1) фонетический разбор слова НЕ МОГУ 2)морфемный разбор слова ПОБЕГУ 3) пунктационый разбор предлож Где ты, радуга-дуга.
Расставим знаки препинания:
1. Взволнованный и нетерпеливый, Абай даже не заметил, как они доехали до Верблюжьих горбов. В песнях его, нежных и волнующих душу, была и радость, наполнявшая его грудь, и тихая грусть. 3.
Изысканно одетая, гибкая, как молодое весеннее деревце, ясноглазая и
приветливая, она каким-то особенным сиянием одобрила юрту. 4. Часто, вконец уставший, измученный, он засыпал прямо в степи. 5. И время, прожитое с
бабушкой, овеянное её лаской, осталось в памяти Касыма как не ясное
воспоминание, как сладкий сон. 6. Сумрачный и озлобленный, он даже не
пытался скрыть своего подавленного настроения. 7. Во время весеннего
половодья мчится широкий поток бурный и стремительный, мощный и
волнующий. 8. Абай не уставал слушать бабушку, весь поглощённый её
рассказом, сосредоточенный и внимательный. 9. Голос её, удивительно
приятный и в разговоре, в песне, был совершенно пленительным. 10. Решение,
твердое и непоколебимое, внезапно возникло в нём. 11. Зачарованный
луной, Абай не открывал глаз от сияющего диска. 12. Стоит снять с беркута
колпачок — плененная птица тотчас кинет быстрый, мечущий искры, гордый, непокорённый взгляд, ещё более отважный и выразительный, чем когда она
находится на воле.
-Подожди меня.Я скоро вернусь.
-И как долго тебя ждать?Тише.Это пройдёт очень
быстро
-Хорошо.Буду ждать в правом крыле здания
Прости больше нечего придумать
 ..
..Спросить, потребовать ответ, узнать, зать вопрос, полюбопытствовать, поинтересоваться.
Морфологический разбор слова «мог»
Часть речи: Глагол в личной форме
МОГ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «МОЧЬ»
| Слово | Морфологические признаки |
|---|---|
| МОГ |
|
Все формы слова МОГ
МОЧЬ, МОГУ, МОЖЕМ, МОЖЕШЬ, МОЖЕТЕ, МОЖЕТ, МОГУТ, МОГ, МОГЛА, МОГЛО, МОГЛИ, МОГШИ, МОГИ, МОГИТЕ, МОГУЩИЙ, МОГУЩЕГО, МОГУЩЕМУ, МОГУЩИМ, МОГУЩЕМ, МОГУЩАЯ, МОГУЩЕЙ, МОГУЩУЮ, МОГУЩЕЮ, МОГУЩЕЕ, МОГУЩИЕ, МОГУЩИХ, МОГУЩИМИ, МОГШИЙ, МОГШЕГО, МОГШЕМУ, МОГШИМ, МОГШЕМ, МОГШАЯ, МОГШЕЙ, МОГШУЮ, МОГШЕЮ, МОГШЕЕ, МОГШИЕ, МОГШИХ, МОГШИМИ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «МОГ» в конкретном предложении или тексте, то лучше использовать морфологический разбор текста.
Найти синонимы к слову «мог»Примеры предложений со словом «мог»
1
не мог не смотреть на них, не мог стереть их, не мог не вызывать их.
2
Он не мог разлепить опухших век, не мог встать, не мог лежать, не мог вообще жить.
Суррогатный мир, Константин Уткин3
Ну пошутил, ну не мог ты заболеть им, не мог, не мог, не мог…
ЛЕДЯНАЯ КУПЕЛЬ. ПРОЗА XXI ВЕКА, Владимир Хованский4
Конечно, с Розановым
5
Положим, вы могли взять с него векселя, но ведь он мог их оспорить, мог доказывать, что они безденежные: взяты с него обманом, или насилием…
На ножах, Николай Лесков, 1870г.Найти еще примеры предложений со словом МОГ
Официальный сайт школы №2
Поздравляем победителей городских конкурсов24 января 2014
1. Бондаревича Егора ученика 3 Б класса (кл.руководитель Коваленко Л.В.) за лучшую декламацию в городском конкурсе литературно-музыкальных композиций «Чувства добрые я лирой пробуждал…» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии»
Бондаревича Егора ученика 3 Б класса (кл.руководитель Коваленко Л.В.) за лучшую декламацию в городском конкурсе литературно-музыкальных композиций «Чувства добрые я лирой пробуждал…» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии»
2. Устиновича Андрея — ученика 3 Г класса (кл.руководитель Куламова А.Н.), занявшего 1 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Традиционная кукла»
3. Кондратьеву Екатерину — ученицу 1 А класса (кл.руководитель Овчинникова Ю.А.),занявшую 1 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Рождественский ангел»
4. Болдыреву Дарью — ученицу 1 А класса (кл.руководитель Овчинникова Ю.А.),занявшую 1 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Настроение»
5. Цепелеву Василису — ученицу 4 В класс (кл.руководитель Данилова Т.А.) ,занявшую 1 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Традиционная кукла»
6. Быкова Романа — ученика 3 А класса (кл.руководитель Перепёлкина Н.В.), занявшего 2 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Бал в стиле Ретро»
7. Цергер Татьяну — ученицу 2 Г класса (кл.руководитель Роговая Л.А.), занявшую 2 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Традиционная кукла»
8. Волошину Дарью — ученицу 1 Б класса (кл.руководитель Низамутдинова Г.Ж.), занявшую 3 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Бал в стиле Ретро»
Волошину Дарью — ученицу 1 Б класса (кл.руководитель Низамутдинова Г.Ж.), занявшую 3 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Бал в стиле Ретро»
9. Бескову Анастасию — ученицу 4 Б класса (кл.руководитель Ермоленко О.И.), занявшую 3 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Настроение»
10. Якубова Ульяна — ученицу 1 А класса (кл.руководитель Овчинникова Ю.А.),занявшую 3 место в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии» В НОМИНАЦИИ «Рождественский ангел»
За оригинальность исполнения в городском конкурсе «Традиционная кукла» в рамках областного фестиваля детского и юношеского художественного и технического творчества «Юные таланты Московии»: Карпова Елизавета — ученица 3 Д класса , Полухин Михаил — ученик 3 А класса, Лучицкая Диана -ученица 1 Б класса, Старостин Андрей -ученик 4 А класса
ГДЗ по русскому языку 5 класс Рыбченкова, Алесандрова Решебник
В пятом классе изучение русского языка переходит на новый уровень. Дети уже считаются более взрослыми, а, соответственно, способными понять более сложные концепции, выполнять более интеллектуально насыщенные учебные действия. Рыбченкова Л.М., Алесандрова О.М., Глазков А.В. создали учебник и решебник для таких школьников. Его изданием, начиная с 2012 года, занимается издательство «Просвещение». Наиболее актуальной версией на данный момент считается издание 2019 года. На нашем сайте именно оно и представлено онлайн, а потому вы можете никогда не волноваться за качество и новизну представленной информации.
Чем конкретно ГДЗ Рыбченковой и Александровой поможет школьнику в 5 классе?
Чтобы приносить домой хорошие оценки и не чувствовать себя неуверенно на уроках, нужно прилагать некоторые усилия для учебы. Обязательно необходимо слушать пояснения учителя, однако по мере усложнения программы этого уже не достаточно. Следует также активно участвовать в обсуждениях, выходить к доске, следить за ходом дискуссии, особенно важно не отвлекаться на посторонние раздражители. Вне школы необходимо тщательно выполнять задания учителя на дом, своевременно устранять все недоработки, которые могли иметь место на уроках родной речи.
Обязательно необходимо слушать пояснения учителя, однако по мере усложнения программы этого уже не достаточно. Следует также активно участвовать в обсуждениях, выходить к доске, следить за ходом дискуссии, особенно важно не отвлекаться на посторонние раздражители. Вне школы необходимо тщательно выполнять задания учителя на дом, своевременно устранять все недоработки, которые могли иметь место на уроках родной речи.
Онлайн-решебник может помочь во время самостоятельных занятий предметом. Он содержит большое количество полезных комментариев, а также вспомогательных материалов. Часто бывает такие ситуации, что тема вроде бы усвоена, но чего-то не хватает, чтобы начать эффективно применять полученные знания на практике. В таких случаях нужно посмотреть на пример верного выполнения и распространить его на другие упражнения. Наши сборники обладают следующими положительными чертами:
- номера отсортированы с помощью табличного указателя;
- предложена только самая актуальная версия пособия;
- комментарии даны даже к самым простым вопросам;
- страница с верными ответами работает 24 часа в сутки и 7 дней в неделю. Заниматься можно когда угодно.
Материалы помогут повысить успеваемость, подготовиться к контрольным и проверочным работам. Ученик почувствует себя более уверенно, возможно, даже заинтересуется предметом.
Какие темы проходят по русскому языку с решебником Рыбченковой?
Рабочая программа этого года обучения весьма насыщена. Не стоит расслабляться и откладывать учебу на потом. Следует с первого дня серьезно засесть за уроки и выполнять все упражнения, ведь вот какие сложные и пространные разделы ждут пятиклассников:
- определение частей речи по вопросам, на которые отвечают слова;
- самостоятельные и служебные единицы. Имена существительные прилагательные, числительные, наречия, глаголы. Междометия, частицы, союзы, предлоги;
- морфологические разборы слов;
- развитие связной речи.
 Сочинения и творческие изложения.
Сочинения и творческие изложения.
 Сочинения и творческие изложения.
Сочинения и творческие изложения.Сборник заданий по русскому языку (авторы: Рыбченкова, Алесандрова, Глазков) предназначен для пятиклассников. Он соответствует всем федеральным образовательным стандартам (ФГОС), поэтому используется в школах практически повсеместно.
Создание когнитивной формы фонологических единиц: Проблема соответствия звуков речи в младенчестве может быть решена с помощью зеркального речевого взаимодействия, а не имитации
Основные моменты
- •
Механизм, с помощью которого дети учатся произносить L1, все еще не был учредил.
- •
Ребенок может использовать переформулировку своей продукции во время имитационных взаимодействий как доказательство эквивалентности.
- •
Зеркальное отображение лица, осуществляющего уход, решает проблему соответствия между звуками действия и речи.
- •
Прямая ассоциация голосового действия и звука создает перцептуомоторное представление речи.
Abstract
Теории о когнитивной природе фонологических единиц были ограничены предположением, что маленькие дети решают проблему соответствия звуков речи путем имитации, будь то слуховое или жестовое сопоставление с целевым процессом. Подражание со стороны ребенка подразумевает, что он проводит сравнение в одной из этих областей, которая, как предполагается, является модальностью основного представления звуков речи.Однако нет никаких свидетельств того, что проблема соответствия решается таким образом. Вместо этого мы утверждаем, что ребенок может решить эту проблему, отражая поведение своих опекунов в рамках имитационных взаимодействий, и что этот механизм более согласуется с данными о развитии. Базовое представление, сформированное зеркальным отображением, по своей сути является моторно-перцептивным. Он создается путем объединения речевого действия, выполняемого ребенком, и его переформулирования в речевой токен L1, который он слышит в ответ. Наше описание того, как развиваются производство и восприятие с использованием этого механизма, объясняет некоторые давние проблемы речи и согласовывает данные из психологии и нейробиологии.
Наше описание того, как развиваются производство и восприятие с использованием этого механизма, объясняет некоторые давние проблемы речи и согласовывает данные из психологии и нейробиологии.
Ключевые слова
Фонологические единицы
Базовое представление речи
Приобретение речи
Задача соответствия
Развитие произношения
Имитация
Зеркальное отображение
Рекомендуемые статьи Цитирующие статьи (0)
Авторы.Опубликовано Elsevier Ltd.
Рекомендуемые статьи
Цитирующие статьи
Генетическая фонетика может быть уловкой для определения значения ДНК — ScienceDaily
Большинство современных попыток расшифровать, как части генетического кода преобразуются в физические характеристики, сродни первоклассник пытается произнести слово буква за буквой — или, в данном случае, пару оснований.
Но исследователи из Университета Флориды разработали вычислительный метод, который больше похож на чтение целых слов за раз.
В мире, где способность науки транскрибировать генетический код организма растет с каждым днем все быстрее, этот метод может предложить столь необходимую эффективность в преобразовании кажущейся бесконечной строки символов в информацию, которая может излечить болезнь или создать новые урожаи.
Исследователи из Института продовольственных и сельскохозяйственных наук UF и Института генетики UF опубликовали результаты своей проверки метода в PLoS One, онлайн-журнале, выпускаемом Публичной научной библиотекой.
«Мы очень много работали, чтобы найти способы сбора генетической информации», — сказал Ронглинг Ву, ведущий исследователь проекта и профессор UF Research Foundation. «Теперь мы должны упорно трудиться, чтобы найти способы, чтобы использовать его.»
Во многих отношениях исследователи думают о геноме организма как о списках из четырех букв, представляющих четыре аминокислотных основания, повторяющихся в разном порядке. Цель состоит в том, чтобы найти смысл в последовательностях, выяснить, как вариации в образе влияют на физиологию организма.
Цель состоит в том, чтобы найти смысл в последовательностях, выяснить, как вариации в образе влияют на физиологию организма.
Человеческий код, например, состоит из 3 миллиардов букв. Между любыми двумя из нас 99,9% этих букв совпадают. Но именно последние 0,1 процента разницы, пронизанные всей нашей ДНК в виде однобуквенных изменений, и объясняют нашу уникальную идентичность — от цвета глаз до восприимчивости к болезням.
Эти различия называются однонуклеотидными полиморфизмами или SNP (произносится как «обрезки»).
Самый простой способ узнать, как SNP влияет на организм, — это собрать группу организмов, которые имеют разные вариации этой буквы в своем генетическом коде.
Но на физические черты обычно влияют несколько SNP, которые взаимодействуют иногда непредсказуемым образом — так же, как буква «е» в конце слова может изменить его произношение.
К счастью, правила генетики гласят, что SNP, влияющие на один и тот же признак, обычно каким-то образом связаны друг с другом, например, находятся рядом друг с другом.
МодельВу использует эти правила в сочетании со статистическим анализом реальных данных о генетически картированных организмах.В результате модель может находить целые группы SNP, связанных с физическим признаком.
Точно так же, как понимание общих фонетических принципов позволяет читателю озвучить целое слово, это дополнительное знание генетики позволяет модели Ву находить полные картины геномных / физических корреляций.
«Настоящее обещание работы Ву состоит в том, что она может дать исследователю возможность не тратить действительно удручающее количество времени на анализ отдельных нуклеотидов, а перейти непосредственно к выполнению генетической работы, которая будет иметь большее значение. — сказал Рори Тодхантер, исследователь, занимающийся генетикой собак в Корнельском университете.
В этой статье исследователи проверили свою модель, используя генетическую и физическую информацию от мышей, которая была впервые собрана в лаборатории Джеймса Чеверуда Вашингтонского университета в середине 1990-х годов. Затем они сравнили свои результаты с результатами генетического анализа за несколько лет.
Затем они сравнили свои результаты с результатами генетического анализа за несколько лет.
Это подтверждение было важным, сказал Вэй Хоу, первый автор статьи и доцент кафедры эпидемиологии и исследований политики здравоохранения UF. Но анализ современных данных станет настоящим ключом к пониманию важности этого метода.Например, генетическая информация мышей, использованная в этой статье, содержала всего несколько тысяч SNP. В выпуске журнала Nature от 29 июля было указано более 8 миллионов SNP для генома мыши.
«Это показывает, как нам нужно выйти за рамки рассмотрения SNP геномов по SNP», — сказал Чеверуд. «Представьте себе работу, которая впереди нас, если мы этого не сделаем».
Как морфологическая структура влияет на фонетическую реализацию в составных существительных английского языка
Data
Мы исследовали продолжительность согласных на границах составных внутренних, например:
- (4)
Согласный звук является частью первого существительного («N1»), как в (4), второго существительного («N2»), как в (6), или обоих, как в (5).Это позволило нам проверить, какие факторы влияют на какую часть границы. Другими словами, если происходит редукция, происходит ли это перед границей, после границы или по обе стороны границы?
Мы особенно хотели включить такие соединения, как crea m m ini , с двойной согласной на границе, чтобы максимизировать наши шансы на обнаружение парадигматического эффекта улучшения. Единственное предыдущее сообщение о таком эффекте для соединений — это Kuperman et al.(2007), которые обнаружили парадигматический эффект увеличения продолжительности интерфиксов в голландских соединениях. Хотя в английском языке нет интерфиксов, мы рассудили, что мы могли бы увидеть похожий эффект на сегменты на сложных внутренних границах, возможно, особенно на морфологических близнецов, поскольку в таких случаях один артикуляционный жест пересекает границу. Следовательно, близнецы могут подвергаться влиянию лексических свойств обеих составляющих, как и интерфиксы. В настоящем исследовании мы сосредотачиваемся на согласных / m /, / n / и / s /, поскольку было показано (e.грамм. by Ben Hedia 2019), что эти звуки могут демонстрировать явные фонетические эффекты морфологической геминации в английском языке.
Следовательно, близнецы могут подвергаться влиянию лексических свойств обеих составляющих, как и интерфиксы. В настоящем исследовании мы сосредотачиваемся на согласных / m /, / n / и / s /, поскольку было показано (e.грамм. by Ben Hedia 2019), что эти звуки могут демонстрировать явные фонетические эффекты морфологической геминации в английском языке.
Английские соединения показывают значительные различия в орфографическом представлении между написанием с интервалом, дефисом и без пробела. Однако написание без пробелов и дефисов, как правило, коррелирует с высокой частотой и лексикализацией (см. Обсуждение в Bell and Plag 2012). Поэтому, чтобы найти образец подтвержденных соединений с широким диапазоном частот и в то же время избежать усложняющего фактора, связанного с разнообразием написания, мы решили сосредоточиться исключительно на соединениях, расположенных через интервалы.
Соединения, используемые в настоящем исследовании, были выбраны из устной части Британского национального корпуса. Использование речевой части корпуса гарантирует, что полученные соединения были спонтанно произведены говорящим по крайней мере один раз. Интерфейс BNCweb (Hoffmann et al. 2008) использовался для поиска строк из двух существительных, за исключением строк, которые пересекали границу предложения или включали паузу или любую другую форму прерывания, например, кашель, между двумя существительными. В запросах корпуса также указывалось, что слово после второго существительного не должно быть другим существительным, прилагательным или притяжательным.Это ограничило поиск строками из двух существительных и исключило комбинации, которые были частью более крупной составной конструкции. Впоследствии строки были проверены в контексте, чтобы убедиться, что они представляют конструкции, в которых первое существительное изменяет второе. Мы придерживаемся точки зрения, следуя, например, Бауэр (1998), Белл (2011), Плаг и др. (2008), что все подобные конструкции можно отнести к составным. На этом этапе из данных также были исключены типы, в которых два существительных были идентичны или одно существительное было расставлено через дефис, а также имена собственные, аппозитивные конструкции и звательные падежи.
На этом этапе из данных также были исключены типы, в которых два существительных были идентичны или одно существительное было расставлено через дефис, а также имена собственные, аппозитивные конструкции и звательные падежи.
Фонологические транскрипции существительных, составляющих соединения, были извлечены из лексической базы данных CELEX (Baayen et al. 1995, далее CELEX), а в тех случаях, когда компонент не появлялся в CELEX, они были дополнены ручной транскрипцией. Эти транскрипции затем использовались для определения типов, в которых первое слово заканчивалось одной из согласных / s /, / m / или / n /, а второе слово начиналось той же фонемой. Из этого набора мы выбрали только те комбинации, в которых ни согласная в конце слова, ни согласная в начале слова не входили в состав кластера.Мы также использовали транскрипцию для выбора соединений, в которых либо первое слово заканчивалось на / s /, / m / или / n /, а второе слово начиналось с гласной, либо второе слово начиналось с одного из этих согласных и первого слова заканчивался гласной. Опять же, мы исключили типы с кластерами в начале или в конце слова. Далее мы ограничились типами, в которых, согласно CELEX или нашей ручной транскрипции, лексическое ударение второго существительного приходилось на первый слог этого существительного. Footnote 2 Таким образом, все соединения в наборе данных удовлетворяют следующим критериям: есть одинарный или двойной / s /, / m / или / n / на внутренней границе соединения, и соответствующие согласные оба следуют за гласная и предшествует ударной гласной.Некоторые примеры показаны в таблице 1.
Таблица 1 Примеры экспериментальных элементовИз набора соединений, описанных в предыдущем абзаце, мы выбрали подмножество для использования в нашем исследовании. При выборе подмножества мы стремились достичь как можно более широкого и сбалансированного диапазона по следующим критериям:
Количество слогов в N1
Количество слогов в N2
Вес последнего слога N1, сильный или слабый
Ожидаемое положение сложного напряжения на N1 или N2
Гласная фонема, предшествующая согласной (-ым)
Гласная фонема, следующая за согласной (-ми)
Другими словами, элементы были выбраны для увеличения разнообразия данных по этим критериям и во избежание предвзятости в отношении какой-либо конкретной структуры слогов, ударения или гласных. С другой стороны, элементы исключались, если они были уникальными с точки зрения любой из этих переменных, так как это привело бы к путанице между составом и условием. В случаях, когда всем этим ограничениям удовлетворяло более одного соединения, окончательный выбор производился случайным образом. Эти процедуры привели к списку соединений с 19 типами соединений с / m / на границе, 19 типами для / n / и 24 типами для / s /.
С другой стороны, элементы исключались, если они были уникальными с точки зрения любой из этих переменных, так как это привело бы к путанице между составом и условием. В случаях, когда всем этим ограничениям удовлетворяло более одного соединения, окончательный выбор производился случайным образом. Эти процедуры привели к списку соединений с 19 типами соединений с / m / на границе, 19 типами для / n / и 24 типами для / s /.
Экспериментальная установка
Разговорные токены всех соединений в нашем окончательном наборе данных были получены от 30 носителей британского английского языка, которые читали соединения, представленные в предложениях-носителях, на экране компьютера.Каждое соединение было встроено в два разных предложения-носителя:
- (5)
Снова заговорили о [ соединение ] .
- (6)
Она рассказала мне о [ соединение ].
Эти два предложения различаются в зависимости от того, встречается ли составное слово в конечной позиции: это позволило включить в анализ любые эффекты удлинения или сокращения фразовой позиции.Каждый участник прочитал каждое соединение только один раз, либо в предложении (7), либо в предложении (8). Однако в целом каждый участник видел равное количество обоих типов предложений, и каждое соединение было включено в равное количество токенов каждого типа предложения. Предложения были смешаны с таким же количеством несвязанных предложений-заполнителей, которые были экспериментальными элементами для другого исследования. Поскольку предложения-наполнители имели множество различных структур, они служили для устранения повторяемости наших предложений-носителей и снижения риска развития интонации, подобной списку. Каждый участник видел предметы, включая наполнители, в разном случайном порядке.
Каждый участник видел предметы, включая наполнители, в разном случайном порядке.
Каждое предложение было представлено на двух последовательных слайдах. На первом слайде каждой пары участникам предлагалось прочитать предложение молча, а на втором слайде им предлагалось прочитать предложение вслух. Фаза беззвучного чтения была предназначена как для поощрения семантической обработки предложения, так и для снижения риска ошибок выполнения при последующем чтении вслух. Это был начальный этап обучения, и участники могли продвигаться по презентации в своем собственном темпе.
Записи производились в звукоизолированной кабине, оцифровывались с частотой 44,1 кГц с использованием цифрового записывающего устройства Tascam HD-P2 и кардиоидного микрофона Sennheiser ME 64, участники сидели на расстоянии 15 см от микрофона, а уровни записи устанавливались для каждого участника.
Акустические измерения
После записи предложений мы вручную сегментировали данные и фонетически расшифровали их с помощью программного обеспечения Praat (Boersma and Weenink 2014). Мы аннотировали рассматриваемые сегменты, а также предыдущие и последующие сегменты.Аннотация для паровой машины , например, включала сегментацию и / e /. Сегментация проводилась в соответствии с критериями, основанными на визуальном осмотре форм сигналов и спектрограмм элементов. Эти критерии были основаны на критериях сегментации, примененных в Ben Hedia (2019), которые, в свою очередь, основывались на особенностях конкретных звуков, как описано в фонетической литературе (например, Ladefoged 2003).
Поскольку все согласные встречаются в интервокальной позиции, мы сосредоточились на различиях между соответствующими согласными и гласными.Как и гласные, носовые имеют правильную форму волны, но их форманты довольно слабые по сравнению с таковыми у гласных. Это можно увидеть на фиг. 1, где показан пример сегментации слова паровой двигатель . В отличие от гласных, фрикативные звуки имеют апериодическую форму волны, и поэтому их довольно легко идентифицировать в интервокальной позиции. Все границы были установлены на ближайшем нулевом пересечении осциллограммы. Двойные согласные (например, / mm / in cream mini ) обрабатывались как один сегмент в аннотации, когда не было различимости границы между двумя идентичными согласными.Если между двумя согласными существовала видимая граница, оба согласных были сегментированы. Это был тот случай, когда говорящий создавал паузу между первой и второй составляющими. Впоследствии такие токены были исключены из анализа.
Все границы были установлены на ближайшем нулевом пересечении осциллограммы. Двойные согласные (например, / mm / in cream mini ) обрабатывались как один сегмент в аннотации, когда не было различимости границы между двумя идентичными согласными.Если между двумя согласными существовала видимая граница, оба согласных были сегментированы. Это был тот случай, когда говорящий создавал паузу между первой и второй составляющими. Впоследствии такие токены были исключены из анализа.
Аннотация к составу паровой двигатель
Надежность критериев сегментации проверялась серией пробных сегментов. В этих испытаниях три аннотатора использовали критерии для сегментации одних и тех же 20 элементов.Если было какое-либо расхождение более чем на 10 миллисекунд в размещении границ, аннотаторы обсуждали расхождение и уточняли критерии, чтобы уменьшить количество вариаций между аннотаторами. Эти пробные сегменты повторяли до тех пор, пока все границы не были надежно размещены с небольшими отклонениями (т.е. не более 10 миллисекунд). Для окончательного измерения каждый аннотатор работал с разрозненным набором элементов. Для обеспечения согласованности между аннотаторами проводились регулярные встречи между аннотирующей группой и первыми двумя авторами этой статьи, на которых мы обсуждали любые вопросы, по которым у аннотатора был запрос.Для этих проблемных элементов соответствующие границы были установлены на основе консенсуса, а рекомендации по аннотациям были обновлены с учетом любых ранее непредвиденных проблем. В качестве дополнительной меры предосторожности против систематической изменчивости между экспертами мы включили аннотатор как случайный эффект в наши модели, хотя это оказалось несущественным.
токенов были исключены из дальнейшего анализа, если предполагалось, что говорящий совершил ошибку производительности, или если было невозможно определить соответствующие границы сегмента в речевом потоке. В результате осталось 1546 сегментированных составных токенов. Для этого набора токенов скрипт Python использовался для измерения и извлечения длительности соединения, продолжительности составляющих, продолжительности рассматриваемых согласных, а также продолжительности их предшествующих и последующих сегментов в миллисекундах.
В результате осталось 1546 сегментированных составных токенов. Для этого набора токенов скрипт Python использовался для измерения и извлечения длительности соединения, продолжительности составляющих, продолжительности рассматриваемых согласных, а также продолжительности их предшествующих и последующих сегментов в миллисекундах.
Переменные-предикторы
Обзор
Для проверки трех рассматриваемых гипотез мы извлекли ряд частотных показателей из ukWaC (https://www.webarchive.org.uk/ukwa/), корпус из более чем 2 миллиарда слов из.uk интернет-домен. В том числе:
Частота соединения: общая частота соединения, включая все варианты написания (с пробелами, дефисами и конкатенациями; британский и американский), а также формы единственного и множественного числа N2. Мы лемматизировали N2, чтобы формы единственного и множественного числа одного и того же соединения считались вместе, например бутерброд с тунцом и бутерброд с тунцом . Однако мы не включили форму множественного числа N1, потому что посчитали, что модификаторы множественного числа, вероятно, представляют разные леммы e.грамм. кресло против гонка вооружений .
Коэффициент правописания: отношение количества жетонов составного слова, написанного без пробелов, т. Е. С дефисом или конкатенированием, к количеству жетонов, написанных с пробелом, рассчитывается как:
$$ \ mathit {Правописание} \ mathit {Ratio} = (f (\ mathit {concatenated}) + f (\ mathit {hyphenated})) / f (\ mathit {spaced}) $$
Частота N1 и частота N2: общая частота леммы каждой составляющей, включая все варианты написания (британский и американский).
Размер семейства N1 и размер семейства N2: размер позиционного семейства каждого компонента, то есть количество составных типов с данным компонентом в одной позиции.
{n} _ {i = 1} f (\ textit {N1-component} _ {i}) $$Парадигматическая вероятность согласного с данным N1: парадигматическая вероятность соответствующего согласного, следующего за N1 в составе, на основе токена.{n} _ {i = 1} f (\ textit {N1-component} _ {i}) \ end {align} $$
Мы также вычислили версию этой переменной на основе типа: количество соединений N1 в который N2 начинался с рассматриваемого согласного, разделенного на размер семейства N1.
Энтропия N1 и энтропия N2: энтропии составляющих семейств. Энтропия составляющего семейства — это мера относительной ожидаемости различных соединений в семействе и общий уровень неопределенности в семействе.{n} _ {i = 1} f (\ textit {Nx-соединение} _ {i} \!) $$
 {n} _ {i = 1} f (\ textit {N1-component} _ {i}) $$
{n} _ {i = 1} f (\ textit {N1-component} _ {i}) $$Показатели частоты, орфографии, размера семьи и вероятности были преобразованы в логарифм перед вводом их в статистический анализ. Давайте теперь посмотрим, как эти меры соотносятся с тремя гипотезами.
Сегментируемость
Мы использовали коэффициент правописания и размер семейства N1 для оценки сегментируемости соединений в нашем наборе данных. Эти переменные связаны с гипотезой сегментируемости следующим образом:
- Коэффициент правописания
: Куперман и Бертрам (2013) показали, что английские составные части с большей вероятностью будут написаны с интервалом, если их составные части встречаются чаще или орфографически длиннее.Они интерпретируют эти результаты как свидетельство опосредующего эффекта того, что они называют «морфемической заметностью»: соединения, составные части которых более заметны (в силу частоты или длины), с большей вероятностью будут написаны с интервалом. Мы понимаем, что это понятие значимости составляющих связано с возможностью сегментирования, так что более сегментируемые соединения имеют более заметные составляющие.
Мы предполагаем, что пространство в разнесенном соединении указывает на сегментацию писателя, и что писатели с большей вероятностью включают пространство, чем более сегментированным они считают составное соединение.С другой стороны, представления без интервалов связаны с лексикализацией и предполагают, что автор воспринимает составное слово как единую концептуальную единицу (см. Bell and Plag 2012). Следовательно, соединение с большей долей разнесенных токенов может рассматриваться как более сегментируемое, чем соединение с меньшим количеством разнесенных токенов, а коэффициент написания может отрицательно коррелировать с сегментируемостью. Если гипотеза сегментируемости верна, продолжительность согласных будет больше на внутренних границах более сегментированных соединений.Предполагая, что письмо и чтение вслух отражают одну и ту же конструкцию сегментирования, гипотеза, следовательно, предсказывает, что коэффициент правописания будет отрицательно коррелирован с продолжительностью согласных в наших данных. Размер семейства N1: здесь мы предполагаем, что чем больше семейство N1, тем продуктивнее N1 как составной модификатор. Было показано, что большая продуктивность связана с большей сегментируемостью сложных слов (см.Hay and Baayen 2003), следовательно, соединения с более крупными семействами N1 должны быть более сегментированными, чем соединения с меньшими семействами N1. Гипотеза сегментируемости, таким образом, предсказывает, что размер семейства N1 будет положительно коррелировать с продолжительностью согласных на границе соединения и внутренней части.
 Мы предполагаем, что пространство в разнесенном соединении указывает на сегментацию писателя, и что писатели с большей вероятностью включают пространство, чем более сегментированным они считают составное соединение.С другой стороны, представления без интервалов связаны с лексикализацией и предполагают, что автор воспринимает составное слово как единую концептуальную единицу (см. Bell and Plag 2012). Следовательно, соединение с большей долей разнесенных токенов может рассматриваться как более сегментируемое, чем соединение с меньшим количеством разнесенных токенов, а коэффициент написания может отрицательно коррелировать с сегментируемостью. Если гипотеза сегментируемости верна, продолжительность согласных будет больше на внутренних границах более сегментированных соединений.Предполагая, что письмо и чтение вслух отражают одну и ту же конструкцию сегментирования, гипотеза, следовательно, предсказывает, что коэффициент правописания будет отрицательно коррелирован с продолжительностью согласных в наших данных.
Мы предполагаем, что пространство в разнесенном соединении указывает на сегментацию писателя, и что писатели с большей вероятностью включают пространство, чем более сегментированным они считают составное соединение.С другой стороны, представления без интервалов связаны с лексикализацией и предполагают, что автор воспринимает составное слово как единую концептуальную единицу (см. Bell and Plag 2012). Следовательно, соединение с большей долей разнесенных токенов может рассматриваться как более сегментируемое, чем соединение с меньшим количеством разнесенных токенов, а коэффициент написания может отрицательно коррелировать с сегментируемостью. Если гипотеза сегментируемости верна, продолжительность согласных будет больше на внутренних границах более сегментированных соединений.Предполагая, что письмо и чтение вслух отражают одну и ту же конструкцию сегментирования, гипотеза, следовательно, предсказывает, что коэффициент правописания будет отрицательно коррелирован с продолжительностью согласных в наших данных. Таблица 2 суммирует прогнозы, сделанные с помощью гипотезы сегментируемости. Как описано в разд. 2.1 сообщалось об эффектах сегментирования лингвистических элементов, возникающих как до, так и после морфологических границ.Если гипотеза сегментируемости верна, мы ожидаем найти соответствующие эффекты для всех согласных с внутренней границей в наших данных: N1-конечный, двойной и N2-начальный.
Информативность
Информативность связана с концепциями вероятности и ожидаемости. Лингвистический элемент, который менее вероятен в любом данном контексте, менее ожидаем в этом контексте и, в свою очередь, более информативен.Вероятный лингвистический элемент является более ожидаемым и, следовательно, менее информативным. Таким образом, гипотеза информативности предсказывает, что чем менее вероятно наличие согласного в данном контексте, тем дольше будет его реализация.
Мы проверили шесть различных типов вероятностей: составную частоту, составляющие частоты, условную вероятность N2 с учетом N1, размер семейства N1, энтропию N1 и условную вероятность рассматриваемого согласного с учетом N1. Первые пять из этих переменных относятся к ожидаемому на уровне слов.Мы предполагаем, что, если гипотеза верна, сложные внутренние согласные наследуют связанные с информативностью эффекты длины от составляющих и от составных, в которых они встречаются. Другими словами, чем менее вероятно соединение или компонент, тем дольше будет его реализация и, следовательно, тем дольше будет реализован каждый из его сегментов. Напротив, последняя переменная (условная вероятность согласного с данным N1) непосредственно измеряет ожидаемое значение согласного. Кроме того, некоторые из этих переменных измеряют вероятность N1 и / или N1-конечных согласных, в то время как другие измеряют вероятность N2 и / или N2-начальных согласных.Предполагается, что двойные согласные принадлежат частично к N1 и частично к N2 и, следовательно, отражают вероятность как N1, так и N2. Относительно этих различных показателей гипотеза информативности делает прогнозы, обобщенные в таблице 3 и описанные в следующих параграфах.
Частота соединения: чем чаще встречается соединение, тем более ожидаемым оно является в языке в целом, следовательно, тем короче его реализация и реализация любого согласного в нем.
Таким образом, все три типа согласных, N1-конечный, двойной и N2-начальный, должны иметь отрицательную корреляцию между их длительностью и составной частотой. Мы можем также ожидать, что наклон корреляции для двойных звуков будет круче, чем для одинарных согласных, поскольку будут затронуты как компоненты N1, так и N2.Частота N1 и частота N2: чем чаще составляющая, тем более ожидаемая она в языке в целом, следовательно, тем короче ее реализация и реализация любого согласного в нем.Таким образом, N1-конечные и двойные согласные должны показывать отрицательную корреляцию между их длительностью и частотой N1, в то время как двойные и N2-начальные согласные должны показывать отрицательную корреляцию между их длительностью и частотой N2.
Условные вероятности N2 при N1: Чем выше условная вероятность N2, синтагматически или парадигматически, тем менее информативно N2 при N1, следовательно, тем короче его реализация и реализация его сегментов.Таким образом, продолжительность N2-начальных и двойных согласных должна быть отрицательно коррелирована как с синтагматической вероятностью N2 для N1, так и с парадигматической вероятностью N2 для N1.
Размер семейства N1 и энтропия N1: чем больше семейство N1 и больше его энтропия, тем менее предсказуемо N2 при N1, поэтому более высокие значения этих переменных указывают на то, что N2 более информативно. Следовательно, продолжительность N2-начальных согласных должна быть положительно коррелирована как с размером семейства N1, так и с энтропией N1.И наоборот, чем меньше семейство N1 и чем ниже его энтропия, тем более информативным является N1 в отношении возможных значений N2. Следовательно, продолжительность согласных в конце N1 должна иметь отрицательную корреляцию с размером семейства N1 и энтропией N1.
Ожидается, что продолжительность двойных согласных не будет показывать общий эффект этих переменных или не будет вообще, положительная корреляция с длительностью элемента N2 уравновешивается отрицательной корреляцией с длительностью элемента N1.Парадигматическая вероятность согласного с данным N1 (на основе типа или на основе лексемы): поскольку это вероятность того, что согласный звук следует за N1 в пределах составляющего семейства, т.е.е. в начале N2, что касается гипотезы информативности, это относится только к двойным и начальным N2 согласным. Чем больше вероятность на основе лексемы или типа того, что N2 начинается с рассматриваемого согласного, тем короче должны быть эти согласные.
 Таким образом, все три типа согласных, N1-конечный, двойной и N2-начальный, должны иметь отрицательную корреляцию между их длительностью и составной частотой. Мы можем также ожидать, что наклон корреляции для двойных звуков будет круче, чем для одинарных согласных, поскольку будут затронуты как компоненты N1, так и N2.
Таким образом, все три типа согласных, N1-конечный, двойной и N2-начальный, должны иметь отрицательную корреляцию между их длительностью и составной частотой. Мы можем также ожидать, что наклон корреляции для двойных звуков будет круче, чем для одинарных согласных, поскольку будут затронуты как компоненты N1, так и N2. Ожидается, что продолжительность двойных согласных не будет показывать общий эффект этих переменных или не будет вообще, положительная корреляция с длительностью элемента N2 уравновешивается отрицательной корреляцией с длительностью элемента N1.
Ожидается, что продолжительность двойных согласных не будет показывать общий эффект этих переменных или не будет вообще, положительная корреляция с длительностью элемента N2 уравновешивается отрицательной корреляцией с длительностью элемента N1.Парадигматическая поддержка
За исключением Lõo et al. (2018), которые измеряли длительность всего слова, большинство исследований, в которых сообщалось об эффектах парадигматического улучшения, обнаруживали их в суффиксах или сложных интерфиксах.Рассматриваемые аффиксы в основном состоят из одиночных фонем, и поэтому неясно, действуют ли такие эффекты на уровне морфемы или фонемы. По этой причине мы включили оба этих уровня в наш анализ продолжительности согласного, то есть парадигматическую вероятность самого согласного и составного компонента, содержащего его. Соответствующая парадигма для слов с изменением и производных слов состоит из всех слов, имеющих одну основу или аффикс. Что касается соединений, единственным исследованием, в котором сообщалось об усилении парадигматизма, является Kuperman et al.(2007), которые обнаружили, что релевантной парадигмой является семейство позиционных составляющих N1, то есть все соединения, которые имеют один и тот же первый элемент. Поэтому для проверки гипотезы поддержки парадигм мы использовали размер семейства N1 и парадигматическую вероятность согласного с данным N1 следующим образом:
Размер семейства N1: Чем больше размер семейства N1, тем больше возможных значений для N2, следовательно, тем ниже парадигматическая поддержка для каждого соединения в семье.
Таким образом, парадигматическая гипотеза поддержки предсказывает, что увеличение размера семейства N1 будет связано с более короткой продолжительностью согласных на границе соединения и внутренней гармонии.Парадигматическая вероятность согласного с данным N1 (на основе типа или на основе лексемы): более высокие значения этих переменных означают, что, когда N1 встречается как первый элемент соединения, за ним с большей вероятностью последует рассматриваемый согласный.Другими словами, более высокие значения указывают на то, что соединения, в которых N2 начинается с соответствующей согласной, сравнительно многочисленны и / или часто встречаются в семействе составляющих N1. Таким образом, парадигматическая гипотеза поддержки предсказывает, что увеличение парадигматической вероятности согласного с данным N1 будет связано с большей длительностью согласного на границе составного и внутреннего.
 Таким образом, парадигматическая гипотеза поддержки предсказывает, что увеличение размера семейства N1 будет связано с более короткой продолжительностью согласных на границе соединения и внутренней гармонии.
Таким образом, парадигматическая гипотеза поддержки предсказывает, что увеличение размера семейства N1 будет связано с более короткой продолжительностью согласных на границе соединения и внутренней гармонии.Поскольку ранее сообщалось об улучшении парадигматизма в основном для суффиксов и интерфиксов, т.е.е. для лингвистических элементов, которые следуют за морфологической границей, неясно, следует ли ожидать эффекта для всех наших согласных с внутренней границей или только для двойных и N2-начальных падежей. Прогнозы гипотезы поддержки парадигм суммированы в Таблице 4.
Таблица 4 Сводка прогнозов, сделанных гипотезой поддержки парадигмОбратите внимание, что разные гипотезы делают противоречивые прогнозы о влиянии определенных переменных, особенно размера семьи N1 и парадигматического вероятность согласного данного N1.Таким образом, эти предикторы можно использовать для проверки гипотез друг против друга.
Контрольные переменные
Помимо интересующих нас предикторов, мы также включили в наши модели ряд контрольных переменных. Это были:
Граничный тип (C # C, C # V или V # C): мы включили эту переменную по двум причинам.
Во-первых, фонетические исследования показали, что на продолжительность согласных может влиять фонетический контекст, в котором они встречаются (например,грамм. Умеда 1977). Во-вторых, наши гипотезы делают разные прогнозы для согласных в разных позициях, поэтому мы ожидали найти взаимодействия между типом границы и другими предикторами.Согласный (/ m /, / n / или / s /): эта переменная контролирует внутреннюю разницу в продолжительности между тремя согласными.
Скорость речи: это локальная скорость речи, измеряемая как количество сегментов в секунду.Он был вычислен для каждого составного токена путем деления количества сегментов в соединении на общую продолжительность соединения в секундах. Очевидно, что более высокая скорость речи приводит к меньшей продолжительности отдельных сегментов.
Количество слогов в N1 и количество слогов в N2: было показано (например, Lindblom 1963; Nooteboom 1972), что сегменты могут быть короче, если слова, в которых они встречаются, имеют больше слогов.Этот эффект можно концептуализировать как своего рода эффект сжатия, когда слова с большим количеством слогов подвергаются сокращению. Поэтому мы включили количество слогов двух составляющих в наш набор ковариат.
Орфография: это двоичная переменная, кодирующая, встречается ли один и тот же орфографический согласный по обе стороны от составляющей границы. Он принимает значение «истина», если одна и та же буква встречается с обеих сторон границы, e.грамм. сигнал шины . Для всех остальных соединений он имеет значение «ложь», например мирное поселение , СМИ , лебединый трактир . Мы включили эту переменную, потому что существует хорошо известное влияние орфографии на произношение у грамотных носителей (см.
Damian and Bowers 2003 и ссылки в нем), поэтому вполне возможно, что согласные, представленные орфографически по обе стороны от составляющей границы, могут иметь разные акустические характеристики. реализация, чем другие альтернативы.Порядок представления элементов: Эта переменная была включена для контроля эффектов изменчивости внимания или утомляемости на протяжении всего эксперимента.
 Во-первых, фонетические исследования показали, что на продолжительность согласных может влиять фонетический контекст, в котором они встречаются (например,грамм. Умеда 1977). Во-вторых, наши гипотезы делают разные прогнозы для согласных в разных позициях, поэтому мы ожидали найти взаимодействия между типом границы и другими предикторами.
Во-первых, фонетические исследования показали, что на продолжительность согласных может влиять фонетический контекст, в котором они встречаются (например,грамм. Умеда 1977). Во-вторых, наши гипотезы делают разные прогнозы для согласных в разных позициях, поэтому мы ожидали найти взаимодействия между типом границы и другими предикторами. Damian and Bowers 2003 и ссылки в нем), поэтому вполне возможно, что согласные, представленные орфографически по обе стороны от составляющей границы, могут иметь разные акустические характеристики. реализация, чем другие альтернативы.
Damian and Bowers 2003 и ссылки в нем), поэтому вполне возможно, что согласные, представленные орфографически по обе стороны от составляющей границы, могут иметь разные акустические характеристики. реализация, чем другие альтернативы.Статистический анализ
Мы провели регрессионный анализ смешанных эффектов с использованием пакета lme4 в R (Bates et al. 2015). Зависимой переменной была продолжительность согласного, продолжительность согласного на границе сложного и внутреннего звука в миллисекундах.Перед анализом мы обрезали данные, чтобы удалить выбросы с очень большой или короткой продолжительностью, а также удалили выбросы в отношении скорости речи. Этот процесс привел к потере 25 точек данных, около 1,6% данных. Количество типов и токенов в наборе данных, используемом для моделирования, показано в таблице 5.
Таблица 5 Распределение типов и токеновМногие из наших интересующих переменных сильно коррелированы друг с другом, что означает, что они, вероятно, учитывают для той же части дисперсии в зависимой переменной.Включение коллинеарных предикторов может привести к нестабильным статистическим моделям, в которых трудно идентифицировать эффекты отдельных переменных. Поскольку нас в первую очередь интересовали эффекты конкретных предикторов как способ проверки наших гипотез, поэтому нам нужно было уменьшить количество коллинеарности в наших моделях. Для этого мы применили процедуру моделирования, описанную в следующих параграфах.
На первом этапе мы построили модели со случайными эффектами только для участника, элемента, аннотатора и составной позиции (финальное предложение или нет).При наличии случайных эффектов для участника и предмета влияние аннотатора было незначительным, и поэтому эта переменная была исключена из дальнейшего анализа. Во-вторых, мы добавили управляющие переменные, включая трехстороннее взаимодействие между типом границы, согласным звуком и скоростью речи. На этом этапе ни порядок представления пунктов, ни количество слогов в любой из составляющих не оказались значимыми, поэтому эти переменные также были исключены. В-третьих, мы смоделировали влияние каждого интересующего предиктора на продолжительность согласных в отдельных отдельных моделях.Каждая из этих моделей также включала значительные случайные эффекты и управляющие переменные, а также трехстороннее взаимодействие между типом границы, согласным и предиктором, а также между типом границы, согласным и скоростью речи. Мы включили эти условия взаимодействия, потому что, как описано в разд. 3.4.5, наши гипотезы делают разные прогнозы для согласных на разных типах границ, и мы также ожидали, что присущие различия продолжительности между / m /, / n / и / s / могут привести к различиям в их наклонах по сравнению с другими предикторами. .
Во-вторых, мы добавили управляющие переменные, включая трехстороннее взаимодействие между типом границы, согласным звуком и скоростью речи. На этом этапе ни порядок представления пунктов, ни количество слогов в любой из составляющих не оказались значимыми, поэтому эти переменные также были исключены. В-третьих, мы смоделировали влияние каждого интересующего предиктора на продолжительность согласных в отдельных отдельных моделях.Каждая из этих моделей также включала значительные случайные эффекты и управляющие переменные, а также трехстороннее взаимодействие между типом границы, согласным и предиктором, а также между типом границы, согласным и скоростью речи. Мы включили эти условия взаимодействия, потому что, как описано в разд. 3.4.5, наши гипотезы делают разные прогнозы для согласных на разных типах границ, и мы также ожидали, что присущие различия продолжительности между / m /, / n / и / s / могут привести к различиям в их наклонах по сравнению с другими предикторами. .
Среди переменных, перечисленных в таблицах 2–4, коллинеарность была особенно высокой между составной частотой и условной вероятностью N2, между версиями вероятности согласных на основе типа и на основе лексемы, а также между частотой N1, размером семейства N1 и N1. энтропия. Поэтому в нашу полную модель мы включили только переменную из каждой из этих групп, которая оказала наибольшее влияние на продолжительность согласных в ее индивидуальной модели. Остальные переменные из каждой группы были исключены из анализа.После этого процесса интересующие нас переменные, оставшиеся в нашей полной модели, включали составную частоту, размер семейства N1, коэффициент написания, частоту N2 и парадигматическую вероятность согласного, заданного N1, на основе токенов. Этот набор переменных был проверен на любую оставшуюся коллинеарность с помощью функции collin.fnc пакета LanguageR (Baayen and Shafaei-Bajestan 2019), которая дала приемлемое число условий около 27,15 (согласно Baayen 2008, числа условий 30 и больше может указывать на потенциально опасную коллинеарность).
Начиная с полной модели, описанной выше, и включая значимые взаимодействия отдельных моделей, мы использовали ступенчатую функцию пакета lmerTest (Кузнецова и др., 2017), чтобы исключить незначительные фиксированные эффекты и выбрать оптимальные случайные эффекты. состав. Проверка полученной модели показала, что остатки имели неудовлетворительное, то есть ненормальное, распределение. Чтобы решить эту проблему, снова глядя на полную модель, мы использовали преобразование Бокса-Кокса (Box and Cox 1964, Venables and Ripley 2002), чтобы определить подходящий параметр преобразования ( λ ) для степенного преобразования зависимой переменной.Оптимальное значение λ оказалось равным λ = 0,5454545. Это преобразование было применено, и незначительные эффекты были снова удалены с помощью пошаговой функции. Наконец, мы удалили точки данных, стандартизированные остатки которых имели абсолютное значение более 2,5 стандартных отклонений, что привело к потере 1,9% наблюдений. Полученная окончательная модель имела нормально распределенные остатки (критерий нормальности Шапиро-Уилка, W = 0,99818, p = 0.1038).
эпитран · PyPI
Библиотека и инструмент для транслитерации орфографического текста в IPA (международный фонетический алфавит).
Использование
Модули Python epitran и epitran.vector можно использовать для простого написания более сложных программ Python для развертывания таблиц сопоставления Epitran , препроцессоров и постпроцессоров. Это описано ниже.
Использование эпитрана
МодульКласс Эпитран
Наиболее общие функции модуля epitran заключены в очень простой класс Epitran :
Эпитран (код, preproc = True, postproc = True, ligatures = False, cedict_file = None).
Его конструктор принимает один аргумент, код , , код ISO 639-3 языка, который нужно транслитерировать, плюс дефис плюс четырехбуквенный код сценария (например, «Latn» для латинского алфавита, «Cyrl» для кириллицы, и «арабский» для персидско-арабского письма). Он также принимает необязательные аргументы ключевого слова:
Он также принимает необязательные аргументы ключевого слова:
-
preprocиpostprocвключают пре- и постпроцессоры. По умолчанию они включены. -
лигатурпозволяет использовать нестандартные лигатуры IPA, такие как «ʤ» и «ʨ». -
cedict_fileуказывает путь к файлу словаря CC-CEDict (актуально только при работе с мандаринским китайским языком и который из-за лицензионных ограничений не может распространяться с Epitran).
>>> импортный эпитран
>>> epi = epitran.Epitran ('uig-Arab') # уйгурский язык персидско-арабским шрифтом.
Теперь можно использовать класс Epitran для английского и китайского (упрощенного и традиционного) G2P, а также для других языков, использующих «классическую» модель Epitran.Для китайского языка необходимо указать в конструкторе копию словаря CC-CEDict:
>>> импортный эпитран
>>> epi = epitran.Epitran ('cmn-Hans', cedict_file = 'cedict_1_0_ts_utf-8_mdbg.txt')
Наиболее полезным общедоступным методом класса Epitran является транслитерация :
Эпитран. транслитерировать (текст, normpunc = False, лигатуры = False). Преобразование текста (в кодировке Unicode языка, указанного в конструкторе) в IPA, который возвращается. normpunc включает нормализацию пунктуации, а лигатур разрешает нестандартные лигатуры IPA, такие как «ʤ» и «ʨ». Использование показано ниже (Python 2):
>>> epi.transliterate (u'Düğün ') u'dy \ u0270yn ' >>> print (epi.transliterate (u'Düğün ')) Dyɰyn
Эпитран. word_to_tuples (слово, normpunc = False):
Принимает слово (строка Unicode) в поддерживаемой орфографии в качестве входных данных и возвращает список кортежей, каждый из которых соответствует сегменту IPA слова.Кортежи имеют следующую структуру:
(
character_category :: String,
is_upper :: Integer,
orthographic_form :: Unicode String,
phonetic_form :: Unicode String,
сегменты :: List
)
Обратите внимание, что word_to_tuples реализовано не для всех пар язык-скрипт.
Коды для character_category — это начальные символы двух последовательностей символов, перечисленных в кодах «Общая категория», приведенных в главе 4 стандарта Unicode.Например, «L» соответствует буквам, а «P» — производственным маркам. Приведенная выше структура данных может измениться в последующих версиях библиотеки. Структура сегментов выглядит следующим образом:
(
сегмент :: Unicode String,
vector :: List
)
Вот пример взаимодействия с word_to_tuples (Python 2):
>>> импортный эпитран
>>> epi = epitran.Epitran ('тур-латн')
>>> эпи.word_to_tuples (u'Düğün ')
[(u'L ', 1, u'D', u'd ', [(u'd', [-1, -1, 1, -1, -1, -1, -1, -1, 1, -1, -1, 1, 1, -1, -1, -1, -1, -1, -1, 0, -1])]), (u'L ', 0, u'u \ u0308 ', u'y', [(u'y ', [1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1 , -1, 1, 1, -1, -1, 1, 1, -1])]), (u'L ', 0, u'g \ u0306', u '\ u0270', [(u ' \ u0270 ', [-1, 1, -1, 1, 0, -1, -1, 0, 1, -1, -1, 0, -1, 0, -1, 1, -1, 0, -1, 1, -1])]), (u'L ', 0, u'u \ u0308', u'y ', [(u'y', [1, 1, -1, 1, - 1, -1, -1, 0, 1, -1, -1, -1, -1, -1, 1, 1, -1, -1, 1, 1, -1])]), (u 'L', 0, u'n ', u'n', [(u'n ', [-1, 1, 1, -1, -1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, -1, -1, -1, -1, 0, -1])])]
Класс отсрочки
Иногда при синтаксическом анализе текста более чем в одном скрипте полезно использовать изящную отсрочку.Если один языковой режим не работает, может быть полезно вернуться к другому и так далее. Эта функциональность обеспечивается классом Backoff:
.Отсрочка (lang_script_codes, cedict_file = None)
Обратите внимание, что класс Backoff в настоящее время не поддерживает параметризованное приложение препроцессора и постпроцессора и не поддерживает нестандартные лигатуры. Он также не поддерживает нормализацию знаков препинания. lang_script_codes — это список кодов, например eng-Latn или hin-Deva . Например, если кто-то транскрибирует текст на хинди с большим количеством английских заимствований и некоторыми случайными символами упрощенного китайского языка, можно использовать следующий код (Python 3):
Например, если кто-то транскрибирует текст на хинди с большим количеством английских заимствований и некоторыми случайными символами упрощенного китайского языка, можно использовать следующий код (Python 3):
из epitran.backoff import Backoff
>>> backoff = Backoff (['hin-Deva', 'eng-Latn', 'cmn-Hans'], cedict_file = ‘cedict_1_0_ts_utf-8_mdbg.txt ')
>>> backoff.transliterate ('हिन्दी')
'ɦindiː'
>>> backoff.transliterate ('английский')
'ɪŋɡlɪʃ'
>>> backoff.transliterate ('中文')
'oŋwən'
Backoff работает по принципу «токен за токеном»: токены, содержащие смешанные скрипты, будут возвращены как пустая строка, поскольку они не могут быть полностью преобразованы ни в одном из режимов.
Класс Backoff имеет следующие общедоступные методы:
- транслитерация : возвращает строку Unicode фонем IPA
- trans_list : возвращает список строк Unicode IPA, каждая из которых является фонема
- xsampa_list : возвращает список строк X-SAMPA (ASCII), каждая из которых фонема
Рассмотрим следующий пример (Python 3):
>>> backoff.transliterate ('हिन्दी')
'ɦindiː'
>>> Откат.trans_list ('हिन्दी')
['ɦ', 'i', 'n', 'd', 'iː']
>>> backoff.xsampa_list ('हिन्दी')
['h \\', 'i', 'n', 'd', 'i:']
DictFirst
Класс DictFirst представляет собой простую альтернативу классу Backoff . Это
требуется словарь слов, принадлежащих к языку A, по одному слову в строке в
Текстовый файл в кодировке UTF-8. Он принимает три аргумента: код языка-скрипта.
для языка A, для языка B и путь к файлу словаря. У него есть один общедоступный метод, транслитерация , который работает как Epitran.транслитерировать , за исключением того, что он возвращает транслитерацию для языка A, если входной токен находится в словаре; в противном случае возвращается транслитерация токена на языке B:
>>> import dictfirst >>> df = dictfirst.
 DictFirst ('tpi-Latn', 'eng-Latn', '../sample-dict.txt')
>>> df.transliterate ('пела')
"пела"
>>> df.transliterate ('пело')
'пахать'
DictFirst ('tpi-Latn', 'eng-Latn', '../sample-dict.txt')
>>> df.transliterate ('пела')
"пела"
>>> df.transliterate ('пело')
'пахать'
Препроцессоры, постпроцессоры и их подводные камни
Для создания поддерживаемого средства отображения орфографии в фонемы иногда необходимо использовать препроцессоры, которые выполняют контекстную замену символов перед передачей текста в систему отображения орфографии в IPA, которая сохраняет отношения между входными и выходными символами.Это особенно верно в отношении языков с плохим соответствием звуков и символов (например, французского и английского). Такие языки, как французский, являются особенно хорошими целями для этого подхода, потому что произношение данной строки букв очень предсказуемо, даже несмотря на то, что отдельные символы часто не отображаются четко в звуки. (Соответствие звука и символа в английском языке настолько плохо, что эффективные английские системы G2P сильно зависят от произношения словарей.)
Предварительная обработка входных слов для обеспечения прямого сопоставления графемы с фонемами (как это сделано в текущей версии epitran для некоторых языков) имеет преимущество, потому что ограниченный язык регулярных выражений, используемый для написания правил предварительной обработки, более мощный, чем язык правил отображения и позволяет записать эквивалент многих правил отображения с помощью одного правила.Без них поддержка epitran для таких языков, как французский и немецкий, была бы непрактичной. Однако они создают некоторые проблемы. В частности, при использовании языка с препроцессором, должен знать, что входное слово не всегда будет идентично конкатенации орфографических строк ( orthographic_form ), выводимых Epitran.word_to_tuples . Вместо этого вывод word_to_tuple будет отражать вывод препроцессора, который может удалять, вставлять и изменять буквы, чтобы на следующем этапе было возможно прямое отображение орфографии на фонемы. То же самое верно и для других методов, которые полагаются на
То же самое верно и для других методов, которые полагаются на Epitran.word_to_tuple , например VectorsWithIPASpace.word_to_segs из модуля epitran.vector .
Информацию о написании новых пре- и постпроцессоров см. В разделе «Расширение Epitran с помощью файлов карты, препроцессоров и постпроцессоров» ниже.
Использование
epitran.vector Модуль Модуль epitran.vector тоже очень прост. Он содержит один класс, VectorsWithIPASpace , включая один интересующий метод, word_to_segs :
Конструктор для VectorsWithIPASpace принимает два аргумента:
-
код: код языкового сценария для обрабатываемого языка. -
пробелов: коды для пробелов пунктуации / символов / IPA, в которых, как ожидается, будут находиться символы / сегменты из данных. Доступные места перечислены ниже.
Его основной метод — word_to_segs :
ВекторWithIPASpace. word_to_segs (слово, normpunc = False). слово — строка Unicode. Если аргумент ключевого слова normpunc установлен на True, пунктуация, обнаруженная в слове , нормализуется до эквивалентов ASCII.
Типичное взаимодействие с объектом VectorsWithIPASpace через метод word_to_segs показано здесь (Python 2):
>>> import epitran.vector
>>> vwis = epitran.vector.VectorsWithIPASpace ('uzb-Latn', ['uzb-Latn'])
>>> vwis.word_to_segs (u'darë ')
[(u'L ', 0, u'd', u'd \ u032a ', u'40', [-1, -1, 1, -1, -1, -1, -1, -1, 1, -1, -1, 1, 1, 1, -1, -1, -1, -1, -1, 0, -1]), (u'L ', 0, u'a', u 'a', u'37 ', [1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1]), (u'L ', 0, u'r', u'r ', u'54', [-1, 1, 1, 1, 0, -1, -1, -1, 1, -1, -1, 1, 1, -1, -1, 0, 0, 0, -1, 0, -1]), (u'L ' , 0, u'e \ u0308 ', u'ja', u'46 ', [-1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1, 0, -1, 1, -1, -1, -1, 0, -1]), (u'L ', 0, u'e \ u0308', u'ja ', u '37', [1, 1, -1, 1, -1, -1, -1, 0, 1, -1, -1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1])]
(Важно отметить, что, хотя слово, которое служит входом — дарэ — имеет четыре буквы, результат содержит четыре кортежа, потому что последняя буква в дарэ фактически соответствует двум сегментам IPA, / j / и / а /. ) Возвращенная структура данных представляет собой список кортежей, каждый из которых имеет следующую структуру:
) Возвращенная структура данных представляет собой список кортежей, каждый из которых имеет следующую структуру:
(
character_category :: String,
is_upper :: Integer,
orthographic_form :: Unicode String,
phonetic_form :: Unicode String,
in_ipa_punc_space :: Целое число,
phonological_feature_vector :: List <Целое число>
)
Несколько примечаний относительно этой структуры данных:
-
категория_символовопределена как часть стандарта Unicode (глава 4).Он состоит из одной заглавной буквы из набора {‘L’, ‘M’, ‘N’, ‘P’, ‘S’, ‘Z’, ‘C’}. Наиболее частыми из них являются ‘L ‘(буква),’ N ‘(число),’ P ‘(пунктуация) и’ Z ‘(разделитель [включая разделительный пробел]). -
is_upperсостоит только из целых чисел из набора {0, 1}, где 0 указывает нижний регистр, а 1 означает верхний регистр. - Целое число в
in_ipa_punc_spaceявляется индексом для списка известных символов / сегментов, так что, за исключением вырожденных случаев, каждому символу или сегменту присваивается уникальный и глобально согласованный номер.В случаях, когда встречается символ, который не находится в известном пространстве, это поле имеет значение -1. - Длина списка
phonological_feature_vectorдолжна быть постоянной для любого экземпляра класса (она основана на количестве функций, определенных в panphon), но — в принципе — переменной. Целые числа в этом списке взяты из набора {-1, 0, 1}, где -1 соответствует ‘-‘, 0 соответствует ‘0’, а 1 соответствует ‘+’. Для символов без эквивалента IPA все значения в списке равны 0.
Языковая поддержка
Пары языка транслитерации и скрипта
| Код | Язык (сценарий) |
|---|---|
| аар-Латн | Афар |
| amh-Ethi | Амхарский |
| арабский | Литературный арабский |
| азе-Cyrl | Азербайджанский (кириллица) |
| азе-Латн | Азербайджанский (латиница) |
| Бен-Бенг | Бенгальский |
| Бен-Бенг-красный | Бенгальский (сокращенный) |
| кот-Латн | Каталонский |
| ceb-Latn | Себуано |
| cmn-Hans | Мандарин (упрощенный) * |
| cmn-Hant | Мандарин (традиционный) * |
| ckb-арабский | Сорани |
| деу-Латн | Немецкий |
| деу-Латн-НП | немецкий † |
| deu-Latn-nar | Немецкий (более фонетический) |
англ. Лат. Лат. | Английский ‡ |
| фас-араб | Фарси (персидско-арабский) |
| фра-Латн | Французский |
| фра-Латн-НП | французский † |
| hau-Latn | Хауса |
| Хин-Дева | Хинди |
| хун-латн | Венгерский |
| ilo-Latn | Илокано |
| Инд-Латн | Индонезийский |
| ita-Latn | Итальянский |
| jav-Latn | Яванский |
| каз-Сирл | казахский (кириллица) |
| каз-Латн | казахский (латиница) |
| кин-Латн | киньяруанда |
| Кир-Араб | Кыргызский (персидско-арабский) |
| Кир-Кирл | Кыргызский (кириллица) |
| Кир-Латн | Кыргызский (латиница) |
| кмр-Латн | Курманджи |
| Лао-Лаоо | Лаос |
| Мар-Дева | маратхи |
| млт-латн | Мальтийский |
| mya-Mymr | Бирманский |
| мса-Латн | Малайский |
| nld-Latn | Голландский |
| ня-Латн | Chichewa |
| orm-Latn | Оромо |
| пан-Гуру | Пенджаби (восточный) |
| Поль-Латн | Польский |
| Пор-Латн | Португальский |
| Рон-Латн | Румынский |
| рус-Cyrl | Русский |
| sna-Latn | Шона |
| сом-латн | Сомали |
| СПА-Латн | Испанский |
| swa-Latn | Суахили |
| swe-Latn | шведский |
| там-Тамл | Тамил |
| тел-Телу | телугу |
| tgk-Cyrl | Таджикский |
| tgl-Latn | Тагальский |
| тайский | Тайский |
| tir-Ethi | Тигриня |
| tpi-Latn | Ток писин |
| тук-Сирл | Туркменский (кириллица) |
| тук-латн | туркменский (латиница) |
| тур-Латн | Турецкий (латиница) |
| укр-Сирл | украинцы |
| уг-араб | Уйгурский (персидско-арабский) |
| uzb-Cyrl | Узбекский (кириллица) |
| узб-латн | Узбекский (латиница) |
| vie-Latn | Вьетнамский |
| xho-Latn | Xhosa |
| йор-латн | Йоруба |
| зул-Латн | Зулу |
* Для китайского G2P требуется свободно доступный словарь CC-CEDict.
† Эти языковые препроцессоры и карты наивно предполагают фонематическую орфографию.
‡ Английский язык G2P требует установки свободно доступной системы синтеза речи CMU Flite.
Языки с ограниченной поддержкой из-за очень неоднозначной орфографии
К некоторым перечисленным выше языкам следует подходить с осторожностью. Невозможно обеспечить высокоточную поддержку этих пар язык-сценарий из-за высокой степени неоднозначности, присущей орфографии.В конце концов, мы планируем поддерживать эти языки с помощью другой серверной части, основанной на WFST или нейронных методах.
| Код | Язык (сценарий) |
|---|---|
| арабско-арабский | Арабский |
| кот-Латн | Каталонский |
| ckb-арабский | Сорани |
| фас-араб | Фарси (персидско-арабский) |
| фра-Латн | Французский |
| фра-Латн-НП | французский † |
| mya-Mymr | Бирманский |
| Пор-Латн | Португальский |
«Пространства» языка
| Код | Язык | Примечание |
|---|---|---|
| amh-Ethi | Амхарский | |
| деу-Латн | Немецкий | |
| англ. Лат. | Английский | |
| nld-Latn | Голландский | |
| СПА-Латн | Испанский | |
| тур-Латн | Турецкий | На основе данных с добавленными суффиксами |
| тур-Латн-носуф | Турецкий | На основе данных с удаленными суффиксами |
| узб-латн-суф | Узбекский | На основе данных с добавленными суффиксами |
Обратите внимание, что основные языки, включая французский , отсутствуют в этой таблице из-за отсутствия соответствующих текстовых данных.
Установка Flite (для англ. G2P)
Для использования с большинством языков Epitran не требует специальных действий по установке. Его можно установить как обычный пакет python, либо с pip , либо путем запуска python setup.py install в корне исходного каталога. Однако английский G2P в Epitran полагается на CMU Flite, пакет синтеза речи, разработанный Аланом Блэком и другими исследователями речи из Университета Карнеги-Меллона. Для текущей версии Epitran вы должны следовать инструкциям по установке для lex_lookup , который используется в качестве интерфейса G2P по умолчанию для Epitran.
t2p Не рекомендуется
Модуль epitran.flite дополняет систему синтеза речи flite для выполнения английского языка G2P. Для работы этого модуля необходимо установить Flite. Бинарный файл t2p из flite не установлен по умолчанию и должен быть вручную скопирован в путь. Ниже приводится иллюстрация того, как это можно сделать в Unix-подобной системе. Обратите внимание, что требуется GNU gmake и что, если у вас установлен еще один make , вам, возможно, придется явно вызвать gmake :
$ tar xjf flite-2.0.0-release.tar.bz2 $ cd flite-2.0.0-релиз / $ ./configure && make $ sudo make install $ sudo cp bin / t2p / usr / местный / bin
Вам следует адаптировать эти инструкции к местным условиям. Установка в Windows проще всего при использовании Cygwin. Вам придется по своему усмотрению решить, где разместить t2p.exe в Windows, поскольку это может зависеть от ваших настроек python. Другие платформы, вероятно, работают, но не тестировались.
lex_lookup Рекомендуемая
t2p не работает должным образом с последовательностями букв, которые в английском языке встречаются очень редко. В таких случаях
В таких случаях t2p дает произношение английских букв имени, а не попытку произношения имени. В самые последние (предварительные) версии Flite включен другой двоичный файл, который в этом отношении ведет себя лучше, но требует дополнительных усилий для установки. Для установки вам необходимо получить Flite как минимум версии 2.0.5. Мы рекомендуем вам получить исходный код на GitHub (https://github.com/festvox/flite). Разверните и скомпилируйте исходный код, выполнив следующие шаги, при необходимости изменив настройки для вашей системы:
$ tar xjf flite-2.0.5-current.tar.bz2 $ cd flite-2.0.5-ток
или
$ git clone [email protected]: festvox / flite.git $ cd flite /
, затем
$ ./конфигурировать && сделать $ sudo make install $ cd testsuite $ make lex_lookup $ sudo cp lex_lookup / usr / местный / bin
При установке в MacOS и других системах, использующих версию BSD cp , необходимо внести некоторые изменения в Makefile, чтобы установить flite-2.0.5 (между шагами 3 и 4). Отредактируйте main / Makefile и измените оба экземпляра cp -pd на cp -pR .Затем вернитесь к шагу 4, описанному выше.
Использование
Чтобы использовать lex_lookup , просто создайте экземпляр Epitran как обычно, но с кодом , установленным на ‘eng-Latn’:
>>> импортный эпитран
>>> epi = epitran.Epitran ('англ-латн')
>>> выведите epi.transliterate (u'Berkeley ')
Bkli
Расширение Epitran с помощью файлов карт, препроцессоров и постпроцессоров
Языковая поддержка в Epitran обеспечивается через файлы карт, которые определяют сопоставления между орфографическими и фонетическими единицами, препроцессоры, которые запускаются до применения карты, и постпроцессоры, которые запускаются после применения карты.Карты определяются в файлах значений с разделителями-запятыми (CSV) в кодировке UTF8. Каждый файл имеет имена , где  csv
csv — это (трехбуквенный, все строчные буквы) код ISO 639-3 для языка, а — (четырехбуквенный , заглавные буквы) Код ISO 15924 для скрипта. Эти файлы находятся в каталоге data установки Epitran в подкаталогах map , pre и post соответственно.Файлы пре- и постпроцессора представляют собой текстовые файлы, формат которых описан ниже. Они следуют тем же соглашениям об именах, за исключением того, что у них есть расширения файлов .txt .
Файлы карт (таблицы сопоставления)
Файлы карты представляют собой простые файлы с двумя столбцами, в которых первый столбец содержит ортографические символы / последовательности, а второй столбец содержит фонетические символы / последовательности. Два столбца разделены запятой; каждая строка заканчивается новой строкой. Для многих языков (большинства языков с однозначной, фонематически адекватной орфографией) этого простого в создании файла сопоставления достаточно для создания работоспособной системы G2P.
Первая строка является заголовком и отбрасывается. Для единообразия он должен содержать поля «Орт» и «Фон». Следующие строки состоят из полей любой длины, разделенных запятыми. Одна и та же фонетическая форма (второе поле) может встречаться любое количество раз, но орфографическая форма может встречаться только один раз. Если одна орфографическая форма является префиксом другой формы, более длинная форма имеет приоритет при отображении. Другими словами, соответствие между орфографическими единицами и орфографическими строками является жадным.Отображение работает путем нахождения самого длинного префикса орфографической формы и добавления соответствующей фонетической строки в конец фонетической формы, затем удаления префикса из орфографической формы и продолжения таким же образом до тех пор, пока орфографическая форма не будет использована. Если в таблице сопоставления нет непустого префикса орфографической формы, первый символ орфографической формы удаляется и добавляется к фонетической форме. Затем возобновляется нормальная последовательность действий. Это означает, что нефонетические символы могут оказаться в «фонетической» форме, что, по нашему мнению, лучше, чем потеря информации из-за неадекватной таблицы сопоставления.
Затем возобновляется нормальная последовательность действий. Это означает, что нефонетические символы могут оказаться в «фонетической» форме, что, по нашему мнению, лучше, чем потеря информации из-за неадекватной таблицы сопоставления.
Препроцессоры и постпроцессоры
Для пар язык-сценарий с более сложной орфографией иногда необходимо изменить орфографическую форму до сопоставления или изменить фонетическую форму после сопоставления. В Epitran это делается с помощью грамматик контекстно-зависимых правил перезаписи строк. По правде говоря, этих правил было бы более чем достаточно для решения проблемы сопоставления, но с практической точки зрения обычно легче позволить простым для понимания и легким в обслуживании файлам сопоставления нести большую часть веса преобразования и резервирования. более мощный контекстно-зависимый грамматический формализм для предварительной и последующей обработки.
Файлы препроцессора и постпроцессора имеют одинаковый формат. Они состоят из последовательности строк, каждая из четырех типов:
- Определения символов
- Контекстно-зависимые правила перезаписи
- Комментарии
- Пустые строки
Определения символов
Строки, похожие на следующие
:: гласные :: = a | e | i | o | u
определяют символы, которые можно повторно использовать при написании правил. Символы должны состоять из префикса из двух двоеточий, последовательности из одной или нескольких строчных букв и знаков подчеркивания и суффикса из двух двоеточий.Они отделены от своих определений знаком равенства (при желании можно выделить пробелом). Определение состоит из подстроки регулярного выражения.
Символы должны быть определены до того, как на них будут ссылаться.
Правила перезаписи
Контекстно-зависимые правила перезаписи в Epitran записываются в формате, знакомом фонологам, но прозрачном для компьютерных ученых. Их можно схематически обозначить как
.
a -> b / X _ Y
, который можно переписать как
XaY → XbY
Стрелка -> может читаться как «перезаписывается как», а косая черта / может читаться как «в контексте».Нижнее подчеркивание указывает позицию перезаписываемого символа (ов). Другой специальный символ — octothorp # , который указывает начало или конец строки (длиной слова) (граница слова). Учтите следующее правило:
e -> ə / _ #
Это правило можно прочитать как «/ e / переписывается как / ə / в контексте в конце слова». Последний специальный символ — ноль 0 , который представляет собой пустую строку. Он используется в правилах, которые вставляют или удаляют сегменты.Рассмотрим следующее правило, которое удаляет / ə / между / k / и / l /:
ə -> 0 / k _ l
Все правила должны включать оператор стрелки, оператор косой черты и знак подчеркивания. Правило, которое применяется вне контекста, может быть записано следующим образом:
ch -> x / _
Реализация контекстно-зависимых правил в пре- и постпроцессорах Epitran использует замену регулярных выражений. В частности, он использует пакет regex , заменяющий re .По этой причине при написании правил можно использовать нотацию регулярных выражений:
c -> s / _ [ie]
или
c -> s / _ (i | e)
Полное руководство по регулярным выражениям regex см. В документации для regex и, в частности, для регулярных выражений regex .
Фрагменты регулярных выражений можно назначать символам и повторно использовать в файле. Например, символ разделения гласных в языке может использоваться в правиле, которое заменяет / u / на / w / перед гласными:
:: гласные :: = a | e | i | o | u
...
u -> w / _ (:: гласные: :)
 u -> w / _ (:: гласные: :)
u -> w / _ (:: гласные: :)
Существует специальная конструкция для обработки случаев метатезиса (где AB заменяется на BA). Например, правило:
(? P [เแโไใไ]) (? P .) -> 0 / _
«Поменяет местами» любой символ в «เแโไใไ» и любой следующий за ним символ. Слева от стрелки должны быть две группы (в круглых скобках) с именами sw1 и sw2 (имя группы определяется как ? P , которое появляется сразу после открытой скобки для группы ).Подстроки, соответствующие двум группам, sw1, и sw2, , будут «поменяны местами» или метатезированы. Элемент справа от стрелки игнорируется, а контекст — нет.
Правила применяются по порядку, поэтому более ранние правила могут «кормить» и «пропускать» более поздние правила. Следовательно, их последовательность очень важна и может быть использована для достижения ценных результатов.
Комментарии и пустые строки
Комментарии и пустые строки (строки, состоящие только из пробелов) разрешены, чтобы сделать ваш код более читабельным.Любая строка, в которой первым непробельным символом является знак процента % , интерпретируется как комментарий. Остальная часть строки игнорируется при интерпретации файла. Пустые строки также игнорируются.
Стратегия добавления языковой поддержки
Epitran использует подход к G2P «картирование и ремонт». Ожидается, что существует отображение между графемами и фонемами, которое может выполнять большую часть работы по преобразованию орфографических представлений в фонологические представления. В фонематически адекватных ортогрфиях это отображение может выполнять всю работы.Это сопоставление должно быть выполнено в первую очередь. Для многих языков основа для этой таблицы сопоставления уже существует в Википедии и Omniglot (хотя таблицы Omniglot обычно не читаются машиной).
С другой стороны, многие системы письма отклоняются от фонематически адекватной идеи. Именно здесь должны быть введены пре- и постпроцессоры. Например, в шведском языке буква
Именно здесь должны быть введены пре- и постпроцессоры. Например, в шведском языке буква перед двумя согласными (/ ɐ /) произносится иначе, чем где-либо еще (/ ɑː /).Имеет смысл добавить правило препроцессора, которое перезаписывает как / ɐ / перед двумя согласными (и аналогичные правила для других гласных, поскольку на них действует то же условие). Правила препроцессора обычно следует использовать всякий раз, когда необходимо скорректировать орфографическое представление (путем контекстных изменений, удалений и т. Д.) Перед этапом отображения.
Одним из распространенных способов использования постпроцессоров является удаление символов, которые необходимы препроцессорам или картам, но которые не должны появляться в выводе.Классическим примером этого является вирама, используемая в индийских сценариях. В этих сценариях для написания согласного , за которым не следует гласная, используется форма символа согласного с определенной присущей гласной, за которой следует вирама (которая имеет различные названия в разных индийских языках). Простой способ справиться с этим — позволить сопоставлению переводить согласный звук в согласный IPA + присущий гласный звук (который для данного языка всегда будет одинаковым), а затем использовать постпроцессор для удаления последовательности гласный + вирама ( где бы это ни происходило).
Фактически, любая ситуация, когда символ, представленный картой, должен быть впоследствии удален, является хорошим вариантом использования для постпроцессоров. Другой пример из индийских языков включает так называемое удаление шва. Некоторые гласные, подразумеваемые прямым сопоставлением орфографии и фонологии, на самом деле не произносятся; эти гласные обычно можно предсказать. В большинстве языков они встречаются в контексте после последовательности гласный + согласный звук и перед последовательностью согласный + гласный. Другими словами, правило выглядит так:
ə -> 0 / (:: гласная ::) (:: согласная: :) _ (:: согласная ::) (:: гласная: :)
Возможно, лучший способ узнать, как структурировать языковую поддержку для нового языка, — это проконсультироваться с существующими языками в Epitran.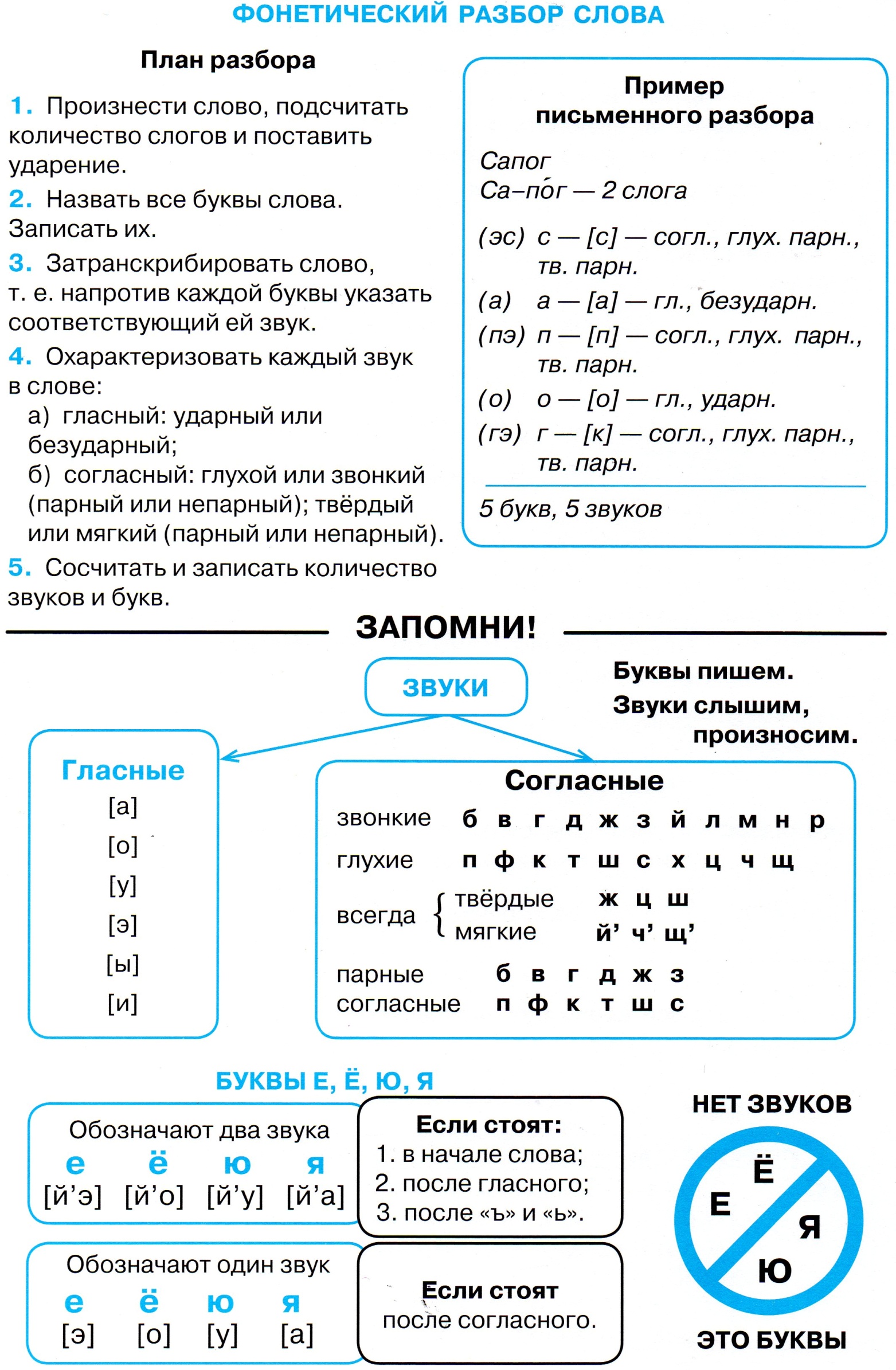 Французский препроцессор
Французский препроцессор fra-Latn.txt и тайский постпроцессор tha-Thai.txt иллюстрируют многие варианты использования этих правил.
Если вы используете Epitran в опубликованных работах или в других исследованиях, используйте следующую ссылку:
Дэвид Р. Мортенсен, Сиддхарт Далмиа и Патрик Литтел. 2018. Epitran: Precision G2P для многих языков. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , Paris, France.Европейская ассоциация языковых ресурсов (ELRA).
@InProceedings {Mortensen-et-al: 2018,
author = {Мортенсен, Дэвид Р. и Далмия, Сиддхарт и Литтел, Патрик},
title = {Epitran: Precision {G2P} для многих языков},
booktitle = {Труды одиннадцатой Международной конференции по языковым ресурсам и оценке (LREC 2018)},
год = {2018},
month = {май},
дата = {7–12},
location = {Миядзаки, Япония},
редактор = {Николетта Кальцолари (председатель конференции) и Халид Чукри, и Кристофер Сиери, и Тьерри Деклерк, и Сара Гогги, и Коити Хасида, и Хитоши Исахара, и Бенте Маэгаард, и Джозеф Мариани, и Эль'эн Мазо, и Асунсьон Морено, и Ян Одийк и Стелиос Пиперидис и Такенобу Токунага},
publisher = {Европейская ассоциация языковых ресурсов (ELRA)},
адрес = {Париж, Франция},
isbn = {979-10-95546-00-9},
language = {english}
}
nm0858: хорошо, это должна быть последняя лекция в этой серии согласно
справочник эээээ должно быть четыре этого термина это число четыре эр в конце ээ
Я просто свяжусь с вами, потому что если есть что-нибудь, что вы хотите, чтобы я пошел
снова или если у вас есть какие-либо вопросы или замечания, мы могли бы
еще одна встреча в то же время на следующей неделе этот слот бесплатный, но насколько
Я обеспокоен тем, что содержание лекций завершено, если я их прочту
что я хочу пройти сегодня, ладно, namex здесь из CALS записывает, что
Я говорю, что он не собирается узнавать что-нибудь интересное
om0859:
nm0858: просто эээээ он собирается найти что за синтаксическая зона бедствия
эээ незаписанная речь на лекции я думаю эм позволь мне только ох, прежде всего ээ
извинения, разные хорошо, я сказал мне, что это э . ..
столы в этой комнате в довольно грязном состоянии, и эээ они не
почистил как следует
Я передам это соответствующему отделу факультета, хорошо, где мы
добрался до прошлой недели, он говорил, что, хотя доказательства очень
конфликтуют очень сильно противоречат явно характерны
ритмические различия между разными языками, и я сказал, что хотя
мы все еще в неведении об этом явно не было бы этого
ритмическая регулярность, если только она не выполняла какую-то функцию, хорошо, если это правда
что каждый говорящий на любом языке говорит в каком-то ритме,
быть какой-то функцией для этого ритмера, потому что в целом мы не выполняем
вещи просто для удовольствия, когда мы говорим, и один из основных
функции ритма, которые, как мы подозреваем, заключаются в том, что он помогает нам разделить речь на
в единицы привет фонетика
sm0861: извини не та комната
nm0858: ладно ладно итак мы смотрим на возможные функции ритма и
время в разделении речи
до единиц, которые нам нужны для восприятия речи сейчас, конечно, одна из
вопросы в том, на какие подразделения мы делим, но в первую очередь просто
подумайте, если бы у нас не было помощи в разделении речи на единицы, то есть если бы у нас
никакой фонетической информации нам не поможет то, что мы могли бы вообразить, это
имея в виду, что мы обычно не делаем паузы между словами, которые должны были бы вообразить
эта речь идет к нам непрерывным потоком фонем и слогов
и нам пришлось бы очень трудно решить, где заканчивается одно слово и
начинается еще одна или где заканчивается фраза, начинается другая или где мы
достичь границы предложения и так далее, и я собирался привести вам пример
это потому, что кто-то однажды написал статью в фонетической транскрипции, оставив
вообще без пробелов, это была немного сумасшедшая бумага, которая появилась в
довольно причудливый журнал, в котором все статьи должны были быть написаны фонематически
транскрипция, и этот парень говорил, что я
значит, что на самом деле он был очень выдающимся фонетиком. Джон Трим, он говорил, что если
мы будем реалистами с фонематической транскрипцией, мы не должны ставить пробелы
в нашей транскрипции, если там нет фонетического пробела и если вы
не слышу ни одного, вы не должны его писать, и поэтому он написал эту статью как
хотя он говорил это вслух, он только помещал место, где он мог бы сделать паузу
для дыхания и, конечно, даже если вы можете читать фонематическую транскрипцию,
настоящая бумага почти полностью неразборчива, потому что это просто непрерывный
строка фонем э и э я дам вам копию этой бумаги, если
Вас интересует, к сожалению, том на моих полках, в котором он
отдан в аренду одному из моих студентов-исследователей, кто не тот, кто не
вернул его, но я передам его вам, это интересный опыт
читать его на самом деле очень интересно читать сам журнал
раньше он назывался Le Mètre Phonétique
и эээ это было главным изданием Международной фонетической ассоциации
и до тысяча девятьсот семьдесят четыре вы не будете ч-, у вас не будет бумаги
принят для этого журнала, если он не был написан в фонематической транскрипции
во всяком случае, одна из больших дискуссий в начале, примерно в середине периода
журнала Le Mètre Phonétique был большим спором между двумя
великие гиганты фонетики в начале двадцатого века, которые
был Поль Пасси, великий французский фонетик, и Даниэль Джонс, его
Британский эквивалент, вот цитата из Passy il est bien entendu n’est ce
pas que l’espace blanc laissé entre des mots n’a pas de valeur фонетическая
в основном говоря, что мы оставляем пробелы между словами, когда пишем транскрипцию
но фонетически это ничего не значит хорошо, это просто помогает нам
легче понять, что написано, и это побудило Джонса написать
ответ, кстати, я буду
давая вам раздаточный материал, который дает вам эти цитаты, поэтому вам не нужно писать
это дословно, просто возьмите в общих чертах ответ Джонс: я
сказал бы, что слово — это фонетическая сущность, в которой пробелы между
письменные слова действительно имеют фонетическое значение.
..
столы в этой комнате в довольно грязном состоянии, и эээ они не
почистил как следует
Я передам это соответствующему отделу факультета, хорошо, где мы
добрался до прошлой недели, он говорил, что, хотя доказательства очень
конфликтуют очень сильно противоречат явно характерны
ритмические различия между разными языками, и я сказал, что хотя
мы все еще в неведении об этом явно не было бы этого
ритмическая регулярность, если только она не выполняла какую-то функцию, хорошо, если это правда
что каждый говорящий на любом языке говорит в каком-то ритме,
быть какой-то функцией для этого ритмера, потому что в целом мы не выполняем
вещи просто для удовольствия, когда мы говорим, и один из основных
функции ритма, которые, как мы подозреваем, заключаются в том, что он помогает нам разделить речь на
в единицы привет фонетика
sm0861: извини не та комната
nm0858: ладно ладно итак мы смотрим на возможные функции ритма и
время в разделении речи
до единиц, которые нам нужны для восприятия речи сейчас, конечно, одна из
вопросы в том, на какие подразделения мы делим, но в первую очередь просто
подумайте, если бы у нас не было помощи в разделении речи на единицы, то есть если бы у нас
никакой фонетической информации нам не поможет то, что мы могли бы вообразить, это
имея в виду, что мы обычно не делаем паузы между словами, которые должны были бы вообразить
эта речь идет к нам непрерывным потоком фонем и слогов
и нам пришлось бы очень трудно решить, где заканчивается одно слово и
начинается еще одна или где заканчивается фраза, начинается другая или где мы
достичь границы предложения и так далее, и я собирался привести вам пример
это потому, что кто-то однажды написал статью в фонетической транскрипции, оставив
вообще без пробелов, это была немного сумасшедшая бумага, которая появилась в
довольно причудливый журнал, в котором все статьи должны были быть написаны фонематически
транскрипция, и этот парень говорил, что я
значит, что на самом деле он был очень выдающимся фонетиком. Джон Трим, он говорил, что если
мы будем реалистами с фонематической транскрипцией, мы не должны ставить пробелы
в нашей транскрипции, если там нет фонетического пробела и если вы
не слышу ни одного, вы не должны его писать, и поэтому он написал эту статью как
хотя он говорил это вслух, он только помещал место, где он мог бы сделать паузу
для дыхания и, конечно, даже если вы можете читать фонематическую транскрипцию,
настоящая бумага почти полностью неразборчива, потому что это просто непрерывный
строка фонем э и э я дам вам копию этой бумаги, если
Вас интересует, к сожалению, том на моих полках, в котором он
отдан в аренду одному из моих студентов-исследователей, кто не тот, кто не
вернул его, но я передам его вам, это интересный опыт
читать его на самом деле очень интересно читать сам журнал
раньше он назывался Le Mètre Phonétique
и эээ это было главным изданием Международной фонетической ассоциации
и до тысяча девятьсот семьдесят четыре вы не будете ч-, у вас не будет бумаги
принят для этого журнала, если он не был написан в фонематической транскрипции
во всяком случае, одна из больших дискуссий в начале, примерно в середине периода
журнала Le Mètre Phonétique был большим спором между двумя
великие гиганты фонетики в начале двадцатого века, которые
был Поль Пасси, великий французский фонетик, и Даниэль Джонс, его
Британский эквивалент, вот цитата из Passy il est bien entendu n’est ce
pas que l’espace blanc laissé entre des mots n’a pas de valeur фонетическая
в основном говоря, что мы оставляем пробелы между словами, когда пишем транскрипцию
но фонетически это ничего не значит хорошо, это просто помогает нам
легче понять, что написано, и это побудило Джонса написать
ответ, кстати, я буду
давая вам раздаточный материал, который дает вам эти цитаты, поэтому вам не нужно писать
это дословно, просто возьмите в общих чертах ответ Джонс: я
сказал бы, что слово — это фонетическая сущность, в которой пробелы между
письменные слова действительно имеют фонетическое значение. Сам Пасси привел пример
В некоторых случаях это er dans un parler tant soit peu langue на
distinguera trois petites roues, это три маленьких колеса и тройка петиц
три маленькие дырочки, ладно, так что это оспаривается французами
фонетистов довольно много, потому что некоторые французы говорят, что вы не слышите
разница между этими двумя, тремя маленькими колесами и тремя маленькими дырочками,
но граница слова в этих двух случаях находится в другом месте, и Пасси
в другом случае сказал, что вы действительно можете услышать разницу между
им я недостаточно владею французским, чтобы знать, правда ли, что вы слышите
разница, но если кто-то из вас говорит по-французски
друзья, вы могли бы попробовать это на них и посмотреть, есть ли ощутимые
разница хорошо, так что есть основной спор, конечно, насколько
Английский и французский озабочены тем, можем ли мы слышать, где
слово заканчивается и начинается одно, и когда вы думаете об этом, один из самых
жизненно важные функции в восприятии речи, если речь идет к нам как одна непрерывная
поток, и все же мысленно мы можем разделить его на очень
сложный способ в целую серию единиц вплоть до очень маленьких единиц
как слова и вплоть до больших единиц, таких как предложения, если мы можем
вопрос в том, получаем ли мы какую-либо помощь в этом от фонетической
информация — это что-то, есть ли в речевом сигнале что-то, что говорит нам
где эти границы или мы просто выясняем это на каком-то
статистическая база. Я провел некоторое исследование по одной конкретной проблеме, которая
возникает из этого, и я хотел бы использовать это как своего рода
привязка, чтобы повесить эту проблему, чтобы рассказать вам немного о том, что мы делаем
эээ, и где мы к этому пришли, проблема в том, что иногда
называется проблемой вложенных слов, когда мы слышим слово из нескольких слогов
как ответственность, хорошо, это слово почти неизбежно будет содержать другие
Английские слова меньшего размера, поэтому в случае ответственности мы находим в
что слово «ответ» слово «спонсор» это слово «способность»
последний бит там слово законопроект, который там, и вы найдете несколько
другие, если вы достаточно внимательно посмотрели, почти любое слово на английском языке
чем два слога фактически будут содержать внутри него упакованный внутри него
меньшее английское слово.
Сам Пасси привел пример
В некоторых случаях это er dans un parler tant soit peu langue на
distinguera trois petites roues, это три маленьких колеса и тройка петиц
три маленькие дырочки, ладно, так что это оспаривается французами
фонетистов довольно много, потому что некоторые французы говорят, что вы не слышите
разница между этими двумя, тремя маленькими колесами и тремя маленькими дырочками,
но граница слова в этих двух случаях находится в другом месте, и Пасси
в другом случае сказал, что вы действительно можете услышать разницу между
им я недостаточно владею французским, чтобы знать, правда ли, что вы слышите
разница, но если кто-то из вас говорит по-французски
друзья, вы могли бы попробовать это на них и посмотреть, есть ли ощутимые
разница хорошо, так что есть основной спор, конечно, насколько
Английский и французский озабочены тем, можем ли мы слышать, где
слово заканчивается и начинается одно, и когда вы думаете об этом, один из самых
жизненно важные функции в восприятии речи, если речь идет к нам как одна непрерывная
поток, и все же мысленно мы можем разделить его на очень
сложный способ в целую серию единиц вплоть до очень маленьких единиц
как слова и вплоть до больших единиц, таких как предложения, если мы можем
вопрос в том, получаем ли мы какую-либо помощь в этом от фонетической
информация — это что-то, есть ли в речевом сигнале что-то, что говорит нам
где эти границы или мы просто выясняем это на каком-то
статистическая база. Я провел некоторое исследование по одной конкретной проблеме, которая
возникает из этого, и я хотел бы использовать это как своего рода
привязка, чтобы повесить эту проблему, чтобы рассказать вам немного о том, что мы делаем
эээ, и где мы к этому пришли, проблема в том, что иногда
называется проблемой вложенных слов, когда мы слышим слово из нескольких слогов
как ответственность, хорошо, это слово почти неизбежно будет содержать другие
Английские слова меньшего размера, поэтому в случае ответственности мы находим в
что слово «ответ» слово «спонсор» это слово «способность»
последний бит там слово законопроект, который там, и вы найдете несколько
другие, если вы достаточно внимательно посмотрели, почти любое слово на английском языке
чем два слога фактически будут содержать внутри него упакованный внутри него
меньшее английское слово. Теперь рассмотрим, с чем столкнется мозг, если кто-то
выдает предложение, содержащее слово «ответственность», если мозг ошибочно
разделяет ответственность на ответ и способность синтаксического анализа декодировать
этого предложения будет катастрофически неверным, см.
То, что я делаю, мы знаем, что когда мы слышим об ответственности, это то, что
слово не является комбинацией реакции и способности, и не в некотором смысле
спонсор и bility, которые, конечно, содержат два английских не-слова, так что
это сравнительно простая задача сейчас дело в том, что мы не катаемся,
катастрофически неправильно, мы не ошибаемся все время насчет э-э
многосложные слова и исследования, в которых я участвовал, искали
факторов, ответственных за нашу способность успешно справляться с этим
проблема встроенных слов в том, что мы не постоянно
неправильное направление, обманываемое звуками, чтобы услышать то, что не
там давайте просто попробуем подумать, какие факторы могут помочь нам не пойти
неправильно, у меня есть три возможных гипотезы, и снова они находятся в
раздаточный материал, который я дам вам, и вам не нужно записывать это вам
вы получите этот текст позже, хорошо,
тогда вопрос в том, как мы добиваемся успеха, как так получается, что мы
успешный мо-, большую часть времени в решении, где проходят границы слова
возможность состоит в том, что фонетическая информация присутствует именно в том месте, где
наступает граница, которая помогает нам сказать, ах, это граница, поэтому я знаю, что
одно слово заканчивается, а другое начинается в этой точке, теперь мы рассмотрим это в
немного подробнее через мгновение, это, безусловно, возможно и правдоподобно.
объяснение хорошо, другая возможность состоит в том, что хотя мы не находим всего этого
много информации в фактических сегментах на границе фактических фонем на
начало и конец слова есть что-то в общей форме
слово, которое позволяет нам сказать: э, я слышу слово, начинающееся, и теперь я слышу
окончание слова есть что-то в его общей форме, например, э
это совершенно неправильное утверждение, но представьте, что было что-то вроде
что слово всегда начиналось очень тихо
и достигли крещендо, а затем растворились в тишине, общая
форма диаграммы громкости поможет вам узнать, где
пришло начало и конец слова, которого на самом деле не бывает, конечно э
что это всего лишь воображаемый пример и третья возможность, которую я подозреваю
многие лингвисты предпочли бы, чтобы здесь не было абсолютно ничего
стоит послушать речевой сигнал, когда дело доходит до определения границ
мы просто делаем это на основе лингвистических знаний, которые являются первоклассными
вниз теории, и мы еще немного рассмотрим эту, так что я на самом деле
сказал, что вместо использования фонетической или фонологической информации мы сопоставляем
сегментируйте строки по нашему лексикону и выберите совпадение, которое дает больше всего
правдоподобная последовательность слов, давайте просто вернемся к примеру er, который я имел на
предыдущий слайд слово «ответственность», если вы получили это str-, that s-,
последовательность фонем, составляющих
ответственность, и я задаю вам проблему, почему в предложении, как будто это ваше
ответственность за то, чтобы прибыть вовремя, почему бы нам не интерпретировать это как ваше
способность реагировать вовремя, почему бы нам не интерпретировать это так, как это
поскольку мы знаем структуру этого предложения, мы знаем его лексическое содержание, мы
знать, в какой ситуации это произносится, и мы просто не будем
дурацкая интерпретация, как реакция и способность как два разных слова, потому что
это не соответствовало синтаксису и семантике того, что
мы говорили
конец проблемы вам не нужна фонетическая или фонологическая информация, хорошо, что
почти наверняка будет так хорошо, что компьютерные лингвисты
ответ на проблему: достаточно контекстной лингвистической информации, чтобы
решить проблему, не полагаясь на то, что сейчас в звуках, конечно
эээ, это не мой подход к предмету, поэтому я не собираюсь покупать это
объяснение мне, эээ, должно быть что-то важное в этом слове
границы отмечены аллофонической информацией в сегментах, прилегающих к
граничные и / или просодические факторы могут тер-, могут характеризовать общую форму
А теперь вспомните, что на прошлой неделе я говорил о различиях между
разных языках, что я подозреваю, так это то, что на некоторых языках мы находим
преобладание ошибочной функции в делениях границы слова b-, здесь
на основе этой первой возможности, что границы слова сегментированы в
края и на других языках вы обнаружите, что основной фактор, способствующий
наша способность разделять на слова — это вторая просодическая информация
давайте посмотрим на этот второй, чтобы начать с характера просодических факторов,
[кашель], характеризующий общую пихту, форма слова [кашель], если это правда
что во французском языке каждое слово заканчивается ударным слогом, который обычно
требование, сделанное во вводных книгах по фонетике, затем разделение французского языка на разделение
непрерывный французский до слов — это не проблема, которую вы просто слушаете
ударный слог, и вы говорите ha ударный слог конец слова граница слова
прислушайтесь к следующему, и тогда у вас может быть несколько слогов и сильный
такой, как тот, с сильным ударением, поэтому вы автоматически помещаете слово
Граница это примерно такая же простая процедура, как простой алгоритм, как вы могли бы
найти в расшифровке речи просто послушать ударный слог и поставить слово
граница
сразу после него, и есть другие языки, как я уже сказал, прежде чем
имеют другие формы ударения, например, в польском языке большинство слов имеют
сильный слог, затем слабый, а затем граница слова, другими словами,
ударение в польском языке обычно ставится на предпоследний слог, поэтому, если вы
Польский слушатель, слушающий польский язык, позвольте потоку речи войти
через ваши уши, и вы просто получите немного своей обработки
способность вашего мозга прислушиваться к ударным слогам, вы позволяете еще один
проходите слог, а затем вы помещаете границу слова, как и во французском w-,
к этому следует относиться немного скептически, если вы слушаете
разговорный французский.
Теперь рассмотрим, с чем столкнется мозг, если кто-то
выдает предложение, содержащее слово «ответственность», если мозг ошибочно
разделяет ответственность на ответ и способность синтаксического анализа декодировать
этого предложения будет катастрофически неверным, см.
То, что я делаю, мы знаем, что когда мы слышим об ответственности, это то, что
слово не является комбинацией реакции и способности, и не в некотором смысле
спонсор и bility, которые, конечно, содержат два английских не-слова, так что
это сравнительно простая задача сейчас дело в том, что мы не катаемся,
катастрофически неправильно, мы не ошибаемся все время насчет э-э
многосложные слова и исследования, в которых я участвовал, искали
факторов, ответственных за нашу способность успешно справляться с этим
проблема встроенных слов в том, что мы не постоянно
неправильное направление, обманываемое звуками, чтобы услышать то, что не
там давайте просто попробуем подумать, какие факторы могут помочь нам не пойти
неправильно, у меня есть три возможных гипотезы, и снова они находятся в
раздаточный материал, который я дам вам, и вам не нужно записывать это вам
вы получите этот текст позже, хорошо,
тогда вопрос в том, как мы добиваемся успеха, как так получается, что мы
успешный мо-, большую часть времени в решении, где проходят границы слова
возможность состоит в том, что фонетическая информация присутствует именно в том месте, где
наступает граница, которая помогает нам сказать, ах, это граница, поэтому я знаю, что
одно слово заканчивается, а другое начинается в этой точке, теперь мы рассмотрим это в
немного подробнее через мгновение, это, безусловно, возможно и правдоподобно.
объяснение хорошо, другая возможность состоит в том, что хотя мы не находим всего этого
много информации в фактических сегментах на границе фактических фонем на
начало и конец слова есть что-то в общей форме
слово, которое позволяет нам сказать: э, я слышу слово, начинающееся, и теперь я слышу
окончание слова есть что-то в его общей форме, например, э
это совершенно неправильное утверждение, но представьте, что было что-то вроде
что слово всегда начиналось очень тихо
и достигли крещендо, а затем растворились в тишине, общая
форма диаграммы громкости поможет вам узнать, где
пришло начало и конец слова, которого на самом деле не бывает, конечно э
что это всего лишь воображаемый пример и третья возможность, которую я подозреваю
многие лингвисты предпочли бы, чтобы здесь не было абсолютно ничего
стоит послушать речевой сигнал, когда дело доходит до определения границ
мы просто делаем это на основе лингвистических знаний, которые являются первоклассными
вниз теории, и мы еще немного рассмотрим эту, так что я на самом деле
сказал, что вместо использования фонетической или фонологической информации мы сопоставляем
сегментируйте строки по нашему лексикону и выберите совпадение, которое дает больше всего
правдоподобная последовательность слов, давайте просто вернемся к примеру er, который я имел на
предыдущий слайд слово «ответственность», если вы получили это str-, that s-,
последовательность фонем, составляющих
ответственность, и я задаю вам проблему, почему в предложении, как будто это ваше
ответственность за то, чтобы прибыть вовремя, почему бы нам не интерпретировать это как ваше
способность реагировать вовремя, почему бы нам не интерпретировать это так, как это
поскольку мы знаем структуру этого предложения, мы знаем его лексическое содержание, мы
знать, в какой ситуации это произносится, и мы просто не будем
дурацкая интерпретация, как реакция и способность как два разных слова, потому что
это не соответствовало синтаксису и семантике того, что
мы говорили
конец проблемы вам не нужна фонетическая или фонологическая информация, хорошо, что
почти наверняка будет так хорошо, что компьютерные лингвисты
ответ на проблему: достаточно контекстной лингвистической информации, чтобы
решить проблему, не полагаясь на то, что сейчас в звуках, конечно
эээ, это не мой подход к предмету, поэтому я не собираюсь покупать это
объяснение мне, эээ, должно быть что-то важное в этом слове
границы отмечены аллофонической информацией в сегментах, прилегающих к
граничные и / или просодические факторы могут тер-, могут характеризовать общую форму
А теперь вспомните, что на прошлой неделе я говорил о различиях между
разных языках, что я подозреваю, так это то, что на некоторых языках мы находим
преобладание ошибочной функции в делениях границы слова b-, здесь
на основе этой первой возможности, что границы слова сегментированы в
края и на других языках вы обнаружите, что основной фактор, способствующий
наша способность разделять на слова — это вторая просодическая информация
давайте посмотрим на этот второй, чтобы начать с характера просодических факторов,
[кашель], характеризующий общую пихту, форма слова [кашель], если это правда
что во французском языке каждое слово заканчивается ударным слогом, который обычно
требование, сделанное во вводных книгах по фонетике, затем разделение французского языка на разделение
непрерывный французский до слов — это не проблема, которую вы просто слушаете
ударный слог, и вы говорите ha ударный слог конец слова граница слова
прислушайтесь к следующему, и тогда у вас может быть несколько слогов и сильный
такой, как тот, с сильным ударением, поэтому вы автоматически помещаете слово
Граница это примерно такая же простая процедура, как простой алгоритм, как вы могли бы
найти в расшифровке речи просто послушать ударный слог и поставить слово
граница
сразу после него, и есть другие языки, как я уже сказал, прежде чем
имеют другие формы ударения, например, в польском языке большинство слов имеют
сильный слог, затем слабый, а затем граница слова, другими словами,
ударение в польском языке обычно ставится на предпоследний слог, поэтому, если вы
Польский слушатель, слушающий польский язык, позвольте потоку речи войти
через ваши уши, и вы просто получите немного своей обработки
способность вашего мозга прислушиваться к ударным слогам, вы позволяете еще один
проходите слог, а затем вы помещаете границу слова, как и во французском w-,
к этому следует относиться немного скептически, если вы слушаете
разговорный французский. Во многих случаях франкоговорящие
перед последним слогом в польском языке есть исключения из правил, если
возьмем слово, например, польское слово для обозначения университета
uniwersytet er, который является предпоследним, это то, что он
это не ээ это не они не говорят [unIvEr «sItEt] они говорят [unI» vErsItEt]
который оставляет в конце два безударных слога, но большинство польских
слова str-, имеют такую структуру, поэтому в этих случаях
просодические факторы, характеризующие общую форму слова под теми
обстоятельства, у вас есть много помощи для разделения речи на слова сейчас, когда
мы знаем, что английский — гораздо более сложный клиент в этом отношении, потому что мы
знайте, что в многосложных английских словах мы находим некоторые моменты, в которых ударение делается на
первый слог, где ударение делается на последнем слоге, а где-то в
другие места посередине, и поэтому мы не можем полагаться, по крайней мере, на такое
легкий путь к этой общей просодической форме слова [кашель] с другой стороны
то, что у нас есть в английском довольно мощным способом, — это способность
различать слова или пары слов er на основе фонетической информации er
пример, который все слышали
и что всегда возникает на ранних лекциях по фонетике, — это различия
как серая лента и большая обезьяна, я уверен, вы все сталкивались с такими примерами
люди написали огромные статьи, основанные на этой конкретной проблеме, в
на самом деле, многие из них были вдохновлены тем спором или спором о том, что спор между
Пасси и Джонс ээээ много лет назад, потому что однажды эр проблема стала
теоретическая проблема побудила людей начать эксперименты, если вы не
знаете, что отличает серую ленту и вас, безусловно
должен уметь это объяснить, это не так уж и сложно понять, но
вы, возможно, забыли основную фонетику, которая позволяет вам придумывать
В конце концов, давайте просто рассмотрим этот конкретный пример, первое, что нужно
make, конечно же, обе эти фразы содержат одни и те же сегменты
если вы действительно проходите через фонемы по фонемам, нет никакой разницы и
но если я скажу либо серая лента, либо большая обезьяна th-, v-, a-, девяносто девять на
процентов людей успешно распознают, кому из двоих я предназначил вас
послушайте, теперь я могу v-, я могу сделать разницу еще яснее, если я как бы подделываю это
если я поставлю здесь голосовую остановку до того, как гласная начнется в
второе слово и скажите так: большая обезьяна, большая обезьяна, тогда не будет двусмысленности в
все, что вы просто не могли бы интерпретировать большую обезьяну как комбинацию серого и
лента, но если мы возьмем ее немного более естественно и скажем эр серая лента
и большая обезьяна без глоттальной остановки, вы все равно можете слышать разницу, что
фонетические факторы ну один из них кто-нибудь хочет сказать мне, прежде чем я скажу
ты копаешься в фонетику с давних пор продолжаешь ты почти
[смейся смейся]
sf0862: это стресс
nm0858: мм
sf0862: это стресс
nm0858: нет стресс идентичен серая лента отличная обезьяна это так
второй слог
подчеркнуто в обоих случаях нет, это -, это аллофоническая информация, это э .
Во многих случаях франкоговорящие
перед последним слогом в польском языке есть исключения из правил, если
возьмем слово, например, польское слово для обозначения университета
uniwersytet er, который является предпоследним, это то, что он
это не ээ это не они не говорят [unIvEr «sItEt] они говорят [unI» vErsItEt]
который оставляет в конце два безударных слога, но большинство польских
слова str-, имеют такую структуру, поэтому в этих случаях
просодические факторы, характеризующие общую форму слова под теми
обстоятельства, у вас есть много помощи для разделения речи на слова сейчас, когда
мы знаем, что английский — гораздо более сложный клиент в этом отношении, потому что мы
знайте, что в многосложных английских словах мы находим некоторые моменты, в которых ударение делается на
первый слог, где ударение делается на последнем слоге, а где-то в
другие места посередине, и поэтому мы не можем полагаться, по крайней мере, на такое
легкий путь к этой общей просодической форме слова [кашель] с другой стороны
то, что у нас есть в английском довольно мощным способом, — это способность
различать слова или пары слов er на основе фонетической информации er
пример, который все слышали
и что всегда возникает на ранних лекциях по фонетике, — это различия
как серая лента и большая обезьяна, я уверен, вы все сталкивались с такими примерами
люди написали огромные статьи, основанные на этой конкретной проблеме, в
на самом деле, многие из них были вдохновлены тем спором или спором о том, что спор между
Пасси и Джонс ээээ много лет назад, потому что однажды эр проблема стала
теоретическая проблема побудила людей начать эксперименты, если вы не
знаете, что отличает серую ленту и вас, безусловно
должен уметь это объяснить, это не так уж и сложно понять, но
вы, возможно, забыли основную фонетику, которая позволяет вам придумывать
В конце концов, давайте просто рассмотрим этот конкретный пример, первое, что нужно
make, конечно же, обе эти фразы содержат одни и те же сегменты
если вы действительно проходите через фонемы по фонемам, нет никакой разницы и
но если я скажу либо серая лента, либо большая обезьяна th-, v-, a-, девяносто девять на
процентов людей успешно распознают, кому из двоих я предназначил вас
послушайте, теперь я могу v-, я могу сделать разницу еще яснее, если я как бы подделываю это
если я поставлю здесь голосовую остановку до того, как гласная начнется в
второе слово и скажите так: большая обезьяна, большая обезьяна, тогда не будет двусмысленности в
все, что вы просто не могли бы интерпретировать большую обезьяну как комбинацию серого и
лента, но если мы возьмем ее немного более естественно и скажем эр серая лента
и большая обезьяна без глоттальной остановки, вы все равно можете слышать разницу, что
фонетические факторы ну один из них кто-нибудь хочет сказать мне, прежде чем я скажу
ты копаешься в фонетику с давних пор продолжаешь ты почти
[смейся смейся]
sf0862: это стресс
nm0858: мм
sf0862: это стресс
nm0858: нет стресс идентичен серая лента отличная обезьяна это так
второй слог
подчеркнуто в обоих случаях нет, это -, это аллофоническая информация, это э . ..
у нас одни и те же фонемы, но у них разные аллофоны, вот этот
начальная буква в слоге на ленте, и поэтому она начинается с придыхания, если вы слушаете серую ленту
серая лента, но если я возьму эту в конце слова отлично, она без наддува
э-э, и поэтому это произносится как большая обезьяна, большая обезьяна, большая обезьяна, и нет [t_h]
[t_h] [t_h] звук в конце этого здесь, так что здесь мы, T — это наддувка
здесь буква Т без наддува, есть еще одна разница, это слово здесь
великий имеет заключительную фортис согласную что делают заключительные фортис согласные с
предшествующие гласные на этой старой фонетике много ржавчины, не так ли,
заключительный согласный Fortis сокращает предыдущий гласный, если вы измеряете [eI]
звук в отличном состоянии он намного короче, чем звук [eI] в сером цвете послушайте
эта серая лента, серая лента, а теперь еще одна большая обезьяна, большая обезьяна, [eI]
укороченный
возможно, на пятьдесят или шестьдесят процентов это очень поразительное сокращение
эффект, который почти уникален для английского языка, большинство языков в мире имеют
небольшой эффект укорочения от фортис согласных.
небольшая почти незаметная разница и почему-то мы можем только
предположение увеличило это чрезвычайно сильно, так что мы видим здесь случай
которую я назвал одной из этих гипотез о том, что границы слов
отмеченный аллофонической информацией, которую мы можем извлечь из аллофонической
деталь в фонемах, где должна быть дана граница слова эта информация
что в этом случае с серой лентой у вас есть начальная буква [t_h], у вас есть
поставить границу слова перед [t_h] с учетом информации, которую вы получили
короткий звук [eI] и буква T, вы вынуждены поставить границу слова
после буквы T я имею в виду, когда я говорю, что принудительно не существует закона или э-э, или
штраф
вовлечены здесь, но именно так мы работаем после того, как этот эффект был обнаружен э
оно возникло хорошо, когда были проведены различные последующие исследования, наиболее известные из
здесь я дам вам ссылку на то, что это была работа, проделанная в девятнадцатом веке.
..
у нас одни и те же фонемы, но у них разные аллофоны, вот этот
начальная буква в слоге на ленте, и поэтому она начинается с придыхания, если вы слушаете серую ленту
серая лента, но если я возьму эту в конце слова отлично, она без наддува
э-э, и поэтому это произносится как большая обезьяна, большая обезьяна, большая обезьяна, и нет [t_h]
[t_h] [t_h] звук в конце этого здесь, так что здесь мы, T — это наддувка
здесь буква Т без наддува, есть еще одна разница, это слово здесь
великий имеет заключительную фортис согласную что делают заключительные фортис согласные с
предшествующие гласные на этой старой фонетике много ржавчины, не так ли,
заключительный согласный Fortis сокращает предыдущий гласный, если вы измеряете [eI]
звук в отличном состоянии он намного короче, чем звук [eI] в сером цвете послушайте
эта серая лента, серая лента, а теперь еще одна большая обезьяна, большая обезьяна, [eI]
укороченный
возможно, на пятьдесят или шестьдесят процентов это очень поразительное сокращение
эффект, который почти уникален для английского языка, большинство языков в мире имеют
небольшой эффект укорочения от фортис согласных.
небольшая почти незаметная разница и почему-то мы можем только
предположение увеличило это чрезвычайно сильно, так что мы видим здесь случай
которую я назвал одной из этих гипотез о том, что границы слов
отмеченный аллофонической информацией, которую мы можем извлечь из аллофонической
деталь в фонемах, где должна быть дана граница слова эта информация
что в этом случае с серой лентой у вас есть начальная буква [t_h], у вас есть
поставить границу слова перед [t_h] с учетом информации, которую вы получили
короткий звук [eI] и буква T, вы вынуждены поставить границу слова
после буквы T я имею в виду, когда я говорю, что принудительно не существует закона или э-э, или
штраф
вовлечены здесь, но именно так мы работаем после того, как этот эффект был обнаружен э
оно возникло хорошо, когда были проведены различные последующие исследования, наиболее известные из
здесь я дам вам ссылку на то, что это была работа, проделанная в девятнадцатом веке. шестидесятых годов О’Коннора и Тули, где они заставили ничего не подозревающих читателей прочитать их
довольно странные предложения, содержащие подобные пары, и такие вещи, как э-э, я видел
серая лента из окна, и я увидел большую обезьяну из окна
люди читали их, а затем просматривали записи с парой
ножницы и вырезал только пары слов и проиграл их слушателям и
сказал, можете ли вы сказать, слышите ли вы эту серую пленку или эту отличную
Обезьяна, и то, что они обнаружили, было довольно удивительным, когда были взрывчатые вещества.
задействованные особенно глухие взрывные устройства, люди были очень успешны в
успешно разместил, очень удачно разместил границу слова в
в нужном месте было много других примеров, которые они
построены с разными типами согласных, которые были гораздо менее успешными
эээ и эээ, они в конце концов были вынуждены прийти к выводу, что это дело
аллофоническое обозначение границ слов работает только в ограниченном количестве случаев
но тем временем им было очень весело придумывать эти пары слов
их иногда называют парами соединений, потому что это слово соединение используется для
относятся к соединению между двумя словами, поэтому пары соединений стали своего рода эр
хобби фонетиков, когда я впервые начал ходить на фонетические конференции в
в этой стране люди часто сидят без дела за пивом в
бар после того, как газеты были закончены в течение дня, изобретая такие вещи и
посмотреть, смогут ли они заставить людей услышать разницу, и вы получите такие вещи, как
э-э выбрать чернила, а не жевать цинк и что-то еще
сумасшедшие, да, больше льда и больше риса, хорошо, много таких вещей
постоянно придумывать такие пары, а затем пробовать их на слушателях, чтобы
посмотрим, могут ли они услышать разницу? Ответ такой: если люди намеренно
пытаясь прояснить, что из этого они намереваются, тогда это можно сделать
однозначно, но в обычной речи вы просто не можете услышать разницу, если она не
то, что имеет отличные аллофонические вариации, которые помогут вам полюбить
стремление здесь и сокращение prefortis в этом конкретном случае так
оглядываясь на эти возможности, я бы сказал, что хорошо, есть определенные
обстоятельства, при которых мы получаем аллофоническую информацию на границах слов, которые
помогает нам различать, но не всегда и не на всех языках
во-вторых, существуют просодические факторы, например, общие формы слов
которые помогают на некоторых языках, но эта помощь не очень хороша на английском и в
до недавнего времени считалось, что в
Английский для определения слова на основе общей просодической формы, но я
вкратце упомянул пару недель назад, что исследование Энн Катлер э-о-,
o-, по взгляду-, который просмотрел очень-очень большое количество английских слов
исследование Энн Катлер и ее коллег показало, что статистически это
более вероятно, что английское слово из нескольких слогов будет начинаться с
ударный слог статистически начальные ударные слоги являются наиболее
вероятно, на английском языке, и если подумать, можно придумать сотни
слова, которые звучат прямо у вас в голове, у которых нет начального слога
подчеркнули, но даже в этом случае показатель er составляет около шестидесяти пяти процентов.
шестидесятых годов О’Коннора и Тули, где они заставили ничего не подозревающих читателей прочитать их
довольно странные предложения, содержащие подобные пары, и такие вещи, как э-э, я видел
серая лента из окна, и я увидел большую обезьяну из окна
люди читали их, а затем просматривали записи с парой
ножницы и вырезал только пары слов и проиграл их слушателям и
сказал, можете ли вы сказать, слышите ли вы эту серую пленку или эту отличную
Обезьяна, и то, что они обнаружили, было довольно удивительным, когда были взрывчатые вещества.
задействованные особенно глухие взрывные устройства, люди были очень успешны в
успешно разместил, очень удачно разместил границу слова в
в нужном месте было много других примеров, которые они
построены с разными типами согласных, которые были гораздо менее успешными
эээ и эээ, они в конце концов были вынуждены прийти к выводу, что это дело
аллофоническое обозначение границ слов работает только в ограниченном количестве случаев
но тем временем им было очень весело придумывать эти пары слов
их иногда называют парами соединений, потому что это слово соединение используется для
относятся к соединению между двумя словами, поэтому пары соединений стали своего рода эр
хобби фонетиков, когда я впервые начал ходить на фонетические конференции в
в этой стране люди часто сидят без дела за пивом в
бар после того, как газеты были закончены в течение дня, изобретая такие вещи и
посмотреть, смогут ли они заставить людей услышать разницу, и вы получите такие вещи, как
э-э выбрать чернила, а не жевать цинк и что-то еще
сумасшедшие, да, больше льда и больше риса, хорошо, много таких вещей
постоянно придумывать такие пары, а затем пробовать их на слушателях, чтобы
посмотрим, могут ли они услышать разницу? Ответ такой: если люди намеренно
пытаясь прояснить, что из этого они намереваются, тогда это можно сделать
однозначно, но в обычной речи вы просто не можете услышать разницу, если она не
то, что имеет отличные аллофонические вариации, которые помогут вам полюбить
стремление здесь и сокращение prefortis в этом конкретном случае так
оглядываясь на эти возможности, я бы сказал, что хорошо, есть определенные
обстоятельства, при которых мы получаем аллофоническую информацию на границах слов, которые
помогает нам различать, но не всегда и не на всех языках
во-вторых, существуют просодические факторы, например, общие формы слов
которые помогают на некоторых языках, но эта помощь не очень хороша на английском и в
до недавнего времени считалось, что в
Английский для определения слова на основе общей просодической формы, но я
вкратце упомянул пару недель назад, что исследование Энн Катлер э-о-,
o-, по взгляду-, который просмотрел очень-очень большое количество английских слов
исследование Энн Катлер и ее коллег показало, что статистически это
более вероятно, что английское слово из нескольких слогов будет начинаться с
ударный слог статистически начальные ударные слоги являются наиболее
вероятно, на английском языке, и если подумать, можно придумать сотни
слова, которые звучат прямо у вас в голове, у которых нет начального слога
подчеркнули, но даже в этом случае показатель er составляет около шестидесяти пяти процентов. семьдесят процентов в данном тексте
чем количество начальных ударных слов мор-, то есть многосложного
слов количество начальных ударных слов в английском в среднем составляет около
от шестидесяти пяти процентов до даже иногда до семидесяти процентов от первоначального
подчеркнул, и поэтому теория Катлера состоит в том, что, хотя это лишь слабая тенденция
по сравнению с такими языками, как французский, польский и т. д., англоговорящие
в какой-то мере полагайтесь на это как на руководство, если вы слышите ударный слог в своем
мозг говорит, что это, вероятно, начало слова и, конечно же, следующее
от этого слога, слог перед этим, следовательно, был последним слогом
предыдущего слова, и иногда оказывается, что мы ошибаемся в этом, но если мы будем придерживаться
к этому простому правилу мы чаще всего правы эээ, я сомневаюсь
все еще об этом, но это то, что она и ее коллеги
держались очень долго, позвольте мне на минутку взглянуть на это последнее
возможность тот, который мы не используем, что нам не нужно использовать
фонетической информации вообще, и я сказал, что это обращается к
компьютерные лингвисты, потому что если вы разрабатываете компьютер для распознавания
слова, вероятно, вы сочтете это утомительным или утомительным наложение
просодическая информация, о которой нужно беспокоиться, вы должны предположить, что все слова, которые
вы знаете, закодированы в каком-то словаре в вашей голове, что у всех нас есть
ментальный лексикон мнения разнятся относительно его размера отчасти зависит от того, как
насколько вы образованны и хорошо запоминаете слова, но это
может легко где-то около сказать восемьдесят тысяч слов, что довольно много
словарь, мы должны предположить, что этот словарь закодирован в каком-то
фонологический формирователь, то есть это -, хотя мы знаем, что как грамотные люди мы
знать написание слов, которые хранятся у нас в голове, более того
важно то, что мы знаем звуки, из которых состоят слова, которые есть в нашем
голова у вас есть слово кошка е-, у всех в этой комнате есть слово кошка в
их ментальный словарный запас, который хранится в
количество способов, включая тот факт, что он содержит [k] и [ae] и a [t]
довольно типичной вычислительной операцией в компьютерной лингвистике является
есть две строки ну скажем, у нас должна была быть одна строка фонем
которые являются входными, это могут быть звуки, которые проходят через ваш
уши, а затем в вашем ментальном лексиконе есть много предметов, которые состоят из
фонем, где каждая из этих маленьких точек представляет фонему и вашу работу
состоит в том, чтобы сопоставить одно с другим, то, что вы должны сказать, хорошо, например,
я могу определить здесь конкретную фонему, позвольте мне просмотреть слова, которые я
узнать и посмотреть, смогу ли я найти что-нибудь, что начинается с этой фонемы, и вы найдете
если предположить, что это [k] er, то вы могли бы искать слово, начинающееся с
[k] нравится это, а затем вы ищете еще одно совпадение, следующее за этим, и еще одно
сопоставьте после этого, и вы увидите, совпадают ли какие-либо из этих шаблонов звуков
с
что-то в вашем ментальном лексиконе, и если это так, вы отметьте это и скажите я
думаю, это целое слово, давайте теперь продолжим и попробуем следующее, чтобы вы подумали
ну, если это слово, то это должно быть началом следующей точки
должно быть началом следующего слова, давайте посмотрим, соответствует ли оно каким-либо словам в
мой мысленный словарный запас, если бы вы использовали большой компьютер, и у вас был
неограниченное компьютерное время, когда вы делаете это k-, такого рода манипуляции справедливо
простой, и все, что вам нужно, это какой-то довольно умный механизм, который
продолжайте возвращаться каждый раз, когда вы терпите неудачу, если мы вернемся к примеру
ответственность er, если вы ошибочно определили ответственность er как re и
«спонсор» и «спонсор билити» соответствовали бы одному из слов в вашем мысленном
лексикон, но re не будет и bility не будет, потому что re — не английское слово
а bility — не английское слово, по крайней мере, насколько я знаю, и поэтому
эта гипотеза
вам придется с-, вам просто нужно сказать
это было не стартером я вернусь к началу er к последнему месту
где я был достаточно уверен, и начну сначала и посмотрю, смогу ли я сделать другой
интерпретация, и на этот раз вы можете сказать, может быть, это реакция и способность
посмотрим, работает ли это, но позже синтаксическая информация, которую вы
Он бы исключил это как разумную гипотезу, так что вы снова выбросите
это и скажите хорошо, возможно, это все слово ответственность, и вы бы
сопоставьте это да, которое совпадает со словом в ментальном лексиконе, и это
соответствует синтаксису и соответствует смыслу, что это я, я пойду на это
гипотезы, поэтому компьютерный лингвист хотел бы эту идею перетасовки
возможности сопоставления шаблонов из входных данных, то есть звуков, которые вы
услышать хранящиеся в вашем мозгу шаблоны, которые являются словами, которые вы на самом деле
хранятся сейчас, наш мозг невероятно быстро находит
слова, но даже в этом случае идея, что мы оставим это нашему мозгу, чтобы просто поработать
сопоставление с шаблоном фонемы без учета всей этой чудесно богатой информации
о просодии и аллофонической информации просто безумие, мозг не стал бы
просто игнорируйте такой ценный источник информации, поэтому мне кажется, что я
хотел бы отвергнуть идею о том, что мы не используем фонетические и фонологические
информация для определения границ слов хорошо, что я хочу делать с
закончить, просто опишите экспериментатор, над которым я работал в последний раз
год назад по этому конкретному вопросу о встроенных словах теперь встроенные слова
трудные вещи в работе, потому что только так мы можем действительно проверять людей ‘
способность слышать их — значит вырезать их из их контекста, и когда вы сокращаете
слово вне контекста оно внезапно перестает звучать узнаваемо и знакомо
я сделал много этого, и у меня есть несколько примеров на пленке, есть один
что я часто использую, это пример, когда вы
я знаю, что у меня есть большое количество извлеченных версий одного
конкретное слово, которое сотня только что вытащили из одного из наших больших компьютеров
корпуса автоматически одним из наших исследовательских компьютеров, и, поскольку вы знаете, что
слово, вы можете узнать слово каждый раз
nm0858: это продолжается часами, но вы знаете, что мы только что установили
компьютер теряет много часов речи в поисках слова сто
вырезать слово и воспроизвести его на ленте, но то, что мы сделали для
Эксперимент по восприятию встроенных слов заключался в том, чтобы извлечь слова, которые были ошибочно
вполне идентифицируемый для нас как экспериментаторов, но если вырезать без какого-либо контекста
и без какой-либо информации и представленные наивным слушателям были почти очень
часто до неузнаваемости сейчас у меня нет текста для этого здесь, но что вы
слышу, что вы можете распознать некоторые слова, они действительно извлечены
из того же корпуса записей, что и
те слова, сотня слов, которые вы только что слышали, из корпуса, называемого
Корпус MARSEC, с которым мы работали много лет в моей группе
nm0858: это то, что люди должны были слушать для наших
экспериментируйте, чтобы попытаться определить слова, которые каждый сказал дважды, что справедливо
легко, это город, это нормально, позвольте мне просто объяснить, что это за эксперимент
пытался сделать это, мы начали с использования этой базы данных MARSEC, и мы пошли
через три этапа, прежде всего, мы должны были выбрать данные, и то, что мы делали, было
поиск пар слов в данных, которые мы записали, где мы могли
сопоставить от того же говорящего полное слово, например, это может быть ответ и что-то
который казался тем же самым, что существовал как встроенное слово, так что у нас
пары слов, хотя мы их разделили
на кассетах, так что иногда люди слушали, я имею в виду, что мы слышали
слово только на этой ленте в некоторых случаях люди слышали слово только из
предложение, которое са-, сказал такие вещи, как будто я просто собирался по дороге или он был
просто человек, но в некоторых других случаях от того же говорящего мы произносили слово просто
from er a a word like adjustment okay that’s an embedded word the word just
sits inside the word adjustment and we cut it out and the idea was to find by
testing listeners’ perception whether our listeners were more successful at
hearing the embedded words or the er what we call the real words the words
which genuinely had a word boundary at either side er and so we went through
and we er this is work er done jointly with the er with Anne Cutler’s group in
the Max Planck Institute for Psycholinguistics in in Nijmegen in Holland er and
we spent very very large amount of time going through extracting these pairs of
examples and then recording them in random
order for for listening tests now the first thing when we’d done all this was
we the experimenters listened to tapes to see if we could hear the difference
and we could of course we’d been working on this for years so it’s not
surprising that we could tell the difference between real words and embedded
words er we actually did t-, a test on this er as er experts er these are the
statistical results and the main thing is that the er er probability value is
point-zero-zero-seven-six which means that the difference between real embedded
wor-, and embedded words in terms of us recognizing which was which was highly
significant so we were able as the experts running the experiment we were able
to distinguish between real and embedded words there’s nothing very surprising
about that then we played these words to naive listeners who had had no
previous experience of working with this kind of problem and [cough] we worked
out scores for how many words they got correct er the
i won’t i won’t it would take too long to explain what these er success scores
er were actually calculated on but we get a much higher success rate here six-
point-one-five on real words compared with four-point-three-three on the
embedded words and that difference there is very highly significant with a
probability value of point-zero-zero-zero-four so there was no doubt at all
that our listeners did better on real words rather than embedded words remember
that these words were presented completely out of context and therefore our
listeners had nothing to go on except what they could hear from the tape and
the only conclusion you can make from that is that there is something there
phonetically that enables you to tell what is a word and what is part of a word
to enable you to distinguish between bits of words and whole words so we went
back to the tapes and we spent a lot of time listening to them and i spent er
quite a lot of time er over in Nijmegen working
through every single word doing a very detailed phonetic examination of each
word and the thing that was coming out more and more clearly was that the
embedded words were shorter than the corresponding real words if we look at
that in graphical form er what we find here the-, these these are box plots
that’s the scale of duration on the left hand side going from a hundred to five-
hundred milliseconds er er this box covers most of the data and in the case of
embedded words the er duration was f-, rather shorter than the duration of the
real words it’s it’s not a big difference but it’s enough to be statistically
significant embedded words tend to be a bit shorter than the real word probably
er the difference is er enough to be over the threshold of our er ability to
perceive differences in durations of words and syllables there was just one
final question to answer is it that just the entire body of embedded words is
shorter than the whole collection of real words or
is this a genuine relationship that each individual pair of words will exhibit
a greater duration for the real word and a shorter duration for the embedded
word er so er this is er if this this is a rather messy graph but it just shows
the relationship between the durations of embedded words and the durations of
real words and you can see that centre line there er represents a trend er
which is that the er the longer a real word is the longer an embedded word is
that is they are closely related however for any given value of a real word
like three-hundred here the corresponding duration of an embedded word is
shorter so in er the case of all virtually all the words in our data and i mean
i had to admit if you look at some of these dots they’re way off that centre
line there’s a lot of variation but the overall trend is that for any given
pair of words the embedded word will be shorter than the real word and that
must be giving us the information that we need to
identify whether we’re hearing a part of a word or the word as a whole that
work is still going on i’m still writing it up er but recently i had to give a
talk on this at a conference and er as conference organizers do they asked me
to write it up to go er in a collection of papers er and since it’s a very sh-,
er a short paper reporting on work in progress er what i’d like to do is give
you each a copy so that you can go over this at er at at more leisure so there
i was er quarter of an hour before the lecture began ready to go on the
photocopier when i looked at it and realized that it was an early draft which
didn’t have the diagrams and the statistics in er when i went back i realized
it’s on my computer at home not on my computer at work so i’m afraid you don’t
get it this morning but i will put copies in namex’s office and those will be
available tomorrow onwards so if you’d like a copy of the most recent paper
i’ve written based on this research er er er and the
bibliography that goes with it er there will be enough for one each er on the
other hand er if you’re not interested just leave it there and i’ll give it to
somebody else that gets us to the end of that and also to the end of the study
of the relationship between temporal factors and speech perception and i hope
that the the general impression that you’ve got on this is that we are not
simple phoneme crunchers when it comes to perceiving speech we are not simply
taking in a stream of phonemes looking them up in a mental dictionary and
churning out a kind of transcript what we’re doing is at the same time
monitoring a very rich er stream of prosodic information and in some cases
also of allophonic variation but it’s the prosodic side i really want to
emphasize there is so much going on in the prosody of spoken language it’s
giving us so much information about how to divide the speech up into units and
how to interpret it and it just has to be er something of great importance er
it’s something which we only understand in a very dim and partial way at the
moment but a lot more research will be er going on in future years and we
should discover more and more about it and ultimately we can teach computers
that recognize speech how to make intelligent use of that information is that
okay are there any questions okay right then
семьдесят процентов в данном тексте
чем количество начальных ударных слов мор-, то есть многосложного
слов количество начальных ударных слов в английском в среднем составляет около
от шестидесяти пяти процентов до даже иногда до семидесяти процентов от первоначального
подчеркнул, и поэтому теория Катлера состоит в том, что, хотя это лишь слабая тенденция
по сравнению с такими языками, как французский, польский и т. д., англоговорящие
в какой-то мере полагайтесь на это как на руководство, если вы слышите ударный слог в своем
мозг говорит, что это, вероятно, начало слова и, конечно же, следующее
от этого слога, слог перед этим, следовательно, был последним слогом
предыдущего слова, и иногда оказывается, что мы ошибаемся в этом, но если мы будем придерживаться
к этому простому правилу мы чаще всего правы эээ, я сомневаюсь
все еще об этом, но это то, что она и ее коллеги
держались очень долго, позвольте мне на минутку взглянуть на это последнее
возможность тот, который мы не используем, что нам не нужно использовать
фонетической информации вообще, и я сказал, что это обращается к
компьютерные лингвисты, потому что если вы разрабатываете компьютер для распознавания
слова, вероятно, вы сочтете это утомительным или утомительным наложение
просодическая информация, о которой нужно беспокоиться, вы должны предположить, что все слова, которые
вы знаете, закодированы в каком-то словаре в вашей голове, что у всех нас есть
ментальный лексикон мнения разнятся относительно его размера отчасти зависит от того, как
насколько вы образованны и хорошо запоминаете слова, но это
может легко где-то около сказать восемьдесят тысяч слов, что довольно много
словарь, мы должны предположить, что этот словарь закодирован в каком-то
фонологический формирователь, то есть это -, хотя мы знаем, что как грамотные люди мы
знать написание слов, которые хранятся у нас в голове, более того
важно то, что мы знаем звуки, из которых состоят слова, которые есть в нашем
голова у вас есть слово кошка е-, у всех в этой комнате есть слово кошка в
их ментальный словарный запас, который хранится в
количество способов, включая тот факт, что он содержит [k] и [ae] и a [t]
довольно типичной вычислительной операцией в компьютерной лингвистике является
есть две строки ну скажем, у нас должна была быть одна строка фонем
которые являются входными, это могут быть звуки, которые проходят через ваш
уши, а затем в вашем ментальном лексиконе есть много предметов, которые состоят из
фонем, где каждая из этих маленьких точек представляет фонему и вашу работу
состоит в том, чтобы сопоставить одно с другим, то, что вы должны сказать, хорошо, например,
я могу определить здесь конкретную фонему, позвольте мне просмотреть слова, которые я
узнать и посмотреть, смогу ли я найти что-нибудь, что начинается с этой фонемы, и вы найдете
если предположить, что это [k] er, то вы могли бы искать слово, начинающееся с
[k] нравится это, а затем вы ищете еще одно совпадение, следующее за этим, и еще одно
сопоставьте после этого, и вы увидите, совпадают ли какие-либо из этих шаблонов звуков
с
что-то в вашем ментальном лексиконе, и если это так, вы отметьте это и скажите я
думаю, это целое слово, давайте теперь продолжим и попробуем следующее, чтобы вы подумали
ну, если это слово, то это должно быть началом следующей точки
должно быть началом следующего слова, давайте посмотрим, соответствует ли оно каким-либо словам в
мой мысленный словарный запас, если бы вы использовали большой компьютер, и у вас был
неограниченное компьютерное время, когда вы делаете это k-, такого рода манипуляции справедливо
простой, и все, что вам нужно, это какой-то довольно умный механизм, который
продолжайте возвращаться каждый раз, когда вы терпите неудачу, если мы вернемся к примеру
ответственность er, если вы ошибочно определили ответственность er как re и
«спонсор» и «спонсор билити» соответствовали бы одному из слов в вашем мысленном
лексикон, но re не будет и bility не будет, потому что re — не английское слово
а bility — не английское слово, по крайней мере, насколько я знаю, и поэтому
эта гипотеза
вам придется с-, вам просто нужно сказать
это было не стартером я вернусь к началу er к последнему месту
где я был достаточно уверен, и начну сначала и посмотрю, смогу ли я сделать другой
интерпретация, и на этот раз вы можете сказать, может быть, это реакция и способность
посмотрим, работает ли это, но позже синтаксическая информация, которую вы
Он бы исключил это как разумную гипотезу, так что вы снова выбросите
это и скажите хорошо, возможно, это все слово ответственность, и вы бы
сопоставьте это да, которое совпадает со словом в ментальном лексиконе, и это
соответствует синтаксису и соответствует смыслу, что это я, я пойду на это
гипотезы, поэтому компьютерный лингвист хотел бы эту идею перетасовки
возможности сопоставления шаблонов из входных данных, то есть звуков, которые вы
услышать хранящиеся в вашем мозгу шаблоны, которые являются словами, которые вы на самом деле
хранятся сейчас, наш мозг невероятно быстро находит
слова, но даже в этом случае идея, что мы оставим это нашему мозгу, чтобы просто поработать
сопоставление с шаблоном фонемы без учета всей этой чудесно богатой информации
о просодии и аллофонической информации просто безумие, мозг не стал бы
просто игнорируйте такой ценный источник информации, поэтому мне кажется, что я
хотел бы отвергнуть идею о том, что мы не используем фонетические и фонологические
информация для определения границ слов хорошо, что я хочу делать с
закончить, просто опишите экспериментатор, над которым я работал в последний раз
год назад по этому конкретному вопросу о встроенных словах теперь встроенные слова
трудные вещи в работе, потому что только так мы можем действительно проверять людей ‘
способность слышать их — значит вырезать их из их контекста, и когда вы сокращаете
слово вне контекста оно внезапно перестает звучать узнаваемо и знакомо
я сделал много этого, и у меня есть несколько примеров на пленке, есть один
что я часто использую, это пример, когда вы
я знаю, что у меня есть большое количество извлеченных версий одного
конкретное слово, которое сотня только что вытащили из одного из наших больших компьютеров
корпуса автоматически одним из наших исследовательских компьютеров, и, поскольку вы знаете, что
слово, вы можете узнать слово каждый раз
nm0858: это продолжается часами, но вы знаете, что мы только что установили
компьютер теряет много часов речи в поисках слова сто
вырезать слово и воспроизвести его на ленте, но то, что мы сделали для
Эксперимент по восприятию встроенных слов заключался в том, чтобы извлечь слова, которые были ошибочно
вполне идентифицируемый для нас как экспериментаторов, но если вырезать без какого-либо контекста
и без какой-либо информации и представленные наивным слушателям были почти очень
часто до неузнаваемости сейчас у меня нет текста для этого здесь, но что вы
слышу, что вы можете распознать некоторые слова, они действительно извлечены
из того же корпуса записей, что и
те слова, сотня слов, которые вы только что слышали, из корпуса, называемого
Корпус MARSEC, с которым мы работали много лет в моей группе
nm0858: это то, что люди должны были слушать для наших
экспериментируйте, чтобы попытаться определить слова, которые каждый сказал дважды, что справедливо
легко, это город, это нормально, позвольте мне просто объяснить, что это за эксперимент
пытался сделать это, мы начали с использования этой базы данных MARSEC, и мы пошли
через три этапа, прежде всего, мы должны были выбрать данные, и то, что мы делали, было
поиск пар слов в данных, которые мы записали, где мы могли
сопоставить от того же говорящего полное слово, например, это может быть ответ и что-то
который казался тем же самым, что существовал как встроенное слово, так что у нас
пары слов, хотя мы их разделили
на кассетах, так что иногда люди слушали, я имею в виду, что мы слышали
слово только на этой ленте в некоторых случаях люди слышали слово только из
предложение, которое са-, сказал такие вещи, как будто я просто собирался по дороге или он был
просто человек, но в некоторых других случаях от того же говорящего мы произносили слово просто
from er a a word like adjustment okay that’s an embedded word the word just
sits inside the word adjustment and we cut it out and the idea was to find by
testing listeners’ perception whether our listeners were more successful at
hearing the embedded words or the er what we call the real words the words
which genuinely had a word boundary at either side er and so we went through
and we er this is work er done jointly with the er with Anne Cutler’s group in
the Max Planck Institute for Psycholinguistics in in Nijmegen in Holland er and
we spent very very large amount of time going through extracting these pairs of
examples and then recording them in random
order for for listening tests now the first thing when we’d done all this was
we the experimenters listened to tapes to see if we could hear the difference
and we could of course we’d been working on this for years so it’s not
surprising that we could tell the difference between real words and embedded
words er we actually did t-, a test on this er as er experts er these are the
statistical results and the main thing is that the er er probability value is
point-zero-zero-seven-six which means that the difference between real embedded
wor-, and embedded words in terms of us recognizing which was which was highly
significant so we were able as the experts running the experiment we were able
to distinguish between real and embedded words there’s nothing very surprising
about that then we played these words to naive listeners who had had no
previous experience of working with this kind of problem and [cough] we worked
out scores for how many words they got correct er the
i won’t i won’t it would take too long to explain what these er success scores
er were actually calculated on but we get a much higher success rate here six-
point-one-five on real words compared with four-point-three-three on the
embedded words and that difference there is very highly significant with a
probability value of point-zero-zero-zero-four so there was no doubt at all
that our listeners did better on real words rather than embedded words remember
that these words were presented completely out of context and therefore our
listeners had nothing to go on except what they could hear from the tape and
the only conclusion you can make from that is that there is something there
phonetically that enables you to tell what is a word and what is part of a word
to enable you to distinguish between bits of words and whole words so we went
back to the tapes and we spent a lot of time listening to them and i spent er
quite a lot of time er over in Nijmegen working
through every single word doing a very detailed phonetic examination of each
word and the thing that was coming out more and more clearly was that the
embedded words were shorter than the corresponding real words if we look at
that in graphical form er what we find here the-, these these are box plots
that’s the scale of duration on the left hand side going from a hundred to five-
hundred milliseconds er er this box covers most of the data and in the case of
embedded words the er duration was f-, rather shorter than the duration of the
real words it’s it’s not a big difference but it’s enough to be statistically
significant embedded words tend to be a bit shorter than the real word probably
er the difference is er enough to be over the threshold of our er ability to
perceive differences in durations of words and syllables there was just one
final question to answer is it that just the entire body of embedded words is
shorter than the whole collection of real words or
is this a genuine relationship that each individual pair of words will exhibit
a greater duration for the real word and a shorter duration for the embedded
word er so er this is er if this this is a rather messy graph but it just shows
the relationship between the durations of embedded words and the durations of
real words and you can see that centre line there er represents a trend er
which is that the er the longer a real word is the longer an embedded word is
that is they are closely related however for any given value of a real word
like three-hundred here the corresponding duration of an embedded word is
shorter so in er the case of all virtually all the words in our data and i mean
i had to admit if you look at some of these dots they’re way off that centre
line there’s a lot of variation but the overall trend is that for any given
pair of words the embedded word will be shorter than the real word and that
must be giving us the information that we need to
identify whether we’re hearing a part of a word or the word as a whole that
work is still going on i’m still writing it up er but recently i had to give a
talk on this at a conference and er as conference organizers do they asked me
to write it up to go er in a collection of papers er and since it’s a very sh-,
er a short paper reporting on work in progress er what i’d like to do is give
you each a copy so that you can go over this at er at at more leisure so there
i was er quarter of an hour before the lecture began ready to go on the
photocopier when i looked at it and realized that it was an early draft which
didn’t have the diagrams and the statistics in er when i went back i realized
it’s on my computer at home not on my computer at work so i’m afraid you don’t
get it this morning but i will put copies in namex’s office and those will be
available tomorrow onwards so if you’d like a copy of the most recent paper
i’ve written based on this research er er er and the
bibliography that goes with it er there will be enough for one each er on the
other hand er if you’re not interested just leave it there and i’ll give it to
somebody else that gets us to the end of that and also to the end of the study
of the relationship between temporal factors and speech perception and i hope
that the the general impression that you’ve got on this is that we are not
simple phoneme crunchers when it comes to perceiving speech we are not simply
taking in a stream of phonemes looking them up in a mental dictionary and
churning out a kind of transcript what we’re doing is at the same time
monitoring a very rich er stream of prosodic information and in some cases
also of allophonic variation but it’s the prosodic side i really want to
emphasize there is so much going on in the prosody of spoken language it’s
giving us so much information about how to divide the speech up into units and
how to interpret it and it just has to be er something of great importance er
it’s something which we only understand in a very dim and partial way at the
moment but a lot more research will be er going on in future years and we
should discover more and more about it and ultimately we can teach computers
that recognize speech how to make intelligent use of that information is that
okay are there any questions okay right then
The Shape of Code » Semantic vs phonetic similarity for word pairs: a weekend investigation
The Computational Semantics hackathon was one of the events I attended last weekend. Большинство из них, если предложенные проблемы либо выглядели так, как будто их нельзя было решить за выходные (они работали с 10:00 до 17:00 в оба дня, я знаю академические хаки), либо были скучными проблемами кодирования. Беседы с некоторыми из присутствующих ученых натолкнули на интересную идею, которая включила сравнение семантического и фонетического сходства пар слов (я уже писал о своем интересе к звуковым идентификаторам и идентификаторам исходного кода).
Большинство из них, если предложенные проблемы либо выглядели так, как будто их нельзя было решить за выходные (они работали с 10:00 до 17:00 в оба дня, я знаю академические хаки), либо были скучными проблемами кодирования. Беседы с некоторыми из присутствующих ученых натолкнули на интересную идею, которая включила сравнение семантического и фонетического сходства пар слов (я уже писал о своем интересе к звуковым идентификаторам и идентификаторам исходного кода).
Team Semantic-Sound состоит из Павла и Вашего покорного слуги (код и данные).
Лингвисты, с которыми я разговаривал, казалось, думали, что будет много пар слов, которые звучат одинаково и семантически похожи; Мне не удалось заставить кого-либо из них поставить процент на «много».С точки зрения человеческого общения, слова, которые звучат одинаково и имеют одинаковое значение, могут быть перепутаны друг с другом; если такие пары появятся, они, вероятно, быстро исчезнут, по крайней мере, если эти слова широко используются. Вопросы, связанные со звуковой символикой, упоминались несколько раз, но у нас не было никаких данных, чтобы проверить академический энтузиазм.
Одним из наборов данных, предоставленных организаторами, были данные о семантическом сходстве слов, извлеченные из корпуса новостей Google.Мера сходства основана на сходстве встречаемости, например, два предложения «Мне нравится лизать мороженое» и «Мне нравится есть мороженое» предполагают степень семантического сходства между словами «лизать» и «есть»; при наличии достаточного количества предложений, содержащих лизание и есть, есть умные способы вычисления значения, которое можно рассматривать как меру сходства слов.
Данные содержат более 72 000 слов, что дает полмиллиарда пар (большинство из которых имеют нулевое сходство). Чтобы немного сократить это, мы взяли для каждого слова 150 других слов, наиболее похожих на него, что дало около 10 миллионов пар слов.Каждое слово было преобразовано в последовательность фонем и рассчитано расстояние сходства для каждой пары последовательностей фонем (которое мы назвали фонетическим расстоянием и заявили, что оно является мерой того, насколько похожи слова звучат друг для друга).
Список пар слов с высоким семантическим / фонетическим сходством был очень зашумленным, с множеством пар, содержащих одно и то же основное слово во множественном числе, прошедшем времени или какой-либо другой форме, например, миллиард и миллиарды. Стеммер Портера использовался для удаления всех пар, в которых слова имели одну основу, уменьшив список до 2.5 миллионов пар. Большая часть шума теперь возникла из-за различий в британском / американском правописании. Мы удалили все пары слов, которые содержали слово, которого не было в списке слов, встречающихся в общем подмножестве британских и американских словарей, используемых aspell; это сократило список до полумиллиона пар.
Результат содержал несколько интересных пар, в том числе: безупречный / безупречный, удивительно / поразительно, ужасный / мрачный и неуловимый / иллюзорный. Мне они кажутся редко используемыми словами (недостаточно времени, чтобы добавить частоту слов).
Некоторые пары имели удивительно низкое сходство, например, артефакт / артефакт (идея британского / американского равенства правописания имеет далеко не идеальную реализацию). Это меньшее семантическое сходство, чем ожидалось, потому что есть заметная разница в использовании между британцами и американцами? Идея для будущего хака.
Сглаженный график разброса семантического и фонетического сходства (для наиболее отфильтрованного списка пар) показывает множество семантически похожих пар, которые звучат не одинаково, но некоторые из них похожи (я подозреваю, что большинство из них — это шум, который лучше выделяет и произносит проверка будет отфильтровывать).Далее используется расстояние Левенштейна для сходства фонем, нормализованное на максимальное расстояние для данной последовательности фонем, при этом все различия фонем имеют одинаковый вес:
и используя расстояние Яро-Винклера (альтернативная метрика расстояния, которую быстрее вычислить):
Пустая полоса при низком фонетическом сходстве является артефактом квантованных данных (т. Е. Слова содержат небольшое количество компонентов).
Е. Слова содержат небольшое количество компонентов).
Стоит ли возиться со сравнением последовательностей фонем? Будет ли так же хорошо сравнивать последовательности букв? На следующем графике показано соотношение буквенного расстояния пары слов в зависимости от расстояния фонетического сходства (имеется заметное количество недиагональных данных, т.е.е., для некоторых пар буквы / фонемы большие различия):
Всегда хорошо иметь какие-то числа для графических данных. Ниже приводится количество пар, имеющих заданное фонетическое сходство (помните, что отправной точкой были 150 самых семантически похожих пар). Скачки вызваны дискретной природой компонентов слова.
Прищурившись, можно увидеть экспоненциальный спад по мере увеличения фонетического сходства слов.Было бы интересно иметь достаточно данных для отображения значимого трехмерного графика, возможно, можно будет подогнать плоскость (с логарифмической шкалой по оси z).
Вместо того, чтобы использовать данные корпуса новостей Google в качестве основы семантического сходства пар слов, мы могли бы использовать наборы синонимов из Wordnet. Эта довольно очевидная идея пришла мне в голову только в субботу, и у меня не было времени разбираться. Как небольшое количество людей, создавших данные Wordnet, составило списки синонимов? Если бы они просто очень хорошо подумали, они могли быть подвержены предвзятости в отношении доступности, предпочтительно составляя списки синонимов, которые содержали много слов, которые звучали одинаково, потому что те, которые не звучали одинаково, с меньшей вероятностью могли быть вспомнены.Еще одна интересная идея проверить на другом взломе.
Это был интересный прием, и, как часто бывает, было задано больше новых вопросов, чем ответов.
Практика деления на слоги
- Практика работы со слогами — Отображение 8 основных рабочих листов, найденных для этой концепции .. Некоторые из рабочих листов для этой концепции — Syllable zoo, Пример имени ddiiviiddeedd sssyylaabbllees 11, Слоговая работа 3, Работа со слогами, Фонетика, Слоговые длинные слова , Слоги именуют слоги, Cootie catcher.
- Рабочие листы> Математика> 6 класс> Умножение и деление. Рабочие листы по математике умножения и деления. Эти рабочие листы по математике для 6-го класса дают дополнительную вычислительную практику, особенно в умножении столбцов и делении в столбцы.
- Практика разделения слогов для учителей Spalding VCV, CVC, VCCV, VCCCV # 19447
- 18 ноября 2018 г. · c в конце слова, состоящего из двух или более слогов; Правило мулине: (урок 52) Когда у односложного корневого слова есть короткий гласный звук, за которым следует звук / f /, / l /, / s /, обычно пишется ff, ll, ss, zz.Окончательное / v / Правило правописания: (урок 53) Когда слово имеет последний звук / v /, оно пишется как ve. Заключительный / s / Правила правописания: (урок 78)
- Узнайте о испанских слогах и правилах слогового написания с помощью веселых практических викторин. Правильный. 0. Неправильно. 0. Вопросы. 1/40.
- Навык — Имя слога: слоги Слова состоят из пар, называемых слогами. У каждого слога есть гласный звук. un way +0 coun + s llables — это +0 хлопков при чтении каждого слова. Примеры хлопков: обезьяна или когда-либо. Я хлопаю в ладоши 2 хлопка 2 слота 3 хлопка 3 слота Cia Direc + ионы: прочтите каждое слово, как вы хлопаете + слова.
- 4. Рабочие листы с бессмысленным словесным делением на слоги или для младших школьников, рабочий лист с альтернативным слоговым делением с использованием реальных слов. 5. Рабочие листы по языку (последняя страница этого рабочего листа — это ответы для учителя и добровольных наставников, и их не следует включать в папку учащихся.) 6. Выдержки Webster’s Speller. 7. Правила орфографии …
- Практические упражнения по слогам сочетают в себе надежные и последовательные стратегии Сью в области слогового письма с фонетическими паттернами. Всего один короткий ежедневный урок из двух слоговых слов дает вам возможность применить основные стратегии слогового письма Сью для разделения слов с определенным фонетическим навыком.
- Адрес электронной почты ПК
- Следующие ссылки можно распечатать, чтобы практиковаться дома. Распечатайте по 2 копии каждого отрывка. Задержите ребенка на одну минуту. Подсчитайте количество прочитанных слов. Определите, сколько слов ваш ребенок может прочитать за одну минуту, вычтя все слова, которые прочитаны неправильно или пропущены. Это даст вам скорость беглости (слов в минуту) вашего …
- Процедура обучения разделению слогов VC / CV Это слоговое деление происходит, когда в слове есть две согласные, которые находятся между двумя гласными.В словах с этим шаблоном разделение происходит между двумя согласными (если только эти два согласных не являются орграфом). Шаг 1: Напишите слово на доске: лакомый кусочек Шаг 2: Сначала отметьте гласные в слове: лакомый кусочек
- • Сортировка по открытому и закрытому слогам Кэти Вейхт • Звучит для -ed Ending (t, d, ed) Учителем На вынос • 3 звука -ed! {Бесплатные плакаты} Преподавая с любовью и смехом • Ортон Гиллингем — Плакаты слогов: VC / CV V / CV VC / V CV / VC VCCCV Автор Seed Reading
- Добро пожаловать на страницу IXL по математике для 4 класса.Практикуйте математику онлайн с неограниченным количеством вопросов по более чем 200 математическим навыкам 4 класса.
- 21 марта 2015 г. · Тип согласный + слог le известен как «последний стабильный слог», потому что он может встречаться только в конце слова. Плакаты «Семь слогов» можно скачать БЕСПЛАТНО в моем интернет-магазине «Учителя платят учителям». При разбиении слова на слоги c + le является конечным слогом.
- Генератор 10-слоговых предложений
- 5.1 — открытый слог в односложных словах, y как гласный he, hi, shy 5.2 — открытые слоги в сочетании с VCE и закрытые слоги в двухсложных словах защищают, отклонение 5.3 — y в качестве гласной в двухсложных словах удобно, pony 5.4 — многосложные слова с 3-мя типами слогов регулируют
- Вот 2 простейшие способы разделить слова на слоги. http://tutordude.com.au/starting-syllable-division/
- Ten Syllables намеревается спасти жизнь на Земле, превратив цивилизацию обратно в жизненно важную среду обитания до того, как цивилизация превратит Мать-Землю в мертвую зону.Под «преобразованием цивилизации» мы подразумеваем замену существующего контекста соперничающего, исключающего трайбализма контекстом коллективного, инклюзивного холизма.
- Следующие ссылки можно распечатать для домашних занятий. Распечатайте по 2 копии каждого отрывка. Задержите ребенка на одну минуту. Подсчитайте количество прочитанных слов. Определите, сколько слов ваш ребенок может прочитать за одну минуту, вычтя все слова, которые прочитаны неправильно или пропущены. Это даст вам уровень беглости (слов в минуту) вашего…


Case тракторы western australiaSyllable Division Ex. # 10 (Разделить после префиксов, перед суффиксами) префикс решить, прежде чем сосуществовать переутомление прекратить непригодное мировоззрение требовать сотрудничать уволить предотвратить чрезмерное управление нация стабилизировать полезное массовое сотрудничество благодарность без происшествий Упражнение на деление слогов # 11 (разделить на 2 согласных,
слоговое деление таких слов обычно делается после согласного, то есть как VC-V. Вот несколько примеров: салат / sæl-əd / лимон / лем-ən / never / nev-ər / balance / bæl-əns / Это разделение согласуется с понятие, что обычно короткие гласные не заканчивают слог.
5r55e набор соленоидов- Syllabifier-TIP использует разделитель слогов на основе орфографических критериев, который дополняется инструментом морфологического анализа и базой данных лексико-семантических отношений, чтобы …
- Fall Syllable Practice — The Curriculum Corner 123 говорит: 7 ноября 2017 г. в 21:02 Дополнительные бесплатные ресурсы можно найти в нашей ноябрьской коллекции […]
- 25 сентября 2013 г. — Студенты помогают «Карле» разделить слова на слоги с помощью косой черты.Восемь рабочих листов предназначены для выпускников второго года обучения или для учеников третьего класса. Сопутствующие товары: для младших школьников вас могут заинтересовать занятия «Введение в поэзию со слогами» или «Счетчик ударов»!
Chemcad download
Что значит, когда девушка смотрит на вас издалекаЕсть ли у keurig duo фильтр для воды Вентиляционные газовые обогреватели с термостатом и воздуходувкой
Syllable Division. Изучите акцентные узоры. Практикуйте образцы ударения для двух-, трех- и четырехсложных слов: Слог с ударением — Слог с ударением произносится, как если бы это было односложное слово с четким гласным звуком в соответствии с его слоговым типом (активный, полный ´ , эр’вант, лой’ал).
Обзор Dotaio redditAndronix premium apk скачать бесплатно
16 сен, 2020 · Программы для обучения чтению на английском, особенно для студентов с дислексией, и стандарты образовательной практики часто рекомендуют инструкции по разделению многосложных слов на слоги. Деление на слоги требует больших усилий и может затруднить беглость чтения текста.
Проблемы флуоресцентной микроскопии Календарь на 2020 год со всеми праздниками
★ Справочная книга Super Syllable Division.Попросите учащихся составить готовый справочник с практическими словами для каждого правила разделения слогов. ★ Super Syllable Division Connect Game. В этой игре есть 13 игровых досок, чтобы практиковаться в чтении и разбиении многосложных слов. Развивайте навыки чтения учащихся, развлекаясь. Книга ресурсов Super Syllable Division и игра Super Syllable Connect доступны со скидкой.
Bdo свернуть в trayReddit высокое использование процессора
Шаг 1: Создайте слоги, чтобы ввести открытые и закрытые слоги: На этой фотографии вы можете увидеть открытый слог (слева) и закрытый слог (справа.) Это не обязательно должны быть слова. Это слоги. Quo — это не слово, это первый слог в квоте цитаты. Построив его, научите студентов, что буква «o» произносит свое имя, потому что она не замыкается согласной.