ГДЗ по русскому языку 3 класс учебник Канакина, Горецкий 1 часть – стр 114
- Тип: ГДЗ, Решебник.
- Автор: Канакина В. П., Горецкий В. Г.
- Год: 2019.
- Издательство: Просвещение.
Подготовили готовое домашнее задание к упражнениям на 6 странице по предмету русский язык за 3 класс. Ответы на вопросы к заданиям 215, 216 и 217.
Учебник 1 часть – Страница 114.
Ответы 2022 года.
Номер 215.
Прочитайте.
А в лесу мороз кружева развесил — ни пером описать, ни в сказке сказать! Невзначай зацепишь — летит на шапки алмазная лёгкая пыль.
И. Соколов-Микитов.
- Объясните, как вы понимаете значение выделенного фразеологизма. В каких случаях так говорят? А что обозначает слово невзначай?
Ответ:
Ни пером описать, ни в сказке сказать — восхищение чем-то прекрасным, невероятным, неописуемым словами. Так говорят, когда передать и выразить восхищение трудно словами.
Так говорят, когда передать и выразить восхищение трудно словами.
- Спишите. Подчеркните в словах изученные орфограммы.
Ответ:
А в лесу мороз кружева развесил — ни пером описать, ни в сказке сказать! Невзначай зацепишь — летит на шапки алмазная лёгкая пыль.
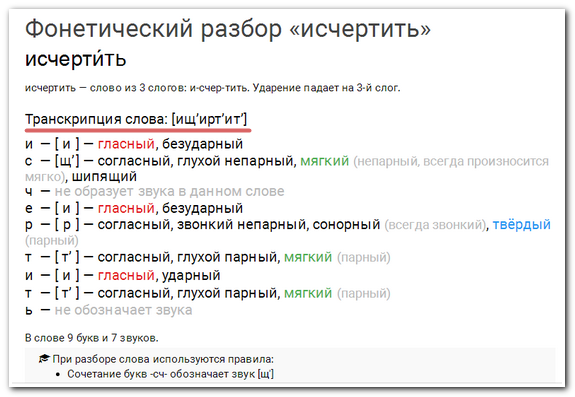
Фонетический разбор
Мороз [маро´с] — 2 слога.
м — [м] — согл., зв. непарн., тв. парн.
о — [а] — гласн., безуд.
р — [р] — согл., зв. непарн., тв. парн.
о — [о´] — гласн., ударн.
з — [с] — согл., глух. парн., тв. парн.
5 букв, 5 звуков.
Разбор слова
Алмазная — прил.
Номер 216.
Прочитайте.
1. Хороший — хорош, свежий, слабый, счастливый, грубый, трусливый, молодой, правдивый.
2. Сберегу — сберёг, отнесу, отвезу, замёрзну, подстерегу, ползу.
3. Много ягод, слёз (книги, лужи, сороки, канавы, колёса, коровы, рыбы).
- Измените слова так, чтобы на конце этих слов был парный по глухости-звонкости согласный звук.
Запишите. Подчеркните букву, обозначающую этот звук в проверочном и проверяемом словах.
Ответ:
1. Хороший — хорош, свежий — свеж, слабый — слаб, счастливый — счастлив, грубый — груб, трусливый — труслив, молодой — молод, правдивый — правдив;
2. Сберегу — сберёг, отнесу — отнес, отвезу — отвез, замёрзну — замёрз, подстерегу — подстерег, ползу — полз;
3. Много ягод, много слёз, много книг, много луж, много сорок, много канав, много колёс, много коров, много рыб.
Хорош [харо´ш] — 2 слога.
х — [х] — согл., глух. непарн., тв. парн.
о — [а] — гласн. , безуд.
, безуд.
р — [р] — согл., зв. непарн., тв. парн.
о — [о´] — гласн., ударн.
ш — [ш] — согл., глух. парн., тв. непар.
5 букв, 5 звуков.
Номер 217.
Прочитайте. Подберите заголовок к стихотворению.
Дружит белка с ши(ш, ж)кой,
За..ц — с кочерыжкой,
Жеребёнок — с тра(ф, в)кой,
В..р..бей — с козя(ф, в)кой,
Шмель — с цв..точною пыльцой…
В. Лунин.
Ответ:
Заголовок: «Кто кому друг?».
- Спишите, выбирая нужную букву из скобок. Объясните, почему вы выбрали именно её.
Ответ:
Дружит белка с шишкой (шишечка),
Заяц — с кочерыжкой,
Жеребёнок — с травкой (травы),
Воробей (чередование –оро-) — с козявкой (козявок),
Шмель — с цветочною (цвет) пыльцой. ..
..
- Придумайте продолжение стихотворения о том, кто с кем дружит.
Ответ:
…Дружит конь с пушистою овцой,
Бык с зайчонком,
Серый волк — с галчонком,
А большой петух — с гордым жеребцом.
Фонетический разбор
Шмель [шм’э´л’] — 1 слог.
ш — [ш] — согл., глух. парн., тв. непарн.
м — [м’] — согл., зв. непарн., мягк. парн.
е — [э´] — гласн., ударн.
л — [л’] — согл., зв. непарн., мягк. парн.
ь — не обозначает звука.
5 букв, 4 звука.
Рейтинг
← Выбрать другую страницу ←
Почему Kaldi хорош для распознавания речи? (обновлено 25.12.2019) / Хабр
Почему мне (и, надеюсь, вам) интересно распознавание речи? Во-первых, это направление является одним из самых популярных по сравнению с другими задачами компьютерной лингвистики, поскольку технология распознавания речи сейчас используется почти повсеместно – от распознавания простого «да/нет» в автоматическом колл-центре банка до способности поддерживать «светскую беседу» в «умной колонке» типа «Алисы». Во-вторых, чтобы система распознавания речи была качественным, необходимо найти самые эффективные средства для создания и настройки такой системы (одному из подобных средств и посвящена эта статья). Наконец, несомненным «плюсом» выбора специализации в области распознавания речи лично для меня является то, что для исследований в этой области необходимо владеть как программистскими, так и лингвистическими навыками. Это весьма стимулирует, заставляя приобретать знания в разных дисциплинах.
Во-вторых, чтобы система распознавания речи была качественным, необходимо найти самые эффективные средства для создания и настройки такой системы (одному из подобных средств и посвящена эта статья). Наконец, несомненным «плюсом» выбора специализации в области распознавания речи лично для меня является то, что для исследований в этой области необходимо владеть как программистскими, так и лингвистическими навыками. Это весьма стимулирует, заставляя приобретать знания в разных дисциплинах.
Почему именно Kaldi, ведь есть же и другие фреймворки для распознавания речи?
Для ответа на этот вопрос стоит рассмотреть существующие аналоги и используемые ими алгоритмы и технологии (алгоритмы, используемые в Kaldi, описаны далее в статье):
- CMU Sphinx
CMU Sphinx (не путать с поисковым движком Sphinx!) – это система распознавания речи, созданная разработчиками из университета Карнеги-Меллон и состоящая из различных модулей для извлечения речевых признаков, распознавания речи (в том числе и на мобильных устройствах) и обучения такому распознаванию. CMU Sphinx использует скрытые марковские модели на акустико-фонетическом уровне распознавания и статистические N-граммные модели на лингвистическом уровне распознавания. Также в системе присутствуют ряд интересных возможностей: распознавание продолжительной речи (например, стенограмм или звукозаписей интервью), возможность подключения большого словаря в сотни тысяч словоформ, и т. п. Важно отметить, что система постоянно развивается, с каждой версией улучшаются качество распознавания и производительность. Также присутствуют кроссплатформенность и удобная документация. Из минусов использования данной системы можно выделить невозможность запустить CMU Sphinx «из коробки», т.к. даже для решения простых задач требуются знания по адаптации акустической модели, в сфере языкового моделирования и т.д.
CMU Sphinx использует скрытые марковские модели на акустико-фонетическом уровне распознавания и статистические N-граммные модели на лингвистическом уровне распознавания. Также в системе присутствуют ряд интересных возможностей: распознавание продолжительной речи (например, стенограмм или звукозаписей интервью), возможность подключения большого словаря в сотни тысяч словоформ, и т. п. Важно отметить, что система постоянно развивается, с каждой версией улучшаются качество распознавания и производительность. Также присутствуют кроссплатформенность и удобная документация. Из минусов использования данной системы можно выделить невозможность запустить CMU Sphinx «из коробки», т.к. даже для решения простых задач требуются знания по адаптации акустической модели, в сфере языкового моделирования и т.д. - Julius
Julius разрабатывалась японскими разработчиками с 1997 года, и сейчас проект поддерживается Advanced Science, Technology & Management Research Institute of Kyoto. Работа модели основана на N-граммах и контекстозависимых скрытых марковских моделях, система способна распознавать речь в реальном времени. В качестве недостатков можно назвать распространение только для модели японского языка (хотя существует проект VoxForge, который создает акустические модели и для других языков, в частности для английского языка) и отсутствие стабильных обновлений. - RWTH ASR
Модель развивается специалистами из Рейнско-Вестфальского технического университета с 2001 года, состоит из нескольких библиотек и инструментов, написанных на языке C++. В проект также входят документация по установке, различные обучающие системы, шаблоны, акустические модели, языковые модели, поддержка нейронных сетей и т. д. При этом RWTH ASR практически не обладает кроссплатформенностью и имеет низкую скорость работы. - HTK
HTK (Hidden Markov Model Toolkit) – это набор инструментов для распознавания речи, который был создан в Кембриджском университете в 1989 году. Инструментарий, основанный на скрытых марковских моделях, используется чаще всего как дополнительное средство для создания систем распознавания речи (например, этот фреймворк используют разработчики Julius). Несмотря на то, что исходный код является общедоступным, использование HTK для создания систем для конечных пользователей запрещено лицензией, из-за чего инструментарий сейчас не является популярным. Также система имеет относительно невысокие скорость и точность работы.
 CMU Sphinx использует скрытые марковские модели на акустико-фонетическом уровне распознавания и статистические N-граммные модели на лингвистическом уровне распознавания. Также в системе присутствуют ряд интересных возможностей: распознавание продолжительной речи (например, стенограмм или звукозаписей интервью), возможность подключения большого словаря в сотни тысяч словоформ, и т. п. Важно отметить, что система постоянно развивается, с каждой версией улучшаются качество распознавания и производительность. Также присутствуют кроссплатформенность и удобная документация. Из минусов использования данной системы можно выделить невозможность запустить CMU Sphinx «из коробки», т.к. даже для решения простых задач требуются знания по адаптации акустической модели, в сфере языкового моделирования и т.д.
CMU Sphinx использует скрытые марковские модели на акустико-фонетическом уровне распознавания и статистические N-граммные модели на лингвистическом уровне распознавания. Также в системе присутствуют ряд интересных возможностей: распознавание продолжительной речи (например, стенограмм или звукозаписей интервью), возможность подключения большого словаря в сотни тысяч словоформ, и т. п. Важно отметить, что система постоянно развивается, с каждой версией улучшаются качество распознавания и производительность. Также присутствуют кроссплатформенность и удобная документация. Из минусов использования данной системы можно выделить невозможность запустить CMU Sphinx «из коробки», т.к. даже для решения простых задач требуются знания по адаптации акустической модели, в сфере языкового моделирования и т.д. Работа модели основана на N-граммах и контекстозависимых скрытых марковских моделях, система способна распознавать речь в реальном времени. В качестве недостатков можно назвать распространение только для модели японского языка (хотя существует проект VoxForge, который создает акустические модели и для других языков, в частности для английского языка) и отсутствие стабильных обновлений.
Работа модели основана на N-граммах и контекстозависимых скрытых марковских моделях, система способна распознавать речь в реальном времени. В качестве недостатков можно назвать распространение только для модели японского языка (хотя существует проект VoxForge, который создает акустические модели и для других языков, в частности для английского языка) и отсутствие стабильных обновлений. Инструментарий, основанный на скрытых марковских моделях, используется чаще всего как дополнительное средство для создания систем распознавания речи (например, этот фреймворк используют разработчики Julius). Несмотря на то, что исходный код является общедоступным, использование HTK для создания систем для конечных пользователей запрещено лицензией, из-за чего инструментарий сейчас не является популярным. Также система имеет относительно невысокие скорость и точность работы.
Инструментарий, основанный на скрытых марковских моделях, используется чаще всего как дополнительное средство для создания систем распознавания речи (например, этот фреймворк используют разработчики Julius). Несмотря на то, что исходный код является общедоступным, использование HTK для создания систем для конечных пользователей запрещено лицензией, из-за чего инструментарий сейчас не является популярным. Также система имеет относительно невысокие скорость и точность работы.
В статье “Сравнительный анализ систем распознавания речи с открытым кодом” (https://research-journal.org/technical/sravnitelnyj-analiz-sistem-raspoznavaniya-rechi-s-otkrytym-kodom/) было проведено исследование, в ходе которого все системы были обучены на корпусе английского языка (160 часов) и применены на небольшом 10-часовом тестовом корпусе. В итоге выяснилось, что Kaldi имеет самую высокую точность распознавания, по скорости работы незначительно проигрывая конкурентам.
Как установить Kaldi
- Скачиваем архив с репозитория на https://github.com/kaldi-asr/kaldi:
- Распаковываем архив, заходим в kaldi-master/tools/extras.
- Выполняем ./check_dependencies.sh:
Если после этого вы увидите не «all ok», то откройте файл kaldi-master/tools/INSTALL и выполните находящиеся там инструкции. - Выполняем make(находясь в kaldi-master/tools, не в kaldi-master/tools/extras):
- Заходим в kaldi-master/src.
- Выполняем ./configure —shared, при этом можно настроить установку с технологией CUDA или без нее, указав путь к установленной CUDA (. /configure —cudatk-dir=/usr/local/cuda-8.0) или поменять изначальное значение «yes» на «no»(./configure —use-cuda=no) соответственно.
Если при этом вы увидите:
то либо вы не выполнили пункт 4, либо нужно самостоятельно скачать и установить OpenFst: http://www.openfst.org/twiki/bin/view/FST/FstDownload.
- Выполняем make depend.
- Выполняем make -j. Здесь рекомендуется ввести правильное число ядер процессора, которые вы будете использовать при сборке, например make -j 2 .
- В результате получаем:
 /configure —cudatk-dir=/usr/local/cuda-8.0) или поменять изначальное значение «yes» на «no»(./configure —use-cuda=no) соответственно.
/configure —cudatk-dir=/usr/local/cuda-8.0) или поменять изначальное значение «yes» на «no»(./configure —use-cuda=no) соответственно.Пример использования модели с установленным Kaldi
В качестве примера я использовал модель kaldi-ru версии 0.6, cкачать её можно по этой ссылке:
- После скачивания заходим в файл kaldi-ru-0.6/decode.sh и указываем путь к установленной Kaldi, у меня это выглядит вот так:
- Запускаем модель, указывая файл, речь в котором нужно распознать. Можно использовать файл decoder-test.wav, это специальный файл для теста, он уже есть в этой папке:
- И вот что распознала модель:
 Можно использовать файл decoder-test.wav, это специальный файл для теста, он уже есть в этой папке:
Можно использовать файл decoder-test.wav, это специальный файл для теста, он уже есть в этой папке:Какие алгоритмы используются, что лежит в основе работы?
Полная информация о проекте находится по адресу http://kaldi-asr.org/doc/, здесь же я выделю несколько главных моментов:
- Для извлечения акустических признаков из входного сигнала используются либо широко известные MFCC (Mel-Frequency Cepstral Coefficients), либо чуть менее популярные PLP (Perceptual Linear prediction – см. H. Hermansky, “Perceptual linear predictive (PLP) analysis of speech”). В первом методе спектр исходного сигнала преобразуется из шкалы Герц в мел-шкалу, а затем с помощью обратного косинусного преобразования вычисляются кепстральные коэффициенты (https://habr.com/ru/post/140828/). Второй метод основан на регрессионном представлении речи: строится модель сигнала, которая описывает предсказание текущего отсчета сигнала линейной комбинацией – произведением известных отсчетов входных и выходных сигналов на коэффициенты линейного предсказания. Задача вычисления признаков речи сводится к нахождению этих коэффициентов при некоторых условиях.
- Модуль акустического моделирования включает в себя скрытые марковские модели (HMM), модель смеси гауссовских распределений (GMM), глубокие нейронные сети, а именно Time-Delay Neural Networks (TDNN).
- Языковое моделирование осуществляется с помощью конечного автомата-преобразователя, или FST (finite-state transducer). FST кодирует отображение из входной последовательности символов в выходную последовательность символов, при этом для перехода существуют веса, которые определяют вероятность вычисления входного символа в выходной.
- Декодирование происходит при помощи алгоритма прямого-обратного хода.
 Задача вычисления признаков речи сводится к нахождению этих коэффициентов при некоторых условиях.
Задача вычисления признаков речи сводится к нахождению этих коэффициентов при некоторых условиях.О создании модели kaldi-ru-0.6
Для русского языка существует предобученная модель распознавания, созданная Николаем Шмырёвым, также известным на многих сайтах и форумах как nsh.
- Для извлечения признаков использовался метод MFCC, а сама акустико-фонетическая модель основана на нейронных сетях типа TDNN.
- В качестве обучающей выборки послужили звуковые дорожки видеозаписей на русском языке, выкачанные с YouTube.
- Для создания языковой модели использовались словарь CMUdict и именно та лексика, которая была в обучающей выборке. Из-за того, что словарь содержал похожие произношения разных слов, было решено присвоить каждому слову значение “вероятности” и их нормализовать.
- Для обучения языковой модели использовался фреймворк RNNLM (recurrent neural network language models), основанный, как можно увидеть из названия, на рекуррентных нейронных сетях (вместо старых добрых N-грамм).

Сравнение с Google Speech API и Yandex Speech Kit
Наверняка у кого-то из читателей при чтении предыдущих пунктов возник вопрос: окей, то что Kaldi превосходит своих прямых аналогов мы разобрались, но что насчет систем распознавания от Google и Яндекс? Может быть, актуальность описанных ранее фреймворков сомнительна, если есть инструменты от этих двух гигантов? Вопрос действительно хорош, поэтому давайте потестируем!
- В качестве датасета возьмем записи и соответствующие текстовые расшифровки с небезызвестного VoxForge. В результате, после распознавания каждой системой 3677 звуковых файлов я получил такие значения WER (Word Error Rate):
- Записи с VoxForge примерно схожи по отсутствию фоновых шумов, интонации, скорости речи и т.д. Давайте усложним задачу: возьмем валидационный подкорпус корпуса open_stt, который включает в себя телефонные разговоры, аудиодорожки роликов YouTube и аудиокниг, и оценим работу с помощью WER и CER (Character Error Rate).
После получения текстовых расшифровок, я заметил, что Google и Яндекс (в отличие от Kaldi) распознали слова типа
«один» как «1». Соответственно, возникла необходимость подкорректировать такие случаи (т.к. в эталонных расшифровках, которые предоставили авторы open_stt, все представлено в буквенном выражении), что повлияло на конечный результат:
 В результате, после распознавания каждой системой 3677 звуковых файлов я получил такие значения WER (Word Error Rate):
В результате, после распознавания каждой системой 3677 звуковых файлов я получил такие значения WER (Word Error Rate):
Подводя итоги, можно сказать, что все системы справились с задачей примерно на одном уровне, и Kaldi не слишком уступила Yandex Speech Kit и Google Speech API. Во втором случае наиболее хорошие показатели у Yandex Speech Kit, т.к. он лучше всего распознаёт короткие аудиофайлы в сравнении с конкурентами, которые оказались неспособны распознать какую-то их часть (для Google количество этих файлов даже слишком велико). Наконец, стоит отметить, что Kaldi понадобилось более 12 часов для распознавания 28111 файлов, другие системы справились за гораздо меньшее время. Но при этом Yandex Speech Kit и Google Speech API – это «чёрные ящики», которые работают где-то далеко-далеко на чужих серверах и недоступны для тюнинга, а вот Kaldi можно своими руками адаптировать под особенности решаемой задачи – характерную лексику (профессионализмы, жаргон, разговорный слэнг), особенности произношения и т.п. И всё это бесплатно и без СМС! Система является своеобразным конструктором, который мы все можем использовать для создания чего-то необычного и интересного.
Во втором случае наиболее хорошие показатели у Yandex Speech Kit, т.к. он лучше всего распознаёт короткие аудиофайлы в сравнении с конкурентами, которые оказались неспособны распознать какую-то их часть (для Google количество этих файлов даже слишком велико). Наконец, стоит отметить, что Kaldi понадобилось более 12 часов для распознавания 28111 файлов, другие системы справились за гораздо меньшее время. Но при этом Yandex Speech Kit и Google Speech API – это «чёрные ящики», которые работают где-то далеко-далеко на чужих серверах и недоступны для тюнинга, а вот Kaldi можно своими руками адаптировать под особенности решаемой задачи – характерную лексику (профессионализмы, жаргон, разговорный слэнг), особенности произношения и т.п. И всё это бесплатно и без СМС! Система является своеобразным конструктором, который мы все можем использовать для создания чего-то необычного и интересного.
Выражаю благодарность команде Яндекс.Облако, которая помогла мне в осуществлении распознавания корпуса open_stt.
Я работаю в лаборатории АПДиМО НГУ:
Сайт: https://bigdata.nsu.ru/
Группа VK: https://vk.com/lapdimo
RFC 2849 — Формат обмена данными LDAP (LDIF)
Сетевая рабочая группа G. Хорошо Запрос комментариев: 2849 решений для электронной коммерции iPlanet Категория: Трек стандартов, июнь 2000 г. Формат обмена данными LDAP (LDIF) — техническая спецификация Статус этого меморандума Этот документ определяет протокол отслеживания стандартов Интернета для Интернет-сообщество, а также запросы на обсуждение и предложения по улучшения. Пожалуйста, обратитесь к текущему выпуску «Интернет Стандарты официальных протоколов» (STD 1) для состояния стандартизации и статус этого протокола. Распространение этой памятки не ограничено. Уведомление об авторских правах Авторское право (C) Общество Интернета (2000 г.). Все права защищены. Абстрактный Этот документ описывает формат файла, подходящий для описания справочная информация или изменения, внесенные в справочную информацию.
 Формат файла, известный как LDIF, для формата обмена данными LDAP,
обычно используется для импорта и экспорта информации каталога между
серверы каталогов на основе LDAP, или для описания набора изменений, которые
должны быть применены к каталогу.
Предыстория и предполагаемое использование
Существует ряд ситуаций, когда общий формат обмена
желательно. Например, может потребоваться экспортировать копию
содержимое сервера каталогов в файл, переместите этот файл в
другую машину и импортировать содержимое во второй каталог
сервер.
Кроме того, используя четко определенный формат обмена, разработка
инструментов импорта данных из устаревших систем. довольно
простой набор инструментов, написанных на awk или perl, может, например, конвертировать
базу данных кадровой информации в файл LDIF. Этот файл может
затем импортироваться на сервер каталогов, независимо от внутреннего
представление базы данных, которое использует целевой сервер каталогов.
Формат LDIF изначально был разработан и использовался в университете.
Формат файла, известный как LDIF, для формата обмена данными LDAP,
обычно используется для импорта и экспорта информации каталога между
серверы каталогов на основе LDAP, или для описания набора изменений, которые
должны быть применены к каталогу.
Предыстория и предполагаемое использование
Существует ряд ситуаций, когда общий формат обмена
желательно. Например, может потребоваться экспортировать копию
содержимое сервера каталогов в файл, переместите этот файл в
другую машину и импортировать содержимое во второй каталог
сервер.
Кроме того, используя четко определенный формат обмена, разработка
инструментов импорта данных из устаревших систем. довольно
простой набор инструментов, написанных на awk или perl, может, например, конвертировать
базу данных кадровой информации в файл LDIF. Этот файл может
затем импортироваться на сервер каталогов, независимо от внутреннего
представление базы данных, которое использует целевой сервер каталогов.
Формат LDIF изначально был разработан и использовался в университете. внедрения LDAP в штате Мичиган. Первое использование LDIF было в
описание записей каталога. Позже формат был расширен до
разрешить представление изменений в записях каталога.
Отслеживание хороших стандартов [Страница 1]
внедрения LDAP в штате Мичиган. Первое использование LDIF было в
описание записей каталога. Позже формат был расширен до
разрешить представление изменений в записях каталога.
Отслеживание хороших стандартов [Страница 1] RFC 2849 Формат обмена данными LDAP, июнь 2000 г. Отношение к типу содержимого MIME приложения/каталога: Тип содержимого MIME приложения/каталога [1] является общим структура и формат для передачи информации каталога, и независимо от какой-либо конкретной службы каталогов. Формат LDIF более простой формат, который, возможно, легче создать, а также может быть используется, как уже отмечалось, для описания набора изменений, которые должны быть применены к каталог. Ключевые слова «ДОЛЖЕН», «НЕ ДОЛЖЕН», «МОЖЕТ», «СЛЕДУЕТ» и «НЕ ДОЛЖЕН» используемые в этом документе, следует интерпретировать, как описано в [7]. Определение формата обмена данными LDAP Формат LDIF используется для передачи информации каталога или описание набора изменений, внесенных в записи справочника.
 LDIF
файл состоит из набора записей, разделенных разделителями строк. А
запись состоит из последовательности строк, описывающих запись каталога,
или последовательность строк, описывающая набор изменений в каталоге
вход. Файл LDIF определяет набор записей каталога или набор
изменений, которые должны быть применены к записям каталога, но не к обоим.
Между операциями LDAP, изменяющими
каталог (добавить, удалить, изменить и модрдн) и типы
записи изменений, описанные ниже («добавить», «удалить», «изменить» и
"modrdn" или "moddn"). Эта переписка является преднамеренной, и
позволяет напрямую переводить записи изменений LDIF в
протокольные операции.
Формальное определение синтаксиса LDIF
В следующем определении используется расширенная форма Бэкуса-Наура.
указан в RFC 2234 [2].
ldif-файл = ldif-содержимое / ldif-изменения
ldif-content = спецификация версии 1*(1*SEP ldif-attrval-record)
ldif-changes = спецификация версии 1*(1*SEP ldif-change-record)
ldif-attrval-record = dn-spec SEP 1*attrval-spec
ldif-change-record = dn-spec SEP *control changerecord
version-spec = "версия:" ЗАПОЛНИТЕ номер версии
Отслеживание хороших стандартов [Страница 2]
LDIF
файл состоит из набора записей, разделенных разделителями строк. А
запись состоит из последовательности строк, описывающих запись каталога,
или последовательность строк, описывающая набор изменений в каталоге
вход. Файл LDIF определяет набор записей каталога или набор
изменений, которые должны быть применены к записям каталога, но не к обоим.
Между операциями LDAP, изменяющими
каталог (добавить, удалить, изменить и модрдн) и типы
записи изменений, описанные ниже («добавить», «удалить», «изменить» и
"modrdn" или "moddn"). Эта переписка является преднамеренной, и
позволяет напрямую переводить записи изменений LDIF в
протокольные операции.
Формальное определение синтаксиса LDIF
В следующем определении используется расширенная форма Бэкуса-Наура.
указан в RFC 2234 [2].
ldif-файл = ldif-содержимое / ldif-изменения
ldif-content = спецификация версии 1*(1*SEP ldif-attrval-record)
ldif-changes = спецификация версии 1*(1*SEP ldif-change-record)
ldif-attrval-record = dn-spec SEP 1*attrval-spec
ldif-change-record = dn-spec SEP *control changerecord
version-spec = "версия:" ЗАПОЛНИТЕ номер версии
Отслеживание хороших стандартов [Страница 2] RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
 номер версии = 1*ЦИФРА
; номер версии ДОЛЖЕН быть "1" для
; Формат LDIF, описанный в этом документе.
dn-spec = "dn:" (ЗАПОЛНИТЕ отличительное имя /
":" ЗАПОЛНИТЬ base64-distinguishedName)
выделенное имя = БЕЗОПАСНАЯ СТРОКА
; отличительное имя, как определено в [3]
base64-distinguishedName = BASE64-UTF8-STRING
; различающееся имя, которое было base64
; закодировано (см. примечание 10 ниже)
rdn = БЕЗОПАСНАЯ СТРОКА
; относительное различающееся имя, определяемое как
; <имя-компонент> в [3]
base64-rdn = BASE64-UTF8-STRING
; rdn, закодированный в base64 (см.
; примечание 10 ниже)
control = "control:" ЗАПОЛНИТЬ ldap-oid ; тип управления
0*1(1*ПРОБЕЛ ("истина"/"ложь")) ; критичность
0*1 (спецификация значения) ; контрольное значение
Сентябрь
; (см.
номер версии = 1*ЦИФРА
; номер версии ДОЛЖЕН быть "1" для
; Формат LDIF, описанный в этом документе.
dn-spec = "dn:" (ЗАПОЛНИТЕ отличительное имя /
":" ЗАПОЛНИТЬ base64-distinguishedName)
выделенное имя = БЕЗОПАСНАЯ СТРОКА
; отличительное имя, как определено в [3]
base64-distinguishedName = BASE64-UTF8-STRING
; различающееся имя, которое было base64
; закодировано (см. примечание 10 ниже)
rdn = БЕЗОПАСНАЯ СТРОКА
; относительное различающееся имя, определяемое как
; <имя-компонент> в [3]
base64-rdn = BASE64-UTF8-STRING
; rdn, закодированный в base64 (см.
; примечание 10 ниже)
control = "control:" ЗАПОЛНИТЬ ldap-oid ; тип управления
0*1(1*ПРОБЕЛ ("истина"/"ложь")) ; критичность
0*1 (спецификация значения) ; контрольное значение
Сентябрь
; (см. примечание 9, ниже)
ldap-oid = 1*ЦИФРА 0*1("." 1*ЦИФРА)
; LDAPOID, как определено в [4]
attrval-spec = значение-спецификация AttributeDescription SEP
спецификация значения = ":" ( ЗАПОЛНИТЬ 0*1 (БЕЗОПАСНАЯ СТРОКА) /
":" ЗАПОЛНИТЬ (BASE64-СТРОКА) /
"<" ЗАПОЛНИТЕ URL)
; См. примечания 7 и 8 ниже.
url = <унифицированный указатель ресурсов,
как определено в [6]>
; (См. примечание 6 ниже)
ОписаниеАтрибута = ТипАтрибута [";" параметры]
; Определение взято из [4]
AttributeType = ldap-oid/(ALPHA *(attr-type-chars))
опции = опция / (опция ";" опции)
Отслеживание хороших стандартов [Страница 3]
примечание 9, ниже)
ldap-oid = 1*ЦИФРА 0*1("." 1*ЦИФРА)
; LDAPOID, как определено в [4]
attrval-spec = значение-спецификация AttributeDescription SEP
спецификация значения = ":" ( ЗАПОЛНИТЬ 0*1 (БЕЗОПАСНАЯ СТРОКА) /
":" ЗАПОЛНИТЬ (BASE64-СТРОКА) /
"<" ЗАПОЛНИТЕ URL)
; См. примечания 7 и 8 ниже.
url = <унифицированный указатель ресурсов,
как определено в [6]>
; (См. примечание 6 ниже)
ОписаниеАтрибута = ТипАтрибута [";" параметры]
; Определение взято из [4]
AttributeType = ldap-oid/(ALPHA *(attr-type-chars))
опции = опция / (опция ";" опции)
Отслеживание хороших стандартов [Страница 3]
RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
option = 1*opt-char
attr-type-chars = АЛЬФА / ЦИФРА / "-"
opt-char = attr-type-chars
changerecord = "тип изменения:" ЗАПОЛНИТЬ
(изменить-добавить/изменить-удалить/
изменить-изменить / изменить-моддн)
change-add = "добавить" SEP 1*attrval-spec
change-delete = "удалить" SEP
change-moddn = ("modrdn" / "moddn") SEP
"newrdn:" ( ЗАПОЛНИТЬ rdn /
":" FILL base64-rdn) SEP
"deleteoldrdn:" FILL ("0" / "1") SEP
0*1("Новости супериор:"
( ЗАПОЛНИТЕ отличительное имя /
":" FILL base64-distinguishedName) SEP)
change-modify = "изменить" SEP *mod-spec
mod-spec = ("добавить:" / "удалить:" / "заменить:")
ЗАПОЛНИТЬ Атрибут Описание SEP
* атрибут-спецификация
"-" СЭП
ПРОБЕЛ = %x20
; ASCII SP, пробел
ЗАПОЛНИТЬ = *ПРОБЕЛ
SEP = (CR LF / LF)
CR = %x0D
; ASCII CR, возврат каретки
НЧ = %x0A
; ASCII LF, перевод строки
АЛЬФА = %x41-5A / %x61-7A
; А-Я / а-я
ЦИФРА = %x30-39; 0-9
Отслеживание хороших стандартов [Страница 4] RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
 UTF8-1 = %x80-BF
UTF8-2 = %xC0-DF UTF8-1
UTF8-3 = %xE0-EF 2UTF8-1
UTF8-4 = %xF0-F7 3UTF8-1
UTF8-5 = %xF8-FB 4UTF8-1
UTF8-6 = %xFC-FD 5UTF8-1
БЕЗОПАСНЫЙ СИМВОЛ = %x01-09/%x0B-0C/%x0E-7F
; любое значение <= 127 десятичное, кроме NUL, LF,
; и CR
БЕЗОПАСНЫЙ-ИНИТ-СИМВОЛ = %x01-09/%x0B-0C/%x0E-1F/
%x21-39 / %x3B / %x3D-7F
; любое значение <= 127, кроме NUL, LF, CR,
; ПРОБЕЛ, двоеточие (":", десятичный код ASCII 58)
; и меньше ("<" , десятичное число ASCII 60)
SAFE-STRING = [SAFE-INIT-CHAR *SAFE-CHAR]
UTF8-СИМВОЛ = БЕЗОПАСНЫЙ СИМВОЛ / UTF8-2 / UTF8-3 /
UTF8-4/UTF8-5/UTF8-6
UTF8-СТРОКА = *UTF8-СИМВОЛ
BASE64-UTF8-СТРОКА = BASE64-СТРОКА
; ДОЛЖНА быть кодировка base64 для
; UTF8-СТРОКА
BASE64-CHAR = %x2B / %x2F / %x30-39/%x3D/%x41-5A/
%x61-7A
; +, /, 0-9, =, A-Z и az
; как указано в [5]
BASE64-СТРОКА = [*(BASE64-СИМВОЛ)]
Примечания о синтаксисе LDIF
1) Для формата LDIF, описанного в этом документе, версия
номер ДОЛЖЕН быть "1".
UTF8-1 = %x80-BF
UTF8-2 = %xC0-DF UTF8-1
UTF8-3 = %xE0-EF 2UTF8-1
UTF8-4 = %xF0-F7 3UTF8-1
UTF8-5 = %xF8-FB 4UTF8-1
UTF8-6 = %xFC-FD 5UTF8-1
БЕЗОПАСНЫЙ СИМВОЛ = %x01-09/%x0B-0C/%x0E-7F
; любое значение <= 127 десятичное, кроме NUL, LF,
; и CR
БЕЗОПАСНЫЙ-ИНИТ-СИМВОЛ = %x01-09/%x0B-0C/%x0E-1F/
%x21-39 / %x3B / %x3D-7F
; любое значение <= 127, кроме NUL, LF, CR,
; ПРОБЕЛ, двоеточие (":", десятичный код ASCII 58)
; и меньше ("<" , десятичное число ASCII 60)
SAFE-STRING = [SAFE-INIT-CHAR *SAFE-CHAR]
UTF8-СИМВОЛ = БЕЗОПАСНЫЙ СИМВОЛ / UTF8-2 / UTF8-3 /
UTF8-4/UTF8-5/UTF8-6
UTF8-СТРОКА = *UTF8-СИМВОЛ
BASE64-UTF8-СТРОКА = BASE64-СТРОКА
; ДОЛЖНА быть кодировка base64 для
; UTF8-СТРОКА
BASE64-CHAR = %x2B / %x2F / %x30-39/%x3D/%x41-5A/
%x61-7A
; +, /, 0-9, =, A-Z и az
; как указано в [5]
BASE64-СТРОКА = [*(BASE64-СИМВОЛ)]
Примечания о синтаксисе LDIF
1) Для формата LDIF, описанного в этом документе, версия
номер ДОЛЖЕН быть "1". Если номер версии отсутствует,
реализации МОГУТ интерпретировать содержимое как
старый формат файла LDIF, поддерживаемый Университетом
Мичиганская реализация ldap-3.3 [8].
Отслеживание хороших стандартов [Страница 5]
Если номер версии отсутствует,
реализации МОГУТ интерпретировать содержимое как
старый формат файла LDIF, поддерживаемый Университетом
Мичиганская реализация ldap-3.3 [8].
Отслеживание хороших стандартов [Страница 5]
RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
2) Любая непустая строка, включая строки комментариев, в файле LDIF.
МОЖЕТ быть свернут, вставив разделитель строк (SEP) и ПРОБЕЛ.
Свертывание НЕ ДОЛЖНО происходить перед первым символом строки.
Другими словами, складывая строку в две строки, первая из
который пуст, не разрешен. Любая строка, начинающаяся с
один пробел ДОЛЖЕН рассматриваться как продолжение предыдущего
(непустая) строка. При соединении сложенных строк ровно один пробел
символ в начале каждой продолжающейся строки должен быть
отброшен. Реализации НЕ ДОЛЖНЫ складывать линии посередине
многобайтового символа UTF-8.
3) Любая строка, начинающаяся со знака решетки ("#", ASCII 35), является
строку комментария и ДОЛЖЕН игнорироваться при синтаксическом анализе файла LDIF.
4) Любое dn или rdn, содержащее символы, отличные от указанных.
определяется как "SAFE-UTF8-CHAR" или начинается с другого символа
чем те, которые определены как «SAFE-INIT-UTF8-CHAR» выше, ДОЛЖНЫ быть
кодировка base-64. Другие значения МОГУТ быть закодированы по основанию 64. Любой
значение, которое содержит символы, отличные от тех, которые определены как
"SAFE-CHAR" или начинается с символа, отличного от
определенный выше как "SAFE-INIT-CHAR", ДОЛЖЕН быть закодирован в base-64.
Другие значения МОГУТ быть закодированы по основанию 64.
5) Когда значение атрибута нулевой длины должно быть включено напрямую
в файле LDIF он ДОЛЖЕН быть представлен как
AttributeDescription ":" FILL SEP. Например, "см. также:"
за которым следует новая строка, представляет собой "seeAlso" нулевой длины.
значение атрибута. Допустимо также значение
на который ссылается URL-адрес, имеет нулевую длину.
6) Когда URL-адрес указан в атрибуте-спецификации, следующее
применяются соглашения:
а) Реализациям СЛЕДУЕТ поддерживать формат URL-адреса file://.
содержимое ссылочного файла должно быть включено дословно
в интерпретируемом выводе файла LDIF.
b) Реализации МОГУТ поддерживать другие форматы URL.
семантика, связанная с каждым поддерживаемым URL, будет
задокументированы в соответствующем заявлении о применимости.
7) Отличительные имена, относительные отличительные имена и
значения атрибутов синтаксиса DirectoryString ДОЛЖНЫ быть действительными UTF-8
струны. Реализации, которые читают LDIF, МОГУТ интерпретировать файлы
в котором эти сущности хранятся в каком-то другом наборе символов
кодирование, но реализации НЕ ДОЛЖНЫ генерировать LDIF-контент
который не содержит действительных данных UTF-8.
Отслеживание хороших стандартов [Страница 6]  4) Любое dn или rdn, содержащее символы, отличные от указанных.
определяется как "SAFE-UTF8-CHAR" или начинается с другого символа
чем те, которые определены как «SAFE-INIT-UTF8-CHAR» выше, ДОЛЖНЫ быть
кодировка base-64. Другие значения МОГУТ быть закодированы по основанию 64. Любой
значение, которое содержит символы, отличные от тех, которые определены как
"SAFE-CHAR" или начинается с символа, отличного от
определенный выше как "SAFE-INIT-CHAR", ДОЛЖЕН быть закодирован в base-64.
Другие значения МОГУТ быть закодированы по основанию 64.
5) Когда значение атрибута нулевой длины должно быть включено напрямую
в файле LDIF он ДОЛЖЕН быть представлен как
AttributeDescription ":" FILL SEP. Например, "см. также:"
за которым следует новая строка, представляет собой "seeAlso" нулевой длины.
значение атрибута. Допустимо также значение
на который ссылается URL-адрес, имеет нулевую длину.
4) Любое dn или rdn, содержащее символы, отличные от указанных.
определяется как "SAFE-UTF8-CHAR" или начинается с другого символа
чем те, которые определены как «SAFE-INIT-UTF8-CHAR» выше, ДОЛЖНЫ быть
кодировка base-64. Другие значения МОГУТ быть закодированы по основанию 64. Любой
значение, которое содержит символы, отличные от тех, которые определены как
"SAFE-CHAR" или начинается с символа, отличного от
определенный выше как "SAFE-INIT-CHAR", ДОЛЖЕН быть закодирован в base-64.
Другие значения МОГУТ быть закодированы по основанию 64.
5) Когда значение атрибута нулевой длины должно быть включено напрямую
в файле LDIF он ДОЛЖЕН быть представлен как
AttributeDescription ":" FILL SEP. Например, "см. также:"
за которым следует новая строка, представляет собой "seeAlso" нулевой длины.
значение атрибута. Допустимо также значение
на который ссылается URL-адрес, имеет нулевую длину. 6) Когда URL-адрес указан в атрибуте-спецификации, следующее
применяются соглашения:
а) Реализациям СЛЕДУЕТ поддерживать формат URL-адреса file://.
содержимое ссылочного файла должно быть включено дословно
в интерпретируемом выводе файла LDIF.
b) Реализации МОГУТ поддерживать другие форматы URL.
семантика, связанная с каждым поддерживаемым URL, будет
задокументированы в соответствующем заявлении о применимости.
7) Отличительные имена, относительные отличительные имена и
значения атрибутов синтаксиса DirectoryString ДОЛЖНЫ быть действительными UTF-8
струны. Реализации, которые читают LDIF, МОГУТ интерпретировать файлы
в котором эти сущности хранятся в каком-то другом наборе символов
кодирование, но реализации НЕ ДОЛЖНЫ генерировать LDIF-контент
который не содержит действительных данных UTF-8.
Отслеживание хороших стандартов [Страница 6]
6) Когда URL-адрес указан в атрибуте-спецификации, следующее
применяются соглашения:
а) Реализациям СЛЕДУЕТ поддерживать формат URL-адреса file://.
содержимое ссылочного файла должно быть включено дословно
в интерпретируемом выводе файла LDIF.
b) Реализации МОГУТ поддерживать другие форматы URL.
семантика, связанная с каждым поддерживаемым URL, будет
задокументированы в соответствующем заявлении о применимости.
7) Отличительные имена, относительные отличительные имена и
значения атрибутов синтаксиса DirectoryString ДОЛЖНЫ быть действительными UTF-8
струны. Реализации, которые читают LDIF, МОГУТ интерпретировать файлы
в котором эти сущности хранятся в каком-то другом наборе символов
кодирование, но реализации НЕ ДОЛЖНЫ генерировать LDIF-контент
который не содержит действительных данных UTF-8.
Отслеживание хороших стандартов [Страница 6] RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
 8) Значения или отличительные имена, оканчивающиеся на ПРОБЕЛ, ДОЛЖНЫ быть
кодировка base-64.
9) Когда элементы управления включены в файл LDIF, реализации
МОЖЕТ игнорировать некоторые или все из них. Это может быть
необходимо, если изменения, описанные в файле LDIF,
отправлено по соединению LDAPv2 (LDAPv2 не поддерживает
элементы управления), или определенные элементы управления не поддерживаются
удаленный сервер. Если критичность управления «истинна», то
реализация ДОЛЖНА либо включать элемент управления, либо ДОЛЖНА
НЕ отправляйте операцию на удаленный сервер.
10) Когда attrval-spec, disabledName или rdn имеет base64-
закодированы, правила кодирования, указанные в [5], используются с
следующие исключения: а) Требование, чтобы вывод base64
потоки должны быть представлены строками не более 76
символы удалены. Строки в файлах LDIF можно только сворачивать
по правилам складывания, описанным в примечании 2 выше.
8) Значения или отличительные имена, оканчивающиеся на ПРОБЕЛ, ДОЛЖНЫ быть
кодировка base-64.
9) Когда элементы управления включены в файл LDIF, реализации
МОЖЕТ игнорировать некоторые или все из них. Это может быть
необходимо, если изменения, описанные в файле LDIF,
отправлено по соединению LDAPv2 (LDAPv2 не поддерживает
элементы управления), или определенные элементы управления не поддерживаются
удаленный сервер. Если критичность управления «истинна», то
реализация ДОЛЖНА либо включать элемент управления, либо ДОЛЖНА
НЕ отправляйте операцию на удаленный сервер.
10) Когда attrval-spec, disabledName или rdn имеет base64-
закодированы, правила кодирования, указанные в [5], используются с
следующие исключения: а) Требование, чтобы вывод base64
потоки должны быть представлены строками не более 76
символы удалены. Строки в файлах LDIF можно только сворачивать
по правилам складывания, описанным в примечании 2 выше. б)
Строки Base64 в [5] могут содержать символы, отличные от тех, которые
определены в BASE64-CHAR и игнорируются. LDIF не позволяет
любые посторонние символы, кроме тех, которые используются для строки
складной.
Примеры формата обмена данными LDAP
Пример 1: Простой файл LDAP с двумя записями
версия: 1
dn: cn=Барбара Дженсен, ou=Разработка продукта, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Барбара Дженсен
cn: Барбара Дж. Дженсен
cn: Бэбс Дженсен
sn: Дженсен
ИД: Бьенсен
номер телефона: +1 408 555 1212
описание: Большой поклонник парусного спорта.
dn: cn=Бьорн Дженсен, ou=бухгалтерский учет, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Бьорн Дженсен
sn: Дженсен
номер телефона: +1 408 555 1212
Отслеживание хороших стандартов [Страница 7]
б)
Строки Base64 в [5] могут содержать символы, отличные от тех, которые
определены в BASE64-CHAR и игнорируются. LDIF не позволяет
любые посторонние символы, кроме тех, которые используются для строки
складной.
Примеры формата обмена данными LDAP
Пример 1: Простой файл LDAP с двумя записями
версия: 1
dn: cn=Барбара Дженсен, ou=Разработка продукта, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Барбара Дженсен
cn: Барбара Дж. Дженсен
cn: Бэбс Дженсен
sn: Дженсен
ИД: Бьенсен
номер телефона: +1 408 555 1212
описание: Большой поклонник парусного спорта.
dn: cn=Бьорн Дженсен, ou=бухгалтерский учет, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Бьорн Дженсен
sn: Дженсен
номер телефона: +1 408 555 1212
Отслеживание хороших стандартов [Страница 7] RFC 2849 Формат обмена данными LDAP, июнь 2000 г. Пример 2: файл, содержащий запись со свернутым значением атрибута версия: 1 dn:cn=Барбара Дженсен, ou=Разработка продукта, dc=airius, dc=com объектный класс:верхний объектный класс:человек объектный класс:organizationalPerson cn: Барбара Дженсен cn: Барбара Дж.ou;lang-ja;фонетический:: 44GI44GE44GO44Kh54GG44G2 Отслеживание хороших стандартов [Страница 8]
 Дженсен
cn: Бэбс Дженсен
sn: Дженсен
uid: Бьенсен
номер телефона:+1 408 555 1212
описание: Бэбс большой поклонник парусного спорта и много путешествует по морю.
rch идеальных условий для плавания.
title:Менеджер по продукции, подразделение удилищ и катушек
Пример 3: файл, содержащий значение в кодировке base-64
версия: 1
dn: cn=Герн Дженсен, ou=Тестирование продукта, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Герн Йенсен
cn: Герн О Дженсен
sn: Дженсен
идентификатор: gernj
номер телефона: +1 408 555 1212
описание:: V2hhdCBhIGNhcmVmdWwgcmVhZGVyIHlvdSBhcmUhICBUaGlzIHZhbHVl
IGlzIGJhc2UtNjQtZW5jb2RlZCBiZWNhdXNlIGl0IGhhcyBhIGNvbnRyb2wgY2hhcmFjdG
VYIGLUIGL0ICHIENSKS4NICBCeSB0aGUgd2F5LCB5b3Ugc2hvdWxkIHJlYWxseSBnZXQg
b3V0IG1vcmUu
Пример 4: файл, содержащий записи с атрибутом в кодировке UTF-8
значения, включая языковые теги. Комментарии указывают на содержание
атрибутов и отличительных имен в кодировке UTF-8.
версия: 1
дн:: b3U95Za25qWt6YOoLG89QWlyaXVz
# dn:: ou=<японскийOU>,o=Airius
класс объекта: верхний
класс объекта: организационная единица
ou:: 5Za25qWt6YOo
# ou::<японскийOU>
ou;lang-ja:: 5Za25qWt6YOo
# ou;lang-ja::
Дженсен
cn: Бэбс Дженсен
sn: Дженсен
uid: Бьенсен
номер телефона:+1 408 555 1212
описание: Бэбс большой поклонник парусного спорта и много путешествует по морю.
rch идеальных условий для плавания.
title:Менеджер по продукции, подразделение удилищ и катушек
Пример 3: файл, содержащий значение в кодировке base-64
версия: 1
dn: cn=Герн Дженсен, ou=Тестирование продукта, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Герн Йенсен
cn: Герн О Дженсен
sn: Дженсен
идентификатор: gernj
номер телефона: +1 408 555 1212
описание:: V2hhdCBhIGNhcmVmdWwgcmVhZGVyIHlvdSBhcmUhICBUaGlzIHZhbHVl
IGlzIGJhc2UtNjQtZW5jb2RlZCBiZWNhdXNlIGl0IGhhcyBhIGNvbnRyb2wgY2hhcmFjdG
VYIGLUIGL0ICHIENSKS4NICBCeSB0aGUgd2F5LCB5b3Ugc2hvdWxkIHJlYWxseSBnZXQg
b3V0IG1vcmUu
Пример 4: файл, содержащий записи с атрибутом в кодировке UTF-8
значения, включая языковые теги. Комментарии указывают на содержание
атрибутов и отличительных имен в кодировке UTF-8.
версия: 1
дн:: b3U95Za25qWt6YOoLG89QWlyaXVz
# dn:: ou=<японскийOU>,o=Airius
класс объекта: верхний
класс объекта: организационная единица
ou:: 5Za25qWt6YOo
# ou::<японскийOU>
ou;lang-ja:: 5Za25qWt6YOo
# ou;lang-ja:: RFC 2849 Формат обмена данными LDAP, июнь 2000 г.,ou=<японскийOU>,o=Airius пароль пользователя: {SHA}O3HSv1MusyL4kTjP+HKI5uxuNoM= класс объекта: верхний объектный класс: человек класс объекта: OrganizationPerson объектный класс: inetOrgPerson ИД: Рогасавара почта: [email protected] имя;lang-ja:: 44Ot44OJ44OL44O8 # данное имя;lang-ja:: sn;lang-ja:: 5bCP56yg5Y6f # sn;lang-ja:: cn;lang-ja:: 5bCP56yg5Y6fIOODreODieODi+ODvA== # cn;lang-ja:: title;lang-ja:: 5Za25qWt6YOoIOmDqOmVtw== # title;lang-ja:: предпочитаемый язык: ja имя:: 44Ot44OJ44OL44O8 # данное имя:: sn:: 5bCP56yg5Y6f # sn:: <японскийSn> cn:: 5bCP56yg5Y6fIOODreODieODi+ODvA== # cn::<японскийCn> название:: 5Za25qWt6YOoIOmDqOmVtw== # title:: <ЯпонскийTitle> имя;lang-ja;фонетический:: 44KN44Gp44Gr44O8 # имя;lang-ja;фонетический:: <японское имя_in_phonetic_representation_kana> sn;lang-ja;фонетический:: 44GK44GM44GV44KP44KJ # sn;lang-ja;phonetic:: <японскийSn_in_phonetic_representation_kana> cn;lang-ja;фонетический:: 44GK44GM44GV44KP44KJIOOCjeOBqeOBq+ODvA== # cn;lang-ja;phonetic:: название;lang-ja;фонетический:: 44GI44GE44GO44Kh54GG44G2IOOBtuOBoeOCh+OBhg== # title;lang-ja;phonetic:: # имя;язык-ан: Rodney sn;lang-en: Огасавара cn;lang-en: Родни Огасавара title;lang-en: Продажи, Директор Дорожка хороших стандартов [Страница 9]
 # ou;lang-ja:: <японскийOU_in_phonetic_representation>
ou;lang-en: Продажи
описание: японский офис
имя:: dWlkPXJvZ2FzYXdhcmEsb3U95Za25qWt6YOoLG89QWlyaXVz
# dn:: uid=
# ou;lang-ja:: <японскийOU_in_phonetic_representation>
ou;lang-en: Продажи
описание: японский офис
имя:: dWlkPXJvZ2FzYXdhcmEsb3U95Za25qWt6YOoLG89QWlyaXVz
# dn:: uid=RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
 Пример 5: файл, содержащий ссылку на внешний файл
версия: 1
dn: cn=Горацио Дженсен, ou=Тестирование продукта, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Горацио Дженсен
cn: Горацио Н. Дженсен
sn: Дженсен
ИД: Хьенсен
номер телефона: +1 408 555 1212
jpegphoto: < файл:///usr/local/directory/photos/hjensen.jpg
Пример 6: файл, содержащий ряд записей об изменениях и комментариев
версия: 1
# Добавить новую запись
dn: cn=Fiona Jensen, ou=Marketing, dc=airius, dc=com
тип изменения: добавить
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
сп: Фиона Дженсен
sn: Дженсен
ИД: Фиона
номер телефона: +1 408 555 1212
jpegphoto: < файл:///usr/local/directory/photos/fiona.jpg
# Удалить существующую запись
dn: cn=Роберт Дженсен, ou=Маркетинг, dc=airius, dc=com
тип изменения: удалить
# Изменить относительное отличительное имя записи
dn: cn=Пол Дженсен, ou=Разработка продукта, dc=airius, dc=com
тип изменения: modrdn
newrdn: cn=Паула Дженсен
удалитьoldrdn: 1
# Переименовать запись и переместить всех ее дочерних элементов в новое место в
# дерево каталогов (реализуется только серверами LDAPv3).
Пример 5: файл, содержащий ссылку на внешний файл
версия: 1
dn: cn=Горацио Дженсен, ou=Тестирование продукта, dc=airius, dc=com
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
cn: Горацио Дженсен
cn: Горацио Н. Дженсен
sn: Дженсен
ИД: Хьенсен
номер телефона: +1 408 555 1212
jpegphoto: < файл:///usr/local/directory/photos/hjensen.jpg
Пример 6: файл, содержащий ряд записей об изменениях и комментариев
версия: 1
# Добавить новую запись
dn: cn=Fiona Jensen, ou=Marketing, dc=airius, dc=com
тип изменения: добавить
класс объекта: верхний
объектный класс: человек
класс объекта: OrganizationPerson
сп: Фиона Дженсен
sn: Дженсен
ИД: Фиона
номер телефона: +1 408 555 1212
jpegphoto: < файл:///usr/local/directory/photos/fiona.jpg
# Удалить существующую запись
dn: cn=Роберт Дженсен, ou=Маркетинг, dc=airius, dc=com
тип изменения: удалить
# Изменить относительное отличительное имя записи
dn: cn=Пол Дженсен, ou=Разработка продукта, dc=airius, dc=com
тип изменения: modrdn
newrdn: cn=Паула Дженсен
удалитьoldrdn: 1
# Переименовать запись и переместить всех ее дочерних элементов в новое место в
# дерево каталогов (реализуется только серверами LDAPv3). dn: ou=PD Бухгалтеры, ou=Разработка продуктов, dc=airius, dc=com
тип изменения: modrdn
newrdn: ou=Бухгалтеры по разработке продуктов
удалитьoldrdn: 0
newsuperior: ou=бухгалтерский учет, dc=airius, dc=com
Дорожка хороших стандартов [Страница 10]
dn: ou=PD Бухгалтеры, ou=Разработка продуктов, dc=airius, dc=com
тип изменения: modrdn
newrdn: ou=Бухгалтеры по разработке продуктов
удалитьoldrdn: 0
newsuperior: ou=бухгалтерский учет, dc=airius, dc=com
Дорожка хороших стандартов [Страница 10] RFC 2849 Формат обмена данными LDAP, июнь 2000 г. # Изменить запись: добавить дополнительное значение к почтовому адресу # атрибут, полностью удалить атрибут description, заменить # атрибут phonenumber с двумя значениями и удалить конкретный # значение из атрибута facsimiletelephonenumber dn: cn=Paula Jensen, ou=Product Development, dc=airius, dc=com тип изменения: изменить добавить: почтовый адрес почтовый адрес: 123 Anystreet $ Sunnyvale, CA $ 94086 - удалить: описание - заменить: номер телефона номер телефона: +1 408 555 1234 номер телефона: +1 408 555 5678 - удалить: номер факсателефон факсимильный телефон: +1 408 555 9876 - # Измените запись: замените атрибут postaladdress пустым # набор значений (которые приведут к удалению атрибута) и # удалить весь атрибут описания.
 Обратите внимание, что первое будет
# всегда удается, в то время как второе будет успешным, только если хотя бы
# присутствует одно значение атрибута описания.
dn: cn=Ингрид Дженсен, ou=Поддержка продукта, dc=airius, dc=com
тип изменения: изменить
заменить: почтовый адрес
-
удалить: описание
-
Пример 7. Файл LDIF, содержащий запись об изменении с элементом управления
версия: 1
# Удалить запись. Операция подключит LDAPv3
# Элемент управления удалением дерева, определенный в [9]. Критичность
# поле "true", а поле controlValue равно
# отсутствует, как того требует [9].
DN: ou=Разработка продукта, dc=airius, dc=com
контроль: 1.2.840.113556.1.4.805 правда
тип изменения: удалить
Отслеживание хороших стандартов [Страница 11]
Обратите внимание, что первое будет
# всегда удается, в то время как второе будет успешным, только если хотя бы
# присутствует одно значение атрибута описания.
dn: cn=Ингрид Дженсен, ou=Поддержка продукта, dc=airius, dc=com
тип изменения: изменить
заменить: почтовый адрес
-
удалить: описание
-
Пример 7. Файл LDIF, содержащий запись об изменении с элементом управления
версия: 1
# Удалить запись. Операция подключит LDAPv3
# Элемент управления удалением дерева, определенный в [9]. Критичность
# поле "true", а поле controlValue равно
# отсутствует, как того требует [9].
DN: ou=Разработка продукта, dc=airius, dc=com
контроль: 1.2.840.113556.1.4.805 правда
тип изменения: удалить
Отслеживание хороших стандартов [Страница 11] RFC 2849 Формат обмена данными LDAP, июнь 2000 г. Вопросы безопасности Учитывая типичные приложения каталогов, файл LDIF, скорее всего, содержат конфиденциальные личные данные. Соответствующие меры должны быть приняты для защиты конфиденциальности тех лиц, чьи данные содержатся в файле LDIF.
 Поскольку директивы ":<" могут привести к включению внешнего содержимого, когда
при обработке LDIF-файла следует с осторожностью принимать LDIF-файлы.
файлы из внешних источников. «Троянский» файл LDIF может называть файл
с конфиденциальным содержимым и заставить его быть включенным в каталог
запись, которую враждебный объект может прочитать через LDAP.
LDIF не предоставляет никаких способов аутентификации.
информацию с файлом LDIF. Пользователи файлов LDIF должны позаботиться о том, чтобы
проверить целостность файла LDIF, полученного от внешнего
источник.
Благодарности
Формат обмена LDAP был разработан в рамках
эталонной реализации LDAP в Мичигане и был разработан Тимом
Хоуза, Марка Смита и Гордона Гуда. Он частично основан на работе
при поддержке Национального научного фонда в рамках гранта № NCR-
9416667.
Члены рабочей группы IETF LDAP Extensions предоставили множество
полезные предложения. В частности, Халвард Б. Фурусет из
Университет Осло внес значительный вклад в это
документ, включая тщательный обзор и переписывание БНФ.
Поскольку директивы ":<" могут привести к включению внешнего содержимого, когда
при обработке LDIF-файла следует с осторожностью принимать LDIF-файлы.
файлы из внешних источников. «Троянский» файл LDIF может называть файл
с конфиденциальным содержимым и заставить его быть включенным в каталог
запись, которую враждебный объект может прочитать через LDAP.
LDIF не предоставляет никаких способов аутентификации.
информацию с файлом LDIF. Пользователи файлов LDIF должны позаботиться о том, чтобы
проверить целостность файла LDIF, полученного от внешнего
источник.
Благодарности
Формат обмена LDAP был разработан в рамках
эталонной реализации LDAP в Мичигане и был разработан Тимом
Хоуза, Марка Смита и Гордона Гуда. Он частично основан на работе
при поддержке Национального научного фонда в рамках гранта № NCR-
9416667.
Члены рабочей группы IETF LDAP Extensions предоставили множество
полезные предложения. В частности, Халвард Б. Фурусет из
Университет Осло внес значительный вклад в это
документ, включая тщательный обзор и переписывание БНФ. использованная литература
[1] Хоуз, Т. и М. Смит, «Тип содержимого MIME для
Информация", RFC 2425, сентябрь 1998 г.
[2] Крокер, Д., и П. Оверелл, "Расширенный BNF для синтаксиса".
Спецификации: ABNF", RFC 2234, 19 ноября.97.
[3] Валь, М., Килле, С. и Т. Хоус, «Строковое представление
Выдающиеся имена», RFC 2253, декабрь 1997 г.
[4] Валь, М., Хоус, Т. и С. Килле, «Упрощенный доступ к каталогам».
Протокол (v3)", RFC 2251, июль 1997 г.
[5] Фрид, Н. и Н. Боренштейн, «Многоцелевая Интернет-почта».
Расширения (MIME), часть первая: формат тел интернет-сообщений»,
RFC 2045, ноябрь 1996 г.
Дорожка хороших стандартов [Страница 12]
использованная литература
[1] Хоуз, Т. и М. Смит, «Тип содержимого MIME для
Информация", RFC 2425, сентябрь 1998 г.
[2] Крокер, Д., и П. Оверелл, "Расширенный BNF для синтаксиса".
Спецификации: ABNF", RFC 2234, 19 ноября.97.
[3] Валь, М., Килле, С. и Т. Хоус, «Строковое представление
Выдающиеся имена», RFC 2253, декабрь 1997 г.
[4] Валь, М., Хоус, Т. и С. Килле, «Упрощенный доступ к каталогам».
Протокол (v3)", RFC 2251, июль 1997 г.
[5] Фрид, Н. и Н. Боренштейн, «Многоцелевая Интернет-почта».
Расширения (MIME), часть первая: формат тел интернет-сообщений»,
RFC 2045, ноябрь 1996 г.
Дорожка хороших стандартов [Страница 12]
RFC 2849 Формат обмена данными LDAP, июнь 2000 г.
[6] Бернерс-Ли, Т., Масинтер, Л. и М. МакКахилл, "Униформа
Локаторы ресурсов (URL)», RFC 1738, декабрь 1994 г.
[7] Браднер, С., «Ключевые слова для использования в RFC для обозначения требований
Уровни», BCP 14, RFC 2119, март 1997 г.
[8] Руководство администратора SLAPD и SLURPD. Университет
Мичиган, апрель 1996 г.
[9] MP Armijo, «Управление удалением дерева», работа в процессе.
Адрес автора
Гордон Гуд
Решения iPlanet для электронной коммерции
150 Сетевой круг
Почтовый ящик USCA17-201
Санта-Клара, Калифорния 95054, США
Телефон: +1 408 276 4351
Электронная почта: [email protected]
Отслеживание хороших стандартов [Страница 13]  [8] Руководство администратора SLAPD и SLURPD. Университет
Мичиган, апрель 1996 г.
[8] Руководство администратора SLAPD и SLURPD. Университет
Мичиган, апрель 1996 г. RFC 2849 Формат обмена данными LDAP, июнь 2000 г. Полное заявление об авторских правах Авторское право (C) Общество Интернета (2000 г.). Все права защищены. Этот документ и его переводы могут быть скопированы и предоставлены другие и производные работы, которые комментируют или иным образом объясняют это или содействовать в его реализации, могут быть подготовлены, скопированы, опубликованы и распространяется полностью или частично без ограничения каких-либо вид, при условии, что приведенное выше уведомление об авторских правах и этот параграф включены во все такие копии и производные работы.
 Однако это
сам документ не может быть изменен каким-либо образом, например, путем удаления
уведомление об авторских правах или ссылки на Internet Society или другие
Интернет-организациям, за исключением случаев, когда это необходимо для целей
разработка интернет-стандартов, и в этом случае процедуры для
авторские права, определенные в процессе Интернет-стандартов, должны быть
следовала или по мере необходимости переводила его на языки, отличные от
Английский.
Ограниченные разрешения, предоставленные выше, являются бессрочными и не будут
отозвано Internet Society или его правопреемниками или правопреемниками.
Настоящий документ и информация, содержащаяся в нем, предоставлены на
Основа «КАК ЕСТЬ» и ИНТЕРНЕТ-ОБЩЕСТВО И ИНТЕРНЕТ-ИНЖИНИРИНГ
TASK FORCE ОТКАЗЫВАЕТСЯ ОТ ВСЕХ ГАРАНТИЙ, ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ, ВКЛЮЧАЯ
НО НЕ ОГРАНИЧИВАЯСЯ ЛЮБОЙ ГАРАНТИЕЙ ТОГО, ЧТО ИСПОЛЬЗОВАНИЕ ИНФОРМАЦИИ
ЗДЕСЬ НЕ БУДЕТ НАРУШАТЬ НИКАКИХ ПРАВ ИЛИ ЛЮБЫХ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ
КОММЕРЧЕСКАЯ ПРИГОДНОСТЬ ИЛИ ПРИГОДНОСТЬ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ.
Однако это
сам документ не может быть изменен каким-либо образом, например, путем удаления
уведомление об авторских правах или ссылки на Internet Society или другие
Интернет-организациям, за исключением случаев, когда это необходимо для целей
разработка интернет-стандартов, и в этом случае процедуры для
авторские права, определенные в процессе Интернет-стандартов, должны быть
следовала или по мере необходимости переводила его на языки, отличные от
Английский.
Ограниченные разрешения, предоставленные выше, являются бессрочными и не будут
отозвано Internet Society или его правопреемниками или правопреемниками.
Настоящий документ и информация, содержащаяся в нем, предоставлены на
Основа «КАК ЕСТЬ» и ИНТЕРНЕТ-ОБЩЕСТВО И ИНТЕРНЕТ-ИНЖИНИРИНГ
TASK FORCE ОТКАЗЫВАЕТСЯ ОТ ВСЕХ ГАРАНТИЙ, ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ, ВКЛЮЧАЯ
НО НЕ ОГРАНИЧИВАЯСЯ ЛЮБОЙ ГАРАНТИЕЙ ТОГО, ЧТО ИСПОЛЬЗОВАНИЕ ИНФОРМАЦИИ
ЗДЕСЬ НЕ БУДЕТ НАРУШАТЬ НИКАКИХ ПРАВ ИЛИ ЛЮБЫХ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ
КОММЕРЧЕСКАЯ ПРИГОДНОСТЬ ИЛИ ПРИГОДНОСТЬ ДЛЯ ОПРЕДЕЛЕННОЙ ЦЕЛИ. Подтверждение
Финансирование функции редактора RFC в настоящее время предоставляется
Интернет-общество.
Отслеживание хороших стандартов [Страница 14]
Подтверждение
Финансирование функции редактора RFC в настоящее время предоставляется
Интернет-общество.
Отслеживание хороших стандартов [Страница 14]
DT 30167 (Подсказки) – Блог о кроссвордах Большого Дейва
Daily Telegraph Cryptic No 30167 (Подсказки)
Субботний клуб кроссвордов (организуемый crypticsue)
+ – + – + – + – + – + – + – +
Доброе утро прекрасным солнечным морозным утром здесь, в Восточном Кенте. Очень холодно – пока я печатаю, температура достигла головокружительных высот -1 o C, было -4 o C, когда я отправился в Сейнсбери в 8 часов.
Я думаю, что количество анаграмм дает нам четкое представление о том, кто установил призовую головоломку в эту субботу. Если я не намекнул на подсказки, на которых вы действительно застряли, просто спросите, и я посмотрю, что я могу сделать
трудные, были выбраны и снабжены подсказками для них.
Большинство терминов, используемых в этих подсказках, объясняются в Глоссарии, а примеры доступны, если щелкнуть запись в разделе «См. также». Если подсказка описывает конструкцию как «обычную», это означает, что дополнительную помощь можно найти в «Обычных подозреваемых», где приводится ряд элементов, обычно используемых в игре слов. Еще одна полезная страница — «Волки в овечьей шкуре», на которой представлены слова со значениями, которые не всегда сразу очевидны.
также». Если подсказка описывает конструкцию как «обычную», это означает, что дополнительную помощь можно найти в «Обычных подозреваемых», где приводится ряд элементов, обычно используемых в игре слов. Еще одна полезная страница — «Волки в овечьей шкуре», на которой представлены слова со значениями, которые не всегда сразу очевидны.
Полный обзор этой головоломки будет опубликован после окончания приема заявок.
Ниже приведены некоторые подсказки.
Через
1a См. следующую сводку точно (9)
Любимая епархия Crosswordland (см.) после сводки
11a Только одно транспортное средство в плотном потоке? (5)
Загадочное определение мощного автомобиля для перевозки тяжелых грузов
17a Он, возможно, включает гребца, который хаски (6)
Я предполагаю, что слово возможно y означает, что мы должны составить анаграмму HES — хотя на самом деле мы просто переставляем две последние буквы — и затем вставляем (включая) гребца
19a Капитан должен контролировать здесь, в игра (6)
Где капитану дальнего плавания нужно управлять или карточная игра
27a Последние вещи, которые снимают (13)
Последние вещи, которые снимают перед сном, или, может быть, в ванна
28a Химические рассеянные животные позже (9)
Анаграмма (рассеянная) PETS LATER
Down
2d Раздраженный трезвенник Raymond снаружи (5)
Уменьшительная форма Raymond выходит за пределы букв, используемых для обозначения исключенного трезвенника 60 524 39d )
Буква, представленная Чарли в фонетическом алфавите НАТО, и анаграмма (вне) RULED
6d Разделение мелких различий (4-9) твоя голова
7d Символы очевидны в документе (7,6)
Некоторые символы и значение прилагательного очевидны
10d Участок балансировки возле литейного цеха? (9)
Тип весов, который работает путем уравновешивания измеряемого предмета с помощью веса, может, если разделить 5,4, быть областью рядом с литейным цехом
26d Наркоторговец, не стартующий в качестве сопровождающего (5)
A торговец наркотиками без первой буквы (не начиная)
Просьба к новым читателям прочитать приветственный пост и часто задаваемые вопросы, прежде чем публиковать комментарии или задавать вопросы о сайте.