What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «исполнить», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
1.
ИСПОЛНИТЬ1, ню, нишь; ненный; сов., что.
1. То же, что выполнить. И. приказ. И. своё обещание. И. свой долг. И. желание. Хорошо исполненный чертёж.
То же, что выполнить. И. приказ. И. своё обещание. И. свой долг. И. желание. Хорошо исполненный чертёж.
2. Воспроизвести перед слушателями, зрителями (какое-н. произведение искусства). И. романс. И. танец.
| несов. исполнять, яю, яешь.
| сущ. исполнение, я, ср. Привести в и. Проверка исполнения. Изделие в экспортном исполнении
| прил. исполнительный, ая, ое. Исполнительная власть. И. комитет. И. механизм (в автоматическом регулировании и управлении; спец.). И. лист (документ на право взыскания по суду).
2.
ИСПОЛНИТЬ2, ню, нишь; ненный; сов., кого-что чем или чего (устар. и книжн.). Наполнить каким-н. чувством. И. радостью. И. сердце надеждой. Исполненный энергии.
| несов. исполнять, яю, яешь.
исполнять, яю, яешь.
Фонетический (звуко-буквенный) разбор
испо́лнить
исполнить — слово из 3 слогов: и-спол-нить. Ударение падает на 2-й слог.
Транскрипция слова: [исполн’ит’]
и — [и] — гласный, безударный
с — [с] — согласный, глухой парный, твёрдый (парный)
о — [о] — гласный, ударный
л — [л] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
и — [и] — гласный, безударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 9 букв и 8 звуков.
Цветовая схема: исполнить
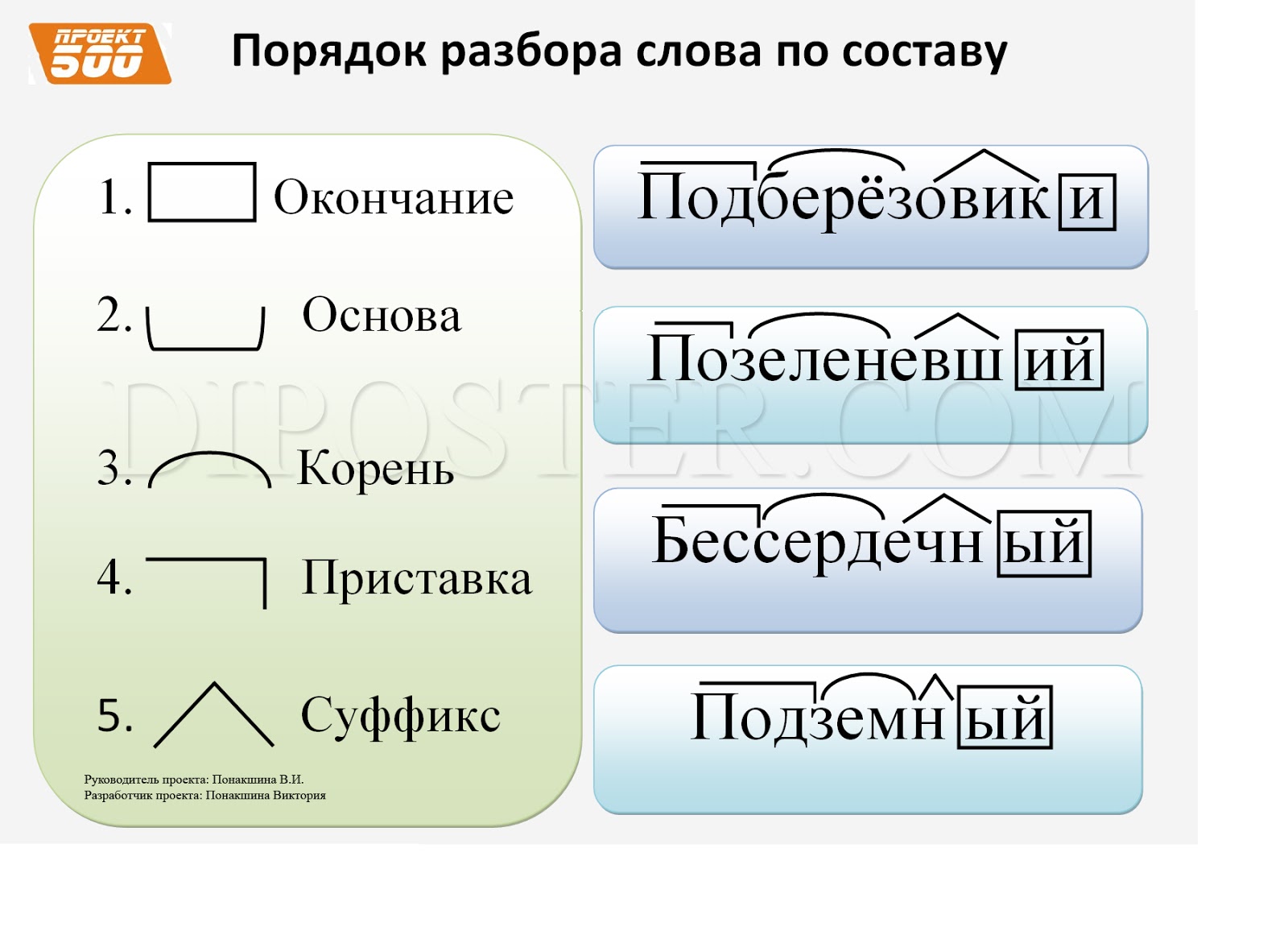
Разбор слова «исполнить» по составу
исполнить (программа института)
исполнить (школьная программа)
Части слова «исполнить»: ис/полн/и/ть
Часть речи: глагол
Состав слова:
ис — приставка,
полн — корень,
и, ть — суффиксы,
нет окончания,
исполни — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
«ИсполнеНо» или «исполнеННо» ℹ️ как правильно пишется, значение, корень слова
Часть речи
Чтобы понять, как правильно пишется «исполнено», необходимо для начала определить, в роли какой части речи (ЧР) выступает это слово. Ведь если не знать этого нюанса, то подобрать верное правило правописания будет невозможно, в результате придется снова тыкать пальцем в небо. Проще всего будет взять в качестве примера предложение, в котором употребляется эта конструкция, после чего провести его синтаксический разбор: «Песня была исполнена просто великолепно, отличная работа!». Здесь рекомендуется следовать определенному алгоритму действий, чтобы не упустить ничего важного:
- Для начала потребуется найти грамматическую основу предложения.
 Для этого необходимо внимательно прочесть конструкцию, после чего определить, о чем именно в ней говорится. В предложении сказано, что «песня (подлежащее) была исполнена (составное именное сказуемое)». Также в нем говорится о «работе» (второе подлежащее) и о том, что она «отличная» (сказуемое). Становится понятно, что предложение сложное, а интересующее слово входит в состав грамматической основы.
Для этого необходимо внимательно прочесть конструкцию, после чего определить, о чем именно в ней говорится. В предложении сказано, что «песня (подлежащее) была исполнена (составное именное сказуемое)». Также в нем говорится о «работе» (второе подлежащее) и о том, что она «отличная» (сказуемое). Становится понятно, что предложение сложное, а интересующее слово входит в состав грамматической основы. - Как только главные члены предложения будут найдены, рекомендуется заняться определением второстепенных конструкций. Для этого следует задать вопрос от основных слов к зависимым, а также посмотреть на роль, которую они выполняют. К примеру, в предложении присутствует обстоятельство «просто великолепно», которое относится к сказуемому. Не стоит пренебрегать этим пунктом даже в том случае, если то, чем выражена интересующая конструкция, уже стало понятно. Лишь полный синтаксический анализ предложения позволит удостовериться в том, что все выделено верно.
- Завершающим этапом является определение того, чем выражены те или иные члены предложения.
 Для этого необходимо внимательно прочесть конструкцию, после чего определить, о чем именно в ней говорится. В предложении сказано, что «песня (подлежащее) была исполнена (составное именное сказуемое)». Также в нем говорится о «работе» (второе подлежащее) и о том, что она «отличная» (сказуемое). Становится понятно, что предложение сложное, а интересующее слово входит в состав грамматической основы.
Для этого необходимо внимательно прочесть конструкцию, после чего определить, о чем именно в ней говорится. В предложении сказано, что «песня (подлежащее) была исполнена (составное именное сказуемое)». Также в нем говорится о «работе» (второе подлежащее) и о том, что она «отличная» (сказуемое). Становится понятно, что предложение сложное, а интересующее слово входит в состав грамматической основы.
Еще один полезный момент — не стоит забывать, что каждая ЧР имеет определенную синтаксическую роль. К примеру, глаголы обозначают действие предмета, а наречие — признак действия. КП же говорят о признаке предмета, однако неразрывно связаны с глаголом.
Нн- в страдательных причастиях
Чтобы понять, почему в слове «неисполненный» пишутся две буквы «н», а в «исполнено» — одна, недостаточно просто уметь различать между собой краткие и полные причастия. Важно знать все пункты правил, касающиеся этой темы, найти которые можно в учебнике по русскому языку.
- Если причастие имеет любую приставку, кроме отрицательной частицы «не». Вот несколько примеров употребления таких конструкций в предложениях: «Сложно переоценить значение сделанного вовремя задания», «На вспаханном поле нам удалось расположить несколько единиц техники», «Убранная комната обещала нам долгий и качественный отдых». Во всех этих случаях в выделенных причастиях имеется приставка, поэтому в их суффиксах пишется «нн». Кстати, корень слова «исполнял» или «исполнено» — «пол», так что в этой конструкции тоже имеется приставка.
- Если причастие входит в состав причастного оборота. Проще говоря, слово должно выступать вместе с конструкциями, к которым можно задать вопрос. Несколько примеров помогут понять, о чем конкретно идет речь: «Согласно поручению от учителя, жаренный на костре картофель должен был быть доставлен на кухню», «Трудность заключалось в том, что раненный в лапу зверь все еще был агрессивно настроен к людям», «Я мог произвести на гостей приятное впечатление, если бы достал с чердака высушенные на солнце яблоки».
- Если причастие было образовано от глагола совершенного вида. Определить это можно по вопросу, который задается к самому глаголу. Если в нем присутствует приставка «с» — «что сделать?», то это значит, что вид совершенный. Вопрос «что делать?» характерен для глаголов несовершенного вида. Вот несколько примеров: «Мое главное желание — исполнить данное старику обещание», «Решенный вопрос до сих пор приносил страдания не только мне, но и близким», «Если брошенные вещи не будут убраны сейчас, то мама может осуществить то самое наказание».

Особого упоминания заслуживают глаголы, образованные с помощью прибавления суффиксов «ирова», «ева» и «ова». В русском языке их не так много, однако их легко не заметить в предложении: «подкованная лошадь», «отремонтированная машина», «маринованные грибы» и так далее.
Одна буква в суффиксе
Последним пунктом правила, которое говорит о количестве букв «н» в суффиксе, является раздел, посвященный кратким причастиям. Эта такая часть речи, которая была образована от полного причастия путем усечения окончания и части основы слова.
Эта такая часть речи, которая была образована от полного причастия путем усечения окончания и части основы слова.
- неисполненный — неисполнен;
- исполняемый — исполняем;
- выполненный — выполнен;
- незаполненный — незаполнен;
- исполнимый — исполним.
В некоторых случаях краткие причастия могут образоваться от слов, в суффиксах которых присутствовало несколько согласных «н». Однако какой бы сложной ни была конструкция, усечение неизбежно затрагивает суффикс, в результате чего слово начинает писаться с одной буквой.
Стоит отметить, что правило: «В суффиксах кратких причастий не могут писаться две буквы н» является незыблемым, а также главенствующим. Если такая часть речи будет выступать в составе причастного оборота или же у него будет иметься приставка, то эти пункты никак не повлияют на его правописание.
Запомнить столь простое правило не так сложно, как научиться определять краткие причастия на письме.
- Неисполнение обязанностей — это тяжкий проступок, даже если правила не были прочитан (н)ы и изучен (н)ы.
- Иногда задуман (н)ое начинает сбываться, а желания — исполняться, однако очень важно, чтобы были приложен (н)ы усилия.
- Я не смог наполнить ведро водой, поскольку оно было сломан (н)о кем-то из безответствен (н)ых отдыхающих.
- Обязательства вынуждают нас начать располагать клиентов по парам, поскольку все комнаты уже переполнен (н)ы.
- Повторное заключение ранее разорван (н)ого договора — это и есть соисполнение.
Если человеку удастся безошибочно определить, сколько букв «н» следует вставить в суффиксах причастий, то можно смело заявить, что тема разобрана практически полностью.

Осталось узнать лишь один очень важный нюанс — краткие причастия могут быть легко спутаны с краткими отглагольными прилагательными (КОП) — еще одной частью речи, которая может вызывать вопросы даже у опытных писателей.
Отличия КОП от КП на примерах
Чтобы отличить краткие причастия от кратких отглагольных прилагательных, необходимо сперва разобраться, в чем заключаются различия полных частей речи. Обычно учителя выделяют четыре пункта, на основе которых можно провести успешный анализ:
- Взглянуть на слово, от которого образована конструкция. Отглагольные прилагательные обычно образуются от причастия, а также обозначают постоянный признак предмета: «рассеянный человек», «летучие лепестки», «раненый солдат» и т. д. Причастия всегда образуются от глаголов и в той или иной степени связаны со временем: «рассеянные (когда-то) по полю семена», «летящие (в этот момент) по небу птицы», «раненый (давно) в руку солдат» и т. д.
- Иногда отличить эти две части речи можно по приставке, которая может быть только у причастий. На протяжении нескольких лет ярким примером служат конструкции: «позолоченный кубок» (причастие) и «золоченое кольцо» (отглагольное прилагательное). Если в тексте попадется конструкция, в которой имеется любая приставка, кроме «не», то можно смело говорить, что она является ОП.
- Посмотреть на наличие зависимых слов. Только у причастий они могут быть, а отглагольные прилагательные обычно выступают лишь с определяемым словом: «солдат ранен» (ОП в краткой форме), «солдат ранен в руку» (причастие в краткой форме). Однако не стоит путать зависимые слова с существительными в творительном падеже, например, «золоченое мастером кольцо».
 д.
д.
Ну и самым простым способом определения того, где находится ОП или краткое причастие, является замена конструкции на глагол с союзным словом «который». Поскольку только причастия образованы от глаголов, лишь с ними пройдет такой «фокус» — неисполненное обещание — обещание, которое не исполнили (н. ф. — не исполнить). К КП обычно удается подобрать лишь синоним: рассеянный человек — невнимательный человек.
ф. — не исполнить). К КП обычно удается подобрать лишь синоним: рассеянный человек — невнимательный человек.
Отглагольное прилагательное
Что делать человеку, если перед ним все-таки оказалось ОП, которое имеет совершенно иное правило, гласящее о количестве «н» в суффиксе, не говоря уже о том, что конструкции будут иначе писаться с отрицательными частицами (слитно или раздельно)? Многие люди начинают выбирать наугад. Однако достаточно просто знать нюансы, которые касаются правила для отглагольных прилагательных. Вот несколько разделов, которыми можно дополнить знания:
- Если ОП образовано от глагола совершенного вида, то в нем необходимо писать «нн»: «Мой страшный кошмар не мог не сбыться — закованный солдат лежал и истекал кровью, а я ничем не мог ему помочь». ОП образовано от причастия «закованный», которое произошло от глагола «заковать» — что сделать? — совершенный вид. Однако есть и несколько исключений: раненый солдат, крещеная мать, смышленый ребенок, названая сестра (но названная по фамилии).
- «Нн» пишется в тех случаях, если ОП образовалось от глагола с приставкой, кроме «не»: «Мы не знали, куда деть неисполненный договор, ведь все сроки уже давно прошли, поэтому просто решили разместить копию на и без того перегруженном сервере». Но есть и несколько исключений: «непуганый», «нечищеный», «названый» — в этих конструкциях всегда пишется одна буква «н».
- Две «н» необходимо писать в словах, которые образованы путем прибавления суффиксов «еванный» или «ованный»: «Наконец-то наша мечта исполнится — лакированный паркет и инструкция по установке с переводом на русский язык в этом помогут». В этом правиле исключений нет, однако стоит помнить, что такие конструкции можно перепутать с теми, в которых присутствуют отдельные суффиксы «ова» и «нн», а также окончание «ый».

Еще профессионалы умудряются определять, сколько букв «н» пишется в слове, по спряжению глагола, от которого оно образуется. Однако такой подход имеет много подводных камней, так что им лучше не пользоваться. Во всем остальном правописание слова «исполнено» не должно вызвать каких-либо вопросов. Важно правильно определить часть речи и не забывать о том, что в любом правиле есть исключения. Чего только стоит зависимость суффиксов от наличия причастного оборота в конструкции.
Во всем остальном правописание слова «исполнено» не должно вызвать каких-либо вопросов. Важно правильно определить часть речи и не забывать о том, что в любом правиле есть исключения. Чего только стоит зависимость суффиксов от наличия причастного оборота в конструкции.
для переноса, на слоги, по составу
Что такое Рулада? Это ж. итал. перекат, переливы голоса в пении…. Все значения на СловоПоиск.ру
Словарь Ушакова
рулада
рулада, рулады, жен. (франц. roulade, букв. перекат) (муз.). Украшение, преим. в пении, – быстрый пассаж (см. пассаж во 2 знач.).
Ингредиенты для «Рулады по-немецки»:
- Мясо (говядина или свинина, филе, тонко порезанное) — 4 шт
- Огурец (маринованный, корнишон, + 70 мл огуречного рассола) — 8 шт
- Лук репчатый (1 средн. для рулад + 1 бол. для соуса) — 2 шт
- Горчица (среднеострая, 2ст. л. в соус + 4 ч. л. для рулад)
- Перец болгарский (крупный) — 1 шт
- Бекон (полосками) — 8 шт
- Сливки — 50 мл
- Вода
- Томатная паста (густая, 1-2 ст.л.)
- Специи (соль, перец + другие по желанию)
 л. для рулад)
л. для рулад)Время приготовления: 90 минут
Количество порций: 2
Рулада
ж. итал. перекат, переливы голоса в пении.
Толковый словарь Даля
≈ см. Пассаж.
Энциклопедический словарь. Брокгауз Ф.А., Ефрон И.А.
РУЛАДА, -ы, ж. Раскатистый и виртуозный пассаж2 в пении – исполненная вбыстром темпе часть мелодии. Р. в партии колоратурного сопрано. Руладысоловья (перен.).
Толковый словарь русского языка Ожегова и Шведовой
РУЛАДА, рулады, ж. (фр. roulade, букв. перекат) (муз.). Украшение,преимущ. в пении, -быстрый пассаж (см. пассаж во 2 знач.).
Толковый словарь Ушакова
РУЛАДА (франц. roulade – от rouler – катать взад и вперед), быстрый,виртуозный пассаж в пении (преимущественно в партиях колоратурногосопрано).
Большой Энциклопедический Словарь
Рулада (франц. roulade, от rouler ≈ катать взад и вперёд), в пении быстрый виртуозный пассаж; обычно исходит от акцентированного выдержанного звука. Распространены Р. хроматические, а также складывающиеся из терцовых ходов голоса.
Большая Советская Энциклопедия
Синонимы к слову Рулада
Переливы
Определения для сканвордов
Существительные из 6 букв, начинающиеся на Р
Глаголы из 6 букв, начинающиеся на Р
Прилагательные из 6 букв, начинающиеся на Р
Города из 6 букв, начинающиеся на Р
Имена из 6 букв, начинающиеся на Р
Страны из 6 букв, начинающиеся на Р
Реки из 6 букв, начинающиеся на Р
Острова из 6 букв, начинающиеся на Р
Горы из 6 букв, начинающиеся на Р
Озера из 6 букв, начинающиеся на Р
Фильмы из 6 букв, начинающиеся на Р
Растения из 6 букв, начинающиеся на Р
Грибы из 6 букв, начинающиеся на Р
Клички животных из 6 букв, начинающиеся на Р
Животные из 6 букв, начинающиеся на Р
Актеры и актрисы из 6 букв, начинающиеся на Р
Писатели из 6 букв, начинающиеся на Р
Поэты из 6 букв, начинающиеся на Р
Художники из 6 букв, начинающиеся на Р
Композиторы из 6 букв, начинающиеся на Р
Певцы и певицы из 6 букв, начинающиеся на Р
Ткани из 6 букв, начинающиеся на Р
Танцы из 6 букв, начинающиеся на Р
Боги из 6 букв, начинающиеся на Р
Монеты из 6 букв, начинающиеся на Р
Камни, минералы из 6 букв, начинающиеся на Р
Развернуть
Существительные из 6 букв, заканчивающиеся на А
Прилагательные из 6 букв, заканчивающиеся на А
Города из 6 букв, заканчивающиеся на А
Имена из 6 букв, заканчивающиеся на А
Страны из 6 букв, заканчивающиеся на А
Реки из 6 букв, заканчивающиеся на А
Острова из 6 букв, заканчивающиеся на А
Горы из 6 букв, заканчивающиеся на А
Моря из 6 букв, заканчивающиеся на А
Озера из 6 букв, заканчивающиеся на А
Фильмы из 6 букв, заканчивающиеся на А
Растения из 6 букв, заканчивающиеся на А
Грибы из 6 букв, заканчивающиеся на А
Клички животных из 6 букв, заканчивающиеся на А
Животные из 6 букв, заканчивающиеся на А
Актеры и актрисы из 6 букв, заканчивающиеся на А
Писатели из 6 букв, заканчивающиеся на А
Поэты из 6 букв, заканчивающиеся на А
Художники из 6 букв, заканчивающиеся на А
Композиторы из 6 букв, заканчивающиеся на А
Певцы и певицы из 6 букв, заканчивающиеся на А
Ткани из 6 букв, заканчивающиеся на А
Танцы из 6 букв, заканчивающиеся на А
Боги из 6 букв, заканчивающиеся на А
Монеты из 6 букв, заканчивающиеся на А
Камни, минералы из 6 букв, заканчивающиеся на А
Развернуть
ОПИСАНИЕ
Популярный, сытный и праздничный рецепт. Представляю два варианта начинки: одна известная и повседневная из бекона и соленого огурчика. Вторая начинка из фарша, морковки и (или) кукурузы. Рецепт из книги “Доктор Ёткер”.
Ингредиенты
4 кусочка мяса для рулад( примерно по 180 гр. каждый)
соль, свежемолотый перец
////////////////////////////////////
Начинка 1 для 4-х рулад:
горчица
бекон – 60 гр.
лук – 100 гр.
2 средних, соленых огурчика
////////////////////////////////////
Начинка 2 для 4-х рулад:
300 грамм фарша или метт
2 ст.л. рубленной петрушки
1 ч.л. горчицы
соль, свежемолотый перец, сладкая паприка по-вкусу
100 гр. кукурузы из баночки
или 150 гр. отварной моркови(у меня фиолетовая)
////////////////////////////////////
3 ст.л. растительного масла
2 средние луковицы
зеленый набор для супа: кусочек корня сельдерея, 2 морковки, пучок пертушки, кусочек порея
немного горячей воды
20 гр. муки
3 ст.л. холодной воды
Ингредиенты
- говядина 600 г
- большая луковица 1 шт.
- большая морковка 1 шт.
- лук-порей 1 шт.
- пастернак 1 шт.
- красное сухое вино 250 мл
- мука пшеничная 1 ст.л.
- горчица готовая не острая
- бекон, тонко нарезанный пластинками 150 г
- маринованные огурцы 2-3 шт.
- соль, черный молотый перец
- лавровый лист
- растительное масло 2 ст.л.
Пищевая и энергетическая ценность:
| Готового блюда | |||
| ккал 9070.3 ккал | белки 43.4 г | жиры 73.9 г | углеводы 60.3 г |
| Порции | |||
| ккал 4535.2 ккал | белки 21.7 г | жиры 37 г | углеводы 30.2 г |
| 100 г блюда | |||
| ккал 167.3 ккал | белки 0.8 г | жиры 1.4 г | углеводы 1.1 г |
Энциклопедия Брокгауза и Ефрона
Добавить свое значение
Предложите свой вариант значения к слову рулада
Синонимы к слову рулада
- вокал
- гармония
- звук
- игра
- искусство
- колено
- коленце
- колоратура
- концерт
- концертино
- кривизна
- напевание
- пассаж
- пение
- перелив
Показать комментарии
Добавьте комментарий первым!
В словаре Полная акцентуированная парадигма по А. А. Зализня
рула́да,
рула́ды,
рула́ды,
рула́д,
рула́де,
рула́дам,
рула́ду,
рула́ды,
рула́дой,
рула́дою,
рула́дами,
рула́де,
рула́дах
( 1 оценка, среднее 5 из 5 )
Обособление согласованных определений
I. Обособляются определения, стоящие в постпозиции, т. е. после определяемого существительного (или субстантивированного слова):
1. выраженные причастным оборотом.
- Город, разрушенный в центре, с кое-как прибранными и подметёнными улицами, утомлённо затихал.
- (В. П. Астафьев)
- Всё, связанное с железной дорогой, до сих пор овеяно для меня поэзией путешествий.
- (К. Г. Паустовский)
2. выраженные прилагательным с зависимыми от него словами.
- Стоят и те трое, хмурые все.
- (М. Горький)
II. Одиночные определения, стоящие после определяемого существительного, обособляются:
1. если перед определяемым существительным уже есть определение.*
- Весь облик Аркадиева дяди, изящный и породистый, сохранил юношескую стройность.
- (И. С. Тургенев)
- Маленькая Анечка, нарядная и красивая, с нетерпением поджидала Деда Мороза.
3. если к одиночному определению относится сравнительный оборот.
- Список литературы, огромный, как у настоящего старшеклассника, нужно было успеть прочитать за лето.
III. Обособляются распространённые или одиночные определения, стоящие непосредственно перед определяемым существительным (в препозиции), если имеют дополнительное обстоятельственное значение (причинное, условное, уступительное, временно́е).
- Оглушённый тяжким гулом,
- Тёркин никнет головой.
- (А. Т. Твардовский)
- Взъерошенный, немытый, Нежданов имел вид дикий и странный.
- (И. С. Тургенев)
Перед такими определениями можно поставить слово «будучи» или преобразовать их в придаточные обстоятельственные. (Ср.: Будучи оглушённым тяжким гулом, Тёркин никнет головой. Или: Тёркин никнет головой, так как он оглушён тяжким гулом.)
IV. Независимо от местоположения в предложении всегда обособляются распространённые или одиночные определения:
1. относящиеся к личному местоимению.
- Она, невозмутимая и спокойная, долго готовилась к предстоящему разговору.
- Полный раздумья, шёл я однажды по большой дороге.
- (И. С. Тургенев)
- А он, мятежный, просит бури,
- Как будто в бурях есть покой!
- (М. Ю. Лермонтов)
2. отделённые от определяемого существительного текстом.
- Юные путешественники очень устали и, обессиленные, еле-еле плелись к своему ночлегу.
- А на дворе, унылый и докучный,
- Раздался колокольчик однозвучный.
- (М. Ю. Лермонтов)
V. Не обособляются распространённые (или одиночные определения):
1. стоящие в препозиции и не имеющие дополнительного обстоятельственного значения.
- Простор равнины вливался в обвешанное редкими облаками небо.
- (К. А. Федин)
- Её большие глаза, исполненные неизъяснимой грусти, казалось, искали в моих что-нибудь похожее на надежду.
- (М. Ю. Лермонтов)
3. выраженные сложной формой сравнительной или превосходной степени имени прилагательного, т. к. такие формы не образуют оборота и являются неделимым членом предложения.
- В кружке самом близком к невесте были её две сестры.
- (Л. Н. Толстой)
_____________
* Примечание.
Если перед определяемым существительным определение отсутствует — обособление одиночных определений, стоящих в постпозиции, факультативно: определения обособляются, когда передают значение дополнительной характеристики, и не обособляются, если с определяемым словом имеют тесную интонационно-смысловую связь.
- А запорожцы, и пешие и конные, выступали на три дороги к трём воротам.
- (Н. В. Гоголь)
- Под этой толстой серой шинелью билось сердце страстное и благородное…
- (М. Ю. Лермонтов)
В первом предложении определения пешие и конные передают значение дополнительной характеристики; их можно опустить без существенного ущерба для смысловой структуры предложения.
Во втором предложении определения страстное и благородное тесно связаны по смыслу с определяемым словом сердце. Герой М. Ю. Лермонтова подчёркивает, что сердце умеет любить, а именно страстное, благородное сердце.
Поделиться публикацией:
Истребитель гадов | Сайт учителя русского языка и литературы
Во времена незапамятные один из первых на земле людей попросил бога помочь ему в каком-то деле. Исполнив просьбу, бог вручил ему туго завязанный мешок с разными гадами и повелел выбросить куда угодно: в огонь, воду, пропасть или затащить на высокую скалу. Но остерег заглядывать в мешок: «Иначе не миновать тебе, смертный, беды!»
Любопытный человек пренебрег запретом всевышнего, развязал мешок — и всякая гадость расползлась по лику земли. Разгневанный господь отхлестал ослушника по заду раскаленным прутом, превратил в аиста-черногуза и повелел истреблять всех ползучих и поскакучих гадов. С тех пор зад у аистов черный, словно обожженный, а нос — красный от стыда.
Говорят также, будто осенью аисты перелетают зимовать в райские земли. Там они купаются в волшебном Человечьем озере — и превращаются в людей, а по весне, искупавшись в другом озере, Птичьем, возвращаются назад. В этом долгом путешествии туда и обратно они несут на своих спинах ласточек и трясогузок.
Аисты исконно селятся рядом с человеческим жильем, и еще в древности были подмечены в их поведении некоторые человеческие черты. Например, у аистов, как и у людей, по пять пальцев, птицы тоже плачут слезами. Они справляют свадьбы, собравшись вместе; привязаны к своим детям. Если самец погибает, самка тоже уходит из жизни. Она может пойти на смерть даже из-за ревности. Тогда по решению общего суда — своеобразного аистиного вече — неверного супруга тут же убивают клювом, причем он даже не сопротивляется.
Аисты, согласно молве, приносят людям детей, разгоняют грозовые тучи, предвещают счастливое замужество, избавляют от прострелов в спине и лихорадки. Разорить гнездо аиста, а тем более убить птицу — значит накликать на себя беду неминучую: смерть близких, слепоту, глухоту. Изба такого нечестивца обязательно сгорит, ибо аисты умеют «приворожить» молнию или принесут в клюве горящие головни. Убитый аист плачет три, девять, десять, сорок дней, и все это время будут лить нескончаемые ливни, опустошая посевы. Чтобы их прекратить, в древности такого убитого аиста хоронили в гробике, подобном человеческому.
Шостакович. Симфония No. 7 («Ленинградская») (Symphony No. 7 (C-dur), Op. 60, «Leningrad»)
Symphony No. 7 (C-dur), Op. 60, «Leningrad»
Композитор
Год создания
1941
Дата премьеры
05.03.1942
Жанр
Страна
СССР
Состав оркестра: 2 флейты, альтовая флейта, флейта-пикколо, 2 гобоя, английский рожок, 2 кларнета, кларнет-пикколо, бас-кларнет, 2 фагота, контрафагот, 4 валторны, 3 трубы, 3 тромбона, туба, 5 литавр, треугольник, бубен, малый барабан, тарелки, большой барабан, тамтам, ксилофон, 2 арфы, рояль, струнные.
История создания
Неизвестно когда именно, в конце 30-х или в 1940 году, но во всяком случае еще до начала Великой Отечественной войны Шостакович написал вариации на неизменную тему — пассакалью, сходную по замыслу с Болеро Равеля. Он показывал ее своим младшим коллегам и ученикам (с осени 1937 года Шостакович преподавал в Ленинградской консерватории композицию и оркестровку). Тема простая, как бы приплясывающая, развивалась на фоне сухого стука малого барабана и разрасталась до огромной мощи. Сначала она звучала безобидно, даже несколько фривольно, но вырастала в страшный символ подавления. Композитор отложил это сочинение, не исполнив и не опубликовав его.
22 июня 1941 года его жизнь, как и жизнь всех людей в нашей стране, резко изменилась. Началась война, прежние планы оказались перечеркнутыми. Все стали работать на нужды фронта. Шостакович вместе со всеми рыл окопы, дежурил во время воздушных тревог. Делал аранжировки для концертных бригад, отправлявшихся в действующие части. Естественно, роялей на передовых не было, и он перекладывал аккомпанементы для небольших ансамблей, делал другую необходимую, как ему казалось, работу. Но как всегда у этого уникального музыканта-публициста — как было с детства, когда в музыке передавались сиюминутные впечатления бурных революционных лет, — стал созревать крупный симфонический замысел, посвященный непосредственно происходящему. Он начал писать Седьмую симфонию. Летом была закончена первая часть. Ее он успел показать самому близкому другу И. Соллертинскому, который 22 августа уезжал в Новосибирск вместе с филармонией, художественным руководителем которой был многие годы. В сентябре, уже в блокированном Ленинграде, композитор создал вторую часть, показал ее коллегам. Начал работу над третьей частью.
1 октября по специальному распоряжению властей его вместе с женой и двумя детьми самолетом переправили в Москву. Оттуда, через полмесяца поездом он отправился дальше на восток. Первоначально планировалось ехать на Урал, но Шостакович решил остановиться в Куйбышеве (так в те годы называлась Самара). Здесь базировался Большой театр, было много знакомых, которые на первое время приняли композитора с семьей к себе, но очень быстро руководство города выделило ему комнату, а в начале декабря — двухкомнатную квартиру. В нее поставили рояль, переданный на время местной музыкальной школой. Можно было продолжать работу.
В отличие от первых трех частей, созданных буквально на одномды хании, работа над финалом продвигалась медленно. Было тоскливо, тревожно на душе. Мать с сестрой остались в осажденном Ленинграде, переживавшем самые страшные, голодные и холодные дни. Боль за них не оставляла ни на минуту. Плохо было и без Соллертинского. Композитор привык к тому, что друг всегда рядом, что с ним можно делиться самыми сокровенными мыслями — а это в те времена всеобщего доносительства становилось самой большой ценностью. Шостакович часто писал ему. Сообщал буквально обо всем, что можно было доверить цензурируемой почте. В частности, о том, что финал «не пишется». Не удивительно, что последняя часть долго не получалась. Шостакович понимал, что в симфонии, посвященной событиям войны, все ожидали торжественного победного апофеоза с хором, праздника грядущей победы. Но для этого не было пока никаких оснований, а он писал так, как подсказывало сердце. Не случайно позднее распространилось мнение, что финал по значимости уступает первой части, что силы зла оказались воплощенными значительно сильнее, чем противостоящее им гуманистическое начало.
27 декабря 1941 года Седьмая симфония была закончена. Конечно, Шостаковичу хотелось, чтобы ее исполнил любимый оркестр — оркестр Ленинградской филармонии под управлением Мравинского. Но он был далеко, в Новосибирске, а власти настаивали на срочной премьере: исполнению симфонии, которую композитор назвал Ленинградской и посвятил подвигу родного города, придавалось политическое значение. Премьера состоялась в Куйбышеве 5 марта 1942 года. Играл оркестр Большого театра под управлением Самуила Самосуда.
Очень любопытно, что написал о симфонии «официальный писатель» того времени Алексей Толстой: «Седьмая симфония посвящена торжеству человеческого в человеке. Постараемся (хотя бы отчасти) проникнуть в путь музыкального мышления Шостаковича — в грозные темные ночи Ленинграда, под грохот разрывов, в зареве пожаров, оно привело его к написанию этого откровенного произведения. <…> Седьмая симфония возникла из совести русского народа, принявшего без колебания смертный бой с черными силами. Написанная в Ленинграде, она выросла до размеров большого мирового искусства, понятного на всех широтах и меридианах, потому что она рассказывает правду о человеке в небывалую годину его бедствий и испытаний. Симфония прозрачна в своей огромной сложности, она и сурова, и по-мужски лирична, и вся летит в будущее, раскрывающееся за рубежом победы человека над зверем.
…Скрипки рассказывают о безбурном счастьице, — в нем таится беда, оно еще слепое и ограниченное, как у той птички, что «ходит весело по тропинке бедствий»… В этом благополучии из темной глубины неразрешенных противоречий возникает тема войны — короткая, сухая, четкая, похожая на стальной крючок. Оговариваемся, человек Седьмой симфонии — это некто типичный, обобщенный и некто — любимый автором. Национален в симфонии сам Шостакович, национальна его русская рассвирепевшая совесть, обрушившая седьмое небо симфонии на головы разрушителей.
Тема войны возникает отдаленно и вначале похожа на какую-то простенькую и жутковатую пляску, на приплясывание ученых крыс под дудку крысолова. Как усиливающийся ветер, эта тема начинает колыхать оркестр, она овладевает им, вырастает, крепнет. Крысолов, со своими железными крысами, поднимается из-за холма… Это движется война. Она торжествует в литаврах и барабанах, воплем боли и отчаяния отвечают скрипки. И вам, стиснувшему пальцами дубовые перила, кажется: неужели, неужели уже все смято и растерзано? В оркестре — смятение, хаос.
Нет. Человек сильнее стихии. Струнные инструменты начинают бороться. Гармония скрипок и человеческие голоса фаготов, могущественнее грохота ослиной кожи, натянутой на барабаны. Отчаянным биением сердца вы помогаете торжеству гармонии. И скрипки гармонизируют хаос войны, заставляют замолкнуть ее пещерный рев.
Проклятого крысолова больше нет, он унесен в черную пропасть времени. Слышен только раздумчивый и суровый — после стольких потерь и бедствий — человеческий голос фагота. Возврата нет к безбурному счастьицу. Перед умудренным в страданиях взором человека — пройденный путь, где он ищет оправдания жизни.
За красоту мира льется кровь. Красота — это не забава, не услада и не праздничные одежды, красота — это пересоздание и устроение дикой природы руками и гением человека. Симфония как будто прикасается легким дуновением к великому наследию человеческого пути, и оно оживает.
Средняя (третья — Л. М.) часть симфонии — это ренессанс, возрождение красоты из праха и пепла. Как будто перед глазами нового Данте силой сурового и лирического раздумья вызваны тени великого искусства, великого добра.
Заключительная часть симфонии летит в будущее. Перед слушателями… раскрывается величественный мир идей и страстей. Ради этого стоит жить и стоит бороться. Не о счастьице, но о счастье теперь рассказывает могущественная тема человека. Вот — вы подхвачены светом, вы словно в вихре его… И снова покачиваетесь на лазурных волнах океана будущего. С возрастающим напряжением вы ожидаете… завершения огромного музыкального переживания. Вас подхватывают скрипки, вам нечем дышать, как на горных высотах, и вместе с гармонической бурей оркестра, в немыслимом напряжении вы устремляетесь в прорыв, в будущее, к голубым городам высшего устроения…» («Правда», 1942, 16 февраля).
После куйбышевской премьеры симфонии прошли в Москве и Новосибирске (под управлением Мравинского), но самая замечательная, поистине героическая состоялась под управлением Карла Элиасберга в осажденном Ленинграде. Чтобы исполнить монументальную симфонию с огромным составом оркестра, музыкантов отзывали из военных частей. Некоторых перед началом репетиций пришлось положить в больницу — подкормить, подлечить, поскольку все простые жители города стали дистрофиками. В день исполнения симфонии — 9 августа 1942 года — все артиллерийские силы осажденного города были брошены на подавление огневых точек врага: ничто не должно было помешать знаменательной премьере.
И белоколонный зал филармонии был полон. Бледные, истощенные ленинградцы заполнили его, чтобы услышать музыку, посвященную им. Динамики разносили ее по всему городу.
Общественность всего мира восприняла исполнение Седьмой как событие огромной важности. Вскоре из-за рубежа стали поступать просьбы выслать партитуру. Между крупнейшими оркестрами западного полушария разгорелось соперничество за право первого исполнения симфонии. Выбор Шостаковича пал на Тосканини. Через мир, охваченный огнем войны, полетел самолет с драгоценными микропленками, и 19 июля 1942 года Седьмая симфония была исполнена в Нью-Йорке. Началось ее победное шествие по земному шару.
Музыка
Первая часть начинается в ясном светлом до мажоре широкой, распевной мелодией эпического характера, с ярко выраженным русским национальным колоритом. Она развивается, растет, наполняется все большей мощью. Побочная партия также песенна. Она напоминает мягкую спокойную колыбельную. Заключение экспозиции звучит умиротворенно. Все дышит спокойствием мирной жизни. Но вот откуда-то издалека раздается дробь барабана, а потом появляется и мелодия: примитивная, похожая на банальные куплеты шансонетки — олицетворение обыденности и пошлости. Это начинается «эпизод нашествия» (таким образом, форма первой части — сонатная с эпизодом вместо разработки). Поначалу звучание кажется безобидным. Однако тема повторяется одиннадцать раз, все более усиливаясь. Она не изменяется мелодически, только уплотняется фактура, присоединяются все новые инструменты, потом тема излагается не одноголосно, а аккордовыми комплексами. И в результате она вырастает в колоссальное чудовище — скрежещущую машину уничтожения, которая кажется, сотрет все живое. Но начинается противодействие. После мощной кульминации реприза наступает омраченной, в сгущенно минорных красках. Особенно выразительна мелодия побочной партии, сделавшаяся тоскливой, одинокой. Слышно выразительнейшее соло фагота. Это больше не колыбельная, а скорее плач, прерываемый мучительными спазмами. Лишь в коде впервые главная партия звучит в мажоре, утверждая наконец столь трудно доставшееся преодоление сил зла.
Вторая часть — скерцо — выдержано в мягких, камерных тонах. Первая тема, излагаемая струнными, соединяет в себе светлую печаль и улыбку, чуть приметный юмор и самоуглубленность. Гобой выразительно исполняет вторую тему — романсовую, протяженную. Затем вступают другие духовые инструменты. Темы чередуются в сложной трехчастности, создавая образ привлекательный и светлый, в котором многие критики усматривают музыкальную картину Ленинграда прозрачными белыми ночами. Лишь в среднем разделе скерцо появляются иные, жесткие черты, рождается карикатурный, искаженный образ, исполненный лихорадочного возбуждения. Реприза скерцо звучит приглушенно и печально.
Третья часть — величавое и проникновенное адажио. Оно открывается хоральным вступлением, звучащим словно реквием по погибшим. За ним следует патетическое высказывание скрипок. Вторая тема близка скрипичной, но тембр флейты и более песенный характер передают, по словам самого композитора, «упоение жизнью, преклонение перед природой». Средний эпизод части отличается бурным драматизмом, романтической напряженностью. Его можно воспринимать как воспоминание о прошедшем, реакцию на трагические события первой части, обостренные впечатлением непреходящей красоты во второй. Реприза начинается речитативом скрипок, еще раз звучит хорал, и все истаивает в таинственно рокочущих ударах тамтама, шелестящем тремоло литавр. Начинается переход к последней части.
В начале финала — то же еле слышное тремоло литавр, тихое звучание скрипок с сурдинами, приглушенные сигналы. Происходит постепенное, медленное собирание сил. В сумеречной мгле зарождается главная тема, полная неукротимой энергии. Ее развертывание колоссально по масштабам. Это образ борьбы, народного гнева. Его сменяет эпизод в ритме сарабанды — печальный и величественный, как память о павших. А затем начинается неуклонное восхождение к торжеству заключения симфонии, где главная тема первой части, как символ мира и грядущей победы, звучит ослепительно у труб и тромбонов.
Л. Михеева
Я рекомендую
Это интересно
Твитнуть
реклама
вам может быть интересно
Публикации
Главы из книг
| Разбор | Термин имеет несколько разные значения в разных областях лингвистики и информатики. Традиционный анализ предложения часто выполняется как метод понимания точного значения предложения или слова, иногда с помощью таких устройств, как диаграммы предложений.Обычно в нем подчеркивается важность таких грамматических подразделений, как подлежащее и сказуемое. |
| Разбор | Синтаксический анализ ранее занимал центральное место в преподавании грамматики во всем англоязычном мире и широко рассматривался как базовый для использования и понимания письменного языка. Однако общее обучение таким техникам больше не актуально. |
| Разбор | Обычно при синтаксическом анализе определяется как разделение.Разделить предложение на грамматическое значение или слова, фразы, числа. В некоторых системах машинного перевода и обработки естественного языка письменные тексты на человеческих языках анализируются компьютерными программами. Человеческие предложения нелегко анализировать программами, поскольку существует значительная неоднозначность в структуре человеческого языка, использование которого заключается в передаче значения (или семантики) среди потенциально неограниченного диапазона возможностей, но только некоторые из них имеют отношение к конкретному случаю. Таким образом, высказывание «Человек кусает собаку» по сравнению с «Собака кусает человека» определенно по одной детали, но на другом языке может выглядеть как «Человек кусает собаку» с опорой на более широкий контекст, чтобы различать эти две возможности, если это действительно так беспокойства.Трудно подготовить формальные правила для описания неформального поведения, хотя очевидно, что некоторые правила соблюдаются. |
| Разбор | В психолингвистике синтаксический анализ включает не только присвоение слов категориям, но и оценку значения предложения в соответствии с правилами синтаксиса, сделанными на основе выводов, сделанных из каждого слова в предложении.Обычно это происходит, когда слова слышны или читаются. Следовательно, психолингвистические модели синтаксического анализа обязательно являются «инкрементными», что означает, что они создают интерпретацию по мере обработки предложения, которая обычно выражается в терминах частичной синтаксической структуры. При толковании предложений садовой дорожки происходит создание изначально неправильных структур. |
| Разбор | Первый этап — это генерация токена или лексический анализ, с помощью которого входной поток символов разбивается на значимые символы, определяемые грамматикой регулярных выражений.Например, программа калькулятора будет смотреть на ввод, такой как «codice_1», и разделять его на токены codice_2, codice_3, codice_4, codice_5, codice_6, codice_7, codice_8, codice_9, codice_10, каждый из которых является значимым символом в контексте. арифметического выражения. Лексический анализатор будет содержать правила, сообщающие ему, что символы codice_3, codice_6, codice_9, codice_4 и codice_8 отмечают начало нового токена, поэтому бессмысленные токены, такие как «codice_16» или «codice_17», не будут сгенерированы. |
| Разбор | Большинство языков программирования, которые являются основной целью синтаксических анализаторов, тщательно определены таким образом, чтобы синтаксический анализатор с ограниченным просмотром вперед, обычно один, мог анализировать их, потому что синтаксические анализаторы с ограниченным прогнозом часто более эффективны.Одно важное изменение в этой тенденции произошло в 1990 году, когда Теренс Парр создал ANTLR для своей докторской степени. thesis, генератор парсеров для эффективных парсеров LL («k»), где «k» — любое фиксированное значение. |
| Разбор | Сгенерированное дерево синтаксического анализа является правильным и просто более эффективным, чем парсеры без предварительного просмотра. Это стратегия, которой следуют парсеры LALR. |
| Разбор | Синтаксический анализ (;), синтаксический анализ или синтаксический анализ — это процесс анализа строки символов на естественном языке или на компьютерных языках в соответствии с правилами формальной грамматики.Термин «, анализируя » происходит от латинского «pars» («orationis»), что означает часть (речи). |
| Разбор | В информатике этот термин используется при анализе компьютерных языков, имея в виду синтаксический анализ входного кода на его составные части, чтобы облегчить написание компиляторов и интерпретаторов. Этот термин также может использоваться для описания разделения или разделения. |
| Разбор | Использование парсеров зависит от ввода. В случае языков данных синтаксический анализатор часто используется как средство чтения файлов программы, например, чтение текста HTML или XML; эти примеры являются языками разметки. В случае языков программирования синтаксический анализатор — это компонент компилятора или интерпретатора, который анализирует исходный код языка компьютерного программирования для создания некоторой формы внутреннего представления; парсер — это ключевой шаг во внешнем интерфейсе компилятора.Языки программирования, как правило, определяются в терминах детерминированной контекстно-свободной грамматики, потому что для них могут быть написаны быстрые и эффективные синтаксические анализаторы. Для компиляторов синтаксический анализ может быть выполнен за один проход или за несколько проходов — см. Однопроходный компилятор и многопроходный компилятор. |
Информатика | Бесплатный полнотекстовый | О словосочетаниях и их взаимодействии с синтаксическим анализом и переводом
1. Введение
Выражения из нескольких слов — «своеобразные интерпретации, которые пересекают границы слов» [1] — широко признаны ключевой проблемой для обработки естественного языка (НЛП).Действительно, они рассматриваются как «боль в шее» для НЛП [1] или «крепкий орешек» [2]. Выражения из нескольких слов (далее — MWE) охватывают широкий спектр явлений 1, таких как именованные сущности, функциональные слова из нескольких слов, именные соединения, конструкции глагол-частица, глагольные выражения, идиомы, пословицы и т. Д., Которые все имеют Общим является тот факт, что они должны рассматриваться как единое целое, а не пословно и, следовательно, требуют особого, целостного подхода в системах НЛП. Особенно важный подкласс MWE представлен так называемыми « институционализированные »фразы или словосочетания (напр.г., проливной дождь, заядлый курильщик, серьезная травма, удовлетворить потребность, выразить благодарность, глубоко влюблен). Словосочетания — это выражения, которые относительно регулярны с синтаксической и семантической точки зрения, но статистически уникальны. Составляющие слова, в принципе, связаны с помощью обычных грамматических процессов, таких как сочетание существительного с модификатором, дающее номинальную фразу, значение которой может быть выведено из значения частей. Тем не менее, что характерно, своеобразно или нерегулярно в таких выражениях, так это то, что они предпочтительнее альтернативных лексикализаций: сравните, например, светофор, который представляет собой словосочетание, институциональную фразу, с такими сочетаниями, как * директор дорожного движения или * регулятор перекрестков, которые почти не встречаются в языке (пример из [1]).Такие комбинации сильно зависят от языка и в значительной степени указывают на степень беглости языкового высказывания или вывода, производимого системой НЛП. Даже если они поддаются разложению на части, вычислительные системы все равно должны их обрабатывать целостным образом, чтобы избежать неестественных или неудобных формулировок. По мнению нескольких исследователей (например, [4,5,6]), словосочетания являются наиболее многочисленными. среди всех типов MWE. Фактически, «ни один фрагмент естественного устного или письменного английского языка не свободен от словосочетаний» [7].Важность словосочетаний «стоит в их вездесущности» [5]. Также важно отметить, что, в отличие от большинства других типов многословных выражений, словосочетания могут встречаться в широком диапазоне синтаксических шаблонов. Ниже приводится список синтаксических конфигураций, обычно связанных с словосочетаниями в английском языке: прилагательное-существительное (заядлый курильщик), существительное- (сказуемое) -адъективное (усилия [быть] посвященными), существительное-существительное (суицидальная атака), существительное-предлог- существительное (раунд переговоров), существительное-предлог (исследование), прилагательное-предлог (без ума от), подлежащее-глагол (возникает проблема), глагол-объект (удовлетворить требование), глагол-предлог-аргумент (довести до кипения), глагол-предлог (зависит от), наречие-глагол (полностью поддерживаю), наречие-прилагательное (очень важно), прилагательное-согласование-прилагательное (приятный и теплый).Кроме того, лексикографические данные показывают, что этот список можно значительно расширить [8]. Подводя итог, можно сказать, что словосочетания — это идиосинкратические синтагматические комбинации, которые не ограничиваются данным классом слов или данным набором синтаксических паттернов [9].Исследователи уже давно пытались охарактеризовать феномен словосочетания, обращаясь к нему с разных точек зрения. Однако до сих пор нет согласованного определения, а понятие словосочетания обычно сопровождается расплывчатостью и путаницей.Словосочетания остаются менее изученными и менее понятными, чем другие типы MWE, в частности, идиомы (пнуть ведро), конструкции со светлым глаголом (прогуляться) или конструкции глагол-частица (искать).
В этой статье мы делаем акцент на особом аспекте, который отличает словосочетания от других выражений и который делает их особенно трудными для обработки вычислительными системами: высокая морфосинтаксическая гибкость словосочетаний. Составляющие слова в словосочетании, в принципе, могут подвергаться полному спектру морфологических и синтаксических преобразований, которые возможны для регулярных сочетаний в языке (см. Примеры 1 и 2).Напротив, другие выражения, такие как именованные сущности (Нью-Йорк), соединения (инвалидное кресло) или идиомы (быть на седьмом небе, «быть чрезвычайно довольным»), относительно фиксированы или заморожены, и эта характеристика действует как полезное различение. функция и позволяющая более локальную (и, следовательно, более экономичную в вычислительном отношении) автоматическую обработку.Что касается гибкой природы словосочетаний, стоит отметить, что в области НЛП и перевода стандарт категорий данных ISO 12620 описывает словосочетания как «[] повторяющееся словосочетание, характеризующееся связностью в том смысле, что компоненты словосочетания должны сосуществуют в высказывании или серии высказываний, даже если они не обязательно должны находиться в непосредственной близости друг от друга »(курсив наш).Это определение подчеркивает важную особенность словосочетаний, а именно несмежность составных слов, которая является следствием синтаксической гибкости этих выражений.
В самом деле, эта несмежность, возможно, является одной из самых больших проблем, с которыми сталкиваются системы НЛП при обработке словосочетаний. Поскольку словосочетания демонстрируют (почти) полную синтаксическую изменчивость, их обработка требует работы с широким спектром синтаксических преобразований, в которых могут возникать словосочетания. Их высокая вариативность требует сложных лингвистических подходов, способных точно определять словосочетания во многих синтаксических контекстах и учитывать зависимости между ними, чтобы в конечном итоге обеспечить их надлежащую обработку в таких приложениях, как синтаксический анализ или перевод.
Другой аспект, на котором мы особенно сосредоточены, — это интеграция коллокаций в реальные конвейеры NLP, то есть их использование в клиентских приложениях на естественном языке. Разработка точных методов идентификации коллокаций была главной заботой в области НЛП уже пару десятилетий; однако использованию коллокаций в других приложениях НЛП уделялось значительно меньше внимания. В этой статье мы обращаемся к проблеме соединения приложения извлечения (или идентификации) коллокации с двумя основными приложениями НЛП, а именно синтаксическим синтаксическим анализом и машинным переводом.Мы исследуем, является ли синергетический подход, при котором информация распределяется между задачей идентификации коллокации и двумя другими задачами, более эффективен, чем стандартный подход, в котором задачи выполняются независимо друг от друга.
В статье исследуются четыре основных направления работы, которые в большей или меньшей степени проводились в области НЛП до настоящего времени. Сосредоточив внимание на взаимосвязи между задачами идентификации коллокаций и синтаксического синтаксического анализа, мы смотрим на преимущества, которые можно получить, полагаясь на синтаксический синтаксический анализ для извлечения словосочетаний, и, наоборот, от использования словосочетаний во время синтаксического анализа.Затем, сосредоточив внимание на взаимосвязи между идентификацией словосочетания и переводом, мы исследуем, могут ли технологии перевода внести свой вклад в задачу автоматического обнаружения словосочетаний в корпусах текста и, наоборот, полезны ли словосочетания для машинного перевода. По каждой основной теме предоставляется обзор литературы, а также отчеты о наших собственных экспериментах, подтверждающие, что синергетический подход предпочтительнее индивидуальных. Эти результаты, подкрепленные результатами других исследований синергетических подходов (например, использования синергетического анализа для семантического анализа [10]), предполагают, что работа НЛП, часто фрагментированная, выиграет от большего взаимодействия между различными задачами.Статья построена следующим образом. В разделе 2 мы сосредоточимся на использовании синтаксического анализа для извлечения словосочетаний. Мы исследуем соответствующую работу и обрисовываем нашу собственную методологию извлечения, которая опирается на полный синтаксический анализ для получения словосочетаний из текстовых корпусов на нескольких языках. В Разделе 3 мы рассматриваем работу, в которой связанные с переводом технологии, такие как выравнивание предложений и слов, используются для определения словосочетаний. Кроме того, мы описываем наш собственный метод определения эквивалентов перевода для словосочетаний с использованием архивов переводов.Раздел 4 и Раздел 5 посвящены использованию знаний о коллокациях для синтаксического анализа и перевода. В разделе 4 мы обсуждаем степень, в которой словосочетания в настоящее время учитываются в системах синтаксического анализа; Затем мы представляем подход, в котором идентификация словосочетания и синтаксический анализ выполняются одновременно, а не по отдельности, как в предыдущей работе. В разделе 5 рассматривается вопрос интеграции словосочетаний и других типов многословных выражений в системы машинного перевода.В нем также представлено исследование, направленное на оценку влияния словосочетаний на результаты внутренней системы перевода, основанной на правилах. Наконец, в Разделе 6 статья завершается анализом текущей обработки словосочетаний и, при необходимости, указанием более адекватных альтернатив обработки.2. Использование синтаксического анализа для идентификации словосочетаний
Развитие извлечения словосочетаний как области исследований привело к все более широкому внедрению лингвистического анализа в качестве важного этапа предварительной обработки.Этот шаг позволяет более точно идентифицировать кандидатов, которые затем оцениваются с использованием статистических методов и, в частности, так называемых показателей ассоциации (например, взаимная информация, t-оценка, z-оценка, χ2, логарифмическое отношение правдоподобия; см. описания и сравнительные оценки ассоциативных показателей в [11,12,13,14]. Методы предварительной обработки постепенно эволюционировали от более мелких форм анализа к более глубоким, по мере того, как становились доступными все более совершенные технологии, от токенизации, стемминга и лемматизации до разбиения на мелкие фрагменты. синтаксический анализ, анализ зависимостей или полный синтаксический анализ.Необходимость лингвистического анализа входного текста оправдана необходимостью учитывать высокую морфосинтаксическую вариативность, характеризующую словосочетания. Стаббс [15] проанализировал, например, появление пары «медведь-подобие» в корпусе и обнаружил следующее распределение флективных форм для словесного компонента to bear: медведи 18%, медведь 11%, нос 11%, подшипник 4 %. Вместе эти формы составляют большую долю (44%) от общего числа словосочетаний существительного сходства (1085).Пример 1 суммирует эту информацию в обозначениях Стаббса.Пример 1. Морфологические вариации в словосочетаниях: нотация Стаббса для группирования изменяемых форм словосочетаний.
сходство 1085 <несет 18%, несет 11%, диаметр отверстия 11%, подшипник 4%> 44%
Этот пример иллюстрирует важность выполнения лексического анализа входящего текста, чтобы лучше определять возможные сочетания слов. Фактически, большая часть работы по извлечению словосочетаний [16,17,18,19] основана на лексическом анализе в сочетании с фильтрацией на основе части речи (POS) комбинаций, рассматриваемых в окне из пяти слов, называемом коллокационный диапазон.В дополнение к лексическому анализу, синтаксический анализ входного текста часто считался необходимым, особенно для языков, которые демонстрируют более свободный порядок слов, таких как немецкий или корейский. Для таких языков методы извлечения, разработанные для английского языка (например, Xtract [20]), неэффективны, так как они не могут восстановить систематические зависимости на большом расстоянии и учесть позиционную неоднозначность аргументов. Как сообщает, например, Брейдт [21], даже отличить субъекты от объектов на немецком языке сложно без синтаксического анализа.Поэтому автор предложил сократить коллокационный диапазон до трех слов, чтобы исключить существительные, не связанные с глаголами. Эта стратегия привела к повышению точности, но это улучшение произошло за счет отзыва. Аналогичным образом Kim et al. [22] сообщили, что такая методика, как Xtract [20], которая очень популярна для английского языка и основана на выборе вариантов словосочетания среди пар слов, одновременно встречающихся на стабильном расстоянии в тексте, совершенно не подходит для корейского языка из-за высокой синтаксическая гибкость.Учитывая заметную гибкость словосочетаний, некоторые исследователи указали, что извлечение словосочетаний в идеале должно полагаться на синтаксический анализ исходных корпусов [12,13,20,23,24]. Однако, несмотря на их теоретические аргументы, синтаксический анализ использовался лишь в небольшом количестве практических работ. В таких (исключительных) случаях кандидаты на коллокацию идентифицируются как пары слов в синтаксической взаимосвязи, а не как пары слов в коллокационной области, как в преобладающих бессинтаксических подходах.Есть сообщения, например, о работе с коллокациями с использованием полного синтаксического анализа для немецкого [25], китайского [26] и голландского [27]. Аналогичная работа была проделана для английского языка [28], языка, на котором также проводились эксперименты по извлечению словосочетаний с использованием аннотированных вручную синтаксических банков дерева [29,30]. Кроме того, анализ зависимостей использовался для ряда языков, включая английский [31,32], французский [33] и чешский [34]. Кроме того, относительно больший объем работы был посвящен извлечению словосочетаний на основе неглубокого синтаксического анализа, например.g., для английского [35], немецкого [36], французского [11,37,38] и, в частности, в многоязычной системе Sketch Engine [39]. Важным фактором, отличающим эти системы извлечения на основе синтаксиса, является производительность задействованный парсер. В некоторых случаях авторы сообщают о довольно высокой частоте ошибок синтаксического анализа, а также о проблемах с надежностью, что приводит к исключению более длинных предложений, состоящих из 20 слов и более [27,31,32]. В других случаях грамматический охват синтаксического анализатора сообщается как ограниченный, так как система извлечения неспособна справиться с некоторыми типами синтаксических преобразований, такими как релятивизация [28].Помимо базовой технологии предварительной обработки и конкретных мер ассоциации, используемых для ранжирования кандидатов, системы извлечения также сильно различаются по диапазону синтаксических конфигураций, которые они принимают во внимание. Некоторые системы идентифицируют кандидатов одного типа или нескольких конкретных синтаксических типов, например, глагол-предлог [29], предлог-существительное-предлог, предложная фраза-глагол [27], глагол-объект, существительное-прилагательное, глагол-наречие [ 26] или словосочетаний [11,37,38]. Тем не менее, другие системы нацелены на более широкий охват, например.г., [25,39].Хотя обычно считается необходимым для получения высококачественных результатов, извлечение на основе синтаксиса не всегда рассматривается как жизнеспособное решение в сообществе НЛП. Иногда от него отказываются из-за недоступности синтаксических анализаторов; в других случаях причина отсутствия предварительной обработки исходных корпусов синтаксическим анализатором берется на основе различных аргументов, таких как неэффективность по времени, отсутствие точности или отсутствие устойчивости. Чтобы усилить скептицизм, не было проведено никакой сравнительной оценки, чтобы убедительно доказать превосходство извлечения на основе синтаксиса над более простой альтернативой без синтаксиса.
Наша собственная работа [44] была посвящена разработке полноценной методологии извлечения, основанной на полном синтаксическом анализе. Мы использовали многоязычный синтаксический анализатор Fips [40] для предварительной обработки исходных корпусов и выбора в качестве кандидатов комбинаций слов, обнаруженных в определенных синтаксических отношениях (см. Раздел 1). Для ранжирования отобранных кандидатов может применяться ряд ассоциативных мер; мера, предлагаемая по умолчанию, представляет собой логарифмическое отношение правдоподобия, которое считается эффективным как для высокочастотных, так и для низкочастотных данных [41].Система извлечения, первоначально разработанная для английского и французского языков, позже была расширена на новые языки, поддерживаемые парсером Fips, то есть испанский, итальянский, немецкий, греческий и румынский. Fips — надежный символьный парсер, основанный на концепциях генеративной грамматики. Он выполняет «глубокий» синтаксический анализ входного предложения, используя совместную индексацию для отслеживания экстрапозиционных составляющих, т. Е. Составляющих, которые «переместились» из исходного (канонического) положения в поверхностное из-за синтаксических преобразований, например, показанные в Примере 2:Пример 2. Синтаксические вариации в словосочетаниях: примеры преобразований.
- 2.
пассивирование
- 3.
опрос
Пример 3. Пример вывода синтаксического анализа (A = прилагательное, Adv = наречие, C = дополняющее, D = определяющее, N = существительное, P = фраза, T = время, V = глагол).
Второй эксперимент был проведен кросс-лингвистически, на французском, английском, итальянском и испанском параллельных данных из корпуса Европарламента о заседаниях Европейского парламента, всего около трех.В среднем 7 миллионов слов на каждый язык. Для выбора данных оценки использовалась стратегия стратифицированной выборки с последовательностями из 50 типов пар, взятых с разных уровней в выходном списке (верхний — 0%, 1%, 3%, 5% и 10%). Команды из двух судей вручную оценили в общей сложности 2000 типов пар. Результаты снова показали статистически значимые улучшения по сравнению с исходным уровнем (средняя грамматическая точность 88,8% против 33,2%; средняя лексикографическая точность 43,2% против 17,2%; и средняя точность коллокации 32,9% против 12,8%).Важно отметить, что самые лучшие результаты базовой линии относительно свободны от шума, поскольку мера ассоциации успешно устраняет множество ошибочных пар из верхних позиций. Однако точность быстро ухудшается для предметов на более низких позициях: по мере того, как частота пар уменьшается, одна мера неэффективна для устранения шума. Напротив, подход, основанный на синтаксисе, гарантирует лучшее глобальное качество результатов, а это означает, что даже кандидаты с более низкими оценками не имеют шума.Это особенно важно, поскольку лексические данные имеют асимметричное распределение Ципфа, и большинство возможных комбинаций получают низкие оценки из-за их низкой частоты совпадения; тем не менее, они потенциально интересны с лексикографической точки зрения. Проведение лексикографической работы над списком без шума — одно из основных преимуществ синтаксических подходов к извлечению словосочетаний.
Результаты этих экспериментов развеяли сомнения в возможности синтаксического подхода к извлечению словосочетаний и показали преимущества, полученные по сравнению с бессинтаксическим подходом.Они подтвердили, что анализ информации способствует статистически значимому увеличению производительности извлечения словосочетаний, и подтвердили аналогичные результаты, полученные с использованием синтаксических подходов к другим задачам, например, извлечение терминов [42], маркировка семантических ролей [10] и вычисление семантического сходства [43]. ].4. Использование словосочетаний для синтаксического анализа
Как указано Sag et al. [1], MWE являются ключевой проблемой для обработки естественного языка, потому что они не могут быть обработаны композиционными методами, так как они могут привести к избыточной генерации (например.g., создание фразы типа * регулятор перекрестка вместо светофора). Более того, они не могут быть проанализированы с помощью обычных грамматических процессов, поскольку они идиосинкразические (например, в выражении в строке отсутствует определитель: * в строке). Для учета MWE, присутствующих в языке, в практической работе по НЛП обычно используется решение, состоящее из перечисления MWE в лексиконе и разметки входящего текста с использованием подхода слов с пробелами для распознавания MWE. У этого подхода есть два основных недостатка.Во-первых, это отсутствие гибкости, так как многие выражения позволяют лексическому материалу располагаться между составляющими словами, и подход слов с пробелами неадекватен для обработки таких ситуаций. Вторая — проблема лексического распространения, поскольку выражения обычно имеют вариативность, и перечисление всех возможных форм в лексиконе было бы непрактичным. Таким образом, подход слов с пробелами не может обобщать и плохо справляется с вариациями [1]. Эти проблемы становятся еще более острыми в случае словосочетаний.Как указано в разделе 1, словосочетания являются наиболее гибкими среди всех видов MWE, что делает подход слов с пробелами совершенно неадекватным для их представления и обработки. Нет систематических ограничений на количество форм компонента словосочетания (например, глагол), порядок компонентов словосочетания или количество слов, которые могут вставлять между ними (см. Пример 2). Коллокации расположены на пересечении лексики и грамматики; следовательно, они не могут быть объяснены исключительно лексическим компонентом системы синтаксического анализа.Вместо этого они также должны быть интегрированы в грамматический компонент, поскольку синтаксический анализатор должен учитывать все их возможные синтаксические реализации. В качестве альтернативы подходу предварительной обработки слов с пробелами коллокации могут распознаваться синтаксическим анализатором после анализа входное предложение было выполнено в соответствии с подходом, подобным тому, который описан в разделе 2. Опять же, этот подход не полностью уместен с точки зрения синтаксического анализа, и причина кроется в важном наблюдении, что предшествующие коллокационные знания очень важны для парсинг.Совместные предпочтения, наряду с другими типами информации, такими как ограничения выбора и рамки подкатегории, являются основным средством структурного разрешения неоднозначности. Фактически, коллокационные отношения между словами в предложении оказались полезными для выбора наиболее правдоподобного среди всех деревьев синтаксического анализа, сгенерированных для предложения [56,57,58,59]. Как мы покажем позже в этом разделе, более подходящим подходом является включение словосочетаний в грамматический компонент синтаксического анализатора, так что идентификация словосочетаний и построение дерева синтаксического анализа становятся взаимодействующими процессами, которые происходят одновременно и информируют каждого Другие.Далее мы рассмотрим, в какой степени MWE / коллокационные знания были включены в системы синтаксического анализа для повышения их производительности. Ряд исследований предоставили эмпирические доказательства того, что действительно распознавание MWE / коллокаций приводит к лучшим результатам синтаксического анализа. Например, Брун [60] сравнил покрытие французского синтаксического анализатора с распознаванием терминологии и без него на этапе предварительной обработки. Она обнаружила, что интеграция 210 номинальных терминов в компоненты предварительной обработки синтаксического анализатора привела к значительному сокращению количества альтернативных синтаксических анализов (в среднем по 4.21-2,79). Автор сообщает, что исключенные синтаксические разборы были семантически нежелательными и что не был исключен какой-либо достоверный анализ. Аналогичным образом Zhang et al. [61] расширили лексикон на 373 дополнительных лексических элемента MWE и получили значительное увеличение грамматического охвата синтаксического анализатора английского языка (на 14,4%, с 4,3% до 18,7%). В случаях, упомянутых выше, слова с пробелами подход был использован для представления MWE. Напротив, Alegria et al. [62] и Villavicencio et al. [63] использовали композиционный подход к кодированию MWEs, способный улавливать более морфосинтаксически гибкие MWE.Алегрия и др. [62] показали, что при использовании процессора MWE на этапе предварительной обработки своего парсера (в разработке) для Basque достигается значительное улучшение точности тегов POS. Вильявисенсио и др. [63] обнаружили, что простое добавление 21 нового MWE в лексикон привело к значительному увеличению охвата грамматики (с 7,1% до 22,7%) без изменения грамматической точности. Кроме того, область интенсивных исследований в области синтаксического анализа — это особенно касается использования лексических предпочтений, частот совпадения, словосочетаний и контекстуально схожих слов для устранения неоднозначности присоединения предложных фраз (PP).Таким образом, для этой цели было разработано большое количество неконтролируемых методов [56,64,65], контролируемых методов [57,58] и комбинированных методов [66]. Однако, как указано в [56], узким местом этого направления работы является то, что синтаксическим анализаторам не хватает именно той информации на основе корпуса, которая требуется для разрешения неоднозначности. Выполнение синтаксического анализа и идентификации словосочетаний, таким образом, является круговой проблемой, для которой в предыдущей литературе не было решения. В оставшейся части этого раздела мы описываем новый подход к обработке словосочетаний, реализованный в связи с разработкой парсера Fips, состоящий из одновременного выполнения. из двух задач, анализ предложения и определение словосочетания [67].Вкратце, идея состоит в том, что когда синтаксический анализатор обрабатывает лексический элемент, который отмечен в лексике как часть словосочетания, при попытке присоединить его к другому элементу, он сначала проверяет словарный запас словосочетания на наличие синтаксически совместимой записи и, если он найден , он дает высокий приоритет конструкции, в которой прикреплены два компонента. Таким образом, механизм идентификации коллокации включен в составную процедуру присоединения анализатора.Хорошо известно, что, учитывая высокую частоту лексических двусмысленностей и высокий уровень недетерминированности грамматик естественного языка, грамматические синтаксические анализаторы сталкиваются с рядом альтернатив, число которых растет экспоненциально с увеличением длины входного предложения.Алгоритмы синтаксического анализа используют различные эвристики, чтобы ограничить количество альтернатив и, таким образом, гарантировать, что производительность синтаксического анализа удовлетворительна для обработки больших корпусов. Коллокации вносят решающий вклад в процесс устранения неоднозначности, помогая синтаксическому анализатору пройти через лабиринт альтернатив. Таким образом, идентификация коллокации — это не бремя — дополнительная задача, которую необходимо решить, — а процесс, который помогает синтаксическому анализатору. Словосочетания, как правило, состоят из очень неоднозначных слов, и их определение помогает выбрать между альтернативами.Например, в случае побития рекорда оба компонента неоднозначны, если взяты по отдельности, и именно их комбинация помогает синтаксическому анализатору выбрать подходящие категории и показания.
Помимо лексического устранения неоднозначности, словосочетания также способствуют устранению структурной неоднозначности, как показано в Примере 4 ниже для фразы «Управление человеческими ресурсами». Чтобы выбрать между конкурирующими анализами, например, одним, в котором слово человек прикреплено к ресурсу, и другим, в котором оно прикреплено к управлению, синтаксический анализатор использует информацию из своего лексикона словосочетаний.Если найдена запись о человеческом ресурсе, указанная как пара прилагательное-существительное, то синтаксический анализатор отдает предпочтение первому анализу, а не второму, поскольку он соответствует структуре, указанной в лексиконе.Пример 4. Альтернативный анализ для фразы «Управление человеческими ресурсами».
Чтобы измерить влияние сочетания идентификации коллокации и задач синтаксического анализа, мы провели эксперименты, в которых мы сравнили новую версию синтаксического анализатора с предыдущей версией, которая не использует коллокации для принятия решений о присоединении.Мы оценили влияние процедуры, объединяющей синтаксический анализ и идентификацию коллокации, на выполнение обеих задач, синтаксический анализ и идентификацию коллокации. На корпусе новостных статей из журнала The Economist [68], насчитывающем чуть более 0,5 миллиона слов, мы получили ощутимое увеличение охвата синтаксического анализатора, выраженного в количестве полностью проанализированных предложений (83,3% против 81,7%), а также повышение точности идентификации словосочетаний (93,7% против 81,6%).Результаты соответствуют предыдущим отчетам о влиянии включения MWE в системы синтаксического анализа; разница заключается в том, что в нашем подходе полностью учтена синтаксическая гибкость MWE.Вместе эти результаты показывают значительную роль, которую эти выражения играют в производительности систем языкового анализа.
5. Использование коллокаций в машинном переводе
Помимо того, что они полезны для приложений NLP, связанных с анализом языка, информация о коллокациях, полученная из корпусов, имеет решающее значение для приложений, связанных с производством текста, таких как генерация естественного языка и машинный перевод. Совместное использование считается ключевым фактором для получения более приемлемого результата в этих приложениях [28,69].Несмотря на их относительно прозрачное значение, словосочетания создают значительные проблемы с точки зрения языкового производства, поскольку они являются «идиомами кодирования» [70]. Лексический выбор ограничен стилизованной формой, которая зависит от языка. Поэтому регулярный выбор и, в случае машинного перевода, дословный перевод неуместны, так как они могут привести к неестественным, если не к неудобным, формулировкам, известным как антиколлокации [30] (например, * обвинять задержку, дословный перевод французского обвинителя ретард, «задержка опыта»).Чтобы проиллюстрировать важность словосочетаний для машинного перевода, рассмотрим французские комбинации grande Внимание, grande diversité и grande vitesse, в которых прилагательное grande «большой» изменяет существительные «внимание», разнообразие и скорость. Дословный перевод приведет к неадекватным формулировкам на английском языке: * большое внимание, * большое разнообразие, * большая скорость. Правильный перевод, большое внимание, широкий диапазон и высокая скорость показывают необходимость использования словосочетаний в целевом языке: одно и то же прилагательное, grande, переводится тремя разными способами, в зависимости от изменяемого существительного.
Как обсуждалось в Разделе 3, значительный объем работы был посвящен извлечению эквивалентов перевода из корпусов, например [26,45,47,48], и представлению коллокационных знаний в вычислительной лексике для машинного перевода и генерация естественного языка [69,71]. Однако имеется очень мало отчетов о фактическом использовании коллокационных знаний в таких системах. Один из таких отчетов относится к системе машинного перевода Logos, которая использует словосочетания, извлеченные с помощью метода Орлиака и Диллинджера [28].Утверждается, что контекстно-зависимый выбор целевых лексических элементов, обеспечиваемый коллокациями, «обеспечивает значительное улучшение читабельности и воспринимаемого качества произведенного перевода» [28]. Другой отчет Лю и др. [72] касается интеграции словосочетаний в систему статистического машинного перевода (SMT). Авторы показывают, что их метод значительно улучшает производительность как выравнивания слов, так и качества перевода. В последующем эксперименте Liu et al. [73] используют словосочетания исходного языка для переупорядочения для SMT, что снова приводит к значительным улучшениям.В более общем плане, что касается MWE, есть дополнительные доказательства, поступающие из отчетов, показывающих, что включение двуязычных MWE в системы SMT приводит к повышению качества результатов перевода. Например, Bai et al. [49] добавили 1171 китайско-английских MWE в свои системы SMT и получили значительное улучшение в баллах BLEU. Точно так же Цветков и Винтнер [74] сообщили, что добавив 2955 пар переводов MWE в систему SMT с иврита на английский, они получили статистически значимое улучшение показателей BLEU и Meteor.Кроме того, Bouamor et al. [75] использовали различные стратегии для интеграции в свою англо-французскую систему SMT двуязычных фраз, извлеченных из обучающего корпуса из 100 000 предложений, обнаружив увеличение показателей BLEU и Meteor. Стоит отметить, что системы SMT на основе фраз уже включают MWE / коллокационную систему. знания как результат обучения их языку и моделям перевода на больших (параллельных) корпусах. Эти системы успешно справляются с локальными сопоставлениями, но, возможно, плохо подходят для обработки сопоставлений, компоненты которых не находятся в непосредственной близости друг от друга.Как отмечает Бабич и соавт. [76] выразился,В том же духе Бод [77] указывает, что несмежные фразы представляют собой реальную проблему для систем SMT, и предоставляет эмпирические доказательства того, что такие фразы значительно способствуют повышению точности перевода. В самом деле, мы также обнаружили, что SMT-системы очень чувствительны к синтаксической среде исходных словосочетаний, а также к лексической среде [78].Как видно из примера 5, одно и то же исходное словосочетание правильно переводится с английского на французский, когда встречается в данном контексте и неправильно переводится в другом контексте:«Вывод SMT часто на удивление хорош в отношении коротких словосочетаний, но часто (…) правильный выбор упускается в случаях, когда ограничения выбора влияют на удаленные слова».
Пример 5. Устные переводы с английского на французский.
люди, которые рассчитывают на нашу полную поддержку, когда это необходимо les gens qui comptent sur nous pour apporter un soutien complete quand il est néecessaire
и, безусловно, правильно оказывать массовую поддержку этим областям […] и это уверенность в праве собственности на массивные домены.
Требуется дальнейшее исследование, чтобы проверить, сопровождается ли положительный результат улучшенного перевода словосочетания аналогичным улучшением общего качества предложения.Однако, учитывая массовое присутствие словосочетаний в языке и их роль в беглости языка, мы предполагаем, что улучшение перевода словосочетаний является одним из основных компонентов повышения общего качества переводов.
Обнаружение модификации биомедицинских событий с использованием подхода глубокого анализа | BMC Medical Informatics and Decision Making
Наш основной подход заключается в синтаксическом анализе данных и построении входных векторов признаков для машинного обучения на основе выходных данных парсера.Мы строим отдельные классификаторы для каждой из двух подзадач SPECULATION и NEGATION. В этом разделе мы описываем парсеры и методологию извлечения признаков.
Глубокий синтаксический анализ с помощью ERG
Интуитивно мы могли бы ожидать, что глубокий синтаксико-семантический анализ будет полезен для обнаружения как ОТРИЦАТЕЛЬСТВА, так и СПЕКУЛЯЦИИ события, поскольку знание взаимосвязей возможно удаленных элементов (таких как частица ОТРИЦАТЕЛЬСТВО , а не ) с конкретное целевое слово может предоставить ценную информацию для классификации.В самом деле, как отмечалось выше, синтаксический анализ того или иного рода оказался полезным для этой задачи (например, [9]) и связанных задач (например, [15]).
В дополнение к этому, мы намеревались оценить полезность глубокого синтаксический анализ [16] для задачи, а не более мелкую аннотацию, такую как вывод синтаксического анализатора зависимостей. Имея это в виду, мы выбрали English Resource Grammar ( ERG : [17, 18]), высокоточную грамматику английского языка с открытым исходным кодом и широким охватом в рамках HPSG [19]; эксперименты, описанные в этой статье, основаны на версии грамматики «0902».В этой работе мы объединяем ERG с механизмом синтаксического анализа PET [20].
Хотя ERG относительно надежен в различных областях, это ресурс общего назначения, и есть некоторые аспекты языка, используемого в биомедицинских рефератах, которые вызывают трудности; обработка неизвестных слов особенно важна с учетом природы терминов в предметной области. К счастью, мы можем сделать некоторые оптимизации, чтобы смягчить это. Теггер GENIA [21] предоставляет как POS-аннотации, так и аннотации именованных объектов, которые мы использовали для ограничения ввода в ERG двумя способами, используя механизм отображения карт из [22]:
Биологические именованные объекты, идентифицированные теггером GENIA, помечаются как таковые, и синтаксический анализатор не пытается их разложить.
- К каждому входному токену добавляются теги
POS, чтобы ограничить токен соответствующей категорией, если он отсутствует в лексиконе ERG.
В дополнение к созданию деревьев синтаксического анализа и полных матриц значений атрибутов, ERG может также производить выходные данные в определенных семантических формализмах: семантика минимальной рекурсии (MRS: [23]) и тесно связанная с ней робастная семантика минимальной рекурсии (RMRS: [24]).Для генерации функций здесь мы используем последний из-за его совместимости с более мелкими синтаксическими анализаторами, такими как RASP .
В то время как ERG имеет различные внутренние механизмы грамматики для увеличения охвата (например, разрешая несоответствие номера субъект-глагол), у него нет никаких средств для создания фрагментов синтаксического анализа в том случае, если для данного ввода не обнаружено никакого связующего синтаксического анализа. Это неизбежно ограничивает охват грамматики, и в случае данных BioNLP 2009 Shared Task было обнаружено, что охват на уровне предложений составляет респектабельные, но все же несовершенные 76%.Очевидно, что для 24% предложений, которые ERG не может разобрать, требуется запасная стратегия. Некоторые методы достижения этого обсуждаются в следующем разделе.
Расширение охвата синтаксическим анализом
Одним из очевидных подходов к расширению ERG и получению полного охвата всех входных данных является объединение его с более упрощенным подходом, основанным на словах, и это действительно то, что мы исследуем. Однако в соответствии с нашей интуицией и экспериментальными доказательствами того, что синтаксико-семантические функции полезны для этой задачи, мы также исследовали улучшение охвата путем добавления альтернативного синтаксического анализатора.
Очевидным выбором может быть любой из синтаксических анализов зависимостей, предоставляемых организаторами общей задачи. Эти синтаксические анализы имеют некоторые преимущества — очевиден широкий охват данных и настройка на биомедицинскую область. Тем не менее, мы хотели использовать нашу предыдущую работу по проектированию функций для получения основных индикаторов из RMRS и, следовательно, решили использовать RASP [25], статистический анализатор общего назначения с широким охватом, применяя метод [26] для генерации РМРС.
В нашей настройке мы не разрешили анализ фрагментов из RASP из-за сложности их преобразования в выходные данные RMRS и сомнений в их надежности. Подобно нашему подходу с ERG , мы использовали только анализ с самым высоким рейтингом.
В этих условиях мы обнаружили, что RASP смог достичь такого же покрытия, что и ERG , получив анализ 76% предложений в данных разработки. Однако, объединяя наборы анализируемых входных данных от двух синтаксических анализаторов, мы увеличиваем охват на уровне предложений до 93% от набора для разработки, делая функции, производные от RMRS, гораздо более реалистичной перспективой в качестве средства обнаружения модификации событий.
Извлечение признаков из RMRS
На рисунке 1 показан RMRS, полученный из одного из учебных документов. Несмотря на то, что здесь недостаточно места для полного рассмотрения, мы выделяем несколько важных аспектов этой статьи. Первичный компонент RMRS — это набор элементарных предикатов или EP. В каждом EP есть:
- 1.
Наклейка, например l104 . Индексы меток уникальны, но произвольно назначаются грамматикой.Таким образом, они не обязательно начинаются с нуля и обычно имеют приращение больше единицы.
- 2.
Имя предиката, например _ дифференциация _ n _ 1 . n перед последней цифрой означает, что слово является существительным; a v обозначает глагол, a обозначает прилагательное или наречие, а q обозначает количественный показатель, такой как определитель.
- 3.
Индексы символов исходного предложения, например 〈130: 146〉, указывающие, что предикат соответствует символам 130–146 в исходном тексте.
- 4.
Набор аргументов.
Образец РМРС .RMRS-представление предложения Таким образом, активация NF-каппа B не требуется для дифференцировки клеток нейробластомы , показывая по порядку элементарные предикаты (каждый из которых состоит из метки, имени предиката, диапазона символов и аргументов), qeq-ограничений и in- g ограничения. Непомеченный первый аргумент каждого предиката — это обязательный аргумент ARG0 , который тесно связан с предикатом. Предикаты udef_q_rel — это квантификаторы по умолчанию, введенные для сохранения правильного формата RMRS, которые не имеют непосредственно соответствующих слов в предложении.
Аргументами могут быть переменные, такие как e30 или x23 (где первая буква указывает на природу переменной — e относится к событиям, x относится к объектам и u указывает на занижение) или обрабатывает например х43 . Первым аргументом всегда является ARG0 , и ему предоставляется специальный статус, обычно относящийся к переменной, введенной предикатом. Последующие аргументы помечаются в соответствии с отношением аргумента к предикату.Для предикатов открытого класса, таких как глаголы, это необязательные имена формы ARG n, но следуют определенным соглашениям — например, в английском (глубокое) подлежащее глагола обычно ARG1 и ( deep) объект ARG2 . Некоторые слова закрытого класса, такие как определители и союзы, следуют различным соглашениям для именования аргументов — это видно для кванторов udef_q_rel на рисунке 1. Эти дескрипторы обычно используются в ограничениях qeq , которые связывают дескриптор с меткой, указывающий на конкретный вид отношения выхода за пределы области между дескриптором и меткой — либо дескриптор и метка равны, либо дескриптор равен метке, за исключением одного или нескольких квантификаторов, встречающихся между ними (имя получено из ‘равенства по модулю кванторы ‘).Наконец, есть ограничений in-g , которые указывают, что метки можно рассматривать как равные. Для наших целей это просто влияет на то, в каких ограничениях qeq они участвуют — например, из ограничения in-g l28 in-g l104 и ограничения qeq h37 qeq l28 , мы также можем вывести, что h37 qeq l104 .
При конструировании элементов мы используем:
выходит за пределы отношения (в частности, qeq-outcopes) — если в EP A есть аргумент дескриптора, который qeq-выходит за метку EP B , говорят, что A сразу выходит за пределы B ; превосходит — это переходное закрытие этого.Например, на рисунке 1 EP 13 : _ Таким образом_a_1 имеет аргумент дескриптора h5 в качестве своего ARG1 , что в сочетании с ограничением qeq h5 qeq l17 означает, что l3 немедленно превосходит EP l17 : neg_rel . Точно так же l17 , в свою очередь, сразу превосходит l20 : _ require _ v _ 1 . Из переходного замыкания мы можем использовать оба из них, чтобы сделать вывод, что l3 также превосходит l20 , поскольку l3 что-то превосходит (в данном случае l17 ), что, в свою очередь, превышает l20 .
Отношение с общим аргументом , где EP C и D ссылаются на одну и ту же переменную в одной или нескольких позициях своих аргументов. Например, на рисунке 1 l28 : complex_rel имеет общий ARG1 с ARG0 из l104 : _ diffation_n_of , поскольку оба слота заполнены одной и той же переменной x23 .Мы также в некоторых случаях налагаем дополнительные ограничения на типы аргументов ( ARG0 , RSTR и т. Д.), Которые могут совместно использоваться на любом конце связи.
Наборы признаков и классификация
Векторы признаков для данного события конструируются на основе триггерного слова для этого события, которое, как мы предполагаем, уже было идентифицировано. Мы используем термин триггерные EPs , чтобы описать EP (ы), которые соответствуют этому триггерному слову — i.е. те, чей диапазон символов охватывает слово триггера. У нас есть потенциально большой набор связанных EP (с типами отношений, описанными выше), которые мы фильтруем для создания различных наборов функций, как описано ниже.
Следующие функции используются для определения ОТРИЦАТЕЛЬСТВА. В каждом случае устанавливается общая характеристика (например, NegOutscope2), а также конкретная функция для соответствующего предиката.
NegOutscope2: EP в RMRS принадлежит набору из девяти семантически отрицательных предикатов (например,грамм. _ cannot_a или _ never_a ) определяется путем ручной проверки небольшого подмножества данных разработки, и этот EP превосходит триггерный EP.
NegConjIndex: EP в RMRS принадлежит набору из трех отрицательных конъюнкций (_ nor_c, _not_c и _ , но + not_c ), идентифицированных из грамматики, и отрицательные дочерние элементы этого EP являются ARG0 триггера ЭП.
Arg0NegOutscopeeSA: EP имеет аргумент, который соответствует ARG0 триггерного EP, который, в свою очередь, превосходит тот же набор отрицательных EP, что и для NegOutscope2. Эта функция предназначена для перехвата триггерных EP, которые являются существительными, в которых доминирующий предикат семантически инвертируется.
TrigPredProps: имя предиката каждого EP триггера, а также его POS.
Ниже перечислены особенности, позволяющие идентифицировать СПЕКУЛЯЦИЮ. Еще раз, в каждом случае устанавливаются как общая функция, так и специальная функция на основе предикатов.
SpecVObj2 + WN: найден один из предварительно идентифицированного начального набора из шести умозрительных глаголов (например, _ test или _ study ), где его ARG2 (то есть объект) — это ARG0 триггерного EP .Мы дополнительно включаем сестры умозрительных глаголов WordNet, а в случае совпадения сестры WordNet добавляем дополнительную функцию для спекулятивных глаголов-семян (в исходном наборе). Первоначальные глаголы были идентифицированы путем изучения подмножества данных о развитии.
ModalOutscope: модальный глагол (например, должен ) превосходит триггерный EP.
AnalysisSA: ARG0 триггерного EP также является аргументом EP с именем предиката _ analysis _ n .Такие конструкции с использованием слова анализ относительно часто встречаются в спекулятивных событиях в данных.
ModAdj: любые прилагательные или наречные EP, которые имеют ARG1 (соответствует измененному существительному или глаголу), который соответствует ARG0 триггерного EP (т.е. которые являются модификаторами).
Оба этих набора функций такие же, как наиболее успешные наборы функций «N4» и «S3», использованные в [7].
Объединение RMRS из разных источников
Учитывая, что у нас есть несколько потенциальных источников RMRS для создания векторов признаков, существует несколько возможных способов их объединения. Первый — это запасной метод. Мы больше уверены в синтаксических анализах ERG и их способности создавать RMRS по ряду причин: ERG — более глубокая грамматика, в отличие от преднамеренной поверхностности синтаксического анализатора RASP , поэтому мы ожидаем, что где он может найти синтаксический анализ, чтобы его анализ содержал больше полезной информации; Кроме того, RMRS ближе к собственному формату для ERG , поскольку он построен композиционно как часть процесса синтаксического анализа, а не на этапе постобработки, как в случае с RASP .На основе этого мы используем RMRS, производный от ERG , где он доступен, а где его нет, возвращаемся к RMRS, производному от RASP .
Альтернативой является равное доверие к обоим источникам RMRS. В каждом предложении будет ноль, один или два доступных RMRS. В первом случае, когда у нас есть один РМРС, мы строим из него фичи как обычно. Там, где есть два RMRS, мы создаем признаки из каждого и берем объединение, чтобы сформировать единый вектор признаков. Вариантом этого метода является создание одного и того же объединенного вывода, если имеется несколько входных RMRS, но также создание версии каждой функции, которая помечена источником RMRS.Интуиция здесь заключается в том, что, хотя между выходными данными RMRS есть некоторые общие черты, каждая грамматика может иметь разные сильные и слабые стороны с точки зрения создания RMRS, поэтому для алгоритма машинного обучения может быть полезно иметь (косвенное) знание того, какая грамматика создала особенность.
Функции пакета слов
Чтобы оценить повышение производительности, полученное за счет синтаксического анализа, по сравнению с более простыми методами, мы также экспериментировали с наборами функций, основанными на подходе набора слов с скользящим контекстным окном токенов по обе стороны от токен, соответствующий триггеру, как определено токенизацией теггера GENIA, без пересечения границ предложения.Мы оценили диапазон комбинаций размеров предшествующего и последующего контекстных окон от 0 до 5 (никогда не пересекали границы предложения) и оптимизировали размер окна для каждой из подзадач SPECULATION и NEGATION.
Контекстное окно мешка слов является надежным и дает 100% охват, поэтому оно дает нам возможность классифицировать предложения, которые не поддаются синтаксическому анализу с помощью любого синтаксического анализатора. Также возможно, что даже в предложениях, которые мы можем анализировать с помощью ERG и / или RASP , модификации событий, которые он может обнаружить, по крайней мере частично дополняют те, которые обнаруживаются с помощью функций, полученных из RMRS, что предполагает комбинированный подход. .
Реализация классификатора
Для создания обучающих данных для подачи в классификатор мы проанализировали как можно больше предложений, используя ERG и / или RASP , и использовали выходные RMRS для создания обучающих данных, опираясь на описанные функции выше. Однако построение функций предполагает аннотации для событий и триггерных слов. Для создания обучающих данных мы использовали предоставленные аннотации триггеров. На этапе тестирования мы просто используем выходные данные различных классификаторов Задачи 1 в качестве источника аннотаций триггеров, выбирая комбинацию с лучшей производительностью по всему набору разработки.Мы использовали классификатор максимальной энтропии, применив Maxent Toolkit Чжан Ле (http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html).
POS-теги с помощью NLTK и фрагменты в NLP [ПРИМЕРЫ]
POS-теги
POS-теги (теги частей речи) — это процесс разметки слов в текстовом формате для определенной части речи на основе его определение и контекст. Он отвечает за чтение текста на языке и присвоение определенного токена (частей речи) каждому слову.Это также называется грамматической разметкой.
Давайте учимся на примере части речи NLTK:
Входные данные: все, что нам разрешено.
Выход : [(‘Everything’, NN), (‘to’, TO), (‘allow’, VB), (‘us’, PRP)]
Шаги, задействованные в примере тегов POS:
- Токенизируйте текст (word_tokenize)
- примените pos_tag к вышеуказанному шагу, то есть nltk.pos_tag (tokenize_text)
Примеры тегов POS NLTK: координирующее соединение Приведенный выше список тегов POS NLTK содержит все теги POS NLTK.NLTK POS tagger используется для присвоения грамматической информации каждому слову предложения. Установка, импорт и загрузка всех пакетов POS NLTK завершены. Разделение на части в НЛП — это процесс, позволяющий взять небольшие фрагменты информации и сгруппировать их в большие единицы. Основное использование Chunking — это создание групп из «именных фраз». Он используется для добавления структуры к предложению с помощью тегов POS в сочетании с регулярными выражениями. Полученная группа слов называется «чанками».»Это также называется поверхностным анализом. При поверхностном анализе существует максимум один уровень между корнями и листьями, в то время как глубокий анализ включает более одного уровня. Мелкий анализ также называется легким анализом или разбиением на части. Предварительно определенных правил нет, но вы можете комбинировать их в соответствии с потребностями и требованиями. Например, вам нужно пометить существительное, глагол (прошедшее время), прилагательное и координирующее соединение из предложения. Вы можете использовать правило, как показано ниже кусок: { В следующей таблице показано, что означают различные символы: Теперь давайте напишем код, чтобы лучше понять правило Выход Вывод из приведенного выше примера тегирования части речи в Python: «make» — это глагол, который не включен в правило, поэтому он не помечен как mychunk Chunking используется для обнаружения сущностей.Сущность — это часть предложения, с помощью которой машина получает значение для любого намерения Другими словами, разбиение на части используется для выбора подмножеств токенов. Пожалуйста, следуйте приведенному ниже коду, чтобы понять, как фрагменты используются для выбора токенов. В этом примере вы увидите график, который будет соответствовать фрагменту именной фразы. Напишем код и нарисуем график для лучшего понимания. Выход : График Разделение словосочетаний на существительное График Из графика мы можем заключить, что «выучить» и «guru99» — это два разных токена, но они относятся к категории существительных, тогда как токен «от» не принадлежит существительному Фраза. Разделение на части используется для разделения разных токенов на один и тот же фрагмент. Результат будет зависеть от выбранной грамматики. Дальнейшее разбиение на части NLTK используется для тегирования шаблонов и исследования текстовых корпусов. Этап парсера состоит из двух частей: Анализатор , определенный в Процесс преобразования вносит изменения и дополнения в структуры данных, возвращаемые анализатором. Синтаксический анализатор должен проверить строку запроса (которая поступает в виде обычного текста) на предмет допустимого синтаксиса. Если синтаксис правильный, создается дерево синтаксического анализа и передается обратно; в противном случае возвращается ошибка. Синтаксический анализатор и лексер реализованы с использованием хорошо известных инструментов Unix bison и flex. Лексер определен в файле Анализатор определен в файле Файл Упомянутые преобразования и компиляции обычно выполняются автоматически с использованием make-файлов , поставляемых с исходным кодом PostgreSQL. Подробное описание зубров или грамматических правил, приведенных в Этап синтаксического анализатора создает дерево синтаксического анализа, используя только фиксированные правила о синтаксической структуре SQL. Он не выполняет поиск в системных каталогах, поэтому нет возможности понять подробную семантику запрошенных операций.После завершения синтаксического анализа процесс преобразования принимает дерево, возвращенное синтаксическим анализатором, в качестве входных данных и выполняет семантическую интерпретацию, необходимую для понимания того, на какие таблицы, функции и операторы ссылается запрос. Структура данных, созданная для представления этой информации, называется деревом запросов . Причина отделения необработанного синтаксического анализа от семантического анализа заключается в том, что поиск в системном каталоге может выполняться только внутри транзакции, и мы не хотим начинать транзакцию сразу после получения строки запроса.Стадии необработанного синтаксического анализа достаточно для идентификации команд управления транзакцией ( Дерево запросов, созданное в процессе преобразования, во многих местах структурно похоже на необработанное дерево синтаксического анализа, но имеет много отличий в деталях.Например, узел CD кардинальная цифра DT определитель EX экзистенциальный там FW иностранное слово 2 9000 подчиненное слово 2 IN JJ Этот тег POS NLTK является прилагательным (большим) JJR прилагательным, сравнительным (большим) JJ S прилагательное, превосходная степень (наибольшее) LS список рынка MD модальный (мог бы, будет) NN существительное, единственное число (кошка, дерево) 2 NNS существительное множественное число (столы) NNP существительное собственное, единственное число (sarah) NNPS существительное собственное, множественное число (индейцы или американцы) PDT оба предшествуют , половина) POS притяжательное окончание (родитель) PRP личное местоимение (ее, она, он, сам) PRP $ притяжательное местоимение (ее, его , мое, мое, наше) RB наречие (изредка, быстро) RBR наречие, сравнительное (большее) RBS наречие, превосходное (самый большой) RP частица (около) TO бесконечный маркер (to) UH междометие (до свидания) 2 (спросить) VBG глагол герундий (судейство) VBD глагол прошедшего времени (признанный) VBN глагол прошедшего времени причастия (воссоединенный) 2 настоящее время, а не 3-е лицо единственного числа (перенос) VBZ глагол, настоящее время с 3-м лицом единственного числа (основания) WDT wh-определитель (то, что) WP wh — местоимение (кто) WRB наречие (как) Что такое фрагменты в НЛП?
Правила разбиения на части:
Название символа Описание . Любой символ, кроме новой строки * Соответствует 0 или более повторений ? Совпадение 0 или 1 повторений
из nltk import pos_tag
из nltk import RegexpParser
text = "изучите php у guru99 и сделайте обучение легким".расколоть()
print ("После разделения:", текст)
tokens_tag = pos_tag (текст)
print ("После токена:", tokens_tag)
patterns = "" "mychunk: {
После разделения: ['learn', 'php', 'from', 'guru99', 'and', 'make', 'study', 'easy']
После токена: [('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('guru99', 'NN'), ('and', ' CC '), (' make ',' VB '), (' study ',' NN '), (' easy ',' JJ ')]
После Regex: чанк.RegexpParser с 1 этапом:
RegexpChunkParser с 1 правилом:
Use Case of Chunking
Пример:
Температура Нью-Йорка.
Здесь температура - это намерение, а Нью-Йорк - это сущность.
Код для демонстрации варианта использования
импортировать nltk
text = "учить php у guru99"
tokens = nltk.word_tokenize (текст)
печать (токены)
tag = nltk.pos_tag (токены)
печать (тег)
грамматика = "NP: {
['learn', 'php', 'from', 'guru99'] - это токены
[('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('guru99', 'NN')] - это pos_tag
(S (NP learn / JJ php / NN) от / IN (NP guru99 / NN)) - Разделение фраз существительного
Резюме
PostgreSQL: Документация: 11: 51.3. Этап парсера
грамм. Год и scan.l , построен с использованием инструментов Unix bison и flex. scan.l и отвечает за распознавание идентификаторов , ключевых слов и т. Д.Для каждого найденного ключевого слова или идентификатора создается токен и передается синтаксическому анализатору. gram.y и состоит из набора из грамматических правил и действий , которые выполняются всякий раз, когда правило срабатывает. Код действий (который на самом деле является кодом C) используется для построения дерева синтаксического анализа. scan.l преобразуется в исходный файл C scan.c с помощью программы flex и gram.y преобразуется в грамм. c с помощью зубра. После того, как эти преобразования были выполнены, для создания синтаксического анализатора можно использовать обычный компилятор C. Никогда не вносите никаких изменений в сгенерированные файлы C, так как они будут перезаписаны при следующем вызове flex или bison. Примечание
грамм.y выходит за рамки данной статьи. Есть много книг и документов, посвященных гибкости и бизону. Вы должны познакомиться с бизоном, прежде чем начнете изучать грамматику, данную в грамм на , иначе вы не поймете, что там происходит. 51.3.2. Процесс трансформации
BEGIN, , ROLLBACK, и т. Д.), И они затем могут быть правильно выполнены без какого-либо дальнейшего анализа. Как только мы узнаем, что имеем дело с фактическим запросом (например, SELECT или UPDATE ), можно начать транзакцию, если мы еще не в ней. Только после этого может быть запущен процесс преобразования. FuncCall в дереве синтаксического анализа представляет нечто синтаксически похожее на вызов функции. Это может быть преобразовано в узел FuncExpr или Aggref в зависимости от того, является ли указанное имя обычной функцией или агрегатной функцией. Кроме того, в дерево запроса добавляется информация о фактических типах данных столбцов и результатах выражений.