Фонетикалық талдау (Фонетический разбор)
Дыбыстар (Звуки)
Қазақ тілінде 42 әріп, 37 дыбыс бар.
В казахском языке 42 буквы и 37 звуков.
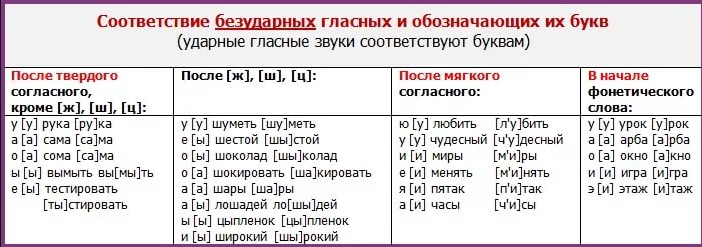
| Дауысты дыбыстар түрлері Виды гласных звуков |
|||||
| Тілдің қатынасына қарай По подъему языка |
Жақтың қатынасына қарай По положению челюсти |
Еріннің қатынасына қарай По участию губ |
|||
| жуан твердые |
жіңішке мягкие |
ашық открытые |
қысаң сжатые |
еріндік губные | езулік неогубленные |
| а, о, ы, ұ, э, у | ә, ө, і, ү, е, и | а, ә, е, о, ө, э | ы, и, і, у, ұ, ү | о, ө, у, ұ, ү | а, ә, е, э, ы, і, и |
| Дауыссыз дыбыстар түрлері Виды согласных звуков |
||
| Ұяң Звонкие |
Үнді Сонорные |
Қатаң Глухие |
| б, в, г, ғ, д, ж, з, һ | й, л, м, н, ң, р, у | к, қ, п, с, т, ф, х, ч, ц, ш, щ |
Буындар (Слоги)
- Ашық: A, BA
- Тұйық: AB
- Бітеу: BAB
A – дауысты дыбыс (гласный звук)
B – дауыссыз дыбыс (согласный звук)
Мысалы (Пример фонетического разбора)
Өсімдік1 — 3 буын, ө – ашық, сім – бітеу, дік – бітеу.
Ө – дауысты, ашық, еріндік, жіңішке;
с – дауыссыз, қатаң;
і – дауысты, қысаң, езулік, жіңішке;
м – дауыссыз, үнді;
д – дауыссыз, ұяң;
і – дауысты, қысаң, езулік, жіңішке;
к – дауыссыз, қатаң.
Сөзде 7 әріп, 7 дыбыс бар.
Дополнительно
Кроме фонетического разбора слова на казахском языке, Вам также могут быть интересны следующие темы:
- Синтаксический разбор
- Морфологический разбор
- Разбор слова по составу
ДЕКТ | Представление содержимого
Представление содержимого
Контент DECTE предоставляется в нескольких типах представления: аудио, орфографическая транскрипция, орфографическая транскрипция с тегами частей речи и фонетическая транскрипция. Однако не все типы представления доступны для всех компонентов TLS, PVC и NECTE2.
В таблице 1 указано, какие типы представления доступны в настоящее время в каждом из трех подкорпусов:
Таблица 1 . Уровни представления в трех подкорпусах DECTE Уровни представления в трех подкорпусах DECTE | ||||
| Подкорпус | Аудио | Орфографическая транскрипция | Части речи с тегами Орфографическая транскрипция | Фонетическая транскрипция |
| TLS | ✔ | ✔ | ✔ | ✔ |
| ПВХ | ✔ | ✔ | ✔ | ✖ |
| NECTE2 | ✔ | ✔ | ✖ | ✖ |
1. Аудио
Основным представлением интервью TLS, PVC и NECTE2 является аудиозапись речи.
- Записи TLS находятся на аналоговой катушечной ленте, датируемой началом 1970-х годов, и на кассетах с аналоговой лентой, снятых с оригинальных лент 1994-95 годов. Поскольку они являются перезаписями, кассеты неизбежно имеют более низкое качество, чем оригиналы. Однако оригиналы сильно испортились, особенно в последние годы, и во многих случаях кассеты содержат информацию, которую уже невозможно восстановить с катушечных лент.

- Все записи TLS, включенные в DECTE, были оцифрованы с кассетных версий в формате .wav с частотой 12000 Гц, 16-битное моно (192 кбит/с), дополненный регулировкой амплитуды, графическим выравниванием, устранением клипов и шипения, а также регулировкой скорости.
- Все записи PVC были оцифрованы в формате .wav (256 кбит/с, 16 кГц, 16 бит моно) непосредственно с оригинальных лент DAT.
- Все аудиофайлы NECTE2 представляют собой оригинальные цифровые записи, сделанные с использованием различного записывающего оборудования. Записи 2010-2011 годов сделаны в формате .wav (подавляющее большинство 705кбит/с, 44кГц, 16-бит моно). Из-за соображений емкости хранилища во время более ранних записей NECTE2 аудиофайлы 2007–2008 и 2008–2009 гг.существуют только в формате .mp3 (64 кбит/с, 12 кГц моно).

2. Орфографическая транскрипция
DECTE включает орфографические расшифровки всех аудиозаписей интервью, включенных в коллекции TLS, PVC и NECTE2.
Транскрипции материалов TLS и PVC были взяты из NECTE, которая руководствовалась протоколами, используемыми в сопоставимых и успешных проектах, таких как Poplack (1989), Poplack и Tagliamonte (19).91) и Тальямонте (2004). Процесс транскрипции NECTE состоял из четырех проходов по аудиофайлам, где:
- Первая созданная база текста.
- Второй и третий проходы были корректирующими для повышения точности транскрипции.
- Четвертый установил единообразие практики транскрипции по всему корпусу.
Для NECTE2 процесс был двухэтапным: начальная транскрипция и корректирующий проход.
(а) Заглавные буквы и знаки препинания
Заглавные буквы и знаки препинания являются синтаксическими маркерами. Чтобы избежать предварительной оценки структуры дискурса, NECTE взяла за правило не использовать их в транскрипции. DECTE немного изменил это, так что файлы TLS и PVC теперь имеют заглавные буквы имен собственных и местоимений от первого лица.
В файлах NECTE2 используются как заглавные буквы, так и знаки препинания, но они делают это непоследовательно, потому что каждый из них был расшифрован разными учениками, и разные люди по-разному интерпретировали рекомендации по протоколу транскрипции NECTE2, которые им были даны. Это несоответствие не является оптимальным, и цель команды DECTE состоит в том, чтобы урегулировать его как можно скорее.
(б) Правописание
В качестве общего принципа DECTE стремилась использовать стандартную английскую орфографию для транскрипции, где «стандартный английский» означает написание слов из Оксфордского словаря английского языка . Это означает, что там, где британские и американские соглашения различаются, используются британские соглашения, например. цвет , театр , путешественник и т. д.
Поскольку TLS и PVC являются корпусами диалектов, они часто содержат морфологические и лексические сегменты, для которых не существует стандартного английского правописания. В таких случаях:
В таких случаях:
- Если сегменты представляют собой фонетические варианты тех, для которых существует стандартное английское написание, используется это написание. Эта политика была принята, потому что DECTE предоставляет звуковые файлы, поэтому в орфографической транскрипции не требуется указаний на акцент или неформальность. Это также было принципиальным решением, учитывая ненадежность полуфонетического написания и мнения, высказанные Кэмероном (2001), Престоном (2000), Макалаем (1991).
- Если сегменты действительно диалектные и встречаются в любом из диалектных словарей Хеслоп (1892) и/или Wright (1905), то используется словарная орфография.
- В противном случае правописание было изобретено DECTE; они перечислены в Приложении 2.
DECTE также включает орфографические транскрипции, созданные в рамках проекта TLS. Они включены частично по историческим причинам, а частично потому, что иногда они имеют показания, которые больше не могут быть восстановлены транскриберами DECTE из-за ухудшения качества аудиокассет.
Изготовлены электронные копии текста орфографической транскрипции на учетных карточках, копии вычитаны относительно карточек. Никаких изменений, в том числе исправлений, не вносилось. Обратите внимание, что TLS только транскрибирует высказывания интервьюируемых, полностью игнорируя интервьюера.
3. Орфографическая транскрипция с тегами частей речи
Орфографические транскрипции DECTE аудио TLS и PVC — но не транскрипции NECTE2 — были помечены частью речи во время проекта NECTE (2001-2005) Университетским центром компьютерных корпусных исследований языка (UCREL) в Университет Ланкастера, Великобритания, с помощью тегера CLAWS4. Интерпретация результатов осуществляется через листинг набора тегов UCREL C8.
4. Фонетическая транскрипция
DECTE включает частичные фонетические транскрипции интервью TLS. Они требуют подробного обсуждения.
Для достижения основной цели исследования команда TLS должна была сравнить собранные ими аудиоинтервью на фонетическом уровне репрезентации.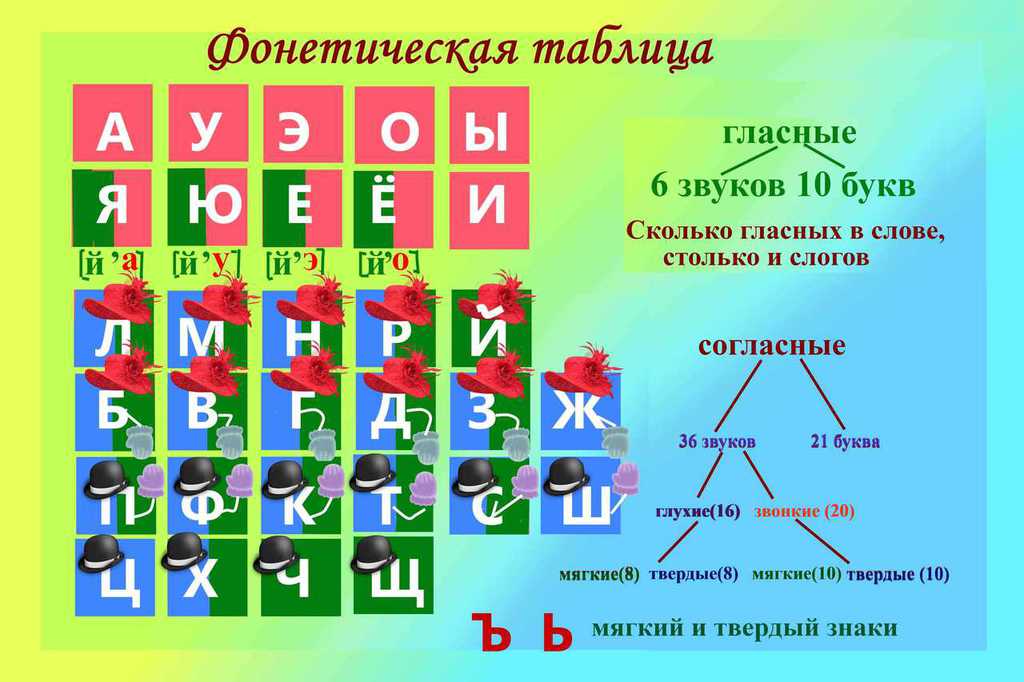 Это требовало дискретизации аналогового речевого сигнала на последовательности фонетических сегментов или, другими словами, фонетической расшифровки.
Это требовало дискретизации аналогового речевого сигнала на последовательности фонетических сегментов или, другими словами, фонетической расшифровки.
Результатом является набор строк символов, каждая из которых фонетически представляет соответствующее интервью. Затем эти строки можно сравнить, и, если также имеется цифровое электронное представление, сравнение можно выполнить с помощью вычислений.
В рамках проекта TLS были созданы фонетические транскрипции значительной части его аудиоматериалов, и они включены в DECTE, но для того, чтобы сделать их пригодными для использования в контексте DECTE, они потребовали обширной реставрации.
В этом разделе описывается (1) схема фонетической транскрипции TLS и (2) восстановление электронных фонетических файлов TLS.
4.1 Фонетическая транскрипция TLS и схемы цифрового кодирования
Команда TLS сделала описанную выше простую, чисто последовательную процедуру транскрипции основой для довольно сложной иерархической схемы представления фонетики корпуса. Эта схема должна быть понята, если ее фонетические данные должны быть компетентно интерпретированы, и поэтому она подробно объяснена.
Схема иерархической фонетической транскрипции TLS была разработана для того, чтобы зафиксировать как можно больше фонетической изменчивости в интервью. Чтобы убедиться в этом, рассмотрим, что происходит, когда анализируются данные, полученные с помощью процедуры последовательной транскрипции, и, более конкретно, сравниваются расшифрованные интервью.
Очевидный способ провести сравнение — подсчитать для каждого интервью, сколько раз встречается каждый из фонетических символов в используемой схеме транскрипции; это дает фонетический частотный профиль для каждого из интервью, и полученные профили затем можно сравнивать с использованием самых разных методов.
Но такие профили не принимают во внимание распространенную вариацию между отдельными говорящими и группами говорящих: разные говорящие и группы обычно по-разному распределяют фонетику своей речи в разных лексических средах.
Частотные профили рассматриваемого здесь типа говорят только о том, сколько раз каждый из говорящих использует фонетический сегмент X, не принимая во внимание возможность того, что они по-разному распределяют X по своему лексическому репертуару. Иерархическая схема транскрипции TLS была разработана, чтобы зафиксировать такие вариации распределения.
Схема основана на способе определения фонем любого данного диалекта, который вслед за Уэллсом (1982) стал известен как «лексические наборы» и довольно широко используется в английской диалектологии и исторической фонологии.
Как видно из названия, лексический набор — это набор слов. Более конкретно, это набор слов, который содержит определенную фонему и, таким образом, дает экстенсиональное определение фонемы. Набор {корабль, ребро, тусклый, молоко, скользить, миф, хорошенький, построить, женщины, занят}, например, определяет фонему /i/ в стандартном американском и британском английском английском.
Набор {корабль, ребро, тусклый, молоко, скользить, миф, хорошенький, построить, женщины, занят}, например, определяет фонему /i/ в стандартном американском и британском английском английском.
Иерархическая схема транскрипции TLS имеет три уровня:
- Верхний уровень, обозначенный как уровень «общая единица» (OU), представляет собой набор лексических наборов OU = {{ls 1 }, {ls 2 }…{ls m }}, такие, что каждый {ls i } для 1 < i < m экстенсивно определяет одну фонему в Received Pronunciation (RP) British английском, а m — это количество фонем в RP. Цель этого уровня заключалась в том, чтобы обеспечить стандарт, относительно которого можно было бы охарактеризовать лексическое распределение фонетических вариаций Тайнсайда.
- Нижний уровень, обозначенный как «Состояние», представляет собой набор наборов фонетических символов. Состояние = {{ps 1 }, {пс 2 }…{пс м }}. Существует взаимно однозначное соответствие лексических наборов на уровне OU и наборов фонетических символов на уровне штата, так что символы в {ps i } для 1 < i < m обозначают фонетические сегменты которые реализуют OU {ls i } во фрагменте английского языка Тайнсайд, который содержится в корпусе TLS.
- Промежуточный уровень предполагаемых дисистемных переменных (PDV) предлагает (таким образом, «предполагаемые») группы фонетических символов в заданном наборе состояний {ps и } основаны, насколько позволяет судить существующая документация по TLS, на представлениях проектной группы о родстве фонетических сегментов, которые обозначают символы. Эти группы PDV представляют фонетические реализации своих вышестоящих OU менее детализированным способом, чем наборы фонетических символов State.
 Существует взаимно однозначное соответствие лексических наборов на уровне OU и наборов фонетических символов на уровне штата, так что символы в {ps i } для 1 < i < m обозначают фонетические сегменты которые реализуют OU {ls i } во фрагменте английского языка Тайнсайд, который содержится в корпусе TLS.
Существует взаимно однозначное соответствие лексических наборов на уровне OU и наборов фонетических символов на уровне штата, так что символы в {ps i } для 1 < i < m обозначают фонетические сегменты которые реализуют OU {ls i } во фрагменте английского языка Тайнсайд, который содержится в корпусе TLS.Например (Джонс-Сарджент 1983: 295):
ОУ/ i:/, определенные лексическим набором, из которого есть примеры в крайнем правом столбце, могут быть реализованы символами фонетического сегмента в столбце Состояния, и эти символы сгруппированы по фонетическому родству в столбце PDV.
Эта схема транскрипции фиксирует требуемую фонетическую информацию о распределении, позволяя любому заданному сегменту состояния реализовать более одного OU. Обратите внимание, что на приведенном выше рисунке несколько символов состояния для OU/ i: / встречаются и в OU / I /. Это означает, что в схеме транскрипции TLS символ фонетического сегмента состояния представляет не звук, независимый от распределения, а звук по отношению к фонемам, по которым он распределен.
Последствия этого можно увидеть в схеме кодирования, которую TLS разработал для своей схемы транскрипции, чтобы его фонетические данные можно было анализировать с помощью вычислений. Каждый символ состояния кодируется как пятизначное целое число. Первые четыре цифры любого заданного символа штата обозначают PDV, которому принадлежит этот символ, а пятая цифра указывает конкретное государство в этом PDV.
Таким образом, для ОУ / i:/ имеется 6 ПДВ, каждому из которых присвоен уникальный четырехзначный код; особенности того, какие числа используются, не имеют значения и могли быть чем-то другим. Для данного ПДВ в пределах / i:/OU, скажем ‘ I ‘ (0004), первый из символов состояния в порядке слева направо кодируется как 00041, второй как 00042 и так далее.
Для данного ПДВ в пределах / i:/OU, скажем ‘ I ‘ (0004), первый из символов состояния в порядке слева направо кодируется как 00041, второй как 00042 и так далее.
Теперь обратите внимание, что символы состояния 00023 и 00141 идентичны, то есть обозначают один и тот же звук. Важно, однако, то, что они имеют разные коды, потому что они реализуют разные фонемы относительно OU, или, другими словами, разные коды представляют фонематическое распределение одного звука, который обозначают оба кода.
Полная схема фонетической транскрипции TLS доступна в Приложении 1.
4.2 Восстановление фонетических транскрипций TLS
Фонетические транскрипции интервью TLS сохранились в двух формах: в виде набора каталожных карточек и в виде электронных файлов. Каждый электронный файл представляет собой последовательность только что описанных 5-значных кодов; случайный отрывок из одного из этих файлов выглядит так (последовательности &&&& являются маркерами конца строки):
| 02441 02301 02621 02363 02741 02881 02301 01123 00906 02081-&&&& 02322 02741 02201 02383 02801 02421 02501 01443 01284 00421 02021 00342 02642 02164 02721 02741 04321-&&&& 02621 02825 02301 02721 02341 02642 02541 00503 00161 00246 12601 01284 02781 02561 02363 02561 02881 07641 02941-&&&& |
Первоначально казалось, что электронные файлы представляют собой экономящую труд и время альтернативу вводу числовых кодов с каталожных карточек, но особенность, связанная с первоначальным вводом электронных данных с помощью TLS, означала, что их приходилось тщательно редактировать. Проблема возникла из-за того, как 5-значные коды были расположены на учетных карточках:
Проблема возникла из-за того, как 5-значные коды были расположены на учетных карточках:
По причинам, которые уже не ясны, все коды согласных были записаны в одной строке, а все коды гласных в строке или строках ниже. Когда команда TLS передала эти каталожные карточки службе ввода данных Университета Ньюкасла, машинистки вводили коды строка за строкой, в результате чего в любой данной электронной строке сначала идут все коды согласных, а затем коды гласных. Эта проблема характерна для файлов электронной фонетической транскрипции TLS.
Простое сохранение этого порядка затруднило бы сопоставление фонетического представления с другими уровнями представления (орфографической транскрипцией и аудио). Поэтому во время проекта NECTE файлы TLS редактировались со ссылкой на каталожные карточки, чтобы восстановить правильную последовательность кода, и результат был проверен.
Единственным исключением из этой реставрации являются файлы для колонок Newcastle. Поскольку ни аудиозаписи, ни наборы каталожных карточек для этих ораторов не сохранились, восстановление правильной последовательности было бы чрезвычайно трудоемкой задачей, которую невозможно было бы выполнить в кратчайшие сроки. ограниченное время, которое было доступно для проекта NECTE.
ограниченное время, которое было доступно для проекта NECTE.
Однако даже в неупорядоченном состоянии эти файлы можно использовать для определенных типов фонетического анализа, таких как подсчет частоты сегментов, и поэтому они были включены в NECTE (и теперь включены в DECTE) в их нынешнем состоянии для этого. причина.
Более того, формат числовых кодов в этих файлах отличается от форматирования в других файлах на основе TLS, где коды находятся в непрерывной последовательности. Для файлов Ньюкасла было сохранено исходное форматирование TLS: числовые коды расположены в виде последовательности кодовых строк, каждая из которых заканчивается разрывом строки, где кодовая строка в последовательности соответствует одному высказыванию информанта. .
Мотивация состояла в том, чтобы облегчить переупорядочивание кодов, если это когда-либо будет предпринято в будущем — если, например, аудиофайлы или наборы учетных карточек для группы Ньюкасла когда-либо обнаружатся.
Следует, наконец, отметить, что транскрипции Гейтсхеда TLS были сделаны исключительно одним участником проекта, Винсом Макнини, который был одновременно обученным фонетиком и носителем диалекта Тайнсайд, образцом которого является корпус TLS. Это важно для анализа фонетического уровня, поскольку сводит к минимуму субъективность и вариации, которые неизбежно мешают фонетической транскрипции. Однако неизвестно, кто сделал транскрипцию TLS Newcastle.
Это важно для анализа фонетического уровня, поскольку сводит к минимуму субъективность и вариации, которые неизбежно мешают фонетической транскрипции. Однако неизвестно, кто сделал транскрипцию TLS Newcastle.
Таблица 3 из Корпусно-фонетического словаря тунисского арабского языка для распознавания речи
- Идентификатор корпуса: 11851475
title={Корпусно-фонетический словарь для распознавания тунисской арабской речи},
автор = {Абир Масмуди и Марием Эллуз, а также Ю. Эстеве и Ламия Хадрич Белгуит и Низар Хабаш},
booktitle={Международная конференция по языковым ресурсам и оценке},
год = {2014}
} В этой статье мы описываем усилия по созданию корпуса и фонетического словаря для автоматического распознавания речи тунисского арабского языка (ASR). Корпус под названием TARIC (Tunisian Arabic Railway Interaction Corpus) содержит коллекцию аудиозаписей и транскрипций диалогов в сети тунисского железнодорожного транспорта. Фонетический (или произносительный) словарь является важным компонентом ASR, который служит посредником между акустическими моделями и языковыми моделями в системах ASR. Метод…
Фонетический (или произносительный) словарь является важным компонентом ASR, который служит посредником между акустическими моделями и языковыми моделями в системах ASR. Метод…
Посмотреть на ACL
lrec-conf.org
Фонетический инструмент для тунисского арабского языка
- Абир Масмуди, Ю. Эстев, М. Эллуз, Фетхи Бугарес, Л. Бельгуит
- 5 SL 900, SL 900, 5 Лингвистика
- 2014
Описаны этапы создания учебного корпуса T TARIC: Tunisian Arabic Railway Interaction Corpus и проиллюстрированы некоторые правила, используемые для построения фонетического словаря.
Автоматическая система распознавания речи для тунисского диалекта
- Abir Masmoudi, Fethi Bougares, M. Ellouze, Y. Estève, L. Belguith
Лингвистика, информатика
Language Resources and Evaluation
- 2017 представлены характеристики, а также описан и оценен фонетический инструмент, основанный на правилах, который используется для создания первой системы ASR для тунисского диалекта с уровнем ошибок в словах 22,6%.
Автоматическая система распознавания речи для тунисского диалекта
- Абир Масмуди, Фети Бугарес, М. Эллуз, Ю. Эстев, Л. Белгуит
Лингвистика, информатика
Яз. Ресурс. Оценка
- 2018
Представлен исторический обзор тунисского диалекта и его лингвистических характеристик, а также описан и оценен основанный на правилах фонетический инструмент, который используется для создания первой системы ASR для тунисского диалекта с коэффициентом ошибок в словах. 22,6%.
Обработка вариантов произношения внутри слова и кроссворда для распознавания арабской речи (подход, основанный на знаниях)
- Ибрагим Эль-Хенави, Марва Або Або-Элазм
Лингвистика, информатика
Журнал интеллектуальных систем и Интернета вещей
- 2020
не повышает производительность распознавания, но использование этих правил для обработки вариантов кроссвордов обеспечивает хорошую производительность.
Усовершенствованная система распознавания арабской речи за счет автоматического создания тонких фонетических транскрипций
- Эйман Альшархан, А. Рамзи
Лингвистика, информатика
Инф. Процесс. Управление
- 2019
ComputerAutomatic Robust Rule-Based Phonetization of Standard Arabic
- Fadi Sindran, F. Mualla, Katharina Bobzin, E. Nöth
Computer Science, Linguistics
TSD
- 2015
This В статье представлена надежная автоматическая фонетическая транскрипция стандартного арабского языка на пяти уровнях: фонема, аллофон, слог, слово и предложение, а также предложена кодировка, охватывающая все звуки стандартного арабского языка.
Влияние фонологических правил на распознавание арабской речи
- Фаваз С. Аль-Анзи, Диа Абузейна
Лингвистика, информатика
Межд. Дж. Речевые технологии.
- 2017
Экспериментальные результаты не дают четких доказательств того, что использование фонологических правил для адаптации словаря ASR может улучшить производительность при изменении произношения внутри слова и может быть указанием на переосмысление или использование других аспектов производительности ASR, таких как вариации произношения кроссвордов и оптимальный набор фонем арабского языка.
Влияние фонологических правил на распознавание арабской речи
- Фаваз С. Аль-Анзи, Диа Абузейна
Лингвистика, информатика
International Journal of Speech Technology
- 8 2017 900 результаты не показаны 4 Экспериментальные 3 900 четкие доказательства того, что использование фонологических правил для адаптации словаря ASR может повысить эффективность изменения произношения внутри слова и может быть указанием на переосмысление или использование других аспектов производительности ASR, таких как изменение произношения кроссвордов и оптимальный набор фонем арабского языка. язык.
Rule-Based Standard Arabic Phonetization at Phoneme , Allophone , and Syllable Level
- Fadi Sindran, F. Mualla, T. Haderlein, K. Daqrouq
Computer Science, Linguistics
- 2016
A comprehensive algorithm Предлагается охват феномена фарингализации в стандартном арабском языке и представлена надежная автоматическая фонетическая транскрипция стандартного арабского языка на пяти уровнях: фонема, аллофон, слог, слово и предложение.
Новое рождение арабского фонетического словаря
Новое исследование указывает на слабость HMM при представлении изменчивости длины гласных и показывает, что построение арабской системы автоматического распознавания речи будет полезно только в том случае, если фонетический словарь принимает принимая во внимание независимость между фонемами гласных и фонемами согласных.
ПОКАЗЫВАЕТ 1-10 ИЗ 24 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантностьНаиболее влиятельные документыНедавность
Разработка фонетической системы для распознавания арабской речи с большим словарным запасом
Описана простая схема автоматической генерации произношений для использования в обучении и снижения уровня фонетического отсутствия словарного запаса, а также результаты использования фонетической и графемной систем в многопроходная/комбинированная структура.
Фонетическое произношение для арабских систем преобразования речи в текст
- Frank Diehl, M. Gales, M. Tomalin, P. Woodland
Информатика, лингвистика
Международная конференция IEEE по акустике, обработке речи и сигналов, 2008 г. с многопроходной/комбинированной структурой.
Улучшение словаря арабского произношения для распознавания телефона и слов с помощью лингвистических правил произношения
- Fadi Biadsy, Nizar Habash, Julia Hirschberg
Информатика
NAACL
- 2009
Продемонстрировано, что лингвистически мотивированное использование системы распознавания произношения слов по сравнению с базовой системой распознавания MSA по телефону может значительно повысить точность распознавания слов и MSA.
правила произношения, которые обычно использовались в предыдущей работе над автоматическим распознаванием речи MSA (ASR).Распознавание арабской речи с использованием движка SPHINX
В этой работе представлен первый распознаватель арабского языка на основе SPHINX-IV и предлагается автоматический инструментарий, способный создавать (PD) как для священного Корана, так и для стандартного арабского языка, и является приглашением для всех разработчиков распознавания речи с открытым исходным кодом. и группы, чтобы взять на себя и извлечь выгоду из того, что начато.
Диалектный арабский телефонный корпус речи: принципы, дизайн инструментов и правила транскрипции
- М. Маамури, Тим Баквалтер, К. Сиери
Языкознание
- 2004
В данной статье представлен опыт, полученный в LDC по сбору и транскрипции корпуса разговорной телефонной речи на диалектном арабском языке.
Статья будет охватывать следующее: (a)…Фонетизация арабского языка: правила и алгоритмы
- Й. Эль-Имам
Лингвистика, информатика
Вычисл. Речь Ланг.
- 2004
Низар Ю. Хабаш, Введение в обработку арабского естественного языка (Обобщающие лекции по технологиям человеческого языка)
- К. Шаалан
Лингвистика
Машинный перевод
- 2011
Эта книга дает достаточный объем вводной информации по ANLP, что делает ее первой в своем роде и наиболее подходящей для всех фундаментальные сведения об ANLP для целей исследования, изучения или разработки.
Арабский Вычислительная морфология: основанные на знаниях и эмпирические методы
- А. Суди, Антал ван ден Бош, Г. Нейманн
Информатика
- 2007
Поскольку морфологическое знание играет важную роль в понимании и обработке арабского текста на любом более высоком уровне, в книге также есть раздел о роли арабской морфологии в более крупных приложениях, например, в поиске информации.

 Аль-Анзи, Диа Абузейна
Аль-Анзи, Диа Абузейна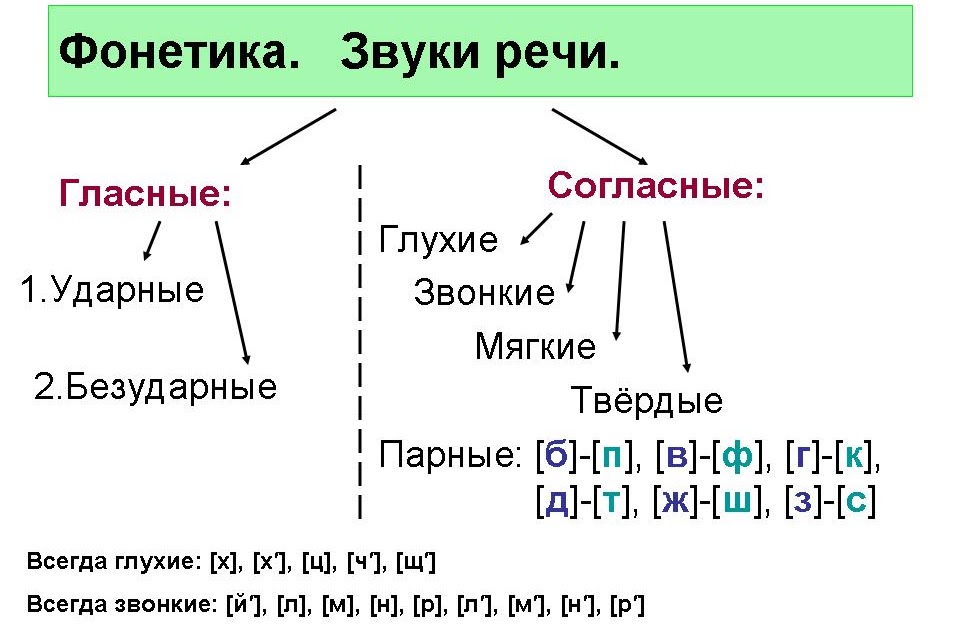 язык.
язык.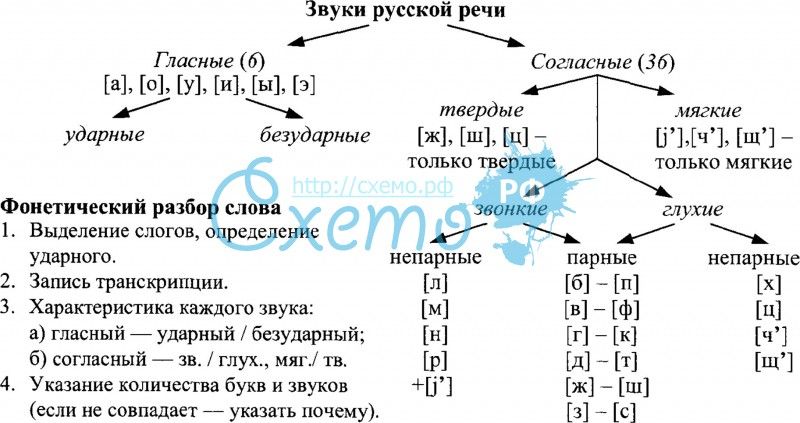 правила произношения, которые обычно использовались в предыдущей работе над автоматическим распознаванием речи MSA (ASR).
правила произношения, которые обычно использовались в предыдущей работе над автоматическим распознаванием речи MSA (ASR). Статья будет охватывать следующее: (a)…
Статья будет охватывать следующее: (a)…