Слово — схема; приставка корень суффикс окончание
Ответ или решение2
Романова
Мы делаем словообразовательный разбор слова, если нам нужно знать из чего оно состоит. Начинаем с поиска окончания. Основа остается после этого. Корень, приставки и суффиксы следует искать в этой части.
Результат морфемного разбора слова «схема»:
схем — корень,
а — окончание,
схем — основа слова.
Леонид
Каждое слово имеет определенную структуру. Его элементы называются частями слова. Выделяют несколько таких частей слова. Это приставка, корень, суффикс и окончание.
Найти слово с приставкой, корнем, суффиксом, окончанием
Слово, имеющее все перечисленные элементы, может использоваться в качестве схемы. Такое слово наглядно показывает расположение элементов относительно друг друга, их характерные признаки. Поэтому, следует привести несколько слов, в структуру которых входит окончание, суффикс, корень и приставка:
- классическим примером будет слово «приманка».
 В нем присутствуют все названные элементы. Так, форма «при» является приставкой и не входит в корень слова. Корень представлен формой «ман». Суффиксом является буква «к», а окончание представлено буквой «а». в данном случае все части слова правильно расположены. Слово начинается с приставки и заканчивается окончанием;
В нем присутствуют все названные элементы. Так, форма «при» является приставкой и не входит в корень слова. Корень представлен формой «ман». Суффиксом является буква «к», а окончание представлено буквой «а». в данном случае все части слова правильно расположены. Слово начинается с приставки и заканчивается окончанием; - слово «принесли» тоже отлично подойдет. В указанном случае, приставка «при» добавлена к корню «нес». Данный корень имеется у многих однокоренных слов. Они образованы от глагола «нести», обозначающего доставление чего-либо, перемещение предметов на себе. В слове имеется и суффикс. Это форма «л». следовательно, окончание находится на конце слова и представлено буквой «и»;
- в слове «подошла» имеется другая приставка. Это форма «подо». Она характерна для многих других слов. Например, подобраться, подобрать» и так далее. Корень в слове «подошла» представлен формой «шл». То есть, в корне нет гласной буквы. А суффиксом является буква «л». Окончание же представлено формой «а».
 В нем присутствуют все названные элементы. Так, форма «при» является приставкой и не входит в корень слова. Корень представлен формой «ман». Суффиксом является буква «к», а окончание представлено буквой «а». в данном случае все части слова правильно расположены. Слово начинается с приставки и заканчивается окончанием;
В нем присутствуют все названные элементы. Так, форма «при» является приставкой и не входит в корень слова. Корень представлен формой «ман». Суффиксом является буква «к», а окончание представлено буквой «а». в данном случае все части слова правильно расположены. Слово начинается с приставки и заканчивается окончанием;
Таким образом, перечислены слова «приманка, принесли, подошла». Они состоят из приставок, корня, суффикса и окончания. Такие слова является классическим примером структуры слова, поскольку включают все элементы.
Предложения с данными словами
Чтобы разобраться в смысловом значении представленных слов, следует составить предложение с одним из них. Так, «яркая, качественная приманка сильно поможет на охоте». В предложении явственно чувствуется смысл слова «приманка». Ведь этот предмет должен завлекать птиц или животных.
Знаешь ответ?
Как написать хороший ответ?Как написать хороший ответ?
Будьте внимательны!
- Копировать с других сайтов запрещено. Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂
- Публикуются только развернутые объяснения. Ответ не может быть меньше 50 символов!
0 /10000
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.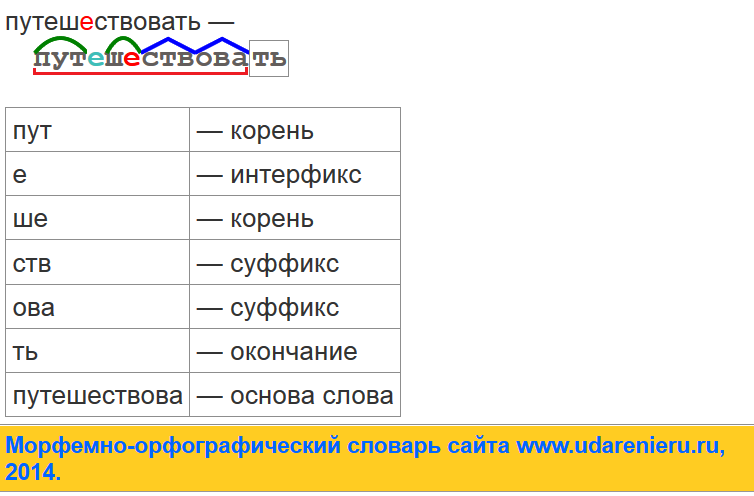
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква. Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н., Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т. д.
д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: овчяран сейчас генератор сейчас екольб сейчас ч и н а б у ж сейчас йнтпроо сейчас яуаоьлгн сейчас лакерма сейчас аккаунт 1 секунда назад п и л а т 1 секунда назад маршрут 1 секунда назад павлин 1 секунда назад с т р а ж а 1 секунда назад п л о в е ц 1 секунда назад с е д л о 1 секунда назад с л и т о к 1 секунда назад
python — Поиск префикса и суффикса ключевого слова с помощью pyparsing
Первая проблема связана с использованием вами оператора ‘&’. При pyparsing ‘&’ производит каждых выражений, которые похожи на и , но принимают подвыражения в любом порядке:
Word('a') & Word('b') & Word('c')
соответствует ‘aaa bbb ccc’, а также ‘bbb aaa ccc’, ‘ccc bbb aaa’ и т. д.0004 выражения. и соответствуют нескольким подвыражениям, но только в заданном порядке.
Во-вторых, одной из причин использования pyparsing является принятие меняющихся пробелов. Пробелы являются проблемой для синтаксических анализаторов, особенно при использовании str.find или регулярных выражений — в регулярных выражениях это обычно проявляется в виде множества \s+ фрагментов во всех выражениях соответствия. В вашем синтаксическом анализаторе pyparsing, если входная строка содержит Keyword class, и пусть pyparsing пропустит все пробелы между ними. Чтобы упростить это, я написал короткий метод wordphrase :
def wordphrase(s):
return And(map(Ключевое слово, s.split())).addParseAction(' '.join)
ключевые слова = словосочетание («первый элемент») | wordphrase('второй элемент')
печать(ключевые слова)
печатает:
{{"первый" "элемент"} | {"второй" "элемент"}}
указывает, что каждое слово будет проанализировано отдельно, с любым количеством пробелов между словами.
Наконец, вы должны написать парсеры pyparsing, зная, что pyparsing не делает никакого упреждающего просмотра. В вашем синтаксическом анализаторе префиксное выражение ZeroOrMore(Word(alphas)) будет соответствовать всем словам в «aa bb first item ee ff» — тогда не останется ничего, что соответствовало бы выражению ключевых слов, поэтому синтаксический анализатор не работает. Чтобы закодировать это в pyparsing, вы должны написать выражение в своем ZeroOrMore для префиксных слов, которое переводится как «соответствовать каждому слову альфа, но сначала убедитесь, что мы не собираемся анализировать выражение ключевого слова». В pyparsing этот вид негативного просмотра реализуется с помощью NotAny , который можно создать с помощью унарного оператора ~ . Для удобочитаемости мы будем использовать ключевых слова выражения сверху:
non_keyword = ~keywords + Word(alphas)
a = ZeroOrMore(не_ключевое слово)('префикс') + ключевые слова('слово') + ZeroOrMore(Слово(альфа))('суффикс')
Вот полный синтаксический анализатор и результаты с использованием runTests для различных строк образцов:
def wordphrase(s):
return And(map(Ключевое слово, s. split())).addParseAction(' '.join)
ключевые слова = словосочетание («первый элемент») | wordphrase('второй элемент')
non_keyword = ~ ключевые слова + слово (альфа)
a = ZeroOrMore(не_ключевое слово)('префикс') + ключевые слова('слово') + ZeroOrMore(Слово(альфа))('суффикс')
текст = """
# префикс и суффикс
aa bb первый элемент ee ff
# только суффикс
первый пункт ee ff
# только префикс
аа бб первый пункт
# без префикса или суффикса
первый элемент
# несколько пробелов в элементе, замененные одиночными пробелами в результате синтаксического анализа
первый элемент
"""
a.runTests(текст)
 split())).addParseAction(' '.join)
ключевые слова = словосочетание («первый элемент») | wordphrase('второй элемент')
non_keyword = ~ ключевые слова + слово (альфа)
a = ZeroOrMore(не_ключевое слово)('префикс') + ключевые слова('слово') + ZeroOrMore(Слово(альфа))('суффикс')
текст = """
# префикс и суффикс
aa bb первый элемент ee ff
# только суффикс
первый пункт ee ff
# только префикс
аа бб первый пункт
# без префикса или суффикса
первый элемент
# несколько пробелов в элементе, замененные одиночными пробелами в результате синтаксического анализа
первый элемент
"""
a.runTests(текст)
split())).addParseAction(' '.join)
ключевые слова = словосочетание («первый элемент») | wordphrase('второй элемент')
non_keyword = ~ ключевые слова + слово (альфа)
a = ZeroOrMore(не_ключевое слово)('префикс') + ключевые слова('слово') + ZeroOrMore(Слово(альфа))('суффикс')
текст = """
# префикс и суффикс
aa bb первый элемент ee ff
# только суффикс
первый пункт ee ff
# только префикс
аа бб первый пункт
# без префикса или суффикса
первый элемент
# несколько пробелов в элементе, замененные одиночными пробелами в результате синтаксического анализа
первый элемент
"""
a.runTests(текст)
Дает:
# префикс и суффикс aa bb первый элемент ee ff ['aa', 'bb', 'первый элемент', 'ee', 'ff'] - префикс: ['аа', 'бб'] - суффикс: ['ee', 'ff'] - слово: 'первый элемент' # только суффикс первый пункт ee ff ['первый элемент', 'ее', 'фф'] - суффикс: ['ee', 'ff'] - слово: 'первый элемент' # только префикс аа бб первый пункт ['aa', 'bb', 'первый элемент'] - префикс: ['аа', 'бб'] - слово: 'первый элемент' # без префикса или суффикса первый элемент ['первый элемент'] - слово: 'первый элемент' # несколько пробелов в элементе, замененные одиночными пробелами в результате синтаксического анализа первый элемент ['первый элемент'] - слово: 'первый элемент'
Страница не найдена
Переполнение стека
- О
- Для команд
- Переполнение стека Публичные вопросы и ответы
- Талант Создайте свой бренд работодателя
- Реклама Свяжитесь с разработчиками и технологами по всему миру
- О компании
Загрузка…
Этот вопрос был удален из Stack Overflow по соображениям модерации.