зачем он нужен, и как его сделать
Изучение русского языка начинается с первых же классов общеобразовательной школы. Это непростая задача. Школьники младшего возраста изучают целую группу дисциплин, которые имеют преимущественно научную направленность. В меньшей степени — прикладную. Например, синтаксис, морфемику и не только. Раздел, который занимается изучением звуковых особенностей слов называется фонетикой. На нашем сайте вы можете заказать услуги по написанию диссертационных работ, а также курсовых, дипломных и многих других на выгодных условиях.
СОДЕРЖАНИЕ
Что такое фонетика?Звуковой или фонетический разбор слова — это типичный формат, с которым школьники сталкиваются в младших классах. В некоторых учебных заведениях его изучают с 1-го, в других — со 2-го класса. Суть фонетического разбора — понять, из скольких слогов состоит слово, сколько в нем звуков и какие они по составу.
Кажется, что принципиальной пользы такое занятие не несет. Но это не так. Специалисты по педагогике и логопеды указывают на большое значение звукового разбора слова как элемента развития специфического слуха, чувства русского языка. Точно так же при изучении иностранных языков используются транскрипции.
Но это не так. Специалисты по педагогике и логопеды указывают на большое значение звукового разбора слова как элемента развития специфического слуха, чувства русского языка. Точно так же при изучении иностранных языков используются транскрипции.
Звуковой разбор проводится по определенным правилам. Но нередко вызывает сложности даже у более старших школьников. Разберемся же, как и зачем его проводить.
Подробнее о структуре фонетического разбора словаЗвуковой разбор слова представляет собой распространенный и отработанный формат работы. Фонетический анализ включает в себя несколько составных компонентов:
- Первый — определение количества слогов, из которых состоит рассматриваемое слово. С этим проблемы возникают, как правило, редко. Обычно лишь в самом начале, когда школьники только постигают азы анализа, учатся.
- Второй — транскрипция. Переведение слова в фонематическую схему. Основные сложности касаются того факта, что количество букв и число звуков могут различаться.
 Это особенно путает. Но по мере опыта все становится нормально.
Это особенно путает. Но по мере опыта все становится нормально. - Определение точного ударения. Имеет место еще и запоминание. Это необходимо для того, чтобы грамотно говорить.
- Разбор каждого звука в слове. Гласный он или согласный. Глухой или звонкий и т.д.
- Определение общего количества звуков и букв. Подсчет и описание.
 Это особенно путает. Но по мере опыта все становится нормально.
Это особенно путает. Но по мере опыта все становится нормально.Эти структурные элементы входят в состав любого звукового анализа слова. Нередко задания на разбор дают в самостоятельных и контрольных работах. Диктантах, чтобы закрепить знания ученика и помочь ему натренировать соответствующий навык. Обычно по мере наработки умения, накопления опыта, проблем с определением звукобуквенного состава уже не возникает. Это вопрос времени и часов правильной практики. Как и остальные виды разборов слов, предложений в русском языке и не только.
Подробнее о структуре фонетического разбора словаЗвуковой анализ при изучении иностранных языков проводится несколько по-другому. В основе его лежит перевод слова в транскрипцию. Имеет значение не столько звукобуквенный состав, сколько правильное произношение. С определением верного ударения и точного звукового состава.
Имеет значение не столько звукобуквенный состав, сколько правильное произношение. С определением верного ударения и точного звукового состава.
Звуковой разбор — это работа, с которой сталкиваются преимущественно школьники младших классов. Формат используется для наработки навыка слушания. В первую очередь. Также благодаря использованию методов фонетического анализа у учащихся появляется возможность более грамотно писать.
Задачу звукового разбора могут решать и другие категории:
- Иностранцы. Русский язык славится своими правилами и многочисленными исключениями. Если не брать в расчет синтаксис, пунктуацию, фонетика считается одним из самых сложных разделов. Наравне с общей грамматикой. Чтобы лучше понять русский, иностранцы систематически занимаются разными видами анализа. И звуковой разбор — это основа изучения. Для тех, кому русский язык не родной, фонетический анализ требуется как инструмент понимания свойств слов, их состава. В некоторых случаях еще и правил построения слов.
 В некоторых случаях еще и правил построения слов.
В некоторых случаях еще и правил построения слов.Звуковое исследование слова может быть интересно и специалистам по лингвистике, филологам. Профессионалам в области словесности и русского языка в целом. Поскольку звуковой состав слова играет большую роль в выявлении закономерностей построения слов, определении их происхождения и функциональной направленности.
Следовательно, изучением звукового состава слова могут заниматься еще и ученые. Но их задачи совсем другие.
Зачем вообще нужен фонетический разбор словаЗвуковой разбор слова на составляющие на первый взгляд не имеет никакого смысла. По крайней мере, если говорить о школьниках младших классов. Это довольно сложный формат, котором нужно учиться. И даже в это случае сначала совершается множество ошибок.
И даже в это случае сначала совершается множество ошибок.
Как отмечают специалисты по лингвистике и педагоги, избыточным программа с разными формами анализа не считается. Русский язык в рамках общеобразовательной школы изучают не только как прикладную дисциплину, но и как науку. Знакомят подрастающее поколение с некоторыми инструментами. Теми, которые им помогут.
Фонетический разбор помогает развить общее чувство языка, а также улучшить собственные навыки, понимание речевых структур, конструкций, инструментов и приемов. Если говорит точнее, фонетический разбор нужен для решения нескольких задач:
- Получение углубленных знаний в области орфографии. Как именно пишется слово, где располагается ударение. Почему оно пишется именно так, а не иначе. Все это подспудно проникает в подсознание ученика, помогая ему говорить и писать более грамотно.
- Определение правописания. Многие звуки появляются в словах не просто так. Суть в том, чтобы помочь учащимся определить правила чередования гласных.
- Формирование четкого понимания, что слова пишутся не так как слышатся. Это очевидная вещь может быть не до конца понятна школьнику в 6-7 лет. Изучая правила фонетики правило четко фиксируется в сознании учащегося. На всю оставшуюся жизнь.
- Развитие орфографической зоркости. Она проявляет себя как ощущение. Например, при взгляде на слово, написанное с ошибкой, даже если оно не знакомо, школьник, хорошо знающий фонетику, без проблем определить проблему. Будет, что называется, резать глаз.
- Общее развитие чувства русского языка, понимания его правил.

Фонетика изучается в системе с грамматикой, синтаксисом, морфемикой, стилистикой и прочими разделами лингвистики. Школа дает ровно тот объем знаний, который требуется грамотному и всесторонне развитому человеку.
Большую роль фонетика играет в коррекционной педагогике, логопедии. Дети с расстройствами слуха, нарушениями артикуляции, заиканием практически всегда имеют речевые проблемы. И это может привести к расстройствам интеллектуального развития.
И это может привести к расстройствам интеллектуального развития.
Задача звукового разбора состоит в том, чтобы помочь ребенку научиться слушать и слышать русскую речь, ее оттенки и элементы. Фонетика в этом отношении играет основную роль. И применять ее можно по-разному. Можно учить ребенка на слух, а затем закреплять пройденный материал с помощью фонетического разбора, определения звукового состава конкретного слова. Или же действовать от обратного, сначала писать, потом проговаривать и слушать. Тут все зависит от принятой методики.
Правила и принципы поведения разбораПравила проведения звукового разбора слова довольно многочисленны. Главная задача — научиться ими пользоваться. И легче всего сделать это на практике. Звуковой анализ проводится в несколько стадий.
На первой необходимо понять, сколько именно слогов входит в состав слова. Далее, после определения, важно отметить тот, который находится под ударением.
Например, слово «восход» включает в себя 2 слога. Под ударением 2-й. А слово «человек» — 3 слога. Удаление падает на третий.
Под ударением 2-й. А слово «человек» — 3 слога. Удаление падает на третий.
На втором этапе пишется транскрипция. Сложность в том, что количество букв и звуков часто не совпадает. Потому как некоторые буквы при подготовке транскрипции выражаются несколькими звуками. Это может создать дополнительную путаница в головах учащихся.
Например, буква «ю» транскрибируется как сочетание «йу». То же самое касается «е» и «ё». Таких примеров довольно много. Их нужно знать.
Правила и принципы поведения разбораПосле составления транскрипции и определения количества слогов, на третьем этапе, прописывается анализ всех звуков. Глухой он или звонкий, гласный или согласный, твердый или мягкий. И так до конца слова. Это может быть сложно на первых этапах изучения русского языка на академическом уровне.
Особняком стоят гласные, для которых характеристики мягкости, твердости и пр. неприменимы. В этом случае пишут, гласный он или согласный.
На четвертом этапе, в самом конце, необходимо описать, сколько звуков и букв в составе определенного слова. Так, в уже приведенном слове «восход» количество букв и звуков совпадает. Их 7. В слове «человек» ситуация точно такая же.
Так, в уже приведенном слове «восход» количество букв и звуков совпадает. Их 7. В слове «человек» ситуация точно такая же.
По такому принципу разбирают все слова русского языка. Важно иметь в виду, что звуковой состав пишется в разрез с орфографическим. Как слышится. В том же слове «человек» на втором месте будет не «е»,а «и», что логично, если вслушаться в произношение.
Порядок строгий, требует выполнения по отдельным этапам.
СложностиОсновный сложности, как показывает практика, возникают у школьников младших классов, которые только-только начинают свое изучение русского языка. Но это временное явление. Возможны трудности и у школьников более старшего возраста. Но это скорее результат торопливости и невнимательности.
Наиболее характерные сложности можно перечислить коротким списком:
- Проблемы при определении количества звуков. Число звуков нередко отличается от количества букв. Это типичная ситуация. Особенно в словах со сложной структурой.
- Проблемы в анализе составляющих звуков. Неверно понятые концепции твердости и мягкости, звонких и глухих согласных и пр.
- Трудности с определением количества слогов. Происходит на начальных этапах. Действительно надолго на этой части застревают очень немногие школьники.
- Непонимание концепции двойных звуков. Тех, которые выражаются одной буквой. Это может вызвать путаницу. И нередко требует дополнительных объяснений со стороны учителей.

К счастью, звуковой анализ не так сложен, как может показаться на первый взгляд. Все решается изрядной долей опыта, постоянной кропотливой практикой. Как правило, все проблемы устраняются через несколько недель или месяцев работы.
Частые ошибки при проведении работыОшибки, которые совершают школьники, частично совпадают с проблемами, описанными выше. Наиболее частые оплошности со стороны учащихся:
- Неправильный подсчет слогов или неграмотное деление на слоги. Случается, если слог состоит из одной буквы. Например, в слове «океан» 3 слога. Но делятся они следующим образом: о-ке-ан. Школьник может верно сосчитать количество слогов. Но вычленить их неверно: ок-е-ан. Возможны и другие грубые ошибки, которые. Как вариант, неправильный подсчет слогов. Тогда получается оке-ан.
- Неверная транскрипция. Встречается куда чаще. Поскольку многие слова при транскрибировании пишутся совсем не так, как в целом по нормам русского языка. В такой ситуации остается практиковаться и дальше.
- Неправильное описание отдельных составляющих слова. С этим также встречались все. Корневая ошибка может заключаться в неправильном определении звукового состава. Тогда и все остальное будет неверно. Если же говорить о менее серьезных ошибках, они затрагивают отдельные звуковые единицы.
- Наконец, возможен неправильный подсчет количества звуков и букв. В том случае, если имеется корневая, базовая ошибка. Такое тоже встречается часто.
 Например, в слове «океан» 3 слога. Но делятся они следующим образом: о-ке-ан. Школьник может верно сосчитать количество слогов. Но вычленить их неверно: ок-е-ан. Возможны и другие грубые ошибки, которые. Как вариант, неправильный подсчет слогов. Тогда получается оке-ан.
Например, в слове «океан» 3 слога. Но делятся они следующим образом: о-ке-ан. Школьник может верно сосчитать количество слогов. Но вычленить их неверно: ок-е-ан. Возможны и другие грубые ошибки, которые. Как вариант, неправильный подсчет слогов. Тогда получается оке-ан.Ошибки в первых классах, да и потом, не считаются трагедией. Поскольку все вопросы лингвистических разборов решаются опытом и достаточным пониманием. А оно приходит по мере практики.
Поскольку все вопросы лингвистических разборов решаются опытом и достаточным пониманием. А оно приходит по мере практики.
Научиться фонетическому разбор самостоятельно можно в достаточно зрелые годы. Как правило, такая необходимость возникает, если за изучение русского языка берется человек, которые не владеет им или владеет в недостаточной мере — иностранец. У носителя такое желание может возникнуть, если появился интерес к серьезной лингвистике, и хочется освежить память.
Если за дело берется не носитель языка, оптимальный выбором может стать работа с преподавателем, под контролем опытного учителя. Учебники тут вряд ли помогут. Разве что уровень говорения и письма находится на высоком или выше среднего уровне. Тогда на помощь придут книги для начальных классов школы.
Когда изучение фонетики, русского языка затрагивает интерес носителя, можно найти учебники за первые несколько классов. Затем, по мере проработки, перейти к более серьезной литературе. Возможно самообучение Как именно работать — зависит от поставленных целей. Желаемого конечного результата.
Возможно самообучение Как именно работать — зависит от поставленных целей. Желаемого конечного результата.
Обучение фонетическому разбору ребенка может частично лечь на плечи родителей. Поскольку учителя ограничены в возможностях и времени, а репетиторы даже в рамках обучения дисциплинам начальной школы — дороги. Есть три основных правила:
- Для начала нужно досконально разобраться в теме. На помощь приходят учебники, литература уровня самоучителей и прочая. Плюс качественный интернет-ресурсы и каналы на видеохостингах.
- Затем нужно подробно объяснить ребенку, как и что именно делать. Оценить сложности, задать вопросы, все ли он понял. Если нет — обрисовать суть непонятных моментов и прояснить их специально, прицельно.
- После этого нужно давать ребенку задания. Чем больше он практикуется, тем выше результаты. Главное не переусердствовать. Иначе возникнет много новых вопросов.
Обучение проводится стандартными методами. Но если есть возможность обратиться к педагогу, лучше сделать именно так.
Но если есть возможность обратиться к педагогу, лучше сделать именно так.
Знания об особенностях звукового анализа слова суммируются с остальными, создавая единый информационный пласт. Комплексное понимание особенностей русского языка, фонетики, грамматики и прочего. С точки зрения практики, весь комплекс знаний позволяет грамотно пользоваться всеми инструментами, палитрой красок русского языка. Как в устной, так и в письменной речи.
Фонетический разбор слова — подробный алгоритм действий. Задания для самопроверки.
Если около слова стоит цифра 1, то требуется выполнить
Фонетический разбор слова.
Алгоритм действий:
1. Запиши слово и поставь ударение.
ПОМНИ:
Þ Ударение ставится только на гласную букву или на гласный звук!
Þ Запрещено ставить ударение на букву Ё
Þ Запрещено ставить ударение в словах, где только одна гласная буква (односложные слова)
ü
Чтобы правильно поставить ударение,
поочередно «бей» голосом по каждой ГЛАСНОЙ букве данного слова или ГЛАСНОМУ
звуку данного слова, (если надо поставить ударение в транскрипции).
v Например, нельзя ставить ударение в словах: ёжик, ёлка, мёд, пень, сон, шторм, краб и т.д.
Пройди самопроверку №1 на стр.6
2. Посчитай количество БУКВ в слове.
ПОМНИ:
Þ В русском алфавите 33 буквы!
Þ Знай, что ь (мягкий) и ъ (твердый знак), в том числе, — тоже буквы!
ü С подсчетом букв справиться легко, — внимательно сосчитай ВСЕ значки в слове.
v Например, в слове день – 4 буквы, в слове пеньки – 6 букв, в слове подъезд – 7 букв.
Пройди самопроверку №2 на стр.7
3. Посчитай количество ЗВУКОВ в слове.
ПОМНИ:
При счете звуков есть ДВА опасных момента, это:
1. Йотированные гласные Е Ё Ю Я;
2. Ь (мягкий) и Ъ(твёрдый) знаки;
Рассмотри ПРИЛОЖЕНИЕ1
[
] – Все звуки, — как мы их произносим и слышим, записываются ТОЛЬКО в
квадратных скобках, — это транскрипция.
[ ̕ ] – апостро́ф. Указывает, что данный звук, — мягкий. Мягкость и твёрдость определяется ТОЛЬКО у СОГЛАСНЫХ звуков.
v Например, слово счастье мы произноcим и слышим, как [щ̓аст’э], а слово корова мы произносим и слышим, как [карова]. Слово мороз звучит как [марос].
Как же понять, — данный согласный звук мягкий или твёрдый? Надо ли поставить апостро́́ф? Ознакомься с ПРИЛОЖЕНИЕМ 2 на странице 5.
Знакомство с глухими — звокими согласными звуками, парными – непарными согласными звуками. ПРИЛОЖЕНИЕ 3 на странице 6.
4. Посчитай количество СЛОГОВ в слове.
ПОМНИ:
В слове столько слогов, сколько в нем гласных букв.
Посчитать количество слогов просто. Сосчитай все гласные буквы в слове.
Гласные буквы: А, Е, Ё, И, О, У, Ы, Э, Ю, Я
v Например,
в слове крот – 1 слог, в слове платье – 2 слога, в слове яблоко – 3 слога. Пройди самопроверку на странице 8.
Пройди самопроверку на странице 8.
ПРИЛОЖЕНИЕ1
ТЕПЕРЬ РАССМОТРИМ ДВА ОПАСНЫХ МОМЕНТА ПРИ ПОДСЧЁТЕ ЗВУКОВ:
Первый момент: Е Ё Ю Я | Второй момент: Ь и Ъ |
|
|
Гласные буквы (Е, Ё, Ю, Я) обозначают ВСЕГДА ДВА звука, КРОМЕ тех случаев, когда они стоят после согласной буквы.
ВСЕГДА ДВА ЗВУКА: Е [Й ̓ Э] Ё [Й ̓ О] Ю [Й ̓ У] Я [Й ̓ А]
НО, ПОСЛЕ СОГЛАСНОЙ БУКВЫ ТОЛЬКО ОДИН ЗВУК: Е [Э] Ё [О] Ю [У] Я [А]
|
НЕ ОБОЗНАЧАЮТ ЗВУКА!
Ь [ ] Ъ [ ] |
Пример,
2 звука:
ёлка – [й̓ о́ л к а], енот – [й̓ э н о́ т], юла – [й̓ у л а́], яма –
[й̓ а́ м а], маяк – [м а й̓ а́ к].
Пример, 1 звук: мёд – [м̕ о т], кедр – [к̕ э д р], люк – [л̕ у к], мяч – [м̕ а ч̕ ]. | Пример: дождь [д о́ ш т̓ ], льдинка [л̕ д и́ н к а], боль [б о л̓ ], долька [д о́ л̓ к а]. |

ПРИЛОЖЕНИЕ 2
Как же определить мягкий звук или твёрдый?
ЗАПОМНИ!
Есть неизменно мягкие согласные звуки: [й̕] [ч̓] [щ̕]
Предложение-подсказка: Чёрный щенок.
Есть неизменно твёрдые согласные звуки: [ц] [ш] [ж]
Предложение-подсказка: Цапля швырнула жука. (Клюв
у цапли твёрдый – звуки твёрдые, да и жуков она не предпочитает).
Все остальные согласные буквы (Б, В, Г, Д, З, К, Л, М, Н, П, Р, С, Т, Ф, Х) могут обозначать как твёрдый, так и мягкий звуки, — в зависимости от того какая гласная идёт за ними.
Þ А О У Ы Э (придают твёрдость предшествующему согласному звуку)
Þ Я Ё Ю И Е (придают мягкость предшествующему согласному звуку)
v Например:
В слове земля, согласные буквы З и Л будут давать мягкие звуки [з̓ ] [л̕ ]
В слове зола, эти же согласные звуки З и Л будут давать твёрдые звуки [з] [л]
ПРИЛОЖЕНИЕ 3
Парные: Б-звонкий П-глухой
Д-звонкий Т-глухой
В-звонкий Ф-глухой
Г-звонкий К-глухой
Ж-звонкий Ш-глухой
З-звонкий С-глухой
Непарные звонкие:
слово-подсказка — ЛиМоНаРиЙ. (Все согласные звуки
в этом слове непарные и звонкие).
(Все согласные звуки
в этом слове непарные и звонкие).
Непарные глухие: Предложение-подсказка: Хвастает царь чем щедр. (Выделенные согласные звуки – непарные и глухие). (Царь был одинок и глуховат, звуки непарные и глухие)
Можно отличить их и на слух. Если закрыть уши ладошками, а затем произнести в полголоса звук, то звонкость можно определить по звуку, а глухость — по шуму. Обязательно произносить их именно с голосом, а не шепотом, иначе глухими окажется большинство звуков!
Самопроверка №1. Ответы в нижней части листа.
Выпиши те слова, в которых нужно поставить ударение:
Конь, лак, яблоко, мак, пол, фрукт, мел, клад, киви, улей, флаг, орех, ёжик, батон, ель, пряник, хлеб, пруд, факел, лампа, кнут, индюк, стол, ракета, дом, салют, котик, потолок, моль, кот, книга, пыль, палка, школа, цветок, бумага, трава, солнце, нос, свет, карандаш, лёд, пенал, учебник, полёт,
ОТВЕТЫ.
Слова, в которых нужно поставить ударение:
Раке́та, ко́тик, па́́лка, пря́ник, фа́кел, индю́к, потоло́к, кни́га, шко́ла, я́блоко, ки́ви, бато́н, ла́мпа, салю́т, цвето́к, бума́га, трава́, со́лнце, каранда́ш, пена́л, уче́бник.
Самопроверка №2. Ответы в нижней части листа.
Посчитай количество букв в словах.
Конь, лак, яблоко, мак, пол, фрукт, мел, клад, киви, улей, флаг, орех, ёжик, батон, ель, пряник, хлеб, пруд, факел, лампа, кнут, индюк, стол, ракета, дом, салют, котик, потолок, моль, кот, книга, пыль, палка, школа, цветок, бумага, трава, солнце, нос, свет, карандаш.
ОТВЕТЫ.
_______________________________________________________________
Конь -4 б., лак – 3 б., яблоко – 6 б., мак
– 3 б., пол – 3 б., фрукт – 5 б., мел – 3 б. , клад – 4 б., киви – 4 б., улей –
4 б., флаг – 4 б., орех – 4 б., ёжик – 4 б., батон – 5 б.., ель – 3 б.,, пряник
– 6 б., хлеб – 4 б., пруд – 4 б., факел – 5 б., лампа – 5 б., кнут – 4 б.,
индюк – 5 б.,, стол – 4 б., ракета – 6 б., дом – 3 б., салют – 5 б., котик –
5 б., потолок – 7 б., моль – 4 б., кот – 3 б., книга – 5 б., пыль – 4 б., палка
– 5 б., школа – 5 б., цветок – 6 б., бумага – 6 б., трава – 5б., солнце – 6 б.,
нос – 3 б., свет – 4 б., карандаш – 8 б.
, клад – 4 б., киви – 4 б., улей –
4 б., флаг – 4 б., орех – 4 б., ёжик – 4 б., батон – 5 б.., ель – 3 б.,, пряник
– 6 б., хлеб – 4 б., пруд – 4 б., факел – 5 б., лампа – 5 б., кнут – 4 б.,
индюк – 5 б.,, стол – 4 б., ракета – 6 б., дом – 3 б., салют – 5 б., котик –
5 б., потолок – 7 б., моль – 4 б., кот – 3 б., книга – 5 б., пыль – 4 б., палка
– 5 б., школа – 5 б., цветок – 6 б., бумага – 6 б., трава – 5б., солнце – 6 б.,
нос – 3 б., свет – 4 б., карандаш – 8 б.
Посчитай количество слогов в словах.
Заяц, белка, ёж, медведь, земляника, малина, цветок, улей, мышь, жук, пчела, деревья, трава, земля, река, озеро, океан, семья, дом, шкаф, полка, комод, пол.
ОТВЕТЫ.
Заяц
– 2 слога, белка – 2 слога, ёж – 1 слог, медведь – 2 слога, земляника – 4 слога,
малина – 3 слога, цветок – 2 слога, улей – 2 слога, мышь – 1 слог, жук -1 слог,
пчела – 2 слога, деревья – 3 слога, трава – 2 слога, земля – 2 слога, река – 2
слога, озеро – 3 слога, океан – 3 слога, семья – 2 слога, дом -1 слог, шкаф – 1
слог, полка – 2 слога, комод – 2 слога, пол – 1 слог.
ПРИМЕРЫ ФОНЕТИЧЕСКОГО РАЗБОРА СЛОВ.
Я́блоко – 6 букв, 7 звуков, 3 слога. [й̕ а́ б л а к а]
я [й̕] – согласный, звонкий, твёрдый, непарный;
[а́] – гласный, ударный;
б [б] – согласный, звонкий, твёрдый, парный;
л [л] – согласный, звонкий, твёрдый, непарный;
а [а] – гласный, безударный;
к [к] – согласный, звонкий;
а [а] – гласный, безударный;
Мел – 3 буквы, 3 звука, 1 слог. [м̕ э л]
м [м̕ ] – согласный, звонкий, мягкий, непарный;
э [э] – гласный, ударный;
л [л] – согласный, звонкий, твёрдый, непарный;
Ию́нь – 4 буквы, 3 звука, 2 слога. [и й̕ у́ н̕ ]
и [и] – гласный, безударный;
ю [й̕ ] – согласный, звонкий, мягкий, непарный;
[у́] – гласный, ударный;
н [н̕ ] – согласный, звонкий, мягкий, непарный;
ь [ — ] – нет звука
Ша́рф – 4 буквы, 4 звука, 1 слог. [ша́рф]
ш [ш] – согласный, глухой, твёрдый, парный;
а [а́] – гласный, ударный;
р [р] – согласный, звонкий, твёрдый, непарный;
ф [ф] – согласный, глухой, твёрдый, парный;
ПРИЛОЖЕНИЕ 5
Как
правильно сокращать слова в тетради.
Согласный – согл.
Гласный – гласн.
Звуки – зв.
Звонкий – звонк.
Глухой – глух.
Твёрдый – твёрд.
Мягкий – мягк.
Парный – парн.
Непарный – непарн.
Ударный – ударн.
Безударный – безударн.
Снегурочка разбор слова по составу: морфемный анализ слова
Содержание
- Морфемный разбор
- Зачем это надо
- Смысловое содержание морфем
- О пользе понимания смысла
- Значение корня
Снегурочка знакома каждому ребенку. Но каждый ли может разобраться в смысле слова? Ведь, для этого надо выделить все части слова, объяснить их значение и только после этого можно узнать подлинный смысл имени, которое знает каждый малыш.
Присмотримся поближе к слову Снегурочка разбор слова по составу станет для нас главным инструментом познания.
Морфемный разбор
Напомним читателю как проводится морфемный разбор:
Определяется часть речи.
В слове Снегурочка разбор слова по составу на первом этапе видно, что перед нами имя существительное.Определяется окончание, если оно присутствует в слове. Просклоняем слово Снегурочка. Меняется окончание —а.
Определяется основа слова. Проведенный в слове Снегурочка разбор слова по составу указывает, что основа слова составляет «снегурочк».
Подобрать однокоренные слова чтобы выделить корень. Если сделать разбор слова по составу снегурочка явно имеет общий корень с таким словом как «снег».
Выделить приставку или приставки. Проведенный разбор слова по составу снегурочка показывает, что приставка отсутствует. Слово начинается с корня, поэтому дополнительно искать не требуется.
Выделить суффикс или суффиксы. Проведенный разбор слова по составу снегурочка показывает наличие сразу двух суффиксов. Косвенно на это указывает существование слова «Снегурка».
Значит, получается всего два суффикса — уроч и к.
 В слове Снегурочка разбор слова по составу на первом этапе видно, что перед нами имя существительное.
В слове Снегурочка разбор слова по составу на первом этапе видно, что перед нами имя существительное. Значит, получается всего два суффикса — уроч и к.
Значит, получается всего два суффикса — уроч и к.Как видите, разобрать слово по составу снегурочка совсем несложно. Главное — знать правила морфемного разбора.
Таким образом вот окончательный морфемный разбор слова Снегурочка:
Снегурочка
Зачем это надо
Кто-то может спросить: а зачем это вообще надо уметь? Зачем надо знать как разобрать слово по составу снегурочка, если можно прожить и без этого навыка?
Ответ одновременно и простой и сложный. Простой ответ состоит в необходимости быть грамотным, уметь правильно выражать свои мысли. Но этот ответ сродни тому, который представлен в конце учебника. Можно подглядеть, списать, но разве это дает подлинное понимание?
Нет, не дает. Так можно только записать верный ответ, не понимая смысла сказанного и написанного. Хорошо, если в конце учебника будет записано правильное решение. Но если автор ошибется? Случайная опечатка приведет к неверной записи решения ученика.
В школе от этого зависит только полученная оценка. Если, например, вы решили разобрать слово по составу снегурочка, но сделали это неправильно, максимальное наказание заключается в простой двойке. Безусловно, наказание серьезное, но не смертельное.
Гораздо хуже, если от правильности решения задачи зависит что-то важное. Например, есть такое имя Снегурочка состав слова указывает на наличие суффикса -к. То есть, перед нами уменьшительно-ласкательная форма. Если сказать «старая Снегурочка» смысл слова при этом указывает на юность или молодость девушки, вы будете не поняты окружающими.
Если перед вами окажется живой человек, а не сказочный персонаж, он может обидеться и ваши отношения испортятся.
Морфемный анализ слова помогает лучше понять описываемый предмет. Например, в разбираемом примере «Снегурочка» состав слова содержит корень «снег». Даже, если не знать ничего о Снегурочке, других сказочных персонажах, все равно можно многое понять об этом предмете если просто провести разбор слова.
Смысловое содержание морфем
Нам известен состав слова Снегурочка и известно его значение. Если бы здесь внезапно оказался сторонний наблюдатель, который каким-то образом ничего не знает ни о Снегурочке, ни о Новом годе, что бы он мог рассказать о слове, если бы знал только его состав?
Во-первых, состав слова Снегурочка напрямую указывает на женский род имени существительного в единственном числе. Во-вторых, корень «снег» говорит о том, что перед нами что-то зимнее и напрямую связано со снегом. Уменьшительно-ласкательные суффиксы говорят, что это нечто хорошее, доброе и ласковое.
Это все нам было бы известно только если слово «Снегурочка» по составу разобрать по всем правилам. Скорее всего, наш выдуманный наблюдатель услышал бы еще и контекст разговора, из которого было бы приблизительно понятно о чем идет речь.
Если вы разберете не только слово «Снегурочка» по составу, но и какие-то другие, потренируетесь самостоятельно это делать, тогда даже незнакомые слова вдруг приобретут смысл.
О пользе понимания смысла
Русский язык это живая, постоянно развивающаяся система, существующая по собственным правилам. Не существует более значимой или менее значимой части правил родной речи. Выше читатель увидел как разбор слова снегурочка помогает понять лексическое значение слова.
В дальнейшем это поможет правильно изъясняться и быть понятым другими людьми. Каждый может самостоятельно поделать простое, но интересное упражнение. Подобно тому, как мы узнали больше о том, кто такая Снегурочка разбор слова проведя по правилам русского языка, сделайте то же самое с другим незнакомым словом.
Инструкция выше должна помочь решить эту задачу.
Значение корня
Читатель уже знает корень в слове Снегурочка. Это самая важная, самая значимая часть слова. Зная корень, можно понять основное значение слова. Очень важно уметь правильно определять корень.
Некоторые могут смешивать корень с приставкой или суффиксом, тем самым, внося искажение в собственное понимание лексического значения рассматриваемого предмета. Чтобы избежать такой ошибки вспоминайте самые короткие однокоренные слова. Желательно, чтобы в них не было ни приставок, ни суффиксов. Так вносится наименьшее количество искажений в морфемный разбор и гарантируется наилучшее понимание лексического значения.
Чтобы избежать такой ошибки вспоминайте самые короткие однокоренные слова. Желательно, чтобы в них не было ни приставок, ни суффиксов. Так вносится наименьшее количество искажений в морфемный разбор и гарантируется наилучшее понимание лексического значения.
Кто-то однажды заметил, что корень слова в русском языке подобен личности человека. Если бы у слова была личность, она была бы его корнем. Проводя морфемный разбор, вы в прямом смысле, знакомитесь со словом, узнаете его.
Поэтому пробуйте делать морфемный разбор незнакомых слов. Очень вероятно, что узнаете что-то новое о русском языке, его правилах и словах, которыми можно пользоваться для выражения мыслей.
Источник
Фонетический разбор. Морфемный анализ. Словообразовательный анализ. Этимологический анализ
Учащиеся средней школы должны овладеть не
только глубокими теоретическими познаниями, но и
прочными практическими навыками. С этой целью
немаловажная роль в учебном процессе отведена
грамматическому разбору, который помогает
практически усвоить изучаемые в курсе
современного русского языка грамматические
категории, осмыслить правила орфографии и
пунктуации, систематизировать и закрепить
полученные знания.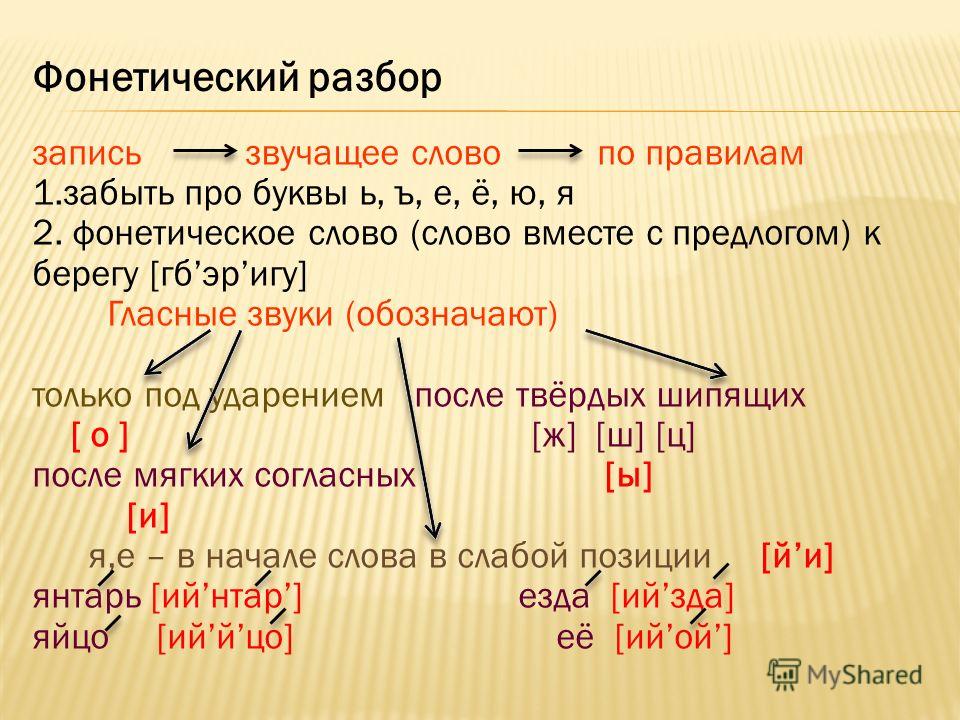 Этот вид упражнений служит
эффективным приёмом организации
самостоятельных занятий по русскому языку,
приёмом самоконтроля и проверки знаний.
Грамматический разбор широко используется при
изучении всех разделов грамматики.
Этот вид упражнений служит
эффективным приёмом организации
самостоятельных занятий по русскому языку,
приёмом самоконтроля и проверки знаний.
Грамматический разбор широко используется при
изучении всех разделов грамматики.
Предмет данной серии статей – грамматический разбор на уроках русского языка в школе. Грамматический разбор – это анализ в данном тексте определённых грамматических явлений (целые предложения или их части, члены предложения, отдельные морфемы и т.д.), отнесение их к тому или иному грамматическому разряду и грамматическую характеристики разбиваемого предложения или отдельного слова.
На уроках русского языка любой вид разбора предполагает мотивировку ответа: от ученика требуется развёрнутый, логически обоснованный, связный ответ, в котором даётся описание языкового явления и обосновывается отнесение его к той или иной грамматической категории.
Таким образом, грамматический разбор
содействует повышению общей языковой культуры
детей, развивает их речь, помогает осмыслить
логическую связь явлений языка.
Актуальность статей заключается в осмыслении важности разграничения понятий и видов грамматического разбора. В данной серии статей рассматриваются образцы фонетического, различных видов морфологического и синтаксического, а также орфографического и пунктуационного разбора.
Новизна работы заключается в широте привлеченного материала для анализа различных видов грамматического разбора.
В первой статье рассматривается порядок и образцы фонетического разбора, морфемный, словообразовательный и этимологический анализ. Фонетика – немаловажна и трудная часть курса русского языка в школе. Предлагаемые схемы помогут учащимся организовать самостоятельное изучение данной темы и систематизировать полученные знания.
Во второй статье рассмотрены порядок и примеры морфологического разбора.
Орфографическому и пунктуационному разбору
отведено важное место в школьном курсе,
следовательно, учащиеся должны хорошо владеть
этими видами разбора. Так как орфография,
пунктуация тесно связаны с грамматикой, в данную
статью включены схемы орфографического и
пунктуационного разбора.
Так как орфография,
пунктуация тесно связаны с грамматикой, в данную
статью включены схемы орфографического и
пунктуационного разбора.
В третьей статье дан подробный анализ орфографического разбора, синтакчического разбора словосочетания, простого предложения: всех его типов (назывного, определенно-личного, неопределенно-личного, обобщенно-личного и бессоюзного предложения), дан порядок их анализа и образцы разбора односоставных предложений.
В четвертой статье рассмотрен анализ осложненных предложений, дан порядок и образец разбора по членам предложения, анализ сложносочиненного и сложноподчиненного предложения и предложения сложноподчиненного усложненного типа.
И, наконец, в пятой статье рассматриваются вопросы, связанные с бессоюзным сложным предложением (многочленные бессоюзные сложные предложения с разными видами союзной и бессоюзной связи)
Цель данной серии статей – помочь учащимся в
подготовке к ЕГЭ и к урокам русского языка.
Одна из задач подготовки учащихся к экзаменам – научить их применять на практике теоретические знания, полученные при изучении школьного курса русского языка.
Определить круг вопросов по каждой теме и основное направление в работе учителям русского языка и учащимся помогут содержащиеся в каждом разделе статьи краткие методические указания. Рекомендации даны к наиболее трудным темам.
Целесообразно приступать к полному грамматическому разбору после изучения всего материала данной темы или раздела.
При упражнениях в грамматическом разборе по предлагаемым схемам учителю необходимо добиваться исчерпывающих ответов на вопросы. Это позволит сознательно усвоить и закрепить почти весь теоретический материал курса.
Выполняя предложенные упражнения, учащийся
должен осмыслить и запомнить порядок разбора и
его объём и научиться излагать свои наблюдения
литературным языком в виде связного рассуждения.
Методологическую основу работы составили методы и способы грамматического разбора в вузе и в школе. В статью включен анализ многочисленных предложений с разными видами связи (союзной – сочинительной и подчинительной; союзной и бессоюзной), а также анализ бессоюзных предложений.
Опорными стали труды акад. В.В. Виноградова, Д.Э Розенталя, Н.С. Валгиной, Т.Ф.Ивановой, Н.М.Шанского и др.
Фонетический разбор
На уроках русского языка учащиеся изучают прежде всего звуковые единицы языка, систему гласных и согласных звуков, их классификацию, основные звуковые законы в области гласных и согласных звуков. Школьная программа и построенные в соответствии с ней школьные учебники дают достаточный объём сведений о звуках речи, их соотношении с буквами, о слоге и слогоделении и основных фонетических законах в области гласных и согласных звуков.
Учащиеся в итоге изучении фонетики должны
иметь ясное представление о делении звуков на
гласные и согласные, гласных – на ударные и
безударные, а согласных – на звонкие и глухие,
твёрдые и мягкие. Анализ звукового состава слова
предполагает введение в школьную практи-ку
элементов транскрипции. В схемы фонетического
разбора введены элементы графического
анализа в виде сопоставления звукового и
буквенного состава слова.
При составлении схем фонетического разбора использовались следующие пособия:
Современный русский язык: Учебник/ Под
редакцией Н.С. Валгиной. – 6-е изд., перераб. и доп.
Москва: Логос, 2002. 528 с.
Современный русский язык: учебник
/Галкина-Федорук Е.М., Горшкова К.В., Шанский Н.М.
–Москва, Либроком, 2009, 200 с.
Грамматика русского языка, т 1, М., Наука, 1980
Иванова Т.Ф. Новый орфоэпический словарь
русского языка. Произношение. Ударение.
Грамматические формы. Москва:Русский язык –
Медиа, 2005,893 с.
Порядок фонетического разбора
1. Письменная передача звучания слова.
2. Слоги.
3. Ударение (назвать ударный слог)
4. Гласные звуки: ударные, безударные, какими
буквами обозначены.
5. Согласные звуки: звонкие, глухие, твёрдые,
мягкие; какими буквами обозначены.
6. Количество звуков и букв. Чем вызвано
несоответствие количества звуков и букв
(йотированные, которые передают иногда два звука,
ъ и ь, которые не передают звуков, и т.д.)
Образец фонетического разбора
Ельник – [й’эл’н’ик]
2. В слове два слога: ель-ник
3. Ударение падает на первый слог.
4. [ й’] – согласный, звонкий, мягкий, обозначен
буквой е.
[ э ] – гласный, ударный, обозначен буквой
е.
[ л’] – согласный, звонкий, сонорный,
мягкий, непарный. Обозначен буквой «эль». Буква
«мягкий знак» обозначает её мягкость.
[ н’] – согласный, звонкий, сонорный,
мягкий, непарный. Обозначен буквой «эн».
[ и ] – гласный, безударный. Обозначен
буквой и.
[ к ] – согласный, глухой, твёрдый, парный (
к/ г). Обозначен буквой «ка»
__________________
6. В слове 6 звуков и 6 букв (2 гласных и 4
согласных звуков).
Типы членения слова на морфемы
Рассмотрение слова в словообразовательном плане предполагает три уровня его членения:
1. Выделение значимых частей слова (корень, приставка, суффикс, окончание), установление связи этого слова с другими словами в современном языке. Этот вид анализа называют мор-фемным (разбор слова по составу).
2. Словообразовательный анализ (как
образовалось данное слово, т.е. на базе какой
произво-дящей основы и с помощью каких
словообразовательных средств.) При
словообразовательном разборе членение слова
всегда состоит из двух частей: выделяется часть,
относящаяся к произ-водящей основе, от которой
образовалось данное слово, и словообразующий
аффикс, т. е. часть, с помощью которой это слово
образовано. При словообразовательном анализе мы
не только выделяет в этом слове морфемы, но и
определяет последовательность их
присоеди-нения. Словообразовательный анализ
подразумевает серьёзные изучение способов
русского словообразования вообще и в каждой
части речи в частности.
3. Строение слова может быть рассмотрено с точки зрения его происхождения. В этом случае мы имеем дело с этимологическим анализом, который восстанавливает связи слова в момент его возникновения. При этимологическом анализе слово делится на те морфемы, из которых оно состояло раньше.
Все три указанных типа членения слова взаимосвязаны, поэтому иногда трудно провести между ними границу и противопоставлять их друг другу.
Если в основе слова не произошло опрoщения или переразложения, то морфемный и этимо-логический анализ окажутся одинаковыми. Особенно заметной бывает связь морфемного и словообразовательного анализа: правильное деление слова на морфемы возможно только при учёте современных словообразовательных связей этого слова.
Каждый из рассмотренных типов анализа построен
на своих принципах. Учащиеся должны хорошо
представлять разницу между этими типами
членения слова, знать задачи и цели каждого из
них.
Морфемный анализ
Цели разбора слова по составу (морфемного анализа) и типы членения слова при этом виде разбора – выделить в слове морфемы (значимые части слова). Основной приём в этом виде работы – подбор однокоренных и одноструктурных слов (т. е. слов с той же приставкой и суффиксом). При выделении суффиксов необходимо учитывать производящую основу, т. е. вводить элементы словообразовательного анализа. Ср. выделение двух (а не трёх) суффиксов (-ва-, -емость-) в слове успеваемость.
Порядок морфемного разбора
1. Окончание и основа слова. Значение окончания.
2. Корень, два-три однокоренных слова.
3. Суффикс (суффиксы), значение суффикса (если
ясно).
4. Приставка (приставки), её значение (если ясно).
Образцы морфемного разбора
Попутчик
1. В слове нулевое окончание, основа – попутчик.
Окончание указывает на именительный падеж,
единственное число.
2. Корень слова – -пут-;
однокоренные слова – путь, пут-ев-ой, рас-
путь- е.
3. Суффикс -чик обозначает название
предмета.
4. Приставка по- указывает на
совместность действия.
Рыбачий
1. В слове нулевое окончание, основа рыбачий.
Окончание указывает на мужской род,
имени-тельный падеж, единственное число.
2. Корень слова -рыбач-;
однокоренные слова рыбак (чередование к//ч),
рыбач-к-а, по-рыбач- ить.
3. Суффикс притяжательного прилагательного -ий
со значением родовой принадлежности (вариант
суффикса -j-). Слова с этим суффиксом – волчий,
заячий.
Словообразовательный анализ
Задачи словообразовательного анализа несколько иные: установить, от чего образовалось данное слово (найти производящую основу) и с помощью чего (выделить словообразующий аффикс), и в итоге этих исследований определить способ словообразования.
Порядок словообразовательного разбора
1. Дать лексическое значение слова.
2. Сравнить состав данного слова с однокоренными;
определить ту часть слова, с помощью которого
оно образовано.
3. Определить, от чего образована основа.
Образцы словообразовательного разбора
Мыслитель.
1. Мыслитель – тот, кто мыслит.
2. Мыслитель – мыслить. Первое слово
образовалось с помощью суффикса -тель.
3. Мысли-.
4. Мыслитель < мыслить.
Способ словообразования – суффиксальный.
Безводный
1. Безводный – лишённый воды, влаги.
2. Безводный – водный – вода. Первое слово
образовалось с помощью приставки без-
от слова водный, второе слово образовалось с
помощью суффикса прилагательного -н-
от слова вода.
3. Вод-.
4. Способ словообразования – суффиксальный.
Этимологический анализ
Этимологический разбор нужен для выяснения первоначальной структуры слова, его прежних словообразовательных связей, для определения производящей основы и способа словообразо-вания и восстановления первичного значения слова. На уроках русского языка этимологичес-кий разбор производится под руководством учителя для объяснения прав описания слов, их происхождения и первичного значения.
Образцы этимологического разбора
Вождь
Заимствовано из старославянского языка.
Образовано с помощью суф. -j- от той же
основы, что и вод «вождь, вожак» (ср.
пословицу Парень бы не мот, да деньгам-то не
вод).
Порошок
Слово исконно русское. В современном русском языке имеет непроизводную основу. По пер-воначальный словообразовательным связям соотносилось со словом порох в значении «пыль», суффикс -ок имел уменьшительно-ласкательное значение. В основе слова произошли исторические изменения – опрощение. Причина: разрыв смысловых связей. Итак, слово порошок имеет этимологический корень порох- и уменьшительно-ласкательный суффикс -ок.
её — фонетический (звуко-буквенный) разбор слова — «Семья и Школа»
Содержание
Как делать звуко-буквенный разбор слова?
Звуко-буквенный разбор слова — это характеристика звукового и буквенного состава слова. Чтобы его выполнить, пишется транскрипция — точная запись звукового состава слова.
Звуко-буквенный (фонетический) разбор слова необходим для осознанного овладения русским языком, грамотного написания слов, особенно в тех случаях, когда в словах есть безударные гласные, непроизносимые согласные, буквы, обозначающие два звука, буквы, не обозначающие звуков и пр.
Определение
Звуко-буквенный разбор — это анализ звукового состава слова и его буквенного отображения на письме.
Фонетический разбор выполняется в несколько этапов. Звуко-буквенный разбор предполагает деление слова на слоги в соответствии с количеством гласных звуков, постановку ударения, запись звучания слова. Затем проводится фонетический анализ каждого звука. Фонетический разбор завершается подсчетом количества букв и звуков.
Буквы и звуки
Чтобы правильно выполнить звуко-буквенный разбор слова, научимся различать, что на бумаге мы видим буквы, а когда произносим слово, то слышим звуки. Буквы — это графические знаки, с помощью которых можно обозначить звуки речи.
В русском языке различают гласные и согласные звуки.
Гласные буквы и звуки
Гласные звуки образуются при свободном прохождении воздуха изо рта. Они состоят только из голоса. В русском языке имеются
6 гласных звуков: [а], [о], [у], [э], [и], [ы]
и
10 гласных букв: а, о, у, э, и, ы, я, е, ё, ю, я
Гласные звуки [а], [о], [у], [э], [ы] звучат после твердых согласных звуков, а буквы «и», «е», «ё», «ю», «я» и «ь» обозначают, что предыдущий согласный звук является мягким. Эта фонетическая мягкость обозначается специальным значком — апострофом:
- лён [л’ о н]
- редис [р’ и д’ и с]
- соль [с о л’]
Для выполнения звуко-буквенного разбора следует поставить в слове ударение.
Под ударением гласные звуки звучат отчетливо, а без ударения они искажаются:
- буква «о» обозначает звук [а];
Пример
до́мик [д о м’ и к], окно́ [а к н о]
- после согласных буквы «е», «я» без ударения соответствует звуку [и]
Пример
cтена́ [с т’ и н а] , ряби́на [р’ и б’ и н а]
Каждый гласный звук в одиночку или в сочетании с одним или с несколькими согласными согласными образует фонетический слог:
- бо-ло-то
- кра-со-та
- у-ди-ви-тель-ный
- ли-ни-я
Согласные буквы и звуки
В русской речи звучат 36 согласных звуков. При их произношении выдыхаемый воздух трется об губы, язык и щеки, в результате чего возникает шум.
Всегда звонкие согласные [л], [м], [н], [р] произносятся с участием голоса и минимальным шумом.
Если согласные звуки произносятся с бо́льшей долей голоса и шума, то образуются звонкие согласные:
[б], [в], [г], [д], [ж], [з]
Каждому звонкому согласному соответствует парный глухой согласный, который произносится с большей долей шума, чем голоса:
- [б] — [п];
- [в] — [ф];
- [г] — [ к];
- [д] — [т];
- [ж] — [ш];
- [з] — [с].
Буквы «х», «ц», «ч», «щ» обозначают глухие согласные [х], [ц], [ч’], [щ’], у которых нет парных звонких согласных.
Согласные звуки бывают твердые и мягкие:
[б] — [б’], [в] — [в’], [г] — [г’], [д] — [д’], [з] — [з’], [к] — [к’], [л] — [л’], [м] — [м’], [н] — [н’], [п] — [п’], [р] — [р’], [с] — [с’], [т] — [т’], [ф] — [ф’], [х] — [х’]
Выполняя звуко-буквенный анализ, учитываем, что буквы «й», «ч» и «щ» обозначают всегда мягкие звуки [й’], [ч’], [щ’],
а буквы «ж», «ш», «ц» — твердые звуки [ж], [ш], [ц].
Как научиться делать звуко-буквенный разбор
Для того, чтобы научиться делать звуко-буквенный разбор слова, важно понимать, что часто орфографическая запись слова и его звучание не совпадают. В слове может быть:
- одинаковое количество звуков;
- звуков больше, чем букв;
- букв больше, чем звуков.
Примеры
- не́бо [н’ э б а] — 4 буквы, 4 звука
- ярлы́к [й ‘а р л ы к] — 5 букв, 6 звуков
- купа́ть [к у п а т’] — 6 букв, 5 звуков
При записи звукового состава слова следует учитывать, что буквы «е», «ё», «ю», «я» могут обозначать два звука в следующих позициях в слове:
1. в начале слова:
- е́дкий [й’ э т к’и й’]
- ёмкий [й’ о м к’ и й’]
- ю́ный [й’ у н ы й’]
- я́сли [й’ а с’ л’ и]
2. после других гласных звуков:
- поезди́ть [п а й’ э з’ д’ и т’]
- поём [п а й’ о м]
- каю́та [к а й’ у т а]
- мая́к [м а й’ а к]
3. после разделительных «ь» и «ъ»:
- жюлье́н [ж у л’ й’ э’ н]
- въе́хать [в й ‘э х а т’]
- курьёз [к у р’ й’ о с]
- отъём [а т й’ о м]
- рья́ный [р’ й’ а н ы й’]
- изъя́н [и з’ й’ а н]
- вью́нок [в’ й’ у н о к]
- предъюбиле́йный [п р’ и д й’ у б’ и л’ э й’ н ы й’]
Как видим, в таких словах всегда больше звуков, чем букв.
После согласных звуков буквы «е», «ё», «ю», «я» обозначают их мягкость:
- сел [с’ э л]
- нёс [н’ о с]
- люк [л’ у к]
- пять [п’ а т’]
Записывая звучание слова, следует учитывать, что в русском языке происходит фонетический процесс оглушения звонких согласных, находящихся перед глухим согласным и в конце слова, и, наоборот, озвончения глухих согласных перед звонким согласным, кроме «л», «м», «н», «р», «в», «й»:
ло́жка [ло ш к а], ви́тязь [в’ и т’a с’], о́тблеск [о д б л’ и с к]
сма́зка [с м а с к а], дробь [д р о п’], сдви́нуть [з д в’ и н у т’]
все [ф с’ э], пруд [п р у т], вокза́л [в а г з а л]
В словах с буквосочетанием «зж» слышится длинный мягкий звук [ж’]:
- брюзжа́ть [б р’ у ж’ а т’]
- мозжечо́к [м а ж’ и ч’ о к]
В конце глаголов буквосочетания -тся и -ться звучат как [ца]:
- бои́тся [б а и ц а];
- стели́ться [с’ т’ и л и ц а].
В словах, в которых есть «ь», который обозначает мягкость предыдущего согласного звука или является морфологическим знаком, указывающим на принадлежность слова к женскому роду, букв насчитываем больше, а звуков меньше:
- знать [з н а т’] — 5 букв, 4 звука;
- речь [р ‘э ч’] — 4 буквы, 3 звука.
Мягкие согласные звуки могут смягчать предыдущий согласный звук.
Послушаем, как звучат слова:
- све́чка [с’ в’ э ч’ к а]
- гво́зди [г во з’ д’ и]
- жизнь [ж ы з’ н’]
- зо́нтик [з о н’ т’ и к]
Образец фонетического разбора
Источник изображения: fedsp.com
Пример звуко-буквенного разбора
Чтобы выполнить звуко-буквенный разбор, запишем слово и поставим в нем ударение. Разделим его на фонетические слоги. Учитывая все фонетические изменения в слове, запишем по вертикали буквы и соответствующие им звуки слова в квадратных скобках. Дадим фонетическую характеристику каждому звуку.
Например, выполним фонетический разбор слова «ёлочный»:
ёлочный [й’ о л а ч’ н ы й’]
ё-ло-чный — 3 слога. Первый слог ударный.
- буква «ё» — [й’] — согласный, звонкий непарный, мягкий непарный;
- [о] — гласный ударный;
- буква «л» — [л] — согласный звонкий непарный, твердый парный;
- буква «о» — [а] — гласный безударный;
- буква «ч» — [ч’] — согласный, глухой непарный, мягкий непарный;
- буква «н»- [н] — согласный звонкий непарный, твердый парный;
- буква «ы» — [ы] — гласный безударный;
- буква «й» — [й’] — согласный, звонкий непарный, мягкий непарный.
В слове «ёлочный» 7 букв, 8 звуков.
Дополнительный материал
Если у вас возникнут трудности при проведении звуко-буквенного (фонетического) разбора слова, то всегда можно проверить себя на сайте phoneticonline.ru.
Видео «Фонетический разбор слов»
Для закрепления материала посмотрите видео по теме урока.
Фонетический разбор слова.
Начальная школа.
14.12.2011 | Автор: svetrus | Рубрика: Фонетика
Что надо знать для фонетического разбора слов в начальной школе.
Фонетика – раздел науки о языке, в котором изучаются звуки речи.
Буквы – это графические знаки, с помощью которых звуки речи обозначаются при письме.
Звуки мы произносим и слышим, буквы – видим и пишем. Читая слова, мы видим буквы, а произносим звуки.
Звуки бывают гласные и согласные.
Гласные звуки.
При произнесении гласных выдыхаемый воздух свободно выходит изо рта и не встречает преград. Гласные звуки можно петь. Они состоят только из голоса, который образуется при дрожании голосовых связок.
В русском языке 10 гласных букв: А-Я,О-Ё, У-Ю, Ы-И, Э-Е,
но 6 гласных звуков: [А], [О], [У], [Ы], [ Э], [И
- А, О, У, Ы, Э – это буквы, которые дают предыдущему согласному команду: «Читайся твёрдо!», но звуки [ч’], [щ’] – всегда мягкие:
сон [сон], дым [дым], чаща [ч’ащ’а], часы [ч’асы].
- Я, Ё, Ю, И, Е – это буквы, которые дают предыдущему согласному команду: «Читайся мягко!» (обозначают мягкость предыдущего согласного), но звуки [ж], [ш], [ц] остаются всегда твердыми:
мята [м’ата], тёрка [т’орка], мюсли [м’усл‘и], мел [м’эл], лес [л’эс], жир [жыр], ширь [шыр’], цифра [цыфра].
- Буквы Я, Ё, Ю, Е – йотированные. Они могут давать один или два звука, в зависимости от положения в слове.
- Я, Ё, Ю, Е стоят после согласных, то обозначают мягкость предыдущего согласного (кроме всегда твердых [ж], [ш], [ц]) и дают один гласный звук : я – [а], ё – [о], ю – [у], е – [э] :
Мяч[м‘ач], тёрн [т‘орн], тюль [т‘ул’], пена [п‘эна]. - Я, Ё, Ю, Е дают два звука: согласный [й’] и соответствующий гласный, если они стоят
- в начале слова: яма [й’aма ], ёлка [й’олка], юла [й’у ла ], ель [й’э
л’]; - после гласных: маяк [май’ак], поёт [пай’от], поют [пай’ут], поел [пай’эл];
- после разделительных Ъ и Ь знаков: деревья [д’ир’эв’й’а ], объём [абй’ом], вьюга [вй’уга], съезд [сй’эст].
- в начале слова: яма [й’aма ], ёлка [й’олка], юла [й’у ла ], ель [й’э
- Я, Ё, Ю, Е стоят после согласных, то обозначают мягкость предыдущего согласного (кроме всегда твердых [ж], [ш], [ц]) и дают один гласный звук : я – [а], ё – [о], ю – [у], е – [э] :
- В транскрипции буквы Я, Ё, Ю, Е не используются. Звуков [е], [ё], [ю], [я] не существует.
- Буква И после Ь обозначает два звука: чьи [ч’й’и], лисьи [лис’й’и]
- [й’] – согласный, всегда звонкий, всегда мягкий звук .
В состав слога обязательно входит гласный звук: “Сколько в слове гласных, столько и слогов. Это знает каждый из учеников!”
Для малышей! Чтобы определить количество слогов в слове, надо приложить раскрытую ладошку под подбородок и четко произнести слово. На гласных подбородок ударит по ладошке. Посчитайте количество таких ударов и узнаете количество слогов.
Согласные звуки.
При произнесении согласных выдыхаемый воздух встречает преграды (губы, зубы и язык) в ротовой полости. Всего 36 согласных звуков.
Согласные звуки бывают твердые и мягкие, звонкие и глухие.
- Звонкие
- образуются при помощи голоса (вибрируют голосовые связки) и шума.
- Л, М, Н, Р, Й – самые звонкие согласные (больше голоса и совсем мало шума в звуке), всегда звонкие.
- Б, В, Г, Д, Ж, З –
звонкие [б], [в], [г], [д], [ж], [з], [б’], [в’], [г’], [д’], [з’], имеют парные звуки по звонкости/глухости. - Фраза для запоминания содержит все звонкие согласные: Мы же не забывали друга.
- Глухие
- произносятся без голоса (без колебания голосовых связок) и состоят только из шума:
- П, Ф, К, Т, Ш, С – глухие [п], [ф], [к], [т], [ш], [с], [п’], [ф’], [к’], [т’], [с’] имеют парные звонкие;
- X, Ц, Ч, Щ – [х], [х’], [ц], [ч’], [щ’] – всегда глухие, не имеют парных по звонкости/глухости .
- Фразы для запоминания, которые содержат все глухие согласные:
- «Степка, хочешь щец?» – «Фи!»
- Фока, хочешь поесть щец?
Для того чтобы определить, звонкий или глухой согласный, ребёнок закрывает уши ладошками и произносит этот звук. Если ребёнок при произнесении слышит голос, то это звонкий согласный. Если слышит не голос, а шум, то этот согласный глухой.
- Твердые: [б], [в], [г], [д], [ж], [з], [к], [л], [м], [н], [п], [р], [с], [т], [ф], [х], [ц], [ш].
- Мягкие: [б’], [в’], [г’], [д’], [з’], [й’], [к’], [л’], [м’], [н’], [п’], [р’], [с’], [т’], [ф’], [х’], [ч’], [щ’]. При фонетическом разборе мягкие звуки обозначаются знаком [‘].
Твердые и мягкие согласные при произношении различаются положением языка. Важно различать для правильного произношения и написания слов: мол [мол] – моль [мол’], угол [угол] – уголь [угол’], нос [нос] – нёс [н’ос].
- Л, М, Н, Р, Й – всегда звонкие.
- Б-П, В-Ф, Г-К, Д-Т, Ж-Ш, З-С – парные согласные по звонкости-глухости.
- X, Ц, Ч, Щ – всегда глухие согласные.
- Ч, Щ, Й – всегда мягкие согласные.
- Ж, Ш, Ц – всегда твердые согласные.
- Ж, Ш,Ч, Щ – шипящие.
ФОНЕТИЧЕСКИЙ (ЗВУКО-БУКВЕННЫЙ) АНАЛИЗ СЛОВА
- Запишите слово.
- Поставьте ударение.
- Разделите слово на слоги. Сосчитайте и запишите их количество.
- Выпишите все буквы этого слова в столбик одну под другой. Сосчитайте и запишите их количество.
- Напишите справа от каждой буквы, в квадратных скобках, звук, который эта буква обозначает.
- Опишите звуки:
- Гласный, ударный или безударный.
- Согласный, глухой или звонкий, парный или непарный; твёрдый или мягкий, парный или непарный.
- Гласный, ударный или безударный.
- Сосчитайте и запишите количество звуков.
- Иногда требуется объяснить особенности правописания (орфографические правила).
Примеры
| ко|леч|ко – 3 слога, 7 б., 7 зв. | ||
|---|---|---|
| К | [к] | согл., глух., тв. |
| О | [а] | глас, безудар. |
| Л | [л’] | согл., звон., мягк. |
| Е | [э] | глас, удар. |
| Ч | [ч’] | согл., глух., мягк. |
| К | [к] | согл., глух., тв. |
| О | [а] | глас, безудар. |
| Ель – 1 слог, 3 б. 3 зв. | ||
| Е | [й’] | согл., звон., мягк. |
| [э] | глас, удар. | |
| Л | [л’] | согл. , звон., мягк. |
| Ь | [-] | не обозначает звука, обозначает мягкость предыдущего согласного звука Л |
Обратите внимание !
Для гласных.
- Буквы Я, Ё, Ю, Е – йотированные.
- Если эти буквы стоят после согласных, то они дают один звук:
- Я – [а], Ё – [о], Ю – [у], Е – [э]: Лён – [л’ о н] – 3 буквы, 3 звука.
- Если эти буквы стоят в начале слова, после гласных и разделительных Ъ и Ь знаков, то они дают 2 звука:
- Я – [й’а], Ё – [й’о], Ю – [й’у], Е – [й’э]: Ёлка – [й’ о л к а] – 4 буквы, 5 звуков. Поёт [пай’о т ] – 4 буквы, 5 звуков.
- Если эти буквы стоят после согласных, то они дают один звук:
- Буква И
- после Ь обозначает два звука: чьи [ч’ й’и], лисьи [лис’й’и];
- после согласных Ж, Ш, Ц даёт звук [ы]:
- зажим [зажым], шины [ш ы н ы], цирк [цырк] ;
- гласная О под ударением даёт звук [о], а без ударения [а]:
- кОтик – [ кОт ‘ и к], скворцы – [с к в а р ц ы];
- гласная Е под ударением даёт звук [э], а без ударения [и]:
- лес [л’эс], лесА [л’исА] (см. лисА [л’исА]), весна [в’исна];
- лес [л’эс], лесА [л’исА] (см.
- в некоторых иноязычных словах перед гласной Е согласный произносится твёрдо:
- кафе [кафэ], купе [купэ], свитер [свитэр], отель [атэл’];
- гласная Я под ударением даёт звук [а], а без ударения [э], [и]:
- мяч – [м’ач’], рябина – [р’эб’ина], пятно – [п’итно].
- Буквы Я, Ё, Ю, Е – йотированные.
Для согласных.
- парные по глухости/звонкости согласные в конце слова, перед глухой согласной произносятся глухо (оглушаются):
- гриб – [гр’ и п], лавка – [л а ф к а];
- Й, Ч, Щ – [й’], [ч’], [щ’] – всегда мягкие;
- Ж, Ш, Ц – [ж], [ш], [ц] – всегда твердые;
- Если в слове рядом стоят несколько согласных, то в некоторых словах звуки [в], [д], [л], [т] не произносятся (непроизносимые согласные), но буквы в,д, л, т пишутся:
- чувство [ч’Уства], солнце [сОнцэ], сердце [с’Эрцэ], радостный [рАдасный’].
- чувство [ч’Уства], солнце [сОнцэ], сердце [с’Эрцэ], радостный [рАдасный’].
- сочетание СТН произносится как [сн], ЗДН – [зн]:
- звёздный – [з в’ о з н ы й’], лестница – [л’ эс ‘н’и ц а].
- иногда на месте буквы Г перед глухой согласной произносятся звуки [к], [х]:
- когти – [к о к т’ и], мягкий – [м’ ах ‘ к ‘ и й’];
- иногда буква С в начале слова перед звонкой согласной озвончается:
- сделал – [з’ д’ э л а л].
- между корнем и суффиксом перед мягкими согласными согласные могут звучать мягко :
- зонтик – [з о н’ т ‘и к];
- иногда буква Н обозначает мягкий согласный звук перед согласными Ч, Щ:
- стаканчик – [с т а к а н’ ч’ и к], сменщик – [см’э н’ щ’ и к];
- Удвоенные согласные располагаются
- после ударного гласного, то дают длинный звук : грУппа [ груп:а], вАнна [ ван:а];
- перед ударным гласным, то образуется обычный согласный звук: миллиОн [м’ил‘иОн], аккОрд [акОрт], аллЕя [ал‘Эй’а] ;
- сочетания ТСЯ, ТЬСЯ (у глаголов) произносятся как длинный [ц]:
- бриться – [бр’ иц:а];
- иногда сочетание ЧН, ЧТ произносится как [ш]:
- конечно – [ кан ‘ эшна ], скучно – [ скушна ], что – [ш т о], чтобы – [штобы];
- буква Щ и сочетания букв СЧ, ЗЧ, ЖЧ обозначают звук [щ’]:
- щавель [щ ‘ав ‘ эл ‘ ], счастливый [ щ ‘асливый ‘ ], извозчик [извощ ‘ик], перебежчик [п ‘ир ‘иб’Эщ ‘ик];
- в окончаниях имён прилагательных ОГО, ЕГО согласный Г произносится как [в]:
- белого – [б’ Э л а в а].
- белого – [б’ Э л а в а].
- парные по глухости/звонкости согласные в конце слова, перед глухой согласной произносятся глухо (оглушаются):
комментариев 914 Теги: гласный, начальная школа, порядок фонетического разбора слова, согласные звуки, фонетический разбор
Добавить комментарий
© 2011 — 2022 Учим русский язык
Карта сайта
Сколько звуков букв в английском языке?
Опубликовано 9 октября 2013 г. | Оставить комментарий
Это зависит.
Международная фонетическая ассоциация (IPA), разработавшая метод классификации звуков речи, сообщает, что в американском английском 44 звука — 20 гласных и 24 согласных (и диграф). IPA разработала символы для каждого из этих звуков — большинство из них представляют собой буквы латинского алфавита с некоторыми добавленными греческими буквами и другими символами. Логопеды используют эти символы, чтобы записать точные звуки, которые произносит учащийся, когда они выявляют проблемы с речью.
Нажмите на график для увеличения.
В целом в американском английском меньше звуков, чем в британском английском. Стандартный английский (обычно считается, что на английском говорят жители Среднего Запада) имеет 16 гласных звуков, что как минимум на четыре гласных звука меньше, чем в стандартном британском английском. Поскольку акценты варьируются от региона к региону, в некоторых частях США может быть больше или меньше гласных звуков.
Когда ребенок учится читать по-английски, произнести звук не проблема; это множество способов, которыми один звук может быть показан буквами.
Некоторые учителя пытались помочь учащимся, особенно ученикам ESL, освоить звуки, добавляя символы к буквам с несколькими звуками: кривая над короткой гласной, горизонтальная черта над долгой гласной и печатая две буквы, которые имеют одну звучат как одна буква без пробела между ними. Это облегчает учащимся связывание звуков с символами, но учителя обнаружили, что учащиеся становятся зависимыми от символов и не могут перейти к чтению букв без этих символов.
Из-за того, что учащимся очень трудно подобрать звук к букве, было разработано множество методов чтения. Однако исследование, проведенное правительством США несколько лет назад, показало, что систематический фонетический подход лучше всего работает с маленькими детьми, которые учатся читать.
Нравится:
Нравится Загрузка…
Эта запись была опубликована в рубрике Звуки букв, фонетика и отмечены гласные звуки. Добавьте постоянную ссылку в закладки.
Поиск:
Ваш ребенок готов к написанию сочинения? Я обучаю онлайн написанию сочинений для средних и старших классов. Нажмите на рисунок выше, чтобы увидеть мой блог «как сделать» и информацию о репетиторстве.
Вы можете подумать, что исправление означает поиск грамматических и орфографических ошибок, когда на самом деле это означает переписывание — перемещение идей, добавление дополнительных деталей, использование конкретных глаголов, изменение структуры предложений и добавление образного языка. Узнайте, как улучшить свое письмо с помощью этих идей по переписыванию и многого другого.
НАЖМИТЕ НА фото выше, чтобы увидеть больше.Комические рассказы, повторяющиеся фразы и выразительные иллюстрации привлекают первых читателей и укрепляют доверие к чтению. Каждая история включает в себя легко произносимые двух-, трех- и четырехбуквенные слова, которые следуют правилам фонетики. Результатом является увлекательный опыт чтения, ведущий к пониманию, запоминанию и стимулированию обсуждения. Каждая история — это настоящая детская литература с началом, серединой и концом. Каждая книга также содержит раздел «развлечения и игры» для дальнейшего развития опыта обучения начинающего читателя. НАЖМИТЕ на коллекцию книг выше, чтобы увидеть больше.
НАЖМИТЕ НА картину выше, чтобы увидеть самую последнюю работу миссис А.
Следите за этим блогом по электронной почте
Введите свой адрес электронной почты, чтобы следить за этим блогом и получать уведомления о новых сообщениях по электронной почте.
Адрес электронной почты:
Присоединиться к 96 другим подписчикам
Хотите вести блог?
RSS – Сообщения
RSS – Комментарии
Последние сообщения
- 1/3 детей в США хорошо читают, поскольку способность к чтению снижается
- В 2022 году планируется запретить 1651 название книг
- Две игры делают фонетику увлекательной для начинающих читателей
- Действительно ли шрифты, специально разработанные для читателей с дислексией, помогают им читать быстрее или лучше?
- Какие шрифты могут помочь людям с дислексией лучше читать?
Categories
CategoriesSelect Categorya right to learn to readABC’sacademic vocabularyADHDalternate perspectivesannotating textsarticlesasking questionsautismAward Winning Booksbanned booksbeginning readersblendsboard booksBook Apps for Early Readersbooks for beginning readersbooks on bikescolored pencilsComicphonics viewerscommitted parejtsCommon Core Standardscompound wordscomprehensionconsonantscoordinating conjunctionscovid slidecritical thinkingcursive handwritingCVC wordsdiagramsdigraphsDISTARdistinguishing b from dDolch wordsdouble vowel wordsdyslexiaearly книги по главамдошкольное образованиеэлектронные книгианглийский как второй язык (ESL)грамматика английского языка изучающие английский язык (ELL)написание эссеисключения из правил фонетикиExplode the Codeпроблемы слежения за глазамиFANBOYчтение художественной литературыизобразительный языкбеглостьвеселые страницыДокументы Googleугадывание словуровни чтения с подсказкамиПочеркистория обучения чтениюдомашнее обучениесоветы по выполнению домашних заданийПодсел на Phonicshow to ma как писать эссе для 5-го класса (или любого другого класса)гиперактивностьидиомыиллюстрированные книгивыводыАлфавит начального обучениявнутренние системы вознаграждениякенестетическое обучениеклавиатураготовность к детскому садукинестетическое обучениезнание когда бросить обучениеобучение в младенчествезвуки буквбуквенные плиткилексический счетпрослушиваниеграмотностьМаленькая бесплатная библиотекадлинные гласныеосновная идея отрывка для чтенияMcGuffey Readersметоды обучения правописаниюметоды обучения чтениюметоды обучения чтению письмоспособы образованиямногозадачность при обучениимиопияНейт ВеликийНациональная оценка образовательного прогрессановости для юных читателейНи один ребенок не остался без вниманиячтение научно-популярных книготказатьсяпревзойти школывыбор родителей в обучениителефонмефоникакниги с картинкамиточка зрениятренировать навыки чтениянавыки предварительного чтенияпримитивные рефлексыпечатный почеркместоимение-предшествующее соглашениепроизношение словвикторинаготовность к следующему классуРепетитор по чтениюпонимание чтениянарушение чтения iesчтение в детском садуготовность к чтению. Reading Recoveryисследование чтениястратегии чтениятесты чтениявремя чтениясоветычтение-письменная связьучет успеваемости ребенкаповторение класса в школеэкранное время для маленьких детейсенсорная интеграцияструктура предложенийкраткие гласныезрительные слованемые слова на букву «е»простой взгляд на чтениепение как навык чтенияпропуск словнеразборчивое чтение слов вслухрешениязвуки английского языкарасстановка букв в словахОрфографияразговорный язык вехаспорт против академиковлето слайдысистематическое обучение фонетикеобучение в условиях пандемииобучение онлайнсоветы преподавателятехнологиибуква Qqнациональный табель успеваемости в третьем классетри подсказкирепетиторствошрифты/шрифтыпонимание Шекспираобразование в СШАиспользование жестов для изучения словарного запасагласныецелый языкПочему Джонни не может читатькниги без словрабочая памятьВсемирный день чтения вслухконкурс письма делает читателей лучшеZoom
Объяснение букв и звуков — Акустика с ручкой и бумагой
Буквы и звуки являются основными строительными блоками всей фонетики.
- «Буквы» относятся к фактическим физическим или письменным буквам алфавита (также называемым «графемами»).
- «Звуки» — это звуки, издаваемые этими буквами (также называемые «фонемами»).
В алфавите 26 букв.
Все слова английского языка состоят примерно из 44 звуков.
Мы используем 26 букв алфавита, чтобы записать эти 44 звука.
Некоторые звуки написаны с Одна буква:
Некоторые звуки написаны с Две буквы:
Некоторые звуки написаны с Три буквы:
Некоторые звуки — это пишется четырьмя буквами :
В этих примерах один звук представлен более чем одним звуком.
Например, звук в начале слова «магазин» представлен двумя буквами: «с» и «ч». Если бы вы разобрали звуки в слове магазин (не видя слова), то получили бы три звука «ш-о-п»:
Если бы вы разобрали слово «восемь», вы бы только получить два звука «восемь-т», потому что четыре буквы «восемь» дают только один звук:
Соответствие букв и звуков
Соответствие букв и звуков относится к способности знать, какой звук звучит в каждой букве (и в каждой комбинации букв) делает.
Чтобы ребенок научился читать слово «кошка»:
- Он должен знать, что буква «с» обозначает звук /с/ в слове, буква «а» обозначает звук /а/ и буква «т» представляет звук /т/.
- Затем они должны уметь произносить и смешивать эти звуки вместе. (См. Смешивание и сегментирование).
Все это звучит вполне управляемо.
Соответствие между буквами и звуками затруднено тем, что один и тот же звук может быть записан разными комбинациями букв, а одна и та же комбинация букв может давать разные звуки… э, да!
- Известным примером является слово внизу. Что бы вы сказали, что он сказал?
- На самом деле это альтернативное написание очень распространенного слова…
…рыба!
Итак, в английском языке может быть более одного способа написания звука:
И более одного способа произношения одних и тех же букв:
90244 Как звучит15 звучит 90 произносятся важно.
Word Pronunciation: Example & Symbols
Большинство носителей английского языка не склонны слишком много думать о произношении английских слов — мы просто произносим их. Но вы когда-нибудь пытались выучить другой язык и осознавали, насколько сложным может быть произношение слов?
В этом объяснении мы рассмотрим важность навыков произношения, символы, которые мы используем для расшифровки произношения, наиболее важные элементы произношения на английском языке и множество примеров.
Произношение слов Английский
То, как мы произносим слова, может зависеть от нескольких факторов. Конечно, написание слова может помочь нам «выяснить» произношение, но не все слова произносятся так, как они выглядят.
Есть советы и рекомендации по английскому языку, которым мы можем научиться, чтобы улучшить произношение. Например:
Когда определенные буквы появляются вместе, они создают определенные звуки, например, ch, sh, igh — мы называем эти фонические сочетания.
Теперь рассмотрим букву G в гном или К в ноже; это немые буквы и их не следует произносить.
Или, как насчет модификации E, , которая может превратить короткий гласный звук в долгий, например, шляпа —> ненависть.
Наконец, рассмотрим разницу в произношении между винил записывать и глаголом записывать. Здесь мы можем увидеть влияние словесного ударения на значение слова.
Это всего лишь небольшой экскурс в сложный мир произношения.
Чтобы помочь нам понять и рассказать другим, как должно произноситься слово, мы можем транскрибировать слова, используя Международный фонетический алфавит (IPA). IPA представляет собой систему, состоящую из букв и символов, представляющих различные звуки, и используется во всем мире для улучшения произношения.
Прежде чем мы углубимся в важные элементы произношения, давайте внимательно рассмотрим транскрипцию и IPA. Это поможет вам понять оставшуюся часть объяснения, поскольку примеры произношения будут расшифрованы с использованием IPA.
Word Pronunciation Symbols
Have you ever looked up a word in the dictionary or online, such as morphology, and seen something that looks like this: mor · FAA · LUH · JEE или равно, как это: [ ˈMɔːRF.0060 фонетическое написание для «озвучивания» произношения слог за слогом, тогда как во втором используется транскрипция IPA t .
Начнем с фонетического написания.
Фонетическое правописание
Прежде чем мы сможем обсудить фонетическое правописание, необходимо определить два важных термина: фонемы и графемы.
Фонема — Фонема – это звук речи. Это физический шум, который мы производим. Мы представляем фонемы, помещая их между двумя косыми чертами, например, /f/
Графема — Графема — это буква или символ, используемый для представления отдельного звука речи, например, f
Если мы снова посмотрим на слово канморф 6,
морфология видим, что в центре слова фонема /f/ представлена графемой ph.
Когда мы пишем слово, используя фонетическое написание, мы используем фонемы, а не графемы, и разбиваем слово на слоги.
Creation = kree · ay · shn
Celebrate = seh · luh · brayt
Happy = ha · pee
Light = lite (Здесь мы можем увидеть изменение e в действии. e дает нам понять, что i — это долгий гласный звук, а не короткий. Мы знать, чтобы не произносить e в том виде, в котором оно появляется во втором слоге, например, так lit.e
Международная транскрипция фонетического алфавита
Второе представление произношения, которое мы видели ( /ˈmɔːrfəloʊgiː/
6 900 фонетическая транскрипция.Фонетическая транскрипция использует символы из IPA для расшифровки произношения любого слова на любом языке. Эти символы включают:
Способ и место артикуляции — Ваши артикуляторы — это органы речи, которые помогают вам производить звуки, такие как зубы, язык и губы. Способ и место артикуляции относятся к тому, где вы размещаете и как вы используете свои артикуляторы для произнесения определенных звуков.
Звонкие и глухие согласные — произношение одних согласных вызывает вибрацию в вашем голосовом аппарате (это звонкие согласные), а других нет (глухие).
Диакритические знаки — это небольшие метки, которые появляются рядом с согласными и гласными, чтобы предоставить дополнительную информацию о произношении, например, звонкий или глухой, с придыханием или без придыхания (с выдохом или без него), или как округляется гласный звук должен быть.
Hat = [ˈhæt]
Если присмотреться, то можно увидеть, что над согласной h есть небольшая отметка. Это дает нам понять, что звук аспирационный, то есть создается при небольшом выдохе воздуха.
Супрасегменты — они аналогичны диакритическим знакам, за исключением того, что они применяются к просодическим характеристикам, которые появляются в связанной речи, таким как тон, интонация, изменения высоты тона и ударение. Эти просодические особенности представлены небольшими знаками.
- Другие функции — IPA также содержит символы для обозначения других особенностей произношения, таких как щелчки и звуки; однако это не обязательно для английского языка.
Рис. 1. Недавняя копия Международного фонетического алфавита
Как видите, IPA довольно всеобъемлющий, и вся включенная информация не является необходимой для выполнения простых транскрипций c английских слов. Чтобы упростить ситуацию, мы можем использовать английский фонематический алфавит, упрощенную версию IPA, которая фокусируется только на гласных и согласных, встречающихся в английском языке.
Рис.2. Пример английской фонематической таблицы
Фонетическая и фонематическая транскрипция
Фонетическая транскрипция включает в себя все дополнительные детали того, как произносится слово, с использованием диакритических знаков и надсегментов, которые появляются в IPA. Они называются узкими транскрипциями и заключаются в две квадратные скобки, например:
Clean = [kl̥i:n]
С другой стороны, фонематическая транскрипция намного проще и обычно включает только произношение согласных и гласных. Они называются широкими транскрипциями и появляются между двумя косыми чертами, например:
Чистый = /klin/
Нет ничего необычного в том, что люди называют фонематическую транскрипцию фонетической транскрипцией слова или фонематические транскрипции включают наиболее распространенные диакритические знаки/супрасегменты.
Элементы произношения слов
Теперь, когда мы знаем основы произношения и способы представления произношения слов, давайте рассмотрим некоторые важные элементы правильного произношения, специфичные для английского языка.
Ударение слога
К настоящему моменту вы, вероятно, уже знаете, что произношение — это нечто большее, чем произношение согласных и гласных звуков.
Когда мы произносим слово, состоящее из нескольких слогов, ударение на слоге может быть очень важным, поскольку это может затруднить понимание слова или даже полностью изменить его значение. Ударные слоги могут быть на длиннее, громче, на иметь на более высокий тон или просто на четче , чем другие слоги.
Это особенно важно для омонимов (слов, которые выглядят/звучат одинаково, но имеют разные значения). В английском языке есть много омонимов, которые могут функционировать как существительное или глагол, в зависимости от того, на какое ударение падает слог.
RE-cord (существительное) — re-CORD (глагол)
PRE-sent (существительное) — pre-SENT (глагол)
RE-bel (существительное) — re-BEL (глагол)
Как видите, если поставить ударение на первый слог, получится существительное.
Акустические смеси
Есть определенные звуки, которые мы можем создавать, когда соединяем фонемы вместе — они называются фоническими сочетаниями . При произнесении фонических смесей каждая фонема не должна произноситься по отдельности, а связка должна произноситься как единое целое.
ch как в церков — здесь c и h объединены для создания особого звука, который представлен как /ʧ/
th как в зубы представлены как /θ /
igh как в ночь — представлено как /aɪ/
Когда звуковая смесь содержит две гласные, мы обычно произносим первую гласную. Например, слово мозг содержит длинный звук а (тоже слово содержит!)
Минимальные пары
Минимальные пары — это слова, которые звучат очень похоже, но отличаются единственным звуком. Отличающийся звук обычно появляется в одном и том же месте в каждом слове.
Ш ээ P и SH I P
D E SK и D I SK
F AN и 9006. ANMALE VAIL . важность четкого произношения.
Изменение ‘E’
Изменение e (также известное как волшебное e ) — это немая буква, которая появляется в конце слова и изменяет гласный звук, стоящий перед ним. e преобразует короткий гласный звук в долгий, например, rat —> rate.
Безмолвные буквы
В английском языке есть много слов, содержащих немые буквы; они могут быть гласными или согласными. Это буквы, которые появляются при написании слов, но не должны произноситься. Когда мы рассматриваем такие вещи, как вторая гласная в фонических смесях и изменение e, , по оценкам, 60% английских слов на самом деле содержат немые буквы.
G NOME
H Наш
K NIFE
Colum N
DO B T
СИЛОВЫЕ ЗАГРУЗКИ ИЗДЕЛА ИЗНАЯ ИЗНАЧЕНИЕ ИЗНАЧЕНИЕ, как это, так и на языке. , и правописание было перенесено. Безмолвные буквы также могут помочь нам различать омофоны (слова, которые звучат одинаково), например, час и наш .
Пример произношения слова
Давайте закончим примерами слов, которые включают в себя некоторые элементы, которые мы рассмотрели сегодня. Каждый пример будет включать английское написание, фонетическое написание и транскрипцию IPA.
Words with silent letters
Climb — klime — /klaɪm/
Read — reed — /riːd/
Knight — nite — /naɪt/
Words with модификация e
Плана — Playn — / pleɪn /
Shine — Shine — / ʃaɪn /
Главная — Дом — / HOʊM /
с Phonic Blends
12с Phonic Blends 12
R AI N — RAYN — / REɪN /
BR OUGH T — BRAAT — / BRɔːT /
На произношение слова могут влиять несколько элементов, таких как написание, слоговое ударение, фонические сочетания, немые буквы и модификаторы.Каталожные номера
- Рис. 1. Таблица Международного фонетического алфавита (IPA) по состоянию на 2020 г. Этот файл находится под лицензией Creative Commons Attribution-Share Alike 3.0 Unported. https://commons.wikimedia.org/wiki/File:IPA_chart_2020.svg#filelinks
- Рис. 2. Категория: Диаграммы IPA CC-BY-SA-3.0 Пользователь: Snowwhite1991 https://commons. wikimedia.org/wiki /File:Phonetic_alphabet.gif
Энтропия | Бесплатный полнотекстовый | Энтропийно-аргументативная концепция вычислительно-фонетического анализа речи с учетом диалектности и индивидуальности звучания
1. Введение
Вычислительный фонетический анализ является фундаментальным компонентом большинства информационных технологий для распознавания естественного языка, когнитивного анализа речи, автоматической транскрипции речи и т.д. Высокая достоверность фонетического анализа является гарантией качественного результата функционирования всех этих типов систем. Особенно актуален первичный фонетико-морфологический анализ флективных языков и речи. Основным источником ошибок в этом процессе является слияние [1,2,3,4]. Это явление характеризует высокую вариативность индивидуального звучания фонем, особенно на стыке морфем. Феномен слияния объективно обусловлен фонологической эволюцией естественного языка и не может быть проигнорирован при создании прецизионных технологий вычислительного фонетического анализа речи.
Задача вычислительного фонетико-морфологического анализа языка или речи объективно усложняется, во-первых, особенностями самого языка как процесса физиологико-познавательной деятельности человека, а, во-вторых, особенностями привлекаемых профильных информационных технологий.
Отметим основные интегральные факторы первого источника осложнений [5,6,7,8,9].
Омонимия флексий. Флексии могут быть омонимичными, если они принадлежат к одной мироизменяющей парадигме или характеризуют одну лексико-грамматическую категорию, но относятся к разным мироизменяющим парадигмам, а иногда встречаются и в парадигмах разных частей языка. Этот фактор является источником неоднозначности в фонетико-морфологическом анализе. Негативное влияние этого фактора можно уменьшить, используя информационные технологии лингвистического контекстного анализа и вычислительного фонетического анализа.
Внутреннее сгибание. Этот тип флексии проявляется при использовании основного набора языковых единиц, репрезентативность которых зависит от содержания словоформ. Если коллекция не используется, необходимо сформулировать правила языкового полиморфизма, присущие изучаемому языку.
Сложные лексемы. Лексемы, фонация (написание) которых включает в себя специфические приемы артикуляции (специальные символы), требуют определения склонения для каждого компонента в словоформе.
Аналитические словоформы. Аналитические словоформы встречаются во многих языках и могут вызывать значительные сложности при фонетико-морфологическом анализе, поскольку компоненты словоформы могут быть разделены и даже находиться в разных позициях в предложении.
Большой словарный фонд языка. Несмотря на быструю положительную динамику характеристик вычислительной мощности и большой объем памяти современной вычислительной техники, работа с базовым набором языковых единиц изучаемого языка (особенно с базовым набором словоформ) при выполнении фонетико-морфологического анализа остается актуальной. задача высоких вычислений.
Изменчивость лексического уровня языка. Обновление коллекций языковых единиц под соответствующий тип системы фонетико-морфологического анализа не поспевает за полиморфизмом естественного языка (особенно с учетом диалектов), который проявляется в бытовом явлении новых лексем (в частности, терминов). ) и словоформы. Системы вычислительного фонетико-морфологического анализа бесколлекторного типа менее подвержены влиянию этого усложняющего фактора.
Мы упомянули лишь наиболее распространенные факторы естественно-языкового происхождения, негативно влияющие на эффективность вычислительного фонетико-морфологического анализа речи. В зависимости от используемых информационных технологий этот список расширяется.
Исследуется современное состояние теоретико-аналитической базы современных информационных технологий вычислительного фонетико-морфологического анализа. Основываясь на результатах информационного поиска [10,11], мы выделяем два соответствующих подхода — рационалистический и эмпирический. Первый подход использует лингвистические знания для анализа и синтеза языковых единиц. Второй подход основан на обобщении эмпирических данных, например, в виде статистической модели языка (речи) [12,13]. Однако в современной компьютерной лингвистике наиболее продуктивными являются технологии, интегрирующие в определенной пропорции оба этих подхода. По содержанию используемого набора языковых единиц как системообразующего элемента для реализации вычислительного фонетико-морфологического анализа технологии-анализаторы можно разделить на [14,15,16,17]: (1) системы с коллекция фонем и морфем; (2) системы с набором лексем и словоформ; и (3) системы без базовых коллекций.
Центральным элементом систем первого типа является совокупность относительно фонетически и лингвистически устойчивых языковых единиц (морфем, фонем, выделенных аллофонов) изучаемого языка. Соответствующий технологический анализатор разлагает речевой сигнал (текст) на определенную последовательность неделимых порций, осуществляя для каждой из них процедуру распознавания. Такая элементарная комбинаторная модель чаще всего используется для анализа флективных и агглютинативных языков. Порядок частей лексем определяется как конкатенация соответствующих классов морфем в наборе. Для определения порядка перехода между классами морфем обычно используют математический аппарат конечных автоматов или цепей Маркова [18]. Количество классов морфем в коллекции определяется результатом предыдущей морфологической классификации изучаемого языка. Кроме декларативной информации о составе морфем коллекция может хранить и процедурную информацию. Такая информация определяет допустимый диапазон варьирования паттернов морфем и чаще всего оформляется в виде системы продукционных правил [10,11,14,19].]. Эмпирические вероятностно-статистические методы чаще всего используются для распознавания в системах этого типа [4,12,20].
Системы второго типа ориентированы на вычислительно-морфологический анализ. Соответственно, содержание коллекций эталонов языковых единиц в таких системах формируют морфемы и краткие лексемы. Системы этого типа рассматривают словоформы как последовательность таких языковых единиц, образованных по композиционным и (или) продукционным правилам. При изучении словоформ система генерирует для него лемму по определенным правилам [21,22]. Если такая лемма присутствует в базовой коллекции, то словоформа считается распознанной. Если учитывать ресурсоемкость, то эффективность таких систем определяется в основном репрезентативностью содержания базовой коллекции. Наборы морфем или лексем используются при фонетико-морфологическом анализе для нормализации изучаемых словоформ. При наличии набора морфем нормализация реализуется в виде стемминга. При наличии набора лексем нормализация реализуется в виде лемм. Отдельно упомянем подкласс систем второго типа, в котором используется совокупность словоформ. Целью таких систем является грамматико-морфологический анализ, при котором в коллекции представлен набор сочетаний словоформ, которому соответствует набор грамматических меток [11,19].,23]. При достаточно богатой коллекции источником ошибок анализа в этих системах является только омонимия полной словоформы.
Недостатком всех систем фонетико-морфологического анализа первого и второго типов является использование больших коллекций языковых единиц. Однако по этому критерию системы, ориентированные на использование фонетических и морфологических коллекций, выглядят лучше, если эффективность процесса распознавания приемлема.
Системы третьего типа выполняют фонетико-морфологический анализ исключительно на основе математических методов машинного обучения (машины опорных векторов, ЭМ-метод, генетические алгоритмы, сети Кохонена и др.) [24,25,26,27,28,29,30,31,32,33,34]. Допустимы любые методы графемного анализа [24], результатом которого является автоматическое или автоматизированное формирование фонетико-морфологических коллекций. Преимуществом систем третьего типа является методологически обусловленная высокая эвристика и адаптивность, которые потенциально позволяют распознавать языковые единицы в речевом материале с явной неопределенностью. Недостатком таких систем является сложность и нестабильность обучения этими псевдоинтеллектуальными методами, а также потребность в исходных данных и вычислительных ресурсах, объем которых превышает требуемый для систем первого и второго типа не в разы, но заказы.
Ниже мы сформулируем основные положения нашего исследования.
Объект изучения — слияние процесса слитной речи.
Учитывая указанные преимущества и недостатки систем фонетико-лингвистического анализа, сформулируем цель исследования как формализация в парадигме теории информации статистически адекватной аналитически строгой концепции фонетического анализа речи, вариативность которой будут учтены.
Предметом исследований будут методы теории вероятностей и математической статистики, теории информации, теории распознавания образов и акустической теории формирования языка.
В связи с этим задачами исследования являются: создание концепции процесса вычислительного фонетического анализа речи с учетом диалектов и специфики фонации, привносимой говорящим; сформулировать критерий оценки фонетической насыщенности речи на основе предложенной модели с учетом искажающего действия канала распространения речевых сигналов в процессе фонации; и доказать адекватность и функциональность полученных теоретических результатов.
Основным вкладом исследования является концепция вычислительного фонетического анализа речи. В концепции, в отличие от существующих методов, строго формально представлена задача многокритериального решения процесса когнитивного восприятия речи человеком в теоретико-аналитическом аппарате теории информации, теории распознавания образов и акустической теории речи. формирование. Полученная концепция позволяет точно определять фонетический алфавит человека с учетом присущего ему диалекта речи и индивидуальных особенностей фонации, а также выявлять и исправлять ошибки в распознавании языковых единиц и достоверно оценивать фонетическую насыщенность речи.
Основные моменты данного исследования:
- —
Энтропийно-аргументативная концепция (т.е. математическая модель и методы) вычислительного фонетического анализа речи с учетом диалектности и индивидуальности звучания;
- —
Энтропийно-аргументативная концепция обнаружения и исправления ошибок вычислительного фонетического анализа речи.
2. Материалы и методы
2.1. Положение о НИР
Функциональное назначение типовой современной информационной технологии вычислительного анализа речевых паттернов реализуется путем сопоставления параметризованного представления изучаемой языковой единицы и соответствующего ей эталона в некотором параметрическом пространстве. Основным источником неопределенности в процессе сравнения является биологическое происхождение речевого сигнала и его искажение при передаче и обработке. Однако акустическая вариативность звучания языковых единиц (прежде всего фонем), благодаря существованию диалектов, относительно стабильна. Исходя из этого, мы предполагаем одновременное сопоставление исследуемого образа фонограммы с ярко выраженной фонемой x с каждым элементом xr,j множества эталонов Xr=xr,j, где j=1,Jr¯ — индекс эталон, характеризующий соответствующий диалект фонемы r=1,R¯, где R – разрядность фонетического алфавита, Jr – разрядность множества распознаваемых диалектов для фонемы r. Тогда, если расстояние ρx/xr,j, r=1,Jr¯, между изучаемым образцом x и хотя бы одним из элементов xr,j кластера r-й фонемы не превышает заданного порогового значения
тогда мы можем распознать образец x как фонему r∈Xr. Такой процесс распознавания языковых единиц будет объективным (в частности, нечувствительным к диалектам звучания языковых единиц), так как кластеры xr,j для фонетического алфавита Xr репрезентативно определены. В зависимости от значения порога ρ0 результатом анализа изучаемого образа x по правилу (1) будет: его распознавание как одной из фонем: x=r; его отождествление с несколькими фонемами: x=ri, ri∈Xr, i≤Jr; либо признание его маргинальным по отношению к изучаемому фонетическому алфавиту: x≠∀r∈Xr. Для упрощения вычислений приведем правило (1) к виду
где в процессе распознавания образа x внутри кластера Xr вычисляется одно расстояние ρrx≜ρx/xr∗ от него до центра кластера xr∗, координаты которого определяют диалектно-осредненный фонемный эталон r∈Xr.
На основании правила (2) определим процедуру вычислительного фонетического анализа речи как сравнение эмпирических (произносимых человеком) xv∗ и эталонных xr∗ множеств равной емкости, попарные элементы которых обобщают соответствующие фонемы изучаемого языка как на стороне говорящего v∈V, так и на стороне эталонного фонетического набора r∈R.
2.2. Энтропийно-аргументативная концепция вычислительно-фонетического анализа речи с учетом диалекта и индивидуальности звучания
На основе положений теории информации аргументируем правило решения (2) в контексте функционала относительной энтропии [35,36,37 ] (3):
где Px — выборочное распределение вероятностей исследуемого (эмпирического) речевого сигнала x относительно эталонного распределения вероятностей Prx, r=1,R¯. Предположим, что закон распределения Px нормальный: Px=NKX, где KX – выборочная матрица автокорреляции речевого сигнала x размерности n×n. Рассмотрим это в выражении (3): ρrx=12trKxKr−lnKxKr−n, где trA — операция нахождения следа матрицы A. Если считать, что исследуемый речевой сигнал нормирован на его энтропию, то последнее выражение можно дальнейшее упрощение до формы
Представим функцию (3) в частотном пространстве как оптимальную решающую статистику [35]. Для одной выборки исследуемого речевого сигнала получаем (4):
где f — значение дискретной частоты анализируемой выборки речевого сигнала, F — верхнее предельное значение частоты речевого сигнала, равное половине его частоты дискретизации, а arm и axm — векторы коэффициентов линейной авторегрессии порядка p для эталонный сигнал xr∗ и эмпирический сигнал x соответственно. Выражение в числителе (4) представляет собой амплитудно-частотную характеристику отбеливающего фильтра, настроенного на выделение признаков r-й фонемы xr∗, r=1,R¯.
Выражения (2) и (4) позволяют вычислить количественные характеристики, на основании которых можно обоснованно решить, принадлежит ли исследуемый образец x кластеру xr∗ соответствующей фонемы r∈Xr. Варьировать ошибки этого процесса распознавания можно, изменяя значение порога ρ0. С учетом гауссовой аппроксимации речевого сигнала вероятность ошибки первого рода α для процесса распознавания фонем с учетом диалектов изучаемого языка предлагается определять через χ2-критерий с M степенями свободы:
где Р. — вероятность случайного события, М=const.
В общем случае значение константы M вычисляется по выражению M≈L−p, где p – порядок отбеливающего фильтра, а L=2Fτ – параметр, значение которого зависит от числа стационарных интервалов τ выделяется в исследуемом речевом сигнале x. Величина ошибки α, определяемая выражением (5), обратно пропорциональна величине порога ρ0. Например, для заданного значения α=0,1 при τ=5 мс, F=8 кГц, p=20 получаем L=80 и, соответственно, М=60. Использование таблиц χ2-распределения для уровня значимости β=1−α=1−0,99=0,01, находим значение квантиля χM;β2=χ60;0,012=88,38, по которому вычисляем значение порога ρ0: ρ0=χM;β2/M−1=0,473.
Ошибка второго рода β в контексте задачи вычислительного фонетического анализа речи при учете диалектов представляет собой вероятность смешения фонем r и v, r,v∈Xr, центров кластеров xr∗ и xv∗ из которых достаточно близки в параметрическом пространстве ρrv≜ρrxx=xv∗. Следовательно, величина ошибки β обратно пропорциональна величине расстояния ρrv. Анализ результатов статистически репрезентативного ряда экспериментов показал, что минимальное значение ρrv у фонетических алфавитов английского языка xr∗ находится в пределах 0,2;0,3. Соответственно по аналогии с (5) формализуем выражение для вычисления ошибки второго рода β процесса распознавания фонем с учетом диалектов изучаемого языка:
Суммируя соображения, заложенные в выражениях (5) и (6), для практического использования выберем значение порога ρ0 в решающем правиле (2) исходя из выражения
Значение порога ρ0, рассчитанное по выражению (7), обеспечивает баланс между значениями ошибок первого и второго рода процесса распознавания фонем из фонетического алфавита Xr с учетом диалектов исследуемого язык и вариативность процесса фонации. Однако вопрос о влиянии индивидуальных особенностей артикуляции говорящих на результат фонетического анализа речи требует более детальной аналитической формализации.
В контексте положений теории информации мы рассматриваем говорящего как источник дискретных сообщений X, определенный на множестве эталонов языковых единиц xr∗. Такой источник может быть комплексно охарактеризован количеством информации, приходящейся на единицу языка, порожденной им.
Если пренебречь влиянием индивидуальных особенностей артикуляционного аппарата говорящего на процесс фонации и предположить, что речевое сообщение передается в условиях отсутствия фонового акустического шума, то необходимое количество информации определяется как энтропия Шеннона для дискретного источника сообщения [35]:
Если упомянуть нормализацию ∑r=1Rpr=1, то, учитывая равновероятность появления языковых единиц ∀r≤R: pr=1/R, получим упрощенную форму выражения (8): HX=logR. Однако в реальных условиях невозможно игнорировать артикуляционную условную изменчивость фонации. Речевой сигнал на выходе артикуляционного тракта диктора X′ может существенно отличаться от эталона X: X′≠X.
Эта аксиома верна даже для отдельных фонем, не говоря уже о более массивных языковых единицах. В таких условиях адекватная математическая модель дискретного источника речевых сообщений должна быть создана на основе фонем, определяемых выражением (5), четко сгруппированных в параметрическом пространстве: qr≜PX′≠xr∗, r=1,R¯, и с учетом вероятности абстрактной, R+1-й, языковой единицы, к которой относятся случаи недостоверного распознавания сигнала X′: qR+1≜PX′≠xr∗,∀r≤R. Суммируем эти соображения для решающего правила (2):
где PX′=xr∗X=xr∗=1−α — условная вероятность узнавания r-й фонемы при условии, что не учитывается вариативность ее фонации, вносимая говорящим.
Отметим, что выражение (8) характеризует дискретный источник речевых сообщений без учета возмущающего влияния канала их распространения на конечный результат фонации. Рассмотрим эту информацию, используя в качестве базового выражения [35]:
где X — образец звучания эталона xr∗ фонемы r∈Xr, X′ — образец звучания этой фонемы говорящим (эмпирический образец), HXX′ — апостериорная энтропия, характеризующая рассеяние полезной информации о процессе фонации из-за возмущающих воздействий в канале его распространения. С учетом выражения (9), сформулируем эквивалентное представление выражения (10):
На основании выражения (11) можно сказать, что апостериорная энтропия рассеяния информации при фонации речевого сообщения HXX′ прямо пропорциональна энтропии источник дискретного речевого сообщения (8):
На основании выражения (12) можно сказать, что при равновероятном распределении фонем в фонетическом алфавите говорящего верхняя граница рассеяния полезной информации в процессе фонации может описываться выражением
Полученный результат коррелирует с известным неравенством Фано [38] для произвольных правил решения: экспериментальные данные для 0≤α≤1 и 1
Таким образом, решающее правило (2), решающая статистика (4) и выражения (7)–(9) вместе образуют искомую концепцию процесса вычислительного фонетического анализа речи с учетом диалектов и специфики фонации. представил спикер. Центральным элементом концепции является матрица информационного несоответствия ρr,v размерностей R×R. Данные матрицы ρr,v являются основой для расчета порога ρ0 по выражению (7). При известном значении ρ0 на основании выражений (2) и (5) процедура сегментации фонетического алфавита Xr=xr,j на набор фонем, которые с вероятностью β=1−α надежно распознаются, несмотря на вышеизложенное -описанные возмущающие факторы, и другой набор фонем, которые с вероятностью α достоверно не распознаются. Существенным фактором для такой сегментации является вероятность ошибки первого рода, которая рассчитывается по выражению (5). Вероятность ошибки второго рода (6) в этой процедуре учитывается косвенно как ограничение при определении порога ρ0 по выражению (7). Использование выражений (9) и (10) позволяет уточнить результат процедуры сегментации с учетом вариативности фонации изучаемых языковых единиц, обусловленной индивидуальными особенностями артикуляции конкретного говорящего. Отметим, что хотя представленное понятие было сформулировано на основе фонем, лежащие в его основе положения годятся и для анализа речи о содержании таких языковых единиц, как морфемы и лексемы. На основе предложенной концепции (8)–(10) правило (11) позволяет оценить ошибку первого рода (5) и персонифицированную энтропию фонетического словаря (8) в результате анализа эмпирических данных , размер выборки которого составляет N=2FT. Статистически репрезентативный объем N=106 при исследовании фонетического алфавита из R=102 элементов по правилу (11) в результате анализа фонограмм речевых сигналов с частотой дискретизации 16 кГц достигается при цензурированной длительности.
2.3. Энтропийно-аргументативная концепция обнаружения и исправления ошибок вычислительно-фонетического анализа речи
Пусть Xr=xr,j, r=1,R¯, j=1,M¯ — множество независимых классифицированных выборок типа xr,j =xr,j1,xr,j2,…,xr,jnT с емкостью n гауссовских распределений R≥2 Pr=NKr с нулевым математическим ожиданием и неизвестной автокорреляционной матрицей Kr=ΕXxr,jxr,jT размерности n×n, где j — идентификатор цикла наблюдений r-го распределения, T — операция транспонирования, EX — математическое ожидание выборки множеств X. Обозначим через X0 выборку вида Xr мощностью M0 для исследуемого сигнала с неизвестное распределение PX⊂Pr. Задача распознавания сигнала X0 предполагает R-альтернативную проверку статистических гипотез Wr относительно закона распределения этого сигнала:
Пусть R=2, т.е. две конкурирующие гипотезы, W1:PX=P1 и W2:PX=P2, проверяются для априори неизвестных матриц автокорреляции K1 и K2. Проверка будет проводиться с использованием асимптотического минимаксного критерия отношения правдоподобия [35,36,37] на основе данных выборки XXi, i=0,2¯. При таких условиях гипотеза W1 будет считаться верной, если выполняется условие
где pX0Wr — функция правдоподобия сигнала X0 при подтверждении гипотезы Wr, а pXr — функция правдоподобия сигнала Xr.
Используя известный вычислительный алгоритм [38] при условии независимости наблюдений Xr=xr,j запишем систему уравнений вида
где Kr – определитель матрицы Kr, а Sr≜1Mr∑j=1Mrxr,jxr,jT – оценка максимального правдоподобия для матрицы Kr, определенная на выборке Xr, r=0,2¯. Опишем на основе Rxpression (17) тот факт, что верхние пределы lnpXr достигаются при Kr=Sr:
где r=1,2, c=ln2π+1.
Аналогично получаем выражение для определения верхних пределов для lnpX0WrpXr:
где r=1,2, а S0r=M0M0+MS0+Sr — оценка максимального правдоподобия для матрицы Kr, определяемая по объединенной выборке X0r+X0,Xr мощностью M0+M.
Подставим выражения (18) и (19) в выражение (16) и получим условие, при котором гипотеза W1 будет считаться верной:
где γk,0r=12trSkS0r−lnSk+lnS0r−n≥0 — значение функционала относительной энтропии между двумя гипотетическими распределениями вероятностей с автокорреляционными матрицами Sk и S0r.
Воспользуемся правилом масштабирования (20) для задачи распознавания сигналов вида (15) при произвольном числе гипотез R≥2:
Предполагая однородность пары сигналов X0 и Xr в выборке X0r и учитывая что γ0,0r≤γ0,r, γr,0r≤γr,0 и M=M0, правило (21) представим в виде
где решающая статистика функционала относительной энтропии
определяются на R-множестве пар выборочных распределений NS0, NSr, r=1,R¯.
Альтернативой выражениям (23) и (24) может быть учет принципа минимального значения информационного ненаправленного рассогласования JX0,Xr≜12γ0,r+γr,0 между стохастическими сигналами X0 и Xr, r =1,R¯, в правиле (22):
где решающие статистики γ0,r определяются выражением (23).
Выражение (25) является частным случаем критерия (22) при условии, что при неограниченном увеличении объема обучающих выборок M второй член в выражении (21) асимптотически сводится к нулю: γr,0r→γr,r =0∀r≤R. Таким образом, переход от правила (22) к (25) целесообразен при наличии существенной асимметрии значений решающих статистик (23), (24).
Вероятность αv→r≜PWrXWr смешения v-го и r-го сигналов, v≠r≤R, из пользовательской базы априорных данных Xr в формализме правила (22) может быть описана формулой выражение
Если учесть, что эмпирический сигнал перед распознаванием нормирован на величину его удельной энтропии, то выполняется система асимптотических уравнений ∀r≤R:1nlnSr=1nlnS0=n→∞lnσ02=const. Учтем этот факт, представив решающую статистику γv,r в формализме χ2-распределения с K≤M степенями свободы: γv,r=12nσr,v2σ02χr,v2KM−1, где вспомогательная переменная. Подставим полученное выражение для статистики γv,r в выражение (26):
где ρr,v≜σr,v2σ02−1 и ρv,r≜σv,r2σ02−1 – удельные значения информационной невязки для исследуемой пары распределений NS0 и NSr при n→∞, а σv,r2≜σ02nlimn→∞ MtrSrSv — вспомогательная переменная того же типа, что и σr,v2. Если предположить взаимную некоррелированность трех χ2-распределений в выражении (27), то выражение (26) для расчета вероятности путаницы αv→r можно представить в виде αv→r=P121+ρr,vFr,v1,K+ 1+ρv,rFv,r1,K<1, где Fr,v1,K=χr,v2χv,v2 и Fv,r1,K=χv,r2χv,v2 — статистики F-распределения с 1,K степенями свободы . Соответственно, верхний предел вероятности смешения αv→r можно оценить по выражению
где F1,K=maxFr,v1,K;Fv,r1,K и FK,1=1F1,K — статистики F-распределения с 1,K и K,1 степенями свободы соответственно; ΦK,1 — интегральная функция F-распределения с K,1 степенями свободы.
Из выражения (28) следует, что существуют существенно неравные распределения статистик χv,v2 и пары статистик χr,v2, χv,r2 при условии, что r≠v. Таким образом, выражение (28) теоретически доказывает правильность выражений (23) и (24) относительно асимметрии величины информационной невязки, учитываемой в решающем правиле (22). Это означает, что при выполнении условия ∃v,r≤R:ρv,r>>ρr,v более целесообразно применять решающее правило (22), а не (25) для принятия решений о распознавании языковых единиц. в речевом сигнале, параметризованном в парадигме понятия (8)–(10). Этот тезис будет проверен в экспериментальной части статьи.
Предположим, что при распознавании исследуемого сигнала по решающему правилу (25) был ошибочно вынесен вердикт в пользу гипотезы WμX, а не гипотезы WvX. Предположим также, что при распознавании того же сигнала по решающему правилу (22) был вынесен вердикт в пользу гипотезы WvX. Сделанные предположения предполагают, что согласно выражениям (25) и (26) одновременно выполнялись неравенства γv,v≥γv,µ и 2γv,v≥γv,µ+γµ,v, что возможно только при выполнении условия γµ,v >>γv,µ выполняется. Таким образом, аналитическим признаком ошибочности решения, принятого по правилу (25) относительно анализируемой выборки X0, может быть неравенство вида W¯µX:γµ,0>>γ0,µ или
где γ˜0,µ=2γ0,µn, γ˜0,µ=2γ0,µn – конкретные значения решающих статистик (23), (24) соответственно; c0 – пороговое значение (минимальное значение коэффициента асимметрии величин (23) и (24) в правиле (22)), устанавливаемое в зависимости от максимально допустимой погрешности
Повторяя рассуждения, сопровождавшие переход от выражений (26) к (28), перепишем полученное выражение для определения вероятности β через F-распределение:
Анализируя выражение (30), получаем уравнение minc0 =fK,K1−β0, где fK,K1−β0 – квантиль F-распределения с K,K степенями свободы и уровнем значимости 1−β0. Например, для K=100 и β0=0,01 из таблиц для F-распределения имеем: c0≥f100,1000,99=1,59.
Таким образом, правило (29) позволяет оценить вероятность события маргинального распознавания правильного результата процедуры распознавания фонемы, используя решающее правило (25). Стохастическая оценка такого события характеризуется выражением
и определяется результатом сравнения противоположных элементов ρr,v и ρv,r в матрице ρr,v.
3. Результаты
Воспользуемся правилом (11), основанным на концепции (8)–(10), для оценки фонетической насыщенности речи лиц в коллективе из 30 человек. Кадровый состав этой команды был сформирован сбалансированно. При этом учитывались такие критерии, как возраст (три возрастные группы: 20–29, 30–39, 40–49 лет), пол (мужской, женский), высшее образование (университет), родной язык (украинский), уровень владения английским языком по CEFR-B2. Каждый человек один раз прослушал фонограмму англоязычного журналистского текста из 1800 символов, произнесенную сервисом Google Translate. В дальнейшем каждый человек пересчитывал прослушанный текст для записи на персональную цифровую фонограмму продолжительностью 3 мин. Фонация пересказа происходила в том же темпе и тембре и с четкой фиксацией на языковых единицах. Фонограммы записывались с помощью микрофона AKG P420 без усилителя, подключенного к встроенной в персональный компьютер звуковой карте Creative Audigy Rx с частотой дискретизации 16 кГц. Каждая фонограмма была сохранена в файле формата .wav. Для дальнейшего анализа фонограммы были разбиты на отрезки длительностью τ=5 мс (L=80 отсчетов). На основе анализа соответствующих фонограмм пересказов для каждого человека формировались индивидуальные фонетические алфавиты Xr, для которых по выражению (2) определялись центры кластеров фонем xr∗. Для каждого человека были сформированы два варианта индивидуального фонетического алфавита с жесткими и мягкими условиями формирования. Эти условия были обусловлены уровнем рассогласования Δρ=0,5;1,0 для одноименных фонем и их минимальной длительностью ΔL=8L;4L, τ=40;20. Значения коэффициентов авторегрессии arm, avm, необходимые для расчета матрицы информационного рассогласования ρr,v, определялись с помощью рекуррентной процедуры Берга–Левинсона с однозначно установленным порядком моделей p=20.
На рис. 1 представлены фрагменты полученных матриц для человека №1, рассчитанных при выбранных жестком (рис. 1а) и мягком (рис. 1б) наборах условий формирования. Емкость фонетических алфавитов составляла Rhard1=32 и Rsoft1=87 языковых единиц соответственно. Минимальное значение информационного расхождения между фонемами составило ΔρrvRhard1=0,324.
Соответственно по решающему правилу (2) с учетом выражения (7) определяется значение порога ρ0=0,324. По таблицам χ2-распределения для числа степеней свободы M=60 определена вероятность ошибки первого рода α=0,047. Тогда согласно выражению (13) верхняя граница рассеяния полезной информации процесса фонации для человека №1 равна supHXX′=αlogR=0,235, а верхняя граница фонетической насыщенности речи для человека №1, согласно выражению (11), равно supIXX′=1−αlogR=4,765.
Аналогичные расчеты были произведены для остальных членов команды. Для наглядности эти результаты были усреднены для каждой из трех возрастных групп и визуализированы на рисунке 2. Кроме того, для сравнения, для лиц из первой возрастной группы были рассчитаны матрицы несоответствия при выбранном мягком наборе условий формирования, и мы выполнили все остальные вычислительные операции, описанные выше. Эти результаты, обозначенные как «1softAG», также показаны на рисунке 2.
Исследуем эмпирически функциональность понятий принятия решений, обобщенных путем решения Правил (22) и (25) в задаче вычислительного фонетического анализа речи (статистическая классификация без учителя в парадигме понятий (8)–(10)). . Эмпирическим материалом для исследования послужили две фонограммы с записью одинакового содержания языкового материала, произнесенного человеком №1. Фонограммы были представлены образцами X0, Xr равной емкости М=120. Сначала была рассчитана матрица несоответствия информации ρr,v для четырех гласных фонем лица №1. Содержание матрицы наглядно представлено на рис. 3. Аллофоны u:1 и u:2 представляют личностно-специфические диалекты произношения фонемы u:.
Дальнейшее использование данных, представленных на рисунке 3, будет продемонстрировано на примере. Рассмотрим данные матрицы ρr,v для пары фонем a:,u:1. Эти данные характеризуют ситуацию, когда фонема а: опознается как фонема и:1. На рис. 3 видно, что ρa:,u:1=5,76. Число степеней свободы для F-распределения в выражении (28) принимается равным K=M−p=100. Если решение о результате распознавания фонемы принимается по правилу решения (25), то K,1=100,1, и имеем α˜v→r=1−ΦK,11+ρr,v=1− Φ100,15,76≈0,3. Если решение о результате распознавания фонемы принимается по решающему правилу (22), то имеем max1+ρvr;1+ρrv=max87,2;6,76=6,76. Согласно выражению (28) имеем αv→r≤1−Φ100,15,76≈0,12. Таким образом, вероятность путаницы при решении вопроса о результате фонетического анализа на примере фонем а: и и:1 с использованием правила решения (22) по сравнению с правилом (25) почти в три раза меньше. Вычисления, аналогичные приведенным выше, были выполнены для всех пар фонем с разными именами на рис. 3. Для всех реализаций Правило (22) позволило получить более низкую оценку вероятности смешения по сравнению с Правилом (25).
Завершим этот этап исследования вычислением с помощью выражения (31) вероятности события маргинального распознавания правильного результата процедуры распознавания фонем по решающему правилу (25): πr→v=1−Φ1 ,11+86,21,591+5,76=1−Φ1,18,11≈0,21. Можно констатировать, что чем больше асимметрия между противоположными элементами матрицы ρrv, тем больше значение вероятности πr→v.
Мы обобщаем экспериментальный раздел путем проверки моделей, предложенных в разделе 2, в парадигме теории практического планирования. Формируем определенные наборы входных воздействий (синалов речи): Xk=x1k,x2k,…,xnk и Xk¯=x1k¯,x2k¯,…,xmk¯. Реакция системы на входные воздействия из множества Xk прогнозируется в концепции. Входные воздействия из множества Xk¯ структурно идентичны обобщенному множеству Xk, но отличаются значениями, которые могут выходить за пределы, установленные на этапе проектирования системы (посторонние шумы, существенные проблемы с дикцией и т.п.) Реакция системы на входное воздействие из множества Xk¯ может быть некорректным распознаванием единиц речи. Количество элементов в множествах Xk и Xk¯ равно n=3000 и m=7000 соответственно. Эксперименты проводились с фиксацией реакции системы на входные воздействия из множеств Xk и Xk¯ (в матричной форме Bek=Bijk, i=1,n¯ и Bek¯=Bijk¯, i=1,m соответственно). Рассчитаем для i-го входного воздействия дисперсию реализации ситуации распознавания некорректной единицы речи: si2=M−1∑j=1MBij−B′ij2, где Bij – определенное в модели состояние; Б’идж — это действительное состояние. Рассчитываем среднее значение дисперсии для всех входных воздействий: s2=N−1∑i=1Nsi2. Оценка существенных отклонений si2 от s2 по критерию Фишера показала, что все отклонения не превышают табличных значений, что подтверждает адекватность предложенного математического аппарата.
4. Дискуссия
Задача вычислительного фонетического анализа речи в общем случае сводится к циклически повторяемой процедуре оценки отклонения текущего отрезка исследуемого речевого сигнала от эталонов, определенных в пределах конечного списка языковых единиц . Длительность отрезков, последовательностью которых предъявляется выходной речевой сигнал, выбирается исходя из средней длительности изучаемых единиц языка; например, для фонем это τ∈5,10¯ мс. В парадигме байесовской теории распознавания образов такая задача решается путем проверки стохастических гипотез об однородности закона распределения речевого сигнала. Если эмпирический закон распределения можно надежно оценить с помощью гауссовой аппроксимации, то указанная выше задача имеет оптимальное решение. Если процедура сопоставления эмпирического сегмента с эталоном тривиальна, то вопрос об определении эталона для языковой единицы является краеугольным камнем. Общепринятого определения эталона языковой единицы в контексте вычислительного фонетического анализа речи не существует. Типичным подходом является определение искомого эталона на основе одной из вариаций метода экспертных оценок. Однако при таком подходе исследуется не столько фонация языковой единицы, сколько среда распространения сигнала и формат его представления. В этом контексте вывод задачи вычислительного фонетического анализа в предметной области теории информации позволяет рассматривать определение эталона в абсолютной метрике критерия относительной энтропии, а не в относительной метрике, как это реализовано в аналоги.
Из эмпирических результатов, представленных на рис. 2, можно сделать выводы о репрезентативности предложенной метрики НХХ’;IXX’ для оценки персонифицированной фонетической насыщенности речи. Оказалось, что наибольшей фонетической насыщенностью (11) обладает речь лиц второй возрастной группы. Особого внимания заслуживают данные, характеризующие фонетическую насыщенность речи лиц первой возрастной группы, фонетические алфавиты которых определялись путем выбора жесткого и мягкого набора условий формирования — 1жесткий АГ и 1мягкий АГ соответственно. Видно, что фонетическая насыщенность речи лиц первой возрастной группы jIhard1AG=4,765, оцененная на основе фонетических алфавитов Rhard1AG=32, определенная выбором жесткого набора условий формирования, оказалась выше аналогичного показателя для той же группы лица Isoft1AG=4,304, оцененные на основе фонетических алфавитов Rsoft1AG=87, определяемые выбором мягкого набора условий формирования. Это не считая того, что емкость фонетического алфавита второго варианта Rsoft1AG=87 превышает емкость фонетического алфавита первого варианта Rhard1AG=32 более чем в два раза. Этот факт позволяет наметить перспективное направление исследования функции IX,X′=fR,Δρ,ΔL, экстремум которой потенциально может указывать на элементы персонифицированного фонетического алфавита, в которых индивидуальность и информативность речи наиболее выражено.
На основе функции относительной энтропии в разделе 2.3 теоретически обосновываются два безошибочных подхода к принятию решений WvX в задаче вычислительного фонетического анализа речи (15) на основе решающих правил (22) или (25). Результаты вычислительного эксперимента, представленные на рис. 3, убедительно доказывают работоспособность обоих этих подходов. Особое значение имеет выражение (31) для оценки надежности решения, принятого на основании правила (25). Действительно, если решение WµX окажется ошибочным согласно выражению (29), то этот факт, согласно положениям теории планирования эксперимента, обяжет исследователя повторить эксперимент по схеме (15) со всеми уже отвергнутыми альтернативами распределения, поскольку решение об их маргинальности скомпрометировано. Результат такого повторного эксперимента
определяемая на сокращенной выборке альтернатив емкостью R−1, совместно с правилами решения (25), (29) определяет энтропийную концепцию обнаружения и исправления ошибок при вычислительном фонетическом анализе речи. Потенциал, заложенный в предложенной концепции, и продемонстрированные результаты доказывают ее превосходство над такими байесовскими концепциями принятия решений с использованием метрик рассогласования евклидова типа, как метод максимального правдоподобия и метод идеального наблюдателя.
Наконец, следует отметить, что математический аппарат, предложенный в данной статье, оказался адекватным, поскольку основан на проверенном математическом аппарате теории информации. Этот факт, а также строгость и обратимость аналитических преобразований, проводимых при формализации соответствующей метрики, обосновывают адекватность представленного в статье математического аппарата.
5.
Выводы Изучение краеугольного для современной лингвистики объекта процесса речевого и текстового межличностного общения, учитывая масштабы инфосферы ХХI века, невозможно без всестороннего и целенаправленного привлечения информационных технологий из других областей знаний, включая информатику. Созданная в результате относительно молодой науки, компьютерная лингвистика нацелена на автоматический анализ естественных языков во всех спектрах их реализации. Из длинного списка текущих задач, активно изучаемых в парадигме компьютерной лингвистики, отметим автоматизацию составления и лингвистической обработки языковых корпусов, автоматизированную классификацию и реферирование документов, создание точных лингвистических моделей естественных языков, извлечение фактической информации из неформальных лингвистических данных. Эффективная, строго формализованная технология вычислительного фонетического анализа лингвистической информации, особенно речевой, потенциально является движущей силой улучшения результатов решения этих исследовательских задач. Данный тезис полностью соответствует содержанию статьи, что доказывает актуальность представленных научных и прикладных результатов.
Предлагаемая в данной статье концепция (т.е. математическая модель и методы) вычислительного фонетического анализа речи определяет научную новизну исследования. В концепции, в отличие от существующих методов, строго формально представлена задача многокритериального решения процесса когнитивного восприятия речи человеком в теоретико-аналитическом аппарате теории информации, теории распознавания образов и акустической теории речи. формирование. Полученная концепция позволяет точно определять фонетический алфавит человека с учетом присущего ему диалекта речи и индивидуальных особенностей фонации, а также выявлять и исправлять ошибки в распознавании языковых единиц и достоверно оценивать фонетическую насыщенность речи.
Предлагаемая концепция представлена решающим правилом (2), решающей статистикой (4) и выражениями (7)–(9). Центральным элементом концепции является матрица информационного несоответствия ρr,v языковых единиц персонифицированного фонетического алфавита говорящего. Матрица ρr,v является основой для вычисления порога ρ0 реализации вычислительного фонетического анализа по выражению (7). При известном значении ρ0 на основе выражений (2) и (5) процедура сегментации изучаемого фонетического алфавита диктора на набор фонем, которые с вероятностью β=1−α надежно распознаются, несмотря на возмущающие факторы , и другой набор фонем, которые с вероятностью α достоверно не распознаются. Использование выражений (9) и (10) позволяет уточнить результат процедуры сегментации с учетом вариативности фонации изучаемых языковых единиц, вносимой индивидуальными особенностями артикуляции конкретного говорящего.
Изучение результатов вычислительного фонетического анализа на основе функции относительной энтропии позволило теоретически обосновать две выявляемые ошибки процесса распознавания языковых единиц (15) на основе решения правил (22) и (25). Отметим возможность, формализованную выражением (31), оценить надежность решения, принятого на основании правила (25). Если обнаружено, что решение скомпрометировано в соответствии с Выражением (29), то с помощью вычислительной процедуры со схемой (15) можно найти ошибочно распознанные недостоверные результаты фонетического анализа и реабилитировать их. Таким образом, практическая значимость предлагаемой концепции вычислительного фонетического анализа речи заключается в том, что с ее помощью можно не только выделять фонетические единицы в речевых сигналах с учетом индивидуальных особенностей речеобразования, но и обнаруживать и исправлять ошибки в результатах такого анализа.
Потенциал, присущий предложенной концепции, и экспериментальные результаты, представленные после рисунка 3, доказывают ее превосходство над такими байесовскими концепциями принятия решений, использующими метрики несоответствия евклидова типа в качестве метода максимального правдоподобия и метода идеального наблюдателя. Анализ исследуемого речевого сигнала, проведенный в метрике НХХ’;IXX’ на основе предложенной концепции, позволяет достоверно установить фонетическую насыщенность речи, объективно характеризующую среду распространения речевого сигнала и его источник.
Дальнейшее исследование планируется для анализа функции IX,X′=fR,Δρ,ΔL, экстремум которой потенциально может указывать на элементы персонифицированного фонетического алфавита, в которых проявляется индивидуальность и информативность речи человека являются наиболее очевидными. Авторы надеются, что результаты такого исследования повысят практическую ценность предложенной системы моделей для прецизионного фонетического анализа речи [39].
Вклад авторов
Концептуализация, В.К. и ОК; методология, В.К. и ОК; программное обеспечение, В.К. и ОК; валидация, В.К. и ОК; формальный анализ, В.К. и ОК; расследование, В.К. и ОК; ресурсы, В.К. и в качестве.; курирование данных, В.К. и ОК; написание — черновая подготовка, В.К. и ОК; написание-обзор и редактирование, В.К. и ОК; визуализации, В.К. и ОК; надзор, В.К. и ОК; администрация проекта, В.К. и ОК; приобретение финансирования, А.С. и В.К. Все авторы прочитали и согласились с опубликованной версией рукописи.
Финансирование
Это исследование не получило внешнего финансирования.
Заявление Институционального контрольного совета
Неприменимо.
Заявление об информированном согласии
Неприменимо.
Заявление о доступности данных
Большая часть данных содержится в статье. Все данные доступны по запросу из-за ограничений, например, конфиденциальности или этических норм.
Благодарности
Авторы хотели бы поблагодарить анонимных рецензентов, которые помогли лучше представить результаты исследования.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов.
Ссылки
- Альмутири, Т.; Надим, Ф. Марковские модели приложений в обработке естественного языка: обзор. Междунар. Дж. Инф. Технол. вычисл. науч. 2022 , 2, 1–16. [Google Scholar] [CrossRef]
- Бханджа, CC; Ласкар, Массачусетс; Ласкар, Р. Х. Моделирование многоуровневых просодических и спектральных характеристик с использованием глубокой нейронной сети для автоматической системы идентификации индийского языка на основе тональной и нетональной предварительной классификации. Ланг. Ресурс. оценка 2021 , 55, 689–730. [Google Scholar] [CrossRef]
- Umasankar, CD; Рам, М.С.С. Улучшение речи за счет реализации адаптивного шумоподавителя с использованием адаптивного алгоритма FHEDS. Междунар. J. График изображения. Сигнальный процесс. 2022 , 3, 11–22. [Google Scholar] [CrossRef]
- Firooz, S.G.; Реза, С .; Шекофте, Ю. Распознавание разговорного языка с использованием нового условного каскадного метода для объединения акустических и фонетических результатов. Междунар. Дж. Речевые технологии. 2018 , 21, 649–657. [Google Scholar] [CrossRef]
- Сунита П.; Прасад, К.С. Улучшение речи на основе вейвлет-порога многоконтурного спектра в сочетании с алгоритмом оценки шума. Междунар. J. График изображения. Сигнальный процесс. 2019 , 11, 44–55. [Google Scholar] [CrossRef]
- Pujar, R.S. Алгоритм шумоподавления на основе фильтра Винера с постфильтрацией восприятия для слуховых аппаратов. Междунар. J. График изображения. Сигнальный процесс. 2019 , 11, 69–81. [Академия Google] [CrossRef]
- Бендер, Э.М.; Дреллишак, С.; Фоккенс, А .; Поулсон, Л.; Салим, С. Настройка грамматики. Рез. Ланг. вычисл. 2010 , 8, 23–72. [Google Scholar] [CrossRef]
- Аль-Бакери, А.А. ASR для правил таджвида: интегрировано со средами самообучения. Междунар. Дж. Инф. англ. Электрон. Автобус. 2017 , 9, 1–9. [Google Scholar] [CrossRef][Зеленая версия]
- Моран, С.; Гроссман, Э.; Веркерк, А. Исследование диахронических тенденций в фонологических инвентаризациях с использованием BDPROTO. Ланг Ресурс. оценка 2020 , 55, 79–103. [Google Scholar] [CrossRef][Green Version]
- Пелешко Д.; Рак, Т .; Изонин И. Сверхразрешение изображения с помощью матрицы расхождения и автоматического обнаружения кроссовера. Междунар. Дж. Интелл. Сист. заявл. 2016 , 8, 1–8. [Google Scholar] [CrossRef]
- Изонин И.; Тростянчин, А.; Дурягина З.; Ткаченко Р.; Тепла, Т .; Лотошинская Н. Совместное использование полинома Винера и SVM для задачи классификации материалов в производстве медицинских имплантатов. Междунар. Дж. Интелл. Сист. заявл. 2018 , 10, 40–47. [Google Scholar] [CrossRef][Зеленая версия]
- Куримо, М.; Энарви, С.; Тилк, О .; Варджокаллио, М .; Мансикканиеми, А .; Алумяэ, Т. Моделирование языков с ограниченными ресурсами для распознавания речи. Ланг. Ресурс. оценка 2017 , 51, 961–987. [Google Scholar] [CrossRef][Зеленая версия]
- Масмуди, А.; Бугарес, Ф.; Эллуз, М.; Эстев, Ю.; Бельгит, Л. Автоматическая система распознавания речи для тунисского диалекта. Ланг. Ресурс. оценка 2018 , 52, 249–267. [Google Scholar] [CrossRef]
- Эльвира-Гарсия, В.; Розано, П.; Фернандес-Планас, AM; Мартинес-Сельдран, Э. Инструмент для автоматической транскрипции интонации: Eti_ToBI, транскрибатор ToBI для испанского и каталанского языков. Ланг. Ресурс. оценка 2016 , 50, 767–792. [Google Scholar] [CrossRef]
- Hu, Z.; Машталир, С.В.; Тищенко О.К.; Столбовой, М.И. Кластеризация матричных последовательностей на основе итеративной процедуры динамической временной деформации. Междунар. Дж. Интелл. Сист. заявл. 2018 , 10, 66–73. [Google Scholar] [CrossRef][Green Version]
- Aissiou, M. Генетическая модель акустического и фонетического декодирования стандартных арабских гласных в непрерывной речи. Междунар. Дж. Интелл. Сист. заявл. 2020 , 23, 425–434. [Академия Google] [CrossRef]
- Ху З.; Терейковский, И.А.; Терейковская, Л. О.; Погорелов, В.В. Определение конструктивных параметров многослойного персептрона, предназначенного для оценки параметров технических систем. Междунар. Дж. Интелл. Сист. заявл. 2017 , 9, 57–62. [Google Scholar] [CrossRef][Зеленая версия]
- Читтараги, Н.Б.; Кулагуди, С.Г. Идентификация диалекта каннада на основе акустико-фонетических признаков по гласным звукам. Междунар. Дж. Речевые технологии. 2019 , 22, 1099–1113. [Академия Google] [CrossRef]
- Клейнханс, Северная Каролина; Барнард, Э. Эффективный выбор данных для ASR. Ланг. Ресурс. оценка 2015 , 49, 327–353. [Google Scholar] [CrossRef]
- Hu, Z.; Иващенко, М.; Лющенко, Л.; Клюшник Д. Формулировка критерия обучения искусственной нейронной сети с использованием непрерывной области ошибок. Междунар. Дж. Мод. Образовательный вычисл. науч. 2021 , 13, 13–22. [Google Scholar] [CrossRef]
- Винола, Ф. А.Ф.; Падма, Г. Вероятностная стохастическая модель для анализа эпилептического синдрома с использованием синтеза речи и представления в пространстве состояний. Междунар. Дж. Речевые технологии. 2020 , 23, 355–360. [Google Scholar] [CrossRef]
- Мехрабани, М.; Хансен, Дж.Х.Л. Автоматический анализ наборов диалектов/языков. Междунар. Дж. Речевые технологии. 2015 , 18, 277–286. [Google Scholar] [CrossRef][Green Version]
- Релло, Л.; Баеза-Йейтс, Р.; Ллистерри, Дж. Ресурс ошибок, написанных на испанском языке людьми с дислексией, и их лингвистический, фонетический и визуальный анализ. Ланг. Ресурс. оценка 2016 , 51, 379–408. [Академия Google] [CrossRef]
- Чаки, Дж. Обработка акустических сигналов на основе анализа образов: обзор современного уровня техники. Междунар. Дж. Речевые технологии. 2020 , 24, 913–955. [Google Scholar] [CrossRef]
- Бхангале, К. Б.; Моханапрасад, К. Обзор обработки речи с использованием парадигмы машинного обучения. Междунар. Дж. Речевые технологии. 2021 , 24, 367–388. [Google Scholar] [CrossRef]
- Верма П.; Дас, П.К. i-векторы в приложениях для обработки речи: обзор. Междунар. Дж. Речевые технологии. 2015 , 18, 529–546. [Google Scholar] [CrossRef]
- Другман Т.; Дютуа, Т. Детерминированная плюс стохастическая модель остаточного сигнала и ее приложения. IEEE транс. Аудио язык речи. Процесс. 2011 , 20, 968–981. [Google Scholar] [CrossRef][Green Version]
- Chen, X.; Бао, К. Нейронная сеть с временной задержкой, зависящая от фонемы, для проверки говорящего. IEEE ACM Trans. Аудио язык речи. Процесс. 2021 , 29, 1243–1255. [Академия Google] [CrossRef]
- Ху, З.; Терейковский, И.; Чернышев Д.; Терейковская, Л.; Терейковский, О.; Ван Д. Процедура обработки биометрических параметров на основе вейвлет-преобразований. Междунар. Дж. Мод. Образовательный вычисл. науч. 2021 , 13, 11–22. [Google Scholar] [CrossRef]
- Омер, А.И.; Зампиери, М.; Оукс, М.М. Фонетические различия для кластеризации диалектов. В материалах 9-й Международной конференции по информационным и коммуникационным системам (ICICS), Ирбид, Иордания, 3–5 апреля 2018 г.; стр. 145–150. [Академия Google] [CrossRef]
- Вячеслав К.; Ковтун О. Система методов автоматизированного когнитивно-лингвистического анализа речевых сигналов с шумом. Приложение «Мультимедийные инструменты». 2022 , 1–20. [Google Scholar] [CrossRef]
- Бисикало, О.; Бойван, О .; Ковтун, О .; Ковтун В. Исследование влияния фонационной вариативности на результат процесса опознания языковых единиц. Протокол семинара CEUR. 2022 , 3156, 82–93. [Google Scholar]
- Каннадагули, П.; Бхат, В. Сравнение подходов, основанных на байесовском многомерном моделировании и скрытом марковском моделировании (HMM), для автоматического распознавания фонем в каннаде. Недавнее появление Вычисление трендов. вычисл. науч. 2015 , 1–5. [Google Scholar] [CrossRef]
- Laleye, FAA; Эзин, EC; Мотамед, К. Автоматическая независимая от текста сегментация слогов с использованием показателей сингулярности и энтропии Реньи. J. Сигнальный процесс. Сист. 2016 , 88, 439–451. [Google Scholar] [CrossRef]
- Канг, Дж.; Чжан, W.-Q.; Лю, В.-В.; Лю, Дж.; Джонсон, М.Т. Потеря транскрипции на основе решетки для сквозного распознавания речи. J. Сигнальный процесс. Сист. 2017 , 90, 1013–1023. [Академия Google] [CrossRef]
- Цянь Ю.; Убале, Р.; Ланге, П.; Эванини, К.; Раманараянан, В .; Сун, Ф.К. Понимание разговорного языка в разговорах между человеком и машиной для приложений для изучения языка. J. Сигнальный процесс. Сист. 2019 , 92, 805–817. [Google Scholar] [CrossRef]
- Cui, Y.; Сирен, Дж.; Коски, Т .; Корандер, Дж. Одновременные прогнозирующие гауссовские классификаторы. Дж. Классиф. 2016 , 33, 73–102. [Google Scholar] [CrossRef]
- Бисикало, О.; Бойван, О .; Хаирова, Н.; Ковтун, О .; Ковтун В.В. Прецизионный автоматизированный фонетический анализ речевых сигналов для информационных технологий текстозависимой аутентификации человека по голосу. Протокол семинара CEUR. 2021 , 2853, 276–288. [Google Scholar]
Рисунок 1. Визуализация фрагментов матриц информационных несоответствий ρr,v для человека №1, рассчитанных при выбранных жестком ( a ) и мягком ( b ) наборах условий формирования.
Рис. 1. Визуализация фрагментов матриц информационных несоответствий ρr,v для человека №1, рассчитанных при выбранных жестком ( a ) и мягком ( b ) наборах условий формирования.
Рисунок 2. Оценка фонетической насыщенности персонифицированной речи (формат чисел определяется используемой вычислительной программой).
Рисунок 2. Оценка фонетической насыщенности персонифицированной речи (формат чисел определяется используемой вычислительной программой).
Рисунок 3. Визуализация матрицы ρr,v, рассчитанной для случаев произношения четырех фонем человеком №1 (формат чисел определяется используемой вычислительной программой).
Рис. 3. Визуализация матрицы ρr,v, рассчитанной для случаев произношения четырех фонем человеком №1 (формат чисел определяется используемой вычислительной программой).
Примечание издателя: MDPI остается нейтральным в отношении юрисдикционных претензий в опубликованных картах и институциональной принадлежности. |
© 2022 авторами. Лицензиат MDPI, Базель, Швейцария. Эта статья находится в открытом доступе и распространяется на условиях лицензии Creative Commons Attribution (CC BY) (https://creativecommons.org/licenses/by/4.0/).
Под капотом речевой аналитики
Речевая аналитика позволяет предприятиям использовать голос клиента как бизнес-актив. Его можно использовать для диагностики и решения проблем обслуживания клиентов, повышения эффективности работы контакт-центра, обучения операторов и многого другого. В решениях для разговорной аналитики обычно используются два подхода к распознаванию речи: фонетический и LVCSR, каждый со своими плюсами и минусами. Так что же лучше для добычи информации из контакт-центров?
Фонетическая речевая аналитика
Основной единицей распознавания фонетической системы является фонема (последовательность звуков). Поиск фонетической речевой аналитики предварительно обрабатывает аудио в фонемы и кодирует результат в решетку возможностей. Любые поисковые термины, используемые позже агентами или менеджерами колл-центра, также переводятся в фонемы, и поиск ищет ту же последовательность в существующей решетке.
Плюсы и минусы систем фонетики
Наибольшее преимущество системы фонетического распознавания заключается в том, что слова, не входящие в предопределенный словарь, все же могут быть найдены при условии, что фонемы распознаваемы. Например, при поиске названия препарата «сиалис» термин все еще может быть найден в тексте, если эта последовательность фонем существует, «S IY AH LIH S». Недостатком является то, что, поскольку в решетке существует много возможных последовательностей, термин может быть найден во многих местах, где он никогда не произносился на самом деле, например, если фактическими словами были «см. список». Фонемы очень похожи, но это ложноположительное совпадение. Фонетические подходы, как правило, имеют более высокую скорость припоминания (показатель того, сколько элементов, которые действительно были в искомых документах, были найдены), но этому противостоит низкая точность, поскольку эти ложные срабатывания должны быть вручную отфильтрованы из набора результатов. .
Фонетические системы также обычно быстрее обрабатывают (превращают телефонные звонки в данные), в основном из-за того, что размер используемого «словаря» очень мал, поскольку фонетика опирается только на звуки языка и существует всего несколько десятков звуков. уникальные фонемы в большинстве языков. Однако сам процесс поиска намного медленнее, поскольку фонемы не могут быть проиндексированы так же эффективно, как целые слова. Для фонетики также требуется больше места для хранения, так как в слове в среднем 4 фонемы, что может быть проблемой для крупномасштабных проектов.
Несмотря на то, что фонетические подходы учитывают возможные последовательности звуков и их частоту (например, группы согласных, такие как «stldr», никогда не встречаются в английском языке), они не принимают во внимание какие-либо знания более высокого уровня о языке. язык, что означает, что «скорее всего» используемые фразы не могут быть правильно отфильтрованы, что потребует дополнительной ручной работы позже.
LVCSR Speech Analytics
Непрерывное распознавание речи большого словаря (LVCSR) начинается с распознавания фонем, как в фонетической системе, но затем применяет словарь или языковую модель, содержащую потенциально 50 000–100 000 слов и фраз, для создания полной стенограммы. В LVCSR распознается каждое слово, ничего не отбрасывается и не пропускается. Хотя первоначальный процесс распознавания полной расшифровки, а не только отдельных фонем, требует большей вычислительной мощности, чем распознавание только фонем, результирующая расшифровка значительно упрощает и ускоряет поиск и использование контакт-центрами собранной информации.
Плюсы и минусы LVCSR Speech Analytics
LVCSR использует статистические методы для подтверждения вероятности различных последовательностей слов (например, «побочный эффект сиалиса включает» или «таблетки сиалиса»), поэтому точность намного выше, чем просто поиск слов фонетического подхода, поэтому более вероятно, что если слово найдено, оно действительно было произнесено. Недостатком, однако, является то, что слова в условиях поиска должны быть в словаре, чтобы быть найденными поисковой системой транскрипции. В редких случаях, когда слов нет в 50 000–100 000 словарном запасе, интересующее слово или фразу часто можно найти, комбинируя слова (например, «см. Алису» для «сиалиса») или используя «звукоподобные» подходы к сопоставлению слов. (например, Horizon и Verizon).
Первоначальная обработка звука также занимает немного больше времени, чем при фонетическом подходе, из-за большого словарного запаса, который необходимо проанализировать, хотя время поиска на самом деле намного быстрее и точнее. Представьте, что вы управляете колл-центром и пытаетесь выявить основные причины внезапного всплеска трафика вызовов. Если есть проблема с одним из ваших каналов самообслуживания (или, возможно, проблема с продуктом), вам необходимо выяснить это как можно скорее. Более высокая скорость поиска означает, что вы можете обработать больше звонков клиентов за более короткий промежуток времени и быстро добраться до сути проблемы с меньшими затратами человеческих ресурсов, а также получить множество удовлетворенных клиентов.
При подходе LVCSR также учитываются более крупные контексты, в которых встречаются звуки. Это компенсирует тот факт, что некоторые звуки очень неоднозначны и имеют тенденцию сливаться с соседними звуками (например, «мыло для посуды»), а одна и та же последовательность звуков может быть разной последовательностью слов: «помолимся» и «салатные брызги». Подход LVCSR алгоритмически определяет, какие альтернативы более вероятны, позволяя компьютеру выполнять большую часть работы.
Системы LVCSR обычно имеют гораздо более высокую точность, поскольку они с большей вероятностью содержат слова, которые были фактически сказаны, но хуже запоминаются из-за необычных слов или ошибок распознавания. Чтобы компенсировать это, подход LVCSR предоставляет расшифровку слов вокруг ключевого термина, позволяя пользователям визуально просмотреть «фрагмент» и определить, является ли он релевантным или нет. Кроме того, наличие фактической стенограммы разговора позволяет автоматически анализировать частотность различных слов и фраз. Это может выявить тенденции и показатели, которые системе не было специально указано искать.
Какая система распознавания речи лучше?
Окончательное решение сводится к тому, чтобы определить, что лучше всего подходит для вашей бизнес-задачи с точки зрения стоимости, ценности и ручного труда. В целом, фонетика подходит для приложений с редким поиском. Для более крупных корпоративных приложений, таких как речевая аналитика и бизнес-аналитика, лучше подходит подход LVCSR к речевой аналитике. По большому счету, использование фонетики немного похоже на использование кассет в эпоху MP3. Он по-прежнему работает и имеет нишевые преимущества, но по большей части технология устарела, и для контакт-центров доступны более мощные возможности.
Узнайте больше об анализе речи и повышении эффективности вашего контакт-центра.
Операции контакт-центра Аналитика речи и разговоров Северная Америка EMEA Азиатско-Тихоокеанский регион
Фонология, часть 2
Фонология, часть 2
| Английские конструкции Фонология
| ||||||||||||||||||||||||||||||||||||||||||||||||||
Фонемы и аллофоны
| |||||||||||||||||||||||||||||||||||||||||||||||||||
Американский язык жестов Язык жестов, используемый сообществом глухих в Соединенных Штатах.
Тест по английскому языку для международного общения . Стандартизированный экзамен для образовательных служб тестирования, предназначенный для определения общей способности NNSE использовать английский язык для ведения бизнеса. Он используется некоторыми предприятиями, преимущественно в Азии, при найме.
Тест по английскому языку как иностранному . Стандартизированный экзамен от Educational Testing Services, который предназначен для определения общей способности NNSE использовать английский язык в качестве языка обучения. Он используется в качестве требования для поступления в большинство университетов и колледжей США для иностранных студентов.
Преподавание английского языка носителям других языков . Термин, который охватывает как TEFL, так и TESL. Это название профессиональной организации, к которой принадлежат многие учителя. Организация TESOL имеет множество региональных филиалов как в США, так и за рубежом.
Преподавание английского как второго языка . Относится к деятельности по обучению английскому языку как инструменту, необходимому для какой-либо повседневной задачи, такой как обучение, покупки или межличностное взаимодействие.
Преподавание английского языка как иностранного . Относится к деятельности по обучению английскому языку как интеллектуальному, академическому занятию для тех, для кого английский язык не является родным.
Носитель английского языка . Относится к человеку, который выучил английский язык в младенчестве и раннем детстве в качестве первого языка.
Носитель языка . Относится к человеку, чье отношение к языку таково, что он встречался в младенчестве и раннем детстве как доминирующий язык окружающей среды.
Английский язык не является родным . Относится к человеку, который не выучил английский как первый язык, но пришел к нему после того, как был установлен другой язык.
Не носитель языка . Относится к человеку, чье отношение к определенному языку заключается в том, что он / она не столкнулся с ним при первоначальном изучении языка, а пришел к нему после того, как был установлен другой язык.
Ограниченное владение английским языком . Фраза-прилагательное, используемая для обозначения тех же учащихся, что и ELL. LEP выходит из употребления, поскольку он фокусирует внимание на недостатках учащихся, а не на положительном аспекте обучения. Заменяется ELL.
Второй язык . Относится к любому языку, приобретенному после первого или родного языка. Он приобретается или изучается вторично по отношению к родному языку. Не относится к порядковой нумерации языков, а только к отношению конкретного языка к родному языку человека.
Первый язык. Относится к языку, с которым человек сталкивается в младенчестве и раннем детстве; родной язык человека.
Английский для специальных целей . Относится к цели изучения английского языка, чтобы использовать его для целенаправленной деятельности, например, для бизнеса или для авиационного общения.
Программа изучения английского как второго языка. относится к школьной программе, специально разработанной для обучения английскому языку для NNSE. Программа ESL обычно не включает обучение каким-либо другим предметам, кроме английского. Программа ESL может быть частью более крупной программы ELL в школе.
Английский как второй язык . Относится к предмету изучения английского языка и методологии преподавания английского языка лицам, не являющимся носителями языка. ESL не относится к другим предметам, кроме английского, но это не только методология, он относится к обучению английскому языку как предметной области. Как правило, ESL относится к изучению английского языка в стране, где он используется по крайней мере для одной ежедневной задачи, такой как обучение, межличностные отношения или покупки.
Программа изучения английского языка . Относится к школьной программе, специально разработанной для обучения английскому языку и обучения другим предметным областям для изучающих английский язык.
Изучающий английский язык . Относится к учащимся, которые находятся в процессе изучения английского языка, независимо от того, посещают ли они исключительно курсы ESL или сочетают занятия ESL и занятия по другим предметам.
Английский как иностранный язык . Относится к изучению английского языка как к интеллектуальному, академическому занятию, а не к языку, использование которого необходимо или желательно в повседневной жизни, хотя он может использоваться в качестве исследовательского инструмента. Как правило, EFL — это изучение английского языка в стране, где английский не является языком обучения или повседневного общения, например, в Италии или Саудовской Аравии.
Английский для академических целей . Относится к цели изучения английского языка, чтобы использовать его в качестве языка обучения для других предметных областей.
Относится к школьной программе, специально построенной таким образом, чтобы учащиеся ежедневно использовали два языка.
Относится к ежедневному использованию двух языков в любом качестве. Двуязычный человек ежедневно использует два языка — например, на работе и дома или по разным предметам в школе. Также может относиться к способности использовать два языка, даже если они не используются ежедневно.
Фонологическая осведомленность
Фонологическая осведомленность тесно связана с ранним успехом в чтении и правописании благодаря ее связи с фоникой (Moats, 2019). Фонологическая осведомленность описывает понимание того, как разговорный язык состоит из различных более мелких компонентов, и способность идентифицировать их и манипулировать ими (Torgenson et al, 2019, Ehri & Flugman, 2018).
Он состоит из нескольких компонентов, в том числе: определение отдельных слов, слогов в словах, распознавание и создание рифм, аллитерация и фонематическое восприятие. Фонематическая осведомленность — это способность сосредотачиваться на отдельных фонемах в словах и манипулировать ими. Этот навык включает в себя работу с началом и рифмой, смешивание и сегментацию звуков в словах, а также удаление и манипулирование фонемами.
Навыки фонологического восприятия могут быть концептуализированы в рамках возрастающей сложности. «Лучше всего рассматривать этапы последовательности не как отдельные последовательные этапы, а скорее как перекрывающиеся этапы» (Schuele & Boudreau, 2008, стр. 9). Студенты не должны демонстрировать мастерство и точность в одном навыке, прежде чем они познакомятся с другим.
- Знание слогов (docx — 274.77kb)
- Осведомленность о рифмах и их производство (docx — 400,87 КБ)
- Аллитерация — сортировка начальных и конечных звуков (docx — 679.3кб)
- Сегментация по времени начала (docx — 250.94kb)
- Начальная и окончательная звуковая сегментация (docx — 422.36kb)
- Слияние звуков в слова (docx — 1.63mb)
- Разделение слов на звуки (docx — 572. 86kb)
- Удаление и обработка звуков (docx – 4,95 МБ)
На приведенной ниже адаптированной диаграмме показана эта пересекающаяся концепция:
Первые три навыка фонологического восприятия – это разложение слов на слоги, понимание рифм, воспроизведение и аллитерация. Эти навыки начинают развивать способность раннего ученика слышать и идентифицировать произносимое слово и части слов как отдельные смысловые единицы.
Фонематическая осведомленность, являющаяся частью фонологической осведомленности, движется дальше по континууму сложности. Это конкретно относится к способности сосредотачиваться на отдельных фонемах в произносимых словах и манипулировать ими (см. Диаграмму выше). Переход от идентификации произносимых слов и частей слов к отдельным звукам в слове сложен и требует явных знаний. Этот навык имеет решающее значение для изучения алфавитного кодирования языка (Hoover & Tunmer, 2020).
В то время как фонологическое осознание включает в себя осознание звуков речи, слогов и рифм, фонетика — это сопоставление звуков речи (фонем) с буквами (или шаблонами букв, например, графемами) (Ehri & Flugman, 2018). Таким образом, фонологическая осведомленность и фонетика — это не одно и то же, но эти направления грамотности, как правило, пересекаются.
Фонетика строится на фундаменте фонологического восприятия, особенно фонематического восприятия. По мере того, как учащиеся учатся читать и писать по буквам, они расширяют свои знания об отношениях между фонемами и графемами в письменной речи. По мере развития навыков чтения и правописания, сосредоточение внимания на фонематическом восприятии улучшает фонематические знания, а сосредоточение внимания на фонетике также улучшает фонематическое восприятие.
В первые годы начальной школы важно предоставить учащимся явные и систематические возможности слышать, идентифицировать, изолировать, смешивать, сегментировать и манипулировать звуками в словах.
В зависимости от потребностей учащихся первоначальный акцент может быть сделан на навыках фонологического восприятия наименьшей сложности. Это включает в себя разбиение слов на слоги, распознавание и воспроизведение рифмы и развитие восприятия начального/конечного звука (аллитерации). Как только учащиеся смогут слышать, идентифицировать и изолировать части произнесенного слова, основное внимание в обучении необходимо переместить на то, чтобы помочь учащимся идентифицировать отдельные звуки в словах. Более сложные навыки фонематического восприятия, включая смешивание звуков, сегментацию и манипулирование, являются самыми сильными предикторами раннего успеха декодирования.
Английское онлайн-интервью (EOI) оценивает фонологическую осведомленность. Продвигаясь по модулям с 1 по 4 EOI, учащиеся оцениваются по их способности распознавать и генерировать рифмующиеся слова, определять начальные/средние/конечные звуки в словах и смешивать звуки.
Теория для практики
Фонологическая осведомленность является ключевым ранним индикатором начального и профессионального чтения, включая явное осознание структуры слов, слогов, времени начала и отдельных фонем. Наряду с фонетикой фонологическая осведомленность (в частности, фонематическая осведомленность) является неотъемлемым компонентом обучения чтению (Torgerson et al. , 2019).). Важность фонетики и фонологической осведомленности подчеркивается в современных моделях чтения, используемых при обучении чтению в школах.
В этом видео учитель ведет урок для всего класса, посвященный рифмовке слов. Также есть
план урока к видео.
В этом видео учитель подробно обучает началу и рифму через мини-урок. Учащиеся составляют дифференцированные буклеты о начале инея, чтобы отработать навык сегментации времени начала. К видео также прилагается план урока.
В этом видео учитель ведет урок для всего класса, который фокусируется на слогах.
Исторические отчеты об обучении чтению в США, Великобритании и Австралии поддерживают включение фонологической осведомленности, особенно навыков фонематической осведомленности, в программы ранней грамотности (NICHD, 2000, Rose, 2006; Rowe, 2005).
Исследования, послужившие основой для этих отчетов, показали, что уровень фонематической осведомленности ребенка дошкольного возраста является сильным предиктором успеха в чтении в дальнейшем (Hill, 2021, стр. 135). Поскольку фонематическое восприятие имеет обратную связь с чтением (Hoover & Tunmer, 2020), этим навыкам необходимо обучать систематически и подробно.
Ссылки на викторианский учебный план – английский язык
Чтение
- Понимание принципов печати и экрана, в том числе принципов работы книг, фильмов и простых цифровых текстов, и знание некоторых особенностей печати, включая направленность (описание контента VCELA142)8 Распознавание все прописные и строчные буквы и наиболее распространенный звук, который представляет каждая буква (Описание содержания VCELA146)
Говорить и слушать
- Определять рифмующиеся слова, схемы аллитерации, слоги и некоторые звуки (фонемы) в произносимых словах (Описание содержания VCELA168)
- Смешивать и сегментировать начало и рифму в односложных произносимых словах и выделять, смешивать и сегментировать фонемы в односложных словах ( первый согласный звук, последний согласный звук, средний гласный звук) (Описание содержания VCELA169)
- Воспроизведение ритмов и звуковых паттернов в рассказах, рифмах, песнях и стихах различных культур (Описание содержания VCELT172)
Письмо
- Понимание того, что пунктуация – это особенность письменного текста, отличная от букв, и понимание того, как заглавные буквы используются для имен, а также то, что заглавные буквы и точки обозначают начало и конец предложений (Описание содержания VCELA156)
- Поймите, что звуки в английском языке представлены прописными и строчными буквами, которые могут быть записаны с использованием выученных шаблонов буквообразования для каждого случая (описание содержания VCELY162)
Чтение
- .
Говорить и слушать
- Идентифицировать отдельные фонемы в сочетаниях согласных или группах согласных в начале и конце слогов (описание содержания VCELA203)
- Управление фонемами путем добавления, удаления и замены начальных, средних и конечных фонем для создания новых слов (Описание содержания VCELA204)
Написание
- Распознавание различных типов знаков препинания, восклицательных знаков, сигнальные предложения, которые делают заявления, задают вопросы, выражают эмоции или дают команды (Описание содержания VCELA190)
Уровень 2
Говорить и слушать
- Манипулировать более сложными звуками в произносимых словах с помощью знаний о смешивании и сегментации звуков, удалении и замене фонем (описание содержания VCELA238) звуки в кластерах (описание содержания VCELA239)
Ссылки на учебную программу викторианской эпохи — английский как дополнительный язык (EAL)
Путь A
Говорение и слушание
Уровень A1
- Имитация произношения, ударения и интонации (VCEALL027)
- Используйте понятное произношение, но с большим количеством пауз и запинок
(VCEALL028)
Уровень A2
- Повторите или измените предложение или фразу, моделируя ритм, интонацию и произношение речи других (VCEALL109)
- Идентификация и воспроизведение фонем в виде смесей или кластеров в начале и конце слогов
(VCEALL110)
Чтение
Уровень A1
- Определение некоторых звуков в словах (VCEALL050)
- Распознавать некоторые распространенные буквы и сочетания букв в словах
(VCEALL051)
Уровень A2
- Соотнесите большинство букв алфавита со звуками (VCEALL131)
- Использовать знание букв и звуков, чтобы читать новое слово или находить ключевые слова
(VCEALL132)
Письмо
Уровень A1
- Точное написание некоторых согласных, гласных и согласных слов и общеупотребительных слов, выученных в классе (VCEALL080)
Уровень A2
- Правильно произносите по буквам знакомые слова и слова с обычными буквами (VCEALL159)
Путь B
Говорить и слушать
Уровень BL
- Использовать понятное произношение знакомых слов (VCEALL183)
Уровень B1
- Используйте понятное произношение для ряда высокочастотных слов, изученных в классе (VCEALL262)
- г. Повторяйте или повторно произносите слова или фразы при появлении запроса, если они не поняты
(VCEALL263)
Уровень B2
- Используйте четкое произношение для общих слов и изученных ключевых слов темы (VCEALL343)
- Самокоррекция и улучшение аспектов произношения, которые мешают общению (VCEALL344)
Уровень B3
- Самокорректируйте и улучшайте аспекты произношения, которые мешают общению, и сосредоточьтесь на исправлении (VCEALL423)
Чтение и просмотр
Уровень BL
- Знать буквы алфавита (VCEALL208)
- Попытка самокоррекции (VCEALL211)
Уровень B1
- Определение общих слогов и моделей в словах (VCEALL288)
- Самокоррекция с подсказкой (VCEALL291)
Уровень B2
- Применять знания о связях между буквами и звуками для чтения новых слов с некоторой поддержкой (VCEALL368)
- Правильное произношение (VCEALL371)
Уровень B3
- Применение знаний о связях между буквами и звуками для определения произношения новых слов (VCEALL447)
- Самокоррекция ряда аспектов речи (VCEALL450)
Письмо
Уровень BL
- Точное написание ряда высокочастотных слов
(VCEALL237)
Уровень B1
- Точное написание общих слов, встречающихся в классе (VCEALL318)
Уровень B2
- Написание часто используемых слов с общими шаблонами с повышенной точностью (VCEALL398)
Уровень B3
- Точное написание большинства слов с использованием ряда стратегий, но с некоторым придуманным правописанием, которое все еще очевидно
(VCEALL477)
Например, мероприятия по развитию основных навыков фонологической осведомленности, посетите Примеры для развития фонологической осведомленности.
Эри, Л. К., и Флюгман, Б. (2018). Наставничество учителей в систематическом обучении фонетике: эффективность интенсивной годовой программы для учителей детского сада через учителей 3-х классов и их учеников. Чтение и письмо: междисциплинарный журнал , 31 (2), 425-456.
Холм. С. (2021). Развитие ранней грамотности: оценка и обучение (3-е изд. -го, -е). Издательство Элеоноры Кёртейн.
Гувер, Вашингтон, и Танмер, Западная Э. (2020). Когнитивные основы чтения и его усвоения: платформа с приложениями, соединяющими преподавание и обучение . Спрингер.
Рвы, Л. (2019). Фоника и правописание: изучение структуры языка на уровне слов. В: Д. А. Килпатрик, Р. М. Джоши и Р. К. Вагнер (ред.), Развитие чтения и трудности: преодоление разрыва между исследованиями и практикой (стр. 39–62). Спрингер.
Национальный институт детского здоровья и развития человека (NICHD) (2000). Национальная комиссия по чтению (NRP): Обучение детей чтению: основанная на фактических данных оценка научно-исследовательской литературы по чтению и ее значение для обучения чтению . Министерство здравоохранения и социальных служб США.
https://www.nichd.nih.gov/sites/default/files/publications/pubs/nrp/Documents/report.pdf
Роуз, Дж. (2006). Независимый обзор обучения раннему чтению : Заключительный отчет, Джим Роуз, март 2006 г. . Публикации DfES.
https://dera.ioe.ac.uk/5551/2/report.pdf
Роу, К. (2005). Обучение чтению: Отчет и рекомендации . Канберра: Департамент образования, науки и обучения.
https://research.acer.edu.au/cgi/viewcontent.cgi?article=1004&context=tll_misc
Торгерсон, К., Брукс, Г., Гаскойн, Л., и Хиггинс, С. (2019 г.). Фонетика: политика чтения и доказательства эффективности из систематического «третичного» обзора. Исследовательские работы в области образования , 34 (2), 208-238.
Как фонематическое восприятие помогает словам стать словами для зрения
Мы хотим, чтобы дети формировали словарный запас слов для зрения, чтобы им было легче читать. В этом сообщении в блоге утверждается, что слова взгляда имеют решающее значение.
Но история зрительных слов в основном касается не только наших глаз. Вместо этого наука о чтении говорит нам, что наш словесный мозг любит звуки. Для тех из нас, кто может слышать, обработка звуков — это то, для чего мы созданы. Так что этот пост также утверждает, что звук имеет решающее значение, когда мы учим детей видеть слова.
Поскольку наш мозг любит звуки, этот пост будет первым на Teach. Учиться. Расти. предложить собственный микстейп 80-х. Выкопайте эту кассетную деку, ребята. Если этого уже давно нет, у меня есть хорошие новости: вместо этого вы можете щелкнуть ссылки на YouTube, чтобы посмотреть эти классические мелодии.
Что со словами-прицелами?(Песня 1: «Word Up» Cameo, 1986)
Когда я говорю «слово взгляда», что приходит мне на ум? Думаю, у многих из нас начинает формироваться список, включающий такие слова, как «сказал», «был» и «имеет». Одна из причин заключается в том, что эти слова нарушают правила, учитывая фонетику, которую мы учим детей в раннем возрасте. У них забавные варианты написания; Например, «сказанный» должен рифмоваться со словом «платный». Вторая причина, по которой многие называют эти зрительные слова, заключается в том, что они появляются с такой высокой частотой.
Визуальное запоминание невероятно неэффективно по сравнению с использованием звуков для нашего мозга.
Но читательский словарный запас выходит за рамки этого понимания. Он включает в себя любые слова, которые читатель распознает автоматически и мгновенно. В моем лексиконе есть и «кошка», и «катастрофа». Неважно, насколько часты или непослушны эти слова; важно только то, что мне больше не нужно произносить их вслух, когда я сталкиваюсь с ними при чтении. Я просто узнаю их.
У меня огромное количество слов, которые я теперь сразу узнаю. Дело в том, что у меня поистине огромный словарный запас. И если вы начинаете думать: «Мм, много хвастаться?» тогда вы должны знать, что вы также имеете огромный словарный запас. Вот откуда я это знаю: вы отслеживали смысл, когда читали это. Это говорит мне о том, что вам не нужно было с усилием произносить многие слова в этом посте. Вместо этого вы читали с высоким уровнем автоматизма. Автоматическое распознавание слов позволяет настроиться на понимание смысла во время чтения.
Мы хотим, чтобы все дети читали со смыслом. И это не может произойти без большого количества автоматического распознавания слов. Слово вверх, действительно.
При чем здесь фонематический слух?(Песня 2: «What’s Love Got to Do with It», Тина Тернер, 1984 г.)
Как построить автоматическое распознавание слов? В прошлом в некоторых учебных материалах подчеркивалась форма слов. Этот подход заключался в том, чтобы отметить, что слово «есть» начинается, например, с высокой черты, а слово «они» имеет высокие буквы впереди, а затем заканчивается той, которая идет ниже линии. Теория заключалась в том, что растущий словарный запас зрительных слов был связан со зрительной памятью, и замечание форм подтверждало это. Это неправильное понимание. Пожалуйста, не учите так.
Текущие исследования предлагают другой путь. Наше нынешнее понимание того, как работает наш словесный мозг, говорит нам, что наш словесный мозг любит звуки. Когда мы можем связать звуки слова с его буквами, мы помогаем себе легче запомнить или распознать это слово в следующий раз.
Вот как это соединение работает в явном виде:
- Произнесите слово вслух.
- Сегментируйте каждый из звуков или фонем в слове.
- Сопоставьте каждую фонему с буквой или буквами, которые представляют ее в слове.
Когда дети могут слышать отдельные звуки в слове, они могут сопоставить букву или буквы, которые они видят, с каждым звуком. Это называется орфографическим картографированием. Вот как это выглядит:
Мы можем поддерживать орфографическое сопоставление даже для неуправляемых слов, таких как «сказал». Мы просто должны быть честными: английский странный. В этом случае звук /eh/ записывается с помощью AI. (Можете ли вы придумать слово, в котором ИИ произносит /eh/ ag ai n?)
Но вот что интересно: не каждый учащийся может легко расслышать отдельные звуки в словах. Когда учащиеся борются с фонематическим восприятием, орфографическое картирование становится серьезной проблемой. Вы просто не можете сопоставить буквы и фонемы, если вы не можете легко различать фонемы.
Что важно и что работает? (Песня 3: «She Blinded Me with Science» Томаса Долби, 1982 г.) Нам нужны наши самые эффективные меры, чтобы помочь детям научиться автоматически распознавать слова. Так что же говорит нам наша исследовательская литература? Все чаще он говорит нам удвоить внимание к фонематическому восприятию. Метаанализ 2016 года был сосредоточен на том, какие виды вмешательств действительно приживаются и приносят наибольшую отдачу в долгосрочной перспективе. Обучение фонематическому восприятию появилось как предложение действительно большой отдачи от затраченных средств через несколько лет.
Когда мы можем связать звуки слова с его буквами, мы помогаем себе легче запомнить или распознать это слово в следующий раз.
Сила сильного фонематического восприятия имеет больше смысла в наши дни, потому что мы знаем больше об орфографическом отображении. Когда учащийся отлично владеет фонематическим восприятием, он подсознательно и автоматически делает это орфографическое сопоставление со словами, с которыми сталкивается. Не задумываясь об этом, они используют ту любовь к звукам, которую имеет наш словесный мозг.
Для учащихся, которые сопоставляют звуки с буквами по мере того, как они сталкиваются со словами, накопление словарного запаса слов с листа становится действительно эффективным. Эти учащиеся строят свой словарный запас слов, просто читая. Эти подсознательные картографы могут навсегда запомнить это слово всего несколько раз, встретившись со словом.
Но некоторые учащиеся остаются в пространстве, где фонематическое осознание является проблемой. Встречи с новыми словами не приводят к подсознательному или автоматическому орфографическому сопоставлению. Слова остаются только визуальными, а те звуки, которые любят их словесные мозги, не прослушиваются.
Визуальное запоминание невероятно неэффективно по сравнению с использованием звуков для нашего мозга. Из-за этого учащиеся, еще не способные сопоставлять фонемы с буквами, испытывают трудности с созданием словарного запаса слов для зрения. Эти студенты повторяют одни и те же слова снова и снова, с усилием, не запоминая эти слова. В то время как их сверстники записывают слова в память после нескольких показов, ученикам, застрявшим без орфографического отображения, требуется гораздо больше повторений слова, прежде чем оно запомнится. Это обескураживает. Такого рода трудности работают против любви к чтению. Читатели, застрявшие здесь, сосредоточены на расшифровке слов и не могут обратить внимание на их значение.
Мы можем научить студентов произносить слова с помощью хороших фонетических навыков. Затем, однако, они должны быть в состоянии перейти от звучания к распознаванию слов. И что мешает слишком многим детям запоминать слова, так это недостаточная фонематическая осведомленность.
Манипулирование фонемами(Песня 4: «You Spin Me Round (Like a Record)» группы Dead or Alive, 1984)
Так как же это выглядит, чтобы помочь детям развить действительно сильное фонематическое восприятие? Это не ограничивается сегментацией и смешиванием фонем, которые полезны для озвучивания слова. Вместо этого мы хотим перейти к обращению фонем, манипулированию и другому анализу на фонемном уровне: некоторые вещи следующего уровня. Не стесняйтесь использовать буквы и здесь; сочетание звуков и букв — это название игры. Мы хотим создать такой уровень мастерства, который дети смогут использовать подсознательно и автоматически, отображая слова в памяти. Это тренировка силы и мышечной памяти в фонематическом восприятии.
Вот два примера манипулирования фонемами. Бонусные баллы: посмотрите, смогут ли учащиеся вставить в них буквы!
- Послушайте слово «застежка». Теперь уберите звук /с/. Какое слово осталось? («Хлоп»)
- Послушайте слово «пламя». Теперь уберите звук /l/ и замените его звуком /r/. Какое слово у тебя получилось? («Рамка»)
Чтобы получить дополнительную помощь в развитии фонемного мастерства следующего уровня, ознакомьтесь с книгой Дэвида Килпатрика Equipped for Reading Success: A Completed, Step-by-Step Program for Development фонематический слух и беглое распознавание слов .
Музыка для моих ушей Хорошо, слушатели микстейпа. Я делаю знаю, что слушать музыку во время чтения — не лучший совет. Но я надеюсь, что сочетание зрительных образов и звуков поможет вам вспомнить: чтобы помочь детям эффективно формировать словарный запас зрительных слов, нам необходимо развивать их фонематическую осведомленность.