Фонетический разбор слова ЖИТЬ — ответ на Uchi.ru
Ответ или решение2
М
Фонетический разбор = звуко-буквенный анализ, в нём нужно дать характеристику всем звукам данного слова.
Жить — 1 слог, 1 гласная, 2 согласных, [жыт’];
ж [ж] — согласный, звонкий, паный, твёрдый, непарный;
и [ы] — гласный, ударный;
т [т’] — согласный, глухой, парный, мягкий, парный;
ь [—] — звука не обозначает.
4 буквы, 3 звука.
К
Фонетический разбор
Для начала определим, что же такое фонетический разбор? Фонетический разбор- это описание характеристики звукового состава слова и его слогов. А фонетика — это Для того, чтобы провести фонетический разбор нужно знать,что:
- Буквы А О У Ы Э — показывают твердые согласные звуки.
- Буквы Я Ё Ю И Е — показывают звонкие согласные звуки.
- Л М Н Р Й — являются непарными звонкими согласными звуками.
- Х Ц Ч Щ — являются непарными глухими согласными звуками.
- Ъ Ь — звука не имеют.

- Б-П, В-Ф, Г-К, Д-Т, Ж-Ш, З-С — парные звонкие-глухие согласные звуки.
- Ж Щ Ц — всегда являются твердыми.
- Ч Щ Й — всегда являются мягкими.
- Я Е Ю Е — в некоторых случаях могут давать два звука.

Фонетический разбор слова «жить»
Теперь мы сделаем фонетический разбор данного нам слова (жить). Для этого мы должны:
- Произнести слово вслух и записать так, как мы его проговариваем : слово жить
- Проговаривая слово, мы понимаем, что его невозможно разделить на слоги, поэтому делаем вывод, что в этом слове один слог — жить.
- Теперь поставим ударение. Здесь оно ставится однозначно: на единственную гласную в слове, гласную «и». То есть, ударение такого: жИть.
- Далее рассматриваем каждую букву по отдельности:
— ж — (ж) — согласный, твердый, парный, глухой звук.
— и — (ы) — гласный, ударный звук.
— т — (т) — парный глухой, мягкий, согласный звук.
— ь — звука не дает.
- Подводим итоги, подсчитывая количество букв и количество звуков. В слове «жить» 4 буквы и 3 звука.

Некоторые тонкости фонетического разбора
Если вдруг не понятно, откуда взялся звук «ы» из буквы «и», то здесь используется такое правило: буква «и» после ряда букв: ж, ш, ц звучит, как звук «ы». Это правило надо запомнить!
Слова с буквой «ё» обязательно нужно писать через букву «ё», а не заменять её на «е». Фонетический разбор слов «её» и «ее» будет различным!
Буква «ь» делает делает предыдущий звук мягким.
Если буква не произносится, но пишется в слове, то она записывается, как буква, но не записывается, как звук.
Знаешь ответ?
Как написать хороший ответ?Как написать хороший ответ?
Будьте внимательны!
- Копировать с других сайтов запрещено. Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂
- Публикуются только развернутые объяснения. Ответ не может быть меньше 50 символов!
 Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂
Стикеры и подарки за такие ответы не начисляются. Используй свои знания. 🙂0 /10000
4.7 Фонологические правила – Основы языкознания, 2-е издание
Глава 4: Фонология
Устранение избыточности с точностью
Если мы запишем наш анализ французских сонорантов как описания того, как произносятся три фонемы, мы получим утверждения, подобные следующим:
- /m/ произносится как [m̥] слово-наконец после глухого шумного
- /m/ в другом месте произносится как [m]
- /l/ произносится как [l̥] слово-наконец после глухого шумного
- /l/ произносится как [l] в другом месте
- /ʀ/ произносится как [ʀ̥] слово-наконец после глухого шумного
- /ʀ/ произносится как [ʀ] в другом месте
Обратите внимание на огромное количество избыточности в этих операторах. Во-первых, каждая фонема /X/ имеет точно такую же формулировку: «/X/ произносится как [X] в другом месте». Это связано с тем, как мы решили представить фонему, используя тот же символ, что и аллофон по умолчанию. Если мы будем последовательно делать это для каждой фонемизации, то у нас всегда будет такое утверждение для произношения по умолчанию для каждой фонемы.
Это связано с тем, как мы решили представить фонему, используя тот же символ, что и аллофон по умолчанию. Если мы будем последовательно делать это для каждой фонемизации, то у нас всегда будет такое утверждение для произношения по умолчанию для каждой фонемы.
Поскольку у нас всегда будет этот оператор по умолчанию, нам не нужно указывать его явно. Вместо этого мы можем просто рассматривать это как неотъемлемую часть работы фонологии: каждая фонема всегда произносится как соответствующий аллофон по умолчанию «где-то еще». Это иногда называют принципом верности : если фонема встречается в среде, не охватываемой никаким другим утверждением произношения этой фонемы, то она произносится одинаково (ее произношение «верно» своей фонеме). Таким образом, мы можем удалить все экземпляры этого утверждения по умолчанию, полагаясь вместо этого на принцип достоверности, чтобы универсально дать нам аллофоны по умолчанию для каждой фонемы в каждом разговорном языке. Это оставляет нам следующие три утверждения для французского языка:
- /m/ произносится как [m̥] слово-наконец после глухого шумного
- /l/ произносится как [l̥] в конце слова после глухого шумного
- /ʀ/ произносится как [ʀ̥] слово-наконец после глухого шумного
Устранение избыточности с помощью естественных классов
Остается некоторая избыточность. Все три утверждения имеют одинаковую форму: «/X/ произносится [X̥] слово-наконец после глухого препятствия». Это еще одна закономерность, и часть фонологии (и лингвистики в целом) состоит в том, чтобы находить закономерности и сводить их к более простым описаниям и объяснениям.
Все три утверждения имеют одинаковую форму: «/X/ произносится [X̥] слово-наконец после глухого препятствия». Это еще одна закономерность, и часть фонологии (и лингвистики в целом) состоит в том, чтобы находить закономерности и сводить их к более простым описаниям и объяснениям.
Обратите внимание, что / m /, / l / и / ʀ / — все это соноранты. Это начало естественного класса, но естественные классы должны быть исчерпывающими, а во французском языке есть и другие соноранты. Например, мы видим в данных [n] и [j], и это предположительно аллофоны /n/ и /j/, которые нужно было бы включить в любой естественный класс сонорных фонем. Это оставляет нам два варианта: либо есть три независимых утверждения о некоторых сонорантах, как указано выше, по одному для каждого из /m/, /l/ и /ʀ/, которые по совпадению все имеют одну и ту же основную форму, или существует единственное утверждение, которое мы можем построить, которое охватывает все соноранты, включая /n/ и /j/.
Каждый вариант делает разные прогнозы относительно французского произношения. Если /m/, /l/ и /ʀ/ ведут себя совершенно независимо от /n/ и /j/, то мы предсказываем, что /n/ и /j/ не будут иметь глухих аллофонов, если они стоят в конце слова после глухого. мешающий. Если вместо этого существует единый шаблон, применимый ко всем сонорантам, мы предсказываем, что /n/ и /j/ должны иметь глухие аллофоны в точно таком же окружении, что и /m/, /l/ и /ʀ/.
Если /m/, /l/ и /ʀ/ ведут себя совершенно независимо от /n/ и /j/, то мы предсказываем, что /n/ и /j/ не будут иметь глухих аллофонов, если они стоят в конце слова после глухого. мешающий. Если вместо этого существует единый шаблон, применимый ко всем сонорантам, мы предсказываем, что /n/ и /j/ должны иметь глухие аллофоны в точно таком же окружении, что и /m/, /l/ и /ʀ/.
Ничто в предоставленных данных не может помочь нам сделать выбор между этими двумя вариантами, потому что в данных нет слов с /n/ или /j/ в соответствующем окружении. На самом деле, французская фонотактика в любом случае предотвращает это, поэтому, к сожалению, мы никогда не сможем проверить наши предсказания!
Простое устранение избыточности
Поскольку у нас есть два конкурирующих анализа, которые оба учитывают данные данные, и не может быть найдено никаких других данных, противоречащих ни одному из анализов, мы можем следовать принципу простоты и выбрать анализ с наименьшим количеством утверждений. Это позволяет нам упростить наши три оператора до одного, примерно такого:
Это позволяет нам упростить наши три оператора до одного, примерно такого:
- сонорный произносится как глухое слово-наконец после глухого шумного
Обратите внимание, что это ничего не говорит о том, что происходит с местом и способом артикуляции сонорных звуков, а только об их звучании. Мы должны предположить, что подобные заявления влияют только на то, что они говорят; все остальное должно оставаться верным (неизменным). Мы не хотим, чтобы /m/ превращался в какой-то случайный безголосый телефон! Мы специально хотим, чтобы оно произносилось как [m̥], поэтому отличается только его звучание.
Написание фонологических правил
Такие заявления часто называют фонологических правил , и есть сокращенное обозначение, которое мы можем использовать, чтобы привести их к форме, с которой легче иметь дело. Мы можем использовать стрелку [латекс]\стрелку вправо[/латекс] , чтобы заменить «произносится как», и использовать косую черту / , чтобы отделить изменение правила от среды, в которой оно применяется.
Это дает нам следующее сокращенное правило:
- сонорный [латекс]\стрелка вправо[/латекс] глухой / глухой шумный #
Существуют более сложные способы упрощения фонологических правил, но для целей данного учебника этой формы будет достаточно. Теперь у нас есть следующий базовый шаблон для фонологического правила, содержащий три ключевых компонента: цель (обозначенная здесь цифрой 9);0067 A ), изменение ( B ) , и окружающая среда ( C D ).
A [латекс]\стрелка вправо[/латекс]
Целью фонологического правила является естественный класс фонем, которые превращаются в соответствующие им аллофоны. Изменение , вызванное фонологическим правилом, представляет собой список всех фонетических свойств, описывающих, насколько последовательно отличаются аллофоны от целевых фонем. Наконец, среда — это то же самое, что мы использовали для разговора о распределении аллофонов. Как мы видели, большинство сред обычно ссылаются только на что-то непосредственно слева и/или непосредственно справа, хотя возможны и более сложные среды.
Изменение , вызванное фонологическим правилом, представляет собой список всех фонетических свойств, описывающих, насколько последовательно отличаются аллофоны от целевых фонем. Наконец, среда — это то же самое, что мы использовали для разговора о распределении аллофонов. Как мы видели, большинство сред обычно ссылаются только на что-то непосредственно слева и/или непосредственно справа, хотя возможны и более сложные среды.
Генеративная фонология и уровни репрезентации
В некоторых версиях фонологии фонемы, аллофоны и фонологические правила являются не просто удобными описаниями паттернов, но важнейшими объектами теории, иногда предлагаемыми для представления некоторых аспектов когнитивной реальности. Одна из самых распространенных таких версий фонологии — генеративная фонология , первоначально разработанная в 1950-х и 1960-х годах (Chomsky 1951, Chomsky et al. 1956, Halle 1959, Chomsky and Halle 1968), основанная на идеях, разработанных в первой половине 20-го века (Saussure 1916, Bloomfield 1939, Swadesh and Voegelin 1939, Trubetzkoy 1939, Jakobson 1942, Harris 1946/1951, Wells 1949) и, в конечном счете, отражающие идеи из работ Дакшипутры Панини, грамматика из древней Индии (ок. 500 г. до н. э.), разработавшего концепции и методы анализа Санскрит, который все еще можно увидеть в современной лингвистике.
500 г. до н. э.), разработавшего концепции и методы анализа Санскрит, который все еще можно увидеть в современной лингвистике.
В генеративной фонологии слова имеют как минимум две различные фонологические формы. Один из них — аппроксимация произношения (узкое или широкое, по мере необходимости), которое мы представляли в квадратных скобках с телефонами. Это представление называется поверхностным представлением
Второе представление состоит из фонем и называется базовым представлением (UR) или фонематическим представлением . Поскольку UR состоит из фонем, это абстрактный объект в нашем теоретическом анализе языка. Как и в случае с фонемами, ведутся споры о том, соответствуют ли UR какой-либо когнитивной реальности, но независимо от того, соответствуют они или нет, они являются полезными инструментами для описания фонологии языка. Здесь нам пришлось бы переписать все наши данные, используя фонемы вместо аллофонов.
Здесь нам пришлось бы переписать все наши данные, используя фонемы вместо аллофонов.
Таким образом, для каждого слова в грузинском языке мы заменим каждый ясный [l] его фонемой /ɫ/. Таким образом, UR для [t͡ʃoli] «жена» и [xeli] «рука» будут /t͡ʃoɫi/ и /xeɫi/.
Точно так же, чтобы получить UR для французских данных, мы заменим все глухие соноранты соответствующими фонемами: UR [ɛtʀ̥] ‘быть’ будет /ɛtʀ/, UR [pœpl̥] ‘люди’ будет /pœpl/, а UR [ʀitm̥] «ритм» будет /ʀitm/. Обратите внимание, что UR заключены в косую черту, потому что они состоят из фонем.
В генеративной фонологии отношения между UR и SR — это не просто статическая связь. Вместо этого UR рассматриваются как входные данные для процесса, который «генерирует» SR в качестве вывода путем активного преобразования фонем в соответствующие им аллофоны. Эта модель предназначена для имитации того, как предположительно работает язык: мы начинаем с некоторого мысленного представления слова в уме, а затем через некоторое время произносим это слово. Этот общий процесс называется фонологической деривацией , а отдельные компоненты этого процесса, изменяющие фонемы, являются нашими фонологическими правилами. Эта модель представлена графически на следующей диаграмме.
Этот общий процесс называется фонологической деривацией , а отдельные компоненты этого процесса, изменяющие фонемы, являются нашими фонологическими правилами. Эта модель представлена графически на следующей диаграмме.
Проверьте свое понимание
Скоро!
Каталожные номера
Блумфилд, Леонард. 1939. Морфофонемика Меномини. В Études phonologiques dédiées à la mémoire de M. le Prince Н. С. Трубецкой , vol. 8, 105–115. Jednota českých matematiků and fyziků.
Хомский, Ноам. 1951. Морфофонема современного иврита . Магистерская работа, Пенсильванский университет, Филадельфия.
Хомски, Ноам и Моррис Холли. 1968. Звуковой рисунок английского языка . Нью-Йорк: Харпер и Роу.
Хомский, Ноам, Моррис Холли и Фред Лукофф. 1956. Об акценте и стыке в английском языке. В Роману Якобсону: Очерки по случаю его шестидесятилетия , изд. Моррис Халле, Гораций Лант, Хью Маклин и Корнелис ван Шунвельд, 65–80 лет. Гаага: Мутон.
Моррис Халле, Гораций Лант, Хью Маклин и Корнелис ван Шунвельд, 65–80 лет. Гаага: Мутон.
Галле, Моррис. 1959. Звуковой образ русского языка: лингвистическое и акустическое исследование . Гаага: Мутон.
Харрис, Зеллиг С. 1946/1951. Методы структурной лингвистики . Чикаго: Издательство Чикагского университета.
Якобсон Роман. 1942. Понятие фонемы. В На языке , изд. Линда Р. Во и Моник Мовилл-Берстон, 218–241. Кембридж, Массачусетс: Издательство Гарвардского университета.
Соссюр, Фердинанд де. 1916. Общий лингвистический курс . Париж: Пайо.
Сводеш, Моррис и Чарльз Фогелин. 1939. Проблема фонологического чередования. Язык 15: 1–10.
Трубецкой Николай Сергеевич. 1939. Grundzüge der Phonologie, Travaux du Cercle languageique de Prague , vol. 7. Прага: Jednota českých matematiků and fyziků.
Wells, Rulon S. 1949. Автоматическое чередование. Язык 25(2): 99–116.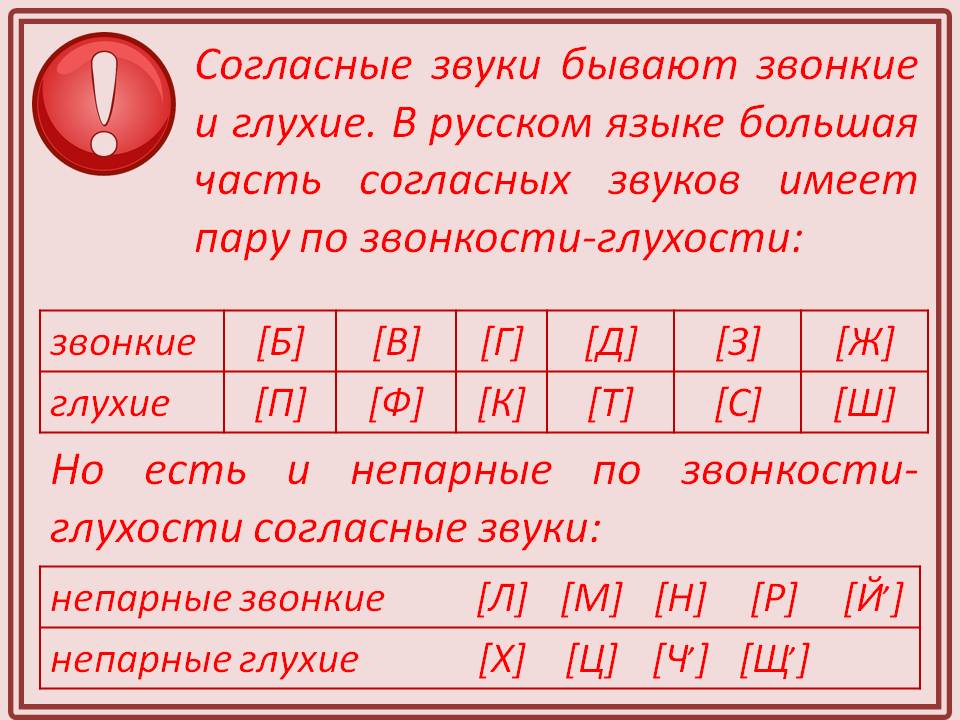
фонология — Вывод правила из набора примеров
Вы не можете ничего вывести из данных. Вы можете делать выводы, но не все выводы являются выводами. до сделать вывод о том, есть или нет контраста в исходной позиции, нужно знать правила игры. Возможное (общее) «правило игры» таково: «если есть минимальные пары, различающие X и Y в позиции, то X и Y контрастируют в этой позиции». В них нет минимальных пар в начальной позиции. Однако тест на минимальную пару — не единственное правило игры. Альтернативное правило игры основано на том, существует ли правило, которое выводит X из Y в этом контексте. В этом случае вам также придется выяснить, по какому правилу выводится X из Y.
Другая проблема правил игры (настоящая универсальная проблема в профессии) заключается в том, что если у вас есть доказательство того, что две вещи контрастируют, вы можете сказать «да», но вы никогда не сможете сказать «нет», потому что вопрос не указано как относящееся к набору данных (например, « в этих примерах . ..»). Насколько нам известно, следующее слово представит нам минимальную пару. Если предположить, что «нет» возможно для случая, когда нет доказательств, то «нет» будет правильным.
..»). Насколько нам известно, следующее слово представит нам минимальную пару. Если предположить, что «нет» возможно для случая, когда нет доказательств, то «нет» будет правильным.
Вы должны гордиться собой за то, что понимаете понятие «фонема» достаточно хорошо, чтобы видеть, что даже если есть контексты, где контраст нейтрализуется, эти звуки — это различных фонем. Я не одобряю метафору о том, что использование X против Y «меняет значение»: слово «собака» изначально не означало «но» и не менялось (и не наоборот), вместо этого одна фонема встречается в одном слове (peɾo) и другая фонема появляется в другом слове (pero). Между прочим, «собака» — это [pero], а не [per̃o], что указывает на назальное r в IPA. Доказательств того, что данные находятся в IPA, почти не существует — пример вроде rancho прояснит, какая система используется.
Развивая альтернативу требованию минимальных пар («можете ли вы написать правило, предсказывающее X из Y»), вот гипотетический набор данных (поскольку он составлен, и я утверждаю, что это разные слова, нам не нужны толкования) .