Слова «обозреватель» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «обозреватель» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «обозреватель» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «обозреватель».
Содержимое:
- 1 Слоги в слове «обозреватель» деление на слоги
- 2 Как перенести слово «обозреватель»
- 3 Морфологический разбор слова «обозреватель»
- 4 Разбор слова «обозреватель» по составу
- 5 Синонимы слова «обозреватель»
- 6 Ударение в слове «обозреватель»
- 7 Фонетическая транскрипция слова «обозреватель»
- 8 Фонетический разбор слова «обозреватель» на буквы и звуки (Звуко-буквенный)
- 9 Предложения со словом «обозреватель»
- 10 Сочетаемость слова «обозреватель»
- 11 Значение слова «обозреватель»
- 12 Как правильно пишется слово «обозреватель»
- 13 Ассоциации к слову «обозреватель»
Слоги в слове «обозреватель» деление на слоги
Количество слогов: 5
По слогам: о-бо-зре-ва-тель
По правилам школьной программы слово «обозреватель» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Допускается вариативность, то есть все варианты правильные. Например, такой:
о-боз-ре-ва-тель
По программе института слоги выделяются на основе восходящей звучности:
о-бо-зре-ва-тель
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
з примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «обозреватель»
обо—зреватель
обоз—реватель
обозре—ватель
обозрева—тель
Морфологический разбор слова «обозреватель»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: одушевлённое;
род: мужской;
число: единственное;
падеж: именительный;
отвечает на вопрос: (есть) Кто?
Начальная форма:
обозреватель
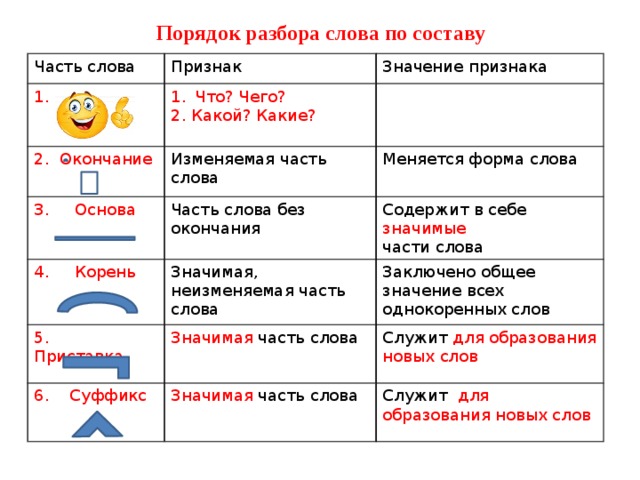
Разбор слова «обозреватель» по составу
| обо | приставка |
| зр | корень |
| е | суффикс |
| ва | суффикс |
| тель | суффикс |
| ø | нулевое окончание |
обозреватель
Синонимы слова «обозреватель»
1. журналист
журналист
2. программа
3. радиообозреватель
4. обозритель
Ударение в слове «обозреватель»
обозрева́тель — ударение падает на 4-й слог
Фонетическая транскрипция слова «обозреватель»
[абазр’ив`ат’ил’]
Фонетический разбор слова «обозреватель» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| о | [а] | гласный, безударный | о |
| б | [б] | согласный, звонкий парный, твёрдый, шумный | б |
| о | [а] | гласный, безударный | о |
| з | [з] | согласный, звонкий парный, твёрдый, шумный | з |
| р | [р’] | согласный, звонкий непарный (сонорный), мягкий | р |
| е | [и] | гласный, безударный | е |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| а | [`а] | гласный, ударный | а |
| т | [т’] | согласный, глухой парный, мягкий, шумный | т |
| е | [и] | гласный, безударный | е |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| ь | — | не обозначает звука | ь |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 12 букв и 11 звуков.
Буквы: 5 гласных букв, 6 согласных букв, 1 буква не означает звука.
Звуки: 5 гласных звуков, 6 согласных звуков.
Предложения со словом «обозреватель»
Я — не политический обозреватель, но, считаю, что это и ценно.
Источник: Николай Ясиновский, Железная правда «Русского кошмара».
В одни дни мы рассылали по пять экземпляров книжным обозревателям в газеты.
Источник: Эми Ньюмарк, Куриный бульон для души. 101 лучшая история.
— Просто мне захотелось вслух прокомментировать, как ребята играют в мяч, представил себя на какое-то время спортивным обозревателем, только и всего.
Источник: А. Н. Рундквист, III единство.
Сочетаемость слова «обозреватель»
1. политические обозреватели
политические обозреватели
2. спортивный обозреватель
3. военный обозреватель
4. обозреватель газеты
5. обозреватель журнала
6. по мнению обозревателей
7. большинство обозревателей
8. (полная таблица сочетаемости)
Значение слова «обозреватель»
ОБОЗРЕВА́ТЕЛЬ , -я, м. Автор, пишущий обозрения, а также лицо, делающее устное обозрение по радио, телевидению. Политический обозреватель. (Малый академический словарь, МАС)
Как правильно пишется слово «обозреватель»
Правописание слова «обозреватель»
Орфография слова «обозреватель»
Правильно слово пишется: обозрева́тель
Гласные: о, о, е, а, е;
Согласные: б, з, р, в, т, л;
Нумерация букв в слове
Номера букв в слове «обозреватель» в прямом и обратном порядке:
- 12
о
1 - 11
б
2 - 10
о
3 - 9
з
4 - 8
р
5 - 7
е
6 - 6
в
7 - 5
а
8 - 4
т
9 - 3
е
10 - 2
л
11 - 1
ь
12
Ассоциации к слову «обозреватель»
Таймс
Комментатор
Рецензия
Корреспондент
Тайм
Редактор
Комсомолец
Газета
Саундтрек
Критик
Колонка
Отзыв
Журнал
Балл
Телеканал
Аналитик
-
Журналист
График
Журналистика
Графика
Радиостанция
Афиша
Публицист
Хроник
Телевидение
Коммерсант
Трек
Критика
Экономист
Фанат
Барабанов
Экранизация
Репортаж
Персонаж
Портал
Оценка
Дизайн
Обозрение
Вердикт
Звучание
Разработчик
Альбом
Издание
Жанр
Сериал
Кравченко
Сюжет
Пресс-конференция
Тематика
Обзор
Индустрия
Ведомость
Рейтинг
Оформление
Консерватор
Балловый
Еженедельный
Игровой
Сюжетный
Редакционный
Криминальный
Газетный
Политический
Комсомольский
Спортивный
Музыкальный
Актёрский
Журналистский
Петровский
Литературный
Авторитетный
Телевизионный
Ежемесячный
Ведущий
Визуальный
Издательский
Положительный
Театральный
Информационный
Штатный
Качественный
Предвыборный
Позитивный
Консервативный
Экономический
Парламентский
Охарактеризовать
Отмечать
Комментировать
Запоминаться
Отметить
Критиковать
Публиковаться
Присудить
Похвалить
Оценить
Хвалить
Посчитать
Положительно
Русско-английский словарь, перевод на английский язык
wordmap
Русско-английский словарь — показательная эрудиция
Русско-английский словарь — прерогатива воспользоваться вариативным функционалом, насчитывающим несколько сотен тысяч уникальных английских слов. Чтобы воспользоваться сервисом, потребуется указать предпочтенное слово на русском языке: перевод на английский будет отображен во всплывающем списке.
Чтобы воспользоваться сервисом, потребуется указать предпочтенное слово на русском языке: перевод на английский будет отображен во всплывающем списке.
Русско-английский словарь — автоматизированная система, которая отображает результаты поиска по релевантности. Нужный перевод на английский будет в верхней части списка: альтернативные слова указываются в порядке частоты их применения носителями языка. При нажатии на запрос откроется страница с выборкой фраз: система отобразит примеры использования искомого слова.
Русско-английский словарь содержит строку для поиска, где указывается запрос, а после запускается непосредственный поиск. Система может «предлагать» пользователю примеры по использованию слова: «здравствуйте» на английском языке, «хризантема» на английском языке. Дополнительные опции системы — отображение частей речи (будет выделена соответствующим цветом). В WordMap русско-английский словарь характеризуется наличием функции фильтрации запросов, что позволит «отсеять» ненужные словосочетания.
Применение сервиса и достоинства
Перевод на английский язык с сервисом WordMap — возможность улучшить словарный запас учащегося. Дополнительные преимущества в эксплуатации WordMap:
- Слова с различным значением, которые оптимизированы под любой уровень владения английским языком;
- Русско-английский словарь содержит примеры, позволяющие усовершенствовать практические навыки разговорного английского;
- В списке результатов указаны всевозможные синонимы и паронимы, которые распространены в сложном английском языке.
Онлайн-сервис WordMap предлагает пространство для совершенствования интеллектуальных способностей, способствует результативной подготовке к сдаче экзамена. Быстрый перевод на английский может быть использован с игровой целью: посоревноваться с коллегой или одноклубником; бросить вызов преподавателю, превзойдя ожидания собственного ментора.
Только что искали:
портившийся только что
средний интеллект только что
катнрат 1 секунда назад
прокрастинант 1 секунда назад
лайтамак 1 секунда назад
гыжег 1 секунда назад
пересиливая себя 1 секунда назад
нерогат 1 секунда назад
логика 3 секунды назад
кофи 4 секунды назад
ганнетт 4 секунды назад
ниаонле 6 секунд назад
блюстители 7 секунд назад
кевалон 7 секунд назад
ракасом 11 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | воздухонепроницаемость | 58 слов | 8 минут назад | 213. 59.248.62 59.248.62 |
| Игрок 2 | фундаментальность | 27 слов | 15 минут назад | 213.59.248.62 |
| Игрок 3 | первооткрывательница | 34 слова | 40 минут назад | 213.59.248.62 |
| Игрок 4 | электролампа | 24 слова | 46 минут назад | 213.59.248.62 |
| Игрок 5 | виноторговля | 21 слово | 52 минуты назад | 213.59.248.62 |
| Игрок 6 | океанография | 22 слова | 58 минут назад | 213.59.248.62 |
| Игрок 7 | катамаран | 14 слов | 1 час назад | 213.59.248.62 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | натаска | 0:0 | 58 минут назад | 213. 59.248.62 59.248.62 |
| Игрок 2 | трасс | 39:39 | 1 час назад | 188.162.187.251 |
| Игрок 3 | шабот | 0:0 | 1 час назад | 213.59.248.62 |
| Игрок 4 | давка | 57:53 | 1 час назад | 188.162.187.251 |
| Игрок 5 | ильма | 42:45 | 1 час назад | 188.162.187.251 |
| Игрок 6 | розан | 46:49 | 2 часа назад | 188.162.187.251 |
| Игрок 7 | лерка | 56:61 | 2 часа назад | 213.24.132.9 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Ляйля | На одного | 10 вопросов | 1 час назад | 213. 59.248.62 59.248.62 |
| Сладкий пупс | На одного | 10 вопросов | 16 часов назад | 188.186.209.238 |
| Сергей | На одного | 5 вопросов | 1 день назад | 83.234.52.224 |
| Оля | На одного | 5 вопросов | 1 день назад | 83.234.52.224 |
| Пенал | На одного | 20 вопросов | 1 день назад | 178.235.191.115 |
| Настя | На одного | 10 вопросов | 1 день назад | 212.58.119.40 |
| Свечка | На одного | 5 вопросов | 2 дня назад | 5.167.26.68 |
| Играть в Чепуху! | ||||
Monadic Parser Combinators: интерактивное учебное пособие по JS (часть 1)
Синтаксический анализ анализирует последовательные данные в структурный результат и является ключевым этапом статического анализа кода и компиляции. Парсеры также демонстрируют различные функциональные концепции, включая чистоту, композицию и монады.
Парсеры также демонстрируют различные функциональные концепции, включая чистоту, композицию и монады.
В этом интерактивном руководстве мы рассмотрим реализацию простой библиотеки комбинатора парсера. Комбинаторы позволяют программистам легко создавать сложные программы за счет использования небольшого количества совместных служебных функций.
const color = P.either(P.literal('красный'), P.literal('синий'))
const animal = P.either(P.literal('зебра'), P.literal('жираф'))
константные пространства = P.many1 (P.literal (' '))
const highTale =
цвет .цепочка (с =>
space.chain(_ =>
animal.chain(a => P.of(`Был ${c} ${a}.`))))
Войти в полноэкранный режимВыйти из полноэкранного режимаЦель состоит в том, чтобы частично изучить синтаксический анализ и частично изучить функциональное программирование. Предварительный опыт ни в том, ни в другом не предполагается.
Мотивы
Серийные данные, напр. из файла или сетевой нагрузки, часто необходимо преобразовать в результат, прежде чем программа сможет с ним работать. Например:
Например:
- HTML — это строковый формат содержимого страницы. Браузеры анализируют HTML в DOM, дереве узлов в памяти, которые можно запрашивать и манипулировать ими, чтобы влиять на визуализируемую веб-страницу.
- JSON — это строковый формат для вложенных данных, часто используемый для файлов конфигурации или сетевых полезных данных. Программы могут использовать
JSON.parseдля преобразования строки JSON в объект JavaScript, который можно легко читать и обновлять во время выполнения. - ESLint — это инструмент статического анализа кода для обнаружения ошибок и отклонений от стиля. ESLint использует анализатор JavaScript (Espree) для чтения авторской программы (текстового файла) и выявления потенциальных проблем.
Кроме того, класс программ, называемых компиляторами , делает еще один шаг вперед, сворачивая дерево синтаксического анализа обратно в формат преобразованной строки. Таким образом, компиляторы действуют как переводчики между строками одного формального языка и строками другого.
константный кодES2018 = 'число => число + 1'
const codeES5 = compileToES5(codeES2018)
console.log(codeES5) // 'функция (число) {возврат числа + 1}'
Войти в полноэкранный режимВыйти из полноэкранного режима- V8 — это механизм JavaScript, который использует компилятор для преобразования JavaScript в исполняемый машинный код.
- Babel компилирует JavaScript, написанный с использованием современного и/или предметно-ориентированного синтаксиса (например, ES2018 + JSX), в более старый синтаксис (например, ES5).
- Prettier компилирует JavaScript с нестандартным форматированием в JavaScript с согласованным форматированием.
В типичном компиляторе синтаксический анализ называется внешним интерфейсом , а генерация кода называется внутренним интерфейсом .
инфикс FE (парсер) + BE (генератор) постфикс
«2 + 3 * 5» -> / \ -> «2 3 5 * +»
2 *
/ \
3 5
Войти в полноэкранный режимВыйти из полноэкранного режима Однако также возможно генерировать результаты во время шага синтаксического анализа. В этом случае явное дерево не строится, хотя синтаксический анализатор неявно следует древовидной структуре, рекурсивно проходя по входной строке.
В этом случае явное дерево не строится, хотя синтаксический анализатор неявно следует древовидной структуре, рекурсивно проходя по входной строке.
Обычно синтаксический анализатор извлекает структуру из начала некоторого последовательного ввода. Входными данными может быть обычная строка, хотя некоторые синтаксические анализаторы могут ожидать поток (последовательно потребляемый источник, например, генератор или наблюдаемый) из токенов (объекты, записывающие как лингвистический тип, так и лексический контент).
Давайте начнем с простого и рассмотрим парсер как функцию от строки к результату.
// разбор :: Строка -> * константный разбор = s => ?Войти в полноэкранный режимВыйти из полноэкранного режима
Напрашивается вопрос, что выдает наш парсер. Ответ зависит от проблемы. Многие синтаксические анализаторы создают узлы дерева, но синтаксические анализаторы могут быть написаны для получения любого желаемого результата, включая необработанные строки, числа, функции и т. д.
д.
Как справиться с неудачей
А пока давайте просто зафиксируем буквальное строковое значение (или лексема ), которым соответствует наш парсер. Вот (неполный) синтаксический анализатор, предназначенный для сопоставления и получения лексемы «Трицератопс»:
// parseTri :: String -> String const parseTri = s => "Трицератопс"Войти в полноэкранный режимВыйти из полноэкранного режима
К сожалению, этот парсер не работает. Что, если наша строка содержит не того динозавра? Разбор «T. Rex» не должен приводить к «Triceratops». Нам нужен способ сбоя сигнала .
Как бы вы решили эту проблему? Придумать свой собственный подход; ваша функция синтаксического анализа должна иметь возможность принимать следующие строки и либо возвращать «Triceratops», либо указывать (каким-то образом), что ей не удалось выполнить синтаксический анализ.
Сбой сигнализации: может быть?
тип Parser = String -> Возможно StringВойти в полноэкранный режимВыйти из полноэкранного режима
Опытный функциональный программист, скорее всего, воспользуется таким типом суммы, как монада Maybe . Тем не менее, правильное рассмотрение этой концепции сейчас существенно сорвет эту статью, поэтому мы вернемся к
Тем не менее, правильное рассмотрение этой концепции сейчас существенно сорвет эту статью, поэтому мы вернемся к Может быть позже.
Ошибка сигнализации: массив?
тип Parser = String -> [String]Войти в полноэкранный режимВыйти из полноэкранного режима
Функциональные синтаксические анализаторы обычно представляют свои результаты в виде списков. Таким образом, сбой может быть представлен пустым списком [] , а при необходимости может быть зафиксировано несколько успехов (из неоднозначной грамматики). Неоднозначные грамматики выходят за рамки этой статьи, поэтому нам строго не нужны списки.
Ошибка сигнализации: ноль
тип Parser = String -> String | НулевойВойти в полноэкранный режимВыйти из полноэкранного режима
Как Может быть, , так и списки — хорошие способы борьбы с ошибками, но пока мы будем придерживаться метода, с которым знакомы JS-разработчики: null . Значение
Значение null , изобретатель которого Тони Хоар однажды назвал его «ошибкой на миллиард долларов», имеет серьезные подводные камни. Тем не менее, это идиоматично, доступно и на данный момент будет достаточно.
Вот наш новый парсер. Попробуйте на некоторых строках и посмотрите, что получится:
Работа с остатками
Когда мы анализируем результат из строки, в большинстве случаев мы используем только часть ввода. У остатка будут другие значения, которые мы можем проанализировать, а это значит, что нам нужно отслеживать, где возобновить работу. В изменяемой настройке, такой как JavaScript, может возникнуть соблазн создать общее значение index .
пусть индекс = 0
const parseTri = s => {
константный остаток = s.slice(index)
если (остаток.startsWith('Трицератопс')) {
index += 'Трицератопс'.length
вернуть «Трицератопс»
}
вернуть ноль
}
Войти в полноэкранный режимВыйти из полноэкранного режимаЭто прекрасно работает для синтаксического анализа одной строки:
Однако общее изменяемое состояние может быстро вызвать проблемы. Что, если мы хотим впоследствии проанализировать другую строку?
Что, если мы хотим впоследствии проанализировать другую строку?
Конечно, есть решения. Мы могли бы создать класс Parser , экземпляры которого управляют внутренним состоянием, или функцию более высокого порядка makeParser , которая закрывается по состоянию. Оба этих решения хоронят состояние, фактически не устраняя его; отладка такого скрытого состояния иногда даже более сложна.
Чистое потребление токенов
Оказывается, для этой задачи нам на самом деле не нужно изменяемое состояние. В функциональном программировании мы предпочитаем чистых -решений.
Чистые функции — это детерминированные отображения без сохранения состояния от входа к выходу без побочных эффектов. Другими словами, чистые функции имеют выходные данные, но не зависят от внешней вселенной и не изменяют ее. Если вы можете определить свою функцию как (потенциально бесконечную) таблицу входов и выходов, это чисто. Попробуйте вызвать как f1 , f2 и f3 определены ниже:
| f1 в | f1 из | f2 в | f2 из | f3 в | f3 из |
|---|---|---|---|---|---|
привет | 2 | [а, б] | б | 0 | -2 |
"что" | 4 | [0, 9, 1] | 9 | 1 | -1 |
"пау" | 3 | [0] | не определено | 2 | 2 |
"лес" | 6 | [] | не определено | 3 | 7 |
«а» | 1 | [1, 2, 3] | 2 | 4 | 14 |
| 0 | [г, у] | г | 5 | 23 |
| … | … | … | … | … | … |
Если синтаксическому анализатору необходимо указать, где должен начинаться следующий синтаксический анализ, это подразумевает, что оставшийся ввод сам должен быть возвращаемым значением. Итак, наши парсеры вернут две вещи: проанализированный результат и оставшиеся входные данные.
Итак, наши парсеры вернут две вещи: проанализированный результат и оставшиеся входные данные.
тип Parser = String -> String & StringВойти в полноэкранный режимВыйти из полноэкранного режима
Как написать функцию, которая возвращает две вещи? Существует более одного жизнеспособного способа; придумайте свой собственный подход ниже, а затем читайте дальше, чтобы узнать о нашем подходе.
Кортежи и друзья
Поскольку функциональное программирование включает в себя большое количество данных, поступающих и исходящих из функций, функциональные языки часто имеют облегченную структуру данных для объединения значений: кортеж.
-- Хаскелл
myTuple = ("привет", 99) -- 2-кортеж
str = fst myTuple -- "привет"
число = snd myTuple -- 99
Войти в полноэкранный режимВыйти из полноэкранного режима В JavaScript нет кортежей, но есть объекты и массивы (которые на самом деле являются типом объектов). Мы можем достаточно легко эмулировать кортежи:
const myTuple = ['привет', 99] const str = myTuple[0] // 'привет' const num = myTuple[1] // ложьВойти в полноэкранный режимВыйти из полноэкранного режима
const myTuple = {str: 'hello', num: 99 }
const { str } = myTuple // 'привет'
const { число } = myTuple // ложь
Войти в полноэкранный режимВыйти из полноэкранного режима Массивы более лаконичны, но объекты более выразительны. Вы, вероятно, использовали один из них в своем решении выше; мы будем использовать объекты.
Вы, вероятно, использовали один из них в своем решении выше; мы будем использовать объекты.
Боковое примечание: изоморфизмы
n -Tuples и n -element Массивы JS (когда они используются исключительно для хранения данных) на самом деле изоморфны . Наборы A и B изоморфны, если можно определить пару функций a2b и b2a , такую что:
-
a2bсопоставляет все значения вAсо значениями вB -
b2aсопоставляет все значения вBсо значениями вA -
b2a(a2b(a)) = а -
а2б(б2а(б)) = б
Изоморфизмы — богатая тема с некоторыми восхитительными результатами, но в результате приятно знать, когда два типа данных эквивалентны для данного варианта использования.
Загадка для размышлений: почему двузначные объекты , а не могут быть изоморфны 2-el массивам? Какая информация будет потеряна при переводе?
Поточные парсеры
Теперь наш синтаксический анализатор может сообщать, какая часть ввода не была использована, но как мы на самом деле используем эту информацию? Строка, оставшаяся от одного синтаксического анализа, становится входными данными для следующего синтаксического анализа.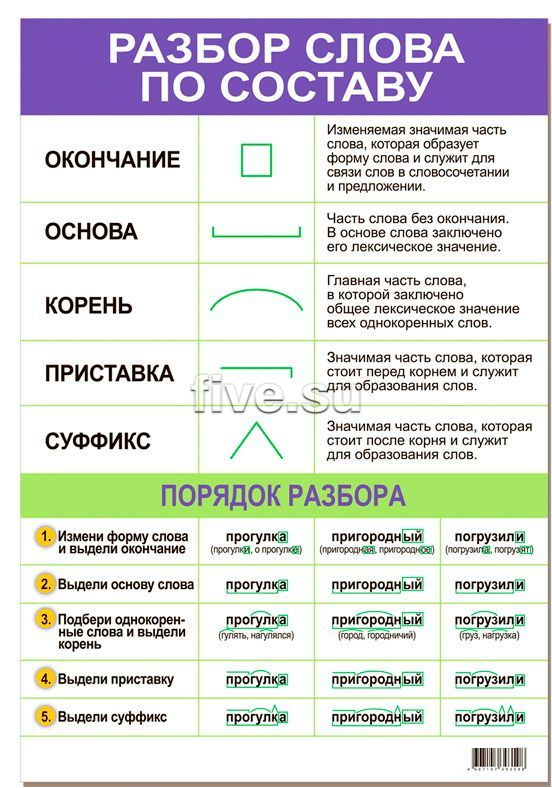 Заполните приведенный ниже код.
Заполните приведенный ниже код.
Чтобы увидеть наше решение, вы можете войти в скрытую переменную решение .
Обобщение
У нас есть единственный парсер, который умеет парсить «Трицератопсов» — не очень интересно. Напишите несколько парсеров для других динозавров.
Это повторяется. Давайте обобщим и сделаем функцию parseLiteral .
Решение приведенной выше задачи демонстрирует общую функциональную технику. Функции высшего порядка сами принимают и/или возвращают функции; parseLiteral делает последнее. Вместо жесткого кодирования отдельных синтаксических анализаторов для каждой строки, parseLiteral обобщает, сопоставляя строки с синтаксическими анализаторами:
| строка | parseLiteral(string) |
|---|---|
привет | парсер для "привет" |
'лет' | парсер для 'лет' |
"вау" | парсер для "вау" |
| … | … |
Различные типы результатов
Парсеры соответствуют в строках, но они не обязаны давать в них результат . Напишите синтаксические анализаторы для цифровых строк, результатом которых являются числа.
Напишите синтаксические анализаторы для цифровых строк, результатом которых являются числа.
Как только мы начнем использовать наши синтаксические анализаторы для практических целей, будет удобно преобразовывать необработанные лексемы в обработанные результаты, специфичные для нашего варианта использования.
Типы, подписи и псевдонимы
Итак, мы рассмотрели два разных типа синтаксических анализаторов: те, которые возвращают строки, и те, которые возвращают числа.
parseRex :: String -> { результат: String, остаток: String } | Нулевой
parseNum1 :: String -> { результат: число, остаток: строка } | Нулевой
Войти в полноэкранный режимВыйти из полноэкранного режима Мы пока не обращали особого внимания на эти комментарии, предпочитая учить на собственном примере, но это примеры подписи типа . Подпись типа документирует, к какому набору принадлежит значение. Например, тип Bool представляет собой набор из двух значений: true и false . Вы можете прочитать нотацию
Вы можете прочитать нотацию :: как «имеет тип» или «есть в наборе»:
true::Bool -- `true` находится в наборе `Bool` false :: Bool -- `false` находится в наборе `Bool`Войти в полноэкранный режимВыйти из полноэкранного режима
Функции также относятся к типам. ! (или «нет») функция находится в набор функций, которые сопоставляют значения в Bool со значениями в Bool . Мы обозначаем это как (!) :: Bool -> Bool . Вот ! Функция определена:
| Логический ввод | Логический выход |
|---|---|
правда | ложный |
ложный | правда |
Головоломка: их ровно три другие функции типа Bool -> Bool . Можете ли вы определить их все? Помните, что каждая функция будет таблицей из двух строк.
Функции — это сопоставления одного типа с другим типом (например, Int -> Bool , String -> String или Object -> String ). Соответственно, функциональные языки часто подчеркивают свою систему типов. Машинное обучение и родственные языки, такие как OCaml, F#, ReasonML, Miranda, Haskell, PureScript, Idris и Elm, являются примерами языков со сложной типизацией, в том числе алгебраические типы данных и полный вывод типа .
JavaScript имеет (иногда печально известную) динамическую систему типов и не имеет официальной нотации типов. Синтаксис здесь заимствован из Haskell и похож на систему, используемую Ramda, служебной библиотекой JS. Это хорошо объясняется как в вики Ramda, так и в документации Fantasy Land.
Мы поднимаем этот вопрос сейчас, потому что становится слишком громоздко записывать весь тип наших парсеров. parseRex и сигнатуры типов parseNum1 различаются только в одном месте, результат :
parseRex :: String -> { результат: String, остаток: String } | Нулевой
parseNum1 :: String -> { результат: число, остаток: строка } | Нулевой
Войти в полноэкранный режимВыйти из полноэкранного режима Соответственно, с этого момента мы будем использовать Parser a для обозначения «функции разбора, результат которой имеет тип a »:
type Parser a = String -> { result: а, остаток: строка } | Нулевой
Войти в полноэкранный режимВыйти из полноэкранного режима Этот псевдоним типа — просто сокращение, которое мы будем использовать для целей документации. Это значительно очистит наши комментарии и облегчит обсуждение парсеров. Например, теперь мы можем классифицировать
Это значительно очистит наши комментарии и облегчит обсуждение парсеров. Например, теперь мы можем классифицировать parseRex и parseNum1 более кратко:
parseRex :: Parser String parseNum1 :: Номер парсераВойти в полноэкранный режимВыйти из полноэкранного режима
Попробуйте сами. Упростите наш parseLiteral 9Подпись 0022 с использованием сокращенной записи:
Комбинаторы наконец
Что, если мы хотим сопоставить более одной возможности? Реализуйте следующие парсеры. Существующие синтаксические анализаторы находятся в области действия, используйте их в своем определении:
Опять же, это повторяется. Что делает функциональный программист, когда сталкивается с повторением? Обобщай! Напишите функцию или , которая принимает два парсера и возвращает новый парсер, соответствующий любому из них.
Поздравляем, вы поставили комбинатор .
Комби-кто?
Комбинатор , как и многие термины программирования, перегружен — в разных контекстах он означает разные вещи.
- Комбинаторная логика — это изучение функций, которые действуют на функции. Например, комбинатор
I(x => x) принимает функцию и возвращает ту же функцию. В этом поле «комбинатор» формально означает функцию без свободных (несвязанных) переменных . - Шаблон комбинатора — это стратегия создания гибких библиотек, в которой небольшое количество совместных служебных функций создает богатые результаты (которые, в свою очередь, могут быть новыми входными данными для тех же самых функций).
- Например, "комбинаторы" CSS принимают селекторы CSS и создают новые, более сложные селекторы.
divиh2являются примитивными селекторами; используя комбинатор direct child (>), вы можете создать новыйdiv > h2 9Селектор 0022.
- Например, "комбинаторы" CSS принимают селекторы CSS и создают новые, более сложные селекторы.
Мы определим комбинатор синтаксических анализаторов как функцию, которая принимает один или несколько синтаксических анализаторов и возвращает новый синтаксический анализатор. Некоторые примеры:
Некоторые примеры:
либо :: (парсер a, парсер b) -> парсер (a | b) оба :: (парсер a, парсер b) -> парсер [a, b] любой :: (... Парсер *) -> Парсер * много :: Парсер a -> Парсер [a]Войти в полноэкранный режимВыйти из полноэкранного режима
Вы уже определили либо ; взломай и и любой следующий. Для ручного тестирования parseLiteral и все наши синтаксические анализаторы dino находятся в области действия:
Кроме того, либо находятся в области действия, если хотите:
Это мощная концепция. Вместо ручного кодирования специальных функций парсера для всех мыслимых целей мы можем определить несколько абстрактных комбинаторов. Добавляйте простые синтаксические анализаторы, получайте более мощные синтаксические анализаторы; эти новые мощные синтаксические анализаторы могут, в свою очередь, стать входными данными для тех же комбинаторов. Таким образом, мы можем создать богатое поведение с помощью нескольких простых в использовании инструментов. В этом суть состав – построение комбинацией.
В этом суть состав – построение комбинацией.
Заключение к части 1
Ниже показано текущее состояние нашей библиотеки комбинаторов парсеров.
// анализатор типов a = String -> { результат: a, остаток: строка } | Нулевой
// parseLiteral :: String -> Строка парсера
const parseLiteral = литерал => s => s.startsWith (литерал)
? {результат: литерал, остаток: s.slice(literal.length)}
: нулевой
// либо :: (парсер a, парсер b) -> парсер (a | b)
const либо = (p1, p2) => s => p1(s) || р2(с)
// оба :: (парсер a, парсер b) -> парсер [a, b]
const оба = (p1, p2) => s => {
const r1 = p1(s)
если (!r1) вернуть ноль
const r2 = p2(r1.остаток)
если (!r2) вернуть ноль
возвращаться {
результат: [r1.результат, r2.результат],
остаток: r2.остаток
}
}
// любой :: (...Парсер *) -> Парсер *
const any = (...parsers) => parsers.reduce(любой)
Войти в полноэкранный режимВыйти из полноэкранного режимаВ этой первой части мы рассмотрели:
- что такое синтаксический анализ
- некоторые варианты использования парсеров
- один (нефункциональный) способ устранения сбоя
- один (функциональный) способ устранения состояния
- чистота функции
- с использованием кортежей (или массивов/объектов) в качестве возвращаемых значений
- потоковый синтаксический анализатор последовательно выдает результаты
- типов, сигнатур и псевдонимов
- основных комбинаторов парсера
В предстоящем продолжении этой статьи мы рассмотрим некоторые более сложные вопросы:
- работа с более длинными последовательностями
- по выбору
- функторы и монады
- имитация нотации инфиксной функции
- формальные грамматики и теория синтаксического анализа
- рекурсивный спуск
- лень
Часть 2 будет размещена здесь после публикации.
об авторе
Габриэль Лебек — инструктор Fullstack Academy of Code, интенсивной программы разработки веб-приложений. У него есть степень бакалавра. по математике и студийному искусству, и слишком много увлечений, включая искусствоведческое исследование старинных японских мечей. Вы можете увидеть больше Габриэля на Medium, YouTube, GitHub и Twitter.
Понимание Repaint и Reflow в JavaScript
Недавно, исследуя, что делает виртуальную DOM React такой быстрой, я понял, как мало мы знаем о производительности javascript. Поэтому я пишу эту статью, чтобы повысить осведомленность о Repaint и Reflow и производительности JavaScript в целом».
Одна картинка стоит тысячи слов. Итак, давайте посмотрим на то, как работает браузер!
хм… что такое «движок браузера» и «движок рендеринга»?
Основной задачей движка браузера является преобразование HTML-документов и других ресурсов веб-страницы в интерактивное визуальное представление на устройстве пользователя.
Помимо «движка браузера», два других термина широко используются в отношении связанных понятий: «движок макета» и «движок рендеринга». Теоретически макет и рендеринг (или «рисование») могут обрабатываться отдельными движками. Однако на практике они тесно связаны и редко рассматриваются отдельно.
Когда вы нажимаете ввод по какой-либо ссылке или URL-адресу, браузер отправляет HTTP-запрос на эту страницу, и соответствующий сервер предоставляет (часто) HTML-документ в ответ. ( ад много вещей происходит между ними)
Пошаговая обработка- Браузер анализирует исходный код HTML и строит DOM-дерево представление данных, в котором каждый тег HTML имеет соответствующий узел в дереве и фрагменты текста между тегами также получают представление текстового узла. Корневой узел в дереве DOM — это
documentElement(тег - Браузер анализирует код CSS, понимает его. Информация о стилях каскадирует : основные правила находятся в таблицах стилей User-Agent (браузер по умолчанию), затем могут быть пользовательские таблицы стилей, авторские (как у автора страницы) таблицы стилей - внешние, импортированные, встроенные и, наконец, стили, закодированные в атрибутах
styleтегов HTML - Затем начинается интересная часть — построение визуализировать дерево .
 Дерево рендеринга похоже на дерево DOM, но не соответствует ему в точности. Дерево рендеринга знает о стилях, поэтому, если вы скрываете
Дерево рендеринга похоже на дерево DOM, но не соответствует ему в точности. Дерево рендеринга знает о стилях, поэтому, если вы скрываете divсdisplay: none, он не будет представлен в дереве рендеринга. То же самое для других невидимых элементов, таких какголоваи все, что в ней. С другой стороны, могут быть элементы DOM, которые представлены более чем одним узлом в рендеринге древовидных текстовых узлов, например, где каждая строка в - После построения дерева рендеринга браузер может рисовать (рисовать) узлы дерева рендеринга на экране
 Дерево рендеринга похоже на дерево DOM, но не соответствует ему в точности. Дерево рендеринга знает о стилях, поэтому, если вы скрываете
Дерево рендеринга похоже на дерево DOM, но не соответствует ему в точности. Дерево рендеринга знает о стилях, поэтому, если вы скрываете Вот снимок того, как браузер отрисовывает пользовательский интерфейс на экране.
Хотите прочитать эту историю позже? Сохрани в Журнал .

Бывает, что за доли секунд мы даже не замечаем, что все это произошло.
Посмотрите внимательно.
Как браузер рисует макет и пытается обнаружить корневой элемент, братьев и сестер и его дочерний элемент в качестве узла и соответствующим образом перестраивает его макет.
Возьмем один пример
Перекрасить и переплавить
Как Джош?
Высокий сэр...
Нечего отображать
...
DOM дерево , которое представляет этот документ HTML, в основном имеет один узел для каждого тега и один текстовый узел для каждого фрагмента текста между узлами (для простоты давайте проигнорируем тот факт, что пробелы также являются текстовыми узлами):
documentElement (html)
head
title
body
p strong
[текстовый узел] p
strong
b
[текстовый узел]
div
[текстовый узел]div
img5
2 .
корень (RenderView)
тело
стр
строка 1
строка 2
строка 3
...div
img...
Корневым узлом дерева рендеринга является кадр (коробка), который содержит все остальные элементы. Вы можете думать об этом как о внутренней части окна браузера, так как это ограниченная область, где страница может распространяться. Технически WebKit вызывает корневой узел
RenderView, и он соответствует начальному содержащему блоку CSS, который в основном представляет собой прямоугольник области просмотра в верхней части страницы (9).0021 0 ,0) to (window.innerWidth,window.innerHeight)Выяснение того, что и как именно отображать на экране, включает рекурсивный обход (поток) по дереву рендеринга.
Всегда есть хотя бы один начальный макет страницы вместе с краской (если, конечно, вы не предпочитаете, чтобы ваши страницы были пустыми :)). После этого изменение входной информации, которая использовалась для построения дерева рендеринга, может привести к одному или обоим из них:
- Части дерева рендеринга (или всего дерева) должны быть повторно проверены, а размеры узлов пересчитаны. Это называется reflow , или верстка, или верстка. Обратите внимание, что есть по крайней мере одна перекомпоновка — первоначальный макет страницы
- частей экрана необходимо будет обновить либо из-за изменения геометрических свойств узла, либо из-за стилистических изменений, таких как изменение цвета фона. Это обновление экрана называется перерисовкой или перерисовкой.
Перерисовка и перекомпоновка могут быть дорогими, они могут повредить пользовательскому опыту и сделать пользовательский интерфейс вялым
Перерисовать
Как следует из названия, перерисовка — это не что иное, как перерисовка элемента на экране, поскольку скин элемента изменяется, который влияет на видимость элемента, но не влияет на макет.
Пример.
1. Изменение видимости элемента.
2. Изменение контура элемента.
3. Изменение фона.
Вызывает перерисовку.Согласно Opera, перерисовка — дорогостоящая операция, поскольку она заставляет браузер проверять/проверять видимость всех других узлов dom.
Перекомпоновка
Перекомпоновка означает перерасчет положения и геометрии элементов в документе с целью повторной визуализации части или всего документа. Поскольку перекомпоновка — это операция, блокирующая пользователя в браузере, разработчикам полезно понять, как улучшить время перекомпоновки, а также понять влияние различных свойств документа (глубина DOM, эффективность правил CSS, различные типы изменений стиля) на перекомпоновку. время. Иногда для перекомпоновки одного элемента в документе может потребоваться перекомпоновка его родительских элементов, а также любых элементов, следующих за ним.Каждый раз, когда DOM изменяется, браузеру необходимо пересчитывать CSS, делать макет и перекрашивать веб-страницу.
Чтобы свести к минимуму это время, Ember использует метод наблюдения ключ/значение, а Angular использует грязную проверку. Используя эту технику, они могут обновлять только измененный узел dom или узел, помеченный как грязный в случае Angular.
Если это не так, то вы не сможете увидеть новое электронное письмо, как только оно придет, при написании нового электронного письма в Gmail.
Но в наши дни браузеры становятся достаточно умными, они пытаются сократить время, необходимое для перерисовки экрана. Самое большое, что можно сделать, это минимизировать и группировать изменения DOM, вызывающие перерисовку.
Стратегия сокращения и объединения изменений DOM, перенесенных на другой уровень абстракции, лежит в основе React Virtual DOM.
React не делает ничего нового. Это просто стратегический ход. Что он делает, так это хранит в памяти копию реального DOM. Когда вы изменяете DOM, он сначала применяет эти изменения к DOM в памяти.
 .. Дерево рендеринга будет визуальной частью дерева DOM. В нем отсутствуют кое-что — заголовок и скрытый div, но есть дополнительные узлы (они же рамки, они же блоки) для строк текста.
.. Дерево рендеринга будет визуальной частью дерева DOM. В нем отсутствуют кое-что — заголовок и скрытый div, но есть дополнительные узлы (они же рамки, они же блоки) для строк текста. 

 Это то, что требует времени в реальном доме.
Это то, что требует времени в реальном доме.