Синонимы и антонимы «заставить» — анализ и ассоциации к слову заставить. Морфологический разбор и склонение слов
Образовательные материалы:
В наличии:
Глаголы
16 275
Прилагательные
27 794
Существительные
68 384
Связи
Свойственные
5 229 366
Действенные
4 639 598
Ассоциативные
8 695 870
Синонимические
46 108
Словарные
1 049 874
Обработано:
13,32 Гб
Анализ прилагательных и глаголов производится с учетом морфологического признака — пол.
- инфинитив
- мужской род
- женский род
- средний род
- Перевод
- Ассоциации
- Анаграммы
- Антонимы
- Синонимы
- Гиперонимы
- Морфологический разбор
- Склонения
- Спряжения
Перевод слова заставить
Мы предлагаем Вам перевод слова заставить на английский, немецкий и французский языки.
Реализовано с помощью сервиса «Яндекс.Словарь»
- На английский
- На немецкий
- На французский
- force — заставлять, обязывать, принуждать
- get — получить, иметь
- make — делать
- заставить людей — make people
- cause — вызывать, приводить
- bring — привести
- keep — держать
- push — толкать
- zwingen — вынудить
- затем заставить — dann zwingen
- in Bewegung setzen — приводить в движение
- versetzen
- nötigen — заставлять
- forcer — заставлять
- заставить пользователей — forcer les utilisateurs
- forcer à — вынудить
- obliger à
- faire — делать
- provoquer — заставлять, вынуждать, вызывать
- conduire — вынудить
- encombrer — мешать
- encourager — призвать
Гипо-гиперонимические отношения
заставитьпринудить
Как можно заставить?
простонужнотруднобыстроневозможноравнобуквальноневольнолегконеобходимомгновенноскоронепременноспособнодействительноугоднонемедленновнезапнонелегкоспециальнообязательнонеожиданнодолгорешительномягкоокончательноважнонарочнонетрудноточносложноличномоментальноодновременнопредварительнопостепенноявнонеизбежноживоосторожнотяжелонепростогрубосознательнонастойчиводостаточнонеобъяснимоопределенновластноловконапраснонасильственноумышленнонезаметнопоспешнобезжалостноприятнобыстреньконеплохобесцеремонномедленнонеминуемоискусноласково
Кто или что может заставить?
мысльголострудзвуквзглядсилавопросбольстрахкриктонжестлюбопытствоотецдевушкаударинстинктветержизньнуждазвонокшумзрелищеобстоятельствофразаприкосновениепоцелуйчувствосмехвыстрелответулыбкагордостьтолчокзамечаниеженщинаматьслучайвоспоминаниевопльглазшорохпричинапредчувствиеголодрывокслововидимядогадкачеловекоткрытиезаявлениекартинаруканеобходимостьзапахотчаяниегромощущениеугрозасудьбавозгласхолод
Ассоциации к слову заставить
времяконецмгновениемигсекундастрахавтоматпомощьгореминутаочередьпаникасмертьнерешительностьколенодулоужастоскаодиночкагипнозугрозапыткасилатечениешколабездельникиспугволякрахпоспешностьночьпозортерриториядостоинствопроформаголоватрудразмахслучайделостонходстолфевральмашинадносарайутропониманиегробуважениежадностьэнтузиазмрукауголцелованиеудивлениенетерпениеотчаяниедосканаступлениекозелдерьмодиктовка
Синонимы слова заставить
заграждатьзапруживатьзаслонитьзатянутьпонудитьпреграждатьпринудитьделать
Гипонимы слова заставить
- принудить подвигнуть
- удалить
- вызвать
Сфера употребления слова заставить
Общая лексикаСленгПословицаРазговорное выражениеДипломатический термин
Морфологический разбор (часть речи) слова заставить
Часть речи:
глагол
Время:
—
Наклонение:
инфинитив
Лицо:
—
Число:
—
Спряжение глагола заставить
Ед. число число | Мн. число | |
|---|---|---|
| 1 лицо | заставлю | заставим |
| 2 лицо | заставишь | заставите |
| 3 лицо | заставит | заставят |
В прошедшем времени
Мужской род:
заставил
Женский род:
заставила
Средний род:
заставило
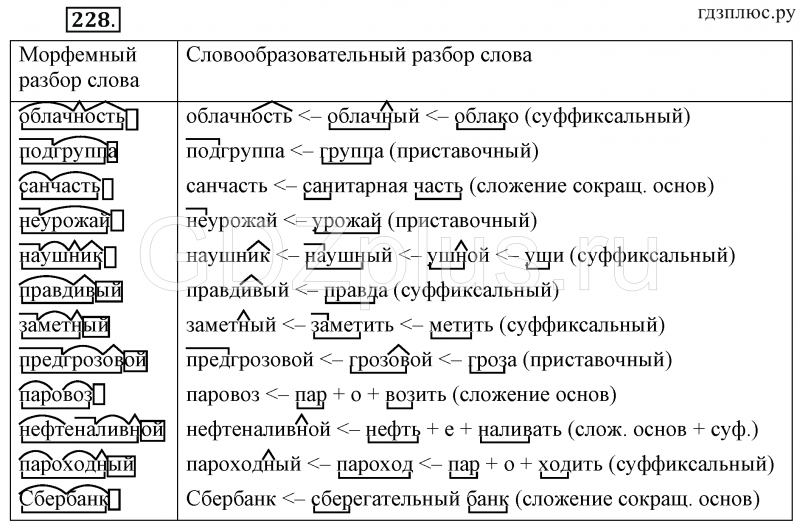
Морфемный разбор. Морфологический разбор — презентация онлайн
Похожие презентации:
Научный стиль речи
Проект по русскому языку — Рассказ о слове Звезда
ЕГЭ-2019 по русскому языку. Задание 9
Технология В.А. Илюхиной «Письмо с открытыми правилами» для учащихся начальных классов
Язык и профессии. Культура речи
Изложение по рассказу В. Бочарникова «Мал, да удал»
Роль русского языка в многонациональной России
ЕГЭ-2019 по русскому языку. Задание 10
Новое в сочинении на ЕГЭ. Комментарий
Художественный стиль речи
Морфемный разбор (2)- разбор слова
по морфемам, частям слова.
Морфологический разбор (3)-разбор
слова как части речи.
Около каждого валика сидела на бронзовом (3) рычажке
медная(3) стрекоза, бабочка или жук.
1. (На) рычажке (каком?) бронзовом, прилаг.
Н.ф.-бронзовый, кач., полное, м. р., ед. ч., предл. Пад.
В предложении является определ.
2. Стрекоза (какая?) медная, прил.
Н.ф.- медный, относ, ж.р, ед.ч,им.п.
В предл. является определ.
Выполните разбор с комментированием.
*** Выполните морфемный разбор этих же прилаг.
Изложение – письменный пересказ
текста.
Упр. 292.
Прочтите текст:
-когда действие происходит?
-где?
-как автор описывает звон?
-откуда взялась эта мелодия?
— как долго играла шкатулка?
— чем закончилась эта встреча автора со шкатулкой?
План текста о шкатулке.
Распределите пункты плана в
соответствии с логикой текста.
1.
Неизвестная мелодия в старом доме.
2.
Замолчала.
3.
Игра с остановками.
4.
Это проснулась шкатулка!
Запишите «тельняшкой».

План «тельняшкой»
1.
Неизвестная мелодия в старом доме.
Как-то осенью, поздней ночью, в гулком доме, раздался звон,
ударял молоточками по колокольчикам, возникал мелодия
2.
Это проснулась шкатулка!
Неожиданно проснулась, заиграла, испугались, соскочила пружина
3.Игра с остановками.
Играла долго, то останавливаясь, то наполняя звоном, ходики
притихли
4. Замолчала.
Замолчала, проиграла, не бились, заставить играть не смогли
К какому стилю относится этот текст?
-есть автор-известный писатель
— сравнение: «…будто кто-то ударял маленькими молоточками по
колокольчикам…»
— -олицетворение: «шкатулка проснулась», »ходики притихли от
изумления», «шкатулка замолчала».
Закройте тексты. Я прочту его
сама. А вы допишите ключевые
слова.
Перескажите текст о шкатулке по
ключевым словам, записанным вами,
не глядя в учебник.
Домашнее задание: написать
изложение по упр. 292.
Правила:
—
использовать ключевые слова в тетради;
—
не заглядывать в текст упражнения, даже если
мысль прервалась.
 Постараться самому ее
Постараться самому еепродолжить, или поменять формулировку;
—
-проверить написанное по словарю;
—
-сдать проверенный вариант вовремя.
English Русский Правила
Формат словаря произношения — документация Montreal Forced Aligner 2.0.0
Предупреждение
Начиная с версии 2.0.5, словари имеют более строгий формат, требующий столбцов, разделенных табуляцией (слова, произношения и т. д.), и произношений, разделенных пробелами, чтобы избежать путаницы при автоматической интерпретации формата словаря для телефонов, содержащих такие числа, как X- САМПА.
Если в вашем словаре в качестве разделителя между орфографией и произношением используются пробелы, вы можете перекодировать его с помощью вкладок в текстовом редакторе, поддерживающем поиск и замену регулярных выражений. Шаблон регулярного выражения 9(S+)s+ заменено на 1t или $1t , в зависимости от рассматриваемого текстового редактора, заменит первый пробел в каждой строке табуляцией.
Нормализация текста и поиск по словарю
Если слово не найдено в словаре и не имеет орфографического маркеры границ морфем (апострофы или дефисы), то заменить в выходе на «UNK>
» для неизвестного слова.Примечание
Список всех неизвестных слов (слова вне словаря; слова OOV) будет
выводиться в файл с именем oovs_found.txt в выходном каталоге, если вы хотите добавить их в словарь
ты используешь. Чтобы помочь найти любые опечатки в транскрипциях, файл с именем utterance_oovs.txt будет помещен в выходной каталог и будет содержать список
неизвестные слова за высказывание.
В рамках разбора орфографической транскрипции удаляются знаки препинания
от конца и начала слов, за исключением скобок , указанных в параметрах словаря и разбора текста. Кроме того, все слова преобразуются в нижний регистр, поэтому поиск в словаре не зависит от регистра.
Примечание
Определение пунктуации, клитических маркеров и составных маркеров можно установить в файле конфигурации, дополнительные сведения см.
Поиск по словарю попытается сгенерировать максимальное покрытие новые формы, если они используют некоторую явную границу морфемы в орфографии.
Например, во французском языке клитики обозначаются апострофами между связанные клитика и ножка. Таким образом, задан словарь вида:
c'est S E в S E с' с ЭТ Э Т Э ип А Н
И два примера орфографической транскрипции:
c'est un c c'etait un c
Нормализация приведет к следующему:
c'est un c c' était un c
Произношение:
С Е А Н С Е С Е Т Е А Н С Е
Важно отметить, что произношение клитики c' равно S а произношение буквы c на французском языке — SE .
Алгоритм попытается связать клитический маркер с элементом
до (как для французских клитик) или элемент после (как для английских клитик
как притяжательный маркер). Климатические маркеры по умолчанию 9.
' (но они свернуты в один
клитический маркер, ' по умолчанию). Составной маркер по умолчанию — дефис ( - ).
Составные маркеры обрабатываются так же, как и клитические маркеры, но они не связаны ни с одним из них.
определенный элемент в слове над другим. Вместо этого они используются для простого разделения сложного слова.
Например, карусель будет
стать карусели , если дефисной формы нет в словаре.
Если при разбиении слова на основе дефисов или апострофов слова не найдены,
тогда слово будет рассматриваться как единое целое (одиночное неизвестное слово).
По умолчанию средство выравнивания очищает эти внутренние разбиения и восстанавливает исходное слово. Если это нежелательно, вы можете отключить очистку с помощью флага
Невероятностный формат
Словари должны быть указаны как файл с двумя столбцами, разделенными табуляцией:
СЛОВА ТЕЛЕФОНА ТЕЛЕФОНАБ ВОРДА ТЕЛЕФОН СЛОВОDB PHONEB PHONEC
В каждой строке есть слово и транскрипция, разделенные табуляцией. Каждый телефон в транскрипции также должен быть разделен пробелом без табуляции.
Каждый телефон в транскрипции также должен быть разделен пробелом без табуляции.
Примечание
До версии 2.0.5 слова и их транскрипции могли быть разделены любым пробелом, а не только табуляцией. Однако, учитывая сложность анализа вероятностных лексиконов с системами транскрипции, такими как X-SAMPA, которые используют числа в качестве символов, мы решили стандартизировать разделитель столбцов в виде табуляции.
Словарь для английского языка с хорошим охватом является производным от лексики из корпуса LibriSpeech (лексикон LibriSpeech). Этот лексикон использует формат транскрипции Arpabet (например, Словарь произношения CMU).
Prosodylab-aligner также имеет два предварительно созданных словаря, один для английского языка (английский словарь Prosodylab-aligner) и один для французского языка Квебек (французский словарь Prosodylab-aligner), список поддерживаемых словарей также см. в словарях MFA.
Примечание
См. страницу Создание нового словаря произношения (mfa g2p), чтобы узнать, как использовать модели G2P для создания словаря. из наших предварительно обученных моделей или как создавать словари произношения из орфографий.
из наших предварительно обученных моделей или как создавать словари произношения из орфографий.
Словари с вероятностью произношения
Словари могут быть проанализированы с вероятностями произношения, обычно в результате добавления вероятностей к словарю (mfa train_dictionary).
Формат для этого формата словаря:
WORDA 1.0 ТЕЛЕФОН PHONEB СЛОВА 0.3 ТЕЛЕФОН WORDB 1.0 ТЕЛЕФОНB PHONEC
Три столбца должны быть разделены символами табуляции, причем первый столбец соответствует орфографической форме, второй — вероятности произношения от 0,01 до 1,0, а последний столбец — произношению, разделенному пробелами.
Примечание
Наиболее вероятная вероятность слова установлена равной 1,0 в алгоритме, реализованном в добавлении вероятностей в словарь (mfa train_dictionary).
Хотя это означает, что сумма вероятностей на слово больше 1, это не наказывает слова за то, что они
несколько произношений, и эти вероятности преобразуются в логарифмические затраты в конечном взвешенном FST.
Вероятность молчания
В рамках моделирования вероятностей произношения также можно оценить вероятности молчания до и после заданного произношения. Например, с произношением английского слова , у нас может быть полная версия [ð i] и более сокращенная версия [ð ə] . В то время как более сокращенная версия будет более вероятным вариантом в целом, полная версия, вероятно, будет иметь более высокую вероятность после молчания или до него.
Формат для этого формата словаря:
0,16 0,08 2,17 1,13 д я 0,99 0,04 2,14 1,15 д ə 0,01 0,14 2,48 1,18 р я 0,02 0,12 1,87 1,23 р ə 0,11 0,15 2,99 1,15 а
Первый столбец с плавающей запятой — это вероятность произношения, следующий с плавающей запятой — это вероятность тишины после произношения, а последние два с плавающей запятой — это корректирующие термины для предшествующей тишины и отсутствия тишины. Учитывая, что каждая запись в словаре независима и нет возможности закодировать информацию о предшествующем контексте, поправочные термины рассчитываются по тому, насколько более распространенным было молчание или отсутствие молчания по сравнению с тем, что мы ожидали бы, исключая вероятность молчания. от предыдущего слова. Дополнительные сведения можно найти в get_prons.sh и связанной с ним статье.
от предыдущего слова. Дополнительные сведения можно найти в get_prons.sh и связанной с ним статье.
Примечание
Вы можете включать записи, которые имеют только произношение или вероятность произношения, смешанную с вероятностью молчания. Если запись не имеет вероятности произношения, по умолчанию она будет равна 1,0 (предполагается равный вес между вариантами произношения, как указано выше). Если в записи нет трех номеров молчания, то для вероятности после молчания будет использоваться значение по умолчанию (по умолчанию 0,5 для необученных моделей или любая другая вероятность, которая была оценена во время обучения), а также без поправки на то, когда произношение следует за молчанием или безмолвие.
Неречевые аннотации
Есть два специальных телефона, которые можно использовать для неречевых аннотаций: sil и spn . Телефон sil используется
для моделирования тишины, а телефон spn используется для моделирования неизвестных слов. Если у вас есть аннотации для неречевых вокализаций, которые
Подобно тишине, такой как дыхание или выдох, вы можете использовать телефон
Если у вас есть аннотации для неречевых вокализаций, которые
Подобно тишине, такой как дыхание или выдох, вы можете использовать телефон sil , чтобы выровнять их. Вы можете использовать телефон spn для выравнивания аннотаций, таких как смех, кашель и т. д.
{LG} шип
{SL} сила
Моделирование отсечек и колебаний
Часто в спонтанной речи говорящие произносят усеченные или обрезанные слова следующего слова/слов. Чтобы помочь смоделировать этот конкретный случай, использование флага --use_cutoff_model активирует режим, в котором генерируются произношения слов-обрезок, соответствующих одному из следующих критериев:
Обрезающее слово соответствует шаблону
{start_bracket}(cutoff|hes), где{start_bracket}— это набор всех левых боковых скобок, определенных в скобках д.).
д.).Обрезное слово соответствует шаблону
{start_bracket}(cutoff|hes)[-_](word){end_bracket}, где начальные и конечные скобки определены в скобках
 д.).
д.).Сгенерированные произношения
Словари для каждого говорящего
В дополнение к указанию одного словаря для использования при выравнивании или расшифровке, MFA также поддерживает указание для каждого говорящего словари через файл yaml, как показано ниже.
по умолчанию: /mnt/d/Data/speech/english_us_mfa.dict Speaker_a: /mnt/d/Data/speech/english_uk_mfa.dict Speaker_b: /mnt/d/Data/speech/english_uk_mfa.dict Speaker_c: /mnt/d/Data/speech/english_uk_mfa.dict
В приведенном выше файле yaml указан словарь «по умолчанию», который будет использоваться для любого говорящего, не указанного явно в
другой словарь, поэтому можно обучать/выравнивать/транскрибировать, используя несколько диалектов или языков, при условии, что модель
указанный совместим со всеми словарями.
Этот словарь для говорящих можно использовать вместо аргумента словаря:
mfa align /path/to/corpus /path/to/speaker_dictionaries.yaml /path/to/acoustic_model.zip /path/to/output
Поддерживаемые телефонные аппараты
В дополнение к основным возможностям, указание телефонного аппарата может помочь в создании акустических моделей, которые лучше подходят для конкретных телефонов, с лучшими контекстуальными вопросами, зависящими от места и способа артикуляции для моделирования трифона.
Rootcast: интенсивные префиксы | Membean
Некоторые префиксы сильно подчеркивают корни слов, к которым они присоединены, и известны как интенсивные префиксы. Эти префиксы можно эффективно перевести как «тщательно», чтобы подчеркнуть их интенсивную функцию. Сегодня мы поговорим о приставках re- и de-, которые могут действовать как интенсивные префиксы.
Префикс re-, который может означать «назад» или «снова», также может означать «тщательно», когда действует как интенсив. Например, слово re splendent означает «совершенно сияющий» или «яркий». Если бы это слово было «великолепным», оно означало бы просто «сияющий». добавление интенсивной приставки вместо к слову «блестящий» превращает корень «сиять» в «полностью» сияющий или «очень» яркий.
Например, слово re splendent означает «совершенно сияющий» или «яркий». Если бы это слово было «великолепным», оно означало бы просто «сияющий». добавление интенсивной приставки вместо к слову «блестящий» превращает корень «сиять» в «полностью» сияющий или «очень» яркий.
Давайте рассмотрим еще пару примеров с использованием интенсивного префикса re-. Когда человек re ticent, он «полностью» молчит, потому что не желает делиться информацией о чем-то. Пертуар музыканта re — это тот список музыки, который он «тщательно» создал. И что вы делаете, когда вам показывают множество и решений? Вы «полностью» ослабляете или развязываете себя для достижения поставленной цели.
Вторым примером интенсива является префикс de-. В то время как de- может означать «от» или «от», оно также может использоваться как интенсивное, опять же полезно переводимое как «тщательно».