Морфологический разбор слова: сделал дело гуляй смело
Введите слово или предложение и получите морфологический разбор с указанием части речи, падежа, рода, времени и т.д.
Начальная форма: СДЕЛАТЬ
Часть речи: глагол в личной форме
Грамматика: действительный залог, единственное число, мужской род, непереходный, прошедшее время, совершенный вид
Формы: сделать, сделал, сделала, сделало, сделали, сделаю, сделаем, сделаешь, сделаете, сделает, сделают, сделав, сделавши, сделаемте, сделай, сделайте, сделавший, сделавшего, сделавшему, сделавшим, сделавшем, сделавшая, сделавшей, сделавшую, сделавшею, сделавшее, сделавшие, сделавших, сделавшими, сделанный, сделанного, сделанному, сделанным, сделанном, сделан, сделанная, сделанной, сделанную, сделанною, сделана, сделанное, сделано, сделанные, сделанных, сделанными, сделаны
Начальная форма: ДЕТЬ
Часть речи: глагол в личной форме
Формы: деть, дел, дела, дело, дели, дену, денем, денешь, денете, денет, денут, дев, девши, денемте, день, деньте, девший, девшего, девшему, девшим, девшем, девшая, девшей, девшую, девшею, девшее, девшие, девших, девшими, детый, детого, детому, детым, детом, дет, детая, детой, детую, детою, дета, детое, дето, детые, детых, детыми, деты
Начальная форма: ДЕЛО
Часть речи: существительное
Грамматика: единственное число, именительный падеж, неодушевленное, средний род
Формы: дело, дела, делу, делом, деле, дел, делам, делами, делах, делов
Начальная форма: ГУЛЯТЬ
Часть речи: глагол в личной форме
Грамматика: второе лицо, действительный залог, единственное число, переходный, несовершенный вид, повелительное наклонение (императив)
Формы: гулять, гуляю, гуляем, гуляешь, гуляете, гуляет, гуляют, гулял, гуляла, гуляло, гуляли, гуляя, гуляв, гулявши, гуляй, гуляйте, гуляющий, гуляющего, гуляющему, гуляющим, гуляющем, гуляющая, гуляющей, гуляющую, гуляющею, гуляющее, гуляющие, гуляющих, гуляющими, гулявший, гулявшего, гулявшему, гулявшим, гулявшем, гулявшая, гулявшей, гулявшую, гулявшею, гулявшее, гулявшие, гулявших, гулявшими
Начальная форма: СМЕЛО
Часть речи: наречие
Грамматика:
Формы: смело
Начальная форма: СМЕТЬ
Часть речи: глагол в личной форме
Грамматика: действительный залог, единственное число, переходный, несовершенный вид, прошедшее время, средний род
Формы: сметь, смею, смеем, смеешь, смеете, смеет, смеют, смел, смела, смело, смели, смея, смев, смевши, смей, смейте, смеющий, смеющего, смеющему, смеющим, смеющем, смеющая, смеющей, смеющую, смеющею, смеющее, смеющие, смеющих, смеющими, смевший, смевшего, смевшему, смевшим, смевшем, смевшая, смевшей, смевшую, смевшею, смевшее, смевшие, смевших, смевшими
Начальная форма: СМЕЛЫЙ
Часть речи: краткое прилагательное
Грамматика: единственное число, качественное прилагательное, неодушевленное, одушевленное, средний род
Формы: смелый, смелого, смелому, смелым, смелом, смелая, смелой, смелую, смелою, смелое, смелые, смелых, смелыми, смел, смела, смело, смелы, смелее, смелей, посмелее, посмелей, смелейший, наисмелейший, смелейшего, наисмелейшего, смелейшему, наисмелейшему, смелейшим, наисмелейшим, смелейшем, наисмелейшем, смелейшая, наисмелейшая, смелейшей, наисмелейшей, смелейшую, наисмелейшую, смелейшею, наисмелейшею, смелейшее, наисмелейшее, смелейшие, наисмелейшие, смелейших, наисмелейших, смелейшими, наисмелейшими
Начальная форма: СМЕСТИ
Часть речи: глагол в личной форме
Грамматика: действительный залог, единственное число, непереходный, прошедшее время, совершенный вид, средний род
Формы: смести, смёл, смела, смело, смели, смету, сметём, сметёшь, сметёте, сметёт, сметут, сметя, сметёмте, смети, сметите, смётший, смётшего, смётшему, смётшим, смётшем, смётшая, смётшей, смётшую, смётшею, смётшее, смётшие, смётших, смётшими, сметённый, сметённого, сметённому, сметённым, сметённом, сметён, сметённая, сметённой, сметённую, сметённою, сметена, сметённое, сметено, сметённые, сметённых, сметёнными, сметены
Начальная школа: морфологический разбор слов
Морфологический разбор слова представляет собой полную грамматическую характеристику данного слова. При этом слова рассматриваются в контексте предложения, восстанавливается и анализируется их изначальная структура. Чтобы проделать правильный морфологический разбор частей речи, необходимо уметь определять начальную форму слов, знать их постоянные и изменяемые морфологические признаки и понимать синтаксическую роль слов в предложении.
При этом слова рассматриваются в контексте предложения, восстанавливается и анализируется их изначальная структура. Чтобы проделать правильный морфологический разбор частей речи, необходимо уметь определять начальную форму слов, знать их постоянные и изменяемые морфологические признаки и понимать синтаксическую роль слов в предложении.
Схемы разбора слов в предложении существенно отличаются друг от друга, поскольку они зависят от признаков этой части речи и формы, в которой стоит слово в данном предложении. Сам план морфологического разбора может варьироваться в зависимости от возраста учащихся. Поэтому ниже мы приведем планы разбора отдельных частей речи для учеников 4-5 класса.
Морфологический разбор существительного:
1. Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
2. Определить начальную форму (поставить слово в единственное число именительного падежа).
3. Указать признаки: собственное существительное или нарицательное, одушевленное – неодушевленное.
4. Определить род (женский – мужской – средний), склонение, падеж, число (единственное – множественное).
5. Указать, каким членом предложения является данное существительное.
Образец разбора слова «лисята» в предложении «Лисята побежали за бабочкой».
Устный разбор: Лисята – это имя существительное. Оно обозначает живое существо (кто?) – лисята. Начальная форма – лисенок. Является нарицательным, одушевленным, мужского рода, 2-е склонение. В данном случае слово употребили в именительном падеже, во множественном числе. Слово «лисята» в предложении является подлежащим.
Письменный разбор:
Лисята – сущ.
(Кто?) – лисята;
Н. ф. (начальная форма) – лисенок;
Нариц., одуш., муж. род;
2-е склон.;
в имен. пад., во множ. числе;
играют (кто?) – лисята – подлежащее.
Морфологический разбор прилагательного
1. Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
2. Поставить в начальную форму (в единственное число именительного падежа мужского рода.
3. Определить род прилагательного, его падеж и число.
4. Указать, каким членом предложения является данное прилагательное.
Образец разбора слова «трудолюбивая» в предложении «Трудолюбивая белочка запасает орешки на зиму».
Устный разбор: Трудолюбивая (белочка) – прилагательное. Белочка (какая?) – трудолюбивая. Обозначает признак предмета. Начальная форма – трудолюбивый. Слово употребили в женском роде, единственном числе, именительном падеже. В данном предложении слово «трудолюбивая» является определением.
Письменный разбор:
Трудолюбивая (белочка) – прилаг.;
Н.ф. – трудолюбивый;
Женск. род, единств. число, именит. падеж;
Какая? – трудолюбивая – определение.
Морфологический разбор числительного:
1. Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
2. Поставить числительное в начальную форму — в именительный падеж.
3. Выявить признаки: простое – составное числительное, количественное – порядковое, в каком падеже стоит.
4. Каким членом предложения является данное числительное.
Образец разбора слова «пять» в предложении «Пять галчат есть хотят».
Устный разбор: «Пять» – числительное. Слово обозначает количество галчат (сколько?) – пять. Начальная форма – пять. Простое, количественное. Слово употребили в именительном падеже. В данном предложении слово «пять» входит в состав подлежащего.
Письменный разбор:
Пять – числит.: галчат (сколько?) – пять;
Н.ф. – пять;
Простое, количеств., в именит. падеже;
(Кто?) – пять галчат – часть подлежащего.
Морфологический разбор местоимения:
1. Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
2. Поставить в начальную форму (т.е. в именительный падеж единственного числа).
3. Определить признаки: лицо, затем (если есть) – род и число, определить падеж.
4. Каким членом предложения является данное местоимение.
Образец разбора слова «мне» в предложении «Не хватило мне целого лета».
Устный разбор: «Мне» – местоимение. Указывает на предмет (кому?) – мне. Начальная форма – «я». Местоимение личное, 1-е лицо. Слово употребили в дательном падеже единственного числа. В данном предложении слово «мне» является дополнением.
Письменный разбор:
Мне – местоим.:
(Кому?) – мне;
Н.ф. – я;
Личное;
Дательн. падеж, единств. число;
Кому? – мне – дополнение.
Морфологический разбор глагола
1. Определить часть речи, найти общее значение, на какой вопрос это слово отвечает.
2. Поставить в неопределенную (начальную) форму.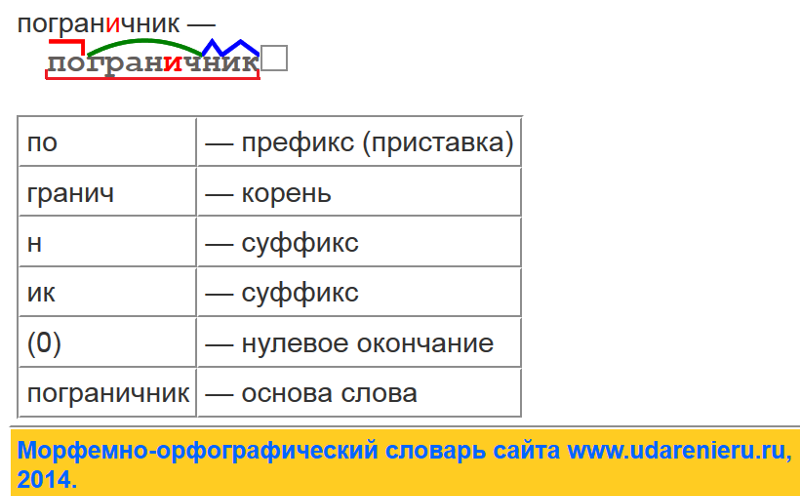
3. Определить признаки: спряжение, число, если есть – время, лицо, род;
4. Каким членом предложения является данный глагол.
Образец разбора слова «вспыхнул» в предложении «Вспыхнул первый луч зари».
Устный разбор: «Вспыхнул» – глагол. Обозначает действие (что сделал?) – вспыхнул.
Начальная форма – вспыхнуть, 1-е спряжение. Слово употребили в единственном числе, в прошедшем времени, в 3-м лице. В данном предложении слово «вспыхнул» является сказуемым.
Письменный разбор:
Вспыхнул – глагол;
(что сделал?) – вспыхнул;
Н.ф. – вспыхнуть;
1 спряж., единств. число, 3-е лицо.
Что сделал? – вспыхнул – сказуемое.
Морфологический разбор наречия:
1. Часть речи, общее значение.
2. Неизменяемое слово.
3. Член предложения.
Образец разбора слова «быстро» в предложении «По небу быстро пробегали темные тучи».
Устный разбор: «Быстро» — наречие. Обозначает признак действия: пробегали (как?) – быстро. Неизменяемое слово. В предложении является обстоятельством.
Письменный разбор:
Быстро – наречие;
Пробегали (как?) быстро;
признак действия, неизм.;
Как? – быстро – обстоятельство.
ЛингТранСофт Вики | FLEx 8 Morphological Parser
Следующий семинар предназначен для того, чтобы показать, как можно использовать FLEx для разбора слов на морфемы. В раннем материале используются данные сена (банту) и английские данные, в то время как в большинстве материалов используются данные ньянгатом (нило-сахарский язык). Модуль «Stem-Names» использует данные на португальском языке.
Семинар посвящен вводу морфем, их алломорфов и вариантов, потому что правильное выполнение этого важно для работы морфологического синтаксического анализатора. То же самое относится и к вводу сложных форм в базу данных FLEx.
При попытке использовать синтаксический анализатор важно понимать некоторые лингвистические различия. Одним из них является различие между словообразовательными аффиксами флективного стиха. Еще одна разница между флективными признаками и флективными классами. Следующие модули предполагают понимание этих важных различий. Для получения дополнительной информации об этих различиях см. документ Introduction to Parsing , который можно найти в меню «Справка» в Fieldworks.
Во FLEx можно разобрать слова как минимум тремя способами, что может вызвать некоторую путаницу. Конечная цель этого семинара — научить участников настраивать FLEx, чтобы морфологический синтаксический анализатор мог автоматически анализировать тексты, которые он никогда раньше не видел, но есть два других способа анализа слов, которые рассматриваются на этом семинаре. Во-первых, это то, что иногда называют ручным синтаксическим анализом, когда пользователь вручную разбивает слова на морфемы, а затем помечает синтаксический анализ как одобренный (называемый «утвержденным анализом слов» во FLEx). Пользователь может сделать это либо в 9Область 0007 Interlinear Texts или область Word Analyzes . Последний тип синтаксического анализа — это когда FLEx применяет одобренный анализ слов к словам, найденным в новых текстах, которые были импортированы в область Interlinear Texts .
Пользователь может сделать это либо в 9Область 0007 Interlinear Texts или область Word Analyzes . Последний тип синтаксического анализа — это когда FLEx применяет одобренный анализ слов к словам, найденным в новых текстах, которые были импортированы в область Interlinear Texts .
В этом курсе будет использоваться программа FLEx Inflectional Affix Gloss Builder (IAGB) для создания глосс для морфем. Использование Inflectional Affix Gloss Builder позволит получить согласованные глоссы, соответствующие Лейпцигским рекомендациям по глоссированию морфем. https://www.eva.mpg.de/lingua/pdf/Glossing-Rules.pdf
1. Хорошо сконфигурированные проекты
2. Введение морфем
3. Алломорфы, варианты и сложные формы
FLEx Session Allomorphs VariantsandComplex Forms
4. Интерлинеаризация
5. Разбор и согласование
6. Классы существительных, число и род
FLEx Session Классы существительных Номер и род Часть 1
7.
 Грамматические шаблоны — существительные
Грамматические шаблоны — существительныеШаблоны грамматики FLEx Session Существительные
8. Существительные, часть 2 — ручной анализ
FLEx Session Nouns, часть 2. Ручной анализ
9. Флексивные признаки существительных
Флексивные признаки существительных сеанса FLEx
10. Автоматический анализ, часть 1
11. Глаголы — грамматические шаблоны и флективные классы
Шаблоны глаголов сеанса FLEx и флективные классы
12. Глаголы — имена основ
13. Автоматический анализ 2
14. Языковые данные ньянгатом
Ньянгатом Глаголы
Nyangatom Verbs
Задание 5, Линг 645/CMSC 723, осень 1997 г.
Задание 5, Линг 645/CMSC 723, осень 1997 г.-------------------------------------------------- -------------- Задание 5: Контекстно-свободные грамматики дополнены функциями -------------------------------------------------- -------------- ОБЗОР В этом задании вы запустите восходящий анализатор диаграмм, который Аллен описывает в своей книге.(Да, код исходит от самого Аллена.) цель этого задания состоит в том, чтобы дать вам возможность изучить синтаксический анализатор, пройтись по его работе и, в конечном счете, получить представление о каково это - немного написать грамматические правила. Я НАСТОЯТЕЛЬНО рекомендую вам ПРОЧИТАТЬ это задание целиком, прежде чем вы делаете что-нибудь еще. A. ПОЛУЧЕНИЕ ПАРСЕРА 1. Создайте каталог с именем hw5 и зайдите в него. мкдир hw5 компакт-диск hw5 2. Получить программу через анонимный ftp на umiacs.umd.edu; вам нужен файл pub/resnik/ling645/hw5/CourseParser1.2.tar.gz (см. предыдущее задание, как получить файлы по анонимному ftp). Затем разархивируйте и разархивируйте файл: gunzip CourseParser1.2.tar.gz tar xvf CourseParser1.2.tar Это создаст подкаталог с именем NLPcode. Войдите в него: cd ParserCode 3. Получите полный путь к каталогу, в котором вы находитесь, используя «pwd». (сокращение от «распечатать рабочий каталог»): pwd Например, вывод «pwd» для того места, где я сейчас нахожусь: /home/research3/resnik/ling645/lisp/hw5/ParserCode 4.
Чтобы увидеть «лучшее» дерево синтаксического анализа (или деревья синтаксического анализа), введите (показать ответы) Вы получите следующую информацию, которую мы рассмотрим в некоторых подробно сейчас. S57:от 0 до 5 из правила -1> NP51:от 0 до 2 из правила -2> ART44: от 0 до 1 из правила NIL N45: от 1 до 2 из правила NIL VP54: от 2 до 5 из правила -5> V46: от 2 до 3 из правила NIL NP53: с 3 по 5 из правила -2> ART49: от 3 до 4 из правила NIL N50: от 4 до 5 из правила NIL Это говорит вам о том, что составной частью верхнего уровня является S со следующим списком характеристик: ((ИНВ -) (СМА |3С|) (1 НП51) (2 ВП54)) Напомним, что функция «ИНВ» касается того, является ли это перевернутым предложение (например, wh-вопрос), которым оно не является, отсюда и "минус" ценность. от 0 до 1 из правила NIL C. РАЗБОР МОРФОЛОГИЧЕСКИ СЛОЖНЫХ СЛОВ 8. Парсер мало что делает за вас с морфологией, поэтому вы должны иногда давайте ему морфологически предварительно проанализированный ввод. То есть, иногда вам придется отделить корни от суффиксов. Например, если вы позвоните (bu-parse '(Мужчина плачет)) парсер пожалуется на неизвестное слово "плачет" Правильный призыв: (bu-parse '(Мужчина плачет +s)) Попробуйте, и вы увидите, что один из компонентов построен это V V79: от 2 до 4 из правила -LEX1> То есть V была построена из V и +S с использованием лексического правила 1. -2> (<АРТ ((СМА |3S|))>) * ( ) от 0 до 1 который говорит вам, что правило НП -> ИСКУССТВО.
 (Да, код исходит от самого Аллена.)
цель этого задания состоит в том, чтобы дать вам возможность изучить
синтаксический анализатор, пройтись по его работе и, в конечном счете, получить представление о
каково это - немного написать грамматические правила.
Я НАСТОЯТЕЛЬНО рекомендую вам ПРОЧИТАТЬ это задание целиком, прежде чем
вы делаете что-нибудь еще.
A. ПОЛУЧЕНИЕ ПАРСЕРА
1. Создайте каталог с именем hw5 и зайдите в него.
мкдир hw5
компакт-диск hw5
2. Получить программу через анонимный ftp на umiacs.umd.edu;
вам нужен файл pub/resnik/ling645/hw5/CourseParser1.2.tar.gz
(см. предыдущее задание, как получить файлы по анонимному ftp).
Затем разархивируйте и разархивируйте файл:
gunzip CourseParser1.2.tar.gz
tar xvf CourseParser1.2.tar
Это создаст подкаталог с именем NLPcode. Войдите в него:
cd ParserCode
3. Получите полный путь к каталогу, в котором вы находитесь, используя «pwd».
(сокращение от «распечатать рабочий каталог»):
pwd
Например, вывод «pwd» для того места, где я сейчас нахожусь:
/home/research3/resnik/ling645/lisp/hw5/ParserCode
4.
(Да, код исходит от самого Аллена.)
цель этого задания состоит в том, чтобы дать вам возможность изучить
синтаксический анализатор, пройтись по его работе и, в конечном счете, получить представление о
каково это - немного написать грамматические правила.
Я НАСТОЯТЕЛЬНО рекомендую вам ПРОЧИТАТЬ это задание целиком, прежде чем
вы делаете что-нибудь еще.
A. ПОЛУЧЕНИЕ ПАРСЕРА
1. Создайте каталог с именем hw5 и зайдите в него.
мкдир hw5
компакт-диск hw5
2. Получить программу через анонимный ftp на umiacs.umd.edu;
вам нужен файл pub/resnik/ling645/hw5/CourseParser1.2.tar.gz
(см. предыдущее задание, как получить файлы по анонимному ftp).
Затем разархивируйте и разархивируйте файл:
gunzip CourseParser1.2.tar.gz
tar xvf CourseParser1.2.tar
Это создаст подкаталог с именем NLPcode. Войдите в него:
cd ParserCode
3. Получите полный путь к каталогу, в котором вы находитесь, используя «pwd».
(сокращение от «распечатать рабочий каталог»):
pwd
Например, вывод «pwd» для того места, где я сейчас нахожусь:
/home/research3/resnik/ling645/lisp/hw5/ParserCode
4. Отредактируйте файл loadFunction и перейдите к строке
где это говорит
(пусть ((*PATH* "/u/james/Code/CourseParser/ParserCode")
Измените то, что находится между двойными кавычками, на каталог, который вы
получил, когда вы сказали «pwd». Например, в моем случае,
это становится:
(пусть ((*ПУТЬ* "/home/research3/resnik/ling645/lisp/hw5/ParserCode")
Затем сохраните файл.
B. ЗАПУСК ПАРСЕРА
5. В вашем каталоге ParserCode перейдите в LISP и загрузите
файл loadFunction.lisp:
(загрузить "loadFunction")
Затем загрузите парсер:
(загрузить "LoadParser")
Не беспокойтесь о различных предупреждениях.
6. Загрузите словарь и грамматику из Аллена, глава 4, с помощью
выполнение следующего:
(загрузить главу 4)
Это определяет грамматики и словари в главе 4.
7. Теперь попробуйте разобрать простое предложение:
(bu-parse '(рыба увидела человека))
То, что вы видите, это след работы парсера
Аллен описывает в своей главе, в том числе то, как он входит
составляющие в таблицу, а затем, в конце, все
компоненты, которые он нашел.
Отредактируйте файл loadFunction и перейдите к строке
где это говорит
(пусть ((*PATH* "/u/james/Code/CourseParser/ParserCode")
Измените то, что находится между двойными кавычками, на каталог, который вы
получил, когда вы сказали «pwd». Например, в моем случае,
это становится:
(пусть ((*ПУТЬ* "/home/research3/resnik/ling645/lisp/hw5/ParserCode")
Затем сохраните файл.
B. ЗАПУСК ПАРСЕРА
5. В вашем каталоге ParserCode перейдите в LISP и загрузите
файл loadFunction.lisp:
(загрузить "loadFunction")
Затем загрузите парсер:
(загрузить "LoadParser")
Не беспокойтесь о различных предупреждениях.
6. Загрузите словарь и грамматику из Аллена, глава 4, с помощью
выполнение следующего:
(загрузить главу 4)
Это определяет грамматики и словари в главе 4.
7. Теперь попробуйте разобрать простое предложение:
(bu-parse '(рыба увидела человека))
То, что вы видите, это след работы парсера
Аллен описывает в своей главе, в том числе то, как он входит
составляющие в таблицу, а затем, в конце, все
компоненты, которые он нашел.
 Функция AGR (соглашение) здесь настроена на 3-е лицо.
единственное число (3s). И два подкомпонента, используемые для построения
это S - именная группа, обозначенная NP51, и глагольная группа,
с маркировкой VP54. Наконец, поскольку элемент диаграммы (соответствующий
«состояние» в синтаксическом анализаторе Эрли) идентифицирует не только правило
себя, но и диапазон, в данном случае от позиции 0 до позиции 5.
А как насчет, скажем, составного VP54? Вы можете видеть, что это
глагольная фраза, занимающая позиции со 2 по 5 («увидел рыбу»). Ты
также можно увидеть, что его функция согласования — 3 с, а его VFORM
особенность (форма глагола), ПРОШЛОЕ. Как вице-президент получил эти
значения характеристик? Когда правило
ВП(...) -> В(...) НП(...)
был вызван (Аллен, стр. 96, правило 5), особенности внутри
VP были определены путем сопоставления правой части
правило против составляющих V и NP. СМА и VFORM
функции пришли от V, который сам получил эти функции от
словарная статья для глагола.
Функция AGR (соглашение) здесь настроена на 3-е лицо.
единственное число (3s). И два подкомпонента, используемые для построения
это S - именная группа, обозначенная NP51, и глагольная группа,
с маркировкой VP54. Наконец, поскольку элемент диаграммы (соответствующий
«состояние» в синтаксическом анализаторе Эрли) идентифицирует не только правило
себя, но и диапазон, в данном случае от позиции 0 до позиции 5.
А как насчет, скажем, составного VP54? Вы можете видеть, что это
глагольная фраза, занимающая позиции со 2 по 5 («увидел рыбу»). Ты
также можно увидеть, что его функция согласования — 3 с, а его VFORM
особенность (форма глагола), ПРОШЛОЕ. Как вице-президент получил эти
значения характеристик? Когда правило
ВП(...) -> В(...) НП(...)
был вызван (Аллен, стр. 96, правило 5), особенности внутри
VP были определены путем сопоставления правой части
правило против составляющих V и NP. СМА и VFORM
функции пришли от V, который сам получил эти функции от
словарная статья для глагола. Как выглядит эта запись в лексиконе? Ну, вы можете либо
перейдите в подкаталог Grammars и посмотрите файл Chapter4.lisp,
где вы увидите, что одна запись для «пилы»:
(saw(v(root SEE1)(VFORM прошлое)(subcat _np)(agr ?a)))
Или вы можете просто разобрать «предложение» из одного слова, содержащее
слово, которое вас интересует:
(бу-разбирать' (увидеть))
и посмотрите на полученные записи диаграммы, одна из которых будет:
V58:
Как выглядит эта запись в лексиконе? Ну, вы можете либо
перейдите в подкаталог Grammars и посмотрите файл Chapter4.lisp,
где вы увидите, что одна запись для «пилы»:
(saw(v(root SEE1)(VFORM прошлое)(subcat _np)(agr ?a)))
Или вы можете просто разобрать «предложение» из одного слова, содержащее
слово, которое вас интересует:
(бу-разбирать' (увидеть))
и посмотрите на полученные записи диаграммы, одна из которых будет:
V58: (Аллен, стр. 92).
сочетание базовой формы «плакать» с морфемой «+s» для
получить составляющую V, соответствующую следующему дереву синтаксического анализа:
В
((СМА |3S|)
(ВФОРМ ПРЕСС)
(КОРЕННОЙ КЛИК1)
(ПОДКАТ _NONE))
/ \
/ \
В + С
((КРИЧИЙ ЛЕКС)
(КОРЕННОЙ КЛИК1)
(VFORM ГОЛЫЙ)
(ПОДКАТ _NONE))
Если вы посмотрите на лексикон на Allen p. 93, вы помните
что прошедшее время построено таким образом в его системе для глаголов
иметь правильную морфологию прошедшего времени (например, «плакать»), так как вы
можно было бы ожидать, что морфологический анализатор правильно их разделит
(например, разбивая «крики» на «плакать + с»), но неправильное прошедшее время
обрабатываются отдельными записями в лексиконе (например, запись
для «пилы», чья VFORM ПРОШЛА).
D. ДОПОЛНЕНИЕ К ГРАММАТИКЕ И ЛЕКСИКОНУ
9. Чтобы получить список всех определенных слов, введите
(определенные-слова)
Это даст вам следующий набор, который я повторно заказал и
немного изменил, чтобы было понятнее:
(
А ; определитель
ОН ; местоимение
ЧЕЛОВЕК-СОБАКА МУЖЧИНЫ ВИДЕЛИ СЕМЯНУЮ РЫБУ; существительное
ПЛАКАТЬ ХОЧУ ВИДЕТЬ ПИЛУ; глагол
БЫЛО БЫЛО ЕСТЬ ; форма «быть»
+ING +S +ED +EN ; флективный суффикс для глаголов
К ; инфинитив "к"
СЧАСТЛИВЫЙ ; имя прилагательное
ДЖЕК) ; имя
Теперь посмотрите на словарную запись слова «Джек»:
(bu-parse '(гнездо))
или эквивалентно, см.
(Аллен, стр. 92).
сочетание базовой формы «плакать» с морфемой «+s» для
получить составляющую V, соответствующую следующему дереву синтаксического анализа:
В
((СМА |3S|)
(ВФОРМ ПРЕСС)
(КОРЕННОЙ КЛИК1)
(ПОДКАТ _NONE))
/ \
/ \
В + С
((КРИЧИЙ ЛЕКС)
(КОРЕННОЙ КЛИК1)
(VFORM ГОЛЫЙ)
(ПОДКАТ _NONE))
Если вы посмотрите на лексикон на Allen p. 93, вы помните
что прошедшее время построено таким образом в его системе для глаголов
иметь правильную морфологию прошедшего времени (например, «плакать»), так как вы
можно было бы ожидать, что морфологический анализатор правильно их разделит
(например, разбивая «крики» на «плакать + с»), но неправильное прошедшее время
обрабатываются отдельными записями в лексиконе (например, запись
для «пилы», чья VFORM ПРОШЛА).
D. ДОПОЛНЕНИЕ К ГРАММАТИКЕ И ЛЕКСИКОНУ
9. Чтобы получить список всех определенных слов, введите
(определенные-слова)
Это даст вам следующий набор, который я повторно заказал и
немного изменил, чтобы было понятнее:
(
А ; определитель
ОН ; местоимение
ЧЕЛОВЕК-СОБАКА МУЖЧИНЫ ВИДЕЛИ СЕМЯНУЮ РЫБУ; существительное
ПЛАКАТЬ ХОЧУ ВИДЕТЬ ПИЛУ; глагол
БЫЛО БЫЛО ЕСТЬ ; форма «быть»
+ING +S +ED +EN ; флективный суффикс для глаголов
К ; инфинитив "к"
СЧАСТЛИВЫЙ ; имя прилагательное
ДЖЕК) ; имя
Теперь посмотрите на словарную запись слова «Джек»:
(bu-parse '(гнездо))
или эквивалентно, см. словарную статью об Аллене, с. 93.
(Джек (имя (агр 3с) (корень ДЖЕК1)))
Обратите внимание, что слово «Джек» определено как элемент
категории ИМЯ -- это не просто старое существительное.
В противном случае «Валет» был бы лицензирован по правилу 2
грамматика как именное словосочетание!
10. В подкаталоге Grammars найдите файл Chapter4.lisp и
в частности, посмотрите на правила NP. (Аналогично смотреть
в правилах NP по Аллену, с. 96.) Выполните любое из правил
сказать что-нибудь о компоненте NAME? Хм. И что
произойдет, когда вы наберете следующее?
(bu-parse '(Джек увидел человека))
Правильно: если вы посмотрите на составляющие, которые
были созданы, для «Джек» нет НП, потому что нет грамматики
Правило гласит, что NP могут быть построены из имен. Вы получаете
ПО охватывает позиции с 1 по 4 («увидел человека»), но есть
нет NP от 0 до 1, поэтому вы не можете получить S от 0 до 5.
Давайте это исправим, а в процессе научимся вносить изменения
и к грамматике и к лексике!
11.
словарную статью об Аллене, с. 93.
(Джек (имя (агр 3с) (корень ДЖЕК1)))
Обратите внимание, что слово «Джек» определено как элемент
категории ИМЯ -- это не просто старое существительное.
В противном случае «Валет» был бы лицензирован по правилу 2
грамматика как именное словосочетание!
10. В подкаталоге Grammars найдите файл Chapter4.lisp и
в частности, посмотрите на правила NP. (Аналогично смотреть
в правилах NP по Аллену, с. 96.) Выполните любое из правил
сказать что-нибудь о компоненте NAME? Хм. И что
произойдет, когда вы наберете следующее?
(bu-parse '(Джек увидел человека))
Правильно: если вы посмотрите на составляющие, которые
были созданы, для «Джек» нет НП, потому что нет грамматики
Правило гласит, что NP могут быть построены из имен. Вы получаете
ПО охватывает позиции с 1 по 4 («увидел человека»), но есть
нет NP от 0 до 1, поэтому вы не можете получить S от 0 до 5.
Давайте это исправим, а в процессе научимся вносить изменения
и к грамматике и к лексике!
11. В каталоге ParserCode создайте подкаталог с именем «new»:
и зайти в этот каталог
мкдир новый
компакт-диск новый
Создайте новый файл с именем «new1.lisp» и поместите следующее
внутрь:
(setq *grammar-new1*
'((головные черты
(нп агр)
(вп вформ агр))
((нп)
-12>
(голова (имя)))))
Это небольшая мини-грамматика, содержащая всего одно правило.
Контекстно-свободная часть правила
НП -> ИМЯ
с ИМЯ, объявленным главой избирательного округа,
и поскольку AGR является головной чертой для NP, это
эквивалентно
(НП (СМА ?а)) -> (НАЗВАНИЕ (СМА ?а))
Также добавьте в new1.lisp следующее:
(setq *lexicon-new1*
'((много (арт (агр 3с) (корень МНОГИЕ1)))
(Эдгар (имя (агр 3с) (корень ЭДГАР1)))))
Это создает небольшой мини-лексикон с записями для
слова «многие» и «Эдгар». (Да, я знаю лексикон
запись для "многих" неверна!)
Наконец, в конец файла добавьте следующее
две строки:
(дополнение-грамматика * грамматика-новая1*)
(расширить-лексикон *лексикон-новый1*)
Первая — это команда, которая говорит, что новая грамматика
следует добавить к существующей грамматике.
В каталоге ParserCode создайте подкаталог с именем «new»:
и зайти в этот каталог
мкдир новый
компакт-диск новый
Создайте новый файл с именем «new1.lisp» и поместите следующее
внутрь:
(setq *grammar-new1*
'((головные черты
(нп агр)
(вп вформ агр))
((нп)
-12>
(голова (имя)))))
Это небольшая мини-грамматика, содержащая всего одно правило.
Контекстно-свободная часть правила
НП -> ИМЯ
с ИМЯ, объявленным главой избирательного округа,
и поскольку AGR является головной чертой для NP, это
эквивалентно
(НП (СМА ?а)) -> (НАЗВАНИЕ (СМА ?а))
Также добавьте в new1.lisp следующее:
(setq *lexicon-new1*
'((много (арт (агр 3с) (корень МНОГИЕ1)))
(Эдгар (имя (агр 3с) (корень ЭДГАР1)))))
Это создает небольшой мини-лексикон с записями для
слова «многие» и «Эдгар». (Да, я знаю лексикон
запись для "многих" неверна!)
Наконец, в конец файла добавьте следующее
две строки:
(дополнение-грамматика * грамматика-новая1*)
(расширить-лексикон *лексикон-новый1*)
Первая — это команда, которая говорит, что новая грамматика
следует добавить к существующей грамматике. Секунда
добавляет новые записи словаря к существующему словарю.
E. ЗАГРУЗКА ДОПОЛНЕНИЙ ИЛИ ИЗМЕНЕНИЙ
12. Теперь вернитесь в каталог ParserCode, войдите в LISP,
и загрузить грамматику и лексику главы 4 --
если вы начинаете все заново, это делается путем выполнения
Шаги 5 и 6 выше. (Если вы работали в системе
с несколькими окнами и поддерживал LISP во время редактирования
new1.lisp, очевидно, эта часть не нужна.)
Если вам так хочется, выполняйте
(определенные-слова)
так что вы можете увидеть текущий список слов в лексиконе.
13. Теперь загрузите дополнительные элементы грамматики и лексики, которые вы
создано путем ввода:
(загрузить "новый" "новый1")
Это говорит синтаксическому анализатору искать в подкаталоге «новый».
и загрузите файл с именем «new1». Выполнить (определенные слова)
снова, и на этот раз вы должны увидеть "Эдгар" и "многие" на
список!
14. Чтобы убедиться, что наша лексическая запись для слова «многие» верна, попробуйте
(бу-разбирать' (много мужчин))
Обратите внимание, что мы не получаем NP, охватывающий от 0 до 2.
Секунда
добавляет новые записи словаря к существующему словарю.
E. ЗАГРУЗКА ДОПОЛНЕНИЙ ИЛИ ИЗМЕНЕНИЙ
12. Теперь вернитесь в каталог ParserCode, войдите в LISP,
и загрузить грамматику и лексику главы 4 --
если вы начинаете все заново, это делается путем выполнения
Шаги 5 и 6 выше. (Если вы работали в системе
с несколькими окнами и поддерживал LISP во время редактирования
new1.lisp, очевидно, эта часть не нужна.)
Если вам так хочется, выполняйте
(определенные-слова)
так что вы можете увидеть текущий список слов в лексиконе.
13. Теперь загрузите дополнительные элементы грамматики и лексики, которые вы
создано путем ввода:
(загрузить "новый" "новый1")
Это говорит синтаксическому анализатору искать в подкаталоге «новый».
и загрузите файл с именем «new1». Выполнить (определенные слова)
снова, и на этот раз вы должны увидеть "Эдгар" и "многие" на
список!
14. Чтобы убедиться, что наша лексическая запись для слова «многие» верна, попробуйте
(бу-разбирать' (много мужчин))
Обратите внимание, что мы не получаем NP, охватывающий от 0 до 2. Почему?
Ага, потому что в нашей новой лексической статье функция AGR для
"много" неверно - должно было быть 3p (третье лицо, МНОЖЕСТВЕННОЕ ЧИСЛО!)
не 3с. Давайте исправим это сейчас.
15. Вернитесь к файлу new1.lisp и измените 3 в записи на
«много» до 3р.
16. Теперь вернитесь к LISP, грамматике и лексике, загруженным и т. д.,
точно так же, как раньше -- то есть то же самое состояние, в котором вы были в начале
шага 12.
Обратите внимание: если вы никогда не выходили из LISP, вы не можете просто сделать
(загрузить "новый" "new1.lisp")
чтобы получить измененные словарные записи - вы получите предупреждение
говоря, что вы дважды пытались определить правило "-12>". К
вернуться в состояние, в котором вы были в начале шага 12,
ты можешь выполнить
(загрузить главу 4)
снова, и это перезагрузит исходную грамматику и лексику,
удаление изменений, сделанных с помощью new1.lisp.
17. Повторите шаги 13 и 14 — на этот раз загруженный словарь должен
содержать ПРАВИЛЬНУЮ запись для «многих» (поскольку вы только что это исправили)
и синтаксический анализ должен дать вам NP, охватывающий от 0 до 2.
Почему?
Ага, потому что в нашей новой лексической статье функция AGR для
"много" неверно - должно было быть 3p (третье лицо, МНОЖЕСТВЕННОЕ ЧИСЛО!)
не 3с. Давайте исправим это сейчас.
15. Вернитесь к файлу new1.lisp и измените 3 в записи на
«много» до 3р.
16. Теперь вернитесь к LISP, грамматике и лексике, загруженным и т. д.,
точно так же, как раньше -- то есть то же самое состояние, в котором вы были в начале
шага 12.
Обратите внимание: если вы никогда не выходили из LISP, вы не можете просто сделать
(загрузить "новый" "new1.lisp")
чтобы получить измененные словарные записи - вы получите предупреждение
говоря, что вы дважды пытались определить правило "-12>". К
вернуться в состояние, в котором вы были в начале шага 12,
ты можешь выполнить
(загрузить главу 4)
снова, и это перезагрузит исходную грамматику и лексику,
удаление изменений, сделанных с помощью new1.lisp.
17. Повторите шаги 13 и 14 — на этот раз загруженный словарь должен
содержать ПРАВИЛЬНУЮ запись для «многих» (поскольку вы только что это исправили)
и синтаксический анализ должен дать вам NP, охватывающий от 0 до 2. Поздравляем,
вам только что удалось написать свой первый словарь!
(Типичный университетский словарь английского языка имеет порядок
100 000 записей, значит у вас только 9Осталось 9999... :-)
18. Теперь давайте проверим, что новое правило грамматики также работает так, как
мы хотим, чтобы:
(bu-parse '(Джек увидел человека))
Как обычно, вы можете ввести
(показать ответы)
чтобы увидеть "лучшее" дерево синтаксического анализа. Вуаля! Обратите внимание, что предмет
предложения является NP с ИМЯ в качестве его головы. Поздравляю,
Вы только что написали свое первое грамматическое правило!
(Есть предположения, сколько еще *тех* вам нужно написать?...)
F. НАЗНАЧЕНИЕ
-------------------------------------------------- --------------
Ты должен сделать:
Проблема 5.1
Задача 5.2
ЛИБО задача 5.3 ЛИБО задача 5.4
(если вы сделаете оба, я возьму более высокий балл из двух)
-------------------------------------------------- --------------
Задача 5.
Поздравляем,
вам только что удалось написать свой первый словарь!
(Типичный университетский словарь английского языка имеет порядок
100 000 записей, значит у вас только 9Осталось 9999... :-)
18. Теперь давайте проверим, что новое правило грамматики также работает так, как
мы хотим, чтобы:
(bu-parse '(Джек увидел человека))
Как обычно, вы можете ввести
(показать ответы)
чтобы увидеть "лучшее" дерево синтаксического анализа. Вуаля! Обратите внимание, что предмет
предложения является NP с ИМЯ в качестве его головы. Поздравляю,
Вы только что написали свое первое грамматическое правило!
(Есть предположения, сколько еще *тех* вам нужно написать?...)
F. НАЗНАЧЕНИЕ
-------------------------------------------------- --------------
Ты должен сделать:
Проблема 5.1
Задача 5.2
ЛИБО задача 5.3 ЛИБО задача 5.4
(если вы сделаете оба, я возьму более высокий балл из двух)
-------------------------------------------------- --------------
Задача 5. 1 [30 баллов]
В new1.lisp добавьте лексические записи для следующих слов:
ресторан
восхищаться
самый
Самый простой способ сделать это, вероятно, будет посмотреть на похожие
лексические записи в Chapter4.lisp, а также копировать и изменять их.
TURN IN: список new1.lisp (или только новые записи),
вместе с капелькой
(bu-parse '(Эдгар восхищается +s в ресторане))
(bu-parse '(Эдгар восхищается +s самый ресторан +s))
Если хотите, можете подождать, пока не решите задачу 5.2.
и сдайте окончательный список new1.lisp после того, как вы решили
обе проблемы.
Задача 5.2 [40 баллов]
В new1.lisp добавьте правила лексики и грамматики, чтобы
разобрать
(bu-parse' (Эдгар видел рыбу в ресторане))
приводит к полному синтаксическому анализу (т. е. завершенному S, охватывающему
все предложение) с «рыбой» в качестве объекта глагола
и "в ресторане" как ПРИСОЕДИНЕНИЕ к ВП. То есть,
общая структура должна соответствовать:
(С
(НП Эдгар)
(ВП (ВП пила
(НП рыба))
(ПП (ПРЕП)
(НП ресторан))))
Вам НЕ нужно уметь разбирать "рыбу в ресторане"
как NP (хотя вы можете добавить правило для этого, если хотите).
1 [30 баллов]
В new1.lisp добавьте лексические записи для следующих слов:
ресторан
восхищаться
самый
Самый простой способ сделать это, вероятно, будет посмотреть на похожие
лексические записи в Chapter4.lisp, а также копировать и изменять их.
TURN IN: список new1.lisp (или только новые записи),
вместе с капелькой
(bu-parse '(Эдгар восхищается +s в ресторане))
(bu-parse '(Эдгар восхищается +s самый ресторан +s))
Если хотите, можете подождать, пока не решите задачу 5.2.
и сдайте окончательный список new1.lisp после того, как вы решили
обе проблемы.
Задача 5.2 [40 баллов]
В new1.lisp добавьте правила лексики и грамматики, чтобы
разобрать
(bu-parse' (Эдгар видел рыбу в ресторане))
приводит к полному синтаксическому анализу (т. е. завершенному S, охватывающему
все предложение) с «рыбой» в качестве объекта глагола
и "в ресторане" как ПРИСОЕДИНЕНИЕ к ВП. То есть,
общая структура должна соответствовать:
(С
(НП Эдгар)
(ВП (ВП пила
(НП рыба))
(ПП (ПРЕП)
(НП ресторан))))
Вам НЕ нужно уметь разбирать "рыбу в ресторане"
как NP (хотя вы можете добавить правило для этого, если хотите). Вот три вещи, которые могут помочь вам в этом. Первый,
помните, что, поскольку это анализатор снизу вверх, вы можете анализировать
составляющие при отладке, а не все предложение, например.
с использованием
(bu-parse '(ресторан))
чтобы убедиться, что он правильно анализируется как NP, используя
(бу-разбор' (в ресторане))
чтобы убедиться, что PP сформирован и т. д. Таким образом, вы не
должны сосредоточиться на всем предложении сразу. При отладке
программу, всегда лучше работать по частям, проверяя
как все работает на каждом этапе пути, а не пытаться сделать
это все сразу.
Во-вторых, если вы выполните
(подробно)
это позволит подробно отслеживать, показывая вам, когда пунктирные правила
(неполные составляющие) добавляются в таблицу. Например.
с подробной трассировкой, когда вы делаете
(bu-parse '(мужчины))
ты увидишь
Добавление активной дуги:
Вот три вещи, которые могут помочь вам в этом. Первый,
помните, что, поскольку это анализатор снизу вверх, вы можете анализировать
составляющие при отладке, а не все предложение, например.
с использованием
(bu-parse '(ресторан))
чтобы убедиться, что он правильно анализируется как NP, используя
(бу-разбор' (в ресторане))
чтобы убедиться, что PP сформирован и т. д. Таким образом, вы не
должны сосредоточиться на всем предложении сразу. При отладке
программу, всегда лучше работать по частям, проверяя
как все работает на каждом этапе пути, а не пытаться сделать
это все сразу.
Во-вторых, если вы выполните
(подробно)
это позволит подробно отслеживать, показывая вам, когда пунктирные правила
(неполные составляющие) добавляются в таблицу. Например.
с подробной трассировкой, когда вы делаете
(bu-parse '(мужчины))
ты увидишь
Добавление активной дуги:  Н
был введен в диаграмму, охватывающую позиции от 0 до 1,
с функцией соглашения, установленной на 3 с. Это дает понять, что
особенности в составе АРТ преуспели в том, чтобы соответствовать
первая часть правила NP -> ART N, а теперь правило ищет
для завершения с помощью N с функцией AGR, также установленной на 3 с.
В этом случае этот NP никогда не будет завершен, потому что N
для "мужчин" есть функция AGR 3p.
Вы можете отключить подробную трассировку, выполнив
(подробно)
В-третьих, если вы используете emacs, вы можете использовать LISP изнутри emacs,
который позволит вам легко вести учет того, что вы делаете,
включая возможность прокрутки. В emacs введите
М-х оболочка
где M — метаключ или, что то же самое,
ESC x оболочка
Это поместит вас в оболочку в emacs. Затем вы можете ввести
шепелявить
как обычно, и запустите LISP. За исключением того, что теперь вы можете делать все
ваша работа с LISP в emacs, включая прокрутку, вырезание и
вставка и переключение буферов (например, для редактирования файлов!).
Н
был введен в диаграмму, охватывающую позиции от 0 до 1,
с функцией соглашения, установленной на 3 с. Это дает понять, что
особенности в составе АРТ преуспели в том, чтобы соответствовать
первая часть правила NP -> ART N, а теперь правило ищет
для завершения с помощью N с функцией AGR, также установленной на 3 с.
В этом случае этот NP никогда не будет завершен, потому что N
для "мужчин" есть функция AGR 3p.
Вы можете отключить подробную трассировку, выполнив
(подробно)
В-третьих, если вы используете emacs, вы можете использовать LISP изнутри emacs,
который позволит вам легко вести учет того, что вы делаете,
включая возможность прокрутки. В emacs введите
М-х оболочка
где M — метаключ или, что то же самое,
ESC x оболочка
Это поместит вас в оболочку в emacs. Затем вы можете ввести
шепелявить
как обычно, и запустите LISP. За исключением того, что теперь вы можете делать все
ваша работа с LISP в emacs, включая прокрутку, вырезание и
вставка и переключение буферов (например, для редактирования файлов!). Убить
буфер, в котором находится оболочка, вы можете войти в этот буфер и
тип
ctl-х к
СДАЧА: листинг new1.lisp вместе с небольшими фрагментами:
(подробно)
(bu-parse' (Эдгар видел рыбу в ресторане))
Задача 5.3 [20 баллов]
[Помните, если вы решаете эту задачу, вам НЕ НУЖНО делать 5.4!]
а. Почему правило VP для подкатегорийных PP (Аллен, стр. 89) быть
неправильное правило для предложения в предыдущей задаче?
б. Рассмотрим следующие данные:
* Искренность восхищает Джона.
Эдгар восхищается Джоном.
Джон восхищается искренностью.
* Искренность восхищает Джона.
Мэри покормила кошку.
*Кошка накормила Мэри.
Опишите словами, что можно попробовать ВНУТРИ грамматики и
формализм лексики, данный до сих пор, чтобы объяснить эти
данные. Какие, если таковые имеются, проблемы или трудности могут возникнуть
работая в рамках текущего формализма?
(Предположим, что Мэри — человек, а не кошка! То же самое для всех остальных
с человеческими именами.
Убить
буфер, в котором находится оболочка, вы можете войти в этот буфер и
тип
ctl-х к
СДАЧА: листинг new1.lisp вместе с небольшими фрагментами:
(подробно)
(bu-parse' (Эдгар видел рыбу в ресторане))
Задача 5.3 [20 баллов]
[Помните, если вы решаете эту задачу, вам НЕ НУЖНО делать 5.4!]
а. Почему правило VP для подкатегорийных PP (Аллен, стр. 89) быть
неправильное правило для предложения в предыдущей задаче?
б. Рассмотрим следующие данные:
* Искренность восхищает Джона.
Эдгар восхищается Джоном.
Джон восхищается искренностью.
* Искренность восхищает Джона.
Мэри покормила кошку.
*Кошка накормила Мэри.
Опишите словами, что можно попробовать ВНУТРИ грамматики и
формализм лексики, данный до сих пор, чтобы объяснить эти
данные. Какие, если таковые имеются, проблемы или трудности могут возникнуть
работая в рамках текущего формализма?
(Предположим, что Мэри — человек, а не кошка! То же самое для всех остальных
с человеческими именами. )
Задача 5.4 [20 баллов]
[Помните, если вы решаете эту задачу, вам НЕ НУЖНО делать 5.3!]
а. Опишите, либо на простом английском языке, либо написав лексику/грамматику
записи вручную, изменения, которые необходимо внести в
лексику и/или грамматику, чтобы объяснить
следующие данные:
Пиво было дорого.
Пиво было дорого.
Пиво было дорого.
* Ресторан был дорогим.
* Пиво было дорогим.
Пиво было дорого.
Пиво в ресторане было дорого.
*Пиво в ресторане было дорого.
Пиво в ресторане дорогое.
б. Опираясь на данные 5.4а, объясните словами двусмысленность
Эдгар купил пиво.
G. ДОПОЛНИТЕЛЬНАЯ ЧАСТЬ ЗАДАНИЯ
Я действительно рекомендую вам попробовать поиграть с системой, добавив
другие лексические единицы, с которыми, по вашему мнению, может быть интересно поиграть, и
пытаясь добавить новые правила грамматики.
С этой целью я предлагаю 10 дополнительных баллов за это задание за
реализация ответа на 5.4a, проиллюстрированная новой грамматикой
и лексика.
)
Задача 5.4 [20 баллов]
[Помните, если вы решаете эту задачу, вам НЕ НУЖНО делать 5.3!]
а. Опишите, либо на простом английском языке, либо написав лексику/грамматику
записи вручную, изменения, которые необходимо внести в
лексику и/или грамматику, чтобы объяснить
следующие данные:
Пиво было дорого.
Пиво было дорого.
Пиво было дорого.
* Ресторан был дорогим.
* Пиво было дорогим.
Пиво было дорого.
Пиво в ресторане было дорого.
*Пиво в ресторане было дорого.
Пиво в ресторане дорогое.
б. Опираясь на данные 5.4а, объясните словами двусмысленность
Эдгар купил пиво.
G. ДОПОЛНИТЕЛЬНАЯ ЧАСТЬ ЗАДАНИЯ
Я действительно рекомендую вам попробовать поиграть с системой, добавив
другие лексические единицы, с которыми, по вашему мнению, может быть интересно поиграть, и
пытаясь добавить новые правила грамматики.
С этой целью я предлагаю 10 дополнительных баллов за это задание за
реализация ответа на 5.4a, проиллюстрированная новой грамматикой
и лексика.