Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: тряпка сейчас выражение 1 секунда назад генерал 1 секунда назад б р я н а ы ш 1 секунда назад рцдвпоеа 1 секунда назад з д б е а н 1 секунда назад к л а а в д 1 секунда назад тритодка 1 секунда назад с а к в о я ж 2 секунды назад хварво 2 секунды назад стажер 2 секунды назад быстро-быстро 2 секунды назад лаунч 3 секунды назад диаметр 3 секунды назад биограф 3 секунды назад
Морфологический разбор слова «научить»
Часть речи: Инфинитив
НАУЧИТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАУЧИТЬ»
| Слово | Морфологические признаки |
|---|---|
| НАУЧИТЬ |
|
Все формы слова НАУЧИТЬ
НАУЧИТЬ, НАУЧИЛ, НАУЧИЛА, НАУЧИЛО, НАУЧИЛИ, НАУЧУ, НАУЧИМ, НАУЧИШЬ, НАУЧИТЕ, НАУЧИТ, НАУЧАТ, НАУЧИВ, НАУЧИВШИ, НАУЧИМТЕ, НАУЧИ, НАУЧИВШИЙ, НАУЧИВШЕГО, НАУЧИВШЕМУ, НАУЧИВШИМ, НАУЧИВШЕМ, НАУЧИВШАЯ, НАУЧИВШЕЙ, НАУЧИВШУЮ, НАУЧИВШЕЮ, НАУЧИВШЕЕ, НАУЧИВШИЕ, НАУЧИВШИХ, НАУЧИВШИМИ, НАУЧЕННЫЙ, НАУЧЕННОГО, НАУЧЕННОМУ, НАУЧЕННЫМ, НАУЧЕННОМ, НАУЧЕН, НАУЧЕННАЯ, НАУЧЕННОЙ, НАУЧЕННУЮ, НАУЧЕННОЮ, НАУЧЕНА, НАУЧЕННОЕ, НАУЧЕНО, НАУЧЕННЫЕ, НАУЧЕННЫХ, НАУЧЕННЫМИ, НАУЧЕНЫ
Разбор слова по составу научить
научи
ть
| Основа слова | научи |
|---|---|
| Приставка | на |
| Корень | уч |
| Суффикс | и |
| Глагольное окончание | ть |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАУЧИТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «научить»
1
«Научить любить, научить узнавать любовь, научить быть счастливым – это значит научить самого себя уважать, научить человеческому достоинству».
Бумеранг всегда возвращается. Книга 2. Дневник матери и свекрови, Тамара Ивановна Пимонова, 2019г.
2
Потому, Вера Николаевна, что, по глубокому моему убеждению, научить какого-нибудь мальца грамоте хуже, чем научить его пить водку.
Цареубийцы, Петр Краснов, 1938г.
3
Он утверждал, что можно научить всем техническим тонкостям исполнения, но совершенно невозможно научить так чувствовать музыку, как чувствовала я.
Между прошлым и будущим, Карен Уайт, 2013г.
4
И если прошлое не может научить настоящее, а отец не может научить сына, то истории не стоит и длиться, а мир впустую потратил много времени.
Лев Боаз-Яхинов и Яхин-Боазов. Кляйнцайт, Рассел Хобан, 1973, 1974г.
5
Научить решать триста задач – это научить решать задачи.
Одинокая звезда, И. Л. Касаткина
Анализ зависимостей — представление PowerLine
Анализ зависимостей — представление PowerLine CC-BY Фабиан М. СуханекDependencyParsing38• Грамматики зависимостей• Алгоритм Конвингтона• SummaryOverview2
В IE часто используются грамматики зависимостей.
 Грамматики зависимостей3detobjsubjЧестное величие не нуждается в похвале. ADJ N V DET Nmod
Грамматики зависимостей3detobjsubjЧестное величие не нуждается в похвале. ADJ N V DET Nmod Определение: Грамматика зависимостей. Грамматика зависимостей — это набор правил формы, где X и Y — POS-теги, L — метка. .AdjNounmoddetobjsubjЧестное величие не нуждается в похвале. ADJ N V DET Nmod
График зависимости графика зависимости предложения — это связанный ациклический график, чьи узлы являются словами, и чьи ребра определяются The Grammar, так что • Каждое слово имеет не более одной головы. • Обычно есть глагол без Head5dayendendeNunVerbverbpndetnoubjobjdetadjnounmoddetobjsubjhoneste Grand. ADJ N V DET Nmod
Примеры: график зависимостей. Попробуйте! 6. Я застрелил слона в пижаме.0002 ПроекцияГрафик зависимости является проективным, если дуги не пересекаются. Мы рассматриваем здесь только графы проективной зависимости. 7 Он говорит, что предложения, которые не являются проективными, встречаются редко.
 • Грамматики зависимостей• Алгоритм Конвингтона• SummaryOverview8
• Грамматики зависимостей• Алгоритм Конвингтона• SummaryOverview8 Алгоритм Ковингтона• Разберите предложение слева направо • Постарайтесь связать каждое слово с каждым предыдущим словом, как это разрешено грамматикой, , двигаясь в обратном направлении по предложению, , допуская только один заголовок на слово9.Прежде чем глотать, вы должны пожевать. Алгоритм Ковингтона • Проанализируйте предложение слева направо. VPRONAUXVADP
Алгоритм Ковингтона • Проанализируйте предложение слева направо VPRONAUXVADP
Алгоритм Ковингтона • Проанализируйте предложение слева направо VPRONAUXVADP
Алгоритм Ковингтона • Проанализируйте предложение слева направо. VPRONAUXVADP
Алгоритм Ковингтона • Проанализируйте предложение слева направо VPRONAUXVADP
Задача: Сам Алгоритм Ковингтона16, над его собственным телом и разумом, человек — суверен. Время выполнения алгоритма Ковингтона • Проанализируйте предложение слева направо.
 АДЖ
АДЖ 18Время выполнения алгоритма Ковингтона• Разбирайте предложение слева направо • Постарайтесь связать каждое слово с каждым предыдущим словом, как это разрешено грамматикой. заметьте, индивидуальность является суверенной. Сложность алгоритма Ковингтона19? Лошадь промчалась мимо сарая felllocsubjdetdetpobj
Сложность алгоритма Ковингтона20. Лошадь промчалась мимо амбара.
Сложность алгоритма Ковингтона21Лошадь промчалась мимо сарая felllocsubjdetpobjattrdet
Сложность AlgoParse Ковингтона слева направо, соединить каждое слово с каждым возможным предшествующим словом (с постоянным доступом к грамматике): С возвратом: 22 Лошадь мчалась мимо сарая Разбор Когда присутствуют лексическая неоднозначность и согласие, синтаксический анализ является NP-полным. 23 Бартон и др.: Вычислительная сложность и естественный язык.
Разбор Наихудшего случая не бывает, т. е. люди на самом деле не произносят фраз, которые ставят любой разумный алгоритм синтаксического анализа в наихудшую ситуацию.
 24 Ковингтон: фундаментальный алгоритм для синтаксического анализа зависимостей : Вычислительная сложность и естественный язык.
24 Ковингтон: фундаментальный алгоритм для синтаксического анализа зависимостей : Вычислительная сложность и естественный язык. Синтаксический анализ Наихудшего случая не происходит, т. е. люди на самом деле не произносят фраз, которые ставят какой-либо разумный алгоритм анализа в наихудшую ситуацию. 25 Ковингтон: фундаментальный алгоритм анализа зависимостей : Вычислительная сложность и естественный язык. Анализ зависимостей очень хорошо работает на практике. Грамматики зависимостей и контекстно-свободные грамматики строго эквивалентны, как показано Х. Гайфманом в 1965.
Опр.: Шаблоны зависимостейШаблон зависимости — это цепной граф, узлами которого являются слова или X или Y. Шаблон зависимости соответствует графу зависимостейg , если есть замена σ для X и Y, такая, что σ(p)⊆g часто является желательным. 27 Плоть если дух слаб.
Резюме: Распокация по сравнению с зависимостью зависимости является стандартным способом извлечения синтаксической промышленности предложения.
 • Грамматики зависимости эквивалентны грамматике структуры. • Использование шаблонов зависимости в извлечении информации может помочь в решении вариаций поверхности в предложениях 28 плоть часто желает, если дух weak.subjcopisXYcopsubj->Formal-grammars->Knowledge-representation
• Грамматики зависимости эквивалентны грамматике структуры. • Использование шаблонов зависимости в извлечении информации может помочь в решении вариаций поверхности в предложениях 28 плоть часто желает, если дух weak.subjcopisXYcopsubj->Formal-grammars->Knowledge-representation References29Michael Covington:“A Fundamental Algorithm for Dependency Parsing”, ACM Southeast 2001Joakim Nivre:“An Efficient Algorithm for Projective Dependency Parsing”, IWPT 2003
Writing for the Novice: Parsing
/ магистр
В 64-м эпизоде «Чая с BVP» Билл упомянул пару вещей, о которых мы слышали раньше, только на этот раз через призму синтаксического анализа (то есть «пошаговое вычисление структуры предложения во время понимания»). Вы сразу же заметите, что это определение отличается от подсказки учителя метода грамматики-перевода «Студент X, не могли бы вы разобрать основной глагол, найденный в строке 2?» в котором ученик дает лицо, число, время, залог и наклонение глагола, что, как мы все знаем, может сделать прилежный ученик, хотя это не имеет ничего общего с психологически реальным пониманием предложения, в котором оно было разобрано. .
.
Принцип первого существительного
Новички, изучающие большинство языков*, обрабатывают первое попавшееся существительное (например, «Caesarem» в Caesarem canis mordit ) в качестве агента (т. е. одного действующего, но не обязательно грамматического подлежащего). Сообразительный учитель языка, знающий о стратегии изучающих язык в отношении первого существительного, мог бы отреагировать на это, используя порядок слов, который избегает вводящей в заблуждение тенденции.
Да, использование «английского порядка слов» может быть более полезным для ваших учащихся, по крайней мере, до тех пор, пока они не создадут достаточное ментальное представление языка, чтобы начать обрабатывать все входящие данные (т. е. Цезарь em ). Это также означает, что повторное формулирование агента — каждого предложения — является одним из способов сделать язык более понятным для учащегося, хотя мы знаем, что латынь может опустить эти вещи.
Различные контексты (т. е. словарный запас приюта)
Учащиеся должны слышать слова в разных контекстах, чтобы обрабатывать язык в моментальных вычислениях, то есть «разборе». Это случай для укрытия словарного запаса. При низком количестве уникальных слов учащийся сталкивается со словами, используемыми в большем количестве контекстов. По мере увеличения количества слов у учащегося может быть только 1 или 2 возможности разобрать структуру предложения. Отсутствие синтаксического анализа приводит к «уменьшению понятного ввода». Плохо. Возьмем фразу, чтобы попросить сходить в туалет, licetne mihi īre ad latrinam? (например, puedo ir al baño? ). Учащийся должен встретить licetne , īre, и mihi в разных контекстах, чтобы сформировать мысленное представление о структуре предложения. Они должны встретить latrīna без окончания в разных контекстах, и они должны встретить ad со словами, которые имеют окончание в разных контекстах.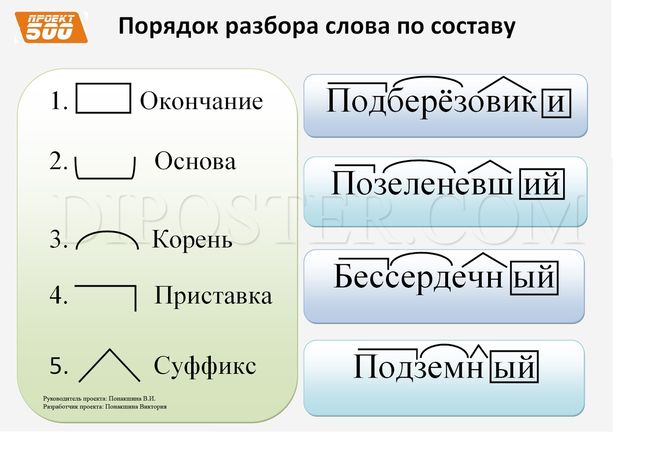 Без разных контекстов licetne mihi īre ad latrīnam становится одной фразой, произнесенной для того, чтобы на несколько минут выйти из класса, но с небольшим смыслом или структурой. Со временем и при достаточном количестве входных данных в различных контекстах учащиеся начнут «выделять отдельные части этой фразы». Это начинается с повторного использования слов, и мы перерабатываем больше слов, когда количество уникальных слов невелико.
Без разных контекстов licetne mihi īre ad latrīnam становится одной фразой, произнесенной для того, чтобы на несколько минут выйти из класса, но с небольшим смыслом или структурой. Со временем и при достаточном количестве входных данных в различных контекстах учащиеся начнут «выделять отдельные части этой фразы». Это начинается с повторного использования слов, и мы перерабатываем больше слов, когда количество уникальных слов невелико.
Принцип лексического предпочтения
Билл усовершенствовал эту идею, заявив, что учащиеся должны закрепить наречия в своем лексиконе (т. е. «надежное представление») до того, как будут усвоены окончания глаголов. Раньше он думал, что временные наречия и личные местоимения на окончание были костылем, но теперь он считает, что они могут быть опорой.0040 необходимо . Это меняет правила игры. Для новичков Билл рекомендовал бы добавить больше временных наречий и подлежащих местоимений. Лично я не стану присоединять местоимения 1 к 1 для каждого изменения окончания глагола, которое происходит в моем письме, но я должен признать, что это поможет сделать латынь более понятной. Таким образом, я намерен сознательно использовать больше местоимений в качестве стратегии в реальном времени в классе при взаимодействии со студентами и начать использовать их для обозначения изменений в предметах в большем количестве моих писем.
Таким образом, я намерен сознательно использовать больше местоимений в качестве стратегии в реальном времени в классе при взаимодействии со студентами и начать использовать их для обозначения изменений в предметах в большем количестве моих писем.
Примечание. «Новичок» — это расплывчатый термин. Для ACTFL это представляет студентов, которые не могут понять прошедшее время, что смешно. Некоторым авторам он представляет студентов, которые понимают 100 уникальных слов в тексте из 175 слов, что я также нахожу смешным. Для других это означает «начинающий» или «легкий», без каких-либо критериев, а материалы «новичка» часто игнорируются в пользу неуместной «строгости», что, вероятно, является самым нелепым. Я использую этот термин для обозначения студентов, которые понимают 20-100 слов в тексте общим объемом 1200-3000 слов соответственно, что является целевой аудиторией моих новелл. Для меня «новичок» относится ко всем учащимся в течение первых 2 лет обучения латыни в государственном образовании, прекрасно зная, что на 3-м и 4-м курсах инклюзивных программ латыни также будет несколько новичков.