Разбор слова «красный» по составу (морфемный разбор)
Выполним морфемный разбор слова «красный», обратившись к его происхождению.
Пламя костра бросало кра́сный отсвет на лица туристов.
Интересующее нас слово обозначает признак предмета и отвечает на вопрос: какой?
По этим грамматическим признакам выясним, что эта лексема является прилагательным. Морфемный разбор слова «кра́сный» начнем с выяснения окончания. Учитываем, что окончание бывает только у изменяемых слов.
Окончание
Прилагательное «красный» изменяется по родам, числам и падежам. Чтобы определить окончание, изменим его по родам и числам:
- красный цветок;
- красная роза;
- красное платье;
- красные листья.
Очевидно, что словоизменительной морфемой, то есть окончанием, в форме прилагательного единственного числа мужского рода «кра́сный» является -ый. Его не включаем в основу слова — красн-.
Корень слова «красный»
При морфемном разборе анализируемого слова может доставить затруднение определения границ корня, так как элемент -н- очень похож на суффикс, как и в составе следующих слов:
- гора — горный хребет;
- вода — водный путь;
- слава — славный.
Отметим, что эти прилагательные являются производными от однокоренных существительных с помощью суффикса -н-.
Чтобы понять, является ли -н- суффиксом в морфемном составе рассматриваемой лексемы, обратимся к его происхождению.
Слово «красный» в старину означало «красивый«, поэтому говорили:
Красна изба углами, а девица — пирогами.
У него ближайшими родственниками являлись существительные:
- краса
- красота
- красавица
Но с течением времени произошло сращение суффикса -н- с этимологическим корнем крас-, и теперь в современном русском языке это качественное прилагательное имеет следующий морфемный состав:
красный — корень/окончание.
Это прилагательное сузило свое лексическое значение и в прямом смысле стало обозначать только алый цвет. Корень красн- прослеживается во множестве родственных слов:
- красненький
- красноватый
- покраснеть
- покраснение
- закраснеться
- краснота
- красноречие
- краснотал.
Аналогично не выделяется -н- в качестве суффикса в морфемном составе качественных прилагательных:
- бедный человек;
- нежный голос.
Морфемный анализ слова / Справочник :: Бингоскул
Морфемный анализ слова – это разбор слова по составу.
Слово состоит из морфем, минимальных, неделимых значимых частей.
Морфемы слова
Корень – значимая часть слова, содержащая в себе основное лексическое значение; с помощью нее подбирается ряд однокоренных слов. При морфемном анализе выделяется значком . Слова, состоящие из двух корней, называются сложными.
Приставка – неизменяемая часть слова, стоящая перед корнем и служащая для образования новых слов. При морфемном анализе обозначается значком .
В слове может быть одна, две и более (реже) приставки.
Суффикс – неизменяемая часть слова, стоящая после корня и служащая для образования новых слов. При морфемном анализе обозначается значком .
Слово может содержат более одного суффикса.
Окончание – изменяемая часть слова, стоящая после суффикса или корня (если нет суффикса) и служащая для образования форм одного и того же слова. При морфемном разборе обозначается значком .
Окончание может быть нулевым.
Основа – часть слова без окончания. При морфемном анализе обозначается значком .
Постфикс – часть слова, стоящая после окончания, служащая для образования новых слов. При морфемном анализе обозначается значками .
существует два постфикса — -СЯ, -СЬ.
Способы и принципы морфемного анализа
Для быстрого и правильного морфемного разбора необходимо придерживаться нескольких принципов.
1. Принадлежность к части речи. Изменяемость-неизменяемость слова. В неизменяемых словах полностью отсутствует флексия (окончание). Чтобы правильно ее выделить, необходимо изменить форму слова, не меняя значения:
- правило (ед.ч.) – правила (мн.ч.)
- худею (1 лицо) – худеешь (2 лицо)
- белый (муж.р.) – белая (жен.р.)
наверно, быстро, учитывая – неизменяемые части речи
Морфемы могут различаться в зависимости от части речной принадлежности слова.
2. Подбор однокоренных слов. Нельзя забывать о существующей омонимии корней (одинаковое написание, но разное значение).
Соленый, соль, посолить, пересолить
Солист, солировать, соло
3. Необходимо указать, если в слове есть формообразующие аффиксы (служат для образования формы слова).
Короткий – короче – суффикс образует форму простой сравнительной степени
Служит, служил – суффикс образует форму прошедшего времени
4. Учитывать словообразовательные связи, т.е. для правильного вычленения морфем составить словообразовательную цепочку («способ матрешки»). Вычленять аффиксы, постепенно подбирая производящие основы для конкретного слова.
Вычленять аффиксы, постепенно подбирая производящие основы для конкретного слова.
В данном примере словообразовательная цепочка помогла определить, что в слове льдинка – два суффикса, в слове снежинка один суффикс.
План морфемного анализа слова
- Определить часть речи
- Изменить форму слова и выделить окончание (если есть)
- Определить, есть ли формообразующие суффиксы.
- Выделить основу слова, формообразующие суффиксы не входят в основу слова
- Подобрать однокоренные слова и выделить корень
- Составить словообразовательную цепочку, выделить приставку, суффикс, постфикс
Этапы морфемного анализа
(Как разобрать слово?)
Подберезовика
- Определяем часть речи. Подберезовик – существительное, изменяемая часть речи, значит в нем есть окончание.
- Изменим форму слова, чтобы выделить окончание: подберезовика – подберезовик – подберезовиков – подберезовиком. В исходном слове изменилась часть слова – У, следовательно, это окончание.
- Часть слова без окончания выделим как основу: подберезовик-.
- Для выделения корня подберем однокоренные слова. Лучше, если это будут разные части речи: подберезовик – береза – березовый – березняк. Одинаковая часть слова, передающая основное лексическое значение –БЕРЕЗ—. Для проверки определим лексическое значение исходного слова: подберезовик – гриб, который растет в березовом лесу, вблизи берез.
- Для вычленения словообразующих морфем составим словообразовательную цепочку в обратном порядке, т.е. к каждому производному слову подберем производящую основу.
подберезовик – березовый – береза.
Видим, что в слове отделилась приставка ПОД-, суффиксы –ИК-, -ОВ-.
- Выделим словообразующие аффиксы.
- В слове подберезовик нет формообразующих морфем.

Схема (порядок) морфемного анализа
Окончание → основа слова → корень → приставка, суффикс, постфикс
Примеры морфемного анализа
Устный разборКласс – существительное, изменяется по родам, числам и падежам: класс-класса-классы. Окончание нулевое.
Все слово является основой – класс-.
Однокоренные слова: классный, классовый. Корень слова – класс-.
Словообразовательная цепочка: класс – классный – классовый. «Способ матрешки» (из большего – меньшее) применить нельзя, т.к. слово состоит из одного корня, основа является производной.
Письменный разборПримеры письменного разбора
(формообразующий суффикс –Л-)
(буква –Л- играет роль соединительной гласной – интерфикса, поэтому в основу слова не входит. Нельзя утверждать, что происходит чередование фонем –Б- и –БЛ-, т.к. ни в одной другой форме слова ЛЮБИТЬ такого чередования нет, только в форме 1 лица)
Смотри также:
Морфемный разбор слова по составу
Что такое морфема? Это минимальная значимая часть слова — корень, приставка, суффикс, окончание.
Все морфемы подразделяются на корневые и некорневые.
Некорневые морфемы в свою очередь, делятся на:
— словообразующие: приставка и словообразующий суффикс
— формообразующие: окончание и формообразующий суффикс.
Все виды формообразующих морфем, а именно — окончание, формообразующий суффикс, не входят в основу слова и, выражая грамматические значения, не изменяют лексического значения слова.
Примечание: основа слова — это обязательный элемент морфемной структуры слова, выражающий лексическое значение слова.
Давайте в режиме онлайн проведём морфемный разбор слова. Кстати, его часто по ошибке называют «морфермный», но это неправильно.
Схема полного морфемного разбора слова по составу
1. Выполните графический разбор слова
3. Запишите основу слова без формообразующих морфем: окончания и формообразующих суффиксов.
4. Составьте словообразовательную цепочку если слово с несвязанными корнями. Если слова со связными корнями — подберите одноструктурные слова.
5. Запишите корень, подберите однокоренные слова, укажите возможные чередования в корнях гласных и согласных звуков.
5. Выпишите суффиксы и приставки.
Примечание:
Иногда можно наблюдать такое явление, как наложение (аппликация) морфем, возникающая путем суффиксации словосочетания по всем местам. Как это выглядит? А вот так:
рас/ссориться,
омск/ский,
розов/оватый,
повсем/местный.
То есть приставка и корень частично накладываются друг на друга. По морфемном разборе слова по составу онлайн обязательно надо это учитывать: при/иду, при/иму и т. д.
Ну и напоследок весёлое стихотворение, которое можно использовать как шпаргалку при разборе.
МОРФЕМИЧЕСКАЯ УЛЫБКА
Переделанная песня «Улыбка » — муз. В.Шаинского, м/ф «Крошка Енот»
От приставки станет смысл точней.
Без приставки любой корень сиротинка.
«по» приставь к простому слову «бег»
и увидишь сразу разницу в картинках.
Прибежать и убежать, забежать, перебежать,
отбежать, вбежать, сбежать… Ну, сколько можно?
А за корнем суффикс есть, не один, их всех не счесть…
Не пугайся, всё не так уж безнадежно.
И пускай меняются они,
и кичатся своей значимостью в слове,
в корень зри, он главный и один
остается неизменным в этой своре.
Корень все слова родит: Родина, народ, родник,
род, родня, родименький, урод бездарный…
Родственников надо знать, звать, искать и выбирать,
тех особенно, в которых слог ударный.
Если слово будем мы склонять,
окончанье можно увидать —
штука нужная для связи слов по смыслу.
Вот теперь, наверняка, услыхав издалека
фразу: «мол, моя твоя не понимает» —
будешь знать, кто говорил — части слова не учил
и в сравнении с тобой морфем не знает.
Но, чтоб точно утверждать, слово надо разобрать,
например, простое слово — «улетаю».
Порядок разбора | Особенности выделения морфемы | Примеры |
окончание | Чтобы выделить в слове окончание, определяем часть речи. Следует помнить, что у неизменяемых слов (н-р: несклоняемые имена существительные, наречия) нельзя выделить окончание. Затем изменяем форму слова ( у сущ.: изменяем число, падеж, у прил.: род, число, падеж.; у глаг.: время, число, род или лицо). Помни, что у неопределенной формы глагола есть показатель ть, ти–(суффикс/окончание), договорились выделять . Изменяемая часть слова- Если окончания в данной форме нет, но оно может проявиться- это нулевое окончание. | Лес, лес-а, лес-у… Морск-ой, морск-ая, морск-ие, морск-ого; Гулял, гулял-а, гулял-и… |
основу | Часть слова без окончания- основа. Выдели основу | Морск-ой, лесник- |
корень | Чтобы определить в слове корень, подбираем родственные (или однокоренные слова). | Лесник-лесной, лесовик- лес-лесок Корень ЛЕС |
приставку | ( Если она есть), стоит вначале слова (попробуйте ее отбросить или заменить, а потом проверьте, есть ли такая приставка в других словах.) Приставки служат для образования новых слов. | Расчёска образовалось от чесать, рас- можно заменить: при-ческа, кроме того, рас- употребляется в других словах: рас-пределить, рас-пил и т.д |
суффикс | (Если есть), стоит после корня, их может быть несколько, приведи примеры других слов с тем же суффиксом. | Например слово «грузовик», корень груз, оставшуюся часть пробуем разделить: грузов-(ой)/-ик, -ик-это суффикс, он употребляется в других словах: мост-ик, двор-ик; -ов- тоже суффикс, так в словах: сосн-ов-ый, порт-ов-ый |
 Их общая часть- это .
Их общая часть- это .Сайт учителя русского языка Гвоздиковой Елены Ивановны
Морфемный разбор слова
Здравствуйте, дорогие ребята!
Сегодня мы повторим, что такое морфемы, а также отработаем и закрепим порядок морфемного разбора слова.
Задание 1.
Запишите в тетрадь слова в составе словосочетаний, графически объясните написание приставок.
Ра_будить, бе_дарный, и_пытать, _жимать, и_возчик, бе_печный, в_карабкаться, и_дательство, ни_кий, ра_писаться, в_бираться.
Вспомним!
— Что такое морфема?
— Посмотрите интерактивную таблицу и вспомните, что называется корнем, приставкой, суффиксом, окончанием.
— Что нужно сделать, чтобы определить основу слова?
— Как найти корень слова?
Задание 2.
Выполните тест.
— Какую роль играет приставка?
Задание 3.
Тренажёр
Запомните!
Потренируемся!
Откройте учебник на стр. 25. Упр. 632. Внимательно прочтите задание. Выполните морфемный разбор слов по образцу, выбрав одну из трёх цифр.
Упр. 636. Спишите слова путём поморфемного письма, распределяя их на 3 группы.
Домашнее задание: Упр. 641. Задания по упражнению смотри ниже.
1. Выпишите слова с приставками, распределяя их на две группы. Какое слово вы выписали в обе группы? Слов с какими приставками нет в орфографическом минимуме? Приведите пять примеров таких слов.
2. Выпишите слова с орфограммой «Гласные а — о в корнях с чередованием» и объсните выбор написания.
3. Запишите существительные и прилагательные с суффиксами. Суффиксы выделите.
4. Составьте словообразовательные цепочки слов лекарство, настроение, радостный.
5. Запишите все глаголы в составе словообразовательных пар со словами, от которых они образованы.
6. Запишите поморфемно слова удивительный, безжалостный, беззаботный
.7. Какие способы словообразования вам известны? Приведите пять примеров слов, образованных с помощью способа, не представленного в орфографическом минимуме.
Подготовиться к контрольной работе по разделу «Словообразование».
Р.S. Вопросы по уроку можно задавать в чате.
Урок русского языка в 5 классе по теме «Морфемный разбор слова»
Тема: Морфемный разбор слова (5 класс)
Цель:
Образовательная:
— познакомить учащихся с порядком морфемного разбора слова;
— формировать практические знания по теме.
Развивающая:
— развивать умения рассуждать, анализировать, делать выводы по теме;
— развивать логическое мышление, память и внимание.
Воспитательная:
— воспитывать ответственность, чувство товарищества и стремление к индивидуальной самореализации;
— воспитать любовь к русскому языку.
Метод: репродуктивный с элементами эвристического
Оборудование:
— карточки с заданиями;
— учебник по русскому языку за 5 класс (под ред. Т.Ладыженской).
Основные проблемы:
1. Повторение теоретических и практический сведений по разделу «Морфемика»;
2. Порядок действий при морфемном разборе.
ХОД УРОКА
Целевая установка.
Актуализация.
Сегодня у нас с вами необычный урок. Мы его начнем с небольшой разминки.
-синтаксический разбор предложения
Зима укутала деревья в шубы, развесила на заборах снежные ковры.
— фонетический разбор слова зима.
Молодцы, ребята! Вы справились с заданием.
Новые понятия и способы действия
Еще раз посмотрите на слово ЗИМА. Давайте разберем это слово по составу, то есть выделим приставку, корень, суффикс, окончание, если таковые здесь есть.
( ЗИМ А )
Совершенно верно. Вот именно об этом мы и будем сегодня говорить.
Вот именно об этом мы и будем сегодня говорить.
Откройте тетради, запишите число, классная работа и тему нашего урока.
( Двадцатое января
Классная работа
Морфемный разбор слова)
И целью урока является: научиться правильно делать морфемный разбор слов.
Ребята, давайте подумаем: А какая наука изучает состав (строение) слова? (Морфемика).
А для того, чтобы вспомнить основные теоретические моменты данной темы, мы повторим основные понятия. Я буду называть вам лексическое значение, а вам нужно узнать морфему и дать ей определение.
Наименьшая значимая часть слова. (морфема)
Главная значимая часть слова. (корень)
Морфема, стоящая перед корнем и служащая для образования новых слов. (приставка)
Слова, имеющие один корень, называются … (однокоренными или родственными)
Морфема, стоящая после корня и служащая для образования слов(суффикс)
Часть слова без окончания. (основа)
Давайте еще раз повторим. Без чего не может существовать слово? (без корня). Что мы еще выделяем при разборе слова по составу (приставку, суффикс, окончание, основу).
Главное – запомните, что разбор слова по составу называется морфемным разбором.
Правильную последовательность морфемного разбора вы мне сами скажите, прочитав её в параграфе учебника. П.81 стр. 27. Давайте его прочитаем, выделим последовательность.
Запомните эту последовательность!!!
Формирование умений и навыков
А теперь закрепим нашу тему:
Морфемный разбор слов: беззаботный, подбежать, садик, игрушка
Задание на смекалку:
ПРИСТАВКА
КОРЕНЬ
СУФФИКС
ОКОНЧАНИЕ
СЛОВО
походка
слово
сестрицы
река
налетели
ученик
куст
молчит
коньки
мудрец
старость
домик
Проверка.
ПРИСТАВКА
КОРЕНЬ
СУФФИКС
ОКОНЧАНИЕ
СЛОВО
походка
слово
сестрицы
река
пословица
налетели
ученик
куст
молчит
научит
коньки
мудрец
старость
домик
мудрость
Физкультминутка
Запишите слова в 4 столбика соответственно схемам.
Прогулка, билет, выход, выскочка, выдумка, проезд, конец, забег, соринка, ягодка.
Составить слова по данным схемам:
РЕЗЕРВ:
Упражнение из учебника 432
Домашнее задание
Выполнить карточки по пройденной теме.
Укажи части слов.
зернышко
загадка
повар
обед
побегут
осенний
умная
снежинка
зёрн
ышк
о
Выводы.
Ребята, что нового мы с вами сегодня узнали?
Опрос:
Что нужно определить в слове прежде, чем выделять морфемы?
Каков порядок выделения морфем?
Как выделить окончание?
Из каких морфем состоит основа?
Итоги, оценки
Выполнить карточку по пройденной теме
Укажи части слов
пёрышко
пёр
ышк
о
зернышко
загадка
повар
обед
побегут
осенний
умная
снежинка
Выполнить карточку по пройденной теме
Укажи части слов
пёрышко
пёр
ышк
о
зернышко
загадка
повар
обед
побегут
осенний
умная
снежинка
Морфемный разбор онлайн, разбор слов по составу, пример морфемного разбора
Морфемный разбор слова – это анализ составляющих слово морфем.
А морфема — минимальная неделима значимая часть слова, которая служит для образования новых слов и форм. Проанализировать состав и назначение морфем в составе конкретного слова позволяет морфемный разбор.
С помощью морфемного разбора слова выявляют какие именно морфемы составляют слово и как оно было образовано. Морфемный разбор дает возможность разобрать, понять структуру слова и слов родственных ему.
Разбор слова по составу
Разбор слова по составу, он же морфемный разбор, — позволяет определить способ образования слова. Наш словарь содержит более 700 000 разборов слов. В табличном варианте Вы можете увидеть все морфемы составляющие слово и онять каким образом оно было образовано.
Порядок морфемного разбора слова
Порядок морфемного разбора слова (разбора по составу) достаточно прост — производим разбор именно той формы слова, которая указана в задании.
Отличие морфемного разбора от словообразовательного разбора
Достаточно часто подразумевается, что морфемный разбор слова и разбор слова по составу (словообразовательный разбор) это одно и то же, но это не совсем так. Так в чем же отличия этих двух способов анализа слов?
- Морфемный разбор слова предполагает, что мы берем слово из задания без изменений, а для разбора по составу нужно использовать начальную форму слова (например, ходили; начальная форма — ходить)
- Морфемный разбор слова не требуется указывать является ли слово производным, а при словообразовательном разборе это обязательно.
- При морфемном разборе необходимо подбирать слова, образованные при использовании тех же морфем, а при слообразовательном разборе необходимо указывать именно способ образования слова.
Отличие морфемного разбора от морфологического разбора
Нужно понимать, что морфемный разбор слова и морфологичский разбор — это принципиально разные вещи. При Морфемном разборе слова анализируются только морфемы, входящие в состав этого слова, а при морфологическом разборе производится анализ слова как части речи, рассматриваются свойственные ему грамматические категории.
В качестве примера давайте сделаем морфемный разбор слова «Травинки» (Предложение: Травинки мягко шелестели в лунном свете)
- Шаг 1. Выписываем слово без изменений — травинки. Это существительное, множественного числа, изменяемое.
- Шаг 2. Определяем окончание слова. Окончание — «и».
- Шаг 3. Определяем основу слова — травинк.
- Шаг 4. Подберем однокоренные слова — для нашего слова это «трава», «травинка», «травка». Определяем корень слова — «трав».
- Шаг 5. Выделяем остальные морфемы — приставки в этом слове нет, суффиксы — «ин» и «к», соединительных гласных — нет.
Схематично морфемный разбор слова будет выглядеть так:
Слово травинка — травинка
Есть ли описание алгоритма mecab (синтаксический анализатор японских слов)?
Некоторые мысли, которые слишком длинные, чтобы уместиться в комментарии.
§ Какие лицензионные ограничения? MeCab имеет двойную лицензию, в том числе BSD, так что это настолько свободно, насколько это вообще возможно для вас. ВНИМАНИЕ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
§ Существует также Java-версия Mecab под названием Kuromoji, лицензированная Apache, также очень удобная для коммерческого использования.
§ MeCab реализует технику машинного обучения, называемую условными случайными полями, для морфологического анализа (разделения свободного текста на морфемы) и тегирования части речи (маркировки этих морфем) японского текста.Он может использовать различные словари в качестве обучающих данных, которые вы видели — IPADIC, UniDic и т. Д. Эти словари представляют собой компиляции морфем и частей речи и являются результатом лингвистических исследований, потраченных на многие человеческие годы. Связанная статья принадлежит авторам MeCab.
§ Другие применяли другие мощные алгоритмы машинного обучения к проблеме японского синтаксического анализа.
- Kytea может использовать как машины опорных векторов, так и логистическую регрессию для решения одной и той же задачи.C ++, Apache под лицензией, и статьи есть, чтобы читать.
- Rakuten MA написан на JavaScript, который также имеет широкую лицензию (опять же Apache), и поставляется с обычным словарем и облегченным словарем для приложений с ограничениями — хотя он не дает вам чтения кандзи. Здесь вы можете найти академические статьи с описанием алгоритма.
§ Учитывая вышесказанное, я думаю, вы можете видеть, что простых словарей, таких как EDICT и JMDICT, недостаточно для проведения расширенного анализа, который делают эти морфологические синтаксические анализаторы.И эти алгоритмы, вероятно, излишни для других, более простых для анализа языков (то есть языков с пробелами).
Если вам нужна мощь этих библиотек, вам, вероятно, лучше написать микросервис, который запускает одну из этих систем (я написал интерфейс REST для Kuromoji под названием clj-kuromoji-jmdictfurigana) вместо того, чтобы пытаться повторно реализовать их на C #.
Обратите внимание, что, похоже, существуют привязки C # к MeCab: см. Этот ответ.
В нескольких небольших проектах я просто просматриваю MeCab, затем читаю и анализирую его вывод.Мой пример TypeScript с использованием UniDic для Node.js.
§ Но, может быть, вам не нужен полный морфологический синтаксический анализ и тегирование части речи? Вы когда-нибудь использовали Rikaichamp, надстройку Firefox, которая использует JMDICT и другие общедоступные ресурсы с низким весом, чтобы добавлять гляды в текст веб-сайта? (Версия для Chrome также существует.) Он использует гораздо более простой деинфлектор, который, откровенно говоря, ужасен по сравнению с MeCab et al. но часто может выполнить свою работу.
§ У вас возник вопрос о структуре словарей (вы назвали их «базами данных»). Это примечание от Кимтаро (автора Jisho.org) о том, как добавить собственный словарь в IPADIC, может прояснить, по крайней мере, как работает IPADIC: https://gist.github.com/Kimtaro/ab137870ad4a385b2d79. Другие, более современные словари (я обычно использую UniDic) используют разные форматы, поэтому вывод MeCab отличается в зависимости от того, какой словарь вы используете.
Это примечание от Кимтаро (автора Jisho.org) о том, как добавить собственный словарь в IPADIC, может прояснить, по крайней мере, как работает IPADIC: https://gist.github.com/Kimtaro/ab137870ad4a385b2d79. Другие, более современные словари (я обычно использую UniDic) используют разные форматы, поэтому вывод MeCab отличается в зависимости от того, какой словарь вы используете.
Язык в Индии
1. ВВЕДЕНИЕ
При машинном переводе санскритских предложений основной задачей перевода является морфологический анализ слов санскрита.Поскольку слова представляют собой комбинацию более чем одного базового слова, они должны быть подразделены, а разделенные слова должны быть проанализированы. Морфологический анализ дает нам полную информацию о классе, к которому принадлежат отдельные слова. Морфологический синтаксический анализатор состоит из набора преобразователей, которые преобразуют заданный ввод в набор приемлемых и вероятных слов, формируя Морфологический словарь. Они также дают синтаксический анализ этих слов. Вторая часть синтаксического анализатора — это модуль Vichcheda, который разбивает ввод на основные слова санскрита.Наконец, компаратор сравнивает слова в словаре и вывод модуля Vichcheda и делает вывод, распознаны ли сгенерированные слова / слова. Анализ санскритских слов необходим, потому что проанализированный ввод определяет, какие фразы заменят санскритский текст при его переводе на любой другой язык.
Настоящий материал состоит из шести разделов, озаглавленных «Морфологический анализ», «Сандхи Виччеда на санскрите», «Разбор слов, основанных на сандхи», «Заключительные замечания» и «Приложение».Первые два раздела дают основу для понимания статьи. Раздел «Морфологический анализ» дает общее введение в морфологический анализ и иллюстрирует его на примерах. Идея о том, как сандхи исполняется на санскрите, дается в следующем разделе, который называется «Сандхи Виччеда на санскрите». Раздел под названием «Разбор слов, основанных на сандхи» составляет основу данной статьи. В нем представлена архитектура предлагаемой идеи синтаксического анализатора и обсуждается каждая из его частей, приводя примеры там, где это необходимо.Критический взгляд на настоящий материал дан в разделе «Заключительные замечания». В этом разделе также рассматриваются преимущества и возможные будущие улучшения. В разделе «Ссылки» перечислены различные книги и материалы, на которые есть ссылки в процессе разработки этого материала. В последнем разделе приведены эквиваленты деванагри римских шрифтов, используемых в этой статье для представления санскритского текста.
В нем представлена архитектура предлагаемой идеи синтаксического анализатора и обсуждается каждая из его частей, приводя примеры там, где это необходимо.Критический взгляд на настоящий материал дан в разделе «Заключительные замечания». В этом разделе также рассматриваются преимущества и возможные будущие улучшения. В разделе «Ссылки» перечислены различные книги и материалы, на которые есть ссылки в процессе разработки этого материала. В последнем разделе приведены эквиваленты деванагри римских шрифтов, используемых в этой статье для представления санскритского текста.
2. МОРФОЛОГИЧЕСКИЙ РАЗБОР
Морфологический синтаксический анализ слов, принадлежащих к естественным языкам, включает в себя обеспечение структуры данного ввода с указанием различных морфем, составляющих ввод, и того, как они связаны друг с другом.Морфемы — это более мелкие смысловые единицы слов. Эти морфемы можно в целом разделить на основы и аффиксы, которые могут быть приставками, суффиксами, инфиксами или циркумфиксами. В то время как префиксы — это те морфемы, которые могут появляться перед основанием, а постфиксы — это те, которые применяются к концу основы, циркумфиксы — это те морфемы, которые могут применяться с обеих сторон основы. Морфемы, классифицируемые как инфиксы, — это те, которые встречаются внутри основы.
Любой морфологический синтаксический анализатор должен состоять из частей, действующих как лексикон, дающий исчерпывающий список всех морфем, присутствующих в языке, морфотактических правил, определяющих положение одной морфемы по отношению к другой, и набора орфографических правил, определяющих, как две данные морфемы объединить.Лексика в сочетании с морфотактикой может быть смоделирована с помощью конечного автомата. Конечный автомат может быть каким-то преобразователем. Орфографические правила могут использоваться на этапе, когда необходимо, чтобы морфемы были объединены вместе, чтобы дать поверхностное слово.
Пример 1
Таким словом, как «книги» — «книга» и «-s» — это две морфемы. Когда слово «книги» разбирается, анализируемые выходные данные говорят нам, что это слово образовалось из-за того, что существительное под названием «книга» использовалось во множественном числе, т.е.е. вывод может быть чем-то вроде — (книга, Существительное, Множественное число). Эта информация впоследствии может быть использована для перевода слова «книги» на другие языки.
Когда слово «книги» разбирается, анализируемые выходные данные говорят нам, что это слово образовалось из-за того, что существительное под названием «книга» использовалось во множественном числе, т.е.е. вывод может быть чем-то вроде — (книга, Существительное, Множественное число). Эта информация впоследствии может быть использована для перевода слова «книги» на другие языки.
3. САНДИ ВИЧЧЕДА В САНСКРИТЕ
Входными данными для синтаксического анализатора являются слова, которые в дальнейшем могут быть объединением более чем одного санскритского слова. Такое систематическое сочетание слов называется сандхи. Санскритское слово сандхи означает «соединяться вместе». Сандхи — это слияние двух букв, вступающих в непосредственный контакт друг с другом.Когда два слова находятся рядом друг с другом, последняя буква одного слова и первая буква следующего слова вступают в непосредственный контакт и могут привести к объединению двух слов в одно слово большего размера. Это объединение происходит по правилам сандхи. На практике слово, составленное по правилам сандхи, может содержать любое количество слов меньшего размера.
В общих чертах, типы сандхи можно разделить на Сварасанди и Халсанди. Сварасанди имеет дело с сочетаниями гласных, а Халсанди — с сочетаниями согласных.
Пример 2
a) a + I = E как в sva + IraH = svEraH (сознательно действующий)
б) a + A = A, как в rAmeNAnIwaH = rAmeNa + AnIwaH (Принесено Рамой)
4. РАЗБОР СЛОВ НА ОСНОВЕ САНДИ
При синтаксическом анализе слов, сформированных с использованием орфографических правил sandhi, необходимо сгенерировать весь набор подслов, содержащихся в каждом входном слове, вместе с проанализированным выводом каждого такого подслова.Модель, которая помогает нам достичь этой цели, представлена на рисунке 1 ниже.
Модуль синтаксического анализа / генератора использует часть входных данных и генерирует возможные результаты разбиения, с которыми можно столкнуться. Эта информация хранится в морфологическом словаре, который действует как временный буфер. Другая строка, которая также генерируется парсером / генератором, используется модулем Vichcheda. Затем модуль Vichcheda преобразует это в соответствующую строку, которая соответствует правилам сандхи.Он также добавляет строку в начало оставшейся строки, полученной после разделения. Этот модуль отправляет измененные строки в компаратор. Компаратор сопоставляет входные данные, которые он получает из Морфологического словаря, с первой строкой, полученной из модуля Vichcheda. Следующая строка возвращается системе в качестве входных данных. Этот процесс повторяется до тех пор, пока входное слово не будет полностью проанализировано.
Эта информация хранится в морфологическом словаре, который действует как временный буфер. Другая строка, которая также генерируется парсером / генератором, используется модулем Vichcheda. Затем модуль Vichcheda преобразует это в соответствующую строку, которая соответствует правилам сандхи.Он также добавляет строку в начало оставшейся строки, полученной после разделения. Этот модуль отправляет измененные строки в компаратор. Компаратор сопоставляет входные данные, которые он получает из Морфологического словаря, с первой строкой, полученной из модуля Vichcheda. Следующая строка возвращается системе в качестве входных данных. Этот процесс повторяется до тех пор, пока входное слово не будет полностью проанализировано.
Различные блоки на рисунке 1 описаны под:
Модуль синтаксического анализатора / генератора:
Этот модуль представляет собой набор датчиков, описанных ранее.Преобразователи — это машины Мура с несколькими выходами. Датчики определены как:
- Конечное множество состояний s0, s1, s2, где s0 — начальное состояние.
- Алфавит A = ({буквы деванагри} U null) для входных строк и двух наборов выходных строк.
- Выходной Алфавит O C (P {часть речи, падеж, число, род, времена,} U null).
- Таблица выходных данных, которая дает три набора выходных данных.
- Графическое изображение, которое представляет переходы между состояниями. Общее представление показано на рисунке 2 ниже.
Все преобразователи объединены в модуль системы морфологического анализа, называемый синтаксическим анализатором / генератором. Конструкция этого набора преобразователей показана на рисунке 3, где каждый преобразователь относится к типу, показанному на рисунке 2. Для каждого слова используется один преобразователь, который, если применимо, учитывает его наклон. Часть склонения обрабатывается добавлением к корню соответствующих суффиксов (полученных из таблиц склонений санскрита). Эту работу выполняет преобразователь. Вход в модуль направлен на преобразователи. Преобразователи разбирают ввод по буквам. Когда было прочитано достаточное количество входных букв, указывающих на возможную грамматическую характеристику, это указывается в выходных данных «синтаксической строки». В каждом состоянии вывод, соответствующий строке, то есть «частичный корень», сохраняется в выходной таблице. Это отправляется в модуль Виччеда. Кроме того, строка «вероятного подслова» генерируется различными преобразователями и сохраняется в морфологическом словаре.
Эту работу выполняет преобразователь. Вход в модуль направлен на преобразователи. Преобразователи разбирают ввод по буквам. Когда было прочитано достаточное количество входных букв, указывающих на возможную грамматическую характеристику, это указывается в выходных данных «синтаксической строки». В каждом состоянии вывод, соответствующий строке, то есть «частичный корень», сохраняется в выходной таблице. Это отправляется в модуль Виччеда. Кроме того, строка «вероятного подслова» генерируется различными преобразователями и сохраняется в морфологическом словаре.
Пример 3
Санскритское слово рамасйакарья (ачарья Рамы) представляет собой сочетание слов «рамасья» (богов) и «ачарья» (ачарья или учитель). Преобразователь сначала проанализирует «рамасья», а затем на следующем ходу проанализирует «Ачарья». Преобразователь для ‘rAma’ приведен в качестве примера на рисунке 4.
Модуль Виччеда
Этот модуль состоит из трех частей, а именно.Word Producer, Split Generator и Правило Сандхи. Модуль принимает в качестве входных данных «частичный корень» и следующую за ним входную букву / буквы. Если такой входной буквы / букв нет, то модуль производителя Word просто передает «частичный корень» компаратору, иначе генератор разделения генерирует возможные разделенные выходные данные, соответствующие прочитанной входной букве / буквам. Он определяет, какие выходные данные разделения должны быть сгенерированы в соответствии с Правилами Сандхи, содержащимися в блоке Правил Сандхи модуля Виччеда.Word Producer объединяет «частичный корень» со всеми первыми частями пары выходных данных, генерируемых модулем Split Generator. Он отправляет эти составные слова вместе со вторыми частями пары выходных данных в Компаратор. Некоторые правила модуля Sandhi Rule приведены ниже:
А-> а, а | а, А | А, А | А, А
I-> i, i | я, я | Я, я | Я, я
U-> u, u | u, U | U, u | U, U
е-> а, я | А, я | а, я | А, Я | е, а | а, е
E-> a, e | A, e | a, E | A, E
о-> а, и | А, и | а, U | A, U | о, а | а, о
О-> а, о | А, о | а, О | А, О
г-> а, д | A, q |
y-> i, (гласная) | Я, (гласная) v-> u, (гласная) | U, (гласная) ау-> е, (гласная) av-> o, (гласная) Ay-> E, (гласная) Av-> O, (гласная) Где, (гласный) = {a, A, i, I, u, U, e, E, o, O}
Морфологический словарь
Набор «вероятных подслов», сгенерированный анализатором / генератором, временно сохраняется в морфологическом словаре. Словарь является изменчивым в том смысле, что он очищается после каждой успешной генерации подслова ввода. Эти слова, присутствующие в настоящее время, сравниваются в компараторе. В меньшей области Морфологический словарь содержит очень мало слов или всего одно слово. Но по мере того, как область слов расширяется, Морфологический словарь может оказаться большим подспорьем в поиске нужного слова.
Словарь является изменчивым в том смысле, что он очищается после каждой успешной генерации подслова ввода. Эти слова, присутствующие в настоящее время, сравниваются в компараторе. В меньшей области Морфологический словарь содержит очень мало слов или всего одно слово. Но по мере того, как область слов расширяется, Морфологический словарь может оказаться большим подспорьем в поиске нужного слова.
Компаратор
Четыре входа, а именно. две строки из Word Producer, вход из Морфологического словаря и правильный синтаксический анализ каждого такого входа достигают Comparator.Этот модуль сравнивает список слов, имеющихся в словаре, с первой выходной строкой пары выходных данных из Word Producer. Если Comparator находит точное совпадение строки в словаре, он отправляет эту строку вместе с соответствующим синтаксическим анализом в качестве вывода. Он также отправляет вторую строку, полученную от Word Producer, обратно в качестве входных данных для всей системы морфологического синтаксического анализатора. Если вторая строка отсутствует, а существование первой строки подтверждено, то Компаратор указывает, что ввод был распознан.На любом этапе, если компаратор не может найти совпадение, это означает, что ввод не распознается.
6. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
В машинном переводе санскритских слов нам нужно выполнить сандхи-виччеда вводимых нам данных. Таким образом, на самом первом этапе морфологического анализа нам необходимо рассмотреть разбиение слов. Таким образом, представленный документ помогает удовлетворить одну из самых основных потребностей переводчика санскрита.Система была обобщена для обработки любого количества возможных подслов для конкретного ввода. Описанная система может быть усовершенствована, чтобы заботиться обо всех возможных типах Сандхи, путем разработки правил, данных для Правила Сандхи. При использовании системы синтаксического анализа этого типа необходимо учитывать множество проблем. Один из них может заключаться в рассмотрении возможной неоднозначности, вызванной тем, что одно и то же слово (пример — «рамАБям» на рисунке 4) встречается в двух разных случаях. Решение этой проблемы должно включать возможность выбора одного синтаксического анализа из предложенных вариантов для каждого вхождения слова.Это может быть реализовано на более поздних этапах перевода.
Один из них может заключаться в рассмотрении возможной неоднозначности, вызванной тем, что одно и то же слово (пример — «рамАБям» на рисунке 4) встречается в двух разных случаях. Решение этой проблемы должно включать возможность выбора одного синтаксического анализа из предложенных вариантов для каждого вхождения слова.Это может быть реализовано на более поздних этапах перевода.
ССЫЛКИ
1. «Обработка речи и языка — введение в обработку естественного языка» Дэниела Джурафски и Джеймса Мартина, перепечатка 2000 г.
2. «Обработка естественного языка» Аксара Бхарати, Винит Чайтанья, Раджив Сангал.
3. «Введение в теорию компьютеров» — второе издание Даниэля И.А. Коэна
4.»Высшая грамматика санскрита» М. Р. Кале
5. «Сандхи Вивека» А.Варадараджа.
С. Апарна
[email protected]
М. Ингл
[email protected]
НАРУШЕНИЕ ЯЗЫКА ПРИ АУТИЗМЕ | ОБ ОБУЧЕНИИ ПОЭЗИИ В ИНДИЙСКОМ КОНТЕКСТЕ — Некоторые наблюдения и предложения | АПОДДХААРАПАДААРТХА — ПРИНЦИП ИНТЕЛЛЕКТУАЛЬНОЙ АБСТРАКЦИИ | МОРФОЛОГИЧЕСКИЙ РАЗБОР СЛОВ НА ОСНОВЕ «САНДИ» В САНСКРИТСКОМ ТЕКСТЕ | КИТАЙСКИЕ ЯЗЫКИ: НОВАЯ ЛЕКСИКОГРАФИЧЕСКАЯ ПЕРСПЕКТИВА ИЗ ГОНКОНГА | ОПАСНЫЕ ЯЗЫКИ — УНИКАЛЬНЫЙ ПРОЕКТ ПО ИХ СПАСЕНИЮ, Отчет Школы восточных и африканских исследований | ГЛАВНАЯ | СВЯЗАТЬСЯ С РЕДАКТОРОМ
Что такое слово? Введение в компьютерную лингвистику.
Что такое слово? Введение в компьютерную лингвистику.
Что это за слово? Это один из самых обманчиво простых вопросов, которые я знаю. Каждый скажет, что знает ответ, или, по крайней мере, скажет, что знает ответ, когда увидит его, но даже носители языка могут с этим не согласиться. Словарь не очень полезен, так как многие словари содержат специальные определения, состоящие из нескольких предложений, которые в основном сводятся к следующему: «слово — это единица языка, которая что-то означает.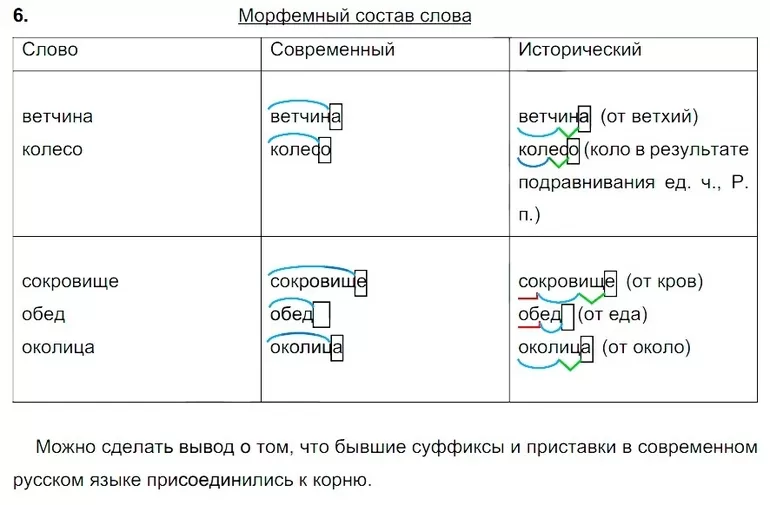 »
»
Давайте забегаем вперед и предположим, что мы знаем, что такое слово, или что мы можем заставить носителей языка определять большинство слов в большинстве случаев. Более того, предположим, что наша цель — научить компьютер понимать данный язык. Поскольку люди изначально изучают языки, изучая слова и базовую грамматику, кажется хорошим выбором попытаться заставить компьютеры распознавать слова. Итак, наша цель: заданную строку английских букв вставить между словами пробелы.
Что такое слово?
Чтобы показать, что приведенное выше упражнение не является полностью надуманным, давайте рассмотрим некоторые тонкости идеи этого слова.Это только для людей, интересующихся «лингвистической» частью «компьютерной лингвистики», но если вы хотите прочитать ее, нажмите здесь.Слова — это лингвистические конструкции, а не орфографические.
Язык предшествует письму. Дети могут говорить и понимать язык до того, как научатся читать и писать на этом языке. Я уже не говорю о неграмотных людях или языках, не имеющих формализованной системы письма. Кроме того, при изучении иностранного языка обычно изучаются слова и основы грамматики задолго до того, как учиться письму, особенно если система письма кардинально отличается, например.g., говорящий по-английски, изучающий китайский или арабский языки. Это все, чтобы сказать, что слова — это не просто формальные орфографические конструкции, такие как кавычки или апострофы. Кажется, что слова обладают некоторой лингвистической реальностью, и поэтому их стоит изучать с точки зрения языка.Ничто из этого не говорит нам, что такое слово, только то, что носители языка верят, что такое слово существует. Тем не менее, англоговорящие люди могут сказать, что то, что мы видим на бумаге, более или менее точно: пробелы представляют собой разрывы между словами.Это позволяет избежать ответа на вопрос, поскольку идея «слова» существует кросс-лингвистически. Следовательно, определение слова должно охватывать все такие непредвиденные обстоятельства.
Синтетические языки
Сначала несколько определений. Морфема — это наименьшая единица языка, имеющая значение. «Dogs» имеет две морфемы: «dog» и «s», причем первая указывает на собаку, а вторая — на множественность. Точно так же «выглядело» как две морфемы с суффиксом «-ed», указывающим на время глагола «смотреть».«Синтетические языки имеют высокое соотношение морфем и слов. Англоговорящие могут быть знакомы с комично длинным немецким словом. На самом деле, немецкий позволяет использовать произвольно длинные слова. Например, Donaudampfschiffahrtsgesellschaftskapitän означает« капитан парохода Дунайской компании. «Это одно слово или четыре? И даже в английском переводе» пароход «одно или два слова?Другой крайностью являются синтетические языки, такие как венгерский, в которых грамматических аффиксов гораздо больше, чем в английском или немецком.Идеи «условного», «будущего» и т. Д. Отмечены отдельными морфемами, прикрепленными к слову. По-английски «Я бы пошел» — это три слова, а по-венгерски — всего одно или, возможно, два.
Фонетика против орфографии
Но большинство лингвистов даже не сказали бы, что вышесказанное не так уж и актуально. В лучшем случае это просто дает нам больше доказательств того, что слова — это что-то реальное. Однако, когда мы говорим, между словами нет «пробела», как в английском языке.Если вы когда-либо учили иностранный язык, вы, вероятно, помните момент, когда осознали, что слышите слова, а не звуки. Раньше это звучало как один непрерывный поток чепухи — и в любом случае вы были правы насчет части «одного непрерывного потока».Однако после того, как вы немного выучите язык, в вашем уме проясняются закономерности, и вам бросаются в глаза слова. То есть люди могут взять одну непрерывную цепочку «символов» (то есть звуков) и разбить их на слова.Представьте, что вместо анализа строки английских символов мы анализируем некоторое фонетическое представление предложения.
Внезапно наши упражнения перестают казаться такими неинтересными; на самом деле, мы будем делать что-то очень похожее на то, что делают люди, когда разбирают язык, который они понимают.

 Внезапно наши упражнения перестают казаться такими неинтересными; на самом деле, мы будем делать что-то очень похожее на то, что делают люди, когда разбирают язык, который они понимают.
Внезапно наши упражнения перестают казаться такими неинтересными; на самом деле, мы будем делать что-то очень похожее на то, что делают люди, когда разбирают язык, который они понимают.Предположения
Очевидно, что мы не можем интегрировать все вышеупомянутые тонкости, поскольку это было бы равносильно написанию компьютерной программы, которая фактически обрабатывала бы текст так же, как это делают люди.Скорее, мы будем работать при следующих предположениях: во-первых, у нас уже есть база данных (называемая «лексиконом») слов; во-вторых, это полная база данных. Первое предположение не совсем неожиданное, поскольку среди лингвистов широко распространено предположение, что у людей есть именно такая база данных. Второе, однако, гораздо труднее проглотить, поскольку обычно понимается, что лексика содержит корневые морфемы плюс общую информацию о морфологии, фонологии, фонотактике и т. Д. Языка.Если бы я сказал, что «koop» было глаголом, вы бы сразу поняли, что «kooped», «koops», «kooper» и т. Д. Также были действительными словами. Точно так же, хотя «cromulent» на самом деле не является английским словом, говорящий по-английски знает, что это могло быть (и что, кроме того, это, вероятно, было бы прилагательным), но что «plkdjfhg» никогда не могло быть английским словом. Наша база данных, однако, очень тупая и очень несжатая: должна присутствовать каждая перестановка каждого слова, иначе эта перестановка не будет считаться словом.Мы делаем это предположение только для упрощения проблемы. Я могу быть довольно хорошим программистом, но я недостаточно хорош, чтобы написать компьютерную программу, которая автоматически изучает синтаксис, морфологию и фонологию языка.
Хватит болтовни, перейдем к коду.
Алгоритм
Алгоритм, который я собираюсь использовать, представляет собой простой вероятностный алгоритм динамического программирования. Допустим, у нас есть строка типа «therentisdue», и мы хотим проанализировать ее как «причитающаяся арендная плата». Предполагая, что наши обучающие данные являются репрезентативными для языка в целом (большое предположение, конечно), тогда мы знаем, что вероятность каждого слова равна # ошибочности слова в данных по общему количеству слов в данных.Идея состоит в том, что лучший синтаксический анализ строки с учетом наших обучающих данных — это синтаксический анализ, который имеет наибольшую вероятность возникновения.
Предполагая, что наши обучающие данные являются репрезентативными для языка в целом (большое предположение, конечно), тогда мы знаем, что вероятность каждого слова равна # ошибочности слова в данных по общему количеству слов в данных.Идея состоит в том, что лучший синтаксический анализ строки с учетом наших обучающих данных — это синтаксический анализ, который имеет наибольшую вероятность возникновения.Для студентов CS это должно кричать «динамическое программирование». Для всех остальных я объясню. Самый очевидный способ найти синтаксический анализ с наибольшей вероятностью — это найти все возможные синтаксические анализы, а затем найти тот синтаксический анализ, который имеет наибольшую вероятность. Реализовать алгоритм таким образом невозможно, поскольку имеется 2 синтаксических анализа n-1 (почему?).Вместо этого мы сделаем следующее. Псевдокод:
BestParse [0]: = "" FOR i in [1..length of StringToParse] DO FOR j в [0..i) DO parse: = BestParse [j] + StringToParse [j, i] ЕСЛИ СТОИМОСТЬ (анализ)Пусть входная строка будет s. В каждой точке i, то есть для начальной подстроки s длиной i, определите, какой будет лучший синтаксический анализ до i. Теперь предположим, что мы знаем, как лучше всего выполнять синтаксический анализ в i для некоторого фиксированного i. Чтобы найти лучший синтаксический анализ в i + 1, мы пытаемся вставить разрыв после каждой начальной подстроки j для j
Вот иллюстрация, опять же со словом «нет». Допустим, мы уже разобрали "therenti". Это означает, что мы знаем лучший синтаксический анализ для каждой начальной подстроки этой строки, например, "t", "th", "the" и т. Д. Лучшим синтаксическим анализом, вероятно, будет "the-rent-i", поскольку каждая из них является word и любой другой синтаксический анализ содержит по крайней мере одно неслово.
После каждого символа в строке нам нужно решить, вставлять ли разрыв. Стоит ли вставлять пробел после первого символа? Что ж, да, поскольку лучший синтаксический анализ отдельного символа определенно является этим символом. Итак, на первом этапе мы получаем «t- | herentis». Если мы отдаем предпочтение отдельным буквам вместо слов (это наш выбор), то лучшим синтаксическим анализом после второго символа будет «t-h- | erentis». Однако после третьего синтаксического анализа будет "the- | rentis", поскольку "the" - это слово, и поэтому лучший синтаксический анализ первых трех букв - "the" (мы знаем это, потому что, по предположению, мы уже вычислили лучший синтаксический анализ для "the").Затем мы получаем «the-r- | entis», за которым следует «the-re- | ntis» и так далее, пока не дойдем до «the-ren- | tis». После этого шага мы пробуем «the-rent- | is». Это очень хороший синтаксический анализ, так как у нас есть три слова. Наконец, мы пробуем «the-rent-i- | s», который имеет меньшую вероятность, чем предыдущий синтаксический анализ, потому что «s» не является словом. Следовательно, «арендная плата есть» - это синтаксический анализ, который мы сохраняем как лучший синтаксический анализ этого слова.
Я реализовал этот алгоритм на C ++, который вы можете скачать здесь. По умолчанию он использует Библию KJV в качестве обучающих данных, а это означает, что то, что он считает словами, может быть немного забавным.Например, слово «грех» считается очень распространенным.
 Теперь посмотрим, как алгоритм определяет из этого наилучший синтаксический анализ «этого».
Теперь посмотрим, как алгоритм определяет из этого наилучший синтаксический анализ «этого».SEM1A5 — Часть 2 — Морфологический анализ
SEM1A5 — Часть 2 — Морфологический анализМорфологический анализ
Этот раздел состоит из трех частей. В первой части вводятся некоторые основные термины по морфологии, в частности, морфема , аффикс, префикс , суффикс , связанный и свободный формы. Во втором рассматриваются традиционные способы группировки языков, такие как , изолирующий , агглютинативный и склоняющийся . В последнем разделе рассматриваются некоторые морфологические процессы, концентрируясь только на тех, которые имеют большее отношение к инженерии естественного языка.
В последнем разделе рассматриваются некоторые морфологические процессы, концентрируясь только на тех, которые имеют большее отношение к инженерии естественного языка.
Некоторая терминология
Лингвистика стремится описывать язык. Любое описание требует некоторой терминологии для его описания. Мы можем рассматривать это как технический словарь дисциплины. В естественных языках есть свои термины для описания самих себя. Например, мы в разговорной речи говорим о «словах», «фразах», «предложениях» и «абзацах».Знаем ли мы, что означают эти слова?
Мы рассмотрим только определение этого слова. В таком тексте мы можем легко обнаружить «слова», потому что они отделены друг от друга пробелами или знаками препинания. Однако, если вы запишете обычную разговорную речь, вы обнаружите, что между словами нет разрывов. Несмотря на это, мы могли снова и снова выделять единицы, которые мы используем в речи, но в разных комбинациях. Это говорит о том, что существует небольшая единица чего-то вроде слова. Но как определить «слово»? Мы все согласимся, что черный и птица — это слова. blackbird одно слово или два слова? blackbird s — это то же слово, что и blackbird , или отдельное слово?
На эти вопросы нет простых ответов. Ситуация более сложная, потому что
- лингвистическая теория также должна учитывать, как звуки ( фонология ) связаны со «словами»
- потому что английский — относительно простой язык на данный момент: в других языках есть гораздо более сложные способы изменения форм слов, чем в английском.
Морфология — это изучение структуры и образования слов. Его наиболее важной единицей является морфема , которая определяется как «минимальная единица значения». (Учебники лингвистики обычно определяют его немного иначе как «минимальную единицу грамматического анализа».) Рассмотрим такое слово, как «несчастье». Он состоит из трех частей:
Есть три морфемы, каждая из которых несет определенное значение. un означает «нет», а ness означает «находиться в состоянии или состоянии». Happy — это свободная морфема , потому что она может появляться сама по себе (как «слово» само по себе). Связанные морфемы должны быть присоединены к свободной морфеме, и поэтому не могут быть словами сами по себе. Таким образом, у вас не может быть предложений на английском языке, таких как «Джейсон чувствует себя сегодня очень беспомощным».
un означает «нет», а ness означает «находиться в состоянии или состоянии». Happy — это свободная морфема , потому что она может появляться сама по себе (как «слово» само по себе). Связанные морфемы должны быть присоединены к свободной морфеме, и поэтому не могут быть словами сами по себе. Таким образом, у вас не может быть предложений на английском языке, таких как «Джейсон чувствует себя сегодня очень беспомощным».
Вооружившись этими определениями, мы можем взглянуть на способы, используемые для классификации языков в соответствии с их морфологической структурой.
Классификация морфологических структурных типов
Выше было высказано предположение, что английский с морфологической точки зрения является довольно простым языком.Подразумевается, что другие языки ведут себя по-другому, и это является основой данной схемы классификации. Лингвисты предыдущих поколений были весьма заинтересованы в создании генеалогических деревьев языков, чтобы показать, какие современные языки произошли от каких более ранних, и, возможно, даже иметь возможность восстановить утраченные языки. Морфологическая структура — это всего лишь один из способов группировки языков.
В этой классификации обычно три класса.
- Изолирующие языки
- Слова изолирующего языка неизменны.Другими словами, он состоит из свободных морфем, поэтому здесь нет морфем для обозначения такой информации, как грамматическое число (например, множественное число) или время (прошлое, настоящее, будущее). Китайский часто цитируется как пример такого языка (хотя некоторые утверждают, что вьетнамский является лучшим примером). Транслитерированное предложение:
gou bú ài chi qingcài
дословно можно перевести как:собака не любит есть овощи
В зависимости от контекста это может означать любое из четырех следующих предложений:собака не любит есть овощи
собаки не любят есть овощи
собаки не любят есть овощи
собаки не любят есть овощи - Агглютинативные языки
- Мой словарь дает определение агглютината как «соединить как с клеем; (языка) объединять простые слова без изменения формы для выражения сложных идей». Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
- ler = множественное число
- i = притяжательный (например, его, ее, его )
- den = аблатив (например, грамматическое окончание «падежа», показывающее источник, например, из дома).
Чтобы завершить наш пример, нам понадобится турецкое существительное, в данном случае ev , что означает «дом».Из этого существительного можно составить следующие слова:
- ev: дом
- evler: домов
- evi: его / ее дом
- evleri: его дома, их дома
- evden: из дома
- evlerden: от домов
- evinden: из его дома
- evlerinden: из его / ее домов, из их домов
(Обратите внимание, что за притяжательной морфемой i обычно следует n перед den.)
В этом примере важно заметить, как все морфемы представляют «единицу значения» и как они остаются абсолютно идентифицируемыми в структуре слов. Это контрастирует с тем, что происходит в последнем классе: склоняющиеся языки.
- Языки склонности
- Слова в склонных языках имеют разные формы, и можно разбить слова на более мелкие единицы и пометить их так же, как турецкий пример был представлен выше.Однако в результате получается очень запутанная и противоречивая версия. Обычные примеры основаны на латыни и основаны на знании латинского грамматического примера, которого нет у большинства английских студентов. В качестве простого примера, латинское слово «я люблю» — это амо. Это означает, что окончание o используется для выражения значений, от первого лица, («я» или «мы»), в единственном числе, , в настоящем времени, , а также других значений.
 Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
В этой классификации всего три класса.Действительно ли возможно объединить все языки мира в три класса? С одной стороны, невозможно поместить какой-либо из языков в какой-либо из классов, потому что каждый язык нечист. То есть, если вы посмотрите достаточно внимательно, вы обнаружите флексию в основном в агглютинативных языках, флексию в изолирующих языках, агглютинацию в флективных языках и так далее.
Какие уроки мы можем извлечь из этого? Я думаю, есть два момента, на которые стоит обратить внимание. Во-первых, языки сильно различаются, и обобщения, основанные на опыте владения только одним языком (например, английским), могут быть легко противопоставлены другим языкам.Во-вторых, язык — это естественное явление, и «инструменты», которые мы используем для его изучения (например, классификации и технические термины), — всего лишь инструменты, которые могут быть несовершенными попытками описать что-то слишком сложное для нашей современной науки.
Морфологические процессы
В приведенном выше примере несчастья, мы видели два вида аффиксов: префикс и суффикс. Чтобы показать, что языки действительно сильно различаются, есть также инфиксы.Например, язык Bontoc с Филиппин использует инфикс um для преобразования прилагательных и существительных в глаголы. Таким образом, слово fikas, , что означает «сильный», преобразовано в глагол «быть сильным» путем добавления инфикса: f-um-ikas.
Существует ряд морфологических процессов, некоторые из которых более важны для НЛП, чем другие. Представленный здесь отчет является выборочным и необычным, поскольку он указывает на практические аспекты выбранных процессов.
- Перегиб
- Флексия — это процесс изменения формы слова так, чтобы оно выражало такую информацию, как число, личность, падеж, пол, время, настроение и аспект, но синтаксическая категория слова остается неизменной. Например, форма множественного числа существительного в английском языке обычно образуется из формы единственного числа путем добавления s.
- легковых / легковых
- стол / столы
- собака / собаки
Не нужно много времени, чтобы найти примеры, где приведенное выше простое правило не подходит. Итак, есть меньшие группы существительных, которые по-разному образуют множественное число:
- волк / волки
- нож / ножи
- переключатель / переключатели.
Еще немного подумайте, и мы сможем подумать о совершенно неправильных формах множественного числа, таких как:
- фут / фут
- ребенок / дет.
Английские глаголы относительно просты (особенно по сравнению с такими языками, как финский, в котором более 12 000 глагольных перегибов).
- косилка — штанга
- mow s — третье лицо единственного числа, настоящее время
- mow ed — прошедшее время и причастие прошедшего времени
- косить ing — настоящее непрерывное время
Аспекты НЛП
Такие языки, как французский или немецкий, имеют гораздо больше интонаций, чем английский, поэтому принято включать морфологические анализаторы в системы, которые обрабатывают эти языки. Системы НЛП для английского языка часто не включают каких-либо морфологических процессов, особенно если это небольшие системы.В тех случаях, когда системы на основе английского языка включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), а исключения (неправильные слова) перечислены отдельно. Это означает, что обычные формы нужно вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации. - Вывод
- Как было показано выше, словоизменение не меняет синтаксическую категорию слова.Деривация не меняет категорию . Лингвисты классифицируют словообразование в английском языке в зависимости от того, вызывает ли оно изменение произношения. Например, добавление суффикса ity изменяет произношение корня слова active , поэтому ударение находится на втором слоге: activity. Добавление суффикса al к Approve не меняет произношения корня: Approve.
Аспекты НЛП
Очевидное использование деривационной морфологии в системах НЛП — уменьшить количество форм слов, которые нужно сохранить.Таким образом, если уже существует запись для базовой формы глагола sing, , тогда должна быть возможность добавить правила для сопоставления существительных singers и singers одной и той же записи. Проблема заключается в том, что обнаружение производных певца от певца должно также позволить морфологическому анализатору вносить информацию, которая является особенной для певца . Это кажется немного непонятным, но пример прояснит это. Добавление к слову er указывает на то, что действие совершает человек.Эта семантическая информация должна быть добавлена к сохраненной информации из словарной статьи для корневой формы и , чтобы можно было найти правильное значение предложения. Это кажется прекрасным, но предположим, что следующие два слова: рекордер, и драгстер. Использование морфемы er не может обязательно означать кого-то, кто предпринимает действие, представленное корневой формой.Любая лингвистическая обработка, вероятно, приведет к обнаружению потенциальной двусмысленности, особенно там, где люди этого не ожидают.Деривационные морфологические анализаторы могут сделать это довольно легко, потому что они всегда пытаются сократить слова до более мелких единиц. Таким образом, слово на самом деле может быть проанализировано как на самом деле (т.е. само слово) и как относительно + союзник. Эта введенная двусмысленность может быть устранена с помощью более поздней синтаксической обработки, но, тем не менее, это означает, что требуется больше обработки (и, следовательно, более медленная система).
Деривационная морфология особенно полезна для машинного перевода.Успешный МП должен обрабатывать большие объемы текста, который может содержать много ранее невидимых слов. Некоторые слова являются неологизмами (то есть новыми словами). Если анализатор сможет преобразовать эти слова в их базовую форму, он сможет перевести это и, по сути, создать новое слово на целевом языке, просто следуя правилам. Приведу пару примеров: неологизмы часто имеют в качестве корня собственное имя. Знание того, как Thatcherite и Majorism образовались из имен собственных, могло позволить системе машинного перевода перевести их в идиоматический эквивалент на целевом языке.
- Полуаффиксы и комбинированные формы
- Полуаффиксы — это связанные морфемы, сохраняющие словесность. Примеры: анти-, контр-, -подобный и -заслуживающий внимания. Итак, мы можем иметь:
- против часовой стрелки или против часовой стрелки
- контрпример или контрпример
- птице или птице
- достойный внимания или заслуживающий внимания
Комбинированные формы даже более похожи на слова, чем полуаффиксы, и часто встречаются в технической литературе, например, индоевропейский или гастроэнтерит. Некоторые слова могут состоять полностью из связанных форм, но без свободной морфемы, например franco-phile.
Аспекты НЛП
Как и в случае деривационной морфологии, полуаффиксы и комбинирующие формы могут быть проанализированы на их морфемы и, как и в случае деривационной морфологии, могут быть использованы для анализа ранее невидимых слов. Расстановка переносов — особая проблема для таких языков, как английский и немецкий, и понимание полуаффиксов и комбинирования форм может способствовать выявлению необязательных и вероятных точек переноса при обработке текста. - Клитицизация
- Клитика — это элемент, который ведет себя как аффикс и слово. Однако они довольно сложны, поскольку также являются частью словообразования. В отличие от других морфологических явлений, клитики встречаются в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии.
Мы подробно остановимся на этом.
- «Клитика — это элемент, который ведет себя как аффикс и слово.«
- Английский язык имеет очевидную клитику, « ‘s », используемую для обозначения притяжательного падежа (иногда известного как родительный падеж). Лингвисты называют его энклитикой , что означает, что это клитика, которая прикрепляется справа от слова, как и суффикс.
- «Однако они довольно сложны в том, что они также являются частью словообразования».
- « ‘s » присоединяется («наклеивается») к слову или фразе, к которой относится притяжательное.
- «В отличие от других морфологических явлений, клитики возникают в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии».
- « ‘s » присоединяется к определенному составному элементу независимо от того, где он встречается в предложении. В следующих двух примерах « ‘s » сначала присоединяется к существительному, а затем к предлогу:
- девочка пингвин
- машина, в которую я врезалась фарами
Английский также показывает другой источник клитификации. Некоторые слова можно сократить до более короткой формы. Например, Я в Бирмингеме можно уменьшить до Я м в Бирмингеме и Это весенний цыпленок можно уменьшить до Я весенний цыпленок. Обратите внимание, что сокращаемое слово имеет свою собственную синтаксическую категорию и будет фигурировать само по себе при любом синтаксическом анализе предложения.
Аспекты НЛП
Клитицизация — интересная проблема для НЛП.Обычные системы НЛП являются модульными и поэтому имеют различные модули морфологической, синтаксической и семантической обработки. Однако такие клитики, как «‘s », не могут быть удовлетворительно проанализированы только на одном уровне. Морфологический анализатор должен уметь отделить клитику от присоединенной к ней морфемы, но он не может сделать это правильно, если не знает синтаксической структуры высказывания. В традиционной архитектуре системы НЛП синтаксическая структура недоступна морфологическому анализатору.Существуют различные методы, которые можно использовать для решения этой проблемы, например, передача как можно большего количества альтернатив от морфологического анализатора синтаксическому анализатору и надежда, что последний сможет разрешить неоднозначности. Другой метод может заключаться в попытке провести морфологический и синтаксический анализ параллельно — или, возможно, морфология и синтаксис — несовершенные способы описания языка, и мы должны найти лучшую описательную модель.

 Лингвисты классифицируют словообразование в английском языке в зависимости от того, вызывает ли оно изменение произношения. Например, добавление суффикса ity изменяет произношение корня слова active , поэтому ударение находится на втором слоге: activity. Добавление суффикса al к Approve не меняет произношения корня: Approve.
Лингвисты классифицируют словообразование в английском языке в зависимости от того, вызывает ли оно изменение произношения. Например, добавление суффикса ity изменяет произношение корня слова active , поэтому ударение находится на втором слоге: activity. Добавление суффикса al к Approve не меняет произношения корня: Approve. 
 Однако они довольно сложны, поскольку также являются частью словообразования. В отличие от других морфологических явлений, клитики встречаются в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии.
Однако они довольно сложны, поскольку также являются частью словообразования. В отличие от других морфологических явлений, клитики встречаются в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии.
Критика морфологии Морфология была частью основной лингвистики на протяжении шестидесяти или более лет.Как, по-видимому, происходит со всеми лингвистическими теориями, время служит только для выявления все новых и новых недостатков в теории и дальнейших разработок, направленных на укрепление исходной теории — даже до той стадии, когда она настолько обременена, что рушится полностью.
Морфология, безусловно, расширилась и представляет собой отдельную область с обширным техническим словарем, таким как morph и allomorph (упомянем только два наиболее распространенных). Более подробное описание см. В Lyons (1968; стр. 180–194), а описание некоторых трудностей с морфемами см. У Палмера (1971, стр. 187–199), который писал:
«Однако сегодня ясно, что концепция морфемы имеет лишь ограниченную ценность.
