Транскрипция русских слов. Фонетический разбор слова онлайн.
Первый раз здесь?
Посмотрите видео «Как перевести текст в фонетическую транскрипцию и послушать аудиозаписи слов»
Ваш браузер не поддерживает HTML5 видео!
Посмотрите видео «Как создавать списки слов»
Ваш браузер не поддерживает HTML5 видео!
Количество слов в нашем словаре русского произношения
| Тимур | 3 200 слов |
|
x0.5 x1 x0.5 x1 |
|
Оформить подписку
Вы изучаете или преподаете русский?
Мы знаем, что иногда русский язык кажется трудным. Мы не хотим, чтобы вы теряли время.
Ознакомьтесь со всеми нашими инструментами и учите русский быстрее!
Приветствие от создателя сайта Тимура:
Узнайте, как активировать мозг и учиться быстрее (4 мин. )
)
Статья Тимура Байтукалова «Учим иностранный язык с нуля. Часть 1. Осваиваем произношение»
Книга Тимура Байтукалова «Быстрое изучение иностранного языка от английского до японского»
Бесплатный вебинар «Фонетическая транскрипция для быстрого изучения иностранных языков» (21 мин.)
Фонетическая транскрипция русских слов
Русское произношение может представлять затруднение даже для людей, для которых русский язык является родным, не говоря уже об иностранцах. Начнем с того, что в словарях фонетическая транскрипция русских слов не указывается. Считается, что правила произношения в русском языке довольно строгие. На самом деле они очень сложные и имеют много исключений.
Произношение русских букв меняется в зависимости от того, под ударением находится данная буква или нет (в случае гласных букв), а также от того, какие согласные буквы окружают данную букву. Буква «а», к примеру, может иметь 5 вариантов произношения!
Буква «а», к примеру, может иметь 5 вариантов произношения!
Этот онлайн-переводчик позволяет перевести текст на русском языке в фонетическую транскрипцию, записанную либо буквами кириллицы, либо символами международного фонетического алфавита (МФА).
Фонетический разбор слова онлайн
Переводчик может быть использован для фонетического разбора слова онлайн. Чтобы произвести фонетический разбор слова, вам нужно:
- записать слово.
- поставить ударение в слове (переводчик умеет это делать).
- разделить слово на слоги.
- записать фонетическую транскрипцию слова (здесь вам также пригодится переводчик).
- записать все буквы слова в столбик.
- записать справа от каждой буквы звук, который данная буква обозначает.
- описать звук: для гласных – ударный или безударный, для согласных – твердый или мягкий (парный/непарный), глухой или звонкий (парный/непарный).

- посчитать буквы и звуки в слове.

Произведем, к примеру, фонетический разбор слова «солнце»:
со́-лнце [со́нцыэ]
| с | с | согласный, твердый парный, глухой парный |
| о | о | гласный, ударный |
| л | не читается | |
| н | н | согласный, твердый парный, звонкий непарный |
| ц | ц | согласный, твердый непарный, глухой непарный |
| е | ыэ | гласный, безударный |
6 букв, 5 звуков.
Обратите внимание на последний звук слова – в школьной практике его записали бы как «э». Профессиональные лингвисты обозначают его как «ы э«, т.к. этот безударный гласный произносится как нечто среднее между звуками «ы» и «э».
Фонетическая транскрипция поможет иностранцам улучшить произношение русских слов
Если вы учите русский язык, этот инструмент послужит вам руководством по произношению русского языка, и поможет вам сэкономить время на первых порах освоения русского, пока вы еще не освоили правила произношения.
Если вы регулярно пользуетесь фонетической транскрипцией в сочетании с аудио- и видеоматериалами на русском языке, вы быстро сможете улучшить свое русское произношение и навыки аудирования.
Чтобы помочь вам, мы создали раздел видео-тренажер русского произношения. Он позволяет тренировать произношение наиболее часто встречающихся русских слов, задавать скорость воспроизведения и количество повторений каждого слова.
Еще один отличный способ улучшить русское произношение — воспользоваться разделом сайта
Дополнительная информация о переводчике
Некоторые русские слова с одинаковым написанием могут иметь разное значение в зависимости от ударения. Cравните: замо́к – за́мок. Эти слова называются «омографы». Наш переводчик выделит транскрипцию таких слов зеленым цветом. Например:
Например:
Если вы наведете мышкой на такое слово или коснетесь его на вашем мобильном устройстве, вы увидите все возможные произношения.
Переводчик работает на основе словаря, содержащего информацию об ударениях в русских словах. Если положение ударения для данного слова не было найдено в словаре, то вместо транскрипции будет показано само слово, окруженное косыми чертами: /экстравагантный/. Вы можете улучшить переводчик, указав положения ударения в подобных словах. Для этого перейдите в режим исправления ошибок.
При создании переводчика мы использовали онлайн-ресурсы из списка ниже, а также книгу Буланина «Фонетика современного русского языка».
Кириллическая транскрипция
Кириллическая транскрипция — не самый точный способ передачи того, как произносятся русские слова. Тем не менее, ее часто изучают в ВУЗах. В таблице ниже вы найдете соответствия кириллической транскрипции некоторым символам международного фонетического алфавита:
| Символ международного фонетического алфавита | Кириллическая транскрипция |
|---|---|
| ударный гласный [ˈe] | [э́] |
| ударный гласный [ˈʉ] | [у́] |
| безударный гласный [ʉ] | [у] |
| заударный гласный [ə] после твердых согласных в абсолютном конце | [ʌ] |
| безударный гласный [ɪ] | [ие] в первом предударном слоге и в абсолютном начале слова, [ь] в остальных безударных слогах |
Выделение цветом часто встречающихся русских слов
Специальная опция позволяет вам выделять различными цветами наиболее часто встречающиеся русские слова. В зависимости от рейтинга частотности слова будут выделены следующими цветами:
В зависимости от рейтинга частотности слова будут выделены следующими цветами:
| 1-1000 | 1001-2000 | 2001-3000 | 3001-4000 | 4001-5000 |
Если вы хотите осуществить детальный анализ вашего текста и увидеть подробную статистику, вы можете воспользоваться онлайн-инструментом для частотного анализа текста на русском языке.
Попробуйте наш фонетический конвертер русских субтитров и получите вот такой результат:
русское произношение – онлайн-ресурсы
Обновления этого переводчика слов в транскрипцию
Поиск в блоге
Слова «подчёркивание» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «подчёркивание» на слоги для переноса.

Слоги в слове «подчёркивание» деление на слоги
Количество слогов: 6
По слогам: по-дчё-рки-ва-ни-е
По правилам школьной программы слово «подчеркивание» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
под-чер-ки-ва-ни-е
По программе института слоги выделяются на основе восходящей звучности:
по-дчер-ки-ва-ни-е
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
р — непарная звонкая согласная (сонорная), примыкает к текущему слогу
Как перенести слово «подчёркивание»
по—дчеркивание
под—черкивание
подче—ркивание
подчер—кивание
подчерки—вание
подчеркива—ние
Морфологический разбор слова «подчёркивание»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: средний;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
подчёркивание
Разбор слова «подчёркивание» по составу
| под | приставка |
| чёрк | корень |
| ива | суффикс |
| ни | суффикс |
| е | окончание |
подчёркивание
Сходные по морфемному строению слова «подчёркивание»
Сходные по морфемному строению слова
Синонимы слова «подчёркивание»
1. акцентирование
акцентирование
2. акцентировка
3. выделение
4. выпячивание
5. напирание
6. отмечание
7. оттенение
8. эмфаза
9. отчеркивание
10. педалирование
Ударение в слове «подчёркивание»
Подчё́ркивание — ударение падает на слог с буквой ё
Фонетическая транскрипция слова «подчёркивание»
[пач’:`орк’иван’ий’э]
Фонетический разбор слова «подчёркивание» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| П | [п] | согласный, глухой парный, твёрдый, шумный | П |
| о | [а] | гласный, безударный | о |
| д | [ч’:] | согласный, глухой парный, твёрдый, долгий | д |
| ч | — | не образует звука | ч |
| ё | [`о] | гласный, ударный | ё |
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| к | [к’] | согласный, глухой парный, мягкий, шумный | к |
| и | [и] | гласный, безударный | и |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| а | [а] | гласный, безударный | а |
| н | [н’] | согласный, звонкий непарный (сонорный), мягкий | н |
| и | [и] | гласный, безударный | и |
| е | [й’] | согласный, звонкий непарный (сонорный), мягкий | е |
| [э] | гласный, безударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 13 букв и 13 звуков.
Буквы: 6 гласных букв, 7 согласных букв.
Звуки: 6 гласных звуков, 7 согласных звуков.
Предложения со словом «подчёркивание»
Релятливизм проистекает из одностороннего подчёркивания постоянной изменчивости действительности и отрицания относительной устойчивости вещей и явлений.Источник: Илья Мельников, Читай как aгент cпецслужб.
Следует избегать использования символа подчёркивания, так как здесь возникают проблемы с разделительными линиями.Источник: А. Н. Остапчук, ПК для ветеринарного врача, 2006.
Поэтому, как правило, вредно подчёркивание особых прав и прерогатив.Источник: В. Т. Томин, Избранные труды, 2004.
Сочетаемость слова «подчёркивание»
1. символ подчёркивания
2. (полная таблица сочетаемости)
Значение слова «подчёркивание»
ПОДЧЁРКИВАНИЕ , -я, ср. 1. Действие по знач. глаг. подчеркивать. Подчеркивание ошибок в диктанте. (Малый академический словарь, МАС)
1. Действие по знач. глаг. подчеркивать. Подчеркивание ошибок в диктанте. (Малый академический словарь, МАС)
Как правильно пишется слово «подчёркивание»
Орфография слова «подчёркивание»Правильно слово пишется: подчёркивание
Нумерация букв в слове
Номера букв в слове «подчёркивание» в прямом и обратном порядке:
- 13
п
1 - 12
о
2 - 11
д
3 - 10
ч
4 - 9
ё
5 - 8
р
6 - 7
к
7 - 6
и
8 - 5
в
9 - 4
а
10 - 3
н
11 - 2
и
12 - 1
е
13
Ассоциации к слову «подчёркивание»
Переменный
Знаковый
Определённый
Характерный
Отдельный
Нижний
Особый
Исторический
Специальный
Различный
Простой
Короткий
Длинный
Следующий
Например
Обычно
Часто
Иногда
Всё
Фонетический разбор слов от А до Я!
В данной статье мы научимся делать фонетический разбор слов. Узнаем все существующие буквы и звуки, изучим основные правила фонетического или звуко-буквенного разбора слов.
Узнаем все существующие буквы и звуки, изучим основные правила фонетического или звуко-буквенного разбора слов.
Для начала рекомендуется посмотреть видео по теме ФОНЕТИКА, в нем освещаются базовые правила и формируется представление о фонетическом разборе слов.
Вводное видео о фонетическом разборе
После просмотра видео обязательно закрепите всё внимательным прочтением статьи!
Итак, всё с самого начала и по порядку!
В русском алфавите, как вы знаете, 33 буквы, а вот звуков, которые могут давать эти буквы в словах при произношении больше, а именно 42 звука.
При фонетическом разборе звуки для обозначения принято заключать в квадратные скобки []. Звучание записанное на письме в фонетике еще называют транскрипцией.
То есть, буква а, звук [а].
Еще можно обозначить, что транскрипция буквы а — [а].
При этом в алфавите 10 гласных букв. Это буквы: А, О, У, Ы, Э, И, Я, Ё, Ю, Е.
Но гласных звуков, как ни странно меньше.
Всего 6 гласных звуков: [А], [О], [У], [Ы], [Э] и [И].
Почему так? Все потому, что гласные буквы Я, Ё, Ю, и Е не дают отдельных гласных звуков.
Когда Я, Ё, Ю, и Е идут после согласных, то чаще всего дают звуки [А], [О], [У] и [Э].
Когда Я, Ё, Ю, и Е идут в начале слов, после гласных, мягкого или твердого знака, то они, как правило, дают сочетания звуков, которые записываются, как [Й’][А], [Й’][О], [Й’][У] и [Й’][Э], соответственно.
В алфавите еще 2 интересных буквы: Ь и Ъ. Мягкий и твердый знак не дают самостоятельных звуков, но для чего они тогда нужны, и где еще 36 звуков…
В алфавите осталась еще 21-на согласная буква:
Б, В, Г, Д, Ж, З, Й, К, Л, М, Н, П, Р, С, Т, Ф, Х, Ц, Ч, Ш, Щ.
Вот они-то, в сочетании с гласными буквами и мягким знаком и дают оставшиеся 36 звуков — это [б], [б’], [в], [в’], [г], [г’], [д], [д’], [ж], [з], [з’], [й’], [к], [к’], [л], [л’], [м], [м’], [н], [н’], [п], [п’], [р], [р’], [с], [с’], [т], [т’], [ф], [ф’], [х], [х’], [ц], [ч’], [ш], [щ’].
То есть, к примеру, буква Б в словах может давать твердый звук, записывается, как [б]. К примеру, в слове «бочка».
Также Б может давать мягкий звук, который записывается почти также, но с маленькой кавычкой(апострофом) — [б’]. К примеру, мягкий звук [б’] в словах: берег, обязан, особь.
Мягкий знак, кстати, в последнем слове вместе с буквой Б и дал необходимый мягкий звук. Собственно для этого он и используется. Твердый знак в свою очередь используется для разделения звуков в слове, к примеру, в словах подъезд, съел, разъединить.
Правила фонетического разбора.
Со всеми буквами и звуками разобрались. Давайте перейдем к непосредственно правилам фонетического разбора.
Как мы поняли, по определению звуки могут быть гласными и согласными.
Фонетический разбор гласных
В зависимости от ударения в слове гласные звуки могут быть ударными и безударными.
Как Вы уже поняли, звуков [я], [ё], [ю], [е] НЕ существует.
Буквы Я, Ё, Ю, и Е после согласных дают звуки [А], [О], [У] и [Э], соответственно.
Когда Я, Ё, Ю, и Е после гласных, мягкого, твердого знака или в начале слова, то дают звуки [Й’][А], [Й’][О], [Й’][У] и [Й’][Э].
Для Я и Е есть исключение, когда они безударные, тогда дают звук [И] после всех согласных, кроме Ж, Ш и Ц. К примеру, ряби́на [р’иб’ина], степно́й [ст❜ипной❜].
После Ж, Ш и Ц безударные Е и Я дают вместо [И] звук [Ы]. К примеру, в слове за́йцев [зай’цыф].
В других случаях безударные Я и Е дают [Й’][И]. К примеру, в слове язы́к [й’изык].
Все остальные гласные буквы А, О, У, Ы, Э и И дают соответствующие звуки [А], [О], [У], [Ы], [Э] и [И], за исключением случая, когда буква О без ударения, тогда она дает звук [А], к примеру в слове окно [акно].
Как запомнить фонетику гласных звуков?
С гласными всё довольно просто. Необходимо запомнить 4 буквы не дающие самостоятельных звуков Я, Ё, Ю, и Е. Они дают соответствующие звуки [А], [О], [У] и [Э] после согласных, смягчая их. В других ситуациях при фонетическом разборе Я, Ё, Ю, и Е перед [А], [О], [У] и [Э] добавляется [Й’].
В других ситуациях при фонетическом разборе Я, Ё, Ю, и Е перед [А], [О], [У] и [Э] добавляется [Й’].
Исключение, когда Я и Е без ударения, то дают [И] после согласных, иногда [Ы](после Ж, Ш и Ц), и [Й’][И] в остальных случаях.
Оставшиеся 6 гласных букв А, О, У, Ы, Э и И дают такие же звуки [А], [О], [У], [Ы], [Э] и [И], за исключением безударной О, которое дает звук [А].
Фонетический разбор согласных
Согласные в свою очередь делятся на звонкие и глухие/парные и непарные.
Звонкие и глухие парные звуки это соответственно:
[б]-[п]
[в]-[ф]
[г]-[к]
[д]-[т]
[ж]-[ш]
[з]-[с]
и их мягкие «аналоги» [б’]-[п’],[в’]-[ф’] и т.д.
Звонкие непарные звуки(они же сонорные): [Й’], твердые [Л],[М],[Н] [Р] и мягкие [Л’],[М’],[Н’] [Р’].
Глухие непарные: [Х],[Х’],[Ц],[Ч’] и [Щ’].
Согласные также в словах могут быть твердыми или мягкими.
По общему правилу фонетики перед буквами А, О, У, Ы, Э и Ъ согласные буквы дают твердые звуки, кроме букв Ч, Щ и Й они дают всегда мягкие звуки, вне зависимости от того, какая буква за ними следует.
Перед И, Я, Ё, Ю, Е и Ь согласные буквы дают мягкие звуки, кроме Ж, Ш и Ц, они дают всегда твердые звуки.
Помним также, что Я, Ё, Ю, Е после согласных дают звуки [а],[о],[у],[э] без [Й’].
В отдельных словах Е может слышится, как [Э], без смягчения предшествующей согласной и без добавления [Й’], когда предыдущая буква не согласная. К примеру слово тест слышится, как [тэст], кафе [кафэ], проект [проэкт].
Также по фонетического разбору согласных важно знать:
1. Звонкая согласная буква может давать глухой звук. Если в слове буква, дающая парный звонкий звук, последняя или за ней следует буква, дающая глухой звук, то звонкий звук «приглушается», то есть вместо звонкого в транскрипции записывается его глухая пара.
К примеру, слово когти, дает в транскрипции [кокт’и], ров в транскрипции [роф].
2. Сочетания согласных букв могут давать другие звуки. СЧ, ЗЧ произносятся как [Щ]. Сочетание ТЬС, ТС, ДС дают [Ц]. ЧН и ЧТ в некоторых словах могут давать звуки [ШН] и [ШТ].
ЧН и ЧТ в некоторых словах могут давать звуки [ШН] и [ШТ].
К примеру, в слове счётный транскрипция [щ’отный’], учи́ться [уч’и́ца], подска́зка [пацка́ска], конечно [кан’э́шна], что [што].
3. Отдельные согласные в словах могут НЕ давать звуков в ряде случаев.
3.1 Когда в слове друг за другом идут буквы СТН и СТЛ, согласный [Т], как правило, не произносится. К примеру, постный транскрипция [посный], страстный [страсный’] , счастливый [щ’асл’ивый’].
3.2. Когда одинаковые согласные идут друг за другом. К примеру, в слове класс, транскрипция [клас]. Или к примеру, в слове коленный транскрипция [кол’эн:ый’]. НН в данном случаев в транскрипции помечается двоеточием, что означает, что звук продленный, то есть немного тянется при произношении.
3.3. Также в ряде случаев, когда две и более согласные буквы идут друг за другом, одна из них не произноситься. К примеру, в слове отдохну́ть транскрипция [ад:ахну́т’], ле́тчик [л’о́ч’ик], солнце [сонцэ], поздно [по́зна], се́рдце [с’э́рц:э], сши́ть [шыт’], сже́чь [жэч’].
На практике проблем с фонетическим разбором таких случаев, как правило не возникает, так как пропадание звуков естественным образом слышится при произношении слова.
Как легко запомнить фонетические характеристики согласных звуков?
Запомнить основные характеристики согласных звуков на самом деле несложно.
Звонкий звук или глухой легко определить по звучанию. Глухие звуки произносятся как бы «выдыханием» или «шумом», произносить глухие звуки немного легче, чем звонкие. Перебирая произношение глухих и звонких звуков, вы быстро уловите разницу и научитесь без труда их отличать.
Также не сложно запомнить парные звуки. Всего 6 основных пар звуков, перепутать их между собой довольно сложно. Причем все 6 звонких звуков из пар — это звуки первых 6 согласных букв алфавита друг за другом.
А, Б, В, Г, Д, Е, Ё, Ж, З…
Твердость и мягкость в большинстве случаев легко понять, просто произнеся слово. К примеру, просто сравните звучание буквы д в словах дом и дети.
Это основные знания, которые важно усвоить для фонетического разбора. Осталось только освоить сам разбор на практике. Из-за большого количества особенностей и исключений, у вас вряд ли получиться сразу разбирать слова без ошибок, но чем больше вы будете практиковаться, тем лучше у вас будет получаться.
Фонетический разбор слов по шагам.
1. Запишите слово, поставьте ударение.
Если вы потерялись и не можете точно поставить ударение, попробуйте, перенося ударение между слогами, выбрать самый благозвучный для вас вариант. К примеру, большинство людей из вариантов ударения: мОлоко, молОко, молокО, естественно, выберут последний, как наиболее понятный и правильный.
2. Внизу распишите буквы и звуки, которые они дают, каждый звук с новой строки.
Если на этапе разложения по звукам вы не знаете, как правильно произносится слово, записывайте звуки так, как слышите, полагаясь на свое собственное произношение конкретного слова.
3. Отметьте гласные звуки, обозначьте ударный и безударные.
С гласными буквами по-проще, поэтому их мы описываем в первую очередь, чтобы не отвлекаться потом, анализируя согласные. Частые ошибки связаны с безударными гласными буквами Я, Е после согласных, которые дают звук [И], а также с безударной О, дающей звук [А].
4. Отметьте оставшиеся согласные звуки, укажите звонкие они или глухие, парные или непарные, твердые или мягкие.
Если вы забыли, какие есть звонкие и глухие звуки, то попробуйте понять интуитивно, звонкий звук или глухой по произношению. Самостоятельно попробуйте подобрать пару, вспомните первых 6 согласных букв алфавита, если парного звука на ум не приходит, значит скорее всего звук непарный. Твердость или мягкость также можно отчетливо различить по произношению, даже не помня правил.
5. Посчитайте итоговое количество звуков и букв.
Звуков может быть может быть меньше, больше или столько же, сколько букв в слове. Будьте внимательны на финишном этапе фонетического разбора!
Будьте внимательны на финишном этапе фонетического разбора!
Фонетический разбор, на примере слова ЗВОНИТ
1. Записываем слово, ставим ударение
звонИт (ударение на второй слог верное)
2. Расписываем буквы и звуки
звонИт (обращаем внимание, что в слове безударное О, дающее звук [А])
з [з]
в [в]
о [а]
н [н’]
и [и]
т [т]
3. Отмечаем гласные, ударные и безударные.
звонИт
з [з]
в [в]
о [а] гласный, безударный
н [н’]
и [и] гласный, ударный
т [т]
4. Отмечаем согласные, звонки и глухие, парные и непарные, твердые и мягкие.
звонИт
з [з] согласный, звонкий парный, твердый
в [в] согласный, звонкий парный, твердый
о [а] гласный, безударный
н [н’] согласный, звонкий непарный, мягкий
и [и] гласный, ударный
т [т] согласный, глухой парный, твердый
5. Считаем количество букв и звуков
звонИт
з [з] согласный, звонкий парный, твердый
в [в] согласный, звонкий парный, твердый
о [а] гласный, безударный
н [н’] согласный, звонкий непарный, мягкий
и [и] гласный, ударный
т [т] согласный, глухой парный, твердый
6 букв, 6 звуков.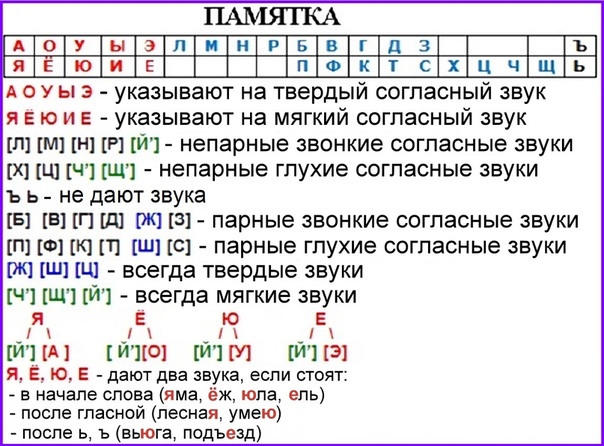
Больше примеров разборов по ссылкам: язык, русский, класс, день, солнце, щука, выполнить, обед, схема, дне, листьев, листья, звук, крючок, осень, чайка, щуку, ключ, ночь, слез, век, съем, съел, честь, ель, кольцо, яблоко, вьюга, деревья, роса, уши, елка, буквенно, жизни, поля, вдруг, юг, друзья, пять, предложения, улыбка, семья, счастье, транскрипция, ежик, ягода, слышится, дождь, земля, мороз, безделья, якорь, поем, поешь, яркий, мяч, чай, буква, правила, маяк, певец, лес, поет, лоб, береза, подъезд, выделяет, яма, белый, люлька, выделить, морозов, таблица, полный, комок, багаж, бывшего, юла, еж, такси, ружье, зайцев, заяц, чашка, произведите, гляжу, работа, веки, легкий, звуки, жирный, ручьи, другом, снег, мягкий, праздник, как, какой, цветок, образец, ясный, объявит, урок, согласных, ветер, школа, медведь, течет, цирк, сердце, лей, вьюн, время, вода, стоящей, стоит, стояла, гриб, лил, льет, сделайте, большой, слоги, птичьим, задания, воробьев, памятка, бьет, воробьи, берег, будете, путем, тетрадь, нашел, тема, близко, мышь, ел, люди, очень, гласных, текста, ответ, октябрь, гуашь, желтый, поздний, жил, жить, жило, жили, живете, цвет, калач, зяблик, найти, ярмарка, звезды, коньки, глаз, дуб, вновь, черных, черный, водой, бела, лишь, анализом, юбка, линия, мед, скользят, дети, клен, объявление, осенний, букву, идите, шел, бил, лиса, лис, крылья, грустно, белка, белок, анализ, контрольная, весна, лесной, края, съесть, морковь, компьютер, правит, обсуждали, стоять, стоящий, стоял, русском, литая, синтаксический, аллея, какие, сознание, березка, река, книга, россия, слог, пила, согласными, степью, любовь
Обязательно отработайте предложенный алгоритм на практике. Для хорошего усвоения навыка фонетического разбора слов, рекомендуется произвести самостоятельный разбор хотя бы 10 слов разной длины и структуры. При этом мы рекомендуем на начальных этапах делать это, имея под рукой описанные выше правила разбора.
Для хорошего усвоения навыка фонетического разбора слов, рекомендуется произвести самостоятельный разбор хотя бы 10 слов разной длины и структуры. При этом мы рекомендуем на начальных этапах делать это, имея под рукой описанные выше правила разбора.
Зная правила, которые мы изложили, и изучив примеры в нашем онлайн сервисе фонетического разбора, вы быстро научитесь без ошибок делать это самостоятельно с минимальным числом ошибок.
Удачных вам фонетических разборов!
Если материал был полезен, вы можете отправить донат или поделиться данным материалом в социальных сетях:
| 25 | æ | a, ai, au | кот, плед, смех |
| 26 | eɪ | et, ei, au, a_e, ea, ey | bay, горничная, взвешивать, прямо, платить, фойе, филе, восемь, калибр, товарищ, перерыв, они |
| 27 | e | e, ea, u, ie, ai, a, eo, ei, ae | end, хлеб, закопать, друг, сказал, много, леопард, телка, эстетика |
| 28 | i: | e, ee, ea, y , ey, oe, ie, i, ei, eo, ay | быть, пчела, мясо, леди, ключ, феникс, горе, лыжи, обмануть, люди, набережная |
| 29 | ɪ | i, e , o, u, ui, y, т. е. е. | it, england, women, busy, guild, gym, sieve |
| 30 | aɪ | i, y, igh, то есть, uy, ye, ai, is , восьмерка, i_e | паук, небо, ночь, пирог, парень, ячмень, проход, остров, высота, воздушный змей 900 05 |
| 31 | ɒ | a, ho, au, aw, ough | лебедь, честный, maul, slaw, дрался |
| 32 | oʊ | o, oa, o_e, oe, ow, ough, eau, oo, ew | open, ров, кость, палец, сеять, тесто, beau, brooch, sew |
| 33 | ʊ | o, oo, u, ou | волк, взгляд, куст , будет |
| 34 | ʌ | u, o, oo, ou | lug, monkey, blood, double |
| 35 | u: | o, oo, ew, ue, u_e, oe , ough, ui, oew, ou | who, loon, dew, blue, flute, shoe, through, fruit, maneuver, group |
| 36 | ɔɪ | oi, oy, uoy | присоединиться, мальчик, буй |
| 37 | aʊ | ow, ou, ough | сейчас, крик, сука |
| 38 | ə | a, er, i, ar, наш, ur | about, лестница, Penc il, доллар, честь, авгур |
| 39 | eəʳ | air, are, ear, ere, eir, ayer | стул, dare, pear, где, их, молитва |
| 40 | ɑ: | a | рука |
| 41 | ɜ: ʳ | ir, er, ur, ear, or, our, yr | птица, термин, ожог, жемчуг, слово, путешествие, мирт |
| 42 | ɔ: | aw, a, or, oor, ore, oar, our, augh, ar, ough, au | paw, ball, fork, бедный, перед, доска, четыре, научил, война, купил, соус |
| 43 | ɪəʳ | ear, eer, ere, ier | ear, steer, here, уровень |
| 44 | ʊəʳ | ure, наш | cureme, туристический телефон — обзор | Темы ScienceDirectИсторическая справка Таксономическая фонема тесно связана с алфавитным представлением речи и отражает свойства греческого алфавита и многих алфавитов, которые были производными от него. Различие между формой буквы и ее звуком или «голосом» было знакомо со времен средневековья, а концепция звука речи была прояснена в 16 веке, сначала благодаря реконструкции произношения древнегреческого языка Эразмом, а позже трудами английских реформаторов правописания. Изучение звуков речи было развито в 19 веке, и к концу века существовало две разные традиции. Доминирующей традицией было изучение звуковых изменений, что привело к великому триумфу филологии. К концу XIX века речь обычно представлялась на трех уровнях: на очень абстрактном уровне филологических «реконструкций», на уровне звуков речи и на уровне узкой транскрипции.Интуитивное представление о том, что речь состоит из звуков речи, было исследовано в XX веке. «Широкая транскрипция» Свита представляла речь на уровне, удобном для общих лингвистических целей, и была развита в практические фонематические транскрипции 20-го века, такие как та, которая использовалась для английского словаря произношения Дэниела Джонса . Практическая транскрипция также использовалась для создания систем письма для ранее ненаписанных языков, как провозглашается в книге Кеннета Пайка о фонемах, вышедшей в 1947 году и озаглавленной «Методика сведения языков к письму». Проблема, известная филологам, но обычно игнорируемая в возникающей теории фонем, заключалась в том, что было трудно согласовать фонемы со звуковыми изменениями. В некоторых случаях введение фонематического уровня усложняло объяснение. В древнеанглийском, например, / f / озвучивался как [v] между гласными, как в wifas «жены», но оставался в конечном положении, как в wif «жена». Легко понять изменение звука и полученное чередование жен и жен .Гораздо труднее установить фонематические последствия этого изменения, тем более что английскому языку пришлось ждать до окончания Норманнского завоевания a / v / фонемы, заимствованной из французского в таких словах, как , лоза . Обычное объяснение состоит в том, что [v] был аллофоном / f / и позже претерпел структурные изменения, которые переназначили его новой фонеме / v /. Это «структурное изменение» — это безразличное изменение, не имеющее наблюдаемых явлений, чтобы его оправдать, и должно быть установлено исключительно как логическое следствие установления фонематического уровня. В начале 20 века наблюдался спад интереса к филологии и быстрый рост фонемики со сложными процедурами открытия, позволяющими установить фонемы языка. Историческая случайность заключается в том, что лингвисты, особенно в Америке, пытались дать точное определение фонеме до того, как связь между фонемами и формами волны была адекватно понята. Фонема была определена как характерный речевой звук, и предполагалось, что она играет роль в речи, примерно соответствующую роли букв в письме, в связывании фонетических данных с грамматикой и лексикой, так что фонематическое представление воспринималось как само собой разумеющееся как способ представления слов. Некоторые из этих свойств предполагали простую связь между фонемами и их фонетическими реализациями. Изучение акустической фонетики, в частности разработка звукового спектрографа, показало, что отношения между фонетическими сегментами и фонемами были гораздо более сложными, чем считалось ранее.Например, предполагается, что фонема составляет минимальный заменяемый сегмент речи. Это кажется простым, когда говорящий-человек меняет / t / на / d / в минимальной паре, такой как ten ∼ den , но фонетически это означает изменение относительного времени артикуляционных событий. Символы в транскрипции подразумевают последовательность дискретных звуков, но может быть сложно или невозможно найти единственную точку в форме волны, соответствующую их границам. Традиционная фонетическая терминология, e.g., «звонкая velar stop» или «закругленная гласная с закругленными углами», распознает частичное сходство между реализациями фонем и подразумевает некую систему признаков, связывающую фонемы друг с другом. Исследования Николая Трубецкого привели к значительному прогрессу в фонологической теории, а именно к выявлению отличительных черт. Нет логической причины, по которой признаки должны быть исключительной собственностью фонем, и они могут быть свойствами слогов, морфем, слов или даже фраз. Также нет никаких причин для того, чтобы функции аккуратно выстраивались по границам фонем, а на практике это не так.Например, назализация носового согласного звука часто ожидается и может продолжаться до следующего сегмента. Время устремления и начала голоса связано с перекрывающимися артикуляциями и не может быть привязано к одному фонематическому сегменту. С отличительными чертами связан более широкий вопрос контраста, поскольку фонемы считаются контрастирующими по определению с другими фонемами. Наряду с теоретической проблемой была практическая проблема организации данных. Структурные лингвисты использовали процедуры открытия, включающие сортировку больших объемов фонетических данных, чтобы установить фонемы языка. Однако эффективная классификация и манипулирование большим количеством объектов либо занимает очень много времени, либо требует базы данных, которая не стала доступной до конца 20 века. В отсутствие реальных баз данных и процедур сортировки базы данных были воображаемыми, а многие процедуры на самом деле были псевдо-процедурами (Abercrombie, 1963), которые на самом деле не выполнялись в реальности, но которые, возможно, когда-нибудь будут выполнены. Международный фонетический алфавит | Определение, использование и таблицаМеждународный фонетический алфавит (IPA) , алфавит, разработанный в XIX веке для точного отображения произношения языков. Одна из целей Международного фонетического алфавита (IPA) состояла в том, чтобы предоставить уникальный символ для каждого отличительного звука в языке, то есть каждого звука или фонемы, которые служат для отличия одного слова от другого. Международный фонетический алфавитТаблица международного фонетического алфавита. Международная фонетическая ассоциация, факультет лингвистики, Университет Виктории, Виктория, Британская Колумбия, Канада Концепция IPA была впервые предложена Отто Джесперсеном в письме к Полу Пасси из Международной фонетической ассоциации и была разработана А. IPA в основном использует латинские буквы. Другие буквы заимствованы из других шрифтов (например, греческого) и изменены, чтобы соответствовать римскому стилю. Диакритические знаки используются для тонкого различения звуков и для обозначения назализации гласных, длины, ударения и тона. IPA можно использовать для широкой и узкой транскрипции. Например, в английском языке есть только один звук t , который распознают носители языка. Следовательно, для обозначения каждого звука t необходим только один символ в широкой транскрипции. IPA не стал универсальной системой фонетической транскрипции, которую задумывали его создатели, и в Америке он используется реже, чем в Европе. Несмотря на общепризнанные недостатки, он широко используется лингвистами и в словарях, хотя часто с некоторыми модификациями. Певцы также используют IPA. Фонетический анализ речевых корпусовСвязь между машиночитаемым (MRPA) и международным фонетическим алфавитом (IPA) для австралийского английского языка.Связь между машиночитаемым (MRPA) и международным фонетическим алфавитом (IPA) для немецкого языка. Загружаемые речевые базы данных, используемые в этой книге. Предисловие. Примечания по загрузке программного обеспечения. 1. Использование речевых корпусов в фонетических исследованиях. 1.1. Место корпусов в фонетическом анализе речи. 1.2 Существующие речевые корпуса для фонетического анализа. 1.3 Создание собственного корпуса. 1.4 Краткое содержание и структура книги. 2. Некоторые инструменты для создания аннотированных речевых баз данных и запросов к ним.2.1 Обзор. 2.2 Начало работы с существующими речевыми базами данных. 2.3 Интерфейс между Praat и Emu. 2.4 Интерфейс с R. 2.5 Создание новой речевой базы данных: от Praat до Emu и R. 2.6 Первый взгляд на файл шаблона. 2.7 Резюме. 2.8 Вопросы. 3. Применение подпрограмм для обработки речевых сигналов. 3.1 Введение. 3.2. Вычисление, отображение и исправление формант. 3.3 Считывание формант в R. 3.4 Резюме. 3.5 Вопросы. 3.6 Ответы. 4. Запрос структур аннотаций.4.1 Инструмент запросов Emu, уровни сегментов и уровни событий. 4.2 Расширение диапазона запросов: аннотации одного уровня. 4.3 Межуровневые ссылки и запросы. Примечания по загрузке программного обеспечения. 1. Использование речевых корпусов в фонетических исследованиях. 1.1. Место корпусов в фонетическом анализе речи. 1.2 Существующие речевые корпуса для фонетического анализа. 1.3 Создание собственного корпуса. 1.4 Краткое содержание и структура книги. 2. Некоторые инструменты для создания аннотированных речевых баз данных и запросов к ним.2.1 Обзор. 2.2 Начало работы с существующими речевыми базами данных. 2.3 Интерфейс между Praat и Emu. 2.4 Интерфейс с R. 2.5 Создание новой речевой базы данных: от Praat до Emu и R. 2.6 Первый взгляд на файл шаблона. 2.7 Резюме. 2.8 Вопросы. 3. Применение подпрограмм для обработки речевых сигналов. 3.1 Введение. 3.2. Вычисление, отображение и исправление формант. 3.3 Считывание формант в R. 3.4 Резюме. 3.5 Вопросы. 3.6 Ответы. 4. Запрос структур аннотаций.4.1 Инструмент запросов Emu, уровни сегментов и уровни событий. 4.2 Расширение диапазона запросов: аннотации одного уровня. 4.3 Межуровневые ссылки и запросы. 4.4 Ввод структурированных аннотаций с Emu. 4.5 Преобразование структурированной аннотации в текстовую сетку Praat. 4.6 Графический интерфейс пользователя к языку запросов Emu. 4.7 Повторный запрос списков сегментов. 4.8. Построение структур аннотаций в полуавтоматическом режиме с помощью Emu-Tcl. 4.9 Ветвящиеся пути. 4.10 Резюме. 4.11 Вопросы. 4.12 Ответы.5. Введение в анализ речевых данных в R: исследование базы данных EMA. 5.1 Записи EMA и база данных ema5. 5.2. Обработка списков сегментов и векторов в Emu-R. 5.3. Анализ времени начала голоса. 5.4. Межгестковая координация и ансамблевые графики. 5.5. Внутригестральный анализ. 5.6 Резюме. 5.7 Вопросы. 5.8 Ответы. 6. Анализ формант и переходов формант. 6.1. Эллипсы гласных на плоскости F2ÍF1. 6.2 Выбросы. 6.3 Целевые значения гласных. 6.4 Нормализация гласных. 6.5 евклидовых расстояний. 6.6 Подчеркивание гласных и сглаживание формант. 6.7 Локус F2, место сочленения и изменчивость. 6.8 Вопросы. 6.9 Ответы. 7. Электропалатография. 7.1 Палатография и электропалатография. 4.4 Ввод структурированных аннотаций с Emu. 4.5 Преобразование структурированной аннотации в текстовую сетку Praat. 4.6 Графический интерфейс пользователя к языку запросов Emu. 4.7 Повторный запрос списков сегментов. 4.8. Построение структур аннотаций в полуавтоматическом режиме с помощью Emu-Tcl. 4.9 Ветвящиеся пути. 4.10 Резюме. 4.11 Вопросы. 4.12 Ответы.5. Введение в анализ речевых данных в R: исследование базы данных EMA. 5.1 Записи EMA и база данных ema5. 5.2. Обработка списков сегментов и векторов в Emu-R. 5.3. Анализ времени начала голоса. 5.4. Межгестковая координация и ансамблевые графики. 5.5. Внутригестральный анализ. 5.6 Резюме. 5.7 Вопросы. 5.8 Ответы. 6. Анализ формант и переходов формант. 6.1. Эллипсы гласных на плоскости F2ÍF1. 6.2 Выбросы. 6.3 Целевые значения гласных. 6.4 Нормализация гласных. 6.5 евклидовых расстояний. 6.6 Подчеркивание гласных и сглаживание формант. 6.7 Локус F2, место сочленения и изменчивость. 6.8 Вопросы. 6.9 Ответы. 7. Электропалатография. 7.1 Палатография и электропалатография. 7.2 Обзор электропалатографии в Emu-R. 7.3 Объекты EPG с ограниченным объемом данных. 7.4 Анализ данных EPG. 7.5 Резюме. 7.6 Вопросы. 7.7 Ответы. 8. Спектральный анализ. 8.1. Предпосылки к спектральному анализу. 8.2 Спектральное среднее, сумма, отношение, разность, наклон.8.3 Спектральные моменты. 8.4. Дискретное косинусное преобразование. 8.5 Вопросы. 8.6 Ответы. 9. Классификация. 9.1 Вероятность и теорема Байеса. 9.2 Классификация: непрерывные данные. 9.3. Вычисление условных вероятностей. 9.4. Расчет апостериорной вероятности. 9.5. Два параметра: двумерное нормальное распределение и эллипсы. 9.6 Классификация в двух измерениях. 9.7 Классификации в многомерных пространствах. 9.8 Классификация во времени. 9.9 Машины опорных векторов.9.10 Резюме. 9.11 Вопросы. 9.12 Ответы. Рекомендации. Индекс. 7.2 Обзор электропалатографии в Emu-R. 7.3 Объекты EPG с ограниченным объемом данных. 7.4 Анализ данных EPG. 7.5 Резюме. 7.6 Вопросы. 7.7 Ответы. 8. Спектральный анализ. 8.1. Предпосылки к спектральному анализу. 8.2 Спектральное среднее, сумма, отношение, разность, наклон.8.3 Спектральные моменты. 8.4. Дискретное косинусное преобразование. 8.5 Вопросы. 8.6 Ответы. 9. Классификация. 9.1 Вероятность и теорема Байеса. 9.2 Классификация: непрерывные данные. 9.3. Вычисление условных вероятностей. 9.4. Расчет апостериорной вероятности. 9.5. Два параметра: двумерное нормальное распределение и эллипсы. 9.6 Классификация в двух измерениях. 9.7 Классификации в многомерных пространствах. 9.8 Классификация во времени. 9.9 Машины опорных векторов.9.10 Резюме. 9.11 Вопросы. 9.12 Ответы. Рекомендации. Индекс.Фонетическая релевантность и фонематическая группировка речи в автоматическом обнаружении болезни ПаркинсонаМатериалы: речевые корпуса В этом исследовании использовались пять речевых корпусов: Neurovoz, GITA, CzechPD, FisherSP и Albayzin. Neurovoz Этот корпус содержит 47 человек с паркинсонизмом и 32 человека контрольной группы, родным языком которых является испанский кастильский. Подмножество, используемое в настоящем исследовании, содержит задание диадохокинетики (DDK) (повторение слоговой последовательности «па-та-ка»), шесть текстозависимых высказываний (TDU) и монолог (описание изображения). Речь производилась на комфортном голосовом уровне. Таблица 1 содержит транскрипцию и транскрипцию Международного фонетического алфавита (IPA) TDU.Все пациенты проходили фармакологическое лечение и принимали лекарство за 2–5 ч до записи речи 39 . Комитет по этике больницы General Universitario Gregorio Marañón одобрил запись речи и соответствующие экспериментальные протоколы и методы в соответствии с Хельсинкской декларацией, разработанной Всемирной медицинской ассоциацией, и производными европейскими директивами. GitaЭтот корпус содержит множество речевых задач от 50 пациентов с БП и 50 контрольных говорящих, чей родной язык — испанский колумбийский 40 . В этом исследовании использовались три типа речевых задач из GITA: задание DDK («па-та-ка»), шесть TDU и монолог. Таблица 2 содержит транскрипцию и транскрипцию Международного фонетического алфавита (IPA) TDU. Запись этого корпуса и связанных с ним экспериментов соответствует Хельсинкской декларации и одобрена этическим комитетом клиники Ноэль в Медельине, Колумбия.Письменное информированное согласие было подписано каждым участником по данным авторов корпуса 40 . Таблица 2 Транскрипция шести GITA TDU (испанский), транскрипция IPA и перевод на английский.CzechPD Подмножество CzechPD, использованное в этом исследовании, содержит только DDK-задачу (повторение слоговой последовательности «pa-ta-ka») от 20 недавно диагностированных и нелеченных носителей с PD и 14 контрольных, чей родной язык — чешский 21 . В таблице 3 показаны статистические данные о возрасте, поле, UPDRS и годах с момента постановки диагноза говорящих в трех корпусах. Таблица 3 Демографическая статистика корпусов Нейровоза, GITA и CzechPD.Вспомогательные корпусаФонетический набор данных из корпуса Albayzin 41 также используется в настоящем исследовании. Этот фонетически сбалансированный набор данных, отобранный с частотой 16 кГц и квантованный с помощью 16 бит, содержит более 4800 высказываний (4,1 ч) на кастильском испанском языке вместе с их транскрипциями. Кроме того, в этом исследовании использовался корпус FisherSP (Fisher Spanish), записанный Консорциумом лингвистических данных (8 кГц как частота дискретизации и 16 бит) для обучения и оценки автоматических распознавателей речи на испанском языке. МетодологияОбщая методология этого исследования включала следующие основные этапы:
Общие соображения Во всех предложенных подходах использовался один и тот же интерфейс; высказывания фильтровались и субдискретизировались до 16 кГц, если их частота дискретизации была выше. Затем сигналы были нормализованы и охарактеризованы с использованием производных Rasta-PLP + (Δ + ΔΔ) 34 , при этом количество коэффициентов PLP ( F ) варьировалось в диапазоне {10… 20} с шагом 2. Длина кадров была установлена на 15 мс с перекрытием 50%, с использованием окна Хэмминга и 5 коэффициентов в КИХ-фильтре, используемом для вычисления производных, поскольку это установка, которая привела к оптимальным результатам в предыдущем исследовании 35 . Наконец, что касается стадии классификации с использованием GMM-UBM в базовой линии и предлагаемых подходов, количество гауссиан G варьировалось в степенях 2 от 4 до 256. Baseline В базовых испытаниях все доступные речевые задачи из каждого корпуса паркинсонизма были использованы для адаптации нескольких UBM, обученных с помощью Албайзина.UBM — это модель GMM, которая оценивает функцию плотности вероятности, которая характеризует группу векторов признаков размерности D из определенного корпуса, используя линейную комбинацию гауссовых компонентов G . Предлагаемые подходы и фонематическая группировка Было проведено несколько типов испытаний с использованием только определенных акустических сегментов в речевом сигнале, которые соответствуют единственному предполагаемому классу манеры (идентифицированному посредством фонематической группировки), для обучения UBM и адаптировать его после адаптации MAP. В зависимости от того, где применялся процесс фонематической группировки, использовались три разных подхода: в наборе тестирования адаптации (GITA, Neurovoz или CzechPD), в корпусе UBM или в обоих. Чтобы разделить акустические сегменты фонемно на группы, каждая из которых соответствует одному намеченному классу манеры, в Kaldi 43 был создан испанский FAM 39 , который затем использовался для сегментации и маркировки GITA, Neurovoz и Albayzin. В первом подходе ( raw-phon ) фонематическая группировка применялась только к TDU корпусов тестирования адаптации (Нейровоз и GITA, используемые отдельно). Описание этого подхода показано на рис. 3. Обозначение raw-phon указывает на то, что мы не применяли процесс фонематической группировки к корпусу UBM ( raw ), в то время как мы применяли его к корпусу адаптации ( phon ). Рисунок 3Первый предложенный подход 5 .Методология фонематической группировки применяется к паркинсоническому корпусу ( raw-phon ). Во втором подходе ( фон-фон ) был проведен новый раунд испытаний, исходя из тех же предпосылок, но преследуя теперь также фонематическую группировку в UBM (Албайзин). Второй предлагаемый подход 5 . Методология фонематической группировки применяется к корпусам паркинсонизма и UBM ( фон-фон, ). Удобно отметить, что в этих двух первых подходах фонематическая группировка применялась как к обучению (адаптации), так и к проверке высказываний в паркинсонических телах. Таким образом, полученные системы моделировали только одну категорию фонематической манеры за раз (фрикативный, взрывной и т. Д.), И на этапе тестирования использовались только определенные акустические сегменты, связанные с каждой категорией. Таким образом, два первых подхода и связанные с ними раунды испытаний позволили проанализировать важность различных категорий фонематической манеры в автоматическом обнаружении частичных разрядов с использованием связанной речи.В этих двух первых подходах использовались только TDU от GITA и Neurovoz, поскольку это были единственные записи, которые включали транскрипции. В третьем подходе ( phon-raw ) фонематическая группировка применялась только к корпусу UBM, чтобы проанализировать важность инициализации GMM-UBM. В этом последнем подходе были задействованы все три паркинсонических корпуса без какого-либо принудительного выравнивания. Отдельно рассматривались TDU, монологи и DDK-задания от ГИТА и Нейровоза.Также использовалась задача DDK от CzechPD, поскольку считалось, что эта задача имеет аналогичные фонетические характеристики в трех паркинсонических корпусах и может использоваться для адаптации UBM независимо от родного языка говорящего (испанского или чешского). На рисунке 5 показана схема третьего подхода. Рисунок 5Третий предлагаемый подход 5 . Методология фонематической группировки применяется к корпусу UBM ( phon-raw ). Цель этого последнего подхода состояла в том, чтобы предоставить классификаторы GMM-UBM, которые более точны при моделировании определенного типа акустического сегмента, но без полного исключения остальных акустических сегментов, присутствующих в подмножестве адаптации; Таким образом, последний подход отличался от двух предложенных ранее подходов. Представление гауссианов в третьем подходе ( фон-сырье ). {c}) \, , $$ (1) , где p ( x n | Γ c ) — гауссова плотность класса c ( c может быть PD или Ctrl) для вектора признаков x № .{{\ rm {Ctrl}}}. $$ (2) Чтобы вычислить классовую принадлежность определенного высказывания из тестового набора, его оценка сравнивалась с порогом, λ , чтобы доказать гипотезу принадлежности этого высказывания к паркинсоническому классу, H PD . Если оценка Λ u была выше, чем λ , гипотеза принималась; в противном случае гипотеза была отвергнута. Во всех подходах, проанализированных в этом исследовании, этот порог определялся равной частотой ошибок (EER) 44 баллов, полученных с оценками данных адаптации. Объединение оценокПосле анализа результатов всех подходов было изучено объединение оценок из подхода, обеспечивающего наилучшую точность, и площади под кривой ROC (AUC). Для каждого корпуса оценки говорящего, полученные из пяти возможных фонематических групп (фрикативный, жидкий, назальный, взрывной и гласный), были объединены после всех возможных комбинаций из n — кортежей , начиная от 2- кортежей от до 5. — кортежей . Чтобы получить окончательную оценку, полученную путем объединения нескольких оценок, была использована логистическая регрессия.Следовательно, для данного говорящего и речевого задания новый балл был рассчитан с учетом от двух до пяти баллов, полученных этим говорящим и заданием, причем каждый балл получен из другой фонематической группы. Учитывая, что F — это количество коэффициентов PLP, а G — количество гауссиан на GMM, были объединены только оценки, полученные с теми же F и G . Например, для получения слияния оценок «фрикативный-жидкий-гласный» для определенного испытания использовались три отдельных балла от каждого говорящего для категорий «фрикативный», «жидкий» и «гласный» соответственно, полученные с одинаковыми F и G сплав. Межкорпоративная проверкаНаконец, была проведена процедура межкорпоративной проверки с учетом базовой линии и третьего подхода ( phon-raw ), в котором мы применили процесс фонематической группировки к корпусу Albayzin для получения пяти различных типы UBM, которые впоследствии были адаптированы и протестированы с помощью задач DDK из паркинсонических корпусов. В частности, было проведено три раунда испытаний: в каждом из них два корпуса использовались совместно для адаптации модели, а оставшийся корпус использовался исключительно для тестирования.Поэтому было создано несколько моделей с колонками от GITA и Neurovoz и протестированных на CzechPD; другие модели, созданные в GITA и CzechPD и протестированные в «Нейровозе»; и третья группа моделей адаптирована с использованием высказываний из Нейровоза и CzechPD и протестирована с GITA. В этом случае использовались те же интерфейс, параметры классификации и процедуры оценки, что и для остальной части экспериментального набора. Различия между кросс-валидацией и кросс-корпоративной валидацией показаны на рис.7. Рисунок 7Схема испытаний. На диаграмме классификаторами являются GMM-UBM, где UBM обучается с помощью Албайзина. ( A ) Схема перекрестных проверок (11 раз). Классификаторы могут быть отнесены к любому типу фонематической группировки (щелевой, жидкий, носовой, взрывной или гласный) или подходу (базовый уровень, raw-phon, phon-phon или phon-raw ). ( B ) Схема межкорпоративных испытаний. Классификаторы можно отнести к любому типу фонематической группировки.В кросс-корпусных исследованиях использовались только исходный уровень и предлагаемый подход, приводящие к наилучшим результатам в испытаниях с перекрестной проверкой. Фонетический анализ речевых корпусов (9781405199575): Харрингтон, Джонатан: Книги«Книга, несомненно, полностью достигает своей цели — предоставить доступное и эффективное практическое введение в использование системы речевой базы данных Emu и функций Emu-R для анализа фонетических данных. Она написана ясным и доступным языком, а темы представлены в связном и простой в использовании способ, при котором сложность материала постепенно увеличивается от начала к концу книги.Даже довольно сложные концепции становятся легкими для понимания благодаря исключительному использованию аналогий и похвальному воздержанию от слишком большого количества математических и технических деталей … это хорошо написанная, хорошо структурированная, простая в использовании рабочая тетрадь, которая может похвастаться отличный набор практических упражнений и демонстраций, охватывающий широкий спектр техник. В целом, те читатели, которые имеют базовые знания в области фонетики и статистики и готовы тщательно изучить эту книгу, будут значительно вознаграждены ее информативностью и эффективностью.»( LINGUIST List , январь 2011 г.) Фонетический анализ речевых корпусов представляет методы анализа речевых корпусов с фонетической маркировкой с целью проверки гипотез, которые часто возникают в экспериментальной фонетике и лабораторной фонологии. Книга начинается с обсуждения некоторых методов цифровой обработки речи, а также структурирования и запроса аннотаций из речевых корпусов. Вторая половина книги посвящена анализу, в том числе измерению жестовой синхронизации с помощью электромагнитной артикулометрии (EMA), акустике гласных, перекрытию согласных с помощью электропалатографии (EPG), спектральному анализу фрикативных и препятствующих звуков и вероятностной классификации акустических речевых данных.В каждой главе есть обширный набор упражнений с ответами, чтобы закрепить представленные техники. Обзор необходимых программных инструментов, включая язык программирования R, позволяет читателю дублировать этапы анализа в вычислительном отношении. Ясно изложенная, с простыми для понимания компьютерными командами, спектрограммами речевых корпусов и сопутствующим веб-сайтом с большим количеством иллюстраций и загружаемых речевых корпусов для целей тестирования, эта книга представляет собой полный ресурс для исследований, все чаще проводимых в области фонетики. с задней стороны обложкиФонетический анализ речевых корпусов представляет методы анализа речевых корпусов с фонетической маркировкой с целью проверки гипотез, которые часто возникают в экспериментальной фонетике и лабораторной фонологии. Книга начинается с обсуждения некоторых методов цифровой обработки речи, а также структурирования и запроса аннотаций из речевых корпусов. Вторая половина книги посвящена анализу, в том числе измерению жестовой синхронизации с помощью электромагнитной артикулометрии (EMA), акустике гласных, перекрытию согласных с помощью электропалатографии (EPG), спектральному анализу фрикативных и препятствующих звуков и вероятностной классификации акустических речевых данных.В каждой главе есть обширный набор упражнений с ответами, чтобы закрепить представленные техники. Обзор необходимых программных инструментов, включая язык программирования R, позволяет читателю дублировать этапы анализа в вычислительном отношении. Ясно изложенная, с простыми для понимания компьютерными командами, спектрограммами речевых корпусов и сопутствующим веб-сайтом с большим количеством иллюстраций и загружаемых речевых корпусов для целей тестирования, эта книга представляет собой полный ресурс для исследований, все чаще проводимых в области фонетики. Об автореДжонатан Харрингтон — профессор Института фонетики и обработки речи (IPS) Мюнхенского университета, Германия. Его недавние исследования были в основном сосредоточены на моделировании акустических и перцептивных механизмов изменения звука. Он является соредактором книг Speech Production: Models, Phonetic Processes, and Techniques (с Марией Табейн, 2006) и Techniques in Speech Acoustics (со Стивом Кэссиди, 1999). Справочник МПА | Международная фонетическая ассоциацияАссоциация издала «Справочник Международной фонетической ассоциации: руководство по использованию международного фонетического алфавита», опубликованный издательством Cambridge University Press (1999). Он заменяет буклет «Принципы Международной фонетической ассоциации» (Лондон, 1949 г.). Он доступен в твердом переплете, мягком переплете и электронных книгах. На более чем 200 страницах он содержит десять глав, в которых обсуждается и иллюстрируется использование IPA в лингвистическом анализе.Затем следуют иллюстрации использования IPA на 29 языках. Пять приложений включают заявление о принципах ассоциации, полные таблицы соглашений о компьютерном кодировании для символов IPA и расширенных символов IPA, а также таблицы международного фонетического алфавита, номеров IPA и расширенных символов IPA. Подробнее см. Ниже. Основы фонетического анализа представлены таким образом, чтобы можно было легко понять принципы, лежащие в основе алфавита.Приведены примеры использования каждого из фонетических символов. Применение алфавита широко демонстрируется включением 29 «иллюстраций» — краткого анализа звуковых систем языков, сопровождаемого фонетической транскрипцией отрывка речи. Эти иллюстрации охватывают языки со всего мира. Кроме того, отсюда можно загрузить аудиофайлов для сопровождения языковых иллюстраций и редакций текста . Справочник включает в себя ряд другой полезной информации. «Расширения» Международного фонетического алфавита (ExtIPA) охватывают звуки речи за пределами звуковых систем языков, например, с паралингвистическими функциями и те, которые встречаются в патологической речи. |
 Греческий алфавит остается источником некоторых фундаментальных предположений о речи, таких как представление о том, что разговорный язык может быть сегментирован на дискретные фонетические единицы и что речь может быть адекватно представлена с помощью специальных букв для расшифровки каждой из этих фонетических единиц. В качестве теоретической концепции буква является очень грубой, но практически полезной, и, учитывая различие между согласными и гласными, становится возможным говорить о слогах, что приводит к структуре слов и даже к словесному ударению.
Греческий алфавит остается источником некоторых фундаментальных предположений о речи, таких как представление о том, что разговорный язык может быть сегментирован на дискретные фонетические единицы и что речь может быть адекватно представлена с помощью специальных букв для расшифровки каждой из этих фонетических единиц. В качестве теоретической концепции буква является очень грубой, но практически полезной, и, учитывая различие между согласными и гласными, становится возможным говорить о слогах, что приводит к структуре слов и даже к словесному ударению. К 1870-м годам филологи начали конструировать то, что они считали совокупностью научных знаний, с явными здравыми законами и доказательствами. Их представления включали символы не только звуков речи, но и абстрактных сущностей, которые, как считалось, когда-то в прошлом соответствовали звукам речи. Их величайшим достижением было создание алгоритмов сопоставления между различными стадиями одного и того же языка (которые, как они считали, воспроизводили исторические звуковые изменения), что привело к косвенным, но явным заявлениям о фонологических отношениях между родственными диалектами и языками.Другая традиция была связана с тщательным изучением самих звуков речи и частично мотивировалась необходимостью понимать звуковые изменения. Ко времени Генри Свита фонетики могли сегментировать речь гораздо точнее, чем буквы письменной системы, и даже эти более мелкие сегменты, например, части дифтонга или стадии закрытия-удержания-отпускания остановки, могли быть даны. точное описание. Подробное представление речи, которое Свит называл «узкой транскрипцией», содержало гораздо больше деталей, необходимых для общего лингвистического описания, и становилось все труднее согласовывать с алфавитным представлением о речи.
К 1870-м годам филологи начали конструировать то, что они считали совокупностью научных знаний, с явными здравыми законами и доказательствами. Их представления включали символы не только звуков речи, но и абстрактных сущностей, которые, как считалось, когда-то в прошлом соответствовали звукам речи. Их величайшим достижением было создание алгоритмов сопоставления между различными стадиями одного и того же языка (которые, как они считали, воспроизводили исторические звуковые изменения), что привело к косвенным, но явным заявлениям о фонологических отношениях между родственными диалектами и языками.Другая традиция была связана с тщательным изучением самих звуков речи и частично мотивировалась необходимостью понимать звуковые изменения. Ко времени Генри Свита фонетики могли сегментировать речь гораздо точнее, чем буквы письменной системы, и даже эти более мелкие сегменты, например, части дифтонга или стадии закрытия-удержания-отпускания остановки, могли быть даны. точное описание. Подробное представление речи, которое Свит называл «узкой транскрипцией», содержало гораздо больше деталей, необходимых для общего лингвистического описания, и становилось все труднее согласовывать с алфавитным представлением о речи. Опыт, необходимый для узкой транскрипции, был развит в Великобритании в традициях импрессионистической фонетики, процветавшей до 1960-х годов, и был обогащен изучением акустической фонетики. При детальном изучении фонетики стало ясно, что речь включает в себя артикуляционные жесты, которые накладываются сложным образом, что несовместимо с простым алфавитным представлением о речи.
Опыт, необходимый для узкой транскрипции, был развит в Великобритании в традициях импрессионистической фонетики, процветавшей до 1960-х годов, и был обогащен изучением акустической фонетики. При детальном изучении фонетики стало ясно, что речь включает в себя артикуляционные жесты, которые накладываются сложным образом, что несовместимо с простым алфавитным представлением о речи. ‘
‘ Другой хорошо известный случай касается потери / g / после [] в sing , что, как говорят, имеет эффект повышения [ŋ] до фонематического статуса. В традиционной речи Северо-Западной Англии / g / иногда присутствует, а иногда отсутствует, что означает, что [ŋ] иногда является независимой фонемой, а иногда — аллофоном / n /. Понятие фонемы неполного рабочего дня противоречит, и нет удовлетворительного фонематического объяснения потери / g / в этих диалектах. Неспособность решить проблемы такого рода имела печальные последствия.
Другой хорошо известный случай касается потери / g / после [] в sing , что, как говорят, имеет эффект повышения [ŋ] до фонематического статуса. В традиционной речи Северо-Западной Англии / g / иногда присутствует, а иногда отсутствует, что означает, что [ŋ] иногда является независимой фонемой, а иногда — аллофоном / n /. Понятие фонемы неполного рабочего дня противоречит, и нет удовлетворительного фонематического объяснения потери / g / в этих диалектах. Неспособность решить проблемы такого рода имела печальные последствия. в произношении словарей.В то же время фонеме был присвоен ряд свойств без проверки того, что эти свойства логически принадлежат одному и тому же объекту, и в результате фонема превратилась не в единое понятие, а в сеть тесно связанных понятий.
в произношении словарей.В то же время фонеме был присвоен ряд свойств без проверки того, что эти свойства логически принадлежат одному и тому же объекту, и в результате фонема превратилась не в единое понятие, а в сеть тесно связанных понятий.
 Многие фонетические контрасты действительно связаны с фонемами, но в принципе нет причин, по которым они должны быть все вместе.Например, голосовой контраст английского train ∼ сток является свойством начала / tr ∼ dr / в целом, и, если что-либо, голосовых и глухих аллофонов / r /, а не / t ∼ d /. В этом отношении контраст между английскими beat и bit на самом деле не между флисовыми и наборными гласными как таковыми, а между их аллофонами, возникающими до глухих остановок. Контраст становится еще более проблематичным в связанных естественных текстах. Liverpool English имеет контраст a / k ∼ g /, но в текстах, записанных в 1960-х годах, guitar легко можно было принять за catarrh .Более тонкий случай — фраза / li dʊn i /, которая, вероятно, будет интерпретирована как «ну, он сделал это», если она начинается с фарингализации / l /, превращая / l / в «темный» аллофон, но интерпретация » Ли сделал это ‘более вероятно, если / l / имеет чистый аллофон.
Многие фонетические контрасты действительно связаны с фонемами, но в принципе нет причин, по которым они должны быть все вместе.Например, голосовой контраст английского train ∼ сток является свойством начала / tr ∼ dr / в целом, и, если что-либо, голосовых и глухих аллофонов / r /, а не / t ∼ d /. В этом отношении контраст между английскими beat и bit на самом деле не между флисовыми и наборными гласными как таковыми, а между их аллофонами, возникающими до глухих остановок. Контраст становится еще более проблематичным в связанных естественных текстах. Liverpool English имеет контраст a / k ∼ g /, но в текстах, записанных в 1960-х годах, guitar легко можно было принять за catarrh .Более тонкий случай — фраза / li dʊn i /, которая, вероятно, будет интерпретирована как «ну, он сделал это», если она начинается с фарингализации / l /, превращая / l / в «темный» аллофон, но интерпретация » Ли сделал это ‘более вероятно, если / l / имеет чистый аллофон. Теперь предполагается, что аллофоны вообще не должны контрастировать, а контраст должен различать фонемы; но здесь различие аллофона приводит к разному толкованию фраз. К началу 1960-х годов стало ясно, что попытка дать единое точное определение фонемы провалилась, и что reductio ad absurdum концепции фонемы оказалось слишком легким делом.
Теперь предполагается, что аллофоны вообще не должны контрастировать, а контраст должен различать фонемы; но здесь различие аллофона приводит к разному толкованию фраз. К началу 1960-х годов стало ясно, что попытка дать единое точное определение фонемы провалилась, и что reductio ad absurdum концепции фонемы оказалось слишком легким делом. Доверие к этому подходу во многом зависело от строгого характера процедур открытия, и к началу 1960-х годов они тоже утратили свою способность убеждать.
Доверие к этому подходу во многом зависело от строгого характера процедур открытия, и к началу 1960-х годов они тоже утратили свою способность убеждать. Дж. Эллис, Генри Свит, Дэниел Джонс и Пасси в конце 19 века. Его создатели стремились стандартизировать представление разговорной речи, тем самым избежав путаницы, вызванной несогласованными традиционными написаниями, используемыми на всех языках.IPA также должен был заменить существующее множество индивидуальных систем транскрипции. Впервые он был опубликован в 1888 году и несколько раз пересматривался в 20-м и 21-м веках. Международная фонетическая ассоциация отвечает за алфавит и публикует таблицу с его кратким изложением.
Дж. Эллис, Генри Свит, Дэниел Джонс и Пасси в конце 19 века. Его создатели стремились стандартизировать представление разговорной речи, тем самым избежав путаницы, вызванной несогласованными традиционными написаниями, используемыми на всех языках.IPA также должен был заменить существующее множество индивидуальных систем транскрипции. Впервые он был опубликован в 1888 году и несколько раз пересматривался в 20-м и 21-м веках. Международная фонетическая ассоциация отвечает за алфавит и публикует таблицу с его кратким изложением. Если необходимо выполнить узкую расшифровку на английском языке, можно добавить диакритические знаки, чтобы указать, что буквы t в словах tap , pat и stem немного отличаются по произношению.
Если необходимо выполнить узкую расшифровку на английском языке, можно добавить диакритические знаки, чтобы указать, что буквы t в словах tap , pat и stem немного отличаются по произношению. Первые три состоят из различных речевых задач пациентов с БП и соответствующих контрольных говорящих. Albayzin — это вспомогательный корпус, используемый для обучения различных UBM, как описано в подразделе «Методы», в то время как FisherSP использовался для создания FAM 39 .
Первые три состоят из различных речевых задач пациентов с БП и соответствующих контрольных говорящих. Albayzin — это вспомогательный корпус, используемый для обучения различных UBM, как описано в подразделе «Методы», в то время как FisherSP использовался для создания FAM 39 . Подписанное информированное согласие было получено от всех выступающих.
Подписанное информированное согласие было получено от всех выступающих. Это подмножество содержит только говорящих мужского пола.Запись этого корпуса и связанных с ним экспериментов соответствует Хельсинкской декларации и одобрена Комитетом по этике Главной университетской больницы в Праге. Все участники предоставили письменное информированное согласие, по словам авторов корпуса 28 .
Это подмножество содержит только говорящих мужского пола.Запись этого корпуса и связанных с ним экспериментов соответствует Хельсинкской декларации и одобрена Комитетом по этике Главной университетской больницы в Праге. Все участники предоставили письменное информированное согласие, по словам авторов корпуса 28 . Он включает около 163 часов телефонной речи носителей испанского языка из более чем 20 стран, а также их транскрипцию.
Он включает около 163 часов телефонной речи носителей испанского языка из более чем 20 стран, а также их транскрипцию. По возможности, также проводились испытания с использованием CzechPD для адаптации UBM.
По возможности, также проводились испытания с использованием CzechPD для адаптации UBM. В исходном состоянии и в новых предлагаемых подходах все доступные TDU были объединены для обучения одной и той же модели для всех испытаний, связанных с одним конкретным корпусом. Следовательно, изучаемые аллофоны не зависели от предложения.Испытания с перекрестной проверкой следовали стратегии k-кратных (11 раз). Ни одно из высказываний или кадров из динамика, используемого для адаптации UBM, не использовалось на этапе тестирования во время перекрестной проверки.
В исходном состоянии и в новых предлагаемых подходах все доступные TDU были объединены для обучения одной и той же модели для всех испытаний, связанных с одним конкретным корпусом. Следовательно, изучаемые аллофоны не зависели от предложения.Испытания с перекрестной проверкой следовали стратегии k-кратных (11 раз). Ни одно из высказываний или кадров из динамика, используемого для адаптации UBM, не использовалось на этапе тестирования во время перекрестной проверки. Этот UBM служит инициализацией окончательной модели GMM-UBM, которая в данном случае используется для обнаружения частичных разрядов. В этой работе результирующий GMM-UBM был получен посредством максимальной апостериорной (MAP) адаптации UBM с использованием каждого паркинсонического тела отдельно, метод, который аналогичен некоторым системам распознавания говорящих 33 .Эта методология обеспечила точность до 85% в процитированном предыдущем исследовании 35 .
Этот UBM служит инициализацией окончательной модели GMM-UBM, которая в данном случае используется для обнаружения частичных разрядов. В этой работе результирующий GMM-UBM был получен посредством максимальной апостериорной (MAP) адаптации UBM с использованием каждого паркинсонического тела отдельно, метод, который аналогичен некоторым системам распознавания говорящих 33 .Эта методология обеспечила точность до 85% в процитированном предыдущем исследовании 35 . В каждом испытании GMM-UBM сначала адаптировались, а затем тестировались с использованием только одного конкретного паркинсонического корпуса и акустических сегментов, связанных только с одним классом манер: фрикативный, жидкий, носовой, взрывной или гласный. Аффрикатные сегменты не анализировались, так как они недостаточно представлены в TDU от GITA и Neurovoz (см. Таблицу 4). Одна из основных причин, по которой эта группа не представлена, заключается в том, что среди всех обсуждаемых здесь классов манер аффрикаты являются наименее распространенным классом в испанском языке, составляя менее 3% от общего числа фонем 42 .
В каждом испытании GMM-UBM сначала адаптировались, а затем тестировались с использованием только одного конкретного паркинсонического корпуса и акустических сегментов, связанных только с одним классом манер: фрикативный, жидкий, носовой, взрывной или гласный. Аффрикатные сегменты не анализировались, так как они недостаточно представлены в TDU от GITA и Neurovoz (см. Таблицу 4). Одна из основных причин, по которой эта группа не представлена, заключается в том, что среди всех обсуждаемых здесь классов манер аффрикаты являются наименее распространенным классом в испанском языке, составляя менее 3% от общего числа фонем 42 . Затем, после вычисления векторов признаков, содержащих коэффициенты D Rasta-PLP + Δ + ΔΔ для всех кадров речевых высказываний, они были распределены в соответствующие группировки в соответствии с их фонематическими метками для обучения, адаптации или тестирования в корпуса, в которых применялась фонематическая группировка, в зависимости от эксперимента.
Затем, после вычисления векторов признаков, содержащих коэффициенты D Rasta-PLP + Δ + ΔΔ для всех кадров речевых высказываний, они были распределены в соответствующие группировки в соответствии с их фонематическими метками для обучения, адаптации или тестирования в корпуса, в которых применялась фонематическая группировка, в зависимости от эксперимента. Описание второго подхода представлено на рисунке 4.
Описание второго подхода представлено на рисунке 4.
 Во-первых, мы считаем, что после взрывной группировки (как и для любой другой фонематической группировки) корпуса UBM мы получим два типа акустических сегментов: те, которые включают только кадры, относящиеся к взрывчатым веществам, и те, которые содержат кадры, которые также имеют информацию о соседних звуках. Этот последний тип кадров возникает около начальной или конечной частей взрывного, где кадр может включать в себя часть начала (или окончания) взрывного устройства и часть соседнего звука, когда кадр совпадает с переходом в или из соседний гласный.Учитывая это, рис. 6 иллюстрирует пример взрывной группировки только в UBM. В этом примере большинство гауссиан UBM в верхней части рисунка — в данном случае пять — были смоделированы с использованием только взрывных веществ (plos), тогда как два других гауссиана UBM в нижней части возникли из менее обильных кадров, содержащих информацию о взрывных звуках вместе с информацией о других соседних акустических сегментах — в основном гласных- (plos-vow). Учитывая использование задачи DDK («па-та-ка») в качестве речевого материала для адаптации MAP, наша гипотеза состоит в том, что достаточная статистика 33 получена из взрывных сегментов, присутствующих в высказываниях адаптации ([p], [ t], [k]) имеют тенденцию выполнять адаптацию гауссиан, созданных в UBM, с использованием только взрывных устройств.С другой стороны, достаточная статистика, полученная из оставшихся сегментов ([a]), имеет тенденцию адаптировать два других гауссиана из UBM, которые находятся ближе к этим сегментам. Таким образом, полученный GMM-UBM моделирует особенности, происходящие из нескольких типов акустических сегментов, но больше ориентирован на взрывные вещества. Следовательно, обобщая, фонематическая группировка корпуса UBM дает модели GMM-UBM, ориентированные либо на фрикативные, жидкостные, носовые, взрывные или гласные, в зависимости от фонематической группировки, но с учетом также в меньшей степени остальных акустических сегментов.
Во-первых, мы считаем, что после взрывной группировки (как и для любой другой фонематической группировки) корпуса UBM мы получим два типа акустических сегментов: те, которые включают только кадры, относящиеся к взрывчатым веществам, и те, которые содержат кадры, которые также имеют информацию о соседних звуках. Этот последний тип кадров возникает около начальной или конечной частей взрывного, где кадр может включать в себя часть начала (или окончания) взрывного устройства и часть соседнего звука, когда кадр совпадает с переходом в или из соседний гласный.Учитывая это, рис. 6 иллюстрирует пример взрывной группировки только в UBM. В этом примере большинство гауссиан UBM в верхней части рисунка — в данном случае пять — были смоделированы с использованием только взрывных веществ (plos), тогда как два других гауссиана UBM в нижней части возникли из менее обильных кадров, содержащих информацию о взрывных звуках вместе с информацией о других соседних акустических сегментах — в основном гласных- (plos-vow). Учитывая использование задачи DDK («па-та-ка») в качестве речевого материала для адаптации MAP, наша гипотеза состоит в том, что достаточная статистика 33 получена из взрывных сегментов, присутствующих в высказываниях адаптации ([p], [ t], [k]) имеют тенденцию выполнять адаптацию гауссиан, созданных в UBM, с использованием только взрывных устройств.С другой стороны, достаточная статистика, полученная из оставшихся сегментов ([a]), имеет тенденцию адаптировать два других гауссиана из UBM, которые находятся ближе к этим сегментам. Таким образом, полученный GMM-UBM моделирует особенности, происходящие из нескольких типов акустических сегментов, но больше ориентирован на взрывные вещества. Следовательно, обобщая, фонематическая группировка корпуса UBM дает модели GMM-UBM, ориентированные либо на фрикативные, жидкостные, носовые, взрывные или гласные, в зависимости от фонематической группировки, но с учетом также в меньшей степени остальных акустических сегментов.