Синтаксический разбор предложения (5 онлайн-сервисов)
Автор Сергей Почекутов На чтение 3 мин Опубликовано Обновлено
Синтаксический разбор предложения — стандартная задача при изучении русского или иностранного языка. Сейчас её выполнение можно переложить на онлайн-сервисы. Они автоматически определяют структуру каждого предложения и выдают результат в удобном виде.
Содержание
- Как сделать синтаксический разбор предложения на русском языке
- ProgaOnline
- Школьный помощник
- Учим Орг
- Синтаксический разбор англоязычных предложений
- LinguaKit
- Delph-in
К сожалению, подобные сервисы не всегда делают разбор на 100% правильно, поэтому к результатам их работы следует относиться критично. Чтобы убедиться в отсутствии ошибок, рекомендуем проверять результат разбора на нескольких ресурсах или сверяться с учебниками.
Как сделать синтаксический разбор предложения на русском языке
ProgaOnline
ProgaOnline — единственный веб-ресурс, в состав которого входит сервис для синтаксического разбора предложений на русском языке. Он обрабатывает тексты размером до 15 000 символов.
Сервис не только определяет и подчеркивает члены предложения, но и показывает морфологию каждого слова: часть речи, число, род, падеж.
К сожалению, ProgaOnline не описывает предложение, как этого требует полноценный синтаксический разбор. Он показывает только основную информацию. Давать описание (повествовательное, невосклицательное, простое, двусоставное и т.п.) вам придётся самостоятельно.
Плюс этого ресурса в том, что у него есть версия для Android, которая показывает части речи в предложении. Приложение доступно для бесплатного скачивания в Google Play.
Школьный помощник
«Школьный помощник» — сервис, помогающий закрепить знания или изучить материал, пропущенный в школе. Здесь нет такого функционала, как у ProgaOnline. Помощник не выдает готовый результат, он предлагает лишь прокачать навыки синтаксического разбора предложений, чтобы эта задача перестала вызывать у вас затруднения.
Помощник не выдает готовый результат, он предлагает лишь прокачать навыки синтаксического разбора предложений, чтобы эта задача перестала вызывать у вас затруднения.
Тест «Синтаксический разбор простого предложения» состоит из четырёх заданий. В первом требуется выбрать правильный вариант синтаксического разбора. Во втором, третьем и четвёртом нужно определить члены предложения.
Для каждого задания есть готовое решение, но оно доступно только зарегистрированным пользователям.
В самом тесте никакой справочной информации нет. После проверки задания вы получите ответ, правильно или неправильно оно выполнено.
Учим Орг
«УчимОрг» — сайт, на котором публикуются различные материалы для учёбы. Функции синтаксического разбора предложений он также не содержит, но здесь есть полезные материалы для освоения этой темы. На этой странице подробно описано, как делать синтаксический разбор. Есть наглядные примеры с подчеркиванием грамматической основы и других членов предложения.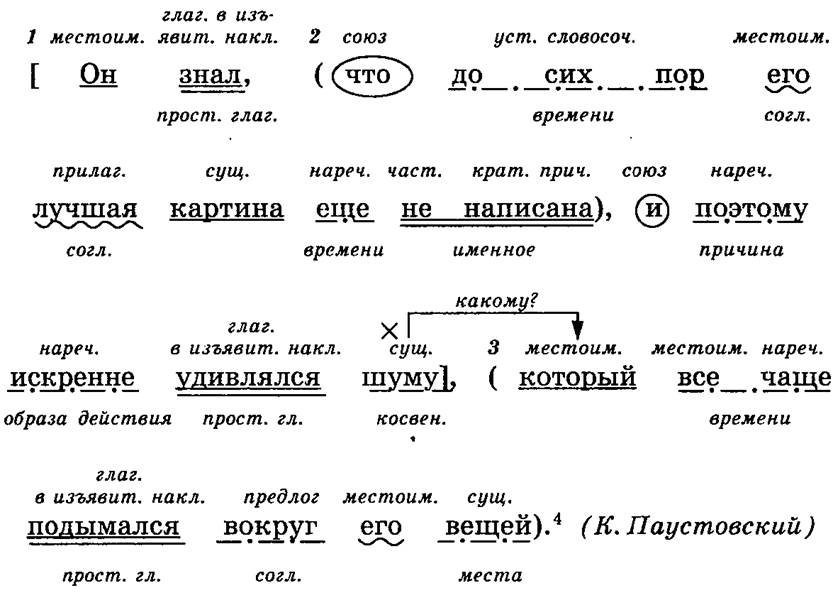
Синтаксический разбор англоязычных предложений
LinguaKit
LinguaKit — сервис для анализа текстов на английском, испанском, португальском и галисийском языках. На нём, как и на ProgaOnline, есть полноценное веб-приложение для синтаксического разбора предложений.
Ресурс поддерживает загрузку текста тремя способами:
- Путем вставки в окно редактора фрагмента объёмом до 5000 символов.
- Указанием ссылки на веб-страницу, где он опубликован.
- Чтением из файла в форматах DOC, DOCX, ODT, TXT, EPUB или HTML.
После обработки предложения вы получите его синтаксический разбор в графическом виде с указанием связей между его частями. В результатах также отмечается часть речи и грамматическая роль каждого слова.
С одного IP-адреса в сутки доступно не более 20 проверок. Для снятия ограничений, вероятно, нужно оформить подписку, однако на странице с тарифами нет никакой информации о ее условиях и стоимости.
Delph-in
Delph-in — сервис для профессиональных лингвистов, где собраны материалы про разные языки. В его состав также входит приложение для синтаксического разбора предложений на английском языке.
В его состав также входит приложение для синтаксического разбора предложений на английском языке.
Результат обработки представлен в виде схемы с указанием связей между частями предложения. Интерпретировать его без специальной подготовки довольно сложно. Однако если вы занимаетесь лингвистикой, то найдёте на этом ресурсе большое количество полезной информации, рецензируемой профессионалами.
Как разбить абзац текста на предложения? (желательно на Ruby)
Я не пробовал, но если английский — единственный язык, который вас интересует, я бы посоветовал взглянуть на Lingua::EN::Readability.
Lingua::EN::Readability — это модуль Ruby, который вычисляет статистику по английскому тексту. Он может подсчитывать количество слов, предложений и слогов. Он также может рассчитать несколько показателей удобочитаемости, таких как индекс тумана и уровень Флеша-Кинкейда. Пакет включает в себя модуль Lingua::EN::Sentence, который разбивает английский текст на предложения с учетом аббревиатур, и Lingua::EN::Syllable, который может угадать количество слогов в написанном английском слове.
Если доступен словарь произношения, он может искать количество слогов в словаре для большей точности
 Если доступен словарь произношения, он может искать количество слогов в словаре для большей точности
Если доступен словарь произношения, он может искать количество слогов в словаре для большей точности Нужный вам бит находится в предложение.rb следующим образом:
модуль Lingua
модуль EN
# Модуль Lingua::EN::Sentence берет английский текст и пытается его разделить
# в предложения, соблюдая аббревиатуры.
модуль Предложение
EOS = "\001" # временный маркер конца предложения
Титулы = [ 'младший', 'мистер', 'миссис', 'мисс', 'доктор', 'проф', 'старший', 'сен', 'реп',
'rev', 'gov', 'atty', 'supt', 'det', 'rev', 'col', 'gen', 'lt',
«командир», «админ», «капитан», «сержант», «капитан», «майор»]
Entities = [ 'отдел', 'университет', 'уни', 'ассн', 'брата', 'инк', 'лтд', 'ко',
'корпорация', 'plc' ]
Месяцы = [ 'январь', 'февраль', 'март', 'апрель', 'май', 'июнь', 'июль',
'август', 'сен', 'октябрь', 'ноябрь', 'декабрь', 'сентябрь']
Дни = ['пн', 'вт', 'ср', 'чт', 'пт', 'сб', 'вс']
Разное = [ 'против', 'и т. д.', 'нет', 'исп', 'ср' ]
Улицы = ['авеню', 'блд', 'бульвар', 'cl', 'ct', 'cres', 'dr', 'rd', 'st']
@@abbreviations = Заголовки + Объекты + Месяцы + Дни + Улицы + Разное
# Разбить переданный текст на отдельные предложения, обрезать их и вернуть
# как массив. Предложение помечается одним из знаков препинания «.», «?»
# или же "!" с последующим пробелом. Последовательности полных остановок (например,
# маркер многоточия "..." и остановки после известной аббревиатуры игнорируются.
def Sentence.sentences(текст)
текст = text.dup
# начальное разделение после знаков препинания - необходимо сохранить пробелы в конце
# для коррекции многоточия next
# было бы лучше использовать проверки назад и вперед, чтобы пропустить
# знаки многоточия, но Ruby не поддерживает просмотр назад
text.gsub!( /([\.?!](?:\"|\'|\)|\]|\})?)(\s+)/ ) { $1 << EOS << $2 }
# правильные знаки многоточия и ряды остановок
text.gsub!( /(\.\.\.*)#{EOS}/ ) { $1 }
# правильные сокращения
# TODO - предварительно скомпилировать это регулярное выражение?
text. gsub!( /(#{@@abbreviations.join("|")})\.#{EOS}/i ) { $1 << '.' }
# разделить на маркер EOS, убрать пробелы в конце
text.split(EOS).map { | предложение | предложение.strip }
конец
# добавить список аббревиатур в список, который используется для обнаружения ложных
# предложение заканчивается. Возвращает текущий список используемых сокращений.
def Sentence.abbreviation(*аббревиатуры)
@@аббревиатуры += аббревиатуры
@@аббревиатуры
конец
конец
конец
конец
 д.', 'нет', 'исп', 'ср' ]
Улицы = ['авеню', 'блд', 'бульвар', 'cl', 'ct', 'cres', 'dr', 'rd', 'st']
@@abbreviations = Заголовки + Объекты + Месяцы + Дни + Улицы + Разное
# Разбить переданный текст на отдельные предложения, обрезать их и вернуть
# как массив. Предложение помечается одним из знаков препинания «.», «?»
# или же "!" с последующим пробелом. Последовательности полных остановок (например,
# маркер многоточия "..." и остановки после известной аббревиатуры игнорируются.
def Sentence.sentences(текст)
текст = text.dup
# начальное разделение после знаков препинания - необходимо сохранить пробелы в конце
# для коррекции многоточия next
# было бы лучше использовать проверки назад и вперед, чтобы пропустить
# знаки многоточия, но Ruby не поддерживает просмотр назад
text.gsub!( /([\.?!](?:\"|\'|\)|\]|\})?)(\s+)/ ) { $1 << EOS << $2 }
# правильные знаки многоточия и ряды остановок
text.gsub!( /(\.\.\.*)#{EOS}/ ) { $1 }
# правильные сокращения
# TODO - предварительно скомпилировать это регулярное выражение?
text.
д.', 'нет', 'исп', 'ср' ]
Улицы = ['авеню', 'блд', 'бульвар', 'cl', 'ct', 'cres', 'dr', 'rd', 'st']
@@abbreviations = Заголовки + Объекты + Месяцы + Дни + Улицы + Разное
# Разбить переданный текст на отдельные предложения, обрезать их и вернуть
# как массив. Предложение помечается одним из знаков препинания «.», «?»
# или же "!" с последующим пробелом. Последовательности полных остановок (например,
# маркер многоточия "..." и остановки после известной аббревиатуры игнорируются.
def Sentence.sentences(текст)
текст = text.dup
# начальное разделение после знаков препинания - необходимо сохранить пробелы в конце
# для коррекции многоточия next
# было бы лучше использовать проверки назад и вперед, чтобы пропустить
# знаки многоточия, но Ruby не поддерживает просмотр назад
text.gsub!( /([\.?!](?:\"|\'|\)|\]|\})?)(\s+)/ ) { $1 << EOS << $2 }
# правильные знаки многоточия и ряды остановок
text.gsub!( /(\.\.\.*)#{EOS}/ ) { $1 }
# правильные сокращения
# TODO - предварительно скомпилировать это регулярное выражение?
text.
nltk — Как разобрать файл предложение за предложением в Python
спросил
Изменено 4 года, 9 месяцев назад
Просмотрено 3к раз
Мне нужно прочитать большое количество больших текстовых файлов.
Для каждого файла мне нужно открыть его и прочитать в тексте предложение за предложением.
Большинство подходов, которые я нашел, читаются построчно.
Как это сделать с помощью Python?
- питон
- nltk
- токенизация
9
Если вам нужна токенизация предложений, nltk, вероятно, самый быстрый способ сделать это. http://www.nltk.org/api/nltk.tokenize.html#module-nltk.tokenize.punkt Уведет вас довольно далеко.
т.е. код из документации
>>> import nltk.data >>> текст = ''' ... Пунктт знает, что периоды у мистера Смита и Иоганна С. Баха ... не отмечайте границы предложений. А иногда предложения ... может начинаться со слов, написанных без заглавных букв. я хорошая переменная ... имя. ... ''' >>> sent_detector = nltk.data.load('tokenizers/punkt/english.pickle') >>> print('\n-----\n'.join(sent_detector.tokenize(text.strip()))) Пункт знает, что периоды у мистера Смита и Иоганна С. Баха не отмечайте границы предложения. ----- А иногда предложения может начинаться со слов, написанных без заглавных букв.
