕ ПОСОБИЕ ДЛЯ ПРАКТИЧЕСКИХ ЗАНЯТИЙ Допущено УМО по классическому университетскому образованию для студентов высших учебных заведений в качестве учебного пособия
Подробнее1.Цели и задачи дисциплины.
1.Цели и задачи дисциплины. 1.1. Цели преподавания дисциплины: Основными целями курса русского языка в колледже являются следующие: закрепить и углубить знания, развивать умения студентов по фонетике,
ПодробнееРабочая программа по русскому языку 5 класс
Департамент социальной политики Администрации города Кургана муниципальное бюджетное общеобразовательное учреждение города Кургана «Средняя общеобразовательная школа 35» Рассмотрена на заседании методического
ПодробнееПРОВЕРЬ СЕБЯ! КОНКУРС «ОДИН ИЗ ЧЕТЫРЁХ»
К поставленному вопросу выберите из предложенных вариантов ответов только один тот, который, на ваш взгляд, является верным, и запишите его в таблице, помещённой в правом нижнем углу. Вторая графа, расположенная
Вторая графа, расположенная
Кодификатор по русскому языку 3 класс
Кодификатор по русскому языку 3 класс Тема планируемого результата Проверяемые умения Код Система языка. Фонетика, орфоэпия, графика.. 1 Звуки и буквы. Выполнять звукобуквенный анализ доступных слов; видеть
Русский язык среди других языков
Урок 1 Русский язык среди других языков Цель: сформировать у школьников представление о многообразии языков в мире; дать учащимся понятие родственных и близкородственных языков; особо обратить внимание
Подробнее5 класс учитель Ястребова Н.В.
Муниципальное бюджетное общеобразовательное учреждение средняя общеобразовательная школа 45 СОГЛАСОВАНО Заместитель директора по УР УТВЕРЖДАЮ Директор МБОУ СОШ 45 Барон С. А. Зарипова М.С 20 г. 20 г. КАЛЕНДАРНО-ТЕМАТИЧЕСКИЙ
А. Зарипова М.С 20 г. 20 г. КАЛЕНДАРНО-ТЕМАТИЧЕСКИЙ
ПРИМЕРНОЕ ТЕМАТИЧЕСКОЕ ПЛАНИРОВАНИЕ
ПРИМЕРНОЕ ТЕМАТИЧЕСКОЕ ПЛАНИРОВАНИЕ уроков русского языка в 5-м классе из расчёта 6 часов в (210 часов) и 5 часов в (175 часов) Раздел и учебника Ты изучаешь русский язык (2 ч/1 ч) расчёта в при 6 ч в
Подробнееаудирование и чтение:
2 1. Планируемые результаты освоения учебного предмета Личностные: — понимать значимость русского языка как одной из основных национально-культурных ценностей русского народа; — пополнять объём словарного
ПодробнееРусский язык 10 класс. подготовки
Тема а Колво часов Тип а 1 Язык и общество 1 Урок усвоения 2 «Язык каждого народа создан самим народом» Русский язык 10 класс Требования к уровню подготовки Раздел 1. Общие сведения о языке (7 часов) Понимать
Общие сведения о языке (7 часов) Понимать
Пояснительная записка
1 Пояснительная записка Программа разработана в соответствии с Федеральным государственным образовательным стандартом основного общего образования на основе Примерной программы основного общего образования
ПодробнееСодержание предмета русский язык 10 класс
2 Содержание предмета русский язык 10 класс Русский язык среди языков мира. Богатство и выразительность русского языка. Русские писатели о выразительности русского языка. Русский язык как государственный
ПодробнееПланируемые результаты курса
Планируемые результаты курса Учащиеся должны уметь: — раскрывать роль русского языка в межкультурном общении; — по стилям речи: определять стилевую принадлежность текста по его языковым особенностям; обнаруживать
ПодробнееРАБОЧАЯ ПРОГРАММА по русскому языку
Муниципальное бюджетное общеобразовательное учреждение «Средняя школа 21» РАБОЧАЯ ПРОГРАММА по русскому языку Классы: 3А, 3 Б, 3 Д Учитель: Шевченко Наталья Викторовна, Гнездилова Лариса Ивановна, Нигматуллина
ПодробнееБазовый уровень для 7-8 классов
Содержание Базовый уровень по русскому языку для 7-8 классов. 3 Профильный уровень по русскому языку для 7-8 классов.7 Базовый уровень по русскому языку для 9-10 классов. 12 Профильный уровень по русскому
3 Профильный уровень по русскому языку для 7-8 классов.7 Базовый уровень по русскому языку для 9-10 классов. 12 Профильный уровень по русскому
Суффиксы имен прилагательных
| Суффиксы имен прилагательных | Примеры |
Слегка сырой (сыроватый), лес из сосен (сосновый), почва из глины (глинистая), чуткий человек (отзывчивый), салат из овощей (овощной), гриб небольшого размера (маленький).
Затем учащимся дается задание дополнить правую сторону таблицы примерами.
Мыльная (пена), дубовая (роща), лесистый (берег), заботливый (сын), голубоватый (цвет), прелестный (ребенок), тепленький (хлеб).
IV. Упр. 394 (устно).
V. Составьте слова по данным схемам.
VI. От корней —черн-, -ред— образуйте существительное, прилагательное, глагол.
VI. Запись под диктовку.
Учащиеся выделяют суффиксы прилагательных.
ОСЕНЬ В ЛЕСУ
В осеннем лесу за сто шагов слышно, как пробегает маленькая мышь по сухим листьям. Умолкли звонкие голоса птиц. Золотистые кленовые листья беззвучно повисли на ветвях серебряной паутины. На желтоватом ковре из листьев играют последние солнечные зайчики.
(По В. Пескову.)
Домашнее задание: упр. 399 (письменно).
Урок 96. Суффикс — значимая часть слова(продолжение темы)
Знать: суффикс — значимая часть слова; средство образования новых слов (существительных, прилагательных, глаголов).
Уметь: выделять суффиксы; образовывать слова с различными суффиксами.
I. Устная синтаксическая пятиминутка.
Составьте схемы предложений.
1. Сильнее припекает солнышко, и веселее булькают по склонам оврага ручьи. 2. Уцелел только маленький сугробик под лапами ели, которая растет на краю обрыва.
2. Уцелел только маленький сугробик под лапами ели, которая растет на краю обрыва.
— Что общего в структуре этих предложений? (Оба предложения сложные.)
— Чем они отличаются? (В первом — предложения, входящие в состав сложного, не зависят друг от друга; во втором — одно подчиняется другому, т. е. первое — сложносочиненное, второе — сложноподчиненное.)
II. Выпишите и разберите по составу.
1. Солнышко, сугробик, маленький (определить в словах значения суффиксов).
2. Припекает, булькают, уцелел.
При разборе глаголов учитель обращает внимание учащихся на суффикс -л-, который указывает на форму прошедшего времени, а также на то, что глаголы в настоящем (и будущем) времени имеют личные, а в прошедшем времени — родовые окончания.
III. Разбор слов по составу.
Видит — видел — видеть; слышит — слышала — слышать; тает — таяло — таять; пилит пилили; крикнул — крикнуть.
— На что указывают окончания -ит, -ет, -ть, -а, -о, -и, в глаголах? Можно ли определить форму глагола по суффиксу -л-? Приведите примеры.
IV. Игра «Кто больше?»
Запись примеров слов различных частей речи с корнями -да-, -един-, -ясн-.
V. Запись текста под диктовку и его анализ по вопросам.
Однажды охотник встретил на лесной дороге маленькую девчушку с золотистыми волосами. Это была дочка лесника. Она собирала в корзинку еловые шишки.
У девочки были зеленоватые глаза, и в них отражался огонь осиновых листьев.
Она проводила охотника до избушки лесника.
Вопросы к тексту.
1. Указать средства связи предложений в тексте.
2. Составить схему четвертого предложения. Что связывает в нем союз и?
3. Найти однокоренные слова. Чем они отличаются по составу?
4. Назвать слова с нулевым окончанием. Какие это части речи? На что указывают в них нулевые окончания?
Назвать слова с нулевым окончанием. Какие это части речи? На что указывают в них нулевые окончания?
5. Есть ли в тексте слова без окончания? Что это за части речи?
6. Подчеркнуть суффиксы в именах прилагательных. Назвать слова с уменьшительно-ласкательными суффиксами. Какие это части речи?
7. В какой форме стоят глаголы? Какая морфема указывает на данную форму глагола?
Домашнее задание:упр.396.
Урок 97. Приставка
Знать: приставка — значимая часть слова; средство образования слов.
Уметь: выделять приставки в словах; определять (в простых случаях) их значение.
I. Наблюдения на с. 156.
В процессе работы с этим материалом и устного выполнения упр. 402 заполняется таблица.
Т а б л и ц а 15
Приставки
Делается вывод: приставка — значимая часть слова, которая служит для образования новых слов.
Читается записанное заранее на доске высказывание К. И. Чуковского: «Приставки придают русской речи столько богатейших оттенков. Чудесная выразительная речь в значительной мере зависит от них. В разнообразии приставок таится разнообразие смысла».
— Докажите правильность слов писателя: образуйте с помощью приставок глаголы, составьте и запишите с некоторыми из них словосочетания.
С-, вы-, пере-: давать, звенеть, бежать, лететь, кричать, говорить.
II. Выразительное чтение записанного (или спроецированного) на доске текста.
Учащиеся должны определить стиль высказывания тип речи, выписать из текста глаголы с приставкой и разобрать их по составу.
(Стиль речи — художественный. Один из его признаков — использование слов в переносном значении. Учащиеся должны найти эти слова. Тип речи — повествование, в котором последовательно раскрываются действия.)
Впереди видна мутная сталь воды.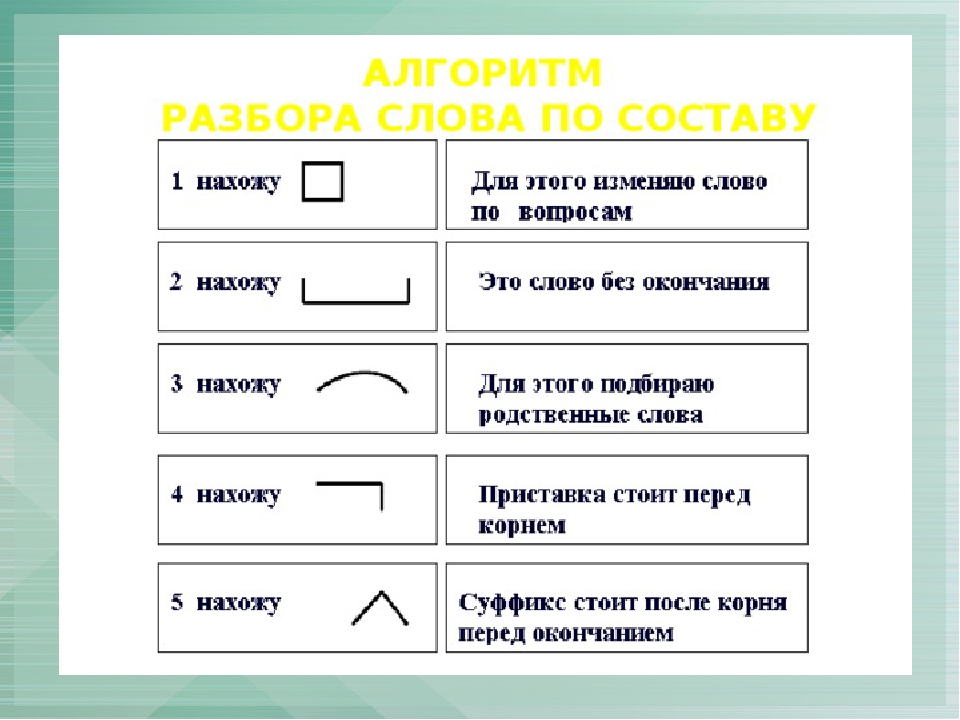 Из-за озера, из темных еловых перелесков выплывают орлы. Они выделяются грозными силуэтами на фоне закатного солнца. Испуганный их внезапным появлением, замирает весь пернатый мир. Прекратили драку селезни. Смолкла лебединая перекличка, Орлы дозором облетают озера.
Из-за озера, из темных еловых перелесков выплывают орлы. Они выделяются грозными силуэтами на фоне закатного солнца. Испуганный их внезапным появлением, замирает весь пернатый мир. Прекратили драку селезни. Смолкла лебединая перекличка, Орлы дозором облетают озера.
(Г. Федосеев.)
III. Игра «Составь слово».
Школьники должны составить слово, взяв из других слов указанные морфемы.
Домашнее задание: § 76, упр. 404, 405.
Свежесть по составу разобрать
Как выполнить разбор слова свежесть по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, суффикс .
Схема разбора по составу: свеж есть
Строение слова по морфемам: свеж/есть/
Структура слова по морфемам: приставка/корень/суффикс/окончание
Конструкция слова по составу: корень [свеж] + суффикс [есть] + окончание [нулевое]
Основа слова: свежесть
Словообразование: производное, так как образовано 1 (одним) способом, способы словообразования: суффиксальный.
Характеристики основы слова: непрерывная, простая (1 корень), производная, членимая (есть словообразовательные афиксы) .
| свеж | корень |
| есть | суффикс |
| ø | нулевое окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова адвентист (существительное):
Ассоциации к слову «свежесть»
Синонимы к слову «свежесть»
Предложения со словом «свежесть»
- Ткань едва уловимо пахла ледяной свежестью, апельсинами и ванилью.
- Мои лёгкие наполнились запахом прошедшего ночью дождя, утренней свежести, сжигаемых во дворах помоек и лета.

- По саду стелилась сырая ночная свежесть, багровое небо покрыли сетью вспухшие вены умирающего дня.
- (все предложения)

Цитаты из русской классики со словом «свежесть»
- В воздухе, на солнце, было тепло, и тепло это, смешиваясь с крепительною свежестью утреннего заморозка, еще чувствовавшегося в воздухе, было особенно приятно.
Сочетаемость слова «свежесть»
Какой бывает «свежесть»
Значение слова «свежесть»
СВЕ́ЖЕСТЬ , -и, ж. 1. Свойство и состояние по знач. прил. свежий. Свежесть цветов. Свежесть белья. Свежесть утра. Свежесть красок. Свежесть впечатлений. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «свежесть»
СВЕ́ЖЕСТЬ , -и, ж. 1. Свойство и состояние по знач. прил. свежий. Свежесть цветов. Свежесть белья. Свежесть утра. Свежесть красок. Свежесть впечатлений.
Предложения со словом «свежесть»:
Ткань едва уловимо пахла ледяной свежестью, апельсинами и ванилью.
Мои лёгкие наполнились запахом прошедшего ночью дождя, утренней свежести, сжигаемых во дворах помоек и лета.
По саду стелилась сырая ночная свежесть, багровое небо покрыли сетью вспухшие вены умирающего дня.
Синонимы к слову «свежесть»
Ассоциации к слову «свежесть»
Сочетаемость слова «свежесть»
Какой бывает «свежесть»
Морфология
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
Морфемный состав существительного свежесть соответствует схеме:
Существительное свежесть образовано от прилагательного свежий с помощью суффикса -есть, который обозначает качество. После шипящего в суффиксе пишется е, а после твердых согласных — буква о:
После шипящего в суффиксе пишется е, а после твердых согласных — буква о:
скорость, ясность, меткость, молодость.
Слово свежесть изменяемое, значит, выделим в его морфемном составе окончание, которое материально не обозначено ни звуками, ни буквами, и поэтому называется нулевым. При изменении слова нулевое окончание проявляется в его составе:
свежесть_ — свежест-и, свежесть-ю.
Корнем слова является часть свеж-, которая существует в родственных словах:
свеженький, свежатина, свежина, свежо, освежить, освежитель.
Суммируя все вышеизложенное, морфемный состав слова свежесть таков:
свеж-есть_ — корень/суффикс/нулевое окончание.
— 7 . 2014-2015 (. 4 )
— н-нн в прилагательных;
— написание -тся – ться в глаголах;
— правильное написание глагольных окончаний;
— написание не с глаголами.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— разбор слова по составу;
— синтаксический разбор предложения;
— умение вычерчивать схемы к предложениям;
— разбирать слово морфологически и фонетически.
Диктант
Всё время держится прекрасная погода. Дни стоят солнечные, а по ночам подмораживает. Звёзды усеивают тёмное небо и блестят чисто и нежно.
Наступает пора листопада, и листья падают дни и ночи. Они то косо летят по ветру, то отвесно ложатся на сырую траву.
Из леса веет прохладой. По утрам серебряные капли росы покрывают осеннюю листву и низкий кустарник около речки. Леса обнажаются, и среди деревьев светло и просторно. Это время совпадает с отлётом пернатых в далёкие края. Они собираются в большие стаи. Когда на небе догорает последний луч, из прибрежных зарослей раздаются какие-то таинственные шорохи.
Когда на небе догорает последний луч, из прибрежных зарослей раздаются какие-то таинственные шорохи.
Чёрными облаками перелетают по полям и лугам стаи скворцов. Высоко в небе тянутся журавлиные косяки.
До свидания, осень, — говорим мы и приветствуем приход зимы.
Грамматические задания
1. Сделать фонетический разбор слова:
Деревьев — 1-й вариант листья — 2-й вариант
2. Разобрать слова по составу:
Подмораживает, серебряные, кустарник — 1-й вариант
Обнажаются, журавлиную, зарослей — 2-й вариант
3. Составить схему к предложению: Когда на небе догорает последний луч, из прибрежных зарослей раздаются какие-то таинственные шорохи. — 1-й вариант До свидания, осень, — говорим мы и приветствуем приход зимы. — 2-й вариант
4. Сделать синтаксический разбор предложения:
Диктанты 3 класс
Просмотр содержимого документа
«Диктанты 3 класс»
Контроль знаний за 1 четверть.
Диктант
Прощание с осенью.
В октябре стоит сырая погода. Весь месяц льют дожди. Дует осенний ветер. Шумят в саду деревья.
Ночью перестал дождь. Выпал первый снег. Кругом светло. Все вокруг стало нарядным. Две вороны сели на березу. Посыпался пушистый снежок. Дорога подмерзла. Хрустят листья и трава на тропе у дома.
Слова для справок: стало, подмерзла.
Грамматическое задание:
В первом предложении подчеркнуть подлежащие и сказуемое.
Разобрать по составу слова: осенний, саду.
Выписать из текста слово, в котором букв больше чем звуков.
Контроль знаний за 2 четверть.
Диктант.
Снеговик.
Стоит чудесный зимний день. Падает легкий снег. Деревья одеты в белые шубки. Спит пруд под ледяной коркой. Яркое солнце на небе.
Деревья одеты в белые шубки. Спит пруд под ледяной коркой. Яркое солнце на небе.
Выбежала группа ребят. Они стали лепить снеговика. Глазки сделали ему из светлых льдинок, рот и нос из морковок, а брови из угольков. Радостно и весело всем!
Грамматическое задание:
Подчеркнуть главные члены во втором предложении.
Разобрать по составу слова (1 вариант: зимний, шубки; 2 вариант: белые, морковки).
Найти в тексте слова с проверяемым безударным гласным в корне. Подобрать к ним проверочные слова. Написать эти слова.
Контроль знаний за 3 четверть.
Диктант.
Первые дни весны.
Над полями и лесами светит яркое солнце. Потемнели в полях дороги. Посинел на реке лед. В долинах зажурчали звонкие ручьи. Надулись на деревьях смолистые почки. На ивах появились мягкие пуховики.
На ивах появились мягкие пуховики.
Выбежал на опушку робкий заяц. Вышла на поляну старая лосиха с лосенком. Вывела медведица на первую прогулку своих медвежат.
Грамматическое задание:
Разобрать по членам предложения: 1 вариант: четвертое предложение; 2 вариант: пятое предложение. Главные члены предложения подчеркнуть, словосочетания выписать.
Подобрать прилагательные, противоположные по смыслу.
1 вариант: узкий ручей — …; старательный ученик — …; 2 вариант: трусливый мальчик — …; высокий куст — …
Контроль знаний за 4 четверть.
Диктант.
Весеннее утро.
Это случилось в апреле. Рано утром проснулось солнце и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Снегом покрыли поля и холмы. На деревьях сосульки развесили.
Засветило солнце и съело утренний лед. По долине побежал, говорливый ручеек. Вдруг под корнями березки он заметил глубокую норку. В норке сладко спал ежик. Еж осенью нашел это укромное местечко. Он еще не хотел вставать. Но холодный ручей забрался в сухую постельку и разбудил ежа.
По долине побежал, говорливый ручеек. Вдруг под корнями березки он заметил глубокую норку. В норке сладко спал ежик. Еж осенью нашел это укромное местечко. Он еще не хотел вставать. Но холодный ручей забрался в сухую постельку и разбудил ежа.
Грамматическое задание:
Разобрать по членам 7-ое и 9-ое предложения.
Разобрать по составу слова: 1 вариант: засветило, утренний, березки; 2 вариант: развесили, веселый, местечко).
Определить время, число и род глаголов: побежал, взглянуло, покрыли.
Контроль знаний.
Диктант за год.
Утро в степи.
Раннее весеннее утро. Степь весело пестреет цветочками. Ярко желтеет дрок. Скромно синеют колокольчики. Белеет пахучая ромашка. Дикая гвоздика горит пунцовыми пятнами. В утренней прохладе разлит горький, здоровый запах полыни.
Все радостно потянулось к солнцу. Степь проснулась и ожила. Высоко в воздухе затрепетали жаворонки. Кузнечики подняли свою торопливую трескотню.
Грамматическое задание:
Выписать из текста два слова с безударными гласными в корне. Написать к ним проверочные слова.
Выписать два слова с приставками. Выделить приставки.
2-ое и 4-ое предложения разобрать по членам (по вариантам).
Диктант Пришла осень
Диктант
Пришла осень.
Быстро пролетело жаркое лето. Часто моросит мелкий дождь. По небу поползли серые тучи. На лесной поляне порыжела трава. В лужах плавают осенние листья.
Хмуро темнеет среди травы муравьиная куча. Муравьи начали уходить в свои жилища. Они редко теперь выползают наружу. Возле старого пня росли два подосиновика. Шляпки грибов весело глядели из травы. Их заметила белка. Она схватила один гриб и скрылась.
Слова для справок: наружу, заметила.
Диктант
В осеннем лесу.
Красиво было в лесу в этот ранний час. Тихо шумели, качались деревья. С листьев стекали свинцовые капли росы. На мху, в траве уже лежали следы осени. Остро пахло сырой землей, прелыми листьями. Из вороха старых листьев, травы, валежника выглядывают грибы. Мы вошли в редкий березняк. А вот и лесной царь — белый гриб. Он стоял на крепкой ножке, в золотисто-коричневой шапке. Гриб был очень хорош.
Слова для справок: свинцовые, золотисто-коричневый, ворох.
Найти в тексте предложение с однородными дополнениями, разобрать его по членам, выписать словосочетания.
Диктант
Чудесная пора осени.
Летели и летели осеннее листья. Ветер подхватил их и погнал к речке. По зеркальной воде поплыли золотые монетки. На краю деревни заиграл рожок. Это пастух собирал стадо.
Я выхожу из дома, беру весла и иду к речке. Восток светлеет, розовеет. Удивительная тишь кругом. Река словно похорошела, выпрямилась. Под первыми лучами солнца засверкали, заискрились капельки воды. Стояла чудесная пора осени.
Слова для справок: собирал, словно.
1-й вариант. В 6-м предложении подчеркнуть главные члены, разобрать его по составу, указать части речи.
2-й вариант. В 10-м предложении подчеркнуть главные члены, рать его по составу, указать части речи.
Диктант
Друзья леса.
Круглый год ребята нашей школы охраняют лес. Перед новогодним праздником проводят дежурство на дороге. Сотню лесных красавиц они спасли от гибели. Весной оберегают русские березки от любителей березового сока. В лесу много посадок. Саженцы прижились, окрепли, подросли. Радостно смотреть на них, переходя от поляны к поляне. На скатерти снега следы птиц и зверей. Вот к норке прибежала мышь. Тишина в лесу. Красив наш лес. Береги его красоту!
Слова для справок: новогодним, любителей, прижились.
Примечание: предупредить о постановке запятых.
Задания:
1. Разобрать по членам второе и четвертое предложения (по вариантам). Выписать из предложения словосочетание с именем существительным, указать его склонение и падеж.
2. Разобрать слова по составу:
1-й вариант: ослепил, просьбой.
2-й вариант: повязал, записку.
Диктант__Запах_свежего_хлеба.’>Диктант
Запах свежего хлеба.
Каждую ночь по деревне плыл запах теплого хлеба. Утром Филька с ребятами подошел к мельнице. Ветер гнал по небу рыхлые облака. Шалун спустился к деревьям, пробежал от осинки к осинке, раскачал верхушку березки. Филька вытащил буханку теплого хлеба. Панкрат выпустил коня. Конь осторожно вытянул шею и взял из рук мальчика хлеб мягкими губами.
Все улыбались. Только старая сорока сидела на раките и сердито трещала. Чем она была огорчена? (К. Паустовский)
Слова для справок: Панкрат, ракита, огорчена.
Диктант
Прогулка.
Удивительная была прогулка. Мать с сыновьями гуськом шли к дальнему роднику по узенькой тропке. Сияло холодное небо. В морозной тишине громко трещали сороки. В густых кедровых ветвях прятались белки. Ловкие зверьки весело прыгали с ветки на ветку. Под деревьями на мягком снегу отпечатались следы птиц. Вот свалилась с верхушки старой ели большая гора снега. Геку показалось, что вся земля достоит из высокого дремучего леса. (А. Гайдар)
Слово для справки: дремучего.
Диктант
Весенняя осень?
Я вхожу в лес. На сухом пригорке проклюнулась первая травка. Голубые перелески цветут. На ветках почки лопнули.
Вот поляна. Тут хозяйничает настоящая осень. Молодые дубки в желтой осенней листве. На земле пушистый ковер. Около старого пенька на толстой ножке гриб в красной шапке.
Здесь вечная осень?
Но вот с ближней ветки сорвался сухой лист. Он закачался в холодном воздухе и упал. Открылась на месте листа тугая коричневая почка. Под листом она укрылась от зимнего холода. (Э. Шим)
Задания:
В девятом предложении найти существительные, указать и склонение и падеж. Выделить окончания.
Выписать из диктанта три слова с проверяемой безударной гласной в корне. Написать проверочные слова.
В последнем абзаце указать род, число, падеж имен прилагательных. Выделить окончания.
Диктант
Половодье.
На сирени, тополе, березе набухли почки. Наступает пора бурного таяния снега. Лед на реке намокает, темнеет. Недалеко от берега показались талые оконца. Придешь через неделю и не узнаешь реки. Кругом вода. Проснулась, ожила река и затопила кусты у берега. Вода наступает и на покрытый сухой травой луг. Над водой на тихом месте торчат верхушки стебельков. Быстро проносятся мимо сухие листья, ветки, доски.
Грамматические задания:
1. Над первым словом каждого предложения надпишите, какое предложение: пр. (простое), с одн. чл. (с однородными членами).
2. Укажите падежи имен прилагательных и выделите окончания.
3. Выделите безударные окончания глаголов 3-го лица в форме единственного числа.
Диктант
Подземная охота.
Трюфели — удивительные грибы. Они растут под землей. Как же найти их? Бывалый охотник за трюфелями берет с собой поросенка или собаку. Настоящая охотничья собака не подойдет. В чаще часто мелькает дичь. Дичь заставляет такую собаку сразу позабыть о грибах. Годятся для грибной охоты пудели, болонки, дворняжки. Разыскивать трюфели могут даже коровы. Животные разрывают лесную подстилку и откусывают часть вкусного гриба. В России эти грибы часто называют коровьим хлебом. В прошлом веке под Москвой для сбора трюфелей использовали даже ручных медведей! В древнем Риме эти грибы называли пищей богов. Таинственный, редчайший гриб! И где? У нас в Подмосковье!
Грамматические задания:
1. Выписать из диктанта предложение с однородными подлежащими. Разобрать это предложение по членам предложения, указать части речи, выписать словосочетания.
2. Разобрать по составу слова: грибной, подстилку, разрывают.
3. Объяснить, почему трюфели называли коровьим хлебом.
Изложение__Горькая_вода.’>Изложение
Горькая вода.
Толя с Васей возвращались из леса в лагерь. По дороге шла старушка с ведром воды. Тяжело ей было его нести. Мальчики это заметили. Но Толя быстро зашагал в лагерь. Витя побежал помогать старушке.
Однажды Толя шел с прогулки. Он захотел пить, постучал в избу. Дверь открыла знакомая старушка. Она встретила Толю приветливо, дала воды. Мальчик покраснел. Он выпил воды и выбежал на улицу. Вода ему показалась горькой. (В. Осеева)
Изложение
Моя поляна.
Я меня есть любимая поляна. Красива она. На рябину прилетают кормиться дрозды. В сухих листьях здесь живут ежи. Осенью приходят лоси.
Рядом с поляной находится сад. Деревья засохли, выродились. Дикие ветки дают кислые мелкие яблоки. Однажды я услышал хруст. Я осмотрелся. Это были лоси. Один из лосей мягкими губами срывал яблоки с дерева. Другой лось собирал их на земле. Он подгибал длинные ноги и вставал на колени.
Зимой я часто вспоминаю свою поляну и лосей, жующих кислые яблоки.
(В. Песков)
Изложение
1) На пригорке обсохла земля. На груди у Зои Петровны сверкал орден. Тропинка вывела нас к реке. Сережа приехал к бабушке. Медведь выбрал место для берлоги.
2) Стрелял охотник в медведя, да только ранил зверя. Кинулся медведь на человека.
Бросил охотник ружье и полез по сосне. А медведи умеют лазить по деревьям. Вот медведь и вскарабкался за охотником.
Видит охотник: сейчас медведь его за ногу схватит. Сбросил он с себя тулуп.
Медведь подумал, что это охотник упал. Кинулся зверь за тулупом, да и сорвался с вершины. Разбился медведь.
Слез охотник с дерева и стал плясать от радости.
— Ничего, что тулуп в крови, зато медвежью шкуру даром получил!
Изложение
Тополя.
От станции до поселка более километра. Дорога была на редкость прямой. По обе ее стороны росли стройные тополя. Они украшали местность, радовали глаз. Мне рассказали удивительную историю о них.
Мальчик прочитал статью о тополях. Он узнал, что из веточки может вырасти дерево. Об этом он сообщил другу. Ранней весной обрезали тополя. Мальчики собрали все веточки. Ранним утром и поздним вечером ребята бежали на дорогу. Они высаживали свои тополя, ухаживали за молодыми деревцами.
Прошло несколько лет. Чудесная аллея из тополей шумела на дороге. Как много могут сделать настойчивые руки! (Е. Пермяк)
Изложение
В выходной день папа с Серёжей сделали кормушку. Папа прибил её под самой форточкой.
Каждое утро Серёжа сыпал в кормушку разные крошки, зёрна.
Воробьи садились на большой тополь, но к кормушке не подлетали.
Однако с каждым днём птицы становились всё смелее. Они садились на ближние ветки тополя, потом начинали слетаться на столик-кормушку. А как осторожно они это делали! Пролетят мимо, кусочек хлеба схватят и скорей с ним в укромное местечко отлетают. Склюют там потихоньку и опять к кормушке летят. Серёжа наблюдал за птицами и радовался.
(По В. Чаплиной)
Контрольное списывание
Родничок.
Из-под каменистого берега бьет родник его открыли охотники, они вырыли лунку, очистили от песка, обложили его камнем родничок наполнил лунку, и потек теперь черпают воду из лунки, как из колодца я часто бывал на Кавказе и видел в горах родники их находят по росяной влажности на скалах скалу прорубают, выводят родник наружу из камней у самой тропы выкладывают колодец здесь усталый путник может утолить жажду в горах каждый родник имеет свое имя, он назван именем человека, открывшего его. (И. Васильев)
Контрольное списывание
Коростель и крот.
Из долгого теплого края возвращался домой маленький коростель. Он всю зиму прожил в Африке.
Крылышки у коростеля маленькие. Иногда он летит, но в основном идет пешком. Он шел и пел о далеком родном крае, о милой Родине, о своем гнездышке на зеленом лугу.
Коростель повстречался с кротом. Крот спросил коростеля, куда он так спешит. Коростель рассказал о своей северной Родине и о теплой Африке.
Крот удивился. Почему коростель не живет в теплых краях? Что зовет коростеля на холодный Север? Не мог понять крот, что у каждого есть своя Родина. (В. Сухомлинский)
Достарыңызбен бөлісу:
Контрольный диктант в 7 классе № 3 | Сборник диктантов по Русскому языку в 7 классе с русским языком обучения
Контрольный диктант в 7 классе № 3
24.09.2014 116699 0Цель: проверить знания, умения и навыки учащихся на начало учебного года.
Содержание контрольного диктанта направлено на выявление качества усвоения программного материала за 6-й класс, а также уровня сформированности орфографической зоркости и пунктуационных умений и навыков:
— правописание проверяемых безударных гласных;
— правописание непроверяемых безударных гласных;
— написание корней с чередованием;
— написание е-и в суффиксах существительных;
— н-нн в прилагательных;
— написание -тся – ться в глаголах;
— правильное написание глагольных окончаний;
— написание не с глаголами.
Знаки препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— разбор слова по составу;
— синтаксический разбор предложения;
— умение вычерчивать схемы к предложениям;
— разбирать слово морфологически и фонетически.
Диктант
Всё время держится прекрасная погода. Дни стоят солнечные, а по ночам подмораживает. Звёзды усеивают тёмное небо и блестят чисто и нежно.
Наступает пора листопада, и листья падают дни и ночи. Они то косо летят по ветру, то отвесно ложатся на сырую траву.
Из леса веет прохладой. По утрам серебряные капли росы покрывают осеннюю листву и низкий кустарник около речки. Леса обнажаются, и среди деревьев светло и просторно. Это время совпадает с отлётом пернатых в далёкие края. Они собираются в большие стаи. Когда на небе догорает последний луч, из прибрежных зарослей раздаются какие-то таинственные шорохи.
Чёрными облаками перелетают по полям и лугам стаи скворцов. Высоко в небе тянутся журавлиные косяки.
«До свидания, осень», — говорим мы и приветствуем приход зимы.
(119 слов)
Грамматические задания
1. Сделать фонетический разбор слова:
Деревьев — 1-й вариант листья — 2-й вариант
2. Разобрать слова по составу:
Подмораживает, серебряные, кустарник — 1-й вариант
Обнажаются, журавлиную, зарослей — 2-й вариант
3. Составить схему к предложению:
Когда на небе догорает последний луч, из прибрежных зарослей раздаются какие-то таинственные шорохи. — 1-й вариант
«До свидания, осень», — говорим мы и приветствуем приход зимы. — 2-й вариант
4. Сделать синтаксический разбор предложения:
Звёзды усеивают тёмное небо и блестят чисто и нежно. — 1-й вариант
По утрам серебряные капли росы покрывают осеннюю листву и низкий кустарник около речки. — 2- вариант
Введение в обработку текста на естественном языке | автор: Венцислав Йорданов
Прочитав этот пост в блоге, вы узнаете некоторые основные методы извлечения функций из , некоторого текста , чтобы вы могли использовать эти функции как входных для моделей машинного обучения .
NLP — это подраздел компьютерных наук и искусственного интеллекта, связанный с взаимодействием между компьютерами и человеческими (естественными) языками. Он используется для применения алгоритмов машинного обучения к тексту и речи .
Например, мы можем использовать NLP для создания таких систем, как распознавания речи , суммирования документов , машинного перевода , обнаружения спама , распознавания именованных объектов , ответов на вопросы, автозаполнения, предиктивного набора и т. Д. на.
В настоящее время у большинства из нас есть смартфоны с функцией распознавания речи. Эти смартфоны используют НЛП, чтобы понимать, что говорится. Также многие люди используют ноутбуки, операционная система которых имеет встроенную функцию распознавания речи.
Некоторые примеры
Cortana
Источник: https://blogs.technet.microsoft.com/microsoft_presse/auf-diesen-4-saeulen-basiert-cortanas-persoenlichkeit/В ОС Microsoft есть виртуальный помощник под названием Cortana , способная распознавать естественный голос . Вы можете использовать его, чтобы настраивать напоминания, открывать приложения, отправлять электронные письма, играть в игры, отслеживать рейсы и посылки, проверять погоду и т. Д.
Подробнее о командах Кортаны можно прочитать здесь.
Siri
Источник: https://www.analyticsindiamag.com/behind-hello-siri-how-apples-ai-powered-personal-assistant-uses-dnn/Siri — виртуальный помощник Apple Inc. операционные системы iOS, watchOS, macOS, HomePod и tvOS. Опять же, вы можете делать много вещей с помощью voice команд : начать звонок, написать кому-нибудь, отправить электронное письмо, установить таймер, сделать снимок, открыть приложение, установить будильник, использовать навигацию и так далее.
Вот полный список всех команд Siri.
Gmail
Источник: https://i.gifer.com/Ou1t.gifЗнаменитая служба электронной почты Gmail , разработанная Google, использует для обнаружения спама для фильтрации некоторых спам-писем.
NLTK ( Natural Language Toolkit ) — это ведущая платформа для создания программ Python для работы с данными на человеческом языке . Он предоставляет простые в использовании интерфейсы для многих корпусов и лексических ресурсов .Кроме того, он содержит набор из библиотек обработки текста для классификации, токенизации, выделения корней, тегов, синтаксического анализа и семантического обоснования. Лучше всего то, что NLTK — это бесплатный проект с открытым исходным кодом, управляемый сообществом.
Мы воспользуемся этим набором инструментов, чтобы показать некоторые основы обработки естественного языка. В приведенных ниже примерах я предполагаю, что мы импортировали набор инструментов NLTK. Сделать это можно так: import nltk .
В этой статье мы рассмотрим следующие темы:
- Токенизация предложений
- Токенизация слов
- Лемматизация и построение текста
- Стоп-слова
- Регулярное выражение
- Пакет слов
- TF-IDF
1.Токенизация предложений
Токенизация предложений (также называемая сегментацией предложений ) — это проблема деления строки письменного языка на , составляющих предложений . Идея здесь выглядит очень простой. На английском и некоторых других языках мы можем разделить предложения, когда увидим знак препинания.
Однако даже в английском языке эта проблема не является тривиальной из-за использования символа полной остановки для сокращений. При обработке обычного текста таблицы сокращений, содержащие точки, могут помочь нам предотвратить неправильное присвоение границ предложения .Во многих случаях мы используем библиотеки, чтобы сделать эту работу за нас, поэтому пока не особо беспокойтесь о деталях.
Пример :
Давайте посмотрим отрывок из текста об известной настольной игре под названием нарды.
Нарды — одна из старейших известных настольных игр. Его историю можно проследить почти 5000 лет назад до археологических открытий на Ближнем Востоке. Это игра для двух игроков, в которой каждый игрок имеет пятнадцать шашек, которые перемещаются между двадцатью четырьмя точками в соответствии с броском двух кубиков.
Чтобы применить токенизацию предложения с помощью NLTK, мы можем использовать функцию nltk.sent_tokenize .
В качестве вывода мы получаем 3 составных предложения по отдельности.
Нарды - одна из старейших известных настольных игр.Его история насчитывает почти 5000 лет, начиная с археологических открытий на Ближнем Востоке.
Это игра для двух игроков, в которой каждый игрок имеет пятнадцать шашек, которые перемещаются между двадцатью четырьмя точками в соответствии с броском двух кубиков.
2. Разметка слов
Разметка слов (также называемая сегментацией слов ) — это проблема деления строки письменного языка на , составляющих слов . В английском и многих других языках, в которых используется латинский алфавит, пробел является хорошим приближением к разделителю слов.
Тем не менее, у нас все еще могут быть проблемы, если мы будем разделять только по пробелам для достижения желаемых результатов. Некоторые составные существительные в английском языке пишутся по-разному и иногда содержат пробел.В большинстве случаев мы используем библиотеку для достижения желаемых результатов, поэтому снова не беспокойтесь о деталях.
Пример :
Давайте воспользуемся предложениями из предыдущего шага и посмотрим, как мы можем применить к ним токенизацию слов. Мы можем использовать функцию nltk.word_tokenize .
Вывод:
['Нарды', 'есть', 'один', 'из', 'самый', 'самый старый', 'известный', 'доска', 'игры', '.'][' Его ',' история ',' может ',' быть ',' прослеживаться ',' назад ',' почти ',' 5000 ',' лет ',' до ',' археологические ',' открытия ',' в ' , 'средний Восток', '.']
[' Это ',' есть ',' a ',' два ',' игрок ',' игра ',' где ',' каждый ',' игрок ',' имеет ',' пятнадцать ',' шашки ',' которые ',' двигаться ',' между ',' двадцать четыре ',' очки ',' согласно ',' до ',' the ',' roll ',' of ',' two ',' dice ','. ']
Лемматизация текста и формирование корней
По грамматическим причинам документы могут содержать различных форм слова , например, , привод , , привод , , ведущий . Кроме того, иногда у нас есть связанных слов со схожим значением, например, нация , нация , национальность .
Целью как , порождающего , так и лемматизации является сокращение флективных форм и иногда производных слова до общей основной формы .
Источник: https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Примеры :
- am, is, is
=>быть - собака, собаки, собаки, собаки ‘
=>собака
Результат этого сопоставления, примененного к тексту, будет примерно таким:
- собаки мальчика разных размеров
=>мальчик собака быть разным размером
Стемминг и лемматизация являются частными случаями нормализации .Однако они отличаются друг от друга.
Стемминг обычно относится к грубому эвристическому процессу , который обрезает концы слов в надежде на правильное достижение этой цели большую часть времени и часто включает удаление деривационных аффиксов.
Лемматизация обычно относится к , делающим вещи правильно с использованием словаря и морфологического анализа слов, обычно направленных на удаление только флективных окончаний и возвращение базовой или словарной формы слова, то есть известная как лемма .
Источник: https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Разница в том, что стеммер управляет без знания контекста , и поэтому не может понять разницу между словами, которые имеют разное значение в зависимости от части речи. Но у стеммеров есть и некоторые преимущества: их легче внедрить, и обычно работают быстрее . Кроме того, пониженная «точность» может не иметь значения для некоторых приложений.
Примеры:
- Слово «лучше» имеет лемму «хорошо». Эта ссылка пропущена при поиске по словарю.
- Слово «играть» является базовой формой слова «игра», и, следовательно, оно совпадает как в стемминге, так и в лемматизации.
- Слово «встреча» может быть как основной формой существительного, так и формой глагола («встречаться») в зависимости от контекста; например, «на нашей последней встрече» или «Мы снова встречаемся завтра». В отличие от стемминга, лемматизация пытается выбрать правильную лемму в зависимости от контекста.
После того, как мы узнаем, в чем разница, давайте рассмотрим несколько примеров с использованием инструмента NLTK.
Вывод:
Ствол: видно
Лемматизатор: см.Стеммер: водил
Лемматизатор: привод
Стоп-слова
Источник: http://www.nepalinlp.com/detail/stop-words-removal_nepali/Стоп-слова это слова, которые отфильтрованы до или после обработки текста. При применении машинного обучения к тексту эти слова могут добавить шума .Вот почему мы хотим удалить эти нерелевантных слов .
Стоп-слова обычно относятся к наиболее распространенным словам , таким как « и », « », « a » в языке, но не существует единого универсального списка стоп-слов. Список стоп-слов может меняться в зависимости от вашего приложения.
Инструмент NLTK имеет заранее определенный список стоп-слов, которые относятся к наиболее распространенным словам. Если вы используете его впервые, вам необходимо загрузить стоп-слова, используя этот код: nltk.скачать («стоп-слова») . После завершения загрузки мы можем загрузить пакет стоп-слов из nltk.corpus и использовать его для загрузки стоп-слов.
Вывод:
['я', 'я', 'мой', 'я', 'мы', 'наш', 'наш', 'мы', 'ты', "ты", " вы "," вы "," вы бы ", 'ваш', 'ваш', 'себя', 'себя', 'он', 'его', 'его', 'сам', ' she ', «она», «ее», «ее», «она», «это», «это», «ее», «сама», «они», «они», «их», «их» , 'сами', 'что', 'which', 'who', 'who', 'this', 'that', "that will", 'this', 'that', 'am', 'is' , 'есть', 'был', 'были', 'быть', 'был', 'быть', 'иметь', 'иметь', 'иметь', 'иметь', 'делать', 'делает', ' сделал ',' делаю ',' а ',' ан ',' то ',' и ',' но ',' если ',' или ',' потому что ',' как ',' до ',' пока ' , 'of', 'at', 'by', 'for', 'with', 'about', 'Again', 'between', 'into', 'through', 'во время', 'до', ' после ',' выше ',' ниже ',' в ',' от ',' вверх ',' вниз ',' внутрь ',' вне ',' вкл ',' выкл ',' над ',' под ' , 'снова', 'далее', 'затем', 'один раз', 'здесь', 'там', 'когда', 'где', 'почему', 'как', 'все', 'любое', ' оба ',' каждый ',' несколько ',' больше ',' большинство ',' другие ',' некоторые ',' такие ',' нет ',' ни ',' не ',' только y ',' own ',' same ',' so ',' than ',' too ',' very ',' s ',' t ',' can ',' will ',' просто ',' не ' , «не», «должен», «должен был», «сейчас», «d», «ll», «m», «o», «re», «ve», «y», « ain ',' aren ', "not",' couldn ', "could",' didn ', "didn", "not",' doesn ', "not",' hadn ', "hadn" t ", 'hasn'," hasn't ", 'haven'," Have ", 'isn'," not ", 'ma', 'mightn'," could not ", 'mustn' , «нельзя», «не нужно», «не нужно», «шань», «не нужно», «не следует», «не следует», «не было», «не было», «не было» , «не было», «выиграл», «не буду», «не стал бы», «не стал бы»]
Давайте посмотрим, как мы можем удалить стоп-слова из предложения.
Вывод:
['Нарды', 'один', 'самый старый', 'известный', 'доска', 'игры', '.']
Если вы не знакомы с пониманием списка в Python. Вот еще один способ добиться того же результата.
Однако имейте в виду, что составных частей списков на быстрее , потому что они оптимизированы для интерпретатора Python, чтобы определить предсказуемую закономерность во время цикла.
Вы можете спросить, почему мы конвертируем наш список в набор .Set — это абстрактный тип данных, который может хранить уникальные значения без какого-либо определенного порядка. Операция поиска в наборе намного быстрее , чем операция поиска в списке . Для небольшого количества слов большой разницы нет, но если у вас много слов, настоятельно рекомендуется использовать заданный тип.
Если вы хотите узнать больше о времени, затрачиваемом между различными операциями для разных структур данных, вы можете взглянуть на эту замечательную шпаргалку.
Regex
Источник: https://digitalfortress.tech/tricks/top-15-commonly-used-regex/Регулярное выражение , regex или regexp представляет собой последовательность символов, определяющих шаблон поиска . Давайте посмотрим основы.
-
.— соответствует любому символу , кроме символа новой строки -
\ w— соответствует слову -
\ d— соответствует цифре -
\ s— соответствует пробелам -
\ W— соответствует не слову -
\ D— соответствует не цифре -
\ S— соответствует без пробелов -
[abc]— соответствует любым из a, b или c -
[ ^ abc]— не соответствует a, b или c -
[a - g]— соответствует символу между a & g
Регулярные выражения используют символ обратной косой черты (
'\') для обозначения специальных форм или для разрешения использования специальных символов без обращения к их особому значению.Это противоречит использованию Python того же символа для той же цели в строковых литералах; например, чтобы соответствовать буквальной обратной косой черте, можно было бы написать'\\\\'в качестве строки шаблона, потому что регулярное выражение должно быть\, а каждая обратная косая черта должна быть выражена как\внутри обычный строковый литерал Python.Решение состоит в том, чтобы использовать нотацию необработанной строки Python для шаблонов регулярных выражений; Обратные косые черты не обрабатываются каким-либо особым образом в строковом литерале с префиксом
'r'.Итак,r "\ n"— это двухсимвольная строка, содержащая'\'и'n', а"\ n"— это односимвольная строка, содержащая новую строку. Обычно шаблоны выражаются в коде Python с использованием этой нотации необработанных строк.
Источник: https://docs.python.org/3/library/re.html?highlight=regex
Мы можем использовать регулярное выражение для применения дополнительной фильтрации к нашему тексту. Например, мы можем удалить все символы, не являющиеся словами. Во многих случаях знаки препинания не нужны, и их легко удалить с помощью регулярного выражения.
В Python модуль re предоставляет операции сопоставления регулярных выражений, аналогичные тем, что используются в Perl. Мы можем использовать функцию re.sub , чтобы заменить совпадения для шаблона строкой замены. Давайте посмотрим на пример, когда мы заменяем все не-слова символом пробела.
Продукт:
«Развитие сноуборда было вдохновлено катанием на скейтборде, санках, серфинге и лыжах»
Регулярное выражение — мощный инструмент, и мы можем создавать гораздо более сложные модели.Если вы хотите узнать больше о регулярных выражениях, я могу порекомендовать вам попробовать эти 2 веб-приложения: regexr, regex101.
Пакет слов
Источник: https://www.iconfinder.com/icons/299088/bag_iconАлгоритмы машинного обучения не могут работать напрямую с необработанным текстом, нам нужно преобразовать текст в векторы чисел. Это называется извлечением признаков .
Модель словаря — это популярная модель и простая методика извлечения признаков , используемая при работе с текстом.Он описывает появление каждого слова в документе.
Чтобы использовать эту модель, нам необходимо:
- Составить словарь известных слов (также называемых токенами )
- Выбрать показатель присутствия известных слов
Любая информация о словах порядок или структура слов отбрасывается . Вот почему он называется сумкой слов. Эта модель пытается понять, встречается ли в документе известное слово, но не знает, где это слово в документе.
Интуиция подсказывает, что похожих документов имеют похожих документов . Кроме того, из контента мы можем кое-что узнать о значении документа.
ПримерДавайте посмотрим, что нужно сделать для создания модели набора слов. В этом примере мы воспользуемся всего четырьмя предложениями, чтобы увидеть, как работает эта модель. В реальных задачах вы будете работать с гораздо большими объемами данных.
1. Загрузите данные
Источник: https: // www.iconfinder.com/icons/315166/note_text_iconДопустим, это наши данные, и мы хотим загрузить их как массив.
Для этого мы можем просто прочитать файл и разбить его по строкам.
Вывод:
[«Мне нравится этот фильм, он забавный.», «Я ненавижу этот фильм.», «Это было круто! Мне это нравится »,« Хороший. Мне это нравится. ']
2. Создайте словарь
Источник: https://www.iconfinder.com/icons/2109153/book_contact_dairy_google_service_iconДавайте возьмем все уникальные слова из четырех загруженных предложений, игнорируя регистр , пунктуация и односимвольные токены.Эти слова будут нашим словарным запасом (известные слова).
Мы можем использовать класс CountVectorizer из библиотеки sklearn для разработки нашего словаря. Мы увидим, как его можно использовать, после прочтения следующего шага.
3. Создайте векторы документов
Источник: https://www.iconfinder.com/icons/1574/binary_iconЗатем нам нужно оценить слова в каждом документе. Задача здесь — преобразовать каждый необработанный текст в вектор чисел. После этого мы можем использовать эти векторы в качестве входных данных для модели машинного обучения.Самый простой метод выставления оценок — отметить наличие слов цифрой 1 для присутствия и 0 для отсутствия.
Теперь давайте посмотрим, как мы можем создать модель набора слов, используя упомянутый выше класс CountVectorizer.
Выход :
Вот наши предложения. Теперь мы можем увидеть, как работает модель «мешка слов».
Дополнительные примечания к модели мешка слов
Источник: https://www.iconfinder.com/icons/1118207/clipboard_notes_pen_pencil_iconСложность модели мешка слов определяет, как разработать словарь известных слов (токенов) и как баллов за наличие известных слов.
Разработка словаря
Когда размер словаря увеличивается на , векторное представление документов также увеличивается. В приведенном выше примере длина вектора документа равна количеству известных слов.
В некоторых случаях у нас может быть огромных объемов данных , и в этих случаях длина вектора, представляющего документ, может составлять тысяч или миллионов элементов. Кроме того, каждый документ может содержать только несколько известных слов из словаря.
Следовательно, векторные представления будут содержать нулей . Эти векторы с большим количеством нулей называются разреженными векторами . Они требуют больше памяти и вычислительных ресурсов.
Мы можем уменьшить число известных слов при использовании модели набора слов, чтобы уменьшить требуемую память и вычислительные ресурсы. Мы можем использовать техник очистки текста , которые мы уже видели в этой статье, прежде чем создавать нашу модель набора слов:
- Игнорирование регистра слов
- Игнорирование знаков препинания
- Удаление стоп-слов из наших документов
- Приведение слов к их базовой форме ( Лемматизация текста и составление стемминга )
- Исправление слов с ошибками
Другой более сложный способ создания словаря — использование сгруппированных слов .Это изменяет объем словаря и позволяет модели набора слов получить дополнительных сведений о документе. Такой подход называется н-грамм .
N-грамма — это последовательность из , число из элементов (слова, буквы, цифры, цифры и т. Д.). В контексте корпусов n-граммы обычно относятся к последовательности слов. Униграмма , — это одно слово, биграмма , — это последовательность из двух слов, триграмма , — это последовательность из трех слов и т. Д.Буква «n» в «n-грамме» относится к количеству сгруппированных слов. Моделируются только n-граммы, которые появляются в корпусе, а не все возможные n-граммы.
Пример
Давайте посмотрим на все биграммы для следующего предложения:
Офисное здание открыто сегодня
Все биграммы:
- офис
- офисное здание
- здание
- открыто
- открыто сегодня
Пакет биграмм более эффективен, чем подход «мешка слов».
Оценка слов
После того, как мы создали наш словарь известных слов, нам нужно оценить вхождение слов в наши данные. Мы видели один очень простой подход — бинарный подход (1 для присутствия, 0 для отсутствия).
Некоторые дополнительные методы подсчета очков:
- Подсчет . Подсчитайте, сколько раз каждое слово встречается в документе.
- Частоты . Вычислите частоту появления каждого слова в документе из всех слов в документе.
TF-IDF
Одна из проблем с частотой слов для оценки заключается в том, что наиболее часто встречающиеся слова в документе начинают получать самые высокие оценки. Эти частые слова могут не содержать столько « информационного прироста » для модели по сравнению с некоторыми более редкими и специфическими для предметной области словами. Один из подходов к решению этой проблемы — оштрафовать слов, которые встречаются на часто во всех документах. Такой подход называется TF-IDF.
TF-IDF, сокращенно от термина частота-обратная частота документа — это статистический показатель , используемый для оценки важности слова для документа в коллекции или корпусе.
Значение оценки TF-IDF увеличивается пропорционально тому, сколько раз слово появляется в документе, но компенсируется количеством документов в корпусе, содержащих это слово.
Давайте посмотрим на формулу, используемую для расчета показателя TF-IDF для данного термина x в документе y .
Формула TF-IDF. Источник: http://filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlТеперь давайте немного разделим эту формулу и посмотрим, как разные части формулы Работа.
- Term Frequency (TF) : оценка частоты встречаемости слова в текущем документе.
- Частота обратного члена (ITF) : оценка того, насколько редко слово встречается в документах.
- Наконец, мы можем использовать предыдущие формулы для вычисления оценки TF-IDF для данного термина следующим образом:
Пример
В Python мы можем использовать Класс TfidfVectorizer из библиотеки sklearn для расчета оценок TF-IDF для заданных документов.Давайте использовать те же предложения, что и в примере с набором слов.
Вывод:
Опять же, я добавлю сюда предложения, чтобы упростить сравнение и лучше понять, как работает этот подход.
В этом сообщении в блоге вы узнаете основы НЛП для текста. В частности, вы изучили следующие концепции с дополнительными деталями:
- NLP используется для применения алгоритмов машинного обучения , текста и речи .
- NLTK ( Natural Language Toolkit ) — это ведущая платформа для создания программ Python для работы с данными человеческого языка
- Токенизация предложений — это проблема деления строки письменного языка на ее компонент предложений
- Токенизация слов — это проблема деления строки письменного языка на его составляющих слов
- Целью корня и лемматизации является уменьшить перегиб образует и иногда производные формы слова до общей базовой формы .
- Стоп-слова — это слова, которые отфильтровываются до или после обработки текста. Они обычно относятся к наиболее распространенным словам в языке.
- Регулярное выражение — это последовательность символов , определяющая шаблон поиска .
- Модель словаря — это популярная и простая техника извлечения признаков , используемая при работе с текстом. Он описывает появление каждого слова в документе.
- TF-IDF — это статистический показатель , используемый для оценки важности слова для документа в коллекции или корпусе.
Отлично! Теперь мы знаем основы извлечения функций из текста. Затем мы можем использовать эти функции в качестве входных данных для алгоритмов машинного обучения.
Вы хотите увидеть все концепции , используемые в еще одном большом примере ?
— Вот и ты! Если вы читаете с мобильного, прокрутите вниз до конца и нажмите ссылку « Desktop version ».
Вот интерактивная версия этой статьи, загруженная в Deepnote (облачная платформа Jupyter Notebook). Не стесняйтесь проверить это и поиграть с примерами.
Вы также можете проверить мои предыдущие сообщения в блоге.
Если вы хотите получать уведомления, когда я публикую новый пост в блоге, вы можете подписаться на мой свежий информационный бюллетень.
Вот мой профиль в LinkedIn на случай, если вы захотите связаться со мной. Я буду счастлив быть на связи с вами.
Спасибо за прочитанное.Надеюсь, статья вам понравилась. Если вам это нравится, пожалуйста, удерживайте кнопку хлопка и поделитесь ею с друзьями. Буду рад услышать ваш отзыв. Если у вас есть вопросы, не стесняйтесь их задавать. 😉
python — Как разбирать имена из необработанного текста
Я не знаю, почему вы думаете, что вам нужен NLTK только для исключения словарных слов; простой словарь (который вы могли установить где-нибудь, например, / usr / share / dict / words , или вы можете скачать его из Интернета) — это все, что вам нужно:
с открытым ('/ usr / share / dict / words') как f:
dictwords = {слово.strip () вместо слова в f}
с открытым (mypath) как f:
names = [слово в строке в f вместо слова в строке.rstrip (). split ()
если word.lower () не в dictwords]
Ваш список из слов может включать имена, но если это так, они будут включать их с заглавной буквы, поэтому:
dictwords = {word.strip () вместо слова в f, если word.islower ()}
Или, если вы хотите занести в белый список имена собственные, а не слова из словаря в черный список:
с open ('/ usr / share / dict / ownnames') как f:
namewords = {слово.strip () вместо слова в f}
с открытым (mypath) как f:
names = [слово в строке в f вместо слова в строке.rstrip (). split ()
if word.title () в словах имен]
Но это действительно не сработает. Взгляните на «Джима Уайта» из своего примера. Его фамилия, очевидно, будет в любом словаре, а его имя будет во многих (как краткая версия «джимми», как обычная латинизация арабской буквы «jīm» и т. Д.). «Марк» также является обычным словарным словом. И наоборот, «Воля» — очень распространенное имя, даже если вы хотите трактовать его как слово, а «Счастье» — необычное имя, но оно есть по крайней мере у некоторых людей.
Итак, чтобы эта работа хоть немного сработала, вы, вероятно, захотите объединить несколько эвристик. Во-первых, вместо того, чтобы слово всегда было именем или никогда не было именем, каждое слово с вероятностью может быть использовано в качестве имени в некотором соответствующем корпусе — Уайт может быть именем в 13,7% случаев, Марк — 41,3%, Джим — 99,1%. , Счастье 0,1% и т. Д. Далее, если это не первое слово в предложении, а написано с заглавной буквы, то гораздо более вероятно, что это будет имя (сколько еще? Я не знаю, вам нужно проверить и настроить для вашего конкретного ввода), а если это строчные буквы, то вряд ли это будет имя.Вы можете добавить больше контекста — например, у вас много полных имен, поэтому, если какое-то возможное имя и оно появляется рядом с чем-то, что является общей фамилией, это, скорее всего, будет имя. Вы даже можете попытаться проанализировать грамматику (это нормально, если вы откажетесь от некоторых предложений; они просто не получат никакого ввода из правила грамматики), поэтому, если два соседних слова работают только как часть предложения, первое, если второе глагол, они, вероятно, не имя и фамилия, даже если то же самое второе слово могло быть существительным (и именем) в других контекстах.И так далее.
14 струн | R для науки о данных
Введение
Эта глава знакомит вас с манипуляциями со строками в R. Вы узнаете основы того, как работают строки и как создавать их вручную, но основное внимание в этой главе будет уделено регулярным выражениям или, для краткости, регулярным выражениям. Регулярные выражения полезны, потому что строки обычно содержат неструктурированные или частично структурированные данные, а регулярные выражения — это краткий язык для описания шаблонов в строках.Когда вы впервые посмотрите на регулярное выражение, вы подумаете, что кошка шла по клавиатуре, но по мере того, как ваше понимание улучшится, они скоро начнут обретать смысл.
Предпосылки
В этой главе основное внимание уделяется пакету stringr для манипуляций со строками, который является частью основного тидиверса.
Основы работы со струнами
Вы можете создавать строки как в одинарных, так и в двойных кавычках. В отличие от других языков, нет никакой разницы в поведении.Я рекомендую всегда использовать ", если вы не хотите создать строку, содержащую несколько " .
string1 <- "Это строка"
string2 <- 'Если я хочу включить в строку «кавычки», я использую одинарные кавычки' Если вы забудете закрыть цитату, вы увидите + , символ продолжения:
> "Это строка без закрывающей кавычки.
+
+
+ ПОМОГИТЕ Я застрял Если это случилось с вами, нажмите Escape и попробуйте еще раз!
Чтобы включить буквальную одинарную или двойную кавычку в строку, вы можете использовать \ , чтобы «экранировать» ее:
double_quote <- "\" "# или '"'
single_quote <- '\' '# или "'" Это означает, что если вы хотите включить буквальную обратную косую черту, вам нужно будет удвоить ее: "\\" .
Помните, что напечатанное представление строки не совпадает с самой строкой, потому что напечатанное представление показывает escape-последовательности. Чтобы увидеть необработанное содержимое строки, используйте writeLines () :
x <- c ("\" "," \\ ")
Икс
#> [1] "\" "" \\ "
writeLines (x)
#> "
#> \ Есть несколько других специальных символов. Наиболее распространены "\ n" , новая строка и "\ t" , вкладка, но вы можете увидеть полный список, запросив помощь по телефону ": ? '"' или ? "' «.Иногда встречаются строки вроде "\ u00b5" , это способ написания неанглийских символов, который работает на всех платформах:
x <- "\ u00b5"
Икс
#> [1] "µ" Несколько строк часто хранятся в векторе символов, который можно создать с помощью c () :
c («один», «два», «три»)
#> [1] "один" "два" "три" Длина струны
Base R содержит множество функций для работы со строками, но мы будем избегать их, потому что они могут быть несовместимыми, что затрудняет их запоминание.Вместо этого мы будем использовать функции из stringr. У них более интуитивно понятные имена, и все они начинаются с str_ . Например, str_length () сообщает количество символов в строке:
str_length (c ("a", "R для науки о данных", NA))
#> [1] 1 18 NA Общий префикс str_ особенно полезен, если вы используете RStudio, потому что ввод str_ вызовет автозаполнение, что позволит вам увидеть все функции строкового набора:
Объединение струн
Чтобы объединить две или более строк, используйте str_c () :
str_c ("x", "y")
#> [1] "ху"
str_c ("x", "y", "z")
#> [1] "xyz" Используйте аргумент sep , чтобы контролировать, как они разделяются:
str_c ("x", "y", sep = ",")
#> [1] "x, y" Как и в большинстве других функций в R, пропущенные значения заразительны.Если вы хотите, чтобы они печатались как «NA» , используйте str_replace_na () :
x <- c ("abc", нет данных)
str_c ("| -", x, "- |")
#> [1] "| -abc- |" NA
str_c ("| -", str_replace_na (x), "- |")
#> [1] "| -abc- |" "| -NA- |" Как показано выше, str_c () векторизован и автоматически перерабатывает более короткие векторы до той же длины, что и самый длинный:
str_c ("префикс-", c ("a", "b", "c"), "-suffix")
#> [1] «префикс-а-суффикс» «префикс-b-суффикс» «префикс-с-суффикс» Объекты длины 0 отбрасываются без уведомления.Это особенно полезно в сочетании с , если :
имя <- "Хэдли"
time_of_day <- "утро"
день рождения <- ЛОЖЬ
str_c (
"Хорошо", время_дня, "", имя,
if (день рождения) "и С ДНЕМ РОЖДЕНИЯ",
"."
)
#> [1] "Доброе утро, Хэдли". Чтобы свернуть вектор строк в одну строку, используйте collapse :
str_c (c ("x", "y", "z"), collapse = ",")
#> [1] "x, y, z" Подмножество строк
Вы можете извлечь части строки с помощью str_sub () .Помимо строки, str_sub () принимает аргументы start и end , которые задают (включительно) позицию подстроки:
x <- c («Яблоко», «Банан», «Груша»)
str_sub (х, 1, 3)
#> [1] "App" "Ban" "Pea"
# отрицательные числа считают в обратном порядке от конца
str_sub (х, -3, -1)
#> [1] "ple" "ana" "ear" Обратите внимание, что str_sub () не завершится ошибкой, если строка слишком короткая: она просто вернет столько, сколько возможно:
str_sub ("а", 1, 5)
#> [1] "a" Вы также можете использовать форму назначения str_sub () для изменения строк:
str_sub (x, 1, 1) <- str_to_lower (str_sub (x, 1, 1))
Икс
#> [1] "яблоко" "банан" "груша" Регионы
Выше я использовал str_to_lower () , чтобы изменить текст на нижний регистр.Вы также можете использовать str_to_upper () или str_to_title () . Однако изменить регистр сложнее, чем может показаться на первый взгляд, потому что разные языки имеют разные правила изменения регистра. Вы можете выбрать, какой набор правил использовать, указав локаль:
# Турецкий имеет два "i": с точкой и без нее, и это
# имеет другое правило использования заглавных букв:
str_to_upper (c ("я", "ı"))
#> [1] «Я» «Я»
str_to_upper (c ("i", "ı"), locale = "tr")
#> [1] "İ" "I" Локаль указывается в виде кода языка ISO 639, который представляет собой двух- или трехбуквенное сокращение.Если вы еще не знаете код своего языка, в Википедии есть хороший список. Если вы оставите языковой стандарт пустым, он будет использовать текущий языковой стандарт, предоставленный вашей операционной системой.
Еще одна важная операция, на которую влияет локаль, - это сортировка. Базовые функции order () и sort () в R сортируют строки, используя текущую локаль. Если вы хотите надежного поведения на разных компьютерах, вы можете использовать str_sort () и str_order () , которые принимают дополнительный аргумент locale :
x <- c («яблоко», «баклажан», «банан»)
str_sort (x, locale = "en") # английский
#> [1] "яблоко" "банан" "баклажан"
str_sort (x, locale = "haw") # гавайский
#> [1] "яблоко" "баклажан" "банан" Упражнения
В коде, который не использует stringr, вы часто встретите
paste ()иpaste0 ().В чем разница между двумя функциями? Какие функции Stringr они эквивалентны? Чем отличаются функции по обработкеNA?Своими словами опишите разницу между
sepиcollapseаргументы дляstr_c ().Используйте
str_length ()иstr_sub ()для извлечения среднего символа из строка. Что вы будете делать, если в строке будет четное количество символов?Что делает
str_wrap ()? Когда вы можете захотеть его использовать?Что делает
str_trim ()? Что противоположноstr_trim ()?Напишите функцию, которая поворачивает (например,g.) вектор
c ("a", "b", "c")в строкаa, b и c. Тщательно подумайте, что ему делать, если задан вектор длиной 0, 1 или 2.
Сопоставление шаблонов с регулярными выражениями
Регулярные выражения - очень сжатый язык, который позволяет описывать шаблоны в строках. На их понимание уходит время, но как только вы их поймете, вы найдете их чрезвычайно полезными.
Для изучения регулярных выражений мы будем использовать str_view () и str_view_all () .Эти функции принимают вектор символов и регулярное выражение и показывают, как они совпадают. Мы начнем с очень простых регулярных выражений, а затем постепенно будем усложнять их. Освоив сопоставление с образцом, вы научитесь применять эти идеи с различными строковыми функциями.
Основные матчи
Самые простые шаблоны соответствуют точным строкам:
x <- c («яблоко», «банан», «груша»)
str_view (x, "an") Следующая ступень сложности - ., что соответствует любому символу (кроме новой строки):
Но если «. »соответствует любому символу, как сопоставить символ« . ”? Вам нужно использовать «escape», чтобы указать регулярному выражению, которое вы хотите точно сопоставить с ним, а не использовать его особое поведение. Как и строки, регулярные выражения используют обратную косую черту \ , чтобы избежать особого поведения. Таким образом, чтобы соответствовать . , вам нужно регулярное выражение \. . К сожалению, это создает проблему. Мы используем строки для представления регулярных выражений, а \ также используется как escape-символ в строках.Итак, чтобы создать регулярное выражение \. нам нужна строка "\\." .
# Для создания регулярного выражения нам понадобится \\
точка <- "\\."
# Но само выражение содержит только один:
writeLines (точка)
#> \.
# И это говорит R искать явное.
str_view (c ("abc", "a.c", "bef"), "a \\. c") Если \ используется как escape-символ в регулярных выражениях, как сопоставить литерал \ ? Что ж, вам нужно избежать этого, создав регулярное выражение \ .Чтобы создать это регулярное выражение, вам нужно использовать строку, которая также должна экранировать \ . Это означает, что для сопоставления букв \ вам нужно написать "\\\\" - вам нужно четыре обратной косой черты, чтобы соответствовать одной!
х <- "а \\ б"
writeLines (x)
#> a \ b
str_view (x, "\\\\") В этой книге я буду писать регулярное выражение как \. и строки, представляющие регулярное выражение как "\\." .
Упражнения
Объясните, почему каждая из этих строк не соответствует
\:"\","\\","\\\".Как бы вы соответствовали последовательности
"'\?Каким шаблонам будет соответствовать регулярное выражение
\ ., чтобы соответствовать началу строки. и$:x <- c («яблочный пирог», «яблоко», «яблочный пирог») str_view (x, "яблоко")Вы также можете сопоставить границу между словами с помощью
\ b. Я не часто использую это в R, но иногда я использую его, когда выполняю поиск в RStudio, когда я хочу найти имя функции, которая является компонентом других функций. Например, я буду искать\ bsum \ b, чтобы не совпадатьсводка, сводкастрокаи т. Д.$ "?Учитывая совокупность общих слов в строке
stringr :: words, создайте регулярный выражения, которые находят все слова которые:- Начать с «y».
- Окончание на «x»
- Ровно три буквы. (Не обманывайте, используя
str_length ()!) - Имейте семь или более букв.
Поскольку этот список длинный, вы можете использовать аргумент
matchдляstr_view (), чтобы показать только совпадающие или несоответствующие слова. abc] : соответствует чему угодно, кроме a, b или c.Создайте регулярные выражения, чтобы найти все слова, которые:
Начните с гласной.
Это только согласные. (Подсказка: подумайте о сопоставлении «Не» -гласные.)
Заканчивается на
ed, но не наeed.Заканчивается на
ingилиise.
Эмпирически проверьте правило «i до e, кроме c».
Всегда ли за «q» следует «u»?
Напишите регулярное выражение, которое соответствует слову, если оно, вероятно, написано на британском, а не на американском английском.
Создайте регулярное выражение, которое будет соответствовать телефонным номерам, как обычно написано в вашей стране.
-
?: 0 или 1 -
+: 1 или более -
*: 0 или более -
{n}: ровно n -
{n,}: n или более -
{, m}: не более m -
{n, m}: между n и m -
"\\ {. + \\}" -
\ d {4} - \ d {2} - \ d {2} -
"\\\\ {4}"
Помните, чтобы создать регулярное выражение, содержащее \ d или \ s , вам нужно экранировать \ для строки, поэтому вы наберете "\\ d" или "\ \ s ".
Символьный класс, содержащий один символ, является хорошей альтернативой экранированию обратной косой черты, когда вы хотите включить один метасимвол в регулярное выражение. Многим это кажется более читаемым.
# Ищите буквальный символ, который обычно имеет особое значение в регулярном выражении
str_view (c ("abc", "a.c »,« a * c »,« a c »),« a [.] c »)
str_view (c («abc», «a.c», «a * c», «a c»), «. [*] C»)
str_view (c («abc», «a.c», «a * c», «a c»), «a []») Это работает для большинства (но не для всех) метасимволов регулярных выражений: $ . | ? * + ( ) [ {. и - .
Вы можете использовать чередование , чтобы выбрать один или несколько альтернативных шаблонов. Например, abc | d..f будет соответствовать либо «abc», либо «глухой» . Обратите внимание, что приоритет для | является низким, поэтому abc | xyz соответствует abc или xyz , а не abcyz или abxyz . Как и в случае с математическими выражениями, если приоритеты когда-либо сбиваются с толку, используйте круглые скобки, чтобы прояснить, что вы хотите:
str_view (c ("серый", "серый"), "gr (e | a) y") Упражнения
Повторение
Следующий шаг в развитии - это контроль количества совпадений шаблона:
x <- "1888 год - самый длинный год в римских цифрах: MDCCCLXXXVIII"
str_view (x, "CC?") Обратите внимание, что приоритет этих операторов высок, поэтому вы можете написать: colou? R для соответствия американскому или британскому написанию.Это означает, что в большинстве случаев требуются круглые скобки, например bana (na) + .
Также можно точно указать количество совпадений:
По умолчанию эти совпадения являются «жадными»: они будут соответствовать самой длинной возможной строке. Вы можете сделать их «ленивыми», сопоставив самую короткую строку, указав ? после них.* $
Создайте регулярные выражения, чтобы найти все слова, которые:
- Начните с трех согласных.
- Имеет три или более гласных подряд.
- Имеются две или более пары гласный-согласный подряд.
Решите кроссворды с регулярными выражениями для начинающих на https://regexcrossword.com/challenges/beginner.
Группировка и обратные ссылки
Ранее вы узнали о скобках как о способе устранения неоднозначности сложных выражений. Скобки также создают группу захвата с номером (номер 1, 2 и т. Д.). Группа захвата хранит часть строки , совпадающую с частью регулярного выражения в круглых скобках. Вы можете ссылаться на тот же текст, который ранее соответствовал группе захвата с обратными ссылками , например \ 1 , \ 2 и т. Д.Например, следующее регулярное выражение находит все фрукты с повторяющейся парой букв.
str_view (fruit, "(..) \\ 1", match = TRUE) (Вскоре вы также увидите, насколько они полезны в сочетании с str_match () .)
Упражнения
Опишите словами, чему будут соответствовать эти выражения:
-
(.) \ 1 \ 1 -
"(.) (.) \\ 2 \\ 1" -
(..) \ 1 -
"(.). \\ 1. \\ 1" -
"(.) (.) (.). * \\ 3 \\ 2 \\ 1"
-
Создавать регулярные выражения для соответствия словам, которые:
Начало и конец одного и того же символа.
Содержит повторяющуюся пару букв (например, «церковь» содержит дважды повторяемую букву «ч».)
Содержит одну букву, повторяющуюся как минимум в трех местах (например, «одиннадцать» содержит три «е».)
Инструменты
Теперь, когда вы изучили основы регулярных выражений, пора научиться применять их к реальным задачам.В этом разделе вы познакомитесь с широким спектром строковых функций, которые позволят вам:
- Определите, какие строки соответствуют шаблону.
- Найдите позиции совпадений.
- Извлечь содержимое совпадений.
- Заменить совпадения новыми значениями.
- Разделить строку на основе совпадения.
Перед тем, как продолжить, сделаем небольшое предостережение: поскольку регулярные выражения настолько эффективны, легко попытаться решить любую проблему с помощью одного регулярного выражения.\ [\] \ r \\] | \\.) * \] (?: (?: \ r \ n)? [\ t]) *)) * \> (? 🙁 ?: \ r \ n)? [\ t]) *)) *)?; \ s *)
Это несколько патологический пример (потому что адреса электронной почты на самом деле удивительно сложны), но он используется в реальном коде. Подробнее см. Обсуждение stackoverflow на http://stackoverflow.com/a/201378.
Не забывайте, что вы изучаете язык программирования и в вашем распоряжении есть другие инструменты. Вместо создания одного сложного регулярного выражения часто проще написать серию более простых регулярных выражений.Если вы застряли, пытаясь создать одно регулярное выражение, которое решает вашу проблему, сделайте шаг назад и подумайте, можете ли вы разбить проблему на более мелкие части, решая каждую задачу, прежде чем переходить к следующей.
Обнаружить совпадения
Чтобы определить, соответствует ли вектор символов шаблону, используйте str_detect () . Он возвращает логический вектор той же длины, что и вход:
x <- c («яблоко», «банан», «груша»)
str_detect (x, "e")
#> [1] ИСТИНА ЛОЖЬ ИСТИНА Помните, что когда вы используете логический вектор в числовом контексте, FALSE становится 0, а TRUE становится 1.т "))
#> [1] 65
# Какая доля общих слов оканчивается на гласную?
означает (str_detect (слова, "[aeiou] $"))
#> [1] 0,2765306
Когда у вас есть сложные логические условия (например, соответствие a или b, но не c, кроме d), часто проще объединить несколько вызовов str_detect () с логическими операторами, чем пытаться создать одно регулярное выражение. Например, вот два способа найти все слова, не содержащие гласных:
# Найти все слова, содержащие хотя бы одну гласную, и убрать
no_vowels_1 <-! str_detect (слова, «[aeiou]»)
# Найти все слова, состоящие только из согласных (не гласных)
no_vowels_2 <- str_detect (слова, "^ [^ aeiou] + $")
идентичные (no_vowels_1, no_vowels_2)
#> [1] ИСТИНА Результаты идентичны, но я думаю, что первый подход значительно легче понять.Если ваше регулярное выражение становится слишком сложным, попробуйте разбить его на более мелкие части, дать каждой части имя, а затем объединить части с помощью логических операций.
Обычно str_detect () используется для выбора элементов, соответствующих шаблону. Вы можете сделать это с помощью логического подмножества или удобной оболочки str_subset () :
слово [str_detect (words, "x $")]
#> [1] "коробка" "секс" "шестерка" "налог"
str_subset (слова, "x $")
#> [1] "коробка" "пол" "шестерка" "налог" Однако, как правило, ваши строки представляют собой один столбец фрейма данных, и вместо этого вы хотите использовать фильтр:
df <- tibble (
слово = слова,
я = seq_along (слово)
)
df%>%
фильтр (str_detect (слово, "x $"))
#> # Стол: 4 x 2
#> слово i
#>
#> 1 коробка 108
#> 2 пол 747
#> 3 шесть 772
#> 4 налог 841 Вариантом str_detect () является str_count () : вместо простого да или нет он сообщает вам, сколько совпадений в строке:
x <- c («яблоко», «банан», «груша»)
str_count (x, «а»)
#> [1] 1 3 1
# Сколько в среднем гласных в слове?
означает (str_count (слова, "[aeiou]"))
#> [1] 1.aeiou] ")
)
#> # Стол: 980 x 4
#> слово i гласные согласные
#>
#> 1 а 1 1 0
#> 2 в состоянии 2 2 2
#> 3 примерно 3 3 2
#> 4 абсолютное 4 4 4
#> 5 принять 5 2 4
#> 6 счет 6 3 4
#> #… С еще 974 строками Обратите внимание, что совпадения никогда не перекрываются. Например, в «abababa» , сколько раз будет совпадать шаблон «aba» ? Регулярные выражения говорят два, а не три:
str_count ("abababa", "aba")
#> [1] 2
str_view_all ("abababa", "aba") Обратите внимание на использование str_view_all () .Как вы вскоре узнаете, многие строковые функции работают парами: одна функция работает с одним совпадением, а другая - со всеми совпадениями. Вторая функция будет иметь суффикс _all .
Упражнения
Для каждой из следующих задач попробуйте решить ее, используя как одну регулярное выражение и комбинация нескольких вызовов
str_detect ().Найдите все слова, которые начинаются или заканчиваются на
x.Найдите все слова, которые начинаются с гласной и заканчиваются согласной.
Существуют ли слова, содержащие хотя бы одно из разных гласный звук?
В каком слове больше всего гласных? Какое слово имеет высшее доля гласных? (Подсказка: какой знаменатель?)
Групповые матчи
Ранее в этой главе мы говорили об использовании круглых скобок для уточнения приоритета и для обратных ссылок при сопоставлении.] +) " has_noun <- предложения%>% str_subset (имя существительное)%>% голова (10) has_noun%>% str_extract (имя существительное) #> [1] "гладкая" "простыня" "глубина" "курица" "припаркованная" #> [6] "солнышко" "огромный" "мяч" "женщина" "помогает"
str_extract () дает нам полное совпадение; str_match () дает каждый отдельный компонент. Вместо вектора символов он возвращает матрицу с одним столбцом для полного соответствия, за которым следует один столбец для каждой группы:
has_noun%>%
str_match (имя существительное)
#> [, 1] [, 2] [, 3]
#> [1,] "гладкий" "" "гладкий"
#> [2,] "лист" "" "лист"
#> [3,] "глубина" "" "глубина"
#> [4,] "курица" "a" "курица"
#> [5,] "припаркованный" "" "припаркованный"
#> [6,] "солнце" "" "солнце"
#> [7,] "огромный" "" "огромный"
#> [8,] "мяч" "" "мяч"
#> [9,] "женщина" "" женщина "
#> [10,] «а помогает» «а» «помогает» (Неудивительно, что наша эвристика для определения существительных неубедительна, и мы также подбираем такие прилагательные, как гладкий и припаркованный.] +) ",
remove = FALSE
)
#> # Таблица: 720 x 3
#> предложение статья существительное
#> Как и Найдите все слова, которые идут после «числа», например «один», «два», «три» и т. Д.
Вытяните и число, и слово. Найдите все схватки.Разделите части до и после
апостроф. С помощью Вместо замены на фиксированную строку вы можете использовать обратные ссылки для вставки компонентов соответствия.] +) "," \\ 1 \\ 3 \\ 2 ")%>%
голова (5)
#> [1] «Каноэ-береза скользила по гладким доскам».
#> [2] "Приклейте лист к темно-синему фону".
#> [3] «Глубину колодца легко определить».
#> [4] «В наши дни куриная ножка - редкое блюдо».
#> [5] «Рис часто подают в круглых мисках». Заменить все косые черты в строке обратными. Реализуйте простую версию Поменять местами первую и последнюю буквы в Используйте Поскольку каждый компонент может содержать разное количество частей, возвращается список. Если вы работаете с вектором длины 1, проще всего просто извлечь первый элемент списка: В противном случае, как и другие строковые функции, возвращающие список, вы можете использовать Вы также можете запросить максимальное количество штук: Вместо того, чтобы разделять строки по шаблонам, вы также можете разделить их по символу, строке, предложению и слову Разделите строку, например Почему лучше разбить на Что делает разделение с пустой строкой ( Общий выход экстракции трубопровода составляет 28%, что означает, что из 53 538 параграфов в твердом состоянии только 15 144 из них вызывают сбалансированную химическую реакцию. В качестве теста полного конвейера извлечения мы случайным образом извлекли 100 абзацев из набора абзацев, классифицированных как твердотельный синтез, и проверили их на полноту извлеченных данных.Из 100 абзацев мы нашли 30, которые не содержали полного набора исходных материалов и конечных продуктов, а это означает, что эксперт-человек не сможет восстановить реакцию по этим абзацам. Остальные 70 абзацев потенциально могут внести свой вклад в набор данных, поскольку они предоставляют всю информацию о исходных материалах и конечных продуктах. Проверка этих 70 параграфов показала, что 42 потенциальных реакции не были реконструированы из-за неполного или чрезмерного набора извлеченных материалов-предшественников / мишеней или невозможности проанализировать химический состав, что делает невозможным балансировку реакции.Первая потеря возникает из-за более низкого повторного вызова алгоритма MER, который мы обменяли на более высокую точность, в то время как проблема синтаксического анализа возникает из-за сложной записи, используемой для объекта материалов. Оценка точности записей набора данных была проведена путем случайного отбора 100 записей и ручной проверки каждого извлеченного поля на соответствие исходному абзацу. Расчетная точность, полнота и оценка F1 для каждого атрибута ввода данных приведены в таблице 2. В целом мы достигли высокой точности при извлечении целей (точность 97%), предшественников (оценка F1 99%), операций ( F1-оценка 90%) и уравновешивающие реакции (точность 95%).Более низкая точность условий нагрева (F1-оценка <90%) в основном вызвана случаями, когда этап нагрева пропускается алгоритмом извлечения операций. Восстановление условий смешивания показывает относительно низкую точность с оценкой F1 65%. Это в значительной степени связано с ошибочной идентификацией MER материала устройства или вещества среды, используемой для смешивания, а также потому, что эти условия часто не упоминаются в том же предложении, что и процедура смешивания. Этот анализ приводит нас к выводу, что на химическом уровне (правильные прекурсоры, мишени, реакции) точность набора данных составляет 93%. При включении всех операций и их условий точность извлечения и правильного назначения всех элементов рецепта (химии, операций и атрибутов операций) составляет 51%, что является низким показателем из-за низкой производительности при извлечении атрибутов смешивания. Для многих твердотельных рецептов особенности смешивания прекурсоров менее важны, поэтому этот сбой экстракции менее критичен.При рассмотрении только правильности рецепта без условий нагрева и смешивания (т.е. химии, операций и реакций) точность возрастает до 64%. Стоит отметить, что для этого набора данных мы стремились достичь более высокой точности извлечения данных за счет меньшего количества повторных вызовов (т.е. лучше пропустить запись данных, чем предоставить неправильную), поэтому скорость извлечения низкая. Тем не менее, построение сбалансированного химического уравнения устанавливает дополнительные ограничения для целей и прекурсоров и помогает уменьшить потенциальные ошибки, которые могли быть вызваны анализом состава.Это приводит к перекосу показателей в сторону более высокой точности идентификации целей и предшественников по сравнению с операциями. Чтобы проверить разнообразие записей, представляющих набор данных, мы сначала получили список уникальных материалов (целей и прекурсоров) и реакций. Набор данных содержит 13 009 уникальных целей, 1845 уникальных предшественников и 16 290 уникальных реакций. Почти в 10 раз меньшее разнообразие прекурсоров по сравнению с мишенями можно объяснить тем фактом, что в целом исследователи работают с набором общих, хорошо зарекомендовавших себя прекурсоров.В таблице 3 представлены десять наиболее частых целей, предшественников и реакций в наборе данных. Целевые соединения точно охватывают типы материалов, наиболее часто изучаемые в последние два десятилетия с помощью твердотельного синтеза. Это катодные материалы для литий-ионных аккумуляторов (LiFePO 4 , LiMn 2 O 4 и LiNi 0,5 Mn 1,5 O 4 ), а также перовскиты для мультиферроиков, светодиодов и приложений CMOS 920 (BaTiO 3 , BiFeO 3 , SrTiO 3 , Y 3 Al 5 O 12 ).Возможно, что этот список «первой десятки» материалов смещен из-за набора издателей, которые дали нам разрешение на доступ к их научному корпусу. Например, Американское физическое общество не было включено и, возможно, внесло в список другие соединения. Затем мы оцениваем химическое пространство, охватываемое набором данных. Для каждого химического элемента мы вычислили количество реакций, которые включают данный элемент в мишень.Результаты отображены на рис. 2 в рамке с градиентом от желтого к зеленому в верхней части окна каждого элемента. В базе данных преобладают целевые материалы, содержащие Ti, Sr, Ba, La, Fe -> 3000 реакций включают эти мишени с этими элементами. Это также отражено в списке из десяти наиболее часто встречающихся целевых материалов, появляющихся в наборе данных (Таблица 3). Следующими по распространенности мишенями являются материалы с Li, Ca, Nb, Mn, Bi - 2 000–3 000 реакций с этими элементами в мишенях. Наименее распространенными элементами являются Au, Pt, Os, Be - <13 реакций в наборе данных содержат эти элементы.Редкие и радиоактивные элементы, такие как франций, радий, технеций или прометий, не представлены в целевых материалах набора данных. Карта химического пространства, охваченного набором данных. Для каждого элемента рамка, окрашенная в градиент от желтого к зеленому, представляет собой общее количество реакций, в результате которых образуется целевое соединение, содержащее элемент. Гистограмма под каждым элементом показывает список ионов, сопряженных с элементом в соединениях-предшественниках. Длина полоски соответствует средней температуре обжига по всем реакциям с использованием данного прекурсора (т.е.е. элемент + противоион). Элементы, встречающиеся в пяти и менее целях, отображаются серым цветом. «Ас» означает ацетатный радикал CH 3 COO - в формуле соединения. Мы также исследовали совместное присутствие химических элементов и наиболее типичных противоионов в материалах-прекурсорах и определили среднюю температуру обжига, используемую с каждым из этих прекурсоров. Здесь мы оперативно определяем температуру обжига как температуру, используемую на последнем этапе нагрева в последовательности операций синтеза.Результаты показаны на рис. 2 в виде гистограмм для каждого элемента. Цвет полоски соответствует определенному противоиону. Чистый элемент в качестве предшественника показан пурпурным цветом. Длина полосы обозначает среднюю температуру обжига. В этом представлении мы видим, что набор данных точно отображает известные аспекты химии твердого тела. Например, катионы щелочных и переходных металлов часто вводятся в реакцию через различные предшественники, включая бинарные оксиды, нитриды, сульфиды и т.д .; или простые соли, такие как карбонаты, фосфаты и нитраты.В то же время некоторые катионы в соединениях-предшественниках можно найти только в форме оксидов или чистых элементов (например, Be, Sc, Hf, Ru, Os, Rh, Pb, Nb, Pt, Au,…). В твердотельном синтезе противоион управляет температурой плавления или разложения предшественника и может определять, когда предшественник становится активным во время синтеза. Распределение температур обжига на рис. 2 очень хорошо согласуется с этим утверждением и показывает, как разные прекурсоры используются в разных температурных режимах во время твердотельного синтеза.Например, синие полосы обычно имеют большую длину (высокая средняя температура), чем красные, потому что бориды, карбиды и нитриды переходных металлов часто имеют более высокие температуры реакции, чем их соответствующие оксиды, из-за тугоплавкой природы их предшественников. С другой стороны, зеленые полоски относительно короче (более низкая средняя температура обжига), чем красные, потому что по сравнению с оксидами и сложными оксидными анионами (карбонаты, фосфаты и т. Д.) Синтез с гидроксидами, оксалатами и ацетатами облегчает реакции при более низких температурах. поскольку они часто гомогенно смешиваются путем осаждения из раствора.Этот анализ температуры на основе данных основан на прекурсоре, и мы признаем, что температуры реакции также зависят от термической стабильности и реакционной способности целевых соединений. Тем не менее, эта цифра представляет собой полуколичественную отправную точку для исследователей: если целевой материал разлагается при относительно низкой температуре, может быть лучше выбрать прекурсор, который имеет тенденцию становиться активным при более низкой температуре. Чтобы продемонстрировать разнообразие маршрутов синтеза, представленных в наборе данных, мы отсортировали последовательность шагов синтеза в соответствии со следующими заранее заданными шаблонами (таблица на рис.3): одностадийный синтез состоит только из операций перемешивания / измельчения твердых веществ и не более одного этапа нагрева (окончательный обжиг) без доизмельчения, синтез с измельчением в жидкой среде до гомогенизации без растворения) исходные материалы в любой жидкой среде, синтез на основе раствора содержит любой тип растворения исходных материалов в растворителе, синтез с промежуточным нагревом имеет одну или несколько стадий нагрева (не включая сушку после смешивания с жидкой частью) перед окончательным обжигом материалов. Соответствие между выбором пути синтеза и противоионами прекурсоров. В верхней таблице приведен пример четырех определенных типов синтеза: одностадийный синтез, на основе раствора, синтез с промежуточными стадиями нагрева, синтез, включая измельчение прекурсоров в жидких средах. Круговые диаграммы справа отображают долю каждого маршрута синтеза в наборе данных. Диаграммы, похожие на пончики, представляют доли четырех маршрутов синтеза (приведенных в таблице) для каждого противоиона, используемого в прекурсорах.«Ас» означает ацетатный радикал CH 3 COO - в формуле соединения. «Org» означает органический радикал (–CH–) в формуле соединения. Во-первых, мы обнаружили, что различные типы синтеза представлены в базе данных почти равномерно (верхняя круговая диаграмма на рис. 3): 26% материалов синтезируются в один этап, 25% маршрутов синтеза выполняются с промежуточным нагревом. стадия (и) перед окончательным обжигом, 21% синтезов содержат измельчение (гомогенизацию) в жидкости, а 14% требуют растворения прекурсоров в растворителе.Остальные рецепты (14%) либо не содержат подробной процедуры синтеза (6%), либо путь более сложен (8%). Поскольку выбор противоиона, используемого в прекурсоре, часто сильно зависит от метода синтеза, мы рассмотрели, какой тип синтеза является общим для конкретного иона в прекурсоре. Мы запросили подмножество реакций, которые включают данный противоион в соединении-предшественнике, и рассчитали долю каждого типа синтеза в этом подмножестве. Полученные круговые диаграммы показаны на рис.3. Возникающая картина согласуется с известными аспектами твердотельного синтеза. Например, при осаждении твердых веществ во время синтеза предшественник растворяется в растворе. Как показано на рис. 3, в синтезе на основе раствора (оранжевая фракция) часто используются растворимые предшественники с нитратами, ацетатами и органическими (СН-содержащими) радикалами. Некоторые противоионы более поддаются одностадийному синтезу, чем другие, например, хлориды, сульфиды и гидриды не требуют большой дополнительной обработки.С другой стороны, относительно стабильные предшественники, такие как оксиды и карбонаты, обрабатываются различными способами, часто требующими промежуточного нагрева и измельчения. Это, вероятно, связано с обычным образованием реакционных примесей и неравновесных промежуточных продуктов во время последовательностей реакций 45,46 . Разработанный нами конвейер экстракции позволяет автоматически обрабатывать научные абзацы и определять оттуда ключевую информацию о твердотельном синтезе. Однако конвейер по-прежнему страдает от некоторых проблем с интеллектуальным анализом текста.Во-первых, большинство ошибок в конвейере возникает из-за неправильной токенизации абзацев и предложений. Хотя токенизатор ChemDataExtractor 22 значительно превосходит другие пакеты НЛП в текстах, связанных с химией, он по-прежнему не может правильно обрабатывать формулы больших смесей и твердых растворов, а также химические названия, состоящие из нескольких слов. Мы связываем эту проблему с тем, что ChemDataExtractor был обучен на органических химических объектах, и его использование для распознавания неорганических токенов требует модификации алгоритмов.Во-вторых, не существует установленного шаблона или шаблона для описания процедуры синтеза, что приводит к значительной неоднозначности и трудностям, когда метод синтеза интерпретируется даже экспертом 47 . Это требует разработки более совершенных моделей извлечения текста, учитывающих особенности научного потока текста. В-третьих, хотя набор данных был сгенерирован из параграфов, описывающих твердотельный синтез (как определено алгоритмом классификации), он также содержит реакции для синтеза прекурсоров на основе раствора, такие как золь-гель (рис.3). Тем не менее, эти записи в основном выпадали позже, потому что в большинстве из них используются органические предшественники со сложными радикалами, и балансирование таких химических уравнений становится сложным. Наконец, мы обнаружили, что большинство материалов, изученных и синтезированных после 2000-х годов, часто являются модифицированными (например, легированными, замещенными элементами) соединениями, смесями, стеклами или твердыми растворами. Разбить такие материалы на состав и построить сбалансированные уравнения реакций непросто. Для некоторых соединений с легированными и замещенными элементами мы включили информацию о модифицирующих элементах и соответствующих прекурсорах в цепочку реакций (см. Методы).Один из способов реконструировать реакции для смесей, твердых растворов, сплавов и т. Д. - разделить весь материал на соединения и сопоставить их с соответствующими предшественниками. Вместо того, чтобы полностью решить эту проблему, мы решили настроить гибкую структуру данных, которая позволяет пользователю ее развивать. На этой странице описаны объекты данных и аннотации, используемые в Станце, и их взаимодействие друг с другом. Объект Объект Объект Объект Объект Новое в v1.1 Все объекты данных Stanza могут быть легко расширены, если вам нужно присоединить к ним новые интересующие их аннотации, либо с помощью нового процессора Чтобы добавить новую аннотацию или свойство к объекту Stanza, скажем, И тогда вы сможете получить доступ к свойству По умолчанию все созданные свойства доступны только для чтения, если вы явно не назначили установщик Авторские права © 2020 Stanford NLP Group. Планирование потребности в материалах (MRP) - это компьютерная система управления запасами, предназначенная для повышения производительности предприятий. Компании используют системы планирования потребности в материалах для оценки количества сырья и планирования своих поставок. MRP разработан, чтобы ответить на три вопроса: MRP работает в обратном направлении от производственного плана для готовой продукции, который преобразуется в список требований для узлов, компонентов и сырья, необходимых для производства конечного продукта в рамках установленного графика. Другими словами, это в основном система для попытки выяснить материалы и предметы, необходимые для производства данного продукта. MRP помогает производителям понять потребности в товарных запасах, уравновешивая спрос и предложение. Путем анализа необработанных данных, таких как коносаменты и срок годности хранимых материалов, эта технология предоставляет менеджерам значимую информацию об их потребностях в рабочей силе и расходных материалах, что может помочь компаниям повысить эффективность производства. Процесс MRP можно разбить на четыре основных этапа: Важнейшим входным параметром для планирования потребности в материалах является ведомость материалов (BOM) - обширный список сырья, компонентов и сборок, необходимых для конструирования, производства или ремонта продукта или услуги. Спецификация определяет отношения между конечным продуктом (независимый спрос) и компонентами (зависимый спрос). Независимый спрос возникает за пределами завода или производственной системы, а зависимый спрос относится к компонентам. Компаниям необходимо стратегически управлять типами и количеством закупаемых материалов; спланировать, какие продукты производить и в каких количествах; и гарантировать, что они могут удовлетворить текущий и будущий потребительский спрос - и все это с минимально возможными затратами. MRP помогает компаниям поддерживать низкий уровень запасов. Принятие неверного решения в любой области производственного цикла приведет к потере денег компании. Поддерживая соответствующий уровень запасов, производители могут лучше согласовывать свое производство с растущим и падающим спросом. Данные, которые необходимо учитывать в схеме MRP, включают: У процесса MRP есть несколько преимуществ: Конечно, у MRP есть и недостатки: Планирование требований к материалам было самой ранней из интегрированных систем информационных технологий (ИТ), направленных на повышение производительности предприятий за счет использования компьютеров и программного обеспечения. Первые MRP-системы управления запасами появились в 1940-х и 1950-х годах. Они использовали мэйнфреймы для экстраполяции информации из ведомости материалов для конкретного готового продукта в план производства и закупок. Вскоре системы MRP расширились и стали включать в себя контуры обратной связи с информацией, чтобы руководители производства могли изменять и обновлять входные данные системы по мере необходимости. Следующее поколение MRP, планирование производственных ресурсов (MRP II), также включило в процесс планирования аспекты маркетинга, финансов, бухгалтерского учета, инженерии и человеческих ресурсов.Связанная концепция, расширяющая MRP, - это планирование ресурсов предприятия (ERP), в котором используются компьютерные технологии для связи различных функциональных областей всего предприятия. По мере того, как анализ данных и технологии становились все более сложными, были разработаны более комплексные системы для интеграции MRP с другими аспектами производственного процесса. Планирование потребности в материалах (MRP) - это система, которая помогает производителям планировать, составлять график и управлять своими запасами во время производственного процесса.Это в первую очередь программная система. MRP преследует три цели: MRP приносит пользу бизнесу следующими способами: Три основных входа системы MRP - это основной производственный график (MPS), файл состояния запасов (ISF) и спецификация материалов (BOM). MPS - это просто количество и сроки производства всех конечных товаров за определенный период времени. MPS оценивается на основе заказов клиентов и прогнозов спроса. ISF содержит важную информацию о запасах компании в режиме реального времени. Это позволяет менеджерам знать, что у них есть под рукой, где находится этот инвентарь, и общий статус инвентаря. Спецификация - это подробный список сырья, компонентов и узлов, необходимых для конструирования, производства или ремонта продукта или услуги. Мед является побочным продуктом цветочного нектара и верхних дыхательных путей медоносной пчелы, который концентрируется в процессе обезвоживания внутри пчелы. улей. Мед имеет очень сложный химический состав, который варьируется в зависимости от ботанического источника. С древних времен он использовался как в пищу, так и в медицине. Человеческое употребление меда восходит к 8000 лет назад, как это изображено на картинах каменного века.Помимо важной роли натурального меда в традиционной медицине, в течение последних нескольких десятилетий он подвергался лабораторным и клиническим исследованиям несколькими исследовательскими группами и нашел свое место в современной медицине. Сообщается, что мед оказывает ингибирующее действие на около 60 видов бактерий, некоторые виды грибов и вирусов. Антиоксидантная способность меда важна при многих заболеваниях и обусловлена широким спектром соединений, включая фенольные, пептиды, органические кислоты, ферменты и продукты реакции Майяра.Мед также используется при некоторых желудочно-кишечных, сердечно-сосудистых, воспалительных и опухолевых состояниях. В этом обзоре рассматриваются состав, физико-химические свойства и наиболее важные применения натурального меда при заболеваниях человека. Ключевые слова: Мед, болезни человека, народная медицина, современная медицина Мед - натуральный продукт, который широко используется благодаря своим терапевтическим эффектам. Сообщается, что он содержит около 200 веществ.Мед состоит в основном из фруктозы и глюкозы, но также содержит фруктоолигосахариды (1) и многие аминокислоты, витамины, минералы и ферменты (2). Состав меда варьируется в зависимости от растений, которыми питается пчела. Однако почти весь натуральный мед содержит флавоноиды (такие как апигенин, пиноцембрин, кемпферол, кверцетин, галангин, хризин и гесперетин), фенольные кислоты (такие как эллаговая, кофейная, пара-кумаровая и феруловая кислоты), аскорбиновую кислоту, токоферолы, каталазу ( CAT), супероксиддисмутаза (SOD), восстановленный глутатион (GSH), продукты реакции Милларда и пептиды.Большая часть этих соединений работает вместе, обеспечивая синергетический антиоксидантный эффект (3-7). Мед на протяжении веков занимал важное место в традиционной медицине (8, 9). Однако его применение в современной медицине ограничено из-за отсутствия научной поддержки (10). В течение долгого времени было замечено, что мед можно использовать для решения проблем с печенью, сердечно-сосудистой системой и желудочно-кишечным трактом (11). Древние египтяне, ассирийцы, китайцы, греки и римляне использовали мед для лечения ран и болезней кишечника (12).Несколько десятилетий назад мед подвергался лабораторным и клиническим исследованиям несколькими исследовательскими группами. Самым замечательным открытием стала антибактериальная активность меда, о которой упоминалось в многочисленных исследованиях (13, 14). Натуральный мед проявляет бактерицидную активность против многих организмов, включая Salmonella, Shigella , Escherichia col i (3, 15), Helicobacter pylori (9) и т. Д. В воспалительной модели колита мед был так же эффективен, как и лечение преднизолоном (16).Исследования также показали, что мед может обладать противовоспалительным действием и стимулировать иммунные реакции в ране (17, 18). Аль-Вайли и Бони (2003) продемонстрировали противовоспалительное действие меда на человека после приема меда (19). Интересно, что в некоторых исследованиях in vitro было показано, что мед предотвращает индуцированное реактивными формами кислорода (АФК) окисление липопротеинов низкой плотности (ЛПНП), таким образом демонстрируя полезную защиту сердечно-сосудистой системы (20, 21). Мед также обладал противоопухолевой активностью при экспериментальном раке мочевого пузыря (22).В этой статье рассмотрены важные традиционные и современные способы использования натурального меда при заболеваниях человека. Химический состав меда натурального Натуральный мед содержит около 200 веществ, включая аминокислоты, витамины, минералы и ферменты, но в основном он содержит сахар и воду. Сахар составляет 95–99% от сухого вещества меда. Основными углеводными составляющими меда являются фруктоза (от 32,56 до 38,2%) и глюкоза (от 28,54 до 31,3%), что составляет 85–95% от общего количества сахаров, которые легко всасываются в желудочно-кишечном тракте (23, 11). Другие сахара включают дисахариды, такие как мальтоза, сахароза, изомальтоза, тураноза, нигероза, мели-биоза, паноза, мальтотриоза, мелецитоза. Также присутствует несколько олигосахаридов. Мед содержит от 4 до 5% фруктоолигосахаридов, которые служат пробиотическими агентами (1, 11). Вода - второй по важности компонент меда. Органические кислоты составляют 0,57% меда и включают глюконовую кислоту, которая является побочным продуктом ферментативного переваривания глюкозы. Органические кислоты отвечают за кислотность меда и в значительной степени определяют его характерный вкус (24).Концентрация минеральных соединений колеблется от 0,1% до 1,0%. Калий является основным металлом, за ним следуют кальций, магний, натрий, сера и фосфор. Микроэлементы включают железо, медь, цинк и марганец (25-27). Азотистые соединения, витамины C, B 1 (тиамин) и B 2 комплексные витамины, такие как рибофлавин, никотиновая кислота, B 6 и пантотеновая кислота (24). Мед содержит белки только в незначительных количествах 0,1–0,5% (28, 29).Согласно недавнему отчету, конкретные количества белка различаются в зависимости от происхождения пчелы (30). Средний состав меда приведен в (31). Средний состав меда (31) В меде присутствуют различные ферменты, такие как оксидаза, инвертаза, амилаза, каталаза и т. Д. Однако основными ферментами меда являются инвертаза (сахараза), диастаза (амилаза) и глюкозооксидаза. Они играют важную роль в образовании меда (24). Фермент глюкозооксидаза производит перекись водорода (которая обеспечивает антимикробные свойства) вместе с глюконовой кислотой из глюкозы, которая помогает в абсорбции кальция. Инвертаза превращает сахарозу во фруктозу и глюкозу.Декстрин и мальтоза производятся из длинных цепей крахмала под действием фермента амилазы. Каталаза помогает производить кислород и воду из перекиси водорода (32). Физические свойства натурального меда Мед помимо состава и вкуса обладает несколькими важными качествами. Свежевыжатый мед - вязкая жидкость. Его вязкость зависит от большого количества веществ и, следовательно, зависит от его состава и, в частности, от содержания воды.Гигроскопичность - еще одно свойство меда, которое описывает способность меда поглощать и удерживать влагу из окружающей среды. Обычный мед с содержанием воды 18,8% или меньше впитывает влагу из воздуха с относительной влажностью выше 60%. Поверхностное натяжение меда зависит от его происхождения и, вероятно, связано с коллоидными веществами. Вместе с высокой вязкостью он отвечает за пенообразование меда (24). Цвет жидкого меда варьируется от прозрачного и бесцветного (как вода) до темно-янтарного или черного.Различные медовые цвета в основном представлены всеми оттенками желтого и янтарного. Цвет варьируется в зависимости от ботанического происхождения, возраста и условий хранения, но прозрачность или прозрачность зависит от количества взвешенных частиц, таких как пыльца (24). Менее распространенные цвета меда - ярко-желтый (подсолнечник), красноватый оттенок (каштан), сероватый (эвкалипт) и зеленоватый (падь). После кристаллизации мед становится светлее, потому что кристаллы глюкозы белые. Кристаллизация меда является результатом образования кристаллов моногидрата глюкозы, количество, форма, размер и качество которых различаются в зависимости от состава меда и условий хранения.Чем меньше воды и выше содержание глюкозы в меде, тем быстрее кристаллизуется (24). Традиционное использование натурального меда Использование меда человеком восходит к 8000 лет назад, как это изображено на картинах каменного века (32). Древние египтяне, ассирийцы, китайцы, греки и римляне использовали мед для лечения ран и болезней кишечника (12). Здесь кратко описаны некоторые полезные эффекты меда, которые использовались древними народами. Мед в и Индийская система а юрведа Аюрведа - сложное слово, то есть âyus , означающее «жизнь» или «жизненный принцип», и слово veda , которое относится к «системе знаний». Следовательно, «Аюрведа» примерно переводится как «знание жизни» (33). Древняя цивилизация ведиков считала мед одним из самых замечательных даров природы человечеству.Традиционно, согласно текстам Аюрведы, мед является благом для людей со слабым пищеварением. Также было подчеркнуто, что использование меда очень полезно при лечении раздражающего кашля. Аюрведические эксперты считают мед ценным средством для сохранения здоровья зубов и десен (34). Он веками использовался для лечения бессонницы, поскольку обладает снотворным действием. Кроме того, традиционные аюрведические эксперты рекомендуют мед при кожных заболеваниях (таких как раны и ожоги), сердечной боли и сердцебиении, всех нарушениях баланса легких и анемии.Мед имеет давнюю историю аюрведического использования при различных заболеваниях глаз. Ежедневно наносить на глаза, улучшает зрение. Более того, мед считается полезным средством профилактики катаракты (34). Мед в Древнем Египте Мед был самым популярным египетским лекарством, его 500 раз упоминали в 900 лекарствах (12). Его рецепт для стандартной раневой мази, обнаруженный в папирусе Смита (египетский текст, датируемый между 2600 и 2200 годами до нашей эры), требует смеси mrht (жир), byt (мед) и ftt (ворс / волокно), как транслитерируется с иероглифических символов. (35).Почти все египетские лекарства содержали мед вместе с вином и молоком. Древние египтяне приносили мед своим божествам в жертву (36). Мед также использовали для бальзамирования умерших. Мед использовался из-за его антибактериальных свойств, которые помогали заживлять инфицированные раны. Кроме того, мед использовался в качестве мази для местного применения (31). Мед в Древней Греции Эномель - древнегреческий напиток, состоящий из меда и неферментированного виноградного сока. Иногда его используют как народное средство от подагры и некоторых нервных расстройств (31).Гиппократ, великий греческий ученый, прописал простую диету, отдавая предпочтение меду в виде оксимела (уксуса и меда) от боли, гидромела (вода и мед) от жажды и смеси меда, воды и различных лекарственных веществ при острой лихорадке (35). ). Также он использовал мед от облысения, контрацепции, заживления ран, слабительного действия, кашля и боли в горле, глазных болезней, местной антисептики, профилактики и лечения шрамов (32). Мед в и Сламическая медицина В исламской медицинской системе мед считается полезным напитком.Священный Коран ярко иллюстрирует потенциальную терапевтическую ценность меда: «И Господь твой научил пчелу строить свои клетки на холмах, на деревьях и в жилищах (людей); затем есть все продукты (земли) , и умело найди просторные пути своего Господа: из их тел исходит питье разного цвета, которое исцеляет людей: воистину, в этом знамение для тех, кто думает ». Более того, мусульманский пророк Мохаммад (СА) рекомендовал использовать мед для лечения диареи (37).Авиценна, великий иранский ученый и врач, почти 1000 лет назад рекомендовал мед как одно из лучших средств при лечении туберкулеза (38). Место меда в современной медицине Антимикробные свойства меда Помимо важной роли натурального меда в традиционной медицине, в течение последних нескольких десятилетий он подвергался лабораторным и клиническим исследованиям. Антибактериальная активность меда - одно из важнейших открытий, впервые обнаруженных в 1892 году; Ван Кетеля (39). Патогены, чувствительные к меду Мед, как сообщается, оказывает ингибирующее действие на около 60 видов бактерий, включая аэробы и анаэробы, грамположительные и грамотрицательные бактерии (24). Было обнаружено, что патогены, чувствительные к противоинфекционным свойствам меда, многочисленны (40). Различные результаты свидетельствуют в пользу его активности против Bacillus anthracis, Corynebacterium diptheriae, Haemophilus influenzae, Klebsiella pneumoniae, Listeria monocytogenes, Mycobacterium tuberculosis, Pasteurella multicoda, Yersinia enterocolitica , виды Proteus, Pseudomonas aeruginosa , Acinetobacter spp , Salmonella diarrhea , Sal.typhi , Serratia marcescens, Shigella dysentery , Staphylococcus aureus, Streptococcus faecalis, Strep. mutans, Strep. pneumoniae, Strep. pyogenes и Vibrio холеры (15, 38, 32). Ранее было проведено небольшое количество тематических исследований, посвященных антимикробной активности меда против метициллин-устойчивого стафилококка . aureus ( MRSA ) продемонстрировали, что натуральный мед обладает антимикробной активностью против , связанных с сообществом организмов MRSA в условиях in vitro (41-43).Было обнаружено, что МПК (минимальная ингибирующая концентрация) меда колеблется от 1,8% до 10,8% (об. / Об.), То есть мед обладал достаточной антибактериальной активностью, чтобы остановить рост бактерий, если его разбавить по крайней мере в девять раз и до 56 раз для золотистого стафилококка , наиболее распространенного раневого возбудителя (44). Было показано, что разбавленный мед лечит инфекции мочевыводящих путей, потому что некоторые бактерии вызывают инфекции мочевыводящих путей, например E. coli , Proteus видов и Strep.faecalis , оказались чувствительны к антибактериальной активности меда (45). In vitro исследований изолятов H. pylori , вызывающих гастрит, было показано, что они подавляются 20% -ным раствором меда. Чувствительны были даже изоляты, которые проявляли устойчивость к другим антимикробным препаратам (10, 15). Сообщалось, что в отличие от большинства обычных антибиотиков доза меда не приводит к развитию устойчивых к антибиотикам бактерий, и ее можно использовать постоянно (14). Мед может действовать как бактериостатическое, так и бактерицидное, в зависимости от используемой концентрации. Пастбищный мед (4-8%) и 5-11% мед манука были бактериостатическими, тогда как бактерицидная активность была достигнута при концентрациях 5-10% и 8-15% (об. / Об.), Соответственно. Напротив, искусственный мед (сахарный раствор, имитирующий состав меда) был только бактериостатическим (20-30%), а не бактерицидным (32). Возможные механизмы антимикробного действия меда Механизмы антимикробного действия меда отличаются от антибиотиков, которые разрушают клеточную стенку бактерий или ингибируют внутриклеточные метаболические пути.Антибактериальная активность связана с четырьмя свойствами меда. Во-первых, мед вытягивает влагу из окружающей среды и тем самым обезвоживает бактерии. Содержание сахара в меде также достаточно велико, чтобы препятствовать росту микробов, но само содержание сахара не является единственной причиной антибактериальных свойств меда (46). Во-вторых, pH меда составляет от 3,2 до 4,5, и эта кислотность достаточно низкая, чтобы подавить рост большинства микроорганизмов. Перекись водорода, продуцируемая глюкозооксидазой, является третьим и, вероятно, наиболее важным антибактериальным компонентом, хотя некоторые авторы считают, что непероксидная активность более важна.Наконец, в меде были идентифицированы несколько фитохимических факторов антибактериальной активности (13, 14). Перекись водорода, глюкозооксидаза, каталаза, фитохимические факторы были описаны как неперекисные антибактериальные факторы (24). Кроме того, летучие вещества, органические кислоты, лизоцим, пчелиный воск, нектар, пыльца и прополис являются важными химическими факторами, которые придают меду антибактериальные свойства (32, 47, 48). Мед также содержит в небольших количествах олигосахариды. Shin & Ustunol (2005) связали сахарный состав меда из разных цветочных источников с ингибированием роста различных кишечных бактерий (49, 50).Кроме того, сообщается, что часть антибактериальной активности может быть отнесена к компонентам растительного происхождения (47). Все эти физические и химические факторы придают меду уникальные свойства в качестве перевязочного материала для ран: он обеспечивает быстрое избавление от инфекций, быстрое очищение ран, быстрое подавление воспаления, минимизацию рубцевания и стимуляцию ангиогенеза, а также грануляции тканей и роста эпителия ( 50, 51). Заживление ран Одно из наиболее изученных и наиболее эффективных применений меда - заживление ран (17).Русские использовали мед во время Первой мировой войны, чтобы предотвратить инфицирование ран и ускорить их заживление. Немцы смешивали рыбий жир и мед для лечения язв, ожогов, свищей и фурункулов (32). Почти все типы ран, такие как ссадины, абсцесс, ампутация, пролежни / пролежни, ожоги, озноб, разрывная рана живота, трещины сосков, свищи, диабетические, злокачественные, лепрозные, травматические, шейные, варикозные и серповидно-клеточные язвы, гнойно-септические раны. , хирургическая рана или раны брюшной стенки и промежности поддаются лечению медом.Применение меда в качестве перевязочного материала приводит к стимуляции процесса заживления и быстрому избавлению от инфекции. Мед оказывает очищающее действие на раны, стимулирует регенерацию тканей и снимает воспаление. Подушечки, пропитанные медом, действуют как неклейкая тканевая повязка (32, 52, 53). Точный молекулярный механизм заживления ран с помощью меда еще предстоит выяснить. Однако есть несколько рекомендаций относительно правильной перевязки ран медом. Тип раны и степень тяжести влияют на эффективность.Отборный мед следует использовать в достаточном количестве, чтобы он оставался там при разбавлении раневым экссудатом. Он должен покрывать края раны и выходить за ее пределы. Лучшие результаты достигаются при наложении на повязку, чем на рану. Все полости должны быть адекватно заполнены медом и наложены окклюзионные повязки, чтобы предотвратить просачивание из раны (32, 54, 55). При ожогах оказывает сначала успокаивающее, а затем быстрое заживляющее действие. Он использовался в качестве раневого барьера против имплантации опухоли в лапароскопической онкологической хирургии.Не сообщалось об инфекциях при нанесении меда на открытые раны. Он имеет потенциальную терапевтическую роль при лечении гингивита и заболеваний пародонта (56). В одном из случаев ампутации колена у мальчика, который был сильно инфицирован Pseudo. и Staph. aureus и не поддается традиционному лечению, применение стерилизованных активных повязок с медом манука привело к полному заживлению за десять недель (57). Аналогичные результаты наблюдаются при ожогах. Медовая повязка ускоряет процесс заживления, стерилизует рану и уменьшает боль (58).Исследования гангрены Фурнье показали быстрое улучшение с уменьшением отека и выделений, быстрой регенерацией и небольшим или отсутствием рубцов, эффективной обработкой раны и снижением смертности (59). Мед успешно применяется для лечения язв после радикальной операции по поводу рака груди и варикозного расширения вен. Он также используется после радикальной операции по поводу рака вульвы, в результате чего образуется безинфекционная рана с минимальной обработкой раны и пребыванием в больнице (60). У пациентов с послеоперационными раневыми инфекциями после кесарева сечения или гистерэктомии местное применение меда вызывает более быстрое искоренение бактериальных инфекций, сокращает использование антибиотиков и время пребывания в больнице, ускоряет заживление ран и приводит к минимальному образованию рубцов (53).Аналогичная эффективность наблюдается при пролежнях и пролежнях (61). Клинические испытания проводятся по сравнению медовой повязки при ожогах с повязкой из околоплодных вод; заправка из сульфадиазина серебра и заправка из отварной картофельной кожуры. Медовая повязка показала лучшее улучшение в этих случаях и показала раннее заживление с меньшей степенью контрактуры и рубцевания (32, 45). Также была описана хорошая гистологическая сохранность кожных трансплантатов после обработки медом (62). Motallebnejad et. al. (2008) сообщили, что применение натурального меда эффективно при лечении радиационно-индуцированного мукозита (63). Необычным применением меда было его использование в качестве средства подтверждения наличия кори на ранних стадиях. Сообщается, что мед массируют высыпания, которые, в случае кори, становятся более выраженными на следующий день. Продолжительное нанесение меда проводят до полного исчезновения высыпаний (45). Преимущества меда в качестве перевязочного материала Невероятно быстрый эффект меда при очистке ран объясняется сочетанием осмотического оттока и биоактивного действия меда.Фермент глюкозооксидаза меда обеспечивает лейкоциты глюкозой, которая необходима при респираторном взрыве для выработки перекиси водорода, что приводит к антибактериальной активности макрофагов. Кислотность меда дополнительно способствует антибактериальной активности (52). Присутствие широкого спектра аминокислот, витаминов и микроэлементов также оказывает прямое питательное действие на регенерирующие ткани. Осмотический отток после нанесения меда помогает удалить грязь и мусор с ложа раны. Таким образом, повязка становится нелипкой и позволяет безболезненно менять одежду.Однако некоторые люди испытывали боль или дискомфорт. Это может быть связано с тем, что обнаженные нервные окончания контактируют с кислотностью меда (32). Устранение инфекции, наблюдаемое при нанесении меда на рану, может отражать не только антибактериальные свойства. Недавние исследования показывают, что пролиферация В-лимфоцитов и Т-лимфоцитов периферической крови в культуре клеток стимулируется медом в таких низких концентрациях, как 0,1%; и фагоциты активируются медом при концентрациях всего 0.1% (24). В одном исследовании натуральный мед значительно увеличивал высвобождение фактора некроза опухоли-α (TNF-α), интерлейкина (IL) -1β и IL-6 из клеток MonoMac-6 (и человеческих моноцитов), которые активируют иммунный ответ на инфекцию. Поэтому было высказано предположение, что влияние меда на заживление ран может частично быть связано со стимуляцией воспалительных цитокинов из моноцитарных клеток (18, 25, 64, 65). Кроме того, медовая повязка дает пациенту экономические преимущества. Быстрое заживление сокращает время пребывания в больнице, снижает затраты на перевязочный материал и хирургические операции (35). Болезни желудочно-кишечного тракта Сообщалось о пероральном приеме меда для лечения и защиты от желудочно-кишечных инфекций, таких как гастрит, дуоденит и язва желудка, вызванные бактериями и ротавирусом (66-70). Присоединение бактерий к эпителиальным клеткам слизистой оболочки считается начальным событием в развитии бактериальных инфекций желудочно-кишечного тракта. Блокирование прикрепления патогенных микроорганизмов к кишечному эпителию представляет собой потенциальную стратегию профилактики заболеваний.Alnaqdy и др. (2005) продемонстрировали, что предотвращение прикрепления бактерий, вызванное медом, осуществляется посредством воздействия на бактерии, а не на эпителиальные клетки. Существует несколько возможных объяснений предотвращения прилипания бактерий, продемонстрированного медом: (а) неспецифическое механическое ингибирование, возможно, через покрытие бактерий медом; (б) некоторые фракции в меде могут изменять электростатический заряд или гидрофобность бактерий, которые, как сообщается, являются важными факторами во взаимодействии бактерий с клетками-хозяевами (70-72) или (в) уничтожении бактерий из-за ранее упомянутые антибактериальные факторы в меде (70). Обнаружено, что диарея и гастроэнтерит быстро проходят с медом (32, 67, 73). При концентрации 5% (об. / Об.) Мед сокращал продолжительность диареи в случаях бактериального гастроэнтерита по сравнению с группой, использующей сахар в качестве заменителя жидкости. В отношении вирусного гастроэнтерита изменений не наблюдалось. В жидкости для регидратации мед увеличивает потребление калия и воды, не увеличивая потребление натрия. Он также помогает восстановить поврежденную слизистую оболочку кишечника, стимулирует рост новых тканей и действует как противовоспалительное средство (32).Nasutia et al (2006) продемонстрировали, что предварительная пероральная обработка меда (2 г / кг) предотвращает индуцированные индометацином поражения желудка, проницаемость микрососудов и активность миелопероксидазы желудка (74). H. Pylori оказался чувствительным к меду со средним уровнем антибактериальной активности из-за присутствия перекиси водорода в концентрации 20% (32, 68). Для оценки цитопротекторных свойств натурального меда в желудке перфузия желудка изотоническим медом привела к значительному уменьшению площади поражений, вызванных этанолом (75).Кроме того, было высказано предположение, что натуральный мед обладает лечебными свойствами для заживления язв антрального отдела и может использоваться, как сукральфат, при лечении язвенной болезни (76). Грибковые инфекции Сообщается, что мед оказывает подавляющее действие на грибки. Чистый мед подавляет рост грибков, а разбавленный мед, по-видимому, способен подавлять выработку токсинов (13). Противогрибковое действие также наблюдалось в отношении некоторых дрожжей и видов Aspergillus и Penicillium, а также всех распространенных дерматофитов (25, 77).Кандидоз, вызываемый Candida albicans , может реагировать на мед (78, 32). Обнаружено, что кожные и поверхностные микозы, такие как стригущий лишай и спортивные стопы, чувствительны к меду. Эта реакция частично связана с подавлением роста грибков и частично с подавлением бактериальной инфекции (32). Кроме того, в некоторых исследованиях сообщалось, что местное применение меда было эффективным при лечении себорейного дерматита и перхоти (53, 79). Противовирусное действие меда Натуральный мед, помимо антибактериального и противогрибкового действия, обладает противовирусным действием.Аль-Вайли (2004) исследовал влияние местного применения меда на повторяющиеся приступы герпетических поражений и пришел к выводу, что местное нанесение меда было безопасным и эффективным в лечении признаков и симптомов рецидивирующих поражений при губном и генитальном герпесе по сравнению с ацикловиром. крем (80) . Также сообщалось, что мед оказывает ингибирующее действие на активность вируса краснухи (13). Офтальмология и мед Мед используется во всем мире для лечения различных офтальмологических состояний, таких как блефарит, кератит, конъюнктивит, травмы роговицы, химические и термические ожоги глаз (45, 81).В одном исследовании с местным применением меда в виде мази у 102 пациентов с невосприимчивыми глазными заболеваниями улучшение наблюдалось у 85% пациентов, а у остальных 15% не было прогрессирования заболевания. Применение меда при инфекционном конъюнктивите уменьшило покраснение, отек, выделения гноя и уменьшило время до уничтожения бактерий (32, 78, 80). Мед как источник углеводов Мед - это натуральная смесь фруктозы и глюкозы, а также некоторых олигосахаридов, белков, витаминов и минералов.Некоторые исследования показали, что мед является эффективным источником углеводов для спортсменов до и после тренировок с отягощениями, а также во время упражнений на выносливость (32). Мед и диабет Использование меда при диабете I и II типа было связано со значительно более низким гликемическим индексом, чем глюкоза или сахароза при нормальном диабете. Мед по сравнению с декстрозой вызывал значительно меньшее повышение уровня глюкозы в плазме у пациентов с диабетом. Это также вызвало снижение уровней липидов в крови, гомоцистеина и С-реактивного белка (СРБ) у нормальных и гиперлипидемических субъектов (32, 40).В более ранних наблюдениях было обнаружено, что мед стимулирует секрецию инсулина, снижает уровень глюкозы в крови, повышает концентрацию гемоглобина и улучшает липидный профиль (13). Мед как пищевой консервант и пребиотик Установлено, что перекись водорода и непероксидные компоненты, такие как антиоксиданты, подавляют рост шигелл , Listeria monocytogenes и Staph. aureus помогает в сохранении пищевых продуктов. Clostridium botulinum , однако, в небольших количествах может присутствовать в меде.Он имеет хороший потенциал для использования в качестве природного источника антиоксидантов для снижения негативных эффектов потемнения полифенолоксидазы при переработке фруктов и овощей (32, 82). Пребиотик - это неперевариваемая пищевая добавка, которая изменяет баланс микрофлоры кишечника, стимулируя рост и активность полезных организмов и подавляя потенциально вредные бактерии. Мед является подходящим подсластителем в кисломолочных продуктах, не подавляя рост обычных бактерий, таких как Strep. thermophilus, Lactobacillus acidophilus, Лакто. delbruekii и Bifidobacterium bifidum , которые важны для поддержания здоровья желудочно-кишечного тракта. Мед также увеличивал и поддерживал рост бифидобактерий (32, 83), что в основном связано с присутствием различных олигосахаридов (1, 11, 32). Противовоспалительное действие меда В недавнем исследовании сообщалось, что мед снижает активность циклооксигеназы-1 и циклооксигеназы-2, тем самым проявляя противовоспалительное действие (84).Мед также демонстрирует иммуномодулирующую активность (85). Более того, прием разбавленного натурального меда показал эффект снижения концентрации простагландинов, таких как PGE 2 , PGF 2α и тромбоксан B 2 в плазме здоровых людей (19)). Поражения, обработанные медом, демонстрируют меньший отек, инфильтрацию меньшим количеством гранулярных и мононуклеарных клеток, меньший некроз, лучшее сокращение раны, улучшенную эпителизацию и низкие концентрации гликозаминогликанов и протеогликанов.Кроме того, он уменьшает воспаление и экссудацию, способствует заживлению, уменьшает размер рубцов и стимулирует регенерацию тканей (19). Сообщалось также, что мед помогает при экземе, псориазе и перхоти (19, 85). В воспалительной модели колита мед был так же эффективен, как и лечение преднизолоном (16). Лекарства для лечения воспаления имеют серьезные ограничения: кортикостероиды подавляют рост тканей и подавляют иммунный ответ, а нестероидные противовоспалительные препараты вредны для клеток, особенно в желудке.Но мед обладает противовоспалительным действием без побочных эффектов (44). Наши недавно полученные и неопубликованные лабораторные данные показывают, что мед способен подавлять воспалительные параметры, ангиогенез, а также проявлять мощную ингибирующую активность против TNF-α и PGE 2 в модели воспаления с воздушным мешком. Антиоксидантная активность меда Сегодня мы хорошо знаем, что радикалы вызывают молекулярные трансформации и генные мутации во многих типах организмов.Хорошо известно, что оксидативный стресс вызывает множество заболеваний (86), и ученые из многих различных дисциплин стали больше интересоваться природными источниками, которые могут обеспечить активные компоненты для предотвращения или уменьшения его воздействия на клетки (47, 87, 88). Натуральный мед содержит много флавоноидов (таких как апигенин, пиноцембрин, кемпферол, кверцетин, галангин, хризин и гесперетин), фенольные кислоты (такие как эллаговая, кофейная, пара-кумаровая и феруловая кислоты), аскорбиновую кислоту, токоферолы, каталазу, супероксид. дисмутаза, восстановленный глутатион, продукты реакции Майяра и пептиды.Большинство вышеперечисленных соединений работают вместе, обеспечивая синергетический антиоксидантный эффект (4-6). Следовательно, было высказано предположение, что мед, как природный антиоксидант, может служить альтернативой некоторым консервантам, таким как триполифосфат натрия, при консервировании пищевых продуктов для замедления окисления липидов (4). Растительное происхождение меда оказывает наибольшее влияние на его антиоксидантную активность, в то время как обработка, обращение и хранение влияют на антиоксидантную активность меда лишь в незначительной степени (7, 89-92).Антиоксидантная активность сильно коррелирует с содержанием общих фенолов (7, 45, 9, 92–94). Кроме того, была обнаружена сильная корреляция между антиоксидантной активностью и цветом меда. Многие исследователи обнаружили, что темный мед имеет более высокое общее содержание фенолов и, следовательно, более высокую антиоксидантную способность (89, 92, 95). Blasa et al (2007) показали, что антиоксидантная активность проявляется как в эфирной, так и в водной фракциях, что указывает на то, что флавоноиды меда могут быть доступны в различных частях человеческого тела, где они могут оказывать различные физиологические эффекты (96). . Свойства фенольных соединений меда Фенольные соединения - одна из важнейших групп соединений, встречающихся в растениях, включающая не менее 8000 различных известных структур (48, 97). Сообщается, что эти соединения проявляют антиканцерогенное, противовоспалительное, антиатерогенное, антитромботическое, иммуномодулирующее и обезболивающее действие, среди прочего, и выполняют эти функции как антиоксиданты (48, 98). Фенольные соединения меда - это фенольные кислоты и флавоноиды, которые считаются потенциальными маркерами ботанического происхождения меда (7, 48, 99).Антиоксидантная активность фенольных соединений связана с рядом различных механизмов, таких как улавливание свободных радикалов, передача водорода, тушение синглетного кислорода, хелатирование ионов металлов и их действие в качестве субстрата для таких радикалов, как супероксид и гидроксил (47). Сердечно-сосудистые заболевания Ишемическая болезнь сердца (ИБС) вызывает больше случаев смерти и инвалидности и требует больших экономических затрат, чем любая другая болезнь в развитом мире (100). Аритмии и инфаркт миокарда (ИМ) - серьезные проявления ИБС.В ходе кардиохирургии и инфаркта миокарда желудочковые аритмии, такие как желудочковая тахикардия и фибрилляция желудочков, являются наиболее важными причинами смертности (100). При лечении таких состояний лекарственная терапия (особенно антиаритмические препараты) может спасти жизнь. С другой стороны, опасность антиаритмических препаратов (например, летальная аритмия у некоторых пациентов) привела к ограничению приема антиаритмических препаратов (101). Следовательно, существует тенденция к использованию лекарств с меньшим количеством побочных эффектов и большей эффективностью.Натуральный мед применялся в лечебных целях с древних времен (102), однако в случае сердечно-сосудистых заболеваний большинство предыдущих исследований проводилось на животных и в основном было сосредоточено на воздействии меда на факторы риска сердечно-сосудистых заболеваний, такие как гиперлипидемия и выработка медикаментов. свободные радикалы (103-106). Антиоксиданты, присутствующие в меде, включают витамин С, монофенолы, флавоноиды и полифенолы. Регулярный прием флавоноидов снижает риск сердечно-сосудистых заболеваний.В меде присутствует широкий спектр фенольных соединений, которые имеют многообещающий эффект при лечении сердечно-сосудистых заболеваний. При ишемической болезни сердца (ИБС) защитные эффекты фенольных соединений включают в основном антитромботическое, противоишемическое, антиоксидантное и сосудорасширяющее действие. Предполагается, что флавоноиды снижают риск ИБС за счет трех основных действий: улучшения коронарной вазодилатации, снижения способности тромбоцитов в крови к свертыванию и предотвращения окисления ЛПНП (107). У 38 человек с избыточным весом было исследовано влияние натурального меда на общий холестерин, ХС-ЛПНП, холестерин липопротеинов высокой плотности (ХС-ЛПВП), триацилглицерин, С-реактивный белок (СРБ), уровень глюкозы в крови натощак и массу тела.Результаты показали, что прием 70 г натурального меда в течение 30 дней вызывал снижение общего холестерина, холестерина ЛПНП, триацилглицерола и СРБ ( P <0,05). Авторы пришли к выводу, что натуральный мед снижает факторы риска сердечно-сосудистых заболеваний, особенно у людей с повышенными факторами риска, и не увеличивает массу тела у людей с избыточным весом или ожирением (106). Эффекты приема 75 г натурального меда по сравнению с таким же количеством искусственного меда (фруктоза плюс глюкоза) были изучены на людях.Повышение уровня инсулина и СРБ после приема глюкозы было значительно выше, чем после употребления меда. Кроме того, мед снижает уровень холестерина, холестерина ЛПНП и ТГ и немного повышает уровень холестерина ЛПВП. У пациентов с гипертриглицеридемией искусственный мед увеличивал ТГ, а мед снижал ТГ. У пациентов с гиперлипидемией искусственный мед увеличивал ХС-ЛПНП, а мед снижал ХС-ЛПНП. У пациентов с диабетом мед по сравнению с декстрозой вызывал значительно меньшее повышение уровня глюкозы в плазме. Мед может содержать метаболиты оксида азота (NO), и повышенный уровень NO в меде может иметь защитную функцию при сердечно-сосудистых заболеваниях (108). Мед также снижает венозное кровяное давление, что может снизить предварительную нагрузку на сердце и, как следствие, уменьшить застой в венозной системе (6). Наджафи и др. (2008) продемонстрировали профилактическое действие натурального меда в качестве фармакологического прекондиционирующего агента на повреждения, вызванные ишемией / реперфузией (I / R), при которых кратковременная перфузия обогащенного раствора Кребса натуральным медом в течение 10 минут до через 10 мин после ишемии перфузировали изолированное сердце крысы (109).Результаты другого исследования in vitro показали, что хронический пероральный прием натурального меда (в течение 45 дней) оказывает сильное антиаритмическое и противоинфарктное действие у крыс (110). В исследовании предварительная обработка анестезированных нормальных крыс или крыс, подвергшихся стрессу, натуральным медом (5 г / кг) в течение 1 часа до инъекции адреналина (100 мкг / кг) может защитить их от индуцированной адреналином вазомоторной дисфункции и сердечных расстройств и сохранить положительный инотропный эффект. эффект адреналина. Авторы пришли к выводу, что натуральный мед может оказывать свое кардиозащитное и терапевтическое действие против индуцированной адреналином сердечной и вазомоторной дисфункции напрямую ( через - его высокая общая антиоксидантная способность и ферментативные и неферментативные антиоксиданты, помимо значительного количества минеральных элементов, таких как магний, натрий и хлор) и / или косвенно путем стимуляции высвобождения оксида азота из эндотелия за счет влияния витамина С (6). Мед также подавляет окислительный стресс, который может частично отвечать за его нейропротекторную активность против in vitro, гибели клеток и in vivo, очаговой ишемии головного мозга (111). Что касается наличия в составе меда многих органических соединений с антиоксидантной и улавливающей радикалы активностью, кажется, что мед потенциально может служить важным источником природных антиоксидантов в питании человека (112). Кроме того, что касается противовоспалительного действия, мед вызывает уменьшение некроза тканей (38, 113). Другие эффекты меда Положительный эффект меда как антиканцерогенного средства отмечен в некоторых исследованиях (32, 114, 115). Мед показал противоопухолевую активность при экспериментальном раке мочевого пузыря (22). Натуральный мед может сыграть важную роль в лечении боли в груди, усталости и головокружения. Вероятно, это связано с высокой энергетической ценностью меда, который обеспечивает сразу же доступными калориями после употребления (45). Преимущества меда также были замечены при боли при удалении зубов и инфекциях или кариесе из-за радиационно-индуцированной ксеростомии (32,114, 115).Было показано, что мед является очень эффективным средством для фиксации кожных трансплантатов разделенной толщины и может быть легко использован (14). В ходе исследования, проведенного в центральной части Буркина-Фасо, было обнаружено, что местные жители используют мед терапевтически для лечения респираторных заболеваний, кори, менструальных болей, послеродовых расстройств, мужской импотенции и фарингита из-за его антибактериального и противовоспалительного действия (45). . Сообщалось также, что мед проявляет антилейшманиозные эффекты in vitro (13). В одном исследовании ежедневное потребление меда показало множество положительных эффектов на гематологические показатели, уровень минералов и ферментов в крови, а также на эндокринную систему (85). В другом исследовании пероральный мед стимулировал выработку антител во время первичных и вторичных иммунных ответов против тимус-зависимых и тимус-независимых антигенов (13). Согласно Guerrini et al (2009) пчелиный мед без жала действует как защитный агент против повреждения ДНК и может представлять интересное свидетельство в отношении определенной антиоксидантной способности (116).Kilicoglu и др. (2008) изучили влияние меда на окислительный стресс и апоптоз при экспериментальной механической желтухе и обнаружили, что мед уменьшает негативное влияние перевязки желчных протоков на ультраструктуру печени. Этот эффект может быть связан с его антиоксидантной и противовоспалительной активностью (117). В другом исследовании введение меда изучали при повреждении печени у крыс, вызванном N -этилмалеимидом (NEM-индуцированным). NEM является блокатором сульфгидрила, который нарушает работу сульфгидрил-зависимой антиоксидантной системы (в основном глутатиона) в организме.Полученные данные предполагают, что снижение концентрации глутатиона играет причинную роль в повреждении печени, вызванном NEM, и что гепатопротекторный эффект меда может быть опосредован посредством сульфгидрил-чувствительных процессов (118). При гепатоцеллюлярной карциноме мед может рассматриваться как перспективный благодаря ингибированию пролиферации, протеазной активности и активности желатиназы клеток HepG2 независимым образом (119). Заид и др. (2010) показали, что мед оказывает благотворное влияние на крыс в период менопаузы, предотвращая атрофию матки, увеличивая плотность костей и подавляя увеличение массы тела.Они пришли к выводу, что мед может быть альтернативой заместительной гормональной терапии (120). Побочные эффекты меда Мед относительно не имеет побочных эффектов. Местное применение меда может вызвать кратковременное ощущение жжения. В противном случае его описывают в различных формах как успокаивающее, снимающее боль, не вызывающее раздражения и безболезненное изменение повязки. Аллергия на мед встречается редко, но может возникнуть аллергическая реакция либо на пыльцу, либо на пчелиные белки в меде.Чрезмерное применение меда может привести к обезвоживанию тканей, которое, однако, можно восстановить с помощью солевых компрессов. Теоретический риск повышения уровня глюкозы в крови всегда может присутствовать при применении к большой открытой ране у диабетиков. Риск раневого ботулизма из-за наличия спор Clostridia можно минимизировать с помощью гамма-облучения, которое убивает споры клостридий без потери антибактериальной активности (32, 121). Заключительные замечания На сегодняшний день исследователи уделяют больше внимания лекарствам природного происхождения и считают, что натуральные продукты могут быть эффективными терапевтическими средствами по сравнению с синтетическими лекарствами.Одним из важнейших натуральных продуктов является мед, который издревле использовался в различных лечебных целях. Помимо важной роли меда в традиционной медицине, ученые также считают мед новым эффективным лекарством от многих заболеваний. Самый известный эффект меда - антибактериальная активность. Сообщалось также, что мед оказывает ингибирующее действие на дрожжи, грибки, лейшманию и некоторые вирусы. str_extract () , если вам нужны все совпадения для каждой строки, вам понадобится str_match_all () . Упражнения
Замена спичек
str_replace () и str_replace_all () позволяют заменять совпадения новыми строками. Самый простой способ - заменить шаблон фиксированной строкой:
x <- c («яблоко», «груша», «банан»)
str_replace (x, «[aeiou]», «-»)
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all (x, «[aeiou]», «-»)
#> [1] "-ppl-" "p - r" "b-n-n-" str_replace_all () вы можете выполнить несколько замен, указав именованный вектор:
x <- c («1 дом», «2 машины», «3 человека»)
str_replace_all (x, c ("1" = "один", "2" = "два", "3" = "три"))
#> [1] "один дом" "две машины" "три человека" Упражнения
str_to_lower () , используя replace_all () . слове . Какая из этих струн
еще слова? Колки
str_split () , чтобы разделить строку на части. Например, мы можем разбить предложения на слова:
предложений%>%
голова (5)%>%
str_split ("")
#> [[1]]
#> [1] "" березовая "каноэ" скользнула "" по "" "гладью"
#> [8] "доски".
#>
#> [[2]]
#> [1] "Приклейте" "" лист "" к "" "
#> [6] "темный" "синий" "фон."
#>
#> [[3]]
#> [1] «Легко» «сказать» «о« глубине »» «колодца».
#>
#> [[4]]
#> [1] "В эти" "дни" "" "курица" "нога" "" "" а "
#> [8] «редкое» «блюдо».
#>
#> [[5]]
#> [1] "Рис" "часто" подается "в" круглых "мисках."
"a | b | c | d"%>%
str_split ("\\ |")%>%
.[[1]]
#> [1] "a" "b" "c" "d" simpleify = TRUE для возврата матрицы:
предложений%>%
голова (5)%>%
str_split ("", simpleify = ИСТИНА)
#> [, 1] [, 2] [, 3] [, 4] [, 5] [, 6] [, 7] [, 8]
#> [1,] "" березовое "каноэ" скользило "" по "" гладким "доскам".
#> [2,] "Приклейте" "" лист "" к "" "" темному "" синему "" фону."
#> [3,] "" легко "" "сказать" "" глубину "" "" а "
#> [4,] "В эти" "дни" "" курица "" ножка "" "" а "" редко "
#> [5,] "Рис" "часто" подается "в" круглых "мисках." ""
#> [, 9]
#> [1,] ""
#> [2,] ""
#> [3,] "хорошо".
#> [4,] "блюдо".
#> [5,] ""
полей <- c ("Имя: Хэдли", "Страна: Новая Зеландия", "Возраст: 35")
поля%>% str_split (":", n = 2, simpleify = TRUE)
#> [, 1] [, 2]
#> [1,] "Имя" "Хэдли"
#> [2,] "Country" "NZ"
#> [3,] "Возраст" "35" border () s:
x <- "Это приговор.Это еще одно предложение ».
str_view_all (x, граница ("слово"))
str_split (x, "") [[1]]
#> [1] «Это» «есть» «предложение». "" "Этот"
#> [7] "это" еще одно "предложение".
str_split (x, граница ("слово")) [[1]]
#> [1] "This" "is" "" предложение "" This "" is "" другое "
#> [8] "предложение" Упражнения
"яблоки, груши и бананы" на отдельные
составные части. границу ("слово") , чем на "" ? "" )? Экспериментируйте и
затем прочтите документацию. Найти совпадения
str_locate () и str_locate_all () дают вам начальную и конечную позиции каждого совпадения. Это особенно полезно, когда ни одна из других функций не делает именно то, что вы хотите.Вы можете использовать str_locate (), , чтобы найти соответствующий шаблон, str_sub (), , чтобы извлечь и / или изменить их. Текстовый набор данных рецептов синтеза неорганических материалов
Точность экстракции
Извлечение данных из набора
Рис. 3 Объекты данных и аннотации - Станца
Оглавление
Document
Document содержит аннотацию всего документа и автоматически создается, когда строка аннотируется конвейером Pipeline . Он содержит набор из предложений и сущностей (которые представлены как Span s) и может быть легко преобразован в собственный объект Python. Документ содержит следующие свойства: Свойство Тип Описание текст str Исходный текст документа. предложений Список [предложение] Список предложений в этом документе. сущностей (энтов) Список [диапазон] Список сущностей в этом документе. num_tokens int Общее количество токенов в этом документе. num_words int Общее количество слов в этом документе. Документ также содержит следующие методы: Метод Тип возвращаемого значения Описание iter_words Итератор возвращает все слова в этом документе по порядку. Итератор iter_tokens Итератор [токен] Итератор, который возвращает все токены в этом документе по порядку. to_dict List [List [Dict]] Выгружает весь документ в список списков словарей, каждый словарь представляет токен, которые сгруппированы по предложениям в документе. to_serialized байт Выгружает (с помощью pickle) весь документ, включая текст, в массив байтов, содержащий список словарей для каждого токена в каждом предложении в документе. from_serialized Document Метод класса для создания и инициализации нового документа из сериализованной строки, созданной Document.to_serialized_string (). Sentence
Sentence представляет предложение (которое сегментировано TokenizeProcessor или предоставлено пользователем) и содержит список Token s в предложении, список всех его Word с, а также список сущностей в предложении (представленный как Span s). Предложение содержит следующие свойства: Свойство Тип Описание doc Документ «обратный указатель» на родительский документ этого предложения. текст str Исходный текст этого предложения. зависимости Список [(Word, str, Word)] Список зависимостей для этого предложения, где каждый элемент содержит заголовок Word отношения зависимости, тип отношения зависимости и зависимое Слово в этом отношении. токенов Список [токен] Список токенов в этом предложении. слов Список [Слово] Список слов в этом предложении. сущностей (энтов) Список [диапазон] Список сущностей в этом предложении. тональность str Тональность этого предложения в виде строки. Обратите внимание, что модель тональности есть только в нескольких языках. Предложение также содержит следующие методы: Метод Тип возврата Описание to_dict Список [Dict] список Dump the list [Dict] словарей, где каждый словарь представляет собой лексему в предложении. print_dependencies Нет Распечатайте синтаксические зависимости для этого предложения. print_tokens Нет Распечатайте токены для этого предложения. print_words Нет Напечатайте слова для этого предложения. tokens_string str Аналогично print_tokens , но вместо печати токенов выгрузите токены в строку. words_string str Подобно print_words , но вместо того, чтобы печатать слова, выгрузите слова в строку. Token
Token содержит токен и список его базовых синтаксических Word s. В случае, если токен является токеном из нескольких слов (например, французский au = à le ), токен будет иметь диапазон id , как описано в спецификациях формата CoNLL-U (например,g., 3-4 ), со свойством слова , содержащим лежащее в основе слово , соответствующее этим id . В других случаях объект Token будет функционировать как простая оболочка вокруг одного объекта Word , где его свойство word является одноэлементным. Токен содержит следующие свойства: Свойство Тип Описание id Tuple [int] Индекс этого токена в предложении, 1- на основе.Этот индекс содержит два элемента (например, (1, 2) ), когда соответствующий токен является токеном из нескольких слов, в противном случае он содержит только один элемент (например, (1,) ). текст str Текст этого токена. Пример: «The». разное str Разные примечания относительно этого токена. Используется в конвейере, например, для хранения того, является ли токен токеном из нескольких слов. слов Список [слово] Список синтаксических слов, лежащих в основе этого токена. start_char int Индекс начального символа для этого токена в необработанном тексте документа. Особенно полезно, если вы хотите детокенизировать в какой-то момент или применить аннотации к исходному тексту. end_char int Индекс конечного символа для этого токена в необработанном тексте документа.Особенно полезно, если вы хотите детокенизировать в какой-то момент или применить аннотации к исходному тексту. ner str Тег NER этого токена в формате BIOES. Пример: «B-ORG». Токен также содержит следующие методы: Метод Тип возврата Описание to_dict Список [Dict] Dumps список [Dict] 92 Dumps словарей, каждый словарь представляет одно из слов, лежащих в основе этого токена. pretty_print str Распечатайте этот токен со словами, которые он расширяет в одну строку. Word
Word содержит синтаксическое слово и все его примечания на уровне слова. В случае токенов, состоящих из нескольких слов (MWT), слова генерируются в результате применения MWTProcessor и используются во всех последующих синтаксических анализах, таких как тегирование, лемматизация и синтаксический анализ. Если Word является результатом расширения MWT, его текст обычно не будет найден во входном необработанном тексте.Помимо токенов, состоящих из нескольких слов, Word должны быть похожи на знакомые «токены», которые можно встретить в другом месте. Слово содержит следующие свойства: Свойство Тип Описание id int Индекс этого слова в предложении, на основе 1 (индекс 0 зарезервирован для искусственного символа, представляющего корень синтаксического дерева). текст str Текст этого слова.Пример: «The». лемма str Лемма этого слова. упос (поз) str Универсальная часть речи этого слова. Пример: «СУЩЕСТВИТЕЛЬНОЕ». xpos str Часть речи этого слова, относящаяся к дереву. Пример: «NNP». feats str Морфологические особенности этого слова.Пример: «Пол = Женщина | Человек = 3». head int Идентификатор синтаксической главы этого слова в предложении, на основе 1 для реальных слов в предложении (0 зарезервирован для искусственного символа, который представляет корень синтаксического дерева ). deprel str Отношение зависимости между этим словом и его синтаксической головкой. Пример: «nmod». deps str Комбинация head и deprel, которая захватывает всю информацию о синтаксических зависимостях.Встречается в файлах CoNLL-U, выпущенных из универсальных зависимостей, но не предсказывается нашим конвейером . разное str Разные примечания к этому слову. Конвейер использует это поле, например, для внутреннего хранения информации о смещении символов. родительский Token «обратный указатель» на родительский токен, частью которого является это слово. В случае токена, состоящего из нескольких слов, токен может быть родительским для нескольких слов. Word также содержит следующие методы: Метод Тип возврата Описание to_dict Dict в словарь Dict D. Информация. pretty_print str Печатает слово в одну строку со всей его информацией. Span
Span хранит атрибуты непрерывного отрезка текста.Диапазон объектов (например, именованных сущностей) может быть представлен как Span . Span содержит следующие свойства: Свойство Тип Описание doc Document «обратный указатель» на родительский документ этого диапазона. текст str Текст этого промежутка. токенов Список [токен] Список токенов, соответствующих этому диапазону. слов Список [слово] Список слов, соответствующих этому диапазону. тип str Тип объекта этого диапазона. Пример: «ЛИЦО». start_char int Смещение начального символа этого диапазона в документе. end_char int Смещение конечного символа этого диапазона в документе. Span также содержит следующие методы: Метод Тип возврата Описание to_dict Dict Dumps, содержащий весь диапазон . Информация. pretty_print str Печатает диапазон в одной строке со всей его информацией. Добавление новых свойств к объектам данных Stanza
Processor , который вы разрабатываете, либо из некоторого пользовательского кода, который вы пишете. Document , просто вызовите
Document.add_property ('char_count', default = 0, getter = lambda self: len (self.text), setter = Нет)
char_count из всех экземпляров класса Document .Интерфейс здесь должен быть знаком, если вы использовали свойства класса в Python или другом объектно-ориентированном языке - первый и единственный обязательный аргумент - это имя свойства, которое вы хотите создать, за которым следует default для значения по умолчанию этого свойства. , геттер для чтения значения свойства и установщик для установки значения свойства. .Базовая переменная для нового свойства называется _ {property_name} , поэтому в нашем примере выше Stanza автоматически создаст переменную класса с именем _char_count для хранения значения этого свойства, если это необходимо. Это переменная, которую должны использовать ваши функции получения и установщика , если это необходимо. Определение потребности в материалах (MRP)
Что такое планирование потребности в материалах (MRP)?
Ключевые выводы
Как работает планирование потребности в материалах
Этапы планирования потребности в материалах (MRP)
Планирование потребности в материалах (MRP) в производстве
Типы данных, учитываемых при планировании потребности в материалах (MRP)
Преимущества и недостатки планирования потребности в материалах (MRP)
Системы MRP: история вопроса
Часто задаваемые вопросы по MRP
Что такое MRP?
Какую пользу MRP приносит бизнесу?
Каковы входы MRP?
Традиционное и современное использование натурального меда при заболеваниях человека: обзор
Abstract
Введение
Таблица 1
Мед (Пищевая ценность на 100 г) Компонент Среднее значение Углеводы 82.Г 1 г Другие сахара 11,7 г Пищевые волокна 9220.2 г Жир 0 г Белок 0,3 г Вода 17,1 г Рибофлавин (Вит. B 2 ) 0.038 мг Ниацин (витамин B 3 ) 0,121 мг Пантотеновая кислота (витамин B 5 74 208 5 74208 5 74208 0,068 мг Пиридоксин (Вит. B 6 ) 0,024 мг Фолат (Вит. 0.002 мг Витамин C 0,5 мг Кальций 9324 9324 9324 9324 9327 9324 3 0,42 мг Магний 2 мг Фосфор 9327 52 мг Натрий 4 мг Цинк 20 20.22 мг