Морфемный разбор слова приносит!!!помогите пожалуйста
Какая общая идея объединяет тексты №1, №2 А) Искусство – это грустный мир далекого будущего. В) Искусство – это захватывающие изобретения. С) Искусств … о –это поступки знаменитого человека. Д) Искусство –это робот, запрограммированный на опеку. Е) Искусство – это слово, брошенное в воздух.
напишите эссе на тему «Будущее в руках образованной молодёжи » 80-100 предложение. дам 15 баллов помогите пожалуйста это соч
Выпишите ключевые слова из текста Помагите плиз в подарок лайк, подписка, лутчши ответ и 5 балла
6. Выбери вариант, в котором верно указаны падежиимён существительных, употреблённых в предложении.Мальчик зашёл к своему другу и рассказал интересную … историюо предстоящем путешествии.1) И. п., Д. п., П. П., В. п.2) И. п., Р. п., В. п., П. п.3) И. п., Д. п., В. п., П. П.4) В. П., Д. п., И. п., П. п.5) В. п., д. п., И. П. П. п.6) И. п., Р. п., П. П. В. п.
Составьте предложения по схемам
1).
Помогите пожалуйста даю 30 баллов
Напиши эссе (повествование, описание, рассуждение) на одну из предложенных тем. Используй вводные конструкции, предложения с прямой и косвенной речью. … (80 — 100 слов)1. Мир будущего. Каким я его вижу?даю 25 баллов
1)Пентатлон- вид спорта. Догадайся, как он называется по- русски: зимнее двоеборье, троеборье, пятиборье, семиборье, десятиборье._________________2)Уп
… асть навзничь- это как:на бок, вниз головой, вверх лицом, вниз лицом, на спину?_______________________3)Слово диджей появилось как слитное прочтение «по буквам» англоязычной аббревиатуры DJ- «disk jockey». Какое из данных заимствованных из английского языка слов образовано таким же образом?Модем, пейджер, пиар, хакер, ток-шоу.___________________4)В каком примере слово редкий имеет не такое значение, как в остальных?А.

. Что объединяет два текста? В чем их различие?.Общие признаки_______________________________________________________________________________________ … _______________Отличительные признаки____________________________________________________________________________________________[2]
пожалуйста помогите только ответьте правильно инче я СОЧ провалю :((((( быстрее срочно Соч Соч
Морфологический разбор глагола «приносит» онлайн. План разбора.
Для слова «приносит» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «приносит» — глагол - Морфологические признаки.
- приносить (инфинитив)
- Постоянные признаки:
- 2-е спряжение
- переходный
- несовершенный вид
- изъявительное наклонение
- единственное число
- настоящее время
- 3-е лицо.

Каждому из нас пища приносит огромное удовольствие.
Выполняет роль сказуемого.

Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).
- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)
Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
7 голосов, оценка 4. 571 из 5
571 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «приносит» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфологический разбор глагола. 5 класс
1. Тема Морфологический разбор глагола
2. тест
1.Глагол –этоА) часть слова
Б) часть целого В) часть речи
2. Глагол обозначает:
А) предмет
Б) действие предмета В) признак
предмета
3. Отвечает на вопросы:
А) кто? что? Б) что делать?что сделать?
В) какой?чей?
4.Глаголы изменяются:
А) по числам и лицам Б) по родам и по падежам
В)по числам,родам и временам
5. В предложении являются:
А) сказуемым Б)подлежащим
В) определением
3. Ответы
1 В)2 Б)
3 Б)
4 В)
5 А)
Что такое глагол?
Что обозначает глагол?
На какие вопросы отвечает глагол?
На какие виды делится глагол?
Сколько временных форм у глагола?
Сколько спряжений у глагола?
Каким членом предложения является
глагол?
5.
 Цель урока: научиться
Цель урока: научитьсяопределять глагол по его
морфологическим признакам
6. АЛГОРИТМ – ПОРЯДОК РАЗБОРА (ПОСЛЕДОВАТЕЛЬНОСТЬ ДЕЙСТВИЙ )
Имясуществительное
Имя
прилагательное
1. Часть речи.
2. Начальная форма
3. Постоянные признаки
4. Непостоянные признаки
5. Член предложения
7. глагол
Постоянныепризнаки
Вид
Совершенный
Спряжение
Несовершенный
1 спряжение
2 спряжение
8. глагол
Непостоянныепризнаки
Время
Прошедшее: род,
число
Настоящее и
будущее: лицо,
число
Число
Лицо
9. План морфологического разбора глагола:
I. Часть речи. Общее значение.II.Морфологические признаки.
1.Начальная форма (неопределенная форма)
2. Постоянные признаки: а) вид, б)спряжение.
3.Непостоянные признаки: а)число, б) время
(если есть), в) лицо (если есть), г) род (если есть).
III. Синтаксическая роль
10.
 Образец письменного разбора глагола: Скоро наступит прекрасное время года.
Образец письменного разбора глагола: Скоро наступит прекрасное время года.Наступит- глагол.
I. (Что сделает?)наступит. Н.ф.- наступить.
Обозначает действие предмета.
II. Пост.: сов.вид, II спр.;
непост.: буд. вр., в ед.ч., в 3-м л.
III. Время года (что сделает?) наступит.
11. Образец письменного разбора
Ласковый ветерок приносит горьковатый аромат.Приносит – глагол
I. (Что делает?) приносит. Н. ф. – приносить.
Обозначает действие предмета.
II. Пост.: несов. вид., II спр.;
непост.: наст. вр., ед. ч., 3 л.
III. Ветерок (что делает?) приносит.
12. Диктант «Северный олень»
Списать, вставить недостающие буквы и знаки препинания.На Север.. снег да лёд и лето быва..т
короткое-короткое. Сена там (не)накос..шь
ни корову ни лошадь зимой (не)прокорм..шь.
Только северный олень уме..т там жить. Он
копытами снег разгреба..т доста..т
лишайник- ягель. Чьё молоко пьёт на Север..
человек? Оленье.
 На чём езд..т? На олен… Не
На чём езд..т? На олен… Непрожит.. без оленя в тех местах человеку.
13. Диктант «Северный олень»
Проверь знаки препинания.На Север.. снег да лёд, и лето быва..т
короткое-короткое. Сена там (не)накос..шь,
ни корову, ни лошадь зимой (не)прокорм..шь.
Только северный олень уме..т там жить. Он
копытами снег разгреба..т, доста..т
лишайник- ягель. Чьё молоко пьёт на Север..
прожит.. без оленя в тех местах человеку.
14. Задание к диктанту
1. Выписать по 1 глаголу совершенного инесовершенного вида.
2. Выписать по 1 глаголу 2лица
единственного числа, 3 лица единственного
числа.
3. Выписать по 1 глаголу 1 и 2 спряжения.
4. Выполнить морфологический разбор
одного глагола.
Домашнее задание
Параграф 120
Знать и уметь выполнять
морфологический разбор глагола
Чувствительность к флективным морфемам в отсутствие смысла: данные из новой задачи
Регулярные, нерегулярные и квазирегулярные флексии
В психолингвистике было проведено большое количество исследований, связанных с обработкой изменяемых глаголов (Joanisse and Seidenberg 1999 ; Marslen-Wilson and Tyler 1997; Pinker 1991; Bybee and Slobin 1982; Kuczaj 1977; Stowell 2007; Jackendoff 1975; Seidenberg and Plaut 2014). Согласно одной точке зрения, правильные и неправильные глаголы различаются тем, что неправильные глаголы обрабатываются и хранятся как единицы, тогда как с правильными глаголами можно бороться, (де) объединяя их в основы и аффиксы (Marslen-Wilson and Tyler 1997; Pinker and Ullman 2002 ; Post et al.2008 г.). Основная работа Aronoff (1976), Halle (1973) и Jackendoff (1977) была сосредоточена на производстве, а не на восприятии, и это исследование выявило флективную морфологию как форму синтаксиса в словах. Джекендофф (1975) предлагает различие между регулярным и нерегулярным перегибом: в то время как все неправильные формы хранятся как отдельные записи, обычные формы формируются с помощью правил, которые напоминают правила, предложенные для синтаксиса. В частности, сочетание основы и аффикса напоминает базовую операцию нашей синтаксической системы, описанную Хомским (1995) с термином , слияние .Психолингвистические данные показали, что это комбинаторное, похожее на правила объяснение регулярной флективной морфологии может быть правильным и применимо также к восприятию.
Согласно одной точке зрения, правильные и неправильные глаголы различаются тем, что неправильные глаголы обрабатываются и хранятся как единицы, тогда как с правильными глаголами можно бороться, (де) объединяя их в основы и аффиксы (Marslen-Wilson and Tyler 1997; Pinker and Ullman 2002 ; Post et al.2008 г.). Основная работа Aronoff (1976), Halle (1973) и Jackendoff (1977) была сосредоточена на производстве, а не на восприятии, и это исследование выявило флективную морфологию как форму синтаксиса в словах. Джекендофф (1975) предлагает различие между регулярным и нерегулярным перегибом: в то время как все неправильные формы хранятся как отдельные записи, обычные формы формируются с помощью правил, которые напоминают правила, предложенные для синтаксиса. В частности, сочетание основы и аффикса напоминает базовую операцию нашей синтаксической системы, описанную Хомским (1995) с термином , слияние .Психолингвистические данные показали, что это комбинаторное, похожее на правила объяснение регулярной флективной морфологии может быть правильным и применимо также к восприятию. В своей серии экспериментов Stanners et al. (1979) показали, что основы правильных глаголов являются хорошими простыми числами для их изменяемых форм, в то время как основы неправильных глаголов являются менее эффективными простыми числами их изменяемых форм. Это говорит о том, что обычные глаголы хранятся с использованием основы и добавления флективных морфем, в то время как неправильные формы хранятся с несколькими разными записями, по одной для основы и по одной для каждой измененной формы.Обсуждая данные различных исследований, Пинкер и Принс (1994) отметили, что, хотя время реакции для распознавания неправильных глаголов сильно зависит от частоты их формы в лексиконе, время реакции для распознавания правильных глаголов меньше зависит от этого. мера. Это предполагает, по мнению авторов, что в то время как для неправильных форм вся склонная форма может храниться в лексиконе, для обычных форм основа может храниться отдельно.
В своей серии экспериментов Stanners et al. (1979) показали, что основы правильных глаголов являются хорошими простыми числами для их изменяемых форм, в то время как основы неправильных глаголов являются менее эффективными простыми числами их изменяемых форм. Это говорит о том, что обычные глаголы хранятся с использованием основы и добавления флективных морфем, в то время как неправильные формы хранятся с несколькими разными записями, по одной для основы и по одной для каждой измененной формы.Обсуждая данные различных исследований, Пинкер и Принс (1994) отметили, что, хотя время реакции для распознавания неправильных глаголов сильно зависит от частоты их формы в лексиконе, время реакции для распознавания правильных глаголов меньше зависит от этого. мера. Это предполагает, по мнению авторов, что в то время как для неправильных форм вся склонная форма может храниться в лексиконе, для обычных форм основа может храниться отдельно.
Изучение детского языка также показало наличие явлений, подобных правилам, особенно в производстве. В влиятельной публикации Marcus et al. (1992) показали, что дети постоянно создают чрезмерно регуляризованные формы глаголов. Этот тип шаблона можно легко объяснить, если предположить, что дети применяют правило к любому элементу, который можно классифицировать как глагол. На более позднем этапе развития дети сохраняют неправильные формы перегиба и блокируют активацию регулярных перегибов. В недавней работе по расстройству развития, известному как грамматически-специфические языковые нарушения (Gra-SLI), van der Lely и Pinker (2014) показали, что образование правильных глаголов может быть нарушено диссоциированным образом от образования неправильных глаголов, снова предполагая существование основанной на правилах системы для морфологии, по крайней мере, в производстве.
В влиятельной публикации Marcus et al. (1992) показали, что дети постоянно создают чрезмерно регуляризованные формы глаголов. Этот тип шаблона можно легко объяснить, если предположить, что дети применяют правило к любому элементу, который можно классифицировать как глагол. На более позднем этапе развития дети сохраняют неправильные формы перегиба и блокируют активацию регулярных перегибов. В недавней работе по расстройству развития, известному как грамматически-специфические языковые нарушения (Gra-SLI), van der Lely и Pinker (2014) показали, что образование правильных глаголов может быть нарушено диссоциированным образом от образования неправильных глаголов, снова предполагая существование основанной на правилах системы для морфологии, по крайней мере, в производстве.
Неврологические и нейрокогнитивные данные подтвердили утверждение о том, что регулярные и нерегулярные формы требуют двух различных механизмов, и что механизм регулярных форм — это процесс, подобный правилам. В исследовании восприятия Марслен-Уилсон и Тайлер (1997) сообщают о случае двух пациентов с афазией с приобретенным неврологическим повреждением, демонстрирующих нарушение обработки правильных изменяемых глаголов, но у которых сохранялась производительность при неправильных наклонных глаголах. Участники были протестированы с заданием на прайминг, в котором изменяемая форма использовалась для прайминга несгибаемой формы.Соответствующие по возрасту участники показали прайминг для обоих типов глаголов (правильные и неправильные формы), в то время как два пациента показали прайминг только для неправильных форм. Это открытие предполагает различие между регулярным и нерегулярным перегибом и предполагает, что регулярные и нерегулярные элементы поддерживаются разными нейронными системами (Marslen-Wilson and Tyler 1997, p. 592). Этот результат оправдывает идею о качественно отличной системе для двух типов глаголов (а именно, система, подобная правилам для регулярных слов, и основанное на хранении объяснение для неправильных слов).
Участники были протестированы с заданием на прайминг, в котором изменяемая форма использовалась для прайминга несгибаемой формы.Соответствующие по возрасту участники показали прайминг для обоих типов глаголов (правильные и неправильные формы), в то время как два пациента показали прайминг только для неправильных форм. Это открытие предполагает различие между регулярным и нерегулярным перегибом и предполагает, что регулярные и нерегулярные элементы поддерживаются разными нейронными системами (Marslen-Wilson and Tyler 1997, p. 592). Этот результат оправдывает идею о качественно отличной системе для двух типов глаголов (а именно, система, подобная правилам для регулярных слов, и основанное на хранении объяснение для неправильных слов).
Развитие электрофизиологических и нейровизуализационных методов предоставило дополнительные доказательства этих утверждений. В исследовании функциональной магнитно-резонансной томографии (фМРТ), проведенном на носителях английского языка, Tyler et al. (2005) показали, что восприятие регулярно изменяемых форм по сравнению с неправильными формами требует активации обширной лобно-височной сети мозга. Результат был получен с минимальной парной оценкой, выполненной над здоровыми взрослыми.Этот результат предполагает, что человеческий мозг по-разному работает с регулярными и нерегулярными формами, скорее всего, используя правила для регулярных форм. Исследование, проведенное Newman et al. (2007) с помощью Event Related Potentials (ERP) подтвердили открытие Tyler et al. (2005). В этом эксперименте участникам были представлены правильные и неправильные глаголы, склоняющиеся в прошлом. Важно отметить, что прошедшее время было либо правильно сформировано, либо содержало нарушение. Когда нарушение применялось к неправильному глаголу, участники генерировали мозговой компонент под названием P600, в то время как когда нарушение применялось к правильному глаголу, участники дополнительно генерировали мозговой компонент под названием Left Anterior Negativity (LAN).
(2005) показали, что восприятие регулярно изменяемых форм по сравнению с неправильными формами требует активации обширной лобно-височной сети мозга. Результат был получен с минимальной парной оценкой, выполненной над здоровыми взрослыми.Этот результат предполагает, что человеческий мозг по-разному работает с регулярными и нерегулярными формами, скорее всего, используя правила для регулярных форм. Исследование, проведенное Newman et al. (2007) с помощью Event Related Potentials (ERP) подтвердили открытие Tyler et al. (2005). В этом эксперименте участникам были представлены правильные и неправильные глаголы, склоняющиеся в прошлом. Важно отметить, что прошедшее время было либо правильно сформировано, либо содержало нарушение. Когда нарушение применялось к неправильному глаголу, участники генерировали мозговой компонент под названием P600, в то время как когда нарушение применялось к правильному глаголу, участники дополнительно генерировали мозговой компонент под названием Left Anterior Negativity (LAN). Компонент LAN обычно ассоциируется с грамматической композиционностью и построением структуры (см. Friederici 2002; Ullman 2001). Это говорит о том, что нарушение правильного глагола соответствует нарушению морфосинтаксического правила, а нарушение неправильного глагола не влечет за собой нарушение морфосинтаксического правила. Пинкер и Ульман (2002) предполагают, что различия, наблюдаемые между правильными и неправильными формами, связаны с тем, что эти два типа глаголов опираются на качественно разные системы.В то время как (стр. 464) «нерегулярные формы хранятся в лексиконе, разделении декларативной памяти, обычные формы могут быть вычислены с помощью правила конкатенации, которое требует процедурной системы». Согласно этой точке зрения, производство происходит посредством композиционного правила, в котором аффикс добавляется к основе, в то время как восприятие происходит посредством зеркального декомпозиционного правила, в котором аффикс удаляется из изменяемой формы.
Компонент LAN обычно ассоциируется с грамматической композиционностью и построением структуры (см. Friederici 2002; Ullman 2001). Это говорит о том, что нарушение правильного глагола соответствует нарушению морфосинтаксического правила, а нарушение неправильного глагола не влечет за собой нарушение морфосинтаксического правила. Пинкер и Ульман (2002) предполагают, что различия, наблюдаемые между правильными и неправильными формами, связаны с тем, что эти два типа глаголов опираются на качественно разные системы.В то время как (стр. 464) «нерегулярные формы хранятся в лексиконе, разделении декларативной памяти, обычные формы могут быть вычислены с помощью правила конкатенации, которое требует процедурной системы». Согласно этой точке зрения, производство происходит посредством композиционного правила, в котором аффикс добавляется к основе, в то время как восприятие происходит посредством зеркального декомпозиционного правила, в котором аффикс удаляется из изменяемой формы.
Этот тип счетов часто рассматривается в отличие от так называемых счетов на основе единиц (McClelland and Patterson 2002; Rumelhart and McClelland 1986).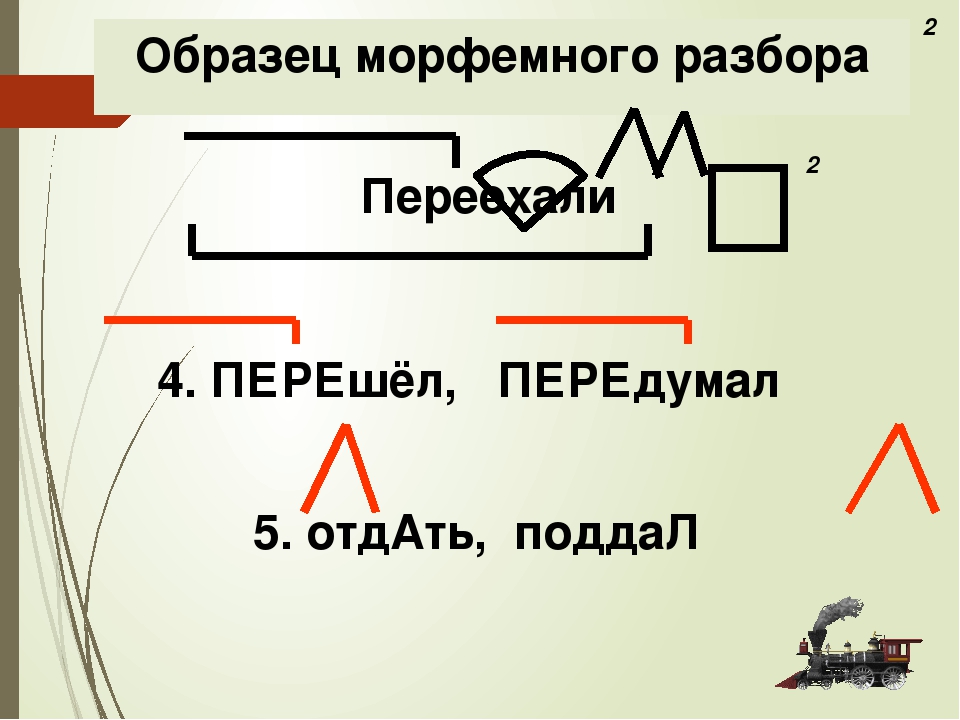 Модели на основе единиц, обычно относящиеся к коннекционизму, отрицают существование системы, разделяющей основы и аффиксы при обработке флексионных форм, и предусматривают, что все флективные формы (регулярные и нерегулярные) обрабатываются с помощью одной и той же системы. Подчеркивая тот факт, что усвоение напряжения у детей происходит постепенно, Макклелланд и Паттерсон (2002) защищают идею о том, что формирование флективных форм зависит не от абстрактного правила, а, скорее, от способности ребенка сочетать фонологическую и семантическую информацию.В этом подходе четко указано, что различать правильные и неправильные формы не обязательно, поскольку единая система может учитывать все глаголы. Авторы предлагают модель коннекционизма, которая генерирует измененные глаголы на основе закономерностей во входных данных. Интересно, что авторы подчеркивают, что (стр. 471) «вопреки некоторым утверждениям, коннекционистские сети — это не просто механизмы аналогий, которые основывают свою тенденцию к обобщению на исходном сходстве между предметами.
Модели на основе единиц, обычно относящиеся к коннекционизму, отрицают существование системы, разделяющей основы и аффиксы при обработке флексионных форм, и предусматривают, что все флективные формы (регулярные и нерегулярные) обрабатываются с помощью одной и той же системы. Подчеркивая тот факт, что усвоение напряжения у детей происходит постепенно, Макклелланд и Паттерсон (2002) защищают идею о том, что формирование флективных форм зависит не от абстрактного правила, а, скорее, от способности ребенка сочетать фонологическую и семантическую информацию.В этом подходе четко указано, что различать правильные и неправильные формы не обязательно, поскольку единая система может учитывать все глаголы. Авторы предлагают модель коннекционизма, которая генерирует измененные глаголы на основе закономерностей во входных данных. Интересно, что авторы подчеркивают, что (стр. 471) «вопреки некоторым утверждениям, коннекционистские сети — это не просто механизмы аналогий, которые основывают свою тенденцию к обобщению на исходном сходстве между предметами. Вместо этого они чувствительны к закономерностям, так что, если отношения ввода-вывода полностью регулярны, сеть может точно соответствовать категориальному, символическому правилу ».
Вместо этого они чувствительны к закономерностям, так что, если отношения ввода-вывода полностью регулярны, сеть может точно соответствовать категориальному, символическому правилу ».
Эти типы коннекционистских моделей подвергались критике по ряду причин. Как уже отмечалось Массаро (1988), «коннекционистские модели обычно делают нереалистичные предположения о психофизических отношениях, которые действуют при выполнении задачи» (стр. 213). Маркус (2003) отметил, что большинство коннекционистских моделей не могут объяснить важнейшие свойства человеческого познания (и человеческого синтаксиса), такие как, например, рекурсия. Bowers et al. (2009) объясняет, что коннекционистские модели часто слишком сильны и чувствительны к статистическим свойствам, что не отражает человеческого познания.Однако, несмотря на эту критику и вопреки общему мнению, чувствительность к правилам иногда встроена в модели коннекционизма. Roelofs (1997), например, реализовал основанную на правилах коннекционистскую систему кодирования словоформ, основанную на данных, полученных в результате когнитивных исследований участников-людей. Модели коннекционистов не являются моделями, основанными на правилах, потому что ввод не такой регулярный, как того требует правило. Если бы это было так, эти модели были бы моделями, основанными на правилах.
Модели коннекционистов не являются моделями, основанными на правилах, потому что ввод не такой регулярный, как того требует правило. Если бы это было так, эти модели были бы моделями, основанными на правилах.
Один аспект, который коннекционистские аккаунты, кажется, улавливают лучше, чем основанные на правилах, — это относительная распространенность квазирегулярных форм в языке.Как отмечает Зайденберг (2005), значительное количество изменяемых форм не подпадают под обычный паттерн и не ведут себя как полностью идиосинкразические формы: вместо этого многие формы являются квазирегулярными. Этот паттерн вполне очевиден, например, в прошедшем времени английского языка. Квазирегулярные формы — это формы, полученные по продуктивному образцу, который, однако, встречается реже, чем тот, который обычно обозначается как регулярный (однако этот тип ярлыка избегается в объяснениях, основанных на единицах, поскольку различие между регулярными и неправильными формами опровергается).Примеры из них: построить / построить, сохранить / сохранить, почувствовать / почувствовать и так далее. Оглядываясь на дебаты задним числом, Зайденберг и Плаут (2014) замечают, что, хотя единый аналогичный механизм может объяснять производство и восприятие этих форм, теории, основанные на правилах (которые предполагают, что регулярные и нерегулярные личности требуют двух отдельных механизмов, а не единого механизма). один) требуют сложных дополнений для отражения явления.
Оглядываясь на дебаты задним числом, Зайденберг и Плаут (2014) замечают, что, хотя единый аналогичный механизм может объяснять производство и восприятие этих форм, теории, основанные на правилах (которые предполагают, что регулярные и нерегулярные личности требуют двух отдельных механизмов, а не единого механизма). один) требуют сложных дополнений для отражения явления.
Кроме того, существуют инклюзивные счета, которые предлагают избыточную систему, в которой сосуществуют объяснения, основанные на правилах, и объяснения, подобные единичным (Schreuder et al.1999; Hay and Baayen 2005). Эти типы объяснений успешно учитывают большое количество доказательств, предполагающих основанное на правилах перегибание, и подтверждают объяснительную силу моделей коннекционизма, а также учитывают, например, частотные эффекты, наблюдаемые в правильных глаголах. Как Schreuder et al. (1999) объясняют, что есть ошибка в предположении, что одна система несовместима с другой. Наша лингвистическая система может быть избыточной, работая, таким образом, с правилами в сочетании с единичными процессами. Аналогичный вывод предлагает Taft (2004). По мнению автора, единичный и правилоподобный процессы действуют параллельно. В правильных формах оба процесса успешно работают, в то время как в неправильных формах только попытки перегиба.
Аналогичный вывод предлагает Taft (2004). По мнению автора, единичный и правилоподобный процессы действуют параллельно. В правильных формах оба процесса успешно работают, в то время как в неправильных формах только попытки перегиба.
Независимо от того, задействованы ли правила или нет, как поляризованный, так и менее поляризованный подходы согласны с существованием некоторой формы чувствительности, которую говорящие имеют к флективной морфологии, когда дело доходит до восприятия изменчивой формы. Фактически, единичные объяснения (Seidenberg and Plaut 2014), основанные на правилах объяснения (Pinker and Ullman 2002), а также повторяющиеся объяснения (Hay and Baayen 2005) согласны с существованием системы, которая обнаруживает флективную информацию.Является ли эта информация новой чертой в выборке случаев (Seidenberg and Plaut 2014), полностью определенной связанной морфемой (Pinker and Ullman 2002) или точкой контраста, возникающей в разных формах (Baayen et al. 2011, 2016), в Во всех случаях говорящий проявляет некоторую чувствительность, которая затем отражается на следующих этапах отображения речи. В данной работе мы сосредоточили наше внимание на этой чувствительности, переместив свет с реальных глаголов со значением на наклонных форм без значения .Таким образом, наша задача не связана с какой-либо конкретной теорией, а скорее сосредоточена на явлении, которое потенциально предсказывается различными теориями, но которое до сих пор исследовалось только несколько раз, и, насколько нам известно, только один раз на английском языке.
В данной работе мы сосредоточили наше внимание на этой чувствительности, переместив свет с реальных глаголов со значением на наклонных форм без значения .Таким образом, наша задача не связана с какой-либо конкретной теорией, а скорее сосредоточена на явлении, которое потенциально предсказывается различными теориями, но которое до сих пор исследовалось только несколько раз, и, насколько нам известно, только один раз на английском языке.
Чувствительность к флективной морфологии в несловах
Неслова — полезный инструмент в психолингвистических исследованиях, поскольку они позволяют изучать фонологические и морфологические проблемы без активации семантических представлений. Морфологический (де) состав правильных глаголов давно исследуется с использованием неслов.Основная работа Берко (1958) показывает, что на производстве дети и взрослые могут довольно умело и с раннего возраста применять флективные морфемы к несловам. В своей новаторской работе Берко (1958) выявила множественное число неслов и показала, что дети в возрасте 4 лет могут применять морфофонологические правила, необходимые для создания формы множественного числа.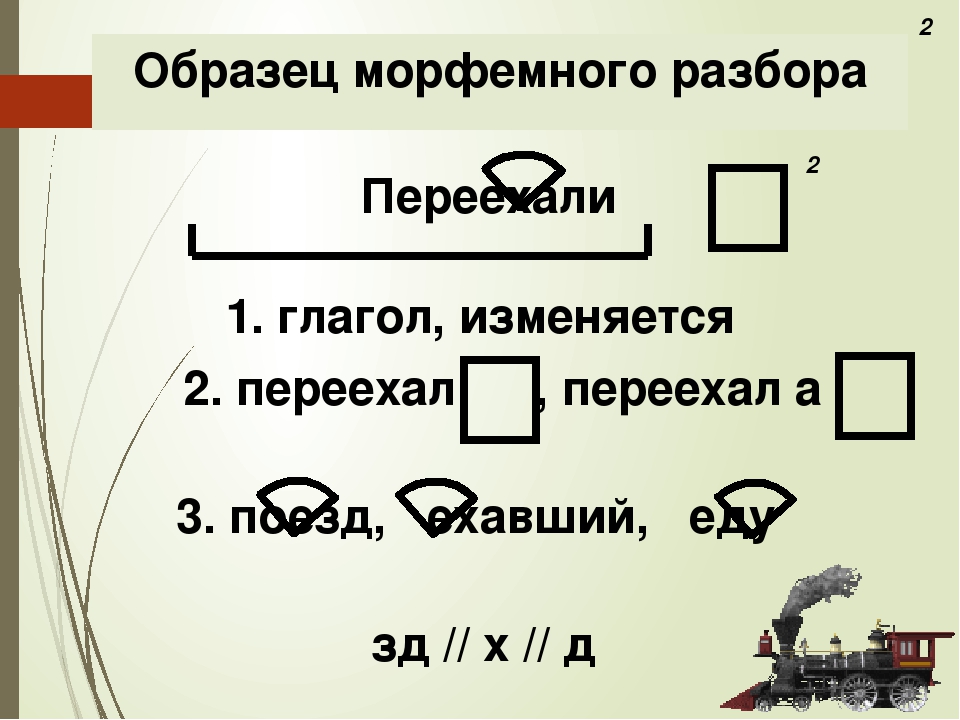
Это человек, который умеет глинг / gliŋ /. Он глотает. Он сделал то же самое вчера. Что он делал вчера? Вчера он _______.
Доказательства показывают, что дети и взрослые способны создавать изменяемые формы неслов, а также что они могут правильно выбирать правильную алломорфную форму (в последнее время Blything et al. (2018) уточнили этот классический вывод, и показали, что придуманные глаголы не всегда изменяются детьми с использованием правильной формы, и вероятность изменения придуманного глагола как правильного зависит от того, насколько этот глагол похож на другие существующие глаголы.)
Аналогичные результаты были получены в восприятии: в задаче визуального распознавания слов, выполненной итальянско-говорящими участниками, Caramazza et al. (1988) показали, что морфологические перегибы неслов могут применяться и в восприятии. В своей статье авторы сообщают о серии задач по принятию лексических решений, в которых участников просили решить, был ли данный стимул словом или не словом. Создаваемые стимулы варьировались по двум различным переменным: (1) они могли начинаться с существующей основы или несуществующей основы и (2) они могли заканчиваться существующими флективными морфемами или окончаниями, которые не являются флективными морфемами в итальянском языке.Авторы сообщили, что неслова с возможными флективными морфемами требовали значительно больше времени для распознавания, чем неслова, которые не могли быть разложены. Фактически, неслова, которые нельзя было разложить на основы и словоизменительные морфемы, распознавались быстрее всего. Неслова с частичной морфологической структурой (реальная основа или реальный аффикс) занимали немного больше времени, а морфологически легальные неслова требовалось дольше всего для распознавания.
(1988) показали, что морфологические перегибы неслов могут применяться и в восприятии. В своей статье авторы сообщают о серии задач по принятию лексических решений, в которых участников просили решить, был ли данный стимул словом или не словом. Создаваемые стимулы варьировались по двум различным переменным: (1) они могли начинаться с существующей основы или несуществующей основы и (2) они могли заканчиваться существующими флективными морфемами или окончаниями, которые не являются флективными морфемами в итальянском языке.Авторы сообщили, что неслова с возможными флективными морфемами требовали значительно больше времени для распознавания, чем неслова, которые не могли быть разложены. Фактически, неслова, которые нельзя было разложить на основы и словоизменительные морфемы, распознавались быстрее всего. Неслова с частичной морфологической структурой (реальная основа или реальный аффикс) занимали немного больше времени, а морфологически легальные неслова требовалось дольше всего для распознавания.
Следует отметить, что в этом эксперименте участникам никогда не предъявлялись голые стебли.Это сделало маловероятным, чтобы участники знали о типе выполненных манипуляций. Еще один новый аспект, вытекающий из работы Caramazza et al. (1988) заключается в том, что некоторая форма обработки словоизменений имеет место, даже когда мы не обращаемся к лексикону. Этот результат более ясен, чем тот, который наблюдал Берко (1958): хотя можно утверждать, что в производственной задаче Берко участники идентифицировали неслова с конкретным элементом или действием, этого нельзя утверждать в задачах, разработанных Карамазза и др.(1988).
Clahsen et al. (1997) разработали серию задач, которые поддерживают Caramazza et al. (1988) также для немецкого языка. По словам авторов, задания на немецком языке показали, что неслова, как и настоящие слова, разлагаются. Особый интерес для нашей работы представляет первый эксперимент Clahsen et al. (1997). В этом задании участники были ознакомлены с регулярно изменяемыми несловами. Позже участников попросили выполнить задание на лексическое решение, используя те же неслова.Эти неслова могут быть либо регулярно изменяемыми (в другом времени, чем во фразе для ознакомления), либо они могут изменяться нерегулярно. Результаты показали, что участники были значительно быстрее в распознавании регулярно изменяемых неслов, что свидетельствует о том, что они умело оперировали морфологическим изменением словоформ. Можно отметить, что в отличие от Caramazza et al. (1988), а также вопреки более позднему исследованию Post et al. (2008), что обсуждается ниже, правильно изменяемые формы распознавались медленнее, чем неправильные.Как объясняют авторы, это может быть связано с тем, что неправильные формы из-за фазы ознакомления могли быть восприняты как незаконные формы, в то время как в Caramazza et al. (1988) и в Post et al. (2008), из-за отсутствия фазы ознакомления неслова могли просто восприниматься как неправильные.
Позже участников попросили выполнить задание на лексическое решение, используя те же неслова.Эти неслова могут быть либо регулярно изменяемыми (в другом времени, чем во фразе для ознакомления), либо они могут изменяться нерегулярно. Результаты показали, что участники были значительно быстрее в распознавании регулярно изменяемых неслов, что свидетельствует о том, что они умело оперировали морфологическим изменением словоформ. Можно отметить, что в отличие от Caramazza et al. (1988), а также вопреки более позднему исследованию Post et al. (2008), что обсуждается ниже, правильно изменяемые формы распознавались медленнее, чем неправильные.Как объясняют авторы, это может быть связано с тем, что неправильные формы из-за фазы ознакомления могли быть восприняты как незаконные формы, в то время как в Caramazza et al. (1988) и в Post et al. (2008), из-за отсутствия фазы ознакомления неслова могли просто восприниматься как неправильные.
В более позднем исследовании Post et al. (2008) сообщили об аналогичных результатах для английского языка. Их эксперимент состоял из минимальной задачи распознавания пар, в которой участников просили оценить, являются ли два слова или неслова, представленные в паре, одинаковыми или разными.Пары состояли либо из основы и флексированной формы, либо из первого элемента, повторяющегося дважды. Используемые стимулы были весьма разнообразными. Задача содержала несколько условий, в том числе реальные слова с обычным прошедшим (заполнено / заполнено), псевдопрошедшие обычные слова (мягкое / миля), множественное число (еда / еда), неслова, оканчивающиеся на потенциальное прошлое (gubbed / gub), неслова, не заканчивающиеся в прошлом (steet / stee). Результаты показали, что участникам потребовалось больше времени, чтобы отличить потенциально изменяемые неслова (gubbed / gub) и реальные слова с наклонением (заполненные / заполнить) от их основы, чем различать неслова без потенциальных склонений (steet / stee).
Их эксперимент состоял из минимальной задачи распознавания пар, в которой участников просили оценить, являются ли два слова или неслова, представленные в паре, одинаковыми или разными.Пары состояли либо из основы и флексированной формы, либо из первого элемента, повторяющегося дважды. Используемые стимулы были весьма разнообразными. Задача содержала несколько условий, в том числе реальные слова с обычным прошедшим (заполнено / заполнено), псевдопрошедшие обычные слова (мягкое / миля), множественное число (еда / еда), неслова, оканчивающиеся на потенциальное прошлое (gubbed / gub), неслова, не заканчивающиеся в прошлом (steet / stee). Результаты показали, что участникам потребовалось больше времени, чтобы отличить потенциально изменяемые неслова (gubbed / gub) и реальные слова с наклонением (заполненные / заполнить) от их основы, чем различать неслова без потенциальных склонений (steet / stee).
Новым аспектом в работе Поста и др. (2008) было то, что разработанная ими задача лучше проясняет связь между фонологией и морфологией при выявлении потенциальных перегибов. В частности, работа Post et al. показывает, как основа дает фонологические сигналы к морфологическому перегибу: это не природа аффикса как такового определяет RT (фактически, / t / может быть связанной морфемой в другом фонологическом контексте, а именно после выделенного слова, заканчивающегося фонемой ), но именно отношение между последней фонемой и предыдущими сегментами определяет RT.Однако стимулы, использованные Post et al. (2008) представляют потенциальную путаницу в том, что минимальные пары сравнивают изогнутые формы с голыми основами. Это сильный сигнал о характере манипуляции, выполняемой в тесте, и может склонить участников к выполнению морфологического разложения. Задача, представленная в этой статье, не имеет этого ограничения. Вместо того, чтобы сравнивать флексивные формы и их основы, наша задача всегда сравнивать только флексивные формы. В отличие от Post et al. (2008) неслова в наших минимальных парах всегда были перегибаемыми.Участникам никогда не предъявляли неотраженный ствол, из-за чего им было сложно или невозможно понять тип предоставляемой манипуляции.
В частности, работа Post et al. показывает, как основа дает фонологические сигналы к морфологическому перегибу: это не природа аффикса как такового определяет RT (фактически, / t / может быть связанной морфемой в другом фонологическом контексте, а именно после выделенного слова, заканчивающегося фонемой ), но именно отношение между последней фонемой и предыдущими сегментами определяет RT.Однако стимулы, использованные Post et al. (2008) представляют потенциальную путаницу в том, что минимальные пары сравнивают изогнутые формы с голыми основами. Это сильный сигнал о характере манипуляции, выполняемой в тесте, и может склонить участников к выполнению морфологического разложения. Задача, представленная в этой статье, не имеет этого ограничения. Вместо того, чтобы сравнивать флексивные формы и их основы, наша задача всегда сравнивать только флексивные формы. В отличие от Post et al. (2008) неслова в наших минимальных парах всегда были перегибаемыми.Участникам никогда не предъявляли неотраженный ствол, из-за чего им было сложно или невозможно понять тип предоставляемой манипуляции. Еще одним преимуществом нашей задачи является наличие третьего набора неслов, в котором озвучены две конечные фонемы, но окончание не может быть связанной морфемой (vɛlb / vɛlm). Наличие этого состояния особенно важно, поскольку оно позволяет исключить чисто голосовое объяснение для более длительного времени реакции в состоянии с флективными морфемами.Если морфологическое состояние не только медленнее, чем неморфологическое, но также и контрольное (vɛlb / vɛlm), озвучивание не может использоваться в качестве объяснения.
Еще одним преимуществом нашей задачи является наличие третьего набора неслов, в котором озвучены две конечные фонемы, но окончание не может быть связанной морфемой (vɛlb / vɛlm). Наличие этого состояния особенно важно, поскольку оно позволяет исключить чисто голосовое объяснение для более длительного времени реакции в состоянии с флективными морфемами.Если морфологическое состояние не только медленнее, чем неморфологическое, но также и контрольное (vɛlb / vɛlm), озвучивание не может использоваться в качестве объяснения.
Создание материалов
В этом эксперименте мы исследовали чувствительность к регулярным флективным морфемам, не использующим слова. В английском языке правильные глаголы, оканчивающиеся на / l /, принимают окончание / d / при склонении в прошлом (например, kill – kill) и окончание / z / при склонении в третьем лице настоящего (например,грамм. kill – убивает). Хотя морфологически в других контекстах, / t / и / s / не несут грамматической информации после / l /. Мы сравнили различение не слов, оканчивающихся на / ld / vs / lz /, и не слов, оканчивающихся на / lt / vs / ls /. Все неслова были признаны фонотаксически законными с помощью калькулятора Витевича и Люса (2004). Для создания стимулов использовалась следующая процедура: в первую очередь выбирались 4 стартовых согласных. Это были: / v /, / n /, / θ / и / dʒ /. Выбор был мотивирован двумя факторами:
Мы сравнили различение не слов, оканчивающихся на / ld / vs / lz /, и не слов, оканчивающихся на / lt / vs / ls /. Все неслова были признаны фонотаксически законными с помощью калькулятора Витевича и Люса (2004). Для создания стимулов использовалась следующая процедура: в первую очередь выбирались 4 стартовых согласных. Это были: / v /, / n /, / θ / и / dʒ /. Выбор был мотивирован двумя факторами:
- 1.
Все эти согласные разрешены в начальной позиции слова в английском языке, о чем свидетельствует тот факт, что значение частоты позиционного сегмента для этих согласных в исходной позиции никогда не равно нулю. Частота позиционного сегмента — это статистическая мера, полученная путем анализа корпусов. Мера указывает, как часто определенная фонема появляется в определенном месте в словах. Например, / v / имеет частоту позиционного сегмента 0,02, если используется в начальной позиции слова.Это означает, что / v / появляется в начальной позиции слова в 2 словах из 100.
Если бы / v / не было разрешено в начальной позиции слова в английском языке, частота его позиционного сегмента в качестве начала слова была бы равна нулю. Частоты позиционных сегментов для начала слов, выбранных для этого исследования, никогда не были равны нулю во всем тесте. Кроме того, выбранные согласные имеют относительно низкую частоту в начальной позиции слова. Фактически, значения частот позиционных сегментов варьируются от 0,02 до 0,006 для исходных фонем слова в нашем тесте. - 2.
Выбор использования начала слова с относительно низкой частотой был преимуществом с точки зрения генерации несловых слов. Фактически, наличие нечастых слов в начале существенно снижает риск создания существующих слов.
 Если бы / v / не было разрешено в начальной позиции слова в английском языке, частота его позиционного сегмента в качестве начала слова была бы равна нулю. Частоты позиционных сегментов для начала слов, выбранных для этого исследования, никогда не были равны нулю во всем тесте. Кроме того, выбранные согласные имеют относительно низкую частоту в начальной позиции слова. Фактически, значения частот позиционных сегментов варьируются от 0,02 до 0,006 для исходных фонем слова в нашем тесте.
Если бы / v / не было разрешено в начальной позиции слова в английском языке, частота его позиционного сегмента в качестве начала слова была бы равна нулю. Частоты позиционных сегментов для начала слов, выбранных для этого исследования, никогда не были равны нулю во всем тесте. Кроме того, выбранные согласные имеют относительно низкую частоту в начальной позиции слова. Фактически, значения частот позиционных сегментов варьируются от 0,02 до 0,006 для исходных фонем слова в нашем тесте. Все неслова в этом задании односложны, поэтому в каждом слове есть только одна гласная.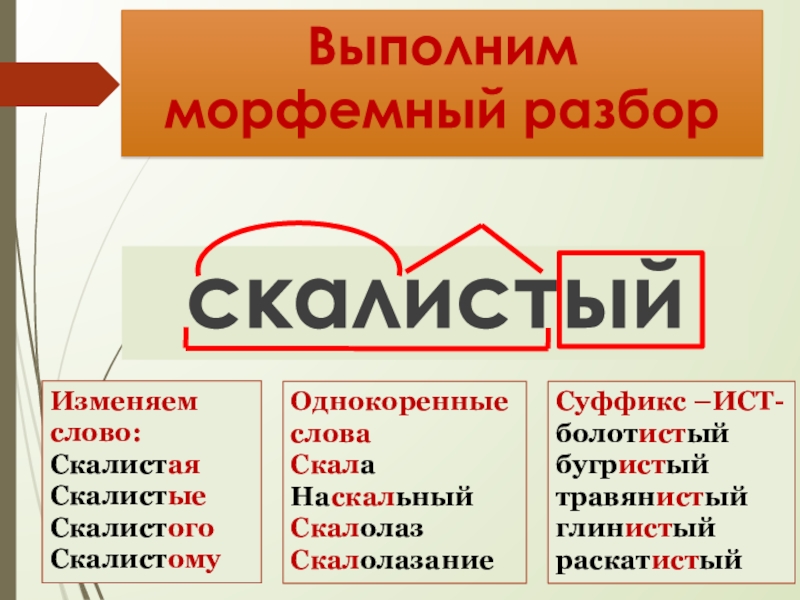 В этом эксперименте используются следующие гласные: / ɪ /, / aɪ /, / æ /, / ɔ /, / ʌ /. Выбор этих гласных мотивировался частотами сегментов бифона и частотами позиционных сегментов. Все эти гласные разрешены во второй позиции слова, и все они разрешены в качестве второй фонемы бифона, имеющего любую из согласных, представленных выше, в качестве первой фонемы. Тот факт, что они разрешены во второй позиции, демонстрируется тем фактом, что частота позиционных сегментов этих гласных никогда не равна нулю.Значения можно проверить в Cilibrasi (2016) (частота позиционного сегмента гласного — это второе значение слева, указанное в каждом поле). Тот факт, что эти гласные разрешены в качестве членов бифона, имеющего одну из согласных, представленных выше, в исходном положении, демонстрируется тем фактом, что частота сегмента бифона этих бифонов никогда не равна нулю. Затем начало и ядро несловых слов были объединены с потенциально морфологическими кодами, представленными в начале этого раздела: / lz / и / ld /, и неморфологическими кодами, / ls / и / lt / (Таблица 1).
В этом эксперименте используются следующие гласные: / ɪ /, / aɪ /, / æ /, / ɔ /, / ʌ /. Выбор этих гласных мотивировался частотами сегментов бифона и частотами позиционных сегментов. Все эти гласные разрешены во второй позиции слова, и все они разрешены в качестве второй фонемы бифона, имеющего любую из согласных, представленных выше, в качестве первой фонемы. Тот факт, что они разрешены во второй позиции, демонстрируется тем фактом, что частота позиционных сегментов этих гласных никогда не равна нулю.Значения можно проверить в Cilibrasi (2016) (частота позиционного сегмента гласного — это второе значение слева, указанное в каждом поле). Тот факт, что эти гласные разрешены в качестве членов бифона, имеющего одну из согласных, представленных выше, в исходном положении, демонстрируется тем фактом, что частота сегмента бифона этих бифонов никогда не равна нулю. Затем начало и ядро несловых слов были объединены с потенциально морфологическими кодами, представленными в начале этого раздела: / lz / и / ld /, и неморфологическими кодами, / ls / и / lt / (Таблица 1).
Не-слова были созданы с использованием правил, которые позволили нам комбинировать начала, ядра и коды. Продуктивные правила создания несловесных слов заключались в том, что каждое начало сочеталось с каждым ядром. Это позволило получить 20 базовых форм. Четыре разных кода были добавлены к каждой базовой форме, таким образом получилось 80 неслов. Сорок из них содержали потенциальные флективные морфемы, а 40 не содержали флективных морфем.
Третье условие управления было добавлено для управления эффектами озвучивания.Без третьего условия контраст между потенциально морфосинтаксическими и неморфосинтаксическими минимальными парами можно объяснить тем фактом, что две последние фонемы в первом условии являются звонкими, а две последние фонемы во втором условии — нет. Третьим условием мы исключаем такую возможность. В третьем условии обе последние фонемы озвучены, но не несут флективных морфем. В контрольных условиях использовались следующие коды: / фунт / и / мкм /.Базовые формы также были применены к этим кодам для создания условия управления, что привело к появлению еще 40 неслов. Таким образом, финальный тест содержал 120 неслов. Краткое описание типов стимулов, использованных в тесте, представлено в таблице 1. Полный список стимулов доступен в «Приложении» в фонетической транскрипции. В отличие от Post et al. (2008), все наши основы во всех условиях оканчивались на / l /, создавая очень согласованный образец, в котором 6 неслов в трех условиях имеют одну основу, в то время как в Post et al.(2008) стебли были разными в зависимости от условий. Короче говоря, в нашу задачу входит морфофонологическая чувствительность Post et al. (2008), но он избегает путаницы, связанной с голым основанием, что делает его более похожим на Caramazza et al. (1988).
Таким образом, финальный тест содержал 120 неслов. Краткое описание типов стимулов, использованных в тесте, представлено в таблице 1. Полный список стимулов доступен в «Приложении» в фонетической транскрипции. В отличие от Post et al. (2008), все наши основы во всех условиях оканчивались на / l /, создавая очень согласованный образец, в котором 6 неслов в трех условиях имеют одну основу, в то время как в Post et al.(2008) стебли были разными в зависимости от условий. Короче говоря, в нашу задачу входит морфофонологическая чувствительность Post et al. (2008), но он избегает путаницы, связанной с голым основанием, что делает его более похожим на Caramazza et al. (1988).
Запись стимулов: стимулы были записаны в звуковой кабине Школы психологии и клинических языковых наук Университета Рединга опытным лингвистом-женщиной, чей родной язык — английский. Оратор прошел фонетическое обучение и записал со стандартным британским произношением.Лингвисту было предложено записывать стимулы попарно. Это соответствует чтению слов построчно в фонетическом списке в «Приложении».
Это соответствует чтению слов построчно в фонетическом списке в «Приложении».
Лингвист был проинформирован о характере задачи, и она записала пару за парой, чтобы обеспечить запись едва уловимого удлинения гласных в морфологическом состоянии, что типично для британцев, говорящих по-английски, при создании склоняемых глаголов [средняя продолжительность в мс (SD) для каждого условия: 224 (45), 146 (37), 178 (33)]. На первый взгляд этот выбор может показаться необоснованным, так как он выглядит как выбор, который может повысить риск возникновения путаницы.Однако эта инструкция необходима, если цель состоит в том, чтобы использовать стимулы, которые звучали бы как можно ближе к «естественным» склонным глаголам. Относительно темный / l / использовался на протяжении всего задания, как это обычно бывает в стандартном британском английском.
Используемое программное обеспечение — Audacity, работающее на компьютере под управлением Windows. Микрофон — AKG D80, микшер — Behringer Mini Mon, предварительный усилитель — фонокорректор B-tech.
Shoebox и не только — Amazonian Linguistics
Обсудив ранее финансирование исследований, позвольте мне теперь перейти к другому вопросу, который мне довольно часто задают люди, которые думают о том, чтобы впервые отправиться в поле: какое программное обеспечение мне нужно — и, более конкретно: что такое Shoebox и что ты думаешь об этом? Далее следует мое очень личное мнение о программе Shoebox.
Вкратце, Shoebox — это программа для создания словарей и подстрочных текстов, производимая SIL. Что я об этом думаю? Что ж, я думаю о Shoebox как о той древней громадине машины, которую ваш дядя подарил вам на 18-летие, которую вы все еще используете, потому что не можете себе позволить ничего лучшего, которая хрипит, гремит, изрыгает дым и пахнет маслом и бензином. который выходит из строя настолько регулярно, что вам приходится держать в багажнике ящик с инструментами для ремонта на обочине дороги — и который вы должны подавать на газ, когда подходите к знаку остановки, чтобы он не заглох — но который, в конце концов, доставит вас к месту назначения — возможно, не стильно и определенно не с комфортом — но доставит вас туда.
Большинство людей, которых я знаю, которые работают в полевых условиях, используют Shoebox, но мечтают о том дне, что появится что-нибудь получше, и они смогут вынести грохочущую тушу на заднее поле и оставить там ржаветь. (Кстати, самая последняя версия Shoebox была переименована в Toolbox, хотя она отличается лишь несколькими способами. Совсем недавно SIL выпустила новую программу под названием FLEx, которая выполняет ту же базовую функцию, что и Shoebox / Toolbox. , и который рассматривается здесь. Я еще не пробовал это, но похоже, что это значительное улучшение Shoebox во многих отношениях.)
Что такое Shoebox? Shoebox — это, по сути, программа лексической базы данных, соединенная с программой морфологического анализа. База данных разработана с учетом создания словарей, и одним из ее основных достоинств является то, что она включает функцию экспорта, которая позволяет экспортировать базу данных словарей в виде документа Microsoft Word, отформатированного в узнаваемом словарном стиле, с заголовками и подстатьями. . База данных имеет базовые функции фильтрации и поиска.
. База данных имеет базовые функции фильтрации и поиска.
Морфологический синтаксический анализатор предназначен для разделения слов в тексте на составляющие их морфемы и назначения глосс и частей речи сегментированным морфемам.Результаты процессов синтаксического анализа выводятся в виде подстрочного текста. Синтаксический анализатор ищет морфемы, выполняя поиск в базе данных словарей, и потенциально очень полезной функцией является то, что можно установить предпочтения, чтобы открывать новую запись словаря всякий раз, когда встречается морфема, которую синтаксический анализатор не обнаруживает в словаре, тем самым позволяя вы можете пополнять свой словарь, анализируя тексты. Таким же образом можно создать корпус проанализированных текстов, в которых затем можно будет искать интересующие глоссы или морфемы.
На мой взгляд, сильные стороны Shoebox заключаются в его выводе в словарном формате и в том, что лексическая база данных и синтаксический анализатор довольно хорошо интегрированы. В течение долгого времени мало что еще могло так удобно выполнять эти функции в одном пакете, хотя сейчас это меняется (см. Ниже). SIL, который написал и поддерживал программу, также сделал ее доступной бесплатно, что является хорошей ценой.
В течение долгого времени мало что еще могло так удобно выполнять эти функции в одном пакете, хотя сейчас это меняется (см. Ниже). SIL, который написал и поддерживал программу, также сделал ее доступной бесплатно, что является хорошей ценой.
Однако, как следует из приведенного выше описания, Shoebox меня разочаровывает в нескольких отношениях.
Возможно, самая большая слабость Shoebox — это его документация, которая на , к сожалению, на неадекватна. Я знаю нескольких человек, которые пытались использовать Shoebox, но разочаровались. Программа поставляется с учебным пособием, которое хорошо, насколько это возможно, и имеет функцию справки, но многое из того, что вам нужно знать для использования программы, просто нигде не задокументировано. Если у вас есть опыт программирования или вы в целом разбираетесь в программном обеспечении, вы можете с большим терпением и скрежетом зубами выяснить большую часть того, что вам нужно знать (хотя есть еще ряд вещей, которые остаются для меня загадочными даже после несколько лет). В противном случае я настоятельно рекомендую получить обучение у кого-то, кто пользуется программой в течение длительного времени. Это сэкономит вам много времени.
В противном случае я настоятельно рекомендую получить обучение у кого-то, кто пользуется программой в течение длительного времени. Это сэкономит вам много времени.
Из-за того, что документация Shoebox очень неоднородна, некоторые люди написали свои собственные примечания для настройки, такие как this и this. Вот статья, в которой обсуждается использование Shoebox.
Форматированный по словарю вывод, на мой взгляд, одна из лучших вещей в Shoebox, но по-прежнему оставляет желать лучшего. У пользователя довольно мало контроля над форматированием, если только он не хочет редактировать файлы, которые управляют преобразованием из базы данных Shoebox с открытым текстом в Word (или RTF).Это не то, что нравится большинству людей.
Морфологический синтаксический анализатор хорошо работает с языками с агглютинативной морфологией и лучше всего работает, когда имеется небольшая алломорфия или морфофонология. Существуют способы обработки алломорфии и морфофонологии, в том числе способ ввода условных правил или правил окружения, но я обнаружил, что в языках с большим количеством морфологии и сложной алломорфией или морфофонологией синтаксический анализатор имеет тенденцию делать много ошибок, и приходится много тратить. времени, говоря синтаксическому анализатору, что делать, или, что еще хуже, нужно потратить много времени на усиление своих лексических статей, чтобы иметь дело с двусмысленностями и проблемами синтаксического анализа.В Nanti, языке Кампана, над которым я работаю, синтаксический анализатор работает довольно хорошо, но для Икито, языка Запаро, над которым я работаю, синтаксический анализатор действительно не стоит проблем, по крайней мере, пока. (Полагаю, это может отражать мою нехватку вычислительных навыков; я не компьютерный лингвист, но и я не умею вычислять. Если лингвисту с моими способностями трудно заставить синтаксический анализатор работать хорошо, это говорит мне, что он не очень хорошо спроектирован.)
времени, говоря синтаксическому анализатору, что делать, или, что еще хуже, нужно потратить много времени на усиление своих лексических статей, чтобы иметь дело с двусмысленностями и проблемами синтаксического анализа.В Nanti, языке Кампана, над которым я работаю, синтаксический анализатор работает довольно хорошо, но для Икито, языка Запаро, над которым я работаю, синтаксический анализатор действительно не стоит проблем, по крайней мере, пока. (Полагаю, это может отражать мою нехватку вычислительных навыков; я не компьютерный лингвист, но и я не умею вычислять. Если лингвисту с моими способностями трудно заставить синтаксический анализатор работать хорошо, это говорит мне, что он не очень хорошо спроектирован.)
Еще одна серьезная слабость парсера, на мой взгляд, — это форматирование выходного файла с подстрочной линией.Подстрочный вывод выглядит на экране нормально, но это очень трудоемкий процесс вырезания, вставки и переформатирования, чтобы переместить его из текстового файла Shoebox в другой документ. Как следствие, довольно непрактично использовать Shoebox для создания готовых к публикации подстрочных текстов (сравните это с выводом словаря).
Как следствие, довольно непрактично использовать Shoebox для создания готовых к публикации подстрочных текстов (сравните это с выводом словаря).
Наконец, я считаю, что общий дизайн и организация пользовательского интерфейса оставляют желать лучшего. Во многих случаях важные функции скрыты таким образом, что нужно проходить через вложенные наборы диалоговых окон, чтобы добраться до них.Поиск функций также может быть сложной задачей, поскольку иногда они размещаются в довольно непонятных местах. Кроме того, текстовые окна и меню иногда очень маленькие, поэтому трудно увидеть все, что нужно видеть. В результате этих проблем фактическое использование программы может вызывать разочарование. Может быть, это потому, что я пользователь Mac, но я также считаю, что чувствительность Shoebox к расположению файлов и его глупость расстраивают, поскольку это делает перенос баз данных между файлами или между машинами сложным делом.
Таким образом, Shoebox намного лучше, чем ничего, но я считаю, что программа оставляет желать лучшего. Однако долгое время это была единственная игра в городе, так что ситуация была в значительной степени «мириться или заткнуться» (или для тех, кто склонен к вычислениям: напишите что-нибудь получше). Однако ситуация начинает меняться…
Однако долгое время это была единственная игра в городе, так что ситуация была в значительной степени «мириться или заткнуться» (или для тех, кто склонен к вычислениям: напишите что-нибудь получше). Однако ситуация начинает меняться…
Движение за пределы обувной коробки
Как я упоминал выше, SIL выпустила новый пакет FLEx, который предназначен для замены Shoebox / Toolbox. Я еще не пробовал, но похоже, что это значительное улучшение по сравнению с Shoebox. Это рассмотрено здесь.Как только у меня появится время (т.е. когда я закончу диссертацию), я планирую взять FLEx на пробу и посмотреть, как он работает.
TshwaneLex — это коммерчески доступная программа лексикографии для создания словарей. В этом обзоре он выглядит довольно привлекательным вариантом, за исключением того, что он платный (150 евро за академическую лицензию). Кроме того, он не интегрирован с парсером, как Shoebox, поэтому, если это важно для вас, то Tshwanelex не для вас.
Есть и другие инструменты, но, насколько я могу судить, большинство из них еще не готовы к использованию в прайм-тайм. Школа передового опыта E-MELD — отличный ресурс для любого лингвиста, впервые отправляющегося на работу, и здесь у них есть большое количество информации о программном обеспечении.
Школа передового опыта E-MELD — отличный ресурс для любого лингвиста, впервые отправляющегося на работу, и здесь у них есть большое количество информации о программном обеспечении.
Нравится:
Нравится Загрузка …
СвязанныеМорфология в лексиконе ● Полный синтаксический анализ — слова для понимания, анализируемые в морфемы — в производственных словах, построенных из морфем.
Презентация на тему: «Морфология в лексике ● Полный синтаксический анализ — в понимании слова, разбираемые на морфемы — в продуктивных словах, построенных из морфем.»- стенограмма презентации:
ins [data-ad-slot = «4502451947»] {display: none! important;}} @media (max-width: 800px) {# place_14> ins: not ([data-ad-slot = «4502451947»]) {display: none! important;}} @media (max-width: 800px) {# place_14 {width: 250px;}} @media (max-width: 500 пикселей) {# place_14 {width: 120px;}} ]]>1 Морфология в лексиконе ● Полный синтаксический анализ — слова для понимания разбираются на морфемы — производные слова, построенные из морфем
2 Морфология в лексиконе ● Полный анализ — для понимания слова разбираются в морфемы — в производственных словах, построенных из морфем ● Полный список — в понимании люди получают доступ к целым словам — в производстве люди дают целые слова
3 Морфология в лексиконе ● Модель расы — в понимании слова оба разбираются на морфемы и ищутся как единое целое — побеждает самый быстрый путь — в производстве (???)
4
Морфология в лексике ● Модель расы — в понимании слова оба анализируются на морфемы и ищутся как единое целое — выигрывает самый быстрый маршрут — в производстве (???) ● Модель двойного маршрута — в понимании (??) — в производстве создаются регуляры. из морфем нерегулярные элементы извлекаются как целое из памяти
из морфем нерегулярные элементы извлекаются как целое из памяти
5 Морфология в лексике ● По-разному ли обрабатываются словообразование и словообразование? –Инфлективные аффиксы: -s, -ed, -ing, -er, -est –Деривационные аффиксы: re-, -ment, -ly, -hood, -ate
6 Морфология в лексиконе ● По-разному ли обрабатываются словообразование и словообразование? –Инфлективные аффиксы: -s, -ed, -ing, -er, -est –Деривационные аффиксы: re-, -ment, -ly, -hood, -ate ● Деривация изменяет основное значение ● Флективное добавляет такую информацию, как время, число, человек
7 Морфология в лексиконе ● Доказательства того, что интонации добавлены, а не предопределены — оговорки Слава Чаксу… Доктрины и Завет — Регуляризация »найдены, волы, опалены
8
Морфология в лексиконе ● Свидетельства того, что интонации добавлены, а не прописаны — оговорки Слава Чаксу Он ходит повсюду, рассказывая людям . .. Доктрины и Завет — Регуляризация »найдены, волы, опалены — Варианты Свекрови / свекрови
.. Доктрины и Завет — Регуляризация »найдены, волы, опалены — Варианты Свекрови / свекрови
9 Морфология в лексиконе ● Доказательства того, что интонации добавлены, а не предопределены — оговорки Слава Чаксу… Доктрины и Завет — Регуляризация »найдены, волы, опалены — Варианты Свекрови / Свекрови Книги Мормона / Книга Мормонов
10 Морфология в лексиконе –Лексическое решение задачи регулярные перегибы, простые, нерегулярные — не играют, простые — играют так же, как и пьесы — пения не пели пели так же хорошо, как пели
11 Морфология в лексиконе –Лексическое решение задачи регулярные перегибы, простые, нерегулярные — не играют, простые — играют, а играют — пели, пели, пели, пели, пели »Может ли это быть из-за орфографического сходства?
12 Морфология в лексике — ПЭТ-сканирование регулярные и нерегулярные перегибы используют разные части мозга
13 Морфология в лексиконе — регулярные и нерегулярные изменения в ПЭТ-сканировании задействуют разные части мозга — Проблема: все регулярные элементы обрабатываются вместе, затем все нерегулярные »Различные стратегии в каждом случае
14
Морфология в лексиконе. Обычные и нерегулярные изменения в ПЭТ-сканировании задействуют разные части мозга. Проблема: все регулярные элементы обрабатываются вместе, а затем все нерегулярные. »В каждом случае разные стратегии» Необходимо их перемежать »ПЭТ-сканирование слишком медленное.
Обычные и нерегулярные изменения в ПЭТ-сканировании задействуют разные части мозга. Проблема: все регулярные элементы обрабатываются вместе, а затем все нерегулярные. »В каждом случае разные стратегии» Необходимо их перемежать »ПЭТ-сканирование слишком медленное.
15 Морфология в лексиконе — Обычные и нерегулярные перегибы ПЭТ-сканирования используют разные части мозга — Проблема: все регулярные элементы обрабатываются вместе, затем все нерегулярные »В каждом случае разные стратегии» Необходимо чередовать их »Вы не можете использовать ПЭТ-сканирование, слишком медленно — Проблема: другие исследования не обнаружили разницы
16 Морфология в лексиконе ● LDT –Некоторые находят разные степени прайминга для словообразовательных и флективных слов baker> bake walking> walk
17 Морфология в лексиконе ● LDT –Некоторые находят разные степени прайминга для словообразовательного и флективного пекаря> запекать на ходу> ходить — другие не находят разницы
18
Морфология в лексиконе ● Удаление префикса (полный синтаксический анализ) — мы разлагаем слова на морфемы, затем ищем базу в ментальном лексиконе. Без префикса: слово с префиксом: слово с префиксом: переиздать слово с псевдопрефиксом: омолаживать, обмануть
Без префикса: слово с префиксом: слово с префиксом: переиздать слово с псевдопрефиксом: омолаживать, обмануть
19 Морфология в лексиконе ● Удаление префикса (полный синтаксический анализ) — мы разлагаем слова на морфемы, затем ищем базу в ментальном лексиконе без префикса: слово быстро RT с префиксом: переиздать быстрое слово RT с псевдопрефиксом: омолаживать, обмануть медленное RT — медленное, потому что у людей есть удаленный аффикс и поиск по запросу * juvenate и * ceive
20 Морфология в лексиконе ● Удаление префикса (полный синтаксический анализ) — мы разлагаем слова на морфемы, затем ищем базу в ментальном лексиконе без префикса: слово быстро RT с префиксом: переиздать быстрое слово RT с псевдопрефиксом: омолаживать, обмануть медленное RT — медленное, потому что у людей есть удаленный аффикс и поиск по запросу * juvenate и * ceive
21 год Морфология в лексиконе ● Полный список — если слова состоят из морфем (имеющих значение) в Интернете, как вы учитываете de- и con-, которые не имеют постоянного значения? –Любители языка сохраняют приставки дикобразы <наложницы
22 Морфология в лексиконе ● Полный список — если слова построены в Интернете по морфемам, вам часто приходится менять произношение тоже propel> propel +tion condense> condense + ation destroy> destroy + tion произнесение> произносится + iation seduce> seduce + ion
23 Морфология в лексиконе ● Полный список — если слова построены в Интернете по морфемам, вам часто придется также изменять произношение propel> propel +tion condense> condense + ation destroy> destroy + tion произнесение> произносится + iation seduce> seduce + ion –Wouldn не проще ли хранить их целиком с поверхностным произношением?
24
Морфология в лексиконе ● Полный список — если слова построены онлайн на основе деривационных морфем, то можно ожидать оговорок, которые переключают морфемы indulge + ment 25
Морфология в лексиконе ● Полный список — если слова построены онлайн на основе деривационных морфем, то можно ожидать оговорок, которые переключают морфемы indulge + ment 26
Морфология в лексиконе ● Полный список — сложные и простые слова распознаются одинаково быстро bak + er vs. 27
Морфология в лексиконе ● LDT с парами слов –не слово в паре лафтор прогресс –обе мономорфная атака дикобраза –обе суффиксный строитель принтер –один суффиксный, один без суффиксов, но с тем же орфографическим принтером клеветы 28 год
Морфология в лексиконе ● LDT с парами слов — не слово в паре лафтор или прогресс — обе мономорфные атаки дикобраза — оба суффикса Builder printer — один суффиксный, один без суффиксов, но с тем же орфографическим клеветническим принтером — они обрабатывались дольше, чем строитель / принтер –Это показывает, что мы можем идентифицировать морфемы, а не то, что мы должны 29
Морфология в лексиконе ● Частота влияет на RT — это частота отдельного слова (окно, окна)? –Или частота помещения (частота окна + частота окон)? 30
Морфология в лексиконе ● Частота влияет на RT — это частота отдельного слова (окно, окна)? –Или частота помещения (частота окна + частота окон)? –Кумулятивная частота поддерживает синтаксический анализ –Отдельная частота поддерживает хранение всего слова 31 год
Морфология в лексиконе ● Частота влияет на RT — река чаще, чем реки — окна чаще, чем окна — частота реки + реки такая же, как частота окна + окна riverrivers windo ws window 32
Морфология в лексиконе ● Частота влияет на RT –RT к реке быстрее, чем к рекам –RT –RT к окнам быстрее, чем к реке River River Windowwindow 33
Морфология в лексиконе ● Частота влияет на RT –RT к реке быстрее, чем к рекам –RT к окнам быстрее, чем к реке –Похоже, что сохраняются отдельные слова, а не только root riverrivers windowswindow 34
Морфология в лексике ● Эксперимент на испанском языке –Кумулятивная частота miedo (s) «страх» –Кумулятивная частота labio (s) “lip” labios 322labio 24 miedos 25miedo 338 35 год
Морфология в лексике ● Эксперимент в испанском labios 322labio 24 miedos 25miedo 338 36
Морфология в лексике ● Эксперимент в испанском labios 322labio 24 miedos 25miedo 338 37
Морфология в лексике ● Что это значит? labios 322labio 24 miedos 25miedo 338 38
Морфология в лексике ● Что это значит? ● То же самое, что и в голландском и итальянском labios 322labio 24 miedos 25miedo 338. 39
Морфология в лексиконе ● Середина подхода к дороге — слова хранятся как целые. 40
Морфология в лексиконе ● Середина подхода к дороге — Слова хранятся как целые — Слова связаны с другими словами, которые фонологически, семантически и орфографически похожи 41 год
Фонология в лексике ● Эффект ванны — начало и конец слов более заметны. В состоянии ToT люди чаще запоминают звуки начала и конца. Это должно относиться к хранению 42
Фонология в лексиконе ● Эффект ванны — начало и конец слов более заметны. В состоянии ToT люди чаще запоминают начальные и конечные звуки. Это должно иметь отношение к хранению — сохраняется ритмический образец. 43 год
Фонология в лексиконе ● Сохраняется слоговая информация — смеси сохраняют в неизменном виде завтрак + обед = поздний завтрак, * нарушение 44 год
Фонология в лексиконе ● Сохраняется слоговая информация — смеси сохраняют в неизменном виде завтрак + обед = поздний завтрак, * утолить жажду + голод = голод, * голод 45
Фонология в лексиконе ● Сохраняется слоговая информация — смеси сохраняют иней в неизменном виде завтрак + обед = поздний завтрак, * утолить жажду + голод = голод, * thirgry — речевые ошибки сохраняют неизменность крик + вопль = оболочка, * должен 46
Фонология в лексиконе ● Сохраняется слоговая информация — смеси сохраняют иней в неизменном виде завтрак + обед = поздний завтрак, * утолить жажду + голод = голод, * thirgry — речевые ошибки сохраняют неизменность крик + вопль = оболочка, * большой + сильный = стриг, * строгий 47
Фонология в лексиконе ● Слова с похожими звуками связаны между собой — ошибки связаны с похожими звуками. 48
Фонология в лексиконе ● Слова с похожими звуками связаны между собой — ошибки связаны с похожими звуками религиозная профессия (процессия) включает фрикативные слова, забит мозг (утечка), включает озвученные остановки 49
Фонология в лексиконе ● Связи между похожими словами приводят к образцу, который можно обобщить на другие слова –tollude + ion =? 50
Фонология в лексиконе ● Связи между похожими словами приводят к образцу, который можно обобщить на другие слова –tollude + ion =? толлюдион толлюзионный сбор 51
Фонология в лексиконе ● Связи между похожими словами приводят к образцу, который можно обобщить на другие слова –tollude + ion =? tolludion tollusion tollution — это знание происходит из коллизии> коллизии, заблуждения> заблуждения насмешки> насмешек 52
Фонология в лексиконе ● Связи между похожими словами приводят к образцу, который можно обобщить на другие слова — скажите эти слова: setty rotain fitguard 53
Фонология в лексиконе ● Связи между похожими словами приводят к образцу, который можно обобщить на другие слова — скажите эти слова: settyflap rotain [t] fitguardglottal stop — Как вы знаете, как их произносить? 54
Вариант реализации ● Идея о том, что пониманию звуков способствует активация части мозга, контролирующей артикуляцию. 55
Воплощение ● Идея о том, что пониманию звуков способствует активация части мозга, которая контролирует артикуляцию ● Когда вы слышите слово, загорается область вашего голосового тракта. 56
Воплощение ● Идея о том, что восприятию звуков способствует активация части мозга, которая контролирует артикуляцию ● Когда вы слышите слово, загорается область вашего голосового тракта ● Когда вы смотрите спорт, загораются зоны контроля мышц — зрители движутся синхронно со спортсменами 57
Воплощение ● Идея о том, что восприятию звуков способствует активация части мозга, которая контролирует артикуляцию ● Когда вы слышите слово, загорается область вашего голосового тракта ● Когда вы смотрите спорт, загораются зоны контроля мышц — зрители движутся синхронно со спортсменами –Смотреть футбол — все равно что играть в него 58
Воплощение ● Когда вы видите, что кто-то улыбается, плачет, смеется, вы чувствуете то же самое. 59
Воплощение ● Когда вы видите, что кто-то улыбается, плачет, смеется, вы чувствуете то же самое — Эксперимент: люди смотрят на лица и описывают, что они делают. 60
Воплощение ● Когда вы видите, что кто-то улыбается, плачет или смеется, вы чувствуете то же самое — Эксперимент: люди смотрят на лица и описывают, что они делают — Когда они видят улыбающееся лицо, они улыбаются, прежде чем назвать действие 61 год
Воплощение ● Как воплощен язык? –LDT по предложениям, которые я принимаю на себя (плохое предложение) Я беру деньги у Боба Я передаю деньги Бобу 62
Воплощение ● Как воплощен язык? –LDT по предложениям, которые я беру начало за (плохое предложение) Я беру деньги у Боба. 63
Воплощение ● Как воплощен язык? –LDT в предложениях, которые я беру начало за окончание (плохое предложение) Официант несет поднос Боксер бьет рефери — Субъекты ответили нажатием кнопки открытой ладонью или сжатым кулаком RT, когда кулак означал «хорошее предложение» — быстро для «боксера» бьет рефери »- медленное означает« Официант несет поднос » 64
Воплощение ● Как воплощен язык? –LDT в предложениях, которые я беру начало за окончание (плохое предложение) Официант несет поднос Боксер бьет рефери — Субъекты ответили нажатием кнопки открытой ладонью или сжатым кулаком RT, когда кулак означал «хорошее предложение» — быстро для «боксера» бьет рефери »- медленно для« Официант несет поднос »RT, когда открытая рука означает« хорошее предложение »- медленно для« Боксер бьет рефери »- быстро для« Официант несет поднос » 65
Воплощение ● Как воплощен язык? –Люди читали предложение, а затем видели картинку. 66
Воплощение ● Как воплощен язык? –Люди читали предложение, а затем видели картинку. Соответствует ли картинка предложению? –Далее и рядом противопоставлены в предложениях. Овца подходит к вам и блеет. Овца блуждает на другую сторону холма от вас и блеет. –Далее и рядом были противопоставлены на фотографиях Овца крупным планом и овца вдали 67
Воплощение ● Когда овца была близко в предложении и на изображении RT была быстрой ● Когда овца была близко в предложении и далеко на картинке RT была медленнее 68
Воплощение ● Когда овца была близка в предложении, а изображение RT было быстрым ● Когда овца была близко в предложении и далеко на картинке RT была медленнее ● Когда овца была далеко в предложении и далеко на картинке RT была быстрой ● Когда овца была далеко в предложении и близко на картинке RT был медленнее 69
Воплощение ● Как воплощен язык? –LDT по предложениям, которые я беру начало за (плохое предложение) Я беру деньги у Боба. моторная пыль + y против фантазийной печати + er против камбалы
моторная пыль + y против фантазийной печати + er против камбалы


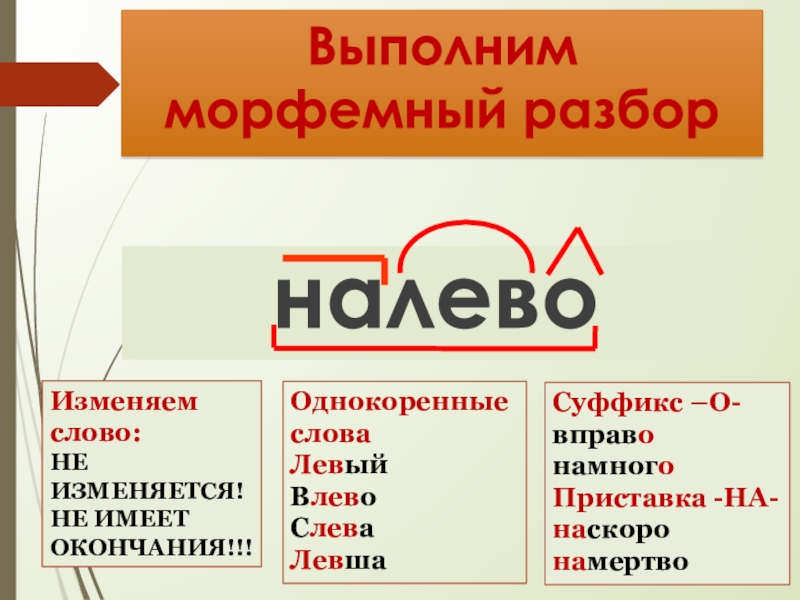
 Я отдаю деньги Бобу — Субъекты ответили джойстиком »в сторону или от RT, когда« в сторону »означало« хорошее предложение »- быстро для« Я беру деньги » деньги от Боба »- медленно на« Я отдаю Бобу деньги ».
Я отдаю деньги Бобу — Субъекты ответили джойстиком »в сторону или от RT, когда« в сторону »означало« хорошее предложение »- быстро для« Я беру деньги » деньги от Боба »- медленно на« Я отдаю Бобу деньги ». Соответствует ли картинка предложению? –Далее и рядом были противопоставлены в предложениях Овца подходит к вам и блеет Овца блуждает на другую сторону холма от вас и блеет
Соответствует ли картинка предложению? –Далее и рядом были противопоставлены в предложениях Овца подходит к вам и блеет Овца блуждает на другую сторону холма от вас и блеет