«Синтаксический разбор предложения » — Яндекс Кью
ПопулярноеЮля Ж. · ·
2,3 K
На Кью задали 7 похожих вопросовЭльса М.
Всем трям, то есть здравствуйте. 🙂 Я по жизни… · 23 янв 2019
Чтобы сделать синтаксический разбор предложения, сначала нужно найти и подчеркнуть главные члены (подлежащее и сказуемое). Потом задать от них вопросы к второстепенным членам, узнать, чем они являются и подчеркнуть их. Подписать над каждым словом часть речи.
Определить тип предложения по цели высказывания (повествовательное, вопросительное, побудительное). Указать вид предложения по эмоциональной окраске (восклицательное, невосклицательное). Далее понять, простое предложение или сложное.
Если сложное, то: по грамматическим основам определить количество простых предложений и найти их границы и определить средства связи простых предложений (союзное или безсоюзное).
В конце составить схему предложения.
55 оценили·
12,7 K
Наталья
19 сент 2019
Смотрите учебники по русскому языку. Все виды разбора там есть
Комментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
Ответы на похожие вопросы
Помогите пожалуйста сделать полный синтаксический разбор предложений🙏 — 1 ответ, заданNas tae
6 окт 2020
1.Правильная речь -это одна из весьма существенных сторон общей культуры человека.
2.Поэт в России-больше чем поэт.
3.Наш дар бесценный-речь.
Заранее ОГРОМНОЕ СПАСИБО!)
·
1,9 K
Комментировать ответ…Комментировать…
Как делается синтаксический разбор предложения? — 11 ответов, задан 056Z»>26 янв 2018
056Z»>26 янв 2018Анастасия BonneFee
Препод-IT-шник. · 12 нояб 2018
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
Для простого:
- Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое).
- Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое.
- Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено.
- Подчеркнуть все члены предложения, указать части речи.
- Составить схему предложения, указав грамматическую основу и осложнение, если оно есть.
Для сложного:
- Указать, какая связь в предложении: союзная или бессоюзная.

- Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы.
- Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП).
- Разобрать каждую часть сложного предложения, как простое (см. выше).

·
145,3 K
Комментировать ответ…Комментировать…
Как делается синтаксический разбор предложения? — 11 ответов, заданВоланд Орле
Люблю сочинять и фотошопить · 12 нояб 2020
Предложение…
Рекомендуется подчеркнуть слова,и подписать часть речи
Подчёркивания
1)Подлежащее-(одной чертой)
2)Сказуемое-(двумя чертами)
3)Обстоятельство-(точка тире,точка тире и т.д.)
4)дополнение-(пунктиром)
5)определение-(волнистой линеей)
Части речи
1)Имя прилогательное
2)Имя существительное
3)Глагол
4)Наречие
5)Числительное
6)Местоимение
7)Предлог
8)Союз
9)Нарецательное
Характеристика(пишиться под предложением)
1. По цели высказывание-вопросительное,повествовательное,побудительное.
По цели высказывание-вопросительное,повествовательное,побудительное.
2.По интонации-восклицательное,невосклицательное.
3.По наличию грамматических основ-простое,сложное.
4.По наличию главных членов предложения-односоставное,двухсоставное.
5.По наличию второстипенных членов-распространённое,нераспростронённое.
6.По граматике-осложнено,несложнено.
7.Схема предложения-[…]
Если чтото непонравилось пишите причину в коментарии
34 оценили·
10,0 K
Комментировать ответ…Комментировать…
Как провести синтаксический разбор предложения? — 1 ответ, заданВера Зобова
Я очень люблю русский язык и попытаюсь ответить… · 4 нояб 2020
1.Охарактеризоватьпредложение по цели высказывания:повествовательное,вопросительное,побудительное.
2.По эмоциональной окраске:восклицательное или невосклицательное.
3.По наличиюграмматических основ:простое,сложное.
4.Затем,в зависимостиот того простое или сложное.
Нет оценок ·
1,9 K
Комментировать ответ…Комментировать…
Синтаксический разбор предложения — 29 ответов, заданКто-то
Человек, который любит помогать. · 22 сент 2021
Чтобы сделать синтаксический разбор предложения, сначала нужно найти и подчеркнуть главные члены (подлежащее и сказуемое). Потом задать от них вопросы к второстепенным членам, узнать, чем они являются и подчеркнуть их. Подписать над каждым словом часть речи.
Определить тип предложения по цели высказывания (повествовательное, вопросительное, побудительное). Указать вид предложения по эмоциональной окраске (восклицательное, невосклицательное). Далее понять, простое предложение или сложное.
Если сложное, то: по грамматическим основам определить количество простых предложений и найти их границы и определить средства связи простых предложений (союзное или безсоюзное).
В конце составить схему предложения.
15 оценили·
11,8 K
Комментировать ответ…Комментировать…
Как делается синтаксический разбор предложения? — 11 ответов, заданAM KOLA
22 янв 2020
1) Выделить главные и второстепенные члены предложения 2)по цели высказывания (вопросительное,побудительное,повествовательное.) 3)по интронации(восклицательное,не восклицательно.) 4)просто или сложное предоложение. 5)распростронёное или не распростронёное
102 оценили·
17,5 K
Комментировать ответ…Комментировать…
Синтаксический разбор предложения — как сделать, схема разбора предложения, полная схема анализа
Русский язык
20077 709 2 0
Каждый из нас учился в школе. Наверное, ещё свежи в памяти те воспоминания о тетрадках, ручках, прописях, азбуках и других важных и нужных вещей в школе. А также правила, правила и ещё раз правила. Правил действительно было много — сложение, вычитание, правила русского языка, правила грамматики. Когда-то это всё было в новизну, и яростно впитывалось пытливым детским умом, чтобы затем использоваться в тестах и контрольных.
Наверное, ещё свежи в памяти те воспоминания о тетрадках, ручках, прописях, азбуках и других важных и нужных вещей в школе. А также правила, правила и ещё раз правила. Правил действительно было много — сложение, вычитание, правила русского языка, правила грамматики. Когда-то это всё было в новизну, и яростно впитывалось пытливым детским умом, чтобы затем использоваться в тестах и контрольных.
Через определённое время многое просто забывается. Вряд ли взрослый человек сможет сейчас по требованию быстро сделать морфологический разбор слова. Ну, конечно, если он сам не является учителем русского языка и литературы. Русский язык очень красив и могуч, он яркий и разнообразный. Но в то же время грамматика русского языка довольно сложна, особенно если в какой-то момент все правила, которые когда-то были выучены за партой в школе, просто испарились из памяти.
Как и морфологический разбор слова, не каждый сможет с ходу сделать синтаксический разбор предложения. Статья позволит ответить на следующие вопросы: «Как делать синтаксический разбор предложения?», «Как делать синтаксический разбор?», «Как осуществить синтаксический анализ предложения?». В данной статье речь пойдёт именно об этом. Читатель сможет освежить свои знания, вспомнить уже забытые правила синтаксического разбора, а затем применить их на практике, если в этом появится необходимость.
Статья позволит ответить на следующие вопросы: «Как делать синтаксический разбор предложения?», «Как делать синтаксический разбор?», «Как осуществить синтаксический анализ предложения?». В данной статье речь пойдёт именно об этом. Читатель сможет освежить свои знания, вспомнить уже забытые правила синтаксического разбора, а затем применить их на практике, если в этом появится необходимость.
Содержание:
- Полная общая схема синтаксического разбора предложения
- Типы придаточных предложений
- Основные моменты
- Разряд придаточного обстоятельственного предложения
- Видео
Полная общая схема синтаксического разбора предложения
Существует общая схема для осуществления синтаксического разбора предложений. Она может варьироваться в зависимости от того, какую конструкцию требуется разобрать, но, в принципе, основная база остаётся без изменений.
Итак, для синтаксического разбора нужно следовать следующим пунктам упомянутой выше схемы:
- Для начала следует указать цель предложения. Предложение может быть повествовательным, вопросительным, или же побудительным. Определить это совсем легко — обычное образование считается повествовательным, так как сообщает определённую информацию, вопросительное имеет в конце вопросительный знак, а побудительное — соответственно, восклицательный, так как побуждает к действию.
- Далее определяется интонация разбираемого высказывание. По этому критерию предложения делятся на восклицательные и невосклицательные.
- При разборе обязательно нужно указать, простое предложение или сложное, состоящее из нескольких простых.
- У сложных предложений потребуется указать тип конструкции. Тут может быть два варианта — простая конструкция (однотипная) или сложная (подразумевается наличие разных видов связи между несколькими простыми конструкциями в сложном).
- Если сочетание сложное, то понадобится указать тип связи нескольких простых в нём. Связь может быть союзной и бессоюзной.
- Союзные конструкции могут быть сложноподчинёнными и сложносочинёнными.
- Если конструкция является сложноподчинённой, то придётся указать также и тип придаточного: изъяснительное, определительное, присоединительное и обстоятельственное.
- В случае наличия последнего, то потребуется обозначить тип такого придаточного предложения:
- образа действия;
- времени;
- места;
- меры и степени;
- условия;
- уступки;
- сравнения;
- цели;
- причины;
- следствия.
- В том случае, если предложения является сложным, при его разборе потребуется обязательно выполнить описание связи его частей. Все части понадобится пронумеровать и при этом указать все виду связи (союзная и бессоюзная, сочинительная и подчинительная), также если есть необходимость, нужно сделать членение на уровни.
- Затем, указывая номер простого предложения, сделать характеристику каждого из них.
- При осуществлении анализа простых конструкций, обязательно нужно указать, односоставное предложение или двусоставное.
- Если предложение односоставное, то следует определить его тип: назывное, обобщённо-личное, безличное, определённо-личное или неопределённо-личное.
- Затем понадобится обозначить тип имеющегося в конструкции сказуемого. Сказуемое может быть следующего типа: простое глагольное сказуемое (ПГС), составное глагольное сказуемое (СГС), составное именное сказуемое (СИС).
- На данном этапе потребуется обозначить распространённое образование или нераспространённое. Сделать это очень легко. Если в нём есть второстепенные члены, то оно распространённое, если же они отсутствуют, то оно, соответственно, нераспространённое.
- Потом обязательно указывается осложнено ли предложение, и чем.
- Напоследок, требуется указать, полная ли конструкция или неполная, то есть присутствуют ли все второстепенные члены, или же они опущены.
 Предложение может быть повествовательным, вопросительным, или же побудительным. Определить это совсем легко — обычное образование считается повествовательным, так как сообщает определённую информацию, вопросительное имеет в конце вопросительный знак, а побудительное — соответственно, восклицательный, так как побуждает к действию.
Предложение может быть повествовательным, вопросительным, или же побудительным. Определить это совсем легко — обычное образование считается повествовательным, так как сообщает определённую информацию, вопросительное имеет в конце вопросительный знак, а побудительное — соответственно, восклицательный, так как побуждает к действию.

Типы придаточных предложений
Большую трудность зачастую вызывает определение типа придаточных частей в сложноподчинённых конструкциях. Чтобы в этом разобраться, далее будет представлена информация, ознакомление с которой позволит легче осуществить синтаксический разбор, если оно является сложноподчинённым.
Чтобы в этом разобраться, далее будет представлена информация, ознакомление с которой позволит легче осуществить синтаксический разбор, если оно является сложноподчинённым.
Основные моменты
Итак, что следует уяснить при разборе:
- Придаточные предложения изъяснительного типа отвечают на вопросы косвенных падежей. В качестве связующих средств выступают союзные слова или просто союзы.
- К существительному относятся придаточные конструкции определительного типа. Чаще всего присоединяются с помощью союзных слов, но бывают случаи, когда используются и союзы. Отвечают на вопросы «какой?, «чей?».
- Возможно, больше всего проблем возникает при определении придаточного обстоятельственного предложения (ПО). Они различаются в зависимости от разряда.
Разряд придаточного обстоятельственного предложения
Следует помнить о следующих разрядах:
- ПО времени отвечают на следующие вопросы: «когда?», «до каких пор?», «как долго?», «на сколько времени?».Обычно для присоединения используются союзы «когда», «только», «как только», «пока» и другие.
- ПО цели отвечают на вопросы «зачем?», «с какой целью?».
- ПО следствия — союз «так что».
- ПО места — вопросы «куда?», «где?», «откуда?».
- ПО образа действия — «как?», в главную часть конструкции можно вставить слова «так», «таким образом».
- ПО причины раскрывают вопрос «почему?».
- ПО уступки — вопросы «несмотря на что?», «вопреки чему?». Используются союзы «даром», «пускай», «несмотря на то что».
- Сравнительные придаточные обстоятельственные предложения отвечают на следующие вопросы: «подобно чему?», «как что?», при этом обычно используются союзы «словно», «как», «будто», «точно».

Видео
Понять, что такое синтаксический разбор предложения и как его правильно выполнить, вам может этот видеоурок.
Понравилась статья?
Поставь лайк, это важно для наших авторов, подпишись на наш канал в Яндекс. Дзен и вступай в группу Вконтакте
Дзен и вступай в группу Вконтакте
Отзывы и Комментарии
Зарегистрируйтесь
Пройдите легкую процедуру регистрации, чтобы получить свой личный кабинет
Напишите первую статью
Все новые публикации отображаются на главной странице
Получайте постоянный доход
Мы платим не за объем, а за то, насколько ваши тексты интересны читателям
Зарегистрироваться сейчас
синтаксис — Синтаксический разбор — Русский язык
Вопрос задан
Изменён 6 месяцев назад
Просмотрен 2k раз
Опять обращаюсь с предложением,которое надо проверить:
Я не знаю, сколько их, монументов славы и победы, в нашей стране и за ее пределами.
Теперь надо сделать синтаксический разбор.
Вот что получилось:
Я (подлеж-ее,), не знаю (ПГС), сколько их (уточняющее дополнение, выраженное местоимениями ?), монументов славы и победы (согл. приложения, которые относятся к личному местоим.), в нашей (согл. определение) стране (обстоятельство места) и за её (согл. определен.) пределами (обст. места).
приложения, которые относятся к личному местоим.), в нашей (согл. определение) стране (обстоятельство места) и за её (согл. определен.) пределами (обст. места).
Предлоги, союзы, частицы не беру, с ними всё ясно. С частями речи тоже почти всё ясно. И ещё вопрос: нужна всё-таки запятая после слова «победы»?
- синтаксис
3
…сколько их, монументов славы и победы, в нашей стране и за ее пределами» — это все является придаточным предложением, осложненным обособленным приложением «монументов славы и победы». В каждой из частей сложного предложения надо делать разбор по членам предложения
4
Я практически во всём согласен с Людмилой… Не согласен с этим:
сколько — обстоят. меры и степени
их — дополнение
При таком подходе придаточное предложение окажется не только без сказуемого, но и без подлежащего.
На мой взгляд, «сколько их» — подлежащее, выраженное количественно-именным сочетанием.
5
Я не знаю, сколько их, монументов славы и победы, в нашей стране и за ее пределами. — предл. повествоват., невоскл., сложное, сложноподчинённое, сост. из 2-х простых.
Я не знаю — главное, нерапростр., двусост. полное, неосложнённое. Я — подлеж, не знаю — ПГС.
сколько их, монументов славы и победы, в нашей стране и за ее пределами — придаточное изъяснительное; распространённое, неполное двусоставное с пропуском сказуемого (находится, есть), осложнённое уточняющим распростр. соглас. приложением (монументов славы и победы) и однородными обстоятельствами места (в стране и за пределами).
сколько их — подлежащее; монументов каких? — славы и победы — несогл. определение; в стране — обст.; нашей — согл. опред.; за пределами — обст. места; её — определение, выраж. притяж мест.
7
А если немного отвлечься от школьных задач, то как правильно разобрать предложение?
«Я не знаю, сколько их, монументов славы и победы, в нашей стране и за ее пределами».
Главный вопрос — как определить вид придаточного «сколько их». В грамматике выделяются КОЛИЧЕСТВЕННО-БЫТИЙНЫЕ БЕЗЛИЧНЫЕ ПРЕДЛОЖЕНИЯ: «Времени хватает/не хватает. Сил прибавилось/убавилось. Снегу намело!»
Наверное, сюда же можно отнести такие предложения: Снегу много. Их много. Это тоже количественно-бытийная оценка. Тогда «сколько» — это сказуемое в безличном предложении, а «их» — дополнение.
Как вы думаете?
Что касается школы, то о каком правильном разборе может идти речь, если школьники еще не изучали сложноподчиненные предложения. И тем более не стоит предлагать варианты, которые и филологами определяются неоднозначно.
1
Знакомое предложение, его недавно предлагали для разбора, но вопрос был закрыт. Домашнее задание!
Оно, конечно, верно, но сам разбор интересный. Вот мой вариант ответа.
- Грамматическая основа придаточного предложения: СКОЛЬКО (ИХ).
Это односоставное безличное предложение, при этом субъект (носитель признака) выражен формой Р. п. «их». И конечно же, ИХ – это дополнение.
п. «их». И конечно же, ИХ – это дополнение.
- Сказуемое составное именное, связка «быть» пропущена, именная часть выражена относительным местоимением с количественным значением «сколько». Для сравнения: сколько их было, их было много (в прошедшем времени связка «было» присутствует).
ПРИМЕЧАНИЕ. Безличные предложения иногда считают бессубъектными. Это неточно. Субъект (носитель признака или состояния) в таких предложениях есть и обычно выражен формой Д.п. или Р.п.
Меня же удивляет количество вариантов при разборе, но давно это было… А как сегодня участники форума разберут это предложение?
Ваш ответ
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Особенности синтаксического разбора / Синтаксический разбор / Русский на 5
В данной статье:
- Что такое синтаксический разбор, в чём его специфика
- Что нужно знать и уметь делать
- Порядок разбора разных синтаксических единиц
§1.
 Что такое синтаксический разбор, в чём его специфика
Что такое синтаксический разбор, в чём его спецификаСинтаксический разбор – это полная грамматическая характеристика синтаксической единицы:
- словосочетания
- простого предложения
- сложного предложения
При синтаксическом анализе важно уметь различать единицы синтаксиса, осознавать, что это единицы разных уровней, и понимать, какими признаками характеризуется каждая из них. Синтаксический анализ требует не путать словосочетание и простое предложение, а также простое и сложное предложения и знать, как следует разбирать каждое из них.
§2. Что нужно знать и уметь делать
Синтаксический разбор требует знаний и умений.
Нужно знать:
- в чём различие между словосочетанием и предложением
- в чём различие между простым и сложным предложением
- как строится словосочетание, и какими они бывают (вид по главному слову)
- синтаксические связи слов в словосочетании: согласование, управление, примыкание
- какие признаки характеризуют предложение: цель высказывания, смысловая и интонационная законченность, наличие грамматической основы
- какими бывают предложения по количеству грамматических основ: простое, сложное
- какими бывают простые предложения по своей структуре: двусоставное, односоставное (назывное, определённо-личное, неопределённо-личное, обобщённо-личное, безличное)
- какими бывают сложные предложения: по характеру синтаксической связи их частей: союзные, бессоюзные; союзные: сложносочинённые и сложноподчинённые)
- какова синтаксическая роль слов в предложении ( разбор по членам предложения)
Нужно уметь:
- определять, к каким синтаксическим единицам относится данная для разбора единица
- выделять словосочетания в предложении
- находить главное и зависимое слово в словосочетании
- определять вид синтаксической связи
- определять грамматическую основу предложения
- определять тип предложения по грамматической основе (двусоставное – односоставное) и по характеру главного члена (для односоставных предложений)
- определять члены предложения
- определять осложняющие компоненты: однородные члены, обособления, вводные элементы ( вводные слова и предложения, вставные конструкции), обращения, прямая речь и цитирование
- определять количество частей в сложном предложении
- определять тип синтаксической связи и тип сложного предложения
§3.
 Порядок разбора синтаксических единиц
Порядок разбора синтаксических единицСловосочетание
1. Определить главное и зависимое слова, выделить главное, от него поставить вопрос к зависимому.
2. Определить вид словосочетания по главному слову: именное, глагольное, наречное.
3. Определить вид синтаксической связи: согласование, управление, примыкание.
Простое предложение
1. Выполнить разбор по членам предложения: подчеркнуть все члены предложения, определить, чем (словом какой частью речи) они выражены.
2. Дать характеристику по цели высказывания:
- повествовательное
- вопросительное
- побудительное
3. Дать характеристику по выражаемым эмоциям и интонации:
- невосклицательное
- восклицательное
4. Определить количество грамматических основ и определить тип предложения по их количеству:
- простое
- сложное
5. Дать характеристику по наличию главных членов:
- двусоставное
- односоставное
а)односоставное с главным членом подлежащим: назывное
б)односоставное с главным членом сказуемым: определённо-личное, неопределённо- личное, обобщённо-личное, безличное
6. Дать характеристику по наличию второстепенных членов:
Дать характеристику по наличию второстепенных членов:
- распространённое
- нераспространённое
7. Дать характеристику по полноте (наличию членов предложения, необходимых по смыслу):
- полное
- неполное
8. Определить наличие осложняющих компонентов:
- неосложнённое
- осложнённое:
а) однородными членами предложения
б) обособленными членами: определением (согласованным – несогласованным), дополнением, обстоятельством
в) вводными словами, вводными предложениями и вставными конструкциями
г) обращением
д) конструкции с прямой речью или цитированием
Примечание:
При выражении обособлений причастными и деепричастными оборотами, а также сравнительными конструкциями, охарактеризовать, чем именно выражено обособление
Сложное предложение
1. Как и в простом предложении, определить члены предложения.
2. Как и в простом предложении, дать характеристику по цели высказывания:
- повествовательное
- вопросительное
- побудительное
3. Как и в простом предложении, дать характеристику по выражаемым эмоциям и интонации:
Как и в простом предложении, дать характеристику по выражаемым эмоциям и интонации:
- невосклицательное
- восклицательное
4. По количеству грамматических основ (более одной), определить, что предложение сложное.
5. Определить тип синтаксической связи между частями сложного предложения:
- с союзной связью
- с бессоюзной связью
- с сочетанием союзной и бессоюзной связи
6. Определить тип сложного предложения и средства связи:
- сложносочинённое (с соединительными союзами: соединительными, разделительными, противительными, присоединительными, пояснительными или градационными )
- сложноподчинённое (c подчинительными союзами: временными, причинными, условными, целевыми, следствия, уступительными, сравнительными и изъяснительными, а также союзными словами)
- бессоюзное (связь по смыслу, выраженная интонационно)
7. Определить вид сложного предложения (например: сложноподчинённое с придаточным изъяснительным).
8. Далее характеризуется каждая часть сложного предложения (по схеме простого предложения – см. схему разбора простого предложения, пп. 5-8)
9. Составить схему сложного предложения, отражающую
- количество частей
- связи частей
- союзные средства связи
Смотрите также
- А9. Грамматическая основа предложения
- А10. Как не ошибиться в синтаксической характеристике предложения
- Синтаксический разбор
- Глава 20. Синтаксис. Предмет и единицы синтаксиса
- Глава 21. Синтаксис. Словосочетание. Синтаксические связи слов в словосочетании
- Глава 22. Синтаксис. Предложение
- Советы. Как приступить к делу
- Примеры и комментарии
- Типичные ошибки
- Первые шаги. Подготовительные задания.
- Тренинг «Синтаксический разбор»
- Итоговый тест «Синтаксический разбор в формате ЕГЭ»
— Понравилась статья?:)
Как обозначается синтаксический разбор
Содержание
- Просто о синтаксическом разборе предложения
- Пример синтаксического разбора простого предложения
- Пример разбора сложного предложения
- Пример схемы (предложение, после него схема)
- Другой вариант синтаксического разбора
- В словосочетаниях:
- В простом предложении:
- Сказуемое
- В предложении, имеющем однородные члены.
- В предложениях с обособленными членами:
- В предложениях с обособленными членами речи:
- В сложносочиненном предложении:
- В сложноподчинённом предложении с придаточным (одним)
- В сложноподчинённом предложении с придаточными (несколькими)
- В сложном бессоюзном предложении:
- В сложном предложении, в котором присутствуют разные виды связи.
- Пример синтаксического разбора простого предложения.
- Пример разбора сложного предложения.
- Единицы синтаксиса
- Зачем нужен синтаксический разбор предложения
- Члены предложения
- Характеристика предложения
- Осложнённое предложение
- Если предложение сложное
- Пример синтаксического разбора предложения
- Что мы узнали?

Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:

| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Пример разбора сложного предложения
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
 Далее указываем, каким синтаксическим способом связано данное словосочетание.
Далее указываем, каким синтаксическим способом связано данное словосочетание.В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.
 Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.Сказуемое
- Отмечаем, чем является сказуемое — простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое — какой формой глагола;
- составное глагольное — из чего оно состоит;
- составное именное — какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.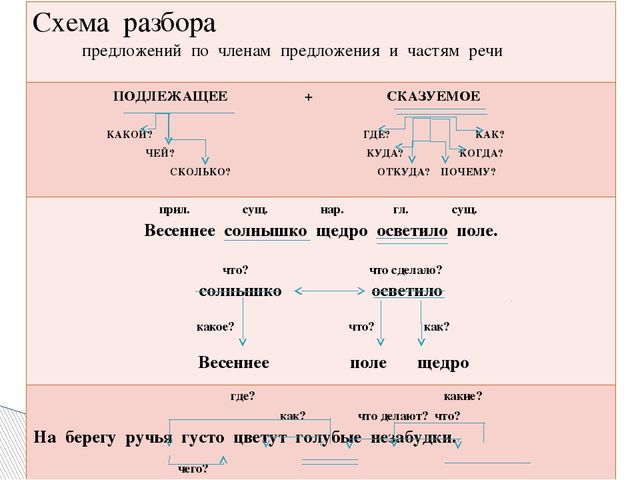
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Синтаксический разбор предложения в русском языке осуществляется по схеме ответов на следующие вопросы:
1) Каково данное предложение по цели высказывания? (Повествовательное, побудительное или вопросительное).
2) Какова эмоциональная окраска предложения ? (Восклицательное или невосклицательное).
3) Сколько грамматических основ есть у данного предложения? (Простое – одна основа, сложное – две и более).
Далее, если предложение простое:
4) Односоставное предложение или двусоставное? (Если имеется и подлежащее, и сказуемое – то двусоставное, если только один главные член – то односоставное).
5) Распространенное предложение или нераспространенное? (Есть ли второстепенные члены предложения?).
6) Осложненное предложение или неосложненное?(Имеются ли однородные члены, вводное слово, причастный/деепричастный оборот, обращение?)
7) Какими частями речи выражены все члены предложения? Подчеркните все члены предложения.
8) Составьте схему предложения, обозначив грамматическую основу и осложнение, если таковое присутствует.
Если предложение сложное, то следуем следующей схеме.
4) Какая связь имеется в сложном предложении: союзная или бессоюзная?
5) Какой именно способ связи используется в предложении: подчинительная, сочинительная или интонация?
6) На основе ответа на предыдущий пункт, обозначить, к какому типу сложного предложения относится данное: сложносочиненное, сложноподчиненное или бессоюзное?
7) Следуя инструкции разбора простого предложение, разобрать каждую из частей сложного предложения.
Пример синтаксического разбора простого предложения.
В букете были розы и лилии.
Устный разбор простого предложения.
Предложение повествовательное, невосклицательное, простое, двусоставное; грамматическая основа: розы и лилии были; распространенное, осложнено однородными подлежащими.
Письменный разбор простого предложения.
Повест., невоскл., прост., двусост., г/о розы и лилии были, распростр., осложн. однород. подл.
Пример разбора сложного предложения.
В букете были розы и лилии, но ей больше нравились тюльпаны.
Устный разбор сложного предложения.
Предложение повествовательное, невосклицательное, сложное, связь союзная, предложения связываются сочинительным союзом «но», сложносочиненное предложение. Первое предложение двусоставное, грамматическая основа розы и лилии были; распространенное, осложнено однородными подлежащими. Второе предложение двусоставное, грамматическая основа: тюльпаны нравились, распространенное, не осложнено.
Письменный разбор сложного предложения.
Повеств., невоскл., сложн., сложносоч., с союзом но. 1-е ПП: двусост., г/о розы и лилии были, распр., осложн. однор. подл. 2-е ПП: двусост., г/о: тюльпаны нравились, распростр., не осложн.
Единицы синтаксиса
Синтаксис изучает связь слов внутри словосочетаний или предложений. Таким образом, единицами синтаксиса являются словосочетания и предложения – простые или сложные. В этой статье мы будем говорить о том, как сделать синтаксический разбор предложения, а не словосочетания, хотя нередко в школе просят сделать и его.
Зачем нужен синтаксический разбор предложения
Синтаксический разбор предложения предполагает подробное рассмотрение его структуры. Это совершенно необходимо для того, чтобы правильно поставить знаки препинания. Кроме того, это помогает понять связь слов внутри фразы. В ходе синтаксического разбора, как правило, даётся характеристика предложения, определяются все члены предложения и вытесняется, какими частями речи они выражены. Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Это так называемый полный синтаксический разбор. Но иногда этот термин используется в отношении короткого, частичного, синтаксического разбора, в ходе которого ученик только подчёркивает члены предложения.
Члены предложения
Среди членов предложения всегда сначала выделяют главные: подлежащее и сказуемое. Они, как правило, составляют грамматическую основу. Если в предложении одна грамматическая основа, оно простое, более одной – сложное.
Грамматическая основа может состоять как из двух главных членов, так и включать в себя только один из них: или только подлежащее, или только сказуемое. Во втором случае мы говорим, что предложение односоставное. Если же присутствуют оба главных члена – двусоставное.
Если, кроме грамматической основы, слов в предложении нет, оно называется нераспространённым. В распространенном предложении есть также второстепенные члены: дополнение, определение, обстоятельство; частным случаем определения является приложение.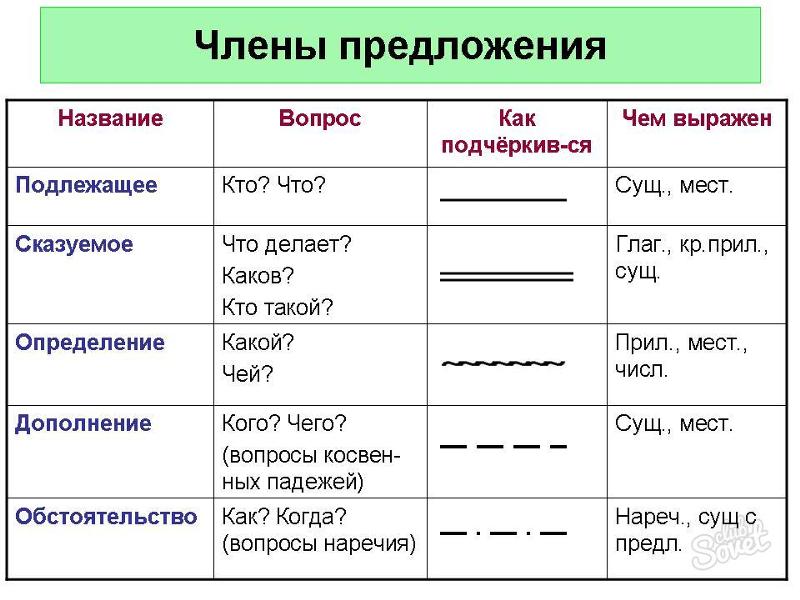
если в предложении есть слова, которые членами предложения не являются (например, обращение), оно все равно считается нераспространенным.
Выполняя разбор, необходимо называть и часть речи, которой выражен тот или иной член предложения. Этот навык ребята отрабатывают, изучая в 5 классе русский язык.
Характеристика предложения
Чтобы дать характеристику предложению, надо указать надо его описать
- по цели высказывания;
- по интонации;
- по количеству грамматических основ и так далее.
Ниже мы предлагаем план характеристики предложения.
По цели высказывания: повествовательное, вопросительное, побудительное.
По интонации: восклицательное или невосклицательное.
Восклицательными могут быть любые по цели высказывания предложения, а не только побудительные.
По количеству грамматических основ: простое или сложное.
Если предложение простое, движемся дальше по плану; если сложное, путь отсюда придется пройти несколько раз: столько, сколько частей в сложном.
По количеству главных членов в грамматической основе: односоставное или двусоставное.
Если предложение односоставное, надо определить его вид: назывное, определённо-личное, неопределённо-личное, безличное.
По наличию второстепенных членов: распространённое или нераспространённое.
Если предложение чем-то осложнено, то это также надо указать. Это план синтаксического разбора предложения; лучше его придерживаться.
Осложнённое предложение
Предложение может быть осложнено обращением, вводными и вставными конструкциями, однородными членами, обособленными членами, прямой речью. Если какой-то из этих видов осложнений присутствует, то надо указать, что предложение осложненное, и написать чем.
Если предложение сложное
Если необходимо сделать разбор сложного предложения, надо сначала указать, что оно сложное, и определить его тип: союзное или бессоюзное, а если союзное, то еще и сложносочиненное или сложноподчиненное. Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
Затем охарактеризовать каждую из частей с точки зрения состава грамматической основы (двусоставное или односоставное, тип односоставного) и наличия/ отсутствия второстепенных членов.
В таблице приведены второстепенные члены и их вопросы.
Второстепенные члены предложения
Вопросы
Кого? чего? кому? чему? кем? чем? о ком? о чем?
Какой? чей? который по счету?
Где? когда? куда? откуда? почему? зачем? как? в какой степени?
Второстепенные члены могут быть выражены разными частями речи, например определение:
шерстяная юбка – прилагательное;
юбка из шерсти – существительное;
юбка отглаженная – причастие;
привычка побеждать – инфинитив…
Пример синтаксического разбора предложения
Подчеркнем грамматические основы. Их две: знал и ты переехала . Определим части речи: знал – сказуемое, выражено глаголом в личной форме и т. д.
д.
Теперь подчеркиваем второстепенные члены:
Переехала откуда? из деревни – обстоятельство, выражено существительным; куда? в город – тоже обстоятельство, тоже выражено существительным. Маша – это обращение, оно не является членом предложения.
Теперь дадим характеристику. Предложение повествовательное, невосклицательное, сложное, союзное, сложноподчиненное.
Первая часть «не знал» неполная, нераспространенная.
Вторая часть двусоставная, распространенная. Осложнено обращением.
По окончании разбора надо составить схему сложного предложения.
Что мы узнали?
Синтаксический разбор призван помочь понять структуру предложения, поэтому необходимо указать все, что может быть с ней связано. Выполнять разбор лучше по плану, тогда больше шансов, что вы ничего не забудете. Необходимо не только подчеркнуть члены предложения, но и определить части речи, и дать характеристику предложению.
Синтаксический разбор слова в русском языке
Просто о синтаксическом разборе предложения
- Охарактеризовать предложение по цели высказывания: повествовательное, вопросительное или побудительное.
- По эмоциональной окраске: восклицательное или невосклицательное.
- По наличию грамматических основ: простое или сложное.
- Затем, в зависимости от того, простое предложение или сложное:

| Если простое: 5. Охарактеризовать предложение по наличию главных членов предложения: двусоставное или односоставное, указать, какой главный член предложения, если оно односоставное (подлежащее или сказуемое). 6. Охарактеризовать по наличию второстепенных членов предложения: распространённое или нераспространённое. 7. Указать, осложнено ли чем-либо предложение (однородными членами, обращением, вводными словами) или не осложнено. 8. Подчеркнуть все члены предложения, указать части речи. 9. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. | Если сложное: 5. Указать, какая связь в предложении: союзная или бессоюзная. 6. Указать, что является средством связи в предложении: интонация, сочинительные союзы или подчинительные союзы. 7. Сделать вывод, какое это предложение: бессоюзное (БСП), сложносочинённое (ССП) сложноподчинённое (СПП). 8. Разобрать каждую часть сложного предложения, как простое, начиная с пункта №5 соседнего столбца. 9. Подчеркнуть все члены предложения, указать части речи. 10. Составить схему предложения, указав грамматическую основу и осложнение, если оно есть. |

Пример синтаксического разбора простого предложения
Устный разбор:
Предложение повествовательное, невосклицательное, простое, двусоставное, грамматическая основа: ученики и ученицы учатся, распространённое, осложнено однородными подлежащими.
Письменный:
Повествовательное, невосклицательное, простое, двусоставное, грамматическая основа ученики и ученицы учатся, распространенное, осложненное однородными подлежащими.
Устный разбор:
Предложение повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, сложноподчинённое предложение. Первое простое предложение: односоставное, с главным членом – сказуемым не задали, распространённое, не осложнено. Второе простое предложение: двусоставное, грамматическая основа мы с классом поехали, распространённое, не осложнено.
Письменный:
Повествовательное, невосклицательное, сложное, связь союзная, средство связи подчинительный союз потому что, СПП.
1-е ПП: односоставное, с главным членом – сказуемым не задали, распространенное, не осложнено.
2-е ПП: двусоставное, грамматическая основа – мы с классом поехали, распраненное, не осложнено.
Пример схемы (предложение, после него схема)
Другой вариант синтаксического разбора
Синтаксический разбор. Порядок при синтаксическом разборе.
Порядок при синтаксическом разборе.
В словосочетаниях:
- Выделяем из предложения нужное словосочетание.
- Рассматриваем строение – выделяем главное слово и зависимое. Указываем, какой частью речи является главное и зависимое слово. Далее указываем, каким синтаксическим способом связано данное словосочетание.
- И, наконец, обозначаем каким является его грамматическое значение.
В простом предложении:
- Определяем, каково предложение по цели высказывания – повествовательное, побудительное или вопросительное.
- Находим основу предложения, устанавливаем, что предложение простое.
- Далее, необходимо рассказать о том, как построено данное предложение.
- Двусоставное оно, либо односоставное. Если односоставное, то определить тип: личное, безличное, назывное или неопределенно личное.
- Распространённое или нераспространённое
- Неполное или полное. Если предложение является неполным, то необходимо указать, какого члена предложения в нём не хватает.
- Если данное предложение чем–либо осложнено, будь то однородные члены или обособленные члены предложения, необходимо это отметить.
- Дальше нужно сделать разбор предложения по членам, при этом указав, какими частями речи они являются. Важно соблюдать порядок разбора. Сначала определяются сказуемое и подлежащее, затем второстепенные, которые входят в состав сначала – подлежащего, затем – сказуемого.
- Объясняем, почему так или иначе расставлены знаки препинания в предложении.

Сказуемое
- Отмечаем, чем является сказуемое – простым глагольным или составным (именным или глагольным).
- Указать, чем выражено сказуемое:
- простое – какой формой глагола;
- составное глагольное – из чего оно состоит;
- составное именное – какая употреблена связка, чем выражается именная часть.
В предложении, имеющем однородные члены.
Если перед нами простое предложение, то при его разборе нужно отметить, что это за однородные члены предложения и каким образом связаны друг с другом. Либо посредством интонации, либо и интонации с союзами.
Либо посредством интонации, либо и интонации с союзами.
В предложениях с обособленными членами:
Если перед нами простое предложение, то при его разборе, нужно отметить, чем будет являться оборот. Далее, разбираем слова, которые входят в этот оборот по членам предложения.
В предложениях с обособленными членами речи:
Сначала отмечаем, что в данном предложении, есть прямая речь. Указываем прямую речь и текст автора. Разбираем, объясняем, почему так, а не иначе расставлены знаки препинания в предложении. Чертим схему предложения.
В сложносочиненном предложении:
Сначала, указываем, какое предложение по цели высказывания – вопросительное, повествовательное или побудительное. Находим в предложении простые предложения, выделяем в них грамматическую основу.
Находим союзы, с помощью которых соединяются простые предложения в сложном. Отмечаем что это за союзы – противительные, соединительные или разделительные. Определяем значение всего данного сложносочиненного предложения – противопоставление, чередование или перечисление. Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания. Затем каждое простое предложение, из которых состоит сложное, необходимо разобрать таким же образом, как разбирается простое предложение.
В сложноподчинённом предложении с придаточным (одним)
Сначала, указываем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное. Зачитываем их.
Называем, какое предложение является главным, а какое придаточным. Объясняем, каким именно сложноподчинённым предложением оно является, обращаем внимание на то, как оно построено, чем соединяется придаточное к главному предложению и к чему оно относится.
Объясняем, почему именно так расставлены знаки препинания в данном предложении. Затем, придаточное и главное предложения необходимо разобрать, таким образом, как разбираются простые предложения.
В сложноподчинённом предложении с придаточными (несколькими)
Называем, каким предложение является по цели высказывания. Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
Выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Указываем, какое предложение является главным, а какое придаточным. Необходимо указать, каковым является подчинение в предложении – либо это параллельное подчинение, либо последовательное, либо однородное. Если существует комбинация нескольких видов подчинения, необходимо это отметить. Объясняем, почему, таким образом, в предложении расставлены знаки препинания. И, в конце, делаем разбор придаточного и главного предложений как простых предложений.
В сложном бессоюзном предложении:
Называем, каким предложение является по цели высказывания. Находим грамматическую основу всех простых предложений, из которых состоит данное сложное предложение. Зачитываем их, называем количество простых предложений, входящих в состав сложного. Определяем, какими по смыслу являются отношения между простыми предложениями. Это может быть – последовательность, причина со следствием, противопоставление, одновременность, пояснение или дополнение.
Отмечаем, каковы особенности строения данного предложения, каким именно сложноподчинённым предложением оно является. Чем в данном предложении соединены простые и к чему они относятся.
Объясняем, почему именно таким образом в предложении расставлены знаки препинания.
В сложном предложении, в котором присутствуют разные виды связи.
Называем, каким по цели высказывания, является данное предложение. Находим и выделяем грамматическую основу всех простых предложений, из которых состоит сложное, зачитываем их. Устанавливаем, что данное предложение будет являться предложением, в котором присутствуют разные виды связи. Почему? Определяем, какие связи присутствуют в данном предложении – союзная сочинительная, подчинительная или какие – либо другие.
По смыслу устанавливаем, каким образом в сложном предложении сформированы простые. Объясняем, почему именно таким образом расставлены в предложении знаки препинания. Все простые предложения, из которых составлено сложное, разбираем таким образом, как разбирается простое предложение.
Всё для учебы » Русский язык » Синтаксический разбор предложения
Чтобы добавить страницу в закладки, нажмите Ctrl+D.
Если страница помогла, сохраните её и поделитесь ссылкой с друзьями:
Группа с кучей полезной информации (подпишитесь, если предстоит ЕГЭ или ОГЭ):
Описание
Сервис позволяет провести автоматический бесплатный синтаксический и морфологический разбор предложения или текста онлайн. Сервис выделяет члены предложения: подлежащее, сказуемое, определение, дополнение, обстоятельство, над каждым словом приводится морфологическая информация о части речи по данному слову. При использовании сервиса учитывайте, что правильность разбора на данный момент составляет примерно 80%, поэтому представленный результат необходимо подвергать тщательной проверке. В комментариях можете указывать найденные ошибки, мы будем стараться их исправить 🙂
Буквы Е и Ё (две разные буквы), наличие орфографических и пунктуационных ошибок в тексте влияют на результат разбора.
Результаты хранятся 7 дней (сохраняйте адрес страницы с разбором вашего предложения).
Понятие синтаксиса
Синтаксис изучает строение текста, связь между частями речи, предложениями и словосочетаниями. Какие же именно темы затрагивает синтаксис?
Правильное построение и верный состав предложений, а также словосочетаний.
Рассмотрение связующих слов внутри синтаксических единиц.
Темы, относящиеся к синтаксическим единицам, их главная роль в языке.
Определение главных и второстепенных членов предложения, упор на грамматическую основу.
Если обратиться к созданию науки о синтаксисе, то придется углубиться в 19 век. А сами предпосылки появления термина «синтаксис» появились еще в далеком античном мире. Люди принимали синтаксические разбор, как нечто, которое способно прояснить предложение и длинное словосочетание. Спустя время синтаксис помог разбирать не только отдельные части, но и целые тексты.
Понятие синтаксического разбора предложения
Вся наша речь строится на словах, которые мы постоянно собираем в одно предложение. Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Для того, чтобы понять смысл, идею и посыл, важно провести анализ. Так, в каждом отрывке существуют особые составные части. Синтаксический разбор включает в себя способность найти и выделить основные моменты в тексте, при этом поняв, каким именно является каждое предложение. Оно делится на простое и сложное. Помимо этого, важно учитывать, какой тип связи в тексте. Например, существует согласование, управление или примыкание. Обычно, для этого устанавливается главное слово, по которому и определяется смысл синтаксиса. Затем, по правилу определяется время, наклонение, действующие лица и число главных членов.
Члены предложения: подлежащее, сказуемое, определение, обстоятельство, дополнение
Если бы не было деления на определенные названия, то нельзя бы было вообще понять суть синтаксиса в речи. Но, русскому языку повезло. Здесь есть всё, что необходимо для разбора.
Подлежащее. Главнейший член предложения, без которого буквально не существует нашей речи. Это может быть, как неодушевленный предмет, так и обычный живой человек. Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Единственные два вопроса, на которые отвечает подлежащие – это «Кто?» и «Что?». Часто употребляемые в роли подлежащего части речи – это существительное или местоимение. На письме выделять необходимо одной неразрывной чертой. Смотрите пример: моя кошка очень любит молоко. В данном предложении подлежащим будет слово «кошка», выраженное обычным существительным женского пола. Или такой пример: он обожает пиццу и морепродукты. А вот здесь подлежащим станет местоимение «он» мужского пола.
Сказуемое. Еще один важный член предложения, которые необходимо подчеркивать двумя неразрывными линиями. Основной вопрос, на который отвечает сказуемое – это «Что делать?» и «Что сделать?», «Каков?», «Кто он / Что он?». Как правило, в 80% случаев сказуемое – это глагол, т.е. действие. Например: мама любит цветы. В данном предложении слово «любит» является сказуемым, так как это действие.
Дополнение. Важный член в предложении, но не являющийся главным. Наоборот, дополнение – второстепенно. Оно относится к предмету, который отвечает на вопрос «Что?» или «Кто?», поставленный в винительном падеже. Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Подчеркивается такая основа пунктирной линией. Смотрите: я пишу письмо, слушаю песню. Слово «песню» будет дополнением, так как именно оно отвечает на вопрос винительного падежа.
Обстоятельство. Вспомогательная часть в тексте, важная для наполнения и красочности речи. Не было бы данного пункта – было бы скучно, уж поверьте. Итак, обстоятельство – это качество, признак, отвечающий на вопрос «Куда?», «Зачем?», «Когда?», «Как?». А вот и пример подоспел: мы уехали в Париж. Смотрите, было бы неинтересно знать, что люди просто уехали. Намного важнее узнать информация, куда именно было направление. Отсюда находим обстоятельство «в Париж», отвечающее на вопрос «Куда?».
Определение. Для того, чтобы речь была красочной, многогранной, нескучной и разной – важно включать определения. Они отвечают на вопрос «Какой?», «Какая?». Часто в речи определение выражается прилагательным, т.е. частью речь, которая описывает предмет от и до. Поглядите на пример: животные обитают в дремучих джунглях. Слово «дремучий» – как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Слово «дремучий» – как раз является определением, так как отвечает на вопрос «Какой?» помогает конкретнее представить и понять, какими именно являются джунгли.
Как выполнять синтаксический анализ простого и сложного предложения
Чтобы было понятнее, давайте возьмем несколько примеров.
Разбор простого предложения
Алексею вручили медаль за отвагу, мужество и героизм, проявленные в жестоких боях во время Великой Отечественной Войны.
Во-первых, определите основы в предложении: первая часть главная, так как здесь присутствует основное сказуемое, а вторая – придаточная, дополняющая то, о чем говорится в самом начале. По структуре предложение является утвердительным, повествовательным. По эмоциональной окраске восклицание отсутствует. Считая основы, предложение простое, двусоставное и распространенное. Здесь есть осложнение, которое выделяется запятой – как видите, вторая часть четко выражена причастным оборотом.
Разбор сложного предложения
Вчера учитель по английскому языку не записал домашнее задание, мы всем классом ничего не сделали на сегодняшний урок.
Обратите внимание на предложение, в нем есть повествование, т.е. содержится определенный факт, мини-сообщение. Если же судить по эмоциональной окраске, то восклицание отсутствует. Посчитав грамматические основы, делаем вывод, что их целых две. А это означает, что предложение сложное. Смотрите: в первой части основа слова «учитель не записал», а во второй – «мы не сделали». Союзов здесь тоже нет, а это значит, что оно – бессоюзное, но с запятой, которая разделяет две важные части.
Вот, наглядный пример того, как выглядит синтаксический разбор двух типов предложения. Нас учат в школе точно также, просто со временем все забывается.
Порядок разбора
Нас учат по-разному, с чего лучше начинать анализ. Кто-то считает, что приоритетно дать общую характеристику предложению. Другие же, наоборот, придерживаются мнения, что важно определить все части в предложении, а только затем приступать к основной характеристике. Лучше всего более верный вариант скомпоновать в небольшую памятку, чтобы вам же было впоследствии удобнее ею пользоваться.
Для начала прочитайте внимательно исходное предложение с простым карандашом в руке, определив, какова цель высказывания.
После этого посмотрите внимательно на интонацию, которая всегда прописывается в самом конце (вопросительный знак или восклицательный).
Теперь, найдите состав предложения, выделяя карандашом основу. Это может быть, как простое, так и сложное предложение.
Посмотрите, есть ли средства связи между частями, т.е. союзы, которые соединяют две части.
Имеются ли второстепенные члены. Если да, то предложение считается распространенным, т.е. включает в себя разные части речи.
Если можно, то найдите обороты. Они бывают причастными и деепричастными.
Вот так легко можно понять, что же такое синтаксический анализ. На самом деле, все это не сложно, если выучить и понять алгоритм выполнения. Вспомните, как на уроках нас часто «гоняли» и заставляли выполнять домашнее задание на синтаксис каждый раз. Набив руку, каждый школьник за считанные минуты сделает разбор предложения и представит его классу. И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
И еще один момент: никогда не бойтесь больших текстов. Да, они оснащены огромными основами, описаниями, моментами и знаками препинания, но тем они и красочные! Мы охотнее представляем себе что-то в подробных деталях, нежели сухое предложение из пяти слов. Так что, не паникуйте при виде предложения, где полно основ и частей речи. Зато синтаксический анализ получится громоздким, но максимально открытым.
Морфологический разбор слова
Под морфологическим разбором слова понимают полную грамматическую характеристику той или иной словоформы. В ходе данного процесса нужно чётко определить, к какой из частей речи необходимо отнести анализируемое слово, какие у него постоянные и изменяемые признаки, а также в какой из форм его следует употреблять. Кроме того, определяется роль слова в заданном предложении.
Морфологическому разбору подвергаются лишь слова, которые представлены в определённом предложении. Это имеет большое значение, поскольку для русского языка характерно распространение омонимии форм, а также частей речи. Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Дать правильную характеристику слова, которое представляется изолированно, в отрыве от контекста, практически невозможно.
Важность морфологического разбора слова заключается в том, что быстрее осваиваются грамматические категории, а также они становятся легкоразличимыми в процессе практической деятельности.
При выполнении морфологического разбора, нужно помнить, что не для каждого слова характерно наличие стандартного набора категорий. Кроме того, могут возникнуть затруднения с чёткой идентификацией той или иной категории.
Несмотря на то, что имеются разночтения в сфере морфологического разбора слов, на текущий момент разработаны общие требования. Прежде всего, нужно следовать чёткому алгоритму. При соблюдении установленных требований, гораздо легче осуществлять морфологический разбор того или иного слова. Если отступать от правил, то это будет приводить к возникновению ошибок в ходе анализа, поскольку даже неправильный порядок разбора внесёт хаос в данный процесс.
Действия по морфологическому разбору слова осуществляют в следующей последовательности:
Записывается словоформа слова, которое анализируется – оно должно быть указано так, как его используют в контексте, не подвергая каким-либо изменениям.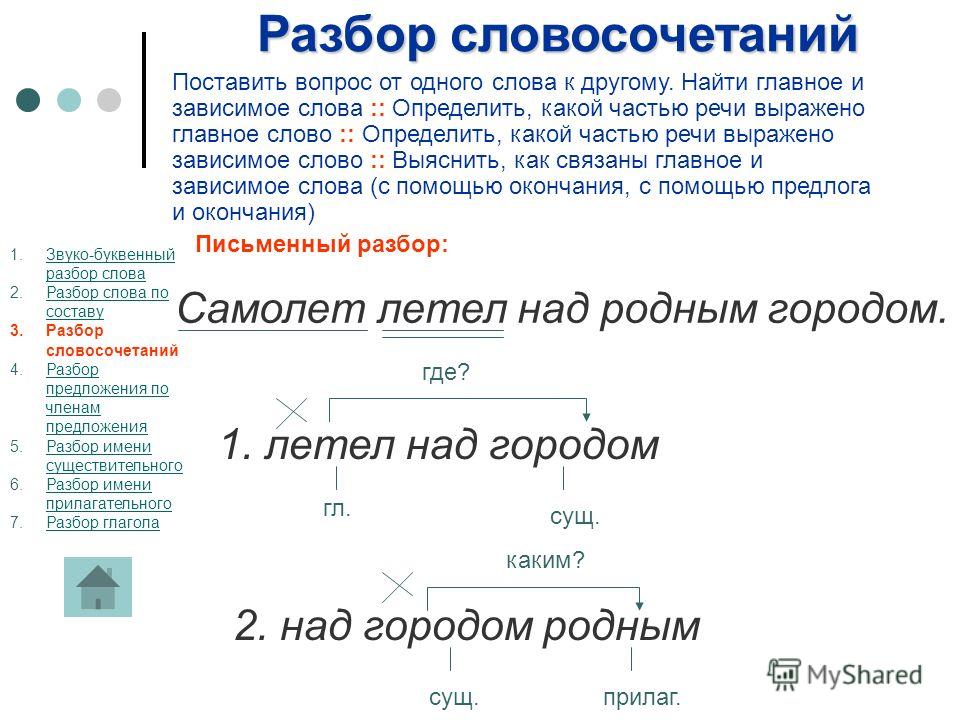
Определяется для слова начальная форма. Каждая часть речи характеризуется индивидуальными правилами приведения слов в эту форму. К примеру, для существительного характерно наличие именительного падежа и единственного числа. Что касается глагола, то здесь всегда используется неопределённая форма.
Указывается грамматическое значение анализируемого слова в качестве части речи. К примеру, для существительного это будет предмет, а для глагола – действие.
Определяются грамматические категории, которые являются неизменяемыми. Такие категории также находятся в зависимости от частей речи. Если рассматривать существительное, то оно может быть собственное и нарицательное. Кроме того, используется род, склонение, а также одушевлённость и неодушевлённость. Для глагола характерно наличие возвратности, переходности, вида и спряжения.
Указывается, в какой из форм применяется слово в обозначенном контексте. Категории, которые изменяются, определяются исключительно по словоформе.
Определяется синтаксическая роль слова в указанном предложении. При этом данное предложение рассматривается очень внимательно, так как порой слова выполняют те функции, которые для них несвойственны. Например, существительное преимущественно выступает в качестве подлежащего и дополнения. Что касается глагола, то он бывает сказуемым.
Если в точности придерживаться данного алгоритма, то осуществлять морфологический разбор любого слова становится гораздо удобнее. Более того, это способствует высокому качеству выполняемой работы по проведения морфологического разбора того или иного слова.
Часто пользователи ищут в сети синтаксический разбор какого-либо слова. По этому запросу обычно получают результаты по разбору предложений и словосочетаний. Но почему так происходит? Давайте в этом разберемся далее и приведем примеры такого разбора.
Все дело в том, что разобрать слово синтаксически нельзя . Можно сделать разбор только словосочетания или всего предложения. В школьной программе этой теме выделено довольно много времени для усвоения материала, а также большое количество практических уроков, чтобы ученики сами научились делать такой разбор. Но мы с вами сегодня опишем в общих чертах, как делать синтаксический анализ.
Но мы с вами сегодня опишем в общих чертах, как делать синтаксический анализ.
Как делать синтаксический разбор предложения
Если нужно выполнить синтаксический анализ словосочетания, сделайте следующее:
- Определите словосочетание. Выделите в нем главное и второстепенное слово. Уточните к каким частям речи относятся слова.
- Определите синтаксическое общее между словами.
- Выделите грамматическое значение для каждого.
Порядок разбора предложения по словам
Порядок действий будет следующим:
- Установите, каким выступает предложение по типу высказывания (вопросительное, побудительное, повествовательное).
- Далее нужно указать, из каких частей состоит предложение, его состав. Нужно сказать, что оно простое, односоставное/двусоставное, определить тип – безличное/личное. Предложение является нераспространенным или наоборот. Полное/неполное, если нет, то указать, каких именно частей в нем не достает.
- Если простое предложение осложнено обособленными, однородными членами предложения, отметьте это в синтаксическом разборе.
- Сделайте разбор простого предложения по членам, по ходу отмечая, к каким частям речи их отнести. Для этого соблюдайте порядок: первыми в предложении определите сказуемое и подлежащее, после них найдите второстепенные члены предложения.
- Предоставьте доводы о знаках препинания, если они имеются в предложении.

Синтаксический разбор. Порядок.
Для сказуемого нужно определить, каким оно является – составным или глагольным. Определите чем оно выступает. Если простое – укажите для него форму глагола, для составного глагольного – определить его состав, составное именное – чем выступает именная часть, какая связка применяется.
Если предложение имеет однородные члены предложения, укажите, чем выражены эти члены, и какими средствами они соединяются (союзы, интонация и союзы). В предложениях, которые имеют обособления, необходимо определить, чем выступает весь оборот. После этого нужно определить, чем выступает каждое слово в обороте, каким членом предложения является. Укажите, что предложение в своем составе имеет прямую речь. Определите слова говорящего, а также прямую речь.
Укажите, что предложение в своем составе имеет прямую речь. Определите слова говорящего, а также прямую речь.
Анализ сложносочиненной конструкции
- Аналогично, как и с простым предложением, назовите и определить тип высказывания.
- Определите грамматический фундамент каждого отдельного простого предложения. Прочитайте их по отдельности.
- Обозначите вид союзов, которыми связываются простые предложения в составе сложного (разделительные, соединительные, противительные). Определите, каким выступает сложное предложение (противопоставление, чередование событий, перечисление).
- Определите роль знаков препинания, объясните их расстановку.
- Затем нужно разобрать каждое предложение по отдельности как простое.
Далее рассмотрим пошаговый синтаксический разбор сложноподчиненного предложения (в составе одно придаточное):
- Отметить, каким сложноподчиненное предложение является (вопросительным, повествовательным).
- Разбить на простые предложения, найти грамматическую основу для каждого.
- Выделить, какое предложение из простых является главным.
- Определить по особенностям строения, чем присоединяется, к чему относится, чем выступает это сложноподчиненное предложение.
- Пояснить расстановку знаков препинания.
- Придаточное и главное разобрать подобно простым.

Синтаксический разбор сложноподчиненных предложений с придаточными
Анализ состоит из следующих этапов:
- Определите цель высказывания сложноподчиненного предложения, отметьте это.
- Установите грамматическую роль каждого простого предложения.
- Определить среди простых придаточное и главное.
- Укажите признаки подчиненного предложения – параллельное, однородное, последовательное (возможно комбинированное).
- Объясните надобность каждого знака препинания.
Анализ сложной конструкции с различными связными элементами
- Установите цели высказывания.
- Укажите основу грамматики отдельного простого предложения.
- Указать, что предложение имеет разные виды связи.
- Выделите по смысловому признаку, каким образом соединены простые предложения.
- Объясните каждый знак препинания, его значение.

В статье мы рассмотрели, почему нельзя выполнить синтаксический разбор какого-либо слова, и как правильно выполнять анализ предложений.
“>
Синтаксический анализ в НЛП — Analytics Vidhya
Промежуточный уровень НЛП Текст
Эта статья была опубликована в рамках блога по науке о данных.
Одним из важных вариантов использования обработки естественного языка (NLP) является генеративный текст. Генеративный текст предсказывает, какое слово должно быть следующим в предложении. Приложения генеративного текста — это чат-боты, отвечающие на вопросы, автокоррекция предложений или слов, а также автозаполнение, проверка грамматики, и эти случаи теперь стали незаменимыми и частью нашей повседневной жизни.
Чтобы понять, какое слово будет следующим, нам нужно узнать как можно больше, какие слова ранее встречались в предложении. Чтобы удовлетворить эту потребность и понять, какие слова появились раньше, части речи и синтаксический анализ являются очень важными и неотъемлемыми темами НЛП.
Чтобы удовлетворить эту потребность и понять, какие слова появились раньше, части речи и синтаксический анализ являются очень важными и неотъемлемыми темами НЛП.
Синтаксис языка является фундаментальным для генеративного текста и устанавливает основу для частей речи и деревьев синтаксического анализа.
Слово 9Синтаксис 0019 происходит от греческого слова «syntaxis», означающего «расположение», и относится к тому, как слова расположены вместе. Отныне синтаксис языка означает, как язык структурирован или устроен.
Как слова расположены вместе?
Существует множество различных способов классификации этих структур или устройств. Один из способов классифицировать расположение слов — это сгруппировать их по мере того, как слова ведут себя как единая единица или фраза, которая также известна как составная часть.
К предложению могут применяться разные языковые правила, и оно может иметь разную структуру. Поскольку разные части предложения основаны на разных частях синтаксиса, которые следуют тем же грамматическим правилам, что и именная группа, глагольная группа и предложная группа.
Поскольку разные части предложения основаны на разных частях синтаксиса, которые следуют тем же грамматическим правилам, что и именная группа, глагольная группа и предложная группа.
Предложение построено следующим образом:
Предложение = S = Фраза существительного + Фраза глагола + Фраза предлога
С = НП + ВП + ПП
В соответствии с правилами грамматики английского языка существуют следующие группы слов:
- Фраза существительного (NP): определитель + именные существительные = DET + номинальные
- Verb Phrase (VP): Глагол + ряд комбинаций
- Предложная фраза (PP): предлог + именная фраза = P + NP
Мы можем создавать различные формы и структуры вариантов именной, глагольной и предложной групп и соединять их в предложение.
Например, давайте посмотрим на предложение: Мальчик съел блины. Это предложение имеет следующую структуру:
- Мальчик: Фраза существительного
- ел: Глагол
- блины: фраза существительного (определитель + существительное)
Это предложение правильно как по структуре, так и по контексту.
Однако, теперь беру другое предложение: Мальчик ел блины под дверью.
- Мальчик: Фраза существительного
- ел: Глагол
- блины: фраза существительного (определитель + существительное)
- под: предлог
- дверь: фраза существительного (определитель + существительное)
Здесь за предлогом под следует именная группа дверь, , которая синтаксически верна, но неверна в контексте.
То же самое по-другому: Мальчик съел блины со стола для прыжков.
- Мальчик: Фраза существительного
- ел: Глагол
- блины: фраза существительного (определитель + существительное)
- от: предлог
- таблица прыжков: Verb Phrase
Это предложение синтаксически неверно, так как за предлогом формы следует глагольная фраза jumping table .
Компоненты синтаксиса текста Существует два императивных атрибута синтаксиса текста: теги части речи и грамматика зависимостей.
Тегирование части речи или тегирование POS указывает свойство или атрибут слова или токена. Каждое слово в предложении связано с частью речи, такой как существительные, глаголы, прилагательные, наречия. Теги POS определяют использование и функцию слова в предложении.
Зачем нам нужно дерево зависимостей, когда существуют теги POS?
Часть речи помечает только отдельные слова, а не фразы, поэтому недостаточно создать дерево синтаксического анализа. Деревья синтаксического анализа — это место, где мы помечаем фразы как фразу существительного, фразу глагола или фразу с предлогом, и они должны быть в этом конкретном порядке.
Синтаксический анализ по существу означает, как присвоить структуру последовательности текста. Синтаксический анализ включает в себя анализ слов в предложении на грамматику и их расположение таким образом, чтобы показать отношения между словами.
Грамматика зависимостей — это сегмент синтаксического анализа текста. Он определяет отношения между словами в предложении. Каждое из этих отношений представлено в виде тройки: отношение, управляющий и зависимый. В результате рекурсивного разбора наблюдаемая связь между словами представляется нисходящим образом и изображается в виде дерева, известного как дерево зависимостей.
Он определяет отношения между словами в предложении. Каждое из этих отношений представлено в виде тройки: отношение, управляющий и зависимый. В результате рекурсивного разбора наблюдаемая связь между словами представляется нисходящим образом и изображается в виде дерева, известного как дерево зависимостей.
Эти грамматические отношения можно использовать в качестве признаков для многих задач НЛП, таких как анализ настроений по сущностям, идентификация сущностей и классификация текста.
Например: давайте визуально представим предложение «Счета о портах и иммиграции были представлены сенатором Браунбеком, республиканцем от штата Канзас». как дерево зависимостей:
Источник: https://nlp.stanford.edu/software/stanford-dependencies.html
Анализатор естественного языка — это программа, которая определяет, какая группа слов сочетается (как «фразы») и какие слова являются подлежащим или дополнением глагола. Синтаксический анализатор НЛП разделяет серию текста на более мелкие фрагменты на основе правил грамматики. Если в предложении, которое невозможно разобрать, могут быть грамматические ошибки.
Если в предложении, которое невозможно разобрать, могут быть грамматические ошибки.
Первым шагом является определение субъекта предложения. Поскольку синтаксический анализатор разбивает последовательность текста на набор слов, которые связаны в своего рода фразе. Итак, этот набор слов, которые мы получаем, которые связаны друг с другом, и есть то, что называется предметом.
Синтаксический разбор и части речи, эти языковые структуры являются контекстно-свободными, грамматика основана на структуре или расположении слов. Это не основано на контексте.
Важно отметить, что грамматика всегда синтаксически верна, т. е. синтаксически мудра, и может не иметь контекстуального смысла.
Реализация на PythonТеперь давайте посмотрим, как пометить слова и создать деревья зависимостей в Python.
Использование библиотеки NLTK:
Библиотека NLTK включает:
- предварительно обученный токенизатор Punkt, который используется для токенизации слов.
- mediumd_perceptron_tagger: используется для пометки этих токенизированных слов частями речи 9.0040
Теггер части речи персептрона реализует тегирование части речи с помощью метода, называемого усредненным_перцептроном_tagger, структурированного алгоритма персептрона. Этот алгоритм используется для определения того, какое слово или токен необходимо пометить вместе с соответствующими частями речи.
импорт нлтк
nltk.download('пункт')
nltk.download('averaged_perceptron_tagger') из nltk import pos_tag, word_tokenize, RegexpParser
text = «Reliance Retail приобретает контрольный пакет акций дизайнерского бренда Abraham & Thakore».
токена = word_tokenize(текст)
тега = pos_tag(токены)
теги
Извлечение чанка или частичный анализ — это процесс извлечения из предложения коротких фраз (помеченных частью речи).
Разделение на фрагменты использует специальный синтаксис регулярных выражений для правил, ограничивающих фрагменты. Эти правила должны быть преобразованы в «обычные» регулярные выражения, прежде чем предложение можно будет разделить на части.
Эти правила должны быть преобразованы в «обычные» регулярные выражения, прежде чем предложение можно будет разделить на части.
Для этого нам нужно вызвать формулу регулярного выражения, шаблон регулярного выражения — где мы назначаем шаблон, который является глагольной фразой или именной фразой, и эти небольшие шаблоны могут быть распознаны, и это называется извлечением фрагментов.
чанкер = RegexpParser("""
NP: {?*} #Извлечение словосочетаний с существительными
P: {} #Чтобы извлечь предлоги
V: {} #Для извлечения глаголов
ПП: { } #Чтобы извлечь предложные фразы
VP: { *} #Чтобы извлечь глагольные фразы
«»»)
результат = chunker.parse(теги)
print('Наша запись синтаксического анализа:n', результат) результат.draw()
Использование библиотеки spacy:
импортировать пространство # Загрузка модели nlp=spacy.
 load('en_core_web_sm')
load('en_core_web_sm') text = «Reliance Retail приобретает контрольный пакет акций дизайнерского бренда Abraham & Thakore».
# Создание объекта документа документ = НЛП (текст)
# Получение тегов зависимостей
для токена в документе:
печать (токен.текст, '=>', токен.dep_) # Импорт визуализатора от импортного смещения
# Визуализация дерева зависимостей
displacy.render(doc,jupyter=True)
Сноска
Часть речи (POS) и синтаксический анализ используются для извлечения существительных, глаголов и предложных фраз и являются контекстно-свободными грамматиками. Поскольку они синтаксически верны и могут быть неправильными с точки зрения контекста, нам нужна некоторая форма ассоциации, то есть встраивание слов, которые помогут добавить контекст в предложение.
Самый простой подход к тегированию POS с использованием алгоритма структурированного персептрона состоит в том, чтобы разбить предложение на своего рода теги и идти слева направо.
Надеюсь, статья была вам полезна и вы узнали что-то новое. Большое спасибо, что заглянули, чтобы прочитать и помочь поделиться статьей с вашей сетью 🙂
Счастливого обучения!
Обо мнеПривет! Я Неха Сет. У меня есть последипломная программа по науке о данных и инженерии в Институте менеджмента Великих озер и степень бакалавра статистики. Я вошел в десятку самых популярных приглашенных авторов в 2020 году по Analytics Vidhya (AV).
Область моих интересов — НЛП и глубокое обучение. Я также прошел программу CFA. Вы можете связаться со мной по LinkedIn и прочитать другие мои блоги для AV.
Медиафайлы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
blogathonNLPСинтаксический анализ
Содержание
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Примите
Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Примите
Политику конфиденциальности и использования файлов cookie
Станьте полноценным специалистом по данным
Продвиньтесь вперед в своей карьере AI ML | Предварительные условия не требуютсяЗагрузить брошюруСинтаксический анализ с помощью НЛП
Синтаксический анализ — это третий этап обработки естественного языка (НЛП). По его названию легко понять, что он используется для анализа синтаксиса, иногда называемого синтаксическим анализом или синтаксическим анализом. Этот шаг направлен на извлечение точной или словарной семантики из текста. Синтаксический анализ сравнивает текст с формальными правилами грамматики, чтобы определить его значение. Например, выражение «горячее мороженое» будет отброшено семантическим анализатором.
Концепция синтаксического анализатора
Используется для выполнения процесса синтаксического анализа. Это программный компонент, который берет входные данные (текст) и преобразует их в структурное представление после проверки правильности синтаксиса с использованием формальной грамматики. Он создает структуру данных, которая может быть деревом синтаксического анализа, абстрактным синтаксическим деревом или другой иерархической структурой.
Это программный компонент, который берет входные данные (текст) и преобразует их в структурное представление после проверки правильности синтаксиса с использованием формальной грамматики. Он создает структуру данных, которая может быть деревом синтаксического анализа, абстрактным синтаксическим деревом или другой иерархической структурой.
Основные функции синтаксического анализа включают:
Сообщать о любых ошибках в синтаксисе.
Для восстановления после часто повторяющейся ошибки, чтобы можно было обработать остальную часть программы.
Сделать дерево разбора.
Для создания таблицы символов.
Создание промежуточных представлений (IR).
Методы синтаксического анализа
Синтаксический анализ делится на две категории по происхождению
Синтаксический анализ сверху вниз
Синтаксический анализатор строит дерево синтаксического анализа, а затем переходит к преобразованию начального символа во входные данные в этом типе синтаксического анализа. Для синтаксического анализа ввода наиболее распространенный вид синтаксического анализа сверху вниз использует рекурсивный подход. Возврат является фундаментальным недостатком синтаксического анализа рекурсивного спуска.
Для синтаксического анализа ввода наиболее распространенный вид синтаксического анализа сверху вниз использует рекурсивный подход. Возврат является фундаментальным недостатком синтаксического анализа рекурсивного спуска.
Анализ снизу вверх
В этом типе анализа анализатор начинает с входного символа и пытается построить дерево анализатора до начала.
Концепция деривации
Нам потребуется ряд производственных правил для получения входной строки. Совокупность продукционных правил называется деривацией. Во время синтаксического анализа мы должны выбрать нетерминал, который будет заменен, и продукционное правило, которое будет использоваться для замены нетерминала.
Различные типы производных
В этой части есть два вида производных, которые можно использовать для определения того, какой нетерминал следует заменить продукционным правилом.
Крайний левый производный
Предложенная форма ввода читается и заменяется слева направо в крайнем левом производном. Левая сентенциальная форма является сентенциальной формой в этом случае.
Левая сентенциальная форма является сентенциальной формой в этом случае.
Крайний правый производный
Предложенная форма ввода читается и заменяется справа налево в крайнем правом производном. Правая сентенциальная форма является сентенциальной формой в этом случае.
Понятие дерева синтаксического анализа
Его можно охарактеризовать как визуальное представление деривации. Корневой узел дерева синтаксического анализа является начальным элементом вывода. Листовые узлы являются конечными точками в каждом дереве синтаксического анализа, а внутренние узлы не являются терминалами. Обход по порядку создает исходную входную строку, что является особенностью деревьев синтаксического анализа.
Грамматика избирательного округа или структура фразы
Отношение избирательного округа является основой грамматики структуры фразы, введенной Ноамом Хомским. В результате она также известна как грамматика избирательного округа. Грамматика зависимости является полной противоположностью этому.
Прежде чем приводить пример, мы должны усвоить основы соединения групп и грамматики групп.
Во всех связанных структурах структура предложения рассматривается с точки зрения отношений субъектов.
Разделение субъекта и сказуемого в латинской и греческой грамматике является источником связи избирательного округа.
Чтобы понять основную форму предложения, используйте глагольную группу VP и именную группу NP.
Мы будем использовать предложение «Это дерево иллюстрирует отношение избирательных округов» , чтобы понять, как синтаксический анализ работает с помощью кода.
Код
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
импорт нлтк
от нлтк
импортировать pos_tag, word_tokenize, RegexpParser
# Строка для разбора
to_parse = "Это дерево иллюстрирует отношение избирательных округов"
# Найти все части речи в предложении выше
tagged_parts = pos_tag (word_tokenize (to_parse))
# Определяем грамматику, на основе которой мы должны извлечь
грамматика = г ""
" НП: {?*}
П: {
}
В: {<В. *>}
ПП: { }
ПО: { *}"""
#Извлечение всех частей речи
синтаксический анализатор = RegexpParser (грамматика)
# Вывести все части речи в предыдущем предложении
вывод = parser.parse(tagged_parts)
print("\nПосле извлечения частей\n\n", output,"\n")
 *>}
ПП: {
*>}
ПП: {Примечание: nltk — это библиотека Python для НЛП. также известен как N атуральный L язык T оол K ит.
Выходные данные
Выделенные слова — это части предложения, которые мы передали для построения синтаксического дерева.
Ниже перечислены некоторые из синтаксических категорий естественного языка, которые используются в грамматической части приведенного выше кода:
Графическое представление приведенного выше вывода кода 9.0271
Чтобы получить графическое представление, мы должны запустить еще одну строку кода, т. е. output.draw()
Контекстно-свободная грамматика
Контекстно-свободная грамматика (CFG) — это надмножество обычной грамматики и метод для описания языков. Его можно увидеть на диаграмме ниже.
Его можно увидеть на диаграмме ниже.
Abstract
Чтобы обрабатывать синтаксические структуры языка способами, совместимыми с человеческими ожиданиями, нам нужны вычислительные представления лексических и синтаксических свойств, которые составляют основу человеческого знания слов и предложений. Недавние методы распределенной семантики, основанные на нейронных сетях, позволили разработать системы со значительным практическим успехом и впечатляющей производительностью. Однако, как утверждают многие, таким системам по-прежнему не хватает свойств, подобных человеческим. В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченным отношениям. Стремясь лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе нескольких языков.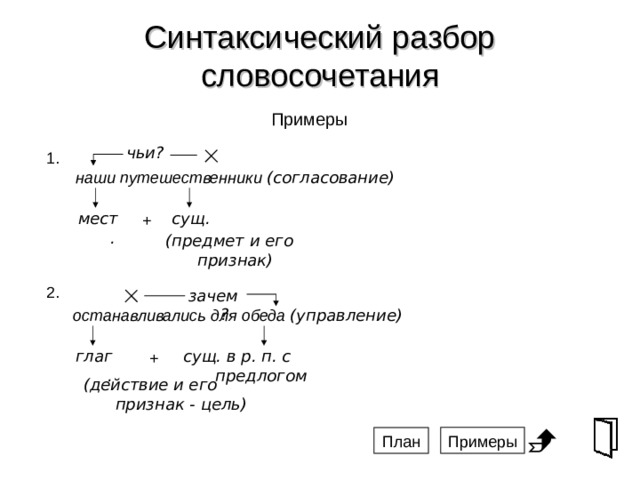 В то время как определенные наборы результатов в литературе указывают на то, что нейронные языковые модели демонстрируют способность к согласию на расстоянии, другое более детальное исследование того, как вычисляются эти эффекты, указывает на то, что определяемые ими пространства сходства не коррелируют с экспериментальными результатами человеческих экспериментов по сходству вмешательства в дальние зависимости. Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей.
В то время как определенные наборы результатов в литературе указывают на то, что нейронные языковые модели демонстрируют способность к согласию на расстоянии, другое более детальное исследование того, как вычисляются эти эффекты, указывает на то, что определяемые ими пространства сходства не коррелируют с экспериментальными результатами человеческих экспериментов по сходству вмешательства в дальние зависимости. Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей.- Anthology ID:
- 2020.iwpt-1.1
- Volume:
- Proceedings of the 16th International Conference on Parsing Technologies and the IWPT 2020 Shared Task on Parsing into Enhanced Universal Dependencies
- Month:
- July
- Year :
- 2020
- Адрес:
- Онлайн
- Места:
- ACL | ИВПТ | WS
- SIG:
- SIGPARSE
- Издатель:
- Ассоциация компьютерной лингвистики
- ПРИМЕЧАНИЕ:
- Страницы:
- 1
- Язык:
- URL:
- https://aclanthology. org/2020.iwpt-1.111111108.
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- 8
- . 1.1
- 8
- Биб-ключ:
- Cite (ACL):
- Паола Мерло. 2020. Синтаксический анализ у людей и машин. В Материалах 16-й Международной конференции по технологиям синтаксического анализа и общей задаче IWPT 2020 по синтаксическому анализу в расширенные универсальные зависимости , стр. 1, онлайн. Ассоциация компьютерной лингвистики.
- Ссылка (неофициальная):
- Синтаксический анализ в людях и машинах (Merlo, IWPT 2020)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2020.iwpt-1.1.pdf
- Видео:
- http://slideslive.com/38929668
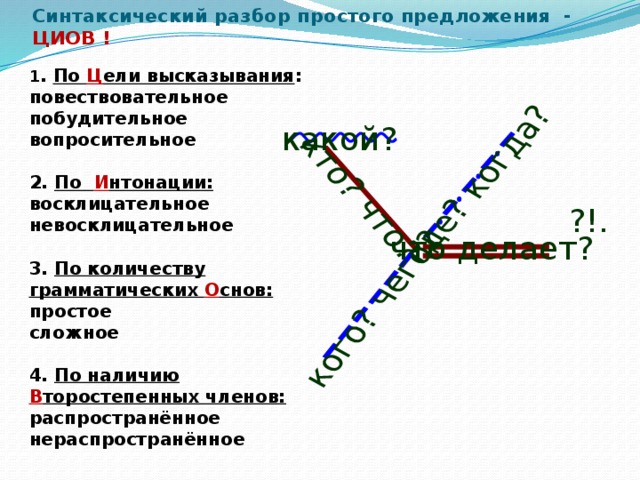 org/2020.iwpt-1.111111108.
org/2020.iwpt-1.111111108.PDF Процитировать Поиск Видео
- BibTeX
- MODS XML
- Сноска
- Предварительно отформатированный
@inproceedings{merlo-2020-syntactic,
title = "Синтаксический анализ у людей и машин",
автор = "Мерло, Паола",
booktitle = "Материалы 16-й Международной конференции по технологиям синтаксического анализа и общая задача IWPT 2020 по синтаксическому анализу в расширенные универсальные зависимости",
месяц = июль,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2020.iwpt-1.1",
doi = "10.18653/v1/2020.iwpt-1.1",
страницы = "1",
abstract = «Чтобы обрабатывать синтаксические структуры языка способами, совместимыми с человеческими ожиданиями, нам нужны вычислительные представления лексических и синтаксических свойств, которые составляют основу человеческого знания слов и предложений. Недавняя распределенная семантика на основе нейронных сетей В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченные отношения. Чтобы лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе на нескольких языках. Хотя некоторые наборы результатов в литературе указывают что модели нейронного языка демонстрируют согласие на расстоянии способности, другое более детальное исследование того, как рассчитываются эти эффекты, показывает, что пространства сходства, которые они определяют, не коррелируют с результатами экспериментов на людях по сходству вмешательства в зависимостях на расстоянии. Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей».
}
 org/2020.iwpt-1.1",
doi = "10.18653/v1/2020.iwpt-1.1",
страницы = "1",
abstract = «Чтобы обрабатывать синтаксические структуры языка способами, совместимыми с человеческими ожиданиями, нам нужны вычислительные представления лексических и синтаксических свойств, которые составляют основу человеческого знания слов и предложений. Недавняя распределенная семантика на основе нейронных сетей В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченные отношения. Чтобы лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе на нескольких языках. Хотя некоторые наборы результатов в литературе указывают что модели нейронного языка демонстрируют согласие на расстоянии способности, другое более детальное исследование того, как рассчитываются эти эффекты, показывает, что пространства сходства, которые они определяют, не коррелируют с результатами экспериментов на людях по сходству вмешательства в зависимостях на расстоянии.
org/2020.iwpt-1.1",
doi = "10.18653/v1/2020.iwpt-1.1",
страницы = "1",
abstract = «Чтобы обрабатывать синтаксические структуры языка способами, совместимыми с человеческими ожиданиями, нам нужны вычислительные представления лексических и синтаксических свойств, которые составляют основу человеческого знания слов и предложений. Недавняя распределенная семантика на основе нейронных сетей В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченные отношения. Чтобы лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе на нескольких языках. Хотя некоторые наборы результатов в литературе указывают что модели нейронного языка демонстрируют согласие на расстоянии способности, другое более детальное исследование того, как рассчитываются эти эффекты, показывает, что пространства сходства, которые они определяют, не коррелируют с результатами экспериментов на людях по сходству вмешательства в зависимостях на расстоянии. Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей».
}
Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей».
}
<моды> <информация о заголовке> Синтаксический анализ у людей и машин <название типа="личное">Паола Мерло <роль>автор <информация о происхождении>2020-07 текст <информация о заголовке> Материалы 16-й Международной конференции по технологиям синтаксического анализа и общая задача IWPT 2020 по синтаксическому анализу в расширенные универсальные зависимости <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Чтобы обрабатывать синтаксические структуры языка способами, совместимыми с человеческими ожиданиями, нам нужны вычислительные представления лексических и синтаксических свойств, которые составляют основу человеческого знания слов и предложений. merlo-2020-syntactic 10.18653/v1/2020.iwpt-1.1 <местоположение>https://aclanthology.org/2020.iwpt-1.1 <часть> <дата>2020-071
 Недавние методы распределенной семантики, основанные на нейронных сетях, позволили разработать системы со значительным практическим успехом и впечатляющей производительностью. Однако, как утверждают многие, таким системам по-прежнему не хватает свойств, подобных человеческим. В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченным отношениям. Стремясь лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе нескольких языков. В то время как определенные наборы результатов в литературе указывают на то, что нейронные языковые модели демонстрируют способность к согласию на расстоянии, другое более детальное исследование того, как вычисляются эти эффекты, указывает на то, что определяемые ими пространства сходства не коррелируют с экспериментальными результатами человеческих экспериментов по сходству вмешательства в дальние зависимости.
Недавние методы распределенной семантики, основанные на нейронных сетях, позволили разработать системы со значительным практическим успехом и впечатляющей производительностью. Однако, как утверждают многие, таким системам по-прежнему не хватает свойств, подобных человеческим. В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченным отношениям. Стремясь лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе нескольких языков. В то время как определенные наборы результатов в литературе указывают на то, что нейронные языковые модели демонстрируют способность к согласию на расстоянии, другое более детальное исследование того, как вычисляются эти эффекты, указывает на то, что определяемые ими пространства сходства не коррелируют с экспериментальными результатами человеческих экспериментов по сходству вмешательства в дальние зависимости. Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей.
Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей.%0 Материалы конференции Синтаксический анализ %T в людях и машинах %А Мерло, Паола %S Материалы 16-й Международной конференции по технологиям синтаксического анализа и общая задача IWPT 2020 по синтаксическому анализу в расширенные универсальные зависимости %D 2020 %8 июля %I Ассоциация компьютерной лингвистики %С онлайн %F merlo-2020-синтаксический %X Чтобы обрабатывать синтаксические структуры языка способами, совместимыми с человеческими ожиданиями, нам нужны вычислительные представления лексических и синтаксических свойств, которые составляют основу человеческого знания слов и предложений.
 Недавние методы распределенной семантики, основанные на нейронных сетях, позволили разработать системы со значительным практическим успехом и впечатляющей производительностью. Однако, как утверждают многие, таким системам по-прежнему не хватает свойств, подобных человеческим. В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченным отношениям. Стремясь лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе нескольких языков. В то время как определенные наборы результатов в литературе указывают на то, что нейронные языковые модели демонстрируют способность к согласию на расстоянии, другое более детальное исследование того, как вычисляются эти эффекты, указывает на то, что определяемые ими пространства сходства не коррелируют с экспериментальными результатами человеческих экспериментов по сходству вмешательства в дальние зависимости.
Недавние методы распределенной семантики, основанные на нейронных сетях, позволили разработать системы со значительным практическим успехом и впечатляющей производительностью. Однако, как утверждают многие, таким системам по-прежнему не хватает свойств, подобных человеческим. В частности, лингвистические, психолингвистические и нейробиологические исследования показали, что обработка предложений человеком чувствительна к структуре и неограниченным отношениям. Стремясь лучше понять построение структуры и свойства нейронных сетей на большие расстояния, я представлю обзор недавних результатов по согласованию и островным эффектам в синтаксисе нескольких языков. В то время как определенные наборы результатов в литературе указывают на то, что нейронные языковые модели демонстрируют способность к согласию на расстоянии, другое более детальное исследование того, как вычисляются эти эффекты, указывает на то, что определяемые ими пространства сходства не коррелируют с экспериментальными результатами человеческих экспериментов по сходству вмешательства в дальние зависимости. Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей.
%R 10.18653/v1/2020.iwpt-1.1
%U https://aclanthology.org/2020.iwpt-1.1
%U https://doi.org/10.18653/v1/2020.iwpt-1.1
%Р 1
Это открывает путь к размышлениям о том, как лучше сопоставить синтаксические свойства естественных языков в представлениях нейронных моделей.
%R 10.18653/v1/2020.iwpt-1.1
%U https://aclanthology.org/2020.iwpt-1.1
%U https://doi.org/10.18653/v1/2020.iwpt-1.1
%Р 1
Уценка (неформальная)
[Синтаксический анализ в людях и машинах](https://aclanthology.org/2020.iwpt-1.1) (Merlo, IWPT 2020)
- Синтаксический анализ в людях и машинах (Merlo, IWPT 2020)
ACL
- Паола Мерло. 2020. Синтаксический анализ у людей и машин. В Материалах 16-й Международной конференции по технологиям синтаксического анализа и общей задаче IWPT 2020 по синтаксическому анализу в расширенные универсальные зависимости , стр. 1, онлайн. Ассоциация компьютерной лингвистики.
Синтаксический анализ | Engati
Что такое синтаксический анализ?
Синтаксический анализ — это анализ, направленный на понимание логического значения предложений или частей предложений.
В то время как лемматизация сосредоточена исключительно на извлечении признаков и очистке данных, синтаксический анализ анализирует отношения между словами и грамматической структурой предложений. Это очень важно для понимания фактического смысла предложения.
Рассмотрим эти предложения:
- Лев — свирепое животное.
- Свирепый зверь лев.
Поскольку в обоих предложениях одни и те же слова, лексический анализ не сможет сказать, что второе предложение синтаксически неверно и не имеет смысла.
Синтаксический анализ необходим для изучения взаимосвязи между словами в предложении и грамматической структурой предложения, чтобы установить истинное значение предложения.
Под синтаксическим анализом можно понимать процесс анализа строк символов естественного языка в соответствии с грамматическими правилами.
Есть много элементов предложений, которые игнорируются лексическим анализом, но учитывается синтаксическим анализом. Например, лексический анализ игнорирует стоп-слова, которые могут изменить весь смысл предложения. Лексический анализ даже не занимается определением частей речи слов из анализируемого предложения.
Например, лексический анализ игнорирует стоп-слова, которые могут изменить весь смысл предложения. Лексический анализ даже не занимается определением частей речи слов из анализируемого предложения.
Синтаксический анализ также обращает внимание на порядок слов в предложении, еще один аспект, который полностью игнорируется лексическим анализом. Он также учитывает морфологию слов в предложении, которую лексический анализ просто не может объяснить.
Источник: ResearchGate
Как мы проводим синтаксический анализ?
При выполнении синтаксического анализа предложений с помощью инструментов традиционной грамматики можно выполнить шесть шагов:
- Сегмент I: Определение границ предложений и границ слов
- Классификация I: Определение частей речи
- Сегмент II: Определение составляющих
- Классификация II: Определение синтаксических категорий для составляющих
- Определение грамматических функций составляющих
- Рисование синтаксической структуры
Какова цель синтаксического анализа?
Его цель — понять структуру вводимого текста, от мельчайших основных символов до предложений, а затем извлечь из него логическое значение.
Синтаксический анализ — чрезвычайно важный аспект обработки естественного языка (НЛП), поскольку он помогает выяснить грамматическое значение любого предложения.
Увеличьте свой доход в 3 раза с помощью чат-ботов и живого чата
Запланируйте демонстрацию
Какие существуют уровни синтаксического анализа?
Вот уровни синтаксического анализа:
1. Тегирование части речи (POS)
Это первый уровень синтаксического анализа. Определение частей речи является важной частью синтаксического анализа и включает в себя определение слов в предложении как глаголов, наречий, существительных, прилагательных, предлогов и т. д.
Пометка части речи помогает нам понять смысл предложения. Все другие методы синтаксического анализа используют теги частей речи.
2. Анализ составляющих
Анализ составляющих включает разделение слов из предложения на группы на основе их грамматической роли в предложении.
Фразы существительных, фразы глаголов и фразы с предлогами являются наиболее распространенными группами, в то время как другие группы, такие как группы наречий и именные, также существуют.
3. Анализ зависимостей
Анализ зависимостей широко используется в языках со свободным порядком слов. При разборе зависимостей зависимости формируются между самими словами.
Когда между двумя словами есть зависимости, одно слово является головным, а другое — дочерним или зависимым.
В чем разница между лексическим и синтаксическим анализом?
Лексический анализ фокусируется на очистке данных и извлечении признаков с помощью таких методов, как выделение корней, леммитизация, исправление слов с ошибками и т. д.
С другой стороны, синтаксический анализ направлен на определение роли слов в предложении, интерпретацию отношений между словами и интерпретацию грамматической структуры предложений.
Если вам нужен пример, посмотрите на эти предложения:
Том — мудрый человек.
Том мудр?
Все слова одинаковы в обоих предложениях, но только первое предложение является синтаксически правильным и его легко понять.
Однако вы не сможете провести эти различия, если будете использовать только базовые методы лексической обработки. Чтобы сделать эти различия, вам нужно будет использовать более сложные методы обработки синтаксиса, чтобы вы могли понять отношения между отдельными словами в предложении.
Есть довольно много аспектов предложения, которые учитываются синтаксическим анализом, но не учитываются лексическим анализом. Некоторые из этих аспектов включают:
Порядок и значение слов
Синтаксический анализ направлен на выявление зависимости слов от других слов в содержании. Если порядок слов изменить, то будет труднее понять предложение.
Сохранение стоп-слов
Если удалить стоп-слова, весь смысл предложения может измениться.
Морфология слов
Синтез и лемматизация приведут слова к их базовой форме, тем самым изменив грамматику предложения.
Части речи слов в предложении
Очень важно определить правильную часть речи слова.
Что такое деривация в синтаксическом анализе?
Если вы хотите получить входную строку, вам потребуется последовательность правил производства. Вывод – это набор правил производства. Пока идет процесс парсинга, необходимо определить нетерминал, который подлежит замене, а также определить продукционное правило, с помощью которого нетерминал будет заменен.
Мы объясним два типа производных, которые вы можете использовать, чтобы решить, какой нетерминал заменить продукционным правилом.
Крайний левый вывод
В крайнем левом выводе сентенциальная форма ввода сканируется и заменяется слева направо. В этом случае сентенциальная форма называется левой сентенциальной формой.
Крайний правый вывод
В крайнем правом выводе сентенциальная форма ввода сканируется и заменяется справа налево. В этом случае сентенциальная форма называется право-сентенциальной формой.
Синтаксический анализ: Обзор | Шаги аналитики
Обработка естественного языка (NLP) — очень интересная область изучения машинного обучения, которая позволяет компьютерам понимать естественный язык людей. Чтобы понять сложность языков, необходимо изучить и проанализировать сложные закономерности с помощью различных процессов, начиная с шумной и неполной обработки голосового ввода и заканчивая лексической идентификацией, синтаксическим и семантическим анализом и интерпретацией языка в контексте.
В этой статье мы в основном сосредоточимся на синтаксическом анализе, который является важной частью НЛП. Мы собираемся обсудить следующее вкратце:
(Подробнее, чтобы узнать: Руководство по NLP для начинающих)
33. всеми, что такое синтаксический анализ? Синтаксический анализ описывается как изучение логического значения определенных фраз или частей предложений.
Это процесс анализа естественного языка с помощью правил формальной грамматики для выяснения словарного значения любого предложения.
Это третья фаза НЛП, и она работает только с группой слов или предложений.
Не работает с отдельными словами, поскольку отдельные слова не определяют общую грамматику любого предложения.
Синтаксический анализ также известен как синтаксический анализ или анализ. Для реализации задачи парсинга используем парсеры. Теперь давайте узнаем, что такое парсеры.
(необходимо прочитать: вопросы NLP)
О Darser Мы уже знаем, что парсеры используются для реализации парировки, но что является определением Pars? Он описывается как программный компонент, предназначенный для приема входных текстовых данных и предоставления структурного представления данных после проверки правильности синтаксиса с использованием формальной грамматики.
Он также создает структуру данных, которая часто имеет форму дерева синтаксического анализа, абстрактного синтаксического дерева или другой иерархической структуры. После поиска в пространстве множества деревьев он пытается определить идеальное дерево для определенного текста.
Какие существуют типы синтаксического анализа ?
Как правило, существует два типа синтаксического анализа: синтаксический анализ сверху вниз и синтаксический анализ снизу вверх.
При анализе сверху вниз синтаксический анализатор строит дерево анализа из начального символа, а затем пытается преобразовать начальный символ во входные данные. Рекурсивный метод используется для обработки ввода в наиболее популярном типе нисходящего анализа, но у него есть один существенный недостаток: поиск с возвратом.
Принимая во внимание, что при анализе снизу вверх синтаксический анализатор начинает с входного символа и продвигается вверх до начального символа, пытаясь создать дерево синтаксического анализатора.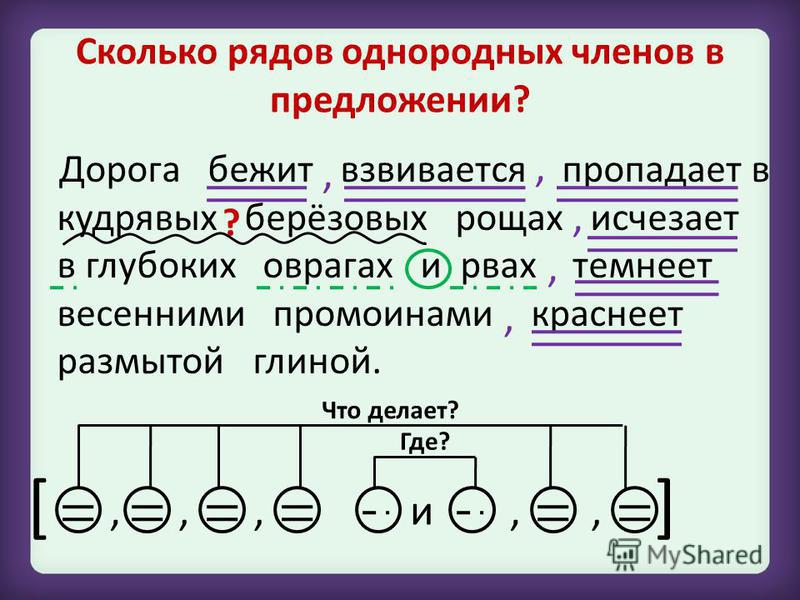 Теперь эти типы парсинга используются разными парсерами.
Теперь эти типы парсинга используются разными парсерами.
(Также читайте: Применение НЛП)
Какие существуют типы синтаксических анализаторов ?
Доступны следующие типы синтаксических анализаторов:
- Анализатор рекурсивного спуска:
Это точечный синтаксический анализатор, часто используемый при синтаксическом анализе. Он следует нисходящему процессу, в котором он проверяет правильность синтаксиса ввода, сканируя текст слева направо.
Для парсеров такого типа требуется операция чтения символов из входного потока и сопоставления их с терминалами с использованием грамматики. Мы узнаем о грамматике позже в этой статье.
- Анализатор сдвига-уменьшения:
Синтаксические анализаторы Shift-Reduce используют восходящий процесс, в отличие от рекурсивных синтаксических анализаторов.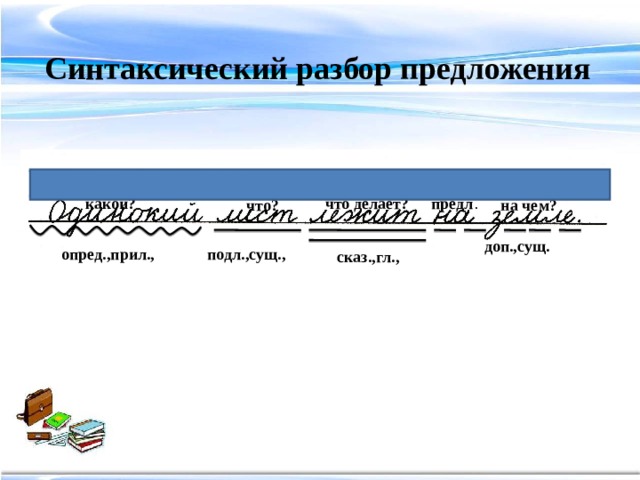 Его цель состоит в том, чтобы найти слова и фразы, соответствующие правой части грамматического произведения, заменить их левой частью и попытаться найти последовательность слов, которая продолжается до тех пор, пока не будет сокращено все предложение.
Его цель состоит в том, чтобы найти слова и фразы, соответствующие правой части грамматического произведения, заменить их левой частью и попытаться найти последовательность слов, которая продолжается до тех пор, пока не будет сокращено все предложение.
Таким образом, этот синтаксический анализатор начинается с входного символа и строит дерево синтаксического анализа вплоть до начального символа.
- Анализатор диаграмм:
Анализатор диаграмм в основном используется для неоднозначных грамматик, таких как грамматики естественных языков. Он решает трудности синтаксического анализа, используя идею динамического программирования. Он сохраняет частично теоретические выводы в структуре, называемой «диаграммой», как следствие динамического программирования. «Диаграмму» также можно использовать в различных ситуациях.
- Анализатор регулярных выражений:
Это один из самых популярных парсеров. Поверх строки с POS-тегом он применяет регулярное выражение, определенное в форме грамматики. По сути, он анализирует входные фразы с помощью регулярных выражений и в результате генерирует дерево разбора.
Поверх строки с POS-тегом он применяет регулярное выражение, определенное в форме грамматики. По сути, он анализирует входные фразы с помощью регулярных выражений и в результате генерирует дерево разбора.
Теперь, когда мы знаем типы синтаксического анализа и типы синтаксических анализаторов, давайте изучим еще одну важную тему — Деревья синтаксического анализа. (Источник)
(Предлагаемый блог: Методы анализа текста)
Деревья синтаксического анализа
Дерево синтаксического анализа представляет собой производное графическое представление дерева синтаксического анализа. Корневой узел дерева синтаксического анализа является начальным символом вывода, тогда как листовые узлы являются терминалами, а внутренние узлы не являются терминалами. Самая полезная характеристика дерева синтаксического анализа заключается в том, что оно создает исходную входную строку при последовательном обходе.
Анализ выполняется для анализа грамматики предложения, поэтому мы должны иметь базовое представление о концепции грамматики. Для объяснения синтаксической структуры правильно построенных программ большое значение имеет грамматика. Они подразумевают синтаксические нормы диалога на естественных языках в литературном смысле.
С момента появления естественных языков, таких как английский, хинди и другие, лингвисты стремились определить грамматику. Теория формальных языков также полезна в компьютерных науках, особенно в области языков программирования и структур данных.
В языке программирования C, например, точные грамматические правила определяют, как функции создаются из списков и инструкций.
(Рекомендуемый блог: Очистка текста и предварительная обработка в НЛП)
Какие существуют типы грамматики ?
Здесь мы перечислим три типа грамматики: грамматика составляющих, грамматика зависимостей и контекстно-свободная грамматика.
- Грамматика избирательного округа:
Грамматика избирательного округа, также известная как структура фраз, была предложена Ноамом Хомским. Он основан на отношении избирательности (отсюда и название) и полностью противоположен грамматике зависимостей.
Структура предложения в этом типе грамматики рассматривается через призму отношений субъектов во всех соответствующих рамках. Связь с избирательным округом происходит от разделения подлежащего и сказуемого в латинской и греческой грамматике.
Именная группа NP и глагольная группа VP используются для понимания основной структуры предложения. Дерево синтаксического анализа, использующее грамматику избирательного округа, известно как дерево синтаксического анализа на основе избирательного округа.
- Грамматика зависимостей:
Ниже приведены наиболее важные аспекты грамматики зависимостей и отношений зависимостей:
Лингвистические единицы, т.
е. слова, связаны между собой направленными связями в DG.Глагол занимает центральное место в структуре предложения.
По направленной связи все остальные синтаксические элементы связаны с глаголом. Зависимости — это рассматриваемые синтаксические компоненты.
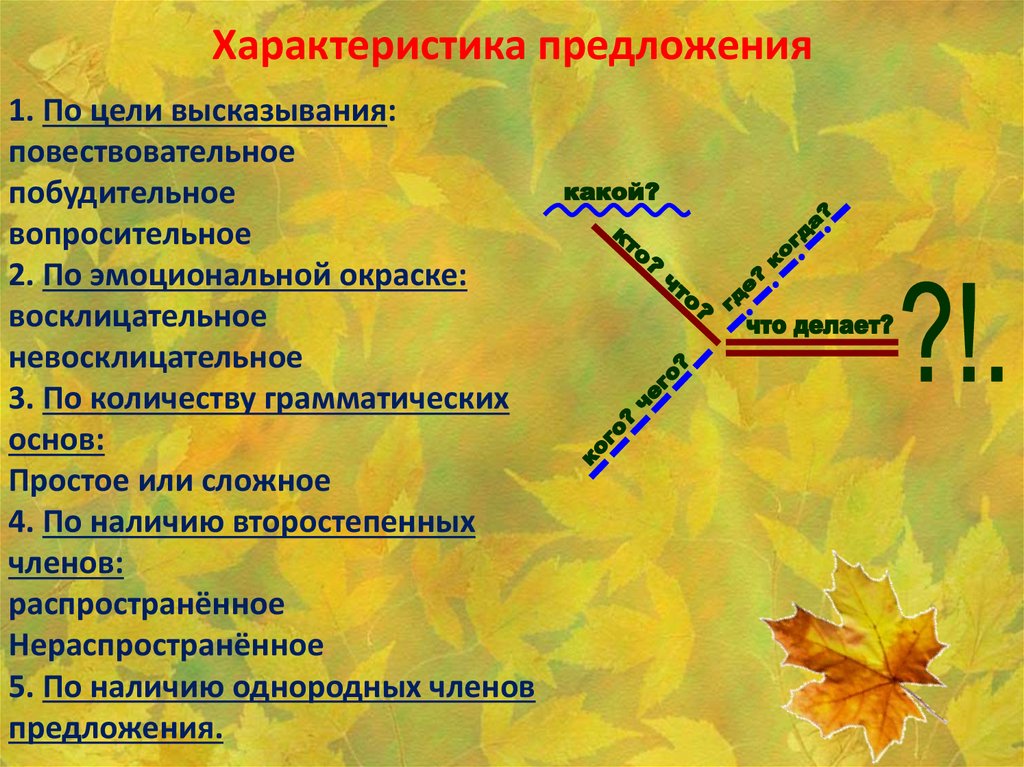 е. слова, связаны между собой направленными связями в DG.
е. слова, связаны между собой направленными связями в DG.
Деревья синтаксического анализа, в которых используется грамматика зависимостей, называются деревьями синтаксического анализа на основе зависимостей.
- Контекстно-свободная грамматика:
Контекстно-свободная грамматика (CFG) — это надмножество регулярной грамматики и нотации для описания языков. Следующие 4 компонента состоят из конечного набора правил грамматики:
Обозначается буквой V. Нетерминалы — это синтаксические переменные, представляющие группы строк, которые грамматика генерирует для помощи в определении языка.
- Набор клемм:
Он также известен как токены и определяется символом Σ. Основные символы терминалов используются для создания строк.
- Комплект продукции:
P — его символ. Набор определяет возможные комбинации терминалов и нетерминалов. Нетерминалы, стрелка и терминалы составляют каждую продукцию (P) (последовательность терминалов). Нетерминалы называются левой стороной производства, тогда как терминалы называются правой стороной.
- Стартовый символ:
Производственный процесс начинается со стартового знака. Буква S обозначает это. Начальный символ всегда является неконечным символом.
 Тогда как при синтаксическом анализе анализируются роли, которые играют слова в предложении, определяются отношения между разными словами в предложении и интерпретируется грамматическая структура предложения.
Тогда как при синтаксическом анализе анализируются роли, которые играют слова в предложении, определяются отношения между разными словами в предложении и интерпретируется грамматическая структура предложения.
Например, если мы рассмотрим два предложения:
«Дели — столица Индии» и «Дели — столица Индии?»
В этих двух предложениях слова одинаковы, однако первое предложение легче расшифровать, чем второе, что делает первое синтаксически правильным. Однако, используя базовые подходы к лексической обработке, мы не можем провести эти различия.
В результате для понимания связи между отдельными словами во фразе требуются более совершенные алгоритмы обработки синтаксиса. На следующей диаграмме показана связь между лексическим анализом и синтаксическим анализом:
Взаимодействие между лексическим анализатором и парсером
В синтаксическом анализе используются следующие приемы, которые не используются в лексическом анализе.
Целью синтаксического анализа является выделение связи между словами в документе. Будет сложно понять высказывание, если слова переставлены в другой последовательности.
Можно полностью изменить значение фразы, удалив стоп-слова. Таким образом, стоп-слова должны быть сохранены.
Основы и лемматизация приведут слова к их простейшей форме, изменив синтаксис предложения.
Очень важно определить правильную часть речи слова.
(Лучшее чтение: Текстовая аналитика и модели в НЛП)
НЛП с каждым днем становится все более и более популярным, поскольку оно имеет множество приложений, таких как чат-боты, голосовые помощники, распознавание речи и многое другое. Синтаксический анализ — очень важная часть НЛП, помогающая понять грамматическое значение любого предложения. В этой статье мы обсудили определение синтаксического анализа или синтаксического анализа, поговорили о типах парсеров и разобрались с базовой концепцией грамматики. Мы также узнали разницу между синтаксическим анализом и лексическим анализом.
В этой статье мы обсудили определение синтаксического анализа или синтаксического анализа, поговорили о типах парсеров и разобрались с базовой концепцией грамматики. Мы также узнали разницу между синтаксическим анализом и лексическим анализом.
Типы синтаксического анализа компилятора сверху вниз и снизу вверх
Автор: John Smith
ЧасовОбновлено
Что такое синтаксический анализ?
Анализ синтаксиса — это вторая фаза процесса проектирования компилятора, в которой заданная входная строка проверяется на предмет подтверждения правил и структуры формальной грамматики. Он анализирует синтаксическую структуру и проверяет, соответствует ли данный ввод правильному синтаксису языка программирования или нет.
Анализ синтаксиса в компиляторе Процесс проектирования следует за этапом лексического анализа. Он также известен как дерево синтаксического анализа или дерево синтаксиса. Дерево синтаксического анализа разработано с помощью предопределенной грамматики языка. Анализатор синтаксиса также проверяет, соответствует ли данная программа правилам, подразумеваемым контекстно-свободной грамматикой. Если он удовлетворяет, синтаксический анализатор создает дерево синтаксического анализа этой исходной программы. В противном случае он будет отображать сообщения об ошибках.
Он также известен как дерево синтаксического анализа или дерево синтаксиса. Дерево синтаксического анализа разработано с помощью предопределенной грамматики языка. Анализатор синтаксиса также проверяет, соответствует ли данная программа правилам, подразумеваемым контекстно-свободной грамматикой. Если он удовлетворяет, синтаксический анализатор создает дерево синтаксического анализа этой исходной программы. В противном случае он будет отображать сообщения об ошибках.
В этом уроке вы узнаете
- Зачем вам нужен синтаксический анализатор?
- Важная терминология синтаксического анализатора
- Зачем нужен парсинг?
- Методы синтаксического анализа Ошибка
- — Методы восстановления
- Грамматика:
- Условные обозначения
- Грамматика без контекста
- Грамматический вывод
- Сравнение синтаксиса и лексического анализатора
- Недостатки использования синтаксических анализаторов
Зачем нужен синтаксический анализатор?
- Проверить правильность кода
- Синтаксический анализатор поможет применить правила к коду
- Помогает убедиться, что каждая открывающая фигурная скобка имеет соответствующий закрывающий баланс
- Каждое объявление имеет тип, и этот тип должен существовать
Важная терминология синтаксического анализатора
Важная терминология, используемая в процессе синтаксического анализа:
- Предложение: Предложение — это группа символов в некотором алфавите.
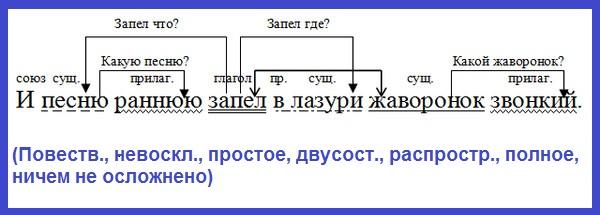
- Лексема: Лексема — это синтаксическая единица языка низшего уровня (например, итог, начало).
- Токен: Токен — это просто категория лексем.
- Ключевые слова и зарезервированные слова – это идентификатор, который используется как фиксированная часть синтаксиса оператора. Это зарезервированное слово, которое нельзя использовать в качестве имени переменной или идентификатора.
- Слова-помехи – Слова-помехи необязательны и вставляются в утверждение для улучшения читаемости предложения.
- Комментарии – Это очень важная часть документации. В основном он отображается с помощью /* */ или//Пусто (пробелы)
- Разделители – это синтаксический элемент, обозначающий начало или конец некоторой синтаксической единицы. Подобно утверждению или выражению, «начало»… «конец» или {}.

- Набор символов – ASCII, Unicode
- Идентификаторы – Это ограничение на длину, которое помогает уменьшить читабельность предложения.
- Операторские символы – + и – выполняют две основные арифметические операции.
- Синтаксические элементы языка
Зачем нужен парсинг?
Анализ также проверяет, правильно ли сформирована входная строка, и, если нет, отклоняет ее.
Ниже перечислены важные задачи, выполняемые синтаксическим анализатором при разработке компилятора:
- Помогает обнаруживать все типы синтаксических ошибок
- Найти позицию, в которой произошла ошибка
- Четкое и точное описание ошибки.
- Восстановление после ошибки для продолжения и поиска дополнительных ошибок в коде.
- Не должно влиять на компиляцию «правильных» программ.
- Анализатор должен отклонять недопустимые тексты, сообщая о синтаксических ошибках
Методы анализа
Методы анализа делятся на две разные группы:
- Анализ сверху вниз,
- Анализ снизу вверх
Анализ сверху вниз:
При анализе сверху вниз построение дерева разбора начинается с корня и затем продолжается к листьям.
Два типа анализа сверху вниз:
- Прогнозирующий анализ:
Предиктивный анализ может предсказать, какую продукцию следует использовать для замены конкретной входной строки. Предиктивный синтаксический анализатор использует точку просмотра вперед, которая указывает на следующие входные символы. При использовании этого метода синтаксического анализа возврат не является проблемой. Он известен как LL(1) Parser 9.0003
- Анализ рекурсивного спуска:
Этот метод синтаксического анализа рекурсивно анализирует входные данные для создания дерева празе. Он состоит из нескольких небольших функций, по одной для каждого нетерминала в грамматике.
Анализ снизу вверх:
При анализе снизу вверх в дизайне компилятора построение дерева анализа начинается с конца, а затем оно обрабатывается к его корню. Это также называется синтаксическим анализом сдвига-уменьшения. Этот тип синтаксического анализа в дизайне компилятора создается с помощью некоторых программных инструментов.
Ошибка — методы восстановления
Распространенные ошибки, возникающие при синтаксическом анализе в системном программном обеспечении
- Лексический : Имя неверно введенного идентификатора
- Синтаксический : несбалансированная скобка или отсутствие точки с запятой
- Семантический : несовместимое присвоение значения
- Логический : Бесконечный цикл и недостижимый код
Анализатор должен обнаруживать и сообщать о любых ошибках, обнаруженных в программе. Таким образом, всякий раз, когда возникает ошибка, парсер. Он должен быть в состоянии справиться с этим и продолжить синтаксический анализ оставшегося ввода. Программа может иметь следующие типы ошибок на различных этапах процесса компиляции. Существует пять распространенных методов исправления ошибок, которые могут быть реализованы в синтаксическом анализаторе 9.0003
Восстановление режима оператора
- В случае, если синтаксический анализатор обнаруживает ошибку, он помогает вам принять меры по ее устранению. Это позволяет заранее анализировать остальные входные данные и состояния.
- Например, добавление отсутствующей точки с запятой происходит в методе восстановления в режиме оператора. Тем не менее, разработчик синтаксического анализа должен быть осторожен при внесении этих изменений, так как одно неправильное исправление может привести к бесконечному циклу.
 Это позволяет заранее анализировать остальные входные данные и состояния.
Это позволяет заранее анализировать остальные входные данные и состояния.Восстановление в режиме паники
- В случае, когда синтаксический анализатор обнаруживает ошибку, этот режим игнорирует остальную часть оператора и не обрабатывает ввод от ошибочного ввода до разделителя, например точки с запятой. Это простой метод исправления ошибок.
- В этом типе метода восстановления синтаксический анализатор отклоняет входные символы один за другим, пока не будет найдена одна назначенная группа синхронизирующих токенов. Синхронизирующие токены обычно используют разделители, такие как или.
Восстановление на уровне фраз:
- Компилятор исправляет программу, вставляя или удаляя токены. Это позволяет продолжить синтаксический анализ с того места, где оно было. Он выполняет коррекцию на оставшемся входе. Он может заменить префикс оставшегося ввода некоторой строкой, что поможет синтаксическому анализатору продолжить процесс.
 Это позволяет продолжить синтаксический анализ с того места, где оно было. Он выполняет коррекцию на оставшемся входе. Он может заменить префикс оставшегося ввода некоторой строкой, что поможет синтаксическому анализатору продолжить процесс.
Это позволяет продолжить синтаксический анализ с того места, где оно было. Он выполняет коррекцию на оставшемся входе. Он может заменить префикс оставшегося ввода некоторой строкой, что поможет синтаксическому анализатору продолжить процесс.Производство ошибок
- Восстановление производства ошибок расширяет грамматику языка, который генерирует ошибочные конструкции. Затем синтаксический анализатор выполняет диагностику ошибок этой конструкции.
Глобальное исправление:
- Компилятор должен делать как можно меньше изменений при обработке неверной входной строки. Учитывая неправильную входную строку a и грамматику c, алгоритмы будут искать дерево синтаксического анализа для связанной строки b. Как и некоторые вставки, удаления и модификации, сделанные из токенов, необходимых для преобразования a в b, настолько мало, насколько это возможно.
Грамматика:
Грамматика — это набор структурных правил, описывающих язык. Грамматика определяет структуру любого предложения. Этот термин также относится к изучению этих правил, и этот файл включает морфологию, фонологию и синтаксис. Он способен описывать многие синтаксис языков программирования.
Грамматика определяет структуру любого предложения. Этот термин также относится к изучению этих правил, и этот файл включает морфологию, фонологию и синтаксис. Он способен описывать многие синтаксис языков программирования.
Правила грамматики форм
- Нетерминальный символ должен стоять слева хотя бы от одного произведения
- Символ цели никогда не должен отображаться справа от ::= любой продукции
- Правило является рекурсивным, если LHS появляется в его RHS
Условные обозначения
Условные обозначения Символ может быть указан путем заключения элемента в квадратные скобки. Это произвольная последовательность экземпляров элемента, которую можно указать, заключив элемент в фигурные скобки, за которыми следует символ звездочки {…}*.
Это выбор альтернативы, которая может использовать символ в рамках единого правила. При необходимости он может быть заключен в круглые скобки ([]).
Два типа области условных обозначений Терминал и нетерминал
1. Терминал:
Терминал:
- Строчные буквы алфавита, такие как a, b, c,
- Символы операторов, такие как +,-, * и т. д.
- Знаки пунктуации, такие как круглые скобки, решетка, запятая
- 0, 1, …, 9 цифр
- Строки, выделенные жирным шрифтом, такие как id или if, все, что представляет один символ терминала
2. Нетерминалы:
- Прописные буквы, такие как A, B, C
- Имена, выделенные курсивом в нижнем регистре: выражение или что-то
Контекстно-свободная грамматика
CFG — это леворекурсивная грамматика, имеющая хотя бы одно произведение данного типа. Правила в контекстно-свободной грамматике в основном рекурсивны. Анализатор синтаксиса проверяет, удовлетворяет ли конкретная программа всем правилам контекстно-свободной грамматики или нет. Если он соответствует, анализаторы синтаксиса этих правил могут создать дерево синтаксического анализа для этой программы.
выражение -> выражение --+ термин выражение -> выражение – термин выражение-> термин срок -> срок * фактор термин -> выражение/ фактор термин -> фактор фактор фактор -> ( выражение ) фактор -> идентификатор
Грамматическая производная
Грамматическая производная — это последовательность грамматических правил, которая преобразует начальный символ в строку.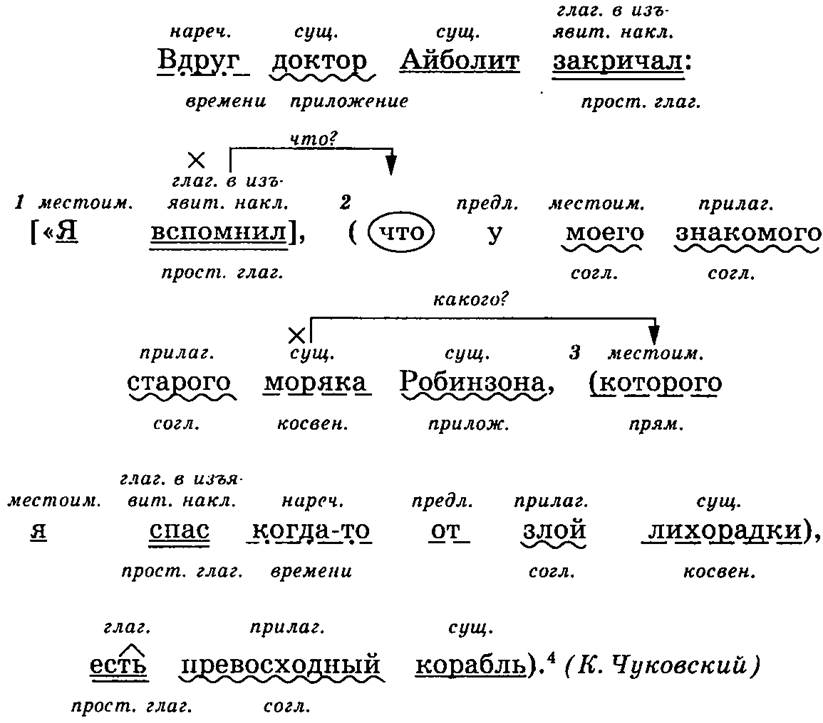 Вывод доказывает, что строка принадлежит языку грамматики.
Вывод доказывает, что строка принадлежит языку грамматики.
Крайняя левая производная
Когда сентенциальная форма ввода сканируется и заменяется в последовательности слева направо, это называется крайней левой производной. Форма предложения, полученная самым левым производным, называется формой предложения слева.
Самая правая производная
Крайняя правая производная сканирует и заменяет ввод продукционными правилами, справа налево, последовательно. Он известен как самый правый вывод. Форма предложения, полученная из самого правого производного, известна как правая форма предложения.
Сравнение синтаксиса и лексического анализатора
| Анализатор синтаксиса | Лексический анализатор |
|---|---|
| Анализатор синтаксиса в основном работает с рекурсивными конструкциями языка. | Лексический анализатор облегчает задачу синтаксического анализатора. |
Анализатор синтаксиса работает с токенами в исходной программе, чтобы распознавать значимые структуры в языке программирования.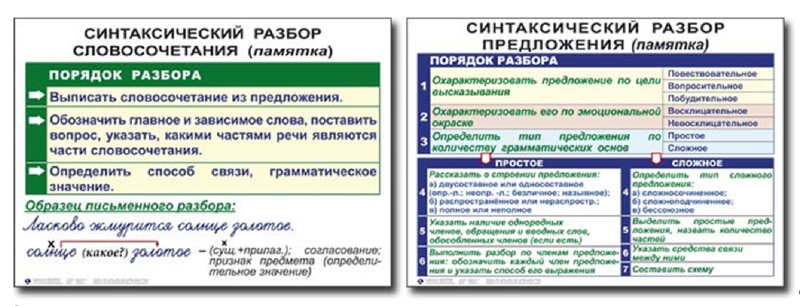 | Лексический анализатор распознал токен в исходной программе. |
| Он получает входные данные в виде токенов от лексических анализаторов. | Он отвечает за достоверность токена, предоставленного синтаксический анализатор |
Недостатки использования синтаксических анализаторов
- Он никогда не определит, действителен ли токен или нет
- Не помогает определить, является ли операция, выполняемая над типом токена, допустимой или нет
- Вы не можете решить, что токен объявлен и инициализирован до того, как он будет использован
Резюме
- Синтаксический анализ — это вторая фаза процесса разработки компилятора, которая следует за лексическим анализом
- Синтаксический анализатор поможет применить правила к коду
- Предложение, лексема, токен, ключевые слова и зарезервированные слова, шумовые слова, комментарии, разделители, набор символов, идентификаторы — некоторые важные термины, используемые при анализе синтаксиса при построении компилятора
- Parse проверяет, правильно ли сформирована входная строка, и, если нет, отклоняет ее
- Методы синтаксического анализа делятся на две разные группы: синтаксический анализ сверху вниз, синтаксический анализ снизу вверх
- Лексические, синтаксические, семантические и логические — некоторые распространенные ошибки, возникающие при синтаксическом анализе метода
- Грамматика — это набор структурных правил, описывающих язык
- Символ условных обозначений может быть указан путем заключения элемента в квадратные скобки
- CFG — это леворекурсивная грамматика, имеющая по крайней мере одну продукцию типа .
