Словарь синонимов русского языка — онлайн подбор
Синонимы: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ы Э Ю Я
Антонимы: А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ы Э Ю Я
Ассоциации: А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я
Морфемный разбор: А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Синонимы — слова, звучание и написание которых различно, но при этом у них похожее значение (например, огонь — пламя, трудный — тяжелый). Чаще всего они принадлежат к одной и той же части речи.
Подробнее почитать про синонимы можно по этой ссылке. А чтобы найти синоним к слову, воспользуйтесь формой наверху. Именно с помощью неё вы можете получить доступ к нашему словарю синонимов русского языка (также его называют генератором синонимов).
Если вы копирайтер, поэт, писатель, студент, школьник, ищете, чем заменить слово, либо желаете улучшить свою речь, то этот сайт обязательно поможет вам. С помощью нашего онлайн словаря синонимов русского языка можно легко найти слова с похожим смыслом. Просто введите слово или устойчивое выражение в поле формы поиска и нажмите кнопку «Найти синонимы». Сервис сделает хороший подбор слов и фраз (всего их – несколько сотен тысяч, а связей слово-синоним – более двух миллионов). Если слово набрано неправильно (с орфографической ошибкой или в неправильной раскладке), то будет предложено исправленное слово. Также есть следующие возможности:
С помощью нашего онлайн словаря синонимов русского языка можно легко найти слова с похожим смыслом. Просто введите слово или устойчивое выражение в поле формы поиска и нажмите кнопку «Найти синонимы». Сервис сделает хороший подбор слов и фраз (всего их – несколько сотен тысяч, а связей слово-синоним – более двух миллионов). Если слово набрано неправильно (с орфографической ошибкой или в неправильной раскладке), то будет предложено исправленное слово. Также есть следующие возможности:
- Скрыть словосочетания.
- Показать синонимы строкой вместо таблицы.
- Открыть предложения с искомым словом (для поиска предложений есть также специальная страница).
- Показать значение слова из толкового словаря.
- Посмотреть исходную (как в искомом слове), начальную форму синонимов, частоту слов (насколько часто слово встречается в текстах). В скобках указывается количество синонимов.
- Предложить свой синоним при помощи специальной формы, если их количество недостаточное.

- Можно оставить комментарий к любой странице.
- Есть ссылки для печати и скачивания синонимов.
- Словарь антонимов русского языка.
- Словарь ассоциаций.
- Морфемный разбор.
- Фонетический разбор.
- Посчитать количество символов/слов в тексте.

Если у вас есть еще какие-либо идеи, пишите их в комментариях. Наша цель – быть лучшим сайтом для поиска синонимов онлайн в рунете.
sinonim.org — не онлайн синонимайзер, но хороший помощник для подбора синонимов. При разработке был использован словарь синонимов Тришина В.Н. (http://trishin.ru) – один из лучших, наиболее полных словарей, проверка правописания: Яндекс.Спеллер, phpMorphy, а также некоторые наши дополнения. Часто добавляются слова, предложенные пользователями и нашими редакторами. Почти все нецензурные выражения отфильтрованы и скрыты. Есть возможность пожаловаться на слова, нажав в таблице (появляется после 20 переходов по сайту).
Синоним — это слово, которое имеет то же или почти то же значение, что и другое слово. Например, «счастливый» и «радостный» — это синонимы. При изучении нового языка полезно иметь разнообразные синонимы, чтобы точнее выражать свои мысли. Синонимы могут пригодиться и при написании текста, чтобы он не звучал повторяющимся.
Например, «счастливый» и «радостный» — это синонимы. При изучении нового языка полезно иметь разнообразные синонимы, чтобы точнее выражать свои мысли. Синонимы могут пригодиться и при написании текста, чтобы он не звучал повторяющимся.
В современном мире коммуникация – важнейший фактор успеха. Чем лучше владеешь языком, тем больше возможностей у тебя открываются. А значит, тем больше шансов на успех в жизни.
Словарь синонимов – это незаменимый помощник в повседневной жизни. С его помощью можно научиться грамотно выражать свои мысли, а также подобрать слова для более эффективной коммуникации с окружающими.
Словарь синонимов русского языка поможет тебе найти нужное слово в любой ситуации. С его помощью можно легко отличать синонимы по значению и понять, какое слово лучше подходит в конкретный контекст.
Поделиться
Популярное: является, таким образом, возможность, информация, проблема, развитие, также, красивый, работа, процесс, мероприятие, мечта, жизнь, необходимо, рассмотреть, изменение, анализ, в соответствии, тема, пример, интересный, решение, необходимость, новый, однако, отсутствие, доброта, в связи с этим, важный, аспект, проект, согласно, деятельность, изучение, результат, спасибо, супер, радость, вопрос, подарок, отсутствует, актуальный, книга, разработка, человек, изучить, искусство, формирование, любовь, эффективный, ситуация, природа, современный, реализация, участие, благодаря, особенность, цель, использовать, система, ошибка, кроме того, определение, большой, организация, в рамках, счастье, помощь, молодец, исследование, прекрасный, тенденция, образ, приятно, создание, совокупность, предоставить, понятие, история, обусловлено, необычный, использование, выбор, поэтому, определить, концепция, разный, контроль, поддержка, красота, нравится, было, будет, эффективность, условие, небо, предложение, учитывая, требование, привет
Случайное: отравленный, многократно, измазавший, проявивший себя, виниловый, сболтнутый, резко и часто необоснованно менявший характер дейс, визуализировавший, поднимавший тарарам, потерявший здоровье, покрывший собой, считаю необходимым, хозвзвод, нарицавший, вязалово, эпидурит, сулившийся, околдовываемый, хроматограмм, креатинин
Контакты
Пишите, мы рады комментариям
Вверх ↑
Разбор слова по составу.
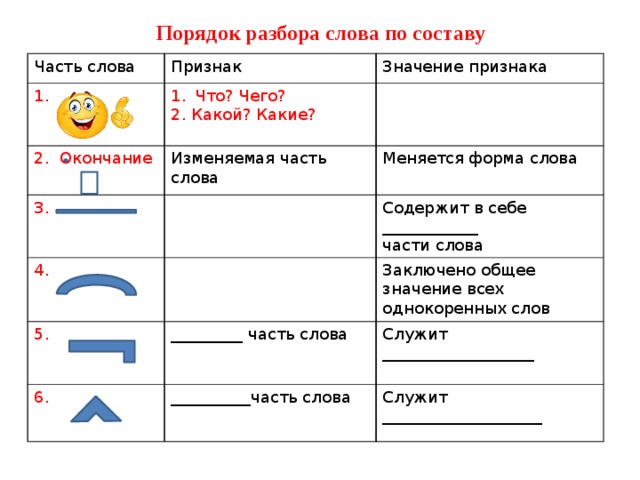 2 класс — Балабақша әлемі
2 класс — Балабақша әлеміКраткосрочное планирование открытого урока по русскому языку
Сквозная тема: Моя школа.
Школа: начальная школа сад №31
Дата:. ФИО учителя: Байдуллаева Ж
Класс: 2 « _» класс. Количество присутствующих: —
отсутствующих: —
Лексическая тема: История школьных вещей.
Тема урока: Разбор слова по составу. (Повторение).
Цели обучения, которые достигаются на данном уроке (ссылка на учебную программу):
2.1.1.1 определять с помощью учителя опорные слова, фиксировать их; отвечать на закрытые вопросы.
2.2.3.1 формулировать вопросы с опорой на ключевые слова, отвечать на вопросы по содержанию прочитанного
2.3.8.2 определять значимые части слова, выделять корень в слове и подбирать однокоренные слова.
Развитие
навыков: 1.1 Понимание содержания информации/ сообщения
2.3 Формулирование вопросов и ответов
3.8 Соблюдение грамматических норм.
Критерии успеха (Предполагаемый результат): Все учащиеся смогут:
Повторить значимые части слова.
Большинство учащихся смогут:
Определять опорные слова и отвечать на закрытые вопросы самостоятельно.
Находить информацию по двум источникам.
Выделять значимые части слова.
Подбирать однокоренные слова.
Подбирать слова к схемам.
Некоторые учащиеся смогут:.
Составить и разыграть ситуации общения.
Записать рекомендации учащимся.
Языковая
цель Основные термины и словосочетания:
Состав слова, части слова, приставка, корень, суффикс, окончание, одноко-
ренные слова, родственные слова, вопрос, текст, стихо-
творение, предложение, упражнение, ответ.
Используемый язык для диалога/письма на уроке:
Вопросы для обсуждения:
Какое значение может иметь слово “состав”?
-А как вы думаете,что же такое Словообразование?
Что вы знаете о происхождении линейки?
Привитие
ценностей Ценности, основанные на национальной идее «Мәңгілік ел»: казахстанский патриотизм и гражданская ответственность; уважение; сотрудничество; труд и творчество; открытость; образование в течение всей жизни.
Межпредметные
связи – литература
– самопознание
– трудовое обучение
Навыки
использования ИКТ На данном уроке учащиеся не используют ИКТ
Предварительные
знания Звуки и буквы, гласные и согласные звуки, печатные и рукописные буквы,
алфавитные названия букв, слог, язык – средство человеческого общения,
высказывание, текст, языковые и неязыковые средства общения, устная и
письменная речь, предложение, прописная буква в начале предложения и в
именах собственных, сила голоса и темп речи, алфавитный порядок слов,
перенос слов, ударные и безударные гласные, мягкий знак на конце и в се-
редине слов, твердые и мягкие согласные, правописание жи-ши, ча-ща, чу-
щу, чк, чн, нщ, рщ, шн, звонкие и глухие согласные, звук [й], разделитель-
ный Ь, состав слова, окончание, корень, приставка, суффикс, родственные
и однокоренные слова.
Ход урока
Этапы урока, t Запланированная деятельность на уроке
Ресурсы
Начало урока
0-4 Создание положительного эмоционального настроя
Громко прозвенел звонок,
Начинается урок.
Наши ушки на макушке,
Глазки широко открыты,
Слушаем, запоминаем,
Ни минутки не теряем!
— Я рада видеть всех вас на уроке. Давайте, друзья, улыбнемся друг другу! Улыбки подарим гостям! К уроку готовы? Я рада! Желаю успехов всем нам!
5-10 мин Актуализация знаний. Целеполагание.
Цель: ввод ситуации для открытия и постановки целей
урока.
(П, И)
На доске: Р, С, М, Л, О, С, Ц, Т, А, Н, Х, В, Щ
Учитель просит учащихся убрать не парные согласные и прочитать главное слово нашего урока.
Какое значение может иметь слово “состав”?
1. Железнодорожный состав.
2. Состав – структура, строение.
Но мы на уроке русского языка. Состав чего мы можем изучать?
Тема нашего урока – состав слова. (Учитель открывает тему урока на доске)
Какие задачи поставим перед собой и будем решать на уроке?
Ученик: Повторим все, что знаем о частях слова.
Постановка задач:
-Скажите, это урок новых знаний или урок повторения?
• Что вы должены знать ?
• Алгоритм разбора слов по составу.
• Как находить корень, суффикс, приставку слова.
• Что вы должены уметь?
• Разбирать слова по составу.
Критерии успеха Учащиеся с помощью учителя формулируют тему урока.
Середина урока
11-20 мин
21-22 мин Работа по теме урока.
Цель: выполнение практических заданий.
(К, И) Минутка чистописания
Ученики пишут запись слова «состав» с соблюдением высоты,ширины и наклона прописных и строчных букв,их соединений.
Учитель:
— Сегодня у нас необыкновенный урок. Это будет урок — приключение, полное неожиданностей. Мы отправимся в путешествие к планетам знаний в галактику Словообразования.
-А как вы думаете,что же такое Словообразование?
-Что он изучает?
— Из чего же состоят слова?(из корней,приставок,суффиксов,окончаний)
-Слова сделаны из своего « строительного материала»,»строительные блоки» для слов называются МОРФЕМАМИ.
Дети берутся за руки .
В космосе так здорово!
Звёзды и планеты
В чёрной невесомости
Медленно плывут!
В космосе так здорово!
Острые ракеты
На огромной скорости
Мчатся там и тут!
1 планета –планета Корней
В гости к — Корней Корнеевичу.
— Как вы думаете, с какая морфема живет на этой планете? ( появляется Корень с заданиями)
Корней Корнеевич предлагает конверт с заданиями и вопросами
1)- Что такое корень? Как правильно выделить в слове корень?
2)– Посмотрите на эти необычные деревья. Какие слова могли бы «вырасти» на них? (На доске изображены деревья, в корнях которых даны слова лес, сад,ход,рыба,дом.) Ребята работают в группах..
— Напишите эти слова. (Две группы работают на задней стороне доски) Сколько веток «выросло» на вашем дереве? Давайте проверим ребят у доски
. (Д, К) Пальчиковая физминутка.
На моей руке пять пальцев,
Пять хватальцев, пять держальцев.
Чтоб строгать и чтоб пилить,
Чтобы брать и чтоб дарить.
Их не трудно сосчитать:
Раз, два, три, четыре, пять.
(Сплести пальцы рук, соединить ладони и стиснуть их как можно сильнее.
Потом опустить руки и слегка потрясти ими.)
Работа по учебнику.
(К, И) Упр. 15.
Ученики находят лишнее слово (линь) и объясняют
свой выбор; выписывают однокоренные слова; выделяют корень.
— Молодцы, ребята! Вы так хорошо справились с заданием. А нам пора двигаться дальше.
Тетрадь
Запись буквы Сс
Запись слова «состав»
Изображение деревьев
Учебник
23-26 мин
Дети берутся за руки ,читают стих о космосе
Планета Приставок.
В гости к приставке . (появляется Приставка с заданиями в конверте )
— Расскажите, что вы знаете о приставке как части слова?
Выполнение заданий в парах С взаимопроверкой
Работа по теме урока
Цель: выполнение практических заданий.
Работа с учебником
(Г) упр 17. учащиеся подбирают слова к схемам.
— Молодцы, ребята! Вы так хорошо справились с заданием. А нам пора двигаться дальше.
Конверт с заданиями
Задания для
парных работ
карточки.
Учебник
26-35 мин Планета Суффиксов.(появляется Суффикс с конвертом заданий)
— Расскажите, что вы знаете о суффиксах. Какую «стро¬ительную» работу они выполняют? (Образуют новые слова: придают словам различные смысловые оттенки. )
)
(П.И.)
(Д, К) Физминутка для глаз. Буратино
Предложить детям закрыть глаза и посмотреть на кончик своего носа. Учитель медленно считает до 8. Дети должны представить, что их носик начинает расти, они продолжают с закрытыми глазами следить за кончиком носа. Затем, не открывая глаз, с обратным счетом от 8 до 1, ребята следят за уменьшением.
(Дети закрывают глаза ладонями, держат их так до тех
пор, пока не почувствуют глазами тепло от рук.)
Раз, два, три, четыре, пять – можно глазки открывать!
— Отлично! Вы так хорошо справились с заданием. А нам пора двигаться дальше на планету Окончаний.
Планета Окончаний. Встреча с Окончанием
-Расскажите что вы знаете об окончаниях?
Задание:
-Догадайся , какие окончания пропущены.Выдели окончания.
ХИТРЫЕ САНКИ
Мои санк едут сам ,
Без мотор , без кон ,
То и дел мои санк
Убегают от мен .
(П) Учащиеся выбирают правильный порядок разбора
слов по составу. Упр. 21.
Объясняют, почему нужно выполнять разбор слова по порядку. ,
,
(И) Подобрать к соответствующей схеме слово и записать в тетради.
Прощаются с Окончанием, благодарят за интересные задания, возвращаются в класс.
Самостоятельная работа на карточках
Физминутка
Тетрадь
Учебник
Критерии успеха Учащиеся составляют новые слова из частей данных слов;
записывают их и разбирают по составу .
(К, И) Учащиеся рассказывают по схеме о частях слова.
Конец урока
36-37 мин
-Я поздравляю вас с окончанием путешествия.Вы проявили себя знающими и любознательными путешественниками,хорошо работали на уроке.
— А теперь подведём итог нашего урока.
— Над чем мы сегодня работали? Что повторяли сегодня на уроке?
— Чтобы разобрать слово по составу, нужно выделить,?
— Что понравилось на уроке?
38-40 Цель: оценка уровня усвоения навыка по теме.
Итог урока. Рефлексия.
Итог урока
На доску вывешиваются маршрут полёта по галактике.
— если вам все понравилось давайте украсим нашу галактику звездами,так как скоро 16 декабря день Независимости РК вся наша страна будет праздновать этот знаменательный день,так пусть же и на нашей вселенной тоже будет отражатся праздничная атмосфера.
— Если вам все было по плечу на уроке выберите зелёную звезду.
— Если вам было все понятно выберите голубую звездочку
— А если вам на уроке было немного трудно ,то выберите красную звёздочку.
Звездочки.
Критерии успеха
Дифференциация
Оценивание
Здоровье и соблюдение техники безопасности
Способные учащиеся строят свои высказывания, а менее способным учитель оказывает поддержку,задавая наводящие вопросы Формативное оценивание.
— Взаимооценивание при работе в паре, группе, классом.
— Результаты наблюдения учителем качества ответов учащихся на уроке.
Определение уровня усвоения навыка по теме . Физминутка для глаз. Буратино
Предложить детям закрыть глаза и посмотреть на кончик своего носа. Учитель медленно считает до 8. Дети должны представить, что их носик начинает расти, они продолжают с закрытыми глазами следить за кончиком носа. Затем, не открывая глаз, с обратным счетом от 8 до 1, ребята следят за уменьшением.
(Дети закрывают глаза ладонями, держат их так до тех
пор, пока не почувствуют глазами тепло от рук. )
)
Раз, два, три, четыре, пять – можно глазки открывать!
Какие виды разборов в русском языке значат цифры 1, 2, 3 и 4? — Спрашивалка
Какие виды разборов в русском языке значат цифры 1, 2, 3 и 4? — СпрашивалкаВИ
Виолетта Иванова
- язык
- русский
- вид
- цифра
- разбор
Ло
Лола
разборы.
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
Ксения Фёдорова
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор
Евгений Горячев
1. фонетический (звуки и буквы)
2. морфемный (состав)
3.
4. синтаксический (предложение по составу)
5. пунктуационный
Лариса ))))))))))
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор
НД
Наталия Денисенко
1-Фонетический (по звукам и буквам)
2-морфемный (по составу (корень, суффикс, окончание)
3-морфеологический (разбор слова как часть речи)
4-Синтактический (разбор предложения)
в начале книг по русскому языку написано.
Ол
Олеся
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
Ли
Лилия
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор
ЮР
Юра Ракитин
1-фонетический
3- как часть речи разобрать
4- синтаксический разбор
ВС
Валентина Степанова
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор
СМ
Сергей Меньшов
1. фонетический (звуки и буквы)
фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
АА
Анастасия Айрон
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
 1 Нравится Пожаловаться
ГС
Геннадий Солодов
1-Фонетический (по звукам и буквам)
2-морфемный (по составу (корень, суффикс, окончание)
4-Синтактический (разбор предложения)
в начале книг по русскому языку написано.
Екатерина
1-Фонетический (по звукам и буквам)
2-морфемный (по составу (корень, суффикс, окончание)
3-морфеологический (разбор слова как часть речи)
4-Синтактический (разбор предложения)
в начале книг по русскому языку написано.
Екатерина
1)фонетический (по звукам и буквам)
2)морфемный (по составу)
3)морфологический (как часть речи)
4)синтаксический (разбор предложения, обычно со схемой и описанием)
5)пунктуационный (объяснение запятых, ковычек, двоеточий и т. п.)
п.)
Евгений Хартов
разборы.
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
5. пунктуационный
НМ
Наталья Метальникова
разборы.
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
Да
Дарья
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
Ирина))))))))))
1фонетический2морфемный3морфологический4синтаксический
ЮК
Юлия Кипяткова
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
пунктуационный
Марина Бондарева
1. фонетический
2. морфемный
3. морфологический
4. синтаксический
АК
Алексей Казанцев
разборы.
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
EG
Elena Golovkina
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор пунктуационный синтаксический морфологический
ОР
Ольга Рябова
1. фонетический (звуки и буквы) 2. морфемный (состав) 3. морфологический (как часть речи) 4. синтаксический (предложение по составу)
ОФ
Ольга Федорова
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
в
все вроде
Юлия
1. фонетический (звуки и буквы)
фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
РР
Роман Руднев
разборы.
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
АК
Александра Колосова
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
ЮЯ
Юлия Ягодкина
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
ПВ
Павел Васильев
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
синтаксический (предложение по составу)
Viktor Eremkin
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор
ИС
Илья С
1-Фонетический (по звукам и буквам)
2-морфемный (по составу (корень, суффикс, окончание)
3-морфеологический (разбор слова как часть речи)
4-Синтактический (разбор предложения или СЛОВОСОЧЕТАНИЯ)
АЧ
Алексей Чиженок
разборы.
1. фонетический (звуки и буквы)
2. морфемный (состав)
4. синтаксический (предложение по составу)
5. пунктуационный
SA
Sherzod Abdulov
кросс
спс
ЛM
Лана M
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
МС
Мария Сироткина
1фонетический
2по составу
3 как часть речи разобрать
4 синтаксический разбор
Юлия
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
SF
Slavik Foros
1-фонетический
2-по составу
3- как часть речи разобрать
4- синтаксический разбор
АС
Лохи вы все
Ма
Марина
ЪуЪ
АМ
Анатолий Милкин
1. фонетический (звуки и буквы)
2. морфемный (состав)
3. морфологический (как часть речи)
4. синтаксический (предложение по составу)
5. пунктуационный
Похожие вопросы
Русский язык. Морфологический разбор.
Что значит цифра 4 над словом в русском языке?
что в русском языке обозначает цифра 4
что значит цифра 1, 2, 3, 4?(русский язык)
школьный разбор русский язык
Русский язык. Разбор предложения.
Есть четыре кубика с цифрами 1, 2, 3, 4, 5, 6 на гранях и одна правильная пирамидка с цифрами 1, 2, 3, 4 на гранях.
Что значит цифра 4 в русском языке? Как это делать?
Напишите обозначение цифр; И примеры. Русский язык 1 2 3 4 5
допоможіть розвязати методом Гаусса 1 -1 3 -2 = 3 3 2 -1 2 =1 1 -1 4 3 = 2 2 -3 -4 4 = -2 4 1 3 5 = 3
Парфюмерный журнал, парфюмерная энциклопедия, описание ароматов и online-сообщество Фрагрантика — Fragrantica.ru
Новые Élixir Précieux от Dior — Jasmine и Patchouli
Новые ароматы
Долгожданное пополнение роскошной коллекции бренда.
Новинки от OLFATTOLOGY: Lofoten и Olifant
Новые ароматы
Два новых аромата, по традиции бренда посвященных воде.
2 отзыва
VAST Perfume Week 2022
События
Четыре насыщенных парфюмерией московских дня: 29, 30 сентября и 1, 2 октября.
13 отзывов
Новые ароматы
WIDIAN
Rose Arabia White
Le Frag
Meluzyna
Anna Sui
Cosmic Sky
Profumum Roma
Vir
Dior
Patchouli Elixir Precieux
Dior
Jasmin Elixir Precieux
Xerjoff
Amphorae 56
Xerjoff
Amphorae 48
Amphorae 39
Xerjoff
Amphorae 27
Xerjoff
Amphorae 17
Xerjoff
Amphorae 16
Olfattology
Lofoten
Olfattology
Olifant
Giorgio Armani
Emporio Armani Stronger With You Oud
Leme
1415 Ceuta
Leme
1419 Madeira
Leme
1498 Índia
Leme
1500 Brasil
Leme
1543 Japão
Leme
1488 Cabo das Tormentas
DSH Perfumes
Estancia
DSH Perfumes
Green Rhubarb and Cane Sugar
DSH Perfumes
Kale
DS&Durga
Leatherize
Dr. Vranjes Firenze
Rosa Tabacco
DSH Perfumes
Halfeti
DSH Perfumes
Rosé
DSH Perfumes
Countess Olenska
Electimuss
Vici Leather
Pierre Balmain
Balmain Homme Hair Perfume
DSH Perfumes
The Absinthe Drinkers
DSH Perfumes
Rattlesnake Musk
DSH Perfumes
Sagebrush & Cactus
Francesca Bianchi
Unspoken Musk
Полынная осень: L’Eau d’Armoise Serge Lutens
Обзоры ароматов
Сушим на зиму ароматные травы.
8 отзывов
Rosa Tabacco от Dr. Vranjes
Новые ароматы
Дамасская роза в сочетании с теплым обволакивающим табаком, амброй и сладкими анималистичными аккордами мускуса и ванили.
3 отзыва
Два аромата Vertus Paris: Majeste и Auramber
Обзоры ароматов
«Стойкость — моё второе имя».
34 отзыва
Balmain Homme Hair Perfume
Для тела и душа
Мужской древесно-амбровый парфюм для волос от Balmain.
2 отзыва
Vici Leather — новый аромат от Electimuss
Новые ароматы
Этой осенью бренд Electimuss представил свой новый тёмный кожаный аромат.
Один комментарий
Citrus Grandis: новый аромат Chris Collins
Обзоры ароматов
Большие плоды и зеленые листья для обожателей цитрусовых ароматов.
2 отзыва
Bois Dormant – новый аромат коллекции Celine Haute Parfumerie
Новые ароматы
Парфюмерное отражение двубортного английского пиджака из фланели от бренда Celine.
2 отзыва
Matiere Premiere Crystal Saffron
Нишевые ароматы
Бренд Орельена Гишара, Matière Première, представляет новый аромат, посвящённый шафрану.
4 отзыва
В ПАМЯТЬ О КОРОЛЕВЕ: A FRAGRANCED TRIBUTE TO QUEEN ELIZABETH
Авторские очерки
Смена эпохи, истории и духи.
120 отзывов
Esxence-2022: Перебирая впечатления
События
Большое видится на расстоянии.
5 отзывов
Francesca Bianchi Unspoken Musk
Нишевые ароматы
«Сексуальный, насыщенный, но при этом нежный и кокетливый.» Собственная интерпретация мускуса от Франчески Бьянки.
3 отзыва
Princesse Marina de Bourbon Princess Style
Новые ароматы
Второй аромат линии Style описывается как «стильный аксессуар парижской принцессы».
09/11/22 06:06
16 отзывов
SPORTS CAR CLUB PENHALIGON’S: ВОЗВРАЩЕНИЕ ЛЕГЕНДЫ
Обзоры ароматов
Обзор нового аромата Penhaligon’s – «Sports Car Club».
09/10/22 18:20
10 отзывов
Annayake — KOGAÏ for Her и KOGAÏ for Him
Новые ароматы
Новый дуэт ароматов от Annayake, вдохновлённый ветром.
09/10/22 13:34
Новые ароматы от бренда Scents of Woods
Нишевые ароматы
Ароматы, вдохновлённые лесом и деревьями, созданные на основе спирта, который предварительно выдерживается в деревянных бочках.
09/10/22 08:51
4 отзыва
Роза, бархатистая и сияющая
Обзоры ароматов
Итало Перейра рассказывает о своём любимом розовом аромате.
09/10/22 04:37
8 отзывов
Сделано в Таиланде: Another Tea Mith
Обзоры ароматов
Цветущий жасмин на чайном кусте.
09/09/22 22:13
6 отзывов
Caron Tabac Blanc, новый, мля
Обзоры ароматов
Caron рубит с плеча: «Being different is a fucking blessing».
09/09/22 16:11
195 отзывов
Pitti Fragranze будет проходить во Флоренции 16-18 сентября 2022
События
Международная парфюмерная выставка Pitti Fragranze пройдёт 16-18 сентября на Станции Леопольда (Флоренция). Специальным гостем мероприятия станет Алессандро Гуалтьери.
09/09/22 07:51
2 отзыва
Loewe представляют Earth
Новые ароматы
Новый цветочно-амброво-мускусный аромат с нотой трюфеля.
09/09/22 06:31
10 отзывов
Сентябрь. Прозрачная осень
Авторские очерки
Ароматы ранней осени и духи, в которых их можно почувствовать.
09/09/22 01:13
39 отзывов
MiN Magic Circus: странная «гурманка» с сахарной ватой и бензином
Обзоры ароматов
«Исключительный гурманский аромат со смелым, амбициозным сочетанием материалов и специфическими эффектами, которые вы не найдёте больше нигде.»
09/08/22 08:26
10 отзывов
Благоухающие поля туберозы Matière Première
Нишевые ароматы
Новый аромат от Matière Première, созданный парфюмером Орельеном Гишаром, посвящён восхитительному запаху полей туберозы.
09/08/22 04:29
6 отзывов
Интервью с Джоном Пеггом из Kerosene и обзор его нового аромата Followed
Интервью
Джон Пегг, один из первых парфюмеров американской инди-волны 21 века, рассказывает о своей работе и своём последнем творении.
09/08/22 03:23
6 отзывов
Aymara: новый аромат Miller et Bertaux
Обзоры ароматов
Горные леса в Боливии пахнут очень знакомо…
09/08/22 00:11
5 отзывов
Guerlain Shalimar Millésime Tonka
Новые ароматы
Новая версия Shalimar увидит свет в октябре 2022 года.
09/07/22 11:45
20 отзывов
Елена Новой Зари: тихий вечер из прошлого
Винтажные ароматы
«Елена» винтажная и «Елена» современная.
09/07/22 09:15
18 отзывов
Atelier Materi Cacao Porcelana: недетское лакомство
Обзоры ароматов
Какао с горьким привкусом увядания.
09/07/22 06:56
9 отзывов
Hermès Violette Volynka
Новые ароматы
Элегантная и неожиданная встреча: мужского и женского, двух уникальных материалов, которые отражают друг друга, как два альтер-эго — кожи и фиалки.
09/06/22 06:07
12 отзывов
Обзор Soul Batik Moresque
Обзоры ароматов
Индонезия. Остров Ява. Девушка рисует батик.
Остров Ява. Девушка рисует батик.
09/06/22 03:23
Один комментарий
Энциклопедия Ароматов
Ароматы: 74,557
Мнения об ароматах: 770,395
Всего членов: 279,190
Онлайн прямо сейчас: 1,416
Регистрация
Войти Регистрация
Мнения об ароматах
ByBozo
Habibi от Asya_Asya
Givenchy
Very Irresistible Eau de Toilette от ДобраяКошка
Chanel
Gabrielle Essence от Sandra1499
Zoologist Perfumes
Sacred Scarab от Veranica
Dior
Les Creations de Monsieur Dior Eau Fraiche от stone13
Serge Lutens
Chergui от Ruby Ray
Kamila Robinson
Tentazione Lunar от S_Anna_S
Creed
Love in White от NinaMrk
Amouage
Crimson Rocks от elka34
Narciso Rodriguez
Pure Musc For Her от Kejti
L’Occitane en Provence
Eau des Baux от Stanislavkbr
Gucci
The Virgin Violet Eau de Parfum от Cateyes
Marc-Antoine Barrois
Encelade от tamarasurenkova
Antonio Banderas
Blue Seduction от doremidont
Nina Ricci
L’Extase Caresse de Roses от ЮлияЕр
Calvin Klein
CK All от Dev0tee
Guerlain
Shalimar Eau de Toilette от Ksenia70
Alex Simone
Encore Un Peu от rinaMD
Paco Rabanne
Fame от Elena1
Estée Lauder
Pleasures от Ambersky
Новые комментарии
Комментарии к статьям
Rosa Tabacco от Dr. Vranjes от SweetMonster
Vranjes от SweetMonster
Два аромата Vertus Paris: Majeste и Auramber от SweetMonster
В ПАМЯТЬ О КОРОЛЕВЕ: A FRAGRANCED TRIBUTE TO QUEEN ELIZABETH от Torsada
Полынная осень: L’Eau d’Armoise Serge Lutens от Альта Виста
Новинки от OLFATTOLOGY: Lofoten и Olifant от BorisV
VAST Perfume Week 2022 от Sinnarn
Ещё раз о фужерах от Vibia Sabina
Caron Tabac Blanc, новый, мля от Parfumfeja
Ароматы на все случаи жизни от sevtsovan
Звезда Полынь: о самой горькой траве от Vniv52NN
Дешево, но мило: Doriane Yves de Sistelle и Marquis Remy Marquis от Надежда К.
Bana Banana — ‘барочный банан’ от L’Artisan Parfumeur от silverware
Princesse Marina de Bourbon Princess Style от Torsada
Страсть и соблазн красных ароматов от Katti Karim
Matiere Premiere Crystal Saffron от StereoNomad
Новые ароматы от бренда Scents of Woods от Yish
Esxence-2022: Перебирая впечатления от Nemashka
Праздник осеннего равноденствия – Мабон от Vibia Sabina
Сентябрь. Прозрачная осень от lautar
История снова в тренде от Vibia Sabina
Addicted: когда «хороший» аромат становится «плохим» от Vibia Sabina
Парфюмерная мастерская Galimard в Грассе от Ixygon
Citrus Grandis: новый аромат Chris Collins от Венераизшифоньера
Clean Classic и Clean Reserve — скоро в России! от VeraMax
Prada Paradoxe — Фильм от Uxia
Bois Dormant – новый аромат коллекции Celine Haute Parfumerie от Тирвазия Аргираки
История Iso E Super в парфюмерии от Ixygon
Balmain Homme Hair Perfume от Vniv52NN
Vici Leather — новый аромат от Electimuss от Vniv52NN
Francesca Bianchi Unspoken Musk от gdeev
Пиковая дама в черной короне от Vibia Sabina
Аромат Youth-Dew от Estee Lauder отмечает свой 60-ый день рождения! от Vibia Sabina
NafNaf My Five, My Emotions: Crazy Drop, Hello Paradise, Magic Fizz, Magnetic Kiss и Spicy Rose от Marilla
Новые ароматы
WIDIAN
Rose Arabia White
Le Frag
Meluzyna
Anna Sui
Cosmic Sky
Profumum Roma
Vir
Dior
Patchouli Elixir Precieux
Dior
Jasmin Elixir Precieux
Xerjoff
Amphorae 56
Xerjoff
Amphorae 48
Xerjoff
Amphorae 39
Xerjoff
Amphorae 27
Xerjoff
Amphorae 17
Xerjoff
Amphorae 16
Olfattology
Lofoten
Olfattology
Olifant
Giorgio Armani
Emporio Armani Stronger With You Oud
Leme
1415 Ceuta
Leme
1419 Madeira
Leme
1498 Índia
Leme
1500 Brasil
Leme
1543 Japão
Leme
1488 Cabo das Tormentas
DSH Perfumes
Estancia
DSH Perfumes
Green Rhubarb and Cane Sugar
DSH Perfumes
Kale
DS&Durga
Leatherize
Dr. Vranjes Firenze
Vranjes Firenze
Rosa Tabacco
DSH Perfumes
Halfeti
DSH Perfumes
Rosé
DSH Perfumes
Countess Olenska
Electimuss
Vici Leather
Pierre Balmain
Balmain Homme Hair Perfume
DSH Perfumes
The Absinthe Drinkers
DSH Perfumes
Rattlesnake Musk
DSH Perfumes
Sagebrush & Cactus
Francesca Bianchi
Unspoken Musk
Новости из категории
Новые ароматы
События
Обзоры ароматов
Для тела и душа
Нишевые ароматы
Авторские очерки
Интервью
Винтажные ароматы
Оригинал vs фланкер
О парфюмерии и не только
Best in Show
Сейчас в магазинах
Аромахимия
Парфюмерные ингредиенты
Fragrantica Talks
Новости парфюмерии
Натуральная парфюмерия
Дом и сад
Рекламные кампании
Fragrantica
История
Колонка гл. редактора
редактора
Обновления энциклопедии
Coty
Jacq’s
Antonio Puig
Sport Man
Avon
Elégante
Jequiti
Capricórnio
Jequiti
Sagitário
Jequiti
Escorpião
Jequiti
Libra
Jequiti
Virgem
Jequiti
Leão
Jequiti
Câncer
Jequiti
Gêmeos
Jequiti
Touro
Jequiti
Áries
Jequiti
Peixes
Jequiti
Aquário
Simone Andreoli
Mandorla Del Sud
Dr. Vranjes Firenze
Vranjes Firenze
Milano
Dr. Vranjes Firenze
Ginger Lime
Dr. Vranjes Firenze
Ambra
Dr. Vranjes Firenze
Leather Oud
Messinian SPA
Bronze Shimmering Oil
Messinian SPA
Pomegranate & Honey Oil
Messinian SPA
Royal Jelly & Helichrysum Oil
Messinian SPA
Orange, Vanilla Orchid & Blueberry Oil
Messinian SPA
Christmas Joy Chai Latte Oil
Messinian SPA
Absolute Love for Daughter & Mommy Oil
Messinian SPA
Christmas Joy Chai Latte
Messinian SPA
Christmas Joy Chai Latte
Messinian SPA
Black Truffle
Messinian SPA
Fig & Lemon
Популярные бренды и ароматы
Acqua di Parma Alien Amouage Angels’ Share Ariana Grande Armaf
Avon Azzaro Baccarat Rouge 540 Black Opium Burberry Bvlgari
By Kilian By the Fireplace Byredo Calvin Klein Carolina Herrera Chanel
Chloé Cloud Club de Nuit Intense Man Creed Dior Diptyque
Dolce&Gabbana Estée Lauder Etat Libre d’Orange Frederic Malle Giorgio Armani Givenchy
Good Girl Gucci Guerlain Hermès Hugo Boss Issey Miyake
Jean Paul Gaultier Jo Malone London Juliette Has A Gun Kenzo La Vie Est Belle Lalique
Lancôme Le Labo Libre Maison Francis Kurkdjian Maison Martin Margiela Mancera
Marc Jacobs Montale Montblanc Mugler Narciso Rodriguez Natura
Nishane O Boticário Paco Rabanne Parfums de Marly Penhaligon’s Prada
Ralph Lauren Sauvage Serge Lutens Tobacco Vanille Tom Ford Valentino
Versace Victoria’s Secret Viktor&Rolf Xerjoff Yves Saint Laurent Zara
Наверх страницы
Fragrantica in your language:
| English | Deutsch | Español | Français | Čeština | Italiano | Polski | Português | Ελληνικά | 汉语 | Nederlands | Srpski | Română | العربية | Українська | Монгол | עברית |
Пользовательское соглашение и Политика конфиденциальности
Авторские права © 2006-2022 Fragrantica. ru Парфюмерный журнал. Все права защищены. Материалы с сайта не подлежат копированию без письменного разрешения редакции.
ru Парфюмерный журнал. Все права защищены. Материалы с сайта не подлежат копированию без письменного разрешения редакции.
Fragrantica® Inc, United States
Состав энергетических напитков | Tervisliku toitumise informatsioon
Большинство энергетических напитков содержит кофеин, а также комбинацию других компонентов, в т.ч. глюкуронолактон, растительные стимуляторы (гуаранин, падуб парагвайский – мате), простые сахара (глюкоза, фруктоза), аминокислоты (таурин, карнитин, креатин), биологически активные растения (гинкго двухлопастной, женьшень) и витамины группы B (например, никотиновая кислота, витамины B6 и B12).
Кофеин
Кофеин – это алкалоид метилксантин, химическое название которого – 1,3,7-триметилксантин. Самые высокие концентрации кофеина обнаружены в бобах и листьях кофейных растений, в чае, мате, ягодах гуараны, орехах кола и какао. В общей сложности кофеин присутствует в бобах, листьях и плодах более чем 100 растений, где, как считается, он действует в качестве естественного пестицида, который парализует и убивает определенных насекомых, поедающих эти растения.
Главный фармакологический эффект кофеина – стимуляция центральной нервной системы. Воздействие кофеина может проявляться в спонтанном повышении электрической активности мозга, увеличении опасности возникновения судорог, росте двигательной активности, а также в увеличении скорости реакции.
Кофеин существенным образом влияет на сердечно-сосудистую систему. Отмечаются следующие эффекты:
- умеренный рост кровяного давления (как систолического, так и диастолического),
- изменение частоты сердечных сокращений,
- нейро-эндокринные проявления, такие как выброс адреналина, норадреналина и ренина.
Помимо нервной и сердечно-сосудистой систем, кофеин оказывает воздействие и на другие системы органов. Кофеин увеличивает частоту дыхания; через органы выделения, в частности через почки, кофеин выводит из организма натрий и воду. Отмечено стимулирующее воздействие кофеина на секрецию в желудке соляной кислоты и пепсина.
Известно влияние кофеина на сон. При употреблении человеком кофеина по 400 мг три раза в день эффективность сна падает до уровня, эквивалентного бессоннице. Прием непосредственно перед отходом ко сну 300-400 мг кофеина связан с сокращением времени сна на 30-80 минут. На сон могут оказывать влияние и более мелкие дозы. Известно, что 100 мг кофеина (т.е. маленькая чашка крепкого кофе) отодвигает время засыпания и ухудшает качество сна в течение последующих 3–4 часов. У привычных потребителей кофе кофеин влияния на сон не оказывает.
Большие количества кофеина могут оказывать разное воздействие, проявляясь, например, в раздражительности, повышенной возбудимости, тревожности, беспокойстве, спутанности сознания, паранойе, галлюцинациях, состоянии напряжения, головной боли, головокружении, бессоннице, потере аппетита, диарее, тошноте, покраснении, дрожании рук, нарушениях кровообращения, аритмии, пониженном кровяном давлении или нечувствительности к боли. Эти симптомы могут проявляться как при длительном, так и при кратковременном употреблении и могут являться признаками отравления кофеином. Длительное злоупотребление кофеином может привести у взрослых и к психическим расстройствам: нарушениям сна и повышенной тревожности.
Длительное злоупотребление кофеином может привести у взрослых и к психическим расстройствам: нарушениям сна и повышенной тревожности.
У детей и подростков, которые в течение дня получают большие дозы кофеина, могут возникать вызванные кофеином головные боли. Также отмечается высокое кровяное давление, бессонница, хронические головные боли, раздражительность, проблемы с учебой и усиление других вредных побочных эффектов, причем многие из этих эффектов зависят от употребленного количества.
Кроме детей, серьезные нарушения здоровья употребление кофеина вызывает у беременных (приводя в числе прочего к самопроизвольному прерыванию беременности), кормящих матерей, диабетиков, пациентов с пептическими язвами и у людей с заболеваниями сердечно-сосудистой системы, такими как гипертензия, сердечная недостаточность и нарушения сердечного ритма.
Для здорового взрослого человека безопасной дневной дозой кофеина считается 400 мг.
Отравление у взрослых проявляется при дозах кофеина, превышающих 7–8 мг на килограмм массы тела в день, то есть 500–600 мг в день, что эквивалентно примерно пяти чашкам кофе.
Для детей и подростков доза кофеина не должна превышать 3 мг на килограмм массы тела в день.
В подавляющем большинстве энергетических напитков, продающихся в магазинах Эстонии, содержание кофеина составляет 32 мг / 100 мл.
Гуаранин
Гуаранин получают из растения гуарана (Paullinia cupana) родом из Южной Америки. Его семена содержат значительные количества кофеина: 1 г гуаранина эквивалентен примерно 40 мг кофеина.
В последние годы гуаранин из-за своего стимулирующего воздействия все чаще используется в качестве природного компонента энергетических напитков. Кофеин, полученный из гуараны, выводится медленнее, чем чистый кофеин, что приводит к более длительному стимулирующему эффекту.
Как утверждается, гуаранин повышает когнитивные способности и настроение, а также снимает психическую усталость. Гуаранин также связывают с улучшением липидного метаболизма.
Таурин
Таурин – серосодержащая аминокислота, которая встречается в организме человека и многих животных. Таурин, используемый в промышленности, получают путем химического синтеза, поскольку потребность в этом веществе велика.
Таурин, используемый в промышленности, получают путем химического синтеза, поскольку потребность в этом веществе велика.
За последние 10 лет таурин стали все чаще добавлять в энергетические напитки, причем его можно обнаружить в таких напитках в очень значительных количествах. Исследования 80 различных энергетических напитков показали, что среднее содержание таурина в них составляет 3180 мг на литр.
Таурин имеет отношение ко многим физиологическим функциям, в т.ч. к нейромодуляции, стабильности клеточных мембран и модуляции внутриклеточного уровня кальция.
Несмотря на то, что доказательств вредного воздействия таурина на организм человека нет, вызывает беспокойство отсутствие достаточного количества исследований влияния на здоровье существенных доз таурина совместно с другими компонентами энергетических напитков.
Женьшень
Существует множество видов женьшеня, наиболее исследованный из них – Panax ginseng, известный также как корейский или азиатский женьшень.
Женьшень стимулирует иммунные функции, улучшает физическую и атлетическую выносливость и общее самочувствие, а также улучшает сопротивляемость стрессовым факторам окружающей среды.
Помимо потенциально поддерживающих здоровье свойств женьшеня, его употребление связывают и с неблагоприятными воздействиями. Речь идет об эстрагеноподобных действиях вроде увеличения чувствительности груди и ее болезненности, исчезновения менструального цикла, вагинальных кровотечений после менопаузы, роста груди у женщин. Другими последствиями употребления женьшеня могут быть бессонница, сердцебиение, высокое кровяное давление, отеки, головная боль, головокружение.
Несмотря на нередкие заявления производителей энергетических напитков о том, что женьшень улучшает физические возможности, исследования этого в заметном масштабе не выявили. Содержащиеся в энергетических напитках количества женьшеня, как правило, существенно меньше тех, которые могли бы принести пользу или причинить вред здоровью.
Левокарнитин
Эту аминокислоту производят в основном печень и почки, чтобы улучшить обмен веществ. Последние достоверные исследования свидетельствуют, что левокарнитин играет важную роль в предотвращении повреждения клеток и способствует восстановлению после тренировочного стресса.
О положительных эффектах содержащихся в энергетических напитках количеств этого вещества не известно. Высокие дозы левокарнитина могут вызвать тошноту, рвоту, боли в животе, диарею, известны случаи возникновения судорог.
Глюкуронолактон
Печень человека синтезирует глюкуронолактон, который выступает в качестве структурного компонента почти всей соединительной ткани, из глюкозы. Это вещество встречается также в некоторых растениях. Клинически доказано, что глюкуронолактон уменьшает сонливость, повышает психическую выносливость и скорость реакции.
В обычной 250-миллилитровой банке энергетического напитка может содержаться около 60 мг глюкуронолактона. Вред или польза глюкуронолактона для здоровья человека не доказаны, поскольку до сих пор исследования проводились только на животных.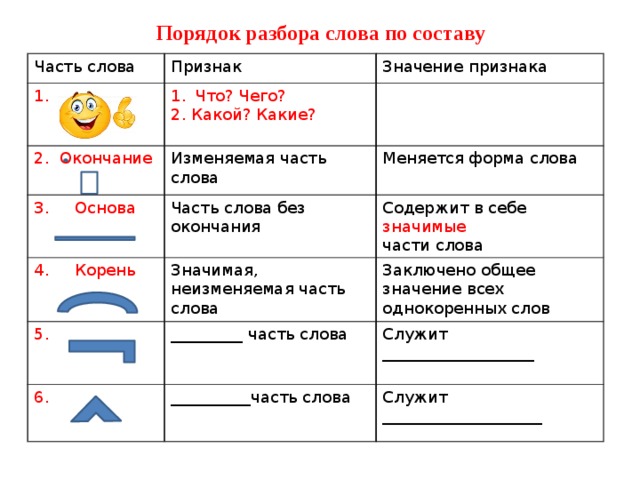
Витамины группы B
Витамины группы B – это группа из восьми отдельных водорастворимых витаминов, играющих важную роль в клеточных процессах.
Поскольку энергетические напитки содержат большие количества сахара, витамины группы B считаются компонентами, которые необходимы для преобразования этого сахара в энергию. Таким образом, витамины группы B играют ключевую роль в высвобождении всей энергии, которая имеется в содержащихся в энергетических напитках простых сахарах. Отсюда появляется понятие «дополнительной энергии», которую, как утверждают производители энергетических напитков, их продукция дает потребителям.
Как правило, из витаминов группы B в энергетические напитки добавляют витамин B2 (рибофлавин), витамин B3 (ниацин), витамин B6 (пиридоксин) и витамин B12 (цианокобаламин).
Хотя употребление любых витаминов группы B в больших количествах не причиняет здоровью никакого вреда, их присутствие в больших количествах в энергетических напитках нерационально.
Сахар
В большинстве энергетических напитков содержится сахароза, глюкоза и/или кукурузный сироп с высоким содержанием фруктозы. Исключение составляют не содержащие сахара энергетические напитки.
Гинкго двулопастной
Экстракт гинкго получают из листьев гинкго двухлопастного (Ginko biloba) и в течение веков применяют в традиционной китайской медицине.
Экстракт гинкго, как утверждается, обладает антиокислительными свойствами, улучшает вазомоторную функцию, снижает адгезию кровяных телец в эндотелий, ингибирует активность тромбоцитов и разглаживает мышечные клетки.
О положительных эффектах содержащихся в энергетических напитках количеств этого вещества не известно.
Падуб парагвайский (мате)
Мате (иногда матэ, ударение правильнее ставить на первый слог), также называемый парагвайским чаем, изготавливают из листьев растения Ilex paraguariensis, которые накапливают в себе значительные количества (0,4–2 %) кофеина.
В падубе парагвайском содержится множество растительных питательных веществ, и их связывают с различного рода пользой для здоровья. Мате обладает противовоспалительными и антидиабетическими свойствами, подавляет оксидативный стресс.
Мате обладает противовоспалительными и антидиабетическими свойствами, подавляет оксидативный стресс.
По причине высокого содержания кофеина мате является стимулятором центральной нервной системы, и это главная причина, по которой его добавляют в энергетические напитки. Содержание кофеина в одной чашке (250 мл) мате составляет примерно 78 мг.
Инозитол
Инозитол (ранее называвшийся витамином B8) в организме человека синтезируется из глюкозы. Мио-инозитол – является частью клеточных мембран, он помогает печени обрабатывать жиры и способствует функционированию мышц и нервов.
О положительных эффектах содержащихся в энергетических напитках количеств этого вещества не известно.
Народные приметы на 13 сентября: что нельзя делать в этот день
Общество 1660
Поделиться
13 сентября 2022 года проходит церковный праздник Положение честного Пояса Пресвятой Богородицы и народный праздник Куприянов день. Что нельзя делать, народные приметы, все праздники 13.09.2022. Что можно делать, традиции и поверья, которые дошли до нас из глубины веков, обряды, ритуалы, запреты и церковный календарь.
Что нельзя делать, народные приметы, все праздники 13.09.2022. Что можно делать, традиции и поверья, которые дошли до нас из глубины веков, обряды, ритуалы, запреты и церковный календарь.
13 сентября 2022 года что нельзя делать
В этот день действует запрет на любые конфликты, ссоры с окружающими. Нельзя повышать голос на другого человека, употреблять бранные слова, чертыхаться. После такого поведения в жизни может наступить полоса неудач. По этой же причине, старались не устраивать праздников, которые предполагают большое количество людей, шум, песни, употребление горячительных напитков.
Нельзя завязывать узлы, потому рекомендуется не заниматься рукоделием, которые связаны с тем, что нужно на нитках, верёвках или лентах вязать узелки.
Нельзя рябину собирать. По приметам, так можно потревожить птиц, которые готовятся к перелёту.
Нельзя деньги занимать — до конца года с финансами будут проблемы.
Плохой день для путешествий и дальней дороги. Если есть такая возможность, то лучше не выходить из дома и не отправляться в путь. Если же этого не избежать, то перед выходом стоит помолиться, взять с собой крестик, иконку, оберег, амулет или другой символ веры.
Если же этого не избежать, то перед выходом стоит помолиться, взять с собой крестик, иконку, оберег, амулет или другой символ веры.
Нельзя сажать и пересаживать растения — в саду, на огороде или домашние цветы. В противном случае они будут плохо расти.
Не принимают подарки от незнакомых или малознакомых людей. Считается, что вместе с подарком к человеку могут перейти проблемы и болезни того, кто их дарит.
13 сентября 2022 года что можно делать
Православная церковь чтит память епископа Карфагенского священномученика Киприана, который жил в III веке. В народном календаре его имя было изменено на более привычное — Куприянов день. Другое название праздника — Журавлиное вече. Связано это с тем, что, по народным приметам, журавли собираются на болотах, чтобы обсудить полёт в южные края — когда лететь, как, каким именно путём, кто будет стаю вести, после чего начинается их окончательный сбор и отлёт.
В церковном православном календаре отмечается праздник Положение честного Пояса Пресвятой Богородицы. Частицы христианской реликвии, пояса Девы Марии, хранятся и в России — Храме Илии Пророка Обыденного в Москве и Казанском соборе в Санкт-Петербурге.
Частицы христианской реликвии, пояса Девы Марии, хранятся и в России — Храме Илии Пророка Обыденного в Москве и Казанском соборе в Санкт-Петербурге.
Именно с этого дня начинался сбор клюквы. По старинным представлениям, клюкву (журавлиная ягода) можно начинать собирать тогда, когда она полностью покраснела. Только поспевшая клюква способна отгонять нечистую силу, а до этого времени нечисть шастает по болотам и может сильно навредить ягодникам.
Соответственно, с этого же дня начинались приготовления блюд и заготовок из клюквы — варенье, компоты, морсы и так далее.
Из клюквы делали и обереги. Для этого зашивали ягоды в меленький синий мешочек, чтобы его можно было носить с собой. Считается, что пока мешочек с человеком, его во всём будет сопровождать удача.
Если есть человек, у которого день рождения именно 13 сентября, во время похода за клюквой его нужно пустить вперёд, чтобы он выбирал дорогу. Именинник способен найти самое урожайное место, где много крупной клюквы.
Помимо всего прочего, продолжается сбор корнеплодов. Выкапывают картофель, морковь, свеклу, репу. Готовятся блюда из свежих продуктов.
Хороший день для труда, работы, той или иной деятельности. Человек, который в такой день трудится, получит удачу и благополучие в своих начинаниях, свершениях и стремлениях.
Устраивают уборку и разбор вещей. Можно выбросить те вещи, которые уже старые, изношенные, никому не нужные, не будут больше использоваться. На место старых вещей придут новые, которые принесут с собой ещё и позитивную энергию.
В порядок следует привести не только жилище, но и свои мысли — забыть плохое, перестать думать о мести или дурных вещах. Очистив свои помыслы, можно заметить, как освободившееся место заняли светлые и радостные мысли, жизнь в разных сферах начнёт стремительно налаживаться.
В этот день можно поставить точку в общении с людьми, которые вам не нравятся, неприятны, вызывают постоянные переживания и проблемы, впутывают в проблемы и неприятности. Если с такими людьми расстаться сегодня, всё пройдёт максимально удачно.
Если с такими людьми расстаться сегодня, всё пройдёт максимально удачно.
А вот если у вас в недавнем времени произошли конфликтные ситуации с членами семьи или родственниками, нужно сделать первый шаг к примирению, чтобы возобновить добрые взаимоотношения.
Рождённые в этот день посвящают себя своему делу, не жалеют сил и времени на достижение мечты, ставят всё ради того, чтобы получить желаемое. Сильные и решительные, они также отличаются умением сосредотачиваться, просчитывать все детали и нюансы, способны решать сложные задачи.
Народные приметы на 13 сентября 2022 года
• Одуванчик зацвёл — к тёплой осени.
• Лягушки прячутся глубоко под водой — к сильному похолоданию.
• Снег выпал — скоро растает.
• Муравьи сделали большие муравейники — зима окажется суровой.
• Журавли низко летят — к тёплой зиме.
• Лебеди летят над головой — можно ждать снегопад.
• Туман на восходе — день будет безветренным.
• Пауков не видно, попрятались — перед дождём.
• Во время дождя куры стали выходить во двор — скоро закончится и наступит тёплая сухая погода.
• Журавли громко курлыкают — перед дождём.
• Журавли не держат клин, летят небольшими группами или поодиночке — в следующем году будет засуха и плохой урожай.
Какой праздник 13 сентября 2022 года
Какие праздники проходят 13.09.2022 в России и мире. Профессиональные, церковные православные, народные, памятные, знаменательные события в истории, кто родился из звёзд и знаменитостей.
• День программиста в России (256-й день года — 13 сентября, в високосный год — 12 сентября).
• День парикмахера в России.
• День позитивного мышления.
• День шарлоток и осенних пирогов.
• День основания Краснодарского края (1937 год).
• Праздник железных материалов.
• День рождения бионики.
• Куприянов день, Журавлиное вече (народный праздник).
• Положение честного Пояса Пресвятой Богородицы.
• Собор новомучеников Ясеновацких.
• В церковном православном календаре проходит память святых: епископа Карфагенского священномученика Киприана, патриарха Цареградского святителя Геннадия, священномучеников Александра Любимова и Владимира Двинского, священномучеников Михаила Косухина и Мирона Ржепика, священномученика Димитрия Смирнова.
• В 1736 году был основан город Челябинск.
• В 1922 году был зафиксирован мировой рекорд максимальной температуры воздуха +57,7°C.
• В 1983 году была создана группа «Несчастный случай».
В этот день родились исторические деятели и знаменитости: нидерландский художник Ян Брейгель Младший (1601-1678), советская партизанка Зоя Космодемьянская (1923-1941), американский художник Роберт Индиана (1928-2018), английская актриса Жаклин Биссет (1944), певец Александр Розенбаум (1951), диктор российского телевидения Татьяна Миткова (1955), советский и российский журналист Артём Боровик (1960-2000), российский певец Ираклий Пирцхалава (1977).
Подписаться
Россия Москва Санкт-Петербург Челябинск Краснодарский край
- 30 авг
Престиж и пополнение бюджета: названы плюсы коротких автомобильных номеров
- 22 авг
Штраф за невыгул: назван способ перевоспитания российских собаководов
- 16 авг
Названо лучшее средство от пробок на дорогах России
Что еще почитать
Побывавшая в Европе туристка рассказала о нынешнем отношении к россиянам
26572
Анатолий Ильин
Пропавшего в Москве экс-зампреда правительства Пензенской области нашли
23723
Анатолий Ильин
Россиянин из ревности сбил соперника машиной и зарезал на глазах у очевидцев
14526
Анатолий Ильин
Не знавшая о беременности девочка родила во время сборов в школу
19153
Олег Цыганов
В Крыму проводят проверку из-за гимна «Азова»* на свадьбе
15133
Александр Шляпников
Что почитать:Ещё материалы
В регионах
Аксенов ответил Киеву на фейки об эвакуации: «эвакуаторы хреновы»
16338
КрымФото: управление информации и пресс-службы Главы Республики Крым
Самые вкусные оладьи из кабачков по-новому
11672
КалугаЕлена Одинцова
Полиция задержала 50 девушек в красном на петрозаводской площади Кирова.
ФОТОФото 8914
КарелияИрина Стафеева
За час до рассвета: пропавший на трассе в Челябинской области дальнобойщик покончил с собой
Фото 5277
ЧелябинскИрина Меньшикова
Действия руководства свердловских управлений Росреестра и Росимущества подрывают авторитет местной и федеральной власти
3059
ЕкатеринбургМаксим Бойков
Как получить звание ветерана труда
2002
Великий НовгородБелобородько Мария
 ФОТО
ФОТОВ регионах:Ещё материалы
Автоматизированный конвейер для данных о суперсплавах путем интеллектуального анализа текста
Введение
Искусственный интеллект (ИИ)/машинное обучение (МО) трансформируют исследования материалов, меняя парадигму с «проб и ошибок» на методологию, основанную на данных, тем самым ускоряя открытие новых материалов 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 . Хорошо охарактеризованные данные остаются необходимым условием успеха AI/ML. В настоящее время существует два основных источника научных данных: (1) экспериментальные и расчетные результаты из собственной лаборатории исследователя и (2) данные, собранные из статей, опубликованных другими исследователями. Научная литература содержит огромное количество рецензируемых и в основном высококачественных надежных данных. Тем не менее, ручное извлечение данных с помощью экспертных знаний требует много времени и труда для десятков тысяч статей, передаваемых с использованием свободного естественного языка 9.0005 17 . С постоянно растущим числом новых публикаций ведение и обновление базы данных вручную становится все труднее для отдельного исследователя. Поэтому разработка методов автоматического быстрого и точного извлечения данных становится все более необходимой.
Хорошо охарактеризованные данные остаются необходимым условием успеха AI/ML. В настоящее время существует два основных источника научных данных: (1) экспериментальные и расчетные результаты из собственной лаборатории исследователя и (2) данные, собранные из статей, опубликованных другими исследователями. Научная литература содержит огромное количество рецензируемых и в основном высококачественных надежных данных. Тем не менее, ручное извлечение данных с помощью экспертных знаний требует много времени и труда для десятков тысяч статей, передаваемых с использованием свободного естественного языка 9.0005 17 . С постоянно растущим числом новых публикаций ведение и обновление базы данных вручную становится все труднее для отдельного исследователя. Поэтому разработка методов автоматического быстрого и точного извлечения данных становится все более необходимой.
В последнее время внедрены конвейеры для автоматического извлечения данных об органических и неорганических химических веществах из статей в области химии и материаловедения 18,19,20,21,22 с использованием методов обработки естественного языка (NLP). Задачи распознавания именованных сущностей (NER) и извлечения отношений считаются критическими компонентами извлечения данных из статей. Общие методы NER варьируются от поиска по словарю до подходов на основе правил и машинного обучения. Случаи, которые не могут быть обработаны словарями или правилами, исследуются с использованием подходов машинного обучения, которые требуют существенных данных, аннотированных экспертами, для обучения, а также подробных руководств по аннотации 23 . Ким и др. использовали методы на основе нейронных сетей и синтаксического анализа для распознавания и извлечения параметров синтеза с оценкой F1 81% из более чем 640 000 журнальных статей 24 . «ChemDataExtractor» был разработан для распознавания объектов с химическими названиями для извлечения отношений органических и неорганических соединений из массивного корпуса статей (сотни тысяч) с использованием словаря с ML и несколькими грамматическими правилами 18 . Корт и др.
Задачи распознавания именованных сущностей (NER) и извлечения отношений считаются критическими компонентами извлечения данных из статей. Общие методы NER варьируются от поиска по словарю до подходов на основе правил и машинного обучения. Случаи, которые не могут быть обработаны словарями или правилами, исследуются с использованием подходов машинного обучения, которые требуют существенных данных, аннотированных экспертами, для обучения, а также подробных руководств по аннотации 23 . Ким и др. использовали методы на основе нейронных сетей и синтаксического анализа для распознавания и извлечения параметров синтеза с оценкой F1 81% из более чем 640 000 журнальных статей 24 . «ChemDataExtractor» был разработан для распознавания объектов с химическими названиями для извлечения отношений органических и неорганических соединений из массивного корпуса статей (сотни тысяч) с использованием словаря с ML и несколькими грамматическими правилами 18 . Корт и др.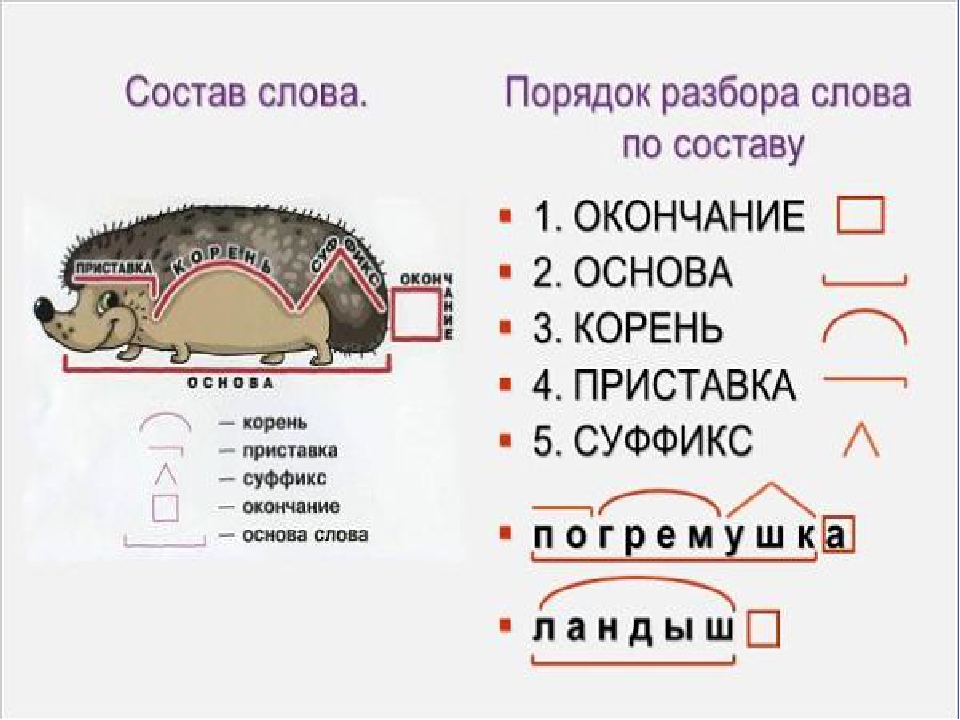 использовали «ChemDataExtractor» с модифицированным алгоритмом «Snowball» для извлечения температур Кюри и Нееля для магнитных материалов с предполагаемой общей точностью 73% из корпуса из 68078 статей 22 . Хотя эта база данных предназначена для магнитных материалов, сегнетоэлектрики и антисегнетоэлектрики также используют терминологию Кюри и Нееля для температур перехода. Эти термины часто не обязательно используются так же, как соответствующие магнитные системы; следовательно, база данных также включает те материалы, которые не являются «магнитными».
использовали «ChemDataExtractor» с модифицированным алгоритмом «Snowball» для извлечения температур Кюри и Нееля для магнитных материалов с предполагаемой общей точностью 73% из корпуса из 68078 статей 22 . Хотя эта база данных предназначена для магнитных материалов, сегнетоэлектрики и антисегнетоэлектрики также используют терминологию Кюри и Нееля для температур перехода. Эти термины часто не обязательно используются так же, как соответствующие магнитные системы; следовательно, база данных также включает те материалы, которые не являются «магнитными».
Суперсплавы широко используются в турбинных лопатках и лопатках самых современных авиационных двигателей и промышленных газовых турбин. Знание их свойств, в том числе связанных с температурами перехода на фазовых диаграммах многокомпонентных сплавов, их химического состава и условий синтеза, является необходимой информацией для проектирования сплавов. Более того, по жаропрочным сплавам имеется около 20 000 статей; следовательно, для ускорения проектирования суперсплавов на основе данных 25,26,27,28,29,30 , извлечение и усвоение существующих данных из литературы имеет решающее значение. Прямое применение контролируемых методов глубокого обучения для NER или извлечения отношений требует адекватных и эффективных больших наборов данных с ручной маркировкой для обучения. Даже некоторые полууправляемые методы, такие как «Снежный ком», требуют определенного количества помеченных образцов в качестве исходных для начала обучения, и это создает трудности в достижении высокой точности и одновременном воспроизведении 31 .
Прямое применение контролируемых методов глубокого обучения для NER или извлечения отношений требует адекватных и эффективных больших наборов данных с ручной маркировкой для обучения. Даже некоторые полууправляемые методы, такие как «Снежный ком», требуют определенного количества помеченных образцов в качестве исходных для начала обучения, и это создает трудности в достижении высокой точности и одновременном воспроизведении 31 .
В этой статье мы предлагаем автоматизированный конвейер NLP для сбора данных о химическом составе и свойствах суперсплава в единый набор данных, что впоследствии позволяет нам выполнять глобальный анализ суперсплавов с использованием данных, извлеченных из 14425 журнальных статей из литературы. . В частности, для небольшого корпуса разработаны основанный на правилах метод NER и эвристический текстовый алгоритм извлечения множественных отношений, основанный на расстоянии, который не требует помеченных образцов. Кроме того, также разработан общий алгоритм анализа таблиц и извлечения отношений, отвечающий потребностям обработки таблиц. Оценка F1 NER для сплава с названным объектом достигает 92,07%, что намного выше, чем 42,91% и 24,86%, достигнутые с использованием двунаправленной сети с долговременной кратковременной памятью (BiLSTM) с моделью уровня условного случайного поля (CRF) (BiLSTM-CRF) и инструментом «ChemDataExtractor» соответственно. Оценка F1 извлечения текстовых отношений для температуры сольвуса γ ′ составила 79,37%, что выше, чем 33,21% и 43,28%, полученные с помощью хорошо известного алгоритма Snowball и модифицированного полууправляемого алгоритма Snowball соответственно. Таким образом, наш алгоритм на основе расстояния, не требующий помеченных выборок для извлечения множественных отношений, лучше работает в условиях небольшого корпуса. Этот метод приводит к более высокому запоминанию, чем «Снежный ком», который не очень хорош, поскольку начальных кортежей, используемых для начала обучения, слишком мало, что делает процесс кластеризации предложений в «Снежном коме» неэффективным для охвата всех форм предложений, и только некоторые из них отношения кортежей могут быть извлечены с низкой полнотой.
Оценка F1 NER для сплава с названным объектом достигает 92,07%, что намного выше, чем 42,91% и 24,86%, достигнутые с использованием двунаправленной сети с долговременной кратковременной памятью (BiLSTM) с моделью уровня условного случайного поля (CRF) (BiLSTM-CRF) и инструментом «ChemDataExtractor» соответственно. Оценка F1 извлечения текстовых отношений для температуры сольвуса γ ′ составила 79,37%, что выше, чем 33,21% и 43,28%, полученные с помощью хорошо известного алгоритма Snowball и модифицированного полууправляемого алгоритма Snowball соответственно. Таким образом, наш алгоритм на основе расстояния, не требующий помеченных выборок для извлечения множественных отношений, лучше работает в условиях небольшого корпуса. Этот метод приводит к более высокому запоминанию, чем «Снежный ком», который не очень хорош, поскольку начальных кортежей, используемых для начала обучения, слишком мало, что делает процесс кластеризации предложений в «Снежном коме» неэффективным для охвата всех форм предложений, и только некоторые из них отношения кортежей могут быть извлечены с низкой полнотой. Инструмент анализа таблиц и извлечения отношений показал хорошие результаты с оценкой F1 9.5,23%. В общей сложности набор данных с 2531 экземпляром, охватывающим химические составы и физические свойства, такие как температура сольвуса γ ′, плотность, температура солидуса и температура ликвидуса, был автоматически извлечен из корпуса из 14 425 статей от Elsevier и других издателей.
Инструмент анализа таблиц и извлечения отношений показал хорошие результаты с оценкой F1 9.5,23%. В общей сложности набор данных с 2531 экземпляром, охватывающим химические составы и физические свойства, такие как температура сольвуса γ ′, плотность, температура солидуса и температура ликвидуса, был автоматически извлечен из корпуса из 14 425 статей от Elsevier и других издателей.
Мы изучаем базу данных, чтобы выявить тенденции, которые согласуются с известным поведением суперсплавов. Наша база данных не включает условия синтеза или обработки и другие экспериментальные аспекты, включая погрешности измерений, которые важны для разработки суперсплавов. Поэтому, чтобы оценить, насколько предсказуемы извлеченные данные, мы построили модель машинного обучения, управляемую данными, для прогнозирования и сравнения с γ ′ Температуры сольвуса 15 суперсплавов не являются частью наших извлеченных данных, поскольку они были представлены впоследствии в 2020 и 2021 годах. Прогнозы находятся в пределах относительной ошибки 2,27%. Далее модель использовалась для прогнозирования трех неисследованных суперсплавов на основе кобальта: Co-36Ni-12Al-2Ti-1W-4Ta-4Cr, Co-36Ni-12Al-2Ti-1W-4Ta-6Cr и Co-12Al-4,5Ta-35Ni. -2Ti с температурой сольвуса γ ′ >1250 °C. Синтезируя и охарактеризовав сплавы, мы показываем, что температуры согласуются в пределах средней относительной погрешности 0,81%. Следовательно, наши исследования машинного обучения показывают потенциал трубопровода, а точность извлеченной базы данных с помощью интеллектуального анализа текста обеспечивает ценный ресурс для разработки суперсплавов.
Далее модель использовалась для прогнозирования трех неисследованных суперсплавов на основе кобальта: Co-36Ni-12Al-2Ti-1W-4Ta-4Cr, Co-36Ni-12Al-2Ti-1W-4Ta-6Cr и Co-12Al-4,5Ta-35Ni. -2Ti с температурой сольвуса γ ′ >1250 °C. Синтезируя и охарактеризовав сплавы, мы показываем, что температуры согласуются в пределах средней относительной погрешности 0,81%. Следовательно, наши исследования машинного обучения показывают потенциал трубопровода, а точность извлеченной базы данных с помощью интеллектуального анализа текста обеспечивает ценный ресурс для разработки суперсплавов.
Весь исходный код, используемый в этой работе, доступен по адресу https://github.com/MGEdata/SuperalloyDigger. Кроме того, был разработан веб-инструментарий; дополнительные примеры того, как использовать и адаптировать инструментарий, можно найти по адресу http://SuperalloyDigger.mgedata.cn. Эту стратегию извлечения и исходный код можно использовать для других сплавов путем изменения регулярных выражений. Он представляет собой практичное и эффективное средство извлечения данных из статей для ускорения разработки дизайна материалов на основе данных.
Он представляет собой практичное и эффективное средство извлечения данных из статей для ускорения разработки дизайна материалов на основе данных.
Результаты
Стратегия извлечения
Наш конвейер автоматизированного анализа текста для суперсплавов включает несколько этапов загрузки научных документов, предварительной обработки, анализа таблиц, классификации текста, распознавания именованных объектов, извлечения отношений между таблицами и текстом и разрешения взаимозависимостей, которые схематически показаны на рис. 1. Начиная с корпуса научных статей, извлеченных на расширяемом языке разметки (XML), языке гипертекстовой разметки (HTML) или в текстовом формате, мы предварительно обрабатываем необработанный архивный корпус для создания полной записи документа и отфильтровываем ненужную информацию ( см. Поиск статей и предварительная обработка в разделе «Методы»). Идея, лежащая в основе классификации текста, состоит в том, чтобы определить, какое предложение содержит извлекаемую информацию о целевом свойстве (см. Классификацию текста в разделе «Методы»). Анализ таблицы преобразует полный заголовок и тело таблицы в структурный формат, а затем классифицирует, какая таблица содержит информацию о химическом составе и целевом свойстве, которую необходимо извлечь (см. Анализ таблицы в разделе «Методы»). Методы NER предназначены для распознавания именованного объекта сплава, спецификатора свойства и значения свойства из текста и таблицы на английском языке, после чего следует извлечение отношения. Извлечение отношения текста и таблицы дает конкретные отношения кортежа для содержимого и свойства элемента, а разрешение взаимозависимостей разрешает связь с фрагментами данных о химическом составе и свойствах для одного конкретного материала. Наконец, извлеченные сущности кортежа, содержащие цифровой идентификатор объекта (DOI) изделия, именованную сущность сплава, химический элемент, содержимое, спецификатор свойства и значение свойства, автоматически компилируются в высокоструктурированный формат для формирования базы данных материалов.
Классификацию текста в разделе «Методы»). Анализ таблицы преобразует полный заголовок и тело таблицы в структурный формат, а затем классифицирует, какая таблица содержит информацию о химическом составе и целевом свойстве, которую необходимо извлечь (см. Анализ таблицы в разделе «Методы»). Методы NER предназначены для распознавания именованного объекта сплава, спецификатора свойства и значения свойства из текста и таблицы на английском языке, после чего следует извлечение отношения. Извлечение отношения текста и таблицы дает конкретные отношения кортежа для содержимого и свойства элемента, а разрешение взаимозависимостей разрешает связь с фрагментами данных о химическом составе и свойствах для одного конкретного материала. Наконец, извлеченные сущности кортежа, содержащие цифровой идентификатор объекта (DOI) изделия, именованную сущность сплава, химический элемент, содержимое, спецификатор свойства и значение свойства, автоматически компилируются в высокоструктурированный формат для формирования базы данных материалов.
Рабочий процесс включает в себя несколько этапов загрузки научных документов, предварительной обработки, анализа таблиц, классификации текста, распознавания именованных объектов, извлечения связей между таблицами и текстом и разрешения взаимозависимостей. Корпус научных статей очищается, а ненужная информация в необработанном корпусе затем фильтруется во время предварительной обработки. В соответствии с анализом таблиц и классификацией текста таблицы и предложения с целевой информацией определяются для распознавания именованных объектов и извлечения отношений. Именованный объект сплава, спецификатор свойства и значение свойства распознаются распознаванием именованного объекта, а извлечение отношения текста и таблицы дает конкретные отношения кортежа. Разрешение взаимозависимостей устраняет связь с фрагментами данных о химическом составе и свойствах для одного конкретного материала и, наконец, выводит полную запись в базу данных материалов.
Полноразмерное изображение
Распознавание именованных объектов
Проблема извлечения химического состава и свойств из литературы по суперсплавам может быть резюмирована как извлечение 6-кортежного отношения, где 6-кортеж состоит из статьи DOI, именованного объекта сплава, химического элемент, содержимое, спецификатор свойства и значение свойства. Именованный объект сплава обычно описывается в виде элементного состава (например, Co-9Al-9.8W и 8Al1W2Mo), обозначения суперсплава (например, ERBOCo-0 и U720Li) или местоимения (например, этот сплав). Химический элемент может быть идентифицирован по таблице Менделеева, а его состав выражается числовым значением с единицами в виде ат.% или мас.%. Спецификатор свойства ссылается на имя целевого свойства, например γ ′ температура или плотность сольвуса. Значение свойства дает значение и единицу измерения каждого свойства. Технология NER для распознавания именованного объекта сплава из англоязычного текста и таблицы необходима для последующего извлечения связи 32 . В этой работе, основанной на автоматически заархивированных документах по суперсплавам ~14 000, был исследован основанный на правилах метод для NER с последующей текстовой и табличной классификацией. Здесь мы берем температуру сольвуса γ ′ в качестве примера для спецификатора свойств, чтобы проиллюстрировать процедуру NER для жаропрочных сплавов (рис. 2), которая обеспечивает последовательности сущностей для последующего извлечения отношений.
В этой работе, основанной на автоматически заархивированных документах по суперсплавам ~14 000, был исследован основанный на правилах метод для NER с последующей текстовой и табличной классификацией. Здесь мы берем температуру сольвуса γ ′ в качестве примера для спецификатора свойств, чтобы проиллюстрировать процедуру NER для жаропрочных сплавов (рис. 2), которая обеспечивает последовательности сущностей для последующего извлечения отношений.
Именованный объект сплава, спецификатор свойства и значение свойства распознаются как последовательность объектов из текста и таблицы на английском языке.
Полноразмерное изображение
Несколько специализированных грамматических правил адаптированы для распознавания определенных типов информации о суперсплавах. В таблице 1 приведены девять моделей распространенных форм письма для суперсплавов. [0–9[A-Z]\S + [0–9]$». Если слово или фрагмент слова, принадлежащий именованному объекту сплава или значению свойства, успешно распознаны, слово или фрагмент слова можно считать положительным. Правила были применены к 545 предложениям (~ 19 000 слов) из 283 статей, а полученные точность, полнота и оценка F1 перечислены в таблице 2. Процедура распознавания значений свойств во время классификации текста иллюстрируется правилом в таблице 1, а его точность, полнота и оценка F1 для 845 предложений также показаны в таблице 2.
[0–9[A-Z]\S + [0–9]$». Если слово или фрагмент слова, принадлежащий именованному объекту сплава или значению свойства, успешно распознаны, слово или фрагмент слова можно считать положительным. Правила были применены к 545 предложениям (~ 19 000 слов) из 283 статей, а полученные точность, полнота и оценка F1 перечислены в таблице 2. Процедура распознавания значений свойств во время классификации текста иллюстрируется правилом в таблице 1, а его точность, полнота и оценка F1 для 845 предложений также показаны в таблице 2.
Полноразмерная таблица
Таблица 2 Точность, полнота и показатель F1 NER.Полноразмерная таблица
Мы также использовали модель BiLSTM-CRF для задач NER 33 (см. модель BiLSTM-CRF в разделе «Методы»). Кроме того, инструмент NER в «ChemDataExtractor» также использовался для выполнения NER суперсплава. По сравнению с моделью BiLSTM-CRF и «ChemDataExtractor» предлагаемый нами метод, основанный на правилах, работает лучше для названия сплава (таблица 2). Что касается модели BiLSTM-CRF, ее обширное пространство параметров модели приводит к чрезмерной подгонке для обучения модели на небольшом размеченном корпусе. «ChemDataExtractor» использует методы на основе CRF, правил и словарей для распознавания химических веществ. Поскольку правила и словари разные, это не очень хорошо работает для суперсплавов.
По сравнению с моделью BiLSTM-CRF и «ChemDataExtractor» предлагаемый нами метод, основанный на правилах, работает лучше для названия сплава (таблица 2). Что касается модели BiLSTM-CRF, ее обширное пространство параметров модели приводит к чрезмерной подгонке для обучения модели на небольшом размеченном корпусе. «ChemDataExtractor» использует методы на основе CRF, правил и словарей для распознавания химических веществ. Поскольку правила и словари разные, это не очень хорошо работает для суперсплавов.
Извлечение текстовых отношений
Извлечение отношений идентифицирует и устраняет неоднозначности в семантических отношениях между двумя объектами в неструктурированных текстовых данных 34 . Для извлечения свойств из изделий из жаропрочных сплавов отношение можно рассматривать как четверичный кортеж  Наиболее сложной задачей для извлечения свойства суперсплава является извлечение нескольких отношений из одного предложения 35 . В частности, обычно несколько именованных объектов сплава (≥1) сообщаются с соответствующими значениями свойств для указанного свойства в одном предложении, или указанный именованный объект сплава может сообщаться с несколькими свойствами (≥1) и соответствующими значениями. (≥1). Это приводит к нескольким препятствиям для извлечения отношений на основе ограниченного корпуса суперсплава. Алгоритм извлечения зависимостей с учителем требует большого количества помеченных выборок свыше ~70 000 36 , и даже полууправляемые методы требуют определенного количества помеченных выборок в качестве начальных значений для начала обучения. Здесь мы предлагаем основанный на расстоянии алгоритм, не требующий помеченных выборок для обработки извлечения множественных отношений; рабочий процесс извлечения отношения показан на рис. 3а. В методах извлечения отношений на основе признаков количество слов и последовательностей слов между сущностями может выступать в качестве основных синтаксических признаков 37 .
Наиболее сложной задачей для извлечения свойства суперсплава является извлечение нескольких отношений из одного предложения 35 . В частности, обычно несколько именованных объектов сплава (≥1) сообщаются с соответствующими значениями свойств для указанного свойства в одном предложении, или указанный именованный объект сплава может сообщаться с несколькими свойствами (≥1) и соответствующими значениями. (≥1). Это приводит к нескольким препятствиям для извлечения отношений на основе ограниченного корпуса суперсплава. Алгоритм извлечения зависимостей с учителем требует большого количества помеченных выборок свыше ~70 000 36 , и даже полууправляемые методы требуют определенного количества помеченных выборок в качестве начальных значений для начала обучения. Здесь мы предлагаем основанный на расстоянии алгоритм, не требующий помеченных выборок для обработки извлечения множественных отношений; рабочий процесс извлечения отношения показан на рис. 3а. В методах извлечения отношений на основе признаков количество слов и последовательностей слов между сущностями может выступать в качестве основных синтаксических признаков 37 . Таким образом, количество сущностей и расстояние между сущностями служат основой для оценки взаимозависимости.
Таким образом, количество сущностей и расстояние между сущностями служат основой для оценки взаимозависимости.
a Блок-схема алгоритма извлечения отношения путем сопоставления кратчайшего расстояния и последовательного сопоставления. Количество слов и последовательностей слов между сущностями может выступать в качестве основных синтаксических признаков в методах извлечения отношений на основе признаков. b Схема алгоритма поиска кратчайшего расстояния. c Схема алгоритма последовательного сопоставления. Фразы в синем, зеленом и желтом прямоугольниках распознаются NER как именованная сущность сплава, спецификатор свойства и значение свойства соответственно.
Изображение полного размера
После NER целевые предложения организованы в виде последовательностей сущностей с индексом позиции для сплава именованной сущности, свойства и значения. Алгоритм сопоставления кратчайшего расстояния применяется, когда (i) количество именованных объектов сплава не равно количеству значений свойств ( n ≠ k как поток 1 на рис.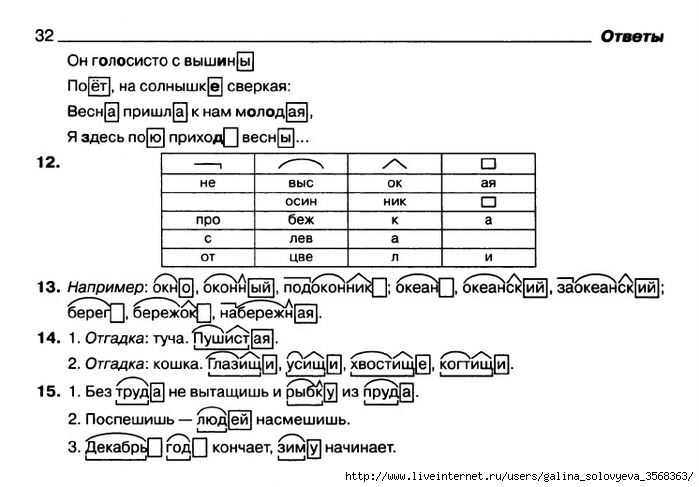 3а) и (ii) количество спецификаторов свойств не равно количеству значений свойств ( p ≠ k как поток 2 на рис. 3а), n = k , p > 1 как поток 3 и p = k , n > 1 как поток 5. Рис. 1. Берем условную ветвь n ≤ k in Supplementary Fig. 1 as an example, for each alloy named entity, N i , the distance between each property value entity K i and N i рассчитывается по уравнению. (1) найти ближайший объект стоимости недвижимости K m к текущему N i .
3а) и (ii) количество спецификаторов свойств не равно количеству значений свойств ( p ≠ k как поток 2 на рис. 3а), n = k , p > 1 как поток 3 и p = k , n > 1 как поток 5. Рис. 1. Берем условную ветвь n ≤ k in Supplementary Fig. 1 as an example, for each alloy named entity, N i , the distance between each property value entity K i and N i рассчитывается по уравнению. (1) найти ближайший объект стоимости недвижимости K m к текущему N i .
$${{{\mathrm{Distance}}}}\left( {x_1,x_2} \right) = \left| {{{{\mathrm{pi}}}}\left( {x_1} \right) — {{{\mathrm{pi}}}}\left( {x_2} \right)} \right|$$
(1)
, где x 1 и x 2 — две сущности, а pi ( x ) — целевой индекс позиции сущности 9003. 9 x 9003.9 K m рассматривается как якорь для поиска ближайшего объекта недвижимости P m среди всех объектов недвижимости. Следовательно, набор троек < N i , P m , K m > успешно извлекается и добавляется в набор отношений. Схематическая диаграмма алгоритма согласования кратчайшего расстояния показана на рис. 3б; фразы в синем, зеленом и желтом прямоугольниках распознаются как именованный объект сплава, объект спецификатора свойства и значение свойства, соответственно, во время предыдущего процесса NER.
9 x 9003.9 K m рассматривается как якорь для поиска ближайшего объекта недвижимости P m среди всех объектов недвижимости. Следовательно, набор троек < N i , P m , K m > успешно извлекается и добавляется в набор отношений. Схематическая диаграмма алгоритма согласования кратчайшего расстояния показана на рис. 3б; фразы в синем, зеленом и желтом прямоугольниках распознаются как именованный объект сплава, объект спецификатора свойства и значение свойства, соответственно, во время предыдущего процесса NER.
Для ситуации, когда n = k и когда в предложении есть только один объект свойства ( p = 1 как поток 4), алгоритм последовательного сопоставления выполняется для сопоставления именованного объекта сплава и значения свойства для указанного свойства по порядку; то же самое верно для p = k , n = 1. На дополнительном рисунке 2 показан псевдокод алгоритма последовательного сопоставления, а его схематическая диаграмма показана на рисунке 3c.
На дополнительном рисунке 2 показан псевдокод алгоритма последовательного сопоставления, а его схематическая диаграмма показана на рисунке 3c.
Если связь между именованным объектом сплава, спецификатором свойства и значением свойства в предложении правильно зафиксирована, извлеченный четверичный кортеж <статья DOI, именованный объект сплава, спецификатор свойства, значение свойства> считается положительной выборкой. Приведенный выше алгоритм извлечения отношений был применен к 458 целевым предложениям, классифицированным из примерно 14 000 статей, и 680 9Всего 0029 γ ′ экземпляров температуры сольвуса были извлечены автоматически. После ручной проверки случайно выбранных 329 предложений точность, полнота и оценка F1 алгоритма извлечения отношений для температуры сольвуса γ ′ составили 75,86%, 83,22% и 79,37% соответственно.
Мы также использовали исходный алгоритм «Снежный ком» 31 и модифицированный алгоритм «Снежный ком» 22 с начальными значениями 50 и 100 для извлечения отношений свойство-кортеж (см. Алгоритм Снежного кома в разделе «Методы»). Наш метод показал более высокий отзыв и балл F1, чем алгоритм «Снежный ком», как показано в таблице 3. Припоминание «Снежного кома» было хуже, чем у нашего метода, потому что начальных кортежей, используемых для начала обучения, было слишком мало, поэтому каждый кластер предложений формы содержали меньше обучающих кортежей. Это сделало процесс кластеризации предложений в «Snowball» неэффективным, поскольку он не мог охватить все формы предложений, и можно было извлечь только несколько отношений кортежа с очень низким отзывом. Таким образом, наш алгоритм на основе расстояния, не требующий помеченных выборок для обработки извлечения множественных отношений, работал лучше в условиях такого небольшого корпуса.
Алгоритм Снежного кома в разделе «Методы»). Наш метод показал более высокий отзыв и балл F1, чем алгоритм «Снежный ком», как показано в таблице 3. Припоминание «Снежного кома» было хуже, чем у нашего метода, потому что начальных кортежей, используемых для начала обучения, было слишком мало, поэтому каждый кластер предложений формы содержали меньше обучающих кортежей. Это сделало процесс кластеризации предложений в «Snowball» неэффективным, поскольку он не мог охватить все формы предложений, и можно было извлечь только несколько отношений кортежа с очень низким отзывом. Таким образом, наш алгоритм на основе расстояния, не требующий помеченных выборок для обработки извлечения множественных отношений, работал лучше в условиях такого небольшого корпуса.
Полноразмерная таблица
Извлечение отношений между таблицами
Таблицы являются привлекательными объектами для извлечения информации из-за их высокой плотности данных и полуструктурированного характера.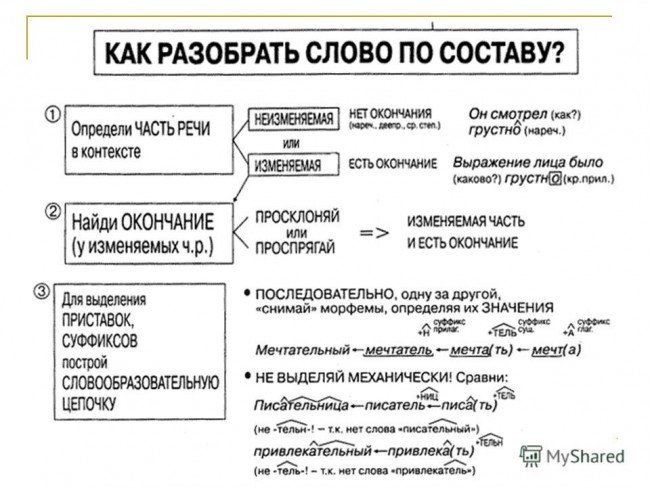 По сравнению с полностью неструктурированным естественным языком таблицы в формате XML и HTML более интерпретируемы. Синтаксический анализ таблицы преобразует полную информацию о таблице, включая заголовок и тело таблицы, в структурный формат списка ячеек вложенной таблицы, а затем классифицирует, какая таблица содержит информацию о химическом составе и целевом свойстве, которую необходимо извлечь. После парсинга таблиц было получено 5327 таблиц составов и 114 таблиц с температурой сольвуса. Извлечение отношения таблицы дает конкретные отношения кортежа для содержимого и свойства конкретного элемента. Возьмем, к примеру, извлечение состава. Во время извлечения отношения таблицы направление таблицы («по строке» или «по столбцу») сначала определяется путем оценки положения строки или столбца химических элементов в теле таблицы. Затем проверяется заголовок таблицы, чтобы увидеть, существует ли объект с именем сплава. На рис. 4 изображена схематическая диаграмма в соответствии с описанным выше сценарием.
По сравнению с полностью неструктурированным естественным языком таблицы в формате XML и HTML более интерпретируемы. Синтаксический анализ таблицы преобразует полную информацию о таблице, включая заголовок и тело таблицы, в структурный формат списка ячеек вложенной таблицы, а затем классифицирует, какая таблица содержит информацию о химическом составе и целевом свойстве, которую необходимо извлечь. После парсинга таблиц было получено 5327 таблиц составов и 114 таблиц с температурой сольвуса. Извлечение отношения таблицы дает конкретные отношения кортежа для содержимого и свойства конкретного элемента. Возьмем, к примеру, извлечение состава. Во время извлечения отношения таблицы направление таблицы («по строке» или «по столбцу») сначала определяется путем оценки положения строки или столбца химических элементов в теле таблицы. Затем проверяется заголовок таблицы, чтобы увидеть, существует ли объект с именем сплава. На рис. 4 изображена схематическая диаграмма в соответствии с описанным выше сценарием.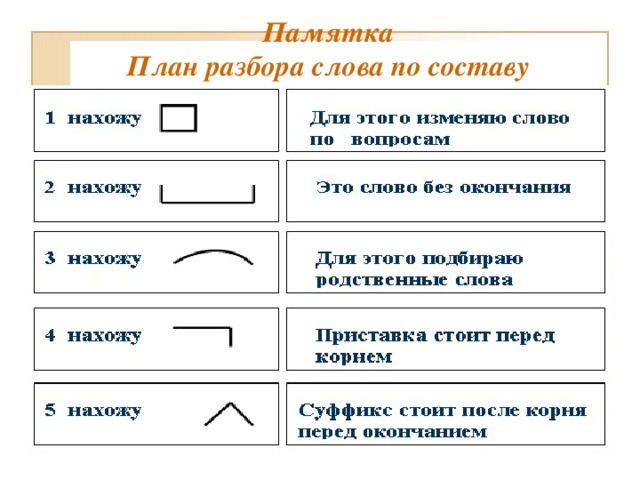 Возьмем случай «по строке» в качестве примера, если распознанных именованных объектов сплава более одного или ни один из них не указан в заголовке таблицы, именованные объекты и элементы сплава адресуются по индексу строки и столбца каждой ячейки таблицы из Alloy_named_entity body и element_heading последовательности соответственно. Если в заголовке таблицы имеется только один именованный объект сплава, элементы адресуются по индексу столбца каждой ячейки таблицы из последовательности element_heading . Извлечение табличных отношений, наконец, выводит составные кортежи. Псевдокод алгоритма извлечения табличных отношений можно найти на дополнительном рис. 3. Процесс извлечения свойств из таблицы такой же, как и композиция, за исключением того, что объекты из NER из заголовков таблицы изменены.
Возьмем случай «по строке» в качестве примера, если распознанных именованных объектов сплава более одного или ни один из них не указан в заголовке таблицы, именованные объекты и элементы сплава адресуются по индексу строки и столбца каждой ячейки таблицы из Alloy_named_entity body и element_heading последовательности соответственно. Если в заголовке таблицы имеется только один именованный объект сплава, элементы адресуются по индексу столбца каждой ячейки таблицы из последовательности element_heading . Извлечение табличных отношений, наконец, выводит составные кортежи. Псевдокод алгоритма извлечения табличных отношений можно найти на дополнительном рис. 3. Процесс извлечения свойств из таблицы такой же, как и композиция, за исключением того, что объекты из NER из заголовков таблицы изменены.
Направление таблицы («по строке» или «по столбцу») сначала определяется путем оценки положения строки или столбца целевой информации в теле таблицы, например, химических элементов. Объекты с именами сплавов в зеленых ячейках и элементы в оранжевых ячейках объединяются индексом строки и столбца каждой ячейки таблицы из соответствующих последовательностей соответственно и, наконец, записываются в четверичный кортеж <статья DOI, объект с именем сплава, спецификатор свойства (элемент), значение свойства (содержание)>.
Объекты с именами сплавов в зеленых ячейках и элементы в оранжевых ячейках объединяются индексом строки и столбца каждой ячейки таблицы из соответствующих последовательностей соответственно и, наконец, записываются в четверичный кортеж <статья DOI, объект с именем сплава, спецификатор свойства (элемент), значение свойства (содержание)>.
Полноразмерное изображение
Если отношение между именованным объектом сплава, спецификатором свойства (элементом) и значением свойства (содержимым) в ячейках таблицы зафиксировано правильно, извлеченный четверичный кортеж <статья DOI, именованный объект сплава, спецификатор свойства (элемент ), свойство value(content)> считается положительным образцом. Приведенный выше алгоритм извлечения отношения был применен к 5441 таблице химического состава (5327 таблиц) и свойству γ ′ температура сольвуса (114 таблиц) из ~14 000 статей после разбора таблицы, всего 12703 экземпляров отношения композиция-кортеж и 579Экземпляры связи свойство-кортеж из таблиц извлекались автоматически. После ручной проверки 45 статей методом случайной повторной выборки точность, полнота и показатель F1 составили 90,89%, 100% и 95,23% соответственно.
После ручной проверки 45 статей методом случайной повторной выборки точность, полнота и показатель F1 составили 90,89%, 100% и 95,23% соответственно.
Разрешение на взаимозависимость данных
Во многих случаях конструкционных материалов из сплавов выделение свойств суперсплавов, отличающихся от конкретных химических составов, недопустимо. Следовательно, разрешение взаимозависимостей направлено на устранение связи с фрагментами данных о химическом составе и свойствах для конкретного материала. После извлечения связи между текстом и таблицей кортежи химического состава  Стратегия «разделяй и властвуй» применяется нашим алгоритмом во время связывания фрагментов данных о составе и свойствах, как показано на рис. 5. Детали алгоритма показаны на дополнительном рис. 4. Для Tuple composition and Tuple property from text and table relation extraction, all the tuples are divided into three sets ( DOIs intersection , DOIs composition – DOI пересечение , и DOI свойство – DOI пересечение 9013DOI) Для кортежей в наборе DOI состав – DOI пересечение , информация о соответствующем свойстве не найдена. Для кортежей в наборе DOI свойство − DOI пересечение информация о химическом составе не извлекается. Для кортежей в DOI пересечение информация о химическом составе и свойствах извлекается из одной статьи одновременно.
Стратегия «разделяй и властвуй» применяется нашим алгоритмом во время связывания фрагментов данных о составе и свойствах, как показано на рис. 5. Детали алгоритма показаны на дополнительном рис. 4. Для Tuple composition and Tuple property from text and table relation extraction, all the tuples are divided into three sets ( DOIs intersection , DOIs composition – DOI пересечение , и DOI свойство – DOI пересечение 9013DOI) Для кортежей в наборе DOI состав – DOI пересечение , информация о соответствующем свойстве не найдена. Для кортежей в наборе DOI свойство − DOI пересечение информация о химическом составе не извлекается. Для кортежей в DOI пересечение информация о химическом составе и свойствах извлекается из одной статьи одновременно. Эти кортежи под одной и той же статьей DOI будут по-прежнему разделены на три набора в зависимости от того, имеют ли они один и тот же именованный объект сплава. Наконец, кортежи в наборе ALLOY_NAMED_ENTITY пересечение объединены в полную запись как с химической композицией, так и с свойством для одного сплава по имени каждой статьи DOI, в то время как в ALLOY_NAMED_ENTITY COMPOSION 8.MADETION или Alloy_named_entity Свойство – Alloy_named_entity пересечение может получить информацию о химическом составе или свойствах только для одного именованного объекта сплава. Всего за γ ′ температура сольвуса, мы получили 743 полных записи из 12703 экземпляров химического состава и 1259 экземпляров свойств из ~14000 статей.
Эти кортежи под одной и той же статьей DOI будут по-прежнему разделены на три набора в зависимости от того, имеют ли они один и тот же именованный объект сплава. Наконец, кортежи в наборе ALLOY_NAMED_ENTITY пересечение объединены в полную запись как с химической композицией, так и с свойством для одного сплава по имени каждой статьи DOI, в то время как в ALLOY_NAMED_ENTITY COMPOSION 8.MADETION или Alloy_named_entity Свойство – Alloy_named_entity пересечение может получить информацию о химическом составе или свойствах только для одного именованного объекта сплава. Всего за γ ′ температура сольвуса, мы получили 743 полных записи из 12703 экземпляров химического состава и 1259 экземпляров свойств из ~14000 статей.
Чтобы объединить фрагменты химического состава и свойств, экземпляры одного и того же именованного объекта сплава с одним и тем же артикулом DOI объединяются в полную запись в 6-кортеже: <статья DOI, сплав именованный объект, элемент, содержание, свойство_спецификатор , значение_свойства>.
Увеличенное изображение
Стоит отметить, что при объединении на основе одного и того же сплава именуемой сущности, местоимения (например, этот сплав) и аббревиатуры (например, Cr-5) как сплава именуемой сущности в свойство результата извлечения вызывает затруднения в подборе химического состава. Это связано с тем, что именованный объект сплава обычно появляется в форме полного названия в результате экстракции таблицы химического состава. Поэтому мы искали полное наименование, соответствующее аббревиатуре в предыдущем контексте по шаблону «полное наименование (аббревиатура)». Среди 1259 полных записей с химическим составом бетона 743.экземпляры свойства, и разница в основном связана с местоимениями, выступающими в качестве сплава именованных сущностей в результате извлечения свойства. Некоторые химические составы выражены в тексте, а не в таблице, поэтому их нельзя извлечь.
Обсуждение
Представленные выше методология и конвейер демонстрируют возможность точного извлечения химического состава и свойств, таких как температура сольвуса γ ′, из научной литературы по суперсплавам даже для корпуса ограниченного размера.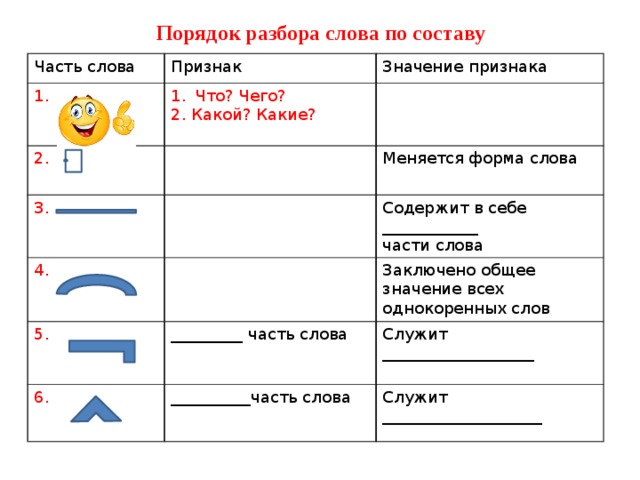 Кроме того, мы применили наш автоматизированный конвейер интеллектуального анализа текста к другим физическим свойствам суперсплавов, включая плотность, температуры солидуса и ликвидуса, регенерировав словарь синонимов спецификатора свойств на основе предварительно обученной модели встраивания слов и скорректировав правила записи для стоимость и единица. Итого получаем 5136 экземпляров свойств из γ ′ температуры сольвуса (1259), плотности (2296), температуры солидуса (793), температуры ликвидуса (788) и 12703 химических составов из 14425 изделий из жаропрочных сплавов. Оценки точности, полноты и F1 приведены в дополнительной таблице 1. Средняя точность, полнота и оценка F1 для температуры сольвуса γ ′, плотности, температуры солидуса и ликвидуса составляют 83,67%, 93,08% и 88,13%. соответственно. Среди них 2531 экземпляр успешно соответствовал своему химическому составу, а точность, полнота и оценка F1 были проверены на 30 случайно выбранных предметах для химического состава и каждого свойства.
Кроме того, мы применили наш автоматизированный конвейер интеллектуального анализа текста к другим физическим свойствам суперсплавов, включая плотность, температуры солидуса и ликвидуса, регенерировав словарь синонимов спецификатора свойств на основе предварительно обученной модели встраивания слов и скорректировав правила записи для стоимость и единица. Итого получаем 5136 экземпляров свойств из γ ′ температуры сольвуса (1259), плотности (2296), температуры солидуса (793), температуры ликвидуса (788) и 12703 химических составов из 14425 изделий из жаропрочных сплавов. Оценки точности, полноты и F1 приведены в дополнительной таблице 1. Средняя точность, полнота и оценка F1 для температуры сольвуса γ ′, плотности, температуры солидуса и ликвидуса составляют 83,67%, 93,08% и 88,13%. соответственно. Среди них 2531 экземпляр успешно соответствовал своему химическому составу, а точность, полнота и оценка F1 были проверены на 30 случайно выбранных предметах для химического состава и каждого свойства. Мы получили аналогичную производительность, применив конвейер для извлечения информации о твердости для сплавов с высокой энтропией (https://github.com/MGEdata/Superalloydigger_HEas_use_case).
Мы получили аналогичную производительность, применив конвейер для извлечения информации о твердости для сплавов с высокой энтропией (https://github.com/MGEdata/Superalloydigger_HEas_use_case).
Для относительно небольшого корпуса, такого как суперсплавы, мы представили основанный на правилах метод NER и эффективный основанный на расстоянии эвристический алгоритм извлечения множественных отношений для конвейера, чтобы преодолеть недостаток ограниченных меток обучающего корпуса. Мы получили оценку F1 92,07% для названного сплава и среднюю оценку F1 77,92% для извлечения отношений для температуры сольвуса γ ′, плотности, температуры солидуса и ликвидуса. Наш конвейер не требует никакого размеченного корпуса для достижения высокой точности и отзыва, избегая проблемы переобучения контролируемого и полууправляемого обучения с низким отзывом, вызванным недостаточным размеченным корпусом. Кроме того, наш общий инструмент обработки таблиц с алгоритмом разбора таблиц и извлечения отношений показал хорошие результаты с оценкой F1 9. 5,23%. Поэтому ожидается, что представленная здесь методология будет хорошо работать для предметно-ориентированного извлечения информации даже для небольшого корпуса, поскольку отсутствие адекватных размеченных данных часто создает проблемы при использовании контролируемых или полуконтролируемых методов обучения.
5,23%. Поэтому ожидается, что представленная здесь методология будет хорошо работать для предметно-ориентированного извлечения информации даже для небольшого корпуса, поскольку отсутствие адекватных размеченных данных часто создает проблемы при использовании контролируемых или полуконтролируемых методов обучения.
С точки зрения разработки суперсплавов на рис. 6а показаны температурные тренды сольвуса γ ′ суперсплавов на основе кобальта и никеля, сгруппированные по годам. Сообщается, что самая высокая температура сольвуса γ ′ суперсплава на основе никеля составляет 1308 ° C в 2012 году Pang 9.0005 38 , в то время как для суперсплава на основе кобальта температура составляет 1269 ° C в 2017 году по Lass EA 39 , на которую ссылался Ли в 2019 году 40 . Диаграмма Эшби, показывающая суперсплавы в зависимости от температуры и плотности сольвуса γ ′, представлена на рис. 6b. Суперсплавы в синих кружках с высоким содержанием Ni и Ta имеют более высокую температуру сольвуса γ ′, чем другие жаропрочные сплавы, тогда как жаропрочные сплавы в оранжевых и розовых кружках без содержания Ni демонстрируют относительно низкую γ ′ температуры сольвуса.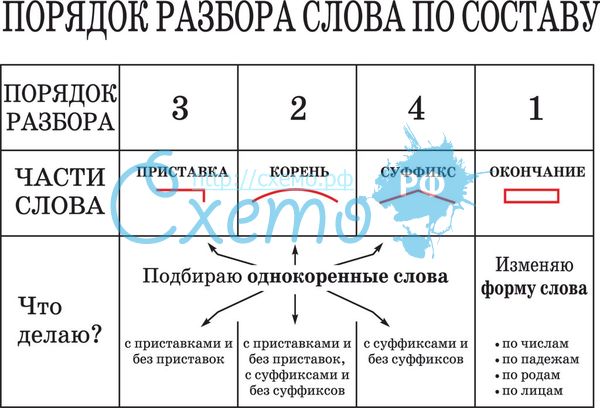 Это согласуется с заявленным поведением 41,42 . На рис. 6в показано, что добавка W в тройной тройной суперсплав Co-9Al-xW способствует повышению температуры сольвуса γ ′. Это связано с тем, что W имеет тенденцию накапливаться в фазе γ ‘ и занимать B-позиции упорядоченной фазы A 3 B. Кроме того, по планкам погрешностей мы видим изменение измеренных значений температуры сольвуса γ ′ для одного и того же суперсплава в разных изделиях. Так, для Co-9Al-10W наблюдается распределение значений от 980 до 1060 °С по трем статьям. На рис. 6d для суперсплава на основе Co-Ni-Al-Mo температура и плотность сольвуса γ ‘ значительно увеличиваются при добавлении Ta по сравнению с Nb, что согласуется с результатами, представленными Lass EA . 42 . После добавления Ti значение температуры сольвуса γ ′ дополнительно увеличивается, поскольку Ti является формирующим элементом фазы γ ′, и его промотирующее действие на 9Температура сольвуса 0029 γ ′ выше, чем у Co.
Это согласуется с заявленным поведением 41,42 . На рис. 6в показано, что добавка W в тройной тройной суперсплав Co-9Al-xW способствует повышению температуры сольвуса γ ′. Это связано с тем, что W имеет тенденцию накапливаться в фазе γ ‘ и занимать B-позиции упорядоченной фазы A 3 B. Кроме того, по планкам погрешностей мы видим изменение измеренных значений температуры сольвуса γ ′ для одного и того же суперсплава в разных изделиях. Так, для Co-9Al-10W наблюдается распределение значений от 980 до 1060 °С по трем статьям. На рис. 6d для суперсплава на основе Co-Ni-Al-Mo температура и плотность сольвуса γ ‘ значительно увеличиваются при добавлении Ta по сравнению с Nb, что согласуется с результатами, представленными Lass EA . 42 . После добавления Ti значение температуры сольвуса γ ′ дополнительно увеличивается, поскольку Ti является формирующим элементом фазы γ ′, и его промотирующее действие на 9Температура сольвуса 0029 γ ′ выше, чем у Co. Таким образом, полученные нами данные подтверждают известное поведение жаропрочных сплавов.
Таким образом, полученные нами данные подтверждают известное поведение жаропрочных сплавов.
a Извлеченный набор данных о температуре сольвуса γ ′, опубликованный за 2004–2020 годы. b Диаграмма Эшби для γ ′ данных температуры и плотности сольвуса. c Влияние элемента W на температуру сольвуса γ ′ сплава Co-9Al-xW. d Влияние различных элементов (Nb, Ta и Ti) на температуру сольвуса γ ′ и плотность сплава Co-30Ni-10Al-5Mo-x.
Полноразмерное изображение
Поскольку скрытая информация о будущих открытиях может заключаться в прошлых публикациях, мы затем изучили ценность извлеченных данных, чтобы получить полезную информацию для обнаружения материалов. Поэтому мы построили управляемую данными модель из извлеченных 743 записей с химическим составом и температурой сольвуса γ ′. Из 743 записей мы сосредоточились на 259. на основе кобальта и 73 соединения на основе никеля после проверки и очистки данных путем удаления дубликатов и ошибок (см. Предварительная обработка данных для машинного обучения в разделе «Методы»). На рис. 7а представлено распределение температуры сольвуса γ ′ для суперсплавов Co-9Al-9W, Mar-M247, U720Li, IN738LC, CMSX-4 и CMSX-10 с температурой сольвуса γ ′ 993 ± 9 °C, 1206 ± 28 °C, 1160 ± 20 °C, 1168 ± 31 °C, 1286 ± 30 °C, 1343 ± 9 °C соответственно, со средним и стандартным отклонением. Все композиционное пространство состоит из Co, Al, W, Ni, Ti, Cr, Ta, B, Mo, Re, Nb, Si, V, Fe, Hf, Ru, Ir, Cu, Pt и C, и мы построили модель прогнозирования с помощью регрессии опорных векторов с ядром радиальной базисной функции для γ ′ температура сольвуса жаропрочных сплавов (см. Модель прогноза температуры сольвуса γ ′ в методах). Процесс выбора и оценки модели показан на рис. 7b и рис. 7c. Модель использовалась для прогнозирования температуры сольвуса γ ′ последних 15 суперсплавов из 12 различных опубликованных статей в 2020 и 2021 годах, которых нет в наборе данных, извлеченном нашим пайплайном (дополнительная таблица 2).
на основе кобальта и 73 соединения на основе никеля после проверки и очистки данных путем удаления дубликатов и ошибок (см. Предварительная обработка данных для машинного обучения в разделе «Методы»). На рис. 7а представлено распределение температуры сольвуса γ ′ для суперсплавов Co-9Al-9W, Mar-M247, U720Li, IN738LC, CMSX-4 и CMSX-10 с температурой сольвуса γ ′ 993 ± 9 °C, 1206 ± 28 °C, 1160 ± 20 °C, 1168 ± 31 °C, 1286 ± 30 °C, 1343 ± 9 °C соответственно, со средним и стандартным отклонением. Все композиционное пространство состоит из Co, Al, W, Ni, Ti, Cr, Ta, B, Mo, Re, Nb, Si, V, Fe, Hf, Ru, Ir, Cu, Pt и C, и мы построили модель прогнозирования с помощью регрессии опорных векторов с ядром радиальной базисной функции для γ ′ температура сольвуса жаропрочных сплавов (см. Модель прогноза температуры сольвуса γ ′ в методах). Процесс выбора и оценки модели показан на рис. 7b и рис. 7c. Модель использовалась для прогнозирования температуры сольвуса γ ′ последних 15 суперсплавов из 12 различных опубликованных статей в 2020 и 2021 годах, которых нет в наборе данных, извлеченном нашим пайплайном (дополнительная таблица 2). Средняя относительная ошибка между зарегистрированным и предсказанным γ ′ температура сольвуса по модели SVR.rbf составляет 2,27%. На рисунке 7d показаны заявленные и предсказанные температуры сольвуса γ ‘ для 15 заявленных жаропрочных сплавов, а относительная погрешность температур в оранжевой рамке составляет <1%. Кроме того, обученная модель SVR.rbf использовалась для проектирования жаропрочных сплавов на основе кобальта, предназначенных для высоких температур сольвуса γ' (> 1250 °C). Рассматривали Co 1-a-b-c-d-e-f Al a W b Ni c Ti d Ta e Cr f сплавы составов a, b, c, d, e и f, где каждый элемент изменяется с шагом 0,5% с ограничениями 11%≤a ≤ 12%, 0%≤b ≤ 1%, 35 %≤c ≤ 37%, 1%≤d ≤ 2%, 4%≤e ≤ 5% и 0%≤f ≤ 6%. Три сплава Co-36Ni-12Al-2Ti-1W-4Ta-4Cr, Co-36Ni-12Al-2Ti-1W-4Ta-6Cr и Co-12Al-4,5Ta-35Ni-2Ti с прогнозируемой температурой сольвуса γ’ >1250 °C , о которых ранее не сообщалось, были выбраны из 15 795 возможностей для экспериментального синтеза.
Средняя относительная ошибка между зарегистрированным и предсказанным γ ′ температура сольвуса по модели SVR.rbf составляет 2,27%. На рисунке 7d показаны заявленные и предсказанные температуры сольвуса γ ‘ для 15 заявленных жаропрочных сплавов, а относительная погрешность температур в оранжевой рамке составляет <1%. Кроме того, обученная модель SVR.rbf использовалась для проектирования жаропрочных сплавов на основе кобальта, предназначенных для высоких температур сольвуса γ' (> 1250 °C). Рассматривали Co 1-a-b-c-d-e-f Al a W b Ni c Ti d Ta e Cr f сплавы составов a, b, c, d, e и f, где каждый элемент изменяется с шагом 0,5% с ограничениями 11%≤a ≤ 12%, 0%≤b ≤ 1%, 35 %≤c ≤ 37%, 1%≤d ≤ 2%, 4%≤e ≤ 5% и 0%≤f ≤ 6%. Три сплава Co-36Ni-12Al-2Ti-1W-4Ta-4Cr, Co-36Ni-12Al-2Ti-1W-4Ta-6Cr и Co-12Al-4,5Ta-35Ni-2Ti с прогнозируемой температурой сольвуса γ’ >1250 °C , о которых ранее не сообщалось, были выбраны из 15 795 возможностей для экспериментального синтеза. Согласно экспертным знаниям, они, как считалось, осаждали γ’-фазу. Измеренные температуры сольвуса γ′ составляют 1251 °C, 12390,3 °C и 1263 °C соответственно, определенные с помощью дифференциальной сканирующей калориметрии (ДСК) (см. Синтез и характеристика в разделе «Методы»). На рис. 7e–g соответственно. Относительные ошибки между экспериментальными значениями и прогнозируемыми значениями составляют 0,56%, 1,41% и 0,48% соответственно, а подробности приведены в дополнительной таблице 3.
Согласно экспертным знаниям, они, как считалось, осаждали γ’-фазу. Измеренные температуры сольвуса γ′ составляют 1251 °C, 12390,3 °C и 1263 °C соответственно, определенные с помощью дифференциальной сканирующей калориметрии (ДСК) (см. Синтез и характеристика в разделе «Методы»). На рис. 7e–g соответственно. Относительные ошибки между экспериментальными значениями и прогнозируемыми значениями составляют 0,56%, 1,41% и 0,48% соответственно, а подробности приведены в дополнительной таблице 3.
a γ ′ распределение температуры сольвуса для некоторых суперсплавов. b Среднеквадратическая ошибка для выбора модели с помощью 5-кратной перекрестной проверки. c Прогнозируемые значения по сравнению со значениями, извлеченными из нашего конвейера для модели SVR. rbf, демонстрирующие поведение наборов обучающих и тестовых данных. д Измеренные и предсказанные температуры сольвуса γ ′ 15 суперсплавов, о которых недавно сообщалось в 2020 и 2021 годах, не были частью нашей базы данных. e Микроструктура и кривая ДСК нагрева сплава Co-36Ni-12Al-2Ti-1W-4Ta-4Cr. f Микроструктура и кривая ДСК нагрева сплава Co-36Ni-12Al-2Ti-1W-4Ta-6Cr. г Микроструктура и кривая ДСК нагрева сплава Co-12Al-4,5Ta-35Ni-2Ti.
rbf, демонстрирующие поведение наборов обучающих и тестовых данных. д Измеренные и предсказанные температуры сольвуса γ ′ 15 суперсплавов, о которых недавно сообщалось в 2020 и 2021 годах, не были частью нашей базы данных. e Микроструктура и кривая ДСК нагрева сплава Co-36Ni-12Al-2Ti-1W-4Ta-4Cr. f Микроструктура и кривая ДСК нагрева сплава Co-36Ni-12Al-2Ti-1W-4Ta-6Cr. г Микроструктура и кривая ДСК нагрева сплава Co-12Al-4,5Ta-35Ni-2Ti.
Изображение в натуральную величину
Наконец, мы обсудим аспекты, которые мы не включили и в которых необходим дальнейший прогресс. Среди 2531 записей, автоматически извлекаемых конвейером, ошибки и дубликаты неизбежны, и их нелегко автоматически устранить. Использование записей по-прежнему требует ручного вмешательства для очистки. Кроме того, предлагаемый конвейер не точно фиксирует значения свойств, описанные как диапазон, например «между… и…». Кроме того, необходимо разрешить сценарий, в котором полная информация о кортеже свойств распределяется по двум или более отдельным предложениям. Мы не включили условия синтеза или обработки или другие экспериментальные параметры, а также погрешности измерения. Эти аспекты важны для разработки сплавов и нуждаются в дополнении для обогащения существующей базы данных. По мере того, как база данных продолжает пополняться новыми свойствами, экспериментальными параметрами и составами, модели будут становиться более предсказуемыми. По мере роста количества научной литературы НЛП предоставляет средства, позволяющие сделать обширную научную информацию доступной для реализации новой парадигмы открытий с помощью машин.
Мы не включили условия синтеза или обработки или другие экспериментальные параметры, а также погрешности измерения. Эти аспекты важны для разработки сплавов и нуждаются в дополнении для обогащения существующей базы данных. По мере того, как база данных продолжает пополняться новыми свойствами, экспериментальными параметрами и составами, модели будут становиться более предсказуемыми. По мере роста количества научной литературы НЛП предоставляет средства, позволяющие сделать обширную научную информацию доступной для реализации новой парадигмы открытий с помощью машин.
Таким образом, мы предложили автоматизированный конвейер извлечения данных для суперсплавов для создания структурной базы данных с помощью NLP, включая загрузку научных документов, предварительную обработку, анализ таблиц и классификацию текста, NER, извлечение отношений текста и таблицы соответственно и автоматическое разрешение взаимозависимостей. . Извлеченные объекты с общим количеством экземпляров 2531, охватывающих физические свойства температуры сольвуса γ ′, плотности, температуры солидуса и температуры ликвидуса, были скомпилированы в хорошо структурированную базу данных материалов, содержащую DOI статьи, названный объект сплава, химический элемент, содержание , спецификатор свойства и значение свойства. Для предметно-ориентированной задачи анализа текста небольшого корпуса, такого как суперсплавы, для конвейера были предложены практический метод NER на основе правил и эффективный эвристический алгоритм извлечения множественных отношений, чтобы преодолеть препятствие ограниченных меток обучающего корпуса, и мы достигли F1 оценка 92,07% для названного сплава и средний балл F1, равный 77,92%, для отношения извлечения γ ‘ температуры сольвуса, плотности, температуры солидуса и температуры ликвидуса. Мы также разработали общий инструмент обработки таблиц с алгоритмом анализа таблиц и извлечения отношений, который хорошо работает с оценкой F1 95,23%. Наконец, мы использовали базу данных для построения управляемой данными модели температуры сольвуса γ ′ для прогнозирования температуры сольвуса 15 новых суперсплавов, о которых сообщалось в 2020 и 2021 годах, которые не были частью нашего корпуса. Мы получили хорошее согласие с относительной ошибкой 2,27 %. В дальнейшем модель использовалась для разработки неисследованных жаропрочных сплавов на основе кобальта с высокой твердостью 9.
Для предметно-ориентированной задачи анализа текста небольшого корпуса, такого как суперсплавы, для конвейера были предложены практический метод NER на основе правил и эффективный эвристический алгоритм извлечения множественных отношений, чтобы преодолеть препятствие ограниченных меток обучающего корпуса, и мы достигли F1 оценка 92,07% для названного сплава и средний балл F1, равный 77,92%, для отношения извлечения γ ‘ температуры сольвуса, плотности, температуры солидуса и температуры ликвидуса. Мы также разработали общий инструмент обработки таблиц с алгоритмом анализа таблиц и извлечения отношений, который хорошо работает с оценкой F1 95,23%. Наконец, мы использовали базу данных для построения управляемой данными модели температуры сольвуса γ ′ для прогнозирования температуры сольвуса 15 новых суперсплавов, о которых сообщалось в 2020 и 2021 годах, которые не были частью нашего корпуса. Мы получили хорошее согласие с относительной ошибкой 2,27 %. В дальнейшем модель использовалась для разработки неисследованных жаропрочных сплавов на основе кобальта с высокой твердостью 9. 0029 γ ′ температура сольвуса (>1250 °C). Таким образом, наша работа подчеркивает, как знания, представленные в прошлых публикациях, могут дать полезную информацию для обнаружения материалов с помощью анализа текста. Код конвейера доступен по адресу https://github.com/MGEdata/SuperalloyDigger. Веб-инструментарий также доступен по адресу http://SuperalloyDigger.mgedata.cn для онлайн-использования. Ранее не сообщалось об автоматизированных методах анализа текста и инструментах для извлечения литературных данных по суперсплавам (и другим сплавам). Наша стратегия извлечения и исходный код предназначены не только для суперсплавов; они представляют собой общий метод извлечения текста для сплавов.
0029 γ ′ температура сольвуса (>1250 °C). Таким образом, наша работа подчеркивает, как знания, представленные в прошлых публикациях, могут дать полезную информацию для обнаружения материалов с помощью анализа текста. Код конвейера доступен по адресу https://github.com/MGEdata/SuperalloyDigger. Веб-инструментарий также доступен по адресу http://SuperalloyDigger.mgedata.cn для онлайн-использования. Ранее не сообщалось об автоматизированных методах анализа текста и инструментах для извлечения литературных данных по суперсплавам (и другим сплавам). Наша стратегия извлечения и исходный код предназначены не только для суперсплавов; они представляют собой общий метод извлечения текста для сплавов.
Методы
Метрики для задач классификации
Точность, полнота и оценка F1 на основе матрицы путаницы использовались в качестве метрик для задач классификации, включая классификацию текста, анализ таблиц, распознавание именованных сущностей, извлечение текста и связей между таблицами.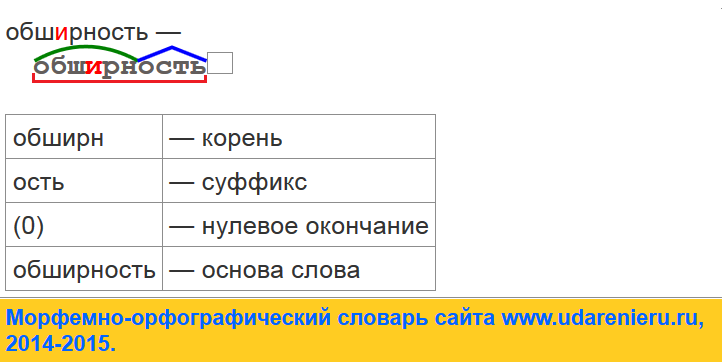 Точность оценивает долю правильно классифицированных экземпляров среди тех, которые классифицированы как положительные 43 . Отзыв определяет количество правильных положительных прогнозов, сделанных из всех реальных положительных случаев 44 . Оценка F1, которая одинаково взвешивает точность и полноту, рассчитывается по уравнению. (2) чаще всего используется при обучении на несбалансированных данных 45 .
Точность оценивает долю правильно классифицированных экземпляров среди тех, которые классифицированы как положительные 43 . Отзыв определяет количество правильных положительных прогнозов, сделанных из всех реальных положительных случаев 44 . Оценка F1, которая одинаково взвешивает точность и полноту, рассчитывается по уравнению. (2) чаще всего используется при обучении на несбалансированных данных 45 .
$${{{\mathrm{F1}}}}\;{{{\mathrm{score}}}} = \frac{{{{{\mathrm{2}}}} \ast {{{\ mathrm{Precision}}}} \ast {{{\mathrm{Recall}}}}}}{{{{{\mathrm{Precision}}}} + {{{\mathrm{Recall}}}}}}$ $
(2)
Поиск статей и предварительная обработка
Научные статьи, использованные в этой работе, в основном взяты из издательства Elsevier. В сочетании с интерфейсом прикладного программирования (API) поиска CrossRef 46 и поисковой системы Web of Science был составлен список DOI для статей из суперсплавов. Затем в общей сложности 14425 журнальных статей в формате простого текста, XML и HTML, соответствующих этим DOI, были программно заархивированы с использованием API-интерфейсов Elsevier Scopus и Science Direct (https://dev. elsevier.com/) и расширенного пакета очистки « ChemDataExtractor».
elsevier.com/) и расширенного пакета очистки « ChemDataExtractor».
Первым этапом предварительной обработки файлов HTML и XML было выделение соответствующих доменов документа, извлечение необработанного текста и объединение потенциально фрагментированных данных для создания полной записи документа. Для текста из источников HTML и XML семантическая разметка абзацев анализировалась и объединялась в простой текстовый документ в виде списка абзацев. Для таблиц отдельные ячейки обрабатываются как отдельные текстовые домены и сохраняются во вложенных списках, которые представляют исходную структуру таблицы в следующем процессе синтаксического анализа таблицы. В частности, для публикаций Elsevier его полнотекстовый API поддерживает доступ к форматам XML и обычного текста одной конкретной статьи. Здесь мы использовали XML и обычные текстовые файлы от Elsevier для извлечения его табличного и текстового содержимого соответственно. Следующим этапом является фильтрация метаданных программно загруженных статей, таких как DOI, идентификатор статьи, название статьи, журнал, информация о публикации и множество URL-адресов. Эти метаданные создают препятствия для последующего извлечения NER и отношений. Поэтому мы программно отфильтровали метаданные из необработанных загруженных документов статей по ключевым словам и сохранили только аннотацию и основную часть каждого полного текста. Кроме того, существовало много непоследовательных стилей обозначения величин и единиц, например, «1039°C» и «1039□°C» (здесь «□» представляет интервал между 1039 и °C). Последнее обозначение с пробелом было разделено на «1039» и «°C» после токенизации слов с помощью Natural Language Toolkit (NLTK), библиотеки Python с открытым исходным кодом для NLP 47 . Мы использовали регулярные выражения, чтобы найти все значения, за которыми следует единица, в полнотекстовом корпусе и унифицировать их, убрав пробелы.
Эти метаданные создают препятствия для последующего извлечения NER и отношений. Поэтому мы программно отфильтровали метаданные из необработанных загруженных документов статей по ключевым словам и сохранили только аннотацию и основную часть каждого полного текста. Кроме того, существовало много непоследовательных стилей обозначения величин и единиц, например, «1039°C» и «1039□°C» (здесь «□» представляет интервал между 1039 и °C). Последнее обозначение с пробелом было разделено на «1039» и «°C» после токенизации слов с помощью Natural Language Toolkit (NLTK), библиотеки Python с открытым исходным кодом для NLP 47 . Мы использовали регулярные выражения, чтобы найти все значения, за которыми следует единица, в полнотекстовом корпусе и унифицировать их, убрав пробелы.
Классификация текста
Среди сотен предложений в документе классификация позволяет нам определить, какое предложение содержит извлекаемую информацию о целевом свойстве. При классификации абзацев обычной практикой является обучение бинарного классификатора положительными образцами, представляющими связанные абзацы, и отрицательными образцами, представляющими все остальные абзацы. 0005 24 . Для этого необходимо вручную присвоить абзацам достаточное количество двоичных меток. Для классификации предложений количество положительных образцов предложений, подлежащих маркировке, ограничено, подавляющее большинство предложений в документе из суперсплава являются отрицательными образцами. Следовательно, для такого несбалансированного набора данных контролируемый двоичный классификатор плохо работает с высокой степенью точности и отзыва. Поэтому мы использовали метод, основанный на правилах, с помощью полуавтоматически сгенерированного словаря, чтобы различать целевые предложения. Уместно ли предложение или нет, определялось путем распознавания имени суперсплава, спецификатора целевого свойства вместе с указанным значением и единицей измерения.
0005 24 . Для этого необходимо вручную присвоить абзацам достаточное количество двоичных меток. Для классификации предложений количество положительных образцов предложений, подлежащих маркировке, ограничено, подавляющее большинство предложений в документе из суперсплава являются отрицательными образцами. Следовательно, для такого несбалансированного набора данных контролируемый двоичный классификатор плохо работает с высокой степенью точности и отзыва. Поэтому мы использовали метод, основанный на правилах, с помощью полуавтоматически сгенерированного словаря, чтобы различать целевые предложения. Уместно ли предложение или нет, определялось путем распознавания имени суперсплава, спецификатора целевого свойства вместе с указанным значением и единицей измерения.
Спецификатор свойства, такой как температура сольвуса γ ′ для жаропрочного сплава, может быть записан в предложении в различных формах, например: γ ′-температура сольвуса, и ее необходимо зафиксировать соответствующим образом. Чтобы создать словарь синонимов, мы предварительно обучили модель встраивания слов для корпуса суперсплавов на ~14 000 немаркированных полнотекстовых статей о суперсплавах, используя непрерывный набор слов Word2Vec (CBOW) в коде gensim (https://radimrehurek.com/ gensim/) 48 . При этом используется информация о совпадениях слов путем назначения многомерных векторов (вложений) словам в текстовом корпусе для сохранения их синтаксических и семантических отношений. Предполагая, что у нас есть V = 360 000 уникальных слов в словаре всего корпуса суперсплавов, Word2vec CBOW перебирает все слова в обучающем тексте и использует его однократное кодирование в качестве входных данных для нейронной сети с размером окна 10. Веса скрытого слоя задаются V × N размерная матрица, где N — размер пробела (в нашем случае 100) для «встраивания» слов. модели встраивания, и это может привести к тому, что вложения слов не будут изучены должным образом. Поэтому после обучения Word2Vec мы выполнили внутреннюю оценку вложений слов по соотношению слов и аналогиям слов.
Чтобы создать словарь синонимов, мы предварительно обучили модель встраивания слов для корпуса суперсплавов на ~14 000 немаркированных полнотекстовых статей о суперсплавах, используя непрерывный набор слов Word2Vec (CBOW) в коде gensim (https://radimrehurek.com/ gensim/) 48 . При этом используется информация о совпадениях слов путем назначения многомерных векторов (вложений) словам в текстовом корпусе для сохранения их синтаксических и семантических отношений. Предполагая, что у нас есть V = 360 000 уникальных слов в словаре всего корпуса суперсплавов, Word2vec CBOW перебирает все слова в обучающем тексте и использует его однократное кодирование в качестве входных данных для нейронной сети с размером окна 10. Веса скрытого слоя задаются V × N размерная матрица, где N — размер пробела (в нашем случае 100) для «встраивания» слов. модели встраивания, и это может привести к тому, что вложения слов не будут изучены должным образом. Поэтому после обучения Word2Vec мы выполнили внутреннюю оценку вложений слов по соотношению слов и аналогиям слов. Мы проверили 100 слов, наиболее похожих на слово «суперсплав», и среди них 38 слов, являющихся альтернативными формами слова «суперсплавы», например {суперсплавы, 0,884}, {суперсплавы, 0,815} и {суперсплавы, 0,810}, или формы с орфографическими ошибками. {суперсплав, 0,805}, {суперсплав, 0,729}, {superallys, 0,719}, {superlloys, 0,705} и т. д. (Число после запятой представляет собой косинусное сходство.) Слово «superalloys» и их подобные варианты написания очень важны в соответствии с моделью встраивания слов. Кроме того, вектор «на основе кобальта»– «на основе никеля» + «ИН-792» наиболее близок к вектору «Хейнс-188» по модели встраивания слов. Его можно было бы представить как «на основе кобальта» — «на основе никеля» + «ИН-792» = «Хейнс-188» (сходство = 0,508027). Точно так же мы также получили некоторые отношения как «на основе никеля» — «на основе кобальта» + «на основе Co-9».Al-10W» = «GH690»(сходство = 0,570067), «на основе никеля»-«на основе кобальта»+«Co-9Al-9W» = «Gh5742»(сходство = 0,540617), «на основе никеля»-« на основе кобальта»+«Co-9Al-9W-2Zr» = «GH690»(сходство = 0,588166), «на основе никеля»-«на основе кобальта»+«Co-30Ni-10Al-5Mo-2Nb-2Re» = «Gh5169» (сходство = 0,556948).
Мы проверили 100 слов, наиболее похожих на слово «суперсплав», и среди них 38 слов, являющихся альтернативными формами слова «суперсплавы», например {суперсплавы, 0,884}, {суперсплавы, 0,815} и {суперсплавы, 0,810}, или формы с орфографическими ошибками. {суперсплав, 0,805}, {суперсплав, 0,729}, {superallys, 0,719}, {superlloys, 0,705} и т. д. (Число после запятой представляет собой косинусное сходство.) Слово «superalloys» и их подобные варианты написания очень важны в соответствии с моделью встраивания слов. Кроме того, вектор «на основе кобальта»– «на основе никеля» + «ИН-792» наиболее близок к вектору «Хейнс-188» по модели встраивания слов. Его можно было бы представить как «на основе кобальта» — «на основе никеля» + «ИН-792» = «Хейнс-188» (сходство = 0,508027). Точно так же мы также получили некоторые отношения как «на основе никеля» — «на основе кобальта» + «на основе Co-9».Al-10W» = «GH690»(сходство = 0,570067), «на основе никеля»-«на основе кобальта»+«Co-9Al-9W» = «Gh5742»(сходство = 0,540617), «на основе никеля»-« на основе кобальта»+«Co-9Al-9W-2Zr» = «GH690»(сходство = 0,588166), «на основе никеля»-«на основе кобальта»+«Co-30Ni-10Al-5Mo-2Nb-2Re» = «Gh5169» (сходство = 0,556948). Это показывает, что встраивание слов по-прежнему в определенной степени отражает полезные отношения.
Это показывает, что встраивание слов по-прежнему в определенной степени отражает полезные отношения.
После обучения мы отобрали 100 слов, наиболее похожих на целевое свойство «solvus», вычислив косинусное сходство в Word2Vec на основе полученной модели встраивания слов. На дополнительном рисунке 5 показаны Word2Vec CBOW и 100 лучших слов со сходством в порядке убывания синтаксических и семантических отношений в корпусе. Мы вручную выбрали наиболее вероятный синоним solvus из этих 100 слов с помощью экспертных знаний (показаны как слова розовым цветом в рамке на дополнительном рис. 5), сформировав словарь синонимов целевого «solvus». Значение свойства может быть одним числом или диапазоном, а единицей измерения может быть °C или K (Кельвин), что может быть распознано регулярным выражением, как показано в Таблице 1. Затем это позволяет нам определить, что предложение является целевое предложение (положительный образец для классификации предложений) в одном документе, когда в предложении одновременно встречается слово из словаря синонимов и значение свойства с определенной единицей. Наш метод классификации предложений показал точность, полноту и оценку F1 88,46%, 97,87% и 92,93% соответственно, оцененные путем случайной выборки 30 статей (~ 3000 предложений).
Наш метод классификации предложений показал точность, полноту и оценку F1 88,46%, 97,87% и 92,93% соответственно, оцененные путем случайной выборки 30 статей (~ 3000 предложений).
Анализ таблицы
Анализ таблицы преобразует полную информацию о таблице, включая заголовок и тело таблицы, в структурный формат списка ячеек вложенной таблицы, а затем классифицирует, какая таблица содержит информацию о химическом составе и целевых свойствах, которые необходимо извлечь. Первоначально мы выполняли синтаксический анализ таблиц в документах XML и HTML, учитывая, что обычный текст не содержит структурной информации таблицы. Для публикаций Elsevier мы модифицировали инструмент table_extractor с открытым исходным кодом для извлечения таблиц в формате списка из файлов XML 9.0005 49 ; тогда как для публикаций, содержащих HTML-файлы, для обработки HTML-разметки использовались панды, простая в использовании структура данных и инструмент анализа данных с открытым исходным кодом для языка программирования Python. Наконец, таблица в формате XML или HTML была преобразована в формат списка ячеек по строке с заголовком таблицы. Впоследствии мы выполнили классификацию таблиц для просмотра таблиц, содержащих химический состав и целевые свойства. Подобно классификации текста, ключевое слово «композиция» и спецификатор целевого свойства, например, « γ ′ температура сольвуса», совпадали в подписях к таблицам; рабочий процесс показан на дополнительном рис. 6. Если содержимое и положение ячейки таблицы преобразованы правильно, то ячейка таблицы считается положительным образцом. Всего было успешно извлечено 9158 таблиц из ~14 000 статей с F1 98,8 % путем ручной проверки из 4593 ячеек таблицы из 20 статей. Классификация таблиц дала 5327 таблиц составов и 114 таблиц с температурой сольвуса соответственно.
Наконец, таблица в формате XML или HTML была преобразована в формат списка ячеек по строке с заголовком таблицы. Впоследствии мы выполнили классификацию таблиц для просмотра таблиц, содержащих химический состав и целевые свойства. Подобно классификации текста, ключевое слово «композиция» и спецификатор целевого свойства, например, « γ ′ температура сольвуса», совпадали в подписях к таблицам; рабочий процесс показан на дополнительном рис. 6. Если содержимое и положение ячейки таблицы преобразованы правильно, то ячейка таблицы считается положительным образцом. Всего было успешно извлечено 9158 таблиц из ~14 000 статей с F1 98,8 % путем ручной проверки из 4593 ячеек таблицы из 20 статей. Классификация таблиц дала 5327 таблиц составов и 114 таблиц с температурой сольвуса соответственно.
Модель BiLSTM-CRF
Обычно для задач NER 33 можно использовать двунаправленную сеть с долговременной кратковременной памятью (BiLSTM) со слоем условного случайного поля (CRF), а именно модель BiLSTM-CRF. На дополнительном рисунке 7 показана нейронная архитектура нашей модели BiLSTM-CRF. BiLSTM — это двунаправленная рекуррентная нейронная сеть с ячейкой LSTM для решения проблемы долговременной зависимости текстовых данных, захватывая более семантическую контекстную зависимость предложений 50 . Входные данные BiLSTM представляют собой слой встраивания слов (предварительно обученный классификации текста) для получения функции преобразования, которая принимает простое текстовое слово и выводит плотный, действительный вектор фиксированной длины. Выходными данными BiLSTM являются соответствующие вероятности для всех меток каждого слова в последовательности, которые впоследствии вводятся в слой CRF для рассмотрения корреляций между метками в окрестностях и совместного декодирования наилучшей цепочки меток для заданного входного предложения 51 .
На дополнительном рисунке 7 показана нейронная архитектура нашей модели BiLSTM-CRF. BiLSTM — это двунаправленная рекуррентная нейронная сеть с ячейкой LSTM для решения проблемы долговременной зависимости текстовых данных, захватывая более семантическую контекстную зависимость предложений 50 . Входные данные BiLSTM представляют собой слой встраивания слов (предварительно обученный классификации текста) для получения функции преобразования, которая принимает простое текстовое слово и выводит плотный, действительный вектор фиксированной длины. Выходными данными BiLSTM являются соответствующие вероятности для всех меток каждого слова в последовательности, которые впоследствии вводятся в слой CRF для рассмотрения корреляций между метками в окрестностях и совместного декодирования наилучшей цепочки меток для заданного входного предложения 51 .
Для обучения такой модели BiLSTM-CRF метки на уровне фраз были применены с использованием метода маркировки последовательностей «BIO» к 47777 словам из 1090 предложений из 507 статей, написанных людьми 52 . «B» используется для начала именованного объекта, «I» — для средней части именованного объекта, а «O» — для несвязанных слов. Например, сплав с названием «Inconel 718» может быть помечен как «BI». 1090 аннотированных образцов были разделены на наборы поездов и наборы тестов, где соотношение наборов поездов и тестов составляло 1:1. Настройка параметров использовалась путем 5-кратной перекрестной проверки со случайно выбранными гиперпараметрами, а затем модель BiLSTM-CRF обучалась с лучшими параметрами. Окончательные параметры BiLSTM-CRF были установлены как: embedding_dim = 100, num_layers = 1, hidden_size = 16, lr = 0,01, отсев = 0,9. Он достиг категориальной точности 81,87%, отзыва 66,97% и оценки F1 73,67%. Затем модель была применена к набору тестов с 545 предложениями (тот же набор тестов с ChemDataExtractor и нашим методом NER), а точность, полнота и F1 составили 51,99%, 36,53% и 42,91% соответственно.
«B» используется для начала именованного объекта, «I» — для средней части именованного объекта, а «O» — для несвязанных слов. Например, сплав с названием «Inconel 718» может быть помечен как «BI». 1090 аннотированных образцов были разделены на наборы поездов и наборы тестов, где соотношение наборов поездов и тестов составляло 1:1. Настройка параметров использовалась путем 5-кратной перекрестной проверки со случайно выбранными гиперпараметрами, а затем модель BiLSTM-CRF обучалась с лучшими параметрами. Окончательные параметры BiLSTM-CRF были установлены как: embedding_dim = 100, num_layers = 1, hidden_size = 16, lr = 0,01, отсев = 0,9. Он достиг категориальной точности 81,87%, отзыва 66,97% и оценки F1 73,67%. Затем модель была применена к набору тестов с 545 предложениями (тот же набор тестов с ChemDataExtractor и нашим методом NER), а точность, полнота и F1 составили 51,99%, 36,53% и 42,91% соответственно.
Алгоритм снежного кома
Система снежного кома — это полууправляемый алгоритм для генерации шаблонов и извлечения кортежей из текстовых документов, особенно для ограниченных образцов с метками 31 . Snowball представляет стратегию оценки качества паттерна и извлеченного кортежа на основе DIPRE 9.0005 53 . Модифицированный алгоритм Snowball 22 может работать с четвертичными отношениями и выполняет кластеризацию на основе порядка и количества объектов. Он может достичь высокой точности с меньшим количеством начальных значений, чем исходный алгоритм Snowball. В этой работе мы вручную пометили 329 предложений, содержащих информацию о температуре сольвуса γ ′, и отдельно получили 467 кортежей в двоичной и четверичной форме для оценки алгоритма Snowball и модифицированного алгоритма Snowball. Кортежи в двоичной форме включают именованный объект суперсплава, значение свойства и их контекстную информацию между различными категориями объектов, кортежи в четвертичной форме включают именованный объект суперсплава, спецификатор свойства, значение свойства, единицу свойства и их контекстную информацию между различными категориями объектов. Количество начальных начальных значений сильно влияет на производительность алгоритма, поэтому 50 и 100 помеченных вручную кортежей были использованы в качестве начальных для запуска системы Snowball и модифицированной системы Snowball для обучения соответственно.
Snowball представляет стратегию оценки качества паттерна и извлеченного кортежа на основе DIPRE 9.0005 53 . Модифицированный алгоритм Snowball 22 может работать с четвертичными отношениями и выполняет кластеризацию на основе порядка и количества объектов. Он может достичь высокой точности с меньшим количеством начальных значений, чем исходный алгоритм Snowball. В этой работе мы вручную пометили 329 предложений, содержащих информацию о температуре сольвуса γ ′, и отдельно получили 467 кортежей в двоичной и четверичной форме для оценки алгоритма Snowball и модифицированного алгоритма Snowball. Кортежи в двоичной форме включают именованный объект суперсплава, значение свойства и их контекстную информацию между различными категориями объектов, кортежи в четвертичной форме включают именованный объект суперсплава, спецификатор свойства, значение свойства, единицу свойства и их контекстную информацию между различными категориями объектов. Количество начальных начальных значений сильно влияет на производительность алгоритма, поэтому 50 и 100 помеченных вручную кортежей были использованы в качестве начальных для запуска системы Snowball и модифицированной системы Snowball для обучения соответственно. Наконец, обученная система Snowball и модифицированная система Snowball использовались для извлечения отношений из оставшегося корпуса, а точность, полнота и оценка F1 алгоритма Snowball и модифицированного алгоритма Snowball были рассчитаны путем ручной проверки.
Наконец, обученная система Snowball и модифицированная система Snowball использовались для извлечения отношений из оставшегося корпуса, а точность, полнота и оценка F1 алгоритма Snowball и модифицированного алгоритма Snowball были рассчитаны путем ручной проверки.
Параметры после ручной настройки для оценки Snowball и модифицированного Snowball на тестовом наборе приведены в дополнительной таблице 4. В таблице 3 показаны точность, полнота и оценка F1 алгоритма Snowball и модифицированного Snowball для разных семян.
Предварительная обработка данных для машинного обучения
После автоматического извлечения данных конвейером было получено 743 экземпляра как с химическим составом, так и с температурой сольвуса γ ′. Для некоторых суперсплавов извлекаемый γ ′ температуры сольвуса для одного и того же суперсплава представляют различия. С одной стороны, мы не учитываем условия синтеза или обработки и другие экспериментальные аспекты, включая погрешности измерения; с другой стороны, для того же суперсплава некоторые температуры рассчитаны, но некоторые получены экспериментально, а некоторые указаны в диапазоне.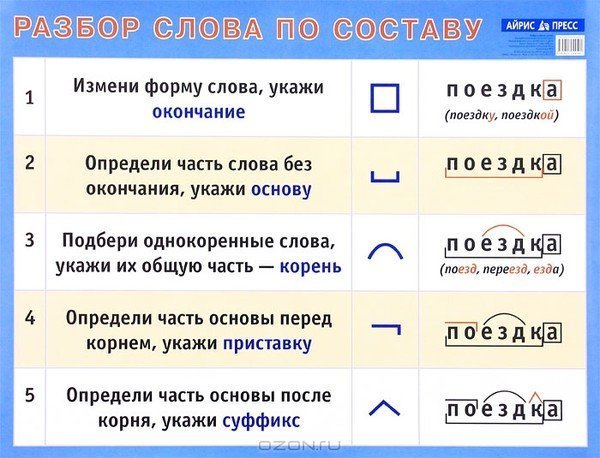 На рис. 7а представлено распределение температуры сольвуса γ ′ для суперсплавов Co-9Al-9W, Mar-M247, U720Li, IN738LC, CMSX-4 и CMSX-10 с γ ′ температура сольвуса 993 ± 9 °С, 1206 ± 28 °С, 1160 ± 20 °С, 1168 ± 31 °С, 1286 ± 30 °С, 1343 стандартное отклонение, 1343 9 соответственно. Чтобы использовать эти данные для дальнейшего анализа, некоторые этапы предварительной обработки данных были выполнены вручную следующим образом:
На рис. 7а представлено распределение температуры сольвуса γ ′ для суперсплавов Co-9Al-9W, Mar-M247, U720Li, IN738LC, CMSX-4 и CMSX-10 с γ ′ температура сольвуса 993 ± 9 °С, 1206 ± 28 °С, 1160 ± 20 °С, 1168 ± 31 °С, 1286 ± 30 °С, 1343 стандартное отклонение, 1343 9 соответственно. Чтобы использовать эти данные для дальнейшего анализа, некоторые этапы предварительной обработки данных были выполнены вручную следующим образом:
- 1.
Когда для одного и того же жаропрочного сплава в таблицах и тексте извлекались разные температуры сольвуса γ ′, данные из таблиц сохранялись, а другие данные исключались.
- 2.
При одновременном извлечении экспериментальных и расчетных температур сольвуса γ ′ конкретного жаропрочного сплава значение свойства из эксперимента было сохранено, а другие данные исключены.
- 3.
Когда одновременно получают несколько разных температур сольвуса γ ′ конкретного жаропрочного сплава для разных изделий, значение с наибольшей частотой встречаемости сохранялось, а другие данные исключались.
- 4.
Когда значение температуры или состава сольвуса γ ′, полученное для конкретного жаропрочного сплава, задано в виде диапазона (например, 1140–1150 °C), сохраняется среднее значение (1145 °C) этого диапазона.
- 5.
Единицы состава и температуры сольвуса γ ′ были унифицированы как атомные проценты и градусы Цельсия соответственно.
Модель прогноза температуры сольвуса
γ ′ После предварительной обработки данных извлечены 743 записи с химическим составом и γ ′ температура сольвуса была снижена до 340 записей, включая 262 записи на основе кобальта и 78 записей на основе никеля. Мы использовали 20 элементов с 332 экземплярами, отделенными от 340 экземпляров, для обучения моделей машинного обучения. Несколько известных алгоритмов машинного обучения использовались для выбора модели и оптимизации параметров путем поиска по сетке, включая регрессию опорных векторов (SVR) с линейным ядром (SVR.lin) и ядром радиальной базисной функции (SVR.rbf), байесовскую линейную регрессию (BR ), регрессия стохастического градиента с понижением (SGDR), регрессия k-ближайших соседей (KNR), регрессия случайного леса (RFR), регрессия с повышением градиента (GBR), лассо-регрессия (LR) и эластичная чистая регрессия (ENR), менее 100 раз 5-кратной перекрестной проверки. Модель SVR.rbf лучше всего работает с наименьшей среднеквадратичной ошибкой (RMSE) в наборах тестов. Процесс выбора модели показан на рис. 7б.
Мы использовали 20 элементов с 332 экземплярами, отделенными от 340 экземпляров, для обучения моделей машинного обучения. Несколько известных алгоритмов машинного обучения использовались для выбора модели и оптимизации параметров путем поиска по сетке, включая регрессию опорных векторов (SVR) с линейным ядром (SVR.lin) и ядром радиальной базисной функции (SVR.rbf), байесовскую линейную регрессию (BR ), регрессия стохастического градиента с понижением (SGDR), регрессия k-ближайших соседей (KNR), регрессия случайного леса (RFR), регрессия с повышением градиента (GBR), лассо-регрессия (LR) и эластичная чистая регрессия (ENR), менее 100 раз 5-кратной перекрестной проверки. Модель SVR.rbf лучше всего работает с наименьшей среднеквадратичной ошибкой (RMSE) в наборах тестов. Процесс выбора модели показан на рис. 7б.
Мы разделили 332 точки данных на 298 данных (90%) для обучения и проверки и оставшиеся 34 данных (10%) для тестирования и повторно обучили модель SVR.rbf с оптимизированными параметрами. Во время обучения мы использовали 1000 бутстреп-выборок, выбранных случайным образом с заменой (238 данных в качестве обучающего набора из 298 каждый раз, а остальные — в качестве проверочного набора) и обучили 1000 различных моделей SVR.rbf. Модели были применены к тестовому набору, чтобы получить 1000 соответствующих прогнозов. RMSE со средним значением и стандартным отклонением на тестовом наборе показан на рис. 7c (для обучающего набора неопределенности взяты из 1000 бутстреп-выборок).
Во время обучения мы использовали 1000 бутстреп-выборок, выбранных случайным образом с заменой (238 данных в качестве обучающего набора из 298 каждый раз, а остальные — в качестве проверочного набора) и обучили 1000 различных моделей SVR.rbf. Модели были применены к тестовому набору, чтобы получить 1000 соответствующих прогнозов. RMSE со средним значением и стандартным отклонением на тестовом наборе показан на рис. 7c (для обучающего набора неопределенности взяты из 1000 бутстреп-выборок).
Синтез и характеристика
Использовались сырые металлы чистотой >99,95%, а оксиды и примеси на поверхности сырых металлов удалялись перед обработкой сплава. Для обеспечения однородности состава сплава и облегчения сравнения слитки пуговиц из сплава были изготовлены методом вакуумно-дуговой плавки, при котором каждый 30 г сплава переплавлялся не менее шести раз. После ультразвуковой очистки литой слиток запаивали в кварцевую трубку, заполненную аргоном высокой чистоты, и подвергали термообработке на твердый раствор при 1245–1260°С в течение 12 ч с последующим охлаждением на воздухе. Все образцы были вырезаны и подвергнуты последующему старению при 1000°С в течение 50 ч с последующим охлаждением водой. Температуры сольвуса γ’ определяли методом ДСК (NETZSCH STA 449C) с потоком аргона высокой чистоты. Образцы для ДСК размером φ 3 мм × 1 мм испытывали в интервале температур 800–1400 °С при скорости нагрева 5 °С мин -1 . Метод пересечения линии использовали для измерения температур превращения на основе кривых нагрева ДСК.
Все образцы были вырезаны и подвергнуты последующему старению при 1000°С в течение 50 ч с последующим охлаждением водой. Температуры сольвуса γ’ определяли методом ДСК (NETZSCH STA 449C) с потоком аргона высокой чистоты. Образцы для ДСК размером φ 3 мм × 1 мм испытывали в интервале температур 800–1400 °С при скорости нагрева 5 °С мин -1 . Метод пересечения линии использовали для измерения температур превращения на основе кривых нагрева ДСК.
Коды нашего конвейера и модели машинного обучения были запущены на процессоре Intel(R) core (TM) i7-9700U с частотой 3,00 ГГц и 8 ГБ ОЗУ, а также на графическом процессоре (GPU) от NVIDIA GeForce RTX 2080 Ti.
Ссылки
Чжан, Х., Фу, Х., Чжу, С., Юн, В. и Се, Дж. Эффективный дизайн композиции с помощью машинного обучения для дисперсионно-упрочненных медных сплавов. Acta Mater. 215 , 117118 (2021).
КАС Google ученый
Гранда, Дж. М., Донина, Л., Драгон, В., Лонг, Д. Л. и Кронин, Л. Управление роботом органического синтеза с машинным обучением для поиска новой реактивности. Природа 559 , 377–381 (2018).
КАС Google ученый
Gesmundo, N.J. et al. Наноразмерный синтез и ранжирование по сродству. Природа 557 , 228–232 (2018).
КАС Google ученый
Батлер К.Т., Дэвис Д.В., Картрайт Х., Исаев О. и Уолш А. Машинное обучение для молекулярной науки и материаловедения. Природа 559 , 547–555 (2018).
КАС Google ученый
Ван, К., Фу, Х., Цзян, Л., Сюэ, Д. и Се, Дж. Ориентированная на свойства стратегия проектирования высокоэффективных медных сплавов с помощью машинного обучения. npj Вычисл. Матер 5 , 1–8 (2019).
Google ученый
Рикман Дж. М., Лукман Т., Калинин С. В. Информатика материалов: от атомарного уровня к континууму. Acta Mater. 168 , 473–510 (2019).
КАС Google ученый
Лукман, Т., Балачандран, П.В., Сюэ, Д. и Юань, Р. Активное обучение материаловедению с упором на адаптивную выборку с использованием неопределенностей для целевого проектирования. npj Вычисл. Матер. 5 , 1–17 (2019).
Google ученый
Сюэ, Д. и др. Ускоренный поиск материалов с заданными свойствами за счет адаптивного проектирования. Нац. коммун. 7 , 1–9 (2016).
Google ученый
Wen, C. et al. Машинное обучение помогает создавать высокоэнтропийные сплавы с заданными свойствами. Acta Mater. 170 , 109–117 (2019).
КАС Google ученый
Сеглер, М. Х. С., Прейс, М. и Уоллер, М. П. Планирование химических синтезов с помощью глубоких нейронных сетей и символического ИИ. Природа 555 , 604–610 (2018).
КАС Google ученый
Wen, C. et al. Моделирование упрочнения твердого раствора в сплавах с высокой энтропией с использованием машинного обучения. Acta Mater. 212 , 116917 (2021).
КАС Google ученый
Zhang, Y. et al. Фазовое предсказание в высокоэнтропийных сплавах с рациональным выбором дескрипторов материалов и моделей машинного обучения. Acta Mater. 185 , 528–539 (2020).
КАС Google ученый
Jiang, X. et al. Стратегия, сочетающая машинное обучение и многомасштабный расчет для прогнозирования прочности на растяжение перлитной стальной проволоки с использованием промышленных данных.
Скр. Матер. 186 , 272–277 (2020).КАС Google ученый
Читоян В. и др. Неконтролируемые вложения слов собирают скрытые знания из литературы по материаловедению. Природа 571 , 95–98 (2019).
КАС Google ученый
Swain, M.C. & Cole, J.M. ChemDataExtractor: набор инструментов для автоматического извлечения химической информации из научной литературы. J. Chem. Инф. Модель. 56 , 1894–1904 (2016).
КАС Google ученый
Краллингер, М., Рабал, О., Лоуренсо, А., Оярсабал, Дж. и Валенсия, А. Технологии поиска информации и анализа текстов для химии. Хим. Ред. 117 , 7673–7761 (2017 г.).
КАС Google ученый
Ким Э., Хуанг К., Джегелька С. и Оливетти Э. Виртуальный скрининг параметров синтеза неорганических материалов с помощью глубокого обучения. npj Вычисл. Матер. 3 , 1–9 (2017).
КАС Google ученый
Корт, С. Дж. и Коул, Дж. М. Автоматически созданная база данных материалов с температурами Кюри и Нееля с помощью полуконтролируемого извлечения зависимостей. Науч. данные 5 , 1–12 (2018).
Google ученый
Olivetti, E. A. et al. Исследование материалов на основе данных благодаря обработке естественного языка и извлечению информации.
Заяв. физ. Ред. 7 , 41317 (2020 г.).КАС Google ученый
Kim, E. et al. Машинное обучение и систематизированные параметры синтеза оксидных материалов. Науч. данные 4 , 170127 (2017).
КАС Google ученый
Руан, Дж. и др. Ускоренное проектирование новых высокопрочных суперсплавов на основе кобальта, не содержащих W, с чрезвычайно широкой областью γ/γʹ с помощью методов машинного обучения и CALPHAD. Acta Mater. 186 , 425–433 (2020).
КАС Google ученый
Лю, Ю. и др. Прогнозирование долговечности монокристаллических жаропрочных сплавов на основе никеля с использованием подхода «разделяй и властвуй», основанного на машинном обучении. Acta Mater. 195 , 454–467 (2020).
КАС Google ученый
Лю, П. и др. Машинное обучение помогло разработать суперсплавы на основе кобальта, упрочненные γ’, с многофункциональной оптимизацией. npj Вычисл. Матер. 6 , 1–9 (2020).
Google ученый
Jiang, X. et al. Подход информатики материалов к прогнозированию несоответствия решетки монокристаллических суперсплавов на основе никеля. Вычисл. Матер. науч. 143 , 295–300 (2018).
КАС Google ученый
Су, Ю., Фу, Х., Бай, Ю., Цзян, X. и Се, Дж. Прогресс в области геномной инженерии материалов в Китае. Акта Мет. Грех. 56 , 1313–1323 (2020).
КАС Google ученый
Се, Дж. и др. Машинное обучение для исследования и разработки материалов.
Акта Мет. Грех. 57 , 1343–1361 (2021).Google ученый
Agichtein, E. & Gravano, L. Snowball: извлечение отношений из больших коллекций открытого текста. В проц. 5-я конференция ACM по электронным библиотекам 85–94 (ACM, 2000 г.).
Nadeau, D. & Sekine, S. Обзор распознавания и классификации именованных объектов. Лингвистические исследования. 30 , 3–26 (2007).
Google ученый
Huang, Z., Xu, W. & Yu, K. Двунаправленные модели LSTM-CRF для маркировки последовательностей . Препринт на https://arxiv.org/abs/1508.01991 (2015).
Чжоу, Г., Су, Дж., Чжан, Дж. и Чжан, М. Proc. 43-е ежегодное собрание ассоциации компьютерной лингвистики 427–434 (ACL, 2005).
Сорокин Д.
и Гуревич И. Контекстно-зависимые представления для извлечения отношений из базы знаний. В Проц. Конференция 2017 г. по эмпирическим методам обработки естественного языка (изд. Палмер, М. и др.) 1784–1789 (ACL, 2017).Таканобу Р., Чжан Т., Лю Дж. и Хуанг М. Иерархическая структура для извлечения отношений с помощью обучения с подкреплением. Проц. Конф. АААИ. Артиф. Интел. 33 , 7072–7079 (2019).
Google ученый
Бах Н. и Бадаскар С. Обзор извлечения отношений. Лит. Преподобный Ланг. Стат. II 2 , 1–15 (2007).
Google ученый
Панг, Х. Т., Чжан, Л., Хоббс, Р. А., Стоун, Х. Дж. и Рэй, К. М. Ф. Оптимизация термообработки на твердый раствор монокристаллических жаропрочных сплавов на основе никеля четвертого поколения. Металл. Матер. Транс. А 43 , 3264–3282 (2012).
КАС Google ученый
Ласс, Э. А. Применение вычислительной термодинамики к конструкции суперсплава на основе Co-Ni, упрочненного γ’. Металл. Матер. Транс. А 48 , 2443–2459 (2017).
КАС Google ученый
Li, W., Li, L., Antonov, S. & Feng, Q. Эффективный дизайн сплава Co-Ni-Al-W-Ta-Ti с высокой температурой сольвуса γ’ и стабильностью микроструктуры с использованием комбинированного CALPHAD и экспериментальные подходы. Матер. Дес. 180 , 107912 (2019).
КАС Google ученый
Оошима, М., Танака, К., Окамото, Н.Л., Кисида, К. и Инуи, Х. Влияние четвертичных легирующих элементов на температуру γ’ сольвуса сплавов на основе Co–Al–W с ГЦК/L12 двухфазные микроструктуры. Дж. Сплав. комп. 508 , 71–78 (2010).
КАС Google ученый
Ласс, Э. А., Сауза, Д. Дж., Дунанд, Д. К. и Зайдман, Д. Н. Многокомпонентные γ’-упрочненные суперсплавы на основе кобальта с повышенными температурами сольвуса и пониженной массовой плотностью. Acta Mater. 147 , 284–295 (2018).
КАС Google ученый
Снегула А., Понишевска-Марарида А. и Хоматек Л. Изучение методов распознавания именованных объектов в области биомедицины. Процедиа Компьютер. Sci 160 , 260–265 (2019).
Google ученый
Goutte, C. & Gaussier, E. Вероятностная интерпретация точности, отзыва и F-показателя с учетом оценки. Европейская конференция по информационному поиску (Лосада, Д.Е. и Фернандес-Луна, Дж.М.) 345–359 (Springer, 2005).
Lammey, R. Услуги CrossRef по интеллектуальному анализу текстов и данных. Учиться. Опубл. 27 , 245–250 (2014).
Google ученый
Берд С., Кляйн Э. и Лопер Э. Обработка естественного языка с помощью Python: анализ текста с помощью набора инструментов для работы с естественным языком . («О’Рейли Медиа, Инк.», 2009 г.).
Рехурек, Р. и Сойка, П. Программная среда для тематического моделирования с большими корпусами. В проц. семинара LREC 2010 по новым задачам для структур НЛП 45–50 (Citeseer, 2010).
Jensen, Z. et al. Подход машинного обучения к синтезу цеолитов благодаря автоматическому извлечению литературных данных.
АКЦ Цент. науч. 5 , 892–899 (2019).КАС Google ученый
Герс, Ф. А., Шмидхубер, Дж. и Камминс, Ф. Учимся забывать: непрерывное предсказание с помощью LSTM. Нейронные вычисления. 12 , 2451–2471 (2000).
КАС Google ученый
Лафферти, Дж., МакКаллум, А. и Перейра, Ф. С. Н. Условные случайные поля: вероятностные модели для сегментации и маркировки данных последовательности. В проц. 18-я Международная конференция по машинному обучению (изд. Бродли, К.Э. и Данилюк, А.П.) 282–289(ICML, 2001).
Реймерс Н. и Гуревич И. Оптимальные гиперпараметры для глубоких LSTM-сетей для задач маркировки последовательностей. Препринт на https://arxiv.org/abs/1707.06799 (2017).
Брин, С. В Международном семинаре по Всемирной паутине и базам данных (под редакцией Ацени, П.
и др.) 172–183 (Springer, 1998).
 «>
«>Zhang, H. et al. Значительно улучшенное сочетание предела прочности при растяжении и электропроводности сплавов благодаря скринингу с помощью машинного обучения. Acta Mater. 200 , 803–810 (2020).
КАС Google ученый
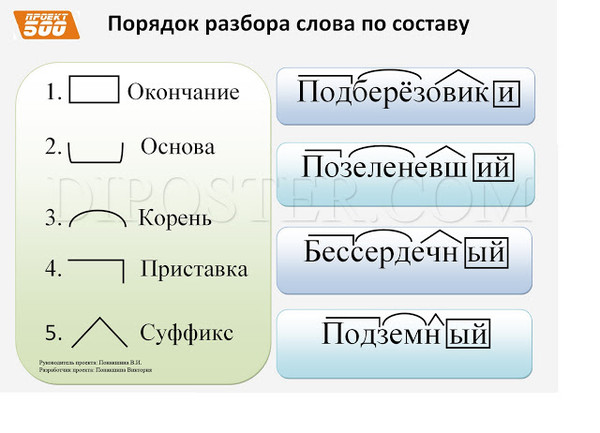
 «>
«>Сюэ, Д. и др. Информатический подход к температуре превращения сплавов с памятью формы на основе NiTi. Acta Mater. 125 , 532–541 (2017).
КАС Google ученый
 «>
«>Raccullia, P. et al. Обнаружение материалов с помощью машинного обучения с использованием неудачных экспериментов. Природа 533 , 73–76 (2016).
КАС Google ученый
 Скр. Матер. 186 , 272–277 (2020).
Скр. Матер. 186 , 272–277 (2020). «>
«>Kim, E. et al. Планирование синтеза неорганических материалов с помощью обученных по литературе нейронных сетей. J. Chem. Инф. Модель. 60 , 1194–1201 (2020).
КАС Google ученый
 Заяв. физ. Ред. 7 , 41317 (2020 г.).
Заяв. физ. Ред. 7 , 41317 (2020 г.).
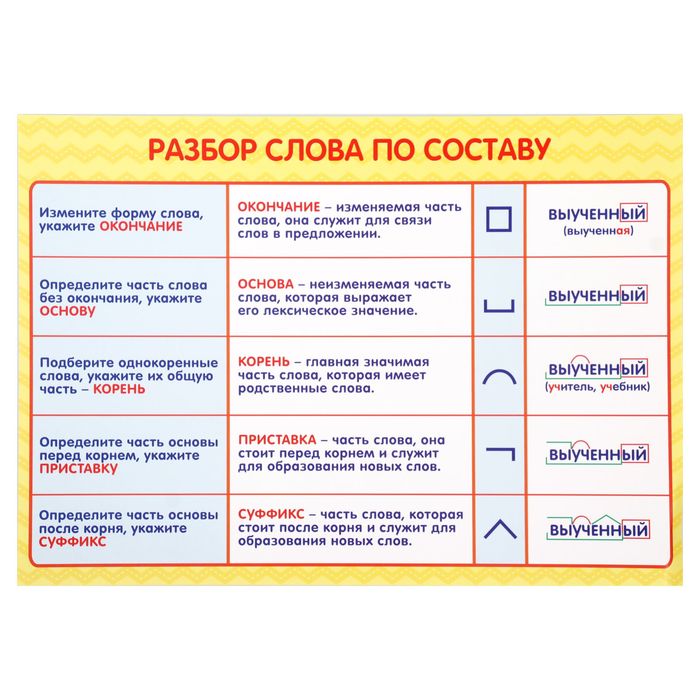 Акта Мет. Грех. 57 , 1343–1361 (2021).
Акта Мет. Грех. 57 , 1343–1361 (2021). и Гуревич И. Контекстно-зависимые представления для извлечения отношений из базы знаний. В Проц. Конференция 2017 г. по эмпирическим методам обработки естественного языка (изд. Палмер, М. и др.) 1784–1789 (ACL, 2017).
и Гуревич И. Контекстно-зависимые представления для извлечения отношений из базы знаний. В Проц. Конференция 2017 г. по эмпирическим методам обработки естественного языка (изд. Палмер, М. и др.) 1784–1789 (ACL, 2017).

 «>
«>Япкович, Н. Зачем подвергать сомнению методы оценки машинного обучения. В Семинар AAAI по методам оценки машинного обучения (2006 г.).
 АКЦ Цент. науч. 5 , 892–899 (2019).
АКЦ Цент. науч. 5 , 892–899 (2019). и др.) 172–183 (Springer, 1998).
и др.) 172–183 (Springer, 1998).Скачать ссылки
Корень пьешь. «Питьевой»
Схема разбора состава напитка:
напиток e
Разбор слова состав.
Состав слова «напиток»:
Соединительная гласная: пропущено
Постфикс: пропущено
Морфемы — части слова пить
напиток4 Подробная разбивка слова напиток по составу . Словосочетание, префикс, суффикс и окончание слова. Мофемный состав слова напиток, его структура и части слова (морфология).
- Схема морфем: пи / т / е
- Структура слова по морфемам: корень / корень / окончание
- Схема (построение) слова напиток по составу: корень пи + корень т + окончание е
- Список морфем в слово напиток:
- пи — корень
- т корень
- е — конец
- Виды морф и их количество в слове напиток:
- доставка: отсутствует — 0
- матка: напиток — 2
- соединительный глас: отсутствует — 0
- cyffix: отсутствует — 0
- постфикс: отсутствует — 0
- конец: e — 83 1 — 0
Всего морфем в слове: 3.
Словообразовательный разбор слова пить
- Основа слова: пить ;
- Словообразовательные аффиксы: префикс отсутствует , суффикс отсутствует , постфикс отсутствует ;
- Словообразование: ○ сложение или сращивание основ (или целых слов), неправильное сложение, так как оно образуется без соединительной гласной ;
- Способ образования: производный, так как образован 1 (одним) способом .
См. также другие словари:
Однокоренные слова… это слова, имеющие корень…, принадлежащие к разным частям речи, и в то же время близкие по значению… Слова с одним корнем к слово напиток
Что такое питье во множественном числе…. Что такое питье?
Полный морфологический разбор слова «напиток»: Часть речи, начальная форма, морфологические признаки и словоформы. Направление науки о языке, где изучается слово… Морфологический разбор пить
Ударение в слове пить: на какой слог ставится ударение и как. .. Слово «пить» правильно пишется как… Ударение в слове пить
Синонимы к слову «пить». Онлайн-словарь синонимов: найдите синонимы к слову «напиток». Синонимичные слова, похожие слова и похожие выражения в… Алкогольные синонимы
Анаграммы (составить анаграмму) к слову пить, смешав буквы… Анаграммы к слову пить
К чему снится пить — толкование снов, узнайте бесплатно в нашем соннике к чему снится пить во сне. … Увиденный во сне напиток означает, что… Сонник: к чему снится пить
Морфемный разбор слова напиток
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова пить очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем разбор морфем правильным, но для этого пройдем всего 5 шагов:
- определение части речи слова — первый шаг;
- второй — подбираем окончания: для изменяемых слов спрягаем или раздуваем, для неизменяемых (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- то ищем основу. Это самая простая часть, потому что вам просто нужно обрезать конец, чтобы определить основу. Это будет основой слова;
- Следующим шагом будет поиск корня слова. Подбираем родственные слова для питья (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
Как видите, 9009Разбор 9 морфем делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слов (разбор слов) — поиск корня, префиксов, суффиксов, окончаний и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора.напиток
Состав слова «пить» :
корень — [пи], формообразующий суффикс- [й]
Предложения со словом «пить»
Единственное шампанское, которое можно пить из маленькой 200 мл бутылочки через соломинку прямо на дискотеке.
После плодотворной работы можно было полностью расслабиться, забыть на время рутинные заботы, выпить молодого вина и спеть озорные песни.
Ей запретили пить и чуть ли не курить.
Маленькие капризничали, просили попить, а большие дрались и играли в фантики.
Лариса гладила его по головке за то, что он рос и умнел, Марина снисходительно ухмылялась над детской наивностью, Степан полностью его игнорировал, а Алексей Тихонович вместо того, чтобы пить дальше рюмки и расспрашивать окружающих, не лучше ли жить в такой квартире или в своем доме, встал, подошел к окну и задумался.
Вечером пошел к старушке Клавдии Петровне пить чай.
Он аккуратно держал себя и свою жизнь; когда он бросил пить, то не мог сдвинуться с места.
И подумал, как хорошо сидеть в таком буфете, слушать тонкие гудки проезжающих мимо электропоездов, греться у печки и пить пиво из кружки.
Разобрать слово по составу, что оно означает?
Разбор слова по составу один из видов лингвистического исследования, целью которого является определение структуры или состава слова, классификация морфем по месту в слове и установление значения каждой из них. В школьной программе его еще называют разбор морфем . Сайт-инструкция поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово?
При разборе морфем соблюдайте определенную последовательность выделения значащих частей. Начните с того, чтобы «снять» морфемы с конца, используя прием «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
- Запишите слово так же, как в домашнем задании. Перед тем, как начать разбирать сочинение, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи оно относится. Вспомните признаки слов, принадлежащих к этой части речи:
- изменяемый (имеет окончание) или неизменяемый (не имеет окончания)
- имеет ли он формообразующий суффикс?
- Найдите концовку. Для этого склоняйте по падежам, меняйте число, род или лицо, спрягайте — переменная часть будет окончанием. Помните об изменяемых словах с нулевым окончанием, обязательно обозначьте, если оно есть: сон (), друг (), слышимость (), благодарность (), съел ().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить префикс в базе (если есть). Для этого сравните однокоренные слова с приставками и без них.
- Определите суффикс (если есть). Для проверки подберите слова с разными корнями и с одинаковым суффиксом, чтобы они выражали одинаковое значение.
- Найдите корень в основании. Для этого сравните ряд родственных слов. Их общей частью является корень. Запомните однокоренные слова с чередующимися корнями.
- Если слово имеет два (и более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Пометить формообразующие суффиксы и постфиксы (если есть)
- Перепроверить синтаксический анализ и выделить все значимые части значками
В начальных классах разобрать слово — значит выделить окончание и основу, затем обозначить приставку суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, и все.
* Примечание: Министерство образования Российской Федерации рекомендует три учебных комплекса по русскому языку в 5-9 классах для общеобразовательных школ. У разных авторов подход к разбору морфем по составу отличается. Чтобы избежать проблем с выполнением домашнего задания, сравните приведенную ниже процедуру разбора с вашим учебником.
Порядок полного разбора морфем по составу
Во избежание ошибок желательно связать разбор морфем с словообразовательным разбором. Такой анализ называется формально-семантическим.
- Установите часть речи и проведите графоморфемный анализ слова, т.е. обозначьте все имеющиеся морфемы.
- Выпишите окончание, определите его грамматическое значение… Укажите суффиксы словоформ (если они есть)
- Выпишите основу слова (без формообразующих морфем: окончания и формообразующие суффиксы)
- Найдите морфемы. Выпишите суффиксы и приставки, обоснуйте их выделение, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «пи-а-й → пи-а-й → пи-а-й», «сух(ой) → суши-ар() → суши-ар-ниц -(но)». Для слов со связными корнями подберите одноструктурные слова: «одеть-раздеть-переодеться».
- Запишите корень, подберите однокоренные слова, отметьте возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «спать»:
- окончание «а» указывает на форму глагола женского пола, единицы числа, прошедшее время, ср.: проспал;
- основание гандикапа «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением потери, невыгоды, ср.: просчитаться, потерять, упустить;
- словообразовательная цепь: сон — проспал — проспал;
- корень «сп» — в родственных словах возможны чередования сп//сп/сон//сып. Однокоренные слова: сон, засыпание, сонливость, недосыпание, бессонница.
Схема разбора состава напитков:
drink em
Разбор слова состав.
Состав слов «напитки»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова напитки
напиткиПодробная разбивка слова напитки по составу. Словосочетание, префикс, суффикс и окончание слова. Мофема рода слов напитки, его структура и части слова (морфы).
- Схема морфем: п/э
- Структура слова по морфемам: корень/окончание
- Схема (построение) слова напитки по составу: корень пт + окончание em
- Список морфем в слове drink:
- p — корень
- em — конец
- Типы морфов и их число в словах напитка:
- Доставка: Отсутствует — 0
- Королева: P — 1
- Подключение GLAC: Отсутствует — 0
- 3333. Связывание: — — 0
- 3333333. 0
- постфикс: отсутствует — 0
- конец: нет — 1
Всего морфем в слове: 2.
Словообразовательный разбор слова напитки
См. также другие словари:
Полный морфологический разбор слова «напитки»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово… Морфологический разбор напитки
Ударение в слове напитки: на какой слог падает ударение и как… Слово «напитки» правильно пишется как.. Ударение в слове напитки
Анаграммы (составить анаграмму) к слову напитки, путем смешивания букв… Анаграммы к слову напитки
Морфемный разбор слова напиток
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова напиток очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого пройдем всего 5 шагов:
- определение части речи слова — первый шаг;
- второй — подбираем окончания: для изменяемых слов спрягаем или раздуваем, для неизменяемых (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- потом ищем основу. Это самая простая часть, потому что вам просто нужно обрезать конец, чтобы определить основу. Это будет основой слова;
- Следующим шагом будет поиск корня слова. К напиткам подбираем родственные слова (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
Как видите, разбор морфем делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слов (разбор слов) — поиск корня, префиксов, суффиксов, окончаний и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора. Вычисление подобия исходного кода программы по композиции дерева синтаксического анализа и графа вызовов
На этой странице
РезюмеВведениеСвязанные работыЗаключениеБлагодарностиСсылкиАвторское правоСтатьи по теме
В этой статье предлагается новый метод вычисления степени сходства исходных кодов двух программ. Поскольку исходный код программы представлен в виде структурной формы, в предлагаемом методе в качестве меры подобия используются функции ядра свертки. На самом деле исходный код программы содержит два вида структурной информации. Одна — синтаксическая информация, а другая — зависимости вызовов функций, лежащие в программе. Поскольку синтаксическая информация программы выражается в виде ее дерева синтаксического анализа, синтаксическое сходство между двумя программами вычисляется ядром дерева синтаксического анализа. Вызовы функций внутри программы обеспечивают глобальную структуру программы и могут быть представлены в виде графа. Следовательно, сходство вызовов функций вычисляется с помощью ядра графа. Затем оба структурных сходства отражаются одновременно в сравнении исходных кодов программ путем составления дерева синтаксического анализа и ядер графов на основе цикломатической сложности. Согласно экспериментальным результатам на реальном наборе данных для обнаружения плагиата программ, предложенный метод доказал свою эффективность в выявлении сходства между программами. Эксперименты показывают, что плагиатные пары программ обнаруживаются корректно и тщательно предложенным методом.
1. Введение
Многие реальные ресурсы данных, такие как веб-таблицы и шаблоны PowerPoint, обычно представлены в структурной форме для предоставления более систематизированной и обобщенной информации. Поскольку этот тип данных содержит в целом различную и полезную информацию, они часто являются источником информации для приложений интеллектуального анализа данных [1]. Однако в настоящее время существует ряд дублирующих данных из-за характеристик цифровых данных. Это явление делает интеллектуальный анализ таких данных перегруженным. Исходный код программы — это тип данных, который часто дублируется, как веб-таблицы и шаблоны PowerPoint. Поэтому плагиат исходных кодов программ становится одной из самых острых проблем в обучении информатике. Студенты могут сдавать свои программные задания путем плагиата чужой работы без какого-либо понимания предмета или какой-либо ссылки на работу [2]. Однако крайне нецелесообразно выявлять все пары плагиата вручную, особенно когда размер исходных кодов значительно велик. Таким образом, требуется метод удаления таких дубликатов, и первым шагом для этого является автоматическое измерение сходства между двумя исходными кодами.
Исходный код программы является одним из репрезентативных структурированных данных. Хотя исходный код программы выглядит как непрерывная строка, его легко представить в виде структурной формы, то есть дерева синтаксического анализа. Исходный код представляется в виде древовидной структуры после его компиляции с грамматикой для определенного языка программирования. Следовательно, сходство исходных кодов программ должно учитывать их структуру. Во многих предыдущих исследованиях предлагались меры подобия для сравнения исходного кода программ, и большинство из них в той или иной степени отражают структурную информацию [3, 4]. Тем не менее, есть некоторые недостатки мер подобия. Во-первых, они не могут отражать всю структуру исходного кода, поскольку представляют структурную информацию исходного кода в виде структурных признаков, определенных на лексическом уровне. Чтобы преодолеть эту проблему, в некоторых исследованиях структурная информация рассматривается на структурном уровне, таком как дерево синтаксического анализа [5] и граф вызовов функций [6]. Во-вторых, нет исследований, в которых одновременно рассматривались бы дерево синтаксического анализа и граф вызовов, даже несмотря на то, что каждая структура обеспечивает различное структурное представление исходного кода программы. Дерево синтаксического анализа дает относительно локальное структурное представление, в то время как граф вызовов обеспечивает структурное представление высокого и глобального уровня. Поскольку оба представления полезны для обнаружения плагиатных пар исходных кодов программ, мера подобия для сравнения исходных кодов программ должна отражать оба вида структурной информации одновременно.
В этой статье предлагается новый метод вычисления сходства между двумя исходными кодами программ. Предлагаемый метод использует два вида структурной информации, основанной на функциях ядра. Функция ядра — один из известных методов сравнения структурированных данных [7]. Его можно использовать в качестве меры подобия, поскольку он вычисляет скалярное произведение двух элементов [8]. Предлагаемый метод отражает синтаксическую структуру исходного кода программы с использованием ядра дерева разбора [9]. Ядро дерева синтаксического анализа вычисляет сходство между парой деревьев синтаксического анализа. Таким образом, синтаксическая структурная информация исходного кода полностью отражается им в предлагаемом методе. Предлагаемый метод учитывает также динамическую структуру исходного кода с использованием графового ядра [10]. Ядро графа в предлагаемом методе вычисляет значение сходства между парой графов вызовов функций. Поскольку эти два ядра являются экземплярами ядер -свертки Хаусслера [7], они эффективно сравнивают деревья и графы без явного перечисления признаков соответственно.
Каждое ядро создает собственное подобие, основанное на его собственном структурном представлении. Предлагаемый метод включает оба вида структурной информации в сравнение исходного кода программы путем составления ядра дерева синтаксического анализа и ядра графа в составное ядро. Поскольку предлагаемое составное ядро основано на композиции взвешенных сумм, оптимизация весов базовых ядер является важнейшей задачей. В этой статье веса определяются автоматически с учетом сложности исходных кодов. Таким образом, если заданы любые два исходных кода программ, предлагаемый метод может вычислить их сходство.
Предлагаемый метод оценивается на обнаружение плагиата исходного кода с использованием реального набора данных, использованного в работе [5]. Наши эксперименты показывают три важных результата. Во-первых, мера подобия, основанная на ядре дерева синтаксического анализа, более надежна, чем мера, основанная на ядре графа, с точки зрения общей производительности. Во-вторых, чем сложнее исходный код, тем полезнее сходство, основанное на ядре графа, при обнаружении плагиатных пар. Наконец, предложенный метод, который объединяет ядро дерева синтаксического анализа и ядро графа, успешно обнаруживает плагиат исходных кодов реальных программ. Эти результаты доказывают, что структурная информация глобального уровня является важным фактором для сравнения программ и что предложенная мера подобия, которая объединяет синтаксическую и динамическую структурную информацию, дает хорошие результаты для обнаружения плагиата исходного кода программы.
Подводя итог, в этой статье мы делаем следующие выводы. (1) Мы разрабатываем и реализуем меру подобия исходного кода для обнаружения плагиата на основе двух видов структурной информации: синтаксической информации и зависимостей вызовов функций. Благодаря тому факту, что изменение структуры исходного кода сложнее, чем изменение пользовательского словаря, предлагаемый метод является надежным для обнаружения пар плагиата. (2) Чтобы одновременно использовать два вида структурной информации. , мы разрабатываем новый метод комбинирования, основанный на сложности исходного кода. Это делает предлагаемый метод более надежным, даже если мы сравниваем сложные исходные коды.
Остальная часть статьи организована следующим образом. Раздел 2 посвящен смежным исследованиям по сравнению исходного кода программы и обнаружению плагиата исходного кода программы. Раздел 3 знакомит с проблемами обнаружения плагиата исходного кода. Мера подобия, основанная на ядре дерева разбора и ядре графа функциональных вызовов, дана в разделах 4 и 5 соответственно. В разделе 6 предлагается составное ядро, которое объединяет ядро дерева синтаксического анализа и ядро графа. Раздел 7 объясняет экспериментальные настройки и результаты, полученные с помощью предлагаемого метода. Наконец, в разделе 8 делается вывод.
Измерение сходства между двумя объектами является фундаментальным и важным во многих областях науки. Например, в молекулярной биологии часто требуется измерить сходство последовательностей между парами белков. Таким образом, было предложено множество мер подобия, таких как измерения на основе расстояния, включая евклидово расстояние и расстояние Левенштейна, взаимная информация [11], информационный контент с использованием wordNet [12] и сходство на основе цитирования [13]. Кроме того, меры были применены к различным приложениям, таким как поиск информации [14, 15] и кластеризация [16], как их основная часть.
Мера подобия для исходных кодов давно вызывает интерес. Большинство ранних исследований основано на сходстве подсчета атрибутов [17, 18]. Подобие представляет программу как вектор различных элементов, таких как количество операторов и операндов. Затем для обнаружения плагиатных пар обычно используется сходство векторов. Однако производительность этого подхода относительно низкая по сравнению с другими методами, учитывающими структуру исходных кодов, поскольку этот подход использует только информацию абстрактного уровня.
Чтобы преодолеть недостатки подхода, основанного на метрике подсчета атрибутов, некоторые исследования включают структурную информацию исходного кода в свою меру сходства. В общем случае структура исходных кодов представляет собой дерево или граф. Из-за того, что исходный код компилируется в синтаксическую структуру, как описано грамматикой языка программирования, в некоторых исследованиях использовался алгоритм сопоставления деревьев для вычисления сходства между исходными кодами [4, 19]. Однако алгоритм представляет исходный код в виде строки, содержащей определенную структурную информацию, поэтому он не может отразить всю структуру исходного кода в мере подобия. С другой стороны, в некоторых других исследованиях использовались знания, полученные из топологии исходных кодов. Хорвиц впервые применил графовые структуры для сравнения двух программ [3] и определил, какие компоненты изменяются от одной к другой, на основе графа зависимостей программы [20]. Лю и др. также использовал граф зависимостей программы для представления исходного кода и принял упрощенную проверку изоморфизма подграфа для эффективного сравнения двух исходных кодов [21]. Каммер создал инструмент обнаружения плагиата для языка Haskell [6]. Сначала он извлек граф вызовов из исходного кода. Узлы на графике — это функции, а ребро указывает на то, что одна функция вызывает другую функцию. Затем он преобразовал граф в дерево для эффективного сравнения исходных кодов. Наконец, он применил расстояние редактирования дерева на основе — и алгоритм изоморфизма дерева для сравнения исходных кодов. Однако при таком подходе теряется много информации, лежащей на графе. так как граф превращается в дерево. Лим и др. предложил метод обнаружения плагиата Java-программ посредством анализа путей потока байт-кодов Java [22]. Поскольку поток программы представляет собой последовательность основных блоков при выполнении программы, они попытались выровнять пути потока, используя алгоритм полуглобального выравнивания, а затем обнаружили пары плагиата исходного кода программы. Че и др. также пытались обнаружить плагиат бинарной программы (исполняемого файла) [23]. Они построили первые A-CFG (график потока управления, помеченный API), который представляет собой функциональную абстракцию программы, а затем генерирует вектор предопределенного измерения из A-CFG с использованием интерфейса прикладного программирования Microsoft Development Network (MSDN API), чтобы избежать вычислительной сложности . Наконец, они использовали алгоритм случайного блуждания (ранжирования страниц) для вычисления сходства между программами. К сожалению, этот подход нельзя применить к другим языкам, не имеющим MSDN API. В последнее время в некоторых исследованиях для измерения сходства использовались стоп-слова-граммы [24] и тематическая модель [25].
В Интернете доступно несколько средств обнаружения плагиата исходного кода программы. Большинство из них используют токенизацию строк и алгоритм сопоставления строк для измерения сходства между исходными кодами. Пречелт и др. предложил JPlag. Это система, которую можно использовать для обнаружения плагиата исходных кодов, написанных на C, C++, Java и Scheme [26]. Сначала он извлекал токены из исходных кодов, а затем сравнивал токены из каждого исходного кода, используя алгоритм Karp-Rabin Greedy String Tiling. Еще одна широко используемая система обнаружения плагиата — 9.0029 MOSS (Measure Of Software Similarity), предложенный Айкеном [27]. Он также основан на алгоритме сопоставления строк. Он делит программы на -граммы, где -грамма — это непрерывная подстрока длины . Затем сходство определяется количеством одинаковых -граммов, используемых программами. Одной из современных и хорошо известных систем обнаружения плагиата является CCFinder, предложенная Kamiya et al. [28]. Он использует как метрику подсчета атрибутов, так и информацию о структуре. Исходный код преобразуется в набор нормализованных последовательностей токенов по собственным правилам преобразования. Правила преобразования создаются вручную для каждого языка, чтобы выразить структурные характеристики языков. Затем нормализованные токены сравниваются для выявления пар клонов в исходных кодах. Они показали относительно хорошую производительность и в некоторой степени использовали структурную информацию, но она не полностью отражает структурную информацию исходных кодов в своей мере подобия.
Предлагаемый в этой статье метод расширяет ядерный метод, предложенный Son et al. [5]. Они сравнили структуру исходных кодов, напрямую используя функцию ядра. Они использовали ядро дерева синтаксического анализа, в частности [9], своего рода ядра -свертки [7], для сравнения древовидной структуры исходных кодов. По сравнению с этой работой предлагаемый метод дополнительно включает информацию о вызове функции. Функциональные вызовы являются одной из важных структурных данных при сравнении исходных кодов. Основная проблема Son et al. заключается в том, что они сосредоточены только на синтаксической структурной информации, которая является локальной и статической. С другой стороны, информация о вызове функции обеспечивает глобальное представление о выполнении исходного кода. Таким образом, плагиатные пары исходных кодов обнаруживаются более точно, учитывая не только синтаксическую структуру, но и информацию о вызове функции.
3. Обнаружение плагиата исходного кода программы
Обнаружение плагиата для исходных кодов программ, также известное как обнаружение плагиата программирования, направлено на обнаружение пар исходного кода с плагиатом среди набора исходных кодов. Обнаружение плагиата в исходном коде обычно состоит из трех шагов, как показано на рис. 1. Первый шаг — это этап предварительной обработки, при котором из исходного кода извлекаются такие функции, как токены и деревья синтаксического анализа. На втором этапе вычисляется попарное сходство с извлеченными функциями и мерой сходства. Поэтому значения сходства среди всех пар записываются в матрицу сходства. Наконец, группы исходных кодов, которые с наибольшей вероятностью могут быть плагиатом, выбираются в соответствии с их значениями сходства.
Формально пусть — набор исходных кодов. Обнаружение плагиата направлено на создание списка плагиатных исходных кодов на основе сходства между и . Если сходство пары превышает заранее заданный порог, пара определяется как плагиат. Таким образом, для исходного кода набор плагиатных исходных кодов определяется как
Мера сходства определяется типом информации, извлеченной из исходных кодов. Исходный код содержит два вида информации: лексическую и структурную информацию. Лексическая информация соответствует переменным и зарезервированным словам, например 9.0029 public , для и для . Этот словарь состоит из большого набора редко встречающихся определяемых пользователем слов (переменных) и небольшого набора часто встречающихся слов (зарезервированных слов). С другой стороны, структурная информация соответствует структуре, которая определяется зарезервированными словами. Среди них структурная информация является более важной подсказкой для обнаружения плагиата, поскольку токены могут быть легко преобразованы в другие токены без понимания предмета исходного кода. Поэтому в данной статье основное внимание уделяется структурной информации. Обратите внимание, что исходная программа имеет два вида структурной информации. Одна представляет собой синтаксическую структуру, которая обычно выражается в виде дерева синтаксического анализа, а другая представляет собой структуру графа вызовов функций.
4. Мера сходства исходных кодов на основе ядра дерева синтаксического анализа
4.
1. Исходный код в виде дереваИсходный код программы естественно представить в виде дерева синтаксического анализа, каждый узел которого обозначает переменные, зарезервированные слова, операторы и т.д. На рис. 2 показан пример дерева синтаксического анализа, извлеченного из кода Java в блоке 1 (это дерево синтаксического анализа немного отличается от дерева синтаксического анализа, используемого в Son et al. [5]. Это связано с тем, что в этом документе используется более поздняя версия грамматики Java). бумага). Код Java во вставке 1 реализует последовательность Фибоначчи. Из-за недостатка ширины бумаги на рисунке 2 показана только одна функция, rFibonacci, , в то время как в блоке 1 существует пять функций. Как показано в этом алгоритме, дерево разбора из простого исходного кода может быть очень большим и глубоким. -укорененный.
В этой статье мы используем ANTLR (другой инструмент для распознавания языка) (http://www.antlr.org/) для извлечения дерева синтаксического анализа из исходного кода. ANTLR , предложенный Парром и Куонгом, представляет собой языковой инструмент, обеспечивающий основу для построения распознавателей, интерпретаторов, компиляторов и трансляторов из грамматических описаний [29]. С помощью ANTLR и грамматики языка можно легко построить синтаксический анализатор дерева, который переводит исходный код в дерево синтаксического анализа.
Поскольку дерево синтаксического анализа содержит синтаксическую структурную информацию, требуется метрика для дерева синтаксического анализа, отражающая всю структурную информацию. Ядро дерева синтаксического анализа является одной из таких метрик. Он сравнивает деревья синтаксического анализа без структурных признаков, разработанных вручную.
4.2. Ядро дерева синтаксического анализа
Ядро дерева синтаксического анализа — это ядро, предназначенное для сравнения древовидных структур, таких как деревья синтаксического анализа предложений естественного языка. Это ядро отображает дерево синтаксического анализа в пространство, охватываемое всеми поддеревьями, которые могут появиться в дереве синтаксического анализа. Явное перечисление всех поддеревьев вычислительно невозможно, поскольку количество поддеревьев увеличивается экспоненциально по мере роста размера дерева. Коллинз и Даффи предложили метод вычисления скалярного произведения двух деревьев без необходимости перечисления всех поддеревьев [9].].
Позвольте быть всем поддеревьям в дереве синтаксического анализа. Затем можно представить в виде вектора, где частота в дереве синтаксического анализа. Функция ядра между двумя деревьями синтаксического анализа и определяется как и определяется как где и все узлы в деревьях и . Индикаторная функция равна 1, если корнем является узел, и 0 в противном случае. это функция, которая определяется как Эта функция может быть вычислена за полиномиальное время, используя следующее рекурсивное определение. (i) Если продукты в и различны, (ii) Если оба и являются предтерминалом, (iii) В противном случае функция может быть определена следующим образом: где — количество потомков узла в дереве.
Так как производство в и одинаково, также равно . Здесь обозначает th дочерний узел . Этот рекурсивный алгоритм основан на том факте, что все поддеревья с корнями в определенном узле могут быть построены путем объединения поддеревьев с корнями в каждом из его потомков.
4.3. Модифицированное ядро дерева синтаксического анализа
Ядро дерева синтаксического анализа показало хорошую производительность для деревьев синтаксического анализа естественного языка, но оно плохо работает для сравнения исходного кода программы из-за двух проблем. Первая проблема — асимметричное влияние изменений узла. Дерево синтаксического анализа из исходного кода, как правило, намного больше и глубже, чем из предложения на естественном языке. Следовательно, изменения вблизи корневого узла отражались чаще, чем изменения вблизи листовых узлов. Второй проблемой является последовательность поддеревьев. Исходное ядро дерева синтаксического анализа подсчитывает последовательность поддеревьев, учитывая их порядок. Однако порядок двух подструктур в исходном коде не имеет смысла в языках программирования.
Сон и др. предложил модифицированное ядро дерева синтаксического анализа, чтобы справиться с этими проблемами [5]. Чтобы решить первую проблему, они ввели коэффициент затухания и порог, контролирующие влияние больших поддеревьев. Коэффициент затухания масштабирует относительную важность поддеревьев по их размеру. По мере увеличения глубины поддерева значение ядра поддерева уменьшается на , где — глубина поддерева. Кроме того, ограничение максимальной глубины возможных поддеревьев установлено как , чтобы можно было уменьшить влияние больших поддеревьев. Вторая проблема решается путем изменения функции в (7), чтобы игнорировать порядок двух узлов.
С коэффициентом затухания и порогом рекурсивные правила ядра дерева синтаксического анализа изменяются следующим образом. (i) Если и различны, (ii) Если оба и являются терминалами или текущая глубина равна , Уравнение (7 ) нельзя использовать с этими новыми рекурсивными правилами, так как количество дочерних узлов может быть разным в и . Таким образом, мы принимаем максимальное сходство между дочерними узлами. В результате функция в (7) принимает вид где множество дочерних узлов .
Ядро дерева разбора с измененной функцией не удовлетворяет условию Мерсера. Однако многие функции, не удовлетворяющие условию Мерсера [30, 31], хорошо работают при вычислении подобия [32]. Наконец, это ядро дерева синтаксического анализа используется в качестве меры подобия в (1) для синтаксического структурного сравнения исходных кодов.
5. Мера сходства исходных кодов на основе ядра графа
5.1. Исходный код в виде графика
В последнее время исходные коды программ пишутся с использованием объектно-ориентированных концепций и нескольких методов рефакторинга, так что коды становятся все более и более модульными на функциональном уровне. Поскольку исходный код кодирует логику программы для решения проблемы, поток выполнения на функциональном уровне является одним из важных факторов для идентификации исходного кода. Следовательно, этот поток на функциональном уровне следует рассматривать для сравнения исходных кодов.
Одним из возможных представлений потока на уровне функций является граф вызовов функций, который представляет зависимости между функциями в программе. Пусть будет исходным кодом. Тогда граф вызовов функции представляет собой ориентированный граф, извлеченный из , где функция в . Таким образом, число функций в . представляет собой набор ребер, и каждое ребро представляет отношение зависимости между функциями. То есть ребро, соединяющее узлы и подразумевающее, что функция вызывает другую функцию. Вес ребра равен
На рис. 3 показан пример графа вызовов функций, извлеченный из кода Java во вставке 1. Этот код содержит пять функций, включая main. Во-первых, main вызывает rFibonacci и iFibonacci по порядку. Поскольку rFibonacci — рекурсивная функция, она вызывает сама себя. iFibonacci вызывает две функции, initOne и sum, для инициализации переменной и получения суммы. Наконец, main вызывает println для вывода результатов.
Для извлечения графа вызовов из исходного кода используется подход, основанный на правилах. Простые правила используются для нахождения отношения вызывающий-вызываемый из дерева синтаксического анализа. Например, в Java правило «, если ‘выражение (expressionList)’ найдено, , то выражение является именем вызываемой функции» используется для поиска поддеревьев из дерева разбора. Затем имена функций и параметры извлекаются из соответствующих поддеревьев. Узлы для извлеченных имен функций подключаются к вызывающему узлу.
График вызовов функций программы показывает, как программа выполняется на функциональном уровне и как функции связаны друг с другом. Поскольку поток программы достаточно уникален в зависимости от задачи, сходство между двумя источниками может быть рассчитано с использованием потоков программ. Поскольку этот поток представлен в виде графа вызовов функций, ядро графа является лучшим методом для сравнения графов вызовов функций. Он показал хорошие результаты в нескольких областях, включая биологию и анализ социальных сетей.
5.2. Ядро графа
Ядро графа — это ядро, предназначенное для сравнения структур графов. Подобно ядру дерева синтаксического анализа, граф отображается в пространство признаков, натянутое их подграфами в ядре графа. Интуитивным свойством ядра графа является изоморфизм графа, определяющий топологическую идентичность. Согласно Гертнеру и соавт. [10], однако так же сложно, как решить, изоморфны ли два графа, вычислить любое полное ядро графа с инъективной функцией отображения для всех графов, где изоморфизм графов является NP-полной задачей [33]. Таким образом, большинство ядер графов фокусируются на альтернативном представлении признаков графов.
Ядро графа случайного блуждания — одно из наиболее широко используемых ядер графа. Он использует все возможные случайные блуждания в качестве признаков для графиков. Позвольте быть множество всех возможных случайных блужданий и обозначает множество всех возможных блужданий с ребрами в графе. Для каждого случайного блуждания, длина которого равна , соответствующая функция отображения признаков графа задается как где — вес для длины , и — th метка случайного блуждания и , соответственно. Функция ядра между двумя графиками и , обозначаемая , может быть определена как
Гертнер и др. предложил подход для вычисления всех случайных блужданий в пределах двух графов без явного перебора всех случайных блужданий [10]. Граф прямого произведения двух графов и , обозначаемый где его набор узлов и его набор ребер, определяется следующим образом: где метка узла и метка ребра между узлом и узлом . На основе графа прямого произведения можно рассчитать ядро случайного блуждания. Обозначим через матрицу смежности прямого произведения . С весовым коэффициентом в (13) можно переписать как Это ядро случайных блужданий можно вычислить с помощью уравнения Сильвестра или метода сопряженных градиентов, где — количество узлов [34].
5.3. Модифицированное ядро графа
Когда ядро графа используется для сравнения исходных кодов, не ожидается хорошей производительности из-за того, что ядро графа измеряет сходство между обходами с одинаковой меткой. Поскольку метки (имена функций) узлов в графе вызовов функций определяются разработчиками-людьми, они редко идентичны, даже если исходные коды просты. Следовательно, ядро графа должно учитывать неидентичные метки.
Боргвардт и др. модифицировал ядро случайных блужданий для сравнения неидентичных меток, изменив граф прямого произведения, включив в него все пары узлов и ребер [35]. Предположим, что узлы сравниваются ядром узла, а ребра сравниваются ядром ребра kedge. То есть вычисляет сходство между двумя метками по узлам и , а также вычисляет сходство между двумя ребрами и . С этими двумя ядрами ядро случайного блуждания между двумя графами вызовов функций и теперь определяется как где
Если это модифицированное ядро случайного блуждания используется для сравнения исходного кода, необходимо определить ядро узла и пограничное ядро. Обратите внимание, что метки ребер в графе вызовов функций являются двоичными значениями по (11). Таким образом, он просто предназначен для сравнения двоичных значений. Простейшая форма for — это функция, которая возвращает 1, когда имеет похожие шаблоны строк, и 0 в противном случае. То есть он возвращает 1, если расстояние между и меньше предопределенного порога. В этой статье мы просто используем расстояние Левенштейна в качестве расстояния и устанавливаем порог 0,5.
Модифицированное ядро случайных блужданий также можно вычислить с помощью (15). Однако матрица смежности прямого произведения должна быть изменена как где является краткой формой , а ребра и принадлежат и , соответственно. Как и в ядре дерева синтаксического анализа, это ядро модифицированного графа используется для сравнения исходных кодов в качестве меры сходства в (1).
6. Мера сходства для исходных кодов, основанных на составном ядре
Модифицированное ядро дерева синтаксического анализа управляет синтаксической структурной информацией, тогда как модифицированное ядро графа учитывает высокоуровневую топологическую информацию исходных кодов. Чтобы использовать оба вида информации, требуется композиция двух ядер. Кристианини и Шоу-Тейлор доказали, что новое ядро можно получить, объединив несколько существующих ядер с некоторыми свойствами замыкания, такими как взвешенная сумма и умножение [36]. Среди различных свойств замыкания в этой статье используется взвешенная сумма, поскольку она проста и широко используется.
Перед объединением двух ядер ядра должны быть нормализованы, поскольку модифицированное ядро дерева синтаксического анализа и модифицированное ядро графа не связаны. Поэтому в их составе одно ядро может доминировать над другим. Чтобы убрать этот эффект, ядра сначала нормализуются. Когда задано ядро, его нормализованное ядро определяется как Следовательно, ограничено между 0 и 1. То есть .
Наше составное ядро состоит из ядра нормализованного модифицированного дерева синтаксического анализа и ядра нормализованного модифицированного графа. То есть составное ядро, , для заданных двух исходных кодов и определяется как где — вес смешивания между двумя ядрами. и – деревья разбора, извлеченные из исходных кодов и , соответственно, и – графы вызовов из и , соответственно. Чем больше, тем значительнее. С другой стороны, по мере того, как значение становится маленьким, ядро графа становится более значимым, чем ядро дерева синтаксического анализа . Это составное ядро используется в качестве окончательной меры подобия в (1).
Ядро дерева синтаксического анализа сравнивает исходные коды с представлением локального уровня , поскольку оно основано на сравнении поддеревьев. Большинство исходных кодов с плагиатом изменяют небольшую часть исходного кода. Таким образом, ядро дерева синтаксического анализа в целом показало хорошие результаты. Однако он не отражает потока программы, который является динамической структурной информацией. Ядро графа, с другой стороны, вычисляет сходство с точки зрения динамического представления высокого уровня . Таким образом, когда исходный код состоит из нескольких функций, графовое ядро обеспечивает приемлемую производительность. В результате должна определяться сложность исходных кодов, поскольку это параметр для управления относительной важностью между ядром дерева синтаксического анализа и ядром графа.
Существует множество методов измерения сложности исходного кода. Одним из широко используемых методов является цикломатическая сложность, предложенная Маккейбом [37]. Цикломатическая сложность — это теоретико-графовая количественная метрика, измеряющая количество путей в исходном коде. Он просто рассчитывается с использованием графа потока управления исходного кода, где узлы графа соответствуют объектам исходного кода, а (направленное) ребро между двумя узлами подразумевает отношение зависимости между объектами. Учитывая граф потока управления исходного кода, цикломатическая сложность исходного кода определяется как где число ребер графа, количество узлов и количество связанных компонентов. Чем он больше, тем сложнее исходный код.
В этой статье мы измеряем сложность исходного кода с помощью графа вызовов функций. Поскольку граф вызовов функций представляет зависимости между функциями внутри программы, его можно рассматривать как своего рода графы потока управления, где объекты исходного кода являются функциями в исходном коде, а ребро подразумевает зависимости между функциями.
Пусть и будет цикломатическая сложность двух исходных кодов и , соответственно. Так как это вес двух нормализованных ядер, он должен нормализоваться между 0 и 1. Сигмоидальная функция определена для всех действительных входных значений и возвращает положительное значение между 0 и 1. Таким образом, сигмоидальная функция принимается для (20) , и определяется как где возвращает минимальное значение между и . Согласно (22), с ростом цикломатической сложности также увеличивается. должно быть 0,5, когда цикломатическая сложность исходного кода равна 25. Это указывает на то, что, когда цикломатическая сложность исходного кода равна 25, ядро дерева синтаксического анализа и ядро графа имеют одинаковую важность в составном ядре. Ряд приложений для анализа исходного кода рассматривает исходные коды, цикломатическая сложность которых превышает 25, как сложные коды (http://msdn.microsoft.com/en-us/library/ms182212.aspx). Таким образом, мы устанавливаем 25 как точку равенства важности между ядром дерева разбора и ядром графа.
7. Эксперименты
7.1. Experimental Settings
Для экспериментов тот же набор данных, что и в работе Son et al. [5]. Этот набор данных собран из реальных заданий по программированию классов Java, выполненных студентами бакалавриата в период с 2005 по 2009 год. В таблице 1 показана простая статистика набора данных. Общее количество заданий по программированию составляет 36, а количество представленных исходных кодов составляет 555 для 36 заданий. Таким образом, среднее количество исходников на одно задание составляет 15,42.
На рис. 4 показана гистограмма исходных кодов по строкам. По оси — количество строк программы, а по оси — количество исходных кодов. Как показано на этом рисунке, около 75% исходных кодов содержат менее 400 строк. Минимальное количество строк исходного кода — 49, максимальное — 2863. Среднее количество строк в коде — 305,07.
В нашем наборе данных минимальное количество функций в программе равно 12, а максимальное — 447. Программы с большим количеством программ — это программы рисования с любыми кнопками. В программах рисования учащиеся должны установить макет вручную с помощью необработанных функций, таких как setBounds. Таким образом, программы рисования имеют ряд функций. Среднее количество функций — 64,27.
Два аннотатора создали золотой стандарт для этого набора данных. Они исследовали все исходные коды и вручную отметили плагиат. Чтобы измерить надежность и достоверность аннотаторов, измеряется каппа-соглашение Коэна [38]. Каппа-соглашение аннотаторов соответствует категории «почти идеальное согласие». Только те пары, которые оба аннотатора оценивают как пары с плагиатом, считаются настоящими парами с плагиатом. Всего 175 пар помечены как плагиат.
В качестве меры оценки используются три показателя: точность, полнота и -мера. Они рассчитываются следующим образом:
Для оценки предложенного метода используется несколько базовых систем. Его сравнивают с JPlag и CCFinder. Во всех экспериментах для ядра дерева синтаксического анализа пороговое значение глубины поддерева установлено равным 3, а коэффициент затухания равен 0,1. Фактор затухания ядра графа эмпирически установлен равным 0,1. в (21) устанавливается равным 1, потому что каждый исходный код в нашем наборе данных представляет собой одну программу.
7.2. Экспериментальные результаты
Перед оценкой эффективности обнаружения плагиата мы сначала исследуем взаимосвязь между количеством строк исходного кода и цикломатической сложностью. Это исследование пытается показать, что (22) выполнимо. Поскольку определяется цикломатической сложностью, ожидается, что она будет пропорциональна цикломатической сложности. На рис. 5 показан график разброса между количеством строк и цикломатической сложностью. Как показано на этом рисунке, они сильно коррелируют друг с другом в нашем наборе данных. Коэффициент корреляции Пирсона равен 0,714. Этот результат означает, что в (22) можно установить пропорциональную цикломатической сложности.
Чтобы увидеть влияние порога в (1) в нашем методе, производительность измеряется в соответствии со значениями . На рис. 6 показана производительность предлагаемого метода для различных . По мере увеличения точность также увеличивается, а полнота немного уменьшается. Наилучшие характеристики достигаются при 0,87 меры. Таким образом, используется во всех приведенных ниже экспериментах.
На рис. 7 предложенный метод сравнивается с различными ядрами по количеству строк исходного кода. На этом рисунке по оси -количество строк исходного кода, а по оси -среднее значение. Как показано на этом рисунке, исходное ядро графа показывает наихудшую производительность. Поскольку он использует только структуру графа вызовов функций, он часто не может вычислить сходство между исходными кодами. Например, предположим, что есть два исходных кода. В одном исходном коде main вызывает функцию add, and add вызывает другую функцию multiple. В другом исходном коде main вызовы умножаются и умножаются вызовы добавляются. Эти два исходных кода одинаковы для ядра графа, поскольку ядро графа игнорирует информацию о метках. Без меток эти два графика идентичны. С другой стороны, модифицированное ядро графа использует информацию о метках. В результате достигается лучшая производительность, чем у ядра графа.
Ядро дерева синтаксического анализа обеспечивает более высокую производительность, чем другие методы, для исходных кодов с менее чем 300 строками. Когда количество строк в исходных кодах невелико, плагиат кода часто делается путем локального изменения исходного кода. Таким образом, ядро дерева синтаксического анализа точно обнаруживает плагиатные пары для кодов с небольшим количеством строк. Когда исходный код содержит более 300 строк, модифицированное ядро графа показывает немного лучшую производительность, чем ядро дерева синтаксического анализа. Этот результат подразумевает, что структурная информация высокого уровня является еще одним фактором для сравнения (больших) исходных кодов, и модифицированное ядро графа может хорошо отражать эту структурную информацию.
Предлагаемый метод, сочетающий ядро дерева синтаксического анализа и модифицированное ядро графа, обеспечивает наилучшую производительность для всех исходных кодов, кроме строковых. Поскольку цикломатическая сложность исходных кодов со строками близка к 25, предлагаемый метод в равной степени отражает ядро дерева синтаксического анализа и ядро модифицированного графа. Таким образом достигается средняя производительность ядер. Из-за цикломатической сложности исходных кодов на предлагаемый метод больше влияет ядро дерева разбора, когда исходный код небольшой. Если исходный код большой, эффект ядра графа больше, чем эффект ядра дерева синтаксического анализа. Из результатов можно сделать вывод, что предлагаемый метод эффективно учитывает не только структурную информацию локального уровня, но и структурную информацию высокого уровня.
Окончательная -мера обнаружения плагиата исходного кода программы приведена в таблице 2. Предлагаемый метод показывает наилучшую -меру по сравнению с другими ядрами или системами с открытым исходным кодом для выявления плагиата. Разница -measure составляет 0,29 по сравнению с JPlag, 0,17 по сравнению с CCFinder, 0,08 по сравнению с модифицированным графом и 0,05 по сравнению с модифицированным ядром дерева синтаксического анализа. Этот результат означает, что для обнаружения плагиата исходного кода мера сходства в (1) должна одновременно учитывать не только синтаксическую структурную информацию, но и структуру динамического вызова.
8. Заключение
В этой статье мы предложили новый метод сравнения исходного кода программы. Предлагаемый метод вычисляет сходство между двумя исходными кодами по составу двух видов структурной информации, извлеченной из исходных кодов. То есть метод использует как синтаксическую информацию, так и динамическую информацию. Синтаксическая информация, обеспечивающая представление структуры на локальном уровне, включена в дерево синтаксического анализа. Чтобы сравнить деревья синтаксического анализа, в этой статье используется специализированное ядро дерева для деревьев синтаксического анализа исходных кодов. Динамическая информация, содержащаяся в графе вызовов функций, дает структурное представление высокого и глобального уровня. Ядро графа с именами функций рассмотрения принято для отражения структуры графа. Наконец, предлагаемый метод использует составное ядро из ядер для использования обоих видов информации. Кроме того, веса ядер в составном ядре автоматически определяются цикломатической сложностью.
В экспериментах по обнаружению плагиата исходного кода программы Java на реальном наборе данных показано, что предложенный метод превосходит существующие методы в обнаружении плагиатных пар. В частности, эксперименты с различным количеством строк показывают, что предложенный метод всегда хорошо работает независимо от размера исходных кодов.
Одним из преимуществ предложенного метода является то, что его можно использовать с другими языками, такими как C, C++ и Python, даже если эксперименты проводились только с Java. Поскольку для предлагаемого метода требуются только деревья синтаксического анализа и графы вызовов функций исходных кодов, его можно применять к любым другим языкам, если доступен синтаксический анализатор для этих языков. Все виды информации о предлагаемом методе доступны по адресу http://ml. knu.ac.kr/plagiarism.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов в связи с публикацией данной статьи.
Благодарности
Это исследование было поддержано проектом BK21 Plus (Программа развития человеческих ресурсов SW для поддержки умной жизни), финансируемым Министерством образования, Школа компьютерных наук и инженерии, Национальный университет Кёнпук, Корея (21A20131600005), и Программа исследований и разработок в области ИКТ MSIP/IITP (10044494, WiseKB: саморазвивающаяся база знаний и платформа рассуждений на основе больших данных).
Каталожные номера
J.-W. Сын и С.-Б. Парк, «Распознавание веб-таблиц с композицией богатой структурной и содержательной информации», Applied Soft Computing , vol. 13, нет. 1, стр. 47–57, 2013 г.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Д. Л. Маккейб, «Обман среди студентов колледжей и университетов: взгляд Северной Америки», International Journal for Educational Integrity , vol.
1, нет. 1, стр. 1–11, 2005.Просмотр по адресу:
Google Scholar
С. Хорвиц, «Выявление семантических и текстовых различий между двумя версиями программы», в Трудах конференции ACM SIGPLAN по разработке и реализации языков программирования , стр. 234–245, 1990.
Посмотреть по адресу:
Google Scholar
В. Ян, «Выявление синтаксических различий между двумя программами», Программное обеспечение: практика и опыт , том. 21, нет. 7, стр. 739–755, 1991.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Ж.-В. Сын, Т.-Г. Но, Х.-Дж. Сонг и С.-Б. Парк, «Приложение для обнаружения плагиата исходного кода на основе ядра дерева синтаксического анализа», Engineering Applications of Artificial Intelligence , vol.
26, нет. 8, стр. 1911–1918, 2013.Посмотреть по адресу:
Сайт издателя | Google Scholar
М. Л. Каммер, Обнаружение плагиата в программах Haskell с использованием сопоставления графа вызовов [M.S. диссертация] , Утрехтский университет, 2011.
Д. Хаусслер, «Ядра свертки на дискретных структурах», Tech. Представитель UCS-CRL-99-10, Калифорнийский университет, Санта-Крус, Калифорния, США, 1999 г.
Посмотреть по адресу:
Google Scholar
Б. Шолкопф, К. Цуда и Дж.-П. Vert, Kernel Methods in Computational Biology , MIT Press, 2004.
М. Коллинз и Н. Даффи, «Ядра свертки для естественного языка», в Достижения в системах обработки нейронной информации , стр. 625–632, 2001.
Посмотреть по адресу:
Google Scholar
Т.
Гартнер, П. Флах и С. Врубель, «О графовых ядрах: результаты твердости и эффективные альтернативы», в Proceedings of the 16th Annual Conference on Learning Theory , стр. 129–143, август 2003 г. 28-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL ’90) , стр. 268–275, Страудсбург, Пенсильвания, США, июнь 1990 г.Посмотреть по адресу:
Сайт издателя | Google Scholar
П. Резник, «Использование информационного содержания для оценки семантического сходства в таксономии», в Proceedings of the 13th International Joint Conference on Artificial Intelligence , стр. 448–453, 1995.
Посмотреть по адресу:
Google Scholar
Б. Гипп, Н. Меушке и К. Брайтингер, «Обнаружение плагиата на основе цитирования: осуществимость в крупномасштабном научном корпусе», Журнал Ассоциации информационных наук и технологий , том.
65, нет. 8, стр. 1527–1540, 2014.Посмотреть по адресу:
Сайт издателя | Google Scholar
Г. Варелас, Э. Вутсакис, П. Рафтопулу, Э. Г. Петракис и Э. Э. Милиос, «Методы семантического подобия в wordnet и их применение для поиска информации в Интернете», в Proceedings of 7th Annual ACM. Международный семинар по веб-информации и управлению данными , стр. 10–16, 2005 г.
Посмотреть по адресу:
Google Scholar
К. Уильямс, Х.-Х. Чен и С. Л. Джайлс, «Классификация и ранжирование результатов поисковых систем как потенциальных источников плагиата», в Proceedings of the ACM Symposium on Document Engineering , стр. 97–106, Форт-Коллинз, Колорадо, США, сентябрь 2014 г.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Р.
А. Джарвис и Э. А. Патрик, «Кластеризация с использованием меры подобия на основе общих ближайших соседей», Транзакции IEEE на компьютерах , том. 22, нет. 11, стр. 1025–1034, 1973.Посмотреть по адресу:
Сайт издателя | Google Scholar
KJ Ottenstein, «Алгоритмический подход к обнаружению и предотвращению плагиата», ACM SIGCSE Bulletin , vol. 8, нет. 4, стр. 30–41, 1976.
Посмотреть по адресу:
Сайт издателя | Google Scholar
M. Halstead, Elements of Software Science , Elsevier, 1977.
И. Д. Бакстер, А. Яхин, Л. Моура, М. Сант-Анна и Л. Бир, «Обнаружение клонов с использованием абстрактных синтаксических деревьев», в Трудах Международной конференции IEEE по обслуживанию программного обеспечения (ICSM ’98). ) , стр. 368–377, ноябрь 1998 г.
Просмотр по адресу:
Google Scholar
Дж.
Ферранте, К. Дж. Оттенштейн и Дж. Д. Уоррен, «График зависимости программы и его использование в оптимизации», ACM Сделки по языкам и системам программирования , том. 9, нет. 3, стр. 319–349, 1987.Посмотреть по адресу:
Сайт издателя | Google Scholar
C. Liu, C. Chen, J. Han и PS Yu, «Gplag: обнаружение плагиата программного обеспечения с помощью анализа графа программной зависимости», в Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , стр. 872–881, 2006.
Просмотр по адресу:
Google Scholar
Лим, Х. Парк, С. Чой и Т. Хан, «Метод обнаружения кражи программ Java посредством анализа информации о потоке управления», Информационные и программные технологии , том. 51, нет. 9, стр. 1338–1350, 2009.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Д.
-К. Че, Дж. Ха, С.-В. Ким, Б. Дж. Кан и Э. Г. Им, «Обнаружение плагиата в программном обеспечении: подход на основе графов», в Трудах 22-й Международной конференции ACM по управлению информацией и знаниями (CIKM ’13) , стр. 1577–1580, Burlingame, Калифорния, США, ноябрь 2013 г.Посмотреть по адресу:
Сайт издателя | Google Scholar
Э. Стамататос, «Обнаружение плагиата с использованием стоп-слов n-грамм», Журнал Американского общества информационных наук и технологий , том. 62, нет. 12, стр. 2512–2527, 2011.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Г. Косма и М. Джой, «Подход к обнаружению и расследованию плагиата исходного кода с использованием скрытого семантического анализа», IEEE Transactions on Computers , том. 61, нет. 3, стр. 379–394, 2012 г.
Посмотреть по адресу:
Сайт издателя | ученый Google | MathSciNet
Л.
Пречелт, Г. Малполь и М. Филипсен, «Поиск плагиата среди набора программ с помощью jplag», Journal of Universal Computer Science , vol. 8, нет. 11, pp. 1016–1038, 2002.Посмотреть по адресу:
Google Scholar
A. Aiken, «Moss: система обнаружения программного плагиата», 1998, http://theory.stanford.edu/ ~айкен/мосс/.
Посмотреть по адресу:
Google Scholar
Т. Камия, С. Кусумото и К. Иноуэ, «CCFinder: многоязычная система обнаружения клонов кода на основе токенов для крупномасштабного исходного кода», IEEE Transactions on Software Машиностроение , вып. 28, нет. 7, стр. 654–670, 2002.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Т. Дж. Парр и Р. В. Куонг, «ANTLR: генератор парсеров с предикативным LL (k)», Программное обеспечение: практика и опыт , том.
25, нет. 7, стр. 789–810, 1995.Посмотреть по адресу:
Сайт издателя | Google Scholar
В. Н. Вапник, The Nature of Statistical Learning Theory , Springer, New York, NY, USA, 1995.
Посмотреть по адресу:
Сайт издателя | MathSciNet
R. Courant and D. Hilbert, Methods of Mathematical Physics , Interscience, New York, NY, USA, 1953.
A. Moschitti and FM Zanzottos, из текстов», в Материалы 24-й Международной конференции по машинному обучению (ICML ’07) , стр. 649–656, Корваллис, штат Орегон, США, июнь 2007 г.
Посмотреть по адресу:
Сайт издателя | Google Scholar
M. R. Garey and D. S. Johnson, Computers and Intractability: A Guide to the Theory of NP-Completeness , WH Freeman, 1990.
S.V.N. , «Ядра графа», Journal of Machine Learning Research , том. 11, стр. 1201–1242, 2010.
Посмотреть по адресу:
Сайт издателя | ученый Google | MathSciNet
К. М. Боргвардт, К. С. Онг, С. Шёнауэр, С. В. Н. Вишванатан, А. Дж. Смола и Х.-П. Кригель, «Прогнозирование функции белков с помощью ядер графа», Bioinformatics , vol. 21, приложение 1, стр. i47–i56, 2005.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Н. Кристианини и Дж. Шоу-Тейлор, Введение в машины опорных векторов , Cambridge University Press, Cambridge, UK, 2000.
Посмотреть по адресу:
Сайт издателя
Т. Дж. Маккейб, «Мера сложности», IEEE Transactions on Software Engineering , vol.