Слова «светом» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «светом» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «светом» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «светом».
Содержимое:
- 1 Слоги в слове «светом» деление на слоги
- 2 Как перенести слово «светом»
- 3 Морфологический разбор слова «светом»
- 4 Разбор слова «светом» по составу
- 5 Сходные по морфемному строению слова «светом»
- 6 Синонимы слова «светом»
- 7 Антонимы слова «светом»
- 8 Ударение в слове «светом»
- 9 Фонетическая транскрипция слова «светом»
- 10 Фонетический разбор слова «светом» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «светом»
- 12 Сочетаемость слова «светом»
- 13 Значение слова «светом»
- 14 Как правильно пишется слово «светом»
- 15 Ассоциации к слову «светом»
Слоги в слове «светом» деление на слоги
Количество слогов: 2
По слогам: све-том
Как перенести слово «светом»
све—том
Морфологический разбор слова «светом»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: мужской;
число: единственное;
падеж: творительный;
остальные признаки: singularia tantum;
отвечает на вопрос: (доволен;
творю под/между/за) Чем?
Начальная форма:
свет
Разбор слова «светом» по составу
| свет | корень |
| ø | нулевое окончание |
свет
Сходные по морфемному строению слова «светом»
Сходные по морфемному строению слова
Синонимы слова «светом»
1. огонь
огонь
2. бомонд
3. аристократия
4. знать
5. цвет
6. пламя
7. пламень
8. сияние
9. блеск
10. блистание
11. мерцание
12. освещение
13. электросвет
14. заря
15. земля
16. мир
17. общество
18. свечение
19. сверкание
20. рассвет
21. зорька
22. подлунная
23. поднебесная
24. подсолнечная
25. планета
26. вселенная
27. излучение
28. отсвет
29. проблеск
30. источник
31. лампа
32. свеча
33. освещенность
34. восход
35. светик
36. солнце
37. земной шар
38. наша планета
39. белый свет
40. божий мир
41. божий свет
42. подлунный мир
43. дольний мир
44. бренный мир
45. земная юдоль
46. юдоль плача
47. юдоль скорби
48. высший свет
49. большой свет
50. царство покоя
51. высшее общество
52. сливки общества
53.
54. светка
55. быша
Антонимы слова «светом»
1. тьма
2. мрак
3. темнота
4. тень
5. затемнение
Ударение в слове «светом»
све́том — ударение падает на 1-й слог
Фонетическая транскрипция слова «светом»
[св’`этам]
Фонетический разбор слова «светом» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| в | [в’] | согласный, звонкий парный, мягкий | в |
| е | [`э] | гласный, ударный | е |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| о | [а] | гласный, безударный | о |
| м | [м] | согласный, звонкий непарный (сонорный), твёрдый | м |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 6 букв и 6 звуков.
Буквы: 2 гласных буквы, 4 согласных букв.
Звуки: 2 гласных звука, 4 согласных звука.
Предложения со словом «светом»
Но уже на полпути к селению мы должны были неизбежно оказаться в полосе яркого лунного света
.Источник: Р. Л. Стивенсон, Остров Сокровищ, 1883.
Именно там и вспыхнул яркий свет первой месопотамской цивилизации.
Источник: В. И. Гуляев, Шумер. Вавилон. Ассирия: 5000 лет истории, 2005.
Шоссе всё так же одиноко внизу, в лучах яркого дневного света и в пыли.
Источник: Назым Хикмет, Жизнь прекрасна, братец мой, 2013.
Сочетаемость слова «светом»
1. солнечный свет
2. яркий свет
3. лунный свет
4. свет фонаря
свет фонаря
5. свет лампы
6. свет солнца
7. луч света
8. конец света
9. на край света
10. свет погас
12. свет исчез
13. включить свет
14. выключить свет
15. увидеть свет
16. (полная таблица сочетаемости)
Значение слова «светом»
СВЕТ1 , -а (-у), предл. в све́те, на свету́, м. 1. Электромагнитное излучение, воспринимаемое глазом и делающее видимым окружающий мир. Солнечный свет. Свет луны. Свет свечи. Луч света. Скорость света. Преломление света. Свет и тьма.
СВЕТ2 , -а, м. 1. Земля со всем существующим на ней, мир1, вселенная. Части света. Путешествие вокруг света. (Малый академический словарь, МАС)
Как правильно пишется слово «светом»
Правописание слова «светом»
Орфография слова «светом»
Правильно слово пишется:
Нумерация букв в слове
Номера букв в слове «светом» в прямом и обратном порядке:
Ассоциации к слову «светом»
Фара
Лампа
Фонарь
Прожектор
Заря
Факел
Абажур
Выключатель
Канделябр
Бел
Лампочка
Люстра
Луна
Оконце
Свеча
Светильник
Жалюзи
Фонарик
Штора
Светофор
Витраж
Неяркий
Лунный
Тусклый
Дневной
Мертвенный
Керосиновый
Солнечный
Неоновый
Яркий
Горелый
Сумеречный
Голубоватый
Ослепительный
Красноватый
Рассеянный
Призрачный
Настольный
Зеленоватый
Масляный
Желтоватый
Матовый
Закатный
Розоватый
Неверный
Дневный
Озарять
Меркнуть
Померкнуть
Озариться
Забрезжить
Залить
Литься
Озарить
Заливать
Погасить
Пробиваться
Мерцать
Погаснуть
Просачиваться
Освещать
Проникать
Выключать
Ослепить
Выключить
Пролить
Освещаться
Проливать
Зажечь
Излучать
Видывать
Слепить
Потушить
Зажигать
Гасить
Засиять
Струиться
Осветиться
Ослеплять
Поблескивать
Отражаться
Гаснуть
Клясть
Отливать
Угасать
Переливаться
Отбрасывать
Сочиться
Испускать
Осветить
Лучиться
Отражать
Отсвечивать
Потухнуть
Выхватывать
Искриться
Высветить
Пронизать
Блеснуть
Тускло
Опубликовано: 2020-08-06
Популярные слова
воспитанник , беседами , взбежавшие , взъерошив , выскребу , высчитанною , вытравлявшей , вячеславом , гемолизом , геннадиевичи , гимнастерочку , домоустройство , завибрируют , завинчивающимся , павлиньего , парабеллумами , парковавшемся , перебираемыми , плакатная , подающее , подлетать , подросту , положительнейшего , помпонах , поохотившимся , пражского , прогульном , прокашливаться , проституируя , противогазовые , развернувшее , разделе , раскрутилось , раскусывают , расторгну , резервированного , реорганизовавшем , респонсорною , сильванер , солея
Как работает voice2json | voice2json
На высоком уровне voice2json преобразует аудиоданные (голосовые команды) в события JSON.
Голосовые команды указываются заранее в компактном текстовом формате:
[Состояние света]
состояния = (вкл | выкл)
включите (<состояния>){состояние} [the] свет
Этот формат поддерживает:
-
[дополнительные слова] -
(альтернативный | выбор) -
имя = тело— правила -
<имя правила>— ссылки на правила -
(значение) {имя}— теги -
ввод: вывод— замены -
$movies— списки слотов -
1..100— числовые серии -
ТЕКСТ!поплавок— преобразователи
Во время обучения voice2json генерирует артефакты, которые могут распознавать и декодировать указанные голосовые команды. Если эти команды изменятся, voice2json необходимо переобучить.
Основные компоненты
Основные функции voice2json можно разделить на компоненты распознавания речи и намерений.
Когда голосовые команды распознаются речевым компонентом, транскрипция передается распознавателю намерений для обработки. Конечным результатом является структурированное событие JSON с:
- Имя намерения
- Распознанные слоты/сущности
- Необязательные метаданные о процессе распознавания речи
- Ввод текста, времени, жетонов и т. д.
Например:
{
"текст": "включи свет",
"намерение": {
"имя": "LightState"
},
"слоты": {
"состояние": "включено"
}
}
Преобразование речи в текст
Автономная транскрипция голосовых команд в voice2json обрабатывается одной из трех систем с открытым исходным кодом:
- Карманный сфинкс
- КМУ (2000)
- Калди
- Джонс Хопкинс (2009)
- Глубокая речь
- Мозилла (v0.6, 2019)
Для Pocketsphinx и Kaldi требуется:
- Акустическая модель
- Сопоставляет звуковые функции с фонемами
- Словарь произношения
- Преобразование фонем в слова
- Языковая модель
- Описывает, как часто слова следуют за другими словами
DeepSpeech объединяет акустическую модель и словарь произношения в единую нейронную сеть. Однако он по-прежнему использует языковую модель.
Однако он по-прежнему использует языковую модель.
Акустическая модель
Акустическая модель сопоставляет акустические/речевые характеристики с вероятными фонемами данного языка.
Обычно в качестве акустических признаков используются коэффициенты кепстра частот Mel (сокращенно MFCC). Они математически выделяют полезные аспекты человеческой речи.
Фонемы зависят от языка (и даже от локали). Это неделимых единиц произношения слов. Определение фонем языка требует лингвистического анализа, и могут возникнуть споры по поводу окончательного набора. Отдельные человеческие языки обычно имеют не более нескольких десятков фонем. Набор всех возможных фонем может быть представлен с помощью Международного фонетического алфавита.
Акустическая модель представляет собой статистическое сопоставление между звуковыми характеристиками (MFCC) и одной или несколькими фонемами. Это сопоставление изучается из большой коллекции речевых примеров вместе с их соответствующими транскрипциями. Предварительно созданный словарь произношения необходим для сопоставления транскрипций с фонемами, прежде чем можно будет обучить модель. Сбор, расшифровка и проверка этих больших наборов речевых данных является ограничивающим фактором в распознавании речи с открытым исходным кодом.
Предварительно созданный словарь произношения необходим для сопоставления транскрипций с фонемами, прежде чем можно будет обучить модель. Сбор, расшифровка и проверка этих больших наборов речевых данных является ограничивающим фактором в распознавании речи с открытым исходным кодом.
Словарь произношений
Словарь, отображающий последовательности фонем в слова, необходим как для обучения акустической модели, так и для распознавания речи. Для каждого слова возможно более одного сопоставления (произношения).
Для практических целей давайте будем считать слово просто «вещью между пробелами» в тексте. Независимо от того, как именно вы определяете, что такое «слово», важнее всего последовательность: кто-то должен решить, являются ли сложные слова (например, «предварительно построенные»), сокращения и т. д. отдельными («предварительно построенными») или составными словами ( «предварительно» и «построено»).
Ниже приведена таблица примеров фонем для американского английского языка из Словаря произношения CMU.
| Фонема | Слово | Произношение |
|---|---|---|
| АА | нечетный | АА Д |
| АЕ | в | АЕ Т |
| АХ | хижина | НХ АХ Т |
| АО | должен | АО Т |
| AW | корова | К AW |
| АЮ | скрыть | ЧЧ АУ Д |
| Б | будет | Б ИЮ |
| Ч | сыр | Ч Й З |
| Д | ди | Д ИЙ |
| ДХ | тэ | ДХ IY |
| ЕН | Эд | ЭХ Д |
| ЕР | ранить | ЧЕР Т |
| ЭЙ | съел | ЭЙ Т |
| Ф | плата | Ф 1Г |
| Г | зеленый | Г Р И Я N |
| ЧЧ | он | ЧЧ IY |
| ИХ | это | ИХ Т |
| ИГ | есть | ИЮ Т |
| ДЖХ | гы | JH IY |
| К | ключ | К ИЮ |
| Л | ли | Л ИЙ |
| М | я | М ИГ |
| Н | колено | Н Й |
| НГ | пинг | ПИХ НГ |
| ОВ | овес | ВОВ Т |
| ОУ | игрушка | ТОЙ |
| П | пописать | П ИЙ |
| Р | читать | Р ИЙ Д |
| С | море | S IY |
| Ш | она | Ш ИЮ |
| Т | чай | Т ИЙ |
| ТХ | тета | ТЭЙ Т АХ |
| UH | капот | ЧХ УХ Д |
| ВВ | два | Т УВ |
| В | и | В ИГ |
| Ш | мы | Вт IY |
| Д | выход | Г ИГ Л Д |
| З | зи | З IY |
| Ж | изъятие | С ИЙ Ж ЭР |
Более поздние версии этого словаря включают ударение, указывающее, на какие части слова делается ударение во время произношения.
Во время обучения voice2json копирует произношения для каждого слова в ваших шаблонах голосовых команд из большого предварительно созданного словаря произношений. Произношение слов, которых нет в этом словаре, угадывается с использованием предварительно обученной модели графемы в фонему.
Графема в фонему
Модель графема-фонема (G2P) может использоваться для угадывания фонетического произношения слов. Это статистическая модель, которая сопоставляет последовательности символов (графем) с последовательностями фонем и обычно обучается на основе большого предварительно созданного словаря произношения. voice2json использует для этой цели инструмент под названием Phonetisaurus.
Модель языка
Языковая модель описывает, как часто одни слова следуют за другими. Обычно можно увидеть модели, которые состоят из одного-трех слов подряд.
Языковые модели создаются из большого массива текстов, таких как книги, новостные сайты, Википедия и т.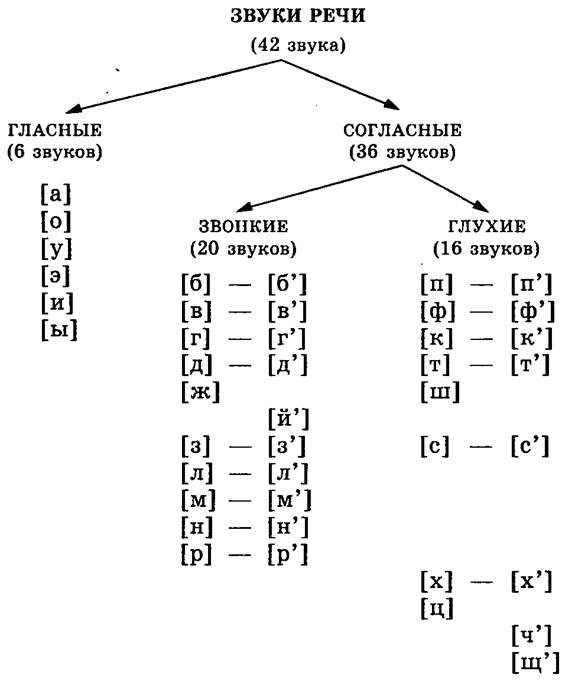 д. Не все комбинации будут присутствовать в обучающем материале, поэтому их вероятности необходимо предсказывать с помощью эвристики.
д. Не все комбинации будут присутствовать в обучающем материале, поэтому их вероятности необходимо предсказывать с помощью эвристики.
Ниже приведен вымышленный пример вероятностей одиночных/парных/тройных слов для корпуса, который содержит только слова «sod», «sawed», «that», «that’s» и «odd».
0,2 дерн 0,2 распиленный 0,2 что 0,2 это 0,2 нечетный 0,25 странно 0.25 что распилил 0.25 это дерьмо 0,25 странно, что 0.5 как то странно 0,5 черт возьми
Во время распознавания речи входящие фонемы могут соответствовать более чем одному слову из словаря произношения. Языковая модель помогает сузить круг возможных вариантов, сообщая распознавателю речи, что некоторые сочетания слов очень маловероятны и могут быть проигнорированы.
Фрагменты предложений
Языковая модель не содержит вероятности целых предложений, только фрагментов предложения . Для получения полного предложения от распознавателя речи требуется несколько приемов:
- Добавление виртуального начального/конечного предложения «слова» (
-
какое время -
это— конец предложения «…это?»
-
- Использовать скользящие временные окна
- Фрагменты сшиваются с помощью перекрывающихся окон
- «который час», «время», «это» для предложения «который час»
- Прерывание звука при длительных паузах или постоянное использование одного предложения
- Вы всегда можете предположить, что первое «слово»
- Но куда поставить
- Вы всегда можете предположить, что первое «слово»
При использовании этих трюков распознаваемые «предложения» могут оставаться бессмысленными и иметь мало общего с предыдущими предложениями. Например:
Например:
тот дерн, что тот дерн, который пилил...
Современные нейронные сети-трансформеры могут намного лучше обрабатывать долгосрочные зависимости внутри и между предложениями, но:
- Им требуется огромное количество обучающих данных
- Они могут быть медленными/ресурсоемкими для (повторного) обучения и выполнения без специализированного оборудования
Для предполагаемого использования voice2json (заранее заданные короткие голосовые команды) приведенные выше приемы обычно достаточно хороши. Хотя облачные сервисы можно использовать с voice2json , существует компромисс между конфиденциальностью и отказоустойчивостью (потеря Интернета или облачной учетной записи).
Обучение языковой модели
Во время обучения voice2json генерирует пользовательскую языковую модель на основе ваших шаблонов голосовых команд (обычно в формате ARPA). Благодаря библиотеке opengrm, voice2json может брать промежуточный граф предложений, созданный на начальных этапах обучения, и напрямую генерировать языковую модель! Это включает voice2json для обучения за считанные секунды даже миллионам возможных голосовых команд.
Смешивание языковых моделей
Пользовательскую языковую модель voice2json можно при желании смешивать с гораздо большей заранее созданной языковой моделью. В зависимости от того, какой вес придается той или иной модели, это повысит вероятность ваших голосовых команд на фоне общих предложений на языке профиля.
При правильном смешивании voice2json способен к (почти) неограниченному распознаванию речи с предпочтением голосовых команд пользователя. К сожалению, это обычно приводит к снижению производительности распознавания речи и множеству других сбоев распознавания намерений (которые обучаются только на голосовых командах пользователя).
Текст для намерения
Система(ы) распознавания речи в voice2json создает текстовые транскрипции, которые затем передаются в систему распознавания намерений. Когда и речь, и система намерений обучаются вместе с одним и тем же файлом шаблона, все допустимые команды (с небольшими вариациями) должны быть правильно преобразованы в события JSON.
voice2json преобразует набор возможных голосовых команд в граф, который действует как преобразователь конечного состояния (FST). При получении действительного предложения в качестве входных данных этот преобразователь будет выводить (преобразованное) предложение вместе с «мета»-словами, которые определяют намерение предложения и именованные сущности.
В качестве примера рассмотрим приведенный ниже шаблон предложения для намерения LightState :
[Состояние света]
состояния = (вкл | выкл)
включите (<состояния>){состояние} [the] свет
При обучении с этим шаблоном voice2json сгенерирует такой график:
Каждое состояние помечено цифрой, а ребра (стрелки) тоже имеют метки. Метки ребер имеют специальный формат, который представляет входные данные, необходимые для прохождения ребра, и соответствующие выходные данные. Двоеточие («:») разделяет входные/выходные слова по краю и опускается, если входные и выходные данные совпадают. Выходные «слова», начинающиеся с двух символов подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении.
Выходные «слова», начинающиеся с двух символов подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении.
Приведенный выше FST примет все возможные предложения в файле шаблона:
- включить свет
- включить свет
- выключить свет
- выключить свет
Это вывод, когда FST принимает каждое предложение:
| Вход | Выход |
|---|---|
включи свет | __label__LightState включить __begin__state on __end__state свет |
включить свет | __label__LightState включите __begin__state on __end__state свет |
выключить свет | __label__LightState включить __begin__state выключить __end__state свет |
выключить свет | __label__LightState включить __begin__state выключить __end__state свет |
Обозначение __label__ взято из fasttext, высокопроизводительной системы классификации предложений. Для каждого предложения создается одно мета-слово
Для каждого предложения создается одно мета-слово __label__ , помечающее его именем намерения свойства.
Метаслова __begin__ и __end__ используются voice2json для создания события JSON для каждого предложения. Они отмечают начало и конец помеченного блока текста в исходном файле шаблона — например, (вкл | выкл) {состояние} . Эти начальные/конечные символы можно легко преобразовать в общую схему аннотирования корпусов текстов (IOB) для обучения распознавателя именованных сущностей (NER). Например, flair может читать такие корпуса и обучать NER с помощью PyTorch.
Библиотека voice2json NLU в настоящее время использует следующий набор метаслов:
-
__label__INTENT- Предложение принадлежит намерению с именем
НАМЕРЕНИЕ
- Предложение принадлежит намерению с именем
-
__begin__TAG- Начало тега с именем
TAG
- Начало тега с именем
-
__end__TAG- Конец тега с именем
TAG
- Конец тега с именем
-
__convert__CONV- Начало преобразователя имени
CONV
- Начало преобразователя имени
-
__converted__CONV- Конец преобразователя с именем
CONV
- Конец преобразователя с именем
-
__source__SLOT- Имя списка слотов, откуда был взят текст
-
__unpack__PAYLOAD- Декодирует
PAYLOADкак строку в кодировке base64, а затем интерпретирует как метку края
- Декодирует
фастфуды
voice2json Распознаватель намерений на основе FST называется fsticuffs .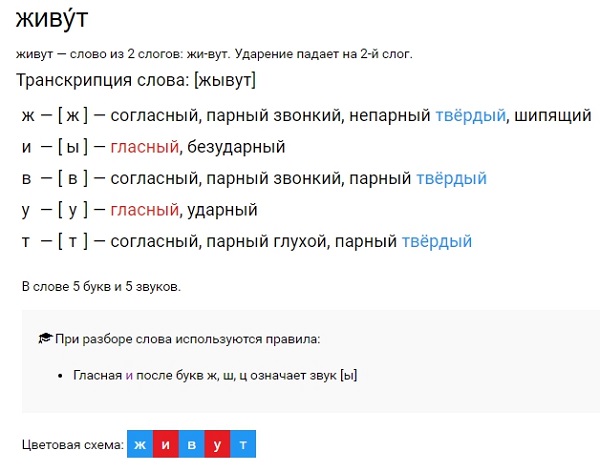 Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON.
Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON.
Распознавание намерений выполняется путем простого запуска транскрипции через граф намерений и анализа выходных слов (и метаслов). Транскрипция «включи свет» разбивается (по пробелам) на слова поворот на свет .
Следуя пути через приведенный выше пример графа намерений со словами в качестве входных символов, будет выведено:
__метка__LightState очередь __begin__state на __end__state свет
Довольно простой конечный автомат получает эти символы/слова и создает структурированное намерение, которое в конечном итоге преобразуется в JSON. Имя намерения и именованные объекты восстанавливаются с использованием метаслов __label__ , __begin__ и __end__ . Все немета-слова собираются для окончательной текстовой строки, включая замены и преобразования. Окончательный результат примерно такой:
Все немета-слова собираются для окончательной текстовой строки, включая замены и преобразования. Окончательный результат примерно такой:
{
"текст": "включи свет",
"намерение": {
"имя": "LightState"
},
"слоты": {
"состояние": "включено"
}
}
Нечеткие FST
Что, если fsticuffs должны были получить транскрипцию «вы бы включили свет»? Это недопустимый пример голосовой команды, но представляется разумным принять ее с помощью ввода текста (например, в чате).
Поскольку будет , а вы не являются словами, закодированными в намерении, FST не сможет его распознать. Чтобы справиться с этим, voice2json позволяет молча пропускать стоп-слова во время распознавания, если они не были бы приняты. Этот «нечеткий» режим распознавания работает медленнее, но позволяет принять больше предложений.
Заключение
При обучении voice2json выдает следующие артефакты:
- Словарь произношения, содержащий только слов из ваших шаблонов голосовых команд
- Произношение слов, отсутствующих в словаре, угадывается с использованием модели графемы к фонеме
- Граф намерений, который используется для распознавания намерений из предложений
- При желании можно игнорировать общие слова, чтобы обеспечить более «нечеткое» распознавание
- Языковая модель, сгенерированная непосредственно из графа намерений с помощью opengrm
- Это может быть опционально смешано с большой предварительно созданной языковой моделью
Обзор языка разметки синтеза речи (SSML) — служба распознавания речи — Azure Cognitive Services
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
Язык разметки синтеза речи (SSML) — это язык разметки на основе XML, который можно использовать для точной настройки выходных атрибутов преобразования текста в речь, таких как высота тона, произношение, скорость речи, громкость и т. д. У вас больше контроля и гибкости по сравнению с обычным вводом текста.
Подсказка
Вы можете слушать голоса в разных стилях и тональностях, читая пример текста через голосовую галерею.
Сценарии
С помощью SSML можно:
- Определить структуру входного текста, которая определяет структуру, содержание и другие характеристики преобразования текста в речь. Например, вы можете использовать SSML для определения абзаца, предложения, разрыва или паузы или тишины. Вы можете обернуть текст тегами событий, такими как закладка или визема, которые позже могут быть обработаны вашим приложением.
- Выберите голос, язык, имя, стиль и роль. Вы можете использовать несколько голосов в одном документе SSML.
 Отрегулируйте акцент, скорость речи, высоту тона и громкость. Вы также можете использовать SSML для вставки предварительно записанного звука, например звукового эффекта или музыкальной ноты.
Отрегулируйте акцент, скорость речи, высоту тона и громкость. Вы также можете использовать SSML для вставки предварительно записанного звука, например звукового эффекта или музыкальной ноты. - Управление произношением выходного звука. Например, вы можете использовать SSML с фонемами и пользовательским словарем для улучшения произношения. Вы также можете использовать SSML, чтобы определить, как произносится слово или математическое выражение.
 Отрегулируйте акцент, скорость речи, высоту тона и громкость. Вы также можете использовать SSML для вставки предварительно записанного звука, например звукового эффекта или музыкальной ноты.
Отрегулируйте акцент, скорость речи, высоту тона и громкость. Вы также можете использовать SSML для вставки предварительно записанного звука, например звукового эффекта или музыкальной ноты.Использовать SSML
Важно
Плата взимается за каждый символ, преобразованный в речь, включая знаки препинания. Хотя сам документ SSML не подлежит оплате, необязательные элементы, которые используются для настройки преобразования текста в речь, такие как фонемы и высота тона, учитываются как оплачиваемые символы. Дополнительные сведения см. в примечаниях к ценам на преобразование текста в речь.
Вы можете использовать SSML следующими способами:
- Инструмент для создания аудиоконтента: создавайте обычный текст и SSML в Speech Studio: вы можете прослушивать выходной звук и настраивать SSML для улучшения синтеза речи.
