Как определить морфемный состав глагола?
Содержание
- — Что такое морфемный состав глагола?
- — Какой раздел словообразование изучает морфемный состав слова?
- — Что значит слово для морфемного разбора?
- — Как указать морфемный состав?
- — Что такое морфемный состав в русском языке?
- — Что значит разобрать по составу глаголы?
- — Что входит в состав морфем?
- — Какой раздел языка изучает состав слова?
- — В чем состоят отличия Морфемного словообразовательного и этимологического анализа слов?
- — Как разобрать слово по составу уборка?
- — Как разобрать слово для морфемного разбора?
- — Что Разбор слова по составу?
- — Как называется выделенная часть в составе слова малинка?
- — Какой корень у слова указать?
- — Как делать морфемный разбор прилагательного?
Что такое морфемный состав глагола?
Морфемный разбор глагола проходит по следующему плану: Определяем окончание, которое указывает на лицо, род, падежи, число.
Какой раздел словообразование изучает морфемный состав слова?
Морфемика – раздел языкознания, в котором изучается система морфем языка и морфемная структура слов и их форм.
Что значит слово для морфемного разбора?
Разбор слова по составу (морфемный анализ, от слова морфема – значимая часть слова) – один из видов лингвистического анализа, целью которого является определение состава, или структуры, слова. Он играет значительную роль в формировании орфографических навыков.
Как указать морфемный состав?
В любом производном слове выделяются минимальные значимые части — морфемы. Морфемы могут указываться при этом в их линейной последовательности; например, в глаголе наперестраиваться приставки на-, пере-, корень cmpaj (cmpoj), суффиксы -ива-, -ть-, постфикс -ся.
Что такое морфемный состав в русском языке?
Морфемный разбор – это разбор слова по составу или разбор слова на морфемы. Всего в русском языке 4 морфемы. Приставка, корень, суффикс и окончание. … Окончание – это часть слова, которая стоит в конце слова и служит для связи слов в предложении.
Что значит разобрать по составу глаголы?
Что значит «разобрать глагол по составу»? Для этого необходимо обозначить в глаголе части слова (корень, суффикс, приставку, окончание, основу), т. е. выделить морфемы.
Что входит в состав морфем?
В составе русского слова возможны 6 типов морфем: корень, приставка (префикс), суффикс, окончание (флексия), соединительная гласная (интерфикс), постфикс. Значимая часть слова (морфема), за исключением корня, называется аффиксом.
Какой раздел языка изучает состав слова?
Морфемика – раздел науки о языке, в котором изучается состав слова. Морфология – раздел науки о языке, в котором изучаются слова как части речи. Синтаксис – раздел науки о языке, который изучает строение предложения и словосочетания. Фонетика – раздел науки о языке, который изучает звуки речи.
В чем состоят отличия Морфемного словообразовательного и этимологического анализа слов?
Морфемный, словообразовательный, этимологический анализ. Морфемный анализ предполагает выяснение морфемной структуры слова. … в методичке «Морфемика и словообразование». Этимологический анализ выясняет первоисточник слова – его этимон.
Как разобрать слово по составу уборка?
«уборка» по составу
бор — корень, к — суффикс, а — окончание, уборк — основа слова.
Как разобрать слово для морфемного разбора?
Порядок разбора слова по составу
- Определить часть речи.
- Обозначить окончание слова (если есть).
- Выделить основу.
- Через ряд однокоренных слов найти корень слова, отметить чередование звуков.
- Установить приставку или приставки.
- Установить суффикс или суффиксы.
Что Разбор слова по составу?
Разбор слова по составу, или морфемный разбор – разбор, при котором у слова выделяют все его части: основу, приставку, корень, суффикс, окончания, префиксы, постфиксы. Морфемный разбор слова важен потому, что в русском языке морфемный принцип лежит в основе правописания.
Как называется выделенная часть в составе слова малинка?
малин — корень, к — суффикс, а — окончание, малинк — основа слова.
Какой корень у слова указать?
Разбор по составу слова «указать»
| указ | корень |
|---|---|
| а | суффикс |
| ть | глагольное окончание |
Как делать морфемный разбор прилагательного?
План разбора.
- Начальная форма (имен. падеж ед. числа муж. рода).
- Постоянные признаки: разряд (качественное, относительное, притяжательное).
- Непостоянные признаки: 1) у качественных: а) степень сравнения, б) краткая или полная форма; 2) у всех прилагательных: а) падеж, б) число, в) род (в ед. ч.).
Интересные материалы:
Как с мобильного телефона позвонить за границу?
Как с мобильного телефона вызвать?
Как с помощью телефона узнать где находится ребенок?
Как с сотового телефона вызвать скорую?
Как с телефона передать игру на ПК?
Как с телефона посмотреть подписчиков в ВК?
Как с телефона удаленно подключиться к компьютеру?
Как самому себе отправить сообщение в Вконтакте с телефона?
Как самостоятельно заменить стекло на телефоне?
пример.
 Исторические изменения в морфемном составе слова
Исторические изменения в морфемном составе словаМорфемный состав слова в ходе развития языка не всегда оставался неизменным. Исторические трансформации, произошедшие в языке, сильно отразились на основах. Морфемный состав менялся в результате действия определенных процессов, о которых мы и поговорим в этой статье.
Историческое изменение основы
Основным элементом словообразования в современном русском языке является основа, как производная, так и непроизводная. Способ ее образования в ходе истории развития языка претерпевал изменения. А в некоторых случаях менялся даже морфемный состав слова. В основе утратили свое значение многие морфемы. Приведем пример. В основе слова запад ранее морфема за- имела значение приставки. В ходе истории она его утратила. Таким образом, основа превратилась в непроизводную.
Подробнее об изменении морфемного состава
Не обязательно в ходе истории менялся морфемный состав слова, как в приведенном выше примере. Только в отдельных случаях можно говорить об этом. В современном языке многие слова членятся на морфемы таким же образом, как в прошлом. Но сегодня имеется немало примеров того, когда они теряют связь с первоначальной основой, от которой образовались. Кроме того, может быть так, что слово начинает соотноситься лишь с частью производящей основы, а не целиком с ней. Морфемный состав в этих случаях изменился. Расскажем о причинах, по которым происходят подобные трансформации.
Только в отдельных случаях можно говорить об этом. В современном языке многие слова членятся на морфемы таким же образом, как в прошлом. Но сегодня имеется немало примеров того, когда они теряют связь с первоначальной основой, от которой образовались. Кроме того, может быть так, что слово начинает соотноситься лишь с частью производящей основы, а не целиком с ней. Морфемный состав в этих случаях изменился. Расскажем о причинах, по которым происходят подобные трансформации.
Причины изменения морфологического состава
Во-первых, лексические значения основ, соотносимых раньше как производящая и производная, становятся другими. К примеру, в русском языке сегодня отсутствует семантическая соотносительность таких слов, как крыльцо (часть дома) и крыло (птицы), поскольку они в настоящее время различны по значению. Однако в древнерусском она наблюдалась. Основы этих слов не соотносятся как производная и производящая.
Еще одна причина, по которой наблюдаются изменения в морфемной структуре, — звуковой состав слов, который тоже не всегда остается неизменным. Приведем примеры. Слова обволакивать, наволочка, поволока, облако, оболочка — однокоренные, однако у них различная морфологическая структура. Производные основы — обволакивать (об-волак-ива-ть), наволочка (на-волоч-к-а), поволока (по-волок-а). А облако и оболочка стали непроизводными, поскольку у них изменилась основа из-за утраты звука «в». Современный и исторический морфемный состав слова, таким образом, в этих случаях неодинаков.
Приведем примеры. Слова обволакивать, наволочка, поволока, облако, оболочка — однокоренные, однако у них различная морфологическая структура. Производные основы — обволакивать (об-волак-ива-ть), наволочка (на-волоч-к-а), поволока (по-волок-а). А облако и оболочка стали непроизводными, поскольку у них изменилась основа из-за утраты звука «в». Современный и исторический морфемный состав слова, таким образом, в этих случаях неодинаков.
Еще одна причина — выпадение родственных слов или соотносительных производящих основ из словаря. Вот какие можно привести в современном русском языке примеры непроизводных основ — ямщик, лебедка, рубаха. Из словаря в настоящее время выпали соотносительные производные основы (ям — остановка на дороге; лебедь — вал, имеющий коленчатую рукоять; руб — кусок ткани).
Современный и исторический морфемный состав слова в ряде случаев не совпадает из-за влияния продуктивного типа структуры на строение слов этимологически изолированных, то есть непродуктивных типов. К примеру, зонтик имеет иноязычное происхождение. Сначала это слово было осмыслено как корневое. Однако с течением времени по аналогии с русскими словами ротик, хвостик и др. оно начало члениться на основу зонт- (непроизводную) и суффикс -ик.
К примеру, зонтик имеет иноязычное происхождение. Сначала это слово было осмыслено как корневое. Однако с течением времени по аналогии с русскими словами ротик, хвостик и др. оно начало члениться на основу зонт- (непроизводную) и суффикс -ик.
Наблюдаемые исторические изменения в морфемном составе слова в тех или иных случаях называются усложнением, переразложением и опрощением основы. Расскажем о каждом из них.
Опрощение
Оно представляет собой превращение в непроизводную производной основы слова. В этом случае последнее теряет членимость на морфемы. Опрощение играет важную роль в языке. Благодаря ему он обогащается корневыми непроизводными словами. В языке появляются новые центры словообразования. Примеры: успех — успешный и др., спех-спешный и др., спеть — спелый и др. С другой стороны, благодаря опрощению словообразовательные суффиксы переходят в разряд непродуктивных. Порой наблюдается и полное их исчезновение, что еще сильнее меняет морфемный состав. Пример: в основах слов стар-ый, добр-ый, которые в современном языке являются непроизводными, не вычленяется суффикс -р-. Этот же суффикс выпал в слове брат.
Этот же суффикс выпал в слове брат.
Причины опрощения
Подверглись опрощению основы слов позор, красный, дворец. Они стали непроизводными потому, что утратили в процессе употребления связь по значению с теми словами, от которых они были когда-то образованы. Примеры: позор — зоркий, красный (цвет) — краса, дворец — двор.
Морфемный состав частей речи изменился из-за фонетических процессов у основ следующих слов: пестрый, весло, усопший. Они потеряли связь с основами, от которых произошли, и перестали выделяться отдельные морфемы (пестрый — писать, весло — везти, усопший — уснувший).
Причины, которые приводят к опрощению, могут действовать одновременно, перекрещиваться. В результате всех этих процессов не совпадают современный и исторический морфемный состав. Например, отсутствие соотносительности между ядро — еда — яд, звук — звон, узы — узел — союз — язык — это результат не только лишь наблюдаемого между данными словами семантического разрыва, но и следствие фонетических изменений, произошедших в их основах.
Переразложение
Переразложение представляет собой перераспределение внутри слова отдельных морфем, которое приводит к тому, что основа (остающаяся производной) в своем составе выделяет иные морфемы. Так, например, живность, горячность имеют суффикс -часть (а не -ость), если говорить о живых словообразовательных связях. Дело в том, что прилагательные, от которых они образованы (живный, горячный), не употребляются в современном языке. Суффикс -ность- по отношению к суффиксу -ость- является производным. Он является сочетанием следующих двух суффиксов: — н, который был отсечен от основы прилагательного, и — ость.
Образование от -ость производного -ность — выражение своеобразного процесса, который сопровождает в русском языке переразложение основ. Он заключается в том, что один словообразовательный элемент поглощается другим, или же в растворении того или иного из них в корне. Например, в основе удилище мы можем выделить суффикс -лищ-, который включает в свой состав другой, -л-. Последний суффикс относится к слову удило, утраченному в современном языке.
Последний суффикс относится к слову удило, утраченному в современном языке.
Переразложение может быть также между корнем и приставкой. Например, в глаголе снять раньше была приставка сн- и следующий за ней корень -я-. Сегодня же это слово членится следующим образом: с-ня(ть).
Значение переразложения
Процесс переразложения обогащает язык тем, что появляются новые словообразовательные модели и аффиксы, становящиеся с течением времени продуктивными. Чаще всего этим путем образуются новые суффиксы: — очк- (кост-очк-а), -инк- (пыл-инк-а), -ность (сущ-ность). Гораздо реже появляются приставки (обез-, небез-, недо-), которые являются результатом слияния двух других приставок (обез-волеть, небез-дарный, недо-смотреть).
Аналогия
К переразложению и опрощению основ очень часто приводят разные виды аналогии. Под последней подразумевается уподобление формам одного слова форм другого, родственного грамматически. Благодаря ей часто подвергается изменению исторический морфемный состав слова. Аналогия — естественный процесс, который наблюдается в языке. Малопродуктивные типы формо- и словообразования в силу ее действия уподобляются определенным продуктивным типам форм и слов. При этом теряется прежняя членимость на морфемы или же их производный характер.
Аналогия — естественный процесс, который наблюдается в языке. Малопродуктивные типы формо- и словообразования в силу ее действия уподобляются определенным продуктивным типам форм и слов. При этом теряется прежняя членимость на морфемы или же их производный характер.
В современном русском языке ряд форм обязан происхождением действию именно аналогии. В частности, это окончания существительных среднего и мужского родаов -ах, -ами, -ом (сел-ах, дом-ах, дом-ами, сел-ам). Они появились в результате действия аналогии форм существительных женского рода (книг-ам — стол-ам, а не стол-ом). Результатом ее стало переразложение основы (вместо книга-м — книгам). Так изменился исторический морфемный состав.
От корня вор- было образовано слово отворить. Это произошло посредством преффикса от-. Данное слово подвергалось влиянию другого — творить. В результате аналогии отворить-творить первая основа подверглась переразложению. Она начала осмысляться как образование, имеющее приставку о-. Так в языке появилась новая база словообразования (при-творить, за-творить, рас-творить и т. д.).
д.).
Усложнение
В некоторых случаях действие аналогии или возникновение слов, которые родственны имеющим непроизводную основу, приводит к усложнению последней. Из-за этого она становится производной, то есть начинает члениться.
Процесс усложнения противоположен рассмотренному нами процессу опрощения. Это превращение в производную основу той, которая ранее была непроизводной. В частности, слово гравюра, заимствованное русским из французского языка, осмыслялось первоначально как непроизводное. Но после того как в системе нашего языка возникли поздние заимствования гравер и гравировать, оно «усложнилось». Это слово сделалось производным. В нем выделяется корень грав-, а также суффикс -ур-. Подобного рода изменениям подверглись многие заимствованные слова. Например, анархия, греческое по происхождению, имело раньше непроизводную основу. Однако из-за того, что в языке были родственные ей анархичный, анархический, анархист и др., она начала делиться. Так образовалась непроизводная основа анарх-, а также суффикс -и j-.
Наложение морфем
Выделяется, кроме названных выше явлений, и наложение морфем. Оно происходит тогда, когда части тех из них, которые сочетаются, совпадают. К примеру, это возможно между основой и суффиксом (динамовец — Динамо + овец; свердловский — Свердловск + ский). Однако наложение не может произойти, если речь идет о корне и приставке (Прииртышье, Заамурье).
Все вышеперечисленные изменения в строении слова (усложнение, переразложение, опрощение) говорят о том, что морфемный состав менялся в процессе исторического развития языка. Все эти изменения изучает этимология. Скажем в заключение несколько слов и о ней.
Этимология
Этимология — учение о происхождении различных слов. Их возникновение может быть установлено с помощью этимологического анализа. Он дает возможность выяснить исторические словообразовательные связи, то, какой была первоначальная морфемная структура у того или иного слова, а также причины, по которым оно претерпело изменения с момента появления.
Определение морфемного состава слова
Репетиторы ❯ Русский язык ❯ Определение морфемного состава слова
Автор: Наталья Л., онлайн репетитор по русскому языку и литературе
●
10.01.2012
●
Раздел: Русский язык
 В толкование производного слова обязательно входит производящее слово (основа). Данный критерий называется критерием мотивированности.
В толкование производного слова обязательно входит производящее слово (основа). Данный критерий называется критерием мотивированности.Обратим внимание, что между производной и производящей основой смысловая связь должна прослеживаться на синхронном (современном) уровне языка. Многие слова когда-то имели определённый морфемный состав, который изменился с течением времени. Например, древний корень руб- в слове рубаха теперь не осознается отдельно от древнего суффикса -ах-, корень и суффикс слились в одну новую корневую морфему рубах-; а слово красный уже не употребляется в значении «красивый» и не мотивируется словом краса и древний корень крас- и шедший за ним суффикс -ьн- слились в одну морфему – красн-. Смешение синхронного морфемного и этимологического (исторического) анализа слов при изучении современного русского языка недопустимо, поэтому при разборе слов следует уделять данному факту особое внимание и при возникновении сложностей использовать словообразовательные словари современного русского языка.
Иногда при словообразовании приставка и суффикс присоединяются к производящей основе одновременно, например,
Но чаще словообразующие морфемы последовательно присоединяются к производящей основе:
бел-ый → бел-е-ть → по-белеть.
Так образуется словообразовательная цепочка. Каждое звено этой цепочки отличается от предыдущего новой словообразовательной морфемой. Для того, чтобы не ошибиться в определении морфемного состава слова, следует восстановить эту словообразовательную цепочку и последовательно «отнять» с производной основы словообразующие морфемы.
К данному слову подбирают однокоренное, подходящее по форме и наиболее близкое по значению слово (производящую основу). Далее сравнивают основу производящего слова и основу производного от него. Разница между ними является словообразующим средством. После этого к производящему слову, если оно является производным, подбирают его производящее.
Чтобы найти следующее звено цепочки, следует указать лексическое значение данного слова, уже в толковании может присутствовать производящее слово: слоник – маленький слон; лунная ночь – ночь, когда на небе видна луна. Для проверки правильности подобранного производящего слова необходимо с его помощью объяснить значение производного.
Например:
выздоровл-ениj-е → выздорове-ть → здоров-ый
Мотивация: выздоровление – то же, что выздороветь (результат) или выздоравливать (процесс), обозначает действие или его результат, выздороветь – стать здоровым.
Таким образом, при морфемном разборе через словообразовательную цепочку

Данный алгоритм не подходит для разбора слов со связанными корнями. Связанным является корень, который не употребляется самостоятельно (только с формообразующими морфемами), а всегда присоединяет словообразующие морфемы (приставки и суффиксы). Разбор таких слов осуществляется с помощью подбора слов, в которых данный корень должен быть употреблён с другим суффиксом (приставкой), а суффикс (приставка) – с другим корнем:
об-у-ть – раз-у-ть
о-де-ть – раз-де-ть.
Этот приём называется построение морфемных квадратов. Описанный выше алгоритм морфемного разбора основы для слов со свободным корнем и построение морфемного квадрата для слов со связанным корнем наиболее обоснованы и помогают избежать ошибок.
Остались вопросы? Не знаете, как сделать морфемный разбор слова?
Чтобы получить помощь репетитора – зарегистрируйтесь.
Первый урок – бесплатно!
© blog.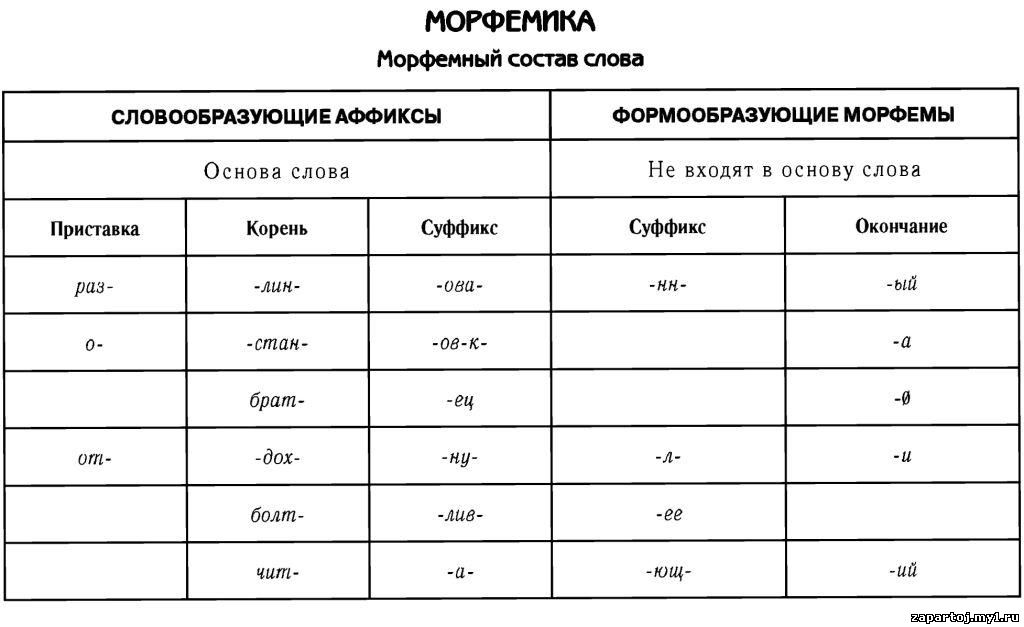 tutoronline.ru,
при полном или частичном копировании материала ссылка на первоисточник обязательна.
tutoronline.ru,
при полном или частичном копировании материала ссылка на первоисточник обязательна.
Остались вопросы?
Задайте свой вопрос и получите ответ от профессионального преподавателя.
Задать вопрос
Физика
Курсы по физике 10 класс
Математика
Математика 11 класс
Математика
Курсы по геометрии 8 класс
История России
Курс подготовки к ГИА по «Истории»
Испанский язык
Курсы испанского для начинающих
Цифровая фотография
Курс цифровой фотографии
Математика
Курсы по математике 10 класс
Математика
Курсы по алгебре 7 класс
ОСНОВА СЛОВА.
 ВИДЫ ОСНОВ. МОРФЕМНЫЙ АНАЛИЗ СЛОВА
ВИДЫ ОСНОВ. МОРФЕМНЫЙ АНАЛИЗ СЛОВА⇐ ПредыдущаяСтр 3 из 3
Основой слова называется часть слова без окончания или все неизменяемое слово. Все слова, способные к словоизменению, состоят из двух частей — основы и окончания. Неизменяемые слова состоят только из одной основы.
К основе слова относят все слово- и формообразующие аффиксы, кроме окончаний. В основу глаголов традиционно не включаются суффиксы инфинитива –ть-, -ти-.
По степени членимости основы могут быть нечленимыми (состоящими из одной корневой морфемы) и членимыми (состоящими из двух и более морфем).
В зависимости от количества корневых морфем основы делят на простые (одна морфема) и сложные (две и более): грязеводолечебница.
По степени спаянности морфемного состава основы слов делятся на свободные и связанные.
Свободная основа содержит корень, который может быть употреблен без приставок и суффиксов в одном из родственных слов и совпадать с границами основы этого слова: мор-ск-ой — мор-е; смел-ость — смел-ый. Т.е., свободной основой является такая, которая содержит свободный корень.
Т.е., свободной основой является такая, которая содержит свободный корень.
Связанная основа всегда содержит в своем составе связанный корень ( такую корневую морфему, которая не совпадает с границами основы ни в одном из родственных слов: слад-к-ий – слад-ость).
Морфемный анализ слова предполагает синхронный подход к определению состава слова. Его главная задача – определить из каких морфем состоит данное слово в современном языке. При характеристике морфем нужно учитывать, к какой части речи относится слово. Так, у существительного зимой —ой является окончанием, а у наречия зимой – суффиксом. Поэтому начинать морфемный анализ рекомендуется с выявления частиречной принадлежности слова.
Рекомендуемый порядок разбора:
1. Часть речи, окончание и его значение
2. Основа
3. Корень
4. Суффикс
5. Приставка
6. Вывод о членимости основы. Указать, свободная она или связанная, простая или сложная.
Вывод о членимости основы. Указать, свободная она или связанная, простая или сложная.
Морфемный анализ существительного подснежник
1. Имя существительное изменяется по родам и числам: подснежник-а, подснежник-у и т.д., подснежник-и, подснежник-ов и т.д. Окончание в слове подснежник нулевое. Оно указывает на мужской род, именительный падеж и единственное число.
2. Основой слова является его часть без окончания, т.е. подснежник-.
3. Корень слова –снеж-. Однокоренные, родственные слова: снег, снеж-н-ый, снеж-инк-а (чередование г//ж). Корень свободный.
4. Суффикс –ник- ; одноструктурные слова с этим суффиксом: подстакан-ник, подокон-ник. Существительные с этим суффиксом имеют значение: «..предмет (одушевленный или неодушевленный), характеризующийся отношением к предмету, явлению, названному корневой морфемой».
5. Приставка под-; слова с этой приставкой: под-березовик, под-бородок. Слова с этой приставкой обозначают «нечто, находящееся ниже или в непосредственной близости от того, что названо корневой морфемой».
6. Основа членимая. Она состоит из корня, суффикса и приставки. Поскольку она содержит свободный корень (снег-снеж), то и сама является свободной. Основа слова простая.
*Самостоятельно сделайте морфемный анализ слов МЕДВЕДЬ, ВЫГНУЛАСЬ, ГОРОДСКОЙ,
СПОСОБЫ СЛОВООБРАЗОВАНИЯ В РУССКОМ ЯЗЫКЕ.
Новые слова в языке возникают двумя способами- путем словообразования и путем заимствования из других языков. Первый способ является основным.
Различают морфологические и неморфологические способы словообразования и словопроизводства.( Под словообразованием понимают стихийно возникающие в языке новообразования, а под словопроизводством – намеренное создание новых слов, которые могут затем войти или не войти в общее употребление).
В процессе словопроизводства используются уже имеющиеся в языке слова, которые используются в качестве производящих основ: город – при-город, рыб-ак — рыбач-ий. Получившиеся новые основы называют производными.Они в свою очередь могут стать производящими, если от них образуются новые слова. Так выстраивается словообразовательная цепочка: рыб-а – рыб-ак— рыбач-ий. Основа, для которой невозможно найти производящую, считается непроизводной(немотивированной(. Такую основу имеют, например, слова день, ночь, жи-ть, ал-ый, син-ий и т.п.
Производные слова в процессе словопроизводства объединяются в системе языка в словообразовательные типы. Словообразовательные тип –это структурно-семантический образец производства слов, характеризующийся строго определенной смысловой зависимостью производного слова от производящего: читать — читатель, слушать –слушатель ( наименование лица по производимому им действию) и наличием строго определенного словообразующего аффикса ( в данном случае это суффикс-тель). Различают продуктивные и непродуктивные словообразовательные типы. По образцу продуктивных словопроизводство в языке продолжается, а непродуктивные уже не используются ( жил-ец, брат-нин).
Различают продуктивные и непродуктивные словообразовательные типы. По образцу продуктивных словопроизводство в языке продолжается, а непродуктивные уже не используются ( жил-ец, брат-нин).
Способы словопроизводства — это морфологические способы, которые заключаются в присоединении различных аффиксов к производящим основам или в объединении двух (или более) основ в одно новое слово. Различают суффиксальный, префиксальный, суффиксально-префиксальный и постфиксальный способы словопроизводства, а также способ основосложения и аббревиацию.
Суффиксальный способ является одним из ведущих в русском языке. Этим способом образовано большинство слов, относящихся к разным частям речи. Так, от глаголов образуются существительные( преподавать- преподаватель, работать- работник, носить — носильщик, кормить- кормилец, прыгать- прыгун.От прилагательных образуются существительные: храбрый- храбрец, производственный- производственник, лихой- лихач. Прилагательные в свою могут быть образованы от существительных: лиса- лисий, поинер-пионерский, серебро- серебристый. Суффиксальный способ используется также при образовании глаголов, наречий, местоимений: слесарь- слесарничать, привычный- привычно, кто- кто-либо, пять- пятеро. Необходимо отметить, что каждый суффикс в русском языке закреплен за определенной частью речи.
Суффиксальный способ используется также при образовании глаголов, наречий, местоимений: слесарь- слесарничать, привычный- привычно, кто- кто-либо, пять- пятеро. Необходимо отметить, что каждый суффикс в русском языке закреплен за определенной частью речи.
Префиксальный способ также считается продуктивным. Особенно активно он используется при образовании глаголов. Приставки присоединяются не к производящей основе, а ко всему производящему слову в целом, поэтому с помощью приставок обычно образуются слова одной и той же части речи: внук- правнук, лить-влить, всегда- навсегда, красивый- некрасивый.
Суффиксально-префиксальный способ предполагает присоединение к производящей основе одновременно приставки и суффикса: стакан- подстаканник. Этим способом образуются слова, относящиеся как к одной, так и к разным частям речи: беседа- собеседник, жир — обезжирить. Так образуются многие существительные, прилагательные, глаголы, наречия. Ухо- наушник, Счастье- несчастный
Постфиксальныйспособ используется только при производстве глаголов: шептать-шептаться, радовать- радоваться. Если не обнаруживается производящее слово без –ся, значит, в данном слове использован другой, смешанный способ образования: дозвониться — до + звонить+ся( префиксально—постфиксальный), упрямиться- упрям+ и+ть+ся (суффиксально-постфиксальный, перезваниваться – пере+зван+ива+ ть+ся (префиксально-суффиксально-постфиксальный). Такие способы используются достаточно редко.
Если не обнаруживается производящее слово без –ся, значит, в данном слове использован другой, смешанный способ образования: дозвониться — до + звонить+ся( префиксально—постфиксальный), упрямиться- упрям+ и+ть+ся (суффиксально-постфиксальный, перезваниваться – пере+зван+ива+ ть+ся (префиксально-суффиксально-постфиксальный). Такие способы используются достаточно редко.
Способ основосложениязаключается в объединении двух или более производящих основ в одно сложное слово с помощью гласны –о-,-е-. .Этим способом образуются существительные и прилагательные. Отношения между основами могут быть сочинительными( равноправными) и подчинительными.Ср. лес-о-степь, север-о-запад, научн-о-технический, торгов-о-промышленный и птиц-е-фабрика, звук-о-режиссер, огн-е-упорный, ярк-о-красный. Эти слова следует отличать от слов типа «малообеспеченный», «вечнозеленый» и т.п., которые образованны от словосочетаний лексико-синтаксическим способом (см. далее).
Способ аббревиации заключается в объединении сокращенных основ нескольких слов, входящих в состав устойчивого словосочетания: ООН- Организация Объединенных Наций, профком- профсоюзный комитет. Известны следующие разновидности аббревиации:
Известны следующие разновидности аббревиации:
1) соединение начальных частей производящих основ – комсомол- коммунистический союз молодежи.
2) объединение начальных звуков производящих основ- загс, вуз
3) сочетание наименований начальных букв- СССР, МЧС.
4) Сочетание начальной части первой основы с целым словом- оргвыводы, замдекана, завкафедрой.
Наряду с морфологическими способами словопроизводства, которые мы перечислили ранее, существуют неморфологические способы, характерные для словообразования. К ним относят лексико-семантический, лексико-грамматический и лексико-синтаксический.
Лексико-семантическим способом считается образование омонимов в кругу одной части речи( ключ-ручей и ключ от двери).Сущностью этого способа является появление новых значений в структуре производящего слова. Грамматические свойства исходного слова и его морфемный состав при этом способе не затрагиваются.
Лексико-грамматическим способом происходит появление омонимичных слов в сфере разных частей речи ( мороженое мясо- вкусное мороженое). Этот способ иногда называют переходом из одной части речи в другую. В отличие от предыдущего способа словообразования, здесь изменяется не только значение, но и грамматические свойства исходного слова, а иногда и его морфемный состав. Обычно таким способом образуются существительные от прилагательных и причастий.( столовая, ученый, раненый, гостиная). Этот процесс называется субстантивацией. Таким же способом пополняется состав служебных слов- предлогов, союзов, частиц,- которые не только теряют свое лексическое значение, но и изменяют морфемную структуру, приобретая основу непроизводную и нечленимую.Сравним благодар-я (деепр.) и благодаря ( предлог).
Этот способ иногда называют переходом из одной части речи в другую. В отличие от предыдущего способа словообразования, здесь изменяется не только значение, но и грамматические свойства исходного слова, а иногда и его морфемный состав. Обычно таким способом образуются существительные от прилагательных и причастий.( столовая, ученый, раненый, гостиная). Этот процесс называется субстантивацией. Таким же способом пополняется состав служебных слов- предлогов, союзов, частиц,- которые не только теряют свое лексическое значение, но и изменяют морфемную структуру, приобретая основу непроизводную и нечленимую.Сравним благодар-я (деепр.) и благодаря ( предлог).
Лексико-синтаксический способ словообразования представляет собой сращение в одно слово двух или более слов, входящих в состав устойчивого или свободного словосочетания – высокообразованный, вышестоящий, малообеспеченный, вечнозеленый, глубокоуважаемый. В результате такого словообразования утрачивается семантическая, фонетическая и грамматическая независимость исходных компонентов производящего словосочетания.
Все виды словообразования и словопроизводства можно представить схематически в виде ТАБЛИЦЫ.(*Заполните таблицу самостоятельно, подпишите по 1 примеру из текста лекции на каждый способ)
СЛОВООБРАЗОВАТЕЛЬНЫЙ АНАЛИЗ СОСТАВА СЛОВА.
При словообразовательном анализе устанавливается, как образовано данное слово. Для этого необходимо:
1. установить принадлежность слова к той или иной части речи
2. определить окончание и основу
3. установить тип основы ( производная/непроизводная)
4. для производной найти производящую
5. определить, с помощью какой морфемы создана производная основа на базе производящей.
Например, увлекательность – от увлекательн-ый + ость ( суффиксальный способ)
Возможен также полный словообразовательный анализ, при котором прослеживается вся словообразовательная цепочка, приведшая к образованию анализируемого слова: увлекательность – увлекательный – увлекать – увлечь – влечь.
*Самостоятельно определить способ образования в каждом звене цепочки.
* Выполните обычный и полный словообразовательный анализ слова НАВОДНЕНИЕ,
⇐ Предыдущая123
Поиск по сайту:
Цели и принципы морфемного и словообразовательного анализа —
Аффиксация в современном английском языке : Производные и функциональные аффиксы
1.2 Цели и принципы морфемного и словообразовательного анализа
Синхроническое описание английской лексики рассматривает ее современную систему и закономерности словообразования путем сопоставления одновременно существующих в ней слов.
Если анализ ограничивается указанием количества и типа морфем, составляющих слово, он называется морфемным. Например, слово girlishness можно разделить на три морфемы: корень girl и два суффикса ish и ness. Морфемная классификация слов следующая: одна корневая морфема — корневое слово (девушка), одна корневая морфема плюс один или несколько аффиксов — производное слово (девичий, девчачий), две или более основы составное слово (подружка), два или несколько основ и общий аффикс сложного производного (старо-девичья). Морфемный анализ устанавливает только конечные составляющие, из которых состоит слово.
Морфемная классификация слов следующая: одна корневая морфема — корневое слово (девушка), одна корневая морфема плюс один или несколько аффиксов — производное слово (девичий, девчачий), две или более основы составное слово (подружка), два или несколько основ и общий аффикс сложного производного (старо-девичья). Морфемный анализ устанавливает только конечные составляющие, из которых состоит слово.
Далее идет структурный словообразовательный анализ; он изучает структурную корреляцию с другими словами, структурные закономерности или правила, по которым строятся слова.
Это делается с помощью принципа противопоставления, т.е. путем изучения частично сходных элементов, различия между которыми функционально значимы; в нашем случае этой разницы достаточно, чтобы создать новое слово. Girl и girlish являются членами морфемной оппозиции. Они похожи, так как корневая морфема девушка одинакова. Их отличительной чертой является суффикс ish. Благодаря этому суффиксу вторым членом оппозиции является другое слово, принадлежащее к другой части речи. Эта бинарная оппозиция состоит из двух элементов.
Эта бинарная оппозиция состоит из двух элементов.
Корреляция – это набор бинарных оппозиций. Оно состоит из двух подмножеств, образованных первым и вторым элементами каждой пары, т. е. оппозиции. Каждый элемент первого множества связан ровно с одним элементом второго множества и наоборот. Каждый второй элемент может быть получен из соответствующего первого элемента по общему правилу, справедливому для всех членов отношения.0005
ребяческий женственный обезьяний старый книжный
можно заключить, что в английском языке существует тип производных прилагательных, состоящий из основы существительного и суффикса ish. Наблюдение также показывает, что в основном это основы одушевленных существительных, и позволяет нам определить отношение между структурным паттерном слова и его значением. Любое отдельное слово, построенное по этому образцу, содержит общий для всей группы семантический компонент, а именно: типичный или обладающий плохими качествами.
В приведенном примере результаты морфемного анализа и структурного словообразовательного анализа практически совпадают. Однако есть и другие случаи, когда они по необходимости разделены. Например, морфемного анализа недостаточно, чтобы показать различие между структурой неудобства v и нетерпения n; он классифицирует оба как производные. Однако с точки зрения словообразовательной модели они принципиально различны. Только второе образуется путем деривации. Сравните:
Однако есть и другие случаи, когда они по необходимости разделены. Например, морфемного анализа недостаточно, чтобы показать различие между структурой неудобства v и нетерпения n; он классифицирует оба как производные. Однако с точки зрения словообразовательной модели они принципиально различны. Только второе образуется путем деривации. Сравните:
нетерпение n = терпение n = тучность n
нетерпеливый терпеливый тучный a
Соотношение, которое можно установить для глагола неудобство, различно, а именно:
неудобство v = боль v = отвращение v = гнев v = восторг v
неудобство n боль n отвращение n гнев n восторг n
Здесь существительные, обозначающие какое-то чувство или состояние, соотносятся с глаголами, вызывающими это чувство или состояние, причем нет разницы в основах между членами каждой отдельной оппозиции. Не имеет значения, структурированы ли разные пары в корреляции одинаково или по-разному. Одни из них являются простыми корневыми словами, другие — производными; они также могут быть составными. С точки зрения словообразования констатируем, что глагол неудобство при сопоставлении с существительным неудобство проявляет отношения, характерные для процесса обращения. См. к позиции, где суффикс не классифицирует это слово как абстрактное существительное, но показывает, что оно образовано от него. Этот подход также дает возможность различать сложные слова, образованные композицией, и слова, образованные другими процессами. Слова honeymoon n и honeymoon v являются составными, содержащими две свободные основы, однако первое образовано композицией: honey n+moon n=honeymoon n, а второе – преобразованием: honeymoon n>honeymoon v. Трактовка остается синхронной, потому что устанавливается не происхождение слова, а его нынешние корреляции в словарном запасе и образцы, продуктивные в современном английском языке.
С точки зрения словообразования констатируем, что глагол неудобство при сопоставлении с существительным неудобство проявляет отношения, характерные для процесса обращения. См. к позиции, где суффикс не классифицирует это слово как абстрактное существительное, но показывает, что оно образовано от него. Этот подход также дает возможность различать сложные слова, образованные композицией, и слова, образованные другими процессами. Слова honeymoon n и honeymoon v являются составными, содержащими две свободные основы, однако первое образовано композицией: honey n+moon n=honeymoon n, а второе – преобразованием: honeymoon n>honeymoon v. Трактовка остается синхронной, потому что устанавливается не происхождение слова, а его нынешние корреляции в словарном запасе и образцы, продуктивные в современном английском языке.
Анализ на непосредственные составляющие, описанный ниже, позволяет получить морфемную структуру и дает основу для дальнейшего словообразовательного анализа.
Анализ на непосредственные составляющие
Синхронный морфологический анализ наиболее эффективно осуществляется с помощью процедуры, известной как анализ на непосредственные составляющие1 (ИС). Впервые предложенный Л. Блумфилдом2, он впоследствии был развит многими лингвистами3. Основное противопоставление, с которым приходится иметь дело, — это противопоставление основы и аффикса. Это своего рода сегментация, раскрывающая не историю слова, а его мотивацию, т. е. те данные, на которые должен ориентироваться слушатель, чтобы понять его. Само собой разумеется, что немотивированные слова и слова со стертой мотивировкой должны запоминаться и пониматься как отдельные знаки, а не как сочетания других знаков.
Впервые предложенный Л. Блумфилдом2, он впоследствии был развит многими лингвистами3. Основное противопоставление, с которым приходится иметь дело, — это противопоставление основы и аффикса. Это своего рода сегментация, раскрывающая не историю слова, а его мотивацию, т. е. те данные, на которые должен ориентироваться слушатель, чтобы понять его. Само собой разумеется, что немотивированные слова и слова со стертой мотивировкой должны запоминаться и пониматься как отдельные знаки, а не как сочетания других знаков.
Метод основан на том, что слово, характеризующееся морфологической делимостью (разлагаемое на морфемы), вовлекается в определенные структурные соотношения. Это означает, что, по выражению З. Харриса, морфемные границы в высказывании определяются не на основе внутренних по отношению к высказыванию соображений, а на основе сопоставления с другими высказываниями. Сравнения контролируются, т. е. мы не просто просматриваем различные случайные высказывания, а ищем высказывания, отличающиеся от нашего исходного только указанными частями. Последний тест — в высказываниях, лишь минимально отличающихся от наших. 1
Последний тест — в высказываниях, лишь минимально отличающихся от наших. 1
Образец анализа, ставший почти классическим и многократно повторяемый многими авторами, — это анализ Блумфилдом слова неджентльменский. Поскольку слово удобно, возьмем тот же пример. Сопоставляя это слово с другими высказываниями, слушатель узнает морфему un- как отрицательную приставку, потому что ему часто встречались слова, построенные по образцу не-прилагательной основы: неуверенный, неосознанный, беспокойный, неудачный, безошибочный, неестественный. Некоторые падежи напоминали это слово еще больше; это были: неземные, неприглядные, несвоевременные, неженские и тому подобные. Можно также встретить прилагательное джентльменский. Таким образом, при первом разрезе мы получаем следующие непосредственные составляющие: un + джентльменский. Если мы продолжим наш анализ, мы увидим, что, хотя gent встречается как свободная форма в низком разговорном употреблении, такое слово, как lemanly, не может быть найдено ни в качестве свободной, ни в качестве связанной составляющей, поэтому на этот раз мы должны отделить последнюю морфему. Мы имеем право так поступать, поскольку есть много прилагательных, следующих за образцом существительного основа+ли, например, женственный, мастерский, ученый, солдатский, с теми же семантическими отношениями «обладать качествами личности, обозначаемыми основой»; существительное джентльмен мы встречаем и в других высказываниях. Два первых этапа анализа привели к выделению свободной и связанной формы: 1) un + джентльменский, 2) джентльменский + ly. Третий разрез имеет свои особенности. Деление на gent-+-leman, очевидно, невозможно, так как в английском языке таких шаблонов не существует, поэтому огранка Gent+man. Аналогичная закономерность наблюдается и у дворянина, поэтому мы констатируем основу прилагательного + человек. Теперь элемент человек может быть по-разному классифицирован как полуаффиксор как вариант свободной формы человека. Слово нежный открыто для обсуждения. Очевидно, что с этимологической точки зрения оно разделимо: нежный<.0Fr gentil<лат. gentilis позволяет различить корень или, вернее, корневой элемент gens и суффикс il.
Мы имеем право так поступать, поскольку есть много прилагательных, следующих за образцом существительного основа+ли, например, женственный, мастерский, ученый, солдатский, с теми же семантическими отношениями «обладать качествами личности, обозначаемыми основой»; существительное джентльмен мы встречаем и в других высказываниях. Два первых этапа анализа привели к выделению свободной и связанной формы: 1) un + джентльменский, 2) джентльменский + ly. Третий разрез имеет свои особенности. Деление на gent-+-leman, очевидно, невозможно, так как в английском языке таких шаблонов не существует, поэтому огранка Gent+man. Аналогичная закономерность наблюдается и у дворянина, поэтому мы констатируем основу прилагательного + человек. Теперь элемент человек может быть по-разному классифицирован как полуаффиксор как вариант свободной формы человека. Слово нежный открыто для обсуждения. Очевидно, что с этимологической точки зрения оно разделимо: нежный<.0Fr gentil<лат. gentilis позволяет различить корень или, вернее, корневой элемент gens и суффикс il. Но поскольку нас интересует только синхронный анализ, это деление неуместно.
Но поскольку нас интересует только синхронный анализ, это деление неуместно.
Если же мы сравним прилагательное нежный с такими прилагательными, как хрупкий, плодородный, непостоянный, юный, маленький, благородный, тонкий и некоторыми другими, содержащими суффикс le-ile, присоединенный к связанной основе, они образуют образец для нашего падежа . Связанная основа, которая осталась, присутствует в следующей группе: нежно, нежно, нежность, джентльмен, джентльмен, джентльмен, и т. д.
Можно заметить, что наша процедура поиска подобных высказываний показала, что английский словарь содержит вульгарное слово джентльмен упомянутое выше, означающее ‘лицо, претендующее на статус джентльмена’ или просто ‘мужчина’, но тогда нет такой структуры, как основа существительного + le, поэтому слово gent следует трактовать как омоним связанного ствол под вопросом.
Подытожим: разбивая слово, мы получаем на любом уровне только две ИС, одна из которых является основой данного слова. Все время анализ строится на закономерностях, характерных для английской лексики. В качестве закономерности, показывающей взаимозависимость всех составляющих, выделяющихся на разных стадиях, мы получаем следующую формулу:
В качестве закономерности, показывающей взаимозависимость всех составляющих, выделяющихся на разных стадиях, мы получаем следующую формулу:
Un + {[(gent —+ le) + man] + ly-}
Разбивая слово на его непосредственные составляющие, мы наблюдаем в каждом разрезе структурный порядок составляющих (который может отличаться от их фактической последовательности). Кроме того, мы получим только две составляющие на каждом разрезе, но последние составляющие можно расположить в соответствии с их последовательностью в слове: un-un + gent-+ le +-man +-ly.
Можно повторить анализ на словообразовательном уровне, показывающий не только морфемные составляющие слова, но и структурную схему, на которой оно построено, это можно осуществить в терминах пропорциональных оппозиций. Основные требования, по сути, те же: анализ должен выявить закономерности, наблюдаемые в других словах того же языка, основы, полученные после изъятия аффикса, должны соответствовать отдельному слову, выделение словообразовательного аффикса основано на пропорциональных противопоставлениях слова, имеющие один и тот же аффикс с одинаковым лексическим и лексико-грамматическим значением. Неджентльменский, таким образом, противопоставляется не неджентльменскому (такого слова не существует), а джентльменскому. С этим противопоставлением соотносятся и другие пары, сходным образом связанные. Примеры:
Неджентльменский, таким образом, противопоставляется не неджентльменскому (такого слова не существует), а джентльменскому. С этим противопоставлением соотносятся и другие пары, сходным образом связанные. Примеры:
неджентльменский = нечестный = недобрый = бескорыстный
джентльменский честный добрый эгоистичный
Эта корреляция выявляет структуру не-+прилагательного.
Словообразовательный тип определяется как словообразовательный. Значение не-, используемое в этом паттерне, означает либо просто «не», либо, чаще, «обратное значение» с намеком на порицание или похвалу.
Следующий шаг аналогичен, только на этот раз убирается суффикс:
джентльменский = женственный = ученый
джентльмен женщина ученый
Серия показывает, что эти прилагательные образованы в соответствии с образцом основы существительного-Mi/. Обычное значение термина числителя — «характеристика (джентльмена, женщины, ученого).
Анализ на непосредственные составляющие, предложенный в американской лингвистике, получил дальнейшее развитие в приведенной выше трактовке путем сочетания чисто формальной процедуры с семантическим анализом. Семантическая проверка означает, например, что мы можем отличить тип «джентльменский» от типа «ежемесячный», хотя оба они следуют структурному образцу существительного «стебель+-ли». Семантическая связь различна, так как ly качественная в первом случае и частотная во втором, т. е. месячный означает «выходящий каждый месяц».
Семантическая проверка означает, например, что мы можем отличить тип «джентльменский» от типа «ежемесячный», хотя оба они следуют структурному образцу существительного «стебель+-ли». Семантическая связь различна, так как ly качественная в первом случае и частотная во втором, т. е. месячный означает «выходящий каждый месяц».
Этот пункт подтверждается следующими корреляциями: любое прилагательное, построенное по образцу личное существительное основа +-ly, эквивалентно ‘характерному или имеющему качество лица, обозначенное основой’.
джентльменский→ обладающий качествами джентльмена
виртуозный→ обладающий качествами господина
солдатский→ обладающий качествами солдата
женственный→ обладающий качествами женщины
Месячный не вписывается в этот ряд, поэтому пишем:
ежемесячный ↔ обладающий качествами месяца
С другой стороны, прилагательные этой группы, т. е. слова, построенные на шаблонной основе существительного, обозначающего период времени +-ly, эквивалентны формуле «встречающийся каждый период» времени, обозначенного стеблем’:
ежемесячно → происходит каждый месяц
ежечасно → происходит каждый час
ежегодно → происходит каждый год
Gentlemanly не показывает такой эквивалентности, преобразование, очевидно, невозможно, поэтому мы пишем:
джентльменский ↔*встречается каждому джентльмену
Приведенная выше процедура показа процесса словообразования является элементарным случаем трансформационного анализа, при котором смысловое сходство или различие слов выявляется возможностью или невозможностью преобразования их по к предписанной модели и следуя определенным правилам в другую форму, называемую их «преобразованием». Условия эквивалентности между исходной формой и преобразованием предваряются. В нашем случае должны выполняться условия тождества значения и морфемы ядра. Трансформационный анализ будет обсуждаться в главе о методах лингвистического исследования. Э.О. Нида1 обсуждает еще один сложный случай: неистинное, по-видимому, может быть разделено на две стороны, причем ИС либо не-+—, либо не——. Тем не менее, наблюдая за другими высказываниями, мы замечаем, что префикс un~ лишь изредка сочетается с основами наречий и очень часто с основами прилагательных; примеры уже приводились выше. Таким образом, у нас есть основания полагать, что ИС не соответствует действительности. Другие примеры того же шаблона: необычно, маловероятно.
Условия эквивалентности между исходной формой и преобразованием предваряются. В нашем случае должны выполняться условия тождества значения и морфемы ядра. Трансформационный анализ будет обсуждаться в главе о методах лингвистического исследования. Э.О. Нида1 обсуждает еще один сложный случай: неистинное, по-видимому, может быть разделено на две стороны, причем ИС либо не-+—, либо не——. Тем не менее, наблюдая за другими высказываниями, мы замечаем, что префикс un~ лишь изредка сочетается с основами наречий и очень часто с основами прилагательных; примеры уже приводились выше. Таким образом, у нас есть основания полагать, что ИС не соответствует действительности. Другие примеры того же шаблона: необычно, маловероятно.
Бывают, конечно, случаи, особенно среди заимствованных слов, которые вообще не поддаются анализу; таковы, например, календарь, настурция или хризантема. Анализ других слов может остаться открытым или нерешенным. Некоторые лингвисты, например, придерживаются мнения, что такие слова, как карман, не могут быть подвергнуты морфологическому анализу. Их аргумент заключается в том, что, хотя мы вправе выделить элемент et, поскольку соотношение можно считать правильным (hog: hogget, lock: медальон), значение суффикса в обоих случаях отчетливо уменьшительно-ласкательное, оставшаяся часть pock не может быть считается стеблем, поскольку больше нигде не встречается. Другие, как проф. А. И. Смирницкий, считают основу морфологически делимой, если можно показать, что хотя бы один из ее элементов принадлежит регулярному соотношению 2 9 .0005
Их аргумент заключается в том, что, хотя мы вправе выделить элемент et, поскольку соотношение можно считать правильным (hog: hogget, lock: медальон), значение суффикса в обоих случаях отчетливо уменьшительно-ласкательное, оставшаяся часть pock не может быть считается стеблем, поскольку больше нигде не встречается. Другие, как проф. А. И. Смирницкий, считают основу морфологически делимой, если можно показать, что хотя бы один из ее элементов принадлежит регулярному соотношению 2 9 .0005
Спорные вопросы такого рода не отменяют принцип анализа на непосредственные составляющие. Вторая точка зрения представляется более убедительной. Чтобы проиллюстрировать это, возьмем слово hamlet «небольшая деревня». В современном английском языке нет слов с этой основой, но оно ясно делится диахронически, так как происходит от OFr hamelet германского происхождения, уменьшительного от hamel и родственного английскому существительному home. Нельзя забывать, что сотни английских топонимов оканчиваются на ham, например Shoreham, Wyndham и т. д. Тем не менее, смешение исторического и структурного подходов никогда не годится. Если мы остановимся на втором и будем искать повторяющиеся тождества в соответствии со структурными процедурами, мы найдем слова буклет, облачко, плошка, листочек, колечко, twnlet и т. д. Во всех этих словах let — явно уменьшительно-ласкательный суффикс, не противоречащий смыслу деревушки. Таким образом, подход Смирницкого подтверждается данными языкового материала, а также позволяет нам оставаться в строго синхронных пределах.
д. Тем не менее, смешение исторического и структурного подходов никогда не годится. Если мы остановимся на втором и будем искать повторяющиеся тождества в соответствии со структурными процедурами, мы найдем слова буклет, облачко, плошка, листочек, колечко, twnlet и т. д. Во всех этих словах let — явно уменьшительно-ласкательный суффикс, не противоречащий смыслу деревушки. Таким образом, подход Смирницкого подтверждается данными языкового материала, а также позволяет нам оставаться в строго синхронных пределах.
Другим примером того же характера, обсуждаемым рядом авторов, является слово потолок. Содержит ли он одну морфему или две? Можно возразить, что в настоящее время потолок следует считать корневым словом, потому что корень ceil уже не актуален, и говорящий больше не понимает его как покрытие или облицовку крыши, хотя существование слов покрытие и облицовка как мы видели, само по себе достаточно, чтобы считать слово делимым. Однако есть и другие слова, в которых тот же суффикс выполняет аналогичную функцию. Таким образом, в напольных покрытиях, настилах, трубопроводах, мощении и т. д. ing эквивалентен полуаффиксной работе, так что обрамление является синонимом каркаса.
Таким образом, в напольных покрытиях, настилах, трубопроводах, мощении и т. д. ing эквивалентен полуаффиксной работе, так что обрамление является синонимом каркаса.
Существует еще одна процедура, которая помогает дифференцировать и может быть предложена в качестве теста. Это замена в похожих или идентичных контекстах. Это свидетельствует в пользу понимания потолка как состоящего из двух морфем, так как можно противопоставить потолок и пол. С. Поттер приводит следующий пример: Пол в каждой квартире сандаловый, а потолок — перламутровый.
Это позволяет сделать еще один вывод, а именно, что при лексикологическом анализе слова можно группировать не только по корневым морфемам, но и по аффиксам.
2. Вторая часть
Аффиксация в современном английском языке : Производные и функциональные аффиксы
71869
1
0
… то, как он интерпретирует такие слова, как доход, наблюдатель, уборная, определяя их как соединения с локативными частицами в качестве первых элементов. Р. С. Гинзбург [24] утверждает, что в системе современного английского словообразования около 51 префикса. В отличие от суффиксации, которая обычно более тесно связана с парадигмой определенной части речи, префиксация считается в этой части более нейтральной…
Р. С. Гинзбург [24] утверждает, что в системе современного английского словообразования около 51 префикса. В отличие от суффиксации, которая обычно более тесно связана с парадигмой определенной части речи, префиксация считается в этой части более нейтральной…
17480
0
0
… на составляющие его морфемы основные единицы на данном уровне анализа и при определении их количества и видов. Четыре типа (корневые слова, производные слова, составные слова, сокращения) представляют собой основные структурные типы современных английских слов, а преобразование, деривация и композиция являются наиболее продуктивными способами словообразования. По количеству морфем слова можно разделить на …
151952
0
0
…
составно-сокращенное слово, образованное от словосочетания, в котором один из компонентов был укорочен, напр. Busnapper был сформирован из похитителя автобусов, minijet из миниатюрного самолета. В английском языке второй половины ХХ века сложились так называемые блочные соединения, то есть сложные слова, имеющие объединяющее ударение, но раздвоенное написание, такие как chat show, pinguin . ..
..
149185
1
0
… . 6. Скандинавский элемент в английской лексике. 7. Нормандско-французский элемент в английской лексике. 8. Различные другие элементы лексики английского и украинского языков. 9. Ложная этимология. 10.Виды заимствований. 1. Родной элемент и заимствованные слова Обычно говорят, что наиболее характерной чертой английского языка является его смешанный характер. Многие лингвисты…
Морфология / Вавилон :: lingvo.info
- Фонетика, звуковой инвентарь
«Звуки, которые мы произносим» - Морфология
«Слова, как они образуются и как изменяются» - Синтаксис
«Как складывать слова» - Семантика, лексикология
«Значение слов»
Морфология — это часть языкознания, которая анализирует внутреннюю структуру слов и ее связь с их значением.
Большинство людей думают о языке в терминах слов, но слова не являются основным объектом анализа в морфологии. Вместо этого лингвистов больше всего интересует морфема, которую можно определить либо как наименьшую единицу значения в грамматике языка, либо как «наименьшую функциональную единицу в составе слов». Что объединяет оба подхода, так это идея наименьшей единицы в построении слов или грамматики языка.
Вместо этого лингвистов больше всего интересует морфема, которую можно определить либо как наименьшую единицу значения в грамматике языка, либо как «наименьшую функциональную единицу в составе слов». Что объединяет оба подхода, так это идея наименьшей единицы в построении слов или грамматики языка.
Каждое слово содержит по крайней мере одну морфему, а некоторые могут иметь гораздо больше. Например, слово plimalboniĝintus на эсперанто (глагол, означающий «становилось бы хуже») состоит из шести морфем.
- пли-
еще
- плохо-
напротив
- Бон-
хорошо
- iĝ-
стало
- между-
активное причастие прошедшего времени
- -нас
условно
Может показаться, что это много, но слова в некоторых языках могут состоять из гораздо большего количества морфем.
Морфемы могут быть либо свободными, и в этом случае они могут появляться сами по себе, как cat в английском или kot в польском, либо они могут быть связаны, что означает, что они должны появляться вместе в одном слове с каким-либо другим элементом. Окончания множественного числа -s и -y в английском и польском языках связаны.
- кошка
кот
- кот-с
кот-й
Языки отличаются тем, какие морфемы связаны, а какие свободны. Испанское слово gato (кошка) содержит две связанные морфемы gat- и -o, которые обозначают существительное как мужской род. Если заменить на -a, получится женщина-кошка:
- гат-о
(самец) кошка
- гат-а
(самка) кат
Слово «кошка» на эсперанто — «като», состоящее из двух морфем: корня «кат-» и «о», который встречается со всеми нарицательными существительными.
Часто морфемы не всегда имеют одинаковую форму. Различные варианты одной и той же морфемы называются алломорфами. Венгерское слово «кошка» — macska. Перед окончанием множественного числа -k может быть добавлена последняя гласная, так что macska и macská- являются алломорфами одной и той же морфемы: macska + k = macskák.
Типы слов
В каждом языке слова можно разделить на группы в соответствии с их функцией в предложении, эти группы называются классами слов (или частями речи).
Единственные две части речи, встречающиеся в любом языке, это существительные и глаголы. Оба являются большими классами со многими подклассами.
Существительные включают:
- нарицательные: названия вещей как класса: собака, дом, дружба
- имена собственные: имена конкретных людей, животных или мест: John, Spot, Berlin
- личные местоимения:
обращаться к людям как к отправителю, я, получателю, вам или теме, они, предложения.

- указательные местоимения: относиться к вещам как к близким и непосредственным (это или дальше то).

Существуют и другие типы местоимений, в том числе вопросительные (кто, что), отрицательные (никто) и относительные местоимения (кто, что, что), неопределенные (кто-то, что-то).
Наиболее важное различие между глаголами заключается в лексических глаголах (также называемых полными глаголами), которые указывают на то, что кто-то или что-то делает, например, плавают, говорят или думают. С другой стороны, вспомогательные глаголы имеют грамматические значения, то есть они используются вместе с лексическими глаголами, как правило, для обозначения определенного времени или наклонения. Примеры включают: идет, ушел.
Прилагательные, описывающие качества, могут функционировать как отдельный класс слов (как во многих европейских языках) или рассматриваться как подкласс существительных или глаголов.
В большинстве европейских языков прилагательные более тесно связаны с существительными, и в результате они выражают те же категории, что и существительные (например, число, род и падеж). В некоторых языках, таких как японский, они являются подклассом глаголов и выражают категории, типичные для глаголов, такие как время.
В некоторых языках, таких как японский, они являются подклассом глаголов и выражают категории, типичные для глаголов, такие как время.
taberu = есть (настоящее время)
tabeta = ate
akai = красный
akakatta = красный
Другие важные классы слов включают союзы, которые объединяют слова или предложения, наречия, которые изменяют различные части предложения, и прилагательные, которые указывают на расположение или другие отношения между существительное они изменяют и глагол.
Способы изменения слов
Морфологические процессы можно разделить на две категории. Флексионные изменения не меняют основного значения слова. Вместо этого они указывают на грамматическую функцию слова. Список всех грамматических форм слова можно назвать парадигмой. Вот парадигма эсперанто-слова имени (номо), которое имеет два числа (единственное и множественное число) и два падежа (именительный и винительный падежи).
| единственное число | множественное число | |
|---|---|---|
| Именительный падеж | номер | номой |
| винительный падеж | номон | номойн |
Носители языка не мыслят парадигмами (часто к удивлению не носителей языка). Но парадигмы — полезный инструмент в описании языка и изучении языка. Удобным способом обозначения всех грамматических форм слова является лексема (или лексическое слово). Четыре слова эсперанто в парадигме прежде всего принадлежат к одной и той же лексеме nomo.
Производные изменения бывают двух типов. Один тип может изменить часть речи, к которой принадлежит слово (например, превратить существительное в глагол или прилагательное, прилагательное в существительное или наречие или глагол в существительное). В польском языке существительное pytanie (вопрос) происходит от глагола pytać (спрашивать). К корню pyta- добавляется окончание -ние.
В польском языке существительное pytanie (вопрос) происходит от глагола pytać (спрашивать). К корню pyta- добавляется окончание -ние.
Другой вид деривационных изменений не меняет тип слова, но изменяет его значение настолько, что в результате получается новая лексема. В немецком языке добавление aus- (из) к глаголу sprechen (говорить) меняет значение произношения.
аус- + sprechen = аусsprechen
Большинство морфологических изменений осуществляется с помощью аффиксов, представляющих собой связанные морфемы, присоединяемые к корню. Наиболее распространенными аффиксами являются префиксы, добавленные перед корнем, и суффиксы, добавленные после него.
Удобный способ думать о словах в терминах корней и основ. Корень является основным словом или лексическим и всегда присутствует. Основа — это корень плюс любые производные аффиксы, к которым могут быть добавлены флективные аффиксы. Например, английское слово алфавит является одновременно и корнем, и основой. Слово в алфавитном порядке имеет тот же корень, но основа теперь в алфавитном порядке с добавлением производного суффикса -ize, который превращает его в глагол.
Слово в алфавитном порядке имеет тот же корень, но основа теперь в алфавитном порядке с добавлением производного суффикса -ize, который превращает его в глагол.
Флексивные аффиксы, такие как -d для прошедшего времени или -ing для настоящего причастия, добавляются к основе с результирующими формами в алфавитном порядке и в алфавитном порядке.
Точно так же польское слово przeczytam (я прочитаю его (все)) может быть проанализировано как основанное на корне czyta- (читать), к которому добавляется словообразовательный префикс prze- (через), чтобы сделать основу przeczyta- (прочитайте, прочитайте все). Наконец, добавляется флективное окончание -m (первое лицо единственного числа).
Префиксы и суффиксы являются примерами линейной морфологии (где морфемы добавляются в линейном порядке). В нелинейной морфологии новая морфема начинается раньше, чем заканчивается первая.
Циркумфикс состоит из двух частей, расположенных в разных местах. В немецком языке многие причастия прошедшего времени образуются с циркумфиксом ge- -t, например gesagt (сказал):
sag- + ge- -t = gesagt
Инфикс появляется внутри другой морфемы или, другими словами, прерывает ее. В тагальском языке lingua franca филиппинского sulat является корнем, означающим писать. Инфикс -um- превращает его в конечный глагол, который фокусирует внимание на предмете. Так что сумулат значит (кто-то) пишет.
В тагальском языке lingua franca филиппинского sulat является корнем, означающим писать. Инфикс -um- превращает его в конечный глагол, который фокусирует внимание на предмете. Так что сумулат значит (кто-то) пишет.
Аблаут — это фонематическая модификация корня без добавления какого-либо другого элемента. В европейских германских языках есть много глаголов, которые образуют прошедшее время, изменяя гласную. В английском языке прошедшее время и причастия прошедшего времени часто образуются путем изменения гласной корня, как в слове «плавать», которое становится «плавал в прошлом».
Один из наиболее сложных типов морфологии представлен трансфиксом, который накладывает узор на корень. В мальтийском языке некоторые прилагательные имеют совершенно разные, но родственные формы в зависимости от пола. Для этих прилагательных мужская форма — vCCvC (v = гласная, C = согласная), а женская форма — CvCCa.
| корень | мужской род | женский | |
|---|---|---|---|
| белый | б д , | абджад | байда |
| черный | с ш д | iswed | швда |
Другие типы морфологических конструкций включают сложные слова, которые объединяют более одного корня для образования новой основы. Немецкое слово для лингвистики — Sprachwissenschaft, составное слово, состоящее из корня Sprache (язык) и Wissenschaft (наука).
Немецкое слово для лингвистики — Sprachwissenschaft, составное слово, состоящее из корня Sprache (язык) и Wissenschaft (наука).
Некоторые языки предпочитают составлять новые слова гораздо больше, чем другие, которые предпочитают другие методы, такие как существительные, модифицированные предложными фразами. Кофемолка — это составное слово в немецком Kaffemühle и венгерском kavédaraló, а во французском moulin à cafe и польском młynek do kawy — это существительное плюс предложная фраза.
Дублирование — это повторение слова для выражения какой-либо грамматической функции. В индонезийском языке существительные повторяются, образуя формы множественного числа, как в buku (книга) и buku-buku (книги). Иногда повторяется только часть слова, как, например, в турецких beyaz (белый) и bembeyaz (очень белый).
Дополнение — это полная замена слова для выражения грамматической функции. Часто это связано с историческими причинами. В испанском языке инфинитив и будущее время глагола идти происходят от латинского глагола ire, а настоящее время основано на другом латинском глаголе vadere (продвигаться).
| инфинитив | и | идти |
|---|---|---|
| будущее время | ире | я пойду |
| настоящее время | вой | иду, иду |
Типология морфологических структур
Различные языки любят добавлять аффиксы по-разному. Иногда языки обозначаются типом морфологии, на который они больше всего полагаются. В агглютинирующих языках различные грамматические функции, такие как лицо, число и падеж, выражаются отдельными аффиксами, которые добавляются к основам. В турецком языке пример эвлеримин (моих домов) можно разбить на один корень, за которым следуют три суффикса.
- даже-
дом
- лер-
во множественном числе
- -я-
мой
- -в
из
- знак равно
- эвлеримин
моих домов
В фузионных языках аффиксы сочетают в себе разные функции, так что чешское окончание -ů указывает одновременно на множественное число и родительный падеж. Кроме того, при добавлении к существительному dům (дом) изменяется гласная корня, и в результате получается domů.
Кроме того, при добавлении к существительному dům (дом) изменяется гласная корня, и в результате получается domů.
Изолирующие языки используют гораздо меньше аффиксов, чем агглютинирующие или фузионные языки. Чтобы показать грамматические отношения, они используют комбинацию порядка слов и добавления отдельных слов для видов функций, часто обозначаемых аффиксами в более морфологически ориентированных языках. Например, во вьетнамском языке время выражается добавлением частиц перед лексическим глаголом.
- Tôi đã xem phim.
(Я прошлый фильм)
Я смотрел фильм. - Toi đang xem phim.
(представляю посмотреть фильм)
Я смотрю фильм. - Tôi sẽ xem phim.
(В будущем я увижу фильм.)
Я посмотрю фильм.
Разнообразие способов, которыми разные языки изменяют слова для изменения их функции, намного шире, чем можно здесь описать.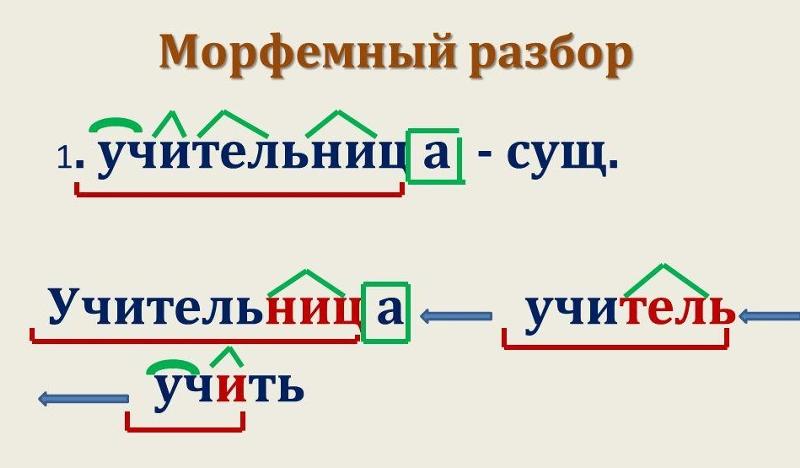 Кроме того, морфологические процессы, как и другие аспекты языка, никогда не бывают полностью статичными, и носители языка постоянно изменяют их небольшими способами, что со временем может привести к большим различиям в языке.
Кроме того, морфологические процессы, как и другие аспекты языка, никогда не бывают полностью статичными, и носители языка постоянно изменяют их небольшими способами, что со временем может привести к большим различиям в языке.
Лексика: MA
Морфология занимается словообразованием. Уникальные слова на этих рисунках иллюстрируют морфологический процесс. Как были объединены целые слова и/или части слов, чтобы передать смысл?
(Посмотрите это чудесное маленькое видео о словообразовании или посетите Popular Linguistics Online, где Коррин Маккарти (Университет Джорджа Мейсона) аккуратно описывает, как слова образуются посредством морфологических процессов.)
Чтобы генерировать слова, мы объединяем целые слова и их части в новые конфигурации, новые конкатенации. Неологизмы придумываются ежедневно; английский язык быстро развивается (подробнее). МакФедрис на сайте wordspy. com отслеживает неологизмы, которые были опубликованы в печати, в том числе post-Potter и Spillionaire . С кажущейся легкостью и удовольствием люди создают слова на живых языках, включая язык жестов. Эта способность проявляется в раннем возрасте: когда я делала леденец, дочь моего друга спросила: «Папа, это леденец 9».0485 качает еще?»
com отслеживает неологизмы, которые были опубликованы в печати, в том числе post-Potter и Spillionaire . С кажущейся легкостью и удовольствием люди создают слова на живых языках, включая язык жестов. Эта способность проявляется в раннем возрасте: когда я делала леденец, дочь моего друга спросила: «Папа, это леденец 9».0485 качает еще?»
« Морфология относится к ментальной системе, участвующей в словообразовании, или к области лингвистики, изучающей слова, их внутреннюю структуру и способы их образования» (Aronoff & Fudeman, 2005, стр. 2). Морфема является неделимой единицей значения — префиксом, суффиксом, корнем или основой.Английский язык содержит слова с морфемами, плавно соединенными вместе, как, например, dis- + вкус + -ful или sym- + phon + -ic . Однако многие слова не вписываются в эту структуру, и этому тоже стоит научиться. Английский язык гибкий, толерантный, экспансивный. Греческий корень morph означает «структура, форма», и морфолога интересует, как образуются и понимаются все слова, включая слова с вариантами, неправильными морфемами ( учить-учить , ребенок-дети ), аббревиатуры типа . НАСА и инициализмы (аббревиатуры) типа НЛО. Морфологические процессы также участвуют, когда мы создаем сложные слова, такие как солнечный свет и зять, и когда мы разбиваем слова вместе в лингвистические смеси (также известные как слова портманто), такие как Texarkana, skort, smog, FedEx и zootique , сувенирный магазин в зоопарке в Центральный парк.
НАСА и инициализмы (аббревиатуры) типа НЛО. Морфологические процессы также участвуют, когда мы создаем сложные слова, такие как солнечный свет и зять, и когда мы разбиваем слова вместе в лингвистические смеси (также известные как слова портманто), такие как Texarkana, skort, smog, FedEx и zootique , сувенирный магазин в зоопарке в Центральный парк.
В конце концов мы привыкаем к целому ряду морфологических типов слов, включая базовые слова (например, обед ), флексии ( обед ), составные слова ( коробка для завтрака , стол для обеда ), производные ( ланчонетт ) и смеси ( поздний завтрак ). Поскольку мы ищем в словах узнаваемые фрагменты, поскольку мы знаем и даже знаем о префиксах, суффиксах, основах и корнях, мы можем уловить морфологически сложные производные, в том числе Lunchables (эй!), эпиграмматические и экзотермические реакции . Способность понимать эти слова, по-видимому, в значительной степени обусловлена конструктом, который мы называем MA или морфологической осведомленностью (Carlisle, 2003; Kuo & Anderson, 2006).
Морфологическая осведомленность определяется как «способность размышлять над морфемами и манипулировать ими, а также использовать правила словообразования в своем языке» (Kuo & Anderson, 2006, стр. 161). Он концептуализируется как один из аспектов словесного сознания (Graves, 2006), один из аспектов металингвистического осознания (Nagy, 2007) и считается связанным с метапознанием (McBride-Chang et al., 2005; Nagy, 2007). Также считается, что в ментальном лексиконе морфологически родственные слова, такие как сладкий, подсластить, подсластитель, сладко, сладость активируйтесь вместе, подталкивая друг друга, подталкивая друг друга, если хотите. Таким образом, в целом мы распознаем слова быстрее и точнее, если они подкреплены большим морфологическим семейством и/или если они являются высокочастотными словами (Baayen, 2007; Carlisle & Katz, 2006; Dorfman, 1998; Nagy et al. , 1989). (мы ЛЮБИМ игру слов)0485 желтый и песня но к четвертому классу мы должны вплотную заняться такими сложными словами как биологический и непредсказуемость . Мы анализируем составные части слова и сравниваем его с уже известным нам словом. Мы ищем сходство в форме и значении, глядя внутри и между словами. Таким образом, кажется, что МА со временем развивается, внося больший вклад в знание слов, поскольку учащиеся все чаще сталкиваются с морфологически сложными производными, но вот загвоздка: при ограниченном МА рост словарного запаса значительно затруднен (Anglin, 19).93; Карлайл, 2000, 2003; Макбрайд-Чанг, Вагнер, Муза, Чоу и Шу, 2005 г .; Надь, 2007).
Мы анализируем составные части слова и сравниваем его с уже известным нам словом. Мы ищем сходство в форме и значении, глядя внутри и между словами. Таким образом, кажется, что МА со временем развивается, внося больший вклад в знание слов, поскольку учащиеся все чаще сталкиваются с морфологически сложными производными, но вот загвоздка: при ограниченном МА рост словарного запаса значительно затруднен (Anglin, 19).93; Карлайл, 2000, 2003; Макбрайд-Чанг, Вагнер, Муза, Чоу и Шу, 2005 г .; Надь, 2007).
Значение для преподавания и обучения:
Если мы не заглядываем внутрь слов, чтобы найти смысловые фрагменты, то нас нужно научить, как это делать. В конце концов, после обучения, мы сможем предложить гипотезу о структуре и значении каждого слова, изображенного на этой странице. Более того, мы должны уметь придумывать слова более сложные, чем те, что изображены здесь. Начните в начальных классах с простого морфологического семейства, такого как d уловка, уклонение, уклонение, уклонение от мяча, уклонение . Я предполагаю, что ко второму классу дети должны понимать, как сложные слова передают смысл, и для того, чтобы читать тексты четвертого класса, они должны понимать более сложные слова, содержащие префиксы и суффиксы, окружающие корень или основу, как описано Марсией Генри. Обучение должно быть более эффективным, если уроки координируют контекст, семантику, морфологию, орфографию и фонологию, потому что это то, что разум делает, чтобы понять смысл письменного языка (Nagy, Berninger, Abbott, Vaughan, & Vermeulen, 2003). Разум также учитывает синтаксис, в том числе морфосинтаксические свойства слов (например, слова, оканчивающиеся на суффикс -ness , как правило, являются абстрактными существительными — понятиями, чувствами, идеями — как в счастье, печали, умиротворении, благодарности ). Фактически, Мэриэнн Вольф (2007) использует аббревиатуру POSSM для обозначения пяти языковых компонентов, которые мы должны координировать при обучении словам. POSSM расшифровывается как фонология/фоника, орфография, семантика, синтаксис, морфология.
Я предполагаю, что ко второму классу дети должны понимать, как сложные слова передают смысл, и для того, чтобы читать тексты четвертого класса, они должны понимать более сложные слова, содержащие префиксы и суффиксы, окружающие корень или основу, как описано Марсией Генри. Обучение должно быть более эффективным, если уроки координируют контекст, семантику, морфологию, орфографию и фонологию, потому что это то, что разум делает, чтобы понять смысл письменного языка (Nagy, Berninger, Abbott, Vaughan, & Vermeulen, 2003). Разум также учитывает синтаксис, в том числе морфосинтаксические свойства слов (например, слова, оканчивающиеся на суффикс -ness , как правило, являются абстрактными существительными — понятиями, чувствами, идеями — как в счастье, печали, умиротворении, благодарности ). Фактически, Мэриэнн Вольф (2007) использует аббревиатуру POSSM для обозначения пяти языковых компонентов, которые мы должны координировать при обучении словам. POSSM расшифровывается как фонология/фоника, орфография, семантика, синтаксис, морфология. Дополнительные сведения о синтаксисе и морфологии см. в разделе Суффиксы. Кроме того, если вы обучаете изучающих английский язык, ознакомьтесь с постом Кэролайн Эдди о том, как мы можем помочь носителям испанского языка изучить синтаксические свойства английских слов.
Дополнительные сведения о синтаксисе и морфологии см. в разделе Суффиксы. Кроме того, если вы обучаете изучающих английский язык, ознакомьтесь с постом Кэролайн Эдди о том, как мы можем помочь носителям испанского языка изучить синтаксические свойства английских слов.
Изучение морфологии доступно каждому. Все учащиеся, в том числе с нарушениями чтения, могут получить пользу от такого интегрированного обучения. Алексис Филиппини описывает мотивационные и когнитивные преимущества для читателей из групп риска. Это относится как к маленьким детям, так и к подросткам (см. идеи сортировки и детскую книгу для изучения суффикса -ish как красноватый и см. пост Пита Бауэрса). Было обнаружено, что знакомство с морфологией приносит пользу и взрослым: профессор Том Белломо показал, что преподавание морфологии для ELL в английском колледже способствует увеличению словарного запаса у студентов, изучающих испанский язык, а также, в меньшей степени, изучающих азиатские языки. 0005
0005
Поскольку развитие большого словарного запаса зависит от развития морфологического понимания, эта тема часто поднимается в этом блоге. Однако следует отметить, что морфологическая осведомленность также способствует правописанию (кодированию), чтению (декодированию) и пониманию, как упоминалось в «Металингвистическом понимании, понимании и общих стандартах основного состояния». Рассуждения морфологически интересны для познания, как обсуждал Шейн Темплтон в книге «Больше, чем сумма их частей».
Ограничения: Морфемный анализ помогает нам понять очень много слов, но неделимые морфологические элементы, такие как аффиксы и корни, не могут объяснить все слова и фразы в ментальном лексиконе (Aronoff & Fudeman, 2005). Многие слова кажутся проглоченными целиком, включая базовые слова, такие как стебель, зонт и скрипка , а также производные, такие как счастливый — несчастный — случайный . Количество смешанных слов значительно увеличилось, даже резко, за последнее столетие, как показывают многие рекламные объявления на этой странице, и английский язык продолжает перенимать заимствованные слова из других языков. Поэтому мы также должны освоить стратегию аналогии, научиться использовать контекстные подсказки и ознакомиться со словарем. Например, изучив контекст для бэби-лаг в клипе Word Spy ниже, и, проводя аналогию с чем-то с похожей структурой слова, которое мы уже знаем — биоритм — мы можем сделать вывод о значении бэби-лаг . Однако простое знание значения ребенок и значение отставание нам не очень поможет. Морфологическая обработка лучше всего работает с контекстом.
Поэтому мы также должны освоить стратегию аналогии, научиться использовать контекстные подсказки и ознакомиться со словарем. Например, изучив контекст для бэби-лаг в клипе Word Spy ниже, и, проводя аналогию с чем-то с похожей структурой слова, которое мы уже знаем — биоритм — мы можем сделать вывод о значении бэби-лаг . Однако простое знание значения ребенок и значение отставание нам не очень поможет. Морфологическая обработка лучше всего работает с контекстом.
Связанное с этим ограничение заключается в том, что морфемный анализ не применим в равной степени ко всем словам. Слова, принадлежащие большому семейству, более доступны, чем, например, 9.0485 белка, саботаж и контрабанда . Мы хотим выучить более производящие базовые слова, корни и аффиксы. Например, если мы знаем слово стабильный , мы должны быть в состоянии использовать морфологические решения задач и контекстные подсказки, чтобы расшифровать нестабильный, стабильность, нестабильность, стабилизация, стабилизация — возможно, даже установление, установление и — как вы уже догадались. — антидезистестментарианство .
— антидезистестментарианство .
Каталожные номера
— Аронофф, М., и Фудеман, К. (2005). Что такое морфология? Молден, Массачусетс: Издательство Блэквелл.
— Энглин, Дж. М. (1993). Развитие словарного запаса: морфологический анализ. Монографии Общества исследований детского развития, 58(10)[238], v-165.
— Баайен Р. Х. (2007 г.). Хранение и вычисление в ментальном лексиконе. В Г. Джарема и Г. Либбен (ред.), The Mental Lexicon: Core Perspectives, Elsevier, 81-104.
—Бауэрс, П. Н., Кирби, Дж. Р., и С. Х. Дикон. (2010). Влияние морфологического обучения на навыки грамотности: систематический обзор литературы. Обзор образовательных исследований, 80.
—Карлайл, Дж. Ф. (2003). Морфология имеет значение в обучении чтению: комментарий. Психология чтения, 24 (3), 291-322.
—Карлайл, Дж.Ф., и Кац, Л. (2006). Влияние знакомства со словом и морфемой на чтение производных слов. Чтение и письмо, 19(7), 669-693.
— Дорфман, Дж. (1998). Еще одно свидетельство наличия подлексических компонентов в имплицитной памяти новых слов. Память и познание, 26(6), 1157-1172.
(1998). Еще одно свидетельство наличия подлексических компонентов в имплицитной памяти новых слов. Память и познание, 26(6), 1157-1172.
—Грейвс, М.Ф. (2006). Словарная книга: Обучение и инструкция. Нью-Йорк: Издательство педагогического колледжа.
— Куо, Л.Дж., и Андерсон, Р.К. (2006). Морфологическая осведомленность и обучение чтению: межъязыковая перспектива. Педагог-психолог, 41-3, 161-180.
— Макбрайд-Чанг, К., Вагнер, Р.К., Мьюз, А., Чоу, Б.В., и Шу, Х. (2005). Роль морфологической осведомленности в овладении детьми английским словарным запасом. Прикладная психолингвистика, 26, 415-435.
—Надь, В.Е. (2007). Металингвистическое осознание и связь словарного запаса с пониманием. В Р.К. Вагнер, А.Е. Муза и К.Р. Танненбаум (ред.), Приобретение словарного запаса: значение для понимания прочитанного (стр. 52-77). Нью-Йорк: Гилфорд Пресс.
—Надь, У.Э., Андерсон, Р., Шоммер, М., Скотт, Дж.А. и Столлман А. (1989) Морфологические семейства во внутреннем лексиконе. Reading Research Quarterly 24, 3: 263-282.
Reading Research Quarterly 24, 3: 263-282.
—Надь, В.Е., Бернингер, В., Эбботт, Р., Воан, К., и Вермёлен, К. (2003). Взаимосвязь морфологии и других языковых навыков с навыками грамотности у читателей из группы риска во втором классе и писателей из группы риска в четвертом классе. Журнал педагогической психологии, 95, 730-742.
— Вольф, М. (2007). Пруст и кальмар: история и наука о читающем мозге. Нью-Йорк: Харпер.
Gale Apps — Технические трудности
Приложение, к которому вы пытаетесь получить доступ, в настоящее время недоступно. Приносим свои извинения за доставленные неудобства. Повторите попытку через несколько секунд.
Если проблемы с доступом сохраняются, обратитесь за помощью в наш отдел технической поддержки по телефону 1-800-877-4253. Еще раз спасибо, что выбрали Gale, обучающую компанию Cengage.
org.springframework.remoting.RemoteAccessException: невозможно получить доступ к удаленной службе [authorizationService@theBLISAuthorizationService]; вложенным исключением является com.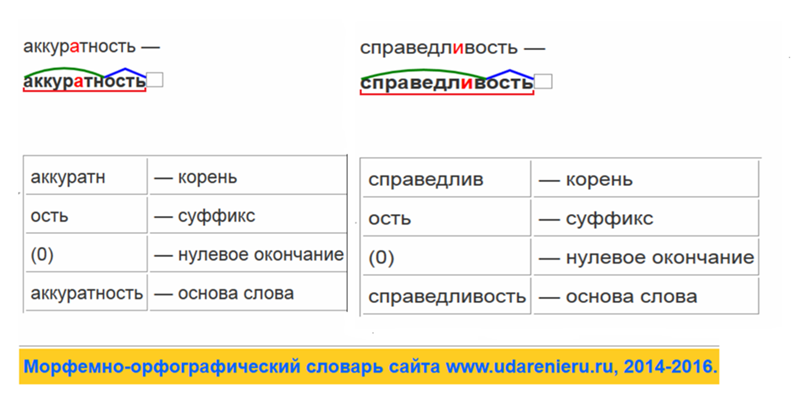 zeroc.Ice.UnknownException
unknown = «java.lang.IndexOutOfBoundsException: индекс 0 выходит за границы для длины 0
в java.base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64)
в java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70)
в java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:248)
в java.base/java.util.Objects.checkIndex(Objects.java:372)
в java.base/java.util.ArrayList.get(ArrayList.java:458)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.populateSessionProperties(LazyUserSessionDataLoaderStoredProcedure.java:60)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.reQuery(LazyUserSessionDataLoaderStoredProcedure.java:53)
в com.gale.blis.data.model.session.UserGroupEntitlementsManager.reinitializeUserGroupEntitlements(UserGroupEntitlementsManager.
zeroc.Ice.UnknownException
unknown = «java.lang.IndexOutOfBoundsException: индекс 0 выходит за границы для длины 0
в java.base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64)
в java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70)
в java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:248)
в java.base/java.util.Objects.checkIndex(Objects.java:372)
в java.base/java.util.ArrayList.get(ArrayList.java:458)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.populateSessionProperties(LazyUserSessionDataLoaderStoredProcedure.java:60)
в com.gale.blis.data.subscription.dao.LazyUserSessionDataLoaderStoredProcedure.reQuery(LazyUserSessionDataLoaderStoredProcedure.java:53)
в com.gale.blis.data.model.session.UserGroupEntitlementsManager.reinitializeUserGroupEntitlements(UserGroupEntitlementsManager.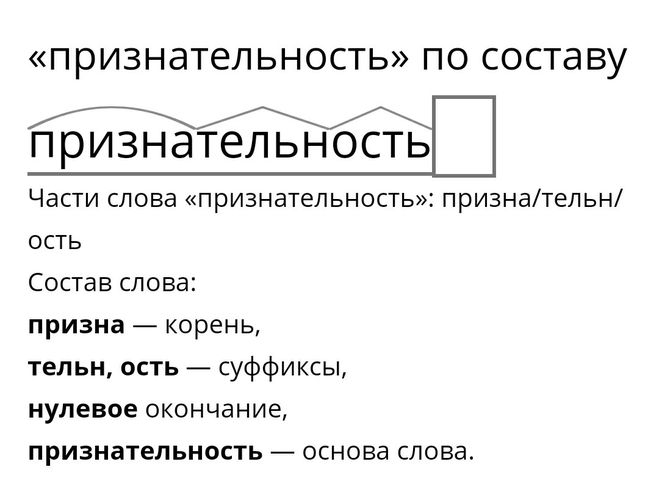 java:30)
в com.gale.blis.data.model.session.UserGroupSessionManager.getUserGroupEntitlements(UserGroupSessionManager.java:17)
в com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getProductSubscriptionCriteria(CrossSearchProductContentModuleFetcher.java:244)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getSubscribedCrossSearchProductsForUser(CrossSearchProductContentModuleFetcher.java:71)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getAvailableContentModulesForProduct(CrossSearchProductContentModuleFetcher.java:52)
на com.gale.blis.api.authorize.strategy.productentry.strategy.AbstractProductEntryAuthorizer.getContentModules(AbstractProductEntryAuthorizer.java:130)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.isAuthorized(CrossSearchProductEntryAuthorizer.
java:30)
в com.gale.blis.data.model.session.UserGroupSessionManager.getUserGroupEntitlements(UserGroupSessionManager.java:17)
в com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getProductSubscriptionCriteria(CrossSearchProductContentModuleFetcher.java:244)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getSubscribedCrossSearchProductsForUser(CrossSearchProductContentModuleFetcher.java:71)
на com.gale.blis.api.authorize.contentmodulefetchers.CrossSearchProductContentModuleFetcher.getAvailableContentModulesForProduct(CrossSearchProductContentModuleFetcher.java:52)
на com.gale.blis.api.authorize.strategy.productentry.strategy.AbstractProductEntryAuthorizer.getContentModules(AbstractProductEntryAuthorizer.java:130)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.isAuthorized(CrossSearchProductEntryAuthorizer. java:82)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.authorizeProductEntry(CrossSearchProductEntryAuthorizer.java:44)
на com.gale.blis.api.authorize.strategy.ProductEntryAuthorizer.authorize(ProductEntryAuthorizer.java:31)
в com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody0(BLISAuthorizationServiceImpl.java:57)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody1$advice(BLISAuthorizationServiceImpl.java:61)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize(BLISAuthorizationServiceImpl.java:1)
в com.gale.blis.auth.AuthorizationService._iceD_authorize(AuthorizationService.java:97)
в com.gale.blis.auth.AuthorizationService._iceDispatch(AuthorizationService.java:406)
в com.zeroc.IceInternal.Incoming.invoke(Incoming.java:221)
в com.zeroc.Ice.ConnectionI.invokeAll(ConnectionI.
java:82)
на com.gale.blis.api.authorize.strategy.productentry.strategy.CrossSearchProductEntryAuthorizer.authorizeProductEntry(CrossSearchProductEntryAuthorizer.java:44)
на com.gale.blis.api.authorize.strategy.ProductEntryAuthorizer.authorize(ProductEntryAuthorizer.java:31)
в com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody0(BLISAuthorizationServiceImpl.java:57)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize_aroundBody1$advice(BLISAuthorizationServiceImpl.java:61)
на com.gale.blis.api.BLISAuthorizationServiceImpl.authorize(BLISAuthorizationServiceImpl.java:1)
в com.gale.blis.auth.AuthorizationService._iceD_authorize(AuthorizationService.java:97)
в com.gale.blis.auth.AuthorizationService._iceDispatch(AuthorizationService.java:406)
в com.zeroc.IceInternal.Incoming.invoke(Incoming.java:221)
в com.zeroc.Ice.ConnectionI.invokeAll(ConnectionI. java:2706)
на com.zeroc.Ice.ConnectionI.dispatch(ConnectionI.java:1292)
в com.zeroc.Ice.ConnectionI.message(ConnectionI.java:1203)
в com.zeroc.IceInternal.ThreadPool.run(ThreadPool.java:412)
в com.zeroc.IceInternal.ThreadPool.access$500(ThreadPool.java:7)
в com.zeroc.IceInternal.ThreadPool$EventHandlerThread.run(ThreadPool.java:781)
в java.base/java.lang.Thread.run(Thread.java:834)
»
org.springframework.remoting.ice.IceClientInterceptor.convertIceAccessException(IceClientInterceptor.java:348)
org.springframework.remoting.ice.IceClientInterceptor.invoke(IceClientInterceptor.java:310)
org.springframework.remoting.ice.MonitoringIceProxyFactoryBean.
java:2706)
на com.zeroc.Ice.ConnectionI.dispatch(ConnectionI.java:1292)
в com.zeroc.Ice.ConnectionI.message(ConnectionI.java:1203)
в com.zeroc.IceInternal.ThreadPool.run(ThreadPool.java:412)
в com.zeroc.IceInternal.ThreadPool.access$500(ThreadPool.java:7)
в com.zeroc.IceInternal.ThreadPool$EventHandlerThread.run(ThreadPool.java:781)
в java.base/java.lang.Thread.run(Thread.java:834)
»
org.springframework.remoting.ice.IceClientInterceptor.convertIceAccessException(IceClientInterceptor.java:348)
org.springframework.remoting.ice.IceClientInterceptor.invoke(IceClientInterceptor.java:310)
org.springframework.remoting.ice.MonitoringIceProxyFactoryBean. invoke(MonitoringIceProxyFactoryBean.java:71)
org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:215)
com.sun.proxy.$Proxy151.authorize(Неизвестный источник)
com.gale.auth.service.BlisService.getAuthorizationResponse(BlisService.java:61)
com.gale.apps.service.impl.MetadataResolverService.resolveMetadata(MetadataResolverService.java:65)
com.gale.apps.
invoke(MonitoringIceProxyFactoryBean.java:71)
org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:215)
com.sun.proxy.$Proxy151.authorize(Неизвестный источник)
com.gale.auth.service.BlisService.getAuthorizationResponse(BlisService.java:61)
com.gale.apps.service.impl.MetadataResolverService.resolveMetadata(MetadataResolverService.java:65)
com.gale.apps. controllers.DiscoveryController.resolveDocument(DiscoveryController.java:57)
com.gale.apps.controllers.DocumentController.redirectToDocument(DocumentController.java:22)
jdk.internal.reflect.GeneratedMethodAccessor302.invoke (неизвестный источник)
java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.base/java.lang.reflect.Method.invoke(Method.java:566)
org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:205)
org.
controllers.DiscoveryController.resolveDocument(DiscoveryController.java:57)
com.gale.apps.controllers.DocumentController.redirectToDocument(DocumentController.java:22)
jdk.internal.reflect.GeneratedMethodAccessor302.invoke (неизвестный источник)
java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.base/java.lang.reflect.Method.invoke(Method.java:566)
org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:205)
org. springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:150)
org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:117)
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod (RequestMappingHandlerAdapter.java:895)
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal (RequestMappingHandlerAdapter.java:808)
org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87)
org.
springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:150)
org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:117)
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod (RequestMappingHandlerAdapter.java:895)
org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal (RequestMappingHandlerAdapter.java:808)
org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87)
org.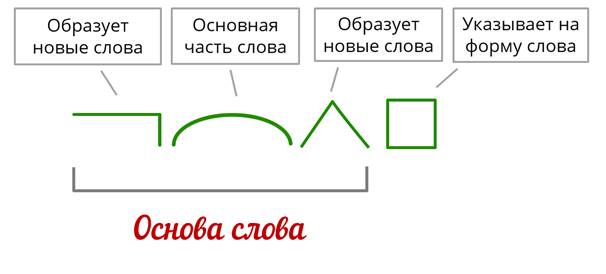 springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1067)
org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:963)
org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006)
org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:898)
javax.servlet.http.HttpServlet.service(HttpServlet.java:626)
org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883)
javax.
springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1067)
org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:963)
org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006)
org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:898)
javax.servlet.http.HttpServlet.service(HttpServlet.java:626)
org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883)
javax. servlet.http.HttpServlet.service(HttpServlet.java:733)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.
servlet.http.HttpServlet.service(HttpServlet.java:733)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org. apache.catalina.filters.HttpHeaderSecurityFilter.doFilter(HttpHeaderSecurityFilter.java:126)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.servlet.resource.ResourceUrlEncodingFilter.doFilter(ResourceUrlEncodingFilter.java:67)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.
apache.catalina.filters.HttpHeaderSecurityFilter.doFilter(HttpHeaderSecurityFilter.java:126)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.servlet.resource.ResourceUrlEncodingFilter.doFilter(ResourceUrlEncodingFilter.java:67)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.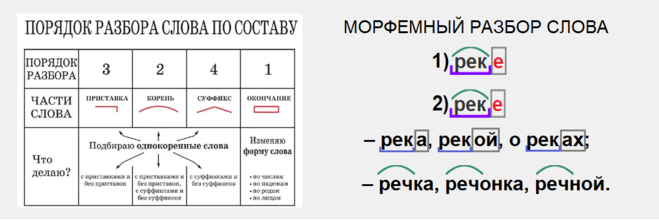 springframework.web.filter.RequestContextFilter.doFilterInternal (RequestContextFilter.java:100)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:102)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.
springframework.web.filter.RequestContextFilter.doFilterInternal (RequestContextFilter.java:100)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:102)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org. apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
com.gale.common.http.filter.SecurityHeaderFilter.doFilterInternal(SecurityHeaderFilter.java:29)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:102)
org.
apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
com.gale.common.http.filter.SecurityHeaderFilter.doFilterInternal(SecurityHeaderFilter.java:29)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:102)
org. apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.owasp.validation.GaleParameterValidationFilter.doFilterInternal(GaleParameterValidationFilter.java:97)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.
apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.owasp.validation.GaleParameterValidationFilter.doFilterInternal(GaleParameterValidationFilter.java:97)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org. springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:126)
org.springframework.boot.web.servlet.support.ErrorPageFilter.access$000(ErrorPageFilter.java:64)
org.springframework.boot.web.servlet.support.ErrorPageFilter$1.doFilterInternal(ErrorPageFilter.java:101)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:119)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.
springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:126)
org.springframework.boot.web.servlet.support.ErrorPageFilter.access$000(ErrorPageFilter.java:64)
org.springframework.boot.web.servlet.support.ErrorPageFilter$1.doFilterInternal(ErrorPageFilter.java:101)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.springframework.boot.web.servlet.support.ErrorPageFilter.doFilter(ErrorPageFilter.java:119)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org. apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.FormContentFilter.doFilterInternal (FormContentFilter.java:93)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal (WebMvcMetricsFilter.java:96)
org.
apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.FormContentFilter.doFilterInternal (FormContentFilter.java:93)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal (WebMvcMetricsFilter.java:96)
org. springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal (CharacterEncodingFilter.java:201)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.
springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal (CharacterEncodingFilter.java:201)
org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:117)
org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
org. apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202)
org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97)
org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542)
org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143)
org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92)
org.
apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202)
org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97)
org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542)
org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143)
org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92)
org. apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:687)
org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78)
org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357)
org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:374)
org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65)
org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893)
org.
apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:687)
org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78)
org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357)
org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:374)
org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65)
org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893)
org.