Синтаксический разбор предложения — смотреть инструкцию
Главная » Гуманитарные науки
Гуманитарные наукиАвтор admin На чтение 3 мин Просмотров 151 Опубликовано Обновлено
Синтаксический разбор предложения – это процесс анализа структуры предложения с целью выделения в нем отдельных слов и определение связей между ними. Это важный этап в изучении русского языка, а также при написании текстов на родном языке или на других языках.
При проведении синтаксического разбора мы можем:
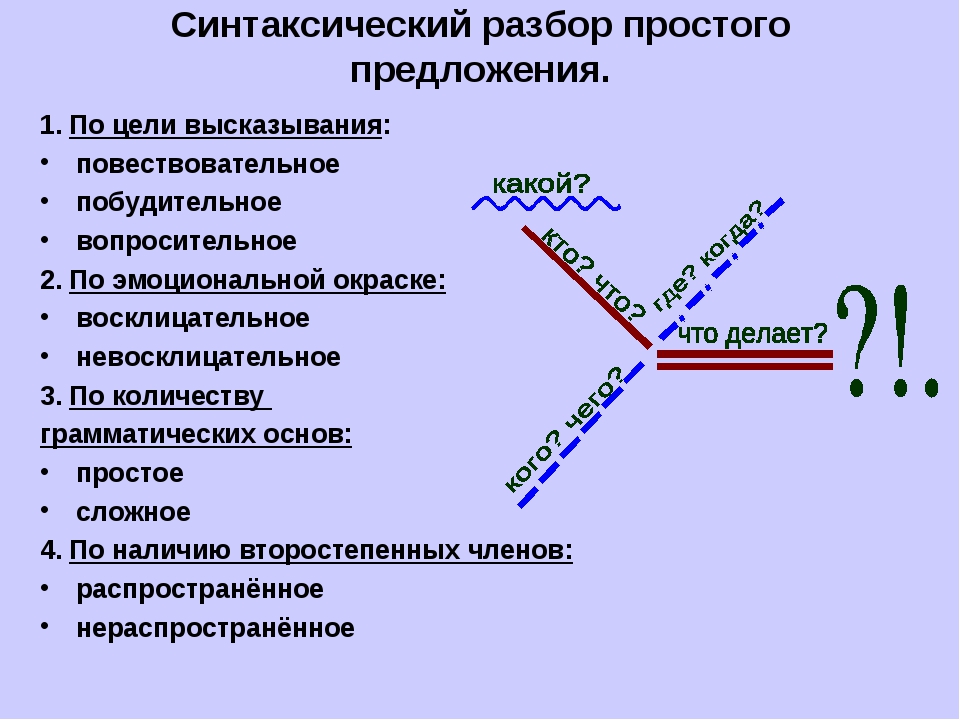
- Определить тип предложения (вопросительное, повествовательное, побудительное).
- Выделить подлежащее и сказуемое.

- Определить дополнение и обстоятельства.
- Определить связь между словами (однородные члены предложения).

Содержание
- Пошаговая инструкция, как провести полный синтаксический разбор простого предложения
- Примеры
- Различные аспекты синтаксического разбора предложения
- Однородные члены предложения
- Связанные группы слов
- Определение частей речи слов
Пошаговая инструкция, как провести полный синтаксический разбор простого предложения
Шаг №1:
Прочитайте предложение несколько раз. Сначала просто прочитайте его вслух для понимания его содержания. Затем более внимательно остановитесь на каждом слове, пытаясь определить его роль в предложении.
Шаг №2:
Выделите подлежащее и сказуемое. Подлежащее – это тот, о ком говорится в предложении (обычно выражен существительным или местоимением). Сказуемое – это то, что говорится о подлежащем (обычно выражено глаголом).
Шаг №3:
Определите тип предложения. Вопросительное предложение имеет в конце знак вопроса. Побудительное – обращение к адресату с просьбой или приказом. Повествовательное – самый распространенный тип, который не подразумевает никаких особенных интонационных особенностей.
Вопросительное предложение имеет в конце знак вопроса. Побудительное – обращение к адресату с просьбой или приказом. Повествовательное – самый распространенный тип, который не подразумевает никаких особенных интонационных особенностей.
Шаг №4:
Определите дополнения и обстоятельства. Дополнение – это то, что дает полный смысл глаголу и отвечает на вопрос «кого?», «чего?» или «кому?». Обстоятельства указывают на условия, при которых происходит действие.
Примеры
Пример 1:
«Саша читает книгу»
- Подлежащее: Саша
- Сказуемое: читает
- Дополнение: книгу
Пример 2:
«Я сегодня поеду в город на машине»
- Подлежащее: Я
- Сказуемое: поеду
- Дополнение: на машине
*Обратите внимание, что здесь есть и другие обстоятельства (сегодня, в город).
Пример 3:
«Как тебя зовут?» – вопросительное предложение.
Различные аспекты синтаксического разбора предложения
Кроме выделения подлежащего, сказуемого, дополнений и обстоятельств, при проведении синтаксического разбора предложения можно обращать внимание на другие аспекты:
Однородные члены предложения
Однородными называются словосочетания или члены предложения, которые выполняют одну и ту же функцию в рамках данного предложения.
Пример:
«Я люблю спать и готовить.»
- «Спать» и «готовить» — однородные члены предложения.
- «И» — союз-связка между ними.
Связанные группы слов
Возможно выделение так называемых связанных групп слов. Это касается случая, когда несколько слов формально относятся к разным частям речи или имеют различные грамматические формы, но на практике выполняют единую функцию.
Пример:
«Пошли гулять!»
- «Гулять» — инфинитив, который определяет цель действия.
- «Пошли» — личная форма глагола в повелительном наклонении, выражает призыв к действию.
Определение частей речи слов
При проведении синтаксического разбора можно также определять части речи слов. Для этого нужно знать правила склонения и спряжения и уметь распознавать морфемы.
Пример:
«Мама любит свой новый автомобиль. »
»
- «Мама» — существительное женского рода в именительном падеже единственного числа.
- «Любит» — личная форма глагола настоящего времени третьего лица единственного числа (от «любить»).
- «Свой» — местоимение-прилагательное в именительном падеже единственного числа, относящееся к подлежащему.
- «Новый» — прилагательное в именительном падеже единственного числа, относящееся к дополнению «автомобиль».
- «Автомобиль» — существительное мужского рода в именительном падеже единственного числа.
Синтаксический разбор предложения позволяет более глубоко понимать структуру языка и его правила. Это необходимый навык для любого человека, желающего овладеть русским языком или учить другие языки. С помощью HTML-разметки можно выделить ключевые элементы анализа текста и облегчить его чтение.
Title
— Карта сайта
|
|
Товар добавлен в корзину
Оформить заказПродолжить покупкиРазбор строк в Swift | Swift от Sundell
Почти каждой программе на планете так или иначе приходится иметь дело со строками, поскольку текст играет фундаментальную роль в том, как мы общаемся и представляем различные формы данных. Но обработка и синтаксический анализ строк таким образом, чтобы они были надежными и эффективными, иногда могут быть очень сложными. В то время как некоторые строки представлены в очень строгом и удобном для компьютера формате, таком как JSON или XML, другие строки могут быть гораздо более хаотичными .
Но обработка и синтаксический анализ строк таким образом, чтобы они были надежными и эффективными, иногда могут быть очень сложными. В то время как некоторые строки представлены в очень строгом и удобном для компьютера формате, таком как JSON или XML, другие строки могут быть гораздо более хаотичными .
На этой неделе давайте рассмотрим различные способы разбора и извлечения информации из таких строк, а также то, как различные методы и API приводят к различным компромиссам.
В некотором смысле Swift заработал репутацию устройства, с которым сложно работать, когда дело доходит до синтаксического анализа строк. Хотя это правда, что реализация Swift String не предлагает такого же количества удобства , как многие другие языки (например, вы не можете просто случайным образом получить доступ к заданному символу, используя целое число, например string[7] ), это упрощает написание правильного кода разбора строки .
Потому что, хотя приятно иметь возможность случайного доступа к любому заданному символу в строке на основе его воспринимаемой позиции, многоязычный (или, возможно, emoji-lingual ?) мир, в котором мы живем сегодня, делает такие API очень подверженными ошибкам.
В Swift строка состоит из набора значений символов , сохраненных с использованием кодировки UTF-8 . Это означает, что если мы перебираем строку (например, используя цикл для ), каждый элемент будет символом , который может быть буквой, смайликом или какой-либо другой формой символа. Для идентификации групп символов (таких как буквы или цифры) мы можем использовать набор символов , который можно передать нескольким различным API на Строка и связанные с ней типы.
Допустим, мы работаем над приложением, которое позволяет нескольким пользователям совместно работать над документом, и мы хотим реализовать функцию, позволяющую пользователям упоминать других людей, используя синтаксис 
Определение пользователей, которые были упомянуты в данной строке, — это задача, которая на самом деле очень похожа на то, что должен делать компилятор Swift при идентификации различных частей в строке кода — процесс, известный как lexing или tokenizing — вот только наша реализация будет на порядки проще, так как нам нужно искать только одного вида токена.
Первоначальная реализация может выглядеть примерно так: вычисляемое свойство String , в котором мы разбиваем строку на основе @ символов, отбрасываем первый элемент (поскольку это будет текст перед первым @- знак), а затем compactMap над результатом — идентифицирующие строки непустых буквенных символов:
строка расширения {
var упомянутые имена пользователей: [строка] {
пусть части = разделить (разделитель: "@").dropFirst()
// Наборы символов могут быть инвертированы, чтобы идентифицировать все
// символы, которые *не* входят в набор.
пусть delimiterSet = CharacterSet.letters.inverted
return parts.compactMap {часть в
// Здесь мы берем первую последовательность букв справа
// после знака @ и проверяем, что он не пустой.
пусть имя = part.components(separatedBy: delimiterSet)[0]
вернуть name.isEmpty ? ноль: имя
}
}
}  пусть delimiterSet = CharacterSet.letters.inverted
return parts.compactMap {часть в
// Здесь мы берем первую последовательность букв справа
// после знака @ и проверяем, что он не пустой.
пусть имя = part.components(separatedBy: delimiterSet)[0]
вернуть name.isEmpty ? ноль: имя
}
}
}
пусть delimiterSet = CharacterSet.letters.inverted
return parts.compactMap {часть в
// Здесь мы берем первую последовательность букв справа
// после знака @ и проверяем, что он не пустой.
пусть имя = part.components(separatedBy: delimiterSet)[0]
вернуть name.isEmpty ? ноль: имя
}
}
} Приведенная выше реализация довольно проста и использует некоторые действительно полезные функции Swift, такие как изменение коллекций, использование compactMap для отбрасывания нулевых значений и так далее. Но у него есть одна проблема — требуется три итерации , одна для разделения строки на основе @ символов, одна для итерации по всем этим частям, а затем одна для разделения каждой части на основе небуквенных символов.
Пока каждая итерация меньше предыдущей (поэтому сложность нашего алгоритма не совсем O(3N) ), многократные итерации чаще всего приводят к некоторой форме узких мест по мере роста набора входных данных. В нашем случае это может стать проблемой, так как мы планируем применить этот алгоритм к документам любого размера (может быть, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), поэтому давайте посмотрим, сможем ли мы что-то сделать. оптимизировать его.
В нашем случае это может стать проблемой, так как мы планируем применить этот алгоритм к документам любого размера (может быть, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), поэтому давайте посмотрим, сможем ли мы что-то сделать. оптимизировать его.
Вместо того, чтобы разбивать нашу строку на компоненты, а затем перебирать эти компоненты, давайте пройдемся по нашей строке за один раз — перебирая ее символы. Хотя для этого потребуется немного больше кода для ручного синтаксического анализа, это позволит нам сократить наш алгоритм до одной итерации — например:
строка расширения {
var упомянутые имена пользователей: [строка] {
// Настройка нашего состояния, которое представляет собой любое частичное имя, которое мы
// текущий анализ и массив всех найденных имен.
var partialName: Строка?
имена переменных = [Строка]()
// Вложенная функция разбора, которую мы применим к каждому
// символ внутри строки.
func parse(_ символ: Символ) {
если имя переменной = частичное имя {
охранять character.isLetter еще {
// Если мы встретим небуквенный символ
// при разборе имени это означает, что
// имя готово, и мы можем добавить его в
// наш массив (если не пустой):
если !name.isEmpty {
имена.добавлять(имя)
}
// Сбросить наше состояние и разобрать символ
// еще раз, так как это может быть @-знак.
частичное имя = ноль
вернуть синтаксический анализ (символ)
}
name.append(символ)
частичное имя = имя
} иначе, если символ == "@" {
// Устанавливаем пустое состояние, чтобы сигнализировать нашему выше
// код, что пора начинать парсить имя.
частичное имя = ""
}
}
// Применяем нашу функцию разбора к каждому символу
для каждого (разбор)
// Когда мы дойдем до конца, мы обязательно
// захватить любое имя, которое было ранее найдено.
если пусть lastName = частичное имя, !lastName.isEmpty {
имена.append(фамилия)
}
вернуть имена
}
}  func parse(_ символ: Символ) {
если имя переменной = частичное имя {
охранять character.isLetter еще {
// Если мы встретим небуквенный символ
// при разборе имени это означает, что
// имя готово, и мы можем добавить его в
// наш массив (если не пустой):
если !name.isEmpty {
имена.добавлять(имя)
}
// Сбросить наше состояние и разобрать символ
// еще раз, так как это может быть @-знак.
частичное имя = ноль
вернуть синтаксический анализ (символ)
}
name.append(символ)
частичное имя = имя
} иначе, если символ == "@" {
// Устанавливаем пустое состояние, чтобы сигнализировать нашему выше
// код, что пора начинать парсить имя.
частичное имя = ""
}
}
// Применяем нашу функцию разбора к каждому символу
для каждого (разбор)
// Когда мы дойдем до конца, мы обязательно
// захватить любое имя, которое было ранее найдено.
func parse(_ символ: Символ) {
если имя переменной = частичное имя {
охранять character.isLetter еще {
// Если мы встретим небуквенный символ
// при разборе имени это означает, что
// имя готово, и мы можем добавить его в
// наш массив (если не пустой):
если !name.isEmpty {
имена.добавлять(имя)
}
// Сбросить наше состояние и разобрать символ
// еще раз, так как это может быть @-знак.
частичное имя = ноль
вернуть синтаксический анализ (символ)
}
name.append(символ)
частичное имя = имя
} иначе, если символ == "@" {
// Устанавливаем пустое состояние, чтобы сигнализировать нашему выше
// код, что пора начинать парсить имя.
частичное имя = ""
}
}
// Применяем нашу функцию разбора к каждому символу
для каждого (разбор)
// Когда мы дойдем до конца, мы обязательно
// захватить любое имя, которое было ранее найдено. если пусть lastName = частичное имя, !lastName.isEmpty {
имена.append(фамилия)
}
вернуть имена
}
}
если пусть lastName = частичное имя, !lastName.isEmpty {
имена.append(фамилия)
}
вернуть имена
}
} Обратите внимание, что приведенный выше API isLetter для Character был добавлен в Swift 5. наш первый явный компромисс : выбираем ли мы более простое решение за счет потенциальной потери производительности — или мы выбираем более сложный, а также более эффективный алгоритм?
Обсуждение того, какой компромисс принять, становится еще более интересным по мере роста нашего списка требований. Допустим, после успешного развертывания функции упоминания для наших пользователей мы начинаем получать запросы на добавление поддержки хэштегов, и мы решили сделать именно это.
Поскольку обнаружение и имени пользователя, и хэштега представляет собой одну и ту же проблему (отличается только начальный символ — @ против # ), имеет смысл использовать одну и ту же реализацию для обнаружения обоих. Чтобы это произошло, давайте сначала определим тип
Чтобы это произошло, давайте сначала определим тип Symbol , который мы будем использовать для представления упоминания или хэштега:
struct Symbol {
enum Kind {упоминание регистра, хэштег}
пусть вид: Вид
переменная строка: строка
} Хотя у нас могло бы быть вместо этого использовал перечисление со связанными строковыми значениями — поскольку и упоминания, и хэштеги имеют одну и ту же структуру, наш алгоритм немного упростится, если мы будем использовать структуру. Однако, чтобы позволить Symbol использоваться в enum-подобном стиле , мы также можем добавить некоторые статические фабричные методы, чтобы упростить создание значений с использованием точечного синтаксиса:
extension Symbol {
упоминание статической функции (_ строка: строка) -> символ {
return Symbol (вид: .mention, строка: строка)
}
статическая функция хэштега (_ строка: строка) -> символ {
вернуть символ (вид: . хэштег, строка: строка)
}
}  хэштег, строка: строка)
}
}
хэштег, строка: строка)
}
} Имея вышеизложенное, давайте теперь обновим наш алгоритм упомянутых имен пользователей , чтобы он обнаруживал символы, а не только имена пользователей:
extension String {
var символы: [Символ] {
var partialSymbol: Символ?
символы var = [Символ]()
func parse(_ символ: Символ) {
если символ var = partialSymbol {
охранять character.isLetter еще {
если !symbol.string.isEmpty {
символы .append(символ)
}
частичный символ = ноль
вернуть синтаксический анализ (символ)
}
symbol.string.append(символ)
частичный символ = символ
} еще {
// Вот единственная реальная разница по сравнению с
// предыдущая версия, так как мы сейчас решим
// на основе какого символа мы разбираем
// его ведущий символ:
переключить символ {
случай "@":
частичное символ = . упоминание ("")
случай "#":
частичный символ = .хэштег ("")
по умолчанию:
перерыв
}
}
}
для каждого (разбор)
если пусть lastSymbol = partialSymbol, !lastSymbol.string.isEmpty {
символы .append (последний символ)
}
символы возврата
}
}  упоминание ("")
случай "#":
частичный символ = .хэштег ("")
по умолчанию:
перерыв
}
}
}
для каждого (разбор)
если пусть lastSymbol = partialSymbol, !lastSymbol.string.isEmpty {
символы .append (последний символ)
}
символы возврата
}
}
упоминание ("")
случай "#":
частичный символ = .хэштег ("")
по умолчанию:
перерыв
}
}
}
для каждого (разбор)
если пусть lastSymbol = partialSymbol, !lastSymbol.string.isEmpty {
символы .append (последний символ)
}
символы возврата
}
} С приведенным выше изменением разница между нашей первоначальной реализацией на основе разделения строк и нашим последним алгоритмом становится еще больше — поскольку, если бы мы должны были токенизировать имена пользователей и хэштеги путем разделения строк, нам потребовалось бы 6 различных итераций (2 раза). 3) — два из которых будут полными проходами через исходную строку.
Однако было бы неплохо, если бы мы смогли найти нечто среднее между простотой нашей первоначальной реализации и мощью нашего ручного алгоритма. Одним из способов сделать это может быть введение абстракции, которая разделяет токенизация часть нашего алгоритма из логики фактической работы с любыми найденными токенами.
Для этого давайте переместим большую часть нашего последнего алгоритма в метод tokenize , который принимает словарь обработчиков, хешированный на основе того, какой символ они обрабатывают, например:
extension String {
func tokenize (используя обработчики: [Character: (String) -> Void]) {
// Нам больше не нужно поддерживать массив символов,
// но нам нужно отслеживать как текущую
// разбираемый символ, а также для какого он обработчика.
var parsingData: (символ: String, обработчик: (String) -> Void)?
func parse(_ символ: Символ) {
если var data = parsingData {
охранять character.isLetter еще {
если !data.symbol.isEmpty {
data.handler(данные.символ)
}
парсингданные = ноль
вернуть синтаксический анализ (символ)
}
data.symbol.append(символ)
синтаксический анализ = данные
} еще {
// Если у нас есть обработчик для данного символа,
// тогда мы его разберем.
защитный пусть обработчик = обработчики [символ] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
для каждого (разбор)
если пусть lastData = parsingData, !lastData.symbol.isEmpty {
lastData.handler(lastData.symbol)
}
}
}  защитный пусть обработчик = обработчики [символ] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
для каждого (разбор)
если пусть lastData = parsingData, !lastData.symbol.isEmpty {
lastData.handler(lastData.symbol)
}
}
}
защитный пусть обработчик = обработчики [символ] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
для каждого (разбор)
если пусть lastData = parsingData, !lastData.symbol.isEmpty {
lastData.handler(lastData.symbol)
}
}
} Приведенное выше не только немного очищает нашу реализацию, но и дает нам гораздо больше гибкости, поскольку теперь мы можем повторно использовать один и тот же алгоритм токенизации в разных контекстах и выбирать, как каждый токен должен обрабатываться на сайте вызова.
Теперь мы можем сократить наш код разбора символов до следующего:
extension String {
var символы: [Символ] {
символы var = [Символ]()
токенизировать (используя: [
"@": {символы.добавление(.упоминание($0))},
"#": {символы.приложение(.хэштег($0))}
])
символы возврата
}
} Очень красиво и чисто! 👍 Но, как и прежде, есть ряд компромиссов. Хотя абстракции — отличный способ скрыть сложную логику за гораздо более удобным API — они не бесплатны. Фактически, наша последняя версия требует примерно на 40% больше времени для запуска по сравнению с тем, когда алгоритм был встроен в свойство
Хотя абстракции — отличный способ скрыть сложную логику за гораздо более удобным API — они не бесплатны. Фактически, наша последняя версия требует примерно на 40% больше времени для запуска по сравнению с тем, когда алгоритм был встроен в свойство символов . Тем не менее, это все еще примерно в два раза быстрее, чем делать то же самое, разделяя строки, поэтому на самом деле это может быть та золотая середина, которую мы искали.
До сих пор мы в основном сравнивали ручную итерацию символов строки с разбиением ее на компоненты, но, как и во многих других случаях, есть и другие варианты, которые следует учитывать.
Одним из таких вариантов является использование сканера Foundation типа для непрерывного сканирования строки для идентификации искомых токенов. Как и в нашей последней реализации, она позволяет нам полагаться на абстракцию (на этот раз предоставленную Apple) для обработки большей части нашего алгоритма.0003 «тяжелый подъем» . Вот как может выглядеть такая реализация:
extension String {
var символы: [Символ] {
пусть сканер = Сканер (строка: сам)
пусть symbolSet = CharacterSet (charactersIn: "@#")
символы var = [Символ]()
var symbolKind: Symbol. Kind?
// Сканер не предоставляет API, похожий на последовательность, а скорее
// требует, чтобы мы проверили его текущее состояние, чтобы принять решение
// когда итерация закончилась.
в то время как !scanner.isAtEnd {
если пусть вид = symbolKind {
символВид = ноль
// Так как Scanner на самом деле просто интерфейс Swift
// для класса NSScanner Objective-C требуется
// нам передать указатель NSString, который
// записываем результат в.
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
продолжать
}
символы.append (Символ (вид: вид, строка: строка как строка))
} еще {
// Здесь мы сканируем, пока не найдем либо @, либо
// символ #, а затем использовать этот символ
// при назначении вида символа для разбора.
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
}
}
символы возврата
}
}  Kind?
// Сканер не предоставляет API, похожий на последовательность, а скорее
// требует, чтобы мы проверили его текущее состояние, чтобы принять решение
// когда итерация закончилась.
в то время как !scanner.isAtEnd {
если пусть вид = symbolKind {
символВид = ноль
// Так как Scanner на самом деле просто интерфейс Swift
// для класса NSScanner Objective-C требуется
// нам передать указатель NSString, который
// записываем результат в.
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
продолжать
}
символы.append (Символ (вид: вид, строка: строка как строка))
} еще {
// Здесь мы сканируем, пока не найдем либо @, либо
// символ #, а затем использовать этот символ
// при назначении вида символа для разбора.
Kind?
// Сканер не предоставляет API, похожий на последовательность, а скорее
// требует, чтобы мы проверили его текущее состояние, чтобы принять решение
// когда итерация закончилась.
в то время как !scanner.isAtEnd {
если пусть вид = symbolKind {
символВид = ноль
// Так как Scanner на самом деле просто интерфейс Swift
// для класса NSScanner Objective-C требуется
// нам передать указатель NSString, который
// записываем результат в.
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
продолжать
}
символы.append (Символ (вид: вид, строка: строка как строка))
} еще {
// Здесь мы сканируем, пока не найдем либо @, либо
// символ #, а затем использовать этот символ
// при назначении вида символа для разбора. Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
}
}
символы возврата
}
}
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
}
}
символы возврата
}
} Хотя «Objective-C-ness» из Scanner наш код может выглядеть немного хуже «Swifty» , это допустимый вариант для такого рода проблем — и его характеристики производительности находятся на одном уровне. с нашей реализацией, основанной на ручной итерации, из предыдущей. Можно также утверждать, что использование Scanner дает немного более читаемый код, поскольку его API явно заявляют, что мы сканируем для заданной строки в каждой части алгоритма, но это будет очень субъективно.
Давайте взглянем на последний вариант оптимизации — использование ленивых коллекций . До этого момента все реализации, которые мы исследовали, имели одну общую черту — все они сразу анализировали всю строку. Хотя это совершенно нормально для вариантов использования, которые также будут потреблять все результаты немедленно, мы могли бы потенциально оптимизировать вещи, вместо этого выполняя наш синтаксический анализ более ленивым способом .
До этого момента все реализации, которые мы исследовали, имели одну общую черту — все они сразу анализировали всю строку. Хотя это совершенно нормально для вариантов использования, которые также будут потреблять все результаты немедленно, мы могли бы потенциально оптимизировать вещи, вместо этого выполняя наш синтаксический анализ более ленивым способом .
Как мы рассмотрели в «Быстрые последовательности: искусство быть ленивым» , откладывая вычисление элемента в последовательности до тех пор, пока он не станет действительно необходимым.
Давайте обновим нашу последнюю реализацию на основе Scanner , чтобы она выполнялась лениво. Для этого мы завернем наш алгоритм в AnySequence и AnyIterator , что позволит нам формировать ленивые последовательности, не требуя от нас реализации нового типа с нуля:0005
строка расширения {
var символы: AnySequence {
// Поскольку наш набор символов является константой, мы можем вычислить
// это немедленно, вне нашей итерации закрытия.
пусть symbolSet = CharacterSet (charactersIn: "@#")
// AnySequence позволяет нам использовать замыкания для определения обоих
// наша последовательность и лежащий в ее основе итератор.
return AnySequence { () -> AnyIterator в
пусть сканер = Сканер (строка: сам)
var symbolKind: Symbol.Kind?
// Мы немного переработали наш алгоритм, чтобы вместо этого
// используем вложенную функцию, которая будет вызываться
// итератор для извлечения следующего элемента (или nil, как только
// мы достигли конца последовательности).
func iterate() -> Символ? {
охранять !scanner.isAtEnd еще {
вернуть ноль
}
охранять let kind = symbolKind else {
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = . упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
вернуть итерацию ()
}
символВид = ноль
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
вернуть итерацию ()
}
return Symbol (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (повторить)
}
}
}  пусть symbolSet = CharacterSet (charactersIn: "@#")
// AnySequence позволяет нам использовать замыкания для определения обоих
// наша последовательность и лежащий в ее основе итератор.
return AnySequence
пусть symbolSet = CharacterSet (charactersIn: "@#")
// AnySequence позволяет нам использовать замыкания для определения обоих
// наша последовательность и лежащий в ее основе итератор.
return AnySequence упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
вернуть итерацию ()
}
символВид = ноль
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
вернуть итерацию ()
}
return Symbol (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (повторить)
}
}
}
упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
вернуть итерацию ()
}
символВид = ноль
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
вернуть итерацию ()
}
return Symbol (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (повторить)
}
}
} С приведенным выше изменением мы теперь получим довольно значительный прирост производительности для такого кода, который только итерирует нашу последовательность из символов до заданной точки:
let firstHashtag = string.symbols.first { $0. kind == .hashtag } И это ставит нас перед окончательным компромиссом для этой статьи — готовы ли мы принять дополнительную сложность (и, возможно, немного более сложную отладку), чтобы сделать более короткие итерации более производительными?
Как и при написании любого типа алгоритмов, конкретная реализация, которая будет наиболее подходящей, сильно зависит как от того, с какой проблемой мы имеем дело, насколько велики наборы данных, на которых мы планируем ее запустить, и как результат будет съеден.
Конечно, в Swift есть много других способов анализа строк, которые не были рассмотрены в этой статье, например, использование регулярных выражений или углубление для анализа на базовом уровне Unicode, но, надеюсь, он дал вам обзор около инструментов и методов, находящихся в нашем распоряжении, и различные компромиссы, с которыми все они связаны.
Мой личный подход почти всегда состоит в том, чтобы начинать с простейшей возможной реализации и, постоянно измеряя результаты и характеристики производительности моих алгоритмов, расширять их по мере необходимости — как в этой статье. Мы также более подробно рассмотрим, как именно измерять наш код по различным показателям производительности, в следующей статье.
Что вы думаете? Есть ли у вас любимый способ анализа строк в Swift или вы попробуете один из методов из этой статьи в следующий раз, когда столкнетесь с проблемой такого рода? Дайте мне знать — вместе с вашими вопросами, комментариями и отзывами — в Твиттере @johnsundell или связавшись со мной.
Спасибо за внимание! 🚀
Лучшее программное обеспечение для анализа электронной почты в 2023 году
В вашем почтовом ящике больше, чем просто электронные письма — он полон данных. Особенно это актуально, если вы занимаетесь бизнесом. Возможно, ваши лиды приходят по электронной почте, может быть, там заканчиваются определенные счета, или, может быть, туда попадают все результаты ваших вступительных опросов.
Но вы ничего не сможете сделать с этими данными, если они останутся глубоко в вашем почтовом ящике среди информационных бюллетеней, уведомлений о доставке и спама. Квитанции более полезны, например, в вашем бухгалтерском программном обеспечении. Контакты более полезны в вашей CRM. Хотя вы можете вручную скопировать всю эту информацию, особенно если есть только несколько релевантных электронных писем, это все равно раздражает — и определенно не масштабируется до десятков или даже сотен электронных писем в день.
Здесь на помощь приходят инструменты анализа электронной почты. Эти инструменты делают всю работу за вас, собирая информацию из вашего почтового ящика и организуя ее таким образом, чтобы ее могли использовать другие приложения.
Эти инструменты делают всю работу за вас, собирая информацию из вашего почтового ящика и организуя ее таким образом, чтобы ее могли использовать другие приложения.
Но сейчас эти инструменты находятся в странном месте. Это одна из многих категорий приложений, которые, я думаю, будут серьезно нарушены инструментами искусственного интеллекта . Их еще не было, поэтому приложения из этого списка по-прежнему являются лучшим способом извлечения важных данных из вашего почтового ящика, но к тому времени, когда я обновлю этот список в следующем году, это может быть совершенно другая история.
Лучшее программное обеспечение для анализа электронной почты
Mailparser для быстрой настройки мощных правил анализа электронной почты
Email Parser от Zapier для парсера начального уровня для пользователей Zapier
Parsio для парсера электронной почты на базе AI 226
Parseur для продвинутых пользователей и для анализа вложений электронной почты
SigParser для очистки подписей электронной почты
Что делает программное обеспечение для анализа электронной почты отличным?
Как мы оцениваем и тестируем приложения
Все наши обзоры лучших приложений написаны людьми, которые большую часть своей карьеры использовали, тестировали и писали о программном обеспечении. Мы тратим десятки часов на изучение и тестирование приложений, используя каждое приложение по назначению и оценивая его по критериям, которые мы установили для категории. Нам никогда не платят за размещение в наших статьях из какого-либо приложения или за ссылки на какой-либо сайт — мы ценим доверие, которое читатели оказывают нам, предлагая достоверные оценки категорий и приложений, которые мы просматриваем. Для получения более подробной информации о нашем процессе прочитайте полное изложение того, как мы выбираем приложения для размещения в блоге Zapier.
Мы тратим десятки часов на изучение и тестирование приложений, используя каждое приложение по назначению и оценивая его по критериям, которые мы установили для категории. Нам никогда не платят за размещение в наших статьях из какого-либо приложения или за ссылки на какой-либо сайт — мы ценим доверие, которое читатели оказывают нам, предлагая достоверные оценки категорий и приложений, которые мы просматриваем. Для получения более подробной информации о нашем процессе прочитайте полное изложение того, как мы выбираем приложения для размещения в блоге Zapier.
Существует около дюжины настоящих парсеров электронной почты, поэтому я протестировал каждый из них, который мне попался в руки, и выбрал лучший. Я тестирую и проверяю программное обеспечение для автоматизации более десяти лет, поэтому у меня большой опыт оценки таких приложений. Лучшие приложения для анализа электронной почты соответствуют следующим критериям (а некоторые даже превосходят их).
Они извлекают определенную информацию из вашей электронной почты и ее вложений .
Это можно сделать с помощью настраиваемых правил, шаблонов, предлагаемых самим приложением, путем автоматического сканирования всех входящих электронных писем на наличие определенных данных или, в некоторых случаях, с использованием моделей ИИ для обнаружения соответствующей информации. Здесь важна точность, так как вам нужен анализатор электронной почты, чтобы надежно получать нужные данные каждый раз.Их легко или, по крайней мере, легко настроить . Вы могли бы, имея достаточно времени или ресурсов, создать собственные сценарии, которые выполняли бы эту работу за вас. Сервисы очистки электронной почты означают, что вам не нужно этого делать, поэтому лучшие из них должны быть удобными для пользователя — или, по крайней мере, такими же удобными для пользователя, как парсер электронной почты. Это по-прежнему мощные, чрезвычайно настраиваемые приложения, и знакомство с такими функциями, как регулярные выражения и базовая обработка данных, будет иметь большое значение для того, чтобы сделать ваш опыт менее сложным, даже с самыми простыми в использовании приложениями.
Это также очень помогает, если вы пытаетесь очистить данные, которые каждый раз поступают в одном и том же формате. Чем разнообразнее представлены данные, тем сложнее будет настройка.Они помещают эти данные туда, куда вы хотите. Некоторые люди время от времени захотят загружать электронные таблицы, и большинство приложений этой категории предлагают это. Однако лучшие из них могут отправлять данные в другие приложения, которые вы уже используете. Таким образом, ваши квитанции могут быть отправлены прямо в вашу бухгалтерскую программу, или контактные данные ваших новых клиентов могут быть автоматически добавлены в вашу CRM и список рассылки.
Ими приятно пользоваться. Специализированные инструменты, такие как синтаксические анализаторы электронной почты, часто разрабатываются с расчетом на технического конечного пользователя, а это означает, что многие приложения экономят на таких вещах, как адаптация и приятный пользовательский интерфейс.
Хотя это и не обязательно, полезные советы, учебные пособия и безобидный интерфейс делают лучшие парсеры электронной почты более приятными в использовании. Это, конечно, не приложения для всех, но в идеале они должны быть приложениями для всех.
 Это можно сделать с помощью настраиваемых правил, шаблонов, предлагаемых самим приложением, путем автоматического сканирования всех входящих электронных писем на наличие определенных данных или, в некоторых случаях, с использованием моделей ИИ для обнаружения соответствующей информации. Здесь важна точность, так как вам нужен анализатор электронной почты, чтобы надежно получать нужные данные каждый раз.
Это можно сделать с помощью настраиваемых правил, шаблонов, предлагаемых самим приложением, путем автоматического сканирования всех входящих электронных писем на наличие определенных данных или, в некоторых случаях, с использованием моделей ИИ для обнаружения соответствующей информации. Здесь важна точность, так как вам нужен анализатор электронной почты, чтобы надежно получать нужные данные каждый раз. Это также очень помогает, если вы пытаетесь очистить данные, которые каждый раз поступают в одном и том же формате. Чем разнообразнее представлены данные, тем сложнее будет настройка.
Это также очень помогает, если вы пытаетесь очистить данные, которые каждый раз поступают в одном и том же формате. Чем разнообразнее представлены данные, тем сложнее будет настройка. Хотя это и не обязательно, полезные советы, учебные пособия и безобидный интерфейс делают лучшие парсеры электронной почты более приятными в использовании. Это, конечно, не приложения для всех, но в идеале они должны быть приложениями для всех.
Хотя это и не обязательно, полезные советы, учебные пособия и безобидный интерфейс делают лучшие парсеры электронной почты более приятными в использовании. Это, конечно, не приложения для всех, но в идеале они должны быть приложениями для всех.В некоторых случаях я находил приложения, предлагающие схожие функции и качество по разным ценам, и в этих случаях я предпочитал более доступный или простой в использовании вариант. Вот приложения, которые, по моему мнению, работали лучше всего.
Зачем анализировать электронную почту? Анализаторы электронной почты и правила электронной почты
Большинство почтовых служб, таких как Gmail и Outlook, имеют своего рода автоматизированную систему правил, которую можно использовать для фильтрации и сортировки электронных писем. Разница между специальными парсерами электронной почты и этими правилами сводится к одному ключевому различию: Gmail и Outlook могут сортировать ваши электронные письма на основе их содержимого, в то время как парсер электронной почты может напрямую сортировать содержимое.
Например, в Gmail вы можете автоматически помечать все электронные письма, содержащие счета, чтобы отправлять их своему бухгалтеру в конце года. С помощью анализатора электронной почты вы можете извлечь дату отправки, номер счета и дату его оплаты, а с помощью приложения, такого как Zapier, добавить это в электронную таблицу и автоматически отправить ее своему бухгалтеру. во второй вторник каждого месяца.
Многих людей, вероятно, устраивает встроенная автоматизация их службы электронной почты, но если вы занимаетесь бизнесом, вам нужно обрабатывать данные, которые на самом деле находятся в ваших электронных письмах, просто у вас есть огромный объем электронных писем, с которыми нужно справиться, или действительно , как автоматизировать такие вещи , тогда парсер электронной почты определенно для вас.
Лучший синтаксический анализатор электронной почты для быстрой настройки эффективных правил
Mailparser (Интернет) Анализ электронной почты не совсем прост — вам нужно указать компьютеру, как смотреть электронное письмо, и извлекать точные биты нужных вам данных. Mailparser неплохо справляется с процессом кажутся простыми, и это впечатляет.
Mailparser неплохо справляется с процессом кажутся простыми, и это впечатляет.
Вы создали почтовый ящик, который имеет собственный адрес электронной почты. Перешлите несколько электронных писем на этот адрес, и Mailparser угадает, какую информацию вы хотите получить. Очевидно, что это не будет идеально каждый раз, но если вы пытаетесь извлечь что-то логичное и шаблонное, например, квитанцию, это довольно хорошо работает само по себе. Если нет, вы можете создать свои собственные правила.
Mailparser может анализировать тему, тело, получателей и заголовки для каждого электронного письма. Он также может анализировать вложения: PDF, XLS, CSV, TXT, DOCX и другие файлы можно очистить. Но для меня отличительной чертой здесь является то, насколько прост пользовательский интерфейс. Я просмотрел довольно много парсеров электронной почты, и интуитивно понятный интерфейс ни в коем случае не является данностью. Если вы никогда не пользовались службой разбора электронной почты и не знаете, с чего начать, это инструмент, который вы должны проверить в первую очередь. Он упрощает обработку простых электронных писем, но при этом обладает достаточной мощностью и возможностью настройки для обработки более сложного анализа.
Он упрощает обработку простых электронных писем, но при этом обладает достаточной мощностью и возможностью настройки для обработки более сложного анализа.
Mailparser интегрируется с Zapier, что означает, что вы можете отправлять проанализированные данные в тысячи приложений, как только приходят электронные письма. Например, вы можете добавлять вещи в базу данных, отправлять новые электронные письма или даже получать уведомления о новых очищенных электронных письмах. в Слаке.
Отправка новых писем Gmail из обработанных Mailparser писем
Отправка новых писем Gmail из обработанных писем MailparserПопробуйте
Mailparser + Gmail
Получить новые проанализированные электронные письма Mailparser.io в Slack
Получить новые проанализированные электронные письма Mailparser.io в SlackПопробовать
- 9 0226
Mailparser, Slack
Mailparser + Slack
Добавить новые заказы Shopify в базу Airtable
Добавить новые заказы Shopify в базу AirtableПопробовать
Mailparser, Airtable
Mailparser + Airtable
Стоимость Mailparser : Бесплатно для 30 писем в месяц; от 39,95 долларов США в месяц за профессиональный план на 500 электронных писем в месяц
Лучший парсер электронной почты начального уровня для пользователей Zapier
Парсер электронной почты от Zapier (Интернет) Это продукт Zapier в сообщении блога Zapier, так что я понимаю, если вы скептически относитесь к моей способности быть нейтральным. Но я не собираюсь делать вид, что это самый мощный инструмент для анализа электронной почты, и если вам не нужны другие решения, предлагаемые Zapier, возможно, это вам не подходит. Но если синтаксический анализ электронной почты — это лишь один из многих способов автоматизации, которые вы будете использовать, он сделает свою работу. Если вы уже платите за Zapier, даже лучше.
Но я не собираюсь делать вид, что это самый мощный инструмент для анализа электронной почты, и если вам не нужны другие решения, предлагаемые Zapier, возможно, это вам не подходит. Но если синтаксический анализ электронной почты — это лишь один из многих способов автоматизации, которые вы будете использовать, он сделает свою работу. Если вы уже платите за Zapier, даже лучше.
Начните работу с Email Parser от Zapier, и вы сможете настроить столько почтовых ящиков, сколько захотите, каждый со своим собственным адресом электронной почты @robot.zapier.com. Вы можете пересылать электронные письма на этот адрес либо вручную, либо с помощью чего-то вроде системы фильтров Gmail. Отправьте несколько образцов электронных писем, затем выделите и назовите информацию, которую вы хотите извлечь из будущих электронных писем. Здесь вы не найдете много дополнительных функций — например, вы не можете очистить содержимое вложений электронной почты.
Затем вы настроите Zap, наш термин для автоматизированного рабочего процесса, который будет отправлять эту информацию в любое другое приложение, которое вы хотите — вы можете выбирать из тысяч приложений. Несколько примеров: отправка информации из электронной почты в электронную таблицу, добавление новых контактов в список Mailchimp или создание события Календаря Google на основе информации в электронной почте.
Несколько примеров: отправка информации из электронной почты в электронную таблицу, добавление новых контактов в список Mailchimp или создание события Календаря Google на основе информации в электронной почте.
Сохранять новые проанализированные электронные письма в строках Google Таблиц
Сохранять новые проанализированные электронные письма в строках Google ТаблицПопробовать
Парсер электронной почты от Zapier + Google Таблицы
Разобрать адреса электронной почты из сообщения электронной почты и добавить в список Mailchimp
Разобрать адреса электронной почты из сообщения электронной почты и добавить в список MailchimpПопробовать
Парсер электронной почты от Zapier, Mailchimp
Парсер электронной почты от Zapier + Mailchimp
Создать Календарь Google, подробные события из электронной почты Парсера электронной почты Zapier
Создать Календарь Google, подробные события из электронной почты Zapier Par сер электронная почтаПопробуйте
Парсер электронной почты от Zapier, Календарь Google
Парсер электронной почты от Zapier + Календарь Google
Парсер электронной почты от Zapier цены : включено во все планы Zapier.
Чтобы узнать, как использовать Email Parser от Zapier, ознакомьтесь с нашим руководством по анализатору электронной почты.
Лучший парсер электронной почты для функций ИИ
Parsio (Интернет)Хотя я ожидаю, что функции ИИ будут доминировать в парсерах электронной почты в ближайшие год или два, Parsio — первое приложение, которое я тестировал с ними, которое я могу рекомендовать. В настоящее время он предлагает синтаксический анализ электронных писем и вложений на основе шаблонов, включая PDF, XLS, DOCX, CSV и JSON, а также синтаксический анализ PDF-файлов и изображений отсканированных документов с помощью ИИ.
Синтаксический анализ на основе шаблонов так же хорош, как и любое другое приложение в этом списке, и его очень легко настроить. Его пользовательский интерфейс является одним из самых современных из протестированных мной приложений, что немного облегчает понимание. При желании вы также можете попросить Parsio проанализировать любые подписи электронной почты и получить контактную информацию, хотя это стоит дополнительных денег.
Но парсинг PDF-файлов и вложенных изображений с помощью искусственного интеллекта — это то, чем Parsio действительно выделяется. Прямо сейчас у него есть предварительно обученные модели для извлечения данных из счетов-фактур, квитанций, визитных карточек, документов, удостоверяющих личность, форм W-2, а также общих документов и форм. Он автоматически смог извлечь всю важную информацию из всех счетов, с которыми я его тестировал. Команда также работает над функцией, которая позволит вам обучать собственную модель, хотя она пока недоступна.
Парсио работает по кредитной системе. Использование синтаксического анализатора на основе шаблона стоит один кредит на страницу (и еще один кредит на анализ подписи электронной почты) или пять кредитов на страницу на анализ вложения с помощью модели ИИ. Бесплатный план предлагает 30 кредитов в месяц, а платные планы начинаются с 49 долларов в месяц с 1000 кредитов.
Parsio предлагает постобработку и изначально интегрируется со Slack, Shopify и множеством других приложений — , включая Zapier . Это означает, что вы можете делать такие вещи, как автоматическое создание записей Google Sheets или Airtable из проанализированных документов.
Это означает, что вы можете делать такие вещи, как автоматическое создание записей Google Sheets или Airtable из проанализированных документов.
Создать строки Google Таблиц для новых проанализированных документов в Parsio
Создать строки Google Таблиц для новых проанализированных документов в ParsioПопробовать
- 9024 7
Parsio, Google Таблицы
Parsio + Google Таблицы
Создание записей Airtable из недавно проанализированных документов Parsio
Создание записей Airtable из недавно проанализированных документов ParsioПопробуйте
Parsio, Airtable
Parsio + Airtable
Цена Parsio: Бесплатно за 30 кредитов в месяц. От 49 долларов США в месяц для плана Starter с 1000 кредитов в месяц.
Лучший встроенный инструмент для анализа электронной почты Windows правила сами.
 Это будет непросто, но компромисс — мощность, которую не предлагают другие приложения.
Это будет непросто, но компромисс — мощность, которую не предлагают другие приложения.Частично это связано с тем, что Email Parser доступен как фактическое приложение Windows. Он также подключается напрямую к Gmail (хотя мне пришлось следовать инструкциям, чтобы подключить его через IMAP из-за последних усилий Google по защите подключений сторонних приложений), серверам Exchange и POP/IMAP, вместо того, чтобы полагаться на вас для переадресации. сообщения на пользовательский адрес, как и большинство других парсеров электронной почты.
Работа в Windows имеет одно очевидное преимущество: поддержка локальных файлов. Приложение может передавать данные электронной почты непосредственно в электронную таблицу Excel, файл CSV или даже текстовый документ на вашем компьютере — облачное хранилище не требуется. Также имеется поддержка локальных сценариев PowerScript и C#, что означает, что нет ограничений на то, что вы можете делать с данными, которые вы анализируете, если у вас есть навыки кодирования.
Существует также веб-версия: она предлагает возможность создания пользовательского почтового ящика, на который вы можете пересылать электронные письма, подобно тому, как работают такие службы, как Mailparser. Веб-версия не очень хорошо сравнивается с некоторыми другими приложениями здесь, но приятно иметь возможность, особенно если вы предпочитаете более подробный подход к созданию правил, предлагаемый Email Parser.
Цены на анализатор электронной почты : веб-приложение за 24 доллара в месяц; Приложение для Windows за 145 долларов в год.
Лучший парсер электронной почты для опытных пользователей и обработки вложенных документов
Parseur (Интернет) Во многих отношениях Parseur является выбором для обновления Mailparser. Он так же прост в использовании, имеет еще более приятный пользовательский интерфейс и выделяется одним ключевым моментом: огромным количеством форматов файлов вложений, которые он может очищать. Если вы получаете много квитанций, которые (по необъяснимым причинам) отправляются в виде документов текстового процессора, вам нужно попробовать этот инструмент. Parseur может извлекать данные из всех типов файлов, что и Mailparser, но он также поддерживает форматы обработки текстов, такие как ODT, RTF, Apple Pages и даже WordPerfect (по какой-то причине).
Если вы получаете много квитанций, которые (по необъяснимым причинам) отправляются в виде документов текстового процессора, вам нужно попробовать этот инструмент. Parseur может извлекать данные из всех типов файлов, что и Mailparser, но он также поддерживает форматы обработки текстов, такие как ODT, RTF, Apple Pages и даже WordPerfect (по какой-то причине).
И еще многое другое. Существует поддержка постобработки, например, с использованием сценариев Python (по более высокой цене) и OCR, поэтому можно анализировать даже изображения и снимки экрана. И есть шаблоны для обработки электронных писем от общих служб, включая оповещения Google, списки вакансий, бронирование недвижимости и заказы еды.
Вы можете интегрировать Parseur с Zapier, что позволит вам отправлять очищенные данные из вашей электронной почты в тысячи приложений. Например, вы можете автоматически создавать строки в электронной таблице или записи в Airtable при поступлении новых электронных писем.
Добавить новые данные электронной почты, проанализированные Parseur, в строки Microsoft Excel
Добавить новые данные электронной почты, проанализированные Parseur, в строки Microsoft ExcelПопробовать
- 9024 7
Parseur, Microsoft Excel
Parseur + Microsoft Excel
Создание новых записей Airtable из данных электронной почты, проанализированных Parseur
Создание новых записей Airtable из данных электронной почты, проанализированных ParseurПопробуйте
Parseur, Airtable
Parseur + Airtable
Недостаток: Parseur дороже альтернатив, особенно при обработке небольших объемов электронной почты. Он использует кредитную систему: анализ одного электронного письма или одной страницы вложения стоит один кредит. Бесплатный план дает вам 20 кредитов в месяц, но после этого самый дешевый план — 100 кредитов в месяц за 39 долларов. 0,39 доллара США за электронное письмо или страницу вложения могут быть полезными, в зависимости от ваших потребностей, а цена за кредит быстро снижается с более высокими ежемесячными платежами, поэтому попробуйте Parseur, прежде чем выбрать услугу.
Он использует кредитную систему: анализ одного электронного письма или одной страницы вложения стоит один кредит. Бесплатный план дает вам 20 кредитов в месяц, но после этого самый дешевый план — 100 кредитов в месяц за 39 долларов. 0,39 доллара США за электронное письмо или страницу вложения могут быть полезными, в зависимости от ваших потребностей, а цена за кредит быстро снижается с более высокими ежемесячными платежами, поэтому попробуйте Parseur, прежде чем выбрать услугу.
Цена Parseur: Бесплатно для 20 документов в месяц; от 39 долларов США в месяц для плана со 100 кредитами в месяц.
Лучший парсер электронной почты для автоматического извлечения подписей электронной почты
SigParser (Интернет) SigParser является наиболее специализированным из всех инструментов: он фокусируется исключительно на контактной информации в электронных письмах и подписях электронной почты. Но подумайте о потенциальной ценности этого — у большинства электронных писем есть подписи, а это означает, что в вашем почтовом ящике есть всевозможная контактная информация, о которой вы даже не думаете.
Вы можете скопировать и вставить эту контактную информацию в свою адресную книгу или CRM по выбору, но с SigParser вам не нужно этого делать. Бесплатная версия SigParser просматривает ваши электронные письма за последние 90 дней — вы можете заплатить единовременную плату, чтобы вернуться назад. Или вы можете подписаться на ежемесячную подписку, и приложение будет ежедневно сканировать новые электронные письма, что означает, что вся контактная информация в вашем почтовом ящике автоматически захватывается. Затем вы можете отправить эту информацию в свою CRM, адресную книгу или куда-нибудь еще, где она может пригодиться.
Теоретически вы можете использовать любой из представленных здесь инструментов для очистки контактной информации, но это потребует некоторой работы. Контактная информация может быть представлена в электронном письме множеством различных способов, и подписи электронной почты у всех немного разные — простых правил недостаточно для последовательного анализа. Это приложение предназначено для одной работы, и в наших тестах за последние несколько лет оно отлично справилось с задачей извлечения контактной информации из множества различных электронных писем и подписей. Это может показаться простой вещью, но она может изменить правила игры, если ваш бизнес зависит от работы с потенциальными клиентами.
Это приложение предназначено для одной работы, и в наших тестах за последние несколько лет оно отлично справилось с задачей извлечения контактной информации из множества различных электронных писем и подписей. Это может показаться простой вещью, но она может изменить правила игры, если ваш бизнес зависит от работы с потенциальными клиентами.
Вы также можете интегрировать SigParser с Zapier, что позволит вам отправлять очищенную контактную информацию в тысячи приложений, включая вашу CRM и инструменты маркетинга по электронной почте.
Добавить подписчиков в Mailchimp из новых контактов в SigParser
Добавить подписчиков в Mailchimp из новых контактов в SigParserПопробовать
- 9 0247
SigParser, Mailchimp
SigParser + Mailchimp
Добавить новое обновление Контакты SigParser для постоянного контакта
Добавить новые обновленные контакты SigParser в постоянный контактПопробуйте
SigParser, постоянный контакт
SigParser + постоянный контакт 90 005
Цены на SigParser : Бесплатная обработка ваших писем за последние 90 дней.